
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Настройка SMS уведомлений в zabbix
Вопрос SMS уведомлений в zabbix уже [освещался](http://habrahabr.ru/post/81630/) на Хабре и проблема решалась с использованием СМС-шлюзов. Также упоминали про [Отправку SMS c помощью Delphi](http://habrahabr.ru/post/133085/). Я же хочу рассказать, как настроить SMS уведомления испо... | https://habr.com/ru/post/155321/ | null | ru | null |
# Инструкция по Selenium Docker
В этой статье мы расскажем о том, как запускать Selenium-тесты в Docker и выполнять их в браузерах Chrome и Firefox. И мы, вероятно, также поймем, зачем запускать Selenium-тест... | https://habr.com/ru/post/650477/ | null | ru | null |
# Новое в CSS3: многоколоночность, flexbox, сеточная разметка
Веб развивается, появляются все новые возможности разметки страниц для верстальщиков, в том числе в этом помогают новые свойства в CSS. В этой статье я описал некоторые из них: многоколоночность, flexbox и сеточная разметка.
Поддержку новых функций брауз... | https://habr.com/ru/post/153925/ | null | ru | null |
# Паттерны по-моему: chain of responsibility и command

В этой статье описываются два паттерна проектирования из широко известной книги «Банда Четырёх» на примере конкретного кода. Паттерны описаны в множестве мест, поэтому если вы... | https://habr.com/ru/post/538954/ | null | ru | null |
# Переходим с STM32 на российский микроконтроллер К1986ВЕ92QI. Опрашиваем клавиши, генерируем ШИМ. Часть первая
#### Вступление
##### Отступление
С последней написанной мною статьи прошло уже довольно много времени, за что прошу прощения: ЕГЭ, поступление, начало учебы. Теперь же, когда до сессии еще далеко, а учебн... | https://habr.com/ru/post/267051/ | null | ru | null |
# Введение в автономную навигацию для дополненной реальности
[](https://habrahabr.ru/company/intel/blog/282141/)
Компьютерные системы с управлением без помощи контроллеров — новый этап во взаимодействии человека и компьютера. К этой... | https://habr.com/ru/post/282141/ | null | ru | null |
# Enrolling and using Token2 USB Security keys with UserLock MFA
[UserLock](https://www.isdecisions.com/products/userlock/) is a user login security system for on-premises Windows Active Directory designed by ISDecisions. It works alongside Active Directory to protect access to Windows systems. With specific and custo... | https://habr.com/ru/post/542384/ | null | en | null |
# Try/Catch/Finally
Когда вы используете **Try/Catch/Finally**, команда которая будет выполняться помещается в блок **Try**. Если произойдет ошибка в процессе выполнения команды, то она будет записана в переменную **$Error**, и выполнение скрипта перейдет к блоку **Catch**.
Скрипт *TestTryCatchFinally.ps1* использу... | https://habr.com/ru/post/248217/ | null | ru | null |
# Стать мэинтейнером. Часть третья
И был день третий, и задумался хабрапользователь-убунтоид: а как мне запаковать свой любимый пакет, чтобы был он красивый и правильный и чтобы гордость от его кошерности распирала ого-го как. Именно этим мы с вами сегодня и займёмся.
(Части [1](http://habrahabr.ru/blogs/ubuntu/505... | https://habr.com/ru/post/50716/ | null | ru | null |
# Возвращаем Thread.Abort() в .NET Core. Поставка приложения со своей версией CoreCLR и CoreFX
В процессе миграции с *.NET Framework* на *.NET Core* могут всплыть некоторые неприятные моменты. Например, если ваше приложение использует домены — логику придется переписывать. Аналогичная ситуация с *Thread.Abort()*: *Mic... | https://habr.com/ru/post/467475/ | null | ru | null |
# Поднимает телефонию с нуля: Asterisk, FreePBX, GSM-шлюз на Huawei E173 в Debian

Сначала маленькая предыстория. Не так давно наша фирма практически лишилась городской связи, один телефонный оператор, что-то не поделил ... | https://habr.com/ru/post/151011/ | null | ru | null |
# Организуем древовидные комментарии к статьям c помощью JavaScript
Сразу оговорюсь, что не являюсь профессиональным web-разработчиком, а занимаюсь этим just for fun, а также для саморазвития.
Потребовалось реализовать в моих разработках возможность комментирования. Простые структуры комментариев меня уже не интере... | https://habr.com/ru/post/49668/ | null | ru | null |
# Делаем iBeacon и Eddystone Beacon «на коленке»
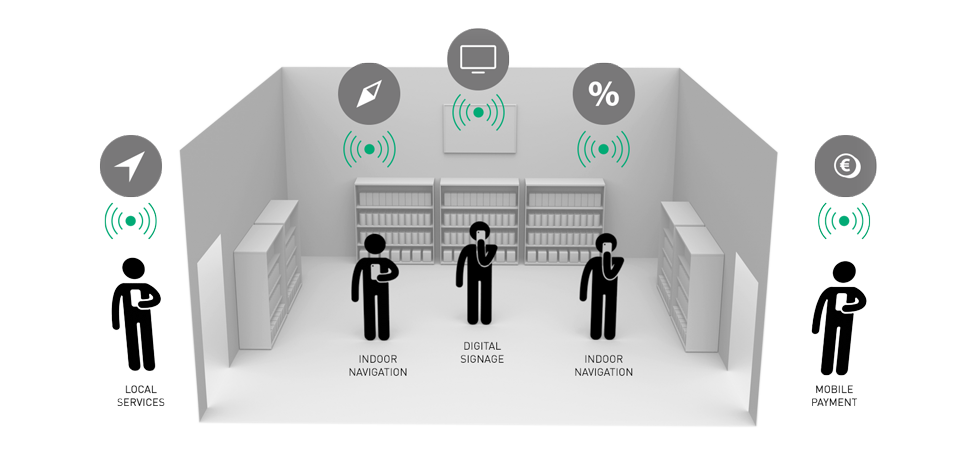
iBeacon и Eddystone — это сервисы Apple и Google соответственно, использующие BLE (Bluetooth Low Energy) для локального позиционирования внутри помещений. Базовый принцип у о... | https://habr.com/ru/post/273865/ | null | ru | null |
# Python и Samila. Делаем красиво
 Содержание:
* Введение
* Установка | Запуск без установки
* Работа с библиотекой Samila
* Полезные ссылки
### Введение
[Samila](https://github.com/sepandhaghighi/samila... | https://habr.com/ru/post/648955/ | null | ru | null |
# Строго типизированное представление неполных данных
В предыдущей статье [«Конструирование типов»](http://habrahabr.ru/post/222553/) была описана идея, как можно сконструировать типы, похожие на классы. Это даёт возможность отделить хранимые данные от метаинформации и сделать акцент на представлении самих свойств сущ... | https://habr.com/ru/post/229035/ | null | ru | null |
# Удобный BDD: SpecFlow+TFS
В сети есть много статей о том как использовать SpecFlow, как настраивать TFS для запуска тестов, но нет ни одной которая содержала бы в себе все аспекты. В статье я расскажу, как можно сделать запуск и редактирование сценариев SpecFlow удобным для всех.
### Под катом вы узнаете как получ... | https://habr.com/ru/post/497730/ | null | ru | null |
# Профилирование и оптимизация символьных вычислений для будущего сервера
Привет, Хабр! Сегодня хочу поделиться своим небольшим опытом выбора инструментов для организации расчетов на будущем сервере. Отмечу сразу, что в этой публикации речь пойдет не о самом сервере, а скорее об оптимизации символьных вычислений на не... | https://habr.com/ru/post/328170/ | null | ru | null |
# Service Locator — развенчивание мифов

Удивительно, как практика, демонстрирующая хорошую производительность и удобство работы для одной платформы демонизируется в лагере приверженцев другой платформы. Эту участь в полной мере ощ... | https://habr.com/ru/post/498194/ | null | ru | null |
# Экспорт избранного Хабра в FB2 — скоростная PHP-версия
В своё время я уже видел такой конвертер здесь же на Хабре, написанный на питоне, но он на моей машинке сжирал много-много-много ресурсов и ни разу не смог моё избранное (а это 400+ постов) до конца сохранить, падая то на некорректном файле, то на «кривой» стать... | https://habr.com/ru/post/170755/ | null | ru | null |
# Новости из мира OpenStreetMap № 501 (18.02.2020-24.02.2020)
Исходный код blender-osm — плагина для Blender 3D — выложен GitHub [1](#wn501_21985) | vvoovv | map data OpenStreetMap contributors
... | https://habr.com/ru/post/491518/ | null | ru | null |
# Враг внутри: как я попался на инсайдерском редтиминге

У меня были все преимущества. Я уже был внутри сети. Я был вне подозрений. Но они обнаружили мой взлом, выкинули из сети… и выследили физически.
Многие тестирования на про... | https://habr.com/ru/post/430252/ | null | ru | null |
# Сортировка вставками
***Всем привет. Сегодня продолжаем серию статей, которые я написал специально к запуску курса [«Алгоритмы и структуры данных»](https://otus.pw/0BpP/) от OTUS.***
---

Введение
--------
Сортировка массива я... | https://habr.com/ru/post/510244/ | null | ru | null |
# Hack The Box. Прохождение Compromised. RCE LiteCart и бэкдор pam_unix
Продолжаю публикацию решений отправленных на дорешивание машин с площадки [HackTheBox](https://www.hackthebox.eu). Надеюсь, что это помо... | https://habr.com/ru/post/538470/ | null | ru | null |
# Создание эффекта быстрого полета сквозь космос (или падающего снега) за 10 минут на p5.js

Недавно под вдохновением от канала [The Coding Train](https://www.youtube.com/channel/UCvjgXvBlbQiydffZU7m1_aw) я решил поучаствовать в одном и... | https://habr.com/ru/post/505658/ | null | ru | null |
# Авторизация на сайте средствами phpBB/XenForo
Примерно год назад мне потребовалось дать возможность пользователям зарегистрированным на форуме (phpBB) авторизовываться на сайте (modX). На тот момент форум уже работал и пользователи активно общались. Решения [MODxBB](http://i--gu.ru/phpbb-i-modxbb) тогда еще не было ... | https://habr.com/ru/post/136833/ | null | ru | null |
# У Steam проблемы с кешированием, из-за которой пользователи видят информацию о чужих аккаунтах

Steam сегодня испытывает большие проблемы с кешированием страниц.
Началось все при старте 4го дня новогодней распродаж... | https://habr.com/ru/post/388475/ | null | ru | null |
# Что такое базовые методы компрессии нейронных сетей и где этому учат
Сегодня нейросетевые подходы составляют большую часть решений задач в области компьютерного зрения, но при этом работа инженеров в этой области не ограничивается обучением state-of-the-art архитектур на своих данных. Часто такие задачи требуют анал... | https://habr.com/ru/post/567584/ | null | ru | null |
# Оптимизация и автоматизация тестирования веб-приложений

В этой статье я расскажу о том, как оптимизировать и автоматизировать процессы тестирования на проникновение с помощью специализированных утили... | https://habr.com/ru/post/335140/ | null | ru | null |
# Как избавиться от ошибок с таблицами Active Object при восстановлении Jira из бэкапа

В этой статье поговорим о том, как избавиться от ошибок с таблицами Active Objects при восстановлении Jira из бэкапа и напишем плагин для удале... | https://habr.com/ru/post/421699/ | null | ru | null |
# Переполнение кучи в Linux для начинающих
Данный туториал для начинающих, но подразумевается, что читатель уже знаком с основами работы функции [**malloc**](https://azeria-labs.com/heap-exploitation-part-1-understanding-the-glibc-heap-implementation/)библиотеки glibc. Подробно рассмотрим как эксплуатировать переполне... | https://habr.com/ru/post/547712/ | null | ru | null |
# Generic Math: суперфича C#, доступная в .NET 6 Preview 7
10 августа 2021 года Microsoft в [блоге](https://devblogs.microsoft.com/dotnet/announcing-net-6-preview-7/) опубликовала информацию о свежевыпущенном .NET 6 Preview 7.
Помимо добавления очередной порции синтаксического сахара, расширения функционала библиотек... | https://habr.com/ru/post/572902/ | null | ru | null |
# OpenCL. Как начать
### Тяжелый старт
Всем привет! Какое-то время назад я начал копать тему с OpenCL под C#. Но наткнулся на трудности, связанные с тем, что не то, что под C#, а вообще по этой теме очень мало материала. Какую-то вводную по OpenCL можно почерпнуть [здесь](http://habrahabr.ru/post/72650/). Так же прос... | https://habr.com/ru/post/261323/ | null | ru | null |
# ECMAscript 5: Строгий режим, JSON, и так далее
Раньше я проанализировал функциональность [обьектов и свойств ECMAScript 5](http://habrahabr.ru/blogs/javascript/60234/). Это огромный новый аспект языка и он заслуживает особого рассмотрения.
Есть целый ряд других новых функций и API, которые также требуют внимания.... | https://habr.com/ru/post/60282/ | null | ru | null |
# Laravel Timestamp Validator

Laravel 5.1, Laravel 5.2, Lara… Код прогрессирует, оптимизируется и развивается. В новой (5.2) версии появился валидатор массивов, например, но что делать, если необходим... | https://habr.com/ru/post/281827/ | null | ru | null |
# Использую Рисоваську для публикации новостей на сайте
На сайте интернет-магазина [Магазинчика HandMade](http://hand-made-shop.ru) я использую трансляцию моего аккаунта в [Рисоваське](http://risovaska.ru/) НandMade-news для публикаций новостей и обновлений в магазине.
Новость я рисую прямо в программе Рисоваськи,... | https://habr.com/ru/post/55383/ | null | ru | null |
# Судьба баг-репорта
Довольно частый (и логичный) вопрос к нашим статьям с проверкой открытых проектов: отправляются ли разработчикам баг-репорты? Так вот, ответ – да. Более того, мы на этом не останавливаемся и иногда отслеживаем прогресс. Сегодня хотелось бы рассказать об одном из случаев, где именно эта педантичнос... | https://habr.com/ru/post/651887/ | null | ru | null |
# Определение плотности газа по результатам измерения давления и температуры датчиками Arduino
### Введение
Задача измерения параметров газовой смеси широко распространена в промышленности и торговле. Проблема получения достоверной информации при измерении параметров состояния газовой среды и её характеристик с помощ... | https://habr.com/ru/post/412915/ | null | ru | null |
# Свой облачный бэкенд в одну строчку кода. Обзор BaaS платформы «Backendless»
Привет Хабр!
Пост будет интересен тем, кого интересует, как выиграть время при разработке мобильных, десктопных или браузерных приложений. Данная информация поможет вашим приложениям быть более функциональными и выходить в мир в разы быс... | https://habr.com/ru/post/180367/ | null | ru | null |
# Более безопасный способ сбора потоков данных из пользовательских интерфейсов Android
В приложении для Android [потоки Kotlin](https://developer.android.com/kotlin/flow) обычно собираются из пользовательског... | https://habr.com/ru/post/564050/ | null | ru | null |
# Java и паттерн Public Morozov
Однажды понадобилось мне переопределить на работающей программе поле, помеченное как private final. Причем останавливать программу было нельзя, ибо сервер. Ну и как маленькое дополнение тип переменной был определен как inner класс. Разумеется тоже private.
К счастью, программа позвол... | https://habr.com/ru/post/75661/ | null | ru | null |
# Простейший аттенюатор для аудиокарты
В любительской радиотехнике, а именно в области проектирования усилителей низкой (звуковой) частоты, очень удобно использовать для измерений компьютер.
Профессиональные измерительные приборы стоят немалых денег, тогда как аудиокарта имеется почти в любом домашнем компьютере. В... | https://habr.com/ru/post/138448/ | null | ru | null |
# Создаем собственный фреймворк на основе Symfony2. (Часть 4)
* [Часть 1](http://habrahabr.ru/blogs/symfony/136110/)
* [Часть 2](http://habrahabr.ru/blogs/symfony/136430/)
* [Часть 3](http://habrahabr.ru/blogs/symfony/136471/)
* **Часть 4**
* [Часть 5](http://habrahabr.ru/blogs/symfony/138010/)
Прежде чем мы перейдем... | https://habr.com/ru/post/136656/ | null | ru | null |
# Pautomount — демон автоматического монтирования, запуска скриптов и всего такого прочего

Возникла передо мной задача — автоматически выполнять действие при вставке какого-нибудь storage device в Де... | https://habr.com/ru/post/220301/ | null | ru | null |
# Covid fake FAQ___draft_final_4 (окончательное доказательство)
Covid
-----
Вирус SARS-CoV-2 (2019-nCoV) не был выделен
> Затем из образца нижних дыхательных путей был выделен новый коронавирус, получивший название 2019-nCoV, и вскоре после этого был разработан диагностический тест на этот вирус. ([Источник, переведе... | https://habr.com/ru/post/565892/ | null | ru | null |
# Принцип работы планировщика задач в Linux
[](https://habr.com/ru/company/ruvds/blog/578788/)
Планирование – это процесс распределения ресурсов системы для выполнения задач. В статье мы рассмотрим его вариант, в котором ресурсом явл... | https://habr.com/ru/post/578788/ | null | ru | null |
# Собираем ваш первый WebAssembly-компонент
Когда я впервые услышал о технологии [WebAssembly](https://webassembly.github.io/) — она сразу показалось мне крутой вещью и мне сразу захотелось попробовать её в деле. От первого желания, до чего-то работающего мне, однако, пришлось потратить немало времени и порой испытат... | https://habr.com/ru/post/304362/ | null | ru | null |
# Фильтруй базар: пишем простой и функциональный фильтр данных

Кто-то спросит, каким образом фильтры грубой очистки топлива на картинке справа относятся к PHP\IT в целом? Очень просто! Скрипт, о котором пойдет... | https://habr.com/ru/post/98752/ | null | ru | null |
# Плагин для Redmine: отчеты по работе
Продолжаем разрабатывать плагины для автоматизации работы [нашей команды.](http://centos-admin.ru/)
В качестве следующего этапа автоматизации решено было создать плагин отчетов по объемам работ.
Это полезно как для статистики работы по проектам, так и для контроля работы со... | https://habr.com/ru/post/273951/ | null | ru | null |
# Запуск кода под другим пользователем в Windows из Java
Добрый день! Сейчас я расскажу вам, как запускать код под учётной записью другого пользователя в Windows из Java с помощью JNA.
#### Практическое значени
В общем случае это может понадобиться, когда нужно обратиться к ресурсам, которые доступны какому-либо о... | https://habr.com/ru/post/123945/ | null | ru | null |
# Как вырезать сабсет города (любого отношения) из OSM данных
Однажды мне потребовалось получить из сырых ОСМ данных чистый сабсет города (потому что так удобно, компактно и просто красиво). К моему удивлению я не нашел готового рецепта, из-за чего для выполнения этой задачи потребовалось немного попотеть.
Ввиду вы... | https://habr.com/ru/post/463251/ | null | ru | null |
# Разбираемся с разработкой Windows 8 приложений на XAML/С#, реализуя простой RSS Reader. Ч.2
Продолжаем разрабатывать простой RSS Reader. Начало было положено в статье [Разбираемся с разработкой Windows 8 приложений на ... | https://habr.com/ru/post/163837/ | null | ru | null |
# Wireshark — приручение акулы

Wireshark — это достаточно известный инструмент для захвата и анализа сетевого трафика, фактически стандарт как для образования, так и для траблшутинга.
Wireshark работае... | https://habr.com/ru/post/204274/ | null | ru | null |
# Поддержка Django приложений в Google App Engine
Недавно google [анонсировал](http://habrahabr.ru/blogs/gae/129907/) [Cloud SQL](https://developers.google.com/cloud-sql/) для своего облака. Но вначале подержки django не было, и вот в начале февраля выходит [App Engine 1.6.2](http://googleappengine.blogspot.com/2012/0... | https://habr.com/ru/post/139354/ | null | ru | null |
# Простейший способ добавить WebSocket в Django
*Примечение переводчика: вебсокеты и Django — это довольно сложная тема, которая уже не раз поднималась на хабрахабре и основной идеей является написание параллельного бэкенда для вебсокетов. Автор же предлагает довольно лаконичное решение этой проблемы, которому правда ... | https://habr.com/ru/post/211094/ | null | ru | null |
# Пора завязывать
Может быть, стоило написать в «[Я негодую](http://habrahabr.ru/blogs/i_am_angry/)». Не знаю. Пока писал, расколотил чашку с чаем и таким образом достиг хладнокровия.
Я про вот... | https://habr.com/ru/post/118510/ | null | ru | null |
# flash-видео на веб-страницах и PHP
Эта статья — перепечатка статьи от 16 ноября 2007 г. с моего блога, ссылку на который можно найти в моем же профайле — но, поскольку так уж вышло, что тема эта, кажется, до сих пор многим интересна, к тому же не так давно я читал на эту тему доклад на конференции PHPConf… в общем —... | https://habr.com/ru/post/30402/ | null | ru | null |
# Туда и обратно: как мы пытались отследить актуальное время в Android
Марти, серия еще доступна ?Эта статья будет посвящена тому, как мы в команде PRE... | https://habr.com/ru/post/695178/ | null | ru | null |
# Способ проксирования JPA сущностей для клиента (борьба с lazy initialization)
Недавно, увидев на Хабре [пост](http://habrahabr.ru/blogs/java/111911/) про борьбу с lazy initialization в Hibernate, я заинтересовался – прочитал сам пост и ждал пока наберется побольше комментариев – не предложит ли кто-нибудь способ, ко... | https://habr.com/ru/post/112621/ | null | ru | null |
# Макрос для Autodesk Revit, который подравнивает стены
Автодеск сделал стены разными, но пришли проектировщики и начертили стены под углом 0,045 и 89,915 градусов. Поэтому не ставятся размеры между стенами. Так продолжалось долго, но теперь появился Великий Макрос Уравнитель, он вернет стенам углы в 0,000 и 90,000 гр... | https://habr.com/ru/post/352948/ | null | ru | null |
# Чего мне никогда не говорили о CSS

*Фото [Джантин Дурнбос](https://unsplash.com/photos/xt9tb6oa42o) на [Unsplash](https://unsplash.com/search/photos/css)*
*Это ни в коем случае не критика коллег, а в... | https://habr.com/ru/post/445292/ | null | ru | null |
# Надёжная и воспроизводимая установка Linux с NixOS
[NixOS](https://nixos.org/) — это дистрибутив Linux, обеспечивающий надёжность и позволяющий легко воспроизводить состояния системы. [Знакомим](https://www... | https://habr.com/ru/post/657507/ | null | ru | null |
# Борьба со спамом c использованием css
Смысл состоит в том, чтобы сделать в форме дополнительное поле и спрятать его стилями от пользователя. Пользователь не видит поле и не заполняет его, а бот заполнит. На стороне сервера проверять заполнено поле или нет.
html:
>
>
>
css:
> `body {`
>
>
По увере... | https://habr.com/ru/post/12970/ | null | ru | null |
# BitTorrent Tracker на C#
Долгое время я искал в сети пример простейшего tracker-а на C#, но, к сожалению, мои поиски успехом не увенчались. Поэтому я решил попробовать себя в написании tracker-а на C#, а получив более-менее рабочую версию — поделиться опытом ее создания со всеми. А заодно и получить как можно больше... | https://habr.com/ru/post/187544/ | null | ru | null |
# Магия SwiftUI или о Function builders

Вы пробовали добавить в `VStack` больше 10 вьюх?
```
var body: some View {
VStack {
Text("Placeholder1")
Text("Placeholder2")
// ... тут вьюшки с 3... | https://habr.com/ru/post/455760/ | null | ru | null |
# Передача центров затрат с привязкой к дополнительным объектам Employee Central
Введение
--------
Программа ODTF\_REPL\_CC используется для передачи центров затрат из SAP ERP CO в Employee Central, что включает следующие данные: уникальный код центра затрат (поле externalCode), краткий код центра затрат (поле costCe... | https://habr.com/ru/post/661353/ | null | ru | null |
# Используем join в SQLite-запросах Room для android
Совсем недавно вышла [2.4.0-alpha04](https://developer.android.com/jetpack/androidx/releases/room#2.4.0-alpha04) -версия Room, которая упрощают написание методов DAO и позволяет возвращать данные запросов в формате Map. В этом посте мы вспомним про форматы JOIN в SQ... | https://habr.com/ru/post/570400/ | null | ru | null |
# Узнаем оператора и регион мобильного телефона

Как то гуляя в интернете наткнулся на интересную ссылку — [Коды мобильных операторов](http://mtt.ru/info/def/index.wbp). И очень мне захотелось иметь такую базу локально.
Под катом дамп mysql базы, php код для е... | https://habr.com/ru/post/45865/ | null | ru | null |
# Рядовой SNAFU идет в DBA

Для тех, кто не знает, [SNAFU](https://en.wikipedia.org/wiki/Private_Snafu) — персонаж военных патриотических мультфильмов, созданных американцами во время войны. Этот раздолбай, ввиду природного идиотиз... | https://habr.com/ru/post/490282/ | null | ru | null |
# К вопросу расчета себестоимости
Несколько дней назад проводил партнерский семинар — обучение новых сотрудников. Касались вопроса расчета итогов (регистров) системы, в частности расчета себестоимости.
Вечером один из слушателей прислал ссылку на [статью, подробно рассматривающую проблематику расчета себестоимости ... | https://habr.com/ru/post/243743/ | null | ru | null |
# Dat — что это за протокол, и кто его использует
Говорим о принципах работы этого P2P-протокола и проектах, построенных на его основе.
[](https://habr.com/ru/company/vasexperts/blog/462359/)
*/ Unsplash / [Alina Grubnyak](http... | https://habr.com/ru/post/462359/ | null | ru | null |
# Создание приложений на GTK+/gtkmm с использованием среды Glade
Данный пост является дополнением к статье [«Создание приложений на GTK+ с использованием среды Glade»](http://habrahabr.ru/post/107403/). Когда я начинал её читать, и наткнулся на слова о том, что пример будет на C++, то заранее обрадовался, так как на т... | https://habr.com/ru/post/145160/ | null | ru | null |
# Svelte 3: Переосмысление реактивности
Буквально на днях произошло большое событие для сообщества SvelteJS, да и вообще, как мне кажется, для всего современного фронтенда — долгожданный релиз Svelte 3! Посему, под катом перевод статьи автора Svelte и прекрасное видео с его доклада на YGLF 2019.
(*[Источник рисунка](https://commons.wikimedia.org/wiki/File:New_Animation_Sieve_of_Eratosthenes.gif?uselang=ru)* )
Общеизвестно, что Решето Эратосфена (РЭ) один из др... | https://habr.com/ru/post/450604/ | null | ru | null |
# Repeatable, еще один способ рендерить списки
(из серии «малая механизация web страниц»)
#### Что такое Repeatable?
Repeatable это способ вывода (популяции) всякого рода списков, таблиц и пр. по массивам данных. Данный механизм
использует шаблон описанный в самом коде разметки (в отличие от, скажем, {{mustach... | https://habr.com/ru/post/211590/ | null | ru | null |
# Windows 7 Tips and Tricks ;)
**Салют Хабралюди, хабражители :)**
[Продолжая](http://iden.habrahabr.ru/blog/58557/) рубрику статей посвященных Windows 7, решил предаставить сборник несколько полезностей которые могут облегчить работу в этой ОСи.
.
[Year old article about general concepts of the project](https://habr.com/en/post/526002/).
So you want to build a multitasking system using python? But you actually hesitate because you know you'll ... | https://habr.com/ru/post/585320/ | null | en | null |
# Как я участвовал в конкурсе маленьких игр js13kGames

В программерских конкурсах широко принято и приветствуется написание постмортемов. Никаких похорон: фактически, это сочинение на тему «Что я узнал, участвуя в конкурсе»... | https://habr.com/ru/post/237127/ | null | ru | null |
# Как я разбирал docx с помощью XSLT
Задача обработки документов в формате docx, а также таблиц xlsx и презентаций pptx является весьма нетривиальной. В этой статье расскажу как научиться парсить, создавать и обрабатывать такие документы используя только XSLT и ZIP архиватор.
Зачем?
------
docx — самый популярный фо... | https://habr.com/ru/post/321044/ | null | ru | null |
# Экстенсивный подход. Как много техник можно обнаружить в одном образце вредоносного программного обеспечения (ВПО)
— "Прошу расшифровать трафик в адрес …" - описание задачи в трекере.
— "Давай, Морти! Пр... | https://habr.com/ru/post/647335/ | null | ru | null |
# Фишки XAML-разработчика: композитные конвертеры
Статья будет посвящена простому, но эффективному паттерну — *Composite Converter* [*составной конвертер*].

Встречаются ситуации, когда уже есть несколько конвертеро... | https://habr.com/ru/post/276273/ | null | ru | null |
# Как поставить Django на сервер heroku в 2020 году. 10 шагов
Решил поделиться с вами тем, как поставить проект написаный на Python/Django на сервер heroku. Heroku — это бесплатный хостинг для тестирования своих проектов. Если вам нужно посмотреть как действует проект в боевом режиме — вперед!
1. **Надо пройти реги... | https://habr.com/ru/post/523308/ | null | ru | null |
# C/C++ из Python (boost)

Заключительная статья из серии как вызывать **C/C++** из **Python3**, перебрал все известные способы как можно это сделать. На этот раз добрался до [**boost**](https://www.boost.org/doc/libs/1_66_0/li... | https://habr.com/ru/post/471618/ | null | ru | null |
# Минимизация Javascript кода и CSS с помощью Microsoft Ajax Minifier
Скачивание объёмных ресурсов, связанных с веб-страницей, таких как JavaScript файлы и CSS, влияет не только на скорость загрузки страницы, но и увеличивает трафик, проходящий от сервера к клиентскому браузеру. Последнее обстоятельство особенно важно... | https://habr.com/ru/post/86067/ | null | ru | null |
# Много тестов не бывает
Некоторое время назад я принял решение потихоньку внедрять в свою практику автоматизированное тестирование и TDD. Признаюсь честно, получалось все это с переменным успехом. Но то, что жить стало ... | https://habr.com/ru/post/191164/ | null | ru | null |
# Дружим RaspberryPi с TP-Link TL-WN727N
Привет, Хабр!
Задумал как-то я подключить свою малинку к интернету по воздуху.
Сказано-сделано, для этого был приобретен в ближайшем магазине usb wi-fi свисток небезызвестной фирмы TP-Link. Сразу скажу, что это не какой-то там нано usb модуль, а вполне себе габаритный де... | https://habr.com/ru/post/471564/ | null | ru | null |
# LDAP авторизация в SVN с помощью Apache
Привет, товарищи
Выложу я свою версию настройки LDAP авторизации с помощью Apache.
Она более подробная, чем [чем уже описанная](http://habrahabr.ru/blogs/sysadm/53383/).
Что понадобится:
* Apache 2.2 + open SSL. можно скачать с [apache.org](http://apache.org).
* SV... | https://habr.com/ru/post/73403/ | null | ru | null |
# Как создать переводчик, который переводит лучше, чем Google Translate
Помню, как еще в школе на Basic я писал программу-переводчик. И это было то время, когда ты сам составлял словарь, зашивал перевод каждого слова, а затем разбивал строки на слова и переводил каждое слово в отдельности. В то время я, конечно же, не... | https://habr.com/ru/post/689580/ | null | ru | null |
# ООП на ASM
Как говорится, и на Марсе будут яблони цвести!
`register AX extends AL implements AH {
}
register EAX extends AX {
}` | https://habr.com/ru/post/25469/ | null | ru | null |
# Сервер очередей Gearman: опыт практического использования и веб-приложение Gearman Monitor && Control
Сервер очередей Gearman — прекрасный инструмент. Но в работе сервер очередей в чем-то напоминает системный блок: что-то делает, но для того чтобы знать, что именно, и управлять процессом, нужен монитор с клавиатурой... | https://habr.com/ru/post/212761/ | null | ru | null |
# Рисуем волну .wav-файла
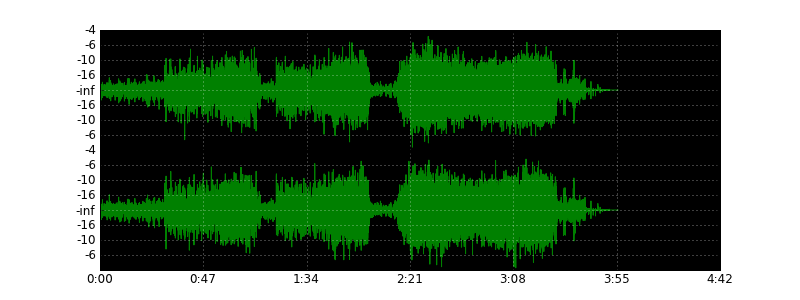
Некоторое время назад я решил посвятить себя решению экзотической задачи — нарисовать волну wave-файла, как это делают аудио- и видеоредакторы, используя для этого Питон. В результате у меня получился неб... | https://habr.com/ru/post/113239/ | null | ru | null |
# Учебное пособие по кэшированию, часть 2
Вторая часть довольно подробного и интересного изложения материала, касающегося кэша и его использования. [Часть 1](http://habrahabr.ru/post/203548/).
Автор, [Mark Nottingham](http://www.mnot.net/personal/), — признанный эксперт в области HTTP-протокола и веб-кэширования. Я... | https://habr.com/ru/post/204464/ | null | ru | null |
# Логи в Kubernetes (и не только) сегодня: ожидания и реальность

Шёл 2019 год, а у нас всё ещё нет стандартного решения для агрегации логов в Kubernetes. В этой статье мы хотели бы, используя примеры из реальной практики, поделиться... | https://habr.com/ru/post/480946/ | null | ru | null |
# Инфраструктура System.Transactions в мире .NET

Встречали ли вы в C# конструкцию типа `using (var scope = new TransactionScope(TransactionScopeOption.Required))`? Это значит, что код, выполняющийся в блоке `using`, заключается в тр... | https://habr.com/ru/post/433136/ | null | ru | null |
# Третье практическое задание с сайта unity3dstudent.com
Продолжим разбирать практические задания с [unity3dstudent.com](http://unity3dstudent.com). На очереди последняя на данный момент задачка. Статья слегка задержалась, но, надеюсь, будет кому-то полезна.
Вот ссылка на оригинальное задание: [www.unity3dstudent.c... | https://habr.com/ru/post/146301/ | null | ru | null |
# Debian-пакеты с человеческим лицом на примере Zabbix 1.8
Написать эту статью меня заставили две вещи: во-первых, есть ощущение, что после [статей](http://habrahabr.ru/blogs/linux/78049/) типа "[делаем debian-пакет на коленке](http://habrahabr.ru/blogs/ubuntu/72633/)", большинство хабравчан утвердятся во мнении, что ... | https://habr.com/ru/post/78086/ | null | ru | null |
# Алгоритм Кэхэна: как получить точную разность произведений
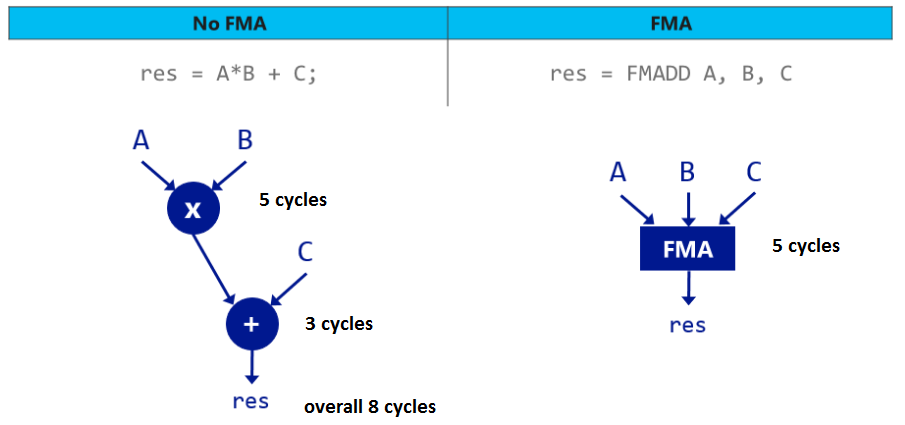
Недавно я вернулся к анализу погрешностей чисел с плавающей запятой, чтобы усовершенствовать некоторые детали в следующей редакции книги *P... | https://habr.com/ru/post/475370/ | null | ru | null |
# Асинхронное программирование: Примитивы высокого уровня
После появления асинхронного каркаса Twisted концепция отложенного результата (continuable) стала очень популярной.
Прежде всего рекомендую прочитать статьи: [Асинхронное программирование: концепция Deferred](http://habrahabr.ru/blogs/twisted/51762/), [Deffe... | https://habr.com/ru/post/84709/ | null | ru | null |
# Введение в безопасность на основе мандатных ссылок (англ. Capability-based security)
В большинстве сегодняшних операционных систем модель безопасности своими корнями уходит в Unix, наследуя предположение о том, что пользователь может доверять программам, которые он запускает. Однако, как показывает практика – это ут... | https://habr.com/ru/post/148743/ | null | ru | null |
# Улучшенные четыре правила проектирования ПО
Привет, Хабр! Представляю вашему вниманию статью "Four Better Rules for Software Design" автора David Bryant Copeland. David Bryant Copeland — архитектор ПО и технический директор Stitch Fix. Он ведет [свой блог](https://naildrivin5.com/) и является [автором нескольких кни... | https://habr.com/ru/post/461823/ | null | ru | null |
# Сборка и дeплой приложений в Kubernetes с помощью dapp и GitLab CI

В предыдущих статьях о **dapp** было рассказано про сборку приложений и про запуск в Minikube. При этом dapp запускался локально на машине разработчика. Однако инс... | https://habr.com/ru/post/345580/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.