
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Docker Swarm+Consul+Gobetween в виде движка для гео распределенного кластера
Преамбула
---------
Некоторе время назад перед нами стала задача спроектировать и развернуть систему для потокового видео. Суть была в массовом запуске/остановке инстанций, на которых происходит обратная сборка потокового видео и стриминг ... | https://habr.com/ru/post/308182/ | null | ru | null |
# MAC OS X Leopard и ASUS Eee PC 1000H

#### **Не без шаманства**
Прежде чем установить на ASUS Eee PC 1000(H) — MAC OS X Leopard, необходимо прошить его BIOS модифицированной версией прошивки, на да... | https://habr.com/ru/post/41243/ | null | ru | null |
# Firefox будет отображать переводы строк (LF) во всплывающих подсказках (атрибутах title)
Как известно, спецификация HTML 4.01 чёрным по белому [требует](http://www.w3.org/TR/html4/types.html#h-6.2) того, чт... | https://habr.com/ru/post/137232/ | null | ru | null |
# Баг в ESP-IDF: MDNS, Wireshark и при чём тут единороги
Всем привет. Я занимаюсь коммерческой разработкой в IoT, в основном мы используем модули от Espressif - ESP8266 и ESP32.
В рамках "[догфудинга](https://en.wikipedia.org/wiki/Eating_your_own_dog_food)" мы иногда берём свои продукты домой и используем в повседне... | https://habr.com/ru/post/530466/ | null | ru | null |
# Деплой Docker Image на Dokku с помощью Ansible

Пролог
------
Недавно я узнал о "карманном" PaaS похожем на Heroku с довольно очевидным названием — Dokku. Очень привлекла возможность простого добавления сертификата к приложен... | https://habr.com/ru/post/504236/ | null | ru | null |
# PHP 8.1: до и после
[PHP 8.1](https://wiki.php.net/todo/php81) выйдет через несколько месяцев и я в восторге от множества нововведений! Хочу поделиться реальным влиянием PHP 8.1 на мой собственный код.
### Перечисления
Долгожданный функционал, перечисления скоро будут доступны!
О них можно сказать не так много, к... | https://habr.com/ru/post/569652/ | null | ru | null |
# Как не проиграть с производительностью в длительном скроллинге
### Привет, хабр!
Меня зовут Михаил Кириченко. Я разрабатываю клиентскую часть в компании Bimeister.
В этой статье хочу поделиться своим оп... | https://habr.com/ru/post/686096/ | null | ru | null |
# Матчинг шаблона в Python 3.10
В Python 3.10 имплементирован своего рода оператор `switch` — что-то вроде него. Оператор `switch` в других языках, таких как C или Java, выполняет простой матчинг значения пер... | https://habr.com/ru/post/664662/ | null | ru | null |
# Сaжаем на диету индексы PostgreSQL для Zabbix
 Недавно мы перевели Zabbix на работу с БД PostgreSQL. Вместе с переездом на сервер с SSD это дало существенный прирост скорости работы. Также решили проблему с дублирующими хост... | https://habr.com/ru/post/310462/ | null | ru | null |
# Раз, два, три и готово! 3 месяца, 1 проект и новая команда
Привет, Хабр! Меня зовут Дмитрий Адмакин, руководитель отдела архитектурных решений и перспективной разработки одного из бизнес-центров в компании... | https://habr.com/ru/post/673008/ | null | ru | null |
# Metaobject Protocol для базового Perl 5
Идея создания *Metaobject Protocol* (MOP) для Perl 5 витала достаточно давно. Хорошо известна одна из реализаций — *Class::MOP*, которая используется в *Moose*. Но попасть в базовую поставку Perl 5 может лишь такое решение, которое будет совместимо с существующей объектной мод... | https://habr.com/ru/post/198274/ | null | ru | null |
# Добавляем места на диске для Linux–сервера в облаке Azure Pack Infrastructure, а заодно и разбираемся с LVM
В этой статье будет рассмотрен процесс увеличения места на диске Linux–сервера в облаке [Azure Pack Infrastructure](https://infoboxcloud.ru/services/azurepack/) от [InfoboxCloud](https://infoboxcloud.ru). Это ... | https://habr.com/ru/post/313356/ | null | ru | null |
# Как я изобретал велосипед, или мой первый MEAN-проект

Сегодня, в период стремительного развития веб-технологий, опытному фронтэнд-разработчику нужно всегда оставаться в тренде, каждый день углубляя свои познания. А что де... | https://habr.com/ru/post/307896/ | null | ru | null |
# Зачем нам jQuery?
Здравствуйте, дамы и господа! Вот уже без малого десять лет минуло с первого релиза библиотеки jQuery, и мы решили отряхнуть пыль веков с классики. Подумываем о выпуске третьего издания гусарской баллады об этой библиотеке:

Невозможно, просто взять и вникнуть в этот глубокий смысл, изучая События (event) в просторах базового и, на первый взгляд, бесконечного C#.
Когда я изучал События (не в ра... | https://habr.com/ru/post/213809/ | null | ru | null |
# Mocking RESP API in 20 minutes via Yakbak

Imagine this: you are an ordinary frontend developer. When you open your mailbox you found a message — tomorrow DevOps team will make an optimization with Kubernetes. You are experienced dev... | https://habr.com/ru/post/700848/ | null | en | null |
# Как работать с иерархической структурой классов
Задача классификации — одна из самых известных в машинном обучении. Очень многие проблемы, решаемые с помощью ML, так или иначе сводятся к классификации — распознавание изображений, например. И все выглядит просто и понятно, когда нам нужно определить объект в один из ... | https://habr.com/ru/post/553618/ | null | ru | null |
# Canon i-SENSYS LBP6020 в CentOS 6 или никогда не пишите в тех. поддержку
Приветствую дорогие хабражители и хабрагости.
После долгого копания по форумам и решения так и не решённой с их помощью проблемы, решил поделиться рецептом.
Заранее приношу извинения за графоманию, конкретика будет, но не сразу.
*Немно... | https://habr.com/ru/post/188212/ | null | ru | null |
# Работа с datetime_select и time_select при использовании опции: minute_step
Хелперы datetime\_select и time\_select используются для генерации блока dropdown-полей выбора даты и времени (или только времени) внутри формы. По умолчанию минуты выводятся от 00 до 59 с шагом 1.
Зачастую такая точность не нужна, а кром... | https://habr.com/ru/post/36718/ | null | ru | null |
# Автоматическая блокировка экрана в MacOSX
Читая данное сообщество как простой ~~смертный~~ незарегестрированный читатель натолкнулся на данную [статью](http://habrahabr.ru/blogs/macosx/63444/), которая меня просто вынудила получить инвайт и зарегиться. В данном топике было предложено очень много вариантов блокировки... | https://habr.com/ru/post/63653/ | null | ru | null |
# Списки с разными типами элементов и разными провайдерами данных
#### Предисловие
Однажды понадобилось мне выводить в одном ListView карточки разных типов, да еще и полученные с сервера по разным API. Мол, пусть пользователь порадуется и в одной ленте новостей увидит:
* карточки видео, с тамнейлами и описаниями;
... | https://habr.com/ru/post/221851/ | null | ru | null |
# arr[-1] или самые редкие конструкции в С
С - это неоднозначный язык. Сам по себе он небольшой, об этом писал Брайан Керниган в своей знаменитой книге "Язык программирования С". Но это не мешает комбинируя базовые возможности языка составлять более комплексные и запутанные конструкции. Иногда они встречаются в кодах ... | https://habr.com/ru/post/652621/ | null | ru | null |
# Widgets. Custom fonts
Столкнулся с ситуацией, когда было необходимо в виджете, на экране андофона, отобразить текст красивым нестандартным шрифтом. С того момента и начался сей пост.
Разработка виджета немного отличается от разработки *activity*, и вот это «немного» иногда ставит палки в колеса. Подробно расписыв... | https://habr.com/ru/post/117672/ | null | ru | null |
# Кроссплатформенный переключатель прокси-сервера на Python + Qt
Устав искать нормальный портативный инструмент для переключения между моим рабочим прокси-сервером и прямым подключением дома (который, к тому ... | https://habr.com/ru/post/646407/ | null | ru | null |
# Расширяем класс Imagick
Приветствую всех своих первых читателей!
#### Завязка
Написать эту самую первую статью меня толкнул всего один единственный баг в библиотеки Imagick, который отнял у меня некоторое время.
Началось всё с того, что была задача написать некий класс на php для работы с изображениями. Решил... | https://habr.com/ru/post/138179/ | null | ru | null |
# Kubernetes в ДомКлик: как спать спокойно, управляя кластером на 1000 микросервисов
Меня зовут Виктор Ягофаров, и я занимаюсь развитием Kubernetes-платформы в компании ДомКлик в должности технического руководителя разработки в команде Ops (эксплуатация). Я хотел бы рассказать об устройстве наших процессов Dev <-> Ops... | https://habr.com/ru/post/501122/ | null | ru | null |
# Разрешаем доступ к веб-серверу только через CloudFlare (iptables)

Cloudflare — отличная штука для защиты сайтов от разных компьютерных жуликов — хацкеров. Однако, если они всё же узнали как-то оригинальный IP веб-сервера, на котор... | https://habr.com/ru/post/414837/ | null | ru | null |
# CSS разработчики — почему они нужны миру?
*[Аудио версия на русском (яндекс.музыка)](https://music.yandex.ru/album/10034426/track/63612500?lang=en) / [iTunes](https://podcasts.apple.com/us/podcast/5-css-%D1%80%D0%B0%D0%B7%D1%80%D0%B0%D0%B1%D0%BE%D1%82%D1%87%D0%B8%D0%BA%D0%B8-%D0%BF%D0%BE%D1%87%D0%B5%D0%BC%D1%83-%D0%... | https://habr.com/ru/post/492822/ | null | ru | null |
# STM32F4: GNU AS: Мигаем светодиодом (Оживление) (Часть 2)
Это вторая публикация на тему программирования микроконтроллеров STM32 на языке ассемблера, первая часть находится [Здесь](http://habrahabr.ru/post/274541/).
Если у вас возникли вопросы или пожелания, но вы не можете здесь писать то переходите в VK: [vk.co... | https://habr.com/ru/post/274579/ | null | ru | null |
# Балльно-рейтинговая технология оценки знаний
Приветствую всех и каждого в отдельности кто читает данную статью так как речь в ней пойдет о том, что в той или иной мере касается каждого из нас — об ... | https://habr.com/ru/post/130572/ | null | ru | null |
# Захват видео с сетевых камер, часть 1
 Сетевые видеокамеры постепенно вытесняют аналоговые, хоть и стоят они сейчас гораздо дороже. Сетевые обладают рядом очевидных приемуществ:
* нет необходимости в отдельном регистраторе или п... | https://habr.com/ru/post/115808/ | null | ru | null |
# Проброс нескольких одинаковых устройств USB в виртуальную машину libvirt+QEMU
### Конфигурация.
Сервер виртуальных машин на GNU/Linux. Виртуальные машины Windows. Гипервизор QEMU-KVM.
Виртуальные машины запускаются автоматически.
### Описание проблемы.
Для двух программ есть два электронных (лицензионных) кл... | https://habr.com/ru/post/259401/ | null | ru | null |
# Краткий обзор NLP библиотеки SpaСy
Обработка естественного языка(Natural Language Processing — NLP) сегодня становится очень востребованной, так как людям несомненно проще общаться с машинами также, как они общаются с людьми.
Привет, Хабр! Недавно в нашем корпоративном блоге мы рассказали о выходе [**новой версии**](https://habr.com/ru/compan... | https://habr.com/ru/post/575336/ | null | ru | null |
# Практическое знакомство с пакетным менеджером для Kubernetes — Helm

Статья является логическим продолжение нашей [недавней публикации](https://habr.com/company/flant/blog/417079/) об истории пакетного менеджера для Kubernetes — [*... | https://habr.com/ru/post/420437/ | null | ru | null |
# Podget + rsync + BashPod + GUI = KBashPod для подкастофилов
#### Вступление
В прошлой серии мы Вам рассказали о том, как собирались [“убивать” FineReader](http://habrahabr.ru/blogs/linux/109052/#habracut). Однако это было далеко не первое начинание нашего дуэта. В этот раз центром нашего повествования станет програ... | https://habr.com/ru/post/109296/ | null | ru | null |
# Подводные камни Terraform
[](https://habr.com/ru/company/piter/blog/496820/)
Выделим несколько подводных камней, включая те, что связаны с циклами, выражениями if и методиками развертывания, а также с более общими проблемами... | https://habr.com/ru/post/496820/ | null | ru | null |
# RPM-репозиторий — своими руками
Итак, начнём.
При внедрении DevOps-процесса в компании одним из возможных вариантов хранилища артефактов сборки может стать rpm-репозиторий. По существу — это просто веб-сервер, раздающий определённым образом организованное содержимое. Есть, конечно, коммерческие варианты maven-репо... | https://habr.com/ru/post/337736/ | null | ru | null |
# DIY Электрическая система переключения скоростей для шоссейного велосипеда
При езде на шоссейном велосипеде особенно важно минимизировать изменения в необходимом усилии и скорости вращения педалей, для этого в зависимости от рельефа необходимо часто переключать скорости велосипеда. На бюджетных шоссейных велосипедах... | https://habr.com/ru/post/517236/ | null | ru | null |
# Мониторинг приложений с помощью Pinba
 Привет, Хабр! Мы в Badoo стараемся активно участвовать в жизни IT-сообщества: используем многие open-source-технологии и инструменты, а также делимся своими разработками.
Один из... | https://habr.com/ru/post/319934/ | null | ru | null |
# Нулевой год в БД Oracle
На третьем курсе в СПБПУ Петра Великого у меня был экзамен по SQL в БД Oracle. Экзамен состоял из трех задач. Этот экзамен был одним из самых сложных за все четыре года обучения в университете. Дается три задачи на несколько часов. Если решил все три задачи, то получаешь оценку 5, один недоче... | https://habr.com/ru/post/589733/ | null | ru | null |
# C#. Создаем приложение, требующие повышения прав выполнения через UAC
Недавно столкнулся с необходимостью создания приложения, требующего повышения привилегий для запуска в Windows 7. Оказалось, создать такое приложение совсем несложно. Сейчас на практическом примере мы рассмотрим, как это можно сделать.
**Настро... | https://habr.com/ru/post/82609/ | null | ru | null |
# Мошенничество в системах Телебанк и Альфа-Клик
Уже порядка 2 месяца клиенты онлайн-систем Телебанк (банк ВТБ24) и Альфа-Клик (Альфа-банк) рискуют стать (и становятся) жертвами мошенничества. Мы, к сожалению, таковыми стали.
Если кратко, то вирус (или троян, не знаю) изменяет файл hosts, добавляя в него такие стро... | https://habr.com/ru/post/108720/ | null | ru | null |
# Брокер сообщений NATS: как мы решали проблему скоростной и стабильной доставки сообщений
Всем привет. Меня зовут Женя, я работаю, как это сейчас модно говорить, DevOps-инженером в компании Garage Eight.
В... | https://habr.com/ru/post/708250/ | null | ru | null |
# Скроллер для видео и понимание представления времени в Objective-C

Здраствуй, Хабражитель!
В этой статье я хочу поделиться своим опытом работы с видео в одном из своих последних проектов для iOS. Не б... | https://habr.com/ru/post/204440/ | null | ru | null |
# Как рассуждать, чтобы проходить Capture The Flag игры
Capture The Flag - название ряда соревнований в информатике, чаще всего - в информационной безопасности. Как веб-разработчик, я интересуюсь только CTF в области web'а - поиск уязвимостей, атаки, сетевое взаимодействие. На старте решения первого CTF было трудно по... | https://habr.com/ru/post/682986/ | null | ru | null |
# Flutter. Keys! Для чего они?

Параметр `key` можно найти практически в каждом конструкторе виджета, но используют этот параметр при разработке достаточно редко. `Keys` сохраняют состояние при перемещении виджетов в дереве виджетов.... | https://habr.com/ru/post/446050/ | null | ru | null |
# MongoDB и MySQL в Ruby и PHP
Некоторое время назад довольно заинтересовался разработкой для [MongoDB](http://www.mongodb.org) и провел некоторые бенчмарки в сравнении с MySQL.
Изначально только в Rub... | https://habr.com/ru/post/74683/ | null | ru | null |
# Разработка телеграм-бота на Kotlin + Spring Boot
Привет, читателям Хабра!
В этой статье я расскажу о том, как быстро и легко разработать свой собственный телеграм-бот на языке Kotlin с использованием Spring Boot.
Основная задумка заключается в том, чтобы архитектура Бота была абстрагирована от бизнес процессов. Т... | https://habr.com/ru/post/588474/ | null | ru | null |
# How to push parameters into methods without parameters in safe code
Hello. This time we continue to laugh at the normal method call. I propose to get acquainted with the method call with parameters without passing parameters. We will also try to convert the reference type to a number — its address, without using poi... | https://habr.com/ru/post/447254/ | null | en | null |
# Информационные сообщения в 1С. Как это можно сделать

Здравствуйте.
Сегодня речь пойдет о реализации подсистемы выдачи информационных сообщений пользователю. Стандартный способ проинформировать о чем-либо пользователя ... | https://habr.com/ru/post/278521/ | null | ru | null |
# Тюнинг производительности для ASP.NET. Часть 1
[](http://www.gotdotnet.ru/upload/blog/jeje/ef7/Untitled-1_2.png)В первой части уловок с производительностью для ASP.NET и IIS7 мы рассмотрим некоторые простые, но тем не менее ... | https://habr.com/ru/post/99296/ | null | ru | null |
# Разбор настройки ELK 7.5 для анализа логов Mikrotik
Давно была мысль посмотреть, что можно делать с ELK и подручными источниками логов и статистики. На страницах хабра планирую показать практический пример, как с помощью домашнего мини-сервера можно сделать, например, honeypot с системой анализа логов на основе ELK ... | https://habr.com/ru/post/481596/ | null | ru | null |
# Selenium: работаем с элементами страницы, используя @FindBy и PageFactory
В этой статье будет рассмотрена возможность использования аннотации @FindBy для поиска элементов на странице, а так же создание своих классов для работы с элементами и контейнерами вроде форм, таблиц и т.д.
#### Введение в @FindBy
Для нача... | https://habr.com/ru/post/134462/ | null | ru | null |
# demiurGo.cms Вступление
История создания.
=================
*«Делайте сегодня то, о чем другие завтра только подумают…»
Сократ.*
В 2005 году работая верстальщиком в одной web студии я впервые столкнулся с понятием CMS, первой же системой с которой я познакомился, была NetCat, а точнее все что от нее осталось ... | https://habr.com/ru/post/56271/ | null | ru | null |
# Все начинается с анонса на Хабре
Привет Хабр! Путь многих стартапов от идеи до коммерчески успешных проектов начинается с анонса на Хабре. Для кого-то анонс является [хорошим подспорьем](http://habrahabr.ru/company/lingualeo/blog/89288/) для быстрого роста, [для других](http://habrahabr.ru/company/lpcloud/blog/23530... | https://habr.com/ru/post/243127/ | null | ru | null |
# Сервис уведомлений в NextJS или ReactJS-приложении с помощью RxJS
В данной заметке я бы хотел поделиться опытом реализации простого, но достаточно функционального сервиса уведомлений, который можно легко реализовать в своем React (или NextJS, как в моем случае) приложении. Приложение будет написано на TypeScript, ба... | https://habr.com/ru/post/590377/ | null | ru | null |
# Linux: Приучаем Time Machine к домашнему серверу
Поставил себе задачу — бэкапить свой iMac при помощи Time Machine на домашний сервак под Gentoo
emerge net-fs/netatalk
nano /etc/netatalk/netatalk.conf
`Оставляем только нужное
ATALKD_RUN=no
PAPD_RUN=no
CNID_METAD_RUN=yes
AFPD_RUN=yes
TIMELORD_... | https://habr.com/ru/post/59605/ | null | ru | null |
# BI с Redshift от ETL до бордов
Привет, Хабр, я Node.js разработчик, и я хочу поделиться с вами опытом по реализации business intelligence (BI) процесса.
В какой-то момент бизнес вырос до размера, пусть и небольш... | https://habr.com/ru/post/669240/ | null | ru | null |
# Сделайте свое приложение масштабируемым, оптимизировав производительность ORM
***Перевод статьи подготовлен в преддверии старта курса [«Backend-разработчик на PHP»](https://otus.pw/8haY/).***

---
Привет! Я Валерио, разработчик... | https://habr.com/ru/post/521488/ | null | ru | null |
# STM32 и FreeRTOS. 4. Шаг в сторону HAL
> HAL 9000: I'm completely operational, and all my circuits are functioning perfectly.
*или это должно быть первой статьей, но я почему-то всегда пишу подобное ближе к концу*
Раньше было [про потоки](http://habrahabr.ru/post/249273/), [про семафоры](http://habrahabr.ru/po... | https://habr.com/ru/post/249395/ | null | ru | null |
# Почему для нового проекта я взял Robot Framework
Недавно я сменил проект — пришел в новую разработку, где до меня не было никакого тестирования, ни ручного, ни автоматического. Условий на инструментарий (за исключением того, что это Python) заказчик не накладывал, так что я сделал собственный выбор. В этой статье я ... | https://habr.com/ru/post/470924/ | null | ru | null |
# Честный MVC на React + Redux
[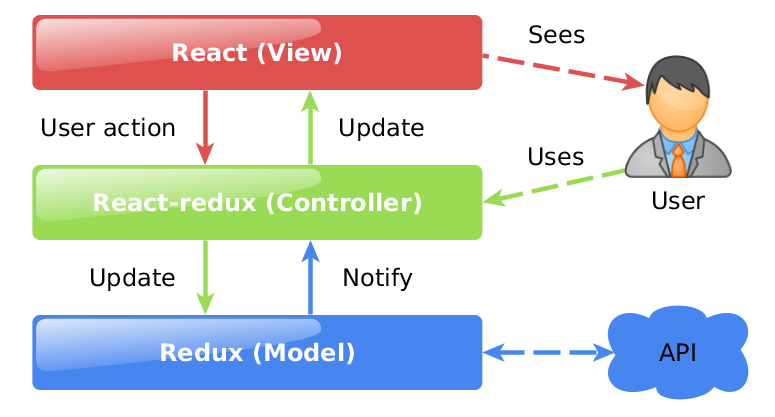](https://habrahabr.ru/company/devexpress/blog/305812/)
Эта статья о том, как построить архитектуру web-приложения в соответствии с принципами MVC на основе [React](https://github.com/faceboo... | https://habr.com/ru/post/305812/ | null | ru | null |
# Чини свою Теслу сам, тыжпрограммист
Тыжпрограммист, честь тебе и хвала. Возможно, твоя юность прошла в растянутом шерстяном свитере, но сейчас ты гордо смеешься в лицо любому приколу об айтишниках. Возможно, прошло время ремонта авт... | https://habr.com/ru/post/551534/ | null | ru | null |
# Амнезия FreeBSD
Я никогда не понимал как работает распределение памяти во FreeBSD. Из всего многообразия документации полезное помнилось, лишь
> An urban myth has circulated for years that Linux did a better job avoiding swapouts than FreeBSD, but this in fact is not true. What was actually occurring was that Fre... | https://habr.com/ru/post/275917/ | null | ru | null |
# Petya и другие. ESET раскрывает детали кибератак на корпоративные сети
Эпидемия шифратора Petya в центре внимания. Проблема в том, что это лишь последний инцидент в серии атак на украинские компании. Отчет ESET раскрывает некоторые возможности Diskcoder.C (он же ExPetr, PetrWrap, Petya или NotPetya) и включает инфор... | https://habr.com/ru/post/332058/ | null | ru | null |
# The Best Golang framework: no framework?
Best Framework?Вольный перевод статьи на ресурсе [threedots.tech](https://threedots.tech/post/best-go-framework/) от Robert Laszcza... | https://habr.com/ru/post/705078/ | null | ru | null |
# Язык Bosque — новый язык программирования от Microsoft
Буквально несколько дней назад компания Microsoft представила публике новый язык программирования. Языку дали название Bosque. Главная миссия дизайна языка — ~~лучше быть богатым и здоровым, чем бедным и больным~~ чтобы он был прост и понятен как для человека, т... | https://habr.com/ru/post/448814/ | null | ru | null |
# Собираем XGBoost под OS X
[XGBoost](https://github.com/dmlc/xgboost) — С++ библиотека, реализующая методы градиентного бустинга, которую все чаще можно встретить в описаниях алгоритмов-победителей на Kaggle. Для использования из R или Python есть соответствующие обвязки, но саму библиотеку необходимо собрать из исхо... | https://habr.com/ru/post/277189/ | null | ru | null |
# Приложение в честь Дня святого Валентина на libgdx
Периодически появляются топики, посвященные дню Валентина. В этом году я тоже решился включиться в эту тему и сделать что-нибудь оригинальное и необычное. Было решено создать простенькое приложение под Android с сердечками, которые бы имели свои физические модели и ... | https://habr.com/ru/post/137861/ | null | ru | null |
# Книга «C# 9 и .NET 5. Разработка и оптимизация»
[](https://habr.com/ru/company/piter/blog/585370/) Привет, Хаброжители! В этой книге опытный преподаватель Марк Прайс дает все необходимое для разработки приложений на C#. В пятом... | https://habr.com/ru/post/585370/ | null | ru | null |
# Методика формирования измерения с атрибутами типа 1 и 2
Мы работаем над DWH в телекоммуникациях, поэтому пример, который я рассматриваю, называется «Абонент». Принцип универсален и это мог быть «Клиент» или «Пациент» — в зависимости от отрасли. Я надеюсь методику найдут полезной разработчики DWH из разных отраслей. ... | https://habr.com/ru/post/195838/ | null | ru | null |
# Использование V8, часть 3
Использование V8, часть 3
Часть 3. Многопоточность, расширения и оформление кода
Часть 2 находится здесь: [habrahabr.ru/blogs/development/72592](http://habrahabr.ru/blogs/development/72592/)
Часть 1 находится здесь: [habrahabr.ru/blogs/development/72474](http://habrahabr.ru/blogs/d... | https://habr.com/ru/post/72765/ | null | ru | null |
# Реализация списка использованных библиотек в Android приложении. Попытка №2
Совсем недавно наткнулся на [статью](http://habrahabr.ru/post/274859/) на Хабре о том, как реализовать диалоговое окно со списком использованных библиотек. Мне предложенный вариант показался слишком сложным, да и сам список смотрелся криво. ... | https://habr.com/ru/post/275097/ | null | ru | null |
# Корректный ASP.NET Core
[](https://habr.com/ru/post/437002/)
Специально для любителей книг из серии "С++ за 24 часа" решил написать статью про ASP.NET Core.
Если вы раньше не разрабатывали под .NET или под ... | https://habr.com/ru/post/437002/ | null | ru | null |
# Решаем Project Euler на F#: Задача 1
Прочитав первые несколько статей из цикла [Влюбляемся в F#](http://habrahabr.ru/blogs/starting_programming/51607/), я и в самом деле, если не влюбился в него, то по меньшей мере заинтересовался. Настолько, что не вытерпел ожидания следующей дозы и решил продолжить изучение самост... | https://habr.com/ru/post/52150/ | null | ru | null |
# Нативный segue слева направо в iOS
Предупреждаю сразу, это трюк. Он подойдёт далеко не всем и не всегда, но если вам нужно вывести окно с какой-то информацией слева от основного — то мой способ будет в самый раз.
Вполне возможно, что он всем уже известен, и я изобрёл велосипед, но я изобрёл его самостоятельно, по... | https://habr.com/ru/post/239093/ | null | ru | null |
# Иерархические (рекурсивные) запросы
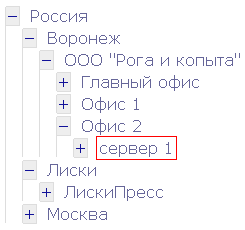
Чтобы понять рекурсию, сначала надо понять рекурсию. Возможно, поэтому рекурсивные запросы применяют так редко. Наверняка вы представляете что такое SQ... | https://habr.com/ru/post/43955/ | null | ru | null |
# CsConsoleFormat: форматирование в консоли по-новому (.NET)
 Всем хорошо известны богатые средства форматирования в консоли: выравнивание пробелами, изменение текущего цвета текста и фона. Если вы хотите выв... | https://habr.com/ru/post/271299/ | null | ru | null |
# Детекторы и дескрипторы особых точек FAST, BRIEF, ORB
В этой статье речь пойдёт о некоторых алгоритмах поиска и описания особых точек изображений. Здесь эта тема уже [поднималась](https://habr.com/post/244541/), и [не раз](https://habr.com/post/106302/). Буду считать, что основные определения читателю уже знакомы, р... | https://habr.com/ru/post/414459/ | null | ru | null |
# Вычислительная геология и визуализация: пример Python 3 Jupyter Notebook
Сегодня вместо обсуждения геологических моделей мы посмотрим пример их программирования в среде Jupyter Notebook на языке Python 3 и с библиотеками Pandas, NumPy, SciPy, XArray, Dask Distributed, Numba, VTK, PyVista, Matplotlib. Это довольно пр... | https://habr.com/ru/post/546800/ | null | ru | null |
# Запуск двух и более инстансов MySQL на одном Linux-сервере
Хочу поделиться еще одним способом решения такой проблемы, как запуск более одного mysql-server на одном linux-сервере. Я думаю, что некоторые из вас уже пробовали это делать, запуская руками, например, вот так:
```
mysqld_safe --defaults-file=...my2.cnf... | https://habr.com/ru/post/250929/ | null | ru | null |
# Планирование потоков в Windows. Часть 1 из 4
Ниже представлена не простая расшифровка доклада с [семинара CLRium](https://clrium.ru/), а переработанная версия для книги [.NET Platform Architecture](https://github.com/sidristij/dotnetbook). Той её части, что относится к потокам.
Потоки и планирование потоков
-------... | https://habr.com/ru/post/488260/ | null | ru | null |
# 20 ноября — запуск первой стратегической MMO-игры для… программистов
В следующий четверг состоится запуск проекта, над которым мы работали последние несколько месяцев. [Screeps](http://www.screeps.com) — первая известная мне стратегическая игра в MMO-песочнице, созданная **для программистов**. Вместо традиционного P... | https://habr.com/ru/post/242963/ | null | ru | null |
# Как мы доработали чат-бота «Дану» и сделали её проницательнее и сообразительнее
Привет! Меня зовут Даир, я Data Scientist. Эту статью мы писали вместе с Санжаром, моим коллегой, который тоже занимался проектом. Мы расскажем, как научили понимать любые клиентские запросы уже разработанным ранее в Beeline чат-бота.
Ф... | https://habr.com/ru/post/691996/ | null | ru | null |
# Программирование диммера на радиомодуле nrf24le1 от COOLRF
Продолжаем тему программирования радиомодулей nrf24le1 — на этот раз мы научим диммер от [COOLRF](http://habrahabr.ru/company/coolrf/) работать. После публикации мною [статьи](http://habrahabr.ru/post/210974/) про программирование радиомодулей мне предложили... | https://habr.com/ru/post/230785/ | null | ru | null |
# Минимальное окружение для JS-разработки: ava, standard, chokidar-cli и precommit-hook
Вокруг полно JavaScript-фреймворков, библиотек и разнообразных инструментов. Что выбрать? Глядя на такое разнообразие, разработчику непросто ответить на этот вопрос.
[
Есть много вопросов, решений и заблуждений, как мы можем улучшить производительность нашего Flutter приложения. Необходимо сразу уточнить, что Flutter является производительн... | https://habr.com/ru/post/502882/ | null | ru | null |
# Node.js + Chromium = node-webkit: ещё более перспективный вариант второго шага эволюции веборазработчика
**Предисловие от переводчика.** В постскриптуме к моей [вчерашней блогозаписи](http://habrahabr.ru/post/15... | https://habr.com/ru/post/153095/ | null | ru | null |
# Сборка бинарных файлов Android с помощью исходников и Android NDK. Прокачиваем утилиту screencap
Я занимаюсь автоматизацией Android устройств и часто SDK или ОС Android не имеют нужного функционала или его работа выполняется медленно/очень медленно.
Используя возможности Native Development Kit (NDK) мы можем напи... | https://habr.com/ru/post/456264/ | null | ru | null |
# Осторожно, snap
Из к/ф "Иван Васильевич меняет профессию"Использую KeePassXC уже года три. Жил, работал, радовался и проблем не знал с паролями. Решил, что лучше так, чем забуду или каждый... | https://habr.com/ru/post/559270/ | null | ru | null |
# Blazor: SPA без джаваскрипта для SaaS на практике
 Когда в любой момент времени стало понятно, что такое this... Когда неявное преобразование типов осталось только в былинах аксакалов эпохи зарождения веба.... | https://habr.com/ru/post/586130/ | null | ru | null |
# Работа с большими файлами экселя
Что такое большой файл? Ну так чтобы реально большой? В бытность свою я думал, что это файлик на 50-60 тыс строк записей. И оставался я бы в таком неведении до сих пор, но пришлось выполнять один проект, в котором надо было работать с файлами на 600-800 тыс строк. Хождение по мукам —... | https://habr.com/ru/post/139706/ | null | ru | null |
# Вредные советы для «идеального» REST API
Всем привет!
**Почему 'идеального' написано в кавычках?!**
То, что написано ниже относится к разряду "так делать не надо", однако, если вы считаете иначе — интересно будет услышать ваше мнение на этот счёт )
Наверное, многие из нас делали REST API, либо пользовались чьим-то... | https://habr.com/ru/post/528110/ | null | ru | null |
# Шпоры по сертификатам X.509
> *Чудище обло, озорно, огромно, стозевно и лаяй*.
Набор технологий, который мы по привычке именуем сертификатами SSL, представляет из себя здоровенный айсберг, на вершине которого зеленый замочек слева от доменного имени в адресной строке вашего браузера. Правильное название `X.509 серт... | https://habr.com/ru/post/346798/ | null | ru | null |
# Как мы развернули коммунальный Apache Airflow для 30+ команд и сотни разработчиков
Всем привет!
В этой статье я расскажу, как мы внедряли сервис Apache Airflow для использования различными командами в нашей компании, какие задачи мы хотели решить этим сервисом, опишу архитектуру деплоя и наш IaC (Infrastructure as ... | https://habr.com/ru/post/580944/ | null | ru | null |
# Визуализация данных при помощи Angular и D3
D3.js — это JavaScript библотека для манипулирования документами на основе входных данных. Angular — фреймворк, который может похвастаться высокой производительностью привязки данных.
Ниже я рассмотрю один хороший подход по использованию всей этой мощи. От симуляций D3 ... | https://habr.com/ru/post/414785/ | null | ru | null |
# Как настроить Linux для входа в домен с использованием алгоритмов ГОСТ
Введение
--------

Протокол Kerberos 5 сейчас активно используется для аутентификации. Особенностью данного протокола является то, что он осуществляет аутентиф... | https://habr.com/ru/post/467707/ | null | ru | null |
# Блокчейн на JavaScript
В последнее время криптовалюты и блокчейн-технологии стали невероятно популярными. Сегодня я расскажу о моём подходе к созданию блокчейн-платформы на JavaScript с использованием всего 60 строк кода. Я — начинающий блокчейн-разработчик, поэтому если я в чём-то ошибаюсь — поправьте меня в коммен... | https://habr.com/ru/post/587726/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.