
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Делаем отзывчивый и максимально возможный размер шрифта динамического текста относительно контейнера
Перед нами часто возникает задача, сделать текст отзывчивым в зависимости от размера экрана устройства. Казалось бы, задача вполне тривиальна, и сходу можно назвать несколько вариантов её решения, не ломая голову, но... | https://habr.com/ru/post/672148/ | null | ru | null |
# Kernel Queue: The Complete Guide On The Most Essential Technology For High-Performance I/O
When talking about high-performance software we probably think of server software (such as nginx) which processes millions requests from thousands clients in parallel. Surely, what makes server software work so fast is high-en... | https://habr.com/ru/post/600123/ | null | en | null |
# Образование программисту – Что? Где? Когда?

Привет, Хабр! Уже много сказано об образовании, в частности для программистов, о программах, что лучше подходят или не подходят, но каждый год ситуация меняется и как бы грустно не было, в... | https://habr.com/ru/post/434908/ | null | ru | null |
# Запускаем .NET nanoFramework на Raspberry Pi Pico

Платформа .NET nanoFramework позволяет разрабатывать приложения на C# для различных микроконтроллеров. В предыдущей [публикации работали с ESP32 и STM32](https://habr.com/ru... | https://habr.com/ru/post/667648/ | null | ru | null |
# Зеркалирование оргструктуры SAP HCM в оргструктуру Employee Central
Введение
--------
Организационные структуры являются сердцем системы SAP SuccessFactors и требуют обстоятельного дизайна, чтобы снабжать все модули SuccessFactors и интегрированные системы достоверными основными данными. И самой базовой частью орга... | https://habr.com/ru/post/657141/ | null | ru | null |
# Засеки 25 минут!
Как часто вам бывает нужно просто засечь время? Я думаю, что такая необходимость периодически возникает у всех. Кто-то просто смотрит на часы, кто-то использует специальные программы, кто-то ставит будильник на телефоне.
Но помимо всех этих способов можно ещё сделать вот так:
```
sleep 25m ; x... | https://habr.com/ru/post/144638/ | null | ru | null |
# Пишем свой capped expirationd модуль для tarantool
Какое-то время назад перед нами встала проблема чистки кортежей в спейсах [tarantool](https://www.tarantool.io). Чистку нужно было запускать не тогда, когда у tarantool уже з... | https://habr.com/ru/post/479166/ | null | ru | null |
# Находим ошибки в коде проекта LLVM с помощью анализатора PVS-Studio
Около двух месяцев назад я написал статью о проверке компилятора GCC с помощью анализатора PVS-Studio. Идея статьи была с... | https://habr.com/ru/post/314044/ | null | ru | null |
# ОСРВ QNX: Немного о микроядре, потоках и процессах
Поскольку мой первый [небольшой обзор](http://habrahabr.ru/blogs/nix/124656/) операционной системы реального времени QNX показал, что среди жителей Хабра есть к ней интерес, то я решил продолжить цикл заметок. Мне кажется, что стоит немного рассказать о системной ар... | https://habr.com/ru/post/125243/ | null | ru | null |
# Как при помощи ИИ сделать распознавание вводимых вами рукописных цифр прямо в браузере
Эта статья для новичков и не претендует на высокий технический уровень, а если вам интересны сложные современные реше... | https://habr.com/ru/post/570096/ | null | ru | null |
# Версия 0.3.5
[Web Optimizer](http://code.google.com/p/web-optimizator/) (Веб Оптимизатор) — приложение, автоматизирующее все действия по клиентской оптимизации для произвольного сайта. На данный момент оно существует в виде отдельного приложения (которое нужно самостоятельно установить на сайт). Приложение протестир... | https://habr.com/ru/post/56745/ | null | ru | null |
# Транслируем WebRTC, RTSP и RTMP потоки на Media Source Extensions по протоколу Websocket
Media Source Extensions
-----------------------
Media Source Extensions (далее MSE) — это API браузера, позволяющее играть аудио и в... | https://habr.com/ru/post/337112/ | null | ru | null |
# Что вы читаете мой принц? Слова, слова, слова…
Замечали ли вы какое значение мы придаем словам которые произносим? Или мы просто их произносим даже не замечая как они меняют нашу жизнь.
Слова-паразиты которые я периодически замечаю у окружающих и у себя самого
`Давай, Удачи*(внезависимости от контекста)*, неко... | https://habr.com/ru/post/57493/ | null | ru | null |
# Хэш таблицы в Go. Детали реализации

Порассуждаем об имплементации map в языке без дженериков, рассмотрим что такое хэш таблица, как она устроена в Go, какие есть плюсы и минусы данной реализации и н... | https://habr.com/ru/post/457728/ | null | ru | null |
# Операционные системы с нуля; уровень 1 (старшая половина)
 Настало время следующей части. Это вторая половина перевода [лабы №1](https://web.stanford.edu/class/cs140e/assignments/1-shell/). В этом выпуске мы будем писать драйверы периферии (т... | https://habr.com/ru/post/351774/ | null | ru | null |
# 15 тривиальных фактов о правильной работе с протоколом HTTP
*Внимание! Реклама! Пост оплачен Капитаном Очевидность!*
Ниже под катом вы найдёте 15 пунктов, описывающих правильную организацию ресурсов, доступных по протоколу HTTP — веб-сайтов, «ручек» бэкенда, API и прочая. «Правильный» здесь означает «соответствую... | https://habr.com/ru/post/265569/ | null | ru | null |
# Автоматическая виртуализация рендеринга произвольной вёрстки
Здравствуйте, меня зовут Дмитрий Карловский и я.. прибыл к вам из недалёкого будущего. Недалёкого, потому что там уже всё и все тормозят. Писец подкрался к нам незаметно: сначала перестали расти мощности компьютеров, потом пропускная способность сетей. А п... | https://habr.com/ru/post/537388/ | null | ru | null |
# Windows Server 2012 — жизнь без GUI
Windows Server 2012 позиционируется как система, которой GUI для полноценной работы не нужен. При установке по умолчанию выбран пункт Server Core, добавлена возможность удаления графического интерфейса без переустановки сервера, список ролей, не нуждающихся в GUI в сравнении с 200... | https://habr.com/ru/post/183012/ | null | ru | null |
# Коварный вопрос по Event \ Delegate
На собеседованиях собеседователи любят задавать всякие каверзные вопросы. Одним из любимых вопросов на понимание .net платформы является вопрос про события и делегаты. В лучшем случае спрашивают отличия, в худшем могут задать такой вопрос на засыпку.
Дан код:
> `public class... | https://habr.com/ru/post/65697/ | null | ru | null |
# GitLab CI: 6 фич из последних релизов, которых мы так ждали

В эпоху повсеместного CI/CD мы сталкиваемся с большим спектром сопутствующих инструментов, в том числе и CI-систем. Однако именно GitLab стал для нас самым близким, по-на... | https://habr.com/ru/post/491888/ | null | ru | null |
# Менеджеры паролей RoboForm и Kaspersky Password Manager
Логины, пароли, адреса, контакты, личные и банковские данные — все это непременные атрибуты сегодняшнего Интернета. Мы каждый день сталкиваемся с заполнением всевозможных веб-форм для доступа к той или иной информации, будь-то вход под своим логином на сервер б... | https://habr.com/ru/post/90577/ | null | ru | null |
# Как мы писали iOS-библиотеку для работы с Wargaming API

*[World of Tanks Assistant](https://itunes.apple.com/us/app/wot-assistant/id500174696?mt=8) (WOT Assistant)* и *[World of Warplanes Assitant](https://itunes.apple.... | https://habr.com/ru/post/232037/ | null | ru | null |
# JavaScript: Zoom как в картах для SVG/HTML
Рис 1. Zoom в редакторе блок-схем dgrm.net[dgrm.net](https://dgrm.net/) | [GitHub](h... | https://habr.com/ru/post/696266/ | null | ru | null |
# Делаем асинхронность асинхронной, разбираемся в планировщике Go, ругаем Linux
В айтишном мире есть две весьма обсуждаемые темы:
1. Что является главным недостатком в Go;
2. Linux vs <что угодно>;
В этой ... | https://habr.com/ru/post/646073/ | null | ru | null |
# PHP 8 — Что нового?
PHP, начиная с 7 версии, кардинально изменился. Код стал куда быстрее и надёжнее, и писать его стало намного приятнее. Но вот, уже релиз 8 версии! Ноябрь 26, 2020 — примерно на год раньше, чем обещали сами разработчики. И всё же, не смотря на это, мажорная версия получилась особенно удачной. В эт... | https://habr.com/ru/post/526220/ | null | ru | null |
# Разработка документации при помощи DocBook

Так уж сложилось, что в наших проектах ведение технической документации полностью лежит на плечах разработчиков, по принципу: внес изменения в код проекта — акт... | https://habr.com/ru/post/212881/ | null | ru | null |
# Интеграция социальных сетей в iOS 6
На WWDC 2012, которая проходила в июне этого года, среди нововведений был представлен Social framework. Это фреймворк даёт возможность интегрировать кнопки шаринга в социальных сетях быстро и просто. Social framework вытеснил Twitter framework, представленный в iOS 5. Теперь у нас... | https://habr.com/ru/post/159093/ | null | ru | null |
# Свистать всех на Linux, гром и молния
Привет, Хабр! Сегодня я хочу рассказать о собственном опыте перевода рабочего места на Linux. Статья не претендует на 100% охват всех проблем и их решений, но кое-какие рецепты, позволяющие сделать жизнь лучше, тут все же будут. Также в статье будет некоторое количество флешбеко... | https://habr.com/ru/post/472144/ | null | ru | null |
# Как быстро запустить добровольные распределённые вычисления на сотне машин
Работая в ИТ-подразделении, я постоянно наблюдаю простаивающие по разным организационным причинам компьютеры, которые очень скучают. Золотые времена майнинга биткойнов на CPU прошли, и в поисках нового полезного дела я пришёл к добровольным р... | https://habr.com/ru/post/234697/ | null | ru | null |
# Параллельная быстрая сортировка на Хаскеле и как нелегко её оказалось написать
*Прим. перев.: Это перевод [истории](http://flyingfrogblog.blogspot.de/2010/08/parallel-generic-quicksort-in-haskell.html) о том, как нелегко оказалось написать параллельную быструю сортировку (quicksort) на Хаскеле. Оригинал статьи напис... | https://habr.com/ru/post/317348/ | null | ru | null |
# Именованные параметры C++. Не пригодились
Время от времени вдруг начинает хотеться именованных параметров в C++. Не так давно была [статья](http://habrahabr.ru/company/infopulse/blog/246663/), да и сам какое-то время назад [писал](http://habrahabr.ru/post/213015/) на эту тему. И вот что удивительно — со времен той с... | https://habr.com/ru/post/246711/ | null | ru | null |
# Верстка для самых маленьких. Верстаем страницу по БЭМу
Недавно хабраюзер [Mirantus](http://habrahabr.ru/users/mirantus/) написал статью [«Как сверстать веб-страницу»](http://habrahabr.ru/post/202408/), в которой рассказывал о том, как же сверстать веб-страничку. В его статье было подробно рассмотрено, как выделить о... | https://habr.com/ru/post/203440/ | null | ru | null |
# Журналирование Windows EventLog и система оповещения для администраторов
Некоторое количество времени(года три) назад, в попытке найти способ экспорта Windows EventLog, была найдена возможность в удобном виде осуществлять аудит различных событий происходящих на сервере.
Microsoft своими «добрыми» технологиями сде... | https://habr.com/ru/post/65652/ | null | ru | null |
# Nginx: точно вовремя
Хочу написать о небольшом трюке с SSI, который недавно мне пригодился.
Предположим, вам нужно выкатить немного изменённый вариант некоей странички ровно в полночь, или в любое другое очень неудобное время, когда все нормальные люди давно спят. Также, предположим, вам не хочется возиться с кро... | https://habr.com/ru/post/69509/ | null | ru | null |
# Огромный открытый датасет русской речи версия 1.0

В начале этого года по ряду причин мы загорелись идеей создать самый большой открытый датасет русской речи. Подробнее о нашей мотивации и о том, как ... | https://habr.com/ru/post/474462/ | null | ru | null |
# yandex-speech — wrapper к речевым технологиям Яндекса
Ознакомившись с [обзором движков для распознавания речи](http://habrahabr.ru/post/231629/), заметил там API от Яндекса. И на выходных написал небольшую обертку для Node.js для распознавания речи с целью поиска мата в своих телефонных разговорах. По мотивам [топик... | https://habr.com/ru/post/232861/ | null | ru | null |
# Как CrowdSec помогает справиться с уязвимостью в Log4j
*Привет, Хабр! Обнаружение уязвимости нулевого дня в Log4j (CVE-2021-44228) привело к резкому росту числа атак на различные сервисы, использующие эту популярную библиотеку Java. Это связано в первую очередь с простотой, с которой уязвимостью могут воспользоватьс... | https://habr.com/ru/post/597011/ | null | ru | null |
# Часть 1. Установка и настройка авторитетного DNS сервера на основе решения PowerDNS // Базовая установка
Добрый день!
В этой статье я опишу настройку авторитетного DNS сервера, на основе решения PowerDNS. PowerDNS — высокопроизводительный, бесплатный DNS сервер с открытым исходным кодом.
PowerDNS — представля... | https://habr.com/ru/post/278153/ | null | ru | null |
# Свежий взгляд на честное 3D в браузере
Приветствую.
Так получилось, что некоторое время назад я принимал участие в проекте, разрабатывал браузерную игру с принципиально новым подходом в хранении данных - предполагалось создать некую вариацию на тему .krieger, игру, которая использовала бы экстремально мало памяти д... | https://habr.com/ru/post/543700/ | null | ru | null |
# О функциональности Go
Насколько объектно Go ориентирован многократно и эмоционально обсуждалось. Попробуем теперь оценить насколько он функционален. Заметим сразу, оптимизацию хвостовой рекурсии компилятор не делает. Почему бы? «Это не нужно в языке с циклами. Когда программист пишет рекурсивный код, он хочет предст... | https://habr.com/ru/post/280210/ | null | ru | null |
# Devise: вход и регистрация в модальных окнах
На проекте необходимо было сделать логин через модальные окна и «обычные» страницы для разных типов устройств. После поиска понял, что зачастую описывается не совсем то, что нужно. Так [здесь](http://strandcode.com/2013/08/23/embedding-devise-forms-in-twitter-bootstrap-mo... | https://habr.com/ru/post/216837/ | null | ru | null |
# Универсальный обмен сообщениями между страницами в расширениях
Привет! Сегодня мне хочется показать вам свой маленьких хобби проект, который позволяет сильно упростить разработку расширений в разных браузерах. Сразу хочу предупредить, это не фреймворк который делает везде одно и то же, это библиотека, которая органи... | https://habr.com/ru/post/246351/ | null | ru | null |
# От кипящего свинца до компьютеров: история математической типографики

*Математические шрифты шести разных систем печати, изображение [Chalkdust](http://chalkdustmagazine.com/blog/is-there-a-perfect-maths-... | https://habr.com/ru/post/371031/ | null | ru | null |
# Создание прокси-dll для запуска DirectDraw игр в окне
В продолжение темы [расширения функциональности готовых программ](http://habrahabr.ru/blogs/asm/51857/) хотелось бы рассказать об ещё одном способе измен... | https://habr.com/ru/post/133956/ | null | ru | null |
# Hibernate. Основные принципы работы с сессиями и транзакциями
В моей первой статье на Хабре я хотел бы поделиться некоторыми соображениями и замечаниями по работе с Hibernate, касающихся сессий и транзакций. Я остановился на некоторых нюансах, которые возникают при начале освоения этой темы. Признаюсь, сам пока Juni... | https://habr.com/ru/post/271115/ | null | ru | null |
# Julia, Градиентный спуск и симплекс метод
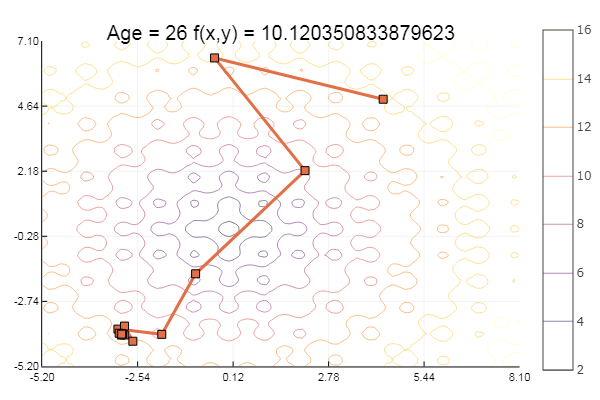
[Продолжаем](https://habr.com/ru/post/439900/) знакомство с методами многомерной оптимизации.
Далее предложена реализация метода наискорейшего спуска с анализом скорости выполнения, а также... | https://habr.com/ru/post/440070/ | null | ru | null |
# Kernel Pool Overflow: от теории к практике
Ядро Windows всегда было лакомым кусочком для хакера, особенно при наличии законченных методик его эксплуатирования, приводящих к повышению прав. Учитывая тот факт, что за последние несколько лет количество уязвимостей, связанных с переполнением динамической памяти ядра, ре... | https://habr.com/ru/post/108618/ | null | ru | null |
# YAF — самый быстрый php фреймворк*
Yaf — это PHP микро-фреймворк, взявший за основу структуру приложения Zend Framework, но написанный на С и является PHP extension доступным через [PECL](http://pecl.php.net/package/yaf/).
Основной (и единственной) задачей для написания его послужила необходимость максимально быс... | https://habr.com/ru/post/128271/ | null | ru | null |
# Букмарклет для отображения макетной сетки
Не так давно на хабре уже [обсуждалась](http://habrahabr.ru/blogs/javascript/28113/) тема наложения макетной сетки поверх страницы. В голову пришла идея наложения сетки при помощи букмарклетов.
Собственно, вот они.
#### 12 колонок
`javascript:(function(a){for(var i=0,... | https://habr.com/ru/post/39472/ | null | ru | null |
# Барахолка для Пентестера
Цель статьи - собрать интересные инструменты, техники и команды, которые можно использовать для выполнения задач при проведении тестирования на проникновение. Краткий список того, ч... | https://habr.com/ru/post/563296/ | null | ru | null |
# Implementation of Linked List in PHP
A linked list is a linear data structure, which contains node structure and each node contains two elements. A data part that stores the value at that node and next part that stores the link to the next node as shown in the below image:
.
Графическая схема
-----------------

Уверен, что многим кто работает с С++ хотелось, чтобы в этом, дивном языке, была возможность сериализовать объекты так же просто, как скажем в С#. Вот и мне этого захотелось. И я подумал, а почему бы... | https://habr.com/ru/post/244963/ | null | ru | null |
# Как научить преодолевать трудности, а заодно и писать циклы
Несмотря на то, что речь пойдет об одной из базовых тем, данная статья написана для опытных специалистов. Цель — показать какие заблуждения бывают у новичков в программировании. Для практикующих разработчиков эти проблемы уже давно решены, позабыты или вооб... | https://habr.com/ru/post/456500/ | null | ru | null |
# Микроразметка сайта для Яндекс и Google с примерами
Микроразметка сайта для поисковых систем Яндекс и Google в формате Schema.org, JSON-LD и Open Graph. Разметку старался делать без js, т.к. Яндекс ее не учитывает. Микроформат Schema.org подходит для Яндекс/Google. Преимущество данного метода - не нужно ждать бота, ... | https://habr.com/ru/post/715036/ | null | ru | null |
# Кража персональных данных пользователя (PII) с помощью вызова API напрямую
> Сегодня решили обсудить тему информационной безопасности. Публикуем перевод [статьи](https://medium.com/@kunal94/stealing-users-pii-info-by-visiting-api-endpoint-directly-5062e0147f67) Kunal pandey, обнаруживаем уязвимости и работаем на опе... | https://habr.com/ru/post/529894/ | null | ru | null |
# Как я переписывал поисковик авиабилетов с PHP на NodeJS
Привет. Меня зовут Андрей, я студент-магистрант в одном из технических ВУЗов Москвы и по совместительству ~~очень скромный~~ начинающий предприниматель и разработчик. В этой статье я решил поделиться своим опытом перехода от PHP (который когда-то мне нравился и... | https://habr.com/ru/post/444400/ | null | ru | null |
# Четыре API для базы данных
Одновременный сеанс в IRIS: SQL, объекты, REST, GraphQL
-------------------------------------------------------
 мы изучили, как читать внешние необработанные данные. А сегодня познакомимся с оператором SET, который считывает стандартные наборы данных SAS (SAS Data Set), научимся создавать с... | https://habr.com/ru/post/426765/ | null | ru | null |
# Как использовать systemd-nspawn для восстановления Linux-системы
***Перевод статьи подготовлен специально для студентов курса [«Администратор Linux»](https://otus.pw/cB8Q/).***

---
*Разбираемся со способностью **systemd** запу... | https://habr.com/ru/post/470497/ | null | ru | null |
# Bacula: для тех кому надо по-быстрому и в картинках
Доброго времени суток всем тем, кто собирается делать Backup'ы постоянно.
В этом посте я попытаюсь облегчить жизнь тем, кто пробует познакомится с этой системой. Ничего сверхъестественного я не расскажу, просто добавлю то, что мне бы самому пригодилось. За основ... | https://habr.com/ru/post/211755/ | null | ru | null |
# Избавляемся от JavaScript в социальных кнопках (Facebook, VK, Twitter и др.)
Как мы избавились от JavaScript-библиотек социальных сетей, ускорили скорость загрузки страниц и использовали RESTful API для “шаринга” и “лайков”.
, я решил показать еще один альтернативный подход, для решения этой задачи. Возможно он даст немного большее представ... | https://habr.com/ru/post/142149/ | null | ru | null |
# Maraquia — ORM для MongoDB
После прочтения заголовка у многих наверняка возникает вопрос — зачем ещё один велосипед при наличии уже обкатанных Mongoose, Mongorito, TypeORM и т. д.? Для ответа нужно разобраться в чём отличие ORM от ODM. Смотрим википедию:
> ORM (англ. Object-Relational Mapping, рус. объектно-реляцио... | https://habr.com/ru/post/358972/ | null | ru | null |
# Я хочу писать тесты
Я всегда с интересом читаю статьи про тестирование кода. И я очень хочу использовать тесты в своих проектах.
Но я не могу. Не могу найти для себя стимул.
Да, тесты из примеров... | https://habr.com/ru/post/177799/ | null | ru | null |
# node-sync — псевдо-синхронное программирование на nodejs с использованием fibers
Надавно была опубликована библиотека [node-fibers](https://github.com/laverdet/node-fibers), вносящая в nodejs и v8 поддержку замечательного [fiber](http://en.wikipedia.org/wiki/Fiber_(computer_science))/[coroutine](http://en.wikipedia.... | https://habr.com/ru/post/116124/ | null | ru | null |
# Создаем Todo приложение c помощью Django. Часть 1
*И снова здравствуйте. В преддверии старта курса [«Web-разработчик на Python»](https://otus.pw/2ZBR/) наш внештатный автор подготовил интересный материал, которым с радостью делимся с вами.*
, один из ключевых проектов [Лаборатории параллельных вычислений](https://research.jetbrains.org/ru/groups/conc... | https://habr.com/ru/post/540048/ | null | ru | null |
# Несколько полезностей по работе с NPM

NPM — пакетный менеджер для **node.js**, аналог GEM в RoR. В статье несколько советов по его использованию.
#### Установка пакетов
Все знают
```
# Устан... | https://habr.com/ru/post/206678/ | null | ru | null |
# Размещение иконок на странице сайта. Делать проще, поддерживать легче
> Все должно быть изложено так просто, как только возможно, но не проще.
А. Эйнштейн
Добрый день уважаемые разработчики. Довольно часто ~~просматривая~~ копаясь в чужом коде я наталкиваюсь на такое написание кода для кнопки с иконкой.
**HTM... | https://habr.com/ru/post/335632/ | null | ru | null |
# Краткий и бодрый обзор архитектуры компиляторов

Большинство компиляторов имеют следующую архитектуру:

В данной... | https://habr.com/ru/post/451894/ | null | ru | null |
# Использование dynamic для быстрого создания Xml
Не так давно разрабатывал функционал, формирующий по некоторому алгоритму разнообразный xml.
Логично, что при написании первого же теста возник традиционный вопрос ленивого программиста: как сэкономить себе силы, а читающим тесты нервы и быстро и наглядно представи... | https://habr.com/ru/post/175051/ | null | ru | null |
# 10 вещей, которые вы могли не знать о scikit-learn
В этой переведенной статье ее автор, Rebecca Vickery, делится интересными функциями scikit-learn. [Оригинал](https://towardsdatascience.com/10-things-you-didnt-know-about-scikit-learn-cccc94c50e4f) опубликован в блоге towardsdatascience.com.
. Часть 2
Продолжение [первой части](http://habrahabr.ru/post/166045/ "Введение в NikaFramework (NKF). Часть 1").
**4. Система сборки проекта**
За что я люблю системы сборки — так это за то, что я могу создавать множество разных файлов и не волноваться, как потом это организовать,... | https://habr.com/ru/post/166135/ | null | ru | null |
# Quadstor — виртуальный SAN для бюджетников
Еще примерно год назад я наткнулся на статью [«50 инструментов для автоматизации облачной ифраструктуры»](https://habrahabr.ru/company/it-grad/blog/281801/) в котором описывались инструменты для работы с виртуализацией и в нем промелькнул инструмент под названием Quadstor. ... | https://habr.com/ru/post/323114/ | null | ru | null |
# На гребне волны со спамом, или как наказать негодяев?
Пришел давеча спам на почту, примерно следующего содержания (оригинал дома, доберусь — поменяю):
`Соберем для Вас по сети интернет базу данных потенциальных клиентов для Вашего Бизнеса
......
С Уважением к Вам и Вашему Бизнесу
"Базы данных потенциальн... | https://habr.com/ru/post/45214/ | null | ru | null |
# Получаем снимок с веб-камеры и скриншот экрана с помощью VLC
### Предыстория
Всё началось с того, что кто-то постоянно брал мой планшет, причём без моего ведома. Планшет [ASUS VivoTab Smart](http://habrahabr.ru/company/asus/blog/179447/) с Windows 8 на борту. Было решено сделать на рабочем столе фейковый ярлык, зап... | https://habr.com/ru/post/211927/ | null | ru | null |
# Метеостанция Arduino
Метеостанция Arduino
--------------------
Я решил написать подробную статью, рассказывающую все аспекты создания метеостанции Arduino, по скольку сразу сложно охватить весь процесс. Мое исполнение метеостанции удобно тем, что ее данные сохраняются на компьютере.
**Что необходимо**
* локальная ... | https://habr.com/ru/post/443664/ | null | ru | null |
# Взлет, перепрофилирование, креатив и подноготная: истории родом из BigDataCamp
Борьба за студентов, из которых вырастают хорошие IT-специалисты, заставляет потенциальных работодателей придумывать новые форматы поиска и привлечения талантов. Один из них выстрелил осенью 2019 года — это BigDataCamp — пятидневный интен... | https://habr.com/ru/post/488350/ | null | ru | null |
# InlineKeyboard в Телеграмм ботах (Telegram Bots)
InlineKeyboard — клавиатура привязанная к сообщению, изпользующая обратный вызов (CallbackQuery), вместо отправки сообщения с обыкновенной клавиатуры.
**Пример**

Взаимодействие между клиентом и сервером как правило устроено очень просто и опирается на довольно примитивный инструментарий. Это не создает проблем са... | https://habr.com/ru/post/224261/ | null | ru | null |
# Январская починка дыр в .NET Framework и Core
Аккурат к концу новогодних каникул в России, 9-го января, Microsoft выпустили обновления, исправляющие [CVE-2018-0786](https://github.com/dotnet/announcements/issues/51) и [CVE-2018-0764](https://github.com/dotnet/announcements/issues/52). Починили так, что кое-где ещё и... | https://habr.com/ru/post/346764/ | null | ru | null |
# Вышел Riot.js 3.0
22 ноября года сиего [вышло обновление Riot.js](http://riotjs.com/release-notes/#november-22-2016) — минималистичной библиотеки для создания веб-интерфейсов. Как пишут её авторы на гла... | https://habr.com/ru/post/316090/ | null | ru | null |
# Функциональное мышление. Часть 4
После небольшого экскурса в базовые типы, мы можем снова вернуться к функциям. В частности, к ранее упомянутой загадке: если математическая функция может принимать только один параметр, то как в F# может существовать функция, принимающая большее число параметров? Подробнее под катом!... | https://habr.com/ru/post/430620/ | null | ru | null |
# Ещё раз про скринкасты в линуксе
Совсем недавно [была](http://habrahabr.ru/post/140006/) статья [pomeo](https://habrahabr.ru/users/pomeo/) на эту тему. Не то чтобы у меня какой-то альтернативный взгляд на это или существенно мой вариант отличается. Просто я знаю, что некоторые проблемы в Linux не решаются только одн... | https://habr.com/ru/post/141031/ | null | ru | null |
# Клиентская оптимизация как сервис
 Еще с самого начала своей деятельности как web-разработчика я мечтал иметь инструмент, который позволял бы автоматически получать оптимизированую версию ... | https://habr.com/ru/post/94109/ | null | ru | null |
# Как на Raspberry Pi запустить модель ML и сэкономить пространство одноплатника
Представьте ситуацию: впереди выходные, а у вас есть достаточно нагруженная малинка и вы — ради эксперимента — хотите посмотрет... | https://habr.com/ru/post/566926/ | null | ru | null |
# Хакеры SolarWinds размазали свои байты в HTTP-трафике через регулярные выражения

*Валидная цифровая подпись на DLL со встроенным бэкдором*
Практически по всем профильным СМИ [прошла новость](https://habr.com/ru/news/t/533220/) ... | https://habr.com/ru/post/534094/ | null | ru | null |
# Настоящая валидация на уникальность
Каждый рубист, поработавший с [Ruby On Rails](https://rubyonrails.org/) знаком с [ORM](https://ru.wikipedia.org/wiki/ORM) [ActiveRecord](https://github.com/rails/rails/tree/master/activerecord). Обсудим одну из предложенных из коробки валидаций, а именно, валидации на уникальность... | https://habr.com/ru/post/431298/ | null | ru | null |
# Секреты производительности Spark, или Почему важна компиляция запросов
> **Для будущих студентов курсов**[**"Data Engineer"**](https://otus.pw/lH2x/) **и** [**"Экосистема Hadoop, Spark, Hive"**](https://otus.pw/XO0N/) **подготовили еще один перевод полезной статьи.**
>
>

*От переводчика: части обзора имеют небольшой размер, поэтому решил переводить сразу по две части.*
**Ссылки на другие части серии:**
[Часть 1: твердые тайл... | https://habr.com/ru/post/278373/ | null | ru | null |
# Лёгкая интеграция tor в android приложение на примере клиента для рутрекера
Мне давно было интересно, можно ли легко добавить проксирование через тор в Android приложение. Вроде бы довольно очевидная задача, плюс тор браузеры уже под эту платформу давно есть… Но есть много задач, которые сложнее, чем кажутся. Для не... | https://habr.com/ru/post/313030/ | null | ru | null |
# Vue.js компонент для справки/документации
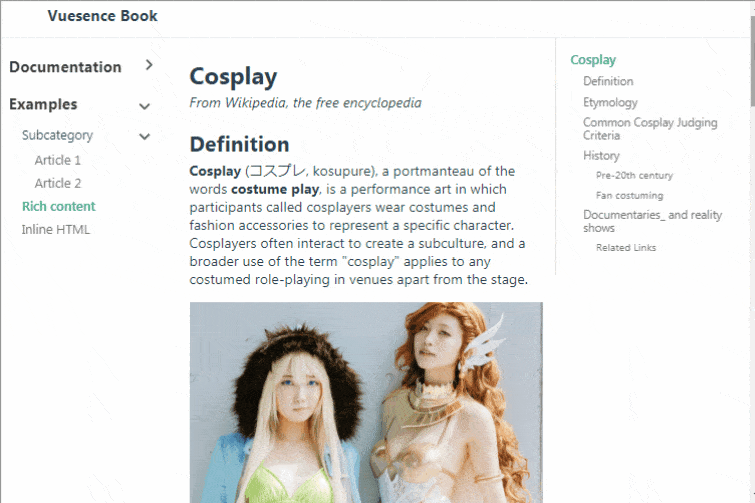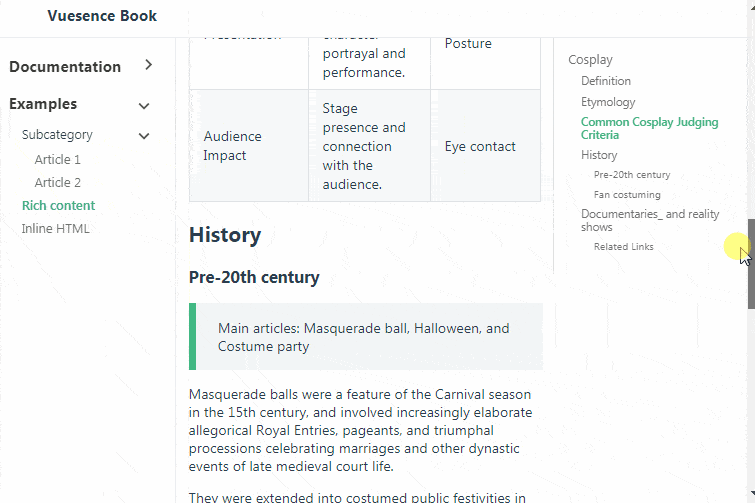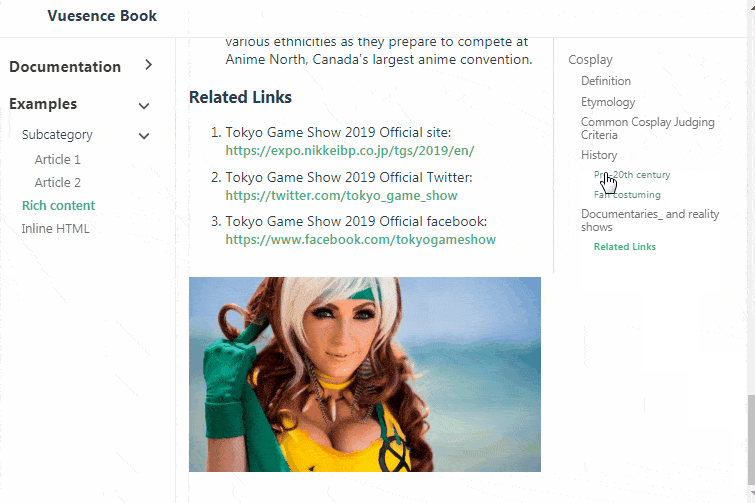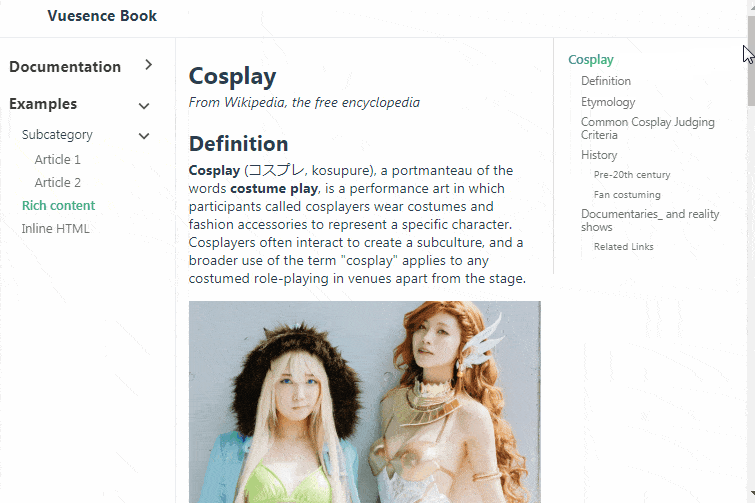
Пару раз понадобилось встроить в сайт справочную систему. Простенькую, с тремя колонками — общее меню, текущая статья и меню содержания статьи. Поиски готового к... | https://habr.com/ru/post/502258/ | null | ru | null |
# Управление голосом в приложениях на Android
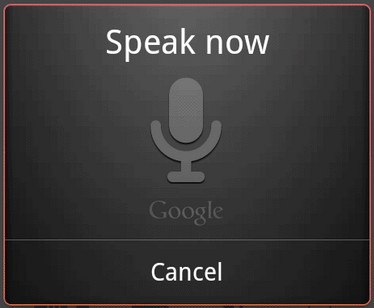
Началось все с того, что я посмотрел неплохой обзор (сравнение) Siri и Google Now. Кто из них лучше, спорить не буду, однако у меня лично планшет на Андроиде. Я подумал, а ч... | https://habr.com/ru/post/180515/ | null | ru | null |
# Собственные валидации полей для Rules в одном классе
Валидация входных данных заслуженно является одним из важнейших правил во всей сфере IT. Если сузить сферу деятельности до разработки веб-сайтов, речь пойдет в основном про валидацию данных из форм.
. И хотя год еще не закончился, но как известно, летом произошли изменения в правилах, соответственно, стало интересно посмотреть, ... | https://habr.com/ru/post/466963/ | null | ru | null |
# Введение в Nashorn
#### Введение
Nashorn\* — движок JavaScript, разрабатываемый полностью на языке программирования Java компанией Oracle. Основан на [Da Vinci Machine](http://en.wikipedia.org/wiki/Da_Vinci_Machine)... | https://habr.com/ru/post/195870/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.