
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Исполняемый обвес. Часть 2
Вторая статья небольшой серии о защите, которая используется для сокрытия алгоритма приложения. В [прошлой статье](https://habr.com/ru/company/otus/blog/545576/) мы разобрали осно... | https://habr.com/ru/post/547372/ | null | ru | null |
# NAT на Cisco. Часть 2
И снова добрый день, коллеги!
Продолжаю серию статей про NAT на Cisco, т.к. предыдущая статья все нашла некоторое количество положительных отзывов.
В этой статье мы рассмотрим, как и было обещано, inside destination NAT. Кому интересно — велкам под кат.
*Прежде чем читать дальше — **ди... | https://habr.com/ru/post/108978/ | null | ru | null |
# Демистификация Join в Apache Spark
> Привет, Хабр. Для будущих студентов курса [**«Экосистема Hadoop, Spark, Hive»**](https://otus.pw/B7hd/) подготовили перевод материала.
>
> Также приглашаем всех желающих на вебинар [**«Тестирование Spark приложений»**](https://otus.pw/dzUC/). На этом открытом уроке рассмотри... | https://habr.com/ru/post/556722/ | null | ru | null |
# OpenLDAP в качестве центра аутентификации для Nextcloud и ProFTPD
Привет, Хабр! На связи Холодаев Алексей, младший системный администратор Cloud4Y. Сегодня хочу поделиться опытом использования OpenLDAP в качестве центра аутентификации для Nextcloud и ProFTPD.
В ходе работы над одним из проектов возникла задача по с... | https://habr.com/ru/post/656651/ | null | ru | null |
# Как в языке сформировать существительное? Сигнал («Видел мамонта»)
Попробуем сформировать описание процесса появления новой звуковой единицы в естественном языке.
Для этого рассмотрим отдельно живущее племя. И построим цепочку ситуаций, которую необходимо совместно пережить нескольким особям этого племени, приводящ... | https://habr.com/ru/post/446834/ | null | ru | null |
# Захват контроллера домена с помощью атаки PetitPotam
В этой статье я расскажу про атаку PetitPotam, которая позволяет при определенных условиях захватить контроллер домена всего за несколько действий. Атака... | https://habr.com/ru/post/581758/ | null | ru | null |
# Кнопка для поворота экрана на X220 tablet
Взамен убитого почти всусмерть X220i купил себе X220 tablet. Замечательная железка — ноутбук с вращающимся экраном, тачскрином и пером (которое понимает «силу нажатия»). Однако, увы, часть хардварных кнопок (в т.ч. на вращающемся экране) не работала.
Одна из них — кнопка ... | https://habr.com/ru/post/105219/ | null | ru | null |
# Windows Forms & Invoke from parallel threads
При переделке старой формы столкнулся с забавной проблемой.
Задача – классическая: вывести пользователю информацию о происходящем в фоне процессе.
Казалось бы, ничего сложного. В основной форме мы стартуем поток, в нем проводим обработку данных, при получении новых ... | https://habr.com/ru/post/242937/ | null | ru | null |
# Паттерны проектирования в JavaScript
Автор материала, перевод которого мы публикуем, говорит, что, начиная проект, к написанию кода приступают не сразу. В первую очередь определяют цель и границы проекта, затем — выявляют те возможности, которыми он должен обладать. Уже после этого либо сразу пишут код, либо, если р... | https://habr.com/ru/post/427293/ | null | ru | null |
# Конвертирование видео в Ogg Theora. UNIX Way
Прежде чем приступить к практике, зададимся некоторыми весьма интересными вопросами: почему консоль, зачем использовать видеокодек Ogg Theora, каким образом и с какими параметрами лучше конвертировать видео.
Начнём с матчасти:
> Видеокодек — это программа/алгоритм с... | https://habr.com/ru/post/91963/ | null | ru | null |
# Как я угнал национальный домен Демократической Республики Конго
*Примечание: проблема решена. Сейчас национальный домен .cd уже не делегирует полномочия скомпрометированному нейм-серверу*
**TL;DR** Представьте, что может произойти, если национальный домен верхнего уровня (ccTLD) суверенного государства попадет в... | https://habr.com/ru/post/544166/ | null | ru | null |
# Руководство по написанию JS скриптов для front-end разработчиков под Drupal 7
Существуют разные способы создания верстки под Drupal. Кто-то верстает уже затемленные страницы, кто-то пытается обойтись стандартными темами, но как правило, сначала верстальщик верстает страницы по дизайну, и на выходе получается набор h... | https://habr.com/ru/post/161039/ | null | ru | null |
# Улучшенное наследование в CoffeeScript
CoffeeScript принёс в JS неплохую абстракцию классов, основанную на прототипах.
Реализовав известную модель наследования и дополнив её наследованием методов касса,
он позволяет легко строить иерархии классов, даже не зная о цепочках прототипов.
Но и эта модель может бы... | https://habr.com/ru/post/190494/ | null | ru | null |
# CoffeeScript: Подробное руководство по циклам

Как известно, *CoffeeScript*предлагает несколько иной набор управляющих конструкций, нежели *JavaScript*.
Не с... | https://habr.com/ru/post/140764/ | null | ru | null |
# Управляя Github-ом: через Terraform к самописному решению на Ansible
У нас 350+ человек и 400+ репозиториев на Github-е. В каждой репе может быть несколько админов, и они творят, что считают нужным, — естественно, случается так, что один человек не знает, что делает другой. Когда нам в инфре надоело смотреть на муче... | https://habr.com/ru/post/516192/ | null | ru | null |
# Математическая модель восприятия (Часть 3)
[Часть 1](https://habrahabr.ru/post/282081/)
[Часть 2](https://habrahabr.ru/post/282327/)
**Предисловие**
История знает примеры, когда открытия давались человечеству волей случая: так оно узнало об обжиге глины, порохе и резине, а вот кремниевый транзистор или поли... | https://habr.com/ru/post/283370/ | null | ru | null |
# Делаем собственную баннерную крутилку
Делаем функционал, который позволит:
1. В одном месте хранить все баннеры
2. Выставлять страницы на которых будет показан баннер
3. Соблюдать лимит показа
4. Указывать для баннера адрес назначения (URL)
Будет точно работать на 0.9.6.3 (на версиях выше ничего не пр... | https://habr.com/ru/post/66277/ | null | ru | null |
# Вышел GitLab 11.0: Auto DevOps и управление лицензиями

Создание качественного ПО — непростой процесс. Во-первых, нужно решать бизнес-проблемы и писать качественный код. Однако, на этом сложности не заканчиваютс... | https://habr.com/ru/post/416557/ | null | ru | null |
# Pineapple Nano своими руками Часть 2. Прошивка устройства
Сборка своего "хакерского чемоданчика", или как я портировал ПО от Pineapple Nano в доработанный роутер MR3020, все подробности в статье. Вперед!
... | https://habr.com/ru/post/652943/ | null | ru | null |
# Запуск WebRTC медиасервера в облаке Amazon EC2 для Live видеотрансляций из браузеров и мобильных приложений

AWS Marketplace
---------------
Прежде всего хотелось бы сказать несколько слов о маркете [Amazon AWS Marketplac... | https://habr.com/ru/post/323376/ | null | ru | null |
# Квантовая механика для всех, даром, и пусть никто не уйдёт обиженным: часть первая
*Здравствуйте! Я хотел бы представить вашему вниманию отличное введение в квантовую механику, написанное Элиезером Юдковским; быть может, он известен вам по своему сайту lesswrong.com, посвящённому рационализму, предрассудкам, когнити... | https://habr.com/ru/post/171489/ | null | ru | null |
# work&dev fun(damentals) #0. Что ожидать и как помогать расти разработчику из trainee в уверенного junior?
> Это цикл статей. [Следующую можно прочесть тут](https://habr.com/ru/post/478210/)
### Что ожидать и как помогать расти разработчику из trainee в уверенного junior?
Уровень разработчика — то чем все привыкли... | https://habr.com/ru/post/477894/ | null | ru | null |
# Дисциплина, Точность, Внимание к деталям
### Введение:
В этой статье речь пойдет о работе с **Microsoft Analysis Services** и немного о хранилище на **Microsoft SQL Server**, с которым SSAS работает. Мне пришлось столкнуться с не совсем тривиальными вещами и порой приходилось “прыгать через голову” ради того, чтобы... | https://habr.com/ru/post/323276/ | null | ru | null |
# Рефакторинг с использованием C++17 std::optional

В разработке существует множество ситуаций, когда вам надо выразить что-то с помощью "`optional`" — объекта, который может содержать какое-либо значение, а может и не содержать. Вы мо... | https://habr.com/ru/post/369811/ | null | ru | null |
# Постраничная навигация на PHP
Часто при разработке и выводе контента появляется необходимость использования постраничной навигации. Кто-то скорее всего использует готовые решения от своего фреймворка. Кто-то, возможно, не заморачивается и лупит страницы просто циклом. У кого-то есть свои наработки в этом направлении... | https://habr.com/ru/post/340246/ | null | ru | null |
# Достоинства и недостатки Xamarin
Привет, Хабр! Сегодня расскажем вам о том, что пользователям нравится в Xamarin, нашем инструменте для кросс-платформенной разработки мобильных приложений. Кроме того, затронем и недостатки платформы. Кстати, под катом вы найдете много кода и показательные примеры, а не только текст ... | https://habr.com/ru/post/415833/ | null | ru | null |
# Будни багхантинга: еще одна уязвимость в Facebook
[](http://habrahabr.ru/company/pt/blog/247709/)
Декабрь для меня получился наиболее удачным за четыре года участия в разнообразных программах bug bounty, и я хотел бы подел... | https://habr.com/ru/post/247709/ | null | ru | null |
# Сохранение исходных пропорций видео

Вы когда-нибудь хотели изменять размеры видео *на лету*, масштабировать его как изображение? Используя внутренние пропорции для видео, можно. Эта техника позволяет бр... | https://habr.com/ru/post/62178/ | null | ru | null |
# Grape: не рельсами едиными

В этом посте я хотел бы познакомить вас с Grape — веб-фреймворком, написанным на ruby, предназначенным для быстрой и удобной разработки API, а также немного порассуждать о судьбе Rails в свете п... | https://habr.com/ru/post/238321/ | null | ru | null |
# Подписание PDF на JS и вставка подписи на C#, используя Крипто ПРО
Итак. Пришла задача. Используя браузер предложить пользователю подписать PDF электронной подписью (далее ЭП). У пользователя должен быть токен, содержащий сертификат, открытый и закрытый ключ. Далее на сервере надо вставить подпись в PDF документ. По... | https://habr.com/ru/post/426087/ | null | ru | null |
# Скрипты в UltraEdit32 v.14

Есть программисты которые пользуются таким инструментом как [UltraEdit32](http://www.ultraedit.com/ "www.ultraedit.com").
Ни в коем случае не реклам... | https://habr.com/ru/post/62392/ | null | ru | null |
# Django: запуск при помощи xinetd
Итак, еще один способ запуска Django. Но зачем? Ведь уже каких только способов запуска нет. Казалось бы на любой вкус. Обоснование и описание — под катом.
### Введение
Задумал я одну задумку. А именно, использовать веб приложения в качестве приложений на своем компьютере. Посколь... | https://habr.com/ru/post/153165/ | null | ru | null |
# System Management Mode: From Zero to Hero
Исследования в области безопасности UEFI BIOS уже не являются чем-то новомодным, но в последнее время чувствуется некоторый дефицит образовательных материалов по этой теме (особенно — на русском языке). В этой статье мы постараемся пройти весь путь от нахождения уязвимости и... | https://habr.com/ru/post/557166/ | null | ru | null |
# Сравнение качества кода Firebird, MySQL и PostgreSQL

Сегодняшняя статья несколько необычна. Как минимум по той причине, что вместо анализа одного проекта, будем искать ошибки сразу в трёх, а также посмот... | https://habr.com/ru/post/343410/ | null | ru | null |
# Телефония для домена

Изучение протокола SIP привело к пониманию того, что он изначально поддерживает работу с доменными именами. В частности, достаточно создать DNS записи типа SRV и NAPTR для указания SIP клиентам где и... | https://habr.com/ru/post/276977/ | null | ru | null |
# Как я написал telegram бота на Rust для отслеживания рейтинга при поступлении в вуз
Привет, меня зовут Илья, я сейчас сдаю вступительные экзамены в магистратуру. Столкнулся при поступлении с проблемой, что результаты экзаменов в рейтинговом списке появляются не сразу, а постоянно его открывать и находить себя на стр... | https://habr.com/ru/post/681648/ | null | ru | null |
# Субпиксельный рендеринг произвольных векторных изображений (Haarmony LCD)
Субпиксельный рендеринг ([вики](https://en.wikipedia.org/wiki/Subpixel_rendering))— способ увеличить видимое разрешение LCD или OLED дисплея путем рендеринга пикселей с учетом свойств экрана. Используется тот факт, что каждый пиксель экрана фа... | https://habr.com/ru/post/474876/ | null | ru | null |
# Страшная сказка на ночь для пользователей Android
Каждый, наверное, сталкивался с сайтами, предлагающими пользователю платную подписку на ту или иную услугу. В силу специфики моей работы мне иногда приходится проверять подобные ресурсы. Чаще всего они наспех набиты контентом, фальшивыми комментариями и созданы специ... | https://habr.com/ru/post/168573/ | null | ru | null |
# Использование геолокационных данных в машинном обучении: основные методы
Геолокац... | https://habr.com/ru/post/554438/ | null | ru | null |
# Улучшаем работу в консоли или как я написал команду sshcdvim
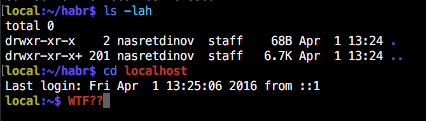Наверняка многие делали так, как на картинке, но вот только у них при этом выдалась ошибка типа «файл не найден». Давайте исправим эту проблему, чтобы при таких оче... | https://habr.com/ru/post/280690/ | null | ru | null |
# ABAP: Красивый #2
**Эта публикация предназначена ABAP-разработчикам в SAP ERP и всем им сочувствующим.**
[Часть1](https://habrahabr.ru/post/275677/)
Не все знают, что в ALV-отчет можно добавить красивый заголовок на HTML.
Результат будет похож на это:

Небольшое резюме: статья про успешное внедрение Zabbix с автоматизацией большинства процессов, не претендует на tutorial, но если нужны будут подробности, то могу предоставить.
Вот уже... | https://habr.com/ru/post/243843/ | null | ru | null |
# Перенос данных из VisionFlow в ServiceNow
Одни из самых интересных задач в работе администратора приложений, на мой взгляд, это осуществление миграции данных при переходе на новую систему. Сегодня я хочу поделится собственным опытом переноса данных с не очень известной helpdesk системы VisionFlow в более известную с... | https://habr.com/ru/post/549400/ | null | ru | null |
# Консоль для маководов: Beyond the GUI
Доброго дня, уважаемые хабравчане-маководы!
Сегодня я расскажу как увеличить эффективность работы в Mac OS X за счёт использования консоли.
Лирическое отступление
===============... | https://habr.com/ru/post/143341/ | null | ru | null |
# Disposable без границ

В своей [предыдущей статье](http://habrahabr.ru/post/270929/) я рассказал, как объект может просто и надежно нести ответственность за свои ресурсы.
Но есть множество вариантов владения, которые н... | https://habr.com/ru/post/272497/ | null | ru | null |
# NeDB: аналог SQLite для NodeJS

NeDB (**N**ode.js **E**mbedded **D**ata**b**ase) — встраиваемая база данных для NodeJS, реализующая подмножество MongoDB API. Эта легкая NoSQL СУБД написана на чистом JavaScript, не имеет би... | https://habr.com/ru/post/301916/ | null | ru | null |
# How-to: Прозрачная NTLM авторизация на корпоративном портале
Привет Хабрасообществу.
Хотел бы посвятить этот топик корпоративному порталу от Bitrix 14 версии, а точнее тому, как его подружить с доменной структурой.

Всё началось с проблемы с которой мы столкнулись в [BitClave](https://bitclave.com): во время подготовки нашего ICO некоторый объем криптовалюты ETH (эфир) был отправлен н... | https://habr.com/ru/post/341518/ | null | ru | null |
# Обучающая игра за неделю или попытка таймкиллера по английскому
Я провел в играх сотни часов по статистике Стима, и тысячи, если считать на всех платформах. Но что меня поразило, так это соотношение времени в некоторых случаях. На прохождение великолепного Bioshock Infinite у меня ушло 8.5 часов, но на Sacura Clicke... | https://habr.com/ru/post/413391/ | null | ru | null |
# Java-дайджест за 4 мая

* Вышла совершенно новая библиотека [Enriched Beans](https://github.com/stCarolas/enriched-beans) — генератор исходников, совместимый с [JSR 330: Dependency Injection for Java](https://jcp.org/en/jsr/detail?id... | https://habr.com/ru/post/500332/ | null | ru | null |
# X-Notifier. Пишем оповещалку для трекера и диалогов на Хабарахабр

Есть хороший плагин для всех популярных браузеров, [X-Notifier](http://xnotifier.tobwithu.com/dp/). Он позволяет получать уведомления о новых пис... | https://habr.com/ru/post/210020/ | null | ru | null |
# Основы Flutter для начинающих (Часть VI)
Когда вы создаете различные формы (например: регистрации или входа) на Flutter, вы не заморачиваетесь с кастомизацией компонентов, потому что вы можете изменить любое поле формы под свой стиль.
Помимо кастомизации, Flutter предоставляет возможность обработки ошибок и валидац... | https://habr.com/ru/post/561174/ | null | ru | null |
# Вдохновение для юнит-тестов
Много слов сказано о достоинствах юнит-тестов (TDD, [BDD](http://www.devclub.eu/2010/10/31/asolntsev-bdd/) — в данном случае неважно), а также о том, почему люди [всё-таки их не используют](http://habrahabr.ru/blogs/tdd/112685/).
Но я думаю, что одна из главных причин заключается в том... | https://habr.com/ru/post/113487/ | null | ru | null |
# Информационная панель распространения Коронавируса COVID-19 (React + Chart.js + BootstrapTable)
Я [выложил в "оупен-сорс"](https://github.com/trekhleb/covid-19) новую [**информационную панель распространения Коронавируса COVID-19**](https://trekhleb.github.io/covid-19/), которая позволяет анализировать динамику (кри... | https://habr.com/ru/post/493832/ | null | ru | null |
# События и потоки. Часть 1
Сразу скажу, что статья не про потоки, а про события в контексте потоков в .NET. Поэтому я не буду пытаться организовать работу потоков правильно (со всеми блокировками, колбэками, отменой и тд). Для правильной организации потоков есть другие статьи.
Все примеры будут написаны на языке C... | https://habr.com/ru/post/321544/ | null | ru | null |
# Ребенок в семье гика или видеоняня своими руками
Постоянно читаю хабр, но из-за январского отпуска мимо меня прошла статья [«Ребенок в семье гика или у нас свой подход»](http://habrahabr.ru/post/137107/). И только сей... | https://habr.com/ru/post/141090/ | null | ru | null |
# Следящий фокус для зеркалки. Raspberry Pi + HC-SR04 + SG90 servo
Данный пост описывает как за один вечер из говна и палок был сделан следящий фокус для зеркали. Видео того что получилось:
<https://youtu.be/zsAiAQ65iUM>
### Предисловие
Малина здесь избыточна, бесспорно. Но если речь идет о более сложном устрой... | https://habr.com/ru/post/410917/ | null | ru | null |
# Улучшаем страницу 404-ой ошибки
Если пользователь попадает на стандартную страницу ошибки 404, велика вероятность того, что он покинет веб-сайт и вряд ли вернется. Кастомная страница 404, полезная и привлекательная, способствует дальнейшему пребываниваю на вашем веб-сайте.

Эта статья представляет собой обучающий материал, который предназначен для начинающих системных администраторов, поэтому опытным специалистам можно смело его п... | https://habr.com/ru/post/674088/ | null | ru | null |
# Почему нужна инструментальная поддержка пагинации на ключах
Всем привет! Я бэкэнд-разработчик, пишу микросервисы на Java + Spring. Работаю в одной из команд разработки внутренних продуктов в компании Тинькофф.

У нас в команде часто... | https://habr.com/ru/post/485036/ | null | ru | null |
# Strict mode in TypeScript: описание флагов, примеры
#### --strict флаг включает следующие флаги (и в какой версии добавлены):
--strictNullChecks (2.0)
--alwaysStrict (2.1)
--noImplicitAny
--noImplicitThis (2.0)
--strictBindCallApply (3.2)
--strictFunctionTypes (2.6)
--strictPropertyInitialization ... | https://habr.com/ru/post/490970/ | null | ru | null |
# Электронная подпись физического лица (часть 2)
В [первой части](http://habrahabr.ru/blogs/e_gov/131367/) мы разобрали, что такое квалифицированная электронная подпись физического лица, как получить ключи для генерирования этой подписи, а также сертификат для ее верификации. В этом топике я предложу инструмент для ге... | https://habr.com/ru/post/131448/ | null | ru | null |
# Новые уязвимости доступа к файлам в PHP
Какой-нибудь год назад все просто с ума сходили от Error-based MySQL, а unserialize казался чем-то сложным и не встречающимся в реальной жизни. Теперь это уже классические техники. Что уж говорить о таких динозаврах как нуль-байт в инклудах, на смену которому пришел file name ... | https://habr.com/ru/post/112691/ | null | ru | null |
# Лямбды в C++. Как это работает
Рассмотрим такой пример кода:
```
void f(int i)
{
auto g = [i](auto j)
{
return i + j;
};
g = [i](auto j)
{
return i - j;
};
g(1);
}
```
При компиляции [возникнет](https://godbolt.org/z/5zjv1djae) ошибка в строке `g = [i](auto j)`.
По... | https://habr.com/ru/post/691028/ | null | ru | null |
# Разработка более быстрых приложений на Vue.js
JavaScript — это душа современных веб-приложений. Это — главный ингредиент фронтенд-разработки. Существуют различные JavaScript-фреймворки для создания интерфейсов веб-проектов. Vue.js — это один из таких фреймворков, который можно отнести к довольно популярным решениям.... | https://habr.com/ru/post/487684/ | null | ru | null |
# Функции высшего порядка в Spark 3.1
#### Обработка массивов в Spark SQL
Сложные типы данных, такие как массивы (arrays), структуры (structs) и карты (maps), очень часто встречаются при обработке больших да... | https://habr.com/ru/post/575740/ | null | ru | null |
# Как сделать греческие буквы в формулах прямым шрифтом в LaTeX
Как известно, в формулах LaTeX греческие буквы и интегралы являются наклонными. В старой советской литературе в формулах греческие буквы и интегралы были прямые и некоторые люди требуют, чтобы в статьях, диссертациях, авторефератах и прочих документах гре... | https://habr.com/ru/post/245785/ | null | ru | null |
# PHP-Дайджест № 157 (20 мая – 3 июня 2019)
[](https://habr.com/ru/post/454558/)
Свежая подборка со ссылками на новости и материалы. В выпуске: обновления безопасности PHP, коммерческая компания Doctrine, PhpStorm 2019.2 EAP, Symfo... | https://habr.com/ru/post/454558/ | null | ru | null |
# История одного расследования о странном поведении XMLHttpRequest в новых версиях Firefox
#### I. Суть проблемы.
В список основных предназначений XMLHttpRequest, конечно, не входит запрос HTML, чаще этот инструмент взаимодействует с XML, JSON или простым текстом.
Однако связка XMLHttpRequest + HTML хорошо работае... | https://habr.com/ru/post/145953/ | null | ru | null |
# FLProg + Nextion HMI Enhanced

Компания ITEAD выпустила новую линейку Enhanced своих панелей Nextion HMI. Представители компании предоставили мне экземпляр этой линейки для интеграции новых возможностей панели в программу FLProg. ... | https://habr.com/ru/post/400463/ | null | ru | null |
# SwayWM — сам себе UnixPorn
Всем привет. В этой статье я опишу свой опыт настройки и использования sway — тайлингового оконного менеджера для Linux.
Что это такое и зачем оно нужно?
================================
Официально, sway — тайлинговый оконный менеджер, прозрачная замена i3wm, работающая поверх Wayland.
... | https://habr.com/ru/post/484378/ | null | ru | null |
# Размышление об Active Object в контексте Qt6. Часть 2
#### Ссылки на статьи
* [Часть 1](https://habr.com/ru/post/709768/)
* [Часть 2](https://habr.com/ru/post/710368/)
* [Часть 2.5](https://habr.com/ru/post/710550/)
* [Часть 2.6](https://habr.com/ru/post/712328/)
* [Часть 3](https://habr.com/ru/post/710656/)
Преди... | https://habr.com/ru/post/710368/ | null | ru | null |
# Автоматизация тестирования веб-приложений под ключ, без регистрации и смс
Часто бывает так, что веб-приложение состоит из большого количества динамически перестраивающихся форм с разным текстом и элементами управления. Тестирование такого приложения превращается в кошмар.
Нужно прокликать 100500 страниц и провери... | https://habr.com/ru/post/499476/ | null | ru | null |
# Автоматизация тестирования Java EE веб-сервисов с помощью SoapUI и Arquillian
Одним из преимуществ веб-сервисов является относительная простота тестирования. Действительно, в простейшем случае все, что нам нужно для проверки работы веб-сервиса – это отправить правильно сформированный HTTP-запрос любым удобным способ... | https://habr.com/ru/post/267301/ | null | ru | null |
# Кибергруппа RTM специализируется на краже средств у российских компаний
Известно несколько кибергрупп, специализирующихся на краже средств у российских компаний. Мы наблюдали атаки с применением лазеек в системах безопасности, открывающих доступ в сети целевых объектов. Получив доступ, атакующие изучают структуру се... | https://habr.com/ru/post/322364/ | null | ru | null |
# Phalcon Framework на продакшене
Последним временем известность набирает необычный в среде php фреймворк Phalcon, который является расширением языка. Думаю, что многим интересно узнать, каков фреймворк в бою, однако по тем или иным причинам не могут позволить себе использовать его в разработке. В моей компании решили... | https://habr.com/ru/post/225851/ | null | ru | null |
# React 18
В нашем последнем посте мы поделились пошаговыми инструкциями по [обновлению вашего приложения до React 18](https://reactjs.org/blog/2022/03/08/react-18-upgrade-guide.html). В текущем посте мы дадим обзор того, что нового появилось в React 18, и что это означает для будущего.
Наша последняя мажорная версия... | https://habr.com/ru/post/659537/ | null | ru | null |
# Пример реализации общего индикатора производительности MS SQL Server
### Предисловие
Часто возникает потребность в создании такого индикатора производительности, который бы показывал состояние СУБД относительно предыдущего периода или конкретного дня. В статье [Реализация индикатора производительности запросов, хра... | https://habr.com/ru/post/342794/ | null | ru | null |
# Пишем whois-клиент под Android

В своей прошлой [статье](http://habrahabr.ru/blogs/android_development/115127/) я рассказал, что есть довольно много библиотек для парсинга html, в этот раз я решил показать к... | https://habr.com/ru/post/115812/ | null | ru | null |
# Примеры Google Maps API №3: Делаем инфо-окно функциональным
Итак, пока что последняя статейка с примерами. Речь пойдет о том, как сделать инфо-окошко более функциональным.
#### ДЕЛАЕМ ИНФО-ОКНО ФУНКЦИОНАЛЬНЫМ
Отображать какую-либо информацию о месте, в котором установлен маркер, — это, конечно, хорошо. Но давайт... | https://habr.com/ru/post/39435/ | null | ru | null |
# Запускаем инспекции IntelliJ IDEA на Jenkins
IntelliJ IDEA на сегодня обладает наиболее продвинутым статическим анализатором кода Java, по своим возможностям оставившим далеко позади таких «ветеранов», как [Checkstyle](http://checkstyle.sourceforge.net/) и [Spotbugs](https://spotbugs.github.io/). Её многочисленные «... | https://habr.com/ru/post/450214/ | null | ru | null |
# Асинхронный python без головной боли (часть 2)
***Это продолжение цикла статей про*** `asyncio`***. Начало*** [***здесь***](https://habr.com/ru/post/667630/)***.***
6. Веб-сервер aiohttp и другие жители асинхронного мира
-------------------------------------------------------
Продолжаем готовить `asyncio`. Теперь ... | https://habr.com/ru/post/671798/ | null | ru | null |
# Распознавание речи в Asterisk с использованием Yandex SpeechKit HTTP API

Статья написана по мотивам [Синтез и распознавание речи от Google для Asterisk](http://habrahabr.ru/post/133869/), с ~~не~~ больш... | https://habr.com/ru/post/225179/ | null | ru | null |
# Процедурная гидрология: динамическая симуляция рек и озёр

> **Примечание:** полный исходный код проекта выложен на Github [[здесь](https://github.com/weigert/SimpleHydrology)]. В репозитории также содержится подробная информация о том, как чи... | https://habr.com/ru/post/498290/ | null | ru | null |
# Настало время офигительных историй
Привет, GT! В новом году мы хотим сделать наши материалы лучше и полезнее, а поэтому предлагаем поучаствовать в обмене знаниями: вы нам — интересные концепции, истории и жизненный опыт, ну а мы — приятные призы и подарки.
Материал переведен. *Ссылка на* [*оригинал*](https://devblogs.microsoft.com/dotnet/date-time-and-time-zone-enhancements-in-net-6/)
В этой статье я расскажу о... | https://habr.com/ru/post/567338/ | null | ru | null |
# Вычисление значения выражения
*В продолжение поста [Компилятор выражений](http://habrahabr.ru/blogs/development/50139/). По просьбам читающих. Специально для [michurin](https://habrahabr.ru/users/michurin/)*
Есть много способов вычислить значение выражения мне больше всего нравится метод с двумя стеками.
Нрави... | https://habr.com/ru/post/50196/ | null | ru | null |
# Внедрение предметно-ориентированного проектирования в PHP
И снова здравствуйте!
Что ж очередной «новый» курс, который стартовал в конце декабря, подходит к концу — [«Backend разработчик на PHP»](https://otus.pw/EAx8/). Учли разные мелкие шероховатости и запускаем новый. Осталось только посмотреть на выпуск и всё,... | https://habr.com/ru/post/353500/ | null | ru | null |
# Model-View в QML. Часть первая: Представления на основе готовых компонентов
В этой части моего цикла статей про Model-View в QML мы начнем рассматривать представления и начнем с тех, которые делаются на основе готовых компонентов.
Model-View в QML:
1. [Model-View в QML. Часть нулевая, вводная](http://habrahabr... | https://habr.com/ru/post/184416/ | null | ru | null |
# Тактовый механизм управления DWH: как разгрести бесконечную очередь и не умереть
Привет, Хабр! Я хочу поделиться с тобой тем, как работает наш сервис по управлению загрузками данных – в общих чертах, не по... | https://habr.com/ru/post/695416/ | null | ru | null |
# Обратный websocket/http туннель данных на .NET + SignalR
Возникла необходимость организовать трафик к внешнему сервису из сегмента сети с ограничением на исходящие соединения. Этот внешний сервис работал од... | https://habr.com/ru/post/709002/ | null | ru | null |
# ICMP port knocking в OpenWRT
Впечатлённый [статьёй](http://habrahabr.ru/post/186488/) решил реализовать подобное решение на домашнем роутере, под управлением OpenWRT (Bleeding Edge r38381). Решение наверно не настолько элегантное как на Mikrotik, но главное что рабочее и без скриптов и cron. Так же его можно взять з... | https://habr.com/ru/post/198108/ | null | ru | null |
# Сказ о Selenium тестировании
Когда перед вашей командой стоит задача написать действительно крупный проект, всегда становится задача тестировать написанный код. Если сервер тестировать относительно легко, то JS код чаще вс... | https://habr.com/ru/post/196152/ | null | ru | null |
# Как машинное обучение позволяет создавать музыку
[](http://geektimes.ru/company/audiomania/blog/250458/)
*Сегодня мы поговорим об [исследовании](http://zx.rs/3/Markov-Composer---Using-machine-learning-and-a-Markov-chain-t... | https://habr.com/ru/post/379535/ | null | ru | null |
# Автоматическое выполнение задач с Gnome Schedule
Хотели ли бы вы, чтобы регулярно выполняемые задачи на компьютере запускались автоматически? В линуксе для расписания и выполнения задач проще всего исп... | https://habr.com/ru/post/50944/ | null | ru | null |
# Bare-Metal Provisioning своими руками, или Автоматическая подготовка серверов с нуля
Привет, я Денис и одно из моих направлений деятельности – разработка инфраструктурных решений в X5. Сегодня хотел бы поделиться с вами о том, как можно на базе общедоступных инструментов развернуть автоматическую систему подготовки ... | https://habr.com/ru/post/493124/ | null | ru | null |
# Двухфакторная аутентификация в Redmine
С давних пор для второго шага аутентификации мы использовали одноразовые пароли отправляемые через СМС. Такой функционал появился в Redmine в 2013, когда мы разработали плагин [redmine\_sms\_auth](https://github.com/centosadmin/redmine_sms_auth). Об этом мы писали в [давней ста... | https://habr.com/ru/post/312656/ | null | ru | null |
# Преимущества коворкинга, обсуждение
#### Предисловие
В данной статье я хочу поделиться своим видением преимуществ и недостатков коворкинг-центров, которые все еще набирают популярность в России. Некоторые из них стали особенно успешны и окупили затраты менее, чем за полгода, другие закрылись, не начав приносить дос... | https://habr.com/ru/post/200052/ | null | ru | null |
# Продвинутое использование объектов в JavaScript
Этот пост выходит за рамки повседневного использования объектов в JavaScript. Основы работы с объектами по большей части так же просты, как использование JSON-нотации. Тем не менее, JavaScript дает возможность использовать тонкий инструментарий, с помощью которого можн... | https://habr.com/ru/post/241465/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.