
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Play! in the Cloud
Уже длительный период времени мы предоставляем нашим пользователям возможность поучаствовать в усовершенствовании платформы [Jelastic](http://jelastic.com/ru/java-paas) путем голосова... | https://habr.com/ru/post/139104/ | null | ru | null |
# Как я спарсил WebGL карту с Федерального сайта
Пишу статью для тех, у кого появилась похожая задача, но они не знают как ее решать. Не уверен что мой способ работает везде (недостаточно опытен), но считаю, что если бы я увидел эту статью, загуглив "как парсить webgl" или что-то типо такого, я бы потратил на нескольк... | https://habr.com/ru/post/591229/ | null | ru | null |
# Согласованное хеширование: не самые очевидные вещи
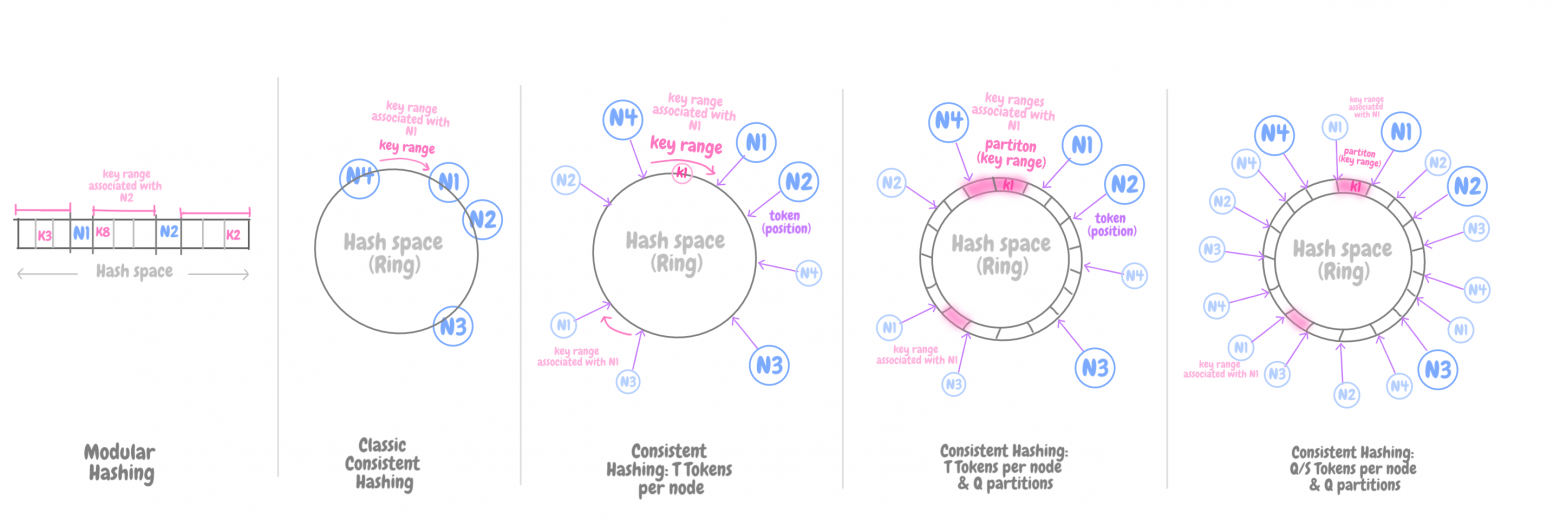
Классический алгоритм согласованного хеширования решает проблемы, присущие алгоритму модульного хеширования, где хеш-функция (позиция ключа K) привязана к числу элементов хра... | https://habr.com/ru/post/691506/ | null | ru | null |
# Как перестать писать прошивки для микроконтроллеров. Начинаем жить…

И снова мы разбираемся как не писать прошивки для микроконтроллеров. Прошлая статья вызвала у людей много эмоций и, мне кажется, осталось мало кем понята и, может... | https://habr.com/ru/post/434080/ | null | ru | null |
# Базовые знания в безопасности сайтов
Привет, Хабр!
Безопасность — дело серьезное. И зачастую проблемы в этой области всплывают неожиданно и несут крайне неприятные последствия. Поэтому знания в этой теме крайне важны для каждого веб разработчика.
Оговорюсь сразу — я далеко не профи, но стремлюсь к этому. Поэто... | https://habr.com/ru/post/451420/ | null | ru | null |
# SSO используя Jasig CAS Server 4.0.0. Часть 2
Мы уже подняли сервер Jasig CAS теперь пора немного его кастомизировать. Зачем это нужно? Сейчас ми авторизируемся используя статического пользователя, но мы это исправим и сделаем возможность получать пользователя из внешних систем или БД.
Хочу напомнить что ранее уж... | https://habr.com/ru/post/226839/ | null | ru | null |
# Инфекция на сайте — история на примере
###### Инъекция вредоносного кода в WordPress ([Источник картинки](http://girmacea.com/blog/issues-fix/wordpress-virus-and-how-to-remove-it))
Эта история начинается м... | https://habr.com/ru/post/193882/ | null | ru | null |
# Продолжаем прокачивать Ansible
Поводом для этой статьи послужил [пост](https://t.me/pro_ansible/179191) в чате [@pro\_ansible:](/users/pro_ansible:)
> Vladislav ? Shishkov, [17.02.21 20:59]
> Господа, есть два вопроса, касаются кастомной долгой операции, например, бекапа:
> 1. Можно ли через ансибл прикрутить прог... | https://habr.com/ru/post/543598/ | null | ru | null |
# Как работает basic-авторизация в ExpressJS
В Express.JS есть встроенный middleware для авторизации. Если очень хочется заблокировать доступ к приложению — достаточно всего лишь добавить одну строчку в сетап express-приложения:
```
app.use(express.basicAuth('username', 'password'));
```
Так же middleware поддер... | https://habr.com/ru/post/201924/ | null | ru | null |
# О Twitter'е бедном замолвите слово
### Попытка РКН «замедлить» связь с Twitter вылилась в локальные «интернет-катаклизмы»
К сожалению, сколько-нибудь полезной технической информации о том, как именно РКН ... | https://habr.com/ru/post/546362/ | null | ru | null |
# Device Guard в Windows 10. Политика целостности кода
> *Автор статьи — Андрей Каптелин, участник ИТ-сообщества*
Device Guard – набор программно-аппаратных технологий защиты, доступный для устройств с Windows 10. Статья посвящена одной из компонент Device Guard – политике Code Integrity (CI). С деталями настройки и ... | https://habr.com/ru/post/280332/ | null | ru | null |
# Персональный рейтинг депутатов каждому при помощи JavaScript и браузера Chrome
Скоро некоторые из нас пойдут отдавать свои голоса за очередных кандидатов в депутаты. Депутаты являются нашими представителями и им мы предоставляем право принимать некоторые законодательные решения за нас. В данных условиях логично выби... | https://habr.com/ru/post/306744/ | null | ru | null |
# История одного Crash-а, и NSLog'а его лечившего
> *Лечу Crash'и NSLog'ами. Недорого. Многолетний опыт. 100% гарантия.*
>
>
Примерно таким заголовком можно было бы описать то, что три с половиной месяца назад происходило у меня на одном из проектов. Вернее, это даже был не мой проект, но с проблемой crash'а при... | https://habr.com/ru/post/161921/ | null | ru | null |
# Объектно-ориентированное программирование в Java и Python: сходства и отличия
Привет, Хабр! Представляю вашему вниманию перевод статьи [“Object-Oriented Programming in Python vs Java”](https://realpython.com/oop-in-python-vs-java/) автора Джона Финчера.
Реализация объектно-ориентированного программирования (ООП) в ... | https://habr.com/ru/post/455796/ | null | ru | null |
# Через Shodan оказалась доступна база с 13 млн аккаунтов MacKeeper
Компания-разработчик MacKeeper постоянно напоминает владельцам компьютеров Apple Mac, что им нужна защита. Сегодня в защите нуждается сама компания после того... | https://habr.com/ru/post/356954/ | null | ru | null |
# Построение надежных веб-приложений на React: Часть 1, браузерные прототипы
Перевод статьи «Building robust web apps with React: Part 1, in-browser prototypes», Matt Hinchliffe
От переводчика: это первая статья из цикла «Building robust web apps with React».
Переводы:
* Построение надежных веб-приложений на... | https://habr.com/ru/post/229655/ | null | ru | null |
# Можно ли выиграть в азартные игры? Симуляция на языке Python
Привет, Geektimes.
В процессе праздного ничегонеделания возникла идея поизучать разные азартные игры, заодно получше разобраться с тем как это работает. Результаты оказались хотя и в целом очевидными, но достаточно интересными, чтобы поделиться ими с об... | https://habr.com/ru/post/411209/ | null | ru | null |
# Обрезаем большую таблицу PostgreSQL в production
Всем привет. Меня зовут Олег, я техлид в команде разработки CRM для менеджеров ипотечного кредитования в Домклике.
Сегодня я хотел бы поделиться рецептом по обрезанию большой таблицы PostgreSQL в production. Пример: мы имеем в продовой БД достаточно большую таблицу ... | https://habr.com/ru/post/546008/ | null | ru | null |
# Реверс-инжиниринг радиоуправляемого танка с помощью GNU Radio и HackRF
Год назад наша CTF-команда на крупном международном соревновании RuCTF в Екатеринбурге в качестве одного из призов получила радиоуправляемый танк.
Зачем команде хакеров игрушечный радиоуправляемый танк? Чтобы его реверсить, конечно.
В статье я ... | https://habr.com/ru/post/325894/ | null | ru | null |
# Создаем собственный фреймворк на основе Symfony2. (Часть 6)
В шестой части серии, мы научимся использовать компонент HttpKernel.
* [Часть 1](http://habrahabr.ru/blogs/symfony/136110/)
* [Часть 2](http://habrahabr.ru/blogs/symfony/136430/)
* [Часть 3](http://habrahabr.ru/blogs/symfony/136471/)
* [Часть 4](http://h... | https://habr.com/ru/post/138893/ | null | ru | null |
# Особенности работы и внутреннего устройства express.js
Если вы занимались разработкой для платформы node.js, то вы, наверняка, слышали об [express.js](https://expressjs.com/). Это — один из самых популярных легковесных фреймворков, используемых при создании веб-приложений для node.
[ в хаб «Фотографии» сегодня раскроем тему [Fast Application Resume](http://msdn.microsoft.com/en-us/library/windowsphone/develop/jj735579), которая появилась в WP... | https://habr.com/ru/post/214933/ | null | ru | null |
# Ванильный JSX
Привет всем любителям покопаться в технологиях фронтенда! В этой статье я расскажу про то, как можно встроить JSX в проект на ванильном TypeScript со сборщиком Vite. Материал будет интересен, если вы:
* Работали с React, но не знаете, что у него под капотом.
* Интересуетесь всей теорией, связанной с ф... | https://habr.com/ru/post/659483/ | null | ru | null |
# Howto Установка Redmine2.2.0 Debian+Apache+PostgreSQL+passenger
Потратив 4 дня в осмыслении на чем это все работает и как ставится, перелопатив тонны более чем странных ошибок, написал себе шпаргалку… и с остальными поделится не прочь. Нижеописанное с малыми исправлениями ИМХО годно и для убунтария
redmine + PG
=... | https://habr.com/ru/post/165451/ | null | ru | null |
# Установка и настройка Microsoft Hyper-V Server 2008 R2
#### Вступление
Сегодня я расскажу вам как установить и настроить гипервизор от Microsoft, а так же как управлять им.
Итак, сначала небольшое лирическое отступление.
По мере оптимизации существующей инфраструктуры встал вопрос о виртуализации. Я тут же в... | https://habr.com/ru/post/79292/ | null | ru | null |
# Графики в Nagios — зачем и чем
#### Введение.
Выбрав Nagios в качестве системы мониторинга, получаем систему слежения за качественными характеристиками окружения и историю изменения состояний. И, если посмотреть текст сообщения пробника на данный момент и во время прошлых изменений состояния еще возможно, то данные... | https://habr.com/ru/post/79354/ | null | ru | null |
# Tinc — настройка VPN в Ubuntu
Tinc — это открытый сетевой протокол и программная реализация, используемая для сжатых и зашифрованных виртуальных частных сетей. Это проект был начат в 1998 году Гусом Слипеном, Иво Тиммермансом и Весселем Данкерсом под лицензией GPL.
К его основным достоинствам относится:
1) Рас... | https://habr.com/ru/post/470243/ | null | ru | null |
# Advanced PowerShell vol. 1: повторное использование кода
Привет! Как большой поклонник и активный практик **PowerShell** я часто сталкиваюсь с тем, что мне необходимо повторно использовать ранее написанные куски кода.
Собственно, для современных языков программирования code reuse — это обычное дело.
**PowerShe... | https://habr.com/ru/post/245875/ | null | ru | null |
# Интерактивная выгрузка файлов на сервер с помощью RxJS

Прошло много времени с тех пор, как я написал свою последнюю статью по основам RxJS. В комментариях меня попросили показать более сложные примеры, которые могут пригодиться на... | https://habr.com/ru/post/487836/ | null | ru | null |
# Тестирование OpenStack с помощью Tempest
Tempest — это официальный компонент OpenStack для интеграционного тестирования. Tempest поддерживает три вида тестов: API, сценарии (scenario) и стресс-тесты (stress... | https://habr.com/ru/post/699220/ | null | ru | null |
# Разделение отсканированных вместе фотографий (Python 3 + OpenCV3)
По ящикам шкафов да пыльным полкам уже десятилетиями складируются дюжины семейных фотоальбомов. Состояние некоторых из них давно заставляет задумываться об «оцифровке» накопившегося материала. И чтобы хоть чуточку ускорить предстоящий процесс, было пр... | https://habr.com/ru/post/281669/ | null | ru | null |
# О том как создать простое Scala SBT-приложение для Android
Доброго времени суток, друзья. Занимаясь разработкой инструментов для разработчиков, я столкнулся с вопросом о взаимодействии вышеупомянутых инструмента, языка программирования и платформы. Если первые две сущности просто созданы друг для друга (SBT — основн... | https://habr.com/ru/post/327782/ | null | ru | null |
# Magento 2 UI Components. Часть 2: конфигурация
Привет! Меня зовут Павел и я Magento 2 бэкенд-разработчик. [В прошлой части саги](https://habr.com/ru/company/rshb/blog/550772/) о Magento 2 UI Components мы п... | https://habr.com/ru/post/561442/ | null | ru | null |
# Удалённый узел K-root в Селектеле
Увеличение числа пользователей Интернета в развивающихся странах влечёт за собой необходимость развития соответствующей инфраструктуры, в том числе и DNS-серверов.
За последнее н... | https://habr.com/ru/post/268675/ | null | ru | null |
# HTC выпустит версии коммуникаторов HTC Desire и Google Nexus One с Super LCD дисплеями
Доброго времени суток.
26 июня HTC официально объявили, что выпустят обновленные версии уже известных коммуникаторов — **HTC Desire** и **Google Nexus One** с Super LCD дисплеями. Предположительно это произойдет в конце лета 20... | https://habr.com/ru/post/100191/ | null | ru | null |
# PeopleBlending: создаём Science Art с помощью когнитивных сервисов и небольшого количества креативности
Я верю в то, что не только красота спасёт мир, но ещё и *междисциплинарность*. Поскольку моя дочь любит искусство, а я люблю программировать — я часто присматриваюсь к пересечению этих областей, которое можно назв... | https://habr.com/ru/post/478356/ | null | ru | null |
# A tiny Rate Limiter Library for Spring MVC
In microservice world the problem of high load is exteremely big especially when we have a REST API which is accessed quite extensively. Why do we need throttling? The main answer is to decrease the load of the service at the moment.
Different frameworks have different so... | https://habr.com/ru/post/547062/ | null | en | null |
# Удалённое исполнение системных команд по запросу через сокеты на Python 3. Часть 2. Протокол передачи данных
В [предыдущей статье](http://habrahabr.ru/post/268993/) я рассказал как создать сервер и клиент на Python 3, используя встроенные сокеты. Но у этого приложения было много недостатков, которые я попытаюсь испр... | https://habr.com/ru/post/269019/ | null | ru | null |
# Практическое применение Kotlin в стартапах и энтерпрайзе
**Disclaimer:** Я не имею никакого отношения к JetBrains, не получаю денег от продвижения Kotlin или от написания данной статьи. Весь материал — это лишь отражение моего личного опыта.
Выбор того или иного языка (и вообще любого инструмента) как правило проди... | https://habr.com/ru/post/506548/ | null | ru | null |
# 3D CAD из облака на Linux
 В последнее время на Хабр появилось несколько статей про Системы Автоматизированного Проектирования (САПР), главным образом речь шла об CAD системах, предназначенных для автоматизации двумер... | https://habr.com/ru/post/117133/ | null | ru | null |
# Памятка по базовой верстке статьи для Хабра без использования Markdown-разметки
На Хабре, по меркам старожилов, я совсем недавно, всего два года, но пишу активно, по возможности каждый день. Так вот, читая статьи, да и просто прокручивая ленту свежих публикаций как на Хабре, так и на GT, я понял, что многие просто н... | https://habr.com/ru/post/277577/ | null | ru | null |
# NLP: выделяем факты из текста с помощью Томита-парсера
NLP - natural language processing
Большая часть данных в мире не структурирована – это просто тексты на русском или на любом другом языке. Извлеченные факты из таких текстов могут представлять особый интерес для бизнеса, поэтому подобные задачи возникают сплошь... | https://habr.com/ru/post/547472/ | null | ru | null |
# Мой MikroTik – моя цифровая крепость (часть 4)
[](https://habr.com/ru/company/ruvds/blog/576352/)
Статья является продолжением [первой](https://habr.com/ru/company/ruvds/blog/575808/), [второй](https://ha... | https://habr.com/ru/post/576352/ | null | ru | null |
# Аудиореклама: спрашивали — отвечаем
И снова привет, Хабр! Наш [первый пост](https://habrahabr.ru/company/instreamatic/blog/276567/) в блоге вызвал оживлённую дискуссию. Мы ожидали, что грянет буря, но масштаб её оказался грандиозным. Наша команда получила множество вопросов, которые интересны, действительно заслужив... | https://habr.com/ru/post/277501/ | null | ru | null |
# Взаимодействие с роботом на базе конструктора Lego Mindstorms EV3 через RCML
В статье содержится описание опыта использования конструктора Lego Mindstorms EV3 для создания прототипа робота с его последующим программным и ручным управлением при помощи Robot Control Meta Language (RCML).
Далее будут рассмотрены сле... | https://habr.com/ru/post/371909/ | null | ru | null |
# Современная Android разработка на Kotlin. Часть 1
*Данная статья является перевом статьи от [Mladen Rakonjac](https://proandroiddev.com/modern-android-development-with-kotlin-september-2017-part-1-f976483f7bd6)*
Очень сложно найти один проект, который охватывал бы всё новое в разработке под Android в Android Stud... | https://habr.com/ru/post/341602/ | null | ru | null |
# Алгоритм Верхуффа для произвольной чётной системы счисления
 Иногда возникает задача защитить строку-идентификатор от случайных ошибок, сделанных человеком. Например, номер платёжной карты. Для этого к строке добавляется вычисле... | https://habr.com/ru/post/435446/ | null | ru | null |
# Разработка для SailfishOS: основы
Здравствуйте! На прошлой неделе я написал о том [как начать разрабатывать под мобильную платформу Sailfish OS](https://habrahabr.ru/post/305510/). Сегодня же я хотел бы рассказать о жизненном цикле приложений Sailfish, о создании страниц приложения и управления ими, а также о некото... | https://habr.com/ru/post/306188/ | null | ru | null |
# Самодельный бот с камерой и управлением по wifi
Прочитав опубликованную статью [Однажды фанера, atmega, да малина](http://habrahabr.ru/post/175889/), я решил поделиться своей поделкой, которая доступна (не сложна) для повторения.
При создании бота ставились следующие задачи:
* Управление ботом по беспроводной ... | https://habr.com/ru/post/176307/ | null | ru | null |
# NProgress: прогресс-бар как на YouTube и Medium
Многие заметили, что на YouTube и на Medium появился небольшой новый элемент UI — прогресс-бар в виде тонкой цветной полоски в самом верху страницы, который примостился прямо под панелью браузера.
 Привет, Хаброжители! Вы наверняка слышали о книге Майкла Доусона (Michael Dawson), в которой он учит языку программирования Python тем же самым путем, то есть через программирование несл... | https://habr.com/ru/post/325782/ | null | ru | null |
# Пишем расширение-читалку для Habr
Каждому разработчику однажды приходит в голову мысль написать что-то, чтобы упростить себе жизнь. Например, сократить время, проведённое за выполнением рутинных задач, или же позволить себе выполнять несколько действий одновременно.
В данной статье я хочу показать, как можно совмес... | https://habr.com/ru/post/542028/ | null | ru | null |
# Koin – это Dependency Injection или Service Locator?
Введение
========
В Android-разработке для DI традиционно используют [Dagger 2](https://dagger.dev), очень мощный фреймворк с кодогенерацией. Но есть проблема: новичкам сложно его использовать. Сами принципы DI просты и понятны, но Dagger усложняет их. Можно жало... | https://habr.com/ru/post/488072/ | null | ru | null |
# Улучшаем производительность HTML5 canvas
*В последнее время мне везет натыкаться на интересные статьи для перевода. На этот раз – статья на [HTML5Rocks](http://www.html5rocks.com/en/tutorials/canvas/performance/) о производительности HTML5 canvas. Автор пишет о некоей стене, в которую упираются разработчики при созд... | https://habr.com/ru/post/127014/ | null | ru | null |
# Получение фото с android-смартфона прямо в html форму
Здравствуйте!

Возникла задача для интернет-магазина сфотографировать большое количество товаров. Специфика товара такова, что не столько важна красивая кар... | https://habr.com/ru/post/140974/ | null | ru | null |
# 5 способов сравнить два байтовых массива. Сравнительное тестирование
В результате профилирования моей софтины я сделал вывод о необходимости оптимизации функции сравнения буферов.
Т.к. CLR не п... | https://habr.com/ru/post/214841/ | null | ru | null |
# Решение задач линейного программирования с использованием Python
### Зачем решать экстремальные задачи
На практике очень часто возникают задачи, для решения которых используются методы оптимизации. В обычной жизни при множественном выборе, например, подарков к новому году мы интуитивно решаем задачу минимальных зат... | https://habr.com/ru/post/330648/ | null | ru | null |
# Как моя жизнь превратилась в книгу Кафки
Это печальная и долгая история и о взаимоотношениях в IT-коллективе, и корпоративной культуре, и о совместной разработке. Надеюсь, кому-то она поможет не совершать наших ошибок и выстроить лучшие отношения с коллегами.
### Вступление
В конце марта 2018 я начала работать, ... | https://habr.com/ru/post/441528/ | null | ru | null |
# Основы Linux от основателя Gentoo. Часть 3 (3/4): Управление аккаунтами в Linux
Продолжение третьей части серии руководств Linux для новичков. Основы управления пользователями и группами.
> [](http://www.gnu.org/gr... | https://habr.com/ru/post/110012/ | null | ru | null |
# Создаем конвейер потоковой обработки данных. Часть 1
Всем привет. Друзья, делимся с вами переводом статьи, подготовленным специально для студентов курса [«Data Engineer»](https://otus.pw/lVQx/). Поехали!

Apache Beam и DataFlow ... | https://habr.com/ru/post/454186/ | null | ru | null |
# Как я выбирал СЭД — о чем молчат вендоры
Недавно хорошие знакомые попросили помочь им выбрать систему документооборота со словами «ну ты же занимаешься этой всякой автоматизацией».
Я согласился, хотя и работаю в немного другом направлении и раньше вплотную не сталкивался с СЭД. То что я обнаружил в процессе изуч... | https://habr.com/ru/post/198536/ | null | ru | null |
# Работа с анимацией. AnimatedVectorDrawableCompat
В этой стате хотел бы всем рассказать и показать на практике, как можно делать анимацию в Android приложении при помощи AnimatedVectorDrawableCompat, например свои кастомные кнопки, ImageView, FloatingActionButton.
На сегодняшний день информации по этому поводу в с... | https://habr.com/ru/post/302480/ | null | ru | null |
# WebSocket Akka HTTP на практике
Довольно продолжительное время существовала только одна достойная реализация работы с HTTP поверх Akka — [spray](http://spray.io/). К этой библиотеке пару умельцев написали расширения для WebSocket,
которое было вполне понятно в использовании и проблем не возникало. Но годы шли и s... | https://habr.com/ru/post/319978/ | null | ru | null |
# React Intl: интернационализация React-приложений

Библиотека `React Intl` предоставляет механизм для перевода текста на другие языки.
В данном "туториале" мы используем названную библиотеку для реализации интернационализации в про... | https://habr.com/ru/post/564824/ | null | ru | null |
# Изучаем данные, собранные Xiaomi Mi Band за год
Введение
--------
Люди носят фитнес-браслеты по разным причинам, я могу предположить некоторые из них:
1. Для того, чтобы поддерживать себя в форме и выполнять цели по активности;
2. Потому что это некая модная штучка;
3. Чтобы ставить над собой эксперименты или узна... | https://habr.com/ru/post/464055/ | null | ru | null |
# Spring boot: маленькое приложение для самых маленьких
Всем привет! Меня зовут Варвара и я Java Developer в компании “Цифровые привычки”. Я прошла их курс по Java-разработке и по окончании получила оффер от... | https://habr.com/ru/post/565242/ | null | ru | null |
# Конвертируем svg to png
Иногда появляется необходимость сохранить svg в png средствами браузера. К сожалению, браузер не имеет волшебного api, который позволил бы это сделать без различных хаков. Что же делать, если все та... | https://habr.com/ru/post/254973/ | null | ru | null |
# Введение в IDAPython

На русском языке (и на Хабре, в частности) не так много статей по работе с IDAPython, попытаемся восполнить этот пробел.
**Для кого.** Для тех, кто уже умеет работать в IDA Pro, но ни разу не писал скрипты на I... | https://habr.com/ru/post/499382/ | null | ru | null |
# Библиотека генератора ассемблерного кода для микроконтроллеров AVR. Часть 2
[← Часть 1. Первое знакомство](https://habr.com/ru/post/462409/)
[Часть 3. Косвенная адресация и управление потоком исполнения →](https://habr.com/ru/post/463123/)
Библиотека генератора ассемблерного кода для микроконтроллеров AVR
-------... | https://habr.com/ru/post/462701/ | null | ru | null |
# Дайджест статей машинного обучения и искусственного интеллекта
Хабр, привет.
Отфильтровав большое количество статей, конференций и подписок — собрал для вас все наиболее значимые гайды, статьи и лайфхаки из мира машинного обучения и искусственного интеллекта. Всем приятного чтения!
**1.** Проекты искусственно... | https://habr.com/ru/post/458804/ | null | ru | null |
# Краткое руководство: связываем ASP.NET Core Web API + Angular 5
История о том, как подружить два отдельных проекта ASP.NET Core Web API и Angular 5, и заставить их работать, как одно целое.
Вступление
----------
*Данная статья рассчитана на новичков, которые делают первые шаги в изучении Angular в связке с .NET ... | https://habr.com/ru/post/349522/ | null | ru | null |
# Команда разработчиков графического языка Processing представила официальную JavaScript-библиотеку p5.js
[Язык Processing](http://habrahabr.ru/post/58314//), основанный на Java, был написан в 2001 году для создания графики и анимаций. Для использования этого языка в интернете в 2008 году Джон Резиг написал библиотеку... | https://habr.com/ru/post/236621/ | null | ru | null |
# Настройка PHP-FPM: используем pm static для максимальной производительности

*Неотредактированная версия статьи была изначально опубликована на [haydenjames.io](https://haydenjames.io/php-fpm-tuning-using-pm-static-max-performance/) ... | https://habr.com/ru/post/460511/ | null | ru | null |
# Жесткая приоритизация, или 5 первых шагов к отличному приложению для Windows 8. От персонажей к сценариям
Одна из сложностей, с которой, по моему опыту, сталкиваются практически все разработчики и дизайнеры, работая над приложениями для Windows 8 и Windows Phone, начинается прямо с порога – с проектирования того, ка... | https://habr.com/ru/post/149484/ | null | ru | null |
# Пишем собственный CustomStepper в Swift
[Тут можно найти реализацию готового проекта](https://github.com/zontz/CustomStepper)
На сегодняшний день во многих приложениях мы можем наблюдать stepper, большинство из них кастомные. Несмотря на то, что Apple предоставляет уже реализацию готового степпера, иногда он не под... | https://habr.com/ru/post/701202/ | null | ru | null |
# Мониторинг SAAS-сервиса интернет-магазинов с помощью Zabbix. Часть 2
В [прошлой статье](https://habr.com/ru/company/first/blog/676864/) мы рассказали, что нужно учитывать при мониторинге SAAS-сервиса интерн... | https://habr.com/ru/post/680614/ | null | ru | null |
# Создание gulp-плагина на примере построения графа зависимостей для модулей Angular JS
Предисловие
-----------
В данной статье я поделюсь с вами опытом, как быстро и безболезненно создавать простые плагины для gulp. Статья ориентирована на таких же чайников, как и я. На тех, кто до сих пор лишь использовал готовые п... | https://habr.com/ru/post/257275/ | null | ru | null |
# Active Restore: С чего начать разработку в UEFI
Всем привет. В рамках проекта от компании Acronis со студентами Университета Иннополис (подробнее о проекте мы уже описали это [тут](https://habr.com/ru/company/acronis/blog/477658/) и [тут](https://habr.com/ru/company/acronis/blog/479524/)) мы изучали последовательнос... | https://habr.com/ru/post/511172/ | null | ru | null |
# Руководство по PHP7

#### **php7-tutorial.com**
Цель этого [сайта](http://php7-tutorial.com/) помочь вам обнаружить нововведения в PHP 7. Это руководство представляет из себя набор простых упражнений, в которых вам будет ... | https://habr.com/ru/post/302942/ | null | ru | null |
# Бот для Starcraft на Rust, C и на любом другом языке
 [StarCraft: Brood War](https://ru.wikipedia.org/wiki/StarCraft:_Brood_War). Как много это значит для меня. И для многих из вас. Настолько много, что я засомневался, давать ли ссылк... | https://habr.com/ru/post/416743/ | null | ru | null |
# EF Core + Oracle: как сделать миграции идемпотентными

Обычно фреймворк EF Core используют в сочетании с MS SQL — другим продуктом Microsoft. Однако это не догма. Например, мы в CUSTIS пишем бизнес-логику на C#, а для управления ба... | https://habr.com/ru/post/494278/ | null | ru | null |
# Java Core для самых маленьких. Часть 1. Подготовка и первая программа
Вступление. Краткая история и особенности языка
-----------------------------------------------
Как-то давно мы с моим товарищем и коллегой [Егором](https://www.linkedin.com/in/yegor-logachev-0352a7109/) готовили обучающий курс по Java Core. Но к... | https://habr.com/ru/post/541696/ | null | ru | null |
# Пишем компонент — таблицу, не совсем обычным способом
Еще одна небольшая статейка попроще вдогонку. Расскажу, как я рисую таблицы во **Vue**.
Компонентов-таблиц для Vue наделано немало. С различными возможностями. И везде по-разному таблица собирается в **template** страницы или какого-то компонента.
В основн... | https://habr.com/ru/post/350292/ | null | ru | null |
# Использовать Lua c С++ легче, чем вы думаете. Tutorial по LuaBridge
Данная статья — перевод моего [туториала](http://eliasdaler.wordpress.com/2014/07/18/using-lua-with-cpp-luabridge/), который я изначально писал на английском. Однако этот перевод содержит дополнения и улучшения по сравнению с оригиналом.
Туториал... | https://habr.com/ru/post/237503/ | null | ru | null |
# Python3. Автоматизация конфигурации мультивендорного сетевого оборудования
#### Предисловие
Всем доброго времени суток!
Работаю сетевым инженером у крупного оператора связи, и под моим управлением имеется целый зоопарк разного сетевого оборудования, но речь пойдет о коммутаторах доступа.
Данная статья это не ... | https://habr.com/ru/post/415453/ | null | ru | null |
# Выгрузка данных из SAP через RFC на Python
Поговорим о выгрузке данных из SAP ERP или S/4 HANA с использованием механизма SAP RFC.
Такая выгрузка может служить для наполнения аналитического хранилища данных или для интеграции с другой системой.
Интерфейс SAP RFC (remote function call) позволяет вызывать различные... | https://habr.com/ru/post/542346/ | null | ru | null |
# Total Commander + AutoHotKey: Меню пользователя
Помните Norton Commander и его возможность создания меню пользователя?
Реализуем подобное для TC на AutoHotKey.
Создаём файл DirMenu.ahk, внутри которого вызываем меню с несколькими действиями:
`Menu, MyMenu, Add, Набрать заметку, mp1
Menu, MyMenu, Add, з... | https://habr.com/ru/post/52400/ | null | ru | null |
# Высокодоступный и масштабируемый Elasticsearch в Kubernetes

В [предыдущем посте](https://medium.com/@thakur.vaibhav23/scaling-mongodb-on-kubernetes-32e446c16b82) мы масштабировали набор реплик Mong... | https://habr.com/ru/post/432374/ | null | ru | null |
# Spark SQL. Немного об оптимизаторе запросов
Всем привет. В качестве введения, хочется рассказать, как я дошел до жизни такой.
До того как встретиться с Big Data и Spark, в частности, мне довелось много и часто оптимизировать SQL запросы, сначала для MSSQL, потом для Oracle, и вот теперь я столкнулся со SparkSQL.... | https://habr.com/ru/post/417103/ | null | ru | null |
# Разработка Chromecast Ready приложения под платформу Android

#### 1. Что такое Chromecast и как он работает?
Chromecast это гаджет, который позволяет пользователям передавать медиа контент с мобил... | https://habr.com/ru/post/218425/ | null | ru | null |
# По следам бага и немного о событиях MotionEvent в Android
Думаю, многие из нас писали код вида:
```
@Override
public boolean onTouch(View view, MotionEvent event) {
final float x = event.getX();
final float y = event.getY();
// использование x и y...
return false;
}
``... | https://habr.com/ru/post/209910/ | null | ru | null |
# How Deep the Rabbit Hole Goes, or C++ Job Interviews at PVS-Studio

Authors: Andrey Karpov, [khandeliants](https://habr.com/ru/users/khandeliants/) Phillip Khandeliants.
Her... | https://habr.com/ru/post/495564/ | null | en | null |
# Опционалы в Swift
Несмотря на некоторый опыт в мобильной разработке (в том числе с применением Swift), регулярно на почве свифтовых опционалов возникали ситуации, когда я знал **что** нужно делать, но не совсем внятно представлял, **почему** именно так. Приходилось отвлекаться и углубляться в документацию — количест... | https://habr.com/ru/post/338766/ | null | ru | null |
# Как я хотел поработать нативным Android разработчиком, но устроился Flutter разрабом
Небольшое вступление
--------------------
После праздничных каникул (это было в январе) я решил немного поработать Android разработчиком на пол ставки, дабы совмещать работу с учебой.
Ещё в декабре я познакомился с главным програ... | https://habr.com/ru/post/559228/ | null | ru | null |
# «Жизнь после Java 10»: какие изменения принесет Java 11
Буквально недавно, в конце марта, [вышел](https://habr.com/company/jugru/blog/351694/) Java 10. Но в связи с тем, что компания Oracle [внесла изменения](https://www.infoworld.com/article/3222867/java/the-road-to-java-9-twice-yearly-releases-are-coming.html) в р... | https://habr.com/ru/post/358810/ | null | ru | null |
# Динамическое расширение ядра Linux — добавляем функцию «удалить в корзину»
Многим пользователям Linux, особенно тем, кто по тем или иным причинам перешёл на эту ОС с Windows, не хватает возможности удаления файлов «в корзину». Кроме того, наверняка, каждый, кто пользовался Linux'ом и по ошибке удалял какой-либо файл... | https://habr.com/ru/post/210364/ | null | ru | null |
# STM32F429 + IL9341 = LVGL, DOOM1
Воспользовавшись Новогодними праздниками, продолжил поднимать элементы на своей плате. Первым делом после того как запустился дисплей провел тест Lvgl графической библиотеки. Результаты показались удовлетворительным. Около 20 FPS. Иногда были просадки но в целом, без использования DM... | https://habr.com/ru/post/536424/ | null | ru | null |
# Orb. DIY-cервер новостей
Привет всем!
Перед закрытием Google Reader в 2013-м году захотелось написать что-то свое на эту тему. Чтобы оно собирало новости из RSS и было видно, что читал, а что — нет. Плюс было желание поработать с GAE и Angular. Позднее, после нескольких разочарований в собственных CSS cross-brows... | https://habr.com/ru/post/242099/ | null | ru | null |
# Easy Video Cutter — простой обрезальщик видео
Один мой друг решил внести свой посильный вклад в развитие сообщества open source. Результатом его желания явилась не большая, но, как ему кажется, полезная программка, о которой он попросил меня рассказать.
![](https://habrastorage.org/r/w1560/getpro/geektimes/post_... | https://habr.com/ru/post/65571/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.