
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Нагрузочное тестирование Skyforge. Год спустя
Прошло уже больше года после [публикации](http://habrahabr.ru/company/mailru/blog/191378/) [статей](http://habrahabr.ru/company/mailru/blog/193452/), посвященных нагрузочному тестированию [Skyforge](http://sf.mail.ru/) — новой MMORPG от студии Allods Team. С тех пор изме... | https://habr.com/ru/post/234223/ | null | ru | null |
# Подтесты в Python
Недавно я сделал опрометчивый твит, в котором намекнул на то, что у меня имеется глубоко продуманное мнение по одному важному вопросу. Я написал, что пакет [pytest-subtests](https://github.com/pytest-dev/pytest-subtests) достоин того, чтобы им пользовалось бы больше программистов. Я даже дошёл до т... | https://habr.com/ru/post/685890/ | null | ru | null |
# Поднимаем сервис мониторинга цен конкурентов
Любой, кто работает в сфере e-commerce, рано или поздно сталкивается с необходимостью быть первым среди конкурентов. Одним из наиболее эффективных инструментов в данном вопросе является управление ценой. Результаты маркетинговых исследований показывают, что среди тех потр... | https://habr.com/ru/post/328734/ | null | ru | null |
# Релиз Go 1.9
Сегодня (прим. переводчика: 24-08-2017), наша команда рада Вам представить релиз Go 1.9. Вы можете скачать его [отсюда](https://golang.org/dl/). В этом релизе очень много изменений касательно самого языка, стандартных библиотек, райнтайма и инструментов экосистемы. В этом посте я расскажу Вам о наиболее... | https://habr.com/ru/post/336368/ | null | ru | null |
# Зеркало справочных архивов Visual Studio 2010
#### Введение
Одним из немногих полезных нововведений справочной системы Visual Studio 2010 (aka Microsoft Help System 1.1) является возможность установки и обновления архивов содержимого справки из онлайн-каталога. Однако, необходимость вытягивания порядка гигабайта ар... | https://habr.com/ru/post/133266/ | null | ru | null |
# Concurrency структуры в .net. ConcurrentQueue изнутри
ConcurrentQueue можно отнести к lock-free конкурентным структурам данных. В ее реализации нет блокировок (lock, Mutex…) и реализована она с использованием:
— классической функции CompareExchange;
— SpinWait
— volatile (используется как memory-barrier)... | https://habr.com/ru/post/245837/ | null | ru | null |
# Разработка Adblock Radio

> **tl;dr:** [Adblock Radio](https://www.adblockradio.com/) распознаёт аудиорекламу с помощью машинного обучения и Shazam-подобных техник. Основной движок с [открытым исходным кодом](https://github.com/a... | https://habr.com/ru/post/435720/ | null | ru | null |
# jClever — умный jNice с плюшками. Стилизация HTML-форм

Автор статьи и плагина — хабраюзер [DenisZ](https://habrahabr.ru/users/denisz/)
**jClever Forms** — это плагин для стилизации HTML форм, который... | https://habr.com/ru/post/144720/ | null | ru | null |
# Погружение в технологию блокчейн: Экосистема цифровой стоматологии
Представляем вторую статью из серии «Погружение в технологию блокчейн». В этом материалы вы узнаете о медицинском проекте Digital Dentistry Exchange, который представляет собой часть экосистемы цифровой стоматологии под названием Digital Dentistry Sp... | https://habr.com/ru/post/313130/ | null | ru | null |
# Делаем из ENC28J60 внешнюю USB сетевую карту
ENC28J60 - простой Ethernet контроллер, который может выступать в роли внешней сетевой карты у одноплатных компьютеров с GPIO (для raspberry есть даже готовый д... | https://habr.com/ru/post/530730/ | null | ru | null |
# XOWML, который преобразуется в XHTML
XOWML, — новый язык разметки, разработанный в студии Onlyweb. Читается, — хоумл.
Язык имеет единственное предназначение, — дать XHTML верстальщику возможность **быстро и эффективно писать валидный XHTML код**. Т.е. работает это так: пишешь код в XOWML, нажимаешь сохранить, авт... | https://habr.com/ru/post/13723/ | null | ru | null |
# Retain внутри, а снаружи ViewModel

В какой-то момент я заметил периодические разговоры о том, как же на самом деле работает [ViewModel](https://developer.android.com/topic/libraries/architecture/viewmodel) из гугловых архит... | https://habr.com/ru/post/439926/ | null | ru | null |
# «Дело было вечером, делать было нечего» или краткая история о сравнении производительности языков программирования
"Бенч" дело такое... После нескольких дней бездействия начинается ломка, хочется занять себя чем-нибудь. Иногда я отвлекался на pet-проекты, иногда на чтение литературы... Сейчас же я расскажу о том что... | https://habr.com/ru/post/563078/ | null | ru | null |
# Как мы отличали тележку от прораба — видеоаналитика для кассовой зоны гипермаркета (и продолжение про кота-терминатора)
В одном строительном гипермаркете есть 18 касс, и надо уметь делать так, чтобы кассиры открывали их вовремя, чтобы очередь не была больше 4 человек. Ну, и чтобы лишние кассы не простаивали открытым... | https://habr.com/ru/post/314318/ | null | ru | null |
# Как работает JS: классы и наследование, транспиляция в Babel и TypeScript
В наши дни использование классов являются одним из самых популярных способов структурирования программных проектов. Этот подход к программированию применяется и в JavaScript. Сегодня мы публикуем перевод 15 части серии материалов, посвящённых ... | https://habr.com/ru/post/415377/ | null | ru | null |
# Flutter + чистая архитектура: разбираем на примере
На определённом этапе изучения новой технологии начинаешь задаваться вопросом - как правильно организовать архитектуру проекта? Мне в своё время повезло - попались опытные наставники, которые дали мудрые советы. Однако я считаю, что знания не должны лежать мёртвым г... | https://habr.com/ru/post/522640/ | null | ru | null |
# Современный Web-UI для SVN в 2020 году
**cSvn** — это web-интерфейс к **Subversion**-репозиториям. Основу **cSvn** представляет CGI-скрипт написанный на языке **С**.
В мае 2020 года был опубликован релиз очередной версии [Apache Su... | https://habr.com/ru/post/528068/ | null | ru | null |
# Как я писал компилятор С++. Пересказ спустя 15 лет
15 лет назад не было Хабрахабра, не было фейсбука, и что характерно, не было компилятора С++, с выводом диагностических сообщений на русском. С тех пор, вышло несколько новых стандартов С++, технологии разработки сделали гигантский скачок, а для написания своего язы... | https://habr.com/ru/post/322656/ | null | ru | null |
# Авторизация по SSH с использованием ключей в условиях шифрования домашней директории
Хрестоматийный вариант настройки авторизации по SSH с использованием ключей знают все: открытый ключ записывается в *~/.ssh/authorized\_keys*. В случае, если применяется шифрование домашней папки, то система не сможет прочесть данны... | https://habr.com/ru/post/103668/ | null | ru | null |
# Графический интерфейс на Python за 5 минут
Python легко использовать. В нем вы можете найти огромное количество библиотек для чего угодно. И это его основное преимущество. Из нескольких строк кода ... | https://habr.com/ru/post/480884/ | null | ru | null |
# 5NO — NodeJS ORM for Postgres
#### Кратко об этом модуле
Этот модуль разработан мной для упрощения взаимодействия между Postgres и JS.
Я понимаю что есть много подобных модулей, но хотелось сделать что то гибкое и простое в обращение средство для разных нужд.
Модуль объединяет в себе три важные функции: вали... | https://habr.com/ru/post/495242/ | null | ru | null |
# Impress: многоцелевой сервер приложений для Node.js
Несмотря на заметные успехи, [Node.js](http://nodejs.org/) все еще остается специализированной технологией, которой преимущественно закрывают узкие места ... | https://habr.com/ru/post/194250/ | null | ru | null |
# На волнах эффекта Ли: Питонизируем генерацию DAF
По статистике 1-4 % населения Земли подвержены дефекту речи, характеризующимся частой пролонгацией звуков (слогов, слов) и/или частыми остановками в речи... | https://habr.com/ru/post/347580/ | null | ru | null |
# Осторожно — несанкционированный трафик!
Ни для кого не секрет, что при подключении любого сетевого устройства к Интернет генерируется трафик, который мы «не заказывали». Основные источники:
* Паразитный трафик;
* Нежелательный трафик от программного обеспечения;
* Вирусная активность;
* Несанкционированное исполь... | https://habr.com/ru/post/106061/ | null | ru | null |
# Сказание о Клеопатре и о российской криптографии (Продолжение)
С появлением библиотеки GCrypt-1.7.0 с поддержкой российской криптографии (ГОСТ 28147-89, ГОСТ Р 34.11-94/2012 и ГОСТ Р 34.10-2001/2012), стало возможным гов... | https://habr.com/ru/post/316736/ | null | ru | null |
# Организация удаленной работы SMB организации на OpenVPN
### Постановка задачи
Статья описывает организацию удаленного доступа сотрудников на продуктах с открытым исходным кодом и может быть использована как для построения полностью автономной системы, так и окажется полезной для расширения, когда в имеющейся коммер... | https://habr.com/ru/post/501048/ | null | ru | null |
# Разработка игр с использованием Cocos2d на Python

#### Введение
Имплементация Cocos2d на Objective-C используется для разработки игр для iPhone весьма широко. По данным [официального сайта](http://www.cocos2... | https://habr.com/ru/post/120438/ | null | ru | null |
# Управляем зависимостями в iOS-приложениях правильно: Typhoon Tips & Tricks

*В предыдущих частях цикла мы рассмотрели основные аспекты работы **Typhoon** и подготовились к полноценному применению его на практике. Тем не м... | https://habr.com/ru/post/264683/ | null | ru | null |
# Альтернативные модули GBIC для Cisco Catalyst
**Дано:** коммутатор Cisco Catalyst 4503 c многопортовым оптическим модулем, поддерживающем GBIC’и.
**Не дано:** родной цисковский GBIC WS-G5486 (их сейчас не найдёшь в Москве и, к тому же, они дорогие).
**Задача:** найти модуль от другого производителя, который бы... | https://habr.com/ru/post/23332/ | null | ru | null |
# Оптимизация гиперпараметров с помощью поиска по сетке и случайного поиска в Python
### Введение
Все модели машинного обучения имеют набор гиперпараметров или аргументов, которые должны быть заданы специали... | https://habr.com/ru/post/698370/ | null | ru | null |
# Генерация текста с помощью GPT2 и PyTorch
Быстрая и легкая генерация текста на любом языке с помощью фреймворка Huggingface
---------------------------------------------------------------------------------
> В рамках курса [«Machine Learning. Advanced»](https://otus.pw/TS4r/) подготовили перевод интересного материа... | https://habr.com/ru/post/542116/ | null | ru | null |
# Как подключить скрипт на сторонний сайт
Привет, Хабр! Это первый пост в нашем блоге. Многие знают нас как чат для сайта, именно с него мы начинали, а сейчас занимаем лидирующие позиции в сфере бизнес-мессенджеров. Мы постепенно эволюционировали в комплексное бизнес-решение, которое предоставляет множество возможност... | https://habr.com/ru/post/452802/ | null | ru | null |
# Дружба OkayCMS и модуля для SMTP
После того, как почтовые сервисы перешли на свою строгую политику, многие клиенты стали жаловаться, что письма с интернет-магазина падают как минимум в спам, а в худшем случае, хостинг просто блочит письмо и не отправляет клиенту. В связи с этим, мы стали прикручивать на сайты популя... | https://habr.com/ru/post/319454/ | null | ru | null |
# Выполнение заданий потоковой обработки раз в день для 10-кратного снижения затрат
**Часть 6 Масштабируемые данные @ Databricks**
*Это шестой пост из* [*серии статей*](https://databricks.com/blog/2017/01/1... | https://habr.com/ru/post/670266/ | null | ru | null |
# Аналитические панели в реальном времени. В поисках (Apache) Doris
Можно было бы назвать эту статью "Yet another analytical database", если бы не тот факт, что Apache Doris построен на архитектуре MPP, котор... | https://habr.com/ru/post/699268/ | null | ru | null |
# Бесплатные сетевые IP-сканеры
[](https://habr.com/ru/company/ruvds/blog/693710/)
В локальной сети (LAN) обычно есть множество обменивающихся данными хостов. Сканирование сетей при помощи IP-сканера позволяет отделам ИТ, сетевым адм... | https://habr.com/ru/post/693710/ | null | ru | null |
# Победное решение конкурса ML Boot Camp III
Добрый день! В этой статье я хотел бы вкратце рассказать о решении которое принесло мне первое место на конкурсе по машинному обучению ML Boot Camp III от mail.ru.
Представлюсь, меня зовут Карачун Михаил, я являюсь так же победителем и предыдущего конкурса mail.ru. Мое п... | https://habr.com/ru/post/324916/ | null | ru | null |
# Опыт разработки управляющего ПО для квеструма
Последние год-полтора пользуются большой популярностью т.н. квеструмы, квесты «выйди из комнаты» реализованные в реальной жизни. Когда я ходил на первые квесты, большая часть задачек сводилась к поиску ключей и кодов для механических замков, магнитные замки были чем-то к... | https://habr.com/ru/post/303742/ | null | ru | null |
# Реактивное программирование со Spring, часть 2 Project Reactor
Это вторая часть [**серии заметок о реактивном программировании**](https://habr.com/ru/post/565000/), в которой представлен обзор Project Reactor, реактивной библиотеки, основанной на спецификации Reactive Streams.
### 1. Введение в Project Reactor
Р... | https://habr.com/ru/post/565050/ | null | ru | null |
# Анонимные типы за пределами функции
Анонимные типы — очень приятное расширение C#, появившееся в версии 3.0. С помощью анонимных типов мы можем налету создать объект-хранилище и наполнить его данными.
Основное применение анонимных типов — это, конечно, LINQ. Фактически, они и были созданы для него (вообще говоря,... | https://habr.com/ru/post/37170/ | null | ru | null |
# Не всплывай! Прерываемые транзишены в iOS
Вас тоже бесят всплывающие окна в приложениях? В этой статье я покажу, как интерактивно скрывать и показывать всплывающие окна, делать анимацию прерываемой и не бесить своих клиентов.

> Сер... | https://habr.com/ru/post/465073/ | null | ru | null |
# MIDI2USB – музыка нас связала
*Рис.1 Российско-китайско-американский конвертер MIDI в USB. Фото автора.*
Люди любят музыку. Многие умеют играть на музыкальных инструментах. А н... | https://habr.com/ru/post/522808/ | null | ru | null |
# Делаем веб-формы удобнее для заполнения
Привет, Хабр! Сегодня для работы в Интернете все чаще используются мобильные устройства, а не компьютеры. При этом, на многих сайтах есть формы для ввода данных, позволяющие совершить покупку или подписаться на рассылку. Как результат, пользователям приходится много раз вводит... | https://habr.com/ru/post/253585/ | null | ru | null |
# Load test of WebRTC recording on AWS
Do you remember how just a few years ago it was a disaster to lose a camera at the end of a vacation? All memorable pictures and videos then disappeared along with the ... | https://habr.com/ru/post/570360/ | null | en | null |
# Neovim для full stack программиста
Я немного расскажу, как использую vim в работе full stack программиста, со своей колокольни, но для начала отвечу на некоторые вопросы, которые задают мне, когда узнают, ... | https://habr.com/ru/post/585222/ | null | ru | null |
# Хостинг статических сайтов на AWS
В данной статье я хочу подробно разобрать тему хостинга статических сайтов на [AWS](https://aws.amazon.com/). Тему нельзя назвать сильно сложной, но нюансов хватает. Для настройки вручную потребуется ... | https://habr.com/ru/post/526454/ | null | ru | null |
# Songo: Desktop-ный плеер Вконтакте
 Я часто видел, как люди слушают музыку вконтакте из браузера. Причем слушают, как обычный десктопный плеер. Я же испытываю отвращение к такого рода использованию ибо люблю вкладки в брау... | https://habr.com/ru/post/162255/ | null | ru | null |
# Типы, где их не ждали
Давайте представим себе реализацию модуля `Scaffold`, который генерирует структуру с предопределенными пользовательскими полями и инжектит ее в вызываемый модуль при помощи `use Scaffold`. При вызове `use Scaffold, fields: foo: [custom_type()], ...` — мы хотим реализовать правильный тип в `Cons... | https://habr.com/ru/post/527646/ | null | ru | null |
# DeepFake в условиях современности: что, почему и возможно ли защититься
Дипфейк. Что первое приходит на ум, когда вы слышите или видите это слово? Наверное, какие-то картинки или видео откровенного характе... | https://habr.com/ru/post/707246/ | null | ru | null |
# QSerializer: решение для простой сериализации JSON/XML
Привет, Хабр!
Подумалось мне, что как-то несправедливо получается — у Java, С#, Go, Python и т.д. есть библиотеки для комфортной сериализации объектных данных в модные нынче JSON и XML, а в С++ то ли забыли, то ли не захотели, то ли и не особо надо, то ли сло... | https://habr.com/ru/post/496836/ | null | ru | null |
# PostgreSQL: занимательный пример работы индексов, планировщика запросов и магии
В начале месяца я прочитал [доклад](https://www.youtube.com/watch?v=BhI2BnOTrQs&t=3905s) про индексы в базах данных для Saint P Ruby Community и буквально через несколько дней жизнь не замедлила подкинуть мне показательный пример работы ... | https://habr.com/ru/post/597651/ | null | ru | null |
# SXB: инкрементальный бэкап MySQL
Эта статья является продолжением статьи [Разрабатываем новый формат файла для бэкапа сайтов](http://habrahabr.ru/post/165947/), в которой рассматривался перспективный формат для бэкапа сайт... | https://habr.com/ru/post/167469/ | null | ru | null |
# The Ember Times — Выпуск 130

*От переводчика: После позитивного отклика на [прошлый выпуск](https://habr.com/ru/post/482988/) дайджеста, я решил продолжить перевод этого популярного источника последних новостей из мира Ember.js. ... | https://habr.com/ru/post/483630/ | null | ru | null |
# Контроль покрытия кода при unit-тестировании в Windows Phone

Приветствую хабражителей!
Хочу поделиться своими достижениями в налаживании контроля покрытия кода при модульном тестировании приложений под Windows Phone... | https://habr.com/ru/post/196992/ | null | ru | null |
# Улучшаем формы с jqTransform
Если у вас не хватает времени привести в порядок формы на вашем сайте, в помощь придет небольшой плагин **jqTransform**.
Подключите его и скормите форму. На выходе получится визуально более приятная форма с подсветкой полей в фокусе.
[Посмотреть демо](http://www.dfc-e.com/metiers/m... | https://habr.com/ru/post/101659/ | null | ru | null |
# PowerAR — объединяем PowerBI и ARKit на поверхности стола
Привет, Хабр! Помните недавнюю конференцию Apple, на которой был представлен ARKit? Ой, стоп-стоп, это же блог Microsoft. Хотя, почему бы и нет. Ведь наши партнеры решили поэкспериментировать и совместить новый фреймворк от Apple с возможностями сервиса Power... | https://habr.com/ru/post/348522/ | null | ru | null |
# Обучение с подкреплением в Super Mario Bros. Сравнение алгоритмов DQN и Dueling DQN
Этой весной Питерская Вышка и JetBrains впервые провели проектную смену для старшеклассников — [Школу по практическому программированию и анализу данных](https://spb.hse.ru/fmcs/programming/). В течение пяти дней 50 участников со все... | https://habr.com/ru/post/563118/ | null | ru | null |
# RESTinio — это асинхронный HTTP-сервер. Асинхронный
Пару лет назад мы опубликовали [RESTinio](https://bitbucket.org/sobjectizerteam/restinio-0.4) — свой небольшой OpenSource C++фреймворк для встраивания HTTP-сервера в C++ приложения. Мегапопулярным за это время RESTinio не стал, но и [не потерялся](https://www.reddi... | https://habr.com/ru/post/451728/ | null | ru | null |
# Решение рекурсивной логической головоломки на Oracle SQL
Однажды в своем блоге коллега разместил картинку:

Вспомнив про статью [Задача о восьми Ферзях на Oracle SQL](http://habrahabr.ru/post/128... | https://habr.com/ru/post/163975/ | null | ru | null |
# Как заварить чай по MQTT или доступная умная розетка с контролем температуры и тока
> Зачем?
> ------
>
>
Даже в этом хабе наблюдается повышение интереса к IoT, по моему субъективному мнению это глобальная тенденция, выходящая далеко за рамки этого сайта. А значит стоит вставить и свои 5 копеек в развитие направл... | https://habr.com/ru/post/407541/ | null | ru | null |
# Прокачиваем Angular NGSW с помощью кастомной логики в Service Worker
### Использование Angular для создания прогрессивных веб-приложений (PWA)

Angular — отличный выбор для разработки PWA. Поддержка Service Worker'ов включена в An... | https://habr.com/ru/post/435718/ | null | ru | null |
# Списки в Kotlin. Haskell подход
Haskell является полностью функциональным и чрезвычайно лаконичным языком. Любой, кто когда-нибудь пробовал писать код на Haskell, замечает, насколько он получается более кратким и изящным, чем написать то же самое на императивном языке. Добиться такого же на Java, на мой взгляд, нево... | https://habr.com/ru/post/425527/ | null | ru | null |
# XML-сериализация для развёртывания начальных данных в Caché. Часть I
Думаю, не преувеличением будет сказать, что почти каждый разработчик информационной системы сталкивается с задачей формирования н... | https://habr.com/ru/post/148287/ | null | ru | null |
# Vulnhub. Прохождение Sunset: 1
HackTheBox — популярная площадка среди специалистов информационной безопасности, проводящих тестирование на проникновение. Однако существуют не менее интересные CTF площадки для проверки и тренировки своих навыков, которые подойдут как начинающим, так и опытным пентестерам.
Одной и... | https://habr.com/ru/post/529718/ | null | ru | null |
# Когда фильтр Блума не подходит
Я ещё с университета знал о [фильтре Блума](https://en.wikipedia.org/wiki/Bloom_filter) — вероятностной структуре данных, названной в честь Бёртона Блума. Но у меня не было возможности её использоват... | https://habr.com/ru/post/491132/ | null | ru | null |
# Ресайз изображений на лету с помощью Nginx и LuaJIT (OpenResty)
Уже довольно давно, вдохновившись статьей [Ресайз изображений на лету](https://habr.com/ru/post/77873/) был настроен ресайз изображений с помощью [ngx\_http\_image\_filter\_module](https://nginx.org/ru/docs/http/ngx_http_image_filter_module.html) и все ... | https://habr.com/ru/post/489544/ | null | ru | null |
# Программное ядро бортовой киберинфраструктуры унифицированного ударного истребителя F-35
Обзор ключевых компонентов «автономной информационной системы логистики» (ALIS) унифицированного ударного истребителя F-35. Подробный разбор «блока обеспечения боевого применения» и четырёх его ключевых компонентов: 1) человеко-... | https://habr.com/ru/post/453650/ | null | ru | null |
# Пишем универсальный UICollectionViewLayout
UICollectionView может иметь практически любое расположение элементов. Элементы могут иметь как фиксированные размеры, так и динамические. В данной публикации внимание будет уделено только тем UICollectionViewLayout, размеры элементов которых фиксированы и задаются определе... | https://habr.com/ru/post/320072/ | null | ru | null |
# Подключение акселерометра к Raspberry Pi с использованием библиотеки Pi4J
#### Предисловие
Привет, Хабр! Буквально недавно меня взяли в кружок по робототехнике. Конечно, я с радостью согласился, это же новый опыт и все такое… Тем более я всего лишь первокурсник. Мой преподаватель, объяснив мне общую концепцию, пред... | https://habr.com/ru/post/192258/ | null | ru | null |
# STI — одна таблица и много моделей
Вчера, в [заметке](http://habrahabr.ru/blogs/ror/79431/) про полиморфные связи в комментариях был упомянут паттерн STI. Как выяснилось, не все знают что это такое, как работает и зачем нужно. Решил восполнить этот информационный пробел и вкратце рассказать об этом шаблоне проектиро... | https://habr.com/ru/post/79630/ | null | ru | null |
# Software Defined Radio — как это работает? Часть 9
Привет, Хабр.
В [предыдущей части](https://habr.com/ru/post/456184/) было рассмотрено декодирование сигналов RDS для FM-радиостанций, и идея следующей статьи возникла сама собой — нужно сделать свой собственный FM-трансмиттер.
Вариантов будет два — простой, и... | https://habr.com/ru/post/456262/ | null | ru | null |
# Основы Linux от основателя Gentoo. Часть 3 (4/4): Настройка пользовательского окружения
Заключительная глава третьей части серии руководств Linux для новичков. Основы конфигурирования рабочей оболочки, настройка переменных окружения, а также подведение итогов всей третьей части.
> [
Все кто занимается разработкой сайтов под windows, наверняка сталкивались с различными проблемами после запуска сайта на сервере. Проблемы эти появляются из-за того, что сервера обычно работают под ОС Linux. Кроме того, время от времени по... | https://habr.com/ru/post/127090/ | null | ru | null |
# Шахматы льда и пламени
***Игра эта зовется кайвассой. Ее завезли в Дощатый город на волантинской торговой галере, а сироты разнесли ее вверх и вниз по Зеленой Крови. При дорнийском дворе все помешались на ней…
Десять фиг... | https://habr.com/ru/post/283502/ | null | ru | null |
# SOLID на примере JavaScript с chatGPT
Наверно уже все наслышаны про технологию **ChatGPT**. Вкратце недавно решил сам поюзать и вынести отнюдь пользу для программиста, на примере расскажу как я понял очередной пример SOLID и поделюсь примером с теми кто только вникает в шаблоны проектирования.
**Запрос:**
*write ... | https://habr.com/ru/post/712630/ | null | ru | null |
# Реализуем алгоритм поиска в глубину
В этом туториале описан алгоритм поиска в глубину (depth first search, DFS) с псевдокодом и примерами. Кроме того, расписаны способы реализации поиска в глубину в C, Java... | https://habr.com/ru/post/660725/ | null | ru | null |
# Автоматический контроль качества документации в Asciidoc или DocOps для Хабра

Один из шагов выпуска документации — это применение алгоритмов автоматического контроля качества. Часть подходов будет применим... | https://habr.com/ru/post/571326/ | null | ru | null |
# Zen coding — пишем HTML/CSS быстрее
Добрый день смотрим сразу как это работает:
[Zen Coding](http://code.google.com/p/zen-coding/)
[chikuyonok](https://habrahabr.ru/users/chikuyonok/) — Сергей Чикуёнок
[pepelsbey](https://habrahabr.ru/users/pepelsbey/) — Вадим Макеев
Этот способ ускоренного написания HTM... | https://habr.com/ru/post/76069/ | null | ru | null |
# Node.JS и выгрузка каталога из 1С на сайт
На днях закрыли очередной проект. Суть: создание новой версии интернет-каталога. Старая версия сайта, в силу ряда причин, клиента не устраивала. Особенностью проекта была его номенклатурная база. Объём номенклатуры каталога составлял ~26000 позиций раскиданных по дереву из 5... | https://habr.com/ru/post/189812/ | null | ru | null |
# Syncman — развертывание и синхронизация проектов на удаленном сервере

Прежде, чем начать свой рассказ, задам один маленький вопрос: Как вы разворачиваете свои проекты сервере?
Если вами управляется оди... | https://habr.com/ru/post/207288/ | null | ru | null |
# Делиться не всегда полезно: оптимизируем работу с кэш-памятью
 Делиться с ближним своим для нас, божьих тварей, это очень характерно, считается добродетелью, и вообще, как утверждает [первоисточник](http://... | https://habr.com/ru/post/143446/ | null | ru | null |
# Бесплатная книга «HTML5. Руководство разработчика»
 ХО-ХО-ХО! Праздник к нам приходит! Всегда ~~coca-co…~~ HTML5!
Выпал снежок и как-то незаметно пришло праздничное, предновогоднее настроение. Чтобы как-то поддержать п... | https://habr.com/ru/post/162161/ | null | ru | null |
# Исследование Google Play Services: Place Picker & Autocomplete
Виджет Place Picker и компонент Autocomplete являются мощными функциями Google Play сервисов. В данной статье мы рассмотрим их детально, а так же способы их реализации в приложениях.

В статье про [скалярные подзапросы](https://habr.com/ru/post/661901/) было несколько примеров, в которых оптимизатор мог переписать запрос с корре... | https://habr.com/ru/post/674414/ | null | ru | null |
# Model View Dispatcher (cqrs over mvc)

Доброго всем времени суток, в этой статье хочу осветить ещё один компонент из библиотеки Incoding Framework.
**Model View Dispatcher (MVD)** — позволяет изба... | https://habr.com/ru/post/221585/ | null | ru | null |
# Стандартный браузерный API Payment Request
Знаете ли вы о том, что во многих современных браузерах имеется встроенный API, который называется Payment Request? Этот API описан в [стандарте](https://www.w3.org/TR/payment-request/) W3C, который направлен на поддержку работы с платёжной и контактной информацией. [Вот](h... | https://habr.com/ru/post/460799/ | null | ru | null |
# Несколько версий PHP на Windows машине
Весьма актуальная задача: Иметь возможность по клику мыши менять версию PHP на Windows машине. Ранее была подобная [статья](https://habrahabr.ru/post/312202/), в которой создаётся 3 копии httpd.conf. Зачем? Когда есть наипростейшее решение.
Скачиваем архив с [Apache HTTPd](h... | https://habr.com/ru/post/312316/ | null | ru | null |
# Обзор фреймворка Luigi для построения последовательностей выполнения задач
Доброго времени суток! У нас открылось совершенно новое направление обучения — [BigData](https://otus.ru/lessons/BigData/?utm_source=habr&utm_medium=affilate&utm_campaign=bigdata&utm_term=profi11.10), а это значит, что немного расширяется гор... | https://habr.com/ru/post/339904/ | null | ru | null |
# RSA-рандом на блокчейне
Есть проблема – сложно сгенерировать случайное число в децентрализованной сети. Чуть ли не все блокчейны уже с этим столкнулись. Ведь в сетях, где нет доверия между пользователями, создание неоспоримого случайного числа решает множество задач.
В статье рассказываем, как удалось решить про... | https://habr.com/ru/post/464357/ | null | ru | null |
# Книга «Прагматичный ИИ. Машинное обучение и облачные технологии»
[](https://habr.com/ru/company/piter/blog/439990/) Привет, Хаброжители! Эта книга Ноя Гифта предназначена для всех, кого интересуют ИИ, машинное обучение, облачны... | https://habr.com/ru/post/439990/ | null | ru | null |
# Замена системных файлов Android с помощью adb
Способ может быть полезен в том случае, если «уже ничего не помогает», доступа к Root Explorer нет или телефон вообще не может загрузиться. В моем случае, пришлось в «боевом» режиме восстанавливать удалённый по глупости SystemUI.apk. При этом на телефоне что-то делать мо... | https://habr.com/ru/post/305288/ | null | ru | null |
# Lavritech V7.1 Lite: программируем ESP32 и Wirenboard модули
[](https://habr.com/ru/post/691994/)
В двух предыдущих статьях я дал общее описание контроллера Lavritech V7.1 Lite и рассказал о его схемотехнике, сегодня я попытаюсь ... | https://habr.com/ru/post/691994/ | null | ru | null |
# Настройка приложения — Spring Configuration Metadata
Настройка приложения с помощью `@ConfigurationProperties`, как альтернатива использованию `@Value`.
В статье
* Настройка и изменение функционала приложения через application.properties с использованием ConfigurationProperties
* Интеграция application.proper... | https://habr.com/ru/post/430256/ | null | ru | null |
# Использование шаблонов Cheetah совместно с Django
Однажды появилась необходимость выбрать шаблонизатор для использования с Django. На одном встроенном решении останавливаться я не хотел, а провел небольшое исследование производительности и удобства использования разных продуктов.
На данный момент я выбрал Cheetah... | https://habr.com/ru/post/49636/ | null | ru | null |
# syncProj – утилита для генерации Visual Studio C++ проектов
syncProj – утилита для генерации Visual Studio C++ проектов.
Привет. Хочу поделится опытом написания генератора проектов для Visual Studio.
В общем до данного момента я сам активно применял [premake5](https://premake.github.io/) — да и в принципе по прежн... | https://habr.com/ru/post/337138/ | null | ru | null |
# Как не надо индексировать
Развитие происходит по спирали: когда-то люди не умели правильно индексировать, потом (в основном) научились, потом пришли **noSQL** и все снова забыли знание древних. Что вы будет... | https://habr.com/ru/post/648731/ | null | ru | null |
# Данные из Google Таблиц на вашем сайте
Привет!
Для тех, кто пользуется Google Таблицами, есть хорошая новость — ниже описано решение, которое позволит импортировать данные из таблицы на ваш сайт.
Поехали.
1. Открываем Т... | https://habr.com/ru/post/343082/ | null | ru | null |
# Уменьшаем боль в навигации приложения на Yii2

Доброго времени суток! Большую часть проектов [мы](http://extpoint.com) пишем на Yii2, потому что он клёвый и мы его любим.
Однако, всегда есть что улучшить (благо этого н... | https://habr.com/ru/post/302954/ | null | ru | null |
# Альтернативная прошивка для датчика температуры и влажности Sonoff SNZB-02 Zigbee
Приветствую всех читателей Habr. В этой статье хочу поделиться с вами своим новым небольшим проектом.

Звездой этого проекта является датчик тем... | https://habr.com/ru/post/690144/ | null | ru | null |
# Звездный год (365 дней 369 минут), Тропический год(+ 348.5 минут) и звездные сутки(1436 минут) в радиоактивном распаде
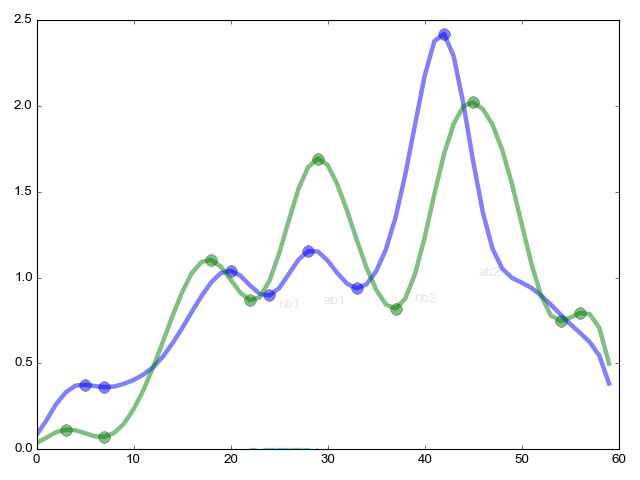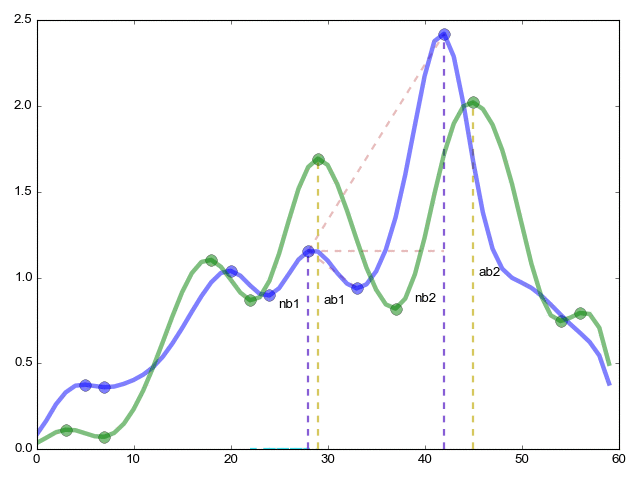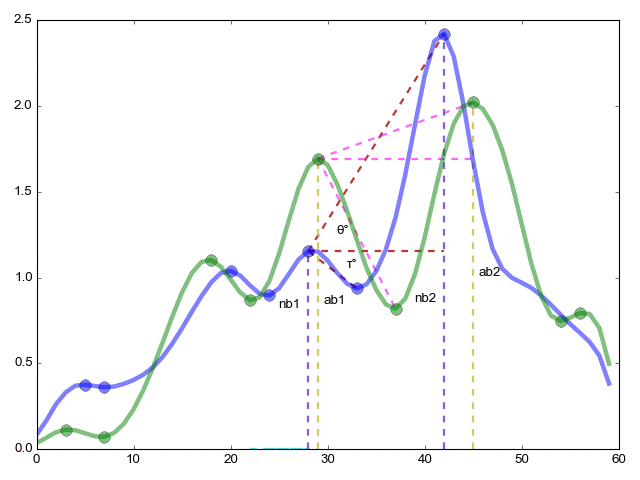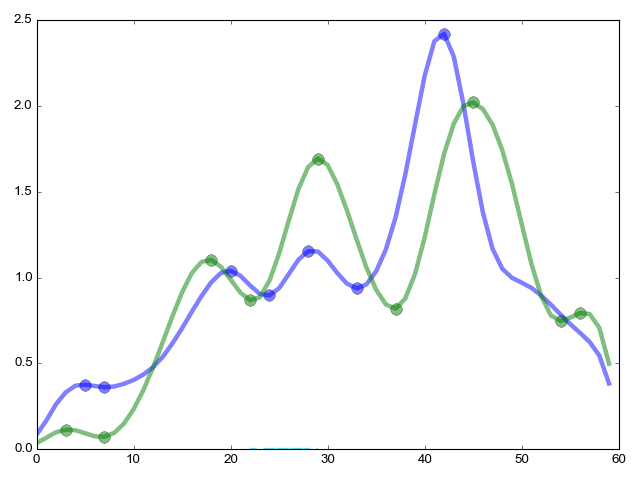
В этой статье будет приведен очень короткий код поиска периодов тропического года, звездного года и звездных суток в данных ... | https://habr.com/ru/post/534996/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.