
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Как виртуальная реальность пришла в проект на Unity
*«Веяния моды ~~привносят в жизнь новые проблемы~~ заставляют меняться»* Наверно именно от этой мысли было принято решение подключить в проект на Unity, шлем виртуальной реальности, всем известный Oculus Rift DK2. Вопреки суровому прощупыванию рублем финансового дн... | https://habr.com/ru/post/249053/ | null | ru | null |
# Вероятностная интерпретация классических моделей машинного обучения
Этой статьей я начинаю серию, посвященную генеративным моделям в машинном обучении. Мы посмотрим на классические задачи машинного обучения, определим, что такое генеративное моделирование, посмотрим на его отличия от классических задач машинного обу... | https://habr.com/ru/post/343800/ | null | ru | null |
# Эффектное программирование. Часть 1: итераторы и генераторы
Javascript на данный момент является самым популярным языком программирования по версиям многих площадок (например Github). Является ли при этом он самым продвинутым или самым любимым языком? В нём отсутствуют конструкции, которые для других языков являются... | https://habr.com/ru/post/522864/ | null | ru | null |
# Парсер математических выражений
**Спасибо всем! Статья набрала необходимое число плюсов и автор к нам присоединяется! Вот и он: [elw00d](https://habrahabr.ru/users/elw00d/)**
Представляю вниманию товарищей-дотнетчиков библиотечку собственного написания, с помощью которой можно легко обращаться с несложными матема... | https://habr.com/ru/post/50158/ | null | ru | null |
# Pow — легкий, быстрый, удобный
Как много у вас приложений, сайтов, систем на Ruby, запускаемых под Rails и другие frameworks? Как часто вам приходится лезть в терминал и запускать приложения через 'rails s' и другие консольные команды? Это трата времени, сложность в управлении (в плане организации проектов). Как ... | https://habr.com/ru/post/156819/ | null | ru | null |
# BigBlueButton: открытое решение организации конференций
[](https://habrastorage.org/storage/habraeffect/5e/44/5e446e8ba9ff6f8aa9e8fcaf1d84f95e.png "Хабрэффект.ру")
Почти уверен что перед каждым ИТ отделом ставилась... | https://habr.com/ru/post/112066/ | null | ru | null |
# Телепортируем мемы в telegram, или как вернуть нажитое непосильным трудом
По разным причинам я уже как пару лет я не использовал ВК для связи с друзьями/коллегами - все ушли в telegram. Но в ВК все равно приходилось заходить, так как там осталось самое дорогое - группы с мемами, картиночками, анекдотами и всякое так... | https://habr.com/ru/post/706116/ | null | ru | null |
# Как мы переходили на Java 15 или история одного бага в jvm длиной в 6 лет
Мы готовились к выходу Java 15 ради некоторых её новых возможностей. В частности — текстовых блоков. Да, они появились в Java 14 (о новых функциях в Java 14 можно посмотреть [здесь](https://habr.com/ru/post/491546/)), но только как превью-фича... | https://habr.com/ru/post/536906/ | null | ru | null |
# Docstring coverage — покрытие python-кода документацией
Как проверить, что python-разработчики (или вы сами) хорошо задокументировали код, кроме как просматривать все руками или генерировать pydoc'ом документацию и сравнивать с исходниками? Вот и я не нашел никакого решения, пока случайно не натолкнулся на старый-пр... | https://habr.com/ru/post/149371/ | null | ru | null |
# Чего ждать при работе с API: 5 (не)обычных проблем при интеграции приложений
Где-то на просторах мультивселенной…
Представьте на минуту, что вы капитан [Сиракузии](https://ru.wikipedia.org/wiki/%D0%A1%D0%B8%D1%80%D0%B... | https://habr.com/ru/post/523810/ | null | ru | null |
# Перевод: Трагедия common lisp
Вашему вниманию предлагается перевод письма [Марка Миллера](https://en.wikipedia.org/wiki/Mark_S._Miller), одного из участников комитета по стандартизации JavaScript. В этом письме Марк рассказывает, к чему может привести «ползучий фичеризм» при дизайне языков программирования. И почему... | https://habr.com/ru/post/274739/ | null | ru | null |
# Как собрать коллег в братство
Привет, Хабр! Меня зовут Мария, работаю в ISPmanager QA-инженером и сегодня хочу рассказать, как мы замутили эпический ДНД-квест. По сути, история о том, как мы заморочились с ... | https://habr.com/ru/post/678024/ | null | ru | null |
# Светодиодный куб 8х8х8, интересно и красиво
#### Введение
Идея эта в голову пришла спонтанно, до осени этого года я и догадываться не мог, что люди занимаются чем-то подобным в жизни. На самом деле про то, что такие «кубики» существуют, рассказал преподаватель схемотехники и предложил взять данную тему в качестве к... | https://habr.com/ru/post/357934/ | null | ru | null |
# Введение в HTML5 History API
До появления HTML5 единственное, что мы не могли контролировать и управлять (без перезагрузки контента или хаков с location.hash) — это история одного таба. С появлением [HTML5 history API](http://dev.w3.org/html5/spec/history.html) все изменилось — теперь мы можем гулять по истории (ран... | https://habr.com/ru/post/123106/ | null | ru | null |
# Обзор библиотеки react-testing-library
В материале, перевод которого мы публикуем сегодня, Кент Доддс рассказывает о библиотеке собственной разработки для тестирования React-приложений, [react-testing-library](https://github.com/kentcdodds/react-testing-library), в которой он видит простой инструмент, способный заме... | https://habr.com/ru/post/353076/ | null | ru | null |
# Cross-nested ordered probit: мой первый разработческий проект, ML и эконометрика
В далёком 2014 я ещё учился на экономиста, но уже очень мечтал уйти в анализ данных. И когда мне предложили выполнить мой первый платный разработческий проект для моего университета, я был счастлив. Проект заключался в написании кода эк... | https://habr.com/ru/post/548100/ | null | ru | null |
# Не заставляйте (не)равенства в JavaScript выглядеть хуже, чем они есть
Время от времени я встречаю публикации, где рассказывается о том, какие из значений оператора `==` эквивалентны (как, например, [здесь](http://dorey.github.io/JavaScript-Equality-Table/)). Часто при этом оговаривается, что приведённые в таблице д... | https://habr.com/ru/post/218061/ | null | ru | null |
# Как подключить содержимое любых файлов для использования в коде C / C++
Привет, Хабровчане!
Это моя первая статья и у меня есть чем поделиться. Возможно мой велосипед не нов и этим способом пользуется каждый, но когда-то давно искал решения, с ходу найти не получилось.
### О чем речь?
Задача состояла в подключени... | https://habr.com/ru/post/545946/ | null | ru | null |
# Начинающему веб-мастеру: делаем одностраничник на Bootstrap 4 за полчаса
[Фреймворк Bootstrap](https://ru.wikipedia.org/wiki/Bootstrap_(%D1%84%D1%80%D0%B5%D0%B9%D0%BC%D0%B2%D0%BE%D1%80%D0%BA)) — это свободный набор инструментов для создания интерфейсов сайтов и веб-приложений. Его возможности ориентированы исключите... | https://habr.com/ru/post/350758/ | null | ru | null |
# Как прокачать belongs_to чтобы работал в два раза быстрее (database_validations gem)
В данной статье, я покажу почему нужно использовать `db_belongs_to` из [database\_validations](https://github.com/toptal/database_validations) гема вместо привычного нам `belongs_to`.
Я уверен, что большинство из вас знакомо с `be... | https://habr.com/ru/post/431734/ | null | ru | null |
# PostgreSQL: Серверное программирование на «человеческом» языке (PL/Perl, PL/Python, PL/v8)
Postgres знаменит своей расширяемостью, что относится и к поддержке процедурных языков (PL). Никто не может похвастаться ~~языком~~ списком языков такой длины, а потенциально этот список и вовсе не ограничен: для того, чтобы п... | https://habr.com/ru/post/502254/ | null | ru | null |
# Производительность встроенных функций высшего порядка в сравнении с циклом for-in в Swift
Произво... | https://habr.com/ru/post/661101/ | null | ru | null |
# Разбираемся с сессиями в SQLAlchemy
В этой небольшой статье я хочу дать ответ на вопрос, который возник у меня, когда я познакомился с сессиями в SQLAlchemy. Если сформулировать его кратко, то звучит он примерно так: “А зачем оно надо вообще”? Меня, как человека пришедшего из мира джанги, сессии приводили в уныние и... | https://habr.com/ru/post/597999/ | null | ru | null |
# Покрываем проект smoke-тестами, пока он не сгорел

Привет, Хабр! Как-то раз на нашем внутреннем семинаре мой руководитель – глава отдела тестирования – начал свою речь со слов «тестирование не нужно». В зале все притихли, ... | https://habr.com/ru/post/316874/ | null | ru | null |
# Valentine's Day Application on Libgdx
Every year there are a lot of articles dedicated to Valentine's Day. I also decided to get involved in this topic and create something original and unusual. The idea was to create a simple Android application with hearts that would have their physical models and interact with ea... | https://habr.com/ru/post/440298/ | null | en | null |
# Женщины и убийства: есть ли тут взаимосвязь? [часть 1 из 2]

**UPD** Добавил `R` код ([gist](https://goo.gl/bhOmxp)) для воспроизведения всех результатов
Исследование, недавно [опубликованное в престижном научном журнале... | https://habr.com/ru/post/311970/ | null | ru | null |
# Rails 4 Engines. Разработка gem'а через mountable engine — читаем логи сервера

Так уж случилось, что возникло непреодолимое желание написать свой Rails gem. Во-первых, академический интерес — такого еще... | https://habr.com/ru/post/216141/ | null | ru | null |
# Тернистый путь внедрения Swift Package Manager. Доклад Яндекса
Доклад будет интересен iOS-разработчикам, которые хотят внедрить технологию Swift Package Manager (SPM) в существующий проект. Руководитель iOS-разработки Яндекс Go Вадим Белотицкий рассказал о причинах, по которым его команда решила внедрять SPM, и о ре... | https://habr.com/ru/post/559938/ | null | ru | null |
# Изобретаем велосипед или пишем персептрон на С++. Часть 1 и 2
Изобретаем велосипед или пишем персептрон на C++. Часть 1
=========================================================
Напишем простую библиотеку для реализации персептрона на C++

*В [вводной статье](http://habrahabr.ru/post/269417/) мы рассмотрели преимущества реактивного подхода в программировании на Java, а также ситуации в которых библиотека Rx бывает боле... | https://habr.com/ru/post/270023/ | null | ru | null |
# Копируем формулу из Windows 7 Math Input Panel в буфер обмена с помощью Powershell 2.0
MathML.ps1
```
Add-Type -AssemblyName PresentationCore
$dataObject = [Windows.Clipboard]::GetDataObject()
$memoryStream = $dataObject.GetData("MathML")
if ($memoryStream) {
$streamReader = [System.IO.StreamReader]($memoryS... | https://habr.com/ru/post/93736/ | null | ru | null |
# Телега для датасайентиста
*How to deploy Python Telegram bot using Webhooks on Google Cloud Platform*
Вместо предисловия
------------------

*— Напиши телеграм-бота. Сейчас даже школьники пишут, — сказала она.
— А почем... | https://habr.com/ru/post/462141/ | null | ru | null |
# Laravel: объясняем основные понятия. Часть вторая: «Практика»
Всем привет! Продолжаем серию авторских публикаций в преддверии старта курса [«Framework Laravel»](https://otus.pw/naCJ/). В прошлой [статье](https://habr.com/ru/company/otus/blog/470794/) мы с вами посмотрели на теоретические основы Laravel. Однако теор... | https://habr.com/ru/post/471776/ | null | ru | null |
# Четыре простых лайфхака при написании тестов на Go + testify
Хотя язык программирования Go идёт в комплекте со встроенным тестовым фреймворком, мне сложно себе представить написание всего того количества тестов, что я написал, без [testify](https://github.com/stretchr/testify). В этой заметке я расскажу про нескольк... | https://habr.com/ru/post/666440/ | null | ru | null |
# NetApp ONTAP: UNMAP в SAN окружении
Команда UNMAP стандартизирована в рамках набора команд T10 SCSI и используется для высвобождения пространства из тонких лунов назад хрнилищу данных в SAN окружении. Как я [писал ранее](http://habrahabr.ru/post/224869/), протоколы SAN и NAS понемногу заимствуют друг у друга всё луч... | https://habr.com/ru/post/271959/ | null | ru | null |
# Батники против эксплойтов
Доброго времени суток, многоуважаемый %USERNAME%. Меня зовут Голованов Сергей, и я всё еще являюсь ведущим вирусным аналитиком в «Лаборатории Касперского». Я понимаю, что название этого поста в корпоративном блоге компании может вызвать смех, грусть, а у некоторых даже эпилептический припад... | https://habr.com/ru/post/137304/ | null | ru | null |
# [Пятничное] Требуются системный программист с высоким болевым порогом. Высокая З/П

#### `**[9:45]**`
«Требуются системный программист с высоким болевым порогом. Высокая З.П.»
Может быть года два назад, увидев такое объявлени... | https://habr.com/ru/post/412493/ | null | ru | null |
# Обфускация строк на этапе компиляции
Возник на днях у нас вопрос: «Как спрятать от любителей hex-редаторов строчки текста в скомпилированном приложении?». Но спрятать так, чтобы это не требовало особых усилий, так, между прочим…
Задача состоит в том, что бы использовать в коде строки как обычно, но при этом в исп... | https://habr.com/ru/post/245719/ | null | ru | null |
# Вечные студенты: когда программирование — это постоянная «учеба»
Если вы выбрали для себя профессию программиста, учеба, как правило, становится вашим постоянным спутником, хотите вы этого или нет. В этой области «выучить что-то раз и навсегда» маловероятно — постоянно появляются новые решения, новые фреймворки, в к... | https://habr.com/ru/post/340294/ | null | ru | null |
# Конец хайпа: Что ждёт язык Scala дальше

Вокруг языка Scala всегда было много хайпа и неоднозначных суждений.
Сейчас споры поутихли, но в твиттере появились сообщения об уходе некоторых значимых участников из компаний активно разв... | https://habr.com/ru/post/497908/ | null | ru | null |
# ML-обработка результатов голосований Госдумы (2016-2021)

Всем привет! Недавно я наткнулся на сайт [vote.duma.gov.ru](http://vote.duma.gov.ru), на котором представлены результаты голосований Госдумы РФ за весь период её работы — с 19... | https://habr.com/ru/post/564806/ | null | ru | null |
# Передаем React компоненты по WebSocket
Год назад команда реакта представила [серверные компоненты](https://ru.reactjs.org/blog/2020/12/21/data-fetching-with-react-server-components.html) (не путать с SSR). Если вкратце, то суть в том, что компонент создается на сервере, сериализуется в хитрый json, отправляется клие... | https://habr.com/ru/post/596237/ | null | ru | null |
# LibGDX. Практические вопросы и ответы
Привет Хабр!
Закончился конкурс от ВКонтакте и мой 2-х недельный марафон в интернете по поиску нужной информации. Хочу поделится небольшим опытом работы с графическим движком LibGD... | https://habr.com/ru/post/338398/ | null | ru | null |
# Знакомство с графовыми API
Привет, Хабр! Мы не перестаем отслеживать тему проектирования API после того, как встретили в портфеле издательства «Manning» [вот эту](https://www.manning.com/books/irresistible-apis) книгу. Сегодня мы решили опубликовать обзорную статью об относительно новых Graph API и предлагаем еще ра... | https://habr.com/ru/post/349290/ | null | ru | null |
# Как мы переводили MIKOPBX с chan_sip на PJSIP
Предыстория
-----------
Материал изначально готовился как доклад для **asterconf 2020**. Теперь постараюсь описать все **более** подробно в этой статье.
**MIKOPBX** - это **бесплатная** АТС с открытым исходным кодом на базе **Asterisk 16**. Год назад мы взялись за пер... | https://habr.com/ru/post/521236/ | null | ru | null |
# Опыт разработки первой игры на Unity, часть 2
Часть вторая — в которой я сдаюсь и опускаю руки
------------------------------------------------
[Ссылка на часть 1](https://habr.com/ru/post/593399/)
Первая часть была написана 24 ноября, прошло 10 дней...
Оказалось, что вытянуть нужные мне данные — крайне сложная з... | https://habr.com/ru/post/593401/ | null | ru | null |
# Тестирование в F#
### Введение
Вы наверное уже слышали много хорошего о языке F#, и даже наверное успели его опробовать на небольших личных проектах. Но как быть если речь идет о чем-то немного большем чем просто запуск и отладка простого консольного приложения или скрипта? В этой статье я поведаю вам о моем личном... | https://habr.com/ru/post/280410/ | null | ru | null |
# Решение проблемы с кодировками в Mono
Проблема.
=========
В целом, эта проблема может по-разному проявляться. В моём случае это был SharpDevelop, напрочь отказавшийся компилировать Hello world, который в командной оболочке (в том числе, через NAnt) собирается без ошибок. При этом, SharpDevelop был скуп на информац... | https://habr.com/ru/post/38204/ | null | ru | null |
# Акустическая емкость: Зачем рестораны снижают уровень шума
[](http://geektimes.ru/company/jowi/blog/260828/)
В нашем блоге мы уже рассказывали о том, как рестораны внедряют системы автоматизации работы (например, [Jowi](h... | https://habr.com/ru/post/383285/ | null | ru | null |
# Поговорим про градиенты в Unity
Всём привет. Меня зовут Григорий Дядиченко. Я в Unity разработке около 7 лет, и за это время повидал многое. Одна из основных проблем, которая встречается, когда забираешь у неопытных ребят проект - градиенты в интерфейсах. В целом ошибки в разработке интерфейсов не редкость. Вроде то... | https://habr.com/ru/post/537256/ | null | ru | null |
# Вышел Blazor 0.9.0
Blazor 0.9.0 уже доступен! Этот релиз добавляет в Blazor улучшения компонентов Razor в .NET Core 3.0 Preview 3.
Новые улучшения Razor Component теперь доступны для приложений Blazor:
* Улучшена обработка событий
* Формы и валидация
](https://habr.com/ru/company/ruvds/blog/506334/)*кдпв — Reuters*
Если вы арендовали сервер, то полного контроля у вас над ним нет. Это значит, что в любой момент к хостеру могут... | https://habr.com/ru/post/506334/ | null | ru | null |
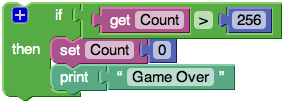
# Визуальный язык программирования Google Blockly
[Blockly](http://code.google.com/p/google-blockly/) — визуальный язык программирования с веб-интерфейсом. Создание программы осуществляется путём соединения блоков.
Не... | https://habr.com/ru/post/145067/ | null | ru | null |
# Проброс NVIDIA Quadro 4000 в виртуальную машину с использованием гипервизора Xen
Прочитав однажды пост [[1](#cite-1)] про успешный проброс видеокарты в виртуальную машину я подумал, что неплохо бы мне завести себе такую рабочую станцию.
При разработке кроссплатформенного программного обеспечения часто возникают п... | https://habr.com/ru/post/161747/ | null | ru | null |
# 11 MacOS приложений для продуктивной работы с трекпадом
MacOS имеет большой набор возможностей по управлению с помощью трекпада, но следующие 11 приложений сделают вашу работу с ним ещё продуктивнее.
Нативные возможности MacOS
--------------------------
Если вы не новичок в использовании трекпада на Мак, то можете... | https://habr.com/ru/post/709402/ | null | ru | null |
# Как быстро получить много данных от Битрикс24 через REST API
Нередко при работе с Bitrix24 REST API возникает необходимость быстро получить содержимое определенных полей всех элементов какого-то списка (например, лидов). Традиционный способ для этого - обращение к серверу через метод `*.list` (например, `crm.lead.li... | https://habr.com/ru/post/537694/ | null | ru | null |
# Использование Direct2D и DirectWrite в .Net-среде
Несмотря что «нагуглить» в интернете можно все, для новых технологий это далеко не так. В частности, когда я захотел использовать достаточно новые технологии [Direct2D](http://msdn.microsoft.com/en-us/library/dd370990(VS.85).aspx) (не бойтесь, это никак не связано с ... | https://habr.com/ru/post/70240/ | null | ru | null |
# 1.5 схемы на отечественном IPsec VPN. Тестирую демоверсии

### Ситуация
Я получил демоверсию продуктов С-Терра VPN версии 4.3 на три месяца. Хочу разобраться, станет ли моя инженерная жизнь легче после перехода на новую версию.
... | https://habr.com/ru/post/514190/ | null | ru | null |
# Введение в разработку web-приложений на PSGI/Plack
Автор: [Дмитрий Шаматрин.](http://pragmaticperl.com/authors/6)
С разрешения автора оригинальных статей цикла я публикую цикл на Хабре.
[Оригинальная статья на сайте журнала pragmaticperl.com](http://pragmaticperl.com/issues/02/pragmaticperl-02-введение-в-разр... | https://habr.com/ru/post/247545/ | null | ru | null |
# Правильные способы исключения файлов в Git
Иногда встречаю в файле `.gitignore` то, чего там быть никак не должно. Например, папка `.idea`, в которой лежат конфиги известных IDE от JetBrains. Это часть вашего рабочего окружения и она никаким боком не относится к проекту и репозиторию. Если над проектом работает неск... | https://habr.com/ru/post/202696/ | null | ru | null |
# Подсветка синтаксиса Midnight Commander: добавляем свой синтаксис
Всем хорош exim но его конфигурация не похожа ни на что соответственно и подсветка в нем скучно-серая (см.ниже)и чтобы исправить эту досадную ошибку решено было покопаться в недрах гугла на предмет Midnight commander syntax highlight.
Краткий консп... | https://habr.com/ru/post/128239/ | null | ru | null |
# Вышел test.it v1.1.0 — что дальше?
Добрый день хабр.
Вчера вышла версия 1.1.0 **test.it** — фреймворка для тестирования js кода.
Он, наконец, обзавёлся функционалом, отсутствие которого делало его неполноценным:* Асинхронные тесты/группы
* Запуск отдельных тестов/групп
А так же прочими мелочами.
](https://habrahabr.ru/company/itinvest/blog/331542/)
Технологии стали активом — финансовые организации теперь не только занимаются своим о... | https://habr.com/ru/post/331542/ | null | ru | null |
# Простейшая интернет радио колонка «Kodi» или спасение «Малинового» кирпича

##### Основные предпосылки:
1. Есть старая неиспользуемая плата Raspberry Pi первого поколения;
2. Плата лежит на шкафу мертвым грузом и не используется ... | https://habr.com/ru/post/482714/ | null | ru | null |
# OutOfMemory и использование векторных изображений в Android Studio
Привет, Хабр! В данной статье, ориентированной на новичков, я бы хотел дать несколько советов по оптимизации использования приложением памяти устройства, дабы постоянно не получать OutOfMemory, а также рассмотреть использование векторных изображений ... | https://habr.com/ru/post/450566/ | null | ru | null |
# RAR: получение списка файлов без PECL
Не так давно я писал о получении текста из всевозможных файловых форматов, будь то [DOC](http://habrahabr.ru/blogs/php/72745/) или [PDF](http://habrahabr.ru/blogs/php/69568/). Сегодня мы рассмотрим не менее интересный формат — формат сжатия RAR. Не буду обнадёживать страждущих —... | https://habr.com/ru/post/73637/ | null | ru | null |
# Введение в реверс-инжиниринг: взламываем формат данных игры
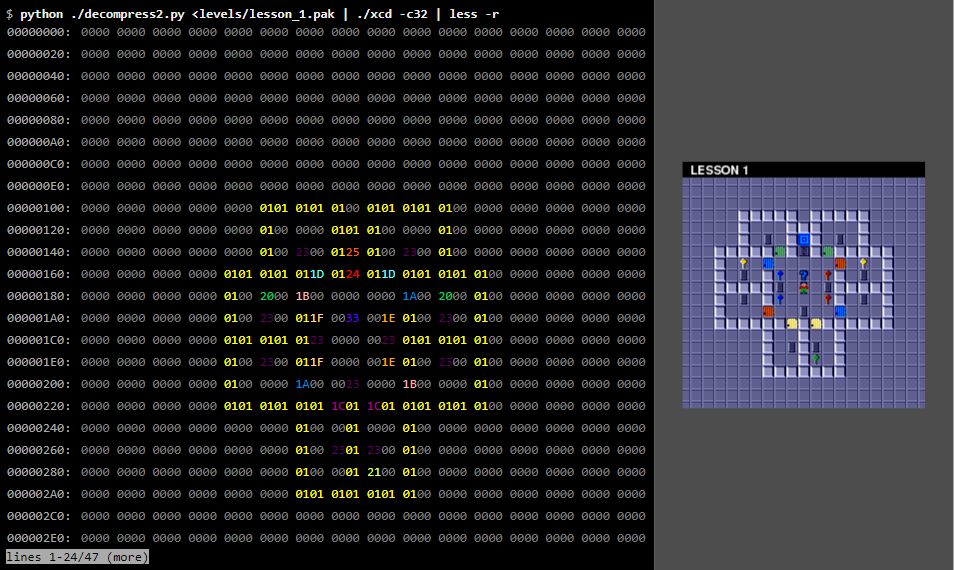
### Введение
Реверс-инжиниринг незнакомого файла данных можно описать как процесс постепенного понимания. Он во многом напоминает научный метод, только применённый к соз... | https://habr.com/ru/post/447562/ | null | ru | null |
# Custom Google Search View
Вы знаете, сколько данных вы качаете из сети каждый раз, чтобы увидеть вот эту страничку?

Если без браузерного кэша, то 600 килобайт (в gzip-e) и 38 запросов. Если с кэшем, то 70 килобайт и 7-8 запро... | https://habr.com/ru/post/421173/ | null | ru | null |
# Humane VimScript: минималистичная объектная ориентация
 Я считаю VimScript крайне недружелюбным, но неожиданно мощным языком. К счастью его возможно одружелюбить, чем я и предлагаю вам заняться в этом цикле статей. Здесь мы... | https://habr.com/ru/post/278623/ | null | ru | null |
# Книга «Kali Linux: библия пентестера»
[](https://habr.com/ru/company/piter/blog/688486/) Как дела, Хаброжители?
Пентестеры должны в совершенстве знать Kali, чтобы эффективно выполнять свои обязанности. В книге есть все об ин... | https://habr.com/ru/post/688486/ | null | ru | null |
# Ansible: 30 самых важных модулей для DevOps-профессионалов (часть 3)
В [первой](https://habr.com/ru/company/southbridge/blog/707130/) части этой серии мы обсудили модули проверки подключения, установки неко... | https://habr.com/ru/post/709860/ | null | ru | null |
# Как я существенно облегчил работу с Raspberry Pi («всё новое — хорошо забытое старое»)

*-Как начать работу с Raspberry Pi?
-Залить на SD-карту образ, подключить к питанию и пойти в магазин докупить всё, чего не хватае... | https://habr.com/ru/post/400159/ | null | ru | null |
# Горячие клавиши в терминале Linux
Давным-давно, такие слова как "hot keys" и "keyboard shortcuts" мне не всегда удавалось перевести на русский без потери лица. Как-то раз, я написал "клавиатурные сокращения... | https://habr.com/ru/post/663758/ | null | ru | null |
# Yii2-advanced: Гибкая настройка Yii2 RBAC (роли, разрешения, правила)
### У админа может и не быть доступа к разрешению пользователя и в пределах одной роли пользователи могут иметь разный доступ к разрешениям
#### Как организовать сущности Role,Permission,Rule
Роли (role): типовые роли supper\_admin,admin,custome... | https://habr.com/ru/post/327170/ | null | ru | null |
# Передача файла сигналами
Добрый день, хабражители. Наверняка все знают что такое сигналы в Linux и для чего они нужны. Но сегодня, я хотел бы рассказать о, как мне кажется, нетрадиционном их применении.
Задача очень надуманная и направленна на тренировку своих навыков работы с сигналами и, немножко, побитовыми о... | https://habr.com/ru/post/122823/ | null | ru | null |
# Global WHEAT CHALLENGE 2021 или как накормить весь мир
Представляю вашему внимаю обзор на соревнование [Global Wheat Challenge 2021](https://www.aicrowd.com/challenges/global-wheat-challenge-2021), а такж... | https://habr.com/ru/post/570434/ | null | ru | null |
# Переписываем приложение под Blockchain

Отмечу сразу, что данная статья не о том как писать код на Solidity, а как существующую классическую архитектуру вашего приложения можно перевести на рельсы blockchain и думать ... | https://habr.com/ru/post/351398/ | null | ru | null |
# Создание универсального UIAlertController'а для различных версий iOS
Одними из самых востребованных классов в UIKit до выхода iOS версии 8 являлись UIAlertView и UIActionSheet. Наверное, каждый разработчик приложений под мобильную платформу от Apple рано или поздно сталкивался с ними. Показ сообщений или меню выбора... | https://habr.com/ru/post/242801/ | null | ru | null |
# 14 компьютерных игр выставлены в музее современного искусства
Музей современного искусства в Нью-Йорке начал собирать коллекцию компьютерных игр. Планируется, что там разместится около 40 наиболее заметных явлений. Пока в список попали 14 компьютерных игр. В том числе и [тетрис Алексея Пажитнова](http://www.moma.org... | https://habr.com/ru/post/171765/ | null | ru | null |
# Конференция DEFCON 22. Группа GTVHacker. Взламываем всё: 20 устройств за 45 минут. Часть 2
[Конференция DEFCON 22. Группа GTVHacker. Взламываем всё: 20 устройств за 45 минут. Часть 1](https://habr.com/company/ua-hosting/blog/424907/)
**Майк Бейкер:** следующее, 14-е устройство, к которому мы получили root-доступ ... | https://habr.com/ru/post/424915/ | null | ru | null |
# Сравнение аналитических in-memory баз данных
 В последние два месяца лета в управлении хранилищ данных (Data Warehouse, DWH) Тинькофф Банка появилась новая тема для кухонных споров.
Всё это время мы проводили масштабное ... | https://habr.com/ru/post/310620/ | null | ru | null |
# Распределённая система управления на базе SoC FPGA
Реализация связки прошивки ПЛИС, ПО микроконтроллера NIOS и управляющего ПО под Linux на базе Altera Cyclone V SoC с использованием Avalon Mailbox для создания на их основе распределенной системы управления.
Введение
========
В распределенной системе управления... | https://habr.com/ru/post/353680/ | null | ru | null |
# Готовим Physically Based Rendering + Image-based Lighting. Теория+практика. Шаг за шагом
Хей, привет. 2017 год на дворе. Даже простенькие мобильные и браузерные приложения начинают потихоньку рисовать физически корректное освещ... | https://habr.com/ru/post/326852/ | null | ru | null |
# PostgreSQL. Как правильно хранить котов или история одной миграции
История взята из реального проекта. Но поскольку реальный проект слишком скучный (и под NDA), в этой статье используется упрощенный пример.
Жил-был один проект. И была у него база данных. И была в базе таблица для хранения, ну, скажем, котов. Вот ... | https://habr.com/ru/post/306728/ | null | ru | null |
# «Computer, how is my build doing?» и другие волшебные заклинания
Барух Садогурский рассказывает, как с помощью сервиса голосовых команд Alexa можно добавить голосовой интерфейс к совершенно неожиданным вещам, таким как IntelliJ IDEA и Jenkins, а также, откинувшись в кресле с бокалом любимого напитка, управлять всем,... | https://habr.com/ru/post/352372/ | null | ru | null |
# Build tools in machine learning projects, an overview
I was wondering about machine learning/data science project structure/workflow and was reading different opinions on the subject. And when people start to talk about workflow they want their workflows to be reproducible. There are a lot of posts out there that su... | https://habr.com/ru/post/451962/ | null | en | null |
# Data Mining: Первичная обработка данных при помощи СУБД. Часть 3 (Сводные таблицы)
Данная серия посвящена анализу данных для поиска закономерностей. В качестве примера используется одна из обучающих задач сообщества спортивного анализа данных Kaggle. Хотя размеры данных для задачи не большие, методы обработки, котор... | https://habr.com/ru/post/165283/ | null | ru | null |
# Реализация блочного шифра «Кузнечик» с режимом CFB на С++
Сегодня речь пойдёт о новом алгоритме блочного шифрования «Кузнечик» из стандарта ГОСТ Р 34.12 2015. В последнее время выходит множество публикаций, посвященных этому стандарту. В них с теоретической точки зрения описываются приведённый алгоритм, изучаются ос... | https://habr.com/ru/post/313932/ | null | ru | null |
# Авторизация через ВКонтакте, Mail.ru и другие для самых начинающих — 1
На хабре и других ресурсах есть туториалы, однако в каждом упущен какой-нибудь незначительный момент, вопросы по которому можно видеть на различных форумах. Так как недавно столкнулся с задачей подружить один сайт с Контактиком и Майл.ру, то реши... | https://habr.com/ru/post/126717/ | null | ru | null |
# Selenium WebDriver – Метрика тестов в реальном времени с использованием Grafana и InfluxDB
Всем привет! Уже на следующей неделе стартуют занятия в группе [«Java QA Engineer»](https://otus.pw/x5Eg/). Этому и будет приурочена нынешняя публикация.

Привет, Хабр! Недавно мы вышли в релиз с [нашей игрой](https://itunes.apple.com/ru/app/railway-tycoon/id1297227175?ls=1&mt=8), которую долго и упорно готовили и в процессе которой на... | https://habr.com/ru/post/415051/ | null | ru | null |
# Введение в JavaFx и работа с layout в примерах
Доброго времени суток. В этой статье я расскажу основы работы с классами пакета javafx.scene.layout.\* (BorderPane, AnchorPane, StackPane, GridPane, FlowPane, TilePane, HBox, VBox) и их особенностями в пошаговых примера и иллюстрациях. Также в кратце пробежимся по иерар... | https://habr.com/ru/post/305282/ | null | ru | null |
# Паттерны Command и Strategy с точки зрения функционального программирования
В результате изучения функционального программирования в моей голове появились некоторые мысли, которыми я хочу с вами поделиться.
#### Паттерны проектирования и функциональное программирование? Как это вообще связано?
В умах многих разр... | https://habr.com/ru/post/120375/ | null | ru | null |
# Как распознавание лиц помогает находить тестовые телефоны
Привет, хабровчане! В EastBanc Technologies ведётся большое количество проектов, связанных с мобильной разработкой. В связи с чем необходим целый зоопарк устройств для тестирования на всех этапах. И, что характерно, каждый отдельный девайс постоянно оказывает... | https://habr.com/ru/post/426437/ | null | ru | null |
# Рецепты PostgreSQL: auto-failover и auto-rejoin в docker swarm
Для приготовления auto-failover и auto-rejoin в docker swarm нам понадобится [docker](https://www.docker.com), [postgres](https://www.postgresql.org), [repmgr](https://repmgr.org), [pgbouncer](https://www.pgbouncer.org), [runit](http://smarden.org/runit)... | https://habr.com/ru/post/498132/ | null | ru | null |
# Мини датчик света и удара | nRF52840
В сегодняшней статье хочу расказать о новым датчике освещенности и вибрации. Датчик работает на модуле E73-2G4M08S1C(nRF52840). Поводом к освоению МК стало довольно несложное добавление поддержки в Arduino IDE на основе библиотеки Sandeep Mistry, небольшая стоимость, отличные хар... | https://habr.com/ru/post/478960/ | null | ru | null |
# Rails и полиморфные связи
В большинстве руководств по Rails, которые мне попадались в руки, в примерах по полиморфным связям есть интересная особенность выбора типа для этих связей, о которой и пойдет речь в этом посте.
В Rails полиморфными считаются связи, устанавливаемые между объектами разных типов. Предполага... | https://habr.com/ru/post/79389/ | null | ru | null |
# Учебный курс по React, часть 9: свойства компонентов
В сегодняшней части перевода учебного курса по React мы поговорим о свойствах компонентов. Это — одна из важнейших концепций, нашедших отражение в данной библиотеке.
[](http... | https://habr.com/ru/post/436032/ | null | ru | null |
# Глобальная блокировка интерпретатора (GIL) и её воздействие на многопоточность в Python
Как вы, наверное, знаете, глобальная блокировка интерпретатора (GIL, Global Interpreter Lock) — это механизм, обеспечивающий, при использовании интерпретатора CPython, безопасную работу с потоками. Но из-за GIL в конкретный момен... | https://habr.com/ru/post/586360/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.