
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Пишем 3D игру под Windows Mobile, ч.1
На хабре достаточно много пользователей коммуникаторов. И вы рассказывали достаточно много историй о том, как вы их использовали в своё время: раскладывали пасьянс, играли в шарики, сидели в интернете, читали книги и в конце-концов, использовали как телефон. А что, если я вам ск... | https://habr.com/ru/post/695428/ | null | ru | null |
# Создание приложения с использованием Styled-Components в Vue.js
Привет, Хабр! На днях наткнулся на одну очень интересную статью на португальском. К счастью, удалось найти её английскую версию. Предлагаю вашему вниманию перевод на русский. Другие мои переводы вы можете найти на мой странице на хабре.
Ссылка на ори... | https://habr.com/ru/post/467977/ | null | ru | null |
# Windows Phone 7 XNA: гнем пиксели или нет шейдерам
Привет дорогой друг.
Опять прошло много времени и я не радовал вас интересной информацией по
поводу разработки игр. Сегодня эту статью я хочу посветить разработке игр под **WP7**, используя
замечательный фреймворк **XNA**, о котором я писал [здесь](http:/... | https://habr.com/ru/post/137869/ | null | ru | null |
# Путешествие через вычислительный конвейер процессора
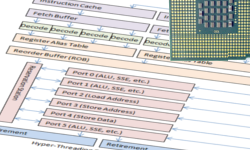Так как карьера программиста тесно связана с процессором, неплохо бы знать как он работает.
Что происходит внутри процессора? Сколько времени уходит на исполнение одн... | https://habr.com/ru/post/182002/ | null | ru | null |
# Мы сократили время разработки нового сценария публикации объявления с 6 дней до 42 секунд
Всем привет! Меня зовут Артем Пескишев, я iOS-разработчик в Авито. Хочу рассказать, как мы завели управляемый с бэкенда сценарий публикации новых объявлений в наших мобильных приложениях.
Разберём, что такое пошаговые сценари... | https://habr.com/ru/post/501698/ | null | ru | null |
# Практический пример использования Backbone
В данной заметке речь пойдет об использовании Backbone, а в частности, примеры кода работающего с сервером. Это должен быть некий промежуточный пункт в блужданиях Ищущего, так как иначе начать им пользоваться очень сложно, а вероятность отказаться от идеи перехода стремится... | https://habr.com/ru/post/132728/ | null | ru | null |
# Python, исследование данных и выборы: часть 5
Заключительный пост №5 **для** **начинающих** посвящен сопоставительной визуализации электоральных данных. Предыдущий пост см. [здесь](https://habr.com/ru/post/556044/).
Сопоставительная визуализация электоральных данных
-------------------------------------------------... | https://habr.com/ru/post/556048/ | null | ru | null |
# Простые числа — насколько велико наше бессилие?
Представьте, что вас окружает бесконечно высокая стена, а о том, что находится за стеной абсолютно ничего неизвестно. Теперь представьте, что олицетворением данной стены является вот это уравнение:
Логирование бывает разным. Часто в проектах можно встретить следующие виды логов:
* Системные об ошибках и исключениях;
* Авторизационные о попытках входа;
* Почтовые о работе, на... | https://habr.com/ru/post/711110/ | null | ru | null |
# «Реверс-инжиниринг» клиентского приложения в образовательном центре
Привет, Хабр. Хочу поделиться историей из жизненного опыта. Несколько месяцев назад я записался на платные курсы по изучению языка программирования JavaScript в прекрасном городе Минск. Потратил около недели времени на подробное изучение отзывов о к... | https://habr.com/ru/post/251705/ | null | ru | null |
# На мгновение быстрее: измеряем время упаковки и распаковки значимых типов данных
#### Доброго дня, Хабр!

Многие неопытные разработчики не всегда знают и понимают, что же происходит за кулисами их кода.... | https://habr.com/ru/post/210108/ | null | ru | null |
# Kaboom: необычный сапёр

*В детстве я три раза в неделю по часу-полтора сидел на работе у отца. Меня пускали за компьютер, где из развлечений был лишь сапёр и Paint. Рисовать мне быстро надоедало, зато желание открыть всё поле и не... | https://habr.com/ru/post/487052/ | null | ru | null |
# Как работает JS: технология Shadow DOM и веб-компоненты
**[Советуем почитать] Другие 19 частей цикла**Часть 1: [Обзор движка, механизмов времени выполнения, стека вызовов](https://habrahabr.ru/company/ruvds/blog/337042/)
Часть 2: [О внутреннем устройстве V8 и оптимизации кода](https://habrahabr.ru/company/ruvds/b... | https://habr.com/ru/post/415881/ | null | ru | null |
# Как общаются машины — протокол MQTT

В предыдущей статье мы разбирали [протокол Modbus](https://habr.com/ru/company/advantech/blog/450234/), являющийся стандартом де-факто в промышленности для M2M-взаимодействия. Разработанный в да... | https://habr.com/ru/post/452904/ | null | ru | null |
# Продвинутые CSS фильтры
*Перевод [статьи advanced css filters](http://iamvdo.me/en/blog/advanced-css-filters), авторства Vincent De Oliveira, найденная мною в последнем [дайджесте](http://habrahabr.ru/company/zfort/blog/263997/).*
*Я не смог коротко перевести на русский backdrop и background, сохранив смысловую р... | https://habr.com/ru/post/264037/ | null | ru | null |
# Организация и оптимизация стилей
В этом посте я приведу пример организации стилей на типичном проекте.
Небольшое вступление, попробую объяснить актуальность проблемы и зачем это нужно.
Рассмотрим такую ситуацию. Разработчику ставят задачу, реализовать очередной функционал на сайте. Это допустим включает добавл... | https://habr.com/ru/post/114497/ | null | ru | null |
# Консольный проигрыватель .wav для pc-speaker в Linux
Давно хотел написать проигрыватель для pc-speaker и чтобы не только ноты и монофонические мелодии. Но в то время когда это было актуально (DOS — навсегда!) у меня не было ни знаний, ни способностей, ни помыслов. Позже я не смог пробиться к нему сквозь Windows DDK ... | https://habr.com/ru/post/138144/ | null | ru | null |
# Процесcы в операционной системе Linux (основные понятия)
Основными активными сущностями в системе Linux являются процессы. Каждый процесс выполняет одну программу и изначально получает один поток управления. Иначе говоря, у процесса есть один счетчик команд, который отслеживает следующую исполняемую команду. Linux п... | https://habr.com/ru/post/125369/ | null | ru | null |
# Звуковые отпечатки: распознавание рекламы на радио
Из этой статьи вы узнаете, что распознавание даже коротких звуковых фрагментов в зашумленной записи — вполне решаемая задача, а прототип так вообще реализуется за 30 строчек кода на Python. Мы увидим, как тут помогает преобразование Фурье, и наглядно посмотрим, как ... | https://habr.com/ru/post/252937/ | null | ru | null |
# SharePoint + Reporting Services = нюансы
Я и мои коллеги занимаемся разработкой и внедрением прикладных внутрикорпоративных решений на базе платформы Microsoft SharePoint, а так же Российских СЭД, внедрение которых обосновано накопленным годами опытом и целесообразно в определенных случаях.
На своих проектах обож... | https://habr.com/ru/post/177639/ | null | ru | null |
# Разработка простой игры в Game Maker. Эпизод 0. Первые строки
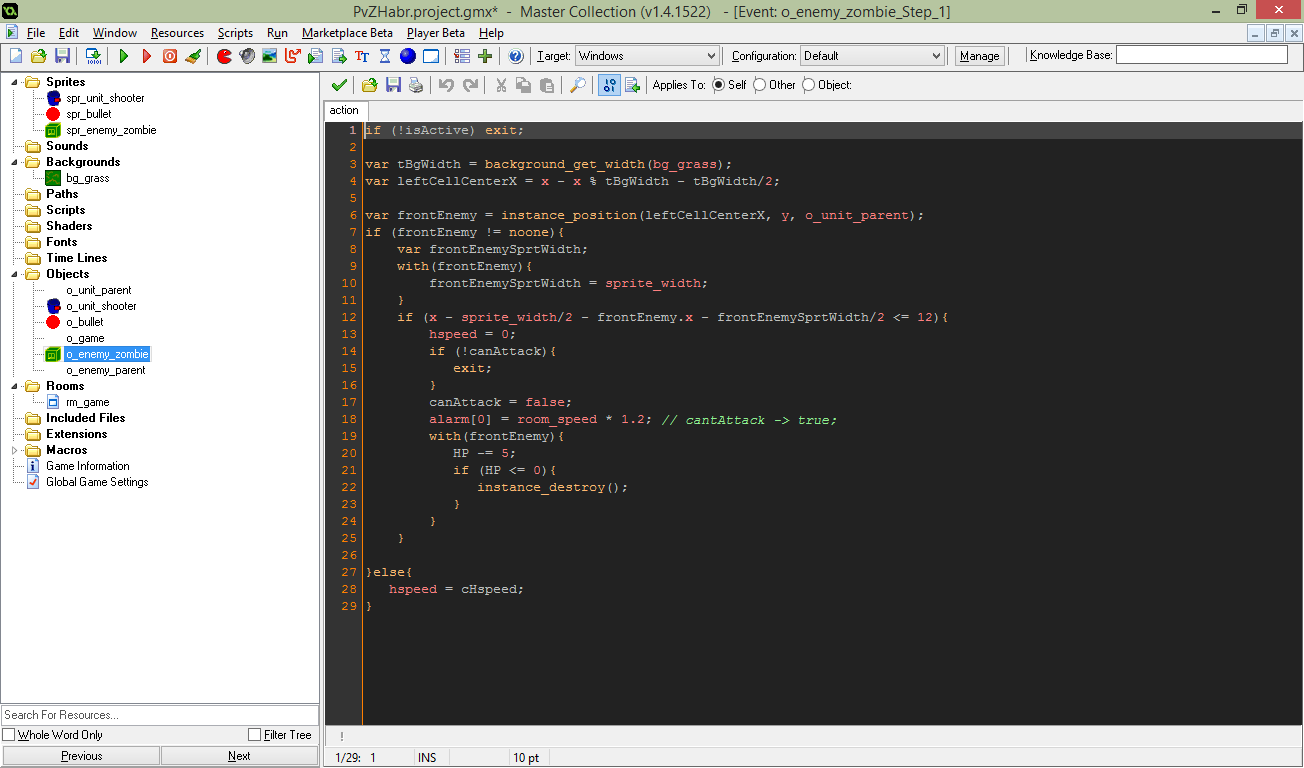
Если вы любите игры, несомненно задавались вопросом о том, как их делают. Если у вас есть (или будет) желание делать игры, но нет опыта, в этой статье я расска... | https://habr.com/ru/post/255995/ | null | ru | null |
# Нечеткий динамический текстовый поиск? Не так уж и страшно

Существует устойчивое мнение, что нечеткий поиск в динамике (онлайн)
малодоступен в силу ... | https://habr.com/ru/post/206066/ | null | ru | null |
# Преодолеваем скрытые опасности KVO в Objective C
*The major difference between a thing that might go wrong and a thing that cannot possibly go wrong is that when a thing that cannot possibly go wrong goes wrong it usually turns out to be impossible to get at or repair.
— Douglas Adams*
Objective C существует у... | https://habr.com/ru/post/202884/ | null | ru | null |
# Wuala отменяет «облачный коммунизм»
[Wuala](http://wuala.com/), аналог заслуженно популярного Dropbox, известный своей политикой «облачного коммунизма» (сколько дискового пространства предоставишь — столько получишь места в облаке), меняет правила. Буквально пару часов назад я получил письмо следующего содержания: ... | https://habr.com/ru/post/129656/ | null | ru | null |
# И снова о кешировании в Django
Для django уже есть множество библиотек для кеширования и они уже [обсуждалось на хабре](https://habrahabr.ru/post/143789/), но, к сожалению, проблемы с производительностью не решить добавлением строчки в INSTALLED\_APPS. В библиотеках патчащих queryset кеш инвалидируется либо слишком ... | https://habr.com/ru/post/337998/ | null | ru | null |
# Импорт views из модуля
[](http://habrahabr.ru/blogs/drupal/108990/)
Штука очень удобная, т.к. позволяет запихать в модуль все что ему необходимо для работы, не нужно в ручную бегать, экспортировать/импортировать вь... | https://habr.com/ru/post/108990/ | null | ru | null |
# Создаем оберточный HStack с помощью протокола Layout SwiftUI
Компонент, который мы собираемся создать, доступен как [Swift Package](https://github.com/ksemianov/WrappingHStack).
### Вступление
Утро понедельника,... | https://habr.com/ru/post/705722/ | null | ru | null |
# Введение в комлексные числа
Привет!
Выяснив, что многие знакомые программисты не помнят комплексные числа или помнят их очень плохо, я решил сделать небольшую шпаргалку по формулам.
А школьник... | https://habr.com/ru/post/354548/ | null | ru | null |
# Автоматизация перезагрузки роутера CISCO RVS4000
Так уж случилось, что домашний роутер после двух лет безглючной работы начал время от времени подвисать. Проявлялось это в подвисании WAN порта и отсутствии интернета у всей подсети, LAN работает нормально. Решение оказалось не таким простым, как может показаться снач... | https://habr.com/ru/post/200328/ | null | ru | null |
# Как отличить хороший ремонт от плохого, или как мы в SRG сделали из Томита-парсера многопоточную Java-библиотеку
В этой статье речь пойдет о том, как мы интегрировали разработанный Яндексом Томита-парсер в нашу систему, превратили его в динамическую библиотеку, подружили с Java, сделали многопоточной и решили с её п... | https://habr.com/ru/post/439614/ | null | ru | null |
# Ajax на мобильном браузере или мобильный Ajax (с примерами)
Ajax, судя по тенденциям, всё больше овладевает умами девелоперов. Особенно активно сейчас начинает развиваться Ajax для мобильных браузеров. Об этом собственно и поговорим.
Технология Ajax очень востребована пользователями мобильных устройств. Причина в... | https://habr.com/ru/post/31551/ | null | ru | null |
# Just for fun: команда PVS-Studio придумала мониторить качество некоторых открытых проектов
Статический анализ кода — это важная составляющая всех современных проектов. Еще более значимым является его правильное применение. Мы решили организовать регулярную проверку некоторых открытых проектов, чтобы увидеть эффект о... | https://habr.com/ru/post/541922/ | null | ru | null |
# Коллекции объектов в PHP
На протяжении последних 5 лет я работаю с PHP. У него есть достаточно разных проблем, но это никогда не мешало создавать отлично работающие продукты.
Не смотря на это, есть ряд вещей, которые выполняются внутри достаточно «криво». Один из вопросов, который постоянно тратил мои нервы, был ... | https://habr.com/ru/post/144182/ | null | ru | null |
# Делаем часы из электронной книжки PRS-505
[](https://habr.com/ru/company/ruvds/blog/526546/)
Удивительно, но старинная электронная книга Sony prs-505 является очень классным конструктором всевозможных самоделок. В очередной раз в... | https://habr.com/ru/post/526546/ | null | ru | null |
# Об одной уязвимости в…

Год назад, 21 марта 2019, в [баг баунти программу Mail.ru](https://hackerone.com/mailru) на HackerOne пришел очень хороший [багрепорт](https://hackerone.com/reports/513236) от [maxarr](https://hackerone.co... | https://habr.com/ru/post/493920/ | null | ru | null |
# Как понять свойство clip-path в CSS
В те далёкие времена, когда я впервые столкнулся со свойством CSS `clip-path`, мне потребовалось больше времени, чем я ожидал, и я изо всех сил старался запомнить, как работает свойство. Не знаю точно, почему так получилось, но, может быть, потому, что я не пользовался им часто? В... | https://habr.com/ru/post/539064/ | null | ru | null |
# Создаем GAN с помощью PyTorch
### Реалистичные изображения из ничего?
Генеративно-состязательные сети (Generative Adversarial Networks — **GAN**), предложенные Goodfellow и др. в 2014 году, произвели револ... | https://habr.com/ru/post/569858/ | null | ru | null |
# Облачный гейминг в браузере
В облако сегодня перебирается всё больше категорий приложений, в том числе игры. У VK Play Cloud уже есть свои нативные приложения под Windows, Mac, Android и Android TV, которы... | https://habr.com/ru/post/710760/ | null | ru | null |
# External Interrupts in the x86 system. Part 2. Linux kernel boot options
In the [last part](https://habr.com/ru/post/446312/) we discussed evolution of the interrupt delivery process from the devices in the x86 system (PIC → APIC → MSI), general theory, and all the necessary terminology.
In this practical part we w... | https://habr.com/ru/post/501660/ | null | en | null |
# Построение нейронных сетей в php используя FANN, пример реализации
Передо мной предстала задача анализа большого количества информации и выявления закономерностей. И первое, что пришло в голову — построить математическую модель с помощью [нейронной сети](http://ru.wikipedia.org/wiki/%D0%98%D1%81%D0%BA%D1%83%D1%81%D1... | https://habr.com/ru/post/158729/ | null | ru | null |
# Neo4j. Вместо тысячи join-ов…
Если вы столкнулись с задачей хранения сильно связанных данных, то отличным вариантом будет использовать графовую модель данных. Мы в Текфорс сделали именно так. Почему - разберем в этой статье, где я:
* приведу общую информацию о том, где применяются графовые БД;
* расскажу про Neo4j... | https://habr.com/ru/post/711646/ | null | ru | null |
# jl-sql: SQL-запросы по JSON-логами в командной строке
Вступление никому не интересно, поэтому начну сразу с примеров использования

```
% cat log.json
```
```
{"type": "hit", "client": {"ip": "127.1.2.3"}}
{... | https://habr.com/ru/post/319722/ | null | ru | null |
# Модуль Mock: макеты-пустышки в тестировании
*Mock* на английском значит «имитация», «подделка». Модуль с таким названием помогает сильно упростить тесты модулей на Питоне.
Принцип его работы простой: если нужно тестировать функцию, то всё, что не относится к ней самой (например, чтение с диска или из сети), можно... | https://habr.com/ru/post/141209/ | null | ru | null |
# Сравнение алгоритмов вычисления чисел Фибоначчи
В комментариях к статьям [N-е число Фибоначчи за O(log N)](http://habrahabr.ru/post/148336/) и [Еще один алгоритм вычисления чисел Фибоначчи](http://habrahabr.ru/post/148531/) указывалось на тот факт, что уже 100-е число Фибоначчи не помещается в 4 байта, а в «длинной»... | https://habr.com/ru/post/148667/ | null | ru | null |
# К вопросу о константах
### Есть ли в мире что либо более постоянное, чем временные переменные
Просматривая тематический форум, увидел традиционное «Не работает скетч, подскажите, в чем дело» — таких постов чуть меньше, чем все, но в заголовке фигурировала работа с SD карточкой, поэтому решил глянуть. Больше всего п... | https://habr.com/ru/post/329546/ | null | ru | null |
# Ясные печеньки
Привет, Хабр! В свете информации, посвященной безопасности аккаунтов крупных порталов, появившейся в последнее время, я решила немного пересмотреть cookie авторизацию в своих проектах. В перв... | https://habr.com/ru/post/210416/ | null | ru | null |
# Как я решил защищать документы от подделки и «изобрел» электронную цифровую подпись
О чем это
---------
На идею создать свой маленький интернет-проект по защите документов от подделки, меня натолкнула дискуссия на форуме дефектоскопистов, посвященная повальной подделке выданных ими заключений по контролю качества. ... | https://habr.com/ru/post/442210/ | null | ru | null |
# Реализации машины в qemu
В процессе обратной разработки прошивок иногда возникает задача по ее эмуляции, например, для фаззинг тестирования или детального изучения поведения в динамике. На практике обычно для этого хватает фреймворков avatar2, unicorn, qiling и подобных. Однако они поддерживают далеко не все платфор... | https://habr.com/ru/post/593495/ | null | ru | null |
# MU-MIMO: один из алгоритмов реализации
Предисловие
===========
В качестве дополнения к моей [недавней статье](https://habr.com/ru/post/448570/) хотелось бы также поговорить о теме MU (**M**ulti **U**ser) MIMO. Есть у мною уже упомянутого профессора Хаардта одна очень известная [статья](https://www.researchgate.net/... | https://habr.com/ru/post/450948/ | null | ru | null |
# Транслируем видеопоток с веб-страницы по WebRTC на Facebook и YouTube одновременно
Facebook и YouTube предоставляют сервисы трансляций, которые позволяют вещать Live-видеопотоки на широкую аудиторию зрителей. В этой статье мы расскажем, как захватить видеопоток с веб-страницы по технологии WebRTC и отправить этот ви... | https://habr.com/ru/post/327986/ | null | ru | null |
# Упрощаем работу с CloudKit, или синхронизация в духе Zen
### Введение
Облачная синхронизация — закономерный тренд нескольких последних лет. Если вы разрабатываете под одну или несколько Apple платформ (iOS, macOS, tvOS, watchOS) и задачей является реализация функционала синхронизации между приложениями, то в вашем ... | https://habr.com/ru/post/326050/ | null | ru | null |
# Защищаем веб-сервер на Linux
Привет, Хабр!
У нас давно не выходило новых книг по Linux для начинающих — и вот мы беремся за перевод новинки именно такого плана. Книга "[Linux in Action](https://www.manning.com/books/linux-in-action)" Дэвида Клинтона вышла в издательстве Manning и рассказывает не только о [внутрен... | https://habr.com/ru/post/425571/ | null | ru | null |
# Skype For Linux перестал поддерживать процессоры AMD старше 5 лет
Вот уже несколько месяцев, как вход в программу для владельцев многих AMD процессоров знаменуется белым окном, и никак не реагирующими пунктами меню. Насколько известно, пользователей Windows и Mac данная проблема пока не коснулась. Радость от выпуска... | https://habr.com/ru/post/407729/ | null | ru | null |
# Дорог ли native метод? «Секретное» расширение JNI

Для чего Java-программисты прибегают к native методам? Иногда, чтобы воспользоваться сторонней DLL библиотекой. В других случаях, чтобы ускорить критичны... | https://habr.com/ru/post/222997/ | null | ru | null |
# Ускоренная сборка Kotlin с помощью Kotlin Symbol Processing 1.0
[Kotlin Symbol Processing](https://github.com/google/ksp) (KSP), наш новый инструмент для создания легких плагинов компилятора на языке Kotlin... | https://habr.com/ru/post/583234/ | null | ru | null |
# Как устроен Kubernetes as a Service на платформе VK Cloud Solutions

Российские провайдеры давно умеют делать облачные платформы сами, а не только реселлить зарубежные. Это снижает стоимость сервисов, но их пользователям бывает и... | https://habr.com/ru/post/519366/ | null | ru | null |
# Canvas & SVG: работаем с графикой
В HTML5 представлено два элемента для работы с web графикой: Canvas и SVG. Две эти технологии достаточно сильно отличаются друг от друга. Важно знать об их преимуществах и недостатках, чтобы выбрать наиболее подходящую для конкретной задачи технологию. Элемент SVG позволяет создават... | https://habr.com/ru/post/332750/ | null | ru | null |
# Полуфабрикат Windows-службы
Один из способов доморощенной классификации служб основывается на времени их жизни: некоторые из них запускаются сразу же при старте ОС, оставаясь активными постоянно (сюда, скажем, можно отнести веб-серверы и СУБД), другие же запускаются лишь при необходимости, делают свои архиважные дел... | https://habr.com/ru/post/661697/ | null | ru | null |
# В тестовой сборке Windows 10 появилась утилита Disk Usage — анализатор дискового пространства из командной строки
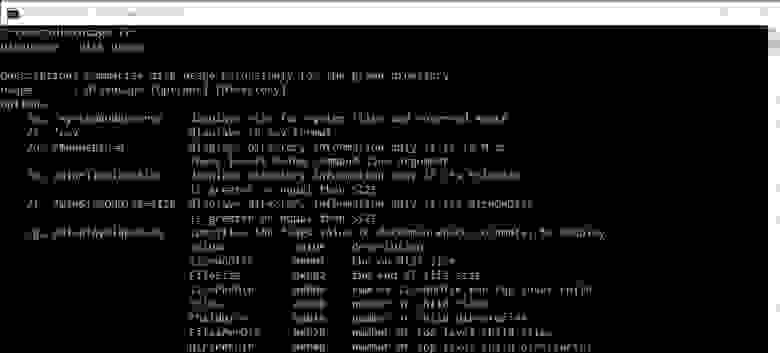
По [информации](https://www.bleepingcomputer.com/news/microsoft/windows-10-to-get-a-built-in-command-line-disk-spa... | https://habr.com/ru/post/533094/ | null | ru | null |
# Идея будильника, или как объединить для этого книжку, CD-ROM, фен, старую нокию и немного shell'a?

Если интересно — прошу под кат!
#### Книжный выключатель.
Откройте ваш любимый текстовый редак... | https://habr.com/ru/post/156151/ | null | ru | null |
# Глубокое обучение с R и Keras на примере Carvana Image Masking Challenge

Привет, Хабр!
Пользователи R долгое время были лишены возможности приобщиться к deep learning-у, оставаясь в рамках одного языка программирования. С вых... | https://habr.com/ru/post/340212/ | null | ru | null |
# Cloud-AI – искусственный интеллект в облаке, нашедший 10 уязвимостей LinkedIn
В 2015 году команда проекта CloudSek задалась целью разработки системы искусственного интеллекта, которая сможет взаимодействовать с интернетом как разумный человек. Первый прототип системы был представлен публике в марте 2016 года на конф... | https://habr.com/ru/post/326212/ | null | ru | null |
# Заменяем встроенный поиск по Хабру на гугловский
В последнее время активно ищу на Хабре заметки, связанные с VoIP. «Родной» поисковик меня давно разочаровал, а каждый раз обращаться к Гуглы стало лениво. Т.к. для вырезания нежелательного контента давно использую [Proxomitron](http://ru.wikipedia.org/wiki/Proxomitron... | https://habr.com/ru/post/46841/ | null | ru | null |
# HashiСorp Vault & Kubernetes Secret: используем vault-secrets-operator
[Vault](https://www.vaultproject.io/) от HashiСorp — довольно известное open-source-решение для хранения секретов и неплохая альтернатива реализации секретов в Kubernetes. Vault использует свой сайдкар-контейнер на каждом поде, который получает с... | https://habr.com/ru/post/571356/ | null | ru | null |
# Vulkan. Руководство разработчика. Window surface

Я из IT-компании CGTribe и здесь я перевожу руководство к Vulkan API. Ссылка на оригинал — [vulkan-tutorial.com](https://vulkan-tutorial.com/).
Моя следующая публикация посвящена... | https://habr.com/ru/post/539174/ | null | ru | null |
# Веб-приложение на Kotlin + Spring Boot + Vue.js (дополнение)
Добрый день, дорогие обитатели Хабра!
Как и следует из названия, данная статья является дополнением к написанной ранее [Веб-приложение на Kotlin + Spring Boot + Vue.js](https://habr.com/ru/post/467161/), позволяющим усовершенствовать скелет будущего при... | https://habr.com/ru/post/482222/ | null | ru | null |
# Кроссплатформенный IoT: Операции с устройствами
Привет, Хабр! IoT Hub Explorer — это кроссплатформенный инструмент на базе node.js по управлению устройствами в использующемся IoT Hub, который может работать в среде Windows, Mac или Linux. Сегодня поговорим о нем в рамках диагностики и усовершенствования IoT Hub Azur... | https://habr.com/ru/post/343802/ | null | ru | null |
# JavaScript ES6: оператор расширения
JavaScript постоянно развивается, в нём появляются различные новшества и улучшения. Одно из таких новшеств, появившееся в ES6 — оператор расширения. Он выглядит как троеточие (`...`). Этот оператор позволяет разделять итерируемые объекты там, где ожидается либо полное отсутствие, ... | https://habr.com/ru/post/348612/ | null | ru | null |
# Программирование необычных шахмат
Написание своего шахматного движка - обширная тема, про которую пишут целые книги.
Однако очень многие шахматные программы работают со "стандартными" правилами шахмат и не... | https://habr.com/ru/post/654745/ | null | ru | null |
# htop и многое другое на пальцах
На протяжении долгого времени я не до конца понимал htop. Я думал, что средняя загрузка [load average] в 1.0 означает, что процессор загружен на 50%, но это не совсем так.... | https://habr.com/ru/post/316806/ | null | ru | null |
# Пагинация во Vue.js
Привет, Хабр! Представляю вашему вниманию перевод статьи "[Pagination in Vue.js](https://medium.com/@denny.headrick/pagination-in-vue-js-4bfce47e573b)" автора Denny Headrick.
Пагинация увеличивает UX, позволяя пользователям визуализировать данные в небольших блоках или на страницах. Вот и комп... | https://habr.com/ru/post/417119/ | null | ru | null |
# Рисование собственных представлений (View) в Android
### Получите полный контроль над представлением и оптимизируйте его производительность
> **В преддверии старта курса** [**"Android Developer. Professional"**](https://otus.pw/QY0e/) **приглашаем всех желающих принять участие в открытом вебинаре на тему** [**"Пише... | https://habr.com/ru/post/530618/ | null | ru | null |
# И снова про App Transport Security: что это и зачем
Привет, Хабр!
Меня зовут Юрий Шабалин, и, как я пишу в начале каждой своей статьи, мы разрабатываем платформу анализа защищенности мобильных приложений iOS и Android.
В этой статье мне бы хотелось затронуть тему безопасной конфигурации сетевого взаимодействия, ... | https://habr.com/ru/post/661345/ | null | ru | null |
# 1000+1 способ определения того, являются ли все элементы в списке одинаковыми
В жизни у нас всегда есть выбор, знаем мы о нем или нет. То же самое происходит и в кодировании. Существует множество способов, с помощью которых мы можем подойти к какой-то конкретной задаче. Мы можем изначально не рассматривать эти спосо... | https://habr.com/ru/post/358284/ | null | ru | null |
# Все ли вы знаете о useCallback
Привет, Хабр!
Начиная с версии *ReactJS* 16.8 в наш обиход вошли хуки. Этот функционал вызвал много споров, и на это есть свои причины. В данной статье мы рассмотрим одно из самых популярных заблуждений использования хуков и заодно разберемся стоит ли писать компоненты на классах ([д... | https://habr.com/ru/post/529950/ | null | ru | null |
# Глубокое погружение в Linux namespaces
**Часть 1**
[Часть 2](https://habr.com/ru/post/459574/)
[Часть 3](https://habr.com/ru/post/541304/)
[Часть 4](https://habr.com/ru/post/549414/)
В этой серии постов мы внимательно рассмотрим один из главных ингредиентов в [контейнере](https://www.docker.com/resources/w... | https://habr.com/ru/post/458462/ | null | ru | null |
# ZTools for Apache Zeppelin

Zeppelin is a web-based notebook for data engineers that enables data-driven, interactive data analytics with Spark, Scala, and more.
The project recently reached version *0.... | https://habr.com/ru/post/522272/ | null | en | null |
# Photoshop Scripting для автоматизации печати многотиражной полиграфической продукции
Здравствуйте. Хотелось бы поделиться опытом автоматизации процесса печати большого количества документов из Adobe Photoshop.
Задача состоит в следующем:
имеется большое количество (в моем случае — 100 000 шт.) уже напечатанных... | https://habr.com/ru/post/165517/ | null | ru | null |
# Первые шаги в Java: как начать разрабатывать ничего не устанавливая
По прошествию многих лет я подумал, а как бы я разрабатывал свою первую программу на Java, если бы я начал сегодня?

Знакомство с Java было в универс... | https://habr.com/ru/post/310438/ | null | ru | null |
# Patroni cluster (with Zookeeper) in a docker swarm on a local machine
Intro
-----
There probably is no way one who stores some crucial data (in particular, using SQL databases) can possibly dodge from the thoughts of building some kind of safe cluster, distant guardian to protect consistency and availability at all... | https://habr.com/ru/post/527370/ | null | en | null |
# Несколько находок
#### Кроссдоменные запросы с помощью YQL
Как клиентский веб разработчик, я всегда хочу уменьшить расходы потребления серверных ресурсов. Может быть, я один такой, не знаю. Но есть группа задач, которые просто-напросто не реализуемы на стороне клиента. Одна из таких задач: запрос на чужой домен. На... | https://habr.com/ru/post/135413/ | null | ru | null |
# Руководство APPIUM по тестированию мобильных приложений для Android и iOS
### Что такое Appium?
Appium — это свободно распространяемый фреймворк с открытым исходным кодом, предназначенный для тестирования ... | https://habr.com/ru/post/682268/ | null | ru | null |
# Загрузка c iso образов при помощи memdisk и grub4dos
Вы наверняка слышали о таких девайсах как нетбук. И знаете, что в них не предусмотрен оптический привод (CD\DVD).
Приобретя нетбук я столкнулся с проблемой — мне необходимо было выложить еще 60$ за внешний оптический привод, что для бедного студента в условиях ... | https://habr.com/ru/post/111045/ | null | ru | null |
# Как мы боролись с проблемами производительности в «Redmine». Кто виноват и как помочь?

Конечно, статья не совсем верно названа. В чистом Redmine особо больших проблем с производительностью нет. Но мы, в ... | https://habr.com/ru/post/227155/ | null | ru | null |
# React. Не вглубь, а вширь. Композиция против реальности
Давайте рассмотрим искусственный пример кода, который, как и в жизни, постепенно будет расширяться и усложняться, а наша задача, глядя на это всё, по... | https://habr.com/ru/post/550532/ | null | ru | null |
# Measurement Protocol — просто о несложном
На днях Universal Analytics вышел из статуса беты и теперь становится основной версией Google Analytics. Это событие позволяет использовать его без ряда ограничений, существовавших ранее. Новая версия несет также ряд новых возможностей для отслеживания посетителей сайта и да... | https://habr.com/ru/post/222169/ | null | ru | null |
# WEBO Site SpeedUp версия 0.9.5 (публичная бета)
[](http://www.web-optimizer.ru/)После почти трех недель дорисовки макетов, интеграции и усиленного тестирования (да-да, все отдыхали, а мы работали!) вышла нов... | https://habr.com/ru/post/80527/ | null | ru | null |
# JEP 181: контроль доступа ко вложенным классам

Продолжаем знакомиться с не слишком известными JEPами. На этот раз, у нас еще один подпроект из Valhalla, который так и называется — ***nestmates***. Эта фича позволяет вложенным... | https://habr.com/ru/post/336768/ | null | ru | null |
# Пишем свой DSL на Clojure для работы с БД

Давайте напишем Clojure-библиотеку для работы с реляционными БД. Заодно потренируемся в написании макросов, попробуем использовать протоколы и мультиметоды. Ведь... | https://habr.com/ru/post/204992/ | null | ru | null |
# Как мы подружились с PayPal

Дорогой иностранный гость с фамилией слишком известной, чтобы ее называть, гражданин PayPal только-только «сошел с корабля» на отечественный «причал», но уже успел стать свои... | https://habr.com/ru/post/199370/ | null | ru | null |
# Точки останова на ручной тяге (для архитектуры x86)
Любой программист хоть раз заглядывавший в отладчик знаком с понятием точки останова (aka бряк, breakpoint). Казалось бы нет ничего проще, чем поставить точку останова пара кликов мышкой в графическом интерфейсе или команда в консоли отладчика, но не всегда жизнь с... | https://habr.com/ru/post/103073/ | null | ru | null |
# Разработчики в борьбе за эффективность программиста, команды, команд
Всем привет.
Сегодня мы хотели бы обсудить один очень важный аспект эффективной работы — повторное использование.
##### Речь пойдет, конечно, о коде.
Рутинном, который не хочется писать дважды, а тем более трижды. Инфраструктурном, который ... | https://habr.com/ru/post/191406/ | null | ru | null |
# От песочных часов к пирамиде: как усовершенствовать структуру тестов
Меня зовут Владислав Романенко, я Senior iOS QA Engineer в Badoo и Bumble. Мы регулярно внедряем новые фичи в приложения, и автоматизация тестирования — один из способов не пропустить баги. Фактически автотесты входят в жизненный цикл всех частей н... | https://habr.com/ru/post/652025/ | null | ru | null |
# Настройка pfBlockerNG на pfSense (часть 2)
Продолжим знакомство c pfBlockerNG - многофункциональным IP/DNSBL фильтром файровола pfSense, позволяющего использовать скачанные из интернета списки блокировки, ф... | https://habr.com/ru/post/583974/ | null | ru | null |
# Знакомство с Apache Ignite: первые шаги
 Рискну предположить, что среднестатистический читатель этой статьи с продуктом [Apache Ignite](https://ignite.apache.org/) не знаком. Хотя, возможно, слышал или даже читал [статью](ht... | https://habr.com/ru/post/310334/ | null | ru | null |
# Регулярные выражениия в Java на примере адреса электронной почты
Известно, что регулярные выражения – это, по сути, шаблоны из символов, которые задают определённое правило поиска. И, среди прочего, с их помощью возможно... | https://habr.com/ru/post/267205/ | null | ru | null |
# Обмануть Мигеля?
Как-то раз Мигель…
*(Хотя нет, история не совсем о нем, попробую начать иначе)*
Однажды в мире Open Source…
*(Тоже мимо, OSS в истории затронуто лишь частично)*
Когда жажду н... | https://habr.com/ru/post/217529/ | null | ru | null |
# Уж+ёж: реактивные компоненты в сервлетном окружении (3/3)
В [предыдущей](https://habr.com/ru/company/cft/blog/648821/) заметке было подробно рассмотрено одно из решений для обеспечения повсеместной доступности текущего обрабатываемого запроса. В отличие от неё, нынешняя заметка не будет посвящена глубокому рассмотре... | https://habr.com/ru/post/650165/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.