
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Чистим домашний интернет от очень назойливой рекламы (Ad's blocker для OpenWRT)

*Дело было вечером, делать было нечего...* © С. В. Михалков
*Навеяно публикацией [«Как я bind`ом вирусы искал…»](http://habrahabr.ru/post/... | https://habr.com/ru/post/263081/ | null | ru | null |
# Обеспечение качества кода в масштабных проектах

Когда осенью 2012 года я пришёл в Airbnb, то здесь мягко выражаясь, был некоторый разброд и шатание. Некоторое время назад компания начала расти и развиваться огромными тем... | https://habr.com/ru/post/252125/ | null | ru | null |
# Тонкость определения EIGRP Feasible Distance
EIGRP – это дистанционно-векторный протокол маршрутизации, изначально разработанный Cisco. Одним из ключевых отличий от предшественника, IGRP, является использование DUAL – алгоритма, который позволяет исключить появление постоянных петель маршрутизации в топологии. Однак... | https://habr.com/ru/post/546022/ | null | ru | null |
# Функции в скриптах Роутер ОС Микротик. Интересные решения и недокументированные возможности
Роутер ОС Микротик, как известно, имеет мощнейший LUA-подобный встроенный скриптовый язык, позволяющий осуществлять исполнение сценариев, в том числе при наступлении каких-либо событий в сети или по расписанию. Скрипты могут ... | https://habr.com/ru/post/646663/ | null | ru | null |
# Статические Generic таблицы

Всем нам часто приходится сталкиваться со статическими таблицами, они могут являться настройками нашего приложения, экранами авторизации, экранами «о нас» и многими други... | https://habr.com/ru/post/439016/ | null | ru | null |
# Опыт перевода большого проекта с Flow на TypeScript

JavaScript – это один из языков с динамической типизацией. Такие языки удобны для быстрой разработки приложений, но когда несколько команд берутся за разработку... | https://habr.com/ru/post/462055/ | null | ru | null |
# STM32. Про синус
Вместо вступления
-----------------
В статье алгоритмическая оптимизация функции sin() для бюджетных микроконтроллеров stm32, повышающая производительность в 10 и более раз.
Тригонометри... | https://habr.com/ru/post/659089/ | null | ru | null |
# Google Chrome и Microsoft Edge планируют круто расширить возможности копипаста
[](https://habr.com/ru/company/ruvds/news/t/567618/)
Копирование контента из интернета вскоре станет намного более гибким благодаря ряду новых API, разр... | https://habr.com/ru/post/567618/ | null | ru | null |
# Создание капчи только своими руками
Вот на днях решил, что на страницу регистрации в срочном порядке нужно ставить капчу, боты на столько обнаглели, что без неё там хорошо себя чувствуют и зовут ещё больше ботов.
По запросу в поисковике *«Скрипт капчи»*, выпадает столько готовых вариантов — что грех жаловаться, н... | https://habr.com/ru/post/164733/ | null | ru | null |
# Настоящий веб-сайт на Common Lisp за 9 шагов
Введение
--------

Эта вводная статья предназначена для желающих попробовать применить Common Lisp в задачах веб-программирования. Я не буду останавливаться на преимуществах этого яз... | https://habr.com/ru/post/111365/ | null | ru | null |
# Популярный плагин для WordPress содержит в себе бэкдор

Специалисты в области информационной безопасности нашли бэкдор в плагине для [WordPress](https://wordpress.org/plugins/custom-content-type-manager/), который вносил изменения в основные файлы платформы с целью дальнейш... | https://habr.com/ru/post/279539/ | null | ru | null |
# Драйвер внешнего оборудования для 1С на примере фискального регистратора Мария-301МТМ

При реализации проектов на 1С зачастую приходится сталкиваться с разного рода устройствами и их сопряжением. Покуда будут существо... | https://habr.com/ru/post/250341/ | null | ru | null |
# Имитируем управление устройствами с помощью акторов
Корни [SObjectizer](https://habrahabr.ru/post/304386/) берут свое начало в теме автоматизированных систем управления технологическими процессами (АСУТП). Но использовали мы SObjectizer в далеких от АСУТП областях. Поэтому иногда возникает ностальгия из категории «э... | https://habr.com/ru/post/332166/ | null | ru | null |
# Алиасы в bash для быстрого набора команд Git
Командный интерпретатор bash позволяет задавать произвольные алиасы для разных команд и выражений. Алиасы не являются командами сами по себе, но им, как и командам, можно передавать аргументы. Алиасы позволяют сделать вызов громоздких команд очень простым, с легко запомин... | https://habr.com/ru/post/660615/ | null | ru | null |
# Миграция с Gitolite на GitLab с помощью Shell-скрипта
*Процесс миграции нередко представляет собой трудную задачу, особенно, когда объем информации, который необходимо перенести, настолько велик, что выгоднее становится его автоматизировать. Именно необходимость миграции с Gitolite на GitLab и побудила меня написать... | https://habr.com/ru/post/492122/ | null | ru | null |
# Продвинутые принципы безопасности в Kubernetes
Kubernetes используется для автоматизации таких процессов, как развертывание, администрирование и масштабирование контейнерных приложений. Например, в Kubernet... | https://habr.com/ru/post/697806/ | null | ru | null |
# Web3.0 на Python, часть 2: advanced
Привет, хабр! В [первой части](https://habr.com/ru/post/674204/) мы рассмотрели базовые операции на web3py, которые закроют большинство ваших потребностей для проектов на ранних этапах. Здесь же речь в основном пойдет про улучшение производительности и различные "фишки", которые, ... | https://habr.com/ru/post/699560/ | null | ru | null |
# Работа отдела техподдержки системы локального позиционирования
Проработав в разных компаниях инженером службы технической поддержки, впоследствии замечаешь абсолютно разный подход к решению задач/пробл... | https://habr.com/ru/post/305568/ | null | ru | null |
# WPF: использование Attached Property и Behavior
Пожалуй, любой разработчик WPF знает о механизме Attached Property, но многие даже не слышали о Behavior. Хотя эти механизмы и имеют схожие функциональные возможности, они, все же, имеют совершенно разную смысловую нагрузку, и очень важно правильно различать их и испол... | https://habr.com/ru/post/254887/ | null | ru | null |
# Приемы использования масочных регистров в AVX512 коде
В процессорах компании Intel на смену AVX2 приходит новый набор инструкций [AVX512](https://software.intel.com/en-us/isa-extensions/intel-avx), в котором появилась концепция масочных регистров. Автор этой статьи уже несколько лет занимается разработкой версии биб... | https://habr.com/ru/post/266055/ | null | ru | null |
# Скачивание любого сайта с помощью Python себе на компьютер
Здравствуйте!
Сегодня я Вам расскажу про интересную библиотеку для Python под названием [Pywebcopy](https://github.com/rajatomar788/pywebcopy/).
PyWebCopy – бесплатный инструмент для копирования отдельных веб-страниц или же полного копирования сайта на ж... | https://habr.com/ru/post/669766/ | null | ru | null |
# Руководство разработчика Prism — часть 3, управление зависимостями между компонентами
> **Оглавление**
>
> 1. [Введение](http://habrahabr.ru/post/176851/)
> 2. [Инициализация приложений Prism](http://habrahabr.ru/post/176853/)
> 3. [Управление зависимостями между компонентами](http://habrahabr.ru/post/176861/)
> ... | https://habr.com/ru/post/176861/ | null | ru | null |
# C++. Убираем приватные поля из описания класса или немного дурачества
Всем привет! Решил на выходных продолжить писать свой домашний проект и наступила пора реализовать платформозависимый код. Самым просты... | https://habr.com/ru/post/676058/ | null | ru | null |
# Chosen: сделай выпадающие списки более дружественными
Плагин Chosen создан для оформления красивых и удобных выпадающих списков с помощью jQuery и Prototype. Для установки плагина достаточно просто скачать [файлы](https://github.com/harvesthq/chosen) и прописать одну строчку:
```
$(".chzn-select").chosen()
```
(... | https://habr.com/ru/post/124899/ | null | ru | null |
# Выгружаем данные в Excel. Цивилизованно
Есть в IT-отрасли задачи, которые на фоне успехов в *big data*, *machine learning*, *blockchain* и прочих модных течений выглядят совершенно непривлекательно, но на протяжении десятков лет не перестают быть актуальными для целой армии разработчиков. Речь пойдёт о старой как ми... | https://habr.com/ru/post/422059/ | null | ru | null |
# Dropbox — прекращение отображения в браузере HTML-контента
Сегодня утром (01.09.2016) на мой имейл пришло письмо со следующим содержанием:
```
Приветствуем, username!
Сообщаем вам, что мы отменим функцию передачи контента HTML в браузере по ссылке на доступ или общую папку.
Если вы используете ссылки на общий д... | https://habr.com/ru/post/308998/ | null | ru | null |
# Библиотеки для глубокого обучения: Keras
Привет, Хабр! Мы уже говорили про [Theano](https://habrahabr.ru/company/ods/blog/323272/) и [Tensorflow](https://habrahabr.ru/company/ods/blog/324898/) (а также много про что еще), а сегодня сегодня пришло время поговорить про Keras.
Изначально Keras вырос как удобная надстр... | https://habr.com/ru/post/325432/ | null | ru | null |
# Кривые и что это такое ч.2
Всем привет!
Итак, это продолжение предыдущей статьи с той же темой - кривые, их разбор.
---
Основная часть
--------------
Как вы помните, в прошлой части я предложил два примера кривой. Одна интерполирует на отрезке между двумя точками, но учитывает еще и соседние точки. Другая интерп... | https://habr.com/ru/post/671078/ | null | ru | null |
# Международный конкурс по обфускации кода на C
[IOCCC](http://www.ioccc.org/) возвращается! Знаменитый конкурс на самый запутанный код призван «проверять компиляторы на стресс, демонстрировать тонкости языка программирования Си и ва... | https://habr.com/ru/post/132665/ | null | ru | null |
# Новости из мира OpenStreetMap № 488 (19.11.2019-25.11.2019)
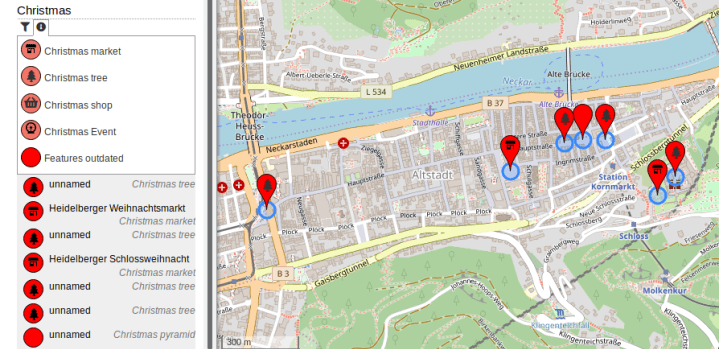
Каждый год – Карта сезона [1](#wn488_21388) | OpenStreetBrowser – Map data OpenStreetMap contributors
Картографирование
------------... | https://habr.com/ru/post/479234/ | null | ru | null |
# Можно всё: решение NLP задач при помощи spacy

Обработка естественного языка сейчас используется повсеместно: стремительно развиваются голосовые интерфейсы и чат-боты, разрабатываются модели для обработки больших текстовых данных... | https://habr.com/ru/post/531940/ | null | ru | null |
# Mysql performance
Написание этой статьи навеяно вот этой трилогией: [один](http://habrahabr.ru/blogs/mysql/38907/), [два](http://habrahabr.ru/blogs/mysql/39260/), [три](http://habrahabr.ru/blogs/mysql/39818/). Захотелось добавить свои 0.02$, по использованию трюков и особенностей.
Чтоб мне не запутаться в мыслях,... | https://habr.com/ru/post/135775/ | null | ru | null |
# Введение в юнит-тестирование в Unity

Вам любопытно, как работает юнит-тестирование в Unity? Не знаете, что такое юнит-тестирование в целом? Если вы ответили положительно на эти вопросы, то данный т... | https://habr.com/ru/post/456090/ | null | ru | null |
# Как я воровал данные с пользовательских аккаунтов в Google
Вы со мной не знакомы, но существует известная вероятность, что я знаком с вами. Причина в том, что у меня есть полный, неограниченный доступ к приватной информации миллионов людей, размещённой на аккаунтах Google. Отправленные по почте выписки по банковским... | https://habr.com/ru/post/539890/ | null | ru | null |
# Примеры работы с разными map API

Есть много статей на тему знакомства с Google Map Api и Yandex Map Api, но про остальные картографические сервисы не так много практического материала. В недавнем времени работал с Api:
1. G... | https://habr.com/ru/post/131249/ | null | ru | null |
# Модификация Android приложения от новичка и для новичков
Добрый день!
Хочу поделиться с вами историей как я модифицировал одно из системных приложений Adroid'а, точнее его модификации [LeWa OS](http://lewa.org.ua/). С Андроидом я познакомился недавно, всего месяц назад, и постараюсь тут описать весь ход своих мыс... | https://habr.com/ru/post/169767/ | null | ru | null |
# Сeph — от «на коленке» до «production»
Выбор CEPH. Часть 1
===================
*У нас было пять стоек, десять оптических свичей, настроенный BGP, пару десятков SSD и куча SAS дисков всех цветов и размеров, а ещё proxmox и желание засунуть всю статику в собственное S3 хранилище. Не то чтобы это всё было нужно для ви... | https://habr.com/ru/post/456446/ | null | ru | null |
# Практическое применение MSP430 для web-разработчика
На хабре предостаточно статей для начинающих о том, какой волшебный и замечательный этот MSP430 LaunchPad от Texas Instruments. Однако дальше стандартной мигалки светодиодом обычно никто не заходит. Пора исправлять эту ситуацию.
Работая в команде, мы пользуемся ... | https://habr.com/ru/post/151709/ | null | ru | null |
# Расширение и использование Linux Crypto API
[0] Интро
---------
Криптографический *API* в *Linux* введён с версии 2.5.45 ядра. С тех пор *Crypto API* оброс всеми популярными (и не только) международными стандартами:
* симметричного шифрования: *AES*, *Blowfish*, ...
* хэширования: *SHA1/256/512*, *MD5*, ...
* имит... | https://habr.com/ru/post/348552/ | null | ru | null |
# JavaScript библиотека Webix глазами новичка. Часть 3. Модули, диаграммы, древовидные таблицы

Я — начинающий front-end разработчик. Сейчас я учусь и стажируюсь в одной минской IT компании. Изучение основ web-ui проходит на примере ... | https://habr.com/ru/post/486050/ | null | ru | null |
# mov Программирование на Ассемблере без знаний Ассемблера, habr
Самый короткий мультфильм про программирование. **Пр... | https://habr.com/ru/post/707862/ | null | ru | null |
# Полное сокрытие полей свойствами в C#
Сперва я подумал, что стоит начать статью с описания основного назначения свойств в языке C#, но потом понял, что с этим можно на самом деле “развернуться” на целую статью. Поэтому, чтобы не затягивать со вступительной частью, я начну сразу с конкретной задачи.
#### Постановк... | https://habr.com/ru/post/116234/ | null | ru | null |
# Создаем html5 мини-бродилку на CraftyJS
Хочу раcсказать, как без особых сложностей сделать свою первую мини игру на html5 (если точнее: js, html5, css).
Суть игры будет в следующем: человечек ходит по полю, между камнями и собирает цветочки, у каждого цветочка есть 1 охранник. Количество цветов с каждым уровнем у... | https://habr.com/ru/post/125857/ | null | ru | null |
# Объектно ориентированный подход на функциях в Scheme
Привет. В данной статье хотелось бы еще разок осветить вопрос объектного программирования на языке Scheme, так, как его рассматривают в книге «Структ... | https://habr.com/ru/post/144598/ | null | ru | null |
# DEF CON CTF 22 Final
С 7 по 10 августа в Лас-Вегасе (США) прошла крупнейшая конференция по информационной безопасности — DEF CON. Мероприятие проходит уже 22 год. Мы принимали участие в финальном этапе DEF CON CTF. На самой конференции народу очень много. Сначала я слышал что-то про 6 тысяч человек, потом — про 15. ... | https://habr.com/ru/post/234191/ | null | ru | null |
# Герои прошлого и наши дни: тестирование AGP-видеокарты на более современной системе

— А ведь у меня есть такая плата, настоящий динозавр! — написал один из читателей предыдущей статьи, — поддержка 2-ядерных процессоров, 4 слота... | https://habr.com/ru/post/410805/ | null | ru | null |
# Новые директивы HTTP для кеширования с учётом CDN
[, а продолжалась [здесь](https://habr.com/ru/post/436348/) и [здесь](https://habr.com/ru/post/436546/).
В прошлой части я написал интеграционный тест, демонстрирующий ... | https://habr.com/ru/post/436654/ | null | ru | null |
# Определяем Phantom-ных ботов
» Перевод статьи [Detecting PhantomJS Based Visitors](http://engineering.shapesecurity.com/2015/01/detecting-phantomjs-based-visitors.html) | Неплохое обсуждение статьи на [Hacker News](https://news.ycombinator.com/item?id=8901117)
Статья старая, помидорами не кидайтесь — лучше делите... | https://habr.com/ru/post/303378/ | null | ru | null |
# Оконные функции своими руками
В цифровой обработке сигналов оконные функции широко используются для ограничения сигнала во времени и их названия хорошо известны всем, кто так или иначе сталкивался с дискретным преобразованием Фурье: Ханна, Хэмминга, Блэкмана, Харриса и прочие. Но являются ли они достаточными, можно ... | https://habr.com/ru/post/514170/ | null | ru | null |
# Экономим на RAID-контроллере, или как накормить Варю иопсами
 В наш век облачных сервисов, AWS Lambda и прочих ~~шаред хостингов~~ абсолютно неосязаемых вычислительных ресурсов иногда хочется немножко своего. Кроме желания, иногда б... | https://habr.com/ru/post/423513/ | null | ru | null |
# Расширяем возможности процедурных макросов с помощью WASM
В рамках продолжения своих исследований различных аспектов процедурных макросов хочу поделиться подходом к расширению их возможностей. Напомню, что процедурные макросы позволяют добавить в язык элемент метапрограммирования и тем самым существенно упростить ру... | https://habr.com/ru/post/497916/ | null | ru | null |
# Resharper и IoC контейнеры: теперь знакомы! или плагин Agent Mulder
Доброго времени,
Как известно, [Resharper](http://www.jetbrains.com/resharper/) решает много проблем по работе с кодом, но все-таки не все.
Одной из такой, не очень решенной, проблемой является навигация по зарегистрированным в IoC контайнерах... | https://habr.com/ru/post/145958/ | null | ru | null |
# «Переезжаем» в офлайн: Web Storage, Application Cache и WebSQL
Чтобы делать приложения, которые могут работать в полностью автономном режиме, нам нужно познакомиться со следующими технологиями: HTML5 Application Cache, Web Storage и WebSQL.
Мной уже были опубликованы вводные статьи, касающиеся [Web Storage](http:... | https://habr.com/ru/post/117123/ | null | ru | null |
# Шпаргалка => Cross Domain AJAX. Dynamic script Tag Hack
Так сложилось исторически (из-за соображений безопасности), что Javascript-обьект *XMLHttpRequest*, который лежит в основе AJAX, не может делать кросс-доменные вызовы. Это бесполезное ограничение: для злоумышленников не представляет особой проблемы, а для разра... | https://habr.com/ru/post/63353/ | null | ru | null |
# Qt: работа с Vkontakte API и Phonon

Статья описывает взаимодействие Qt c такими программными интерфейсами как Vkontakte API и Phonon, в реальных примерах и подробным описанием.
В конце статьи ссыл... | https://habr.com/ru/post/115397/ | null | ru | null |
# Wi-Fi is over: вычисляем нарушителей беспроводного эфира

Для выявления атак и аномалий беспроводного эфира можно использовать высокотехнологичные решения (как правило дорогие), которые позволяют контролировать беспроводные сети и выя... | https://habr.com/ru/post/339270/ | null | ru | null |
# Создаем свой язык на Groovy
Основная проблема императивных языков программирования — их низкая приближенность к естественным языкам.
ООП эту проблему частями решил, упорядочив данные и логику по классам объектов, но все равно это выглядит сложно для понимания. Основная проблема здесь в том, что императивные язык... | https://habr.com/ru/post/174683/ | null | ru | null |
# Визуальный редактор логики для Unity3d. Часть 2
Введение
--------
Здравствуйте уважаемые читатели, в сегодняшней статье я хотел бы осветить тему архитектуры ядра визуального редактора логики для **Unity3d**. Это вторая часть из серии. Предыдущую вы можете прочитать [здесь](https://habr.com/ru/post/448190/). Итак, о... | https://habr.com/ru/post/466187/ | null | ru | null |
# Использование сервера очередей beanstalkd для распределения нашей почтовой рассылки
В нашей системе (сервис покупок за рубежом [Shopozz.RU](http://shopozz.ru/) и бесплатный mail forwarding в США [Shopozz.COM](http://shopozz.com)), как и во многих других, присутствует множество почтовых рассылок разного содержания. Б... | https://habr.com/ru/post/240483/ | null | ru | null |
# Коран по поискам дублей в Google Spreadsheet
Доброго времени суток, дорогие читатели.
Помните ли вы [овцу Долли](http://en.wikipedia.org/wiki/Dolly_(sheep))? При работе с документами google, особенно со spreadsheet (MS Excel) таблицами для решения многих нетипичных задач, таких как: специальное форматирование по ... | https://habr.com/ru/post/198898/ | null | ru | null |
# Минимальные API в .NET 6
Создание REST API является основной частью многих проектов разработки. Выбор для создания таких проектов широк, но если вы разработчик на C#, варианты будут весьма ограничены. API н... | https://habr.com/ru/post/666676/ | null | ru | null |
# Расширенные шаблоны многоэтапной сборки
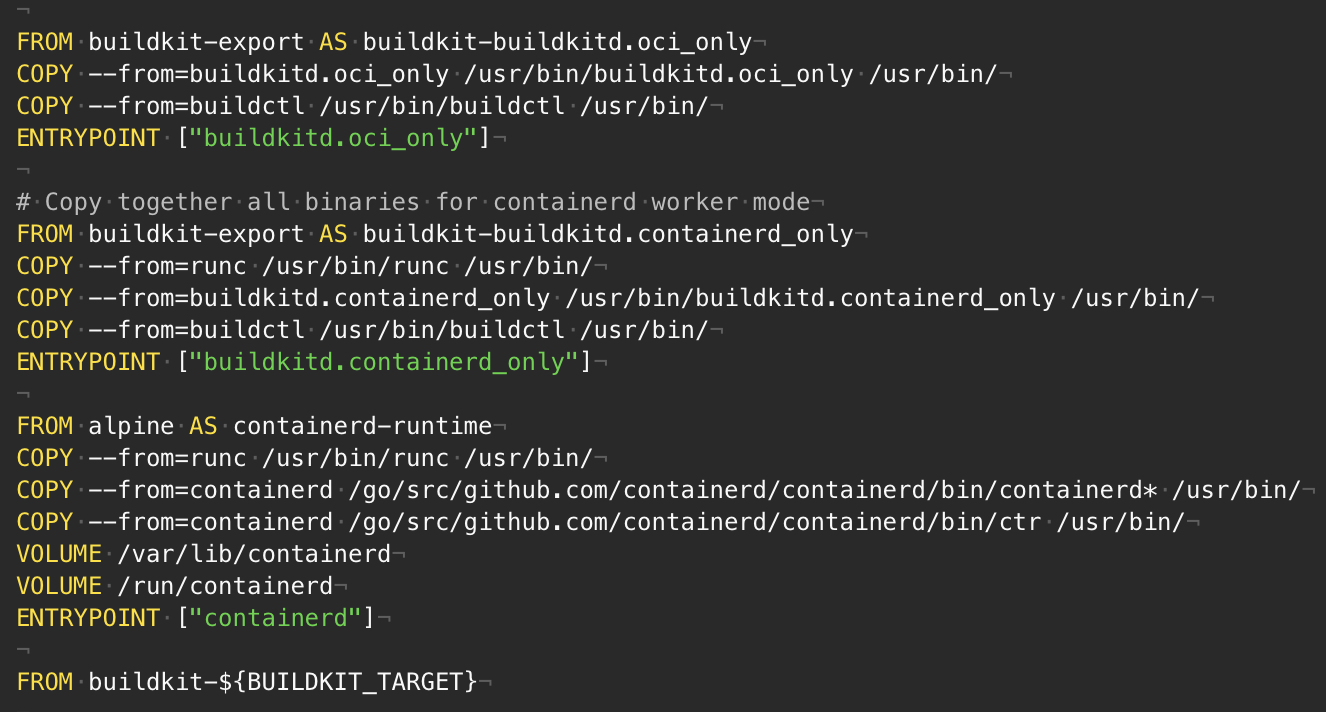
Функция многоэтапной сборки в файлах Dockerfile позволяет создавать небольшие образы контейнеров с более высоким уровнем кэширования и меньшим объемом защиты. В... | https://habr.com/ru/post/433790/ | null | ru | null |
# Обзор релиз-кандидата React v0.14
Мы рады представить вам наш первый релиз-кандидат версии React 0.14! Мы опубликовали в июле [анонс](http://facebook.github.io/react/blog/2015/07/03/react-v0.14-beta-1.html) предстоящих изменениях, но сейчас мы еще больше стабилизировали релиз и нам бы хотелось, чтобы вы попробовали ... | https://habr.com/ru/post/266683/ | null | ru | null |
# Достаём потерянные статьи из сетевых хранилищ
Решение рассматривается (пока) только для одного сайта — того, на котором мы находимся. Идея появилась в результате того, что один пользователь сделал юзерскрипт, который переадресует страницу на кеш Гугла, если вместо статьи видим «Доступ к публикации закрыт». Понятно, ... | https://habr.com/ru/post/146200/ | null | ru | null |
# Youtube снова экспериментирует с дизайном
Привет, *%username%*! Уже по традиции, без лишнего шума, Google дала возможность посмотреть на новый экспериментальный интерфейс YouTube.
**Вот и он**:
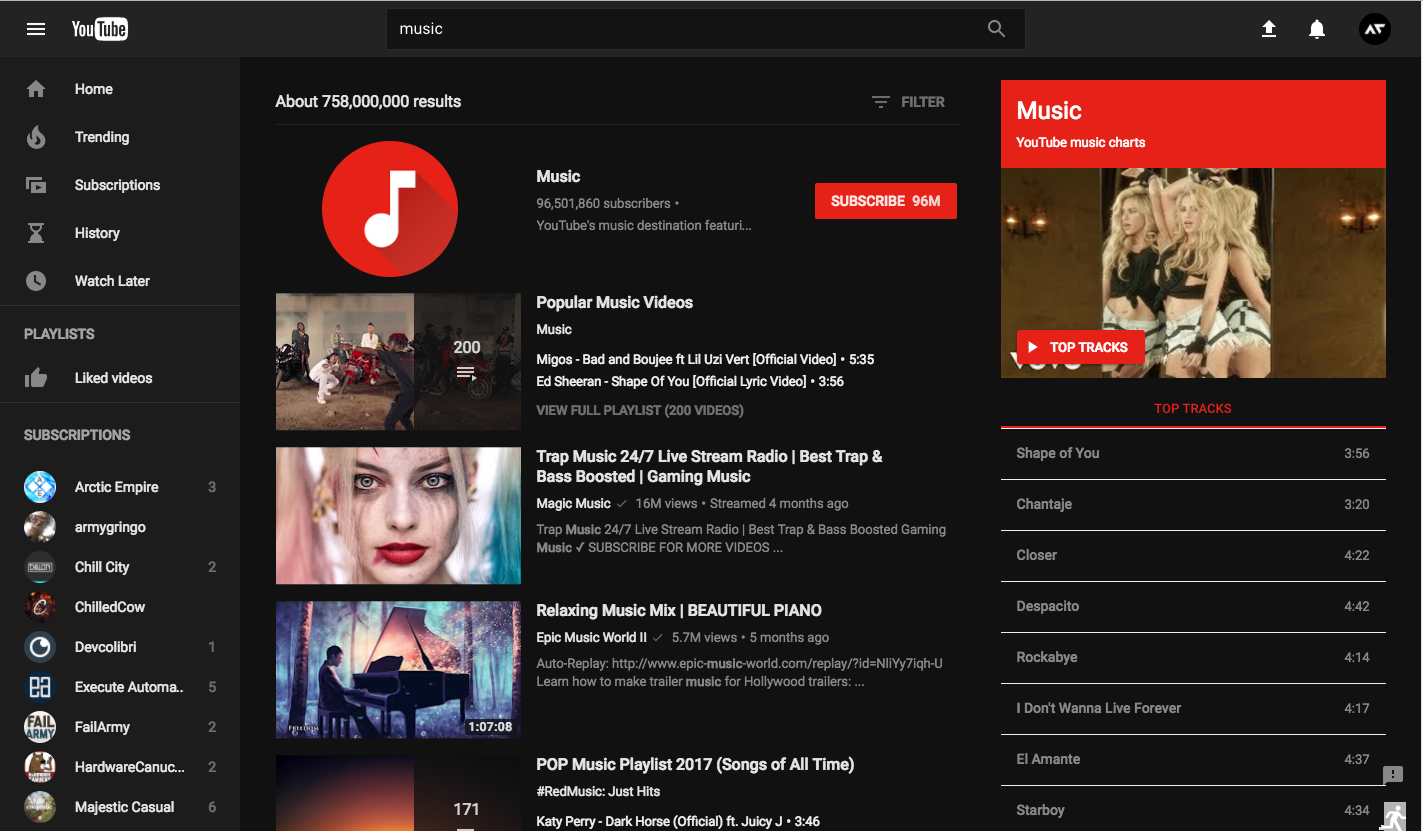
На этот раз изм... | https://habr.com/ru/post/401625/ | null | ru | null |
# Разработка нативных расширений для Node.js
В этом материале мы поговорим о важнейших концепциях разработки нативных расширений для Node.js. В частности, здесь будет рассмотрен практический пример создания такого расширения, который вполне может стать вашим первым проектом в этой области.
[» в Питерской Вышке делают [командные проекты по С++](https://habr.com/ru/company/hsespb/blog/508394/). Мы занимались ... | https://habr.com/ru/post/513794/ | null | ru | null |
# О новом простом методе снижения высокой размерности данных
[](https://habr.com/ru/company/skillfactory/blog/683498/)
О новом методе решения проблемы оценки ковариационной матрицы в данных высокой размерности [научная работа опубл... | https://habr.com/ru/post/683498/ | null | ru | null |
# Плагины Jira: несколько примеров успешного изобретения велосипеда

Мы в Mail.ru Group вкладываем много сил в развитие продуктов компании Atlassian и, в частности, Jira. Благодаря нашим усилиям свет увидели плагины MyGroovy, JsInc... | https://habr.com/ru/post/476446/ | null | ru | null |
# Multi-page SPA на Питоне
**Мост между Python и React**
Сова – это нано-фреймворк, который можно встроить в другие фреймворки.
Картинка с sova.online, на котором запущено 3 http сервера:
<http://sova.online/> — просто Falcon
<http://sova.online:8000/> — просто Django
<http://sova.online:8001/> — просто... | https://habr.com/ru/post/424779/ | null | ru | null |
# Демка MONOSPACE, победитель Assembly ONLINE 2020, умещается в 1021 байт

Первое место в соревновании разработчиков [Assembly ONLINE 2020](https://archive.assembly.org/2020) в категории «Online 1k intro» заняла демка MONOSPACE. Пр... | https://habr.com/ru/post/524116/ | null | ru | null |
# Gem ice_cube для повторяющихся событий
В некоторых проектах требуется дать возможность пользователю настроить правила для повторяющихся событий. Иногда правила событий могут быть достаточно сложными, к примеру, “каждый предпоследний день месяца” или “каждую вторую пятницу месяца до определенной даты“. Для решения по... | https://habr.com/ru/post/161123/ | null | ru | null |
# Абсолютный поворотный энкодер с однодорожечным кодом Грея
В этом материале речь пойдёт о физической реализации абсолютного поворотного энкодера. Разрешение этого энкодера составляет 6 градусов, то есть — 60 шагов. Этого достаточно для того чтобы сделать на его основе часы. Здесь используется [одношаговый код Грея](h... | https://habr.com/ru/post/592201/ | null | ru | null |
# PeerVPN – пиринговый VPN с открытым кодом
*Перевод анонса и небольшой документации проекта [PeerVPN](http://www.peervpn.net/), который показался мне интересным.*
#### PeerVPN
Это программа, создающая виртуальную локалку из нескольких удалённых компьютеров. Такие сети могут быть полезны для непосредственного обще... | https://habr.com/ru/post/250277/ | null | ru | null |
# Использование библиотеки OpenCV для распознавания эллиптических дуг на 2D сечениях 3D облаков точек
В связи с все более широким распространением доступных лазерных сканеров (лидаров), способных получать 3D облака точек (*3dОТ*) и все более широким применением этой технологии в различных областях (от машиностроения д... | https://habr.com/ru/post/490400/ | null | ru | null |
# Когда в gcc 16-битные адреса, а памяти внезапно 256к
### … или как выстрелить себе в ногу на Arduino

В летней компьютерной школе мы используем для обучения разработке игр [собственноручно сделанный старый компьютер](https://hab... | https://habr.com/ru/post/421601/ | null | ru | null |
# Сказ о том, как я настраивал Azure AD B2C на React и React Native Часть 4 (Туториал)

### Предисловие
Продолжение цикла по работе с Azure B2C. В данной статье я расскажу о том, как подключить аутентификацию на React Native. ... | https://habr.com/ru/post/505408/ | null | ru | null |
# Пишем бот для рыбалки в игре Albion Online на языке Python

Всем привет, я являюсь счастливым пользователем операционной системы GNU/Linux.И как многим известно, игрушек идущих на линукс без дополнительных танцев с бубном намного меньше чем в «Винде». ... | https://habr.com/ru/post/459110/ | null | ru | null |
# Трансляция h264 видео без перекодирования и задержки
Не секрет, что при управлении летательными аппаратами часто используется передача видео с самого аппарата на землю. Обычно такую возможность предоставляют производители самих БПЛА. Однако что же делать, если дрон собран своими руками?
Перед нами и нашими швейца... | https://habr.com/ru/post/343362/ | null | ru | null |
# Почему я ненавижу YouTube*
###### \*Желтый заголовок, не обращайте внимания. На самом деле название поста «Почему я не люблю смотреть длинные видео, когда можно сказать тоже самое в двух словах», но он бы был не таким привлекательным.
Я не против YouTube, как и не против всех других видео-хостингов(наверное, исключ... | https://habr.com/ru/post/146645/ | null | ru | null |
# Нейросети для детей: объясняем максимально просто
***Всем привет. Ни для кого не секрет, что практически все статьи в нашем блоге публикуются к запуску того или иного курса. Следующую статью можно было бы приурочить к запуску курса «Нейронные сети на Python», но с учетом простоты материала, я не хочу связывать его с... | https://habr.com/ru/post/498898/ | null | ru | null |
# История реверс-инжиниринга одного пушистого зверька

Тихим утром третьего января, когда Москва уже дремала после новогодних праздников, в нашей квартире раздался звонок в дверь. Почта наконец-то доставила посылку с нов... | https://habr.com/ru/post/166377/ | null | ru | null |
# Методы доступа. Наиболее популярные ситуации
Статья в первую очередь расчитана на начинающих разработчиков, либо для тех, кто только начинает переходить от процедурного стиля программирования к ООП, посему матерых гуру просьба не вгонять в минуса :)
Права доступа к свойствам и методам — это на первый взгляд всего... | https://habr.com/ru/post/21357/ | null | ru | null |
# Как устроен Grunt: смотрим исходники

[Grunt.js](http://gruntjs.com/) уже давно обрел популярность отличного инструмента для оптимизации и автоматизации рабочего процесса. [Признан](https://thenetawards.c... | https://habr.com/ru/post/230753/ | null | ru | null |
# Делаем сами простые часы за выходные
Статья о том, как за выходные с нуля сделать простые электронные часы с использованием микроконтроллера. Показана только основа часов, количество программных и аппаратных фич ограничивается только вашей фантазией).

Scrub — это процесс фоновой проверки консистентности данных в Ceph. Он позволяет выявить и устранить несоответствия в копиях, а также найти рассыпающиеся диски, чтобы вовремя и... | https://habr.com/ru/post/536884/ | null | ru | null |
# Выгрузка сотрудников из 1C ЗУП в Битрикс24 или правдивая история о том как настроить интеграцию 1С-Битрикс24 c 1С ЗУП
В жизни так бывает, причём бывает чаще чем хотелось бы, хоть в целом и довольно редко – надо интегрировать Битрикс24 с ЗУП. Сими дружественными компаниями заявлена штатная интеграция (но только для к... | https://habr.com/ru/post/541694/ | null | ru | null |
# Билд-светофор: история еще одного внедрения
Обсуждая реализацию автотестирования в нашей компании, была предложена идея визуализации результатов с помощью светофора. Данный инструмент прост и понятен каждому, да и к тому же производит небольшой вау эффект. Под катом будет история внедрения светофора в нашу систему а... | https://habr.com/ru/post/216743/ | null | ru | null |
# Как Netflix поддерживает надежность сервиса: ограничение нагрузки на основе приоритетов
> ***В преддверии старта курса*** [***"Highload Architect"***](https://otus.pw/4JNj/) ***приглашаем всех желающих посетить открытый вебинар на тему*** [***"Паттерны горизонтального масштабирования хранилищ"***](https://otus.pw/zB... | https://habr.com/ru/post/531320/ | null | ru | null |
# ElasticSearch — агрегация данных

В статье мы рассмотрим, как правильно реализовывать агрегацию данных, зачем это может понадобиться, и сдобрим это кучей рабочих примеров.
Для всех, кому интересно как... | https://habr.com/ru/post/227131/ | null | ru | null |
# Метод Finite Volume — реализация на примере теплопроводности
В статье описывается реализация известного метода конечных объемов для численного решения уравнений в частных производных.Используется разбиение области на любые стандартные элементы(конечные объемы) — треугольники, четырехугольники и т.д.Метод визуализаци... | https://habr.com/ru/post/276193/ | null | ru | null |
# Скрытые зависимости как «запах» проектирования
[Марк Симан](http://blog.ploeh.dk/about.html) написал [замечательный пост «Service Locator нарушает инкапсуляцию».](http://habrahabr.ru/post/270005/) Название поста говорит само за себя о том, что он посвящён паттерну (анти-паттерну) *Service Locator*. Когда программист... | https://habr.com/ru/post/270547/ | null | ru | null |
# Uni Localization. Абсолютная кастомизация, работает на любом сайте (Vue, React, Angular, ...)
**Disclaimer:** Эта статья про веб компоненты и уже реализованное UI решение на них. Если вам нравится все новое и нестандартное, тогда, я уверен вам понравится и наша реализация.
Я всегда мечтал о функциональности, котору... | https://habr.com/ru/post/598319/ | null | ru | null |
# Визуализация в IoT: или как самому развернуть систему сбора и отображения данных на MQTT+Telegraf+InfluxDB+Grafana
Введение
--------
В данной статье приведен скоуп информации о том, что взять за основу, чт... | https://habr.com/ru/post/680902/ | null | ru | null |
# Ускорения параллельных вычислений
Главной целью создания и разработки многочисленных типов параллельных машин, о которых мы говорили в [прошлой](http://habrahabr.ru/blogs/hi/126930/) статье, это скорость. Суперкомпьютеры и многопроцессорные системы могут и должны делать все быстрее! Давайте постараемся расчитать, на... | https://habr.com/ru/post/127007/ | null | ru | null |
# Трассировка и мониторинг в Istio: микросервисы и принцип неопределенности
Принцип неопределенности Гейзенберга гласит, что нельзя одновременно измерить положение объекта и его скорость. Если объект движется, то у него нет местоположения. А если местоположение есть – значит у него нет скорости.
 о страницах веб-сайта, которые подлежат индексации. Sitemaps может помочь поисковикам определить местонахождение страниц сайта, время их последнего обн... | https://habr.com/ru/post/73303/ | null | ru | null |
# CRUD API на Deno и PostgreSQL: работаем с динозавром
***Всем привет. В преддверии старта курса [«Fullstack разработчик JavaScript»](https://otus.pw/7TM5/), хотим поделиться интересным материалом, который прислал наш внештатный автор. Данная статья не имеет отношения к программе курса, но наверняка будет интересна, к... | https://habr.com/ru/post/505476/ | null | ru | null |
# Книга «Angular для профессионалов»
[](https://habrahabr.ru/company/piter/blog/340826/) Выжмите из Angular — ведущего фреймворка для динамических приложений JavaScript — всё. Адам Фримен начинает с описания MVC и его преимуществ, зат... | https://habr.com/ru/post/340826/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.