
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Виртуальный 4-битный микроконтроллер с программированием тремя кнопками и четырьмя переключателями

Предлагаемое устройство эмулирует на микроконтроллере ATmega4809 абстрактный 4-битный микроконтроллер с адресным пространством в 25... | https://habr.com/ru/post/451670/ | null | ru | null |
# [Перевод] Cross-Storage: Сделайте локальные данные доступными между доменами

Как мы знаем [localStorage API](http://diveintohtml5.info/storage.html) имеет некоторые ограничения, которые, возможно, п... | https://habr.com/ru/post/236223/ | null | ru | null |
# Простой экспорт в Excel XML
При разработке системы электронного документооборота потребовалось реализовать функции для экспорта данных в популярных форматах. В частности, в формате Microsoft Excel. Требования к экспорту были довольно простые – экспортировать данные с минимумом форматирования, т.е. никаких объединенн... | https://habr.com/ru/post/235973/ | null | ru | null |
# Вышел релиз Laravel 5.3
Команда Laravel с гордостью объявляет о релизе Laravel 5.3, доступной для всех. Новые возможности версии 5.3 направлены на улучшение скорости разработчика за счет добавления и улучшения функций «из коробки».
Этот релиз будет получать общие обновления в течение шести месяцев, и обновления б... | https://habr.com/ru/post/308380/ | null | ru | null |
# Ограничение скорости обработки запросов в nginx

*Фотография пользователя Wonderlane, [Flickr](https://www.flickr.com/photos/wonderlane/5516928454/)*
NGINX великолепен! Вот только его [документация](http://nginx.org/ru/do... | https://habr.com/ru/post/329876/ | null | ru | null |
# Светильник «чёрная дыра»

Предлагаю вашему вниманию светильник, одновременно являющийся наглядным пособием «чёрная дыра в двумерном пространстве».
Общая теория относительности Эйнштейна гласит, что предметы с массой искажают т... | https://habr.com/ru/post/411915/ | null | ru | null |
# Символьная регрессия и еще один подход
Символьная регрессия считается очень интересной. "Найди мне функцию, которая будет лучше всего подходить для решения поставленной задачи". И на Хабре я уже встречал пост, в котором автор рассматривал один из эволюционных алгоритмов в применении к этой проблеме ([вот он](https:/... | https://habr.com/ru/post/281334/ | null | ru | null |
# JaCarta Authentication Server и JaCarta WebPass для OTP-аутентификации в Linux SSH
В этой статье мы поговорим об основных этапах настройки аутентификации в Linux SSH для замены парольной аутентификации одноразовыми паролями — в статье описан сценарий аутентификации в сессию SSH-подключения к Linux OS посредством одн... | https://habr.com/ru/post/331908/ | null | ru | null |
# Как мы обновили поисковые подсказки в Яндексе и нашли для них правильную метрику
Поисковым подсказкам в Яндексе уже почти 10 лет. На первый взгляд, они кажутся довольно простой фичей — многие до сих пор уверены, что саджест учитывает только то, как часто люди вводят те или иные запросы. Несколько лет назад мы [расск... | https://habr.com/ru/post/340552/ | null | ru | null |
# Делаем простенький web-сервис с помощью API Яндекс.Метрики
Всем привет!
Не так давно Яндекс открыл для использования API Яндекс.Метрики. В этой статье я расскажу для чего оно нужно, как им пользоваться и кратко опишу отличия от API Google Analytics.
Кроме того, я покажу, как с помощью этого API сделать web-сер... | https://habr.com/ru/post/123207/ | null | ru | null |
# node-direct — один NodeJS сервер на несколько сайтов
tl;dr
=====
С [node-direct](https://github.com/finom/node-direct) можно заливать серверные **.js** файлы и обращаться к ним так же, как к **.php** скриптам: **example.com/foo.srv.js**.
1. Установка.
```
npm install -g node-direct
```
2. Конфигурация nginx.
```... | https://habr.com/ru/post/312558/ | null | ru | null |
# Асинхронность 3: Субъекторная модель

Предисловие
-----------
Эта статья является продолжением цикла статей про асинхронность:
1. [Асинхронность: назад в будущее.](https://habrahabr.ru/post/201826/)
2. [Асинхронность ... | https://habr.com/ru/post/340732/ | null | ru | null |
# Методы доступа к данным в Oracle
Не найдя на хабре статьи, объединяющей в удобном для чтения виде информацию о методах доступа к данным, используемых СУБД Oracle, я решил совершить «пробу пера» и написать эту статью.
#### Общая информация
Не углубляясь в детали, можно утверждать что Oracle хранит данные в таблиц... | https://habr.com/ru/post/189574/ | null | ru | null |
# Protected методы в JavaScript ES5
Про объектную модель в JavaScript написано много замечательных статей. Да и про различные способы создания приватных членов класса в интернете полно достойных описаний. А вот про protected методы — данных очень немного. Я бы хотел восполнить этот пробел и рассказать, как можно созда... | https://habr.com/ru/post/425521/ | null | ru | null |
# KISS + Ruby = нагрузим сервер по быстрому
Опишу я тут историю как на коленках сделал «нагрузочное» тестирование сервиса, и некоторые соображения по поводу Ruby;)
Жила-была себе одна большая система, жила уже не первый год, не первый релиз.
Система представляет из себя центральные сервера, через которые бегает ... | https://habr.com/ru/post/113420/ | null | ru | null |
# Google Maps API: схема проезда, анимация и стилизация
Многие из нас часто вставляют на свои сайты карты. Обычно, это карта на странице контактов с единственным маркером, которым отмечено место офис... | https://habr.com/ru/post/197448/ | null | ru | null |
# Переход на MySQL 5.6, а стоит ли?
После выхода новой версии MySQL в начале этого года, многие задумались о том стоит ли на неё переходить с более старых версий. Чтобы ответить на этот вопрос для себя, вначале необходимо понять, а что именно даст этот переход. В этой статье я постараюсь осветить новые, важные для мен... | https://habr.com/ru/post/179481/ | null | ru | null |
# Как я пишу конспекты по математике на LaTeX в Vim
Некоторое время назад на Quora я отвечал на вопрос: [как успевать записывать за лектором конспект по математике на LaTeX](https://www.quora.com/Can-people-actually-keep-up-with-note-taking-in-Mathematics-lectures-with-LaTeX/answer/Gilles-Castel-1). Там я объяснил сво... | https://habr.com/ru/post/445066/ | null | ru | null |
# Гайдлайны и бритвы компании Bungie по кодингу на C++

Для создания игры наподобие Destiny требуется много командной работы и мастерства. У нас есть талантливые люди во всех областях знаний, однако было непросто достичь уровня коо... | https://habr.com/ru/post/588881/ | null | ru | null |
# Checking the Ark Compiler Recently Made Open-Source by Huawei

During the summer of 2019, Huawei gave a series of presentations announcing the Ark Compiler technology. The company claims that thi... | https://habr.com/ru/post/478282/ | null | en | null |
# Решение закрытой транспортной задачи с дополнительными условиями средствами Python
### Постановка задачи
Необходимость решения транспортных задач в связи с территориальной разобщённостью поставщиков и потребителей очевидна. Однако, когда необходимо решить транспортную задачу без дополнительных условий это как прави... | https://habr.com/ru/post/335104/ | null | ru | null |
# Diff-алгоритм React
[React](http://facebook.github.io/react/) — это JavaScript библиотека для создания пользовательских интерфейсов от Facebook. Она была разработана «с нуля», с упором на производительность. В этой статье я расскажу вам о diff-алгоритме и механизме рендеринга, который использует React, что позволит ... | https://habr.com/ru/post/217295/ | null | ru | null |
# Еще раз о визуализации input типа checkbox и radio. Для тех, кто забыл как
Тема старая и уже, как выяснилось, подзабытая.
Недавно у меня была короткая работа по разработке ТЗ на модернизацию давно существующего проекта. И, в частности дело касалось стилизации пресловутых . Выяснилось, что исполнитель, программист... | https://habr.com/ru/post/511080/ | null | ru | null |
# Пишем игровую логику на C#. Часть 1/2
Всем привет. В связи с выходом моей игры SpaceLab на GreenLight я решил начать серию статей о разработке игры на C#/Unity. Она будет основываться на реальном опыте её разработки и немног... | https://habr.com/ru/post/322258/ | null | ru | null |
# Ускоряем время сборки и доставки java web приложения
**TLTD**
1. удалил jar из сборки проекта
2. заменил его таском, который быстрее в 7 раз
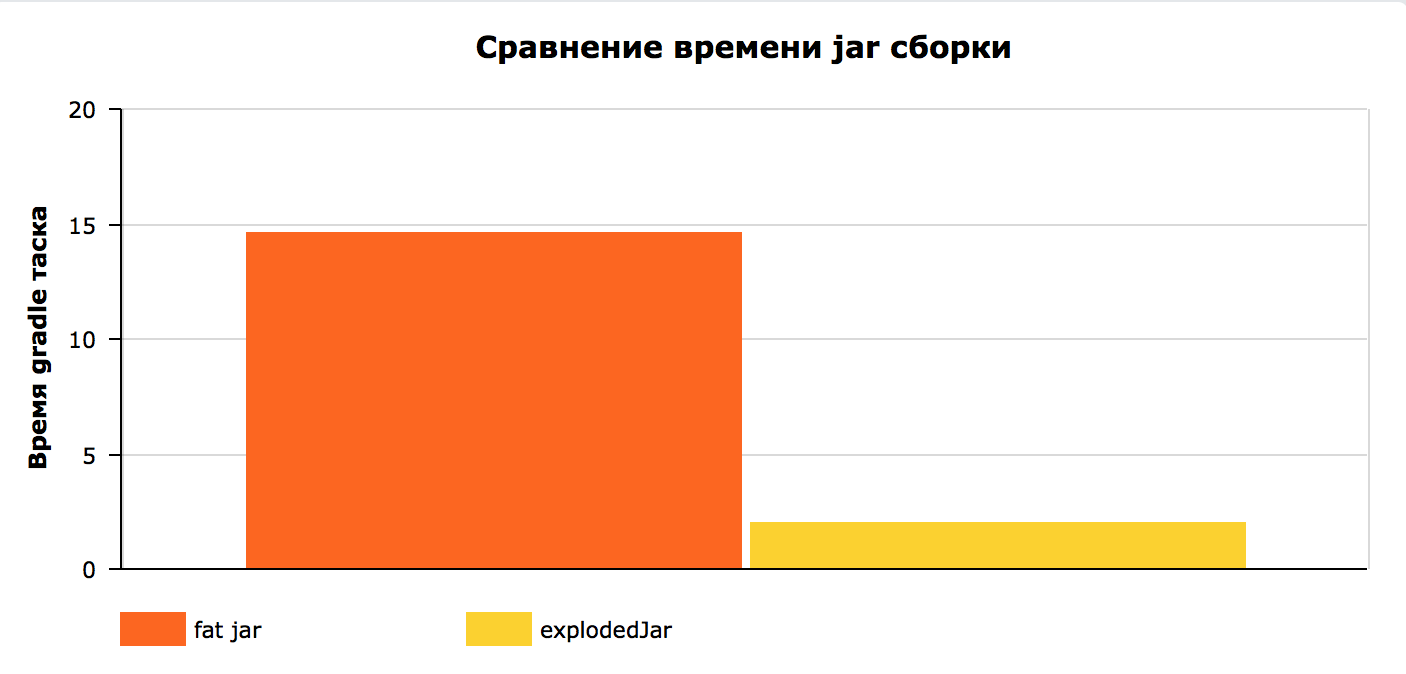
Детали и результат под катом.
О проекте
---------
Веб сервис на java, который отдает н... | https://habr.com/ru/post/351636/ | null | ru | null |
# ERRORLEVEL это не %ERRORLEVEL%
У командный процессора cmd.exe есть такая вещь — уровень ошибки (error level). Это код выхода (exit code) программы, которую вы запускали последней. Проверить уровень ошибки можно при помощи команды `IF ERRORLEVEL`.
`IF ERRORLEVEL 1 ECHO error level is 1 or more`
Проверка `IF ERR... | https://habr.com/ru/post/41028/ | null | ru | null |
# Неочевидные фишки Sailfish OS
Здравствуй, читатель!
Сегодня хотел бы осветить некоторые неочевидные фишки Sailfish OS. Статья в большей степени ориентирована на пользователей Sailfish OS, но и «адептам» других платформ, надеюсь, будет тоже интересно, они могут оценить степень удобства и готовность системы для кон... | https://habr.com/ru/post/397117/ | null | ru | null |
# Разработка Unix подобной OS — Многозадачность и системные вызовы (7)
В предыдущей статье мы научились работать с виртуальным адресным пространством. Сегодня мы добавим поддержку многозадачности.
#### Оглавление
Система сборки (make, gcc, gas). Первоначальная загрузка (multiboot). Запуск (qemu). Библиотека C (str... | https://habr.com/ru/post/468057/ | null | ru | null |
# Рецепты PostgreSQL: планировщик асинхронных задач
Для приготовления планировщика асинхронных задач нам понадобится сам [postgres](https://github.com/RekGRpth/postgres) и его расширение [pg\_task](https://github.com/RekGRpth/pg_task). (Я дал ссылки на свой форк postgres, т.к. делал некоторые изменения, которые пока н... | https://habr.com/ru/post/456722/ | null | ru | null |
# Поддержка транзакций, тестового окружения и другие удобные надстройки над commons-dbutils
Поддержка транзакций, тестового окружения и другие удобные надстройки над **commons-dbutils**.
==============================================================================================
.
В этот раз мы рассмотрим события нажатия клавиш клавиатуры и мыши, отрисовку текста с помощью готовой библиотеки и руками. Да к тому же получим моральное удовлетворение, дописав игру до конца.
... | https://habr.com/ru/post/135035/ | null | ru | null |
# Умные часы своими руками за 1500 рублей. Часть 3 – программа на МК

Вот и пришло время выложить исходный код прошивки МК, но сначала я хочу поблагодарить [bigbee](http://geektimes.ru/users/bigbee/) за но... | https://habr.com/ru/post/219773/ | null | ru | null |
# Telephone Directory
Телефонный справочник для Active Directory
------------------------------------------
Для тех, кто статью читать не захочет, сразу репозиторий на [github](https://github.com/titulus/Telephone-Director... | https://habr.com/ru/post/251955/ | null | ru | null |
# Однострочники на С++

На хабе появилось несколько топиков об «однострочниках» на разных языках, которые решали простые задачи. Я решил опубликовать несколько алгоритмов на языке C/С++.
Итак, поех... | https://habr.com/ru/post/146793/ | null | ru | null |
# Доверяй, но проверяй
[](https://habr.com/ru/company/ruvds/blog/708296/)
Не так давно я считал, что обновление программного обеспечения от производителя на роутерах и подобных им «железках» обязательно, и переход на новую стабильную... | https://habr.com/ru/post/708296/ | null | ru | null |
# Профессиональная литература для разработчиков: Роберт Мартин, Эрик Эванс, Вон Вернон
Наша компания постоянно проводит митапы для сотрудников: на них мы делимся опытом, интересными фишками – и прочитанными нами книгами. Недавно наш ведущий разработчик Максим Лядов рассказал о том, какие книги он может порекомендовать... | https://habr.com/ru/post/700838/ | null | ru | null |
# Кодирование речи на 1600 бит/с нейронным вокодером LPCNet

Это продолжение [первой статьи о LPCNet](https://people.xiph.org/~jm/demo/lpcnet/). В первом демо мы представили [архитектуру](https://jmvalin.c... | https://habr.com/ru/post/446656/ | null | ru | null |
# Telegram объявил конкурс на алгоритм ранжирования новостей с призовым фондом $100 000

Telegram продолжает традицию проведения «народных» конкурсов для своих пользователей с выплатой крупных денежных вознаграждений. На этот раз з... | https://habr.com/ru/post/476470/ | null | ru | null |
# Исследуем .NET 6. Часть 6. Поддержка интеграционных тестов в WebApplicationFactory
[Часть 1. ConfigurationManager](https://habr.com/ru/post/594423/)
[Часть 2. WebApplicationBuilder](https://habr.com/ru/post/594971/)
[Часть 3. Рассматриваем код WebApplicationBuilder](https://habr.com/ru/post/596207/)
[Часть 4. ... | https://habr.com/ru/post/647315/ | null | ru | null |
# .NET – Tools for working with multithreading and asynchrony – Part 2
*I have originally posted this article in [CodingSight](https://codingsight.com/net-tools-for-working-with-multithreading-and-asynchrony-part-2/) blog.
It's also available in Russian [here](https://habr.com/ru/post/459514/).*
This article com... | https://habr.com/ru/post/461471/ | null | en | null |
# Системы хранения данных: как выбирать?!
Проект любой сложности, как ни крути, сталкивается с задачей хранения данных. Таким хранилищем могут быть разные системы: Block storage, File storage, Object sto... | https://habr.com/ru/post/239381/ | null | ru | null |
# iOS+Kotlin. Что можно сделать сейчас
В ветке master проекта Kotlin Native появился пример [uikit](https://github.com/JetBrains/kotlin-native/tree/master/samples/uikit). Это простое приложение под iOS, которое выводит на экран строку, введённую в поле ввода, и да, 100% кода написано на Kotlin. Выглядит оно так:

*КДПВ «Ой, всё».*
Мало шансов, что сей лонгрид станет живительным источником мудрости интеллектуалам, искушенным в тайнах гадания на картах Карн... | https://habr.com/ru/post/443188/ | null | ru | null |
# Иллюзия иммутабельности и доверие как основа командной разработки
Вообще я C++ программист. Ну так получилось. Подавляющее большинство коммерческого кода, который я написал за свою карьеру, — это именно C++. Мне не очень нравится такой сильный перекос моего личного опыта в сторону одного языка, и я стараюсь не упуск... | https://habr.com/ru/post/447478/ | null | ru | null |
# «OOC для C, — это как Scala для Java»
Сегодня на *Hacker News* наткнулся на пост о (похоже очень) новом языке "[ooc](http://ooc-lang.org/)". Бросил на день все дела, занялся ковырятельством — уж больно интересно выглядит.
Итак, "*ooc* — это современный, объектно-ориентированный, фу... | https://habr.com/ru/post/72538/ | null | ru | null |
# Как работает сжатие GZIP
В жизни каждого мужчины наступает момент, когда трафик растёт и ~~сервак умирает~~ необходимо задуматься об оптимизации. В последнем дайджесте PHP ([№ 40](http://habrahabr.ru/co... | https://habr.com/ru/post/221849/ | null | ru | null |
# Ускоряем выборку произвольных записей MySQL
Последнее время оживилась публика с вопросом случайной выборки из таблицы. Решений по оптимизации полно, и нового сейчас я вам наверное ничего не покажу, просто напомню про основные методы оптимизации — упрощение запроса и индексацию. Без предисловий про фриленсеров, сразу... | https://habr.com/ru/post/55864/ | null | ru | null |
# По следам meetup «Новые возможности PostgreSQL 11»
Сегодня мы расскажем о самых главных фичах PostgreSQL 11. Почему только о них — потому что некоторые возможности нужны далеко не всем, поэтому мы остановились на самых востребованных.
### Содержание
 выступил на конфере... | https://habr.com/ru/post/690040/ | null | ru | null |
# How-to: Как создать красивый и функциональный баннер ротатор средствами Drupal 7
Обычно я не пишу статьи на тему как использовать те или иные готовые модули для реализации некоторой функциональности. Гораздо больше меня интересует непосредственно создание модулей, взаимодействие с ядром, работа с различными API и т.... | https://habr.com/ru/post/136377/ | null | ru | null |
# Заметки по выбору шифров для TLS 1.3
После [дискуссии](https://www.dcbase.org/hub-history.txt) с коллегами о TLS 1.3 в целом и прикладном использовании идущих в комплекте с ним шифров я решил кратко изложить основы, которые не худо было бы знать любому разработчику. Мне хотелось бы показать, на какую нишу направлен ... | https://habr.com/ru/post/554070/ | null | ru | null |
# Подборка @pythonetc, январь 2019

Это восьмая подборка советов про Python и программирование из моего авторского канала @pythonetc.
Предыдущие подборки:
* [Декабрь 2018](https://habr.com/ru/company... | https://habr.com/ru/post/438778/ | null | ru | null |
# Rust и Swift (третья, четвёртая, пятая и шестая части)
Продолжаю переводить цикл, в котором автор параллельно изучает Rust и Swift и сравнивает их между собой. Перевод вступления и первых двух частей вы можете найти [тут](https://habrahabr.ru/post/280274/). В этой части речь пойдёт о перегрузке операторов, манипуляц... | https://habr.com/ru/post/280902/ | null | ru | null |
# MVCC-3. Версии строк
Итак, мы рассмотрели вопросы, связанные с [изоляцией](https://habr.com/ru/company/postgrespro/blog/442804/), и сделали отступление об [организации данных на низком уровне](https://habr.com/ru/company/postgrespro/blog/444536/). И наконец добрались до самого интересного — до версий строк.
Заго... | https://habr.com/ru/post/445820/ | null | ru | null |
# Применение протокола NMEA в задачах определения текущего времени
Публикуется по следам статьи [Делаем собственный NTP-сервер Stratum-1](http://habrahabr.ru/blogs/sysadm/79629/).
В статье было рассказано о том, что можно использовать внешний приёмник GPS, подключенный по последовательному порту (COM) для определен... | https://habr.com/ru/post/79701/ | null | ru | null |
# Необычный оператор диапазона
Должен предупредить, что это ещё одна статья, не содержащая никаких откровений. Для тех супер-гиков, которые назубок знают весь perldoc, она будет абсолютно бесполезной, так что, уважаемые супер-гики, можете проходить мимо и не информировать, что всё это есть в доках. Я и так это знаю. :... | https://habr.com/ru/post/87272/ | null | ru | null |
# Free Wireguard VPN service on AWS
Free Wireguard VPN service on AWS
=================================
The reasoning
-------------
The increase of Internet censorship by authoritarian regimes expands the blockage of useful internet resources making impossible the use of the WEB and in essence violates the fundament... | https://habr.com/ru/post/449234/ | null | en | null |
# Пробуем Xcode Live Rendering
Как вы знаете, в Xcode 6 и iOS 8 SDK Apple добавила возможность рендеринга кастомных компонентов и редактирования их свойств прямо в стандартном Interface Builder ~~(здесь должно быть едкое упоминание о том, что это было еще в Delphi древних версий)~~.
Основы
======
Для начала нам по... | https://habr.com/ru/post/239257/ | null | ru | null |
# Linux exploits
> ***Привет, хабровчане. В преддверии старта курса*** [***«Administrator Linux. Professional»***](https://otus.pw/Kc86/) ***наш эксперт - Александр Колесников подготовил интересную статью, которой мы с радостью делимся с вами.
>
> Также приглашаем будущих студентов и всех желающих посетить открыт... | https://habr.com/ru/post/537192/ | null | ru | null |
# Yggdrasil Network 0.4 — Скачок в развитии защищенной самоорганизующейся сети
Продолжение статьи "[Yggdrasil Network: Заря бытовых меш-сетей, или Интернет будущего](https://habr.com/ru/post/547250/)".
Если вы знакомы с сетью, либо читали предыдущую статью, должно быть знаете о феномене «сетевых штормов», которые всп... | https://habr.com/ru/post/566072/ | null | ru | null |
# Знакомство с AviSynth
В этой статье будет рассказано о том, что такое AviSynth и его применение в походных условиях, не без помощи VirtualDub, конечно.
AviSynth это нелинейный видео-редактор, контролируемый скриптовым языком или, перефразируя, скриптовый язык для обработки видео. AviSynth выступает в качестве про... | https://habr.com/ru/post/49735/ | null | ru | null |
# PHP-Дайджест № 100 – интересные новости, материалы и инструменты (1 – 15 января 2017)
[](https://habrahabr.ru/company/zfort/blog/319580/)
Предлагаем вашему вниманию очередную подборку со ссылками на новости и материалы. ... | https://habr.com/ru/post/319580/ | null | ru | null |
# Интеграция CrowdSec в Kubernetes
*Архитектура микросервисов — самая серьёзная угроза безопасности в кластере Kubernetes (K8s), так как каждое развёртываемое приложение открывает для злоумышленников новый потенциальный вектор атаки. При этом, развёрнутые приложения генерируют логи, а наша платформа CrowdSec может зап... | https://habr.com/ru/post/592305/ | null | ru | null |
# Самодокументированные микросервисы (ArangoDB + swagger)
Поддержание документации к микросервисам в актуальном состоянии по прежнему требует предельной дисциплины при разработке, ну и больших трудозарат. Очень разумный подход к созданию документации предлагает, например, GraphQL, где документация неразрывно связана с... | https://habr.com/ru/post/429532/ | null | ru | null |
# Cicerone — простая навигация в Андроид приложении

На этой схеме не скелет древнего обитателя водных глубин и не схема метро какого-то мегаполиса, это карта переходов по экранам вполне реального Андроид приложения! Но, несм... | https://habr.com/ru/post/314838/ | null | ru | null |
# Sparrow плагины и Ansible модули — сравнительный анализ
Введение
========
[Ansible](https://www.ansible.com/) модули и [sparrow](https://github.com/melezhik/sparrow) плагины представляют собой строительные блоки для решения простейших задач из области configuration management и автоматизации деплоя. Ansible модули ... | https://habr.com/ru/post/320220/ | null | ru | null |
# Semi-join Transformation
По материалам статьи Craig Freedman: [Semi-join Transformation](https://docs.microsoft.com/en-us/archive/blogs/craigfr/semi-join-transformation)
В предыдущих статьях я приводил примеры полу-соединений (semi-joins). Вспомним, что полу-соединение возвращает строку из таблицы, если для этой ст... | https://habr.com/ru/post/661757/ | null | ru | null |
# Свой скриптовый движок для игр средствами С++ и Lua (часть — 1)
### Предисловие
Возможно у вас наступал такой момент, что хотелось написать свой движок для игр, или просто вы хотели узнать, как такое реализовать, но по каким — то причинам вам это не удавалось.
Ну что ж, тема довольно обширная, поэтому я начинаю ... | https://habr.com/ru/post/330062/ | null | ru | null |
# Настраиваем Vim для работы с Python кодом
Сейчас достаточно много постов и видео на тему как сделать из Vim Python IDE. Написать эту статью я решил потому, что уже долгое время пользуюсь этим редактором и надеюсь что мой опыт по его настройке, о котором я напишу в этой статье не помешает. Я не собираюсь делать из Vi... | https://habr.com/ru/post/196550/ | null | ru | null |
# Размер директорий не стоит наших усилий
Это совершенно бесполезный, ненужный в практическом применении, но забавный небольшой пост про директории в \*nix системах. Пятница же.
На собеседованиях часто проскакивают скучные вопросы про айноды, всё-есть-файлы, на которые мало кто может вменяемо ответить. Но если копн... | https://habr.com/ru/post/462295/ | null | ru | null |
# Расчетный листок, полученный римским солдатом X легиона. 2000 лет пролетело — ничего не изменилось…
Листок папируса, найденный близ крепости Масады в Израиле, представляет собой расписку о получении жалования (и вычетах из него) одного из солдат римской армии.

Года полтора назад встал вопрос совместимости написанного кода с `Python3`. Поскольку уже стало более менее очевидно, что развивается только `Pytho... | https://habr.com/ru/post/242541/ | null | ru | null |
# Простейший цикл на MySQL
Сегодня, работая над сайтом, мне надо было отделить основной каталог от дополнительного. А в дополнительном каталоге надо было пронумеровать нужные записи в виде «Проект 1», «Проект 2». И тут какой то неведомый зверь не позволил мне сделать это по-быстрому на каком нибудь распространенном яз... | https://habr.com/ru/post/150491/ | null | ru | null |
# Разбиение цикла как пример высокоуровневой оптимизации

В предыдущих посте [Основные проблемы влияющие на производительность ...](http://habrahabr.ru/company/intel/blog/158759/) я написал о том, что анализ произво... | https://habr.com/ru/post/161155/ | null | ru | null |
# «Hello, World!» на Qt
[Qt](http://www.qtsoftware.com/) — это кросс-платформенный инструментарий разработки ПО на языке программирования C++. Есть также «привязки» ко многим другим языкам программирования: Python — PyQt, Ruby — QtRuby, Java — Qt Jambi, PHP — PHP-Qt и другие.
Позволяет запускать написанное с его по... | https://habr.com/ru/post/50765/ | null | ru | null |
# Как управлять виртуальными машинами, если их много
После того, как у нас вышли в релиз еще несколько проектов, а количество тикетов в трекере на тему «создать пользователя, развернуть виртуалку, дать доступ» превысило все мыслимые пределы, назрела необходимость что-то менять.
**Задача:** организовать рабочее окру... | https://habr.com/ru/post/120216/ | null | ru | null |
# Gray Hat Python — DLL и Code Injection
#### **Intro**
Порой, когда вы реверсите или атакуете программу, полезно иметь возможность загрузить и выполнить свой код в контексте исследуемого процесса. Крадете ли вы хэши паролей или получаете доступ к удаленному рабочему столу целевой системы, методы внедрения кода и dll... | https://habr.com/ru/post/151621/ | null | ru | null |
# Создание PDF-документа на Python с помощью pText
Один из самых гибких и привычных способов сгенерировать pdf — написать код на LaTeX и воспользоваться соответствующей программой. Но есть и другие способы, к... | https://habr.com/ru/post/556936/ | null | ru | null |
# Skype-бот для голосовых конференций

Вероятно, некоторые помнят сервис Skype Casts — публичные голосовые конференции, где каждый мог создать конференцию, которая анонсировалась на сайте skype.com. В 2008 году сервис был... | https://habr.com/ru/post/163329/ | null | ru | null |
# MMO с нуля. С помощью Netty и Unreal Engine. Часть 1
Всем привет! В нескольких статьях я хотел бы поделиться опытом создания подобия ММО игры используя Unreal Engine и Netty. Возможно архитектура и мой опыт кому-то пригодится и поможет начать создавать свой игровой сервер в противовес unreal dedicated server, которы... | https://habr.com/ru/post/333788/ | null | ru | null |
# Тестирование приемников цифрового TV: как перенести тестовую модель с TestRail на новый инструмент
Меня зовут Иванов Александр, я тестирую приёмники цифрового телевидения в **GS Labs**.
В статье расскажу о том, как наша команда набралась смелости и **сменила неудобный и дорогой TestRail на новый инструмент** управ... | https://habr.com/ru/post/566284/ | null | ru | null |
# LJV: Чему нас может научить визуализация структур данных в Java
Эта статья является пересказом [моего доклада](https://www.youtube.com/watch?v=eIUsCTsLXlM) на Java-конференции [SnowOne](https://snowone.ru/) 2021 года. LJV — проект, созданный в 2004 году как инструмент для преподавания языка Java студентам. Он позвол... | https://habr.com/ru/post/599045/ | null | ru | null |
# Пишем эффективный blur на Android

Сегодня мы попытаемся разобраться с методами размытия (blur) доступными для Android разработчиков. Прочитав определенное число статей и постов на StackOverflow, мо... | https://habr.com/ru/post/215077/ | null | ru | null |
# Не используйте фикстуры в Cypress и юнит-тесты — используйте фабричные функции
> Для будущих учащихся на курсе [**«JavaScript QA Engineer»**](https://otus.pw/pykU/) и всех интересующихся темой автоматизацией тестирования подготовили перевод полезной статьи.
>
> Также приглашаем принять участие в открытом вебина... | https://habr.com/ru/post/540512/ | null | ru | null |
# Миграция контроллера домена с SAMBA на ActiveDirectory

Вот и пришло время рассказать о способе, который методом научного тыка, нескольких умных людей и несколько часов свободного времени помогли мне... | https://habr.com/ru/post/173985/ | null | ru | null |
# Вышла Java 17
Вышла общедоступная версия [Java 17](http://openjdk.java.net/projects/jdk/17/). В этот релиз попало более [2700 закрытых задач и 14 JEP'ов](https://builds.shipilev.net/backports-monitor/release-notes-17.html). Изменения API можно посмотреть по [этой ссылке](https://javaalmanac.io/jdk/17/apidiff/16/).
... | https://habr.com/ru/post/577924/ | null | ru | null |
# Работа с часовыми поясами в JavaScript
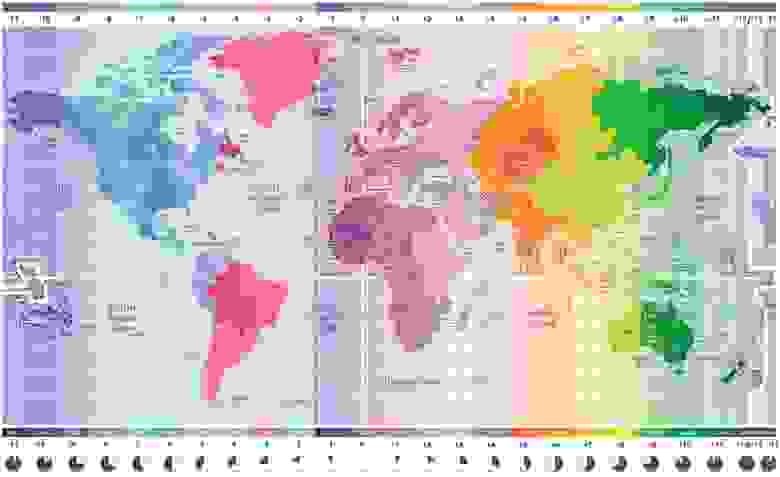
Недавно я работал над задачей добавления часовых поясов в JS-библиотеку календаря, которую ведёт моя команда. Мне было хорошо известно о никудышной поддержке часов... | https://habr.com/ru/post/438286/ | null | ru | null |
# Реализация шаблона «Состояние» в Unity

В процессе программирования внутриигровых сущностей возникают ситуации, когда они должны действовать в различных условиях по-разному, что наводит на мысль об и... | https://habr.com/ru/post/484176/ | null | ru | null |
# Хаброкаст «Заход Солнца Вручную» #1. Пытаемся настроить среду для разработки игрушки под Windows
Только что пришла в голову мысль — нужно найти какое-то хобби. Иначе с катушек можно съехать. А поскольку я весьма бесполезный человек, ничего кроме как тыкать кнопки не умеющий, хобби будет такое: не реже раза в неделю ... | https://habr.com/ru/post/424971/ | null | ru | null |
# Использование диаграммы классов UML при проектировании и документировании программного обеспечения
Предисловие
-----------
Парадигма объектно-ориентированного программирования (далее просто ООП) повсеместн... | https://habr.com/ru/post/572234/ | null | ru | null |
# Spiral: высокопроизводительный PHP/Go фреймворк

Привет, Хабр. Меня зовут Антон Титов, CTO компании Spiral Scout. Сегодня я хотел бы рассказать вам про нашего PHP-слона. А точнее про вторую версию опен-сорсного full-stack PHP/Go фр... | https://habr.com/ru/post/495224/ | null | ru | null |
# ENTRYPOINT vs CMD: назад к основам

Название `ENTRYPOINT` всегда меня смущало. Это название подразумевает, что каждый контейнер должен иметь определенную инструкцию `ENTRYPOINT`. Но после прочтения [официальной до... | https://habr.com/ru/post/329138/ | null | ru | null |
# AngularJS 1.x – перевод курса от CodeSchool
*Данная публикация является переводом оригинального курса CoodSchool с небольшими дополнениями, которые показались мне уместными в данном контексте. Публикация рассчитана на тех, кто только начинает знакомится с Angular.*
#### Введение
AngularJS — популярная JavaScript... | https://habr.com/ru/post/244925/ | null | ru | null |
# Сетевые извращения на ассемблере v. 1.1
Мой первый пост в хабра-мире, прошу сильно не пинать ногами, а адекватную критику очень приветствую…
Все началось с курсового проекта по предмету ЯПНУ (Языки Программирования Низкого Уровня) по завершению которого нам в обязательном порядке следовало вложить все наши творче... | https://habr.com/ru/post/73453/ | null | ru | null |
# Zabbix под замком: включаем опции безопасности компонентов Zabbix для доступа изнутри и снаружи
А не пришло ли время разобраться и навести наконец-то порядок с безопасностью в мониторинге? Тем более, в одной из популярных систем мониторинга и встроенная возможность такая имеется.

Это первая статья в моей серии статей с обзором изменений в Scala 3.
Давайте начнем с наиболее противоречивых нововведений: [опциональных фигурных скобок](https://dotty.epfl.ch/docs/refer... | https://habr.com/ru/post/533320/ | null | ru | null |
# Управление конфигурациями в Drupal 8, обзор для разработчиков
Drupal 8 приносит с собой множество улучшений и моё любимое — [управление конфигурациями](https://www.drupal.org/documentation/administer/config). Я попытаюсь сделать быстрый обзор на эту тему.
*Пожалуйста помните, что этот обзор был написан во время р... | https://habr.com/ru/post/248629/ | null | ru | null |
# Оптимизация ORDER BY — о чем многие забывают
На тему оптимизации MySQL запросов написано очень много, все знают как оптимизировать SELECT, INSERT, что нужно джоинить по ключу и т.д. и т.п.
Но есть один момент, тоже неоднократно описанный во всех мануалах, но почему-то про него все забывают.
#### Оптимизация O... | https://habr.com/ru/post/138163/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.