
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Немного про кино или как делать интерактивные визуализации в python
Введение
--------
В этой заметке я хочу рассказать о том, как можно достаточно легко строить интерактивные графики в Jupyter Notebook'e с помощью библиоте... | https://habr.com/ru/post/308162/ | null | ru | null |
# InterSystems iKnow. Загружаем данные из Вконтакте
Эта статья продолжает цикл рассказов ([раз](http://habrahabr.ru/company/intersystems/blog/243217/), [два](http://habrahabr.ru/company/intersystems/blog/244697/)) об основных способах/сценариях использования iKnow — инструмента Natural Language Processing'а из стека т... | https://habr.com/ru/post/246719/ | null | ru | null |
# Динамическая CDN для WebRTC стриминга с низкой задержкой и транскодингом

В [первой части](https://habr.com/en/company/flashphoner/blog/477310/) мы развернули простую динамическую CDN для трансляции WebRTC потоков на два континента и... | https://habr.com/ru/post/477874/ | null | ru | null |
# Обобщение медианного фильтра
#### Аннотация
В данной статье рассказывается об уникальном фильтре, статья о котором появилась в 1990 году: *Маслов А.М., Сергеев В.В. Идентификация линейной искажающей системы с использованием ранговой обработки сигналов // Компьютерная оптика. — М., 1990. — Вып.6. — С.97-102.* Данный... | https://habr.com/ru/post/114551/ | null | ru | null |
# Считаем комбинации мозаик при помощи APL
Это короткая статья о том, как я воспользовался APL для проверки своих комбинаторных вычислений.
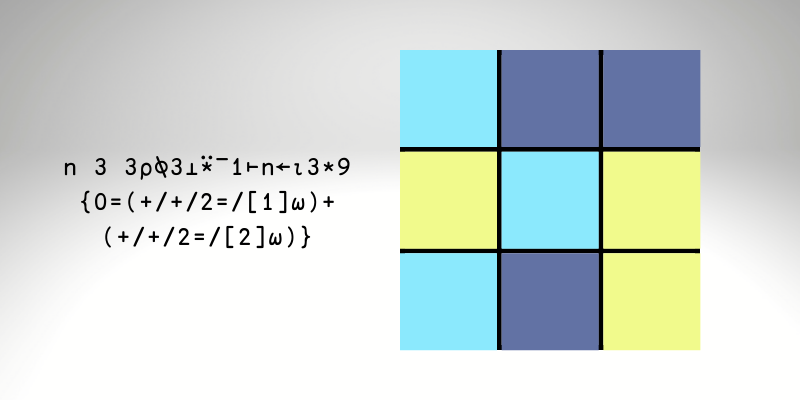
Преамбула
=========
Наш местный университет проводит еженедел... | https://habr.com/ru/post/589449/ | null | ru | null |
# HackTheBox. Прохождение Mango. NoSQL инъекция и LPE через JJS
Продолжаю публикацию решений отправленных на дорешивание машин с площадки [HackTheBox](https://www.hackthebox.eu).
В данной статье эксплуатируем NoSQL инъекцию... | https://habr.com/ru/post/497912/ | null | ru | null |
# Делаем интерактивный план местности за 15 минут
На Тостере часто спрашивают о том, как сделать интерактивную схему дома, план его внутреннего устройства, возможность выбора этажей или квартир с выводом информации о них, вывод инфо... | https://habr.com/ru/post/478698/ | null | ru | null |
# Сравнение производительности различных систем шифрования под linux
В данной статье я попытаюсь сравнить производительность различных систем шифрования под linux. В теории, конечно, известно, какая система производительнее, и попытки посчитать производительность разных систем были ([например](http://habrahabr.ru/post... | https://habr.com/ru/post/201694/ | null | ru | null |
# Программирование для Palm в 2017 году
*Я, в трезвом уме и доброй памяти, рассказываю как, в 2017 году начать программировать для исчезнувшей платформы.*
Шло 12 мая 2017 года. Лежащий снег за окном и включённое отопление навевали мысли о вечном, и мой взор упал на шикарный промышленный КПК под управлением PalmOS. ... | https://habr.com/ru/post/358168/ | null | ru | null |
# Пряморукий DNS: делаем правильно
Представляем вашему вниманию очень эмоциональный рассказ Льва Николаева ([@maniaque](https://habrahabr.ru/users/maniaque/)) о том, как надо настраивать DNS и особенно, как делать не надо. Вот прямо после каждого пункта можете мысленно добавлять: «Пожалуйста, не делайте этого!» В свое... | https://habr.com/ru/post/350550/ | null | ru | null |
# RestKit — описание одной из возможностей
Привет Хабр!
#### Предыстория
Давно заметил, что на хабре нет ни одной статьи о такой замечательной библиотеке как [RestKit](http://restkit.org/), написанной на Objective-C и предоставляющая прекрасные возможности для работы с [RESTful](http://ru.wikipedia.org/wiki/REST)-... | https://habr.com/ru/post/172233/ | null | ru | null |
# Конечные автоматы. Пишем ДКА
Если вы когда-нибудь пытались написать своего бота, программу-переговорщик (negotiator), интерпретатор протокола связи и тому подобные вещи, то наверняка сталкивались с конечными автоматами. Данная тема в принципе не представляет большой сложности, но если вдруг у вас не было курса «теор... | https://habr.com/ru/post/141503/ | null | ru | null |
# Angular Universal: работа в крупном e-commerce
Привет, меня зовут Дмитрий Дружков, я тимлид фронтенд команды в Утконос Онлайн. В этой статье я расскажу, чем полезен Angular Universal в e-commerce проектах, как выбрать вид рендеринга, как выглядит первоначальная настройка технологии на примере нашего сайта и шаги по ... | https://habr.com/ru/post/663518/ | null | ru | null |
# Переходим от MongoDB Full Text к ElasticSearch
В своем прошлом [посте](http://habrahabr.ru/company/likeastore/blog/222515/), с анонсом Google Chrome расширения для [Likeastore](https://likeastore.com), я упомянул тот факт, что в качестве поискового индекса мы начали использовать [ElasticSeach](http://elasticsearch.c... | https://habr.com/ru/post/223109/ | null | ru | null |
# Простые шаги по сокращению кода после применения паттерна «стратегия» с помощью generic-классов
Эта заметка содержит ряд хитростей, позволяющих сократить код, получившийся после применения паттерна «стратегия». Как нетрудно догадаться из названия, все они будут так или иначе связаны с использованием generic-типов. ... | https://habr.com/ru/post/322762/ | null | ru | null |
# Использование переменных окружения в Node.js
Материал, посвящённый переменным окружения в Node.js, перевод которого мы сегодня публикуем, написал [Берк Холланд](https://developer.microsoft.com/ru-ru/advocates/burke-holland), веб-разработчик, в сферу интересов которого входят JavaScript, Node.js и VS Code. Кроме того... | https://habr.com/ru/post/351254/ | null | ru | null |
# Quarkus — новый взгляд на Cloud Native Java
Привет, Хабр!
В наступившем новом году мы планируем всерьез развивать темы контейнеров, [Cloud-Native Java](https://www.piter.com/product_by_id/112863337) и [Kubernetes](https://www.piter.com/product_by_id/125705747). Логичным продолжением этих тем на русском языке буде... | https://habr.com/ru/post/482968/ | null | ru | null |
# QoS в Linux: издеваемся над трафиком
В [предыдущей статье](http://habrahabr.ru/blogs/sysadm/138463/) я рассказывал про фильтр U32. В этой статье речь пойдёт о так называемых tc actions — действиях, которые можно производить над трафиком. Например, можно построить файерволл без использования iptables/netfilter, или и... | https://habr.com/ru/post/138562/ | null | ru | null |
# Штриховое кодирование: программная реализация на С#
Приветствую! Речь пойдет о создании программы, которая сможет кодировать информацию в штрих код. Рассмотрим мы два варианта: EAN13 и Code 128.
Для начала разберемся что же предоставляет собой штрих код, и начнем с формата EAN 13. Внешне штрих код состоит из чер... | https://habr.com/ru/post/127799/ | null | ru | null |
# Компонент AGE, Another Graphic Engine in .NET
Итак сразу к делу. Компонент можно достать [здесь](http://www.codeproject.com/KB/dotnet/another_graphic_engine.aspx?fid=356826&df=90&mpp=25&noise=3&sort=Position&view=Quick&select=1891853) и там же есть описание его.
Компонент неплох. Хорошо рисует, можно понастраиват... | https://habr.com/ru/post/61930/ | null | ru | null |
# Понимание конфликтов банков разделяемой (shared) памяти в NVIDIA CUDA
Разделяемая (shared) память является очень эффективным средством оптимизации за счет очень быстрого доступа (в 100 раз быстрее чем глобальная память). Однако, при неправильном использовании ее возможны конфликты банков, которые существенно замедля... | https://habr.com/ru/post/100363/ | null | ru | null |
# Twitter забанил часть украинских IP?
Несколько дней назад я заметил, что твиттер перестал открываться. Пропинговав, я увидел, что пинги не доходят, но списал это на проблемы сервиса. Когда на следующее утро ситуация не изменилась, я заподозрил неладное и пошёл на неофициальный форум пользователей ОГО!(услуга интерне... | https://habr.com/ru/post/128802/ | null | ru | null |
# Python для сетевых инженеров: начало пути
Наверное, многие сетевые инженеры уже поняли, что администрирование сетевого оборудования только через CLI слишком трудоёмко и непродуктивно. Особенно когда под управлением находятся десятки или сотни устройств, часто настроенных по единому шаблону. Удалить локального пользо... | https://habr.com/ru/post/336608/ | null | ru | null |
# Dependency Injection: анти-паттерны
*Слабая связанность (low coupling) часто является признаком хорошо структурированной компьютерной системы и признаком хорошего дизайна.* Wikipedia
Dependency Injection (DI) — это набор паттернов и принципов разработки програмного обеспечения, которые позволяют писать слабосвязн... | https://habr.com/ru/post/166287/ | null | ru | null |
# graphql — оптимизация запросов к базе данных
При работе с базами данных существует проблема которую принято называть «SELECT N + 1» — это когда приложение вместо одного запроса к базе данных, который выбирает все необходимые данные из нескольких связанных таблиц, коллекций, — делает дополнительный подзапрос для кажд... | https://habr.com/ru/post/412847/ | null | ru | null |
# Распознаём тексты на Android Things с ABBYY RTR SDK и django
Привет! Меня зовут Азат Калмыков, я студент второго курса ОП “[Прикладная математика и информатика](https://www.hse.ru/ba/ami/)” Факультета компьютерных наук НИУ ВШЭ и стажёр в отделе мобильной разработки компании ABBYY. В этом материале я расскажу про сво... | https://habr.com/ru/post/432514/ | null | ru | null |
# Как написать игру на Monogame, не привлекая внимания санитаров. Часть 3, уменьшаем энтропию
Предыдущие части: [Часть 0](https://habr.com/ru/post/676850/), [Часть 1](https://habr.com/ru/post/676998/), [Часть2](https://habr.com/ru/post/677718/)
*4.5* *Создаем вселенную*
Итак, мы закончили делать базовый каркас и до... | https://habr.com/ru/post/679456/ | null | ru | null |
# Прототипирование с помощью Wireframesketcher
Как-то раз у меня возникла задача нарисовать для дизайнера небольшой, по возможности интерактивный прототип сайта. Естественно первым делом полез искать достойный инструмент на любимый хабрахабр.
Поиск инструмента
-----------------
Быстро нашел две хорошие статьи с пе... | https://habr.com/ru/post/165711/ | null | ru | null |
# Пишем CLI модуль для Zend Framework 2

Приветствую!
Недавно начал работать с Zend Framework 2, и возникла потребность написать cli модуль работающий с миграциями базы данных.
В этой статье я оп... | https://habr.com/ru/post/159155/ | null | ru | null |
# Опыт разработки под Android Wear
Спешу поделиться с коллегами накопленным опытом при разработке для Android Wear.
Все важные моменты проще всего показать на примере приложения, которое показывает уровень заряда батареи на часах и смартфоне.
Загрузим Android Studio.
Создадим новый проект:
](https://habr.com/ru/company/ruvds/blog/585986/)
Третья, заключительная часть серии, посвященной пробросу видеокарт в виртуальную машину и организации облачной... | https://habr.com/ru/post/585986/ | null | ru | null |
# Подводные камни бенчмаркинга в .NET: фрагмент книги Андрея Акиньшина
**Андрей Акиньшин** [@DreamWalker](https://t.me/DreamWalker) хорошо известен в .NET-сообществе: он мейнтейнер BenchmarkDotNet и perfolize... | https://habr.com/ru/post/599927/ | null | ru | null |
# Проблема модификации даты через strtotime
Добрый день хабравчане.
Хочу поведать вам о небольшой проблеме с вычислением даты функцией [strtotime](http://ru.php.net/strtotime).
Суть в следующем. Мне нужно было получить название предыдущего месяца. Ничего сложного в этой задаче нет:
```
$t = strtotime('-1 mont... | https://habr.com/ru/post/144959/ | null | ru | null |
# Учите других, чтобы стать лучшим программистом
Это перевод. [Статья](https://www.zeroequalsfalse.press/2018/06/10/teach/) опубликована 10 июня 2018 года

Надоело программирование? **Попробуйте учить ... | https://habr.com/ru/post/413951/ | null | ru | null |
# PHP-Дайджест № 104 – интересные новости, материалы и инструменты (1 – 12 марта 2017)
[](https://habrahabr.ru/company/zfort/blog/323750/)
Предлагаем вашему вниманию очередную подборку со ссылками на новос... | https://habr.com/ru/post/323750/ | null | ru | null |
# Обучаемое управление роботом по ИК пульту

Недавно я присоединился к [проекту Робот-Митя](http://habrahabr.ru/post/135043/). Спасибо большое Дмитрию [DmitryDzz](https://geektimes.ru/users/dmitrydzz/), что сделал такой ... | https://habr.com/ru/post/168197/ | null | ru | null |
# Комбинаторика в Python
Стандартная библиотека python, начиная с версии 2.2, предоставляет множество средств для генерирования комбинаторных объектов, но в интернете мне не удалось найти ни одной статьи, которая подробно рассказывала бы о работе с ними. Поэтому я решил исправить это упущение.
Начну с того, что расск... | https://habr.com/ru/post/479816/ | null | ru | null |
# Стартуем на ПЛИС, но сначала припаяем его с конструктором беспилотного автомобиля Zoox
Однажды мне не спалось ночью и я залип на сайтах про паяльники. Возникло желание купить и сразу появились вопросы: на с... | https://habr.com/ru/post/715012/ | null | ru | null |
# Яндекс. Директ. Анализируем конкурентное окружение

Представьте ситуацию. Вы разрабатываете сайты. Хорошие сайты для хороших людей. Ваши рекламные кампании работают давно, вы вышли на хороший уровень ROI, заказы идут с завидной... | https://habr.com/ru/post/107790/ | null | ru | null |
# Метод Виолы-Джонса (Viola-Jones) как основа для распознавания лиц
Хотя метод был разработан и представлен в 2001 году Полом Виолой и Майклом Джонсом [1, 2], он до сих пор на момент написания моего поста является основополагающим для поиска объектов на изображении в реальном времени [2]. По следам [топика](http://hab... | https://habr.com/ru/post/133826/ | null | ru | null |
# Объяснение эксперимента о ветвлениях, или философские изыскания на тему бенчмарков в вакууме и в… реальности
Надеюсь, кто хотел, ознакомился с моим пробным экспериментом на Хабре [в этой](https://habrahabr.ru/post/281629/) статье. Теперь я считаю, что будет правильным огласить его результаты и даже дать более деталь... | https://habr.com/ru/post/281769/ | null | ru | null |
# jQuery.keyboard v0.2.0
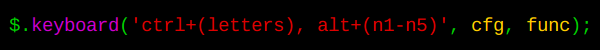
Снова приветствую Хабрасообщество. Недельку назад я [выкладывал свою либу jQuery.keyboard](http://habrahabr.ru/blogs/jquery/76424/). Там было несколько недостатков, нереализованных... | https://habr.com/ru/post/77021/ | null | ru | null |
# Awless — мощная альтернативная CLI-утилита для работы с сервисами AWS

Все пользователи облачных сервисов Amazon давно знают про родной консольный инструмент для работы с ними — aws-cli. Но оказалось, что далеко не всем его ... | https://habr.com/ru/post/330398/ | null | ru | null |
# Использование SEH в 32 разрядных приложениях Windows с компилятором Mingw-W64
#### Что такое SEH
Из всех механизмов, предоставляемых операционными системами семейства Windows, возможно наиболее широко используемым, но не полностью документированным, является механизм структурной обработки исключений (он же Structur... | https://habr.com/ru/post/533882/ | null | ru | null |
# Новые API в .NET 6
.NET 6 в процессе [разработки](https://devblogs.microsoft.com/dotnet/announcing-net-6-preview-7/), и я хотел поделиться некоторыми из моих любимых новых API в .NET и ASP.NET Core, которые вам обязательно понравятся. Почему они понравятся? Потому что они разработаны при прямом участии нашего фантас... | https://habr.com/ru/post/574434/ | null | ru | null |
# Введение в программирование шейдеров для верстальщиков

WebGL существует уже давно, про шейдеры написано немало статей, есть серии уроков. Но в основной массе они слишком сложные для верстальщика. Даже лучше сказать, что они охваты... | https://habr.com/ru/post/420847/ | null | ru | null |
# Квадрарный поиск
**Тернарный (или троичный) поиск** — это алгоритм поиска минимума (или максимума) **выпуклой** функции на отрезке. Можно искать минимум (максимум) функции от вещественного аргумента, можно минимум (максимум) на массиве. Будем, для определённости, искать минимум функции f(x).
Он многим знаком, а ... | https://habr.com/ru/post/92591/ | null | ru | null |
# Мониторинг окружающей среды в серверном помещении (Bolid + Zabbix)
Наверное самым простым способом для ИТ-специалиста при решении задачи мониторинга окружающей среды в серверном помещении будет использование специализированных контроллеров с выдачей данных по SNMP (например, NetBotz или NetPing). Но для тех кто не б... | https://habr.com/ru/post/438788/ | null | ru | null |
# Автоматический прием Яндекс.Денег на сайте на php
Документация по приему Яндекс.Денег не содержит конкретного примера на PHP, чтобы можно было максимально быстро все прикрутить, не разбираясь во всех деталях того, как работает прием Яндекс.Денег на PHP. Сделав автоматический прием Яндекс.Денег для нашего [дата-центр... | https://habr.com/ru/post/160969/ | null | ru | null |
# Ещё 10 батареек для джанго

Продолжаем делиться своим опытом использования полезных батареек для Django.
[Первая часть](http://habrahabr.ru/blogs/django/115754/)
Ещё рекомендуем [«Сумбурные заметки про python и ... | https://habr.com/ru/post/136168/ | null | ru | null |
# Как работают регулярные выражения, или Движок regex с анимацией
##### Aydin Schwartz
Студент магистратуры Data Science Университета Сан-Франциско
. Для мобильных игр такое требование обусловлено не только желанием обеспечить долгую пост-релизную поддержку игры, но также необходимостью учитывать технические о... | https://habr.com/ru/post/572554/ | null | ru | null |
# Управление рекламой (android)
Реклама в приложении — это очень важный момент, а иногда и единственный заработок.
Думаю, многие задавались вопросом о том, какая реклама лучше и где ее лучше размещать. Каждое приложение индивидуально, поэтому нужно экспериментировать.
Выпускать каждый раз обновления приложения с... | https://habr.com/ru/post/208984/ | null | ru | null |
# SHISHUA: самый быстрый в мире генератор псевдослучайных чисел

Полгода назад мне захотелось создать лучший генератор псевдослучайных чисел (ГПСЧ) с какой-нибудь необычной архитектурой. Я думал, что начало будет лёгким, а по мере ... | https://habr.com/ru/post/498352/ | null | ru | null |
# Правильный хостинг для MODx своими руками

Топик рассказывает о настройке быстрого и недорогого хостинга для MODx Revolution. В принципе, вещи тут описаны общие, так что информация подойдет для **любой** CMS. Позже была... | https://habr.com/ru/post/139461/ | null | ru | null |
# Мониторинг NetApp Volumes через SSH

Всем привет, меня зовут Игорь Сидоренко. Одной из основных сфер моей работы, а также моим хобби является мониторинг. Я расскажу о Zabbix и о том, как с его помощью замониторить необходимую нам... | https://habr.com/ru/post/517206/ | null | ru | null |
# Имя enum'a C++ в рантайме
Получение имени типа, не важно это структура или перечисление, в C++ — проблема. То, что тривиально известно компилятору на этапе парсинга исходников, не получится перевести в человеко-читаемый вид в рантайме. Можно использовать std::type\_info::name, который не является переносимым решение... | https://habr.com/ru/post/697198/ | null | ru | null |
# Многоэтапные (multi-stage builds) сборки в Docker
Docker начиная с версии 17.05 и выше стал поддерживать многоэтапные сборки (multi-stage builds). С удивлением обнаружил, что никто еще не написал об этом на хабре. Поэтому давайте исправим этот пробел.
Изменения будут особенно полезны тем, кто собирает образы (im... | https://habr.com/ru/post/349802/ | null | ru | null |
# Продвинутая работа с JSON в MySQL
У MySQL нет возможности напрямую индексировать документы JSON, но есть альтернатива: генерируемые столбцы.
С момента введения поддержки типа данных JSON в MySQL 5.7.8 не хватает одной вещи: способности индексировать значения JSON. Для того, чтобы обойти это ограничение, можно испол... | https://habr.com/ru/post/348854/ | null | ru | null |
# Хостим сайт в межпланетной файловой системе IPFS под Windows
Прошло некоторое время от начала моих экспериментов с хостингом простых сайтов в IPFS. Запустил я свой IPFS клиент под Windows и у меня есть теперь что дополнить к предыдущей статье ["Публикуем сайт в межпланетной файловой системе IPFS"](https://habrahabr.... | https://habr.com/ru/post/325176/ | null | ru | null |
# Как начать писать программный код Си в ОС Linux (Руководство для совсем начинающих)
Введение
--------
Добрый день. Этот материал рассчитан на людей, будущих программистов, которые только начинают разбираться в программировании под ОС Linux. Я попробую здесь показать прямое руководство к действию на примере тех прос... | https://habr.com/ru/post/657209/ | null | ru | null |
# Mtt, или что-то посложнее, чем нарисовать треугольник
Забавно, куда порой могут привести несколько экспериментов. Вроде бы план был простой — посмотреть, что там такого интересного в этом вот вашем вулкане,... | https://habr.com/ru/post/689176/ | null | ru | null |
# Генерация HTML: удобнее чем хелперы и чистый HTML
Писать чистый HTML часто неудобно, особенно если нужно делать динамические вставки.
Шаблонизаторы частично решают эту проблему, но их причудливый синтаксис нужно изучать, мириться с ограничениями, вкладывать одни шаблоны в другие для повторного использования, в це... | https://habr.com/ru/post/241710/ | null | ru | null |
# RE Crypto Part#2
Наверное самое популярное действие, которое приходится выполнять для исследования криптографии сегодня это процедура анализа зловредного кода, который блокирует чьи-то данные с использовани... | https://habr.com/ru/post/695182/ | null | ru | null |
# Публикация приложения в Elastic Beanstalk
Привет! 
Сегодня я расскажу как легко создавать приложения в Elastic Beanstalk и публиковать их прямо из Git!
Для начала предлагаю установить утилиты командной строки дл... | https://habr.com/ru/post/163489/ | null | ru | null |
# Cloudera Streaming Analytics: унификация пакетной и потоковой обработки в SQL
В октябре 2020 года Cloudera приобрела компанию Eventador, а в начале 2021 года был выпущен продукт [Cloudera Streaming Analytics (CSA) 1.3.0](https://blog.cloudera.com/accelerated-integration-of-eventador-with-cloudera-sql-stream-builder/... | https://habr.com/ru/post/571532/ | null | ru | null |
# Технические рекомендации и ресурсы Google для мобильных сайтов

Предлагаем вашему вниманию материалы доклада Андрея Липатцева, Google, с последней конференции [Bitrix Summer Fest](http://conf.1c-bitrix.ru/summer2015/onlin... | https://habr.com/ru/post/267945/ | null | ru | null |
# Android interop with SWIG (a guide). From simple to weird. Part 2 — weird
*This is Part 2. Part 1 is*[*here*](https://habr.com/ru/post/536314/)*.*
*Part 2* covers the use of typemaps, complex & weird cases, and debugging suggestions. This part requires an understanding of Part 1 - usage of [SWIG](http://swig.org/) ... | https://habr.com/ru/post/536868/ | null | en | null |
# Настраиваем и автоматизируем развёртывание Active Directory

В этой статье я бы хотел предложить вам пошаговый туториал по развёртыванию контроллера домена Active Directory на Windows Server 2016 (с графической оболочкой), а также по... | https://habr.com/ru/post/525326/ | null | ru | null |
# [Перевод] CSS Filters
CSS Filters были созданы для получения различных визуальных эффектов при применении их к DOM элементам. В данной статье мы поговорим об истории фильтров, о том, что они делают и как их применять. Так... | https://habr.com/ru/post/144852/ | null | ru | null |
# Уменьшаем время сборки ваших Android-проектов
Доброе утро! Начинаем понедельник с материала, перевод которого подготовлен специально для студентов курса [«Android-разработчик. Продвинутый курс»](https://otus.pw/GBGF/).

Недавно ... | https://habr.com/ru/post/457374/ | null | ru | null |
# Angular 2 Beta, обучающий курс «Тур героев» часть 1
[Часть 1](https://habrahabr.ru/post/281190/) [Часть 2](https://habrahabr.ru/post/281727/) [Часть 3](https://habrahabr.ru/post/282634/) [Часть 4](https://habrahabr.ru/post/283556/)
Вступление
----------
*Эта статья основана на [документации](https://angular.io/doc... | https://habr.com/ru/post/281190/ | null | ru | null |
# Малоизвестные функции в WordPress
Случалось ли с вами, что во время разбора кода стороннего плагина или темы, вы находили довольно полезную стандартную функцию, о которой раньше не знали? В такие моменты любой разработчик ощущает чувство собственной ничтожности, вспоминая какие велосипеды он городил в предыдущих про... | https://habr.com/ru/post/233089/ | null | ru | null |
# Умный дом, как я до такого докатился. Часть 2-я
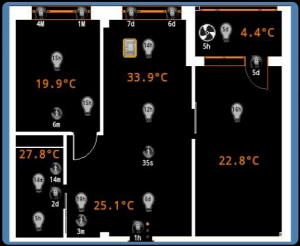
В [первой](http://habrahabr.ru/post/158911/) части я рассказал о причинах, побудивших меня заняться построением своего “умного дома”, и об используемом “же... | https://habr.com/ru/post/167797/ | null | ru | null |
# Знакомство с виртуальными интерфейсами Linux: туннели
Linux поддерживает множество видов туннелей. Это запутывает новичков, которым бывает сложно разобраться в различиях технологий, и понять то, каким туннелем лучше воспользоваться в конкретной ситуации. В материале, перевод которого мы сегодня публикуем, будет дан ... | https://habr.com/ru/post/457386/ | null | ru | null |
# Okta: безопасный доступ к приложениям на Angular + Spring Boot

> Перевод статьи подготовлен в рамках набора учащихся на курс [**«Разработчик на Spring Framework».**](https://otus.pw/EB9K/)
>
> Приглаш... | https://habr.com/ru/post/555298/ | null | ru | null |
# Как посмотреть плоские фильмы в 3D
Это расширенная версия моей публикации на [Medium](https://medium.com/swlh/how-to-convert-a-2d-movie-to-3d-d54ec5f9f233)
Недавно я сидел в баре с другом зашел разговор о том, в к... | https://habr.com/ru/post/529602/ | null | ru | null |
# Очень типобезопасно! Концепт продвинутой расширяемой системы единиц измерения с generic math для .NET
Привет!
Хочу предложить концепт системы единиц измерения с полной типобезопасностью, хорошей производительностью и полной расширяемостью!
Для нетерпеливых: [github](https://github.com/WhiteBlackGoose/UnitsOfMeasur... | https://habr.com/ru/post/597437/ | null | ru | null |
# Vim: поиск по документации на Javascript
Обычно я работаю в Kate или Geany. Но иногда, как и всем людям, мне хочется освоить Vim. И каждый раз, примерно на второй минуте «освоения» возникает какой-нибудь совершенно дурацкий вопрос. Например, почему при нажатии стрелок (или клавиш jk) курсор скачет сразу через все ст... | https://habr.com/ru/post/346196/ | null | ru | null |
# Сайт знакомств с программистами Love++
Оплотом современного мира являются программисты. Программисты — это самые надежные и умные люди в мире. Любая проблема обычного человека является элементарной для программиста. Программисты умеют находить решение любой проблемы в считанные минуты.
Небольшой загвоздкой в жизн... | https://habr.com/ru/post/169405/ | null | ru | null |
# Распознавание жестов с помощью APDS-9960

Читая комментарии к моей предыдущей [статье](https://habr.com/post/423847/) про APDS-9960, где речь шла про распознавание цвета и уровня освещенности для меня стали очевидными две ве... | https://habr.com/ru/post/424947/ | null | ru | null |
# Особенности работы с переменными и литералами в Perl6
Не так давно я решил начать изучать Perl6, даже не смотря на то, что фактически полностью работающего компилятора ещё нету. Подумал что можно смотреть [Synopsis'ы](http://feather.perl6.nl/syn/), смотреть что из написанного в них уже работает, и изучать как именно... | https://habr.com/ru/post/152403/ | null | ru | null |
# Самый полный стартовый гайд по ботам Telegram (python)
QQ Хабр! В этом гайде мы пройдемся по каждому шагу создания ботов в Telegram - от регистрации бота до публикации репозитория на GitHub. Некоторым может показаться, что все разжевано и слишком много элементарной информации, но этот гайд создан для новичков, хотя ... | https://habr.com/ru/post/697052/ | null | ru | null |
# Пишем простую игру на python
Сегодня мы создадим всем известную игру камень, ножницы, бумага. В этом нам поможет ЯП python и библиотека tkinter, но если вы не знаете что это такое, советую почитать данную [статью.](https://habr.com/ru/post/133337/)

*Преамбула от переводчика: пару месяцев назад я искал решение для возможности использовать исключения в сервере игры, написанном на node.js. К сожалению, исключения в чи... | https://habr.com/ru/post/147233/ | null | ru | null |
# Улучшаем качество кода React-приложения с помощью Compound Components
Я люблю сталкиваться с трудностями. Но с такими, которые можно решить, подумать над интересным решением, подобрать технологию. Люблю быть в потоке, а после решения чувствую себя настоящим профессионалом.
Но есть кое-что, из-за чего я не люблю про... | https://habr.com/ru/post/691976/ | null | ru | null |
# Автоматизация создания аккаунтов в Thunderbird v3

В линейке Thunderbird 3 появилась полезная возможность «подхватывать» настройки доступа к почтовому серверу. Но для этого необходимо немного «почеса... | https://habr.com/ru/post/106666/ | null | ru | null |
# Создание собственной темы usplash
Как и обещал в [предыдущем топике](http://lavi.habrahabr.ru/blog/82655/), подробно описываю создание собственной темы usplash. Для начала нам понадобятся: GIMP и некоторые навыки работы в нем, а так же следующие пакеты:
gcc, libbogl-dev, libusplash-dev
Любая тема Usplash состо... | https://habr.com/ru/post/82661/ | null | ru | null |
# Создание приложения Sticky Notes с использованием 8base, GraphQL и React

Посмотреть демо версию программы [здесь](https://note-app.now.sh/).
Во все времена тайм менеджмент был связан для меня с о... | https://habr.com/ru/post/463907/ | null | ru | null |
# А что если перейти на Удобный Шестидневный календарь?
Примерно месяц назад я добавлял в интерфейс кнопку, которая устанавливала дату календаря, соответствующую понедельнику прошлой недели. В процессе разработки я понял, что было бы хорошо изменить требования, потому что реализовывать их достаточно сложно. Только мен... | https://habr.com/ru/post/530116/ | null | ru | null |
# Улучшаем админку
Одно из слабых мест джанго-админки — главная страница. Идея авто-группировки моделей по приложениям и вывод столбиком в одну колонку работает только на начальных этапах, дальше это становится просто неудобно — куча лишней информации и довольно сложные пути для того, чтобы добавить полезную. Ну, напр... | https://habr.com/ru/post/98539/ | null | ru | null |
# Мультитул для управления Хранилищем Данных — кейс Wheely + dbt
Уже более двух лет *data build tool* активно используется в компании Wheely для управления Хранилищем Данных. За это время накоплен немалый опы... | https://habr.com/ru/post/549614/ | null | ru | null |
# Прозрачное перенаправление почты через iptables
Заголовок можно продолжить:… *или плавный перевод почты на другой сервер*.
Недавно встала задача — реализовать возможность использования почтового сервера, не имеющего прямого выхода в интернет. Причем работать он должен вместо старого, который работает, естественно... | https://habr.com/ru/post/99898/ | null | ru | null |
# How to make your home ‘smart’ without going crazy

Smart furniture, which keeps your house in order, is a must for almost any futuristic set. In fact, an auto-regulating climate, automatic lights and voice control over househo... | https://habr.com/ru/post/515484/ | null | en | null |
# Создаем приложение Art-pixel на Angular и Nest.js. Часть 2
Во второй части мы займемся созданием возможности сохранения рисунка, добавим возможность редактирования наших сохраненных рисунков, а также добавим возможность просмотра пользователем примеров работ, по которым при желании можно будет создавать такие же или... | https://habr.com/ru/post/648619/ | null | ru | null |
# Пишем простое, но полезное приложение для Nokia N900 за 20 минут
Приветствую, уважаемый хабраюзер!
В данной заметке я расскажу об интересных свойствах операционной системы Maemo с точки зрения
системного администратора Unix.... | https://habr.com/ru/post/125404/ | null | ru | null |
# Ломаем хаКс полностью. Читаем машинные коды как открытую книгу
[](https://habrastorage.org/web/3f4/29f/fbf/3f429ffbff974842a7656d2521c9f2db.png)Если haXe оттранслирован в C++, а из него — в машинные коды, это может показаться б... | https://habr.com/ru/post/335970/ | null | ru | null |
# PostgreSQL в «Тензоре» — публикации за год
Ровно год назад с [рассказа о нашем сервисе визуализации планов запросов](https://habr.com/ru/post/477624/) мы начали публикацию на Хабре серии статей, посвященных работе с PostgreSQL и его особенностям. Это уже пройденные нами **«грабли», интересные наработки, накопившиеся... | https://habr.com/ru/post/529624/ | null | ru | null |
# STM32 + linux
Для разработки системы управления одной железякой после длительных поисков мною был выбран ARM-микроконтроллер семейства STM32 — STM32F103 (в «стоножечном» исполнении). А в качестве макетки для разработки и отладки — STM32P103 (там ножек хоть и меньше, но ядро то же самое). «Истории успеха» я понемногу... | https://habr.com/ru/post/161863/ | null | ru | null |
# Как превратить книгу о Гарри Поттере в граф знаний
Обработка естественного языка — это не только нейронные сети, а данные — это не только строки, числа и перечисления. Область работы с данными простирается... | https://habr.com/ru/post/570582/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.