
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# PyQt4 — Управление расположением виджетов
Важной частью программирования является управление расположением элементов. Управление расположением это то, как мы размещаем виджеты на форме. Тут есть два пути: использование абсолютного позиционирования (absolute positioning) или же использование классов расположения (lay... | https://habr.com/ru/post/31687/ | null | ru | null |
# Оптимизация производительности фронтенда. Часть 2. Event loop, layout, paint, composite
*Ночь. Стук в дверь. Открыть. Стоят двое. "Верите ли вы в Event loop, нашу главную браузерную цепочку?" Вздохнуть. Закрыть дверь. Лечь досыпать. До начала рабочего дня еще 4 часа. А там уже ивент лупы, лейауты и прочая радость…*
... | https://habr.com/ru/post/517594/ | null | ru | null |
# Bucardo: Multimaster репликация
В процессе мучений перелопатил тонну статей и решил написать подробнокомментируемый мануал. Тем более, что информации по конфигурированию multimaster и на русском языке очень мало и она какая-то кусочная.
Немного вводной. Чтобы Bucardo заработал, мы должы:
1) Сказать ему какие б... | https://habr.com/ru/post/327674/ | null | ru | null |
# Кэш, хэш и няш-меш
**UPD0 (2016-07-19 23-31): судя по всему, первая половина моей статьи — успешно изобретённый велосипед. Спасибо хабравчанам за [ссылку на спецификацию](https://www.w3.org/TR/2016/REC-SRI-20160623/)**
Статья ценна не более, чем вольное описание уже придуманной технологии.
Предыстория
==========... | https://habr.com/ru/post/305898/ | null | ru | null |
# Виртуальная сетевая среда для тестирования сетевых протоколов. Используем QEMU+YOCTO+TAP

Идея создания сетевой тестовой среды возникла когда пришла необходимость запускать и отлаживать устройства с IPsec и GRE протоколами. ... | https://habr.com/ru/post/335038/ | null | ru | null |
# Ещё больше простых багов [язык Ада]

Примечание переводчика. На Хабре практически полностью отсутствуют публикации, связанные с языком Ада. А ведь это — живой язык, на котором п... | https://habr.com/ru/post/329270/ | null | ru | null |
# Прошивка Arduino Pro Mini через Nano
Не так давно столкнулся с необходимостью использования Arduino Pro Mini в своем проекте и сразу же встал вопрос как заливать в нее скетч. Конечно продаются различные переходники UART при помощи которых этот вопрос снимается быстро, но в тот момент такого переходника не оказалось ... | https://habr.com/ru/post/222201/ | null | ru | null |
# Dagster | Туториал
Исходники: <https://github.com/dagster-io/dagster>
Документация: <https://docs.dagster.io>
Лицензия: распространяется под [Apache License 2.0](https://github.com/dagster-io/dagster/bl... | https://habr.com/ru/post/690342/ | null | ru | null |
# Лоукост VDS хостинг в России и его техподдержка
Доброго времени суток, дамы и господа.
Есть тут на Хабре одна компания, которая имеет свой блог и отчаянно пиарится как "[Лоукост VDS хостинг в России".](https://habrahabr.ru/company/marosnet/blog/269561/)
Я ничего не имею против лоукоста и сразу же оплатил у них сер... | https://habr.com/ru/post/306570/ | null | ru | null |
# Универсальный компонент для графиков на React + D3.js
Привет! Меня зовут Лёня, я фронтенд-разработчик в [hh.ru](http://hh.ru). Как-то мы рисовали графики на React с использованием библиотеки D3.js и столкнулись с одной проблемой. В наш существующий компонент потребовалось добавить функциональность, которая вообще не... | https://habr.com/ru/post/660819/ | null | ru | null |
# Портируем Quake на iPod Classic
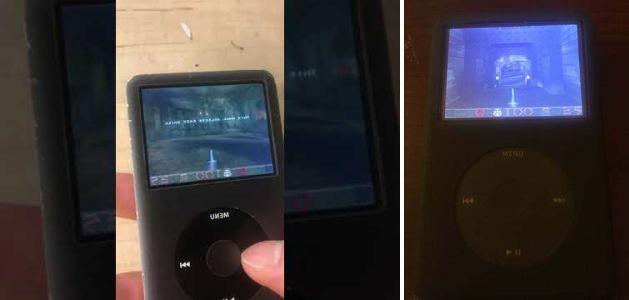
*Запускаем Quake на iPod Classic ([видео](https://www.youtube.com/watch?v=r6V-4AZ7pkA)).*
**TL;DR**: мне удалось запустить Quake на MP3-плеере. В статье описывается, как это произошло.
Часть п... | https://habr.com/ru/post/486818/ | null | ru | null |
# BEMIT: Следующий шаг в развитии BEM по версии Гарри Робертса
Все, кто следил за мной или моей работой на протяжении какого-либо времени, бесспорно знают, что я огромный фанат соглашения о наименованиях БЭМ. То, о чем я расскажу в этой статье, является не альтернативным или другим соглашением о наименованиях БЭМ, а д... | https://habr.com/ru/post/264569/ | null | ru | null |
# Заметки о метапрограммировании в Python
По мере накопления опыта программирования на одном языке, все мы нарабатываем стандартные для себя приемы программирования. Чем выше наш опыт, тем больше количество, более разносторонни методы их работы. При переходе на другой язык, мы стараемся их воспроизвести. Иногда, такое... | https://habr.com/ru/post/64359/ | null | ru | null |
# Как мы :hover на iOS побеждали…
Ни для кого, думаю, не секрет, что touch-устройства обрабатывают «мышиные» события несколько иначе, не так, как это происходит на десктоп-браузерах…
Самый яркий для меня пример, это обработка псевдокласса `:hover`. Для начала iOS7, например, не будет реагировать на hover если толь... | https://habr.com/ru/post/212959/ | null | ru | null |
# Windows Forth +
### Конструирование оснастки для обработки оконных сообщений Windows
Язык Форт большинству кажется наименее подходящим, чтобы программировать на нем, да еще и под Windows. Ведь в нем нет никакой графики, только унылая черная текстовая консоль.
Попробуем преодолеть этот миф.
Во-первых, програм... | https://habr.com/ru/post/324108/ | null | ru | null |
# Еще пара плагинов для Redmine

Ну а [мы](http://centos-admin.ru) продолжаем допиливать Redmine под свои нужды с целью повышения удобства работы и расширения функционала.
На этот раз было разработа... | https://habr.com/ru/post/231445/ | null | ru | null |
# Озвучка закрытия и открытия крышки ноутбука и синтез речи в Ubuntu
Можно заставить ноутбук разговаривать при открытии и закрытии крышки, это поднимет настроение вам и повеселит ваших друзей.
Выглядеть это будет примерно так: [видео на youtube](http://www.youtube... | https://habr.com/ru/post/38012/ | null | ru | null |
# JSX: антипаттерн или нет?
Довольно часто приходится слышать, что React и особенно JSX-шаблоны – это плохо, и хороший разработчик так не делает. Однако нечасто объясняется, *чем именно* вредит смешивание верстки и шаблонов в одном файле. И с этим мы попробуем сегодня разобраться.
Подход "каждой технологии свой файл"... | https://habr.com/ru/post/311226/ | null | ru | null |
# Эксперименты со Schedulers в Stable Diffusion
В этой статье разберём, что есть scheduler в диффузионных моделях и как можно подменять их, пользуясь возможностями библиотеки diffusers.
Stable Diffusion
----... | https://habr.com/ru/post/709242/ | null | ru | null |
# Небольшое замечание для тех, кто переходит на 1.4.3
Особенность в 1.4.3 — проявляется в FF3.6.11
Простой пример:
```
| | | | |
| --- | --- | --- | --- |
| 1.1 | 1.2 | 1.3 | 1.4 |
| 2.1 | 2.2 | 2.3 | 2.4 |
```
Ранее, до 1.4.3, результат выполнения следующей jQuery-инструкции был равен 2 (выбраны элементы... | https://habr.com/ru/post/106865/ | null | ru | null |
# vkontakte_api: ruby-адаптер для ВКонтакте API
В начале этого года мне понадобилось работать с API ВКонтакте из rails-приложения. Увы, я не нашел сколько-нибудь устраивающего меня гема: где-то меня принуждали писать названия методов в camelCase (что в ruby-коде выглядит неестественно), где-то — обязательно проходить ... | https://habr.com/ru/post/151585/ | null | ru | null |
# Телевизор в сети
**Дано:** современный телевизор, модель не играет большой роли, главное чтобы был сетевой плеер.
**Требуется:** подцепить его к домашней сети чтобы он проигрывал хранящиеся на серваке фильмы.

Ещ... | https://habr.com/ru/post/158717/ | null | ru | null |
# VariFlight ADS-B – Flightradar по-китайски
**«Flightradar»,** в некотором роде, стало именем нарицательным, фактически подменяя понятие *«сайт, где можно за самолетами наблюдать в реальном времени»*. Хотя фактически таких крупных сайтов несколько, а небольших проектов еще больше, но нередко можно увидеть в СМИ новос... | https://habr.com/ru/post/423989/ | null | ru | null |
# Как мы делали небольшую охранную систему на RPi. Часть 1
Здравствуйте Хабражители!
Думаю многие из вас слышали о Raspberry Pi, более того, думаю довольно большое количество из вас видели его вживую. В начале 2014 года я решил, что пора мне тоже заказать себе парочку RPi и сделать на них что-то интересное. Так как... | https://habr.com/ru/post/231869/ | null | ru | null |
# Универсальный пульт на Arduino
Есть много статей в интернете о том, как сделать свой пульт к телевизору на Arduino, но мне понадобился универсальный пульт для управления телевизором и медиа-плеером. Главное преимущество моего универсального пульта в том, что кнопки в приложении для андроид телефона двух-целевые, а в... | https://habr.com/ru/post/254761/ | null | ru | null |
# Microsoft ♥️ Python
Традиционно считается, что Microsoft хорошо поддерживает языки программирования на [платформе .NET](https://docs.microsoft.com/ru-ru/dotnet/?WT.mc_id=habr-blog-dmitryso): C# или F#. Но это не совсем так — облако Azure поддерживает целый спектр языков, среди которых Python [занимает почетное место... | https://habr.com/ru/post/508172/ | null | ru | null |
# 13 распространенных задач в Kubernetes и способы их решения
Команда [VK Cloud](https://mcs.mail.ru/) перевела статью о проблемах в Kubernetes, с которыми часто сталкиваются инженеры-разработчики при запуске новых масштабируемых от... | https://habr.com/ru/post/710852/ | null | ru | null |
# Обнаружение новизны изображений с помощью Python и библиотеки scikit-learn
В этой статье я расскажу, как с помощью библиотек scikit-learn, opencv, numpy, imutilsс выявить новизну входных изображений. Многие программы требуют наличия возможности решить, принадлежит ли новый объект тому же распределению, что и существ... | https://habr.com/ru/post/652851/ | null | ru | null |
# PHP, статические переменные внутри методов класса и история одного бага
Вообще я разработчик фронтенда. Но порой приходится работать и с серверной частью. Команда у нас небольшая, и когда все ~~настоящие~~бэкенд-программисты заняты, бывает быстрее реализовать какой-то метод самому. А иногда мы садимся вместе поработ... | https://habr.com/ru/post/301478/ | null | ru | null |
# Пишем REST приложение на Sinatra и прикручиваем Redactor. Часть 1
Данная статья рассчитана первым делом на новичков, которые только начинают изучать Ruby. После 3 недель изучения этого замечательного языка, накопились некоторые знания, которыми хочется поделиться.
[Sinatra](http://www.sinatrarb.com/) — бесплатный... | https://habr.com/ru/post/144277/ | null | ru | null |
# Чудесный мир Word Embeddings: какие они бывают и зачем нужны?
Начать стоит от печки, то есть с постановки задачи. Откуда берется сама задача word embedding?
*Лирическое отступление:* К сожалению, русскоязычное сообщество еще не выработало единого термина для этого понятия, поэтому мы будем использовать англоязычн... | https://habr.com/ru/post/329410/ | null | ru | null |
# 1000 глаз, которые не хотят проверять код открытых проектов

Есть такой миф, что открытое программное обеспечение более качественное и безопасное, чем закрытое. Много раз это обоснованно ставилось п... | https://habr.com/ru/post/596109/ | null | ru | null |
# Правильный захват контекста в Javascript
 Довольно часто во многих статьях я вижу, как люди захватывают контекст this для использования в анонимной функции и удивляюсь — то, что уже стало стандартом — просто ужасная практика, котор... | https://habr.com/ru/post/103760/ | null | ru | null |
# HackTheBox. Прохождение Academy. RCE в Laravel и LPE через composer
Продолжаю публикацию решений отправленных на дорешивание машин с площадки [HackTheBox](https://www.hackthebox.eu). Надеюсь, что это поможе... | https://habr.com/ru/post/542622/ | null | ru | null |
# Веб-компоненты в реальном проекте

Всем привет! Меня зовут Артур, я работаю frontend-разработчиком в Exness. Не так давно мы перевели один из наших проектов на веб-компоненты. Расскажу, с какими проблемами пришлось столкнуться, и о т... | https://habr.com/ru/post/498560/ | null | ru | null |
# Протокол безопасности транспортного уровня (TLS), версия 1.2 (RFC 5246) (Часть 2)
#### T. Dierks, E. Rescorla
#### Протокол безопасности транспортного уровня (TLS)
#### Версия 1.2
#### Запрос на комментарии 5246 (RFC 5246)
#### Август 2008
#### Часть 2
Данная статья является второй частью перевода протокола бе... | https://habr.com/ru/post/574424/ | null | ru | null |
# Как и зачем мы добавили новый тип треков для Sequencer UE4
В ходе разработки нашей игры мы столкнулись с необходимостью добавить возможность показывать элементы игрового интерфейса (виджеты) во время проигр... | https://habr.com/ru/post/546386/ | null | ru | null |
# ExtJS – учимся правильно писать компоненты
Хочу открыть небольшой цикл статей посвященный проблеме создания custom-компонентов в ExtJS. В них хочу поделится с читателями Хабра своим опытом в данной области, опишу подробно все тонкости данного процесса, на что следует всегда обращать внимание, какие ошибки подстерега... | https://habr.com/ru/post/88261/ | null | ru | null |
# Креативное программирование: openFrameworks — установка и пример визуализации музыки

Когда вы последний раз программировали на C++?
Может быть это ваша каждодневная работа, а мой последний (до вчерашнего дня) проект н... | https://habr.com/ru/post/244265/ | null | ru | null |
# Контекстно-зависимая форма в Yii
При работе с фреймворками всегда приходится создавать основной функционал самим, желательно, используя при этом возможности фреймворка (зачем тогда он нам нужен). Как понятно по заголовку речь пойдет про контекстно-зависимые формы в Yii. В статье описана реализация подобной формы, ис... | https://habr.com/ru/post/178303/ | null | ru | null |
# SaltStack: использование salt-ssh
В этом посте я хотел бы поделиться своим опытом использования системы управления конфигурациями [SaltStack](https://saltstack.com/), и, в частности, её применением в *Masterless* режи... | https://habr.com/ru/post/303418/ | null | ru | null |
# Использование MEF (Managed Extensibility Framework) для разработки Asp.Net WebForms приложений
MEF является хорошим фреймворком для написания расширяемых приложений. Он позволяет легко отделять реализацию от абстракции, добавлять/изменять/удалять реализации во время работы приложения (рекомпозиция), работать с множе... | https://habr.com/ru/post/106762/ | null | ru | null |
# Workflow просмотра сериалов для Alfred
В конце [предыдущей своей статьи](https://habrahabr.ru/post/304770/) я начал рассказывать о том как у меня организован просмотр сериалов, но решил что это — тема для отдельной заметки.
**Для тех кто не знает что такое Alfred**[Alfred](https://www.alfredapp.com) — это [Spotligh... | https://habr.com/ru/post/305346/ | null | ru | null |
# Свойства блочной модели CSS. Объяснение с примерами
Приветствую всех жителей хабравиля! Сегодня я подготовил для вас материал по основам по блочной модели CSS. Безусловно, многие из вас знают о чём идёт речь, но сегодня я постараюсь объяснить прописные истины более понятно и наглядно, что поможет вам создавать веб-с... | https://habr.com/ru/post/569530/ | null | ru | null |
# Простой rpm репозиторий используя Inotify и webdav
В этом посте рассмотрим хранилище rpm артефактов c помощью простого скрипта с inotify + createrepo. Заливка артефактов осуществляется через webdav используя apache httpd. Почему apache httpd будет написано ближе к концу поста.
### Итак, решение должно отвечать cлед... | https://habr.com/ru/post/490644/ | null | ru | null |
# Как iOS 'ник Telegram бота писал, на Swift
Речь пойдет о [Telegrammer, Telegram Bot фреймворк для Linux/macOS](https://github.com/givip/Telegrammer), полностью написанный на Swift 4.1

Экспозиция: Как же пришла в голову такая мысль?... | https://habr.com/ru/post/416023/ | null | ru | null |
# Attention для чайников и реализация в Keras
О статьях по искусственному интеллекту на русском языке
-------------------------------------------------------
Не смотря на то что механизм Attention описан в англоязычной литературе, в русскоязычном секторе достойного описание данной технологии я до сих пор не встречал.... | https://habr.com/ru/post/458992/ | null | ru | null |
# Как работает JS: цикл событий, асинхронность и пять способов улучшения кода с помощью async / await
**[Советуем почитать] Другие 19 частей цикла**Часть 1: [Обзор движка, механизмов времени выполнения, стека вызовов](https://habrahabr.ru/company/ruvds/blog/337042/)
Часть 2: [О внутреннем устройстве V8 и оптимизаци... | https://habr.com/ru/post/340508/ | null | ru | null |
# Равертывание Emercoin blockchain с веб-кошельком на RedHat/CentOS 7 и Ubuntu 16.04
Одним из современных технических мейнстримов является блокчейн. В этой статье я расскажу как можно быстро развернуть Emercoin блокчейн на RedHat/CentOS 7 и Ubuntu 16.04 LTS.
1. Введение
-----------
В этом материале мы будем исходи... | https://habr.com/ru/post/304100/ | null | ru | null |
# Юникод и .NET
*От переводчика. На Хабре уже неоднократно публиковались статьи как по Юникоду, так и по строкам в .NET. Однако статьи о Юникоде применительно к .NET ещё не было, поэтому я решил перевести статью общепризнанного гуру .NET Джона Скита. Она закрывает обещанный мною цикл из трёх статей-переводов Дж. Скита... | https://habr.com/ru/post/193048/ | null | ru | null |
# Интуитивное использование методов Монте-Карло с цепями Маркова
#### Легко ли это? Я попробовал
*Алексей Кузьмин, директор разработки и работы с данными «ДомКлик», преподаватель направления [Data Science](https://netology.ru/data-science/programs?utm_source=blog&utm_medium=747&utm_campaign=bds_ou_cat_habr_18072019ms... | https://habr.com/ru/post/460497/ | null | ru | null |
# Взламываем Asus RT-AC66U и подготавливаемся к SOHOpelesslyBroken CTF
Наконец-то настал июль, время собираться на DEFCON. Фолловьте [@defconparties](https://twitter.com/defconparties) в твиттере и определяйтесь, какие [местечки](http://defcne.net/villages/22) посетить и на какие [доклады](https://www.defcon.org/html/... | https://habr.com/ru/post/230469/ | null | ru | null |
# Получение скриншотов и информации с видео
В этой заметке я рассказываю, как сделать скриншот с видео, а так же о том, как получить информацию о видео файле.
Конечно, многие уже знают, как сделать скриншот с видео. Но у кого то, как говорится, руки не доходят. Вот для таких людей я и написал эту небольшую заметку.... | https://habr.com/ru/post/22481/ | null | ru | null |
# Архитектура клиентского приложения (механизмы структуризации)
История первая
==============
Некоторое время назад я работал в одной игровой компании, которой руководил немец. Создание игр не было основным бизнесом этого немца. Основные доходы он получал от продажи косметики и от сдачи коммерческой недвижимости в ар... | https://habr.com/ru/post/329032/ | null | ru | null |
# Как я с лагом Navigation Drawer боролся
Привет, Хабр!
Меня зовут Алексей. Я разрабатываю под Android. Отладка в эмуляторе подобна смерти, поэтому я пользуюсь своим HTC Desire HD. Зверёк уже очень древний, за что я не могу его не любить, потому что любые шероховатости и неровности в приложении на нём отдаются слав... | https://habr.com/ru/post/220835/ | null | ru | null |
# Безопасность ваших юзеров: OAuth, SSL, P2P-чат с RSA, гейт в i2p
Утопающие не собираются спасать себя самостоятельно, поэтому предлагаем вам сделать четыре простых шага к увеличению безопасности посетителей вашего сайта.

Причина:
`...
[HTTP_USER_AGENT] => Mozilla/5.0 (Wind... | https://habr.com/ru/post/77313/ | null | ru | null |
# QSerializer умер, да здравствует QSerializer
Прошло несколько месяцев с тех пор, как я [здесь](https://habr.com/ru/post/496836/) рассказал о своем проекте Qt-based библиотеки для сериализации данных из объектного вида в JSON/XML и обратно. Надо признать — реализация получилась, прямо скажем, спорной.
Все это выл... | https://habr.com/ru/post/515094/ | null | ru | null |
# Опыт разработки и проектирования на AngularJS
Всем привет!
В нашей компании, помимо разработки собственной [СУБД](http://linter.ru/ru/), также занимаются заказными разработками по самым разным направлениям, от суровых java-энтерпрайз приложений до небольших мобильных приложений. Наши команды стараются использоват... | https://habr.com/ru/post/262529/ | null | ru | null |
# Эффективные шаблоны case-классов в Scala
**Обзор**
Это руководство, прочитать которое я хотел бы много лет назад, когда только начинал свой путь в Scala. Мне пришлось потратить большое количество времени н... | https://habr.com/ru/post/672374/ | null | ru | null |
# JSON vs. XML
Для меня скорее это **не противостояние**, а выбор более подходящего и удобного вида обмена данными между клиентом и сервером, для кого-то этот выбор может быть совершенно другим…
Так как на клиенте я часто (90%) использую JavaScript, то JSON является моим **де-факто**! Кто он за зверь?
**JavaScri... | https://habr.com/ru/post/51657/ | null | ru | null |
# Представляем новый UWP Community Toolkit
[](http://habrahabr.ru/post/308020/)
Недавно мы выпустили юбилейное обновление Windows 10 и новый [Windows Software Developer Kit (SDK)](https://developer.microsoft.com/en-us/window... | https://habr.com/ru/post/308020/ | null | ru | null |
# Семь смертных грехов разработки ПО
*Перевод статьи [Seven Deadly Sins of a Software Project](http://www.yegor256.com/2015/06/08/deadly-sins-software-project.html) автора [Yegor Bugayenko](http://www.yegor256.com/about-me.html).*
*Сопровождаемость* — это [наиболее ценное достоинство](http://www.yegor256.com/2014/1... | https://habr.com/ru/post/260241/ | null | ru | null |
# Как в Spring logger получить
Разрабатывая приложения используя IoC-контейнер Spring думаю каждый задумывался, а как же «правильнее и красивее» создать логгер. В данной публикации хочу привести несколько примеров решения данной задачи.
#### Решение 1
Получаем логгер напрямую через LoggerFactory:
```
@Component... | https://habr.com/ru/post/276729/ | null | ru | null |
# Радиоуправляемый выключатель своими руками. Часть 4 — Центр управления
Собственно, выключатель [спроектирован, произведен](http://habrahabr.ru/post/211126/), [протестирован](http://habrahabr.ru/post/212785/... | https://habr.com/ru/post/215419/ | null | ru | null |
# Решение задачи второго конкурса CUBRID it!
Привет, Хабраюзер! Предлагаю твоему вниманию решение задачи, победившее на [втором конкурсе CUBRID it!](http://www.cubrid.org/cubrid_it) Суть конкурса заключается в поиске наиболее оптимального решения SQL задачи, используя Java или PHP. Решение чисто алгоритмическое, поэто... | https://habr.com/ru/post/125608/ | null | ru | null |
# Что нового в Rails 4
 Четвёртая версия фреймворка Ruby on Rails уже не за горами. Хотя официальной даты релиза еще нет, многие ожидают release candidate уже в начале этого года.
Эта версия фреймворка разрабатывается у... | https://habr.com/ru/post/170473/ | null | ru | null |
# Рендеринг картинок через WPF на примере Pivot
[Pivot](http://www.microsoft.com/silverlight/pivotviewer/) не нуждается в представлении. Если вбить это слово в поиск хабра, результатом будут 37 статей, среди которых есть как обзоры, т... | https://habr.com/ru/post/109387/ | null | ru | null |
# Недостатки Navigation Component deep linking и как их обойти
Недавно, на одном из небольших проектов передо мной встала задача открытия различных экранов приложения из вне через deep links, захотелось попробовать и понять, что такого для deep linking смогли придумать ребята из Google, учитывая как красиво они об это... | https://habr.com/ru/post/684224/ | null | ru | null |
# Исчерпывающее руководство по использованию HTTP/2 Server Push

*Привет! Меня зовут Александр, и я – фронтенд-разработчик в компании Badoo. Пожалуй, одной из самых обсуждаемых тем в мире фронтенда в последние несколько лет явл... | https://habr.com/ru/post/329722/ | null | ru | null |
# Пишем систему логирования в InterSystems Caché

Введение
--------
В [предыдущей](http://habrahabr.ru/company/intersystems/blog/258081/) статье мы рассмотрели основные ва... | https://habr.com/ru/post/258805/ | null | ru | null |
# Asterisk. Интеграция с amoCRM, step-by-step guide
В сети можно найти инструкции разной степени давности и полноты представленной информации по теме вынесенной в заголовок статьи, но даже собрав их все воедино, потребуются прямые руки, напильник и некоторое количество терпения для достижения желанного катарсиса.
!... | https://habr.com/ru/post/325104/ | null | ru | null |
# Выпуск#28: ITренировка — актуальные вопросы и задачи от ведущих компаний
Привет!
Сегодня в нашей рубрике задачи с собеседований в LinkedIn.
Если с ходу-с лету решите их все и всерьез задумаетесь о том, чтобы податься ... | https://habr.com/ru/post/479320/ | null | ru | null |
# Делегаты и колбэки в Swift простым языком. Что же такое этот delegate, и как работает callback
В Swift при изучении UI (User Interface) каждый рано или поздно приходит к необходимости использования делегата. Все гайды о них пишут, и вроде бы делаешь, как там написано, и вроде бы работает, но почему и как это работае... | https://habr.com/ru/post/510882/ | null | ru | null |
# Добавление тысяч клипов в плейлист YouTube с канала Telegram
С приобретением телевизора с функцией просмотра YouTube и с подпиской на множество каналов Telegram, где ежедневно выкладываются клипы **захотелось убрать лишние движения между мобильным телефоном и телевизором** для просмотра очередного свежего контента. ... | https://habr.com/ru/post/501276/ | null | ru | null |
# Производительность анимаций на сайтах
При разработке сайтов, выходящих за рамки условного бутстрапа, рано или поздно возникают вопросы, связанные с производительностью анимаций. Особенно важными они являются в дизайнерских са... | https://habr.com/ru/post/450484/ | null | ru | null |
# Шпаргалка по OPC DA 2 в .NET
На днях пришлось крепко повозиться с настройкой вызова удалённого сервера по протоколу OPC DA 2.05a, и эта информация бы очень пригодилась, знай я её заранее.
#### 1. Что такое OPC DA и в частности OPC DA 2.05a
В общем случае OPC — это набор открытых протоколов, регламентирующих взаи... | https://habr.com/ru/post/132780/ | null | ru | null |
# Построение DWH на основе Greenplum
DBA в Southbridge Иван Чувашов подготовил статью о построении DWH на основе Greenplum. Слово Ивану.
Привет, Хабр! Я администратор баз данных с 15-летним опытом. Сегодня хочу рассказать про Data Warehouse на основе Greenplum — как они устроены, как их поднимать и с какими проблем... | https://habr.com/ru/post/668490/ | null | ru | null |
# Резервное копирование файлов и баз данных
Возможности скрипта:
— бэкапить директории и базы данных
— загрузка архивов в локальную папку или на фтп
— информирование по email о удачном/не удачном завершении
##### Backup директории
Создать бэкап директории просто. Достаточно просто указать пусть (path) ... | https://habr.com/ru/post/141404/ | null | ru | null |
# Xakep.ru — ищем баги лишь в чужом глазу?
Давно заметил, что **на сайте** [www.xakep.ru](http://www.xakep.ru/) бесполезно пытаться зарегистрироваться… Сегодня снова попробовал и, как обычно — безрезультатно…
При любой попытке регистрации почтового ящика вылезает «красноречивое» сообщение, «однозначно» указывающее ... | https://habr.com/ru/post/143006/ | null | ru | null |
# Создаём парсер для ini-файлов на C++
В данной статье я расскажу как написать свой парсер ini-файлов на C++. За основу возьмём контекстно-свободную грамматику, построенную [в моей предыдущей статье](http://avsmal.habrahabr.ru/blog/50973/). Для построения парсера будет использоваться библиотека [Boost Spirit](http://s... | https://habr.com/ru/post/50976/ | null | ru | null |
# Связные списки в функциональном стиле
Рассмотрим вариант реализации связных списков через [замыкания](http://ru.wikipedia.org/wiki/Замыкание_(программирование)).
Для обозначения списков будем использовать нотацию, похожую на Haskell: `x:xs`, где `x` — начало списка (`head`), `xs` — продолжение (`tail`).

**LXD** — это системный менеджер контейнеров следующего поколения, так гласит [источник](https://linuxcontainers.org/lxd/introduction/). Он предлагает пользовательский интерфей... | https://habr.com/ru/post/496492/ | null | ru | null |
# Еще раз об утечке атомов и баге VCL
##### Введение
Просматривая ленту, наткнулся на статью [Неправильное использование атомов и трудноуловимая бага в VCL](http://habrahabr.ru/post/217189/). После прочтения возникла мысль описать еще одну проблему в той же самой области, о которой не рассказано в этой статье. Наша к... | https://habr.com/ru/post/217333/ | null | ru | null |
# Награды в играх. Вариант backend реализации
Я продолжаю развивать механику сундуков и того, как гейм дизайнеры будут их заводить и создавать. [В прошлой статье мы говорили о идее того, как можно реализовать награды и сундуки, так что бы в будущем можно было удобно добавлять новые типы наград и расширять систему](htt... | https://habr.com/ru/post/569500/ | null | ru | null |
# GitHub Copilot
В современном компьютерном и интернет-мире всё взаимодействие, не только пользователей, а в общем со структурой выстраивается с помощью различных программ, интерфейсов, и подобных им оптимизированных для простого человека сложных разработках. Но кто же занимается непосредственно разработкой различного... | https://habr.com/ru/post/674658/ | null | ru | null |
# RubyMine 2018.2: присоединение отладчика к удаленным процессам, chruby, улучшенный анализ кода и многое другое
Привет, Хабр!
Сезон летних обновлений IDE на базе IntelliJ продолжается, и в этой серии мы расскажем, чему новому научился RubyMine в версиях 2018.1 и вышедшей на днях **[RubyMine 2018.2](https://www.jet... | https://habr.com/ru/post/418931/ | null | ru | null |
# Варианты настройки iosMain sourceSet'а в Kotlin Multiplatform Mobile
При использовании Kotlin Multiplatform Mobile сталкиваешься с непривычной особенностью — iOS код рассматривается компилятором в нескольки... | https://habr.com/ru/post/536480/ | null | ru | null |
# Выбираем html-парсер для Apache.JMeter
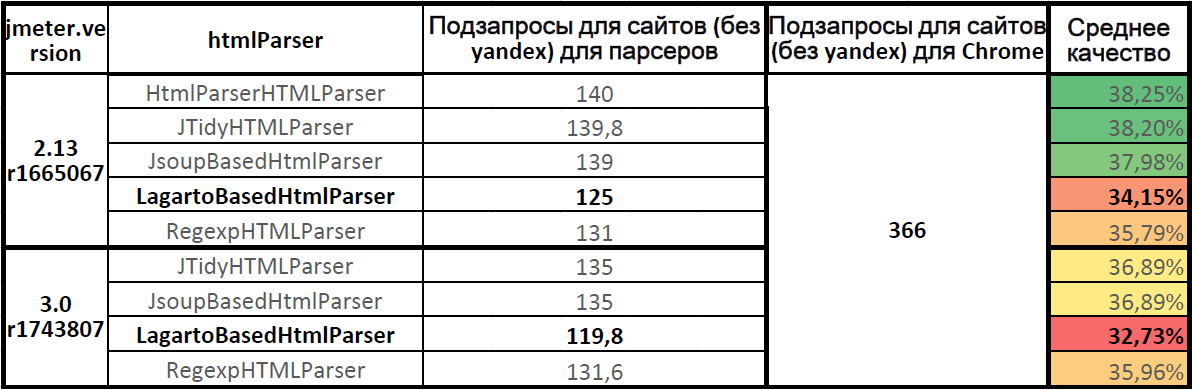
*Среднее качество работы парсеров (для семи сайтов)*
Предлагаю:
* посчитать среднее качеств... | https://habr.com/ru/post/308254/ | null | ru | null |
# Синхронизация статуса учетной записи LanBilling и RTU class 4&5
Добрый день, уважаемые хабропользователи.
Возникла задача по синхронизация статуса учетной записи в LanBilling и RTU.
Хочу поделиться с Вами вариантом реализации.
#### Использовалось
Lanbilling v.1.8
RTU class 4&5
php 5.3
mysql 5.0.51... | https://habr.com/ru/post/126412/ | null | ru | null |
# Художник зашифровал ключи от криптокошельков в Lego-инсталляциях, а мы попробуем их оттуда достать

Привет, Хабр! Предлагаю всем желающим немного размять мозги небольшим крипто-ребусом.
Оговорюсь сразу, сам я загадку до конца... | https://habr.com/ru/post/351950/ | null | ru | null |
# Конфигурационный менеджмент (часть1, вступительная)
Как разрабатывать большое ПО? Ни для кого не секрет, что потребность в разработке больших и сложных программных продуктов была всегда и также всегда была независимой от уровня технологий, существующих на тот или иной момент времени. Но исследуя и анализируя существ... | https://habr.com/ru/post/53687/ | null | ru | null |
# Как я выкинул webpack и написал babel-plugin для транспила scss/sass
### Предыстория
Как-то субботним вечером я сидел и искал способы сборки UI-Kit с помощью webpack. В качестве демо UI-kit я пользуюсь styleguidst. Конечно же, webpack умный и все файлы, которые есть в рабочем каталоге он запихивает в один бандл и о... | https://habr.com/ru/post/513564/ | null | ru | null |
# Чем сложна демонизация POSIX

---
#### Вот как по мнению Стивенс вы должны демонизировать:
```
void daemonize(const char *cmd) {
if ((pid = fork()) < 0)
err(1, "fork fail");
else if (pid != 0) /* par... | https://habr.com/ru/post/554630/ | null | ru | null |
# Используем аннотацию @Transactional like a pro
Привет, Хабр! Меня зовут Никита Летов, я тимлид бэкенд-разработки мобильного приложения Росбанка для физических лиц. Этот пост входит в серию постов по разработке бэкенд-микросервисов на Java и Spring и является адаптацией моего [доклада с JPoint 2022](https://www.youtu... | https://habr.com/ru/post/707378/ | null | ru | null |
# Переход с 1С: УПП на 1C:ERP: Переделываем интеграции с SQL-запросами к СУБД (на примере УПП — QlikView — ERP)
**Одна статья из цикла материалов о практических особенностях перехода с программы 1С:УПП на 1C:ERP.**
***Автор статьи:***
***Дмитрий Малышев, специалист Внедренческого центра «Раздолье», разработчик «1С... | https://habr.com/ru/post/663144/ | null | ru | null |
# Неочевидное про Fragment API. Часть 4. Анимации и меню
Всем привет! С вами снова Максим Бредихин, Android-разработчик в Тинькофф. Мы добрались до заключительной части серии про интересные моменты из Fragmen... | https://habr.com/ru/post/693794/ | null | ru | null |
# Создание очередной казуалки на Flash-платформе с физикой. Часть II
Привет хабра-сообществу.
~~Относительно недавно~~ достаточно давно [писал статью](http://habrahabr.ru/blogs/gdev/121193/) про создание очередной казуалки на Flas... | https://habr.com/ru/post/128157/ | null | ru | null |
# Обход бинарных деревьев: рекурсия, итерации и указатель на родителя
Основы о бинарных деревьях представлены, в том числе, [здесь](http://habrahabr.ru/post/65617/) . Добавлю свои «5 копеек» и данным постом систематизирую материалы, связанные с обходом бинарных деревьев, а именно сравнений возможностей рекурсии и итер... | https://habr.com/ru/post/144850/ | null | ru | null |
# Поиск решений для игр со словами. Применение бора
#### Вступление
Существует множество игр, где игроку необходимо искать слова из определенного набора букв. Вот две наиболее популярные из них.
1. 4 фото 1 слов (4 Pics 1 Word) [AppStore](https://itunes.apple.com/ru/app/id598949838), [Google Play](https://play.go... | https://habr.com/ru/post/216845/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.