
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Создание модели распознавания лиц с использованием глубокого обучения на языке Python
*Переводчик Елена Борноволокова специально для [Нетологии](https://netology.ru/?utm_source=blog&utm_medium=747&utm_campaign=habr&stop=1) адаптировала [статью](https://www.analyticsvidhya.com/blog/2018/12/introduction-face-detection... | https://habr.com/ru/post/434354/ | null | ru | null |
# Ищем причины тормозов БД, используя sys schema в MySQL 5.7
Есть у нас веб-приложение. Относительно большое и старое — много-много кода, в котором много-много разных запросов к базе данных. При этом мы не гугл, но несколько тысяч запросов в секунду на сервер БД приходится.
Ну и безусловно растёт наше приложение в... | https://habr.com/ru/post/351740/ | null | ru | null |
# Кривые Безье. Немного о пересечениях и как можно проще
Вы сталкивались когда-нибудь с построением (непрерывного) пути обхода кривой на плоскости, заданной отрезками и кривыми Безье?
Вроде бы не сильно сложная задача: состыковать отрезки кривых в один путь и обойти его "не отрывая пера". Замкнутая кривая обходится в... | https://habr.com/ru/post/522950/ | null | ru | null |
# Пишем GUI к 1С RAC, или снова о Tcl/Tk
По мере вникания в тему работы 1С-овских продуктов в среде linux, обнаружился один недостаток — отсутствие удобного графического мультиплатформенного инструмента для управления кластером серверов 1С. И решено было этот недостаток исправить, путём написания GUI для консольной ут... | https://habr.com/ru/post/415835/ | null | ru | null |
# Измеряем задержку от клавиатуры до фотона с помощью оптического датчика
Для измерения времени отклика или задержки (latency) на компьютерах и в интерфейсах я давным-давно использую приложение [Is It Snappy](https://isitsnappy.com/) с высокоскоростной камерой iPhone для подсчёта кадров между нажатием клавиши и измене... | https://habr.com/ru/post/505260/ | null | ru | null |
# Возможно ли без Redux?
На сегодняшний день можно найти уйму позиций, где требуется react/redux. React прекрасен, вопросов нет. Вопрос к Redux — возможно ли без него. Если погуглить чуть-чуть, найдется добротная [статья на Хабре](https://habr.com/ru/post/350850/), где автор задается таким же вопросом. В статье на про... | https://habr.com/ru/post/455176/ | null | ru | null |
# Прикладное применение задачи нелинейного программирования
Доброго времени суток, Хабр! В свое время, будучи студентом младших курсов, я начал заниматься научно-исследовательской работой в области теории оптимизации и синтеза оптимальных нелинейных динамических систем. Примерно в то же время появилось желание популяр... | https://habr.com/ru/post/328198/ | null | ru | null |
# Немного о Steam Web Api

Сервис цифровой дистрибуции Steam от компании Valve становится всё более популярным среди игроков. По состоянию на январь 2013, через Steam распространяется более трёх тысяч товаров, на которые ... | https://habr.com/ru/post/172223/ | null | ru | null |
# Fugue-Icons — динамический Sprite
Для одного из проектов мне нужно было использовать набор простых иконок. Сначала я остановил свой выбор на популярный набор [Silk Icons](http://www.famfamfam.com/lab/icons/silk/) и его Sprite-плагин для Blueprint, но чем дальше я с ним работал, тем сильнее требовалось что-то большее... | https://habr.com/ru/post/129546/ | null | ru | null |
# Как мы интегрировали и настроили для работы Conventional Commits в PHPStorm
Поднялся вопрос стандартизации коммитов в команде. До этого были такие правила, мы пишем номер задачи и через тире описание того, что было сделано кратко. Номер задачи берется из номера issue. Например: `#1 - реализован функционал сборки про... | https://habr.com/ru/post/706772/ | null | ru | null |
# Клади плитку эффективно ( Про CSS, SVG, pattern и другое)

Статья ~~про ремонт квартиры~~, про эффективное использование графических ресурсов для современных устройств. От смарт часов до телевизоров на стену.
Сказ о том, как вст... | https://habr.com/ru/post/483470/ | null | ru | null |
# Может, нам слегка успокоиться с JavaScript?
У меня *очень странная* проблема с браузером. Скрипты на некоторых страницах просто не работают, пока не пройдёт около 20 секунд.
Что бы вы ни собирались предло... | https://habr.com/ru/post/490412/ | null | ru | null |
# Thunderbird, RNP и важность хорошего API

Недавно мне довелось побеседовать с разработчиком [Thunderbird](https://thunderbird.net/) о проектировании API. В ходе этой беседы я поделился соображениями о [RNP](https://www.rnpgp.org/),... | https://habr.com/ru/post/556974/ | null | ru | null |
# Переезд на кластер под управлением «1С-Битрикс: Веб-окружение»
В определённый момент появилась задача — перевести, существующий и активно работающий в production, проект на работу в кластере серверов. Т.к. проект разработан на базе 1C-Bitrix, было принято решение построить кластер с использованием «1С-Битрикс»: Веб-... | https://habr.com/ru/post/430080/ | null | ru | null |
# Работа с виртуальными машинами KVM. Клонирование виртуальных машин

Продолжаем серию статей о виртуализации на базе KVM. В предыдущих статьях было рассказано [об инструментарии](http://habrahabr.ru/... | https://habr.com/ru/post/121218/ | null | ru | null |
# Работа с базами данных в Qt в многопоточном окружении
Все кто разрабатывают приложения на Qt, рано или поздно сталкиваются с работой с БД в многопоточном окружении. И если невнимательно читать Ассистант, то можно натолкнуться на одни очень интересные грабли.
Описание окружения
------------------
Рассмотрим типов... | https://habr.com/ru/post/52536/ | null | ru | null |
# Удаляем фон у фото используя CoreML
Всем привет! Однажды передо мной встала задача сделать фон картинки прозрачным, без мам, пап и бекндов... Задача есть, надо её решать! В этой статье вы узнаете, с чем мне пришлось столкнуться и как я реализовал вырезание заднего фона у фотографий в приложении на iOS.

Защита собственного программного обеспечения от реверс инжиниринга достаточно старая проблема, в своё время терзавшая серд... | https://habr.com/ru/post/225963/ | null | ru | null |
# Flutter 2.8: что нового
Повышение производительности, новые фичи Firebase, состояние десктопной версии, новые инструменты и многое другое.
*Я — Евгений Сатуров, Head of Flutter в*[*Surf*](http://go.surf.ru/hr/flutter/habr/flutter2.8) *и ведущий* [*Flutter Dev Podcast*](http://go.surf.ru/hr/flutter/habr/flutter2.8-1... | https://habr.com/ru/post/596405/ | null | ru | null |
# Проверяем формы по стандартам с Validation API
В свое время мне почти всем нравился Angular 2+, это хорошо спроектированный фреймворк, который на голову выше остальных популярных фронтенд фреймворков по инженерному уровню исполнения. Но были у него и весьма странные недоработки. Одна из них это невозможность ручного... | https://habr.com/ru/post/520104/ | null | ru | null |
# Молниеносный JSON в Ruby on Rails
Вывод результата в JSON достаточно прост в Rails:
```
render json: @statuses
```
Это работает отлично, если нужно вывести небольшое количество записей. Но что случится, если нам потребуется вывести сразу 10'000 записей? Производительность серьезно просядет, а самыми затратными ... | https://habr.com/ru/post/152719/ | null | ru | null |
# Вышел GitLab 9.0: Подгруппы и Deploy Boards
Недавно мы выпустили **GitLab 9.0**, через 18 месяцев после [выпуска версии 8.0](https://about.gitlab.com/2015/09/22/gitlab-8-0-released/). За это время мы сделали [множество значительных изменений в GitLab](https://about.gitlab.com/release-list/), выпуская новую версию 22... | https://habr.com/ru/post/326456/ | null | ru | null |
# Автоматизированное создание отчета по тестированию
#### Введение
Так уж сложилось, что у нас в компании ведется учет работ по тестированию в небезызвестных GoogleDocs. Поскольку таким учетом занимаюсь я один, то это идеальный вариант. Плюс еще есть возможность без труда поделиться наработками с коллегами и не нужно... | https://habr.com/ru/post/195820/ | null | ru | null |
# Алгоритм жевания для тачскрина
Не так давно вышла моя первая личная игра для мобильных. Суть заключается в том, что врагов надо пережевывать пальцами. Алгоритм не уникальный, но встречается редко. На первый взгляд, нужно только прослушать зум-движение двух пальцев, вроде ничего сложного, однако в процессе разработки... | https://habr.com/ru/post/282752/ | null | ru | null |
# Риски, связанные с наследованием
Эта статья расскажет о рисках, связанных с наследованием классов. Здесь будет показана альтернатива наследованию классов – композиция. После прочтения вы поймете, почему Kotlin по умолчанию делает все классы конечными. Статья объяснит, почему не следует делать класс Kotlin open (откр... | https://habr.com/ru/post/713608/ | null | ru | null |
# Python в Visual Studio Code — июльский релиз
Мы рады сообщить, что июльский выпуск расширения Python уже доступен для Visual Studio Code. Вы можете [загрузить](https://marketplace.visualstudio.com/items?itemName=ms-python.python) расширение Python из Marketplace или установить его прямо из галереи расширений в Visua... | https://habr.com/ru/post/511762/ | null | ru | null |
# Нагрузочное тестирование на фреймворке Gatling
*Статья публикуется от имени Масленникова Сергея,* [sergeymasle](https://habr.com/users/sergeymasle/)
*UPD. Добавлен раздел "Реализация расширения для Gatling"*

Продолжаем цикл... | https://habr.com/ru/post/344818/ | null | ru | null |
# CIFS over SSH штатными средствами Windows 10
*Я ленивый и потому люблю когда все организовано удобно, без лишних телодвижений. Иногда перебарываю лень, для того чтобы сделать удобно.*
Однажды потребовалось мне организовать доступ к серверу по протоколу SMB и в поиске решения я наткнулся на следующую статью: [Mounti... | https://habr.com/ru/post/528414/ | null | ru | null |
# AppCode 2020.2: поддержка Swift Package Manager, улучшенное быстродействие, Change Signature для Swift и многое другое
КПДВ — это **Change Signature**, уже пятый рефакторинг для Swift. Обо всем остальном в новом AppCode 2020.2 — под катом.

Больше года назад я опубликовал [12 малоизвестных фактов о CSS](http://www.sitepoint.com/12-little-known-css-facts/) ([перевод](http://habrahabr.ru/post/220237/) на хабре), и по сей день это была одна из самых популярных статей на SitePoint. С тех пор я собирал больше инте... | https://habr.com/ru/post/262783/ | null | ru | null |
# DariaDB. Разработка базы данных для хранения временных рядов
Уже больше года, как у меня есть свой хобби-проект, в котором я разрабатываю движок базы данных для хранения временных рядов — dariadb. Задача довольно интересная — тут есть и сложные алгоритмы да и область для меня совершенно новая. За год был сделан сам ... | https://habr.com/ru/post/323256/ | null | ru | null |
# JodaTime — учите матчасть, или важность существительных
Нашел у себя баг. Нужно было по некоторой логике получить временной интервал, причем без привязки к конкретным датам, то есть просто обертку вокруг количества милисекунд между некими событиями.
В моем коде я высчитывал startDate и endDate, и возвращал Durati... | https://habr.com/ru/post/126556/ | null | ru | null |
# Обзор Python-пакета Datatable
*«Пять экзабайт информации создано человечеством с момента зарождения цивилизации до 2003 года, но столько же сейчас создаётся каждые два дня». Эрик Шмидт*
[](https://habr.com/ru/company/ruvds/blog/4... | https://habr.com/ru/post/455507/ | null | ru | null |
# Laravel 7
Введение
--------
3 марта команда Laravel официально выпустила Laravel 7.0. Как указано в политике поддержки Laravel, это одно из основных обновлений. Хоть этот релиз и не обозначен как LTS, в нём всё равно представлено много новых замечательных функций и исправлений. Обновление будет предоставлять исправ... | https://habr.com/ru/post/502058/ | null | ru | null |
# То, что вам никто не говорил о z-index
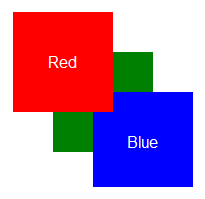
Проблема z-index в том, что многие просто не понимают, как он работает.
Всё, описанное ниже, есть в спецификации W3C. К сожалению, не все её читают.
#### Опис... | https://habr.com/ru/post/166435/ | null | ru | null |
# Hg Init: Часть 1. Переобучение для пользователей Subversion
##### Hg Init: Учебное пособие по Mercurial.
Mercurial — это современная распределенная система контроля версий с открытым кодом. Эта система — заманчивая замена для более... | https://habr.com/ru/post/108443/ | null | ru | null |
# Мониторинг Apache Ignite. Сделали правильно
Мы сделали 2 подсистемы внутри Apache Ignite.
В статье расскажу про их архитектуру:
* Как сделали подсистему метрик и подсистему system view.
* Что сделано и что собираемся сделать?
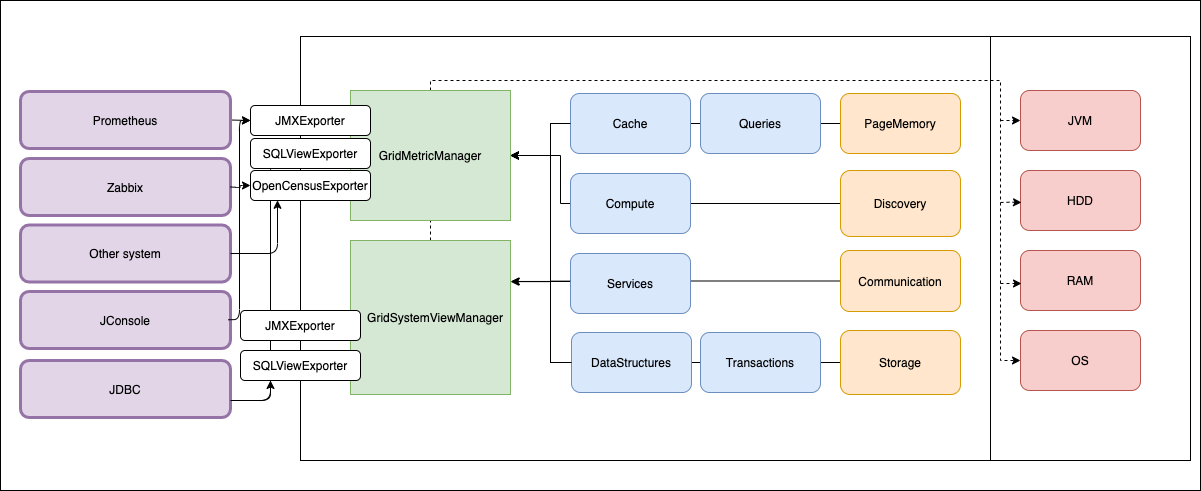
В... | https://habr.com/ru/post/486288/ | null | ru | null |
# Вышла Magento 1.7.0.0
24 апреля мир увидел очередную версию популярного движка для электронной коммерции — Magento 1.7.0.0
###### Основные улучшения по сравнению с предыдущими версиями:
* Оптимизирована слоистая навигация
* Добавлена поддержка CAPTCHA для администратора и пользователей
* Добавлены различные ба... | https://habr.com/ru/post/142764/ | null | ru | null |
# Стиль именования коммитов

Про многие моменты разработки есть очень много информации. Как писать комментарии, как именовать классы, методы, какие паттерны использовать и т.д. и т.п. ... | https://habr.com/ru/post/183646/ | null | ru | null |
# Аккорды с применением высоких технологий
Задача заверстать аппликатуру весьма не тривиальна и от того довольно интересна. Я тоже не устоял перед искушением решить её так как считаю правильным.
Помимо стандартных требований типа кроссбраузерности, масштабираемости, печатаемости и компактности, хотелось бы добиться... | https://habr.com/ru/post/94139/ | null | ru | null |
# Голосования и информационная безопасность
В этом посте я изложу свои мысли о голосованиях с точки зрения информационной безопасности… В первую очередь топик направлен на IT специалистов, которым хочется иметь стройную, понятную им, картину того, что такое честное голосование. Описанное применимо к выборам модератора... | https://habr.com/ru/post/214023/ | null | ru | null |
# Нативный Masonry Layout в CSS Grid Level 3
*Приветствую. Представляю вашему вниманию перевод статьи*[*«Native CSS Masonry Layout In CSS Grid»*](https://www.smashingmagazine.com/native-css-masonry-layout-css-grid/)*, опубликованной 2 ноября 2020 года автором Rachel Andrew*
Недавно был опубликован черновик спецификац... | https://habr.com/ru/post/526008/ | null | ru | null |
# Введение в написание тестов и знакомство с xUnit
Идея статьи возникла после нескольких лекций о том, как писать тесты и как использовать [xUnit](https://xunit.github.io/). Обо всём можно по отдельности почитать подробно. Здесь же я собрал общую информацию о том, как удачно на практике всё это применяется и сопроводи... | https://habr.com/ru/post/357648/ | null | ru | null |
# Генератор SQL запросов на PHP
Где-то полтора года назад я начал заниматься web разработкой. Начинал с функционального программирования. Примерно пол года назад я перешел на ООП и стал использовать MVC архитектуру проектирования. Недавно появилась задача оптимизировать работу с базой данных, т. к. вся связь и работа ... | https://habr.com/ru/post/154245/ | null | ru | null |
# Получаем i18n список стран, регионов, населенных пунктов из ВКонтакте
#### Получить базу данных стран, регионов, населенных пунктов с переводом названий и связями бесплатно и без регистрации? Это реально!
При разработке небольшого стартап-проекта с большими амбициями столкнулся с необходимостью в базе данных стран,... | https://habr.com/ru/post/204840/ | null | ru | null |
# Ускоряем сборку веб-приложения с webpack
По мере того как ваше приложение развивается и растёт, увеличивается и время его сборки — от нескольких минут при пересборке в development-режиме до десятков минут при «холодной» production-сборке. Это совершенно неприемлемо. Мы, разработчики, не любим переключать контекст в ... | https://habr.com/ru/post/451146/ | null | ru | null |
# (Архив) Matreshka.js 1.1: еще больше крутостей
[](http://matreshka.io)
* [Matreshka.js: От простого к простому](http://habrahabr.ru/company/matreshka/blog/254889/)
* [10 причин попробовать Матрешку](... | https://habr.com/ru/post/267483/ | null | ru | null |
# Bender: идейный борец за минимальность CSS / Javascript
Не так давно на Хабре уже была статья про комбинатор CSS / Javascript файлов: [плагин для Smarty — Combine](http://habrahabr.ru/post/193398/). Дело это полезное, поскольку позволяет ускорить загрузку страниц и снизить нагрузку на сервер. Тогда появилась идея со... | https://habr.com/ru/post/199512/ | null | ru | null |
# Мониторинг IP в блэклистах с помощью Zabbix
#### Немного теории
Публичные спам-базы или «черные списки» IP адресов содержат информацию об IP, которые по каким-либо причинам были признаны недружественными по отношению к пользователям. Не будем углубляться в технологические тонкости; важно, что почтовые программы и с... | https://habr.com/ru/post/267189/ | null | ru | null |
# Сборка XGBoost для Python под Windows
*Windows is so evil that consumes extra energy to make the things running.*

Библиотека [XGBoost](https://github.com/dmlc/xgboost) гремит на всех соревнованиях по машинному обучени... | https://habr.com/ru/post/273363/ | null | ru | null |
# Обработка POST запросов AngularJs в Symfony2
**Примечание***Давненько уже читал [пост](http://habrahabr.ru/post/181009/) на хабре, о сабже в контексте php, и все руки не доходили на Symfony2 привести это в какой-то красивый в... | https://habr.com/ru/post/235081/ | null | ru | null |
# Как сверстать веб-страницу. Часть 1
Уважаемый читатель, этой статьей я открываю цикл статей, посвященных вёрстке.
В первой части будет описано, как это сделать с помощью стандартных средств на чистом HTML и CSS. В последующих частях рассмотрим как сделать тоже самое, но с помощью современных фреймворков и CMS.
... | https://habr.com/ru/post/202408/ | null | ru | null |
# Собственное корпоративное облако ownCloud с NGINX во frontend и несколькими серверами backend
#### **1. Схема**
Имеем:
* Frontend — NGINX проксирующий сервер для принятия и распределения нагрузки (IP — 1.2.3.4 — внешний, IP — 192.168.5.10 — внутренний DMZ) *по хорошему он тоже должен стоять за firewall-ом, но ту... | https://habr.com/ru/post/209432/ | null | ru | null |
# Laravel. Установка, настройка, создание и деплой приложения
Итак, у вас есть желание попробовать или узнать о фреймворке [Laravel](http://laravel.com/).
Если вы хорошо знакомы с другими `PHP` фреймворками — для вас это не составит особого труда, если же нет — это отличный выбор для первого фреймворка.
Какой есть общий недостаток у мобильной, front-end и back-end разработки и иногда распила микросервисов? Дублирование л... | https://habr.com/ru/post/682160/ | null | ru | null |
# Как переехать с GKE на Deckhouse, чтобы разработчики этого даже не заметили. Кейс robota.ua
[Robota.ua](http://Robota.ua) — сервис для поиска вакансий и сотрудников в Украине. Включает в себя веб-сайт со средней посещаемостью [7 млн визитов в месяц](https://www.similarweb.com/site/rabota.ua/#traffic) и приложения дл... | https://habr.com/ru/post/598399/ | null | ru | null |
# Возможно, первая игра на Dart + Box2D
На Хабре не слишком много статей, посвященных языку программирования Dart, зато полным полно статей о недоделанных или с трудом доделанных играх, а также о том, как из первых сделать вторые. Данная статья будет смесью этих двух тем.
Дело обстояло так: мы с моим старым другом ... | https://habr.com/ru/post/247809/ | null | ru | null |
# Фотографируем объекты в C#: хроника и сопоставление снимков, реконструкция состояния по снимку
При разработке приложений часто встречается следующий сценарий: имеется некоторый набор данных доступных для просмотра и редактирования, например, это могут быть бизнес-сущности или настройки приложения. В момент, когда по... | https://habr.com/ru/post/333846/ | null | ru | null |
# Как обрабатывать состояния загрузки и ошибки с помощью StateNotifier и AsyncValue во Flutter
Состояния загрузки и ошибки очень часто встречаются в приложениях, работающих асинхронно.
Если мы не отобразим п... | https://habr.com/ru/post/599991/ | null | ru | null |
# Математика машинного обучения, основанного на теории решеток
Это третья статья серии работ (ссылки на [первую](https://habr.com/en/post/509338/) и [вторую](https://habr.com/en/post/510010/) работы), описывающих систему машинного обучения, основанного на теории решеток, озаглавленную "ВКФ-система". Она использует стр... | https://habr.com/ru/post/510580/ | null | ru | null |
# Обзор исходного кода Quake 2
Около месяца свободного времени я уделил чтению исходного кода Quake II. Это был удивительный и поучительный опыт, потому что в движок idTech3 внесено большое изменение: Quake 1, Quake World и QuakeGL объединены в одну к... | https://habr.com/ru/post/328128/ | null | ru | null |
# ООП в картинках
ООП (Объектно-Ориентированное Программирование) стало неотъемлемой частью разработки многих современных проектов, но, не смотря на популярность, эта парадигма является далеко не единственной. Если вы уже умеете работать с другими парадигмами и хотели бы ознакомиться с оккультизмом ООП, то впереди вас... | https://habr.com/ru/post/463125/ | null | ru | null |
# В чем сущность дизайна? Нахожу ответ на вопрос рассматривая UI и UX, новые термины в области веб-дизайна
Давно размышляю о существе дизайна. И постепенно на протяжении продолжительного времени у меня сформировалось мнение, которое позже при изучении материалов для написания статьи получило подтверждение со стороны с... | https://habr.com/ru/post/331136/ | null | ru | null |
# Тематическое моделирование репозиториев на GitHub

[Тематическое моделирование](https://ru.wikipedia.org/wiki/%D0%A2%D0%B5%D0%BC%D0%B0%D1%82%D0%B8%D1%87%D0%B5%D1%81%D0%BA%D0%BE%D0%B5_%D0%BC%D0%B... | https://habr.com/ru/post/312596/ | null | ru | null |
# Автоматизация по методологии BDD. Наш опыт успешного внедрения
*Статья публикуется от имени Трубанова Вадима,* [@vonaburt](https://habrahabr.ru/users/vonaburt/)
Методология BDD все чаще завоевывает внимание IT-индустрии как логически верная ступень развития традиционных подходов к тестированию проектов, в том чис... | https://habr.com/ru/post/322688/ | null | ru | null |
# Области видимости и замыкания в JavaScript
*Данная публикация представляет собой перевод материала «JavaScript Scope and Closures» под авторством Zell Liew, размещенного [здесь](https://css-tricks.com/javascript-scope-closures/).*
Области видимости и замыкания важны в JavaScript, однако они сбивали меня с толку, ... | https://habr.com/ru/post/338462/ | null | ru | null |
# Основы Linux от основателя Gentoo. Часть 2 (4/5): Обработка текста и перенаправления
В этом отрывке вы узнаете про множество интересных и полезных команд по работе с текстовыми данными в Linux. Также даны основы работы с потоками ввода-вывода в bash.
>
>
> [
### Новая игрушка
Мы продолжаем знакомиться с новым материалом от Apple, представленным на WWDC. На этот раз рассмотрим [MetricKit](https://deve... | https://habr.com/ru/post/468347/ | null | ru | null |
# Просмотр запросов к веб серверу apache в реальном времени
Нагрузка на сервер является важным звеном администрирования веб сервера, отслеживание запросов помогает быстро искать ошибочные запросы и устранять их раньше чем они вернуться к вам со статистикой вебмастера. По умолчанию в конфигурационном файле веб сервера ... | https://habr.com/ru/post/309446/ | null | ru | null |
# Таблица Менделеева на школьной информатике
*(Управляющие карты)
(Посвящается Международному году Периодической таблицы химических элементов)
(Последние дополнения сделаны 8 апреля 2019. Список дополнений сразу под катом)

С развитием веб-технологий в окне браузера появляется всё больше полезных сервисов, приложений, программ и даже игр. Пришло время и для [терминала](http://int... | https://habr.com/ru/post/192242/ | null | ru | null |
# Рецепты по приготовлению офлайн-приложений

Доброго времени суток, друзья!
Представляю вашему вниманию перевод замечательной статьи Джейка Арчибальда «Offline Cookbook», посвященной различным вариантам использования сервис-ворке... | https://habr.com/ru/post/517672/ | null | ru | null |
# Оживляем гексапода. Часть третья
Как показала практика, обилие кода в статье не очень хорошо сказывается на ее читабельности. Но для понимания того, как это все работает стоить иногда напрячь мозги. На что и была нацелена предыдущая публикация. Сегодня я постараюсь завершить цикл статей по программной начинке гексап... | https://habr.com/ru/post/490950/ | null | ru | null |
# Selectors API — IE8b1 и Webkit
IE8b1 представляет поддержку очень интересной спецификации — [Selectors API](http://www.w3.org/TR/selectors-api/). Пока что это W3C working draft, но бьюсь об заклад, что т.к. IE и Webkit уже реализовали спецификацию, Presto и Gecko не заставят себя ждать.
**UPDATE**: разработчики F... | https://habr.com/ru/post/25561/ | null | ru | null |
# Асинхронное программирование в однопоточных средах JavaScript
Асинхронное программирование в однопоточных средах JavaScript
=============================================================
Моя прошлая обучающая статья [Введение в Redux & React-redux](https://habr.com/ru/post/498860/) набрала больше 100к просмотров. Чт... | https://habr.com/ru/post/651037/ | null | ru | null |
# IronPython как движок для макросов в .NET приложениях
Подозреваю, многие из вас задумывались — как можно в .NET приложение добавить поддержку макросов — чтобы можно было расширять возможности программы без ее перекомпиляции и предоставить сторонним разработчикам возможность легко и просто получить доступ к API вашег... | https://habr.com/ru/post/48832/ | null | ru | null |
# ReSharper: Call Hierarchy
В ReSharper 5.0 появилась новая функция Call Hierarchy. В сущности, она представляет собой удобный UI для массовых Find Usages или Go To Declaration.
Первоначально в статье я хотел сделать сравнительный анализ этой фичи в R# и в VS 2010, но в процессе написания обнаружилось, что Call Hie... | https://habr.com/ru/post/83769/ | null | ru | null |
# Vue Storefront: оформление заказа
Пятый и завершающий пост о моём знакомстве с [Vue Storefront](https://www.vuestorefront.io/). IMHO, самым современным с технической точки зрения решением в сфере e-commerce на данный момент. Ссылки на предыдущие посты:
* [Vue Storefront: Второй подход к снаряду](https://habr.com/po... | https://habr.com/ru/post/485956/ | null | ru | null |
# Pintask — программируемый таск-трекер
Салют, Хабр!
По статистике, новый таск-трекер появляется раз в 2 недели. «Но мой умеет варить капучино!» — скажет вам разработчик. — «А другие трекеры делают чай такого же качества, как у проводницы поезда „Москва-Геленджик“, либо заваривают только Копи Лювак». Значит, если б... | https://habr.com/ru/post/218091/ | null | ru | null |
# Splunk 7.0. Что нового?

Месяц назад компания Splunk на своей 8-ой ежегодной конференции [Splunk Conf 2017](http://conf.splunk.com) презентовала выпуск нового мажорного релиза Splunk 7.0. В этой статье мы расскажем об основных нововве... | https://habr.com/ru/post/340120/ | null | ru | null |
# Классические алгоритмы генерации лабиринтов. Часть 1: вступление
**Предисловие
-----------**
На написание статьи меня сподвигло практически полное отсутствие материалов на русском языке про алгоритмы генерации лабиринт... | https://habr.com/ru/post/320140/ | null | ru | null |
# Перелистывающийся баннер с кнопками навигации и прогрессбаром: используем плагин Cycle2 для jQuery
При работе над веб-проектом поступило задание от заказчика сделать особый баннер на главной странице сайта.
Баннер должен удовлетворять таким требованиям:
1. Баннер представляет собой несколько изображений, они а... | https://habr.com/ru/post/269351/ | null | ru | null |
# Простой осциллограф за 1 день
Здрасьте!
Ну нет у меня денег на нормальный осциллограф(и на нормальную камеру). Так что сильно не деритесь.
Но было 500 рублей на экран и простой 8-битный микроконтроллер.
Небольшое описание под катом.
Началось все с того, что на руках у меня появился графический LCD экранч... | https://habr.com/ru/post/165611/ | null | ru | null |
# Домашний веб-сервер на солнечных батареях отработал 15 месяцев: аптайм 95,26%
[](https://habrastorage.org/webt/eh/th/2d/ehth2dv7ykrf9lj6lrozxqzmdei.jpeg)
*Первый прототип солнечного сервера с контроллером заряда. Фото: [solar.low... | https://habr.com/ru/post/486378/ | null | ru | null |
# Возможности dapp, которые делают жизнь проще
В статье представлен (и продемонстрирован в коротких видеороликах) инструментарий, облегчающий разработку и отладку конфигураций с [dapp](https://github.com/flant/werf) — Open Source-утилитой, которую мы ежедневно используем при построении и сопровождении процессов CI/CD.... | https://habr.com/ru/post/354866/ | null | ru | null |
# Кодогенерация в Dart. Часть 2. Аннотации, source_gen и build_runner
В [первой части](https://habr.com/post/445824/) мы выяснили зачем нужна кодогенерация и перечислили необходимые инструменты для кодогенерации в Dart. Во второй части мы узнаем как создавать и использовать аннотации в Dart, а также как использовать [... | https://habr.com/ru/post/446264/ | null | ru | null |
# Шпаргалка по JS-методам для работы с DOM
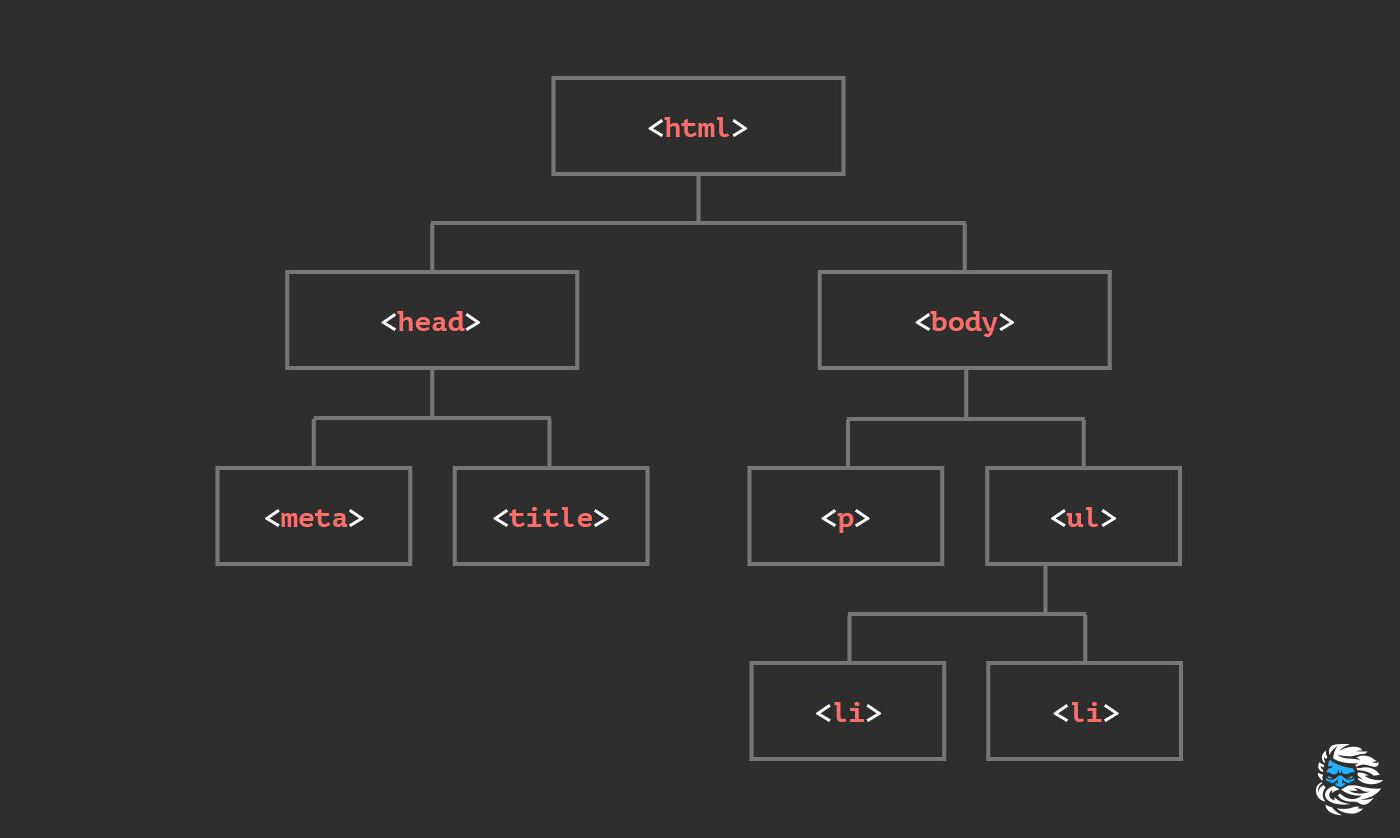
### Основные источники
* [DOM Living Standart](https://dom.spec.whatwg.org/)
* [HTML Living Standart](https://html.spec.whatwg.org/multipage/dom.html)
* [Document Object Model (DOM) Lev... | https://habr.com/ru/post/557422/ | null | ru | null |
# Перевод SDL Game Framework Series. Часть 4 — SDL Tutorial: Tic Tac Toe
В предыдущих уроках мы заложили основу для разработки игры. Мы создали базовый каркас с набором общих процедур, класс для обработки событий, а также класс для работы с поверхностями. В этом уроке мы будем использовать наши наработки и создадим пе... | https://habr.com/ru/post/167443/ | null | ru | null |
# Теория управления шаговым двигателем (или как вертеть PTZ камеру)
Настал тот редкий случай, когда в работе программиста микроконтроллеров появилась потребность в математике и даже физике. У меня на работе была интересная задача по теме разработки тяжелой (70кг) PTZ камеры.
*Истерический, негативно-позитивный пост добра и ненависти, обо всем и ни о чем, из которого вы узнаете: как папа Крузо встретил маму Робинзона, почему трава зеленая а ... | https://habr.com/ru/post/707982/ | null | ru | null |
# Двусторонний binding данных с ECMAScript-2015 без Proxy
Привет, уважаемые читатели Хабра. Эта статья некое противопоставление недавно прочитанной мной статье [«Односторонний binding данных с ECMAScript-2015 Proxy»](https://habrahabr.ru/company/rtl-service/blog/309978/). Если вам интересно узнать, как же сделать двус... | https://habr.com/ru/post/315410/ | null | ru | null |
# Инкрементальный бэкап VDS с сайтом на 1С-Битрикс в Яндекс.Облако
Мне было необходимо делать 2 раза в сутки бэкап сайта на «1С-Битрикс: Управление сайтом» (файлов и базы mysql) и хранить историю изменений за 90 дней.
Сайт расположен на VDS под управлением ОС CentOS 7 с установленным «1С-Битрикс: Веб-окружение». До... | https://habr.com/ru/post/515872/ | null | ru | null |
# Node.js vs Java + Rhino + Jetty + FreeMarker

Хоть Node.js и обзавелся с момента своего появления [множеством модулей](https://github.com/joyent/node/wiki/modules), он все еще существенно уступает по возможностям [мощн... | https://habr.com/ru/post/183334/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.