
text stringlengths 20 1.01M | url stringlengths 14 1.25k | dump stringlengths 9 15 ⌀ | lang stringclasses 4
values | source stringclasses 4
values |
|---|---|---|---|---|
# Почему POST превращается в GET
Долго пытался понять, почему следующий код при нажатии на кнопку дает запрос методом GET, хотя явно указан POST.
> `<html>
>
> <head>
>
> head>
>
> <body>
>
> <form method="POST" action="http://myhost/mydir">
>
> <input type="submit" value="→" />
>
> form>
>
> <... | https://habr.com/ru/post/55403/ | null | ru | null |
# Автоматический backup дисков в Yandex Cloud (с удалением старых версий)
Главная кнопкаЧто-то надоело мне вручную делать бэкапы одного проекта, и я отогнав лень, и собрав волю... | https://habr.com/ru/post/645719/ | null | ru | null |
# Управление зависимостями в Node.js
Управление зависимостями — это часть повседневной работы Node.js-программиста. Сегодня мы поговорим о разных подходах к работе с зависимостями в Node.js, и о том, как система загружает и обрабатывает зависимости.
Писать Node.js-приложения можно так, чтобы абсолютно весь код, обе... | https://habr.com/ru/post/557668/ | null | ru | null |
# Двойка вам, или аудит со взломом
*Как всегда без имен и названий, и так как я дополнительно связан подписью о неразглашении, еще и с немного видоизменённой историей (и опуская некоторые подробности, на публикацию которых я не получил разрешения).
Ниже следует реальная история проникновения на компьютер сотрудника... | https://habr.com/ru/post/416767/ | null | ru | null |
# Разработка статического блога на Gatsby и Strapi
Статические веб-сайты содержат страницы с неизменным содержимым. Технически — это набор HTML-файлов, которые, для каждого посетителя сайта, выглядят одинаково. В отличие от динамических веб-сайтов, для разработки таких сайтов не нужно серверное программирование или ба... | https://habr.com/ru/post/348068/ | null | ru | null |
# Как взломать более 17 000 сайтов за одну ночь
Эта история о том, как я нашел уязвимость в фреймворке Webasyst и, в частности, в ecommerce-движке Shop-Script 7.

Все началось с того, что вечером я решил приобрести мерч русскогоязычн... | https://habr.com/ru/post/340066/ | null | ru | null |
# Установка и настройка терминального сервера на Windows Server + Оптимизация настроек для 1С ч.3
Предисловие
-----------
Наконец то я смог перебороть свою лень и написать третью часть. По итогу мы имеем настроенный терминальный сервер, с разграниченными доступами к данным и списками разрешенных программ. В данной ча... | https://habr.com/ru/post/560652/ | null | ru | null |
# Пишем свою прошивку для модулей Sonoff TH10/16

Недавно на Geektimes был [обзор про модули ITEAD TH10](https://geektimes.ru/company/coolrf/blog/281410/). Хочу поделиться опытом разработки собственной прошивки для этих уст... | https://habr.com/ru/post/372773/ | null | ru | null |
# Корутины C++20 и многозадачность на примере контроллеров stm32
Никого не хотел обидеть КДПВ (в первую очередь @Saalur), действительно далеко не с первого раза становится понятно.
Введение
--------
Одним из наиболее ярких нововведений, которые получил язык в стандарте C++20, является поддержка сопрограмм (или корут... | https://habr.com/ru/post/687266/ | null | ru | null |
# Еще немного RISC-V
Я занимаюсь программированием микроконтроллеров. И не только пишу для них программы, а по большей части программы для программаторов. И хотел поделиться небольшой радостью заработавшего мк. Вдруг кто-то сейчас мучается с gd32vfxx.
МК программирую самые разные. Это и всем известные stm, lattice... | https://habr.com/ru/post/517578/ | null | ru | null |
# Синхронизация AssemblyVersion и Publish Version в ClickOnce приложении
Добрый день.
Сделал приложение ClickOnce. Всё хорошо, но утомляет обновлять номер версии. Дело в том, что при выкладывании обновления нужно менять версию как в AssemblyInfo, так и в csproj. Вот так я сделал:
```
public static class VersionI... | https://habr.com/ru/post/345390/ | null | ru | null |
# opencv4arts: Нарисуй мой город, Винсент
OpenCV — библиотека с историей непрерывной разработки в 20 лет. Возраст, когда начинаешь копаться в себе, искать предназначение. Есть ли проекты на ее основе, которые сделали чью-то жизнь лучше, кого-то счастливее? А можешь ли ты сделать это сам? В поисках ответов и желании от... | https://habr.com/ru/post/437600/ | null | ru | null |
# Исправляем 7 распространенных ошибок обработки исключений в Java
Привет, Хабр! Представляю вашему вниманию перевод статьи [Fixing 7 Common Java Exception Handling Mistakes](https://dzone.com/articles/fixing-7-common-java-exception-handling-mistakes) автора Thorben Janssen.
Обработка исключения является одной из н... | https://habr.com/ru/post/337536/ | null | ru | null |
# DI плагины в Magento 2
В Magento 2 вместо rewrite'ов, использовавшихся в первой версии, появились плагины, которые позволяют переопределить поведение большинства методов, перехватив поток выполнения тремя способами:
* before
* after
* around
Подробнее про плагины можно узнать в [документации](http://devdocs.mage... | https://habr.com/ru/post/279413/ | null | ru | null |
# Расширение возможностей Unity
В этом посте я покажу пример того, как можно расширить стандартные возможности IoC-контейнера [Unity](http://msdn.microsoft.com/en-us/library/cc468366.aspx). Покажу как создается объект в Unity «изнутри». Расскажу про Unity Extensions, Strategies & Policies.
Допустим в нашем приложен... | https://habr.com/ru/post/92549/ | null | ru | null |
# CSRF уязвимость в Wordpress — комментарии
#### Введение
Читал я вчера [про Егора Хомякова](http://habrahabr.ru/post/141277/). Подумал — может и я так смогу? И начал со своего блога на Wordpress. Адрес приводить не буду, иначе сам блог ляжет от Хабраэффекта, а меня обвинят в рекламе :).
#### Теория
Итак, где име... | https://habr.com/ru/post/141414/ | null | ru | null |
# С++20 на подходе! Встреча в Рапперсвил-Йона
В начале июня в городе Рапперсвил-Йона завершилась встреча международной рабочей группы WG21 по стандартизации C++.

Вот что вас ждёт под катом:
* Контракты и друзья
* Концепты (... | https://habr.com/ru/post/413719/ | null | ru | null |
# Изменяемые и неизменяемые объекты в Python
Все в Python – это объект. Каждый новичок должен сразу усвоить, что все объекты в Python могут быть либо изменяемыми (мутабельным), либо неизменяемыми (иммутабельным).
.
Helper... | https://habr.com/ru/post/326168/ | null | ru | null |
# Как в приложении получить список файлов, переданных из проводника посредством Drag-and-Drop
#### О чем данная статья:
Множество программ позволяют пользователю открывать файлы посредством перетаскивания их из проводника в окно приложения. Как правило это более удобно для пользователя, в отличии от стандартной модел... | https://habr.com/ru/post/179131/ | null | ru | null |
# Android ViewPager. Как заменить один фрагмент на другой
В этой статье хочу поделиться опытом использования ViewPager и FragmentStatePagerAdapter, появившихся в compatibility package. Точнее, рассказать, с какими проблемами пришлось столкнуться и как они были решены. В частности, замена одного фрагмента на другой.
... | https://habr.com/ru/post/132406/ | null | ru | null |
# Aspia — бесплатная программа для удаленного управления ПК
Aspia - это OpenSource приложение для удаленного управления компьютерами внутри локальной сети и за её пределами благодаря реализации ID сервера для... | https://habr.com/ru/post/711122/ | null | ru | null |
# Тулзы ручного тестировщика приложений на базе Windows
Моё лицо, ... | https://habr.com/ru/post/554300/ | null | ru | null |
# Подборка @pythonetc, май 2019
Это одиннадцатая подборка советов про Python и программирование из моего авторского канала @pythonetc.
← [Предыдущие подборки](https://habr.com/ru/search/?q=%5Bpythonetc%... | https://habr.com/ru/post/454646/ | null | ru | null |
# Learn OpenGL. Урок 7.1 – Отладка
 Графическое программирование — не только источник веселья, но еще и фрустрации, когда что-либо не отображается так, как задумывалось, или вообще на экране ничего нет. Видя, что большая час... | https://habr.com/ru/post/462897/ | null | ru | null |
# Опыт интеграции онлайн кассы Атол с собственной торговой CRM
Вокруг онлайн касс в последнее время дикий ажиотаж, 1 июля 2019 заканчивается последняя отсрочка, поэтому и мне пришлось заняться этим вопросом. Тем, у кого 1С или другая система особо можно не напрягаться, но если у вас собственная самописная система, то ... | https://habr.com/ru/post/457684/ | null | ru | null |
# Вычисления с плавающей точкой на этапе компиляции
Как известно, в C++ нельзя производить сложные вычисления с плавающей точкой на стадии компиляции. Я решил попробовать избавиться от этого досадного недостатка. Цель, к которой мы будем идти, на примере вычисления корня:
```
typedef RATIONAL(2,0) x;
typedef sqrt::... | https://habr.com/ru/post/124963/ | null | ru | null |
# Итоги квеста, который вы прошли. Или нет
Привет, Хабр!
Подводим итоги [квеста](https://habr.com/company/e-Legion/blog/420873/) от [MBLT DEV 2018](https://mbltdev.ru/ru?utm_source=habr&utm_medium=quiz_results): разбираем задания и дарим подарки — билеты на конференцию, подписки на все продукты JetBrains и сертифика... | https://habr.com/ru/post/422359/ | null | ru | null |
# конфиги: XML vs. API
Я считаю, что использование XML в конфигах — зло и малодушие. Далее попытаюсь обьяснить почему.
Почему пытаются использовать XML? «Потому, что не надо быть программистом, чтобы его редактировать». Но это чушь! Я не видел простых людей (не программистов), которые бы правили xml сами! Ни одна ... | https://habr.com/ru/post/42658/ | null | ru | null |
# lemongrab: плагин валидации веб-форм
Добрый день.
В этом топике я расскажу о удобном jQuery-плагине для валидации веб-форм, простом и мощном, при том — совершенно неизбыточном. Если вам не интересны подробности создания и сравнение с аналогами (точнее — с аналогом), смотрите конец топика, там ссылка на примеры и ... | https://habr.com/ru/post/218559/ | null | ru | null |
# Твикаем VS Code: убираем визуальный шум, доводим до совершенства
 Как при помощи небольших твиков можно улучшить интерфейс VS Code, убрав ненужные визуальные элементы интерфейса.
---
### Содержание:
* В... | https://habr.com/ru/post/650561/ | null | ru | null |
# Дружественное введение в Dagger 2. Часть 2
#### Используем модули, чтобы указать, как должны создаваться объекты
В [предыдущей статье из этой серии](https://habrahabr.ru/post/307434/) мы рассмотрели, как Dagger 2 избавляет нас от рутины написания инициализирующего кода путем внедрения зависимостей.
Если помните,... | https://habr.com/ru/post/308040/ | null | ru | null |
# Разработка REST-серверов на Go. Часть 6: аутентификация
Перед вами — шестой материал из серии статей, посвящённых разработке REST-серверов на Go. Наша сегодняшняя тема — безопасность, а именно — аутентификация. Если бы сервер, разработанный в предыдущих материалах, был бы развёрнут, и к нему мог бы обратиться кто уг... | https://habr.com/ru/post/567280/ | null | ru | null |
# HTML и CSS ошибки, которые я встречаю как человек без ограничений по здоровью
Сейчас много шума по поводу доступности интерфейсов. Здорово, что люди обращают на это внимание и начинают разрабатывать интерфейсы, которыми могут пользоваться люди с какими-то ограничениями.
Но мы забываем про людей, у которых нет огра... | https://habr.com/ru/post/519034/ | null | ru | null |
# Cocos2d-x: Пишем первое кроссплатформенное приложение
#### Предисловие.
Программирование для мобильных платформ становиться все популярнее. Ежедневно, на свет появляются новые приложения и игры, что, естественно, увеличивает конкуренцию на этом рынке. И каждый, уважающий себя разработчик должен разрабатывать и подд... | https://habr.com/ru/post/126582/ | null | ru | null |
# Как ухудшить производительность, улучшая её
*Хотели как лучше, а получилось как всегда.*
Виктор Черномырдин,
русский государственный деятель
Бывают в жизни случаи, когда ты вроде бы всё делаешь правильно, но что-то идёт не так.
Этот рассказ об одном из таких случаев.
Однажды я смотрел на этот код и думал ... | https://habr.com/ru/post/436746/ | null | ru | null |
# «Автономные Агенты» или исполняем код в открытой криптоплатформе Obyte
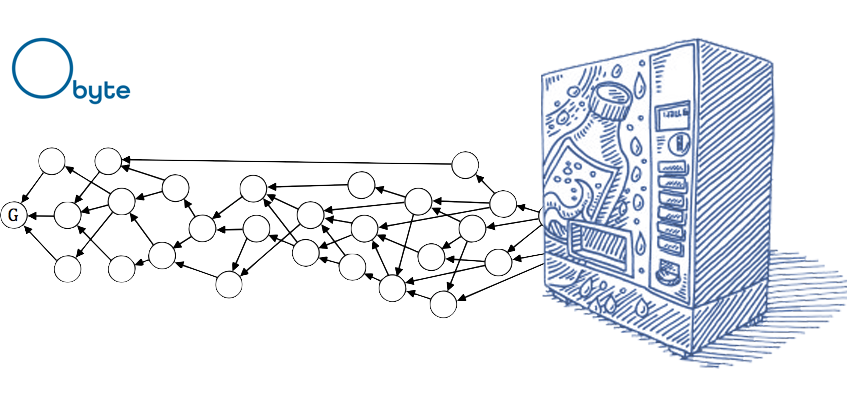
Obyte — это открытая крипто платформа, использующая в качестве реестра транзакций Directed Acyclic Graph (DAG, направленный граф без циклов) вместо блокчейна, ... | https://habr.com/ru/post/467209/ | null | ru | null |
# Пакет use-sound: звуковые эффекты в React-приложениях
Может, дело в том, что я профессионально занимался звуком, но мне хочется, чтобы веб был бы громче.
Знаю, многие меня в этом желании не поддержат. И не без причины! Исторически сложилось так, что звуки в интернете использовались крайне неудачно и некрасиво:
... | https://habr.com/ru/post/495896/ | null | ru | null |
# Пишем SOAP клиент-серверное приложение на PHP
Всем привет!
Так случилось, что в последнее время я стал заниматься разработкой веб-сервисов. Но сегодня топик не обо мне, а о том, как нам написать свой XML Web Service основанный на протоколе SOAP 1.2.
Я надеюсь, что после прочтения топика вы сможете самостоятель... | https://habr.com/ru/post/187390/ | null | ru | null |
# BinaryHTTPService или как помочь HTTPService-у принимать ByteArray данные
В процессе разработки у меня стояла задача найти способ получать бинарные данные от сервера через HTTPService. Сам по себе HTTPService в mx пакете не позволяет получать результат в ByteArray. Это можно увидеть в классе mx.messaging.channels.Di... | https://habr.com/ru/post/91331/ | null | ru | null |
# Работа с периферией из JavaScript: от теории к практике
Работа сотрудника банка опасна и трудна. В Единой фронтальной системе мы стараемся помочь сотруднику банка и автоматизировать его работу. Одна из многочисленных задач, которую нам нужно решить, — доработать тонкий клиент для возможности работы с периферийным ба... | https://habr.com/ru/post/330374/ | null | ru | null |
# Как мы улучшали TFS
Ранее, когда у нас не было своего корпоративного блога, я [писал](https://habrahabr.ru/post/319662/) о том, как мы используем Microsoft TFS (Visual Studio Team Servives on Premises) для управления жизненным циклом разработки ПО и для автоматизации тестирования. В частности мы собрали большой набо... | https://habr.com/ru/post/330078/ | null | ru | null |
# Система SMS поп-апов в приложении на Unity: админ-панель и как удобно работать с информацией
В этой статье мы поделимся нашим опытом разработки **системы SMS поп-апов в Unity**, на базе которого мы реализовываем [проект](https://www.behance.net/gallery/118834969/BI-System-3D-Analytics-Dataviz) в области бизнес-анали... | https://habr.com/ru/post/569808/ | null | ru | null |
# Трюк с тригонометрией
Скорее всего, вам известны следующие соотношения еще со школы:

Если вы PC-геймер, то, вероятно, постоянно обновляете драйверы GPU устройств AMD или NVIDIA. Обновление графических драйверов может повысить прои... | https://habr.com/ru/post/656189/ | null | ru | null |
# VXLAN в NSX-V — траблшутим underlay
Приветствую, и сперва немного лирики. Я иногда завидую коллегам, работающим удалённо — ведь это прекрасно иметь возможность работать из любого конца подключённого к Internet мира, каникулы в любое время, ответственность за проекты и дедлайны, а не нахождение в офисе с 8 до 17. Моя... | https://habr.com/ru/post/490792/ | null | ru | null |
# Пятница программиста, или как я писал библиотеку для лексического и синтаксического анализа кода
Всем привет! Я, как программист, всегда ищу пути для улучшения своих навыков. В один пятничный вечер, в мою голову пришла мысль — «А не написать ли мне компилятор?»
Кому интересно узнать, что из этого получилось, добр... | https://habr.com/ru/post/426151/ | null | ru | null |
# Глушим аномалии в географических данных с помощью Pandas
При обработке данных исходного DataSet часто попадаются аномальные значения, которые поставлены вместо пропусков, и мало того, что они скрываются, так ещё и несут вред общему де... | https://habr.com/ru/post/647319/ | null | ru | null |
# Windows Remote Arduino — управляем настольной лампой прямо из универсального приложения Windows
Завершая [неделю интернета вещей](http://habrahabr.ru/company/microsoft/blog/261367/) на хабре и в продолжение предыдущего поста [о партнерстве с Arduino](http://habrahabr.ru/company/microsoft/blog/262249/), расскажу вам ... | https://habr.com/ru/post/262419/ | null | ru | null |
# Вёрстка c «Ушами» дополнение, работающее в IE7, с подвалом «прибитым» к низу
Добрый день
Этот пост написан по мотивам поста «Вёрстка c «Ушами»». По комментариям в этом поста я понял, что у людей есть реальная проблема сделать такой вид макета для IE7. Вот Я и решил предложить решение, которым уже давно пользуюсь ... | https://habr.com/ru/post/107072/ | null | ru | null |
# HTML5: Доступ к батарее через javascript
HTML5 спецификация наполняется и медленно начинают появляться API, позволяющие получать информацию об устройстве, на котором запущено приложение. Одним из последних является [Battery Status API](http://www.w3.org/TR/battery-status/). Как вы уже догадались, API позволяет получ... | https://habr.com/ru/post/145608/ | null | ru | null |
# История о модульном подходе в digital агентстве
Всем привет. Меня зовут Сергей, я работаю в digital-агентстве Convergent лидером команды бэкенд разработки. Одно из основных направлений работы агентства ⸺ это разработка под заказ веб-приложений. Такая деятельность подразумевает, что зачастую создается достаточно мног... | https://habr.com/ru/post/550008/ | null | ru | null |
# С помощью скотча и жвачки
Защита приложений от обратной разработки - сложный процесс, который может отнимать много сил и нервов. Статья расскажет о нескольких подходах защиты приложений под операционную сис... | https://habr.com/ru/post/573346/ | null | ru | null |
# DSL роутер D-link D2650u для не-DSL провайдера
**В наличии**: Роутер D-link DSL2650U, который имеет встроенный DSL модем, 4-портовый коммутатор и один USB вход и не-DSL провайдер ( обычная витая пара и DHCP на том конце пров... | https://habr.com/ru/post/124744/ | null | ru | null |
# Три способа обновить запрос в Jira из ScriptRunner, используя Jira Java API
В этой статье будут рассмотрены три способа обновления запроса в Jira, используя Jira Java API.
Я буду использовать следующие методы Jira Java API:
* Issue.setCustomFieldValue(CustomField customField, Object value)
* CustomField.updat... | https://habr.com/ru/post/349876/ | null | ru | null |
# Пишу игрушечную ОС (о реализации sleep)

Очередной пост для блога, посвященного работе над игрушечной ОС. В [прошлый раз](http://habrahabr.ru/post/179561/) я писал про необходимость в простеньком драйвере AHCI (SATA).... | https://habr.com/ru/post/181870/ | null | ru | null |
# Сериализация объектов в MultiCAD.NET. Управление совместимостью чертежей и прокси-объектами
При создании пользовательских объектов на традиционном C++ API (NRX в nanoCAD, ObjectARX в AutoCAD) для обеспеч... | https://habr.com/ru/post/219997/ | null | ru | null |
# Потерянная группа. Выясняем назначение «странных» групп в AD
Доброе время суток, хабраграждане!
Спешу с Вами поделиться одной из своих вещиц, которые были призваны облегчить работу мне, как системного администратора, который разбирается в, доставшимся ему по наследству, хламе в Active Directory.
Самые проблем... | https://habr.com/ru/post/138600/ | null | ru | null |
# UUID версии 7, или как не потеряться во времени при создании идентификатора
Будьте аккуратны, при сохранении даты в... | https://habr.com/ru/post/572700/ | null | ru | null |
# Скрипт поиска проектов на odesk.com
Хочу поделиться полезным скриптом для поиска проектов на odesk.com Честно говоря, я не понял, как на odesk.com задать вопрос с OR оператором, чтобы за один присест найти все интерсующие меня проекты, поэтому я искал в несколько подходов, что не очень удобно. Этот скрипт решает про... | https://habr.com/ru/post/132994/ | null | ru | null |
# Regular Avalonia
Sometimes we don’t understand how the regular expression that we have composed works and want to check. There are many applications like regex101.com or vs code. I wanted to add one more to this list.
In this article we will see how you can wrap Regex in cross-platform graphics and create a simpl... | https://habr.com/ru/post/470101/ | null | en | null |
# Настройка IPTV в OpenWRT Asus RT-N13U
Столкнулся с проблемой прошивки на своем роутере. Никак не хотел работать стабильно. В итоге, перепробовав кучу разных прошивок, остановился на OpenWRT. Для желающих установить следуем [сюда](http://wiki.openwrt.org/toh/asus/rt-n13u).
Итак, я отвлёкся. Мой провайдер предостав... | https://habr.com/ru/post/254243/ | null | ru | null |
# 5 лаконичных синтаксисов Java, которых мне не хватает в Kotlin
С 2016 года, после того, как я начал использовать Kotlin в Android-разработке, то ни разу не скучал по Java. В целом, Kotlin дал мне большее уд... | https://habr.com/ru/post/649643/ | null | ru | null |
# Делаем проект по машинному обучению на Python. Часть 2

*Перевод [A Complete Machine Learning Walk-Through in Python: Part Two](https://towardsdatascience.com/a-complete-machine-learning-project-walk-thro... | https://habr.com/ru/post/425907/ | null | ru | null |
# Заметка про NULL
Всем привет!
Долго думал, что бы написать полезного про Оракл, перепробовал кучу тем. Каждый раз получалось слишком длинно, потому что уносило глубоко в дебри. Поэтому решил начать с максимально простой темы, чтобы оценить интерес аудитории и её отношение к моему стилю изложения материала (имхо, ... | https://habr.com/ru/post/127327/ | null | ru | null |
# Правильное использование promise в angular.js
В процессе использования angular.js трудно обойтись без объекта $q (он же promise/deferred), ведь он лежит в основе всего фреймворка. Deferred механизм явля... | https://habr.com/ru/post/221111/ | null | ru | null |
# Wireguard VPN, Yggdrasil, ALFIS DNS и AdGuard
На написание этой статьи спровоцировала [вот эта статья](https://habr.com/ru/post/594877/), с кучей странностей, и необязательных действий. Если коротко, то автор не понимает зачем он ставит те или иные программы, а именно - Unbound и dnsproxy. Но так как кроме исправлен... | https://habr.com/ru/post/595485/ | null | ru | null |
# Собираем Mac mini на Raspberry Pi Zero
[](https://habr.com/ru/topic/edit/545346/)
Несколько лет назад я увидел собранный Джоном Ликом из RetroMacCast [миниатюрный Macintosh](http://retromaccast.ning.com/profiles/blogs/honey-i-shrun... | https://habr.com/ru/post/545346/ | null | ru | null |
# Две недели с F#
А вы когда-нибудь записывали свои впечатления от изучения нового языка? Записывали все, что вам не понравилось, чтобы через пару недель изучения понять, насколько недальновидными и тупыми они были?
[](https://habr.... | https://habr.com/ru/post/545740/ | null | ru | null |
# ASP.NET MVC Урок 1. Начало
**Цель урока:** Изучить Global.asax и поведение запуска веб-приложения, обработки веб-запроса. Изучение Nuget и Подключение протоколирования.
##### Начало
Создадим приложение ASP.NET MVC 4 Web Application «Lesson1» (рис 1.):

Это совершенно обычная фотография, найденная в Гугле по запросу «железная дорога». И сама дорога тоже ничем особенным не отличается. ... | https://habr.com/ru/post/249661/ | null | ru | null |
# Qt — статическая линковка библиотеки под Windows
Всем доброго времени суток, решил написать эту статью специально для тех кто хочет или еще захочет чтобы его программка написанная c помощью Qt под Windows работала даже там где о Qt и не слышали, на Хабре есть статья где данная проблема решается сопровождением нашего... | https://habr.com/ru/post/137233/ | null | ru | null |
# Если у Вас нет Питона, но есть Керас-модель и Джава
Всем привет! В построении ML-моделей Python сегодня занимает лидирующее положение и пользуется широкой популярностью сообщества Data Science специалистов [[1](https://www.geeksforgeeks.org/top-5-best-programming-languages-for-artificial-intelligence-field/)].
Та... | https://habr.com/ru/post/475338/ | null | ru | null |
# Реверс-инжиниринг вредоносного мошеннического скрипта

Несколько дней назад я бродил по сети и зашёл на сайт с вредоносной рекламой. Хотя такие рекламные баннеры не редкость, но этому удалось проникнуть через защиту AdBlocker... | https://habr.com/ru/post/336232/ | null | ru | null |
# Аннотации в Java и их обработка
Аннотация — это специальная конструкция языка, связанная с классом, методом или переменной, предоставляющая программе дополнительную информацию, на основе которой программа м... | https://habr.com/ru/post/655239/ | null | ru | null |
# Социализируем сайт с Facebook
Вдохновившись общением с Эндрю Босвортом на РИТ++, решил воплотить идею Facebook по социализации всего в интернете у себя на проекте [www.bitrixonrails.ru](http://www.bitri... | https://habr.com/ru/post/91327/ | null | ru | null |
# Метод Flask flash() — Как передавать флэш-сообщения в Flask?
*В этом уроке мы узнаем как передавать флэш-сообщения с помощью метода Flask flash()*.
### Что означает передать флэш-сообщение?
Для GUI-прило... | https://habr.com/ru/post/692820/ | null | ru | null |
# Gotta go fast. Поиск в почтовом клиенте IMAP

Приветствую вас в заключительной статье о возможностях IMAP. В предыдущих статьях [Быстрая синхронизация писем по IMAP](https://habr.com/ru/post/492074/) и [Оптимизация запросов содер... | https://habr.com/ru/post/525172/ | null | ru | null |
# Страничное кеширование в WordPress

В последнее время на Хабре появилось довольно много постов по данной теме, но по своей сути их можно назвать: «Смотрите, я поставил Varnish / W3 Total Cache и держу миллион запросо... | https://habr.com/ru/post/251189/ | null | ru | null |
# Идентификация зараженных людей с помощью пересечения GPS-треков
***В преддверии старта курса [«PostgreSQL»](https://otus.pw/km3nA/) подготовили перевод интересной статьи.***

---
Во времена пандемии COVID-19 правительства преду... | https://habr.com/ru/post/503520/ | null | ru | null |
# Проверяем исходный код WPF примеров от компании Infragistics

Мы продолжаем проверять различные C#-проекты с целью демонстрации возможностей статического анализатора кода PVS-Studio. В этой статье мы расс... | https://habr.com/ru/post/276989/ | null | ru | null |
# Методы в примитивных типах PHP
Некоторое время назад назад Энтони Феррара выразил мысли по поводу [будущего PHP](http://blog.ircmaxell.com/2014/03/an-opinion-on-future-of-php.html). Соглашусь с большинством его взглядов, но не со всеми. В статье я остановлюсь на одном конкретном аспекте: преобразования примитивных т... | https://habr.com/ru/post/240561/ | null | ru | null |
# Учебник Thymeleaf: Глава 18. Приложение A: Основные выражения
[Оглавление](https://habrahabr.ru/post/350862/)
18 Приложение A: Основные выражения
-----------------------------------
Некоторые объекты и переменные всегда доступны для вызова. Давайте посмотрим на них:
**Базовые объекты**
**#ctx**: объект кон... | https://habr.com/ru/post/352552/ | null | ru | null |
# Настраиваем официальный шаблон PostgreSQL на Zabbix 4.4
Всем привет.
В Zabbix появился официальный **Template DB PostgreSQL**. В этой статье настроим его в Zabbix 4.4.

> **ПРИМЕЧАНИЕ**
>
>
>
> Если у вас все хорошо с... | https://habr.com/ru/post/475604/ | null | ru | null |
# Vagrant, Python, Pycharm = (удобная, работа, Windows)

##### **Введение**
Django — широко известный и один из наиболее развитых фреймворков для веб-разработки. Django написан на Python и, следовательно, для работы с ним п... | https://habr.com/ru/post/264367/ | null | ru | null |
# Работаем с NPM реестром из Java

[NPM](https://www.npmjs.com/) — уникальный репозиторий пакетов из мира JavaScript. В основном здесь те JS библиотеки, которые можно использовать во фронтэнде/в браузере, но есть и серверные дл... | https://habr.com/ru/post/512912/ | null | ru | null |
# Стандарт управления правами доступа к корпоративным файловым информационным ресурсам
[](https://habrahabr.ru/post/281937/)
Что может быть проще, чем разграничить права на папку в NTFS? Но эта простая задача может преврати... | https://habr.com/ru/post/281937/ | null | ru | null |
# Инструменты для запуска и разработки Java приложений, компиляция, выполнение на JVM
Ни для кого не секрет, что на данный момент Java — один из самых популярных языков программирования в мире. Дата официального выпуска Java — 23 мая 1995 года.
Эта статья посвящена основам основ: в ней изложены базовые особенности ... | https://habr.com/ru/post/471772/ | null | ru | null |
# Эволюция на React+Redux

Привет, Хабр, я тут написал онлайн версию замечательной настольной игры "Эволюция: Происхождение видов" и хотел бы поделиться своими заметками насчет архитектуры и техническ... | https://habr.com/ru/post/325756/ | null | ru | null |
# Linux USB phone howto
Документ описывает установку и настройку USB телефона для Linux, на базе Yealink P1K. В результате было достигнуто полное управление вызовами с телефона, без участия мышки и клавиатуры.
##### Введение
Всегда хотелось иметь мобильный VoIP телефон. Это такой телефон, который всегда с тобой, п... | https://habr.com/ru/post/96814/ | null | ru | null |
# Корневые и промежуточные сертификаты уполномоченных Удостоверяющих Центров России
Как и многие другие страны, Россия для официального электронного документооборота использует x509 сертификаты, выпускаемые уполномоченными Российскими Удостоверяющими Центрами (УЦ). И в отличие от многих других стран, использует свои с... | https://habr.com/ru/post/423187/ | null | ru | null |
# Управление осциллографами Tektronix из Visual Studio
С подобными задачами сталкиваешься редко, однако если это происходит, очень приятно прочитать исчерпывающую статью, которая поможет быстро начать продуктивную работу, а не ломать целый день голову вопросами «Что скачать?», «Где найти?», «Как это вообще работает?».... | https://habr.com/ru/post/271641/ | null | ru | null |
# Инфраструктура + тестирование = любовь
Инфраструктура тестирования обсуждается реже чем проблемы программирования или шестизначные зарплаты. Дьявол кроется в деталях, а если точнее, то дьявол сидит в процессах внутри команды. В небольших командах процессы устраиваются сами собой без обсуждения. Продуктивность команд... | https://habr.com/ru/post/655671/ | null | ru | null |
# Строим эффективный сетевой обмен в PHP-микросервисах
Микросервисы сейчас — это новый черный. Все больше и больше компаний переходят именно на микросервисную архитектуру. И при переходе ловят самые разные ошибки. Самая популярная происходит из-за того, что люди просто не готовы к тому, что их приложения начинают акти... | https://habr.com/ru/post/593297/ | null | ru | null |
# История с Daimler
Как заметили в одном из топиков, Хабр становится оплотом гражданского самосознания, потому хочется добавить еще одну тему.
[](http://tinypic.com) ... | https://habr.com/ru/post/89975/ | null | ru | null |
# Как обеспечить «вдвое больше за половину времени»
Книга [Scrum](https://www.mann-ivanov-ferber.ru/books/scrum/?ysclid=lcx7cqqs62463531052) авторства Джеффа Сазерленда, соавтора одноимённой методологии, в российском переводе имеет следующий подзаголовок: «Революционный метод управления проектами». В оригинале подзаго... | https://habr.com/ru/post/711930/ | null | ru | null |
# Что делает реактивную систему хорошей?
Этот пост является вторым в серии статей об *авто-трекинге* — новой системе реактивности в Ember.js. Я также обсуждаю концепцию реактивности в целом, и как она проявляется в JavaScript.
> *От переводчика: Крис Гарретт — работает в компании LinkedIn и является одним из core-кон... | https://habr.com/ru/post/489530/ | null | ru | null |
# Портируем DOOM на serverless-платформу
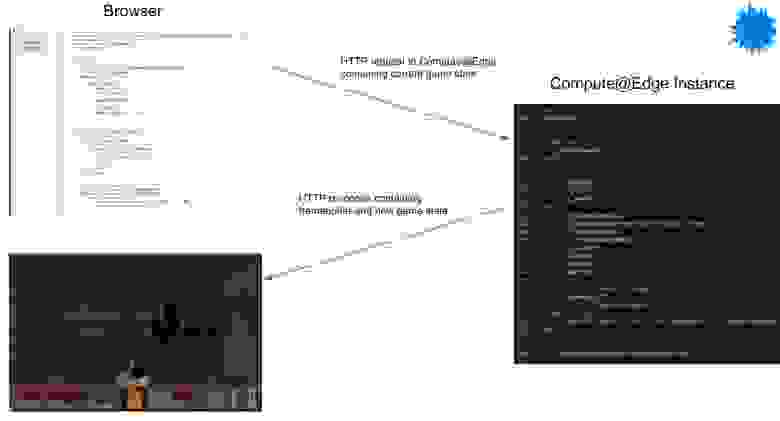
Благодаря своей открытой кодовой базе и чистым абстракциям [DOOM](https://en.wikipedia.org/wiki/Doom_(1993_video_game)) компании id Software стал одной из самых портируемых в истории игр. М... | https://habr.com/ru/post/553802/ | null | ru | null |
# Как мы делали первую сделку-аккредитив на блокчейн в Альфа-Банке
Несколько месяцев назад Альфа-Банк и S7 совершили сделку-аккредитив, используя блокчейн. Если вы ещё не видели, то прошу [сюда](https://vc.ru/n/alfa-s7-blockchain).
![](https://habrastorage.org/r/w1560/files/608/817/1ac/6088171ac3ff4a0483d115d858a... | https://habr.com/ru/post/323070/ | null | ru | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.