
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Автоматизируем и ускоряем процесс настройки облачных серверов с Ansible. Часть 3: Переменные и файл inventory
[В первой части](http://habrahabr.ru/company/infobox/blog/249143/) мы начали изучение Ansible, популярного инструмента для автоматизации настройки и развертывания ИТ-инфраструктуры. Ansible был успешно устан... | https://habr.com/ru/post/252001/ | null | ru | null |
# Знакомство с Helm 3

***Прим. перев.**: 16 мая этого года — значимая веха в развитии менеджера пакетов для Kubernetes — Helm. В этот день был представлен первый альфа-релиз будущей крупной версии проекта — 3.0. Её выход принесёт в ... | https://habr.com/ru/post/453734/ | null | ru | null |
# Поиск по блогам на Хабре
За последнее время Хабр очень сильно вырос. При создании очередного топика у меня возникла необходимость поискать по названиям блогов на хабре. У самого хабра такой возможности нет, но эту проблему можно решить с помощью Google.
Итак, открываем google.com и пишем такой запрос:
`site:h... | https://habr.com/ru/post/49445/ | null | ru | null |
# Обобщаем паттерн посетитель (С++)
Недостатки типичной реализации
------------------------------
В статье намеренно не приведен пример типичной реализации паттерна посетителя в C++.
Если вы не знакомы с эт... | https://habr.com/ru/post/532412/ | null | ru | null |
# Растянуть Canvas и элементы внутри него по всей клиентской области
Во время работы над нашим десктопным приложением столкнулся с такой задачей: имеется элемент-график с некоторыми настройками для отображения (реализован в виде ControlTemplate подключаемого через привязку в ContentControl), к имеющимся настройкам нуж... | https://habr.com/ru/post/306008/ | null | ru | null |
# Телевидение через Acestream на Raspberry PI. Теперь в docker контейнерах
На хабре уже неоднократно упоминался AceStream: технология, предоставляющая пользователю доступ к видеопотокам по закрытому P2P протоколу AceStream, т.н. torrent телевидение. AceStream предоставляет доступ к распределенной сети доставки контент... | https://habr.com/ru/post/316208/ | null | ru | null |
# 10 строк кода, которые уменьшат боль от вашего проекта на Vue
… или знакомство с плагинами Vue JS на примере интегрированной шины событий
---------------------------------------------------------------------------
### Пара слов о…
Всем привет! Сразу оговорюсь. Я очень люблю VueJS, активно пишу на нем уже больше 2-... | https://habr.com/ru/post/488422/ | null | ru | null |
# Интернационализация (i18n) простой текстовой разметки

Введение
========
[Go to English version](https://habr.com/ru/post/599437/)
Несколько лет назад коллега опубликовал [статью](https://habr.com/ru/p... | https://habr.com/ru/post/599775/ | null | ru | null |
# Распознаем номера автомобилей. Разработка multihead-модели в Catalyst
Фиксация различных нарушений, контроль доступа, розыск и отслеживание автомобилей – лишь часть задач, для которых требуется по фотографии определить номер автомобиля (государственный регистрационный знак или ГРЗ).
В этой статье мы рассмотрим соз... | https://habr.com/ru/post/561866/ | null | ru | null |
# ОС с нуля: Глава 1, Часть 2 — 32 лучше 16-ти
### Дисклеймер?
Хай Хабр! Это серия статей по написанию моей ОС с нуля. Я лютый фанат ретропрограммирования, поэтому я мгновенно забуду про существование EDК. Просьба не писать комменты по типу "BIOS давно устарела где UEFI?". Пишу это просто чтобы было, что почитать веч... | https://habr.com/ru/post/670162/ | null | ru | null |
# Создание Zero Player Game, используя libgdx
#### Идея
1. Игровое пространство — клетчатое поле ограниченное рамкой
2. Существующие типы клеток:
* Пустая клетка — белый
* Стена — чёрный
* Зверь — красный
* След — коричневый
* Дом — зелёный
3. Перемещение зверя оставляет неисчезающий след
4. При запуске генериру... | https://habr.com/ru/post/224525/ | null | ru | null |
# Обзор особенностей ядра Андроида
*“А я… карбюратор промываю!”
Анекдот*
**Введение**
В детском садике мы с единомышленниками препарировали кузнечиков в надежде разобраться в их строении. В школе распаивали радиоприёмник “Россия”. В институте дошла очередь до автомобилей, гайки которых были многократно перест... | https://habr.com/ru/post/211663/ | null | ru | null |
# Объединяем Websockets, Lisp и функциональное программирование

Объединяем Websockets, Lisp и функциональное программирование. Но как?
С помощью Clojure.
На Хабре существует достаточно статей — примеры приложений, использующих
вебсокеты ([... | https://habr.com/ru/post/339628/ | null | ru | null |
# Пытаемся управлять освобождением памяти в JavaScript

В JavaScript есть тысячи способов выделить память, но разработчики языка лишили нас права её освобождать. Этим занимается сборщик мусора (Garbage collector, GC), функц... | https://habr.com/ru/post/327426/ | null | ru | null |
# Паттерн Model-Update-View и зависимые типы
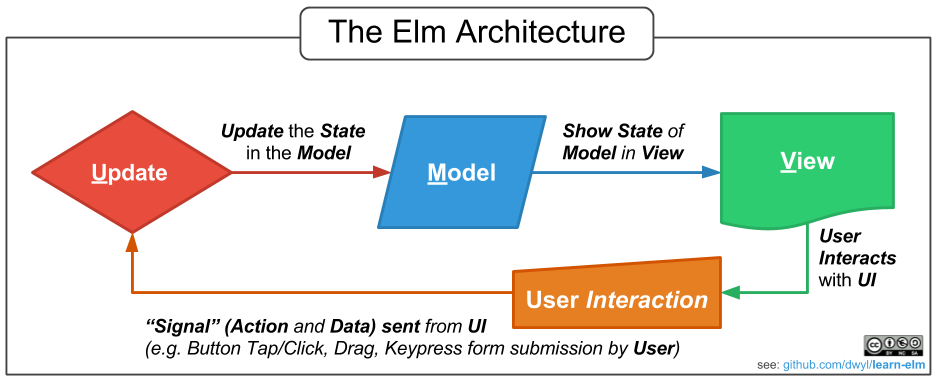
Model-Updater-View — функциональный паттерн, успешно применяемый в языке [Elm](http://elm-lang.org/) в основном для разработки пользовательских интерфейсов. Что... | https://habr.com/ru/post/341988/ | null | ru | null |
# Женщины и убийства: есть ли тут взаимосвязь? [часть 2 из 2]

**`R` код ([gist](https://gist.github.com/ikashnitsky/09618405045ea86aca3484881a9094dc)) для воспроизведения всех результатов**
[В первой части](https://habrah... | https://habr.com/ru/post/312694/ | null | ru | null |
# Звук на чипе AY-3-8910 (или Yamaha YM2149F) родом с ZX Spectrum на PC через USB
Прошло около года, с момента успешного [подключения музыкального синтезатора YM2149F к LPT порту компьютера](http://habrahabr.ru/post/218763/). LPT это конечно хорошо, однако время не стоит на месте, и найти компьютер или ноутбук с LPT п... | https://habr.com/ru/post/248115/ | null | ru | null |
# Введение в Git Merge и Git Rebase: зачем и когда их использовать
Часто у разработчиков возникает выбор между Merge (слияние) и Rebase (перемещение). В Гугле вы увидите разное мнение, многие советуют не использовать Rebase, так как это может вызвать серьезные проблемы. В статье я объясню, что такое слияние и перемеще... | https://habr.com/ru/post/432420/ | null | ru | null |
# rtorrent+rutorrent+nginx+php-fpm. Подводные камни
[Предыдущая статья](http://habrahabr.ru/blogs/linux/120167/) про связку rtorrent+rutorrent+nginx+php-fpm была написана сразу после успешной установки и начальной настройки этой связки. В процессе эксплуатации выявились некоторые подводные камни, о которых я и хочу ра... | https://habr.com/ru/post/121138/ | null | ru | null |
# Intel Parallel Studio XE 2016: новые возможности компилятора C/C++

На прошлой неделе вышла новая версия компилятора С/С++ от Intel — 16.0 aka Parallel Studio XE Composer Edition for C++. Существенно расширилась поддержка ... | https://habr.com/ru/post/265565/ | null | ru | null |
# Продолжаем удалять. [Re: Работа с «плохими» файлами в командной строке в Linux]
Как известно, мир GNU/Linux многообразен. Для одной и той же задачи существует множество решений.
Порой один линуксоид решает проблему, а второй смотрит на данный процесс и испытывает неуемное желание вмешаться, сделать по-своему. В п... | https://habr.com/ru/post/179837/ | null | ru | null |
# Мысли об ООП
Очередная статья про «азы программирования на C++» меня подтолкнула к мысли, что многие программисты не понимают сути объектно-ориентированного программирования (ООП).
В частности, в этой статье утверждается, что
`"С++ очень прост в том смысле, что классы С++ повторяют описание объектов реального... | https://habr.com/ru/post/111125/ | null | ru | null |
# Эксплуатируемая уязвимость в почте Mail.ru
Услышав сегодня на одном из новостных сайтов, что Mail.ru обновили свой поисковый интерфейс, зашёл туда, чтобы узреть его.
Не увидел ничего нового в интерфейсе, писем во «Входящих» не было. Лениво щёлкнул на папочке «Спам», поглядел письма и… Обнаружил, что пришло новое ... | https://habr.com/ru/post/126740/ | null | ru | null |
# Как автоматизировать сбор KPI за месяц и оставить пользователей почти довольными
Во многих организациях оценка подразделений осуществляется с использованием KPI (Key Performance Indicators). В организации, где я работаю, такая система называется «системой показателей деятельности», а в этой статье я хочу рассказать ... | https://habr.com/ru/post/423919/ | null | ru | null |
# Cofree Will Tear Us Apart
Всем привет.
В последнее время я работаю с распределенными системами и часто встречаюсь с проблемами работы с данными, части которых могут находиться в различных местах. Ну и так как я уже продолжительное время пишу на Haskell, описание проблемы и мощная система типов здорово помогли в да... | https://habr.com/ru/post/358976/ | null | ru | null |
# Microsoft открыла исходный код PowerShell

Расширяемое средство автоматизации и конфигурирования [PowerShell](https://msdn.microsoft.com/en-us/powershell), состоящее из оболочки с интерфейсом командной строки и сопутствую... | https://habr.com/ru/post/308076/ | null | ru | null |
# Parallelism in PostgreSQL: treatment of trees and conscience
Database scaling is a continually coming future. DBMS get improved and better scaled on hardware platforms, while the hardware platforms themselves increase the perfor... | https://habr.com/ru/post/500442/ | null | en | null |
# Автоматизированный приём webmoney платежей на вашем сайте.
**0. Вступление**
Ни для кого не секрет, что в последнее время webmoney набрало достаточную популярность для того, чтобы стать одним из самых удобных и доступных средств для безналичного расчёта через интернет. Пополнить баланс своего мобильного, оплатить... | https://habr.com/ru/post/53805/ | null | ru | null |
# Koin — библиотека для внедрения зависимостей, написанная на чистом Kotlin
### Как управлять внедрением зависимостей с помощью механизма временной области (scope)
> Для будущих студентов курса ["Android Developer. Professional"](https://otus.pw/9kA2/) подготовили перевод полезной статьи.
>
> **Также приглашаем при... | https://habr.com/ru/post/530024/ | null | ru | null |
# Строковые коллекции только для чтения: экономим на спичках
Нередко случается, что какие-то данные программа загружает в память и оставляет их там надолго (а то и до конца работы) в неизменном виде. При этом используются структуры данных, оптимизированные как для чтения, так и для записи. Например, вы вычитываете из ... | https://habr.com/ru/post/145145/ | null | ru | null |
# Задача о рюкзаке (Knapsack problem) простыми словами
Пару лет назад столкнулся с так называемой задачей о рюкзаке на одном из собеседований, нашел быстренько решение в интернете. Попытался разобрать и.... ничего не понял. Кое как поменял названия переменных, а кто так не делает когда находит готовое решение для home... | https://habr.com/ru/post/561120/ | null | ru | null |
# Браузер и числа с плавающей запятой

*Изображение — [www.freepik.com](https://www.freepik.com/vectors/design)*
Несколько лет назад я много думал и писал о математике с плавающей запятой. Это было очень интересно, и в процессе ... | https://habr.com/ru/post/525048/ | null | ru | null |
# Как исправить баг с Drawable.setTint в API 21 Android SDK
Привет, в этой заметке наш android-разработчик [Влад Титов](https://habr.com/ru/users/VirtualAD/) расскажет о том, как решить проблему с использован... | https://habr.com/ru/post/527138/ | null | ru | null |
# Разделить пользователей по ролям в FeathersJs

Речь пойдет о недооцененном фреймворке [feathersjs](https://feathersjs.com/).
В двух словах как он работает вы можете почитать [тут](https://habrah... | https://habr.com/ru/post/346170/ | null | ru | null |
# Автоконфигурация с помощью Puppet и AWS Cloud Formation
Вот и настал тот день, когда пришлось отложить в сторону кукбуки, рецепты, нож шеф-повара и немного позаниматься кукловодством.
Для начала по... | https://habr.com/ru/post/208710/ | null | ru | null |
# Блокчейн: организация сети, проверка подписи и задание для студента, часть 2
Предисловие
-----------
[В первой части](https://habrahabr.ru/post/348014/) было рассказано про возможности блокчейна, структуру и ЭЦП, в этой части будет рассказано про: проверку подписи, майнинг и примерную организацию сети. Отмечу, что ... | https://habr.com/ru/post/348020/ | null | ru | null |
# Разработка приложения на SwiftUI. Часть 1: поток данных и Redux
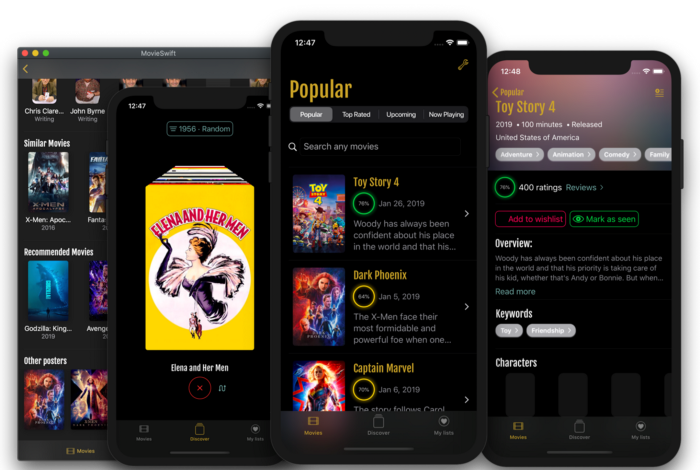
После участия в сессии State of the Union на WWDC 2019 я решил детально изучить SwiftUI. Я потратил много времени на работу с ним и теперь ... | https://habr.com/ru/post/460713/ | null | ru | null |
# Визуализация concurrency в Go с WebGL
Одной из самых сильных сторон языка программирования Go является встроенная поддержка concurrency, основанная на труде Тони Хоара [«Communicating Sequential Processes»](https://en.wikipedia.org/wiki/Communicating_sequential_processes). Go создан для удобной работы с многопоточны... | https://habr.com/ru/post/276255/ | null | ru | null |
# Можно писать код и без переменных
Очень часто после фраз в духе: «Ну к примере в этом языке нету переменных, и от того нету проблем с...» или аналогичных с удивлением замечаю полное удивление в глазах собеседника. Это вызвано тем, что многие программисты не могут себе представить программу без такой вещи, как переме... | https://habr.com/ru/post/72063/ | null | ru | null |
# Мины под производительностью ждут своего часа
В этой статье я расскажу о минах, заложенных под производительность, а также об их обнаружении (желательно ещё до взрыва) и обезвреживании.
**Картинка для привлечения внимания**
#### Что... | https://habr.com/ru/post/443206/ | null | ru | null |
# Предиктивная аналитика на платформе SCP
---
Это третья публикация в рамках помощи участникам конкурса **[«SAP Кодер-2017»](http://sapcoder.ru/)**.
---
Каждое предприятие в процессе своей жизнедеятельности генерирует значительное количество данных, как «больших», так и не очень. Эти данные часто можно использов... | https://habr.com/ru/post/327086/ | null | ru | null |
# Как писать кривые запросы с неоптимальным планом и заставить задуматься СУБД
 Всё просто. Тут можно найти «Основы разбора запросов для чайников» в случае PostgreSQL и замечательные невыдуманные примеры из продакшена о том, ка... | https://habr.com/ru/post/320916/ | null | ru | null |
# Парсер OOXML (docx, xlsx, pptx) на Ruby: наши ошибки и находки
Мы выложили парсер OOXML форматов на Ruby в open-source. Он доступен на [GitHub'е](https://github.com/ONLYOFFICE/ooxml_parser) и [RubyGems.org](https://rubygems.org/gems/ooxml_parser), бесплатен и распространяется под лицензией AGPLv3. Всё как у модненьк... | https://habr.com/ru/post/302826/ | null | ru | null |
# .NET: Инструменты для работы с многопоточностью и асинхронностью. Часть 1
*Публикую на Хабр оригинал статьи, перевод которой размещен в блоге [Codingsight](https://codingsight.com/net-tools-for-working-with-multi-threading-and-asynchrony-part-1/).*
*Вторая часть доступна [здесь](https://habr.com/post/459514/)*
... | https://habr.com/ru/post/452094/ | null | ru | null |
# 3 место за 11 шагов в конкурсе по JavaScript от Hola
Наверняка у многих из вас перед глазами уже мелькали заголовки статей с [конкурсом от Hola](http://habrahabr.ru/company/hola/blog/270847/), который недавно подошел к своему логическому завершению. В [окончательных результатах](http://habrahabr.ru/company/hola/blog... | https://habr.com/ru/post/275343/ | null | ru | null |
# Автоматизируем FreeIPA: как устанавливать клиентов с помощью Ansible и управлять DNS записями через Terraform

У нас в Altenar собралась достаточно большая и продвинутая команда разработчиков. За эти годы внутри компании накоплен... | https://habr.com/ru/post/568524/ | null | ru | null |
# Наступление на свободный интернет на Украине: Закон Украины «О защите общественной морали»
 Две недели назад правительство Украины [утвердило](http://habrahabr.ru/blogs/eCommerce/130426/) законопроект «Про внутреннюю торговлю», в котором описаны правила работы интернет-мага... | https://habr.com/ru/post/131338/ | null | ru | null |
# Сколько математики нужно, чтобы подписать многоугольник в JS API Яндекс.Карт
В JS API Яндекс.Карт существует возможность создавать различные объекты на карте. Один из их них – многоугольник, с помощью которого можно улучшить интерактивность пользовательской карты: выделить отдельные области или отобразить местополож... | https://habr.com/ru/post/353498/ | null | ru | null |
# Chef за 21 день. Часть третья. Chef и AWS
Здравствуй, хабраюзер. Вот и подоспела **третья** часть моей статьи, которая подытожит цикл ([часть 1](http://habrahabr.ru/company/epam_systems/blog/208542) и [часть 2](http://habrahabr.ru/company/epam_systems/blog/209368)) статей для начинающих. Эта часть будет посвящена ко... | https://habr.com/ru/post/211050/ | null | ru | null |
# Внедряем оплату BTC куда угодно (Python)
Предыстория
-----------
Полгода назад взялся за один проект с возможностью оплаты биткойном. Так как проект делали на языке python, то и оплату хотелось реализовать на нем же. Сразу же взялся анализировать готовые решения, доступные библиотеки и Rest API Blockchain.com. С ап... | https://habr.com/ru/post/525638/ | null | ru | null |
# Как обновить October CMS до Laravel 6?
*Продолжаем рассматривать October CMS, вокруг которой мы в LOVATA построили разработку веб-проектов и в особенности интернет-магазинов. Сегодня мы подготовили для вас инструкцию по обновлению вашей текущей установки October до долгожданной версии 1.1.x с Laravel 6 “под капотом”... | https://habr.com/ru/post/531936/ | null | ru | null |
# Новое в Symfony 5.2: атрибуты PHP 8
> В преддверии старта [курса «Symfony Framework»](https://otus.pw/WMg5/) предлагаем будущим студентам и всем желающим посмотреть запись вебинара на тему [«Микрофреймворки: сравнение производительности Symfony и Symlex»](https://otus.pw/NKv3/).
>
> Также делимся переводом поле... | https://habr.com/ru/post/538482/ | null | ru | null |
# Повышаем безопасность стека web-приложений (виртуализация LAMP, шаг 4/6)
Настройка web-сервера Apache на работу с HTML+PHP5 файлами сетевой файловой системы (NFS)
=========================================================================================
В четвертом уроке [цикла статей о настройке стека web-приложени... | https://habr.com/ru/post/148489/ | null | ru | null |
# Юмор в Cisco Systems
Конфигурировал Cisco PIX 501 в режиме ROMMON. Забавно вышло.
`monitor> ping 192.168.1.2
Sending 5,100-byte 07642 ICMP Echoes to 192.168.1.2, timeout is 4 seconds:
AXXXXAXXXXXXXAAAXAAAAAXAAAAAAAAA!!!!!
Success rate is 100 percent (5/5)`
Очень понравилась эта шутка, когда пытался ... | https://habr.com/ru/post/91912/ | null | ru | null |
# Let's Encrypt и nginx: настройка в Debian и Ubuntu

Если вдруг вся эта история прошла мимо вас, [Let's Encrypt](https://letsencrypt.org/) — центр сертификации от некоммерческой организации ISRG, существующий [при поддер... | https://habr.com/ru/post/318952/ | null | ru | null |
# Анимация фотографии. Раскрытие рта
### Описание проблемы
В настоящее время существуют программы,позволяющие анимировать статические фотографии. Прежде всего, речь идёт об анимации лица и создании определённой мимики. Теоретически задача решается достаточно просто. Берём 3Д модель черепа и добавляем к ней основные ... | https://habr.com/ru/post/649465/ | null | ru | null |
# Как сжать загрузчик для STM8 до размера 8 байт в памяти FLASH
Со времени написания предыдущей статьи [” Как сжать загрузчик для STM8 до размера 18 байт в памяти FLASH”](https://habr.com/post/417493/) появились две версии загрузчика [STM8uLoader](http://nflic.ru/STM8/STM8uLoader/000.html) . Загрузчик STM8uLoader ве... | https://habr.com/ru/post/418483/ | null | ru | null |
# Рецепты хорошей типографики
Судя по результатам [голосования](http://nobr.habrahabr.ru/blog/57137/), которое я проводил в своём блоге, большинство пользователей никак не типографируют тексты перед публикациями (НЛО не считается). Те, кто работают над текстами, в большинстве своём делают это вручную, поэтому я решил ... | https://habr.com/ru/post/57351/ | null | ru | null |
# Electron: от мотивации до публикации
*— Хотел бы я иметь приложение, которое умеет что-то такое, что мне надо. Жаль такого нет.
— А почему бы тебе его самому не написать?
— Это сложно, мне потребуется куча времени, чтобы понять теорию, приступить к практике и, скорее всего, ничего хорошего не выйдет. А вообще ... | https://habr.com/ru/post/316880/ | null | ru | null |
# Porting packages to buildroot using the Zabbix example

The basics of porting
---------------------
Originally, Buildroot offers a limited number of packages. It makes sense — there is everything you need, but any other packages can... | https://habr.com/ru/post/500122/ | null | en | null |
# Телефония на Cisco (Call Manager Express) — Часть 2
Во второй части речь пойдет об использовании цифровых транков Е1 которые можно использовать для подключения маршрутизатора к АТС

1. Компоненты ... | https://habr.com/ru/post/107903/ | null | ru | null |
# Опыт публикации в AppGallery
> *Привет. Меня зовут*[*Кирилл Розов*](http://twitter.com/kirill_rozov)*и если вы интересуетесь разработкой под Android, то скорее всего слышали о*[*Telegram канале "Android Broadcast"*](https://t.me/android_broadcast)*, с ежедневными новостями для Android разработчиков, и*[*одноимённом ... | https://habr.com/ru/post/567974/ | null | ru | null |
# Исследуем сопоставление с образцом в C# 7
В C# 7 наконец появилась долгожданная возможность под названием «сопоставление с образцом» (**pattern matching**). Если вы знакомы с функциональными языками, такими как F#, вы можете быть немного разочарованы этой возможностью в ее текущем виде, но даже сегодня она может упр... | https://habr.com/ru/post/347916/ | null | ru | null |
# Расширяем функционал Ansible с помощью плагинов: часть 2

Под капотом сервиса [d2c.io](https://d2c.io/) мы активно используем Ansible – от создания виртуальных машин в облаках провайдеров и установки необходимого программного обе... | https://habr.com/ru/post/345216/ | null | ru | null |
# Создание Push Notification сервиса на основе WCF REST
##### В качестве вступления
Модель [push](http://en.wikipedia.org/wiki/Push_technology)-нотификаций является распространённой моделью для обмена сообщениями. Она подразумевает не получение информации по запросу, а немедленную её передачу отправителю при появлени... | https://habr.com/ru/post/128634/ | null | ru | null |
# Быстрая интеграция Google Chromecast в Android приложение
Добрый день, я Android Team Lead в компании по разработке мобильных приложений Trinity Digital. Наша компания существует на рынке три года и в 2015-м мы вошли в топ-10 лучших разработчиков Москвы. Наш второй офис находится в Петрозаводске, там я и руковожу ко... | https://habr.com/ru/post/310498/ | null | ru | null |
# Настраиваем сервер с Chef (Быстро и просто)
> The best way to learn Chef is to use Chef
>
> — getchef.com

Chef — это инструмент для конфигурирования серверов в концепции Infrastructure as a Code(IaaC).
Лично для... | https://habr.com/ru/post/244111/ | null | ru | null |
# Excel, SQL и легендарный барометр — решаем простую задачу разными способами
На прошлой неделе в каком-то обсуждении всплыл старый хабротекст «[Стратегия для технического интервью](https://habrahabr.ru/company/luxoft/blog/152505/)». Точнее, приведённая в нём задача №4
> Дано: .xls (Excel) файл с одним листом в 4 ч... | https://habr.com/ru/post/312834/ | null | ru | null |
# Результаты конкурса на лучшую #codejoke
Больше месяца назад [Microsoft User Group Винница](http://msug.vn.ua) [объявила конкурс](http://habrahabr.ru/blogs/crazydev/85317/), суть которого была в том, чтобы рассказать анекдот или историю с помощью программного кода. Призы были более чем стимулирующими — это Windows 7 ... | https://habr.com/ru/post/89717/ | null | ru | null |
# POS-terminal VeriFone Tranz 460 и его программирование
Приветствую всех.
Сегодня речь пойдёт о совершенно нетипичном для раздела ретро-железа оборудовании. Встречаются такие девайсы достаточно редко, а интересующихся ими ещё меньше.
Итак, сегодня мы вам расскажем об антикварном представителе банковского оборуд... | https://habr.com/ru/post/689878/ | null | ru | null |
# Глубокое обучение с подкреплением: пинг-понг по сырым пикселям
Это давно назревшая статья об обучении с подкреплением Reinforcement Learning (RL). RL – крутая тема!
Вы, возможно, знаете, что компьютеры теперь могут [автоматически учиться играть в игры ATARI](http://www.nature.com/nature/journal/v518/n7540/abs/na... | https://habr.com/ru/post/439674/ | null | ru | null |
# Недокументированная возможность в WebSphere Portal 5.1 (общая сессия для портлета и сервлета)
#### Была следующая задача:
написать портлет, который отображает график отчета, хранящегося в Когносе. Отчет Когноса может строиться очень и очень долго, от нескольких секунд до 20.
Заставлять ждать пользователя стольк... | https://habr.com/ru/post/26790/ | null | ru | null |
# Регулярные выражения. Сборник рецептов
Мы каждый день работаем с текстом, решая разные задачи. Проверяем текст на правильность ввода некоторых данных, ищем, заменяем некоторые значения, выделем некоторые данные из текста. Порой объём этих данных значительно возрастает и справиться с такими объёмами текстовой информа... | https://habr.com/ru/post/80430/ | null | ru | null |
# Подключение bootstrap в Next.js
Категорически приветствую.
Столкнулся я тут с необходимостью подключить Bootsrtap в Next.js. Беглый гуглёж дал несколько тем на stackoverflow, парочку монструозных (всё в одном и все пакеты устарели ) шаблонов на гитхабе, и немножечко оффдоков. На деле же всё оказалось довольно тр... | https://habr.com/ru/post/417979/ | null | ru | null |
# Salt. О славном pillar'е замолвите слово
В одной из наших прошлых статей [Just add some Salt](https://habr.com/ru/company/timeweb/blog/521370/) мы рассказывали, как мигрировали 700+ серверов на Salt. Мы поделились нашим опытом оптимизации Salt: как его применить и настроить без лишних усилий. Тогда мы только затрону... | https://habr.com/ru/post/532184/ | null | ru | null |
# Новогодние приколы от проекта Arduino Mega Server

Разработка проекта [Arduino Mega Server](http://hi-lab.ru/arduino-mega-server) идёт полным ходом и в процессе работы возникают неожиданные препятствия, которые прихо... | https://habr.com/ru/post/388623/ | null | ru | null |
# «Ленивый сахар» PostgreSQL
Блиц, Блиц, скорость без границ!SQL - декларативный язык - то есть вы описываете **"что"** хотите получить, а ... | https://habr.com/ru/post/667998/ | null | ru | null |
# Обработка всех исключений в контроллерах с помощью атрибута
Всё мы знаем, что в ASP.NET MVC есть такой атрибут `HandleErrorAttribute`, который как сказано в MSDN
> Представляет атрибут, используемый для обработки исключения, вызываемого методом действия.
>
>
Но нигде, в том же MSDN не сказано (~~ткните меня но... | https://habr.com/ru/post/137672/ | null | ru | null |
# Сборка Qt 5.1 приложений под Android на Mac, seriously?

Привет, QHabr.
Сегодня хотел бы рассказать вам про адъ, который кроется за сборкой Qt 5.1 приложения для андрюши на Mac OS X. Чтобы никто ... | https://habr.com/ru/post/185140/ | null | ru | null |
# Особенности настройки коммутаторов ExtremeXOS
Данная статья призвана сократить количество времени, необходимое для понимания принципов работы с **ExtremeXOS (XOS)**. Когда я начинал знакомство с XOS, мне очень не хватало такой статьи на Хабре.
Ниже я расскажу о конфигурации Экстримов и о проблемах, с которыми я ст... | https://habr.com/ru/post/419965/ | null | ru | null |
# Делаем минимальную отладочную плату на STM32G030F6P6 и шьем в Arduino IDE
В разработке оказалось несколько устройств в составе которых кроме прочего планируется использовать F030F6P6. Они маленькие и достаточно производительные. Для мониторинга вполне достаточно. Программист я так себе, занимаюсь в основном железом.... | https://habr.com/ru/post/710984/ | null | ru | null |
# Магия макросов для объединения объявления и реализации
Одна из неприятных проблем — при внесении даже простых изменений приходится править код в нескольких местах. Например, если в класс добавляется поле данных, его нужно добавить в объявление класса, инициализировать в конструкторе(ах), а если переопределены операт... | https://habr.com/ru/post/148494/ | null | ru | null |
# Как выдать Золушку за принца и не сойти с ума. Паттерн Декоратор
Всем привет, я [Максим Кравец](https://www.facebook.com/my.kravets) из Holyweb, и мы продолжаем разговор о паттернах (первую статью о Singleton можно [почитать вот тут](https://habr.com/ru/post/552600/)). Героя нашего сегодняшнего сюжета порой называют... | https://habr.com/ru/post/554930/ | null | ru | null |
# Haskell, как что-то очень близкое, или получаем комиты из github api
> Too late — 'cause I got it now
>
> there are monads all around
>
> IO, State and lists abound
>
> It's easy, like those people say
>
> but my program got abstracted all away!
>
> Maybe — o o o,
>
> It's a monad too, I kno... | https://habr.com/ru/post/205830/ | null | ru | null |
# Микроконтроллеры Megawin серии MG32F02 на базе ядра Cortex-M0
### Вступление
Компания Megawin Technology Co., Ltd. была основана в Тайване в 1999 году. Первые разработки компании были в области создания встроенной flash-памяти и контроллеров ввода-вывода. С 2004 г. было запущено массовое производство 8-битных микро... | https://habr.com/ru/post/674788/ | null | ru | null |
# Первые впечатления от перехода с Ubuntu 16.04 LTS на Ubuntu 18.04 LTS
Как известно, основное визуальное изменение в релизе 18 — это отказ от Unity и переход на Gnome 3. Здесь хочу поделиться своими впечатлениями от перехода с 16 на 18
### Сначала о хорошем...
Релиз 18 принёс нам новое ядро Linux (4.15) с заплатк... | https://habr.com/ru/post/421935/ | null | ru | null |
# Отключение профиля DEP и MDM на Mac OS Big Sur
ДисклеймерОписанные ниже действия лишают компанию или организацию, которая выдала вам компьютер, возможности следить за вашим устройством и получать дистанционно доступ к данным на нем.
Если обязательства перед компанией или закон ограничивает вас от выполнения подобны... | https://habr.com/ru/post/535468/ | null | ru | null |
# Интеграционные возможности easla.com
Ни одна современная система электронного документооборота немыслима без возможности интеграции ее в существующее информационное пространство организации с помощью API или протоколов связи.

Make legacy great again
Для начала запускаем IBM App Connect Entrerprise Toolkit (в десятой версии - IBM Integration Toolkit), слева во вкладке ... | https://habr.com/ru/post/578234/ | null | ru | null |
# Мобильные устройства изнутри. Изменение разметки памяти планшета
Изменение разметки памяти планшета
----------------------------------
**ОГЛАВЛЕНИЕ**[1.Введение.](#1)
[2.Планирование изменений разметки памяти.](#2)
[3.Внесение изменений в прошивку планшета.](#3)
[3.1.Внесение изменений в GPT-файл.](#31) ... | https://habr.com/ru/post/347920/ | null | ru | null |
# Использование DiagnosticSource в .NET Core: теория
DiagnosticSource — это простой, но весьма полезный набор API (доступен в NuGet пакете [System.Diagnostics.DiagnosticSource](https://www.nuget.org/packages/System.Diagnostics.DiagnosticSource/)), который, с одной стороны, позволяет различным библиотекам отправлять им... | https://habr.com/ru/post/435896/ | null | ru | null |
# Часть 4: Всё-таки запускаем Linux на RocketChip RISC-V
 *На картинке Linux kernel шлёт вам привет через GPIO.*
В этой части истории с портированием RISC-V RocketChip на китайскую плату с Cyclone IV мы всё-таки запустим Linux, а так... | https://habr.com/ru/post/459470/ | null | ru | null |
# Аппаратный взлом
[](https://habr.com/ru/company/ruvds/blog/669276/)
Эта статья предназначается для всех, кто имеет опыт в разработке \*nix/ПО/эксплойтов, но не обладает или почти не обладает знаниями оборудования/электроники! Хоть ... | https://habr.com/ru/post/669276/ | null | ru | null |
# Автоматическое подключение css и js файлов в Yii
Доброго времени суток.
На этот раз хочу, рассказать о способе автоматического подключения css и js файлов в Yii. Идея заключается в том, что бы к каждому файлу вида привязывать соответствующую папку с ресурсами (css, js, images). Это удобно, т.к. в большенстве случ... | https://habr.com/ru/post/150885/ | null | ru | null |
# Эволюция Java на примере чтения строк из файла
Приведу небольшой и интересный, на мой взгляд, пример, как изменилась жизнь простого крестьянина Java разработчика, на примере задачи чтения и печати строк из файла.

Многи... | https://habr.com/ru/post/269667/ | null | ru | null |
# Как я не написал эксплоит
Приветствую всех читателей. В своем блоге я опубликовал много статей о том, как я находил уязвимости в разных продуктах. Но все истории-исследования заканчиваются победой. В этот раз я решил поделиться историей неуспеха. Небольшое исследование, которое заняло у меня где-то 5-6 часов, в ходе... | https://habr.com/ru/post/556088/ | null | ru | null |
# Делаем дашборды для Grafana из того, что отдает экспортер метрик Prometheus и автоматизируем это
Во время работы с конвеером данных, в результате работы которого у нас появлялись данные в Timescale, [которые мы визуализировали в виде тепловых карт прошлой статье](https://habr.com/ru/post/668468/), у нас было задейст... | https://habr.com/ru/post/711280/ | null | ru | null |
# REACT + JEST = TDD ❤️
Привет, Хабр! Меня зовут Андрей Хижняк, я фронтенд-разработчик в команде, разрабатывающей App Store внутри ManyChat.
Как и моим коллегам, мне нравится пробовать новые подходы, методологии и практики, заниматься повышением качества и скорости разработки. В начале этого года мы с командой реши... | https://habr.com/ru/post/528794/ | null | ru | null |
# Обучаем нейросеть распознавать цифры на выборке от MNIST. Реализация алгоритма обратного распространения на C#
Доброго дня, хабровчане!
В этой статье поговорим о такой современной, модной и очень важной теме как машинное обучение и нейронные сети. О важности этой темы я писать не буду — каждый день об этом говорят ... | https://habr.com/ru/post/708928/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.