
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Начала отладки и профилирования веб-приложений
#### Вступление
Много существует статей на Хабре, описывающих интересные и сложные аспекты веб-разработки, но много существует читателей, которые, находясь в начале своей карьеры веб-разработчика, хотели бы видеть материал, который позволил бы сделать первый шаг от «PH... | https://habr.com/ru/post/139004/ | null | ru | null |
# Как использовать HTTP заголовки для предупреждения уязвимостей

Знаете ли вы, что в большинстве случаев уязвимость системы безопасности можно устранить добавив необходимые заголовки ответа?
Безопасность не менее важна, ... | https://habr.com/ru/post/315802/ | null | ru | null |
# Модели памяти, лежащие в основе языков программирования
*Предлагаем вашему вниманию перевод [статьи](http://canonical.org/~kragen/memory-models), посвящённой рассмотрению используемых в программировании моделей памяти.*
Сегодня в программировании доминируют шесть основных моделей памяти (не путать с [моделями пам... | https://habr.com/ru/post/323624/ | null | ru | null |
# Do not keep activities
### Не сохранять операции
«Не сохранять операции» — именно таким странным образом переведена фраза «Do not keep activities» в настройках Android. А описание «Удалять все операции сразу после их завершения пользователем» не добавляет ясности. Включается она в меню «Параметры разработчика» (Dev... | https://habr.com/ru/post/221679/ | null | ru | null |
# Оркестрация микросервисов с Activiti BPMN Engine
Микросервисная архитектура предполагает декомпозицию системы на относительно независимые фрагменты с собственными источниками данных, которые могут переиспол... | https://habr.com/ru/post/671360/ | null | ru | null |
# Установка и настройка Asterisk для работы с WebRTC

В сети есть много информации и инструкций по теме, но на текущий момент они уже не актуальны и довольно сложны. Во многих случаях используют [webrtc2sip](https://code.goo... | https://habr.com/ru/post/236291/ | null | ru | null |
# Learn OpenGL. Урок 4.10 — Инстансинг
 Инстансинг
==========
Представьте, что вы задумали сцену, содержащую огромное количество моделей объектов, причем преимущественно эти модели содержат одинаковые вершинные данные, разня... | https://habr.com/ru/post/352962/ | null | ru | null |
# SASS против LESS
«Какой препроцессорный язык стоит использовать для CSS?» является очень актуальным вопросом в последнее время. Несколько раз меня спрашивали об этом лично, и казалось бы, каждые пару дней этот вопрос поднимался в сети. Очень приятно что беседа перешла из темы о плюсах и минусах препроцессинга к обсу... | https://habr.com/ru/post/144309/ | null | ru | null |
# Функция random() у гуглобота работает абсолютно детерминированно
Я проводил некоторые эксперименты, как Googlebot разбирает и рендерит JavaScript, и наткнулся на несколько интересных вещей. Первое — то, что функция `Math.random()` в Googlebot выдаёт полностью детерминированные серии чисел. Я написал маленький скрипт... | https://habr.com/ru/post/348914/ | null | ru | null |
# Tkinter, раскрытие потенциала. + Игра на рабочем столе
Tkinter - это та библиотека, с которой на начальных этапах изучения языка python знакомились все, но обходили стороной по разным причинам. Сейчас я предлагаю вернуться назад, немного поностальгировать и открыть для себя в разы больше фич библиотеки.
ВАЖНО! Tki... | https://habr.com/ru/post/682072/ | null | ru | null |
# Vue.js и как его понять
В своей работе, мне относительно недавно пришлось столкнуться с фреймворком Vue.js, т.к. до этого, я занимался в основном backend разработкой, пришлось со многим разбираться и многое было сложновато понять, особенно, когда раньше использовал только jQuery. В рамках данной статьи, я хочу помоч... | https://habr.com/ru/post/351882/ | null | ru | null |
# Высокопроизводительный GWT. Часть 1

Данный пост является началом серии статей про оптимизацию и улучшение производительности GWT-приложений. Поскольку материала у меня накопилось достаточно много, р... | https://habr.com/ru/post/132996/ | null | ru | null |
# Ёлочка в командной строке
*Скоро Новый Год, думать о серьёзной работе уже не хочется.
Все стараются что-нибудь украсить к празднику: дом, офис, рабочее место… Давайте и мы что-нибудь украсим! Например, приглашение командной строки. В какой-то мере командная строка – тоже рабочее место.
В некоторых дистрибути... | https://habr.com/ru/post/480788/ | null | ru | null |
# Применение смарт-аккаунтов Waves: от аукционов до бонусных программ

*Блокчейн часто ассоциируется лишь с криптовалютами, но области применения технологии DLT значительно шире. Одно из самых перспективных направлений для приме... | https://habr.com/ru/post/442238/ | null | ru | null |
# Миграция с LiveData на Kotlin’s Flow
LiveData была нужна нам еще в 2017 году. Паттерн наблюдателя облегчил нам жизнь, но такие опции, как RxJava, в то время были слишком сложными для новичков. Команда Archi... | https://habr.com/ru/post/561700/ | null | ru | null |
# Xpom-Xpum! SDK — IDE для расширений и приложений Google Chrome
#### Что это такое?
[Xpom Xpum! SDK](http://xpomxpum.codeplex.com/) — это бесплатная IDE с открытым исходным кодом на C# (лицензия — MIT). Назначение — писать всякие-разные расширения и приложения для браузеров на основе Chromium.
#### Как пользовать... | https://habr.com/ru/post/252737/ | null | ru | null |
# Асинхронное модульное тестирование для С++
В наше время разработчику уже крайне затруднительно обойти стороной асинхронное взаимодействие между блоками кода. Это и работа с web службами, работа с браузерными движками, и работа с потоками и т.д. и т.п. можно перечислять до бесконечности. И как следствие встает пробле... | https://habr.com/ru/post/128543/ | null | ru | null |
# Простейший генератор redux types для асинхронных запросов
Для того, чтобы немного сократить шаблонный код при использовании Redux, в голову пришла идея написать максимально простую библиотеку для генерации типов асинхронных запросов.
Картинка с dgraph.ioПрограммисты любят хорошие истории, поэтому надеюсь что пятилетний путь к композитному API с помощью GraphQL в бое... | https://habr.com/ru/post/518554/ | null | ru | null |
# Про резиновую верстку
Навеяно [этим](http://modaz.habrahabr.ru/blog/34669.html).
Для тех, кто, возможно, не знает как сделать так, чтоб всё было хорошо.
Сайт должен тянуться только до определённой величины, и сужаться тоже только до некоторого значения. Я обычно беру 1500 и 980 пикселей соответственно.
Как ... | https://habr.com/ru/post/19328/ | null | ru | null |
# Используем GPG для шифрования сообщений и файлов
Кратко о том, как создавать ключи, шифровать и подписывать файлы и отправлять ключи на сервер ключей.

GPG (также известный как GnuPG) создавался как свободная альтернатива несвобод... | https://habr.com/ru/post/358182/ | null | ru | null |
# Вывод типов в TypeScript с использованием конструкции as const и ключевого слова infer
TypeScript позволяет автоматизировать множество задач, которые, без использования этого языка, разработчикам приходится решать самостоятельно. Но, работая с TypeScript, нет необходимости постоянно использовать аннотации типов. Дел... | https://habr.com/ru/post/493716/ | null | ru | null |
# Управление списками рассылки в Carbonio
Списки рассылки - это удобный корпоративный инструмент для массового оповещения пользователей. Отправленная на один электронный адрес информация автоматически доставляется в почтовые ящики пользователей, благодаря чему процесс их информирования происходит максимально быстро и ... | https://habr.com/ru/post/690552/ | null | ru | null |
# Анализ поведенческих факторов с помощью Apache Spark
Речь пойдёт об использовании Apache Spark для анализа поведенческих факторов на сайте, который имеет очень большую посещаемость. Учёт поведенческих факторов весьма часто используется для повышения конверсии ресурса. Кроме этого, возможности Интернет позволяют очен... | https://habr.com/ru/post/280774/ | null | ru | null |
# Spring Boot 2: что нового?
*От переводчика: несмотря на то, что уже прошел год, вопросы о том что же нового дал нам 2-й Boot не заканчиваются. Писать такой контент с нуля — затея не самая умная. Поэтому решили перевести статью, которая нам кажется наиболее лаконичной и при этом достаточно полной.*
Релиз Spring Boot... | https://habr.com/ru/post/438980/ | null | ru | null |
# Отладка приложений для Android без исходного кода на Java
#### О чем статья
В этой статье я сжато, без «воды», расскажу как отлаживать приложения для Android не имея их исходного кода на Java. Статья не совсем для новичков. Она пригодиться прежде всего тем кто более или менее понимает синтаксис [Smali](http://code.... | https://habr.com/ru/post/150825/ | null | ru | null |
# Как заставить ваши веб-приложения работать в автономном режиме
*Сила JavaScript и браузерного API*
Мир становится все более взаимосвязанным — число людей, имеющих доступ к Интернету, выросло до [4,5 миллиардов](https://www.internetworldstats.com/stats.htm).
Очевидно, баннерная реклама раздражает пользователей. Но насколько сильно? Возможно, она настолько всех бесит, что доход от рекламы не стоит потерь в трафике. А возможно, и нет.... | https://habr.com/ru/post/549778/ | null | ru | null |
# Deconvolutional Neural Network
Использование классических нейронных сетей для распознавания изображений затруднено, как правило, большой размерностью вектора входных значений нейронной сети, большим количеством нейронов в промежуточных слоях и, как следствие, большими затратами вычислительных ресурсов на обучение и ... | https://habr.com/ru/post/253859/ | null | ru | null |
# Возможности метатаблиц в Lua на примере реализации классов
В Lua ООП нет. И оно, в общем-то и не нужно: удобной модульности и функций первого класса достаточно для реализации многих вещей. На этом можно было бы и закончить, но пост не про это. В данном случае я распишу работу с метатаблицами, где в качестве примера ... | https://habr.com/ru/post/228001/ | null | ru | null |
# Вертикальное выравнивание блоков в CSS
Приветствую всех, хочу поделиться своим собственным методом центрирования блока по вертикали. Все наверно и так читали не мало статей как это сделать и я не говорю о каком-то абсолютно новом способе, потому что все браузеры не считая IE всегда отлично понимали простую конструкц... | https://habr.com/ru/post/71700/ | null | ru | null |
# Способы обновления криптографии на оборудовании Check Point до ГОСТ 2012
**В соответствии с требованиями ФСБ России использование схемы подписи ГОСТ Р 34.10-2001 для формирования электронной подписи после 31 декабря 2018 года не допускается. Однако, соответствующий патч для Check Point с криптографией КриптоПро, под... | https://habr.com/ru/post/482202/ | null | ru | null |
# Как быстрее всего передавать данные с PostgreSQL на MS SQL
Однажды мне потребовалось забирать регулярно относительно большие объемы данных в MS SQL из PostgreSQL. Неожиданно выяснилось, что самый очевидный ... | https://habr.com/ru/post/553472/ | null | ru | null |
# Customer Response Solutions: донабор номера
На работе появилась задача реализовать дозвон на внутренние номера организации. В качестве IP АТС у нас используется Cisco CallManager 4.2, а для колл-центра используется Customer Response Solutions 4.0 (IPCC). Для написания скрипта использовался Cisco Customer Response So... | https://habr.com/ru/post/126407/ | null | ru | null |
# Chromium: использование недостоверных данных
Предлагаем вашему вниманию цикл статей, посвященных рекомендациям по написанию качественного кода на примере ошибок, найден... | https://habr.com/ru/post/347938/ | null | ru | null |
# Бесплатный CppCat для студентов

CppCat – это статический анализатор кода, интегрирующийся в среду Visual Studio 2010-2013. Анализатор предназначен для регулярного использов... | https://habr.com/ru/post/243149/ | null | ru | null |
# Найти подстроку в строке
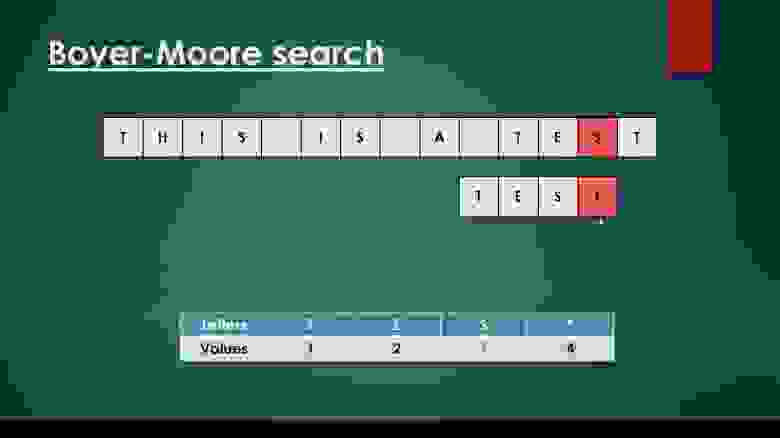**Алгоритм поиска строки Бойера — Мура** — алгоритм общего назначения, предназначенный для поиска подстроки в строке.
Давайте попробуем найти вхождение подстроки в строку.
Наш и... | https://habr.com/ru/post/563972/ | null | ru | null |
# Вся правда об ОСРВ. Статья #24. Очереди: вспомогательные службы и структуры данных

В этой статье мы продолжим рассматривать очереди.
Вспомогательные службы очередей
-------------------------------
Nucleus RTOS имеет четыре в... | https://habr.com/ru/post/432804/ | null | ru | null |
# Пока баг не разлучит нас: как гики делают предложение

Согласно старой ирландской легенде, 29 февраля женщина могла сделать предложение мужчине, и отказаться он не имел права. Выходило, что самый удачный день для предложе... | https://habr.com/ru/post/384319/ | null | ru | null |
# Статистика и аналитика для мобильного приложения: используем Flurry в Windows Phone 8

Разработка и продвижение сравнительно серьезных мобильных приложений практически невозможна без анализа того, что делает пользоват... | https://habr.com/ru/post/240315/ | null | ru | null |
# Исправлять ли unexpected behavior в C# 7 или оставить как есть, усложнив синтаксис языка для компенсации?
В языке C# с давних времён есть оператор 'is' назначение которого довольно ясное
```
if (p is Point) Console.WriteLine("p is Point");
else Console.WriteLine("p is not Point or null");
```
Кроме того его можн... | https://habr.com/ru/post/345102/ | null | ru | null |
# Сборочная среда для проекта Midnight Commander — продолжение
[Начало](http://habrahabr.ru/blogs/linux/128976/)
В [первой части](http://habrahabr.ru/blogs/linux/128976/) я представил новый сервис сборки бинарных пакетов файлового менеджера Midnight Commander для Debian/Ubuntu. В комментариях справедливо указали на... | https://habr.com/ru/post/129989/ | null | ru | null |
# MVCC in PostgreSQL-5. In-page vacuum and HOT updates
Just to remind you, we already discussed issues related to [isolation](https://habr.com/ru/company/postgrespro/blog/467437/), made a digression regarding [low-level data structure](https://habr.com/ru/company/postgrespro/blog/469087/), and then explored [row versi... | https://habr.com/ru/post/483768/ | null | en | null |
# Преобразование асинхронных методов в синхронные с возвращением результата в Java
В данной статье я бы хотел обсудить с уважаемым сообществом методы синхронизации потоков в Java. Чтобы не увязать в теории, попробуем рассмотреть синхронизацию потоков в задаче преобразования асинхронных методов в синхронные.
#### Д... | https://habr.com/ru/post/181680/ | null | ru | null |
# Фатализм в обработке ошибок
Предисловие
-----------
Эта статья является реакцией на статью: [Что будет с обработкой ошибок в С++2a](https://habr.com/post/426965/). После каждого абзаца у меня появлялся зуд, открывались зарубцованные раны и начинали кровоточить. Может, я принимаю слишком близко к сердцу то, что напи... | https://habr.com/ru/post/426971/ | null | ru | null |
# Рассказ о возмутительной лёгкости взлома инфраструктуры разработки современного ПО
В конце октября появилось сообщение о [проблеме](https://github.com/remy/nodemon/issues/1442) в чрезвычайно популярном Node.js-инструменте nodemon. Дело было в том, что в консоль выводилось предупреждение следующего содержания: `Depre... | https://habr.com/ru/post/434116/ | null | ru | null |
# История о том, как заставить Flurry собирать статистику десктопных приложений
В 2014 году по информации Smart Insights количество пользователей мобильных приложений [превысило](http://www.smartinsights.com/mobile-marketing/mobile-marketing-analytics/mobile-marketing-statistics/) число пользователей десктопных. Одним... | https://habr.com/ru/post/304454/ | null | ru | null |
# LyX: Общие замечания. Часть 1
Скопировано с [моего блога](https://matematikaandinformatika.blogspot.com/p/blog-page_83.html) в целях создания еще одного русскоязычного источника информации по данной теме.
Эта статья является продолжением следующих статей одного цикла:
[статья 1](https://habr.com/ru/post/466423... | https://habr.com/ru/post/485496/ | null | ru | null |
# Сравнение MemCache и MongoDb для сетевого кэша
Возникла достаточно неординарная идея: виде средства сетевого кеша взять не **MemCache**, а **MongoDb** и сравнить их производительность. Но для представления и сравнения показателей этих двух «механизмов кеширования» взяли еще и другие средства, позволяющие ускорить ра... | https://habr.com/ru/post/124212/ | null | ru | null |
# Прошлое и будущее Java в интервью с Саймоном Риттером из Azul
 Представляем вам интервью с Саймоном Риттером — человеком, который работал над Java с самого начала и продолжает делать это в роли заместителя технического директора Azu... | https://habr.com/ru/post/443550/ | null | ru | null |
# Модуль dis в Python и свертка констант
Всем привет. Сегодня хотим поделиться еще одним переводом подготовленным в преддверии запуска курса [«Web-разработчик на Python»](https://otus.pw/9Aod/). Поехали!

Недавно я очень удивился, ког... | https://habr.com/ru/post/460143/ | null | ru | null |
# Стриминг Edge2AI на NVIDIA JETSON Nano 2Гб с использованием агентов MiNiFi в приложениях FLaNK
Мне некогда было снимать своё видео распаковки - не терпелось запустить это превосходное устройство. NVIDIA Je... | https://habr.com/ru/post/543116/ | null | ru | null |
# Lingtrain Aligner. How to make parallel books for language learning. Part 1. Python and Colab version

If you're interested in learning new languages or teaching them, then you probably know such a way as parallel reading. It ... | https://habr.com/ru/post/586574/ | null | en | null |
# Украденное оружие FireEye

8 декабря компания FireEye сообщила, что в результате успешной атаки высококвалифицированной APT-группировке удалось получить доступ к инструментам, которые компания использовала как арсенал Red Team ко... | https://habr.com/ru/post/532832/ | null | ru | null |
# Вывод внутриигровых сообщений с помощью Particle System
#### Задача
При разработке нашей игры The Unliving, мы поставили перед собой задачу по отображению различных сообщений, таких, как нанесенны... | https://habr.com/ru/post/486260/ | null | ru | null |
# PyGTK: потоки и магия обёрток
Всем хорош GTK+, но наблюдается большая проблема при работе с ним в многопоточных приложениях. Сам по себе GTK является thread-safe, но требуя принудительной блокировки со стороны пользователя. Вторая проблема заключается в том, что блокировка реализована через мутексы, и вы должны вызы... | https://habr.com/ru/post/120668/ | null | ru | null |
# Проект за пару дней: большой дисплей из светодиодных лент

Полгода назад мы дополнили наш почти традиционный офисный каток 7,6 тыс. светодиодами, чтобы транслировать изображения и видео прямо на поверхность льда. На гикта... | https://habr.com/ru/post/395519/ | null | ru | null |
# Иммутабельность в C#
В разработке программного обеспечения иммутабельным (immutable — неизменяемым) называется объект, который после своего создания не может быть изменен. Зачем вам может понадобиться такой... | https://habr.com/ru/post/676680/ | null | ru | null |
# Poco — UI автоматизация мобильных игр на основе Python в рамках AirTest IDE
Сегодня мы поговорим о втором главном фреймворке для автоматизации UI, который называется Poco. Poco использует Python и здесь уже не обойтись без написания кода, но давайте сначала рассмотрим для чего он применяется, когда стоит к нему обра... | https://habr.com/ru/post/464181/ | null | ru | null |
# CRM в облаках
Привет, Хабр!
В этой статье мы хотим поделиться своим опытом работы с **программным продуктом Microsoft Dymanics CRM 2013 Online** – для чего и как его можно использовать, возможные проблемы типового развертывания, типовой функционал – достоинства, недостатки и пути решения проблем с наименьшими зат... | https://habr.com/ru/post/237841/ | null | ru | null |
# Построение анимированной круговой диаграммы на jQuery
Формы это неплохой способ добавить некую изюминку элементам на вашей веб странице. Круги особенно хороши в этом отношении, потому что они целостны, просты и похожи на пирог. А теперь серьёзно, кто не любит пироги?
, где и обсудим резуль... | https://habr.com/ru/post/133935/ | null | ru | null |
# HP предупреждает о вредоносе RedLine Stealer, маскирующемся под установщик Windows 11
[](https://habr.com/ru/company/ruvds/news/t/651023/)
В [блоге компании HP](https://threatresearch.ext.hp.com/redline-stealer-disguised-as-a-windo... | https://habr.com/ru/post/651023/ | null | ru | null |
# Компиляция. 5: нисходящий разбор
До сих пор занимались восходящим синтаксическим разбором. Какие ещё есть варианты?
Отложим бизона в сторону, и вернёмся к теории.
### Далее в посте:
1. Идея
2. Воплощение
3. Холивар
4. Бэктрекинг
### Идея
Помним, что [общая идея](http://habrahabr.ru/blogs/programming/99298/)... | https://habr.com/ru/post/99466/ | null | ru | null |
# Предупреждение пользователей об истечении пароля и действия учётной записи
Всем привет!
Столкнулись как-то с ситуацией, когда 1 января у многих пользователей истёк срок действия учётной записи и они были заблокированы. Соответственно не смогли работать, шквал телефонных звонков, начиная с утра 1-го числа. Было пр... | https://habr.com/ru/post/204796/ | null | ru | null |
# IDA Pro: каким не должен быть SDK
Приветствую,

Эта статья будет о том, как не нужно делать, когда разрабатываешь SDK для своего продукта. А примером, можно даже сказать, самым ярким, будет IDA Pro. Те, кто хоть раз что-то разрабаты... | https://habr.com/ru/post/509678/ | null | ru | null |
# Оверинжиниринг головного мозга
Попалась мне простая развлекательная задача: собрать данные о температуре воды и воздуха с пары HTML страниц и выдать результат, в JSON из API. Задача тривиальная, решается к... | https://habr.com/ru/post/533556/ | null | ru | null |
# Автоматизация тестирования способна на многое
Начну с того, что не стану открывать для кого-то «Америку», а хочу поделиться собственным опытом и лайфхаками для тех, кто желает что-то изменить в своей работе, но так еще и не определился с подходом к тестированию и/или технологиями.
Отдел QA, как правило, нагружен... | https://habr.com/ru/post/506084/ | null | ru | null |
# ARM MBED OS. Работа с произвольным МК STM32 под PlatformIO
Когда в январе сего года я писал материал о файловой системе **LittleFS** (интегрированной в состав arm mbed os), то обещал в скорейшем времени... | https://habr.com/ru/post/358682/ | null | ru | null |
# Node.JS + taskset == немного странного юмора
Регулярно слышу фразу типа «Node.js не подходит для хайлоада».
Захотелось самому посмотреть.
Хотел написать комментарий к [той](http://habrahabr.ru/post/207460/) статье, но передумал и написал больше. Автору той статьи, большое спасибо за интересный топик, задело. ... | https://habr.com/ru/post/207612/ | null | ru | null |
# Greybox Fuzzing на примере AFLSmart

Наверное, все слышали про крутой фаззер AFL.
Многие используют его как основной фаззер для поиска уязвимостей и ошибок.
Недавно появился форк AFL, [AFLSmart](https://github.com/aflsmart/afls... | https://habr.com/ru/post/492768/ | null | ru | null |
# Атрибуты: взгляд внутрь
Это продолжение статьи "[Введение в атрибуты](/blogs/perl/53451/)". Если Вы не знакомы с идеей атрибутов и их синтаксисом — советую начать с нее. Ну а в этой статье рассматривается, как устроены атрибуты изнутри, как с ними обращаться, и какие могут возникнуть проблемы.
#### Guts
Когда в... | https://habr.com/ru/post/53455/ | null | ru | null |
# Соединение «самопальных» устройств по bluetooth с iOS
Здраствуй, Хабраюзер! Возникла у меня на работе ситуация, что нужно было спроектировать устройство для iOS, которое бы посредством bluetooth передавало данные на iPad. Если в кратце- это устройство, которое должно прятаться в обычной пачке сигарет и передавать на... | https://habr.com/ru/post/152621/ | null | ru | null |
# Как мы распилили монолит. Часть 3, Frame Manager без фреймов
Привет. В [прошлой статье](https://habr.com/ru/company/tinkoff/blog/520476/) я рассказал про Frame manager — оркестратор фронтовых приложений. Описанная реализация решает многие проблемы, но в ней есть недостатки.
Из-за того, что приложения грузятся в i... | https://habr.com/ru/post/527922/ | null | ru | null |
# Создаем несложный шахматный ИИ: 5 простых этапов

Перевели для вас статью Лори Хартикка (Lauri Hartikka) о создании простейшего ИИ для шахмат. Она написана еще в 2017 году, но базовые принципы остались т... | https://habr.com/ru/post/437524/ | null | ru | null |
# MikroTik — 6in4 или IPv6 без поддержки провайдера
Захотелось мне воспользоваться технологией IPv6 по [некоторым причинам](http://version6.ru/why), но мой провайдер не предоставляет данную услугу. Гугл подсказал о [6in4](http://ru.wikipedia.org/wiki/Сервис_туннелей) механизме, позволяющему передавать IPv6 пакеты чере... | https://habr.com/ru/post/189008/ | null | ru | null |
# Векторные вычисления в JS, есть ли смысл, когда и как можно использовать SIMD в браузере
Все больше и больше область применения языка программирования javascript отходит от движения кнопочками в браузере да перекраски фона в сторону сложных и объемных веб-приложений. Уже во всю по миру шагает технология WebGL, позво... | https://habr.com/ru/post/308696/ | null | ru | null |
# Go, я создал: интегрируем Allure в Go красиво
Привет! Меня зовут Антон, я ведущий инженер по тестированию в Ozon: занимаюсь созданием и поддержкой end-to-end Go-тестов бэкенда для QA.
Мы довольно долго пи... | https://habr.com/ru/post/652707/ | null | ru | null |
# Как ServiceStack помогает поставить разработку веб-сервисов на поток
На хабре незаслужено обойден вниманием замечетальный .Net-фреймворк ServiceStack. Упомянут он очень кратко, в одной лишь [статье](http://habrahabr.ru/post/133778/), и то косвенно, мельком, и в самом конце, и упомянута там лишь мизерная его [часть](... | https://habr.com/ru/post/213389/ | null | ru | null |
# Делаем на Android анимацию как в Doom. Приложение-огонь
Всем привет! Меня зовут Юрий Дорофеев, я Android-разработчик и преподаватель в Mail.ru Group. Расскажу про отрисовку в Android на примере анимации огня из игры Doom. Эту игру за многие годы на чём только не запускали, от компьютеров до домофонов. Один программи... | https://habr.com/ru/post/581624/ | null | ru | null |
# AES шифрование и Android клиент

Как говорится, ничего не предвещало беды. Мобильный клиент потихоньку пилился, кофе стыл, задачки закрывались одна за другой, пока вдруг внезапно не пришло письмо на корпоративную почту: ... | https://habr.com/ru/post/279835/ | null | ru | null |
# Вебсокеты на PHP. Часть 3. От чата до игры: Battle City
В предыдущих двух частях ([Делаем вебсокеты на PHP с нуля](http://habrahabr.ru/company/ifree/blog/209864/) и [Межпроцессное взаимодействие](http://habrahabr.ru/company/ifree/blog/210228/)) в качестве демонстрации я использовал чаты, но в этой статье на примере ... | https://habr.com/ru/post/211504/ | null | ru | null |
# Реактивные формы (reactive forms) Angular 5 (2+) Часть 1

### Введение
Одним из достоинств Angular является широкий набор инструментов “из коробки”, которые позволяют быстро создавать формы любой сложности.
В Angular существ... | https://habr.com/ru/post/346242/ | null | ru | null |
# Классический подход к управлению зависимостями в сравнении с RequireJS
Hello World,
[Helios Kernel](http://asvd.github.io/helios-kernel/) — это библиотека для управления зависимостями между javascript-модуями, реализующая «классический» подход, часто встречаемый в других языках и средах — с помощью функции includ... | https://habr.com/ru/post/199162/ | null | ru | null |
# "Лаборатория Касперского": как попасть и чем заняться? Взгляд изнутри
Может показаться, что в крупную ИБ-компанию очень сложно попасть: нужно пройти семь кругов ада, найти подвох в любой задаче, знать биографию всех руководителей и всю подноготную самой компании. Так ли это? Глава управления базовых технологий «Лабо... | https://habr.com/ru/post/353768/ | null | ru | null |
# Как мы автоматизировали процесс генерации Release Notes
Всем привет! Меня зовут Семен. Я Java-разработчик и руководитель группы Java-разработки в Центре Big Data компании MTS Digital. В этом посте я хочу поговорить о Release Notes. Что это такое, почему не стоит писать их вручную и какие есть способы автоматизации. ... | https://habr.com/ru/post/572774/ | null | ru | null |
# Рецепты nginx: виджет Государственного Адресного Реестра
Для приготовления виджета Государственного Адресного Реестра, кроме [базы](https://habr.com/ru/post/585244/), нам также понадобится [nginx](https://nginx.org/ru/) и его плагины [postgres](https://github.com/RekGRpth/ngx_postgres) и [json](https://github.com/Re... | https://habr.com/ru/post/585476/ | null | ru | null |
# Балансируем нагрузку в Jenkins
В Arenadata мы используем Jenkins для CI. Почему? Как бы банально это ни звучало — так исторически сложилось. Мы хранили код в GitHub, когда там ещё не было Actions, и продо... | https://habr.com/ru/post/587262/ | null | ru | null |
# Установка Minix 2 на PC AT-совместимый компьютер с процессором 80286
В своей [предыдущей статье](https://habr.com/ru/post/537698/) я рассказывал о том, как собирал компьютер для экспериментов с 16-битным защищённым режимом Intel. Там же я анонсировал следующую статью, в которой пообещал установить на этот компьютер ... | https://habr.com/ru/post/538382/ | null | ru | null |
# Firefox позволит заходить на сайты под несколькими аккаунтами одновременно
#### У каждого контейнера внутри Firefox — собственный набор куков, indexedDB, localStorage и кэш

*Работа в Twitter одновременно под рабочим и ли... | https://habr.com/ru/post/395131/ | null | ru | null |
# Рецепт установки блога GHost в VMManager для Debian 9
**Цель:** Дать методику написания рецепта для VMManager, с самим рецептом в конце. В итоге упростить установку блога GHost для не подготовленных пользователей.
**Целевая аудитория:** Блогеры и те кто хотят ими стать, а так же хостеры желающие использовать подо... | https://habr.com/ru/post/339360/ | null | ru | null |
# Игра 2048 батником на Windows

Слово muffe — как оказалось с немецкого это муфта. Но придумывалось как исковерканное слово move и coffee.
В игре присутствуют отличия от оригинальной игры 2048.
Так как алгоритм разраб... | https://habr.com/ru/post/379029/ | null | ru | null |
# Улучшаем GNOME 3
Привет, Хабралюди!

После обновления своего дистрибутива (Russian Fedora) я столкнулся с большим количеством проблем в GNOME 3. В этой статье я постараюсь описать все, собранные мной, методы их решения. Кому интересно, под кат!
##### Панель быстрого з... | https://habr.com/ru/post/120150/ | null | ru | null |
# Миграция БД на Windows Azure SQL VM через виртуальный диск
[Предыдущий способ](http://blogs.technet.com/b/isv_team/archive/2012/10/25/3528577.aspx) переноса резервной копии базы с локального компьютера на виртуальную машину с SQL Server в Облаке использовал Azure Storage, который не является NTFS-видимым. Таким обра... | https://habr.com/ru/post/156951/ | null | ru | null |
# Universal Radio Hacker — легкий способ исследовать цифровые радиопротоколы

[Universal Radio Hacker](https://github.com/jopohl/urh) (URH) — невероятно простой и понятный инструмент для анализа цифровых радиопротоколов. В отличие от... | https://habr.com/ru/post/434634/ | null | ru | null |
# Использование slots | Python
Для начала небольшой дисклеймер.
Эта статья вдохновлена моим обучением. Когда я только начинал свой Python-way, на одном из форумов увидел новое для себя понятие - слоты. Но сколько я не искал, в сети было крайне мало статей на эту тему, поэтому понять и осознать слоты было достаточно ... | https://habr.com/ru/post/686220/ | null | ru | null |
# Расширяемый код Android-приложений с MVP
*От переводчика: — я давненько интересуюсь тем, как сделать код Android-приложений чище, и это, наверное, первая статья, после которой у меня не возникло мыслей: "Зачем вот это вот все?" и "Он вообще пробовал когда-то это использовать в жизни?" Поэтому решил перевести, может,... | https://habr.com/ru/post/278769/ | null | ru | null |
# jQuery Timers
При проектировании интерфейсов пользователя когда-нибудь обязательно встанет задача использования таймеров, и в этой статье я хочу рассказать о замечательном плагине **jQuery Timers**, который значительно облегчит работу по созданию и применению таймеров в Ваших приложениях.
**jQuery Timers** — это... | https://habr.com/ru/post/42809/ | null | ru | null |
# Run, config, run: как мы ускорили деплой конфигов в Badoo
Файлы конфигурации (конфиги) — неотъемлемая часть большинства приложений, но, как показывает практика, это не самая популярная тема для обсуждения. ... | https://habr.com/ru/post/544102/ | null | ru | null |
# Создание инсталлятора с помощью WiX. Часть 3
В этот раз мы создадим кое-что посложнее, чем установочный пакет из [первой статьи](http://habrahabr.ru/blogs/development/68616/). Научимся вносить изенять шаги установки и создавать собственные диалоги установщика.
Наш новый инсталлятор будет включать в себя следующие... | https://habr.com/ru/post/70616/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.