
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Установка Web Optimizer
[Web Optimizer](http://code.google.com/p/web-optimizator/) (Веб Оптимизатор) — приложение, автоматизирующее все действия по клиентской оптимизации для произвольного сайта. На данный момент оно существует в виде отдельного приложения (которое нужно самостоятельно установить на сайт). В качеств... | https://habr.com/ru/post/55031/ | null | ru | null |
# Разминки с Прологом
Путешественники, привет.
Если вы это читаете предлагаю продолжение того "занимательного" материала, который я писал перед этим. Если вы немного проследили за мыслью, которая изветвилась в три статьи, а основной то посыл — был, только в том, чтобы показать интерес к декларативному подходу. Он поч... | https://habr.com/ru/post/428704/ | null | ru | null |
# Data Driven Tests & SpecFlow
[SpecFlow](http://www.specflow.org/specflownew/) позволяет использовать встроенные таблицы для Data Driven сценариев. В своей практике я столкнулся с двумя проблемами при таком подходе:
1. Иногда хочется, наоборот, получить авто-документацию из теста (например, тестирование API)
2. Ко... | https://habr.com/ru/post/181311/ | null | ru | null |
# 10 малоизвестных возможностей инструментов разработчика Chrome
Автор заметки, перевод которой мы публикуем, пользуется инструментами разработчика Chrome почти каждый день. Здесь он хочет рассказать о малоизвестных возможностях этих инструментов. Он говорит, что если бы знал о них раньше, то ему они точно бы пригодил... | https://habr.com/ru/post/470411/ | null | ru | null |
# Декларативный подход в Angular
Когда я впервые услышал про compliant-механизмы, был весьма впечатлен. Хоть они и окружают нас в повседневности — в виде застежек рюкзака, кнопок мыши или колпачков от шампуней, — мы редк... | https://habr.com/ru/post/527762/ | null | ru | null |
# Разработка игрового сервера на Nadron
В этой статье я расскажу об основных моментах разработки игрового сервера на фреймворке [Nadron](https://github.com/menacher/java-game-server/tree/netty4), о стеке технологий, используемых мной в разработке, и приведу пример структуру проекта для браузерной игры.
#### Почему ... | https://habr.com/ru/post/354292/ | null | ru | null |
# DoS эксплойт Chrome и некоторых других браузеров
Помните [пост про эксплойт скайпа](http://habrahabr.ru/post/259393/)?
Сегодня [обнаружился](http://andrisatteka.blogspot.ru/2015/09/a-simple-string-to-crash-google-chrome.html) похожий эксплойт для браузера Chrome и некоторых браузеров на его движке, который привод... | https://habr.com/ru/post/267229/ | null | ru | null |
# Учимся общаться между микросервисами на Node.js через RabbitMQ
Это продолжение статьи «[Пишем первый микросервис на Node.js с общением через RabbitMQ](https://habr.com/ru/post/447074/)», которая была неплохо принята пользователями хабра.
В этой статье я расскажу о том, как нужно правильно общаться между микросервис... | https://habr.com/ru/post/447250/ | null | ru | null |
# Траблшутинг DRBD9 в LINSTOR

За последние несколько лет плотной работы с LINSTOR и DRBD9 у меня накопилось достаточное количество проблем и рецептов решения для них, что мне захотелось оформить их в небольшую статью. Не уверен что он... | https://habr.com/ru/post/531344/ | null | ru | null |
# Радио в облаках. Многоканальный имитатор GPS
Cкорости сетей и вычислительные возможности компьютеров непрерывно и быстро растут. Это делает реализуемыми и экономически оправданными некоторые приложения из мира радио. Говоря философскими категориями, количество переходит в качество, и на стыке отраслей появляются нев... | https://habr.com/ru/post/583872/ | null | ru | null |
# Stale Element Reference в Selenide
Всем привет! Данная ошибка является очень популярной при использовании Selenide автотестах в Java. На поиск решения у меня ушло довольно много времени, поэтому в этой статье я хочу подробно рассказать про эту ошибку и как с ней работать.
### Что такое Stale Element Reference и как... | https://habr.com/ru/post/573144/ | null | ru | null |
# Проверка VirtualDub
Только что, я сел и проверил проект VirtualDub с помощью PVS-Studio. Выбор был случаен. Я считаю, самое главное регулярно проверять/перепроверять различные прое... | https://habr.com/ru/post/198060/ | null | ru | null |
# Блокировки в PostgreSQL: 3. Блокировки других объектов
Мы уже поговорили о некоторых [блокировках на уровне объектов](https://habr.com/ru/company/postgrespro/blog/462877/) (в частности — о блокировках отношений), а также о [блокировках на уровне строк](https://habr.com/ru/company/postgrespro/blog/463819/), их связи ... | https://habr.com/ru/post/465263/ | null | ru | null |
# STM32 и Bluetooth или удаленное управление ПК своими руками
#### Вместо введения
День добрый.
Сегодня я попытаюсь рассказать о своей попытке построить систему удаленного управления ПК в пределах одного помещения.
Сразу отмечу для тех кто скажет велосипед. Да это велосипед. И мне было интересно его построить. ... | https://habr.com/ru/post/195368/ | null | ru | null |
# PHP-Дайджест № 148 (14 – 28 января 2019)
[](https://habr.com/ru/post/437752/)
Свежая подборка со ссылками на новости и материалы. В выпуске: взломан репозиторий PEAR, о будущем Xdebug, конференция PHP Russia 2019, свежие релизы, ... | https://habr.com/ru/post/437752/ | null | ru | null |
# Единорог в поисках внеземного разума: анализ кода SETI@home
*Существует две возможности: либо мы одиноки во Вселенной, либо нет. Обе одинаково ужасны. (с) Артур Чарльз Кларк*
Дискуссии о том, одиноки ли ... | https://habr.com/ru/post/259151/ | null | ru | null |
# Текст любой ценой: RTF
Что ж продолжим наши изыскания на предмет получения текста из различных форматов данных. Не так давно мы с вами научились вытаскивать текст из [zipped-xml-based файлов](http://habrahabr.ru/blogs/php/69417/) (odt и docx), а также, в начале этой недели, из [pdf](http://habrahabr.ru/blogs/php/695... | https://habr.com/ru/post/70119/ | null | ru | null |
# Устройство компилятора Swift. Часть 3

Продолжаем изучать компилятор Swift. Эта часть посвящена Swift Intermediate Language.
Если вы не видели предыдущие, рекомендую перейти по ссылке и прочитать:
* [Общий обзор компонентов](http... | https://habr.com/ru/post/438696/ | null | ru | null |
# C++ Variadic templates. Каррирование и частичное применение
Доброго времени суток, уважаемое Хабрасообщество.
Недавно приходилось наблюдать дискуссию о каррировании и частичном применении. Суть этой полемики состояла в том, что лучше, для практических целей, иметь в языке программирования: встроенное частичное пр... | https://habr.com/ru/post/133084/ | null | ru | null |
# Как работает PHPixie — Жизнь одного запроса, контейнер и парадигма

Я уже много раз писал о фреймворке [PHPixie](http://phpixie.com) и программировании на нем. В этот раз мы заглянем внутрь и посмотр... | https://habr.com/ru/post/194470/ | null | ru | null |
# CUDA: Начало

Это первая публикация из цикла статей об использовании GPGPU и nVidia CUDA. Планирую писать не очень объемно, чтобы не слишком утомлять читателей, но достаточно часто.
Я предполагаю, что... | https://habr.com/ru/post/54330/ | null | ru | null |
# Простой способ создать IoT-приложение для мониторинга удаленных серверов на платформе IBM Bluemix
Интернет вещей становится все более привычным не только для ИТ-специалистов, но и для обычных людей. Системы «Умный дом»,... | https://habr.com/ru/post/323006/ | null | ru | null |
# Как я писал аудит запуска Docker-контейнеров на Go
Всеобщая контейнеризация захватывает мир. Не обошла эта эпидемия и меня стороной, и теперь, последние шесть месяцев, я занимаюсь тем, что сегодня принято называть модным словом DevOps. В проектах, которыми я занимаюсь, мы решили использовать [Docker](https://www.doc... | https://habr.com/ru/post/257913/ | null | ru | null |
# MotionLayout + RecyclerView = красивые анимированные списки
В этой статье я расскажу и покажу, как создавать красивые анимированные списки на основе RecyclerView и MotionLayout. Аналогичный метод я использовал в одном из своих проектов.
> От переводчика: репозиторий автора статьи - <https://github.com/mjmanaog/food... | https://habr.com/ru/post/550846/ | null | ru | null |
# Майнкрафт для геологов: 3D-рендеринг миллиарда ячеек на встроенной видеокарте (часть 2)
[В первой части статьи](https://habr.com/ru/company/bashnipineft/blog/544054/) мы реализовали простой (и не очень эффективный) рендерер сетки ГУТ, и пообещали, что оптимизируем рендерер настолько, что он сможет отобразить заявлен... | https://habr.com/ru/post/559508/ | null | ru | null |
# Firefox: размер файла по ссылке, или через тернии к форку
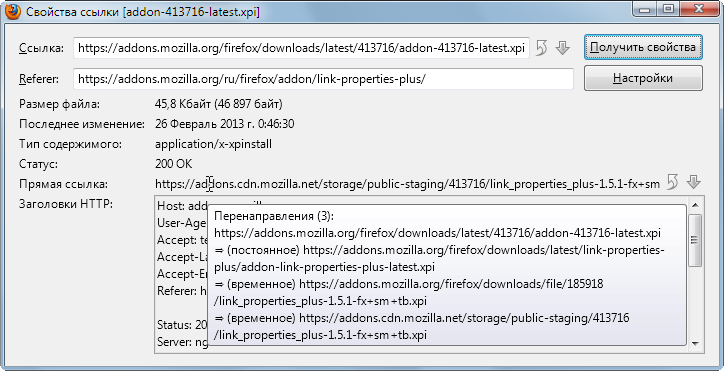
Вашему вниманию представляется небольшая история появления расширения [Link Properties Plus](https://addons.mozilla.org/... | https://habr.com/ru/post/175745/ | null | ru | null |
# Предсказываем время решения тикета с помощью машинного обучения
Оформляя тикет в системе управления проектами и отслеживания задач, каждый из нас рад видеть ориентировочные сроки решения по своему обращению.
Получая поток входящих тикетов, человеку/команде необходимо выстроить их в очередь по приоритету и по врем... | https://habr.com/ru/post/433166/ | null | ru | null |
# Свой CI/CD для Unity

Сейчас я расскажу, как выглядит процесс разработки на Unity в маленькой gamedev компании и как мы его улучшаем и автоматизируем. Всё-таки 2020 год на дворе, хватит уже мышкой водить…
Про мышку, это н... | https://habr.com/ru/post/479884/ | null | ru | null |
# JavaScript по-русски — pycckuu.js

Вы никогда не задумывались, как выглядит код на JavaScript для программиста, у которого родной язык — английский? Представьте, насколько удобнее им читать и писать код на своем «нативном... | https://habr.com/ru/post/283072/ | null | ru | null |
# man!(C => D => Rust)
[Предыдущую статью](https://habrahabr.ru/post/280642/) восприняли лучше, чем я ожидал, так что решился на продолжение эксперимента. Это своеобразный ответ на [перевод статьи](https://habrahabr.ru/post/276227/) [Programming in D for C Programmers](http://dlang.org/ctod.html) за авторством Дмитрия... | https://habr.com/ru/post/280904/ | null | ru | null |
# Doorkeeper CSRF — CVE-2014-8144
Как и многие хабрапользователи, я пользуюсь «облачными» технологиями, в т.ч. арендую VPS (виртуальные сервера) в разных странах мира. Порядка двух лет я пользовался Амазоном и не сказать, чтобы был доволен, но хватало.
В сентябре прошлого года я наткнулся на очень агрессивную PR ко... | https://habr.com/ru/post/246025/ | null | ru | null |
# Уменьшаем размер публикуемых npm модулей
По умолчанию npm публикует в registry весь модуль целиком. За исключением явно указанных в .gitignore файлов. Это отбрасывает зависимости, но все равно позволяет куче не очень нужных ф... | https://habr.com/ru/post/283552/ | null | ru | null |
# Читаем tar за 26 строк ANSI C кода
Архиваторы — это страшно! Огромные и ужасные алгоритмы, которые обычному человеку никогда в жизни не понять! Rar, zip, gzip, tar — современные стандарты де-факто, а значит крайне сложные и навороченные штуки, которые и пытаться понять не стоит. Ну, tar выглядит попроще, может там в... | https://habr.com/ru/post/320834/ | null | ru | null |
# Remote observer
Если проект вышел за рамки локальной машины, скорее всего придётся интегрироваться с какими-нибудь сторонними системами.
Хочу рассмотреть случай, когда упомянутая внешняя система хочет получать уведомления о каких-либо изменениях в нашей системе. Например, обновление каталога товаров.
### Задача
... | https://habr.com/ru/post/503594/ | null | ru | null |
# [SAP] SAPUI5 for dummies part 1: A complete step-by-step exercise

#### Introduction & Recap
In the [previous blog post](https://habr.com/en/post/436608/), we have created a new SAPUI5 application on our SAP SCP WebIDE Full stack an... | https://habr.com/ru/post/436876/ | null | en | null |
# Использование C и C++ в Data Science для новичков
Решим классическую задачу Data Science на C99 и C++11.
В то время как такие языки как Python и R становятся все более популярными для науки о данных, C и C++ могут быть сильным выбором для эффективного решения задач в Data Science. В этой статье мы будем использов... | https://habr.com/ru/post/509534/ | null | ru | null |
# Асинхронный код в синхронный встроенными средствами
Итак, не так давно мне пришлось столкнуться с довольно популярной задачей преобразования асинхронного кода в синхронный в рамках цикла. В моем случае это была работа с AmazonAPI методами productSearch. Все бы ничего, да вот только данный API очень не любит когда к ... | https://habr.com/ru/post/308864/ | null | ru | null |
# Объектно-ориентированный Gradle. Настраиваем Build types в Android, используя Kotlin DSL
В этой статье мы поговорим о том, как наша команда перешла на Kotlin DSL для описания Gradle файлов, и как в итоге м... | https://habr.com/ru/post/669878/ | null | ru | null |
# Прощай, чистый код
[](https://habr.com/ru/company/ruvds/blog/484610/)
Был поздний вечер.
Мой коллега только что записал в репозиторий код, над которым работал целую неделю. Мы делали тогда графический редактор, а в свежем коде... | https://habr.com/ru/post/484610/ | null | ru | null |
# Vision-based SLAM: монокулярный SLAM
Продолжаем серию статей-уроков по визуальному SLAM уроком о работе с его монокулярными вариантами. Мы уже [рассказывали об установке и настройке окружения](http://habrahabr.ru/company/singularis/blog/277109/), а также проводили общий обзор в [статье о навигации квадрокоптера](htt... | https://habr.com/ru/post/277537/ | null | ru | null |
# Супер-юзабильные формы

Как-то на хабре разгорелся спор, как заставить пользователя вводить дату в правильном формате, было множество интересных решений, но заставлять пользователя совершенно не надо — пусть за пользователя основную работу делают м... | https://habr.com/ru/post/37249/ | null | ru | null |
# Генерация PDF на сервере в Ruby
Чуть более месяца назад я устроился верстальщиком в старт-ап, в команду Ruby-разработчиков. Так повезло, что команда оказалась очень хорошей и моё стремление учиться совпало с их желанием по... | https://habr.com/ru/post/157199/ | null | ru | null |
# Две истории как ANKI может вам помочь выучить иностранный язык и подготовиться к интервью
Я всегда считал, что ленивый программист это хороший программист. Почему? Потому что попроси трудолюбивого сделать что-то, он пойдет и сделает. А ленивый программист потратит в 2-3 раза больше времени, но напишет скрипт, которы... | https://habr.com/ru/post/454236/ | null | ru | null |
# Рейтинг процессоров по методике CoreMark
Подбирая новый десктоп столкнулся с хаосом различных оценок быстродействия системы. И вроде бы всем давно известно, что связку компонентов следует подбирать по принципу «морского конвоя» — общая скорость конвоя определяется самым медленным кораблём, коими выступают скорость о... | https://habr.com/ru/post/225853/ | null | ru | null |
# Java-модель памяти (часть 2)
Привет, Хабр! Представляю вашему вниманию перевод второй части статьи [«Java Memory Model»](http://tutorials.jenkov.com/java-concurrency/java-memory-model.html) автора Jakob Jenkov. Первая часть [тут](https://habr.com/ru/post/510454/).
Аппаратная архитектура памяти
===================... | https://habr.com/ru/post/510618/ | null | ru | null |
# Garbage Collector & C++
Ручное управление памятью с С++ — одновременно один из самых больших плюсов и минусов в языке. Действительно, эта парадигма позволяет создавать очень производительные программы, однако она же рождает и кучу проблем. Существует несколько способов избавится от них. Я попробовал несколько и в ит... | https://habr.com/ru/post/282544/ | null | ru | null |
# Продолжаем знакомиться с Intel Xeon Phi: «родной» код
В [прошлой статье](http://habrahabr.ru/post/262019/) было описано знакомство с сопроцессором Intel Xeon Phi используя offload – основной код работает на хосте, а отдельные блоки выгружаются на сопроцессор. В данной заметке рассмотрим компиляцию и использование «р... | https://habr.com/ru/post/263121/ | null | ru | null |
# Мониторинг безопасности облаков
Перенос данных и приложений в облака представляет собой новую проблему для корпоративных SOCов, которые не всегда готовы к мониторингу чужой инфраструктуры. По данным Netoskope среднее предприятие (видимо все-таки в США) использует 1246 различных облачных сервиса, что на 22% больше, ч... | https://habr.com/ru/post/466103/ | null | ru | null |
# Как программно управлять WiFi маршрутизатором TP-Link с помощью Python requests
Однажды передо мной встала задача реализации программного управления одним из распространенных домашних Wi-Fi маршрутизаторов TP-Link TL-WR841N, у которого, к сожалению, нет интерфейса управления через командную строку (telnet, SSH). Я х... | https://habr.com/ru/post/342194/ | null | ru | null |
# Энтерпрайз-домино. 0x13 вредных советов для ниндзя-разработчика
Практически любая enterprise-система (под которой мы будем подразумевать некоторое ПО, где пользователи работают постоянно в течение всего рабочего дня) в современном мире стремится вырасти вместе с управляемым ей бизнесом в высоконагруженное web-решени... | https://habr.com/ru/post/549908/ | null | ru | null |
# Karma — тестируем javascript в консоли
Здравствуйте. Признаюсь честно, я пишу тесты редко. Т.е хотел бы чаще, но все как-то не получается. Вроде и руководство в принципе не против даже, но все равно находятся задачи посрочнее и поважнее. Тем не менее на днях заглянув в redmine обнаружил что задач практически нет (то... | https://habr.com/ru/post/187094/ | null | ru | null |
# Как я писал классические танки с интеллектом
### Вступление
Я являюсь независимым разработчиком приложений под Android (а конкретней — полтора года разработки интеллектуальной версии классической всеми любимой культовой игры "Танчики 1990").
Почему я решил написать эту игру: к играм я имею ещё более непосредствен... | https://habr.com/ru/post/304246/ | null | ru | null |
# Как вынудить процесс использовать новый адрес DNS-сервера из обновлённого resolv.conf без перезапуска самого процесса
Я работаю системным администратором Unix. Однажды к нам в отдел эксплуатации сервисов упал тикет от программиста с выдержой из лога application-сервера в заголовке: "*pgbouncer cannot connect to serv... | https://habr.com/ru/post/209356/ | null | ru | null |
# Создание кроссплатформенных приложений с помощью React Native
*Предлагаем вашему вниманию перевод статьи, которая будет интересна начинающим разработчикам.*
React Native — это JS-фреймворк для создания нативно отображаемых iOS- и Android-приложений. В его основе лежит разработанная в Facebook JS-библиотека React... | https://habr.com/ru/post/324562/ | null | ru | null |
# Как использовать API сайта, у которого нет API?
У меня достаточно часто появляется задача получить данные от стороннего сайта, при этом далеко не всегда этот сайт предоставляет возможность удобно получить эти данные через API. Единственное решение в таком случае — парсить html содержимое страниц. Когда-то я писал ре... | https://habr.com/ru/post/241335/ | null | ru | null |
# Букмарклет: разбор существенных моментов, часть третья, резервная
В продолжение двух предыдущих публикаций про [первую инициирующую](http://habrahabr.ru/company/theonlypage/blog/234427/) и [вторую подгружаемую](http://habrahabr.ru/company/theonlypage/blog/236315/) части букмарклета, для полноты картины, рассмотрим и... | https://habr.com/ru/post/236741/ | null | ru | null |
# Голосовые помощники не учатся на тесте Тьюринга

Три года назад чат-бот Соня Гусева стала победителем [первого теста Тьюринга на русском языке](http://turingtest.inf.net/2015/06/%D1%84%D0%B8%D0%BD%D0%B0%D0%BB-%D1%82%D0%B5%D1%81%D1%... | https://habr.com/ru/post/419549/ | null | ru | null |
# Рефакторинг проекта в SVN с помощью ANT
В статье описывается способ разделения логики и реализации логики в ant-скриптах, примененный для решения одной практической задаче по рефакторингу большого проекта в SVN-репозитории.
##### Предыстория
Имеется проект в SVN из 15 000 файлов и 5 000 папок. Проекту почти 10 л... | https://habr.com/ru/post/119013/ | null | ru | null |
# Отслеживаем «onresize» на элементе
Достаточно древняя задача отслеживания события изменения размеров произвольного элемента на странице. Актуально при создании модульно-независимой структуры для корректировки размеров и иных сss-атрибутов нужного элемента на странице, в частности блоков с периодической Аякс-подгрузк... | https://habr.com/ru/post/166321/ | null | ru | null |
# Простое распознавание лица «на лету» в Django
Доброго дня!
Меня зовут Соболев Андрей и сегодня мы с вами создадим простую «плюшку» к Django, которая будет проверять, что на фотографии именно лицо человека (что бывает полезно в куче ситуаций).
Для этого нам понадобится OpenCV и 5 минут свободного времени. Поеха... | https://habr.com/ru/post/504748/ | null | ru | null |
# Создание приложений для смартфонов BlackBerry средствами WebWorks SDK

BlackBerry WebWorks SDK выгодно отличается среди прочего доступного на настоящий день инструментария для создания приложений Bla... | https://habr.com/ru/post/119675/ | null | ru | null |
# Angular: неочевидные возможности селекторов директив
Если вы когда-нибудь создавали директивы Angular, то вы, вероятно, использовали в качестве селектора конструкцию, в которой используются скобки: `([])`. Такой подход, хотя чаще всего применяется именно он, не является единственно возможным. На самом деле, селектор... | https://habr.com/ru/post/421345/ | null | ru | null |
# Как найти себе место на земле и не попасть на счетчик Яндекса
… эта история началась давным-давно в далекой-далекой стране Краковия, чьи жители беспечно проживали свои жизни и не знали…
Но сам я местный, и сегодня расскажу вам страшную историю, о том, что мешало спать (лично мне) долгие годы. И это не налоги (с н... | https://habr.com/ru/post/263863/ | null | ru | null |
# Как защитить форум на движке phpBB от автоматических регистраций
Форумный движок [phpBB](http://www.phpbbguru.net/) обладает большим количеством достоинств, он удобен и для пользователей и для модераторов и, как следствие, очень популярен. Но именно популярность порождает его главный недостаток — его спамят, причем ... | https://habr.com/ru/post/113405/ | null | ru | null |
# Основы исполнения JavaScript и взаимодействие с сайтами внутри программ на Qt
#### Введение
О кроссплатформенной библиотеке Qt слышали, наверное, многие. О движке отображения веб-страниц WebKit тем более. Не так давно первое стало содержать обертку над вторым, примеры создания браузеров в 50 строчек найти не сложно... | https://habr.com/ru/post/111418/ | null | ru | null |
# Синхронный «запрос-ответ» с использованием REST и Apache Kafka
На одном из проектов Группы «Иннотех» появилась задача перевода асинхронных запросов в синхронные. По сути, нужно было подружить REST и Apache Kafka в одном запросе.
Если разложить задачу по полочкам, то у нас есть два сервиса, которые общаются между со... | https://habr.com/ru/post/693380/ | null | ru | null |
# СЭД на платформе DocsVision (часть 1): как группы доступности MSSQL помогают быстрее выкатывать изменения в прод
Всем привет, меня зовут Александр, я работаю в команде СЭД компании ДОМ.РФ.
Сначала коротко ... | https://habr.com/ru/post/577900/ | null | ru | null |
# 7 полезных расширений VS Code для Python-разработчиков
> Наиболее важные и полезные расширения VS Code для Python-разработчиков в нашем новом переводе.
Я пользуюсь PyCharm, и меня всё устраивает. Скорее всего, я не буду менять редактор в ближайшее время. Но вокруг VS Code столько шумихи, столько людей в Reddit и Tw... | https://habr.com/ru/post/542286/ | null | ru | null |
# Язык Go для начинающих

Цель этой статьи — рассказать о языке программирования **Go** (Golang) тем разработчикам, которые смотрят в сторону этого языка, но еще не решились взяться за его изучение. ... | https://habr.com/ru/post/219459/ | null | ru | null |
# Классика оптимизации: задача рюкзака (knapsack problem)
Рассмотрим следующую ситуацию. Допустим вы хотите поехать за границу, но валюту вам не меняют — вы можете перевезти с собой лишь товары для реализации на свободном рынке «там». С собой в самолет разрешено взять не более 20 кг. Возникает вопрос – какие товары вз... | https://habr.com/ru/post/83918/ | null | ru | null |
# Как написать игру на Monogame, не привлекая внимания санитаров. Часть 4, решаем основной вопрос философии
Предыдущие части: [Часть 0](https://habr.com/ru/post/676850/), [Часть 1](https://habr.com/ru/post/676998/), [Часть 2](https://habr.com/ru/post/677718/), [Часть 3](https://habr.com/ru/post/679456/)
К сожалению, ... | https://habr.com/ru/post/695500/ | null | ru | null |
# Публичные контракты, как обеспечить их согласованность
* ваша система состоит из множества взаимосвязанных сервисов?
* всё ещё вручную актуализируете код сервисов при изменении публичного API?
* изменения в ваших сервисах часто подрывают работу других, а другие разработчики вас за это ненавидят?
Если ответили да хо... | https://habr.com/ru/post/502652/ | null | ru | null |
# Несколько интересностей и полезностей для веб-разработчика #28
Доброго времени суток, уважаемые хабравчане. За последнее время я увидел несколько интересных и полезных инструментов/библиотек/событий, которыми хочу поделиться с Хабром.
#### [roBrowser](https://github.com/vthibault/roBrowser/)
[ определённо одна из мощнейших Javascript библиотек, но у неё есть один небольшой недостаток который зачастую ошибочно принимают за большой — отсутствие родной поддержки связывания селекторов с событиями. Для сравнения — в [jquery.com... | https://habr.com/ru/post/23253/ | null | ru | null |
# React, встроенные функции и производительность
Когда мне приходится рассказывать о React, или когда я даю первую лекцию учебного курса, показывая всякие интересные вещи, кто-нибудь непременно спросит: «Встроенные функции? Слышал, они медленные».
[
Git это еще одна системы для управления исходным кодом, аналогичная subversion, cvs и другим. Почему аналогичная, а не «новая», «быстрая» и тп? SCM (source code management) прежде всего инструмент, который позволяет выполнять операции необходимые для одного разработчика и ... | https://habr.com/ru/post/62557/ | null | ru | null |
# Финансовое latency critical приложение на Java и Akka
Всем привет! В своей статье я поделюсь опытом разработки одного из финансовых приложений на Java в ТехЦентре Дойче Банка, расскажу про стек технологий, который мы используем, и каких результатов достигаем.
 [«Extension Writing Part I: Introduction to PHP and Zend»](http://devzone.zend.com/node/view/id/1021).
Введение
========
Если вы читаете данную статью, скорее всего у вас есть некоторый интере... | https://habr.com/ru/post/98862/ | null | ru | null |
# 35 инструментов для веб-разработчика на каждый день
Кроме редактора кода, терминала, браузера и гита веб-разработчики пользуются вагоном и маленькой тележкой маленьких инструментов, которые выполняют какую-то одну задачу, но могут пригодиться в ежедневной работе. Предлагаем вам нашу подборку — надеемся, что что-то п... | https://habr.com/ru/post/579514/ | null | ru | null |
# Загрузка картинок на стену ВКонтакте
*А вам приходят сообщения от друзей с просьбами отослать куда-нибуть СМС или заглянуть в галерею где ваша знакомая позирует ню? А все потому, что пользуются сомнительным ПО и ходят на сомнительные сайты.*
Мы сейчас напишем скрипт, который будет размещать картинки-граффити на ... | https://habr.com/ru/post/59248/ | null | ru | null |
# Ломаем зашифрованный диск для собеседования от RedBalloonSecurity. Part 0x01
[**По мотивам**](https://habr.com/ru/news/t/536740)[**Часть 0x00**](https://habr.com/ru/post/549090/)[**Часть 0x01**](https://h... | https://habr.com/ru/post/549578/ | null | ru | null |
# «Занимательный XenAPI», или «Новые приключения Citrix XenServer»
Привет, коллеги!
Сегодня я хотел бы продолжить свое повествование о **Citrix XenServer 5.6** и о разных аспектах работы с ним. В этот раз мне пришлось ре... | https://habr.com/ru/post/147736/ | null | ru | null |
# Как отличать птиц от цветов. Или цветы от птиц
В качестве программы выходного дня мне захотелось поиграться с как бы «нейронной» сетью (спойлер — в ней нет нейронов). А чтобы потом не было мучительно больно за бесцельно прожитые ~~годы~~ часы, я подумал, что зря мы его кормим, пусть пользу приносит — пусть заодно эт... | https://habr.com/ru/post/338548/ | null | ru | null |
# Грядёт Ragnarök! Или Opera 11.50 на подходе
[Ragnarök — браузер викингов с новым алгоритмом разбора HTML5!](http://labs.opera.com/news/2011/02/22/)
На этой неделе дебютирует наш лабораторный билд под названием Рагнарёк, который содержит нашу реализацию алгоритма разбора HTML5. Нам хотелось бы что бы вы протестиро... | https://habr.com/ru/post/114507/ | null | ru | null |
# Самотестируемая система с оповещениями на Laravel + Bitbucket + HipChat
В этой статье я расскажу, как можно оперативно настроить автоматическое стягивание нового кода на тестовый сервер вашего laravel-приложения, автозапуск тестов и оповещение о результате в соответствующий корпоративный чат. А также отлавливание но... | https://habr.com/ru/post/341724/ | null | ru | null |
# Пишем класс на php для интерпретации BrainLoller
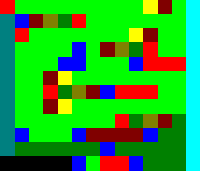
(Пример Brainloller кода увеличенного в несколько раз)
**BrainLoller** — это визуальный диалект языка Brainfuck, в котором символьные команды заменяютс... | https://habr.com/ru/post/128539/ | null | ru | null |
# Как мы делали свой поиск в Ozon: эволюция архитектуры от SQL до O2
Привет, Хабр! Меня зовут Сергей, я руководитель команды поиска в Ozon. Сегодня я расскажу об эволюции наших поисковых систем: как всё начиналось более 20 лет назад с обычных SQL-запросов, как мы осваивали Sphinx и Elasticsearch, и как сейчас наш собс... | https://habr.com/ru/post/667600/ | null | ru | null |
# Решетчатое наследование
Наследование, при кажущейся простоте, часто приводит к сложным, сопротивляющимся изменениям структурам. Иерархии классов растут как самый настоящий лес.
Целью наследование является привязка кода (набора методов) к минимальному набору свойств сущности (как правило — объекта), которые он обе... | https://habr.com/ru/post/242649/ | null | ru | null |
# Как мы читаем код
В рамках исследований движений глаза Майк Хансен и Эрик Холк [провели](http://synesthesiam.com/?p=218) любопытный эксперимент. Используя айтрекер [Tobii TX300](http://www.tobii.com/en/eye-tracking-research/global/products/hardware/tobii-tx300-eye-tracker/) частотой 300 Гц, они сравнили поведение гл... | https://habr.com/ru/post/163259/ | null | ru | null |
# Git снизу вверх
У этого перевода не совсем обычная история. Системы контроля версий далеки от моих профессиональных интересов. Для рабочих проектов они мне требовались нечасто, причем, разные, так что, каждый раз, когда возникала такая необходимость, я заново вспоминала, как в них делается та или иная операция. А дл... | https://habr.com/ru/post/344962/ | null | ru | null |
# HotSpot в Mikrotik, или как заработать $: Часть 2
#### Общие сведения
Это вторая часть статьи, иллюстрирующие возможности использования OS Mikrotik, в качестве HotSpot точки. В первой части я рассказывал как настроить HotSpot, а так же познакомил с возможностью выдачи и покупки карт доступа. Ознакомиться с первой ч... | https://habr.com/ru/post/175303/ | null | ru | null |
# Бот для тетриса и реверс-инжиниринг анимации. Разбор мобильного трека второго чемпионата по программированию

##### Победители мобильного трека
В уходящем году Яндекс провел два онлайн-чемпионата по программированию. Мы продолжа... | https://habr.com/ru/post/482210/ | null | ru | null |
# Ардуино на службе здоровья
*В статье описан путь от идеи до создания домашнего портативного анализатора качества воздуха (CO2, влажность, температура, давление).*
#### Вступление
В сети много гуляет разных кошмаров про безжалостную черную плесень, которая убивает людей, а плесень любит влажные помещения. Боротьс... | https://habr.com/ru/post/242521/ | null | ru | null |
# Ошибки и проблемы серверов большой тройки: часть вторая. HP

Мы продолжаем цикл публикаций о проблемах, с которыми сталкиваемся при подготовке [refurbished-серверов](http://www.pc-administrator.ru). Ранее мы [писали о сер... | https://habr.com/ru/post/302360/ | null | ru | null |
# RATKing: новая кампания с троянами удаленного доступа
В конце мая мы обнаружили кампанию распространения ВПО класса Remote Access Trojan (RAT) — программ, которые позволяют злоумышленникам удаленно управлять зараженной системой.
Рассматриваемая нами группировка отличилась тем, что она не выбрала для заражения как... | https://habr.com/ru/post/508324/ | null | ru | null |
# Новый Redis 2.0 и Rediska 0.5.0!
[](http://rediska.geometria-lab.net/)Дорогие друзья! На прошлой неделе вышел стабильный релиз чудесной key-value базы [Redis](http://code.google.com/p/redis/) версии 2... | https://habr.com/ru/post/103823/ | null | ru | null |
# Адам Лэнгли объяснил причины бага в iOS: лишняя строчка кода поломала всю безопасность
Вчера компания Apple выпустила [обновление безопасности iOS 7.0.6](http://support.apple.com/kb/HT6147) для iPhone 4 и более поздних моделей, iPod touch 5-го поколения и iPad 2+. Одновременно выпущен аналогичный патч 6.1.6 для iPho... | https://habr.com/ru/post/213525/ | null | ru | null |
# Исключения в Java, Часть I (try-catch-finally)
Это первая часть статьи, посвященной такому языковому механизму Java как исключения (вторая [(checked/unchecked) вот](http://habrahabr.ru/company/golovachcourses/blog/225585/)). Она имеет вводный характер и рассчитана на начинающих разработчиков или тех, кто только прис... | https://habr.com/ru/post/223821/ | null | ru | null |
# Пишем HTML-виджет для приложения IBOOK Author
Ни для кого не секрет, что печатные книги уходят в прошлое. Им на смену приходит новое поколение устройств (а вместе с ними и программ), которые позволяют не только прочитать материал, подобно книге, но и разнообразить чтение интерактивными вставками. Это может быть как ... | https://habr.com/ru/post/171141/ | null | ru | null |
# Как использовать Internet Explorer 8 для тестирования сайтов в IE6 и IE7
О чем-то подобном уже писал заблокированный ныне хабраюзер SelenIT. Но австралийский разработчик Elbert F. предлагает новый способ тестирования сайта «в IE6» с помощью кусочка PHP-кода.
Лично я не сильно волнуюсь, как выглядят мои сайты в IE... | https://habr.com/ru/post/75276/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.