
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Вышел релиз GitLab 14.4 с запуском DAST-сканирований по расписанию и встроенным отслеживанием ошибок

Мы рады представить вам релиз GitLab `14.4` с [запуском DAST-сканирований по расписанию](#zapusk-dast-skanirovaniy-po-... | https://habr.com/ru/post/587870/ | null | ru | null |
# Настройка сети в гостевой Ubuntu 16.04 Server на VirtualBox + Windows 7
Весна, снова потянуло на эксперименты. Ну, в моем понимании этого слова. Решил поставить себе в Windows 7 виртуальную машину, а в эту машину — Ubuntu 16.04 Server (под которой работает хостинг для моих сайтов). И не то чтобы меня как-то OpenServ... | https://habr.com/ru/post/324016/ | null | ru | null |
# Бюджетный отладчик к ESP-32 и его настройка
Недавно при написании библиотеки к ESP-32 возникла необходимость ловить дедлоки, которые возникали иногда из-за моей криворукости, что породило необходимость покупки платы-отладчика с интерфейсом JTAG. Что из этого вышло — читайте под катом.
Приборы ~~и материалы~~
------... | https://habr.com/ru/post/421291/ | null | ru | null |
# Вот как Амазон измеряет свою эффективность
*Этот перевод создан для телеграм-канала*[*Инжиниринг Данных*](https://t.me/rockyourdata)*. И, так как, одной из задач создателей телеграм-канала и аналитического курса*[*DataLearn*](https://datalearn.ru/)*является популяризация грамотной работы с данными, мы выкладываем пе... | https://habr.com/ru/post/584918/ | null | ru | null |
# Запуск OLAP-сервера на базе Pentaho по шагам

Итак, дорогие хабровчане, хочу представить на ваше обозрение инструкцию, как нам пришлось поднимать OLAP-сервер в нашей компании. Шаг за шагом мы пройдем по пути, который б... | https://habr.com/ru/post/187782/ | null | ru | null |
# Грузим много CSS для IE в режиме разработки
В [Островке](http://ostrovok.ru/) при разработке сайта используется модульная структура. Логические элементы состоят из разметки, стилей и javascript-файлов.
После перехода на такую структуру, пару месяцев все было хорошо. Потом в IE начали пропадать стили из разных бло... | https://habr.com/ru/post/171519/ | null | ru | null |
# Мой компилятор Паскаля и польское современное искусство
Истоки
------
Несколько лет назад я написал компилятор Паскаля. Мотивация была простой: в юности я узнал из своих первых книжек по программированию, что компилятор — вещь чрезвычайно сложная. Это утверждение засело занозой в мозгу и в конце концов потребовало ... | https://habr.com/ru/post/436694/ | null | ru | null |
# EasyUI: действительно easy?
В этой статье я хочу поделиться опытом избавления от жуткой головной боли, возникшей при разработке веб-приложения для одного маленького, но весьма могучего устройства. Но сначала несколько слов об источнике этой боли — о дизайне.
Дизайн сегодня один из необходимых компонентов любого про... | https://habr.com/ru/post/560128/ | null | ru | null |
# Atomizer vs Minimalist Notation (MN)
Minimalist Notation (MN) (минималистическая нотация) — гибкая адаптивная технология генерации стилей.
Она генерирует стили только для существующих классов разметки html, jsx, и т.п. — благодаря чему отпадает необходимость заботиться о компонентном подходе в CSS, мёртвом CSS коде... | https://habr.com/ru/post/510600/ | null | ru | null |
# Рендеринг капли с прозрачностью и отражениями на OpenGL
В этой статье мы рассмотрим как рендерить капли на OpenGL и расчитывать на лету нормаль для отражения и прозрачности. А так же, что такое Metaballs, баги графических чипсетов и какие трюки оптимизации можно применить для 60 FPS на мобильных девайсах.
. Созданный парсер будет преобразовывать последовательность текстовых символов в *well-formed* JSON-объект, который будет представлять JSON-Документ. **JSON-документ** - эт... | https://habr.com/ru/post/659287/ | null | ru | null |
# Прокрастинация как инструмент перемещения во времени
Все люди делятся на нормальных и прокрастинаторов, и последних абсолютное большинство. Мы разобрались и выявили два типа прокрастинации: неустранимую, которая приводит к неразрешимым жизненным проблемам и болезненным психологическим эффектам, и устранимую, при кот... | https://habr.com/ru/post/446242/ | null | ru | null |
# Меняем CoffeeScript на ES6
*Спешу предположить, что вы наслышаны о ES6 и, возможно, успели попробовать её. Тогда вам наверняка покажется интересной заметка о некоторых фичах спецификации, опубликованная [Блейком Уильямсом](https://twitter.com/BlakeWilliams__) в блоге Thoughtbots. Я же, с позволения автора, публикую ... | https://habr.com/ru/post/249751/ | null | ru | null |
# Ботнет из Linux-серверов
Независимый специалист по безопасности Денис Синегубко из Магнитогорска [обнаружил](http://blog.unmaskparasites.com/2009/09/11/dynamic-dns-and-botnet-of-zombie-web-servers/) в Сети уникальный ботнет, состоящий из Linux-серверов. О своей находке Денис [рассказал](http://www.theregister.co.uk/... | https://habr.com/ru/post/69586/ | null | ru | null |
# Настройка IPsec GRE туннель между FortiOS 6.4.5 и RouterOS 6.48.1
Стояла задача объединить филиалы с головным офисом предприятия, где находилась серверная. Fortigate 60E организовывал доступ в интернет и выполнял роль межсетевого экрана в головном офисе, в филиалах выполняли роль доступа в интернет Микротик разных м... | https://habr.com/ru/post/546326/ | null | ru | null |
# Что нам стоит patch построить, нарисуем будем жить
Сказ о суровых российских инженерах.
### 1. С чего все началось…
> *Ангелы и демоны кружили надо мной
>
> Рассекали тернии и Млечные Пути*
>
> [Origa — Inner Universe](https://youtu.be/EIVgSuuUTwQ)
В одном, не очень отечественном САПР, есть возможность кон... | https://habr.com/ru/post/515876/ | null | ru | null |
# Жизненный цикл статьи на Хабре: пишем хабрапарсер. Часть вторая
Привет Хабр!
В [первой части](https://habr.com/ru/post/440366/) пятничного анализа была рассмотрена методика сбора некоторой статистики этого замечательного сайта. Изначально не было плана делать продолжение, но в комментариях возникли интересные мыс... | https://habr.com/ru/post/440954/ | null | ru | null |
# Как правильно читать объявления в Си
Даже совсем зеленые программисты на Си, не испытывают проблем с чтением таких объявлений:
`int foo[5]; // foo массив из 5 элементов типа int
char *foo; // foo указатель на char
double foo(); // foo функция возвращающая значение типа double`
Но как только объявления ст... | https://habr.com/ru/post/116255/ | null | ru | null |
# 5 простых правил удобного для восприятия кода
*Задаетесь вопросами: «Как написать чисто, понятно? Как быстро разобраться в чужом коде?»
Вспомните о приведенных ниже правилах и примените их!*
В статье не рассматриваются базовые правила именования переменных и функций, синтаксические отступы и масштабная тема ре... | https://habr.com/ru/post/436160/ | null | ru | null |
# Разработка и адаптация игр под мобильные платформы

Адапта́ция (от лат. adapto — приспособляю) — процесс приспособления к изменяющимся условиям внешней среды.
В последние годы мы наблюдаем быстрые эволюционные изменения мобильных систем. Появ... | https://habr.com/ru/post/144241/ | null | ru | null |
# Сжатие информации без потерь. Часть вторая
[Первая часть.](http://habrahabr.ru/post/142242)
Во второй части будут рассмотрены арифметическое кодирование и преобразование Барроуза-Уилера (последнее часто незаслуженно забывают во многих статьях). Я не буду рассматривать семейство алгоритмов LZ, так как про них на х... | https://habr.com/ru/post/142492/ | null | ru | null |
# Самый мощный органайзер и его SDK
Приветствую всех.
Продолжим тему разработки под ушедшие в историю платформы. Сегодня расскажем про органайзеры Casio серии Pocket Viewer, бывшие популярными в узких кругах в первой половине нулевых.
 для всех верстальщиков в группе на ОС Windows. Основная цель — это в минимальные сроки передать минимум необходимых знаний всем участникам группы. Основная пробл... | https://habr.com/ru/post/282003/ | null | ru | null |
# Berkshelf и зависимости Chef cookbook-ов
Привет, Хабрапользователи!
Я продолжаю свое погружение в пикантности *automation*-а и *configuration management*-а, параллельно пытаясь делится опытом с *community... | https://habr.com/ru/post/221791/ | null | ru | null |
# Flutter Flame: ускоряем в 32 раза работу со столкновениями
Как я уже писал ранее, на FPS в Flame в основном влияют операции, производимые на CPU. Если в вашей игре достаточно много взаимодействующих объектов, то одной из самых дорогих операций будет определение столкновений. Настолько дорогой, что на экране performa... | https://habr.com/ru/post/686180/ | null | ru | null |
# Почему Math.Round открывает окно печати из браузера в Try .NET
Сегодня внимание общественности привлек забавный нелогичный баг, обнаруженный в [Try .NET](http://try.dot.net/) – инструменте, предназначенном для встраивания в документацию интерактивных примеров на C#. Посмотреть открытый issue можно на Github [по ссыл... | https://habr.com/ru/post/456880/ | null | ru | null |
# Обзор IDE Monokle, или Рассказ о неоправдавшихся ожиданиях
В погоне за лучшей или, правильнее сказать, удобной жизнью я начал искать решение, которое помогало бы писать чарты для Kubernetes и лучше разбираться в зависимостях — что, куда и откуда подставляется в созданных чартах. Так я наткнулся на программу под назв... | https://habr.com/ru/post/690564/ | null | ru | null |
# Станция для измерения скорости и направления ветра
Обычная бытовая фирменная или самодельная метеостанция измеряет две температуры-влажности (в комнате и на улице), атмосферное давление и дополнительно имеет часы с календарем. Однако, настоящая метеостанция имеет еще много всего — датчик солнечной радиации, измерите... | https://habr.com/ru/post/404385/ | null | ru | null |
# plink: скрыть IP-адрес и зашифровать трафик за 5 минут
Каждый пользователь Интернета хотя бы раз задумывался об анонимности в Сети. В этой заметке я расскажу об одном из самых простых способов настройки собственного прокси-сервера, который надежно скроет ваш IP-адрес и зашифрует передаваемую информацию.
Я не прет... | https://habr.com/ru/post/96294/ | null | ru | null |
# #2 Нейронные сети для начинающих. NumPy. MatplotLib. Операции с изображениями в OpenCV
[](https://habr.com/ru/company/ruvds/blog/682462/)
Это вторая статья из серии введения в «Нейронные сети для начинающих». Здесь и далее мы пос... | https://habr.com/ru/post/682462/ | null | ru | null |
# Кто, где, когда: система компонентов для разделения зон ответственности команды
Меня зовут Евгений Тупиков, я ведущий PHP-разработчик в Badoo и Bumble. У нас в команде более 200 бэкенд-разработчиков, которы... | https://habr.com/ru/post/562000/ | null | ru | null |
# Электронная подпись в доверенной среде на базe загрузочной Ubuntu 14.04 LTS и Рутокен ЭЦП Flash
Процедура наложения электронной подписи, призванная обеспечить подтверждение целостности подписанного документа и его авторства, сама по себе может быть небезопасной.
Основные атаки на ЭП — это кража ключа и подмена п... | https://habr.com/ru/post/253619/ | null | ru | null |
# Kubernetes 1.17: обзор основных новшеств
Вчера, 9 декабря, [состоялся](https://kubernetes.io/blog/2019/12/09/kubernetes-1-17-release-announcement/) очередной релиз Kubernetes — 1.17. По сложившейся для нашего блога традиции, мы рассказываем о наиболее значимых изменениях в новой версии.
 своими экспериментами с API социального сервиса микроблоггинга Twitter.
Сегодня я бы хотел рассказать и показать свой новый проект на ниве... | https://habr.com/ru/post/99905/ | null | ru | null |
# Подключение VFD дисплея Futaba GP1183A01B к Raspberry Pi

Для подключения дисплея 16x2 символов к своей Raspberry Pi я выбрал VFD Futaba GP1183A01B. Чем он хорош? Во-первых, это вымирающий вид, дающий «т... | https://habr.com/ru/post/219251/ | null | ru | null |
# Конспект по методам классификации данных
При изучении Data Science, я решил составить для себя конспект по основным приемам, используемым в анализе данных. В нем отражены названия методов, кратко описана суть и приведен код на Python для быстрого применения. Готовил конспект для себя, но подумал, что кому-то это так... | https://habr.com/ru/post/491326/ | null | ru | null |
# Rejector.ru — обновление
**Статья размещена по просьбе [LMik](https://habrahabr.ru/users/lmik/). Если у вас возникнут какие-либо вопросы, он на них с радостью ответит.**
Прошла неделя с момента публикации статьи о новом сервисе [Rejector.ru](http://rejector.ru "Rejector.ru"). За это время мы получили от вас мешок... | https://habr.com/ru/post/79211/ | null | ru | null |
# TeX-like разметка на Javascript
 При написании [console-like форума](http://habrahabr.ru/blogs/i_am_advertising/67301/) был задан вопрос: «какую разметку лучше использовать?». Среди вариантов были стандартный бб-код ([b]bold[/b]), вики-разметка(\... | https://habr.com/ru/post/67388/ | null | ru | null |
# Интересная задачка: повышаем стабильность (robustness) приложений
Продолжаем отрабатывать корпоративный план по формированию правильного общественного мнения о компании Microsoft и ее технологиях :) Время такое.
Итак, вот вам техническая задачка. Насколько я смог найти, ее разъяснения нет даже у Рихтера. К самому... | https://habr.com/ru/post/69545/ | null | ru | null |
# STM32F4 USB RNDIS драйвер (управление устройством через Web-интерфейс)
Доброе время суток, дорогие друзья!
Первым делом хотелось бы с лучшими пожеланиями поздравить всех с минувшими новогодними праздниками.
Ранее [в статье](http://habrahabr.ru/post/248097) была анонсирована разработка RNDIS USB драйвера для ко... | https://habr.com/ru/post/274663/ | null | ru | null |
# Метод решета в игре «Быки и коровы»
Здравствуйте.
Еще осенью на 2 курсе в качестве лабораторной работы по «Теории автоматов» преподаватель на ходу придумывал нам задания, ориентируяюсь на наши пожелания в оценке. В основном это были игры. Кому-то достался хоккей, кому-то теннис, мне же досталась не столь известна... | https://habr.com/ru/post/148846/ | null | ru | null |
# Как бросить escape room
Статья отчасти является предупреждением допущений, не исключив которые разработчик может ощутить всю их неблагоприятность, отчасти — попыткой объяснить — что же от вас может хотеть заказчик, отчасти — работой над ошибками или признанием «сам дурак». Caution: DotA jargon ahead, «Я не гик!», а ... | https://habr.com/ru/post/406235/ | null | ru | null |
# Алгоритм Джонкера-Волгенанта + t-SNE = супер-сила
До:

После:

Заинтригованы? Но обо всем по порядку.
t-SNE
-----
[t-... | https://habr.com/ru/post/326750/ | null | ru | null |
# Shade: длинные тени трендового плоского дизайна на CSS
Доброго времени суток уважаемые хабражители. Недавно я нашел очень интересный [пример на SCSS](http://codepen.io/hugo/pen/xzjGB) и решил реализовать его на LESS ~~да я люблю LESS больше~~:
[
Кто сейчас вообще слушает радио? Может показаться, что в современном мире не осталось места для радио, однако мы сумели отыскать несколько кейсов его реального использования и немного поиграли с этим.
... | https://habr.com/ru/post/564248/ | null | ru | null |
# О неоправданно хорошей работе [ -z $var ]
Есть такой сабреддит — [/r/nononoyes](https://www.reddit.com/r/nonononoyes/top/?sort=top&t=all), где публикуют видео, в которых происходит что-то такое, что, на первый взгляд, кажется ужасно неправильным, идущим к катастрофе. Но в конце всё, чудесным образом, заканчивается х... | https://habr.com/ru/post/556750/ | null | ru | null |
# Установка FAMP на pfsense
В стандартных пакетах pfsense нет ни MySQL, ни полноценного Apache. PHP присутствует в системе по умолчанию, являясь основным языком сценариев, но отсутствуют нужные модули mysql.so и присутствуют свои pfsense.so, ssh2.so и т.д.
В отличие от FreeBSD, убраны многие стартовые скрипты и фай... | https://habr.com/ru/post/254847/ | null | ru | null |
# Selenium для игр: автоматизируем крестики-нолики
> *В преддверии старта курса* [*"****Java QA Automation Engineer****"*](https://otus.pw/CJph/) *делимся с вами традиционным переводом интересного материала.*
>
>

Xdebug — это расширение для PHP ... | https://habr.com/ru/post/328094/ | null | ru | null |
# CTFzone write-ups — Grand Finale

Друзья, настало время раскрыть последнюю тайну **CTFzone**. Мы готовы опубликовать райтап на одно из самых сложных заданий соревнований – **OSINT** на 1000 очков. Как и в случае с [Rev... | https://habr.com/ru/post/318652/ | null | ru | null |
# Комбинаторное тестирование: генерация тестовых данных и не только
 Хотя популярность buzzword «pairwise» уже не та, на собеседованиях до сих пор задают вопрос о том, что представляет собой эта техника тест-дизайна. Однак... | https://habr.com/ru/post/261381/ | null | ru | null |
# Creating UITableView with a dynamic header
Hello there! Recently, I had very cool experience at my work. I needed to set tableView with a dynamic header. The information in the header was complete in the initial state, and when the user was scrolling the table, some part in the header was smoothly hiding and the mai... | https://habr.com/ru/post/709736/ | null | en | null |
# Компоненты. Make & watch
[в начало заметок о компонентах](http://habrahabr.ru/post/209350/)
make vs. grunt vs. gulp, watch
==============================
task runners — класс утилит, автоматизирующих процесс преобразования файлов. Их много, Make, Rake, Cake, etc. Обычно выполняемые задачи очень важны и выполняют... | https://habr.com/ru/post/209442/ | null | ru | null |
# Кросс-продвижение Android-приложений с помощью сети AppFlood
Каждый, кто хоть раз пробовал разработать и опубликовать свое мобильное приложение, в конце концов сталкивается с двумя проблемами: как его раскрутить и как на нем заработать. Вот и у меня возникли такие же вопросы, когда я впервые выложил свое первое и на... | https://habr.com/ru/post/188132/ | null | ru | null |
# HHVM, Nginx и PHP (а также Laravel)
Множество людей интересовалось установкой HHVM на Nginx для использования с Laravel. Давайте приступим.
***HHVM (или HipHop Virtual Machine)... | https://habr.com/ru/post/208778/ | null | ru | null |
# Умный замок на Android Things и Raspberry Pi3
В декабре 2016 года Google [анонсировал](https://android-developers.googleblog.com/2016/12/announcing-googles-new-internet-of-things-platform-with-weave-and-android-things.html) выход первой Developer Preview версии Android Things. С тех пор проект сильно изменился. Все ... | https://habr.com/ru/post/331888/ | null | ru | null |
# Как рендерится кадр Rise of the Tomb Raider

Rise of the Tomb Raider (2015 год) — это сиквел превосходного перезапуска Tomb Raider (2013 год). Лично я нахожу обе части интересными, потому что они отошли от стагнирующей оригинальной серии и... | https://habr.com/ru/post/436500/ | null | ru | null |
# Топ 20 ошибок при работе с многопоточностью на С++ и способы избежать их
Привет, Хабр! Предлагаю вашему вниманию перевод статьи [«Top 20 C++ multithreading mistakes and how to avoid them»](https://www.acodersjourney.com/top-20-cplusplus-multithreading-mistakes/) автора Deb Haldar.

Заметил, что статьи получаются довольно большими, и вопросы задаются в разных направлениях. Эта статья была написана для того, чтобы собрать вопросы по установке программы ZINB... | https://habr.com/ru/post/137524/ | null | ru | null |
# Как добавить проверки в NoVerify, не написав ни строчки Go-кода
В статическом анализаторе [NoVerify](https://github.com/VKCOM/noverify) появилась киллер-фича: декларативный способ описания инспекций, который не требует программирования на Go и компиляции кода.
Чтобы вас заинтриговать, покажу описание простой, но по... | https://habr.com/ru/post/473718/ | null | ru | null |
# История Half-Life 2
[](https://habrastorage.org/files/00e/089/e88/00e089e887fe4af788273cf5c318db57.jpg)
В понедельник, 9 ноября 1998 года, около четырёх часов вечера в обычном офисном комплексе где-то под Сиэттлом человек... | https://habr.com/ru/post/372747/ | null | ru | null |
# React.js: собираем с нуля изоморфное / универсальное приложение. Часть 3: добавляем авторизацию и обмен данными с API

*Пожалуйста, авторизуйтесь*
Это третья и заключительная часть статьи про разработку изоморфного React... | https://habr.com/ru/post/310952/ | null | ru | null |
# Дополняя SQL. Часть 1. Сложности парсинга. Истории о доработке ANTLR напильником
Публикую на Хабр оригинал статьи, перевод которой размещен в блоге [Codingsight](https://codingsight.com/completing-sql-part-1-the-difficulties-with-parsing-or-tales-of-polishing-antlr/).
Что будет в этой статье?
--------------------... | https://habr.com/ru/post/502416/ | null | ru | null |
# Каждый браузер видит цвета видео по-разному
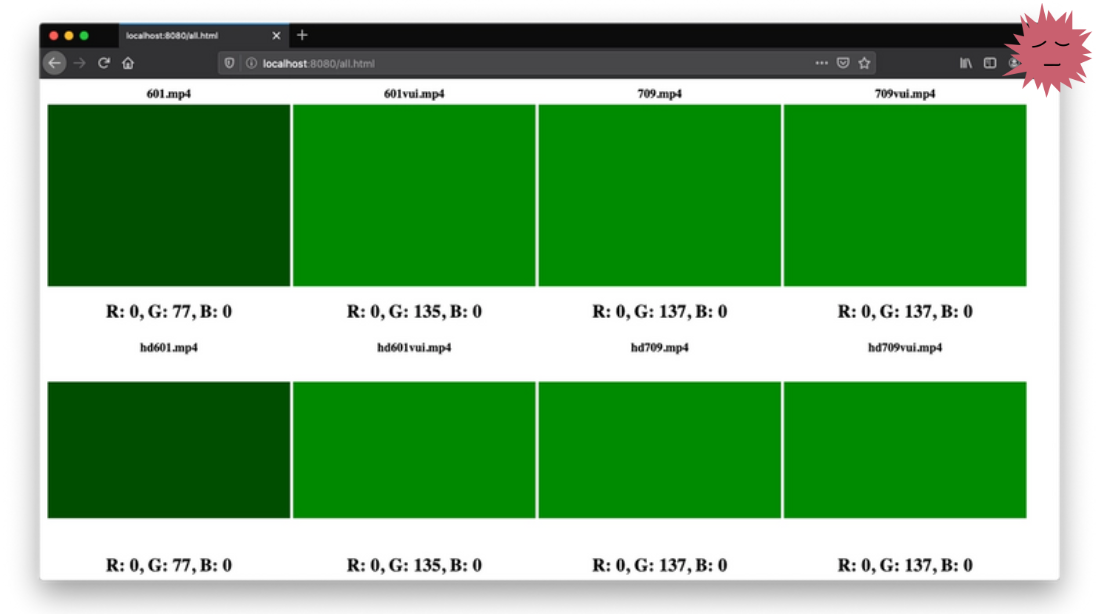
Большинство людей знает основы теории цвета. Сочетая яркости нескольких основных цветов, можно воссоздать любой видимый человеку цвет. Многие люди знают, что отдельные цвета — это просто... | https://habr.com/ru/post/560224/ | null | ru | null |
# RxSwift шпаргалка по операторам (+ PDF)

Заинтересовавшись темой функционального программирования я встал на распутье, — какой фреймворк выбрать для ознакомления. ReactiveCocoa — ветеран в iOS кругах, по нему вдоволь инфор... | https://habr.com/ru/post/281292/ | null | ru | null |
# Учебник по JavaFX: Привет, мир
Перевод статьи «[JavaFX Tutorial: Hello world](https://www.vojtechruzicka.com/javafx-hello-world/)» автора Vojtech Ruzicka.
Как создать ваше первое приложение JavaFX.
Это второй пост в серии о JavaFX. Вы можете прочитать в первой статье о том, как настроить вашу среду для разрабо... | https://habr.com/ru/post/474498/ | null | ru | null |
# Немного о сборке мобильного приложения

Я помню то замечательное время, когда сборка релизной версии мобильного приложения сводилась к тому, что нужно было выставить debug = false и запустить экспор... | https://habr.com/ru/post/273781/ | null | ru | null |
# Kubeflow: новый проект для работы с машинным обучением в Kubernetes
Разработчики Google [объявили](https://jaxenter.com/kubeflow-ml-kubernetes-139610-139610.html) о запуске нового проекта Kubeflow. Проект упрощает работу с машинным обучением, предоставляя необходимый инструментарий для масштабирования и настройки си... | https://habr.com/ru/post/347042/ | null | ru | null |
# Современные спам фильтры и End-to-End шифрование
Привет
======
Тревор (*пер:* — насколько я понял, речь идёт о [Trevor Perrin](http://trevp.net)) попросил написать свои мысли по поводу … спам фильтров и ск... | https://habr.com/ru/post/237745/ | null | ru | null |
# Доступ к элементам std::tuple во время исполнения программы
При тестировании разрабатываемой библиотеки математических алгоритмов для автономного вождения нашей команде приходилось достаточно много манипул... | https://habr.com/ru/post/546506/ | null | ru | null |
# JNI и Delphi. Использование Java методов при помощи JNI
Всем доброго времени суток!
Сегодня мы рассмотрим такую тему, как использовать Java методы при помощи JNI.
На самом деле все очень просто. Давайте сразу начнем с примера:
Допустим у нас есть некое Java приложение на котором есть простая кнопка и при н... | https://habr.com/ru/post/515234/ | null | ru | null |
# «Скользкие» места C++17
[](https://habr.com/ru/company/playrix/blog/465181/)
В последние годы C++ шагает вперед семимильными шагами, и угнаться за всеми тонкостями и хитросплетениями языка бывает весьма и весьма непросто. Уже ... | https://habr.com/ru/post/465181/ | null | ru | null |
# Танчики на node.js — оптимизация
 Спасибо всем, кто пытался поиграть в [первый раз](http://habrahabr.ru/blogs/gdev/132362/). Очень жаль, что я разочаровал столько людей жуткими тормозами игры. Но я мог бы и не догадаться до их прич... | https://habr.com/ru/post/133104/ | null | ru | null |
# Intel научилась обновлять UEFI без перезагрузки
Компания Intel разработала новый механизм обновления UEFI под названием [Intel Seamless Update](https://uefi.org/sites/default/files/resources/Intel_MM_OS_Interface_Spec_Rev100.pdf... | https://habr.com/ru/post/578354/ | null | ru | null |
# Текстовый туториал по react-router, а так же react-router + redux. На русском
Всем добрый день. Немного с задержкой, но все же выходит [третий мини-учебник](https://www.gitbook.com/book/maxfarseer/react-router-course-ru/details). На этот раз разобран [react-router](https://github.com/reactjs/react-router). А так же ... | https://habr.com/ru/post/282369/ | null | ru | null |
# SoftMocks: наша замена runkit для PHP 7
 Компания Badoo одной из первых перешла на PHP 7 — мы совсем недавно [писали об этом](https://habrahabr.ru/company/badoo/blog/279047/). В той статье мы говорили об изменениях в инфраст... | https://habr.com/ru/post/279617/ | null | ru | null |
# Беседы о C++: РГ 21, Boost, конференции
Всем привет!
Недавно в Новосибирске прошла очередная C++ Siberia 2019. На конференции была уютная атмосфера и много хороших докладов. Видеозаписи докладов сейчас готовятся к публикации. Пользуясь случаем, я побеседовал с двумя нашими частыми докладчиками, которые редко пропус... | https://habr.com/ru/post/441800/ | null | ru | null |
# Google Go = Python и C++
Google только что объявил выпуск нового языка с открытым исходным кодом
под названием Go. Компания говорит что, Go эксперементальный язык и
он объединяет производительность и безопасность компилируемых языков(как С++)
со скорость разработки динамических языков (как Python).
Оффиц... | https://habr.com/ru/post/74913/ | null | ru | null |
# Телепатия на стероидах в js/node.js
Этап поддержки продуктов отнимает много сил и нервов. Путь от «я нажимаю а оно не работает» до решения проблемы, даже у первоклассного телепата, может занимать много времени. Времени,... | https://habr.com/ru/post/307482/ | null | ru | null |
# Правильный путь становления безопасника: от ламера до практического эксплойтинга
Приветствую, тебя %хабраюзер%. Прочитал я тут статью на хабре [«Экзамен для будущих «русских хакеров» в Московском Политехе»](https://habrahabr.ru/post/320210/). И мой мозг вошел в бесконечный цикл непонимания происходящего. То ли я сей... | https://habr.com/ru/post/320286/ | null | ru | null |
# Re-checking PascalABC.NET
Welcome all fans of clean code! Today we analyze the PascalABC.NET project. In 2017, we already found errors in this project. We used two static analysis tools (more precisely, plugins for SonarQube): SonarC# and PVS-Studio. Today, we analyze this project with the latest version of the PVS-... | https://habr.com/ru/post/647643/ | null | en | null |
# Граббер для одного книжного сайта
В один прекрасный день я решил написать grabber для книжного сайта и теперь хочу поделиться с вами тонкостями реализации такого рода программных решений. **Вся информация представлена исключительно для ознакомительных целей**
За основу взял [QWebEngineView](http://doc.qt.io/qt-5/qw... | https://habr.com/ru/post/334412/ | null | ru | null |
# Публикация Spring Boot приложения в GitHub Packages с помощью GitHub Actions для самых маленьких
Сегодня я расскажу вам как можно опубликовать своё [Spring Boot](https://spring.io/projects/spring-boot) приложение в [GitHub Packages](https://github.com/features/packages) с помощью [GitHub Actions](https://github.com/... | https://habr.com/ru/post/576412/ | null | ru | null |
# Конструируем XML с использованием LINQ to XML API
До недавнего времени мне ужасно не нравилось работать с XML файлами, я старался избегать этого где только можно, по просту заменяя их стандартными конфигурационными файлами приложения. Но где нужно было использовать обмен данными – от XML’а было не уйти. Приходилось ... | https://habr.com/ru/post/109900/ | null | ru | null |
# Автоматизация доставки flow в Apache NiFi
Всем привет!

Задача заключается в следующем — есть flow, представленный на картинке выше, который надо раскатить на N серверов с [Apache NiFi](https://nifi.apache.org). Flow тестовый — ... | https://habr.com/ru/post/476722/ | null | ru | null |
# Twitter бот на C#

Здравствуйте, уважаемые пользователи Хабрахабра.
В этой статье я хочу рассказать вам об очень простом и полезном боте для Twitter, который поможет контролировать состояние Windows-... | https://habr.com/ru/post/128422/ | null | ru | null |
# Создание бота для участия в Russian AI Cup 2018 CodeBall

Сложилась традиция, что после соревнований по спортивному программированию победитель или просто игрок выкладывает на Хабре статью, чтобы рассказать как здорово было участ... | https://habr.com/ru/post/434838/ | null | ru | null |
# Охватывающий SQL в Postgres
Одна вещь, которая заставляет меня смотреть со стороны на ORM, как они так стараются скрыть и абстрагировать все силу и выразительность SQL. Прежде чем я напишу дальше, позвольте мне сказать что, [Frans Bouma](https://twitter.com/fransbouma) напомнил мне вчера, что есть разница между ORM... | https://habr.com/ru/post/258153/ | null | ru | null |
# 90 рекомендаций по стилю написания программ на C++
> *От переводчика. Искал в интернете простой и легко применимый гайдлайн по написанию программ на C++. Мне понравился один из вариантов, и я решил его перевести и опубликовать. Если хабрапользователи хорошо встретят этот топик, могу перевести и другие связанные доку... | https://habr.com/ru/post/172091/ | null | ru | null |
# Памятка/шпаргалка по SQL

Доброго времени суток, друзья!
Изучение настоящей шпаргалки не сделает вас мастером SQL, но позволит получить общее представление об этом языке программирования и возможностях, которые он предоставляет. Р... | https://habr.com/ru/post/564390/ | null | ru | null |
# Скрапинг современных веб-сайтов без headless-браузеров

Многие разработчики считают скрапинг сложной, медленной и неудобной для масштабирования задачей, особенно при работе с headless-браузерами. По моему опыту, можно заниматься ... | https://habr.com/ru/post/537174/ | null | ru | null |
# Устройство 64-битных счётчиков транзакций в Postgres Pro Enterprise
### Введение
Эта статья описывает реализацию 64-битных счётчиков транзакций (XID, ксидов) в СУБД [Postgres Pro Enterprise](https://postgrespro.ru/docs/enterprise/14/), которая создана на основе свободной, опенсорсной объектно–реляционной СУБД Postg... | https://habr.com/ru/post/707968/ | null | ru | null |
# Простое (не очень) увлажнение квартиры
Начал я плавно переводить громоздкие автоматизации из Home Assistant в NodeRED, и хочу поделиться своим вариантом решения управления увлажнителем. Задача на первый взгляд простая (включи да выключи), но со временем к ней добавилось довольно много дополнительных условий, поэтому... | https://habr.com/ru/post/711710/ | null | ru | null |
# Мобильная игра на HTML, CSS, JavaScript, jQuery, Apache Cordova и Firebase. Как сделать красиво снаружи и плохо внутри
*В данной статье будет рассказана история разработки одной мобильной игры. Также будут освещены следующие вопросы:*
* *Стоит ли использовать jQuery?*
* *Стоит ли вообще разрабатывать мобильные игр... | https://habr.com/ru/post/663316/ | null | ru | null |
# Buildroot — часть 1. Общие сведения, сборка минимальной системы, настройка через меню
Введение
--------
В данной серии статей я хочу рассмотреть систему сборки дистрибутива buildroot и поделиться опытом её кастомизации. Здесь будет практический опыт создания небольшой ОС с графическим интерфейсом и минимальным функ... | https://habr.com/ru/post/448638/ | null | ru | null |
# Микроспутники для дистанционного зондирования Земли

В настоящее время большой интерес проявляется к созданию и использованию малых космических аппаратов — адекватной замене больших космических аппаратов.
Это объясняется многими... | https://habr.com/ru/post/349844/ | null | ru | null |
# Простой способ создания голосового оповещения в системе Домашней автоматизации («Умный дом»)
Протестировав консольный SIP клиент Linphonec, увидел в нём возможность простого и быстрого способа реализации оповещения голосом на мобильный телефон, для домашней системы автоматизации.
Думаю данный способ подойдёт для ... | https://habr.com/ru/post/466735/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.