
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Как я делал себе АВР для генератора

Несколько лет назад делал себе АВР (автоматический ввод резерва) для работы на даче от генератора. Сейчас многие ИТ-шники переходят на удалёнку, работают с дач, где качество электропитания мож... | https://habr.com/ru/post/507764/ | null | ru | null |
# Создаем Telegram бота на API.AI
Чат боты — довольно интересная тема, которой интересуются как гики-энтузиасты, так и компании, которые хотят организовать взаимодействие со своими клиентами наиболее удобным для них способом
Сегодня я опишу вам простой пример создания бота Telegram с использованием платформы для созд... | https://habr.com/ru/post/336668/ | null | ru | null |
# MVIDroid: обзор новой библиотеки MVI (Model-View-Intent)
Всем привет! В этой статье я хочу рассказать о новой библиотеке, которая привносит шаблон проектирования MVI в Android. Эта библиотека называется MVIDroid, написана 100% на языке Kotlin, легковесная и использует RxJava 2.x. Автор библиотеки лично я, исходный к... | https://habr.com/ru/post/417763/ | null | ru | null |
# Анализ Корана при помощи AI
Прошу прощение за возможно «желтый» заголовок, потому срау перехожу к сути. В ходе работы потребовалось протестировать систему осуществляющую качественный анализ текста по различным классификаторам, таким как пол, сентимент (настроение), возраст и прочее. В качестве одного из тестируемых ... | https://habr.com/ru/post/308082/ | null | ru | null |
# Практический взгляд на хранение в Kafka

Kafka повсюду. Где есть микросервисы и распределенные вычисления, а они сейчас популярны, там почти наверняка есть и Kafka. В статье я попытаюсь объяснить, как в Kafka работает механизм хранен... | https://habr.com/ru/post/535374/ | null | ru | null |
# Трезвый взгляд на W7500P — микроконтроллер со встроенным TCP/IP стеком
Платы модулей на основе чипов W5500 и W7500... | https://habr.com/ru/post/569960/ | null | ru | null |
# Расширение PHP для асинхронного ввода-вывода POSIX
#### Бэкграунд
Рискую получить много критики в комментариях. Однако, мне очень интересно узнать, что думают люди о расширении, которое я недавно закончил писать. Возможно, кто-то протестирует, и расширение станет «beta-стабильным».
Речь идёт о расширении PECL **... | https://habr.com/ru/post/131082/ | null | ru | null |
# Интеграция Primefaces в приложение на Spring Boot. Часть 4 — Вывод списка данных в виде таблицы
Во второй части мы научились динамически переключать контент, который выводится в главной части страницы компо... | https://habr.com/ru/post/713770/ | null | ru | null |
# Как за неделю превратить Open redirect в RCE
В этой статье я расскажу вам о том, как ровно год назад я связал в цепочку несколько проблем безопасности для достижения Удаленного выполнения кода (RCE) на нескольких серверах компании [VK](https://vk.company/). Я постарался описать свои шаги в подробностях, так как мне ... | https://habr.com/ru/post/708384/ | null | ru | null |
# Автоматическая суммаризация текстов с помощью трансформеров Hugging Face. Часть 1
В июле 2020 года компания [OpenAI](https://openai.com/) выпустила свою модель машинного обучения третьего поколения, GPT-3, ориентированную на генерирование текстов. Тогда я понял, что мир уже не будет прежним. Эта модель задела меня з... | https://habr.com/ru/post/661239/ | null | ru | null |
# How to create a dark theme without breaking things: learning with the Yandex Mail team
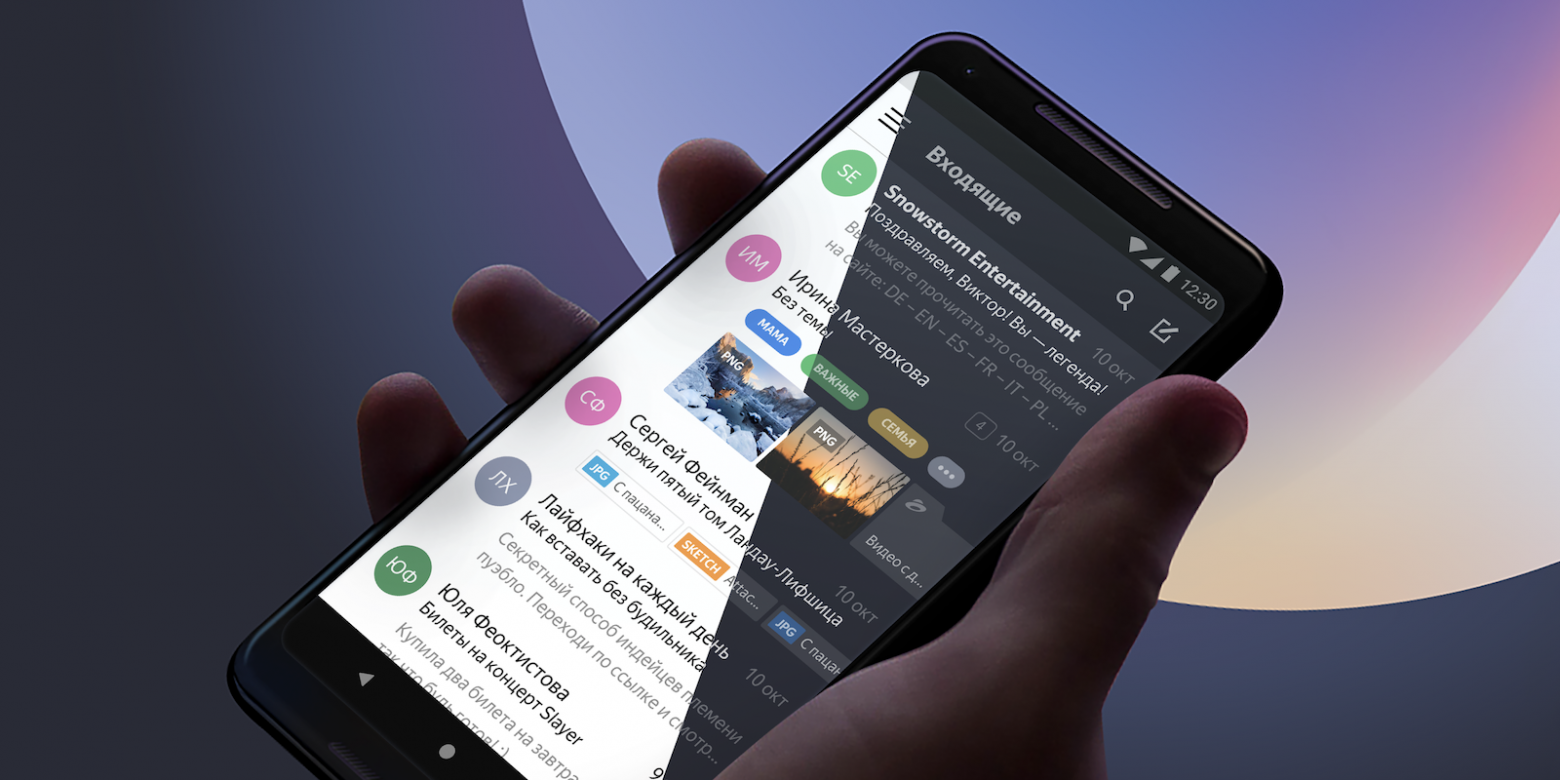
My name is Vladimir, and I develop mobile front-end for Yandex Mail. Our apps have had a dark theme for a while, but it was incomplete: only the ... | https://habr.com/ru/post/450032/ | null | en | null |
# Небезопасные разрешения в Android-приложениях

Сегодня Android является одной из наиболее популярных мобильных платформ, используемой в смартфонах, планшетах, умных часах, телевизорах и даже автомобилях. Открытость платфо... | https://habr.com/ru/post/268219/ | null | ru | null |
# Уведомления могут помочь вам узнать вашу аудиторию лучше + новости + СоХабр
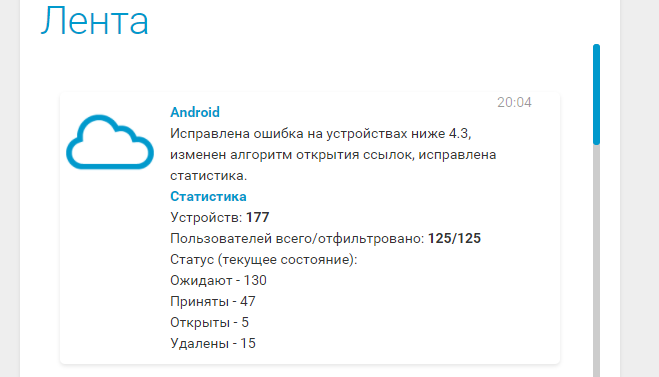
Предисловие
===========
Наверняка вы все ещё используете СМС-сообщения или E-mail для уведомления ваших пользователей. Уведомления просто улетают, и вы не з... | https://habr.com/ru/post/258659/ | null | ru | null |
# Python: коллекции, часть 2/4: индексирование, срезы, сортировка
| [Часть 1](https://habrahabr.ru/post/319164/ "Python: коллекции, часть 1/4: классификация, общие подходы и методы, конвертация") | Часть 2 | [Часть 3](https://habrahabr.ru/post/319876/ "Python: коллекции, часть 3/4: объединение коллекций, добавление и ... | https://habr.com/ru/post/319200/ | null | ru | null |
# Domain-Driven Design: стратегическое проектирование. Часть 1

Здравствуйте, хабрапользователи! В этой статье речь пойдет о предметно-ориентированном проектировании программного обеспечения с использованием, в первую очере... | https://habr.com/ru/post/316438/ | null | ru | null |
# Microsoft представила Edge 100
Microsoft [представила](https://docs.microsoft.com/en-us/deployedge/microsoft-edge-relnote-stable-channel#version-1000118529-april-1) общедоступную версию браузера Edge 100. В обновлении улучшили работу с PDF-файлами и исправили уязвимости. Сообщается, что Edge автоматически обновится ... | https://habr.com/ru/post/659005/ | null | ru | null |
# The Power of Oracle SQL
Прочитав сегодняшний топик [«SQL. Занимательные задачки»](https://habr.com/en/post/461567/), я вспомнил, что давно хотел порекомендовать отличную книгу для продвинутого уровня Oracle SQL от нашего отличного специалиста по Oracle, Алекса Репринцева — «The Power of Oracle SQL». Мало того, что о... | https://habr.com/ru/post/461971/ | null | ru | null |
# С чего начать своё расширение для Photoshop, Illustrator и др. на HTML5
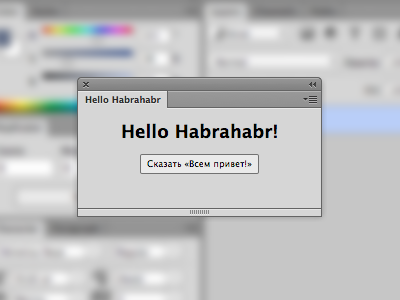
В этой статье я расскажу как при помощи HTML и JavaScript сделать своё собственное расширение для Photoshop, I... | https://habr.com/ru/post/221863/ | null | ru | null |
# Сборка, роутинг и обслуживание метрик
Введение
--------
Неотъемлемой частью любой сложной системы является телеметрия (мониторинг). Она включает в себя сборку логов, сборку различных метрик из разных частей системы, межсервисную трассировку вызовов и в самых критических случаях, если это возможно, — ручное взаимоде... | https://habr.com/ru/post/539080/ | null | ru | null |
# Встраиваем своё устройство «Умного дома» в экосистему SmartThings
Платформы «Умного дома» позволяют интегрировать устройства и создавать новые сценарии их взаимодействия. Известен эффект платформ: пользователи скорее выберут ту, с которой уже совместимы имеющиеся у них устройства, нежели перейдут на какую-либо новую... | https://habr.com/ru/post/489834/ | null | ru | null |
# LAppS сервер приложений для микросервисной архитектуры
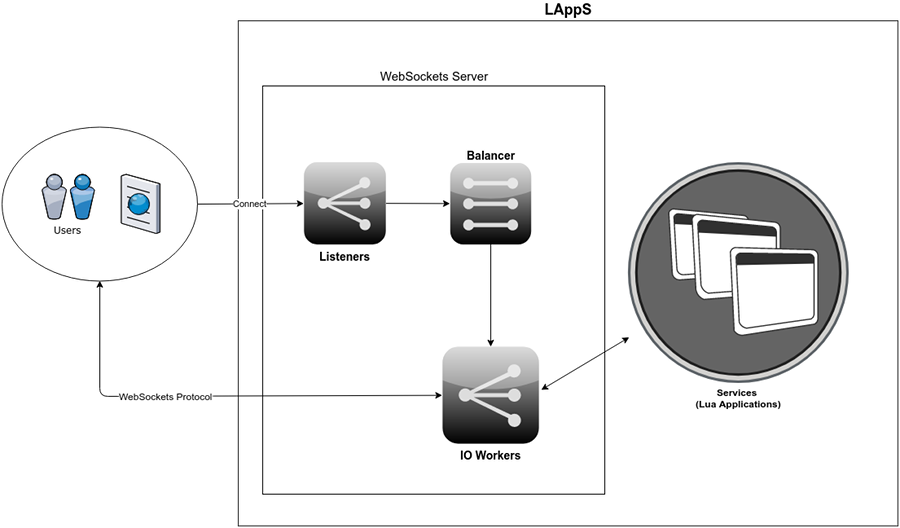
Предыстория
===========
20-го декабря прошлого года я ушёл в отпуск, на целых 2 недели. Чем заняться в отпуске? Правильно, — кодом. Кодом, котор... | https://habr.com/ru/post/354882/ | null | ru | null |
# Как сделать из Ninja систему распределённой сборки?
Привет, Хабр!
Недавно я задумался, ковыряя очередную бесплатную систему сборки, «А нельзя ли взять и самому написать такую систему? Ведь это просто — взять ту же Ninja, ... | https://habr.com/ru/post/321660/ | null | ru | null |
# Office как Платформа, выпуск №1: введение в то, как миллиард пользователей Microsoft Office становятся вашими пользователями
> *Приложениями Microsoft Office 365 сегодня пользуются более миллиарда человек по всему миру. Это крупнейшая платформа, которая доступна на разнообразных устройствах от больших настольных ПК ... | https://habr.com/ru/post/262771/ | null | ru | null |
# Высокоуровневая абстракция в программировании. Наш друг и враг
Большая часть прогресса, который мы наблюдаем за окном, это результат человеческой лени. Лень было красить забор кисточкой, изобрели валик. Лень было красить валиком, изобрели пульверизатор. Ну Вы поняли. Какое это все имеет отношение к программированию?... | https://habr.com/ru/post/93846/ | null | ru | null |
# NETMAP (от Luigi Rizzo). Простой и удобный opensource фреймворк для обработки трафика на скоростях 10Gbit/s или 14 Mpps
Пропускная способность каналов связи непрерывно возрастает, если ещё пару лет назад сервер с каналом 10Gbit/s был привилегией лишь немногих, то теперь на рынке появились предложения, доступные для ... | https://habr.com/ru/post/183832/ | null | ru | null |
# Распознавание волейбольного мяча на видео с дрона
В прошлом году я развлекался [треккингом волейбольного мяча](https://habr.com/ru/post/505672/), используя удаление фона OpenCV с анализом траекторий и даже сделал [сервис](https://vbal.io), который на основе этой информации вырезает скучные моменты из игры.
Основным... | https://habr.com/ru/post/559852/ | null | ru | null |
# Калькулятор Windows портировали на Linux
В марте 2019 года корпорация Microsoft открыла исходный код «Калькулятора» (см. статью [«Подсчитаем баги в калькуляторе Windows»](https://habr.com/ru/company/pvs-studio/blog/443100/) на Ха... | https://habr.com/ru/post/524076/ | null | ru | null |
# Пробы и ошибки при выборе HTTP Reverse Proxy
Всем привет!
Сегодня мы хотим рассказать о том, как команда сервиса бронирования отелей [Ostrovok.ru](https://ostrovok.ru/?utm_source=habr&utm_medium=pr&utm_campaign=bozhok_jan19) решала проблему роста микросервиса, задачей которого является обмен информацией с нашими ... | https://habr.com/ru/post/436992/ | null | ru | null |
# Анонимное подключение к meterpreter/reverse_tcp через промежуточный сервер с помощью SSH-туннелей
Всем привет! Эта статья рассчитана скорее на новичков, которые только начинают своё знакомство с Metasploit Framework, но уже кое-что понимают. Если вы считаете себя опытным специалистом и вас заинтересовало название, м... | https://habr.com/ru/post/272547/ | null | ru | null |
# Речь и VoiceOver в Mac OS X на русском язке
Я кое-что делал для iPhone и столкнулся с интересными «вещами». Эти «вещи» я быстренько приспособил для Mac OS X (развлечения ради), и вот, что получилось… Функционал «Речь» и VoiceOver в Mac OS X на русском языке. Кому-то это может оказаться полезным. Применений можно най... | https://habr.com/ru/post/91587/ | null | ru | null |
# SObjectizer: что это, для чего это и почему это выглядит именно так? Взгляд из 2022-го
Шесть лет назад, в июне 2016-го года, вышла [первая статья](https://habr.com/ru/post/304386/) об инструменте, с разработкой которого я связан уже много лет. Шестилетней давности публикация дала толчок интереса к SObjectizer-у и, к... | https://habr.com/ru/post/671080/ | null | ru | null |
# Альтернатива платному отключению рекламы в бесплатном приложении Android
Доброго времени суток, Хабрахабр!
Меня зовут Александр, я разработчик под ОС Android. Сегодня хочу с вами поделиться опытом реализации альтернативного платному способу отключения рекламы в приложении — отключение рекламы за просмотр рекламы ... | https://habr.com/ru/post/349832/ | null | ru | null |
# Бездисковая загрузка по сети и жизнь после нее
#### История
Однажды к нам пришли (ну, не сами...) серверы с 14 хардами по 2Тб. Избавившись от аппаратного рейда (зачем — вопрос отдельный), мы задумались о том, что неплохо бы сделать для них загрузку по сети, дабы избавиться от возни с разделами. Диски предполагалось... | https://habr.com/ru/post/164147/ | null | ru | null |
# Когнитивные искажения с примерами для айтишников
Про когнитивные искажения много пишут и много говорят.
Однако всегда не хватало более чёткого понимания, как именно это влияет на профессиональную деятельность, мою и моих коллег. Какие решения я как тимлид и программист принимаю неправильно. Что мне подправить, на ч... | https://habr.com/ru/post/555270/ | null | ru | null |
# Хост KVM в паре строчек кода. Примеры на C++ и на Python от эксперта Timeweb
> Привет!
>
>
>
> Сегодня публикуем статью о том, как написать хост KVM. Мы увидели ее в блоге [Serge Zaitsev](https://zserge.com/posts/kvm/), перевели и дополнили собственными примерами на Python для тех, кто не работает с языком С... | https://habr.com/ru/post/526818/ | null | ru | null |
# Сколько может стоить один лишний пробел?
Произошла курьезная и очень болезненная ситуация одновременно.
У нас много зарегистрированных клиентов и много из них тех, кто ни разу не входил в систему.
Писать клиентам по таким вопросами бесполезно — мало кто из обиженных клиентов ответит почему он обиделся.
Поэ... | https://habr.com/ru/post/230401/ | null | ru | null |
# Практические рекомендации по работе с Docker для Python-разработчиков
*Прим. Wunder Fund: в этой длииинной статье вы найдете ряд полезных советов по работе с Docker, как общего характера, так и Python-специ... | https://habr.com/ru/post/586778/ | null | ru | null |
# Редактор TECO: EMACS, я твой отец
Впервые про TECO я прочитал в пародийной статье [Real Programmers Don't Use Pascal](http://web.mit.edu/humor/Computers/real.programmers), написанной незадолго до моего рождения. Там было написано, что настоящие программисты не используют новомодные редакторы EMACS и VI:
> Нет, Наст... | https://habr.com/ru/post/351416/ | null | ru | null |
# Создание Strider Walker V6 — шагающего робота с камерой
В этом материале речь пойдёт о создании шагающего робота Strider Walker V6, оснащённого камерой.
[](https://habr.com/ru/company/ruvds/blog/591701/)
*Шагающий робот*
Мате... | https://habr.com/ru/post/591701/ | null | ru | null |
# Генерация текстовых версий писем из HTML с помощью lynx
#### Введение
Email-рассылки, отправляемые через Печкин, в большинстве своем содержат как html-версию письма, так и plain-text версию. Отправить рассылку без HTML-ве... | https://habr.com/ru/post/180993/ | null | ru | null |
# Лишние join в SQL запросах
Делая отладку производительности небольшого проекта, но с достаточно большой базой, столкнулся с неприятным спецэффектом.
Django при выборках с условиями по внешним ключам, связанным с проверкой на NULL, генерирует запросы, содержащие JOIN по каждому такому ключу. К примеру, для модели ... | https://habr.com/ru/post/165895/ | null | ru | null |
# Сервисы дистрибуции мобильных приложений для iOS. Часть 2: HockeyApp
Вступление
==========
Вторая часть обзора будет посвящена сервису [HockeyApp](http://hockeyapp.net/features/), с первой частью обзора можно ознакомиться [тут](http://habrahabr.ru/company/arcadia/blog/248439/).
По всей видимости, Miscrosoft реши... | https://habr.com/ru/post/250529/ | null | ru | null |
# 90+ полезных инструментов для Kubernetes: развертывание, управление, мониторинг, безопасность и не только

Осенью 2018 года мы опубликовали... | https://habr.com/ru/post/499676/ | null | ru | null |
# Нейросети для самых маленьких
Привет, в данном примере я хочу показать, как можно реализовать сеть Хопфилда для распознавания образов.
Я сам, как и многие в один день решил поинтересоваться программным обучением, ИИ и нейро сетями. Благо в сети есть много разборов и примеров, но все они оперируют изобилием формул... | https://habr.com/ru/post/417063/ | null | ru | null |
# Продвинутый Jekyll

[Jekyll](https://jekyllrb.com) — генератор статических сайтов. Это означает, что на вход ему даётся какая-либо информация, а на выходе получается набор HTML-страничек. Всё отлично когда сайт простой или д... | https://habr.com/ru/post/336266/ | null | ru | null |
# Живые гайдлайны — MDX и другие фреймворки
У вас может быть лучший проект с открытым исходным кодом, но если у него нету хорошей документации, есть вероятность, что он никогда не взлетит. В офисе хорошая документация позволит вам не отвечать на одни и те же вопросы. Документация также гарантирует, что люди могут разо... | https://habr.com/ru/post/454084/ | null | ru | null |
# Пишем свой MooTools-плагин.
Доброго времени суток.
Это мой первый серьезный пост на Хабре, так что критика приветствуется.
Сегодня я расскажу о написании плагина для JavaScript-библиотеки MooTools на примере модального всплывающего окна.
#### HTML, CSS.
Что же из себя будет представлять наше модальное окно... | https://habr.com/ru/post/38187/ | null | ru | null |
# Cufón – используйте шрифты, какие душа пожелает
Если стоит задача использовать в проекте нестандартный шрифт, то есть возможность пойти несколькими путями:
1. *Ъ-метод* – не использовать нестандартные шрифты, достаточно в CSS сказать body {font-family: sans-serif;} и не морочить себе голову.
2. *Быдло-метод* – на... | https://habr.com/ru/post/61033/ | null | ru | null |
# CleanTalk Malware Scanner — эвристический анализ кода
Мы уже рассказывали о запуске Security сервиса для WordPress в [предыдущей статье](https://habrahabr.ru/post/349420/). Сегодня мы хотим рассказать о запуске эвристического анализа для определения вредоносного кода.
Само наличие вредоносного кода может привест... | https://habr.com/ru/post/351572/ | null | ru | null |
# Learn OpenGL. Урок 5.7 — HDR

При записи во фреймбуфер значения яркости цветов приводятся к интервалу от 0.0 до 1.0. Из-за этой, на первый вгляд безобидной, особенности нам всегда приходится выбирать таки... | https://habr.com/ru/post/420409/ | null | ru | null |
# Хешируем строки на этапе компиляции с помощью annotation
Недавно я начал разрабатывать приложение под Android и передо мной возникла задача защитить его от реверса. Беглый просмотр гугла позволил предположить, что ProGuard, входящий в состав Android Studio, с задачей справится. Результат меня действительно устроил з... | https://habr.com/ru/post/200878/ | null | ru | null |
# Dynamic Delivery в многомодульных проектах (часть 1)

Привет! Меня зовут Юрий Влад, я Android-разработчик в компании Badoo и занимаюсь внедрением Dynamic Features в наши проекты.
[Dynamic Delivery](https://developer.android.com/... | https://habr.com/ru/post/489434/ | null | ru | null |
# Разбор полёта C# perfomance
Недавно я опубликовал [топик](http://habrahabr.ru/blogs/code_wtf/47178/)про ~~бред~~ код написанный индусом. В результате в комментариях были высказаны мнения, что это вовсе не бред, а нормальный код в С-style.
Да, спорить не буду — это C-style, но мне стало интересно — а как же произв... | https://habr.com/ru/post/47228/ | null | ru | null |
# Баг в Linux 5.1 приводил к потере данных — корректирующий патч уже вышел
Пару недель назад в версии ядра Linux 5.1 обнаружили баг, который приводил к потере данных на SSD. Недавно разработчики [выпустили](http://lkml.iu.edu/hypermail/linux/kernel/1905.3/01335.html) корректирующий патч Linux 5.1.5, который залатал «б... | https://habr.com/ru/post/454978/ | null | ru | null |
# Использование Java native library на серверах приложений
Java native library (JNL) представляет собой JAR-архив, содержащий в себе JNI-код и объекты, которые операционная система может загрузить в качестве разделяемых библиотек. Это позволяет вызывать из Java-приложения функции, реализованные платформо-зависимыми ме... | https://habr.com/ru/post/266411/ | null | ru | null |
# Запускаем Keycloak в HA режиме на Kubernetes

**TL;DR**: будет описание Keycloak, системы контроля доступа с открытым исходным кодом, разбор внутреннего устройства, детали настройки.
Введение и основные идеи
------------------------... | https://habr.com/ru/post/511380/ | null | ru | null |
# .xlsx изнутри. Разбор структуры файлов. Разбор каждого .xml файла
Недавно мне понадобилось встроить в CRM возможность создания отчетов в Excel посредством PHP, но готовые решения были сильно громоздкими. Поэтому я решил написать собственную библиотеку для работы с Excel файлами через PHP. Но информации о внутренност... | https://habr.com/ru/post/593397/ | null | ru | null |
# Заметки Дата Сайентиста: как измерить время забега марафона лежа на диване
[](https://habr.com/ru/company/ruvds/blog/512884/)
Продолжая цикл заметок про реальные проблемы в Data Science, мы сегодня разберемся с живой задачей и по... | https://habr.com/ru/post/512884/ | null | ru | null |
# Результаты тестирования производительности облачных серверов с помощью Dwarf Fortress
[Dwarf Fortress](http://bay12games.com/dwarves) — легендарная игра, детально симулирующая фэнтезийный мир, а игрок (в одном из режимов) может строить и управлять поселением (крепостью) гномов (дворфов). Про игру написано достаточно... | https://habr.com/ru/post/401485/ | null | ru | null |
# Web-интерфейс для runit
Вы уже используете **[runit](http://smarden.org/runit/ "runit")** на своих серверах? Теперь у Вас есть возможность наблюдать за состоянием сервисов и управлять ими через минималистичный Web-интерфейс.
](https://habrahabr.ru/company/piter/blog/338454/) Современные разработчики занимаются построением кроссплатформенных приложений, их сопровождением и развертыванием. Чтобы обле... | https://habr.com/ru/post/338454/ | null | ru | null |
# Реверс-инжинирим структуру БД PostgreSQL по плану запроса к ней
Большая часть оптимизаций запросов к базам PostgreSQL может выполняться "механически", **следуя разного рода маркерам** в плане выполнения запроса, которые подскажут, [что и как можно ускорить](https://habr.com/ru/post/492694/). Но "глубинные" переработ... | https://habr.com/ru/post/646043/ | null | ru | null |
# bdshemu: эмулятор шелл-кода в Bitdefender
Совсем скоро, 19 ноября, у нас стартует курс [«Этичный хакер»](https://skillfactory.ru/cybersecurity?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_HACKER&utm_term=regular&utm_content=291020), а специально к этому событию мы подготовили этот перевод о bdshemu — на... | https://habr.com/ru/post/527512/ | null | ru | null |
# Проверка Barotrauma статическим анализатором PVS-Studio
Barotrauma – игра, в которой можно поуправлять подлодкой, попрятаться от монстров и даже поиграть на аккордеоне в попытке не пойти ко дну. Посмотрим, как проект, начатый инди-студией Undertow Games и продолженный совместно с FakeFish, выглядит изнутри. Для этог... | https://habr.com/ru/post/658361/ | null | ru | null |
# Педаль в пол: создаём очередной ножной манипулятор для ПК

Буквально месяц назад я натолкнулся на [эту](https://habr.com/ru/post/232177/) статью, где повествуется о педалировании Vim. Чуть позже, после своего длительного трёхминутн... | https://habr.com/ru/post/462263/ | null | ru | null |
# Как обновить необновляемое: кастомная замена для @RabbitListener
У вас есть приложение Spring Boot, которое динамически подгружает собственную конфигурацию из Spring Cloud Config Server, то есть является ег... | https://habr.com/ru/post/670058/ | null | ru | null |
# Архитектура CMS. Модель данных. Часть 3
[В предыдущей статье](http://habrahabr.ru/blogs/about_cms/53615/) на примере создания объектной модели простого сайта производились одиночные загрузки сущностей из базы данных по их идентификаторам конструкцией Object::Create($id), при этом мы знали, у какой сущности (чаще все... | https://habr.com/ru/post/55216/ | null | ru | null |
# Неоморфизм с помощью SwiftUI. Часть 1
***Салют, хабровчане! В преддверии старта продвинутого курса [«Разработчик IOS»](https://otus.pw/qdJv/) мы подготовили еще один интересный перевод.***

---
Неоморфный дизайн — это, пожалуй,... | https://habr.com/ru/post/502592/ | null | ru | null |
# Применение инфраструктуры кеширования в ASP.NET
Полтора года назад я написал статью [про кеширование в ASP.NET MVC](http://habrahabr.ru/post/168869/), в которой описал как повысить производительность ASP.NET MVC приложения за счет кеширования как на сервере, так и на клиенте. В комментариях к статье было упомянто мн... | https://habr.com/ru/post/227129/ | null | ru | null |
# Переводим Chrome extension на manifest_version 2
Владельцам расширений (а также приложений) для Хрома уже пора бы задуматься над поддержкой второй версии манифеста.
Если кто не в курсе, то не так давно были объявлены новые изменения и нововведения в разработку расширений для браузера.
Далее будет выборочный пе... | https://habr.com/ru/post/149948/ | null | ru | null |
# W3C или WHATWG

> Есть две спецификации HTML: W3C и WHATWG, какой из них верить?
Верьте той, которая больше нравится, но не забывайте сверяться с браузерами.
Спецификация — это главный источник знаний: как для браузеров, так и для ра... | https://habr.com/ru/post/339854/ | null | ru | null |
# Катя, Go, Dcoin и Android
[](https://habrahabr.ru/post/277099/)
Продолжение той самой истории.
Первая часть [тут](http://habrahabr.ru/company/dcoin/blog/272695/), вторая [тут](http://habrahabr.ru/post/273333/), третья [... | https://habr.com/ru/post/277099/ | null | ru | null |
# RMI (Remote Method Invocation)
Случилось так, что поставленная задача требовала применения удалённого вызова методов. Порывшись на Хабре, ничего не нашел по данному вопросу (хотелось что-нибудь почитать в качестве первого знакомства, перед чтением документации). Изучив спецификации на java.sun.com спешу поделиться с... | https://habr.com/ru/post/74639/ | null | ru | null |
# learnopengl. Урок 1.2 — Создание окна
 В прошлом уроке мы разобрались с тем, что такое OpenGL. В этом уроке мы поговорим о причине необходимости использования GLFW, GLEW и CMake, а также рассмотрим как их использовать. А также ... | https://habr.com/ru/post/311198/ | null | ru | null |
# Клон Trello на Phoenix и React. Части 6-7

**Оглавление (текущий материал выделен)**1. [Введение и выбор стека технологий](https://habrahabr.ru/post/308056/#1)
2. [Начальная настройка проекта Phoenix Framework](https://hab... | https://habr.com/ru/post/308248/ | null | ru | null |
# Оптимизация майнинга лайткоинов
Всем привет! Я решил рассказать вам о том, как оптимизировал алгоритм майнинга лайткоинов. А представлю я свой рассказ в форме дневника.
День 0: Наткнулся на [топик](https://bitcointalk.org/index.php?topic=22965.0), где некий bitless поделился с сообществом способом ускорить майнин... | https://habr.com/ru/post/186664/ | null | ru | null |
# django-controlcenter
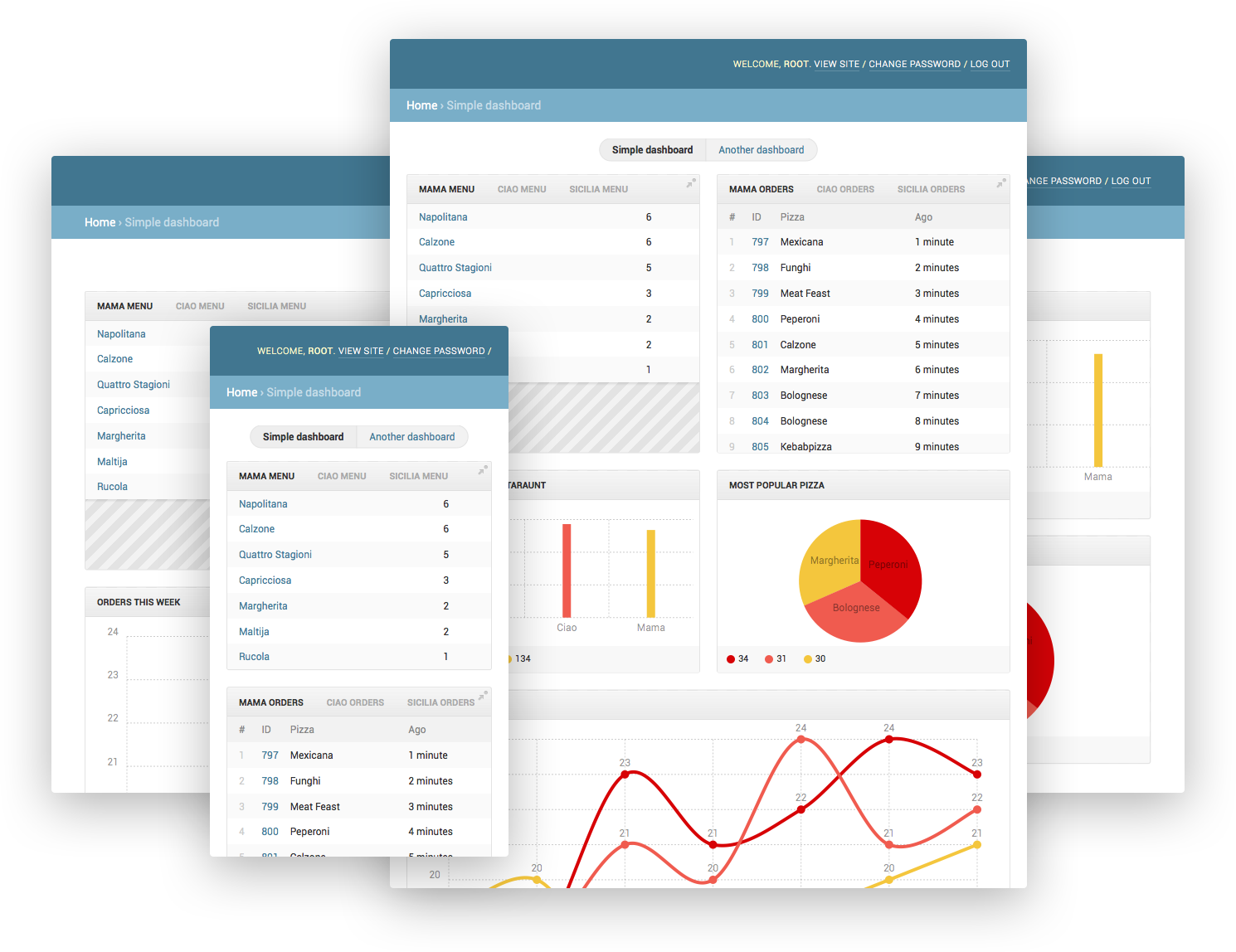
Всем привет, хочу поделиться своей небольшой разработкой — [django-controlcenter](https://github.com/byashimov/django-controlcenter). Это приложение для создания дешбоардов для ваш... | https://habr.com/ru/post/278743/ | null | ru | null |
# Придумал и сделал прибор
Сегодня утром я не стал писать посты и тестировать лампочки, а занялся творчеством. Пару дней назад я «изобрёл» прибор, которого мне очень не хватало при тестировании ламп, и сегодня смог сделать его.
. Наверняка многим понравилось наличие типизации и плагины для Microsoft Visual Studio и других редакторов. Чтобы оценить насколько полезен язык в разработке, я р... | https://habr.com/ru/post/155029/ | null | ru | null |
# Заметка о интеграционном тестировании используя Jenkins на Kubernetes
Добрый день.
Практически сразу после установки и конфигурации CI/CD по инструкции из [предыдущего поста](https://habr.com/ru/post/442614/) у команды возник вопрос как правильно осуществлять интеграционное тестирование. У нас уже был опыт запуска ... | https://habr.com/ru/post/451588/ | null | ru | null |
# Обеспечить январь настроением
Вместо эпилога
--------------
Эта история произошла довольно давно, но некоторые подробности стали ясны только сейчас, отчего и настало время её рассказать.
Не будем останав... | https://habr.com/ru/post/535794/ | null | ru | null |
# Drag и Swipe в RecyclerView. Часть 2: контроллеры перетаскивания, сетки и пользовательские анимации

В [пе... | https://habr.com/ru/post/428419/ | null | ru | null |
# Передача аналогового тв сигнала с помощью STM32
Помните как некто [cnlohr](https://github.com/cnlohr/channel3) запустил передачу ТВ сигнала на ESP8266?
Недавно мне попалось к просмотру это [видео](https://www.youtube.com/watch?v=SSiRkpgwVKY), стало интересно как это возможно и выяснил что автор видео разогнал час... | https://habr.com/ru/post/521282/ | null | ru | null |
# Zend Framework. Сохраняем сессии в БД.
Маленькая статья по Zend Framework.
Точнее интерпретация раздела из руководства пользователя Zend\_Framework.
Оригинал: [Zend\_Session\_SaveHandler\_DbTable](http://framework.zend.com/manual/ru/zend.session.savehandler.dbtable.html)
Этот самый **Zend\_Session\_SaveHan... | https://habr.com/ru/post/42714/ | null | ru | null |
# Font (ещё более) Awesome — узорное изобретение
Привет, Хабр! Представляю вашему вниманию перевод статьи ["Font (More) Awesome — an iconic invention"](https://medium.freecodecamp.org/lets-use-font-more-awesome-to-make-an-iconic-invention-a95324d92ace) автора Pubudu Dodangoda.
Создаёте ли вы веб-сайт, мобильное или н... | https://habr.com/ru/post/351130/ | null | ru | null |
# Облачный Умный Дом. Часть 1: Контроллер и датчики
Сегодня, благодаря бурному развитию микроэлектроники, каналов связи, Интернет-технологий и Искусственного Интеллекта, тема умных домов становится все более и более актуальной. Чело... | https://habr.com/ru/post/467219/ | null | ru | null |
# XAMPP on Linux + Xdebug (Linux 64bit)
Итак, сегодня мне удалось поставить XDebug на XAMPP for Linux. Если у вас 32-битный Линукс, можете не читать оставшийся текст, для вас есть простое решение, и не одно, которое можно с легкостью найти в Сети.
О безумных благах дебаггера для ПХП даже не нужно рассказывать. На 6... | https://habr.com/ru/post/91575/ | null | ru | null |
# Как превратить браузер в notepad за 1 секунду
Открыть новую закладку, скопировать в адресную строку
```
data:text/html,
```
и нажать Enter.
Вуаля.

При клике на белом поле появляется курсор, и можно писать ... | https://habr.com/ru/post/167677/ | null | ru | null |
# Партиционирование таблиц в mySQL
Начиная с версии 5.1 mySQL поддерживает горизонтальное партицирование таблиц. Что это такое? **Партиционирование (partitioning) — это разбиение больших таблиц на логические части по выбранным критериям.**. На нижнем уровне для myISAM таблиц, это физически разные файлы, по 3 на кажду... | https://habr.com/ru/post/66151/ | null | ru | null |
# Введение в нечёткую логику

Вы когда-нибудь подумывали написать такой алгоритм, в соответствии с которым приложение само принимало бы решения, либо справлялось с какими-нибудь странными действиями, при помощи которых клиент от... | https://habr.com/ru/post/713620/ | null | ru | null |
# Testcontainers: тестирование с реальными зависимостями
Программное обеспечение развивается с течением времени, и автоматизированное тестирование является необходимым условием для непрерывной интеграции и непрерывной доставки. Разработчики пишут различные типы тестов, такие как модульные тесты, интеграционные тесты, ... | https://habr.com/ru/post/700286/ | null | ru | null |
# Релиз TypeScript 1.6: не только React
Компания Microsoft активно выпускает новые версии TypeScript. Товарищи разработчики объявили о выпуске бета версии TS версии 1.6 аж второго сентября. А уже 16 сентября был выпущен релиз. ... | https://habr.com/ru/post/269069/ | null | ru | null |
# How-to: Что такое Russian Volatility Index и как он рассчитывается

**Примечание:** *Данный текст публикуется в рамках эксперимента — в нашем блоге мы осветили уже довольно большое количество вводных... | https://habr.com/ru/post/231863/ | null | ru | null |
# Плагин Events для jQuery
Я разработал свободный плагин **Events** для **jQuery**. После чего плагин выложил на [**GitHub**](https://github.com/korenevskiy/Events-plugin-for-jQuery).
Назначение плагина, позволить привязывать теги к переменным.
В последствии чего задав новое значение переменной все привязанные т... | https://habr.com/ru/post/512330/ | null | ru | null |
# Отряд самоубийц. Как мы набираем самых лютых junior-разработчиков
В предыдущей статье [про внедрение в нашем стартапе методологии Agile](https://habr.com/post/421365/) я частично затронул вопрос управления персоналом. В этой статье расскажу как мы этот персонал набираем, какую классификацию применяем, какими испытан... | https://habr.com/ru/post/421949/ | null | ru | null |
# Пишем на Питоне сразу хорошо
Привет Хабр!
Сегодня я сниму [костюм аниматора](https://habr.com/ru/post/550088/) и вместо развлечений расскажу вам немного за питон.
Я довольно посредственный программист, но иногда мне удаётся усыпить чью-нибудь бдительность, и меня считают сеньором. И вот как-то так получилось, что ... | https://habr.com/ru/post/564598/ | null | ru | null |
# История одного виджета
Этот скромный топик повествует о том, как важно уделять достаточно внимания и человеко-часов на побочные проекты сервиса.
#### Интро
Вконтакте — отличный пример сервиса, для людей, в котором: и качественный код, и отличный саппорт. Однако, его минусом являются побочные проекты.
Так бы... | https://habr.com/ru/post/193944/ | null | ru | null |
# NConsoler — парсинг аргументов консольного приложения
Обычно приходится тратить много времени на парсинг консольных аргументов в консольных приложениях. В интернете я нашел несколько систем, которые упрощают эту задачу, но они мне показались громоздкими, поэтому было решено создать новую систему на основе метаинформ... | https://habr.com/ru/post/38896/ | null | ru | null |
# Terraform-модуль для инициализации Vault
При настройке CI/CD для приложений мы в компании, как правило, используем [Vault](https://www.vaultproject.io) от HashiCorp. К тому же сами приложения зачастую испо... | https://habr.com/ru/post/660455/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.