
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Создаём игру на KPHP с помощью FFI и SDL
KPHP теперь поддерживает механизм [Foreign Function Interface](https://www.php.net/manual/ru/class.ffi.php) (FFI). Мы с [Владом](https://github.com/troy4eg) решили продемонстрировать его возможности и за сутки написали первую в мире графическую игру на [KPHP](https://github.c... | https://habr.com/ru/post/581238/ | null | ru | null |
# Динамическое добавление свойств в языке Java
##### Disclaimer
Инструмент родился как [способ побороть недочеты проектирования](http://ru.wikipedia.org/wiki/%D0%9F%D0%B0%D0%BB%D0%BB%D0%B8%D0%B0%D1%82%D0%B8%D0%B2) малой кровью. Я с трудом могу представить ситуацию, где использование инструмента могло бы быть продикто... | https://habr.com/ru/post/223971/ | null | ru | null |
# Настройка Opennebula с Ceph RDB, CephFS
Данная статья расскажет о том, как установить Ceph на несколько нод и установить Opennebula, а так же произвести интеграцию Opennebula с Ceph RDB, CephFS
**ВНИМАНИЕ !!!**
В продакшине не рекомендуется смешивать OSD ноды и ноды, где будет запускаться KVM машины
Ну... поехал... | https://habr.com/ru/post/649741/ | null | ru | null |
# Как посчитать синус быстрее всех на хабре
[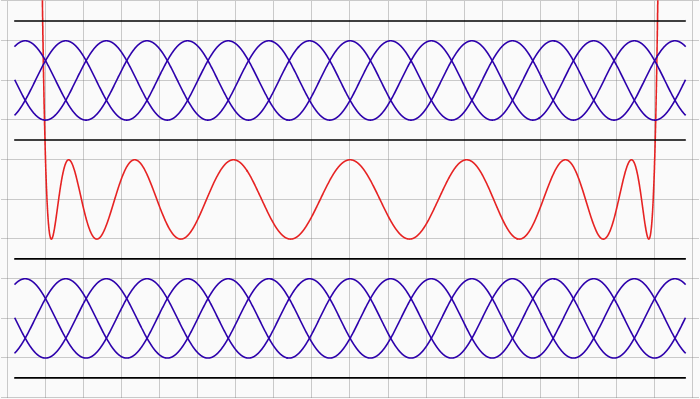](https://habr.com/ru/company/ruvds/blog/584460/)
Несмотря на свою кажущуюся банальность, темы о вычислении синуса достаточно регулярно появляются на хабре. И каждый раз их авторы или делают сомни... | https://habr.com/ru/post/584460/ | null | ru | null |
# Защита целостности кода с помощью PGP. Часть 2. Создание мастер-ключа
Перед вами перевод второй части серии материалов, посвящённых защите целостности кода с помощью PGP. [В прошлый раз](https://habrahabr.ru/company/ruvds/blog/349618/) мы разобрали основы PGP, а сегодня поговорим о том, как создавать 4096-битные мас... | https://habr.com/ru/post/350028/ | null | ru | null |
# FightCode: танковые войны на JavaScript
[FightCode](http://fightcodegame.com/) — это онлайн-игра для программистов, построенная по образу и подобию классической [Robocode](http://habrahabr.ru/post/59784/). Для программирования танков используется JavaScript, все сражения происходят прямо в браузере, а редактор кода ... | https://habr.com/ru/post/174461/ | null | ru | null |
# Генерация типизированных ссылок на элементы управления Avalonia с атрибутом x:Name в XAML с помощью C# Source Generators
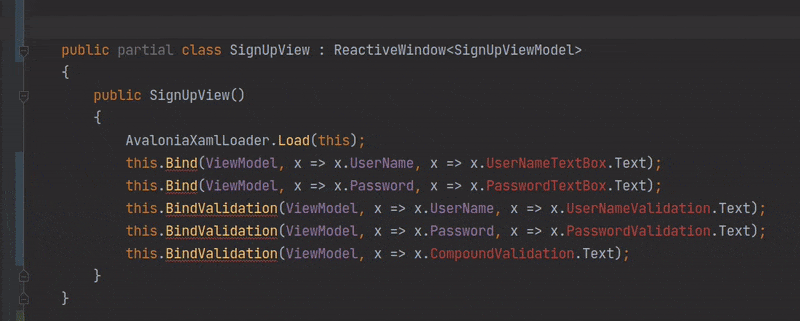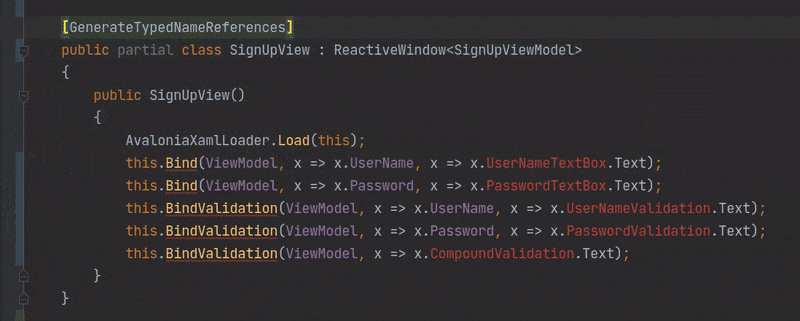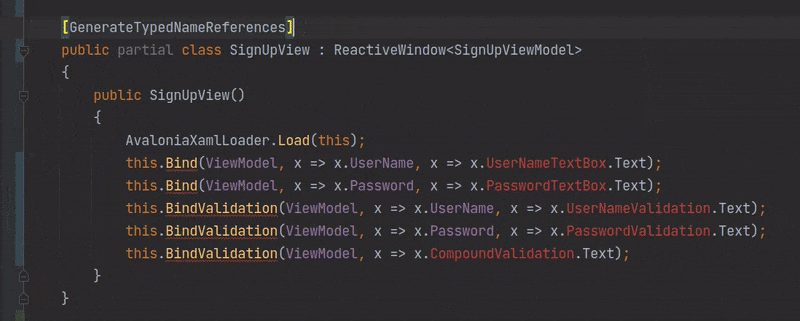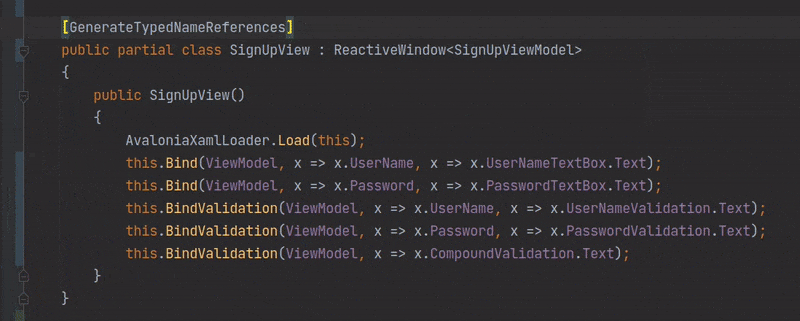
В апреле 2020-го года разработчиками платформы .NET 5 [был анонсирован](https://habr.com/ru/post/503172/) новый спосо... | https://habr.com/ru/post/530454/ | null | ru | null |
# Локализация на основе ScriptableObject для Unity3D
Введение
--------
Приветствую Вас, уважаемые читатели. В данной статье пойдет речь о создании системы локализации приложений, созданных в среде **Unity3D**, в основе которой лежит использование класса **ScriptableObject**, что позволяет локализовать не только текст... | https://habr.com/ru/post/358916/ | null | ru | null |
# JavaScript 1.8
JavaScript 1.8 предоставляет огромное количество вкусного синтаксического сахара, в основном любителями функциональщины. Но очень мало разработчиков знает об этой красоте. Конечно, к сожалению, все эти вкусности не поддерживает даже Chrome (что уж говорить об IE?), а только Firefox 3+, но JavaScript-р... | https://habr.com/ru/post/113344/ | null | ru | null |
# Мой Опыт Работы С Shopify Как Разработчика
С Shopify я работаю практически год, за это время я столкнулся с множеством интересных задач и сейчас постараюсь поделиться своим опытом. Если вы хотите изучить Shopify разработку, то вам будет полезно прочитать эту статью, она должна помочь вам познакомиться с Шопифай и во... | https://habr.com/ru/post/691044/ | null | ru | null |
# Запускаем Nextion Editor 0.34 под Wine
Не так давно был выпущен в свет потрясающий продукт от компании ITEAD — экран Nextion HMI. Многие знают про то как можно подключить экран к микроконтроллеру, например, к тому же arduino и выводить графическую информацию. Если немного постараться, можно добавить резистивную сенс... | https://habr.com/ru/post/393539/ | null | ru | null |
# Интеграция Youtrack со встроенным (embedded) Hub с Teamcity, Gitlab
В этом посте будет рассказано о том как сделать интеграцию Youtrack со встроенным (embedded) Hub с Teamcity, Gitlab.
**[YouTrack](https://www.jetbrains.com/ru-ru/youtrack/)** — коммерческая система отслеживания ошибок, программное обеспечение для у... | https://habr.com/ru/post/512940/ | null | ru | null |
# Критические уязвимости DNS-сервера BIND позволяют удаленно отключать его и проводить DoS-атаки
[](https://habrahabr.ru/company/pt/blog/279503/)
В популярном DNS-сервере BIND обнаружены критические уязвимости. Их эксплуатац... | https://habr.com/ru/post/279503/ | null | ru | null |
# Боярское программирование
Сегодня, во время тестирования русской версии Visual Studio 2008 (привет, [gaidar](https://habrahabr.ru/users/gaidar/)!) было обнаружено, что VS понимает не только переменные на латинице, а и на русском. И пришла идея «боярского программирования»…
«Боярское программирование» от слова «б... | https://habr.com/ru/post/41303/ | null | ru | null |
# Финансы от пасьянсов поют романсы
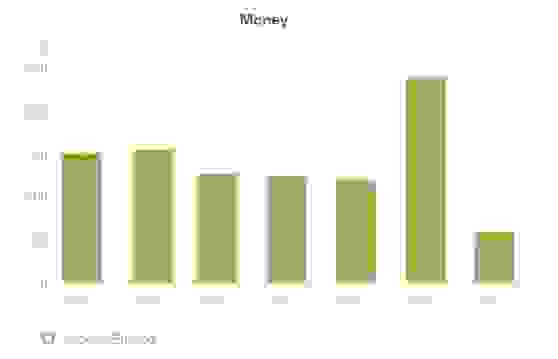
Прошло более месяца, как я выпустил два пасьянса под iOS. Привожу финансовый отчет о доходах с рекламы упомянутых опусов.
Для разнообразия, текст статьи разбавл... | https://habr.com/ru/post/228777/ | null | ru | null |
# User Defined Type. Что это и как его использовать, часть 1
Картинка: [Designed by vectorjuice / Freepik](https://www.freepik.com/free-vector/businessmen-work-with-improvement-diagrams-charts-business-proc... | https://habr.com/ru/post/691000/ | null | ru | null |
# Метод Уэлфорда и одномерная линейная регрессия
[Одномерная линейная регрессия](http://www.machinelearning.ru/wiki/index.php?title=Simple_linear_regression) — один из самых простых регрессионных методов (и вообще один из самых простых методов машинного обучения), который позволяет описывать линейную зависимость наблю... | https://habr.com/ru/post/335522/ | null | ru | null |
# Осторожно при покупке MacBook. Высокотехнологический способ мошенничества в оффлайне
Доброго всем времени суток дорогие друзья. Давно я не писал на хабре и очень жаль что моя новая публикация касается мошенников. И не просто мошенников, про которых я где-то прочитал, а про мошенников, которые меня лично обманули.
... | https://habr.com/ru/post/157969/ | null | ru | null |
# Не очень большие данные
В статье будут рассмотрены возможности, предоставляемые встроенным или декларативным секционированием в 12 версии PostgreSQL. Демонстрация подготовлена для одноименного [доклада](https://www.highload.ru/siberia/2019/abstracts/5361) на конференции HighLoad++Siberia 2019 (upd: появилось [видео]... | https://habr.com/ru/post/456716/ | null | ru | null |
# Двоично-троичная битовая магия
Существует классическая задача для собеседований, часто формулируемая следующим образом:
> Имеется массив натуральных чисел. Каждое из чисел присутствует в массиве ровно два раза, и только одно из чисел не имеет пары. Необходимо предложить алгоритм, который за минимальное число проход... | https://habr.com/ru/post/349996/ | null | ru | null |
# Go 1.20 и арена памяти
Одной из революционных особенностей Go в сравнении с другими компилируемыми языками стало автоматическое управление освобождением памяти от неиспользуемых объектов (сборка мусора). В ... | https://habr.com/ru/post/710124/ | null | ru | null |
# Функция Reactive во Vue: как это работает
После jQuery я попробовал AngularJS и был очарован его возможностями. Несколько строк в AngularJS заменяли кучу спагетти-кода в jQuery. Это было похоже на магию. Се... | https://habr.com/ru/post/664506/ | null | ru | null |
# Технология SQL-файл, препроцессор для T-SQL, “бок-о-бок” файлы и др
Завершив в недавнем прошлом очередную доработку своей легковесной технологии SQL-файл, применяемой для эффективной трансляции файлового SQL-кода в базу данных, автор данной статьи решил в очередной раз представить (в этой заметке теперь, на популярн... | https://habr.com/ru/post/672084/ | null | ru | null |
# АД по имени JSMPP
Видимо в жизни каждого программиста наступает момент, когда ему становится необходимо научиться отправлять [SMS](http://ru.wikipedia.org/wiki/SMS)-сообщения. Вчера такой момент наступил и у меня. Сразу скажу, что эта необходимость никак не связана с рекламными рассылками и прочим спамом. SMS-ки пон... | https://habr.com/ru/post/202142/ | null | ru | null |
# Как подружить LO и MSO. Часть 2: автоматическая генерация тестов для docx и odt
Здравствуй, читатель! [Как и обещал](http://habrahabr.ru/post/214543/#comment_7372087), продолжаю тестировать различные форматы документов в MS Office 2010 и LibreOffice 3.5. За время написания этого поста я успел проверить в работе форм... | https://habr.com/ru/post/215103/ | null | ru | null |
# Как мы в Slack используем Terraform
[](https://habr.com/ru/company/ruvds/blog/707154/)
В Slack всей своей инфраструктурой, опирающейся на AWS, DigitalOcean, NS1 и GCP, мы управляем с помощью Terraform. И хотя большая её часть работ... | https://habr.com/ru/post/707154/ | null | ru | null |
# Javascript — работаем с search-частью произвольного url
Под впечатлением от идеи [создания библиотеки](http://habrahabr.ru/blogs/javascript/65407/) для работы с search-частью произвольной ссылки решил написать функцию (в соавторстве с [Kupyc](https://geektimes.ru/users/kupyc/), респект за учаcтие — ему принадлежит б... | https://habr.com/ru/post/67329/ | null | ru | null |
# Когда 'a' не равно 'а'. По следам одного взлома
Пренеприятнейшая история случилась с одним моим знакомым. Но насколько она оказалась неприятной для Михаила, настолько же занимательной для меня.
Надо сказать, что приятель мой вполне себе *UNIX*-пользователь: может сам поставить систему, установить *mysql*, *php* и... | https://habr.com/ru/post/465355/ | null | ru | null |
# ES6 и за его пределами. Глава 1: ES? Настоящее и Будущее

Хочу уделить внимание книге, которую написал [Kyle Simpson](http://getify.me/) — «ES6 и за его пределами» (англ. «ES6 & Beyond»). Конечно, вклад внес не только он,... | https://habr.com/ru/post/257355/ | null | ru | null |
# I trained a neural network on my drawings and give the model for free (and teach you to create your own)
Great for seamless patterns, abstract drawings, and watercolor-styled images. **How to use it and train a neural network on your own pictures?**
Download the model here: [https://huggingface.co/netsvetaev/netsve... | https://habr.com/ru/post/699002/ | null | en | null |
# Unity3D 3.х Terrain Bump Specular Shader
На данный момент [Unity3D](http://unity3d.com/) не поддерживает наложение на встроенный ландшафт карты нормалей и отражения(specular). Гугление по этому поводу принесло не очень впечатляющие результаты в виде вот [этого](http://sixtimesnothing.wordpress.com/2010/10/10/bump-ma... | https://habr.com/ru/post/144016/ | null | ru | null |
# NeoBook: среда программирования для непрограммистов

NeoBook: среда программирования для непрограммистов
===================================================
Для кого эта статья
-------------------
Статья написана, в первую очеред... | https://habr.com/ru/post/451346/ | null | ru | null |
# ZRouter — пихаем FreeBSD в роутер DLINK
Пару недель назад
Я бегал по хабру как угорелый в поисках рецепта (как оживить умерший роутер DIR-620).
Основная проблема была в том что родная прошивка 620-ки не принимала модем Verizon U175. И после нескольких прошивок DDWRT я наконец-то нашел ту самую которая и угроби... | https://habr.com/ru/post/129451/ | null | ru | null |
# Группа The Shadow Brokers опубликовала новые эксплойты АНБ

*EASYSTREET (rpc.cmsd): удалённый рут для Solaris, один из опубликованных эксплойтов*
В августе 2016 года группа хакеров The Shadow Brokers [выложила](https:/... | https://habr.com/ru/post/357312/ | null | ru | null |
# Отправка сообщения с вложением по e-mail из модуля в Drupal
Понадобилось мне недавно сделать казалось бы простейшую вещь, а именно с помощью некоторой формы на сайте отправить письмо с вложением. И сделать это надо на сайте, построенном на Друпале… Как оказалось, [этот](http://habrahabr.ru/blogs/drupal/65523/) пост ... | https://habr.com/ru/post/89719/ | null | ru | null |
# TailSampler — паралельная отправка GET-запросов в Apache.JMeter

### 1. Назначение плагина «HTTP Request Tail»
Плагин упрощает загрузку встроенных ресурсов, позволяет ***параллельно*** выполнять ***указанные*** GET-запро... | https://habr.com/ru/post/312352/ | null | ru | null |
# Внутренний сервер обновления Adobe Flash Player
### Предыстория
Начальство поставило задачу: нужно поддерживать в актуальном состоянии Flash Player. Масштабы: ~15000 компов, на половине из которых FP действительно нужен.
Казалось бы, в чём проблема — делаем доменную политику, запихиваем MSI пакет и радуемся… Но ... | https://habr.com/ru/post/270283/ | null | ru | null |
# Quip: текстовый процессор от основателя Google Maps и FriendFeed

Сегодня был запущен [Quip](https://quip.com/) — современный текстовый процессор, позволяющий создавать документы на любом устройстве.... | https://habr.com/ru/post/188422/ | null | ru | null |
# Методы расширения в С++
Несколько дней назад Бьёрн Страуструп опубликовал предложение [N4174](http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2014/n4174.pdf) комитету по стандартизации С++ названное "**Call syntax: x.f(y) vs. f(x,y)**". Вот вкратце его суть: объявить выражение **x.f(y)** (вызов для объекта **х** ... | https://habr.com/ru/post/240851/ | null | ru | null |
# Альтернатива firePHP
Пару недель решил взяться за изучение PHP и спустя какое-то количество времени отлаживать скрипты через echo стало неудобно. Вспомнил о существовании такой вещи как firePHP, почитал документацию, скачал, поставил, обрадовался. Ведь так классно отлаживать скрипты через консоль!
Но увы, по непо... | https://habr.com/ru/post/43080/ | null | ru | null |
# Тонкости оператора switch
Да, это целая статья по самому обычному switch в JDK 7. Бывает так, что накопленный материал кажется интересным и малоизвестным, а потом оказывается, что любая бабка у подъезда уже 50 лет знает об особенностях реализации switch. Но я попробую. Для затравки, предлагаю 3 вопроса:
1. (Прост... | https://habr.com/ru/post/174065/ | null | ru | null |
# Постраничная выборка данных — альтернативный взгляд на давно известное
Проблема постраничной выборки информации из БД стара, как сама БД, и соответственно, обсуждена не одну тысячу раз. Нет, пожалуй, ни одной клиент-серверной системы, в которой эта проблема так или иначе не была бы адресована и решена. Сегодня я хоч... | https://habr.com/ru/post/189946/ | null | ru | null |
# Создаем текстовый редактор на React.js
Введение
--------
Привет! Меня зовут Данила, и я фронтенд-разработчик в [KTS](https://kts.studio/).
Однажды в одном из своих проектов мне потребовалось реализовать к... | https://habr.com/ru/post/576682/ | null | ru | null |
# WWDC15. День второй. Подробности
После поверхностных анонсов первого дня наступает пора полноценных сессий для разработчиков, в которых инженеры Apple рассказывают о новых функциях, фреймворках и технологиях. Второй день практически целиком посвящен анонсированным фичам главных платформ и инструментам разработки.
... | https://habr.com/ru/post/259975/ | null | ru | null |
# Swift.assert — жизнь после релиза
Как часто вы используете `Swift.assert()` в вашем коде? Я, честно, использую довольно часто (Если это плохая практика, то, пожалуйста, напишите в комментариях — почему это плохо?). В моем коде часто можно встретить, например, такой вызов:
```
Swift.assert(Thread.isMainThread)
```... | https://habr.com/ru/post/476792/ | null | ru | null |
# PHP-Дайджест № 174 (10 – 24 февраля 2020)
[](https://habr.com/ru/post/489662/)
Свежая подборка со ссылками на новости и материалы. В выпуске: 5 новых RFC из PHP Internals, а также предложение по развитию языка и пара прототипов н... | https://habr.com/ru/post/489662/ | null | ru | null |
# Метод анлока iPhone с помощью SAM просуществовал недолго
#### Уязвимость исправлена
Метод разблокировки (анлока) iPhone c помощью гениальной утилиты SAM больше не работает, так как Apple исправили уязвимость, которая позволяла оживить iPhone практически в независимости от версии baseband и установленной iOS, сообщи... | https://habr.com/ru/post/143256/ | null | ru | null |
# Доступ к данным в многопользовательских приложениях
 Вопрос ограничения доступа к данным встает при разработке многопользовательских систем почти всегда. Основные сценарии следующие:
1. ограничение доступа к данным для пользовате... | https://habr.com/ru/post/414897/ | null | ru | null |
# Spring Boot: от начала до продакшена

В данной статье я попробую расписать все шаги, которые потребуются для создания небольшого п... | https://habr.com/ru/post/257223/ | null | ru | null |
# Дисковая балансировка в Nginx

В этой статье я опишу интересное решение на базе Nginx для случая, когда дисковая система становится узким местом при раздаче контента (например, видео).
#### Постановка задачи
Имеем зад... | https://habr.com/ru/post/233525/ | null | ru | null |
# Собственные уведомления (notify) в Gnome
Речь пойдет об извещениях которые показываю практически все приложения от Rhythmbox до сетевых подключений. Хотелось иметь возможность показывать в таком виде собственные и поэтому я взял бубен и начал капать )
для начала понадобится установить пакет libnotify-bin, я под u... | https://habr.com/ru/post/47892/ | null | ru | null |
# Построение Full-Mesh VPN-сети с использованием fastd, tinc, VpnCloud и тестирование производительности

Привет, Хабр! Меня зовут Олег, я архитектор клиентских решений в Selectel. Недавно мы столкнулись с интересным клиентским кейсо... | https://habr.com/ru/post/697128/ | null | ru | null |
# Настраиваем VTL под Centos 7
Однажды так случилось, что понадобилось протестировать СРК с ленточной библиотекой. Все бы хорошо, но ленточной библиотеки под руками не нашлось, а просить знакомого заказчика о таком крайне не хотелось. И вот тут-то и пришла идея о создании тестовой инфраструктуры с VTL.
Вариантов до... | https://habr.com/ru/post/324192/ | null | ru | null |
# Тестирование инфраструктуры как код с помощью Pulumi. Часть 2
Всем привет. Сегодня делимся с вами заключительной частью статьи [«Тестирование инфраструктуры как код с помощью Pulumi»](https://habr.com/ru/company/otus/blog/463001/), перевод которой подготовлен специально для студентов курса [«DevOps практики и инстру... | https://habr.com/ru/post/463637/ | null | ru | null |
# Безопасность vs юзабилити by Росбанк
С недавних пор Росбанк решил поднять уровень безопасности своего интернет-клиента.
Специалисты Росбанка, решив обезопасить своих клиентов от клавиатурных шпионов, придумали использовать виртуальную клавиатуру для ввода так называемого ПИН2, и реализовав ее с особым наплеватель... | https://habr.com/ru/post/99758/ | null | ru | null |
# Теория Игр и функция Шпрага-Гранди
Доброго времени суток, уважаемое Хабрасообщество.
В последнее время все большее и большее распространение получает олимпиадное программирование, неотъемлемой частью которого является знание алгоритмов (и, разумеется, умение их применять).
Я хочу рассказать вам основы теории И... | https://habr.com/ru/post/124856/ | null | ru | null |
# Установка Ruby on Rails под Windows
Заинтересовал меня Rails. Купил пару книг, прочитал… достаточно чтобы, зачесались руки и пришло время ставить сабж. И приступать… хотя бы к экспериментам.
Задача: поставить Rails под Windows 7 (не спрашивайте меня почему) и запустить сервер.
Оказалось — это квест. Пары щелч... | https://habr.com/ru/post/130689/ | null | ru | null |
# Устройство игрового движка для NES на примере игр «Capcom»
В моей третьей статье про NES-игры я покажу техники, используемые для создания игровых движков, а именно реализацию скроллинга экрана, переключение банков памяти, организацию списка объектов, устройство системы анимаций персонажей, функции обновления игровых... | https://habr.com/ru/post/259761/ | null | ru | null |
# Подключение node-приложения к Google Calendar API
Как-то неожиданно для меня подключение своего nodejs-приложения к Google Calendar API оказалось довольно нетривиальной задачей. Несмотря на подробное описание вариантов подключения на русском языке пришлось продираться через лес различных настроек и конфигураций. В с... | https://habr.com/ru/post/524240/ | null | ru | null |
# Как посчитать ROI от автоматизации тестирования с Selenium?

*Перевод статьи подготовлен специально для студентов курса [«Python QA Engineer»](https://otus.pw/8Iwa/)*
---
Кроссбраузерное тестирование – это именно тот тип тестирован... | https://habr.com/ru/post/461257/ | null | ru | null |
# Система управления микроклиматом теплицы
#### Начало пути
Одним солнечным деньком, придя в универ, я узнал, что в этом семестре у меня курсовой по схемотехнике. Преподаватель предлагал сделать только пояснительную записку «как реализовать проект» или же познать темную сторону инженерии и создать реальное устройство... | https://habr.com/ru/post/388837/ | null | ru | null |
# Использование Paging library совместно с Realm
На одном из митингов Android-отдела я подслушал, как один из [наших](http://magora-systems.com) разработчиков сделал небольшую либу, которая помогает сделать «бесконечный» список при использовании Realm, сохранив «ленивую загрузку» и нотификации.
Сделал и написал чер... | https://habr.com/ru/post/467097/ | null | ru | null |
# Как натренировать и использовать модель машинного обучения из Google таблиц с помощью BigQuery ML
Электронные таблицы используются везде. Это один из самых удобных инструментов для повышения производительн... | https://habr.com/ru/post/545662/ | null | ru | null |
# Just for Fun: PVS-Studio Team Came Up With Monitoring Quality of Some Open Source Projects
Static code analysis is a crucial component of all modern projects. Its proper application is even more important. We decided to set up a regular check of some open source projects to see the effect of the analyzer's frequent ... | https://habr.com/ru/post/541918/ | null | en | null |
# Анализ проникновения бота через эксплоит в старых версиях phpmyadmin и рекомендации по настройкам безопасности php-хостинга
Имею на администрировании несколько серверов, на которых хостятся восновном свои проекты, но кроме них ещё довольно много пришлось разместить левых сайтов — клиентов, знакомых, знакомых знакомы... | https://habr.com/ru/post/109974/ | null | ru | null |
# Реализация фоновой загрузки файлов на сервер Caché
У разработчиков веб-приложений на Caché и Ensemble часто возникает задача «file upload» — загрузки файлов с браузера. Недавно на форуме по Caché на [SQL.ru](http://www.sql.ru/forum/actualtopics.aspx?bid=56) снова возникло несколько вопросов о том, как сделать фонову... | https://habr.com/ru/post/158681/ | null | ru | null |
# WPF Binding: Что означает {Binding}?
Этой первой статьей я бы хотел начать цикл переводов постов с замечательного [блога](http://www.beacosta.com/blog/), в котором Beatriz Costa детально объясняет определенные аспекты Binding'а в WPF. В первом посте затрагивается тема использования Binding'а без указания каких-либо ... | https://habr.com/ru/post/41108/ | null | ru | null |
# О сборке JDK 8 на Ubuntu, качестве кода Hotspot и почему всё валят на C++
Хотел сегодня поспать, но опять не удалось. В Телеграме появилось сообщение, что у кого-то не собирается Java… и мы очнулись только через пару часов, уставшие и довольные.
Привет, меня зовут Евгений, я PHP-разработчик в Broniboy. Ища в очередной раз на Хабре нужную информацию, поймал себя на мысли, что здесь маловато статей, на... | https://habr.com/ru/post/585912/ | null | ru | null |
# Нахождение максимальной общей подпоследовательности
В настоящей статье я хотел бы сделать обзор популярных алгоритмов для решения задачи нахождения максимальной общей подпоследовательности или LCS (longest common sequense). Так как акцент сделан на обучении, а не на реальном использовании, в качестве языка для реали... | https://habr.com/ru/post/142825/ | null | ru | null |
# Свежий плагин интернет-магазина на WordPress
Некоторое время назад мне понадобилось сделать интернет-магазин на WordPress. В официальном репозитории есть немало хороших решений. Среди них уже давно выделился лидер — Woocommerce. Думаю он не нуждается в представлении. Многомилионная армия пользователей, сотни платных... | https://habr.com/ru/post/467937/ | null | ru | null |
# Asterisk и отправка пропущенных в Telegram/Slack/E-mail
Есть колл-центр. Есть Asterisk/FreePBX с настроенными очередями. Есть агенты, которые должны обслуживать вызовы. Но потенциальных клиентов так много, а агентов так мало, что первые никак не могут дозвониться до вторых — повисят-повисят в очереди минуту, да и от... | https://habr.com/ru/post/492728/ | null | ru | null |
# Одна задача с собеса
Год назад моя компания впервые попросила меня провести собеседование для фронтендера. Тогда я и придумал эту задачу на свою злобу дня. Задачка простая, на базовые знания, но, как оказалось, в ней можно сделать много интересных ошибок. Также в ней оказались неочевидные детали, которые могли бы ок... | https://habr.com/ru/post/584924/ | null | ru | null |
# Сквозь порты на оборудовании к пользовательским машинам
Доброе время суток, Хабражители.
Данный пост повествует Вам о том, как с помощью PowerShell мы опять смогли немного облегчить нам жизнь и автоматизировать поиск оборудования и портов, на которых сидят компьютеры пользователей. Это необходимо в тот момент, ко... | https://habr.com/ru/post/149191/ | null | ru | null |
# IcedID – когда лед сжигает банковский счет

Какие три мысли возникали у вирусных аналитиков, когда они слышали о IcedID/BokBot? Конечно же про web-инжекты, proxy-сервер и быстрое обновление версий. Иногда настолько быстрое, что п... | https://habr.com/ru/post/501972/ | null | ru | null |
# Проброс видеокарты в KVM из под ubuntu
#### Предистория
Года два назад я решил перейти полностью на линукс, но необходимость в венде не упала, поэтому всегда держал у себя 2 операционные системы. Около месяца назад попробовал поставить VirtualBox и на нее установить Windows, в общем то работать с 2мя операционными ... | https://habr.com/ru/post/183468/ | null | ru | null |
# Делаем траву в Unity при помощи GPU Instancing
Добрый день! Хочу поделиться с вами некоторым опытом по оптимизации с использованием GPU Instancing.
Постановка задачи примерно такая: игра под мобильные платформы, одним из элементов которой является поле с травой. Фотореалистичность не требуется, low poly стиль. Но п... | https://habr.com/ru/post/656597/ | null | ru | null |
# Текущая разработка Kotlin

На прошлой неделе при поддержке **Redmadrobot SPB** в рамках **SPB Kotlin User Group** прошла встреча со Станиславом Ерохиным, разработчиком из JetBrains. На встрече он поделился информацией о разрабатыва... | https://habr.com/ru/post/351516/ | null | ru | null |
# Scala. Профессиональное программирование. 5-е изд. Гивены
[](https://habr.com/ru/company/piter/blog/671356/) Привет, Хабр! Сдали в типографию новую книгу «[Scala. Профессиональное программирование. 5-е изд.](https://www.piter.c... | https://habr.com/ru/post/671356/ | null | ru | null |
# Конфетти на канвасе
Привет Хабр! Попалась недавно интересная вещичка , которая создает эффект конфетти на страничке. Решил глянуть , что же там внутри находится, как работает и познакомиться с канвасом поближе. Подробности под катом.
Вступление
----------
Повествование будет вестись с точки зрения человека, котор... | https://habr.com/ru/post/537760/ | null | ru | null |
# Обработка аннотаций в процессе компиляции
[](http://habrahabr.ru/company/e-Legion/blog/206208/)[Метапрограммирование](https://ru.wikipedia.org/wiki/Метапрограммирование) — вид программирования, связанный с созданием про... | https://habr.com/ru/post/206208/ | null | ru | null |
# Запускаем скрипты Ruby из Go Lang
Для использования Ruby как скриптового языка, то есть как языка для встраивания, вроде lua, существует легковесная реализация Ruby под названием [MRuby](https://en.wikipedia.org/wiki/Mruby).
. В этом клиенте нам нуж... | https://habr.com/ru/post/358974/ | null | ru | null |
# Разработка картографических мобильных приложений на С++/Qt, с использованием Qt Mobility
#### Этот пост участвует в конкурсе „[Умные телефоны за умные посты](http://habrahabr.ru/company/Nokia/blog/132522/)"
 |
| --- | --- |
**Python DB-API** – это не конкретная библиотека, а набор правил, которым подчиняются отдельные модули, реализующие работу с конкретными базами д... | https://habr.com/ru/post/321510/ | null | ru | null |
# Автоматизация метрик для веб-сервиса с помощью GoogleDocs + Google Script
Меня зовут Чингис, я сооснователь веб-сервиса для командного решения задач [Worksection.com](http://worksection.com)
Мы у себя в сервисе отслеживаем ряд контрольных метрик. Посещения, регистрации, конверсии, активации, удержание, отток и тд... | https://habr.com/ru/post/170109/ | null | ru | null |
# Attention! S in Ethereum stands for Security. Part 4. Tools

Представляем четвертую часть цикла, посвященного типичным уязвимостям, атакам и проблемным местам, которые присущи смарт-контрактам на языке Solidity и платформе Ethereum... | https://habr.com/ru/post/353676/ | null | ru | null |
# Маскируем класс под граф Boost. Часть 1: Не трогаем интерфейс
[Пролог: Концепции Boost](http://habrahabr.ru/post/210838/)
[Часть 2: Завершаем реализацию поддержки концепций](http://habrahabr.ru/post/2... | https://habr.com/ru/post/211558/ | null | ru | null |
# http_handlersocket_json_module
О назначении модуля можно догодаться из названия. О [HandlerSocket](http://habrahabr.ru/search/?q=handlersocket) говорят много и на разных языках (в основном на японском, английском и последнее время немного на русском).
Модуль NGX\_HTTP\_HANDLERSOCKET\_JSON\_MODULE обращается к да... | https://habr.com/ru/post/115920/ | null | ru | null |
# Сравнение производительности ASP.NET Core-проектов на Linux и Windows в службе приложений Azure. Продолжение
В моём [предыдущем материале](https://habr.com/ru/company/ruvds/blog/555650/) речь шла о сравнении производительности [ASP.NET Core](https://docs.microsoft.com/ru-ru/aspnet/core/?view=aspnetcore-5.0)-приложен... | https://habr.com/ru/post/555652/ | null | ru | null |
# Яндекс.переводчик для Linux на Python+GTK3
Приветствую хабражителей!
Довольно давно возникла необходимость в мультиязычном онлайн переводчике при закрытом браузере.
Нет, так то я и словарем в "особо тяжелых" случаях пользоваться не брезгую, но иногда приходится читать немаленький текст, и не все слова я знаю, как ... | https://habr.com/ru/post/472516/ | null | ru | null |
# Знай откуда пришел пользователь
Когда вы открываете свой [проект](http://www.askdev.ru/) вы начинаете писать о нем везде, в том числе и на [хабре](http://habrahabr.ru/blogs/i_am_advertising/63791/).
Сервисы статистики типа Google Analytics дадут вам общую оценку трафика, а именно сколько посетителей пришло с как... | https://habr.com/ru/post/80000/ | null | ru | null |
# Как Google определяет координаты?
Сегодня утром, пока пил кофе, зашел на гугльмапс и обнаружил интересную кнопку «Показать мое местоположение».
[](http://bum.ks.ua/gmaps4.png)
При нажатии на кнопку браузер спросил «разрешать ли сайту сообщить мое местонахождение», я подтверд... | https://habr.com/ru/post/98980/ | null | ru | null |
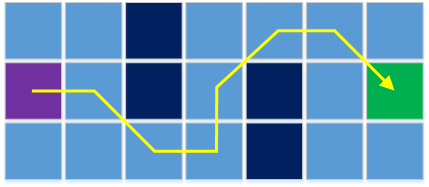
# Как учить протоколы без чтения RFC: как сэкономить время при разработке
Если вы разрабатывает приложение, работающее по сети, или проводите отладку работы такого приложения, доскональное знание работы сетевых протоколов сильно обл... | https://habr.com/ru/post/560406/ | null | ru | null |
# Управление ресурсами с помощью явных специализаций шаблонов
[](http://habrahabr.ru/company/pt/blog/255487/)
[RAII](http://en.wikibooks.org/wiki/More_C++_Idioms/Resource_Acquisition_Is_Initialization) – одна из наиболее ва... | https://habr.com/ru/post/255487/ | null | ru | null |
# Concurrency паттерны в Rust из Java
Под катом находятся заметки, в которых расписано, как реализовать в Rust хитрые concurrency паттерны, которые я с легкостью пишу в Java, и в чем различие в подходах к concurrency у этих языков. Статья будет полезна и тем, кто переходит на Rust из C#, ведь у него аналогичная модель... | https://habr.com/ru/post/337232/ | null | ru | null |
# Введение в новый CoordinatorLayout
В этом году на конференции Google IO компания Google представила новую библиотеку Android Design Support Library, которая создана для того, чтобы помочь разработчикам внедрять материальный дизайн в их приложения. Билиотека содержит много компонентов, нужных для этого нового стиля, ... | https://habr.com/ru/post/265119/ | null | ru | null |
# Opennebula. Короткие записки

Всем привет. Данная статья написана для тех, кто до сих пор мечется между выбором платформ виртуализации и после прочтения статьи из серии «Поставили proxmox и вообще все отлично, 6 лет аптайм не еди... | https://habr.com/ru/post/519898/ | null | ru | null |
# Еще раз о deb пакетах
Deb пакеты очень удобный инструмент, особенно если знаешь как его использовать. Попробую поделиться собственным опытом в данном вопросе.
Подготовка
----------
Чтобы начать создавать deb пакеты, нужно установить несколько пакетов:
```
$ sudo apt-get install dh_make
```
Подготовка папки ... | https://habr.com/ru/post/282217/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.