
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Как написать 2D игру на C++ и чистом STL для терминала в Linux
Привет, Хабр, я PHP разработчик с опытом работы в продакшне более 8 лет. После долгого и упорного труда мне стало скучно пилить микросервисы и бэкенды в хайлоде, я решил постичь магию разработки игр. Выбрал курс по Unreal Engine 5 и C++, так как там все ... | https://habr.com/ru/post/708486/ | null | ru | null |
# Рискованная музыка на линейном принтере старинного мейнфрейма от IBM
Мы в нашем [Музее компьютерной истории](http://www.computerhistory.org/) недавно приобрели набор [перфокарт](https://ru.wikipedia.org/wiki/Перфокарта) для компьютерной музыкальной программы 50-летней давности. Тогда у большинства компьютеров не был... | https://habr.com/ru/post/468647/ | null | ru | null |
# Как проходит собеседование Junior фронтенд-разработчика
Меня зовут Максим Чеченёв, я фронтенд-разработчик уже почти девять лет. Работаю в компании MessageBird в Амстердаме и наставником на курсе [«Веб-разработчик»](https://praktikum.yandex.ru/web/?utm_source=pr&utm_medium=content&utm_content=16_02_21&utm_campaign=pr... | https://habr.com/ru/post/542444/ | null | ru | null |
# Автоматическая загрузка файлов на Яндекс.Диск
Предлагаю вашему вниманию PHP скрипт автоматической загрузки файлов на сервис Яндекс.Диск. Скрипт прост до безобразия, достаточно передать ему в качестве параметров логин, пароль и путь к файлу и в результате он загрузит ваш файл на сервис и выдаст вам ссылку на него. Не... | https://habr.com/ru/post/67111/ | null | ru | null |
# AzaThread — многопоточность для PHP с блэкджеком
В сети гуляет довольно много решений для эмуляции многопоточности в php. Чаще всего они основываются на форках, но есть и вариации на тему с использованием curl, proc\_open и т.п.
Все встреченные варианты по тем или иным причинам меня не устроили и пришлось написат... | https://habr.com/ru/post/134501/ | null | ru | null |
# Google Analytics для игр, приложений соц. сетей
#### Вступление
В последнее время популярны приложения для соц. сетей и браузерные игры. К сожалению, соц. сети предоставляют довольно скудную статистику использовании приложений. Поэтому передо мной стоял выбор: собирать статистику на своем сервере, либо воспользоват... | https://habr.com/ru/post/150334/ | null | ru | null |
# ksuperkey — открытие меню KDE Kickoff по кнопке Win key (Super) в Ubuntu, Kubuntu и других версиях Linux
После перехода с Windows на Linux и KDE многие пользователи испытывают сильные мучения и головокружения из-за невозможности настройки открытия меню запуска программ KDE Kickoff по привычной кнопке Win на клавиату... | https://habr.com/ru/post/185336/ | null | ru | null |
# Внедрение своего кода в адресное пространство процессов
**##### Intro**
Внедрение своего кода( динамически ) в чужие процессы — штука достаточно интересная. Это может служить как во благо, так и во зло. Хотя, понятие «зло», местами, весьма абстрактно в информационном мире, я не могу провести точную границу между ... | https://habr.com/ru/post/168255/ | null | ru | null |
# Трёхмерный фон для сайта в реальном времени на JavaScript при помощи three.js

*Обучающий материал с ресурса Phyramid, у которых именно такая шапка сайта.*
Сегодня Аарон Тюрон — разработчик, недавно присоединившийся к разработке Rust в Mozilla — [объявил](https://github.com/rust-lang/rfcs/pull/243#issuecomment-61559683) о... | https://habr.com/ru/post/242269/ | null | ru | null |
# Поздравление с Новым 2012 годом на 150 языках
Уважаемые Хабравчане!
Поздравляю вас с наступающим новым годом! Желаю Вам творческих успехов, карьерного, интеллектуального и духовного роста!
Хочу сделать вам небольшой подарок: поздравления с новым годом на более чем 150 языках программирования!
 и облачных служб (PaaS), запущенных в облаке Microsoft Azure. Помимо прочих достоинств, балансировка нагрузки позволяет масштабировать ваши приложения и дает возможность мягче реагировать пр... | https://habr.com/ru/post/218797/ | null | ru | null |
# Манименеджмент для гика: для чего их считать?

Привет, Хабр. Появилась внутренняя потребность вновь излить тебе душу. В этой серии публикаци речь пойдёт не про какое-то там унылое IT, а про учёт личны... | https://habr.com/ru/post/423623/ | null | ru | null |
# Установка и настройка rTorrent в Debian
[rTorrent](http://libtorrent.... | https://habr.com/ru/post/88405/ | null | ru | null |
# KnockoutJS: сказ о том, как легко принимать или отклонять изменения
Довольно часто в пользовательском интерфейсе есть кнопки «Сохранить» и «Отмена». Особенно часто эти кнопки используются в формах. Несмотря на то, что в современном мире всё идёт к упрощению интерфейса, но на эти кнопки всё равно есть спрос.
Сегод... | https://habr.com/ru/post/136782/ | null | ru | null |
# REST hooks для WebRTC Click to Call. Опыт внедрения
Кнопка "Click to Call" на сайте — это "инновация", которой уже около 10 лет. Технологии под капотом изменились, а принцип остался прежним - кликаем по кн... | https://habr.com/ru/post/566360/ | null | ru | null |
# Решение проблемы сортировки деревьев с помощью бинарного Materialized Path
Столкнулся с проблемой реализации древовидных комментариев на одном проекте, в этой заметке выкладываю своё решение.
#### Описание задачи
* Хранение иерархических данных (древовидных комментариев) в реляционной БД MySQL
* Простое добавлен... | https://habr.com/ru/post/226741/ | null | ru | null |
# Устройство и работа портов ввода-вывода микроконтроллеров AVR. Часть 3
**Подключение транзистора к линии порта ввода/вывода**
Изучив данный материал, в котором все очень детально и подробно описано с большим количеством примеров, вы сможете легко овладеть и программировать порты ввода/вывода микроконтроллеров AVR... | https://habr.com/ru/post/255715/ | null | ru | null |
# Главный секрет операторов match/case в пайтоне
Не так давно увидела свет версия языка пайтон 3.10. В ней был добавлен pattern matching statement (оператор сопоставления с шаблонами). Как гласит официальное описание этого оператора в [PEP622](https://www.python.org/dev/peps/pep-0622/), разработчики в большей мере вдо... | https://habr.com/ru/post/585518/ | null | ru | null |
# Разработка IM на конкурс Павла Дурова с помощью Xamarin
Добрый день.
Как многие наверное знают, Павел Дуров разрабатывает новый клон What's App и прочих популярных мессенджеров на базе своего соб... | https://habr.com/ru/post/194404/ | null | ru | null |
# Обзор маршрутизатора Draytek серии 2912. Часть вторая
В [первой части обзора](https://geektimes.ru/company/digitalangel/blog/276476/) мы подробно рассмотрели маршрутизатор [Draytek](http://draytek-russia.ru) серии 2912/2912n с таких сторон как позиционирование устройства на рынке, схему использования маршрутизатора,... | https://habr.com/ru/post/395129/ | null | ru | null |
# JUG в каждый город

[Java User Groups](http://en.wikipedia.org/wiki/Java_User_Group) (JUGs) – это волонтерские организации Java-разработчиков призванные объединить Java-программистов, пользователей Java... | https://habr.com/ru/post/198910/ | null | ru | null |
# Усатый стрелок с полигональным пузом. Часть вторая
Рассказ про разработку проекта похож на паутину: повсюду тянутся ниточки ассоциаций, истории про интересные идеи. А иногда нити повествования обвиваются коконом вокруг необыч... | https://habr.com/ru/post/326840/ | null | ru | null |
# Миграция сервиса виртуальных компаньонок на WebRTC
Это история одного проекта по видеостримингу.

### Интересный клиент
Я сидел перед монитором уже битый час, а может и два. Все началось со ссылки на чей-то твиттер, кото... | https://habr.com/ru/post/302814/ | null | ru | null |
# Про MAC-таблицы в коммутаторах
Привет, Хабр!
Случается так, что иногда хочется отойти от скупой теории и перейти к практике. Сейчас как раз такой случай. Желание возникло на фоне воспоминаний того, как мы делали [коммутато... | https://habr.com/ru/post/254183/ | null | ru | null |
# Переопределение функций в PHP 5.3
PHP 5.3 давно уже не новость и написано о нем прилично(да и приелся он как-то после выхода версии 5.4). Тем не менее, хотелось бы поставить акцент на одной его особенности.
Одной из самых ярких фич этой версии является поддержка неймспейсов, что повлекло за собой изменение паради... | https://habr.com/ru/post/140216/ | null | ru | null |
# О позитивном влиянии вариативных шрифтов на производительность веб-проектов
Когда размышляют о веб-шрифтах, и о том, какое влияние они оказывают на производительность сайтов, часто обращают внимание на три следующих показателя:
* Количество запросов на загрузку файлов шрифтов.
* Размеры файлов шрифтов.
* Время до... | https://habr.com/ru/post/494714/ | null | ru | null |
# Экзамен 1z0-819 Oracle Certified Professional: Java 11 Developer — заметки о сдаче

В начале октября Oracle упростил получение сертификации по Java — вместо двух экзаменов теперь нужно сдать один, при том что цена за экзамен не изм... | https://habr.com/ru/post/527284/ | null | ru | null |
# Немного тестов производительности сетевых фреймворков
Привет Хабр! Пару месяцев назад я захотел провести тестирование производительности некоторых сетевых фреймворков, c целью понять насколько большая разбежка между ними. Надо ли использовать Node.js там, где хотелось бы Python с Gevent или нужен Ruby с его EventMac... | https://habr.com/ru/post/228455/ | null | ru | null |
# Не очередной язык программирования. Часть 2: Логика представлений

Вторая часть трилогии о языке и платформе lsFusion. Первую часть можно найти [тут](https://habr.com/ru/company/lsfusion/blog/458376/).
В ней речь пойдет о логике... | https://habr.com/ru/post/460141/ | null | ru | null |
# Как создать первое приложение для торговли на бирже: 3 начальных шага
[](https://habr.com/ru/post/458984/)
Современные биржи – очень технологичны и привлекают внимание ИТ-специалистов (об этом говорят, например, активные обсуждения... | https://habr.com/ru/post/458984/ | null | ru | null |
# Почему нам пришлось писать собственный оператор для логирования в Kubernetes
В данной статье я расскажу про жизненный цикл одной важной задачи - “Настроить сбор/парсер логов в Kubernetes”. Или “Почему мы решили написать свой оператор для сбора логов в Kubernetes”.
#### Оговорочка
Решений по логированию много. Скор... | https://habr.com/ru/post/698526/ | null | ru | null |
# Lifehack FTP: переносим папки и файлы
Иногда требуется перенести ~~*не*~~большое количество файлов и/или папок на сервере, а доступа через ssh нет и не предвидится в будущем.
Попробуем решить эту задачу с помощью Total Commander.
#### Первое решение *«в лоб»* которое приходит в голову:
> 1. Копируем все на л... | https://habr.com/ru/post/103043/ | null | ru | null |
# ZSON: расширение PostgreSQL для прозрачного сжатия JSONB

Недавно мы выложили на GitHub [ZSON](https://github.com/afiskon/zson). ZSON — это расширение к PostgreSQL для прозрачного сжатия JSONB-документов. Сжатие осуществля... | https://habr.com/ru/post/312006/ | null | ru | null |
# Определение серверной логики для конечной точки: три подхода
***Перевод статьи подготовлен в преддверии старта курса [«Scala-разработчик»](https://otus.pw/HvAS/)***
---

Теа, Ральф и Джесси используют [tapir](https://github.com/sof... | https://habr.com/ru/post/510846/ | null | ru | null |
# Windows 2008/2012 c NetApp ONTAP 8 (SAN)
В этой статье я хотел бы рассмотреть тему оптимизации Windows Server (с виртуализацией и без) с использованием СХД NetApp FAS в среде SAN.
Для поиска и устранения узких мест в такой инфраструктуре, нужно опредилиться с компонентами инфраструктуры, среди которых их стоит и... | https://habr.com/ru/post/243153/ | null | ru | null |
# Wicket+лямбды: типобезопасная и лаконичная реализация IModel
Стандартная задача при разработке веб-приложения: есть объект данных, требуется эти данные отобразить (вывести в HTML). В [Apache Wicket](http://wicket.apache.org/) данные для этого привязываются к компонентам (которые и будут заниматься отображением) с по... | https://habr.com/ru/post/244211/ | null | ru | null |
# Беспростойная миграция RabbitMQ в Kubernetes

RabbitMQ – написанный на языке Erlang брокер сообщений, позволяющий организовать отказоустойчивый кластер с полной репликацией данных на несколько узлов, где каждый узел может обслужива... | https://habr.com/ru/post/450662/ | null | ru | null |
# SSL Unpinning для приложений Android
Добрый день, меня зовут Дегтярёв Константин, я senior security engineer в Huawei RRI. В этой статье я хотел бы поделиться методами встраивания в трафик мобильных приложений Android.
Во время оценки безопасности мобильных приложений довольно часто возникает необходимость выполне... | https://habr.com/ru/post/676618/ | null | ru | null |
# «Чем это сделать?»: поиск API — методики и проблемы
Современные программы в значительной степени строятся из готовых кирпичиков — библиотек. Уникального кода и архитектурных решений в каждой программе относительно мало. Очень часто бывает, что существующие библиотеки не слишком высокого качества, но даже самый круто... | https://habr.com/ru/post/204124/ | null | ru | null |
# Что такое grep и с чем его едят
Эта заметка навеяна мелькавшими последнее время на хабре постами двух тематик — «интересные команды unix» и «как я подбирал программиста». И описываемые там команды, конечно, местами интересные, но редко практически полезные, а выясняется, что реально полезным инструментарием мы польз... | https://habr.com/ru/post/229501/ | null | ru | null |
# Кодинг — это просто, а вот программирование — совсем другое дело
В моей жизни был период когда я только начинал заниматься программированием. Я тогда думал: «Программировать так просто… Зачем люди специально ходят учиться этому?», но с опытом и образованием пришло понимание, что программирование — дело трудное.
!... | https://habr.com/ru/post/370667/ | null | ru | null |
# Мне не нравится то, во что превращается PHP

И я уже знаю, что скажете вы, глядя на заголовок статьи:
*— Кто ты такой? Почему ты позволяешь себе так говорить?*
Отвечу сразу, чтобы не было недомолвок:
* Я профессионально ... | https://habr.com/ru/post/511266/ | null | ru | null |
# Qt Graphics Framework — темная сторона. Часть 1
В [первой](http://habrahabr.ru/post/182142/) статье я рассказывал как мог о достоинствах фреймворка. Сегодня я попытаюсь рассказать о его темной стороне, плохо освещенной в документации.
#### Дело №1
Мы хотим изменять размер сцены и объектов в ней согласно размеру ... | https://habr.com/ru/post/182614/ | null | ru | null |
# RabbitMQ + Spring boot + Docker. Отправляем и получаем сообщения через Producer и Consumer. Пошаговое руководство
Всем привет. Поскольку не смог найти полноценной статьи о том, как с нуля написать свой spring boot сервис с подключением к нему rabbitMQ, с конфигурацией всего это чуда через графический интерфейс и усп... | https://habr.com/ru/post/703352/ | null | ru | null |
# Компоновка кода Terraform и использование Terragrunt
Terraform позволяет организовывать свой код так, как вам хочется.
Это обеспечивает большую гибкость и позволяет легко начать работу, просто поместив нес... | https://habr.com/ru/post/594239/ | null | ru | null |
# Переключение звуковых дорожек в Flash с помощью RTMP сервера Wowza2
В данной статье описана древняя история о том, как мне удалось реализовать переключение звуковых дорожек для Flash-плеера с помощью RTMP сервера Wowza Media Server 2.
В далеком 2011 году я занимался исследованием возможностей стриминговых серверо... | https://habr.com/ru/post/263747/ | null | ru | null |
# Создание «нестандартного» кастомного объекта для AutoCAD, работающего без Object Enabler
Добрый день.
Те, кто имеет дело с AutoCAD и сторонними решениями для него, наверняка, сталкивались с проблемой прокси объектов, для отображения или перемещения которых требуется установить библиотеки, с помощью которых были с... | https://habr.com/ru/post/154591/ | null | ru | null |
# Input lag во время рендеринга и как его побеждать
Привет всем. Многие из вас знакомы с лагом ввода. Это бывает, когда вас в очередной раз убивают в компьютерной игре, и вы кричите: «Ну я же нажал блок/атаку/уворот». Ну а затем джойст... | https://habr.com/ru/post/308980/ | null | ru | null |
# Как справиться с более 50 репозиториев на GitHub?
Допустим есть ситуация, когда у тебя много проектов на `github` и ты хочешь хранить локальную копию всех проектов на разных устройствах и носителях. У тебя есть простой вариант - указать список репозиториев, написать `bash` скрипт, который бы клонировал все репозитор... | https://habr.com/ru/post/653345/ | null | ru | null |
# Imagine Cup 2014 глазами C4L
Здравствуй, дорогой Хабр!
Перед Вами история команды C4L, Национального победителя Imagine Cup 2014 в категории «Социальные проекты»!
#### Идея
Все началось с идеи двухлетней давности – создать систему, которая позволит следить за состоянием кровообращения организма и, как следств... | https://habr.com/ru/post/222739/ | null | ru | null |
# Kali Linux NetHunter на Android Ч.3: нарушение дистанции

**Статьи из цикла**
[Kali Linux NetHunter на Android: зачем и как установить](https://habr.com/ru/company/tomhunter/blog/465045/)
[Kali Linux NetHunter на Android Ч.2: ат... | https://habr.com/ru/post/513226/ | null | ru | null |
# Геодезический купол. Об устройстве и моем опыте расчетов
Пожалуй сложно назвать геодезические купола чем-то необычным или новым. В этой заметке я расскажу немного об этих конструкциях в общем, об их устройстве, а также покажу на примере как я кое что на эту тему считал. Код тоже будет.
 мы рассматривали вопрос выноса абонентских телефонных линий при помощи пары голосовых шлюзов Grandstream. За время, прошедшее с момента её выхода, многие наши клиенты отмеча... | https://habr.com/ru/post/404399/ | null | ru | null |
# Canary-релизы в Kubernetes на базе Ingress-NGINX Controller
Тема «канареечных» (canary) релизов поднималась в нашем блоге уже не раз — см. ссылки в конце статьи. Но не будет лишним напомнить, зачем они нужны.
Canary-развертывание используется, чтобы протестировать новую функциональность на отдельной группе пользова... | https://habr.com/ru/post/697030/ | null | ru | null |
# Секреты JDK

Про Unsafe в Java не слышал только ленивый, однако это не единственный магический класс в Sun/Oracle JDK, стирающий границы Java платформы и открывающий тропинки, не нанесенные на карту публичного API. Я расскажу пр... | https://habr.com/ru/post/132703/ | null | ru | null |
# Хеш-таблицы
### Предисловие
Я много раз заглядывал на просторы интернета, нашел много интересных статей о хеш-таблицах, но вразумительного и полного описания того, как они реализованы, так и не нашел. В связи с этим мне просто нетерпелось написать пост на данную, столь интересную, тему.
Возможно, она не столь пол... | https://habr.com/ru/post/509220/ | null | ru | null |
# Алиса, Google Assistant, Siri, Alexa. Как писать приложения для голосовых ассистентов

Рынок голосовых ассистентов расширяется, особенно для русскоязычных пользователей. 2 недели назад Яндекс рассказала впервые про платформу Я... | https://habr.com/ru/post/352982/ | null | ru | null |
# Простое управление Music Player Daemon на Панели Gnome
*Disclaimer: эта статья — для чайников навроде меня.*
---
Я использую [MPD](http://mpd.wikia.com/) в качестве медиапроигрывателя, что очень удобно: ... | https://habr.com/ru/post/87316/ | null | ru | null |
# Пробуем Qt 4.6: Qt Animations и State Machine

На днях вышло так называемое «технологическое превью» (technological preview) Qt 4.6, которое позволяет уже сейчас попробовать новые фичи, которые войдут в релиз 4.6 этого замечательного фреймворка. Перечислять новшества я не буд... | https://habr.com/ru/post/69316/ | null | ru | null |
# Raspberry Pi и iperf — тестер пропускной способности для устройств «Умного дома» и Интернета вещей

В рамках предыдущего моего проекта, «Видеофон из Raspberry Pi», мне довелось для настройки оборудования и решения проблемы, воспо... | https://habr.com/ru/post/482012/ | null | ru | null |
# Компиляция. 4: игрушечный ЯП
С грамматиками калькуляторов поиграли достаточно, переходим к языкам программирования. Бета-тестеры статьи подали идею писать JavaScript-подобный язык: начнём с простейшего скобчатого скелета, и будем его постепенно обращивать наворотами — синтаксическим сахаром, типами данных, поддержко... | https://habr.com/ru/post/99397/ | null | ru | null |
# Обзор одной российской RTOS, часть 6. Средства синхронизации потоков
К сожалению, при разработке реальных многопоточных приложений, невозможно просто написать код всех задач, подключить их к планировщику и просто запустить на исполнение.
Начнём с банальности — если задач много, то они начнут впустую тратить проце... | https://habr.com/ru/post/338682/ | null | ru | null |
# Создаем счетчик-картинку

Всем привет! Сегодня я расскажу Вам, как создавать динамически такую картинку, как выше с использованием PHP. Все наверное задумывались, как такое реализовать. Мне кажется, если очень хорошо подумать, т... | https://habr.com/ru/post/132337/ | null | ru | null |
# Настройка динамического dhcp-pool с привязкой к определенным портам Cisco Catalyst
Так сложилось, что сеть у меня построена таким образом, что IP-адреса выдаются только тем
клиентам, чьи MAC-адреса прописаны в самописной системе управления сетью и учета трафика (назвать это биллингом язык не поворачивается).
... | https://habr.com/ru/post/350678/ | null | ru | null |
# Забытая история ООП
Большинство парадигм программирования, которые мы используем сегодня, были впервые математически изучены в 1930-х годах с использованием идей лямбда-исчисления и машины Тьюринга, которые представляют собой варианты модели универсальных вычислений (это формализованные системы, которые могут выполн... | https://habr.com/ru/post/428582/ | null | ru | null |
# Комфортная работа с Android Studio

Всем доброго времени суток!
Насколько производительно работает Android Studio? Считаете ли Вы, что она работает шустро на Вашем ПК или Mac? Или, иногда, сталкиваетесь с лагами или долгой сборк... | https://habr.com/ru/post/433604/ | null | ru | null |
# String.Format
Те, кто пишут на C# очень хорошо знают и часто используют механизм String.Format, которого сильно не хватает в JavaScript. Несмотря на его простоту и удобство, на просторах Сети мало что можно накопать, в основном вариации на тему sprintf (привет сишникам). Достаточно давно был написан скрипт, который ... | https://habr.com/ru/post/83185/ | null | ru | null |
# Эволюция Material Design для AvaloniaUI
Material.Avalonia — быстрый способ стилизовать под Material Design приложение, написанное на AvaloniaUI — кросс-платформенном XAML фреймворке для .NET.
Примерно с год назад на Хабре уже ... | https://habr.com/ru/post/528620/ | null | ru | null |
# Автозавершение для Rake

Автозавершение в bash’е по Tab’у — это невероятно удобная вещь. И оно точно нужно для [rake](http://rake.rubyforge.org/), которым каждый программист на Ruby пользуется часто.
Особ... | https://habr.com/ru/post/76412/ | null | ru | null |
# Пробуем запустить приложения .Net Core в среде SAP Cloud Foundry и SAP HANA XSA
SAP сейчас активно развивает Cloud Foundry (CF) и внедрила ее в SAP Cloud Platform, в качестве основного элемента облачной инфраструктуры. CF выполняет роль PaaS и позволяет запускать приложения в среде SCP. В этой статье мы расскажем ка... | https://habr.com/ru/post/535530/ | null | ru | null |
# Что может предложить Neovim разработчику на Scala?

В сообществе фанатов текстового редактора Neovim произошло знаменательное событие — [вышла версия 0.5](https://habr.com/ru/post/569550/), в которой появилось большое количест... | https://habr.com/ru/post/570762/ | null | ru | null |
# Сатоши Накамото вошёл в число 50-ти богатейших людей мира
[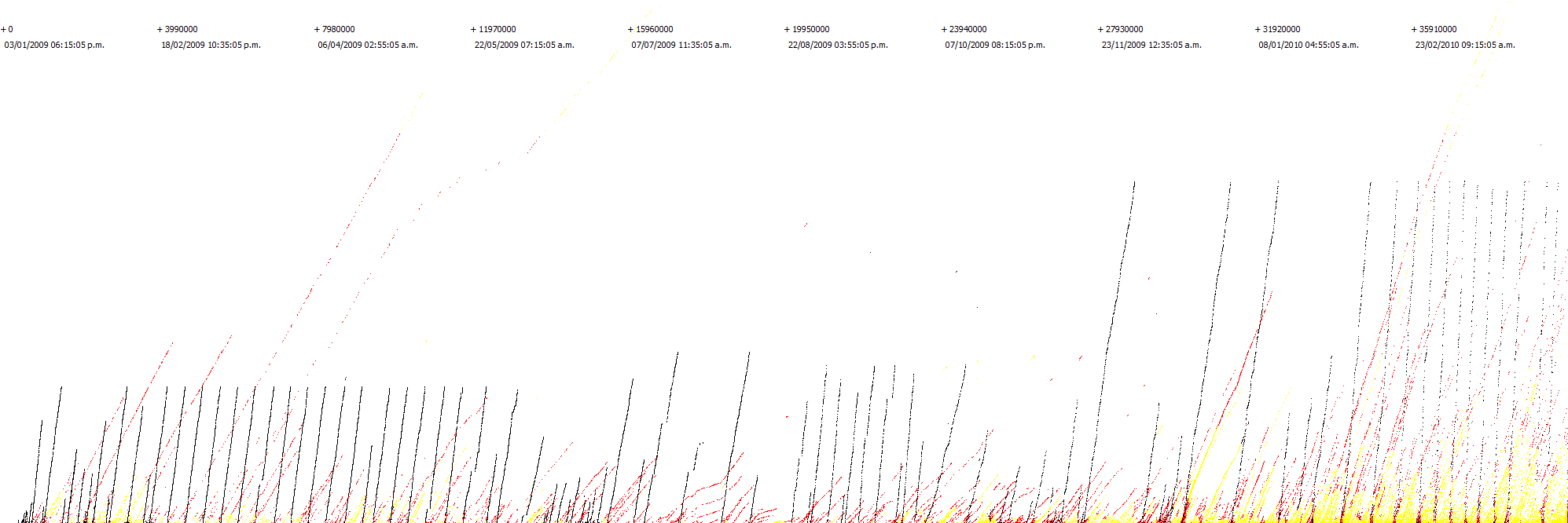](https://habrastorage.org/webt/5p/td/uh/5ptduhi08itg9unvqdhv4wkpnpy.gif)
*График всех блоков Bitcoin с 1 до 50000. Чёрные точки — это непотраченные монеты, которые соответствуют п... | https://habr.com/ru/post/409185/ | null | ru | null |
# Кроссбраузерная отправка формы с файлом или как переписать весь отправщик несколько раз после тестирования в IE
***Задача:*** отправка и обработка файлов с помощью FormData и FileReader в форме со всеми возможными полями и пересылкой дополнительных параметров для каждого поля c объединением всех данных формы (кроме ... | https://habr.com/ru/post/325340/ | null | ru | null |
# Темизация, часть 3. Themeizer – юный попутчик стилей
Вот уже третья статья выходит с темой, которой не существует. Первая статья затевалась для того, чтобы описать полезный и интересный функционал, да ещё и дающий красивый результат. ... | https://habr.com/ru/post/651577/ | null | ru | null |
# Moscow Django Meetup #3

Хотим поделиться впечатлениями от третьей московской встречи Django-девелоперов, она же Moscow Django Meetup. Благодаря организаторам из GreenfieldProject и Seven Quark в этот раз удалось подыс... | https://habr.com/ru/post/143715/ | null | ru | null |
# Пишем тесты производительности под Webflux
##### Александр Леонов
Руководитель группы разработки
Добрый день! Меня зовут [Александр Леонов](https://habr.com/ru/users/venum/), я руководитель группы разраб... | https://habr.com/ru/post/680948/ | null | ru | null |
# Релиз CrystaX NDK 10.2
Новая версия [CrystaX NDK 10.2.0](https://www.crystax.net/android/ndk) доступна для скачивания.
В этой версии мы сконцентрировались в основном на исправлениях и мелких улучшениях, но есть и несколько более крупных фич.
Objective-C v2
--------------
Добавлена поддержка [Objective-C v2](h... | https://habr.com/ru/post/261049/ | null | ru | null |
# Как разочароваться и НЕ перейти на Linux
Недавний конфуз Джима Землина (Jim Zemlin) на Open Source Summit с презентацией, запущенной на Mac OS, не отменяет того факта, что и на десктопном направлении есть крупные успехи в последнее время. О некоторых я уже рассказывал: [Ускорение WiFi](https://habrahabr.ru/post/3175... | https://habr.com/ru/post/338846/ | null | ru | null |
# Поэтапное создание расширения для Magento на примере debug-консоли
Здравствуйте.
Заметно, что Хабр не избалован статьями о Magento, несмотря на то что платформа достаточно популярная и при этом — не простая. В статье будет показан путь создания реального расширения, доступного для скачивания. Это не hello world, ... | https://habr.com/ru/post/124986/ | null | ru | null |
# Генератор конфигураций для сетевого оборудования и не только
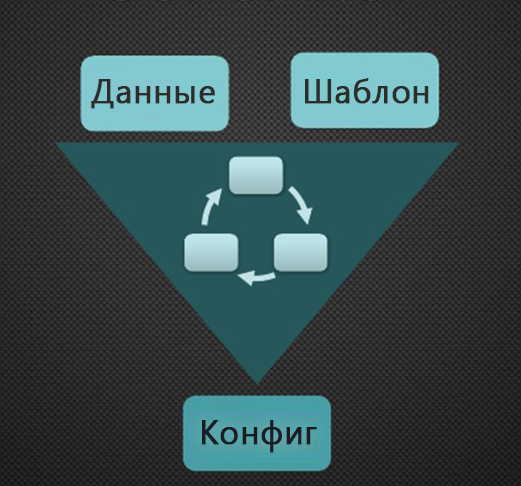
Многие хранят шаблоны конфигураций сетевых устройств (***прим.** да и не только сетевых*) в обычных текстовых файлах. И когда приходит время настраивать новое о... | https://habr.com/ru/post/307054/ | null | ru | null |
# Почему введение проверки QR-кодов не имеет смысла в общественном транспорте и торговых центрах?
Друзья, это моя первая публикация, если что-то не так, не судите строго, конструктивную критику оставляйте в комментариях, постараюсь реагировать и улучшать контент.
Пост раскроет информацию о том, чем является QR-код с... | https://habr.com/ru/post/587400/ | null | ru | null |
# Фракталы в иррациональных числах
Статья является продолжением моей первой статьи [«Фракталы в простых числах»](https://habr.com/ru/post/194406/).
Следующая статья: [Фракталы в иррациональных числах. Часть 2](https://habr.com/post/447326/).
[ автора Francesco Zuppichini.
Это моя первая публикация на Хабре и я решил начать с перевод... | https://habr.com/ru/post/344772/ | null | ru | null |
# PVS-Studio наконец то добрался до Boost

Мы уже давно хотели проверить библиотеку Boost. У нас не было уверенности, что результатов проверки хватит на статью. Однако, желание не пропад... | https://habr.com/ru/post/190888/ | null | ru | null |
# Как мы распилили монолит. Часть 4. И как Angular между приложениями пошарили
В [первой](https://habr.com/ru/company/tinkoff/blog/517230/), [второй](https://habr.com/ru/company/tinkoff/blog/520476/) и [треть... | https://habr.com/ru/post/534522/ | null | ru | null |
# Конструктор интерактивных упражнений для online-обучения
##### Введение
Жизнь в современном мире развивается динамично, технологии появляются и умирают, а вместе с ними устаревают и наши навыки. 20 лет назад нужно было помнить функции Windows API, сейчас многие специалисты даже не знают, что это такое, и это не меш... | https://habr.com/ru/post/254523/ | null | ru | null |
# Из вагона направо: как работают подсказки 2ГИС
Весной мы добавили новую подсказку о том, в какую сторону выходить из вагона метро. Я Влад, программист С++, и на примере этой подсказки хочу рассказать, из чего состоит жизненный цикл релиза новых фич в 2ГИС. И сколько всего происходит, когда добавляешь — казалось бы —... | https://habr.com/ru/post/678030/ | null | ru | null |
# Слушаем Pandora.com с использованием бесплатного VPN
Наверняка многие хабражители уже давно распробовали на вкус замечательный музыкальный сервис, под названием Pandora.com. Наверняка многие из них, проживающие за пределами США, ни раз видели сообщение о «неверном» IP, забыв вовремя заплатить за VPN. Сегодня я попыт... | https://habr.com/ru/post/126276/ | null | ru | null |
# Алгоритм внешней сортировки слиянием
На сегодняшний день сортировка является очень важной частью в любой системе баз данных. Речь идет о расположении данных в порядке возрастания или убывания. Мы используем сортировку для генерации последовательного вывода, а также для выполнения условий различных алгоритмов, работа... | https://habr.com/ru/post/712234/ | null | ru | null |
# Бесплатная отправка SMS уведомлений в Zabbix
Все осознают необходимость непрерывного контроля большой распределенной сети и для этого есть множество систем мониторинга. Сразу замечу, что я работаю у крупного провайдера и на мои, так сказать, плечи ложится контроль состояния большого количества узлов доступа, которые... | https://habr.com/ru/post/81630/ | null | ru | null |
# Приемы повышения производительности инференса глубоких моделей с DL Workbench. Часть 1 — введение и установка
Если у вас есть проект с интенсивной обработкой данных глубокими моделями (или еще нет, но вы с... | https://habr.com/ru/post/549634/ | null | ru | null |
# ООП мертво, да здравствует ООП
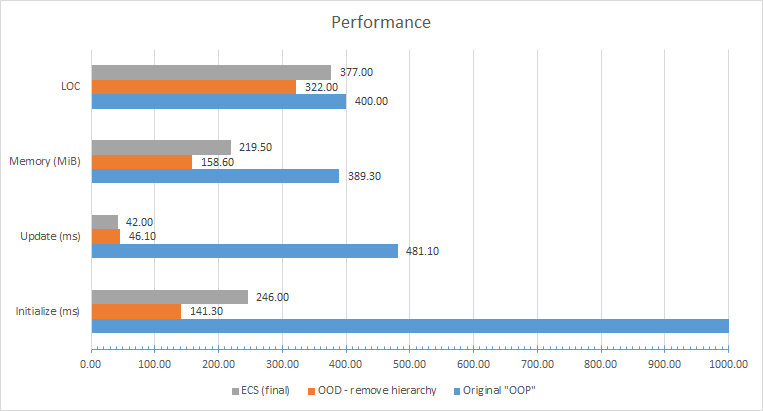
Источники вдохновения
=====================
Этот пост возник благодаря недавней публикации [Араса Пранцкевичуса](https://twitter.com/aras_p) о докладе, предназначенно... | https://habr.com/ru/post/441174/ | null | ru | null |
# Решение проблемы с многократным запуском эффектов в React 18
Введение
--------
В этой статье мы рассмотрим адаптацию компонентов React 18 к много кратному монтированию и повторному вызову эффектов с повторно используемым стоянием (Reusable State). Под эффектами понимается срабатывание хуков: useEffect, useLayoutEff... | https://habr.com/ru/post/712196/ | null | ru | null |
# 2D магия в деталях. Часть вторая. Структура

Помните небезызвестный мем про "корованы"? Наверное, каждый, кто разрабатывает игры (или хотел бы этим заняться) раздумывает о неком "проекте мечты", где можно будет "грабить ко... | https://habr.com/ru/post/312046/ | null | ru | null |
# Настройка Intel Galileo с нуля и до установки полной версии Debian
На днях получил долгожданный Intel Galileo, заказывал у [SparkFun Electronics](https://www.sparkfun.com/products/12720), приехало довольно быстро и дешево. За несколько минут установил [Little Linux от Intel](https://communities.intel.com/docs/DOC-22... | https://habr.com/ru/post/218993/ | null | ru | null |
# Обновление* Ethereum «Constantinople» откладывается из-за найденной в последний момент потенциальной уязвимости

*\*многие называют это событие «hard fork»-ом, но «Виталик» [против](https://twitter.... | https://habr.com/ru/post/436262/ | null | ru | null |
# Kali Linux: упражнения по защите и мониторингу системы
→ Часть 1. [Kali Linux: политика безопасности, защита компьютеров и сетевых служб](https://habrahabr.ru/company/ruvds/blog/338338/)
→ Часть 2. [Kali Linux: фильтрация трафика с помощью netfilter](https://habrahabr.ru/company/ruvds/blog/338480/)
→ Часть 3. ... | https://habr.com/ru/post/338712/ | null | ru | null |
# Hakyll для начинающих
Однажды вы, как и я какое-то время назад, решаете создать свою персональную страничку с блогом (ну или без). Существует множество способов достигнуть задуманного, в зависимости от вашего опыта программирования, уровня лени ну и степени гикнутости. Но лично мне кажется, что заводить хостинг и до... | https://habr.com/ru/post/175877/ | null | ru | null |
# Реактивное программирование со Spring, часть 3 WebFlux
Это третья часть [серии блогов о реактивном программировании](https://habr.com/ru/publication/edit/565000/), в которой я познакомлю вас с WebFlux - реактивным веб-фреймворком Spring.
### 1. Введение в Spring WebFlux
Исходный веб-фреймворк для Spring - Spring ... | https://habr.com/ru/post/565056/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.