
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Умножение длинных чисел методом Карацубы
На днях нужно было разобраться с этим алгоритмом, но беглый поиск в google ничего путнего не дал. На Хабре тоже нашлась только одна [статья](http://habrahabr.ru/blogs/algorithm/121950/), которая мне не особо помогла. Разобравшись, попробую поделиться с общественностью в досту... | https://habr.com/ru/post/124258/ | null | ru | null |
# Запускаем тесты на GitLab Runner с werf — на примере SonarQube

Если в качестве инфраструктуры, где разворачивается приложение, выступает Kubernetes, можно сказать, что существует два способа запуска тестов (и других утилит для ана... | https://habr.com/ru/post/526702/ | null | ru | null |
# Блокировка контента, расширение для браузеров chromium
Основной тренд этого года «блокировка», описанное ниже расширение, позволяет почувствовать власть над контентом в браузере.
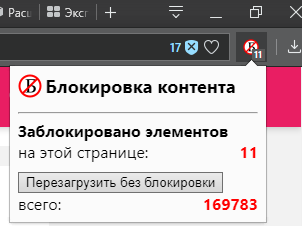
Помню давно, в детстве, при просмотре телевизора... | https://habr.com/ru/post/425361/ | null | ru | null |
# Несколько интересностей и полезностей для веб-разработчика #21
Доброго времени суток, уважаемые хабравчане. За последнее время я увидел несколько интересных и полезных инструментов/библиотек/событий, которыми хочу поделиться с Хабром.
#### [Awesome Python](https://github.com/vinta/awesome-python)
Автор этого ог... | https://habr.com/ru/post/228757/ | null | ru | null |
# Из ошибки в алерт с действиями
Привет, Хабр! Для пользователя сообщения об ошибке часто выглядят как «Что-то не так, АААА!». Конечно, ему бы хотелось вместо ошибок видеть волшебную ошибку «Починить все». Ну или другие варианты действий. Мы начали активно добавлять себе такие, и я хочу рассказать про то, как вы может... | https://habr.com/ru/post/495346/ | null | ru | null |
# Пересечение морд доменов топ 1,000,000 по N-граммам
Задачей исследования является визуализация дуплицированности главных страниц доменов по пятисловным шинглам в рамках общей базы.
[](https://habrahabr.ru/post/307250/)
... | https://habr.com/ru/post/307250/ | null | ru | null |
# Select принципиально неисправен. Мультиплексирование ввода/вывода часть #2
В предыдущей статье блога мы обсудили [краткую историю системного вызова select(2)](https://idea.popcount.org/2016-11-01-a-brief-hi... | https://habr.com/ru/post/689006/ | null | ru | null |
# Я перехожу на JavaScript
После того, как я 5 лет писал на Go, я решил, что мне пора двигаться дальше. Go хорошо послужил мне. Вероятно, это был лучший язык, которым я мог бы пользоваться столько времени, но теперь настал момент оставить Go.
Не могу сказать, что я насмотрелся на ограничения и проблемы Go. За годы ... | https://habr.com/ru/post/499670/ | null | ru | null |
# Реверс-инжиниринг визуальных новелл
Хочу признаться: я обожаю визуальные новеллы. Кто не в курсе — это такие то ли интерактивные книжки, то ли игры-в-которых-надо-в-основном-читать-текст, то ли радиоспектакли-с-картинками, пр... | https://habr.com/ru/post/281595/ | null | ru | null |
# Запрет редактирования свойств модели в ASP.NET MVC
При разработке сложных бизнес приложений часто приходится сталкиваться с ситуацией, когда пользователям необходимо ограничивать права на редактирование некоторых данных. В данной статье будет рассмотрен пример запрета изменения определенных свойств модели в приложен... | https://habr.com/ru/post/156285/ | null | ru | null |
# Старая псина учит новые трюки: Code Kata с использованием QuickCheck
Когда я агитирую коллег-программистов создавать больше различных автотестов на их код, они часто жалуются, что это сложная и унылая работа. И в чём-то они правы. При использовании классических юнит-тестов, действительно, нередко приходится писать у... | https://habr.com/ru/post/240811/ | null | ru | null |
# Drupal, drush & svn
В своём проекте мы используем svn для контроля версий. Однако, как оказалось, «подружить» с ним drupal – нетривиальная задача.
Пока мы не открыли для себя drush, приходилось тратить много телодвижений для выполнения обновления ядра и используемых модулей.
Drush – drupal shell – Инструмент д... | https://habr.com/ru/post/91287/ | null | ru | null |
# Написание бота для Stronghold Kingdoms
##### История написания бота для Stronghold Kingdoms
Долгое время я подходил к вопросу написания бота для этой игры, но то опыта не хватало, то лень, то не с той стороны заходить пытался.
В итоге, набравшись опыта написания и обратной разработки кода на C# я решил добиться ... | https://habr.com/ru/post/225663/ | null | ru | null |
# Часть 2: RocketChip: подключаем оперативную память
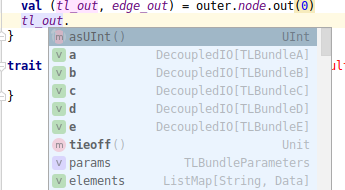 В [предыдущей части](https://habr.com/ru/post/455391/) мы собрали микроконтроллер вообще без оперативной памяти на базе ПЛИС Altera/Intel. Однако на плате есть разъём с установленным... | https://habr.com/ru/post/456172/ | null | ru | null |
# Новые уязвимости 4G LTE: массовая рассылка сообщений, имперсонификация абонентских устройств и другие

*Сетевая архитектура LTE*
На прошедшей конференции по безопасности сетей и распределённых систем в Сан-Диего [NDSS 2018](http... | https://habr.com/ru/post/351470/ | null | ru | null |
# Идиоматичный Redux: Дао Redux'а, Часть 1 — Реализация и Замысел
Мысли о том, какие требования выдвигает Redux, как задумано использование Redux и что возможно с Redux.
Введение
--------
Я потратил много времени, обсуждая онлайн паттерны использования Redux, была ли это помощь тем, кто изучает Redux в [Reactiflux к... | https://habr.com/ru/post/330692/ | null | ru | null |
# Построение RESTful web API на платформе InterSystems — 2
Введение
--------
Четыре года назад я написал свою первую статью на Хабре и она была посвящена [созданию RESTful web API на платформе InterSystems](https://habrahabr.ru/company/intersystems/blog/204576/). С тех пор прошло немало времени и вышло несколько новы... | https://habr.com/ru/post/345532/ | null | ru | null |
# GitLab Container Registry
*В мае этого года вышел релиз [ГитЛаба 8.8](https://habrahabr.ru/company/softmart/blog/302884/). Частью этого релиза был запуск встроенного Docker Container Registry. Ниже перевод майской статьи, посвященной этому.*
Недавно нами был выпущен [GitLab версии 8.8](https://habrahabr.ru/company/... | https://habr.com/ru/post/309102/ | null | ru | null |
# Платформа как сервис в Авито: как это устроено
Привет, Хабр! Меня зовут Александр Лукьянченко, я тимлид команды, которая занимается платформой в Авито. В этой статье я расскажу о проблемах, которые возникали у нас при построении платформы для инженеров и том, какие технические решения мы использовали, чтобы эти проб... | https://habr.com/ru/post/527400/ | null | ru | null |
# Туториал: Frontity — настройка авторизации для приватных эндпоинтов WordPress
### Предисловие
Этот туториал предназначен в первую очередь для новичков в разработке на Frontity (React framework для WordPress).
### Основная цель
Собрать в одном месте всю необходимую информацию для настройки авторизации для приватны... | https://habr.com/ru/post/696650/ | null | ru | null |
# Затемнение изображения в CollapsingToolbarLayout или Image Scrim
Привет, хабражителям и ~~любителям~~ профессионалам разработки под Android. В этой статье я хочу с вами поделиться на мой взгляд нужной и интересной информацией. Речь пойдет о такой вещи, как Image Scrim (скажу сразу, что данное понятие я ввел самостоя... | https://habr.com/ru/post/319088/ | null | ru | null |
# Пишем свой Watermark TextBox и PasswordBox для Win8/RT, Windows Phone
#### Сабж
На самом деле очень тревиальная задача, но, столкнувшись с которой, можно потерять драгоценное время.
Итак, что мы имеем:
[WinRT XAML Toolkit](http://winrtxamltoolkit.codeplex.com/) несет на своем борту Watermark TextBox, но имеет... | https://habr.com/ru/post/179605/ | null | ru | null |
# Сложное решение простых проблем HighLoad WEB-сервисов
Ключевой задачей высоконагруженных WEB-систем является способность обработать большое число запросов. Решить эту проблему можно по-разному. В этой статье я предлагаю рассмотрет... | https://habr.com/ru/post/424415/ | null | ru | null |
# Давид Ян (ABBYY) о том, как был создан FineReader
Был недавно на встрече некого клуба, где выступал Давид Ян (основатель компании ABBYY). Часть выступления записал на телефон. Расшифровку записи представляю Вашему вниманию.
`--------------------------------`
Если компания выходит на рынок и на этом рынке уже е... | https://habr.com/ru/post/88852/ | null | ru | null |
# Oauth 2.1 spring authorization server + SPA
Доброго всем дня, уважаемые хабровчане!
До сего момента я являлся лишь читателем этого замечательного ресурса, но вот кажется и пришло время написать мою первую статью.
Oauth 2.1 - дальнейшее развитие популярного фреймворка авторизации Oauth 2.0, который на момент написа... | https://habr.com/ru/post/688680/ | null | ru | null |
# .NET 4.0: что нового в базовых классах (BCL)? Подробный обзор

Visual Studio 2010 и .NET Framework 4 Beta 2 уже доступны для [загрузки](http://msdn.microsoft.com/en-us/vstudio/dd582936.aspx). .NET 4 Beta 2 содержит некоторое количество нового функционала и улуч... | https://habr.com/ru/post/73359/ | null | ru | null |
# Разработать и опубликовать игру под Android за неделю
Задумал я как-то написать игру. Причем, по-быстрому. Желательно за неделю при условии работы на полставки. Финальным этапом должна была стать публикация на Google Play (что, конечно, недостаточно, но об этом позже). Таким образом, это будет статья о разработке в ... | https://habr.com/ru/post/319260/ | null | ru | null |
# Версионность веб-приложений
Общеизвестно, что каждый программный продукт в конечном итоге обретает номер поставляемой версии. Изначально это может быть цифра в README файле, на борде в JIRA либо просто в г... | https://habr.com/ru/post/541206/ | null | ru | null |
# Введение в GitLab CI
*Публикую перевод [моей статьи](https://about.gitlab.com/2016/07/29/the-basics-of-gitlab-ci/) из блога ГитЛаба про то как начать использовать CI. Остальные переводы гитлабовских постов можно найти в [блоге компании Softmart](https://habrahabr.ru/company/softmart/)*.
---
Представим на секунду, ... | https://habr.com/ru/post/309380/ | null | ru | null |
# Коммутатор Eltex MES 23XX. Шаблон базовой конфигурации
Добрый день, коллеги! В этой статье я попытался создать шаблон базовой настройки коммутаторов Eltex MES 23XX для использования в корпоративных сетях, имеющих вспомогательные сервисы администрирования и мониторинга. Разумеется, невозможно описать весь функционал ... | https://habr.com/ru/post/575830/ | null | ru | null |
# LyX: Общие замечания. Часть 2
Скопировано с [моего блога](https://matematikaandinformatika.blogspot.com/p/blog-page_83.html) в целях создания еще одного русскоязычного источника информации по данной теме.
Эта статья является продолжением следующих статей одного цикла:
[статья 1](https://habr.com/ru/post/466423... | https://habr.com/ru/post/485998/ | null | ru | null |
# Эволюционирующие торгующие системы
AI наступает, и мы этого не боимся. Предлагаю озадачить его зарабатыванием капусты на бирже. Для начала, а там посмотрим.
### Термины
Агент это программа, имеющая счета в различных валютах на одной бирже, работа которой должна вести к увеличению их совокупной стоимости.
Акт... | https://habr.com/ru/post/463357/ | null | ru | null |
# Подборка полезных утилит SCSS
Для успешной реализации проекта разработчикам фронтенда не обойтись без проверенного арсенала расширения SCSS. Ниже представлены утилиты, которые могут пригодиться в работе.
#### Triangle
Примесь triangle (которую дизайнеры Sagi предпочитают называть «chupchick»), добавляет к всплыв... | https://habr.com/ru/post/276509/ | null | ru | null |
# Разрабатываем и развёртываем собственную платформу ИИ с Python и Django
Взлёт искусственного интеллекта привёл к популярности платформ машинного обучения MLaaS. Если ваша компания не собирается строить фреймворк и развёртывать свои собственные модели, есть шанс, что она использует некоторые платформы MLaaS, например... | https://habr.com/ru/post/538320/ | null | ru | null |
# История бесконечного города. На Three.js
WebGL — одна из самых интересных новых технологий, которая способна удивительным образом преобразовать интернет. На базе этой технологии уже создано несколько движков, которые позволяют без лишних усилий создавать удивительные вещи, и наиболее известный из них Three.js. Позна... | https://habr.com/ru/post/278043/ | null | ru | null |
# Цифровой бармен. Arduino проект для совершеннолетних начинающих электронщиков. Часть 1
У меня много друзей. Молодые парни, мужчины средних лет и конечно дамы всех возрастов. Наверное всех. Трудно определить возраст современной женщины. Да и не очень хочется.
Так вот. Детей моих друзей и знакомых в силу своих воз... | https://habr.com/ru/post/403607/ | null | ru | null |
# Работаем с уведомлениями в Windows Phone 8.1
Привет всем!
Сегодня поговорим о новых возможностях, касающихся **уведомлений** в Windows/Windows Phone 8.1. Обсудим какие типы уведомлений существуют, каким способом их организоват... | https://habr.com/ru/post/234727/ | null | ru | null |
# png и IE, еще проще
Во время верстки столкнулся с проблемой отображения png в IE6. Поиск по Хабру дал несколько решений но все они не подходили по разным причинам.
Задача: есть 4 картинки png, необходимо их нормально отображение в IE6.
Итак вот решение которое я нашел:
**HTML:**
`... | https://habr.com/ru/post/36821/ | null | ru | null |
# Как новичок в Go контрибьютил

*Rocky Runs Up The Stairs*
*Привет, Хабр. Вы, наверно, меня помните: я – Марко Кевац, системный программист в Badoo. Недавно я наткнулся на небольшой рассказ о том, как новичок сделал изменен... | https://habr.com/ru/post/336620/ | null | ru | null |
# 7 лучших библиотек для создания молниеносно быстрых приложений ReactJS
### Некоторые необходимые инструменты для rock-star разработчика
> Привет, Хабр. В рамках набора на курс ["**React.js Developer**"](https://otus.pw/92S9/) подготовили перевод материала.
>
> Всех желающих приглашаем на открытый демо-урок [*... | https://habr.com/ru/post/559672/ | null | ru | null |
# Помогаем роботу-сортировщику на почте

#### Короткая предыстория
Беседовал я некоторое время назад со знакомым роботом. Устроился он временно на Почту России сортировщиком писем. Работёнка не пыльная, с... | https://habr.com/ru/post/208444/ | null | ru | null |
# Индикаторы ключевой информации на сайтах для Firefox на скорую руку
У многих из нас есть на примете набор сайтов, которые мы периодически открываем не для внимательного чтения, а чтобы бегло ознакомиться с каким-то небольшим участком информации, посмотреть, нет ли новых статей или комментариев, проверить, не сменилс... | https://habr.com/ru/post/146594/ | null | ru | null |
# Реализация BottomAppBar. Часть 1: Material компоненты для Android

[BottomAppBar](https://material.io/develop/android/components/bottom-app-b... | https://habr.com/ru/post/421879/ | null | ru | null |
# Внутренности JVM, Часть 2 — Структура class-файлов
*Всем привет! Перевод статьи подготовлен специально для студентов курса [«Разработчик Java»](https://otus.pw/JWN7/).*

---
Продолжаем разговор о том, как Java Virtual Machine р... | https://habr.com/ru/post/478584/ | null | ru | null |
# Go-клиент для PayPal API

Всем привет! Мы разрабатываем сервис для сбора, доставки и анализа логов, серверная часть которого написана на [Go](https://golang.org/). В этой статье мы расскажем о проблеме, с которой мы столкн... | https://habr.com/ru/post/274555/ | null | ru | null |
# Как мы переезжали на новую версию GitLab и внедряли LFS. А потом чинили бэкапы
Исторически мы использовали GitLab 8, который работал на хосте Mac на VirtualBox. Потом конфигурация перестала устраивать, поэт... | https://habr.com/ru/post/573686/ | null | ru | null |
# Добавляем Basic Auth в SOAP запрос средствами ksoap2-android
Так получилось, что в рамках своей работы я связался с проектом по разработке приложения для общения Android и 1С. Быстрый поиск в интернете дал достаточно четкие инструкции и куски кода, которые очень быстро оформились в готовую программу, но запускаться ... | https://habr.com/ru/post/340642/ | null | ru | null |
# Архитектура непрерывной потоковой доставки в Cloudera Flow Management
Cloudera Flow Management, основанная на Apache NiFi и являющаяся частью платформы Cloudera DataFlow, используется некоторыми из крупнейш... | https://habr.com/ru/post/557026/ | null | ru | null |
# Ипользование SPI Flash памяти дисплея для хранения графических ресурсов или дисплей домашней метеостанции
Данная статья призвана рассказать о возможности использования имеющейся на борту дисплея Flash памяти для нужд проекта.
Для кого это актуально или просто интересно — добро пожаловать под кат.
Целый год про... | https://habr.com/ru/post/388449/ | null | ru | null |
# Наглядно о том, как работает свёрточная нейронная сеть
К старту курса о [машинном и глубоком обучении](https://skillfactory.ru/ml-and-dl?utm_source=infopartners&utm_medium=habr&utm_campaign=habr_MLDL&utm_t... | https://habr.com/ru/post/565232/ | null | ru | null |
# Вызов управляемого кода из неуправляемого
 С задачей вызова неуправляемого кода из управляемого мы сталкиваемся довольно часто, и эта задача имеет простое решение в виде одного атрибута *[DllImport]* и небольшого набора д... | https://habr.com/ru/post/335620/ | null | ru | null |
# Работа с умом, а не руками: пример увеличения производительности редактирования текста в Emacs
#### История
Я почти закончил один проект и, как это всегда бывает, в последний момент потребовалось внести массовые рутинные изменения.
Это был Bash-скрипт для автоматизации процесса сборки на различных Unix-ах и, реа... | https://habr.com/ru/post/124861/ | null | ru | null |
# Динамические деревья
*Перед прочтением статьи рекомендую посмотреть посты про splay-деревья ([1](http://habrahabr.ru/company/spbau/blog/210296/)) и деревья по неявному ключу ([2](http://habrahabr.ru/post/101818), [3](http://habrahabr.ru/post/102006), [4](http://habrahabr.ru/post/102364))*
](https://habr.com/ru/company/ruvds/blog/707006/)
Эта статья посвящена всем практикующим специалистам по данным, заинтересованным в освоении запуска, стандартизации и автоматизации ... | https://habr.com/ru/post/707006/ | null | ru | null |
# WinPhone DevHub — мобильное приложение, которое должно быть под рукой у каждого WP7 разработчика
Практически все WP7 разработчики используют в своей работе сторонние библиотеки контролов. Вы, как разработчик, прошли через то, что бы скачивать примеры для конкретной библиотеки, компилировать и устанавливать это на св... | https://habr.com/ru/post/142204/ | null | ru | null |
# 5 лайфхаков Python, которые сделают ваш код более читабельным и элегантным
Привет, Хабр! В этой статье я продемонстрирую 5 трюков Python на понятных для новичков примерах, которые помогут вам писать более элегантный Python код в вашей повседневной работе.
В этой статье речь пойдёт о самом ~~скучном~~ интересном в ИТ – об архитектуре ПО, а именно, об одной из самых важных её частей – security.
#### Опред... | https://habr.com/ru/post/277111/ | null | ru | null |
# Как с помощью трех открытых проектов написать диплом
 Не секрет, что в у нас в проекте ~~используют~~ обучают студентов. Точнее, студенты на базе проекта осваивают практические аспекты системного программирования: пишут дипломы, курсо... | https://habr.com/ru/post/347282/ | null | ru | null |
# Безопасный доступ к умному дому при отсутствии публичного IP (часть 2)
Вступление
----------
[В первой части](https://habr.com/ru/post/504716/) я писал о постановке задачи и как трансформировались хотелки. В итоге я решил использовать OpenVPN, но, всвязи с тем, что решил все запускать в Docker контейнерах, это полу... | https://habr.com/ru/post/505412/ | null | ru | null |
# Fixie – тестирование по соглашению
Некоторое время назад попался мне твит о том, что знакомый стал использовать новый тестовый опенсорсный фреймворк **Fixie** и очень этим доволен. Так, что даже решил испр... | https://habr.com/ru/post/263057/ | null | ru | null |
# Spring — Hibernate: ассоциация один ко многим
Продолжаем цикл статей — переводов по Spring и Hibernate, от [krams](http://krams915.blogspot.ru/2011/03/spring-hibernate-one-to-many.html).
Предыдущая статья:
[«Spring MVC 3, Аннотации Hibernate, MySQL. Туториал по интеграции»](http://habrahabr.ru/post/248541/). ... | https://habr.com/ru/post/249073/ | null | ru | null |
# Новый фронтенд Одноклассников: запуск React в Java. Часть I

Многие слышали название GraalVM, но опробовать эту технологию в продакшене пока довелось не всем. Для Однокласснииков эта технология уже стала «священным Граалем», меняющ... | https://habr.com/ru/post/480808/ | null | ru | null |
# FPS не падай, девайс не грейся
В октябре 2020 года в техническую поддержку Авито стали обращаться пользователи с проблемами нагрева девайса и просадками FPS вплоть до полного фриза iOS-приложения. Проблема, как казалось, была глобальной. Она не относилась к какой-то конкретной функциональности приложения и поэтому н... | https://habr.com/ru/post/597417/ | null | ru | null |
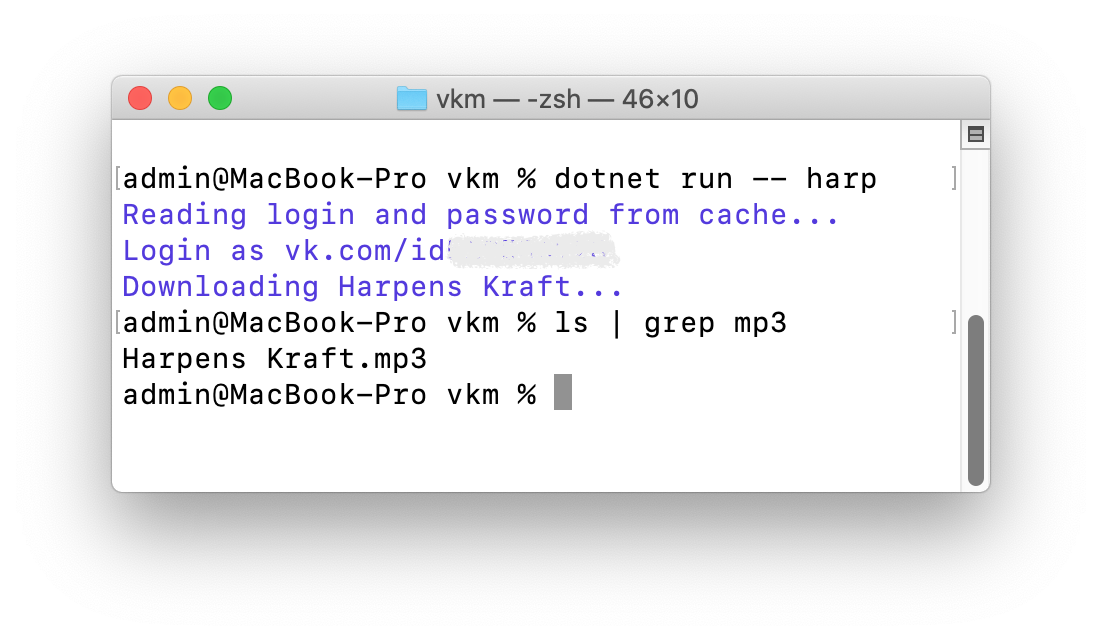
# Сохраняем музыку на C#
В 2020ом мы пользуемся разными музыкальными сервисами, но как реликт ушедшей эпохи, в забытом профиле ВК, у многих хранится музыка. Функции для загрузки нет, но что если позарез нужно спасти аудиозапись... | https://habr.com/ru/post/525346/ | null | ru | null |
# 15 советов, как пробиться в App Store приложению с подписками
В этой статье я расскажу, как увеличить шансы пройти проверку в App Store приложению с подписками. Если вы когда-либо испытывали проблему с аппрувом приложений с подписками или вот-вот планируете релиз, тогда это будет вам полезно.
Всем привет, меня зову... | https://habr.com/ru/post/455443/ | null | ru | null |
# Оффлайн база rutracker с описаниями раздач и возможость поиска по категориям
Популярные в последнее время слухи о блокировке торрент-трекеров ([или уже не слухи?](https://geektimes.ru/post/269592/)) побудили меня написать свой парсер для сайта rutracker.org. В данной статье я опишу опции для скрипта, выходные данные... | https://habr.com/ru/post/357530/ | null | ru | null |
# Делаем патч для Pods библиотеки
Приветствую друзья на связи автор телеграм канала [ReactNative - info](http://t.me/react_native_info), недавно столкнулся с одной интересной проблемой, сборка архива для iOS приложения постоянно завершалась такой ошибкой:
```
error: Abort trap: 6 (in target 'iOSPhotoEditor' from proj... | https://habr.com/ru/post/664316/ | null | ru | null |
# Vite.js и Vue.js
Я нашёл только 3 статьи по Vite.js на Хабр, там были некие обзоры функционала и описание фишек данного .
Хорошо, тогда вопрос, что же это за инструмент такой и в чем преимущества использов... | https://habr.com/ru/post/580064/ | null | ru | null |
# Настройка ToolChain(а) для Win10+GCC+С+Makefile+ARM Cortex-Mx+GDB+Jenkins
Настройка Toolchain(а) для сборки артефактов под STM32. x86-64, Win, Eclipse, GCC, Make, GDB, ST-LinkV2
В этом тексте я расскажу какой путь проходят исходники с момента написания до момента исполнения на микроконтроллере и как сварить прошивк... | https://habr.com/ru/post/673522/ | null | ru | null |
# Пишем первый проект на Play Framework 2.0
13 марта состоялся релиз второй версии scala/java-фреймворка Play. На хабре уже был [обзор новых фич Play 2.0](http://habrahabr.ru/post/140700/). В этой же статье я хочу восполнить пробел в отсутствии мануалов на русском языке по этому интересному фреймворку на примере созда... | https://habr.com/ru/post/141439/ | null | ru | null |
# Ещё один пример генеративных изображений
Все любят генеративное искусство и всё что с ним связано (вот оно слева направо, в конце есть прикольные ссылочки).
, я frontend-разработчик, и мой родной язык - JavaScript, реализовывать нашу нейросеть в рамках данной статьи мы будем именно на нем. Для начала несколько слов о структуре. За исключением... | https://habr.com/ru/post/556180/ | null | ru | null |
# Представляем Spring Data JDBC
В предстоящий релиз Spring Data под кодовым именем *Lovelace* мы собираемся включить новый модуль: [Spring Data JDBC](https://projects.spring.io/spring-data-jdbc/).
Идея Spring Data JDBC заключается в том, чтобы предоставить доступ к реляционным базам данных **без использования всей сл... | https://habr.com/ru/post/423697/ | null | ru | null |
# Пример Makefile
Написание makefile иногда становится головной болью. Однако, если разобраться, все становится на свои места, и написать мощнейший makefile длиной в 40 строк для сколь угодно большого проекта получается быстро и элегантно.
Внимание! Предполагаются базовые знания утилиты GNU make.
Имеем некий тип... | https://habr.com/ru/post/111691/ | null | ru | null |
# Расширение, изменение и создание элементов управления на платформе UWP. Часть 3

Ознакомившись со средствами [расширения](https://habrahabr.ru/company/mobile_dimension/blog/330480/) и [изменения](https://habrahabr.ru/compan... | https://habr.com/ru/post/335240/ | null | ru | null |
# Создание Python-обвязки для библиотек, написанных на C/C++, с помощью SIP. Часть 2
В [первой части](https://habr.com/ru/post/495480/) статьи мы рассмотрели основы работы с утилитой SIP, предназначенной для создания Python-обвязок (Python bindings) для библиотек, написанных на языках C и C++. Мы рассмотрели основные ... | https://habr.com/ru/post/495636/ | null | ru | null |
# Погодная станция из Arduino и Orienteer
Под Новый Год ко мне приходит желание разработать что-нибудь нестандартное. В этот раз я решил начать собирать и обрабатывать погодные данные возле своего дома. И, конечно, выбрал Arduino в качестве железа, а вот в качестве хранилища и инструмента просмотра и анализа — упомина... | https://habr.com/ru/post/319746/ | null | ru | null |
# Стандарты проектирования баз данных

Переходя от проекта к проекту, мы сталкиваемся, к сожалению, с отсутствием единообразных стандартов проектирования баз данных, несмотря на то, что SQL существует уже несколько десятилетий. Под... | https://habr.com/ru/post/484188/ | null | ru | null |
# Reddwarf для создания Java-сервера на примере онлайн-игры «Камень-ножницы-бумага»: Сервер
В статье [RedDwarf — cерверная платформа для разработки онлайн-игр на Java](http://habrahabr.ru/blogs/gdev/129174/) я рассказал об ... | https://habr.com/ru/post/134812/ | null | ru | null |
# Google Chrome для Android: уязвимость UXSS и раскрытие учетных данных
[](http://habrahabr.ru/company/pt/blog/158485/)Итак, начнем. В июле 2011 года Roee Hay и Yair Amit из IBM Research Group обнаружили [UXSS-уязвимость](h... | https://habr.com/ru/post/158485/ | null | ru | null |
# Material Design. Динамический Toolbar на живом примере
Уверен, что те, кто следят за изменениями в мире Android, заметили, что Toolbar начинает играть в приложениях всё более значимую роль. Например в последней версии Gmail клиента в Toolbar вынесен почти весь функционал по работе с почтой, а в новом Google Chrome T... | https://habr.com/ru/post/256643/ | null | ru | null |
# Как я не занял первое место в конкурсе для JavaScript-разработчиков от Telegram
Активные пользователи Телеграма, особенно те, кто подписан на Павла Дурова, наверняка что-то слышали о том, что Телеграм проводил в этих ваших интернетах конкурс для iOS, Android и JavaScript разработчиков, а также для дизайнеров. Несмот... | https://habr.com/ru/post/460625/ | null | ru | null |
# buf2link — Обмен изображениями в локальной сети
Один из [постов](http://habrahabr.ru/blogs/AutoHotKey/50707/) побудил рассказать о том, как я решил одну проблему используя AutoHotKey.
В локальной сети частенько бывает необходимость в ходе общения в чате показать собеседнику то, что происходит у тебя на экране.
... | https://habr.com/ru/post/51099/ | null | ru | null |
# Где искать баги фаззингом и откуда вообще появился этот метод
Подход фаззинг-тестирования родился еще в 80-х годах прошлого века. В некоторых языках он используется давно и плодотворно — соответственно, уже успел занять свою нишу. Сторонние фаззеры для Go были доступны и ранее, но в Go 1.18 появился стандартный. Мы ... | https://habr.com/ru/post/696724/ | null | ru | null |
# Matreshka, или интегрируем Vivaldi в Vivaldi

Всем привет! Для многих из нас браузер Vivaldi стал основным приложением, работающим весь день без перерыва. Это и понятно: сегодня практически вся деяте... | https://habr.com/ru/post/316196/ | null | ru | null |
# Установка Windows 7 по сети при помощи Microsoft Windows AIK

Не так давно столкнулся с ситуацией, которая в принципе не вызывает особых проблем у системных администраторов. Появилась необходимость обновления ОС на мно... | https://habr.com/ru/post/171017/ | null | ru | null |
# Базовые стили и полезные CSS-сниппеты
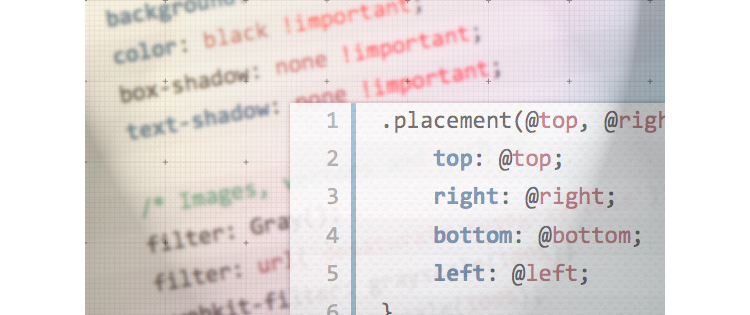
В этой статье собраны полезные и «правильные» стили и сниппеты, которые помогут ускорить процесс разработки сайта, а также оптимизировать верстку.
1. Базовая HTML5 конструкция
... | https://habr.com/ru/post/159101/ | null | ru | null |
# Протокол для общения между iframe и основным окном браузера
Многим разработчикам периодически требуется наладить общение между несколькими вкладками браузера: возможность посылать сообщения из одной в другую и получать ответ. Такая задача встала и перед нами.
Существуют стандартные решения вроде BroadcastChannel, о... | https://habr.com/ru/post/455942/ | null | ru | null |
# Секреты auto и decltype
Новый стандарт языка принят относительно давно и сейчас уже, наверное, нет программиста, который не слышал о новых ключевых словах *auto* и *decltype*. Но как почти с любым аспектом С++, использование этих новых инструментов не обходится без нюансов. Некоторые из них я постараюсь осветить в э... | https://habr.com/ru/post/206458/ | null | ru | null |
# Веб-интерфейс ovpn-admin для управления пользователями OpenVPN обновился до версии 1.7
[ovpn-admin](https://github.com/flant/ovpn-admin) — простой веб-интерфейс для управления сертификатами и маршрутами для пользователей OpenVPN. Утилита изначально была разработана для внутренних проектов «Фланта». Этой весной мы ре... | https://habr.com/ru/post/584316/ | null | ru | null |
# Технопорно с WebAssembly
По просьбам трудящихся, пишу о внутреннем устройстве WebAssembly.
WebAssembly — байткод для стековой виртуальной машины. Значит, для запуска кода такой нужны интерпретатор, стек и хранилище кода. Если мы хотим взаимодействовать с внешним миром, нужен интерфейс к внешней машине, хосту. Допол... | https://habr.com/ru/post/345450/ | null | ru | null |
# Что нового в Node.js 15?
> Делимся переводом статьи, в которой собраны подробности о новых функциях 15-й версии Node.js.
Версия [Node.js 15](https://nodejs.org/en/blog/release/v15.0.0/) была выпущена 20 октября 2020 года. Среди основных изменений:
* режим throw при необработанных отклонениях
* особенности языка ... | https://habr.com/ru/post/538782/ | null | ru | null |
# NuxtJS получил тройку, потерял JS и меняет фронтенд
17 ноября вышла стабильная версия Nuxt 3.0 (*теперь без JS*) - популярного фреймворка для построения фронтенд-приложений на Vue 3.
Поэтому публикую тут с... | https://habr.com/ru/post/700468/ | null | ru | null |
# Блокчейн ≠ Криптовалюта. Блокчейн > Криптовалюта
Криптовалюты постепенно совершают переворот в мире финансов, заставив многих посмотреть на веб более серьезно, и считается, что во многом это заслуга технологии блокчейн, которую напрямую ассоциируют с Биткойном. И, таким образом, сам блокчейн померк в свете славы соб... | https://habr.com/ru/post/313212/ | null | ru | null |
# Создание spring beans из обычных классов и юнит тесты
У нас и rich client, и сервер активно используют Spring. И очень быстро возникла проблема — как использовать спринг бины из обычных классов (которые сами — не бины).
Сначала возникли две идеи — передавать им нужные бины как аргументы в конструкторе или использ... | https://habr.com/ru/post/139093/ | null | ru | null |
# Про SSH Agent
### Введение
SSH-agent является частью OpenSSH. В этом посте я объясню, что такое агент, как его использовать и как он работает, чтобы сохранить ваши ключи в безопасности. Я также опишу переадресацию агента и то, как она работает. Я помогу вам снизить риск при использовании переадресации агента и поде... | https://habr.com/ru/post/503466/ | null | ru | null |
# Почему уходят из 1С?
Всем привет. Я – бывший разработчик 1С. Я устал от 1С и его ограничений, свой "каминг-аут" я совершил в середине 2021 года.
Периодически меня мучают "фантомные боли", и я захожу на сайты 1С-ной тематики в надежде, что в очередном релизе платформы 1С (по сути, это стековая виртуальная машина, ка... | https://habr.com/ru/post/695734/ | null | ru | null |
# Пошаговая установка TRAC на FreeBSD для начинающих
#### The Trac project
Я не буду описывать ее возможности и для чего эта система нужна, все есть на офф. сайте (<http://trac.edgewall.org>) или в [википедии](http://ru.wikipedia.org/wiki/Trac).
Рассмотрю только установку и настройку детально для новичков (статья ... | https://habr.com/ru/post/45389/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.