
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Как я диплом писал/приложение создавал/на Google Play выкладывал
Пожалуй, начну сначала. Шел далекий 2015-й, август, я был студентом 6 курса и начал задумываться о своей дипломной работе. После прохождения курса разработки мобильных приложений на 4 курсе, хотелось написать что-то под Android. А еще дома уже как полг... | https://habr.com/ru/post/308884/ | null | ru | null |
# Безопасная авторизация с PHPixie 3

Сегодня вышел самый долгожданный компонент [PHPixie](http://phpixie.com) 3 — Auth для авторизации пользователей. Авторизация это наиболее критическая часть любого ... | https://habr.com/ru/post/267177/ | null | ru | null |
# Искусство побеждать или что такое квантовая псевдотелепатия
Привет, Хабр!
Решил продолжить серию статей о нестандартных применениях квантовых вычислений. Под катом речь пойдет об игре для двух игроков, в которую лучше всего играть предварительно изучив принципы квантовой механики.

PVS-Studio выполняет анализ C/C++ кода и подсказывает программисту, где скрываются ошибки, или указывает на участки кода, которые могут... | https://habr.com/ru/post/263369/ | null | ru | null |
# Desktop pet на C# WPF
Desktop pet — пусть и бесполезное, но весьма забавное украшение рабочего стола. В данной статье показана, наверное, самая простая его реализация.
*Гифка под катом!*
 ку, товарищи!
Все мы знаем, что такое округление. Если кто-то забыл, то округление — это замена числа на его приближённое значение, записанное с меньшим количеством значащих цифр. Если спросить человека с ходу, что получится при округлении 6,5 до ... | https://habr.com/ru/post/462299/ | null | ru | null |
# Промышленный реверс-инжиниринг
Рассказ о процессе заимствования при разработке электроники на наглядном примере.

*Запись лога работы лифта самодельным сниффером*
Однажды мне понадобилось скопировать довольно простое устройство. ... | https://habr.com/ru/post/459492/ | null | ru | null |
# Еще раз про WOL
Нужно включать комп по сети. А Wake-on-LAN не работает.
Предлагаемый метод универсален, но нестандартен и подразумевает наличие творческого оптимизма «во что бы то ни стало».
Когда-то у меня был FTP-сервер. По факту это был обычный комп образца 2004 года. Вот [тут](http://habrahabr.ru/post/1269... | https://habr.com/ru/post/146404/ | null | ru | null |
# Анализ частоты появления цифр в хеше MD5
Все мы знаем, как выглядит хеш, но задавались ли вы вопросом, как часто встречается тот или иной символ в хеше? Я задался. И решил проверить. Набросал скрипт на Python для подсчета, и вот что из этого вышло.
Для начала я сгенерировал случайную строку символов (длиною от 0 ... | https://habr.com/ru/post/453094/ | null | ru | null |
# Что будет в django 1.3
Релиз django 1.3 совсем скоро. Думаю, многие уже RC в продакшне используют. Но все равно, пробегусь еще раз по тому, что нас ждет, стараясь не скатиться в перевод release notes.
#### django.contrib.staticfiles
Теперь можно организовывать статику (картинки, js, css и т.д.) точно так же, как... | https://habr.com/ru/post/115763/ | null | ru | null |
# Интересные вещи, которые можно делать с dynamic в .NET 4.0
В статье «[Обзор C# 4.0](http://www.thycotic.com/an-overview-of-c-4-0)» я обсуждал некоторые из новых особенностей четвертой версии языка C#. Так получилось, что я не рассмотрел одно из самых важных нововведений: ключевое слово **dynamic**.
Попросту говор... | https://habr.com/ru/post/79139/ | null | ru | null |
# Создаем анимированные гистограммы при помощи R
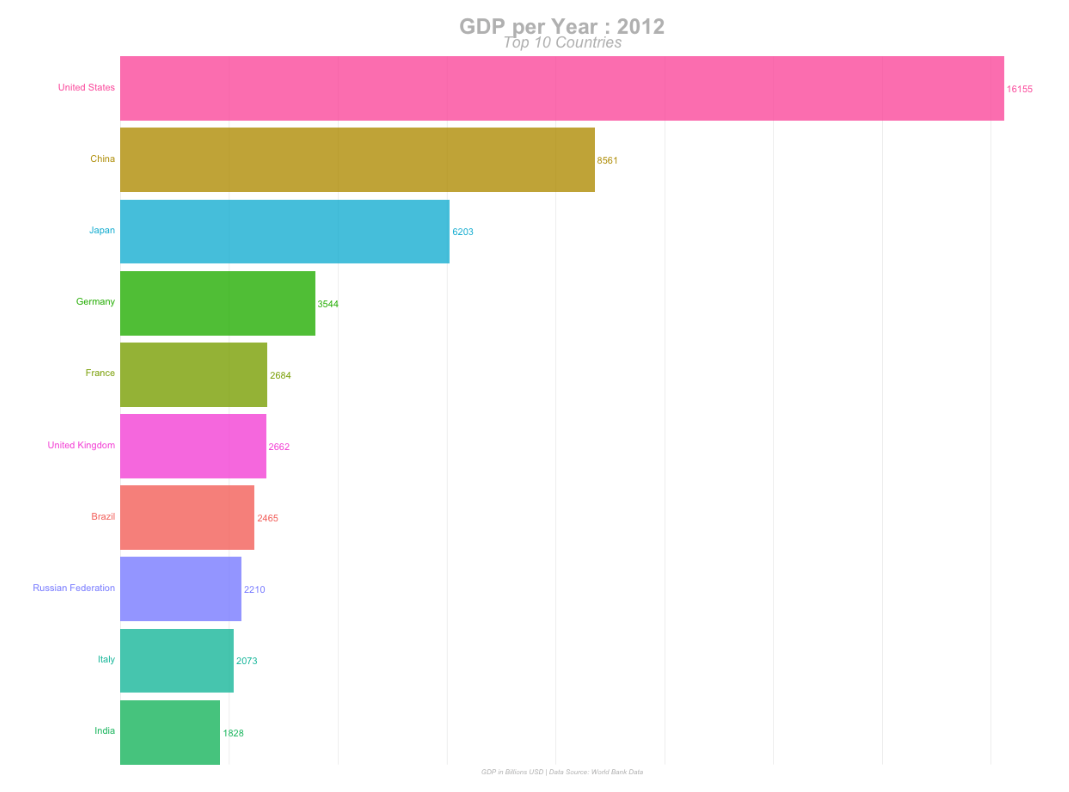
Анимированные гистограммы, которые можно встроить прямо в публикацию на любом сайте, становятся все более популярными. Они отображают динамику изменений любых характеристик за определ... | https://habr.com/ru/post/446952/ | null | ru | null |
# Haskell для ВКонтакте, JavaScript и ReactJS, Или «Чужой против Симпсонов»
Данный пост является попыткой добавить пару капель топлива в машину пропаганды Haskell, демонстрируя его использование в повседневных задачах.

В... | https://habr.com/ru/post/272871/ | null | ru | null |
# Raspberry Pi в картридже от NES

Здравствуйте! Это ретро игровая приставка на базе Raspberry Pi. В картридже от игровой приставки NES. Для игры может использоваться интегрированный экран. При выводе же видео по HDMI он показывает... | https://habr.com/ru/post/422005/ | null | ru | null |
# Нетривиальное слияние репозиториев с помощью git-filter-repo
Это вторая часть [истории про слияние репозиториев](https://habr.com/ru/post/522942/). Суть проблемы вкратце такова: надо слить репозиторий с подрепозиторием с сохранением истории. Решение на gitpython работало за 6 часов и выдавало удовлетворительный резу... | https://habr.com/ru/post/566034/ | null | ru | null |
# Эмулируем PEAR DB при работе с MySQL
В своё время возникла необходимость уйти от использования PEAR DB при работе с MySQL (ввиду очевидных причин: прекращение поддержки в последних версиях php, тормознутость итп) но учитывая мегатонны написанного кода начал искать эмулятор. К своему удивлению ничего более менее год... | https://habr.com/ru/post/135654/ | null | ru | null |
# Среды запуска контейнеров (container runtime) часть2: Анатомия низкоуровневых сред запуска
### От переводчика
Это перевод статьи [ссылка](https://www.ianlewis.org/en/container-runtimes-part-2-anatomy-low-level-contai)
Автор оригинальной статьи: [*Ian Lewis*](https://www.ianlewis.org/en/about/)*.*
Ссылка на перву... | https://habr.com/ru/post/649981/ | null | ru | null |
# Lens JS как менеджер состояния приложения
Обзор библиотеки [lens-js](https://www.npmjs.com/package/@vovikilelik/lens-js) и эксперименты с котиками.
Данные — это, в действительности, важная часть Вашего будущего приложения или отдельной библиотеки. Важна их структура, целостность, а также и подходы к организации их ... | https://habr.com/ru/post/538844/ | null | ru | null |
# Язык Вольфрам и пакет Mathematica доступны бесплатно для Raspberry Pi
Прошло всего три дня с анонса масштабного проекта от Стивена Вольфрама, о котором уже [писали на хабре](http://habrahabr.ru/post/202586/), как стало известно о том, что новый язык Wolfram ([Wolfram Language](http://www.wolfram.com/wolfram-language... | https://habr.com/ru/post/203158/ | null | ru | null |
# Архитектура плагинов в приложениях Angular
Концепция плагинов всегда была популярной и продуктивной в области разработки программного обеспечения. Масштабируемость и возможность коллективной разработки необходимы для приложений уровня предприятия, когда каждая команда разработчиков может представлять своё направлени... | https://habr.com/ru/post/551192/ | null | ru | null |
# С любовью к дизайнерам: внедряем веб-формы в мобильное приложение
При разработке мобильного приложения для проекта, которому приходится работать с большим количеством внешних систем, неизбежно возникают ситуации, в которых приходится проявлять находчивость и смекалку. Особенно часто такие ситуации возникают при попы... | https://habr.com/ru/post/211522/ | null | ru | null |
# Делаем жизнь проще, GruntJS (для новичков)
#### Что такое GruntJS
Большинство JS разработчиков уже используют какие-то инструменты компоновки для своих разработок, даже если не знают или не используют этот термин. Они объединяют файлы при разработке, уменьшают код JavaScript-а, чтобы ускорить загрузку страниц и кон... | https://habr.com/ru/post/177395/ | null | ru | null |
# Test lab 15 writeup: как вам н0в1ч0к?
15-го марта 2021 г. мы запустили пятнадцатую по счёту лабораторию тестирования на проникновение Test lab под кодовым названием названием: **Who is the n0v1ch0k?**
На ... | https://habr.com/ru/post/547806/ | null | ru | null |
# Кросскомпиляция библиотек под iOS, делаем это правильно
Во время разработки большого проекта наступает такой момент, когда надо встроить в приложение библиотеку из мира open source с подходящей лицензией. Например, вам захотелось ускорить декодирование картинок, или понадобился sqlite3 с fts4, или нужны какие-то плю... | https://habr.com/ru/post/222343/ | null | ru | null |
# Все о коллекциях в Oracle
*Статья имеет довольно таки тезисный стиль. Более подробное содержание можно найти в приложенном внизу статьи видео с записью лекции по коллекциям Oracle.*
Коллекции присутствую в том или ином виде в большинстве языков программирования и везде имеют схожую суть в плане использования. А и... | https://habr.com/ru/post/254355/ | null | ru | null |
# Бекап макбуков на удаленный сервер Time Machine для путешественников
Принцип работы утилиты Time Mac... | https://habr.com/ru/post/577226/ | null | ru | null |
# Burp Suite Tips
**Burp Suite** – это платформа для выполнения тестирования по безопасности веб-приложений. В этой заметке я поделюсь несколькими приёмами, как использовать данный инструмент более эффективно.

### Настройки
Для прав... | https://habr.com/ru/post/510612/ | null | ru | null |
# Модульный фронтенд для репликационного масштабирования или как перестать копировать репозитории целиком
В этой статье будут изложены основные идеи и показаны простые примеры для грамотной организации, ска... | https://habr.com/ru/post/647179/ | null | ru | null |
# Как улучшить DJI Spark. Часть 2. Про уголь
*Дело было вечером, делать было нечего (с)*
К [предыдущей](https://habr.com/ru/company/stc_spb/blog/670968/) статье про воздушный винт был комментарий от [@RusikR2D2](/users/RusikR2D2):
`У вас получился винт, оптимизированный для "нулевой" скорости (висение). Ваш коптер ... | https://habr.com/ru/post/693000/ | null | ru | null |
# Быстрее нативной разработки: опыт внедрения Flutter в крупной компании
Хотя сообщество мобильных разработчиков давно нахваливает Flutter, большие компании не спешат переходить на эту технологию. Так получилось, что здесь мы стали одними из первых: когда понадобилось быстро выпустить новое приложение, мы взвесили все... | https://habr.com/ru/post/533848/ | null | ru | null |
# Настройка Squid 3 + QuintoLabs Content Security 1.4 и интеграция с Active Directory

Про [Squid](http://www.squid-cache.org/) рассказывать не буду, а про возможности QCS расскажу.
Что же умеет делать QuintoLabs Content Secur... | https://habr.com/ru/post/136205/ | null | ru | null |
# В США по L-1: от первых собеседований до гринкарты
Привет, Хабр.

*Texas in ~~July~~ January*
Периодически у тебя тут обсуждают иммиграцию в различные страны. Вспоминают и про Штаты: кто-то считает, что туда попасть очень легко... | https://habr.com/ru/post/585466/ | null | ru | null |
# Redis in production
Хотелось бы рассказать о некоторых особенностях [Redis](http://redis.io/) при использовании на боевом сервере. Будут рассмотрены альтернативы при сохранении данных на диск, позволяющие достичь различной степени надёжности при сбоях. Так же будут приведены примеры конфигурации для резервного копир... | https://habr.com/ru/post/140893/ | null | ru | null |
# Управляем самодельными железяками по воздуху при помощи Open Sound Control
В этом материале я постараюсь рассказать, каким образом можно с телефона или планшета на iOS и Android удалённо управлять вашим самодельным устройством подключенным к сети. Любой, хоть сколь-нибудь знакомый с темой, к этому моменту уже решил,... | https://habr.com/ru/post/149838/ | null | ru | null |
# Преобразование ссылки на интерфейс для реализации класса в Delphi 2010
Не все нововведения в Delphi 2010 большие и заметные. Команда потратила массу времени реализуя множество дополнительных функциональных возможностей, исправлений и улучшений. Некоторые из них могут показаться незначительными по отдельности, но они... | https://habr.com/ru/post/85504/ | null | ru | null |
# Влияние протокола языкового сервера (LSP) на будущее IDE
*Перевод статьи* [*How the Language Server Protocol Affects the Future of IDEs*](https://www.freecodecamp.org/news/language-server-protocol-and-the-future-of-ide/)
*Автор оригинала* [*Mehul Mohan*](https://www.freecodecamp.org/news/author/mehulmpt/)
, но имеет представление о том, что такое шаблоны в C++. Специфических знаний или твердого владения программированием на шаблонах для понимания статьи вам не понадобитс... | https://habr.com/ru/post/543098/ | null | ru | null |
# Синхронизация процессов при распараллеливании задачи средствами Caché Event API
Сегодня наличие многоядерных, многопроцессорных и многоузловых систем является уже нормой при обработке большого объёма данных.
Как же можно задействовать все эти вычислительные мощности? Ответ очевиден — распараллелив задачу.
Но т... | https://habr.com/ru/post/167867/ | null | ru | null |
# Поиск оптимального пути для выявления отклонений в бизнес-процессе
Любая крупная компания представляет собой множество обособленных или взаимосвязанных процессов, которые решают задачи различной направлен... | https://habr.com/ru/post/600081/ | null | ru | null |
# Slice, или очень полезные ломтики в Perl
Решая задачи реального мира нам постоянно приходится работать со списками данных. И самые счастливые в этой деятельности — Perl-программисты :)
Это все потому, что для работы с частью массива или хеша у нас есть удобный slice. Slice — это не оператор, это принцип обработки... | https://habr.com/ru/post/92995/ | null | ru | null |
# Roslyn API, или из-за чего PVS-Studio очень долго проект анализировал
Многие ли из вас использовали сторонние библиотеки при написании кода? Вопрос риторический, ведь без применения сторонних библиотек разработка некоторых продуктов затягивалась бы на очень-очень большое время, потому что для решения каждой проблемы... | https://habr.com/ru/post/553788/ | null | ru | null |
# Learn OpenGL. Урок 5.10 – Screen Space Ambient Occlusion
 SSAO
----
Тема фонового освещения была затронута нами в уроке по [основам освещения](https://habrahabr.ru/post/333932), но лишь вскользь. Напомню: фоновая составляю... | https://habr.com/ru/post/421385/ | null | ru | null |
# Определение комбинации в Техасском Холдеме
Всем привет! Меня зовут Григорий Дядиченко, и я технический продюсер. А в прошлом я был профессиональным игроком в покер. Сейчас я решил сделать на Unity пример проекта с покером, который выложу в опенсорс, когда я его доделаю. А пока хочется посмотреть на интересную задачк... | https://habr.com/ru/post/705488/ | null | ru | null |
# Почему OpenVPN тормозит?
**Описанная проблема присуща только ветке OpenVPN 2.3, в 2.4 размеры буферов не меняются без требования пользователя.**
Время от времени, мне встречаются темы на форумах, в которых люди соединяют несколько офисов с использованием OpenVPN и получают низкую скорость, сильно ниже скорости ка... | https://habr.com/ru/post/246953/ | null | ru | null |
# В Asterisk версии 12 появился REST интерфейс (Asterisk REST Interface — ARI)
В Asterisk версии 12 появился REST интерфейс (Asterisk REST Interface — ARI).
Да, это RESTful API в натуре.
Пока имеются следующие ресурсы:
* Asterisk
* Bridges
* Channels
* Endpoints
* Events
* Recordings
* Sounds
* Applications
... | https://habr.com/ru/post/225007/ | null | ru | null |
# Реализация сервисов в MSWin
По рабочей необходимости приходится иногда писать системные сервисы для Microsoft Windows.
На Хабре уже есть статья [Создание своего Windows Service](http://habrahabr.ru/blogs/cpp/71533/) , но по моему мнению — статья не более чем краткий обзор, который можно найти в MSDN. В ней не рас... | https://habr.com/ru/post/91476/ | null | ru | null |
# Триумфальное возвращение Ломуто
*США, Техас, Остин, клуб Continental
Воскресенье, 5 января 1987 г.*
— Спасибо за приглашение, мистер Ломуто. Скоро я возвращаюсь в Англию, так что это было очень вовремя.
— Спасибо, что согласились со мной встретиться, мистер… сэр… Чарльз… Энтони Ричард… Хоар. Это большая честь д... | https://habr.com/ru/post/512106/ | null | ru | null |
# Tree — убийца JSON, XML, YAML и иже с ними
Здравствуйте, меня зовут Дмитрий Карловский и я… много думал. Думал я о том, что не так с XML и почему его в последнее время променяли, на бестолковый JSON. Результатом этих измышлений стал новый ~~стандарт~~ формат данных, который вобрал в себя гибкость XML, простоту JSON ... | https://habr.com/ru/post/248147/ | null | ru | null |
# Создание настраиваемого профиля Default User в Windows XP
При создании собственной сборки Windows XP с помощью [nlite](http://nliteos.com/), мне понадобилось некоторые настройки, которые обычно хранятся в HKEY\_CURRENT\_USER, применить для всех будущих пользователей.
Логично было бы предположить, что ветка реестр... | https://habr.com/ru/post/44012/ | null | ru | null |
# Mathics — бесплатная альтернатива Mathematica
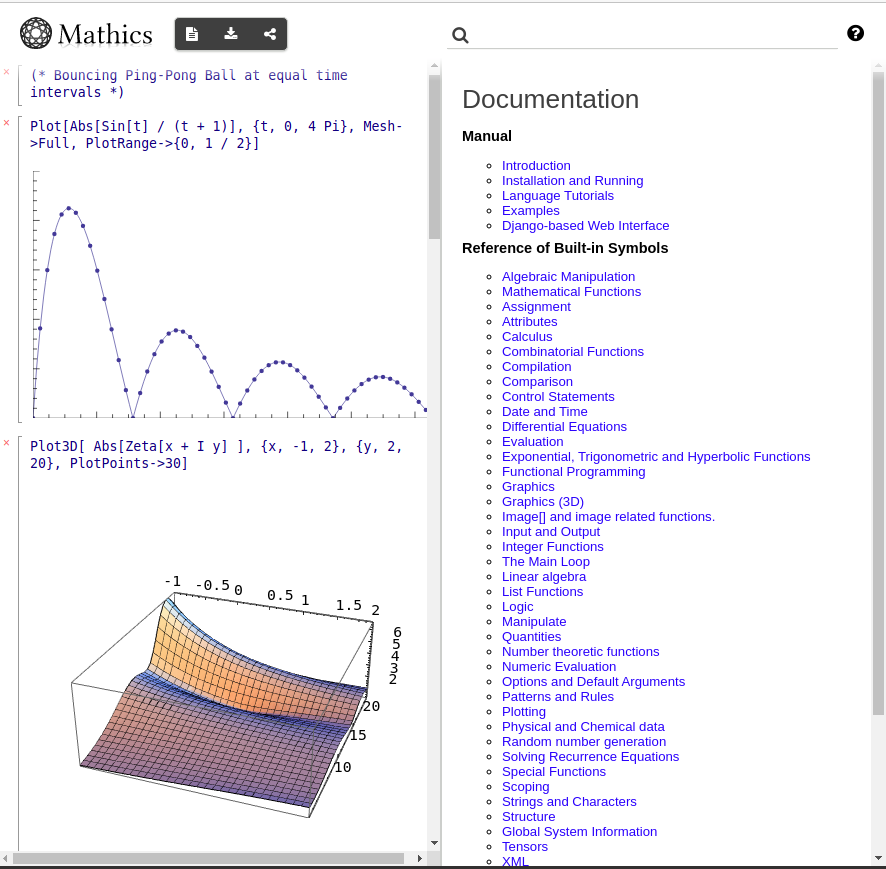
Многие студенты, школьники, инженеры и учёные пользуются великолепными вычислительными инструментами [Wolfram|Alpha](https://www.wolframalpha.com/) (онлайн), и [Wolfram Mathematica](ht... | https://habr.com/ru/post/699932/ | null | ru | null |
# Жизненный цикл кода на Python – модель выполнения CPython
Всем привет! Наступила весна, а это значит, что до запуска курса [«Разработчик Python»](https://otus.pw/Aex9/) остается меньше месяца. Именно этому курсу и будет посвящена наша сегодняшняя публикация.
](https://habrahabr.ru/company/tuturu/blog/326716/)
*В этой статье хочу поделиться переводом статьи о нативных [ECMA... | https://habr.com/ru/post/326716/ | null | ru | null |
# Моделирование простейшего потока
Всего с помощью двух слов можно охарактеризовать такие вещи, как
* поток вызовов на телефонной станции
* поток автомобилей на магистрали
* поток абонентов, звонящих в техподдержку
и многое другое. Всё это называется «простейший поток».
Очевидно, что количество вызовов на станц... | https://habr.com/ru/post/204324/ | null | ru | null |
# Learn OpenGL. Урок 4.3 — Смешивание цветов

Смешивание цветов
=================
Смешивание в OpenGL (да и других графических API, *прим. пер.*) является той техникой, которую обычно связывают с реализацией прозрачности ... | https://habr.com/ru/post/343096/ | null | ru | null |
# Разбираем EM-algorithm на маленькие кирпичики
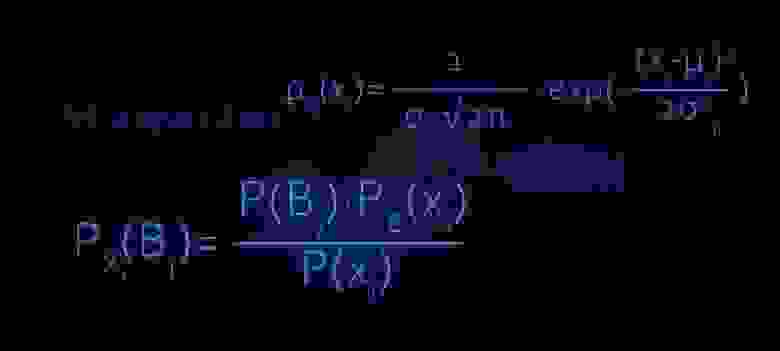
В этой статье, как Вы уже, наверное догадались, речь пойдет об устройстве EM-алгоритма. Статья прежде всего может быть интересна тем, кто потихонечку уже вступает в сообщество датаса... | https://habr.com/ru/post/501850/ | null | ru | null |
# Как внедрить статический анализатор кода в legacy проект и не демотивировать команду

Попробовать статический анализатор кода легко. А вот, чтобы внедрить его, особенно... | https://habr.com/ru/post/507508/ | null | ru | null |
# Ловим утечки памяти в С/С++

Приветствую вас, Хабровчане!
Сегодня я хочу немного приоткрыть свет над тем, как бороться с утечкой памяти в Си или С++.
На Хабре уже существует две статьи, а именно: [Боремся с утечками памяти (C++ C... | https://habr.com/ru/post/480368/ | null | ru | null |
# История одной оптимизации MySQL
Речь пойдет об оптимизации в MySQL базе данных.
Это случилось, когда мы делали систему для email рассылок. Наша система должна была высылать десятки млн. писем в день. Отправка письма — задача не из простых, хотя выглядит все довольно примитивно:
1. Собрать письмо из html креати... | https://habr.com/ru/post/451020/ | null | ru | null |
# Опыт сопряжения Java, JavaScript, Ruby и Python в одном проекте посредством GraalVM
В прошлом месяце вышла стабильная LTS-версия многоязычной среды выполнения [GraalVM 20.3.0](https://www.graalvm.org/ "Официальный сайт GraalVM") от корпорации [Oracle](https://www.oracle.com/ "Официальный сайт Oracle") и мне захотело... | https://habr.com/ru/post/534044/ | null | ru | null |
# Создание терминала для СКУД и УРВ. Часть 2
Всем доброго времени суток! В этой статье мы подробнее остановимся на ПО терминала учета рабочего времени и контроля доступа, о разработке которого я писал в [прошлой статье](https://habr.com/ru/post/563814/). Данная статья является логическим продолжением, т.к. в прошлой с... | https://habr.com/ru/post/592297/ | null | ru | null |
# Сравниваем Swift и Rust

Поводом для написания статьи стала публикация исходного кода языка Swift — мне стало интересно поближе познакомиться с ним. В глаза сразу же бросилась схожесть синтаксиса с другим молодым языком пр... | https://habr.com/ru/post/272681/ | null | ru | null |
# Пишем ОС на Rust. Настройка среды. Бинарник для «голого» железа
Настройка среды. "Голый" бинарник, или Исполняемый файл без main()
==================================================================
Первый шаг в написании своей ОСи — создание бинарника, не зависящего от стандартных библиотек, это делает возможным за... | https://habr.com/ru/post/527682/ | null | ru | null |
# Перенос пользователей и их привилегий в MySQL
Приветствую уважаемое Хабросообщество! Как известно у сервера MySql нет встроенных механизмов для переноса пользователей MySql и их привилегий на другой сервер. В сети готовых решений крайне мало, и в этой небольшой статье мы перенесем наших пользователей MySql и их прив... | https://habr.com/ru/post/328604/ | null | ru | null |
# Недельный геймдев: #101 — 25 декабря, 2022
Из [новостей](https://suvitruf.ru/2022/12/25/13212/weekly-gamedev-101-25-december-2022/): в сеть выложили исходный код отменённой Rayman 4, Rust-gpu 0.4 с трассировкой лучей, Kickstarter изменил правила в отношении ИИ-проектов на платформе.
Из интересностей: фреймворк для ... | https://habr.com/ru/post/707656/ | null | ru | null |
# Реалтайм-система мониторинга активности пользователей на сайте. Теперь на Node.js + Socket.IO
Добрый день.
В этой статье я расскажу о том, как реализовать систему мониторинга активности пользователей с помощью Node.js и Socket.IO. Выглядит это примерно так:
](https://habr.com/post/414653/)
Если описать в паре предложений по какому принципу работают сортировки обменами, то:
1. Попарно сравниваются элементы массива
2. Если элемент слева\* больше элемента справа, ... | https://habr.com/ru/post/414653/ | null | ru | null |
# Краеугольный камень псевдослучайности: с чего начинается поиск чисел

([с](https://www.pinterest.com/pin/442408363382585457/))
Случайные числа постоянно генерируются каждой машиной, которая может обмениваться данными. И даже есл... | https://habr.com/ru/post/351282/ | null | ru | null |
# Анализ и визуализация данных в финансах — анализ ETF с использованием Python
С проникновением аналитики во многие сферы нашей жизни она не могла обойти стороной финансы. В этой статье рассмотрим ее применение для анализа ETF с целью их анализа, в том числе и с применением визуализиции.
**1. О данных**
Для анализа ... | https://habr.com/ru/post/583808/ | null | ru | null |
# Создание игр на Python 3 и Pygame: Часть 3

(Остальные части туториала: [первая](https://habrahabr.ru/post/347138/), [вторая](https://habrahabr.ru/post/347170/), [четвёртая](https://habrahabr.ru/post/347266/... | https://habr.com/ru/post/347256/ | null | ru | null |
# Рулим трафиком в Linux. Часть вторая.
Первую часть читайте [здесь](http://habrahabr.ru/blogs/linux/42581/).
В этой статье мы рассмотрим:
— Авторизацию пользователей из базы данных MySQL.
— Детализацию трафика по направлениям.
#### Авторизация из MySQL. FreeRadius
В предыдущей статье я не стал акцентир... | https://habr.com/ru/post/42977/ | null | ru | null |
# CI/CD из GitHub в Яндекс Облако через Docker
Привет, Habr!
Heroku меньше чем через месяц станет недоступен для бесплатного использования. У многих моих знакомых, и у меня в том числе, на нем хостились несколько проектов. Поэтому встал вопрос миграции в другое облако. Остановился на Яндекс Облаке:
* Относительно не... | https://habr.com/ru/post/697206/ | null | ru | null |
# Полное руководство по расширениям JUnit 5
JUnit - одна из самых [популярных сред модульного тестирования](https://www.lambdatest.com/blog/9-of-the-best-java-testing-frameworks-for-2021/) в экосистеме Java. Версия JUnit 5 (также известная как Jupiter) содержит множество интересных нововведений, включая поддержку новы... | https://habr.com/ru/post/589135/ | null | ru | null |
# Git и Microsoft SQL Server
Привет всем!
В [предыдущем посте](http://habrahabr.ru/post/227185/) было рассказано о трудностях, которые испытывают разработчики при написании SQL-кода (причём актуальны эти проблемы не только для MS SQL Server). Здесь же рассказ о том, как использовать Git для версионного контроля код... | https://habr.com/ru/post/240019/ | null | ru | null |
# Анимации в WPF
#### Предисловие
Приветствую вас, дорогие хабраюзеры! Сегодня я хочу вам рассказать об анимации в WPF. О ней, конечно, писали ранее на хабре, однако я постараюсь рассказать подробнее. Мой пост будет скорее больше теоретический, однако, я надеюсь, вы извлечете из него выгоду.
Анимация в WPF отличае... | https://habr.com/ru/post/111126/ | null | ru | null |
# REDIS — а зачем?
Приветствую читателей! Я уже довольно давно пишу на Python, но как мне кажется серьезно работать начал только в этом году. Раньше единственное чем было наполнено мое портфолио - простейшие ... | https://habr.com/ru/post/705176/ | null | ru | null |
# Виртуальный сервер с Ubuntu 11.04, Software RAID и его восстановление
Привет Хабр. Хотел бы описать решение проблемы с Software RAID на Ubuntu Server 11.04 с которой я столкнулся неправильно перезагрузив сервер.
Пару дней назад, работал я, писал код на php, сервер офисный сильно не грузил. Вообще у нас принято ка... | https://habr.com/ru/post/162423/ | null | ru | null |
# Поиск часто встречающихся элементов в массиве
Задача: в массиве длиной *N* найти элемент, который повторяется больше *N*/2 раз.
Казалось бы, чего тут думать? Возьмём Dictionary<значение элемента, число появлений>, за один проход по массиву сосчитаем появления каждого элемента, потом выберем из словаря искомый эле... | https://habr.com/ru/post/167177/ | null | ru | null |
# Проверка работоспособности кода на множестве версий PHP
Всем доброго времени суток. На днях понадобилось проверить работоспособность 4 вариантов кода на разных версиях PHP (в сумме около 20). Причём изначально было понятно что 4 экземплярами дело не ограничится — в будущем подобных тестов предвидится больше. Вручную... | https://habr.com/ru/post/169311/ | null | ru | null |
# Еще немного про разработку плагинов для IntelliJ
В последнее время на Хабре стали появляться статьи про создание расширений для Intellij IDE — [одна](http://habrahabr.ru/post/148996/), а вот и [другая](http://habrahabr.ru/post/149100/).
Я продолжу эту славную тенденцию и постараюсь описать те места Intellij OpenA... | https://habr.com/ru/post/150829/ | null | ru | null |
# Доработка парсера логов Squid для корректного просмотра посещенных HTTPS ресурсов
Всем привет! Я получал, и получаю множество писем от людей с вопросами по Squid, который работает на основе [моей](https://habrahabr.ru/post/267851/) статьи. Наиболее часто возникает вопрос про просмотр логов Squid каким-либо парсером.... | https://habr.com/ru/post/307686/ | null | ru | null |
# Как с fio проверить диски на достаточную производительность для etcd
***Прим. перев.**: эта статья — итоги мини-исследования, проведенного инженерами IBM Cloud в поисках решения реальной проблемы, связанной с эксплуатацией базы данных etcd. Для нас была актуальна схожая задача, однако ход размышлений и действий авто... | https://habr.com/ru/post/505100/ | null | ru | null |
# Apollo graphql client — разработка приложений на react.js без redux
Apollo graphql client представляет удобный лаконичный спсоб работы с данными в приложениях react. В большинстве случаев все то, что мы привыкли делать с помощью redux, гораздо проще сделать при помощи Apollo graphql client. То, о чем я хотел бы расс... | https://habr.com/ru/post/358292/ | null | ru | null |
# Разработка под Android, грабли большие и не очень
Ниже я попробую описать ряд неприятных особенностей с которыми может столкнуться разработчик для платформы Android. Не все они являются особенностью именно операционной системы Android, но так или иначе шансы встретиться с ними есть.
Грабли большого размера
------... | https://habr.com/ru/post/97909/ | null | ru | null |
# Преобразование инфиксной нотации в постфиксную
Что такое [инфиксная](https://ru.wikipedia.org/wiki/%D0%98%D0%BD%D1%84%D0%B8%D0%BA%D1%81%D0%BD%D0%B0%D1%8F_%D0%BD%D0%BE%D1%82%D0%B0%D1%86%D0%B8%D1%8F) нотация и [постфиксная](https://ru.wikipedia.org/wiki/%D0%9E%D0%B1%D1%80%D0%B0%D1%82%D0%BD%D0%B0%D1%8F_%D0%BF%D0%BE%D0%... | https://habr.com/ru/post/489744/ | null | ru | null |
# Производительность фронтенда. Часть 3 — оптимизация шрифтов
***От переводчика:** Это восьмая статья из [цикла о Node.js](https://hacks.mozilla.org/category/a-node-js-holiday-season/) от команды Mozilla Iden... | https://habr.com/ru/post/197370/ | null | ru | null |
# Вся правда о шаблонизаторах
*Статейка старенькая, но думаю до сих пор актуальная*
Cлишком часто я в последнее время слышу слово «шаблонизатор». Не утихают споры между сторонниками разных шаблонных движков. Одни говорят что логика в шаблонах это хорошо, другие считают что это зло. Даже сейчас очень часто встречают... | https://habr.com/ru/post/27999/ | null | ru | null |
# Выращивание Магических Квадратов с помощью Python
")Шабло... | https://habr.com/ru/post/564394/ | null | ru | null |
# Batfish. Введение

Одной из проблем современных сетей является их хрупкость. Множество правил фильтраций, политик обмена маршрутной информации, протоколов динамического роутинга делают сети запутанными и подверженными влиянию ... | https://habr.com/ru/post/441532/ | null | ru | null |
# Приведение значений к Boolean в JavaScript
Логическое (или булевое) значение - это примитивный тип данных, который может содержать в себе true или false (истина или ложь). JavaScript использует приведение типа, чтобы привести значение... | https://habr.com/ru/post/667662/ | null | ru | null |
# Синергия Graphviz и препроцессора C/C++
Это статья посвящена тому, как использовать популярный инструмент рисования графов *Graphviz* в кооперации с препроцессором C/C++ (далее просто препроцессор).
Ключевым моментом является то, что язык описания графов *dot*, который использует *Graphviz*, по своему синтаксису пр... | https://habr.com/ru/post/499170/ | null | ru | null |
# Использование шаблона Command для организации RPC-вызовов в GWT
В своем прошлогоднем выступлении в рамках [Google I/O Ray Rayan](http://code.google.com/intl/ru-RU/events/io/2009/sessions/GoogleWebToolkitBestPractices.html "Google I/O Ray Rayan") поведал аудитории о том, как правильно стоить архитектуру более-менее к... | https://habr.com/ru/post/94844/ | null | ru | null |
# Python Testing with pytest. Просто, Быстро, Эффективно и Масштабируемо. Предисловие и Ведение
[Дальше](https://habr.com/ru/post/448782/) 
*Систематическое тестирование программного обеспечения, особенно в сообществе Python, часто либ... | https://habr.com/ru/post/426699/ | null | ru | null |
# Раскрашивание изображений с использованием нейронных сетей
[DeOldify](https://github.com/jantic/DeOldify) — это проект, основанный на глубоком обучении, для раскрашивания и восстановления изображений. Модель использует архитектуру NoGAN для обучения модели.
Мы будем использовать эту модель, чтобы преобразовать неко... | https://habr.com/ru/post/681928/ | null | ru | null |
# Работа с Facebook API из приложений UWP
[](http://habrahabr.ru/post/307026/)
Люди, как правило, существа очень забывчивые. Для того чтобы не заставлять пользователей запоминать новый пароль при регистрации в вашем приложе... | https://habr.com/ru/post/307026/ | null | ru | null |
# ML,VR & Robots (и немного облака)
Всем привет!
Хочу рассказать об очень не скучном проекте, где пересеклись робототехника, Machine Learning (а вместе это уже Robot Learning), виртуальная реальность и немного облачных технологий. И все это на самом деле имеет смысл. Ведь это и правда удобно — вселяться в робота, ... | https://habr.com/ru/post/486680/ | null | ru | null |
# Построение тепловой карты именованных сущностей
Именованные сущности – это слово или сочетание, обозначающее объект либо явление определенной категории. Говоря о таких объектах в контексте анализа данных, чаще всего имеют в виду ограниченный набор видов: имя (псевдоним), дата, должность (роль), адрес, денежная сумма... | https://habr.com/ru/post/573024/ | null | ru | null |
# Математика нужна программистам, или задача, которую мне пришлось решать
Всем привет!
Я работаю над [WebRTC](https://webrtc.googlesource.com/src/+/refs/heads/master/README.md) - фреймворком для аудио-видео конференций (или звонков? проще говоря - real time communication). В этой статье я хочу описать интересную зада... | https://habr.com/ru/post/519754/ | null | ru | null |
# Ansible против Puppet
Ansible и Puppet представляют собой системы управления конфигурациями (SCM), необходимые для построения повторяющихся инфраструктур.
Ansible отличается простотой использования, имеет безагентную архитектуру (не требует установки агента/клиента на целевую систему) и YAML-подобный DSL, написа... | https://habr.com/ru/post/490502/ | null | ru | null |
# Предсказание тяжести страховых требований для компании Allstate. Дипломный проект нашего выпускника
Хабр, привет! Наш выпускник 4-го набора программы [«Специалист по большим данным»](http://newprolab.com/bigdata/?utm_source=habr&utm_campaign=danilyuk) Кирилл Данилюк поделился своим исследованием, которое он выполнил... | https://habr.com/ru/post/317246/ | null | ru | null |
# Обработка сигналов в Java
Передо мной частенько вставала задача написать какой-нибудь Java-сервис. В качестве ОС мы используем по большей части линукс, так что удобнее всего управляться с такими сервисами — работать с ними как с демонами. То есть, запускаем:
> start-stop-daemon --start --make-pidfile --pidfile /v... | https://habr.com/ru/post/78035/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.