
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Светодиод, таймер и прерывания на RISC-V с нуля (на примере GD32VF103 и IAR C++)

Сегодня речь пойдет о модном — о RISС-V микроконтроллере. Я давно хотел познакомиться с этим ядром и ждал когда появится что-то похожее на STM32 и вот ... | https://habr.com/ru/post/516006/ | null | ru | null |
# Тестирование в Яндексе. Матчеры: когда они полезны и как легко их использовать
[](//habrastorage.org/files/0e0/e1b/5ab/0e0e1b5ab1a04d969302e81ca7e2984e.png)
*снизу фотографии настоящих жуков, сверху — моя реализация*
Продолжение [предыдущей](http://habrahabr.ru/post/239557/) статьи... | https://habr.com/ru/post/239661/ | null | ru | null |
# Android in-app purchases, часть 5: серверная валидация покупок
Всем привет, я Кирилл, СТО [Adapty](https://adapty.io/?utm_source=habr.com&utm_medium=referral&utm_campaign=blogpost_android-iap_server-validation). Я делал систему серверной валидации для наших SDK и сегодня расскажу про то, как её настроить для приложе... | https://habr.com/ru/post/576164/ | null | ru | null |
# Трансдьюсеры в JS – так ли уж необходимы?
Функциональный подход потихоньку-полегоньку проник почти во все современные языки программирования. Тогда как одни элементы оттуда, вроде монад («всего лишь моноид в категории эндофункторов, в чем проблема?») – очень спорные для мэйнстрима, другие – вроде преобразований map,... | https://habr.com/ru/post/348170/ | null | ru | null |
# Почему циклы должны умереть
Всем привет,
Прочитав недавнее обсуждение по поводу PHP, обнаружилось, что много людей боятся рекурсии как огня. Таковой миф нужно разоблачить!
Сегодня мы обоснуем, почему циклы это плохо, и почему их надо замочеть. В процессе мы будем пейсать на православном языке Хаскель, который ... | https://habr.com/ru/post/47429/ | null | ru | null |
# Компьютер маленького человечка
Все мы знаем машину Тьюринга и машину Поста. Это абстрактные вычислительные машины, придуманные математиками для теории алгоритмов. Компьютер маленького человечка ([Little man computer](http://en.wikipedia.org/wiki/Little_man_computer)) — модель компьютера, предназначенная для обучения... | https://habr.com/ru/post/257331/ | null | ru | null |
# Как работает Activity. Часть 1
Мобильные операционные системы имеют свою специфику. Когда мы пользуемся смартфонами, создается впечатление, что мы находимся в одном приложении и переход между ними происходи... | https://habr.com/ru/post/703548/ | null | ru | null |
# Введение в секционирование таблиц
По материалам статьи Craig Freedman: [Introduction to Partitioned Tables](https://docs.microsoft.com/en-us/archive/blogs/craigfr/introduction-to-partitioned-tables)
В этой статье я собираюсь продемонстрировать особенности планов исполнения запросов при обращении к секционированным ... | https://habr.com/ru/post/661571/ | null | ru | null |
# Как правильно и неправильно спать
Не так давно мимо нас пробегала неплохая статья об ужасном состоянии производительности современного ПО ([оригинал на английском](http://tonsky.me/blog/disenchantment/), [перевод на Хабре](https://habr.com/post/423889/)). Эта статья напомнила мне об одном антипаттерне кода, который ... | https://habr.com/ru/post/427843/ | null | ru | null |
# Кибергруппа Turla использует Metasploit в кампании Mosquito
Turla – известная кибершпионская группировка, действующая не менее десяти лет. Первое упоминание группы датировано 2008 годом и связано с взломом [Министерства обороны США](https://www.nytimes.com/2010/08/26/technology/26cyber.html?_r=1&ref=technology). Впо... | https://habr.com/ru/post/412667/ | null | ru | null |
# Система управления проектами по модели Open Core в госсекторе
Продолжаем рассказывать вам об опенсорсных продуктах реализованных на JS фреймворке — **IONDV. Framework**. Сегодня поговорим о системе управления проектами, которая была одним из наших первых масштабных проектов и которую изначально мы реализовали для пр... | https://habr.com/ru/post/459578/ | null | ru | null |
# 10 шагов к YAML-дзену
Мы все любим Ansible, но Ansible – это YAML. Для конфигурационных файлов существует масса форматов: списки значений, пары «параметр-значение», INI-файлы, YAML, JSON, XML и множество других. Однако по нескольким причинам из всех них YAML часто считается особенно трудным. В частности, несмотря на... | https://habr.com/ru/post/462125/ | null | ru | null |
# Что делать, если к вам попал Android со сломанным сенсорным дисплеем

В один прекрасный день ко мне в руки попал Nexus 4. В наших краях это редкость, поэтому хотелось бы использовать его как основно... | https://habr.com/ru/post/210472/ | null | ru | null |
# Тормозит Mac OS? — Catalina проверяет любой неподписанный код через интернет при запуске
Многие пользователи после перехода на Catalina начали жаловаться на тормоза. Западные коллеги выяснили в чем причина: MacOS отправляет хеш любого неподписанного кода на сервера Apple.
Это создает серьезные задержки в выполнен... | https://habr.com/ru/post/503670/ | null | ru | null |
# Солянка
За последнее время скопилось несколько различных мыслей. Надеюсь, какие-то из них покажутся интересными.
Итак, в солянке:
1. Java: что такое `ThreadLocal` и `InheritableThreadLocal`
2. Palm Pre: личные впечатления
3. Android: как развернуть сервер на телефоне
4. Интерфейсы: концепция страницы... | https://habr.com/ru/post/61388/ | null | ru | null |
# Southbridge в Челябинске и Битрикс в Kubernetes
В Челябинске проходят митапы системных администраторов Sysadminka, и на последнем из них я делал доклад о нашем решении для работы приложений на 1С-Битрикс в Kubernetes.
Битрикс, Kubernetes, Сeph — отличная смесь?
Расскажу, как мы из всего этого собрали работающее ре... | https://habr.com/ru/post/456608/ | null | ru | null |
# Интеграция проекта VueJS+TS с SonarQube
В своей работе мы активно используем платформу *SonarQube* для поддержания качества кода на высоком уровне. При интеграции одного из проектов, написанном на *VueJs+Typescript*, возникли проблемы. Поэтому хотел бы рассказать подробней о том, как удалось их решить.
***Мне понравился механизм аспектно-ориентированного программирования (АОП), который используется в Allure Framework для перехвата вы... | https://habr.com/ru/post/539904/ | null | ru | null |
# Анатомия шаблонов Blogger
#### Вступление
В Сети, как оказалось, не так уж и много информации относительно того, как создавать свои собственные темы оформления для блоговой платформы от Google, во всяком случае, в Рунете.... | https://habr.com/ru/post/166073/ | null | ru | null |
# Как заработать на API Яндекс.Денег

**С вас — идеи монетизации стриминга и реализация на API Яндекс.Денег, с нас — аудитория, реклама и деньги.**
Шестой день рождения API переводов мы решили отпраздновать антихакатоном, на ко... | https://habr.com/ru/post/330096/ | null | ru | null |
# Динамическая типизация C
### Преамбула
Эта статья была написана и опубликована мной на своем сайте более десяти лет назад, сам сайт с тех пор канул в лету, а я так и не начал писать что-то более вразумительное в плане статей. Все ниже описанное является результатом исследования C как языка двадцатилетним парнем, а,... | https://habr.com/ru/post/560730/ | null | ru | null |
# Сказка о поломке или что делать, когда проблема не понятна
Я решил рассказать о ситуации, в которую мы попали по стечению обстоятельств при выполнении обычных работ по перенастройке MS SQL. Т.к. нигде не смогли найти информацию о подобных поломках, то имеет смысл это зафиксировать.
Предыстория такова: понадобилось... | https://habr.com/ru/post/585192/ | null | ru | null |
# Чеклист фронтенд-разработчика
*Глеб Летушов, [редактор-фрилансер](http://gletushov.ru/), адаптировал для блога [Нетологии](https://netology.ru/?utm_source=blog&utm_medium=747&utm_campaign=habr) [чеклист](https://github.com/thedaviddias/Front-End-Checklist/blob/master/README.md) с Github от David Dias. Этот чеклист у... | https://habr.com/ru/post/347740/ | null | ru | null |
# Symfony 2 Internals на практике
Пост навеян вот [этим](http://habrahabr.ru/qa/22083/) вопросом. Будем использовать стандартные эвенты Symfony для переопределения вывода контроллера. Итак, как, в общем, всё это будет работать:
1. Создадим аннотацию Ajax для обработки типа контента контроллера
2. Будем обрабатывать... | https://habr.com/ru/post/149378/ | null | ru | null |
# Разбираемся с Notifications API
Продолжаю серию переводов статей сайта [html5rocks](http://www.html5rocks.com). Мы уже говорили про то, как [внедрять шрифты](http://habrahabr.ru/blogs/webdev/104182/), как работать с [видео](http://habrahabr.ru/blogs/webdev/104591/), сегодня мы поговорим про то как делать всплывающие... | https://habr.com/ru/post/104670/ | null | ru | null |
# Упаковщик для dsniff.db
Доброе время суток.
Поставив для экспериментов dsniff, через пару суток обнаружил, что он насобирал невероятное количество мусора от всяких разных банерных сетей и лог работы стало невозможно читать.
Поискав в интернете скрипты редактирования лога решил написать свой.
Скрипт первым д... | https://habr.com/ru/post/136282/ | null | ru | null |
# Задаём виртуальной машине IP по MAC без использования DHCP

*В статье рассказывается о использовании скриптов для CentOS и Windows XP, которые устанавливают IP в соответствии с MAC сетевого инт... | https://habr.com/ru/post/121137/ | null | ru | null |
# Опыт применения теоремы о свертке с использованием scipy.fft
[Теорема о свёртке](https://mathworld.wolfram.com/ConvolutionTheorem.html) утверждает, что преобразование Фурье от свёртки двух функций является произведением их Фурье образов:

Многие наши статьи посвящаются чему угодно, но только не самому инструменту PVS-Studio. А ведь мы очень много делаем, чтобы разработчикам было удобно пользоваться нашим инст... | https://habr.com/ru/post/458070/ | null | ru | null |
# PHPStamp — честная генерация DOCX документов из шаблона
Это еще одна попытка реализовать стабильный, полноценный шаблонизатор офисных документов, основанных на XML, пользуясь стандартными для PHP средствами DOMDocument и XSL.
Задача состояла именно в генерации шаблона для многократного использования, который не п... | https://habr.com/ru/post/244421/ | null | ru | null |
# Роботы-доставщики, облачные технологии и дополненная реальность: что дал IT-сфере 2021 год
В декабре в отсветах полыхающих дедлайнов бывает трудно разглядеть то, что давало нам вдохновение и помогало двигаться вперёд весь этот год. А ещё труднее распознать вещи, которые могут стать прорывными и, скорее всего, будут ... | https://habr.com/ru/post/598091/ | null | ru | null |
# Routing слой в iOS-приложениях
Случалось ли с вами, что вы открыли *Storyboard* и от увиденного вас начинают переполнять ~~положительные~~ эмоции?
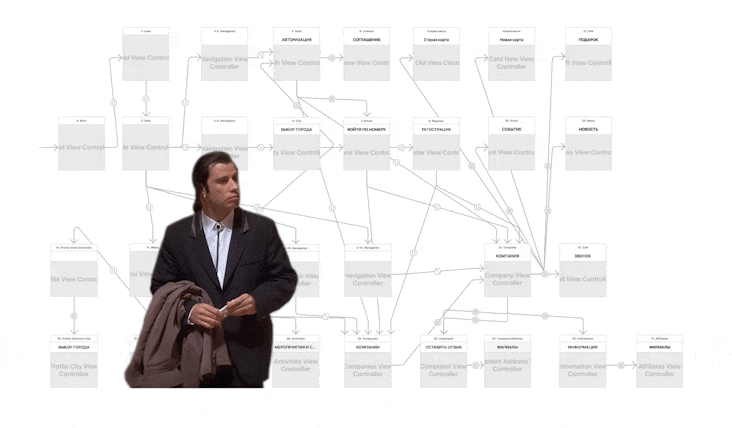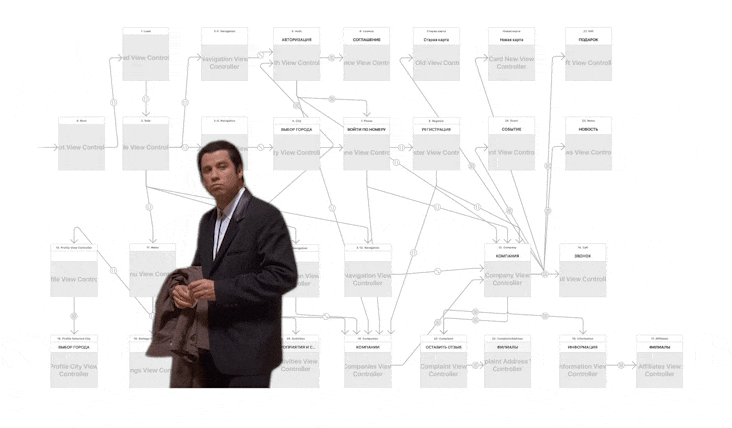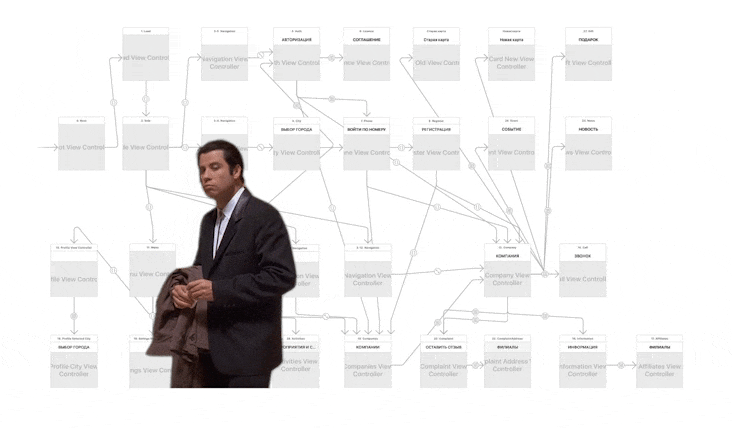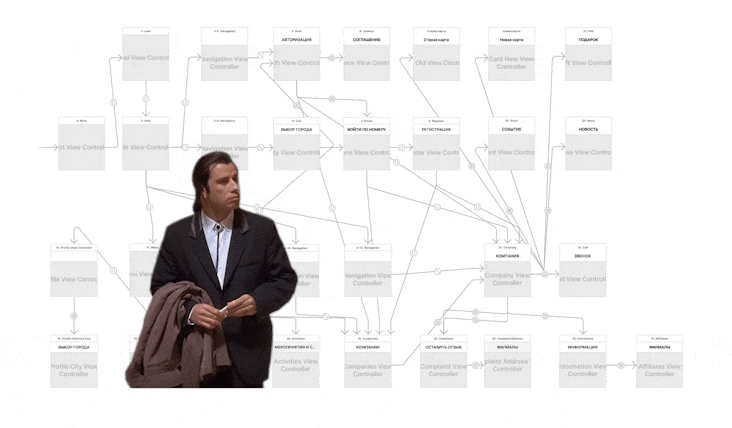
В этот момент, возможно, вы задумываетесь, что хорошо продуманная навигация меж... | https://habr.com/ru/post/321842/ | null | ru | null |
# SafeThreadUpdate() для wpf-контролов
Привет, ребята! Многим, наверно, неудобно обращаться к Dispatcher каждый раз, когда нужно обновить контрол с не UI-потока в WPF… в общем, меня это конкретно достало, поэтому написал очень простенький extension-метод, которым и хочу поделиться с вами всеми:
```
static class exM... | https://habr.com/ru/post/271781/ | null | ru | null |
# Обзор одной российской RTOS, часть 8. Работа с прерываниями
Публикую последнюю статью из первого тома «Книги знаний» ОСРВ МАКС. Надеюсь, это неформальное руководство поможет вам, коллеги, в случае, если придется работать с этой RTOS.
Предыдущие статьи:
[Часть 1. Общие сведения](https://habrahabr.ru/post/336308... | https://habr.com/ru/post/340032/ | null | ru | null |
# Пожалуй, лучшая архитектура для UI тестов

Наверное, где-то есть идеальная статья, сразу и полностью раскрывающая тему архитектуры тестов, легких и в написании, и в чтении, и в поддержке, и так, чтобы быть понятной начинающим, с пр... | https://habr.com/ru/post/523802/ | null | ru | null |
# OpenCart popup, модальные окна
*Статья нашего сотрудника из его личного блога.*
Разрабатывая модуль в админке мне понадобилось использовать **модальные окна OpenCart** для вывода определенной информации, а так же для показа формы. Мой опыт frontend на тот момент был *так себе*, однако коллега подсказал что в OpenCa... | https://habr.com/ru/post/537122/ | null | ru | null |
# Большие бинари в моем Rust?
*Disclaimer: Эта статья является очень вольным переводом и некоторые мометы достаточно сильно отличаются от оригинала*
Бороздя просторы интернета вы наверняка уже успели услышать про Rust. После всех красноречивых отзывов и расхваливаний вы, конечно же, не смогли не потрогать это чудо.... | https://habr.com/ru/post/305246/ | null | ru | null |
# Контроль сложности и архитектура UDF

Сложность — главный враг разработчика. Есть такая гипотеза, хотя я бы отнес ее к аксиомам, что сложность любого программного продукта с течением времени, в процессе д... | https://habr.com/ru/post/353590/ | null | ru | null |
# Работа с библиотекой OrnaJS

OrnaJS — свободная JavaScript библиотека для динамической стилизации HTML элементов без прямого написания JS или CSS кода. Стилизация осуществляется методом прибавления классов к HTML элементу,... | https://habr.com/ru/post/307200/ | null | ru | null |
# Что лучше выбрать: Wireguard или OpenVPN? Любимый VPN Линуса Торвальдса

Технологии VPN редко становятся объектами пристального внимания: есть и есть. Создатель Wireguard Jason A. Donenfeld оказался везунчиком после нетипичной для ... | https://habr.com/ru/post/537010/ | null | ru | null |
# HI-Load — или снимаем ограничения на скачивания с файлообменников
Имею желание пропиарить свой проект. Реализован на php и с++.
**Суть проекта:**
`1) Клиент приходит к нам
2) Вводит ссылку на файл, который желает скачать
3) Получает ссылку для скачивания с нашего сервера.
4) Успешно качает многопоточн... | https://habr.com/ru/post/87256/ | null | ru | null |
# Постраничная навигация с MySQL при большом количестве записей
Рано или поздно многие крупные проекты сталкиваются с проблемами производительности при постраничной навигации по записям. Некоторые из них решают эту проблему ограничением количества доступных для просмотра записей (скажем, не больше 1000). Вполне приемл... | https://habr.com/ru/post/44608/ | null | ru | null |
# Привет из свободного от libc мира! (Часть 1)
*В качестве упражнения* я хочу написать программу на С. Достаточно простую для того, чтобы дизассемблировать ее и объяснить весь код самой себе.
Звучит несложно, правильно?
У читателя предполагается наличие опыта компиляции программ и работы в Линуксе. Небольшое уме... | https://habr.com/ru/post/88101/ | null | ru | null |
# IPTables и удаленный доступ в сеть
Итак, сеть настроена, пакеты ходят, интернет работает, права режутся — в общем момент, когда можно перевести дух и заняться «доводкой» сервера для удобства не пользователя, но администратора. А что хочется правильному системному администратору? Конечно же! Чтобы его рабочие обязанн... | https://habr.com/ru/post/82559/ | null | ru | null |
# OTRS 4.0.10. Ставим на Ubuntu + AD + Kerberos + SSO (Часть первая)
Вииду того, что статья и так получилась слишком большая, а к тому же хочеться добавить к ней её пару нюансов разбиваю её на несколько частей, и дальнейшие дополнения буду публиковать как отдельные части.
[Часть первая: подготовка системы](http://h... | https://habr.com/ru/post/264617/ | null | ru | null |
# User Timing API
*Это перевод [статьи](http://www.html5rocks.com/en/tutorials/webperformance/usertiming/) Alex Danilo о User Timing API, опубликованной 21 января 2014.*
Высокая производительность веб-приложений является решающей для достижения хорошего user experience. В то время, как веб-приложения становятся все... | https://habr.com/ru/post/210564/ | null | ru | null |
# Яндекс практикум, отзыв мазохиста. Курс Аналитик данных
Прелюдия.
---------
Для справки, мазохизм - получение удовольствия человеком от унижений, мучений или насилия над собой, производимых самим собой ил... | https://habr.com/ru/post/695136/ | null | ru | null |
# Система управления конфигурацией сети фильтрации Qrator

**TL;DR**: Описание клиент-серверной архитектуры нашей внутренней системы управления конфигурацией сети, QControl. В основе лежит двухуровневый транспортный протокол, работ... | https://habr.com/ru/post/463739/ | null | ru | null |
# Как быть, если твой провайдер Akado?
Под хабракатом приведены примеры скриптов, упрощающие жизнь :)
#### Часть 1. Проверка получаемого адреса
В своё время у Акадо наблюдались проблемы с авторизацией pppoe.
И поскольку при загрузке системы часть демонов привязывалась к получаемому ip адресу, то нужно было как-... | https://habr.com/ru/post/66644/ | null | ru | null |
# Строим систему доменных событий в модульном монолите
*Статья написана по мотивам* [*моего доклада на митапе*](https://youtu.be/8fu2jHpuZRs)*.*
Всем привет! В этой статье хочу поделиться опытом построения с... | https://habr.com/ru/post/569648/ | null | ru | null |
# Затмение, лисичка и xdebug
#### Длинное и пространное вступление
Смена работы. Смена работы это всегда стресс, каким бы модным перцем
на предыдущем месте вы ни были. Спустя годы сладкой жизни опять надо
напрягаться, разбираться в ворохе написанного без тебя кода,
удивляться не тобою принятым решениям и ужа... | https://habr.com/ru/post/69954/ | null | ru | null |
# Продолжаем чистить память с three.js
Введение
--------
Недавно писал о своем [опыте очистки памяти в приложении, с использованием three.js](https://habr.com/ru/post/519008/). Напомню, что целью была перерисовка нескольких сцен с подгрузкой gltf моделей.
С тех пор я провел ряд экспериментов и считаю необходимым ... | https://habr.com/ru/post/521470/ | null | ru | null |
# Добавляем дополнительные особенности реализации на C++ с помощью «умных» оберток
Представляю сообществу библиотеку feature из состава разрабатываемых мной библиотек под общим названием [ScL](https://gitlab.com/ssoft-scl/complex/scl-kit). Сам набор библиотек ScL систематизирует достаточно скромный набор реализаций и ... | https://habr.com/ru/post/650701/ | null | ru | null |
# Делаем простую RC-аэролодку
Иногда в интернете вижу вопросы от новичков, которые хотят с нуля построить квадрокоптер и написать к нему прошивку. Сам являюсь таким и чтобы попрактиковаться в создании RC моделей решил начать с чего-то более простого.

В середине-конце 2000-х в любой школе США всегда был какой-нибудь ребёнок, записывавший на графический калькулятор игры. Возможно, вас не удивит, что некоторые такие люди не нахо... | https://habr.com/ru/post/582156/ | null | ru | null |
# Проблемы с установкой начального загрузчика на флеш-накопитель
В статье содержатся 5 вопросов и ответов по следующим темам:
**1.** Очистка mbr флешки в Windows
**2.** Конвертирование ISO-файла в гибридный ISO-файл (только Linux)
**3.** Создание загрузочной флешки с сохранением изменений (Linux, Windows, Ma... | https://habr.com/ru/post/313730/ | null | ru | null |
# Использование MagicalRecord при разработке iOS приложений
Хабралюди, добрый день!
Сегодня Вашему вниманию хочу представить очередной перевод, не судите строго :) Надеюсь, Вам этот материал пригодится в работе.
В течение многих лет, Core Data была неотъемлемой частью многих OS X и iOS-приложений, обеспечивая со... | https://habr.com/ru/post/236707/ | null | ru | null |
# Avira Antivir
Однажды вечером бродил я по сайтам, и набрел на одном форуме на пост довольного пользователя, благодаря которому я собственно и решил ознакомится с данным продуктом:). Так же заставило меня быстрей опробовать продукт возможность получить официально лицензию на 6 месяцев, что не могло не радовать.
И ... | https://habr.com/ru/post/53231/ | null | ru | null |
# Команда плагинов для настройки JavaFX компонент в настольном приложении
Всегда приятно общаться с приложением, которое запоминает твои повадки и словно чувствует тебя, того, что ты хочешь. Любая UI библиотека или платформа обладает увы лишь базовым функционалом и набором компонент. Например, если колонка в таблице н... | https://habr.com/ru/post/422693/ | null | ru | null |
# Сравнение строк в C# (по умолчанию)
Часто бывает, что мы соединяем 2 коллекции или группируем коллекцию при помощи [LINQ to Objects](https://msdn.microsoft.com/en-us/library/bb397919.aspx). При этом происходит сравнение ключей, выбранных для группировки или связывания.
К счастью, стоимость этих операций равна O(... | https://habr.com/ru/post/274491/ | null | ru | null |
# Развёртывание django приложения на OpenShift хостинге от Red Hat
Преимущества облачного хостинга в наше время объяснять не приходиться, а Red Hat предлагает нам ещё и опробовать все вкусности бесплатно (естественно с некоторыми ограничениями).
Вы не платите за хостинг и получаете?
* 1 Gb дискового пространств... | https://habr.com/ru/post/177243/ | null | ru | null |
# Нестандартный подход к стандартной разработке дополнения (Add-In’а) на C#
С помощью Add-In'a можно реализовать дополнительную функциональность, серьезно облегчающую повседневное использование приложения. Типовой подход прост – изучаем API приложения для разработки дополнения и реализуем его в виде отдельной библиоте... | https://habr.com/ru/post/272805/ | null | ru | null |
# 10 приёмов работы в терминале Linux, о которых мало кто знает
Близкое знакомство с возможностями терминала — один из признаков человека, который хорошо разбирается в Linux. Хотя некоторые вещи запомнить сложно, есть довольно-таки простые, но эффективные приёмы, которые способны повысить качество и скорость работы в ... | https://habr.com/ru/post/336060/ | null | ru | null |
# Рефакторинг при помощи композиции Клейсли
В течение довольно длительного времени мы поддерживали приложение, которое обрабатывает данные в форматах XML и JSON. Обычно поддержка заключается в исправлении дефектов и незначительном расширении функциональности, но иногда она также требует рефакторинга старого кода.
... | https://habr.com/ru/post/304622/ | null | ru | null |
# Обратимая транслитерация кириллицы
Возможно, кто-то еще помнит, как писали SMS, а иногда и письма, «транслитом». Но зачем транслитерация сегодня, когда везде уже unicode? К сожалению, унаследованные приложения выходят из эксплуатации намного медленнее, чем хотелось бы. Например, и сегодня используются томографы, не ... | https://habr.com/ru/post/265455/ | null | ru | null |
# Функция К.O'Nsole.log для отладки в разных браузерах
[](http://radikal.ru/F/i043.radikal.ru/1107/3c/248e35ed17e1.png)Хорош *console.log*, а нахваливать дальше некуда. И поддерживается не везде, и многобукв... | https://habr.com/ru/post/125308/ | null | ru | null |
# How does Rust treat Strings and Vectors internally
1. Strings
----------
In Rust strings can be represented in two ways:
a) String type
b) String slice
**String type:**
String type is defined as a struct of the following structure:
Depending on arch (in my case x86 64bit it is 24byte)
*{*
*pointe... | https://habr.com/ru/post/657547/ | null | en | null |
# Реализация остальных возможностей PEG
После того, как я собрал все части генератора PEG-парсеров воедино в предыдущем посте, я готов показать как реализовать и некоторые другие интересные штуки.
**Содержание серии статей о PEG-парсере в Python*** [PEG парсеры](https://habr.com/ru/post/471860/)
* [Реализация PEG пар... | https://habr.com/ru/post/471992/ | null | ru | null |
# Сравниваем async/await и then/catch с примерами
 В JavaScript есть два основных способа обработки асинхронного кода: Promise (ES6) и async / await (ES7). Эти синтаксисы дают нам равные базовые функции, но п... | https://habr.com/ru/post/651781/ | null | ru | null |
# Инкрементальные бэкапы PostgreSQL с pgBackRest. Часть 2. Шифрование, загрузка в S3, восстановление на новый сервер, PITR
Данная статья — продолжение статьи [«Инкрементальные бэкапы postgresql с pgbackrest — курс молодого бойца от разработчика».](https://habr.com/ru/post/476206/)
В первой части мы научились делать... | https://habr.com/ru/post/518232/ | null | ru | null |
# Windows 7 Federated Search
Windows Vista включала в себе улучшенный поиск, который позволял пользователям искать локальные файлы, письма и другие необходимые вещи. С выходом Windows Search 4.0, эффективность поиска возрасла, предоставляя дополнительные поисковые настройки.
Сентиментный анализ (анализ тональности) – это область компьютерной лингвистики, занимающаяся изучением эмоций в текстовых документах, в о... | https://habr.com/ru/post/646129/ | null | ru | null |
# Интерфейсы контроллеров HPE Aruba и Cisco

Оборудование HPE Aruba не очень распространено в России, однако на американском рынке вендор достаточно тесно конкурирует с Cisco. Беспроводные решения этих производителей имеют с... | https://habr.com/ru/post/324112/ | null | ru | null |
# Модель эффективности медиа рекламы для интернет-магазинов
Мы в агентстве [People & Screens](https://www.facebook.com/peoplescreens/) много лет работаем с онлайн-бизнесами в качестве рекламного партнера. Когда у нас появилась идея оценить вклад медийной рекламы в продажи интернет-магазинов, она казалась нереализуемой... | https://habr.com/ru/post/479960/ | null | ru | null |
# История Linux (1993–2003): испытание дистрибутивов
Уникальная особенность опенсорсных проектов заключается в том, что жизнь их никогда по-настоящему не заканчивается. Образы дисков, по большей части, доступны для загрузки из интернета, их лицензии не истекают. Поэтому довольно просто совершить прыжок в прошлое, уста... | https://habr.com/ru/post/335898/ | null | ru | null |
# Ogre 3D. Серия обучающих статей. Выпуск 1
В [топике](http://habrahabr.ru/blogs/open_source/85932/) прозвучала просьба написать какие-нибудь статьи про Ogre 3D.
В первой статье я расскажу о установке Ogre и создании простейшего приложения использующего Ogre.
#### Установка
Самый простой вариант, это скачать sd... | https://habr.com/ru/post/86017/ | null | ru | null |
# Code-review тестового задания junior react разработчиков
Что это такое?
--------------
Это код-ревью решений [второго тестового задания](https://github.com/maxfarseer/tz-webinars/tree/tz-2-react-redux-router-async). На видео отмечены удачные решения и указаны ошибки, а так же советы по их исправлению. В данной заме... | https://habr.com/ru/post/413135/ | null | ru | null |
# Лучшая приоритизация HTTP/2 для ускорения веба

HTTP/2 обещал заметно ускорить веб, и Cloudflare давным-давно развернула доступ по HTTP/2 для всех клиентов. Но одна особенность HTTP/2, приоритизация, не с... | https://habr.com/ru/post/452020/ | null | ru | null |
# SPM: модуляризация проекта для увеличения скорости сборки
Привет, Хабр! Меня зовут [Эрик Басаргин](https://twitter.com/Puasonych), я iOS-разработчик в [Surf](https://surf.ru/).
На одном большом проекте мы столкнулись с низкой скоростью сборки — от трёх минут и более. Обычно в таких случаях студии практикуют модул... | https://habr.com/ru/post/527460/ | null | ru | null |
# Lazydocker — GUI для Docker прямо в терминале
Два года назад мы уже [делали](https://habr.com/ru/company/flant/blog/338332/) обзор GUI-интерфейсов для работы с Docker, однако мир любителей подобных решений не стоит на месте. На дн... | https://habr.com/ru/post/446700/ | null | ru | null |
# Установка приложений Google в эмулятор Android

В этой статье описано как установить дополнительные программы (в частности, Google Apps) в эмулятор Android. Это может понадобиться если вы хотите на эмуляторе:
1. Настроить син... | https://habr.com/ru/post/134509/ | null | ru | null |
# Kali Linux получил режим визуальной мимикрии под Windows и другие особенности версии 2019.4
В последнем обновлении популярный среди безопасников и хакеров дистрибутив Kali Linux получил любопытный режим «Undercover» — «под прикрытием», суть которого сводится к визуальной мимикрии под графическую оболочку Windows. ... | https://habr.com/ru/post/478314/ | null | ru | null |
# Как остановить DDoS-атаку + анализ кода WireX Botnet
[](https://habrahabr.ru/company/cloud4y/blog/336614/)
17 августа 2017 года несколько контент-провайдеров и сетей доставки контента (CDN) подверглись масштабным атакам ботн... | https://habr.com/ru/post/336614/ | null | ru | null |
# Как подружить дизайнера, верстальщика и «Фигму» с помощью дизайн-системы, ломика и какой-то матери™

Привет, Хабр. Недавно я [выпендрился](https://habr.com/post/463061/#comment_20495397) в комментариях и пообещал подробно ответит... | https://habr.com/ru/post/464115/ | null | ru | null |
# Вещание онлайн-видео с помощью nginx
#### Что такое онлайн-видео?
Под термином онлайн-видео я понимаю длительное вещание какого-то живого видеосигнала (к примеру, из телестудии). Традиционные средства отдачи видео (flv- и mp4-стриминг) в данном случае не работают, просто потому что файла, содержащего весь видеопото... | https://habr.com/ru/post/145867/ | null | ru | null |
# Зачем использовать статические типы в JavaScript? (Преимущества и недостатки)
Мы о многом рассказали в [первой части](https://habrahabr.ru/post/326304/). Теперь с синтаксисом покончено, давайте наконец перейдём к самому инте... | https://habr.com/ru/post/326394/ | null | ru | null |
# Удаленное выполнение кода на EBay
В мире информационной безопасности пока еще не всё так гладко, как хотелось бы. Примеров этому много, стоит посмотреть последние новости на тематических сайтах, как в голову приходит мысль о том, что, порой даже крупнейшие компании уделяют ИБ недостаточно внимания. В этот раз под пр... | https://habr.com/ru/post/206566/ | null | ru | null |
# Что, черт возьми, такое гидратация и регидратация?
*Если процесс frontend разработки привёл вас к вопросу SEO оптимизации, то почти наверняка, вы столкнётесь с понятием Server Side Rendering (SSR) и тесно связанной с ним **гидратацией** (или регидратацией). Представленная ниже информация является переводом в очень с... | https://habr.com/ru/post/515100/ | null | ru | null |
# Автоматизация Android. Супер простое руководство по созданию первого Espresso-теста
Здравствуйте, друзья. В преддверии старта курса [«Mobile QA Engineer»](https://otus.pw/1sNg/), хотим поделиться с вами переводом интересного материала.

>
> [TDD для микроконтроллеров. Часть 2: Как шпионы избавляют от зависимостей](https://habr.com/ru/company/ntc-vulkan/blog/488370/)
>... | https://habr.com/ru/post/488370/ | null | ru | null |
# Travis CI: автоматическая загрузка собранных модулей на GitHub

В этой очень небольшой заметке я расскажу об очень небольшом усовершенствовании процесса автоматической сборки приложения в Travis CI. Я это проделал на примере А... | https://habr.com/ru/post/338126/ | null | ru | null |
# Операции над IPv6-адресами — краткий экскурс
Введение
--------
Данная статья является переводом конкретного раздела, описывающего базовые операции над IPv6-адресами из учебника CCNA 200-301 Volume 1 от автора *Wendell Odom.*
Сокращение IPv6 адресов
-----------------------
Базовые правила:
* Два двоеточия подряд ... | https://habr.com/ru/post/546814/ | null | ru | null |
# React Native — сохранение фотографий и видео в галерею устройства
Сохранение фотографий и видео на устройство android/ios вызывает у многих разработчиков React Native сложность. В этой статье я покажу как можно легко и безболезненно сохранять фотографии по url на устройство.
Для начала нам понадобятся две библио... | https://habr.com/ru/post/501890/ | null | ru | null |
# Offline-first приложение с Hoodie & React. Часть вторая: авторизация
Наша цель, написать offline-first приложение — SPA которое загружается и сохраняет полную функциональность в отсутствии интернет-соединения. В [первой части](https://habrahabr.ru/post/309166/) повествования мы научились пользоваться браузерной базо... | https://habr.com/ru/post/309572/ | null | ru | null |
# Необычная Java: StackTrace Extends Throwable
#### Прочтите эту статью и узнайте о необычных вещах в Java, которые могут оказаться на удивление полезными.
Есть вещи, которые вы можете делать в Java, но вы их редко видите. В основном потому, что в них нет смысла. Однако в Java есть несколько необычных вещей, которые ... | https://habr.com/ru/post/655259/ | null | ru | null |
# Автоматизируем и ускоряем процесс настройки облачных серверов с Ansible. Часть 5: local_action, условия, циклы и роли
[В первой части](https://infoboxcloud.ru/community/blog/iaas/226.html) мы начали изучение Ansible, популярного инструмента для автоматизации настройки и развертывания ИТ-инфраструктуры. Ansible был у... | https://habr.com/ru/post/252461/ | null | ru | null |
# Android — фильтруем пины на карте, в зависимости от расстояния друг от друга
Довелось как то недавно делать проект с использованием google maps. В один из моментов, увидел я вот такую картину:

![](https://habrastora... | https://habr.com/ru/post/139929/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.