
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Программирование NES (dendy), assembler 6502
У меня с детства была мечта написать игру для любимой приставки денди, шло время, мечта то появлялась то затихала снова. Она меня направляла в сторону магии программирование, и вот прошло больше 20-ти лет я программист, и снова в который раз пытаюсь постигнуть магию той с... | https://habr.com/ru/post/551488/ | null | ru | null |
# [iOS] Создаем кастомный лоадер (спиннер или UIActivityIndicator) в UIKit
Введение
--------
Все мы знаем как выглядит стандартный индикатор загрузки (далее - спиннер или лоадер) на наших iOS устройствах, который отображается при загрузке данных и других кейсах, когда пользователь вынужден ждать окончание какого-либо... | https://habr.com/ru/post/658083/ | null | ru | null |
# Создание и тестирование Firewall в Linux, Часть 1.3. Написание char device. Добавление виртуальной файловой системы…
**Содержание первой части:**
[**1.1** — Создание виртуальной лаборатории (чтобы нам было где работать, я покажу как создать виртуальную сеть на вашем компьютере. Сеть будет состоять из 3х машин Li... | https://habr.com/ru/post/315454/ | null | ru | null |
# Документируем и тестируем REST API с помощью SpringRestDocs
Добрый день, хочу затронуть тему документирования REST API. Сразу же оговорюсь, этот материал будет ориентирован на инженеров работающих в Spring экосистеме.
На нескольких последних проектах я использовал фреймворк SpringRestDocs, он успешно закрепился в... | https://habr.com/ru/post/341636/ | null | ru | null |
# Java/Scala программа, имитирующая анимацию капель дождя
Видео:
Данную заметку, наверное, следует воспринимать больше как отзыв о библиотеке org.fxyz3d, так как сама программа совсем простая.
В [прошлом выпуске "Slicer: нарезка твердотельных объектов под раскрой"](https://habr.com/ru/post/567176/) я упоминал интере... | https://habr.com/ru/post/569230/ | null | ru | null |
# Потоковая передача данных с помощью Apache Spark и MongoDB

MongoDB объявила о выпуске 10.0 версии [коннектора MongoDB для Apache Spark](https://www.mongodb.com/docs/spark-connector/current/). В этой версии используется новый API S... | https://habr.com/ru/post/671104/ | null | ru | null |
# [Перевод] Тепловые карты: Настраиваем геймплей с помощью простой системы сбора и анализа игровых показателей
В [этой статье](http://www.gamasutra.com/view/feature/6155/hot_failure_tuning_gameplay_with_.php), взятой из сентябрьского выпуска 2010 года журнала Game Developer's Magazine, Chris Pruett, работающий в Googl... | https://habr.com/ru/post/115854/ | null | ru | null |
# Игра с открытым API: Swagger Play

В данной статье я хочу рассказать, как использовать Swagger модуль для Play Framework, с примерами из реальной жизни. Я расскажу:
1. Как прикрутить последнюю версию S... | https://habr.com/ru/post/503958/ | null | ru | null |
# Worker Services в .NET
Написание [воркер-сервисов](https://docs.microsoft.com/en-us/dotnet/core/extensions/workers) на .NET часто сопряжено с написанием большого количества повторяющегося boilerplate-кода. Однажды мне это надоело и я попытался упростить этот процесс, перенеся часть бойлерплейта в отдельную библиотек... | https://habr.com/ru/post/587518/ | null | ru | null |
# Как тестировать сайт на Django. Часть 3. Отправка результата на почту, TestExplorer и декоратор tag
Тесты написаны, тимлид рад, а что дальше-то делать? А дальше – автоматизация и отправка отчёта по тестам. Именно об этом мы поговорим в данной статье, попутно затронув полезный инструмент TestExplorer и декоратор tag.... | https://habr.com/ru/post/653933/ | null | ru | null |
# Неблокирующий TCP сервер без использования undocumented features
#### Введение
В замечательной статье с trapexit «Building a Non-blocking TCP server using OTP principles» рассказывается, как построить неблокирующий TCP сервер используя принципы [OTP](http://en.wikipedia.org/wiki/Open_Telecom_Platform). Думаю, кажды... | https://habr.com/ru/post/120815/ | null | ru | null |
# Архитектура приложения моего защищенного чата
В этой статье я хочу описать архитектуру своего приложения. Здесь будут представлен как графический клиент, так и сервер.
Оба приложения написаны на C. Это мой любимый язык и на нем я бы хотел писать код, если смогу когда нибудь устроиться на работу программистом. Попол... | https://habr.com/ru/post/580328/ | null | ru | null |
# Развёртываем инфраструктуру распространения пакетов и обновлений RH-based дистрибутивов в корпоративной сети
[](https://habr.com/ru/company/ruvds/blog/687048/)
Все уже порядком устали от импортозамещения, однако до заветных показ... | https://habr.com/ru/post/687048/ | null | ru | null |
# just2d — создаем «идеальный» игровой движок. Шаг 1
Доброе утро, Хабр.
на досуге посетило меня вдохновение о разработке нового 2d движка для игр. Однако с одной уникальной особенностью. Хочется сделать его реально удобным для разработчиков разного уровня.
Как этого добиться?
Сначала мы придумаем и напишем 2-... | https://habr.com/ru/post/163581/ | null | ru | null |
# mhddfs — Монтирование нескольких разделов в одну директорию
Хочу рассказать о том, как смонтироват в одну директорию два раздела.
Честно говоря, никогда не задумывался о такой возможности, пока не попался клиент с подобным пожеланием. Поначалу мне показалось что это невозможно, но покопавшись в интернете нашел па... | https://habr.com/ru/post/264853/ | null | ru | null |
# Основы Dart Streams
Это вторая часть моей серии по поводу Flutter Architecture:
* [Введение](https://habr.com/ru/post/448776/)
* **Основы Dart Streams (этот пост)**
* [RxDart: магические трансформации потоков](https://habr.com/ru/post/451292/)
* [Основы RxVMS: RxCommand и GetIt](https://habr.com/ru/post/449872/)
* ... | https://habr.com/ru/post/450950/ | null | ru | null |
# Программирование — больше, чем кодинг

Это статья-перевод [Стэнфордского семинара](https://www.youtube.com/watch?v=6QsTfL-uXd8). Но перед ней небольшое вступление. Как образуются зомби? Каждый попадал в ситуацию, когда хочется подт... | https://habr.com/ru/post/454898/ | null | ru | null |
# Проблема UTF-8 Byte Order Mark или кириллица в крякозябах
Столкнулся с проблемой некорректного отображения кириллических шрифтов в браузере, а точнее браузер неправильно определял кодировку. Краткий анализ показал, что данное неудобство проявляется только при включении плагина **ZF debug**. Кинув взгляд на исходный ... | https://habr.com/ru/post/103925/ | null | ru | null |
# Kolab Groupware (Часть 2 — Установка)
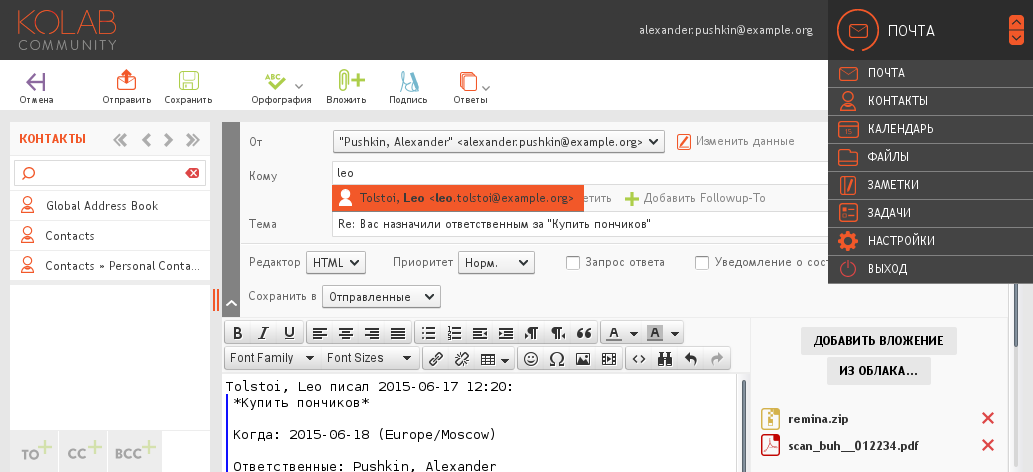
Если вы еще не знаете что такое Kolab, то вы вероятно захотите прочитать [первую статью](http://habrahabr.ru/post/260469/), где я делал подробный обзор на этот довольно функциональный... | https://habr.com/ru/post/260527/ | null | ru | null |
# Усложняем Sci-fi-модели процедурно: что такое Greeble и как его использовать

Для начала позвольте мне пожаловаться, что «greeble» — ужасное слово, которое нужно изгнать из словаря.
Ну, сняв камен... | https://habr.com/ru/post/482316/ | null | ru | null |
# Canvas шаг за шагом: ПОНГ
Сегодня попробуем написать небольшую игру Понг используя html5 тег canvas. Те кто не хочет читать пост тот может сразу [ИГРАТЬ](http://www.html5canvas.ru/2011/04/pong.html).
Если верить [Википедии](http://ru.wikipedia.org/wiki/Pong_(%D0%B8%D0%B3%D1%80%D0%B0)), то можно узнать что **Pong*... | https://habr.com/ru/post/116860/ | null | ru | null |
# Resumable функции
На прошлой неделе в мире С++ произошло интересное событие. Компания Microsoft [объявила](http://herbsutter.com/2013/11/18/visual-c-compiler-november-2013-ctp/) о выходе обновления к компилятору С++ в Visual Studio 2013. Само по себе обновление компилятора отдельно от Visual Studio или её сервис-пак... | https://habr.com/ru/post/203724/ | null | ru | null |
# Песочница в Windows
Песочница — это новый легковесный инструмент в ОС Windows, позволяющий запускать приложения в безопасном изолированном окружении.
Случалось ли Вам оказаться в ситуации, когда необходимо запустить какую-то программу, но Вы не совсем уверены в источнике её происхождения? Или другой пример — необ... | https://habr.com/ru/post/433706/ | null | ru | null |
# Ловим горизонт с Arduino
В комментариях [поста про создание трех-степенной платформы](http://habrahabr.ru/blogs/arduino/126026/) на базе аппаратной платформы Arduino поднимался вопрос управления не только с компьютера, поэтому было решено разобраться с работой акселерометра MMA7260, который можно свободно приобрести... | https://habr.com/ru/post/127165/ | null | ru | null |
# The Implementation of a Custom Domain Name Server by Using С Sockets
### Abstract
We describe the implementation of a custom Domain Name System (DNS) by using C socket programming for network communication, together with SQLite3 database for the storage of Internet Protocol (IP) for Uniform Resource Locator (URL). ... | https://habr.com/ru/post/559884/ | null | en | null |
# Авторизация через Network Policy Server (NPS) для MikroTik
Как быстро и просто настроить авторизацию через RADIUS от Microsoft? Думаю, это поможет тем, кто захочет иметь возможность заходить на устройства MikroTik через дружелюбный WinBox и простой SSH.
#### План:
[Установка роли NPS;](#1)
[Добавление RADIUS ... | https://habr.com/ru/post/343174/ | null | ru | null |
# Go и кэши CPU

*Источник:* [*unsplash.com*](http://unsplash.com/)
По словам Джеки Стюарта, трехкратного чемпиона мира по гонкам Формулы-1, понимание автомобиля помогло ему стать лучшим пилотом: «Гонщику не обязательно быть инжен... | https://habr.com/ru/post/510200/ | null | ru | null |
# Автоматичное отключение пользователей в ISPManager5 lite без BILLmanager
Дано:
1. VPS Сервер с вечной лицензией ispmanager lite 5
2. 10-20 пользователей на сервере
3. Google Calendar с регулярными напоминаниями у кого закончился хостинг
4. Душащая жаба платить за что-либо еще, тем более на подписке
Цель, избави... | https://habr.com/ru/post/514768/ | null | ru | null |
# Вышел PHP 8.1
Спустя год после старта разработки [вышел](https://www.php.net/archive/2021.php#2021-11-25-1) релиз языка программирования PHP 8.1. В версию добавили ряд улучшений.
Изменения в PHP 8.1 включа... | https://habr.com/ru/post/591739/ | null | ru | null |
# Базовая теория столкновения объектов, спрайтов на Javascript
В этой статье я рассмотрю такие приемы как:
* Пересечение габаритов объектов
* Принадлежность точки полигону
И рассмотрим пример реализации механики игры «Астероиды».
#### Пересечение габаритов объектов
Практически любой объект/спрайт можно вписать... | https://habr.com/ru/post/128438/ | null | ru | null |
# Выпуск#6: ITренировка — актуальные вопросы и задачи от ведущих компаний
Пришло время опубликовать следующую подборку задач, которые задают на собеседованиях в ведущих IT-компаниях.

Мы отобрали задачи и вопросы на логику, к... | https://habr.com/ru/post/346424/ | null | ru | null |
# Актуальная статистика доходов от casual игр
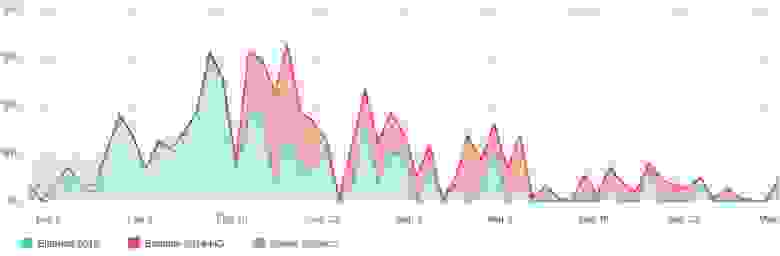
Погода в магазине Apple меняется быстро. Никому не интересны прогнозы за прошлый год. Я рискну рассказать про свой опыт разработки casual игр под iPhone ... | https://habr.com/ru/post/222793/ | null | ru | null |
# Celery: проясняем неочевидные моменты
Содержание статьи:
1. [Обработчики и Брокеры (Workers & Brokers)](https://habr.com/ru/post/686820/#workers-and-brokers)
2. [Очереди (Queues)](https://habr.com/ru/post/686820/#queues)
3. [Задачи (Tasks)](https://habr.com/ru/post/686820/#tasks)
4. [Подтверждение задач (Task Ackn... | https://habr.com/ru/post/686820/ | null | ru | null |
# Тестовое задание для Связного FixedThreadPool на C#. Что здесь не так? UPD
**UPDATE:** Я не мог отказать себе в удовольствии исправить свой ошибочный код. Добавил раздел «Работа над ошибками», в котором привожу исправленный код и описание исправлений, основанное на полученных комментариях.
Это скорее пост-вопрос ... | https://habr.com/ru/post/145551/ | null | ru | null |
# 10 очевидных шагов для подготовки инфраструктуры интернет-магазина к Чёрной пятнице

Несмотря на то, что мы предпочитаем писать про микросервисы, [Kubernetes](https://habrahabr.ru/company/flant/blog/341760/) и прочее из области clo... | https://habr.com/ru/post/342976/ | null | ru | null |
# ¡No PASSarán — менеджер и генератор паролей
На Хабре и Гиктаймсе уже было много написано слов про пароли. В интернете можно встретить много программ и плагинов/аддонов для паролей. Браузеры умеют сохранять пароли. Казалось бы всё уже есть. Но нет, мне не хватало своего велосипеда, потому что все старые велосипеды им... | https://habr.com/ru/post/357172/ | null | ru | null |
# Программируем микроконтроллеры ESP32 и STM32 на C# (nanoFramework)

[.NET nanoFramework](https://nanoframework.net/) — это бесплатная платформа с открытым исходным кодом, основанная на .NET и предназначена для м... | https://habr.com/ru/post/584144/ | null | ru | null |
# Термостат на ThingJS (beta)

Почти год назад я [представил](https://habr.com/ru/post/474356) свой pet-проект — IoT платформу ThingJS. Честно сказать, я не достиг всех целей, которые ставил перед собой публикуя ту статью. Но работа ок... | https://habr.com/ru/post/521174/ | null | ru | null |
# Лечим 100%-широкий textarea, попавший под padding в IE (на Хабре тоже)
Столкнулся в очередной раз с проблемой, возникающей при попытке задать 100%-ю ширину элементу, расположенному в блоках, которые имеют ненулевые padding-и или margin-ы. В случае с textarea получается следующее: при первом отображении ширина устана... | https://habr.com/ru/post/22764/ | null | ru | null |
# Импорт и экспорт данных в PostgreSQL, гайд для начинающих
В процессе обучения аналитике данных у человека неизбежно возникает вопрос о миграции данных из одной среды в другую. Поскольку одним из необходимых навыков для аналитика данных является знание SQL, а одной из наиболее популярных СУБД является PostgreSQL, пре... | https://habr.com/ru/post/658153/ | null | ru | null |
# Зависимости JavaScript: Все, что вы когда-либо хотели знать, но боялись спросить
Ваше подробное руководство по пяти типам зависимости
----------------------------------------------------
> *Привет, хабровчане. Для будущих учащихся на курсе* [*"JavaScript Developer. Professional"*](https://otus.pw/Crj1/) *подготовил... | https://habr.com/ru/post/545008/ | null | ru | null |
# Группируем одинаковые приложения из разных магазинов по иконке
Однажды случилось мне несчастье обратить свой взор на одну заманчивую вакансию. Все бы ничего, но, как обычно, подкинули тестовое задание. Если кратко, то нужно было сгруппировать ссылки на одно и тоже приложение в разных маркетах. По ссылкам были такие ... | https://habr.com/ru/post/266749/ | null | ru | null |
# Разделяй и властвуй: как мы реализовывали разделение сессий на портале Mail.Ru
[](http://habrahabr.ru/company/mailru/blog/228997/)
Mail.Ru — огромный портал, существующий более 15-ти лет. За это время мы прошли путь от не... | https://habr.com/ru/post/228997/ | null | ru | null |
# Собираем Flutter приложение для десктопа
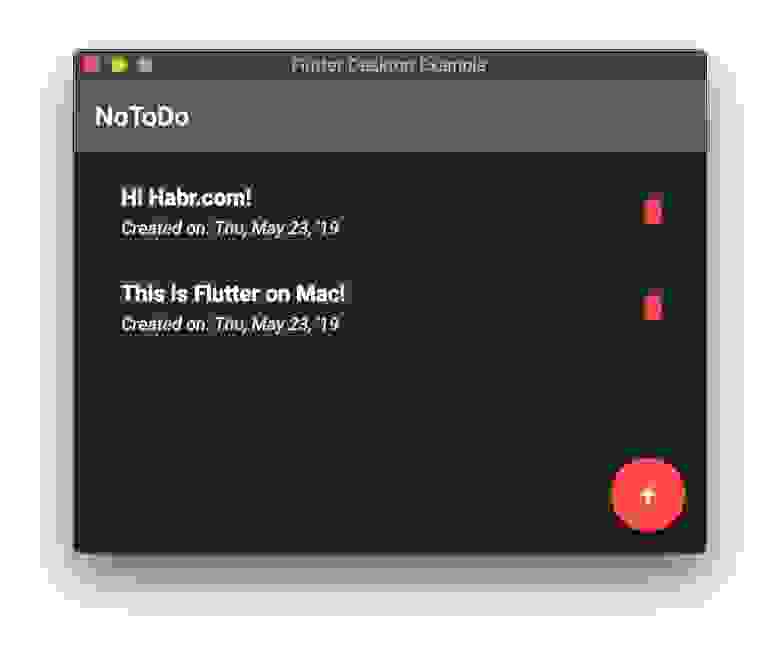
Всем привет!
Сегодня я покажу вам, как же запустить ваше существующие Flutter приложение на десктопе (MacOS, Linux или Windows).
Во-первых, вам прийдется ... | https://habr.com/ru/post/453092/ | null | ru | null |
# Зомби, которые съедают вашу память
Что бы вы там себе не думали, а зомби существуют. И они действительно едят мозги. Не человеческие, правда, а компьютерные. Я говорю сейчас о зомби-процессах и потребляемых ими ресурсах. Это будет душераздирающая история о потерянных и снова найденных 32 ГБ оперативной памяти. Возмо... | https://habr.com/ru/post/349924/ | null | ru | null |
# PHP 8: код «До» и «После» (сравнение с PHP 7.4)

Осталось всего несколько месяцев до выхода PHP 8, и в этой версии действительно есть много хорошего. Под катом расскажем, как эти нововведения уже начали менять подход автора этого... | https://habr.com/ru/post/514512/ | null | ru | null |
# Аналитическое вычисление производной функции на языке Scala
Введение
--------
Данный алгоритм реализован на языке Scala, характерной особенностью которого является использование *case-классов*, так удачно подходящих для написания алгоритма дифференцирования. В этой статье планируется описать лишь часть программы, с... | https://habr.com/ru/post/309676/ | null | ru | null |
# Разбираем в деталях: Технология единого входа (SSO) в Kubernetes с использованием OpenID Connection через G Suite
В настоящее время Kubernetes де-факто является стандартом для оркестрации контейнеров, и лично я использую Kubernetes в production уже более двух лет.
Будучи DevOps инженерами, мы тесно сотрудничаем с р... | https://habr.com/ru/post/565170/ | null | ru | null |
# MOXA Nport — взгляд изнутри
Серверы сбора данных по последовательным портам MOXA Nport и им подобные — в настоящее время являются стандартом де факто в области построения систем передающих или принимающих данные через интерфейсы RS-232,RS-485 и RS-422.
Счетчики электроэнергии, управляемые вентили и задвижки, расх... | https://habr.com/ru/post/478642/ | null | ru | null |
# Лучше в райнтайме, чем никогда: расширяем API JIRA «на лету»
Что делать, если имеющегося в приложении API для решения задачи недостаточно, а возможности оперативно провести изменения в код нет?

Последней надеждой в эт... | https://habr.com/ru/post/316124/ | null | ru | null |
# Построение сервис-ориентированной архитектуры на Rails + Kafka
Привет, Хабр! Представляю вашему вниманию пост, который является текстовой адаптацией выступления [Stella Cotton на RailsConf 2018](https://www.youtube.com/watch?v=Rzl4O1oaVy8) и переводом статьи [«Building a Service-oriented Architecture with Rails and ... | https://habr.com/ru/post/450028/ | null | ru | null |
# Побег из Крипто Про. Режиссерская версия, СМЭВ-edition
Эта статья посвящена тому, как перестать использовать Крипто Про и перейти на Bouncy Castle в девелоперском/тестовом окружении.
В начале статьи будет больше про СМЭВ и его клиент, в конце — больше про конвертирование ключей с готовой копипастой, чтобы можно б... | https://habr.com/ru/post/282225/ | null | ru | null |
# Делаем действительно умный поиск: пошаговый гайд
*Поиск в корпоративной информационной системе* — уже от самой этой фразы вязнет во рту. Хорошо если он вообще есть, о положительном user experience можно даже не задумываться. Как перевернуть отношение пользователей, избалованных поисковыми системами, и создать быстры... | https://habr.com/ru/post/460263/ | null | ru | null |
# Еще один способ увидеть коммуникации приложений
Добрый день, коллеги. Как известно, есть очень полезная утилита — [sysmon](https://docs.microsoft.com/en-us/sysinternals/downloads/sysmon). В двух словах, она позволяет вам собирать и "логировать" события, происходяшие в Windows. Одним из таких событий является попытка... | https://habr.com/ru/post/425375/ | null | ru | null |
# Nix: воспроизводимая сборка
Привет, Хаброюзеры!
Сегодня мы продолжим наш цикл статей о Nix и как мы в Typeable его используем.
Первый пост из серии, рассказывающий об основах языка Nix, можно прочитать [здесь](https://habr.com/r... | https://habr.com/ru/post/556828/ | null | ru | null |
# Программирование на телефоне используя эмулятор терминала Termux
Приветствую читателей! В этой статье я расскажу о том, как можно, имея android телефон, писать программы. Говорю сразу — root права не нужны.
### Что нам понадобится?
Первое, что нам понадобится — андроид телефон со установленным на него приложени... | https://habr.com/ru/post/343760/ | null | ru | null |
# Blackrota, сильно обфусцированный backdoor, написанный на Go
*Самый обфусцированный ELF вредонос на Go, который мы встречали на сегодняшний день.*
### Предисловие
Недавно вредоносный бэкдор, написанный на Go, который эксплуатировал уязвимость несанкционированного доступа в Docker Remote API, был пойман на Honeypot... | https://habr.com/ru/post/535228/ | null | ru | null |
# Об ошибках в коде QuantConnect Lean

В данной статье рассматриваются ошибки в проекте с открытым исходным кодом, найденные с помощью статического анализатора. Говорится о некоторых простых вещах... | https://habr.com/ru/post/533304/ | null | ru | null |
# Заметки о ProgressDialog или как правильно показать прогресс выполнения
Здравствуйте!
В данном посте я хочу поговорить о таком элементе UI Android как **ProgressDialog** и вообще о теме отображения прогресса в приложении, воз... | https://habr.com/ru/post/119023/ | null | ru | null |
# Самопаркующаяся тачка в 500 строк кода
> С помощью генетического алгоритма натренируем тачку парковаться самостоятельно.
>
>
### Вкратце
В этой статье мы "научим" автомобиль выполнять самостоятельную ... | https://habr.com/ru/post/580812/ | null | ru | null |
# Objective-C как первый язык программирования
Данный пост был задуман после того, как на некоторые важные вопросы не было найдено внятных ответов. Я отнюдь не претендую на то, что стал крутым программистом. Нет, всё ещё впереди, но период высиживания уже пройден. Это статья из цикла «Не умеешь сам — научи другого». В... | https://habr.com/ru/post/167981/ | null | ru | null |
# PowerShell для ИТ-безопасности. Часть IV: платформа безопасности с использованием скриптов

В [предыдущей заметке](https://habrahabr.ru/company/varonis/blog/338166/) этой серии я предложил возможность объединения моих отдельных скрипт... | https://habr.com/ru/post/338848/ | null | ru | null |
# Сравнение эффективности поиска: Elasticsearch и конкуренты
В области поисковых систем с открытым исходным кодом появилось несколько новых интересных игроков. Мы решили внимательно изучить некоторые из них, чтобы узнать, насколько они сравнимы с Elasticsearch - как по набору функций, так и по производительности.
Кан... | https://habr.com/ru/post/581394/ | null | ru | null |
# C++14 для Qt программистов
В этой статье описывается каким образом изменения, принесенные стандартом С++14, отразились или могут отразиться на разработке Qt приложений. Данная статья ориентирована не только на Qt программистов, но также на всех тех, кому интересно развитие С++. Автор оригинала — Olivier Goffart, явл... | https://habr.com/ru/post/243981/ | null | ru | null |
# Perl 6 и Rakudo: заметки от 2009 года
*Серия статей о Perl 6 и Rakudo – одном из компиляторов, поддерживающих спецификацию Perl6. Эта статья собрана из заметок от 2009 года.*
#### Устанавливаем Rakudo
В данный момент существует несколько неполных реализаций Perl 6. Самая полная из них – это компилятор [Rakudo](h... | https://habr.com/ru/post/248713/ | null | ru | null |
# Callback или «Повышаем лояльность клиентов»
Имеется asterisk, группа операторов (3-5 человек) с большой нагрузкой (среднее время ожидания > 2 минут)
Задача — для абонентов с определенной географией дать возможность не ждать пока оператор освободится, а нажав 0 услышать «Спасибо за звонок. Мы Вам обязательно перез... | https://habr.com/ru/post/471500/ | null | ru | null |
# Руководство по Discovery.js: быстрый старт
Это и последующие руководства проведут вас через процесс создания решения на основе проекта [Discovery.js](https://github.com/discoveryjs). Наша цель — создать инспектор NPM-зависимостей, то есть интерфейс для исследования структуры `node_modules`.
Вначале отвечу на вопрос «Зачем их дружить». Ответ прост — WPF хорош для пользовательских интерфейсов, XNA для сложной 3D графики и если вы делаете клиентское приложение со сложным интерфейсом и 3D элементами в нем, то св... | https://habr.com/ru/post/101165/ | null | ru | null |
# Частые ошибки программирования на Bash (продолжение)
Продолжаю знакомить сообщество с переводом [Bash Pitfalls](http://wooledge.org:8000/BashPitfalls).
[Часть первая](http://habrahabr.ru/blogs/shells/47706/).
[Первоначальная публикация перевода](http://bappoy.pp.ru/tag/bash-pitfalls).
### 11. cat file | se... | https://habr.com/ru/post/47915/ | null | ru | null |
# Как мы делаем курсы по вёрстке. Опыт из первых рук
Скоро стартует 32 поток нашего курса-долгожителя про профессиональную вёрстку сайтов. Кто-то из читателей запомнил его как «Базовый HTML и CSS» или даже как «Разработку веб-интерфейсов с помощью HTML и CSS».
32 поток — знаковый для нас, и к его началу мы подготови... | https://habr.com/ru/post/577800/ | null | ru | null |
# FAISS: Быстрый поиск лиц и клонов на многомиллионных данных

Однажды в преддверии клиентской конференции, которую [ежегодно проводит](https://dansessions.ru/archive) группа DAN, мы размышляли над тем, что интересного можно придум... | https://habr.com/ru/post/509204/ | null | ru | null |
# Создания Windows Runtime компонента на Visual C++
Тернистая дорога через дебри C# и заросли C++/CX разработки для Windows Runtime в какой-то момент привела меня к библиотеке шаблонов WRL, облегчающей написание приложений и компонентов WinRT и COM. При работе именно с этой библиотекой мне захотелось узнать, что же мо... | https://habr.com/ru/post/252759/ | null | ru | null |
# Добавление пакетов к автономному установщику Lubuntu Alternate ISO
Введение
========
При создании автономных установочных носителей для автоматизированной установки ОС Lubuntu 14.04 с использованием [preseed](https://wiki.debian.org/DebianInstaller/Preseed), я столкнулся с тем, что мне нужно добавить на установочны... | https://habr.com/ru/post/273255/ | null | ru | null |
# Как добавить список лицензий и благодарностей CocoaPods и при чём тут Settings.Bundle?
, рекомендованной в [этом](http://habrahabr.ru/blogs/python/84235/) топике. Если мое начинание будет поддержано, планирую также перевести две остальные упомянутые та... | https://habr.com/ru/post/84330/ | null | ru | null |
# Dropbox на macOS использует приёмы malware, чтобы получить привилегии, которые ему не нужны
Если у вас установлен Dropbox, загляните в `Системные настройки` → `Защита и безопасность` → `Конфиденциальность`.
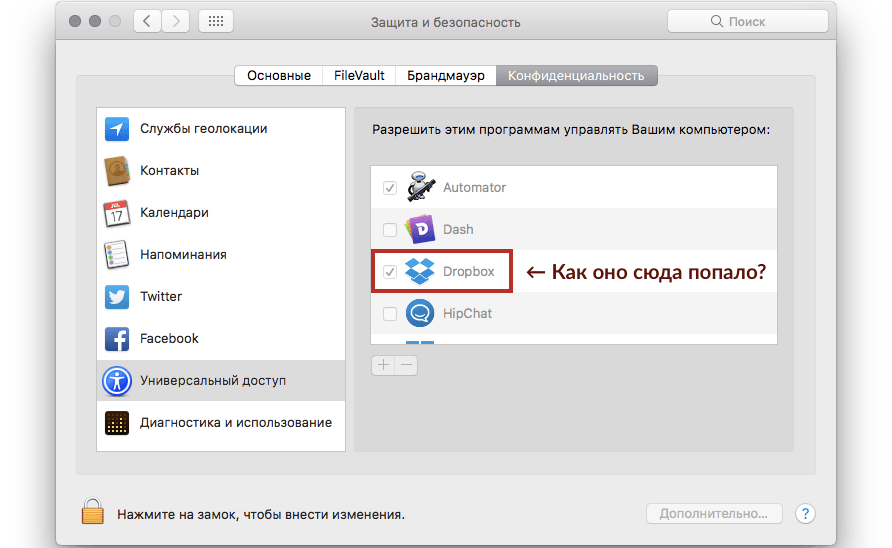
TL;DR: Dropb... | https://habr.com/ru/post/310074/ | null | ru | null |
# Используем backbone.js под node.js
Приветствую, уважаемые читатели Хабрахабра. Хочу поделиться с вами своим опытом использования [backbone.js](http://backbonejs.org) под [node.js](http://nodejs.org). Ранее я активно поработал с backbone.js на клиенте, и эта библиотека оказалась крайне удобной для структурирования ко... | https://habr.com/ru/post/158569/ | null | ru | null |
# Удобый просмотр MAC адресов на портах свитчей huawei, linksys, dlink, extreme при помощи expect
Каждый день взаимодействуя с тех.поддержкой приходится лазить на свитчи и глядеть маки.В принципе ничего сложного, но хотелось как то упросить себе работу.
Освоил expect и сразу в бой. Написал, опробовал, получилось. Т... | https://habr.com/ru/post/271867/ | null | ru | null |
# Динамическое подключение внешних собственных модулей и плагинов в Gradle
### Преамбула
Есть своя «внешняя» библиотека и есть своё приложение, использующее эту библиотеку (подгружается через внешний репозитарий). Требуется внести изменение и в библиотеку и в приложение.
Казалось бы, собери библиотеку и выложи её ... | https://habr.com/ru/post/330162/ | null | ru | null |
# Предсказание стоимости биткоина по новостям на Python
***Перевод статьи подготовлен в преддверии старта курса [«Machine Learning»](https://otus.pw/pHAO/) от OTUS.***

---
### Задача
В этом руководстве мы используем датасет *[... | https://habr.com/ru/post/488912/ | null | ru | null |
# Caché + Java + Flex, или как мы делали систему управления учебным планированием
В этой серии статей мы постараемся подробно рассмотреть основные аспекты использования данной связки. Мы применили этот комбайн для реализации одной из подзадач проекта по разработке интеллектуальной системы автоматизированного управлени... | https://habr.com/ru/post/149704/ | null | ru | null |
# Я два года выпускаю крошечные проекты
Два года назад, утомлённый длинным списком нереализованных идей проектов в телефоне, я решил попробовать осуществлять по идее за неделю в их минимальном виде.
Мне так и не удалось придерж... | https://habr.com/ru/post/666654/ | null | ru | null |
# Что такое Linux? Статья-шпаргалка для новичков
### Что такое Linux?
Салют! Это статья — попытка систематизировать некие базовые знания об Linux’ах, которая может быть полезна для продвинутых пользователей, разработчиков и админов Windows, которые еще не имели (или имели крайне небольшой и отрывочный) опыт работы с ... | https://habr.com/ru/post/668344/ | null | ru | null |
# Анализ аудиоданных (часть 3)
### Машинное обучение
В третьей части анализа аудиоданных мы разберем относительно простой и более быстрый способ классификации аудиофайлов - алгоритм машинного обучения - SVM (Support Vector Machines) / машины опорных векторов.
В двух частях анализа аудиоданных мы рассмотрели характер... | https://habr.com/ru/post/672094/ | null | ru | null |
# Неудобства при работе с переводами в Qt и способы борьбы с ними
В этой статье я хотел бы рассказать о некоторых неудобствах, с которыми столкнулся при работе с системой переводов в Qt, а также поделиться способами борьбы с этими неудобствами.
Для начала кратко напомню о том, как работает система переводов в Qt. ... | https://habr.com/ru/post/247207/ | null | ru | null |
# Год, проведённый с React: выводы и рекомендации
Обычно начало работы с новой технологией — это не так уж и просто. Новичок попадает в бескрайнее море учебных руководств и статей. При этом за каждым из подобных материалов стоит личное мнение его автора, а каждый автор заявляет, что именно его устами глаголет истина. ... | https://habr.com/ru/post/413501/ | null | ru | null |
# Архитектура и программирование Fairchild Channel F
*«Channel F homebrew would be like programming sprites via hardware jumpers...»
/ chadtower, atariage forum /*

Игровая приставка [Fairchild Channel F](https://en.wikipedia... | https://habr.com/ru/post/467811/ | null | ru | null |
# Применение инструментов IaC в облаке

Привет, Хабр! Я Алексей Волков, менеджер продукта компании [VK Cloud Solutions](https://mcs.mail.ru/). Хочу рассказать о подходе IaC (Infrastructure as Code, инфраструктура как код), который по... | https://habr.com/ru/post/674842/ | null | ru | null |
# What the flask?
*Вообще-то, это картинка от wtforms, но у меня гимп почему-то не запускается.*
Эту статью я пишу в баре. Очень хочется похоливарить, но бармен на меня смотрит круглыми глазами, а кальянщик просто улыб... | https://habr.com/ru/post/320360/ | null | ru | null |
# Разбираемся с Opaque Return Types в Swift
> *Привет, Хабр. В рамках стартующего в феврале* [*курса «iOS Developer. Professional»*](https://otus.pw/98B1/) *подготовили для вас перевод полезного материала.
>
> Также предлагаем принять участие в* [*открытом вебинаре на тему «Пишем приложение на SwiftUI и Combine»*... | https://habr.com/ru/post/542080/ | null | ru | null |
# Контроль целостности кода функций
В процессе разработки многокомпонентной системы автоматизированного тестирования сканера безопасности мы столкнулись с проблемой контроля целостности кода отдельных тестовых функций и проведения ревизий.
Число написанных функциональных тестов, которые запускает система, уже превы... | https://habr.com/ru/post/177189/ | null | ru | null |
# Сборка transport-пакета без установки MODX

Писать свои пакеты для MODX не просто для новичка, да и опытному разработчику иногда не сладко приходится. Но новичок пугается, а опытный разбирается :).
Эта заметка рассказывает о т... | https://habr.com/ru/post/439420/ | null | ru | null |
# APRX клиент в радиолюбительскую APRS на базе D-Link Dir-620
Приветствую всех! Отдельная благодарность тем, кто попросил меня осветить этот [вопрос](http://habrahabr.ru/qa/18735/).
Планирую сделать несколько статей, посвященных **APRS**, в котором рассмотрим:
1) Установку стационарных клиентов (а возможно даж... | https://habr.com/ru/post/142900/ | null | ru | null |
# Как мы распознаем фото документов пользователей. Часть I
Привет, Хабр! Я Илья, Data Scientist в inDriver. В работе нам часто приходится распознавать документы водителей или пассажиров для их верификации в приложении. Наша команда выработала свой подход к идентификации текста и фото, которым я хотел бы поделиться.
... | https://habr.com/ru/post/594357/ | null | ru | null |
# Тетрис на C# в 100 строк
UPD. [Ссылка](https://github.com/Limpich/tetris) на github.
Недавно мне в голову пришла идея — написать простенькую игру в минимальное количество строк. Мой выбор пал на тетрис. В этой статье я опишу свой код.
Для начала стоит отметить, что в свою реализацию я включил только базовые во... | https://habr.com/ru/post/433908/ | null | ru | null |
# Как я делал приложение для вКонтакте
Давно хотелось создать продукт, который был бы полезен людям. Сам я флешер. Давно пользуюсь социальной сетью вКонтакте. Желание усилили приложения в Контакте, которые, как правило, носили развлекательный характер. Тогда и родилась идея создать «Гармоничную пару», приложение, кото... | https://habr.com/ru/post/63930/ | null | ru | null |
# Руководство по Git. Часть №2: золотое правило и другие основы rebase
Посмотрим, что происходит, когда вы выполняете git rebase и почему нужно быть внимательным.
Это [вторая](https://www.daolf.com/posts/git-series-part-2/) и [третья](https://www.daolf.com/posts/git-series-part-3/) части гайда по Git из блога Pier... | https://habr.com/ru/post/493818/ | null | ru | null |
# Проектирование непредсказуемого интеллекта в играх. Часть 2 — интеллект толпы
Как сделать smart толпу в игре и почему лидер толпы это важно.
![Толпе нужен лидер, даже толпе зомби.](https://habrastorage.org/r/w780q1/getpro/habr/upload_files/52d/121/8d5/52d1218d52f8b0c7bb12f7247209b5fa.jpeg "Толпе нужен лидер, даже т... | https://habr.com/ru/post/654601/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.