
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Создание нестандартного компонента с нуля. Часть 2
#### Вступление
Вновь приветствую, коллеги.
В своей [предыдущей](http://habrahabr.ru/post/176643/) статье я рассказал об основах создания кастомного компонента на примере простенькой, но симпатичной фортепианной клавиатуры.
На официальном сайте Mozilla Developer Center появилась статья [Firefox 3.6 for developers](https://developer.mozilla.org/en/Firefox_3.6_for_developers), в которой описываются нововведения и изменения ... | https://habr.com/ru/post/65724/ | null | ru | null |
# System.IO.Pipelines — a little-known tool for lovers of high performance
Hello reader. Quite a lot of time has passed since the release of .NET Core 2.1. And such cool innovations as Span and Memory are already widely known, you can read, see and hear a lot about them. However, unfortunately, library called System.I... | https://habr.com/ru/post/466137/ | null | en | null |
# HomeKit для Z-Wave, Raspberry GPIO и устройств с HTTP API с помощью контроллера RaZberry

Тема интернета вещей сейчас как никогда наиболее популярна. Каждый день выходят новые интересные устройства способные общаться друг... | https://habr.com/ru/post/378175/ | null | ru | null |
# Обновление строк на лету в мобильных приложениях: часть 2

Привет, Хабр!
[В недавней статье](https://habrahabr.ru/company/badoo/blog/346458/) наш коллега Дмитрий Марущенко [yojick](https://habrahabr.ru/users/yojick/) рассказал о... | https://habr.com/ru/post/348350/ | null | ru | null |
# Как подружить helm со своим шаблонизатором?
Helm использует [go templates](https://pkg.go.dev/text/template) для рендеринга манифестов. Есть функции, которые были разработаны специально для helm. Но в большинстве своем используется библиотека [Sprig](http://masterminds.github.io/sprig/).
 [rocknrollnerd](https://habrahabr.ru/use... | https://habr.com/ru/post/277671/ | null | ru | null |
# Интегрируем iOS-приложение с Evernote: первые шаги

Одно из преимуществ Evernote — его вездесущность. Наши приложения работают практически на всех значимых мобильных платформах, на двух наиболее популярных компьютерных ОС и во в... | https://habr.com/ru/post/145717/ | null | ru | null |
# Spring Boot 2: чего не пишут в release notes

Когда у масштабного проекта происходит масштабное обновление, всё никогда не бывает просто: неизбежно возникают неочевидные нюансы (проще говоря, грабли). И тогда, как бы хороша ни бы... | https://habr.com/ru/post/439796/ | null | ru | null |
# Ищем и анализируем ошибки в коде GitExtensions

Как изестно Ядро Git представляет собой набор утилит командной строки с параметрами. Для комфортной работы как правило используются утилиты, дающие нам привыч... | https://habr.com/ru/post/312526/ | null | ru | null |
# Ваш пакет Composer сломан: обновите идентификатор лицензии

Если вы, как и я:
* являетесь мэйнтейнером какой-либо библиотеки или фреймворка;
* ваша библиотека или фреймворк выпущены под какой-либо свободной лицензией
* ваша б... | https://habr.com/ru/post/348520/ | null | ru | null |
# Оптимизация при помощи линейного поиска на Python
Линейный поиск — это алгоритм оптимизации, который может использоваться для целевых функций с одной или несколькими переменными. Он предоставляет возможно... | https://habr.com/ru/post/561042/ | null | ru | null |
# Ускоряем PHP (с ReactPHP)
В этом посте я хотел бы поделиться не совсем обычным, для мира PHP, способе построения приложения, если угодно — архитектурой. Данный подход позволяет средствами PHP увеличить количество обрабатываемых запросов в разы. Так же я поделюсь своими наработками в этом направлении. Конечно данный ... | https://habr.com/ru/post/220393/ | null | ru | null |
# Разрабатываем игру на SVG + React. Часть 1
**TL;DR:** в этих сериях вы узнаете, как заставить React и Redux управлять SVG элементами для создания игры. Полученные в этой серии знания позволят вам создавать анимацию не только для игр. Вы можете найти окончательный вариант исходного кода, разработанного в этой части, ... | https://habr.com/ru/post/350274/ | null | ru | null |
# Выбираем правильную структуру данных в Swift
*И снова здравствуйте. Прежде чем уйти на выходные хотим поделиться с вами переводом материала, который был подготовлен специально для базового курса [«iOS-разработчик»](https://otus.pw/8XKY/).*

Однажды в интервью один всем известный российский музыкант сказал: “Мы работаем над тем, чтобы лежать и плевать в потолок”. Не могу не согласиться с этим утверждением, ... | https://habr.com/ru/post/427397/ | null | ru | null |
# Использование NSOperation и NSOperationQueue в Swift
Почти каждый из нас испытывал дискомфорт, когда при нажатии на кнопку или при вводе текста в **iOS** или **Mac** приложениях, как внезапно пользовательский интерфейс переставал отвечать, приложение будто замирало и переставало реагировать на ваши действия.
На *... | https://habr.com/ru/post/267843/ | null | ru | null |
# Helmwave v0.12.8
Прошло уже 8 месяцев с момента первой и пока единственной статьи о инструменте для композинга helm чартов – [helmwave](https://github.com/helmwave/helmwave).
За это время:
* Преодолели п... | https://habr.com/ru/post/575646/ | null | ru | null |
# Backbone.js для «чайников»
Как то поздним вечерком мне пришла мысль изучить Backbone.js и привязать его к уже написанному на jQuery сервису. Сервис уже серьёзно расширился и меня достало это нагромождени... | https://habr.com/ru/post/127049/ | null | ru | null |
# CVE-2017-5689 — уязвимость Intel AMT в подробностях
В начале 2017-го года Максим Малютин (Maksim Malyutin) из компании Embedi обнаружил уязвимость в Intel AMT, которая была официально оглашена Intel первого мая и получила номер CVE-2017-5689 (INTEL-SA-00075 в кодификации Intel). Уязвимости был присвоен тип «повышени... | https://habr.com/ru/post/328232/ | null | ru | null |
# Как серверу на Django знать своих клиентов на React в лицо, практическое руководство
В [предыдущей статье](https://habr.com/ru/post/512526/) я писал веб-приложение и совершенно бездумно реализовал там авторизацию, построенную на JWT. В этой статье я хотел бы устроить небольшое погружение в технические детали того, к... | https://habr.com/ru/post/512746/ | null | ru | null |
# Создание REST API с Node.js и базой данных Oracle
Привет, Хабр! представляю вашему вниманию перевод статьи [«Creating a REST API: Web Server Basics»](https://jsao.io/2018/03/creating-a-rest-api-web-server-basics/).
#### Часть 1. Создание REST API: основы веб-сервера
Веб-сервер является одним из наиболее важных к... | https://habr.com/ru/post/473234/ | null | ru | null |
# Сказки старого DBA
Хотите легкого чтива под новый год? Вот крошечные истории про случаи из моей работы, или случаи, свидетелем которых я стал.
Свинья
------
Моя первая длительная работа была в фирме *"Ниеншанц"*, царствие ей небесное. Она работала на самописной **ERP**, которую писали мы - группа из 3-4 человек. Э... | https://habr.com/ru/post/598611/ | null | ru | null |
# Поднимаем сложный проект на Django с использованием Docker
Добрый день, коллеги.
Сегодня я расскажу о не совсем простой концепции быстрого (до часа после нескольких тренировок) развёртывания проекта для работы команды, состоящей как минимум из отдельных фронтенд и бэкенд разработчиков.
Исходные данные у нас та... | https://habr.com/ru/post/272811/ | null | ru | null |
# Написание программного обеспечения с функционалом клиент-серверных утилит Windows, part 02
Продолжая начатый цикл статей, посвященный кастомным реализациям консольных утилит Windows нельзя не затронуть TFTP (Trivial File Transfer Protocol) — простой протокол передачи файлов.
Как и в прошлой раз, кратко пробежимс... | https://habr.com/ru/post/461083/ | null | ru | null |
# Детектирование позы человека при помощи библиотеки OpenPose
Привет, Хабр! Сегодня расскажу о решении важной для многих из нас и ставшей уже классической задачи - детектировании позы человека на изображении. Решать её я предлагаю с использованием библиотеки OpenPose. Всё самое интересное ― под катом. Сразу скажу, что... | https://habr.com/ru/post/683090/ | null | ru | null |
# Основы Linux от основателя Gentoo. Часть 3 (1/4): Документация
Первый отрывок третьей части серии руководств для новичков. Практически всё, что нужно знать, чтобы найти справочную информацию по вашей системе. Короче, RTFM и не задавайте глупых вопросов.
>
>
> [? Ответ мог быть примерно следующий:
> Для начала создаём новую колонк... | https://habr.com/ru/post/568240/ | null | ru | null |
# Концепции, лежащие в основе Web Audio API

Доброго времени суток, друзья!
В этой статье объясняются некоторые концепции из теории музыки, на основе которых работает Web Audio API (WAA). Зная эти концепции, вы сможете принимать в... | https://habr.com/ru/post/495690/ | null | ru | null |
# Deep Learning, теперь и в OpenCV

Данная статья является кратким обзором возможностей dnn — модуля OpenCV, предназначенного для работы с нейросетями. Если вам интересно, что это такое, что оно умеет и как быстро работает, до... | https://habr.com/ru/post/333612/ | null | ru | null |
# Применение машинного обучения для увеличения производительности PostgreSQL

Машинное обучение занимается поиском скрытых закономерностей в данных. Растущий рост интереса к этой теме в ИТ-сообществе ... | https://habr.com/ru/post/273199/ | null | ru | null |
# Страх и ненависть в переговорке: курим VideoSDK API, Vosk и Python
Каждый год — новая полоса препятствий для человечества. И IT не исключение, а полноценный участник этого забега, особенно в нашей стране.
... | https://habr.com/ru/post/710524/ | null | ru | null |
# Node.js для начинающих: основы работы с файлами
Сегодня мы поговорим о том, как работать с файловой системой средствами Node.js, рассмотрим базовые операции, выполняемые с файлами. К таким операциям относятся следующие:
* Создание файла
* Чтение файла
* Запись данных в файл
* Удаление файла
* Переименование файла... | https://habr.com/ru/post/452566/ | null | ru | null |
# Профессиональный React стек для создания сложных приложений в 2022 году
Выучить React недостаточно для профессиональной разработки больших приложений. Для этого есть две основные причины. Первая, у React ... | https://habr.com/ru/post/646887/ | null | ru | null |
# Пять способов пагинации в Postgres, от базовых до диковинных
Вас может удивить тот факт, что пагинация, распространенная, как таковая, в веб приложениях, с легкостью может быть реализована нерационально. В этой статье мы испробуем различные способы пагинации на стороне сервера и обсудим их удобство при использовании... | https://habr.com/ru/post/301044/ | null | ru | null |
# Google убирает из браузера Chrome строку 'user-agent'
При посещении веб-сайта браузер или другое клиентское приложение обычно посылает веб-серверу информацию о себе. Эта текстовая строка является частью HTTP-запроса. Она начинается с `User-agent:` или `User-Agent:` и обычно содержит название и версию приложения, опе... | https://habr.com/ru/post/494362/ | null | ru | null |
# Математический подход к созданию сайтов
«Математика прекрасна». Это может показаться абсурдным, для людей которые при одном только упоминании математики вздрагивают. Однако некоторые из самых красивых вещей в природе и нашей Вселенной — это проецирование математических свойств, от самых маленьких до крупнейших галак... | https://habr.com/ru/post/154087/ | null | ru | null |
# Эврика! Моменты озарения при изучении React
Светлана Шаповалова, редактор [«Нетологии»](http://netology.ru/development/programs?utm_source=blog&utm_medium=747&utm_campaign=habr), перевела [статью](https://medium.freecodecamp.com/react-aha-moments-4b92bd36cc4e#.x98mxxjvb) Тайлера МакГинниса, в которой он перечислил о... | https://habr.com/ru/post/324788/ | null | ru | null |
# Выпуск Rust 1.22 (и 1.22.1)
Команда Rust рада сообщить о двух новых версиях Rust: 1.22.0 и 1.22.1. Rust — это системный язык программирования, нацеленный на безопасность, скорость и параллельное выполнение кода.
> Подождите, две версии? В последний момент мы [обнаружили проблему с новой macOS High Sierra](https://g... | https://habr.com/ru/post/343058/ | null | ru | null |
# Как обойти некоторые ограничения google translate
Я опишу два финта, с помощью которых можно обойти некоторые ограничения google translate.
1. Ограничение на количество символов у google translate online то ли 3900, то ли 5000 символов. Иногда нужно больше, а создавать html-файл с текстом неохота. Чтобы обойти э... | https://habr.com/ru/post/501018/ | null | ru | null |
# Хабр Конвертер: чтобы версталось легко
Наверняка многие из вас хотя бы однажды пользовались хабраконвертером, который [официально рекомендован](https://habr.com/ru/info/topics/madskillz/) администрацией Хабра — <https://shirixae.github.io/habraconverter-v2/>. Несколько лет назад его [создал](https://habr.com/ru/post... | https://habr.com/ru/post/490968/ | null | ru | null |
# Пример создания одного chrome extension
Приветствую социум! Проработал 7 лет техническим директором. Понял, насколько это сильно бьет по нервам и решил начать жизнь с чистого листа. Пойти javascript-разработчиком.
Почему: потому что люблю писать на этом языке. Он веселый и может влет решать множество реальных зад... | https://habr.com/ru/post/324862/ | null | ru | null |
# Офис как Платформа: как создавался проект Notegram для OneNote
> *Перед вами история успеха проекта [Notegram](http://notegram.me/) от первого лица — Дмитрия Конева — разработчика проекта, который создал интересный проект, расширяющий возможности приложения Office OneNote. Все статьи колонки «Офис как Платформа» вы ... | https://habr.com/ru/post/270213/ | null | ru | null |
# Еще раз об электронной библиотеке для PocketBook
Приветствую тебя, Хабр!
Данная статейка — всего лишь развернутый комментарий к тексту [«Электронная библиотека для PocketBook: автоматическая обработка»](http://habrahabr.ru/post/143492/) от [dsd\_corp](https://geektimes.ru/users/dsd_corp/), поскольку я, будучи бес... | https://habr.com/ru/post/143847/ | null | ru | null |
# Кунг-фу стиля Linux: упрощение работы с awk
Утилита `awk` — это нечто вроде швейцарского ножа для обработки текстовых файлов. Но некоторые ограничения `awk` порой доставляют неудобства тем, кто этой утилитой пользуется. Я, для того чтобы упростить работу с `awk`, создал несколько функций. Но сразу хочу сказать о том... | https://habr.com/ru/post/527244/ | null | ru | null |
# Возможности Java 17 и рекомендации по миграции
#### Java значительно изменилась с годами. Прочтите сравнение версий 8 и 17 и узнайте ответ на вопрос: стоит ли обновляться?
Через несколько месяцев, в марте 2022 года, Java 8 закончится поддержка Oracle Premier Support. Это не означает, что он не будет получать никаки... | https://habr.com/ru/post/591159/ | null | ru | null |
# Mikrotik VRF+NAT — Управляем с одного хоста устройствами с одинаковыми IP-адресами
Недавно знакомый попросил помощи с настройкой микротика. Просьба была не совсем простая. Идея в том, что нужно было одновременно управлять с одного хоста четырьмя устройствами с неуправляемым TCP/IP стеком. На всех этих устройствах бы... | https://habr.com/ru/post/262091/ | null | ru | null |
# Учим HostBinding работать с Observable
Как и многие другие Angular-разработчики, я мирился с одним ограничением. Если мы хотим использовать `Observable` в шаблоне, мы можем взять знакомый всем `async` пайп:
Но его нельзя применить к `@HostBinding`. Давным-давно это было возможно по ошибке, но это [быстро исправили]... | https://habr.com/ru/post/542984/ | null | ru | null |
# История о V8, React и падении производительности. Часть 1
В материале, первую часть перевода которого мы публикуем сегодня, речь пойдёт о том, как JavaScript-движок V8 выбирает оптимальные способы представления различных JS-значений в памяти, и о том, как это влияет на внутренние механизмы V8, касающиеся работы с та... | https://habr.com/ru/post/467247/ | null | ru | null |
# Буфера для буферов или пишем виртуальный буфер обмена на C# не в 30 строк кода

Так случилось, что в такую мрачную погоду, обложив себя таблетками и препаратами от простуды я решил от нечего делать подел... | https://habr.com/ru/post/211653/ | null | ru | null |
# Немного про py2exe
Есть такое приложение. Называется py2exe. Оно позволяет упаковать, сконвертировать программу на python в exe файл (ну, точнее, exe и еще кучку других). Зачем оно все надо? Ну, далеко не у всех пользователей windows установлен интерпретатор python с нужными библиотеками. А вот упакованная программа... | https://habr.com/ru/post/87224/ | null | ru | null |
# openSUSE 11.2 вышла в свет

Новая openSUSE принесла множество приятных изменений как пользователям KDE и Gnome так и тем пользователям, кто предпочитает более аскетичное окружение.
Подробнос... | https://habr.com/ru/post/74925/ | null | ru | null |
# VDOM своими руками
Привет.
У многих frontend-разработчиков бытует мнение, что технология VDOM, которая, в частности, используется в React.js, работает как черный ящик. Так же на просторах npm есть куча библиотек, реализующих эту технологию, однако вот как по мне — так в них черт ногу сломит. Сама тема VDOM-а меня з... | https://habr.com/ru/post/348378/ | null | ru | null |
# Сказ об одной ошибке, так и не попавшей в релиз ядра Linux
Совсем недавно вышло исправление, устраняющее полное зависание 32-битного ядра Linux при загрузке на процессорах Intel. Здесь небольшая история о том, откуда появилась ошибка и какие проводились исследования по поиску причин её возникновения.
Начну с неб... | https://habr.com/ru/post/259535/ | null | ru | null |
# Реализация мьютекса вне ОС на примере микроконтроллера AVR и шины TWI
Решил однажды для себя я соорудить погодную станцию. Датчики там разные, в том числе на шине I2C. И как годится, обычно вначале, сделал все на флагах ожидания. Но путь настоящего джедая иной, и было решено все повесить на прерывания. Вот тут и нач... | https://habr.com/ru/post/193456/ | null | ru | null |
# Confluence для публичной базы знаний: меняем дизайн и настраиваем разделение по языкам
У нас есть шесть продуктов, которые используют в России и за рубежом. Это значит, что документация к ним должна быть в одном месте, но разделена по продуктам и языкам.
Раньше мы использовали MediaWiki, но со временем она устаре... | https://habr.com/ru/post/438236/ | null | ru | null |
# Быстрая публикация скриншотов
Постить скриншоты довольно заморочно если всё делать руками. Но возможен и более лёгкий сценарий:
1) жму Alt+Ctrl+S
2) появляется редактор с готовым скриншотом
3) обрезаю картинку, закрываю редактор
4) картинка сама загружается; ссылка на картинку оказывается в буфере обмена... | https://habr.com/ru/post/125173/ | null | ru | null |
# Распространение приложения под iOS внутри компании (Enterprise Distribute iOS App in-house)
**(Осторожно, под катом трафик)**
Подготовка и распространение приложения IOS внутри компании весьма непростая задача, особенно когда приложение написано на Windows с использованием Visual studio, а большинство туториалов ... | https://habr.com/ru/post/427579/ | null | ru | null |
# Готовим пиццу с помощью SVG
Перевод с английского: [How to cook Pizza with SVG?](http://y3x.ru/2012/08/how-to-cook-pizza-with-svg/)
В этой статье мы научимся готовить низкокалорийную пиццу, котор... | https://habr.com/ru/post/150189/ | null | ru | null |
# Что нового в Perl 5.10?
На днях вышел первый кандидат Perl-а на релиз — [5.10.0 RC1](http://search.cpan.org/~rgarcia/perl-5.10.0-RC1/). А ведь прошло 5 лет с момента предыдущего релиза (5.8).
Так что же интересного нас ждет в 5.10?
Следует заметить, что Perl 5.10 имеет обратную совместимость с предыдущими вер... | https://habr.com/ru/post/16556/ | null | ru | null |
# Абстрактные войны: public interface IAbstraction против абстракции
> Следить за обновлениями блога можно в моём канале: [Эргономичный код](https://t.me/ergonomic_code)
>
>
Введение
--------
Почти 30 ле... | https://habr.com/ru/post/675314/ | null | ru | null |
# 13 полезных приёмов по работе с массивами в JavaScript, которые могут вам пригодиться
Массивы являются одной из самых популярных структур данных в JavaScript, потому что они используются для хранения данных. Кроме этого, массивы дают много возможностей для работы с этими самыми данными. Понимая, что для тех, кто нах... | https://habr.com/ru/post/476042/ | null | ru | null |
# fc.tape — js-библиотека для простой анимации спрайтов
Хочу поделиться с хабросообществом javascript-библиотекой [fc.tape](http://source.futurecolors.ru/fc.tape/). Её назначение — управление анимацией спрайта, представляюще... | https://habr.com/ru/post/141745/ | null | ru | null |
# Хак синтаксиса PHP
Вы когда-нибудь задумывались о том, как расширить ядро PHP? Что нужно для того, чтобы создать новое ключевое слово или даже разработать новый синтаксис? Если у вас есть базовые знания языка C, то проблем с созданием небольших изменений возникнуть не должно. Да, я понимаю, что это может быть немног... | https://habr.com/ru/post/179441/ | null | ru | null |
# OpenShift virtualization: контейнеры, KVM и виртуальные машины
OpenShift virtualization (апстрим проект – Kubernetes: KubeVirt, см. [здесь](https://www.openshift.com/blog/re-imagining-virtualization-with-kubernetes-and-kubevirt) и [здесь](https://www.openshift.com/blog/re-imagining-virtualization-with-kubernetes-and... | https://habr.com/ru/post/506200/ | null | ru | null |
# Основы работы с Shader Graph в Unity

Шейдер — это небольшая программа, содержащая инструкции для GPU. Она описывает способ вычисления экранного цвета для определённого материала.
Хотя у Unity ес... | https://habr.com/ru/post/479302/ | null | ru | null |
# Elixir как цель развития для python async
В книге «Python. К вершинам мастерства» Лучано Рамальо описывает одну историю. В 2000 году Лучано проходил курсы, и однажды в аудиторию заглянул Гвидо ван Россум. Раз подвернулся такой случай, все стали задавать ему вопросы. На вопрос о том, какие функции Python заимствовал ... | https://habr.com/ru/post/476112/ | null | ru | null |
# Sciter — встраиваемый HTML/CSS/scripting engine
Попросили вот [здесь](http://habrahabr.ru/post/153013/) про Sciter слово замолвить… Собственно вот рассказываю.
Sciter есть встраиваемый HTML/CSS/scripting engine для создания UI десктопных и мобильных приложений, классических так и [occasionally-]connected.
В п... | https://habr.com/ru/post/154697/ | null | ru | null |
# For professors' note: use PVS-Studio to get students familiar with code analysis tools

Our support chats and some other indirect signs showed that there are many students among our free users. H... | https://habr.com/ru/post/470069/ | null | en | null |
# Миграция виртуальных машин с Xen 3.2 на XenServer 6.2 в Hetzner
#### Немного предыстории
 В 2010 году для частного проекта я завел себе небольшой выделенный сервер на hezner.de. Время шло, железо совершенствовалось... | https://habr.com/ru/post/231301/ | null | ru | null |
# Простой дополнительный контроль состояния данных memcached
 Мониторинг memcached — дело далеко не последней важности. Как на этапе тестирования, так и на этапе сопровождения уже работающего нагруженног... | https://habr.com/ru/post/122094/ | null | ru | null |
# Как IEEE-488 может сэкономить бюджет и подарить приятные чувства ностальгии?
[](https://habr.com/ru/company/ruvds/blog/649869/)
Не все старые технологии начала компьютерной эры забыты, и некоторые энтузиасты из ностальгии по тем вр... | https://habr.com/ru/post/649869/ | null | ru | null |
# 4,2 гигабайта, или как нарисовать что угодно
> В нашем мире мы можем сделать всё, что захотим. Всё что угодно.
>
>
>
> — *Боб Росс, The Joy Of Painting, сезон 29, эпизод 1*
Однажды, когда я наблюдал за ярким закатом в Сиэтле, внезапно включилось моё воображение. Потусторонний оттенок неба пробудил воспомина... | https://habr.com/ru/post/685848/ | null | ru | null |
# Разбираемся в С, изучая ассемблер
*Перевод статьи Дэвида Альберта — [Understanding C by learning assembly](https://www.hackerschool.com/blog/7-understanding-c-by-learning-assembly).*
В прошлый раз Аллан О’Доннелл рассказывал о том, как [изучать С используя GDB](http://habrahabr.ru/post/181738/). Сегодня же я хочу... | https://habr.com/ru/post/183376/ | null | ru | null |
# Сотня криптовалют, описанных не более чем четырьмя словами

В этом списке каждая из криптовалют описана всего в четырех словах. Их много, и среди них есть как исключительные и знаковые, так и откровенное мошенничество.
```
Назва... | https://habr.com/ru/post/408535/ | null | ru | null |
# Ленивая инициализация в C#
Отложенная инициализация или «ленивая» инициализация — это способ доступа к объекту, скрывающий за собой механизм, позволяющий отложить создание этого объекта до момента первого обращения. Необходимость ленивой инициализации может возникнуть по разным причинам: начиная от желания снизить н... | https://habr.com/ru/post/522184/ | null | ru | null |
# Слёрм DevOps. 3-ий день. ELK, ChatOps, SRE. И тайная молитва разработчика
Наступил третий и последний день первого, но не последнего Слёрма DevOps.
Мы не рассчитывали, что сможем повторить Слёрм DevOps. Но неожиданно для нас все спикеры согласились приехать на Слёрм в феврале, а фидбек показал, как именно доработа... | https://habr.com/ru/post/466803/ | null | ru | null |
# Custom font в Unity3d
Как-то при подготовке [своего проекта](http://habrahabr.ru/post/212665/) в Unity3d у меня возникла необходимость использовать Bitmap font (он же растровый шрифт). Я очень обрадовался, когда обнаружил в Unity инструменты для создания такого шрифта. Но спустя некоторое время понял, что процедура ... | https://habr.com/ru/post/212587/ | null | ru | null |
# Микросервисы. Паттерны разработки и рефакторинга с примерами на языке Java
Привет, Хабр!
Мы приступаем к переводу книги Криса Ричардсона "[Microservices Patterns. With examples in Java](https://www.manning.com/books/microservices-patterns)". До премьеры на русском языке еще с полгода, но мы хотели бы предложить в... | https://habr.com/ru/post/430062/ | null | ru | null |
# Пишем простой анализатор кода на Roslyn
Привет, Хабр!
Не так давно я сходил на конференцию [CLRium](http://clrium.ru/) от [sidristij](http://habrahabr.ru/users/sidristij/), где увидел довольно простой и удобный способ для анализа исходного кода C# в MSVS 2015.
Задача взята из проекта, в котором я участвую: каж... | https://habr.com/ru/post/259213/ | null | ru | null |
# Электроника всем начинающим
Хабр! *Добро пожаловать снова.*
Сегодня мы сделаем одно из самых бесполезных устройств из тех, что можно собрать, но как показывает жизнь, лучше сделать что-то, чем не сделать ничего. Тем не менее, в защиту этой бесполезности можно сказать только что-то вроде: много ли интересных дел, ко... | https://habr.com/ru/post/593421/ | null | ru | null |
# GSM на столе
Разработка под веб: HTTP, HTML, CSS, JavaScript, Python… Ох. Всё одно и то же. Так хочется отвлечься на что-нибудь радикально другое. Я же обитаю в московском хакспейсе [Нейрон](http://neuronspace.ru/)! Почему бы не поспрашивать вокруг?
Например, в Нейроне сидят ребята из компании [Fairwaves](http://... | https://habr.com/ru/post/213845/ | null | ru | null |
# Ломаем датчик утечки газа
 Ежегодно в России из-за утечки бытового газа происходят десятки взрывов. В частности, грустный рекорд был отмечен в 2008 году, когда только в январе произошло 7 [мощнейщих взрывов](http://vz.ru/inf... | https://habr.com/ru/post/256215/ | null | ru | null |
# Особенности метода xPDOObject::save() + транзакции
Совсем недавно Сергей Прохоров ака [proxyfabio](http://habrahabr.ru/users/proxyfabio/) написал статью [Валидация объектов + транзакции](https://modxclub.ru/topics/validacziya-obektov-tranzakczii-1837.html). Немного эта тема [обсуждалась здесь](https://modx.pro/help/... | https://habr.com/ru/post/265485/ | null | ru | null |
# Делаем многоуровневого бота для ВК с Long Poll VK API, Python, MySQL и решаем вопрос многопоточности c помощью threading
Создание ботов - довольно заезжанная тема, но все уроки, статьи и различного рода документация дают информацию только о том, как построить бота в один уровень без возможности создания древа из раз... | https://habr.com/ru/post/648591/ | null | ru | null |
# Liqpay: выставление счета по SMS, гордо названное POS-терминалом
Недавно хабраюзер [упоминал](http://habrahabr.ru/blogs/pay_sistem/85058/) о событии.
Не буду дублировать описание, вот [оригинал](http://privatblog.com.ua/page/468122.html).
Попробую прояснить некоторые непонятные моменты.
Итак, следует помнит... | https://habr.com/ru/post/86965/ | null | ru | null |
# Meteor + JQuery-UI Sortable + Animation + Todos
Анимация и драг-н-дроп на [Метеоре](http://www.meteor.com/) пока больше мечта чем реальность. Умельцы находят пути реализовать такие вещи, но как показывает исследование — это обход основных паттернов метеор разработки
Этот пост о том, как я пытался прикрутить анима... | https://habr.com/ru/post/197296/ | null | ru | null |
# PHP и регулярные выражения: азы для новичков
*В преддверии старта нового потока по курсу [«Backend-разработчик на PHP»](https://otus.pw/vMHA/), а также смежного с ним курса [«Framework Laravel»](https://otus.pw/vS2d/), хотим поделиться статьей, которую подготовил наш внештатный автор.
**Внимание!** данная статья ... | https://habr.com/ru/post/484048/ | null | ru | null |
# Взлом биткоин биржи на Rails
В последнее время появилась масса биткоин сервисов. И то что раньше было проектом «for fun» неожиданно стало хранить десятки и даже сотни тысяч долларов. Цена биткоина выросла, но уровень безопасности биткоин сервисов остался таким же низким.
Ради портфолио мы провели бесплатный аудит... | https://habr.com/ru/post/248887/ | null | ru | null |
# Архитектура и решения безопасности в облаке часть 1
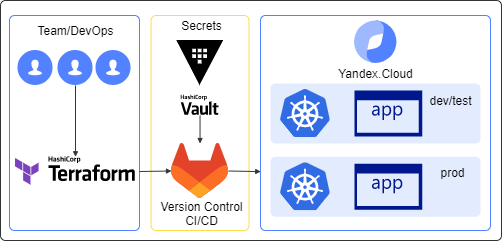При увеличении объёма использования облачных ресурсов возникла необходимость встраивания методологии CI/CD в процесс облачной разработки, так как в текуще... | https://habr.com/ru/post/669526/ | null | ru | null |
# Как работает массив в Swift
В [прошлой статье](https://habr.com/ru/post/645723/) мы поговорили про оценку относительной производительности структуры данных или алгоритма(Big O), теперь я предлагаю взглянуть на самый популярный тип данных - **Массив** и оценить основные методы взаимодействия с ним.
Массив — это набо... | https://habr.com/ru/post/665536/ | null | ru | null |
# NFun — expression evaluator для .Net
[Репозиторий](https://github.com/tmteam/NFun).
[Примеры и спецификация](https://github.com/tmteam/NFun/blob/master/README.md).
### Что есть "Expression evaluator" ?
Expression evaluator позволяет вычислять указанные выражения, например:
* `12*3` это 36
* `[1,2,3].reverse()` э... | https://habr.com/ru/post/698190/ | null | ru | null |
# Играем с огнем: запускаем произвольный код на девелоперском iPhone 7

Под Новый год к нам в руки попал программатор [JC PCIE-7](http://aliexpress.com/item/32964787586.html). В процессе использования выяснилось, что его функциона... | https://habr.com/ru/post/482032/ | null | ru | null |
# Simple automation: фотоальбом
#### Зачем и почему
Эту статью меня побудил написать гневный отзыв одного хабрапользователя, заявившего, что, в переводе на русский, звучит примерно так: «хорош писать комментарии, пиши что-то полезное».
Послав его куда подальше и немного подумав, я решил, что он-таки прав, тем боле... | https://habr.com/ru/post/147964/ | null | ru | null |
# Ruby on Rails + legacy_migrations: односторонняя синхронизация данных между двумя проектами
Эта статья ставит целью описать решение одной нетривиальной задачи — автоматическая односторонняя синхронизация данных в базах двух проекто... | https://habr.com/ru/post/126001/ | null | ru | null |
# Передача треков Google Analytics сторонним доменам без javascript

#### О чем статья?
* О междоменном отслеживании
* О том, что если чего-то нет в [официальной документации](https://developers.google.co... | https://habr.com/ru/post/208706/ | null | ru | null |
# Пишем API для React компонентов, часть 1: не создавайте конфликтующие пропсы
> **Пишем API для React компонентов, часть 1: не создавайте конфликтующие пропсы**
>
>
>
> [Пишем API для React компонентов, часть 2: давайте названия поведению, а не способам взаимодействия](https://habr.com/ru/post/459378/)
>
> ... | https://habr.com/ru/post/459272/ | null | ru | null |
# MLflow: управление многозадачным обучением с независимыми моделями
Введение
--------
Многозадачное обучение (Multi-task learning) - это машинное обучение, где модель обучается на нескольких задачах сразу. Это отличается от обычного обучения на одной задаче, где модель обучается только на одной задаче. Многозадачное... | https://habr.com/ru/post/712904/ | null | ru | null |
# PHP 7 получит в два раза более эффективный Hashtable

Начатый процесс переписывания ядра PHP идет семимильными шагами. Эта статья вольный пересказ [поста](http://nikic.github.io/2014/12/22/PHPs-new-hashtable-implementation... | https://habr.com/ru/post/247145/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.