
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Фаззинг JS-движков с помощью Fuzzilli

[`fuzzilli`](https://github.com/googleprojectzero/fuzzilli) – это фаззер для javascript-движков от команды `googleprojectzero`. Его отличительная черта – это `FuzzIL`, промежуточный язык, кото... | https://habr.com/ru/post/690742/ | null | ru | null |
# Opener 2020: Самый сок
Введение
--------
На протяжении всего апреля мы с командой после учёбы и работы решали увлекательные задачи в рамках конкурса Opener от компании Itransition. Вместе с конкурсом закончился наш лучший месяц на самоизоляции. Теперь, отдохнув, я готов спокойно поделиться этим опытом с вами.
Op... | https://habr.com/ru/post/507904/ | null | ru | null |
# Как я писал свой чат
Привет, Хабр!
В статье я написал, о том как разрабатывал чат. О его архитектуре и о технических решениях принятых в ходе его разработки.
Чат представляет собой клиент-серверное приложение с элементами p2p.
С поддеркжой:
* Личных сообщений.
* Комнат.
* Передачи файлов.
* Голосового ча... | https://habr.com/ru/post/228021/ | null | ru | null |
# Как нейросеть MinD-Vis преобразует активность мозга в изображение
[](https://habr.com/ru/company/ruvds/blog/706694/)
Расшифровка визуальной информации из активности мозга — это способ узнать больше о том, как работает зрительная си... | https://habr.com/ru/post/706694/ | null | ru | null |
# Гибкое управление событиями в jQuery — плагин jquery-behavior
Привет, Хабр!
Меня зовут Вячеслав Гримальский, я работаю над конструктором посадочных страниц, в котором страница собирается перетаскиванием блоков.
Я расскажу об инструменте для работы с событиями, который изначально являлся частью конструктора, но... | https://habr.com/ru/post/237501/ | null | ru | null |
# Экспериментальное определение характеристик кэш-памяти
В ряде случаев (например, для тонкой оптимизации программы под конкретный компьютер) полезно знать характеристики кэш-подсистемы: количество уровней, время доступа к каждому уровню, их размер и ассоциативность, и т.п.
Для одноразовой оптимизации необходимые з... | https://habr.com/ru/post/111011/ | null | ru | null |
# Создание приложения ToDo с помощью Realm и Swift
С развитием смартфонов в последние годы было разработано много инструментов, чтобы упростить жизнь разработчикам, обеспечив их максимальной производительностью и качеством. Занимать лидирующие позиций в App Store сегодня не простое задание. А научить ваше приложение м... | https://habr.com/ru/post/272393/ | null | ru | null |
# Защита от спама в phpBB 3 без капчи
Думаю, многие владельцы форумов на phpBB 3 уже знают, что стандартная капча, идущая в комплекте с форумом, особо не спасает.
В общем, зайдя однажды на свой форум, увидел, что за считанные ча... | https://habr.com/ru/post/131920/ | null | ru | null |
# Вывод результатов поиска и проблемы с производительностью
Один из типовых сценариев во всех привычных нам приложениях — поиск данных по определенным критериям и вывод их в удобном для чтения виде. Тут же могут быть дополнительные возможности по сортировке, группировке, постраничному выводу. Задача, по идее, тривиаль... | https://habr.com/ru/post/493438/ | null | ru | null |
# Переводим раздачу контента на BitTorrent
Под катом описан пример перевода файловых серверов на BitTorrent.
У моего друга есть небольшая локальная сеть, абонентов так на 200-300, собственно обычная локальная сеть. Несколько игровых серверов, несколько файловых серверов и гирлянды неуправляемых свитчей. Типичный П... | https://habr.com/ru/post/97574/ | null | ru | null |
# Закрепляем jQuery — 25 отличных советов
Перевод отличной статейки. Думаю, будет полезна как новичкам, которые только приступили к использованию jQuery, так и тем, кто уже какое-то время с ним работает. А кого-то, возможно, заставит глянуть эту чудесную библиотечку. Многие советы имеют отношение не только к jQuery, н... | https://habr.com/ru/post/52201/ | null | ru | null |
# Реализация и применение Entity Component System на примере python
Немного теории
--------------
Entity Component System (ECS) - это паттерн, используемый при разработке видеоигр, для хранения игровых объектов.
### Компоненты (Components)
Все характеристики объектов находятся в минимальных структурах данных - комп... | https://habr.com/ru/post/702598/ | null | ru | null |
# Портируем старую игру в жанре «shoot 'em up» на JavaScript на коленке
Имеется древняя игрушка LaserAge, которая написана на Flash (на очень древнем Macromedia Flash 4) и работает только под Windows. В детстве она мне очень понравилась, поэтому я решил для души портировать её, чтобы можно было играть с браузера со вс... | https://habr.com/ru/post/508850/ | null | ru | null |
# Почему вам не нужен sshd в Docker-контейнере
Когда люди запускают своей первый Docker-контейнер, они часто спрашивают: «А как мне попасть внуть контейнера?» и ответ «в лоб» на этот вопрос, конечно: «Так запустите в нём SSH-сер... | https://habr.com/ru/post/237737/ | null | ru | null |
# О бедном бите замолвите слово

*Н. Кобринский, В. Пекелис «Быстрее мысли» — Молодая гвардия, 1959*
Когда все вокруг измеряют Гигабайтами, Петабайтами, Зетабайтами и т.д., все компании гордятся своей БигДатой, вспоминать о битах в при... | https://habr.com/ru/post/596399/ | null | ru | null |
# Вероятностный анализ сейсмической опасности
Причиной написания этой статьи стала распространенная рядом СМИ [информация](https://ria.ru/science/20171220/1511300109.html) о прогнозе «мощнейшего» землетрясения, которое может произойти в ближайшие 30 лет в Японии и на Курилах с вероятностью до 40%. Ссылались журналисты... | https://habr.com/ru/post/346734/ | null | ru | null |
# Подтверждение номеров телефона без SMS
Сегодня компаниям все чаще нужно верифицировать клиента не только по email, но и по телефонному номеру. Проблем с подтверждением номера по смс две — это дорогой для компании и не всегда безопасный способ — клиенты часто используют временные виртуальные номера.
Предлагаем пр... | https://habr.com/ru/post/543394/ | null | ru | null |
# Познаём Русский язык. Цистерна первая, полная.
`10 INPUT string$
20 LET from$ = "жы"
30 LET to$ = "жи"
40 GO SUB 1000
50 LET from$ = "шы"
60 LET to$ = "ши"
70 GO SUB 1000
80 LET from$ = "чя"
90 LET to$ = "ча"
100 GO SUB 1000
110 LET from$ = "щя"
120 LET to$ = "ща"
130 ... | https://habr.com/ru/post/49552/ | null | ru | null |
# Техники машинного обучения для прогнозирования цен акций: функции индикаторов и анализ новостей
[](https://habrahabr.ru/company/itinvest/blog/275825/)
В нашем блоге мы уже затрагивали тему предсказания цен акций с помощью ... | https://habr.com/ru/post/275825/ | null | ru | null |
# Библиотека инструментов wxWidgets. Сборка
В продолжение поста (новости) [wxWidgets. Мелочь, но приятно](http://habrahabr.ru/post/212333/), ловите печеньку.

*Картинка взята с ресурса: [ru.wikipedia.org... | https://habr.com/ru/post/212027/ | null | ru | null |
# The Inside Playbook. Сетевые функции в новом Ansible Engine 2.9

В предстоящем выпуске Red Hat Ansible Engine 2.9 вас ждут впечатляющие улучшения, и некоторые из них описаны в этой статье. Как обычно, мы разрабатывали улучшения Ans... | https://habr.com/ru/post/471896/ | null | ru | null |
# Контроль температуры в серверных шкафах с помощью Ардуино
 В [одном](http://habrahabr.ru/company/flprog/blog/240651/) из предыдущих постов я рассказывал о проектах созданных пользователями программы FLProg. А сегодня я хочу ... | https://habr.com/ru/post/244083/ | null | ru | null |
# Spring и @Autowired для ENUM-типов. Факультатив
Как известно, в Spring нельзя сделать бины для перечисляемых типов без «костылей» — у этого типа «нет» конструктора.
> Caused by: org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'demoEnum0' defined in file [...\DemoEnum0.class]... | https://habr.com/ru/post/229955/ | null | ru | null |
# Загрузка реальных ландшафтов в Unity 3D

Введение
========
Тема генерации ландшафтов путем применения разнообразных хитроумных алгоритмов достаточно широко освещалась на хабре ([раз](https://habrahabr.ru/post/226635/), [дв... | https://habr.com/ru/post/329246/ | null | ru | null |
# Бесполезный и красиво ужасный язык программирования ALLang
Введение
--------
Примерно год назад я писал язык программирования под названием ALLang. Расшифровка его звучит так: *Another LISP Language*, что незамысловато даёт понимание его второсортности. Тем не менее, таковой язык всё же предлагает интересные особен... | https://habr.com/ru/post/703036/ | null | ru | null |
# Как сделать ваш код в 80 раз быстрее
Всем бобра!
У нас стартует третий набор на курс [«Разработчик Python»](https://otus.pw/JyLT/), а значит, что впереди и [открытый урок](https://otus.pw/Vm95/), которые у нас частично замещают староформатные дни открытых дверей и где можно ознакомиться с интересным материалом от... | https://habr.com/ru/post/349230/ | null | ru | null |
# Поиск нарушений на видео с помощью компьютерного зрения
Автоматизация обработки видеозаписи с целью выявления нарушений — одно из востребованных направлений компьютерного зрения во многих отраслях.
Сегодня мы попытаемся обнаружить на видео отсутствие клиента в кадре в момент проведения операции в автоматизированно... | https://habr.com/ru/post/547920/ | null | ru | null |
# Как PVS-Studio ищет ошибки: методики и технологии
PVS-Studio — статический анализатор исходного кода для поиска ошибок и уязвимостей в программах на языке C, C++ и C#. В этой статье я ... | https://habr.com/ru/post/319382/ | null | ru | null |
# На землю из облаков: переезд Proxmox на компьютер в офисе в РФ
Доброго времени суток, Хабр!
Предлагаю вниманию краткую историю переезда одного сервера виртуализации на базе Proxmox из Hetzner в РФ на сервер виртуализации, расположенный в стойке в офисе компании.
Кратко о причинах выбора Proxmox, его особеннос... | https://habr.com/ru/post/530690/ | null | ru | null |
# Создание блога с помощью Nuxt Content (часть первая)

> От переводчика: Я собирался сделать собственную статью по Nuxt Content, но наткнулся на готовую [статью](https://nuxtjs.org/blog/creating-blog-wi... | https://habr.com/ru/post/522496/ | null | ru | null |
# Пишем свой сервис авто-обновлений
Большинство разработчиков stand-alone приложение рано или поздно сталкиваются с проблемой доставки обновлений для своего приложения. В этой статье я постараюсь решить эту проблему наилучшим, на мой взгляд, способом — написать свой собственный универсальный сервис авто-обновлений, ко... | https://habr.com/ru/post/131649/ | null | ru | null |
# Точки входа в Python
Многие думают, что точки входа это такие инструкции в **setup.py**, которые позволяют сделать пакет доступным для запуска из командной строки. Это, в целом, верно, но возможности точек входа не ограничиваются этим.
Ниже я покажу как можно реализовать систему плагинов для пакета, чтобы другие ... | https://habr.com/ru/post/479570/ | null | ru | null |
# Скрещиваем WebWorker и XMLHttpRequest
WebWorker+XMLHttpRequest
HTML5 уже никого не удивляет, но у многих новичков возникает много вопросов. Особенно вопросы связаные с параллельными потоками, а именно с WebWorker. Дальнейшее повествование требует знания JS и HTML — я не буду разжевывать основы html и js.
Сегод... | https://habr.com/ru/post/218989/ | null | ru | null |
# Гибридная реализация алгоритма MST с использованием CPU и GPU
Введение
--------
Решение задачи поиска минимальных остовных деревьев ( MST — minimum spanning tree) является распространенной задачей в различных областях исследований: распознавание различных объектов, компьютерное зрение, анализ и построение сетей (на... | https://habr.com/ru/post/253031/ | null | ru | null |
# Postgresso 26

*Жизнь продолжается. А мы продолжаем знакомить вас с самыми интересными новостями PostgreSQL.*
**[Пополнение в Core Team](https://www.postgresql.org/community/contributors/)**
Напоминаем о неписанном правиле ... | https://habr.com/ru/post/523264/ | null | ru | null |
# Работа над ошибками — phppgadmin
Один из наших клиентов поставил задачу — не заливается дамп базы данных через phpPgAdmin. В лог ошибок выводятся сообщения типа: ERROR: relation «public».«company» does not exists.
Схема public в наличии имеется, таблицы company нету. В процессе поиска выясняется, что через консол... | https://habr.com/ru/post/257967/ | null | ru | null |
# Тестирование интеграции Kotlin веб сервиса на Spring Boot с базой данных
Меня зовут Вячеслав Аксёнов, я имею большой опыт разработки веб сервисов на Java / Kotlin с использованием Spring Framework. В своей работе я регулярно встречаюсь с задачами, в которых требуется настроить и протестировать интеграцию веб сервиса... | https://habr.com/ru/post/667632/ | null | ru | null |
# Занимательная вёрстка с единицами измерения области просмотра
Единицы измерения области просмотра используются вот уже несколько лет. Они [практически полностью поддерживаются основными браузерами](http://caniuse.com/#feat=viewport-units). Тем не менее я продолжаю находить новые и любопытные способы их применения. Я... | https://habr.com/ru/post/331184/ | null | ru | null |
# Используем nginx, docker, skydns и skydock для обновления кода на лету (zero-downtime deployment)
Инструменты, которые мы будем использовать
------------------------------------------
### Docker
[Docker](https://www.docker.io/) — простая и элегантная библиотека для создания легковесных изолированных друг от друга ... | https://habr.com/ru/post/215653/ | null | ru | null |
# Разделяемые указатели и многопоточность. И снова о них, в который раз
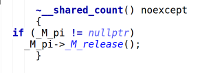 Глава из книги "Современное программирование на C++" называется "В сто первый раз об интеллектуальных указателях". Все бы ничего, но книга была издана в 2... | https://habr.com/ru/post/311560/ | null | ru | null |
# Visual Studio Extensibility. Часть первая: MSBuild
Привет Хабр, в этих статьях я попытаюсь осветить тему расширений Microsoft Visual Studio(а попутно ещё и MSBuild), т.к. эта сфера является крайне плохо документированной и вообще покрыта пеленой какой-то загадочности.
Эта серия статей посвящена мониторингу производительности и стабильности Android-приложений в эксплуатационной среде. В прошлой статье автор писал об измерении вре... | https://habr.com/ru/post/597267/ | null | ru | null |
# UI для Ensemble Workflow на Angular

Те, кто знаком с платформой для интеграции и разработки приложений InterSystems Ensemble, знают, что такое подсистема Ensemble Workflow и как она бывает полезна для автоматизации взаим... | https://habr.com/ru/post/251611/ | null | ru | null |
# Регистры сведений 1С. Универсальная «палочка-выручалочка» разработчика
Основная трудность, с которой сталкиваются начинающие изучать 1С, заключается в том, что быстро разобраться что здесь к чему очень слож... | https://habr.com/ru/post/714712/ | null | ru | null |
# Семь грехов численной линейной алгебры
[](https://habr.com/ru/company/skillfactory/blog/693330/)
В численной линейной алгебре нас интересуют точное и эффективное решение задач и понимание чувствительности задач к возмущениям. ... | https://habr.com/ru/post/693330/ | null | ru | null |
# Dependency Injection в мире Software Engineering
Если полноценно рассматривать Dependency Injection, то вокруг этого термина крутится множество интересных инженерных практик. Несмотря на то, что эта статья про конкретный подход к написанию кода, она будет интересна широкому кругу разработчиков. Я постарался провести... | https://habr.com/ru/post/556924/ | null | ru | null |
# Nginx и https. Получаем класс А+
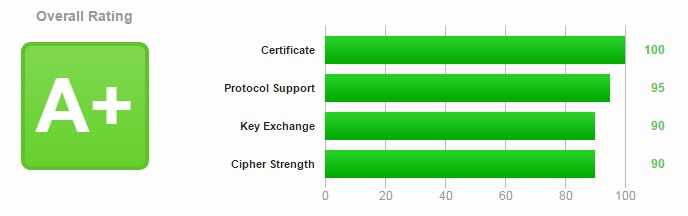
Недавно вспомнилось мне, что есть такой сервис — StartSsl, который совершенно бесплатно раздаёт trusted сертификаты владельцам доменов для личного использования. Да и выходные попали... | https://habr.com/ru/post/252821/ | null | ru | null |
# Публикация десктоп-приложения в Windows Store c помощью Desktop Application Converter
Не так давно мы опубликовали разработанное нами корпоративное приложение для десктопов, которое дополняет функционал Skype for Business. Например, может «по-человечески» сохранять историю переписки, как это делают все «приличные» м... | https://habr.com/ru/post/318072/ | null | ru | null |
# Используем OpenCL в Python
В последнее время параллельные вычисления прочно входят в жизнь, в частности, с использованием GPU.
Здесь было много статей на эту тему, поэтому ограничусь лишь поверхностным описанием технологии. GPGPU — использование графических процессоров для задач общего назначения, т.е. не связанн... | https://habr.com/ru/post/146993/ | null | ru | null |
# Макрос для балансировки исходящих звонков на GSM в Asterisk
##### Привет, Хабр!
В прошлом топике(уже в черновиках) я обещал предоставить хабрасообществу действующий макрос для балансировки исходящих звонков через N-ное количество сим-карт. Сабж, собственно, найден, усовершенствован и протестирован. Плюс — он гарант... | https://habr.com/ru/post/195730/ | null | ru | null |
# Делаем симпатичный виджет регулировки яркости
Давным давно у моей мамы на телефоне было приложение, которое позволяло изменить яркость экрана проведя пальцем по его левому краю. Мама к нему привыкла, а потом перешла на новый телефон и там уже то приложение из магазина исчезло. Собственно, не найдя аналогов, я решил ... | https://habr.com/ru/post/412967/ | null | ru | null |
# CrateDB: снаружи как PostgreSQL, а внутри Elasticsearch
С моей прошлой публикации о распределенной базе данных CrateDB прошло около года. Проект на основе Elasticsearch и PrestoDB написан на Java. Он за это время активно развивался и обрастал новым функционалом в [github](https://github.com/crate/crate) репозитарии:... | https://habr.com/ru/post/323742/ | null | ru | null |
# Учебник по симулятору сети ns-3. Глава 4

[главы 1,2](https://habr.com/ru/post/497106/)
[глава 3](https://habr.com/ru/post/497318/)
4 Обзор концепции
4.1 Ключевые абстракции
4.1.1 Node (Узел)
4.1.2 Application (Приложе... | https://habr.com/ru/post/497478/ | null | ru | null |
# FlaNium: как сделать тестирование Desktop-приложений под Windows проще
На рынке так много программных продуктов для тестирования, что может показаться, будто для всего найдется готовое решение и нет необходимости тратить время и усилия на разработку инструментов тестирования. На самом деле это не так. Мы в [«ЛАНИТ Э... | https://habr.com/ru/post/553588/ | null | ru | null |
# Tic Tac Toe, часть 5: Бэкенд на С++ Boost.Beast, HTTP
> [Tic Tac Toe: содержание цикла статей](https://habr.com/ru/post/461589/)
В этой статье рассмотрим реализацию бэкенда с применением [C++ Boost.Beast](https://www.boost.org/doc/libs/1_70_0/libs/beast/doc/html/index.html) библиотеки на примере синхронного сервера... | https://habr.com/ru/post/460991/ | null | ru | null |
# Создание анимации средствами Python 2.7
Эта статья познакомит вас с основами создания анимации с использованием Python и Pyglet. Pyglet разработан для работы с 3D графикой, но в этой статье мы будем использовать его для создания очень простой 2D анимации. В частности, мы познакомимся с базовыми приемами использовани... | https://habr.com/ru/post/158023/ | null | ru | null |
# Как мы сокращали персонал через Wi-Fi

На одном складе работа была организована так, что сотрудники с навыками работы на ПК все время пребывали в режиме "аврал". При отгрузке заказов толпа комплектовщиков стоя... | https://habr.com/ru/post/315984/ | null | ru | null |
# JavaScript: 12 вопросов и ответов
JavaScript — это [потрясающий инструмент](http://www.creativebloq.com/web-design/examples-of-javascript-1233964), который можно найти буквально в каждом углу современного интернета. Но даже несмотря на его невероятную распространённость, и профессионалам в области JS всегда будет че... | https://habr.com/ru/post/346022/ | null | ru | null |
# Guice всемогущий: assistedinject, multibindings, generics
В последнее время чаще стал встречать команды, которые используют **Guice** в качестве **DI** фреймворка. Стал его бояться (слезать с любимого **Spring**!?), и, как это обычно в жизни и бывает, страхи мои материализовались — я попал на проект, на котором акти... | https://habr.com/ru/post/358278/ | null | ru | null |
# Задача при собеседовании на работу в один крупный шведский сайт
Я — PHP-Developer, живу в Стокгольме. Недавно был на собеседовании в один большой шведский сайт (более миллиарда page views в месяц). Интервью проводили 2 программиста из этой фирмы. В определенном моменте, один из них достал листок бумаги и сказал, что... | https://habr.com/ru/post/116686/ | null | ru | null |
# Один момент: готовим видеоленту без костылей и бубнов
Всем приветы! Меня зовут Ваня, я медиаинженер и занимаюсь разработкой видеоплатформы в Ozon — в основном бэкендом.
В апреле 2022 года мы презентовали сервис Ozon Моменты — ленту коротких видео. Главные фичи, которые мы хотели реализовать:
* скорость отображения... | https://habr.com/ru/post/690596/ | null | ru | null |
# Починка электронного правительства Объединенного Королевства посредством языка Go
Это первая ласточка в серии [публикаций](http://habrahabr.ru/post/243327/) о новом динамическом HTTP маршрутизаторе поддерживающем GOV.UK. Это письмо проливает свет на наш порыв, объясняет решимость и подытоживает приобретенный опыт. ... | https://habr.com/ru/post/205284/ | null | ru | null |
# История одного проникновения
Топики о ловли хакеров заставили меня написать этот пост.
Хочу поделиться с вами историей, которая случилась со мной несколько лет назад.
Сразу скажу, мое увлечение — безопасность веб-приложений.
Случайно гуляя по интернету, мой друг нашел сайт для отправки бесплатных смс на ном... | https://habr.com/ru/post/86368/ | null | ru | null |
# saneex.c: try/catch/finally на базе setjmp/longjmp (C99) быстрее стандартных исключений C++¹
Пока писал эту сугубо техническую статью, Хабр успел превратиться в местное отделение ВОЗ и теперь мне даже стыдно ее публиковать… но в душе теплится надежда, что айтишники еще не разбежались и она найдет своего читателя. Ил... | https://habr.com/ru/post/491084/ | null | ru | null |
# Небольшой лайфхак: смотрим скрытые записи на Хабре, используя Google
Обычно читаю посты Хабра через Google Reader. Бывает начнешь читать какую-нибудь, возможно, интересную запись, кликаешь «Читать дальше» и получаешь «Доступ к публикации закрыт» как вот здесь: [habrahabr.ru/blogs/java/73080](http://habrahabr.ru/blog... | https://habr.com/ru/post/73120/ | null | ru | null |
# Разбираемся с Flux, реактивной архитектурой от facebook

Введение
--------
Добро пожаловать в третью часть серии статей «Изучаем React». Сегодня мы будем изучать, как устроена архитектура Facebook Flux, и как использовать... | https://habr.com/ru/post/246959/ | null | ru | null |
# Angular: ng-content для ng-template
> Macros are comparable with functions in regular programming languages. They are useful to reuse template fragments to not repeat yourself.
> Macros are defined in regular templates.
>
>
[Twig 3.x documentation](https://twig.symfony.com/doc/3.x/tags/macro.html)
В чём пробле... | https://habr.com/ru/post/669656/ | null | ru | null |
# Развертывание .NET Core проекта в Azure Web App для Linux
Web Apps на базе Linux позволяет разработчикам запускать веб-приложения в Docker контейнерах для Linux. Это облегчает перенос существующих приложений, размещенных и оптимизированных для платформы Linux в Azure App Service. Кроме того, разработчики могут разво... | https://habr.com/ru/post/336948/ | null | ru | null |
# Ключевые навыки Python-программиста
В наше динамичное время программисту необходимо держать руку на пульсе и постоянно осваивать новые навыки, чтобы оставаться востребованным специалистом.
Я уже около двух лет программирую на Python, и сейчас наступил момент осознанно подойти к освоению новых навыков. Для этого я... | https://habr.com/ru/post/500952/ | null | ru | null |
# Обход дерева без рекурсии и без стека
Придумал простой итератор для обхода произвольного дерева:
(для облегчения кода прежде всего)
`struct Document
{
Concept \*root;
struct Iter
{
Concept \*start;
Concept \*cur;
Concept \*bottom;
}iter;
Concept\* ... | https://habr.com/ru/post/97841/ | null | ru | null |
# Методики уменьшения размеров образов Docker
Задавались ли вы когда-нибудь вопросом о том, почему размер Docker-контейнера, содержащего всего одно приложение, может находиться в районе 400 Мб? Или, может быть, вас беспокоили немаленькие размеры образа Docker, содержащего единственный бинарник размером в несколько дес... | https://habr.com/ru/post/485650/ | null | ru | null |
# Надоело настраивать кластер? Используйте Ray Lightning
PyTorch Lightning позволяет распараллелить Deep Learning на GPU, но настраивать и объединять процессоры в сеть сложно даже в управляемом кластере SLUR... | https://habr.com/ru/post/577378/ | null | ru | null |
# Текстовый анализатор: распознавание авторства (начало)
Добрый день, уважаемые хабражители. Я давно хотел опубликовать под GPL-лицензией свой «Текстовый анализатор» ([[1]](http://sourceforge.net/projects/textanalyzerv04/)). Након... | https://habr.com/ru/post/114186/ | null | ru | null |
# Сервис, помогающий найти на TaoBao «редкие» товары (+ немного халявного Google Translate API)
Всех приветствую! Думаю очень-очень многие знают что такое TaoBao или по крайней мере слышали.
*Для тех кто не знает: TaoBao — гигантская китайская торговая площадка, количество товаров на которой измеряется числом, бли... | https://habr.com/ru/post/165623/ | null | ru | null |
# PostgreSQL 13: happy pagination WITH TIES
На прошедшей неделе вышло сразу две статьи (от [Hubert 'depesz' Lubaczewski](https://www.depesz.com/2020/09/22/waiting-for-postgresql-13-support-fetch-first-with-ties/) и автора самого патча [Alvaro Herrera](https://www.2ndquadrant.com/en/blog/postgresql-13-limit-with-ties/)... | https://habr.com/ru/post/520294/ | null | ru | null |
# Продвинутая настройка VIM
Одно из правил эффективного использования редактора гласит следующее — определите, на что у Вас тратится больше всего времени при наборе текста, и улучшите это.
Как показывает практика, часто пользователи этого редактора ограничиваются установкой опций, коих конечно не мало. Затем ставят... | https://habr.com/ru/post/165723/ | null | ru | null |
# Veslo — расширение Retrofit для тестирования (Java)
Статья расскажет о расширении для декларативного HTTP клиента [retrofit](https://square.github.io/retrofit/) предназначенного в большей степени для функционального тестирования API. Создан в первую очередь для упрощения и ускорения разработки API тестов. Расширение... | https://habr.com/ru/post/647499/ | null | ru | null |
# Почему я больше не использую MVC-фреймворки
> Уважаемые хабравчане.
>
>
>
> Поскольку дискуссия вокруг статьи идет весьма активно, Жан-Жак Дюбре (он читает комментарии) решил организовать чаты в gitter.
>
> ... | https://habr.com/ru/post/277113/ | null | ru | null |
# Собираем показания датчиков с Android смартфона
В своем первом посте на Хабре я бы хотел рассказать о том, как получать данные датчиков в ОС Android, а конкретно — угол наклона вашего аппарата во всех трех плоскостях. Заинтересовавшихся прошу под кат.
Датчики ОС Android делятся на три категории: движения, положен... | https://habr.com/ru/post/137678/ | null | ru | null |
# История одного фееричного провала тестового задания на C#
Просидев на одном предприятии несколько лет, я решил поискать альтернативы. Специально не привожу детали по моей должности, квалификации и стажу, чтобы не создавать предвзятое впечатление и не влиять на объективность оценки выполнения тестового задания. По мо... | https://habr.com/ru/post/571342/ | null | ru | null |
# Разрабатываем свой Sidebar Gadget

Как часто вы пользуетесь гаджетами боковой панели Windows? А хотелось бы написать свой? Не простой гаджет «Hello World», а действительно полезный, который помог бы оптими... | https://habr.com/ru/post/71958/ | null | ru | null |
# CTFzone write-ups – First comes Forensics

Прошло несколько дней после окончания CTFzone от компании BI.ZONE, а наши смартфоны до сих пор разрываются от уведомлений Telegram – чат с участниками битвы после конференции ста... | https://habr.com/ru/post/315954/ | null | ru | null |
# [Перевод] Как работает Graal — JIT-компилятор JVM на Java
Привет, Хабр! Представляю вашему вниманию перевод статьи "[Understanding How Graal Works — a Java JIT Compiler Written in Java](https://chrisseaton.com/truffleruby/jokerconf17/)".
Введение
--------
Одной из причин по которой я стал исследователем языков про... | https://habr.com/ru/post/419637/ | null | ru | null |
# Реализуем чистую архитектуру на Flutter с cubit
Соблюдать принципы чистой архитектуры – значит обеспечить удобство тестирования, поддержки и модернизации приложения. Понимание архитектуры и state management – это база, необходимая начинающему специалисту для успешной командной работы. В этой статье мы расскажем, как... | https://habr.com/ru/post/573848/ | null | ru | null |
# Без new: Указатели будут удалены из C++
Две недели назад в Джэксонвилле встречался комитет стандарта ISO C++. Сегодня я хочу представить короткую сводку и написать о революционном решении, принятом на собрании в Джэксонвилле. Для получения дополнительной информации я рекомендую к прочтению статью [C++ больше не буде... | https://habr.com/ru/post/352570/ | null | ru | null |
# UICollectionView всему голова: Изменение представления на лету
Привет, Хабр! Представляю вашему вниманию перевод статьи "[UICollectionView Tutorial: Changing presentation on the fly](https://indeema.com/blog/uicollectionview-tutorial--changing-presentation-on-the-fly)".
В данной статье мы рассмотрим использование... | https://habr.com/ru/post/445708/ | null | ru | null |
# Установка распределённого отказоустойчивого хранилища объектов LeoFS, совместимого с клиентами, использующими S3, NFS
Я из компании Luxoft.
Согласно [Opennet](https://www.opennet.ru/opennews/art.shtml?num=48357): [LeoFS](http://leo-project.net/leofs/index.html) — распределённое отказоустойчивое хранилище объектов... | https://habr.com/ru/post/478990/ | null | ru | null |
# Выпуск Rust 1.18
Команда Rust рада представить выпуск Rust 1.18.0. Rust — это системный язык программирования, нацеленный на безопасность, скорость и параллельное выполнение кода.
Если у вас установлена предыдущая версия Rust, то для обновления достаточно выполнить:
```
$ rustup update stable
```
Если у вас ещё н... | https://habr.com/ru/post/330778/ | null | ru | null |
# Контроль расходов мобильной связи в рамках организации: реализация

Хотелось бы рассказать некоторые технические подробности создания системы контроля расходов мобильной связи, концепция которой была описана в предыдущем посте.
В качестве примера будем рассматривать счет... | https://habr.com/ru/post/157871/ | null | ru | null |
# Разбираемся с EXCEPTION_CONTINUE_EXECUTION
Механизм структурированной обработки исключений (Structured Exception Handling, SEH) позволяет вернуться к инструкции, сгенерировавшей исключение и попробовать выполнить ее заново. Для этого в блок **\_\_except** нужно передать значение **EXCEPTION\_CONTINUE\_EXECUTION**. В... | https://habr.com/ru/post/682958/ | null | ru | null |
# Почему набор инструкций AVX 512 полезен для RPCS3?
Часто приходится слышать, что важность отличий между наборами инструкций на современных компьютерах [преувеличена](https://chipsandcheese.com/2021/07/13/arm-or-x86-isa-doesnt-matter/) и, в самом деле, сложно не согласиться с таким наблюдением. Поскольку стандартная ... | https://habr.com/ru/post/697972/ | null | ru | null |
# Как писать условия в JSX
Добрый день, меня зовут Павел Поляков, я `Principal Engineer` в каршеринг компании SHARE NOW, в Гамбурге в 🇩🇪 Германии. А еще я автор телеграм канала [Хороший разработчик знает](https://t.me/gooddevknows), где рассказываю обо всем, что обычно знает хороший разработчик.
Сегодня я хочу пого... | https://habr.com/ru/post/648303/ | null | ru | null |
# Обзор графических оболочек Linux
Наверняка вы хоть раз сталкивались с многообразием графических оболочек для ОС Linux. В этом присутствует частичка красоты этой системы — в множестве вариантов взаимодействия с этой ОС. Без сомнени... | https://habr.com/ru/post/677492/ | null | ru | null |
# Форматы файлов для программ на FASM под Windows
При создании программы на ассемблере (для примера будет приведён FASM) из-под ОС Windows возникает вопрос о том, какой выбрать формат файла.
Для определения формата создаваемого исполняемого файла используется директива «format» со следующим за ним идентификатором ф... | https://habr.com/ru/post/257551/ | null | ru | null |
# Как сделать ячейку таблицы сдвигаемой для отображения дополнительных опций в приложениях iOS
*Как переводчик заранее прошу извинения за возможные ошибки в переводе. Буду признателен сообщениям об ошибках для их скорейшего исправления.*
Когда iOS 7 была впервые анонсирована, одним из многих визуальных нововведений... | https://habr.com/ru/post/255293/ | null | ru | null |
# RBKmoney Payments под капотом — логика работы платежной платформы

Привет, Хабр! Продолжаю публикацию цикла про внутренности платежной платформы RBK.money, начатую в этом [посте](https://habr.com/ru/company/rbkmoney/blog/443518/). ... | https://habr.com/ru/post/447440/ | null | ru | null |
# Защита ваших приложений Xamarin с помощью Dotfuscator
*Это перевод рассказа Джо Сьюэлла, разработчика из команды Dotfuscator на PreEmptiveSolutions.*
Давайте говорить честно: выпуск библиотеки, приложения для рабочего стола или мобильного приложения может стать горьким опытом. Как только вы выкладываете вашу прог... | https://habr.com/ru/post/349084/ | null | ru | null |
# Раздаем файлы с Google Drive посредством nginx
### Предыстория
Так уж случилось, что нужно мне было где-то хранить более 1.5тб данных, да еще и обеспечить возможность скачивания их обычными пользователями по прямой ссылке. Поскольку традиционно такие объемы памяти идут уже на VDS, стоимость аренды которых не слишко... | https://habr.com/ru/post/460685/ | null | ru | null |
# Фильтрация и создание цепочек в функциональном JavaScript

*Предлагаем перевод [статьи](https://www.sitepoint.com/filtering-and-chaining-in-functional-javascript/), которая позволит освежить свои знания по теме, а также бу... | https://habr.com/ru/post/324172/ | null | ru | null |
# Поднимаем Mercurial на Windows-сервере (с Nginx)
Недавно случайно [узнал](https://habr.com/ru/news/t/464475/), что BitBucket, где лежат мои Mercurial-репозитории, прекращает поддержку Mercurial: новые репозитории создавать уже нельзя, а существующие будут удалелы с 1.06.2020. Возможные варианты действий: перейти на ... | https://habr.com/ru/post/487792/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.