
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Программируем под Pebble. Урок первый: Глупые часы
Когда мне привезли часы Pebble, я думал это просто умные часы. Ну, там смс на экранчике показать, время в двух поясах, поставить вместо цифровых — хипстерские аналоговые. И так далее.
, либо к [andilabs/ui](https://github.com/andlabs/ui) (биндинги к C-реализациям нативного UI для каждой платформ... | https://habr.com/ru/post/253519/ | null | ru | null |
# Постигаем Git
*От переводчика: в этой статье нет описания команд git, она подразумевает, что вы уже знакомы с ним. Здесь описывается вполне здравый, на мой взгляд, подход к содержанию публичной истории в чистоте и порядке.*
Если вы не понимаете, что побудило сделать git именно таким, то вас ждут страдания. Исполь... | https://habr.com/ru/post/141160/ | null | ru | null |
# Continuous Integration в Дневник.ру
В этой статье мы решили немного рассказать о средствах continuous integration (CI), которые используем в компании Дневник.ру, и поделиться небольшими наработками в этом направлении. Большая часть материала может показаться банальной рекламой выбранного движка CI или попыткой вызва... | https://habr.com/ru/post/169329/ | null | ru | null |
# Vulkan. Руководство разработчика. Image views

Кто еще со мной не знаком, я технический переводчик из ижевской компании CGTribe, и я занимаюсь переводом руководства к Vulkan API ([vulkan-tutorial.com](https://vulkan-tutorial.com)).... | https://habr.com/ru/post/543288/ | null | ru | null |
# Разгоняем сборку Swift проекта в Xcode

Статья о том как починить инкрементальную компиляцию в Xcode для Swift проектов и ускорить build phases для Cocoapods и Carthage, ничего не поломав.
Небольшой спойлер: на трех разных проектах получилось сократить врем... | https://habr.com/ru/post/317650/ | null | ru | null |
# Макросы в Vim — это просто
### Макросы в Vim
Очень странно, с одной стророны тема довольно банальная, а с другой ни тут, ни на просторах интернета не видно хорошего понимания такой важной темы, которая может иногда сильно упростить задачу редактирования текста. К написанию меня подтолкнуло [обсуждение макросов](htt... | https://habr.com/ru/post/230487/ | null | ru | null |
# Написание web-API к своей системе
Добрый день, %username%!
За последний год столкнулся с несколькими задачами по написанию SOAP/REST API к различным сервисам и вывел для себя боле-менее удобную модель. Я не претендую на фундаментальное исследование, просто хочу поделиться опытом наступания на грабли.
 — международные соревнования по защите информации, которые проводятся по игровому принципу Capture the Flag. Несколько команд в течение заранее отведенного времени защищают свои сети и атакуют чужие. Основная зад... | https://habr.com/ru/post/221991/ | null | ru | null |
# Первые шаги с STM32 и компилятором mikroC для ARM архитектуры — Часть 4 — I2C, pcf8574 и подключение LCD на базе HD4478
Следующую статью я хочу посвятить работе с распространенным интерфейсом i2c, достаточно часто используемом в разнообразных микросхемах, подключаемых к микроконтроллеру.
I2C представляет собой ш... | https://habr.com/ru/post/322184/ | null | ru | null |
# Разработка простого приложения «шагомер» на ReactNative

Сегодня в кругах программистов почти каждый знает о библиотеке Facebook – React.
В основе React лежат компоненты. Они схожи с DOM элементами браузера, только на... | https://habr.com/ru/post/283494/ | null | ru | null |
# Передача функций через JSON
Из этого топика вы узнаете как отправить JavaScript функции, через JSON используя PHP (сама концепция может быть применена и для других языков).
PHP, начиная с версии 5.2.0, включает функции json\_encode() и json\_decode(). Эти функции кодируют данные в формат JSON и декодиуют JSON в а... | https://habr.com/ru/post/63057/ | null | ru | null |
# Подключаем LCD экран к макетной плате LPCXpresso55S69
В рамках проекта All-Hardware довелось мне освоить работу с экраном на макетной плате LPC55S69-EVK фирмы NXP. Пикантность ситуации состоит в том, что штатно эта плата поставляется без экрана, так что в освоение работы также входил поиск экрана, который можно дост... | https://habr.com/ru/post/504322/ | null | ru | null |
# Облако для всех. Строим CI/CD pipeline для бессерверных функций
В публичном облаке SberCloud.Advanced, построенном на технологиях Huawei, имеется крайне полезный сервис бессерверных вычислений – Function Graph. С его помощью можно быстро набросать код для решения конкретной бизнес-задачи и запустить его на выполнени... | https://habr.com/ru/post/568866/ | null | ru | null |
# Телеграм бот для удаления спама
**UPD: Актуальная документация по боту находится по адресу** <https://tgdev.io/bot/daysandbox_bot>
Решил написать эту публикацию т.к. устал объяснять одно и то же людям, которые хотят использовать моего телеграм бота [@daysandbox\_bot](https://tgdev.io/bot/daysandbox_bot). Итак, неск... | https://habr.com/ru/post/348800/ | null | ru | null |
# Бэкап для Linux не пишет писем
Всем привет!
Сегодня хочу поведать о том, как управлять **Veeam Agent for Linux** с помощью командной строки, и о том, какие возможности она открывает в умелых руках программиста.
На написание статьи меня подтолкнул комментарий к предыдущей [статье](https://habr.com/company/veea... | https://habr.com/ru/post/432404/ | null | ru | null |
# Быстрая и удобная генерация IL
Я много раз сталкивался с задачей динамической генерации кода (например, при написании эффективного сериализатора или компилятора [DSL](https://en.wikipedia.org/wiki/Domain-specific_language "Domain Specific Language")). Это можно делать разными способами, какой из них лучший – дискусс... | https://habr.com/ru/post/262711/ | null | ru | null |
# System.exit(). Какой код выхода использовать?
Что является причиной того, что java программа прекращает любую свою активность и завершает свое выполнение? Основных причин может быть 2 ([JLS Секция 12.8](http://docs.oracle.com/javase/specs/jls/se7/html/jls-12.html)):
* Все потоки, которые не являются демонами, вып... | https://habr.com/ru/post/197594/ | null | ru | null |
# Первые шаги с OpenCL или сказ о том как одинаковый код на GPU и CPU запускать
Итак, прошел почти год с момента моего первого поста о программировании видеокарт и страшилок о том, как это все сложно. Теперь настала пора показать, что все не так плохо и как пользоваться этой странной штукой по имени OpenCL, да еще и и... | https://habr.com/ru/post/146823/ | null | ru | null |
# Мониторинг производительности приложений и метрики здоровья без APM
Привет, Habr! Я уже рассказывал про AIOps и методы машинного обучения в работе с ИТ инцидентами, про зонтичный мониторинг и различные подходы к сервис менеджменту. Сейчас хотелось бы поделиться вполне конкретным алгоритмом, как можно без особых затр... | https://habr.com/ru/post/546772/ | null | ru | null |
# О том, как можно проверять значения, введёные пользователем
В любых программных продуктах, будь то windows-приложение или web-сайт, получение информации от пользователей зачастую осуществляется с помощью форм ввода данных.
Конечно же, нельзя быть абсолютно уверенным, что пользователь введёт именно то, что нужно, ... | https://habr.com/ru/post/51131/ | null | ru | null |
# CSS Sprites — зло, не используйте их!
После [многочисленных](http://webo.in/articles/habrahabr/08-all-about-css-sprites/) [статей](http://webo.in/articles/habrahabr/03-presentation-layer-performance-tuning/) (на русском и [английском](http://www.alistapart.com/articles/sprites/)) на тему использования стилей для Rol... | https://habr.com/ru/post/28177/ | null | ru | null |
# Big State Managers Benchmark
Здравствуйте, меня зовут Дмитрий Карловский и я.. большой любитель физики высоких энергий. Сталкиваешь такой совершенно разные вещи между собой, и смотришь на бабахи, уплетая поп-корн.
Так как [в React всё очень плохо с архитектурой](https://mol.hyoo.ru/#!section=articles/author=nin-jin... | https://habr.com/ru/post/707600/ | null | ru | null |
# Пара хитростей ssh
Пара хитростей которые я использую при работе с ssh
Если у вас на машине Linux и вам часто приходится ходить по ssh на разные хосты, то будет полезен небольшой трюк позволяющий не вводить пароль если вы в новом окне соединяетесь с хостом с которым уже есть соединение:
`vi ~/.ssh/config`
д... | https://habr.com/ru/post/39277/ | null | ru | null |
# Создания приложения на Doophp 1.5
Я был очень огорчён что не нашёл на хабре подобной теоретической статьи. И так имеется DooPHP версии 1.5 которая была выпущена 6 октября 2013 года. На официальном сайте переведены такие графики производительности
Основным краеугольным камнем Python как объектно-ориентированного языка программирования является определение связанных классов для управления и обработки данны... | https://habr.com/ru/post/572868/ | null | ru | null |
# Поищем ещё раз «своё» кино на Кинопоиске
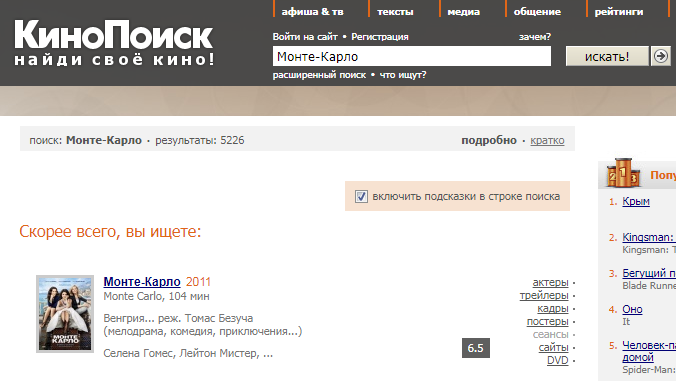
По дороге с работы вспомнил про один замечательный математический метод и решил подробнее рассмотреть этапы развития кинопоиска и узнать чего же больше всего ждут киноботы в этом году.
Мне бы... | https://habr.com/ru/post/407119/ | null | ru | null |
# Полный Гайд по Shopify
Всем привет! В этой статье я постарался посмотреть на Shopify со стороны разработчика и обычного пользователя, рассказал свой опыт и наблюдения при работе на разных темах. Если вы еще не знакомы с Шопифаем, то я также постараюсь донести основную информацию, которую вам нужно знать чтобы работа... | https://habr.com/ru/post/663844/ | null | ru | null |
# Знакомьтесь, Интернет-магазин 2.0 — RIA
Как повысить скорость, юзабилити и user experience посетителей вашего интернет-магазина?
— Сделать его RIA! (Rich Internet Application)

Работая над очередным проектом — веб-модулем ... | https://habr.com/ru/post/109019/ | null | ru | null |
# Мобильные устройства, position: fixed; и во что это выливается

По ходу [редизайна блога](http://blog.romanliutikov.com/) появилось желание создать *'Scroll to Top'* функцию не только для десктопа, но и для мобильных ус... | https://habr.com/ru/post/146049/ | null | ru | null |
# Эволюция Docker. Часть 2.2
Вступление
----------
Данная статья является третьей в цикле ([1](https://habr.com/ru/post/573828/),[2](https://habr.com/ru/post/574750/)), посвященном изучению исходного кода Docker и прямым продолжением [предыдущей статьи](https://habr.com/ru/post/574750/), в которой мы начали разбирать... | https://habr.com/ru/post/575256/ | null | ru | null |
# Conkeror — браузер для понимающих
Я думаю, что большое количество людей слышали, видели, а то и сами пробовали
расширения для Файрфокса, которые облегчают работу с ним с клавиатуры:
[Hit-o-hint](http://hah.mozdev.org/), [Firemacs](http://firemacs.mozdev.org/), [Vimperator](http://vimperator.mozdev.org/). Я как... | https://habr.com/ru/post/19010/ | null | ru | null |
# Профилирование python приложений
Краткая заметка с линками и примерами о профайлинге:
1. производительности: [hotshot](http://docs.python.org/library/hotshot.html) или python profile/cProfile + визуализатор логов [kcachegrind](http://kcachegrind.sourceforge.net/html/Home.html) (есть [порт под windows](http://sour... | https://habr.com/ru/post/110537/ | null | ru | null |
# PostgreSQL 9.3 + Pgpool-II
Решил поделиться с вами опытом настройки кластера PostgreSQL 9.3, состоящего из двух нод, управлением которого занимается pgpool-II, без использования Stream Replication (WAL). Надеюсь, кому-нибудь будет интересно.
Схема:

Одной из основных причин того, что некоторые люди избегают обновления своих ПК, стало то, что «обновления тормозят систему». Особенно это актуально для W... | https://habr.com/ru/post/564900/ | null | ru | null |
# Запускаем Homebrew на Windows 10
Коллеги, которые только начали погружение в мир Cloud Native, часто задаются вопросом, как установить необходимое ПО на Windows. Решение уже давно известно — [Windows Subs... | https://habr.com/ru/post/561492/ | null | ru | null |
# Тестируем S.T.A.L.K.E.R. на Unreal Engine 5 и сравниваем с UE4 (осторожно, трафик)
Признайтесь, вы подумали о S.T.A.L.K.E.R. 2, который как раз разрабатывают на Unreal Engine 5. Но это не он.
В данной ... | https://habr.com/ru/post/598699/ | null | ru | null |
# Простейшее решение «проблемы промежуточных устройств»: организация работы SCTP поверх UDP в ядре Linux
Возможность организации работы SCTP поверх UDP (известная ещё как инкапсуляция SCTP-пакетов в UDP-пакеты) определена в [RFC 6951](https://datatracker.ietf.org/doc/html/rfc6951) и реализована в пространстве ядра Lin... | https://habr.com/ru/post/575344/ | null | ru | null |
# DBA: меняем «слонов» на переправе
Как нормальные DBA, мы подождали выпуск пары минорных версий к PostgreSQL 13, который должен порадовать нас [многими полезными вещами](https://www.postgresql.org/docs/release/13.0/), и теперь готовы перенести базу [нашего сервиса мониторинга](https://habr.com/ru/post/487380/) этой С... | https://habr.com/ru/post/550730/ | null | ru | null |
# Перехват системных вызовов в linux под x86-64
#### Введение
В интернете опубликовано множество статей по перехвату системных вызовов под x32. В рамках решения одной задачи появилась необходимость в перехвате системных вызовов под архитектурой x86-64 при помощи загружаемого модуля ядра. Приступим:
#### Перехват ... | https://habr.com/ru/post/110369/ | null | ru | null |
# Class методы в ruby
Не так давно, занявшись изучением ruby, я столкнулся с тем, что не понимаю, что такое class методы, точнее в чем их отличие от instance и зачем они вообще нужны. В учебнике, который я изучаю на данный момент, эта тема была описана не достаточно подробно или я не дочитал до подробного описания, но... | https://habr.com/ru/post/176763/ | null | ru | null |
# WordPress сокращения
Сегодня мы поговорим о сокращениях которые были введены в WordPress 2.5 и почему-то об этом русские вообще не пишут.
А ведь так много народу пользуется WordPress, но WordPress сокращения у нас непопулярны.
#### Что такое WordPress сокращения ?
Это когда вы набрали например adsense и все в... | https://habr.com/ru/post/51027/ | null | ru | null |
# Дружественная колонка текста
Недавно в посте [«Зум шрифта и верстка»](http://habrahabr.ru/blogs/web_design/118319/) автор выразил обеспокоенность тем, что происходит, когда меняется размер шрифта в колонке, ширина которой фиксирована в пикселях. Хотя сейчас принято зумить всю страницу, но я не уверен, что это всегда... | https://habr.com/ru/post/118978/ | null | ru | null |
# Разработка приложений с Windows Subsystem for Android
Microsoft открыла тестирование Windows Subsystem for Android. Пока это доступно для бета тестеров из США. Но умельцы уже нашли способы установить ее на любую сборку windows 11. Далее опишу эту инструкцию, и запущу приложения из Android Studio, попробую подебажить... | https://habr.com/ru/post/585178/ | null | ru | null |
# Оптимизируй или сдохни: профилирование и оптимизация Jetpack Compose
Привет! На связи Сергей Панов, разработчик мобильных приложений в IceRock. Сегодня я разберу на примере нашего приложения «Кампус», как делать профилирование и оптимизацию Jetpack Compose.
«Кампус» — это приложение для просмотра расписания заняти... | https://habr.com/ru/post/701422/ | null | ru | null |
# От LiveData к Flow…
### Intro
Мы - Дима ([@fonfon](/users/fonfon)) и Настя, Android-разработчики в компании СберЗдоровье. В этой статье мы хотим рассказать о том, как мы перевели весь наш проект с LiveDat... | https://habr.com/ru/post/672400/ | null | ru | null |
# Cassandra Sink для Spark Structured Streaming
Пару месяцев назад я начала изучать Spark, и в какой-то момент столкнулась с проблемой сохранения вычислений Structured Streaming в базе данных Cassandra.
В данном посте я привожу простой пример создания и использования Cassandra Sink для Spark Structured Streaming. Я... | https://habr.com/ru/post/425503/ | null | ru | null |
# Не спешите выкидывать свой PolyCom
Если у вас где-то в углу неприкаянно грустит телефон компании Polycom – не спешите от него избавляться! Он еще сможет вам послужить. По крайней мере ковыряние с ним может доставить массу удовольствия. Все нижеописанное тестировалось на устаревшей модели Polycom SoundPoint IP 450(от... | https://habr.com/ru/post/529128/ | null | ru | null |
# Почему не работал bash-скрипт или про возврат каретки
Я писал свой конфигурационный файл для Conky. Захотел сделать вывод доллара и евро по отношению к рублю и посчитать динамику курсов. Задача не сложная, поэтому я быстро написал bash-скрипт. Курсы валют решил взять с сайта [ЦБРФ](http://www.cbr.ru/).
Скрипт по... | https://habr.com/ru/post/254123/ | null | ru | null |
# Как нанять лучших инженеров не убив при этом себя
[Garena](http://www.garena.com/ "Garena"), в которой я сейчас работаю, находится в процессе роста и я занимаюсь наймом инженеров, сисадминов и подобного персонала, чтобы удовлетворить аппетиты растущей платформы и выдержать планы и сроки выпуска продуктов. Проблема, ... | https://habr.com/ru/post/285334/ | null | ru | null |
# Решение проблемы с появлением 8080 порта в ISP manager (настройка редиректа на 80 порт)
Сегодня столкнулся с проблемой — обнаружилось, что по ошибке старого системного администратора, в одном очень редком случае у нас происходил редирект с обычного 80 порта на порт 8080.
Из-за этого в индекс яндекса попала целая... | https://habr.com/ru/post/138999/ | null | ru | null |
# Новости из мира OpenStreetMap № 514 (19.05.2020-25.05.2020)
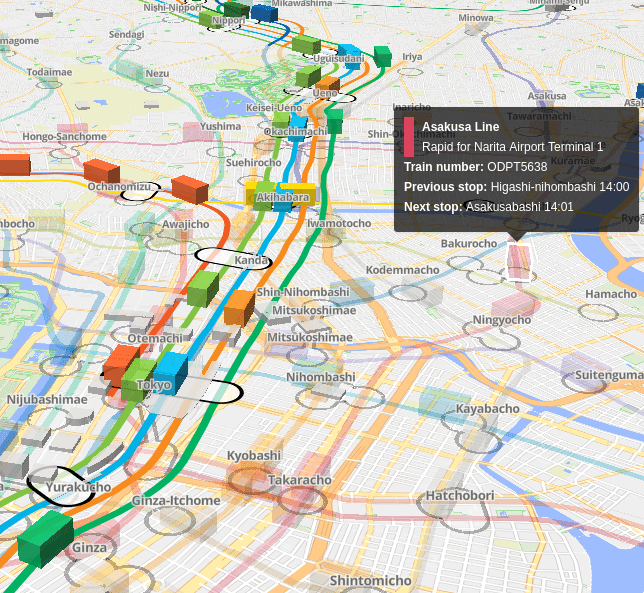
3Д-карта, на которой в режиме онлайн можно увидеть движение поездов в Токио. Автор — Акихико Кусанаги [1](#wn514_22547) | [Akihiko Ku... | https://habr.com/ru/post/505224/ | null | ru | null |
# Ностальгия: роемся у «Танчиков» под капотом
Многие из нас выросли на «Танчиках», «Марио» и прочих нетленных шедеврах времён рассвета игровой индустрии. Приятно порой вспомнить, как днями напролёт резались с ... | https://habr.com/ru/post/142126/ | null | ru | null |
# Реализация минимизации логических функций методом Квайна\Мак-Класки при неполном входном наборе
Данная статья является, в некоторой степени, продолжением моей статьи по минимизации логических функций методом Квайна-Мак’Класки (<https://habr.com/post/328506>). В ней рассматривался случай с полностью определёнными лог... | https://habr.com/ru/post/424517/ | null | ru | null |
# История о том, как я разработал язык программирования
Привет Хабр! Меня зовут Ильдар. Мне 29 лет. Программирую с 2003 года. За свою жизнь создал 4 фреймворка и язык программирования. В этом посте я поделюсь своим опытом, инсайтами, которые я получил при разработке языка программирования BAYRELL Language. Заранее про... | https://habr.com/ru/post/491280/ | null | ru | null |
# Оптимизация производительности SQL Server с использованием индексов
#### Введение
Как известно, [индексы](http://ru.wikipedia.org/wiki/Индекс_(базы_данных)) повышают производительность аналогично оглавлению или предметному указателю в кнгие. Прочитав несколько статей в интернете и пару глав из книжек, хотелось бы у... | https://habr.com/ru/post/164717/ | null | ru | null |
# Внедрение зависимостей в CDI. Часть 1
После статьи о том, как [начать работу с CDI](https://antoniogoncalves.org/2011/01/12/bootstrapping-cdi-in-several-environments/) в вашем окружении и нескольких советов о том, как [интегрировать CDI в существующее Java EE 6 приложение](https://antoniogoncalves.org/2011/02/07/add... | https://habr.com/ru/post/301636/ | null | ru | null |
# Создание плагинов для AutoCAD с помощью .NET API (часть 4 – вставка примитивных объектов)
Добро пожаловать в четвертую часть [цикла](http://habrahabr.ru/post/235723/), посвященного разработке плагинов под AutoCAD. Предыдущие статьи затрагивали общие вопросы создания плагина — а теперь, вооружившись этими знаниями, м... | https://habr.com/ru/post/257129/ | null | ru | null |
# Знакомство фронтендера с WebGL: четкие линии (часть 3)
Это история в несколько частей:
* [Знакомство фронтендера с WebGL: почему WebGL? (часть 1)](https://habr.com/ru/post/567052/)
* [Знакомство фронтендера с WebGL: первые наброски (часть 2)](https://habr.com/ru/post/567082/)
* Знакомство фронтендера с WebGL: четки... | https://habr.com/ru/post/567174/ | null | ru | null |
# Запуск графических приложений в Docker
Введение.
---------
В основном, Docker привыкли использовать для запуска сервисов или процессов не предполагающих визуальной составляющей. Однако могут быть ситуации, когда в контейнере возникает необходимость открыть среду разработки и на месте продебажить один сервис или два... | https://habr.com/ru/post/657927/ | null | ru | null |
# Поднимаем SOCKS прокси для Telegram
Поднять свой socks прокси очень просто — справится даже далекий от Linux и серверного администрирования человек. Достаточно иметь VDS/выделенный сервер за границей.

Пошаговая инструкция для... | https://habr.com/ru/post/353758/ | null | ru | null |
# Рецепт для systemd: принудительный перезапуск сервиса по файловому флагу
Задача:
* имеется некий самописный сервис, запускаемый и отслеживаемый из systemd;
* необходимо при появлении файла-флага рестартовать этот сервис;
* делать это изнутри сервиса нельзя по религиозным соображениям.
Решение:
**restart-myse... | https://habr.com/ru/post/273351/ | null | ru | null |
# Стилизация SVG-графики
Продолжаем изучать SVG-графику, на этот раз коснемся стилизации.
Первая часть: [Знакомство с SVG-графикой](http://habrahabr.ru/post/157087/).

[Демонстрация примеров](http://koulikov.com/wp... | https://habr.com/ru/post/157965/ | null | ru | null |
# Типографика фильма «Бегущий по лезвию»

После подробного исследования [фильма «Чужой»](https://habr.com/ru/post/572826/) настало время взглянуть на типографику и дизайн ещё одного классического научно-фантастического фильма [Ридл... | https://habr.com/ru/post/659153/ | null | ru | null |
# День, когда Dodo IS остановилась. Синхронный сценарий
Dodo IS — глобальная система, которая помогает эффективно управлять бизнесом в Додо Пицце. Она закрывает вопросы по заказу пиццы, помогает франчайзи следить за бизнесом, улучшает эффективность сотрудников и иногда падает. Последнее — самое страшное для нас. Кажда... | https://habr.com/ru/post/440676/ | null | ru | null |
# Удобный дебаг с BlackBird
Хочу представить вам одну библиотеку для яваскрипта, под названием [BlackBird](http://www.gscottolson.com/blackbirdjs/). Основное ее назначение, избавить разработчика от не нужного дебага при помощи alert(), о чем собственно и го... | https://habr.com/ru/post/42534/ | null | ru | null |
# Руководство для практикующего специалиста, как читать научные статьи по языкам программирования
Неделю назад я пошутил, что статьи по принципам языков программирования POPL должны соответствовать критерию «интеллектуального запугивания», чтобы их принимали для публикации. Конечно, это неправда, но факт в том, что ст... | https://habr.com/ru/post/348874/ | null | ru | null |
# Реалистичный Realm. 1 год опыта

Realm давно известен в среде мобильных (и не только) разработчиков. К сожалению, в рунете почти нет статей об этой базе данных. Давайте исправим эту ситуацию.
Год назад в build.gradle наш... | https://habr.com/ru/post/328418/ | null | ru | null |
# Яндекс.Склонятор
Яндекс [выпустил](http://nano.yandex.ru/post/27/) XML-склонятор русских имен. Сервис по адресу `export.yandex.ru/inflect.xml?name=Вася%20Пупкин` берет имя и выдает его склонения в такой форме:
`1. xml version="1.0" encoding="utf-8"?
2.
3. Вася Пупкин
4. Вася Пупкин
5. Васи Пупкина
6. Васе Пупкин... | https://habr.com/ru/post/39327/ | null | ru | null |
# Собираем Actionscript/Flex приложение в Linux
Зададимся задачей собрать HelloWorld.as с помощью Flex SDK, не используя мышь. Зачем? Хотя бы для того, чтобы в голову юзера, листающего поисковую выдачу хабры по запросу «Flex», не закралась мысль о том, что эта технология равна необходимости установить Eclipse.
По к... | https://habr.com/ru/post/106791/ | null | ru | null |
# Создание игры «Крестики-нолики» при помощи TypeScript, React и Mocha
Представляем вам перевод статьи Josh Kuttler, опубликованной на blog.bitsrc.io. Узнайте, как создать приложение «Крестики-нолики», используя React и TypeScript.

❯ Введение
----------
В сегодняшнем туториале по Rust мы откроем для себя мир gRPC. Для этого создадим очень простой микросервис с единственной конечной точкой, который будет о... | https://habr.com/ru/post/715854/ | null | ru | null |
# Методы лечения различных ошибок в Android Studio при разработке проекта
Сегодня хотел бы поделиться своим анализом и способами лечением разных ошибок при разработке своего продукта в Android Studio. Лично я, не раз сталкивался с различными проблемами и ошибками при компиляции и/или тестировании мобильного приложения... | https://habr.com/ru/post/270479/ | null | ru | null |
# Uibook — инструмент для визуального тестирования React-компонентов с медиа-запросами
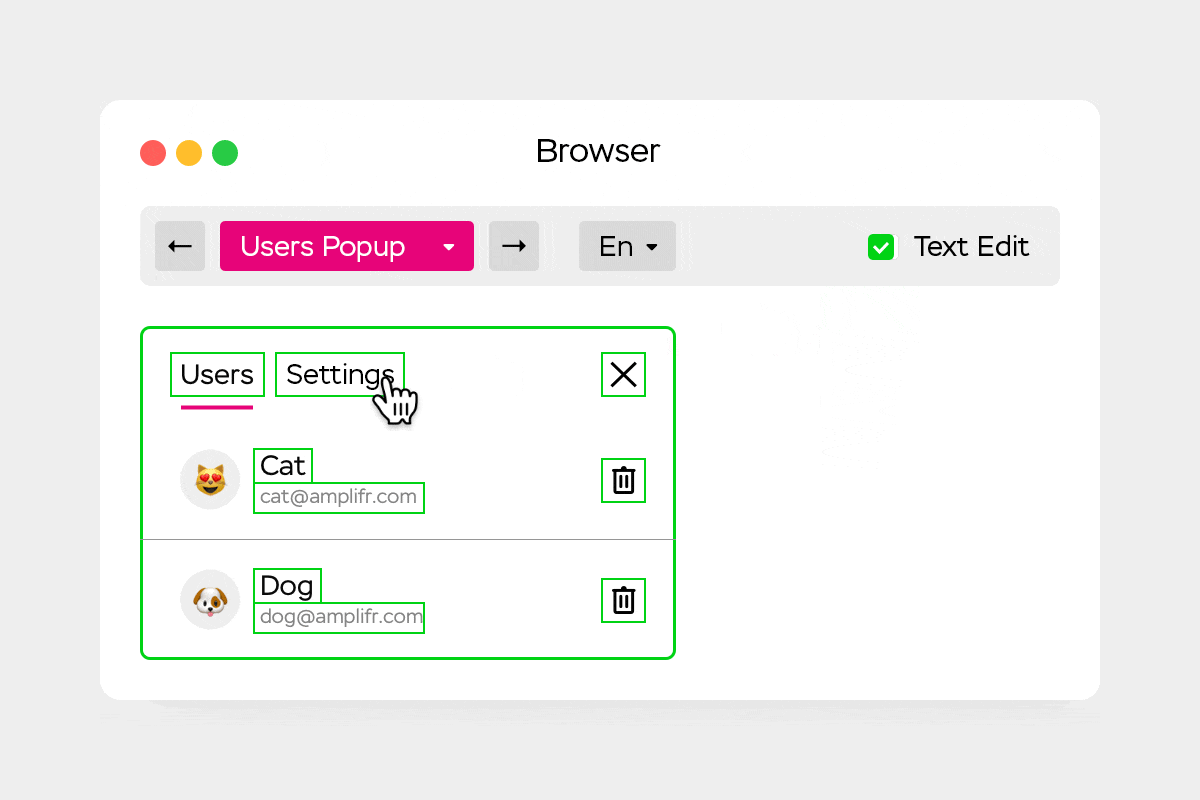
Всем привет! Меня зовут Виталий Ризо, я фронтенд-разработчик в «Амплифере». Мы [сделали](https://amplifr.com/uikit/#AutopilotPopup:ru) Uibook — про... | https://habr.com/ru/post/454176/ | null | ru | null |
# Агрегаторы
В первой части статьи обсуждаются проблемы агрегации данных, подходы и требования к имплементации. Во второй рассматриваются некоторые решения на основе Java и [RACE Framework](https://github.com/aegisql/conveyor/wiki).
Часть I - общий анализ шаблона
------------------------------
### Введение
Слово аг... | https://habr.com/ru/post/689914/ | null | ru | null |
# Создание уникальных тем для приложений ExtJS 6
Добрый день, в данной статье я расскажу про основные нюансы создания тем для ваших приложений на ExtJS 6. Данная статья предполагает, что вы уже имеете опыт работы с ExtJS. В качестве примера будет использоваться **modern toolkit**, для **classic toolkit** особых различ... | https://habr.com/ru/post/271897/ | null | ru | null |
# Event Tracing for Windows на стороне зла. Но это не точно

В предыдущих статьях про [сниффер на PowerShell](https://habr.com/company/pc-administrator/blog/333838/) и [сбор данных о загрузке с удаленного сервера](https://habr.com/co... | https://habr.com/ru/post/418787/ | null | ru | null |
# Передача файлов между двумя компьютерами по интернету (netcat)
Простая и очень нужная утилита, способная передавать данные по сети.
netcat (или nc) должна быть в любом дистрибутиве. Если же ее нету, то на примере дебиана ставится она так:
`apt-get install netcat`
Идея netcat очень проста: он просто перенап... | https://habr.com/ru/post/56049/ | null | ru | null |
# Angular: создание и публикация библиотеки
### Начнем с начала
Если мне не изменяет память, то с версии 6 в angular появилась возможность создавать в одном workspace проекты разных типов: application и library.
До этого момента люди, которые хотели создать библиотеку компонент, скорее всего, пользовались отличным... | https://habr.com/ru/post/452262/ | null | ru | null |
# Как мы внедряли Allure TestOps в стриминговом сервисе
Всем привет! Меня зовут Иван Чечиков, я QA lead в МТС Digital, работаю над проектом стримингового сервиса [WASD.TV](http://wasd.tv/). В этой статье я поделюсь опытом внедрения системы управления тестированием (TMS) Allure TestOps в наш проект и расскажу, что из э... | https://habr.com/ru/post/689330/ | null | ru | null |
# Будущее веб-стандартов
*Примечание: ниже находится перевод статьи [The future of web standards](http://www.b-list.org/weblog/2007/dec/17/standards/), в которой автор рассматривает текущее состояние организаций, связанных с разработкой веб-стандартов, и возможное будущее как организаций, так и самих веб-стандартов во... | https://habr.com/ru/post/31357/ | null | ru | null |
# Struts 2 на Google App Engine. Рецепты настройки

Для использования [одного из самых удобных веб фреймворков для java](http://struts.apache.org/2.x/) на популярной облачной платформе [Google AppEngin... | https://habr.com/ru/post/88979/ | null | ru | null |
# Algorithms in Go: Merge Intervals
This is the third part of a [series](https://habr.com/en/post/545986/) covering the implementation of algorithms in Go. In this article, we discuss the Merge Intervals algorithm. Usually, when you start learning algorithms you have to deal with some problems like finding the least c... | https://habr.com/ru/post/538888/ | null | en | null |
# Российский спутник «СамСат-218» не выходит на связь. Нужна помощь сообщества
### Разработчики обратились к радиолюбителям за помощью в поиске сигналов спутника
28 апреля ракета-носитель «Союз-2.1а» вывела на орбиту три косм... | https://habr.com/ru/post/393823/ | null | ru | null |
# Как 1С и голосовой робот МТТ помогли автоматизировать уведомления клиентов в клинике
«Здравствуйте, Вы записаны на завтра, 5 июня 2022 года, на прием к стоматологу, в 10:05. Вы придете на прием?».
Пожалуй, каждый из нас, в той или иной форме получал подобный звонок от оператора колл-центра клиники. На фоне други... | https://habr.com/ru/post/670282/ | null | ru | null |
# Увеличиваем RPS на Nuxt.js
Все мы знаем что nuxt.js 2 (да и любое node.js приложение с SSR) не держит нагрузку без кеша, в среднем проекте если включить режим SSR то будет держать 20-30 RPS что очень мало.
Стандартные решения это подключить пару пакетов каких нибудь кешеров, и кешировать каждую страницу или запросы... | https://habr.com/ru/post/688858/ | null | ru | null |
# Организация разработки в изолированной сети — как управлять зависимостями?
Как можно собрать актуальный стек используемых библиотек и фреймворков чтобы комфортно заниматься разработкой если вы самоизолировались в глухой деревне, летите 8 часов в самолете или в вашей компании лимитирован доступ к всемирной паутине на... | https://habr.com/ru/post/512966/ | null | ru | null |
# Внедрение премиального медиа-контента с HTML5

Коммерческая медиа-индустрия проходит через большую трансформацию по мере того, как контент-провайдеры отходят от модели доставки контента с использованием закрытых веб-плаги... | https://habr.com/ru/post/265259/ | null | ru | null |
# GlusterFS как внешнее хранилище для Kubernetes

Поиск оптимального хранилища — это довольно сложный процесс, у всего есть плюсы и минусы. Разумеется, лидером в данной категории является CEPH, но это довольно сложная система, хо... | https://habr.com/ru/post/498160/ | null | ru | null |
# Solar InRights: отрицание, гнев, депрессия, торг, переход на Java 16
Привет! Большинство разработчиков не спешат обновляться до новых версий Java. Многие опасаются, что все сломается, что появятся скрытые баги, что это займет очень много времени. Сегодня мы поделимся опытом перевода IGA-системы [Solar InRights](http... | https://habr.com/ru/post/572084/ | null | ru | null |
# Как работает FIFO
FIFO это один из ключевых элементов цифровой техники. Это память типа «первым вошёл-первым ушёл» (first input – first output). Меня как разработчика ПЛИС FIFO окружают повсюду. Собственно я только и делаю что беру данные из одного FIFO и перекладываю в другое. Но как оно работает? В современных САП... | https://habr.com/ru/post/321674/ | null | ru | null |
# Вот что такое тактический Git
Автор книг Dependency Injection in .NET («Внедрение зависимостей на платформе .NET») и Code That Fits in Your Head рассказывает о своём подходе к Git и git stash, позволяющем д... | https://habr.com/ru/post/660335/ | null | ru | null |
# Следуй за денотацией

> На самом деле ученые всегда стремятся к каким-то достижениям. Они думают только о том, удастся ли это им что-то совершить. И они почему-то никогда не задумываются — а стоит ли вообще совершать это «что-то»? ... | https://habr.com/ru/post/539230/ | null | ru | null |
# Создание блога на Symfony 2.8 lts [ Часть 4]
[](https://habrahabr.ru/post/302602/)
**Навигация по частям руководства**
> [Часть 1 — Конфигурация Symfony2 и шаблонов](https://habrahabr.ru/post/301760/)
>
> [Часть 2 — С... | https://habr.com/ru/post/302602/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.