
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Star Trek: текстовая игра 1971 года

Когда на хабре составляли список лучших игр всех времён и народов, в комментариях несколько раз [проскальзывала](http://habrahabr.ru/post/171853/#comment_5966111) [мысль](http://habr... | https://habr.com/ru/post/176125/ | null | ru | null |
# Передача сообщений между потоками. Классические блокирующие алгоритмы
Когда-то я вылез из песочницы с совочком в руке и [постом](http://habrahabr.ru/post/209824/) о неблокирующих очередях и передаче данных между потоками. Тот... | https://habr.com/ru/post/211717/ | null | ru | null |
# Разбор базового решения для задачи «Радар тенденций новостных статей» с Цифрового Прорыва
.

Сохранение данных очень важно для по... | https://habr.com/ru/post/435418/ | null | ru | null |
# Основы работы с Helm чартами и темплейтами — Часть 2
В этом руководстве мы кратко обсудим, как Helm может помочь упростить управление приложениями Kubernetes, и узнаем, как использовать Helm для создания базового чарта.
В этом руководстве объясняется, как шаблон Helm `deployment.yaml` преобразуется из шаблона в ман... | https://habr.com/ru/post/548720/ | null | ru | null |
# Современная MVI-архитектура на базе Kotlin

За последние два года Android-разработчики в Badoo прошли длинный тернистый путь от MVP к совершенно иному подходу к архитектуре приложений. Мы с [ANublo](https://habr.com/users/anublo/) ... | https://habr.com/ru/post/429728/ | null | ru | null |
# Impressive Solids: делаем игру на C# под OpenGL, часть I
### Once Upon a Time in America
Когда-то, году в 2002-м, на мой компьютер попала интересная игрушка, так сказать, класса тетриса (подробное описание геймплея приведено ниже); она очень полюбилась моей маме, которая играла в эту игру часами. Однако был досадны... | https://habr.com/ru/post/133983/ | null | ru | null |
# Телепортация игрока в Unity с OpenXR
Продолжим серию статей про OpenXR. В конце концов получим контроллер игрока, обладающий базовыми навыками — перемещением, поворотом и взаимодействием с объектами. Взаимо... | https://habr.com/ru/post/687286/ | null | ru | null |
# Настройка Yubikey для ssh в Windows и WSL
Когда я стал счастливым обладателем устройства Yubikey 5 nfc и узнал, что при помощи него можно авторизовываться по ssh, я столкнулся с множеством статей про настройку подобной связки на unix-системах… И с полнейшим отсутствием адекватного материала про Windows.
Разобравш... | https://habr.com/ru/post/712018/ | null | ru | null |
# interop mode и IVR на Cisco MDS
Позвольте поделиться небольшим опытом в контексте SAN.
##### Дано:
В одной неизвестной организации есть серверная, в которой была внедрена и успешно функционирует SAN сеть. В сети две фабрики, в каждой фабрике было по коммутатору HP AM869A 8/40. Как оказалось, эти коммутаторы пр... | https://habr.com/ru/post/195648/ | null | ru | null |
# Мобильник HTC Desire может сообщать о себе, что он Macintosh — и сообщает…
~~Проснувшись однажды утром после беспокойного сна, Грегор Замза обнаружил, что он у себя в постели превратился в страшное насекомое~~
Сегодня утром я наконец набрёл на мысль зайти на сайт [whatsmyuseragent.com](http://whatsmyuseragent.com... | https://habr.com/ru/post/112775/ | null | ru | null |
# Алгоритмы диапазонов C++20 — 11 модифицирующих операций
[](https://habr.com/ru/company/skillfactory/blog/707948/)
В предыдущей статье серии «Диапазоны» я рассмотрел основы и некоторые немодифицирующие операции. Сегодня пришло время т... | https://habr.com/ru/post/707948/ | null | ru | null |
# Как перенести нейросеть на мобильное устройство
В статье поговорим как обучить несложную CNN сеть с помощью tensorflow, конвертировать готовое с помощью tensoflow-lite и перенести на мобильное устройство под управлением android.
Описывается личный опыт автора, поэтому нет претензий на всеохватывающее руководство.... | https://habr.com/ru/post/570052/ | null | ru | null |
# Использование GtkApplication. Особенности отрисовки librsvg
Аннотация статьи.
* Использование GtkApplication. Каркас приложения. Makefile.
* Отрисовка библиотекой librsvg.
* Экспорт изображения в GtkImage и его масшабирование.
* Масштабирование SVG самописными функциями.
* Получение полного пути в приложениях.
* ... | https://habr.com/ru/post/435564/ | null | ru | null |
# Чертежи в SVG формате. Часть 4. — Черновик стандарта
В "[Чертежи в SVG формате. Часть 3 — Черновик стандарта](http://habrahabr.ru/post/185294/) " приведён пример заштриховывания областей и примеры шаблонов штриховки разных материалов из CAD систем. В продолжении рассмотрим рисование размеров.
**Рисование размеров... | https://habr.com/ru/post/185496/ | null | ru | null |
# Разработка новой ветки продукта: как избавиться от непрактичного и сохранить полезное

Привет, Хабр! Меня зовут Дмитрий, я разработчик в ISPsystem. Недавно мы выпустили в бета-тестирование новую версию панели управления виртуальн... | https://habr.com/ru/post/441968/ | null | ru | null |
# Практические советы, примеры и туннели SSH

Практические примеры [SSH](https://en.wikipedia.org/wiki/Secure_Shell), которые выведут на новый уровень ваши навыки удалённого системного администратора. Команды и советы помогут не то... | https://habr.com/ru/post/435546/ | null | ru | null |
# GitHub Pages переезжают на github.io
Начиная с сегодняшнего дня все сайты GitHub Pages переходят на новый домен: github.io. Это мера безопасности нацеленна на предотвращение CSRF атак на главный сервер — github.com. Если ваш сайт настроен, как «yoursite.com» вместо «yoursite.github.com» — изменения вас никак не затр... | https://habr.com/ru/post/175685/ | null | ru | null |
# JupyterHub, или как управлять сотнями пользователей Python. Лекция Яндекса
Платформа Jupyter позволяет начинающим разработчикам, аналитикам данных и студентам быстрее начать программировать на Python. Предположим, ваша команда растёт — в ней теперь не только программисты, но и менеджеры, аналитики, исследователи. Ра... | https://habr.com/ru/post/353546/ | null | ru | null |
# Преведно-ориентированный язык. Материал из Абсурдопедии.
Я сегодня долго смеялся. Преведно-ориентированный язык. [Материал из Абсурдопедии](http://absurdopedia.wikia.com/wiki/Преведно-ориентированный_язык). Учитесь писать на русско-преведно-ориентированных языках.
 и [№2](http://habrahabr.ru/post/249529/) (про бесплатные SSL сертификаты от китайских друзей [WoSign](https://www.wosign.com) столкнулся с тем, что многие н... | https://habr.com/ru/post/254231/ | null | ru | null |
# Мониторинг системных вызовов Linux

Если вы инженер в организации, использующей Linux в промышленной эксплуатации, у меня к вам два небольших вопроса.
1. Сколько уникальных исходящих TCP-соединений установили ваши сервер... | https://habr.com/ru/post/316902/ | null | ru | null |
# Qmpot — программируемый звуковой редактор
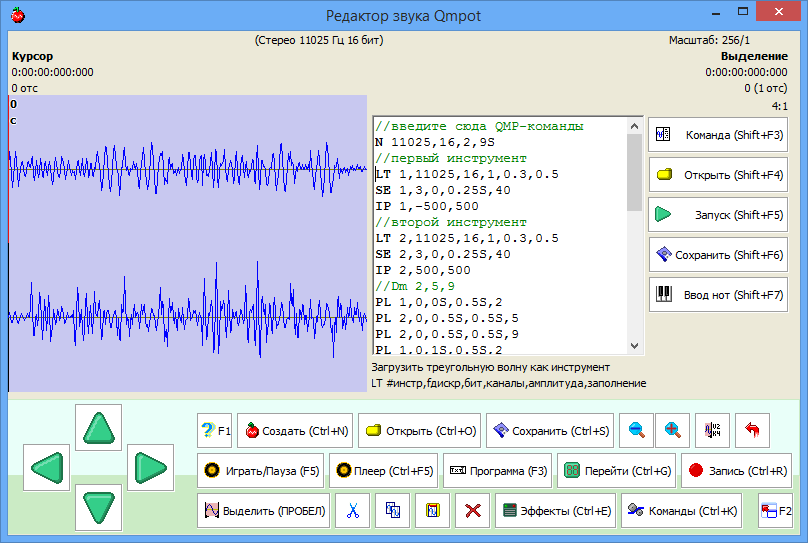
Первым звуковым редактором, который я увидел в своей жизни — был **Фонограф** (sndrec32.exe) в Windows 98. Недолго я игрался с ним, записывал до 1 минуты звука с микрофона (потом ... | https://habr.com/ru/post/247679/ | null | ru | null |
# lerna + CI =? Или как не запутаться в трёх соснах
### Вместо предисловия
Доброго времени суток! Меня зовут Сергей, и я тимлид в компании Медпоинт24-Лаб. Я занимаюсь разработкой на nodejs чуть больше полутора лет - до этого был C#, ну а ещё до того, всякое разное и не очень серьёзно. Ну то есть, опыта у меня не так ... | https://habr.com/ru/post/535944/ | null | ru | null |
# Контравариантный функтор в Scala Cats
В этой статье мы поговорим о функторах. О функторах из библиотеки Cats, а не о классических функторах, которые мы все знаем и любим. Рассмотрим контравариантные функтор... | https://habr.com/ru/post/568096/ | null | ru | null |
# Удобный callback
Надоело каждый раз писать колбеки руками. Написал простенькую скриптину, которая запонимает функцию (функции) с массивом аргументов и контекстом в объекте с методом fire, который не зависит от this, чтобы можно было цеплять колбек не только в «чистом» коде, но и к онклику или таймеру. Набор исполняе... | https://habr.com/ru/post/99636/ | null | ru | null |
# Памятка. AVR. Buzic

### Суть
Я создал уже некоторое количество разных хоббийных электронных устройств, и у меня есть странная особенность: если на плате присутствует звуковой пьезоэлектрический излучатель(buzzer), я, по... | https://habr.com/ru/post/402329/ | null | ru | null |
# Упрощаем работу с Angular с помощью @taiga-ui/cdk: 5 наших лучших практик
CDK — базовый пакет [библиотеки компонентов Taiga UI.](https://github.com/TinkoffCreditSystems/taiga-ui) Он не имеет никакой привязк... | https://habr.com/ru/post/556660/ | null | ru | null |
# Что требуется сделать в языке Java для полноценной поддержки машинного обучения
Здравствуйте, коллеги!
Из последних известий по нашим планируемым новинкам из области ML/DL:
Нишант Шакла, "[Машинное обучение с Tensorflow](https://www.amazon.com/Machine-Learning-TensorFlow-Nishant-Shukla/dp/1617293873/)" — книга... | https://habr.com/ru/post/429596/ | null | ru | null |
# Временные ряды. Простые решения

Привет, Хабр!
В этой статье мы рассмотрим несколько простых подходов прогнозирования временных рядов.
Материал, изложенный в статье, на мой взгляд, хорошо дополняет первую неделю курса «Прик... | https://habr.com/ru/post/553658/ | null | ru | null |
# Осторожнее с итерацией массивов по ссылке
Наткнулся только что на очень не приятную особенность PHP при итерации массивов со ссылкой на элементы (конструкция foreach с &).
Смотрите сами:
```
$test = array('1' => 1, '2' => 2, '3' => 3, '4' => 4, '5' => 5);
print_r($test);
foreach ($test as $key => $value) {... | https://habr.com/ru/post/59299/ | null | ru | null |
# Как писать более чистый CSS и рациональный SASS
Sass заработал репутацию среди разработчиков интерфейсов благодаря переводу сложного CSS в разумный многоразовый код. Это бесспорно важно для масштабирования и поддержки, и позволяет разработчикам устранять недостатки, представленные в традиционном CSS.
Две из наибо... | https://habr.com/ru/post/255981/ | null | ru | null |
# Руководство по Node.js, часть 9: работа с файловой системой
Сегодня, в девятой части перевода руководства по Node.js, мы поговорим о работе с файлами. В частности, речь пойдёт о модулях fs и path — о файловых дескрипторах, о путях к файлам, о получении информации о файлах, об их чтении и записи, о работе с директори... | https://habr.com/ru/post/424969/ | null | ru | null |
# Глобальное освещение с использованием трассировки вокселей конусами
В этой статье я расскажу о реализации одного из алгоритмов расчёта глобального (переотражённого / ambient) освещения, применяемого в некоторых играх и других продуктах, — Voxel Cone Tracing (VCT). Возможно, кто-то читал старенькую [статью](http://re... | https://habr.com/ru/post/353740/ | null | ru | null |
# Математикам доверяй, но проверяй

Я временами бываю озадачен, рассматривая ошибки в очередном программном проекте. Многие из этих ошибок живут в проектах годами. Смотришь на... | https://habr.com/ru/post/217557/ | null | ru | null |
# Как использовать GamePad в браузере и в приложениях для Windows на HTML и JavaScript?
Если вы разрабатываете игры на HTML и JavaScript, то эта статья для вас. Мы уже много писали о том, что под Windows 8.x можно разрабатывать приложения на HTML/JS, причем, как правило, вы можете с легкостью просто взять и использова... | https://habr.com/ru/post/245405/ | null | ru | null |
# Ещё раз о «Mercurial против Git» (с картинками)
Некоторое время назад я опубликовал очень многословное сочинение, где пытался объяснить, почему Git серьёзно поломан, и почему всем следует вместо этого пользоваться Mercurial, до тех пор, пока разработчки Git его не починят. Ну ладно, я был не настолько груб, но близо... | https://habr.com/ru/post/123700/ | null | ru | null |
# Moobile — основанный на MooTools фреймворк для мобильных устройств

Давненько ничего на хабре не слышно новостей о JS фреймворке [MooTools](http://mootools.net). Между тем, он продолжает своё развитие. На данный момент ... | https://habr.com/ru/post/146394/ | null | ru | null |
# How to learn English
One one hand I don't want to be the final authority, but on the other hand, I'd like to share my point of view on how to learn English. The English language is not secret knowledge; it is just a lot of hard training. One of the most important bullets is constantly improving English. You should d... | https://habr.com/ru/post/437928/ | null | en | null |
# Hibernate и PostgreSQL JSON Type
Привет хабр! В этой статье не будет глубокого анализа json типа в PostgreSQL или очередных ~~бесполезных~~ попыток сравнить данную возможность PostgreSQL с NoSQL базами данных типа MongoDB. Я просто расскажу про то, как использовать Hibernate и PostgreSQL json. Думаю кому-нибудь это ... | https://habr.com/ru/post/234841/ | null | ru | null |
# Как упростить пакетную обработку данных со Spring Batch
##### Евгений Тришечкин
Ведущий Java разработчик
***Добрый день! Меня зовут Евгений Тришечкин, я ведущий Java разработчик ростовского офиса компании... | https://habr.com/ru/post/671196/ | null | ru | null |
# Простая Scada на Python и Arduino
В продолжение [статьи](https://habrahabr.ru/post/339678/) о возможности построения собственной scada системы на языке Python, хочу предложить вариант практического применения.
Возникла необходимость контроля температуры воздуха в серверном помещении предприятия.
Такая проблема... | https://habr.com/ru/post/339800/ | null | ru | null |
# Гайд по созданию простого фоторедактора
Сегодня мы предлагаем читателям подробное руководство по созданию простого фоторедактора на iOS. Для опытных разработчиков задача несложная, но новичкам подобный пошаговый разбор всего процесса, возможно, окажется полезен. Речь пойдет о классической среде разработки для выбран... | https://habr.com/ru/post/325352/ | null | ru | null |
# 6 игр за 6 недель — неделя первая
6 ноября я решил выпустить 6 новых игр за 6 недель.

Если Вы еще не выпустили ни одной игрушки в AppStore, то ноябрь, декабрь — самые лучшие месяцы для этого события.
В этом год... | https://habr.com/ru/post/246069/ | null | ru | null |
# DevTips: Советы веб-разработчику (49-64)
Привет, Хабр! В этот прекрасный пятничный день предлагаем вам ознакомиться с очередной частью цикла переводов советов для веб-разработчиков. Предыдущие части: [1-16](http://habrahabr.ru/company/mailru/blog/268519/), [17-32](http://habrahabr.ru/company/mailru/blog/268777/), [3... | https://habr.com/ru/post/278021/ | null | ru | null |
# Пишем на Go простой балансировщик

Балансировщики нагрузки играют в веб-архитектуре ключевую роль. Они позволяют распределять нагрузку по нескольким бэкендам, тем самым улучшая масштабируемость. А поскольку у нас сконфигурировано... | https://habr.com/ru/post/476276/ | null | ru | null |
# Прокачка pointlight теней в Unity

Аналогов подобных теней для точечного источника света (Pointlight с эффектом размытия на расстоянии, имитирующий arealight) в компьютерных играх я почему-то до сих ... | https://habr.com/ru/post/307582/ | null | ru | null |
# Topleaked для анализа утечек памяти
Что делает большинство программистов, когда узнают, что в их программе течёт память? ~~Ничего, пусть пользователь покупает больше оперативы.~~ Посмею предположить, что берут надёжный проверенный в... | https://habr.com/ru/post/516426/ | null | ru | null |
# Введение в Qt Quick3D
*Этот пост участвует в конкурсе [„Умные телефоны за умные посты“](http://habrahabr.ru/company/Nokia/blog/132522/)*
Не так давно фреймворк Qt Quick обзавелся дополнением Qt Quick3D, позволяющим полноценно работать с 3D объектами (поддерживается импорт из 3D Max и Blender), совершать над ними ... | https://habr.com/ru/post/133126/ | null | ru | null |
# Прямая передача файлов между устройствами по WebRTC

Новый сервис [WebWormHole](https://webwormhole.io/) работает как портал, через который файлы передаются с компьютера на другой. Нажимаете кнопку *New Wormhole* — и получаете код ... | https://habr.com/ru/post/500356/ | null | ru | null |
# Основы работы с фьютексами
**Фьютекс** (futex — сокращение от «Fast userspace mutex») — это механизм, предложенный разработчиками Linux из IBM в 2002 году и вошедший в ядро в конце 2003 года. Основной идеей было предоставить более эффективный способ синхронизации пользовательских потоков с минимальным количеством об... | https://habr.com/ru/post/418705/ | null | ru | null |
# Разукрашиваем вывод mysql-client в консоли
Цвет и звук — это те небольшие радости, которые могут разукрасить и облегчить будние администратора при постоянной работе с консолью. Вывод цветовой информации регулируется так называемым escape-последовательностями, определяющими среди прочего цвет текста и цвет фона.
... | https://habr.com/ru/post/151406/ | null | ru | null |
# Поиск недостающих ключей в yaml-файлах
Иногда open source проекты переводятся на множество иностранных языков. С одной стороны это делает их более доступными для широкого круга пользователей, но с другой стороны, все эти переводы нужно поддерживать. Переводы обычно разделены по yaml-файлам и выделены в отдельную дир... | https://habr.com/ru/post/207896/ | null | ru | null |
# Обновление SSL сертификата Let's Encrypt в Zimbra 8
Как многие знают, вчера закончился сертификат Let's Encrypt DST Root CA X3, использовавшийся, в том числе и для почтовых серверов Zimbra.
Я прождал до последнего и столкнулся с несколькими проблемами после его истечения, например перестала отправляться почта из си... | https://habr.com/ru/post/581180/ | null | ru | null |
# Bootstrap 4 вышел в alpha версии
[](http://v4-alpha.getbootstrap.com)
Те кто так или иначе связан с веб разработкой скорее всего знает что такое Bootstrap.
Лично я познакомился с фреймворком Bootstrap версии 2.x и ... | https://habr.com/ru/post/265109/ | null | ru | null |
# Реверс API по его android приложению
### Зачем
У меня есть pet-project, приложение для учета финансов.
На мой взгляд, одной из ключевых проблем подобных приложений является ручной ввод баланса.
У банков есть информация о транзакциях которые я совершаю и даже есть неплохая аналитика.
Но
* Банков несколько и он... | https://habr.com/ru/post/495682/ | null | ru | null |
# Доставка логов с ВМ из systemd в Yandex Cloud Logging
Одна из самых частых и понятных задач в разработке и эксплуатации — доставка логов. И дальше в статье мы с вами используем Fluent Bit для доставки логов... | https://habr.com/ru/post/584718/ | null | ru | null |
# Беспроводная сеть на Dingoo A320
Dingoo A320 уже третий год держит пальму первенства по популярности среди карманных эмуляторов всего-что-только-может-эмулироваться, и неспроста — низкая цена, достойное железо и огромная армия фанатов позволили этой приставке буквально завоевать мир. Но есть один, существенный в XXI... | https://habr.com/ru/post/126881/ | null | ru | null |
# jQuery 1.3
Приятная новость для всех поклонников данного фреймворка. В день рождения библиотеки (которой сегодня исполняется уже три года) команда разработчиков [объявила о выходе новой версии](http://blog.jquery.com/2009/01/14/jquery-13-and-the-jquery-foundation/) — 1.3!
Скачать новую версию фреймворка можно по ... | https://habr.com/ru/post/49115/ | null | ru | null |
# Как в восемь раз уменьшить количество DNS-запросов в Go
Привет, Хабр. Меня зовут Рустам. Я работаю в Ozon: админю Kubernetes и пишу на Go.
У нас очень много сервисов на Go — их количество исчисляется тысяч... | https://habr.com/ru/post/570936/ | null | ru | null |
# Drupal + Git submodules: рецепты
В этой статье будут рассмотрены основные приемы работы с [подмодулями гита](http://git-scm.com/book/ru/%D0%98%D0%BD%D1%81%D1%82%D1%80%D1%83%D0%BC%D0%B5%D0%BD%D1%82%D1%8B-Git-... | https://habr.com/ru/post/164019/ | null | ru | null |
# Основы easygui python. Часть 1
Это статья об основах модуля easygui для языка Python. Рекомендую использовать Python ветки 2-x, так как это позволит совместить табуляцию и пробелы. Конечно же, данный модуль не для написания программ, а в качестве дополнения. Статья написана для самых начинающих, поэтому будет много ... | https://habr.com/ru/post/501286/ | null | ru | null |
# ORM – зло или Как я пытался кэшировать Propel в Symfony
Работая над одним проектом (соц. сетью) передо мной встала задача «подружить» модель данных с memcache. Как Вы уже поняли из заголовка, проект написан на symfony framework, а в качестве ORM используется Propel.
**Зачем кэшировать модель, спросите вы, если мо... | https://habr.com/ru/post/74654/ | null | ru | null |
# Удобное заполнение расписаний с JQuery
*Эта история произошла с Дмитрием Дубовицким — программистом «Бюро Пирогова».*
Однажды случилось мне заниматься одним весьма интересным проектом. По ТЗ нужно было заполнить расписаниие занятий фитнес-клуба в неком XML. В принципе, ничего сложного — прочитал XML, заполнил дан... | https://habr.com/ru/post/94347/ | null | ru | null |
# Парсим URL
Хочу поделиться одной полезной утилиткой, написанной на pure JavaScript, — URL. По сути это небольшой парсер URL'ов, работающий почти как `window.location`, но не перезагружающий страницу браузера при манипуляциях.
А заодно скажу пару слов про getters & setters в JavaScript.
**UPD1:** по просьбам т... | https://habr.com/ru/post/65407/ | null | ru | null |
# Vault+Pydantic: конфигурация с четкой структурой и валидацией

Предисловие
===========
[Продолжение саги. Сразу, на всякий случай](https://habr.com/ru/post/533274/)
В данной статье я расскажу о конфигурации для вашей сервисо... | https://habr.com/ru/post/532032/ | null | ru | null |
# Как мы учили кнопку плавать
Сразу, наверное, стоит предупредить, что мы сделали плавающую кнопку немножко по-своему и собственно до релиза библиотеки, реализующей материальный дизайн как таковой. Но обо всем по порядку.
В нашей концепции ([приложений](https://play.google.com/store/apps/details?id=ru.surf.android.... | https://habr.com/ru/post/245629/ | null | ru | null |
# Динамический контроль доступа: списки свойств ресурсов и классификация файлов
Уже на протяжении трех статей этого цикла мы с вами обсуждаем интересную и относительно новую технологию, которая называется «**... | https://habr.com/ru/post/204212/ | null | ru | null |
# Как разработать микросхему. Собственный процессор (почти)
Как же разработать свою микросхему. Задался я этим вопросом, когда я захотел создать собственный процессор. Пошёл я гуглить и ничего годного не наш... | https://habr.com/ru/post/553356/ | null | ru | null |
# Пишем программу для компьютера ALTAIR 8800 1975г выпуска
Привет, Хабр.
В истории вычислительной техники существуют определенные события, повлиявшие на ход истории. Одним из таких было появление первого массового персонального компьютера.
online редактор контента. Причем я привык пользоваться обычным редактором типа notepad++. Я не сторонник WYSIWYG редакторов, поэтому сделал свой редактор на основе обычного textarea. Какие же преимущества у р... | https://habr.com/ru/post/50281/ | null | ru | null |
# Делаем таблицу с бесконечной прокруткой без event listener
*Что ж оно так лагает-то?*
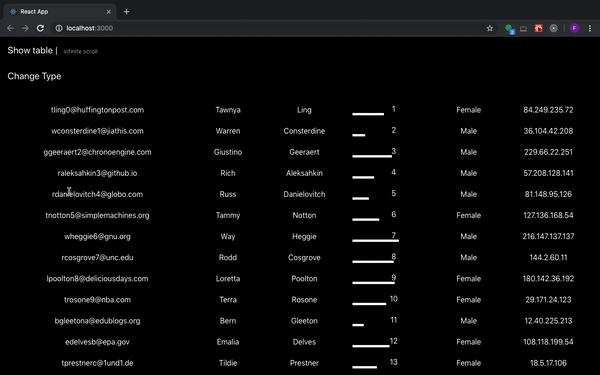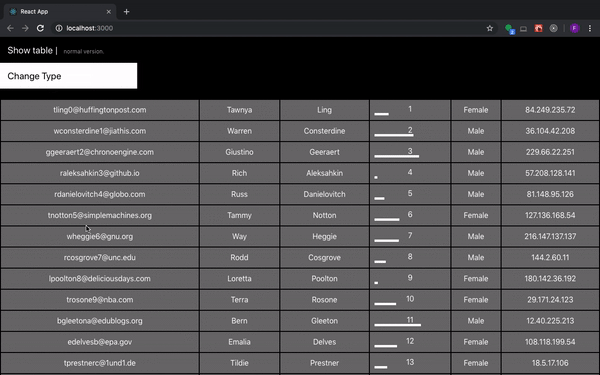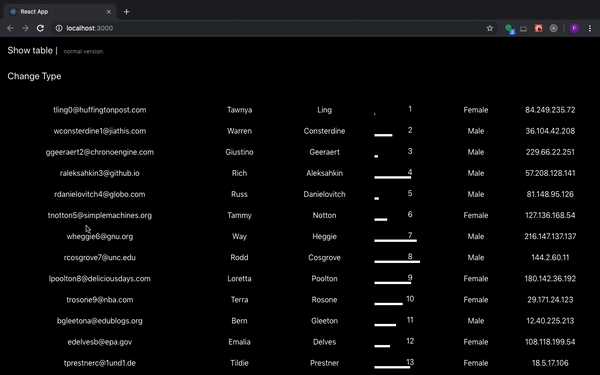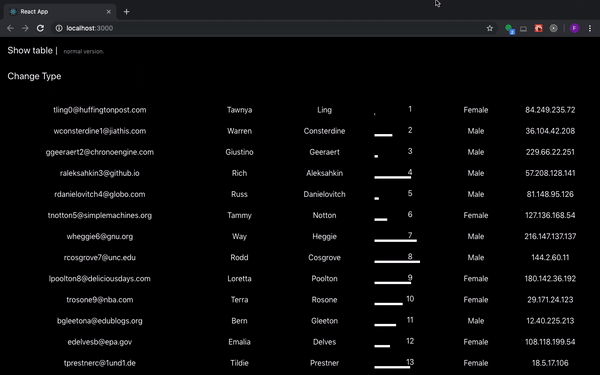
Если при рендеринге огромной таблицы с какой-нибудь transition анимацией не делать ничего дополнительно, то приложение будет... | https://habr.com/ru/post/456046/ | null | ru | null |
# Работаем с Azure IoT устройствами из приложений UWP
[](http://habrahabr.ru/post/303866/)
В продолжение статьи [Отправляем данные с Arduino в Azure IoT Hub](https://habrahabr.ru/post/282912/) я сейчас расскажу о том, как мо... | https://habr.com/ru/post/303866/ | null | ru | null |
# CodingFuture + Puppet. Часть VI: актуальные чёрные списки и защищённый стук

Вкратце:
========
> 1. Защита сервисов и открытие портов по стуку криптографически стойким и не воспроизводимым [Single Packe... | https://habr.com/ru/post/320244/ | null | ru | null |
# Security Week 50: драма вокруг log4j
На прошлой неделе, 9 декабря, были обнародованы детали уязвимости в [Apache log4j](https://logging.apache.org/log4j/2.x/), библиотеке для сбора и обработки логов. Уязвимость [CVE-2021-44228](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2021-44228) приводит к выполнению прои... | https://habr.com/ru/post/595287/ | null | ru | null |
# Платежные технологии – просто о сложном. Часть 2
В [Части 1](https://habr.com/ru/post/582656/) мы разобрали основы проведения платежа. Выяснили, что процесс очень прост и состоит из нескольких участников: Клиента, Витрины, Банка и Мерчанта, а так же двух базовых методов: check и pay.
Теперь поговорим о способе, ко... | https://habr.com/ru/post/588406/ | null | ru | null |
# Реализация 960gs в Drupal (NineSixty theme)
#### О NineSixty
NineSixty это тема для Drupal на основе 960gs, предназначенная для использования в качестве базовой темы.
#### Преимущества NS:
* ко... | https://habr.com/ru/post/80987/ | null | ru | null |
# Разделение вида и контроллера
Что это?
========
Думаю многие из программистов понимают необходимость разделять контроллеры (или, как еще говорят, бизнес-логику) от вида (или логики отображения). Это упрощает поддержку, редизайн и реализацию скинов. Реализаций этого безобразия существует огромное количество и я хоте... | https://habr.com/ru/post/28317/ | null | ru | null |
# Однослойный перцептрон для начинающих
В последнее время всё чаще стали появляться статьи о машинном обучении и о нейронных сетях. «Нейронная сеть написала классическую музыку», «Нейронная сеть распознала стиль по интерьеру», нейронные сети научились очень многому, и на волне возрастющего интереса к этой теме я решил... | https://habr.com/ru/post/265301/ | null | ru | null |
# Использование code style плагина ktlint в Kotlin-проекте. Краткая инструкция для backend-разработчика
Я работаю Java/Kotlin-разработчиком в компании EPAM.
В первой статье я рассказывала про свой проект — [Brain-Up](https://habr.com/ru/company/epam_systems/blog/530824/). В этой статье хочу поделиться опытом настрой... | https://habr.com/ru/post/545040/ | null | ru | null |
# Использование Pinba в Badoo: то, чего вы еще не знаете

Привет, Хабр! Меня зовут Денис, я – PHP-разработчик в Badoo, и сейчас я расскажу, как мы сами используем [Pinba](http://pinba.org). Предполагается, что вы уже знаете, чт... | https://habr.com/ru/post/331866/ | null | ru | null |
# Создание политики паролей в Linux
И снова здравствуйте! Уже завтра начинаются занятия в новой группе курса [«Администратор Linux»](https://otus.pw/IuQz/), в связи с этим публикуем полезную статью по теме.

В прошлом туториале мы... | https://habr.com/ru/post/448996/ | null | ru | null |
# Сетевая недокроссплатформенность
[](http://habrahabr.ru/company/pt/blog/146342/)
Здравствуйте! В этой статье я хотел бы поделиться своим опытом с начинающими разработчиками, которые учатся писать мобильн... | https://habr.com/ru/post/146342/ | null | ru | null |
# Скромное руководство по прохождению интервью: часть 2
Во второй части поста будут рассматриваться **“Алгоритмы и концепции”**, если вы не читали предыдущий пост или хотите “вспомнить” список тем, [то загляните сюда](http://habrahabr.ru/blogs/programming/128665/).
##### Алгоритмы и концепции
###### Сортировка и п... | https://habr.com/ru/post/128730/ | null | ru | null |
# «Dagger-Android & AAC» или «впихнуть невпихиваемое»

Сегодня хотелось бы поговорить о **Dagger 2**, в частности о **dagger-android**, **Android Architecture Components**, а так же о проблеме, с которой я столкнулся при их испо... | https://habr.com/ru/post/350072/ | null | ru | null |
# Пишем свой Google, или асинхронный краулер с rate limits на Python
Привет!
Меня зовут Александр, я руковожу backend-разработкой в [КТS](https://habr.com/ru/company/kts/profile/). Сегодня расскажу, как напи... | https://habr.com/ru/post/583036/ | null | ru | null |
# Применение exception при накате Python-скрипта на Huawei
Обычно мы можем встретить три проблемы при попытке запустить Python-скрипт на сети Huawei (впрочем, и на любой другой): это отсутствие L3 связности с... | https://habr.com/ru/post/655015/ | null | ru | null |
# Spring Security Hello World Java Config
Привет всем!
В этом материале мы постараемся написать приложение защищенное Spring Security с применением Java Config (подхода на основе использования аннотаций и классов для настройки контекста Spring приложения) вместо XML.
#### Используемые Технологии
* Spring 4.0.5 ... | https://habr.com/ru/post/226791/ | null | ru | null |
# Пять перспективных языков программирования со светлым будущим (3 года спустя)

В 2016-м году я опубликовал перевод [статьи про 5 перспективных языков программирования](https://habr.com/ru/post/310252/)... | https://habr.com/ru/post/467207/ | null | ru | null |
# FHRP Nightmare. Ад и кошмар систем отказоустойчивости маршрутизации
Для того, чтобы повысить уровень отказоустойчивости своей сети на уровне маршрутизации, сетевые администраторы в большинстве случаев используют протоколы семейства FHRP. Меня зовут @in9uz, и в рамках данной статьи ты узнаешь какой кошмар может возни... | https://habr.com/ru/post/685072/ | null | ru | null |
# Python и статистический вывод: часть 4
Этот заключительный пост посвящен анализу дисперсии. Предыдущий пост см. [здесь](https://habr.com/ru/post/556852/).
Анализ дисперсии
----------------
*Анализ дисперсии* (варианса), который в специальной литературе также обозначается как ANOVA от англ. ANalysis Of VAriance, — ... | https://habr.com/ru/post/556856/ | null | ru | null |
# # Вышел релиз GitLab 12.10 с управлением требованиями и автоматическим масштабированием CI на AWS Fargate

GitLab 12.10 помогает командам **контролировать и улучшать соотве... | https://habr.com/ru/post/500734/ | null | ru | null |
# Декларативная схема и что с ней не так в Magento 2
Всем привет. Данная публикация не претендует на звание истины в первой инстанции, а лишь является моим личным мнением, если вы его разделяете отлично, если нет — прошу в комментарии для обсуждения.
Так вот, ближе к делу. В версии Magento 2.3 и выше появилась така... | https://habr.com/ru/post/462795/ | null | ru | null |
# Классические алгоритмы и структуры данных на JavaScript
Привет Всем! Я недавно запустил на GitHub проект [JavaScript Algorithms and Data Structures](https://github.com/trekhleb/javascript-algorithms), который содержит примеры классических алгоритмов и структур данных написанных на JavaScript с объяснениями, примерам... | https://habr.com/ru/post/359192/ | null | ru | null |
# Производительность функции unserialize
В PHP есть две замечательные функции serialize и unserialize. Первая преобразует в строку практически любой набор данных, вторая производит обратное преобразование. Эти функции удобно использовать при организации кеширования или хранения сессий в базе данных. Я обнаружил, что в... | https://habr.com/ru/post/104069/ | null | ru | null |
# Рецепты uWSGI: преобразование документов с использованием LibreOffice
Для приготовления преобразования документов нам понадобится [LibreOffice](https://www.libreoffice.org/), [uwsgi-python](http://projects.unbit.it/uwsgi/), [pylokit](https://github.com/xrmx/pylokit) и [webob](https://webob.org/). Можно также восполь... | https://habr.com/ru/post/514220/ | null | ru | null |
# Проблема ООЯП: отсутствует чёткое и обязательное ядро объектно-ориентированного моделирования
Здравствуйте коллеги!
Хотелось бы поделиться мыслями об ООЯП и ООП в целом, а также что можно (и, как мне кажется, нужно) сделать на этой основе.
**Основные идеи:** *В современных ООЯП отсутствует чётко выделенное и обя... | https://habr.com/ru/post/321738/ | null | ru | null |
# Мутационный анализ, или как тестировать тесты
Тестов много не бывает — это все знают. Мемы про unit и интеграционное тестирование уже не очень-то веселят. А мы по-прежнему не знаем, можно ли полагаться на результаты прохождения тестов, и какой процент покрытия позволит не пустить баги в продакшен. Если фатальные изм... | https://habr.com/ru/post/421141/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.