
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Изучаем переменные в CSS на практическом примере

Доброго времени суток, друзья!
Однажды веб серфинг привел меня к [этому замечательному коду](https://codepen.io/robdimarzo/full/LMOLer).
«Замечательность» его (то бишь кода) с... | https://habr.com/ru/post/489294/ | null | ru | null |
# Легенда о серебряной пуле или как я искал логические ошибки кэширования и получения данных
**Отказ от претензий**: не используйте описанные ниже патчи на продакшене; пользуйтесь специально подготовленными тестовыми площадками.
\* \* \*
--------
Когда я был маленьким, то мечтал стать волшебником. Когда немного по... | https://habr.com/ru/post/278675/ | null | ru | null |
# Unity: Что представляет из себя Coroutine и зачем там IEnumerator
Название статьи - это вопрос, который мне задали на собеседовании на позицию Middle. В этой статье мы расмотри корутины в Unity, что они из себя представляют, и заодно захватим тему Enumerator\Enumerable в С# и небольшую тайну foreach. Статья должна б... | https://habr.com/ru/post/682320/ | null | ru | null |
# Голосовое управление web-плеером, или скрещиваем CMU Sphinx с Selenium WebDriver
В [этой статье](http://habrahabr.ru/post/239355/) я описывал создание веб mp3 плеера и домашней аудиосистемы.
Сам плеер можно увидеть [здесь](http://home.tabatsky.ru/mp3player/desktop.jsp).
Возникла идея — прикрутить к плееру голо... | https://habr.com/ru/post/239607/ | null | ru | null |
# Использование custom functions в парсерах OSSIM
Доброго дня, уважаемые!
В продолжение моей [статьи](https://habrahabr.ru/post/304374/) хочу рассмотреть и поделиться опытом работы с функционалом «custom functions», используемом в OSSIM. Это функции, которые предназначены для обработки полученной вследствие разбора... | https://habr.com/ru/post/306258/ | null | ru | null |
# Вышел GitLab 14.7 с трансляцией событий аудита, соответствием GitLab Runner FIPS 140-2 и групповыми токенами доступа

Мы рады представить релиз GitLab 14.7 с [трансляцией с... | https://habr.com/ru/post/651455/ | null | ru | null |
# Ubuntu, KVM, libvirt и Hetzner
По мотивам [Роутим IPv4 и IPv6 в KVM на примере Hetzner](http://habrahabr.ru/blogs/sysadm/104298/) решил описать свой howto по созданию и организации виртуальных машин.
Задача: на выделенном сервере максимально изолировать приложения и отделить от них БД. Для этого понадобятся две в... | https://habr.com/ru/post/104308/ | null | ru | null |
# То, что нужно знать о проверке чека App Store (App Store receipt)
В StackOverflow по-прежнему появляется много вопросов о валидации App Store чеков, поэтому мы решили написать статью на эту тему в формате вопросов и ответов.

Ч... | https://habr.com/ru/post/472188/ | null | ru | null |
# Настройка параметров ядра Linux для оптимизации PostgreSQL
 Оптимальная производительность PostgreSQL зависит от правильно определенных параметров операционной системы. Плохо настроенные параметры ядра ОС могут привести к снижению п... | https://habr.com/ru/post/458860/ | null | ru | null |
# iOs-разработчик берется за Android
Недавно мы выпустили [Android-версию](https://market.android.com/details?id=meridian.app) для нашей платформы для создания приложений, использующих определение местоположения — [Meridian](http://www.meridianapps.com/).

Если Вы разрабатываете более-менее сложный программный продукт, то Вам должна быть знакома ситуация, когда системные (end-to-e... | https://habr.com/ru/post/521682/ | null | ru | null |
# Портирование CUDA проекта на Intel oneAPI DPC++
Наш программный комплекс позволяет проводить численные исследования хаотической динамики в системах, задаваемых обыкновенными дифференциальными уравнениями и точечными отображениями, с использованием методов параллельного программирования и мощных вычислительных сервер... | https://habr.com/ru/post/673416/ | null | ru | null |
# Перерождение Lerna. Что нового в Lerna 6?
Состоялся релиз Lerna 6!!! В статье собрано все, что вы должны знать о **новом опыте, который предлагает Lerna!**
Lerna продолжает развиваться
------------------... | https://habr.com/ru/post/696770/ | null | ru | null |
# Безопасная загрузка изображений на сервер. Часть вторая
*Это вторая часть перевода. Начинать прочтение лучше с [первой](http://habrahabr.ru/blogs/php/44610/).*
Итак, после применения описанных в первой части методов, мы можем прекратить волноваться? К сожалению, нет. То, какие расширения файла будут переданы тран... | https://habr.com/ru/post/44615/ | null | ru | null |
# Связные списки, трюки с указателями и хороший вкус
В [интервью на TED 2016](https://www.ted.com/talks/linus_torvalds_the_mind_behind_linux) (14:10) Линус Торвальдс рассказывает о *хорошем стиле* программирования. В качестве примера приводит два варианта удаления элементов из односвязных списков (см. ниже). В первом ... | https://habr.com/ru/post/532004/ | null | ru | null |
# Факторный анализ для интерпретации исследования клиентского опыта
### Что исследуем
Вы провели опрос клиентского опыта в вашей компании. В данном случае на каждый вопрос клиенты отвечали по 10 бальной шкал... | https://habr.com/ru/post/687338/ | null | ru | null |
# Компиляция. 10: компиляция в ELF
В [прошлый раз](http://habrahabr.ru/blogs/programming/103402/) мы ограничились компиляцией джей-скрипа в файл в нашем собственном формате, которому требовался специальный загрузчик. Кроме того, мы задумали было пару оптимизаций исполнимого кода, требующих анализа соседних команд.
... | https://habr.com/ru/post/104104/ | null | ru | null |
# Пишем простое приложение на jQuery Mobile
Фреймворк [jQuery Mobile](http://jquerymobile.com/) вышел уже относительно давно, но только сейчас мне удалось им заняться. До этого имел дело с jQTouch и Senc... | https://habr.com/ru/post/109739/ | null | ru | null |
# Три редкоиспользуемые оси в XPath
Основная мощь языка XPath заключается в осях, позволяющих добраться до любого элемента в исходном документе. Рассмотрим применение таких редкоиспользуемых осей, как **ancestor**, **descendant** и **self**.
#### ancestor
Задача: получить атрибут id элемента-«прадеда» foo.
Обыч... | https://habr.com/ru/post/52680/ | null | ru | null |
# Разработка React-приложений с использованием ReasonReact
Вы применяете [React](https://reactjs.org/) для создания пользовательских интерфейсов? Автор материала, перевод которого мы публикуем, говорит, что он тоже работает с React. Здесь он хочет рассказать о том, почему для написания React-приложений стоит использов... | https://habr.com/ru/post/424965/ | null | ru | null |
# Ускоряемся в Entity Framework Core
#### Не будь жадиной!
При выборке данных выбирать нужно ровно столько сколько нужно за один раз. Никогда не извлекайте все данные из таблицы!
Неправильно:
```
using var ctx = new EFCoreTestContext(optionsBuilder.Options);
// Мы возвращаем колонку ID с сервера... | https://habr.com/ru/post/487734/ | null | ru | null |
# Детские мечты о width: 90%-20px;
#### Вступление
Те, кто когда-то только-только начинали изучать CSS, особенно имея небольшой опыт программирования десктопных приложений на Delphi или VB, наверняка хотели иметь возможность использовать конструкции вроде left:30%+10;
Потом все мы научились использовать margin, вл... | https://habr.com/ru/post/37349/ | null | ru | null |
# Как работает JS: пользовательские элементы
**[Советуем почитать] Другие 19 частей цикла**
Часть 1: [Обзор движка, механизмов времени выполнения, стека вызовов](https://habrahabr.ru/company/ruvds/blog/337042/)
Часть 2: [О внутреннем устройстве V8 и оптимизации кода](https://habrahabr.ru/company/ruvds/blog/337460/)... | https://habr.com/ru/post/419831/ | null | ru | null |
# Делегаты и Лямбда выражения в C# .Net — Шпаргалка или коротко о главном
Привет, Дорогой читатель!
-------------------------
Почти все кто мало-мальски работал в .Net знает что такое **Делегаты** (Delegates). А те кто не знает о них, почти наверняка хотя бы в курсе о **Лямбда-выражениях** (Lambda expressions). Но ли... | https://habr.com/ru/post/329886/ | null | ru | null |
# Разработка игры для Android на Unity 5. От идеи до монетизации (Live)
Привет Хабр. Хочу поделиться опытом в разработке игры-викторины на Unity 5 версии. Замечу, что подобная игра уже выпускалась мной в 2014 году и набирала 7800 скачиваний. Из-за ужасной реализации игра заработала 80% удалений и проект был заброшен. ... | https://habr.com/ru/post/317236/ | null | ru | null |
# GraphQL, что ты такое?
Привет! Сегодня у нашей статьи два автора — бэкенд-разработчик Артём и фронтенд-разработчик Илья.
Примерно год назад мы решили попробовать ввести graphQL в свой проект и сейчас хотим поделиться, как это происходило. Расскажем, что такое GraphQL, как его внедряли, почему мы вообще решили с ни... | https://habr.com/ru/post/677972/ | null | ru | null |
# Как предсказать победителя премии Оскар по данным социальных сетей или как я провел выходной
Было снежное воскресенье, притом еще и Прощенное, и с утра было принято решение сбросить с себя одеяло и начать подготовку своего отъетого за время масленицы тела к летнему пляжному сезону. Питер не очень благосклонен в данн... | https://habr.com/ru/post/349436/ | null | ru | null |
# Доставка Powershell скриптов через DNS туннель и методы противодействия

В данной статье мы поговорим о новом инструменте, позволяющем передавать Powershell скрипты на целевую машину внутри DNS пакетов с целью сокрытия траф... | https://habr.com/ru/post/337244/ | null | ru | null |
# Как тратить меньше времени на просмотр видео и прослушивание аудиокниг
Несколько лет назад я заметил, что некоторые фильмы смотреть просто не могу. И не из-за страшных сцен или унылого сюжета, а из-за ощущения сильной затянутости действия. Оно, может и не замедленное, а вполне себе происходит в реальном времени… Но ... | https://habr.com/ru/post/111998/ | null | ru | null |
# XBRL: просто о сложном − Глава 5. Открывая новые измерения
5. Открывая новые измерения
---------------------------
Предыдущие главы показали вам, что такое XBRL, и что с его помощью можно сделать. Как вы уже знаете, он является расширяемым стандартом. В этой главе мы рассмотрим один из расширяющих стандартную специ... | https://habr.com/ru/post/334252/ | null | ru | null |
# Полиция США поймала «подарок»

Наверняка, многие слышали или возможно даже сталкивались с такой штукой как криптолокеры. Это вредоносное ПО, которое шифрует файлы пользователя и требует выкуп за рас... | https://habr.com/ru/post/203410/ | null | ru | null |
# Производительность кодирования и декодирования serialize и json — часть вторая
[Первая часть](http://habrahabr.ru/blog/php/47851.html) моей публикации получила ряд конструктивных комментариев, которые дали толчок разобраться в проблеме более детально.
Комментарии к записи подсказали, а мои дальнейшие эксперимент... | https://habr.com/ru/post/30234/ | null | ru | null |
# Полезные навыки аналитиков. Как стать профессионалом
В прошлом году в Санкт-Петербурге прошла конференция бизнес и системных аналитиков в разработке ПО. Был там довольно интересный доклад минчан Марии и Сергея Бондаренко, под названием [«Полезные навыки аналитиков. Как стать профессионалом»](http://analystdays.com/t... | https://habr.com/ru/post/219667/ | null | ru | null |
# Пишем автотест с использованием Selenium Webdriver, Java 8 и паттерна Page Object
В этой статье рассматривается создание достаточного простого автотеста. Статья будет полезна начинающим автоматизаторам.
Материал изложен максимально доступно, однако, будет значительно проще понять о чем здесь идет речь, если Вы буде... | https://habr.com/ru/post/502292/ | null | ru | null |
# Создаём собственный программный 3D-движок
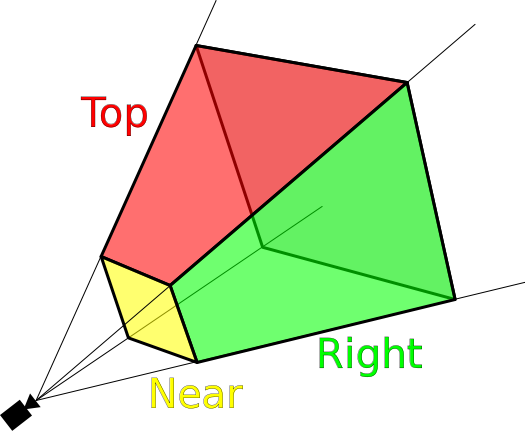
Часть 1: точки, векторы и базовые принципы
==========================================
Современные трёхмерные игровые движки, используемые в крупнейших прое... | https://habr.com/ru/post/334580/ | null | ru | null |
# Яндекс.Функции, Sublime Text и навыки для Алисы
27 июня Яндекс проводил [онлайн-хакатон](https://yandex.ru/promo/events/generated/online-hack-alisa-27-06-2020) по разработке навыков для Алисы.
Решил и я принять в нем участие. Ранее навыки для Алисы я уже делал, но хостил их все на Google App Engine. Тут же я реши... | https://habr.com/ru/post/509670/ | null | ru | null |
# Пять интересных способов использования Array.reduce() (и один скучный путь)
Привет, Хабр! Представляю вашему вниманию перевод статьи ["Five Interesting Ways to Use Array.reduce() (And One Boring Way)"](https://24ways.org/2019/five-interesting-ways-to-use-array-reduce/) автора Chris Ferdinandi.
Из всех современных м... | https://habr.com/ru/post/483182/ | null | ru | null |
# Sampler. Консольная утилита для визуализации результата любых shell команд
В общем случае с помощью shell команды можно получить любую метрику, без написания кода и интеграций. А значит в консоли должен быть простой и удобный инструмент для визуализации.
[
При разработке приложений часто приходится сталкиваться с необходимостью просмотра вывода exception stack trace (в логах или при debug-и... | https://habr.com/ru/post/315690/ | null | ru | null |
# «Шпионская» камера в Android
Привет, %username%! Сегодня я хочу поделиться опытом разработки одного приложения для Android и трудностями, с которыми пришлось столкнуться при не совсем честном использовании ... | https://habr.com/ru/post/215693/ | null | ru | null |
# Unix-way напоминалка
На хабре много пишут о повышении эффективности своей работы, важной составляющей этого процесса является управление своим временем. С моей точки зрения без инструмента хорошо управлять временем не получится, либо ты погрузился в задачу, забыл обо всё и эффективно над ней работаешь, либо ты посто... | https://habr.com/ru/post/130330/ | null | ru | null |
# nanoCAD 3.7 vs 4.0 – что появилось нового? (часть №1)
[](http://habrahabr.ru/company/nanosoft/blog/149873/)
Этим летом в нашей компании произошло два события: выпуск новой версии nanoCAD 4.0 и обновление ... | https://habr.com/ru/post/149873/ | null | ru | null |
# Реактивные приложения с Model-View-Intent. Часть 3: State Reducer

В предыдущей части мы обсудили, как реализовать простой экран с паттерном Model-View-Intent, использующим однонаправленный поток данных. В третьей части мы постро... | https://habr.com/ru/post/348908/ | null | ru | null |
# А может инвесторы не враги, просто кто-то не умеет их готовить?
*Ангелы — это то же самое, что и демоны, только гораздо большие говнюки*
вольный перевод реплики Дина Винчестера из сериала «Сверхъестественное»
Как стало модно сейчас писать — этот топик является частичным ответом (альтернативной точкой зрения) н... | https://habr.com/ru/post/119041/ | null | ru | null |
# Карманная книга по TypeScript. Часть 5. Объектные типы

Доброго времени суток, друзья! Мы продолжаем серию публикаций адаптированного и дополненного перевода [`"Карманной книги по TypeScript`".](https://www.typescriptlang.org/d... | https://habr.com/ru/post/562054/ | null | ru | null |
# Разработчики — никакая не элита, а голые короли индустрии
### ЛОЛШТО?
Пожалуйста, не поймите меня неправильно. Я профессиональный разработчик с 30-летним стажем. Я могу читать и понимать почти двадцать языков, полных по Тюрингу. Я могу писать ясный и выразительный код на доброй дюжине из них. В языках, которые я де... | https://habr.com/ru/post/483592/ | null | ru | null |
# Обучение программированию 2019, или в поисках идеальной программы: Последовательность
Здравствуйте, меня зовут Михаил Капелько. Занимаюсь профессиональной разработкой ПО. Увлекаюсь разработкой игр и обучением программированию.
... | https://habr.com/ru/post/488166/ | null | ru | null |
# Упражнения в эмуляции: инструкция FMA консоли Xbox 360

Много лет назад я работал в отделе Xbox 360 компании Microsoft. Мы думали над выпуском новой консоли, и решили, что было бы здорово, если эта консо... | https://habr.com/ru/post/447680/ | null | ru | null |
# Groovy за 15 минут – краткий обзор
Groovy — объектно-ориентированный язык программирования разработанный для платформы Java как альтернатива языку Java с возможностями Python, Ruby и Smalltalk.
Groovy использует Java-подобный синтаксис с динамической компиляцией в JVM байт-код и напрямую работает с другим Java ко... | https://habr.com/ru/post/122127/ | null | ru | null |
# ANGULARJS + REQUIREJS

Во время разработки проектов мы полюбили AngularJs. Но также мы встретили некоторые трудности в борьбе за чистоту модульности, с которой AngularJs справляется хорошо, но все же пор... | https://habr.com/ru/post/225931/ | null | ru | null |
# Балансировка нагрузки с Pacemaker и IPaddr (Active/Active cluster)
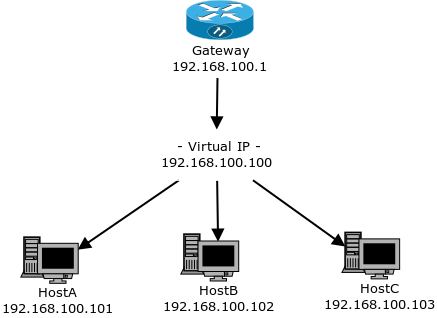
Хочу рассказать вам еще об одном способе балансировки нагрузки. Про Pacemaker и IPaddr (ресурс-агент) и настройке его для Active/Passive кластера сказано уж... | https://habr.com/ru/post/319550/ | null | ru | null |
# Office 365. Пример работы с Microsoft Graph API в Angular5 с помощью ADAL JS. ADAL JS vs MSAL JS
В [прошлый раз](https://habrahabr.ru/post/346552/) мы обсудили механизм авторизации для работы с Office 365 API (в частности с Microsoft Graph API):
* при каждом вызове API нужно передать token. Token имеет ограниченн... | https://habr.com/ru/post/348106/ | null | ru | null |
# Через тернии в маркет

Хочу поделиться опытом разработки приложения на Windows Phone 7.5, миграции его на Windows Phone 8, и что я думаю о перспективах в целом. Информация будет интересна в первую оч... | https://habr.com/ru/post/195796/ | null | ru | null |
# Разработка патчера к игре
После написания первой игры перед нами встала задача, о которой мы даже не задумывались ранее. Это разработка патчера к игре. Для нашего патчера мы определили следующие требования:
* Поддержка юнити игр
* Дружелюбность к пользователю
* Отображение игровых новостей
* Универсальность для в... | https://habr.com/ru/post/163791/ | null | ru | null |
# Делаем data science-портфолио: история через данные
**Предисловие переводчика**Перевод внезапно удачно попал в струю других датасайенсных туториалов на хабре. :)
Этот написан Виком Паручури, основателем [Dataquest.io](https://www.dataquest.io/), где как раз и занимаются подобного рода интерактивным обучением data... | https://habr.com/ru/post/331528/ | null | ru | null |
# PostgreSQL, TCL и другие: Критическая ошибка в RE engine. Возможная уязвимость
Хочу обратить внимание хабрасообщества на возможную «уязвимость» в TCL, PostgreSQL и теоретически в некоторых других системах, использующих модули ругулярных выражений или NFA утилиты, изначально написаные самим Генри Спенсором (Henry Spe... | https://habr.com/ru/post/169183/ | null | ru | null |
# Конвертация даных, или углубление в Talent Open Studio
Утро было вполне обычным и ленивым: душ, кофе, сигарета… Пора собираться на работу…
По приходе в офис был встречен новостью о переходе на новый проект в качестве ETL инженера (что это значит я не знал, ну да ладно). Ну, думаю попробуем. До меня там работал од... | https://habr.com/ru/post/86847/ | null | ru | null |
# SЯP wrong эncяyptioи или как скомпрометировать всех пользователей в SAP JAVA
Всем привет, меня зовут Ваагн Варданян (тут нет опечатки, как многие думают :) ), работаю я в DSec исследователем безопасности SAP-систем, и в этой небольшой статье расскажу о связке уязвимостей в SAP, использование которых может привести к... | https://habr.com/ru/post/303500/ | null | ru | null |
# Partial Update library. Частичное обновление сущности в Java Web Services
Введение
--------
В структуре веб-сервисов типичным базовым набором операций над экземплярами сущностей(объектами) является CRUD (**C**reate, **R**ead, **U**pdate и **D**elete). Этим операциям в REST соответствуют HTTP методы POST, GET, PUT и... | https://habr.com/ru/post/542818/ | null | ru | null |
# Как в Тинькофф запускали HashiCorp Vault
Меня зовут Юрий Шуткин, я инфраструктурный инженер в Тинькофф. В этой статье расскажу, как мы запустили сервис по хранению важной информации и избавились от небезопа... | https://habr.com/ru/post/674582/ | null | ru | null |
# Сборка собственного RPM-пакета, содержащего простую Go-программу
Процесс развёртывания программ обычно состоит из множества этапов. Некоторые из этих этапов могут представлять собой довольно-таки сложные последовательности действий. В наши дни имеется широкое разнообразие инструментов, позволяющих создавать описания... | https://habr.com/ru/post/575346/ | null | ru | null |
# Новая уязвимость позволяет повысить привилегии в Win7/Vista в обход UAC
Интересная уязвимость для повышения локальных привилегий до уровня системы, появилась 24 ноября в виде статьи на ресурсе The Code Project (http://www.codeproject.com/KB/vista-security/uac.aspx). Буквально через несколько часов она была удалена с... | https://habr.com/ru/post/108903/ | null | ru | null |
# Командную строку фотографа-линуксоида — на пенсию!
Я увлекаюсь фотографией ещё со Смены-8М. Тогда были длительные ожидания пятницы или субботы (печать обычно шла в ночь на выходные), а перед этим оочень долгие ожидания фотоплёнки, химикатов, фотобумаги (ибо дефицит). Теперь же я вырос, стал большим и ленивым. Моя мы... | https://habr.com/ru/post/158371/ | null | ru | null |
# Пишем свой аналог UISplitViewController
UISplitViewController получился отличной и красивой штукой, но имеет один существенный недостаток: «The split view controller’s view should always be installed as the root view of your application window. You should never present a split view inside of a navigation or tab bar ... | https://habr.com/ru/post/92928/ | null | ru | null |
# Spring Fu 0.3.0 и не только
> Для будущих учащихся на курсе [**"Kotlin Backend Developer**](https://otus.pw/B3bW/)**"** подготовили перевод материала.
>
> Также приглашаем всех желающих на открытый демо-урок [**«Использование GraphQL в разработке бэкенд на Kotlin».**](https://otus.pw/4C0O/) На этом вебинаре про... | https://habr.com/ru/post/555292/ | null | ru | null |
# Запускаем Internet Explorer под Mac OS X
Всем привет! Хочу поделиться ответом на вопрос, который в свое время сам задавал на различных конференциях, как только обзавелся макинтошем. К сожалению, компания Microsoft давно уже перестала заниматься поддержкой св... | https://habr.com/ru/post/71496/ | null | ru | null |
# Прикручиваем ngx-translate в Angular приложение. Практическое пошаговое руководство
Практическая пошаговая инструкция как прикрутить динамическую локализацию (возможность выбора языков) в веб приложении на Angular 4+ используя [@ngx-translate/core](https://www.npmjs.com/package/@ngx-translate/core).
В принципе можн... | https://habr.com/ru/post/474760/ | null | ru | null |
# Twitter Bootstrap и SharePoint. Как заставить Bootstrap корректно работать под SP
Зачем использовать Bootstrap?
-----------------------------
Разрабатывая и дорабатывая решения на основе SharePoint, я всё больше стал сталкиваться с повышенными ожиданиями пользователей от стандартных форм создания и редактирования э... | https://habr.com/ru/post/249739/ | null | ru | null |
# Справочники и документы. В чем сила 1С
Много узкоспециализированных объектов или небольшое количество универсальных? Истина, как обычно, посередине. Справочники и документы в 1С - это пример удачного попада... | https://habr.com/ru/post/716000/ | null | ru | null |
# Создание минидампов в проектах на C# 4.0, разрабатываемых в VS 2010
Для создания минидампов в управляемой среде используются возможности библиотеки DbgHelp.dll. Рассмотрим применение ее функционала на примере готового проекта на WinForms.
---
Пишем код, создающий минидампы
------------------------------
Прежде ... | https://habr.com/ru/post/153181/ | null | ru | null |
# Postgresso 27

*Ну и год выдался! Подходит к концу. 21-му надо изрядно постараться, чтобы стать хуже. Но он — надеемся — стараться не будет. А жизнь продолжается. И мы продолжаем знакомить вас с самыми интересными новостями Postg... | https://habr.com/ru/post/530444/ | null | ru | null |
# Ресурсы в архиве или как уменьшить количество подгружаемых файлов
Ранним жарким утром спросонья пришла в голову идея. Подозреваю, что у этой идеи есть минусы либо ее уже реализовали куда более годным способом — но, авось да пригодится кому-нибудь.
Очень часто веб-разработчики сталкиваются с проблемой большого кол... | https://habr.com/ru/post/232823/ | null | ru | null |
# Создание игровой анимации на примере Pudding Monsters

Всем привет!
Сегодня я расскажу, как мы упростили процесс создания анимации в играх, используя возможности Adobe Flash.
Каждый, кто сталкивался с созданием 2D... | https://habr.com/ru/post/169861/ | null | ru | null |
# Удаленный оповещатель о критических температуре и влажности на основе МК AVR и датчика DHT22
После подряд 2х поломок кондиционера в серверной и последующего перегрева помещения в течение нескольких суток, встал вопрос о слежении за температурой в ней. Можно было бы ежедневно(ежечасно/ежеминутно) смотреть температуру... | https://habr.com/ru/post/309994/ | null | ru | null |
# USB монитор из Futaba GP1160A02A
Когда-то вакуумно-люминесцентные индикаторы создавались как альтернатива газоразрядным, а также в целях загрузить производство электроламповых заводов, так как в те времена... | https://habr.com/ru/post/706130/ | null | ru | null |
# Мобильный телефон своими руками. Часть 2
В [первой части](http://habrahabr.ru/post/174783/) мы рассмотрели «железную» часть проекта, в этой части мы приступим к экспериментам с устройством.

Модуль M10-TE-A, основа ... | https://habr.com/ru/post/174803/ | null | ru | null |
# Данные высокого рода
Да-да, вам не привиделось и вы не ослышались — именно высокого рода. Род (**kind**) — это термин теории типов, означающий по сути тип типа [данных].
Но вначале немного лирики.
На Хабре вышло несколько статей, где подробно описывался метод валидации данных в функциональных языках.
Эта ст... | https://habr.com/ru/post/429104/ | null | ru | null |
# Да хватит уже писать эти регулярки
Здравствуйте, меня зовут Дмитрий Карловский и раньше я тоже использовал [Perl](https://perldoc.perl.org/perlre) для разработки фронтенда. Только гляньте, каким лаконичным кодом можно распарсить, например, имейл:
```
/^(?:((?:[\w!#\$%&'\*\+\/=\?\^`\{\|\}~-]){1,}(?:\.(?:[\w!#\$%&'\*... | https://habr.com/ru/post/561704/ | null | ru | null |
# PHP-Дайджест № 106 – свежие новости, материалы и инструменты (26 марта – 9 апреля 2017)
[](https://habrahabr.ru/company/zfort/blog/326036/)
Предлагаем вашему вниманию очередную подборку со ссылками на новости и материалы.... | https://habr.com/ru/post/326036/ | null | ru | null |
# Git и Github. Простые рецепты
При разработке собственного проекта, рано или поздно, приходится задуматься о том, где хранить исходный код и как поддерживать работу с несколькими версиями. В случае работы на компанию, обычно это решается за вас и необходимо только поддерживать принятые правила. Есть несколько общеупо... | https://habr.com/ru/post/273897/ | null | ru | null |
# GitLab 11.10

GitLab 11.10 с пайплайнами на панели управления, пайплайнами для объединенных результатов и предложениями по нескольким строкам в мердж-реквестах.
### Удобные сведения о работоспособности пайплайнов в разных проектах... | https://habr.com/ru/post/450378/ | null | ru | null |
# Настройка VSCode для отладки китайского RISC-V SoC
Я всей душой люблю малоизвестных производителей. Зачастую их продукты имеют фичи, недоступные у их более именитых конкурентов, по очень интересной цене (однажды меня очень выручило наличие встроенной в SoC полуамперной зарядки для аккумулятора и нескольких LDO, спос... | https://habr.com/ru/post/652471/ | null | ru | null |
# WebRTC для всех и каждого. Часть 1

Привет, друзья!
Представляю вашему вниманию первую часть перевода [этой замечательной книги по WebRTC](https://webrtcforthecurious.com/). Данная часть посвящена тому, что такое `WebRTC`, процесс... | https://habr.com/ru/post/656947/ | null | ru | null |
# Интеграция Groovy в JEE приложение
######
```
В одну телегу впрячь не можно
Коня и трепетную лань
А.С. Пушкин
```
Всем привет!
В данной заметке я хочу рассказать, как интегрировать язык Groovy в существующее JEE приложение на основе Maven. Выражаю благодарность Антону Щастному [schaan](... | https://habr.com/ru/post/145158/ | null | ru | null |
# Игровое управление моделям в условиях неполной информации
В соавторстве с Юлией Филимоновой.
### Введение
Представьте себе, что летите такой весь победитель на базу, бомб уже нет, и ничего не предвещает беды...

А т... | https://habr.com/ru/post/332142/ | null | ru | null |
# Разработка приложений и Blue-Green deployment, опираясь на методологию The Twelve-Factor App с примерами на php и docker

### Для начала немного теории. Что такое [The Twelve-Factor App](https://12factor.net/ru/)?
Простыми словами... | https://habr.com/ru/post/480020/ | null | ru | null |
# Управляем устройствами NooLite с роутера Zyxel Keenetic
В этой статье я расскажу о том, как управлять устройствами nooLite через USB переходник РС1ххх прямо из роутера Zyxel Keenetic — без учас... | https://habr.com/ru/post/396635/ | null | ru | null |
# Java XML API: выбираем правильно. StAX: работаем с удовольствием
Здравствуйте!
Несмотря на снижение популярности формата XML с начала 2000х, он прочно занял свои ниши. Я сталкивался с обработкой XML ~ в 60% проектов и посвятил ей заняти... | https://habr.com/ru/post/339716/ | null | ru | null |
# Валидация в приложении на PHP (часть 1 — валидация доменного слоя)
Статья рассчитана не на новичков, потому нормально, если по ходу чтения какие-то понятия будут вам неизвестны, я постарался коротко раскрыть их здесь, а также указал ссылки на посты в моём [телеграм канале Beer::PHP](https://t.me/joinchat/-KlDbLhFw-Q... | https://habr.com/ru/post/566394/ | null | ru | null |
# Защита веб-приложения на Phalcon + AngularJS от CSRF атак
Привет всем! Не так давно столкнулся с проблемой защиты веб-приложения написанного на Phalcon PHP Framework вместе с AngularJS. Проблема заключалась в том что на странице есть несколько форм, которые посылают AJAX-запросы на сервер. Как подружить два фреймвор... | https://habr.com/ru/post/245467/ | null | ru | null |
# Как отметить свои TODO, FIXME и ERROR в Xcode

*Этот пост является вольным переводом статьи [How to highlight your TODOs, FIXMEs, & ERRORs in Xcode](http://krakendev.io/blog/generating-warnings-in-xcode)... | https://habr.com/ru/post/306612/ | null | ru | null |
# VectorDrawable — часть вторая
В [предыдущей статье](https://habrahabr.ru/post/301578/) мы рассмотрели, как преобразовать существующий svg-файл в VectorDrawable, который позволяет заменить много растровых изображений на одно, меньшее по размеру и более простое в обслуживании. Однако, это не все полезности, которые мо... | https://habr.com/ru/post/301610/ | null | ru | null |
# Грузовики и рефрижераторы в облаке
В этой статье хотим поделиться с вами историей создания базового прототипа шлюза и его переноса на облачную платформу [Microsoft Azure](https://azure.microsoft.com/ru-ru/free/?wt.mc_id=AID570629_QSG_SCL_139068 https://azure.microsoft.com/ru-ru/free/?wt.mc_id=AID570629_QSG_BLOG_1390... | https://habr.com/ru/post/319856/ | null | ru | null |
# Безопасность DHCP в Windows 10: разбираем критическую уязвимость CVE-2019-0726
[](https://habr.com/ru/company/pt/blog/448378/)
*Изображение: [Pexels](https://www.pexels.com/photo/keyboard-green-51415/)*
С выходом январских обн... | https://habr.com/ru/post/448378/ | null | ru | null |
# Эффективное хранение: как мы из 50 Пб сделали 32 Пб
Видео доклада
-------------
Текстовая Версия
----------------
Изменения курса рубля два года назад заставили нас задуматься о способах снижения стоимости железа для Почты Mail.Ru. Нам понадобилось уменьшить количество закупаемого железа и цену за хостинг. Чтобы н... | https://habr.com/ru/post/316740/ | null | ru | null |
# Centrifugo – 3.5 миллиона оборотов в минуту

Последний раз я писал про [Centrifugo](https://github.com/centrifugal/centrifugo) чуть больше года назад. Пришло время напомнить о существовании проекта и рассказать, что произ... | https://habr.com/ru/post/326236/ | null | ru | null |
# Единая авторизация (SSO) средствами JASIG CAS. Часть 2

Приветствую, уважаемые хабро-читатели. Перед вами продолжение серии статей про JASIG CAS. В этой части я расскажу, как собрать артефакт CAS и начать с ним работат... | https://habr.com/ru/post/146006/ | null | ru | null |
# Что лучше: UIKit или SwiftUI?
Hello, World! Меня зовут Денис. Я IOS разработчик, пишу приложения для App Store. Хочу поделиться своим небольшим опытом на UIKit и SwiftUI.
**Первый запуск**
На [WWDC19](https://developer.apple.com/videos/play/wwdc2019/204) Apple предоставила декларативный фреймворк SwiftUI. Новый ф... | https://habr.com/ru/post/710632/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.