
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# ZFS: архитектура, особенности и отличия от других файловых систем
[*Frozen cells by arbebuk*](https://www.deviantart.com/arbebuk/art/frozen-cells-507629144)
Я, Георгий Меликов, являюсь контрибьютором проектов OpenZFS и ZFS on Linux... | https://habr.com/ru/post/529516/ | null | ru | null |
# Разработка веб-приложений в PicoLisp
> Читатели предыдущей статьи [Радикальный подход к разработке приложений](http://habrahabr.ru/post/177791/) могли справедливо заметить, что статья слишком теоретическая. Поэтому спешу восстановить баланс ~~добра и зла~~ теории и практики.
>
>
>
> Эта статья раскрывает лиш... | https://habr.com/ru/post/178235/ | null | ru | null |
# Делаем сервис по распознаванию изображений с помощью TensorFlow Serving

Всегда наступает то самое время, когда обученную модель нужно выпускать в production. Для этого часто приходится писать велосипеды в виде оберток... | https://habr.com/ru/post/332584/ | null | ru | null |
# Фореве элон 2016/2017 (встреча Нового года в сети)
[](https://telegram.me/habragram)
Друзья, наверняка, многим приходится отмечать наступление Нового года в одиночестве или на работе!
С этим н... | https://habr.com/ru/post/400361/ | null | ru | null |
# Недокументированные изменения или PHP 5.4 и перегрузка функций
##### Как это было
Не так давно столкнулся с одной проблемой, возникшей при переезде на php 5.4. Задача состояла в тестировании функционала, который использовал родные функции. К слову, [Fumocker](http://github.com/formapro/Fumocker) отлично справляется... | https://habr.com/ru/post/153689/ | null | ru | null |
# Kafka и Chronicle Queue
[](https://habr.com/ru/company/ruvds/blog/676804/)
Хотя облачные сервисы удобны и гибки, эксплуатационные затраты на приложения, развёрнутые в облаке, иногда могут быть существенными. В этой статье мы расска... | https://habr.com/ru/post/677454/ | null | ru | null |
# Inversion of Control: Методы реализации с примерами на PHP
> О боже, ещё один пост о Inversion of Control
Каждый более-менее опытный программист встречал в своей практике словосочетание Инверсия управления (Inversion of Control). Но зачастую не все до конца понимают, что оно значит, не говоря уже о том, как правиль... | https://habr.com/ru/post/244517/ | null | ru | null |
# Игры в OLTP
В последнее время на Хабре стала популярной тема реализации высокопроизводительных приложений. Решили тоже немножко поэкспериментировать в этом направлении и поделиться текущими результатами наших изысканий.
Подопытный *«Hello, world!»* представляет собой простейшую OLTP систему:

Molecule — отличный инструмент для тестирования ролей Ansible, он выполняет надежный и гибкий процесс проверки для обеспечения хорошего уровня качества ролей. Почти вся ... | https://habr.com/ru/post/536892/ | null | ru | null |
# Быстрая математика с фиксированной точкой для финансовых приложений на Java
Не секрет, что финансовая информация (счета, проводки и прочая бухгалтерия) не очень дружит с числами с плавающей точкой, и множество статей рекомендует использовать фиксированную точку (fixed point arithmetic). В Java этот формат представле... | https://habr.com/ru/post/425565/ | null | ru | null |
# Как оптимизировать pandas при работе с большими datasetами (очерк)
Когда памяти вагоны и/или dataset небольшой можно смело закидывать его в pandas безо всяких оптимизаций. Однако, если данные большие, остро встает вопрос, как их обрабатывать или хотя бы считать.
Предлагается взглянуть на оптимизацию в миниатюре, ... | https://habr.com/ru/post/467785/ | null | ru | null |
# Сквозная Аналитика на Azure SQL + dbt + Github Actions + Metabase

Привет, Хабр! Меня зовут Артемий Козырь.
За последние годы у меня накопился довольно обширный опыт работы с данными и тем, что сейчас называют *Big Data*.
Не т... | https://habr.com/ru/post/538106/ | null | ru | null |
# Метапрограммирование
[Метапрограммирование](http://en.wikipedia.org/wiki/Metaprogramming) — общее название класса средств автоматизации труда программиста. Под ним понимают и кодогенерацию, и макросы п... | https://habr.com/ru/post/58801/ | null | ru | null |
# Исследуем прародителей Minecraft: Dungeon Keeper
[](http://www.youtube.com/watch?v=_rfU96z0dEw) Я думаю, что о Minecraft слышали почти все. Но, возможно, не все видели одну из замечательных игр, [из которой Нотч брал свои ... | https://habr.com/ru/post/136255/ | null | ru | null |
# JSX — подробности

Этой публикацией я открываю серию переводов раздела "Продвинутые руководства" (Advanced Guides) официальной документации библиотеки React.js.
JSX — подробности... | https://habr.com/ru/post/319270/ | null | ru | null |
# Интеграция Google Pay
Привет, Хабр!
Меня зовут Игорь, я Android-разработчик в команде Trinity Digital. Сегодня я хочу рассказать о классном инструменте — **Google Pay API**.
[
На сегодняшний день ни одно большое **SPA** приложение не обходится без **state management (управления состоянием)**. Для [**Angular**](https://angular.io/) по данному... | https://habr.com/ru/post/418369/ | null | ru | null |
# Книга «Командная строка Linux. Полное руководство. 2-е межд. изд.»
[](https://habr.com/ru/company/piter/blog/465899/) Привет, Хаброжители! Международный бестселлер «Командная строка Linux» поможет преодолеть путь от первых робк... | https://habr.com/ru/post/465899/ | null | ru | null |
# Играем в Haskell

Я замечательно провел время изучая Haskell в последние месяцы, и мне кажется, что сделать первые шаги в этом занятии сложнее, чем это могло бы быть на самом деле. Мне повезло работать в нужное время и... | https://habr.com/ru/post/165559/ | null | ru | null |
# Как связать два asterisk-сервера (часть первая. SIP)
Итак, имеем два астериска.
Задача — организовать прямой дозвон через префикс туда и обратно.
Исходные данные:
Астериск 1.4 на обеих кон... | https://habr.com/ru/post/107668/ | null | ru | null |
# Заговор или совпадение: СПО в школах
В продолжение топика [про внедрение СПО](http://habrahabr.ru/blogs/linux/70765/). Вчера в блогах мелькнуло рассуждение по итогам этого тендера.
Цитирую (заголовок, оформление и орфография сохранены):
`**СПО-распил**
Многие наверняка слышали о проекте внедрения СПО в рос... | https://habr.com/ru/post/71189/ | null | ru | null |
# Шрифт с помощью CSS

Дэвид Дисандро разработал CSS, который рисует шрифт. Шрифт он назвал Curtis.
Оформление каждой буквы выглядит несколько грамоздко:
> `<span class="css\_char r">
>
> R
>
> <span class="inside split\_... | https://habr.com/ru/post/87904/ | null | ru | null |
# Реверс черного тессеракта. Начало
Система с известной спецификацией реакций на входные воздействия и неизвестным содержимым характеризуется как черный ящик. Когда внутренняя структура, устройство и архитектура системы известны, - ящик белый. Есть и промежуточное понятие - серый ящик, частичное знание внутреннего уст... | https://habr.com/ru/post/597625/ | null | ru | null |
# Печатаем книги-брошюры в *nix
Наверняка у многих из тех, кто читает этот пост, возникало желание распечатать некую книгу на бумаге и сделать это так, чтобы книга была по удобству близка к типографской. Конечно, в роли книги может выступать как какой-нибудь pdf-документ, так и какая-нибудь tex'овая научная работа.
... | https://habr.com/ru/post/79921/ | null | ru | null |
# Установка и запуск Android-приложений на Linux
Как известно, многие Android-приложения можно нативно запускать на Chrome OS благодаря библиотеке [Chrome App Runtime](https://developer.chrome.com/apps/app_runtime).
... | https://habr.com/ru/post/253238/ | null | ru | null |
# Захват видео с камеры и передача его по сети
#### Предисловие
Не так давно, возникла необходимость захвата видео с web камеры и передавать его по сети используя .Net.
Так как с подобной задачей я столкнулся впервые, то первым делом начал искать информацию по этому вопросу.
Как выяснилось, что в чистом .Net не... | https://habr.com/ru/post/177793/ | null | ru | null |
# Создание сложных приложений в ExtJS.
Автор: [Jozef Sakalos, aka Saki](http://extjs.eu/)
Статья в оригинале: [Создание сложного приложение в Ext](http://blog.extjs.eu/know-how/writing-a-big-application-in-ext/) на blog.extjs.eu
Предисловие
===========
Я решил написать эту статью для тех пользователей [Ext](ht... | https://habr.com/ru/post/31589/ | null | ru | null |
# Прокси хранилища 1С (IIS, OneScript)
**В этом посте мы поговорим о том, как избавиться от версионной зависимости, проверять комментарии, вызывать веб-хуки и делать красивые пути. И все это на привычном IIS и понятном OneScript.**
### Для чего, зачем и почему
Во всех командах разработки рано или поздно возникает по... | https://habr.com/ru/post/710130/ | null | ru | null |
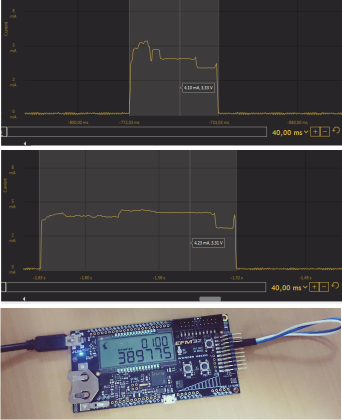
# Как я сделал электронную плату для телеметрии датчиков и для управления периферией
В ходе создания робота-официанта, робота телеприсутствия, селфибота появились некоторые разработки, которыми грех не поделиться с сообществом, то есть сделать open-source. Одной из рабочих версий стала электронная плата под кодовым на... | https://habr.com/ru/post/397493/ | null | ru | null |
# Интеграция Open vSwitch с Р-виртуализацией
Как-то понадобилось интегрировать [Open vSwitch](http://www.openvswitch.org/) (OVS) c [Р-виртуализацией плюс Р-хранилище](https://rosplatforma.ru/)(РП), может пригодится и не только с РП.
Текущая версия РП на момент статьи была [7.0.13-31](http://updates.rosplatforma.ru/r... | https://habr.com/ru/post/508832/ | null | ru | null |
# Руководство по обработке ошибок в JavaScript
Ошибки — это хорошо. Автор материала, перевод которого мы сегодня публикуем, говорит, что уверен в том, что эта идея известна всем. На первый взгляд ошибки кажутся чем-то страшным. Им могут сопутствовать какие-то потери. Ошибка, сделанная на публике, вредит авторитету тог... | https://habr.com/ru/post/431078/ | null | ru | null |
# 1С: Предприятие — Как напечатать адреса для конвертов

Всем, кто ведет свои дела официально, знакома такая рутинная операция, как отправка счетов и актов контрагентам. И с увеличением количеств... | https://habr.com/ru/post/87838/ | null | ru | null |
# Опыт написания рефакторинга
Недавно я столкнулся с проблемой коллизий имен из разных пространств имен. В C# есть возможность ввести синонимы для пространств имен, т.е. вместо использования полного имени класса ввести префикс, с помощью которого можно обращаться к данному пространству имен.
Я не нашел простого пут... | https://habr.com/ru/post/191604/ | null | ru | null |
# Структуры данных в memcached/MemcacheDB. Часть 2
Продолжение [статьи](http://habrahabr.ru/blogs/webdev/50243/) про структуры данных в memcached. В этой завершающей части мы рассмотрим еще три структуры данных: лог событий, массив и таблицу.
Лог событий
-----------
### Задача
Задача этой структуры данных — хране... | https://habr.com/ru/post/50247/ | null | ru | null |
# Ультимативный гайд по дизайн-токенам
##### Евгений Шевцов
Руководитель UX-направления в Usetech
На небе только и разговоров, что о дизайн-системах и дизайн-токенах. Но информация представленная здесь стр... | https://habr.com/ru/post/673196/ | null | ru | null |
# Расширенная настройка Exim и Dovecot с привязкой к OpenLDAP
В этой статье рассматривается расширенная настройка Exim, Dovecot и OpenLDAP для совместной работы на основе моего опыта с этими приложениями. Быть может, кто-то найдет для себя что-либо интересное и новое — в этом и была цель написания очередного howto на ... | https://habr.com/ru/post/262101/ | null | ru | null |
# Как я сделал игру для Блокнота
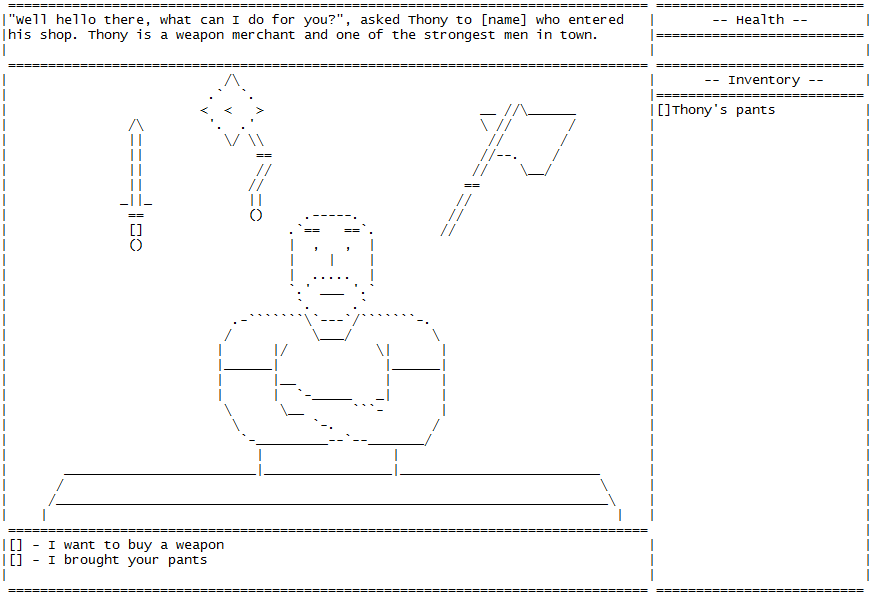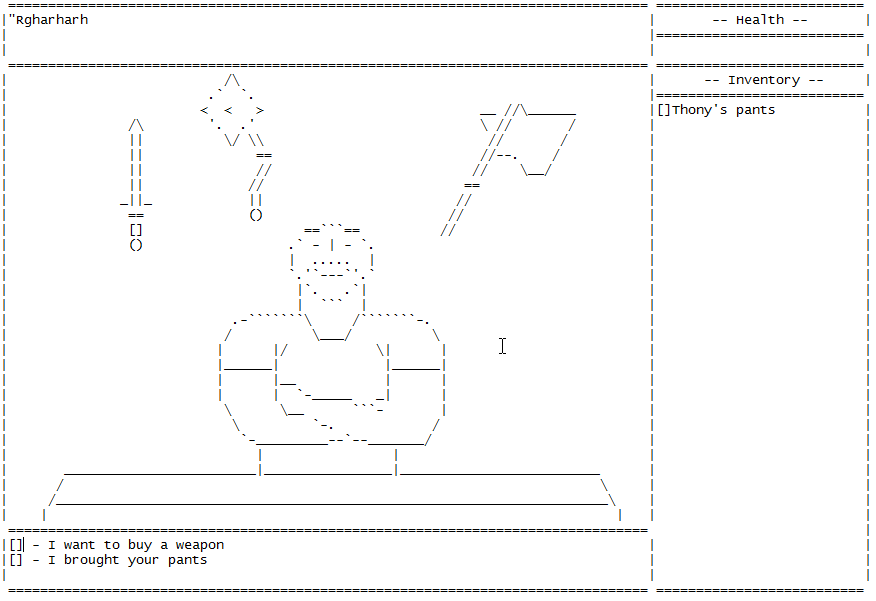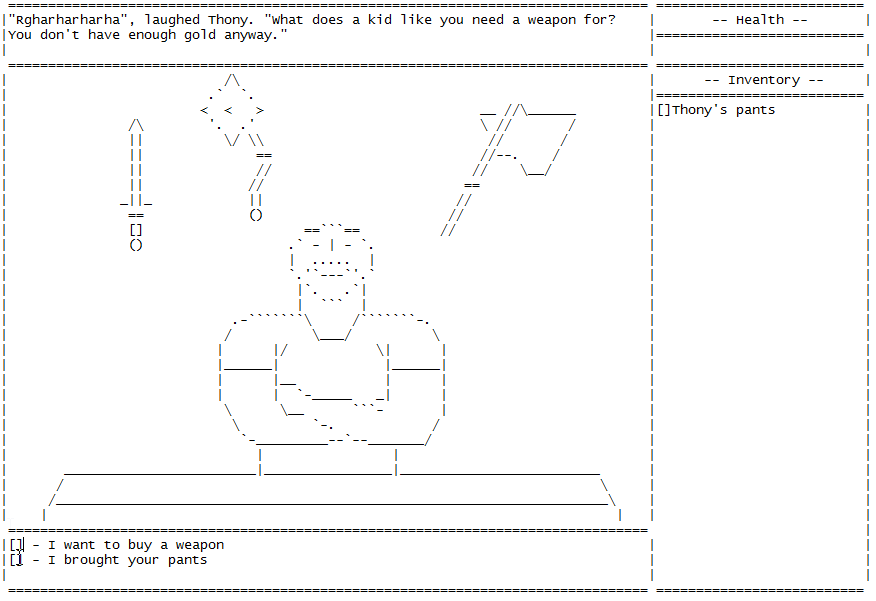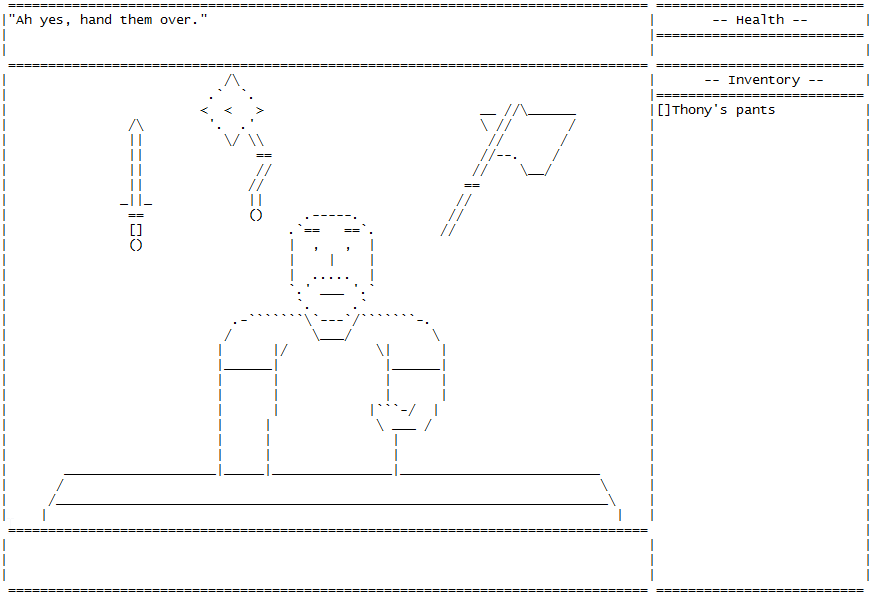
Пока читал про необычные решения от инди-разработчиков, наткнулся на золото. Вот вам статья про игру в текстовом редакторе. Арт, анимация, сюжет — все как положено.
Я создал игру And yet it hurt (*возможн... | https://habr.com/ru/post/488222/ | null | ru | null |
# Osquery выставляет ОС как реляционную СУБД
Facebook выложил на гитхабе фреймворк [OSquery](https://github.com/facebook/osquery), он осуществляет низкоуровневый мониторинг процессов в OS X и Linux и хранит их в виде SQL-таблиц. Такой способ по-своему удобен, ведь в запросе можно объединять разные таблицы.
Например... | https://habr.com/ru/post/242205/ | null | ru | null |
# Рейт-лимитинг ваших Symfony API
В процессе разработке у вас может возникнуть необходимость наложить на ваши API какой-нибудь кастомный рейт-лимит (т.е. ограничить количество запросов для пользователей вашег... | https://habr.com/ru/post/645261/ | null | ru | null |
# Задачи компьютерного зрения — поиск объектов нужного цвета
### Введение
Сегодня я расскажу о том как распознать контур нужного цвета с помощью python/ opencv такая задача часто встречается в робототехнике, и всяких автоматизациях.
С помощью предложенного решения можно например различать контур линии за которую ... | https://habr.com/ru/post/498774/ | null | ru | null |
# Инициализация и работа интерпретатора байткода в JVM HotSpot под x86
Почти каждый Java разработчик знает, что программы, написанные на языке Java изначально компилируются в JVM-байткод и хранятся в виде class-файлов [стандартизованного формата](https://docs.oracle.com/javase/specs/jvms/se7/html/jvms-4.html#jvms-4.1)... | https://habr.com/ru/post/469291/ | null | ru | null |
# C++ Russia: как это было
*Если в начале пьесы вы говорите, что на стене висит код на С++, то к концу он должен непременно выстрелить вам в ногу.
Бьярне Строуструп*
С 31-го октября по 1-е ноября в Петербурге прошла конференция C++ Russia Piter – одна из масштабных конференций по программированию в России, орган... | https://habr.com/ru/post/481358/ | null | ru | null |
# Пишем свои монады на Scala на примере CSV-парсера
За последнее время мы очень многое узнали о монадах. Мы уже разобрались [что это такое](https://habrahabr.ru/post/209510/) и даже знаем [как их можно нарисовать](https://habrahabr.ru/post/183150/), видели [доклады](https://www.youtube.com/watch?v=YCOSAazIi2Q), объясн... | https://habr.com/ru/post/326002/ | null | ru | null |
# Назад в будущее – Декапсуляция

При работе программных модулей, хранящих в оперативной памяти большое количество данных, способ их хранения оказывает сильное влияние на потребление памяти и быстродействие. Один из способов ус... | https://habr.com/ru/post/264063/ | null | ru | null |
# Разработка на ассемблере в Linux
Вообще программирование на ассемблере в Linux мало распространено и занимаются им, разве что, фанаты ассемблера. Сегодня мы и поговорим о программировании на ассемблере и инструментарий.Что нам понадобится:
* FASM. Берем на flatassembler.net версию для Linux
* ald. Берем на ald.so... | https://habr.com/ru/post/79454/ | null | ru | null |
# Учебник по симулятору сети ns-3. Глава 6

[главы 1,2](https://habr.com/ru/post/497106/)
[глава 3](https://habr.com/ru/post/497318/)
[глава 4](https://habr.com/ru/post/497478/)
[глава 5](https://habr.com/ru/post/498372/)
Г... | https://habr.com/ru/post/500170/ | null | ru | null |
# Препарируем электрическое перо Wacom
Недавно ~~впервые в истории~~ автором была осуществлена разборка и слесарная доработка пера графического планшета [Wacom Volito2](http://www.my-volito.com/) с целью корректировки порога чувствительности к нажиму. После обратной сборки изделие чувствует себя хорошо. Подробности ~~... | https://habr.com/ru/post/85639/ | null | ru | null |
# Захвати и визуализируй! Или гистограмма с микрофона средствами Web Audio API
[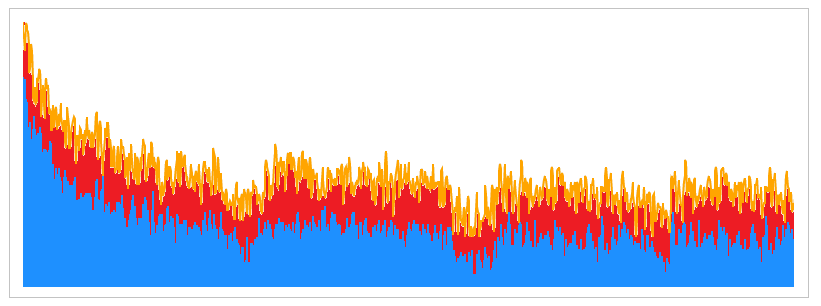](https://habrahabr.ru/company/devexpress/blog/278823/)
Я очень люблю «живые» графики. Смертельная скука — смотреть на статичные картинки с цифр... | https://habr.com/ru/post/278823/ | null | ru | null |
# ABBYY NeoML 2.0: Python и многое другое

Прошел почти год с тех пор, как мы опубликовали на [GitHub](https://github.com/neoml-lib/neoml) библиотеку для машинного обучения NeoML. О чем, конечно же, была статья на [Хабре](https://hab... | https://habr.com/ru/post/563876/ | null | ru | null |
# phpBBex — добавляем автозагрузку классов и обработчики AJAX запросов
phpBBex — это расширенная версия phpBB 3, которая была [анонсирована ранее](http://habrahabr.ru/post/129990/) на Хабре. Проект... | https://habr.com/ru/post/142373/ | null | ru | null |
# Параллакс на чистом CSS
В этой статье показывается, как с помощью CSS трансформаций и махинаций с 3d сделать параллакс-эффект на сайте на чистом CSS.
Параллакс почти всегда создаётся с помощью JavaScript и, чаще всего, получается ресурсоёмким, из-за вешания листенеров на событие скролла, модификации DOM напрямую ... | https://habr.com/ru/post/235531/ | null | ru | null |
# Создание игр для Windows Store c использованием WebGL
 Windows Store на текущий момент, возможно, самая открытая платформа для игровых студий. Для создания приложений вы можете использовать [DirectX 11](http... | https://habr.com/ru/post/203550/ | null | ru | null |
# Как мы делали олимпиаду по SQL (окончание)
Продолжаю рассказ о том, [как мы делали олимпиаду по SQL](https://habrahabr.ru/post/349560/). Это продолжение предыдущей статьи, в которую всё просто не уместилось.
Краткое содержание предыд... | https://habr.com/ru/post/350528/ | null | ru | null |
# Эти забавные BroadcastReceiver'ы
Небольшое наблюдение о различном поведении `BroadcastReceiver`'ов при регистрации через `AndroidManifest.xml` и непосредственно в коде. Данная заметка не является пошаговым руководств... | https://habr.com/ru/post/149875/ | null | ru | null |
# Один день из жизни DBA Microsoft SQL Server
В арсенале Microsoft SQL Server есть одна интересная штука – **service broker**. По сути своей это очередь сообщений, встроенная в СУБД, способная обеспечить тр... | https://habr.com/ru/post/569008/ | null | ru | null |
# Интуитивное программирование
За свой относительно небольшой опыт работы (порядка 6 лет) я довольно часто слышал фразы опытных и начинающих программистов — «Я чувствую, что это должно работать», «У меня есть ощущение, что этот метод работать не будет», «Давайте сделаем интуитивно-понятный интерфейс» и так далее. Всё ... | https://habr.com/ru/post/318502/ | null | ru | null |
# Архитектура фронтенда и какой она должна быть
Все мы знаем про, или слышали про практики и паттерны проектирования ***SOLID, GRASP, MVC, MV\*\**** *и даже применяем их с переменным успехом, стараясь нащупа... | https://habr.com/ru/post/667214/ | null | ru | null |
# Локальные файлы при переносе приложения в Kubernetes

При построении процесса CI/CD с использованием Kubernetes порой возникает проблема несовместимости требований новой инфраструктуры и переносимого в неё приложения. В частности, ... | https://habr.com/ru/post/471582/ | null | ru | null |
# Уменьшение операций чтения/записи на Raspberry Pi
**Введение**
Итак, в интернете можно найти статьи о том что в Raspberry флешки «живут» 2-3 месяца, после чего приходят в негодность. Предложенные решения — заменить стандартную microSD карточку на USB HDD. Решение простое, надёжное, плюс повышается скорость чтения... | https://habr.com/ru/post/330160/ | null | ru | null |
# Уведомление о скачанных торрентах по SMS
Как то вечером, ожидая загрузку любимых LOST и Breaking Bad, захотелось прогуляться по теплому вечернему Минску в сторону парка Горького. Но вот незадача, примерное время скачивания торрента прыгает то вверх, то вниз, ... | https://habr.com/ru/post/95149/ | null | ru | null |
# Новый GitLab 12.0 с визуальными ревью и списком зависимостей

### Dev, Sec и Ops
GitLab 12.0 — это ключевой выпуск на пути к реализации подхода, который будет охватывать все элементы DevSecOps и позволит всем вносить свой вклад.
... | https://habr.com/ru/post/458136/ | null | ru | null |
# Подборка @pythonetc, ноябрь 2019

Новая подборка советов про Python и программирование из моего авторского канала @pythonetc.
← [Previous publications](https://habr.com/en/search/?q=pythonetc#h)

Знакомый линуксоид упрекнул меня, мол, в винде ни переключения языка Caps Lock'ом нет, ни даже раскладку нельзя отредактировать. Посмотрел я, и ... | https://habr.com/ru/post/301882/ | null | ru | null |
# Не делайте лишних колонок в ваших таблицах, вам это не нужно
Всем привет.
Я люблю базы данных, люблю строить запросы, люблю проектировать БД. Раскладывать по полочка, систематизировать это моё любимое занятие. Конечно первые годы я проектировал таблицы БД как меня научили в ВУЗе - каждому свойству отдельная колонка... | https://habr.com/ru/post/661699/ | null | ru | null |
# Готовим ORM, не отходя от плиты. Генерируем SQL — запрос на основе бинарных деревьев выражений

Статья является продолжением [первой части](https://habrahabr.ru/post/317860/). В посте рассмотрим пос... | https://habr.com/ru/post/319422/ | null | ru | null |
# Использование двух редакторов анимаций в игровом проекте
Два редактора анимации в игровом проектеВ последнее время у меня появляется желание делиться с... | https://habr.com/ru/post/600057/ | null | ru | null |
# Meteor — Node.js для гуманитариев
Введение
--------
На хабре уже несколько раз упоминали о проекте [Meteor](https://meteor.com/), основанном в 2011 году [семерыми энтузиастами](http://meteor.com/about/mission) web-технологий из Сан-Франциско. По сути Meteor является просто надстройкой над node.js, который сам ещё д... | https://habr.com/ru/post/166885/ | null | ru | null |
# Автоматическое увеличение номера сборки в Xcode
Пользователи и тестировщики могут найти ошибки, которые вы наверняка уже исправили. Иногда пользователи используют старую версию приложения, иногда ваши исправления не так хороши, как вы думали. В обоих случаях небольшой уникальный номер версии, отображаемый в приложен... | https://habr.com/ru/post/132195/ | null | ru | null |
# Video rip. Часть 2-3. Избавление от обычной чересстрочности (deinterlace)
#### Содержание
1. Подготовка DVD
1. [vStrip](http://habrahabr.ru/blogs/video_processing/50256/)
2. [DGMPGDec](http://habrahabr.ru/blogs/video_processing/50611/)
2. Обработка видео
1. [Что такое interlace и с чем его едят](http://hab... | https://habr.com/ru/post/61822/ | null | ru | null |
# Исследуем .NET 6. Часть 1
В этой серии статей я собираюсь взглянуть на некоторые из новых функций, которые появились в .NET 6. Про .NET 6 уже написано много контента, в том числе множество постов непосредственно от команд .NET и ASP.NET. Я же собираюсь рассмотреть код некоторых из этих новых функций.
Заглянем в Con... | https://habr.com/ru/post/594423/ | null | ru | null |
# Правила хорошего тона для API
Перенос функциональности сайта, интернет-магазина или портала в мобильное приложение имеет ряд преимуществ как для владельца онлайн-сервиса, так и для его клиентов. Владелец получает дополнительный канал связи со своей целевой аудиторией и возможность персонализировать рекламные объявле... | https://habr.com/ru/post/333884/ | null | ru | null |
# Docker: гибкая сеть без NAT на все случаи жизни

Время на месте не стоит, и у горячо любимого всеми Docker от версии к версии появляется новый функционал. Случается так, что когда читаешь Changelog для новой версии, ... | https://habr.com/ru/post/308402/ | null | ru | null |
# 13 интересных моментов из руководства по стилям для JavaScript от Google
Для тех, кто еще не видел: Google опубликовал руководство по стилям для JavaScript, где изложены лучшие стилистические практики (по версии компании) для написания аккуратного, понятного кода.

Несмотря на перманентные похороны Delphi, эта платформа построения Desktop приложений живёт и здравствует, а со сменой владельца даже [обретает второе дыхание](http://habrahabr.ru/post/142979/) ... | https://habr.com/ru/post/144306/ | null | ru | null |
# Как я скачивал онлайн трансляцию Comdi (Startup village)

Мы живем с вами в то время, когда видео с Youtube и других видеохостингов может скачать даже школьник с помощью огромного количества расширений для браузеров.
... | https://habr.com/ru/post/303682/ | null | ru | null |
# Используем TSQL для игры в «Судоку»
После того как при помощи TSQL была успешна решена [«Балда» (статья)](http://habrahabr.ru/post/271795/) я решил попробовать решить на нем «Судоку» (спасибо за идею [shavluk](http://habrahabr.ru/users/shavluk/)).
Решение судоку получилось на удивление достаточно простым.
**Ба... | https://habr.com/ru/post/272373/ | null | ru | null |
# Карта средств защиты ядра Linux
Защита ядра Linux — очень сложная предметная область. Она включает большое количество сложно взаимосвязанных понятий, и было бы полезным иметь ее графическое представление. Поэтому я разработал [карту средств защиты ядра Linux](http://github.com/a13xp0p0v/linux-kernel-defence-map). Во... | https://habr.com/ru/post/457460/ | null | ru | null |
# Учимся готовить: Spring 3 MVC + Spring Security + Hibernate
Добрый день! Меня зовут Антон Щастный.
Это моя очередная статья, посвящённая разработке веб приложений на Java. Хочу предложить вам сделать небольшую систему учёта клиентов, написанную с использованием фреймворка Spring и библиотеки Hibernate.
### Что... | https://habr.com/ru/post/111102/ | null | ru | null |
# Combustion — альтернативный подход к тестированию Rails Engines
*Сегодня мы предоставим вашему вниманию перевод поста Пета Аллана (Pat Allan), известного разработчика, приверженца Ruby, одного из победителей Ruby Hero Award 2009 года. Что это за награда? Она присуждается победителями прошлого года тем участникам соо... | https://habr.com/ru/post/128794/ | null | ru | null |
# Разбираемся что MySQL пишет на диск и зачем [часть 1]
### Оглавление
1. Double Write buffer и Binlogs [эта статья]
2. Redo logs и общая картина [<https://habr.com/ru/post/699342/>]
> **Disclaimer:** автор не является разработчиком MySQL, все нижеописанное может не совпадать с реальным положением дел.
>
>
Часть ... | https://habr.com/ru/post/684474/ | null | ru | null |
# Правила умного дома
Очень часто в статьях про домашнюю автоматизацию на Хабре выкладывают всю техническую подноготную: на каких технологиях сделано, какие программные продукты применены. Но мало статей, которые показывают конкретные примеры правил автоматизации. И сегодня я хочу это исправить.

Некоторое время назад мне предложили немного поработать с одноплатным ПК Orange Pi 2G-IOT (встроенный 2G и цена выглядят очень привлекательно). Прочитав пост об [апельсиновом рае](https://hab... | https://habr.com/ru/post/440960/ | null | ru | null |
# Производительность и рантаймы на конференции JPoint 2018
Все мы имеем какие-то ожидания от конференций. Обычно мы идём на вполне конкретную группу докладов, вполне конкретной тематики. Набор тем отличается от платформы к платформе. Вот что сейчас интересует джавистов:
* Производительность
* Виртуальные машины и осо... | https://habr.com/ru/post/351078/ | null | ru | null |
# ATI Catalyst 8.7/8.8 + WINE OpenGL. Решение проблемы.
Как я уже писал в одном из своих [прошлых топиков](http://alinaki.habrahabr.ru/blog/28043/), новый проприетарный драйвер для видеокарт AMD ATI добавил много улучшений, но поломал совместимость с OpenGL в WINE. Из-за этого я откатился на драйвер 8.4, в котором мер... | https://habr.com/ru/post/37942/ | null | ru | null |
# Трюки при линковке и загрузке файлов Mach-O
*Представляю вашему вниманию перевод моей статьи из блога Проекта Darling. Маленькая справка по используемым понятиям: Darwin – операционная система с открытым исходным кодом, лежащая в основе macOS, iOS и других ОС от Apple; Mach-O – бинарный формат исполняемых файлов и б... | https://habr.com/ru/post/417507/ | null | ru | null |
# Виртуальный мир Intel. Практика
В данной статье я хочу рассмотреть практические аспекты создания простого гипервизора на основе технологии аппаратной виртуализации Intel VMX.
Аппаратная виртуализация достаточно узкоспециализированная область системного программирования и не имеет большого комьюнити, в России уж ... | https://habr.com/ru/post/419065/ | null | ru | null |
# На что стоит променять Cortex-M3?
ARM Cortex-M3 — это, пожалуй, самое популярное на сегодняшний день 32-разрядное процессорное ядро для встраиваемых систем. Микроконтроллеры на его базе выпускают десятки производителей. Причи... | https://habr.com/ru/post/277491/ | null | ru | null |
# Multi-Master репликация в MySQL
В данной статье будет рассмотрен процесс развертывания отказоустойчивой подсистемы баз данных на базе MySQL сервера.
*Перед прочтением советую прочитать [эту статью](http://habrahabr.ru/blogs/mysql/56702/).*
На работе встал вопрос по созданию зеркала сайта для другого региона (А... | https://habr.com/ru/post/87394/ | null | ru | null |
# Как создать telegram бот на C# быстро?
Добрый день, уважаемые друзья!
------------------------------
В этой статье мы рассмотрим заготовку для создания телеграм бота на C#. В связи с последними обновления... | https://habr.com/ru/post/657583/ | null | ru | null |
# Система удалённого мониторинга рабочих мест на базе 360-градусной камеры и Raspberry Pi
Я создал прототип системы удалённого мониторинга рабочих мест. Эта система позволяет организациям, адаптирующимся к ограничениям, связанным с COVID-19, осуществлять наблюдение за сотрудниками и проводить виртуальные инспекции раб... | https://habr.com/ru/post/550192/ | null | ru | null |
# Умные выключатели на основе 8051 ядра, с управлением по Ethernet, Ч. 1
Доброго времени суток, уважаемые хабровчане!
Разрабатываемое устройство в чем-то повторяет [IRemo: Tap](http://habrahabr.ru/blogs/gadgets/118437/), а также некоторые другие аналоги, о которых писалось уже на хабрахабре. Мой же вариант будет бо... | https://habr.com/ru/post/124268/ | null | ru | null |
# Онлайн-трансляция ACM ICPC: Как это устроено
[](http://habrahabr.ru/company/spbifmo/blog/301098/)
#### Про чемпионат
Международная олимпиада ACM ICPC – крупнейшее мероприятие среди командных студенческих соревнований по п... | https://habr.com/ru/post/301098/ | null | ru | null |
# Нескучный Powershell
По работе мне периодически приходится править и дописывать скрипты для авто-тестов. И так исторически сложилось, что написаны они на Powershell. Но статья будет не об этом.
Обычно Powershell описывается как средство автоматизации для системных администраторов. И естественно, что к нему проявл... | https://habr.com/ru/post/319872/ | null | ru | null |
# Парсим NFT транзакции на OpenSea
Примерно раз в год у меня появляется неутолимая жажда накопать много данных и что-то с ними сделать. В этот раз мой выбор пал на маркетплейс NFT OpenSea. Меня осенило что бл... | https://habr.com/ru/post/651771/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.