
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Погружение в разработку на Ethereum. Часть 3: приложение для пользователя
В предыдущих статьях ([часть 1](https://habrahabr.ru/post/336132/) и [часть 2](https://habrahabr.ru/post/336770/)) мы описали как можно пользоваться децентрализованными приложениями на смарт-контрактах, если вы сами не против быть нодом. Но че... | https://habr.com/ru/post/339080/ | null | ru | null |
# Details
How often do you get to 404 pages? Usually, they are not styled and stay default. Recently I’ve found [test.do.am](http://test.do.am/) which interactive character attracts attention and livens up the error page.
Probably, there was just a cat picture, then they thought up eyes movement and developer imple... | https://habr.com/ru/post/443720/ | null | en | null |
# Kubernetes 1.20: обзор основных новшеств
Этой ночью, 8 декабря (по американскому времени), [состоялся](https://kubernetes.io/blog/2020/12/08/kubernetes-1-20-release-announcement/) новый релиз Kubernetes — 1.20. По традиции нашего блога, рассказываем о наиболее значимых изменениях в новой версии.
 мы эмпирически доказали, что на хаскеле можно довольно легко написать этакий игрушечный wc, который при этом существенно быстрее реализации wc из GNU Coreutils. Понятное дело,... | https://habr.com/ru/post/496370/ | null | ru | null |
# Как работать с библиотекой sktime: разбираемся на примере прогнозирования продаж
Одна из самых популярных задач прогнозирования временных рядов — это прогнозы продаж для торговли. Чтобы построить базовую мо... | https://habr.com/ru/post/692392/ | null | ru | null |
# Введение в пользовательские CSS-свойства
*Автор курса [Нетологии](https://netology.ru/?utm_source=blog&utm_medium=747&utm_campaign=habr) «HTML-верстка» Стас Мельников рассказал, что такое пользовательские CSS-свойства и почему их стоит изучить.*
Стандарт CSS Custom Properties изменил CSS. Появились безумные возмо... | https://habr.com/ru/post/431616/ | null | ru | null |
# SingleA: доменный SSO своими руками
TL;DR
-----
[SingleA](https://github.com/nbgrp/singlea) — это набор Symfony бандлов, которые позволяют развернуть свой PHP’шный SSO, реализующий фреймворк [SingleAuth](https://nbgrp.github.io/singlea/singleauth/). Тот, в свою очередь, позволяет пользователям веб-приложений, живущ... | https://habr.com/ru/post/666602/ | null | ru | null |
# Использование перехватов операций для бэкапа файлов в macOS “на лету”
Привет, Хабр! Меня зовут Денис Копырин, и сегодня я хочу рассказать о том, как мы решали проблему бэкапа по требованию на macOS. На самом деле интересная задача, с которой я столкнулся в институте, выросла в итоге в большой исследовательский проек... | https://habr.com/ru/post/484816/ | null | ru | null |
# Анализ одного рефакторинга
В данном крохотном посте речь пойдет об одной из глав, книги «Принципы, паттерны и методики гибкой разработки на языке C#», с названием «Рефакторинг». Глава полностью посвящена рефакторингу. На примере одного большого метода, автор последовательно модифицирует код, попутно объясняя почему ... | https://habr.com/ru/post/231325/ | null | ru | null |
# Gson шпаргалка для Map, List и Array
Постоянно сталкиваясь с парсингом Json всегда подглядываю в старых проектах или на встретившуюся реализацию объекта на [stackoverflow.com](http://stackoverflow.com/).
Решил собрать три основных типа в шпаргалку Map, List, Array.
```
Type itemsMapType = new TypeToken>() {}.g... | https://habr.com/ru/post/253266/ | null | ru | null |
# Реверсим «Нейроманта». Часть 2: Рендерим шрифт

Привет, ты читаешь продолжение статьи, посвящённой реверс-инжинирингу «Нейроманта» — видеоигры, выпущенной компанией *Interplay Productions* в 1988 году по мотивам одноимённого романа... | https://habr.com/ru/post/357972/ | null | ru | null |
# Хватит копипастить, или как превратить Outlook-письмо в Jira-задачу в один клик
Привет! Меня зовут Карина Суворова, в «Северстали» я занимаюсь автоматизацией пользовательских процессов. Как часто вам приходят письма и встречи с задачами, которые надо выполнить в определённые сроки? Мне много. А моим коллегам, особен... | https://habr.com/ru/post/711638/ | null | ru | null |
# Автоматизируем добавление сервера в Zabbix с назначением шаблонов
Самый простой способ добавить новый сервер в Zabbix — через веб интерфейс. Засетапили новый сервер, пошли в web-морду, добавили машинку. Но, когда что-то делается руками, всегда можно забыть, особенно когда ввод серверов в строй происходит часто.
... | https://habr.com/ru/post/211384/ | null | ru | null |
# Подключение советской клавиатуры Электроника МС 7004 к современному ПК
[](https://habr.com/ru/company/timeweb/blog/706422/)
Когда я листал доски объявлений, на глаза попалась отличная клавиатура «Электроника МС 7004». Даже по сов... | https://habr.com/ru/post/706422/ | null | ru | null |
# Поиск уязвимостей у хабросайтов
Время было вечером, делать было нечего… Было решено удивить хабражителей. Но как? Банальные поиски уязвимостей на известных сайтах уже никому не интересны. Чтож, значит включим фантазию… Ведь у пользователей тоже есть сайты! Срочно проверить их на стойкость!
#### Как все происходил... | https://habr.com/ru/post/191434/ | null | ru | null |
# Тайм-киллер из детства

Уверен, многие из читающих иногда занимались на уроках бесполезной ерундой вместо того, чтобы слушать учителя. Я точно так делал, и одним из способов убить время были игры на бумаге. Особенно интересной мне ... | https://habr.com/ru/post/471642/ | null | ru | null |
# Поиск маршрутов за 1 человеко-месяц
Однажды для нашего проекта потребовался функционал прокладки маршрутов. Программистов у нас не то чтобы очень много, а скорее наоборот, поэтому мы хотели найти какое-то готовое решение, поискали и ничего хорошего не нашли.
Данные дорожного графа у нас были, но в таком виде, что... | https://habr.com/ru/post/211388/ | null | ru | null |
# Качественный интерфейс JIRA-плагина с помощью AUI Framework
[](http://habrahabr.ru/company/mailru/blog/243543/)
JIRA широко используется в Mail.Ru Group. Сейчас мы применяем эту систему не только для управления проектами ... | https://habr.com/ru/post/243543/ | null | ru | null |
# Extjs, диалоги и вселенское зло!
Да! Я ошибочно считаю что диалоги типа «а вы точно хотите удалить ндцать выделенных объектов» вселенским злом. Но так считают единицы.
Постоянно требуется втыкать это безобразие в код. Но и тут не все гладко.
В Extjs это как-то через голову делается.
Хочется написать просто:... | https://habr.com/ru/post/23344/ | null | ru | null |
# Добавляем распределенность в SObjectizer-5 с помощью MQTT и libmosquitto
Когда-то в SObjectizer-4 «из коробки» была доступна возможность построения распределенных приложений. Но не всегда это работало так хорошо, как хотелось бы. В итоге в SObjectizer-5 от поддержки распределенности в самом ядре [SObjectizer](https:... | https://habr.com/ru/post/359212/ | null | ru | null |
# OpenGL ES 1.1 в Windows 8 и Windows Phone 8.1
[](http://habrastorage.org/files/a6a/c21/752/a6ac217526e34d3f8efbdad9f92a9039.png)В далеком 1998 году я пытался сделать свою игру с OpenGL. Разработка с трудом дошла до альфы и бы... | https://habr.com/ru/post/246911/ | null | ru | null |
# Конфиденциальность пользователей Telegram снова нарушена. Представители мессенджера требуют не раскрывать подробностей
В конце февраля 2021 года выходит обновленный релиз клиента Telegram с заголовком: ‘*... | https://habr.com/ru/post/580582/ | null | ru | null |
# Прямой VPN-туннель между компьютерами через NAT'ы провайдеров (без VPS, с помощью STUN-сервера и Яндекс.диска)
Продолжение [статьи](https://habr.com/ru/post/478452/) о том, как мне удалось организовать прямой VPN-туннель между двумя компьютерами находящимися за NAT'ами провайдеров. В прошлой статье описывался процес... | https://habr.com/ru/post/481034/ | null | ru | null |
# Gobetween Exec discovery+ Elasticsearch. L4 балансировка с Data Node Discovery
Зачем все это нужно
-------------------
Все кто использовал Elasticsearch каластер для своих нужд (особенно для логирования и как основную базу данных) на больших нагрузках сталкивался с проблемами консистентности и масштабируемости. Ког... | https://habr.com/ru/post/304096/ | null | ru | null |
# Как написать комментарий к задаче?
В этой статье предлагается общий шаблон грамотного написания комментария к проверенным задачам, фичам, багам. Данный формат комментария будет также отлично подходить для отчетов о тестировании. Но для начала, давайте рассмотрим, кому статья будет полезна.
Для кого эта статья?
----... | https://habr.com/ru/post/712700/ | null | ru | null |
# Boids — простой алгоритм перемещения групп юнитов
Во время разработки клона одной игрушки мне понадобилось перемещать группы юнитов от одной планеты к другой. Первое что пришло в голову — заспавнить юниты один за другим и двигать их по прямой. Но это выглядело не очень весело, кроме того — нужно было как-то обходить... | https://habr.com/ru/post/212721/ | null | ru | null |
# Unity UI Toolkit: MVVM ннада?
Изображёные приложения вы м... | https://habr.com/ru/post/689134/ | null | ru | null |
# Вышел OpenSSH 9.0
Вышел релиз OpenSSH 9.0. Он [ориентирован](https://www.openssh.com/releasenotes.html#9.0) на исправление ошибок, а также включает постквантовую криптографию по умолчанию.
В этом выпуске ... | https://habr.com/ru/post/660403/ | null | ru | null |
# Сотрудник Google выложил 0day-эксплойт для маршрутизаторов TP-Link SR20

*Домашний маршрутизатор TP-Link SR20 появился на рынке в 2016 году*
Маршрутизаторы TP-Link известны многочисленными уязвимостями. Но обычно производитель... | https://habr.com/ru/post/446160/ | null | ru | null |
# Интерфейсы командной строки Java: picocli
Всем привет!
Очередной старт группы [«Разработчик Java»](https://otus.pw/88tV/), на котором мы всё продолжаем наш эксперимент того, что процесс обучения не обязан быть непрерывным («Контрамоция должна быть непрерывной?» ). То есть мы чуть переработали и перетасовали прог... | https://habr.com/ru/post/419401/ | null | ru | null |
# Новое в браузерах: Firefox 66 по умолчанию блокирует видео и звук, Chromium ограничивает бюджет страниц
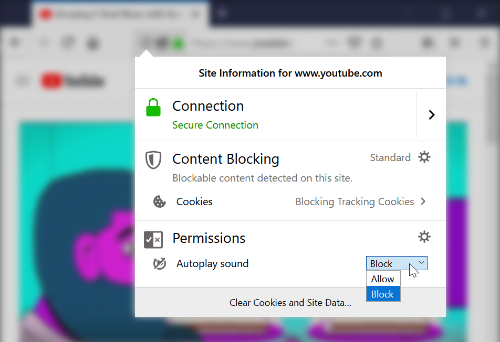
В ближайших версиях Firefox и Chromium могут произойти важные изменения.
Во-первых, в Firefox 66 для десктопов по умолчанию... | https://habr.com/ru/post/439118/ | null | ru | null |
# PHP-Дайджест № 88 – интересные новости, материалы и инструменты (13 июня – 17 июля 2016)

После небольшого перерыва PHP-Дайджест снова в деле! Предлагаем вашему вниманию очередную подборку со ссылками на новости и материа... | https://habr.com/ru/post/305808/ | null | ru | null |
# Делаем собственное Z-Wave устройство на базе Z-Uno
Протокол Z-Wave весьма популярен, и существует огромное множество совместимых устройств. Однако все, кто когда либо автоматизировал своё жилище, сталкивались с тем, что чего-то таки не хватает.
Кому-то не хватает датчика давления, кому-то датчика дождя, кому-то х... | https://habr.com/ru/post/367571/ | null | ru | null |
# Чего ждать от NeoVim: особенности редактора
Привет! Я Антон Губарев, инженер команды Platform as a Service (PaaS) в Авито. Долгое время я пользовался IDE от JetBrains, затем пересел на VS Code. Последние несколько лет работаю с кодом только в NeoVim — адаптировал его под себя и перестал использовать другие IDE.
Я н... | https://habr.com/ru/post/682962/ | null | ru | null |
# SQL запросы быстро. Часть 1
#### Введение
Язык SQL очень прочно влился в жизнь бизнес-аналитиков и требования к кандидатам благодаря простоте, удобству и распространенности. Из собственного опыта могу сказать, что наиболее часто SQL используется для формирования выгрузок, витрин (с последующим построением отчетов ... | https://habr.com/ru/post/480838/ | null | ru | null |
# Как я использовал gem gon в Групоне
На днях я зарелизил новую версию своего gem [Gon](https://github.com/gazay/gon) – 4.0.0 и решил привести пару примеров его возможностей и использования. Данная библиотека служит для упрощения работы с данными в MVC архитектуре. Она позволяет работать с данными контроллера из JS пр... | https://habr.com/ru/post/148437/ | null | ru | null |
# Создаем свой кастомный плагин Style – Темизация Views в Drupal 8
Модуль [Views](https://www.drupal.org/node/1912118) (Представления) является составляющей ядра Drupal 8. На сегодняшний день об этом известно всем. Twig – это новый обработчик шаблонов в Drupal 8. Об этом нам тоже уже известно. Но как же программно вза... | https://habr.com/ru/post/330704/ | null | ru | null |
# DISLIN — высокоуровневая библиотека визуализации пользовательских данных

Думаю каждый сталкивался с проблемой визуализации данных внутри своей программы. Особенно, если программа консольная. В топике ... | https://habr.com/ru/post/125611/ | null | ru | null |
# PHP-Дайджест № 176 (11 – 23 марта 2020)
[](https://habr.com/ru/post/493594/)
Свежая подборка со ссылками на новости и материалы. В выпуске: обновления PHP и Composer 1.10, переносы конференций, 3 новых RFC предложения из PHP Inte... | https://habr.com/ru/post/493594/ | null | ru | null |
# Dispose pattern
*“Не стоит следовать некоторой идиоме только потому, что так делают все или так где-то написано”**Мысли автора статьи во время чтения и рефакторинга чужого кода*
Ни для кого не будет секретом, что платформа .NET поддерживает автоматическое управление памятью. Это значит, что если вы создадите объ... | https://habr.com/ru/post/129283/ | null | ru | null |
# Многопоточное программирование в Android с использованием RxJava 2
Если вы новичок в общении с RxJava или пытались разобраться в этом, но не довели дело до конца, то ниже вы найдете для себя кое-что новое.
](http://xn--80acaphjiwsabsdmca3a.xn--p1ai "Енот, прикольный зверь")
[«Забери мусор с собой!»](http://xn--80acaphjiwsabsdmca3a.xn--p1ai "перейти на сайт, посвящённый борьбе с загрязнен... | https://habr.com/ru/post/118586/ | null | ru | null |
# Сборка ICO файла с иконками в формате PNG при помощи FASM
Иногда я пишу небольшие программы на C++, и часто выходит так, что иконка программы «весит» больше, чем собственно сама программа. Так же вышло и при написании [Sound Keeper](http://geektimes.ru/post/243937/): программа — 14КБ, иконка 16×16 + 32×32 + 48×48 пи... | https://habr.com/ru/post/247425/ | null | ru | null |
# Аппаратные технологии безопасности Intel: новое слово в защите биометрических приложений. Часть 2
В [первой части](https://habrahabr.ru/company/intel/blog/281989/) мы обсудили проблемы современных биометрических приложений распознавания пользователей и рассказали о том, как Intel SGX, Intel VMX и Intel IPT способны ... | https://habr.com/ru/post/282411/ | null | ru | null |
# Свой сервер обложек на Python для интернет-радио

Я перфекционист который любит во всём порядок. Больше всего меня радует когда вещи работают именно так, как они должны работать (в моём, разумеется, понимании). А ещё у... | https://habr.com/ru/post/338564/ | null | ru | null |
# Ультра скорость для C# кода, запуск .NET на FPGA процессоре с HASTLAYER

У многих FPGA или ПЛИС, ассоциируется с низкоуровневым программированием на языках VHDL, Verilog, или OpenCL. Платформа .NET уже давн... | https://habr.com/ru/post/674800/ | null | ru | null |
# Карманная книга по TypeScript. Часть 1. Основы
* [Часть 1. Основы](https://habr.com/ru/company/macloud/blog/559902/)
* [Часть 2. Типы на каждый день](https://habr.com/ru/company/macloud/blog/559976/)
* [Часть 3. Сужение типов](https://habr.com/ru/company/macloud/blog/560594/)
* [Часть 4. Подробнее о функциях](https:... | https://habr.com/ru/post/559902/ | null | ru | null |
# Изменения модальной презентации экранов в iOS 13
Всем привет!
Меня зовут Илья, я из Tinkoff.ru. Я перевел для вас статью от Geoff Hackworth про то, как изменился стиль модальной презентации в iOS 13, на что это повлияло и как работает обратная совместимость с предыдущими версиями iOS и Xcode.

***Прим. перев.** — Этой статьёй мы начинаем цикл переводов, посвященных теме Zero Downtime Deployment. Следующие публикации осветят во... | https://habr.com/ru/post/470568/ | null | ru | null |
# Критическая уязвимость в Saltstack мастере (уже под атакой)
Привет, Хабр!
Этой ночью началась массовая экплуатация свежей уязвимости SaltStack master <=3000.1 версий. Еще один хороший пример того, что нужно закрывать все торчащее наружу апи фаерволом.
В репозитории saltstack [предупреждение](https://github.com... | https://habr.com/ru/post/500174/ | null | ru | null |
# Как использовать soy, requirejs, backbone js в плагинах для Atlassian Jira

В этой статье разработаем плагин, который будет сохранять настройки плагина в Jira. Мы будем использовать библиотеки soy, requirejs, backbone js для отобра... | https://habr.com/ru/post/415809/ | null | ru | null |
# Создание несложного бота для WoW, программирование маршрутов
#### Введение
Прочитал недавно [пост](http://habrahabr.ru/post/113258/), в котором автор рассказал о своём боте для торговли на аукционе в игре World of Warcraft. Его персонаж бегал челноком на небольшие расстояния и выполнял конкретные действия, строго з... | https://habr.com/ru/post/189792/ | null | ru | null |
# Дизайн-система IVI. Взгляд изнутри. Часть 2
Это вторая часть статьи про нашу дизайн-систему. [Первая часть](https://habr.com/ru/post/565500/) выходила раньше.
В этот раз речь пойдёт о философии нашей работы, взаимодействии с дизайнерами и клиентскими разработчиками; о трудностях, с которыми сталкиваемся, и как их п... | https://habr.com/ru/post/565516/ | null | ru | null |
# Использование библиотеки ColorPicker в Android для реализации гибкого выбора цвета
Понадобилось реализовать выбор цвета пользователем для вашего Android-приложения? Эта библиотека — отличный выбор.Без долгих предисловий, начнем.
Как всегда, для начала добавим библиотеку в приложение (файл build.gradle(module.app)... | https://habr.com/ru/post/496136/ | null | ru | null |
# Proxy на работе и отсутствие его дома
##### Или галочка достала
[](http://www.imageup.ru/img38/form111651.jpg)
У меня на работе, как и у многих других, Интернет работает через Proxy, естест... | https://habr.com/ru/post/55348/ | null | ru | null |
# Маркетинговая аналитика на Python. Пишем код для RFM-сегментации
RFM - классический инструмент маркетинга для сегментации вашей клиентской базы. Я использую ее для работы в В2В, В2G сегменте. В основе него - понятные управленцу ценности: LTV и Purchase Frequency.
Как можно применять этот инструмент:
1. Посчитать... | https://habr.com/ru/post/658225/ | null | ru | null |
# [DotNetBook] Stackalloc: забытая команда C#
 С этой статьей я продолжаю публиковать целую серию статей, результатом которой будет книга по работе .NET CLR, и .NET в целом. Вся книга будет доступна на GitHub (ссылка в конце статьи). ... | https://habr.com/ru/post/348130/ | null | ru | null |
# Анонимный Дед Мороз 2015-2016 — Пост хвастовства новогодними подарками

Привет, `%username%`!
20 человек уже отметили, что получили свой подарок. Настало время собрать их фотографии и рассказы в этом традиционном посте... | https://habr.com/ru/post/275355/ | null | ru | null |
# Простой шейдер мультяшной графики в OpenGL своими руками
Недавно я заинтересовался рисунками, состоящими только из контуров, и решил попытаться воспроизвести нечто подобное для трехмерной графики.

*Suzanne, неофициальный маскот... | https://habr.com/ru/post/505726/ | null | ru | null |
# Стратегии по ускорению кода на R, часть 2
Цикл for в R может быть очень медленным, если он применяется в чистом виде, без оптимизации, особенно когда приходится иметь дело с большими наборами данных. Есть ряд способов сделать ваш код быстрее, и вы, вероятно, будете удивлены, узнав насколько.
Эта статья описывает ... | https://habr.com/ru/post/277693/ | null | ru | null |
# Рисуем кнопку в SVG
В настоящее время я работаю над одним веб-приложением, и вот захотелось мне обновить нынешний, довольно-таки топорный интерфейс на что-то более современное, более красивое. Начать решил с кнопок как с наиболее технически нагруженной части: в них требуется не только заменить внешний вид, но и доба... | https://habr.com/ru/post/110869/ | null | ru | null |
# Знакомство с lit-element и веб-компонентами на его основе
В один момент мне предстояло срочно познакомиться с веб-компонентами и найти способ удобно разрабатывать с их помощью. Я планирую написать серию статей, что бы
как-то систематизировать знания по веб-компонентам, lit-element и дать краткое ознакомление с э... | https://habr.com/ru/post/445438/ | null | ru | null |
# Пишем Custom MSBuild Task для деплоя (WMI included)
Добрый день! Одним прекрасным днем мы обнаружили, что наш MSBuild деплой проект не хочет работать в новой среде: для создания и управления сайтами и пулами он использовал MSBuild.ExtensionPack. Падали ошибки, связанные с недоступностью DCOM. Среду менять было нельз... | https://habr.com/ru/post/261603/ | null | ru | null |
# Тюнинг PHP-FPM. Введение
**БОНУС:** в нашем подкасте мы обсудили эту тему с экспертом, членом сообщества PHP программистов: <https://share.transistor.fm/s/6a8637ba>
PHP-FPM (или FastCGI Process Manager) им... | https://habr.com/ru/post/582442/ | null | ru | null |
# Захват всех доменов .io с помощью таргетированной регистрации
В [предыдущей статье](https://thehackerblog.com/the-journey-to-hijacking-a-countrys-tld-the-hidden-risks-of-domain-extensions/index.html) мы обсуждали захват доменн... | https://habr.com/ru/post/333026/ | null | ru | null |
# Избавление .NET программы от регистрации на примере BEM
Не так давно я решил изучить, а заодно попробовать поправить одну библиотечку, избавив программу работающую на данной библиотеке от лицензии.
Началось все с того, что как то мне в руки попала программа для бухгалтерской отчетности, некий бюджетный вариант 1С... | https://habr.com/ru/post/111330/ | null | ru | null |
# Тёмная сторона SQL Server In-Memory OLTP
Пару лет назад, в разговоре с кем-то промелькнула примерно такая фраза: "Мы используем In-Memory OLTP - это очень быстро, зачастую даже вместо временных таблиц создаём In-Memory и всем советуем". Спустя какое-то время, мне задали вопрос как можно держать одну таблицу в памяти... | https://habr.com/ru/post/547220/ | null | ru | null |
# Пишем Guard

Привет, Хабр! Есть несколько способов проверять аргументы на правильность. Например, для проверки на null можно использовать:
1. if (!ReferenceEquals(arg, null)) throw…
2. [Code Contracts](https://msdn.microsoft... | https://habr.com/ru/post/330150/ | null | ru | null |
# Распознавание лиц. Создаем и примеряем маски

Пока сообщество iOS-разработчиков спорит, как писать проекты, пока пытается решить, использовать ли MVVM или VIPER, пока пытается подSOLIDить проект или добавить туда реактивную турбину... | https://habr.com/ru/post/343514/ | null | ru | null |
# Учимся надежному управлению Kubernetes
Всем доброго!
Мы возвращаемся к нашей любимой традиции — раздача полезностей, которые мы собираем и изучаем в рамках наших курсов. Сегодня у нас на повестке дня [курс по DevOps](https://otus.pw/rCwU/) и один из его инструментов — [Kubernetes](https://kubernetes.io/).
Нед... | https://habr.com/ru/post/347810/ | null | ru | null |
# Intel Power Monitoring Tool — на страже энергоэффективности
Мы продолжаем разговор об [энергоэффективности мобильных устройств](http://habrahabr.ru/company/intel/blog/184708/) и [приложениях Intel под Android](http://habr... | https://habr.com/ru/post/188420/ | null | ru | null |
# Система сообщений или “мягкая связь” между компонентами для Unity3D
#### Введение
В данной статье будут затронуты темы, связанные с реализацией возможности “мягкой связи” компонентов игровой логики на основе системы сообщений при разработке игр на Unity3D.
Ни для кого не секрет, что в подавляющем большинстве слу... | https://habr.com/ru/post/282524/ | null | ru | null |
# GPSS-WORLD основы имитационного моделирования на живых примерах
Доброй пятницы уважаемые читатели Хабра.
В данном посте я предлагаю вам бегло ознакомиться с возможностью создания имитационной модели процессов в программе GPSS-WORLD. Данный пост нельзя считать полноценным туториалом, но я поделюсь с Вами теми кру... | https://habr.com/ru/post/192044/ | null | ru | null |
# Process Mining без PM4PY

Построить граф по логам процесса очень просто. В распоряжении аналитиков в настоящее время достаточное многообразие профессиональных разработок, таких как Celonis, Disco, PM4PY, ProM и т.д., призванных о... | https://habr.com/ru/post/521152/ | null | ru | null |
# XMLDSig: php + openssl
Продолжение поста про интеграцию с ГИС ЖКХ - <https://habr.com/en/post/710462/>
В этой части разберём как правильно подписать xml-запрос в `php` при помощи `openssl`
В этой статье я не разбираю почему `xmldsig` формируется именно так - я привожу пример реализации. Поэтому я ожидаю, что вы уж... | https://habr.com/ru/post/710532/ | null | ru | null |
# Конвертирование видео фильмов в формат .mо (Mobiclip)
В этой статье я вам расскажу, как получать и воспроизводить фильмы и клипы, например, в форматах FullHD на экранах ваших КПК. Без тормозов, зависаний, запаздываний аудио- или видео-дорожки друг от друга, а наоборот — в оригинальном качестве и со всеми вытекающими... | https://habr.com/ru/post/140188/ | null | ru | null |
# Решаем проблему родительского контроля в Ubuntu с помощью Dansguardian и Privoxy
Я придерживаюсь мнения, что Ubuntu вполне себе подходит на роль user-friendly десктопной операционной системы.
Соответственно, считаю, что при покупке компьютеров и ноутбуков на стоимости лицензионной Windows вполне можно сэкономить... | https://habr.com/ru/post/119286/ | null | ru | null |
# Создание многопользовательской веб-игры в жанре .io

Вышедшая в 2015 году [Agar.io](https://agar.io) стала прародителем нового жанра [**игр .io**](https://www.google.com/search?q=.io+game), популярн... | https://habr.com/ru/post/450574/ | null | ru | null |
# Навигация по соседним документам (Siblings)
**Задача:** необходимо снабдить каждую дочернюю страницу навигацией « предыдущий следующий »
Всё кол-во скудных решений, которые я нашел — не подходили мне: некоторые не работали, некоторые показались очень объемные для решения такой тривиальной задачи. Решил написать с... | https://habr.com/ru/post/71722/ | null | ru | null |
# Ликбез по типизации в языках программирования

Эта статья содержит необходимый минимум тех вещей, которые просто необходимо знать о типизации, чтобы не называть динамическую типизацию злом, Lisp — б... | https://habr.com/ru/post/161205/ | null | ru | null |
# Библиотека эмуляции терминала ROTE и Lua привязки
[ROTE](http://rote.sourceforge.net/) — простая библиотека на языке C, служащая для эмуляции [терминала VT100](https://en.wikipedia.org/wiki/VT100... | https://habr.com/ru/post/254089/ | null | ru | null |
# Найти и заблокировать: поиск фишера при помощи Maltego
Команда безопасности REG.RU в работе часто сталкивается с мошенниками, любителями спама, фишинговыми доменами, взломом аккаунтов, попытками угона доменов и т. д. На примере поиска создателя фишинговых сайтов я расскажу, как мы вычисляем подобных нарушителей с по... | https://habr.com/ru/post/685656/ | null | ru | null |
# Intel Wireless Display: для разработчика
 Нет, это не ошибка в движке Хабры, и не повтор статьи, опубликованной на прошлой неделе и [посвященной технологии WiDi](http://habrahabr.ru/company/intel/blog/138202... | https://habr.com/ru/post/138795/ | null | ru | null |
# Анализ производительности CSS-анимаций
Что выбрать для анимирования элементов веб-страниц? JavaScript или CSS? Этот вопрос однажды вынужден будет задать себе каждый веб-разработчик. А может — и не однажды.
JavaScript-программисты создали множество библиотек для браузерной анимации. И, похоже, все вокруг оказались... | https://habr.com/ru/post/501644/ | null | ru | null |
# Что ждать от внедрения Istio? (обзор и видео доклада)
Istio — частный случай «сервисной сетки» (Service Mesh), понятия, о котором наверняка все слышали, и многие даже знают, что это такое. Мой доклад на [Kuber Conf 2021](https://cloud.yandex.ru/events/369) *(мероприятие Yandex.Cloud, которое проходило 24 июня в Моск... | https://habr.com/ru/post/569612/ | null | ru | null |
# Интернет вещей в Яндекс.Облаке: как устроены сервисы Yandex IoT Core и Yandex Cloud Functions

В октябре прошлого года состоялась первая облачная конференция Яндекса Yandex Scale. На ней было объявлено о запуске множества новых с... | https://habr.com/ru/post/491740/ | null | ru | null |
# Изучаем Docker, часть 3: файлы Dockerfile
В переводе третьей части серии материалов, посвящённых Docker, мы продолжим вдохновляться выпечкой, а именно — бубликами. Нашей сегодняшней основной темой будет работа с файлами Dockerfile. Мы разберём инструкции, которые используются в этих файлах.
→ [Часть 1: основы](ht... | https://habr.com/ru/post/439980/ | null | ru | null |
# Пишем редактор мнемосхем для SCADA-системы на Fabric.js
Всем добрый день. Сегодня я расскажу как на fabric.js я написал редактор мнемосхем для SCADA-системы. Доля декстопных SCADA-систем медленно но верно уменьшается. Всё переводится на Web, и АСУ ТП тут не исключение.
Итак, что хотим получить в конечном итоге: ... | https://habr.com/ru/post/322990/ | null | ru | null |
# Axios или Fetch: чем пользоваться в 2019 году?
Axios — это широко известная JavaScript-библиотека. Она представляет собой HTTP-клиент, основанный на промисах и предназначенный для браузеров и для Node.js. Если вы работали в последние несколько лет JavaScript-программистом, то вы, совершенно определённо, этой библиот... | https://habr.com/ru/post/477286/ | null | ru | null |
# FAQ по Superjob API (публикация вакансий)
Недавно я [рассказывал о Headhunter API](https://habr.com/ru/post/464013/) для публикации вакансий, упомянув Superjob. Теперь, реализовав тот же функционал на Superjob API будет справедливо поделиться с вами полученным опытом.
*** не является форматом ***WYSIWYG (What You See is What You Get (То, Что Вы Видите, это То, Что Вы Получаете)).*** Он был разработан, чтобы быть независимым от платформы, независимым о... | https://habr.com/ru/post/580016/ | null | ru | null |
# Domain Fronting. версия 1.3
В данной статье я хочу немного поговорить о такой старой и знакомой заядлым пентестерам теме как Domain fronting. Тем более, что после недавних нововведений от компании Cloudflare эта избитая тема заиграла новыми красками.
Краткое содержание предыдущих серий
-----------------------------... | https://habr.com/ru/post/702420/ | null | ru | null |
# Angular: делаем код читаемым для бэкендера. Бонус: подмена API заглушками и кэширование запросов
Очень часто на проекте темпы разработки фронтенда опережают темпы разработки бэкенда. При такой ситуации возникает необходимость двух вещей:
1. возможность запускать фронт без бэкэнда, либо без отдельных эндпоинтов;
... | https://habr.com/ru/post/501674/ | null | ru | null |
# GUI SVN клиент для Linux
Доброго времени пребывания, уважаемые Хабровцы 8)
Наткнулся я недавно, на бескрайних просторах, на очень полезную и долгожданную штуковину. Что за штуковина — читай сабж.
Выглядит всё это, как всем известный TortoiseSVN для Windows. Только называется RabbitVCS и уже для Linux.
Если ... | https://habr.com/ru/post/77967/ | null | ru | null |
# Выразительный JavaScript: JavaScript и браузер
#### Содержание
* [Введение](http://habrahabr.ru/post/240219/)
* [Величины, типы и операторы](http://habrahabr.ru/post/240223/)
* [Структура программ](http://habrahabr.ru/post/240225/)
* [Функции](http://habrahabr.ru/post/240349/)
* [Структуры данных: объекты и массивы... | https://habr.com/ru/post/243311/ | null | ru | null |
# Восхождение на Эльбрус — Разведка боем. Техническая Часть 2. Прерывания, исключения, системный таймер
Продолжаем исследовать [Эльбрус](https://ru.wikipedia.org/wiki/%D0%AD%D0%BB%D1%8C%D0%B1%D1%80%D1%83%D1%81_2000) путем портирования н... | https://habr.com/ru/post/447744/ | null | ru | null |
# Как не потерять ход времени, работая за компьютером. Приложение по мониторингу работы и ведению статистики

Я работаю педагогом в детском технопарке «Кванториум». В период самоизоляции мы так же, как и все перешли на дистанционно... | https://habr.com/ru/post/514414/ | null | ru | null |
# Following in the Footsteps of Calculators: Qalculate
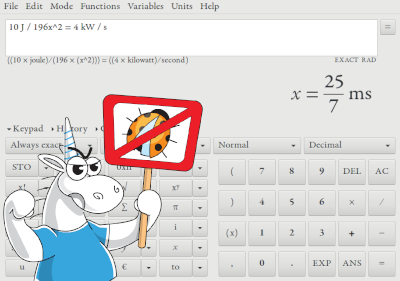
Previously we did code reviews of large mathematical packages, for example, Scilab and Octave, whereby calculators remained aloof as small utilities, in which it is difficult t... | https://habr.com/ru/post/443656/ | null | en | null |
# Правильная типизация: недооцененный аспект чистого кода
Здравствуйте, коллеги.
Не так давно наше внимание привлекла [почти готовая](https://www.manning.com/books/programming-with-types) книга издательства Manning «Programming with types», подробно рассматривающая важность правильной типизации и ее роль при написа... | https://habr.com/ru/post/460149/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.