
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# В PHP 7.4 войдут стрелочные функции (сокращенная запись анонимных функций)
Голосование по сокращенному синтаксису для функций завершено (51 "за", 8 "против").
Было:
```
$result = array_filter($paths, function ($v) use ($names) {
return in_array($v, $names);
});
```
Стало:
```
$result = array_filter($paths,... | https://habr.com/ru/post/450544/ | null | ru | null |
# Разработка дополнения для MODx Revolution. Часть 3

Это перевод [третьей части урока](http://rtfm.modx.com/display/revolution20/Developing+an+Extra+in+MODX+Revolution%2C+Part+III). Как я писал в [предыдущей статье](http://habrah... | https://habr.com/ru/post/132709/ | null | ru | null |
# Кластерный анализ в R
Кластерный анализ решает задачу разбиения множества на группы (кластеры) по принципу наибольшей однородности.
Подобные задачи возникают во множестве сфер деятельности, в частности это реклама и маркетинг. Ситуация, когда нужно выделить группы клиентов, максимально «похожих» друг на друга или о... | https://habr.com/ru/post/685040/ | null | ru | null |
# Небольшие, но важные функции
> ***Будущих студентов курса*** [***"C++ Developer. Professional"***](https://otus.pw/J4eF/) ***приглашаем принять участие в открытом уроке*** [***"Backend на современном С++".***](https://otus.pw/faDm/)*А пока делимся традиционным переводом материала.*
>
>

Каждый владелец сервера с «белым» IP-адресом наблюдал в логах бесчисленные попытки подключиться к серверу по SSH с разных точек мира. Администраторы ставят средства противодействия, та... | https://habr.com/ru/post/567250/ | null | ru | null |
# Как я ускорял strstr
Понадобилось мне недавно написать аналог функции strstr(поиск подстроки в строке). Я решил его ускорить. В результате получился алгоритм. Я не нашел его по первым ссылкам в поисковике, зато там куча других алгоритмов, поэтому и написал это.
График сравнения скорости работы моего алгоритма, с фу... | https://habr.com/ru/post/303830/ | null | ru | null |
# Всё про USB-C: типы кабелей
[](https://habr.com/ru/company/ruvds/blog/705642/)
Тема кабелей и разъёмов стандарта USB-C является довольно запутанной, и тому есть объективные причины. Множество вариантов реализации и нюансов вкупе с ... | https://habr.com/ru/post/705642/ | null | ru | null |
# Breeze Server — разграничиваем доступ к объектам при помощи атрибутов

В прошлой статье [Breeze.js + Entity Framework + Angular.js = удобная работа с сущностями базы данных прямо из браузера](http://habrahabr.ru/post/24644... | https://habr.com/ru/post/249417/ | null | ru | null |
# V8: один год со Spectre
3 января 2018 года Google Project Zero и другие [раскрыли](https://googleprojectzero.blogspot.com/2018/01/reading-privileged-memory-with-side.html) первые три из нового класса уязвимостей, которые затрагивают процессоры со спекулятивным выполнением. Их назвали [Spectre](https://spectreattack.... | https://habr.com/ru/post/449546/ | null | ru | null |
# Тестирование производительности VDS
Усиленно подбираю себе VDS — задумался над вопросом сравнения производительности.
*Цель данной статьи — попытка найти критерий, по которому можно сравнить VDS от различных провайдеров и выбрать объективно наиболее удачную по сочетанию цена/качество. Возможно, изложенные в стать... | https://habr.com/ru/post/54393/ | null | ru | null |
# Секреты быстрого кодинга в WebStorm
Сегодня — немного практических советов по работе с WebStorm.
Вначале пишем совсем простой HTML, после *color:* нажимаем и получаем список цветов.

КО подсказывает: во все... | https://habr.com/ru/post/168267/ | null | ru | null |
# Сравнение форматов сериализации
При выборе формата сериализации сообщений, которые будут записаны в очередь, лог или куда-либо еще, часто возникает ряд вопросов, так или иначе влияющих на конечный выбор. Одними из таких ключевых вопросов являются скорость сериализации и размер полученного сообщения. Так как форматов... | https://habr.com/ru/post/458026/ | null | ru | null |
# Евангелие от GUID
Разбираясь с новым Visual C# 2008 (он настолько бесплатный для начинающих разработчиков, что я не удержался), нашел новое для себя слово в науке и технике — GUID.
Привожу пример интересной, как мне кажется, статьи, призывающей использовать глобально-уникальные идентификаторы во всех сферах наро... | https://habr.com/ru/post/31632/ | null | ru | null |
# Безопасный ввод и сохранение зашифрованных паролей в конфигах Linux: пишем скрипт на Python
Как вывести свою систему на новый уровень безопасности с модулями python-gnupg и getpass4.

***Изображение :*** *freeGraphicToday, via... | https://habr.com/ru/post/566748/ | null | ru | null |
# Простое REST api для сайта на php хостинге
Иногда бывает необходимо развернуть не большое рест апи для своего сайта, сделанного по технологии СПА (Vue, React или др.) без использования каких-либо фреймворков, CMS или чего-то подобного, и при этом хочется воспользоваться обычным php хостингом с минимальными усилиями ... | https://habr.com/ru/post/681784/ | null | ru | null |
# IronPython на стороне зла: как мы раскрыли кибератаку на госслужбы европейской страны
[](https://habr.com/ru/company/pt/blog/458766/)
Наши специалисты из экспертного центра безопасности всегда держат... | https://habr.com/ru/post/458766/ | null | ru | null |
# Копилка знаний для PHPixie — Часть 1

В нашем чате часто встречаются вопросы ответы на которые могли бы пригодится и другим. К тому же в [PHPixie](http://phpixie.com) есть много интересных фишек кото... | https://habr.com/ru/post/317498/ | null | ru | null |
# Поиск источника блокировки пользователя в Active Ditectory
В работе администратора домена Active Directory довольно часто возникает необходимость найти причину блокировки пользователя. Иногда причиной блокировки пользователя является заражённый вирусом ПК — в таких случаях особо важна скорость обнаружения источника ... | https://habr.com/ru/post/171701/ | null | ru | null |
# NPM 2.0.0 & передача аргументов в run-script
22 июля случилось небольшое, но знаментаельное событие: был принят [пулл-реквест](https://github.com/npm/npm/pull/5518), что добавлял поддержку передачи произвольных аргументов в ваши npm script'ы. Уже появился [альфа-релиз](https://github.com/npm/npm/releases/tag/v2.0.0-... | https://habr.com/ru/post/230831/ | null | ru | null |
# ICANN отклонил идею Google о доменах без точки

ICANN проголосовал против возможности создания доменных имён без точки, положив конец идее Google о доменах http://search, http://app, http://blog и h... | https://habr.com/ru/post/190424/ | null | ru | null |
# Как написать вредное API
*Пишите код так, как будто сопровождать его будет склонный к насилию психопат, который знает, где вы живёте.*
Всем привет!
Я работаю тимлидом команды Integration Development в сервисе онлайн-бронирования отелей [Ostrovok.ru](https://ostrovok.ru/?utm_source=habr&utm_medium=pr&utm_campaign=p... | https://habr.com/ru/post/445346/ | null | ru | null |
# Как мы перевели API-модули микросервисного проекта с Feign на OpenFeign
Всем привет! Недавно мы решили задачу, как перейти на новую версию Spring + OpenFeign в мультимодульном проекте, в котором выделен API с навешенными аннотациями `@RestController` и `@FeignClient`. Я, Алексей Скакун [@hyragano](/users/hyragano) в... | https://habr.com/ru/post/666218/ | null | ru | null |
# Как я пытался включить http2 у себя на проекте с nginx
В общем, как я уже читал тут в комментах: «целые статьи пишут на то, как добавить 5 символов и пробел в конфиг». Все бы хорошо, если бы не google chrome. Они решили прекратить поддержку **SPDY** и **NPN**(кому интересно, вот комментарий [chromium](https://blog.c... | https://habr.com/ru/post/314474/ | null | ru | null |
# Развитие валидации форм

Валидация форм была педантичным занятием с момента появления web. Первой пришла серверная валидация. Затем она развилась в валидацию на стороне клиента для проверки результатов в... | https://habr.com/ru/post/105761/ | null | ru | null |
# День рождения JavaScript
[](http://habrahabr.ru/company/mailru/blog/244949/)
Всё-таки странно иногда звучит фраза «люди постарше». Особенно применительно к 30-летним. С другой стороны, мир информационных технологий меняет... | https://habr.com/ru/post/244949/ | null | ru | null |
# Сказ о том как перфекционизм мне контроллер сбрасывал

Задумал я как-то купить йогуртницу. Да такую, чтобы йогурт делала хороший и всегда одного качества. Что для этого нужно? Во-первых, сырье, во-вторых, точная и ст... | https://habr.com/ru/post/386199/ | null | ru | null |
# Пузырьковый вычислитель выражений: простейший синтаксический LR-анализатор вручную
Приветствую уважаемое сообщество.
Последнее время я уделял некоторое внимание теме синтаксического анализа (с целью в том числе улучшить собственные знания и навыки), и у меня создалось впечатление, что почти все курсы по компилято... | https://habr.com/ru/post/357052/ | null | ru | null |
# Подмена обработчика системного вызова
Всем доброго времени суток! Я студентка-второкурсница технического ВУЗа. Пару месяцев назад пришла пора выбирать себе тему курсового проекта. Темы типа калькулятора меня не устраивали. Поэтому я поинтересовалась, есть ли что-нибудь более интересное, и получила утвердительный отв... | https://habr.com/ru/post/182792/ | null | ru | null |
# WebStorm 2019.3: ускоренный запуск, усовершенствованная поддержка Vue.js и другие улучшения
Всем привет!
Давненько на Хабре не было блог-постов от команды WebStorm. Что же, будем исправляться, тем более, есть отличный повод: мы только что выпустили последнее крупное обновление WebStorm в этом году.

Всем привет!
Хочу поделиться с вами моим опытом создания сетевого жесткого диска на Raspberry Pi. Моя статья отлично подойдет тем, кто использует линукс в качестве о... | https://habr.com/ru/post/247783/ | null | ru | null |
# Обзор GUI-интерфейсов для управления Docker-контейнерами

Работа с Docker в консоли — привычная для многих рутина. Тем не менее, бывают случаи, когда GUI-/веб-интерфейс может оказаться полезным даже для них. В статье предст... | https://habr.com/ru/post/338332/ | null | ru | null |
# Энтузиаст добавил в ретроконсоль трассировку лучей
Разработчик и энтузиаст Бен Картер добавил в Super NES аппаратный трассировщик лучей. Напомню, что самой консоли уже 30 лет.
Для реализации этой идеи его надоумил друг и желание получше изучить Verilog и FPGA. Таким образом появился проект SuperRT. Блогер хотел сде... | https://habr.com/ru/post/533378/ | null | ru | null |
# Как сохранить оригинальную расцветку вашего кода из Visual Studio в публикации на Хабрахабр. Сравниваем расцветки. Опрос
Привет, хабраюзер! В этом посте я расскажу, как можно сделать свой код на Хабре более «живым» благодаря простому способу сохранения его оригинальной цветовой схемы. А также предлагаю сравнить разл... | https://habr.com/ru/post/242341/ | null | ru | null |
# Docker для фронтендера. Часть 2. Что ты такое?
[Продолжаю](https://habr.com/ru/post/478932/) делать расшифровку своего доклада [Docker для фронтендера](https://frontendconf.ru/moscow/2019/abstracts/5593) с конференции [FrontendConf 2019](https://frontendconf.ru/moscow/2019).
В предыдущей части я постарался ответить... | https://habr.com/ru/post/479018/ | null | ru | null |
# Пишем «Hello, world!» для Zepp OS и часов Amazfit GTS 3

Совсем недавно Amazfit (партнёр Xiaomi) [представила](https://habr.com/ru/news/t/583026/) новое поколение умных часов, в линейку которого вошли модели GTR 3 Pro, GTR 3 и GT... | https://habr.com/ru/post/651185/ | null | ru | null |
# Адаптивный интерфейс для трансформеров на примере Krita Gemini

Устройства-трансформеры или «2 в 1» (планшет + ультрабук) пока еще не стали мейнстримом, но уже популярны у пользователей, желающих получит... | https://habr.com/ru/post/222883/ | null | ru | null |
# [Кейс] Мониторинг качества атмосферного воздуха в коттеджном поселке
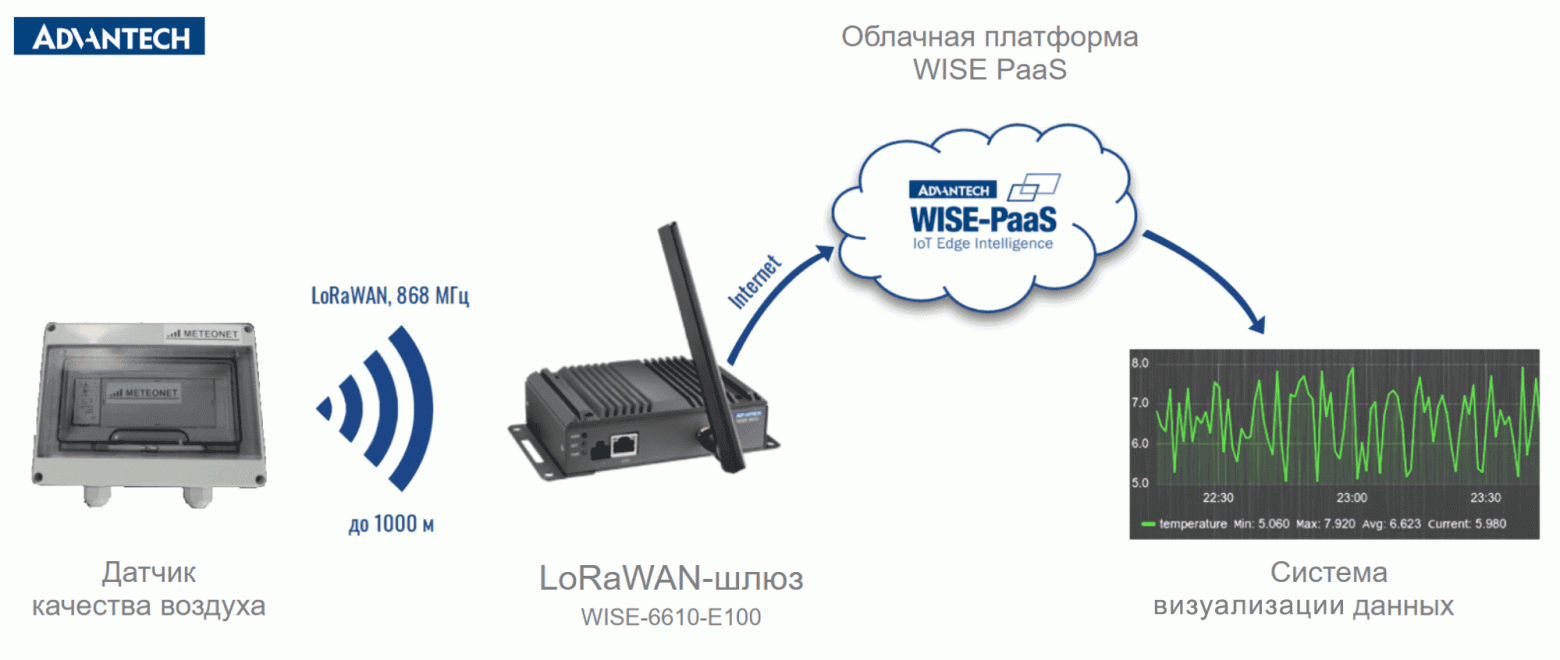
В статье представлен наш опыт разработки решения по мониторингу качества воздуха в поселках с помощью сети эко-датчиков и предоставления информации пользователям... | https://habr.com/ru/post/469921/ | null | ru | null |
# Отказоустойчивый кластер с балансировкой нагрузки с помощью keepalived

Сегодня я расскажу о том, как быстро собрать отказоустойчивый кластер с балансировкой нагрузки с помощью keepalived на примере DNS-серверов.
Итак, предположим... | https://habr.com/ru/post/524688/ | null | ru | null |
# Настраиваем QtCreator для полноценного программирования и отладки микроконтроллеров STM32
Введение
--------
Привет всем.
На данный момент я активно осваиваю разработку ПО для STM32 и хотел бы поделиться моим опытом.
Как известно, для STM32 имеется много сред для разработки, однако часть из них, несмотря на удобн... | https://habr.com/ru/post/705062/ | null | ru | null |
# Лучшие практики AngularJS
По мотивам [этой](http://www.youtube.com/watch?feature=player_embedded&v=ZhfUv0spHCY) трансляции.
Вместо предисловия скажу, что есть такой сайт [yeoman.io](http://yeoman.io), где собраны наиболее популярные технологии, автоматизирующие разработку фронтенда (сборку, параметризацию CSS и п... | https://habr.com/ru/post/181882/ | null | ru | null |
# Jabber-бот для Openfire за час

Вот уже порядка двух лет я занимаюсь разработкой ботов для ICQ. После ряда недавних [событий](http://habrahabr.ru/blogs/im/51000/), из-за которых ICQ-боты часто оказывались неработоспособными, а также после статьи... | https://habr.com/ru/post/52523/ | null | ru | null |
# О качестве отечественных серверов для рядового разработчика
Любые совпадения с реальностью случайны.
Вот вы - рядовой разработчик. Пишите себе код, починяете примус. И вот захотелось вам сделать хобби-пр... | https://habr.com/ru/post/703336/ | null | ru | null |
# Создаём плагин Qt GeoServices на примере ОС Аврора, OpenStreetMap и Sight Safari
Привет, Хабр! Хотим рассказать о том, как создать плагин Qt GeoServices и использовать его в своём приложении на ОС Аврора. В... | https://habr.com/ru/post/555238/ | null | ru | null |
# Как в Hazelcast добавляли распределенный SQL
Чтобы разработать свой распределенный SQL-движок, можно написать свой SQL-оптимизатор для построения движков. Вам придется сделать парсер, семантический анализатор и придумать правила трансформации и оптимизации. Всё протестировать, а потом как-то интегрировать в свою сис... | https://habr.com/ru/post/569258/ | null | ru | null |
# Android — Сontinuous Integration. Часть 1
Не буду описывать в сотый раз что такое CI и зачем это нужно. Выдумщиком данной концепции считается, не безизвестный, Мартин Фаулер, а с его трудом можно ознакомиться [здесь](http://martinfowler.com/articles/continuousIntegration.html).
Я же хочу в серии из нескольких ст... | https://habr.com/ru/post/145907/ | null | ru | null |
# Поиск названия компании с использованием Python и контекстно-свободных грамматик
*Сложно представить задачу более востребованную и частотную, чем задачу текстового поиска. Упростить ее помогают совершенно разные инструменты и методы, однако универсального решения нет. Как один из оптимальных вариантов в статье предс... | https://habr.com/ru/post/590257/ | null | ru | null |
# Курс MIT «Безопасность компьютерных систем». Лекция 11: «Язык программирования Ur/Web», часть 2
### Массачусетский Технологический институт. Курс лекций #6.858. «Безопасность компьютерных систем». Николай Зельдович, Джеймс Микенс. 2014 год
Computer Systems Security — это курс о разработке и внедрении защищенных ком... | https://habr.com/ru/post/425999/ | null | ru | null |
# Лень пораБОТила instagram

Предисловие
-----------
Сейчас многие используют инстаграм (далее инста): кто-то там собирает альбомы, кто-то продает, кто-то покупает, а я там ленюсь. Мне всегда было интересно как там поживают мои друз... | https://habr.com/ru/post/347774/ | null | ru | null |
# Инструкции FMA3 в Ryzen намертво вешают операционную систему

Как выяснилось, выполнение некоторых специфичных инструкций FMA3 на процессоре AMD Ryzen приводит к критическому сбою ОС.
Инструкции ... | https://habr.com/ru/post/402551/ | null | ru | null |
# Краткая история Rust: от хобби до самого популярного ЯП по данным StackOverflow
Rust — это язык системного программирования, создатели которого [уделили](https://www.cleverism.com/skills-and-tools/rust/) внимание [трем вещам](https://ru.wikipedia.org/wiki/Rust_(%D1%8F%D0%B7%D1%8B%D0%BA_%D0%BF%D1%80%D0%BE%D0%B3%D1%80... | https://habr.com/ru/post/349786/ | null | ru | null |
# Восемь принципов программирования, которые могут облегчить вам жизнь
Одна из главных проблем в разработке программного обеспечения – борьба с возрастающей сложностью системы. Решением этой проблемы занимаются с времен появления первых программ. Результатами являются языки, всё более упрощающие взаимодействие с машин... | https://habr.com/ru/post/140827/ | null | ru | null |
# Уличное освещение на основе ESP8266
Привет, Хабр! В этой статье я расскажу о своем опыте разработки системы уличного освещения, построенной на микроконтроллере ESP8266. Хоть данная идея и не нова и в интернете огромное количество готовых проектов на базе данного микроконтроллера, я хотел бы поделиться тем, что у мен... | https://habr.com/ru/post/665226/ | null | ru | null |
# Расширение PHP и Kotlin Native. Часть третья, наверное финальная
 В [первой части](https://habr.com/company/alfa/blog/415471/) рассказываются совсем базовые вещи про настройку инструментария и общие концепции.
[Вторая часть](https:... | https://habr.com/ru/post/423145/ | null | ru | null |
# Вы и Брэд Питт похожи на 99%

Мы в отделе аналитики онлайн-кинотеатра [Okko](https://okko.tv) любим как можно сильнее автоматизировать подсчёты сборов фильмов Александра Невского, а в освободившееся время учиться нов... | https://habr.com/ru/post/417329/ | null | ru | null |
# Active Record Pattern
Хочу рассказать о применении шаблона Active Record для C# на практике. Такой класс реализует извлечение и запись структуры в базу данных. Бизнес логика выносится на следующие уровни абстракции, где с таким объектом можно работать уже как с обычной структурой.
Центральный случай, который я бу... | https://habr.com/ru/post/155545/ | null | ru | null |
# IT-чаты или Выжимаем из Skype все соки
 Часто у новичков в той или иной IT области ощущается острый дефицит знаний и знакомых, у которых можно что-либо «спросить» по теме. Да, StackOverflow, Google и д... | https://habr.com/ru/post/242683/ | null | ru | null |
# Учебный фреймворк на Java по глубокому обучению
Недавно мы выпустили первую версию нового фреймворка по глубокому обучению [DeepJava](https://github.com/DeepJavaUniverse/DJ-core) (DJ) [0.01](https://github.com/DeepJavaUniverse/DJ-core/releases/tag/v0.01).
Основная цель фреймворка, по крайней мере, на текущий момент... | https://habr.com/ru/post/352520/ | null | ru | null |
# Синхронизируем открытые вкладки через Dropbox
Имеется множество Расширений/Дополнений или уже встроенных в браузер решений, позволяющих синхронизировать закладки, пароли, автозаполнения и пр.
Но, пользуясь те... | https://habr.com/ru/post/116708/ | null | ru | null |
# CannyViewAnimator: переключаем состояния красиво
Всем привет! Мне очень нравится работать с анимациями — в каждом Android-приложении, в создании которого я участвую или на которое просто смотрю, я нашёл бы место парочке. В не таком ещё далёком апреле 2016 года [с моей записи](https://habrahabr.ru/company/livetyping/... | https://habr.com/ru/post/309740/ | null | ru | null |
# Make на мыло, redo сила
Приветствую! Хочу рассказать о главных, не всегда очевидных, недостатках системы сборки [Make](https://en.wikipedia.org/wiki/Make_(software)), делающих её часто не пригодной для использования, а также рассказать о прекрасной альтернативе и решении проблемы — гениальнейшей по своей простоте, с... | https://habr.com/ru/post/517490/ | null | ru | null |
# Z-order vs R-tree, продолжение
В [прошлый раз](https://habrahabr.ru/post/319096/) мы пришли к выводу, что для эффективной работы пространственного индекса на основе Z-order необходимо сделать 2 вещи:
* эффективный алго... | https://habr.com/ru/post/319810/ | null | ru | null |
# Rtorrent + PHP + MySQL
После первого моего знакомства с консольным торрент клиентом rtorrent меня не покидала мысль автоматизировать свою работу с торрентами.
Статей по работе с торрентами много, но того, что нужно именно мне, я не нашел.
В этой статье я расскажу и покажу на примере как работать с торрентами ... | https://habr.com/ru/post/147015/ | null | ru | null |
# Функция buildargv с помощью Ragel
Забавное использование Ragel State Machine Compiler для создания функции разбора строки на int argc, char \*argv[].
Все началось с того, что понадобилась функция buildargv, чтобы разбирать строку для последующей передачи в
```
int main (int argc, char *argv[]) { body }
```
Ну лад... | https://habr.com/ru/post/477296/ | null | ru | null |
# ExtJS и CodeIgniter
В статье приведены примеры объединения [ExtJS](http://www.sencha.com) Grid с [CodeIgniter](http://www.code-igniter.ru/), и получение данных из MySQL.
Будем считать, что у Вас уже есть опыт работы с CodeIgniter, поскольку в статье будут размещаться только функции. Я не буду рассказывать как нас... | https://habr.com/ru/post/101975/ | null | ru | null |
# Вышла финальная версия Ubuntu 10.10 Maverick Meerkat

Сегодня была выпущена финальная версия Ubuntu 10.10 Maverick Meerkat.
Скачать:
**CD Версии:**[releases.ubuntu.com/10.10/ubuntu-10.10-desktop-i386.iso](http://releas... | https://habr.com/ru/post/105869/ | null | ru | null |
# Microsoft Server App-V — что это, и с чем его едят
Server App-V — интересный продукт Microsoft, несправедливо, на мой взгляд, обделённый вниманием. Вообще заметил, что пока маркетологи и пиарщики этой корпорации ломают копья, демонстрируя очередные таблицы поддержки максимального количества процессоров и терабайт па... | https://habr.com/ru/post/240971/ | null | ru | null |
# Хакер взломал 150 тысяч принтеров, доступных в Сети

Найденная в лотке принтера распечатка может стать большим сюрпризом
Специалист по компьютерной безопасности с ником Stackoverflowin [рассказал](https://www.bleepingc... | https://habr.com/ru/post/373139/ | null | ru | null |
# Паттерны проектирования, взгляд iOS разработчика. Часть 2. Наблюдатель

Содержание:
===========
[Часть 0. Синглтон-Одиночка](https://habrahabr.ru/post/320728/)
[Часть 1. Стратегия](https://habrahabr.ru/post/321182/) ... | https://habr.com/ru/post/324292/ | null | ru | null |
# Стероидный велосипед: векторная алгебра, на ассемблере, в Delphi
Некоторое время назад понадобилось мне в одной Delphi-шной программе много посчитать, но расчеты шли как-то подозрительно долго. Переписывать около 100 kLOC не хотелось- особенно из-за наличия большого количества форм, а предыдущий мой опыт показывал, ... | https://habr.com/ru/post/545518/ | null | ru | null |
# Squid3 в режиме SSLBump с динамической генерацией сертификатов
Приветствую.
Шифрованный веб-трафик вещь хорошая, но порой совершенно не ясно что пользователь там, внутри, делает. При заходе на любой https ресурс через squid, в логи записывается достаточно строк подобного вида:
1330231066.104 10 172.26.27.8 TCP... | https://habr.com/ru/post/168515/ | null | ru | null |
# Непрерывный рост JSON
Статья написана в сентябре 2017 года
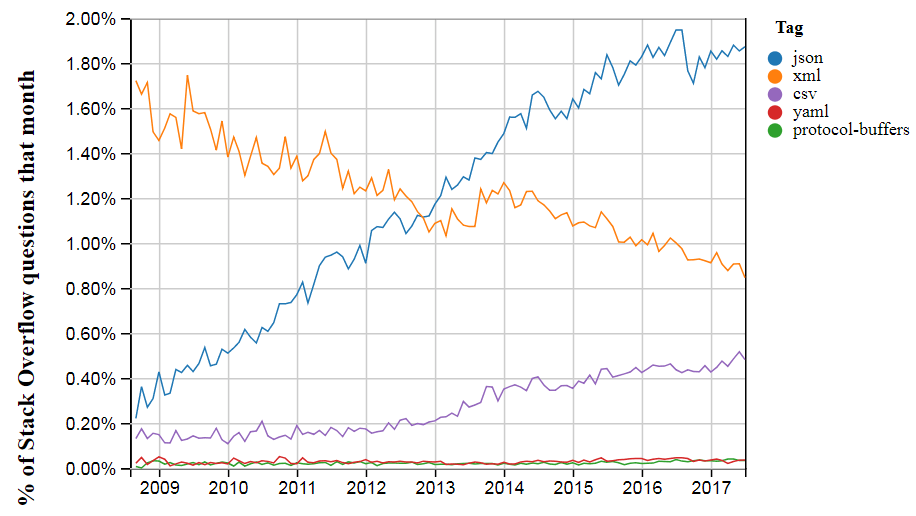
JSON захватил мир. Если сегодня любые два приложения общаются друг с другом через интернет, то скорее всего делают это с помощью JSON. Стандарт принят всеми крупными и... | https://habr.com/ru/post/421657/ | null | ru | null |
# ICQ: 20 лет — не предел

Год назад мы [вспоминали](https://habrahabr.ru/company/mailru/blog/271317/), как от релиза к релизу Аська подвергалась пластическим операциям и фейслифтингу. Но сегодня юбилей — ICQ исполняется 20... | https://habr.com/ru/post/315318/ | null | ru | null |
# Домашний хостинг сайтов с динамическим IP
У меня (как и у многих web-разработчиков) имеется с десяток сайтов которые необходимо где-то размещать (хостить).
Сайты практически не приносят прибыли, поскольку это какие-то старые работы (по разным причинам не пошедшие в продакшн), домашняя страница, сайт заведенный кр... | https://habr.com/ru/post/313426/ | null | ru | null |
# Создаем приложение для ANDROID быстро и просто
[](https://habr.com/ru/company/ruvds/blog/558434/)
Сегодня я хотел бы поделиться с Вами, как быстро и просто можно создать приложение для Android с базовыми знаниями HTML CSS и JS. П... | https://habr.com/ru/post/558434/ | null | ru | null |
# Свежий взгляд на примеси в JavaScript
В этой статье я детально исследую примеси в JavaScript, и покажу менее общепринятую, но, на мой взгляд, более естественную стратегию «примешивания», которую, надеюсь, вы найдете полезной. Закончу я матрицей результатов профилирования, подводящей итог влиянию на производительност... | https://habr.com/ru/post/147901/ | null | ru | null |
# Первое знакомство с Google Maps Javascript API
В данном посте я расскажу о своем опыте использования Google Maps JS API и его внедрение в мобильную версию сайта с весьма крупной посещаемостью.
Совсем недавно на работе пришлось столкнуться с реализацией модуля, рассчитанного на поиск пользователей сайта в пределах... | https://habr.com/ru/post/125118/ | null | ru | null |
# CMYK алгоритм поиска замкнутого контура на двумерной матрице
Это история не столько про алгоритмы сколько про ассоциации. Именно ассоциация с каналами кодирования цветов и послужила причиной написания этой статьи.
, после чего анализирует запрос и формирует ответ. Однако, всем прекрасно известно, что в мире Python и Ruby принят другой под... | https://habr.com/ru/post/250055/ | null | ru | null |
# Сборка гибридного приложения под Android
Многие считают, что гибридные приложения не могут иметь хорошую производительность, особенно в плане построения страницы (то есть имеют низкий FPS). Это ошибочно... | https://habr.com/ru/post/277729/ | null | ru | null |
# 15 HTML-методов элементов, о которых вы, вероятно, никогда не слышали
**От переводчика:** *Дэвид Гилбертсон (David Gilbertson) — известный автор, который пишет о веб- и криптовалютных технологиях. Он смог собрать большую аудиторию читателей, которым рассказывает о всяких хитростях и интересностях этих областей.*
... | https://habr.com/ru/post/417375/ | null | ru | null |
# Wordpress — стандарты кодирования плагинов

Увлекшись написанием плагинов для Wordpress'а составил правила хорошего тона…
Соглашение по именованию
---------------... | https://habr.com/ru/post/48998/ | null | ru | null |
# Как соединить кластеры Kubernetes в разных дата-центрах

**Добро пожаловать в серию кратких руководств по Kubernetes.** Это регулярная колонка с самыми интересными вопросами, которые мы получаем онлайн и на наших тренингах. Отвеч... | https://habr.com/ru/post/454056/ | null | ru | null |
# Основные архитектурные шаблоны построения ПО
[](https://habr.com/ru/company/ruvds/blog/699648/)
Краткий обзор восьми наиболее востребованных архитектурных шаблонов с иллюстрациями:
* [Многоуровневая архитектура](#anchorid);
* [«... | https://habr.com/ru/post/699648/ | null | ru | null |
# PSD parser или как разобрать файл Photoshop на Java
Как-то предложили сделать парсер psd файла. Вроде бы очень просто. Надо найти из каких слоёв состоит документ, вывести перечень слоёв. Если слой текстовый, вывести текст и параметры форматирования. Т.е. названия шрифтов, размеры, отступы и т.д.
С чего начать? Да... | https://habr.com/ru/post/261511/ | null | ru | null |
# Django — обработка ошибок в ajax-формах
Hello everyone!
Все мы знаем что [Django](http://www.djangoproject.com/) — очень мощный и динамично развивающийся фреймворк для создания веб-приложений. Однако, несмотря на наступление эпохи Веб 2.0, в нём всё ещё нет встроенных механизмов для работы с **AJAX**, в частности... | https://habr.com/ru/post/117876/ | null | ru | null |
# DTO в JS
Информационные системы предназначены для обработки данных, а DTO ([Data Transfer Object](https://en.wikipedia.org/wiki/Data_transfer_object)) является важным концептом в современной разработке. В “классическом” понимании DTO являются простыми объектами (без логики), описывающими структуры данных, передаваем... | https://habr.com/ru/post/567040/ | null | ru | null |
# На кого ориентироваться, разрабатывая сайт
Разрабатываем сайт?
===================
Итак, вы решили разработать супер-мега-крутой сайт для русскоязычной аудитории. Вы определились с тематикой, дизайном и прочая-прочая. Но вот интересный вопрос — под какие браузеры писать, использовать ли JavaScript и Cookies и т.д. ... | https://habr.com/ru/post/28929/ | null | ru | null |
# Вышел alpha-релиз Smarty 3
Оказывается, третьего дня, то есть 17 октября сего года, вышел альфа-релиз многими любимого (и многими же презираемого) шаблонизатора [Smarty](http://smarty.net/).
Интерфейс шаблонизатора особо не изменился. Это всё те же `display()`, `fetch()` и `assign()`, которые покрывают процентов... | https://habr.com/ru/post/42810/ | null | ru | null |
# Сравнить две таблицы excel
Решим достаточно тривиальную задачу с помощью языка python — сравним две таблицы excel и выведем результат в третью. Что может быть проще, и почему просто не использовать средства самой программы, входящей в пакет office? Попробуем разобраться.
, [Qualys](https://www.qualys.com/apps/vulnerability-management/), [Max Patrol](https://www.ptsecurity.com/ru-ru/products/mp8/) и ... | https://habr.com/ru/post/416137/ | null | ru | null |
# Пишем shell скрипты на Python и можно ли заменить им Bash
В этой небольшой статье речь пойдет о том, можно ли легко использовать Python для написания скриптов вместо Bash/Sh. Первый вопрос, который возникнет у читателя, пожалуй, а почему, собственно, не использовать Bash/Sh, которые специально были для этого созданы... | https://habr.com/ru/post/277679/ | null | ru | null |
# Как мы автоматизируем iOS: настройка Gitlab CI + Fastlane + Firebase + ItunesConnect
В основном идея использования CI/CD для iOS, да и для других платформ, — это автоматизация рутинной работы. Когда мы работаем над одним приложением, можем вручную собирать небольшой проект. Но команда растёт, хочется тратить время э... | https://habr.com/ru/post/583532/ | null | ru | null |
# Разработка встроенного ПО: введение
*Привет, Хабр! Представляю вашему вниманию перевод статей Chris Svec, оригинал [здесь](https://embedded.fm/blog/ese101). Публикуется с разрешения автора по лицензии [CC-A-NC-ND](https://creativecommons.org/licenses/by-nc-nd/3.0/).*
Embedded software engineering 101: введение
==... | https://habr.com/ru/post/503322/ | null | ru | null |
# Гайд по User Stories для Junior BA / PO / PM
Статья будет полезная Junior-специалистам, которые так или иначе работают с документацией на проекте. В статье рассматриваются как сами пользовательские истории, так и критерии, по которым можно написать хорошую историю. Из статьи читатель сможет подчерпнуть и как писать ... | https://habr.com/ru/post/577420/ | null | ru | null |
# Как профессиональный интерес украл у меня выходные
Всем доброго времени суток! После прочтения данной статьи ([Интернет-магазин цветов, или как мы облажались на День Святого Валентина](https://habrahabr.ru/post/351396/)) решил поделиться опытом оптимизации одного из сайтов на Битриксе. По неизвестной причине именно ... | https://habr.com/ru/post/351676/ | null | ru | null |
# Отопление загородного дома на arduino с передачей данных в internet
Мне хотелось бы представить очередной пример использования Arduino в реальных задачах. Тут я представлю максимально простой, но реально работающий проект регулировки отопления дома с помощью электрокотла на базе Arduino. Я очень надеюсь, что эта ста... | https://habr.com/ru/post/364989/ | null | ru | null |
# Хранение мира в Snake Rattle'n'Roll
Много лет назад мне довелось поиграть на Dendy в игру **Snake Rattle'n'Roll**. Пройти её мне тогда так и не удалось, из-за широко известного в узких кругах [бага](https://cah4e3.wordpress.com/2009/0... | https://habr.com/ru/post/498106/ | null | ru | null |
# Грокаем RxJava, часть третья: Реактивность с пользой
В [первой части](http://habrahabr.ru/post/265269/) мы прошлись по основам RxJava. Во [второй части](http://habrahabr.ru/post/265269/) я показал вам потенциал операторов. Но, быть может, всего показанного мною всё ещё недостаточно для того, чтобы убедить вас. В так... | https://habr.com/ru/post/265727/ | null | ru | null |
# В поиске вопросов, или как создать новый отладчик
Мы уделяем много внимания инструментам разработки: участвуем в горячих спорах о редакторах (Vim или Emacs?), долго настраиваем IDE под свой вкус, и тщательно выбираем языки программирования и библиотеки, которые с каждым днем становятся все лучше и удобнее. Однако, з... | https://habr.com/ru/post/514332/ | null | ru | null |
# Архитектура сетевого балансировщика нагрузки в Яндекс.Облаке

Привет, я Сергей Еланцев, разрабатываю [сетевой балансировщик нагрузки](https://cloud.yandex.ru/services/load-balancer?utm_source=habr&utm_medium=article&utm_campaign=ar... | https://habr.com/ru/post/448588/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.