
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# [BugBounty] Раскрытие 5 миллионов ссылок в приватные чаты Telegram и возможность редактирования любой статьи telegra.ph

Вот уже больше года я пользуюсь мессенджером Telegram: это удобно и, насколько мне казалось, полностью конфи... | https://habr.com/ru/post/347910/ | null | ru | null |
# Кастомные декораторы для NestJS: от простого к сложному
[](https://habr.com/ru/company/qiwi/blog/510864/)
Введение
--------
NestJS — стремительно [набирающий популярность](https://www.npmtrends.com/@nestjs/common) фрeймворк, ... | https://habr.com/ru/post/510864/ | null | ru | null |
# Умные дворники: автоматизируем автомобиль
Меня давно "волновала" микроэлектроника, но все как-то не получалось. Простые поделки из Arduino и т.п. не заводили, не было какой-то идеи, которая бы приносила пользу.
Disclaimer
----------
Стоит заметить, что в электронике в целом я дилетант, закон Ома регулярно гуглю, а... | https://habr.com/ru/post/552726/ | null | ru | null |
# Never Gonna Give Your Terminal
Rick Astley — Never Gonna Give Your Up теперь и в вашем ~~мобильном~~ терминале!
```
curl -s https://raw.github.com/keroserene/rickrollrc/master/roll.sh | bash
```
Используется видео, которое было сконвертировано в ASCII 256-color, и звук в wav или raw, в зависимости от системы.
... | https://habr.com/ru/post/197258/ | null | ru | null |
# Стилизация приложений часть первая

Все идет хорошо, вы успешно пишете свои великолепные (ну у кого-как) приложения, даже бывает публикуете их на маркете, но возникает проблема: весь интерфейс уж слишком скучен и однообр... | https://habr.com/ru/post/133307/ | null | ru | null |
# Exchange 2007/2010, отправка писем пользователям домена имеющим внешние почтовые адреса
Есть интересный баг, а может даже фича в Exchange 2007/2010 с отправкой писем пользователю имеющему внешний почтовый ящик.
##### **Предыстория**
Допустим у вас имеется какой-нибудь OU в вашем домене, который нужен для авториз... | https://habr.com/ru/post/145681/ | null | ru | null |
# Модели глубоких нейронных сетей sequence-to-sequence на PyTorch (Часть 6)
6 - Attention is All You Need
-----------------------------
В этом разделе мы будем реализовывать слегкаизмененнуюверсию модели Transformer из статьи [Attention is All You Need](https://arxiv.org/abs/1706.03762). Все изображения в этой части ... | https://habr.com/ru/post/568304/ | null | ru | null |
# 9 лучших практик для обработки исключений в Java
Независимо от того, новичок вы или профессионал, всегда полезно освежить в памяти методы обработки исключений, чтобы убедиться, что вы и ваша команда можете справиться с проблемами.
Обработка исключений в Java - непростая тема. Новичкам сложно понять, и даже опытные ... | https://habr.com/ru/post/551992/ | null | ru | null |
# Мультиплексирование вывода данных на дисплей с параллельным портом
Мультиплексирование шины данных дисплея с параллельным выводом и последовательного порта Ардуино.
Статья описывает способ мультиплексного использования порта D микропроцессора ATMEL 328P (Ардуино НАНО) с целью обеспечения попеременного побайтного ... | https://habr.com/ru/post/476986/ | null | ru | null |
# Vim по полной: Уровень проекта и файловая система
Оглавление
==========
1. [Введение](http://habrahabr.ru/post/259701/) (vim\_lib)
2. [Менеджер плагинов без фатальных недостатков](http://habrahabr.ru/post/259725/) (vim\_lib, vim\_plugmanager)
3. **Уровень проекта и файловая система** (vim\_prj, nerdtree)
4. [Snippe... | https://habr.com/ru/post/259995/ | null | ru | null |
# Рассылка писем в Google Docs (Drive)
Создание статистики и управление рассылки писем
в Google Docs (с разных аккаунтов) на основе FormEmailer
==========================================================================================================
[Мы, Большой Брат Ltd., решили создать статистику](http://bigbrot... | https://habr.com/ru/post/144880/ | null | ru | null |
# Настройка оповещений о событиях в Zabbix
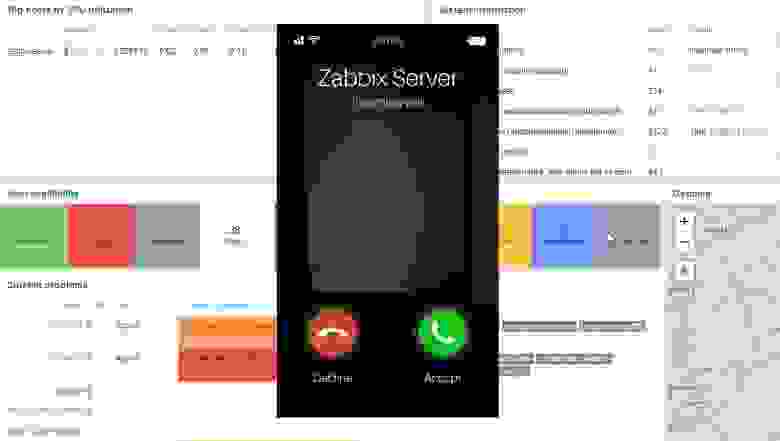В предыдущих статьях серии про Zabbix мы рассказывали о том, как контролировать различное оборудование и сервисы. Однако не менее важно настроить оповещения о собы... | https://habr.com/ru/post/696402/ | null | ru | null |
# Как устроен счетчик ссылок в Swift
Мы в iOS команде Vivid Money стремимся глубже понимать инструменты, которыми пользуемся каждый день. Один из таких – это язык программирования Swift. Он состоит из нескольких частей: компилятора, стандартной библиотеки и рантайма. Компилятор преобразует код, понятный для человека, ... | https://habr.com/ru/post/592599/ | null | ru | null |
# Запускаем HAProxy Kubernetes Ingress Controller вне Kubernetes-кластера
> *Запускаем HAProxy Kubernetes Ingress Controller вне кластера для уменьшения сетевой задержки и числа хопов*
>
>
Содержание:
* ... | https://habr.com/ru/post/591853/ | null | ru | null |
# Книга «Теоретический минимум по Computer Science. Сети, криптография и data science»
[](https://habr.com/ru/company/piter/blog/665894/) Привет, Хаброжители! Хватит тратить время на занудные учебники! Это краткое и простое руков... | https://habr.com/ru/post/665894/ | null | ru | null |
# Готовим приватные репозитории с помощью Artipie
Многочисленные санкционные ограничения могут стать преградой для использования существующих систем управления бинарными репозиториями, например, при приобретении необходимых лицензий. Таким образом, альтернатива существующим инструментам может сыграть положительную рол... | https://habr.com/ru/post/687394/ | null | ru | null |
# Почему Google меняет стандартный интерфейс URL в браузере
В сентябре прошлого года разработчики Chrome выдвинули радикальное предложение: [изменить отображение URL в браузере](https://habr.com/ru/company/globalsign/blog/422601/). В не... | https://habr.com/ru/post/438758/ | null | ru | null |
# Что такое Android Lint и как он помогает писать поддерживаемый код

Когда разработчик недостаточно осторожен, дела могут пойти весьма плохо... | https://habr.com/ru/post/456272/ | null | ru | null |
# Драйвер-фильтр операций в реестре. Практика
Привет, Хабр!
Когда передо мной встала задача написать свой драйвер, осуществляющий мониторинг операций в реестре, я, конечно же, полезла искать на просторах интернета хоть какую-то информацию по этому поводу. Но единственное, что вылезало по запросу «Драйвер-фильтр рее... | https://habr.com/ru/post/485606/ | null | ru | null |
# Unity3d. Уроки от Unity 3D Student (B25-B28)
Всем привет. Это заключительная серия базовых уроков по Unity 3D от сайта [Unity3DStudent](http://www.unity3dstudent.com/). ~~Далее будут еще два урока среднего уровня.~~ *Upd:* планы изменились, этих уроков не будет, так как второй урок (по анимации) уже довольно сильно ... | https://habr.com/ru/post/221755/ | null | ru | null |
# Язык программирования Zig

Первым комментарием к замечательной статье [Субъективное видение идеального языка программирования](https://habr.com/post/435300/) оказалась ссылка на [язык программирования Zig](http://ziglang.org/). Е... | https://habr.com/ru/post/435872/ | null | ru | null |
# Что посмотреть на выходных? Обзор лучших докладов в свободном доступе. Часть вторая, JBreak 2017
Что можно посмотреть вечером или на этих выходных? Можно смотреть какие-нибудь фильмы, а можно — наш непрекращающийся сериал под названием «Java-конференции». Единственный сериал, после просмотра которого у вас может рад... | https://habr.com/ru/post/346490/ | null | ru | null |
# Простой цифровой термометр своими руками
Наткнулся недавно в интернете на интересный [материал](http://www.kusto.com.ru/temperature/), идея заинтересовала, но после сборки отказалась корректно работать, погуглив дальше наткнулся на другой вариант, который и представляю.
Простой цифровой термометр с подключением ч... | https://habr.com/ru/post/55780/ | null | ru | null |
# Тест производительности проектов

Часто у нас стоит задача протестировать какую нагрузку выдерживает сайт [наших клиентов](http://centos-admin.ru/clients). Для себя, в качестве инструмента тестирова... | https://habr.com/ru/post/277897/ | null | ru | null |
# Реализация fork() без MMU
 Здравствуй, читатель! Пару лет назад в [статье про vfork()](https://habrahabr.ru/company/embox/blog/232605/) я обещал рассказать про реализацию fork() для систем без MMU, но руки до этого дошли только сейч... | https://habr.com/ru/post/347542/ | null | ru | null |
# Разбираем классы по косточкам или интроспектируем типы в Typescript

«Крутую ты штуку придумал, Стёпа», — сообщил мне коллега, осознав рассказанную ему идею. Надеюсь это действительно так, хоть и не скажу, что в том, о чём далее по... | https://habr.com/ru/post/535920/ | null | ru | null |
# HDR in CSS
High Dynamic Range (HDR) allows for a wider range of colours and brightness levels. This technology works on displays that support HDR format. Nowadays web advantage of display gamuts such as Display P3 and Rec. 2020, which can display a much larger color space than traditional sRGB displays. It is [50% m... | https://habr.com/ru/post/715084/ | null | en | null |
# Книга «Front-end. Клиентская разработка для профессионалов. Node.js, ES6, REST»
[](https://habrahabr.ru/company/piter/blog/334064/) В книге рассмотрены все важнейшие навыки работы с JavaScript, HTML5 и CSS3, требующиеся р... | https://habr.com/ru/post/334064/ | null | ru | null |
# Как избежать разыменования нулевого указателя, на примере одного исправления в ядре Linux
Идея в следующем. Чтобы не было разыменования нулевого указателя, нужно, чтобы не было нулевого указателя. Ваш КО. Так сложилось, что однажды я исправил небольшую проблему в ядре Linux, но это была не текущая ветка ядра, а стаб... | https://habr.com/ru/post/254097/ | null | ru | null |
# Моделирование данных в слоеной архитектуре
Разделение данных на слои
-------------------------
Согласно [Мартину Фаулеру](https://martinfowler.com/bliki/PresentationDomainDataLayering.html) при разработке архитектуры полезно разделять на 3 слоя: Презентационный, Доменный и Доступа к данным.
](http://farm8.staticflickr.com/7340/8895450591_3c8d025eba_b.jpg)
Привет, хабр.
Я наконец-то дождался заветной коробочки с девайсом [Geeksphone Peak](ht... | https://habr.com/ru/post/181440/ | null | ru | null |
# Мелочи в XSLT 1.0
Реализация функций replace(), uppercase(), lowercase()
Пример реализации функции replace в XSLT 1.0.
Сканируем **text** на совпадение с патэрном **target**, затем замещаем совпавший текст строкой **value** и возвращаем результирующую строку.
> `</fontxml version="1.0" encoding="utf-8"?>
... | https://habr.com/ru/post/71186/ | null | ru | null |
# Syn — библиотека синтетических событий, которая делает тестирование проще
Команда [Jupiter IT](http://jupiterjs.com/) выпустила [Syn](http://jupiterjs.com/#news/syn-a-standalone-synthetic-event-library), библиотеку, которая позволяет вам создавать синтетические события для использования при тестировании. Эта отдельн... | https://habr.com/ru/post/99319/ | null | ru | null |
# Обзор средств синхронизации баз данных MySQL

При разработке современных веб-приложений сложно недооценить пользу от использования систем контроля версий. Применительно к файлам разрабатываемого продукта, мы способ... | https://habr.com/ru/post/178875/ | null | ru | null |
# Путь JavaScript модуля

На момент написания этой статьи в JavaScript еще не существовало официальной модульной системы и все эмулировали модули как могли.
Модули или подобные структуры это неотъемлемая часть любого в... | https://habr.com/ru/post/181536/ | null | ru | null |
# Практическое использование термистора с Arduino

Здравствуй, Хабрасообщество. После прочтения нескольких статей на хабе Arduino я загорелся заполучить эту игрушку. И вот недавно получил посылку ... | https://habr.com/ru/post/141691/ | null | ru | null |
# Splunk 7.1. Что нового? Новый веб интерфейс, интеграция с Apache Kafka и многое другое…
[](https://habr.com/company/tssolution/blog/354474/)
Несколько дней назад компания Splunk выпустила новый релиз своей платформы Splunk 7.1 в ко... | https://habr.com/ru/post/354474/ | null | ru | null |
# Руководство по API Коллекций Vavr
**VAVR** (известная ранее, как Javaslang) — это некоммерческая функциональная библиотека для Java 8+. Она позволяет писать функциональный Scala-подобный код в Java и служит для уменьшения количества кода и повышения его качества. [Сайт библиотеки](http://vavr.io).
Под катом — пер... | https://habr.com/ru/post/474402/ | null | ru | null |
# Как написать сопроводительное письмо при поиске работы в США: 7 советов
[](https://habr.com/ru/post/451600/)
На протяжение многих лет в США была распроcтранена практика требовать претендентов на различные вакансии не только резюме,... | https://habr.com/ru/post/451600/ | null | ru | null |
# Локализация ASP.NET MVC приложения с помощью БД

Данная статья будет узконаправленной и покрывает локализацию через БД, поэтому подробно расписывать как делать локализацию с помощью файлов ресурсов (resx) можно посмотр... | https://habr.com/ru/post/143204/ | null | ru | null |
# Шифруем CoreML
ML модели, как и многие другие формы интеллектуальный собственности, подвержены риску быть украденными и использованными без ведома автора. В случае с CoreML большинство моделей зашиты внут... | https://habr.com/ru/post/701462/ | null | ru | null |
# Микшерный пульт из USB-звучки и опенсорса
Иногда у меня, как у звукача аниме/гик фестивалей/конвентов, появляется задача обеспечить звуком небольшой ивент, на площадке которого нет вообще ничего из оборудования. Такие патички довольно лайтовы и располагают к экспериментам. Так, для нашего осеннего опенэйра я выбрал ... | https://habr.com/ru/post/534348/ | null | ru | null |
# Tzdata — глобальная база знаний о часовых поясах
Если нам где-либо (например, в каких-то приложениях) требуется работать не только с универсальным временем UTC, но и с местным временем в различных точках Земли, то здесь встаёт вопрос о необходимости некой базы знаний о том, как вычисляется локальное время относитель... | https://habr.com/ru/post/130401/ | null | ru | null |
# gettext: рецепт жаркое из антилопы в Javascript

При разработке CMF я столкнулся с необходимостью грамотно реализовать i18n (мультиязычность), и стал рассматривать различные варианты…
Сначала, исходя из прошлого опыта, я хоте... | https://habr.com/ru/post/108348/ | null | ru | null |
# Choosing a server for 1000 WebRTC streams
In any project, a great deal of importance is placed on the selection of server hardware and WebRTC streaming is no exception. One of the key principles of such a ... | https://habr.com/ru/post/570284/ | null | en | null |
# Разделяй и властвуй

При работе с базой данных (в частности с PostgreSQL) у меня появилась идея выбирать данные из таблицы параллельно (используя ЯП Go). И я задался вопросом «возможно ли сканировать строки выборки в отдельных гоур... | https://habr.com/ru/post/485056/ | null | ru | null |
# Разработка игры в Unity3D под геймпад
Для работы на конкурс была поставлена задача: спроектировать небольшую игру про космос, которую дети будут проходить порядка 8 минут. И было одно но. Детям должно быть интересно!
Так как пожертвовать клавиатурой на управление было слишком жалко (да и не так это интересно), всё ... | https://habr.com/ru/post/311962/ | null | ru | null |
# Расширение Nano Defender нужно срочно удалить из браузера

3 октября 2020 года программист *jspenguin2017*, автор расширения Nano Defender, [сообщил](https://github.com/NanoAdblocker/NanoCore/issues/362) в официальном репозитории, ... | https://habr.com/ru/post/523974/ | null | ru | null |
# Just take a look at SObjectizer if you want to use Actors or CSP in your C++ project

A few words about SObjectizer and its history
=============================================
[SObjectizer](https://github.com/Stiffstream/sobject... | https://habr.com/ru/post/458202/ | null | en | null |
# Умная хрущёвка на максималках. Продолжение
В [первой часть статьи](https://habr.com/ru/post/503646/) я рассказал о том, как оснастить двухкомнатную хрущевку различными датчиками и с их помощью собирать информацию о текущем состоянии квартиры. Во второй части речь пойдет о том, как начать активно управлять всеми дост... | https://habr.com/ru/post/506550/ | null | ru | null |
# Вы правда знаете о том, что такое массивы?
Там, где я тружусь, от веб-разработчиков ожидают знания PHP и JavaScript. Я, проводя собеседования, обнаружил, что достаточно задать всего один простой вопрос для того чтобы узнать о том, насколько глубоко разработчик понимает инструменты, которыми пользуется каждый день. В... | https://habr.com/ru/post/495892/ | null | ru | null |
# Встречаем Angular 10
Вышел Angular 10.0.0! Это — [мажорный](https://semver.org/#spec-item-8) релиз, который затрагивает всю платформу, включая сам фреймворк, библиотеку компонентов Angular Material и инструменты командной строки. Размер этого релиза меньше, чем обычно. Дело в том, что с момента выхода Angular 9 прош... | https://habr.com/ru/post/508656/ | null | ru | null |
# Моделирование ракеты для достижения максимальной высоты
[](https://habr.com/ru/company/ruvds/blog/684768/)
Моделисты ракет зачастую стремятся, чтобы их творения наилучшим образом показывали себя в определенной категории состязаний,... | https://habr.com/ru/post/684768/ | null | ru | null |
# Мониторинг аномальной активности в операционной системе «Нейтрино»
Активности в операционной системе могут быть самыми разнообразными. Это может быть и запуск нового процесса или потока, и обращение к файло... | https://habr.com/ru/post/713690/ | null | ru | null |
# Базовая реализация INotifyPropertyChanged
*WPF в чём-то повторил судьбу js — в силу некоторых нерешённых на уровне платформы проблем [многие](http://habrahabr.ru/post/271105/) [пытаются](http://habrahabr.ru/post/270979/) стать первооткрывателями наравне с [Карлом фон Дрезем](https://ru.wikipedia.org/wiki/Дрез,_Карл)... | https://habr.com/ru/post/271305/ | null | ru | null |
# Symfony2: Выпуск финальной версии (Fabien Potencier – 22 июля 2011)
Мы уже готовы выпустить финальный релиз Symfony 2.0. В течение последних пары недель мы сделали несколько существенных изменений, и поэтому публикуем еще один релиз-ка... | https://habr.com/ru/post/124768/ | null | ru | null |
# Ежедневные скрипты
Доброго времени суток всем! Командная строка Linux очень мощная, но многие команды из раза в раз приходится набирать одни и те же, а аргументы часто занимают большую часть командной строки. Если вы согласны — добро пожаловать.
Я накопил некоторый список скриптов, которыми пользуюсь каждый день... | https://habr.com/ru/post/317208/ | null | ru | null |
# Добавление рекордов с OAuth 2: Laravel Passport + Unity. Часть 2

Продолжение статьи про добавление рекордов из игры на сайт от конкретного пользователя. В [первой части](https://habrahabr.ru/post/340282/) мы сделали страничку рекордов ... | https://habr.com/ru/post/340362/ | null | ru | null |
# Отказоустойчивая работа с Redis
Эта статья — переработанная версия доклада [Отказоустойчивая работа с Redis](https://www.youtube.com/watch?v=9qvr920dWtk) с прошедшего 17 октября 2020 митапа PHP-разработчиков Йошкар-Олы.
Мы поговорим о подводных камнях использования Redis в системе, где важна отказоустойчивость — на... | https://habr.com/ru/post/562086/ | null | ru | null |
# Создание полноценного видеохостинга своими руками (nginx+php5-fpm+ffmpeg+cumulusclips)
Добрый день, хабровчане!
Недавно в нашей компании возникла потребность создания своего видеоресурса, закрытого, но в тоже время немного публичного. И вот наконец, он закончен и я готов поделиться знаниями и применениями.
**З... | https://habr.com/ru/post/188380/ | null | ru | null |
# Vue.js для начинающих, урок 11: вкладки, глобальная шина событий
Сегодня, в 11 уроке, который завершает этот учебный курс по основам Vue, мы поговорим о том, как организовать содержимое страницы приложения с помощью вкладок. Здесь же мы обсудим глобальную шину событий — простой механизм по передаче данных внутри при... | https://habr.com/ru/post/514516/ | null | ru | null |
# Настройка OpenVPN в iOS
Тихо и незаметно прошел релиз клиента OpenVPN для iOS. Для многих, в том числе и для меня, это может стать последней причиной для отказа от Jailbreak'а. Для тех, кто желает более подробно узнать о возможностях клиента на текущий момент, а так же о подводных камнях настройки, добро пожаловать ... | https://habr.com/ru/post/168853/ | null | ru | null |
# Приручаем и прокачиваем огнелиса: The Ultimate Guide

#### Лирическое вступление
*Не люблю гонку версий, своей бессмысленностью отдаленно напоминающую гонку вооружений. Не успели как ... | https://habr.com/ru/post/161053/ | null | ru | null |
# Как удобно мониторить Citrix XenDesktop
Привет, расскажу как удобно и красиво можно мониторить Citrix XenDesktop ферму заливая данные в zabbix.
Citrix XenDesktop необходим компаниям, у которых много офисов в разных уголках страны, применяется разнообразное сложное ПО вроде IBSO/RBO требующее поддержки в актуальном ... | https://habr.com/ru/post/571824/ | null | ru | null |
# Абсолютное горизонтальное и вертикальное центрирование
*Сколько уже было сломано копий о задачу выравнивания элементов на странице. Предлагаю вашему вниманию перевод отличной статьи с решением этой проблемы от Стефана Шоу (Stephen Shaw) для Smashing Magazine — [Absolute Horizontal And Vertical Centering In CSS](http... | https://habr.com/ru/post/189696/ | null | ru | null |
# Проверка соблюдения стандартов кодирования РHP через git
В разработке проекта зачастую принимают участие разработчики разного уровня. Это приводит к тому, что нет строгого формата написания кода. За качеством кода на проекте приходится постоянно следить старшим разработчикам и это отнимает у них кучу времени.
Для... | https://habr.com/ru/post/141447/ | null | ru | null |
# Ethereum + Python = Brownie
Салют, дорогой криптоэнтузиаст!
Сегодня речь пойдёт о [Brownie](https://github.com/iamdefinitelyahuman/brownie) — аналоге фреймворка [Truffle](https://github.com/trufflesuite/truffle), который часто используется для разработки умных контрактов на Solidity, их тестирования и развёртывания... | https://habr.com/ru/post/509618/ | null | ru | null |
# Microsoft откатила обновление из-за проблем с запуском приложений
Microsoft пришлось [откатить](https://docs.microsoft.com/en-us/windows/release-health/status-windows-10-21h1#1696msgdesc) обновление Windows 10 для устранения ошибки. Пользователи стали жаловаться, что после обновления приложения перестали открываться... | https://habr.com/ru/post/580182/ | null | ru | null |
# Автогенерация и заливка элементов конфигураций сетевых устройств с помощью Nornir

Привет, Хабр!
Недавно тут проскочила статья [Mikrotik и Linux. Рутина и автоматизация](http://https://habr.com/en/post/480404/) где подобную задачу ... | https://habr.com/ru/post/482194/ | null | ru | null |
# Как построить IIoT архитектуру своими руками. Часть 2: «Вещи»
В предыдущей [статье](https://habr.com/company/itsumma/blog/415933/) мы достаточно кратко рассмотрели организацию и процессинг IoT данных с помощью проекта Apache NiFi. Этой статьей мы открываем серию, в которой детально расскажем о каждом этапе, начиная ... | https://habr.com/ru/post/416291/ | null | ru | null |
# Сбор и анализ логов демонов в Badoo
Введение
--------
В Badoo несколько десятков «самописных» демонов. Большинство из них написаны на Си, остался один на С++ и пять или шесть на Go. Они работают примерно на сотне серверов в четырех дата-центрах.
В Badoo проверка работоспособности и обнаружение проблем с демонами... | https://habr.com/ru/post/280606/ | null | ru | null |
# Кибергруппа PowerPool освоила уязвимость нулевого дня в Advanced Local Procedure Call
27 августа 2018 года в твиттере ИБ-специалиста с ником SandboxEscaper была опубликована информация об уязвимости нулевого дня. Уязвимость затрагивает версии Microsoft Windows с 7 по 10, точнее, интерфейс Advanced Local Procedure Ca... | https://habr.com/ru/post/422613/ | null | ru | null |
# CSS3 градиент для границ блока
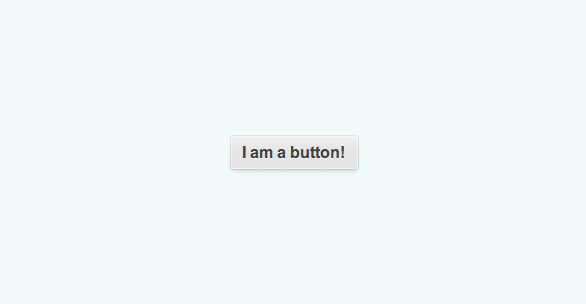
В этой статье я покажу один из вариантов создания градиента для границ у любого блока с помощью CSS3.
В конечном варианте у нас получится кнопка, которая на скриншоте выше.
Работать... | https://habr.com/ru/post/140760/ | null | ru | null |
# The Code Analyzer is wrong. Long live the Analyzer

Combining many actions in a single C++ expression is a bad practice, as such code is hard to understa... | https://habr.com/ru/post/530852/ | null | en | null |
# JavaScript: примеры реализации некоторых математических выражений

Привет, друзья!
Представляю вашему вниманию адаптированный и дополненный перевод [этой замечательной статьи](https://runjs.app/blog/mathematical-notation-for-jav... | https://habr.com/ru/post/673568/ | null | ru | null |
# Баг с position:fixed и backface-visibility в Firefox
В процессе верстки очередного проекта наткнулся на странный баг в Firefox свежих версий, которые поддерживают свойство backface-visibility. Ранее описание этой проблемы не встречал, поэтому решил поделиться. Полезно будет всем, кто прочел [этот пост об антиалиасин... | https://habr.com/ru/post/171813/ | null | ru | null |
# Сборка Colobot Gold
Всё большую популярность набирает компьютерная игра для программистов Colobot Gold. О ней не [раз](https://habr.com/ru/company/geekbrains/blog/276091/) [писали](https://habr.com/ru/post/214287/) на хабре, но материал со временем устаревает. Происходит активное развитие программы. И у многих польз... | https://habr.com/ru/post/527228/ | null | ru | null |
# Консольная утилита на Kotlin/Java с помощью библиотеки args4j
Привет, Habr! Я учусь на программиста в Питерском Политехе. Одно из моих заданий в курсовой работе было написание консольной утилиты. Решил поделиться своим небольшим опытом.
Для начала представлю вам саму формулировку задания, которое мне необходимо б... | https://habr.com/ru/post/496290/ | null | ru | null |
# Построение компонентов с выпадающими блоками с помощью Angular и Material CDK
Каждое приложение использует компоненты с выпадающими блоками. Такие панели используются в выпадающем списке, Autocomplete, Tooltip и т.д. В Material CDK есть инструмент Overlay для создания такого функционала.
. Я использую их для всего, что только можно и пытаюсь избежать кода на стороне сервера как чумы. Я пушу изменения в репозиторий и они тут же отображаются для пользователей без каких-либо хуков или дополнительных шагов. Бесплатность дела... | https://habr.com/ru/post/316790/ | null | ru | null |
# Python: как уменьшить расход памяти вдвое, добавив всего одну строчку кода?
Привет habr.
В одном проекте, где необходимо было хранить и обрабатывать довольно большой динамический список, тестировщики стали жаловаться на нехватку памяти. Простой способ, как «малой кровью» исправить проблему, добавив лишь одну стро... | https://habr.com/ru/post/427909/ | null | ru | null |
# Тестирование React-Redux приложения

#### Время чтения: 13 минут
Много ли вы видели react разработчиков, которые покрывают свой код тестами? А вы-то тестируете свои? Действительно, зачем, если мы м... | https://habr.com/ru/post/340514/ | null | ru | null |
# Консоль в массы. Переход на светлую сторону. Часть вторая
Вступление
----------
Довольно долгое время я использовал в своей работе screen. Но со временем он меня перестал устраивать. Я начал искать альтернат... | https://habr.com/ru/post/318376/ | null | ru | null |
# О бедненьком NULLе замолвите слово
Есть вещи, которые не нравятся, есть вещи, которые бесят, есть вызывающие жгучий гнев, и есть ситуация с NULL в SQL.
Догма
-----
Мы все выучили наизусть: NULL не равен ... | https://habr.com/ru/post/684600/ | null | ru | null |
# Когда использовать неструктурированные типы данных в PostgreSQL? Сравнение Hstore vs. JSON vs. JSONB
С тех пор как PostgreSQL начал поддерживать NoSQL (посредством HStore, JSON и JSONB), вопрос о том, когда использовать PostgreSQL в реляционном режиме, а в каких в режиме NoSQL, стал подниматься достаточно часто. Пол... | https://habr.com/ru/post/306602/ | null | ru | null |
# Delegate Adapter — зачем и как
Практически во всех проектах, которыми я занимался, приходилось отображать список элементов (ленту), и эти элементы были разного типа. Часто задача решалась внутри главного адаптера, определяя тип элемента через instanceOf в getItemViewType(). Когда в ленте 2 или 3 типа, кажется, что т... | https://habr.com/ru/post/341738/ | null | ru | null |
# BSoD — это не баг Windows, это фича такая.
Программисты MS специально создавали ее. Не верите? Вот способ вызвать ее самым обычным нажатием клавиш.
Откройте реестр по адресу: для владельцев usb-клавиатур `HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\kbdhid\Parameters`, а для PS/2 — `HKEY_LOCAL_MACHINE\SYS... | https://habr.com/ru/post/17972/ | null | ru | null |
# Как победить скликивание в Я. Директ и AdWords на 600 тысяч рублей в месяц
За последние полгода нам удалось победить «скликивание» нашей контекстной рекламы с бюджетом в 1 миллион рублей в месяц.
Ключом победы над фродом стал поминутный мониторинг трафика с уведомлениями об аномальных изменениях и отключением пр... | https://habr.com/ru/post/423335/ | null | ru | null |
# Анимация меню при помощи CSS3

В данной статье я хотел бы показать вам некоторые приёмы создания эффектов при помощи CSS3 на примере меню. Идея заключается в простой композиции элементов: иконки, основного названия и вторичного... | https://habr.com/ru/post/131558/ | null | ru | null |
# Поваренная книга разработчика: DDD-рецепты (4-я часть, Структуры)
Введение
========
Итак, мы уже определились с [областью применения](/post/426663/), [методологией](/post/428209/) и [архитектурой](/post/429750/). Перейдем от теории к практике, к написанию кода. Хотелось бы начать с шаблонов проектирования, которые ... | https://habr.com/ru/post/435920/ | null | ru | null |
# Python, корреляция и регрессия: часть 3
Предыдущий пост см. [здесь](https://habr.com/ru/post/558084/).
Прежде чем перейти к изучению нормального уравнения, давайте рассмотрим основы матричного и векторного умножения.
Матрицы
-------
Матрица, — это двумерный массив чисел. Размерность матрицы выражается числом стр... | https://habr.com/ru/post/558146/ | null | ru | null |
# SVG-файлы изнутри и вывод векторных изображений на canvas «вручную» (ч.1)

Эта статья написана по следам создания плагина для чтения SVG файлов для анимационного векторного редактора [NanoFL](http://nanofl.com/). В ней вы ... | https://habr.com/ru/post/276519/ | null | ru | null |
# NLog: правила и фильтры
NLog: правила и фильтры
=======================
В [Confirmit](https://www.confirmit.com) мы используем библиотеку [NLog](https://github.com/NLog/NLog) для логирования в наших .NET-приложениях. Хотя для этой библиотеки существует документация, для меня было сложно понять, как все это работает... | https://habr.com/ru/post/450728/ | null | ru | null |
# Гуру слов, проблемы с Unity3d, и счастливый финал в итоге
Идея игры и ее особенности
==========================

Наверное, все играли в какие-то игры, где нужно составлять слова. Кто не знает, что такое кроссворды? А [Гор... | https://habr.com/ru/post/282491/ | null | ru | null |
# Создание аудиоплагинов, часть 4
Все посты серии:
[Часть 1. Введение и настройка](http://habrahabr.ru/post/224911/)
[Часть 2. Изучение кода](http://habrahabr.ru/post/225019/)
[Часть 3. VST и AU](http://habrahabr.ru/post/225457/)
[Часть 4. Цифровой дисторшн](http://habrahabr.ru/post/225751/)
[Часть 5. П... | https://habr.com/ru/post/225751/ | null | ru | null |
# Собеседования: ожидания vs реальность

Все мы имеем опыт прохождения собеседований. Все когда-то сидели в комнате с зевающим эйчаром, пытающимся разобраться, о чём поговорить, когда ваши планы на ближайшие 5 лет и все 7 силь... | https://habr.com/ru/post/485790/ | null | ru | null |
# Разбираем нестандартный udp dns запрос с помощью tcpdump
Реагируя на очередной «pseudorandom subdomain» ([PRSD](https://indico.dns-oarc.net//getFile.py/access?contribId=9&sessionId=2&resId=0&materialId=slides&confId=20)) DDoS, а они очень хорошо видны на графике исходящих запросов:
![image](https://habrastorage.o... | https://habr.com/ru/post/241375/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.