
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Книга «Паттерны разработки на Python: TDD, DDD и событийно-ориентированная архитектура»
[](https://habr.com/ru/company/piter/blog/588060/) Привет, Хаброжители! Популярность Python продолжает расти, а значит, проекты, созданные ... | https://habr.com/ru/post/588060/ | null | ru | null |
# C++ с кроссплатформенностью и зависимостями
C++ по прежнему используется не только для написания ОС, игр и драйверов, но и для неприхотливых к ресурсам утилит командной строки. Между тем конкуренты на этом поприще, например Rust, предлагают систему сборки c менеджером зависимостей по умолчанию. Для C++ де-факто тоже... | https://habr.com/ru/post/549788/ | null | ru | null |
# Сделаем код чище: Когда применение devres API приносит вред?
Управляемые ресурсы в ядре Linux (также известны как Device Resource Management или devres API), о которых я писал [небольшую заметку](http://habrahabr.ru/post/255459/) ранее, — вещь крайне полезная, но не стоит воспринимать этот вспомогательный набор функ... | https://habr.com/ru/post/265111/ | null | ru | null |
# Перенос физической машины в кластере ProxmoxVE2(3) с DRBD на новое железо
Имея кластер из двух серверов стоящих на Proxmox с объединенным по DRBD хранилищем, бывает нужно обновить узел в этом кластере, без остановки работы машин в нем. Задача не сложная, но некоторые моменты не всегда вспоминаешь в процессе.
Поэт... | https://habr.com/ru/post/180699/ | null | ru | null |
# Julia и оптимизация
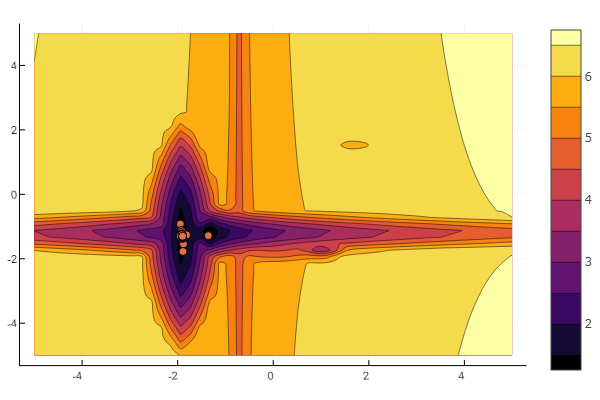
[Пришло время](https://habr.com/ru/post/440234/) рассмотреть пакеты предоставляющие методы решения задач оптимизации. Очень много проблем можно свести к поиску минимума некоторой функции, поэтому следует иметь в ... | https://habr.com/ru/post/440618/ | null | ru | null |
# Методы оптимизации кода для Redd. Часть 1: влияние кэша
В [первой статье](https://habr.com/ru/post/452656/) цикла я активно продвигал идею, что разработка кода под Redd вторична, а первичен основной проект. Redd — вспомогательный инструмент, так что тратить на него уйму времени неправильно. То есть разработка под не... | https://habr.com/ru/post/467353/ | null | ru | null |
# Паттерны отложенной инициализации свойств объектов в JavaScript
Автор статьи, перевод которой мы публикуем сегодня, хочет рассказать о нескольких JavaScript-паттернах, направленных на отложенную инициализацию свойств объектов, для выполнения которой требуется произвести вычисления, создающие серьёзную нагрузку на си... | https://habr.com/ru/post/556166/ | null | ru | null |
# Пишем и отлаживаем приложения для Flipper Zero
Недавно я получил свой флиппер и, решив написать первое приложение, столкнулся с проблемой отсутствия информации по отладке программного кода. Есть несколько статей по разработке приложений для флиппера ([первое приложение](https://habr.com/ru/post/594895/) и [приложени... | https://habr.com/ru/post/710700/ | null | ru | null |
# Microsoft открыла исходный код GW-BASIC

21 мая 2020 года Microsoft [открыла](https://devblogs.microsoft.com/commandline/microsoft-open-sources-gw-basic/) исходный код интерпретатора языка программирования GW-BASIC. Код написан н... | https://habr.com/ru/post/503384/ | null | ru | null |
# JavaScript декораторы наконец-то в Stage 3
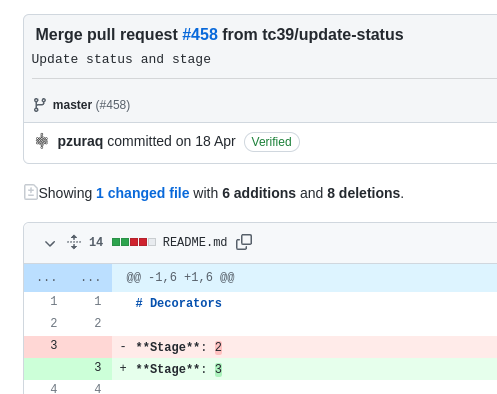18 апреля 2022 года, после 5 лет доработки (первый коммит от 30 апреля 2017 года), proposal по декораторам наконец-то достиг 3 стадии, что означает что у него есть... | https://habr.com/ru/post/666688/ | null | ru | null |
# jQuery плагин Social-feed
#### Social-feed
[](http://pavelk2.github.io/social-feed/)
В настоящее время практически на каждом сайте есть социальный блок, где отображаются [последние посты из *twitter*](http://bower.io/#twi... | https://habr.com/ru/post/239275/ | null | ru | null |
# Обзор докладов C++ Russia Piter 2019
В совместной [магистратуре](http://mse.itmo.ru/) ИТМО и JetBrains мы просим студентов, которые отправляются на конференцию, написать отчёт с обзором докладов.
Публикуем один из таких отчётов о конференции C++ Russia Piter 2019. Автор — студент 2 курса магистратуры Артём Хорош... | https://habr.com/ru/post/480798/ | null | ru | null |
# Лучшие пакеты для машинного обучения в R, часть 2
Один из наиболее частых вопросов, с которыми сталкиваются специалисты по обработке и анализу данных — «Какой язык программирования лучше всего использовать для решения задач, связанных с машинным обучением?» Ответ на этот вопрос всегда приводит к сложному выбору межд... | https://habr.com/ru/post/306184/ | null | ru | null |
# Расшаривание USB-устройства по нескольким клиентам через TCP
[](https://habr.com/ru/company/ruvds/blog/669408/)
Будучи увлечённым астрофотографом, я использовал в комплекте оборудования USB Sky Quality Meter (измеритель качества не... | https://habr.com/ru/post/669408/ | null | ru | null |
# Вредоносные скрипты научились прятаться от googlebot
Google довольно хорошо определяет вредоносный код на HTML-страницах, после чего уличённый сайт попадает в «чёрный список» и понижается в результатах поиска. Хуже того, о заражении мгновенно становится известно владельцу сайта, который получает фидбек от пользовате... | https://habr.com/ru/post/91936/ | null | ru | null |
# STM32 и FreeRTOS. 2. Семафорим по-черному
[Часть первая, про потоки](http://habrahabr.ru/post/249273/)
В реальной жизни часто случается так, что некоторые события происходят с разной переодичностью (а могут и вообще не происходить). Скажем, заказ сока в «Макдональдсе», нажатие кнопки пользователем или заказ лыж в... | https://habr.com/ru/post/249283/ | null | ru | null |
# Прозрачная аутентификация в ASP.Net Core на Linux

Аутентификация в ASP.Net (Core) — тема довольно избитая, казалось бы, о чем тут еще можно писать. Но по какой-то причине за бортом остается небольшой кусочек — сквозная доменная ау... | https://habr.com/ru/post/489852/ | null | ru | null |
# Fast Reverse Proxy как альтернатива Ngrok
Создание общедоступного URL в сети интернет к вашему локальному проекту
Что такое Ngrok, наверное знает каждый разработчик web приложений, и многие им пользуются.
Немного предыстории...
Присоединившись к новому большому проекту, над которым работают десятки разработчиков... | https://habr.com/ru/post/583814/ | null | ru | null |
# 3D своими руками. Часть 1: пиксели и линии

Этот цикл статей я хочу посвятить читателям, желающим изучить мир 3D-программирования с нуля, людям, которые хотят узнать основы создания 3D-составляющей игр и приложений. Каждую операц... | https://habr.com/ru/post/494094/ | null | ru | null |
# Персональные данные пользователей Rozetka.ua в публичном доступе
На этот источник данных я наткнулся случайно. По моему, самое время проверить, какие данные отдают пользователям наши с вами проекты.
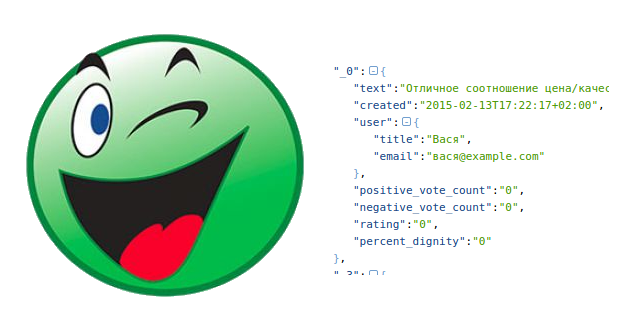
По причинам, которы... | https://habr.com/ru/post/252475/ | null | ru | null |
# Как обойти запрет доступа к страницам с помощью Chrome в headless-режиме
Некоторые сайты блокируют Chrome в headless-режиме, и мы рассмотрим, как обойти эту блокировку.
Диагностика – это ключ ко всем аспектам компьютеров и программирования. Эта статья начинается с того, как самостоятельно разобраться с этой проблем... | https://habr.com/ru/post/509358/ | null | ru | null |
# DroidScript – простой и функциональный инструмент для разработки мобильных приложений под Android

Некоторое время назад мне была поставлена следующая задача: разработать прототип приложения под Android для беспроводной с... | https://habr.com/ru/post/326460/ | null | ru | null |
# PHP и realpath_cache
*От переводчика: разбираясь на днях с ошибкой, возникшей после деплоя сервиса, натолкнулся на эту замечательную статью про механизм кэширования файловых статусов в PHP. Предлагаю сообществу перевод.*
Слышали ли вы про PHP-функции `realpath_cache_get()` и `realpath_cache_size()`? А может быть ... | https://habr.com/ru/post/266909/ | null | ru | null |
# Мониторим Django проекты в top'e
*В этой статье я опишу как настроить Django так, что б на сервере в top'е можно было видеть нагрузку на сервер от каждого из Django-проектов.*
#### 1 — Установка Django на FreeBSD из портов
У меня на сервере стоит FreeBSD 8.0, всяческие полезности типа MySQL, Python2.6, nginx и п... | https://habr.com/ru/post/134208/ | null | ru | null |
# Еще один способ использования условных комментариев
Здравствуйте хабровчане, хотел поделиться еще одним вариантом валидного хака для Internet Explorer'а.
Так как выносить стили для IE отдельный файл не всегда удобно, особенно в некоторых проектах, когда стили для определенной страниц хочется видеть в одном файле.... | https://habr.com/ru/post/138118/ | null | ru | null |
# Протокольно ориентированное программирование, часть 2
В продолжение темы разберемся в протокольных типах и обобщенном (generic) коде.
По ходу будут рассмотрены следующие вопросы:
* реализация полиморфизма без наследования и ссылочных типов
* как объекты протокольных типов хранятся и используются
* как с ними работ... | https://habr.com/ru/post/474558/ | null | ru | null |
# Практический TypeScript. React + Redux

В настоящее время разработка любого современного фронтэнд-приложения сложнее уровня `hello world... | https://habr.com/ru/post/431452/ | null | ru | null |
# Искусство типизации: TypeScript Utility Types
Введение
--------
Что вы чувствуете от познания нового? За себя скажу, что в такие моменты просветления меня переполняет неподдельная детская радость от свершившегося открытия. Жаль, что этих моментов становится всё меньше. К чему я это? Когда мне в голову мне пришла мы... | https://habr.com/ru/post/711686/ | null | ru | null |
# Принцип слоеного теста
> Всем неустрашимым на пути от отрицания до убеждения посвящается…

Среди разработчиков бытует справедливое мнение, что если программист не покрывает код тестами, то попросту не понимает зачем они нуж... | https://habr.com/ru/post/534642/ | null | ru | null |
# Странные операторы в PHP

Если вы прочитаете документацию по PHP, вы узнаете о массе [операторов](http://www.php.net/manual/ru/language.operators.php). Если вы не знаете ещё PHP-операторы, сперва изучите их, а потом вернитесь к прочт... | https://habr.com/ru/post/412603/ | null | ru | null |
# Алгоритм резервуарной выборки
Резервуарная выборка (eng. «reservoir sampling») — это простой и эффективный алгоритм случайной выборки некоторого количества элементов из имеющегося вектора большого и/или неизвестного заранее размера. Я не нашел об этом алгоритме ни одной статьи на Хабре и поэтому решил написать её са... | https://habr.com/ru/post/431652/ | null | ru | null |
# Как я стандартную библиотеку C++11 писал или почему boost такой страшный. Глава 4.3
 ### Краткое содержание предыдущих частей
Из-за ограничений на возможность использовать компиляторы C++ 11 и от безальтернати... | https://habr.com/ru/post/418347/ | null | ru | null |
# Новости из мира OpenStreetMap № 487 (12.11.2019-18.11.2019)

Участники конференции State of the Map Азия 2019 – Дакка, Бангладеш [1](#wn484_21194) | NN
Картографирование
-----------------
* [... | https://habr.com/ru/post/478196/ | null | ru | null |
# Большая Карамельная Ракета
Всем привет! Меня зовут Илья. И у меня есть хобби - это любительское ракетостроение. Точнее даже, скажем так, карамельное ракетостроение. За то время, что я занимаюсь темой, я успел набить себе немало шишек, во многом действуя по наитию и ставя различные, часто неудачные, эксперименты. Воз... | https://habr.com/ru/post/571968/ | null | ru | null |
# Переключение языка в Android-приложении

Есть простой способ реализовать переключение языка в Single-Activity приложении. Стек экранов при этом подходе не сбрасывается, ... | https://habr.com/ru/post/461085/ | null | ru | null |
# Проблемы с Java web start при обновлении до j7u45
Как можно догадаться из названия, пост будет посвящен вышедшему security обновлению джавы, которое наверняка сломает/сломало запуск вебстартового приложения. Всех не равнодушных — прошу под кат.
В нашей компании принята практика обновлять Java на всех серверах, ка... | https://habr.com/ru/post/202016/ | null | ru | null |
# Разбор худшего в мире куска кода
Есть одна итальянская страница на Facebook. Называется она «Il Programmatore di Merda», что в переводе означает «Дерьмовый программист». Мне нравится эта страница.
Там часто публикуют куски отвратительного кода и мемы о программировании. Но однажды я увидел там кое-что совершенно ... | https://habr.com/ru/post/515676/ | null | ru | null |
# Верстаем новостной сайт с помощью Flexbox

*Примечание: этот материал представляет собой свободный перевод [статьи](http://webdesign.tutsplus.com/tutorials/how-to-build-a-news-website-layout-with-fle... | https://habr.com/ru/post/314034/ | null | ru | null |
# Отмена загрузки видео при просмотре в embeded-плеерах
Всем знакома ситуация, когда запущенный ролик YouTube (или другого хостера видео) хочется отменить, если он был запущен по ошибке или дальнейший просмотр не интересен. На текущий момент отменить загрузку через плеер возможности нет. Даже если Вы остановите ролик ... | https://habr.com/ru/post/15285/ | null | ru | null |
# Распознание блоков текста в IOS-приложении с помощью Vision
Работая над приложением, связанным с финансовыми операциями, возникла необходимость распознать и выделить суммы на чеках. Начиная с 11-ой версии в IOS-разработке появился нативный фреймворк Vision, который позволяет распознавать различные объекты на изображ... | https://habr.com/ru/post/542816/ | null | ru | null |
# Пишем распределенное хранилище за полчаса

Привет, меня зовут Игорь и я работаю в команде Tarantool. При разработке мне часто требуется быстрое прототипирование приложений с базой данных, например, для тестирования кода или для созда... | https://habr.com/ru/post/588046/ | null | ru | null |
# Идеальный инструмент для создания прогрессивных веб-приложений или Все, что вы хотели знать о Workbox. Часть 2

Что такое `Workbox`?
--------------------
[`Workbox`](https://developers.google.com/web/tools/workbox) (далее — `WB... | https://habr.com/ru/post/563724/ | null | ru | null |
# Реализация промо-предложений в iOS. Как зарабатывать на подписках больше?

В iOS 12.2 Apple добавила новую классную фичу – промо-предложения. Теперь приложения с авто-возобновляемыми подписками могут предлагать нынешним или бывшим кл... | https://habr.com/ru/post/466819/ | null | ru | null |
# WiFi колонка/плеер на базе Orange Pi Zero или история о потерянном времени
Доброго дня уважаемым хабровчанам!
### Предыстория
История моя началась с того, что по просьбе одного друга нужно было сделать небольшое программируемое устройство с выводом звука и GPIO. Давно хотел поработать с каким-либо одноплатником ... | https://habr.com/ru/post/341650/ | null | ru | null |
# Создаём тематические иконки для приложения на Android 13
В 2021 году Google анонсировал [Material You](https://material.io/blog/announcing-material-you) и тем самым взял курс на персонализацию Android-устройств.
Одним из способов настройки внешнего вида своего рабочего стола для пользователя стала добавленная в это... | https://habr.com/ru/post/709428/ | null | ru | null |
# Загрузка браузером нескольких файлов
Если нужно дать пользователю возможность загрузки нескольких файлов, традиционное решение на данный момент — использовать для этой цели Flash (реже — Java applet или ActiveX). В случае, если соответствующий плагин недоступен, пользователю, как правило, показывают стандартный HTML... | https://habr.com/ru/post/76749/ | null | ru | null |
# Оптимизация в OpenMP
Постепенное развитие проекта шло своим чередом.
На часть полученных по гранту средств было произведено обновление парка личной вычислительной техники. В итоге расчёты сейчас осуществляются не на многострадальном ноутбуке, а на вполне приемлемой машине с псевдовосьмиядерным Intel Core i7-2600 ... | https://habr.com/ru/post/141172/ | null | ru | null |
# Пять причин, по которым следует использовать Apache Wicket
Apache Wicket - это фреймворк для веб-разработки на Java. Я чувствую, что ему не уделяют столько внимания, сколько он того заслуживает. Я профессионально использую Wicket для реальных проектов последние 6 лет и мне это нравится! В этом посте давайте рассмотр... | https://habr.com/ru/post/535876/ | null | ru | null |
# Работаем с SteamWorks. Часть 1
SteamWorks — это интерфейс, который обеспечивает разработку и публикацию инструментов для разработчиков игр. Он предоставляет возможность интеграции с клиентом Steam, интеграция с комьюнити, добавлять и редактировать ... | https://habr.com/ru/post/157999/ | null | ru | null |
# Прокрутка в вебе: букварь
*Автор — Нолан Лоусон, менеджер проекта Microsoft Edge*
Прокрутка — одно из самых древних взаимодействий в вебе. Задолго до появления методов pull-to-refresh и списков бесконечной загрузки скромная полоса прокрутки решила изначальную проблему масштабирования в вебе: как взаимодействовать... | https://habr.com/ru/post/325028/ | null | ru | null |
# Сравниваем производительность целочисленного умножения
Приступая к написанию тестовой программы для этой статьи я внутренне ожидал, что CPU Intel положит на обе лопатки AMD, так же как и одноименный компилятор без боя победит Visua... | https://habr.com/ru/post/147272/ | null | ru | null |
# Используете Kafka с микросервисами? Скорее всего, вы неправильно обрабатываете повторные передачи

Apache Kafka стала ведущей платформой для асинхронной коммуникации между микросервисами. В ней есть мощные функции, которые позволяю... | https://habr.com/ru/post/531838/ | null | ru | null |
# Запрет чтения свойств модели в ASP.NET MVC
В моей [прошлой статье](http://habrahabr.ru/post/156285/) был рассмотрен один из возможных вариантов защиты от редактирования свойств модели в Web приложениях, написанных на ASP.NET MVC. Данная статья будет посвящена рассмотрению одного из вариантов запрета чтения некоторых... | https://habr.com/ru/post/165823/ | null | ru | null |
# Что нового в C# 6.0?

Microsoft выпустила предварительную версию Visual studio 2015 и .Net 4.6 для разработчиков. В новом C# 6.0 несколько новых возможностей, которые могут облегчить кодинг.
В это... | https://habr.com/ru/post/249555/ | null | ru | null |
# Балансировка кэширующего DNS на основе Cisco IP SLA

В сети любого Интернет-провайдера можно встретить такой обязательный элемент, как кэширующий DNS сервис. А поскольку работа сети Интернет без службы DNS невозможно... | https://habr.com/ru/post/307932/ | null | ru | null |
# diff для ленивых разработчиков или как сравнить несравнимое
В былые времена, на Windows, для сравнения oracle-схем (читай баз) я удовлетворялся встроенным в Quest Software TOAD сравнивателем. Он был неплох, и со своей задачей справлялся. Но пересев в linux, меня ждало разочарование. Ни один из [и так небольшого коли... | https://habr.com/ru/post/75716/ | null | ru | null |
# Переlator
По ходу своей работы я сталкиваюсь с маленькими задачами, которые отнимают много времени (при решении «в лоб»). Иногда получается найти средства для быстрого решения этих задач, иногда нет. Во втором случае, чаще всего, я быстренько пишу собственные маленькие программы, которые позволяют максимально упроси... | https://habr.com/ru/post/86299/ | null | ru | null |
# Баг в CSS Chrome, разрушивший наш сайт
Это реальная история, случившаяся с нашим сайтом во время празднования Дня Благодарения.
Сайт перестал работать внезапно, ничего не предвещало такого оборота.
Поначалу я подумал, что проблема в нашем провайдере хостинга, потому что с ним уже случались проблемы ранее. Наш ... | https://habr.com/ru/post/243909/ | null | ru | null |
# Первичный кэш в Kohana 3 с использованием тегов
Приведенный пример является результатом решения одной задачи, которая возникла при разработке системы управления сайтом на фреймворке Kohana 3.1, в которой предполагается одна учетная запись администратора и множество незарегистрированных читателей.
Требовалось надо... | https://habr.com/ru/post/119588/ | null | ru | null |
# Тестирование виртуальных серверов от DigitalOcean, Vultr, Linode и Hetzner. Человеческие жертвы: 0.0
В одной из предыдущих статей я привел результаты [тестирования дешевых виртуальных серверов](https://habr.com/ru/post/467953/) от различных хостеров рунета. Спасибо всем комментаторам и людям, писавшим в личные сообщ... | https://habr.com/ru/post/480674/ | null | ru | null |
# В django появилась возможность использования своей модели вместо contrib.auth.models.User

Через шесть лет после появления [тикета](https://code.djangoproject.com/ticket/3011) с предложением возможн... | https://habr.com/ru/post/152603/ | null | ru | null |
# Кроссбраузерная вёрстка

> Что такое кроссбраузерная вёрстка? Какие есть браузеры и нужен ли пиксель-пёрфект?
Если собрать охапку современных браузеров, то разложить её можно по-разному: по устройствам, по платформам, по типу ра... | https://habr.com/ru/post/341538/ | null | ru | null |
# Что я узнал, протестировав 200 000 строк инфраструктурного кода
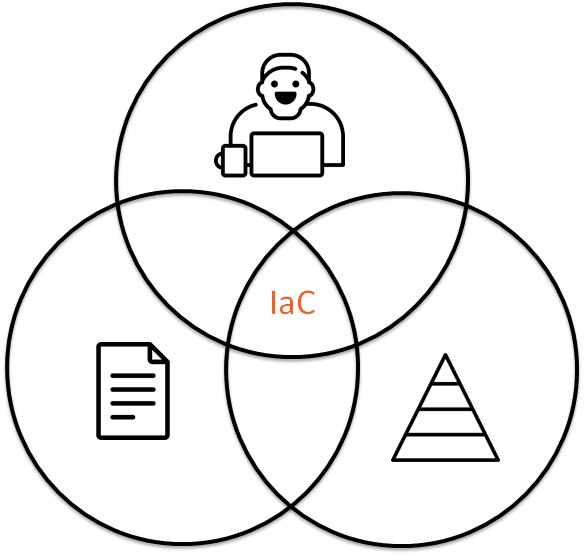
Подход **IaC** (Infrastructure as Code) состоит не только из кода, который хранится в репозитории, но еще людей и процессов, которые этот код окружают. Можно ли переисп... | https://habr.com/ru/post/467171/ | null | ru | null |
# Создание программы передач для IPTV телеканала на базе медиасервера Flussonic
Начнем с небольшого пролога.
**Что такое серверные плейлисты и зачем они нужны? (с офсайта flussonic)**Серверные плейлисты на сегодняшний день не рекомендованы к использованию в интернете.
Эта технология растет корнями из телевизионн... | https://habr.com/ru/post/262755/ | null | ru | null |
# OpenCV — быстрый старт: начало работы с изображениями
Перевожу родной OpenCV-шный [туториал](https://opencv.org/opencv-free-course/). И он хорош! (Сложно сказать, чем не понравились те, что есть.)
Изначально туториал в виде ноутбука, поэтому что-то я убрал. А что-то добавил. В общем, это помесь перевода с пересказ... | https://habr.com/ru/post/678260/ | null | ru | null |
# Еще один разбор пузырьковой сортировки

Однажды, новогодним вечером, вдохновившись [статьей](http://habrahabr.ru/post/204600/) про пузырьковую сортировку и ее модификации, я решил написать свою реализацию, и подумать, как... | https://habr.com/ru/post/274493/ | null | ru | null |
# Исследуем внутренние механизмы работы Hyper-V

Если бы работа хакера, а точнее программиста-исследователя происходила так, как это показано в классических фильмах: пришел, постучал по клавишам, на экране все замелькало зе... | https://habr.com/ru/post/242699/ | null | ru | null |
# Windows 10 по 10. Выпуск #1. Как повысить заметность и частоту установок
Приветствуем в первой статье из [серии Windows 10 по 10](http://wndw.ms/10x10anchor). Мы начнем серию с того, откуда начинается ваше взаимодействие с пользователями — с магазина Windows Store.

Теперь, когда мы понимаем основные принципы Rx, настало время научиться создавать и управлять последовательностями. Стиль управления последовательностями был позаимствов... | https://habr.com/ru/post/281633/ | null | ru | null |
# Rekko Challenge 2019: как это было

Не так давно на платформе [Boosters](http://boosters.pro) прошел контест рекомендательных систем от онлайн-кинотеатра Okko — [Rekko Challenge 2019](https://habr.com/ru/company/okko/blog/439180/).... | https://habr.com/ru/post/461055/ | null | ru | null |
# Тонкости свойства disable у кнопок формы, отправляемой на сервер (Как делать кнопки неактивными)
Уже неоднократно на хабре (вот в [этой](http://habrahabr.ru/blogs/ui_design_and_usability/47315/) публикации и в [этой](http://habrahabr.ru/blogs/ui_design_and_usability/44145/)) ставился вопрос о том, что было бы хорошо... | https://habr.com/ru/post/48381/ | null | ru | null |
# Немного предпятничных задачек на Bash
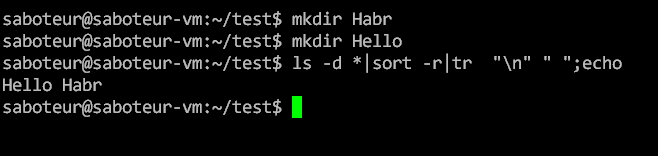
Привет Хабр!
------------
В *bash* частенько можно столкнуться с ситуацией, когда вроде как уже разобрался, и тут внезапно какая-то магия. Ковырнешь ее, а там еще целый пласт вещей, о которых... | https://habr.com/ru/post/339246/ | null | ru | null |
# Apple WWDC 2020: что нового в тестировании iOS
Привет, меня зовут Сергей, и я тестирую iOS приложения в Exness. В конце июня 2020 г. закончилась очередная WWDC. Давайте разберемся, что же она принесла нового в мир тестирования iOS приложений.
](https://habr.com/ru/company/ruvds/blog/679758/)
Osmanip – это библиотека C++, предоставляющая полезные механизмы для работы с [управляющими последовательностями ANSI]... | https://habr.com/ru/post/679758/ | null | ru | null |
# Controller, но не Massive: реализуем список карточек для iOS 13+ и 11+ с учетом практик чистого кода
Привет, Хабр! Меня зовут Евгений, я ведущий iOS-разработчик в Туту. В нашем продукте список карточек испо... | https://habr.com/ru/post/648709/ | null | ru | null |
# Оптимизация запросов в SQLite. Используем rowid
Во время недавней оптимизации запросов в базу данных наткнулся на описание работы SQLite с rowid. Если вкратце: в каждой таблице есть int64 столбец rowid, значение которого является уникальным для каждой записи в таблице. Посмотреть значение можно по имени «rowid» и в ... | https://habr.com/ru/post/160861/ | null | ru | null |
# Уведомления о пропущенных звонках с Asterisk на Битрикс24
Случается, что звонок с офисной АТС приходит на мобильный. И пропускается и на нём тоже.
Причины для этого у каждого свои, но последствия одни и те же — ты смотришь на городской номер офиса и думаешь, а кто же это звонил?
 в Node.js:
* [Экспериментальная поддержка ESM](https://nodejs.org/api/esm.html) была добавлена в [Node.js 8.5.0](https://nodejs.org/en/blog/release/v8.5.0/) 12 сентября 2017 года.
* После этого Технический Руководящий Комитет ... | https://habr.com/ru/post/433964/ | null | ru | null |
# Shader — это не магия. Написание шейдеров в Unity. Вертексные шейдеры
Всем привет! Меня зовут Дядиченко Григорий, и я основатель и CTO студии Foxsys. Сегодня мы поговорим про вершинные шейдеры. В статье будет разбираться практика с точки зрения Unity, очень простые примеры, а также приведено множество ссылок для изу... | https://habr.com/ru/post/474812/ | null | ru | null |
# Kotlin Native. Работаем с новой моделью памяти
*Всем доброго дня! С вами Анна Жаркова, ведущий мобильный разработчик компании Usetech. Продолжаем рассматривать способы многопоточный работы в Kotlin Native. ... | https://habr.com/ru/post/578716/ | null | ru | null |
# Логируем контекст исключений
В преддверии [Дня программиста](https://ru.wikipedia.org/wiki/%D0%94%D0%B5%D0%BD%D1%8C_%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B8%D1%81%D1%82%D0%B0) и по следам [Дня тестировщика](https://ru.wikipedia.org/wiki/%D0%94%D0%B5%D0%BD%D1%8C_%D1%82%D0%B5%D1%81%D1%82%D0%B8%D1%80%D0%B... | https://habr.com/ru/post/266729/ | null | ru | null |
# Как подружить Sphinx с OpenShift для ThinkingSphinx под Rails
Для стейджинга моих небольших проектов на Rails я использую Openshift. Впринципе для небольших проектов он очень удобен — удобный деплой, все самое необходимое из коробки. Чего еще душе может быть необходимо? Но душа захотела сфинкса, при том очень сильно... | https://habr.com/ru/post/157857/ | null | ru | null |
# Новые инструменты для обнаружения HTTPS-перехвата
[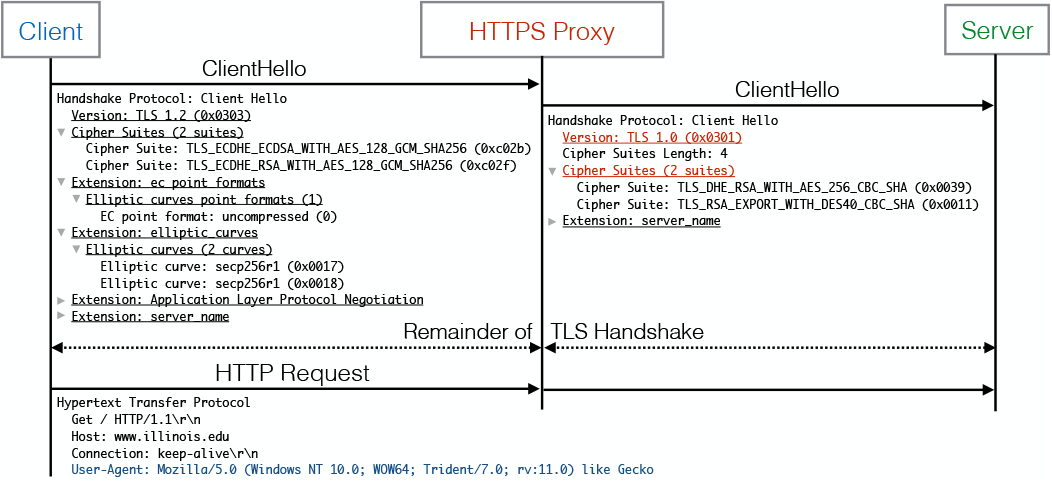](https://habrastorage.org/webt/fo/qw/00/foqw00u6rxe1pz2sawwacn1c6ao.png)
По мере роста использования HTTPS растёт желание посторонних лиц внедриться в защищённый трафик. Исследова... | https://habr.com/ru/post/444496/ | null | ru | null |
# Введение в ARC/ORC в Nim
Nim переходит к более эффективным моделям управления памятью: ARC и ORC. Давайте узнаем, как именно они изменят работу с памятью в нём.

Введение
--------
Всем привет! В этой стат... | https://habr.com/ru/post/523674/ | null | ru | null |
# Программируем AGC (авторегулятор громкости) на VB.Net
Статья предназначена для начинающих аудиофилов, желающих разобраться как работает автоматический регулятор громкости (он же AGC и АРУ). Сразу предупреждаю, что речь не пойдёт о том, как получить звук с микрофона или выставить уровень записи звуковой карты. Входны... | https://habr.com/ru/post/166441/ | null | ru | null |
# Работа с SQL Server в C# с помощью скриптинга. Часть 2
Первую часть статьи читайте [здесь](https://habr.com/ru/company/otus/blog/711866/).
### Хранимые процедуры SQL Server
Вы можете выполнить любую хранимую процедуру SQL Server, используя следующую CSCS-функцию:
```
SQLProcedure(spName, spArguments);
```
Второй ... | https://habr.com/ru/post/712222/ | null | ru | null |
# Подключаем любой (почти) GPS трекер (на примере Sinotrack ST-901) к умному дому HomeAssistant
### Введение
Как то ко мне в руки попал китайский GPS трекер ST-901. Устройство рассчитано в основном для использования в авто- и мото-технике, обладает gsm 2G модулем для связи с внешним миром, герметичным водонепроницаем... | https://habr.com/ru/post/414509/ | null | ru | null |
# Охота за убегающей памятью в Go на этапе разработки
Проблемы
--------
Убегание памяти в кучу влечет за собой следующие потенциально решаемые проблемы:
1. Снижение производительности из-за расходов на выделение памяти
2. Снижение производительности из-за расходов на сборку мусора
3. Появление ошибки`Out of Memory` ... | https://habr.com/ru/post/519534/ | null | ru | null |
# Qt. Создание виджета-консоли для графического приложения
Привет добрым людям.
При прочтении этого заголовка читатели могут подумать: зачем смешивать консольные и графические приложения – консоль в GUI-приложении не нужна. А вот и нет, смею заметить. Иногда совмещение функциональной консоли с полным набором коман... | https://habr.com/ru/post/122831/ | null | ru | null |
# Spacewalk на Рождество
Привет, Хабр!
Незадолго до прихода Рождества, в IT-отделе было решено изучить Spacewalk, — это Red Hat система, бесплатный аналог Satellite, для централизованного управления конфигурациями, обновлений систем, удобной поддержкой всего серверного парка.
Ввиду того, что доступная на официал... | https://habr.com/ru/post/435578/ | null | ru | null |
# Pip-Boy, портативный кластер из Pi 4 и игровая консоль: новые проекты на базе Raspberry Pi

Одноплатник от Raspberry Pi Foundation — один из наиболее универсальных инструментов разработки как в корпоративной среде, так и для люби... | https://habr.com/ru/post/596115/ | null | ru | null |
# Простой пример использования WCF в Visual Studio 2010. Часть 2
Вы читаете вторую часть:
* [Создание простейшего решения (solution) со стандартными конечными точками (default endpoints)](http://habrahabr.ru/blogs/net/116764/)
* Добавление и настройка конечных точек вручную

Linux: Настройка сервера баз данных MySQL
=========================================
Перейдем ко второму практическому уроку серии и поговорим о настройке виртуального окружения выделенного сервера – подготовим узел (VM) предназначенный для хр... | https://habr.com/ru/post/148077/ | null | ru | null |
# Восстановление отдельных страниц в базе данных
##### Предисловие
Статья Gail Shaw [«Help, my database is corrupt. Now what?»](http://www.sqlservercentral.com/articles/Corruption/65804/), [перевод](http://habrahabr.ru/blogs/mssql/136979/) которой я запостил на прошлой неделе, вызвала, вроде бы, определенный интерес,... | https://habr.com/ru/post/137301/ | null | ru | null |
# DoS уязвимость в Open vSwitch
Спойлер: Open vSwitch версий меньше 1.11 уязвим перед атакой вида «flow flood», позволяющей злоумышленнику прервать работу сети отправкой относительно небольшого потока пакетов в адрес любой виртуальной машины. Версии 1.11 и старше проблеме не подвержены. Большинство серверов с OVS до с... | https://habr.com/ru/post/124310/ | null | ru | null |
# Реверс-инжиниринг железа: находим UART и извлекаем прошивку при помощи UBoot
Введение
========
В этом посте мы расскажем об UART, UBoot и USB, а нашей целью станет игровой автомат Arcade 1UP Marvel. Серия автоматов Arcade 1Up предоставляет возможность за приемлемую цену приобрести домашнюю аркадную машину. С момент... | https://habr.com/ru/post/650089/ | null | ru | null |
# Настраиваем просмотр IPTV в Plex Media Server
Телевизор в 2022 году это совершенно другая сущность, если сравнивать и смотреть со стороны даже 2010-х годов. Сейчас мало кто использует телевизор в обычном его понимании - приложения Smart TV, всевозможные сервисы, подписки или домашние медиацентры с сетевыми хранилища... | https://habr.com/ru/post/645155/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.