
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Диалоги подтверждения в SwiftUI
Третья версия SwiftUI принесла нам несколько модификаторов представления (view modifiers), которые позволяют нам одинаково обрабатывать семантически похожие операции для разн... | https://habr.com/ru/post/571570/ | null | ru | null |
# Как выбрать тот самый PHP-фреймворк. Сравнительное тестирование

При разработке любого программного продукта перед командой разработчиков прежде всего стоит задача грамотного выбора программной платформы, определяющей струк... | https://habr.com/ru/post/329718/ | null | ru | null |
# Подсветка кода на android. Мой опыт
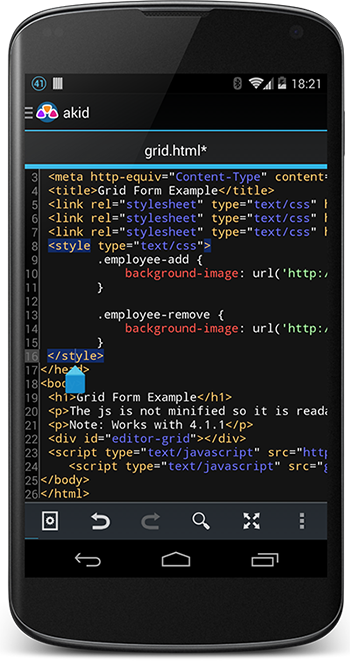
Во время разработки моего последнего приложения мне пришлось провести довольно много времени, экспериментируя с разными подходами к размещению [span'ов](http://develop... | https://habr.com/ru/post/204248/ | null | ru | null |
# Команда awk – примеры использования в Linux и Unix
[](https://habr.com/ru/company/ruvds/blog/665084/)
В этом базовом руководстве вы узнаете самые основы команды `awk`, а также увидите некоторые способы её использования при работе... | https://habr.com/ru/post/665084/ | null | ru | null |
# ECMAScript 4: версия, которой не было
> **Будущих студентов курса** [**"Javascript Developer. Basic"**](https://otus.pw/uQPf/) **приглашаем посетить** [**demo day**](https://otus.pw/HwmR/)**, в рамках которого вы сможете подробно узнать о процессе обучения и программе курса, а также задать вопросы нашим экспертам**[... | https://habr.com/ru/post/529796/ | null | ru | null |
# Еще один open source аналог Github
На данный момент времени, есть следующие альтернативы github:
* Сам github fi (стоит 5000$, не open source)
* [Gitorious](http://gitorious.org/) (open source, написан на RoR, использует ActiveMQ, короче — зверь машина)
* Недавно появившийся [gitlab](http://habrahabr.ru/blogs/Git... | https://habr.com/ru/post/133306/ | null | ru | null |
# SAX-парсер python vs DOM-парсер python. Парсим ФИАС-houses
В предыдущей [статье](https://habr.com/ru/post/468637/) был рассмотрен подход к созданию csv из xml на базе данных, которые публикует ФИАС. В основу парсинга был положен DOM-парсер, загружающий в память весь файл целиком перед обработкой, что приводило к нео... | https://habr.com/ru/post/469995/ | null | ru | null |
# Клиенты GoDaddy недовольны JS-инъекциями со стороны хостера

Один из клиентов GoDaddy [обратил внимание](https://www.igorkromin.net/index.php/2019/01/13/godaddy-is-sneakily-injecting-javascript-into-your-... | https://habr.com/ru/post/436030/ | null | ru | null |
# Девятилетняя оптимизация маршрутизатора
Хочу рассказать историю жизни сервера в кампусной сети Новосибирского университета, которая началась в далеком 2004 году, а так же этапы его оптимизации и *даунгрейдинга*.
Многие вещи в статье покажутся общеизвестными хотя бы по той причине, что речь пойдет о событиях почти... | https://habr.com/ru/post/199480/ | null | ru | null |
# Колоночная верстка
Существует много способов по верстке колоночных макетов. Уже не один нос разбит в течении холиваров, разожженных по поводу использования тех или иных методов. Казалось бы, что все должно быть предельно ясно и понятно, но все-равно возникает много трудностей. Я хочу и свою лепту вложить во всеобщее... | https://habr.com/ru/post/81193/ | null | ru | null |
# Двухфазный коммит и будущее распределённых систем
В этой статье мы смоделируем и исследуем протокол двухфазного коммита с помощью TLA+.
Протокол двухфазного коммита практичный и сегодня используется во многих распределённых системах. Тем не менее, он достаточно краткий. Поэтому мы можем быстро смоделировать его и... | https://habr.com/ru/post/434496/ | null | ru | null |
# Разделяй и властвуй: детерминированный и скриптованный Match-3 движок
Я Павел Щеваев, CTO студии BIT.GAMES, части MY.GAMES. Вы можете знать нас по таким играм, как «Гильдия Героев» и «Домовята» в Одноклассн... | https://habr.com/ru/post/592537/ | null | ru | null |
# Camlex 3.2: реверс-инжиниринг CAML и добавление условий к строковым запросам в Sharepoint с помощью лямбда выражений
Некоторое время назад вышел очередной релиз нашего проекта с открытым исходным кодом [Camlex.Net](http://camlex.codeplex.com/). В версию 3.2 была добавлена достаточно интересная функциональность, о ко... | https://habr.com/ru/post/146313/ | null | ru | null |
# PostgreSQL Antipatterns: когда мешает внешний ключ
[Внешние ключи](https://ru.wikipedia.org/wiki/%D0%92%D0%BD%D0%B5%D1%88%D0%BD%D0%B8%D0%B9_%D0%BA%D0%BB%D1%8E%D1%87) (foreign keys) - мощный и удобный механизм контроля логической целостности данных в базе. Но он бывает не только лишь полезен, и может неплохо пригрузи... | https://habr.com/ru/post/665118/ | null | ru | null |
# SQL HowTo: рейтинг-за-интервал
Одним из наиболее частых требований-"хотелок" бизнеса является построение всяких разных рейтингов - **"самые оборотистые клиенты", "самые продаваемые позиции", "самые активные сотрудники"**, … - любимая тема разных дашбордов.
Например, в нашем решении [для автоматизации ресторанов и к... | https://habr.com/ru/post/536696/ | null | ru | null |
# Как я завел дружбу с асинхронностью в JavaScript
JavaScript встречает разработчиков асинхронностью можно сказать чуть ли не с порога. Начинается все с DOM-событий, ajax, таймерами и библиотечными методами, связанными с анимац... | https://habr.com/ru/post/241161/ | null | ru | null |
# Подводные камни настройки Mikrotik SXT LTE
Доброго времени суток Хабр, попытаюсь рассказать о своём знакомстве с такой вещью, как Mikrotik SXT LTE, муках настройки и последующего доведения до ума.

**Немного предыстории:... | https://habr.com/ru/post/336076/ | null | ru | null |
# Лямбда-выражения бэкпортированы в Java 7, 6 и 5

Хотите использовать лямбда-выражения, но вынуждены использовать стабильный JRE? Теперь это возможно с утилитой [**Retrolambda**](https://github.com/orfjackal/retrolambda)... | https://habr.com/ru/post/187596/ | null | ru | null |
# Алгоритмы на графах — Часть 2: Сортировка сетей
Пролог
======
В продолжение опубликованной на выходных [статьи.](http://habrahabr.ru/blogs/algorithm/66586/)
Компиляторы — пожалуй одна из самых интересных тем системного программирования.
Эта статья не расскажет как написать идеальный, или, хотя бы, работающий ... | https://habr.com/ru/post/66766/ | null | ru | null |
# Разработка сервера для многопользовательской игры с помощью nodejs и magx
Многие разработчики начинают разработку многопользовательского онлайн сервера на основе библиотеки [socket.io](https://socket.io/). Эта библиотека позволяет очень просто реализовать обмен данными между клиентом и сервером в реальном времени, н... | https://habr.com/ru/post/531898/ | null | ru | null |
# Создание простого модуля для CMS Datalife Engine (DLE)
Здравствуйте. Данный топик хочу посветить созданию простейшего модуля для популярной **CMS Datalife Engine**. В России, как впрочем и в странах СНГ она пользуется достаточно большой популярностью, однако на хабре статей об этой cms почему-то до сих пор нету. Я п... | https://habr.com/ru/post/130082/ | null | ru | null |
# Как рассказать об основных компонентах Android за 15 минут
Введение
========
В этой статье пойдет речь о том, как рассказать человеку, ранее не знакомому с программированием под Android, об основных его компонентах. Заинтересовать и показать, что все не так сложно, как многие думают. При этом сделать это за 15 мину... | https://habr.com/ru/post/483878/ | null | ru | null |
# Вглядываясь в зеркала или еще раз о проблеме гетероскедастичности
### Секунда теории
Гетероскедастичность – это ситуация, когда ошибка регрессии не удовлетворяет условию гомоскедастичности, т.е. дисперсия этой самой ошибки непостоянно. Это приводит при использовании метода наименьших квадратов к разным неприятным э... | https://habr.com/ru/post/678834/ | null | ru | null |
# Решение турнирных задач на языке Haskell
Доброго времени суток всем хабражителям
Перед вами статья, посвященная довольно известному, но не сильно популярному языку Haskell. В ней мне хочется показать пример решения простой турнирной задачи на языке Haskell. Надеюсь, что эта статья поможет начинающим программистам... | https://habr.com/ru/post/166763/ | null | ru | null |
# Портал на службе бухгалтерии или автоматизация авансовых отчетов
Всем привет! Сегодня мы решили поделиться результатами небольшого, но важного проекта, как это часто бывает очень простые с первого взгляда вещи решают сложные задачи, которые дают существенную эффективность в повседневной жизни.
С нашей точки зрен... | https://habr.com/ru/post/280526/ | null | ru | null |
# Переезд временной зоны MSD в MSK — новый Y2K локального масштаба
Все, наверное, хоть раз слышали, что в России с 2011 года отменен переход с летнего время на зимнее. Чем же это грозит каждому из нас — и администраторам большого ко... | https://habr.com/ru/post/130363/ | null | ru | null |
# Делаем многопользовательскую игрy на Go и WebSocket'ах

Продолжаем [знакомство](http://habrahabr.ru/post/219459/) с языком программирования Go (golang). В прошлый раз мы посмотрели основные ... | https://habr.com/ru/post/226469/ | null | ru | null |
# Боремся со спамом стандартными средствами почтовика (на примере Exim)
Регулярно натыкаюсь на статьи про прикручивание к почтовикам антиспамовских систем (например spamassassin и подобных). Каждый раз, смотря на эти связки и кучу проблем которые они приносят, «пожимаю плечами» и искренно не понимаю зачем все это? Спа... | https://habr.com/ru/post/179833/ | null | ru | null |
# Дайджест новостей из мира PostgreSQL. Выпуск №6
*Мы продолжаем знакомить вас с самыми интересными новостями по PostgreSQL.*
Релизы
------
**PostgreSQL 11 Beta**
Релизная команда PostgreSQL [определилась](https://www.postgresq... | https://habr.com/ru/post/358560/ | null | ru | null |
# Google AppEngine с самого начала: Контроллер
Мы двигаемся вперед со скоростью реактивного паравоза, и пока хабралюди читают и осмысливают [первую](http://habrahabr.ru/blogs/gae/81895/) и [вторую](http://habrahabr.ru/blogs/gae/81920/) части статьи, я со скоростью пулемета пишу продолжение. На этот раз речь пойдет о с... | https://habr.com/ru/post/81933/ | null | ru | null |
# Работа с цифровым пассивным инфракрасным детектором движения PYD 1588
### 1. Общие сведения о цифровом детекторе PYD 1588
В данной статье приведена работа с цифровым пассивным инфракрасным детектором движения PYD 1588.
Цифровой инфракрасный детектор движения PYD 1588 (далее *детектор*) фирмы Excelitas Technologies... | https://habr.com/ru/post/654277/ | null | ru | null |
# Карта памяти процесса
Задумывались ли вы над тем, как именно используется память, доступная вашей программе, да и вообще, что именно размещается в этих двух-трех гигабайтах виртуальной памяти, с которыми работает ваше ПО?
Спросите, зачем?
Ну как же, для 32-битного приложения 2-3 гигабайта – это ваш лимит за пр... | https://habr.com/ru/post/202242/ | null | ru | null |
# «Хакер»: Как мы с DALL-E 2 делали картинки к статьям
DALL-E 2 — нейросеть, которая рисует картинки по текстовому запросу. Гулявшие в этом году примеры работы с ней просто поражают: иногда она рисует, как настоящий художник, и еще и предлагает варианты на выбор! С августа этого года мы периодически использовали DALL-... | https://habr.com/ru/post/707532/ | null | ru | null |
# Управление облаками в Python
#### Облака
Облачные вычисления стали популярными среди широких масс примерно полтора-два года назад, и огромную роль в этом сыграл сервис [Amazon EC2](http://aws.amazon.com/ec2/). Постепенно активность обсуждений этой технологии только возрастала, появлялись сторонники и противники, сч... | https://habr.com/ru/post/111530/ | null | ru | null |
# Былина о том, как я Drupal и Яндекс.ПДД связывал
Некоторое время назад у меня была идея сделать городской сайт (естественно, очередной) для одного небольшого городка на базе Drupal. Как раз незадолго до этого Яндекс расширил функционал своей Почты для доменов и добавил возможность управлять ящиками через API. И в го... | https://habr.com/ru/post/245117/ | null | ru | null |
# Подключение SignalR для Android на Kotlin
Если ты читаешь эту статью, наверно тебе, как и мне понадобилось подключить SignalR в своем мобильном приложении. К сожалению в русскоязычном сегменте не так уж много информации о том, как это сделать, а то что есть уже устарело.
В рамках этой статьи я не буду касаться серв... | https://habr.com/ru/post/579916/ | null | ru | null |
# ТАУ-Дарвинизм: реализация на Ruby
#### Предисловие
>
>
> | | |
> | --- | --- |
> | *Послушайте, ворона, а может быть собака,
> А может быть корова, но тоже хорошо!
> У вас такие перья, у вас рога такие,
> Копыта очень стройные и добрая душа.* | |
>
>
*Мультфильм «Пластилиновая ворона».*
В этой статье ... | https://habr.com/ru/post/111078/ | null | ru | null |
# Дополненная реальность в Tilda
Всем привет! Меня зовут Григорий Дядиченко, и я занимаюсь разработкой разных проектов на заказ. Настало время тыкв и ужаса! Я люблю эстетику Halloween, но так как самому тыкву вырезать лень, я сделал AR тыкву. И хочу поделиться рецептом с вами. Мы поговорим про такие форматы как USDZ и... | https://habr.com/ru/post/696300/ | null | ru | null |
# Основы атак на Active Directory
По мере роста организации за счет увеличения числа сотрудников, необходимых для поддержки повседневных бизнес-функций, также увеличивается количество устройств, подключенных к сети организации. Несмотря на то, что организация небольшая, в сети очень мало пользователей и компьютеров, и... | https://habr.com/ru/post/681204/ | null | ru | null |
# Пример запуска Django 1.7.4 под Python 3.4.2 на Ubuntu 14.04
Всем привет.

В данном примере я покажу один из способов запуска актуальной версии Django под свежим Python.
[Python 3.4.2 | Release Date: 2014-10-13](http... | https://habr.com/ru/post/250433/ | null | ru | null |
# Абстракции без накладных расходов: типажи в Rust
В [предыдущем посте](http://habrahabr.ru/post/256211/) ([англ.](http://blog.rust-lang.org/2015/04/10/Fearless-Concurrency.html)) мы затронули два столпа дизайна Rust (поскольку во внутренней речи я постоянно склоняю название языка, дальше я буду использовать русскоязы... | https://habr.com/ru/post/257775/ | null | ru | null |
# разбираем файлы MS-office
Недавно передо мной была поставлена задача: вытащить некую информацию из файлов MS-office (.xls, .doc) для ее последующей обработки. По факту, нужно было вытащить текст, содержащийся в документе.
Для .xls быстро нашелся проект [PhpExcelReader](http://sourceforge.net/projects/phpexcelread... | https://habr.com/ru/post/45375/ | null | ru | null |
# XY-робот с удалённым управлением
[](https://habr.com/ru/company/ruvds/blog/712068/)*Картинка [3dtoday.ru](https://3dtoday.ru/blogs/br3dlab/sborka-kinematiki-h-bot-i-corexy)*
Некоторое время назад, автору этой статьи пришла в голо... | https://habr.com/ru/post/713492/ | null | ru | null |
# Строки в кодовой памяти AVR
В нашей компании мы пишем программы для контроллеров серии AVR. В этой статье хочу описать как мы создаем строки, расположенные в кодовой памяти.
Изначально требовалось, чтобы следующий код не выдавал ошибок, а в итоге получили гораздо более мощный инструмент, чем предполагали.
```
... | https://habr.com/ru/post/311874/ | null | ru | null |
# Как я древо семьи строил
В ноябре 2018 года меня вновь посетила идея создания древа моей семьи. Особенно на это подтолкнула [оцифровка архивов Великой Отечественной Войны](https://pamyat-naroda.ru/), в которой я нашел своих предков:
* [Гайворонский Гавриил Степанович](https://pamyat-naroda.ru/heroes/memorial-chelov... | https://habr.com/ru/post/532894/ | null | ru | null |
# От версии 8 к 8.1: новый виток развития PHP

Я уже несколько раз писал о том, что происходило с PHP за год и всегда с нетерпением ждал следующего года. Я делал это в [2020-м](https://stitcher.io/blog/php-in-2020) и [2019-м](https:/... | https://habr.com/ru/post/554008/ | null | ru | null |
# 16 действительно полезных решений для JavaScript
© [shamansir.wordpress.com](http://shamansir.wordpress.com/2007/08/12/16-%D0%B4%D0%B5%D0%B9%D1%81%D1%82%D0%B2%D0%B8%D1%82%D0%B5%D0%BB%D1%8C%D0%BD%D0%BE-%D0%BF%D0%BE%D0%BB%D0%B5%D0%B7%D0%BD%D1%8B%D1%85-%D1%80%D0%B5%D1%88%D0%B5%D0%BD%D0%B8%D0%B9-%D0%B4%D0%BB%D1%8F-javas... | https://habr.com/ru/post/28325/ | null | ru | null |
# Compile-time рефлексия D, практика
Доброго времени суток, хабр!
В прошлой [статье](http://habrahabr.ru/post/261349/) были рассмотренны базовые элементы compile-time рефлексии, те кирпичики, из которых строят «настоящие» метаконструкции. В этой статье я хочу показать некоторые такие приёмы. Попробуем реализовать с... | https://habr.com/ru/post/261641/ | null | ru | null |
# Нововведения в jQuery 1.6

Совсем недавно (3 мая) был зарелизен jQuery 1.6 и вот что нового появилось в этой js-библиотеке давайте и посмотрим.
Самое «веселое» то, что в новом релизе есть важные ... | https://habr.com/ru/post/118713/ | null | ru | null |
# Raspberry Pi Pico на МК RP2040: начало и первые шаги. Что есть поесть за $4
Начало
------
Raspberry Pi Foundation всегда знает чем порадовать или удивить нас, а так же как подталкивать других производителей на интересные шаги и решения для хорошей конкуренции.
В четверг (рыбный день, кстати) 21-ого января 2021 г... | https://habr.com/ru/post/538994/ | null | ru | null |
# PHP-Дайджест № 193 (16 – 30 ноября 2020)
[](https://habr.com/ru/post/530562/)
Парад релизов: обновление языка — PHP 8.0, а также Xdebug 3, DBAL 3.0, Bref 1.0, Symfony 5.2, Flysystem 2.0. Первый принятый RFC для PHP 8.1, долгосроч... | https://habr.com/ru/post/530562/ | null | ru | null |
# Впечатления от конференции Opera Software. Новосибирск.
Итак, вчера, 7.11.2008 благополучно уговорил одногруппников сходить на семинар Opera. А все потому, что я участник [Opera Campus Crew](http://www.opera.com/education/campuscrew/getstarted/russian), или иначе выражаясь представитель Opera в своем университете. ... | https://habr.com/ru/post/44194/ | null | ru | null |
# Укрощаем пользовательский интерфейс на iPhone с MonoTouch.Dialog
В основе пользовательского интерфейса лежит UITableView, мощный виджет по отрисовке таблиц, который использует, почти, каждое... | https://habr.com/ru/post/85564/ | null | ru | null |
# Как мои проблемы с памятью привели к созданию синтаксиса, который невозможно забыть
Около 10 лет назад у меня начались серьёзные проблемы в ментальной сфере, в том числе с памятью {впрочем, в этом есть и свои плюсы: например негативные эмоции [злость на кого-то, раздражение, обида] забываются так быстро, что практич... | https://habr.com/ru/post/696654/ | null | ru | null |
# Разбираемся в особенностях графической подсистемы микроконтроллеров
Привет!
В этой статье я бы хотел рассказать об особенностях реализации графического пользовательского интерфейса с виджетами на микроконтроллере и как при этом иметь и привычный пользовательский интерфейс и приличный FPS. Внимание я хотел бы акце... | https://habr.com/ru/post/518258/ | null | ru | null |
# Создание динамических PDF-файлов с использованием React и Node.js
Материал, перевод которого мы сегодня публикуем, посвящён созданию динамических PDF-файлов с использованием HTML-кода в качестве шаблона. А именно, речь пойдёт о том, как сформировать простой счёт на оплату неких товаров или услуг, динамические данные... | https://habr.com/ru/post/460018/ | null | ru | null |
# Разработка интернет-магазина 13000+ товаров на MODX Revolution. Часть 1
Я уже писал про свой компонент [shopModx](http://community.modx-cms.ru/blog/addons/9892.html). И хотя мало кто его оценил, так как многие ждут именно готовых решений с одной большой кнопкой «Установить и работать», тем не менее этот компонент ра... | https://habr.com/ru/post/171343/ | null | ru | null |
# Неожиданные подвохи при перенаправлениях оболочки в $((i++))
[](https://habr.com/ru/company/ruvds/blog/554580/)
Год назад вышла *ShellCheck v0.7.1*. Главным образом в ней были подчищены и исправлены имеющиеся проверки, но также поя... | https://habr.com/ru/post/554580/ | null | ru | null |
# Поиск файлов по тэгам в XMP / IPTC и операции с найденным
Сначала может показаться, что пост о «ещё одном медиаплеере», и вот уже паникующий хабровчанин бежит с выпученными глазами прочь, кидаясь минусами в людей, животных и программистов. Ну, в общем и целом, да, пост примерно об этом. Но. Есть, на мой взгляд, одно... | https://habr.com/ru/post/339642/ | null | ru | null |
# Прогнозирование
Я уже писал, зачем нужно такое прогнозирование — [Создание искусственного интеллекта](https://geektimes.ru/post/247572/).
Здесь же я буду описывать только алгоритм прогнозирования, без лишней лирики.
Рассматривать буду прогнозирование последовательности байтов или же текста UTF-8. Прогнозирован... | https://habr.com/ru/post/367881/ | null | ru | null |
# F-строки в Python мощнее, чем можно подумать
Форматированные строковые литералы, которые ещё называют f-строками (f-strings), появились довольно давно, в Python 3.6. Поэтому все знают о том, что это такое, и о том, как ими пользоваться. Правда, f-строки обладают кое-какими полезными возможностями, некоторыми особенн... | https://habr.com/ru/post/674866/ | null | ru | null |
# Asterisk Manager Interface в диалплане
Как и все АSTERISK'еры я не раз сталкивался с проблемой того, что на PBX существует несколько транков, которые используются для исходящей связи. И как у многих, у моих заказчиков тоже часть этих транков является основными, а остальные играют роль резервных, на случай падения/за... | https://habr.com/ru/post/264819/ | null | ru | null |
# Генерируем RSS
Все знают про RSS и то как это читать и даже [парсить](http://magpierss.sourceforge.net/), но как переделать из html-кода статью в валидный RSS для веб-разработчика может быть проблематич... | https://habr.com/ru/post/13064/ | null | ru | null |
# Генерация аудио диффузионной нейросетью. Стоит ли использовать обычную диффузию для генерации мел-спектрограмм?
[](https://habr.com/ru/company/ruvds/blog/708182/)
В уходящем году вы могли видеть множеств... | https://habr.com/ru/post/708182/ | null | ru | null |
# Ещё большее ускорение WebAssembly: новый потоковый и многоуровневый компилятор в Firefox
*Оба авторе: Лин Кларк — разработчик в группе Mozilla Developer Relations. Занимается JavaScript, WebAssembly, Rust и Servo, а также рисует комиксы о коде.*
Люди называют WebAssembly фактором, меняющим правила игры, потому чт... | https://habr.com/ru/post/347158/ | null | ru | null |
# Хакатон на школе InterSystems 2015
InterSystems никогда раньше не проводила хакатонов. Школы собирали каждый год, тренировали, разбивали на команды, делали задания, различной продолжительности, но так это не называли. Но время идет. Не хотелось в очередной раз повторять одно и тоже. Хотелось чего-то нового.
Хакат... | https://habr.com/ru/post/267459/ | null | ru | null |
# Raspberry Pi: измеряем влажность и температуру с помощью DHT11/DHT22
На Хабре уже публиковалась [статья](http://habrahabr.ru/post/163575/) о подключении датчика температуры DS18B20 к Raspberry Pi. В нашем новом проекте, ко... | https://habr.com/ru/post/167459/ | null | ru | null |
# Рендеринг DirectX в окне WPF

### Вступление
Добрый день, уважаемые читатели! Не так давно передо мной встала задача реализовать несложный графический редактор под Windows, при этом в перспективе он должен поддерживать ка... | https://habr.com/ru/post/261927/ | null | ru | null |
# В одной лодке с «ублюдком»: 11 продвинутых советов по использованию Git
\*"ублюдок" — вольный перевод слова "git" — "an unpleasant or contemptible person", "неприятный или презренный человек".

В комментариях к статье [15 базовых со... | https://habr.com/ru/post/512490/ | null | ru | null |
# Zabbix Review: как организовать code review для конфигурации мониторинга
Code review — инженерная практика в терминах гибкой методологии разработки. Это анализ (инспекция) кода с целью выявления ошибок, недочетов, расхождения в стиле написания кода и понимания, решает ли код поставленную задачу.

В очередном «конспекте админа» остановимся на еще одной фундаментальной вещи – механизме разрешения имен в IP-сетях. Кстати, знаете почему в доменной с... | https://habr.com/ru/post/330944/ | null | ru | null |
# Xcode: плагины для плагинов
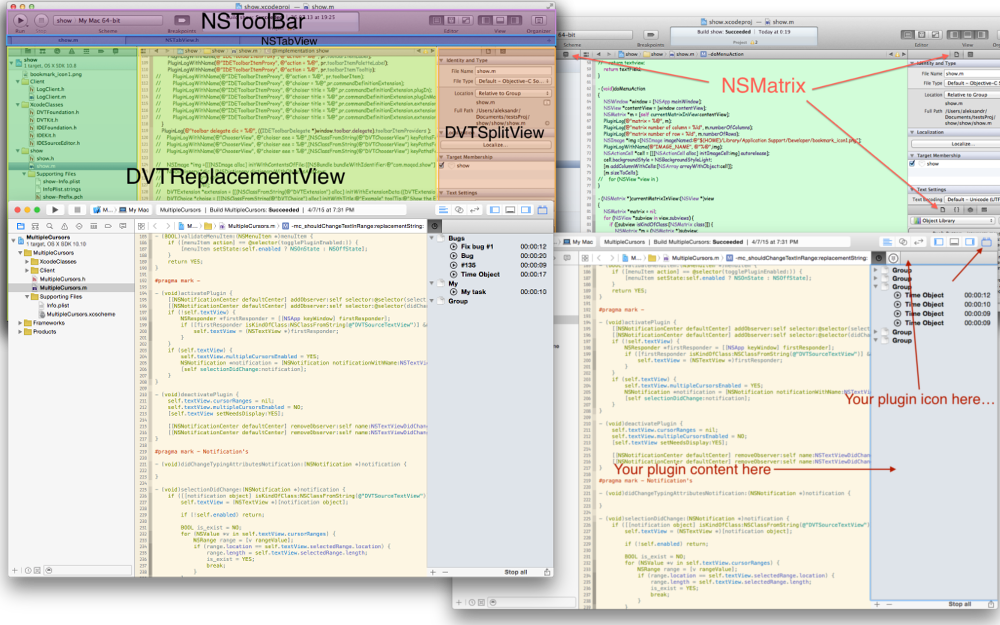
Заинтересовавшись публикацией [«Пишем свой Xcode plugin»](http://habrahabr.ru/post/163795/) решил написать простой тайм-трекер для Xcode. Процесс, через который я прошел — суть данной статьи. В... | https://habr.com/ru/post/256015/ | null | ru | null |
# iBeacon. Мифы и реальность

(картинка с сайта [developer.apple.com](https://developer.apple.com/ibeacon/))
Что это такое?
--------------
В середине 2013 года Apple на конференции для разработчиков внезапно рассказала, что они приготовили новую те... | https://habr.com/ru/post/278689/ | null | ru | null |
# IO Ninja – программируемый эмулятор терминала/сниффер (часть 3). Пишем «автоответчик»
Продолжаем [цикл статей](http://habrahabr.ru/company/tibbo/blog/255221/) о терминале/сниффере [IO Ninja](http://tibb... | https://habr.com/ru/post/256803/ | null | ru | null |
# Slack закрыл уязвимость с «массовым захватом аккаунтов через контрабанду HTTP-запросов»

Техника атаки [HTTP Request Smuggling](https://portswigger.net/web-security/request-smuggling) (контрабанда вредоносных HTT... | https://habr.com/ru/post/493022/ | null | ru | null |
# Пишу игрушечную ОС (о реализации мьютекса)

Продолжаю блог о разработке игрушечной ОС (предыдущие посты: [раз](http://habrahabr.ru/post/175749/), [два](http://habrahabr.ru/post/177403/), [три](http://habrahabr.ru/post/... | https://habr.com/ru/post/179561/ | null | ru | null |
# Второе чувство: разработка ИИ-носа
Шли долгие майские выходные 2020 года. Я, как и многие другие представители рода людского, сидел дома. Из-за пандемии у меня было свободное время, которое я тратил на улучшение моего рецепта хлеба. А несколькими днями ранее я заказал газоанализатор (Рис. A, под катом). Я полагал, ч... | https://habr.com/ru/post/582246/ | null | ru | null |
# EFORTH для МК-161: Структуры данных
*Эта статья — окончание цикла статей про eForth на программируемом калькуляторе. [Начало здесь](https://habr.com/ru/post/452398/).*
Команды входного языка «Электроники МК-161» занимают только половину файла eForth0.mkl. Вторую половину занимают таблицы, разработать которые был... | https://habr.com/ru/post/452572/ | null | ru | null |
# Backports-сервис становится официальным
Время debian — есть еще интересные новости!
Проект Debian рад объявить, что Backports-репозиторий,
ранее доступный на [www.backports.org](http://www.backports.org) [1] теперь также является официальным сервисом Debian и предоставляется на [backports.debian.org](http://ba... | https://habr.com/ru/post/103606/ | null | ru | null |
# Мы развернули платформу Deckhouse на узле с Astra Linux. Рассказываем, как (и зачем)
Astra Linux — российская операционная система специального назначения, актуальная версия которой основана на Debian 10.0 (Buster). В частности, эту ОС используют органы государственной власти, госслужбы и госкорпорации. Astra Linux ... | https://habr.com/ru/post/646683/ | null | ru | null |
# Как запускать поды как сервисы systemd в Podman

Расширять традиционные практики администрирования Linux с помощью контейнеров — естественный путь развития. [Podman](https://podman.io/) без проблем интегрируется в Linux, но подде... | https://habr.com/ru/post/674832/ | null | ru | null |
# Информация о компьютере: просто и быстро

Довольно часто нужно быстро, кратко, но информативно получить информацию о стационарном компьютере или ноутбуке, без дополнительного ПО и не «вскрывая крышку».
Это можно реализовать, нап... | https://habr.com/ru/post/496710/ | null | ru | null |
# Как правильно сложить колоду автоматизации тестирования
*(*[*Эта статья*](https://techbeacon.com/app-dev-testing/how-stack-your-test-automations-deck) *первоначально появилась на* [*TechBeacon.com*](https:/... | https://habr.com/ru/post/571210/ | null | ru | null |
# Установка FreeBSD на флешку для seedbox машины
На многие домашние seedbox'ы довольно часто ставятся старые жесткие диски, из принципа «не жалко». Важных данных туда все равно не пишется, и когда они помирают, ничего страшного не происходит, за исключением... | https://habr.com/ru/post/80480/ | null | ru | null |
# Первое знакомство с SQL-инъекциями
SQL-инъекции (SQL injection, SQLi, внедрение SQL-кода) часто называют самым распространённым методом атак на веб-сайты. Их широко используют хакеры и пентестеры в применении к веб-приложениям. В списке уязвимостей OWASP Топ-10 присутствуют SQL-инъекции, которые, наряду с другими по... | https://habr.com/ru/post/553066/ | null | ru | null |
# Настройка просмотра и загрузки файлов в FCKeditor
В данной статье описываются отдельные приемы настройки редактора FCKeditor и встроенного в него файлового браузера для управления загрузкой файлов на сервер. Эти приемы помогут лучше понять принципы работы редактора и более тесно интегрировать его в вашу CMS, заодно ... | https://habr.com/ru/post/39054/ | null | ru | null |
# Архитектура PlayStation 3, часть 4: Борьба с пиратством
, которая
... | https://habr.com/ru/post/587248/ | null | ru | null |
# Создание базовой сети 5G с Open5GS и UERANSIM
Добрый день, уважаемые хабровчане!
Сегодня и в последующие дни я сделаю перевод статей о развертывании архитектуры сетей 5G для дальнейшего ее изучения. Цель этой статьи - показать, что самые передовые технологии доступны всем и каждому, и что будущее можно создавать св... | https://habr.com/ru/post/708738/ | null | ru | null |
# Анализ хака Kubernetes — бэкдор через kubelet

Чтобы ничего не знать о Kubernetes, надо было последние три года прожить в пещере. В Handy инфраструктура разработки, CI/CD и продакшена построена на многокластерной экосистеме Kuberne... | https://habr.com/ru/post/413565/ | null | ru | null |
# Ошибочные шаблоны при построении образов контейнеров
В этой статье я перечислю список повторяющихся ошибочных шаблонов, которые регулярно встречаю, когда помогаю людям с пайплайнами сборки контейнеров, а т... | https://habr.com/ru/post/664660/ | null | ru | null |
# Интеграция Primefaces в приложение на Spring Boot. Часть 3 — динамическое обновление контента страницы
Во второй части мы сосредоточились главным образом на создании меню на основе компонента Tree ContextMe... | https://habr.com/ru/post/712858/ | null | ru | null |
# Сервисно-ориентированный state management c lamp-luwak
Благодаря тому, что React предоставляет удивительные возможности по работе с отображением, можно сосредоточиться только на организации логики приложения и семантике кода, описывающего работу с данными. Т.е. выбирая state management библиотеку, происходит выбор с... | https://habr.com/ru/post/497572/ | null | ru | null |
# JavaScript: заметка о сканере предварительной загрузки и пропуске невидимого контента

Привет, друзья!
В этой заметке я хочу рассказать о двух вещах:
1. Сканере предварительной загрузки (теоретическая часть).
2. Пропуске невиди... | https://habr.com/ru/post/671762/ | null | ru | null |
# Автоэнкодер в задачах кластеризации политических событий
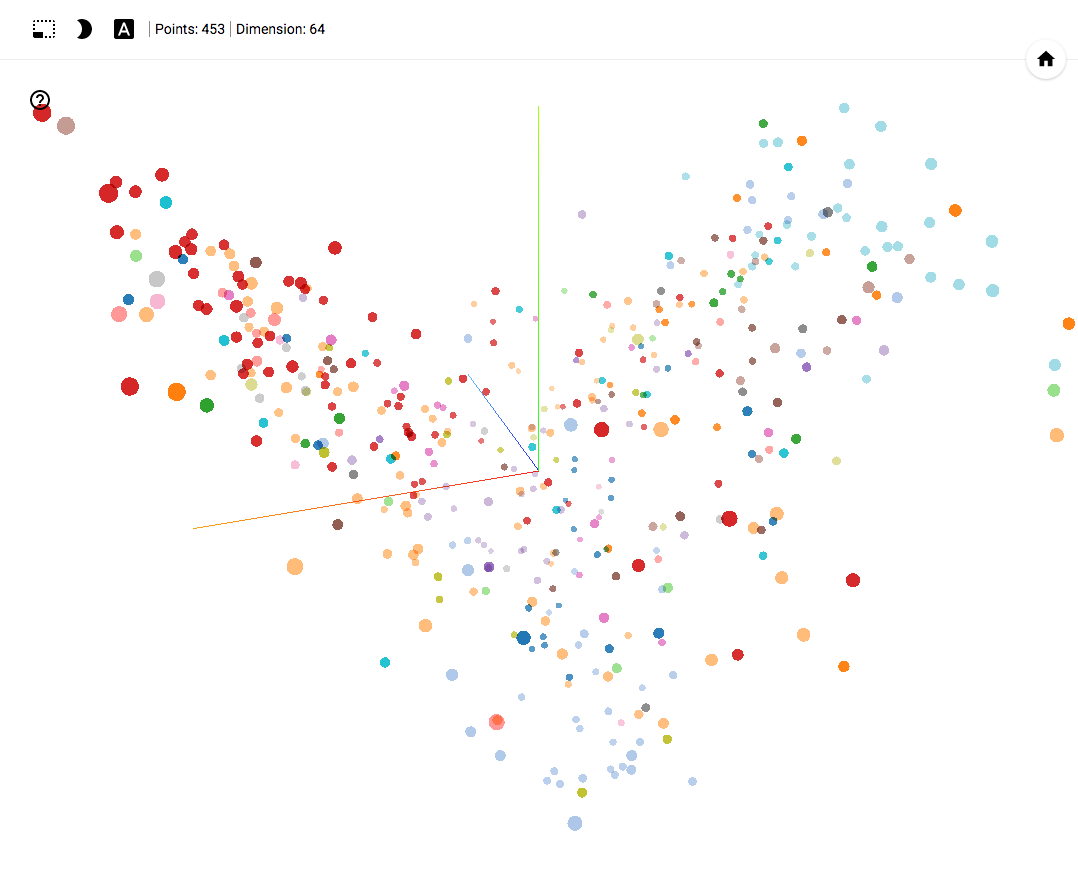
**Я не люблю читать статьи, смотрю demo и код**[Демо TensorBoard Projector](http://octadero.com/event.php?p=http%3A%2F%2Fprojector.tensorflow... | https://habr.com/ru/post/349048/ | null | ru | null |
# Подробно о корутинах в C++
Здравствуйте, коллеги.
В рамках проработки темы С++20 нам в свое время попалась уже довольно старенькая (сентябрь 2018) статья из хаброблога «Яндекса», которая называется "[Готовимся к С++20. Coroutines TS на реальном примере](https://habr.com/ru/company/yandex/blog/420861/)". Заканчива... | https://habr.com/ru/post/491996/ | null | ru | null |
# Автоматизация обслуживания компьютерного класса на Powershell

Вот уже несколько лет занимаюсь в университете поддержкой 10 рабочих станций под управлением ОС Microsoft Windows 8.1. В основном поддержка заключается в установке нужн... | https://habr.com/ru/post/514590/ | null | ru | null |
# NVIDIA Jetson Nano: тесты и первые впечатления — часть 2, тесты AI
Привет, Хабр.
В [первой части](https://habr.com/ru/post/460723/) была рассмотрена NVIDIA Jetson Nano — плата в форм-факторе Raspberry Pi, ориентированная на производительные вычисления с помощью GPU. Настала пора протестировать плату в том, для че... | https://habr.com/ru/post/460971/ | null | ru | null |
# Вокруг Света за 4 Секунды на Columnstore (Часть 1)
В этой статье я собираюсь рассмотреть вопрос повышения скорости отчетов. Под отчетом я понимаю любой запрос в базу данных, который использует агрегирующие функции. Также, я собираюсь затронуть вопросы, касающиеся затрачиваемых ресурсов на производство и поддержку от... | https://habr.com/ru/post/472396/ | null | ru | null |
# Рекомендательный движок за 2 строчки кода
История
-------
Некоторое время назад IT в «Леруа Мерлен» претерпело довольно много [изменений](https://habr.com/ru/company/leroy_merlin/blog/457466/). Было перепилено довольно много систем, практически все писались с нуля. Одной из таких систем была Публикационная Платформ... | https://habr.com/ru/post/540168/ | null | ru | null |
# Microsoft представила версию 1.0 пакетного менеджера winget

26 мая 2021 года Microsoft [представила](https://devblogs.microsoft.com/commandline/windows-package-manager-1-0/) версию 1.0 пакетного менеджера Windows Package Manager... | https://habr.com/ru/post/559922/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.