
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Скачиваем историю переписки со всеми пользователями ВКонтакте с помощью Python
Для лингвистического исследования мне понадобился корпус прямой речи, порожденной одним человеком. Я решил, что для начала удобнее всего использовать собственную переписку в ВК. Это статья о том, как скачать все сообщения, которые Вы когд... | https://habr.com/ru/post/325368/ | null | ru | null |
# Валидация данных в iOS приложениях
Думаю, каждый из нас сталкивался с задачей валидации данных в приложениях. Например, при регистрации пользователя нужно убедиться что email имеет правильный формат, а пароль удовлетворяет требованиям безопасности и так далее. Можно привести массу примеров, но все в итоге сводится к... | https://habr.com/ru/post/485092/ | null | ru | null |
# Инициализация в современном C++

Общеизвестно, что семантика инициализации — одна из наиболее сложных частей C++. Существует множество видов инициализации, описываемых разным синтаксисом, и все они взаимодействуют сложным и вызываю... | https://habr.com/ru/post/469465/ | null | ru | null |
# Руководство по работе с Django REST Framework, Swagger и созданию клиента TypeScript для API
 **Цели:**
* Создать API с помощью Django REST Framework;
* Создать динамическую документацию Swagger;
* Сгенери... | https://habr.com/ru/post/583220/ | null | ru | null |
# Websocket API на nodejs по новому
О чем эта статья?
-----------------
1. [uWebsockets.js](https://github.com/uNetworking/uWebSockets.js/) - высокопроизводительная реализация http/websocket сервера для node... | https://habr.com/ru/post/575122/ | null | ru | null |
# Павел 2.0: консультант-рептилоид на JS, node.js с сокетами и телефонией
Вот и отгремел наш INTERCOM’18, c преферансом и бизнес-кейсами. Как обычно, вход на коференцию был платным: желающие могли купить билеты на TimePad по полной цене, либо… получить скидку у консультанта-рептилоида [прямо на сайте](https://intercom... | https://habr.com/ru/post/426417/ | null | ru | null |
# Создание виртуального SSD для vSphere 5.5
Использование виртуального твердотельного накопителя поможет Вам сэкономить и время и деньги. [VMware vSphere 5.5](https://www.vmware.com/support/vsphere5/doc/vsphere-esx-vcenter-server-55-release-notes.html) новейшая редакция передовой платформы виртуализации, это аппаратны... | https://habr.com/ru/post/244987/ | null | ru | null |
# Node.js: документирование и визуализация API с помощью Swagger

Привет, друзья!
В этой небольшой заметке я расскажу вам о том, как генерировать и визуализировать документацию к `API` с помощью [`Swagger`](https://swagger.io/).
Мы... | https://habr.com/ru/post/594081/ | null | ru | null |
# Разработка для Microsoft SQL Server (и не только): контроль версий, непрерывная интеграция и процедуры — как это делаем мы
Доброго времени суток, уважаемые Хабровчане.
В качестве краткой предыстории: год назад, придя на новое место работы в качестве руководителя отдела разработки БД (на базе Microsoft SQL Se... | https://habr.com/ru/post/258005/ | null | ru | null |
# Как менеджер мини-АТС с GSM и записями разговоров делал
Сегодня, в эру высоких технологий и безупречного клиентского сервиса, всем хочется быть на уровне. Многие компании в независимости от ранга и размера постоянно стараются сделать общение с клиентом удобнее и приятнее. В нашем интерне-агентстве, руководителем, ко... | https://habr.com/ru/post/252845/ | null | ru | null |
# C for Metal — драгоценный металл для вычислений на графических картах Intel
Сколько процессорных ядер Intel в вашем компьютере? Если вы пользуетесь системой на базе Intel, то в абсолютном большинстве случаев к вашему ответу надо будет прибавить единицу. В состав почти всех процессоров Intel — от Atom и до Xeon E3, е... | https://habr.com/ru/post/466521/ | null | ru | null |
# Рукопожатие SSH простыми словами
Secure Shell (SSH) — широко используемый протокол транспортного уровня для защиты соединений между клиентами и серверами. Это базовый протокол в нашей программе [Teleport](https://gravitational.com/teleport) для защищённого доступа к инфраструктуре. Ниже относительно краткое описание... | https://habr.com/ru/post/474654/ | null | ru | null |
# Установка Firebird на D-Link DNS-325
У меня возникла «бюджетная» идея использовать в качестве резервной СУБД (как временное решение на случай отказа) уже имеющийся в наличии NAS D-Link DNS-325. Организация небольшая + безотрывное производство + отсутствие дежурного специалиста, но это только для вступления.
Решая... | https://habr.com/ru/post/304008/ | null | ru | null |
# Организация хранения промежуточных таблиц для алгоритма CART
Доброго времени суток всем читающим. Сначала изложу предысторию данного вопроса. Началось все с того что знакомый попросил меня по работе помочь ему сделать приложение (WinForm на C#), которая бы алгоритмом CART создавала бинарное дерево решений, исходя из... | https://habr.com/ru/post/177797/ | null | ru | null |
# Минимализм Objective-C
Я часто пишу небольшие тестовые проекты на Objective-C, чтобы поэкспериментировать или поиграться с чем-нибудь. Обычно, я помещаю код в main.m и избавляюсь от всего остального:
```
#!/usr/bin/env objc-run
@import Foundation;
@implementation Hello : NSObject
- (void) sayHelloTo:name
{
p... | https://habr.com/ru/post/242621/ | null | ru | null |
# Java Virtual Machine in pure python
Коллеги,
Некоторое время назад я начал работать над обучающим проектом, совмещающим java + python + некоторые базовые алгоритмы. Промежуточный этап разработки — имплементация спецификации jdk7 на python. (Java исполняемая в python)
Код доступен [www.pyjvm.org](http://www.pyj... | https://habr.com/ru/post/218577/ | null | ru | null |
# Zynq. Передача данных между процессорным модулем и программируемой логикой
Как и обещал в предыдущей статье ([Что такое Zynq? Краткий обзор](https://habr.com/ru/post/508292/)), поговорим о передаче данных между процессорным модулем и программируемой логикой. В предыдущей статье упоминалось четыре способа передачи да... | https://habr.com/ru/post/535226/ | null | ru | null |
# Установка связки Carbon + Graphite + Grafana + Nginx + MySQL для сбора и отображения метрик в Ubuntu
Хочу поделиться опытом установки и настройки сервиса для сбора и отображения метрик `Graphite` + `Grafana`.
Искал долго, читал много, нашёл 2 статьи на английском, добавил своё, в итоге получилась данная статья.
... | https://habr.com/ru/post/302720/ | null | ru | null |
# Пишем плагин для Google SketchUp
[Google SketchUp](http://sketchup.google.com/) — программа для быстрого создания и редактирования трёхмерной графики. Удобство и простоту SketchUp оценят, как начинающие работу с трёхмерным моделированием, так и профессионалы.
Но не все знают, что SketchUp обладает мощным API, с п... | https://habr.com/ru/post/115166/ | null | ru | null |
# Превращаем статический сайт в мобильное приложение с помощью jQuery Mobile и PhoneGap

После приобретения телефона на базе Android, возникла задача сделать из сайта [brainexer](http://ru.brainexer.com) мо... | https://habr.com/ru/post/201752/ | null | ru | null |
# Emacs как файл менеджер
Практически каждому пользователю компьютера рано или поздно приходится сталкиваться с проблемой переименования сразу нескольких файлов. Например, сменить расширение файла, поменять имя, вставить порядковый номер и так далее. Кто-то пишет shell скрипты, кто-то использует специально созданные д... | https://habr.com/ru/post/99762/ | null | ru | null |
# PHP-Дайджест № 165 (23 сентября – 7 октября 2019)
[](https://habr.com/ru/post/470373/)
Свежая подборка со ссылками на новости и материалы. В выпуске: PHP 7.4.0 RC3, поддержка Composer-зависимостей на GitHub, обновление стан... | https://habr.com/ru/post/470373/ | null | ru | null |
# Модуляризация доменного слоя в UDF. Часть I
В одной [из предыдущих статей](https://habr.com/ru/company/indriver/blog/571394/) я рассказал, как в inDriver мы пришли к использованию UDF в своем приложении. Так как приложение inDriver — суперапп с множеством модулей, главными задачами для нашей архитектуры являются мас... | https://habr.com/ru/post/594795/ | null | ru | null |
# Разработка WebGPU-приложений
WebGPU — это один из современных [API](https://alain.xyz/blog/comparison-of-modern-graphics-apis), предназначенных для работы с компьютерной графикой. Среди других подобных API можно отметить Vulkan, DirectX 12 и Metal. То, что в сфере веб-графики появляются подобные решения, даёт пользо... | https://habr.com/ru/post/485644/ | null | ru | null |
# Книга «Android. Программирование для профессионалов. 3-е издание»
[](https://habrahabr.ru/company/piter/blog/335146/) Третье издание познакомит вас с интегрированной средой Android Studio, которая сильно облегчает разрабо... | https://habr.com/ru/post/335146/ | null | ru | null |
# Знакомство с Panda Gym
К старту курса о [машинном и глубоком обучении](https://skillfactory.ru/ml-and-dl?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_MLDL&utm_term=regular&utm_content=110821) з... | https://habr.com/ru/post/570580/ | null | ru | null |
# Техническая препарация одной игры, созданной независимыми разработчиками
Здравствуй, суровый, но справедливый хабр!
Хочу вместе с тобой препарировать одну игру, написанную мной совместно с моим хорошим другом. По механике игра – это бой в реальном времени между двумя игроками, у каждого из которых колода карт. А ... | https://habr.com/ru/post/142884/ | null | ru | null |
# Клонируем сами, своими руками
[](https://habr.com/ru/company/ruvds/blog/686812/)*Картина маслом: Опытный сисадмин ищет четырёхлетний бэкап на файл-сервере*
Задача: Вася летел на самолёте. Из-за неисправности двигателя самолёт упал ... | https://habr.com/ru/post/686812/ | null | ru | null |
# Подготовка и запуск "Hello, World!"
В учебном пособии для любого языка программирования есть самый первый пример, каноническая программа вывода строки «Hello, World!» Поскольку Arduino — это не совсем язык программирования, а железка, к тому же (пока) без средств вывода текста, первым делом мы запрограммируем контро... | https://habr.com/ru/post/38047/ | null | ru | null |
# Rss grabber для DLE жжот
Вот такой интересный код можно встретить в HttpClient'e Rss Grabber'а для DLE
`while (true)
{
$this->errormsg = 'Connection failed (' . $errno . ')';
$this->errormsg .= ' ' . $errstr;
$this->debug ($this->errormsg);
if (true)
{
return false;
}
}`
мне так и не... | https://habr.com/ru/post/40907/ | null | ru | null |
# Социальная сеть без интернета
SSB - это децентрализованная offline-first социальная сеть. **Децентрализованная** - это значит, что в ней нет сервера, который можно заблокировать, или на котором админ может закрыть вам доступ. **Offline-first** означает, что всё происходит в первую очередь на вашем устройстве.
Интер... | https://habr.com/ru/post/655155/ | null | ru | null |
# Настройка репликации во FreeIPA 4.4 с domain level 1

У нас в компании для организации и управления доступами для Linux-серверов
используется такой сервис как FreeIPA. FreeIPA — это вполне полноценная замена AD дл... | https://habr.com/ru/post/325546/ | null | ru | null |
# Coffeescript — Javascript в силе Ruby
[CoffeeScript](http://bit.ly/6h5JKO) — язык, чтобы писать на JavaScript с более удобным синтаксисом.
Краткий пример на CoffeeScript (с jQuery):
> `jQuery($ =>
>
> notified: false
>
> $('a').click( =>
>
> if notified
>
> true
>
> else
>
> ... | https://habr.com/ru/post/79586/ | null | ru | null |
# Локализация с AngularJS
Добрый день, уважаемые Хабражители.
AngularJS — отличный Framework для создания ваших сайтов. На Хабре уже достаточно много про него написано, но почему то ни разу не затрагивалась тема локализ... | https://habr.com/ru/post/237867/ | null | ru | null |
# Советы и секреты №2
#### Единый интерфейс для всех мессенджеров, самый удобный способ скачивать видео с YouTube, пакетный менеджер для Windows в стиле линуксового apt-get, встроенный калькулятор Google
**Существует ли универсальный фонтенд, чтобы обмениваться сообщениями в WhatsApp, Messenger, Skype, Slack, Telegra... | https://habr.com/ru/post/372491/ | null | ru | null |
# Мониторинг базы данных Oracle через ODBC в Zabbix

В статье будет рассмотрена возможность мониторинга база данных по средствам встроенной в Zabbix поддержке ODBC, c использованием автообнаружения объ... | https://habr.com/ru/post/226365/ | null | ru | null |
# Не забываем о языковых и культурных особенностях
Рано или поздно все сталкиваются с проблемами связанными с языковым и культурным разнообразием при написании программ. Я был сильно удивлен узнав, что часть моих знакомых, пишущих на... | https://habr.com/ru/post/104417/ | null | ru | null |
# Развертывание облачного приложения Node.js из среды разработки Cloud9
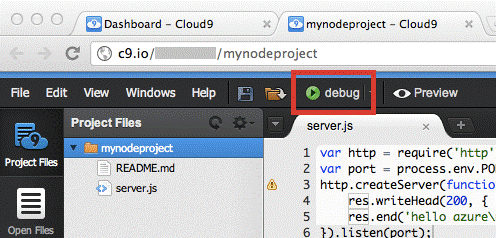
В данном руководстве описана разработка, компиляция и развертывание приложений Node.js в Windows Azure с помощью интегрированной среды р... | https://habr.com/ru/post/150622/ | null | ru | null |
# Как Phoenix убивает React

Около полутора лет назад мы написали внутренний инструмент для корпоративных анонсов. Изначально в нём использовался Phoenix для бэкенда и React для фронтенда. Тем самым мы получали преимущества ... | https://habr.com/ru/post/315666/ | null | ru | null |
# Как в 1995 году писали игры для Sega Saturn
Это документ, написанный мной в 1995 году, когда я работал над первой игрой студии Neversoft: Skeleton Warriors. Это была первая игра, в которой я не использовал язык ассемблера 68K.
Фото сделано примерно в то время. Комплект разработчика (dev kit) («Small Box» и ICE) с... | https://habr.com/ru/post/459622/ | null | ru | null |
# Использование локального .bashrc через ssh и консолидация истории выполнения команд
Если вам приходится работать с большим количеством удаленных машин через ssh то возникает вопрос как унифицировать shell окружение на этих машинах. Копировать заранее .bashrc не очень удобно, а зачастую невозможно. Давайте рассмотрим... | https://habr.com/ru/post/529544/ | null | ru | null |
# Почему Signal — не идеальный мессенджер. Нам нужна децентрализация
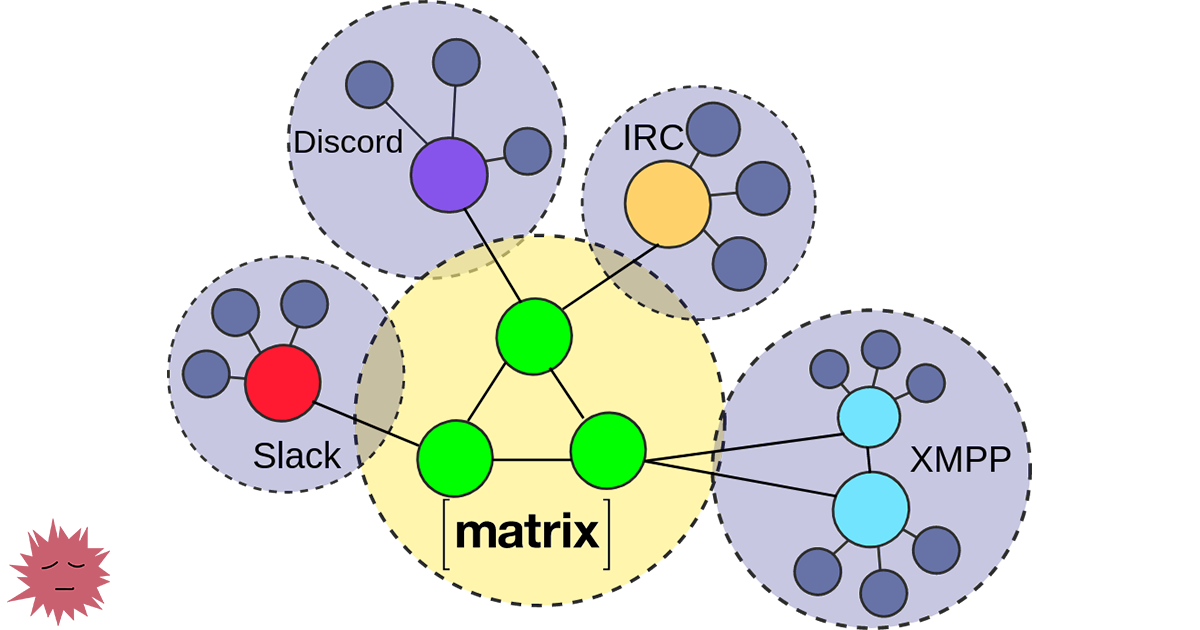
*Федеративная система Matrix поддерживает связь с другими сетями через мосты. Это пример инфраструктуры, к которой нужно стремиться Signal*
4 января 2021 года W... | https://habr.com/ru/post/539330/ | null | ru | null |
# Celery — распределенная очередь заданий
На этот раз мы решили рассказать о замечательном продукте, который мы используем в нашей работе. Речь пойдет о Celery — «distributed task queue». Это распределенная асинхронная очередь заданий, которая обладает широким функционалом. В нашем [конструкторе сайтов](http://cms.big... | https://habr.com/ru/post/102742/ | null | ru | null |
# Отправка файлов на подпись с Adobe Sign API
В документации Adobe сочетается большой объем информации и плохая организация этой информации. Поэтому когда перед мной стала задача отправлять документы через Adobe Sign Api, я потратил несколько дней чтобы понять как всё это работает.
И вот моё решение перед вами. Наде... | https://habr.com/ru/post/709296/ | null | ru | null |
# На чьей стороне вы: Push и Pull в Desired State Configuration
Мы уже рассказали, как описывать конфигурацию в Desired State Configuration (DSC) и разобрали встроенный агент Local Configuration Manager (LCM) для применения конфигурации на сервере. [В первой части статьи](https://habr.com/ru/company/dataline/blog/5030... | https://habr.com/ru/post/503672/ | null | ru | null |
# 12 Способов Отладки и Диагностики FirmWare
В этом тексте перечислены основные способы отлаживать и диагностировать проекты на микроконтроллерах. Для аналогии буду каждому методу отладки метафорично приводить в соответствие аналогию из медицины
**1–\*HeartBeat LED (Стетоскоп)**
Самое важное. Каждое электронное устр... | https://habr.com/ru/post/681280/ | null | ru | null |
# Написание и запуск сценариев SIPP. Часть 2.UAS сценарии
В прошлой статье я рассмотрел базовый сценарий UAC клиента, но зачастую в процессе обучение или тестирование необходимо смоделировать ситуацию в которой sipp будет выступать в качестве вызываемого абонента.
Передо мной стояла задача - узнать что будет слышать ... | https://habr.com/ru/post/648693/ | null | ru | null |
# Составное устройство USB на STM32. Часть 3: Звуковое устройство отдельно, виртуальный СОМ-порт отдельно

В третьей части публикации о составном устройстве *USB* я расскажу о том, как переделать сгенерированный в *STM32CubeMX* *US... | https://habr.com/ru/post/533588/ | null | ru | null |
# Развенчание мифов об x32 ABI
Наверное, некоторые из вас слышали о халяве под названием [x32 ABI](http://ru.wikipedia.org/wiki/X32_ABI).
#### Вкратце о x32 ABI
Если вкратце, то это возможность использовать все преимущества 64-битной архитектуры, но при этом сохраняя 32-битные указатели. Потенциально при этом при... | https://habr.com/ru/post/170407/ | null | ru | null |
# Что скрывается за формой редактирования сложного объекта?
В этой статье мы продолжаем знакомить вас с подходами, реализованными в планировщике XtraScheduler. В [предыдущей статье](http://habrahabr.ru/company/devexpress/blog/106063/) мы рассказывали о синхронизаторе данных, на этот раз поговорим о формах.

У разработчика, который впервые столкнулся с генерированием электронных писем, практически нет шансов написать приложение, которое будет делать это корректно. Около 40... | https://habr.com/ru/post/419591/ | null | ru | null |
# Использование let объявлений переменных и особенности образуемых связываний в замыканиях в JavaScript
Написать данную заметку меня сподвигло прочтение статьи на Хабре [«Var, let или const? Проблемы областей видимости переменных и ES6»](https://habr.com/ru/company/ruvds/blog/420359/) и комментариев к ней, а также соо... | https://habr.com/ru/post/462971/ | null | ru | null |
# Профилирование PHP-кода
Профилирование PHP-кода
Рано или поздно каждый из нас сталкивается с унаследованным кодом и его оптимизацией. Дебаггер и профилировшик в такой ситуации — лучшие помощники программиста. У тех кто работает с PHP, благодаря Дерику Ретансу (Derick Rethans) есть хороший инструмент — xDebug. Инф... | https://habr.com/ru/post/78210/ | null | ru | null |
# Переводчик Google и Волшебная Точка
В своё время очень мне полюбился сервис [translate.google.com](http://translate.google.com/) Как всегда, за простоту и функциональность. Частенько приходится что-то переводить туда-сюда и бывает очень интересно мнение стороннего «разума» на счет своего построения фраз. Ну и слова ... | https://habr.com/ru/post/102582/ | null | ru | null |
# Lazarus как он есть
Довольно часто наше нежелание разбираться в вопросе и уверенность в собственной логике рождает неверные предположения. Эти предположения, высказанные как утверждения на публичной площадке, могут прочно осесть в чужих головах и сформировать ложные отрицательные представления.
Так в комментариях... | https://habr.com/ru/post/151008/ | null | ru | null |
# Хочу middleware, но не хочу ExpressJS
Middleware в случае с HTTP-сервером в Node.JS — это промежуточный код, который выполняется до того, как начнёт выполняться ваш основной код. Это, чаще всего, нужно для того, чтобы сделать какой-то дополнительный тюнинг или проверку входящего запроса. Например, чтобы превратить д... | https://habr.com/ru/post/531982/ | null | ru | null |
# Простой шаблонизатор DOCX-документов с помощью Smart Document Engine
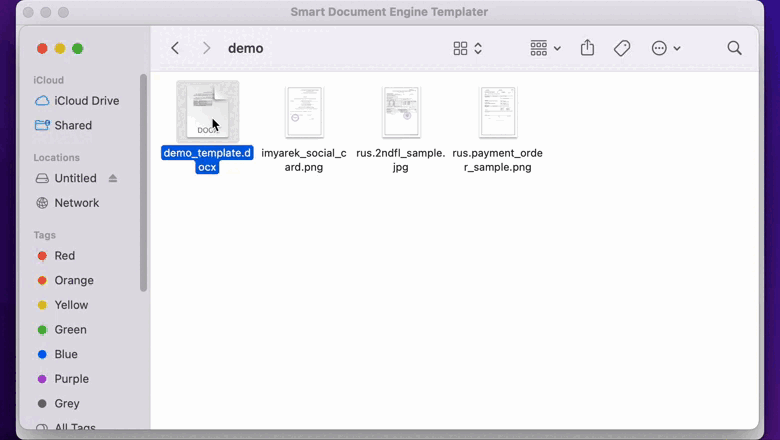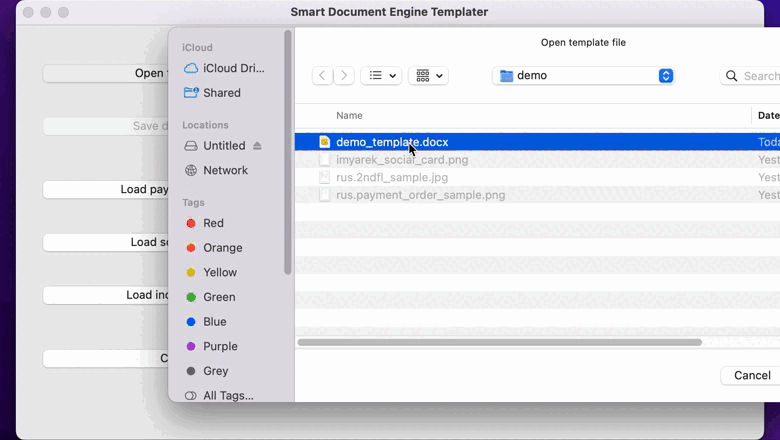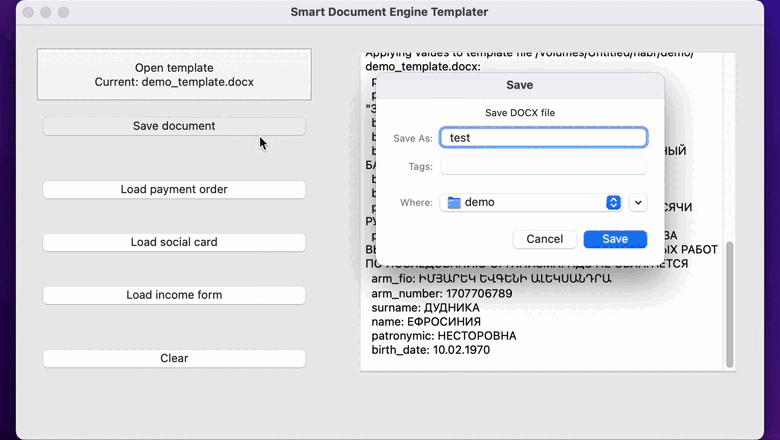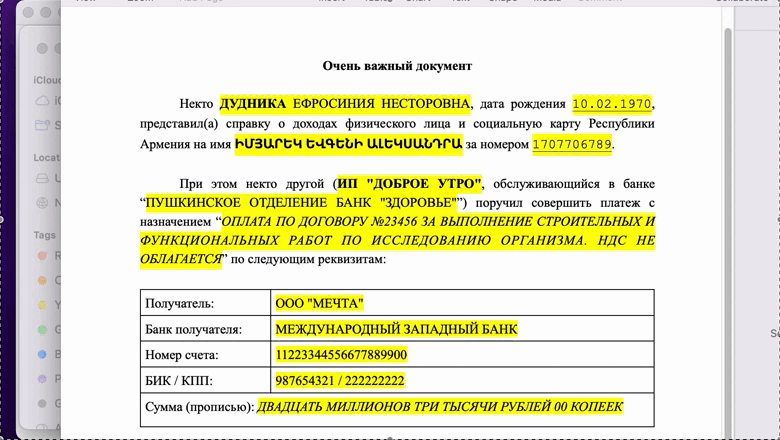Мы в [Smart Engines](https://smartengines.ru/) занимаемся системами распознавания документов, и мы решили проверить, сколько нужно времени, чтобы... | https://habr.com/ru/post/672896/ | null | ru | null |
# Быстрый старт в MODX Revolution
Revolution дорос уже до версии 2.0.8, но большинство разработчиков не спешит его использовать, так как документация еще не полная, да и статей на русском очень мало.
Лично я не нашел ни одной пошаговой инструкции «для чайников», и поэтому решил написать ее сам.
Конечно, это топи... | https://habr.com/ru/post/116614/ | null | ru | null |
# Прецизионное литьё мягким силиконом в домашних условиях, с помощью 3D-печати
Одни люди страдают от фетишизма, но другие им наслаждаются, как православные фермеры на пасху — похмельем. А почему нет? «С утра выпил — день свобо... | https://habr.com/ru/post/370191/ | null | ru | null |
# Организуем поиск молекулярных структур с помощью Lucene и Chemistry Development Kit
Библиотека полнотекстового поиска Lucene предоставляет возможность организовать поиск по текстовым документам. Существуют так же средства, с помощью которых можно организовать поиск «похожих» химических структур, например, OpenBabel.... | https://habr.com/ru/post/185420/ | null | ru | null |
# Checking BitTorrent in honor of the 20th anniversary. Time == quality
Couple of weeks ago (or to be more precise, on July 2, 2021), the legendary BitTorrent protocol turned twenty years old. Created by Bram Cohen, the protocol has been developing rapidly since its inception, and has quickly become one of the most po... | https://habr.com/ru/post/570446/ | null | en | null |
# CSS переменные в Firefox 29
На протяжении многих лет одной из самых частых просьб к рабочей группе CSS была реализация хоть какой-то поддержки объявления и использования переменных в таблицах стилей. После долгих обсуждений, в спецификации [CSS Custom Properties for Cascading Variables](http://dev.w3.org/csswg/css-v... | https://habr.com/ru/post/206096/ | null | ru | null |
# Deployment вашего софта для OS Inferno
К сожалению, встроенного механизма для распространения и установки дополнительного софта в [OS Inferno](http://code.google.com/p/inferno-os/) нет. Если вы написали модуль для [Limbo](http://www.vitanuova.com/inferno/limbo.html) или полноценное приложение, и хотите им поделиться... | https://habr.com/ru/post/87460/ | null | ru | null |
# Заметки о дельта-роботе. Часть 4. Скорости приводов
В результате предыдущих расчётов мы выбрали размеры дельта-робота, построили его рабочую зону. Теперь настало время выбрать приводы. Привод, или устройство, которое вращает входные звенья (рычаги), имеет две главные характеристики – максимальную частоту вращения и ... | https://habr.com/ru/post/585260/ | null | ru | null |
# Navigation Architecture Component. Практический взгляд

На недавнем [Google IO 2018](https://www.youtube.com/playlist?list=PLOU2XLYxmsIInFRc3M44HUTQc3b_YJ4-Y) в числе прочего было [представлено решение](https://www.youtube.com/watch?... | https://habr.com/ru/post/359282/ | null | ru | null |
# Отслеживаем удаление файлов на PowerShell
Привет, Хабр! Тема моего поста уже поднималась здесь, но мне есть, что добавить.
Когда наше файловое хранилище разменяло третий терабайт, все чаще наш отдел стал получать просьбы выяснить, кто удалил важный документ или целую папку с документами. Нередко это происходит по... | https://habr.com/ru/post/238469/ | null | ru | null |
# Учебник по языку SQL (DDL, DML) на примере диалекта MS SQL Server. Часть вторая
Вступление и DDL – Data Definition Language (язык описания данных)
------------------------------------------------------------------
Часть первая — [habrahabr.ru/post/255361](http://habrahabr.ru/post/255361/)
DML – Data Manipulation... | https://habr.com/ru/post/255523/ | null | ru | null |
# Неполадки USB 2.0 в Windows 8 на материнских платах с Intel 6 Series Chipset
После апгрейда на Windows 8 мною была замечена странная проблема: после спящего режима, а иногда и при холодном старте, я не мог войти в систему потому, что ни мышка ни клавиатура не функционировали! Спешу разочаровать тех кто сталкивается ... | https://habr.com/ru/post/174613/ | null | ru | null |
# Обзор обновления Veeam Backup & Replication 9.5 Update 4
В конце января вышло обновление Update 4 для Veeam Availability Suite 9.5, насыщенное фичами как иной полноправный major release. Сегодня я вкратце расскажу об основных новинках, реализованных в Veeam Backup & Replication, а про Veeam ONE обещаю написать в бли... | https://habr.com/ru/post/438714/ | null | ru | null |
# Java ME Embedded на Raspberry Pi

Насколько я могу судить, на Хабре да и не только, наблюдается всплеск интереса к микроконтроллерам — устройствам на базе ARM процессоров и другим не совсем обычным железк... | https://habr.com/ru/post/210592/ | null | ru | null |
# REST-сервисы на ASP.NET Core под Linux в продакшене
В основе этой статьи доклад **Дениса Иванова** ([@DenisIvanov](https://habrahabr.ru/users/DenisIvanov/)) на РИТ++ 2017, в котором он поделился опытом разработки и запуска в продакшен REST-сервиса на ASP.NET Core на Kubernetes. На текущий момент это сделать уже можн... | https://habr.com/ru/post/352168/ | null | ru | null |
# Руководство Google по стилю в C++. Часть 4
[Часть 1. Вступление](https://habr.com/ru/post/480422/)
…
[Часть 3. Область видимости](https://habr.com/ru/post/571334/)
**Часть 4. Классы**
[Часть 5. Функции](https://habr.com/ru/post/580072/)
…
 открытый фреймворк для разработки блокчейнов [Exonum](http://exonum.com/). Он позволит компаниям и правительственным организациям воплощать в жизнь безоп... | https://habr.com/ru/post/332438/ | null | ru | null |
# GitLab 8.11: канбан-доска и разрешение конфликтов одним кликом
*Эта статья — перевод релизной статьи компании GitLab. Релизы выходят каждый месяц 22 числа.*
*Если вы пропустили предыдущие, вот ссылки: [8.10](https://habrahabr.ru/company/softmart/blog/306860/), [8.9](https://habrahabr.ru/company/softmart/blog/305436... | https://habr.com/ru/post/308632/ | null | ru | null |
# Как перенести ESXi сервер на другой сервер
#### Введение
Данный материал описывает способ установки ESXi сервера на оборудование, которое не поддерживается его установщиком. Проблема обходится путем переноса образа ESXi с работающего сервера на сервер, где возникла проблема установки. В моем случае проблема была с ... | https://habr.com/ru/post/57165/ | null | ru | null |
# Быстрый рендеринг океанских волн на мобильных устройствах

Моделирование воды в компьютерной графике в реальном времени до сих пор остается весьма сложной задачей. Особенно актуально это при разработке компьютерных игр, в ко... | https://habr.com/ru/post/336998/ | null | ru | null |
# Прекратите усердствовать с комментариями в коде
Привет, Хабр!
Сегодня вашему вниманию предлагается весьма дискуссионная статья, затрагивающая важный аспект философии "[Чистого Кода](https://www.piter.com/product_by_id/111861023)". Автор статьи берет на себя смелость утверждать, что в большинстве случаев комментар... | https://habr.com/ru/post/458990/ | null | ru | null |
# Анализ Буткита FinFisher
Добрый вечер! Ровно через неделю у нас стартует курс [«Реверс-инжиниринг»](https://otus.pw/gat0/), и сегодня мы хотим поделиться с вами переводом материала, который имеет прямое отношение к этому курсу. Поехали.
Недавно мы [исследовали](http://www-03.ibm.com/security/?ce=ISM0484&ct=SWG&cm... | https://habr.com/ru/post/441970/ | null | ru | null |
# В трафик сайтов опять внедряют посторонний контент. Как защититься?
*[Источник](https://habr.com/ru/post/493402/)*
В последнее время [участились случаи инъекций стороннего контента](https://twitter.com/MosSobyaniin/status/154... | https://habr.com/ru/post/676388/ | null | ru | null |
# Путь в космос

4 июня 2010 года, в 5:45 по Атлантическому времени, с мыса Канаверал взлетел и вышел на низкую околоземную орбиту космический корабль, **не принадлежащий никакой правительственно... | https://habr.com/ru/post/95592/ | null | ru | null |
# Удаленное выключение linux-сервера PHP
Возможно у вас, как и у меня возникала потребность выключения сервера удаленно (странная потребность, он ведь на то и сервер, чтобы постоянно работать). В любом случае у каждого свои мотивы. Итак, мне необходимо было выключить удаленный сервер с другого компьютера, выключение с... | https://habr.com/ru/post/151526/ | null | ru | null |
# Простой DICOM клиент на GO с балансировщиком задач и веб-интерфейсом

Привет Хабр! В последнее время я очень сильно увлекся разработкой на языке GO. Изящный и выразительный язык программирования. Мне давно хотелось сдела... | https://habr.com/ru/post/254581/ | null | ru | null |
# Протокольно ориентированное программирование. Часть 1
Давайте подробнее изучим тему протокольно ориентированного программирования. Для удобства разделили материал на три части.
Данный материал является комментированным переводом [презентации WWDC 2016](https://developer.apple.com/videos/play/wwdc2016/416/). Вопреки... | https://habr.com/ru/post/473798/ | null | ru | null |
# Записки майнтейнера: resurrection
В 2010 я стал майнтейнером в **ALT Linux**: прошёл [все этапы процедуры принятия в Team](https://www.altlinux.org/%D0%9F%D1%80%D0%BE%D1%86%D0%B5%D0%B4%D1%83%D1%80%D0%B0_%D0%BF%D1%80%D0%B8%D0%BD%D1%8F%D1%82%D0%B8%D1%8F_%D0%B2_Team): получил статус кандидата, провёл пробную сборку пак... | https://habr.com/ru/post/324692/ | null | ru | null |
# PHP-Дайджест № 92 – интересные новости, материалы и инструменты (29 августа – 11 сентября 2016)

Предлагаем вашему вниманию очередную подборку со ссылками на новости и материалы.
Приятного чтения!
### Новости и релизы
... | https://habr.com/ru/post/309710/ | null | ru | null |
# Типичные ошибки, которые разработчик допускает при обучении — и как их избежать
[](https://habrahabr.ru/company/alconost/blog/418815/)
**В эпоху подрывных технологий и засилья фреймворков.**
Обучение, развитие навыков и умение... | https://habr.com/ru/post/418815/ | null | ru | null |
# Тонкости работы с PassportJs
Недавно работая над очередным проектом, который использует [passporjs](http://passportjs.org/), наткнулся на несколько проблем, с которыми в интернете сталкивались и другие разработчики. Но ответов в интернете я не нашел (возможно плохо искал).
Расскажу об этих проблемах и как их реша... | https://habr.com/ru/post/262979/ | null | ru | null |
# Как закопать и найти клад на Solidity
Начну с описания кейса, где нам потребовалось решение подобной задачи. Мы реализовали проект [TheWall Global](https://thewall.global), в рамках которого мы создали двумерное пространство или стену, которая разделена на равные области, каждая из которых представляет собой NFT-ток... | https://habr.com/ru/post/585730/ | null | ru | null |
# Настройка Kerberos-аутентификации с использованием смарт-карт
В продолжение [давней темы](http://habrahabr.ru/company/aktiv-company/blog/144700/) про использование двухфакторной аутентификации в ОС GNU/Linux позвольте рас... | https://habr.com/ru/post/170829/ | null | ru | null |
# Странное поведение Task Manager в Windows Server 2012
Краткое содержание: история в картинках, как я «улучшал» Task Manager в Windows Server 2012
#### Преамбула
Началось всё с того, что я в тестовых целях (выяснить, есть ли принципиальное различие), поставил [Windows Server 2012](http://www.microsoft.com/en-us/s... | https://habr.com/ru/post/160161/ | null | ru | null |
# Подключение сенсора освещения от Mac Book Pro к Arduino
Сегодня я хотел бы вам рассказать как я подключил датчик освещенности от мак бук про к ардуино. На самом деле все просто. Главное — немного усидчивости.
Запасная часть у меня оказалась случайно, я выпросил убитый ноутбук MAC book pro 15`, в котором не хватал... | https://habr.com/ru/post/144685/ | null | ru | null |
# Создание сеток шестиугольников
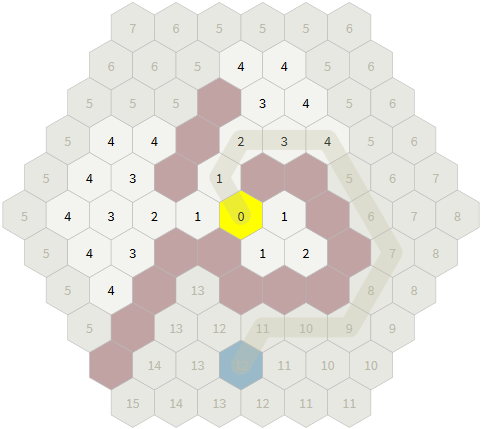
Сетки из шестиугольников (гексагональные сетки) используются в некоторых играх, но они не так просты и распространены, как сетки прямоугольников. Я [коллекционирую ресурсы о сетках шест... | https://habr.com/ru/post/319644/ | null | ru | null |
# Модифицируем Last Epoch — От dnSpy до Ghidra
Last Epoch — это однопользовательская ARPG на Unity и C#. В игре присутствует система крафта — игрок находит модификаторы, которые затем применяет к экипировке. С каждым модификатором накапливается "нестабильность", которая увеличивает шанс поломки предмета
Я преследовал... | https://habr.com/ru/post/514416/ | null | ru | null |
# Exploring JavaScript Symbols. Symbol — новый тип данных в JavaScript
Это первая часть про символы и их использование в JavaScript.
Новая спецификация ECMAScript (ES6) вводит дополнительный тип данных — символ (symbol). Он пополнит список уже доступных примитивных типов (string, number, boolean, null, undefined). ... | https://habr.com/ru/post/255137/ | null | ru | null |
# Особенности Google PageSpeed: улучшение оценки сайта и его рейтинга в поиске
Материал, перевод которого мы сегодня публикуем, посвящён рейтингу скорости сайтов, который можно вычислить с помощью Google PageSpeed Insights.
Ни для кого не секрет то, что скорость сайта в наше время стала одной из его важнейших харак... | https://habr.com/ru/post/462005/ | null | ru | null |
# Prometheus — практическое использование
Одной из важнейших задач при разработке приложений с микросервисной архитектурой является задача мониторинга. Слежение за состоянием сервисов и серверов позволяет не только вовремя реагировать на неисправности, но и анализировать их работу. Наличие такой информации трудно пере... | https://habr.com/ru/post/308610/ | null | ru | null |
# Считаем среднюю ЗП «дата-саентолога». Парсим hh.ru с помощью pandas/python

Хочешь узнать, какая ситуация на рынке труда, особенно в области "дата-сайенс"?
Если знаешь Python и Pandas, парсинг Хедхантера это кажется один с самый н... | https://habr.com/ru/post/464823/ | null | ru | null |
# Крутые трюки с переменными CSS
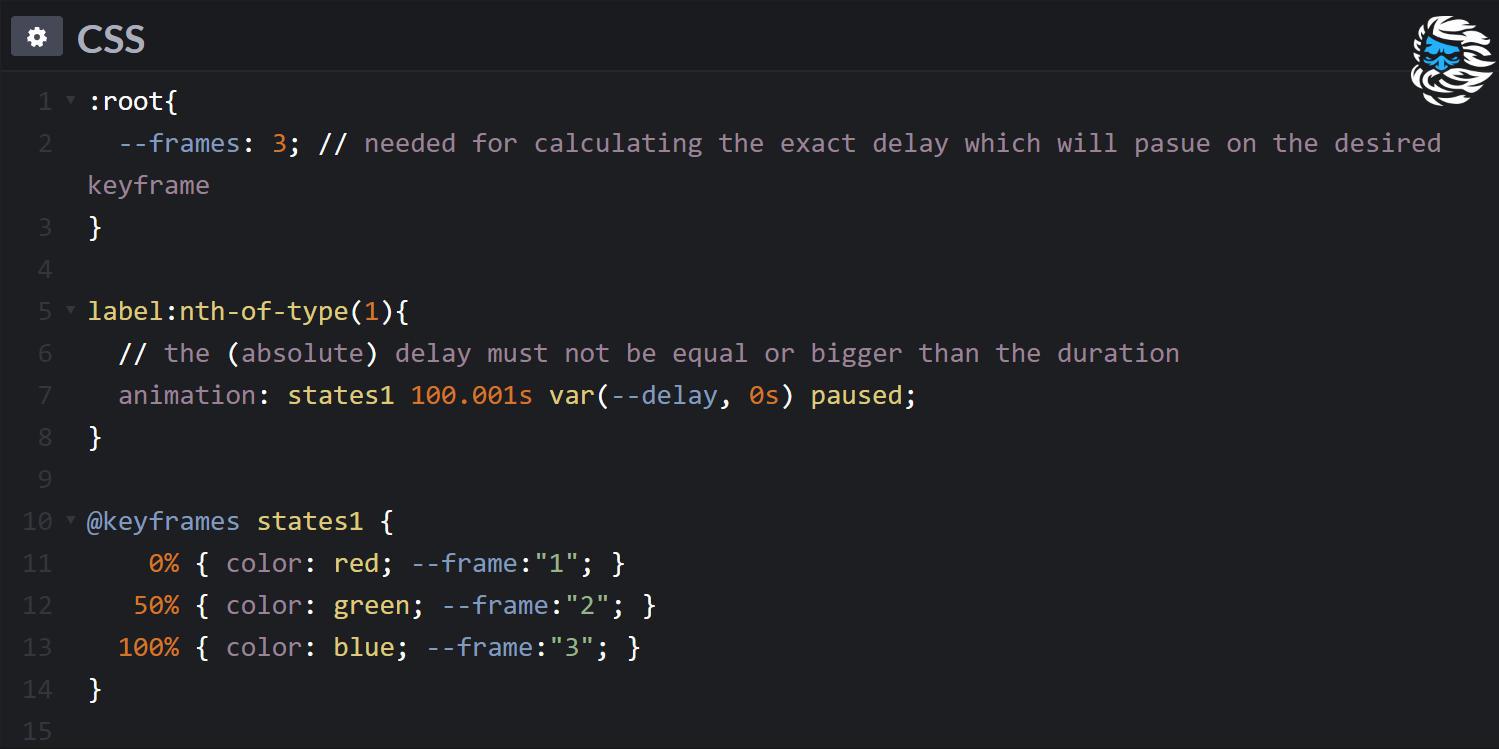
Переменные в CSS (или custom properties, кому как удобнее) изначально задумывались для хранения повторяющихся свойств вроде цветовой палитры или шрифтов в одном месте. В препроцессорах работа с перем... | https://habr.com/ru/post/550168/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.