
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Подборка @pythonetc, апрель 2019

Это десятая подборка советов про Python и программирование из моего авторского канала @pythonetc.
[Предыдущие подборки](https://habr.com/ru/search/?q=%5Bpythonetc%5D&t... | https://habr.com/ru/post/450862/ | null | ru | null |
# Reverse-инжиниринг “чёрного ящика”: зачем поддержке исходный код?
Всем привет! Мы команда сопровождения GlowByte, занимаемся решением багов в различных системах крупного бизнеса. Большая часть продуктов, ко... | https://habr.com/ru/post/698576/ | null | ru | null |
# Мандатная модель распределения прав в FreeBSD
Введение
--------
Для обеспечения дополнительного уровня безопасности сервера можно использовать [мандатную модель](https://ru.wikipedia.org/wiki/%D0%9C%D0%B0%D0%BD%D0%B4%D0%B0%D1%82%D0%BD%D0%BE%D0%B5_%D1%83%D0%BF%D1%80%D0%B0%D0%B2%D0%BB%D0%B5%D0%BD%D0%B8%D0%B5_%D0%B4%D... | https://habr.com/ru/post/448642/ | null | ru | null |
# Опыт внедрения многомодульности в (еще) не разросшееся приложение (Часть 1)
Наше приложение переживает редизайн и добавление новых фич очень даже быстро, во многом, благодаря моему решению несколько недель назад внедрить многомодульность.
### Как родилась идея разбить приложение?
Каналы про разработку, на которые ... | https://habr.com/ru/post/583962/ | null | ru | null |
# Метаклассы в Smalltalk
Эта статья, надеюсь, будет полезна не только тем, кто хочет освоить Smalltalk, но и тем, кто желает получше разобраться в проблемах построения объектных систем. В Smalltalk-е классы являются полноценными объектами, и то, как это реализовано, является отличным примером построения развитой систе... | https://habr.com/ru/post/207982/ | null | ru | null |
# Симуляция подъёмной силы Ньютона методом частиц на CUDA
<https://www.youtube.com/playlist?list=PLwr8DnSlIMg0KABru36pg4CvbfkhBofAi>
Как-то на Хабре мне попалась довольно любопытная статья [“Научно-технические мифы, часть 1. Почему летают самолёты?”](https://habr.com/ru/post/369603/). Статья довольно подробно описыва... | https://habr.com/ru/post/519032/ | null | ru | null |
# Как мутировать код в Angular-схематиках и не поседеть
Чтобы использовать Angular CLI на полную, разработчики должны знать, что такое схематики. Например, команды ng add, ng update и ng generate используют с... | https://habr.com/ru/post/582120/ | null | ru | null |
# FAQ по JavaScript: задавайте вопросы
Предлагаю продолжить [тему](http://habrahabr.ru/blogs/canvas/119364/ "FAQ по Canvas: задавайте вопросы") часто задаваемых вопросов на хабре. Неделя Canvas отгремела, теперь, пришел черед Java... | https://habr.com/ru/post/119851/ | null | ru | null |
# Учебный курс по React, часть 24: второе занятие по работе с формами
Сегодня мы продолжим разговор об использовании форм в React. В прошлый раз мы рассматривали особенности взаимодействия компонентов и текстовых полей. Здесь же мы обсудим работу с другими элементами форм.
[. Хотим подробнее рассказать об этом проекте и о задачах, которые нужно будет решать на... | https://habr.com/ru/post/684108/ | null | ru | null |
# Поём вместе с Sinatra. Часть первая. Первое знакомство
Доброго времени суток!
#### Что такое Sinatra
**Sinatra** — маленький, но довольно интересный DSL (Domain-specific language) фреймворк, написанный на Ruby. В отличие от Ruby on Rails он не следует типичному паттерну MVC (Model — View — Controlller). Sinatra ... | https://habr.com/ru/post/138571/ | null | ru | null |
# BigQuery с функцией анализа данных – теперь и в режиме реального времени
Коммерческие предприятия постоянно получают огромные объемы данных от сетевых приложений, совершающих множество транзакций, обслуживающих миллионы людей и постоянно растущее число подключенных устройств. Важнейшее условие сохранения конкурентос... | https://habr.com/ru/post/194950/ | null | ru | null |
# Оптимизация изображений, часть 5: AlphaImageLoader
*Примечание: ниже перевод очередной заметки [«Image Optimization, Part 5: AlphaImageLoader»](http://yuiblog.com/blog/2008/12/08/imageopt-5/) из блога [YUI](http://yuiblog.com/blog/). Stoyan Stefanov на этот раз рассказывает о тонкостях применения фильтра `AlphaImage... | https://habr.com/ru/post/47540/ | null | ru | null |
# Как развивалась система доменных имен: эра ARPANET
Свое начало система доменных имен берет в 50-х — 60-х годах прошлого века. Тогда она помогла упростить адресацию хостов в сети ARPANET и очень быстро перешла от обслуживания сотен компьютеров к работе с сотнями миллионов. Рассказываем, с чего начиналась DNS.
[![]... | https://habr.com/ru/post/479452/ | null | ru | null |
# Удобное встраивание RESTful API в проект
Ни для кого не секрет, что наличие API идет на пользу любому проекту. Но часто, при ошибке в архитектуре системы или же добавлении его к готовому проекту, накладные расходы на поддержку и тестирование отнимают достаточно много времени.
Я хочу представить сообществу нашу ре... | https://habr.com/ru/post/155021/ | null | ru | null |
# Создание нативной библиотеки расширений для OpenFL, часть вторая
#### Предисловие
Это продолжение перевода серии статей о создании расширений для OpenFL от Laurent Bédubourg. В [первой части](http://habrahabr.ru/post/186230/) мы создали простое расширение и скомпилировали его для нативных платформ (Linux/Windows, A... | https://habr.com/ru/post/186722/ | null | ru | null |
# Аналитика и нотификации для iOS
*В этой статье поделюсь тем, как настроить трекинг событий о получении и об открытии нотификаций на iOS устройствах. Рассматривается вариант, когда приложение уже интегрировано с Firebase Cloud Messaging для получения FCM токенов и отправки нотификаций через собственный сервер, а для ... | https://habr.com/ru/post/694990/ | null | ru | null |
# SQL HowTo: красивые отчеты по «дырявым» данным — GROUPING SETS
Для пользователя [наш СБИС](https://sbis.ru/all_services) представляется единой системой управления бизнесом, но внутри состоит из множества взаимодействующих сервисов. И чем их становится больше — тем выше вероятность возникновения каких-то неприятносте... | https://habr.com/ru/post/511238/ | null | ru | null |
# Запускаем роутер Mikrotik CHR в облаке под управлением VMware vCloud Director 10

Нередко к нам обращаются с вопросом: «Можно ли установить в вашем облаке Router OS (MikroTik)» — первое, что возникает у нас в голове при виде этого ... | https://habr.com/ru/post/526694/ | null | ru | null |
# Подробная статистика запросов из логов
Недавно был [пост](http://habrahabr.ru/blogs/gae/78445/) о сборе статистики в Google App Engine. Вот один из рецептов, который я использую для подобных целей:
````
#!/bin/bash
appcfg.py --num_days=10 request_logs code/ today.txt
visitors -A -m 50 -T --time-delta 10 --trails ... | https://habr.com/ru/post/78485/ | null | ru | null |
# Повышение производительности мультимедиа приложений с помощью аппаратного ускорения

Архитектура процессоров Intel становится все более ориентированной на ГП, что открывает удивительные возможности для резкого повышения п... | https://habr.com/ru/post/301698/ | null | ru | null |
# Terality — автоматически масштабируемая альтернатива Pandas
К старту флагманского [курса по Data Science](https://skillfactory.ru/data-scientist-pro?utm_source=habr&utm_medium=habr&utm_campaign=article&utm... | https://habr.com/ru/post/647271/ | null | ru | null |
# Рефлексия в C++Next на практике
Определение понятия "рефлексия" из Википедии:
> In computer science, **reflective programming** or **reflection** is the ability of a process to examine, introspect, and mod... | https://habr.com/ru/post/598981/ | null | ru | null |
# Основы Flutter для начинающих (Часть II)
Вступление
----------
Добрый денек!
Мы продолжаем изучать Flutter.
И в этой статье мы познакомимся с файлом pubspec.yaml, а также поработаем с Flutter в командной строке.
Ну что ж, приступим!
Наш план* [Часть 1](https://habr.com/en/post/560008/) - введение в разработку,... | https://habr.com/ru/post/560282/ | null | ru | null |
# Собственный софт-процессор на ПЛИС с компилятором языка высокого уровня или Песнь о МышЕ
Собственный софт-процессор на ПЛИС с компилятором языка высокого уровня или Песнь о МышЕ — опыт адаптации компилятора языка высокого уровня к стековому процессорному ядру.
Распространенной проблемой для софт-процессоров являе... | https://habr.com/ru/post/491604/ | null | ru | null |
# Защищённая флешка за 350 рублей своими руками
Всем доброго времени суток. Как-то раз у меня появилась идея купить флешку, с которой не будет страшно лезть ни в огонь ни в воду, ни [стираться](http://habrahabr.ru/company/storelab/blog/150413/#comment_5179621) с ней в стиральной машинке. Нашёл в интернете штуки и за т... | https://habr.com/ru/post/159323/ | null | ru | null |
# Расчеты на прочность в LibreOffice и выбор текстового редактора
Проблемы оформления расчетов и что такое iMath
----------------------------------------------
Наверное, многие, кто учился в техническом ВУЗе, сначала делали вычисления своих курсовых в Mathcad (или другом математическом пакете), а затем старательно на... | https://habr.com/ru/post/536478/ | null | ru | null |
# USB на регистрах: STM32L1 / STM32F1

[Еще более низкий уровень (avr-vusb)](https://habr.com/ru/post/460815/)
[USB на регистрах: bulk endpoint на примере Mass Storage](https://habr.com/ru/post/549016/)
[USB на регистрах: inter... | https://habr.com/ru/post/548150/ | null | ru | null |
# Использование современных графических форматов в веб-проектах
Эдди Османи, в статье «[Цена JavaScript в 2018 году](https://habr.com/ru/company/ruvds/blog/419369/)», озвучил одну ценную мысль: время, необходимое на обработку скрипта размером 200 Кб, и на обработку изображения, имеющего такой же размер, серьёзно разли... | https://habr.com/ru/post/494710/ | null | ru | null |
# Promises 101
Перевод первой части отличной [статьи](https://bitsofco.de/javascript-promises-101/) про промисы. Базовые приемы создания и управления промисами.
Промисы используются для операций, вычисление которых занимает неопределенное время. Примером подобной операции может быть сетевой запрос, когда мы запрашива... | https://habr.com/ru/post/312670/ | null | ru | null |
# Несколько интересностей и полезностей для веб-разработчика #15
Доброго времени суток, уважаемые хабравчане. За последнее время я увидел несколько интересных и полезных инструментов/библиотек/событий, которыми хочу поделиться с Хабром.
#### [Bitcore](http://bitcore.io/)
[ и [вторая](https://habr.com/ru/post/429894/) об использовании fish eye камеры с Raspberry Pi 3 и ROS я бы хотел рассказать об и... | https://habr.com/ru/post/481066/ | null | ru | null |
# Черная археология датамайнинга: что может быть эффективнее атаки по словарю?
Для тех, кому лениво читать дальше, сразу скажу ответ: атака «логин равен паролю». По статистике, логин равный паролю встречается чаще, чем самый распространенный пароль из словаря. Далее в статье будут некоторые статистические исследования... | https://habr.com/ru/post/261331/ | null | ru | null |
# Разбор конкурса IDS Bypass на Positive Hack Days 10
Уже второй раз на конференции Positive Hack Days проходил конкурс IDS Bypass. Как и в прошлый раз (прошлый [разбор](https://habr.com/ru/company/pt/blog/457932/)), участникам предстояло не просто найти слабости в шести сервисах и утащить флаги, но и обойти IDS, кото... | https://habr.com/ru/post/569168/ | null | ru | null |
# Еще один пересказ «туториала» Джека Креншоу
Иногда более-менее не тривиальную задачку приятно решить с чувством легкого базиса под ногами. Базис как бы уже есть, и мы как нечто среднее между художником и архитектором, ловим себя (в данный момент времени) на перекладывании пустого в порожнее, готовя нечто яркое и кре... | https://habr.com/ru/post/685434/ | null | ru | null |
# Joomla 4 – шаблон Cassiopeia – советы и хитрости
Это перевод [статьи](https://slides.woluweb.be/cassiopeia/cassiopeia.html) Марка Дешевра ([Marc Dechèvre](https://www.woluweb.be/)) с подборкой tips and tricks для шаблона Cassiopeia - шаблона фронтенда по умолчанию, поставляемого с Joomla 4.х. Он заменил собой давно ... | https://habr.com/ru/post/647399/ | null | ru | null |
# Передача двумерных списков из python в DLL
Всем привет. Решил несколько дополнить статью [C/C++ из Python](https://habr.com/ru/post/466499/).
Передача стандартных типов, таких как int, bool, float и так далее довольно проста, но мало необходима. С такими данными быстро справится и сам python, и вряд ли у кого-то во... | https://habr.com/ru/post/466575/ | null | ru | null |
# Включение гибридной графики в Ubuntu на ноутбуках Nvidia + Intel (OpenGL, Vulkan)
Введение
--------
Это простая инструкция как включить гибридную графику intel-nvidia на ноутбуке. Чтобы определенные приложения запускались на дискретном чипе, а другие на встроенном. На свое удивление в интернете не нашел простую инс... | https://habr.com/ru/post/556232/ | null | ru | null |
# Как справиться с PAGELATCH при высоко-параллельных INSERT-нагрузках
Эта статья была опубликована на **SQL.RU** Другие опубликованные там статьи на тему MS SQL Server можно найти в блоге <https://mssqlforever.blogspot.com/> Telegram-канал блога тут: <https://t.me/mssqlhelp>
По материалам статьи: «[Resolving PAGELATC... | https://habr.com/ru/post/654891/ | null | ru | null |
# Гена против Сандро: история автоматизации одной сетевой партии в Героях 3
*Сандро не мог поверить своей удаче. Прошло уже две недели после катастрофы с прыжком в экспериментальный портал, который забрал в небытие всю его немаленькую... | https://habr.com/ru/post/533768/ | null | ru | null |
# Опыт создания Ajax-приложения
#### В начале
В данной статье речь пойдет о написании Ajax-приложения. Если говорить проще — то, о написании сайта – работающего без перезагрузок. Быстро, легко, доступно. В этой статье не будет рассматриваться код серверной стороны, будут только примеры, для лучшего понимания.
Мен... | https://habr.com/ru/post/127376/ | null | ru | null |
# Властелин модулей. Продолжение истории
В 2018 году на одной из конференций я представил доклад «Властелин модулей». С тех пор утекло много воды, а многомодульность в нашем проекте приняла финальные очертания. В этой статье я расскажу о допущенных ранее ошибках, как выглядит работа с модулями сейчас и как проектирова... | https://habr.com/ru/post/566450/ | null | ru | null |
# PHP GR8: повысит ли JIT производительность PHP 8

*PHP — один из основных языков разработки в Badoo. В наших дата-центрах тысячи процессорных ядер заняты выполнением миллионов строк кода на PHP. Мы внимательно следим за новинками... | https://habr.com/ru/post/448622/ | null | ru | null |
# Простой личный анонимайзер
В свете последних событий и вероятного будущего, нам всем может понадобиться удобная утилита, которая позволяет смотреть на Web глазами цивилизованного европейца, а лучше голландца. Это может быть нужно для проверки доступности сайта, обхода слишком навязанного геотрекинга, неуместного чер... | https://habr.com/ru/post/158829/ | null | ru | null |
# Симметрическая разность возможностей Swift и Objective-C

В этой статье я расскажу о различии возможностей, которые предоставляют iOS-разработчикам языки Swift и Objective-C. Безусловно, разработчики, которые интересо... | https://habr.com/ru/post/308264/ | null | ru | null |
# Практическое использование Racc — генератора LALR(1) парсера для Ruby
В рамках создания фреймворка для некоторой системы Enterprise класса, у меня стояла задача создания утилиты для автоматизированной генерации кода по UML модели. Ничего наиболее подходящего для быстрого и эффективного решения задачи, кроме как испо... | https://habr.com/ru/post/164091/ | null | ru | null |
# Полуавтоматическое управление насосом скважины
#### Полуавтоматическое управление насосом скважины с помощью STM32 в среде Ардуино
### Почему AWS Lambda ?
1. Удобство деплоя, просто пишешь ... | https://habr.com/ru/post/555518/ | null | ru | null |
# Выразительный JavaScript: Формы и поля форм
#### Содержание
* [Введение](http://habrahabr.ru/post/240219/)
* [Величины, типы и операторы](http://habrahabr.ru/post/240223/)
* [Структура программ](http://habrahabr.ru/post/240225/)
* [Функции](http://habrahabr.ru/post/240349/)
* [Структуры данных: объекты и массивы](h... | https://habr.com/ru/post/245731/ | null | ru | null |
# Моя интеграция с 1С
Привет Хабравчанам!
В этой статье я хочу рассказать о том, как налажена интеграция с платформой 1С в моей организации. Побудило меня это сделать практически полное отсутствие технической информации на эту тему. Читая различные статьи и доклады на тему связки 1С с какой-либо информационной сист... | https://habr.com/ru/post/139272/ | null | ru | null |
# Обновления в ночь на пятницу, 13-е: ReSharper и другие .NET-продукты
Нет, этот пост не про поддержку C++ в решарпере. Это потом.
А пока что мы постарались и обновили почти всю линейку .NET-инструментов. Теперь вы можете их взять и установить:
* [ReSharper 8.1](http://www.jetbrains.com/resharper/download/) (улу... | https://habr.com/ru/post/205854/ | null | ru | null |
# Псевдотонирование изображений: одиннадцать алгоритмов и исходники
### Псевдотонирование: обзор

Про сегодняшнюю тему для программирования графики — псевдотонирование (дизеринг, псевдосмешение цветов) — я получаю много пис... | https://habr.com/ru/post/326936/ | null | ru | null |
# Два аспекта «децентрализованных» одностраничных приложений
В статье мы попытаемся описать два совершенно не связанных с собой аспекта децентрализованных одностраничных приложений. Это соединение двух пользователей и сохранение паролей в одностраничном приложении при помощи браузера.
Информация об используемой тех... | https://habr.com/ru/post/316556/ | null | ru | null |
# Django 3.0 будет асинхронным
*Andrew Godwin опубликовал [DEP 0009: Async-capable Django](https://github.com/django/deps/blob/a7080e6f830815829fcee2f2b061f59bdeed489d/accepted/0009-async.rst) 9 мая, а 21 июля он был принят [техническим советом](https://docs.djangoproject.com/en/dev/internals/organization/#technical-b... | https://habr.com/ru/post/461493/ | null | ru | null |
# Точка обмена трафиком: от истоков к созданию собственной IX

> *«We set up a telephone connection between us and the guys at SRI...», Kleinrock… said in an interview:
>
> «We typed the L and we asked on the phone, „Do you see... | https://habr.com/ru/post/478832/ | null | ru | null |
# Лучшие Copy-Paste алгоритмы для C и C++. Сборник рецептов Haiku OS
Многочисленные опечатки и Copy-Paste код стали темой для дополнительной статьи о проверке кода Haiku анализатором PVS-Studio. Впрочем, будут ошибки, связанные не сколько с опечатками, а скорее с невнимательностью и неудачным рефакторингом. Найденные... | https://habr.com/ru/post/461519/ | null | ru | null |
# Миграция с Nagios на Icinga2 в Австралии
Всем привет.
Я — сисадмин linux, переехал из России в Австралию по независимой профессиональной визе в 2015 году, но статья будет не о том, как поросёнку завести трактор. Таких статей уже и так достаточно (тем не менее, если будет интерес — напишу и про это), так что я хотел... | https://habr.com/ru/post/444060/ | null | ru | null |
# Как мы подружили Flutter с CallKit Call Directory
[](https://habr.com/ru/company/Voximplant/blog/553422/)
Привет!
В этом лонгриде я расскажу о том, как мы в [Voximplant](https://voximplant.ru/?utm_so... | https://habr.com/ru/post/553422/ | null | ru | null |
# Как мы запускали стандартные примеры из библиотеки STM32Cube
 Добрый день! Не секрет, что стандартные примеры, работающие из коробки, — штука неплохая: загрузил на плату и наслаждайся. Это удобно для быстрого ознакомления. Но з... | https://habr.com/ru/post/348930/ | null | ru | null |
# Служба мгновенных собщений своими руками
Все мы привыкли пользоваться аськой, многие этот функционал реализуют в своих проектах, кто-то использует БД, или сервер очередей, например memcacheq. Есть готовые решения, типа eJabber.
Если интересно, как можно сделать это самому, то wellcom под каст, где будет рассмотре... | https://habr.com/ru/post/91927/ | null | ru | null |
# Когда хочется снега…
Всем привет!
Не смотря на все мои 34 года во мне живёт большой ребёнок иногда немножко сентиментальный и весь такой романтический. Ну и как любой ребёнок ещё люблю чего-нибудь творить, главное чтобы это чего-нибудь было не сложным, быстро воспроизводимым и дающим видимый глазу результат.
!... | https://habr.com/ru/post/364905/ | null | ru | null |
# PVS-Studio for Visual Studio 2022
The PVS-Studio team writes articles on various topics. But we rarely make articles on how to interact with the analyzer. Let's fix it with an article about the PVS-Studio plugin for the Visual Studio 2022 environment.
 сертификат при помощи [OpenSSL](https://ru.wikipedia.org/wiki/OpenSSL) в ко... | https://habr.com/ru/post/331014/ | null | ru | null |
# Query Builder библиотека для работы с SphinxQL
Одна из самых важных задач стоящих при разработке сайта, это реализация полнотекстового поиска. Один из популярных и простых вариантов реализации, это использование Sphinx. На хабре уже есть посвящённые ему статьи, но не заслуженно не упомянута библиотека Query Builder.... | https://habr.com/ru/post/242077/ | null | ru | null |
# Моя жизнь с Boost Graph Library
Статья, первая часть которой здесь представлена, содержит различные соображения автора, накопившиеся в ходе длительной разработки специализированной системы поиска социальных связей, базирующейся на библиотеке Boost Graph Library (BGL). В этом (техническом) разделе суммируются впечатл... | https://habr.com/ru/post/471652/ | null | ru | null |
# Рефакторим вместе с Roslyn
Обычно рефакторинг представляется тяжелой работой над ошибками. Монотонное исправление ошибок прошлого вручную. Но если наши действия можно свести к алгоритму преобразований над A, чтобы получить B, то почему бы не автоматизировать этот процесс?
Таких кейсов может быть очень много — инвер... | https://habr.com/ru/post/343244/ | null | ru | null |
# Как определить все мониторы и их разрешения

Недавно возился с нормальной инициализацией окна, и стояла задача задетектить все мониторы и их разрешения. Оставлю тут решение для потомков.
```
appR... | https://habr.com/ru/post/151273/ | null | ru | null |
# LLVM с точки зрения Go
Разработка компилятора — очень тяжёлая задача. Но, к счастью, с развитием проектов наподобие LLVM решение этой задачи значительно упрощается, что позволяет даже программисту-одиночке создать новый язык, близкий по производительности к C. Работа с LLVM осложняется тем, что эта система представл... | https://habr.com/ru/post/451476/ | null | ru | null |
# Двухфакторная Авторизация на Linux сервере
В статье описана установка под Ubuntu. Используется приложение от Google.
#### Установка зависимостей
Ставить google-authenticator надо из исходников, мы же не доверяем левым PPA? Для этого потребуется git, build-essential, libpam0g-dev, checkinstall.
```
git clone... | https://habr.com/ru/post/150271/ | null | ru | null |
# Node.JS: Пример HTTP-сервера в режиме prefork с использованием Web Workers
Как обещал ранее, я публикую исходный код, демонстрирующий, как построить HTTP-сервер в режиме prefork, используя [Web Workers](http://webo.in/articles/all/2009/25-computing-with-web-workers/) и новый API `net.Server.listenFD()`. Я надеюсь, ч... | https://habr.com/ru/post/95972/ | null | ru | null |
# Диагностика и замена дисков в дата-центре: бот для SMART-теста, «черный ящик» для утилизации и лайфхаки

Привет, Хабр! Меня зовут Данил, я системный инженер, работаю с серверами и клиентским оборудованием в дата-центре Selectel в Д... | https://habr.com/ru/post/694336/ | null | ru | null |
# Топ-65 вопросов по SQL с собеседований, к которым вы должны подготовиться в 2019 году. Часть I

*Перевод статьи подготовлен для студентов курса [«MS SQL Server разработчик»](https://otus.pw/pc4Q/)*
---
Реляционные базы данных являю... | https://habr.com/ru/post/461067/ | null | ru | null |
# [конспект админа] Меньше администраторов всем

Продолжим про безопасность операционных систем – на этот раз «жертвой» станет MS Windows и принцип предоставления минимальных прав для задач системного администрирования.
Сотру... | https://habr.com/ru/post/335568/ | null | ru | null |
# Отправка файлов в приложение Xamarin.Forms. Часть 2
На прошлой неделе мы говорили про отправку файлов в приложение Xamarin.Forms для iOS, как и обещали, во второй части речь пойдёт про Android.
Отправка файлов в прило... | https://habr.com/ru/post/324796/ | null | ru | null |
# Обход блокировок WireGuard в Египте
В 2021 году VPN протокол WireGuard стал настолько популярен в Египте, что удостоился чести пополнить список заблокированных, несказанно “обрадовав” не только клиентов Cloudflare Warp+, Mullvad Wireguard и других коммерческих VPN-провайдеров, но и некоторых пользователей [корпорати... | https://habr.com/ru/post/649629/ | null | ru | null |
# Скрытые возможности Windows. Как BitLocker поможет защитить данные?
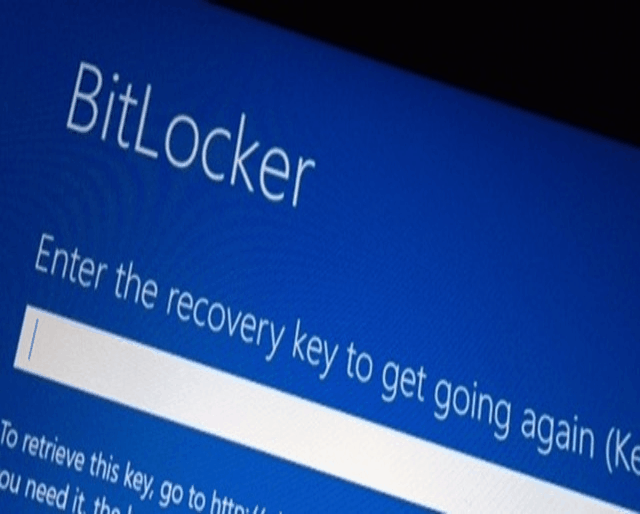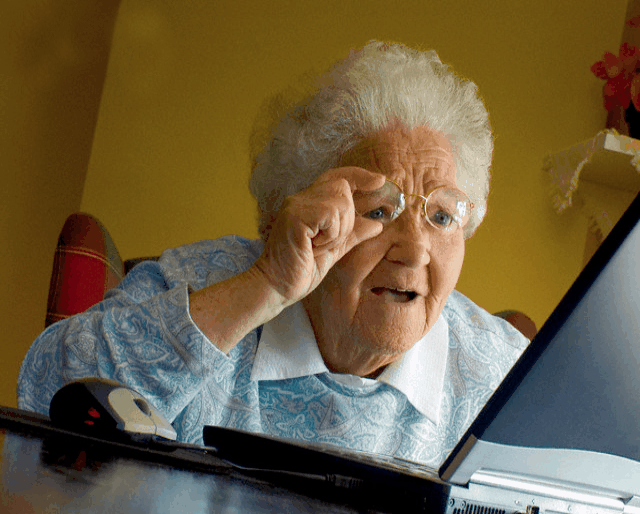
По мнению специалистов, именно кража ноутбука является одной из основных проблем в сфере информационной безопасности (ИБ).
В отличие от других угроз ИБ, природа... | https://habr.com/ru/post/335532/ | null | ru | null |
# Склеивание PDF-документов средствами PHP
Заказчиком была поставлена задача — вконец PDF-документа, который создается с помощью класса [TCPDF](http://www.tecnick.com/public/code/cp_dpage.php?aiocp_dp=tcpdf), нужно присоединить сканы тоже в PDF-формате.
Поиск решения постоянно приводил к необходимости использования... | https://habr.com/ru/post/52652/ | null | ru | null |
# Oxygen-gtk. Единый вид приложений GTK и Qt
#### 0. Intro.
В рамках проекта KDE начал развиваться проект [oxygen-gtk](https://projects.kde.org/projects/playground/artwork/oxygen-gtk), главная задача которого — это создание единства внешнего вида GTK приложений, запущенных под KDE и нативных KDE приложений. В отличии... | https://habr.com/ru/post/109930/ | null | ru | null |
# Short-lived Music or MuseScore Code Analysis
Having only programming background, it is impossible to develop software in some areas. Take the difficulties of medical software development as an example. The same is with music software, which will be discussed in this article. Here you need an advice of subject matter... | https://habr.com/ru/post/545624/ | null | en | null |
# The Clean Architecture на TypeScript и React. Часть 1: Основы

Добрый день, уважаемые читатели. В этой статье мы поговорим об архитектуре программного обеспечения в веб-разработке. Довольно долгое время я и мои коллеги используем... | https://habr.com/ru/post/499078/ | null | ru | null |
# Редактирование текста тоже вас ненавидит
Опубликованная месяц назад статья Алексис Бингесснер [«Рендеринг текста вас ненавидит»](https://habr.com/ru/post/469529/) очень мне близка.
В далёком 2017 году я разрабатывал интерактивный текстовый редактор в браузере. Неудовлетворённый существующими библиотеками на Conte... | https://habr.com/ru/post/474036/ | null | ru | null |
# Прокачиваем Stream API, или нужно больше сахара
Не так давно удалось перевести на Java 8 один из проектов, над которым я работаю. Вначале, конечно, была эйфория от компактности и выразительности конструкций при использовании Stream API, но со временем захотелось писать ещё короче, гибче и выразительнее. Поначалу я д... | https://habr.com/ru/post/255659/ | null | ru | null |
# The state of soft skills
Так сложилось, что софт-скиллы довольно сильно помогли мне в карьере. Например, спустя всего 9 месяцев работы в Rambler, куда я приходил простым frontend-разработчиком, мне предложили стать руководителем группы, потому что мой руководитель увидел во мне потенциал и достаточный уровень развит... | https://habr.com/ru/post/502706/ | null | ru | null |
# ООП-конструктор админки для Битрикс
Чем серьёзнее мы относимся к своим проектам, тем больше нам хочется, чтобы задачи решались лучшим из возможных способов. Например, хотим мы предоставить клиенту качественную админку в адекватные сроки. Лично мне в такие моменты сразу вспоминается Django: создал модель – получи адм... | https://habr.com/ru/post/276481/ | null | ru | null |
# Генетический алгоритм поиска решения для задачи по выбору планировок этажа многоквартирного дома
Вступление
----------
Предложенный алгоритм - это очень ранний прототип рабочей версии. Суть публикации познакомить всех желающих с возможностями генетических алгоритмов в различных сферах бизнеса.
Постановка задачи
--... | https://habr.com/ru/post/664766/ | null | ru | null |
# csync2 или как облегчить работу с кластером
Не так давно мне пришлось поднимать Linux кластер для одного довольно нагруженного проекта. Вернее сказать более важным был вопрос отказоустойчивости, чем нагрузки, но обычно кластер призван решить обе эти проблемы единовременно.
В данном случае я не собираюсь рассматри... | https://habr.com/ru/post/120702/ | null | ru | null |
# jQuery для мобильных устройств, все за и против

Это довольно вольный перевод [статьи](http://modernweb.com/2014/03/10/is-jquery-too-big-for-mobile/), которая попалась мне на просторах интернета. Её... | https://habr.com/ru/post/247029/ | null | ru | null |
# «Cделать красиво». Визуализация обучения с Tensorboard от Google
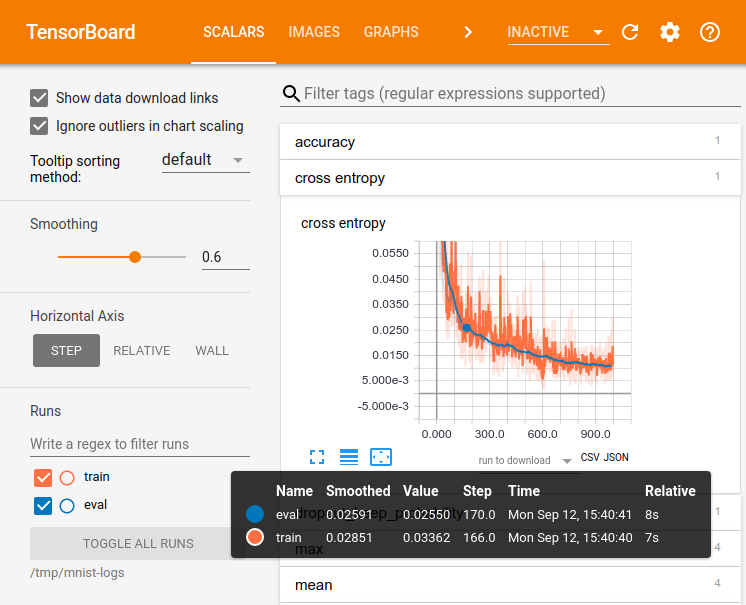
Красота, как известно, требует жертв, но и мир обещает спасти. Достаточно свежий (2015г) визуализатор от Google призван помочь разобр... | https://habr.com/ru/post/349338/ | null | ru | null |
# Как я взломал Facebook и обнаружил чужой бэкдор

Исследователь по безопасности Orange Tsai взломал один из серверов Facebook и обнаружил бэкдор для сбора учетных записей сотрудников компании, оставленный злоумышленником. ... | https://habr.com/ru/post/282179/ | null | ru | null |
# С помощью Python создаём математические анимации, как на канале 3Blue1Brown
Вы наверняка когда-то испытывали трудности в понимании математических концепций алгоритмов машинного обучения и для лучшего понима... | https://habr.com/ru/post/556944/ | null | ru | null |
# Навигатор
Задача: создать навигатор страниц. Вот такой:

1. Подбираем цвета
------------------
Так как навигатор делается для использования в конкретном сайте, цвет нам уже известен: `#0aaafd`. Этот цвет испол... | https://habr.com/ru/post/18036/ | null | ru | null |
# Ошибки в JavaScript и как их исправить
JavaScript может быть кошмаром при отладке: некоторые ошибки, которые он выдает, могут быть очень трудны для понимания с первого взгляда, и выдаваемые номера строк также не всегда полезны. Разве не было бы полезно иметь список, глядя на который, можно понять смысл ошибок и как ... | https://habr.com/ru/post/249525/ | null | ru | null |
# JQuery FormNavigate — плагин для удобной работы с onbeforeunload
Все, кто пользуется веб-интерфейсом [gmail](http://gmail.com), наверняка замечали, как гугл заботится о нас и не даёт закрыть страницу, если мы начали составлять письмо и не сохранили его в черновики. И понадобилось мне для своего проекта сделать нечто... | https://habr.com/ru/post/88071/ | null | ru | null |
# Тюнинг SQL Server 2012 под SharePoint 2013/2016. Часть 2
Здравствуйте! Сегодня с вами снова я — Любовь Волкова, системный архитектор департамента разработки бизнес-решений. В [предыдущей статье](https://habrahabr.ru/company/softline/blog/325242/) мы начали обсуждение темы тюнинга SQL-серверов для работы с базами дан... | https://habr.com/ru/post/325328/ | null | ru | null |
# Используй время правильно: автоматизация процессов в Tinder

Думаю многие любят знакомиться в соц. сетях и пользуются приложениями (например Tinder),
но часто уходит много времени на то, что бы ставить лайки и отправлять первые
сообщ... | https://habr.com/ru/post/494990/ | null | ru | null |
# Разбор задач финала чемпионата мира про программированию ACM ICPC 2013
На прошедшем неделю назад [чемпионате мира по командному программированию ACM ICPC 2013](http://habrahabr.ru/company/yandex/blog/185394/) было 1... | https://habr.com/ru/post/186316/ | null | ru | null |
# Смарт-карты для самых маленьких
 Поскольку статья вводная и обзорная, то рассматриваться будет простейшая разновидность смарт-карт — SIM-карты, полагаю, что таких карт на планете сейчас больше всего.
По... | https://habr.com/ru/post/210062/ | null | ru | null |
# Секреты генерирующего реферирования текстов

Эта статья посвящена основным современным моделям для генерирующего реферирования и генерации текста в целом: BertSumAbs, GPT, BART, T5 и PEGASUS, и их использованию для русского языка.
... | https://habr.com/ru/post/596481/ | null | ru | null |
# Основы Linux от основателя Gentoo. Часть 1 (3/4): Ссылки, а также удаление файлов и директорий
Третий отрывок из перевода первой части руководства. Предыдущие: [первый](/post/99041/), [второй](/post/99291/).
В этом отрывке рассмотрены жесткие и символические ссылки, а также разобрано удаление файлов и директорий ... | https://habr.com/ru/post/99653/ | null | ru | null |
# Kill switch для OpenVPN на основе iptables
Известно, что при подключении к открытым Wi-Fi сетям ваш трафик может быть легко прослушан. Конечно, сейчас всё больше и больше сайтов используют HTTPS. Тем не менее, это ещё далеко не 100%. Возникает естественное желание обезопасить свой трафик при подключении к таким откр... | https://habr.com/ru/post/274445/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.