
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Измеряем температуру: TEMPer + Python + Windows
Всем привет.
На написание поста сподвигла, казалось бы, тривиальная задача — мониторинг температуры в серверной. На эту тему существует довольно много различных решений (например, повесить видеокамеру и градусник перед ней), но большинство из крутых систем мониторин... | https://habr.com/ru/post/230355/ | null | ru | null |
# Настольный клиент для Yandex Speechkit text2speech на коленке
Вчера понадобилось мне записать голос для голосового (IVR) меню.. Решил воспользоваться голосами от яндекс.облака, тем более что они теперь все высококачественные, и от человеческого неотличимы. Но как бы это сделать поудобнее, чтобы не надо было потом фа... | https://habr.com/ru/post/661569/ | null | ru | null |
# STM32 и LCD2004A без I2C интерфейса
Недавно начал изучать STM32 контроллеры и понадобилось взаимодействие с LCD дисплеем. Из дисплеев нашел у себя только 2004A, причем без I2C интерфейса. О нем и пойдет речь в этой статье.
Для начала необходимо подключить дисплей к контроллеру. Подключаем по схеме:

А так как данная тема для ме... | https://habr.com/ru/post/128140/ | null | ru | null |
# Хроника одного запроса «пластиковые окна калькулятор»
Сегодня с утра решил заняться ремонтом и пошел в первую очередь изучать предложения по пластиковым окнам, как стартовой точки ремонта в квартире.
Будучи продвинутым пользователем, я не пошел изучать вопрос по запросу «пластиковые окна», а набрал «пластиковые о... | https://habr.com/ru/post/100192/ | null | ru | null |
# Школа магии PHP
Что такое магия в PHP? Обычно под этим подразумевают методы вроде `_construct()` или `__get()`. Магические методы в PHP — это лазейки, которые помогают разработчикам выполнять удивительные вещи. В сети полно инструкций по их использованию, с которыми вы наверняка знакомы. Но что если мы скажем, что в... | https://habr.com/ru/post/478618/ | null | ru | null |
# DeezLoader + PlexMediaServer. Делаем домашний музыкальный портал
**Attention!**The authors do not call to commit crimes! The usage of this tool may be illegal in your country. The authors give no guarantees at all and aren't responsible for any damage or harm of any kind resulting from the use of this software!
*... | https://habr.com/ru/post/431312/ | null | ru | null |
# Nano: И всё-таки его придётся выучить [3]
Заканчиваем. Предыдущие части: [[1](https://habrahabr.ru/post/106471/)], [[2](https://habrahabr.ru/post/106554/)]. Комбинации для запоминания: undo/redo, поиск/замена.

В конце топик... | https://habr.com/ru/post/106748/ | null | ru | null |
# История одного переключения

У нас в агрегации локальной сети было шесть пар коммутаторов Arista DCS-7050CX3-32S и одна пара коммутаторов Brocade VDX 6940-36Q. Не то, чтобы нас сильно напрягали коммутаторы Brocade в этой сети, они ... | https://habr.com/ru/post/498368/ | null | ru | null |
# Голосовая почта и качественный скачок услуги благодаря Google (FreeSWITCH edition)
При использовании современных телефонных платформ услуга голосовой почты стала настолько привычной и востребованной, что разработчики «софтовых» АТС создают модули голосовой почты, производители «железных» АТС создают целые платы голо... | https://habr.com/ru/post/149750/ | null | ru | null |
# Устанавливаем видеодрайвер для видеокарт семейства SIS M671/M672 под Ubuntu 11.04
От переводчика, т.е. меня:
Я потратил достаточно много времени на то, чтобы заставить корректно работать видеокарту на моем ASUS K50C. Все решения, которые находились поисковиками, были расчитаны на релиз X-Server'а более ранний (1.... | https://habr.com/ru/post/116380/ | null | ru | null |
# Создание пользовательского (индивидуального) макета в SwiftUI. Основы
В настоящее время SwiftUI предоставляет протокол Layout, позволяющий нам создавать суперпользовательские (сверхиндивидуальные мне кажется здесь больше подходит) макеты, копаясь в системе компоновки без использования GeometryReader. Протокол Layout... | https://habr.com/ru/post/701864/ | null | ru | null |
# Doom Boy ESP32
Приставка для Doom на ESP32 своими руками на драйвере MCP23017 для кнопок от UncleRus


В ожидании [Doom часов](https://hab... | https://habr.com/ru/post/495700/ | null | ru | null |
# Вред хранимых процедур
[](https://habr.com/ru/company/ruvds/blog/517302/)
В чат подкаста [«Цинковый прод»](https://www.youtube.com/channel/UC6cTShKx3lJWw-EzSr_ZAfw/videos?view=0&sort=p&flow=grid) скинули [статью](https://habr.com... | https://habr.com/ru/post/517302/ | null | ru | null |
# База данных в коммерческом проекте: как поступить?
Всех с окончанием праздников!… Некоторые скажут, что это поздравление — так себе. Но, наверняка, у многих скоро отпуск, так что поднажмите еще немного. Ну а мы не сдаем обороты и в этот теплый день делимся опытом наших партнеров. Речь пойдет об оптимизации работы с ... | https://habr.com/ru/post/413757/ | null | ru | null |
# Диагностируем проблемы в микросервисной архитектуре на Node.js с помощью OpenTracing и Jaeger

Всем привет! В современном мире крайне важна возможность масштабировать приложение по щелчку пальцев, ведь нагрузка на приложение может ... | https://habr.com/ru/post/489552/ | null | ru | null |
# Перенос Alpine Linux на RISC-V
После нескольких мучительных месяцев ожидания недавно я получил свой [HiFive Unleashed](https://www.sifive.com/boards/hifive-unleashed), и это невероятно круто. Для тех, кто не в курсе, HiFive Unleashed — это первый одноплатник на [RISC-V](https://en.wikipedia.org/wiki/RISC-V) с поддер... | https://habr.com/ru/post/434382/ | null | ru | null |
# Aptly. Как организовать контроль пакетов из внешних репозиториев и делегировать управление в продуктовые команды

Сейчас многие компании работают без возможности прямого управления составом пакетов внешних репозиториев, даже если п... | https://habr.com/ru/post/513958/ | null | ru | null |
# Как я в одиночку сделал игру и выводы
### История разработки одной фанатской компьютерной игры Fallout: The X-Project и попытки сделать из неё «конфетку»
Предупрежу сразу, вы не увидите в этой статье каких-то актуальных и современных знаний, да и в целом, я не стану в ней уделять много внимания техническим аспектам... | https://habr.com/ru/post/317688/ | null | ru | null |
# Оцениваем производительность инфраструктуры с Phoronix Test Suite
Aloha всем хабравчанам! Я Влад, системный администратор Cloud4Y. Хочу рассказать, как и зачем мы используем продукт Phoronix Test Suite, а также каким образом можно точно и легко определить реальную (не заявленную) производительность оборудования, пре... | https://habr.com/ru/post/596833/ | null | ru | null |
# Создание и настройка диаграмм с помощью нового Swift Charts Framework
 складывает их в файлы
* fluent-bit, запущенный на каждой ноде k8s. Он собирает логи, фильтрует их и отпра... | https://habr.com/ru/post/675728/ | null | ru | null |
# Хакаем CAN шину авто. Мобильное приложение вместо панели приборов
Мобильное приложение VAG Virtual CockpitЯ продолжаю изуч... | https://habr.com/ru/post/544144/ | null | ru | null |
# Как разворачивать артефакты Adaptavist ScriptRunner
 В процессе разработки программного обеспечения обычно используется несколько сред: среды для разработки, тестирования и промышленного использования. В этой статье поговорим о том,... | https://habr.com/ru/post/358504/ | null | ru | null |
# Карманный сервер MiniX, или обзор серверных технологий для Android
[](https://picasaweb.google.com/lh/photo/gU1VILZSF-k-WvqV-yMg96SVARZjNKNEt3ROuFGU3eQ?feat=embedwebsite)
На этот раз из [MiniX](http://7d... | https://habr.com/ru/post/149482/ | null | ru | null |
# Используем встроенный микроконтроллер в Intel Edison
Думаю, что многие из вас уже знакомы с [Intel Edison](https://software.intel.com/ru-ru/iot/hardware/edison) по предыдущим заметкам, и у некоторых после прочтения специфика... | https://habr.com/ru/post/260471/ | null | ru | null |
# Построение расширенной системы антивирусной защиты небольшого предприятия. Часть 2. Антивирусный шлюз USG40W от Zyxel

Данная публикация посвящена линейке продуктов Zyxel USG40/USG40W/USG60/USG60W и является продолжением серии стат... | https://habr.com/ru/post/358612/ | null | ru | null |
# Service mesh для микросервисов. Часть III. Более глубокий взгляд на Istio
*Перевод статьи подготовлен специально для студентов курса [«Инфраструктурная платформа на основе Kubernetes»](https://otus.pw/IRoX/).*
---

Это третья с... | https://habr.com/ru/post/478416/ | null | ru | null |
# Как с помощью maven работать с библиотеками, которых в maven нет
В статье я расскажу, как подключить библиотеку, которой в maven по умолчанию нет, и как подключить другую библиотеку, исходники которой давным-давно потеряны.
Также я опишу, как сделать maven проект, который генерирует артефакт, по совместительству яв... | https://habr.com/ru/post/323008/ | null | ru | null |
# Загружаем dSYM в Firebase Crashlytics через Xcode Cloud
Всем привет, в этой статье я бы хотел поделиться опытом о том, как наша команда столкнулась со сложностями загрузки dSYM в Firebase Crashlytics, и как мы эти сложности решили. Важно сказать пару слов о нашем стеке: все зависимости установлены через Swift Packag... | https://habr.com/ru/post/700742/ | null | ru | null |
# Пишем библиотеку DLL для Metastock с нуля.Часть2

В этой статье будут подробно рассмотрены наша функция ([часть1](http://habrahabr.ru/post/219133/), [часть3](http://habrahabr.ru/post/22... | https://habr.com/ru/post/219953/ | null | ru | null |
# Objective-C Runtime для Си-шников. Часть 2

Снова здравствуйте. Мой цикл статей посвящён тем программистам, которые перешли с языка C на Objective-C, и хотели бы ответить для себя на вопросы «каким именно образом Objectiv... | https://habr.com/ru/post/250977/ | null | ru | null |
# Кластеризация беспроводных точек доступа с использованием метода k-средних
Визуализация и анализ данных в настоящее время широко применяется в телекоммуникационной отрасли. В частности, анализ в значительной степени зависит от использования геопространственных данных. Возможно, это связано с тем, что телекоммуникаци... | https://habr.com/ru/post/442094/ | null | ru | null |
# Minimal Value Types
Эта статья — перевод [спецификации](http://cr.openjdk.java.net/~jrose/values/shady-values.html), посвященной описанию минимальной реализации типов-значений в Java, которую с нетерпением ждут уже несколько лет. Добро пожаловать в MVT!
Замечания к переводу
====================
Этот текст предназн... | https://habr.com/ru/post/336378/ | null | ru | null |
# Нюансы MVVM в Ext JS при разработке компонентов
[](http://habrahabr.ru/post/266773/) Всем привет. Прошло немало времени с момента выхода Ext JS 5, где представили возможность разработки приложений с использованием паттерна ... | https://habr.com/ru/post/266773/ | null | ru | null |
# Google Chrome Extension: Печатаем статьи с habrahabr
Как-то вечером, уходя с работы, наткнулся здесь на интересную статью. Так как я люблю читать печатный вариант, да и время было уже позднее — хотелось домой, но и хотелось прочесть — решил распечатать и почитать в дороге.
Ну и полез я печатать, браузер мне предл... | https://habr.com/ru/post/139427/ | null | ru | null |
# Эксплуатация Microsoft Edge от CVE до RCE на Windows 10

В рамках данной статьи мы достаточно подробно рассмотрим процесс написания эксплоита под уязвимость в Microsoft Edge, с последующим выходом из песочницы. Если вам интере... | https://habr.com/ru/post/455594/ | null | ru | null |
# Управляем розеткой по SMS
Хочу представить вам очень простой способ удаленного управления электропитанием.
Мы будем использовать готовые радиоуправляемые розетки, поэтому нам не потребуется ничего паять. Это очень здорово, потому что 220 В (начинающим) лучше не трогать.
![Топик без картинки - деньги на ветер]... | https://habr.com/ru/post/237553/ | null | ru | null |
# Пишем мультиплатформенного бота для перевода денег с карты на карту с помощью Microsoft Bot Framework V1
Во время конференции Microsoft Build 2016 был анонсирован Microsoft Bot Framework (сессия с Build 2016: [видео](https://channel9.msdn.com/Events/Build/2016/B821)). С его помощью можно создать бота (на C# или Node... | https://habr.com/ru/post/307530/ | null | ru | null |
# Сетевые системные вызовы. Часть 3
[Предыдущую часть обсуждения](http://habrahabr.ru/post/267773/) мы завершили на такой вот оптимистической ноте: «Подобным образом мы можем изменить поведение любого системного вызова Linux». И тут я слукавил — любого… да не любого. Исключение составляют (могут составлять) группа сет... | https://habr.com/ru/post/268145/ | null | ru | null |
# Переписываем проект с Zend Framework на Rails
Около пяти месяцев назад я завязал с zend framework и пересел на рельсы. Тогда же начал переписывать свой проект [www.okinfo.ru](http://www.okinfo.ru). Сейчас он уже закончен и sloccount показал что количество строк в проекте уменьшилось с 15000 до 4000. Мои знакомые php... | https://habr.com/ru/post/112966/ | null | ru | null |
# Squid с фильтрацией HTTPS без подмены сертификата, интеграция с Active Directory 2012R2 + WPAD
Этот мануал был написан в связи производственной необходимостью мониторить трафик (http и https) пользователей, а также распределения доступа по белым и черным спискам. За основу были взяты статьи: [эта](http://habrahabr.r... | https://habr.com/ru/post/314918/ | null | ru | null |
# Вышел релиз GitLab 12.6 с оценками безопасности проектов и материалами релиза

Руководителям разработки необходим четкий и понятный обзор состояния [безопасности приложения... | https://habr.com/ru/post/483762/ | null | ru | null |
# Распознаем лица на фото с помощью Python и OpenCV

В этой статье я хотел бы остановиться на алгоритмах распознавания лиц, а заодно познакомить вас с очень интересной и полезной библиотекой OpenCV. Уверен, что этот материа... | https://habr.com/ru/post/301096/ | null | ru | null |
# Малоизвестные CSS-свойства
Существует много CSS-свойств, о которых некоторые дизайнеры просто не знают. Или — знают, но забывают использовать эти свойства там, где они способны принести большую пользу. Некоторые из этих свойств могут помочь отказаться от использования JavaScript ради достижения некоего результата, н... | https://habr.com/ru/post/509704/ | null | ru | null |
# FiM++

Однажды на лекции друг рассказал мне, что существует язык программирования пони, (основанный на сериале, конечно). Он сказал, что видел его на reddit, но даже после продолжительного поиска я с... | https://habr.com/ru/post/155131/ | null | ru | null |
# Режимы работы почтовых серверов
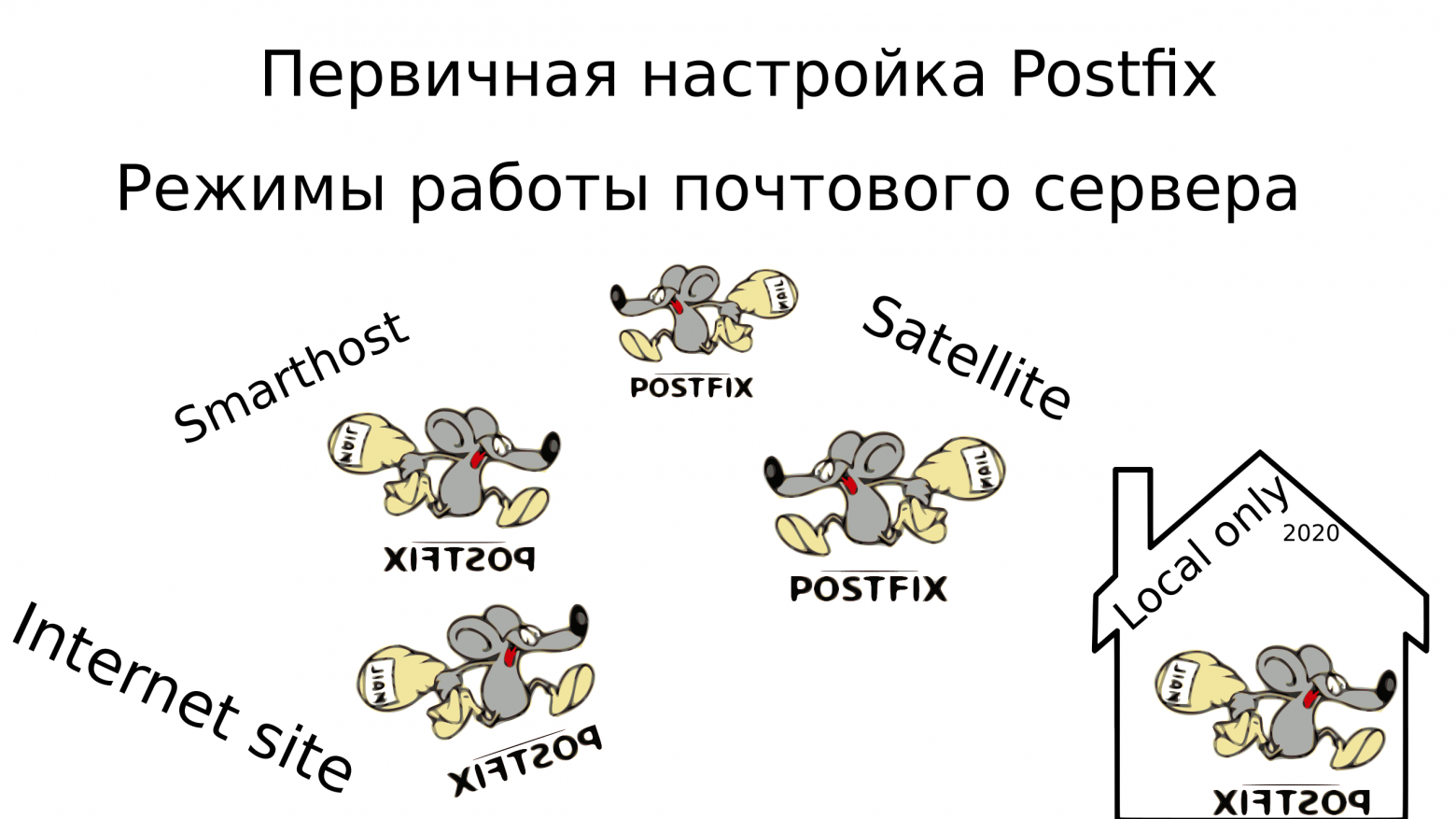
При установке Postfix на Debian-based дистрибутивах запускается псевдографический интерфейс с набором шаблонов для установки. Эти шаблоны нацелены под различные режимы работы почтового сервера,... | https://habr.com/ru/post/494906/ | null | ru | null |
# VLC как служба Windows
После долгого блуждания в гугло-мире я все же нашел решение своей проблемы. Проблема состояла в следующем — компания (вернее непосредственно начальство) узнала о существовании IP-камер, и в срочном порядке приняла решение купить и установить их в офис. Выбор пал на D-link DCS 2102-2121 так как... | https://habr.com/ru/post/115020/ | null | ru | null |
# Python Tips, Tricks, and Hacks (часть 4, заключительная)
Это заключительная часть перевода статьи. Декораторы, switch для функций, некоторая информация о классах.
#### 5. Функции
##### 5.4 Декораторы
Декораторы функций довольно просты, но если вы не видели их раньше, вам будет трудно догадаться, как они работаю... | https://habr.com/ru/post/95721/ | null | ru | null |
# Я готов платить деньги тем, кто удалит свой модуль npm
Культура npm создает серьезную опасность для защиты программного обеспечения в мировых масштабах. Это крайне безответственно – позволять деревьям зависимостей разрастаться до таких размеров, что в них входят тысячи зависимостей, связывающих вас с производителями... | https://habr.com/ru/post/590871/ | null | ru | null |
# Основы использования Cocoapods в разработке приложений под iOS
CocoaPods — это очень мощный инструмент, имеющий статус must have для любого iOS Developer'а. С помощью него мы можем легко, быстро и просто подключать различные вкусные тулзы, утилиты и библиотеки, которые значительно облегчают нам жизнь при разработке ... | https://habr.com/ru/post/261711/ | null | ru | null |
# Discriminated Unions в C#
Всем привет. Среди многих интересных концепций, имеющихся в F#, меня привлекли Discriminated Unions. Я задался вопросом, как их реализовать в C#, ведь в нем отсутствует поддержка (синтаксическая) типов объединений, и я решил найти способ их имитации.
Discriminated Unions - тип данных, пред... | https://habr.com/ru/post/684104/ | null | ru | null |
# Go: конкурентность и привязки к потокам в планировщике
Переключение горутины с одного потока ОС на другой довольно затратно и может значительно замедлить работу приложения, если это происходит слишком часто... | https://habr.com/ru/post/589851/ | null | ru | null |
# Отправка и приём SMS сообщений с помощью VoIP шлюзов GoIP и Yeastar

Так как мы занимаемся продажами VoIP оборудования, к нам часто обращаются с различными техническими вопросами. Иногда доходит до того, что клиенты прося... | https://habr.com/ru/post/395947/ | null | ru | null |
# В разрезе: новостной агрегатор на Android с бэкендом. Библиотека обхода интернет-сайтов на Java (crawler4j)
[Вводная часть (со ссылками на все статьи)](https://habrahabr.ru/post/334510/)
Неотъемлемой частью системы сбора новостей является робот для обхода сайтов (crawler, круалер, «паук»). В его функции входит от... | https://habr.com/ru/post/335340/ | null | ru | null |
# 90 новых фич (и API) в JDK 11
Привет, Хабр! Представляю вашему вниманию перевод статьи «[90 New Features (and APIs) in JDK 11](https://www.azul.com/90-new-features-and-apis-in-jdk-11/)» от автора Simon Ritter.

Новый шестимесячный... | https://habr.com/ru/post/424683/ | null | ru | null |
# Быстрая загрузка данных из файлов в R
Недавно мы писали приложение на Shiny, где нужно было использовать очень большой блок данных (dataframe). Это непосредственно влияло на время запуска приложения, поэтому пришлось рассмотреть ряд способов чтения данных из файлов в R (в нашем случае это были csv-файлы, предоставле... | https://habr.com/ru/post/326616/ | null | ru | null |
# Sparkfun.com FREE day или *как вы относитесь к recaptcha*
[Вдохновение](http://habrahabr.ru/post/155151/).
Пока 55% ненавидит…
А я выбрал «другое». Потому что люблю. Но не за то, что считаю удобнее других, а за то, что…
Раз в год американская компания sparkfun.com, хорошо знакомая всяким DIY-щикам, проводит... | https://habr.com/ru/post/155161/ | null | ru | null |
# Подвалы Вавилонской башни, или Об интернационализации баз данных с доступом через ORM

[*Гравюра М. Эшера «Относительность», 1953*](https://ru.wikipedia.org/wiki/%D0%9E%D1%82%D0%BD%D0%BE%D1%81%D0%B8%D... | https://habr.com/ru/post/313690/ | null | ru | null |
# Взгляд на технологии последнего десятилетия
***Прим. перев.**: Эта статья, ставшая хитом на Medium, — обзор ключевых (за 2010-2019 годы) изменений в мире языков программирования и связанной с ними экосистемы технологий (особое внимание уделяется Docker и Kubernetes). Её оригинальным автором является Cindy Sridharan,... | https://habr.com/ru/post/482664/ | null | ru | null |
# Топ вещей из Java, которых мне не хватает в C#
Спор "Java vs. C#" существует чуть меньше, чем вечность. Есть много статей, затрагивающих разные участки его спектра: Что есть в C# чего нет в Java, что языки... | https://habr.com/ru/post/687412/ | null | ru | null |
# Как «подружить» инженеров и дата-сайентистов с помощью одной библиотеки
Представьте, что у вас имеется большой проект по машинному обучению. Естественно, сначала над ним работали дата-сайентисты, а затем инженеры-программисты, которые оптимизировали модель для быстрого выполнения на определенных GPU. В итоге модель ... | https://habr.com/ru/post/526976/ | null | ru | null |
# Разбираем задачу T9 (predictive text)
Привет, Хабр! На днях ко мне обратился ученик на одном из ресурсов, где я выступаю в качестве frontend-ментора, с просьбой разобрать одну задачу. Суть задачи состояла ... | https://habr.com/ru/post/599029/ | null | ru | null |
# Как запланировать повторяющийся запуск VBA-процедуры в MS Excel без Application.OnTime
В этой статье мы продемонстрируем простую альтернативу Application.OnTime для периодического запуска VBA-процедур в MS Excel.
Предположим, что мы связали рабочую книгу MS Excel с каким-то внешним источником данных (напр., листом ... | https://habr.com/ru/post/677368/ | null | ru | null |
# Python: метапрограммирование в продакшене. Часть вторая
Мы продолжаем говорить о метапрограммировании в Python. При правильном использовании оно позволяет быстро и элегантно реализовывать сложные паттерны проектирования. В [прошлой части](https://habr.com/company/binarydistrict/blog/422409/) этой статьи мы показали,... | https://habr.com/ru/post/422415/ | null | ru | null |
# Обработка XML конфигурации Citrix XenServer 5.6 Free напрямую
В процессе работы с **XenServer** можно менять его конфигурацию разными способами.
Начиная от графической утилиты **XenCenter** и консольной команды **xe** заканчивая прямым вмешательством в XML конфиг.
Вот о последнем и хотелось бы с вами поговорит... | https://habr.com/ru/post/133097/ | null | ru | null |
# Представляя функции как сервис — OpenFaaS
***Прим перев.**: [OpenFaaS](https://www.openfaas.com/) — serverless-фреймворк, формально представленный в августе, но появившийся около года назад и быстро укрепившийся на самой вершине проектов GitHub по [тегу Kubernetes](https://github.com/topics/kubernetes). Опубликованн... | https://habr.com/ru/post/344656/ | null | ru | null |
# Первая игра, которую я просто написал для себя
*Пост ностальгии по игрушкам, которые мы сами для себя писали в детстве.*
Лазая по просторам App Store ища очередную игрушку для своего айпада, наткнулся на старинную игрушку “Братья Пилоты”. Сразу купил, поставил и прошёл на одном дыхании (уже наверное в 3 раз). Но ... | https://habr.com/ru/post/166057/ | null | ru | null |
# WBOIT в OpenGL: прозрачность без сортировки
Речь пойдёт о “Weighted blended order-independent transparency” (далее WBOIT) — приёме, описанном в JCGT в 2013 г. ([ссылка](http://jcgt.org/published/0002/02/09/)).
Когда на экране появляется несколько прозрачных объектов, цвет пикселя зависит от того, какой из них нах... | https://habr.com/ru/post/457284/ | null | ru | null |
# Работа с usb видеокамерой в Linux. Часть 2
Привествую, Хабр!
Продолжаем цикл статей про программирование видеокамеры в Linux. В первой части [[1]](#part1), мы рассмотрели механизм открытия и считывания первичных параметров видеоустройства. Была написана простенькая утилита catvd. Сегодня расширим функционал на... | https://habr.com/ru/post/212531/ | null | ru | null |
# Удобный «паджинатор»
Некоторое время назад озадачился поиском решения, которое позволило бы заменить стандартный «паджинатор» (CLinkPager) Yii на такой, который бы вместо номеров страниц писал что-то более внятное. Скажем, первые символы значений полей на последующих страницах. Не нашел и решил написать свой.
![]... | https://habr.com/ru/post/235579/ | null | ru | null |
# Продолжаем разгонять FizzBuzz
После написания [первой статьи про FizzBuzz](https://habr.com/ru/post/540136/) (которая неожиданно для меня стала выбором редакции на Технотексте 2021) у меня появлялись мысли о том, что можно бы еще ускорить, но все время было не до того. И тут мне прилетает [перчатка](https://habr.com... | https://habr.com/ru/post/682332/ | null | ru | null |
# Интеллектуальные ручки пользовательского объекта в MultiCAD.NET
Удобство редактирования чертежей является одной из ключевых характеристик систем автоматизированного проектирования. Важным инструментом для работы с объекта... | https://habr.com/ru/post/234181/ | null | ru | null |
# Как добавить реализма в path tracing
Здравствуйте, уважаемые хабровчане. Казалось бы: куда уже реальнее, но все же, есть у меня идея. По порядку.
#### Введение
Path tracing — это метод создания сцен виртуальной реальности, основан на оптике.
В трехмерном пространстве из источника света испускается очень много... | https://habr.com/ru/post/164727/ | null | ru | null |
# Pylint: детальная проверка работы анализатора кода
Когда Люк работал с Flake8 и одновременно присматривался к Pylint, у него сложилось впечатление, что 95% ошибок, выдаваемых Pylint, были ложными. У других разработчиков был иной опыт взаимодействия с этими анализаторами, поэтому Люк решил детально разобраться в ситу... | https://habr.com/ru/post/499870/ | null | ru | null |
# Мобильное приложения для управления умным домом на базе Z-Wave с помощью OpenRemote

Не так давно был представлен Z-Wave модуль для Raspberry Pi — RaZBerry, который превращает мини-компьютер в полноценны... | https://habr.com/ru/post/180749/ | null | ru | null |
# Использование Effector в стеке React + TypeScript
Всем привет! Меня зовут Елизавета Добрянская, я frontend-разработчик в компании ДомКлик. Моя команда занимается разработкой сервисов, предназначенных для коммуникаций с клиентом.
В этой статье я поделюсь своим кратким обзором внедрения стейт-менеджера Effector в пр... | https://habr.com/ru/post/532016/ | null | ru | null |
# Apache Spark: оптимизация производительности на реальных примерах
Apache Spark – фреймворк для обработки больших данных, который давно уже стал одним из самых популярных и часто встречаемых во всевозможных... | https://habr.com/ru/post/578654/ | null | ru | null |
# Пишем ИИ для Виндиниума на одноплатных компьютерах. Часть 3: от теории к практике. Эффективно охотимся за рудниками в ПП
Серия статей по написанию ИИ для многопользовательской онлайн игры жанра рогалик, ограниченного производительностью одноплатного компьютера.
В этой части статьи мы посмотрим на один из самых по... | https://habr.com/ru/post/370767/ | null | ru | null |
# Exchange 2016\2019 перестал работать в новогоднюю ночь
Пользователи сообщают о невозможности получения или отправления писем через on-premise Exchange 2016 и 2019. Всему виной автоматически устанавливаемое обновление встроенного антивируса.
В журнале регистрируется сообщение **FIPFS 5300**
`The FIP-FS "Microsoft" ... | https://habr.com/ru/post/599031/ | null | ru | null |
# Типобезопасная работа с массивами PHP, часть 2
Всем привет, прошёл почти год с публикации [первой части](https://habr.com/ru/post/476102/). Обсуждение в комментариях было жарким, выводы я для себя сделал, изменения в либу внёс почти сразу, но написать об этом времени не нашлось.
На днях расширил функционал парой ме... | https://habr.com/ru/post/522348/ | null | ru | null |
# Взаимодействие веб-сервисов через REST
При разработке современных веб-сервисов зачастую появляется вопрос, каким образом обеспечить простое и прозрачное взаимодействие нескольких разнородных систем. Благо, выбор большой: здесь и [SOAP](http://en.wikipedia.org/wiki/SOAP), и [CORBA](http://en.wikipedia.org/wiki/CORBA)... | https://habr.com/ru/post/148492/ | null | ru | null |
# Asterisk Managment Interface (AMI), Часть 2
В продолжение к опубликованной на днях первой части описания работа интерфейса PBX с открытым исходным кодом Asterisk я публикую вторую часть. В этой части приводятся некоторые примеры использования этого интерфейса для взаимодействия с PBX, начиная от подключения и автори... | https://habr.com/ru/post/64243/ | null | ru | null |
# Потоки, блокировки и условные переменные в C++11 [Часть 2]
Для более полного понимания этой статьи, рекомендуется прочитать ее [первую часть](http://habrahabr.ru/post/182610/), где основное внимание было уделено потокам и блокировкам, в ней объяснено много моментов (терминов, функций и т.д.), которые без пояснения б... | https://habr.com/ru/post/182626/ | null | ru | null |
# Лучшие методики журналирования enterprise-приложений (с точки зрения инженера поддержки)

Журналы приложений раскрывают информацию о внешних и внутренних событиях, которые видит приложение в ходе исполнения. Когда при деплое возн... | https://habr.com/ru/post/532996/ | null | ru | null |
# Я — Бренд или как поднять свою ценность?
После написания поста об [алгоритме IT собеседования](http://habrahabr.ru/post/146927/), мы в комментариях обсуждали, что постоянно кому-то нужно что-то доказывать, выполнять глупые тестовые задания и т.д. Область, в которой мы работаем, растет и развивается очень быстро. Кла... | https://habr.com/ru/post/147085/ | null | ru | null |
# Мыслим в стиле React

Перевод туториала официальной документации библиотеки React.js.
Мыслим в стиле React
--------------------
React, на наш взгляд, это лучший способ построить большое, быстрое веб-приложение с помо... | https://habr.com/ru/post/319134/ | null | ru | null |
# Как я сделал систему приема платежей в Minecraft на чистом PowerShell
[](https://habr.com/ru/company/ruvds/blog/501568/)
В этой статье мы прикрутим богомерзкий донат к ванильному серверу Minecraft с помощью Powershell. Преимущест... | https://habr.com/ru/post/501568/ | null | ru | null |
# WPF Tipz #1
Давеча у меня сломались уголки, нет ну натурально — сломались,
нет слава богу не в жизни, а только в приложении.
Жило себе приложение полгода и хоть бы хны, а тут раз и уголки у него сломались.
P.S
Тема уголков в WPF можеть быть не в полной мере раскрыта,
собственно ваши варианты по реа... | https://habr.com/ru/post/40489/ | null | ru | null |
# css Rotate. Возможен и в IE
Буду краток.
css свойство transform:rotate в ИЕ не доступно.
Но все знают что есть фильтр **progid:DXImageTransform.Microsoft.Matrix**, который конечно поворачивает изображение. Но скажем так *не совсем* правильно.
99% статей про использование этого фильтра содержат примерно таку... | https://habr.com/ru/post/107183/ | null | ru | null |
# Сортируем файлы с помощью Python
Штош. Скорее всего, у многих в папке загрузок собиралась куча разных инсталляторов, архивов и прочих файлов. Намного проще найти нужное, когда папки отсортированы в едином с... | https://habr.com/ru/post/562362/ | null | ru | null |
# Пишем эмулятор Кубика Рубика
OpenGL — платформонезависимая спецификация, описывающая программный интерфейс для создания компьютерных приложений, использующих двухмерную и трехмерную графику.
В этой статье я опишу, как можно создать эмулятор Кубика Рубика на OpenGL.
Кубик будет в 3D и его можно будет вращать мы... | https://habr.com/ru/post/173131/ | null | ru | null |
# #4 Нейронные сети для начинающих. Sudoku Solver. Судоку. Часть 1
[](https://habr.com/ru/company/ruvds/blog/706164/)
Предыстория: одним зимним вечером, а скорее ночью, мне пришла в голову интересная идея. Почему бы не попробовать ав... | https://habr.com/ru/post/706164/ | null | ru | null |
# Преимущества systemd-networkd на виртуальных серверах Linux
Обычно на десктопах Linux для управления сетевыми настройками используется NetworkManager, поскольку он отлично справляется со своей работой и имеет GUI фронтенды для всех популярных графических окружений. Однако на серверах Linux его использование не целес... | https://habr.com/ru/post/309010/ | null | ru | null |
# Установка Google Wave сервера FedOne c jabber-сервером ejabberd
В продолжение темы [об установке «волнового» демо-сервера FedOne](http://habrahabr.ru/blogs/google/65964/) публикую заметку Кирилла Агафонова. Он расскажет про свой опыт использования вместо OpenFire другого jabber-сервера.
Автор — [Кирилл Агафонов](... | https://habr.com/ru/post/66483/ | null | ru | null |
# Создание самодокументирующегося сервера на Node.JS
Условия:
* валидация через Joi
* использование Typescript
* Express сервер
* SWAGGER на /api-docs
Задача: **DRY**
Решение:
--------
Для начала необходимо решить что первично: схема Joi, Swagger или TypeScript интерфейс. Эмпирическим путём установлено что первичн... | https://habr.com/ru/post/538260/ | null | ru | null |
# Реализуем промисы на Java
Всем доброго времени суток. Сегодня я хочу рассказать о том, как писал реализацию механизма промисов для своего JS движка. Как известно, не так давно вышел новый стандарт ECMA Script 6, и концепция промисов выглядит довольно интересно, а также уже очень много где применяется веб-разработчик... | https://habr.com/ru/post/350444/ | null | ru | null |
# Бот в качестве таск-менеджера?
Предлагаю читателям "Хабрахабра" историю о том, как я искал удобный таск-менеджер для работы среди множества готовых решений и в итоге остановился на самописном.
Вам будет интересно почитать, если вы:
* Не довольны своим таск-менеджером, так как он очень сложный/неудобный
* Работаете... | https://habr.com/ru/post/305462/ | null | ru | null |
# Mozart CMF: API, основанный на XML
Итак, в своей первой статья я сделал несколько предположений об [архитектуре предметной области в CMF/CMS системах](http://habrahabr.ru/blogs/webdev/71279/). Тогда я сделал предположение об объектной модели я связанном с нею сервисе, который умел обрабатывать входящие запросы и выд... | https://habr.com/ru/post/88877/ | null | ru | null |
# Использование объектов для красивой структуры кода в JavaScript
#### Вступление
Доброго всем времени суток. Поздравляю вас с праздниками и перехожу к теме.
Когда вы выходите за рамки написания простых фрагментов jQuery и приступаете к разработке более сложных взаимодействий пользователей, ваш код может быстро ст... | https://habr.com/ru/post/111290/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.