
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Асинхронная загрузка в iOS
Наверное на эту тему есть достаточно материалов, в том числе и у Apple, но я опишу свой опыт и приведу свой код.
Задача следующая: для некоторого View, имеющего определенное количество subview в которые можно грузить изображения (UIImageView к примеру), нужно асинхронно загрузить некото... | https://habr.com/ru/post/125510/ | null | ru | null |
# TACACS+ на Linux с аутентификацией через Active Directory
В сети присутствует множество различных гайдов на эту тему, но поднять сервис на Linux и связать его с Active Directory в течении 30-60 минут не удалось. Предлагаю свой путь решения задачи, с подробными комментариями.
Приступим к установке сервиса. В качес... | https://habr.com/ru/post/217669/ | null | ru | null |
# Работа с SQL Server в сценариях гибридного Облака
Гибридное Облако является достаточно привлекательной моделью при внедрении облачных вычислений в информационные системы предприятий, поскольку этот подход сочетает преимущества публичного и частного облака. С одной стороны, достигаются возможности гибкого привлечения... | https://habr.com/ru/post/200168/ | null | ru | null |
# Redis Best Practices, часть 1
В серии из нескольких статей я приведу свой адаптированный перевод раздела [Redis Best Practices](https://redislabs.com/redis-best-practices/) с официального сайта «Redis Labs».
Вторая часть находится ... | https://habr.com/ru/post/485672/ | null | ru | null |
# Создаем рекурсивные ярлыки в Windows
Все мы знаем, что такое ярлык. А что будет, если сделать ссылку ярлыка самого на себя?
Создание ярлыка на ярлык приводит к его копированию. И что будет, если принудительно создать побайтно такой ярлык?
Но, расскажу я не об этом, а о том, как можно создать папку, от вида кот... | https://habr.com/ru/post/152747/ | null | ru | null |
# Рекурсивное сохранение вложенностей с помощью $.Deferred
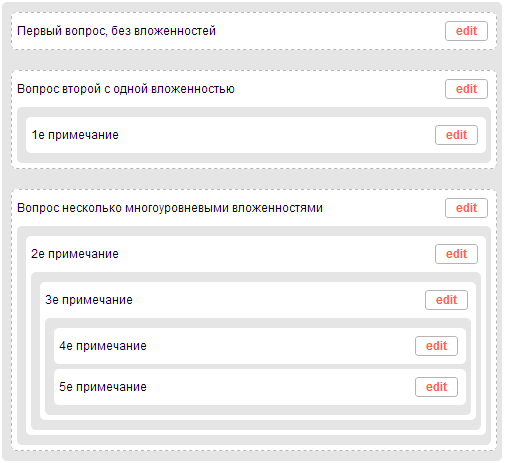
Приветствую хабр, довелось мне недавно писать сервис опросов. В админке этого сервиса была форма с вопросами и вложенными в них примечаниями.... | https://habr.com/ru/post/204456/ | null | ru | null |
# Немного про накрутку счетчиков посещений сайтов
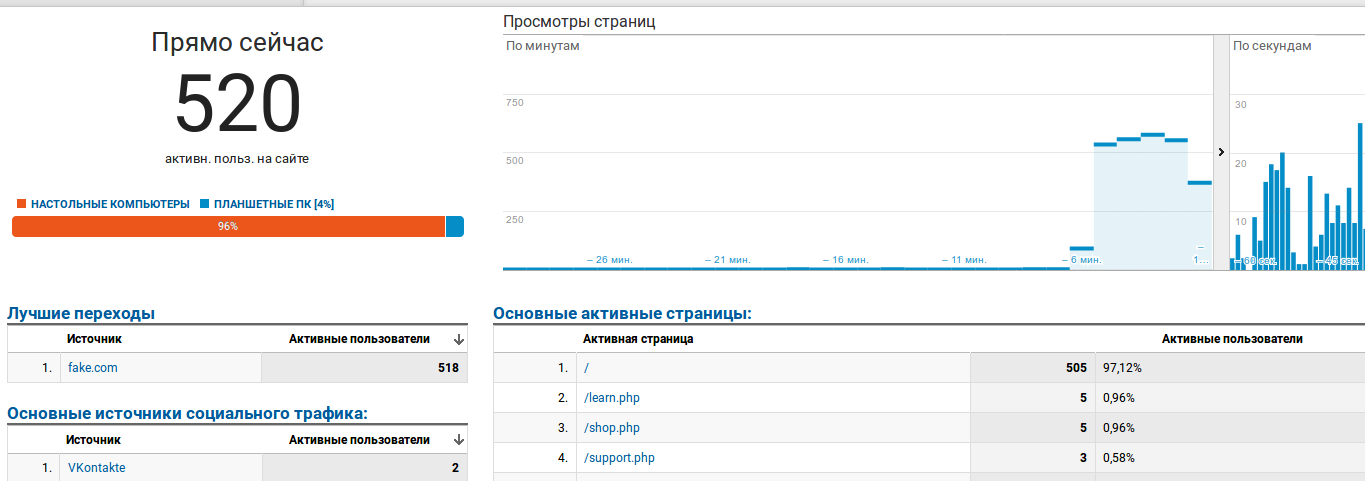
В этой статье я хочу рассказать как накручиваются счетчики посещений на сайтах, подделываются демография, местоположение и другие параметры мониторинговых сервисов.
Как работает... | https://habr.com/ru/post/347712/ | null | ru | null |
# WebRTC CDN на Google Cloud Platform с балансировкой и автоматическим масштабированием
В [предыдущей статье](https://habr.com/ru/company/flashphoner/blog/562788/), мы вспомнили, что такое WebRTC CDN, как эта техноло... | https://habr.com/ru/post/562784/ | null | ru | null |
# Учебник по JavaFX: CSS-стилизация
Это пост о том как стилизовать компоненты JavaFX, используя старый добрый CSS.
Все посты в серии о JavaFX:
1. [Учебник по JavaFX: начало работы](https://habr.com/ru/post/474292/)
2. [Учебник по JavaFX: Hello world!](https://habr.com/ru/post/474498/)
3. [Учебник по JavaFX: FXML... | https://habr.com/ru/post/477924/ | null | ru | null |
# CS Source кратко о создании чита All in One
Добрый день.
Решил поделиться, с Вами, своим небольшим опытом создании чита для Counter-Strike Source v34. Данное приложение было написано исключительно ради спортивного интереса(служит, исключительно, для ознакомления), так как в годы своей юности (изрядно убил времени... | https://habr.com/ru/post/143178/ | null | ru | null |
# Как воспользоваться возможностями R в C++
*R — язык программирования для статистической обработки данных и работы с графикой, а также свободная программная среда вычислений с открытым исходным кодом в рамках проекта GNU © Wikipedia.*
В R собрано огромное число статистических алгоритмов на все случаи жизни и их м... | https://habr.com/ru/post/198012/ | null | ru | null |
# Производительность выгрузки большого количества данных из Mongo в ASP.NET Core Web Api
 Возникла необходимость выгрузки большого количества данных на клиент из базы MongoDB. Данные представляют собой json, с информацией о машине, полу... | https://habr.com/ru/post/343968/ | null | ru | null |
# Реализация бизнес-логики на уровне хранимых функций PostgreSQL
Побудительным мотивом к написанию этюда послужила статья [«В карантин нагрузка выросла в 5 раз, но мы были готовы». Как Lingualeo переехал на PostgreSQL с 23 млн юзеров](https://habr.com/ru/company/lingualeo/blog/515530/). Так же показалось интересной ст... | https://habr.com/ru/post/515628/ | null | ru | null |
# Самоисполняемый phar как способ распространения веб-приложений
Как уже, наверное, всем известно, в PHP 5.3 появилась поддержка специального типа архивов с расширением .phar. Те, кто не в курсе — могут почитать отличную статью [.phar — исполняемые PHP-архивы](http://habrahabr.ru/post/118269/)
Область применения, к... | https://habr.com/ru/post/148773/ | null | ru | null |
# Работа с данными в WinRT. Часть 2. Работа с БД на примере SQLite
В предыдущей [части](http://habrahabr.ru/post/151467/) мы рассматривали как получить доступ к файловому хранилищу приложения. Так как есть прямой доступ к файловому хранилищу, мы можем воспользоваться практически любой встраиваемой БД. На сегодняшний д... | https://habr.com/ru/post/151479/ | null | ru | null |
# Redux Toolkit как средство эффективной Redux-разработки

В настоящее время разработка львиной доли веб-приложений, основанных на фреймворке React, ведется с использованием библиотеки Redux. Данная б... | https://habr.com/ru/post/481288/ | null | ru | null |
# Используем ResourceLoader в MediaWiki
В MediaWiki, начиная с версии 1.17, появился новый механизм сборки и загрузки стилей и скриптов — **ResourceLoader**. В этой статье я опишу его использование на примере расширения [GoogleCodePrettify](http://www.mediawiki.org/wiki/Extension:GoogleCodePrettify), которое добавляет... | https://habr.com/ru/post/130949/ | null | ru | null |
# Google's beacon platform. Часть 1 — Proximity beacon API
[**Google's beacon platform**](https://developers.google.com/beacons/overview) — это решение для работы с Bluetooth маячками. Платформа работает с разными маячками от разных производителей, предоставляя разработчикам единый, простой и гибкий инструмент.
![]... | https://habr.com/ru/post/279381/ | null | ru | null |
# 6 способов: как добавить security для Rest сервиса в Java
В данной статье я попытаюсь описать несколько способов, а точнее 6, как добавить security для rest сервиса на Java.
Перед нашей командой была поставлена задача найти все возможные способы добавить security к rest сервису. Проанализировать все за и против и в... | https://habr.com/ru/post/245415/ | null | ru | null |
# Визуальный граф вызовов: VTune Amplifier и не только
Многим нравится представление структуры программы в виде call graph, «графа вызовов функций». Особенно интересно, если этот граф отражает профиль производительности, наиболее «горячие» ветки кода.
Граф вызовов можно получить с помощью Intel VTune Amplifier XE, ... | https://habr.com/ru/post/259863/ | null | ru | null |
# Реалистичный пейзаж в Ogre 3D
Привет.
Прочитав на хабре [несколько](http://habrahabr.ru/blogs/open_source/86017) [интересных](http://habrahabr.ru/blogs/development/86207) [статей](http://habrahabr.ru/blogs/gdev/120638) об одном из самых мощных рендер-движков [Ogre3D](http://ru.wikipedia.org/wiki/OGRE), я решил по... | https://habr.com/ru/post/128377/ | null | ru | null |
# Подводные камни Java. Часть 1
С какими трудностями встречается начинающий разработчик java?
Хочу представить вашему вниманию небольшую статью. Статья предназначена для начинающих. Но даже если вы опытный разработчик, не делайте поспешных выводов.
Надеюсь данная публикация будет полезна не только начинающим.
... | https://habr.com/ru/post/439642/ | null | ru | null |
# Базовые концепции Unity для программистов
Привет, Хабр! При проработке темы Unity мы нашли интересный [блог](https://blog.eyas.sh), возможно, заслуживающий вашего более пристального внимания. Предлагаем вам перевод статьи о базовых концепциях Unity, также опубликованный на портале Medium
Если вы обладаете опытом ... | https://habr.com/ru/post/529648/ | null | ru | null |
# Objective-C Runtime для Си-шников. Часть 3

Всем привет. Сегодня я продолжу рассказывать вам о внутреннем устройстве Objective-C Runtime, а конкретно — о его реализации на уровне языка C.
В прошлых статьях мы с ва... | https://habr.com/ru/post/251211/ | null | ru | null |
# Глобальные объекты и места их обитания
Глобальные объекты получили широкое распространение из-за удобства их использования. В них хранят настройки, игровые сущности и вообще любые данные, которые могут понадобиться где угодно в коде. Передача же в функцию всех нужных аргументов может раздуть список параметров до оче... | https://habr.com/ru/post/316416/ | null | ru | null |
# Ускоренная разработка с помощью Spring Boot DevTools
Как ускорить разработку на Spring Boot с DevTools и сделать этот процесс более приятным и продуктивным?
### Настройка
Как обычно при разработке на Spring Boot, настройка достаточно проста. Все, что вам нужно сделать, это добавить правильную зависимость, и гото... | https://habr.com/ru/post/479382/ | null | ru | null |
# Делаем нейронную сеть, которая сможет отличить борщ от пельмешек
Как то раз смотря видос про достижения Поднебесной, я увидел прикольную штуку. Столовую будущего, точнее для Китая настоящего, а для нас будущего. Суть заключалась в полном самообслуживание клиента. Он брал блюда на поднос и подносил поднос к видео кам... | https://habr.com/ru/post/519330/ | null | ru | null |
# Как и почему в InnoDB появились индексы на основе В-дерева
Всем хорошо известно, что индексы на основе структуры данных В-дерево помогают нам быстрее читать и находить записи в таблицах. В сети можно найти огромное количество информации по этому поводу, но я постараюсь показать, с какими проблемами нам пришлось бы с... | https://habr.com/ru/post/514596/ | null | ru | null |
# Уязвимость в плагине WP-Slimstat 3.9.5 и ниже для WordPress

Пользователям плагина WP-Slimstat версии 3.9.5 и ниже следует обновиться как можно быстрее! Во время проведения очередного аудита безопасности мы обнаружили ошиб... | https://habr.com/ru/post/251445/ | null | ru | null |
# Работаем с TypeMock Isolator
Для дотнет-разработчика, планирующего юнит-тестирование, редко встает вопрос о том, что подразумевать под этим пресловутым «юнит»-ом: в подавляющем числе случаев, юнит – это кла... | https://habr.com/ru/post/56917/ | null | ru | null |
# Введение в OCaml: Нулевые указатели, утверждения и предупреждения [4]
[прим. пер.: предыдущие части [[1](http://habrahabr.ru/blogs/programming/108529/); [2](http://habrahabr.ru/blogs/programming/108532/); [3](http://habrahabr.ru/blogs/programming/108920/)]
Предыдущие части переводил [amarao](http://amarao.habraha... | https://habr.com/ru/post/118183/ | null | ru | null |
# Prolog. Программируем автоматы
Прочитав [статью](http://habrahabr.ru/blogs/programming/124820/) о Prolog, я решил написать небольшое дополнение к ней в виде 2 небольших задач.
Вот они:
1. Интерпретатор языка brainfuck
2. Машина Тьюринга
Для начала нам требуется [SWI-Prolog](http://www.swi-prolog.org/do... | https://habr.com/ru/post/136670/ | null | ru | null |
# Ускоряем Joomla в 1000 раз
**Целевая аудитория:** программисты, администраторы Joomla и другие пользователи имеющие элементарные навыки работы с PHP.
Joomla — медленная, очень медленная. Joomla «из коробки» редко может выдавать более 4 запросов в секунду. Включим кеш, поставим PHP accelerator, займемся оптимизаци... | https://habr.com/ru/post/92783/ | null | ru | null |
# Аудит Active Directory средствами Powershell с оповещением об изменениях. Часть 2

В [передыдущей](http://habrahabr.ru/post/147750/x) статье я опубликовал свой первый пост на хабре. В продолжении темы соб... | https://habr.com/ru/post/150122/ | null | ru | null |
# Как собирается сайт
В [прошлом посте](http://habrahabr.ru/company/biggo/blog/96847/) мы рассказали о нашем новом конструкторе сайтов.
На этот раз хотелось бы более подробно рассказать о том как работает шаблонная система. Она полностью джанговская, но то, как она построена заслуживает отдельного упоминания. К том... | https://habr.com/ru/post/97026/ | null | ru | null |
# Apple кодирует видео с помощью JPEG, JSON и <canvas>

Фрагмент файла [unlock\_001.jpg](http://www.apple.com/iphone/design/images/unlock/unlock_001.jpg)
Компания Apple имеет огромный опыт в разработке веб-технологий,... | https://habr.com/ru/post/151637/ | null | ru | null |
# Строгая типизация в нестрогих тестах
Уже больше 10 лет \_большая\_ часть моей работы — чистый JavaScript. Но иногда приходится заниматься и чуть более типизированными языками. И каждый раз после такого контакта остается странное чувство «непонятности», почему же в js вот так же сделать нельзя.
Особенно потому, чт... | https://habr.com/ru/post/343720/ | null | ru | null |
# Пишем простой транслятор на Лиспе — III
[Предыдущая статья](https://habr.com/post/421445/)
### Ошибки, Ошибки, Ошибки…
Хорошая программа должна быть защищена от ошибок пользователя. Это совершенно бесспорно. Ошибки нужно обрабатывать, а еще лучше – предупреждать (профилактика всегда лучше лечения!). Высший пилот... | https://habr.com/ru/post/423663/ | null | ru | null |
# По мотивам «трёх интервью о статических анализаторах», или четвертое интервью

Примерно неделю назад на Хабре мною была опубликована статья "[Три интервью о статических анализаторах кода](http://h... | https://habr.com/ru/post/239407/ | null | ru | null |
# Создание системы сцен для игрового движка
Предисловие
-----------
В настоящее время я работаю над собственным игровым движком. С использованием минимального количества сторонних библиотек, после реализации игрового цикла (game loop), отрисовки кадра, функции «update», загрузки текстур и пр., основная «начинка» движ... | https://habr.com/ru/post/272161/ | null | ru | null |
# Elite: Dangerous и CosmosDB

o7 cmdr!
--------
Теплым карантинным вечером, в одном из телеграмных чатиков по Elite: Dangerous разгорелась дискуссия на тему: а у какого типа звезд чаще всего встречаются землеподобные планеты?
Д... | https://habr.com/ru/post/524924/ | null | ru | null |
# memset — сторона тьмы

После прочтения статьи [Самая опасная функция в мире С/С++](http://habrahabr.ru/company/pvs-studio/blog/272243/) я счёл полезным углубиться во зло, таящееся в тёмном погребе *memset*, и написать доп... | https://habr.com/ru/post/272269/ | null | ru | null |
# 15 причин, почему ты всё ещё джун
В каждой приличной IT-компании уделяется достаточно много внимания развитию сотрудников. Проводятся разного рода митапы, тренинги и хакатоны для прокачки хард-скиллов, встречи на тему развития софт-скиллов (на которых сотрудникам объясняют почему панибратство и общение строго матерн... | https://habr.com/ru/post/706122/ | null | ru | null |
# Обертки свойств в Swift с примерами кода
> Перевод статьи подготовлен в рамках онлайн-курса [**"iOS Developer. Professional"**](https://otus.pw/DCPU/). Если вам интересно узнать подробнее о курсе, приходите на [**День открытых дверей**](https://otus.pw/YlpC/) онлайн.
>
>

Началось все с того, что одно из моих веб-приложение перестало корректно работать, после того как я закрепил его на главном ... | https://habr.com/ru/post/148239/ | null | ru | null |
# Мафия на Go, Vanila JS и WebSocket'aх

Речь пойдет о web-реализации популярной карточной игры "[Мафия](https://ru.wikipedia.org/wiki/%D0%9C%D0%B0%D1%84%D0%B8%D1%8F_(%D0%B8%D0%B3%D1%80%D0%B0))". Она писалась для развлечения и получе... | https://habr.com/ru/post/423821/ | null | ru | null |
# Инфраструктура открытых ключей (продолжение): удостоверяющий центр на базе утилиты OpenSSL и SQLite3
Если одним из главных объектов инфраструктуры открытых ключей (ИОК) являются сертификаты X509, то центральным субъектом ИОК явля... | https://habr.com/ru/post/413493/ | null | ru | null |
# Storytelling R отчет против BI, прагматичный подход
Проблематика
============
Когда говорят про отчеты к данным (неважно, какая тема) все хотят гибкие дашборды, МНОГО дашбордов, играют конкурсы про BI, выдумывают разные сложные требования и кейсы, отсматривают массу вендоров и решений, разбиваются на непримиримые л... | https://habr.com/ru/post/556390/ | null | ru | null |
# Forensic resistance 1 или Last-икActivityView. Данные об активности пользователя в Windows 10 и как их удалить
Доброго времени прочтения, уважаемые читатели Хабра.
Побуждением к изысканиям, опубликованным в данной статье, стало набирающее все большую и большую популярность слово «форензика» и желание разобраться ... | https://habr.com/ru/post/424161/ | null | ru | null |
# Layout без layout'ов
Библиотека Swing появилась примерно 15 лет назад и все эти 15 лет КАЖДЫЙ кто начинает программировать на Java задаёт один и тот же вопрос:
— Почему я не могу просто добавить кнопки с полями на форму без изучения всех этих LayoutManager'ов?
В стандарной JRE содержится больше десятка классо... | https://habr.com/ru/post/127339/ | null | ru | null |
# Правильная прозрачность

Однажды мне понадобилось сделать прозрачные боковые поля для одного дизайна. Я решил использовать прозрачность CSS.
Но каково было узнать, что все элементы внутри прозрачного блока тоже становятся прозрачны и это никак не измен... | https://habr.com/ru/post/30565/ | null | ru | null |
# История восстановления базы MySQL из файлов (InnoDB)
Как говорит народная мудрость, “админы делятся на две категории: те, которые делают бэкапы, и те, которые уже делают”. В моем случае ответственность за несделанный бэкап упала на разработчика, то есть на меня самого. Данная статья посвящена тому, как найти выход и... | https://habr.com/ru/post/125358/ | null | ru | null |
# Ставим Ubuntu/Debian через debootstrap из другой Linux-системы
Прошло почти три года с публикации последней и единственной [статьи](http://habrahabr.ru/post/67192/) на хабре про это дело, и с тех пор не... | https://habr.com/ru/post/147522/ | null | ru | null |
# Запуск тестов Siesta из консоли с помощью PhantomJS
Здесь будет рассказано как запустить тесты Siesta из консоли не используя платную (стандартную) версию продукта (которая стоит 499$).
##### Проблема
Дело в том, что бесплатная (лайт) версия инструмента [Siesta](http://www.bryntum.com/products/siesta/) позволяе... | https://habr.com/ru/post/189144/ | null | ru | null |
# Материализованные представления и ReplacingMergeTree в ClickHouse (ч2)
[В первой части](https://habr.com/ru/post/657579/) я прошелся по основным понятиям по работе с материализованным представлением и ReplacingMergeTree в ClickHouse. Разобрал особенности, основные преимущества и недостатки. В этой части я покажу как... | https://habr.com/ru/post/659413/ | null | ru | null |
# Протоколы в Python: утиная типизация по-новому
В новых версиях Python аннотации типов получают всё большую поддержку, всё чаще и чаще используются в библиотеках, фреймворках, и проектах на Python. Помимо дополнительной документированности кода, аннотации типов позволяют таким инструментам, как [mypy](https://mypy.re... | https://habr.com/ru/post/557898/ | null | ru | null |
# Андроид: [DirectoryBind] Простой способ связать внешнюю sd карту и внутреннюю память, чтобы освободить место
Сразу оговорюсь, что речь пойдет не о программах типа link2sd. Принцип похож, но связывать мы будем не программные каталоги, а каталоги данных этих программ, например `/sdcard2/Navigon -> /sdcard/Navigon` или... | https://habr.com/ru/post/169965/ | null | ru | null |
# Манипулирование учетными записями пользователя — шаблоны реализации
 Тема этой публикации вряд ли заинтересует опытного разработчика веб-приложений.
Но для тех, кто впервые сталкивается с необходимо... | https://habr.com/ru/post/239301/ | null | ru | null |
# Переосмысление разметки. Первые шаги с Gantry 5. Часть 2
[В первой части](https://habrahabr.ru/post/325744/) говорилось об основных проблемах с которыми пришлось столкнуться при изучении Gantry 5. Здесь я постараюсь рассказать о вещах на которые стоит обратить внимание перед написанием своего шаблона.
 — мини-JS-библиотеку вывода даты в разных форматах.
Вкратце опишу имеющиеся фичи:
* Выполняет одну и только одну задачу: вывод дат в разных, потребных юзеру форматах;
* Работает в nodejs и в браузерах. В брауз... | https://habr.com/ru/post/149514/ | null | ru | null |
# PHPUnit и его Database Extension. Беглый взгляд
### Пространное и многословное вступление
Уже чуть более года в проекте где я работаю ходят разговоры о модульном тестировании. Помимо разговоров неоднократно делались попытки превратить эти разговоры в жизнь. Все попытки на данный момент закончились тем, что ни один... | https://habr.com/ru/post/61710/ | null | ru | null |
# Пилотажный ДПЛА. Как правильно сделать бочку
Что общего у истребителя с тарой для хранения жидкости и машиной Голдберга? Казалось бы только то, что самолет и бочка могут оказаться частями бесполезного, но завораживающего механизма, ан нет. Фигура пилотажа бочка объединяет все эти вещи и не только.
 в Vim есть множество плагинов и рецептов. Проблема в том, что одни не настраиваются на открытие окон с документацией удобным мне способом, другие не расширяются для поддержки новых источников документации... | https://habr.com/ru/post/136665/ | null | ru | null |
# Новые функции языка, начиная с Java 8 до 16
#### Улучшения языка Java, которые вам следует знать
Последнее обновление **30.03.2021**, включающее изменения до **JDK 16**.
Когда в Java 8 были представлены S... | https://habr.com/ru/post/551492/ | null | ru | null |
# Ты не компилятор
На конференциях часто на стендах раздают подарки. Обычно нужно решить какую-то задачку.
### Невинная головоломка
Некоторые из задач предусматривают решение головоломки с кодом, вроде такой:
> Каким будет результат выполнения следующего кода:
>
>
>
>
> ```
> public class Sum {
>
> ... | https://habr.com/ru/post/336838/ | null | ru | null |
# Наследование таблиц в Postgresql с Ruby On Rails

Что это и зачем нужно?
Предположим у вас есть крупное новостное издание, у которого много разных типов материалов.
Для каждого типа материала существует своя модель: `Topics::Article`, `Topics::O... | https://habr.com/ru/post/282676/ | null | ru | null |
# Клон Trello на Phoenix и React. Части 1-3
[Trello](https://trello.com/) — одно из самых моих любимых приложений. Я пользуюсь им с момента появления, и мне очень нравится то, как оно работает, его простота и гибкость.... | https://habr.com/ru/post/308056/ | null | ru | null |
# NodeJS красивый, модульный, объектный или делаем его таким с помощью redis и nohm
В последнее время в IT-сообществе довольно много шумихи вокруг серверного JavaScript, в частности — NodeJS, однако, как это ни странно, оказалось довольно сложно найти информацию о том, как писать модульный, объектный код. Что я имею в... | https://habr.com/ru/post/188630/ | null | ru | null |
# Как создать кастомный плагин для Dart-анализатора
Привет! Меня зовут Дима, я frontend-разработчик в компании Wrike. В этой статье я расскажу про то, как написать плагин для анализа кода на Dart. Текст будет полезен тем... | https://habr.com/ru/post/541672/ | null | ru | null |
# «Предъявите паспорт» или добавляем поля «должность» и «цветовая схема» в профиль пользователя XWiki
[В прошлой статье про XWiki](https://habr.com/ru/post/551772/) я обещал не затягивать с публикацией новых... | https://habr.com/ru/post/573626/ | null | ru | null |
# Сущности в DDD-стиле с Entity Framework Core
Эта статья о том, как применить принципы Domain-Driven Design (DDD) к классам, отображаемым Entity Framework Core (EF Core) на базу данных, и почему это может быть полезно.
### TLDR
В DDD-подходе есть множество преимуществ, но главное – DDD переносит код операций созд... | https://habr.com/ru/post/432410/ | null | ru | null |
# Использование HTML5 и JavaScript для разработки приложений под Windows Phone
Cегодня я хочу рассказать о том, какие дополнительные возможность разработки приложений под Windows Phone есть у владеющих HTML5 и JavaScript... | https://habr.com/ru/post/136158/ | null | ru | null |
# MarsBoard. Debian. Роутер. HOWTO

Доброго времени суток, сообщество! Я уже [писал](http://habrahabr.ru/post/193390/) по поводу замечательной платы на чипе Allwinner A10 — MarsBoard. Тот пост был чем-то в... | https://habr.com/ru/post/197862/ | null | ru | null |
# Умный дом на основе API Telegram
Как реализовать рабочую IoT систему на API Telegram, создавать устройства, предусмотрев масштабируемость и развитие проекта.
Привет, Хабр! Около года назад я доводил до ум... | https://habr.com/ru/post/655133/ | null | ru | null |
# Как украсть control plane или приготовление EIGRP для Juniper
Как известно, SDN первоначально определялось как возможность физического разделения control и data plane. Хочу показать реализацию этой идеи без openflow и специальных контроллеров. В качестве control plane будет выступать отладочная плата [ODROID-C1](htt... | https://habr.com/ru/post/262047/ | null | ru | null |
# Обновление tzdata для России (системное и java в Ubuntu/Debian, а также в MySQL)
### Предисловие
Как многие помнят, в этом году был принят закон, в связи с которым поменялись часовые пояса в России с 26 октября 2014 г. Само собой, сразу после принятия закона я поставил в календарь напоминалку на начало октября «обя... | https://habr.com/ru/post/240937/ | null | ru | null |
# Открыть нельзя игнорировать
Моя работа связана с тем, что я вру людям и эксплуатирую их доверчивость, любопытство, жадность и так далее. Работу я свою люблю и стараюсь подходить к ней творчески. Специфика моей деятельности связа... | https://habr.com/ru/post/426463/ | null | ru | null |
# Простой слайдер изображений на CSS и Javascript
Автор уже опубликовал скрипт [карусели](https://habr.com/ru/post/467079/), который также использует только CSS и Javascript. Теперь давайте рассмотрим скрипт слайдера. Он отличается от карусели тем, что одновременно виден только один элемент, а не несколько, и элементы... | https://habr.com/ru/post/468253/ | null | ru | null |
# Почему PostgreSQL тормозит: индексы и корреляция данных
"Хочешь ускорить запросы, построй индекс" – классический первый шаг по увеличению производительности в PostgreSQL. Вот только на практике можно встретить ситуацию, когда индексы в PostgreSQL есть, но тормоза никуда не делись. Не все индексы являются эффективным... | https://habr.com/ru/post/564520/ | null | ru | null |
# Использование различных VCS репозиториев в PhpStorm
#### Введение
При развертывании проектов основанных на модульных приложениях (например, Magento) сталкиваешься с тем, что в проекте сосуществует код, находящийся в различных репозиториях. PhpStorm вполне хорошо справляется с подобной ситуацией. Допустим, у нас ест... | https://habr.com/ru/post/246503/ | null | ru | null |
# Портирование API на TypeScript как способ решения проблем
React-фронтенд Execute Program [перевели](https://www.executeprogram.com/blog/porting-a-react-frontend-to-typescript) с JavaScript на TypeScript. А бэкенд, написанный на Ruby, трогать не стали. Однако проблемы, связанные с этим бэкендом, заставили разработчик... | https://habr.com/ru/post/499664/ | null | ru | null |
# Введение в отладку на примере Firefox DevTools, часть 1 из 4
От переводчика.
Я решил переработать [инструкцию, как отлаживать JavaScript в «Firefox DevTools»](https://mozilladevelopers.github.io/playground/debugger), потому что среди знакомых фронтендеров слово DevTools, инструменты разработчика, стало синонимом «C... | https://habr.com/ru/post/586776/ | null | ru | null |
# Демонстрация AresDB: инструмент анализа в реальном времени с открытым исходным кодом на основе GPU от Uber
Благодаря анализу в реальном времени мы, сотрудники компании Uber, получаем представление о состоянии дел и эффективности работы и на основе данных решаем, как повысить качество работы на платформе Uber. Наприм... | https://habr.com/ru/post/440072/ | null | ru | null |
# Разработка веб-приложения для транскрибирования аудиозаписей с использованием Python, Streamlit и AssemblyAI
Автор статьи, перевод которой мы публикуем сегодня, хочет рассказать о том, как, пользуясь Streamlit, создать веб-приложение, которое позволяет пользователям транскрибировать аудиозаписи, выгружая их на специ... | https://habr.com/ru/post/556158/ | null | ru | null |
# Сага опций
[](http://kalevala.onegaborg.eu/)***Чтоб я вновь устроил Сампо,
Сделал короб многострунный,
Вновь пустил на небо месяц,
Солнцу снова дал свободу…
«Калевала»***
Настольные игры... | https://habr.com/ru/post/358870/ | null | ru | null |
# Избавляемся от мусора в Java
> В преддверии старта курса [«**Подготовка к сертификации Oracle Java Programmer (OCAJP)**»](https://otus.pw/XVjm/) подготовили перевод полезного материала. Предлагаем также посмотреть запись демо-занятия [**«Конструкторы и блоки инициализации».**](https://otus.pw/l0kG/)
>
>
 В статье расскажу как достаточно быстро перечислить связные объекты на бинарном растре. Этот алгоритм мы использовали для распознавания изобр... | https://habr.com/ru/post/119461/ | null | ru | null |
# Собственные типы индексов в СУБД Caché
[](http://habrahabr.ru/post/272689/)В объектной и реляционной моделях данных СУБД Caché есть три типа индексов — обычные, [bitmap](http://docs.in... | https://habr.com/ru/post/272689/ | null | ru | null |
# React Code Splitting in 2019
It's 2019! Everybody thinks they know code splitting. So - let's double check!

What does code splitting stand for?
-----------------------------------
In short – code splitting is just about not loadin... | https://habr.com/ru/post/444402/ | null | en | null |
# Beta-Testing of PVS-Studio Plugin for JetBrains CLion

Visual Studio from Microsoft has long been the main development environment to work with the PVS-Studio analyzer. Our analyzer started off on Windows, so Visual Studio was an obv... | https://habr.com/ru/post/565470/ | null | en | null |
# Оттачиваем мастерство работы в консоли
После того, как у меня появился новый монитор на рабочем месте, я начал новую итерацию улучшения своего «безмышечного» (*mouse-less, прим. пер.*) опыта. Вы же знаете, что это значит, не так ли? Это значит, что каждый раз, когда вы беретесь за мышку, убирая руку с клавиатуры, вы... | https://habr.com/ru/post/266933/ | null | ru | null |
# Что нужно знать, если вы хотите вызывать Go функции из ассемблера
> You've run into a really hairy area of asm code.
>
> My first suggestion is not try to call from assembler into Go. — [Ian Lance Taylor](https://groups.google.com/d/msg/golang-nuts/a6NKBbL9fX0/SuMDpME-AgAJ)
До тех пор, пока ваш ассемблерный код... | https://habr.com/ru/post/489482/ | null | ru | null |
# Использование Google Speech API для управления компьютером
Добрый день всем хабражителям.
На хабре уже писалось [несколько статей](http://habrahabr.ru/post/117234/) о использовании Google Speech API, в том числе [о его применении при создании Умного дома](http://habrahabr.ru/blogs/hardware/129936/).
В этой ста... | https://habr.com/ru/post/144535/ | null | ru | null |
# Малоиспользуемые, но от этого не менее прекрасные возможности LESS
Данный пост навеян [коментарием](http://habrahabr.ru/post/233467/#comment_7870847) уважаемого хабраюзера [SerafimArts](http://habrahabr.ru/users/serafimarts/) о том, что LESS много чего не умеет. Хочется развеять эти крамольные заявления и заодно пок... | https://habr.com/ru/post/233653/ | null | ru | null |
# «Магический глаз» тёплых ламповых времён — эмуляция на ардуино
В магнитофонах и приёмниках моей юности использовались исчезнувшие ныне ламповые индикаторы уровня на лампах 6E1П или 6Е5С. Сейчас пришла пора ностальгирования по "старым временам" и на алиэкспрессе или амазоне можно купить собранные индикаторы, они почт... | https://habr.com/ru/post/576582/ | null | ru | null |
# Сквозной функционал через обертки
При разработке мы не редко сталкиваемся с ситуацией, когда при выполнении какой-либо бизнес-логики требуется записать логи, аудиты, разослать оповещения. В общем реализовать некоторый сквозной функционал.
Когда масштабы производства небольшие, можно особо не усердствовать и все э... | https://habr.com/ru/post/511190/ | null | ru | null |
# JSON:API 一 это не JSON API
Я занимаюсь разработкой Ruby с 2011 года. В данный момент я team leader в образовательной онлайн-платформе [UCHi.RU](http://UCHi.RU). Это большая EdTech-компания, которая работает... | https://habr.com/ru/post/699526/ | null | ru | null |
# Занятие на вечер: пишем подсветку синтаксиса
Недавно заинтересовался, как устроена подсветка кода изнутри. Сначала казалось, что там все дико сложно — синтаксическое дерево, рекурсия и вот это все. Однако при более близком рассмотрении оказалось, что ничего трудного здесь нет. Всю работу можно проделать в одном цикл... | https://habr.com/ru/post/482884/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.