
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Создаем видеостену с трансляцией изображения с ip-камер через спутник с минимумом трафика
В статье рассказывается о том, как обеспечить «почти видеотрансляцию» средствами ffmpeg, wget, JS, html ~~и такой-то матери~~. По сути, мы создаем слайдшоу с аккуратным его выводом и динамическим обновлением на веб-страничке. В... | https://habr.com/ru/post/239853/ | null | ru | null |
# не http: ссылки
Можно сделать так, что бы парсер не портил ссылки вида
`<opera:config#AutoUpdate|AutoUpdateState>`
? | https://habr.com/ru/post/49126/ | null | ru | null |
# Понимание Q-learning, проблема «Прогулка по скале»
Привет, Хабр! Предлагаю вашему вниманию перевод статьи [«Understanding Q-Learning, the Cliff Walking problem»](https://medium.com/init27-labs/understanding-q-learning-the-cliff-walking-problem-80198921abbc) автора [Lucas Vazquez](https://medium.com/@lgvaz).

>
> {
>
> if(items == null || items.Count() == 0)
>
> {
>
> // Оповестить о пустом перечислении
>
> }
>
> }`
Метод при... | https://habr.com/ru/post/97464/ | null | ru | null |
# Создание окружения для веб-разработки на основе Docker
Под катом расскажу как я усовершенствовал автоматическое создание и разворачивание окружения для веб-разработки на основе **Docker**, **Fig**, **DNSMasq** и **nsenter**... | https://habr.com/ru/post/247547/ | null | ru | null |
# EventMachine прокси демон
Несмотря на то, что [EventMachine](http://rubyeventmachine.com/) достаточно удобный фреймворк для написания высокопроизводительных и хорошо масштабирующихся сетевых приложений, интернет не радует обилием примеров его использования и тестирования. А те примеры, которые существуют, например, ... | https://habr.com/ru/post/126231/ | null | ru | null |
# Как создатели вредоносного софта пытаются избежать его обнаружения: разбираем на примере Spy.GmFUToMitm
[](https://habr.com/ru/company/pt/blog/477916/)
*Изображение: [Unsplash](https://unsplash.com/photos/NodtnCsLdTE)*
Специалис... | https://habr.com/ru/post/477916/ | null | ru | null |
# Прогнозирование авиапассажиропотока между городами РФ
Всем привет!
Это моя первая статья на Хабре, поэтому буду рад комментариям, советам, предложениям и любой реакции.
Я работаю в авиакомпании, занимаюсь анализом продаж, что сильно связано в том числе с планированием и прогнозированием. В условиях, когда российск... | https://habr.com/ru/post/713160/ | null | ru | null |
# Maven. Собираем только измененное
Работая в многомодульном maven проекте, зачастую приходится вносить изменения в несколько связанных модулей одновременно. И если хочется собрать только задетые модули, то к сожалению maven не предоставляет ничего автоматического. Если чуть погуглить, то на stackoverflow можно найти ... | https://habr.com/ru/post/323228/ | null | ru | null |
# Собираем свой собственный смартфон

Это руководство описывает от начала до конца конструирование своего собственного смартфона. Начинается дело с печати на 3D-принтере корпуса, затем спаиваются печатные платы, всё это дел... | https://habr.com/ru/post/255047/ | null | ru | null |
# Агрегация
По материалам статьи Craig Freedman: [Aggregation](https://docs.microsoft.com/en-us/archive/blogs/craigfr/aggregation)
Агрегация относится к таким операциям, когда больший набор строк свёртывается в меньший. Типичные агрегатные функции - COUNT, MIN, MAX, SUM и AVG. SQL Server поддерживает также и другие а... | https://habr.com/ru/post/658469/ | null | ru | null |
# В очередь, ...! Как управлять состоянием системы через события
Х/ф «Собачье сердце»Существует множество разных подходов к построению архитектуры серверных приложе... | https://habr.com/ru/post/699492/ | null | ru | null |
# VoIP телефония. Asterisk. Нестандартный подход ко всему. Часть 2
Продолжаем наш рассказ о модификации движка для VoIP оператора связи.
[В первой части](https://habrahabr.ru/post/319352/) мы рассказали о начальной структуре базы данных и настройке Asterisk для обслуживания вызовов, с мониторингом состояния вызова. В... | https://habr.com/ru/post/319558/ | null | ru | null |
# [Select-Form]: Пишем свой select-список, используя jQuery и CSS
Здравствуйте, хабраюзеры и просто читающие. Сравнительно недавно задался вопросом, как применить стили к тегу select. Всем же хочется, чтобы стилизация формы соответствовала дизайну сайта, а пока что еще не все можно описать чистым CSS. В данной статье ... | https://habr.com/ru/post/312532/ | null | ru | null |
# Покопаемся в мозгах «умного» свича
Пару лет назад у меня появился сервер мониторинга zabbix. Естественно, сразу захотелось получать как можно больше информации о своём оборудовании. На обычных компьютерных системах zabbix агент даёт для этого самые широкие возможности. С сетевым оборудованием всё сложнее. Команда sn... | https://habr.com/ru/post/201812/ | null | ru | null |
# Семантика в HTML 5
Я собираюсь сделать смелый прогноз. Еще долго после вас и меня HTML будет вокруг. Не только в миллиардах архивных страниц нашей эры, а как живые дыхательные органы. Слишком много сил, энергии и инвестиций пошло на разработку web-инструментов, протоколов и платформ, что бы все это было легко брошен... | https://habr.com/ru/post/49734/ | null | ru | null |
# Тест Си компиляторов под Windows
После многочисленных споров на тему «Какой компилятор лучше генерирует код», появилась идея провести самому испытания. Основной целью испытания была проверка скорости работы программы с оптимизацией по скорости. Результат тестирования: среднее арифметическое время выполнения тестовой... | https://habr.com/ru/post/107664/ | null | ru | null |
# Все, что вы хотели узнать про области видимости в Python, но стеснялись спросить
*В преддверии старта нового потока по курсу [«Разработчик Python»](https://otus.pw/RHDK/), решили поговорить про области видимости в Python. Что из этого вышло? — Читайте в материале ниже.*
, Joxi или [Gyazo](http://habrahabr.ru/post/57587/) уже сложно.
Но есть несколько нюансов, которые могут ... | https://habr.com/ru/post/233491/ | null | ru | null |
# Хорошие новости для тех, кто всё ещё использует row-level локи в PostgreSQL
Привет, меня зовут Дима, я работаю в Ozon в небольшой команде, которая предоставляет разработчикам PostgreSQL as a Service. Мы сопровождаем тысячи кластеров, поэтому разработчики, в основном, сами отвечают за перфоманс PostgreSQL. Иногда они... | https://habr.com/ru/post/555358/ | null | ru | null |
# Эпическая сага про маленький custom hook для React (генераторы, sagas, rxjs)
[Часть 2. Генераторы](https://habr.com/ru/post/532484/)
[Часть 3. Redux-saga](https://habr.com/ru/post/532590/)
Прелюдия
--------
Стояла задача реализовать прелоадер с обратным отсчетом на реакте. Т.к. гуглить не умею и очень люблю лепит... | https://habr.com/ru/post/532440/ | null | ru | null |
# Python Webmoney API
Потребовалось мне как то реализовать поддержку Webmoney API ([Документация](https://wiki.webmoney.ru/projects/webmoney/wiki/XML-%D0%B8%D0%BD%D1%82%D0%B5%D1%80%D1%84%D0%B5%D0%B9%D1%81%D1%8B)) в проекте. Библиотек на питоне я не нашел, поэтому решил написать свою.
[Ссылка на репозиторий](https:... | https://habr.com/ru/post/222411/ | null | ru | null |
# Как драйвер Windows коварно ломает звук в Linux или мучительные поиски бага
Вместо вступления
-----------------
> Дешевая «комната страха» — темно и везде грабли.
Задумчиво поглядывая на ~~падение в глубокие бездны~~ коррекцию курса рубля, я решил, что оставаться со стремительно девальвирующей бумагой на руках смы... | https://habr.com/ru/post/242253/ | null | ru | null |
# Сравнение быстродействия def и lambda функций. Так все таки быстродействие или читабельность?
Идея для кода
-------------
Читая pep8, я наткнулся на пункт об использовании анонимных функций - по версии пепа, они снижают читабельность, если использовать переменную с значением функции как функцию, лучше использовать ... | https://habr.com/ru/post/598999/ | null | ru | null |
# Адаптируем существующее бизнес-решение под SwiftUI. Часть 2
Доброго всем времени суток! С вами я, Анна Жаркова, ведущий мобильный разработчик компании [«Usetech»](https://usetech.ru/)
В этой части мы уже поговорим по делу, как можно адаптировать готовое решение к проекту на SwiftUI. Если вы еще не особо знакомы ... | https://habr.com/ru/post/500386/ | null | ru | null |
# Теория счастья. Термодинамика классового неравенства
*Продолжаю знакомить читателей Хабра с главами из своей книжки «Теория счастья» с подзаголовком «Математические основы законов подлости». Это ещё не изданная научно-популярная книжка, очень неформально рассказывающая о том, как математика позволяет с новой степень... | https://habr.com/ru/post/424071/ | null | ru | null |
# 10 антипаттернов деплоя в Kubernetes: распространенные практики, для которых есть другие решения
[*Rudder by sun-stock*](https://www.deviantart.com/sun-stock/art/Rudder-20343779)
Команда [Kubernetes aaS о... | https://habr.com/ru/post/529152/ | null | ru | null |
# Реальный опыт разработки на Meteor
Это рассказ о моем опыте разработки живого проекта на фреймворке [Meteor](http://meteor.com). Фреймворк очень интересный, подход к разработке концептуально отличается от большинства существующих PHP/JS фреймворков. Фактически, с Meteor приходится заново учиться веб-разработке.
!... | https://habr.com/ru/post/204262/ | null | ru | null |
# Апгрейд AMIGA 500 под современные реалии
[](https://habr.com/ru/company/ruvds/blog/590169/)
Неугасающий энтузиазм ретро-компьютерщиков продолжает поддерживать жизнь старых ПК и даже находит им актуальное применение в современном ми... | https://habr.com/ru/post/590169/ | null | ru | null |
# Java: есть ли жизнь на десктопе?
Привет! Я Виктор Барсуков, Java-разработчик в Lamoda. В этой статье я хочу рассказать о разработке десктопного Java-приложения, что из этого получилось и что можно было бы с... | https://habr.com/ru/post/648949/ | null | ru | null |
# Get Moving with Xamarin.Forms 4.4
We were speaking with a customer last year that builds dozens of mobile applications every year. They said, «We cannot remember the last time we made a mobile app that did NOT include a carousel view.» Many of you have expressed almost identical sentiments to us. So, we are very ple... | https://habr.com/ru/post/480038/ | null | en | null |
# Функции Oracle 11g Pivot, Unpivot
В версии 11g появились функции Pivot/Unpivot(которые сначала появились в MS SQL 2005), позволяющие динамически разносить вертикальные данные по столбцам как нам удобно.
[](https://... | https://habr.com/ru/post/100798/ | null | ru | null |
# XSS уязвимость в Mobli
Совсем недавно мне нужно было загрузить ролик на Mobli, но так как после прошлого [случая](http://habrahabr.ru/post/249589/), у меня появилась привычка проверять сайты на XSS, я решил проверить Mobli.
> [Mobli](http://en.wikipedia.org/wiki/Mobli) — это социальная сеть для обмена фотографиям... | https://habr.com/ru/post/249891/ | null | ru | null |
# Управление памятью в Python

Одна из главных проблем при написании крупных (относительно) программ на Python — минимизация потребления памяти. Однако управлять памятью здесь легко — если вас вообще это волнует. Память в Pytho... | https://habr.com/ru/post/336156/ | null | ru | null |
# Автоконфигурация в облаке Amazon при помощи Chef-Solo
Здравствуйте!
В этой статье я хочу рассказать об автоконфигурации в облаке. Для примера запустим ec2-инстанс, на котором «приготовится» WordPress.
Под автоконфигурацией я понимаю автоматическую установку и настройку пакетов, разворачивание приложений. Про... | https://habr.com/ru/post/155655/ | null | ru | null |
# Заметка про проверку PHP

PHP — скриптовый язык программирования общего назначения, интенсивно применяемый для разработки веб-приложений. В настоящее время поддерживается подавляющим большинством хостинг-... | https://habr.com/ru/post/235189/ | null | ru | null |
# Пишем бесплатный Gerber-вьювер с открытым исходным кодом под Android с нуля
Привет, Хабр! Меня зовут Велеско Сергей, я Android разработчик в настоящее время и инженер-конструктор печатных плат в прошлой ж... | https://habr.com/ru/post/597251/ | null | ru | null |
# Микрофронтенды и виджеты в 2021-м. Доклад Яндекса
Давайте поговорим о микрофронтендах и о встраиваемых виджетах, которые, по сути, были предшественниками концепции микрофронтендов. В докладе я рассказал о способах встраивать виджеты на страницу, об их плюсах и минусах с точки зрения изоляции и производительности код... | https://habr.com/ru/post/554568/ | null | ru | null |
# Через год
Может это и правильно, но как-то неожиданно.
`select
'2008-02-27' + INTERVAL 1 YEAR, -- 2009-02-27
'2008-02-28' + INTERVAL 1 YEAR, -- 2009-02-28
'2008-02-29' + INTERVAL 1 YEAR, -- 2009-02-28
'2008-03-01' + INTERVAL 1 YEAR; -- 2009-03-01`
**UPD** По результатам обсуждения резюмирую:
... | https://habr.com/ru/post/48327/ | null | ru | null |
# Шаблонизатор на основе объектной модели html
Прочитав предыдущий топик (http://habrahabr.ru/blogs/javascript/96588/) в сознании всплыла старая идеи. Подход известный, но то ли у него есть минусы которые я не вижу, то ли мы с гуглом друг друга не поняли. В общем, готового решения я найти не смог, поэтому за пару часо... | https://habr.com/ru/post/96636/ | null | ru | null |
# Снижаем затраты на использование AWS EC2
На странице стоимости компонентов EC2 на Амазоне есть одна строчка, на которую сначала можно не сильно обратить внимание, но которая может привести к серьезным финансовым затратам — Data Transfer, трафик. Если аренду инстансов и EBS-томов можно запланировать и контролировать,... | https://habr.com/ru/post/164271/ | null | ru | null |
# Unit-тестирование от начинающего начинающим
Здравствуйте.
На написание статьи меня сподвигнул [этот](http://habrahabr.ru/blogs/php/138223/) пост. В нём приведено описание инструментов и некоторая теоретическая информация.
Сам я только начинаю разбираться в unit-тестировании и тестировании вообще, поэтому реши... | https://habr.com/ru/post/138350/ | null | ru | null |
# Отображение данных в формате json на структуру c++ и обратно (работа над ошибками)
[Предыдущий вариант](https://habr.com/ru/post/506506/) решения задачи отображения между структурой с++ и json получился как первый блин — комом. К счастью, разработка — процесс итерационный, и за первой версией всегда будет вторая. Ко... | https://habr.com/ru/post/510438/ | null | ru | null |
# Как я в библиотеке реальность дополнял

*Картинка для привлечения внимания.*
Я тот, кто первым использовал технологии навигации для построения дополненной реальности.
Технологии геоло... | https://habr.com/ru/post/258387/ | null | ru | null |
# Недостаточно знать, что такое Mutex, Semaphore и async/await. Надо знать всё, начиная с квантов
Совсем скоро, **29-30 ноября в Санкт-Петербурге** и **06-07 декабря — в Москве** мы запустим [шестой семинар по .NET](http://clrium.ru/register.html). На этот раз — по теме многопоточки и конкурентности. Мы уже писали об ... | https://habr.com/ru/post/473726/ | null | ru | null |
# Microsoft выпустила Linux-версию утилиты ProcDump
[ProcDump для Linux](https://github.com/Microsoft/ProcDump-for-Linux) — реинкарнация классического инструмента [ProcDump](https://docs.microsoft.com/en-us/sysinternals/downloads/procdump) из комплекта технических средств и утилиты для управления, диагностики, устране... | https://habr.com/ru/post/428782/ | null | ru | null |
# Смена региона, зашитого на заводе, в роутерах NETGEAR
При покупке роутера NETGEAR заграницей, многие сталкиваются с тем, что он не поддерживает многие стандарты российских интернет провайдеров, такие как протоколы L2TP и различные вариации функций, необходимых для работы IPTV.
На различных форумах обсуждалось, чт... | https://habr.com/ru/post/195058/ | null | ru | null |
# Scala WAT: Обработка опциональных значений
В сети и на Хабре уже довольно много статей вводного уровня про то, как начать писать на Scala, и раскрывающих особенности функционального подхода.
Какое-то время назад мы пол... | https://habr.com/ru/post/166145/ | null | ru | null |
# Объектный пул и быстрое создание объектов в куче
Хочу поделится очередным велосипедом собственной сборки на С++. Велосипед умеет быстро создавать и выдавать объекты. В результате получаем скорость создания (не отдачи) объектов на 30% быстрее чем просто с new. Объектный пул — вещь не новая, и в общем — чего о нем и г... | https://habr.com/ru/post/205316/ | null | ru | null |
# Создание игры Tower Defense в Unity: враги
*[[Первая часть: тайлы и поиск пути](https://habr.com/ru/post/449798/)]*
* Размещение точек создания врагов.
* Появление врагов и их движение по полю.
* Создание плавного движения с постоянной скоростью.
* Изменение размера, скорости и размещения врагов.
Это вторая част... | https://habr.com/ru/post/452756/ | null | ru | null |
# Проверяем защищённость приложения на Go: с чего начать
Привет! Меня зовут Александра, я инженер по информационной безопасности в Delivery Club. Мы используем Go в качестве основного языка для разработки Web... | https://habr.com/ru/post/658569/ | null | ru | null |
# Интернет убыточных вещей
Зовите детишек! Сейчас дядя Андрей расскажет рождественскую страшилку об NTP (Network Time Protocol).
Почти два года назад, в понедельник 16 января 2017 года, в нашу систему баг-репортов [BitFolk](https://bitfolk.com/) поступил интересный тикет от постороннего лица. Отправитель представил... | https://habr.com/ru/post/434422/ | null | ru | null |
# VoIP телефония. Asterisk. Нестандартный подход ко всему. Часть 1
Ровно год назад к нам обратились бывшие коллеги, с предложением принять участие в модификации движка VoIP оператора связи. Задача сводилась к полной переделке личного кабинета, обеспечению масштабирования системы, создания системы биллинга, LCR, монито... | https://habr.com/ru/post/319352/ | null | ru | null |
# Повторяем дизайн приложений, получивших награду Apple
Привет, Хабр! Дизайнеры рисуют приложения с красивыми кнопочками, тенями, анимациями, градиентами и сложными переходами между экранами. К сожалению, такие дизайны нелегко превращать в рабочие приложения. Можно ли облегчить нашу работу? Разберемся на примере прило... | https://habr.com/ru/post/323308/ | null | ru | null |
# Открытые бенчмарки для нагрузочного тестирования серверов и веб-приложений
Это — подборка утилит, составленная на основе рекомендаций резидентов Hacker News и GitHub. В список вошли: Locust, Vegeta, Slow\_cooker, k6 и Siege. Ими пользуются инженеры из DICE, EA и Buoyant, а также разработчики Kubernetes и Load Impact... | https://habr.com/ru/post/474474/ | null | ru | null |
# Динамическое меню c поддержкой touch move и mouse move на RevolveR
Наверняка многие из вас хотели бы научиться создавать красивые и подвижные меню в духе Android Java и Kotlin приложений. Скорее всего даже многие из вас ради этого уходили в области программирования отдельных приложений и были вынуждены осваивать ино... | https://habr.com/ru/post/523976/ | null | ru | null |
# Атомарность операций и счетчики в memcached
Серия постов про “Web, кэширование и memcached” продолжается. В [первом](http://habrahabr.ru/blogs/webdev/42607/) и [втором](http://habrahabr.ru/blogs/webdev/42972/) постах мы поговорили о memcached, его архитектуре, возможном применении, выборе ключа кэширования и кластер... | https://habr.com/ru/post/43282/ | null | ru | null |
# Открытый проект индуктивного абсолютного энкодера
Без энкодеров не обходится ни один промышленный робот, принтер, лифт, гимбал и проч. Но и в более простых вещах энкодеры тоже нужны. При этом индустриальны... | https://habr.com/ru/post/595025/ | null | ru | null |
# Борьба с INotifyPropertyChanged или как я стал опенсорсником — 2
Начиналось все как и в прошлый раз, достаточно прозаично: мне пришлось разработать \*-надцать ViewModel-ей для своего MVVM-приложения.
Для того, чтобы они оптимально работали как ViewModel-и, мои классы должны были наследоваться от DependencyObject ... | https://habr.com/ru/post/95211/ | null | ru | null |
# Атаки по времени — сказка или реальная угроза?
Первую статью на хабр хотел написать совершенно о другом, но в один прекрасный день коллега по работе решил заморочиться и сделать защиту от «Атаки по времени» (Timing attack). Не долго разбираясь в различных материалах на эту тему, Я загорелся и решил написать свой вел... | https://habr.com/ru/post/217327/ | null | ru | null |
# Беспроводная точка доступа, используя Linux
Что ж, вот и первая статья из обещанной [серии](http://habrahabr.ru/post/188108/).
Первое, что я буду делать — настраивать Software AP, или беспроводную сеть на базе компьютера. На этом этапе, конечно, нужен доступ к консоли сервера с правами рута. Кроме того, нужно та... | https://habr.com/ru/post/188274/ | null | ru | null |
# Мониторинг ресурсов сервера под управлением *nix с помошью RRDtool
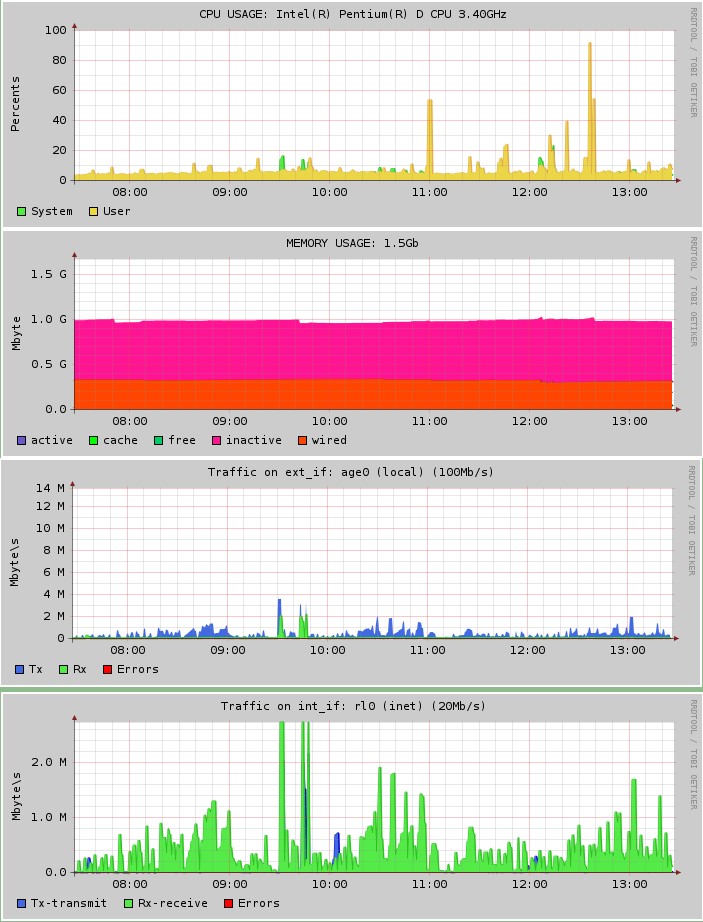
Доброго времени суток уважаемый %user%! Сегодня я расскажу, как поднять мониторинг железа и системы в реальном времени с использованием набора утилит... | https://habr.com/ru/post/186942/ | null | ru | null |
# Разработка мобильного приложения без сервера
Очень часто при [разработке мобильных приложений](https://surf.ru/flutter/) (возможно с веб-приложениями та же проблема) разработчики попадают в ситуацию, когда бэкэнд не работает или не предоставляет нужных методов.
Такая ситуация может происходить по разным причинам... | https://habr.com/ru/post/477506/ | null | ru | null |
# Оптимизация сервера под Drupal с замером результатов
Сама по себе инструкция о том, где что подкрутить на сервере, чтобы Drupal стал работать быстрее, встречаются на просторах интернета в разной степени детализации. Однако все встречавшиеся мне статьи обладали небольшим изъяном: я не встречал каких-либо реальных зам... | https://habr.com/ru/post/208986/ | null | ru | null |
# Памятка евангелиста PostgreSQL: репликанты против репликации

В продолжение серии публикаций «Памятка евангелиста PostgreSQL...» ([1](http://habrahabr.ru/post/268949/), [2](http://habrahabr.ru/post/269463/)) дорогая редак... | https://habr.com/ru/post/269889/ | null | ru | null |
# Создаем Silverlight-приложение для сети Мой Мир@Mail.Ru
 Как известно, наиболее популярные социальные сети в мире позволяют писать под себя специальные приложения. Одним из ярких примеров являет... | https://habr.com/ru/post/52695/ | null | ru | null |
# Мульти-арные функции в Java
[](https://habrahabr.ru/post/344302/)
Напомню: арность (англ. arity) — это количество параметров функции. Соответсвенно мульти-арные (это слово можно писать вместе или раздельно) функции — это функции ... | https://habr.com/ru/post/344302/ | null | ru | null |
# Jython-консоль вашего приложения
Расскажу вам как я использую интерактивную консоль Jython для ускорения разработки Bean'ов в поддерживаемом мной приложении.
#### Суть вопроса
Каждый кто хоть раз сталкивался с долго разрабатыв... | https://habr.com/ru/post/129064/ | null | ru | null |
# Изменение содержимого Web.config в runtime при отладке в Visual Studio и IISExpress
Технологически в этой статье ничего нового, просто еще одно полезное применение winapi-хуков для решения специфичной проблемы.
При работе с веб-проектами в Visual Studio существует одна неприятная мелочь — при использовании в проц... | https://habr.com/ru/post/321768/ | null | ru | null |
# Trace, Info, Warning, Error, Fatal — кто все эти люди..?
Обычно библиотеки логгирования предлагают из коробки сразу несколько "уровней" важности, с которыми Вы можете записывать сообщения. В документации к... | https://habr.com/ru/post/543666/ | null | ru | null |
# Визуальный отладчик для Jupyter
Прогресс большинства программных проектов строится на малых изменениях, которые, перед тем, как двигаться дальше, тщательно оценивают. Быстрое получение результатов выполнения кода и высокая скорость итеративной разработки — это одни из основных причин успеха Jupyter. В особенности — ... | https://habr.com/ru/post/500422/ | null | ru | null |
# Использование возможностей NHibernate в Orchard.CMS
Orchard.CMS одна из популярных свободных open source систем управления веб контентом на базе .NET. В качестве ORM для доступа к данным используется NHibernate. Более детальную информацию можно найти на [официальном сайте проекта](http://docs.orchardproject.net/), к... | https://habr.com/ru/post/241557/ | null | ru | null |
# Интеграция amoCRM с сайтом API
AmoCRM одна из самых популярных CRM, при этом ее API один из самых странных, по моему субъективному мнению. Понадобилось передавать данные формы с сайта в crm. Использовать CRM Формы вместо своих дизайнерских не хочется. Было бы здорово открыть статейку в гугле, подставить ключ и не па... | https://habr.com/ru/post/650019/ | null | ru | null |
# Тонкий бездисковый клиент на базе Ubuntu, не требующий монтирования ФС по сети
**UPDATE 2020-11-06** [Теперь](https://github.com/selivan/thinclient/commit/2e0ad63404027dfdcdb0b997a0b6c7d382048f86) проект поддерживает Ubuntu 20.04 Focal Fossa (LTS) и появился готовый вариант для сборки с использованием VMWare Horizon... | https://habr.com/ru/post/350780/ | null | ru | null |
# Коллбэки в JavaScript на примере миньонов

Коллбэки. Асинхронные. Неблокирующие. Давайте говорить начистоту: все эти JS-концепции заставляют вас рвать волосы на голове каждый раз, когда ваш код СНОВА не работает. Меня то... | https://habr.com/ru/post/282015/ | null | ru | null |
# Глобалы — мечи-кладенцы для хранения данных. Разреженные массивы. Часть 3
В прошлых частях ([1](http://habrahabr.ru/company/intersystems/blog/263791/), [2](http://habrahabr.ru/company/intersystems/blog/264173/)) мы говорили ... | https://habr.com/ru/post/268465/ | null | ru | null |
# Алгоритмы сортировки в Swift
Что нужно знать начинающему разработчику на собеседовании
---------------------------------------------------------
Каков наиболее эффективный способ отсортировать миллион 32-битных пользователей Это частый вопрос на собеседовании в таких компаниях как Google. Чтобы ответить на него нам... | https://habr.com/ru/post/692928/ | null | ru | null |
# Ваша первая нейронная сеть на графическом процессоре (GPU). Руководство для начинающих

В этой статье я расскажу как за 30 минут настроить среду для машинного обучения, создать нейронную сеть для распознавания изображений a потом з... | https://habr.com/ru/post/488564/ | null | ru | null |
# Сворачивание приложений в Dock для ленивых с помощью AppleScript
Как часто вы пользуетесь опциями некоторых программ (iTerm 2, Total Finder, Adium), которые позволяют показать окно приложения по нажатию на глобальный хоткей и скрыть это приложение при потере фокуса? Лично я — постоянно. А что если некая программа не... | https://habr.com/ru/post/202864/ | null | ru | null |
# Сверточный слой: методы оптимизации основанные на матричном умножении
Введение
--------
Данная статья является продолжением [серии статей](https://habr.com/post/471074/) описывающей алгоритмы лежащие в основе
[Synet](https://github.com/ermig1979/Synet) — фреймворка для запуска предварительно обученных нейронных... | https://habr.com/ru/post/448436/ | null | ru | null |
# Использование подсказок, включаемых в исходный код, помогающих GCC выявлять случаи переполнения буфера
Ошибки, связанные с доступом к областям памяти, которые находятся за пределами допустимого адресного пространства (out-of-bounds memory access), в 2021 году всё ещё пребывают в списке [самых опасных уязвимостей ПО ... | https://habr.com/ru/post/572338/ | null | ru | null |
# HackTheBox. Прохождение Multimaster. Burp+Sqlmap. AD users from MSSQL. Уязвимость в VSCode. AMSI bypass и CVE ZeroLogon

Привет, с вами Ральф. Продолжаю публикацию решений, отправленных на дорешивание машин с площадки [HackTheBox](... | https://habr.com/ru/post/519814/ | null | ru | null |
# TSP problem. Mixed algorithm
Всем доброго времени суток. В прошлых статьях мы сравнивали два эвристических алгоритма оптимизации на симметричной задаче коммивояжера таких как: ACS (ant colony system — муравьиный алгоритм) и SA (simulating annealing — алгоритм имитации отжига). Как мы убедились у каждого свои плюсы и... | https://habr.com/ru/post/335016/ | null | ru | null |
# Как из домашнего компьютера сделать «два в одном» – домашний кинотеатр + персональный компьютер

Если вдруг у вас дома есть игровой компьютер, не обязательно топовый, главное чтобы на нем нормально работала Windows 7 и... | https://habr.com/ru/post/137272/ | null | ru | null |
# Индексы в PostgreSQL — 5
В прошлые разы мы рассмотрели [механизм индексирования PostgreSQL](https://habrahabr.ru/company/postgrespro/blog/326096/), [интерфейс методов доступа](https://habrahabr.ru/company/postgrespro/blog/326106/), и два метода: [хеш-индекс](https://habrahabr.ru/company/postgrespro/blog/328280/) и [... | https://habr.com/ru/post/333878/ | null | ru | null |
# Разрабатываем хабраклавиатуру под iOS
Зачастую для чтения хабра я использую мобильное приложение Хабрахабр для iPhone и iPad. Оно достаточно удобное для чтения статей, но не очень удобное для написания комментариев, особе... | https://habr.com/ru/post/235917/ | null | ru | null |
# Как мы оптимизировали сетевой шейпер Linux в облаке с помощью eBPF
Меня зовут Леонид Талалаев, я занимаюсь разработкой внутреннего облака Одноклассников one-cloud, про которое уже [рассказывали](https://hab... | https://habr.com/ru/post/572206/ | null | ru | null |
# Выступает DMN, дирижирует ZeeBe: как использовать бизнес-правила в микросервисах
Меня зовут Николай Первухин, я Senior Java Developer в Райффайзенбанке. Так сложилось, что, единожды попробовав бизнес-процессы на Camunda, я стал адептом этой технологии и стараюсь ее применять в проектах со сложной логикой. Действител... | https://habr.com/ru/post/545492/ | null | ru | null |
# Event-driven архитектура в Kubernetes
Kubernetes, как система оркестрации, позволяет автоматизировать процесс развертывания сложных приложений и восстанавливать ожидаемое состояние кластера после сбоев. В о... | https://habr.com/ru/post/682466/ | null | ru | null |
# Генерирование фейковых данных для вашего JavaScript-приложения с помощью Faker
Для того, чтобы продемонстрировать работу приложения, нам частенько приходится заставлять его работать с выдуманными данными, ведь негоже, чтобы заголовки были пустыми, а таблицы лишь расчерченными, но не заполненными.
Как правило, при... | https://habr.com/ru/post/248999/ | null | ru | null |
# Выразительный JavaScript: Поиск и обработка ошибок
#### Содержание
* [Введение](http://habrahabr.ru/post/240219/)
* [Величины, типы и операторы](http://habrahabr.ru/post/240223/)
* [Структура программ](http://habrahabr.ru/post/240225/)
* [Функции](http://habrahabr.ru/post/240349/)
* [Структуры данных: объекты и мас... | https://habr.com/ru/post/242609/ | null | ru | null |
# Память в браузерах и в Node.js: ограничения, утечки и нестандартные оптимизации
Интро: почему я написал эту статью
----------------------------------
Меня зовут Виктор, я разрабатываю страницу результатов поиска Яндекса. Несмотря на внешнюю простоту, поисковая выдача — сложная штука: на каждый запрос генерируется с... | https://habr.com/ru/post/666870/ | null | ru | null |
# MindStream. Как мы пишем ПО под FireMonkey. Часть 3. DUnit + FireMonkey
[Часть 1](http://habrahabr.ru/post/232955/).
[Часть 2](http://habrahabr.ru/post/234801/).
Здравствуйте.
В этой статье я хочу познакомить читателей с процессом переноса VCL кода в FireMonkey. В стандартной поставке Delphi, начиная по-мое... | https://habr.com/ru/post/241301/ | null | ru | null |
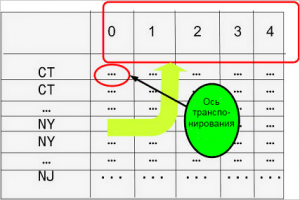
# Подключение внешнего L2-сегмента к Cisco ACI с помощью EPG и L2Out
Сегодня я хотел бы поделиться своим опытом настройки связности Cisco ACI с внешним L2-сегментом. Как известно, есть два подхода к решению этой задачи: классифицировать внешний сегмент в отдельную EPG или же использовать объект External Bridged Networ... | https://habr.com/ru/post/585724/ | null | ru | null |
# Парсинг (разбор) XML документов с помощью CSS селекторов
Привет. Заметил что постов посвященных [Symfony 2.0](http://symfony-reloaded.org/) все еще не много. Постараюсь это исправить в ближайшее время топиками и переводами про компоненты фреймворка. Сейчас же представляю вашему вниманию перевод статьи с блога [Фабье... | https://habr.com/ru/post/90664/ | null | ru | null |
# Подсчёт с приблизительным распределением — чаще всего переизобретаемая сортировка
[](https://habr.com/ru/company/edison/blog/478654/)
Количество более-менее отличающихся друг от друга сортировок гарантированно более сотни. Среди ни... | https://habr.com/ru/post/478654/ | null | ru | null |
# Почтовый сервер быстрого приготовления на t2.micro с EC2 под управлением CentOS 7
Работа из учетной записи администратора, root оставьте для расчетов и проверки состояния счета, последнее рекомендую делать почаще, так как оплата производится за количество использованных ресурсов. Услуги Amazon, задействованые в данн... | https://habr.com/ru/post/264685/ | null | ru | null |
# Network diagram as code / Схема сети как код
В последние пару лет стал больше заниматься документацией. Написать поясняющий текст о том, как работает та или иная система — в целом, это достаточно просто. Нарисовать схему, на которой будут отображены все ключевые объекты, связи между этими объектами, тоже вполне легк... | https://habr.com/ru/post/491814/ | null | ru | null |
# Нам нужно поговорить про Linux IIO
IIO (промышленный ввод / вывод) — это подсистема ядра Linux для аналого-цифровых преобразователей (АЦП), цифро-аналоговых преобразователей (ЦАП) и различных типов датчиков. Может использоваться на высокоскоростных промышленных устройствах. Она, также, включает встроенный API для др... | https://habr.com/ru/post/520488/ | null | ru | null |
# Идеи для Sublime от CudaText
С 2012 года использую для просмотра и изменения почти всех текстовых файлов, логов и программных кодов на языках *VFP/JS/Python/XML/HTML* редакторы, созданные Алексеем Торгашиным: сначала это был **[SynWrite](http://www.uvviewsoft.com/synwrite/)**, теперь его потомок **[CudaText](http://... | https://habr.com/ru/post/427751/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.