
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Отслеживание изменений в SQL Server 2008
Я думаю, каждый разработчик СУБД рано или поздно сталкивается с задачей отслеживания обращений к БД и событий сервера в целом. И прежде чем выбрать инструмент (или написать его самому), конечно, стоит обратить внимание на решения, которые предлагают сами разработчики СУБД. Хо... | https://habr.com/ru/post/111207/ | null | ru | null |
# Погружение в разработку на Ethereum. Часть 2: Web3.js и газ
В [предыдущей статье](https://habrahabr.ru/post/336132/) мы описали деплой контрактов и взаимодействие с ними через пользовательский интерфейс кошелька Mist, но это не подходит для реальной разработки. Нужна библиотека, которая позволит работать с блокчейно... | https://habr.com/ru/post/336770/ | null | ru | null |
# Новости Yii 2020, выпуск 5
Приветствую!
Время очередного выпуска новостей Yii. Как у Yii 2, так и у Yii 3 всё хорошо :)
> На самом деле, в этом году перед этим выпуском было ещё четыре, как следует из порядкового номера. Но я был так увлечён Yii 3, что забыл про хабр… Почитать их можно прямо на главной <https://yi... | https://habr.com/ru/post/510202/ | null | ru | null |
# Современный PHP без фреймворков

У меня есть для вас непростое задание. Когда в следующий раз начнёте новый проект, постарайтесь обойтись без PHP-фреймворка. Я не собираюсь перечислять недостатки фреймворков, и это не проявление [с... | https://habr.com/ru/post/352122/ | null | ru | null |
# Мониторинг работы Ansible Playbook
Как-то раз я решил задействовать [ansible](https://www.ansible.com/) (очень популярный инструмент управления конфигурациями) в системе, развернутой в продакшене. Когда дел... | https://habr.com/ru/post/694470/ | null | ru | null |
# Шейдер для волос туториального персонажа из Vikings: War of Clans
Не так давно мы опубликовали материал о [тестировании Unity Cloth на мобильных устройствах](https://habr.com/ru/company/plarium/blog/520490/). В другой [статье на render.ru](https://render.ru/ru/Plarium/post/20489) рассказали о том, как арт-отделу Pla... | https://habr.com/ru/post/553930/ | null | ru | null |
# Руководство по установке Haiku
Данная статья ознакомит читателя с вопросами установки и подготовки [Haiku](http://haiku-os.org/) к работе. Хотя на звание исчерпывающей она не претендует, охватить круг наиболее важных вопро... | https://habr.com/ru/post/145325/ | null | ru | null |
# Рассказ о том, как не надо проектировать API
Однажды я помогал товарищу, которому нужно было интегрировать с сайтом его клиента данные о свободном и занятом жилье из системы управления имуществом. К моей радости у этой системы было API. Но, к сожалению, устроено оно было из рук вон плохо.
[
Не так давно, а именно 2011-10-05 вышла новая версия фреймворка connect 2.0. На хабре был замечен пробел, а тут выдалось пару свободных часов. Буду писать сразу п... | https://habr.com/ru/post/139203/ | null | ru | null |
# Готовим ASP.NET Core: подробнее про работу с модульным фреймворком
> *Мы продолжаем нашу колонку по теме ASP.NET Core очередной публикацией от Дмитрия Сикорского ( [DmitrySikorsky](https://habrahabr.ru/users/dmitrysikorsky/)) — руководителя компании «Юбрейнианс» из Украины. В этот раз Дмитрий продолжает рассказ о св... | https://habr.com/ru/post/279985/ | null | ru | null |
# Новости из мира Node: DataCollection.js, Supererror, Readability
#### **DataCollection.js**
[DataCollection.js](http://thestorefront.github.io/DataCollection.js/)\* — представляет собой библиотеку для выполнения запросов к источнику данных. Вы можете использовать ее как в браузере так и на стороне *Node*. Пример в ... | https://habr.com/ru/post/236335/ | null | ru | null |
# Достать до звезд: Осваиваем операторы Ansible для управления приложениями в Kubernetes
Посмотрим, как использовать опубликованные в [Ansible Galaxy](https://galaxy.ansible.com/) роли (Role) в качестве операторов (Operator), управляющих приложениями в Kubernetes, и разберем это на примере создания оператора, который ... | https://habr.com/ru/post/440188/ | null | ru | null |
# Yii 2.0: Динамическое добавление валидируемых полей формы через «пиджак»(pjax) для мульти-модельной формы
Доброго времени суток, Хабр!
Не так давно передо мной встала задача разработки формы с возможностью динамического добавления полей, каждое поле являлось отдельной сущностью базы данных, то есть поле = запись ... | https://habr.com/ru/post/239147/ | null | ru | null |
# Arduino: ИК-управление бытовой техникой (применение девайса)
Задравствуй хабр! По отзывам понял, что в статье [«Arduino: ИК-управление бытовой техникой»](http://habrahabr.ru/post/215521/) мало посвятил конечной цели устройства и как его применять на практике, по-этому займусь этим сейчас.
Назначение нашего arduin... | https://habr.com/ru/post/216355/ | null | ru | null |
# С большой силой приходит и большая ответственность — техника безопасности в AngularJS

Несомненно, ангуляр даёт вам силу. Но пользоваться ей нужно с умом. Я постарался сформулировать три простых пра... | https://habr.com/ru/post/230761/ | null | ru | null |
# $mol: reactive micromodular ui-framework
Сколько нужно времени, чтобы просто вывести на экран большой список, используя современные фреймворки?
| [Список на 2000 строк](https://eigenmethod.github.io/mol/perf/render/) | ReactJS | AngularJS | Raw HTML | SAPUI5 | $mol |
| --- | --- | --- | --- | --- | --- |
| Появлени... | https://habr.com/ru/post/311172/ | null | ru | null |
# ORM или простое наполнение класса данными из хранимой процедуры
Привет всем хабраюзерам, решил написать первую свою статью, которая, продолжает серию [очерков](http://habrahabr.ru/blogs/net/48820) про взаимодействие с БД. Так случилось что подвернулся небольшой вэб-проект для реализации. В качестве платформы был выб... | https://habr.com/ru/post/51404/ | null | ru | null |
# SpaceVIL — кроссплатфоремнный GUI фреймворк для разработки на .Net Core, .Net Standard и JVM
В данной статье я постараюсь рассказать о фреймворке SpaceVIL (Space of Visual Items Layout), который служит для построения пользовательских графических интерфейсов на платформах .Net / .Net Core и JVM.
SpaceVIL является кр... | https://habr.com/ru/post/448790/ | null | ru | null |
# Под капотом Redis: Хеш таблица (часть 1)
Если вы знаете, почему после выполнения `hset mySey foo bar` мы потратим не менее 296 байт оперативной памяти, почему инженеры instagram не используют строковые ключи, зачем всегда стоит менять *hash-max-ziplist-entries*/*hash-max-ziplist-val* и почему тип данных, лежащий в о... | https://habr.com/ru/post/271205/ | null | ru | null |
# // бухой, пофиксю позже
```
long long ago; /* in a galaxy far far away */
```
```
//
// _oo0oo_
// o8888888o
// 88" . "88
// (| -_- |)
// 0\ = /0
// ___/`---'\___
... | https://habr.com/ru/post/343168/ | null | ru | null |
# Уравнение теплопроводности в tensorflow
Привет, Хабр! Некоторое время назад увлекся глубоким обучением и стал потихоньку изучать tensorflow. Пока копался в tensorflow вспомнил про свою курсовую по параллельному программированию, которую делал в том году на 4 курсе университета. Задание там формулировалось так:
Ли... | https://habr.com/ru/post/321734/ | null | ru | null |
# «Прикладной» ASCII-арт
Привет, Хабр! Автор [недавней статьи](https://habr.com/ru/post/440830/) рассказал о разновидности ASCII-арта, которая вроде как и не совсем «арт», т.е., искусство. Ибо служит практическим целям: показать небольшой эскиз, график, электрическую или иную схему… Решил и я вспомнить на эту тему что... | https://habr.com/ru/post/441394/ | null | ru | null |
# Качаем с Народ.Диска без капчи и без яндекс.бара
Как известно, чтобы скачать файл с [Народ.Диска](http://narod.ru/disk), необходимо либо ввести капчу, либо установить яндекс.бар. А если не хочется, чтоб яндекс.бар мозолил глаза(либо любимый браузер — опера)? Да, его можно скрыть, но зачем он тогда вообще нужен, если... | https://habr.com/ru/post/37735/ | null | ru | null |
# Разработка изоморфного RealWorld приложения с SSR и Progressive Enhancement. Часть 4 — Компоненты и композиция
В [предыдущей части](https://habrahabr.ru/post/350428/) туториала мы решили проблемы изоморфного роутинга, навигации, фетчинга и начального состояния данных. В итоге, получилась довольно простая и лаконична... | https://habr.com/ru/post/351378/ | null | ru | null |
# Банки. Ошибки и уязвимости
Решил ради интереса посветить день обзору сайтов банков.
Первый из таких стал официальный сайт Россельхоз Банка (реклама дала о себе знать :) ), следующий Русский стандарт банк, далее X банк (X банк — банк, который не ответил на 2 моих уведомления и так не закрыл дыру) и напоследок Альф... | https://habr.com/ru/post/144904/ | null | ru | null |
# RabbitMQ tutorial 1 — Hello World
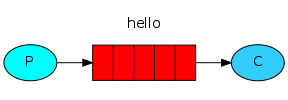
RabbitMQ позволяет взаимодействовать различным программам при помощи протокола AMQP. RabbitMQ является отличным решением для построения SOA (сервис-ориентированной архитектуры) и распр... | https://habr.com/ru/post/149694/ | null | ru | null |
# Элегантное асинхронное программирование с помощью промисов
Доброго времени суток, друзья!
Промисы (обещания) — сравнительно новая особенность JavaScript, которая позволяет откладывать выполнение действия до завершения выполнения предыдущего действия или реагировать на неудачное выполнение действия. Это способству... | https://habr.com/ru/post/488762/ | null | ru | null |
# Lazy Loading в Entity Framework
Хочу рассказать о Lazy Loading в Entity Framework и почему использовать его надо с осторожностью. Сразу скажу, что я предполагаю что читатель использует Entity Framework или хотя бы читал про него.
Что такое Lazy Loading?
-----------------------
Lazy loading это способность EF ав... | https://habr.com/ru/post/336812/ | null | ru | null |
# Unit-тестирование, детальное рассмотрение параметризованных тестов. Часть I
Доброго времени суток, коллеги.
Я решил поделиться своим видением на параметризованные юнит-тесты, как делаем это мы, и как возможно не делаете (но захотите делать) вы.
Хочется написать красивую фразу, о том что тестировать надо правил... | https://habr.com/ru/post/526406/ | null | ru | null |
# Механизм соавторства в MS Office 2010 + SharePoint 2010: протоколы и пакеты
Механизм соавторства появился с выходом MS Office 2010 и SharePoint 2010. Появившуюся функциональность многие называют как «давно ожидаемую», действительно, приуменьшать удобство её использования смысла нет. Но в данной статье речь пойдет о ... | https://habr.com/ru/post/101859/ | null | ru | null |
# Размышление об Active Object в контексте Qt6. Часть 2.6
#### Ссылки на статьи
* [Часть 1](https://habr.com/ru/post/709768/)
* [Часть 2](https://habr.com/ru/post/710368/)
* [Часть 2.5](https://habr.com/ru/post/710550/)
* [Часть 2.6](https://habr.com/ru/post/712328/)
* [Часть 3](https://habr.com/ru/post/710656/)
###... | https://habr.com/ru/post/712328/ | null | ru | null |
# CKEditor + jquery.fancybox/prototype.lightbox или вариант простой фотогалереи
В свет вышел релиз CKEditor 3.0.1, значит надо что нибудь добавить :)
Я уже делал подобное совмещение(если это можно так назвать) для прошлой версии, для текущей подобное совсем не составляет труда.
Точнее, непосредственно при редакт... | https://habr.com/ru/post/73172/ | null | ru | null |
# Turning RTSP into WebRTC: how many cameras will the server withstand?
This article continues the series of articles on load tests. Today we will analyze the testing methodology and answer the question: "Ho... | https://habr.com/ru/post/570370/ | null | en | null |
# Повышаем производительность поиска с помощью партиционирования индекса в Apache Solr

Полнотекстовый поиск используется в [Wrike](https://www.wrike.com/ru?utm_source=habrahabr&utm_medium=blogposts&utm_campaign=Solr) почти ... | https://habr.com/ru/post/274059/ | null | ru | null |
# Data ONTAP 8.3 ADP: FlashPool StoragePools
ОС Data ONTAP 8.3 cDOT это один из наибольших релизов NetApp. Одной из ключевых особенностей релиза является технология Advanced Drive Partitioning (ADP), в предыдущей статье я рассматривал применение этой технологии для [Root-Data Partitioning](http://habrahabr.ru/post/269... | https://habr.com/ru/post/270169/ | null | ru | null |
# Модульные спрайтовые персонажи и их анимация
Эта запись девлога целиком посвящена моей системе анимации персонажей, она наполнена полезными советами и фрагментами кода.
За последние два месяца я создал целых 9 новых действий игрока (такие забавные вещи как блокировка щитом, уворачивание в прыжке и оружие), 17 нов... | https://habr.com/ru/post/468991/ | null | ru | null |
# C++20 укомплектован, C++23 начат. Итоги встречи в Кёльне
На днях прошла встреча международного комитета по стандартизации C++ в Кёльне. В прошлый раз был принят feature freeze на C++20, так что комитет должен был обсуждать только исправления уже принятых вещей, а добавлять новинки уже в C++23…
… но всё было не та... | https://habr.com/ru/post/458938/ | null | ru | null |
# Генерация повторяющихся блоков кода с помощью плагина для Sublime Text 2
В своей работе мне постоянно приходится копипастить большое количество однотипного кода связанного с разметкой, валидацией, форматированием и т.д. большого количества полей из СУБД. Давно хотелось как то автоматизировать эту задачу.


### Postgres и PostgreSQL
**[PostgreSQL 15.1](https://www.postgresql.org/about/news/postgresql-151-146-139-1213-1118-and-1023-released-2543/)**
И, конечно, PostgreSQL 14.6, 13.9, 12.13, 11.18 и 10.23 (у де... | https://habr.com/ru/post/694996/ | null | ru | null |
# Внешние правила доступа в Postfix на примере front-end к GLD
Так получилось, что в организации, где я работаю, в качестве почтового сервера используется Postfix. В связке с ним используются средства для фильтрации спама и вирусов Spamassassin, Amavisd-new и ClamAV. В дополнение ко всему этому реализован greylisting ... | https://habr.com/ru/post/153463/ | null | ru | null |
# Зачем нужен отчёт MISRA Compliance и как его получить в PVS-Studio?
Если вы не понаслышке знаете о MISRA и хотели бы понимать, соответствует ли ваш проект какому-то из стандартов ассоциации MISRA, то есть решение. Имя ему - MISRA Compliance. С недавних пор PVS-Studio научился генерировать отчёт соответствия по этому... | https://habr.com/ru/post/576440/ | null | ru | null |
# Оптимизация работы с SQLite под iOS
> *“Think of SQLite not as a replacement for Oracle but as a replacement for fopen()”*
>
> — About SQLite
>
>
А также, скорее всего, под Android, BlackBerry ... | https://habr.com/ru/post/135337/ | null | ru | null |
# TCP(syn-flood)-netmap-generator производительностью 1,5 mpps
**Дано:**
```
# pciconf -lv | grep -i device | grep -i network
device = I350 Gigabit Network Connection
# dmesg | grep CPU:
CPU: Intel(R) Core(TM)2 Duo CPU E7300 @ 2.66GHz (2666.69-MHz K8-class CPU)
# uname -orp
FreeBSD 9.1-RELEASE ... | https://habr.com/ru/post/183692/ | null | ru | null |
# Yii 1.1.10
Вышел релиз 1.1.10 PHP фреймворка Yii. В данной версии, в основном, исправлены ошибки в `CActiveForm`, `CJuiDatePicker` и невозможность запуска с `yiilite.php`.
* [Полный список изменений](http://www.yiiframework.com/files/CHANGELOG-1.1.10.txt)
* [Обновляемся](http://www.yiiframework.com/download/) | https://habr.com/ru/post/138084/ | null | ru | null |
# Создание плагина разрешения ссылок для PhpStorm (IntelliJ IDEA)
Я работаю веб-программистом, пишу на PHP и использую фреймворк Kohana. Для разработки использую потрясающую, на мой взгляд, среду PhpStorm.
При работе с большими и не очень проектами меня всегда угнетало, что я много времени трачу на навигацию по пр... | https://habr.com/ru/post/161877/ | null | ru | null |
# Generic исключения в лямбда-функциях
**UPD:** Добавлен пример с ленивыми вычислениями поверх стандартных стримов.
Как известно из функциональных интерфейсов в Stream API нельзя выбрасывать контролируемые исключения. Если по каким-то причинам это необходимо (например, работа с файлами, базами данных или по сети), ... | https://habr.com/ru/post/341524/ | null | ru | null |
# Анатомия юнит-теста
Эта статья является конспектом книги «[Принципы юнит-тестирования](https://www.litres.ru/vladimir-horikov/principy-unit-testirovaniya-pdf-epub-64083637/)». Материал статьи посвящен структуре юнит-теста.
В этой статье рассмотрим структуру типичного юнит-теста, которая обычно описывается паттерном... | https://habr.com/ru/post/554808/ | null | ru | null |
# Учим Zend Memcache работать с тегами
В проекте, где я являюсь разработчиком, используется кеш. Сразу хочу оговориться, проект высоконагруженный, порядка двух тысяч человек в сутки. Удобным решением снять нагрузку с базы данных стало использование мемкеша. Поскольку проект на Zend Framework'е реализацию работы кеша с... | https://habr.com/ru/post/137150/ | null | ru | null |
# Асинхронные HTTP-запросы на C++: входящие через RESTinio, исходящие через libcurl. Часть 1
Преамбула
=========
Наша команда занимается разработкой небольшого, удобного в использовании, встраиваемого, асинхронного HTTP-сервера для современного C++ под названием [RESTinio](https://github.com/Stiffstream/restinio). На... | https://habr.com/ru/post/349728/ | null | ru | null |
# Адаптируем существующее бизнес-решение под SwiftUI. Часть 4. Навигация и конфигурация
Доброго всем времени суток! С вами я, Анна Жаркова, ведущий мобильный разработчик компании [«Usetech»](https://usetech.ru/)
Теперь поговорим об еще одном интересном моменте в SwiftUI, о навигации.
Если вы пропустили предыду... | https://habr.com/ru/post/500492/ | null | ru | null |
# Автоматизация развертывания приложений в 1 клик на платформе InfoboxCloud Jelastic с JPS
Цель [платформы Jelastic](http://infoboxcloud.ru/paas/) — сделать использование сложных технологий простым и понятным. Наша цель — сократить время, которое разработчики обычно тратят на выполнение рутинных задач для повышения эф... | https://habr.com/ru/post/220137/ | null | ru | null |
# Разбор базового решения для задачи определения железнодорожной колеи и подвижного состава с Цифрового Прорыва
](https://habr.com/ru/company/ruvds/blog/512318/)
Дисклеймер: инструменты, описанные здесь абсолютно легальны. Это как нож: кто-то режет капусту в салат, ... | https://habr.com/ru/post/512318/ | null | ru | null |
# ActionResult на все случаи жизни
Чем дальше в «лес», тем толще MVC framework. [Вот](http://habrahabr.ru/blogs/net/66030/ "Новость") на днях вышел preview второй версии. Бегло ознакомившись с возможностями, сильно порадовался. Но затем вспомнил о простой и очень интересной возможности RoR, которой пока нет (даже в пл... | https://habr.com/ru/post/66355/ | null | ru | null |
# Простейшая реализация Entity Component System
Всем привет!
У нас стартует четвёртый поток [«Разработчик C++»](https://otus.pw/hEis/), один из самых активных курсов у нас, если судить по реальным встречам, где для того чтобы пообщаться с [Димой Шебордаевым](https://otus.pw/v9Af/) приходят далеко не только «крестон... | https://habr.com/ru/post/422981/ | null | ru | null |
# Пилим каталог товаров не притрагиваясь к реляционной алгебре
Здравствуйте, меня зовут Дмитрий Карловский и я… давно не занимался бэкендом, но на днях вдруг наткнулся на мучения [SbWereWolf](https://habrahabr.ru/users/sbwerewolf/) по [натягиванию ужа на ежа](https://habrahabr.ru/post/323498/) и не смог удержаться от ... | https://habr.com/ru/post/324012/ | null | ru | null |
# Ржавая очевидность
Каждый ищет в языках программирования что-то своё: кому-то важна функциональная сторона, кому-то богатство библиотек, а другой сразу обратит внимание на длину ключевых слов. В данной статье я хотел бы рассказать, что особенно важно для меня в Rust — его очевидность. Не в том, что его легко изучить... | https://habr.com/ru/post/259299/ | null | ru | null |
# Пользовательские CSS-переменные, инверсия светлоты цветов и создание тёмной темы за 5 минут
Вы, наверное, уже знаете о том, что для хранения сведений об отдельных компонентах цвета можно применять пользовательские CSS-переменные. Это позволяет избавиться от необходимости повторения одних и тех же цветовых координат ... | https://habr.com/ru/post/551038/ | null | ru | null |
# 8 распространенных ошибок при разработке Android-приложений
### 1. Все должно быть на своем месте (строки, цвета)
Экосистема Android стремительно растет по всему миру и распространяется на различные группы... | https://habr.com/ru/post/578562/ | null | ru | null |
# Почему я не использую веб-компоненты
Я пишу это в основном для себя в будущем, чтобы у меня было куда сослаться, когда кто-нибудь спросит меня, почему я скептичен в отношении веб-компонентов и почему [Svelte](https://svelte.dev/) не компилируется в веб-компоненты по умолчанию. (Тем не менее, он может компилироваться... | https://habr.com/ru/post/457010/ | null | ru | null |
# Язык в языке или встраиваем XPath в Scala
Scala — великолепный язык. В него можно влюбиться. Код может быть лаконичным, но понятным; гибким, но строго типизированным. Продуманные до мелочей инструменты позволяют не бороться с языком, а выражать на нем свои идеи.
Но эти же инструменты позволяют писать крайне сложн... | https://habr.com/ru/post/176285/ | null | ru | null |
# Фреймворк Camel: сравнение компонентов HTTP и AHC
В данной статье производится сравнение работы простейших сервисов реализованных с помощью фреймворка Camel и двух его компонентов: HTTP и AHC. Углубляться в структуру и работу с самим фреймворком не будем, предполагается что читатель уже немного знаком с ним.
Рассма... | https://habr.com/ru/post/536176/ | null | ru | null |
# Как работает JS: анимация средствами CSS и JavaScript
**[Советуем почитать] Другие 19 частей цикла**Часть 1: [Обзор движка, механизмов времени выполнения, стека вызовов](https://habrahabr.ru/company/ruvds/blog/337042/)
Часть 2: [О внутреннем устройстве V8 и оптимизации кода](https://habrahabr.ru/company/ruvds/blo... | https://habr.com/ru/post/354438/ | null | ru | null |
# Защита целостности кода с помощью PGP. Часть 1. Базовые концепции и инструменты
Если вы пишете код, который попадает в общедоступные репозитории, вам может пригодиться PGP. В этой серии статей, перевод первой из которых мы публикуем сегодня, будут рассмотрены вопросы использования PGP для обеспечения целостности код... | https://habr.com/ru/post/349618/ | null | ru | null |
# Работа с ветками в SVN. Изменения в версии 1.5.
Продолжение [этой статьи](http://habrahabr.ru/blogs/development_tools/45203/)
Долгое время в ветках SVN был один существенный недостаток. Система не помнила мержей, и программисту приходилось самостоятельно заботиться о том, что бы сохранить номер ревизии, когда про... | https://habr.com/ru/post/45222/ | null | ru | null |
# Escape analysis и скаляризация: Пусть GC отдохнет
В этот раз мы решили разнообразить поток технических интервью реальным хардором и подготовили материал на основе доклада Руслана [cheremin](https://habr.com/ru/users/cheremin/) Черемина (Deutsche Bank) про анализ работы пары Escape Analysis и Scalar Replacement, сдел... | https://habr.com/ru/post/322348/ | null | ru | null |
# DataHub: универсальный инструмент поиска и обнаружения метаданных
DataHub: универсальный инструмент поиска и обнаружения метаданных.
Как оператор крупнейшей в мире профессиональной сети и [экономического графика](https://economicgraph.linkedin.com/#video), отдел данных LinkedIn постоянно работает над масштабировани... | https://habr.com/ru/post/520930/ | null | ru | null |
# К вопросу о «потерянном времени»
### Нам представилась замечательная возможность провести небольшое, но крайне поучительное тактическое занятие.
Вопросы оптимизации программ, производящих значительное количество вычислений, к сожалению, недостаточно хорошо освещены в литературе и, как правило, сводятся в некоторым ... | https://habr.com/ru/post/318816/ | null | ru | null |
# Ectognathus, робот-хексапод на микро-сервах своими руками, часть вторая
Добрый день, уважаемые хабровчане. Это вторая часть статьи про разработку робота-хексапода. Первую часть вы можете найти [тут](http://habrahabr.ru/post/148964/).
В этой статье я расскажу непосредственно про производство самого робота, перехо... | https://habr.com/ru/post/149038/ | null | ru | null |
# TRY / CATCH в PostgreSQL
Во встроенном процедурном языке PL/pgSQL для СУБД PostgreSQL отсутствуют привычные операторы **TRY / CATCH** для для перехвата исключений возникающих в коде во время выполнения. Ан... | https://habr.com/ru/post/657667/ | null | ru | null |
# Изменение в PHP 7, ломающее при обновлении с пятой версии некоторые сервера на Ubuntu
Это явно не заслуживает отдельной статьи на Хабре, но ошибка может коснуться большого количества людей, поэтому я всё-таки решил написать.
<http://php.net/manual/en/configuration.file.php#configuration.file.changelog> :
> 7.0.0 H... | https://habr.com/ru/post/310136/ | null | ru | null |
# collectd + front-end

Как показывает практика — б**o**льшая часть клиентов никак не мониторит используемые ресурсы, арендуемых ими услуг (особенно это заметно на дешевых услугах VPS от 3$).То есть, после установки системы ... | https://habr.com/ru/post/272447/ | null | ru | null |
# Blockchain RSA-based random
There’s a problem we needed to address in the course of developing our games. It’s complicated to generate a random number in a distributed network. Almost all blockchains have already faced this issue. Indeed, in networks where there is no trust between anyone, the creation of a random n... | https://habr.com/ru/post/464395/ | null | en | null |
# Определяем «неправильные» слова при борьбе со спамом
При борьбе со спамом на форуме возникла идея автоматически отлавливать слова, внешне похожие на «нормальные», но фактически отличающиеся от шаблонных, имеющихся в базе стоп-слов. Делается это путём замены кириллических символом на латиницу и наоборот. Например, «П... | https://habr.com/ru/post/86303/ | null | ru | null |
# Logmein. Как выйти из замкнутого круга
Добрый день. Я в каком то роде системный администратор. И мне очень-очень нравился logmein. Мне полностью хватало free версии, и будущее казалось достаточно оптимистичным. Я знал, что если понадобится смогу подключиться из любого фактически места к бедному пользователю и помочь... | https://habr.com/ru/post/176425/ | null | ru | null |
# VPN на минималках ч.3
Привет, Хабр!
Несмотря на то, что с момента публикации второй части прошло почти полгода — прокрастинация все-таки выиграла битву, но не войну, и поэтому повествование о нелегких будн... | https://habr.com/ru/post/693750/ | null | ru | null |
# Чистый CSS: 4 метода анимирования цвета ссылок
Автор статьи, перевод которой мы сегодня публикуем, предлагает, пользуясь чистым CSS, создать механизм изменения цвета текста ссылки при наведении на неё мыши. Но это должна быть не обычная смена цвета. Новый цвет должен заполнять ссылку слева направо, заменяя старый. ... | https://habr.com/ru/post/491702/ | null | ru | null |
# Загрузка файлов через FileReader
##### Зачем я сделал ещё один велосипед?
Работая на одним из текущих проектов опять столкнулся с необходимостью реализации удобной и быстрой загрузки файлов. Привычным жестом расчехлил [plupload](http://www.plupload.com/), но потом задумался.
Про FileAPI я слышал очень давно, на ... | https://habr.com/ru/post/154587/ | null | ru | null |
# Анализ популярности YouTube видео участников Евровидения 2020
13 марта на официальном YouTube канале Евровидения была выложена композиция группы Little Big, которая будет представлять Россию на конкурсе. Посмотрев клип, захотелось сравнивать статистику видео нашей группы, с видео других участников; какие ролики самы... | https://habr.com/ru/post/492326/ | null | ru | null |
# Использование ImGui с SFML для создания инструментов для разработки игр
Привет, Хабр!
Данная статья — вольный перевод моей [статьи](https://eliasdaler.github.io/using-imgui-with-sfml-pt1/) на русский с некоторыми небольшими изменениями и улучшениями. Хотелось бы показать как просто и полезно использовать ImGui с SF... | https://habr.com/ru/post/335512/ | null | ru | null |
# Сообщившего о Pegasus журналиста New York Times взломали этой же программой
Канадская лаборатория Citizen Lab, занимающаяся исследованиями в области информационной безопасности, [опубликовала](https://citizenlab.ca/2021/10/breaking-news-new-york-times-journalist-ben-hubbard-pegasus/) отчёт о диагностике телефона жур... | https://habr.com/ru/post/585308/ | null | ru | null |
# Брошюра об Ecto – интерфейсе для работы с базами данных на Elixir

Вступление
----------
Ecto написанный на Elixir DSL для коммуникации с базами данных. Ecto это не ORM. Почему? Да, потому что Elixir не объектно-ориент... | https://habr.com/ru/post/318358/ | null | ru | null |
# Arduino в быту, на работе, в машине
В последнее время все больше и больше постов посвящается поделкам на основе плат Arduino. Я тоже хочу рассказать о нескольких проектах, созданных на основе этих плат. Не являюсь автором этих проектов и имею к ним косвенное отношение. Но настоящие авторы дали мне добро на использов... | https://habr.com/ru/post/240651/ | null | ru | null |
# NTFS Reparse Points
Привет, Хабр. Представляю вам гайд по NTFS Reparse points (далее RP), точкам повторной обработки. Это статья для тех, кто только начинает изучать тонкости разработки ядра Windows и его окружения. В начале объясню теорию с примерами, потом дам интересную задачку.
Всем привет!
Продолжаю рассказывать об инструментах, которые позволяют обезопасить ваше веб-приложение. Сегодня это библиотека для санитизации данных.
Санити... | https://habr.com/ru/post/254045/ | null | ru | null |
# Как в Smarkets улучшили мониторинг для своих Kubernetes-кластеров
***Прим. перев.**: автор этой статьи — ведущий инженер по инфраструктуре в Smarkets, что позиционирует себя как «одну из самых прибыльных [по доходам на каждого сотрудника] компаний в Европе». Работая с большой и чувствительной к мониторингу инфрастру... | https://habr.com/ru/post/528446/ | null | ru | null |
# Backend в проекте на Yii
В сети очень мало информации по созданию административных страничек в приложениях и наверно каждый использует свои решения. Именно сейчас хотел бы рассказать к чему я дошел за пол года разработки сайтов на Yii (статья только для тех, кто разбирается во фремворке).
При постановке цели все... | https://habr.com/ru/post/126576/ | null | ru | null |
# Yii, непрерывная интеграция — как не сломать все
Мы часто экспериментируем с архитектурой, кодом, производительностью. Постоянно добавляем новый функционал. Мы постепенно обвязываем Yii своей “архитектурной” прослойкой — шардинг, работа с временно недоступными данными, разнообразные кеши и многое другое. Да, плод на... | https://habr.com/ru/post/191210/ | null | ru | null |
# Дипломная работа. Аудит информационной безопасности или как я хакнул свою шарагу. Часть 1
Предисловие.
------------
Стоя у истоков своей неудавшейся карьеры, мне выпал карт-бланш на пенетрацию серверов нашего местного педа по-черному. Я был молод, амбициозен и ориентирован на искрометный прыжок сквозь техническую с... | https://habr.com/ru/post/599297/ | null | ru | null |
# Кто сканирует Интернет. Продолжение следует
Всем привет! Прежде всего, хочу поблагодарить всех, кто участвовал в обсуждении моей первой статьи: [«Кто сканирует Интернет и существует ли Австралия»](https://habr.com/post/354726/).
Публиковал статью без всякого умысла, просто поднял тему, которая так или иначе касае... | https://habr.com/ru/post/358056/ | null | ru | null |
# Пишем telegram бота на языке R (часть 3): Как добавить боту поддержку клавиатуры
Это третья статья из серии "Пишем telegram бота на языке R". В предыдущих публикациях мы научились создавать телеграм бота, отправлять через него сообщения, добавили боту команды и фильтры сообщений. Поэтому перед тем как приступить к ч... | https://habr.com/ru/post/516908/ | null | ru | null |
# Бинарная матричная нейронная сеть
Искусственная нейронная сеть в виде матрицы, входами и выходами которой являются наборы битов, а нейроны реализуют функции двоичной логики нескольких переменных. Такая сеть значительно отличается от сетей перцептронного типа и может дать такие преимущества как конечное число вариант... | https://habr.com/ru/post/343304/ | null | ru | null |
# Основы Postgres для администраторов баз данных Oracle
«А кто отвечает за эту базу данных?»
Народ из команды администраторов баз данных пожал плечами, и кто-то спросил: «А сервер Oracle или SQL?»
«По-моему... | https://habr.com/ru/post/650635/ | null | ru | null |
# Так для чего же нам все таки нужен MVI в мобильной разработке
Много уже сказано про MVI, о том как его правильно прожарить и настроить. Однако не так много времени уделяется тому, насколько этот метод упрощает жизнь в определенных ситуациях, в сравнении с остальными подходами.
Цель этой статьи
----------------
... | https://habr.com/ru/post/517962/ | null | ru | null |
# Как поместить весь мир в обычный ноутбук: PostgreSQL и OpenStreetMap
Когда человек раньше говорил что он контролирует весь мир, то его обычно помещали в соседнюю палату с Бонапартом Наполеоном. Надеюсь, что эти времена остались в прошлом и каждый желающий может анализировать геоданные всей Земли и получать ответы на... | https://habr.com/ru/post/714326/ | null | ru | null |
# Настройка и интеграция Google Friend Connect в WordPress
Google Friend Connect = GFC
Вы уже [подключили](http://interblog.org/archives/300) сайт к GFC
В статье рассмотрим 2 момента:
1. Замена системы регистрации пользователей.
2. Замена системы комментариев и рейтинга записей (постов).
#### 1. Заменяе... | https://habr.com/ru/post/53016/ | null | ru | null |
# Я уеду жить в Лейнвуд. Создаем новые слова при помощи GPT
Фантастический город. Нарисовано нейросетью.Предлагаю не... | https://habr.com/ru/post/672434/ | null | ru | null |
# Упрощённые рейкасты в Unity
Всем привет, меня зовут Григорий Дядиченко, и я технический продюсер. Недавно я столкнулся с одной интересной задачкой в ходе реализации проекта, и подумал что стоит наверное рассказать про физику в Unity, про нюансы работы с ней и про то, какие существуют альтернативные варианты в решени... | https://habr.com/ru/post/581712/ | null | ru | null |
# Ошибка в ядре Linux отправляет поврежденные TCP/IP-пакеты в контейнеры Mesos, Kubernetes и Docker

*А обнаружена она была на серверах Twitter*
Ядро Linux имеет ошибку, причиной которой являются к... | https://habr.com/ru/post/278885/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.