
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,873,782 | Linux File System Hierarchy - DevOps Prerequisite 2 | In this article, we will explore the Linux filesystem hierarchy, detailing its directory structure... | 0 | 2024-06-02T15:30:20 | https://dev.to/iaadidev/linux-file-system-hierarchy-devops-prerequisite-2-46ai | linux, beginners, devops, opensource | In this article, we will explore the Linux filesystem hierarchy, detailing its directory structure and how it differs from other operating systems.
**Linux Filesystem**
The Linux OS features a secure, multi-user filesystem with a directory structure designed to balance security and functionality. User-accessible directories are kept separate from those needed by the administrator.
Linux generally adheres to the Filesystem Hierarchy Standard (FHS), established in 1994. This standard outlines the common layout conventions used by most UNIX and UNIX-like systems. It includes a primary (or root) directory with multiple branching sub-directories.
**Root Directory ( / )**
The root directory (/) is the starting point for the entire Linux filesystem hierarchy. It is the top-level directory from which all other filesystems are mounted during system boot. All files and folders branch from the root directory, regardless of where the data is physically stored.
The root directory is owned by the root user (administrator), with permissions tightly controlled to allow only administrators to add, remove, or modify its files and folders.
**Sub-Directories**
Linux conventionally includes several important sub-directories, each with its specific purpose and permissions. Some sub-directories, like /tmp, are accessible to everyone, while others, such as /etc, are restricted to administrators.
Here is a table detailing the purpose of common Linux sub-directories:
| SUB-DIRECTORY | PURPOSE |
| — — — — — — — -| — — — — -|
| /bin | Common binary executables used by all users |
| /boot | Files associated with the boot loader |
| /dev | Attached devices (USB, CD-ROM, mouse, keyboard) |
| /etc | Configuration files |
| /home | Personal directories for each user account |
| /lib | Shared system libraries |
| /media | Directory for mounting removable devices (floppy drive, CD-ROM) |
| /mnt | Directory for mounting filesystems (NFS, SMB) |
| /opt | Optional vendor add-on software |
| /proc | Virtual filesystem for system processes/resources information |
| /root | Home directory for the administrator account |
| /run | Storage for runtime information |
| /sbin | Binary executables used by the administrator |
| /srv | Data for server services |
| /sys | Virtual filesystem for hardware/driver information |
| /tmp | Temporary files purged on reboot |
| /usr | Utilities and read-only user data/programs |
| /var | Variable and log files |
**Linux versus Other Filesystems (macOS and Windows)**
**For Windows User’s Perspective**
Windows and Linux have distinct designs. Unlike Windows’ single-user system, Linux is multi-user. While Windows uses separate data drives (e.g., C:\WINDOWS and D:\DATA), Linux employs a tree-like hierarchy with everything branching from the root. On Windows, program and system files share the same path (C:\Program Files), whereas in Linux, they are separated (e.g., /bin, /boot, /usr/bin).
**For macOS User’s Perspective**
Apple’s macOS, derived from Unix and BSD, has a core file structure similar to Linux. Both have a single primary directory with sub-directories branching from the root (/). Many Linux sub-directory names are found in macOS, though some names differ (e.g., macOS uses /Users instead of /home for user accounts and personal files).
Sub-directory similarities to Linux include:
/bin /etc /dev /usr /sbin /tmp /var
Sub-directories unique to macOS include:
/Applications /Developer /Library /Network /System /Users /Volumes
**Conclusion**
The Linux filesystem, though distinct, shares similarities with other filesystems. This article has highlighted the unique aspects of the Linux filesystem. As you navigate your Linux environment, you will become more familiar with each directory’s purpose.
**Linux Bash Utilities**
Learn about useful Linux Bash utilities!
The Linux shell language, Bash, offers many possibilities for interacting with the OS, including file compression, archiving, and extraction from the command line. It also provides functions for looking up documentation for all commands.
For a foundation in command line basics, consider taking our “Learn the Command Line” course to practice basic navigation and filesystem modifications in Bash. | iaadidev |
1,872,210 | how to use autocomplete in react ant design 5 | In this tutorial, we will create autocomplete in react with ant design 5. First you need to setup... | 0 | 2024-06-02T15:30:00 | https://frontendshape.com/post/how-to-use-autocomplete-in-react-ant-design-5 | react, antdesign, webdev | In this tutorial, we will create autocomplete in react with ant design 5. First you need to setup react with ant design 5 project.
<br>
[install & setup vite + react + typescript + ant design 5](https://frontendshape.com/post/install-setup-vite-react-typescript-ant-design-5)
1.Create a simple autocomplete in React using Ant Design 5's AutoComplete component and the useState hook.
```jsx
import React, { useState } from 'react';
import { AutoComplete } from 'antd';
const mockVal = (str: string, repeat = 1) => ({
value: str.repeat(repeat),
});
const App: React.FC = () => {
const [value, setValue] = useState('');
const [options, setOptions] = useState<{ value: string }[]>([]);
const [anotherOptions, setAnotherOptions] = useState<{ value: string }[]>([]);
const getPanelValue = (searchText: string) =>
!searchText ? [] : [mockVal(searchText), mockVal(searchText, 2), mockVal(searchText, 3)];
const onSelect = (data: string) => {
console.log('onSelect', data);
};
const onChange = (data: string) => {
setValue(data);
};
return (
<>
<AutoComplete
options={options}
style={{ width: 200 }}
onSelect={onSelect}
onSearch={(text) => setOptions(getPanelValue(text))}
placeholder="input here"
/>
<br />
<br />
<AutoComplete
value={value}
options={anotherOptions}
style={{ width: 200 }}
onSelect={onSelect}
onSearch={(text) => setAnotherOptions(getPanelValue(text))}
onChange={onChange}
placeholder="control mode"
/>
</>
);
};
export default App;
```
2.react ant design 5 search autocomplete with options property.
```jsx
import React from 'react';
import { UserOutlined } from '@ant-design/icons';
import { AutoComplete, Input } from 'antd';
const renderTitle = (title: string) => (
<span>
{title}
<a
style={{ float: 'right' }}
href="https://www.google.com/search?q=antd"
target="_blank"
rel="noopener noreferrer"
>
more
</a>
</span>
);
const renderItem = (title: string, count: number) => ({
value: title,
label: (
<div
style={{
display: 'flex',
justifyContent: 'space-between',
}}
>
{title}
<span>
<UserOutlined /> {count}
</span>
</div>
),
});
const options = [
{
label: renderTitle('Libraries'),
options: [renderItem('AntDesign', 10000), renderItem('AntDesign UI', 10600)],
},
{
label: renderTitle('Solutions'),
options: [renderItem('AntDesign UI FAQ', 60100), renderItem('AntDesign FAQ', 30010)],
},
{
label: renderTitle('Articles'),
options: [renderItem('AntDesign design language', 100000)],
},
];
const App: React.FC = () => (
<AutoComplete
popupClassName="certain-category-search-dropdown"
dropdownMatchSelectWidth={500}
style={{ width: 250 }}
options={options}
>
<Input.Search size="large" placeholder="input here" />
</AutoComplete>
);
export default App;
```
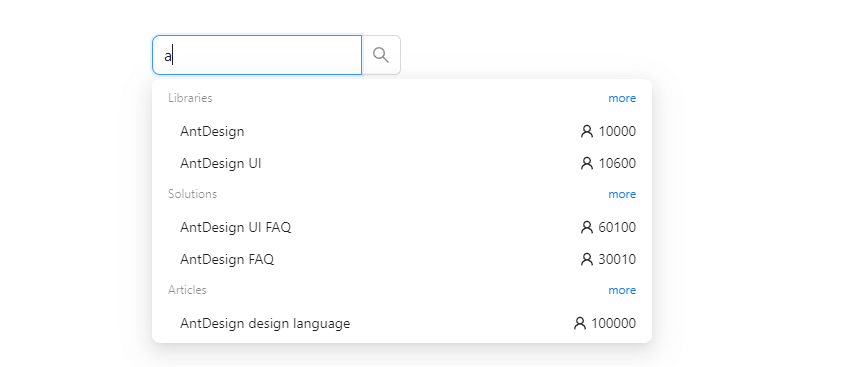
3.react typescript with ant design 5 search autocomplete.
```jsx
import React, { useState } from 'react';
import { AutoComplete, Input } from 'antd';
import type { SelectProps } from 'antd/es/select';
const getRandomInt = (max: number, min = 0) => Math.floor(Math.random() * (max - min + 1)) + min;
const searchResult = (query: string) =>
new Array(getRandomInt(5))
.join('.')
.split('.')
.map((_, idx) => {
const category = `${query}${idx}`;
return {
value: category,
label: (
<div
style={{
display: 'flex',
justifyContent: 'space-between',
}}
>
<span>
Found {query} on{' '}
<a
href={`https://s.taobao.com/search?q=${query}`}
target="_blank"
rel="noopener noreferrer"
>
{category}
</a>
</span>
<span>{getRandomInt(200, 100)} results</span>
</div>
),
};
});
const App: React.FC = () => {
const [options, setOptions] = useState<SelectProps<object>['options']>([]);
const handleSearch = (value: string) => {
setOptions(value ? searchResult(value) : []);
};
const onSelect = (value: string) => {
console.log('onSelect', value);
};
return (
<AutoComplete
dropdownMatchSelectWidth={252}
style={{ width: 300 }}
options={options}
onSelect={onSelect}
onSearch={handleSearch}
>
<Input.Search size="large" placeholder="input here" enterButton />
</AutoComplete>
);
};
export default App;
```
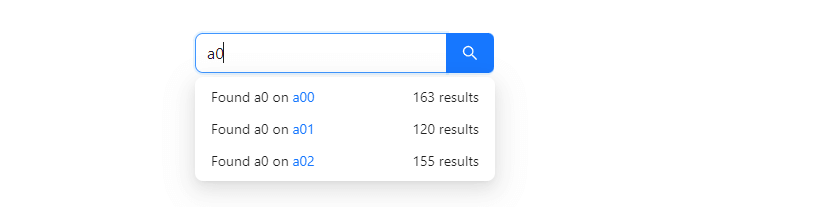 | aaronnfs |
1,873,781 | 10 Metode Terbaik untuk Menjaga Kode Laravel Tetap Bersih dan Terstruktur | Menulis kode program yang bersih dan terstruktur dalam Laravel, seperti dalam framework PHP... | 0 | 2024-06-02T15:29:20 | https://dev.to/yogameleniawan/10-metode-terbaik-untuk-menjaga-kode-laravel-tetap-bersih-dan-terstruktur-14pa | laravel, programming |

Menulis kode program yang bersih dan terstruktur dalam Laravel, seperti dalam framework PHP lainnya, adalah hal yang sangat penting untuk memastikan bahwa kode temen-temen mudah dipahami, dikelola, dan diubah. Berikut adalah beberapa metode dan praktik terbaik yang dapat diikuti untuk mencapai tujuan ini:
### 1. Gunakan PSR (PHP Standard Recommendations)
Laravel secara otomatis mengikuti standar PSR-1 dan PSR-2 dalam penulisan kode. Pastikan temen-temen juga mengikutinya:
- PSR-1: Prinsip dasar penulisan kode PHP seperti penamaan file, penggunaan namespaces, dan deklarasi class.
- PSR-2: Panduan lebih rinci tentang penulisan kode seperti indentasi, panjang baris, dan penempatan kurung.
Contoh format PSR-2:
```php
<?php
namespace Vendor\Package;
use FooInterface;
use BarClass as Bar;
use OtherVendor\OtherPackage\BazClass;
class Foo extends Bar implements FooInterface
{
public function sampleFunction($arg1, $arg2 = null)
{
if ($arg1 === $arg2) {
bar();
} elseif ($arg1 > $arg2) {
$this->bar();
} else {
BazClass::bar($arg1, $arg2);
}
}
}
```
### 2. Gunakan Dependency Injection
Menggunakan Dependency Injection (DI) membuat kode lebih modular dan lebih mudah diuji maupun di-maintenance. Daripada temen-temen membuat instance dari class di dalam method, injeksikan dependensi melalui constructor atau method.
```php
<?php
class UserController extends Controller
{
protected $userService;
public function __construct(UserService $userService)
{
$this->userService = $userService;
}
public function index()
{
$users = $this->userService->getAllUsers();
return view('users.index', compact('users'));
}
}
```
### 3. Gunakan Service Container dan Service Providers
Laravel memiliki Service Container yang kuat dan flexible untuk mengelola dependency injection. Manfaatkan Service Providers untuk mengatur dependency.
Contoh Service Provider:
```php
<?php
namespace App\Providers;
use Illuminate\Support\ServiceProvider;
use App\Services\UserService;
class UserServiceProvider extends ServiceProvider
{
public function register()
{
$this->app->singleton(UserService::class, function ($app) {
return new UserService();
});
}
public function boot()
{
//
}
}
```
### 4. Gunakan Repositories dan Service Layer
Pisahkan logika bisnis dari controller dengan menggunakan pattern Repository dan Service. Repositories berfungsi sebagai layer abstraksi antara model dan controller.
Contoh Repository:
```php
<?php
namespace App\Repositories;
use App\Models\User;
class UserRepository
{
public function getAll()
{
return User::all();
}
public function findById($id)
{
return User::find($id);
}
}
```
Contoh Service:
```php
<?php
namespace App\Services;
use App\Repositories\UserRepository;
class UserService
{
protected $userRepository;
public function __construct(UserRepository $userRepository)
{
$this->userRepository = $userRepository;
}
public function getAllUsers()
{
return $this->userRepository->getAll();
}
public function getUserById($id)
{
return $this->userRepository->findById($id);
}
}
```
### 5. Gunakan Eloquent Mutators dan Accessors
Eloquent menyediakan mutators dan accessors untuk memodifikasi nilai atribut sebelum disimpan (setter) atau setelah diambil (getter) dari database.
**Accessor**
Apa itu Accessor? Accessors digunakan untuk memformat atau memanipulasi nilai atribut setelah diambil dari database.
Laravel 9 kebawah :
```php
<?php
class User extends Model
{
public function getFullNameAttribute()
{
return "{$this->first_name} {$this->last_name}";
}
}
```
Dalam Laravel 9, cara mendefinisikan accessors sedikit berbeda dengan versi sebelumnya. Anda sekarang menggunakan metode berbasis closure yang lebih deklaratif.
Laravel 9 keatas :
```php
namespace App\Models;
use Illuminate\Database\Eloquent\Model;
class User extends Model
{
protected $appends = ['full_name']; // menambahkan atribut 'full_name' ke array model
// Accessor untuk mendapatkan nama lengkap
protected function fullName(): Attribute
{
return Attribute::make(
get: fn ($value, $attributes) => "{$attributes['first_name']} {$attributes['last_name']}",
);
}
}
```
Penggunaan Accessor:
```php
<?php
$user = User::find(1);
echo $user->full_name; // Output: Nama Depan Nama Belakang
```
**Mutators**
Mutators digunakan untuk memformat atau memanipulasi nilai atribut sebelum disimpan ke database.
Misalkan temen-temen memiliki model User dengan atribut password, dan Anda ingin mengenkripsi password setiap kali disimpan ke database.
Laravel 9 kebawah:
```php
<?php
class User extends Model
{
public function setPasswordAttribute($password)
{
$this->attributes['password'] = bcrypt($password);
}
}
```
Laravel 9 keatas:
```php
<?php
namespace App\Models;
use Illuminate\Database\Eloquent\Model;
use Illuminate\Support\Facades\Hash;
class User extends Model
{
// Mutator untuk mengenkripsi password
protected function password(): Attribute
{
return Attribute::make(
set: fn ($value) => Hash::make($value),
);
}
}
```
Penggunaan Mutators:
```php
<?php
$user = new User;
$user->password = 'plain-text-password';
$user->save();
```
### 6. Gunakan Request Validation
Daripada melakukan validasi di dalam controller, temen-temen bisa gunakan Request Validation untuk membuat kode lebih bersih dan terorganisir.
Contoh Request Validation:
```php
<?php
namespace App\Http\Requests;
use Illuminate\Foundation\Http\FormRequest;
class StoreUserRequest extends FormRequest
{
public function authorize()
{
return true;
}
public function rules()
{
return [
'name' => 'required|string|max:255',
'email' => 'required|string|email|max:255|unique:users',
'password' => 'required|string|min:8|confirmed',
];
}
}
```
Penggunaan di Controller:
```php
<?php
public function store(StoreUserRequest $request)
{
$validated = $request->validated();
User::create($validated);
return redirect()->route('users.index');
}
```
### 7. Gunakan Resource Controllers
Laravel menyediakan resource controllers untuk membuat controller yang clean dan mengikuti prinsip RESTful sehingga controller resource di Laravel bisa menentukan operasi CRUD (Create, Read, Update, Delete) standar. Temen-temen bisa menggunakan **php artisan make:controller** untuk membuat resource controller.
Contoh pembuatan resource controller:
```bash
php artisan make:controller UserController --resource
```
Nanti akan menghasilkan controller seperti berikut:
```php
<?php
namespace App\Http\Controllers;
use App\Models\User;
use Illuminate\Http\Request;
class UserController extends Controller
{
// Menampilkan daftar resource
public function index()
{
$users = User::all();
return view('users.index', compact('users'));
}
// Menampilkan form untuk membuat resource baru
public function create()
{
return view('users.create');
}
// Menyimpan resource baru ke database
public function store(Request $request)
{
$validated = $request->validate([
'name' => 'required|string|max:255',
'email' => 'required|string|email|max:255|unique:users',
'password' => 'required|string|min:8',
]);
$user = new User($validated);
$user->password = bcrypt($request->password);
$user->save();
return redirect()->route('users.index');
}
// Menampilkan resource yang spesifik
public function show($id)
{
$user = User::findOrFail($id);
return view('users.show', compact('user'));
}
// Menampilkan form untuk mengedit resource yang spesifik
public function edit($id)
{
$user = User::findOrFail($id);
return view('users.edit', compact('user'));
}
// Memperbarui resource yang spesifik di database
public function update(Request $request, $id)
{
$validated = $request->validate([
'name' => 'required|string|max:255',
'email' => 'required|string|email|max:255|unique:users,email,' . $id,
'password' => 'nullable|string|min:8',
]);
$user = User::findOrFail($id);
$user->update($validated);
if ($request->filled('password')) {
$user->password = bcrypt($request->password);
$user->save();
}
return redirect()->route('users.index');
}
// Menghapus resource yang spesifik dari database
public function destroy($id)
{
$user = User::findOrFail($id);
$user->delete();
return redirect()->route('users.index');
}
}
```
Kemudian jangan lupa menambahkan routing pada web.php
```php
<?php
use App\Http\Controllers\UserController;
Route::resource('users', UserController::class);
```
Dengan menggunakan **Route::resource**, Laravel akan secara otomatis menghasilkan semua route yang diperlukan untuk operasi CRUD:
- GET **/users** - index
- GET **/users/create** - create
- POST **/user**s - store
- GET **/users/{user}** - show
- GET **/users/{user}/edit** - edit
- PUT/PATCH **/users/{user}** - update
- DELETE **/users/{user}** - destroy
### 8. Gunakan Resource untuk JSON Responses
Saat mengembangkan API, gunakan Resources untuk memastikan struktur respons yang konsisten.
Untuk membuatnya temen-temen bisa menjalankan perintah
```bash
php artisan make:resource UserResource
```
Contoh Resource:
```php
<?php
namespace App\Http\Resources;
use Illuminate\Http\Resources\Json\JsonResource;
class UserResource extends JsonResource
{
public function toArray($request)
{
return [
'id' => $this->id,
'name' => $this->name,
'email' => $this->email,
'created_at' => $this->created_at->toDateString(),
'updated_at' => $this->updated_at->toDateString(),
];
}
}
```
Penggunaan di Controller:
```php
<?php
use App\Http\Resources\UserResource;
public function show($id)
{
$user = User::findOrFail($id);
return new UserResource($user);
}
```
### 9. Gunakan Policies dan Gates untuk Authorization
Laravel menyediakan mekanisme untuk mengelola authorization melalui Policies dan Gates.
Contoh Policy:
```php
<?php
namespace App\Policies;
use App\Models\User;
use App\Models\Post;
class PostPolicy
{
public function update(User $user, Post $post)
{
return $user->id === $post->user_id;
}
}
```
Penggunaan Policy:
```php
<?php
public function update(Request $request, Post $post)
{
$this->authorize('update', $post);
// Update logic here
}
```
### 10. Gunakan Route Model Binding
Laravel mendukung route model binding untuk secara otomatis menginjeksikan model instance ke dalam route handler.
Contoh Route Model Binding:
```php
<?php
Route::get('users/{user}', function (User $user) {
return $user;
});
```
Dengan semua _best practice_ ini, temen-temen bisa memastikan bahwa kode Laravel temen-temen tetap _clean_, dapat dikelola, dan mengikuti standar industri. Kode yang clean tidak hanya membuat proses pengembangan lebih efisien tetapi juga meningkatkan kualitas dan pemeliharaan aplikasi jangka panjang. Sampai jumpa di artikel yang lain!!
| yogameleniawan |
1,873,753 | Laravel Reverb: Fitur Websocket Server pada Laravel 11 | Laravel 11 rilis pada tanggal 12 maret 2024 dengan berbagai macam fitur dan improvement baik dari... | 0 | 2024-06-02T15:18:23 | https://dev.to/yogameleniawan/laravel-reverb-fitur-websocket-server-pada-laravel-11-306a | laravel |

Laravel 11 rilis pada tanggal 12 maret 2024 dengan berbagai macam fitur dan improvement baik dari sisi performance, package, command, dan lain-lain. Salah satu fitur yang menarik untuk kita bahas adalah [Laravel Reverb](https://reverb.laravel.com/). Yuk kita bahas sedikit tentang laravel reverb ini.
Apa itu Laravel Reverb? kalau dari penjelasan official dari laravel reverb seperti ini “_Reverb is a first-party WebSocket server for Laravel applications, bringing real-time communication between client and server directly to your fingertips. Open source and an Artisan command away — with love from the Laravel team._”, jadi kurang lebih reverb ini adalah sebuah first party websocket server yang bisa digunakan dan bisa berjalan secara bersama-sama dengan projek laravel kita. Sebelum adanya reverb, ketika kita ingin membuat sebuah websocket server kita bisa menggunakan salah satu servicenya adalah [Pusher](https://pusher.com/), yang mana Pusher ini adalah salah satu service websocket server yang gratis maupun berbayar tetapi berjalan di luar Laravel.
Sekarang kita cobain aja ya bagaimana Laravel Reverb ini bekerja di Laravel. Seperti biasa temen-temen bisa langsung buka _official documentation_ dari [Laravel](https://laravel.com/).
---
Instalasi Laravel 11
```bash
composer create-project laravel/laravel:^11.0 laravel-reverb
```
Instalasi Broadcasting, kenapa kita perlu melakukan instalasi broadcasting? karena by default di laravel 11 broadcasting tidak ditampilkan di folder routes
```bash
php artisan install:broadcasting
```
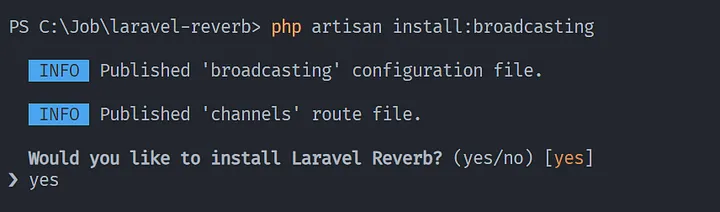
Pilih yes ketika ada pilihan untuk menginstall Laravel Reverb dikarenakan kita membutuhkan credential key dari reverb.

Pilih yes ketika ada pilihan untuk menginstall dependencies untuk broadcasting.
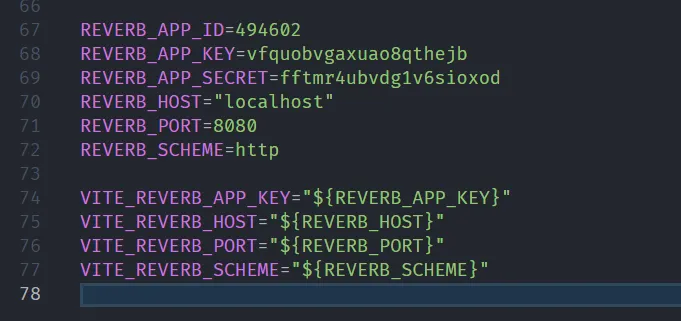
Apabila instalasi berhasil maka ketika temen-temen membuka file .env maka akan ada credential key untuk reverb.
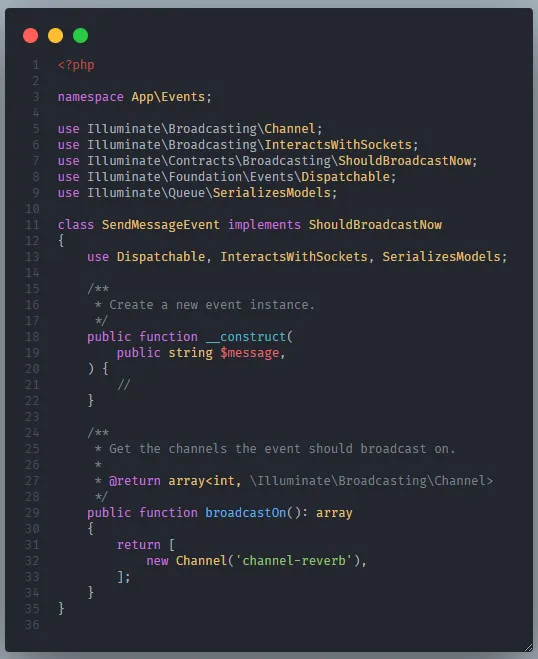
Buat event broadcast class dengan perintah di bawah ini
```bash
php artisan make:event SendMessageEvent
```
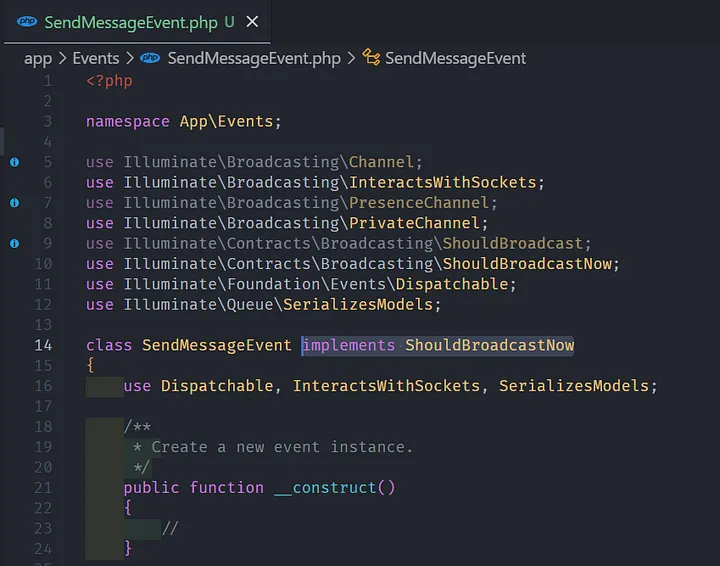
Jangan lupa tambahkan implements terhadap interface ShouldBroadcastNow
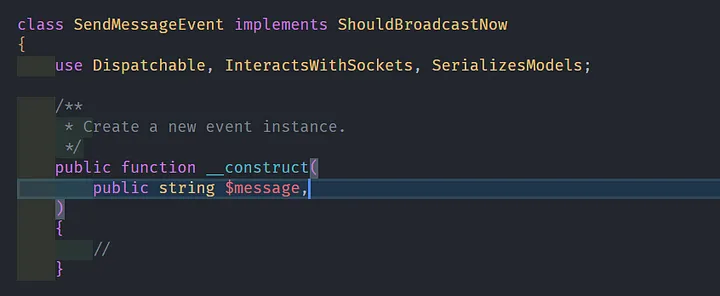
Tambahkan variabel pada constructor function yang akan digunakan sebagai variabel untuk mengirim data dari event broadcast ke channel reverb.
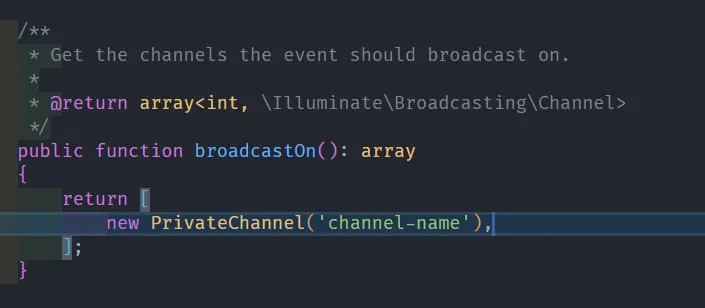
Kemudian silahkan ganti PrivateChannel menjadi Channel, kemudian nama channel default channel-name bisa kita ganti sesuai dengan kebutuhan, disini saya coba ganti menjadi channel-reverb.
Private Channel Default:
Channel Reverb:
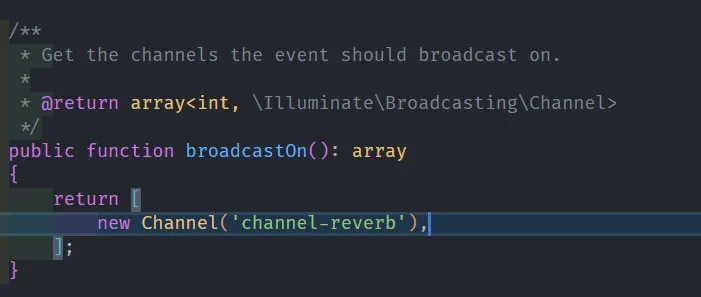
Sehingga hasil akhirnya kurang lebih seperti berikut:
```php
<?php
namespace App\Events;
use Illuminate\Broadcasting\Channel;
use Illuminate\Broadcasting\InteractsWithSockets;
use Illuminate\Contracts\Broadcasting\ShouldBroadcastNow;
use Illuminate\Foundation\Events\Dispatchable;
use Illuminate\Queue\SerializesModels;
class SendMessageEvent implements ShouldBroadcastNow
{
use Dispatchable, InteractsWithSockets, SerializesModels;
/**
* Create a new event instance.
*/
public function __construct(
public string $message,
) {
//
}
/**
* Get the channels the event should broadcast on.
*
* @return array<int, \Illuminate\Broadcasting\Channel>
*/
public function broadcastOn(): array
{
return [
new Channel('channel-reverb'),
];
}
}
```
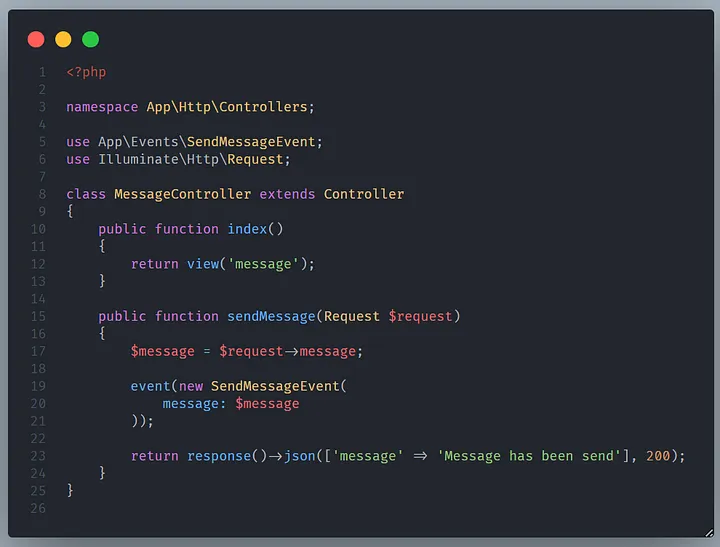
Buat controller untuk mendefinisikan view dan function yang akan digunakan untuk mengirimkan sebuah event.
```bash
php artisan make:controller MessageController
```
Buat 2 function yang digunakan untuk membuat view dan melakukan aksi untuk mengirim event broadcast ke reverb.
```php
<?php
namespace App\Http\Controllers;
use App\Events\SendMessageEvent;
use Illuminate\Http\Request;
class MessageController extends Controller
{
public function index()
{
return view('message');
}
public function sendMessage(Request $request)
{
$message = $request->message;
event(new SendMessageEvent(
message: $message
));
return response()->json(['message' => 'Message has been send'], 200);
}
}
```
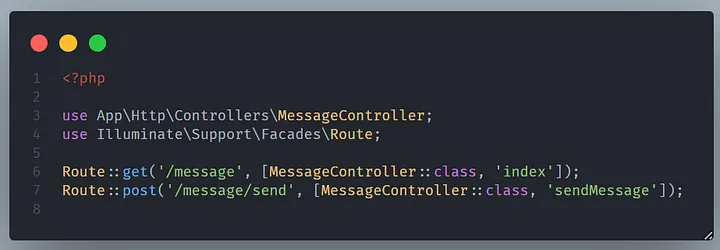
Kemudian definisikan 2 route yang digunakan untuk meng-handle route view dan route action.
```php
<?php
use App\Http\Controllers\MessageController;
use Illuminate\Support\Facades\Route;
Route::get('/message', [MessageController::class, 'index']);
Route::post('/message/send', [MessageController::class, 'sendMessage']);
```
Setelah itu silahkan distart untuk reverb websocket server menggunakan perintah dibawah ini
```bash
php artisan reverb:start
```
Setelah itu bisa kita langsung cobain Reverb ini ya, hasilnya kurang lebih seperti ini, kebetulan disini saya membuat aplikasi todo list sederhana.
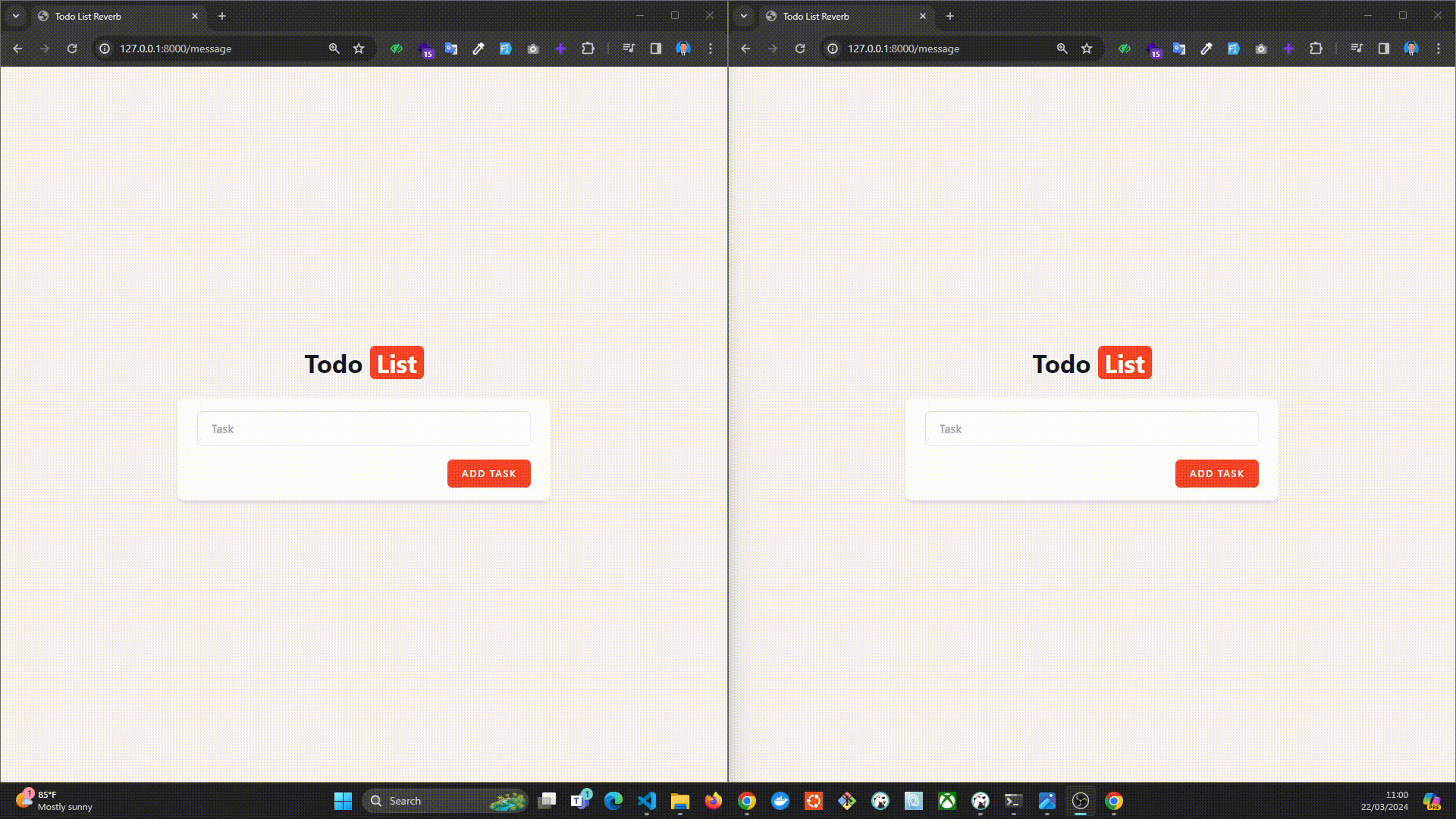
Gimana? Cukup sederhana ya untuk konfigurasi websocket kali ini menggunakan Laravel Reverb. Tentunya dengan menggunakan reverb kita sebagai developer dipermudah untuk menggunakan websocket server pada projek Laravel. Kalau misalkan temen-temen pingin nyobain projek ini bisa diakses di repository github saya di sini : [https://github.com/yogameleniawan/laravel-reverb](https://github.com/yogameleniawan/laravel-reverb)
Oke, pembahasan tentang reverb cukup sampai disini ya temen-temen. See u di kesempatan lain dengan artikel yang berbeda.
| yogameleniawan |
1,873,749 | Bagaimana Cara Memahami useState Hooks pada React/Next JS? | Buat temen-temen yang mungkin baru saja belajar tentang react js/next js atau belum pernah belajar... | 0 | 2024-06-02T15:10:02 | https://dev.to/yogameleniawan/bagaimana-cara-memahami-usestate-hooks-pada-reactnext-js-9p8 | javascript, nextjs, react |

Buat temen-temen yang mungkin baru saja belajar tentang react js/next js atau belum pernah belajar sama sekali. Sepertinya artikel ini wajib untuk dibaca sampai akhir, tenang nggak banyak kok. Kalau temen-temen pernah buka dokumentasi tentang [useEffect](https://legacy.reactjs.org/docs/hooks-effect.html) dan berakhir pusing, saya akan coba bantu jelaskan sedikit.
Gambar diatas merupakan alur kerja react ketika merender sebuah komponen. Nah, tentu saja kita sebagai developer gak mau tau dong bagaimana proses yang berjalan dibelakang yang terpenting kita maunya komponen harus bisa dirender sekali ataupun berkali kali. Tapi, pertanyaanya sekarang, bagaimana cara kita untuk mengubah hasil render komponen yang sudah dirender react? Tenang, jangan dipikir terlalu jauh, useEffect hooks ini adalah solusinya.

Kalau kita lihat dokumentasi yang disediakan oleh React JS, disana dijelaskan bahwa useEffect ini adalah hasil kombinasi dari componentDidMount, componentDidUpdate, dan componentWillUnmount ketika temen-temen menggunakan [Class Component](https://react.dev/reference/react/Component), tetapi jika temen-temen menggunakan [Functional Component](https://react.dev/reference/react/Component#migrating-a-simple-component-from-a-class-to-a-function) maka, temen-temen bisa menggunakan useEffect hooks ini. Kita langsung praktik pakai coding biar gak kebayang-bayang terus.
---
```javascript
import React, { useEffect, useState } from 'react'
const Home = () => {
const [counter, setCounter] = useState<number>(0);
useEffect(() => {
console.log('Running usEffect tanpa Array')
})
useEffect(() => {
console.log('Running usEffect dengan array kosong')
}, [])
useEffect(() => {
console.log('Ada yang berubah nih dari state counter')
}, [counter])
return (
<div className="flex flex-row justify-center items-center gap-2 mt-10">
<span>{counter}</span>
<button className="bg-gray-400 p-2 rounded-md text-white" onClick={() => setCounter((s) => s + 1)}>Increment</button>
</div>
)
}
export default Home
```
Bisa temen-temen lihat kode program diatas, ada 3 cara untuk mendefinisikan useEffect itu sendiri. Nah, perbedaanya ada pada [Array of Dependencies](https://react.dev/reference/react/useEffect#examples-dependencies)
useEffect dengan array of dependencies kosong
```javascript
useEffect(() => {
console.log('Running usEffect dengan array kosong')
}, [])
```
Ketika temen-temen mendefinisikan useEffect dengan cara seperti ini maka semua kode program yang ada di dalam useEffect akan dijalankan hanya 1 kali ketika component itu dirender.
Hasil console useEffect dengan array of dependencies kosong:

useEffect dengan array of dependencies ada isinya
```javascript
const [counter, setCounter] = useState<number>(0);
useEffect(() => {
console.log('Running usEffect dengan array kosong')
}, [counter])
```
Ketika temen-temen mendefinisikan useEffect dengan cara seperti ini maka semua kode program yang ada di dalam useEffect akan dijalankan ketika component dirender dan dijalankan kembali apabila ada perubahan terhadap state yang dimasukkan ke dalam arraynya.
```javascript
import React, { useEffect, useState } from 'react'
const Home = () => {
const [counter, setCounter] = useState<number>(0);
useEffect(() => {
console.log('Ada yang berubah nih dari state counter')
}, [counter])
return (
<div className="flex flex-row justify-center items-center gap-2 mt-10">
<span>{counter}</span>
<button
className="bg-gray-400 p-2 rounded-md text-white"
onClick={() => setCounter((s) => s + 1)}
>Increment</button>
</div>
)
}
export default Home
```
Contohnya misal user itu menekan tombol Increment maka semua kode program yang ada di dalam useEffect itu akan dijalankan kembali, tetapi jika tidak ada perubahan state maka semua kode program yang ada di dalam useEffect tersebut tidak akan dijalankan.
Hasil console useEffect dengan array of dependencies ada isinya:
useEffect tanpa array of dependencies
```javascript
const [counter, setCounter] = useState<number>(0);
const [time, setTime] = useState<number>(0);
useEffect(() => {
console.log('Running usEffect tanpa Array')
})
```
Ketika temen-temen mendefinisikan useEffect dengan cara seperti ini maka semua kode program yang ada di dalam useEffect ini akan dijalankan apabila ada perubahan dari semua state.
```javascript
import React, { useEffect, useState } from 'react'
const Home = () => {
const [counter, setCounter] = useState<number>(0);
const [time, setTime] = useState<number>(0);
useEffect(() => {
console.log(
`Running usEffect tanpa Array
counter: ${counter} time: ${time}
`)
})
return (
<div className="flex flex-row justify-center items-center gap-2 mt-10">
<span>{counter}</span>
<span>{time}</span>
<button
className="bg-gray-400 p-2 rounded-md text-white"
onClick={() => setCounter((s) => s + 1)}
>Increment</button>
<button
className="bg-gray-400 p-2 rounded-md text-white"
onClick={() => setTime((s) => s + 1)}
>Time</button>
</div>
)
}
export default Home
```
Hasil console useEffect dengan array of dependencies kosong:
---
Bagaimana apakah penjelasan diatas mudah dipahami? kalau malah bikin temen-temen pusing maap ye bro wkwk. Kurang lebih seperti itu penjelasan yang bisa saya sampaikan tentang useEffect pada React/Next JS yang mana penjelasannya saya usahakan sesimple mungkin dengan analogi yang cukup sederhana juga. Sampai bertemu di lain artikel yang lebih menarik! Tengkyu brokk!
| yogameleniawan |
1,873,748 | Nhẫn Bạc Nam có gì mà hot??? | Kính thưa quý vị và các bạn, Hôm nay, tôi rất vinh dự được đứng đây để nói về một chủ đề mang tính... | 0 | 2024-06-02T15:05:53 | https://dev.to/suc_mktrang_53933a88068d/nhan-bac-nam-co-gi-ma-hot-7ho | Kính thưa quý vị và các bạn,
Hôm nay, tôi rất vinh dự được đứng đây để nói về một chủ đề mang tính thẩm mỹ và thời trang - nhẫn bạc nam. Đối với nhiều người, nhẫn bạc không chỉ là một phụ kiện thời trang mà còn là biểu tượng của phong cách, cá tính và thậm chí là những giá trị tinh thần sâu sắc.

1. Lịch sử và ý nghĩa của nhẫn bạc nam:
Nhẫn bạc đã xuất hiện từ hàng ngàn năm trước, được sử dụng bởi các nền văn minh cổ đại như Ai Cập, La Mã và Hy Lạp. Ở mỗi thời kỳ, nhẫn bạc mang những ý nghĩa khác nhau. Đối với người Ai Cập, nhẫn bạc tượng trưng cho sự trường tồn và vĩnh cửu. Người La Mã lại coi nhẫn bạc là biểu tượng của quyền lực và sự giàu có.
Ngày nay, nhẫn bạc nam không chỉ đơn thuần là một món trang sức mà còn là biểu tượng của sự mạnh mẽ và nam tính. Nó thể hiện sự quyết đoán, sự tự tin và phong cách riêng của người đàn ông.
2. Lợi ích của việc đeo nhẫn bạc:
Ngoài vẻ đẹp và phong cách, nhẫn bạc còn mang lại nhiều lợi ích cho sức khỏe. Bạc là một kim loại có tính kháng khuẩn và kháng nấm. Đeo nhẫn bạc có thể giúp điều hòa nhiệt độ cơ thể, cải thiện tuần hoàn máu và thậm chí giúp giảm căng thẳng.
3. Chọn nhẫn bạc nam phù hợp:
Khi chọn nhẫn bạc, người mua cần xem xét kỹ về kiểu dáng, kích thước và chất lượng bạc. Một chiếc nhẫn bạc đẹp phải có thiết kế tinh xảo, phù hợp với phong cách cá nhân và được làm từ bạc chất lượng cao. Ngoài ra, cần chú ý đến việc bảo quản và vệ sinh nhẫn bạc để giữ cho nó luôn sáng bóng và bền đẹp.
4. Nhẫn bạc trong phong cách thời trang hiện đại:
Trong thời trang hiện đại, nhẫn bạc nam được thiết kế đa dạng và phong phú. Từ những mẫu đơn giản, thanh lịch đến những mẫu phức tạp, lộng lẫy, nhẫn bạc có thể phù hợp với mọi phong cách từ cổ điển đến hiện đại. Các thương hiệu trang sức hàng đầu cũng luôn cập nhật những xu hướng mới, mang lại sự lựa chọn đa dạng cho phái mạnh.
5. Kết luận:
Nhẫn bạc nam không chỉ là một món trang sức mà còn là một phần của phong cách sống. Nó thể hiện sự tôn trọng đối với bản thân, sự chú trọng đến ngoại hình và mong muốn khẳng định cá tính. Với những ý nghĩa và lợi ích mà nhẫn bạc mang lại, chắc chắn đây sẽ là một lựa chọn hoàn hảo cho bất kỳ người đàn ông nào.
Kính thưa quý vị và các bạn,
Hy vọng qua bài diễn đàn này, chúng ta sẽ có cái nhìn sâu sắc hơn về nhẫn bạc nam và biết cách chọn lựa, sử dụng nó một cách hợp lý. Cảm ơn sự lắng nghe của quý vị và chúc quý vị một ngày vui vẻ!
Để biết bản thân phù hợp với món trang sức nào quý vị và các bạn có thể truy cập trang web [trangsucmk.com](https://trangsucmk.com/) để có thể lựa chọn cho mình một món trang sức sang trọng và phù hợp với bản thân nhất nhé hoặc truy cập [Bài Viết](https://trangsucmk.com/2024/05/31/nhan-nam-sinh/) để biết thêm chi tiết về nhẫn bạn nam.
Xin trân trọng cảm ơn! | suc_mktrang_53933a88068d | |
1,873,747 | NVM Install On Your PC | NVM (Node Version Manager) is a popular tool for managing multiple versions of Node.js on a single... | 0 | 2024-06-02T15:05:26 | https://dev.to/ars_3010/nvm-install-on-your-pc-1l07 | node, nvm, javascript, react | NVM (Node Version Manager) is a popular tool for managing multiple versions of Node.js on a single machine. Here are some important commands for NVM:
### Installation Commands
1. **Install NVM**:
```
curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.39.3/install.sh | bash
```
This script installs the latest version of NVM. Replace `v0.
### NVM (Node Version Manager) Important Commands
#### Installation
1. **Install NVM**:
```
curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.39.3/install.sh | bash
```
This command downloads and runs the NVM install script from the NVM GitHub repository.
2. **Load NVM**:
``` export NVM_DIR="$([ -z "${XDG_CONFIG_HOME-}" ] && printf %s "${HOME}/.nvm" || printf %s "${XDG_CONFIG_HOME}/nvm")"
[ -s "$NVM_DIR/nvm.sh" ] && \. "$NVM_DIR/nvm.sh"
```
This is usually added to your shell profile file (`~/.bashrc`, `~/.zshrc`, etc.) to load NVM when you open a new terminal.
#### Basic Usage
3. **Check NVM Version**:
```
nvm --version
```
4. **List Installed Node Versions**:
```
nvm ls
```
5. **List Available Node Versions**:
```
nvm ls-remote
```
6. **Install a Specific Node Version**:
```
nvm install <version>
```
Replace `<version>` with the desired version number, e.g., `nvm install 16.13.0`.
7. **Use a Specific Node Version**:
```
nvm use <version>
```
Replace `<version>` with the installed version number you want to use.
8. **Set Default Node Version**:
```
nvm alias default <version>
```
This sets the default Node.js version to be used in new shell sessions.
9. **Uninstall a Specific Node Version**:
```
nvm uninstall <version>
```
10. **Show Current Node Version**:
```
nvm current
```
11. **Run Node with a Specific Version**:
```
nvm run <version> <script.js>
```
Replace `<version>` with the Node.js version and `<script.js>` with the script you want to run.
12. **Execute NPM Commands with Specific Node Version**:
```
nvm exec <version> npm <command>
```
For example, `nvm exec 14.17.0 npm install`.
13. **Reinstall Packages from Current Version**:
```
nvm reinstall-packages <version>
```
This reinstalls global packages from the specified version into the current version.
14. **Get Help**:
```
nvm help
```
These commands cover the essential functionality of NVM, helping you to manage different Node.js versions efficiently. | ars_3010 |
1,873,744 | From Chaos to Clarity: Simplify Your Angular Code with Declarative Programming | Not that long ago I bumped into an interesting problem. I wanted to implement a “search user”... | 0 | 2024-06-02T15:01:54 | https://dev.to/krivanek06/from-chaos-to-clarity-simplify-your-angular-code-with-declarative-programming-58gm | webdev, angular, beginners, rxjs | Not that long ago I bumped into an interesting problem. I wanted to implement a “search user” dropdown. When you select a user's name, you make an API call to load more data, meanwhile the loading happens, you display a “loading…” message and once the user details are back from the server, you display those.
Kinda like the following GIF on which I will be describing the two approaches (declarative and imperative) that I used.

## The Problem Description
This is a small representation of the problem which you’ve probably bumped into many times. You have a dropdown and every time you select a value, you want to load more details about the selected item from the backend.
You display a loading message until the data is not there, maybe some fancy animation, and once the data arrives you display it.
We don’t need a server for this example, it’s enough to have a mock data service as follows:
```tsx
import { Injectable } from '@angular/core';
import { Observable, map, of } from 'rxjs';
import { delay } from 'rxjs/operators';
export type DataItem = {
id: string;
name: string;
};
export const dataItems: DataItem[] = [
{ id: 'id_1', name: 'item_1' },
{ id: 'id_2', name: 'item_2' },
{ id: 'id_3', name: 'item_3' },
{ id: 'id_4', name: 'item_4' },
{ id: 'id_5', name: 'item_5' },
];
@Injectable({
providedIn: 'root',
})
export class DataService {
/**
* simulate fake API call to the server
*/
getDataFakeAPI(itemId: string): Observable<DataItem> {
return of(itemId).pipe(
map(() => dataItems.find((d) => d.id === itemId)!),
delay(1000)
);
}
}
```
The `dataItems` are items which will be displayed inside the select dropdown and every time you change the value, you will call `getDataFakeAPI` that returns the same value with some delay - mocking API call.
## Imperative Solution
The following solution is the solution that I used initially. I will post the whole code and then go over some parts which are important in this example.
```tsx
import { Component, inject, signal } from '@angular/core';
import {
DataItem,
DataService,
dataItems
} from './data-service.service';
@Component({
selector: 'app-select-imperative',
standalone: true,
template: `
<!-- dropdown of users -->
<select (change)="onChange($event)">
@for(item of displayData; track item.id){
<option [value]="item.id">{{ item.name }}</option>
}
</select>
<h3>Selected Items </h3>
<!-- displayed selected options -->
@for(item of selectedItems(); track item.id){
<div class="item-selected" (click)="onRemove(item)">
{{ item.name }}
</div>
}
<!-- display loading state -->
@if(isLoadingData()){
<div class="item-loading"> Loading ... </div>
}
<!-- reset button -->
@if(selectedItems().length > 0){
<button type="button" class="remove" (click)="onReset()">
Reset
</button>
}
`,
})
export class SelectImperativeComponent {
private dataService = inject(DataService);
displayData = dataItems;
/**
* displayed data on the UI - loaded from the BE
*/
selectedItems = signal<DataItem[]>([]);
isLoadingData = signal(false);
/**
* on select change - load data from API
*/
onChange(event: any) {
const itemId = event.target.value;
// check if already saved
const savedIds = this.selectedItems().map((d) => d.id);
if (savedIds.includes(itemId)) {
return;
}
// set loading to true
this.isLoadingData.set(true);
// fake load data from BE
this.dataService.getDataFakeAPI(itemId).subscribe((res) => {
// save data
this.selectedItems.update((prev) => [...prev, res]);
// set loading to false
this.isLoadingData.set(false);
});
}
/**
* removes item from selected array
*/
onRemove(item: DataItem) {
this.selectedItems.update(
(prev) => prev.filter((d) => d.id !== item.id)
);
}
onReset() {
this.selectedItems.set([]);
}
}
```
Overall it’s not that complicated and it may be close to a solution that you yourself would write. First of all, there is nothing significantly wrong with this solution, but why exactly do I call this an imperative approach ?
In short, this is imperative, because your signals - `selectedItems` and `isLoadingData` - can be changed all over the places which leads to two major problems - debugging and multiple properties.
Right now the `selectedItems` is changed in 3 places and `isLoadingData` is changed in 2 places, however once the complexity of this feature grows, debugging may become an issue to figure out how the data flow happens in this feature. What if `selectedItems` and `isLoadingData` will be used in 10 places each, suddenly it is not that easy to understand what’s happening.
Also with the growing complexity, you may want to introduce another properties like `isError = signal(false)` .
Now let’s think a bit and ask the question, could we combine the `selectedItems` , `isLoadingData` and potentially a new property `isError` into only one property which would look something like:
```tsx
{
data: DataItem[];
isError: boolean;
isLoading: boolean;
}
```
## Declarative Solution
The result what we want to achieve with the declarative solution is that we want to have only one property (object), which will have the data and loading keys and we want to change the values for this property only in one place.
Here is the solution that I came up with:
```tsx
import { Component, inject, signal } from '@angular/core';
import {
DataItem,
DataService,
dataItems
} from './data-service.service';
import { Subject, map, merge, scan, startWith, switchMap } from 'rxjs';
import { toSignal } from '@angular/core/rxjs-interop';
@Component({
selector: 'app-select-declarative',
standalone: true,
template: `
<!-- dropdown of users -->
<select (change)="onChange($event)">
@for(item of displayData; track item.id){
<option [value]="item.id">{{ item.name }}</option>
}
</select>
<h3>Selected Items </h3>
<!-- displayed selected options -->
@for(item of selectedItems().data; track item.id){
<div class="item-selected" (click)="onRemove(item)">
{{ item.name }}
</div>
}
<!-- display loading state -->
@if(selectedItems().isLoading){
<div class="item-loading"> Loading ... </div>
}
<!-- reset button -->
@if(selectedItems().data.length > 0){
<button type="button" class="remove" (click)="onReset()">
Reset
</button>
}
`,
})
export class SelectDeclarativeComponent {
private dataService = inject(DataService);
displayData = dataItems;
private removeItem$ = new Subject<DataItem>();
private addItem$ = new Subject<string>();
private reset$ = new Subject<void>();
/**
* displayed data on the UI - loaded from the BE
*/
selectedItems = toSignal(
merge(
// create action to add a new item
this.addItem$.pipe(
switchMap((itemId) =>
this.dataService.getDataFakeAPI(itemId).pipe(
map((item) => ({
item,
action: 'add' as const,
})),
startWith({
item: null,
action: 'initLoading' as const,
})
)
)
),
// create action to remove an item
this.removeItem$.pipe(
map((item) => ({
item,
action: 'remove' as const,
}))
),
// create action to reset everything
this.reset$.pipe(
map(() => ({
item: null,
action: 'reset' as const,
}))
)
).pipe(
scan(
(acc, curr) => {
// add reset state
if (curr.action === 'reset') {
return {
isLoading: false,
data: [],
};
}
// display loading
if (curr.action === 'initLoading') {
return {
data: acc.data,
isLoading: true,
};
}
// check to remove item
if (curr.action === 'remove') {
return {
isLoading: false,
data: acc.data.filter((d) => d.id !== curr.item.id),
};
}
// check if already saved
const savedIds = acc.data.map((d) => d.id);
if (savedIds.includes(curr.item.id)) {
return {
isLoading: false,
data: acc.data,
};
}
// add item into the rest
return {
isLoading: false,
data: [...acc.data, curr.item],
};
},
{ data: [] as DataItem[], isLoading: false }
)
),
{
initialValue: {
data: [],
isLoading: false,
},
}
);
/**
* on select change - load data from API
*/
onChange(event: any) {
const itemId = event.target.value;
this.addItem$.next(itemId);
}
/**
* removes item from selected array
*/
onRemove(item: DataItem) {
this.removeItem$.next(item);
}
onReset() {
this.reset$.next();
}
}
```
Yes, this is longer than the previous solution, however is it more complex or simpler than the previous one?
What needs to be first highlighted that instead of changing the `selectedItems` on multiple places, you now have 3 subjects, each of them representing an action that can happen.
```tsx
private removeItem$ = new Subject<DataItem>();
private addItem$ = new Subject<string>();
private reset$ = new Subject<void>();
```
Next inside the `selectedItems` you use these subjects and map them into format you want to work with. For me the following format suited the most
```tsx
item: DataItem;
action: 'add' | 'remove' | 'initLoading' | 'reset'
```
For the `addItem$` you want to use the `startWith` operator at the end of the pipe chain. This will allow that the first action which will be emitted when selecting a new value is `initLoading` and only when the API call (`dataService.getDataFakeAPI`) finishes, it will emit again with the action `add`.
You wrap each pipe mapping with the `merge` operator, because you want to perform some common logic despite of which one of these subjects emit.
Lastly you have the giant `scan` section. The `scan` operator is similar to `reduce` , however `scan` remembers the last computation that happened and if the `scan` happens again, it will use the data from the last computation - [read more about scan](https://www.learnrxjs.io/learn-rxjs/operators/transformation/scan) .
Inside the `scan` section, you create conditions what should happen based on the action of current value that is being processed.
It may reassemble how NgRx works. You have some actions (add, remove and reset subjects) and you create reducers to updated the state of only one property.
## Final Thoughts
Overall it’s up to you, the developer, which approach you choose to solve this problem. Both have some advantages and shortcomings.
If you want to play around with this example, you can [find it on stackblitz](https://stackblitz.com/edit/stackblitz-starters-ingyij) or connect with me on [dev.to](https://dev.to/krivanek06) | [LinkedIn](https://www.linkedin.com/in/eduard-krivanek-714760148/)| [Personal Website](https://eduardkrivanek.com/) | [Github](https://github.com/krivanek06). | krivanek06 |
1,873,746 | Implementasi Lazy Loading pada Component Next JS yang Bisa Bikin Aplikasi Ngebut dengan Dynamic Import | Pernah mengalami aplikasi yang kita kembangkan terasa lemot karena ada banyak component yang sedang... | 0 | 2024-06-02T15:01:42 | https://dev.to/yogameleniawan/implementasi-lazy-loading-pada-component-next-js-yang-bisa-bikin-aplikasi-ngebut-dengan-menggunakan-dynamic-import-22ic | javascript, react, nextjs |

Pernah mengalami aplikasi yang kita kembangkan terasa lemot karena ada banyak _component_ yang sedang di-_render_? Pastinya semua orang yang baru belajar next js akan mengalami hal yang sama. Karena pada dasarnya ketika kita baru pertama kali belajar next js pasti tidak memperhatikan performa dari aplikasi.
Kalau kita bicara masalah performa dari aplikasi memang pengaruh ya? ketika kita menggunakan _lazy loading_ dan tidak menggunakan? Kalau data yang temen-temen gunakan itu masih sedikit dan itu proses running aplikasi dilakukan di lokal ya bisa dipastikan tidak ada pengaruh sama sekali. Tapi, kalau data temen-temen itu sudah jutaan maka itu menjadi issue yang perlu kita perbaiki.
Lalu kira-kira apa perbedaannya ketika kita menggunakan lazy loading atau tidak? Saya akan coba memberikan contoh yang paling sederhana ya temen-temen dengan menggunakan cara _dynamic import_ atau _code splitting_. Oiya, temen-temen juga bisa cobain sendiri ya dengan kode program yang akan saya tuliskan dibawah.
---
#### Tidak Menggunakan Lazy Loading
Disini kita memiliki 1 page dengan 2 component. Dibawah ini merupakan kode program untuk page dari next js.
```javascript
"use client"
import React from 'react'
import ComponentIncrement from './components/ComponentIncrement'
import HeavyComponent from './components/HeavyComponent'
const Home = () => {
return (
<main className="flex flex-col min-h-screen gap-3 m-10">
<ComponentIncrement />
<HeavyComponent/>
</main>
)
}
export default Home
```
Dibawah ini merupakan kode program dari component **ComponentIncrement**
```javascript
"use client"
import React, { useEffect, useState } from 'react'
import { setInterval } from 'timers'
const ComponentIncrement = () => {
const [count, setCount] = useState(0)
useEffect(() => {
setInterval(() => {
setCount((s) => s + 1)
}, 1000)
}, [])
return (
<div className="bg-slate-500 w-10 h-10">
{count}
</div>
)
}
export default ComponentIncrement
```
Dibawah ini merupakan kode program dari component HeavyComponent
```javascript
"use client"
import Image from "next/image";
import { useEffect, useState } from "react";
import Gambar from "../../../public/images/image.jpg"
const fetchData = async () => {
const response = await fetch(`https://jsonplaceholder.typicode.com/posts/1`);
const data = await response.json();
return data;
};
const HeavyComponent = () => {
const [data, setData] = useState<any>();
useEffect(() => {
const fetchDataAsync = async () => {
const result = await fetchData();
if (result) {
setData(result);
}
};
fetchDataAsync();
}, []);
return (
<div className="flex flex-col">
{
data != null ? <>
<Image src={Gambar} alt="Image" width={200} height={200} />
<h2>Heavy Component</h2>
<p>Title: {data.title}</p>
<p>Body: {data.body}</p>
</> : 'Fetching data from API'
}
</div>
);
};
export default HeavyComponent;
```
Untuk hasilnya kurang lebih seperti ini :

Hasil diatas belum bisa kita lihat ya temen-temen, apakah menggunakan lazy loading atau tidak. Tapi, kita akan coba berikan logging berupa teks yang akan ditampilkan pada console browser. Kurang lebih hasilnya seperti ini :
Kita akan simpan hasil itu dan nanti akan kita komparasikan diakhir artikel ini ya temen-temen untuk mengetahui yang sebenarnya fungsi dari lazy loading.
#### Menggunakan Lazy Loading
Disini kita memiliki 1 page dengan 2 component. Dibawah ini merupakan kode program untuk page dari next js.
```javascript
"use client"
import React from 'react'
import ComponentIncrement from './components/ComponentIncrement'
import dynamic from 'next/dynamic'
const DynamicHeavyComponent = dynamic(() => import('./components/HeavyComponent'), {
loading: () => <p className="text-white">Loading Heavy Component...</p>,
ssr: false,
})
const Home = () => {
return (
<main className="flex flex-col min-h-screen gap-3 m-10">
<ComponentIncrement />
<DynamicHeavyComponent />
</main>
)
}
export default Home
```
Dibawah ini merupakan kode program dari component **ComponentIncrement**
```javascript
"use client"
import React, { useEffect, useState } from 'react'
import { setInterval } from 'timers'
const ComponentIncrement = () => {
const [count, setCount] = useState(0)
useEffect(() => {
setInterval(() => {
setCount((s) => s + 1)
}, 1000)
}, [])
return (
<div className="bg-slate-500 w-10 h-10">
{count}
</div>
)
}
export default ComponentIncrement
```
Dibawah ini merupakan kode program dari component **HeavyComponent**
```javascript
"use client"
import Image from "next/image";
import { useEffect, useState } from "react";
import Gambar from "../../../public/images/image.jpg"
const fetchData = async () => {
const response = await fetch(`https://jsonplaceholder.typicode.com/posts/1`);
const data = await response.json();
return data;
};
const HeavyComponent = () => {
const [data, setData] = useState<any>();
useEffect(() => {
const fetchDataAsync = async () => {
const result = await fetchData();
if (result) {
setData(result);
}
};
fetchDataAsync();
}, []);
return (
<div className="flex flex-col">
{
data != null ? <>
<Image src={Gambar} alt="Image" width={200} height={200} />
<h2>Heavy Component</h2>
<p>Title: {data.title}</p>
<p>Body: {data.body}</p>
</> : 'Fetching data from API'
}
</div>
);
};
export default HeavyComponent;
```
Untuk hasilnya kurang lebih seperti ini, sama seperti tanpa menggunakan lazy loading :

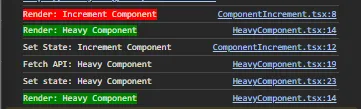
Dan untuk hasil console menggunakan lazy loading seperti ini :
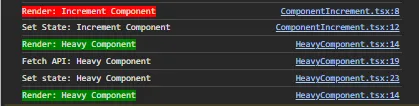
Kira-kira apakah hasil console tidak menggunakan dan menggunakan lazy loading ada perbedaannya? Ada dong. Mari kita bahas ya temen-temen.
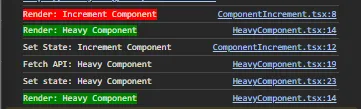
Hasil console tanpa menggunakan lazy loading 2:
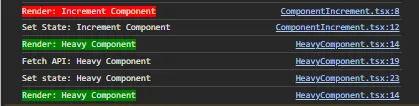
Hasil console menggunakan lazy loading 2
Ketika temen-temen tidak mengimplementasikan lazy loading maka 2 component tersebut akan dirender secara paralel atau secara bersamaan dan perubahan state maupun pemanggilan end point API pun juga dilakukan secara bersamaan. Akibatnya apa? bayangkan jika salah satu component punya behavior yang cukup berat atau proses render maupun proses pengambilan datanya membutuhkan waktu. Maka, component lainnya yang seharusnya sudah selesai render maka harus nunggu sampai component sebelumnya selesai di-render.
Render component secara paralel tanpa lazy loading:

Sedangkan, ketika kita mengimplementasikan lazy loading maka, masing-masing komponen itu tidak akan di-render secara bersama-sama tetapi akan di-render sesuai dengan urutannya. Selain itu, kita juga bisa memberikan UX (User Experience) dengan sebuah teks bahwa komponen tersebut sedang dimuat.
Render component secara bergantian menggunakan lazy loading:
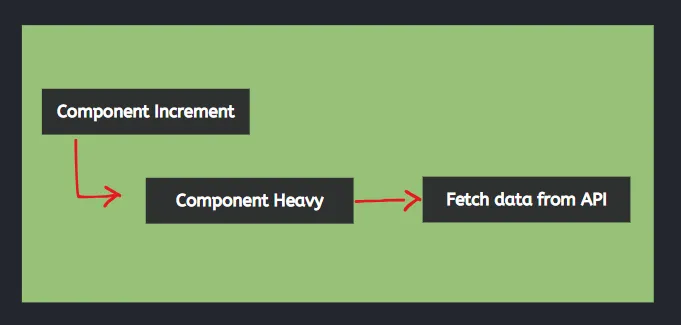
---
Bagaimana? Apakah sudah ada gambaran pentingnya implementasi lazy loading pada aplikasi yang kita kembangkan menggunakan next js? Saya berharap artikel kali ini bisa memberikan ilmu tambahan untuk mengembangkan aplikasi menggunakan Next JS. Sampai bertemu di lain kesempatan dengan artikel yang lebih menarik lagi.
| yogameleniawan |
1,873,745 | SPBU88: Bukan Sekedar Stasiun Pengisian, Tapi Gerbang Menuju Keberuntungan dan Kehidupan Luar Biasa! | Pernahkah Anda membayangkan mengisi bensin dan sekaligus membuka gerbang menuju kekayaan dan... | 0 | 2024-06-02T14:55:06 | https://dev.to/spbu88_com_8f4314b6ea263e/spbu88-bukan-sekedar-stasiun-pengisian-tapi-gerbang-menuju-keberuntungan-dan-kehidupan-luar-biasa-58am | spbu88, spbu88login, spbu88daftar, linkalternatifspbu88 | Pernahkah Anda membayangkan mengisi bensin dan sekaligus membuka gerbang menuju kekayaan dan kehidupan yang luar biasa? Di [SPBU88](https://spbu88.com), bukan hanya tangki yang terisi, tapi juga pundi-pundi dan optimisme Anda!
SPBU88 bukan sekadar singkatan dari Stasiun Pengisian Bahan Bakar Umum. Di era digital ini, SPBU88 menjelma menjadi peluang emas untuk mengubah hidup Anda. Rasakan sensasi bermain slot yang tak terlupakan dan peluang untuk meraih harta karun yang melimpah di dunia penuh kegembiraan dan peluang emas ini.
Lebih dari Sekedar Permainan Slot
SPBU88 menghadirkan beragam jenis permainan slot dari provider ternama seperti Pragmatic Play, Microgaming, dan Slot88. Tema dan fitur unik di setiap permainan siap menantang adrenalin Anda dan membawa Anda berpetualang menjelajahi dunia penuh kegembiraan dan peluang emas.
Bonus dan Promosi yang Menggoda Selera
SPBU88 bagaikan kolam harta karun yang selalu memanjakan para pemainnya dengan bonus dan promosi yang menggoda. Dapatkan bonus deposit, bonus cashback, bonus free spins, dan masih banyak lagi. Semakin sering Anda bermain, semakin besar peluang Anda untuk meraih bonus fantastis yang bisa mengubah hidup Anda.
Kemenangan Besar Menanti di Setiap Putaran
Setiap putaran di SPBU88 penuh dengan kegembiraan dan peluang emas. Dengan sedikit keberuntungan, Anda bisa menjadi jutawan dalam sekejap mata. SPBU88 terkenal dengan jackpotnya yang fantastis, siap mengantarkan Anda pada kehidupan yang Anda impikan, penuh kemakmuran, kebahagiaan, dan pencapaian.
Layanan Terbaik dan Keamanan Terjamin
SPBU88 bukan hanya tentang hadiah dan kemenangan. Di sini, Anda juga akan mendapatkan layanan terbaik dari tim customer service yang siap membantu Anda 24/7. Keamanan data dan transaksi Anda pun terjamin dengan teknologi keamanan terdepan yang digunakan SPBU88.
Lebih dari Sekedar Permainan, SPBU88 Adalah Komunitas
SPBU88 bukan hanya tempat untuk bermain slot, tetapi juga komunitas yang dinamis dan ramah. Berinteraksilah dengan pemain lain dari seluruh dunia, berbagi tips dan strategi, dan ciptakan persahabatan yang tak ternilai.
SPBU88: Pilihan Tepat untuk Pecinta Slot yang Ingin Lebih
Bagi Anda yang haus akan sensasi, tantangan, dan peluang, SPBU88 adalah destinasi yang tepat. Kunjungi SPBU88 sekarang dan rasakan sendiri sensasi bermain slot yang tak terlupakan di surga harta karun digital ini! | spbu88_com_8f4314b6ea263e |
1,873,743 | Meningkatkan User Experiece (UX) Aplikasi Menggunakan useOptimistic Hooks pada React JS/Next JS | Seberapa penting emang user experience (UX) dari user terhadap aplikasi yang kita kembangkan?... | 0 | 2024-06-02T14:53:10 | https://dev.to/yogameleniawan/meningkatkan-user-experiece-ux-aplikasi-menggunakan-useoptimistic-hooks-pada-react-jsnext-js-4cpl | react, nextjs, javascript |

Seberapa penting emang _user experience_ (UX) dari user terhadap aplikasi yang kita kembangkan? Sangat penting bro. Kalau _first impression_ dari user terhadap aplikasi kita sudah jelek gara-gara _user experience_ yang tidak ramah lingkungan, maka user pun juga males buat buka aplikasi yang kita kembangkan. Emang ada parameternya buat nentuin bahwa UX aplikasi kita udah ramah lingkungan? Ada, parameter yang paling minimal itu penggunaan _loading _ ketika melakukan pemrosesan data/perubahan state.
Pada React JS kita bisa meningkatkan UX dari aplikasi yang kita kembangkan menggunakan useOptimistic Hooks yang bisa temen-temen baca dokumentasinya [disini ](https://react.dev/reference/react/useOptimistic) sebelum masuk lebih dalam dan implementasinya. Perlu diketahui ya temen-temen useOptimistic ini hanya tersedia pada React Canary dan Experimental Channel. Tapi, bukan berarti temen-temen kalau tidak menggunakan React Canary tidak mau berkenalan dengan useOptimistic Hooks. Tidak ada salahnya mencari ilmu baru.
Kira-kira dari 2 perbandingan di bawah ini, temen-temen lebih prefer memilih yang mana?
GIF 1. Tanpa menggunakan useOptimistic Hooks:
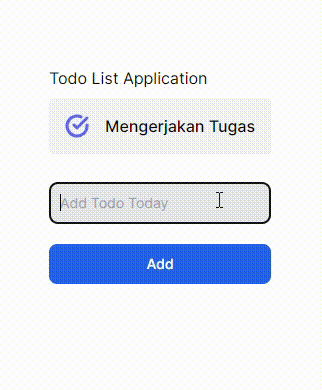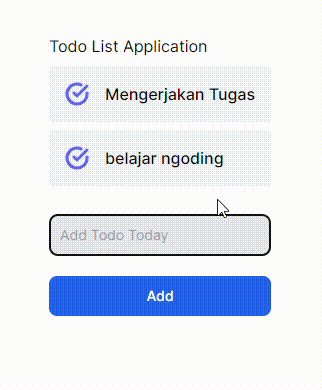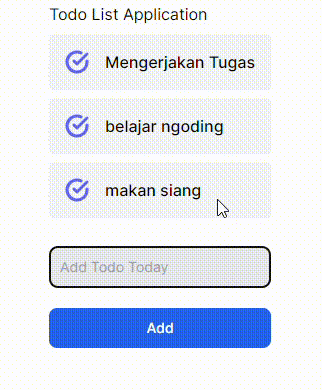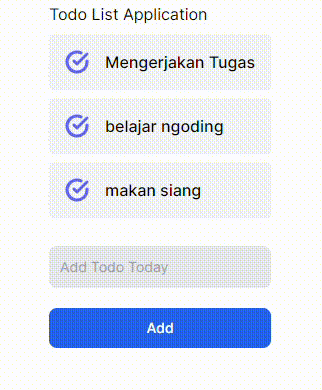
GIF 2. Menggunakan useOptimistic Hooks:
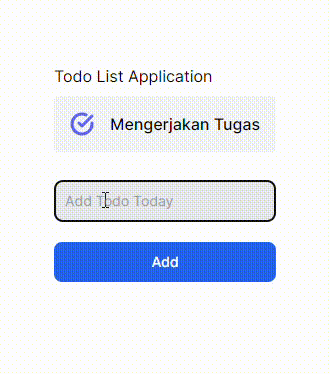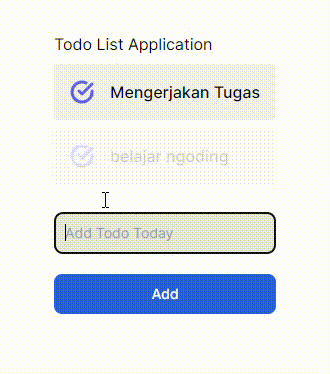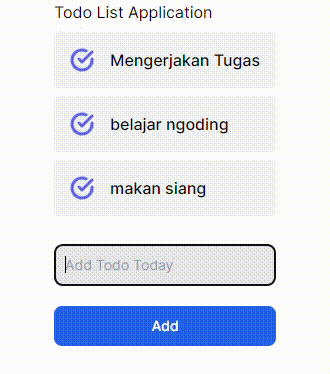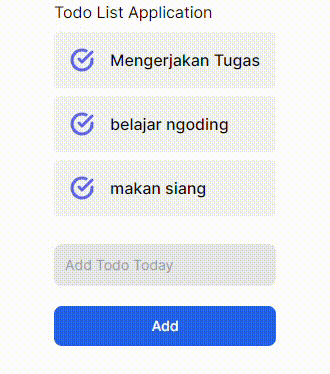
Terdapat perbedaan yang cukup signifikan dari implementasi _useOptimistic_ Hooks pada komponen React JS/Next JS. Gif 1 tidak memberi tahu bahwa ada proses yang sedang terjadi ke _backend_ ketika menambahkan data baru, sedangkan Gif 2 memberi tahu kepada user dengan menambahkan opacity ketika ada proses pengiriman data ke _backend_. Saya pribadi lebih memilih opsi yang kedua karena ketika kita membuat sebuah aplikasi pastinya kita ingin user dapat berinteraksi dengan aplikasi kita sehingga _user experience_ dapat terbentuk hanya dengan hal yang cukup sederhana seperti ini.
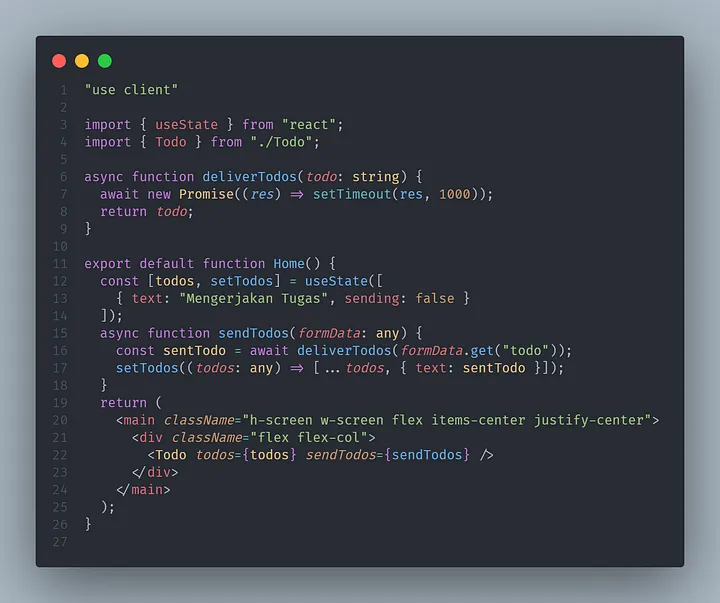
Oke, kita lanjut ke tahap implementasi kode. Kali ini saya menggunakan Next JS untuk implementasi _useOptimistic Hooks_ ini. Disini temen-temen juga bisa praktik dengan menjalankan kode program yang sudah saya buat ya.
```javascript
"use client"
import { useState } from "react";
import { Todo } from "./Todo";
async function deliverTodos(todo: string) {
await new Promise((res) => setTimeout(res, 1000));
return todo;
}
export default function Home() {
const [todos, setTodos] = useState([
{ text: "Mengerjakan Tugas", sending: false }
]);
async function sendTodos(formData: any) {
const sentTodo = await deliverTodos(formData.get("todo"));
setTodos((todos: any) => [...todos, { text: sentTodo }]);
}
return (
<main className="h-screen w-screen flex items-center justify-center">
<div className="flex flex-col">
<Todo todos={todos} sendTodos={sendTodos} />
</div>
</main>
);
}
```
Lanjut, kita akan coba breakdown terlebih dahulu kode program yang sudah saya buat.
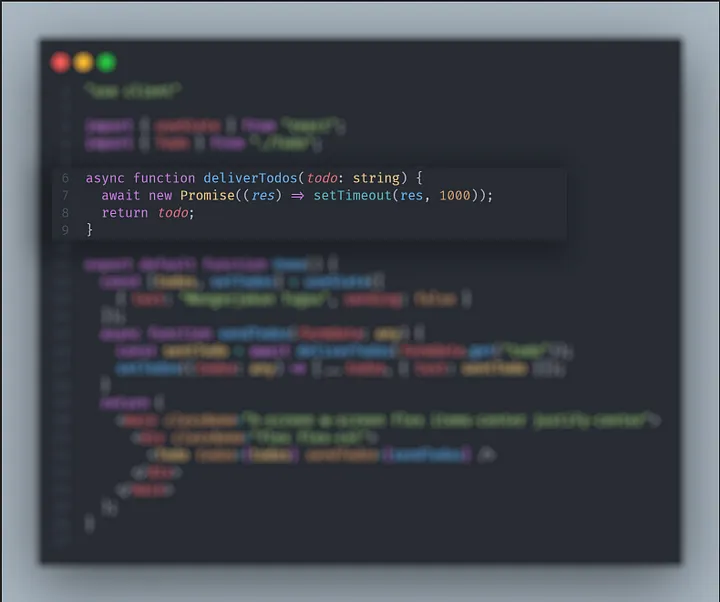
_Function deliverTodos_ ini kita analogikan sebagai function yang digunakan untuk melakukan request ke backend dengan durasi request dan response 1 detik. Jadi, kalau temen-temen udah punya endpoint sendiri bisa diimplementasikan pada function ini.
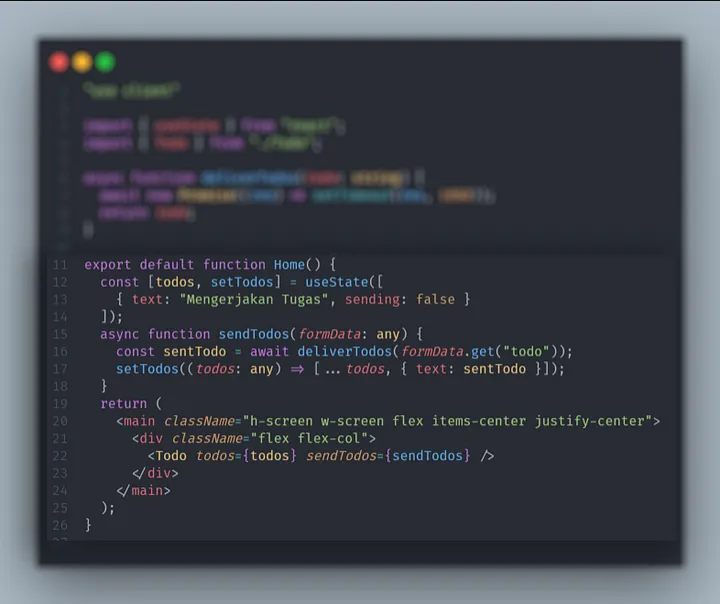
Kita membutuhkan 1 state yaitu todos sebagai initiator value dan digunakan untuk menyimpan perubahan value yang akan kita gunakan pada useOptimistic Hooks.
```javascript
/* eslint-disable react/jsx-key */
"use client";
import { useOptimistic, useRef } from "react";
export function Todo({ todos, sendTodos }: any) {
const formRef = useRef<HTMLFormElement>(null);
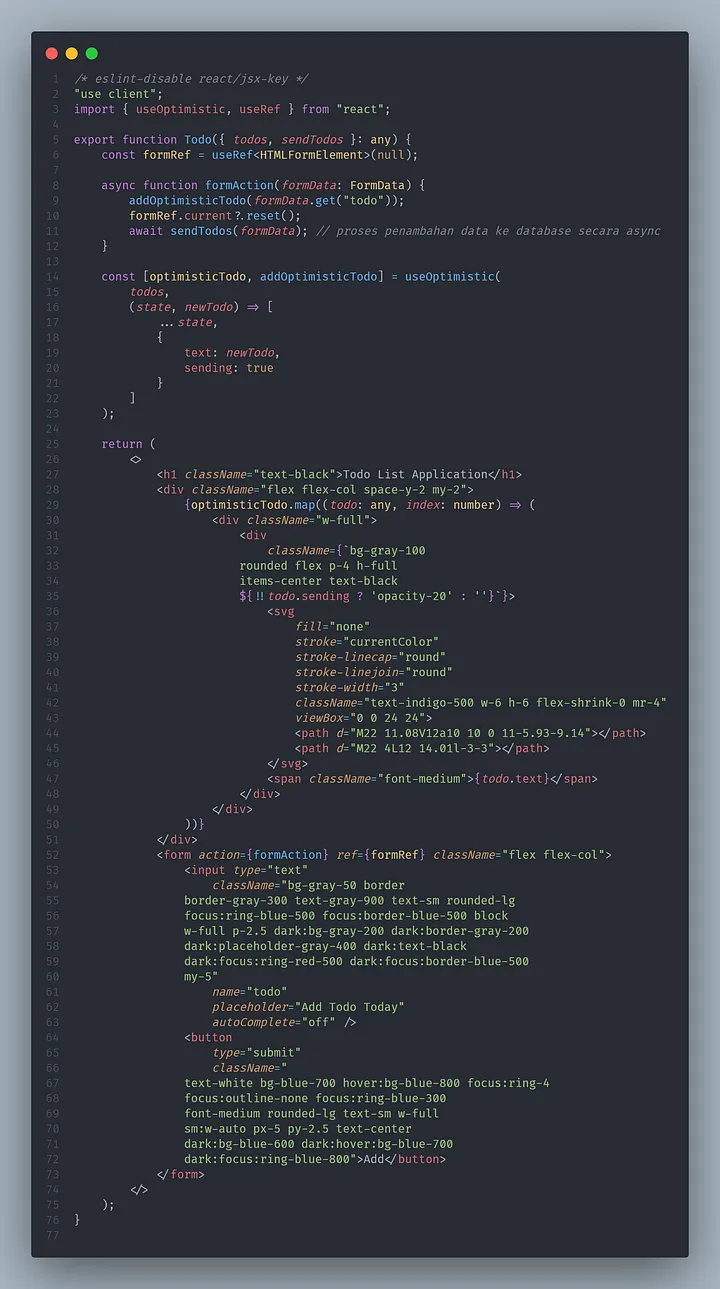
async function formAction(formData: FormData) {
addOptimisticTodo(formData.get("todo"));
formRef.current?.reset();
await sendTodos(formData); // proses penambahan data ke database secara async
}
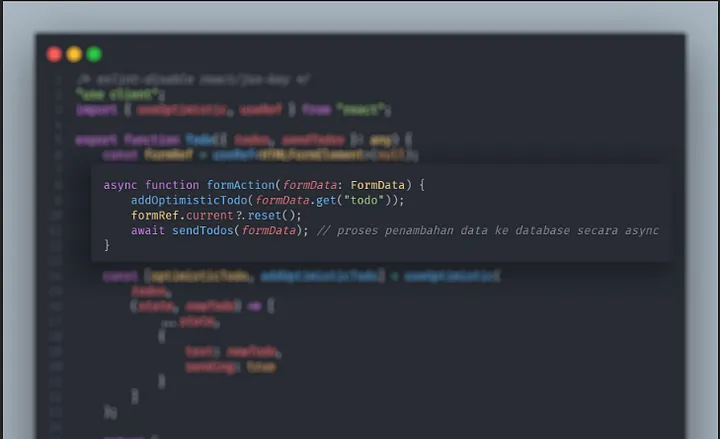
const [optimisticTodo, addOptimisticTodo] = useOptimistic(
todos,
(state, newTodo) => [
...state,
{
text: newTodo,
sending: true
}
]
);
return (
<>
<h1 className="text-black">Todo List Application</h1>
<div className="flex flex-col space-y-2 my-2">
{optimisticTodo.map((todo: any, index: number) => (
<div className="w-full">
<div
className={`bg-gray-100
rounded flex p-4 h-full
items-center text-black
${!!todo.sending ? 'opacity-20' : ''}`}>
<svg
fill="none"
stroke="currentColor"
stroke-linecap="round"
stroke-linejoin="round"
stroke-width="3"
className="text-indigo-500 w-6 h-6 flex-shrink-0 mr-4"
viewBox="0 0 24 24">
<path d="M22 11.08V12a10 10 0 11-5.93-9.14"></path>
<path d="M22 4L12 14.01l-3-3"></path>
</svg>
<span className="font-medium">{todo.text}</span>
</div>
</div>
))}
</div>
<form action={formAction} ref={formRef} className="flex flex-col">
<input type="text"
className="bg-gray-50 border
border-gray-300 text-gray-900 text-sm rounded-lg
focus:ring-blue-500 focus:border-blue-500 block
w-full p-2.5 dark:bg-gray-200 dark:border-gray-200
dark:placeholder-gray-400 dark:text-black
dark:focus:ring-red-500 dark:focus:border-blue-500
my-5"
name="todo"
placeholder="Add Todo Today"
autoComplete="off" />
<button
type="submit"
className="
text-white bg-blue-700 hover:bg-blue-800 focus:ring-4
focus:outline-none focus:ring-blue-300
font-medium rounded-lg text-sm w-full
sm:w-auto px-5 py-2.5 text-center
dark:bg-blue-600 dark:hover:bg-blue-700
dark:focus:ring-blue-800">Add</button>
</form>
</>
);
}
```
Kita akan breakdown lagi kode program yang ada pada <Todo /> component.
_**function formAction**_ merupakan function yang digunakan untuk menambahkan hasil input todo ke dalam _**addOptimisticTodo**_ yang mana function ini merupakan function yang akan kita definisikan pada _useOptimisitic destruct_. Lalu, kita bisa mengirim data ke API secara asynchronous.
Lalu kita bisa mendefinisikan _passthrough_ dan _reducer_ yang ada pada _useOptimistic Hooks_. Disini saya definisikan passthrough dengan nama _optimisticTodo_ dan _reducer_ sebagai _addOptimisticTodo_. Kemudian, didalam parameter _useOptimistic_ kita bisa kirimkan todos sebagai _passthrough_ dan menuliskan _reducer_ sesuai dengan dokumentasi yang sudah disediakan oleh React JS. Di dalam reducer kita kirim 2 value yaitu text dan sending. Dengan demikian, implementasi _useOptimistic_ sudah bisa digunakan.
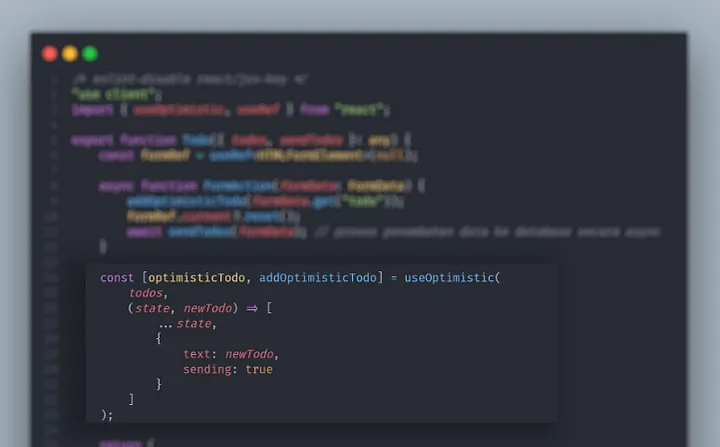
Sekarang, kita bisa langsung gunakan _state useOptimistic_ pada html tag komponennya seperti kode program diatas. Bagaimana? cukup mudah bukan implementasi _useOptimistic Hooks_ ini pada React JS/Next JS?
Dengan menggunakan _useOptimistic Hooks_, sekarang aplikasi yang temen-temen kembangkan sudah memenuhi syarat minimal untuk meningkatkan _user experience_. Cukup sekian ya artikel sederhana yang bisa saya tuliskan, semoga kita bisa bertemu di artikel lain dengan materi yang lebih menarik lagi.
| yogameleniawan |
1,873,741 | Mẫu đèn cầu thang 2024 | Đèn chân tường cầu thang Mẫu đèn chân tường cầu thang là một trong số các loại đèn cầu thang đẹp... | 0 | 2024-06-02T14:49:45 | https://dev.to/noithatnew_noithatnew_e45/mau-den-cau-thang-2024-3aph | Đèn chân tường cầu thang
Mẫu đèn chân tường cầu thang là một trong số các loại đèn cầu thang đẹp hiện đại nhất hiện nay. Bởi đây là một mẫu đèn cầu thang rất được nhiều người ưa thích vì có thể chiếu sáng lối đi, xác định được điểm đến rõ ràng hơn
Đặc biệt, ánh đèn chiếu từ dưới lên, luồng sáng dưới chân cũng khiến bạn cảm giác an toàn hơn khi di chuyển. Tạo lên một khung cảnh hiện đại ngay trong chính ngôi nhà của bạn.
5.Mẫu đèn cầu thang với hình dạng tam giác, vuông, tròn
Theo mình thấy thì ngày nay, các loại đèn được thiết kế với rất nhiều mẫu mã và hình dạng khác nhau. Tùy vào khu vực bạn sử dụng thì bạn có thể trang trí các mẫu đèn cầu thang sao cho phù hợp. Một vài hình dạng mà mình thấy phổ biến như:
- Mẫu đèn cầu thang hình tròn: Hình tròn là một kiểu dáng cơ bản đã quá quen thuộc nhưng tính thẩm mỹ của nó vẫn luôn được đánh giá cao. Bạn có thể trang trí đèn cầu thang bằng đèn tròn trên tường cầu thang. Nó vừa đẹp mắt lại vừa có công dụng chiếu sáng khá tốt.
- Mẫu đèn cầu thang hình tam giác: Có lẽ bạn sẽ ít gặp mẫu sản phẩm này vì nó còn khá mới mẻ với người tiêu dùng. Đèn lắp cầu thang dạng tam giác sở hữu thiết kế đơn giản nhưng vẫn cực kỳ thu hút và lạ mắt.
Không chỉ có vậy, mẫu đèn cầu thang hình tam giác còn được đánh giá cao bởi độ bền của chúng khi đừng dùng để trang trí đèn cầu thang.
- Mẫu đèn cầu thang hình vuông: Với dạng hình hộp vuông, chiếc đèn này tạo được ấn tượng bởi sự tinh tế. Vì vậy mà nó rất phù hợp với thiết kế của những công trình hiện đại.
Thông thường đèn cầu thang hình vuông được cấu tạo từ hợp kim nhôm cao cấp nên có thể điều chỉnh độ mở góc chiếu sáng linh hoạt. Rất phù hợp để trang trí đèn cầu thang.
Các hình dạng và mẫu mã đèn này còn tùy thuộc vào phong cách mà bạn muốn trang trí đèn cầu thang như thế nào. Bạn sẽ không gặp phải quá nhiều khó khăn khi tìm kiếm các loại đèn này để mang về cho ngôi nhà mình đâu nên đừng lo lắng nhé!
Trên đây là một vài mẫu đèn nổi bật dành cho cầu thang trong ngôi nhà của bạn.
Hy vọng là qua bài viết này, bạn có thể đưa ra quyết định xem mẫu trang trí đèn cầu thang nào là phù hợp với mình nhé!
Nếu bạn muốn tìm hiểu thêm nhiều thêm về đèn nội thất thì hãy tới [noithatnew.com](url) ngay nhé! | noithatnew_noithatnew_e45 | |
1,873,740 | Step Up Your Express.js Game: Advanced Middleware and Security Tips for Beginners | Express.js is a popular framework for developing web apps in Node.js. Middleware is a fundamental... | 0 | 2024-06-02T14:49:34 | https://dev.to/a_shokn/step-up-your-expressjs-game-advanced-middleware-and-security-tips-for-beginners-3bk7 | webdev, beginners, node, backenddevelopment | Express.js is a popular framework for developing web apps in Node.js. Middleware is a fundamental aspect that contributes to Express's power and flexibility. If you're familiar with the fundamentals of Express middleware, you'll recognize that it's similar to a set of steps your request takes. But what happens after the basics? Let's get started and examine sophisticated middleware topics in a basic manner.
> Middleware be like: "I'm just a simple middleware, but when things get tough, I call my next()"
### What is Middleware?
Middleware functions have access to the request object (req), the response object (res), and the following middleware function in the application's request-response cycle. These functions can execute a variety of activities, including altering the request or response objects, terminating the request-response cycle, and calling the next middleware in the stack.
Real-World Example: A Bakery
Imagine you own a bakery, and your shop is the server. Customers (requests) come in, and they have to go through several stages (middleware) to get their bread (response).
1. Request logging: A staff member logs the customer’s details.
2. Authorization: Another staff member checks if the customer has a valid membership card.
3. Processing order: The baker prepares the bread.
4. Packaging: Another staff member packs the bread.
5. Sending response: Finally, the cashier hands over the packed bread to the customer.
### 1. Error Handling Middleware:
Sometimes things go wrong, and you need a way to catch and handle errors. Error-handling middleware functions have four arguments: err, req, res, and next.
```
app.use((err, req, res, next) => {
console.error(err.stack);
res.status(500).send('Something broke!');
});
```
### 2.Chaining Middleware:
You can create modular middleware functions and chain them together for reusability and cleaner code.
```
const checkAuth = (req, res, next) => {
if (req.user) {
next();
} else {
res.status(401).send('Unauthorized');
}
};
const logRequest = (req, res, next) => {
console.log(`${req.method} ${req.url}`);
next();
};
app.use(logRequest);
app.use(checkAuth);
```
### 3.Custom Middleware for Specific Tasks
Sometimes you need middleware to perform specific tasks like data validation, rate limiting, or even modifying the request object to include additional information.
```
const addTimestamp = (req, res, next) => {
req.requestTime = Date.now();
next();
};
app.use(addTimestamp);
```
## Security Best Practices
### 1.Helmet Middleware:
When designing applications with Express.js, security is critical. Below are some lesser-known security guidelines and recommended practices that can help protect your application:
Helmet Middleware secures Express apps by setting multiple HTTP headers. It consists of a group of smaller middleware methods that set security-related HTTP headers.
```
const helmet = require('helmet');
app.use(helmet());
```
### 2.Rate Limiting:
Rate restriction prevents brute-force assaults by restricting the amount of requests a user can make in a given time period.
```
const rateLimit = require('express-rate-limit');
const limiter = rateLimit({
windowMs: 15 * 60 * 1000, // 15 minutes
max: 100, // limit each IP to 100 requests per windowMs
});
app.use(limiter);
```
### 3.Content Security Policy (CSP):
CSP helps prevent cross-site scripting (XSS) attacks by specifying which content sources are trusted.
```
app.use(helmet.contentSecurityPolicy({
directives: {
defaultSrc: ["'self'"],
scriptSrc: ["'self'", "trusted.com"]
}
}));
```
Just like you would take every precaution to keep your bakery safe and running properly, these techniques will help keep your web application secure and dependable.
Thank you for the Read!
| a_shokn |
1,873,739 | I am work on a research paper about use of Adaptive Ai in games that tailors itself to the player’s unique playing style | The problem is that traditionally, adpative AI in games considers only the players short term... | 0 | 2024-06-02T14:46:05 | https://dev.to/kwadjo_wusuansah_bf2aae9/i-am-work-on-a-research-paper-about-use-of-adaptive-ai-in-games-that-tailors-itself-to-the-players-unique-playing-style-2195 | ai, productivity, learning, gamedev | The problem is that traditionally, adpative AI in games considers only the players short term behaviours to learn and adapt to make decisions that affect the game but don’t consider the long term behavior over the playthrough time. I beileve that this tends to limit the potential of video games in immersing the user in a unqiue experience only they can have. I wanted to know if this is something valid to research about and if that can help in the space of game development. If you have any suggesting to research paper I can read to get more idea, it would be a big help.
Or even ideas I should explore rather than this in the space of AI. | kwadjo_wusuansah_bf2aae9 |
1,873,738 | Begini Cara Memahami Fungsi useCallback Hooks pada React JS/Next JS dengan Menggunakan Visualisasi yang Sederhana | Pernah dengar useCallback pada React JS? Jika teman-teman pernah dengar berarti teman-teman sudah... | 0 | 2024-06-02T14:45:54 | https://dev.to/yogameleniawan/begini-cara-memahami-fungsi-usecallback-hooks-pada-react-jsnext-js-dengan-menggunakan-visualisasi-yang-sederhana-46a0 | javascript, react, nextjs |

Pernah dengar useCallback pada React JS? Jika teman-teman pernah dengar berarti teman-teman sudah cukup jauh explore framework javascript yang satu ini. Tapi, pernah dengar aja belum cukup. Apakah teman-teman sudah tau bagaimana useCallback itu bekerja? Kalau sudah tau, yaudah jangan dilanjutin. Selesaikan kerjaan yang lain aja, kalau yang udah kerja. Tapi kalau yang belum kerja ya nonton Youtube aja lebih enak, jangan belajar, buang-buang waktu, nanti paling cuma nganggur aja sampai tua.
Saya akan coba kasih insight dengan praktikum kode ya, untuk teori bisa dilihat pada link [disini](https://react.dev/reference/react/useCallback). Karena saya lebih suka menjelaskan berdasarkan praktik bukan teori. Sebelum lanjut lebih dalam pembahasan useCallback Hooks. Teman-teman bisa lihat gambar di bawah ini :
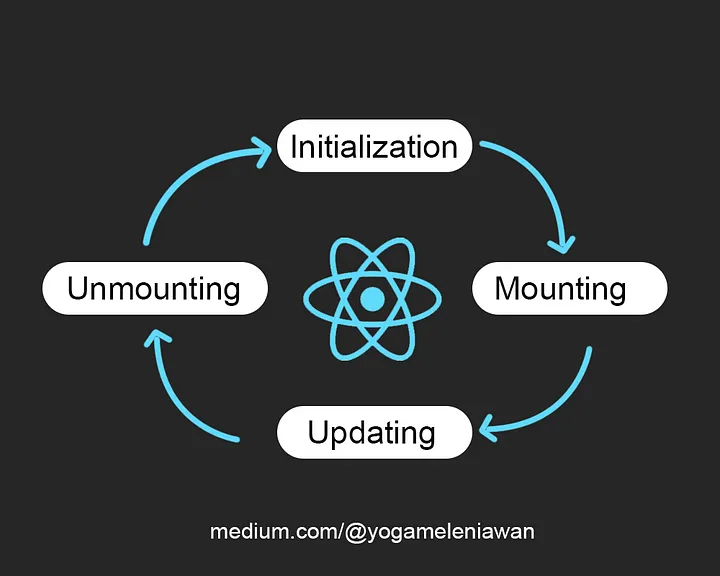
Visualisasi diatas merupakan gambaran lifecycle dalam proses render komponen yang ada pada React JS. Jadi, sebelum tampil di halaman web dan ketika ada perubahan yang dilakukan oleh state maka ada 4 proses yang dilakukan oleh React JS. Nah, 4 proses itu tentunya tidak ada yang salah, tetapi kesalahan itu akan terjadi ketika aplikasi yang kita kembangkan itu terus menerus melakukan 4 proses tersebut tanpa adanya perubahan state pada komponen kita. Kalau teman-teman masih bingung dengan “perubahan state pada komponen” yang saya maksud sebelumnya, maka teman-teman cukup tepat karena sudah bingung. Oke, saya akan coba visualisasikan ke dalam bentuk kode program ya, supaya tidak bingung.
Kali ini, kita mempunyai tampilan pada web browser kurang lebih seperti pada gambar diatas. Border merah merupakan parent dan border kuning merupakan child. Untuk source code bisa temen-temen lihat pada gambar dibawah ini :
Source Code Halaman Home:
Source Code Button Hitung Luas:
Source Code Button Hitung Keliling:
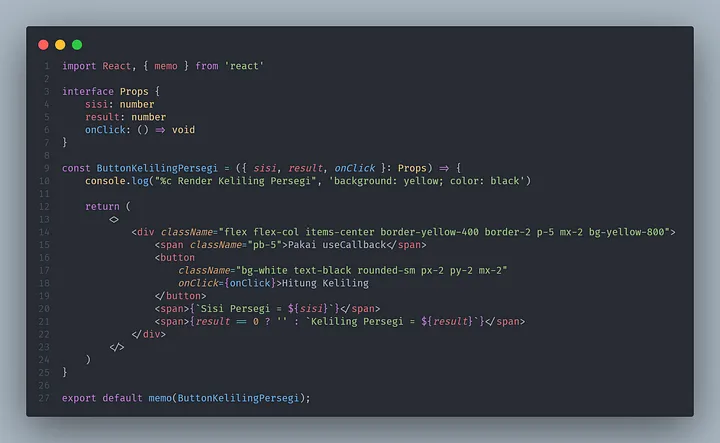
Kemudian, ketika kita baru pertama kali buka pada browser maka React JS akan secara normal melakukan 3 proses render.
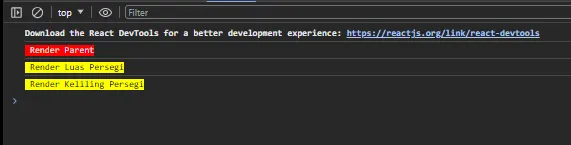
Lalu ketika kita coba lakukan perubahan state sisi yang mana state sisi ini digunakan pada child component Hitung Luas dan Hitung Keliling.
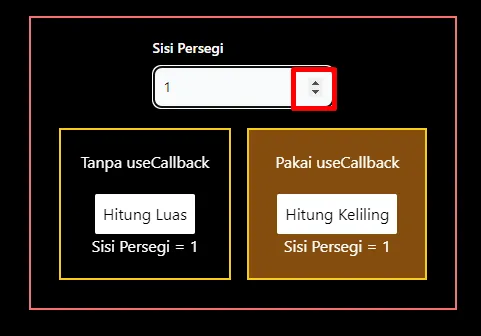
Maka, pada console browser akan melakukan render 3 kali lagi. Karena, state sisi digunakan pada 2 child. Sehingga, ini masih normal.
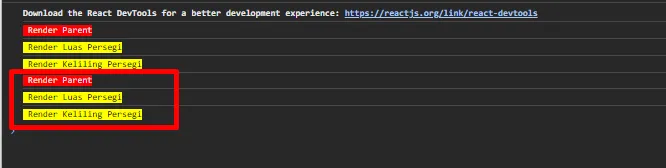
Lalu, kita akan coba klik button Hitung Luas.
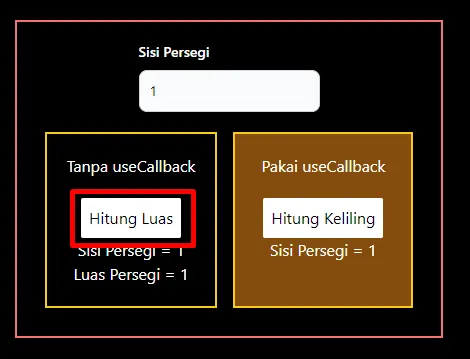
Maka, komponen Hitung Keliling tidak dirender. Hanya melakukan render Parent adn Luas Persegi.
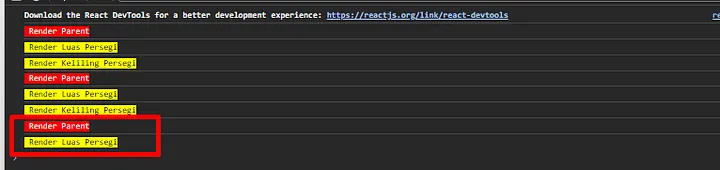
Kok bisa? ya bisa, karena component Hitung Keliling menggunakan _useCallback Hooks_ dan menggunakan [memo ](https://react.dev/reference/react/memo) untuk melakukan skip render apabila tidak ada perubahan pada komponennya.
Penggunaan useCallback pada function hitung keliling:
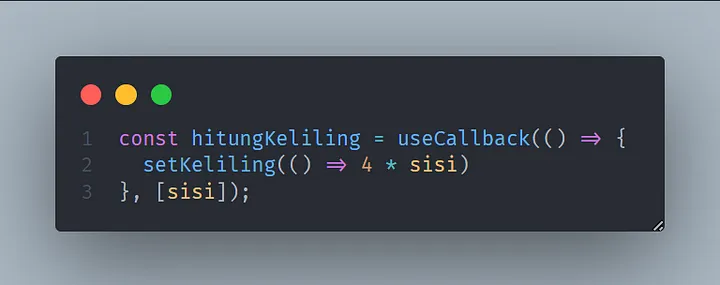
Penggunaan memo pada component Button Keliling Persegi:
Kemudian, ketika kita melakukan klik pada button Hitung Keliling.
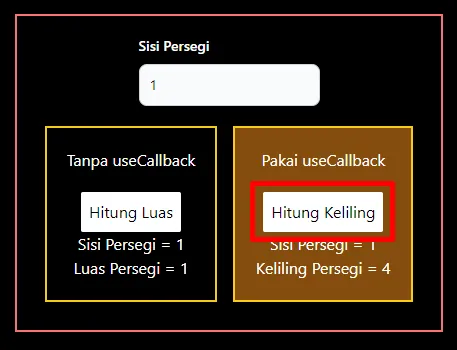
Maka, akan ada 3 kali render yang mana Render Keliling Persegi akan dieksekusi karena ada perubahan pada state keliling.
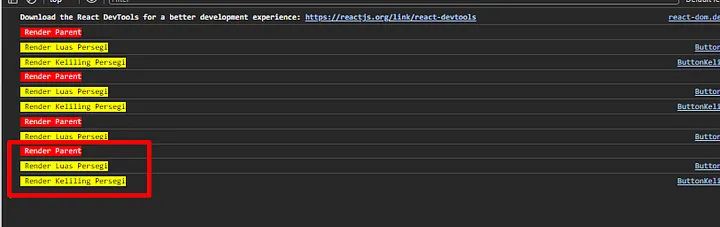
Sampai sini, apakah ada yang salah? **Ada dong**. Ketika kita melakukan klik pada button Hitung Keliling kenapa kok component Hitung Luas dirender juga? kan ngga ada perubahan pada state? Nah itu problemnya, maka dari itu kita harus menggunakan useCallback dan memo untuk mengatasi hal ini. Bayangkan kalau component kita udah banyak, lalu kita cuma melakukan perubahan pada 1 component saja, tetapi component lain juga ikut dirender oleh React padahal tidak ada perubahan pada component lainnya. Otomatis akan menghabiskan resource hanya untuk masalah yang seharusnya tidak terjadi.
Jadi, sekarang kita akan coba implementasikan useCallback dan memo pada component Hitung Luas.
Menggunakan useCallback pada function hitung luas:
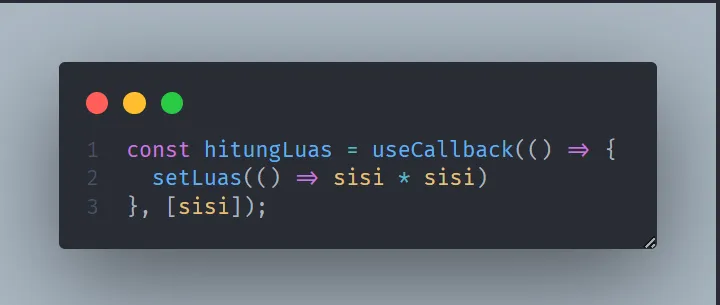
Menggunakan memo pada komponen button luas persegi:
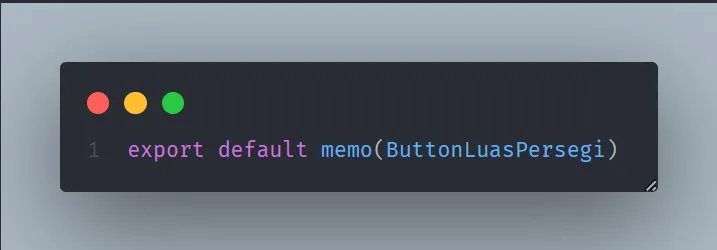
Lalu, kita bisa lihat perbedaanya ketika sudah menggunakan useCallback dan memo pada component Hitung Luas. Ketika kita melakukan klik pada button Hitung Luas.
Melakukan action pada komponen hitung luas:
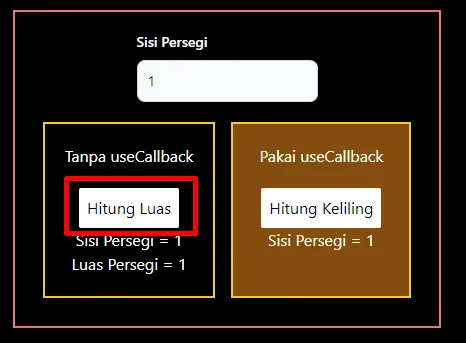
Maka, React hanya akan melakukan render pada komponen parent dan hitung luas.
Hasil render setelah melakukan action terhadap button hitung luas:

Begitu pula, ketika kita melakukan klik pada button Hitung Keliling.
Melakukan action terhadap button Hitung Keliling:
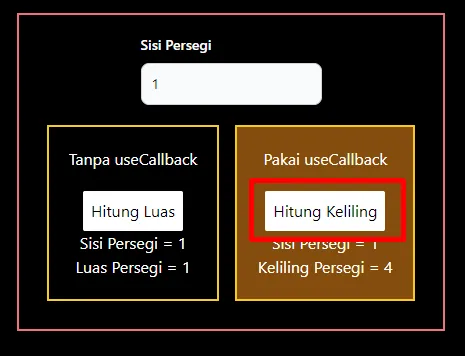
Maka, react js akan melakukan render hanya pada komponen parent dan Hitung Keliling.
Hasil render setelah melakukan action terhadap button Hitung Keliling:

Dengan demikian kita bisa meminimalisir terjadinya proses render yang seharusnya tidak perlu dilakukan oleh React dikarenakan tidak ada perubahan pada komponennya khususnya pada state-nya.
Sampai sini apakah sudah sedikit memahami cara kerja dari useCallback pada React JS? Saya berharap teman-teman bisa memahami meskipun penjelasan yang saya sampaikan malah bikin yang awalnya **nggak tau** malah jadi **nggak mau tau** dan akhirnya temen-temen males belajar React.
Oke, mungkin cukup sekian. Semoga bisa bertemu di lain kesempatan pada artikel yang berbeda. | yogameleniawan |
1,873,722 | JavaScript variables and how to use them. | A variable is an identifier that represents a value. It is a named container for storing data. A... | 0 | 2024-06-02T14:02:42 | https://dev.to/kemiowoyele1/javascript-variables-and-how-to-use-them-i63 | A variable is an identifier that represents a value. It is a named container for storing data. A value is any data that can be manipulated or operated upon within a program.
You do not need to specify the data type, as JavaScript does that on its own behind the scene. Additionally, it allows for dynamic type conversion, meaning you can convert data from one type to another as needed.
## How To Create, Use, And Modify A Variable In JavaScript
The act of creating a variable is called variable declaration. To declare a variable in JavaScript, there are three keywords, var, let and const, followed by the variable name. A variable can be created without initially assigning a value to it. In such case the value of the variable will be “undefined".
For example
`var name;`
To assign value to the variable, use the equal sign. Assigning a value to a variable is known as initializing the variable.
`var name = 'Mark ';
`It can also be created and initialized at the same time.
`Let gender = “male”;`
var, let and const are the three keyword the we can use to create variables in JavaScript. With var and let, we can reassign values to variables whereas values assigned to const variables cannot be reassigned and are treated as constant values.
To use a variable, all you have to do is refer to the variable by name wherever you intend to use it.
`console.log( name + 'is a ' + gender + 'student ')
`trying to reassign the variables will result in an error if you use const but is possible if you use var and let.
**example**
`const age = 14 ;`
trying to reassign age will result in an error
`age = 25 //` Uncaught TypeError: Assignment to constant variable.
`var firstName = 'Ade ';`
`var firstName = 'Ola '; `//will reassign Ola as the new value of firstName
To modify a variable, use the equal to operator without the keyword.
**Example;**
`Let count = 0;
count = count + 1;
console.log(count)`
## The differences between var, let and const
As discussed earlier, there are three keywords for creating variables in JavaScript. Each of these keywords has their unique attributes, and understanding these attributes will be very helpful for us when writing code to avoid unexpected outcomes.
## JavaScript scope
Scope in JavaScript refers to how your variables can be accessed within your code. There are three major types of scope;
I. Global scope: variables with global scope can be accessed from anywhere in the code. They are variables written outside any function or code block. Globally scoped variables should be used only when necessary to avoid variable naming conflicts and ensure code readability
II. Function scope: function scoped variables are accessible from anywhere within the function they are declared in. Variables written in the function, but outside any specific block are accessible everywhere in the function.
III. Block scope: block scope applies to variables declared within any block of code, including if statements, for loops, and even curly braces {}. This means the variable is only accessible within that specific block.
To better illustrate variable scoping, I will use a house. The global variable will be areas outside the house, but inside the fence. Every occupant of that compound can access things or places in the compound, irrespective of the apartment. The function scope will be each apartment. People in each apartment can access things in the apartment that are not in specific bedrooms. The block scope would then be individual bedrooms. Things in the bedroom can be accessed by occupants of the bedroom but not those of another bedroom.
In JavaScript, variables declared with var keyword are function scopes. This means that even if the variable is declared in a block, it will still be available to other blocks in that function. This is not so with variables declared with let and const as they are block scoped and can only be accessed within the block of code they are declared in.
## Hoisting
The default behavior of JavaScript is to move variable and function declaration to the top of the scope. This is why sometimes; it is possible to access a variable before it is declared. Hoisting behaves differently depending on how variable is declared and with functions.
**Variable hoisting:** variables declared with var are hoisted to the top of the function, or the global scope depending on if the variable was declared inside a function or in the global scope. The variable can also be accessed before they are declared but the value will be undefined.
**Example**;
`console.log(x) // undefined
var x = 15;
console.log(x) // 15
`
Variables hoisted with let and const are hoisted to the top of the block scope they are declared in, but they are not initialized. Attempting to access these variables before they are declared will result in error
**Example;**
`console.log(x)
// Uncaught ReferenceError: Cannot access 'x' before initialization
let x = 15;
console.log(x) // 15`
**temporary dead zone:**Temporary dead zone(TDZ) is the zone between the beginning of the scope and the point where the variable is declared. Variables declared with var keyword can be accessed in the temporary dead zone, although the value will be undefined. On the other hand, variables declared with let and const will not be accessible in this zone. Trying to access them will result in reference error.
**Function hoisting:** functions are also hoisted to the top of their containing scope in JavaScript. This allows functions to be accessible before they are declared.
**Example:
**`greet(); // hello
function greet () {
console.log('Hello ');
};`
If the function is assigned to a variable, it will not be accessible before declaration.
**Example**:
`greet(); // index.html:8 Uncaught TypeError: greet is not a function
var greet = function () {
console.log('Hello ');
};
`
Arrow functions are not accessible before declaration.
**Example:
**`greet(); // Uncaught ReferenceError: greet is not defined
greet =()=> {
console.log('Hello');
};
`
## Variable immutability
An immutable variable is read-only, it means that the variable cannot be reassigned or modified. In JavaScript, you can create immutable variables using the const keyword.
The variables declared with const keyword cannot be re-assigned. The values however may still be modified. To achieve true immutability like in some other programming languages, you may have to use a library like immutable.js.
Immutability ensures consistency and predictability in programming. It also makes debugging and code maintenance easier.
## Referencing a variable vs. coping the value of the variable.
There are two major data types in JavaScript. They are;
**1. Primitive data types and;**
I. Number
II. String
III. Boolean
IV. Undefined
V. Null
VI. Symbol
When you assign a variable with a primitive data type to another variable, it copies the value. This means that at that moment, the value of the new variable will be a copy of the old variable; if you change the value of the either variable it does not affect the value of the other.
**Illustration**
According to the illustration above, reassigning another value to firstName did not change the value of name. Neither did reassigning name change the value of firstName.
**2. Non-primitive or object types**
I. Objects
II. Arrays
III. Functions
Object data types could also the referred to as reference types. When you assign a variable holding an object data type as a value, it does not copy the value of the variable to the new variable. Instead, it stores the address of the variable in memory. Any changes/reassignment to either of the variables will affect the other.
**Illustration**

As illustrated above, changes to cities array automatically changed the values of cities2 array. Likewise, changes to cities2 array changed the values of cities.
## The dos and don’ts of naming variables
When giving names to variables in JavaScript, there are a few rules that must be considered. Some of them include
I. Variable names are case sensitive. GetName is not the same as getName
II. Do not begin a variable name with a number
III. Spaces are not allowed in variable names.eg.
`var get name;` // Uncaught SyntaxError: Unexpected identifier 'name'
IV. JavaScript reserve keywords are not allowed as variable names. Reserve keywords are words with special meanings in JavaScript.
Eg.
`var return; //` Uncaught SyntaxError: Unexpected token 'return'
V. Variable names can consist of lower and upper case letters a-z, numbers and $ symbol, and _ underscore.
VI. For best practice and code readability, variable names should be meaningful. The name should properly describe what it is used for.
## Uses of JavaScript variables
Most of the time, while programming, there is going to be a lot of work centered around accessing data, operating on data, manipulating data, retrieving data etc. The implication of these is that variables are inevitable in JavaScript as most of these data are stored in variables. Variables play a crucial role in programming. They are used extensively for various purposes. Some of these purposes include
**1. For storing data:** the primary purpose of variables is to hold data. JavaScript variables store data by associating a unique identifier (name) with the value assigned to it. Variables create named storage location in memory, and values assigned to the variables are stored in that memory location. You can store different data types in that location at different occasions.
**2. Calculating numbers:** variables can be used to perform mathematical calculations.
**Example;**
`Let number1 = 5;
Let number2 = 15;
Let sumNumbers = number1 + number2;
Console.log(sumNumbers);`
**3. Manipulating text:** variables are used to hold textual values. Hence they can be useful in combining/manipulating text, concatenating strings etc.
**Example;
**`Let name = 'Ola';
Let greetName = `welcome ${ name } to this event`;
Console.log(greetName);`
4. **Scope Management:** Variables help manage the scope of data, ensuring that variables are accessible only within the appropriate context or function scope, thus preventing naming conflicts and unintended consequences.
5. **Looping over Arrays and Objects:** Variables are commonly used to hold values while performing repetitive tasks over arrays and objects.
**Example:
**`let numbers = [1, 2, 3, 4, 5];
for (let i = 0; i < numbers.length; i++) {
console.log(numbers[i]);
}
`
6.** Storing User Input:** Variables can store values entered by users through input fields or other interactive elements in web applications.
`let userInput = prompt("Enter your name:");
Let greetUser = `welcome ${ userInput } to this event`;
Console.log(greetUser);`
These are just the few examples that are relatable at this point. Variables are very important in JavaScript. There is very little that a programmer can do without using variables.
**Best practices for Variables**
After learning so much about variables, it is also important to discuss how to ensure that we use variables properly. Following best practices when writing variables will make our work easier, make it easier to avoid and detect bugs, and make our codes easier to read. Some of the recommended best practices include;
**I. Use descriptive names when declaring variables:** Avoid single letter variable names, avoid vague variable names eg.
`Let x = 'something';
Let jhjh;`
Names like this will make your code difficult to read in the future. The name of your variable should tell what that variable is used for. **Example;**
`Let firstName = 'Ola ';
Let userNameInput = prompt('what is your name ');
`
**II. Avoid global variables:** global variables are available throughout the program. To avoid naming conflict or reinitializing variables, avoid them unless it is absolutely necessary.
**III. Always declare variables at the top of the containing scope:** to avoid dead zone related issues, declare variable at the top of the block where you intend to used them.
**IV. Prefer to declare variables with const:** to prevent unexpected behavior related to hoisting and scoping issues, use const if you do not intend to reassign the variable. Use let if you intend to reassign values, and var only when dealing with legacy codes.
**V. Be conscious of JavaScript automatic type conversion:** JavaScript is a dynamically typed language. This means that the data type of your variables is automatically generated. Understanding how JavaScript generates and converts data types will help you write better codes and avoid errors and unexpected outcomes.
**VI. Declare arrays and objects with const:** declaring objects and arrays with const will prevent accidental change of data type.
**VII. Initialize variables immediately you declare them:** to prevent undefined values and errors, always assign values to your variables as you are creating them.
**Example;**
`Let count = 0;
Let userInput = null;`
**VIII. Be consistent:** developing consistent habit in following the variable best practices, especially with naming consistency will make your codes more readable and easier to maintain and debug.
**Conclusion**
Proper understanding of JavaScript variables is very important, as it is fundamental to building any meaningful application in the language. With proper understanding of variables, you are in a better position to write clear and easy to maintain codes, debug errors and build meaningful applications. | kemiowoyele1 | |
1,873,734 | Understanding Javascript Variables Declaration: The Significant of Var, Let, Const, In Modern Development. | Variable is a unique identifier of words or letter put together to store data in your programs.... | 0 | 2024-06-02T14:45:32 | https://dev.to/peter_akojede/understanding-javascript-variables-declaration-the-significant-of-var-let-const-in-modern-development-19aa | javascript, webdev, react, frontend |

Variable is a unique identifier of words or letter put together to store data in your programs. Variable are always declare before use (using let and const), they are the container for storing values and are also use to make reference to functions. Unique name should be given to variables base on what you are working on, for easy identification and making the codebase easy to understand by other or fellow programmers.
```js
let message = "Hello world!"
const countries= ["Usa", "United Kingdom", "Canada"]
const fruits = ["Apple", "Pine Apple", "Banana"]
```
Here!!! message, countries, and fruits are variables. They are sensitive and case sensitive during usage and you can't use Javascript keywords to declara a variables like if, else, for, switch, try, catch. e.t.c. They are reserve words in Javascript and use for their specific purpose. A variable without a value is an undefined varaible.
```js
let message
const countries
const fruits
```
Here!!! message, countries, and fruits are undefined because value have not been assign to them and they hold no meaningful data, but the variables have been initialized and they are undefined.
**Javascript Naming Convention When Declaring Variables**
```js
let fruits // lowercase
let FRUITS // uppercase
//combining 2 words
let FruitJuice // pascal case
let fruitJuice // camel case
let fruit_juice // snake case
// observe the variable naming convention
```
however, the camelCase, "lower case" and the snake_case is commonly used and accepted for naming variables and functions in Javascript.
**Understanding Different Types of Scope In Javascript For Variable Declaration.**
1. Global Scop: The variable can be declared anywhere and can be
accesible from anywhere. They are often declared oustside of the
function or block "{}"
2. Function Scope: variable declared with in the function can be
accessible with in the function.
3. Block Scope: variable declare with in the block can be accessible
with in the block e.g loops, if else statement curly braces "{}".
```js
let name = "john doe" // global scope
if (true) {
// block scoped
}
function name {
// function scoped
}
const name () => {
// function scoped
}
```
**Javascript Best Practices For Modern Development Using Var, Let, and Const,**
**VAR**
Var method of declaring variables in Javascript was used from year 1995 to 2015 and sometimes use now, can also be found in some legacy code base, it was use for old browser and it has drawbacks.
**Feature of Var**
when declaring variable using Var it can be used before it is declared in the code
```js
var number// declaration is hoisted
console.log(number) // outputs undefined instead of error
number = 8; //
console.log(number) //output 8
```
variable declared with var are not limited to the block in which they are defined, they can be used outside of the block in which they are defined. However, this can lead to unintentional variable leaks and conflicts
```js
if (true) {
// block scope
var number= 30
}
console.log(number) // outputs 30 //outside of the block scope
```
in response to these problems, particularly the lack of block scope, ECMA script 6 (ES6) added let and const as improved variable scoping techniques for more understandable and predictable code. let and const are typically preferred over var(function scope) in contemporary javascript and let and const provided block scope.
**LET**
Let is a keyword that is use in javascript, it declare a block scope when use the variable must be declared before use (No hoisting). Let works well with loops, functions, if else ststaement, and curly braces "{}". when using let you can't re-declared same variable name once the initial variable name has been declared in the same scope.
```js
let name = "john doe"
let name = "musa doe" // SyntaxError: Identifier 'name' has already been declared
```
This will throw an error because name has already been declared, but it is possible in var and it will take up the new value. however, you can re-declared variable with the same name in deifferent scope "not in the same scope".
```js
let name= "john doe" // global scope
if (true) {
// block scope
let name= "musa doe"
console.log(name); // musa doe
}
// global scope
console.log(name) // john doe
```
Furthermore, variable declared with let can be re-assiged with in the same scope it was declared, you can change its value as long you are in the sme scope, You can also access the variable with in the block that they are defined.
```js
let name = "john doe" // global scope
if (true) {
// block scope
let name = "musa doe"
name = "jane doe"
console.log(name); // jane doe
}
// global scope
name = "mary doe"
console.log(name) // mary doe
```
**CONST**
when you declare a variable in javascript using const you can't re-declare that variable again, const declaration of variable is only declared once with in the same scope but same variable name can be re-declared in different scope.
```js
const fruit = "mangoe"
const fruit = "apple" // SyntaxError: Identifier 'fruit' has already been declared
```
when a variable is assign using const, you can't re-assign that variable to a new value again after the initial assignment.
```js
const gender = "male"
gender = "female" // uncaught syntax error
```
This is possible using let but it is not possible using const. const declaration of variable is constant. However you can modify the content of an object or an array.
```js
const fruits = ["Apple", "mangoe", "banana"]
fruits [2] = "water melon" // you can change the element
console.log(fruits[2]) // water melon
const fruits = ["Apple", "mangoe", "banana"]
fruits = ["Apple", "mangoe", "water melon"] // uncaught syntax error
```
This will throw an error because you can't re-assign variable in the same scope, but you can change an element / manipulate an element in the array using the variable name. This also apply to an object using const.
```js
const classGroup = {
fruits: "apple",
name: "john doe",
phone: "iphone",
country: "canada",
};
classGroup.phone = "samsung";
console.log (classGroup.phone); // samsung
```
when declaring a variable and you know that the value of the variable will not changed use const, especially for an array, object and funtion.
Re- assignement: var ✓, let ✓, const ✗.
Re-declaration: var ✓, let ✗, const ✗.
Function-scope: var ✓, let ✓, const ✓.
Block-sope: var ✗, let ✓, const ✓.
Hoisting: var ✓, let ✗, const ✗.
Global-scope: var ✓, let ✗, const ✗.
Global object property.[window]: var ✓, let ✗, const ✗.
| peter_akojede |
1,873,737 | Setting Up Project React and TypeScript Application with Vite and Tailwind CSS | Prerequisites Node.js installed on your machine Steps 1. Create a New Project with Vite First,... | 0 | 2024-06-02T14:43:46 | https://dev.to/ars_3010/setting-up-project-react-typescript-application-with-vite-and-tailwind-css-3nd | react, typescript, tailwindcss, vite | **Prerequisites**
Node.js installed on your machine
**Steps**
**1. Create a New Project with Vite**
First, create a new React project using Vite. Open your terminal and run the following commands:
```
npm create vite@latest my-react-app -- --template react-ts
cd my-react-app
npm install
```
**2. Install Tailwind CSS**
Next, install Tailwind CSS and its dependencies:
```
npm install -D tailwindcss postcss autoprefixer
npx tailwindcss init -p
```
**3. Configure Tailwind CSS**
Replace the contents of tailwind.config.cjs with the following configuration:
```
module.exports = {
content: [
"./index.html",
"./src/**/*.{js,ts,jsx,tsx}",
],
theme: {
extend: {},
},
plugins: [],
}
```
**4. Add Tailwind Directives to Your CSS**
Add the following directives to your src/index.css file:
```
@tailwind base;
@tailwind components;
@tailwind utilities;
```
**5. Start the Development Server**
Finally, start the development server to see your project in action:
```
npm run dev
```
| ars_3010 |
1,873,736 | baby developer | A post by KOEUK | 0 | 2024-06-02T14:42:55 | https://dev.to/koeuk/baby-developer-36o8 | koeuk | ||
1,873,573 | Write SOLID React Hooks | SOLID is one of the more commonly used design patterns. It's commonly used in many languages and... | 0 | 2024-06-02T14:40:00 | https://www.perssondennis.com/articles/write-solid-react-hooks | react, architecture, webdev, designpatterns | SOLID is one of the more commonly used design patterns. It's commonly used in many languages and frameworks, and there are some articles out there how to use it in React as well.
Each React article about SOLID presents the model in slightly different ways, some applies it on components, other on TypeScript, but very few of them are applying the principles to hooks.
Since hooks are a part of React's foundation, we will here look at how the SOLID principles applies to those.
## Single Responsibility Principle (SRP)
The first letter in Solid, the S, is the easiest one to understand. In essence it means, let one hook/component do one thing.
// Single Responsibility Principle
A module should be responsible to one, and only one, actor
For example, look at the useUser hook below, it fetches a user and todo tasks, and merges the tasks into the user object.
```react
import { useState } from 'react'
import { getUser, getTodoTasks } from 'somewhere'
const useUser = () => {
const [user, setUser] = useState()
const [todoTasks, setTodoTasks] = useState()
useEffect(() => {
const userInfo = getUser()
setUser(userInfo)
}, [])
useEffect(() => {
const tasks = getTodoTasks()
setTodoTasks(tasks)
}, [])
return { ...user, todoTasks }
}
```
That hook isn't solid, it doesn't adhere to the single responsibility principle. This is because it both has the responsibility to get user data and todo tasks, that's two things.
Instead, the above code should be split in two different hooks, one to get data about the user, and another one to get the tasks.
```react
import { useState } from 'react'
import { getUser, getTodoTasks } from 'somewhere'
// useUser hook is no longer responsible for the todo tasks.
const useUser = () => {
const [user, setUser] = useState()
useEffect(() => {
const userInfo = getUser()
setUser(userInfo)
}, [])
return { user }
}
// Todo tasks do now have their own hook.
// The hook should actually be in its own file as well. Only one hook per file!
const useTodoTasks = () => {
const [todoTasks, setTodoTasks] = useState()
useEffect(() => {
const tasks = getTodoTasks()
setTodoTasks(tasks)
}, [])
return { todoTasks }
}
```
This principle applies to all hooks and components, they all should only do one thing each. Things to ask yourself are:
1. Is this a component which should show a UI (presentational) or handle data (logical)?
1. What single type of data should this hook handle?
1. What layer does this hook/component belong to? Is it handling data storage or is it maybe a part of a UI?
If you find yourself building a hook which doesn't have a single answer to each and every of the above questions, then you're breaking the single responsibility principle.
An interesting thing to note here, is question number one. That one actually means, that a component rendering a UI, should not also handle data. This means, to really follow this principle strictly, each React component displaying data should have a hook to handle its logic and data. In other words, data should not be fetched in the same component which displays it.
### Why Use SRP in React?
This single responsibility principle actually goes very well with React. React follows a component based architecture, meaning that it consists of small components composed together so they all together can build up and form an application. The smaller the components are, the more likely they are to be reusable. This applies to both components and hooks.
For that reason, React is more or less founded on the single responsibility principle. If you don't follow it, you will find yourself always writing new hooks and component and rarely re-use any of them.
Disobeying the single responsibility principle will make your code exhaustive to test. You will often find your test files to have several hundred, maybe up towards 1000, lines of codes, if you don't follow this principle.
{% embed https://dev.to/perssondennis/how-to-use-mvvm-in-react-using-hooks-and-typescript-3o4m %}
## Open/Closed Principle (OCP)
Let's continue with the Open/Closed principle, after all, it's the next letter in SOLID. OCP is as well as SRP one of the easier principle to understand, at least its definition.
// Open/Closed Principle
Software entities (classes, modules, functions, etc.) should
be open for extension, but closed for modification
In words for dummies who recently have started with React, the sentence can be translated to:
Write hooks/component which you never will have a reason to
touch again, only re-use them in other hooks/components
Think back at what was said for the single responsibility principle earlier in this article; in React, your are expected to write small components and compose them together. Let's look at why that is helpful.
```react
import { useState } from 'react'
import { getUser, updateUser } from 'somewhere'
const useUser = ({ userType }) => {
const [user, setUser] = useState()
useEffect(() => {
const userInfo = getUser()
setUser(userInfo)
}, [])
const updateEmail = (newEmail) => {
if (user && userType === 'admin') {
updateUser({ ...user, email: newEmail })
} else {
console.error('Cannot update email')
}
}
return { user, updateEmail }
}
```
The hook above fetches a user and returns it. If the type of the user is an admin, the user is allowed to update its email. A regular user is not allowed to do update its email.
The above code would definitely not get you fired. It would annoy the backend guy in your team though, the dude who reads design pattern books as bedtime stories for his toddlers. Let's call him Pete.
What would Pete complain about? He would ask you to rewrite the component as shown below. To lift out the admin functionalities to it's own useAdmin hook, and leave the useUser hook with no other features than those that should be available for regular users.
```react
import { useState } from 'react'
import { getUser, updateUser } from 'somewhere'
// useUser does now only return the user,
// without any function to update its email.
const useUser = () => {
const [user, setUser] = useState()
useEffect(() => {
const userInfo = getUser()
setUser(userInfo)
}, [])
return { user }
}
// A new hook, useAdmin, extends useUser hook,
// with the additional feature to update its email.
const useAdmin = () => {
const { user } = useUser()
const updateEmail = (newEmail) => {
if (user) {
updateUser({ ...user, email: newEmail })
} else {
console.error('Cannot update email')
}
}
return { user, updateEmail }
}
```
Why did Pete ask for this update? Because that disrespectful picky prick Pete would rather want you to spend time rewriting that hook now, and come back with a new code review tomorrow, instead of potentially having to update the code with a tiny new if statement in the future, if there ever would be another type of user.
Well, that's the negative way to put it... The optimistic way, is that with this new useAdmin hook, you don't have to change anything in the useUser hook when you intend to implement features that affects admin users only, or when you add new types of users.
When new user types are added, or when useAdmin hook is updated, there's no need to mess with the useUser hook or update any of its tests. Meaning, you don't have to accidentally ship a bug to regular users when you add a new user type, e.g. a fake user. Instead, you just add a new userFakeUser hook and your boss won't call you in at 9 pm on a Friday because customers experience problems with fake data being shown for their bank account on a salary weekend.

_Pete's son knows to be careful about spaghetti code developers_
### Why Use OCP in React?
It's arguable how many hooks and components a React project should have. Each one of them comes with a cost of renderings. React isn't a Java where 22 design patterns leads to 422 classes for a simple TODO list implementation. That's the beauty of the Wild West Web (www).
However, open/closed principle is clearly a handful pattern to use in React as well. The example with the hooks above was minimal, the hooks didn't do very much. With more substantive hooks and larger projects this principle becomes highly important.
It might cost you some extra hooks, and take slightly longer to implement, but your hooks will become more extendable, meaning that you can re-use them more often. You will have to rewrite the tests less often, making the hooks more solid. And most important, you won't create bugs in old code if you never touch it.

_God knows not to touch things which aren't broken_
{% embed https://dev.to/perssondennis/react-anti-patterns-and-best-practices-dos-and-donts-3c2g %}
## Liskov Substitution Principle (LSP)
Aaah, the name... Who the hedge is Liskov? And who will substitute her? And the definition, doesn't it even make sense?
If S subtypes T, what holds for T holds for S
This principle is clearly about inheritance, which isn't naturally practiced as much in React or JavaScript as in most of the backend languages. JavaScript didn't even have classes until ES6, that was [introduced around 2015/2016](https://caniuse.com/?search=class) as syntactical sugar to prototype based inheritance.
With that in mind, the use cases of this principle really depends on what your code looks like. A principle similar to Liskov's that would make sense in React, could be:
If a hook/component accepts some props, all hooks and components
which extends that hook/component must accept all the props the
hook/component it extends accepts. The same goes for return values.
To illustrate an example of this, we can look at two storage hooks, useLocalStorage and useLocalAndRemoteStorage.
```react
import { useState } from 'react'
import {
getFromLocalStorage, saveToLocalStorage, getFromRemoteStorage
} from 'somewhere'
// useLocalStorage gets data from local storage.
// When new data is stored, it calls saveToStorage callback.
const useLocalStorage = ({ onDataSaved }) => {
const [data, setData] = useState()
useEffect(() => {
const storageData = getFromLocalStorage()
setData(storageData)
}, [])
const saveToStorage = (newData) => {
saveToLocalStorage(newData)
onDataSaved(newData)
}
return { data, saveToStorage }
}
// useLocalAndRemoteStorage gets data from local and remote storage.
// I doesn't have callback to trigger when data is stored.
const useLocalAndRemoteStorage = () => {
const [localData, setLocalData] = useState()
const [remoteData, setRemoteData] = useState()
useEffect(() => {
const storageData = getFromLocalStorage()
setLocalData(storageData)
}, [])
useEffect(() => {
const storageData = getFromRemoteStorage()
setRemoteData(storageData)
}, [])
const saveToStorage = (newData) => {
saveToLocalStorage(newData)
}
return { localData, remoteData, saveToStorage }
}
```
With the hooks above, useLocalAndRemoteStorage can be seen as a subtype of useLocalStorage, since it does the same thing as useLocalStorage (saves to local storage), but also has extended the capability of the useLocalStorage by saving data to an additional place.
The two hooks have some shared props and return values, but useLocalAndRemoteStorage is missing the onDataSaved callback prop which useLocalStorage accepts. The name of the return properties are also named differently, local data is named as data in useLocalStorage but named as localData in useLocalAndRemoteStorage.
If you would ask Liskov, this would have broken her principle. She would be quite furious actually when she would try to update her web application to also persist data server side, just to realize that she cannot simply replace useLocalStorage with useLocalAndRemoteStorage hook, just because some lazy fingered developer never implemented the onDataSaved callback for the useLocalAndRemoteStorage hook.
Liskov would bitterly update the hook to support that. Meanwhile, she would also update the name of the local data in the useLocalStorage hook to match the name of the local data in useLocalAndRemoteStorage.
```react
import { useState } from 'react'
import {
getFromLocalStorage, saveToLocalStorage, getFromRemoteStorage
} from 'somewhere'
// Liskov has renamed data state variable to localData
// to match the interface (variable name) of useLocalAndRemoteStorage.
const useLocalStorage = ({ onDataSaved }) => {
const [localData, setLocalData] = useState()
useEffect(() => {
const storageData = getFromLocalStorage()
setLocalData(storageData)
}, [])
const saveToStorage = (newData) => {
saveToLocalStorage(newData)
onDataSaved(newData)
}
// This hook does now return "localData" instead of "data".
return { localData, saveToStorage }
}
// Liskov also added onDataSaved callback to this hook,
// to match the props interface of useLocalStorage.
const useLocalAndRemoteStorage = ({ onDataSaved }) => {
const [localData, setLocalData] = useState()
const [remoteData, setRemoteData] = useState()
useEffect(() => {
const storageData = getFromLocalStorage()
setLocalData(storageData)
}, [])
useEffect(() => {
const storageData = getFromRemoteStorage()
setRemoteData(storageData)
}, [])
const saveToStorage = (newData) => {
saveToLocalStorage(newData)
onDataSaved(newData)
}
return { localData, remoteData, saveToStorage }
}
```
By having common interfaces (ingoing props, outgoing return values) to hooks, they can become very easy to exchange. And if we should follow the Liskov substitution principle, hooks and components which inherits another hook/component should be possible to substitute with the hook or component it inherits.

_Liskov gets disappointed when developers don't follow her principles_
### Why Use LSP in React?
Even though inheritance isn't very prominent in React, it's definitely used behind the scenes. Web applications can often have several similar looking components. Texts, titles, links, icon links and so on are all similar types of components and can benefit of being inherited.
An IconLink component may or may not be wrapping a Link component. Either way, they would benefit from being implemented with the same interface (using the same props). In that way, it's trivial to replace a Link component with an IconLink component anywhere in the application at any time, without having to edit any additional code.
The same goes for hooks. A web application fetches data from servers. They might use local storage as well or a state management system. Those can preferably share props to make them interchangeable.
An application might fetch users, tasks, products or any other data from backend servers. Functions like that might as well share interfaces, making it easier to re-use code and tests.
{% embed https://dev.to/perssondennis/the-20-most-common-use-cases-for-javascript-arrays-2j8j %}
## Interface Segregation Principle (ISP)
Another bit more clear principle, is the Interface Segregation Principle. The definition is quite short.
No code should be forced to depend on methods it does not use
As its name tells, it has to do with interfaces, basically meaning that functions and classes should only implement interfaces it explicitly use. That is easiest achieved by keeping interfaces neat and letting classes pick a few of them to implement instead of being forced to implement one big interface with several methods it doesn't care about.
For instance, a class representing a person who owns a website should be implementing two interfaces, one interface called Person describing the details about the person, and another interface for the Website with metadata about the Website it owns.
```react
interface Person {
firstname: string
familyName: string
age: number
}
interface Website {
domain: string
type: string
}
```
If one instead, would create a single interface Website, including both information about the owner and the website, that would disobey the interface segregation principle.
```react
interface Website {
ownerFirstname: string
ownerFamilyName: number
domain: string
type: string
}
```
You may wonder, what is the problem with the interface above? The problem with it is that it makes the interface less usable. Think about it, what would you do if the company wasn't a human, instead a company. A company doesn't really have a family name. Would you then modify the interface to make it usable for both a human and a company? Or would you create a new interface CompanyOwnedWebsite?
You would then end up with an interface with many optional attributes, or respectively, two interfaces called PersonWebsite and CompanyWebsite. Neither of these solutions are optimal.
```react
// Alternative 1
// This interface has the problem that it includes
// optional attributes, even though the attributes
// are mandatory for some consumers of the interface.
interface Website {
companyName?: string
ownerFirstname?: string
ownerFamilyName?: number
domain: string
type: string
}
// Alternative 2
// This is the original Website interface renamed for a person.
// Which means, we had to update old code and tests and
// potentially introduce some bugs.
interface PersonWebsite {
ownerFirstname: string
ownerFamilyName: number
domain: string
type: string
}
// This is a new interface to work for a company.
interface CompanyOwnedWebsite {
companyName: string
domain: string
type: string
}
```
The solution which would follow the ISP, would look like this.
```react
interface Person {
firstname: string
familyName: string
age: number
}
interface Company {
companyName: string
}
interface Website {
domain: string
type: string
}
```
With the proper interfaces above, a class representing a company website could implement the interfaces Company and Website, but would not need to consider the firstname and familyName properties from the Person interface.
### Is ISP Used in React?
So, this principle obviously applies to interfaces, meaning that it should only be relevant if you are writing React code using TypeScript, shouldn't it?
Of course not! Not typing interfaces doesn't mean they aren't there. There are there all over the place, it's just that you don't type them explicitly.
In React, each component and hook has two main interfaces, it's input and its output.
```react
// The input interface to a hook is its props.
const useMyHook = ({ prop1, prop2 }) => {
// ...
// The output interface of a hook is its return values.
return { value1, value2, callback1 }
}
```
With TypeScript, you normally type the input interface, but the output interface is often skipped, since it is optional.
```react
// Input interface.
interface MyHookProps {
prop1: string
prop2: number
}
// Output interface.
interface MyHookOutput {
value1: string
value2: number
callback1: () => void
}
const useMyHook = ({ prop1, prop2 }: MyHookProps): MyHookOutput => {
// ...
return { value1, value2, callback1 }
}
```
If the hook wouldn't use prop2 for anything, then it should not be a part of its props. For a single prop, it would be easy to remove it from the props list and interface. But what if prop2 would be of an object type, for instance the improper Website interface example from the previous chapter?
```react
interface Website {
companyName?: string
ownerFirstname?: string
ownerFamilyName?: number
domain: string
type: string
}
interface MyHookProps {
prop1: string
website: Website
}
const useMyCompanyWebsite = ({ prop1, website }: MyHookProps) => {
// This hook uses domain, type and companyName,
// but not ownerFirstname or ownerFamilyName.
return { value1, value2, callback1 }
}
```
Now we have a useMyCompanyWebsite hook, which has a website prop. If parts of the Website interface is used in the hook, we cannot simple remove the whole website prop. We have to keep the website prop, and thereby also keep the interface props for ownerFirstname and ownerFamiliyName. Which also means, that this hook intended for a company could be used by a human owned website owner, even though this hook likely wouldn't work appropriately for that usage.
### Why Use ISP in React?
We have now seen what ISP means, and how it applies to React, even without the usage of TypeScript. Just by looking at the trivial examples above, we have seen some of the problems with not following the ISP as well.
In more complex projects, readability is of the greatest matter. One of the purpose of the interface segregation principle is to avoid cluttering, the existence of unnecessary code which only are there to disrupt readability. And not to forget about, testability. Should you care about the test coverage of props you are not actually using?
Implementing large interfaces also forces you to make props optional. Leading to more if statements to check presences and potential misusages of functions because it appears on the interface that the function would handle such properties.
{% embed https://dev.to/perssondennis/answers-to-common-nextjs-questions-1oki %}
## Dependency Inversion Principle (DIP)
The last principle, the DIP, includes some terms which are quite misunderstood out there. The confusions are much about what the difference is between dependency inversion, dependency injection and inversion of control. So let's just declare those first.
**Dependency Inversion**
Dependency Inversion Principle (DIP) says that high-level modules should not import anything from low-level modules, both should depend on abstractions. What this means, is that any high level module, which naturally could be dependent on implementation details of modules it uses, shouldn't have that dependency.
The high and low-level modules, should be written in a way so they both can be used without knowing any details about the other module's internal implementation. Each module should be replaceable with an alternative implementation of it as long as the interface to it stays the same.
**Inversion of Control**
Inversion of Control (IoC) is a principle used to address the dependency inversion problem. It states that dependencies of a module should be provided by an external entity or framework. That way, the module itself only has to use the dependency, it never has to create the dependency or manage it in any way.
**Dependency Injection**
Dependency injection (DI) is one common way to implement IoC. It provides dependencies to modules by injecting them through constructors or setter methods. In that way, the module can use a dependency without being responsible of creating it, which would live up to the IoC principle. Worth to mention, is that dependency injection isn't the only way to achieve inversion of control.
### Is DIP Used in React?
With the terms clarified, and knowing that the DIP principle is about dependency inversion, we can look at how that definition looks again.
High-level modules should not import anything from low-level modules.
Both should depend on abstractions
How does that apply to React? React isn't a library which normally is associated with dependency injection, so how can we then solve the problem of dependency inversion?
The most common solution to this problem spells hooks. Hooks cannot be counted as dependency injection, because they are hardcoded into components and it's not possible to replace a hook with another without changing the implementation of the component. The same hook will be there, using the same instance of the hook until a developer updates the code.
But remember, dependency injection is not the only way to achieve dependency inversion. Hooks, could be seen as an external dependency to a React component, with an interface (its props) which abstracts away the code within the hook. In that way, a hook kind of implements the principle of dependency inversion, since the component depends on an abstract interface without needing to know any details about the hook.
Another more intuitive implementations of DIP in React which actually uses dependency injection are the usage of HOCs and contexts. Look at the withAuth HOC below.
```react
const withAuth = (Component) => {
return (props) => {
const { user } = useContext(AuthContext)
if (!user) {
return <LoginComponent>
}
return <Component {...props} user={user} />
}
}
const Profile = () => { // Profile component... }
// Use the withAuth HOC to inject user to Profile component.
const ProfileWithAuth = withAuth(Profile)
```
The withAuth HOC shown above provides a user to the Profile component using dependency injection. The interesting thing about this example is that it not only shows one usage of dependency injection, it actually contains two dependency injections.
The injection of the user to the Profile component isn't the only injection in this example. The withAuth hook does in fact also get the user by dependency injection, through the useContext hook. Somewhere in the code, someone has declared a provider which injects the user into the context. That user instance can even be changed in runtime by updating the user in the context.
### Why Use DIP in React?
Even though dependency injection isn't a pattern commonly associated with React, it is actually there with HOCs and contexts. And hooks, which has taken a lot of market share from both HOCs and contexts, does also confirm well with the dependency inversion principle.
DIP is therefore already built into the React library itself and should of course be utilized. It's both easy to use and provides advantages such as loose coupling between modules, hook and component reusability and testability. It also makes it easier to implement other design patterns such as the Single Responsibility Principle.
What I would discourage from, is trying to implement smart solutions and overusing the pattern when there really is much simpler solutions available. I have seen suggestions on the web and in books to use React contexts for the sole purpose of implementing dependency injection. Something like below.
```react
const User = () => {
const { role } = useContext(RoleContext)
return <div>{`User has role ${role}`}</div>
}
const AdminUser = ({ children }) => {
return (
<RoleContext.Provider value={{ role: 'admin' }}>
{children}
</RoleContext.Provider>
)
}
const NormalUser = ({ children }) => {
return (
<RoleContext.Provider value={{ role: 'normal' }}>
{children}
</RoleContext.Provider>
)
}
```
Although the above example does inject a role into the User component, it's purely overkill to use a context for it. React contexts should be used when appropriate, when the context itself serves a purpose. In this very case, a simple prop would have been a better solution.
```react
const User = ({ role }) => {
return <div>{`User has role ${role}`}</div>
}
const AdminUser = () => <User role='admin' />
const NormalUser = () => <User role='normal' />
```
{% cta https://2e015922.sibforms.com/serve/MUIFAGF3ypa0p6D6nTWI0MHVOIAC7q4TIJd0yXAhiBC9CswkNPnOlQBzeqSbR2XFM95gUn2G1IxWVkpkF0EQekcWpoNfmpxjm4RqEGjQvFrLOTkfFN9Y3X7tjUaaG9tz9UYhn_O_dWg1PPGS8kRM5ROREaJsslnGD8WEHszzZr0geJ9-g7lGsbn_hTT-wZSKWa1C8ay4Ok85ozro %}Subscribe to my articles{% endcta %}
{% embed https://dev.to/perssondennis %} | perssondennis |
1,873,735 | Multitask - Should I stay or should I go? | Should I Multitask? In today's fast-paced world, multitasking is often perceived as a... | 0 | 2024-06-02T14:36:43 | https://dev.to/ferjssilva/multitask-should-i-stay-or-should-i-go-2il9 | mentalhealth, productivity, learning, discuss | # Should I Multitask?
In today's fast-paced world, multitasking is often perceived as a valuable skill. However, recent research has revealed that true multitasking is not possible. Instead, our brains switch rapidly between tasks, similar to how computer processors manage multiple processes. This article explores how multitasking works, why it is particularly challenging for individuals with ADHD, and provides strategies to enhance focus and productivity.
## How Multitasking Works
The concept of multitasking suggests that one can handle multiple tasks simultaneously. In reality, the brain alternates between tasks, a process known as task switching. This rapid switching is managed by the brain's executive functions, which involve short-term memory and cognitive control. According to [Koch et al. (2018)](https://dx.doi.org/10.1037/bul0000144), the brain's ability to switch between tasks relies heavily on these executive functions and short-term memory capacity.
### Multitasking and ADHD
For individuals with ADHD, multitasking poses additional challenges. ADHD is characterized by deficits in executive functioning and short-term memory, making task switching more energy-intensive. This increased cognitive load can deplete their already limited supply of neurotransmitters like dopamine, which are essential for maintaining focus and motivation.
Research indicates that individuals with ADHD often have impairments in both phonological working memory and short-term memory, making multitasking particularly challenging ([Friedman et al., 2023](https://dx.doi.org/10.1080/09297049.2023.2213463)). Additionally, ADHD individuals are more susceptible to distractions, often getting sidetracked by new stimuli that appear while they are trying to multitask. This susceptibility is compounded by the need for frequent task switching, which consumes significant cognitive resources and energy ([Tiffin-Richards et al., 2007](https://dx.doi.org/10.1007/s00702-007-0816-3)).
### Cognitive Load and Memory
Task switching in ADHD individuals can lead to a decline in long-term memory performance, particularly impacting recollection memory processes ([Muhmenthaler & Meier, 2022](https://dx.doi.org/10.3389/fpsyg.2022.1027871)). This decline is a result of the brain's effort to manage the cognitive load associated with switching tasks. Multitasking, such as engaging in a cell phone conversation while performing cognitive tasks, can significantly increase latency and reduce accuracy in various cognitive domains, including reaction time and executive function ([Padmanaban et al., 2020](https://dx.doi.org/10.5455/ijmsph.2020.05069202006062020)).
## Strategies for Effective Task Switching
Despite the challenges, there are strategies that can help improve focus and productivity, even for those with ADHD. One effective technique involves task switching between two tasks: one that you enjoy and another that you find less appealing but necessary. This strategy leverages the motivational boost from the enjoyable task to help manage the less desirable one.
### Tips for Enhancing Focus
1. **Create a To-Do List**: Organize your tasks by writing them down. This helps to clear your mind and gives you a clear roadmap of what needs to be done.
2. **Time Blocking**: Allocate specific time slots for repeated tasks. This method helps in managing time effectively and reduces the mental load of deciding what to do next.
3. **Use Pomodoros**: Break your work into small, focused intervals (typically 25 minutes), separated by short breaks. This technique, known as the Pomodoro Technique, helps maintain high levels of concentration.
4. **Organize Tasks by Batches**: Group similar tasks together to avoid constant task switching. This helps maintain a steady focus and reduces the cognitive load.
5. **Duo Task Strategy**: Pair two tasks—one you enjoy and one you need to do but don't like as much. For example, alternate between studying math and reading a fantasy book. This method can keep you motivated and reduce the monotony of less enjoyable tasks.
## Final Thoughts
Multitasking, as commonly understood, is a myth. Our brains are wired to handle one task at a time, and task switching can be especially draining for those with ADHD. However, by using strategic task switching and focus-enhancing techniques, you can improve your productivity and manage your workload more effectively.
Remember, the key is to find what works best for you. Experiment with different strategies, be patient with yourself, and gradually build habits that enhance your focus and efficiency. With persistence and the right techniques, you can achieve a balanced and productive workflow.
### References
- [Koch et al., 2018](https://dx.doi.org/10.1037/bul0000144). Cognitive Structure, Flexibility, and Plasticity in Human Multitasking—An Integrative Review of Dual-Task and Task-Switching Research.
- [Friedman et al., 2023](https://dx.doi.org/10.1080/09297049.2023.2213463). Working and short-term memory in children with ADHD: an examination of prefrontal cortical functioning using functional Near-Infrared Spectroscopy (fNIRS).
- [Tiffin-Richards et al., 2007](https://dx.doi.org/10.1007/s00702-007-0816-3). Phonological short-term memory and central executive processing in attention-deficit/hyperactivity disorder with/without dyslexia – evidence of cognitive overlap.
- [Muhmenthaler & Meier, 2022](https://dx.doi.org/10.3389/fpsyg.2022.1027871). Attentional attenuation (rather than attentional boost) through task switching leads to a selective long-term memory decline.
- [Padmanaban et al., 2020](https://dx.doi.org/10.5455/ijmsph.2020.05069202006062020). The impact of multitasking on visual processing speed, cognitive inhibition, executive function, and short-term memory. | ferjssilva |
1,873,731 | Sunday Fun: Re-creating a Radiohead cover | The other day, I read an article about how Radiohead's graphic designer, Stanley Donwood, got... | 0 | 2024-06-02T14:34:14 | https://dev.to/madsstoumann/sunday-fun-re-creating-a-radiohead-cover-20ma | css, javascript, webdev, showdev | The other day, I [read an article](https://albumdesignclass.wordpress.com/2014/09/05/radiohead-hail-to-the-thief/) about how Radiohead's graphic designer, Stanley Donwood, got inspired by words from billboards — and the combination of the colors red, green, blue, yellow, orange, black and white — for the cover to "Hail to the Thief" by Radiohead.
The cover has much more graphic elements than this, but let's try to mimic the random color-combinations and the texts in CSS and JavaScript.
First, I asked chatGPT to generate an array of a 100 words, inspired by the cover:
```js
const words = ["Fear", "Control", "Truth", "Lies" ...]
```
Next, I grabbed the primary colors:
```js
const colors = ['#D0001D', '#0D5436', '#093588', '#FDA223', '#F8551A', '#101624', '#EAEFF0'];
```
A small method returns a random background-color, and makes sure that the text-color is **not** the same:
```js
function getRandomColorPair() {
const bgIndex = Math.floor(Math.random() * colors.length);
let cIndex;
do {
cIndex = Math.floor(Math.random() * colors.length);
} while (cIndex === bgIndex);
return { bg: colors[bgIndex], c: colors[cIndex] };
}
```
And finally, the words and colors are added to `<li>`-tags:
```js
const canvas = document.querySelector('ul');
canvas.innerHTML = words.map(word => {
const { bg, c } = getRandomColorPair();
return `<li style="--bg: ${bg};--c: ${c};">${word}</li>`;
}).join('');
```
---
## Styling
I browsed handwriting fonts on Google Fonts, and found a great match: [Pangolin](https://fonts.google.com/specimen/Pangolin).
Next, a few styles for the `<li>`-elements:
```css
li {
background-color: var(--bg);
color: var(--c);
font-family: "Pangolin", system-ui, sans-serif;
font-size: 5cqi;
letter-spacing: -0.075em;
padding-inline: 1ch;
text-transform: uppercase;
}
```
And ... almost done. Just need a few styles on the `<ul>`-element:
```css
ul {
all: unset;
container-type: inline-size;
display: flex;
flex-wrap: wrap;
justify-content: center;
list-style: none;
}
```
And we get:

That looks a **little bit boring**, doesn't it?
Let's add a squiggly SVG-filter:
```css
ul {
filter: url('#squiggly-0');
}
```
> **Note:** See the SVG-code for the filter in the CodePen below.
And _now_ we get:

Much better!
Here's the CodePen demo – re-fresh to get new, random color-combinations:
{% codepen https://codepen.io/stoumann/pen/QWRpJxg %}
| madsstoumann |
1,873,733 | Creating your own database like join using {code} | Joining Algorithm in ETL Frameworks There are several tools to combine datasets and... | 0 | 2024-06-02T14:30:51 | https://dev.to/anisriva/creating-your-own-database-like-join-using-code-1jlh | python, programming, learning, database | ## Joining Algorithm in ETL Frameworks
There are several tools to combine datasets and perform different types of joins namely:
* Inner
* Outer
* Left &
* Right
Tools like Pandas, Spark and other ETL tools does this job exceptionally well, ofcourse apart form the databases themselves.
However, a few years back, I was working on an ETL framework that required join-like features. In this article, I will discuss the idea behind the joining algorithm that I applied to solve that problem.
Before we dive into the algorithm, let's look at the datasets and try to understand the end goal.
## Employees Data
| id | name | dept_id | salary |
| - | - | - | - |
| 1 | Justin | 101 | 7000.0 |
| 2 | Jacob | 102 | 3000.0 |
| 3 | Jolly | 103 | 3800.0 |
| 4 | Jatin | 102 | 4500.0 |
| 5 | Jacky | 101 | 5000.0 |
### Department Data
| dept_id | dept_name |
| - | - |
| 101 | Engineering |
| 102 | Data Science |
| 103 | IT Operations |
### Expected Data after join operation
| id | name | dept_id | salary | dept_id_ | dept_name_ |
| - | - | - | - | - | - |
| 1 | Justin | 101 | 7000.0 | 101 | Engineering |
| 2 | Jacob | 102 | 3000.0 | 102 | Data Science |
| 3 | Jolly | 103 | 3800.0 | 103 | IT Operations |
| 4 | Jatin | 102 | 4500.0 | 102 | Data Science |
| 5 | Jacky | 101 | 5000.0 | 101 | Engineering |
---
With this understanding, I will now start by using the join module to demonstrate these functionalities step by step.
### Implementation
There are 2 implementations that we are going to use:
1. **DataSet** : A wrapper class to create a wrapper on top of "namedtuples" for each row and create a dataset for the whole chunk of data.
2. **joiner** : This method will be our joining algorithm which will actually join the data.
#### Step 1 : Import DataSet, joiner from the module
```python
from core.join import DataSet, joiner
```
#### Step 2 : Prepare the data sets
```python
emp_header = ["id", "name", "dept_id", "salary"]
emp_data = [
(1,"Justin", 101, 7000.00),
(2,"Jacob", 102, 3000.00),
(3,"Jolly", 103, 3800.00),
(4,"Jatin", 102, 4500.00),
(5,"Jacky", 101, 5000.00)
]
dept_header = ["dept_id", "dept_name"]
dept_data = [
(101, "Engineering"),
(102, "Data Science"),
(103, "IT Operations")
]
emp_data_set = DataSet(emp_header, emp_data)
dept_data_set = DataSet(dept_header, dept_data)
```
#### Step 3 : Verify the datasets using count and show methods
> DataSet has implementations for the helper methods like count() for checking the number of rows and printing the dataset using show() methods which we will check later.
```python
print("Employees count : ")
emp_data_set.count()
print("Employees data : ")
emp_data_set.show()
print("Department count :")
dept_data_set.count()
print("Department data :")
dept_data_set.show()
```
##### Output
```python
Employees count :
5
Employees data :
+ | id=1 || name='Justin'|| dept_id=101 || salary=7000.0 | +
+ | id=2 || name='Jacob' || dept_id=102 || salary=3000.0 | +
+ | id=3 || name='Jolly' || dept_id=103 || salary=3800.0 | +
+ | id=4 || name='Jatin' || dept_id=102 || salary=4500.0 | +
+ | id=5 || name='Jacky' || dept_id=101 || salary=5000.0 | +
Department count :
3
Department data :
+ | dept_id=101 || dept_name='Engineering' | +
+ | dept_id=102 || dept_name='Data Science' | +
+ | dept_id=103 || dept_name='IT Operations' | +
```
##### Step 4 : Join the 2 datasets and create a joined dataset
```python
# joining the datasets using the joiner method
joined_data_set = joiner(emp_data_set, dept_data_set, ["dept_id"])
```
#### Step 5 : Check the result for the joiner
```python
print("Joined data count : ")
joined_data_set.count()
print("Joined data : ")
joined_data_set.show()
```
##### Output
```python
Joined data count :
5
Joined data :
id=1 || name='Justin'|| dept_id=101 || salary=7000.0 || dept_id_=101 || dept_name_='Engineering'
id=5 || name='Jacky' || dept_id=101 || salary=5000.0 || dept_id_=101 || dept_name_='Engineering'
id=2 || name='Jacob' || dept_id=102 || salary=3000.0 || dept_id_=102 || dept_name_='Data Science'
id=4 || name='Jatin' || dept_id=102 || salary=4500.0 || dept_id_=102 || dept_name_='Data Science'
id=3 || name='Jolly' || dept_id=103 || salary=3800.0 || dept_id_=103 || dept_name_='IT Operations'
```
## Detailed Implementation
### Storing the data using DataSets with column definitions (type safety in future)
Datasets will be a collection of Row objects which is a wrapper on top of the [namedtuple](https://stackoverflow.com/questions/2970608/what-are-named-tuples-in-python) from pythons collection module.
### Row Object
```python
class Row:
def __init__(self, header:List[str], row:tuple=None)->None:
'''
A wrapper on top of namedtuple to create a Row object.
:param header - List of column names
:param row - A tuple of row [optional]
'''
self.header = header
self.schema = namedtuple("Row", [col_name.lower() for col_name in header])
if row:
self.row = self.schema(*row)
else:
self.row = self.schema(*[None]*len(self.header))
```
> **Note:** Without row argument object will create Row with all values as None.
> Ex : Row(id=None, name=None)
We can go ahead and write helper method to print the row with the column information in a tabular fashion and call it show()
```
def __repr__(self) -> str:
return self.show()
def show(self) -> str:
string = "+ "
field_width = [len(col) for col in self.header]
for col_name, col_val, width in zip(self.row._fields, self.row, field_width):
string += "| {i}={j!r:<{k}} |".format(i=col_name, j=col_val, k=width)
return string += " +"
```
### Dataset
We will use __generate_data_set method to generate a list of Rows object using a simple list of tuple containing the data.
```python
class DataSet:
def __init__(self, header:List[str], rows:List[Tuple[Union[int, str, date, datetime, float]]]) -> None:
'''
A wraper on top of Row class to create a complete dataset.
:param header - List of column names
:param rows - List of tuples of rows
'''
self.header = header
self.rows = rows
self.data_set = self.__generate_data_set()
def __generate_data_set(self)->List[NamedTuple]:
'''
Row object factory; generates a list of row objects
'''
row_set = []
for row in self.rows:
if not len(self.header) == len(row):
raise Exception(f"Columns mismatched expected : [{len(self.header)}] actual : [{len(row)}]")
else:
row_set.append(Row(self.header, row))
else:
return row_set
```
Once we have this implementation we can go ahead and add some helper methods like count() and show() just like spark.
These methods will help us check the count of rows and print the data in pandas / spark like tabular manner.
```python
def size(self)->int:
'''
get the number of rows
'''
return len(self.data_set)
def show(self)->None:
'''
Prints dataset
'''
for row in self.data_set:
print(row.show())
else:
print()
def count(self)->None:
'''
Prints count
'''
print(self.size())
print()
```
### Join Algorithm
Before we go ahead and implement the last and the core part i.e the joiner; lets see a simple sql statement which joins the `emp_data` and `dept_data` on the basis of the `dept_id` as the key.
```sql
select e.*, d.*
from emp_data e
inner join dept_data d
on e.dept_id = d.dept_id
```
Alright; now lets define the body of the method:
```python
from itertools import product
def joiner(left_data_set:DataSet, right_data_set:DataSet, on:List[str])->DataSet:
'''
Performs inner join on datasets
:param left_data_set - dataset with left data
:param right_data_set - dataset with right data
:param on - join on key
Returns -> joined DataSet
'''
left_rows = left_data_set.data_set
right_rows = right_data_set.data_set
# creating the main data-structure to store the Rows for the same keys
data_set = {}
# Final list to contain all the Joined Row objects later to be converted to a data set
joined_set = []
# Form all the left rows by appending at the 0th index
for left_row in left_rows:
left_key = "".join([str(getattr(left_row.row, key)) for key in on])
data_set.setdefault(left_key, ([],[]))[0].append(left_row.row)
# Form all the right rows by appending at the 1st index
for right_row in right_rows:
right_key = "".join([str(getattr(right_row.row, key)) for key in on])
data_set.setdefault(right_key, ([],[]))[1].append(right_row.row)
# Finally perform the cartesian product on the left and right datasets and join them
for ds_cols in data_set.values():
for left_cols, right_cols in product(*ds_cols):
joined_set.append(left_cols+right_cols)
# Get the column names from the left and right data sets for creating the DataSet for the joined data
result_headers = list(left_rows[0].row._fields) + [col+"_" for col in right_rows[0].row._fields]
# Finally return the DataSet object using the joined data
return DataSet(result_headers, joined_set)
```
Thats it; finally we are able to solve the problem of performing inner joins, which can support below operations:
1. Inner join
2. Joining on multiple keys
3. Representation of data in DataSets
However we can further modify this algorithm and create the implementation for the left/right and the outer joins also add type safety for the data by implementing Column type and create DataSets of Rows of Columns.
If you want to improve this or add more functionalities to it then I ll encourage you to contribute using this github repo->[Github_dbjoin_anisriva](https://github.com/anisriva/dbJoins.git)
Finally, I'd like to conclude that this is just an experimental exercise and ofcourse there are better tools to perform this operation. | anisriva |
1,859,011 | Introduction to Containerization on AWS ECS (Elastic Container Service) and Fargate | Pre-requisite: To get the best from this series, it is expected that you understand how Docker works.... | 0 | 2024-06-02T14:24:15 | https://dev.to/sirlawdin/introduction-to-containerization-on-aws-ecs-elastic-container-service-and-fargate-6oo | ecs, fargate, elb, autoscaling | **Pre-requisite:** To get the best from this series, it is expected that you understand how Docker works. You can use this [link](https://docs.docker.com/get-started/overview/) to get an overview of how docker works If you don't have an AWS account yet, you can follow the steps in my blog on [How to create an AWS account](https://dev.to/sirlawdin/how-to-create-an-aws-account-39cn) to create one for the hands-on exercises.
This series will be released weekly over the next couple of weeks. You are going to learn about the following concepts:
ECS (Elastic Container Service)
Fargate
Load Balancing
Auto Scaling
ECR (Elastic Container Registry)
CI/CD (Continuous Integration/Continuous Deployment)
Blue/Green Deployment
AWS X-Ray
Service Discovery
App Mesh
**What is ECS and Fargate?**
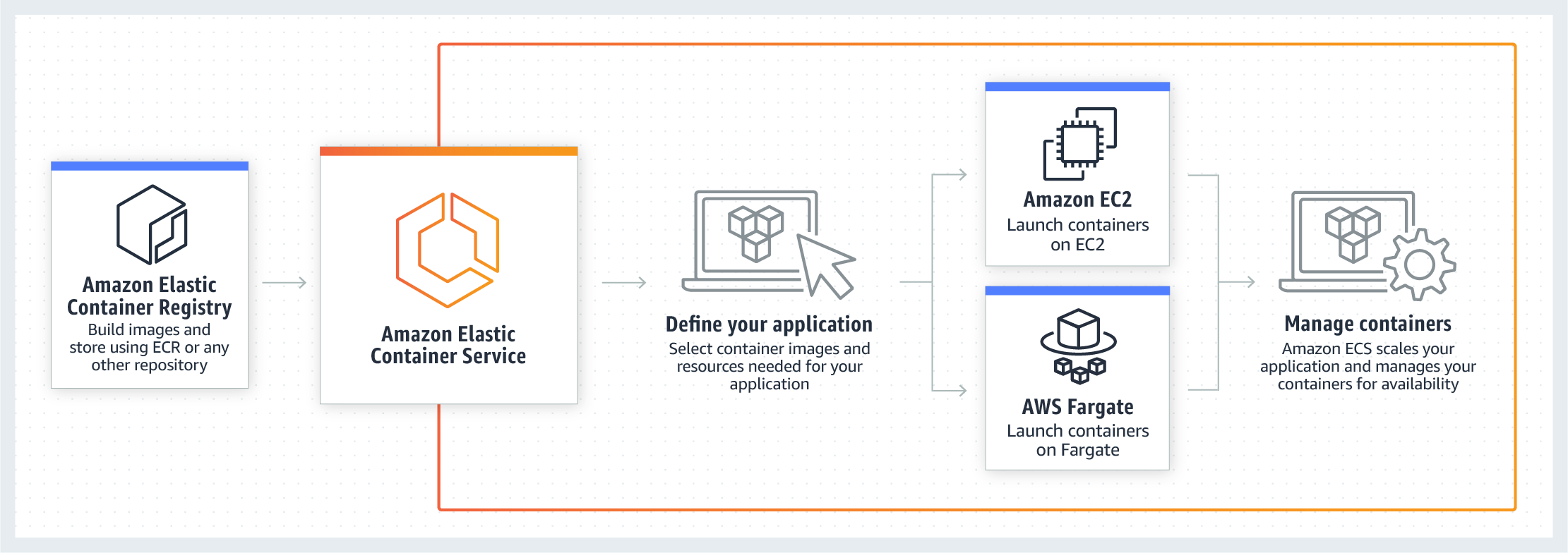
**Amazon ECS** is a fully managed container orchestration service that enables you to run and manage Docker containers at scale. With ECS, you can easily deploy applications in containers without needing to manage the underlying infrastructure. It integrates seamlessly with other AWS services, providing a comprehensive solution for running microservices, batch processes, and long-running applications.
**AWS Fargate** is a serverless compute engine for containers that works with both Amazon ECS (Elastic Container Service) and Amazon EKS (Elastic Kubernetes Service). Fargate eliminates the need to provision and manage servers, allowing you to specify and pay for resources per application. This makes it easier to build and deploy containerized applications without worrying about the underlying infrastructure.
ECS takes care of orchestrating your containerized applications, managing their lifecycle, and integrating with other AWS services.
Fargate provides compute power on-demand, automatically adjusting to the needs of your applications without requiring you to manage any servers.
This restaurant analogy below helps illustrate how ECS and Fargate work together to simplify the process of running containerized applications.
## Understanding Amazon ECS and AWS Fargate with a Restaurant Analogy
Imagine you want to start a restaurant business. To do this, you need a physical restaurant location, kitchen equipment, chefs and staff to prepare and serve the food, and all the necessary supplies.
**Amazon ECS** (Elastic Container Service) is like a professional restaurant management company. They provide you with the restaurant space, organize the kitchen staff, handle the logistics of ordering supplies, and ensure everything runs smoothly. You tell them what kind of cuisine you want to serve, the menu, and any special requirements, and they take care of the rest.
**ECS as the Restaurant Management Company:** ECS handles the orchestration of your "menu items" (the containers), ensuring they are prepared, served, and maintained according to your needs. You don't need to worry about the details of managing the restaurant infrastructure.
Now, let's introduce AWS Fargate into the mix. Fargate is like having a magical, self-adjusting kitchen space. You simply describe your menu and the number of customers you expect, and the kitchen automatically scales to fit your needs, providing all the necessary cooking equipment and staff without any manual intervention.
**Fargate as the Magical, Self-Adjusting Kitchen:** With Fargate, you don't need to worry about the capacity of your kitchen or the logistics of managing the equipment and staff. You specify the requirements for your "menu items" (the containers), and Fargate automatically provides the necessary cooking resources. It's like having a kitchen that can expand or contract to perfectly accommodate your restaurant's needs, ensuring you always have the right amount of space and resources.
**Putting It All Together**
When you combine ECS and Fargate, it's like having the best of both worlds. You have a professional restaurant management company (ECS) handling the overall operations, and a magical, flexible kitchen space (Fargate) that adjusts to perfectly meet your restaurant's needs without any manual setup or management.
Now that you understand on a high level how ECS and Fargate works; let move on the to the next part of this blogs series where you will learn how to [Launch your first ECS container](url).
Up Next: [Launch Your First ECS Container](url)
| sirlawdin |
1,873,730 | Menggunakan Zustand Sebagai State Management pada React/Next JS. | Pengelolaan state pada React JS atau Next JS tentunya adalah hal yang perlu kita perhatikan. Karena... | 0 | 2024-06-02T14:24:04 | https://dev.to/yogameleniawan/menggunakan-zustand-sebagai-state-management-pada-reactnext-js-573f | react, nextjs, javascript |
Pengelolaan state pada React JS atau Next JS tentunya adalah hal yang perlu kita perhatikan. Karena manajemen state merupakan salah satu hal yang cukup krusial dalam pengembangan aplikasi. Tentunya, sekarang kita akan coba sedikit berkenalan dengan Zustand yang memiliki deskripsi “_A small, fast and scalable bearbones state-management solution using simplified flux principles. Has a comfy API based on hooks, isn’t boilerplatey or opinionated_.”.
Tetapi sebelum kita masuk lebih dalam. Kita akan coba sedikit belajar bersama, kenapa state management itu diperlukan. Jika teman-teman sudah pernah membuat page dengan banyak component dan memiliki deep level of component pasti pernah merasakan hal yang cukup meresahkan. Dikarenakan ada case condition tertentu yang mengharuskan mengubah state dari grandchild ke parent. Jika teman-teman mengubah state dari grandchild ke parent dengan mengirimkan state dari parent → child → grandchild. Selamat anda masuk ke dalam kategori developer yang mengimplementasikan Props Drilling. Apakah ini sebuah pencapaian? tentu saja bukan, ini termasuk ke dalam kategori developer yang suka membuat ribet diri sendiri.
Maka dengan permasalahan props drilling ini kita perlu menyelesaikan masalah tersebut dengan state management. Tapi perlu diketahui banyak sekali jenis-jenis state management yang bisa teman-teman gunakan selain Zustand yaitu Redux, Recoil, atau Jotai. Apakah Zustand lebih baik daripada state management yang lain? tentu saja jawabannya tidak. Dikarenakan masing-masing state management pasti punya kelebihan dan kekurangan masing-masing. Sehingga, kita perlu memilih dan menggunakan state management yang sesuai dengan kebutuhan aplikasi yang kita kembangkan.
---
### Persiapan
Sebelum mempelajari lebih lanjut pastikan sudah pernah tau tentang [context ](https://legacy.reactjs.org/docs/context.html) yang ada pada React JS. Saya berasumsi teman-teman pasti sudah tau tentang context dikarenakan sudah pernah dibahas pada sharing session.
### Instalasi Zustand
Jalankan perintah berikut untuk melakukan instalasi Zustand :
```bash
# Menggunakan yarn
yarn add zustand
```
```bash
# Menggunakan NPM
npm install zustand
```
### Implementasi useState vs Zustand
#### Mengubah state menggunakan useState Hooks
Kita akan membuat tampilan seperti diatas dengan 3 komponen utama yaitu menampilkan total number, button increment, dan button decrement. Lalu kita akan melakukan passing useState hooks yang didefinisikan pada layout page Home.
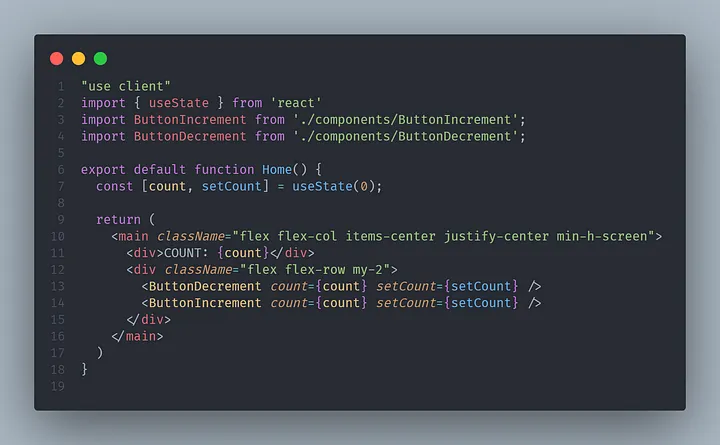
Kode program :
```javascript
"use client"
import { useState } from 'react'
import ButtonIncrement from './components/ButtonIncrement';
import ButtonDecrement from './components/ButtonDecrement';
export default function Home() {
const [count, setCount] = useState(0);
return (
<main className="flex flex-col items-center justify-center min-h-screen">
<div>COUNT: {count}</div>
<div className="flex flex-row my-2">
<ButtonDecrement count={count} setCount={setCount} />
<ButtonIncrement count={count} setCount={setCount} />
</div>
</main>
)
}
```
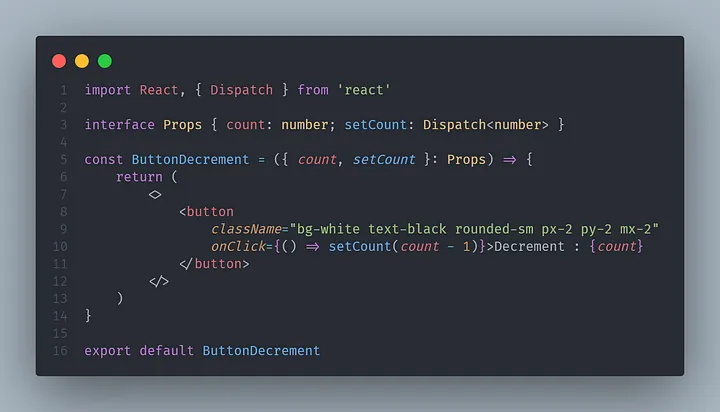
Kode program :
```javascript
import React, { Dispatch } from 'react'
interface Props { count: number; setCount: Dispatch<number> }
const ButtonDecrement = ({ count, setCount }: Props) => {
return (
<>
<button
className="bg-white text-black rounded-sm px-2 py-2 mx-2"
onClick={() => setCount(count - 1)}>Decrement : {count}
</button>
</>
)
}
export default ButtonDecrement
```
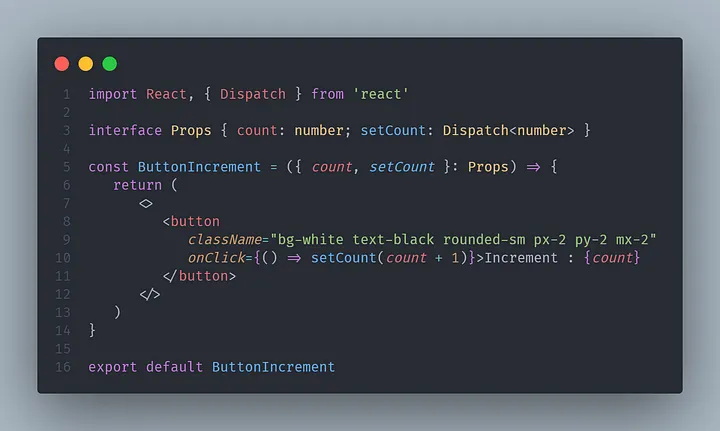
Kode program :
```javascript
import React, { Dispatch } from 'react'
interface Props { count: number; setCount: Dispatch<number> }
const ButtonIncrement = ({ count, setCount }: Props) => {
return (
<>
<button
className="bg-white text-black rounded-sm px-2 py-2 mx-2"
onClick={() => setCount(count + 1)}>Increment : {count}
</button>
</>
)
}
export default ButtonIncrement
```
Dari kode program diatas apakah ada yang salah? jawabannya tidak ada. Tapi kalau pertanyaannya kita ubah menjadi, apakah kode program tersebut efektif untuk mengembangkan aplikasi dengan multi-level component yang banyak? jawabannya tidak efektif.
Kita bisa melihat gambar diatas untuk menggambarkan multi-level component yang dimaksud sebelumnya. Jika kita mengirimkan useState hooks dari parent ke grandchild maka, ini sesuai dengan yang dimaksud props drilling pada penjelasan sebelumnya.
#### Mengubah state menggunakan Zustand
Kita akan membuat tampilan seperti diatas dengan 3 komponen utama yaitu menampilkan total number, button increment, dan button decrement. Lalu kita akan mendefinisikan store yang akan di-consume oleh component yang membutuhkan.
**Membuat File Store**
Kita akan membuat store yang akan digunakan di berbagai macam komponen yang membutuhkannya. Untuk penamaan useCounter merupakan penamaan yang bebas, jadi bisa disesuaikan dengan kebutuhan.
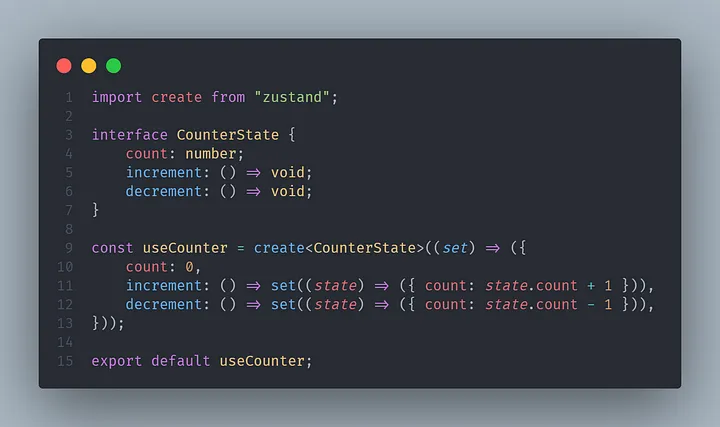
Kode program:
```javascript
import create from "zustand";
interface CounterState {
count: number;
increment: () => void;
decrement: () => void;
}
const useCounter = create<CounterState>((set) => ({
count: 0,
increment: () => set((state) => ({ count: state.count + 1 })),
decrement: () => set((state) => ({ count: state.count - 1 })),
}));
export default useCounter;
```
**Membuat Layout Home**
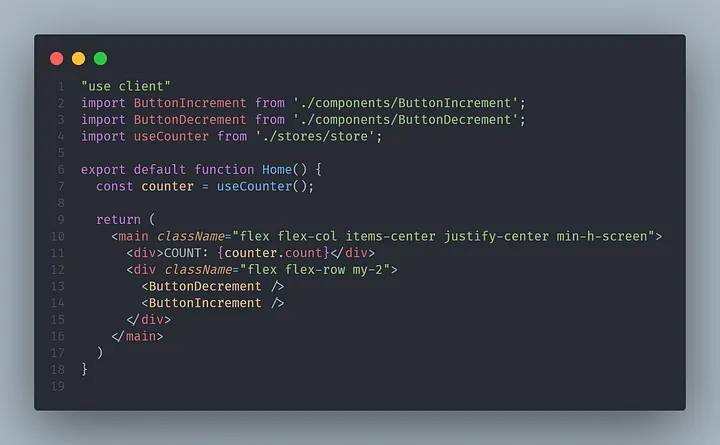
Kode program:
```javascript
"use client"
import ButtonIncrement from './components/ButtonIncrement';
import ButtonDecrement from './components/ButtonDecrement';
import useCounter from './stores/store';
export default function Home() {
const counter = useCounter();
return (
<main className="flex flex-col items-center justify-center min-h-screen">
<div>COUNT: {counter.count}</div>
<div className="flex flex-row my-2">
<ButtonDecrement />
<ButtonIncrement />
</div>
</main>
)
}
```
**Membuat Button Decrement Component**
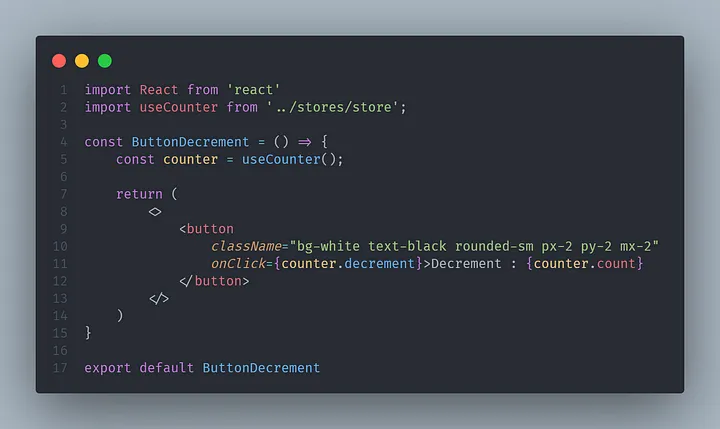
Kode program:
```javascript
import React from 'react'
import useCounter from '../stores/store';
const ButtonDecrement = () => {
const counter = useCounter();
return (
<>
<button
className="bg-white text-black rounded-sm px-2 py-2 mx-2"
onClick={counter.decrement}>Decrement : {counter.count}
</button>
</>
)
}
export default ButtonDecrement
```
**Membuat Button Increment Component**
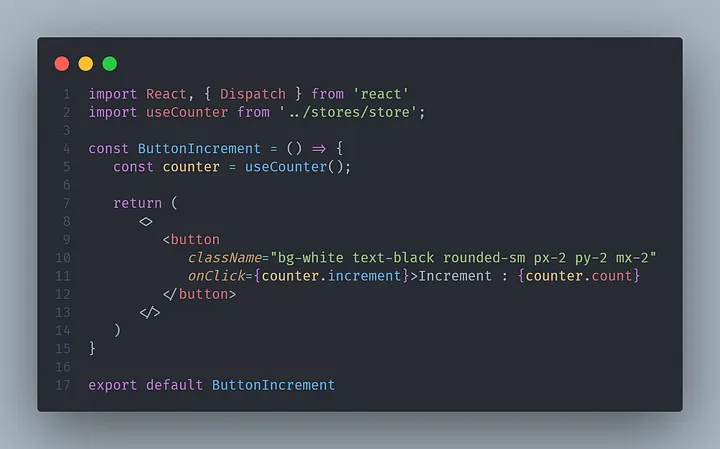
Kode program:
```javascript
import React, { Dispatch } from 'react'
import useCounter from '../stores/store';
const ButtonIncrement = () => {
const counter = useCounter();
return (
<>
<button
className="bg-white text-black rounded-sm px-2 py-2 mx-2"
onClick={counter.increment}>Increment : {counter.count}
</button>
</>
)
}
export default ButtonIncrement
```
Hanya dengan menggunakan 1 baris kode ini
```javascript
const counter = useCounter();
```
yang mana useCounter(); ini merupakan store yang sudah kita definisikan sebelumnya. Kita sudah bisa mengubah state dari komponen yang menggunakannya tanpa memperhatikan deep level of component-nya.
### Kesimpulan
Dengan menggunakan Zustand sebagai state management, kita bisa melihat perbedaan yang cukup signifikan antara penggunaan useState Hooks dan Zustand ketika mengubah sebuah state. Perbedaan yang cukup terlihat yaitu penggunaan Zustand jauh lebih efektif dan fleksibel, karena kita hanya perlu mendefinisikan store kemudian bisa digunakan di berbagai macam component tanpa memperhatikan deep level of component-nya. Tapi, jika skalabilitas aplikasi yang dikembangkan cukup kompleks maka, ada rekomendasi lain sebagai state management yaitu Redux Toolkit yang mana sejauh ini beberapa aplikasi yang mempunyai skalabilitas cukup kompleks masih menggunakan Redux dibandingkan Zustand.
| yogameleniawan |
1,873,728 | Simple Flight Slider HTML & CSS Only | Hi , A simple graph designed to fly as a passenger or helicopter while flying in the sky , moving... | 0 | 2024-06-02T14:18:17 | https://dev.to/hussein09/simple-flight-slider-html-css-only-4cdg | codepen, javascript, beginners, html | Hi ,
A simple graph designed to fly as a passenger or helicopter while flying in the sky ,
moving from Iraq to New York .
You can take theories that may be professional to develop in the design to make them more realistic .
{% codepen https://codepen.io/hussein009/pen/JjqWLaV %} | hussein09 |
1,873,727 | How i migrated my create-react-app legacy code to vite for faster build and compile time | This is just a small article, i will not write a long paras on why i did it, and what improvements i... | 0 | 2024-06-02T14:10:04 | https://dev.to/slimpython/how-i-migrated-my-create-react-app-legacy-code-to-vite-for-faster-build-and-compile-time-149a | webdev, react, vite | This is just a small article, i will not write a long paras on why i did it, and what improvements i experience, i will just tell you how i did it.
About my previous create-react-app legacy code:
it is made in typescript and javascript
## How i migrated:
first i installed these libraries
`npm install vite @vitejs/plugin-react vite-tsconfig-paths`
and create a vite.config.ts file
```js
import { defineConfig } from 'vite';
import react from '@vitejs/plugin-react';
import viteTsconfigPaths from 'vite-tsconfig-paths';
export default defineConfig({
// depending on your application, base can also be "/"
base: '',
plugins: [react(), viteTsconfigPaths()],
server: {
// this ensures that the browser opens upon server start
open: true,
// this sets a default port to 3000
port: 3000
}
});
```
Then i moved my **index.html** file to root directory, earlier it was on src folder
then i converted all my js file to jsx where i had some html inside
> [note: only do this if you are getting error]
i used this script to convert all my js file to jsx file
it is a powershell script for windows, you can search for your os, just run this file in powershell
/.script.ps1
```ps1
Get-ChildItem -Path "src" -Filter *.js -Recurse | ForEach-Object {
$newName = $_.FullName -replace '.js$','.jsx'
if (-Not (Test-Path $newName)) {
Rename-Item -Path $_.FullName -NewName $newName
} else {
Write-Host "Skipping renaming of $($_.FullName) as $newName already exists."
}
}
```
then in my .env file i replaced all **REACT_APP_** to **VITE_REACT_APP_**
and in my code i replaced all **process.env** to **import.meta.env.VITE_REACT_APP**
i also made a **vite-env.d.ts** file and with this and placed it inside src as well as root directory.
```
/// <reference types="vite/client" />
```
and that's it. Thanks for reading.
so far my build time has reduced to more than half. | slimpython |
1,873,726 | Kiếm tiền với POD có thực sự khó! | Thực sự mà nói. việc kiếm tiền với POD thực sự không còn thu hút được cộng đồng MMO như trước. Nhiều... | 0 | 2024-06-02T14:08:17 | https://dev.to/duandigi/kiem-tien-voi-pod-co-thuc-su-kho-26ab | webdev, javascript, beginners, tutorial | Thực sự mà nói. việc kiếm tiền với POD thực sự không còn thu hút được cộng đồng MMO như trước. Nhiều ý kiến cho rằng việc kinh doanh POD bây giờ khó hơn, cạnh tranh hơn. Ngoài ra cũng có nhiều phương thức kiếm tiền online mới xuất hiện, dễ hơn, nhanh hơn POD rất nhiều.
Nói như vậy không có nghĩa rằng POD không còn kiếm tiền được mà thực sự vẫn còn cơ hội cho ai muốn tìm kiếm cơ hội khởi nghiệp. Và dưới đây là cách!

## **POD là gì?**
Print-On-Demand (POD), hay còn gọi là in theo yêu cầu, là mô hình kinh doanh cho phép bạn bán các sản phẩm được in với thiết kế của riêng bạn mà không cần phải lo lắng về khâu sản xuất hay lưu kho. Khi có khách hàng đặt mua, nhà cung cấp POD sẽ in sản phẩm theo thiết kế của bạn và giao hàng trực tiếp cho khách.
## **Đặc điểm**
Ưu điểm của kiếm tiền với POD:
Vốn đầu tư thấp: Bạn không cần phải bỏ ra một khoản tiền lớn để mua sắm hàng hóa hay thuê kho bãi.
Dễ dàng bắt đầu: Chỉ cần có ý tưởng sáng tạo và một chiếc máy tính là bạn có thể bắt đầu kinh doanh POD.
Khả năng mở rộng cao: Bạn có thể bán sản phẩm của mình cho khách hàng trên toàn thế giới.
Không rủi ro: Bạn chỉ phải trả tiền cho nhà cung cấp POD khi có khách hàng đặt mua sản phẩm.
**
## Cách kiếm tiền với POD
**
Để giúp bạn dễ dàng hình dung, tôi sẽ chia quy trình kiếm tiền với POD thành 6 bước chính, bao gồm:
1. Khơi nguồn ý tưởng sáng tạo:
Xác định đối tượng mục tiêu: Bạn muốn bán sản phẩm cho ai? Hiểu rõ sở thích, nhu cầu và xu hướng của họ là chìa khóa để tạo ra những thiết kế thu hút.
Tìm kiếm cảm hứng: Lướt qua các trang web POD, mạng xã hội, tạp chí hoặc tham khảo các sự kiện văn hóa để tìm kiếm ý tưởng thiết kế độc đáo.
Kết hợp sở thích và kỹ năng: Thêm dấu ấn cá nhân vào thiết kế bằng cách kết hợp sở thích, đam mê hoặc kỹ năng của bạn.
2. Lựa chọn nhà cung cấp POD uy tín:
So sánh giá cả, chất lượng sản phẩm, dịch vụ khách hàng và các chính sách của các nhà cung cấp POD khác nhau.
Tham khảo đánh giá từ những người đi trước để có cái nhìn khách quan và lựa chọn nhà cung cấp phù hợp nhất.
Một số nhà cung cấp POD phổ biến tại Việt Nam như: Teepublic, Printify, Printful, Redbubble,...
3. Thiết kế sản phẩm ấn tượng:
Sử dụng công cụ thiết kế online miễn phí như Canva, Adobe Photoshop,... hoặc thuê họa sĩ chuyên nghiệp nếu bạn không có kỹ năng thiết kế.
Đảm bảo thiết kế của bạn có độ phân giải cao, phù hợp với kích thước sản phẩm và đáp ứng các yêu cầu của nhà cung cấp POD.
Tạo nhiều mẫu mã đa dạng để thu hút nhiều đối tượng khách hàng hơn.
4. Tạo cửa hàng online chuyên nghiệp:
Lựa chọn nền tảng bán hàng phù hợp như Shopify, Etsy, Redbubble,... hoặc xây dựng website riêng.
Tạo giao diện cửa hàng bắt mắt, thu hút và dễ dàng sử dụng.
Viết mô tả sản phẩm chi tiết, đầy đủ thông tin và hấp dẫn khách hàng.
Tối ưu hóa hình ảnh sản phẩm chất lượng cao, rõ ràng và thu hút.
5. Tiếp thị sản phẩm hiệu quả:
Quảng bá sản phẩm trên mạng xã hội như Facebook, Instagram, Pinterest,...
Sử dụng email marketing để giới thiệu sản phẩm mới và chương trình khuyến mãi đến khách hàng tiềm năng.
Chạy quảng cáo trả phí trên Google, Facebook,... để tiếp cận tệp khách hàng rộng hơn.
Tham gia các hội nhóm và cộng đồng trực tuyến liên quan đến lĩnh vực bạn kinh doanh.
6. Xử lý đơn hàng nhanh chóng và chuyên nghiệp:
Cung cấp dịch vụ khách hàng chu đáo, giải đáp thắc mắc và hỗ trợ khách hàng tận tình.
Xử lý đơn hàng nhanh chóng, đảm bảo giao hàng đúng hẹn và nguyên trạng sản phẩm.
Theo dõi và thu thập phản hồi của khách hàng để cải thiện chất lượng sản phẩm và dịch vụ.
## **Những lưu ý quan trọng khi kiếm tiền với POD:**
1. Chọn ý tưởng thiết kế độc đáo và thu hút:
Hiểu rõ đối tượng khách hàng mục tiêu: Bạn muốn bán sản phẩm cho ai? Lứa tuổi nào? Sở thích gì? Việc xác định rõ đối tượng mục tiêu sẽ giúp bạn tạo ra những thiết kế phù hợp và thu hút họ.
Tìm kiếm cảm hứng từ nhiều nguồn: Tham khảo các trang web POD, mạng xã hội, tạp chí, sự kiện văn hóa,... để tìm kiếm ý tưởng thiết kế mới mẻ và độc đáo.
Kết hợp sở thích và kỹ năng cá nhân: Thêm dấu ấn cá nhân vào thiết kế bằng cách kết hợp sở thích, đam mê hoặc kỹ năng của bạn. Điều này sẽ giúp sản phẩm của bạn trở nên nổi bật và thu hút khách hàng hơn.
2. Lựa chọn nhà cung cấp POD uy tín:
So sánh giá cả, chất lượng sản phẩm, dịch vụ khách hàng: Đây là những yếu tố quan trọng ảnh hưởng đến lợi nhuận và trải nghiệm mua sắm của khách hàng.
Tham khảo đánh giá từ những người đi trước: Đọc review từ những người đã sử dụng dịch vụ của nhà cung cấp POD để có cái nhìn khách quan và đưa ra lựa chọn phù hợp.
Một số nhà cung cấp POD phổ biến tại Việt Nam: Teepublic, Printify, Printful, Redbubble,...
3. Thiết kế sản phẩm chất lượng cao:
Sử dụng công cụ thiết kế phù hợp: Bạn có thể sử dụng các công cụ thiết kế online miễn phí như Canva, Adobe Photoshop,... hoặc thuê họa sĩ chuyên nghiệp nếu bạn không có kỹ năng thiết kế.
Đảm bảo thiết kế có độ phân giải cao: Hình ảnh sản phẩm cần rõ ràng, sắc nét để thu hút khách hàng.
Tuân thủ các yêu cầu của nhà cung cấp POD: Mỗi nhà cung cấp POD có quy định riêng về kích thước, định dạng file,... thiết kế. Hãy đảm bảo thiết kế của bạn đáp ứng các yêu cầu này để tránh lỗi in ấn.
4. Tạo cửa hàng online chuyên nghiệp:
Lựa chọn nền tảng bán hàng phù hợp: Shopify, [Etsy](https://medium.com/@duandigi/etsy-l%C3%A0-g%C3%AC-thi%C3%AAn-%C4%91%C6%B0%E1%BB%9Dng-mua-s%E1%BA%AFm-h%C3%A0ng-%C4%91%E1%BB%99c-l%E1%BA%A1-e332ebe6bac8), Redbubble,... là những nền tảng phổ biến được nhiều người lựa chọn để bán sản phẩm POD.
Tạo giao diện bắt mắt, thu hút: Giao diện cửa hàng cần đẹp mắt, dễ sử dụng và tạo ấn tượng tốt với khách hàng.
Viết mô tả sản phẩm chi tiết: Cung cấp đầy đủ thông tin về sản phẩm như chất liệu, kích thước, màu sắc,... để khách hàng dễ dàng lựa chọn.
Tối ưu hóa hình ảnh sản phẩm: Hình ảnh sản phẩm cần chất lượng cao, rõ ràng và thu hút để khách hàng chú ý.
5. Tiếp thị sản phẩm hiệu quả:
Quảng bá sản phẩm trên mạng xã hội: Facebook, Instagram, Pinterest,... là những kênh hiệu quả để tiếp cận khách hàng tiềm năng.
Sử dụng email marketing: Gửi email giới thiệu sản phẩm mới, chương trình khuyến mãi đến khách hàng tiềm năng.
Chạy quảng cáo trả phí: Google Ads, Facebook Ads,... giúp bạn tiếp cận tệp khách hàng rộng hơn.
Tham gia các hội nhóm và cộng đồng trực tuyến: Tham gia các hội nhóm và cộng đồng liên quan đến lĩnh vực bạn kinh doanh để quảng bá sản phẩm và thu hút khách hàng.
6. Xử lý đơn hàng nhanh chóng và chuyên nghiệp:
Cung cấp dịch vụ khách hàng chu đáo: Giải đáp thắc mắc và hỗ trợ khách hàng tận tình để tạo dựng uy tín và giữ chân khách hàng.
Xử lý đơn hàng nhanh chóng: Đảm bảo giao hàng đúng hẹn và nguyên trạng sản phẩm.
Theo dõi và thu thập phản hồi của khách hàng: Phản hồi của khách hàng là nguồn dữ liệu quý giá để bạn cải thiện chất lượng sản phẩm và dịch vụ.
Ngoài ra, bạn cần lưu ý:
Kiên trì và không ngừng học hỏi: Kiếm tiền với POD là một quá trình lâu dài và đòi hỏi sự kiên trì. Hãy không ngừng học hỏi những kiến thức mới để nâng cao chất lượng sản phẩm và dịch vụ.
Cập nhật xu hướng thị trường: Nắm bắt xu hướng thị trường để đổi mới thiết kế và tiếp thị sản phẩm hiệu quả hơn.
Cung cấp dịch vụ khách hàng tốt: Dịch vụ khách hàng tốt sẽ giúp bạn tạo dựng uy tín và giữ chân khách hàng.
Chúc bạn thành công với mô hình kinh doanh POD!
| duandigi |
1,873,725 | Syncing ktor project generator with gradle init task | Good morning, Gradle init task generates a project with the very useful structure based on... | 0 | 2024-06-02T14:07:42 | https://dev.to/erfranco/syncing-ktor-project-generator-with-gradle-init-task-36p3 | Good morning, Gradle init task generates a project with the very useful structure based on centralized dependency management, namely libs.versions.toml file in 'gradle' directory.
This is very useful when dependency versions change, and it looks like a good place where insert 'all' dependencies and versions.
It would be a good thing if the ktor project generator followed this structure.
For example, in libs.versions. toml:
`[versions]
kotlin-version = "2.0.0"
ktor-version = "2.3.11"
guava = "32.1.3-jre"
junit-jupiter-engine = "5.10.1"
exposed-version = "0.50.+"toml format
h2 = "2.2.224"
postgres = "42.5.1"
mu-logging = "2.0.11"
logback = "1.4.14"
hikaricp-version = "5.1.0"
ehcache-version = "3.10.8"`
In fact, when I generate a ktor-project, I spend at least one hour to adapt the structure to the toml format, because I'm convinced that the build.gradle.kts is cleaner and more readable, for instance
`plugins {
alias(libs.plugins.jvm)
//ktor
alias(libs.plugins.ktor)
//kotlin.serialization
alias(libs.plugins.kotlin.serialization)
}
repositories {
// Use Maven Central for resolving dependencies.
mavenCentral()
}
group = "org.erfranco"
version = "0.0.1"
application {
mainClass = "org.erfranco.ApplicationKt"
val isDevelopment: Boolean = project.ext.has("development")
println("Property 'development' found? : $isDevelopment")
applicationDefaultJvmArgs = listOf("-Dio.ktor.development=$isDevelopment")
}
dependencies {
//logging
implementation(libs.mu.logging)
implementation(libs.logback)
// Ktor stuff
implementation(libs.ktor.server.core)
implementation(libs.ktor.server.statuspages)
implementation(libs.ktor.server.configyaml)
implementation(libs.ktor.server.serialization.json)
implementation(libs.ktor.server.content.negotiationjvm)
implementation(libs.ktor.server.host.commonjvm)
//Embedded server
//implementation(libs.ktor.server.tomcatjvm)
implementation(libs.ktor.server.nettyjvm)
//implementation(libs.ktor.server.freemarkerjvm)
// Exposed stuff
implementation(libs.exposed.core)
implementation(libs.exposed.jdbc)
//implementation(libs.exposed.crypt)
//implementation(libs.exposed.dao)
//implementation(libs.exposed.kotlin.datetime)
//implementation(libs.exposed.json)
//implementation(libs.exposed.money)
// Database
implementation(libs.h2)
//implementation(libs.postgres)
//pooling and cache
//implementation(libs.ehcache)
//implementation(libs.hikaricp)
testImplementation(libs.ktor.server.testsjvm)
testImplementation(libs.kotlin.test.junit)
// Use the Kotlin JUnit 5 integration.
//testImplementation(libs.kotlin.test.junit5)
// Use the JUnit 5 integration.
//testImplementation(libs.junit.jupiter.engine)
//testRuntimeOnly(libs.junit.platform.launcher)
}`
Moreover, gradle.properties file is clean:
`kotlin.code.style=official
project.ext {
development
}`
This is my libs.versions.toml file, in 'gradle' folder, almost the same for all projects:
`# This file was generated by the Gradle 'init' task.
# https://docs.gradle.org/current/userguide/platforms.html#sub::toml-dependencies-format
# Ermanno Franco 2024-6-02
[versions]
kotlin-version = "2.0.0"
ktor-version = "2.3.11"
guava = "32.1.3-jre"
junit-jupiter-engine = "5.10.1"
exposed-version = "0.50.+"
h2 = "2.2.224"
postgres = "42.5.1"
mu-logging = "2.0.11"
logback = "1.4.14"
hikaricp-version = "5.1.0"
ehcache-version = "3.10.8"
[libraries]
mu-logging = { module = "io.github.microutils:kotlin-logging-jvm", version.ref = "mu-logging" }
logback = { module = "ch.qos.logback:logback-classic", version.ref = "logback" }
kotlin-test-junit = { module = "org.jetbrains.kotlin:kotlin-test-junit", version.ref = "kotlin-version" }
kotlin-test-junit5 = { module = "org.jetbrains.kotlin:kotlin-test-junit5", version.ref = "kotlin-version" }
junit-jupiter-engine = { module = "org.junit.jupiter:junit-jupiter-engine", version.ref = "junit-jupiter-engine" }
junit-platform-launcher = { module = "org.junit.platform:junit-platform-launcher" }
guava = { module = "com.google.guava:guava", version.ref = "guava" }
exposed-core = {module = "org.jetbrains.exposed:exposed-core", version.ref = "exposed-version" }
exposed-crypt = {module = "org.jetbrains.exposed:exposed-crypt", version.ref = "exposed-version" }
exposed-dao = {module = "org.jetbrains.exposed:exposed-dao", version.ref = "exposed-version" }
exposed-jdbc = {module = "org.jetbrains.exposed:exposed-jdbc", version.ref = "exposed-version" }
exposed-kotlin-datetime = {module = "org.jetbrains.exposed:exposed-kotlin-datetime", version.ref = "exposed-version" }
exposed-json = {module = "org.jetbrains.exposed:exposed-json", version.ref = "exposed-version" }
exposed-money = {module = "org.jetbrains.exposed:exposed-money", version.ref = "exposed-version" }
h2 = {module = "com.h2database:h2", version.ref = "h2" }
postgres = {module = "org.postgresql:postgresql", version.ref = "postgres" }
hikaricp = {module = "com.zaxxer:HikariCP", version.ref = "hikaricp-version" }
ehcache = {module = "org.ehcache:ehcache", version.ref = "ehcache-version" }
ktor-server-core = { module = "io.ktor:ktor-server-core-jvm", version.ref = "ktor-version" }
ktor-server-statuspages = { module = "io.ktor:ktor-server-status-pages", version.ref = "ktor-version" }
ktor-server-configyaml = { module = "io.ktor:ktor-server-config-yaml", version.ref = "ktor-version" }
ktor-server-testsjvm = { module = "io.ktor:ktor-server-tests-jvm", version.ref = "ktor-version" }
ktor-server-freemarkerjvm = { module = "io.ktor:ktor-server-freemarker-jvm", version.ref = "ktor-version" }
ktor-server-tomcatjvm = { module = "io.ktor:ktor-server-tomcat-jvm", version.ref = "ktor-version" }
ktor-server-nettyjvm = { module = "io.ktor:ktor-server-netty-jvm", version.ref = "ktor-version" }
ktor-server-serialization-json = { module = "io.ktor:ktor-serialization-kotlinx-json-jvm", version.ref = "ktor-version" }
ktor-server-content-negotiationjvm = { module = "io.ktor:ktor-server-content-negotiation-jvm", version.ref = "ktor-version" }
ktor-server-host-commonjvm = { module = "io.ktor:ktor-server-host-common-jvm", version.ref = "ktor-version" }
[plugins]
jvm = { id = "org.jetbrains.kotlin.jvm", version.ref = "kotlin-version" }
kotlin-serialization = { id = "org.jetbrains.kotlin.plugin.serialization", version.ref = "kotlin-version" }
ktor = { id = "io.ktor.plugin", version.ref = "ktor-version" }
`
Happy coding!
| erfranco | |
1,859,115 | Install Docker and Portainer in a VM using Ansible | Introduction This episode is actually why I started this series in the first place. I am... | 23,326 | 2024-06-02T14:05:28 | https://dev.to/rimelek/install-docker-and-portainer-in-a-vm-using-ansible-21ib | docker, lxd, portainer, tutorial | ## Introduction
This episode is actually why I started this series in the first place. I am an active Docker user and Docker fan, but I like containers and DevOps topics in general. I am a [moderator on the official Docker forums](https://forums.docker.com/u/rimelek) and I see that people often struggle with the installation process of Docker CE or Docker Desktop. Docker Desktop starts a virtual machine, and the GUI is to manage the Docker CE inside the virtual machine even on Linux. Even though I prefer not to use a GUI for creating containers, I admit it can be useful in some situations, but you always need to be ready to use the command line where all the commands are available. In this episode I will use Ansible to install Docker CE in the previously created virtual machine, and I will also install a web-based graphical interface, [Portainer](https://www.portainer.io/).
{% embed https://youtu.be/tfv_C1uMLqI %}
If you want to be notified about other videos as well, you can subscribe to my YouTube channel: https://www.youtube.com/@akos.takacs
## Table of contents
- [Before you begin](#before-you-begin)
- [Requirements](#requirements)
- [Download the already written code of the previous episode](#download-the-already-written-code-of-the-previous-episode)
- [Have an inventory file](#have-the-inventory-file)
- [Activate the Python virtual environment](#activate-the-python-virtual-environment)
- [Small improvements before we start today's main topic](#small-improvements-before-we-start-todays-main-topic)
- [Disable gathering facts automatically](#disable-gathering-facts-automatically)
- [Create an inventory group for LXD playbooks](#create-an-inventory-group-for-lxd-playbooks)
- [Reload ZFS pools after removing LXD to make the playbook more stable](#reload-zfs-pools-after-removing-lxd-to-make-the-playbook-more-stable)
- [Add a host to a dynamically created inventory group](#add-a-host-to-a-dynamically-created-inventory-group)
- [Use a dynamically created inventory group](#use-a-dynamically-created-inventory-group)
- [Install Docker CE in a VM using Ansible](#install-docker-ce-in-a-vm-using-ansible)
- [Using 3rd-party roles to install Docker](#using-3rdparty-roles-to-install-docker)
- [Default variables for the docker role](#default-variables-for-the-docker-role)
- [Add docker to the Ansible roles](#add-docker-to-the-ansible-roles)
- [Install the dependencies of Docker](#install-the-dependencies-of-docker)
- [Configure the official APT repository](#configure-the-official-apt-repository)
- [Install a specific version of Docker CE](#install-a-specific-version-of-docker-ce)
- [Allow non-root users to use the docker commands](#allow-nonroot-users-to-use-the-docker-commands)
- [Install Portainer CE, the web-based GUI for containers](#install-portainer-ce-the-webbased-gui-for-containers)
- [Conclusion](#conclusion)
## Before you begin
### Requirements
[» Back to table of contents «](#table-of-contents)
- The project requires Nix which we discussed in [Install Ansible 8 on Ubuntu 20.04 LTS using Nix](https://dev.to/rimelek/install-ansible-8-on-ubuntu-2004-lts-using-nix-46hm)
- You will also need an Ubuntu remote server. I recommend an Ubuntu 22.04 virtual machine.
### Download the already written code of the previous episode
[» Back to table of contents «](#table-of-contents)
If you started the tutorial with this episode, clone the project from GitHub:
```bash
git clone https://github.com/rimelek/homelab.git
cd homelab
```
If you cloned the project now, or you want to make sure you are using the exact same code I did, switch to the previous episode in a new branch
```bash
git checkout -b tutorial.episode.8b tutorial.episode.9.1
```
### Have the inventory file
[» Back to table of contents «](#table-of-contents)
Copy the inventory template
```bash
cp inventory-example.yml inventory.yml
```
- Change `ansible_host` to the IP address of your Ubuntu server that you use for this tutorial,
- and change `ansible_user` to the username on the remote server that Ansible can use to log in.
- If you still don't have an SSH private key, read the [Generate an SSH key part of Ansible playbook and SSH keys](https://dev.to/rimelek/ansible-playbook-and-ssh-keys-33bo#generate-an-ssh-key)
- If you want to run the playbook called `playbook-lxd-install.yml`, you will need to configure a physical or virtual disk which I wrote about in [The simplest way to install LXD using Ansible](https://dev.to/rimelek/the-simplest-way-to-install-lxd-using-ansible-h5o#install-zfs-utils-and-create-a-zfs-pool). If you don't have a usable physical disk, Look for `truncate -s 50G <PATH>/lxd-default.img` to create a virtual disk.
- You will need an encrypted secret file which I wrote about in the [Encrypt a file section of "Use SOPS in Ansible ro read your secrets"](https://dev.to/rimelek/use-sops-in-ansible-to-read-your-secrets-2gfa#encrypt-a-file).
### Activate the Python virtual environment
[» Back to table of contents «](#table-of-contents)
How you activate the virtual environment, depends on how you created it. In the episode of [The first Ansible playbook](https://dev.to/rimelek/the-first-ansible-playbook-579h#install-ansible) describes the way to create and activate the virtual environment using the "venv" Python module and in the episode of [The first Ansible role](https://dev.to/rimelek/the-first-ansible-role-paf) we created helper scripts as well, so if you haven't created it yet, you can create the environment by running
```bash
./create-nix-env.sh venv
```
Optionally start an ssh agent:
```bash
ssh-agent $SHELL
```
and activate the environment with
```bash
source homelab-env.sh
```
## Small improvements before we start today's main topic
You can skip this part too, if you joined the tutorial at this episode, and you don't want to improve other playbooks.
### Disable gathering facts automatically
[» Back to table of contents «](#table-of-contents)
We discussed facts before in the "[Using facts and the GitHub API in Ansible](https://dev.to/rimelek/using-facts-and-the-github-api-in-ansible-4i00)" episode, but we left this setting on default in other playbooks. Let's quickly add `gather_facts: false` to all playbooks, except `playbook-hello.yml` as that was to demonstrate how a playbook runs.
### Create an inventory group for LXD playbooks
[» Back to table of contents «](#table-of-contents)
Now that we have a separate group for the virtual machines that run Docker, we can also create a new group for LXD, so when we add more machines, we will not install LXD on every single machine, and we will not remove it from a machine on which it was not installed. Let's add the following to the `inventory.yml`
```yaml
lxd_host_machines:
hosts:
YOURHOSTNAME:
```
**NOTE**: Replace `YOURHOSTNAME` with your actual hostname which you used in the inventory under the special group called "`all`".
In my case, it is the following:
```yaml
lxd_host_machines:
hosts:
ta-lxlt:
```
And now, replace `hosts: all` in `playbook-lxd-install.yml` and `playbook-lxd-remove.yml` with `hosts: lxd_host_machines`.
### Reload ZFS pools after removing LXD to make the playbook more stable
[» Back to table of contents «](#table-of-contents)
When I wrote the "[Remove LXD using Ansible](https://dev.to/rimelek/remove-lxd-using-ansible-3i7i)" episode, the playbook worked for me every time. Since then, I noticed that sometimes it cannot delete the ZFS pool, because it's missing. I couldn't actually figure out why it happens, but a workaround can be implemented to make the playbook more stable. We have to restart the `zfs-import-cache` Systemd service, which will reload the ZFS pools so the next task can delete it and the disks can be wiped as well.
Open `roles/zfs_destroy_pool/tasks/main.yml` and look for the following task:
```yaml
- name: Get zpool facts
ignore_errors: true
community.general.zpool_facts:
name: "{{ zfs_destroy_pool_name }}"
register: _zpool_facts_task
```
All we have to do is add a new task before it:
```yaml
# To fix the issue of missing ZFS pool after uninstalling LXD
- name: Restart ZFS import cache
become: true
ansible.builtin.systemd:
state: restarted
name: zfs-import-cache
```
The [built-in systemd module](https://docs.ansible.com/ansible/latest/collections/ansible/builtin/systemd_module.html) can restart a Systemd service if the "state" is "restarted".
## Add a host to a dynamically created inventory group
[» Back to table of contents «](#table-of-contents)
Since we already configured our SSH client for the newly created virtual machine last time, we could create a new inventory group and add the virtual machine to that group. But sometimes you don't want to do that, or you can't. That's why I wanted to show you a way to create a new inventory group without changing the inventory file. Then we can add a host to this group. Since last time we also used Ansible to get the IP address of the new virtual machine, we can add that IP to the inventory group. The next task will show you how you can do that.
```yaml
# region task: Add Docker VM to Ansible inventory
- name: Add Docker VM to Ansible inventory
changed_when: false
ansible.builtin.add_host:
groups: _lxd_docker_vm
hostname: "{{ vm_inventory_hostname }}"
ansible_user: "{{ config_lxd_docker_vm_user }}"
ansible_become_pass: "{{ config_lxd_docker_vm_pass }}"
# ansible_host is not necessary, inventory hostname will be used
ansible_ssh_private_key_file: "{{ vm_ssh_priv_key }}"
#ansible_ssh_common_args: "-o StrictHostKeyChecking=no"
ansible_ssh_host_key_checking: false
# endregion
```
You need to add the above task to the "Create the VM" play in the `playbook-lxd-docker-vm.yml` playbook. The [builtin add_host module](https://docs.ansible.com/ansible/latest/collections/ansible/builtin/add_host_module.html) is what we needed. Despite what you see in the task, it has only 2 parameters. Everything else is a variable which you could use in the inventory file as well. The `groups` and `name` parameters have aliases, and I thought that using the `hostname` alias of `name` would be better as we indeed add a hostname or an IP as its value. `groups` can be a list or a string. I defined it as a string as I have only one group to which I will add the VM.
I mentioned before that I like to start the name of helper variables with an underscore. The name of the group is not a variable, but I start it with an underscore, so I will know it is a temporary, dynamically created inventory group. We have some variables that we defined in the previous episode.
- `vm_inventory_hostname`: The inventory hostname of the VM, which is also used in the SSH client configuration. It actually comes from the value of `config_lxd_docker_vm_inventory_hostname` with a default in case it is not defined.
- `config_lxd_docker_vm_user`: The user that we created using cloud init and with which we can SSH into the VM.
- `config_lxd_docker_vm_pass`: The sudo password of the user. It comes from a secret.
- `vm_ssh_priv_key`: The path of the SSH private key used for the SSH connection. It is just a short alias for `config_lxd_docker_vm_ssh_priv_key` which can be defined in the inventory file.
Using these variables we could configure the SSH connection parameters like `ansible_user`, `ansible_become_pass` and `ansible_ssh_private_key_file`. We also have a new variable, `ansible_ssh_host_key_checking`. When we first SSH to a remote server, we need to accept the fingerprint of the server's SSH host key, which means we know and trust the server. Since we dynamically created this virtual machine and detected its IP address, we would need to accept it every time we recreate our VM, so I just disable host key checking by setting boolean false as value.
## Use a dynamically created inventory group
[» Back to table of contents «](#table-of-contents)
We have a new inventory group, but we still don't use it. Now we need a new play in the paybook which will actually use this group. Add the following play skeleton to the end of `playbook-lxd-docker-vm.yml`.
```yaml
# play: Configure the OS in the VM
- name: Configure the OS in the VM
hosts: _lxd_docker_vm
gather_facts: false
pre_tasks:
roles:
# endregion
```
Even though we forced Ansible to wait until the virtual machine gets an IP address, having an IP address doesn't mean the SSH daemon is ready in the VM. So we need the following pre task:
```yaml
- name: Waiting for SSH connection
ansible.builtin.wait_for_connection:
timeout: 20
delay: 0
sleep: 3
connect_timeout: 2
```
The [built-in wait_for_connection module](https://docs.ansible.com/ansible/latest/collections/ansible/builtin/wait_for_connection_module.html) can be used to retry connecting to the servers. We start checking it immediately, so we set the delay to 0. If we are lucky, it will be ready right away. If it does not connect in 2 seconds (`connect_timeout`), Ansible will "sleep" for 3 seconds and try again. If the connection is not made in 20 seconds (`timeout`), the task will fail.
While I was testing the almost finished playbook, I realized that sometimes the installation of some packages failed like if they were not in the APT cache yet, so I added a new pre task to update the APT cache before we start the VM. We already discussed this module in [Using facts and the GitHub API in Ansible](https://dev.to/rimelek/using-facts-and-the-github-api-in-ansible-4i00)
```yaml
- name: Update APT cache
become: true
changed_when: false
ansible.builtin.apt:
update_cache: true
```
If you don't want to add it, you can just rerun the playbook and it will probably work. Now we have an already written Ansible role which we will want to use here too, which is `cli_tools`. So this is how our second play looks like in `playbook-lxd-docker-vm.yml`:
```yaml
# play: Configure the OS in the VM
- name: Configure the OS in the VM
hosts: _lxd_docker_vm
gather_facts: false
pre_tasks:
- name: Waiting for SSH connection
ansible.builtin.wait_for_connection:
timeout: 20
delay: 0
sleep: 3
connect_timeout: 2
- name: Update APT cache
become: true
changed_when: false
ansible.builtin.apt:
update_cache: true
roles:
- role: cli_tools
# endregion
```
Now you could delete the virtual machine if you already created it last time, and run the playbook with the new play again to create the virtual machine and immediately install the command line tools in it.
## Install Docker CE in a VM using Ansible
### Using 3rd-party roles to install Docker
[» Back to table of contents «](#table-of-contents)
I admit, that there are already existing great roles we could use to Install Docker. For example the one [made by Jeff Geerling](https://galaxy.ansible.com/ui/standalone/roles/geerlingguy/docker/) which supports multiple Linux distributions, so feel free to use it, but we are still practicing writing our own roles, so I made a simple one for you, although that works only on Ubuntu. On the other hand, I will add something that even Jeff Geerling didn't do.
### Default variables for the docker role
[» Back to table of contents «](#table-of-contents)
We will create some default variables in `roles/docker/defaults/main.yml`:
```yaml
docker_version: "*.*.*"
docker_sudo_users: []
```
The first, `docker_version` is to define which version we want to install. When you just start playing with Docker but don't want to use [Play with Docker](https://labs.play-with-docker.com/), you probably want to install the latest version. That's why the default value is "`*.*.*`", which means the latest major, minor and patch version of Docker CE. You will see the implementation soon. The second variable is `docker_sudo_users`, which is an empty list. We will be able to add users to the list who should be able to use Docker. We will discuss it later in more details.
### Add docker to the Ansible roles
[» Back to table of contents «](#table-of-contents)
Before we continue, let's add "docker" as a new role to our second play in `playbook-lxd-docker-vm.yml`:
```yaml
# ...
roles:
- role: cli_tools
- role: docker
docker_sudo_users: "{{ config_lxd_docker_vm_docker_sudo_users | default([]) }}"
```
You know very well now that this way we can add this new config variable to the `inventory.yml`
```yaml
all:
vars:
# ...
config_lxd_docker_vm_user: manager
config_lxd_docker_vm_docker_sudo_users:
- "{{ config_lxd_docker_vm_user }}"
```
Note that `config_lxd_docker_vm_user` is probably already defined if you followed the previous episodes as well.
### Install the dependencies of Docker
[» Back to table of contents «](#table-of-contents)
As I say it very often we should always start with the [official documentation](https://docs.docker.com/engine/install/ubuntu/). It starts with uninstalling old and unofficial packages. Our role will not include it, so you will do it manually or write your own role as a homework. Then it updates the APT cache, which we just did as a pre task, so we will install the dependencies first. The official documentation says:
```bash
sudo apt-get install ca-certificates curl
```
Which looks like this in Ansible in `roles/docker/tasks/main.yml`:
```yaml
- name: Install dependencies
become: true
ansible.builtin.apt:
name:
- ca-certificates
- curl
```
**Note**: We know that the "cli_tools" role already installed curl, but we don't care, because when we create a role, we try to make it without depending on other roles. So even if we decide later not to use the "cli_tools" role, our "docker" role will still work perfectly.
### Configure the official APT repository
[» Back to table of contents «](#table-of-contents)
The official documentation continues with creating a folder, `/etc/apt/keyrings`. It uses the
```bash
sudo install -m 0755 -d /etc/apt/keyrings
```
command, but it really just creates a folder this time, which looks like this in Ansible:
```yaml
- name: Make sure the folder of the keyrings exists
become: true
ansible.builtin.file:
state: directory
mode: 0755
path: /etc/apt/keyrings
```
The next step is downloading the APT key for the repository. Previously, the documentation used the `apt-key` command which was deprecated on Ubuntu, so it was replaced with the following:
```bash
sudo curl -fsSL https://download.docker.com/linux/ubuntu/gpg -o /etc/apt/keyrings/docker.asc
sudo chmod a+r /etc/apt/keyrings/docker.asc
```
Which looks like this in Ansible:
```yaml
- name: Install the APT key of Docker's APT repo
become: true
ansible.builtin.get_url:
url: https://download.docker.com/linux/ubuntu/gpg
dest: /etc/apt/keyrings/docker.asc
mode: a+r
```
Then the official documentation shows how you can add the repository to APT depending on the CPU architecture and Ubuntu release code name, like this:
```bash
# Add the repository to Apt sources:
echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.asc] https://download.docker.com/linux/ubuntu \
$(. /etc/os-release && echo "$VERSION_CODENAME") stable" | \
sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt-get update
```
In the "[Using facts and the GitHub API in Ansible](https://dev.to/rimelek/using-facts-and-the-github-api-in-ansible-4i00)" episode we already learned to get the architecture. We also need the release code name, so we gather the `distribution_release` subset of Ansible facts as well.
```yaml
- name: Get distribution release fact
ansible.builtin.setup:
gather_subset:
- distribution_release
- architecture
```
Before we continue with the next task, we will add some variables to `roles/docker/vars/main.yml`.
```yaml
docker_archs:
x86_64: amd64
amd64: amd64
aarch64: arm64
arm64: arm64
docker_arch: "{{ docker_archs[ansible_facts.architecture] }}"
docker_distribution_release: "{{ ansible_facts.distribution_release }}"
```
Again, this is very similar to what we have done before to separate our helper variables from the tasks, and now we can generate `docker.list` under `/etc/apt/sources.list.d/`. To do that, we add the new task in `roles/docker/tasks/main.yml`:
```yaml
- name: Add Docker APT repository
become: true
ansible.builtin.apt_repository:
filename: docker
repo: "deb [arch={{ docker_arch }} signed-by=/etc/apt/keyrings/docker.asc] https://download.docker.com/linux/ubuntu {{ docker_distribution_release }} stable"
state: present
update_cache: true
```
The [built-in apt_repository module](https://docs.ansible.com/ansible/latest/collections/ansible/builtin/apt_repository_module.html) can also update APT cache after adding the new repo. The filename is automatically generated if we don't set it, but the "filename" parameter is actually a name without the extension, so do not add `.list` at the end of the name.
### Install a specific version of Docker CE
[» Back to table of contents «](#table-of-contents)
The official documentation recommends using the following command to list the available versions of Docker CE on Ubuntu.
```bash
apt-cache madison docker-ce | awk '{ print $3 }'
```
It shows the full package name which includes more than just the version of Docker CE. Fortunately, the actual version number can be parsed like this:
```bash
apt-cache madison docker-ce \
| awk '$3 ~ /^([0-9]+:)([0-9]+\.[0-9]+\.[0-9]+)(-[0-9]+)?(~.*)$/ {print $3}'
```
Where the version number is the second expression in parentheses.
```text
[0-9]+\.[0-9]+\.[0-9]+
```
We can replace it with an actual version number, but keeping the backslashes:
```text
26\.1\.3
```
Let's search for only that version:
```bash
apt-cache madison docker-ce \
| awk '$3 ~ /^([0-9]+:)26\.1\.3(-[0-9]+)?(~.*)$/ {print $3}'
```
Output:
```text
5:26.1.3-1~ubuntu.22.04~jammy
```
This is what we will implement in Ansible:
```yaml
- name: Get full package version for {{ docker_version }}
changed_when: false
ansible.builtin.shell: |
apt-cache madison docker-ce \
| awk '$3 ~ /^([0-9]+:){{ docker_version | replace('*', '[0-9]+') | replace('.', '\.') }}(-[0-9]+)?(~.*)$/ {print $3}'
register: _docker_versions_command
```
I hope now it starts to make sense why the default value of `docker_version` was `*.*.*`. It was because we replace that with regular expressions. We also escape all dots as otherwise it would mean "any character" in the regular expression. This solution allows us to install the latest version unless we override the default value with an actual version number. Even if we override it, we can use a version like `26.0.*` to get a list of available patch version of Docker CE 26.0 instead of the latest major version. Of course, this is still a list of versions unless we set a specific version number, but we can get the first line in the next task. According to the official documentation, we would install Docker CE and related packages like this:
```bash
VERSION_STRING=5:26.1.0-1~ubuntu.24.04~noble
sudo apt-get install docker-ce=$VERSION_STRING docker-ce-cli=$VERSION_STRING containerd.io docker-buildx-plugin docker-compose-plugin
```
Let's do it in Ansible:
```yaml
- name: Install Docker CE
become: true
vars:
_full_version: "{{ _docker_versions_command.stdout_lines[0] }}"
ansible.builtin.apt:
name:
- docker-ce={{ _full_version }}
- docker-ce-cli={{ _full_version }}
- docker-ce-rootless-extras={{ _full_version }}
- containerd.io
- docker-buildx-plugin
- docker-compose-plugin
```
What is not mentioned in the documentation is marking Docker CE packages as held. In the terminal it would be like this:
```bash
apt-mark hold docker-ce docker-ce-cli docker-ce-rootless-extras containerd.io docker-compose-plugin
```
It will be almost the same in Ansible as we need to use the built-in command module:
```yaml
- name: Hold Docker CE packages
become: true
ansible.builtin.command: apt-mark hold docker-ce docker-ce-cli docker-ce-rootless-extras containerd.io docker-compose-plugin
changed_when: false
```
You can check the list of held packages:
```bash
apt-mark showheld
```
Output:
```text
containerd.io
docker-ce
docker-ce-cli
docker-ce-rootless-extras
docker-compose-plugin
```
Note: I never actually saw an upgraded containerd causing problems, but this is a very important component of Docker CE, so I decided to hold that too. If it causes any problem, you can "unhold" that any time by running the following command:
```bash
apt-mark unhold containerd.io
```
## Allow non-root users to use the docker commands
[» Back to table of contents «](#table-of-contents)
This is the part where I don't follow the documentation. The official documentation mentions this on the [Linux post-installation steps for Docker Engine](https://docs.docker.com/engine/install/linux-postinstall/) page:
> The Docker daemon binds to a Unix socket, not a TCP port. By default it's the root user that owns the Unix socket, and other users can only access it using sudo. The Docker daemon always runs as the root user.
>
> If you don't want to preface the docker command with sudo, create a Unix group called docker and add users to it. When the Docker daemon starts, it creates a Unix socket accessible by members of the docker group. On some Linux distributions, the system automatically creates this group when installing Docker Engine using a package manager. In that case, there is no need for you to manually create the group.
Of course, using the `docker` group is not really secure, which is also mentioned right after the previous quote in the documentation:
> The docker group grants root-level privileges to the user. For details on how this impacts security in your system, see [Docker Daemon Attack Surface](https://docs.docker.com/engine/security/#docker-daemon-attack-surface).
If we want to have just a little bit more secure solution, we don't use the `docker` group which can directly access the docker socket, but we create another group like `docker-sudo` and we allow all users in this group to run the docker command as root by using `sudo docker` without a password. It would involve creating a new rule in `/etc/sudoers.d/docker` like:
```text
%docker-sudo ALL=(root) NOPASSWD: /usr/bin/docker
```
This would force users to always run `sudo docker`, not just `docker` and they will often forget it and get an error message. We could add an alias like
```bash
alias docker='sudo \docker'
```
to `~/.bash_aliases`, but that would work only when the user uses the bash shell. Instead of that, we can add a new script in `/usr/local/bin/docker`,
which usually overrides `/usr/bin/docker` and add this command in the script:
```bash
#!/usr/bin/env sh
exec sudo /usr/bin/docker "$@"
```
This is what we will do with Ansible, so our new script will be executed which will call the original docker command as an argument of sudo. Now even when we use Visual Studio Code's Remote Explorer to connect to the remote virtual machine and use Docker in the VM from VSCode, `/var/log/auth.log` on Debian-based systems will contain exactly what docker commands were executed. If you don't find this file, it may be called `/var/log/secure` on your system. This is for example how browsing files from VSCode in containers looks like:
```text
May 19 20:14:36 docker sudo: manager : PWD=/home/manager ; USER=root ; COMMAND=/usr/bin/docker container exec --interactive d71cae80db867ee79ba66fa947ab126ac6f7b0e482ebb8b3320d9f3bfa3fb3e6 /bin/sh -c 'stat -c \'%f %h %g %u %s %X %Y %Z %n\' "/"* || true && stat -c \'%f %h %g %u %s %X %Y %Z %n\' "/".*'
```
This is useful when you want to be able to investigate accidental damage when a Docker user executes a command that they should not have executed, and they don't even know what they executed. It will not protect you from intentional harm as an actual hacker could also delete the logs. On the other hand, if you have a remote logging server where you collect logs from all machines, you will probably have the logs to figure out what happened.
Now let's configure this in Ansible.
First we will create the `docker-sudo` group:
```yaml
- name: Ensure group "docker-sudo" exists
become: true
ansible.builtin.group:
name: docker-sudo
state: present
```
Now we can finally use our `docker_sudo_users` variable which we defined in `roles/docker/defaults/main.yml` and check if there is any user who doesn't exist.
```yaml
- name: Check if docker sudo users are existing users
become: true
ansible.builtin.getent:
database: passwd
key: "{{ item }}"
loop: "{{ docker_sudo_users }}"
```
This [built-in getent module](https://docs.ansible.com/ansible/latest/collections/ansible/builtin/getent_module.html) basically calls the `getent` command on Linux:
```bash
getent passwd manager
```
If the user exists, it returns the passwd record of the user, and it fails otherwise. Now let's add the groups to the users:
```yaml
- name: Add users to the docker-sudo group
become: true
ansible.builtin.user:
name: "{{ item }}"
# users must be added to docker-sudo group without removing them from other groups
append: true
groups:
- docker-sudo
loop: "{{ docker_sudo_users }}"
```
We used the [built-in user module](https://docs.ansible.com/ansible/latest/collections/ansible/builtin/user_module.html), to add the `docker-sudo` group to the users defined in `docker_sudo_users`. We are close to the end. The next step is creating the script using a similar solution we used in the `hello_world` role at the beginning of the series.
```yaml
- name: Create a sudo wrapper for Docker
become: true
ansible.builtin.copy:
content: |
#!/usr/bin/env sh
exec sudo /usr/bin/docker "$@"
dest: /usr/local/bin/docker
mode: 0755
```
And finally, using the same method, we create the sudoers rule:
```yaml
- name: Allow run execute /usr/bin/docker as root without password
become: true
ansible.builtin.copy:
content: |
%docker-sudo ALL=(root) NOPASSWD: /usr/bin/docker
dest: /etc/sudoers.d/docker
```
We could now run the playbook to install Docker in the virtual machine:
```bash
./run.sh playbook-lxd-docker-vm.yml
```
## Install Portainer CE, the web-based GUI for containers
[» Back to table of contents «](#table-of-contents)
Installing [Portainer CE](https://docs.portainer.io/start/install-ce) is the easy part, actually. We will need to use the [built-in pip module](https://docs.ansible.com/ansible/latest/collections/ansible/builtin/pip_module.html) to install a Python dependency for Ansible to be able to manage Docker, and then we will also use a [community module, called docker_container](https://docs.ansible.com/ansible/2.9/modules/docker_container_module.html). Let's create the tasks file first at `roles/portainer/tasks/main.yml`:
```yaml
- name: Install Python requirements
become: true
ansible.builtin.pip:
name: docker
- name: Install portainer
become: true
community.docker.docker_container:
name: "{{ portainer_name }}"
state: started
container_default_behavior: no_defaults
image: "{{ portainer_image }}"
restart_policy: always
ports:
- "{{ portainer_external_port }}:9443"
volumes:
- "{{ portainer_volume_name }}:/data"
- /var/run/docker.sock:/var/run/docker.sock
```
After defining the variables, this will be basically equivalent of running the following in shell:
```bash
docker run \
-p 9443:9443 \
--name portainer \
--restart=always \
-v /var/run/docker.sock:/var/run/docker.sock \
-v portainer_data:/data \
portainer/portainer-ce:2.20.2-alpine
```
Let's add our defaults at `roles/portainer/defaults/main.yml`:
```yaml
portainer_name: portainer
portainer_image: portainer/portainer-ce:2.20.2-alpine
portainer_external_port: 9443
portainer_volume_name: "{{ portainer_name }}_data"
```
That's it, and now we add the role to the playbook:
```yaml
# ...
roles:
- role: cli_tools
- role: docker
docker_sudo_users: "{{ config_lxd_docker_vm_docker_sudo_users | default([]) }}"
- role: portainer
```
When you finished installing Portainer, you need to quickly open it in a web browser on port 9443. If you do it on a publicly available machine in your LAN network, you can simply open it like `https://192.168.4.58:9443`. In this tutorial, our virtual machine needs an SSH tunnel like below, so you can use `https://127.0.0.1:9443`:
```yaml
ssh -L 9443:127.0.0.1:9443 -N docker.lxd.ta-lxlt
```
Your hostname will be different. If you already have other containers with a forwarded port, you can add more ports to the tunnel:
```yaml
ssh \
-L 9443:127.0.0.1:9443 \
-L 32768:127.0.0.1:32768 \
-N \
docker.lxd.ta-lxlt
```
If you have containers without forwarded ports from the host, you can forward your local port directly to the container IP.
```yaml
ssh \
-L 9443:127.0.0.1:9443 \
-L 32768:127.0.0.1:32768 \
-L 8080:172.17.0.4:80 \
-N \
docker.lxd.ta-lxlt
```
When you can finally open Portainer in your browser, create your first user and configure the connection to the local Docker environment. If you wait too long, the webinterface will show an error message, and you will need to go to the terminal in the virtual machine and restart portainer:
```bash
docker restart portainer
```
After that, you can start the configuration. This way if you install Portainer on a publicly available server, there will be less time for others to log in before you do, and after you initialized Portainer, it is no longer possible to log in without a password.
## Conclusion
[» Back to table of contents «](#table-of-contents)
I hope this episode helped you to install Docker and allow non-root users to use the Docker commands in a little more secure way than the documentation suggests. Now you can have a web-basd graphical interface for containers, however, Portainer is definitely not Docker Desktop, so you will not have the extra features like Docker Desktop extensions. Using Ansible can help to deploy your entire dev environment, destroy it and recreate any time. Using containers you can have pre-built and pre-configured applications that you can try and learn more about it to customize the configuration for your needs. When you have a production environment, you need to focus much more on security, but now that you have the tools to begin with a dev environment, you can make that new step more easily.
The final source code of this episode can be found on GitHub:
<https://github.com/rimelek/homelab/tree/tutorial.episode.10>
{% embed https://github.com/rimelek/homelab %} | rimelek |
1,873,723 | Unlocking the Power of Dataverse in Microsoft Power Apps | In the ever-evolving landscape of business applications, Microsoft Power Apps stands out as a... | 0 | 2024-06-02T14:04:21 | https://dev.to/shishsingh/unlocking-the-power-of-dataverse-in-microsoft-power-apps-2hdi | powerplatform, powerautomate, powerapps, powerfuldevs | In the ever-evolving landscape of business applications, Microsoft Power Apps stands out as a powerful tool that empowers organisations to build custom apps with ease. At the heart of this tool is Dataverse, a versatile and robust data platform that underpins the entire Power Platform ecosystem. In this blog, we'll dive deep into what Dataverse is, its role within Power Apps, its benefits, and how it differentiates from connectors. Additionally, we'll explore fundamental concepts such as tables, columns, rows, and relationships, and provide practical examples to illustrate their use.
## **What is Dataverse?**
Microsoft Dataverse, formerly known as the Common Data Service (CDS), is a cloud-based storage space that allows you to securely store and manage data used by business applications. It's designed to work seamlessly with Power Apps, Power Automate, Power BI, and other parts of the Power Platform, providing a unified and scalable data solution.
**The Role of Dataverse in Power Apps**
Dataverse serves multiple crucial roles in the Power Apps ecosystem:
**Centralized Data Management:** Dataverse centralizes data storage, making it easier to manage and access data across multiple applications.
**Data Security:** It offers robust security features, including role-based security, data encryption, and auditing capabilities to ensure data privacy and compliance.
**Data Integration:** With built-in connectors, Dataverse facilitates seamless integration with other Microsoft services and third-party applications.
**Business Logic Implementation:** It allows for the implementation of business rules, workflows, and processes directly within the data layer, ensuring consistency and reducing redundancy.
## **How Dataverse is Helpful**
Simplified App Development: Dataverse abstracts much of the complexity involved in data management, allowing developers to focus on building the functionality of their apps.
Scalability: It can handle data at scale, supporting both small businesses and large enterprises.
Interoperability: Being part of the Power Platform, Dataverse ensures smooth interoperability between Power Apps, Power Automate, and Power BI, enabling comprehensive business solutions.
Enhanced Collaboration: By providing a common data model, Dataverse facilitates better collaboration across departments and teams within an organisation.
## **Connectors vs. Dataverse**
While both connectors and Dataverse play critical roles in Power Apps, they serve different purposes:
**Connectors:** These are integration points that allow Power Apps to connect to external data sources, such as SQL databases, SharePoint lists, or third-party services like Salesforce. Connectors enable apps to interact with data that is not stored within Dataverse.
**Dataverse:** Unlike connectors, Dataverse is a built-in data storage solution within Power Apps. It provides a unified data platform with advanced capabilities such as relationship management, business rules, and security, all within the Microsoft ecosystem.
## **Why Use Dataverse When We Have Connectors?**
Using Dataverse provides several advantages over relying solely on connectors:
**Unified Data Management:** Dataverse centralises your data, making it easier to manage and maintain.
**Advanced Capabilities:** Features like relationship management, business rules, and workflows are built into Dataverse, enhancing the functionality of your applications.
**Security and Compliance:** Dataverse offers robust security features and compliance with industry standards, which can be more challenging to achieve when using disparate data sources through connectors.
## **Understanding Tables, Columns, Rows, and Relationships**
In Dataverse, data is organised into tables (formerly known as entities), which are similar to tables in a relational database. Here's a quick overview of the fundamental concepts:
**Tables (Entities):** These are collections of data, similar to a table in a database. For example, a "Customer" table might store information about customers.
**Columns (Fields):** These represent individual pieces of data within a table. For instance, the "Customer" table might have columns like "Name", "Email", and "Phone Number".
**Rows (Records):** These are individual entries within a table. Each row in the "Customer" table represents a single customer.
## **Creating Relationships Between Tables**
Relationships in Dataverse allow you to define how tables are connected to each other. This is essential for creating comprehensive data models. Relationships can be one-to-many, many-to-one, or many-to-many.
**Example:**
Let's consider a scenario where we have two tables: "Customers" and "Orders".
- **Tables:**
**Customers:** Contains customer information (CustomerID, Name, Email).
**Orders:** Contains order details (OrderID, OrderDate, CustomerID).
- **Relationship:**
A customer can place multiple orders, so the relationship between "Customers" and "Orders" is one-to-many.
This is established by having a foreign key (CustomerID) in the "Orders" table that links back to the "Customers" table.
## **Creating the Relationship:**
- In Dataverse, navigate to the "Customers" table.
- Add a new relationship and select the "Orders" table.
- Define the relationship type (one-to-many) and specify the related fields (CustomerID).
## **Business Rules and Their Purpose**
Business rules in Dataverse allow you to apply logic and validation directly within the data layer, ensuring consistency and enforcing business policies.
**Example:**
Consider a scenario where we want to ensure that all orders have a minimum total value of $50.
**Business Rule Creation:**
Navigate to the "Orders" table in Dataverse.
Create a new business rule to check the "TotalValue" column.
If "TotalValue" is less than $50, display an error message or prevent the record from being saved.
**Purpose:**
This ensures that all orders meet the minimum value requirement, maintaining data integrity and adhering to business policies.
By implementing business rules, you ensure that your data adheres to specific criteria, reducing errors and improving data quality across your applications.
**Conclusion**
Microsoft Dataverse is a powerful and integral part of the Power Apps ecosystem, offering robust data management, security, and integration capabilities. While connectors enable interaction with external data sources, Dataverse provides a unified platform with advanced features to enhance your business applications. Understanding the concepts of tables, columns, rows, and relationships, and leveraging business rules, allows you to create sophisticated and reliable data models that drive business success.
Whether you're building a simple app or a complex enterprise solution, Dataverse equips you with the tools needed to manage your data effectively, ensuring your Power Apps deliver maximum value to your organisation.
## References
Cover: https://community.dynamics.com/blogs/post/?postid=2e6aa4d7-fe63-4eab-a7d7-e10864aa51c3
Image 1: https://selliliar.live/product_details/21225712.html
Image 2: https://microsoft.github.io/Low-Code/blog/2023-day7/
## Connects
Check out my other blogs:
[Travel/Geo Blogs](shishsingh.wordpress.com)
Subscribe to my channel:
[Youtube Channel](youtube.com/@destinationhideout)
Instagram:
[Destination Hideout](https://www.instagram.com/destinationhideout/) | shishsingh |
1,873,721 | Membuat CI/CD Workflow Menggunakan GitHub Action dan Deployer pada Framework Laravel | CI/CD adalah abbreviation atau akronim dari Continuous Integration/Continuous Deployment yang... | 0 | 2024-06-02T14:02:12 | https://dev.to/yogameleniawan/membuat-cicd-workflow-menggunakan-github-action-dan-deployer-pada-framework-laravel-39bh | laravel, programming, devops |

CI/CD adalah _abbreviation_ atau akronim dari _Continuous Integration/Continuous Deployment_ yang merupakan proses distribusi kode dari local development ke repository kemudian dilanjutkan ke server production yang dilakukan secara otomatis. Pastinya dengan metode CI/CD ini para developer akan terbantu sekali dalam distribusi kode program ke server production yang siap digunakan oleh pengguna.
Bicara masalah apa saja yang kita butuhkan ketika membuat CI/CD workflow ini. Pastikan temen-temen mengenal terlebih dahulu dari Deployer yang akan kita gunakan kali ini. Deployer merupakan tools yang digunakan untuk bahasa pemrograman PHP dalam melakukan distribusi kode dengan menggunakan metode CI/CD. Enaknya pakai deployer ini kita bisa mendistribusikan kode program kita kapan pun dan dimanapun. Selain itu, kita juga bisa melakukan rollback version apabila terdapat kesalahan ketika melakukan proses CI/CD.
### Persyaratan
- [PHP 7.4 atau lebih](https://www.php.net/)
- [Laravel 8 atau lebih](https://www.laravel.com/)
- [Deployer](https://deployer.org/)
### Instalasi Deployer
Jalankan perintah berikut untuk melakukan instalasi package Deployer pada projek Laravel
```bash
composer require --dev deployer/deployer
```
Lakukan inisialisasi deployer menggunakan perintah berikut
```bash
vendor/bin/dep init
```
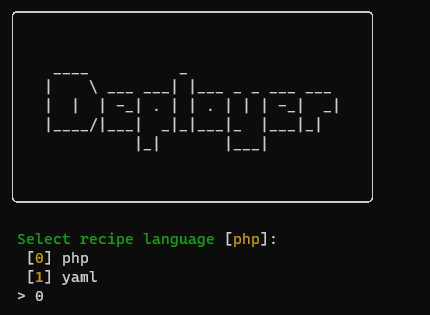
Kemudian pilih [0] php karena kita akan melakukan konfigurasi menggunakan php nantinya.
Lalu pilih [11] Laravel karena kita menggunakan Laravel Framework.
---
### Konfigurasi Deployer
Ubah file deployer.php pada root project dari Laravel menjadi seperti ini :
```php
<?php
namespace Deployer;
require 'recipe/laravel.php';
require 'contrib/npm.php';
set('bin/php', function () {
return '/usr/local/bin/php'; // change
});
// HARUS DIGANTI SESUAI KEBUTUHAN ANDA
set('application', 'Nama Aplikasi');
set('repository', 'SSH_GIT_CLONE'); // Git Repository contoh set('repository', 'git@github.com:yogameleniawan/laravel-cicd-deployer.git');
// HARUS DIGANTI SESUAI KEBUTUHAN ANDA
set('git_tty', true);
set('git_ssh_command', 'ssh -o StrictHostKeyChecking=no');
set('keep_releases', 5);
set('writable_mode', 'chmod'); // jika menggunakan shared hosting tuliskan baris kode ini
// Shared files/dirs between deploys
add('shared_files', ['.env']);
add('shared_dirs', ['storage']);
// Writable dirs by web server
add('writable_dirs', [
"bootstrap/cache",
"storage",
"storage/app",
"storage/framework",
"storage/logs",
]);
set('composer_options', '--verbose --prefer-dist --no-progress --no-interaction --no-dev --optimize-autoloader');
// Hosts
// HARUS DIGANTI SESUAI KEBUTUHAN ANDA
host('NAMA_REMOTE_HOST') // Nama remote host server ssh anda | contoh host('NAMA_REMOTE_HOST')
->setHostname('NAMA_HOSTNAME_ATAU_IP') // Hostname atau IP address server anda | contoh ->setHostname('10.10.10.1')
->set('remote_user', 'USER_SSH') // SSH user server anda | contoh ->set('remote_user', 'u1234567')
->set('port', 65002) // SSH port server anda, untuk kasus ini server yang saya gunakan menggunakan port custom | contoh ->set('remote_user', 65002)
->set('branch', 'master') // Git branch anda
->set('deploy_path', '~/PATH/SUB_PATH'); // Lokasi untuk menyimpan projek laravel pada server | contoh ->set('deploy_path', '~/public_html/api-deploy');
// HARUS DIGANTI SESUAI KEBUTUHAN ANDA
// Tasks
task('deploy:secrets', function () {
file_put_contents(__DIR__ . '/.env', getenv('DOT_ENV'));
upload('.env', get('deploy_path') . '/shared');
});
desc('Build assets');
task('deploy:build', [
'npm:install',
]);
task('deploy', [
'deploy:prepare',
'deploy:secrets',
'deploy:vendors',
'deploy:shared',
'artisan:storage:link',
'artisan:queue:restart',
'deploy:publish',
'deploy:unlock',
]);
// [Optional] jika deploy gagal maka deployer akan otomatis melakukan unlock
after('deploy:failed', 'deploy:unlock');
// uncomment baris kode dibawah jika ingin melakukan migrate database sebelum dilakukan symlink folder
// before('deploy:symlink', 'artisan:migrate');
```
Perlu diperhatikan pada kode program berikut :
```php
// HARUS DIGANTI SESUAI KEBUTUHAN ANDA
host('NAMA_REMOTE_HOST') // Nama remote host server ssh anda | contoh host('NAMA_REMOTE_HOST')
->setHostname('NAMA_HOSTNAME_ATAU_IP') // Hostname atau IP address server anda | contoh ->setHostname('10.10.10.1')
->set('remote_user', 'USER_SSH') // SSH user server anda | contoh ->set('remote_user', 'u1234567')
->set('port', 65002) // SSH port server anda, untuk kasus ini server yang saya gunakan menggunakan port custom | contoh ->set('remote_user', 65002)
->set('branch', 'master') // Git branch anda
->set('deploy_path', '~/PATH/SUB_PATH'); // Lokasi untuk menyimpan projek laravel pada server | contoh ->set('deploy_path', '~/public_html/api-deploy');
// HARUS DIGANTI SESUAI KEBUTUHAN ANDA
```
Contoh penyesuaian pada Server temen-temen :
```php
host('ServerProduction')
->setHostname('10.10.10.1') // Hostname atau IP address server anda | contoh ->setHostname('10.10.10.1')
->set('remote_user', 'u1234567') // SSH user server anda | contoh ->set('remote_user', 'u1234567')
->set('port', 65002) // SSH port server anda, untuk kasus ini server yang saya gunakan menggunakan port custom | contoh ->set('remote_user', 65002)
->set('branch', 'master') // Git branch anda
->set('deploy_path', '~/public_html/api-deploy'); // Lokasi untuk menyimpan projek laravel laravel pada server | contoh ->set('deploy_path', '~/public_html/api-deploy');
```
---
### Membuat GitHub Workflow
Jalankan perintah berikut pada Terminal :
```bash
touch .github/workflows/master.yml
```
> catatan: master.yml merupakan branch yang akan kita gunakan untuk melakukan CI/CD workflow. Jadi ketika ada pembaruan kode pada branch ini maka akan menjalankan proses CI/CD. Jadi silahkan sesuaikan branch yang ingin temen-temen gunakan tidak harus master. Tapi saya sangat menyarankan silahkan buat branch master untuk mengikuti yang ada pada artikel ini.
Silahkan ubah isi master.yml dengan kode berikut :
```yaml
on:
push:
branches:
- master (sesuaikan dengan branch yang digunakan)
jobs:
build-js-production:
name: Build JavaScript/CSS for Production Server
runs-on: ubuntu-latest
if: github.ref == 'refs/heads/master' (sesuaikan dengan branch yang digunakan)
steps:
- uses: actions/checkout@v1
- name: NPM Build
run: |
npm install
npm run build
- name: Put built assets in Artifacts
uses: actions/upload-artifact@v1
with:
name: assets
path: public
retention-days: 3
deploy-production:
name: Deploy Project to Production Server
runs-on: ubuntu-latest
needs: [ build-js-production ]
if: github.ref == 'refs/heads/master' (sesuaikan dengan branch yang digunakan)
steps:
- uses: actions/checkout@v1
- name: Fetch built assets from Artifacts
uses: actions/download-artifact@v1
with:
name: assets
path: public
- name: Setup PHP
uses: shivammathur/setup-php@master
with:
php-version: '8.0'
extension-csv: mbstring, bcmath
- name: Composer install
run: composer install -q --no-ansi --no-interaction --no-scripts --no-progress --prefer-dist
- name: Setup Deployer
uses: atymic/deployer-php-action@master
with:
ssh-private-key: ${{ secrets.SSH_PRIVATE_KEY }}
ssh-known-hosts: ${{ secrets.SSH_KNOWN_HOSTS }}
- name: Deploy to Development
env:
DOT_ENV: ${{ secrets.DOT_ENV_PRODUCTION }}
run: php vendor/bin/dep deploy ServerProduction branch=master (sesuaikan dengan branch yang digunakan)
```
> Jika temen-temen tidak menggunakan branch master, silahkan disesuaikan dengan branch yang temen-temen gunakan.
pada baris kode berikut :
```yaml
run: php vendor/bin/dep deploy ServerProduction branch=master (sesuaikan dengan branch yang digunakan)
```
**ServerProduction** ini akan mengeksekusi host yang sudah kita definisikan pada file deployer.php sebelumnya.
**branch=master** merupakan branch yang digunakan temen-temen.
---
### Menambahkan GitHub Action Credential
Buka repository github kemudian pilih Settings :
Lalu pilih Secrets and variables - Actions
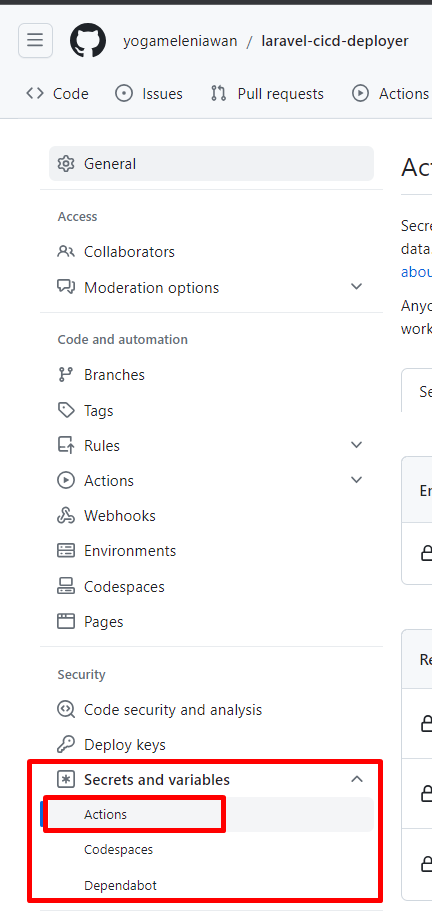
Lalu tambahkan variabel secret baru
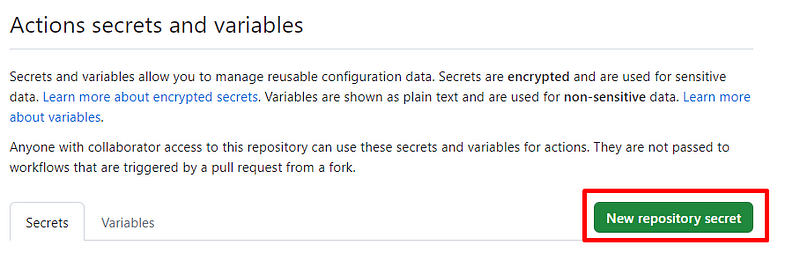
Buat SSH_PRIVATE_KEY
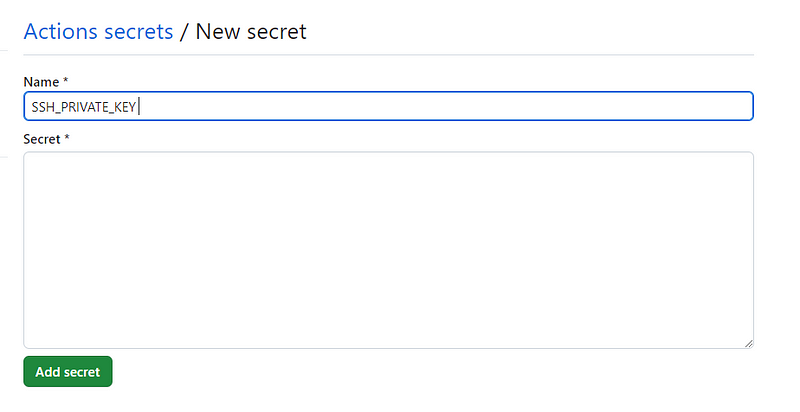
Untuk mendapatkan SSH Private Key bisa menggunakan cara berikut :
- Buka **Terminal Server** bukan **Terminal Lokal** (Laptop/PC). Atau temen-temen bisa akses server temen-temen menggunakan SSH.
- Lalu jalankan perintah berikut :
```bash
ssh-keygen -t ed25519 -C "email_anda@example.com"
```
- Jika muncul tulisan "Enter a file in which to save the key," press Enter. Tekan enter saja sampai selesai.
- Lalu jalankan perintah berikut :
```bash
cat ~/.ssh/id_ed25519
```
Setelah itu akan muncul SSH Private Key seperti ini silahkan di-copy semua

Lalu Pastekan pada **SSH_PRIVATE_KEY** action secrets yang akan temen-temen buat tadi. Lalu **Add Secret**
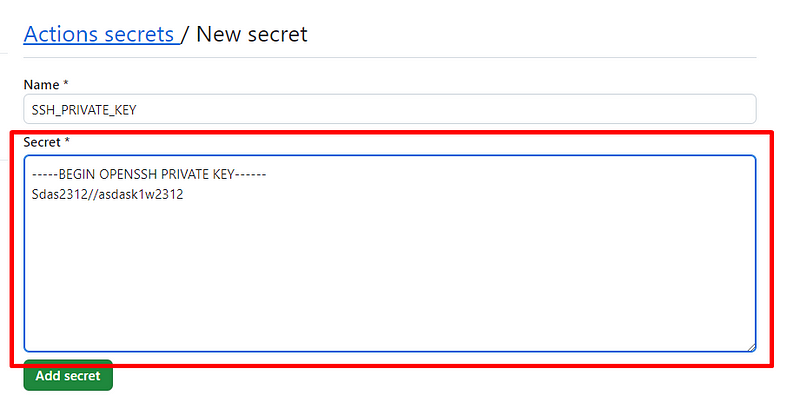
Buat variabel **SSH_KNOWN_HOSTS**
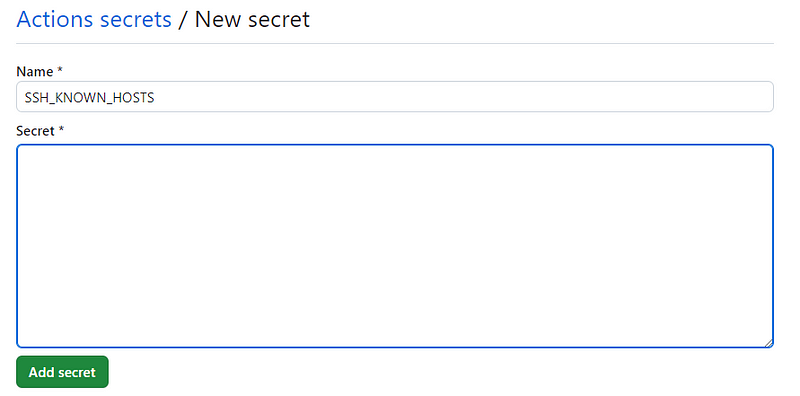
Untuk mendapatkan **SSH Known Hosts** bisa menggunakan cara berikut :
- Buka **Terminal Server** bukan **Terminal Lokal** (Laptop/PC). Atau temen-temen bisa akses server temen-temen menggunakan SSH.
- Lalu jalankan perintah berikut :
```bash
ssh-keyscan -p 65002 IP_SERVER_ANDA
```
Kemudian copy dan isikan pada Secret Action yang temen-temen akan buat tadi.
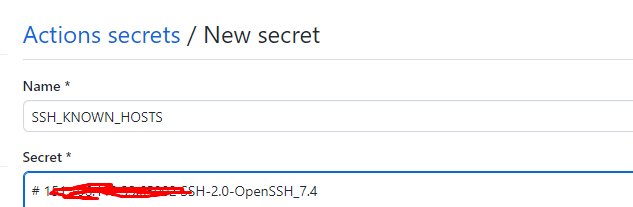
Buat variabel **DOT_ENV_PRODUCTION**.
- Silahkan copy semua isi file .env
- Kemudian isikan pada Actions Secrets seperti ini :
---
### Menjalankan Proses CI/CD Workflow
Silahkan melakukan perubahan atau git push pada repository anda maka Github Actions dan Deployer akan berjalan sebagaimana mestinya.
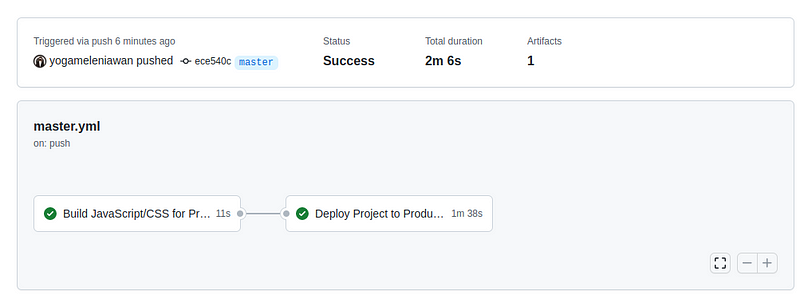
Ketika kode berhasil didistribusikan maka pada direktori server hosting akan seperti ini :
### Penutupan
Kurang lebih pembuatan CI/CD Workflow menggunakan GitHub Action dengan dikombinasikan menggunakan Deployer pada Framework Laravel seperti itu ya temen-temen. Semoga bertemu di lain kesempatan dengan artikel yang berbeda.
| yogameleniawan |
1,873,720 | Affordable web hosting services | Web hosting is a fundamental component of establishing an online presence. It allows individuals... | 0 | 2024-06-02T14:01:28 | https://dev.to/cloudnest_931c4c449b31c07/affordable-web-hosting-services-1ml |

Web hosting is a fundamental component of establishing an online presence. It allows individuals and businesses to make their websites accessible on the internet. A web hosting service provides the necessary infrastructure, storage space, and server resources to store and deliver website content to visitors.
In today's digital age, having a website has become essential for businesses and individuals alike. However, finding the right web hosting service that fits your budget can be a daunting task. This is where affordable web hosting services come into play. These services offer cost-effective solutions without compromising on quality or performance. By choosing an affordable web hosting service, you can get all the features and resources you need to establish a successful online presence without breaking the bank.
Throughout this article, we will delve into different types of web hosting, such as shared hosting, premium hosting, and WordPress hosting. We will also discuss key features to look for in an affordable web hosting service, including reliability, security measures, customer support quality, SSL certificates, and real-time monitoring. Additionally, we will explore tailored hosting solutions for specific needs and highlight advanced tools and technologies offered by reputable providers.
By the end of this article, you will have a comprehensive understanding of affordable web hosting services and be equipped with the knowledge to choose the best option for your website's needs and budget. Let's dive in!
<h2 id="heading-1-types-of-web-hosting">Types of Web Hosting</h2>
<h3 id="heading-2-1-shared-hosting">1. Shared Hosting</h3>
Shared hosting is a popular choice for individuals and small businesses looking to establish their online presence at an affordable cost. In this type of hosting, multiple websites are hosted on a single server, sharing its resources such as storage, bandwidth, and processing power.
<h4>Benefits of Shared Hosting:</h4>
<ul>
<li><strong>Cost-Effective:</strong> Shared hosting plans are generally more budget-friendly compared to other hosting options, making them ideal for those with limited financial resources.</li>
<li><strong>Ease of Use:</strong> Providers often offer user-friendly control panels, simplifying website management for beginners.</li>
<li><strong>Low Maintenance:</strong> With the server being managed by the hosting provider, users can focus on their websites without worrying about server maintenance tasks.</li>
</ul>
<h4>Comparison of Different Shared Hosting Plans:</h4>
When considering shared hosting plans, it’s essential to compare factors such as storage space, bandwidth allocation, email accounts, and additional features offered by different providers. For example:
<ul>
<li><em>Provider A</em> offers unlimited bandwidth and storage space with a free domain name included in their package.</li>
<li><em>Provider B</em> provides a scalable solution with the option to easily upgrade resources as the website grows.</li>
</ul>
By comparing these plans, users can identify which provider aligns best with their specific requirements and growth potential.
With shared hosting accommodating the needs of many small-scale website owners, it serves as an excellent entry point into the world of web hosting for those seeking affordability and simplicity.
<h3 id="heading-3-2-premium-hosting">2. Premium Hosting</h3>
When it comes to web hosting options, premium hosting stands out as a compelling choice for website owners looking to elevate their online presence. Here's a closer look at the <a href="https://cloudnest.in/premium-hosting" target="_blank" rel="noopener noreferrer">description and benefits of premium hosting</a>, along with its advantages over shared hosting:
<h4><strong>Description and Benefits of Premium Hosting:</strong></h4>
<ul>
<li>Premium hosting offers an elevated level of service compared to shared hosting, providing users with <a href="https://cloudnest.in/premium-hosting" target="_blank" rel="noopener noreferrer">dedicated resources</a> and <a href="https://elementor.com/blog/best-vps/" target="_blank" rel="noopener noreferrer">enhanced performance</a> capabilities.</li>
<li>This type of hosting is ideal for websites experiencing higher traffic volumes or requiring advanced features and customization options.</li>
<li>With premium hosting, users can expect greater control over server configurations, leading to improved website speed and overall reliability.</li>
</ul>
<h4><strong>Features and Advantages of Premium Hosting Over Shared Hosting:</strong></h4>
<ul>
<li>Enhanced Performance: Premium hosting ensures faster loading speeds and seamless website performance, even during peak traffic periods.</li>
<li>Dedicated Resources: Unlike shared hosting where resources are distributed among multiple users, premium hosting allocates dedicated resources to each user, minimizing the risk of performance fluctuations.</li>
<li>Advanced Security Measures: Premium hosting often includes robust security features and regular malware scans to fortify websites against cyber threats.</li>
</ul>
By understanding the distinct advantages of premium hosting over shared alternatives, website owners can make informed decisions to support their online endeavors. If you're specifically using WordPress for your website, you may want to explore the concept of <a href="https://cloudnest.in/worpress-hosting" target="_blank" rel="noopener noreferrer">managed WordPress hosting</a> as well.
<h2 id="heading-4-3-wordpress-hosting">3. WordPress Hosting</h2>
WordPress hosting is a specialized type of web hosting that is designed specifically for websites built on the WordPress platform. It offers a range of features and benefits that cater to the needs of WordPress users, particularly beginners. Here's an in-depth look at WordPress hosting and why it may be the right choice for your website:
<h3 id="heading-5-description"><strong>Description</strong></h3>
WordPress hosting is optimized to provide exceptional performance and reliability for WordPress websites. It is tailored to meet the specific requirements of the WordPress platform, ensuring seamless integration and compatibility.
<h3 id="heading-6-benefits"><strong>Benefits</strong></h3>
There are several advantages to choosing WordPress hosting:
<ol>
<li><strong>Improved Speed and Performance</strong>: WordPress hosting is optimized to deliver fast loading times and optimal performance for WordPress sites. This is achieved through server-level caching, content delivery networks (CDNs), and other advanced techniques.</li>
<li><strong>Enhanced Security</strong>: WordPress hosting providers typically offer robust security measures to protect your website from threats such as malware and hacking attempts. These include regular security scans, firewalls, and automatic updates.</li>
<li><strong>Automatic Updates and Backups</strong>: With WordPress hosting, updates to the WordPress core, themes, and plugins are often handled automatically. This ensures that your site remains up-to-date with the latest features and security patches. Additionally, regular backups are usually included, allowing you to restore your site in case of any issues.</li>
<li><strong>Expert Support</strong>: WordPress hosting providers often have dedicated support teams with expertise in troubleshooting common WordPress-related issues. They can assist you with any technical difficulties or questions you may have about managing your WordPress site.</li>
</ol>
<h3 id="heading-7-suitable-for-beginners"><strong>Suitable for Beginners</strong></h3>
One of the main advantages of WordPress hosting is its user-friendly nature, making it an excellent choice for beginners who may not have extensive technical knowledge. The intuitive interface and pre-installed WordPress software simplify the process of setting up and managing a website.
If you're using or planning to use the WordPress platform for your website, WordPress hosting offers a range of benefits that can enhance the performance, security, and ease of management. Whether you're a beginner or an experienced user, WordPress hosting provides the specialized features and support needed to ensure a smooth and successful WordPress experience. By choosing a reliable and affordable WordPress hosting service, you can optimize your website's performance and focus on creating great content without worrying about the technical aspects of hosting.
<h2 id="heading-8-key-features-to-look-for-in-an-affordable-web-hosting-service">Key Features to Look for in an Affordable Web Hosting Service</h2>
<h3 id="heading-9-1-reliability-and-uptime-guarantee">1. Reliability and Uptime Guarantee</h3>
When considering an affordable web hosting service, one of the key features to prioritize is <a href="https://cloudnest.in" target="_blank" rel="noopener noreferrer">reliability and uptime guarantee</a>. A reliable web hosting provider plays a crucial role in ensuring that your website remains accessible to visitors without interruptions. Downtime can significantly impact your online presence, leading to potential loss of customers and revenue. Therefore, it's essential to choose a hosting service that offers a strong uptime guarantee.
<h4><a href="https://cloudnest.in/shared-hosting" target="_blank" rel="noopener noreferrer">How Reliable Web Hosting Ensures Uninterrupted Online Presence</a></h4>
<ul>
<li>Reliable web hosting ensures that your website remains accessible to visitors without interruptions.</li>
<li>Downtime can lead to potential loss of customers and revenue.</li>
<li>Choosing a hosting service with a strong uptime guarantee is crucial for minimizing downtime.</li>
</ul>
<h4>How Affordable Web Hosting Ensures Reliability Through Robust Infrastructure</h4>
<ul>
<li>Affordable web hosting services often prioritize reliability by investing in <a href="https://cloudnest.in/" target="_blank" rel="noopener noreferrer">robust infrastructure</a>.</li>
<li>This includes data centers with redundant power sources, backup systems, and advanced networking capabilities.</li>
<li>By leveraging these resources, affordable hosting providers can offer reliable uptime guarantees, ensuring that your website remains operational around the clock.</li>
</ul>
<h4>How Load Balancers and Server Monitoring Technologies Contribute to Reliability</h4>
<ul>
<li>In addition to infrastructure, the use of <a href="https://convesio.com/knowledgebase/article/the-ultimate-guide-to-database-load-balancing/" target="_blank" rel="noopener noreferrer">load balancers and server monitoring technologies</a> enables affordable web hosting services to maintain consistent performance and minimize downtime.</li>
<li>These proactive measures contribute to the overall reliability of the hosting environment, providing website owners with peace of mind regarding their online presence.</li>
</ul>
By prioritizing reliability in an affordable web hosting service, website owners can confidently establish and maintain a strong online presence without compromising on performance or accessibility.
<h2 id="heading-10-2-security-measures">2. Security Measures</h2>
Security is a critical factor to consider when choosing a web hosting service. Affordable web hosting providers understand this and take various measures to keep your website safe. Here are some important things to know:
<ul>
<li><strong>Robust Infrastructure</strong>: Reliable web hosting services invest in strong infrastructure to protect your website from threats. They use advanced data centers with features like firewalls, intrusion detection systems, and regular backups.</li>
<li><strong>Secure Data Centers</strong>: Affordable web hosting providers make security a priority for their data centers. These facilities have physical measures like CCTV surveillance, biometric access controls, and 24/7 monitoring to prevent unauthorized entry.</li>
<li><strong>Regular Software Updates</strong>: To shield your website from vulnerabilities, affordable web hosting providers frequently update their software and server settings. This ensures that your website is using the latest versions of operating systems, control panels, and other important software.</li>
<li><strong>DDoS Protection</strong>: Distributed Denial of Service (DDoS) attacks can make your website unavailable. Affordable web hosting services use advanced protection methods to minimize these attacks and ensure uninterrupted access to your site.</li>
<li><strong>Secure Socket Layer (SSL) Certificates</strong>: SSL certificates encrypt the communication between your website and its visitors, making sure that sensitive information like passwords and credit card details are transmitted securely. Many affordable web hosting providers offer free Let's Encrypt SSL certificates to enhance website security.</li>
<li><strong>Malware Scanning and Removal</strong>: Affordable web hosting services often provide tools for scanning and removing malware from your website. Regular scans help identify potential threats before they can cause harm.</li>
<li><strong>Backup Solutions</strong>: Creating backups of your website is crucial in case of data loss or accidental deletion. Reliable web hosting services offer real-time monitoring and automated backups to ensure that you always have a recent copy of your website's data that can be easily restored if needed.</li>
</ul>
By choosing an affordable web hosting service that prioritizes security, you can have peace of mind knowing that your website is protected against potential threats. These measures ensure the confidentiality, integrity, and availability of your website's data.
<h3 id="heading-11-3-customer-support-quality">3. Customer Support Quality</h3>
Responsive customer support is a crucial aspect of web hosting services, ensuring that any issues or concerns are promptly addressed for uninterrupted website performance. When considering affordable web hosting services, it's essential to evaluate the quality of customer support offered.
Examples of reliable customer support from affordable web hosting providers include:
<ul>
<li>24/7 Live Chat: Immediate assistance for technical queries and troubleshooting.</li>
<li>Ticketing System: Efficient tracking and resolution of support requests.</li>
<li>Knowledge Base: Comprehensive resources for self-help and quick solutions to common issues.</li>
</ul>
With responsive customer support, website owners can have peace of mind knowing that assistance is readily available whenever needed, contributing to the overall reliability and security of their online presence.
<h3 id="heading-12-4-free-lets-encrypt-ssl-certificates">4. Free Let's Encrypt SSL Certificates</h3>
<h4><strong>Explanation of SSL Certificates</strong></h4>
SSL (Secure Sockets Layer) certificates are cryptographic protocols that provide secure communication over a computer network. They encrypt the data transferred between a website and a user’s browser, ensuring that sensitive information remains private.
<h4><strong>Enhancing Website Security</strong></h4>
Affordable web hosting services often include free Let's Encrypt SSL certificates as part of their packages. This not only helps in securing the website but also builds trust among visitors by displaying the padlock symbol in the address bar, indicating a secure connection.
<h4><strong>Importance of Security</strong></h4>
With the increasing threats of cyber attacks and data breaches, website security is paramount. Let's Encrypt SSL certificates offer a cost-effective yet robust solution for safeguarding websites, especially for small businesses and startups with budget constraints.
By integrating Let's Encrypt SSL certificates into their hosting plans, affordable web hosting services demonstrate their commitment to providing a secure online environment for businesses and individuals. This proactive approach to security aligns with the overall reliability and quality that users expect from their web hosting providers.
<h3 id="heading-13-5-real-time-monitoring-and-backups">5. Real-time Monitoring and Backups</h3>
Real-time monitoring and backups are crucial aspects of reliable web hosting services.
<h4>Benefits of Real-Time Monitoring</h4>
Real-time monitoring allows hosting providers to detect and address potential issues promptly, minimizing the risk of downtime or performance issues for websites. It provides a proactive approach to maintaining website stability and security.
<h4>Affordable Web Hosting Services Provide Real-Time Monitoring</h4>
These services employ advanced monitoring tools to track website performance, server health, and security in real time. By doing so, they can take immediate action in response to any irregularities, ensuring optimal website functionality.
In addition to real-time monitoring, reliable web hosting services also offer robust backup solutions. These backups are essential for safeguarding website data in the event of unexpected incidents such as data corruption, cyberattacks, or hardware failures.
By incorporating real-time monitoring and comprehensive backup systems into their service offerings, affordable web hosting providers prioritize the stability and security of their clients' websites.
These features are among the important factors to consider when choosing an affordable web hosting service. The ability to proactively monitor website performance and maintain secure backups contributes significantly to the overall reliability and security of a web hosting service.
<h2 id="heading-14-tailored-hosting-solutions-for-different-needs">Tailored Hosting Solutions for Different Needs</h2>
When it comes to web hosting, one size does not fit all. Every website has unique requirements based on its purpose and target audience. That's why affordable web hosting services like cloudnest.in offer tailored hosting solutions to cater to specific needs. Here, we will explore the concept of tailored hosting solutions and provide examples of how cloudnest.in showcases their versatility and features.
<h3 id="heading-15-understanding-tailored-hosting-solutions">Understanding Tailored Hosting Solutions</h3>
Tailored hosting solutions refer to hosting plans that are designed to meet the specific requirements of different types of websites. Whether you have an e-commerce store or a personal blog, there are hosting packages available that offer the right resources and features for your website to thrive.
<h3 id="heading-16-examples-of-tailored-hosting-packages">Examples of Tailored Hosting Packages</h3>
Cloudnest.in offers a range of tailored hosting packages that cater to different needs. Let's take a look at a few examples:
<ol>
<li><strong>E-commerce Hosting</strong>: For online stores, cloudnest.in provides specialized e-commerce hosting solutions. These packages come with features such as secure payment gateways, shopping cart integration, and scalability options to handle high traffic volumes during peak seasons.</li>
<li><strong>WordPress Hosting</strong>: If you have a WordPress website, cloudnest.in offers WordPress hosting packages that are optimized for speed, security, and seamless compatibility with WordPress plugins and themes. These packages also come with automatic updates and backups for added convenience.</li>
<li><strong>Business Hosting</strong>: For small businesses looking to establish their online presence, cloudnest.in offers business hosting solutions that provide reliable performance, security features, and professional email services to enhance communication with customers.</li>
</ol>
By offering tailored hosting packages, cloudnest.in ensures that every website owner can find a solution that aligns with their specific needs.
<h3 id="heading-17-domain-registration-services">Domain Registration Services</h3>
In addition to tailored hosting solutions, cloudnest.in also provides domain registration services. Registering a domain is essential for establishing a unique online identity and building brand recognition. Cloudnest.in simplifies the process by offering seamless domain registration along with their hosting plans.
<h3 id="heading-18-advanced-tools-and-technologies">Advanced Tools and Technologies</h3>
Furthermore, cloudnest.in offers advanced tools and technologies to empower website owners. These tools include website builders, content management systems, analytics dashboards, and more. By leveraging these tools, website owners can easily manage their websites, optimize performance, and enhance the overall user experience.
<h2 id="heading-19-domain-registration-services">Domain Registration Services</h2>
<h3 id="heading-20-establishing-a-unique-online-identity"><strong>Establishing a Unique Online Identity</strong></h3>
Domain registration is a crucial step in <a href="https://cloudnest.in/domains" target="_blank" rel="noopener noreferrer">establishing a unique online identity</a> for your website. It serves as the address through which users can access your website, making it an integral part of your online presence.
<h3 id="heading-21-seamless-domain-registration-with-cloudnestin"><strong>Seamless Domain Registration with Cloudnest.in</strong></h3>
Cloudnest.in offers seamless domain registration services along with their hosting plans, providing a convenient one-stop solution for launching your website. By integrating domain registration with hosting services, Cloudnest.in simplifies the process for website owners, ensuring a smooth and efficient experience.
<h3 id="heading-22-importance-of-choosing-the-right-domain"><strong>Importance of Choosing the Right Domain</strong></h3>
Selecting the right domain is essential for creating a memorable and relevant web address that aligns with your brand or content. <a href="https://aicontentfy.com/en/blog/domains-for-business-boosting-brand-with-professional-web-address" target="_blank" rel="noopener noreferrer">Professional web addresses</a>, such as those offered by Cloudnest.in's domain registration services, encompass a wide range of domain extensions. This allows website owners to find the perfect fit for their online presence, boosting their brand credibility in the process.
<h3 id="heading-23-enhancing-brand-credibility"><strong>Enhancing Brand Credibility</strong></h3>
A unique and professional domain name enhances the credibility of your brand or business, making it easier for visitors to trust and engage with your website.
<h3 id="heading-24-integration-with-hosting-plans"><strong>Integration with Hosting Plans</strong></h3>
The seamless integration of domain registration with hosting plans ensures that website owners can manage both aspects within a unified platform, streamlining their online operations.
By offering comprehensive domain registration services alongside hosting solutions, Cloudnest.in empowers website owners to establish and manage their online presence effectively. This convergence of services is akin to how <a href="https://cloudnest.in/" target="_blank" rel="noopener noreferrer">brand experience intersects with customer experience</a>, creating a cohesive and impactful online presence.
<h2 id="heading-25-advanced-tools-and-technologies-for-website-management">Advanced Tools and Technologies for Website Management</h2>
At Cloudnest.in, we offer a wide range of advanced tools and technologies to help website owners improve their online presence. Our goal is to make website management easier and more efficient while also enhancing performance and user experience.
<h3 id="heading-26-performance-optimization"><strong>Performance Optimization</strong></h3>
We understand the importance of having a fast-loading website. That's why we provide advanced caching mechanisms and content delivery networks (CDNs) to optimize website loading speeds. By caching static content and delivering it from servers closer to the user's location, we can significantly reduce loading times. This ensures that visitors experience fast and responsive websites, leading to improved user satisfaction and search engine rankings.
<h3 id="heading-27-scalable-infrastructure"><strong>Scalable Infrastructure</strong></h3>
Every website owner knows that traffic can fluctuate. One day you might have a few visitors, and the next day your site could go viral. That's why it's essential to have a hosting solution that can handle these changes without affecting performance.
With our scalable infrastructure options such as cloud hosting, you can easily adapt to changing traffic demands. Whether you're experiencing rapid growth or seasonal fluctuations in website traffic, our flexible hosting solutions ensure that your site remains fast and accessible at all times.
<h3 id="heading-28-website-analytics"><strong>Website Analytics</strong></h3>
Understanding your audience is key to making informed decisions about your website. That's why we offer advanced analytics tools that allow you to gather valuable insights into visitor behavior, traffic sources, and conversion rates.
With this data, you can identify which pages are performing well, where your traffic is coming from, and how effective your marketing campaigns are. Armed with these insights, you can then make data-driven decisions to optimize your site for better user engagement and higher conversions.
<h3 id="heading-29-content-management-systems-cms"><strong>Content Management Systems (CMS)</strong></h3>
Managing a website can be challenging, especially if you're not familiar with coding or web development. That's where content management systems (CMS) come in handy.
Cloudnest.in seamlessly integrates with popular CMS platforms such as WordPress, Joomla, and Drupal. This integration allows you to leverage the latest updates and features of these CMSs while benefiting from our reliable hosting infrastructure. With just a few clicks, you can install your preferred CMS and start building your website right away.
<h3 id="heading-30-security-enhancements"><strong>Security Enhancements</strong></h3>
Website security is a top priority for us. We understand the importance of keeping your site safe from potential threats such as DDoS attacks, malware infections, and unauthorized access.
That's why we have implemented advanced security measures to protect your website. Our systems include DDoS protection, regular malware scanning, and robust firewalls. These proactive measures help ensure that your site remains secure and provides a safe browsing experience for your visitors.
These advanced tools and technologies provided by Cloudnest.in cater to the diverse needs of website owners, enabling them to take their online presence to new heights.
<h2 id="heading-31-choosing-the-best-affordable-web-hosting-service-for-your-needs">Choosing the Best Affordable Web Hosting Service for Your Needs</h2>
When it comes to selecting an affordable web hosting service, it's important to consider a few key factors that align with your requirements, budget, and scalability needs. Here are some considerations to keep in mind:
<ol>
<li><strong>Reliability and Performance:</strong> Look for a web hosting provider that offers a reliable uptime guarantee and robust infrastructure to ensure your website is accessible to visitors at all times. Check customer reviews and testimonials to gauge the reliability of the service.</li>
<li><strong>Scalability:</strong> Consider the future growth of your website and choose a hosting service that allows you to easily upgrade your resources as needed. This ensures that your website can handle increased traffic and data without any performance issues.</li>
<li><strong>Features and Tools:</strong> Evaluate the features and tools offered by different web hosting providers. Look for features like one-click installations for popular CMS platforms, website builders, email accounts, FTP access, and database management tools.</li>
<li><strong>Customer Support:</strong> Responsive customer support is crucial in case you encounter any technical issues or have questions about your hosting service. Look for a provider that offers 24/7 customer support through various channels such as live chat, email, and phone.</li>
<li><strong>Security Measures:</strong> Website security is essential to protect your data and visitor information. Ensure that the hosting provider offers robust security measures such as firewalls, malware scanning, regular backups, and SSL certificates.</li>
</ol>
Now let's compare different affordable web hosting providers:
<ul>
<li><strong>Cloudnest.in:</strong> Cloudnest.in stands out as an affordable web hosting provider with a range of hosting plans tailored to different needs. They offer reliable uptime guarantees, 24/7 customer support, free SSL certificates, and real-time monitoring for optimal performance.</li>
<li><strong>Provider X:</strong> Provider X also offers affordable hosting plans but lacks some of the advanced features provided by Cloudnest.in. Their customer support may not be as responsive or offer the same level of reliability.</li>
</ul>
When choosing an affordable web hosting service, it's important to weigh the features, reliability, and support offered by different providers. Consider your specific needs and budget to make an informed decision that will support your website's growth and success.
Remember, your web hosting service plays a crucial role in establishing a strong online presence, so choose wisely to ensure a seamless experience for your visitors.
<h2 id="heading-32-conclusion">Conclusion</h2>
In today's digital world, it's crucial to choose the right web hosting service if you want to succeed online. Affordable web hosting services are essential for individuals, small businesses, and startups as they provide reliable and scalable solutions.
By choosing cloudnest.in as your affordable web hosting provider, you can enjoy numerous benefits that will boost your website's performance:
<ol>
<li><strong>Robust Infrastructure</strong>: Cloudnest.in offers a powerful infrastructure that ensures fast loading times and minimal downtime for your website.</li>
<li><strong>Responsive Customer Support</strong>: Their dedicated support team is available 24/7 to assist you with any technical issues or concerns.</li>
<li><strong>Advanced Tools and Technologies</strong>: With cloudnest.in, you'll have access to cutting-edge tools and technologies that can enhance your website's functionality and user experience.</li>
</ol>
Here are the key takeaways:
<ol>
<li><strong>Importance of Choosing the Right Web Hosting Service</strong>: The web hosting service you choose directly impacts your online presence. It affects your website's performance, security, and reliability. Therefore, it is essential to opt for a reliable and affordable web hosting service.</li>
<li><strong>Cloudnest.in: Reliable and Affordable Hosting Solutions</strong>: Cloudnest.in stands out as a reliable and affordable web hosting provider. They offer tailored hosting solutions for different needs, ensuring optimal performance for various types of websites, whether it's e-commerce or blogging.</li>
<li><strong>Empowering Websites with Advanced Tools</strong>: Cloudnest.in provides advanced tools and technologies that empower website owners to manage their sites effectively. These tools enhance website performance and user experience, giving you an edge in the competitive online landscape.</li>
</ol>
To experience the benefits of affordable web hosting services firsthand, we encourage you to check out <a href="https://cloudnest.in" target="_blank" rel="noopener noreferrer">cloudnest.in</a> today! | cloudnest_931c4c449b31c07 | |
1,873,719 | Inaccessible forms | The other day I was attempting to book an airport transfer and came across a terrible form. It took... | 0 | 2024-06-02T13:54:37 | https://dev.to/emmadawsondev/inaccessible-forms-47f6 | webdev, a11y, forms | The other day I was attempting to book an airport transfer and came across a terrible form. It took me quite some time to work out how to actually book the transfer I needed and even then I wasn't convinced I was going to get to the airport on time.
The hotel I was staying at sent me a link to book the transfer. Opening the page, the form looked like this:
Before even touching the form, all fields are marked in red, suggesting errors. It's not great to start off with your form already in an error state before being touched.
Also, these errors are indicated with colour alone which means that anyone that doesn't perceive colours would have difficulty knowing there's supposedly anything wrong with these inputs.
The form does not have any error messages that show if a field is incorrectly filled in. They rely on changing the border of the input from grey to red. If there is an error with an input it should have a written error message close to the input field. An error icon next to the text would also help to indicate that it was an error text and not just supporting information.
Once you fill in the inputs, each one turns from red to grey. There doesn't seem to be any validation aside from the inputs not being empty. But then another problem:
I've filled in all the required fields, all the red is gone but the "Go Forward" button is still disabled. So now I'm sat staring at this form with no idea what is wrong and wondering if I will ever get to the airport in time to catch my flight. Can you work out how to fill in the rest of the form?
I did work it out eventually. There are three icons in circles at the top of the page labelled "Info", "Arlanda" (the name of the airport) and "To the hotel". The Info icon was coloured as that was the step I was on but the other two were greyed out. Turns out, greyed out in this case did not mean disabled, unlike the button at the bottom of the form. Clicking on the Arlanda icon took me to the second part of the form where I could enter the rest of the details needed to make the booking.
I finally got a confirmation, although after the state of this form I did not really trust it and had to double check with the hotel on arrival that it had indeed worked. I'm guessing they never did any user testing before releasing this into the wild!
So how do you make your forms better than this?
- Don't start off in error mode
- Indicate errors with more than just colour alone
- Have clear written error messages for each input field
- Avoid using disabled buttons wherever possible. It's better to let users press the button and see an error for why the form didn't submit than have to guess what they need to do to make the button not disabled
- If something is clickable don't make it look disabled
- Do some user testing! Surely one user test would have picked up how terrible this form is before ever going live in production?!
| emmadawsondev |
1,873,717 | Day 8 of my progress as a vue dev | About today Today was one of those lazy days that come once in a while because for generations our... | 0 | 2024-06-02T13:50:47 | https://dev.to/zain725342/day-8-of-my-progress-as-a-vue-dev-2g8a | webdev, vue, typescript, tailwindcss | **About today**
Today was one of those lazy days that come once in a while because for generations our brain is hardwired that Sunday is a rest day hence that made me a little lazy. But, I did manage to get some basic work done on the project and fine tuned it a bit more, also did some changes in the code of linked list to make it more concise so it made it smell less than before.
**What's next?**
Well plan is the same as before, but primary objective is to not be lazy or waste my time like I did today and at least keep on adding something new to the code to either improve it or grow it in terms of functionality.
**Improvements required**
I need to work on following my schedule and ignore distractions (Netflix) to be more focused on the task at hand to get positive and fast results.
Wish me luck!
| zain725342 |
1,873,716 | C# Fundamentals | 🔍 What is C C# (pronounced "C-sharp") is a modern, object-oriented programming language... | 27,572 | 2024-06-02T13:50:43 | https://dev.to/suneeh/c-fundamentals-3n08 | beginners, csharp, programming, tutorial | ## 🔍 What is C#
C# (pronounced "C-sharp") is a modern, object-oriented programming language developed by [Microsoft](https://www.microsoft.com/). It was first introduced in 2000 and has evolved into one of the most versatile and widely used programming languages since. C# is designed to be simple, yet powerful, making it an excellent choice for both beginners and experienced developers.
### Key Features
1. **Object-Oriented**: C# supports all the core concepts of OOP ([object-oriented programming](https://en.wikipedia.org/wiki/Object-oriented_programming)) such as encapsulation, inheritance and polymorphism, which help in creating modular and reuseable code.
1. **Type-Safe**: C# enforces strict type checking, reducing the chances of runtime errors and enhancing code reliability.
1. **Rich Library**: It provides a comprehensive standard library that simplifies many programming tasks, including file I/O, data manipulation and networking.
1. **Component-Oriented**: C# is designed for creating software components, which are reusable code modules that can be easily integrated into larger systems.
1. **Integrated with .NET Framework**: It has seamless integration with the [.NET framework](https://dotnet.microsoft.com) providing access to a vast array of libraries and tools for building robust applications.
### Uses of C#
1. **Desktop Applications**: C# is widely used to develop Windows desktop applications using frameworks like Windows Forms and WPF (Windows Presentation Foundation).
1. **Web Applications**: [ASP.NET](https://dotnet.microsoft.com/en-us/apps/aspnet), a powerful framework for building web applications, is primarily based on C#. Developers can create dynamic websites, web APIs, and services with ASP.NET.
1. **Mobile Applications**: With [Xamarin](https://dotnet.microsoft.com/en-us/apps/xamarin), a cross-platform mobile development framework, developers can write C# code to build native Android, iOS, and Windows mobile applications.
1. **Game Development**: C# is the primary language for Unity, one of the most popular game engines. It is used extensively in the development of both 2D and 3D games.
1. **Cloud and Enterprise Applications**: C# is commonly used to develop scalable cloud applications and enterprise-level software, particularly in environments that use Microsoft Azure.
1. **IoT Applications**: C# can also be used for developing Internet of Things (IoT) applications, leveraging its ability to interface with hardware and communicate over networks.
Whatever the goal is, there most likely is a way to do it with C#.
## 📝 Basic Synctax and Structure
### ~~Main Method~~ (Deprecated)
Since C# 10 there is no more need for a `static void Main(string args[])` method. Instead you can create a new file that contains `Console.WriteLine("Hello World");` and run it without further code.
### Variables and Data Types
The common data types are the following
```c#
// INT for whole numbers
int age = 30;
// FLOAT for floating point numbers
float height = 5.9f;
// DOUBLE for double-precision floating point numbers
double weight = 70.5;
// CHAR for single characters
char grade = 'A';
// STRING for words / text
string name = "John";
// BOOL for true or false (boolean)
bool isStudent = true;
```
A variable is always declared as seen.
`[TYPE / "var"] [VARIABLE_NAME] [(optional) = [VALUE / VALUABLE EXPRESSION]]`
The `var` keyword can be used instead of any type keyword. Be careful with `var` as it might get unclear what the type the variable is quickly.
### Conditional Statements & Loops
#### If / Else Conditions
```c#
int age = 17;
if (age < 18)
{
Console.WriteLine("You are too young to do this.");
}
else
{
Console.WriteLine("You are old enough.");
}
// Short Form: Ternary Operator: [BOOLEAN] ? [TRUE] : [FALSE]
age < 18
? Console.WriteLine("You are too young to do this.");
: Console.WriteLine("You are old enough.");
```
#### Switch Statements
If there are more than 2 possible outcomes that you want to handle a switch statement can be used. Switch statements should be preferred over multiple ifs to provide better readability.
Attention! You should always cover ALL possible outcomes. A switch can also have a `default` case to cover all paths that are not covered by the `case` provided.
```c#
int age = 19;
switch(age)
{
case < 18:
Console.WriteLine("You are too young to drink in Germany.");
break;
case < 21:
Console.WriteLine("You can drink in Germany but not in the US.");
break;
case > 21:
Console.WriteLine("You can drink.");
break;
}
```
#### For(each)-Loops
For loops are being used to do the same thing multiple times.
```c#
for (int i = 1; i<=5; i++)
{
Console.Write(i);
}
//12345
```
For-Each loops are being used to do something for each element of an Array (a group of data)
```c#
string[] names = {"Martin", "Alexander", "Michael", "Jens"};
foreach (string name in names)
{
Console.WriteLine("Hello "+name);
// Hello Martin
// Hello Alexander
// Hello Michael
// Hello Jens
}
```
#### While-Loops
There is also a `do { ... } while { ... }` syntax, but the shor tform is way more common.
```c#
int x = 1;
while (x < 100)
{
Console.WriteLine($"{x} is still smaller than 100, so I will multiply it by 2.");
x *= 2; // this is the same as x = x * 2;
}
```
### Functions and Methods
Defining and calling functions:
```c#
int Add(int a, int b)
{
return a+b;
}
int result = Add(3, 4);
Console.WriteLine(result); // 7
```
There are numerous built in methods for the most common operations with basic data types. Here some examples:
```c#
string message = "Hello, World!";
// prints the number of characters in the string: 13
Console.WriteLine(message.Length);
// prints the first 5 Characters: Hello
Console.WriteLine(message.Substring(0, 5));
Console.WriteLine(message.IndexOf("World")); // 7
// 2^4 or 2 * 2 * 2 * 2
double result = Math.Pow(2, 4);
Console.WriteLine(result); // 16
// Takes the square root of the result (16): 4
Console.WriteLine(Math.Sqrt(result));
```
### Object Oriented Programming
#### Classes and Objects
When working with multiple data sets of the same quality you can introduce a class to simplify work. Here an example for humans.
```c#
class Human{
public string Name { get; set; } // getter and setter are functions being used to get or set a value.
public int Age { get; set; }
public void Introduce()
{
Console.WriteLine($"Hi! I'm {Name} and I am {Age} years old.");
}
}
Human john = new Person();
john.Name = "Johnny";
john.Age = 35;
person.Introduce(); // "Hi! I'm Johnny and I am 35 years old."
```
To simplify this even further, you could introduce a 'Constructor' to set values in the same step as initializing the Human.
```c#
class Human{
private string Name { get; set; }
private int Age { get; set; }
public Human(string name, int age)
{
Name = name;
Age = age;
}
public void Introduce()
{
Console.WriteLine($"Hi! I'm {Name} and I am {Age} years old.");
}
}
Human john = new Person("Johnny", 35);
person.Introduce(); // "Hi! I'm Johnny and I am 35 years old."
```
#### Inheritance
Sometimes objects are somewhat similar, but yet different. Let's take Animals for example. All of them eat, but only dogs bark. Here the implementation:
```c#
class Animal
{
public void Eat()
{
Console.WriteLine("Eating...");
}
}
class Dog : Animal
{
public void Bark()
{
Console.WriteLine("WUFF!");
}
}
Animal fish = new Animal();
fish.Eat();
Dog dog = new Dog();
dog.Eat();
dog.Bark();
```
### Collections and Generics
#### Lists
Lists are somewhat similar to arrays but they can shrink and grow dynamically. They also provde built-in functions to use this feature.
```c#
List<string> fruits = new List<string>();
fruits.add("Apple");
fruits.add("Banana");
fruits.add("Cherry");
```
#### Dictionaries / Key-Value
```c#
Dictionary<string, int> agesOfPeople = new Dictionary<string, int>();
ages["Johnny"] = 35;
ages["Michael"] = 17;
ages["Alexander"] = 42;
Console.WriteLine(agesOfPeople["Alexander"]); // 42
// Looping through the dictionary
foreach (KeyValuePair<string, int> kvp in agesOfPeople)
{
Console.WriteLine($"Name: {kvp.Key}, Age: {kvp.Value}");
}
```
#### Generics
When you want to write a Method in a way that is reusable for multiple types you can do so by using Generic Types.
```c#
ConvertArrayToList<T>(T[] arr)
{
List<T> list = new List<T>();
foreach (T item in arr)
{
list.add(item);
}
return list;
}
string[] names = {"Martin", "Alexander", "Michael", "Jens"};
List<string> listNames = ConvertArrayToList(names);
```
## 📚 Conclusion
C# is a powerful and feature rich programming language. Together with the [nuget](https://www.nuget.org/packages) package manager you can use pre-built feature from other users or create your own! Either way it is recommended to learn a language by speaking it. So start your own project.
## 🚧 Starter Projects
It is recommended to start with a simple and small project that can be finished within a short amount of time. Common projects to start are:
- Todo App
- Calculator
- Tic-Tac-Toe
- Rock Paper Scissors
- Pinball
- Snake
When you feel comfortable with C# and feel like you want to do more: Check out the .NET Framework to build Webapplications or APIs.
## ⁉ FAQ
### What IDE should i use for C# Development
To start out Visual Studio is your best bet. If you get more serious you can look into a JetBrains subscription for [Rider](https://www.jetbrains.com/rider/).
Working with MacOS will become harder in August 2024, when Visual Studio is discontinued. Microsoft recommends Visual Studio Code with some Plug Ins, but keep in mind Rider is a valid option as well if you want to afford it.
### How to run and debug my C# programs
Visual Studio and Rider both come with a set of robust debugging tools. Set breakpoints and run your app, to see and analyze the state of your program in any given moment. This is also a nice way to learn and understand more about the internals of C#.
### What is the best way to learn C#
Practice! Set yourself a goal of what you want to achieve. For example an Inventory App that tracks the stock of your company. Work until you get there and if you are stuck it is time to read some documentation or in depth guide for the feature you need to learn.
Collaborate with other people or teams. Join hackathons or some open source project. You can learn from others and their code.
Check the patch notes whenever there is a new version of C# coming your way. This way you know about the new features - try to use them in your code and refactor old code to stay up to date!
## 🙏🏽 Thanks
Thank you so much if you read this article all the way! Leave a comment if you have any questions, I'll be more than happy to answer right away. If you are shy you can also message me directly on [GitHub](https://github.com/Suneeh), [Instagram](https://www.instagram.com/_suneeh/) or [TikTok](https://www.tiktok.com/@_suneeh).
| suneeh |
1,873,715 | WHAT IS MANUAL TESTING BENEFITS AND DRAWBACK OF MANUAL TESTING | MANUAL TESTING Manual testing is a software tesing process in which test cases are executed manually... | 0 | 2024-06-02T13:49:48 | https://dev.to/malaiyarasi/what-is-manual-testing-benefits-and-drawback-of-manual-testing-5fc3 | benefits, drawbacks | MANUAL TESTING
Manual testing is a software tesing process in which test cases are executed manually without any automation tool. All test cases executed manually according to the end user perpective. It ensure whether the appliation is working as mentioned in the requirement document or not.Test cases are planned and implemented to complete almost 100 percent of the sofware appliation.test cases reports are also generated anually.
WHY WE NEED MANUAL TESTING:
Whenever application comes to the market and it is unstable or having a bugor creating a bug while end user are using it.
If the test engineer does manual testing, he/she can test the application as an end-user perspective and get more familiar with the product, which helps them to write the correct test cases of the application and give the quick feedback of the application.
BENEFITS OF MANUAL TESTING:
1. High level accuracy
2. Real user experience
3. Flexibility in testing process
4. cost effective of small projects
5. Better understanding of customer needs
6. No need of complex tools
7. Identifying visual issues
8. Easier to learn for new user
9. Better understanding of complex projects
DRAWBACKS OF MANUAL TESTING
1. Time consuming
2. Prone to human error
3. Difficult reproduction
4. Not sustainable long term
5. Limited coverage
6. Limited scalability
7. Dependent on Skill
8. Difficult reporting
| malaiyarasi |
1,873,714 | Taklukkan Gulungan dengan Fire Stampede: Panduan untuk Menang Besar | Mengenal Fire Stampede Fire Stampede adalah permainan slot online yang menarik dan penuh... | 0 | 2024-06-02T13:46:56 | https://dev.to/valentinaseitz/taklukkan-gulungan-dengan-fire-stampede-panduan-untuk-menang-besar-hjc |
# Mengenal Fire Stampede
Fire Stampede adalah permainan slot online yang menarik dan penuh aksi yang dikembangkan oleh pengembang perangkat lunak terkemuka, seperti Playtech. Permainan ini menawarkan tema eksotis dengan latar belakang pemandangan savana Afrika yang indah. Dengan grafik yang mengagumkan dan efek suara yang menghidupkan suasana, Fire Stampede memberikan pengalaman bermain yang mengasyikkan dan mendebarkan.
Fire Stampede memiliki gulungan tradisional dengan 5 gulungan dan 3 baris, serta 243 cara untuk menang. Ini berarti bahwa simbol-simbol yang cocok muncul di gulungan yang berdekatan, dari kiri ke kanan, akan membawa kemenangan kepada pemain. Permainan ini juga memiliki berbagai fitur bonus yang menarik, seperti putaran gratis, simbol liar, dan pengganda. Memahami fitur-fitur ini adalah kunci untuk meningkatkan peluang Anda untuk menang besar dalam permainan.
## Memahami Simbol dan Fitur Bonus
Dalam Fire Stampede, simbol-simbol yang terkait dengan tema Afrika memainkan peran penting dalam menentukan kemenangan Anda. Simbol-simbol yang lebih bernilai tinggi termasuk singa, gajah, kuda nil, dan jerapah. Simbol-simbol ini bisa membawa pembayaran yang besar jika Anda berhasil mencocokkannya dalam kombinasi yang tepat. Selain itu, ada juga simbol-simbol yang bernilai lebih rendah, seperti kartu remi 9 hingga As.
Salah satu simbol yang perlu Anda perhatikan adalah simbol liar yang diwakili oleh ikon api. Simbol liar ini dapat menggantikan simbol lain kecuali simbol pencar untuk membentuk kombinasi pemenang. Selain itu, simbol liar juga berperan sebagai pengganda dan dapat menggandakan kemenangan Anda. Memanfaatkan [**dewa poker asia**](https://185.96.163.225/) simbol liar ini dengan bijak dapat meningkatkan peluang Anda untuk meraih kemenangan yang lebih besar.

Simbol pencar dalam Fire Stampede adalah simbol gajah. Jika Anda berhasil mencocokkan tiga atau lebih simbol gajah di gulungan, Anda akan memicu fitur putaran gratis. Dalam putaran gratis, Anda akan diberikan sejumlah putaran tambahan tanpa harus mempertaruhkan uang Anda. Selama putaran gratis, ada juga simbol liar yang muncul secara acak di gulungan, meningkatkan peluang Anda untuk menciptakan kombinasi pemenang. Putaran gratis dapat menjadi kesempatan yang sangat menguntungkan untuk meningkatkan kemenangan Anda dalam permainan.
### Strategi Bermain yang Efektif
1\. Manajemen Bankroll: Salah satu strategi yang paling penting dalam bermain Fire Stampede adalah manajemen bankroll yang baik. Tetapkan anggaran yang masuk akal sebelum mulai bermain dan patuhi batas itu. Jaga agar taruhan Anda tetap seimbang dengan anggaran Anda untuk memaksimalkan kesempatan Anda untuk bermain lebih lama dan meningkatkan peluang menang Anda.
2\. Maksimalkan Fitur Bonus: Fitur-fitur bonus dalam Fire Stampede, seperti putaran gratis dan simbol liar, adalah kesempatan besar untuk meningkatkan kemenangan Anda. Manfaatkan putaran [**poker 88**](https://185.234.52.32/) gratis dengan bijak dan cari simbol liar selama putaran tersebut. Dengan memaksimalkan fitur-fitur bonus ini, Anda dapat meningkatkan peluang Anda untuk meraih hadiah besar.
3\. Bermain dengan Keberanian: Jangan takut untuk memasang taruhan yang lebih tinggi jika Anda merasa yakin. Meskipun taruhan yang lebih tinggi dapat meningkatkan risiko Anda kehilangan uang, mereka juga bisa membawa kemenangan yang lebih besar. Namun, pastikan untuk selalu bermain dengan bijaksana dan bertanggung jawab, dan jangan tergoda untuk mengambil risiko yang tidak masuk akal.
Dengan mengikuti panduan ini dan mengembangkan strategi bermain yang efektif, Anda dapat meningkatkan peluang Anda untuk menang besar dalam permainanFire Stampede: Panduan untuk Menang Besar di Gulungan
#### Tips dan Trik untuk Menang Besar
1\. Pahami Pola Pembayaran: Setiap permainan slot memiliki pola pembayaran yang berbeda, dan Fire Stampede bukan pengecualian. Penting untuk memahami pola pembayaran dalam permainan [**dominobet**](https://185.96.163.180/) ini sehingga Anda dapat mengatur strategi taruhan Anda dengan bijaksana. Perhatikan simbol-simbol yang bernilai tinggi dan lihat berapa banyak yang diperlukan untuk mencapai kombinasi pemenang. Fokus pada simbol-simbol ini untuk meningkatkan peluang Anda untuk meraih kemenangan besar.
2\. Bermain dengan Taruhan Maksimum: Meskipun taruhan maksimum tidak selalu diperlukan, dalam Fire Stampede, memainkan taruhan maksimum dapat meningkatkan peluang Anda untuk memenangkan jackpot. Beberapa permainan slot memiliki fitur jackpot progresif yang hanya dapat dimenangkan dengan memasang taruhan maksimum. Jika Anda memutuskan untuk bermain dengan taruhan maksimum, pastikan untuk mempertimbangkan anggaran Anda dengan hati-hati dan hanya melakukannya jika Anda merasa nyaman dengan risikonya.
3\. Gunakan Mode demo memungkinkan Anda untuk bermain Fire Stampede tanpa mempertaruhkan uang Anda sendiri. Gunakan kesempatan ini untuk mengenal permainan, memahami fitur-fitur bonus, dan menguji strategi bermain Anda. Ini adalah cara yang bagus untuk meningkatkan pemahaman Anda tentang permainan sebelum mulai bermain dengan uang sungguhan.
4\. Tetapkan Batas Kemenangan dan Kerugian: Penting untuk memiliki batas kemenangan dan kerugian yang jelas sebelum mulai bermain. Tentukan jumlah kemenangan [**domino88 online**](https://67.205.148.8/) yang Anda inginkan sebelum Anda berhenti bermain dan patuhi batas ini. Jika Anda mencapai batas ini, berhenti bermain dan nikmati kemenangan Anda. Demikian pula, tetapkan batas kerugian yang dapat Anda tanggung dan jangan melebihi batas ini. Dengan memiliki batas yang jelas, Anda dapat menghindari kehilangan uang lebih dari yang Anda mampu.
##### Kesimpulan
Fire Stampede adalah permainan slot online yang menarik dan menghibur dengan tema Afrika yang eksotis. Dengan memahami simbol dan fitur bonus, serta mengembangkan strategi bermain yang efektif, Anda dapat meningkatkan peluang Anda untuk menang besar dalam permainan ini. Gunakan tips dan trik yang telah dijelaskan dalam artikel ini, seperti memahami pola pembayaran, bermain dengan bijaksana, dan memanfaatkan fitur-fitur bonus. Tetapkan batas kemenangan dan kerugian yang jelas, dan jangan lupa untuk mengambil kesempatan dengan mode demo sebelum bermain dengan uang sungguhan. Dengan mengikuti panduan ini, Anda akan menjadi master Fire Stampede dan siap untuk menaklukkan gulungan untuk memenangkan hadiah besar. Selamat bermain dan semoga sukses! | valentinaseitz | |
1,873,713 | Laravel Advanced: Lesser-Known, Yet Useful Composer Commands | Composer is the go-to dependency manager for PHP, and if you're working with Laravel, you're already... | 27,571 | 2024-06-02T13:43:59 | https://backpackforlaravel.com/articles/tips-and-tricks/laravel-advanced-lesser-known-yet-useful-composer-commands | laravel, php, learning, productivity | Composer is the go-to dependency manager for PHP, and if you're working with Laravel, you're already familiar with frequently used commands like `composer install` and `composer update`. Composer also offers some commands that are lesser-known but helpful while working on your Laravel app.

Here are five Composer commands you might not know but would love to use.
## 1. `composer outdated`
Ever wondered which of your app dependencies are outdated? **`composer outdated`** gives you a quick rundown of all packages that have newer versions available. This is especially useful for keeping your project up-to-date and secure.
```bash
composer outdated
```
This lists all the outdated packages in your project, showing the current and latest versions. It's a handy way to stay on top of updates without blindly running `composer update`.
## 2. `composer show`
Need an overview of the installed packages? The `composer show` displays information about all the packages installed in your project.
```bash
composer show
```
You can also use it to get details about a specific package by passing the package name:
```bash
composer show vendor/package
# Example: composer show backpack/crud
```
It’s a great way to quickly check the installed version, description, and dependencies of any package in your project.
## 3. `composer why`
Wanna figure out why a particular package is installed? `composer why` helps you trace the dependency tree to understand which package requires it.
```bash!
composer why vendor/package
```
## 4. `composer licenses`
Wanna know the licenses of the packages you are using? `composer licenses` provides a summary of all the licenses of the installed dependencies. This is useful for ensuring compliance with open-source licenses.
```bash!
composer licenses
```
## 5. `composer check-platform-reqs`
Checking all required PHP extensions are installed can be a hassle while working on a project across multiple environments. The `composer check-platform-reqs` command checks if your platform meets the package requirements.
```bash
composer check-platform-reqs
```
This command verifies that the PHP version and all required extensions are installed and meet the version constraints specified in your `composer.json`.
## Conclusion
While basic Composer commands get the job done, these lesser-known commands can save you time and hassle by giving you deeper insights and more control over your project's dependencies. So, the next time you fire up your terminal, try these commands and see how they can improve your Laravel experience.
All of the above have been previously shared on our Twitter, one by one. [Follow us on Twitter](https://twitter.com/laravelbackpack); You'll ❤️ it. You can also check the first article of the series, which is on the [Top 5 Scheduler Functions you might not know about](https://backpackforlaravel.com/articles/tips-and-tricks/laravel-advanced-top-5-scheduler-functions-you-might-not-know-about). Keep exploring, and keep coding with ease using Laravel. Until next time, happy composing! 🚀 | karandatwani92 |
1,873,712 | Custom-built vs. Prebuilt: What's the Difference? | Video communication has become integral to our daily lives—there's simply no avoiding it. If you're a... | 0 | 2024-06-02T13:42:42 | https://dev.to/digitalsamba/custom-built-vs-prebuilt-whats-the-difference-26b7 | api, embed, videoconferencing, prebuilt | Video communication has become integral to our daily lives—there's simply no avoiding it. If you're a product owner keen to incorporate video conferencing into your SaaS application, you have many approaches. In earlier times, the choice was straightforward: Zoom or Teams. However, the market has expanded significantly, and various methods for seamlessly integrating video conferencing have since evolved.
In the ensuing discussion, we'll explore embedded technologies and provide an overview of available options. Not every solution will meet your business needs. Indeed, you might find it more suitable to launch Zoom or Teams from your user interface, which is perfectly acceptable. However, it's crucial to make such a decision consciously.
## Understanding embedded video conferencing solutions
There are standalone video conferencing tools and platforms that enable embedding a video conferencing solution directly into your application.
We're all familiar with standalone tools like Zoom, Google Meet, and Microsoft Teams (commonly called "off the shelf" or OTS tools). While embedding an OTS tool is possible, it doesn't represent a truly embedded solution. It often necessitates meeting management via admin screens and the hardcoding of static meeting links into your code. We will not delve into the merits of this approach here.
A genuinely embeddable video conferencing platform offers access to an API and SDK comprising three key components:
- Embed code: You integrate the video conference into your application by inserting a few "embed code" lines into your source code.
- Setup and administration: Your code utilises the platform’s API for administrative tasks, such as setting the initial parameters of the embedded video conference or retrieving a meeting's chat summary. Consider the API a programmatic interface to the platform’s administrative features—functions typically accessed via admin screens in an OTS tool.
- On-page interaction: Once active, your code employs the platform’s SDK to manage the live video conference. The SDK enables you to create custom UI elements to control aspects of the live conference, such as a button in your application that can mute a stream or toggle the visibility of a certain element in the video conference.
## Types of embedded video conferencing platforms
There are several paths to exploring an embedded video conferencing solution, but they fall into two main categories.
You might construct the entire system—or significant portions of it—yourself. We refer to this as the custom-built approach. This method affords much flexibility but comes with higher financial and time investments.
Alternatively, you could utilise a prebuilt embedded platform with extensive functionality. We call this the prebuilt approach. This method is faster, though you may have to compromise on some flexibility.
Let’s explore these two approaches in more detail.
### Understanding custom-built video conferencing solutions
A custom-built solution means you are effectively developing your embedded video conferencing system from the ground up. There are two subtypes within the custom-built category:
#### Complete in-house build
If you're particularly ambitious and can allocate several years, you might start by creating your own media server. Alternatively, you could begin your in-house build by choosing an existing media server, such as Janus, Jitsi, or Mediasoup. These low-level media servers provide the essential functionality required to transmit and receive streams.
You will need to develop all the collaborative logic yourself. This includes writing frontend code to capture the webcam in the browser, convert it into a stream, connect to the media server, transmit the stream to the server, and then develop backend logic to direct other users to where they can access the stream for viewing.
You’ll also need to create code for room creation and management, bandwidth management, scaling, error detection and correction, and numerous other low-level backend tasks.
After establishing these foundations, you can introduce basic stream-related features (e.g., muting) and elementary conferencing features (e.g., video tile layouts). This forms a basic video conference setup.
If you need collaborative features like a participant list or chat, you will also have to develop them yourself.
In essence, you are building everything from scratch.
#### Custom build using a low-level VPaaS
Instead of starting with a media server, you could choose a Video Platform as a Service (VPaaS) provider, such as Agora, Daily, Vonage, or Twilio. These platforms are still relatively low-level but simplify some initial video streaming logic.
Your task begins by arranging the video elements in your user interface and then progresses to coding basic stream controls, such as muting.
Next, you can develop more advanced application logic—the 'brain' of your application—such as the video layout engine, user role management, and scaling logic.
Finally, if your use case requires it, you must build collaborative features, including a participant list, chat, whiteboard, polling, question and answer sections, and more.
Thus, the process is extensive whether you opt for a completely custom build or use a low-level VPaaS. The benefit is flexibility; you can do anything you want, but you must build it yourself.
**Advantages of custom-built solutions:**
- Complete flexibility to implement your core logic and architecture.
- Full control over implementing end-user features.
- Total control over the codebase.
- Capability to accommodate highly specific or complex use cases.
**Limitations of custom-built solutions:**
- Significant costs for software development, maintenance, and infrastructure.
- There is a need to develop both core application logic and a range of basic to advanced conferencing features.
- A highly competent development team is required.
- Diversion of focus from other areas of your SaaS product development.
## Understanding prebuilt video conferencing solutions
Prebuilt solutions represent higher-level VPaaS offerings (such as Digital Samba, Whereby, or Daily-Prebuilt). The term 'prebuilt' means that various components you would otherwise need to develop yourself are already constructed for you. Decisions have been made on your behalf. There is a broad spectrum of prebuilt solutions available, making them challenging to categorise in terms of visible features and the architectural and logical decisions made by the vendor or platform.
The feature range in prebuilt solutions varies widely: some are minimalistic, while others are feature-rich. Some may align with your needs, while others may make choices that are incompatible with your requirements (for instance, they might implement a video layout that simply doesn't suit your application).
Prebuilt solutions might limit some flexibility, but they offer significant advantages like quicker deployment times and reduced development and maintenance costs.
**Advantages of prebuilt solutions:**
- Rapid market readiness.
- Reduced development costs, focusing only on integration and its maintenance.
- Allows focus to remain on other areas of your SaaS product development.
- Predictable operational costs once integration is complete.
**General limitations of prebuilt solutions:**
- Limited or no influence over vendor decisions.
- Little or no control over the vendor’s development roadmap.
- No control over the video conferencing codebase.
- Potential lack of necessary features.
- May lack detailed control options.
## Key differences between custom-built and prebuilt
Maybe you’d like to see that information in a table, so here it is - [https://www.digitalsamba.com/blog/custom-built-vs-prebuilt-what-is-the-difference](https://www.digitalsamba.com/blog/custom-built-vs-prebuilt-what-is-the-difference)
### When to consider building a custom solution
- You need to control the entire codebase.
- Your use case is highly specific and cannot be met by prebuilt options.
- Your SaaS product itself is a video conferencing tool.
### When to consider choosing a prebuilt solution
- Speed is crucial.
- A prebuilt provider meets most of your requirements, and you can develop the missing components yourself.
- Your development team lacks expertise in real-time communication.
- You wish to keep your focus on your core business activities.
### Prebuilt does not mean inferior
It's important to acknowledge the extensive variety of prebuilt solutions available on the market. Before opting for a custom-built solution, it’s worthwhile to conduct thorough research. Video technology is complex—very complex.
**The key to successfully implementing a prebuilt solution:**
- The provider must make well-considered decisions that satisfy the majority, indicating deep market experience. This isn't just about feature choices but also essential architecture like role management, video layouts, room creation, room scaling, and bandwidth management.
- The provider should also strive to make the system flexible through configurable settings, helping to alleviate some of the limitations imposed by these "well-considered decisions." However, it's important to note that some architectural choices may not be adjustable post-deployment.
- To cater to a broad range of use cases, the prebuilt solution should be rich in features but not overly complex. The provider must clearly communicate that these features are available if needed but can also be disabled easily for simpler applications.
No prebuilt vendor can make decisions that will satisfy everyone completely, and settings are not as adaptable as creating something tailored precisely to your specifications.
However, a prebuilt solution that makes intelligent choices and offers the ability to tweak these decisions with appropriate settings can offer a degree of flexibility close to that of a custom-built solution. Ultimately, the suitability of a prebuilt solution depends on your specific needs.
## Digital Samba: more than just a prebuilt solution
If you're new to this field and are considering a custom-built approach, ensure it's absolutely the right choice for you. How? Dedicate an hour or two to [embed Digital Samba](https://www.digitalsamba.com/), explore the decisions we've made, and experiment with the features we offer. The time you invest here is minimal compared to what you’d spend developing a custom solution. But at least you’ll be making that decision with the full confidence that prebuilt isn't the right path for you.
If you've already opted for a prebuilt solution, consider Digital Samba as your embedded option. Our company originated in standalone video conferencing, and we've undergone the rigorous process of developing a custom-built OTS product from scratch. It’s safe to say we understand both the custom-built and prebuilt realms.
With 20 years of experience, we've incorporated all the expected features of an OTS video conferencing product into a highly customisable prebuilt platform. Our long-standing experience in the market enables us to make well-informed prebuilt decisions that suit almost any use case—likely yours as well. Why not give us a try?
| digitalsamba |
1,873,711 | Linked List, Data Structures | Linked List A linked list is a fundamental data structure used in computer science to... | 0 | 2024-06-02T13:40:26 | https://dev.to/harshm03/linked-list-data-structures-4i35 | datastructures, dsa | ## Linked List
A linked list is a fundamental data structure used in computer science to organize and store data efficiently. Unlike arrays, linked lists consist of nodes, where each node contains data and a reference (or link) to the next node in the sequence. This structure allows for dynamic memory allocation and efficient insertions and deletions, making linked lists highly versatile and useful for various applications.
### Comparison with Arrays
Linked lists and arrays are both used to store collections of elements, but they have key differences that affect their performance and usage:
- **Memory Allocation:**
- **Arrays**: Use contiguous memory allocation. The size of the array is fixed at the time of its creation, which can lead to wasted memory if the array is not fully utilized or insufficient memory if it needs to be resized.
- **Linked Lists**: Use dynamic memory allocation. Each element (node) is allocated separately, allowing the linked list to grow or shrink in size as needed without reallocating memory for the entire structure.
- **Insertion and Deletion:**
- **Arrays**: Inserting or deleting elements in an array requires shifting elements to maintain the order, which can be time-consuming (O(n) time complexity for both operations).
- **Linked Lists**: Insertion and deletion operations are more efficient (O(1) time complexity) as they involve updating pointers rather than shifting elements.
- **Access Time:**
- **Arrays**: Provide constant-time access (O(1)) to elements using their indices, making them suitable for scenarios where frequent access to elements is required.
- **Linked Lists**: Require sequential access (O(n) time complexity) to reach a specific element, which can be slower compared to arrays.
### Basic Terminologies Related to Linked Lists
Understanding the fundamental terminologies associated with linked lists is essential for grasping their structure and operations:
- **Node**: The basic unit of a linked list. Each node contains the data to be stored and a pointer (or reference) to the next node in the list.
- **Head**: The first node in the linked list. It serves as the entry point for accessing the list. If the linked list is empty, the head points to null.
- **Tail**: The last node in the linked list. In a singly linked list, the tail's next pointer points to null, indicating the end of the list.
- **Pointer/Reference**: A field in each node that stores the address of the next node in the sequence. This allows the nodes to be linked together.
- **Singly Linked List**: A type of linked list where each node has a single pointer to the next node. This is the simplest form of a linked list.
- **Doubly Linked List**: A more complex form of a linked list where each node has two pointers: one to the next node and one to the previous node. This allows traversal in both directions.
- **Circular Linked List**: A variation of linked lists where the last node points back to the first node, forming a circular structure. This can be implemented as either a singly or doubly linked list.
### Creating the Node
In a linked list, a node is the fundamental building block. Each node contains data and a pointer to the next node. Here’s how to define and create a node in C++:
```cpp
class Node {
public:
int data;
Node* next;
Node(int val) {
data = val;
next = nullptr;
}
};
// Creating a node with data value 10
Node* newNode = new Node(10);
```
### Operations on Linked List
#### Insertion of Data
**Insertion at the Beginning:**
To insert a node at the beginning of a linked list, create a new node and set its next pointer to the current head. Then, update the head to this new node.
```cpp
void insertAtBeginning(Node*& head, int val) {
Node* newNode = new Node(val);
newNode->next = head;
head = newNode;
}
```
`Time Complexity: O(1)`
**Insertion at the End:**
To insert a node at the end of a linked list, traverse to the last node and set its next pointer to the new node.
```cpp
void insertAtEnd(Node*& head, int val) {
Node* newNode = new Node(val);
if (head == nullptr) {
head = newNode;
return;
}
Node* temp = head;
while (temp->next != nullptr) {
temp = temp->next;
}
temp->next = newNode;
}
```
`Time Complexity: O(n)`
**Insertion at a Specific Position:**
To insert a node at a specific position, traverse to the node just before the desired position and adjust the pointers accordingly.
```cpp
void insertAtPosition(Node*& head, int val, int position) {
Node* newNode = new Node(val);
if (position == 0) {
newNode->next = head;
head = newNode;
return;
}
Node* temp = head;
for (int i = 0; temp != nullptr && i < position - 1; ++i) {
temp = temp->next;
}
if (temp == nullptr) return; // Position is out of bounds
newNode->next = temp->next;
temp->next = newNode;
}
```
`Time Complexity: O(n)`
### Traversing a Linked List
To traverse a linked list means to visit each node in the list, starting from the head, and accessing its data or performing operations on it.
```cpp
void traverseLinkedList(Node* head) {
Node* temp = head;
while (temp != nullptr) {
cout << temp->data << " ";
temp = temp->next;
}
}
```
`Time Complexity: O(n)`
### Deleting Elements from a Linked List
Deleting elements from a linked list involves removing nodes from the list while maintaining the integrity of the structure.
**Deletion from the Beginning:**
To delete a node from the beginning of a linked list, update the head to point to the next node, and deallocate memory for the removed node.
```cpp
void deleteFromBeginning(Node*& head) {
if (head == nullptr) return;
Node* temp = head;
head = head->next;
delete temp;
}
```
`Time Complexity: O(1)`
**Deletion from the End:**
To delete a node from the end of a linked list, traverse to the second-to-last node, update its next pointer to null, and deallocate memory for the last node.
```cpp
void deleteFromEnd(Node*& head) {
if (head == nullptr || head->next == nullptr) {
delete head;
head = nullptr;
return;
}
Node* temp = head;
while (temp->next->next != nullptr) {
temp = temp->next;
}
delete temp->next;
temp->next = nullptr;
}
```
`Time Complexity: O(n)`
**Deletion from a Specific Position:**
To delete a node from a specific position, traverse to the node just before the target position, update its next pointer to skip the target node, and deallocate memory for the removed node.
```cpp
void deleteAtPosition(Node*& head, int position) {
if (head == nullptr) return;
Node* temp = head;
if (position == 0) {
head = head->next;
delete temp;
return;
}
for (int i = 0; temp != nullptr && i < position - 1; ++i) {
temp = temp->next;
}
if (temp == nullptr || temp->next == nullptr) return; // Position is out of bounds
Node* nodeToDelete = temp->next;
temp->next = temp->next->next;
delete nodeToDelete;
}
```
`Time Complexity: O(n)`
### Searching and Updating Values in a Linked List
Searching for a specific value in a linked list involves traversing the list and comparing each node's data with the target value. Updating the value of a node requires locating the node with the target value and modifying its data field.
**Searching for a Value:**
To search for a value in a linked list, traverse the list until the target value is found or the end of the list is reached.
```cpp
bool searchValue(Node* head, int target) {
Node* temp = head;
while (temp != nullptr) {
if (temp->data == target) {
return true; // Value found
}
temp = temp->next;
}
return false; // Value not found
}
```
`Time Complexity: O(n)`
**Updating a Value:**
To update the value of a node in a linked list, locate the node with the target value and modify its data field.
```cpp
void updateValue(Node* head, int oldValue, int newValue) {
Node* temp = head;
while (temp != nullptr) {
if (temp->data == oldValue) {
temp->data = newValue; // Update value
return;
}
temp = temp->next;
}
}
```
`Time Complexity: O(n)`
### Reversing a Linked List
Reversing a linked list involves changing the direction of pointers so that the last node becomes the first node, and so on.
```cpp
Node* reverseLinkedList(Node* head) {
Node* prev = nullptr;
Node* current = head;
Node* nextNode = nullptr;
while (current != nullptr) {
nextNode = current->next; // Store next node
current->next = prev; // Reverse pointer
prev = current; // Move pointers one position ahead
current = nextNode;
}
return prev; // New head of the reversed list
}
```
`Time Complexity: O(n)`
## Full Code Implementation of Singly Linked List
Here's a comprehensive C++ implementation of a singly linked list, encapsulated within a class. The implementation includes various functions such as insertion, deletion, traversal, searching, updating values, and reversing the list.
```cpp
#include <iostream>
using namespace std;
class LinkedList {
private:
class Node {
public:
int data;
Node* next;
Node(int val) {
data = val;
next = nullptr;
}
};
Node* head;
public:
LinkedList() {
head = nullptr;
}
void insertAtBeginning(int val) {
Node* newNode = new Node(val);
newNode->next = head;
head = newNode;
}
void insertAtEnd(int val) {
Node* newNode = new Node(val);
if (head == nullptr) {
head = newNode;
return;
}
Node* temp = head;
while (temp->next != nullptr) {
temp = temp->next;
}
temp->next = newNode;
}
void insertAtPosition(int val, int position) {
Node* newNode = new Node(val);
if (position == 0) {
newNode->next = head;
head = newNode;
return;
}
Node* temp = head;
for (int i = 0; temp != nullptr && i < position - 1; ++i) {
temp = temp->next;
}
if (temp == nullptr) return; // Position is out of bounds
newNode->next = temp->next;
temp->next = newNode;
}
void deleteFromBeginning() {
if (head == nullptr) return;
Node* temp = head;
head = head->next;
delete temp;
}
void deleteFromEnd() {
if (head == nullptr) return;
if (head->next == nullptr) {
delete head;
head = nullptr;
return;
}
Node* temp = head;
while (temp->next->next != nullptr) {
temp = temp->next;
}
delete temp->next;
temp->next = nullptr;
}
void deleteAtPosition(int position) {
if (head == nullptr) return;
Node* temp = head;
if (position == 0) {
head = head->next;
delete temp;
return;
}
for (int i = 0; temp != nullptr && i < position - 1; ++i) {
temp = temp->next;
}
if (temp == nullptr || temp->next == nullptr) return; // Position is out of bounds
Node* nodeToDelete = temp->next;
temp->next = temp->next->next;
delete nodeToDelete;
}
void traverseLinkedList() const {
Node* temp = head;
while (temp != nullptr) {
cout << temp->data << " ";
temp = temp->next;
}
cout << endl;
}
bool searchValue(int target) const {
Node* temp = head;
while (temp != nullptr) {
if (temp->data == target) {
return true; // Value found
}
temp = temp->next;
}
return false; // Value not found
}
void updateValue(int oldValue, int newValue) {
Node* temp = head;
while (temp != nullptr) {
if (temp->data == oldValue) {
temp->data = newValue; // Update value
return;
}
temp = temp->next;
}
}
void reverseLinkedList() {
Node* prev = nullptr;
Node* current = head;
Node* nextNode = nullptr;
while (current != nullptr) {
nextNode = current->next; // Store next node
current->next = prev; // Reverse pointer
prev = current; // Move pointers one position ahead
current = nextNode;
}
head = prev;
}
int getLength() const {
int length = 0;
Node* temp = head;
while (temp != nullptr) {
length++;
temp = temp->next;
}
return length;
}
bool isEmpty() const {
return head == nullptr;
}
~LinkedList() {
Node* temp;
while (head != nullptr) {
temp = head;
head = head->next;
delete temp;
}
}
};
int main() {
LinkedList list;
list.insertAtEnd(10);
list.insertAtEnd(20);
list.insertAtEnd(30);
cout << "List after inserting at the end: ";
list.traverseLinkedList();
list.insertAtBeginning(5);
cout << "List after inserting at the beginning: ";
list.traverseLinkedList();
list.insertAtPosition(15, 2);
cout << "List after inserting at position 2: ";
list.traverseLinkedList();
cout << "Length of the list: " << list.getLength() << endl;
list.deleteFromBeginning();
cout << "List after deleting from the beginning: ";
list.traverseLinkedList();
list.deleteFromEnd();
cout << "List after deleting from the end: ";
list.traverseLinkedList();
list.deleteAtPosition(1);
cout << "List after deleting at position 1: ";
list.traverseLinkedList();
if (list.searchValue(20)) {
cout << "Value 20 found in the list" << endl;
} else {
cout << "Value 20 not found in the list" << endl;
}
list.updateValue(15, 25);
cout << "List after updating value 15 to 25: ";
list.traverseLinkedList();
list.reverseLinkedList();
cout << "List after reversing: ";
list.traverseLinkedList();
return 0;
}
```
This code defines a `LinkedList` class with various methods to manipulate the linked list, such as inserting, deleting, traversing, searching, updating values, reversing, checking if the list is empty, and getting the length of the list. The `main` function demonstrates the usage of these methods.
## Doubly Linked List
A doubly linked list is an extension of a singly linked list where each node contains an additional pointer to the previous node, allowing for traversal in both directions. This bidirectional nature offers greater flexibility in certain operations compared to a singly linked list.
#### Creating a Node
To create a node in a doubly linked list, you need to define a class with data, a pointer to the next node, and a pointer to the previous node.
```cpp
class DoublyNode {
public:
int data;
DoublyNode* next;
DoublyNode* prev;
DoublyNode(int val) {
data = val;
next = nullptr;
prev = nullptr;
}
};
// Creating a node with data value 10
DoublyNode* newNode = new DoublyNode(10);
```
#### Advantages Over Singly Linked List
- **Bidirectional Traversal:**
- **Doubly Linked List**: Can be traversed in both forward and backward directions, making it more versatile for operations that require access to previous elements.
- **Singly Linked List**: Can only be traversed in one direction.
- **Easier Deletion:**
- **Doubly Linked List**: Deleting a node is easier as you have direct access to the previous node.
- **Singly Linked List**: Requires traversal from the head to find the previous node for deletion.
- **Efficient Insertion/Deletion:**
- **Doubly Linked List**: Insertion and deletion operations at both ends (head and tail) and at specific positions are more efficient due to the presence of both next and previous pointers.
- **Singly Linked List**: These operations are generally less efficient because the list can only be traversed in one direction.
#### Time Complexity Advantages
- **Deletion of a Node:**
- **Doubly Linked List**: `O(1)` if you have a pointer to the node to be deleted because you can directly access the previous node.
- **Singly Linked List**: `O(n)` because you need to traverse from the head to find the previous node.
- **Insertion Before a Given Node:**
- **Doubly Linked List**: `O(1)` if you have a pointer to the node, as you can directly adjust the pointers of the previous node.
- **Singly Linked List**: `O(n)` as it requires traversal to the previous node.
- **Reversing the List:**
- **Doubly Linked List**: Slightly more efficient due to bidirectional pointers, though both types have `O(n)` complexity.
- **Singly Linked List**: `O(n)` but requires extra steps to reverse the pointers.
## Circular Linked List
A circular linked list is a variation of a linked list where the last node points back to the first node, forming a circular structure. This type of list can be singly or doubly linked and offers benefits in certain scenarios, such as round-robin scheduling.
#### Creating a Node
To create a node in a circular linked list, you define a class similar to a regular singly or doubly linked list, but with the understanding that the `next` pointer of the last node points back to the head.
```cpp
class CircularNode {
public:
int data;
CircularNode* next;
CircularNode(int val) {
data = val;
next = nullptr;
}
};
// Creating a node with data value 10
CircularNode* newNode = new CircularNode(10);
```
#### Advantages Over Singly Linked List
- **Circular Nature:**
- **Circular Linked List**: The list can be traversed from any node, making it useful for applications like round-robin scheduling and buffering.
- **Singly Linked List**: The list ends at the last node, which does not point back to the head.
- **Efficient Circular Traversal:**
- **Circular Linked List**: Allows continuous traversal without needing to restart from the head after reaching the end.
- **Singly Linked List**: Traversal stops at the end, and restarting requires going back to the head.
#### Time Complexity Advantages
- **Insertion at the End:**
- **Circular Linked List**: `O(1)` if you maintain a tail pointer, as the new node can be added after the tail, and the tail pointer is updated.
- **Singly Linked List**: `O(n)` as it requires traversal to the end of the list.
- **Traversal for Operations:**
- **Circular Linked List**: `O(n)` for traversal, but traversal can continue seamlessly from end to start.
- **Singly Linked List**: `O(n)` for traversal, stopping at the end.
| harshm03 |
1,853,279 | Funções | Queria começar a escrever uns artigos tem um tempo e hoje na aula de estrutura de dados tive essa... | 0 | 2024-05-15T01:29:00 | https://dev.to/leonardosf/funcoes-251b | cpp, beginners | Queria começar a escrever uns artigos tem um tempo e hoje na aula de estrutura de dados tive essa idéia de escrever sobre funções e espero que possa servir para o pessoal da monitoria de algoritmos e pra você que possívelmente ficou curioso e veio ler.
Funções primeiramente servem pra não repetirmos código. Existe um princípio de desenvolvimento de software chamado DRY (Don't repeat yourself), uma versão diferente do que os menudos diriam "Não se repita".
Imagina um código dessa forma:
```cpp
#include <iostream>
#include <cmath>
using namespace std;
int main() {
// Cálculo da área do retângulo
//base 5 - altura 10
float baseRetangulo = 5;
float alturaRetangulo = 10;
float areaRetangulo = baseRetangulo * alturaRetangulo;
cout << "Área do retângulo: " << areaRetangulo << endl;
//base 7 - altura 11
float baseRetangulo = 7;
float alturaRetangulo = 11;
float areaRetangulo = baseRetangulo * alturaRetangulo;
cout << "Área do retângulo: " << areaRetangulo << endl;
//base 8 - altura 12
float baseRetangulo = 8;
float alturaRetangulo = 12;
float areaRetangulo = baseRetangulo * alturaRetangulo;
cout << "Área do retângulo: " << areaRetangulo << endl;
return 0;
}
```
Poderíamos facilmente ter escrito esse código dessa forma abaixo e perceba como ficou mais fácil de ler o que está acontecendo. Além disso, eu repito o código infinitamente menos.
```cpp
#include <iostream>
#include <cmath>
using namespace std;
// Função para calcular a área do retângulo
float calcularAreaRetangulo(float base, float altura) {
return base * altura;
}
int main() {
// Exemplos de uso das funções
cout << "Área do retângulo: " << calcularAreaRetangulo(5, 10) << endl;
cout << "Área do retângulo: " << calcularAreaRetangulo(7, 11) << endl;
cout << "Área do retângulo: " << calcularAreaRetangulo(8, 12) << endl;
return 0;
}
```
Suponho que concorde que fica muito mais fácil de entender o código e usá-lo para calcular as áreas das formas geométrica. Eu escrevo muito menos linhas e consigo usar valores diferentes de uma forma muito mais fácil.
E esse exemplo é bem simples, em um sistema mais complexo, os benefícios são infinitamente maiores.
Para defini-las usamos essa estrutura:
```cpp
tipoDeRetorno nomeDafuncao(tipoParametro1 nomeParametro1, tipoParametro2 nomeParametro2, ...) {
//conteúdo da função
}
```
Primeiramente declaramos o tipo de retorno, ou seja, o que aquela função vai entregar pra gente.
Pode ser void se não retornar nada, pode ser int se retornar um inteiro (igual a função da área do retângulo por exemplo), float se eu retornar números decimais...
Agora entra a parte mais complicadinha, vamos falar sobre os parâmetros. Usando aquela função dá área do retângulo, percebe que no início, avisamos o programa que ela vai retornar um número decimal? E além disso, percebe que depois da abertura dos parênteses, temos duas variáveis?
```cpp
float calcularAreaRetangulo(float base, float altura) {
return base * altura;
}
```
Essas variáveis são chamadas de parâmetros, elas dizem que pro funcionamento da função, eu vou precisar de 2 coisas, no caso o número da base e o número da altura. E se observamos a linha de baixo vemos que a única coisa que essa função faz é pegar esses valores e multiplica-los então claro, precisaremos de 2 valores para isso.
Mas perceba, quando eu declaro essa função como fiz no código de cima, eu NÃO ESTOU PASSANDO VALOR NENHUM. Aquilo ali só diz pro computador, vou precisar de 2 coisas aqui, mas não tem valor nenhum definido ali.
E como eu defino um valor? Simples, primeiro você precisa executar (chamar) essa função. E para isso é só fazer assim.
```cpp
float area = calcularAreaRetangulo();
```
Se você definir a função da forma que fiz e executar esse código, perceberá que terá um erro. O erro nos diz o seguinte:
> candidate function not viable: requires 2 arguments, but 0 were provided
Ou seja, são necessários 2 argumentos mas eu não entreguei nenhum. E você pode se perguntar, mas o que são argumentos? Eles são justamente o valor que eu passo, o que preencherá o vazio que existe nos parâmetros (lembra que eles não existem? eles só avisam que eu vou precisar de alguma coisa ali?).
E agora quando eu chamo a função dessa forma aqui:
```cpp
float area = calcularAreaRetangulo(3, 4);
```
Terei como resultado 12!
Então lembra:
PARÂMETRO É O QUE EU ESPERO RECEBER
ARGUMENTO É O QUE EU MANDO PARA A FUNÇÃO SER EXECUTADA
| leonardosf |
1,873,667 | Functional and Non functional | FUNCTIONAL TESTING It verifys the operations and action of an application. It is based on... | 0 | 2024-06-02T13:27:57 | https://dev.to/malaiyarasi/functional-and-non-functional-4ke3 | functional, testing, non | FUNCTIONAL TESTING
1. It verifys the operations and action of an application.
2. It is based on requirements of customer.
3. It helps to enhance the behaviour of the application.
4. functional testing is easy to execute manually.
5. Functional testing is based on the business requirement.
6. functional testing ensure that the function and features of the application works properly
7. functional testing can be done manually.
functional testing is based on customer's requirement.
8. Functional testing has a goal to validate software actions.
9. A Functional Testing example is to check the login functionality.
10. Functional testing is performed before the non-functional testing.
11. It is easy to define functional requirements.
12. Helps to validate the behavior of the application.
13. Functional testing is carried out using the functional specification.
14. It describes what the product does.
15. Examples of Functional Testing Types
1.Unit testing
2.Smoke testing
3.User Acceptance
4.Integration Testing
5.Regression testing
NON FUNCTIONAL TESTING
Non-Functional Testing is defined as a type of Software testing to check non-functional aspects of a software application. It is designed to test the readiness of a system as per nonfunctional parameters which are never addressed by functional testing.**
1.It is performed after the functional testing.
2.It focusses on customer’s expectation.
3.It is difficult to define the requirements for non-functional testing.
4. It’s very hard to perform non-functional testing manually.
5. It is done to validate the performance of the software.
6. This kind of testing is carried out by performance specifications
7. Non functional testing describe the performance or usability of the software system.
8. This kind of testing is carried out by performance specifications
9. Examples of Non functional testing examples
1.Volume Testing
2.Scalability
3.Usability Testing
4.Load Testing
5.Stress Testing
6.Compliance Testing
7.Portability Testing
8.Disaster Recover Testing
| malaiyarasi |
1,873,708 | Routing and Navigation in React.js 🚀 | Install React Router 🛠️ npm install react-router-dom Enter fullscreen mode ... | 0 | 2024-06-02T13:25:07 | https://dev.to/erasmuskotoka/routing-and-navigation-in-reactjs-1ge6 |
1. Install React Router 🛠️
```bash
npm install react-router-dom
```
2. Set Up Router 🗺️
```jsx
import { BrowserRouter as Router, Route, Switch, Link } from 'react-router-dom';
function App() {
return (
<Router>
<nav>
<Link to="/">Home</Link>
<Link to="/about">About</Link>
<Link to="/contact">Contact</Link>
</nav>
<Switch>
<Route exact path="/" component={Home} />
<Route path="/about" component={About} />
<Route path="/contact" component={Contact} />
</Switch>
</Router>
);
}
```
3. Dynamic Routing 🧩
```jsx
<Route path="/user/:id" component={UserProfile} />
function UserProfile({ match }) {
return <div>User ID: {match.params.id}</div>;
}
```
4. Nested Routes 🏞️
```jsx
function Dashboard() {
return (
<Switch>
<Route path="/dashboard/profile" component={Profile} />
<Route path="/dashboard/settings" component={Settings} />
</Switch>
);
}
```
5. Redirects & 404 🚧
```jsx
import { Redirect } from 'react-router-dom';
<Route path="/old-path">
<Redirect to="/new-path" />
</Route>
<Route path="*">
<NotFound />
</Route>
`
#COdeWith
#KOToka | erasmuskotoka | |
1,873,672 | Mastering Terraform Debugging: Tips and Techniques 🔧 | There is a wealth of information available about Terraform and the various tools within the Terraform... | 0 | 2024-06-02T13:21:41 | https://rgeraskin.hashnode.dev/terraform-expressions-debugging | devops, terraform | There is a wealth of information available about Terraform and the various tools within the Terraform ecosystem. However, there seems to be a noticeable gap when it comes to resources on debugging techniques specific to Terraform.
Let's address this issue and expand the knowledge base to include detailed debugging methods.
## Terraform Console
The built-in Terraform feature can make your life much simpler. It's often been avoided by engineers and is not so popular in blogs.
What can you do with the console? Basically, it can be used not only to show info about a resource in a state.
### 1. Drop state info
When you run `terraform console` in a Terraform project directory, it tries to use the state information to get actual details. It's useful for getting information about created resources or data objects.
But it sometimes slows down the debugging process. For example, if you place your state in an S3 bucket, it fetches it first. Tools like `terraform-repl` run `terraform console` under the hood for every command, making the process really slow. Also, `console` sets a lock on the state while you work with it.
To work with `console` without an S3 state, you can comment out the Terraform `backend` section, remove the `.terraform` folder, and rerun `terraform init`.
### 2. Test your expressions
Often we have to convert data between various formats to meet the requirements of module interfaces or for other cases. And we usually do it blindly, evaluating complicated expressions in our minds only. That leads to unexpected issues in some corner cases.
Just test it:
```plaintext
> coalesce(["", "b"]...)
b
```
Yes, it's a simple example from the tf docs, but you can use `console` for much more complicated things.
> Did you know that terraform console can be launched not only in a directory with a terraform project? To test expressions, you can start it in any directory.
### 3. Define your own `locals` interactively
One of the common drawbacks of terraform console is that it doesn't allow you to set your own variables or locals. To compose a complicated expression, it's handy to use intermediate local variables.
To make it possible, you can use terraform console wrappers such as [terraform-repl](https://github.com/paololazzari/terraform-repl). It also adds a tab-completion feature.
```plaintext
> local.a=1
> local.a+1
2
```
By using the `local` command, you can display all local variables.
There is another tool called [tfrepl](https://github.com/ysoftwareab/tfrepl) with similar functionality. However, it doesn't have tab-completion, and it can't show all of your defined `locals`.
### 4. Debug your modules
Modules are the way to keep your tf code [DRY](https://en.wikipedia.org/wiki/Don%27t_repeat_yourself). But it's a pain in the neck when you debug and refactor it. Use console tools to make it simpler.
If you have default values for your variables defined, just run `terraform console` or `terraform-repl` to debug expressions.
If you have no default values, it's safe to place `terraform.tfvars` just inside the module folder. Terraform will ignore these vars when this module is used somewhere in a parent project.
### 5. Test your modules
The practice of testing Terraform code is not widely used in the infrastructure world. Actually, I've never seen tests in any single company :)
> Personally, I don't see any significant benefit from tests in the way they are meant to be used. See [this](https://developer.hashicorp.com/terraform/language/tests#example) example from the official docs: the test checks if the bucket's name is created as expected.
>
> Do we really need it? We just use the variable in the bucket name, so it's obvious that nothing will happen to it later!
But we can use tests to make sure that we will not break a module's 'interface' sometime in the future while refactoring. Just write a test and do anything with local expressions and variables.
Stupid simple test example:
```bash
# main.tftest.hcl
run "test" {
command = plan
assert {
condition = jsonencode(local.users) == jsonencode({
"john" = {
"grants" = null
"login" = true
"member_of" = [
"admin",
]
"password_enabled" = false
}
})
error_message = "Wrong format of local.users : ${jsonencode(local.users)}"
}
}
```
```bash
❯ terraform test
main.tftest.hcl... in progress
run "test"... pass
main.tftest.hcl... tearing down
main.tftest.hcl... pass
Success! 1 passed, 0 failed.
```
Again, if you already have default values in your `variables.tf`, you are ready to use tests. If you don't, place `terraform.tfvars` as stated above.
I don't recommend placing variables inside `*.tftest.hcl` in simple cases because you will not be able to use those variables with `console` later. Also, avoid complicated tests. Simple tests are easier to support. So, there is a chance that they will be supported in the future at least.
Testing expressions is the way to be confident that you will have the expected value in your resource property.
## Conclusion
I shared a few tricks on debugging Terraform expressions. Do you have any to add? Share them in the comments. | rgeraskin |
1,873,670 | Flutter and GraphQL with Authentication | You will learn, How to get the schema from the backend? How to use a code generation tool to make... | 0 | 2024-06-02T13:16:57 | https://dev.to/alishgiri/flutter-and-graphql-with-authentication-42ef | flutter, graphql | You will learn,
- How to get the schema from the backend?
- How to use a code generation tool to make things easier?
- How to make a GraphQL API request?
- How to renew the access token?
I will jump right in!
## Code Links:
Get the source code from here.
{% embed https://github.com/alishgiri/flutter-graphql-authentication %}
## Tools we will be using:
1. **get-graphql-schema**
This npm package will allow us to download GraphQL schema from our backend.
{% embed https://github.com/prisma-labs/get-graphql-schema %}
2. **graphql_flutter**
We will make GraphQL API requests using this package.
{% embed https://pub.dev/packages/graphql_flutter %}
3. **graphql_codegen**
This code-generation tool will convert our schema (.graphql) to dart types (.dart).
There is another code-generation tool called _Artemis_ as well but I found this to be better.
{% embed https://pub.dev/packages/graphql_codegen %}
Additionally, we will be using,
- **Provider** — For state management.
- **flutter_secure_storage** — to store user auth data locally.
- **get_it** — to locate our registered services and view-models files.
- **build_runner** — to generate files. We will configure graphql_codegen with this to make code generation possible.
## Alternative package to work with GraphQL:
**Ferry**
I found this package very complicated but feel free to try this out.
This package will help in making GraphQL API requests. This will also be a code-generation tool to convert schema files (.graphql) to dart types (.dart).
[Ferry Setup](https://medium.com/r/?url=https%3A%2F%2Fferrygraphql.com%2Fdocs%2Fsetup)
## Files & Folder structure
```
lib
- core
- models
- services
- view_models
- graphql
- __generated__
- your_app.schema.graphql // We will download this using get-graphql-schema
- queries
- __generated__
- auth.graphql // this is equivalent to auth end-points in REST API
- ui
- widgets
- views
- locator.dart
- main.dart
pubspec.yml
build.yaml
```
> Check the comments on top of every file below to place the files in their respective folders.
Make the following changes to your **pubspec.yml** file,
```yaml
dependencies:
flutter_secure_storage: ^9.0.0
jwt_decode: ^0.3.1
provider: ^6.1.1
graphql_flutter: ^5.2.0-beta.6
get_it: ^7.6.7
dev_dependencies:
build_runner: ^2.4.8
flutter_gen: ^5.4.0
flutter_lints: ^4.0.0
graphql_codegen: ^0.14.0
flutter:
generate: true
```
Add the following content to your **build.yaml** file,
```yaml
targets:
$default:
builders:
graphql_codegen:
options:
assetsPath: lib/graphql/**
outputDirectory: __generated__
clients:
- graphql_flutter
```
Here, in the _options_ section we have,
**assetsPath**: All the GraphQL-related code will be placed inside lib/graphql/ so we are pointing it to that folder.
**outputDirectory**: is where we want our generated code to reside. So create the following folders.
- _lib/graphql/__generated__/_
- _lib/graphql/queries/__generated__/_
## Getting the schema file
Install _get-graphql-schema_ globally using npm or yarn and run it from your project root directory.
```bash
# Install using yarn
yarn global add get-graphql-schema
# Install using npm
npm install -g get-graphql-schema
```
```bash
npx get-graphql-schema http://localhost:8000/graphql > lib/graphql/your_app.schema.graphql
```
> We are providing our graphql API link and asking **get-graphql-schema** to store it on the file **your_app.schema.graphql**
Modify the above as required!
## Adding the endpoints to auth.graphql file
The queries and mutations below are defined by the backend so please get the correct GraphQL schema (also called the end-points).
```graphql
# lib/graphql/queries/auth.graphql
mutation RegisterUser($input: UserInput!) {
auth {
register(input: $input) {
...RegisterSuccess
}
}
}
query Login($input: LoginInput!) {
auth {
login(input: $input) {
...LoginSuccess
}
}
}
query RenewAccessToken($input: RenewTokenInput!) {
auth {
renewToken(input: $input) {
...RenewTokenSuccess
}
}
}
fragment RegisterSuccess on RegisterSuccess {
userId
}
fragment LoginSuccess on LoginSuccess {
accessToken
refreshToken
}
fragment RenewTokenSuccess on RenewTokenSuccess {
newAccessToken
}
```
## The Implementation!
Run the following command to generate all dart types for our .graphql files.
```bash
dart run build_runner build
```
Now, setting up the **graphql**, **get_it** and initialising hive (used for caching) in our **main.dart** file,
Create a file _lib/locator.dart_ and add the following content.
```dart
// locator.dart
import 'package:get_it/get_it.dart';
import 'package:auth_app/core/view_models/login.vm.dart';
import 'package:auth_app/core/services/base.service.dart';
import 'package:auth_app/core/services/auth.service.dart';
import 'package:auth_app/core/services/secure_storage.service.dart';
final locator = GetIt.instance;
void setupLocator() async {
locator.registerSingleton(BaseService());
locator.registerLazySingleton(() => AuthService());
locator.registerLazySingleton(() => SecureStorageService());
locator.registerFactory(() => LoginViewModel());
}
```
In the _lib/main.dart_ we will call setupLocator() in the main() function as shown below.
```dart
// main.dart
import 'package:flutter/material.dart';
import 'package:provider/provider.dart';
import 'package:graphql_flutter/graphql_flutter.dart';
import 'package:auth_app/locator.dart';
import 'package:auth_app/ui/views/login.view.dart';
import 'package:auth_app/core/services/base.service.dart';
import 'package:auth_app/core/services/auth.service.dart';
void main() async {
// If you want to use HiveStore() for GraphQL caching.
// await initHiveForFlutter();
setupLocator();
runApp(const App());
}
class App extends StatelessWidget {
const App({Key? key}) : super(key: key);
@override
Widget build(BuildContext context) {
return GraphQLProvider(
client: locator<BaseService>().clientNotifier,
child: ChangeNotifierProvider.value(
value: locator<AuthService>(),
child: const MaterialApp(
title: 'your_app',
debugShowCheckedModeBanner: false,
home: LoginView(),
),
),
);
}
```
Now we will create the remaining files.
Our data models:
```dart
// core/models/auth_data.model.dart
class AuthData {
final String? accessToken;
final String? refreshToken;
const AuthData({
required this.accessToken,
required this.refreshToken,
});
}
```
```dart
// core/models/auth.model.dart
import 'package:jwt_decode/jwt_decode.dart';
import 'package:auth_app/core/models/auth_data.model.dart';
class Auth {
final String name;
final String userId;
final String accessToken;
final String refreshToken;
const Auth({
required this.name,
required this.userId,
required this.accessToken,
required this.refreshToken,
});
factory Auth.fromJson(Map<String, dynamic> data) {
final jwt = Jwt.parseJwt(data["accessToken"]);
return Auth(
name: jwt["name"],
userId: jwt["iss"],
accessToken: data["accessToken"],
refreshToken: data["refreshToken"],
);
}
factory Auth.fromAuthData(AuthData data) {
final jwt = Jwt.parseJwt(data.accessToken!);
return Auth(
name: jwt["name"],
userId: jwt["iss"],
accessToken: data.accessToken!,
refreshToken: data.refreshToken!,
);
}
}
```
Our secure storage service file saves authentication information:
```dart
// core/services/secure_storage.service.dart
import 'package:flutter_secure_storage/flutter_secure_storage.dart';
import 'package:auth_app/core/models/auth.model.dart';
import 'package:auth_app/core/models/auth_data.model.dart';
const accessToken = "access_token";
const refreshToken = "refresh_token";
class SecureStorageService {
final _storage = FlutterSecureStorage(
iOptions: _getIOSOptions(),
aOptions: _getAndroidOptions(),
);
static IOSOptions _getIOSOptions() => const IOSOptions();
static AndroidOptions _getAndroidOptions() => const AndroidOptions(
encryptedSharedPreferences: true,
);
Future<void> storeAuthData(Auth auth) async {
await _storage.write(key: accessToken, value: auth.accessToken);
await _storage.write(key: refreshToken, value: auth.refreshToken);
}
Future<AuthData> getAuthData() async {
final map = await _storage.readAll();
return AuthData(accessToken: map[accessToken], refreshToken: map[refreshToken]);
}
Future<void> updateAccessToken(String token) async {
await _storage.delete(key: accessToken);
await _storage.write(key: accessToken, value: token);
}
Future<void> updateRefreshToken(String token) async {
await _storage.write(key: refreshToken, value: token);
}
Future<void> clearAuthData() async {
await _storage.deleteAll();
}
}
```
Our base service file contains a configured graphql client which will be used to make the API requests to the server:
```dart
// core/services/base.service.dart
import 'dart:async';
import 'package:flutter/foundation.dart';
import 'package:jwt_decode/jwt_decode.dart';
import 'package:graphql_flutter/graphql_flutter.dart';
import 'package:auth_app/locator.dart';
import 'package:auth_app/core/services/auth.service.dart';
import 'package:auth_app/core/services/secure_storage.service.dart';
import 'package:auth_app/graphql/queries/__generated__/auth.graphql.dart';
import 'package:auth_app/graphql/__generated__/your_app.schema.graphql.dart';
class BaseService {
late GraphQLClient _client;
late ValueNotifier<GraphQLClient> _clientNotifier;
bool _renewingToken = false;
GraphQLClient get client => _client;
ValueNotifier<GraphQLClient> get clientNotifier => _clientNotifier;
BaseService() {
final authLink = AuthLink(getToken: _getToken);
final httpLink = HttpLink("http://localhost:8000/graphql");
/// The order of the links in the array matters!
final link = Link.from([authLink, httpLink]);
_client = GraphQLClient(
link: link,
cache: GraphQLCache(),
//
// You have two other caching options.
// But for my example I won't be using caching.
//
// cache: GraphQLCache(store: HiveStore()),
// cache: GraphQLCache(store: InMemoryStore()),
//
defaultPolicies: DefaultPolicies(query: Policies(fetch: FetchPolicy.networkOnly)),
);
_clientNotifier = ValueNotifier(_client);
}
Future<String?> _getToken() async {
if (_renewingToken) return null;
final storageService = locator<SecureStorageService>();
final authData = await storageService.getAuthData();
final aT = authData.accessToken;
final rT = authData.refreshToken;
if (aT == null || rT == null) return null;
if (Jwt.isExpired(aT)) {
final renewedToken = await _renewToken(rT);
if (renewedToken == null) return null;
await storageService.updateAccessToken(renewedToken);
return 'Bearer $renewedToken';
}
return 'Bearer $aT';
}
Future<String?> _renewToken(String refreshToken) async {
try {
_renewingToken = true;
final result = await _client.mutate$RenewAccessToken(Options$Mutation$RenewAccessToken(
fetchPolicy: FetchPolicy.networkOnly,
variables: Variables$Mutation$RenewAccessToken(
input: Input$RenewTokenInput(refreshToken: refreshToken),
),
));
final resp = result.parsedData?.auth.renewToken;
if (resp is Fragment$RenewTokenSuccess) {
return resp.newAccessToken;
} else {
if (result.exception != null && result.exception!.graphqlErrors.isNotEmpty) {
locator<AuthService>().logout();
}
}
} catch (e) {
rethrow;
} finally {
_renewingToken = false;
}
return null;
}
}
```
We will use **_client** in the file above to make the GraphQL API requests. We will also check if our access-token has expired before making an API request and renew it if necessary.
File _auth.service.dart_ contains all Auth APIs service functions:
```dart
// core/services/auth.service.dart
import 'package:flutter/material.dart';
import 'package:graphql_flutter/graphql_flutter.dart';
import 'package:auth_app/locator.dart';
import 'package:auth_app/core/models/auth.model.dart';
import 'package:auth_app/core/services/base.service.dart';
import 'package:auth_app/core/services/secure_storage.service.dart';
import 'package:auth_app/graphql/queries/__generated__/auth.graphql.dart';
import 'package:auth_app/graphql/__generated__/your_app.schema.graphql.dart';
class AuthService extends ChangeNotifier {
Auth? _auth;
final client = locator<BaseService>().client;
final storageService = locator<SecureStorageService>();
Auth? get auth => _auth;
Future<void> initAuthIfPreviouslyLoggedIn() async {
final auth = await storageService.getAuthData();
if (auth.accessToken != null) {
_auth = Auth.fromAuthData(auth);
notifyListeners();
}
}
Future<void> login(Input$LoginInput input) async {
final result = await client.query$Login(Options$Query$Login(
variables: Variables$Query$Login(input: input),
));
final resp = result.parsedData?.auth.login;
if (resp is Fragment$LoginSuccess) {
_auth = Auth.fromJson(resp.toJson());
storageService.storeAuthData(_auth!);
notifyListeners();
} else {
throw gqlErrorHandler(result.exception);
}
}
Future<void> registerUser(Input$UserInput input) async {
final result = await client.mutate$RegisterUser(Options$Mutation$RegisterUser(
variables: Variables$Mutation$RegisterUser(input: input),
));
final resp = result.parsedData?.auth.register;
if (resp is! Fragment$RegisterSuccess) {
throw gqlErrorHandler(result.exception);
}
}
Future<void> logout() async {
await locator<SecureStorageService>().clearAuthData();
_auth = null;
notifyListeners();
}
// You can put this in a common utility functions so
// that you can reuse it in other services file too.
//
String gqlErrorHandler(OperationException? exception) {
if (exception != null && exception.graphqlErrors.isNotEmpty) {
return exception.graphqlErrors.first.message;
}
return "Something went wrong.";
}
}
```
Our base view and base view model:
```dart
// ui/shared/base.view.dart
import 'package:flutter/material.dart';
import 'package:provider/provider.dart';
import 'package:auth_app/locator.dart';
import 'package:auth_app/core/view_models/base.vm.dart';
class BaseView<T extends BaseViewModel> extends StatefulWidget {
final Function(T)? dispose;
final Function(T)? initState;
final Widget Function(BuildContext context, T model, Widget? child) builder;
const BaseView({
super.key,
this.dispose,
this.initState,
required this.builder,
});
@override
BaseViewState<T> createState() => BaseViewState<T>();
}
class BaseViewState<T extends BaseViewModel> extends State<BaseView<T>> {
final T model = locator<T>();
@override
void initState() {
if (widget.initState != null) widget.initState!(model);
super.initState();
}
@override
void dispose() {
if (widget.dispose != null) widget.dispose!(model);
super.dispose();
}
@override
Widget build(BuildContext context) {
return ChangeNotifierProvider<T>.value(
value: model,
child: Consumer<T>(builder: widget.builder),
);
}
}
```
```dart
// core/view_models/base.vm.dart
import 'package:flutter/material.dart';
class BaseViewModel extends ChangeNotifier {
bool _isLoading = false;
final scaffoldKey = GlobalKey<ScaffoldState>();
bool get isLoading => _isLoading;
setIsLoading([bool busy = true]) {
_isLoading = busy;
notifyListeners();
}
void displaySnackBar(String message) {
final scaffoldMessenger = ScaffoldMessenger.of(
scaffoldKey.currentContext!,
);
scaffoldMessenger.showSnackBar(
SnackBar(
content: Row(
children: [
const Icon(Icons.warning, color: Colors.white),
const SizedBox(width: 10),
Flexible(child: Text(message)),
],
),
),
);
}
}
```
In the above base view, we use the Provider as a state management tool. The base view model extends **ChangeNotifier** which notifies its view when the **notifyListeners()** function is called in the View Model.
Now, We will be using the base view and base view model for our login view and login view model:
```dart
// ui/views/login.view.dart
import 'package:flutter/material.dart';
import 'package:auth_app/ui/shared/base.view.dart';
import 'package:auth_app/core/view_models/login.vm.dart';
class LoginView extends StatelessWidget {
const LoginView({super.key});
@override
Widget build(BuildContext context) {
return BaseView<LoginViewModel>(
builder: (context, loginVm, child) {
return Scaffold(
key: loginVm.scaffoldKey,
body: SafeArea(
child: Padding(
padding: const EdgeInsets.all(20.0),
child: Column(
mainAxisAlignment: MainAxisAlignment.center,
children: [
Form(
// Attach form key for validations. I won't be adding validations.
// key: loginVm.formKey,
child: Column(
children: [
Text("Auth App", style: Theme.of(context).textTheme.displayMedium),
const SizedBox(height: 30),
TextFormField(
onChanged: loginVm.onChangedEmail,
keyboardType: TextInputType.emailAddress,
decoration: const InputDecoration(hintText: "Email"),
),
const Divider(height: 2),
TextFormField(
obscureText: true,
onChanged: loginVm.onChangedPassword,
decoration: const InputDecoration(hintText: "Password"),
),
const SizedBox(height: 20),
TextButton(
onPressed: loginVm.onLogin,
child: loginVm.isLoading ? const CircularProgressIndicator() : const Text("Login"),
),
],
),
),
],
),
),
),
);
},
);
}
}
```
The final file in our tutorial and we are all done 🎉:
```dart
// core/view_models/login.vm.dart
import 'package:auth_app/locator.dart';
import 'package:auth_app/core/view_models/base.vm.dart';
import 'package:auth_app/core/services/auth.service.dart';
import 'package:auth_app/graphql/__generated__/your_app.schema.graphql.dart';
class LoginViewModel extends BaseViewModel {
String? _email;
String? _password;
// Used for validation or any other purpose like clearing form and more...
// final formKey = GlobalKey<FormState>();
final _authService = locator<AuthService>();
void onChangedPassword(String value) => _password = value;
void onChangedEmail(String value) => _email = value;
Future<void> onLogin() async {
// Validate login details using [formKey]
// if (!formKey.currentState!.validate()) return;
try {
setIsLoading(true);
final input = Input$LoginInput(identifier: _email!, password: _password!);
await _authService.login(input);
displaySnackBar("Successfully logged in!");
} catch (error) {
displaySnackBar(error.toString());
} finally {
setIsLoading(false);
}
}
}
```
And always use **Provider** to access auth from the AuthService, this will make sure that your UI gets updated when you call _notifyListeners()_ in AuthService.
```dart
// Always access auth using Provider.of
Widget build(BuildContext context) {
final auth = Provider.of<AuthService>(context).auth;
// Set listen to false if you don't want to re-render the widget.
//
// final auth = Provider.of<AuthService>(context, listen: false).auth;
// DO NOT DO THIS!
// If you do this then your UI won't be updated,
// when you call notifyListeners() in AuthService.
//
// final auth = locator<AuthService>().auth;
return Scaffold(...)
}
```
I hope this gives you a complete idea about working with GraphQL in Flutter. If you have any questions feel free to comment.
Awesome! See you next time. | alishgiri |
1,873,671 | Init web project with TS & Webpack from scratch | I'm trying to create web application using TS and Webpack, its name is "Shooter" - a basic game on... | 0 | 2024-06-02T13:16:45 | https://dev.to/thinhkhang97/init-web-project-with-ts-webpack-from-scratch-4c83 | webdev, typescript, beginners, webpack | I'm trying to create web application using TS and Webpack, its name is "Shooter" - a basic game on browser. Today I'll show you how to init the project with Typescript and use Webpack to bundle the code.
## Prerequisites
* Installed nodejs
### Create a new folder, then open it by vscode
```
mkdir shooter
cd shooter
code .
```
### Init npm and git
```
npm init -y
git init
```
In `.gitignore` file, add `node_modules` and `dist` to ignore them.
### Init typescript config and webpack
Init typescript config file
```
npx tsc --init
```
Add `ts-loader` and `webpack-cli` to use webpack with typescript
```
npm install ts-loader --save-dev
npm install webpack-cli --save-dev
```
Create `webpack.config.js` file and add those configurations:
```javascript
const path = require("path");
module.exports = {
entry: "./src/index.ts",
module: {
rules: [
{
test: /\.tsx?$/,
use: "ts-loader",
exclude: /node_modules/,
},
],
},
resolve: {
extensions: [".tsx", ".ts", ".js"],
},
output: {
filename: "bundle.js",
path: path.resolve(__dirname, "dist"),
},
};
```
### Create .ts file and test
Create `src` directory and `index.ts` file with some typescript code to test.
In `package.json` file, add this script inside `scripts` to build the code.
```json
"build": "webpack --mode=development"
```
Build code by using
```
npm run build
```
And you can see file `bundle.js` inside `dist` folder.
### Add `watch` feature
To make webpack bundles code automatically each time you change code in `src` directory, add this script into `package.json`
```json
"watch": "webpack --mode=development --watch"
```
Try to update code inside `src` directory and watch webpack bundles you code immediately.
### Binding `bundle.js` with `index.html`
Create `index.html` file with some code in `public` directory.
Add `html-webpack-plugin`
```
npm install --save-dev html-webpack-plugin
```
Update add the plugin to `webpack.config.js` file
```javascript
const path = require("path");
const HtmlWebpackPlugin = require("html-webpack-plugin");
module.exports = {
entry: "./src/index.ts",
module: {
rules: [
{
test: /\.tsx?$/,
use: "ts-loader",
exclude: /node_modules/,
},
],
},
resolve: {
extensions: [".tsx", ".ts", ".js"],
},
output: {
filename: "bundle.js",
path: path.resolve(__dirname, "dist"),
},
plugins: [
new HtmlWebpackPlugin({
template: "public/index.html",
}),
],
};
```
Now, run the project again, you will see the `bundle.js` is binding in header tag.
### Use `dev-server`
To start you web application and apply watching code change in webpack, we can use `web-pack-dev-server`
```
npm install webpack-dev-server --save-dev
```
Add this configuration in `webpack.config.js`
```javascript
devServer: {
static: {
directory: path.join(__dirname, "dist"),
},
compress: true,
port: 9000,
},
```
Then finally add this script `package.json`
```
"start": "webpack serve --mode=development"
```
Now run the project with
```
npm run start
```
And open [http://localhost:9000/](http://localhost:9000/), you will see your application run there.
| thinhkhang97 |
1,873,669 | Spacy Vs NLTK | Enter fullscreen mode Exit fullscreen mode Spacy: SpaCy... | 0 | 2024-06-02T13:04:41 | https://dev.to/krishnaa192/spacy-vs-nltk-12e5 | python, machinelearning, nlp, programming | ```
```
## Spacy:
SpaCy is an open-source library for advanced Natural Language Processing (NLP) in Python. It is designed specifically for production use and provides efficient, reliable, and easy-to-use NLP tools. SpaCy supports tokenization, part-of-speech tagging, named entity recognition, dependency parsing, and many other NLP tasks.
1. Feature:
- Features
- Support for 75+ languages
- 84 trained pipelines for 25 languages
- Multi-task learning with pretrained transformers like BERT
- Pretrained word vectors
- State-of-the-art speed
- Production-ready training system
- Linguistically-motivated tokenization
- Components for named entity recognition, part-of-speech tagging, dependency parsing, sentence segmentation, text classification, lemmatization, morphological analysis, entity linking and more
- Easily extensible with custom components and attributes
- Support for custom models in PyTorch, TensorFlow and other frameworks
- Built in visualizers for syntax and NER
- Easy model packaging, deployment and workflow management
- Robust, rigorously evaluated accuracy.
##
Installation
```
pip install spacy
#for ubuntu
python3 -m spacy download en_core_web_sm
#for windows
python -m spacy download en_core_web_sm
```
## NLTK(The Natural Language Toolkit)
It is a powerful Python library for working with human language data (text). It provides easy-to-use interfaces to over 50 corpora and lexical resources such as WordNet, along with a suite of text-processing libraries for classification, tokenization, stemming, tagging, parsing, and semantic reasoning. It also includes wrappers for industrial-strength NLP libraries.
##
Installation
```
pip install nltk
import nltk
nltk.download('all')
```
This will download all the datasets and models that NLTK uses. You might only need to download certain datasets for specific tasks, which I'll show in examples.
## Tokenization
- **Spacy**
```
import spacy
# Load the English language model
nlp = spacy.load("en_core_web_sm")
# Process the text
text = "Hello there! How are you doing today? The weather is great, and Python is awesome."
doc = nlp(text)
# Sentence tokenization
sentences = list(doc.sents)
print("Sentences:", [sent.text for sent in sentences])
# Word tokenization
words = [token.text for token in doc]
print("Words:", words)
```
- **NLTK**
```
import nltk
from nltk.tokenize import word_tokenize, sent_tokenize
text = "Hello there! How are you doing today? The weather is great, and Python is awesome."
# Sentence tokenization
sentences = sent_tokenize(text)
print("Sentences:", sentences)
# Word tokenization
words = word_tokenize(text)
print("Words:", words)
```
## Part-of-Speech Tagging
- **NLTK**
```
import nltk
from nltk.tokenize import word_tokenize
from nltk.tag import pos_tag
text = "NLTK is a leading platform for building Python programs to work with human language data."
words = word_tokenize(text)
pos_tags = pos_tag(words)
print("POS Tags:", pos_tags)
```
- **SpaCy**
```
import spacy
# Load the English language model
nlp = spacy.load("en_core_web_sm")
# Process the text
text = "spaCy is a free, open-source library for advanced Natural Language Processing (NLP) in Python."
doc = nlp(text)
pos_tags = [(token.text, token.pos_, token.tag_) for token in doc]
print("POS Tags:", pos_tags)
```
## Named Entity Recognition (NER)
- **NLTK**
```
import nltk
from nltk.tokenize import word_tokenize
from nltk.tag import pos_tag
from nltk.chunk import ne_chunk
text = "Barack Obama was born in Hawaii. He was elected president in 2008."
words = word_tokenize(text)
pos_tags = pos_tag(words)
named_entities = ne_chunk(pos_tags)
print("Named Entities:", named_entities)
```
- **SpaCy**
```
import spacy
# Load the English language model
nlp = spacy.load("en_core_web_sm")
# Process the text
text = "Barack Obama was born in Hawaii. He was elected president in 2008."
doc = nlp(text)
named_entities = [(ent.text, ent.label_) for ent in doc.ents]
print("Named Entities:", named_entities)
```
## Performance
**NLTK:**
- Generally slower due to its design for educational purposes and comprehensive nature.
- More flexible and provides access to various algorithms.
**SpaCy:**
- Optimized for performance and speed.
- Faster processing, making it suitable for real-time applications and large-scale processing.
## Ease of Use
**NLTK:**
-
More complex and requires more code to achieve certain tasks.
-
Great for learning and understanding the intricacies of NLP.
**SpaCy:**
-
Simple and consistent API.
-
Designed to be user-friendly and quick to implement.
## Resources and Datasets
**NLTK:**
-
Comes with numerous corpora and datasets.
-
Provides access to various lexical resources like WordNet.
**spaCy:**
-
Does not include as many built-in datasets.
-
Focuses on practical tools and pre-trained models for immediate use.
## Customization and Extensibility
**NLTK:**
-
Highly customizable and allows for experimenting with different algorithms.
-
Good for research and exploring new techniques.
**SpaCy:**
-
Extensible with custom pipelines and components.
-
Designed for practical application and integration into larger systems.
## When to Use NLTK
**Educational purposes**: If you are learning NLP and want to understand the underlying algorithms and techniques.
**Research:** When you need to experiment with different NLP models and algorithms.
## When to Use spaCy
**Production use**: When you need a reliable and fast NLP library for real-world applications.
**Ease of use:** When you want to implement NLP tasks quickly and efficiently.
## Conclusion
NLTK is excellent for educational purposes, research, and when you need a wide variety of tools and datasets.
spaCy is ideal for production environments, real-time applications, and when you need a fast, efficient, and easy-to-use library.
| krishnaa192 |
1,873,668 | Building a Dynamic Filesystem with FUSE and Node.js: A Practical Approach | Do you ever wonder what happens when you run sshfs user@remote:~/ /mnt/remoteroot? How do files from... | 0 | 2024-06-02T13:04:36 | https://dev.to/pinkiesky/building-a-dynamic-filesystem-with-fuse-and-nodejs-a-practical-approach-2ogo | typescript, node, linux, javascript |
Do you ever wonder what happens when you run `sshfs user@remote:~/ /mnt/remoteroot`? How do files from a remote server appear on your local system and synchronize so quickly?
Have you heard of [WikipediaFS](https://en.wikipedia.org/wiki/WikipediaFS), which allows you to edit a Wikipedia article as if it were a file in your filesystem? It's not magic—it's the power of FUSE (Filesystem in Userspace). FUSE lets you create your own filesystem without needing deep knowledge of the OS kernel or low-level programming languages.
This article introduces a practical solution using FUSE with Node.js and TypeScript. We will explore how FUSE works under the hood and demonstrate its application by solving a real-world task. Join me on an exciting adventure into the world of FUSE and Node.js.
---
## Table Of Contents
* [Introduction](#intro)
* [Let’s choose the tech we would like to use](#thetech)
* [Deep dive into FUSE](#ddfuse)
* [Let's write a minimum-viable product and check Postman’s reaction to it](#mvp)
* [The core idea](#coreidea)
* [Passthrough over classes](#classes)
* [The tree](#classestree)
* [FUSEFacade](#FUSEFacade)
* [A file descriptor](#descriptors)
* [Images: "data transfer object" part](#imagesdto)
* [Images: binary storage and generators](#imagesstorage)
* [Images: variants](#imagesvariants)
* [The tree structure](#treestructure)
* [Testing](#testing)
* [Сonclusion](#conclusion)
## Introduction <a name="intro"></a>
I was responsible for media files (primarily images) in my work. This includes many things: side- or top-banners, media in chats, stickers, etc. Of course, there are a lot of requirements for these, such as "banner is PNG or WEBP, 300x1000 pixels." If the requirements are unmet, our back office will not let an image through. And an object deduplication mechanism is there: no image can enter the same river twice.
This leads us to a situation where we have a massive set of images for testing purposes.
I used shell one-liners or aliases to make my life easier. For instance:
```sh
convert -size 300x1000 xc:gray +noise random /tmp/out.png
```

<figcaption>Example of noise image</figcaption>
A combination of `bash` and `convert` is a great tool, but obviously, this is not the most convenient way to address the problem.
Discussing the QA team’s situation reveals further complications. Apart from the appreciable time spent on image generation, the first question when we investigate a problem is "Are you sure you uploaded a unique image?" I believe you understand how annoying this is.
## Let’s choose the tech we would like to use <a name="thetech"></a>
You could take a simple approach: create a web service that serves a route with a self-explanatory file, like `GET /image/1000x100/random.zip?imagesCount=100`. The route would return a ZIP file with a set of unique images. This sounds good, but it doesn’t address our main issue: all uploaded files need to be unique for testing.
Your next thought might be "Can we replace a payload when sending it?" The QA team uses Postman for API calls. I investigated Postman internals and realized we can't change the request body "on the fly"
Another solution is to replace a file in the file system each time something tries to read the file.
Linux has a notification subsystem called inotify, which alerts you about file system events such as changes in directories or file modifications. If you were getting "Visual Studio Code is unable to watch for file changes in this large workspace" there is a problem with inotify.
It can fire an event when a directory is changed, a file is renamed, a file is opened and so on.
> The full list of events can be found here: https://sites.uclouvain.be/SystInfo/usr/include/linux/inotify.h.html
So the plan is:
1. Listening to the `IN_OPEN` event and counting file descriptors;
2. Listening to the `IN_CLOSE` event; if the count drops to 0, we will replace the file.
Sounds good, but there are a couple of problems with this:
- Only Linux supports `inotify`;
- Parallel requests to the file should return the same data;
- If a file has intensive IO-operations, replacement would never happen;
- If a service that serves inotify events crashes, the files will stay in the user file system.
To address these problems, we can write our own file system. But there is another problem: the regular file system runs in OS kernel space. It requires us to know about OS kernel and using languages like C/Rust. Also, for each kernel we should write a specific module (driver). Therefore, writing a file system is overkill for the problem we want to solve; even if there is a long weekend ahead.
Fortunately, there is a way to tame this beast: **F**ilesystem in **Use**rspace (FUSE). FUSE is a project that lets you create file systems without editing kernel code.
This means that any program or script through FUSE, without any complex core-related logic, is able to emulate a flash, hard-drive or SSD. In other words, an ordinary userspace process can create its own file system, which can be accessed normally through any ordinary program you wish – Nautilus, Dolphin, ls, etc.
Why is FUSE good for covering our requirements?
FUSE-based file systems are built over user-spaced processes. Therefore, you can use any language you know which has a binding to `libfuse`. Also, you get a cross-platform solution with FUSE.
I have had a lot of experience with NodeJS and TypeScript, and I would like to choose this (wonderful) combination as an execution environment for our brand-new FS.
Furthermore, TypeScript provides an excellent object-oriented base. This will allow me to show you not only the source code, which you can find on the public GitHub repo but also the structure of the project.
## Deep dive into FUSE <a name="ddfuse"></a>
Let me provide a speaking quote from [the official FUSE page](https://www.kernel.org/doc/html/next/filesystems/fuse.html):
> FUSE is a userspace filesystem framework. It consists of a kernel module (fuse.ko), a userspace library (libfuse.*), and a mount utility (fusermount).
A framework for writing file systems sounds exciting.
I should explain what each FUSE part means:
1. `fuse.ko` is doing all kernel-related low-level jobs; this allows us to avoid intervention into an OS kernel;
2. `libfuse` is a library that provides a high-level layer for communication with `fuse.ko`;
3. `fusermount` allows users to mount/unmount userspace file systems (call me Captain Obvious!).
The general principles look like this:
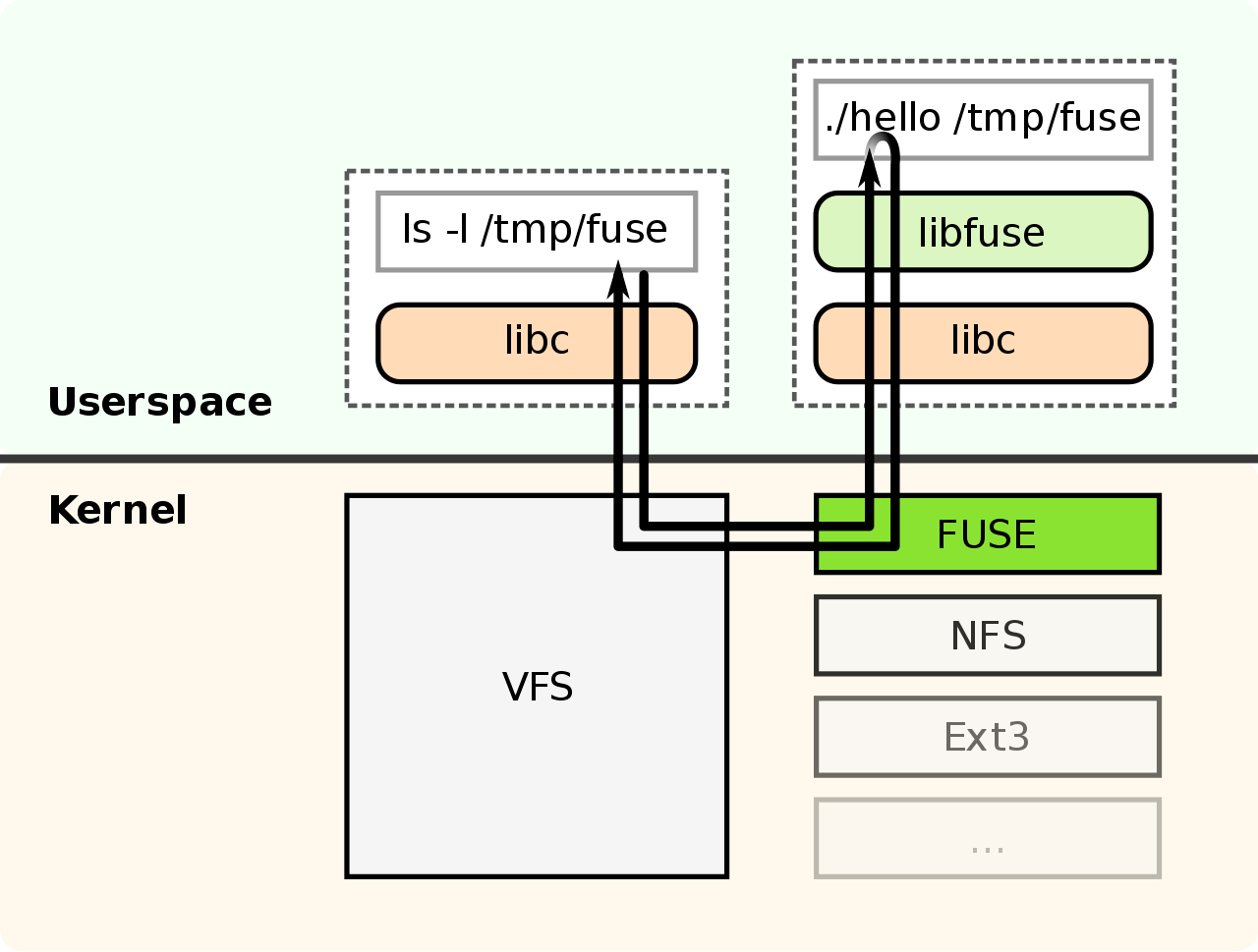
The userspace process (`ls` in this case) makes a request to the Virtual File System kernel that routes the request to the FUSE kernel module. The FUSE module, in turn, routes the request back to userspace to the file system realization (`./hello` in the picture above).
Don't be deceived by the Virtual File System name. It isn't directly related to the FUSE. It is the software layer in the kernel that provides the filesystem interface to userspace programs. For the sake of simplicity, you can perceive it as [a Composite pattern](https://refactoring.guru/design-patterns/composite).
`libfuse` offers two types of APIs: high-level and low-level. They have similarities but crucial differences.
The low-level one is asynchronous and works only with `inodes`. Asynchronous, in this case, means that a client that uses low-level API should call the response methods by itself.
The high-level one provides the ability to use convenient paths (for example, `/etc/shadow`) instead of more "abstract" `inodes` and returns responses in sync way.
In this article, I will explain how the high-level works rather than the low-level and `inodes`.
If you want to implement your own file system, you should implement a set of methods responsible for requests serving from VFS. The most common methods are:
- `open(path, accessFlags): fd` -- open a file by path. The method shall return a number identifier, the so-called File Descriptor (from hereon `fd`). An access flags is a binary mask that describes which operation the client program wants to perform (read-only, write-only, read-write, execute, or search);
- `read(path, fd, Buffer, size, offset): count of bytes read` -- read `size` bytes from a file linked with `fd` File Descriptor to the passed Buffer. The `path` argument is ignored because we will use fd;
- `write(path, fd, Buffer, size, offset): count of bytes written` -- write `size` bytes from the Buffer to a file linked with `fd`;
- `release(fd)` -- close the `fd`;
- `truncate(path, size)` -- change a file size. The method should be defined if you want to rewrite files (and we do);
- `getattr(path)` -- returns file parameters such as size, created at, accessed at, etc. The method is the most callable method by the file system, so make sure you create the optimal one;
- `readdir(path)` -- read all subdirectories.
> The methods above are vital for each fully operable file system built on top of high-level FUSE API. But the list is not complete; the full list you can find on https://libfuse.github.io/doxygen/structfuse__operations.html
To revisit the concept of a file descriptor: In UNIX-like systems, including MacOS, a file descriptor is an abstraction for files and other I/O resources like sockets and pipes. When a program opens a file, the OS returns a numerical identifier called a file descriptor. This integer serves as an index in the OS's file descriptor table for each process. When implementing a filesystem using FUSE, we will need to generate file descriptors ourselves.
Let's consider call flow when the client opens a file:
1. `getattr(path: /random.png) → { size: 98 };` the client got the file size;
2. `open(path: /random.png) → 10;` opened file by path; FUSE implementation returns a file descriptor number;
3. `read(path: /random.png, fd: 10 buffer, size: 50, offset: 0) → 50;` read first 50 bytes
4. `read(path: /random.png, fd: 10 buffer, size: 50, offset: 50) → 48;` read the next 50. The 48 bytes were read due to file size.
5. `release(10);` all data was read, so close the fd.
## Let's write a minimum-viable product and check Postman’s reaction to it <a name="mvp"></a>
Our next step is to develop a minimal file system based on `libfuse` to test how Postman will interact with a custom filesystem.
Acceptance requirements for the FS are straightforward:
The root of the FS should contain a `random.txt` file, whose content should be unique each time it is read (let's call this "always unique read"). The content should contain a random UUID and a current time in ISO format, separated by a new line. For example:
```sh
3790d212-7e47-403a-a695-4d680f21b81c
2012-12-12T04:30:30
```
The minimal product will consist of two parts. The first is a simple web service that will accept HTTP POST requests and print a request body to the terminal. The code is quite simple and isn't worth our time, mainly because the article is about FUSE, not Express.
The second part is the implementation of the file system that meets the requirements. It has only 83 lines of code.
For the code, we will use the node-fuse-bindings library, which provides bindings to the high-level API of `libfuse`.
You can skip the code below; I’m going to write a code summary below.
```javascript
const crypto = require('crypto');
const fuse = require('node-fuse-bindings');
// MOUNT_PATH is the path where our filesystem will be available. For Windows, this will be a path like 'D://'
const MOUNT_PATH = process.env.MOUNT_PATH || './mnt';
function getRandomContent() {
const txt = [crypto.randomUUID(), new Date().toISOString(), ''].join('\n');
return Buffer.from(txt);
}
function main() {
// fdCounter is a simple counter that increments each time a file is opened
// using this we can get the file content, which is unique for each opening
let fdCounter = 0;
// fd2ContentMap is a map that stores file content by fd
const fd2ContentMap = new Map();
// Postman does not work reliably if we give it a file with size 0 or just the wrong size,
// so we precompute the file size
// it is guaranteed that the file size will always be the same within one run, so there will be no problems with this
const randomTxtSize = getRandomContent().length;
// fuse.mount is a function that mounts the filesystem
fuse.mount(
MOUNT_PATH,
{
readdir(path, cb) {
console.log('readdir(%s)', path);
if (path === '/') {
return cb(0, ['random.txt']);
}
return cb(0, []);
},
getattr(path, cb) {
console.log('getattr(%s)', path);
if (path === '/') {
return cb(0, {
// mtime is the file modification time
mtime: new Date(),
// atime is the file access time
atime: new Date(),
// ctime is the metadata or file content change time
ctime: new Date(),
size: 100,
// mode is the file access flags
// this is a mask that defines access rights to the file for different types of users
// and the type of file itself
mode: 16877,
// file owners
// in our case, it will be the owner of the current process
uid: process.getuid(),
gid: process.getgid(),
});
}
if (path === '/random.txt') {
return cb(0, {
mtime: new Date(),
atime: new Date(),
ctime: new Date(),
size: randomTxtSize,
mode: 33188,
uid: process.getuid(),
gid: process.getgid(),
});
}
cb(fuse.ENOENT);
},
open(path, flags, cb) {
console.log('open(%s, %d)', path, flags);
if (path !== '/random.txt') return cb(fuse.ENOENT, 0);
const fd = fdCounter++;
fd2ContentMap.set(fd, getRandomContent());
cb(0, fd);
},
read(path, fd, buf, len, pos, cb) {
console.log('read(%s, %d, %d, %d)', path, fd, len, pos);
const buffer = fd2ContentMap.get(fd);
if (!buffer) {
return cb(fuse.EBADF);
}
const slice = buffer.slice(pos, pos + len);
slice.copy(buf);
return cb(slice.length);
},
release(path, fd, cb) {
console.log('release(%s, %d)', path, fd);
fd2ContentMap.delete(fd);
cb(0);
},
},
function (err) {
if (err) throw err;
console.log('filesystem mounted on ' + MOUNT_PATH);
},
);
}
// Handle the SIGINT signal separately to correctly unmount the filesystem
// Without this, the filesystem will not be unmounted and will hang in the system
// If for some reason unmount was not called, you can forcibly unmount the filesystem using the command
// fusermount -u ./MOUNT_PATH
process.on('SIGINT', function () {
fuse.unmount(MOUNT_PATH, function () {
console.log('filesystem at ' + MOUNT_PATH + ' unmounted');
process.exit();
});
});
main();
```
I suggest refreshing our knowledge about permission bits in a file. Permission bits are a set of bits that are associated with a file; they are a binary representation of who is allowed to read/write/execute the file. "Who" includes three groups: the owner, the owner group, and others.
Permissions can be set for each group separately. Usually, each permission is represented by a three-digit number: read (4 or '100' in binary number system), write (2 or '010'), and execution (1 or '001'). If you add these numbers together, you will create a combined permission. For example, 4 + 2 (or '100' + '010') will make 6 ('110'), which means read + write (RO) permission.
If the file owner has an access mask of 7 (111 in binary, meaning read, write, and execute), the group has 5 (101, meaning read and execute), and others have 4 (100, meaning read-only). Therefore, the complete access mask for the file is 754 in decimal
Bear in mind that execution permission becomes read permission for directories.
Let's go back to the file system implementation and make a text version of this: Each time a file is opened (via an `open` call), the integer counter increments, producing the file descriptor returned by the open call. Random content is then created and saved in a key-value store with the file descriptor as the key. When a read call is made, the corresponding content portion is returned. Upon a release call, the content is deleted.
Remember to handle `SIGINT` to unmount the filesystem after pressing Ctrl+C. Otherwise, we'll have to do it manually in the terminal using `fusermount -u ./MOUNT_PATH`.
Now, jump into testing. We run the web server, then create an empty folder as a root folder for the upcoming FS, and run the main script. After the "Server listening on port 3000" line prints, open Postman and send a couple of requests to the web-server in a row without changing any parameters.
<figcaption>LEFT SIDE IS FS, RIGHT IS WEB-SERVER</figcaption>
Everything looks good! Each request has unique file content, as we foresaw.
The logs also prove that the flow of file open calls described above in the "Deep dive into FUSE" section is correct.
The GitHub repo with MVP: https://github.com/pinkiesky/node-fuse-mvp
You can run this code on your local environment or use this repo as a boilerplate for your own file system implementation.
## The core idea <a name="coreidea"></a>
The approach is checked—now it’s time for the primary implementation.
Before the "always unique read" implementation, the first thing we should implement is create and delete operations for original files. We will implement this interface through a directory within our virtual filesystem. The user will put original images which they want to make "always unique" or "randomized," and the filesystem will prepare the rest.
> Here and in the following sections, "always unique read", "random image" or "random file" refers to a file that returns unique content in a binary sense each time it is read, while visually, it remains as similar as possible to the original.
The file system's root will contain two directories: Image Manager and Images. The first one is a folder for managing the user's original files (you can think of it as a CRUD repository). The second one is the unmanaged directory from the user's point of view that contains random images.
<figcaption>How a user will interact with the upcoming fs</figcaption>
<figcaption>Etalon structure of the fs</figcaption>
As you can see in the image above, we will also implement not only "always unique" images but also a file converter! That's an added bonus.
The core idea of our implementation is that the program will contain an object tree, with each node and leaf providing common FUSE methods.
When the program receives an FS call, it should find a node or a leaf in the tree by the corresponding path. For example, the program gets the `getattr(/Images/1/original/)` call and then tries to find the node to which the path is addressed.
Something like this:
The next question is how we will store the original images. An image in the program will consist of binary data and meta information (a meta includes an original filename, file mime-type, etc).
Binary data will be stored in binary storage. Let's simplify it and build binary storage as a set of binary files in the user (or the host) file system. Meta information will be stored similarly: JSON inside text files in the user file system.
As you may remember, in the "Let's write a minimum-viable product" section, we created a file system that returns a text file by a template. It contains a random UUID plus a current date, so the data's uniqueness wasn't the problem—uniqueness was achieved by the data's definition. However, from this point, the program should work with preloaded user images.
So, how can we create images that are similar but always unique (in terms of bytes and consequently hashes) based on the original one?
The solution I suggest is quite simple. Let's put an RGB noise square in the top-left corner of an image. The noise square should be 16x16 pixels. This provides almost the same picture but guarantees a unique sequence of bytes.
Will it be enough to ensure a lot of different images? Let's do some math. The size of the square is 16. 16×16 = 256 RGB pixels in a single square. Each pixel has 256×256×256 = 16,777,216 variants. Thus, the count of unique squares is 16,777,216^256 -- a number with 1,558 digits, which is much more than the number of atoms in the observable universe.
Does that mean we can reduce a square size? Unfortunately, lossy compression like JPEG would significantly reduce the number of unique squares, so 16x16 is the optimal size.

## Passthrough over classes <a name="classes"></a>
### The tree <a name="classestree"></a>
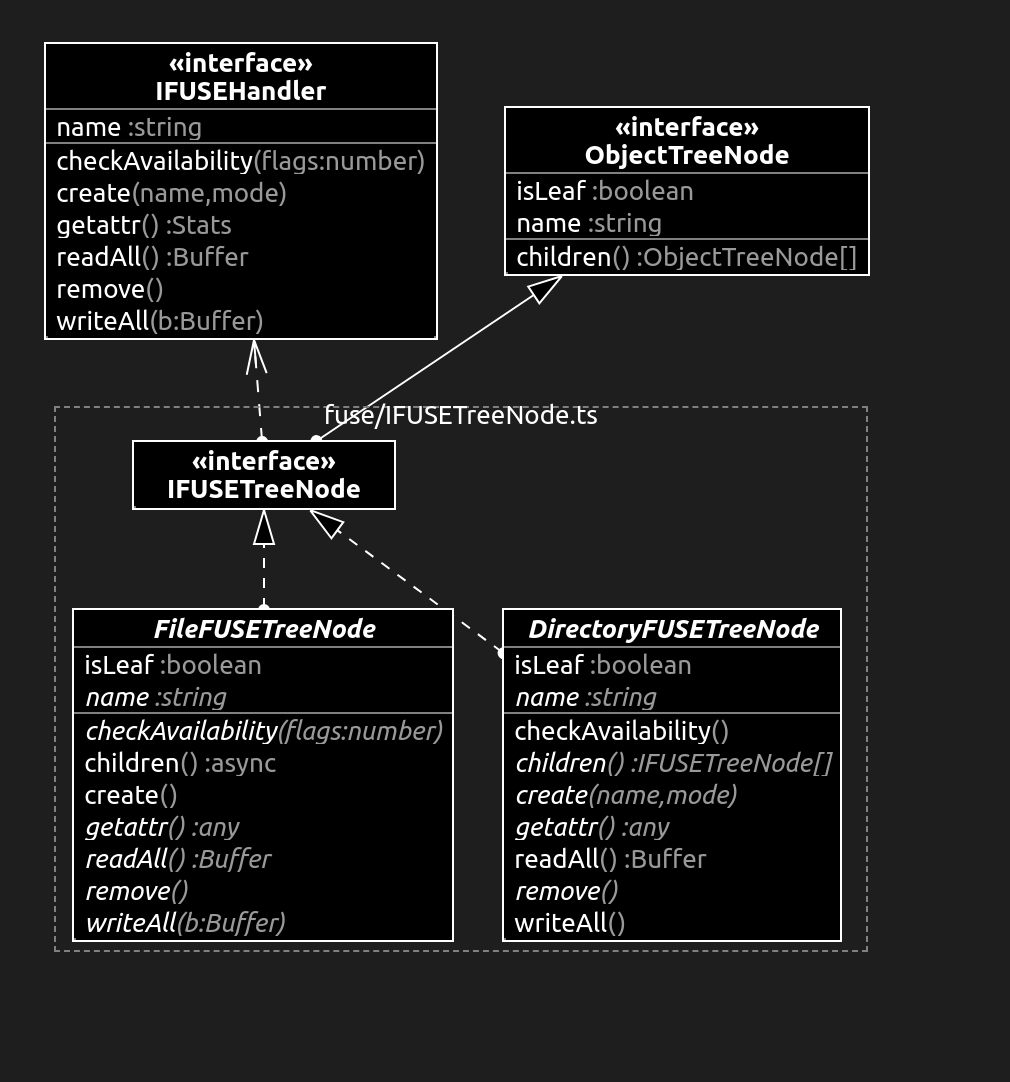
`IFUSEHandler` is an interface that serves common FUSE calls. You can see that I replaced read/write with readAll/writeAll, respectively. I did this to simplify read and write operations: when `IFUSEHandler` makes read/write for a whole part, we are able to move partial read/write logic to another place. This means `IFUSEHandler` does not need to know anything about file descriptors, binary data, etc. The same thing happened with the `open` FUSE method as well.
A notable aspect of the tree is that it is generated on demand. Instead of storing the entire tree in memory, the program creates nodes only when they are accessed. This behavior allows the program to avoid a problem with tree rebuilding in case of node creation or removal. Check the `ObjectTreeNode` interface, and you will find that `children` is not an array but a method, so this is how they are generated on demand.
`FileFUSETreeNode` and `DirectoryFUSETreeNode` are abstract classes where some methods throw a `NotSupported` error (obviously, `FileFUSETreeNode` should never implement `readdir`).
### FUSEFacade <a name="FUSEFacade"></a>
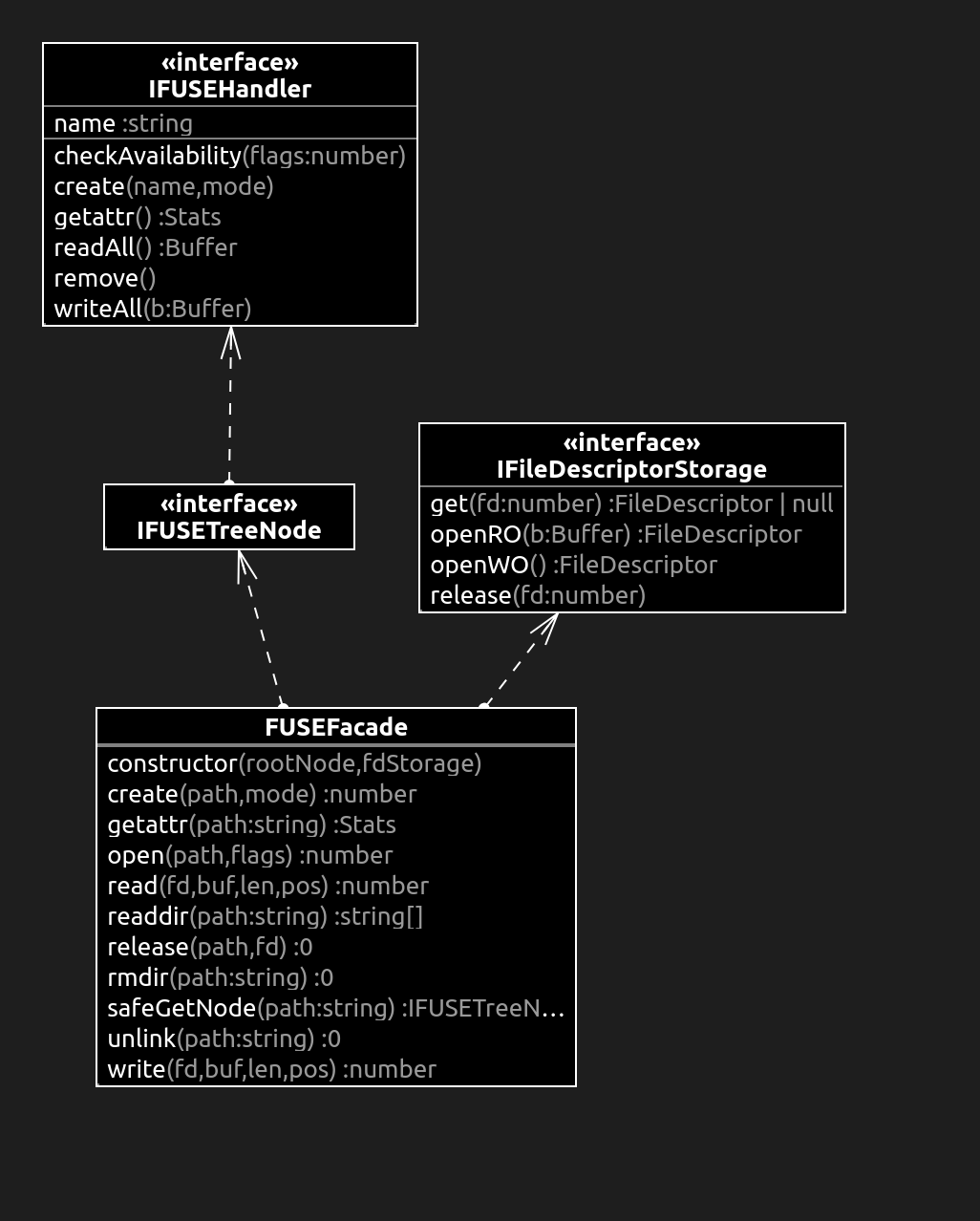
FUSEFacade is the most crucial class that implements the program's main logic and binds different parts together.
`node-fuse-bindings` has a callback-based API, but FUSEFacade methods are made with a Promise-based one. To address this inconvenience, I used a code like this:
```typescript
const handleResultWrapper = <T>(
promise: Promise<T>,
cb: (err: number, result: T) => void,
) => {
promise
.then((result) => {
cb(0, result);
})
.catch((err) => {
if (err instanceof FUSEError) {
fuseLogger.info(`FUSE error: ${err}`);
return cb(err.code, null as T);
}
fuseLogger.warn(err);
cb(fuse.EIO, null as T);
});
};
// Ex. usage:
// open(path, flags, cb) {
// handleResultWrapper(fuseFacade.open(path, flags), cb);
// },
```
The `FUSEFacade` methods are wrapped in `handleResultWrapper`.
Each method of `FUSEFacade` that uses a path simply parses the path, finds a node in the tree, and calls the requested method.
Consider a couple of methods from the `FUSEFacade` class.
```typescript
async create(path: string, mode: number): Promise<number> {
this.logger.info(`create(${path})`);
// Convert path `/Image Manager/1/image.jpg` in
// `['Image Manager', '1', 'image.jpg']`
// splitPath will throw error if something goes wrong
const parsedPath = this.splitPath(path); // `['Image Manager', '1', 'image.jpg']`
const name = parsedPath.pop()!; // ‘image.jpg’
// Get node by path (`/Image Manager/1` after `pop` call)
// or throw an error if node not found
const node = await this.safeGetNode(parsedPath);
// Call the IFUSEHandler method. Pass only a name, not a full path!
await node.create(name, mode);
// Create a file descriptor
const fdObject = this.fdStorage.openWO();
return fdObject.fd;
}
async readdir(path: string): Promise<string[]> {
this.logger.info(`readdir(${path})`);
const node = await this.safeGetNode(path);
// As you see, the tree is generated on the fly
return (await node.children()).map((child) => child.name);
}
async open(path: string, flags: number): Promise<number> {
this.logger.info(`open(${path}, ${flags})`);
const node = await this.safeGetNode(path);
// A leaf node is a directory
if (!node.isLeaf) {
throw new FUSEError(fuse.EACCES, 'invalid path');
}
// Usually checkAvailability checks access
await node.checkAvailability(flags);
// Get node content and put it in created file descriptor
const fileData: Buffer = await node.readAll();
// fdStorage is IFileDescriptorStorage, we will consider it below
const fdObject = this.fdStorage.openRO(fileData);
return fdObject.fd;
}
```
### A file descriptor <a name="descriptors"></a>
Before taking the next step, let’s take a closer look at what a file descriptor is in the context of our program.
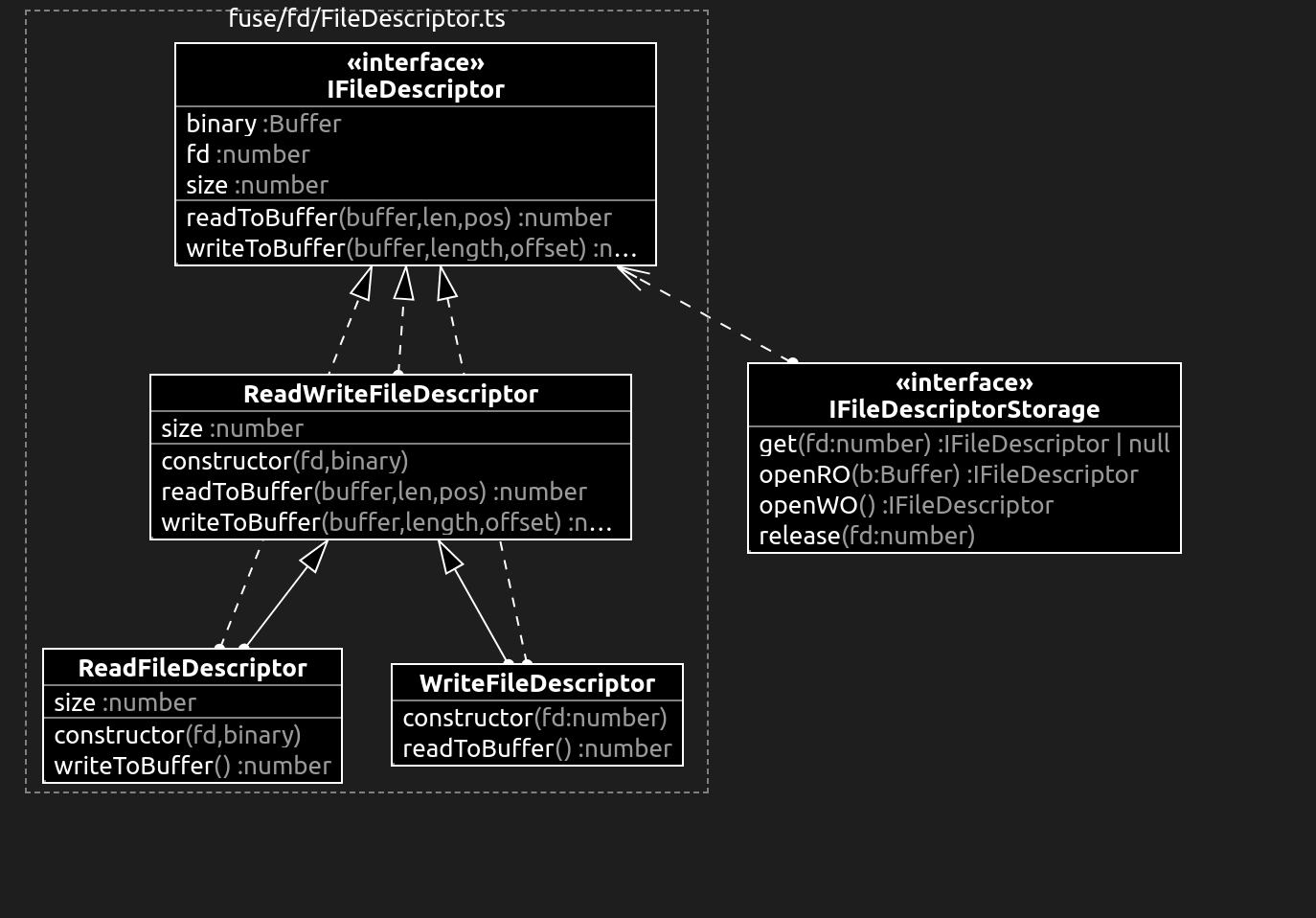
`ReadWriteFileDescriptor` is a class that stores file descriptors as a number and binary data as a buffer. The class has `readToBuffer` and `writeToBuffer` methods that provide the ability to read and write data into a file descriptor buffer. `ReadFileDescriptor` and `WriteFileDescriptor` are implementations of read-only and write-only descriptors.
`IFileDescriptorStorage` is an interface that describes file descriptor storage. The program has only one implementation for this interface: `InMemoryFileDescriptorStorage`. As you can tell from the name, it stores file descriptors in memory because we don't need persistence for descriptors.
Let's check how `FUSEFacade` uses file descriptors and storage:
```typescript
async read(
fd: number, // File descriptor to read from
buf: Buffer, // Buffer to store the read data
len: number, // Length of data to read
pos: number, // Position in the file to start reading from
): Promise<number> {
// Retrieve the file descriptor object from storage
const fdObject = this.fdStorage.get(fd);
if (!fdObject) {
// If the file descriptor is invalid, throw an error
throw new FUSEError(fuse.EBADF, 'invalid fd');
}
// Read data into the buffer and return the number of bytes read
return fdObject.readToBuffer(buf, len, pos);
}
async write(
fd: number, // File descriptor to write to
buf: Buffer, // Buffer containing the data to write
len: number, // Length of data to write
pos: number, // Position in the file to start writing at
): Promise<number> {
// Retrieve the file descriptor object from storage
const fdObject = this.fdStorage.get(fd);
if (!fdObject) {
// If the file descriptor is invalid, throw an error
throw new FUSEError(fuse.EBADF, 'invalid fd');
}
// Write data from the buffer and return the number of bytes written
return fdObject.writeToBuffer(buf, len, pos);
}
async release(path: string, fd: number): Promise<0> {
// Retrieve the file descriptor object from storage
const fdObject = this.fdStorage.get(fd);
if (!fdObject) {
// If the file descriptor is invalid, throw an error
throw new FUSEError(fuse.EBADF, 'invalid fd');
}
// Safely get the node corresponding to the file path
const node = await this.safeGetNode(path);
// Write all the data from the file descriptor object to the node
await node.writeAll(fdObject.binary);
// Release the file descriptor from storage
this.fdStorage.release(fd);
// Return 0 indicating success
return 0;
}
```
The code above is straightforward. It defines methods to read from, write to, and release file descriptors, ensuring the file descriptor is valid before performing operations. The release method also writes data from a file descriptor object to the filesystem node and frees the file descriptor.
We are done with the code around `libfuse` and the tree. It’s time to dive into the image-related code.
### Images: "data transfer object" part <a name="imagesdto"></a>
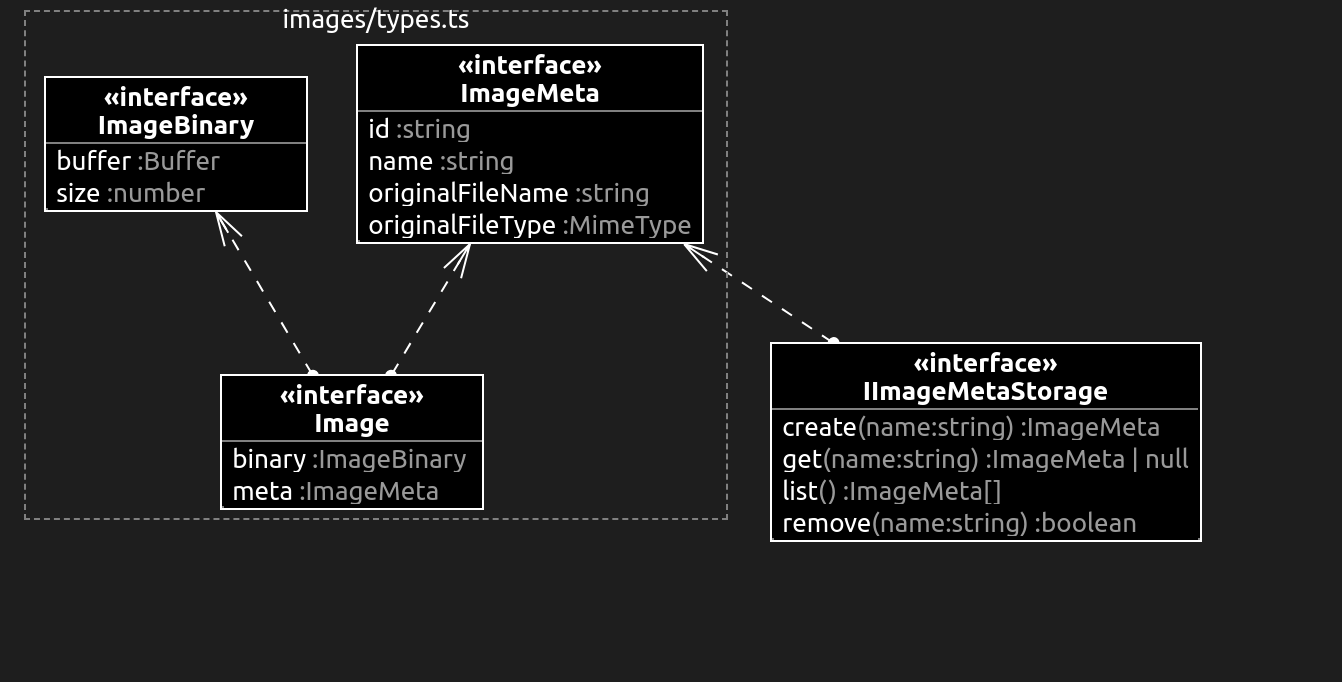
`ImageMeta` is an object that stores meta information about an image.
`IImageMetaStorage` is an interface that describes a storage for meta. The program has only one implementation for the interface: the `FSImageMetaStorage` class implements the `IImageMetaStorage` interface to manage image metadata stored in a single JSON file. It uses a cache to store metadata in memory and ensures the cache is hydrated by reading from the JSON file when needed. The class provides methods to create, retrieve, list, and delete image metadata, and it writes changes back to the JSON file to persist updates. The cache improves performance by reducing an IO operation count.
`ImageBinary`, obviously, is an object that has binary image data.
The `Image` interface is the composition of `ImageMeta` and `ImageBinary`.
### Images: binary storage and generators <a name="imagesstorage"></a>
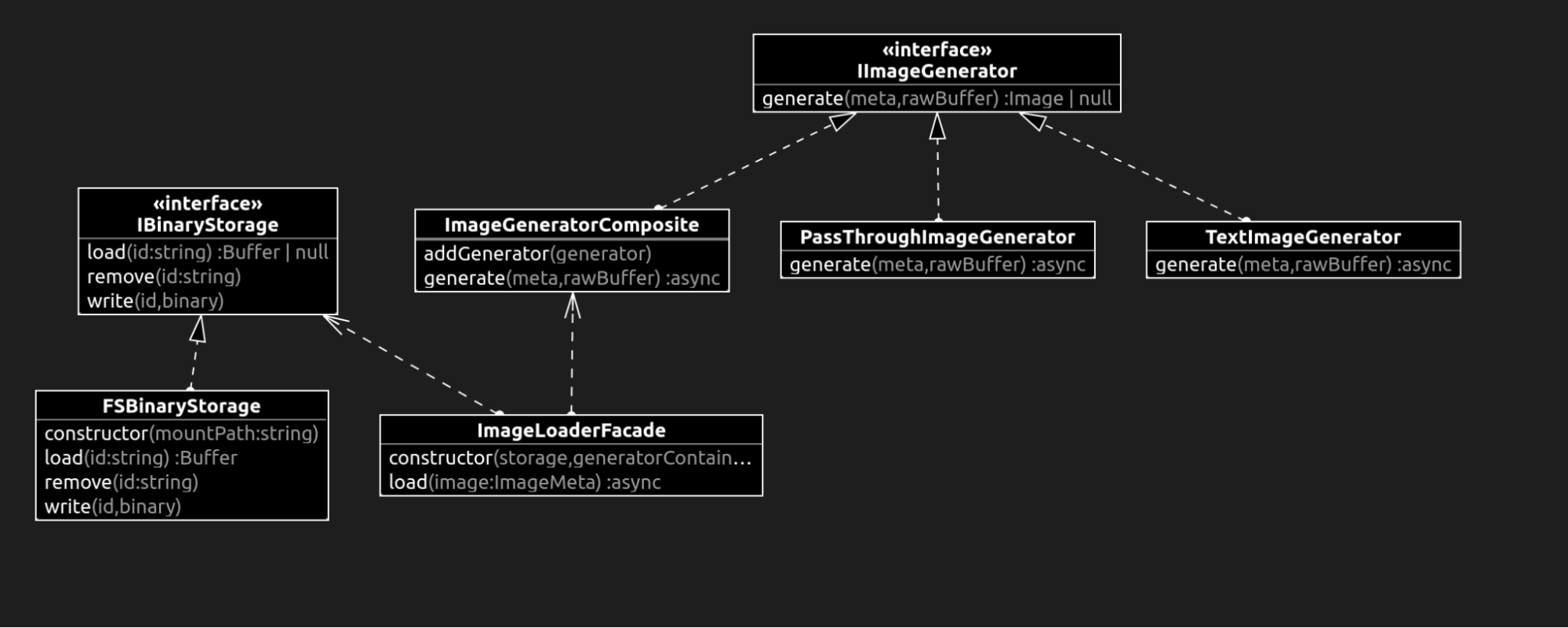
`IBinaryStorage` is an interface for binary data storage. Binary storage should be unlinked from images and can store any data: images, video, JSON, or text. This fact is important to us, and you will see why.
`IImageGenerator` is an interface that describes a generator. The generator is an important part of the program. It takes raw binary data plus meta and generates an image based on it.
Why does the program need generators? Can the program work without them? It can, but generators will add flexibility to the implementation. Generators allow users to upload pictures, text data, and broadly speaking, any data for which you write a generator.
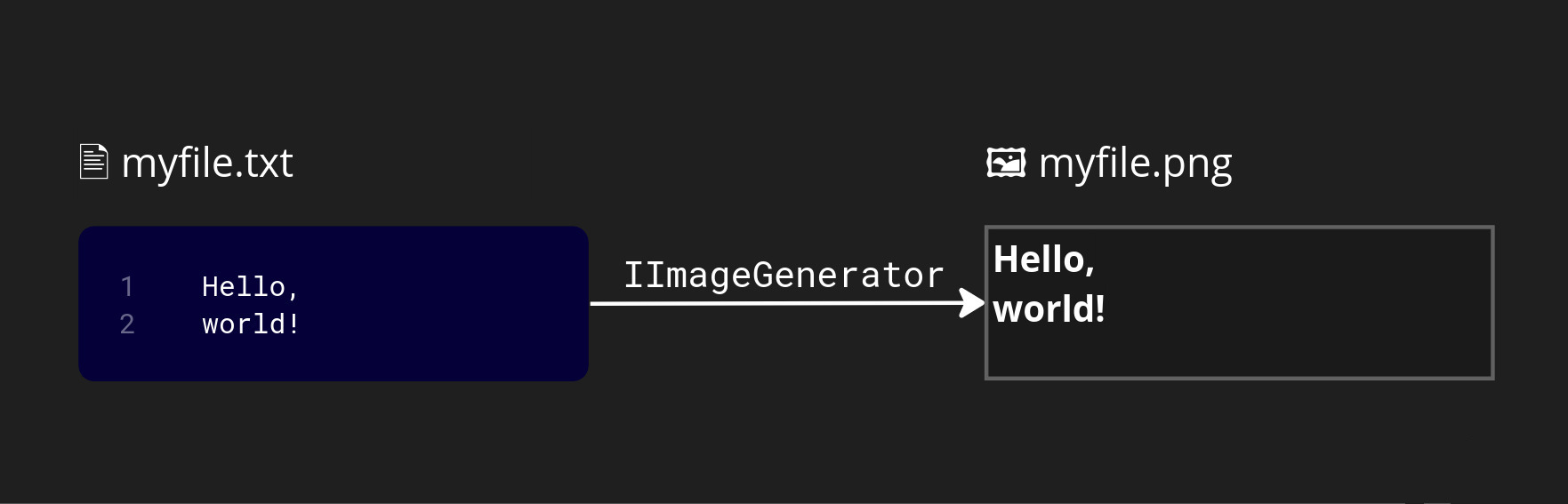
The flow is as follows: binary data is loaded from storage (`myfile.txt` in the picture above), and then the binary passes to a generator. It generates an image "on the fly."
You can perceive it as a converter from one format to another which is more convenient for us.
Let’s check out an example of a generator:
```typescript
import { createCanvas } from 'canvas'; // Import createCanvas function from the canvas library to create and manipulate images
const IMAGE_SIZE_RE = /(\d+)x(\d+)/; // Regular expression to extract width and height dimensions from a string
export class TextImageGenerator implements IImageGenerator {
// method to generate an image from text
async generate(meta: ImageMeta, rawBuffer: Buffer): Promise<Image | null> {
// Step 1: Verify the MIME type is text
if (meta.originalFileType !== MimeType.TXT) {
// If the file type is not text, return null indicating no image generation
return null;
}
// Step 2: Determine the size of the image
const imageSize = {
width: 800, // Default width
height: 600, // Default height
};
// Extract dimensions from the name if present
const imageSizeRaw = IMAGE_SIZE_RE.exec(meta.name);
if (imageSizeRaw) {
// Update the width and height based on extracted values, or keep defaults
imageSize.width = Number(imageSizeRaw[1]) || imageSize.width;
imageSize.height = Number(imageSizeRaw[2]) || imageSize.height;
}
// Step 3: Convert the raw buffer to a string to get the text content
const imageText = rawBuffer.toString('utf-8');
// Step 4: Create a canvas with the determined size
const canvas = createCanvas(imageSize.width, imageSize.height);
const ctx = canvas.getContext('2d'); // Get the 2D drawing context
// Step 5: Prepare the canvas background
ctx.fillStyle = '#000000'; // Set fill color to black
ctx.fillRect(0, 0, imageSize.width, imageSize.height); // Fill the entire canvas with the background color
// Step 6: Draw the text onto the canvas
ctx.textAlign = 'start'; // Align text to the start (left)
ctx.textBaseline = 'top'; // Align text to the top
ctx.fillStyle = '#ffffff'; // Set text color to white
ctx.font = '30px Open Sans'; // Set font style and size
ctx.fillText(imageText, 10, 10); // Draw the text with a margin
// Step 7: Convert the canvas to a PNG buffer and create the Image object
return {
meta, // Include the original metadata
binary: {
buffer: canvas.toBuffer('image/png'), // Convert canvas content to a PNG buffer
},
};
}
}
```
The `ImageLoaderFacade` class is [a facade](https://refactoring.guru/design-patterns/facade) that logically combines the storage and the generator–in other words it implements the flow you read above.
### Images: variants <a name="imagesvariants"></a>
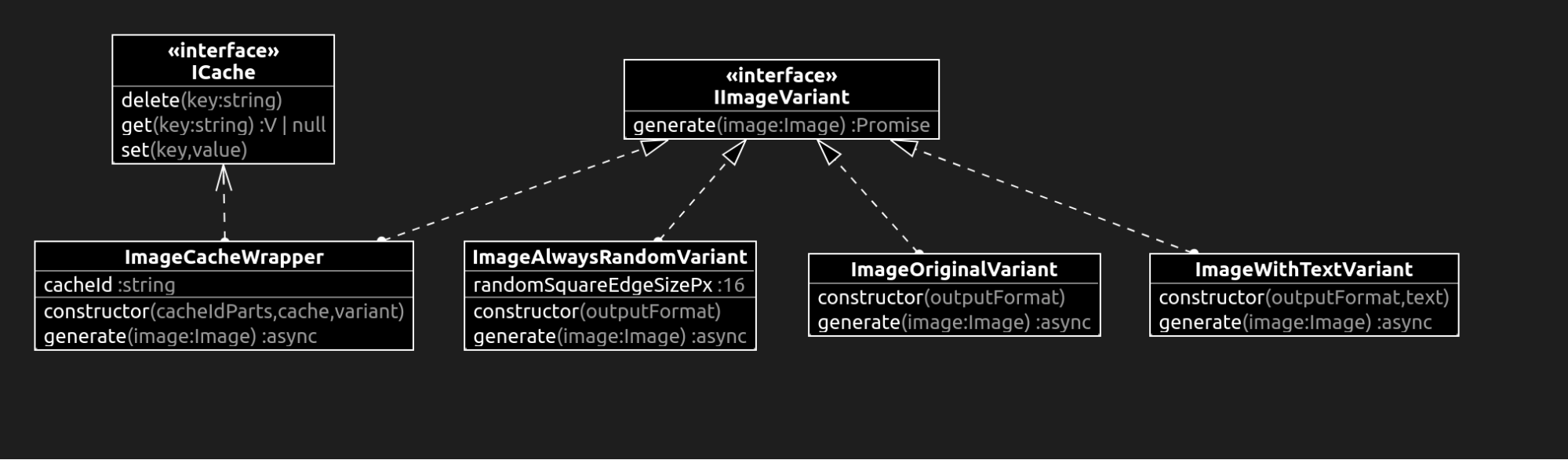
`IImageVariant` is an interface for creating various image variants. In this context, a variant is an image generated "on the fly" that will be displayed to the user when viewing files in our filesystem. The main difference from generators is that it takes an image as input rather than raw data.
The program has three variants: `ImageAlwaysRandom`, `ImageOriginalVariant`, and `ImageWithText`.
`ImageAlwaysRandom` returns the original image with a random RGB noise square.
```typescript
export class ImageAlwaysRandomVariant implements IImageVariant {
// Define a constant for the size of the random square edge in pixels
private readonly randomSquareEdgeSizePx = 16;
// Constructor takes the desired output format for the image
constructor(private readonly outputFormat: ImageFormat) {}
// Asynchronous method to generate a random variant of an image
async generate(image: Image): Promise<ImageBinary> {
// Step 1: Load the image using the sharp library
const sharpImage = sharp(image.binary.buffer);
// Step 2: Retrieve metadata and raw buffer from the image
const metadata = await sharpImage.metadata(); // Get image metadata
const buffer = await sharpImage.raw().toBuffer(); // Get raw pixel data
// the buffer size is plain array with size of image width * image height * channels count (3 or 4)
// Step 3: Apply random pixel values to a small square region in the image
for (let y = 0; y < this.randomSquareEdgeSizePx; y++) {
for (let x = 0; x < this.randomSquareEdgeSizePx; x++) {
// Calculate the buffer offset for the current pixel
const offset = y * metadata.width! * metadata.channels! + x * metadata.channels!;
// Set random values for RGB channels
buffer[offset + 0] = randInt(0, 255); // Red channel
buffer[offset + 1] = randInt(0, 255); // Green channel
buffer[offset + 2] = randInt(0, 255); // Blue channel
// If the image has an alpha channel, set it to 255 (fully opaque)
if (metadata.channels === 4) {
buffer[offset + 3] = 255; // Alpha channel
}
}
}
// Step 4: Create a new sharp image from the modified buffer and convert it to the desired format
const result = await sharp(buffer, {
raw: {
width: metadata.width!,
height: metadata.height!,
channels: metadata.channels!,
},
})
.toFormat(this.outputFormat) // Convert to the specified output format
.toBuffer(); // Get the final image buffer
// Step 5: Return the generated image binary data
return {
buffer: result, // Buffer containing the generated image
};
}
}
```
I use the `sharp` library as the most convenient way to operate over images in NodeJS: https://github.com/lovell/sharp.
`ImageOriginalVariant` returns an image without any change (but it can return an image in a different compression format).
`ImageWithText` returns an image with written text over it. This will be helpful when we create predefined variants of a single image. For example, if we need 10 random variations of one image, we must distinguish these variations from each other. The solution here is to create 10 pictures based on the original, where we render a sequential number from 0 to 9 in the top-left corner of each image.

<figcaption>10 cats in a row.</figcaption>
The `ImageCacheWrapper` has a different purpose from the variants and acts as a wrapper by caching the results of the particular `IImageVariant` class. It will be used to wrap entities that do not change, like an image converter, text-to-image generators, and so on. This caching mechanism enables faster data retrieval, mainly when the same images are read multiple times.
Well, we have covered all primary parts of the program. It's time to combine everything together.
### The tree structure <a name="treestructure"></a>
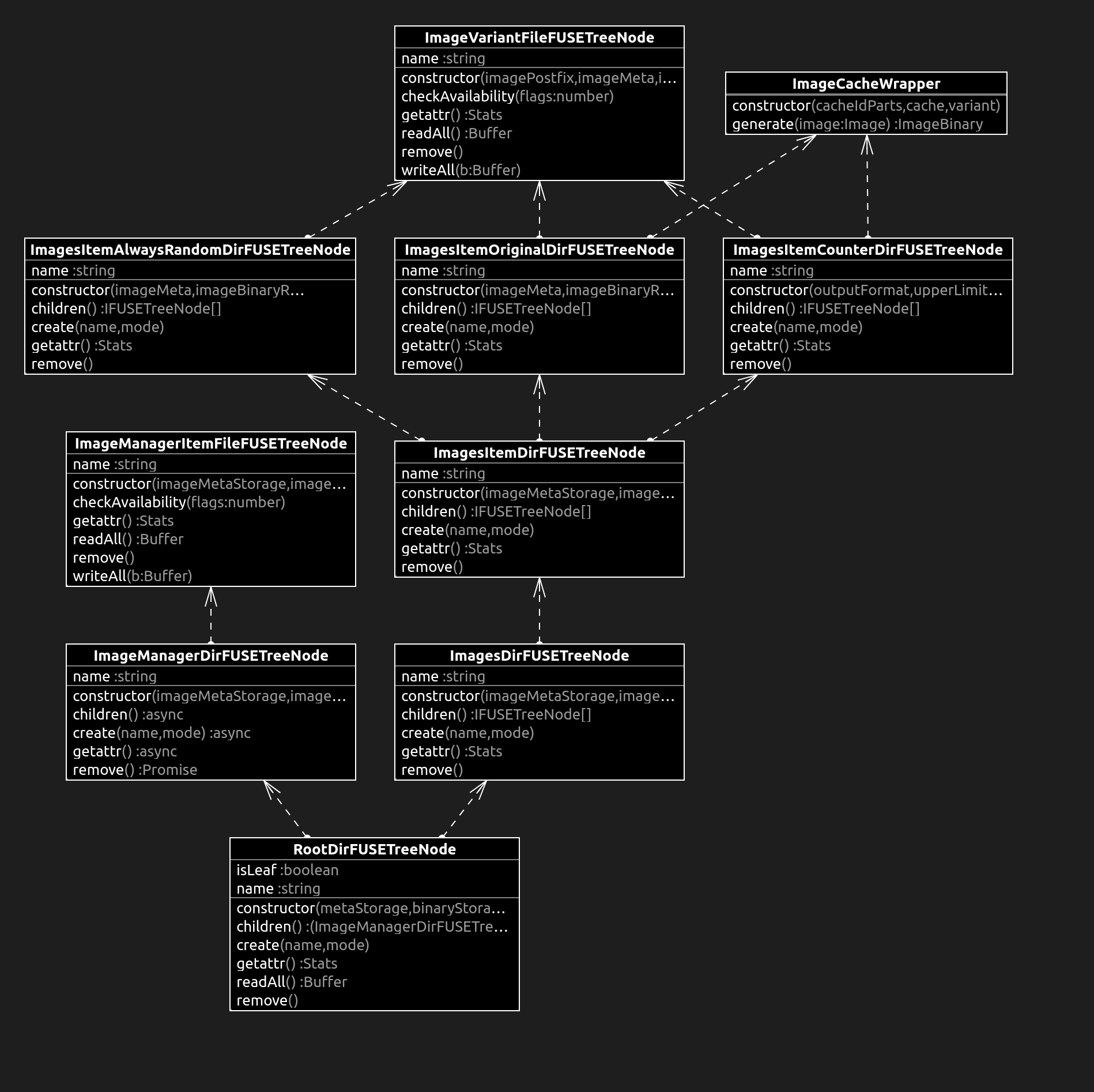
The class diagram below represents how the tree classes are combined with their image counterparts.
The diagram should be read from bottom to top. `RootDir` (let me avoid the `FUSETreeNode` postfix in names) is the root dir for the file system that the program is implementing. Moving to the upper row, see two dirs: `ImagesDir` and `ImagesManagerDir`.
`ImagesManagerDir` contains the user images list and allows control of them. Then, `ImagesManagerItemFile` is a node for a particular file. This class implements CRUD operations.
Consider ImagesManagerDir as a usual implementation of a node:
```typescript
class ImageManagerDirFUSETreeNode extends DirectoryFUSETreeNode {
name = 'Image Manager'; // Name of the directory
constructor(
private readonly imageMetaStorage: IImageMetaStorage,
private readonly imageBinaryStorage: IBinaryStorage,
) {
super(); // Call the parent class constructor
}
async children(): Promise<IFUSETreeNode[]> {
// Dynamically create child nodes
// In some cases, dynamic behavior can be problematic, requiring a cache of child nodes
// to avoid redundant creation of IFUSETreeNode instances
const list = await this.imageMetaStorage.list();
return list.map(
(meta) =>
new ImageManagerItemFileFUSETreeNode(
this.imageMetaStorage,
this.imageBinaryStorage,
meta,
),
);
}
async create(name: string, mode: number): Promise<void> {
// Create a new image metadata entry
await this.imageMetaStorage.create(name);
}
async getattr(): Promise<Stats> {
return {
// File modification date
mtime: new Date(),
// File last access date
atime: new Date(),
// File creation date
// We do not store dates for our images,
// so we simply return the current date
ctime: new Date(),
// Number of links
nlink: 1,
size: 100,
// File access flags
mode: FUSEMode.directory(
FUSEMode.ALLOW_RWX, // Owner access rights
FUSEMode.ALLOW_RX, // Group access rights
FUSEMode.ALLOW_RX, // Access rights for all others
),
// User ID of the file owner
uid: process.getuid ? process.getuid() : 0,
// Group ID for which the file is accessible
gid: process.getgid ? process.getgid() : 0,
};
}
// Explicitly forbid deleting the 'Images Manager' folder
remove(): Promise<void> {
throw FUSEError.accessDenied();
}
}
```
Moving forward, the `ImagesDir` contains subdirectories named after the user's images. `ImagesItemDir` is responsible for each directory. It includes all available variants; as you remember, the variants count is three. Each variant is a directory that contains the final image files in different formats (currently: jpeg, png, and webm).
`ImagesItemOriginalDir` and `ImagesItemCounterDir` wrap all spawned `ImageVariantFile` instances in a cache. This is necessary to avoid constant re-encoding of the original images because encoding is CPU-consuming.
At the top of the diagram is the `ImageVariantFile`. It is the crown jewel of the implementation and the composition of the previously described `IFUSEHandler` and `IImageVariant`. This is the file that all our efforts have been building towards.
## Testing <a name="testing"></a>
Let’s test how the final filesystem handles parallel requests to the same file. To do this, we will run the `md5sum` utility in multiple threads, which will read files from the filesystem and calculate their hashes. Then, we’ll compare these hashes. If everything is working correctly, the hashes should be different.
```bash
#!/bin/bash
# Loop to run the md5sum command 5 times in parallel
for i in {1..5}
do
echo "Run $i..."
# `&` at the end of the command runs it in the background
md5sum ./mnt/Images/2020-09-10_22-43/always_random/2020-09-10_22-43.png &
done
echo 'wait...'
# Wait for all background processes to finish
wait
```
I ran the script and checked the following output (cleaned up a bit for clarity):
```
Run 1...
Run 2...
Run 3...
Run 4...
Run 5...
wait...
bcdda97c480db74e14b8779a4e5c9d64
0954d3b204c849ab553f1f5106d576aa
564eeadfd8d0b3e204f018c6716c36e9
73a92c5ef27992498ee038b1f4cfb05e
77db129e37fdd51ef68d93416fec4f65
```
Excellent! All the hashes are different, meaning the filesystem returns a unique image each time!
## Сonclusion <a name="conclusion"></a>
I hope this article has inspired you to write your own FUSE implementation. Remember, the source code for this project is available here: https://github.com/pinkiesky/node-fuse-images.
The filesystem we’ve built is simplified to demonstrate the core principles of working with FUSE and Node.js. For example, it doesn't take into account the correct dates. There's plenty of room for enhancement. Imagine adding functionalities like frame extraction from user GIF files, video transcoding, or even parallelizing tasks through workers.
However, perfect is the enemy of good. Start with what you have, get it working, and then iterate. Happy coding!
| pinkiesky |
1,873,666 | Changing the Default Password on an EC2 Ubuntu Instance | Changing the Default Password on an EC2 Ubuntu 14 Instance Amazon EC2 (Elastic Compute... | 0 | 2024-06-02T13:00:54 | https://dev.to/sh20raj/changing-the-default-password-on-an-ec2-ubuntu-instance-1c56 | webdev, javascript, beginners, programming | # Changing the Default Password on an EC2 Ubuntu 14 Instance
Amazon EC2 (Elastic Compute Cloud) is a popular web service that provides resizable compute capacity in the cloud. It's often used for hosting applications, websites, and other workloads. When launching an EC2 instance with Ubuntu 14.04, the default user is typically `ubuntu`, and by default, this user doesn't have a password set. Instead, you access the instance using SSH key pairs. However, there might be situations where you need to set or change the password for the `ubuntu` user or other users. This guide will walk you through the process of setting and changing the password on an EC2 Ubuntu 14 instance.
## Prerequisites
- An AWS account.
- An EC2 instance running Ubuntu 14.04.
- SSH key pair associated with your EC2 instance.
- SSH client (e.g., PuTTY for Windows or Terminal for macOS/Linux).
## Step-by-Step Guide
### Step 1: Access Your EC2 Instance
1. **Open your terminal or SSH client.**
2. **Connect to your EC2 instance using SSH.** Replace `<your-key-pair>.pem` with your actual key pair file and `ec2-user@your-instance-public-dns` with your instance's public DNS.
```sh
ssh -i <your-key-pair>.pem ubuntu@your-instance-public-dns
```
Example:
```sh
ssh -i my-key-pair.pem ubuntu@ec2-203-0-113-25.compute-1.amazonaws.com
```
### Step 2: Set or Change the Password for the `ubuntu` User
Once you are logged in to your instance, you can set or change the password for the `ubuntu` user.
1. **Set the password using the `passwd` command.**
```sh
sudo passwd ubuntu
```
2. **Enter a new password when prompted.** You will need to confirm the password by typing it again.
```sh
Enter new UNIX password:
Retype new UNIX password:
passwd: password updated successfully
```
### Step 3: Verify the Password Change
To ensure that the password change was successful, you can try switching to the `ubuntu` user and using the new password.
1. **Switch to the `ubuntu` user.**
```sh
su - ubuntu
```
2. **Enter the new password when prompted.**
```sh
Password:
```
If you are not prompted for the password or if you want to log in using the password, you may need to adjust the SSH settings to allow password authentication.
### Step 4: Enable Password Authentication (Optional)
By default, EC2 instances use key pair authentication, and password authentication might be disabled. To enable password authentication:
1. **Edit the SSH configuration file.**
```sh
sudo nano /etc/ssh/sshd_config
```
2. **Find the following lines and modify them as shown:**
```sh
PasswordAuthentication yes
PermitRootLogin yes
```
3. **Save the file and exit the editor (Ctrl+O, Enter, Ctrl+X in nano).**
4. **Restart the SSH service to apply the changes.**
```sh
sudo service ssh restart
```
### Step 5: Test Password Authentication
1. **Open a new terminal or SSH client window.**
2. **Connect to your EC2 instance using the `ubuntu` username and the new password.**
```sh
ssh ubuntu@your-instance-public-dns
```
You should now be able to log in using the password you set.
## Conclusion
Changing the default password on an EC2 Ubuntu 14 instance is straightforward. By following these steps, you can ensure that your instance is secure and that you have the necessary access methods in place. Always remember to revert the SSH settings to disable password authentication if it is no longer needed to maintain security best practices. | sh20raj |
1,859,119 | GPT as Mentor & Coding Tool | Summary Welcome to the first article in a series where I'm developing a pet project with GPT as my... | 0 | 2024-06-02T13:00:37 | https://dev.to/rashit/gpt-as-mentor-coding-tool-25gp | java, ai, gpt |

> **Summary**
> _Welcome to the first article in a series where I'm developing a pet project with GPT as my Java mentor and coding assistant. In this article, GPT helps me create a plan and writes five Spring Boot microservices, including controllers, services, repositories, entities, DTOs, mappers, table descriptions, and XML scripts for Liquibase._
Recently, I have often heard that artificial intelligence will soon leave non-exceptional programmers without jobs. In my blog, starting with this post, I will try to show you how a non-exceptional programmer can find a job with the help of ChatGPT. I will be using GPT as a Java mentor. It will help me design an application, select technologies, write APIs for each microservice, and draft a database description.
So, let's start with my prompt.
> My goal is to secure a position as a mid-level Java developer. To achieve this, I need to enhance my knowledge of several technologies. Therefore, I plan to develop a pet project for registering stray dogs. This is not a startup; it's an educational project that I aim to implement as quickly as possible.
> The users of the application will be:
> 1. Volunteers who can enter dogs into the database.
> 2. All other users can view this database.
> Any user will be able to send donations to any dog. Each dog's medical history, including vaccinations and sterilizations, will be tracked. The dog's profile will include photos, a number (as most dogs have colored tags with numbers, although not all do), and an approximate location and age. Admins should have the ability to send notifications to all users.
> I plan to use the following technologies: Spring Boot, Spring Security, Liquibase, Maven, REST API, Swagger, PostgreSQL, Hibernate, Redis, Kafka, Elasticsearch, Docker, CI/CD, Stripe or PayPal API, and AWS. I don't have much experience with Redis, Elasticsearch, Docker, CI/CD, Stripe or PayPal API, or AWS, but I'm fairly comfortable with the rest. You can suggest other technologies if necessary.
> I need to design the application architecture to easily add a microservice for image recognition in the future. This microservice will recognize dogs from photos and search for them in the database. Could you act as a Java mentor and suggest which microservices I should develop, and help me write APIs for each one?
GPT response:
> To structure your pet project efficiently, we'll focus on a microservices architecture that aligns with your goal of expanding your knowledge as a mid-level Java developer. We'll design the application to be scalable and ready to integrate future technologies, such as an image recognition microservice. Here's a step-by-step guide to the microservices architecture, the APIs you should implement for each microservice, and how to utilize the technologies you're interested in learning:
> ## Microservices Design and APIs
> **1. Dog Management Service**
> - _Purpose:_ Manages all dog-related information.
> - _Technologies:_ Spring Boot, Maven, PostgreSQL, Hibernate, Spring Security, Redis (for caching).
> - _APIs:_
> - POST /dogs - Create a new dog profile.
> - GET /dogs/{id} - Retrieve a dog's profile by ID.
> - PUT /dogs/{id} - Update a dog's profile.
> - DELETE /dogs/{id} - Delete a dog's profile.
> - GET /dogs - List all dogs with filtering options.
> **2. Medical Records Service**
> - _Purpose:_ Manages medical histories of dogs.
> - _Technologies:_ Spring Boot, Maven, PostgreSQL, Hibernate.
> - _APIs:_
> - POST /medical-records - Add medical record.
> - GET /medical-records/{dogId} - Get medical records for a specific dog.
> - PUT /medical-records/{id} - Update a medical record.
> - DELETE /medical-records/{id} - Delete a medical record.
> **3. Donation Management Service**
> - _Purpose:_ Handles donations made to dogs.
> - _Technologies:_ Spring Boot, Maven, Stripe or PayPal API.
> - _APIs:_
> - POST /donations - Make a donation.
> - GET /donations/{dogId} - Retrieve donations for a specific dog.
> **4. Notification Service**
> - _Purpose:_ Sends notifications to users.
> - _Technologies:_ Spring Boot, Kafka (for messaging).
> - _APIs:_
> - POST /notifications - Send a notification.
> - GET /notifications - List all notifications.
> **5. Search Service**
> - _Purpose:_ Provides advanced search capabilities across the dog database.
> - _Technologies:_ Spring Boot, Elasticsearch.
> - _APIs:_
> - GET /search - Search dogs based on various criteria (e.g., name, location).
> **6. User Management Service**
> - _Purpose:_ Manages user accounts and roles.
> - _Technologies:_ Spring Boot, PostgreSQL, Spring Security.
> - _APIs:_
> - POST /users - Register new user.
> - POST /login - User login.
> - GET /users/{id} - Get user information.
> - PUT /users/{id} - Update user information.
> ## Future Expansion: Image Recognition Service
> - _Purpose:_ To recognize dogs from uploaded photos and match them against the database.
> - _Technologies:_ Potential use of AI/ML libraries or platforms.
> ## Project Execution and Learning Plan
> **Phase 1: Setup and Basic CRUD Operations**
> - Setup Maven projects for each microservice.
> - Implement basic CRUD operations for Dog Management and Medical Records Services.
> **Phase 2: Implement Additional Services**
> - Develop Donation Management, Notification, and User Management Services.
> - Begin integrating Redis for caching commonly retrieved data in the Dog Management Service.
> **Phase 3: Advanced Features and Deployment**
> - Integrate Elasticsearch in the Search Service.
> - Setup Docker containers for each microservice.
> - Establish a CI/CD pipeline using Jenkins or GitHub Actions.
> - Deploy services to AWS.
> **Phase 4: Third-Party Integration and Testing**
> - Integrate Stripe or PayPal for processing donations.
> - Thoroughly test each service and ensure all parts work together seamlessly.
> This approach will not only help you learn each technology but also give you a comprehensive understanding of how modern applications are structured and scaled using microservices. By documenting all APIs with Swagger, you'll ensure that your application is maintainable and understandable.
This looks great; he wrote the API for me. I'll probably need to finish it up and maybe redo some parts, but it's awesome! Now I need to think about the database tables. Or wait, why should I? Let GPT handle that.
> Can you describe the database tables I need to create?
GPT response:
> For your pet project on managing stray dogs, let's design the database schema to support your application's functionality efficiently. We'll consider five primary areas of functionality: dog management, medical records, donations, notifications, and user management. Here's a suggested schema for each:
> **1. Dog Management**
> This service will manage dog profiles, which include their basic information, photos, and location.
> Table: **Dogs**
> - _dog_id_ (Primary Key): Unique identifier for each dog.
> - _name_ (VARCHAR): Name of the dog.
> - _age_ (INTEGER): Age of the dog.
> - _location_ (VARCHAR): Approximate location where the dog is usually found.
> - _photo_url_ (VARCHAR): URL to the dog's photo.
> **2. Medical Records**
> This service will track medical histories, including vaccinations and sterilizations.
> Table: **Medical_Records**
> - _record_id_ (Primary Key): Unique identifier for each record.
> - _dog_id_ (Foreign Key): Linked to the Dogs table.
> - _description_ (TEXT): Description of the medical event.
> - _event_date_ (DATE): Date when the event occurred.
> - _type_ (VARCHAR): Type of medical event (e.g., vaccination, sterilization).
> **3. Donation Management**
> This service will handle donations made to each dog.
> Table: **Donations**
> - _donation_id_ (Primary Key): Unique identifier for each donation.
> - _dog_id_ (Foreign Key): Linked to the Dogs table.
> - _user_id_ (Foreign Key): Linked to the Users table.
> - _amount_ (DECIMAL): Amount of money donated.
> - _date_ (DATE): Date when the donation was made.
> **4. Notification Service**
> This service will store notifications intended to be sent to users.
> Table: **Notifications**
> - _notification_id_ (Primary Key): Unique identifier for each notification.
> - _message_ (TEXT): Notification message content.
> - _date_sent_ (DATE): Date when the notification was sent.
> **5. User Management**
> This service will manage user accounts and their roles (volunteers, admins).
> Table: **Users**
> - _user_id_ (Primary Key): Unique identifier for each user.
> - _username_ (VARCHAR): Username for the account.
> - _password_ (VARCHAR): Hashed password for security.
> - _email_ (VARCHAR): User's email address.
> - _role_ (VARCHAR): Role of the user (e.g., volunteer, admin).
> **Foreign Keys and Indexing**
> - Ensure that _dog_id_ in **Medical_Records** and **Donations** is a foreign key linked to the **Dogs** table.
> - Ensure that _user_id_ in **Donations** is a foreign key linked to the
**Users** table.
> - Consider adding indexes to commonly searched fields like _dog_id_ in
**Dogs**, _user_id_ in **Users**, and _event_date _ in **Medical_Records** to improve query performance.
> **Considerations for Scalability and Performance**
> - Use **PostgreSQL** for its robustness and support for complex queries and relationships.
> - Consider implementing **caching mechanisms** for frequently accessed data like dog profiles using Redis.
> - Optimize your schema and queries as needed based on the actual data access patterns you observe during development and initial testing.
> This schema provides a solid foundation for your application, ensuring that all necessary data is captured efficiently and is easily accessible via your planned APIs.
Great. Now I'd like GPT to generate Liquibase changelogs in XML format so I don't have to write them myself.
> Generate the appropriate Liquibase changelogs in XML format for each microservice
GPT response:
> To create Liquibase changelogs in XML format for each microservice, I'll outline the changelogs for the database schema we discussed. Each changelog will be crafted for specific parts of the application, facilitating modular deployment and easier management.
> ## 1. Dogs Management Service
> File: **db.changelog-dogs.xml**
```
<?xml version="1.0" encoding="UTF-8"?>
<databaseChangeLog
xmlns="http://www.liquibase.org/xml/ns/dbchangelog"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.liquibase.org/xml/ns/dbchangelog
http://www.liquibase.org/xml/ns/dbchangelog/dbchangelog-3.8.xsd">
<changeSet id="1" author="your_username">
<createTable tableName="dogs">
<column name="dog_id" type="serial" autoIncrement="true">
<constraints primaryKey="true" nullable="false"/>
</column>
<column name="name" type="varchar(255)"/>
<column name="age" type="int"/>
<column name="location" type="varchar(255)"/>
<column name="photo_url" type="varchar(255)"/>
</createTable>
</changeSet>
</databaseChangeLog>
```
> ## 2. Medical Records Service
> **File: db.changelog-medical-records.xml**
```
<?xml version="1.0" encoding="UTF-8"?>
<databaseChangeLog
xmlns="http://www.liquibase.org/xml/ns/dbchangelog"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.liquibase.org/xml/ns/dbchangelog
http://www.liquibase.org/xml/ns/dbchangelog/dbchangelog-3.8.xsd">
<changeSet id="1" author="your_username">
<createTable tableName="medical_records">
<column name="record_id" type="serial" autoIncrement="true">
<constraints primaryKey="true" nullable="false"/>
</column>
<column name="dog_id" type="int">
<constraints nullable="false" foreignKeyName="fk_dog_medical"
references="dogs(dog_id)"/>
</column>
<column name="description" type="text"/>
<column name="event_date" type="date"/>
<column name="type" type="varchar(255)"/>
</createTable>
<createIndex indexName="idx_dog_id" tableName="medical_records">
<column name="dog_id"/>
</createIndex>
</changeSet>
</databaseChangeLog>
```
> ## 3. Donation Management Service
> **File: db.changelog-donations.xml**
```
<?xml version="1.0" encoding="UTF-8"?>
<databaseChangeLog
xmlns="http://www.liquibase.org/xml/ns/dbchangelog"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.liquibase.org/xml/ns/dbchangelog
http://www.liquibase.org/xml/ns/dbchangelog/dbchangelog-3.8.xsd">
<changeSet id="1" author="your_username">
<createTable tableName="donations">
<column name="donation_id" type="serial" autoIncrement="true">
<constraints primaryKey="true" nullable="false"/>
</column>
<column name="dog_id" type="int">
<constraints nullable="false" foreignKeyName="fk_dog_donation"
references="dogs(dog_id)"/>
</column>
<column name="user_id" type="int">
<constraints nullable="false" foreignKeyName="fk_user_donation"
references="users(user_id)"/>
</column>
<column name="amount" type="decimal(10,2)"/>
<column name="date" type="date"/>
</createTable>
<createIndex indexName="idx_dog_id" tableName="donations">
<column name="dog_id"/>
</createIndex>
<createIndex indexName="idx_user_id" tableName="donations">
<column name="user_id"/>
</createIndex>
</changeSet>
</databaseChangeLog>
```
> **4. User Management Service**
> **File: db.changelog-users.xml**
```
<?xml version="1.0" encoding="UTF-8"?>
<databaseChangeLog
xmlns="http://www.liquibase.org/xml/ns/dbchangelog"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.liquibase.org/xml/ns/dbchangelog
http://www.liquibase.org/xml/ns/dbchangelog/dbchangelog-3.8.xsd">
<changeSet id="1" author="your_username">
<createTable tableName="users">
<column name="user_id" type="serial" autoIncrement="true">
<constraints primaryKey="true" nullable="false"/>
</column>
<column name="username" type="varchar(255)">
<constraints unique="true" nullable="false"/>
</column>
<column name="password" type="varchar(255)" nullable="false"/>
<column name="email" type="varchar(255)" nullable="false"/>
<column name="role" type="varchar(255)"/>
</createTable>
</changeSet>
</databaseChangeLog>
```
> Each Liquibase changelog file corresponds to a specific microservice and includes the necessary DDL commands to create the respective tables. Make sure to replace "your_username" with your actual username or identifier. This structure will help you manage database versions and changes efficiently as your application evolves.
Initially, GPT created changelogs without adding indexes. When I requested it to include indexes for foreign keys, GPT promptly did so. Now I'll ask GPT to write Java classes for the table entities and include Hibernate annotations.
GPT response:
> For your pet project, I'll provide Java classes for each of the tables you've defined, including Hibernate annotations to map these classes to your database schema. These classes will represent the entities for Dogs, Medical Records, Donations, Notifications, and Users.
> **1. Dog Entity**
```
import javax.persistence.*;
import java.util.Set;
@Entity
@Table(name = "dogs")
public class Dog {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "dog_id")
private Long id;
@Column(name = "name")
private String name;
@Column(name = "age")
private Integer age;
@Column(name = "location")
private String location;
@Column(name = "photo_url")
private String photoUrl;
// Getters and Setters
}
```
> **2. Medical Record Entity**
```
import javax.persistence.*;
@Entity
@Table(name = "medical_records")
public class MedicalRecord {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "record_id")
private Long id;
@ManyToOne
@JoinColumn(name = "dog_id", nullable = false)
private Dog dog;
@Column(name = "description")
private String description;
@Column(name = "event_date")
private Date eventDate;
@Column(name = "type")
private String type;
// Getters and Setters
}
```
> **3. Donation Entity**
```
import javax.persistence.*;
@Entity
@Table(name = "donations")
public class Donation {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "donation_id")
private Long id;
@ManyToOne
@JoinColumn(name = "dog_id", nullable = false)
private Dog dog;
@ManyToOne
@JoinColumn(name = "user_id", nullable = false)
private User user;
@Column(name = "amount")
private BigDecimal amount;
@Column(name = "date")
private Date date;
// Getters and Setters
}
```
> **4. Notification Entity**
```
import javax.persistence.*;
@Entity
@Table(name = "notifications")
public class Notification {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "notification_id")
private Long id;
@Column(name = "message")
private String message;
@Column(name = "date_sent")
private Date dateSent;
// Getters and Setters
}
```
> **5. User Entity**
```
import javax.persistence.*;
import java.util.Set;
@Entity
@Table(name = "users")
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "user_id")
private Long id;
@Column(name = "username", unique = true)
private String username;
@Column(name = "password")
private String password;
@Column(name = "email")
private String email;
@Column(name = "role")
private String role;
// Getters and Setters
}
```
> These classes include basic entity mappings using Hibernate annotations. You may want to customize constructors, methods, and additional fields according to your specific requirements and logic, such as relations between entities (e.g., _@OneToMany_ for relations between **Dog** and **MedicalRecord** or **Donation**). Each class is annotated to correspond to the respective database table and fields, managing the primary keys, relationships, and common columns.
Great job, GPT! Can you write the controllers for me next? My next prompt was: 'Write controllers for each of my microservices.'
GPT wrote the controllers, but I forgot to ask for Swagger descriptions. So, I added another prompt: 'Could you add Swagger descriptions?' GPT did it.
I then realized that the methods in the controllers were returning entities instead of DTOs, so I asked GPT to create and return DTOs. It did, but the mapping code was inside the controllers, and some methods were returning lists of DTOs. I requested pagination to return pages and also asked for the mapping code to be extracted into separate classes. GPT managed to do that too, though it was quite challenging.
Through this process, I realized GPT isn’t as smart as I initially thought—at least not yet. I also noticed that GPT sometimes got lazy because it occasionally didn’t write the full code and instead gave responses like 'The other controllers should be written similarly,' which meant I had to ask it specifically to write the other controllers. But to be fair, it did what I asked. Next time, I should be more specific with my requirements.

GPT response:
> **1. Medical Record DTO**
```
public class MedicalRecordDTO {
private Long id;
private Long dogId;
private String description;
private Date eventDate;
private String type;
// Constructors, Getters and Setters
public MedicalRecordDTO() {}
public MedicalRecordDTO(Long id, Long dogId, String description, Date eventDate, String type) {
this.id = id;
this.dogId = dogId;
this.description = description;
this.eventDate = eventDate;
this.type = type;
}
// Standard getters and setters
}
```
> **2. Donation DTO**
```
public class DonationDTO {
private Long id;
private Long dogId;
private Long userId;
private BigDecimal amount;
private Date date;
// Constructors, Getters and Setters
public DonationDTO() {}
public DonationDTO(Long id, Long dogId, Long userId, BigDecimal amount, Date date) {
this.id = id;
this.dogId = dogId;
this.userId = userId;
this.amount = amount;
this.date = date;
}
// Standard getters and setters
}
```
> **3. Notification DTO**
```
public class NotificationDTO {
private Long id;
private String message;
private Date dateSent;
// Constructors, Getters and Setters
public NotificationDTO() {}
public NotificationDTO(Long id, String message, Date dateSent) {
this.id = id;
this.message = message;
this.dateSent = dateSent;
}
// Standard getters and setters
}
```
> **4. User DTO**
```
public class UserDTO {
private Long id;
private String username;
private String password; // Note: Consider security implications of transmitting passwords
private String email;
private String role;
// Constructors, Getters and Setters
public UserDTO() {}
public UserDTO(Long id, String username, String password, String email, String role) {
this.id = id;
this.username = username;
this.password = password;
this.email = email;
this.role = role;
}
// Standard getters and setters
}
```
> **Dog Management Mapper**
```
public class DogMapper {
public static DogDTO toDogDTO(Dog dog) {
return new DogDTO(
dog.getId(),
dog.getName(),
dog.getAge(),
dog.getLocation(),
dog.getPhotoUrl()
);
}
public static Dog toDogEntity(DogDTO dogDTO) {
Dog dog = new Dog();
dog.setId(dogDTO.getId());
dog.setName(dogDTO.getName());
dog.setAge(dogDTO.getAge());
dog.setLocation(dogDTO.getLocation());
dog.setPhotoUrl(dogDTO.getPhotoUrl());
return dog;
}
}
```
> **Medical Records Mapper**
```
public class MedicalRecordMapper {
public static MedicalRecordDTO toMedicalRecordDTO(MedicalRecord medicalRecord) {
return new MedicalRecordDTO(
medicalRecord.getId(),
medicalRecord.getDog().getId(),
medicalRecord.getDescription(),
medicalRecord.getEventDate(),
medicalRecord.getType()
);
}
public static MedicalRecord toMedicalRecordEntity(MedicalRecordDTO medicalRecordDTO) {
MedicalRecord medicalRecord = new MedicalRecord();
medicalRecord.setId(medicalRecordDTO.getId());
Dog dog = new Dog();
dog.setId(medicalRecordDTO.getDogId());
medicalRecord.setDog(dog);
medicalRecord.setDescription(medicalRecordDTO.getDescription());
medicalRecord.setEventDate(medicalRecordDTO.getEventDate());
medicalRecord.setType(medicalRecordDTO.getType());
return medicalRecord;
}
}
```
> **Donation Mapper**
```
public class DonationMapper {
public static DonationDTO toDonationDTO(Donation donation) {
return new DonationDTO(
donation.getId(),
donation.getDog().getId(),
donation.getUser().getId(),
donation.getAmount(),
donation.getDate()
);
}
public static Donation toDonationEntity(DonationDTO donationDTO) {
Donation donation = new Donation();
donation.setId(donationDTO.getId());
Dog dog = new Dog();
dog.setId(donationDTO.getDogId());
User user = new User();
user.setId(donationDTO.getUserId());
donation.setDog(dog);
donation.setUser(user);
donation.setAmount(donationDTO.getAmount());
donation.setDate(donationDTO.getDate());
return donation;
}
}
```
> **Notification Mapper**
```
public class NotificationMapper {
public static NotificationDTO toNotificationDTO(Notification notification) {
return new NotificationDTO(
notification.getId(),
notification.getMessage(),
notification.getDateSent()
);
}
public static Notification toNotificationEntity(NotificationDTO notificationDTO) {
Notification notification = new Notification();
notification.setId(notificationDTO.getId());
notification.setMessage(notificationDTO.getMessage());
notification.setDateSent(notificationDTO.getDateSent());
return notification;
}
}
```
> **User Mapper**
```
public class UserMapper {
public static UserDTO toUserDTO(User user) {
return new UserDTO(
user.getId(),
user.getUsername(),
user.getPassword(),
user.getEmail(),
user.getRole()
);
}
public static User toUserEntity(UserDTO userDTO) {
User user = new User();
user.setId(userDTO.getId());
user.setUsername(userDTO.getUsername());
user.setPassword(userDTO.getPassword()); // Make sure to hash the password in the service layer
user.setEmail(userDTO.getEmail());
user.setRole(userDTO.getRole());
return user;
}
}
```
> **Medical Records Controller with MedicalRecordMapper**
```
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.PageRequest;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.*;
@RestController
@RequestMapping("/api/medical-records")
@Api(value = "Medical Record Management", description = "Operations pertaining to medical records of dogs in the application")
public class MedicalRecordController {
@Autowired
private MedicalRecordService medicalRecordService;
@ApiOperation(value = "Add a new medical record for a dog", response = MedicalRecordDTO.class)
@PostMapping
public ResponseEntity<MedicalRecordDTO> addMedicalRecord(@RequestBody MedicalRecordDTO medicalRecordDTO) {
MedicalRecord medicalRecord = MedicalRecordMapper.toMedicalRecordEntity(medicalRecordDTO);
MedicalRecord createdMedicalRecord = medicalRecordService.addMedicalRecord(medicalRecord);
return ResponseEntity.ok(MedicalRecordMapper.toMedicalRecordDTO(createdMedicalRecord));
}
@ApiOperation(value = "Retrieve medical records by dog ID with pagination", response = MedicalRecordDTO.class, responseContainer = "List")
@GetMapping("/{dogId}")
public ResponseEntity<Page<MedicalRecordDTO>> getMedicalRecordsByDogId(
@PathVariable Long dogId,
@RequestParam(defaultValue = "0") int page,
@RequestParam(defaultValue = "10") int size) {
Page<MedicalRecord> records = medicalRecordService.getMedicalRecordsByDogId(dogId, PageRequest.of(page, size));
Page<MedicalRecordDTO> recordDTOs = records.map(MedicalRecordMapper::toMedicalRecordDTO);
return ResponseEntity.ok(recordDTOs);
}
@ApiOperation(value = "Update an existing medical record", response = MedicalRecordDTO.class)
@PutMapping("/{id}")
public ResponseEntity<MedicalRecordDTO> updateMedicalRecord(@PathVariable Long id, @RequestBody MedicalRecordDTO medicalRecordDTO) {
MedicalRecord medicalRecord = MedicalRecordMapper.toMedicalRecordEntity(medicalRecordDTO);
medicalRecord.setId(id);
MedicalRecord updatedMedicalRecord = medicalRecordService.updateMedicalRecord(medicalRecord);
return ResponseEntity.ok(MedicalRecordMapper.toMedicalRecordDTO(updatedMedicalRecord));
}
@ApiOperation(value = "Delete a medical record")
@DeleteMapping("/{id}")
public ResponseEntity<Void> deleteMedicalRecord(@PathVariable Long id) {
medicalRecordService.deleteMedicalRecord(id);
return ResponseEntity.ok().build();
}
}
```
> **Donation Management Controller with DonationMapper**
```
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.PageRequest;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.*;
@RestController
@RequestMapping("/api/donations")
@Api(value = "Donation Management", description = "Operations pertaining to donations made to dogs")
public class DonationController {
@Autowired
private DonationService donationService;
@ApiOperation(value = "Make a donation", response = DonationDTO.class)
@PostMapping
public ResponseEntity<DonationDTO> makeDonation(@RequestBody DonationDTO donationDTO) {
Donation donation = DonationMapper.toDonationEntity(donationDTO);
Donation createdDonation = donationService.makeDonation(donation);
return ResponseEntity.ok(DonationMapper.toDonationDTO(createdDonation));
}
@ApiOperation(value = "Get all donations made for a specific dog with pagination", response = DonationDTO.class, responseContainer = "List")
@GetMapping("/{dogId}")
public ResponseEntity<Page<DonationDTO>> getDonationsByDogId(
@PathVariable Long dogId,
@RequestParam(defaultValue = "0") int page,
@RequestParam(defaultValue = "10") int size) {
Page<Donation> donations = donationService.getDonationsByDogId(dogId, PageRequest.of(page, size));
Page<DonationDTO> donationDTOs = donations.map(DonationMapper::toDonationDTO);
return ResponseEntity.ok(donationDTOs);
}
}
```
> **Notification Management Controller with NotificationMapper**
```
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.PageRequest;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.*;
@RestController
@RequestMapping("/api/notifications")
@Api(value = "Notification Management", description = "Management of notifications sent to users")
public class NotificationController {
@Autowired
private NotificationService notificationService;
@ApiOperation(value = "Send a notification", response = NotificationDTO.class)
@PostMapping
public ResponseEntity<NotificationDTO> sendNotification(@RequestBody NotificationDTO notificationDTO) {
Notification notification = NotificationMapper.toNotificationEntity(notificationDTO);
Notification sentNotification = notificationService.sendNotification(notification);
return ResponseEntity.ok(NotificationMapper.toNotificationDTO(sentNotification));
}
@ApiOperation(value = "List all notifications with pagination", response = NotificationDTO.class, responseContainer = "List")
@GetMapping
public ResponseEntity<Page<NotificationDTO>> getAllNotifications(
@RequestParam(defaultValue = "0") int page,
@RequestParam(defaultValue = "10") int size) {
Page<Notification> notifications = notificationService.getAllNotifications(PageRequest.of(page, size));
Page<NotificationDTO> notificationDTOs = notifications.map(NotificationMapper::toNotificationDTO);
return ResponseEntity.ok(notificationDTOs);
}
}
```
> **User Management Controller with UserMapper**
```
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.PageRequest;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.*;
@RestController
@RequestMapping("/api/users")
@Api(value = "User Management", description = "Operations pertaining to users in the application")
public class UserController {
@Autowired
private UserService userService;
@ApiOperation(value = "Register a new user", response = UserDTO.class)
@PostMapping
public ResponseEntity<UserDTO> registerUser(@RequestBody UserDTO userDTO) {
User user = UserMapper.toUserEntity(userDTO);
User registeredUser = userService.registerUser(user);
return ResponseEntity.ok(UserMapper.toUserDTO(registeredUser));
}
@ApiOperation(value = "Get a user by ID", response = UserDTO.class)
@GetMapping("/{id}")
public ResponseEntity<UserDTO> getUserById(@PathVariable Long id) {
User user = userService.getUserById(id);
return ResponseEntity.ok(UserMapper.toUserDTO(user));
}
@ApiOperation(value = "Update an existing user", response = UserDTO.class)
@PutMapping("/{id}")
public ResponseEntity<UserDTO> updateUser(@PathVariable Long id, @RequestBody UserDTO userDTO) {
User user = UserMapper.toUserEntity(userDTO);
user.setId(id);
User updatedUser = userService.updateUser(user);
return ResponseEntity.ok(UserMapper.toUserDTO(updatedUser));
}
@ApiOperation(value = "Delete a user")
@DeleteMapping("/{id}")
public ResponseEntity<Void> deleteUser(@PathVariable Long id) {
userService.deleteUser(id);
return ResponseEntity.ok().build();
}
@ApiOperation(value = "List all users with pagination", response = UserDTO.class, responseContainer = "List")
@GetMapping
public ResponseEntity<Page<UserDTO>> getAllUsers(
@RequestParam(defaultValue = "0") int page,
@RequestParam(defaultValue = "10") int size) {
Page<User> users = userService.getAllUsers(PageRequest.of(page, size));
Page<UserDTO> userDTOs = users.map(UserMapper::toUserDTO);
return ResponseEntity.ok(userDTOs);
}
}
```
Then I wrote, 'Create services and repositories for each microservice.'
GPT response:
> ## Dog Management Service and Repository
> **DogRepository.java**
```
import org.springframework.data.jpa.repository.JpaRepository;
public interface DogRepository extends JpaRepository<Dog, Long> {
}
```
> **DogService.java**
```
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.Optional;
@Service
public class DogService {
@Autowired
private DogRepository dogRepository;
public Dog createDog(Dog dog) {
return dogRepository.save(dog);
}
public Dog updateDog(Dog dog) {
return dogRepository.save(dog);
}
public Dog getDogById(Long id) {
return dogRepository.findById(id).orElseThrow(() -> new RuntimeException("Dog not found"));
}
public void deleteDog(Long id) {
dogRepository.deleteById(id);
}
public Page<Dog> getAllDogs(Pageable pageable) {
return dogRepository.findAll(pageable);
}
}
```
> ## Medical Records Service and Repository
> **MedicalRecordRepository.java**
```
import org.springframework.data.jpa.repository.JpaRepository;
public interface MedicalRecordRepository extends JpaRepository<MedicalRecord, Long> {
Page<MedicalRecord> findByDogId(Long dogId, Pageable pageable);
}
```
> **MedicalRecordService.java**
```
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
@Service
public class MedicalRecordService {
@Autowired
private MedicalRecordRepository medicalRecordRepository;
public MedicalRecord addMedicalRecord(MedicalRecord medicalRecord) {
return medicalRecordRepository.save(medicalRecord);
}
public MedicalRecord updateMedicalRecord(MedicalRecord medicalRecord) {
return medicalRecordRepository.save(medicalRecord);
}
public void deleteMedicalRecord(Long id) {
medicalRecordRepository.deleteById(id);
}
public Page<MedicalRecord> getMedicalRecordsByDogId(Long dogId, Pageable pageable) {
return medicalRecordRepository.findByDogId(dogId, pageable);
}
}
```
> ## Donation Management Service and Repository
> **DonationRepository.java**
```
import org.springframework.data.jpa.repository.JpaRepository;
public interface DonationRepository extends JpaRepository<Donation, Long> {
Page<Donation> findByDogId(Long dogId, Pageable pageable);
}
```
> **DonationService.java**
```
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
@Service
public class DonationService {
@Autowired
private DonationRepository donationRepository;
public Donation makeDonation(Donation donation) {
return donationRepository.save(donation);
}
public Page<Donation> getDonationsByDogId(Long dogId, Pageable pageable) {
return donationRepository.findByDogId(dogId, pageable);
}
}
```
> ## Notification Management Service and Repository
> **NotificationRepository.java**
```
import org.springframework.data.jpa.repository.JpaRepository;
public interface NotificationRepository extends JpaRepository<Notification, Long> {
}
```
> **NotificationService.java**
```
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
@Service
public class NotificationService {
@Autowired
private NotificationRepository notificationRepository;
public Notification sendNotification(Notification notification) {
return notificationRepository.save(notification);
}
public Page<Notification> getAllNotifications(Pageable pageable) {
return notificationRepository.findAll(pageable);
}
}
```
> ## User Management Service and Repository
> **UserRepository.java**
```
import org.springframework.data.jpa.repository.JpaRepository;
public interface UserRepository extends JpaRepository<User, Long> {
}
```
> **UserService.java**
```
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
@Service
public class UserService {
@Autowired
private UserRepository userRepository;
public User registerUser(User user) {
return userRepository.save(user);
}
public User updateUser(User user) {
return userRepository.save(user);
}
public void deleteUser(Long id) {
userRepository.deleteById(id);
}
public User getUserById(Long id) {
return userRepository.findById(id).orElseThrow(() -> new RuntimeException("User not found"));
}
public Page<User> getAllUsers(Pageable pageable) {
return userRepository.findAll(pageable);
}
}
```
> These services and repositories are designed to provide a clean, functional interface for each part of your application, facilitating data management and business logic execution. They are crafted using Spring Data JPA's JpaRepository, which offers a broad range of methods for CRUD operations and paging.
At this point, I wanted to write the conclusion, but I realized we haven't created the Search Service yet. So, my next prompt is, 'What about the search service? We haven't done anything for it.'
GPT response:
> Creating a search service, especially for an application like yours that handles entities such as dogs, medical records, donations, etc., can greatly enhance user experience by allowing quick and efficient retrieval of data based on various criteria. For implementing a search service, we will typically consider integrating a technology optimized for search operations, such as Elasticsearch, which you mentioned earlier, or a simpler implementation using database queries if the scale and complexity are limited.
> Let's outline how you could set up a basic search service using database queries and later discuss how it could be extended to use Elasticsearch.
> ## Basic Search Service Using Spring Data JPA Specifications
> You can use Spring Data JPA Specifications to build a dynamic query for searching dogs based on attributes like name, age, and location. This approach leverages the _JpaSpecificationExecutor_ interface provided by Spring Data.
> **Dog Specification for Search**
> First, let's create a _Specification_ class that will be used to construct the queries based on the search criteria.
```
import org.springframework.data.jpa.domain.Specification;
import javax.persistence.criteria.*;
public class DogSpecification {
public static Specification<Dog> hasName(String name) {
return (root, query, criteriaBuilder) -> {
if (name == null) return criteriaBuilder.isTrue(criteriaBuilder.literal(true)); // always true
return criteriaBuilder.like(criteriaBuilder.lower(root.get("name")), "%" + name.toLowerCase() + "%");
};
}
public static Specification<Dog> hasAge(Integer age) {
return (root, query, criteriaBuilder) -> {
if (age == null) return criteriaBuilder.isTrue(criteriaBuilder.literal(true));
return criteriaBuilder.equal(root.get("age"), age);
};
}
public static Specification<Dog> hasLocation(String location) {
return (root, query, criteriaBuilder) -> {
if (location == null) return criteriaBuilder.isTrue(criteriaBuilder.literal(true));
return criteriaBuilder.like(criteriaBuilder.lower(root.get("location")), "%" + location.toLowerCase() + "%");
};
}
public static Specification<Dog> buildSearchSpec(String name, Integer age, String location) {
return Specification.where(hasName(name)).and(hasAge(age)).and(hasLocation(location));
}
}
```
> **DogRepository Update**
> Extend _DogRepository_ to include _JpaSpecificationExecutor_:
```
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.data.jpa.repository.JpaSpecificationExecutor;
public interface DogRepository extends JpaRepository<Dog, Long>, JpaSpecificationExecutor<Dog> {
}
```
> ## Search Service Implementation
> Now, implement the search logic in the _DogService_.
```
import org.springframework.data.domain.Page;
import org.springframework.data.domain.Pageable;
import org.springframework.stereotype.Service;
@Service
public class DogSearchService {
@Autowired
private DogRepository dogRepository;
public Page<DogDTO> searchDogs(String name, Integer age, String location, Pageable pageable) {
Specification<Dog> spec = DogSpecification.buildSearchSpec(name, age, location);
Page<Dog> dogs = dogRepository.findAll(spec, pageable);
return dogs.map(DogMapper::toDogDTO);
}
}
```
> ## Extending to Use Elasticsearch
> If your application requires more complex search functionalities like full-text search, scalability across a large dataset, or faster response times, integrating Elasticsearch would be beneficial.
> - **1 Elasticsearch Repository:** Use Spring Data Elasticsearch to define a repository for _Dog_.
> - **2 Indexing Service:** Implement a service to handle the indexing of dog entities into Elasticsearch.
> - **3 Search Method:** Create methods in the _DogSearchService_ to utilize Elasticsearch's capabilities, such as full-text search, filtering, and sorting.
> Here's a brief concept for integrating Elasticsearch:
```
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
public interface DogSearchRepository extends ElasticsearchRepository<Dog, Long> {
Page<Dog> findByDescriptionContaining(String description, Pageable pageable);
}
```
> This setup would require additional configuration for Elasticsearch and potentially a synchronization mechanism between your primary database and the Elasticsearch index.
> Using these approaches, you can tailor the complexity and performance of the search functionality to meet the specific demands and scale of your application.
**Conclusion**
GPT is a fascinating tool. It can create a plan for a pet project and write applications based on specific requirements. However, the requirements need to be very clear. GPT will do exactly what I ask without questioning it, even if my request is misguided. This is the biggest difference compared to a human mentor. If my requests are not well-formulated, GPT will write code that no highly qualified developer would find acceptable.
Now it's time to build the projects and move on to learning and applying the next technologies according to the plan.
| rashit |
1,873,665 | KIU student portal login | Kampala International University (KIU) is widely recognized as one of the best private universities... | 0 | 2024-06-02T12:56:56 | https://dev.to/cugkiu84/kiu-student-portal-login-1hga | Kampala International University (KIU) is widely recognized as one of the best private universities in Kampala, Uganda. Established in 2001, KIU has grown into a significant educational institution offering a wide array of undergraduate, postgraduate, and PhD programs. This article delves into various aspects of KIU, highlighting its academic offerings, research opportunities, facilities, and student support services.
Academic Excellence at KIU
Undergraduate and Postgraduate Programs
KIU offers a comprehensive range of undergraduate programs across various disciplines, including medicine, engineering, business, and social sciences. The university is particularly known for its robust medical programs, which are supported by the KIU Teaching Hospital, providing students with hands-on clinical experience.
**_[KIU student portal login](https://kiu.ac.ug/)_**
Postgraduate courses at KIU are designed to enhance professional skills and knowledge, catering to a diverse student body. These programs include Master's and PhD courses in fields such as public health, business administration, law, and education. The university's PhD programs in Uganda are highly regarded, attracting scholars from across the continent.
Research Opportunities
Research is a cornerstone of KIU's mission. The university encourages both students and faculty to engage in innovative research projects. KIU has several research centers and institutes focusing on various areas, including health sciences, technology, and social development. These research opportunities not only contribute to academic knowledge but also address critical issues facing Uganda and the broader region.
Facilities and Resources
KIU Teaching Hospital
The KIU Teaching Hospital is a state-of-the-art facility that serves as a practical training ground for medical students. It is equipped with modern medical equipment and staffed by experienced healthcare professionals. The hospital provides comprehensive healthcare services to the community, further integrating KIU into the local and national health systems.
Library and E-Learning Resources
The KIU library is a vital resource for students and faculty, offering a vast collection of books, journals, and digital resources. The library’s digital platform provides access to numerous e-books and online journals, ensuring that students have the resources they need for their studies and research.
In response to the growing demand for flexible learning options, KIU has developed a robust e-learning platform. This platform allows students to access course materials, participate in online discussions, and submit assignments remotely, making education more accessible to a broader audience.
Admissions and Student Support
Admissions Process
Kampala International University’s admissions process is designed to be straightforward and inclusive. Prospective students can apply online through the KIU student portal, where they can also track their application status and receive updates. The university’s admissions team is available to assist applicants with any queries they may have during the application process.
Scholarships and Financial Aid
KIU is committed to making education accessible to all students. The university offers a variety of scholarships and financial aid programs to support students from different backgrounds. These scholarships are based on academic merit, financial need, and other criteria, ensuring that deserving students have the opportunity to pursue their education.
International Collaboration and Student Diversity
University Collaborations
KIU has established partnerships with numerous international universities and research institutions. These collaborations facilitate student and faculty exchanges, joint research projects, and the sharing of academic resources. Such partnerships enhance the educational experience at KIU and provide students with global perspectives.
International Students
KIU attracts students from all over the world, creating a diverse and vibrant campus community. The university offers support services tailored to international students, including assistance with visas, accommodation, and cultural integration. This inclusive environment helps international students feel welcomed and supported throughout their academic journey.
Alumni Network and Career Support
KIU Alumni Network
The KIU alumni network is a valuable resource for graduates, providing ongoing support and opportunities for professional development. Alumni are encouraged to stay connected with the university through various events, mentorship programs, and networking opportunities. This network helps graduates build strong professional relationships and advance their careers.
Career Services
KIU’s career services team provides students with guidance and resources to help them transition from education to employment. Services include career counseling, resume workshops, job placement assistance, and internship opportunities. These efforts ensure that KIU graduates are well-prepared to enter the workforce and succeed in their chosen fields.
Conclusion
Kampala International University stands out as a premier institution in Uganda, offering high-quality education, comprehensive research opportunities, and extensive student support services. With its wide range of undergraduate and postgraduate programs, state-of-the-art facilities, and commitment to student success, KIU continues to be a leading choice for students seeking a dynamic and enriching educational experience. Whether through on-campus programs or innovative e-learning options, KIU remains dedicated to shaping the future leaders of Uganda and beyond.
For those seeking advanced education, KIU offers numerous postgraduate courses. These programs are designed to deepen knowledge and expertise in specific areas, fostering research and innovation. The postgraduate programs include Master's degrees, postgraduate diplomas, and PhD programmes, catering to professionals aiming to advance their careers or pursue academic research.
PhD Programmes in Uganda
KIU is renowned for its robust PhD programmes, which attract scholars from across the globe. These programmes are rigorous and research-oriented, providing candidates with the opportunity to contribute significantly to their fields. With access to experienced faculty and extensive resources, PhD students at KIU can expect a supportive environment for their academic pursuits.
Admissions and Student Services
Kampala University Admissions
The admissions process at KIU is designed to be straightforward and student-friendly. Prospective students can apply online through the KIU admissions portal, where they can find detailed information about entry requirements, application deadlines, and necessary documentation. KIU prides itself on a transparent and efficient admissions process, ensuring that all qualified candidates have the opportunity to join its vibrant academic community.
KIU Student Portal Login
The KIU student portal is an essential tool for all enrolled students. This online platform allows students to access their academic records, register for courses, view timetables, and communicate with faculty members. The portal is user-friendly and regularly updated to ensure that students have all the information they need at their fingertips.
Academic and Research Excellence
Research Opportunities at KIU
KIU is committed to fostering a strong research culture. The university offers numerous research opportunities for both students and faculty members, encouraging them to undertake innovative projects that address local and global challenges. With well-equipped laboratories, research centers, and funding for various projects, KIU provides a conducive environment for scholarly inquiry.
KIU Teaching Hospital Facilities
The KIU Teaching Hospital is a cornerstone of the university’s medical programs. It provides practical training for medical students and serves as a top-tier healthcare facility for the community. The hospital is equipped with modern medical technologies and staffed by experienced healthcare professionals, ensuring that students receive hands-on training in a real-world setting.
Supportive Learning Environment
Scholarships at Kampala International University
KIU offers a variety of scholarships to support deserving students. These scholarships are awarded based on academic merit, financial need, and other criteria. By providing financial assistance, KIU ensures that education remains accessible to students from diverse backgrounds.
E-Learning at KIU
In response to the growing demand for flexible learning options, KIU has developed a comprehensive e-learning platform. This platform allows students to access course materials, participate in virtual classes, and interact with instructors online. The e-learning system is particularly beneficial for working professionals and international students who may not be able to attend on-campus classes.
KIU Library Resources
The KIU library is a vital resource for students and faculty, offering an extensive collection of books, journals, and digital resources. The library is designed to support academic research and learning, providing quiet study spaces, computer labs, and access to online databases.
Global Connections and Community
University Collaborations in Uganda
KIU actively collaborates with other universities and research institutions both within Uganda and internationally. These collaborations enhance the academic experience by providing opportunities for joint research projects, student exchanges, and academic conferences. Through these partnerships, KIU students and faculty gain exposure to global perspectives and best practices.
International Students at KIU
KIU is a welcoming institution for international students. The university offers dedicated support services to help international students adjust to life in Uganda, including orientation programs, visa assistance, and cultural activities. | cugkiu84 | |
1,831,681 | Introduction of BlueJ | Java is a powerful language used to build amazing things, from websites to mobile apps. But where do... | 0 | 2024-06-02T09:05:22 | https://dev.to/ajeetraina/introduction-of-bluej-4ni1 | Java is a powerful language used to build amazing things, from websites to mobile apps. But where do you begin? Enter BlueJ, a fantastic tool designed specifically for beginners like you!
## Why BlueJ?

Unlike complex IDEs, BlueJ boasts a clean interface that makes learning Java fun and easy. No more getting lost in menus – BlueJ focuses on what matters: getting you coding! Here's what makes it special:
- **Simple Interface:** Forget cluttered toolbars – BlueJ keeps things clear so you can focus on the code.
- **Object-Oriented Fun:** Java uses objects like building blocks. BlueJ helps you visualize these objects, making them easier to understand.
- **Interactive Learning:** Experiment and see the results instantly, keeping you engaged and motivated.
## Let's Code!
### Download and Install
Grab BlueJ from https://www.bluej.org/ for your OS (Windows, Mac, or Linux). Installation is straightforward, just follow the steps.

### Fire Up BlueJ:
Launch BlueJ. You'll see a clean interface with three key areas:
- Package Explorer (Left): This panel shows your project structure, like a map.
- Object Inspector (Right): This panel acts like a detective tool, providing details about your code.
- Code Editor (Center): This is your coding canvas, where you'll write your Java programs.
### Hello, World! – Our First Program:
Time to write your first program! A classic tradition is "Hello, World!":
```
public class HelloWorld {
public static void main(String[] args) {
System.out.println("Hello, World!");
}
}
```
Let's break it down!
- `public class HelloWorld` – This declares a new class named HelloWorld, the blueprint for your program.
- `public static void main(String[] args)` – This is the program's entry point, where everything starts.
- `System.out.println("Hello, World!")` – This line prints the message "Hello, World!" to the screen.
- `System.out` is a class for interacting with the outside world (like the screen).
- `.println` prints something to the screen and adds a new line after.
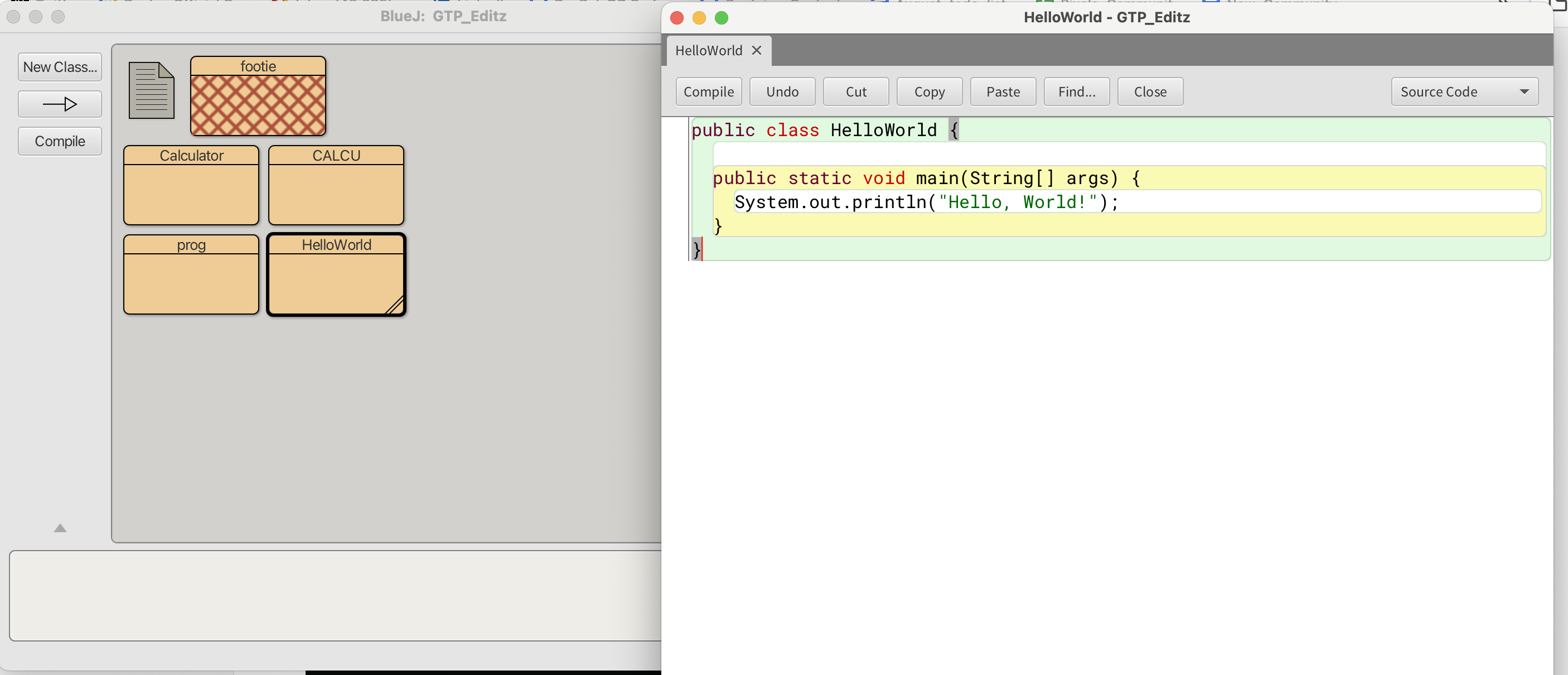
### Compile and Run!
Click the green "Compile" button (play button icon) to check for errors. If there are none (やった – Yatta – Did it!), click the brown "Run" button (right arrow) next to it. You should see "Hello, World!" displayed in the console window at the bottom of BlueJ.
Congratulations! You've just written, compiled, and run your first Java program!
## Beyond Hello, World!
BlueJ is your launchpad for further exploration. Here are some ways to keep coding:
- Experiment with Messages: Change the message inside the println statement. Try your name or a funny quote!
- Object Inspector Spy: Click on the class name "HelloWorld" in the Package Explorer, then peek at the Object Inspector on the right. It shows details about your class!
- Level Up Your Program: BlueJ lets you create new classes and methods to write more complex programs. Imagine creating a class for a car and giving it methods to accelerate, brake, or honk!
Remember, practice is key! BlueJ is your safe space to experiment. Keep coding, keep exploring, and have fun on your Java programming journey! There are tons of online tutorials and resources available to help you learn more as you go. | ajeetraina | |
1,873,664 | Install Homebrew on Amazon Linux in AWS Cloud9 | How To: Install Homebrew on Amazon Linux in AWS... | 0 | 2024-06-02T12:56:05 | https://dev.to/sh20raj/install-homebrew-on-amazon-linux-in-aws-cloud9-12ad | webdev, javascript, beginners, programming | # How To: Install Homebrew on Amazon Linux in AWS Cloud9
> https://docs.brew.sh/Installation#alternative-installs
Homebrew, often referred to as "brew," is a popular package manager that simplifies the installation of software by automating the download, configuration, and setup processes. While traditionally associated with macOS, Homebrew can also be installed on Linux distributions, including Amazon Linux. This guide will walk you through the steps to install Homebrew on an Amazon Linux system within an AWS Cloud9 environment.
## Prerequisites
Before you begin, ensure you have the following:
- An Amazon Linux instance set up within AWS Cloud9.
- SSH access to your AWS Cloud9 environment.
- Basic knowledge of the Linux command line.
## Step 1: Update Your System
First, it's a good practice to update your system to ensure all packages are up-to-date.
```sh
sudo yum update -y
```
## Step 2: Install Required Dependencies
Homebrew requires several dependencies to be installed on your system. These include Git, GCC, and other development tools. Install them using the following command:
```sh
sudo yum groupinstall 'Development Tools' -y
sudo yum install curl file git -y
```
## Step 3: Set a Password for the Default User
AWS Cloud9 environments typically do not have a password set for the default user, which can cause issues during the Homebrew installation. To set a password for the default user (`ec2-user` or your specific user), run the following command:
```sh
sudo passwd $(whoami)
```
You'll be prompted to enter a new password. Choose a password and confirm it.
## Step 4: Install Homebrew
Now that the dependencies are in place and a password is set, you can install Homebrew. Download and execute the official installation script with the following command:
```sh
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
```
During the installation process, you will be prompted to provide your sudo password. Enter the password you set in Step 3.
## Step 5: Configure Your Shell
After installing Homebrew, you need to configure your shell to include Homebrew in your PATH. You can do this by adding the following line to your shell profile file (e.g., `~/.bash_profile`, `~/.bashrc`, or `~/.zshrc`):
```sh
echo 'eval "$(/home/linuxbrew/.linuxbrew/bin/brew shellenv)"' >> ~/.bash_profile
```
Then, apply the changes by sourcing the profile file:
```sh
source ~/.bash_profile
```
## Step 6: Verify the Installation
To ensure that Homebrew is installed correctly, run the following command to check its version:
```sh
brew --version
```
You should see output similar to:
```sh
Homebrew 3.x.x
Homebrew/homebrew-core (git revision xxxxx; last commit yyyy-mm-dd)
```
## Step 7: Install Packages with Homebrew
Now that Homebrew is installed, you can start using it to install packages. For example, to install `wget`, you can use the following command:
```sh
brew install wget
```
## Troubleshooting Tips
- **Permissions Issues**: If you encounter issues with permissions, ensure that your user has the necessary privileges to install software and modify system files.
- **PATH Issues**: If Homebrew commands are not recognized, double-check that the Homebrew path is correctly added to your shell profile and that you have sourced the profile file.
## Conclusion
Congratulations! You have successfully installed Homebrew on your Amazon Linux instance within AWS Cloud9. With Homebrew, you can easily manage and install various software packages, making your development environment more robust and flexible. For more information on using Homebrew, you can refer to the [official Homebrew documentation](https://docs.brew.sh/).
By following this guide, you should have a functional Homebrew installation ready to handle your package management needs on Amazon Linux in AWS Cloud9. Happy brewing! | sh20raj |
1,873,663 | New no-code discord bot tool | Hey everyone we have officially released my no code discord bot builder into open beta. We are... | 0 | 2024-06-02T12:49:41 | https://dev.to/cas_backx_ffaffe42940077d/new-no-code-discord-bot-tool-5fe3 | nocode | Hey everyone we have officially released my no code discord bot builder into open beta. We are looking for people to help us test, any bots you make are 100% free and will stay that way.
Are you interested let us know https://discord.gg/TNS22vKsXt. If you know people that would be interested be sure to invite them.
https://botwiz.dev
We are currently testing a live co-create feature. | cas_backx_ffaffe42940077d |
1,873,662 | How To: Install Homebrew on Amazon Linux | How To: Install Homebrew on Amazon Linux Homebrew, often referred to as "brew," is a... | 0 | 2024-06-02T12:48:52 | https://dev.to/sh20raj/how-to-install-homebrew-on-amazon-linux-1cd3 | # How To: Install Homebrew on Amazon Linux
Homebrew, often referred to as "brew," is a popular package manager for macOS and Linux. It simplifies the installation of software by automating the download, configuration, and setup processes. While traditionally associated with macOS, Homebrew can also be installed on Linux distributions, including Amazon Linux. This guide will walk you through the steps to install Homebrew on an Amazon Linux system.
## Prerequisites
Before you begin, ensure you have the following:
- An Amazon Linux instance up and running.
- SSH access to your Amazon Linux instance.
- Basic knowledge of the Linux command line.
## Step 1: Update Your System
First, it's a good practice to update your system to ensure all packages are up-to-date.
```sh
sudo yum update -y
```
## Step 2: Install Required Dependencies
Homebrew requires several dependencies to be installed on your system. These include Git, GCC, and other development tools. Install them using the following command:
```sh
sudo yum groupinstall 'Development Tools' -y
sudo yum install curl file git -y
```
## Step 3: Install Homebrew
Now that the dependencies are in place, you can install Homebrew. The official installation script can be downloaded and executed with the following command:
```sh
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
```
During the installation process, you will be prompted to provide your sudo password and to confirm the installation path.
## Step 4: Configure Your Shell
After installing Homebrew, you need to configure your shell to include Homebrew in your PATH. You can do this by adding the following line to your shell profile file (e.g., `~/.bash_profile`, `~/.bashrc`, or `~/.zshrc`):
```sh
echo 'eval "$(/home/linuxbrew/.linuxbrew/bin/brew shellenv)"' >> ~/.bash_profile
```
Then, apply the changes by sourcing the profile file:
```sh
source ~/.bash_profile
```
## Step 5: Verify the Installation
To ensure that Homebrew is installed correctly, run the following command to check its version:
```sh
brew --version
```
You should see output similar to:
```sh
Homebrew 3.x.x
Homebrew/homebrew-core (git revision xxxxx; last commit yyyy-mm-dd)
```
## Step 6: Install Packages with Homebrew
Now that Homebrew is installed, you can start using it to install packages. For example, to install `wget`, you can use the following command:
```sh
brew install wget
```
## Troubleshooting Tips
- If you encounter issues with permissions, ensure that your user has the necessary privileges to install software and modify system files.
- If Homebrew commands are not recognized, double-check that the Homebrew path is correctly added to your shell profile and that you have sourced the profile file.
## Conclusion
Congratulations! You have successfully installed Homebrew on your Amazon Linux instance. With Homebrew, you can easily manage and install various software packages, making your development environment more robust and flexible. For more information on using Homebrew, you can refer to the [official Homebrew documentation](https://docs.brew.sh/).
By following this guide, you should have a functional Homebrew installation ready to handle your package management needs on Amazon Linux. Happy brewing!
---
> https://stackoverflow.com/questions/51667876/ec2-ubuntu-14-default-password | sh20raj | |
1,865,978 | Scripting with Java | Introduction As a developer, you sometimes need to write scripts. If your primary... | 0 | 2024-06-02T12:41:53 | https://dev.to/toliyansky/scripting-with-java-3i9k | java, script, shell, tutorial | ### Introduction
As a developer, you sometimes need to write scripts. If your primary expertise is in Java, you might have considered writing scripts in Java instead of Bash or Python. However, if you've tried this, you quickly realized it's not as straightforward as it seems due to Java's verbosity. In this article, I'll explain why scripting with Java now is possible and, more importantly, practical. I'll also introduce a small utility that allows you to write Java scripts that are simple and powerful.
### 1. It's Possible
Writing scripts in Java has been possible since Java 11. [JEP 330: Launch Single-File Source-Code Programs](https://openjdk.org/jeps/330) introduced the ability to run single-file Java scripts without requiring explicit compilation. This feature also allowed adding a shebang to the beginning of the file, enabling scripts to be run directly from the command line.
Even though Java 11 made shebangs possible, nobody started writing scripts in Java because it was cumbersome. Just look at this 'Hello World' example:
```java
#!/usr/bin/env java --source 11
public class Script {
public static void main(String[] args) {
System.out.println("Hello World");
}
}
```
This leads us logically to the next part of the article.
### 2. Now It's Simpler
Starting with Java 22 (in preview mode), [JEP 463: Implicitly Declared Classes and Instance Main Methods (Second Preview)](https://openjdk.org/jeps/463) allows us to omit the class declaration and reduce the `main` function declaration from `public static void main(String[] args)` to simply `void main()`. This is a significant improvement.
```java
#!/usr/bin/env java --source 22 --enable-preview
void main() {
System.out.println("Hello World");
}
```
It will become even simpler in the third iteration of this JEP. Java 23, with [JEP 477: Implicitly Declared Classes and Instance Main Methods (Third Preview)](https://openjdk.org/jeps/477), will allow writing `print(obj)`, `println(obj)`, and `readln(obj)` instead of `System.out.println(obj)`, thanks to the automatic import of the `java.io.IO` package.
### 3. But It's Still Not Practical
Yeah, the newer versions of Java have reduced much of the verbosity, so writing a 'Hello World' script become easier. The problem becomes apparent when trying to do something more complex. Consider the following example:
{% collapsible Example 1 (HTTP request) %}
Let's say you want to make an HTTP request and print the result. Here's how it looks:
```java
#!/usr/bin/env java --source 22 --enable-preview
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
void main() throws Exception {
var url = new URL("https://httpbin.org/get");
var con = (HttpURLConnection) url.openConnection();
con.setRequestMethod("GET");
var in = new BufferedReader(new InputStreamReader(con.getInputStream()));
String inputLine;
var content = new StringBuffer();
while ((inputLine = in.readLine()) != null) {
content.append(inputLine);
}
in.close();
con.disconnect();
System.out.println(content);
}
```
This is a mess. 11 lines of code in `main()`, just to make an HTTP request and print the result, + import lines. Using `HttpClient` introduced in Java 11 doesn't simplify it much:
```java
#!/usr/bin/env java --source 22 --enable-preview
import java.net.URI;
import java.net.http.HttpClient;
import java.net.http.HttpRequest;
import java.net.http.HttpResponse;
void main() throws Exception {
var httpClient = HttpClient.newHttpClient();
var response = httpClient.send(HttpRequest.newBuilder()
.uri(URI.create("https://httpbin.org/get"))
.build(),
HttpResponse.BodyHandlers.ofString());
System.out.println(response.body());
}
```
6 lines of code in `main()`, + import lines.
{% endcollapsible %}
{% collapsible Example 2 (Terminal command) %}
Here's another example, invoking a terminal command:
```java
#!/usr/bin/env java --source 22 --enable-preview
import java.io.BufferedReader;
import java.io.InputStreamReader;
void main() throws Exception {
var process = Runtime.getRuntime().exec("ls -lah");
var reader = new BufferedReader(new InputStreamReader(process.getInputStream()));
String line;
while ((line = reader.readLine()) != null) {
System.out.println(line);
}
int exitCode = process.waitFor();
System.out.println("Exited with code: " + exitCode);
}
```
{% endcollapsible %}
{% collapsible Example 3 (Files IO) %}
Or, working with files... Have you ever tried to delete a directory with all its contents? You'd struggle with `walk()` and nested `try-catch` blocks for handling numerous checked exceptions.
{% endcollapsible %}
All this shows that while Java is powerful, it's not suitable for scripting. But what if I told you it could be?
The problem is that standard mechanisms don't provide default behavior. That's a pity because it simplifies life. Think about why Spring Boot starters became so popular. It includes default behavior. For cases that require detailed configuration, you can always define it, but for most scripting tasks, it's not necessary.
That's why I created a utility that allows you to write Java scripts concisely.
### 4. Introducing **Scripting Utils** for Java
**Scripting Utils** - a single Java file containing several useful wrapper classes with default behavior. Static objects of these wrappers are declared for quick access to functions in this file.
GitHub: [https://github.com/AnatoliyKozlov/scripting-utils](https://github.com/AnatoliyKozlov/scripting-utils)
To see how convenient this is, let's revisit the examples above using Scripting Utils.
```java
#!/usr/bin/env java --source 22 --enable-preview --class-path /Users/toliyansky/scripting-utils
import static scripting.Utils.*;
void main() {
var response = http.get("https://httpbin.org/get");
log.info(response.body());
}
```
As we can see, we need to add `--class-path /Users/toliyansky/scripting-utils` to the shebang line and a static import `import static scripting.Utils.*;`, then we can leverage the full power of Scripting Utils.
Just two lines for an HTTP request and logging the response.
Other examples:
```java
#!/usr/bin/env java --source 22 --enable-preview --class-path /Users/toliyansky/scripting-utils
import static scripting.Utils.*;
void main() {
var terminalResponse = terminal.execute("ls -lah", 100);
log.info(terminalResponse.output);
}
```
Just two lines for executing a command and logging the response.
Scripting Utils includes wrappers for:
- `http` for HTTP requests
- `terminal` for terminal commands
- `file` for file operations
- `log` for logging
- `thread` for threading
Let's look at an example that utilizes the advantages of Scripting Utils.
Imagine our script needs to read a file containing lines in the format `<name> <URL>`. For each line, it should make an HTTP request and save the result to a file named `<name>`. As a bonus, let's do this in parallel, because we want to leverage Java's strengths over Bash or Python.
```java
#!/usr/bin/env java --source 22 --enable-preview --class-path /Users/toliyansky/scripting-utils
import static scripting.Utils.*;
void main() {
var linksFilePath = "links.txt";
if (!file.exists(linksFilePath)) {
log.error("File not found: " + linksFilePath);
return;
}
file.readAllLines(linksFilePath)
.forEach(line -> thread.run(() -> {
var data = line.split(" ");
var fileName = data[0];
var url = data[1];
var response = http.get(url);
if (response.statusCode() == 200) {
file.rewrite(fileName, response.body());
log.info("File " + fileName + " updated from " + url);
} else {
log.warn("File " + fileName + " was not updated. Http code: " + response.statusCode());
}
}));
thread.sleepSeconds(5);
var terminalResponse = terminal.execute("ls -lah", 100);
log.info(terminalResponse.output);
}
```
Only 20 lines of code in `main()` that do tons of work. It uses the `files`, `http`, `log`, `thread`, and `terminal` modules.
Can you imagine the monstrosity this would be without Scripting Utils? Or in Bash 😄? Or in Python?
The downside is that Scripting Utils needs to be installed. The project repository has a one-line command that downloads `Utils.java`, places it in a specific directory, and compiles it. This only needs to be done once. After that, you can use it in your scripts.
### Conclusion
As you can see, Java is actively working towards simplifying the writing of simple programs, including scripts. The numerous JEPs I've mentioned above, and others like [JEP 458: Launch Multi-File Source-Code Programs](https://openjdk.org/jeps/458), attest to this. However, even with these simplifications, Java remains not the most convenient language for scripting. With the advent of Scripting Utils, it has become practical as well. | toliyansky |
1,873,661 | Efficient and Flexible Communication in Software Architecture: Swift custom implementation of NotificationCenter | In many software applications, efficient and flexible communication between various components is... | 0 | 2024-06-02T12:41:34 | https://dev.to/binoy123/efficient-and-flexible-communication-in-software-architecture-exploring-apples-nsnotificationcenter-5g3j | tutorial, observer, notificationcenter, swift | In many software applications, efficient and flexible communication between various components is essential for maintaining a clean and maintainable architecture. Apple’s NSNotificationCenter is a widely used mechanism that facilitates such communication by allowing objects to post and observe notifications without needing to know about each other.
This article aims to guide you through the process of creating a custom notification center, similar to NSNotificationCenter, called MyNotificationCenter. We will explore its key features, including adding and removing observers, posting notifications, and ensuring thread safety. By the end of this guide, you will understand how to implement a robust and efficient notification system tailored to your application's unique needs.
Here are the components explained with the code snippet.
##MyNotificationCenter
MyNotificationCenter is a singleton class designed to facilitate a custom notification center for broadcasting and receiving notifications within an application. It enables objects to register for specific notifications and handle them when posted.
**Properties**
`static let shared: MyNotificationCenter`
**A shared singleton instance of MyNotificationCenter.**
`private var observers: [String: [(AnyObject, Selector)]]`
A dictionary storing observers for each notification name, where the key is the notification name and the value is a list of tuples containing the observer object and its associated selector.
`private let queue: DispatchQueue`
A concurrent dispatch queue used to synchronise access to the observers dictionary.
**Initializer**
`private init()`
Initializes the observers dictionary and the concurrent dispatch queue. The initializer is private to enforce the singleton pattern.
Methods
`func addObserver(object: AnyObject, name: String, selector: Selector)`
Registers an observer for a specific notification.
**Parameters:**
_object: The observer object.
name: The name of the notification.
selector: The selector to be called when the notification is posted._
`func post(name: String, userInfo: [AnyHashable: Any]? = nil)`
Posts a notification to all registered observers.
**Parameters:**
_name: The name of the notification.
userInfo: An optional dictionary containing additional information about the notification._
`func removeObserver(object: AnyObject)`
Removes a specific observer from all notifications it is registered for.
**Parameters:**
_object: The observer object to be removed._
## MyNotificationObserver
MyNotificationObserver is a class that demonstrates how to use MyNotificationCenter to register for and handle notifications. It conforms to the Observable protocol.
**Initializer**
`init()`
Registers the instance as an observer for the "MyNotification" notification with MyNotificationCenter.
**Methods**
`@objc func notificationSelector(_ userInfo: [AnyHashable: Any]?)`
Handles the "MyNotification" notification when it is posted.
**Parameters:**
_userInfo: An optional dictionary containing additional information about the notification._
**Deinitializer**
`deinit`
Removes the instance from the observers of "MyNotification" in MyNotificationCenter.
This documentation provides an overview of the MyNotificationCenter and MyNotificationObserver classes, explaining their purpose and how they interact to enable custom notification handling in your application.
[Here](https://github.com/benoy/MyNotificationCenter/tree/main/MyNotificationCenter) is the complete source code for the same
| binoy123 |
1,873,660 | flying dots | A lot of dots flying around with lines connecting them. You can customize the speed of the dots, how... | 0 | 2024-06-02T12:37:16 | https://dev.to/rafaeldevvv/flying-dots-4l7d | codepen, webdev, javascript, programming | A lot of dots flying around with lines connecting them. You can customize the speed of the dots, how many dots are on the screen, the distance at which the dots will connect through a line, and colors of the dots, lines and background.
{% codepen https://codepen.io/rafaeldevvv/pen/oNRByWd %} | rafaeldevvv |
1,847,803 | Streamlining STM32 Projects: VS Code, CMake and clangd | The STM32CubeIDE software serves as an excellent starting point for STM32 development. However, when... | 0 | 2024-06-02T12:31:32 | https://dev.to/mcmattia/streamlining-stm32-projects-vs-code-cmake-and-clangd-bhp | stm, vscode, cmake, clangd | The STM32CubeIDE software serves as an excellent starting point for STM32 development. However, when it comes to developer experience, the IDE provided by ST can feel sluggish and resource-intensive.
In this article, we’ll explore how to seamlessly transition from STM32CubeIDE to Visual Studio Code for your embedded software development needs. Under the hood, we’ll set up a robust CMake build system, utilize clangd for indexing, formatting and tidy checks, and configure VS Code to efficiently manage the CMake project, clangd, and debugging.
Let’s dive into the details!
## Creating a project with STM32CubeIDE
In this chapter, we’ll walk through the process of setting up a C++ project using STM32CubeIDE. If you’ve already configured a project, feel free to skip ahead to the next section.
**New STM32 project**
Let's create a new project in STM32CubeIDE by clicking on _File -> New -> STM32 Project_

**Micro-controller choice**
In the micro-controller search we are gonna enter the name of the micro-controller that we are using. In my case it's the NUCLEO board with the micro-controller STM32L4A6ZGTX.
**Project name**
Let's now enter the name of the project and it's location.
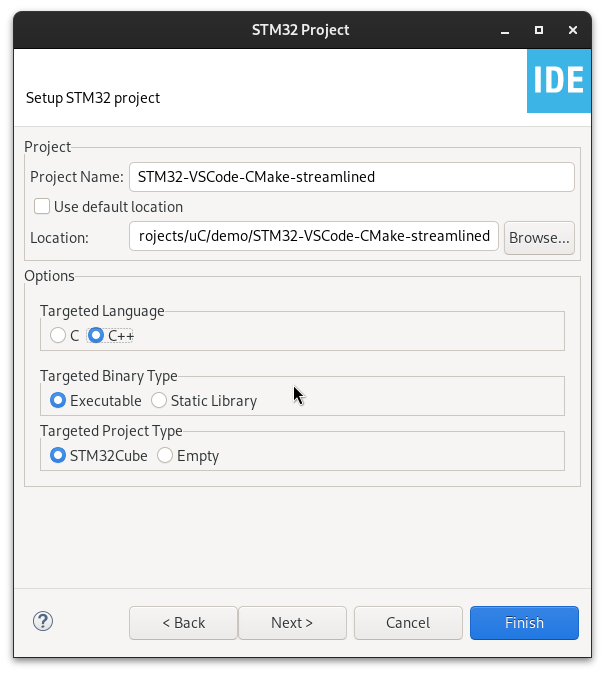
**HAL Configuration**
After clicking finish, the configuration view will open up. Here you will be able to configure your micro-controller hardware. For the purpose of this demo, let's configure a led as GPIO Output and give the pin a name that we can later reference in our source files.
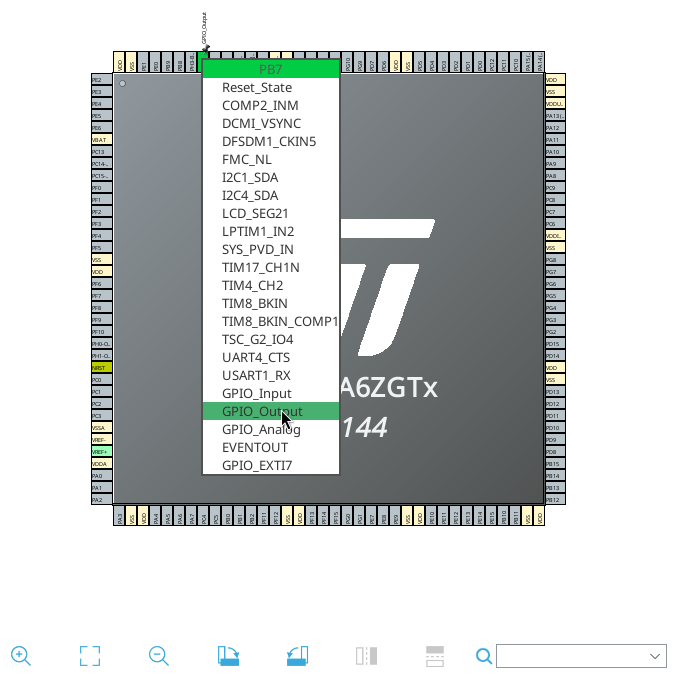
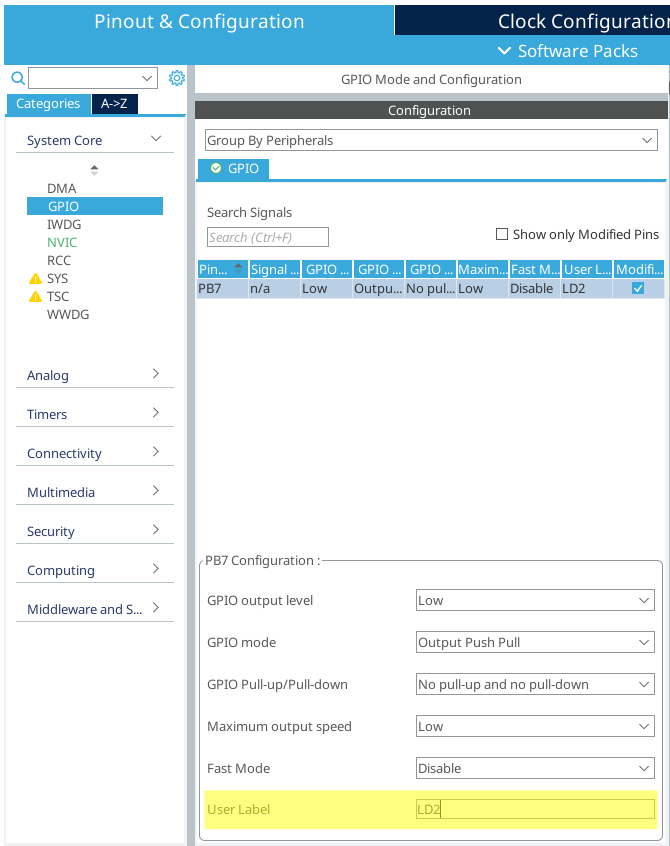
**Code generation settings**
As a last step before letting STM32CubeIDE generate the code, select _Project Manager -> Project -> Do not generate the main()_
And _Project Manager -> Project -> Generate peripheral initialization as a pair of '.c/.h' files for peripheral_


**Generating the HAL code**
We are now ready to generate the code. Click save or the generate code symbol.

**Application folder**
We selected to not generate the main so that we can write a cpp main ourselves. Start by creating a source folder in the root directory by right clicking on the project then clicking on _New -> Source Folder_
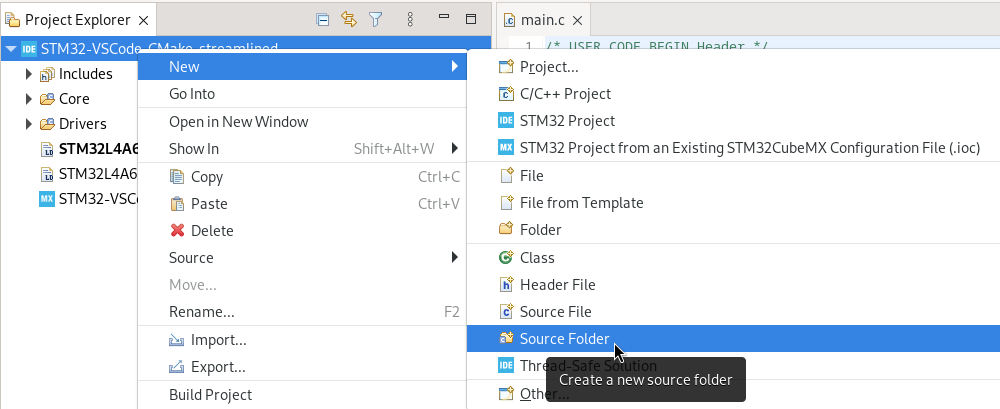
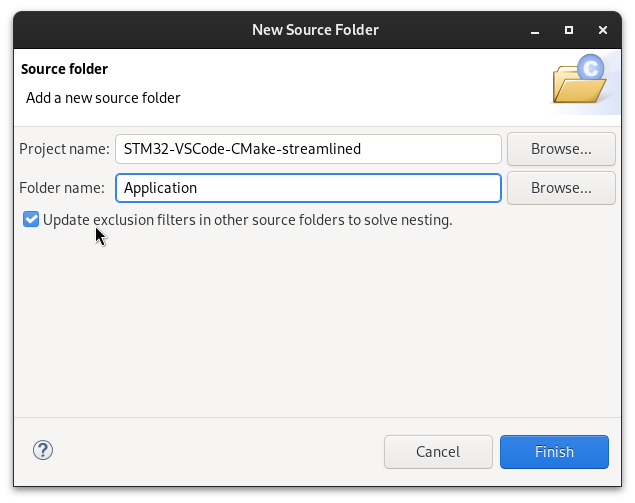
**Creating the main**
And create a `main.cpp` file inside the `Application` folder:
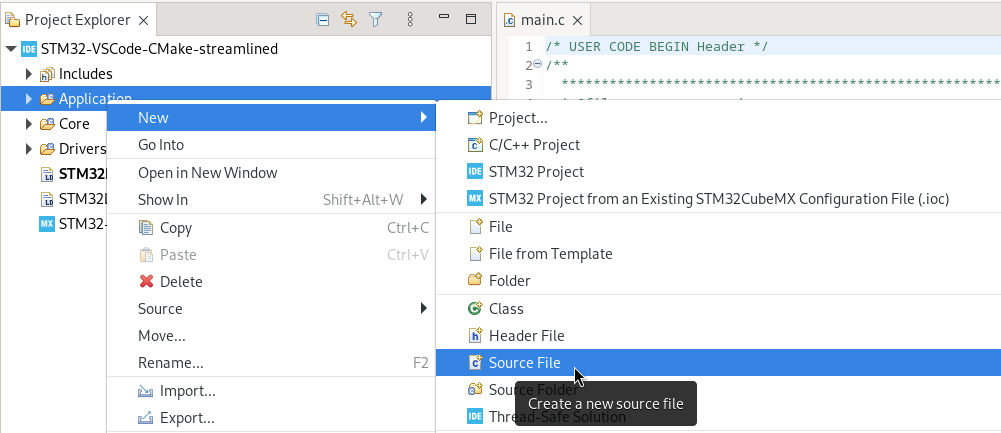
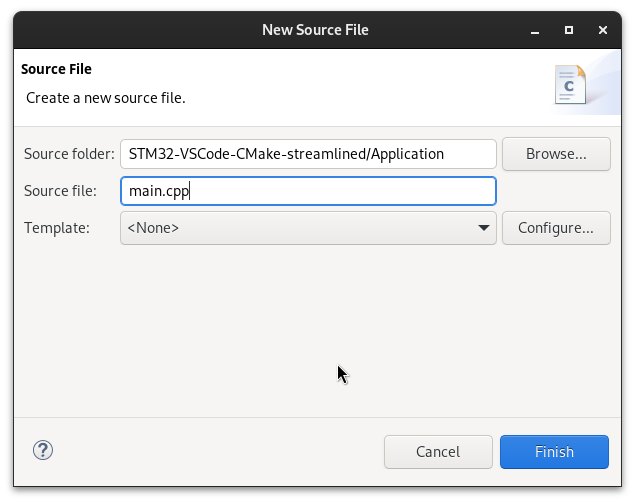
The code for the `main.cpp` used in this demo is the following:
```cpp
#include "main.h"
#include "gpio.h"
extern "C"
{
extern void SystemClock_Config();
}
int main()
{
HAL_Init();
SystemClock_Config();
MX_GPIO_Init();
while (true)
{
HAL_GPIO_WritePin(LD2_GPIO_Port, LD2_Pin, GPIO_PIN_SET);
HAL_Delay(1000);
HAL_GPIO_WritePin(LD2_GPIO_Port, LD2_Pin, GPIO_PIN_RESET);
HAL_Delay(1000);
}
}
```
**Compile and debug**
We are now ready to compile and debug our project with STM32CubeIDE.
## Setting up the CMake project
Let's now close the STM32CubeIDE window and start integrating our STM project in VS code. The first thing to do is to set up the CMake project.
Start by checking if you have CMake and Ninja already installed on your system by typing in the terminal:
```shell
cmake --version
ninja --version
```
If CMake or Ninja are missing, you can install them from your package manager in linux or from the official websites in Windows:
- [https://cmake.org/download/](https://cmake.org/download/)
- [https://ninja-build.org/](https://ninja-build.org/)
In Windows you will have to add the path of your Ninja executable to the system environment variables. For example, if your executable is located in `C:\Ninja\ninja.exe`, you can add the path `C:\Ninja\` to your system environment variables.
Afterward clone the [github folder](https://github.com/MCMattia/STM32-VSCode-CMake-streamlined) associated to this article and copy the following files to your project folder:
- `CMakeLists.txt`
- `CMakePresets.json`
- `gcc-arm-none-eabi.cmake`
### CMakeLists.txt
Open the `CMakeLists.txt` file and if needed adapt the name of the micro-controller from STM32L4A6ZGT to the one that you are using. In the `CMakeLists.txt` file check that your sources are defined in the `PROJECT_SOURCES` variable and that the correct symbols are defined in the `PROJECT_DEFINES` variable.
### CMake toolchain file
The toolchain file `gcc-arm-none-eabi.cmake` defines the location of the compiler toolchain that CMake uses.
The `TOOLCHAIN_PREFIX` variable should point to the location of the compiler included by STM32CubeIDE. In linux it's usually inside `/opt/st/` while in Windows it's usually inside `C:\ST\`.
At this point you should be ready to let CMake configure and build your project. Open a terminal in the root of your project folder and type the following commands:
```shell
cmake --preset Application # configure project
cmake --build --preset Application # build project
```
The output of the last command when the compilation finishes should be something like:
```
[25/25] Linking CXX executable STM32-CMake-base.elf
```
Congratulation you compiled your embedded project with CMake and Ninja !
## Setting up VS Code
From the [github repo](https://github.com/MCMattia/STM32-VSCode-CMake-streamlined) associated with this article, copy the `.vscode` folder to your project folder.
In the `.vscode/settings.json` file you can adapt define the location of gdb and gdb server to allow debugging. Additionally the location of the gcc compiler for clangd can also be adapted.
```json
{
"cortex-debug.gdbPath": "/opt/st/stm32cubeide_1.15.0/plugins/com.st.stm32cube.ide.mcu.externaltools.gnu-tools-for-stm32.12.3.rel1.linux64_1.0.100.202403111256/tools/bin/arm-none-eabi-gdb",
"cortex-debug.JLinkGDBServerPath": "/opt/st/stm32cubeide_1.15.0/plugins/com.st.stm32cube.ide.mcu.externaltools.jlink.linux64_2.2.200.202402092224/tools/bin/JLinkGDBServer",
"clangd.arguments": ["--query-driver=/opt/st/stm32cubeide_1.15.0/plugins/com.st.stm32cube.ide.mcu.externaltools.gnu-tools-for-stm32.12.3.rel1.linux64_1.0.100.202403111256/tools/bin/arm-none-eabi-gcc"]
}
```
The file `.vscode/extensions.json` specifies the recommended extensions to use. If you open the extension menu in VS Code, you will be able to see and install the extension listed in `.vscode/extensions.json`.
After installing the recommended extensions, the VS Code CMake and clangd integration will start working. By opening a source file, clangd will index it and you will be able to start using the advanced functionality that the clangd language server provides.
Here an example of the sometimes very helpful checking that clangd performs by default:
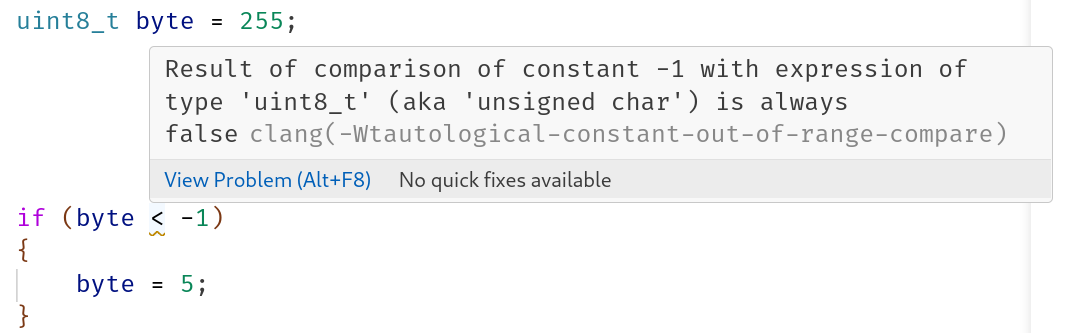
You can now compile the project in VS Code by pressing `CTRL + SHIFT + B`.
### Debugging
The file `.vscode/launch.json` that was copied in the previous chapter from the [github repo](https://github.com/MCMattia/STM32-VSCode-CMake-streamlined) configures the debugging settings. If you open it, you will see two configurations, one for the SEGGER J-Link debugger and the other for the ST-Link debugger.
In the left bar in VS Code, select the Debug symbol, then select the debug configuration compatible with your debugger and finally press the play button to flash the firmware on your micro-controller and start debugging.
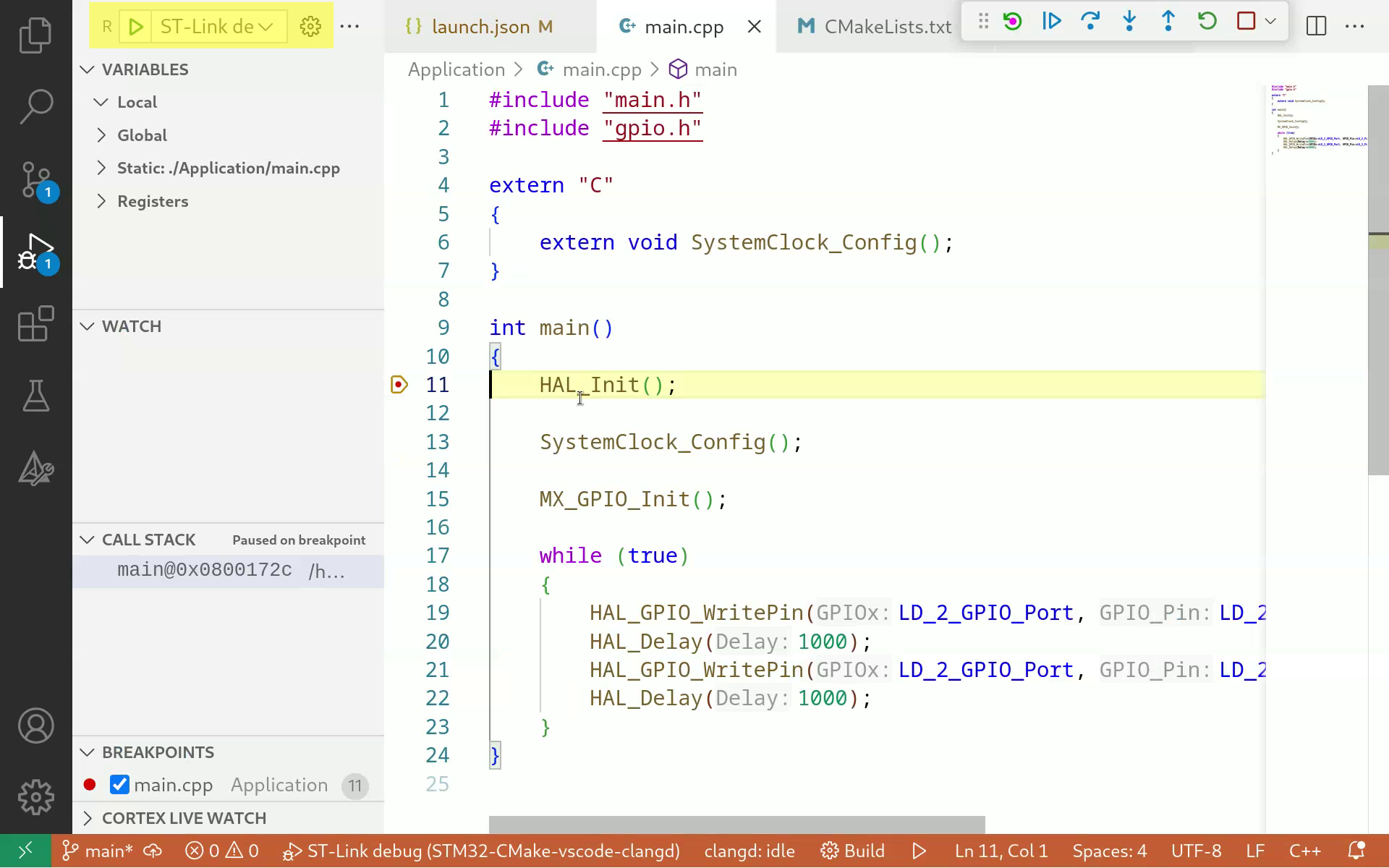
### Formatting and tidy checks
To enable formatting of the sources and clang-tidy checks, copy the following files from the [cloned github folder](https://github.com/MCMattia/STM32-VSCode-CMake-streamlined) to your application folder:
- `Application/.clang-format`: This file defines the formatting rules for your C/C++ code.
- `Application/.clang-tidy`: Here, you’ll find configuration settings for clang-tidy. This tool analyzes your code for potential issues, such as code smells, bugs, and performance bottlenecks.
Note that clang-format and clang-tidy will be active only at the level of the configuration files. In this scenario, their effects will extend to all files residing inside the Application folder. In this way clangd will not format or perform checks on files generated by STM32CubeIDE.
Now you’re all set to streamline your STM32 development workflow using VS Code, CMake, and clangd. Happy coding!
Feel free to ask me any question in the comments.
| mcmattia |
1,873,657 | Day 2: LINUX FUNDAMENTALS | Introduction: Welcome to Day 2 of the 90-Day DevOps Challenge! Today, we will dive into the... | 0 | 2024-06-02T12:29:00 | https://dev.to/oncloud7/day-2-linux-fundamentals-4092 | linux, cloudcomputing, linuxbasic, beginners | **Introduction:**
Welcome to Day 2 of the 90-Day DevOps Challenge! Today, we will dive into the fundamental concepts of Linux, an open-source operating system that plays a crucial role in the world of DevOps. Understanding Linux is essential for any DevOps practitioner, as it forms the foundation of many server environments and provides a powerful platform for running applications and managing resources. In this blog post, we will explore the key components of Linux, its architecture, and some basic commands to get you started on your Linux journey
**What is Linux?**
Linux is an open-source operating system that serves as the foundation for numerous computing systems. Unlike proprietary operating systems, Linux allows users to access and modify its source code, fostering a collaborative and customizable environment. Linux interacts directly with a system's hardware, managing resources such as the CPU, memory, and storage. It provides a robust and secure platform for running applications and servers.
**Components of the Linux File System:**
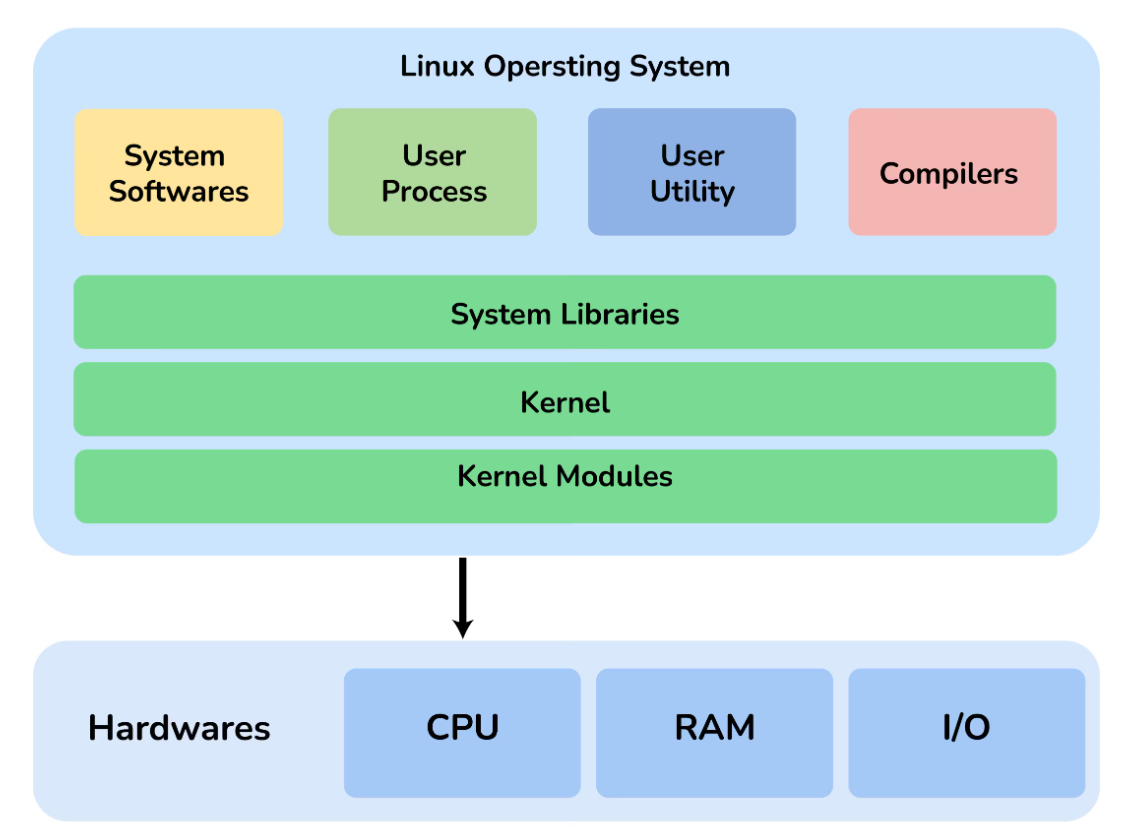
**a. Kernel:** The Linux kernel is the core part of the operating system. It interacts directly with the hardware, providing an abstraction layer that hides low-level hardware details from system and application programs. It handles key activities and manages resources efficiently.
**b. **System Libraries:**** Linux offers a set of system libraries that implement most of the functionalities of the operating system. These libraries provide functions and programs that allow application programs and system utilities to access the kernel's features without requiring direct access rights to the kernel modules.
**c. System Utility Programs:** System utility programs in Linux perform specialized and individual tasks. These programs help manage the system, configure settings, perform administrative functions, and automate various operations.
**The architecture of Linux:**
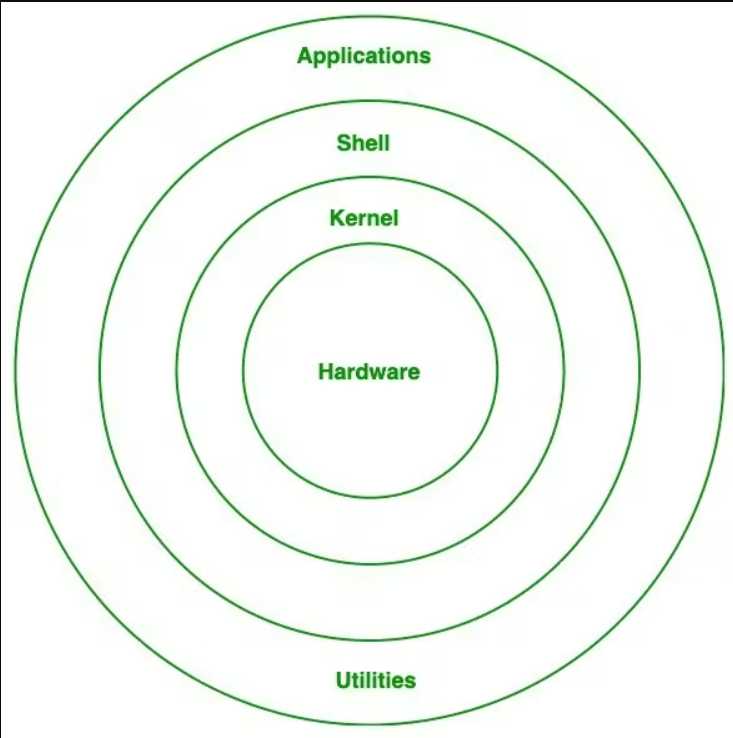
**A Linux system consists of several layers:**
**a. Kernel:** The kernel is the heart of the Linux operating system. It handles critical tasks, manages hardware resources, and provides an interface for system processes and applications.
**b. System Libraries:** These libraries contain pre-compiled functions and code that allow applications to interact with the kernel and access system resources. They provide an abstraction layer, simplifying the development process for software developers.
**c. System Utility Programs:** System utility programs offer a range of functionalities to manage and configure the system. Examples include package managers, network configuration tools, and system monitoring utilities.
**d. Hardware Layer:** This layer comprises the physical components of the system, including the CPU, hard disk drives (HDD), RAM, and other peripheral devices.
**e. Shell:** The shell acts as an interface between the user and the kernel. It can be either a command-line shell or a graphical shell, enabling users to interact with the system and execute commands.
**Basic Linux Commands:**
To get started with Linux, here are some essential commands:
**a. ls:** Lists files and directories in the current location : Command: ls
**b. cd:** Changes the current directory : Command: cd directory_name
**c. mkdir:** Creates a new directory : Command: mkdir directory_name
**d. rm:** Removes a file : Command: rmdir directory_name
**e. cp:** Copies a file : Command: cp source_file destination path
**f. mv:** Moves or renames a file : Command: mv source_file destination
**g. cat:** Displays the contents of a file : Command: cat file_name
**h. clear:** Clears the terminal screen : Command: clear
**i. History:** Shows a list of previously executed commands: Command : history
**j.head:** Display the beginning of a file.
**k.tail:** Display the end of a file.
**l.touch:** Create an empty file or update timestamps.
**m.nano:** Open a simple text editor.
**n.grep:** Search for specific patterns in files.
**o.chmod:** Change file permissions.
**p.chown:** Change file ownership.
**Task: Linux Commands:**
1. ls --> The ls command is used to list files or directories in Linux and other Unix-based operating systems.

2. ls -l--> Type the ls -l command to list the contents of the directory in a table format with columns including.
3. ls -a --> Type the ls -a command to list files or directories including hidden files or directories. In Linux, anything that begins with a . is considered a hidden file.

4. ls -i --> List the files and directories with index numbers in orders

5. ls -d */ --> Type the ls -d */ command to list only directories.

6. pwd --> Print work directory. Gives the present working directory.
7. cd path_to_directory --> Change directory to the provided path.

8. mkdir directoryName --> Use to make a directory in a specific location.

9.mkdir .NewFolder --> Make a hidden directory (also . before a file to make it hidden)
10.mkdir A B C D --> Make multiple directories at the same time.
 | oncloud7 |
1,873,656 | Our free givewa offer of cash 750 you can be today's winner | You can only choose one: $750k CASH 750 CREDIT SCORE 759 ACRES OF LAND🤔👇👇 j oin | 0 | 2024-06-02T12:28:55 | https://dev.to/freecashapp/our-free-givewa-offer-of-cash-750-you-can-be-todays-winner-12og | cryptocurrency, git | You can only choose one:
$750k CASH
750 CREDIT SCORE
759 ACRES OF LAND🤔👇👇
[j
oin](https://shorter.me/DCN_U) | freecashapp |
1,873,594 | How to install lando on mac/windows/linux for Acquia Recipe | Introduction So, you’re ready to embark on the journey of installing Lando on your Mac for Acquia?... | 0 | 2024-06-02T09:54:32 | https://dev.to/sanjay_mogra/how-to-install-lando-on-mac-for-acquia-recipe-3p15 | Introduction
So, you’re ready to embark on the journey of installing Lando on your Mac for Acquia? Strap in! It’s going to be a ride filled with commands, databases, and a sprinkle of humor to keep things light. Let’s dive in!
Step 1: Install Lando
First things first, you need to get Lando up and running on your Mac/Linux. This is as easy as running a single command. Seriously, it’s like magic. Just open your terminal and run:
`/bin/bash -c "$(curl -fsSL https://get.lando.dev/setup-lando.sh)"`
Don’t worry, this won’t summon any spirits (unless you’re coding at 3 AM, then all bets are off).
For those on Windows, Powershell is your friend:
`iex (irm 'https://get.lando.dev/setup-lando.ps1' -UseB)`
For the curious ones, here’s the link to the official installation guide: Lando Installation
Step 2: Pull Your Project from Git
Next up, let’s pull your project from Git. It’s like fishing, but less messy and you don’t need a license.
`git clone <your-repo-url>`
Step 3: Check for the Acquia Plugin
Now, let’s make sure your Lando setup has the Acquia plugin. This is where we get to flex our Lando muscles:
`lando version --component @lando/acquia`
If it’s missing (like your socks after laundry), add it using:
`lando plugin-add @lando/acquia`
For more details, check out the plugin installation guide: Lando Acquia Plugin
Step 4: Initialize Lando
Navigate to your project directory:
`cd /path/to/your/repo`
Then, initialize Lando with the Acquia recipe. This is where the real magic happens:
`lando init \
--source cwd \
--recipe acquia`
For more magical spells, check out the getting started guide: Lando Acquia Getting Started
Step 5: Update Database Configuration
Before you start, you need to check the database info of your Lando container:
`lando info`
Then, update your settings.php file. Add the following lines and comment out the Acquia require line:
`$databases['default']['default'] = array (
'database' => 'acquia',
'username' => 'acquia',
'password' => 'acquia',
'prefix' => '',
'host' => 'acquia',
'port' => '3306',
'namespace' => 'Drupal\\mysql\\Driver\\Database\\mysql',
'driver' => 'mysql',
'autoload' => 'core/modules/mysql/src/Driver/Database/mysql/',
);`
Step 6: Start Lando
Ready, set, go! Start your Lando environment:
`lando start`
Before you pull your project, you might encounter some curl errors. Here’s a handy fix: Fix Curl Error
For corporate network tips, visit: [Lando Corporate Network Tips](https://docs.lando.dev/guides/lando-corporate-network-tips.html)
Step 7: Install Acquia CLI
You’ll need the Acquia CLI for some nifty commands:
[Install Acquia CLI](https://docs.acquia.com/acquia-cli/install)
Step 8: Import Your Database and Files
And finally, import your database and files:
`lando pull`
Step 9: Start the Lando Application
And to wrap it all up, start your Lando application:
`lando start`
Conclusion
And there you have it! You’ve successfully set up Lando on your Mac for Acquia. Now, go forth and conquer your projects, armed with the power of Lando. Remember, coding should be fun, not frightening. Happy coding! | sanjay_mogra | |
1,873,626 | Simplifying Next.js: A Quick Guide to Pros and Cons | Simplifying Next.js: A Quick Guide for React Developers Next.js is a powerful React... | 0 | 2024-06-02T12:13:58 | https://dev.to/saudtech/simplifying-nextjs-a-quick-guide-to-pros-and-cons-1b15 | nextjs, webdev, javascript, softwaredevelopment | ## Simplifying Next.js: A Quick Guide for React Developers
Next.js is a powerful React framework that simplifies building performant and scalable web applications. Its popularity stems from its ability to streamline development workflows while delivering top-notch user experiences. Let's dive into why it is so popular
## Blazing-Fast Performance 🚀
- **Server-Side Rendering (SSR):** Next.js excels at SSR, rendering pages on the server for faster initial loads and improved SEO.
- **Automatic Code Splitting:** Your JavaScript bundles are optimized, ensuring only necessary code is loaded for each page.
- **Image Optimization:** Images are automatically resized and served in modern formats (like WebP), leading to faster page loads.
## **Routing Made Easy: The Magic of Dynamic Routes:**
One of Next.js's most powerful features is its intuitive routing system. It simplifies navigation within your app and makes handling dynamic content a breeze.
- **File-Based Routing:** Forget about complex configuration files. In Next.js, your project's folder structure defines your routes. Create a file named `about.js` in your pages directory, and you instantly have a route at `/about`.
- **Dynamic Routes in Action:** Want to build a blog where each article has its own unique URL (e.g., `/blog/my-awesome-article`)? Next.js has your back. By using square brackets in your file names (e.g., `[slug].js`), you create dynamic route segments. Next.js then matches incoming URLs to these segments and renders the corresponding page.
```
pages/
index.js
blog/
[slug].js
```
In this example, `[slug].js` handles any route under `/blog/`. Next.js will pass the actual slug value (like "my-awesome-article") to your component as a prop, allowing you to fetch and display the relevant article content.
## A Swiss Army Knife for Developers
Next.js comes packed with tools to make your life easier:
- **API Routes:** Build your backend API directly within your Next.js project, streamlining full-stack development.
- **TypeScript Support:** Enjoy the benefits of type safety and catch errors early on, leading to more robust and maintainable code.
## Next.js and SEO
Next.js is a dream come true for SEO enthusiasts. Its server-side rendering capabilities ensure that search engines can easily crawl and index your pages. This means your content is more likely to show up in search results, driving more organic traffic to your website.
Next.js also offers features like automatic image optimization and built-in metadata management, further boosting your SEO efforts. With Next.js, you can rest assured that your website is well-positioned for success in the search rankings.
## Deployment Done Right
Deploying Next.js apps is a breeze, thanks to its compatibility with popular platforms like Vercel, Netlify, or your own server. You get built-in support for serverless functions, global CDN, and automatic scaling.
## When to Choose (and Not Choose) Next.js
Next.js shines for:
* **E-commerce Sites:** Its performance optimizations and SEO capabilities are perfect for online stores.
* **Content-Driven Websites:** Blogs, news portals, and documentation sites benefit greatly from Next.js's static site generation (SSG) and server-side rendering (SSR) features.
* **Complex Web Applications:** Next.js handles dynamic data fetching, user authentication, and complex interactions effortlessly.
However, Next.js might not be the best fit for:
* **Extremely Simple Websites:** If your website is just a few static pages, the added complexity of Next.js might not be worth it.
* **Projects with Limited Resources:** If you have a small team or limited budget, the learning curve of Next.js could be a hurdle.
Have you used Next.js in your projects? Share your experiences and thoughts in the comments below! We'd love to hear from you.
| saudtech |
1,873,624 | Executing long running tasks with AppSync | AWS recently announced a small (but notable) feature for the AppSync service where a data source... | 0 | 2024-06-02T12:11:57 | https://mohdizzy.medium.com/executing-long-running-tasks-with-appsync-bb3c6c903a52 | lambda, eventbridge, appsync, serverless | AWS recently [announced](https://aws.amazon.com/about-aws/whats-new/2024/05/aws-appsync-events-asynchronous-lambda-function-invocations/) a small (but notable) feature for the AppSync service where a data source associated with a Lambda can invoke the function asynchronously. Before this, AppSync was to only process all requests synchronously.
## How does it help
The current update opens the door to handling certain situations which weren’t possible earlier (or at least they were not as straight-forward to implement).
Imagine when you have specific AppSync mutations that take more than 30 seconds to process owing to technical constraints. Since you always need to return a synchronous response, the way to deal with this would typically involve offloading the actual processing of the request to another function either by passing the payload via an SQS (provided payload is under 256KB) or doing a direct asynchronous invocation of the other lambda function and then returning a generic response by the Lambda function associated with the resolver. By offloading the actual processing to another function, the 30 second timeout limitation has been handled.
Assuming the caller needs the final result of that long-running task, it would also need to make a subscription call so that it can receive the response once it has been completed. Triggering a mutation call (without an actual data source) is needed to deliver the subscription response.
Specifying “Event” invocation method type now allows calling the function asynchronously. So now the additional step of handing off the actual processing through an SQS/Lambda can be eliminated.
## The setup
With in the JS resolver request function, all we need to do is specify the invocationType attribute. You would already be familiar with this when a function is invoked using the AWS SDK/CLI.
The response function of the resolver can return a static response to indicate to the caller that AppSync has received the request for processing.
```
export function request(ctx) {
return {
operation: "Invoke",
invocationType: "Event",
payload: ctx,
};
}
export function response(ctx) {
return "Received request";
}
```
## Things to keep in mind
Asynchronous lambda invocations cannot have payload sizes more than 256KB. So if your existing synchronous AppSync request has a payload size beyond this value, switching to async mode is not going to be possible.
Likewise, for the response, an AppSync request (query/mutation) can return a payload with a size limit of 5MB.
The flow indicated above assumes the caller needs the result after the long-running task has finished processing. Eventbridge pipes is a great tool leveraging AWS infrastructure for triggering the mutation call whose response is the result for a Subscription request.
With the use of Subscriptions we are able to deliver the final payload, but the payload size cannot exceed 240 KB. This isn’t something new but just to keep in mind that even though AWS enabled asynchronous request processing with AppSync, the final act of delivering a large payload is still a catch. | mohdizzy |
1,873,619 | How I Made $14,000 with an Language Speaking with AI app | Most software developers dream of making a business by selling their own app? I am one of them. In... | 0 | 2024-06-02T12:09:30 | https://dev.to/davidtran/how-i-made-14000-with-an-language-speaking-with-ai-app-1b77 | ---
title: How I Made $14,000 with an Language Speaking with AI app
published: true
description:
tags:
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 for best results.
# published_at: 2024-06-02 11:30 +0000
---
Most software developers dream of making a business by selling their own app? I am one of them. In October 2022, I decided to try making a living by selling a mobile app. At that time, I didn't know anything about mobile app development because I had only worked on frontend development before.
## Learning New Skills
To achieve my goal, I needed to learn several new skills. I started by learning design with Figma to create user-friendly and attractive interfaces. Then, I learned backend development with Node.js, which was very different from the frontend work I was used to. Finally, I learned mobile development with React Native to build apps for both iOS and Android.
You may ask why I didn't hire a freelancer designer? Well, I did hire a few freelancers but all of them doesn't give me the design that I wanted. At the end, I lost a lot of money on them so I decided to learn design by myself.
Over a few months, I created four apps and one website. Each project taught me something new, but none of them were successful. I realized that making a simple app was easy, but building a profitable business was much harder.
## Facing Challenges
Quitting my job to focus on my startup was risky, especially since my wife was pregnant and we already had a child. I couldn’t afford to waste time and money on something that might not work. The pressure was intense, and I needed a breakthrough.
## Finding the Right Niche
One day, a friend gave me some crucial advice: focus on a single niche. He suggested that I create an English-speaking app with AI. Taking his advice, I started working on the app, which I named FluentPal, using Node.js, React Native, OpenAI, and Azure.
It took me two months to launch FluentPal on [iOS](https://apps.apple.com/us/app/fluentpal/id6462874346), but it was full of bugs, and I got only one subscriber. This was disappointing, but I didn’t give up. I spent three more months fixing the bugs, redesigning the app, creating new content, and launching it on the [Play Store](https://play.google.com/store/apps/details?id=com.fluentai). I also worked with a Key Opinion Leader (KOL) to promote the app.
Even though I was worried about the time and money I had invested, I started to see results. By the end of December 2023, FluentPal had made $1,500. It wasn’t a lot, but it showed that the app had potential.
## Improving and Growing
Encouraged by this small success, I continued to improve FluentPal. I added features like learning lessons, translation support, flashcards, and AI personalities. To get more users, I ran ads on Facebook and Google.
These efforts paid off. In the first five months of 2024, FluentPal made $13,000, bringing my total earnings to $14,000. This was a significant achievement, proving that the app could be a successful business.
## What I Learned
Looking back, I learned several important lessons:
- Don’t Start a Business Without Enough Resources: Starting a business requires a lot of time and money. Make sure you have enough of both before you begin.
- Learn as Much as You Can: The more skills you have, the better you can manage different parts of your business. Hiring freelancers can be expensive, and they might not understand your product as well as you do.
- Be Patient and Persistent: Success doesn’t happen overnight. You need to keep working hard, learning from your mistakes, and improving your product.
- Listen to Your Users: Pay attention to what your users say and make changes based on their feedback. Building a product that meets their needs is crucial for success.
In conclusion, my journey from a frontend developer to a successful app creator was full of challenges and learning experiences. Despite the difficulties, seeing my app grow and make money has been incredibly rewarding. If you’re thinking about starting your own business, be prepared for the ups and downs, and remember to stay focused and persistent.
## Try FluentPal
If you’ve read this article, I encourage you to download FluentPal. It is a really good app. It is not only just teach you English speaking but also six other languages: Chinese, Japanese, Korean, Spanish, French, and German.
Download FluentPal:
- [iOS](https://apps.apple.com/us/app/fluentpal/id6462874346)
- [Android](https://play.google.com/store/apps/details?id=com.fluentai) | davidtran | |
1,873,623 | DAY 2 : NOW ITS TIME FOR CLASS. | how to write class | 0 | 2024-06-02T12:04:03 | https://dev.to/developervignesh/day-2-now-its-time-for-class-3726 | webdev, dotnet, java, oop | [how to write class
](https://medium.com/@developervignesh7/lets-learn-how-to-write-a-class-to-show-our-class-in-a-program-8073027656f3) | developervignesh |
1,873,622 | Membuat Job Queue Batching pada Laravel dengan Indikator Proses Secara Realtime Menggunakan Pusher | Queue adalah salah satu bentuk struktur data dasar dari sebuah proses program atau kita bisa... | 0 | 2024-06-02T12:02:31 | https://dev.to/yogameleniawan/membuat-job-queue-batching-pada-laravel-dengan-indikator-proses-secara-realtime-menggunakan-pusher-5b | laravel, programming | 
Queue adalah salah satu bentuk struktur data dasar dari sebuah proses program atau kita bisa menyebutnya dengan istilah antrian. Konsep yang paling sering didengar dari Queue ini adalah FIFO (First in First out). Konsep FIFO ini dapat kita lihat dalam kehidupan sehari-hari contohnya, ketika kita membeli makanan dengan sistem layanan drive thru maka kendaraan yang pertama datang akan dilayani terlebih dahulu kemudian akan keluar terlebih dahulu juga setelah selesai membeli makanan.
Seberapa penting penerapan queue pada program aplikasi yang kita buat? Tentu jawabannya adalah sangat penting. Contoh kasus sederhananya ketika kita mengeksekusi proses update data ke dalam database dengan jumlah data yang banyak tentunya browser tidak akan mungkin menunggu proses update itu hingga selesai. Biasanya akan terjadi timeout dikarenakan browser tidak mendapatkan respon apapun dari server, sedangkan disisi lain sebenarnya server sedang menjalankan proses itu namun dikarenakan prosesnya lama maka browser akan menganggap waktu tunggunya sudah selesai. Kurang lebih contoh sederhananya seperti itu.
Lalu bagaimana cara menerapkan konsep Queue menggunakan Laravel? disini ada beberapa langkah yang perlu disiapkan supaya kita bisa menerapkan konsep queue pada projek Laravel kita.
### Persyaratan
- [PHP 7.4 atau lebih](https://www.php.net/)
- [Laravel 8 atau lebih](https://laravel.com/)
- [Laravel Queue](https://laravel.com/docs/11.x/queues)
- [Pusher](https://pusher.com/)
### Migration Table Job & Job Batches
Berikut adalah langkah-langkah untuk menyiapkan tabel jobs dan job_batches
Jalankan perintah dibawah ini untuk membuat tabel jobs :
```bash
php artisan queue:table
```
Jalankan perintah dibawah ini untuk membuat tabel job_batches :
```bash
php artisan queue:batches-table
```
Lakukan migrasi tabel menggunakan perintah dibawah ini :
```bash
php artisan migrate
```
### Install Package Realtime Job Batching
Jalankan perintah dibawah ini untuk melakukan instalasi package :
```bash
composer require yogameleniawan/realtime-job-batching
```
### Konfigurasi Pusher
Berikut adalah langkah-langkah untuk konfigurasi Pusher :
Install Pusher PHP SDK
```bash
composer require pusher/pusher-php-server
```
Buat Channels App Pusher [klik disini](https://dashboard.pusher.com/)
Setting file .env untuk Pusher Variable
```bash
PUSHER_APP_ID=your_pusher_app_id
PUSHER_APP_KEY=your_pusher_app_key
PUSHER_APP_SECRET=your_pusher_app_secret
PUSHER_HOST=
PUSHER_PORT=443
PUSHER_SCHEME=https
PUSHER_APP_CLUSTER=mt1
```
### Membuat Repository Class
Berikut langkah-langkah yang dilakukan untuk membuat Repository Class :
Buat file contoh: **VerificationRepository.php** pada folder **root_project/app/Repositories**
> Untuk lokasi folder bisa dibuat secara bebas. Apabila menggunakan arsitektur lain seperti Modular, DDD, dan lain-lain bisa disesuaikan dengan struktur projeknya.
Repository Class yang sudah dibuat mengimplementasikan interface RealtimeJobBatchInterface yang sudah dibuat pada package ini. Kemudian silahkan tambahkan function get_all(): Collection dan save($data): void.
**Penjelasan**
> _public function get_all(): Collection_
> function ini digunakan untuk mengambil semua data pada database kemudian dikembalikan dalam bentuk Collection. Tujuan dikembalikan dalam bentuk collection ini karena kita perlu melakukan looping lalu setiap looping, prosesnya akan kita masukkan ke dalam queue.
**Penjelasan**
> _public function save($data): void_
> function ini digunakan untuk melakukan proses penyimpanan ataupun perubahan yang akan terjadi dalam 1 proses queue. Kita bisa membuat bisnis proses sendiri sesuai dengan kebutuhan di dalam function ini.
```php
<?php
namespace App\Repositories;
use App\Models\User;
use Illuminate\Support\Collection;
use Illuminate\Support\Facades\DB;
use YogaMeleniawan\JobBatchingWithRealtimeProgress\Interfaces\RealtimeJobBatchInterface;
class VerificationRepository implements RealtimeJobBatchInterface {
public function get_all(): Collection {
$sql = "SELECT * FROM users";
return collect(DB::select($sql));
}
public function save($data): void {
DB::table('users')
->where('id', $data->id)
->update([
'is_verification' => true,
]);
}
}
```
Buat Function Controller untuk menjalankan proses yang ada di dalam repository yang sudah dibuat sebelumnya.
Contoh :
Tambahkan 2 baris ini untuk melakukan import class yang kita gunakan.
```php
use App\Repositories\VerificationRepository;
use YogaMeleniawan\JobBatchingWithRealtimeProgress\RealtimeJobBatch;
```
Kemudian buat function untuk menjalankan proses queue.
```php
public function verification() {
$batch = RealtimeJobBatch::setRepository(new VerificationRepository())
->execute(name: 'User Verification');
return response()
->json([
'message' => 'User verification is running in background',
'batch' => $batch
], 200);
}
```
**Penjelasan**
> _setRepository(new VerificationRepository())_
> Pada parameter function setRepository kita bisa mengirim berdasarkan repository class yang kita gunakan. Tujuannya supaya class RealtimeJobBatch dapat digunakan di berbagai jenis service dengan implementasi proses yang berbeda-beda.
> _->execute(name: 'User Verification')_
> Di dalam parameter function execute kita bisa menuliskan nama dari job_batches yang digunakan untuk menyimpan informasi proses job queue yang sedang berjalan.
### Setup Javascript
Berikut langkah-langkah yang dilakukan untuk melakukan setup javascript :
Pada konfigurasi javascript ini menggunakan blade. Apabila ingin menggunakan selain blade dapat dilihat pada dokumentasi berikut ini.
Tambahkan `<script>` ini ke dalam file blade :
```javascript
<script src="https://js.pusher.com/7.2/pusher.min.js"></script>
<script>
var pusher = new Pusher('YOUR_PUSHER_APP_KEY', {
cluster: 'mt1'
});
var channel = pusher.subscribe('channel-job-batching');
channel.bind('broadcast-job-batching', function(data) {
console.log(data)
});
</script>
```
`YOUR_PUSHER_APP_KEY ` bisa diisikan value sesuai dengan `PUSHER_APP_KEY ` pada file `.env`
Untuk sementara waktu "channel-job-batching" dan "broadcast-job-batching" adalah nama default yang harus ditulis. Apabila menggunakan selain nama itu maka tidak akan mendapatkan response dari Pusher. Untuk update package berikutnya akan dikembangkan fitur pemberian nama channel secara bebas.
Hasil response dari Pusher :
```json
{
"finished": false,
"progress": 10,
"pending": 90,
"total": 100,
"data": {}
},
```
Isi dari key "data" akan berupa object sesuai dengan data yang sedang diproses.
Contoh :
Update user dengan id 10 sedang dijalankan. Maka nilai object dari key "data" yaitu sesuai dengan atribut yang dimiliki oleh tabel, contoh :
Atribut Tabel User :
- id
- name
- email
- is_verified
Maka hasil response dari pusher seperti ini :
```json
{
"finished": false,
"progress": 10,
"pending": 90,
"total": 100,
"data": {
"id": 10,
"name": "Yoga Meleniawan Pamungkas",
"email": "yogameleniawan@gmail.com",
"is_verified": true,
}
},
```
### Notes
Package realtime-job-batching masih perlu banyak pengembangan. Seiring berjalannya waktu proses pengembangan package akan dilakukan berdasarkan bug ataupun keperluan penambahan fitur. | yogameleniawan |
1,873,578 | How to get start Elixir | What is the Elixir? Elixir is a dynamic functional programming language built on top of... | 0 | 2024-06-02T11:45:40 | https://dev.to/rhaenyraliang/how-to-get-start-elixir-3l65 | webdev, beginners, tutorial, elixir | ## What is the Elixir?
Elixir is a dynamic functional programming language built on top of the Erlang BEAM virtual machine, for building scalable and maintainable applications. creating low-latency, distributed, and fault-tolerant systems.
## How to Install
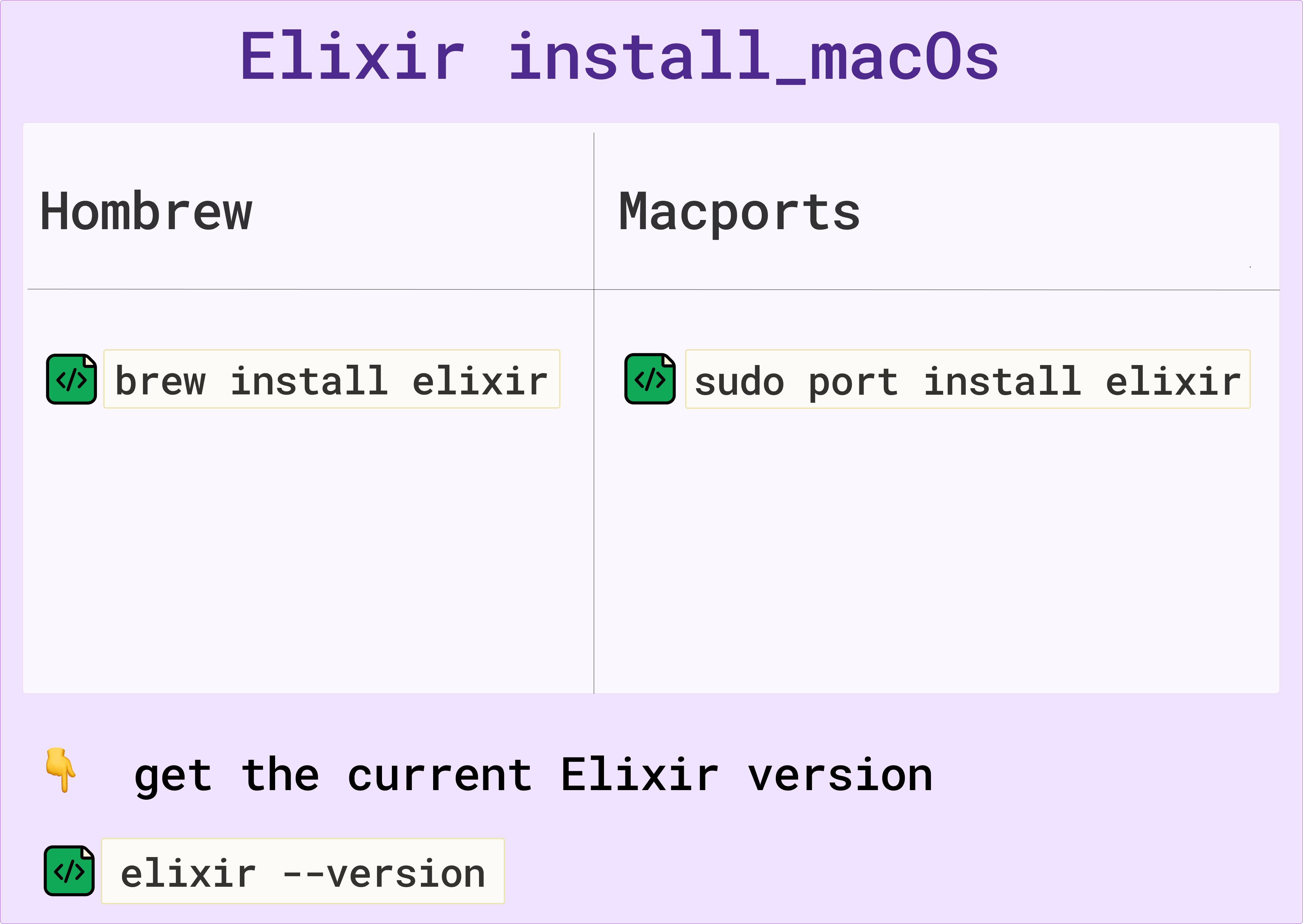
I use mac so the image is how to install in mac
Other operating systems can click the link to read👇
[Other Operation Systems](https://elixir-lang.org/install.html#by-operating-system)
## Interactive mode
We can type any Elixir expression in interactive mode and get its result.

| rhaenyraliang |
1,873,620 | Connect-Four Game - Web Game | Inspiration Creating interactive and engaging web games has always fascinated me. This... | 0 | 2024-06-02T11:44:54 | https://dev.to/sarmittal/connect-four-game-5k5 | frontendchallenge, webdev, javascript, programming | ## Inspiration
Creating interactive and engaging web games has always fascinated me. This time, I took on the challenge of developing the classic Connect Four game using React.js, HTML, and CSS. The primary goal was to enhance my front-end development skills and deepen my understanding of data structures and algorithms.
## Demo
Check out the live demo here.
## Journey
Developing the Connect Four game was a fun and enlightening experience. Here’s a quick overview of my journey:
## Project Overview
- Technologies Used: React.js, HTML, CSS
- Main Feature: A function named checkWin that checks for the winner in the game.
## Key Learnings
Importance of Data Structures: During the development, I realized how crucial data structures are in game development. They not only help in managing the state efficiently but also in optimizing the performance.
Algorithm Optimization: To ensure the game runs smoothly, optimizing the checkWin function was vital. The faster your algorithms, the better the user experience.
## Why DSA Matters
The development of this game highlighted the importance of Data Structures and Algorithms (DSA). Efficient algorithms can drastically improve the performance of an application. Understanding and implementing the right data structures helps in managing and optimizing the game state, making the overall user experience smoother and more enjoyable.
## What's Next?
I plan to continue refining the game, adding more features, and perhaps even incorporating AI to challenge the players. Feel free to check out the project, play the game, and contribute by adding your own features. The project is open source, and I welcome any enhancements!
**Live Demo**: [Connect Four Game](https://connect-four-sarmittal.netlify.app/)
**GitHub Repository**: [Connect Four Source Code](https://github.com/iam-sarthak/connect-four)
Feel free to connect with me to discuss this project, potential collaborations, or any insights you might have. | sarmittal |
1,873,060 | Supabase: The Open-Source Superhero That Saves You From Firebase | As a developer who's built apps and webApps with both React and Flutter, I've spent a fair amount of... | 0 | 2024-06-02T11:40:34 | https://dev.to/anshul_bhartiya_37e68ba7b/supabase-the-open-source-superhero-that-saves-you-from-firebase-3klj | database, opensource, supabase, firebase | As a developer who's built apps and webApps with both React and Flutter, I've spent a fair amount of time navigating the world of backend-as-a-service (BaaS) solutions. Firebase has always been a go-to option with its familiar Google backing and convenient features. But recently, Supabase, the open-source up-and-comer, has caught my eye. This article explores Supabase's potential as the "superhero" that can save developers from Firebase fatigue, especially when it comes to building React and Flutter applications. We'll compare their strengths and weaknesses, focusing on aspects that resonate with my experiences in both frameworks. Let's see if Supabase can truly live up to its name!
**My Flutter Frustration with Firebase: Can Supabase Save the Day?**
In my journey as a Flutter Development, Firebase has undoubtedly been a powerful tool. However, the initial setup, especially configuring Firebase in Flutter projects, often felt like an obstacle course. Juggling platform-specific configurations and navigating the intricacies of getting everything connected could be a time-consuming hurdle. This is where Supabase enters the scene. This article explores Supabase as a potential solution, aiming to see if it offers a smoother and more streamlined initialization experience for mobile development, particularly when working with Flutter. We'll delve into the pros and cons of both platforms, focusing on the ease of getting started and how Supabase might offer a more developer-friendly approach.
## Firebase: The Smooth Operator
**Headline**: Captain Convenience: Your One-Stop Shop for Backend Bliss
**Bio**: Looking for a reliable and easy-going partner to handle your backend needs? Look no further! I'm Firebase, Google's very own managed service. I come pre-packaged with all the bells and whistles you need, from real-time updates to offline capabilities. Plus, I handle all the infrastructure stuff, so you can focus on building your amazing app. (Just don't expect too much customization – I like things my way )
## Supabase: The Wild Card
**Headline**: Data Diva: Independent, Open-Source, and Ready to Rule Your Backend
**Bio**: Tired of the same old managed service routines? Spice up your backend life with Supabase, the open-source rebel with a cause (relational data, that is). I offer ultimate control – self-host me or use my managed service, it's your call! I might require a bit more effort to set up, but hey, the freedom and flexibility are worth it. Plus, my PostgreSQL muscles will handle your complex data like nobody's business. (Just be warned, I'm not for the faint of heart – some infrastructure management skills are a must!)
**Who's Your Backend Match?**
It all boils down to your developer desires. Do you crave a smooth, pre-built experience, or are you a control freak who thrives on open-source adventures?
Whichever you choose, remember: both Firebase and Supabase can be amazing partners for your backend needs. Just make sure you pick the one that makes your developer heart sing (and your data dance)!
## Core Differences: Database Type:
**Firebase**: Leverages a **NoSQL document database** called Firestore. Data is stored in flexible JSON-like documents, making it ideal for unstructured or semi-structured data. Each document has a unique identifier and can contain nested collections for hierarchical data organization.
**Supabase**: Utilizes a powerful **relational database** engine called PostgreSQL. This enables structured data management with tables, rows, and columns. You can define relationships between tables using SQL queries and joins, which is essential for complex data models often found in web applications.
## Real-time Feats: Keeping Your Data in Sync
Both Firebase and Supabase boast impressive real-time features, ensuring your application data stays up-to-date across devices. Let's break down their approaches:
**Firebase**:
Offers a robust real-time database (RTDB) alongside Firestore.
Data is stored as a single JSON tree, allowing efficient updates and retrieval for real-time scenarios like chat applications or collaborative editing.
Firebase excels in ease of use for real-time functionality.
**Supabase**:
Leverages real-time subscriptions directly within its PostgreSQL database.
You can subscribe to specific table changes or queries, enabling granular control over what data updates your application receives.
While Supabase offers more control, it might require slightly more setup effort compared to Firebase's RTDB.
## Open Source Sanctuary vs. Google's Guarded Gates: A Look at Control
When it comes to control and ownership, Firebase and Supabase take vastly different approaches:
**Firebase**:
A Google-backed, managed service.
You benefit from Google's infrastructure and expertise, but it comes with potential vendor lock-in.
You rely on Google's uptime and security measures.
Customization options might be limited compared to a self-hosted solution.
**Supabase**:
An open-source project, offering the freedom to self-host or use a managed service.
This grants you complete control over your data and infrastructure.
You're responsible for managing your own servers and security, which requires additional technical expertise.
Supabase offers a generous free managed tier, so you can experiment without upfront costs.

## The Final Showdown: Firebase or Supabase?
So, have we settled the great backend battle? Not quite. Choosing between Firebase and Supabase depends on your project's needs. It's like picking a superhero: are you looking for Captain Convenience (Firebase) who swoops in with pre-built tools, or do you need a more DIY hero like Data Diva (Supabase) who grants you ultimate control over your data kingdom?
**Here's the scoop on Supabase, the potential secret weapon for your dev arsenal:**
**Relational Data Rockstar**: Forget wrestling with NoSQL's limitations. Supabase's PostgreSQL lets you manage your data like a boss, with tables, rows, and joins that would make even the strictest relational database enthusiast do a happy dance.
**Open-Source Oasis**: Ditch the vendor lock-in blues! Supabase lets you self-host or use their managed service, giving you the freedom to do your backend thing your way.
**Cost Crusader (For Specific Cases)**: While both offer free tiers, Supabase's transparent pricing might just save the day for your budget, especially if you're a self-hosting champion.
## The Verdict?
Firebase is a fantastic choice for convenience and ease of use. But if you crave control, relational data mastery, and the open-source spirit, Supabase might just be the superhero you've been waiting for. So, grab your developer cape and give Supabase a try. You might just be surprised by its power!
Intrigued by Supabase, the open-source hero who vanquishes data woes? Don't be a backend wallflower! Dive into Supabase's docs (https://supabase.com/docs), unleash your inner SQL Jedi, and join the Supabase fam. It's time to ditch the backend blues and level up your dev skills!
https://github.com/supabase/supabase?tab=readme-ov-file
## Want to connect? Let's chat about code, or anything else that sparks your developer curiosity!
Twitter: [Bhartiyaanshul](https://twitter.com/Bhartiyaanshul)
LinkedIn: [anshulbhartiya](https://www.linkedin.com/in/anshulbhartiya/)
Email: bhartiyaanshul@gmail.com | anshul_bhartiya_37e68ba7b |
1,873,639 | Locate Website Visitors in Next.js with IP and Supabase | Using API routes with Next.js as well as an IP address geolocation service is an easy way to display... | 0 | 2024-06-02T13:13:28 | https://felixrunquist.com/posts/locating-last-visitors-in-next-js | ---
title: Locate Website Visitors in Next.js with IP and Supabase
published: true
date: 2024-06-02 11:30:34 UTC
tags:
canonical_url: https://felixrunquist.com/posts/locating-last-visitors-in-next-js
cover_image: https://felixrunquist.com/_next/image?url=%2Fstatic%2F365521cda75b6c790f2f7d59cbaebe81b9488ce8.png&w=3840&q=75
---
Using API routes with Next.js as well as an IP address geolocation service is an easy way to display the last visitor of a website. I wanted to use this in a widget on my website homepage. I got this idea after visiting [Rauno Freiberg's website](https://rauno.me/) – he's a designer at Vercel and I admire his work.
First of all, I mapped out what needs to be done:
- **Locating the user**. There are a few different ways to locate a user on a website, I chose to go with the IP address. This isn't always extremely precise, but it's good enough for getting a rough location to display.
- **Storing user locations in a database**. There obviously needs to be something on the server side remembering locations of users to display to the next user.
- **APIs for updating and retrieving the last user's location**. We also need to think about the order of requests, to make sure that when a user visits the website and the last location is updated, he doesn't get his location back from the database but the location of the previous user.
I also had a few priorities for this project: speed and minimal server load. I don't want the last visitor feature to cause a significant increase in page loading times for the client, or to increase server actions beyond what is provided in the Vercel free tier. We'll have a look at how to do this in the best way possible.
## Fetching the country from IP
As IP addresses change frequently, and the ranges get reallocated, it's difficult to know which range of addresses maps to which country. Luckily, MaxMind has a free IP lookup tool called [GeoLite2](https://dev.maxmind.com/geoip/geolite2-free-geolocation-data), which they update frequently. It's more or less precise, but good enough for what we're trying to do.
After creating an account and getting a license key, getting the city and country from an IP address is quite easy using the `@maxmind/geoip2-node` NPM package. Here's some example code:
```
import { WebServiceClient } from '@maxmind/geoip2-node';
const MAXMIND_USER = '1234567';
const MAXMIND_LICENSE = 'Your license here';
const ip = '43.247.156.26';
const client = new WebServiceClient(MAXMIND_USER, MAXMIND_LICENSE, {host: 'geolite.info'});
const response = await client.city(ip);
const data = {country: response.country ? response.country.names.en : null, city: response.city ? response.city.names.en : null}
console.log(data)
`}</code2>
I added some extra logic after noticing that not all IP addresses map to specific cities in the lookup tool.
## Implementing the database
To simplify things in the database, I decided to create a table with `ip`, `city` and `country` columns. Setting the new country is equivalent to adding a new row, instead of updating the last row. This to make it easier to handle the location of the previous user/current user. There's a primary key, `ID`, which will be automatically set.
I decided to go with Supabase, as I've already used their services and am impressed with the ease of use and the excellent Next.js integration.
I created a country table, and I disabled Row-Level-Security as this would require some form of authentication, and we're going to do all the database queries on the server-side as you'll see next, so the client will not have access to the database.
_The columns of our views table_
## Adding the middleware and APIs
In order to fully separate the user from the database, I decided to perform all database queries on the server, and handle the country updating logic using Next.js middleware. This has the added benefit of not sending any additional client requests to log the users' country, which lightens the client-side stack.
To retrieve the country, instead of using `getServerSideProps`, which would make each page dynamic and block it from loading until the database has responded, we do this on the client side through an API route. Need a refresher on Next.js page generation? [Have a look at this post](https://felixrunquist.com/posts/generating-sitemap-rss-feed-with-next-js).
Let's map this out:

_A diagram of the different requests to the server and database_
### Middleware
Let's first look at the middleware: It makes a request to an API endpoint. For added security, we can prevent the client from interfering with the `set-last-country` API by adding an API key: a secret that will be shared between the middleware and the API to ensure that only the middleware is able to update the country.
To prevent the same user from constantly setting their country as the last, for example if they navigate across multiple pages, we can set a session cookie from the middleware to prevent subsequent requests from triggering the country update.
```
import { NextRequest, NextResponse } from 'next/server'
import { SITE_PATH, COUNTRY_SET_KEY, VIEW_SET_KEY } from '@/lib/constants'
export const config = {
matcher: ['/:path', '/posts/:path*', '/pages/:path*', '/creations/:path*']
}
export async function middleware(req) {
const res = NextResponse.next()
//check if there is no cookie set
if(!req.cookies.has('country')){
res.cookies.set('country', 'true')
const forwarded = req.headers.get("x-forwarded-for")
var ip = forwarded ? forwarded.split(/, /)[0] : req.headers.get("x-real-ip")
try {
fetch('https://' + req.headers.get('host') + '/api/set-last-country', {
method: 'POST',
body: JSON.stringify({ip, key: COUNTRY_SET_KEY})
})
} catch(error){
console.log(error)
}
}
return res
}
```
We're using the matcher to only trigger the middleware on certain routes, and the country cookie is used to check if the user's country has already been uploaded to the database during the current session. We then send the IP to the API, as well as the API key mentioned earlier.
You'll also notice that there's no `await` key preceding the fetch, this speeds up loading times since it isn't necessary to wait for the database to update the last country in order to serve the page to the user.
### API setter
In the `set-last-country` API, we'll need to do the following:
- Use geolite2 to get a country and city from the IP address
- Store the country and city in the Supabase database.
We also need to make sure that the API only accepts POST requests, as it's the method the middleware uses for sending the data.
```
import { WebServiceClient } from '@maxmind/geoip2-node';
import { createClient } from '@supabase/supabase-js'
import { COUNTRY_SET_KEY, MAXMIND_USER, MAXMIND_LICENSE } from '@/lib/constants';
export default async function handler(req, res) {
if(req.method != 'POST'){
console.log("Unauthorized")
return res.status(403).json({error: 'Unauthorized'})
}
const body = JSON.parse(req.body)
if(body.key != COUNTRY_SET_KEY){
console.log("Unauthorized")
return res.status(403).json({error: 'Unauthorized'})
}
//Get country from body.ip
const client = new WebServiceClient(MAXMIND_USER, MAXMIND_LICENSE, {host: 'geolite.info'});
const response = await client.city(body.ip);
const data = {country: response.country ? response.country.names.en : null, city: response.city ? response.city.names.en : null, ip: body.ip}
//Send to SB
const supabase = createClient(process.env.NEXT_PUBLIC_SUPABASE_URL, process.env.NEXT_PUBLIC_SUPABASE_ANON_KEY)
var { error } = await supabase
.from('visitors')
.insert(data)
res.status(200).json(data)
}
```
### API getter
The `get-last-country` is the only API route we want to make available to the client. For this reason, we're not going to be using any API keys. To reduce overhead, caching can be used: since it doesn't really matter if we get the last user, or the 10th last user, we can cache the result for 10 minutes which will reduce server requests as well as database access. Caching on the client and server side can be done using special headers.
We also need to make sure that when the user visits the website and the last location is updated, he doesn't get his location back from the database but the location of the previous user. To do this, we can add an additional column in our `country` table to check if the second to last row has been read or not. If it hasn't been read, we'll return that row, otherwise we'll return the last row. This ensures that the user never gets their location on the first visit, but they might on the next.
```
import { createClient } from '@supabase/supabase-js'
export default async function handler(req, res) {
res.setHeader('Vercel-CDN-Cache-Control', 'max-age=1200');//Cache for 20 minutes
res.setHeader('CDN-Cache-Control', 'max-age=600');//Cache for 10 minutes
res.setHeader('Cache-Control', 'max-age=600');//Cache for 10 minutes
const supabase = createClient(process.env.NEXT_PUBLIC_SUPABASE_URL, process.env.NEXT_PUBLIC_SUPABASE_ANON_KEY)
var { data, error } = await supabase
.from('visitors')
.select('id, country, city, read')
.order('id', { ascending: false })
.limit(2)
if(!data[1].read){
var { error } = await supabase
.from('visitors')
.update({read: true})
.eq('id', data[1].id)
data = data[1]
}else{
data = data[0]
}
delete data.read
delete data.id
res.status(200).json({cached: false, value: data})
}
```
## Client-side logic
Now that we've implemented everything on the server side, all that's left to do is to create a component which will display the location of the last visitor:
[View the article](https://felixrunquist.com/posts/locating-last-visitors-in-next-js) for the live preview below:
`/App.js`:
```
import { useEffect, useState } from 'react'
import styles from './lastvisitor.module.scss';
export default function LastVisitor(){
const [location, setLocation] = useState("")
useEffect(() => {
getLastVisitor()
}, [])
async function getLastVisitor(){
const res = await fetch('http://felixrunquist.com/api/get-last-country')
if(res.status == 200){
const json = await res.json()
setLocation((json.value.city ? json.value.city + ', ' : "") + json.value.country)
}
}
return (
<div classname="{styles.container" styles.hidden :>
<p>Last visitor: {location}</p>
</div>
)
}
`/lastvisitor.module.scss`:
```
.container {transition: opacity .3s ease-in-out; }
.container.hidden {opacity: 0; }
.container:not(.hidden) {opacity: 1; }
```
The last visitor element stays visually hidden until the data has been fetched.
## Closing notes
That's it, we now have a working last visitor system! Since the priority here is to reduce server load, caching and other features are used to prevent too many requests from being made. This comes with a tradeoff: the last visitor might not always be accurate.
For additional safeguards against server usage, we could also implement rate limiting using `@upstash/ratelimit`, as mentioned in [Next.js documentation](https://vercel.com/guides/rate-limiting-edge-middleware-vercel-kv).
If you want to dig further into the different methods of generating content in Next.js, I've [written an article](https://felixrunquist.com/posts/generating-sitemap-rss-feed-with-next-js) which explains how `getServerSideProps`, `getStaticProps` and `revalidate` work.
Have any questions? Feel free to [send me a message on Twitter](https://twitter.com/intent/tweet?via=felixrunquist)!
### References
- [Maxmind documentation](https://dev.maxmind.com/geoip/geolite2-free-geolocation-data), helpful for translating an IP address to a rough geographical location
- [Rauno Freiberg's website](https://rauno.me) with the last visitor counter is what got me inspired to create one!
- [Josh W. Comeau's article](https://www.joshwcomeau.com/react/serverless-hit-counter/) on hit counters explains the integration of serverless functions in static sites
Credits to [Big Loong's template](https://app.spline.design/community/file/8cd53f6b-868e-4fad-a00c-42c76ab73557) which was used as a starting point for the article illustration. I made it with Spline, a [tool I discuss in this article](https://felixrunquist.com/posts/creating-3d-models-spline-three-js).
This article was retrieved from [felixrunquist.com](https://felixrunquist.com/). | felixrunquist | |
1,873,617 | How to add Animations and Transitions in React | Animations can transform your web applications from ordinary to extraordinary, providing visual... | 0 | 2024-06-02T11:22:24 | https://dev.to/jehnz/mastering-animations-and-transitions-in-react-32ki | react, reactspring, framermotion, reactanimations | Animations can transform your web applications from ordinary to extraordinary, providing visual feedback, guiding users, and adding a touch of flair. While basic animations are relatively straightforward, mastering advanced techniques can set your application apart. In this article, we’ll delve into advanced animation techniques in React, explore powerful libraries like Framer Motion and React Spring, and discuss performance considerations to keep your animations smooth and efficient.
### Advanced Animation Techniques in React
React’s declarative nature makes it an excellent choice for handling complex animations. Here are some advanced techniques to consider:
**1. Keyframe Animations with CSS-in-JS**
Using libraries like Styled Components or Emotion, you can define keyframe animations within your React components.
```javascript
import styled, { keyframes } from 'styled-components';
const fadeIn = keyframes`
from {
opacity: 0;
}
to {
opacity: 1;
}
`;
const FadeInDiv = styled.div`
animation: ${fadeIn} 1s ease-in-out;
`;
function App() {
return <FadeInDiv>Hello, world!</FadeInDiv>;
}
```
**2. Transition Groups**
For managing animations when elements enter or leave the DOM, React Transition Group is a powerful utility.
```javascript
import { CSSTransition, TransitionGroup } from 'react-transition-group';
function List({ items }) {
return (
<TransitionGroup>
{items.map(item => (
<CSSTransition key={item.id} timeout={500} classNames="fade">
<div>{item.text}</div>
</CSSTransition>
))}
</TransitionGroup>
);
}
```
```css
.fade-enter {
opacity: 0;
}
.fade-enter-active {
opacity: 1;
transition: opacity 500ms;
}
.fade-exit {
opacity: 1;
}
.fade-exit-active {
opacity: 0;
transition: opacity 500ms;
}
```
### Integrating Libraries like Framer Motion or React Spring
**Framer Motion**
Framer Motion is a powerful library for declarative animations in React. It’s easy to use and comes with built-in support for complex animations and gestures.
```javascript
import { motion } from 'framer-motion';
function App() {
return (
<motion.div
initial={{ opacity: 0 }}
animate={{ opacity: 1 }}
transition={{ duration: 1 }}
>
Hello, world!
</motion.div>
);
}
```
_**Framer Motion** also supports animations on state changes, drag-and-drop interactions, and more._
**React Spring**
React Spring provides a more physics-based approach to animations, making it ideal for fluid, interactive UI elements.
```javascript
import { useSpring, animated } from 'react-spring';
function App() {
const props = useSpring({ opacity: 1, from: { opacity: 0 }, delay: 500 });
return <animated.div style={props}>Hello, world!</animated.div>;
}
```
React Spring excels at creating complex animations with its useTransition, useChain, and other hooks that offer fine-grained control.
**Performance Considerations for Animations**
Animations can be performance-intensive, so it’s crucial to optimize them for a smooth user experience:
**1. Hardware Acceleration**
Use CSS properties that leverage hardware acceleration, such as transform and opacity, rather than top or left.
```css
.element {
transform: translateX(0);
transition: transform 0.5s ease-in-out;
}
```
**2. Avoid Layout Thrashing**
Minimize reflows by avoiding animating properties that trigger layout recalculations. Instead, use properties that affect only paint and compositing.
**3. Throttle Animations**
Use requestAnimationFrame for smoother animations. Libraries like React Spring and Framer Motion handle this internally, but it’s good to be aware of it when implementing custom animations.
**4. Optimize SVG Animations**
For complex SVG animations, consider using the will-change property to hint the browser about animations, improving performance.
```css
.element {
will-change: transform;
}
```
**5. Profiling and Debugging**
Use browser tools like Chrome DevTools to profile and debug your animations. Look for high paint times, layout shifts, and long-running scripts.
### Conclusion
Advanced animations in React can transform your user experience, making it more engaging and dynamic. By leveraging powerful libraries like Framer Motion and React Spring, you can create complex animations with ease.
>Always keep performance in mind to ensure a smooth experience for your users. **Happy animating!** 🙂
Resouces:
[Framer Motion] (https://www.framer.com/motion/introduction/)
[React Spring] (https://www.react-spring.dev/docs/getting-started) | jehnz |
1,873,616 | Building a Chat with PDF - RAG Application - NextJS and NestJS | Connect 👋 Xam LinkedIn Repo 📚 DEMO Approach ... | 0 | 2024-06-02T11:22:10 | https://dev.to/codexam/building-a-chat-with-pdf-rag-application-nextjs-and-nestjs-j88 | nextjs, nestjs, ai, rag | ## Connect 👋
- [Xam](https://github.com/Subham-Maity)
- [LinkedIn](https://www.linkedin.com/in/subham-xam/)
## Repo 📚
[DEMO](https://github.com/Subham-Maity/QChatAi)
## Approach
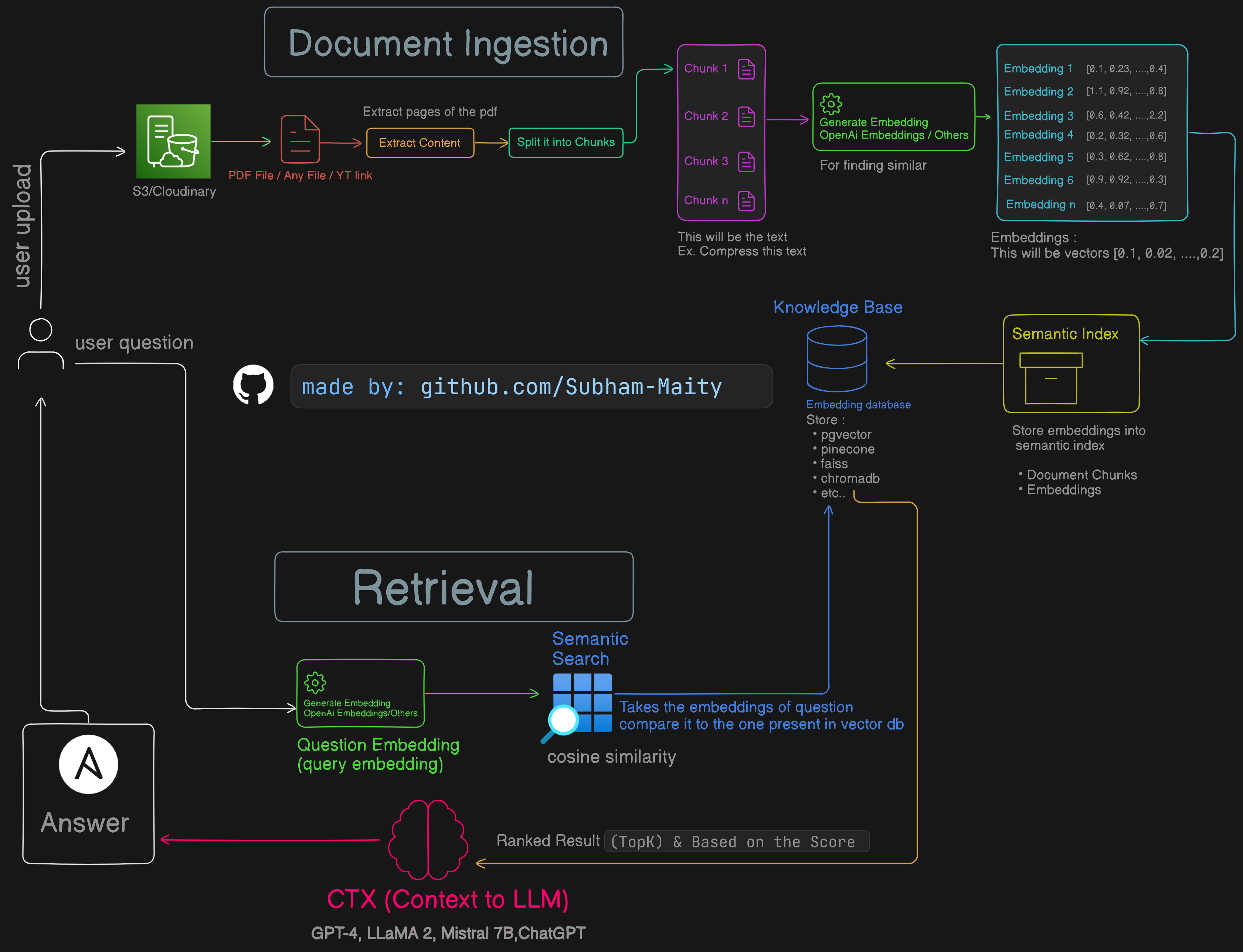
## Introduction
Ever wanted to chat with the content of a PDF, just like you do with ChatGPT? In this blog, I'll show you how I built a system that lets you do exactly that. We'll cover everything from uploading PDFs, processing them to generate vector embeddings, and chatting with the content using a cool interface. This project uses some advanced tech like document processing, vector embeddings, and Docker for easy deployment. Let's dive in!
## Project Overview
So, this project is called **Chat with PDF - RAG (Retrieval-Augmented Generation)**. Users can upload PDF files, and the system processes them to generate vector embeddings. These embeddings are stored in a database, and a chat interface uses them to provide context-aware answers to user queries. Everything is containerized with Docker, making it super easy to deploy and scale.
## How I Made This Project
### Step 1: Setting Up the Environment
First things first, I set up the development environment. Used Node.js, NestJS for the backend, and Next.js for the frontend. We're also using PostgreSQL for data storage, Redis for caching, and BullMQ for handling background tasks.
### Step 2: Implementing Document Ingestion
Users can upload PDF files, which get stored in a cloud storage service like AWS S3. The content of these PDFs is extracted and split into smaller chunks.
### Step 3: Generating Vector Embeddings
Each content chunk is processed to generate vector embeddings using an API like OpenAI Embeddings. These embeddings are numeric representations that capture the meaning of the text, making it easier to search semantically later.
### Step 4: Building the Knowledge Base
The generated embeddings and the corresponding document chunks are stored in a PostgreSQL database. This acts as our knowledge base, making it easy to store and retrieve the embeddings.
### Step 5: Implementing the Chat Interface
Users can interact with the PDF content through a chat interface. When a user asks a question, the system converts it into a query embedding and performs a semantic search on the stored document embeddings. The top results are then used to provide context to a large language model (LLM) like GPT-4, which generates a relevant answer.
### Step 6: Dockerizing the Application
To ensure the app is easy to deploy and scale, I containerized the backend API and BullMQ worker using Docker. This makes deployment a breeze in any environment that supports Docker.
## Logic and Architecture
### 1. Document Ingestion
- **User Upload**: Users upload a PDF file to S3/Cloudinary.
- **Extract Content**: The content of the PDF is extracted.
- **Split into Chunks**: The extracted content is split into manageable chunks.
### 2. Generate Embeddings
- **Generate Embeddings**: Each chunk is processed to generate vector embeddings using an embedding API (e.g., OpenAI Embeddings).
- **Embeddings**: These are numeric representations of the chunks, capturing the semantic meaning.
### 3. Knowledge Base
- **Store Embeddings**: The embeddings and document chunks are stored in a database (like PostgreSQL) that acts as the knowledge base.
- **Embedding Database**: Tools like pgvector, pinecone, faiss, or chromadb can be used for storing and indexing these embeddings.
### 4. Retrieval
- **User Question**: A user asks a question.
- **Generate Query Embedding**: The question is converted into a vector embedding.
- **Semantic Search**: Using the question embedding, a semantic search is performed on the stored document embeddings.
- **Ranked Result**: Results are ranked based on similarity scores (e.g., cosine similarity).
### 5. Context to LLM (Large Language Model)
- **CTX**: The top-k similar results are used to provide context to the LLM (e.g., GPT-4, LLaMA 2, Mistral 7B, ChatGPT).
- **Answer**: The LLM uses this context to generate and return a relevant answer to the user.
Example (Entire code in my repo)
> With frontend and backend
```ts
// 1. Document Ingestion
const uploadedPDF = await uploadFileToS3(pdfFile); // Upload PDF to S3
const pdfContent = await extractContentFromPDF(uploadedPDF.path); // Extract content from PDF
const contentChunks = splitContentIntoChunks(pdfContent); // Split content into smaller chunks
// 2. Generate Embeddings
const embeddingModel = new OpenAIEmbeddings(); // Use OpenAI Embeddings (or any other embedding model)
const embeddings = await Promise.all(contentChunks.map(chunk => embeddingModel.embed(chunk))); // Generate embeddings for each chunk
// 3. Knowledge Base
const vectorStore = new PineconeVectorStore(); // Use Pinecone as the vector store (or any other database/index)
await vectorStore.addDocuments(contentChunks, embeddings); // Store document chunks and embeddings in the vector store
// 4. Retrieval
const userQuestion = "What is the main topic of the PDF?"; // User asks a question
const queryEmbedding = await embeddingModel.embed(userQuestion); // Generate embedding for the user's question
const similarChunks = await vectorStore.search(queryEmbedding, topK=5); // Retrieve top-k similar document chunks
// 5. Context to LLM (Large Language Model)
const llm = new GPT4LLM(); // Use GPT-4 as the LLM (or any other LLM model)
const answer = await llm.generate(similarChunks.map(chunk => chunk.content).join("\n")); // Provide retrieved chunks as context to the LLM to generate an answer
console.log(answer); // Print the generated answer
```
## Conclusion
Building this project was an amazing journey, combining several advanced technologies to create a seamless user experience. From document ingestion and embedding generation to creating a chat interface backed by powerful language models, each step was crucial in making the system robust and user-friendly. I hope this post inspires you to dive into similar projects and explore the vast possibilities of combining document processing and AI.
| codexam |
1,873,615 | Java SE 11 Developer Certification 1Z0-819 Exam Preparation | A Complete Guide to Preparing for Java SE 11 Developer Certification Exam Introduction Oracle... | 0 | 2024-06-02T11:19:55 | https://dev.to/ganesh_p_96bc2f769a6049e1/java-se-11-developer-certification-1z0-819-exam-preparation-38i4 | java, programming, software, coding | A Complete Guide to Preparing for Java SE 11 Developer Certification Exam
**Introduction**
Oracle Certified Professional: Java SE 11 Developer is a well-recognized certification for Java software developers in various industries. It demonstrates a high level of proficiency in Java (Standard Edition) development and a deep understanding of the language, coding practices, and new features in Java SE 11. This article provides information about the certification, its exam, and a 10-week study plan for candidates preparing for the Java SE 11 Developer certification exam.
**Certification Overview**
To become an Oracle Certified Professional: Java SE 11 Developer, candidates must pass the Java SE 11 Developer exam (1Z0-819). The exam is 90 minutes long and consists of 50 multiple choice questions. The passing score is 68% and the exam has been validated for Java version 11.
**Certification Benefits**
Holding this certification demonstrates a strong foundation and proficiency in Java software development. It also showcases the acquisition of valuable professional skills required in Java development, such as knowledge of object-oriented programming, functional programming, and modularity.
**1Z0-819 Preparation Study Plan**
To effectively prepare for the Java SE 11 Developer certification exam, it is recommended to follow a 10-week study plan. This plan is divided into four phases, each with specific objectives and tasks.
**Phase 1: Building a Strong Foundation and Gathering Resources (Week 1-2)
**In the first phase, candidates should familiarize themselves with the Java SE 11 Developer exam syllabus and exam pattern. They should also focus on understanding the significant changes in the Java language since Java SE 11, such as the modular system, try-with-resources, diamond operator extension, and more. Gathering study resources, such as Oracle tutorials and MyExamCloud AI, is also crucial in this phase.
**Phase 2: In-depth Study of Each Topic (Week 3-6)
**The second phase involves a more detailed study of each topic in the exam. Candidates should use relevant study materials and take notes to understand concepts, including forward and reverse indexing in lists.
**Phase 3: Regular Revision and Practice (Week 7-9)
**In the third phase, it is essential to revise regularly and practice through objective-wise tests. This helps in improving weaker areas and preparing for the final exam.
**Phase 4: Attempting Mock Tests and Analyzing Performance (Week 10)
**In the final weeks leading up to the exam, candidates should focus on taking mock tests and analyzing their performance. Full-length mock exams are recommended to assess readiness for the final exam.
**Understanding MyExamCloud's Study Plan**
MyExamCloud provides a well-structured Java SE 11 Developer Certification study plan that individuals can follow for effective preparation. This plan includes a variety of resources such as:
- Java SE 11 Developer [1Z0-829 Practice Tests](https://www.myexamcloud.com/onlineexam/1z0-819-java-se-11-developer-exam-practice-tests.course)
- Java SE 11 Developer 1Z0-819 Mock Questions
- 22 Full-Length Mock Exams
- 1 Free Trial Exam
- Objective and Random Tests
- Answers with brief explanations in eBook format
- Access to course content on both mobile app and web browser
- 1600+ Questions
- Questions arranged by exam topics
- Plan, Practice, Achieve Dashboard for goal setting and progress tracking
- Customizable study plan to suit individual learning styles and needs
By utilizing these resources and tools, individuals can efficiently prepare for the Java SE 11 Developer Certification exam and achieve their certification goal.
**Conclusion**
The Java SE 11 Developer certification is an excellent opportunity for professionals to showcase their skills and knowledge in Java software development. By following a well-structured study plan and utilizing resources like Oracle tutorials and MyExamCloud AI, candidates can increase their chances of passing the exam and becoming an Oracle Certified Professional: Java SE 11 Developer.
| ganesh_p_96bc2f769a6049e1 |
1,873,614 | Buy verified cash app account | https://dmhelpshop.com/product/buy-verified-cash-app-account/ Buy verified cash app account Cash... | 0 | 2024-06-02T11:18:39 | https://dev.to/nufjjcivx731/buy-verified-cash-app-account-3p2c | webdev, javascript, beginners, programming | ERROR: type should be string, got "https://dmhelpshop.com/product/buy-verified-cash-app-account/\n\n\nBuy verified cash app account\nCash app has emerged as a dominant force in the realm of mobile banking within the USA, offering unparalleled convenience for digital money transfers, deposits, and trading. As the foremost provider of fully verified cash app accounts, we take pride in our ability to deliver accounts with substantial limits. Bitcoin enablement, and an unmatched level of security.\n\nOur commitment to facilitating seamless transactions and enabling digital currency trades has garnered significant acclaim, as evidenced by the overwhelming response from our satisfied clientele. Those seeking buy verified cash app account with 100% legitimate documentation and unrestricted access need look no further. Get in touch with us promptly to acquire your verified cash app account and take advantage of all the benefits it has to offer.\n\nWhy dmhelpshop is the best place to buy USA cash app accounts?\nIt’s crucial to stay informed about any updates to the platform you’re using. If an update has been released, it’s important to explore alternative options. Contact the platform’s support team to inquire about the status of the cash app service.\n\nClearly communicate your requirements and inquire whether they can meet your needs and provide the buy verified cash app account promptly. If they assure you that they can fulfill your requirements within the specified timeframe, proceed with the verification process using the required documents.\n\nOur account verification process includes the submission of the following documents: [List of specific documents required for verification].\n\nGenuine and activated email verified\nRegistered phone number (USA)\nSelfie verified\nSSN (social security number) verified\nDriving license\nBTC enable or not enable (BTC enable best)\n100% replacement guaranteed\n100% customer satisfaction\nWhen it comes to staying on top of the latest platform updates, it’s crucial to act fast and ensure you’re positioned in the best possible place. If you’re considering a switch, reaching out to the right contacts and inquiring about the status of the buy verified cash app account service update is essential.\n\nClearly communicate your requirements and gauge their commitment to fulfilling them promptly. Once you’ve confirmed their capability, proceed with the verification process using genuine and activated email verification, a registered USA phone number, selfie verification, social security number (SSN) verification, and a valid driving license.\n\nAdditionally, assessing whether BTC enablement is available is advisable, buy verified cash app account, with a preference for this feature. It’s important to note that a 100% replacement guarantee and ensuring 100% customer satisfaction are essential benchmarks in this process.\n\nHow to use the Cash Card to make purchases?\nTo activate your Cash Card, open the Cash App on your compatible device, locate the Cash Card icon at the bottom of the screen, and tap on it. Then select “Activate Cash Card” and proceed to scan the QR code on your card. Alternatively, you can manually enter the CVV and expiration date. How To Buy Verified Cash App Accounts.\n\nAfter submitting your information, including your registered number, expiration date, and CVV code, you can start making payments by conveniently tapping your card on a contactless-enabled payment terminal. Consider obtaining a buy verified Cash App account for seamless transactions, especially for business purposes. Buy verified cash app account.\n\nWhy we suggest to unchanged the Cash App account username?\nTo activate your Cash Card, open the Cash App on your compatible device, locate the Cash Card icon at the bottom of the screen, and tap on it. Then select “Activate Cash Card” and proceed to scan the QR code on your card.\n\nAlternatively, you can manually enter the CVV and expiration date. After submitting your information, including your registered number, expiration date, and CVV code, you can start making payments by conveniently tapping your card on a contactless-enabled payment terminal. Consider obtaining a verified Cash App account for seamless transactions, especially for business purposes. Buy verified cash app account. Purchase Verified Cash App Accounts.\n\nSelecting a username in an app usually comes with the understanding that it cannot be easily changed within the app’s settings or options. This deliberate control is in place to uphold consistency and minimize potential user confusion, especially for those who have added you as a contact using your username. In addition, purchasing a Cash App account with verified genuine documents already linked to the account ensures a reliable and secure transaction experience.\n\n \n\nBuy verified cash app accounts quickly and easily for all your financial needs.\nAs the user base of our platform continues to grow, the significance of verified accounts cannot be overstated for both businesses and individuals seeking to leverage its full range of features. How To Buy Verified Cash App Accounts.\n\nFor entrepreneurs, freelancers, and investors alike, a verified cash app account opens the door to sending, receiving, and withdrawing substantial amounts of money, offering unparalleled convenience and flexibility. Whether you’re conducting business or managing personal finances, the benefits of a verified account are clear, providing a secure and efficient means to transact and manage funds at scale.\n\nWhen it comes to the rising trend of purchasing buy verified cash app account, it’s crucial to tread carefully and opt for reputable providers to steer clear of potential scams and fraudulent activities. How To Buy Verified Cash App Accounts. With numerous providers offering this service at competitive prices, it is paramount to be diligent in selecting a trusted source.\n\nThis article serves as a comprehensive guide, equipping you with the essential knowledge to navigate the process of procuring buy verified cash app account, ensuring that you are well-informed before making any purchasing decisions. Understanding the fundamentals is key, and by following this guide, you’ll be empowered to make informed choices with confidence.\n\n \n\nIs it safe to buy Cash App Verified Accounts?\nCash App, being a prominent peer-to-peer mobile payment application, is widely utilized by numerous individuals for their transactions. However, concerns regarding its safety have arisen, particularly pertaining to the purchase of “verified” accounts through Cash App. This raises questions about the security of Cash App’s verification process.\n\nUnfortunately, the answer is negative, as buying such verified accounts entails risks and is deemed unsafe. Therefore, it is crucial for everyone to exercise caution and be aware of potential vulnerabilities when using Cash App. How To Buy Verified Cash App Accounts.\n\nCash App has emerged as a widely embraced platform for purchasing Instagram Followers using PayPal, catering to a diverse range of users. This convenient application permits individuals possessing a PayPal account to procure authenticated Instagram Followers.\n\nLeveraging the Cash App, users can either opt to procure followers for a predetermined quantity or exercise patience until their account accrues a substantial follower count, subsequently making a bulk purchase. Although the Cash App provides this service, it is crucial to discern between genuine and counterfeit items. If you find yourself in search of counterfeit products such as a Rolex, a Louis Vuitton item, or a Louis Vuitton bag, there are two viable approaches to consider.\n\n \n\nWhy you need to buy verified Cash App accounts personal or business?\nThe Cash App is a versatile digital wallet enabling seamless money transfers among its users. However, it presents a concern as it facilitates transfer to both verified and unverified individuals.\n\nTo address this, the Cash App offers the option to become a verified user, which unlocks a range of advantages. Verified users can enjoy perks such as express payment, immediate issue resolution, and a generous interest-free period of up to two weeks. With its user-friendly interface and enhanced capabilities, the Cash App caters to the needs of a wide audience, ensuring convenient and secure digital transactions for all.\n\nIf you’re a business person seeking additional funds to expand your business, we have a solution for you. Payroll management can often be a challenging task, regardless of whether you’re a small family-run business or a large corporation. How To Buy Verified Cash App Accounts.\n\nImproper payment practices can lead to potential issues with your employees, as they could report you to the government. However, worry not, as we offer a reliable and efficient way to ensure proper payroll management, avoiding any potential complications. Our services provide you with the funds you need without compromising your reputation or legal standing. With our assistance, you can focus on growing your business while maintaining a professional and compliant relationship with your employees. Purchase Verified Cash App Accounts.\n\nA Cash App has emerged as a leading peer-to-peer payment method, catering to a wide range of users. With its seamless functionality, individuals can effortlessly send and receive cash in a matter of seconds, bypassing the need for a traditional bank account or social security number. Buy verified cash app account.\n\nThis accessibility makes it particularly appealing to millennials, addressing a common challenge they face in accessing physical currency. As a result, ACash App has established itself as a preferred choice among diverse audiences, enabling swift and hassle-free transactions for everyone. Purchase Verified Cash App Accounts.\n\n \n\nHow to verify Cash App accounts\nTo ensure the verification of your Cash App account, it is essential to securely store all your required documents in your account. This process includes accurately supplying your date of birth and verifying the US or UK phone number linked to your Cash App account.\n\nAs part of the verification process, you will be asked to submit accurate personal details such as your date of birth, the last four digits of your SSN, and your email address. If additional information is requested by the Cash App community to validate your account, be prepared to provide it promptly. Upon successful verification, you will gain full access to managing your account balance, as well as sending and receiving funds seamlessly. Buy verified cash app account.\n\n \n\nHow cash used for international transaction?\nExperience the seamless convenience of this innovative platform that simplifies money transfers to the level of sending a text message. It effortlessly connects users within the familiar confines of their respective currency regions, primarily in the United States and the United Kingdom.\n\nNo matter if you’re a freelancer seeking to diversify your clientele or a small business eager to enhance market presence, this solution caters to your financial needs efficiently and securely. Embrace a world of unlimited possibilities while staying connected to your currency domain. Buy verified cash app account.\n\nUnderstanding the currency capabilities of your selected payment application is essential in today’s digital landscape, where versatile financial tools are increasingly sought after. In this era of rapid technological advancements, being well-informed about platforms such as Cash App is crucial.\n\nAs we progress into the digital age, the significance of keeping abreast of such services becomes more pronounced, emphasizing the necessity of staying updated with the evolving financial trends and options available. Buy verified cash app account.\n\nOffers and advantage to buy cash app accounts cheap?\nWith Cash App, the possibilities are endless, offering numerous advantages in online marketing, cryptocurrency trading, and mobile banking while ensuring high security. As a top creator of Cash App accounts, our team possesses unparalleled expertise in navigating the platform.\n\nWe deliver accounts with maximum security and unwavering loyalty at competitive prices unmatched by other agencies. Rest assured, you can trust our services without hesitation, as we prioritize your peace of mind and satisfaction above all else.\n\nEnhance your business operations effortlessly by utilizing the Cash App e-wallet for seamless payment processing, money transfers, and various other essential tasks. Amidst a myriad of transaction platforms in existence today, the Cash App e-wallet stands out as a premier choice, offering users a multitude of functions to streamline their financial activities effectively. Buy verified cash app account.\n\nTrustbizs.com stands by the Cash App’s superiority and recommends acquiring your Cash App accounts from this trusted source to optimize your business potential.\n\nHow Customizable are the Payment Options on Cash App for Businesses?\nDiscover the flexible payment options available to businesses on Cash App, enabling a range of customization features to streamline transactions. Business users have the ability to adjust transaction amounts, incorporate tipping options, and leverage robust reporting tools for enhanced financial management.\n\nExplore trustbizs.com to acquire verified Cash App accounts with LD backup at a competitive price, ensuring a secure and efficient payment solution for your business needs. Buy verified cash app account.\n\nDiscover Cash App, an innovative platform ideal for small business owners and entrepreneurs aiming to simplify their financial operations. With its intuitive interface, Cash App empowers businesses to seamlessly receive payments and effectively oversee their finances. Emphasizing customization, this app accommodates a variety of business requirements and preferences, making it a versatile tool for all.\n\nWhere To Buy Verified Cash App Accounts\nWhen considering purchasing a verified Cash App account, it is imperative to carefully scrutinize the seller’s pricing and payment methods. Look for pricing that aligns with the market value, ensuring transparency and legitimacy. Buy verified cash app account.\n\nEqually important is the need to opt for sellers who provide secure payment channels to safeguard your financial data. Trust your intuition; skepticism towards deals that appear overly advantageous or sellers who raise red flags is warranted. It is always wise to prioritize caution and explore alternative avenues if uncertainties arise.\n\nThe Importance Of Verified Cash App Accounts\nIn today’s digital age, the significance of verified Cash App accounts cannot be overstated, as they serve as a cornerstone for secure and trustworthy online transactions.\n\nBy acquiring verified Cash App accounts, users not only establish credibility but also instill the confidence required to participate in financial endeavors with peace of mind, thus solidifying its status as an indispensable asset for individuals navigating the digital marketplace.\n\nWhen considering purchasing a verified Cash App account, it is imperative to carefully scrutinize the seller’s pricing and payment methods. Look for pricing that aligns with the market value, ensuring transparency and legitimacy. Buy verified cash app account.\n\nEqually important is the need to opt for sellers who provide secure payment channels to safeguard your financial data. Trust your intuition; skepticism towards deals that appear overly advantageous or sellers who raise red flags is warranted. It is always wise to prioritize caution and explore alternative avenues if uncertainties arise.\n\nConclusion\nEnhance your online financial transactions with verified Cash App accounts, a secure and convenient option for all individuals. By purchasing these accounts, you can access exclusive features, benefit from higher transaction limits, and enjoy enhanced protection against fraudulent activities. Streamline your financial interactions and experience peace of mind knowing your transactions are secure and efficient with verified Cash App accounts.\n\nChoose a trusted provider when acquiring accounts to guarantee legitimacy and reliability. In an era where Cash App is increasingly favored for financial transactions, possessing a verified account offers users peace of mind and ease in managing their finances. Make informed decisions to safeguard your financial assets and streamline your personal transactions effectively.\n\nContact Us / 24 Hours Reply\nTelegram:dmhelpshop\nWhatsApp: +1 (980) 277-2786\nSkype:dmhelpshop\nEmail:dmhelpshop@gmail.com" | nufjjcivx731 |
1,873,611 | Deepfake Technologies Can Steal Your Identity Even if You Don’t Use Generative AI | Deepfake Technologies Can Steal Your Identity Even if You Don’t Use Generative... | 0 | 2024-06-02T11:13:08 | https://dev.to/azeem_shafeeq/deepfake-technologies-can-steal-your-identity-even-if-you-dont-use-generative-ai-4ohj | deeplearning, ai, cybersecurity, tutorial | ### Deepfake Technologies Can Steal Your Identity Even if You Don’t Use Generative AI

Generative AI has revolutionized technology, introducing remarkable innovations alongside new risks such as privacy breaches and identity theft. A particularly alarming threat is deepfake technology, where AI generates convincing fake videos or audio of individuals. Even if you don’t use AI platforms, deepfakes can still misuse your online data. Let's delve into how deepfakes work, how to detect them, and how to protect yourself from this emerging threat.
### The Threat of Deepfakes
Deepfakes use AI to create hyper-realistic videos and audio, making it appear that someone is saying or doing something they never did. These manipulations can lead to serious consequences, including identity theft, fraud, and defamation. For instance, a deepfake video of a CEO making false statements can tank a company's stock, or a deepfake audio clip of an individual can be used to authorize fraudulent transactions.
#### Real-Time Examples
1. **Political Manipulation**: In 2018, a deepfake video of former President Barack Obama surfaced, created by filmmaker Jordan Peele to demonstrate the dangers of this technology. The video showed Obama saying things he never actually said, highlighting how deepfakes can be used to spread misinformation.
2. **Corporate Fraud**: In 2019, a UK-based energy firm’s CEO was impersonated using deepfake audio to authorize a fraudulent transfer of €220,000. The AI-generated voice mimicked the CEO's accent and mannerisms, fooling the subordinate into complying.
### How to Detect Deepfakes
Despite their sophistication, deepfakes can often be detected by paying close attention to specific details:
1. **Eye Blinking**: Artificial videos often get blinking wrong. Watch for unnatural blinking patterns, as deepfakes sometimes fail to replicate natural eye movements.
2. **Mouth Movement**: Check if the mouth movements sync correctly with the voice. Mismatched timing between the audio and lip movements is a red flag.
3. **Lighting and Shadows**: Look for inconsistencies in lighting and shadows on the face or background. Deepfake algorithms may struggle to replicate natural lighting accurately.
4. **Facial Expressions**: Notice if facial expressions seem rigid or emotionless. Inaccurate or overly mechanical expressions can indicate a deepfake.
5. **Video Quality**: Spot distortions or visual inconsistencies around the face, hair, or background. These subtle anomalies often betray even high-quality deepfakes.

### How to Protect Yourself from Deepfakes
To safeguard your digital identity against deepfakes, consider implementing the following strategies:
1. **Share with Care**: Be cautious about personal info you post online. Adjust privacy settings on social media to limit access. Avoid sharing high-quality photos and videos that can be used to create deepfakes.
2. **Enable Strong Privacy Settings**: Use robust privacy settings to control who sees your content. This reduces the risk of your images and videos being scraped from social media.
3. **Use Multi-Factor Authentication (MFA)**: Add an extra layer of security to your accounts. MFA can prevent unauthorized access even if your credentials are compromised.
4. **Create Strong Passwords**: Use unique, complex passwords for different accounts and store them in a password manager. This practice helps protect your accounts from being hacked.
5. **Stay Informed**: Keep up with AI and deepfake news to recognize potential threats. Staying aware of the latest developments helps you stay vigilant against new types of attacks.

### Conclusion
The rise of deepfake technology presents significant challenges to personal privacy and security. By understanding how to detect deepfakes and implementing robust protective measures, you can better safeguard your digital identity. Stay vigilant, adopt these cybersecurity habits, and think critically about what you post online and who has access to it.
The fight against deepfakes is ongoing, but with informed and proactive steps, we can mitigate their impact and protect ourselves from this sophisticated form of digital deception. | azeem_shafeeq |
1,873,609 | 关于写博客这件事 | 鉴于之前的n次尝试自建github pages最后都倒向了无尽的捣鼓各种静态网站生成器中。我决定这次绝对不要自建了。 ... | 0 | 2024-06-02T11:02:09 | https://dev.to/woodgear/guan-yu-xie-bo-ke-zhe-jian-shi-3kc0 | 杂谈 | 鉴于之前的n次尝试自建github pages最后都倒向了无尽的捣鼓各种静态网站生成器中。我决定这次绝对不要自建了。
## 要求
1. 可以用纯markdown格式写/可以导出为纯markdown格式。
1. 这个问题本质上在于我希望数据源是我自己的git repo。算是local first的一种变通方式。最起码,我的纯文本格式的blog不能丢。
## 点评
尝试了下我知道的几个博客平台+随便从google几个比较流行的博客平台.
### medium
首先排除的medium,每次查东西,查到medium,结果发现不能看。总是很恼火。medium理论上做的事情是对写作者有益的。但是还是pass
### hashnode
hashnode 之前从来没听过。
#### 编辑
1. 在线的blog 编辑功能,感觉有点类似notion的那种块编辑器的感觉。
1. 编辑器有raw markdown editor模式,好评
2. 现在(2024-0602) 有点在推ai辅助写作的感觉。有ai相关的功能。暂时不做评价
1. 发布的时候可以设置seo title。
3. 可以设置原始url和原始发布日期
1. add original url
2. publish on backdate
#### 后台
1. 各种页面,有配置主题 小组件什么的
2. 好评 可以自动backup markdown格式的文章到github。
1. 每次update,都会有对应的commit。
1. 感动。好正常的做法。
2. 也有import from github的功能但是要付费。 2333
3. 分类的功能叫做series。
4. 好评 会自动生成rss
### 竹白
还在内测(专栏需要邀请)。但我记得他们好像一直在内测?不知道是不是死了。 | woodgear |
1,873,607 | Cross Country Road Trip: Top 4 Methods To Unleash Your Inner Explorer | Imagine the wind whipping through your hair as you cruise down an open highway, the vast expanse of... | 0 | 2024-06-02T10:59:57 | https://dev.to/ealtian/cross-country-road-trip-top-4-methods-to-unleash-your-inner-explorer-kk8 | Imagine the wind whipping through your hair as you cruise down an open highway, the vast expanse of the country unfolding before you. A cross country road trip is an adventure unlike any other, offering the freedom to explore hidden gems, discover diverse landscapes, and create memories that will last a lifetime. A recent study by the Adventure Travel Trade Association found that 72% of travelers are yearning for transformative experiences, and a cross-country road trip perfectly fits that bill.
**[Click Here](https://typewritertale.com/cross-country-road-trip-4-best-methods/)** | ealtian | |
1,859,014 | How to Create a Free Tier AWS account | Amazon Web Services (AWS) is one of the most popular cloud service providers in the world, offering a... | 0 | 2024-06-02T10:59:34 | https://dev.to/sirlawdin/how-to-create-an-aws-account-39cn | aws101, cloudcomputing | Amazon Web Services (AWS) is one of the most popular cloud service providers in the world, offering a range of services from computing power to storage solutions. Creating an AWS account is the first step to accessing these powerful tools. In this blog, we'll guide you through the process of creating and logging into an AWS account, with step-by-step instructions and helpful GIFs to illustrate each part of the process.
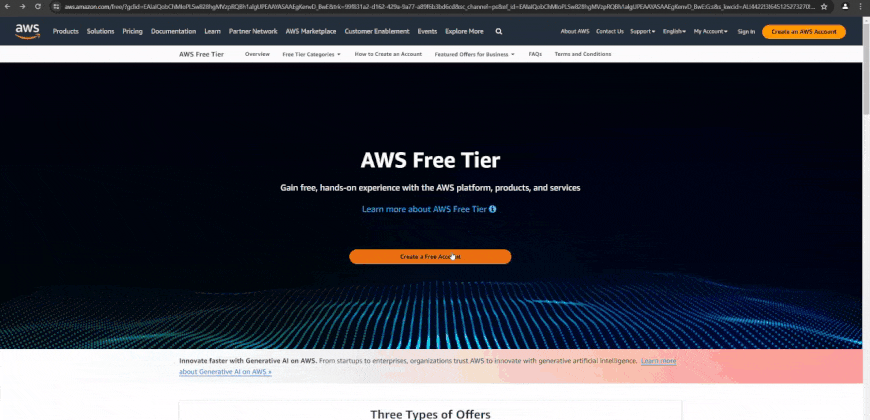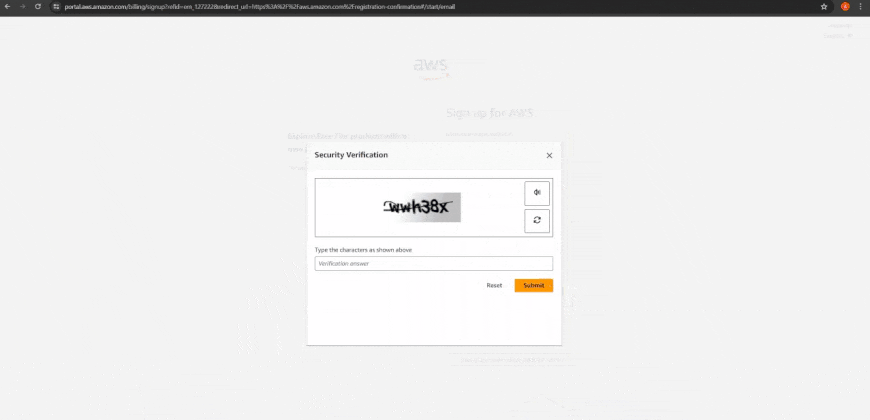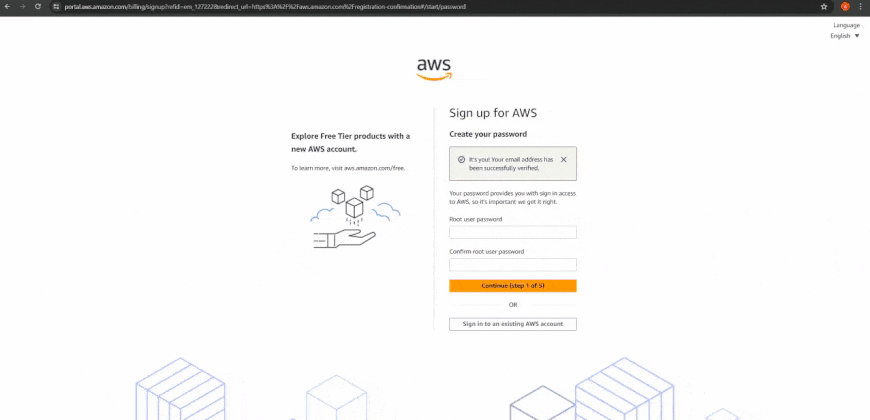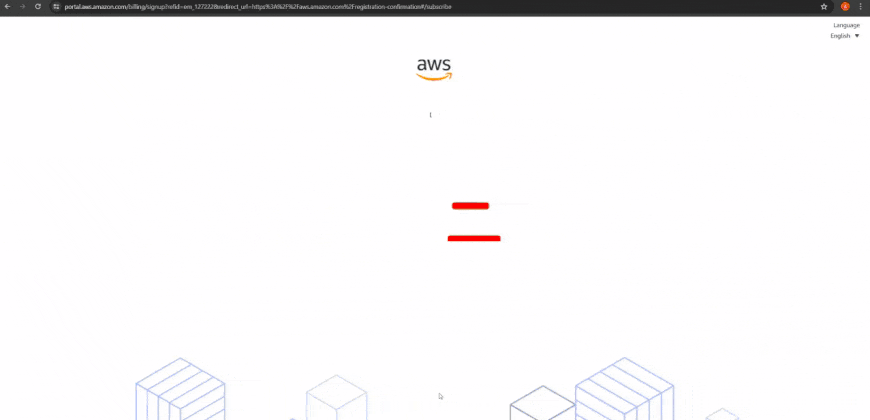
## Step 1: Create Your AWS Account
Creating an AWS account is a straightforward process. Follow these steps:
**Visit the AWS Sign-Up Page:**
Navigate to the [AWS Sign-Up page](https://portal.aws.amazon.com/billing/signup#/start/email) and click on the "Create an AWS Account" button.
**Enter Your Email and Choose a Password:**
Enter a valid email address and choose a secure password. This email will be your root user email address, which has full access to all AWS services.
**Choose an AWS Account Name:**
Enter a unique AWS account name that will be associated with your account.
**Verify Your Email:**
AWS will send a verification email to the address you provided. Enter the verification code from the email to proceed.
**Enter Your Contact Information:**
Provide your contact details, including your full name, address, and phone number.
**Choose Your Account Type:**
Select either a personal or professional account based on your usage needs.
**Enter Payment Information:**
AWS requires a credit card or payment method on file. You won't be charged unless you use services beyond the AWS Free Tier limits.
**Identity Verification:**
AWS will verify your identity by sending a text message or automated phone call with a verification code.
**Select a Support Plan:**
Choose from various support plans based on your needs. The Basic plan is free and suitable for most new users.
**Complete the Setup:**
Review and complete the setup process. Your AWS account is now ready to use!
## Step 2: Log into Your AWS Account
Once your account is set up, logging in is simple:
Go to the AWS Management Console.
Enter Your Root User Email:
Enter the email address you used to create your AWS account.
Enter Your Password:
Provide the password associated with your AWS account.
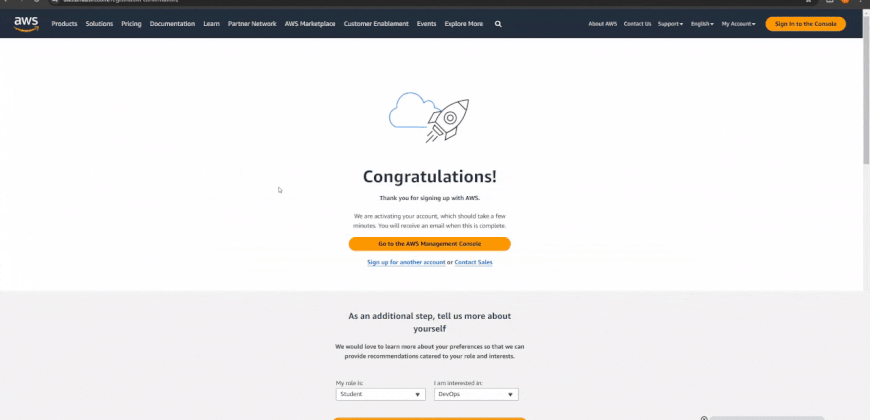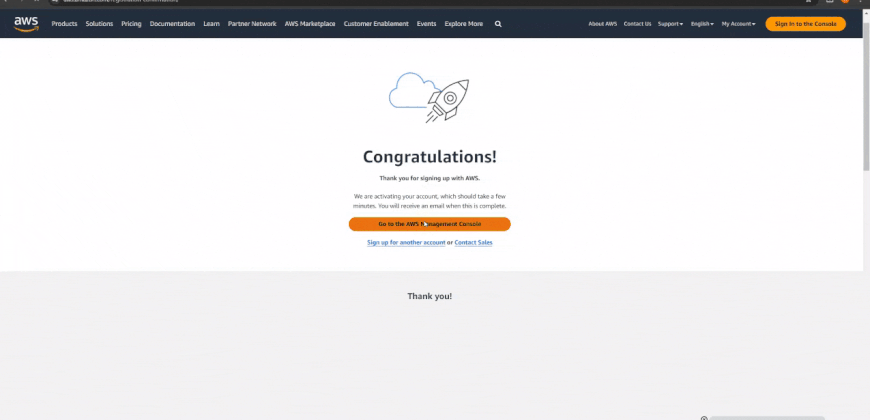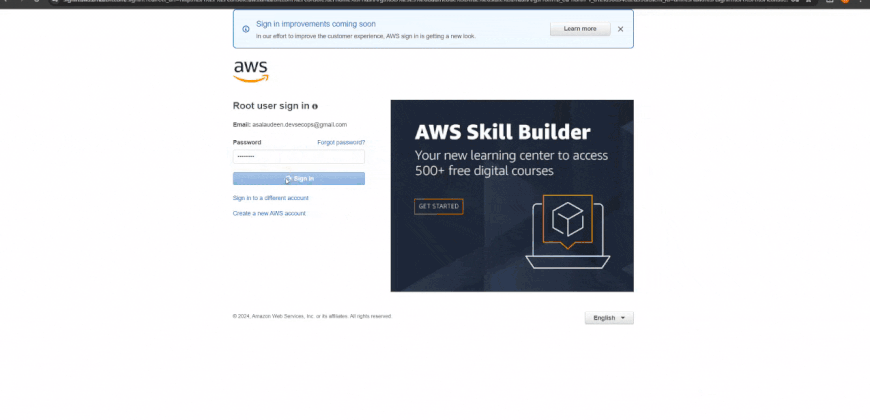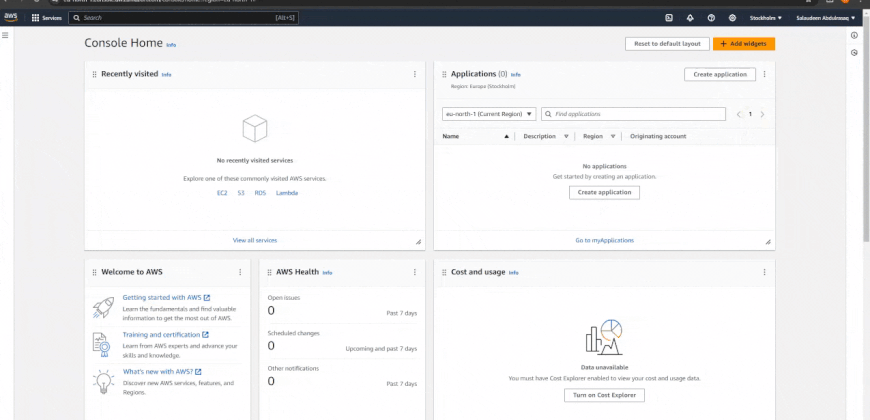
Using the root account for daily operations is not recommended due to security concerns. Instead, create an IAM user with administrative privileges.
Visit the [AWS Management Console](https://aws.amazon.com/)
Navigate to the IAM Service:
In the AWS Management Console, go to the **IAM** (Identity and Access Management) service.
**Create a New User:**
Click on "**_Users_**" in the left-hand menu.
Click the "**_Add user_**" button.
Set User Details:
Enter a username for the new user (e.g., admin-user).
Select "_AWS Management Console access_".
Set a custom password or choose to generate one automatically. Ensure the user is required to reset their password upon first login.
Assign Permissions:
Click "**_Next: Permissions_**".
Choose "**_Attach existing policies directly_**".
Select the "**_AdministratorAccess_**" policy.
Review and Create:
Review the user details and permissions.
Click "**_Create user_**".
Download Credentials:
Download the .csv file containing the user credentials or copy the access details. This file contains the login URL, username, and password for the new IAM user.
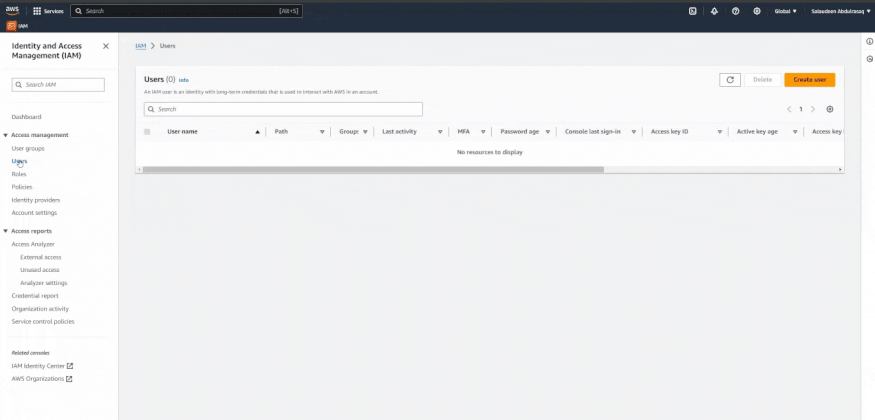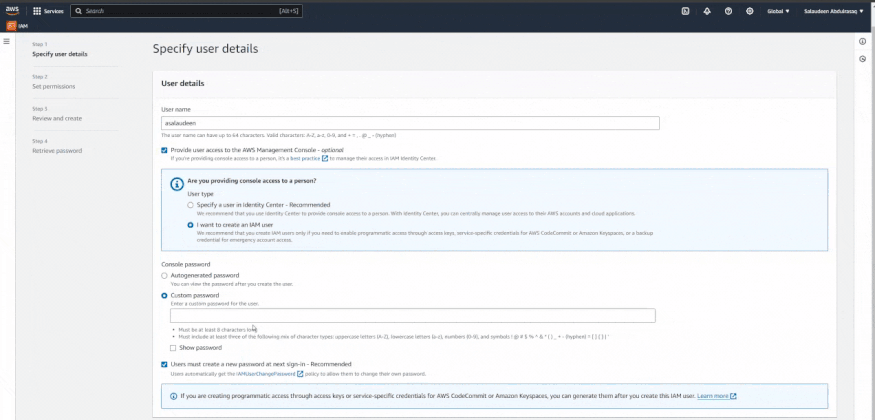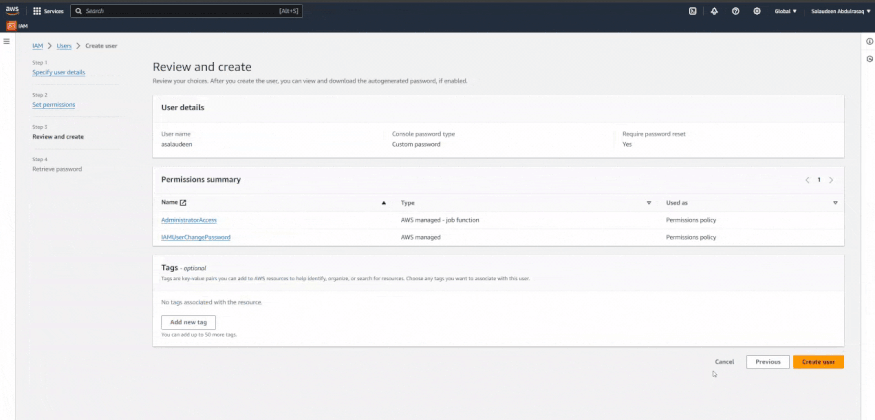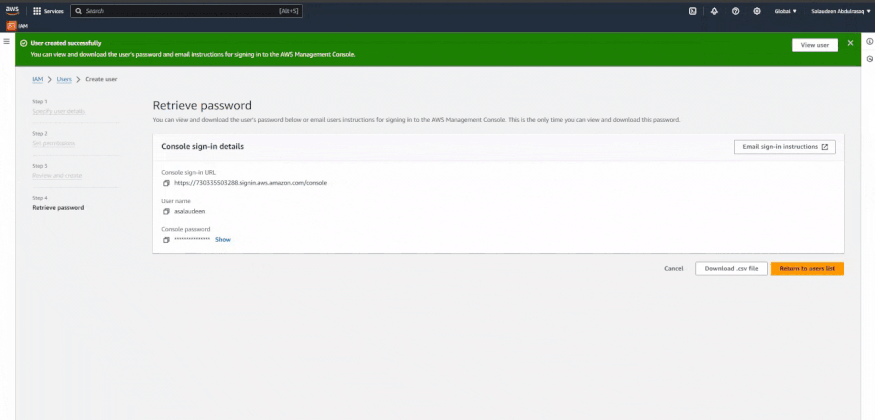
| sirlawdin |
1,873,606 | 5 Powerful Ways to Keep Yourself Safe From Today’s Digital Threats | Imagine this: you settle down with a cup of coffee, eager to catch up on the latest news. As you... | 0 | 2024-06-02T10:59:20 | https://dev.to/ealtian/5-powerful-ways-to-keep-yourself-safe-from-todays-digital-threats-5hdc | Imagine this: you settle down with a cup of coffee, eager to catch up on the latest news. As you scroll through your social media feed, a pop-up ad promises a free vacation – all you need to do is click a link to Keep Yourself Safe and enter your personal details. Intrigued, you hesitate for a moment, then curiosity wins. A click later, your world turns upside down. The link leads to a malicious website designed to steal your information.
**[Clcik Here](https://typewritertale.com/5-powerful-ways-to-keep-yourself-safe/)** | ealtian | |
1,873,605 | How to configure Dependabot on GitHub in only 3 steps | 🚀 In modern software development, managing dependencies is crucial for maintaining the security and... | 0 | 2024-06-02T10:55:32 | https://dev.to/perisicnikola37/how-to-configure-dependabot-on-github-in-only-3-steps-5309 | webdev, programming, dependabot, github | 🚀 In modern software development, managing dependencies is crucial for maintaining the security and stability of your projects. GitHub offers a powerful tool called `Dependabot` that <u>automates</u> the process of updating dependencies, helping you stay up-to-date with the latest releases and security patches 🌟
In this article, we'll walk through the steps to configure Dependabot for your GitHub repositories 🛠️
---
## Step 1: Navigate to your repository page 🌐
Once you're on the repository page, click on the "Settings" tab located at the top-right corner of the page.
---
## Step 2: Enable Dependabot 🔓
In the repository settings, scroll down to the "Security & analysis" section. Here, you'll find the option to enable Dependabot under the "Dependabot alerts" heading. Click on the "Enable Dependabot alerts" button to activate Dependabot for your repository.
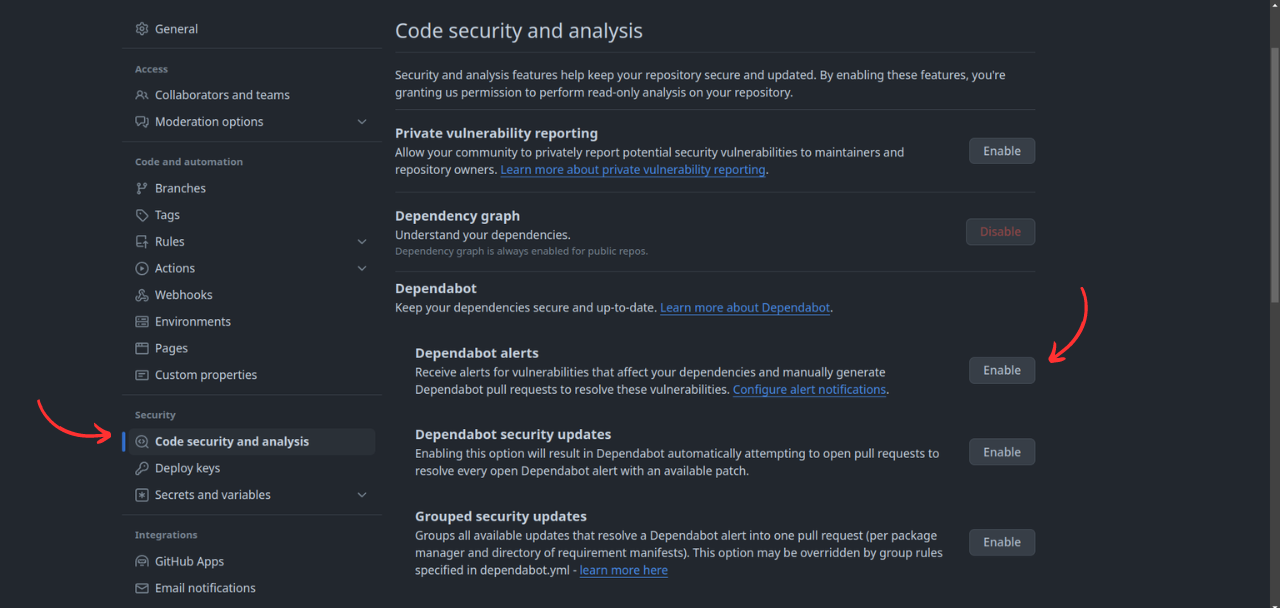
---
## Step 3: Configure Dependabot ⚙️
After enabling Dependabot, you can further configure its settings to suit your preferences.
Click on the `Dependabot version updates` to access the Dependabot configuration page.
Here, you can specify which types of dependencies you want Dependabot to monitor (e.g., npm, composer, Maven), frequency of checks, and version ranges for updates 🔄
For this case, I used `composer` as a package manager and set schedule interval to `daily` which means Dependabot will check daily our dependencies.
```
version: 2
updates:
- package-ecosystem: "composer"
directory: "/"
schedule:
interval: "daily"
```
---
### Reviewing Dependabot Pull Requests 🕵️
Once Dependabot is configured, it will start monitoring your project's dependencies for any updates.
When a new version is available, Dependabot will <u>automatically</u> create a pull request with the necessary changes. You'll receive a notification on GitHub, and you can review the pull request to ensure the updates are compatible with your project 👀
---
### Merging Dependabot Pull Requests ✨
After reviewing the Dependabot pull request and ensuring everything looks good, you can merge it into your main branch. This will apply the dependency updates to your project, keeping it secure and up-to-date 🚢
---
### Example of Dependabot Pull Requests 🚀
This is an example of Pull Requests that were opened by Dependabot. Concretely, this was for a Laravel project. As you can see, it updates versions of our dependencies ensuring to always have the latest version of our dependencies which means a more secure and stable project. 🛡️
[](https://postimg.cc/JDy8dRfj)
---
### Conclusion 🎯
Configuring Dependabot on GitHub is a simple yet powerful way to automate dependency management for your projects. By enabling Dependabot and configuring its settings, you can ensure that your dependencies are regularly updated with the latest releases and security patches, helping you maintain a healthy and secure codebase 🌱
Follow me on [GitHub](https://github.com/perisicnikola37) 🚀 | perisicnikola37 |
1,732,201 | Understanding Docker Caching: Optimizing Image Builds | Docker provides a powerful and efficient way to package and distribute applications using containers.... | 0 | 2024-06-02T09:06:04 | https://dev.to/ajeetraina/understanding-docker-caching-optimizing-image-builds-m1c | Docker provides a powerful and efficient way to package and distribute applications using containers. One key aspect of optimizing the Docker image-building process is understanding how Docker caching works. In this blog post, we'll explore the caching mechanism in Docker and how it impacts the speed and efficiency of your image builds.
## The Basics of Docker Caching
When you build a Docker image, Docker uses a caching mechanism to avoid redundant work and speed up the process. The caching strategy differs for the ADD/COPY commands and the RUN commands.
## 1. ADD/COPY Commands:
When you use ADD or COPY commands to copy files into the container image, Docker calculates a checksum for the files. This checksum acts as a unique identifier for the set of files. If the same files are used in subsequent builds and the checksum matches, Docker can reuse the cache. However, any change to a file, such as modifications to contents, filenames, or permissions, results in a new checksum. This change invalidates the cache, and Docker will rebuild subsequent layers.
## 2. RUN Commands:
For RUN commands, Docker caches the command itself. If the same RUN command is used in multiple builds, Docker can reuse the cache. However, even if the outcome of the command is the same, any change to the command itself will invalidate the cache. This means that modifying the command, even if it produces the same result, will trigger a rebuild of subsequent layers.
## Example: Illustrating Docker Caching in Action
Let's walk through a simple example to see how Docker caching behaves in practice. Consider the following Dockerfile:
```
# Dockerfile
# Step 1: Copy files into the image
COPY ./app /app
# Step 2: Install dependencies using a RUN command
RUN pip install -r /app/requirements.txt
# Step 3: Set the working directory
WORKDIR /app
# Step 4: Start the application
CMD ["python", "app.py"]
```
## Scenario 1: No Changes
In the first build, we copy files, install dependencies, and set the working directory:
```
docker build -t myapp:1.0 .
```
If we make no changes to the files or the RUN command and build again:
```
docker build -t myapp:1.1 .
```
Docker recognizes that nothing has changed, and it efficiently reuses the cache, resulting in a faster build.
## Scenario 2: Changes Made
Now, let's make a change to app.py:
```
# Modify app.py
echo "print('Hello, Docker!')" > /app/app.py
# Build the image
docker build -t myapp:2.0 .
```
Since we modified app.py, the checksum changes, invalidating the cache. Subsequent layers, including the RUN command, will be rebuilt.
```
# Build again with no changes
docker build -t myapp:2.1 .
```
Even though no changes were made to the files this time, the cache from the previous modification is still invalidated, leading to a rebuild of subsequent layers.
## Conclusion
Understanding Docker caching is crucial for optimizing your Docker image builds. By being aware of how changes in files and commands impact the caching mechanism, you can make informed decisions to speed up your development workflow and ensure efficient use of resources.
Remember that Docker caching is a powerful tool, but it requires careful consideration to avoid unexpected behaviors. By striking the right balance between caching and rebuilding when necessary, you can create Docker images that are not only efficient but also consistent and reliable across different environments.
| ajeetraina | |
1,873,603 | Managing Projects in VSCode: Workspaces and Folder Structures | Managing projects efficiently is crucial for any developer, and Visual Studio Code (VSCode) offers a... | 0 | 2024-06-02T10:42:32 | https://dev.to/umeshtharukaofficial/managing-projects-in-vscode-workspaces-and-folder-structures-3n78 | webdev, vscode, devops, programming | Managing projects efficiently is crucial for any developer, and Visual Studio Code (VSCode) offers a variety of features to streamline this process. Among these, workspaces and folder structures stand out as essential tools for organizing and handling multiple projects. This article will delve into the best practices for using VSCode workspaces and optimizing folder structures to enhance your productivity and project management.
## Understanding VSCode Workspaces
### What is a VSCode Workspace?
A workspace in VSCode is a collection of one or more folders that are opened in a single VSCode window. Workspaces can be saved and reopened, allowing you to maintain a specific setup of projects and settings tailored to your needs.
### Types of Workspaces
1. **Single Folder Workspace**: When you open a single folder in VSCode, it’s considered a single-folder workspace. This is suitable for small projects or when working on a single codebase.
2. **Multi-root Workspace**: This allows you to work with multiple folders in the same VSCode instance. Multi-root workspaces are ideal for larger projects that involve multiple repositories or components.
### Benefits of Using Workspaces
- **Centralized Management**: Manage multiple projects or components from a single window.
- **Custom Settings**: Define specific settings for each workspace to tailor the development environment.
- **Task Integration**: Integrate tasks and scripts across projects.
- **Consistent Environment**: Save and restore the workspace state, including opened files, layout, and settings.
## Setting Up Workspaces
### Creating a Single Folder Workspace
1. **Open a Folder**: Go to `File` > `Open Folder...` and select your project folder.
2. **Start Coding**: Once the folder is opened, you can start working on your project.
### Creating a Multi-root Workspace
1. **Add Folders to Workspace**: Go to `File` > `Add Folder to Workspace...` and select additional folders.
2. **Save the Workspace**: To save the workspace, go to `File` > `Save Workspace As...` and provide a name and location for the workspace file (`.code-workspace`).
### Switching Between Workspaces
To switch between workspaces, simply open a new workspace file or open a folder as needed. VSCode allows you to manage your workspace files easily.
### Customizing Workspace Settings
Each workspace can have its own settings, which override global settings. To customize workspace settings:
1. **Open Settings**: Click on the gear icon at the bottom left and select `Settings`.
2. **Workspace Settings**: Click on the `Workspace` tab to configure settings specific to the current workspace.
### Examples of Workspace-Specific Settings
- **Editor Configurations**: Adjust indentation, line endings, and other editor preferences.
- **Extensions**: Enable or disable extensions for specific workspaces.
- **Environment Variables**: Set environment variables required for running or debugging your projects.
## Optimizing Folder Structures
### Importance of a Good Folder Structure
A well-organized folder structure enhances readability, maintainability, and scalability of your projects. It helps in navigating the codebase quickly and efficiently.
### Best Practices for Folder Structures
1. **Consistency**: Maintain a consistent folder structure across projects to reduce confusion and streamline development.
2. **Separation of Concerns**: Organize files based on their purpose and functionality.
3. **Modularity**: Group related files and components together to promote modularity and reusability.
4. **Scalability**: Design the folder structure to accommodate future growth and additional features.
### Common Folder Structures
#### For Frontend Projects
```
/my-frontend-project
│
├── /public
│ ├── index.html
│ └── favicon.ico
│
├── /src
│ ├── /assets
│ │ ├── /images
│ │ └── /styles
│ │
│ ├── /components
│ ├── /pages
│ ├── /services
│ ├── App.js
│ └── index.js
│
├── /tests
│ └── App.test.js
│
├── package.json
└── README.md
```
#### For Backend Projects
```
/my-backend-project
│
├── /src
│ ├── /controllers
│ ├── /models
│ ├── /routes
│ ├── /services
│ ├── /utils
│ └── index.js
│
├── /config
│ └── db.js
│
├── /tests
│ ├── /unit
│ └── /integration
│
├── package.json
└── README.md
```
#### For Full Stack Projects
```
/my-fullstack-project
│
├── /client
│ ├── /public
│ ├── /src
│ ├── /assets
│ ├── /components
│ ├── /pages
│ ├── /services
│ ├── App.js
│ ├── index.js
│ └── package.json
│
├── /server
│ ├── /src
│ │ ├── /controllers
│ │ ├── /models
│ │ ├── /routes
│ │ ├── /services
│ │ ├── /utils
│ │ └── index.js
│ ├── /config
│ ├── /tests
│ └── package.json
│
├── .gitignore
└── README.md
```
### Organizing by Feature vs. Layer
#### Feature-Based Organization
```
/my-project
│
├── /features
│ ├── /auth
│ │ ├── AuthController.js
│ │ ├── AuthService.js
│ │ ├── AuthModel.js
│ │ └── authRoutes.js
│ │
│ ├── /user
│ │ ├── UserController.js
│ │ ├── UserService.js
│ │ ├── UserModel.js
│ │ └── userRoutes.js
│ │
│ └── /product
│ ├── ProductController.js
│ ├── ProductService.js
│ ├── ProductModel.js
│ └── productRoutes.js
│
├── /config
├── /utils
└── /tests
```
#### Layer-Based Organization
```
/my-project
│
├── /controllers
│ ├── AuthController.js
│ ├── UserController.js
│ └── ProductController.js
│
├── /services
│ ├── AuthService.js
│ ├── UserService.js
│ └── ProductService.js
│
├── /models
│ ├── AuthModel.js
│ ├── UserModel.js
│ └── ProductModel.js
│
├── /routes
│ ├── authRoutes.js
│ ├── userRoutes.js
│ └── productRoutes.js
│
├── /config
├── /utils
└── /tests
```
## Tips for Effective Project Management in VSCode
### 1. Use Integrated Source Control
VSCode comes with integrated Git support. You can perform all Git operations directly within the editor, such as committing changes, pushing to a remote repository, and resolving merge conflicts. This integration streamlines version control and enhances collaboration.
### 2. Leverage Task Runner
The Task Runner in VSCode allows you to automate common tasks such as building the project, running tests, and deploying applications. You can define tasks in a `tasks.json` file within the `.vscode` folder.
### 3. Utilize Extensions for Productivity
Extensions can significantly enhance your development experience. Some popular extensions for web development include:
- **Prettier**: For code formatting.
- **ESLint**: For linting JavaScript code.
- **Live Server**: For launching a local development server with live reload.
- **Debugger for Chrome**: For debugging JavaScript code in Chrome.
### 4. Customize Shortcuts
Customizing keyboard shortcuts can boost your productivity by allowing you to perform frequent actions quickly. You can modify shortcuts by navigating to `File` > `Preferences` > `Keyboard Shortcuts`.
### 5. Take Advantage of Snippets
Code snippets provide a quick way to insert commonly used code blocks. You can create custom snippets or install snippets extensions specific to your programming language or framework.
### 6. Use the Integrated Terminal
The integrated terminal in VSCode allows you to run command-line tools and scripts without leaving the editor. This feature is particularly useful for running build scripts, managing dependencies, and using version control systems.
### 7. Enable Auto Save and Format on Save
Enabling auto save ensures that your changes are saved automatically, reducing the risk of losing work. You can also enable format on save to keep your code consistently formatted. These settings can be configured in the `Settings` menu.
### 8. Manage Extensions by Workspace
VSCode allows you to enable or disable extensions on a per-workspace basis. This feature is useful for projects with specific requirements or to reduce clutter in your development environment.
## Conclusion
Effective project management in VSCode relies on leveraging workspaces and organizing your folder structure strategically. By setting up
workspaces, you can streamline your workflow and manage multiple projects with ease. Adopting best practices for folder structures ensures that your codebase remains clean, modular, and scalable.
Incorporating these strategies into your development routine will not only enhance your productivity but also improve the overall quality and maintainability of your projects. VSCode provides a powerful and flexible environment for developers, and mastering these features will help you maximize its potential. Embrace the power of workspaces and well-organized folder structures to take your project management skills to the next level. | umeshtharukaofficial |
1,872,035 | 21 VS Code Extensions To Boost Your Productivity | Hello Devs👋 As developers, we spend most of our time in VS Code. In this post, I will be sharing... | 0 | 2024-06-02T10:38:47 | https://dev.to/dev_kiran/21-vs-code-extensions-to-boost-your-productivity-1fil | webdev, programming, vscode, productivity | Hello Devs👋
As developers, we spend most of our time in VS Code. In this post, I will be sharing some VS Code extensions that can help boost your productivity and save your valuable time.🕧
Lets get started🚀
## Codiumate

> ✨ Codiumate uses AI to Generate tests, Review test results, Fix bugs and errors for code written in various programming languages like Python, JavaScript, TypeScript and Java. It acts as your personal agent or assistant within your IDE.
🔹Link 👉 [marketplace.visualstudio.com](https://marketplace.visualstudio.com/items?itemName=Codium.codium)
## Partial Diff

> ✨ Partial Diff extension allows you to compare different text selections within the same file or across different files, making it easier to spot changes and differences.
🔹Link 👉 [marketplace.visualstudio.com](https://marketplace.visualstudio.com/items?itemName=ryu1kn.partial-diff)
## Git Graph

> ✨ Git Graph extension provides you a visual representation of your Git repository, making it easier to understand and manage branches, commits, and merges also you can perform Git actions from the graph.
🔹Link 👉 [marketplace.visualstudio.com](https://marketplace.visualstudio.com/items?itemName=mhutchie.git-graph)
## Path Intellisense

> ✨ Path Intellisense extension extends the default path completion in VS Code to include all available paths in your workspace, even if they are not yet imported.
🔹Link 👉 [marketplace.visualstudio.com](https://marketplace.visualstudio.com/items?itemName=christian-kohler.path-intellisense)
## Error Lense

> ✨ Error Lens extension enhances your error highlighting in your VS Code by showing error messages directly inline with your code.
🔹Link 👉 [marketplace.visualstudio.com](https://marketplace.visualstudio.com/items?itemName=usernamehw.errorlens)
## SQLTools

> ✨ SQLTools is a lightweight SQL client for VS Code, it offers you database management, query execution, and results the visualization directly within the editor.
🔹Link 👉 [marketplace.visualstudio.com](https://marketplace.visualstudio.com/items?itemName=mtxr.sqltools)
## Markdown All in One

> ✨ Markdown All in One extension provides comprehensive support for Markdown editing, including shortcuts, table of contents generation, and more.
🔹Link 👉 [marketplace.visualstudio.com](https://marketplace.visualstudio.com/items?itemName=yzhang.markdown-all-in-one)
## Turbo Console Log

> ✨ Turbo Console Log extension automatically adds meaningful console.log statements to your code, which can be a huge time-saver during debugging.
🔹Link 👉 [marketplace.visualstudio.com](https://marketplace.visualstudio.com/items?itemName=ChakrounAnas.turbo-console-log)
## Quokka.js

> ✨ Quokka.js is a developer productivity tool for rapid JavaScript / TypeScript prototyping. Runtime values are updated and displayed in your IDE next to your code, as you type.
🔹Link 👉 [marketplace.visualstudio.com](https://marketplace.visualstudio.com/items?itemName=WallabyJs.quokka-vscode)
## Project Manager

> ✨ Project Manager lets you easily switch between different projects in VS Code, make it a quick way to manage and navigate multiple projects.
🔹Link 👉 [marketplace.visualstudio.com](https://marketplace.visualstudio.com/items?itemName=alefragnani.project-manager)
## Todo Tree

> ✨ Todo Tree extension scans your code for comment tags like TODO and FIXME, and displays them in a tree view in the activity bar.
🔹Link 👉 [marketplace.visualstudio.com](https://marketplace.visualstudio.com/items?itemName=Gruntfuggly.todo-tree)
## TabNine

> ✨ TabNine is an AI-powered code completion extension that supports multiple programming language, it offers intelligent code suggestions, real-time code completions, chat, and code generation for you.
🔹Link 👉 [marketplace.visualstudio.com](https://marketplace.visualstudio.com/items?itemName=TabNine.tabnine-vscode)
## Better Comments

> ✨ Better Comments extension helps you create or write more human-friendly comments in your code. It allows you to categorize your annotations into alerts, queries, todos, and more with different colors.
🔹Link 👉 [marketplace.visualstudio.com](https://marketplace.visualstudio.com/items?itemName=aaron-bond.better-comments)
## Polacode

> ✨ Polacode is a stylish code screenshot tool that allows you to create beautiful screenshots of your code directly from VS Code.
🔹Link 👉 [marketplace.visualstudio.com](https://marketplace.visualstudio.com/items?itemName=pnp.polacode)
## REST Client

> ✨ REST Client allows you to send HTTP requests and view the response directly within VS Code, making it easier to test and debug APIs.
🔹Link 👉 [marketplace.visualstudio.com](https://marketplace.visualstudio.com/items?itemName=humao.rest-client)
## HTML CSS Support

> ✨ HTML CSS Support provides CSS class and id name completion for the HTML class attribute based on the CSS files in your workspace.
🔹Link 👉 [marketplace.visualstudio.com](https://marketplace.visualstudio.com/items?itemName=ecmel.vscode-html-css)
## GitLens

> ✨ GitLens extension supercharges the built-in Git capabilities of VS Code. It helps you visualize code authorship, seamlessly navigate and explore Git repositories, and gain insights into your code.
🔹Link 👉 [marketplace.visualstudio.com](https://marketplace.visualstudio.com/items?itemName=eamodio.gitlens)
## WakaTime

> ✨ WakaTime extension provides automatic time tracking for your coding activities. It gives you insights into your coding habits and helps you manage your time more effectively.
🔹Link 👉 [marketplace.visualstudio.com](https://marketplace.visualstudio.com/items?itemName=WakaTime.vscode-wakatime)
## Bookmarks

> ✨ Bookmarks extension helps you to navigate in your code, moving between important positions easily and quickly. No more need to search for code. It also supports a set of selection commands, which allows you to select bookmarked lines and regions between bookmarked lines. It's really useful for log file analysis.
🔹Link 👉 [marketplace.visualstudio.com](https://marketplace.visualstudio.com/items?itemName=alefragnani.Bookmarks)
## PlantUML

> ✨ PlantUML extension allows you to create UML diagrams from plain text descriptions, making it easy to visualize and document your system design.
🔹Link 👉 [marketplace.visualstudio.com](https://marketplace.visualstudio.com/items?itemName=jebbs.plantuml)
## Trailing Spaces

> ✨ Trailing Spaces extension highlights and removes trailing whitespace in your code automatically, it helps to keep your code clean and consistent.
🔹Link 👉 [marketplace.visualstudio.com](https://marketplace.visualstudio.com/items?itemName=shardulm94.trailing-spaces)
That's it for this post. Thank you for reading💖
> Let me know which one you use the most or any other helpful extension in the comments👇
Find Me on 👉 {% cta https://x.com/kiran__a__n %} X {% endcta %} {% cta https://github.com/Kiran1689 %} GitHub {% endcta %}
{% embed https://dev.to/dev_kiran %} | dev_kiran |
1,873,602 | Laravel 11 Custom Component File Structure | Would you like to create a component like this, or do you prefer to develop your own custom component... | 0 | 2024-06-02T10:36:25 | https://dev.to/armanrahman/laravel-11-custom-component-file-structure-33ab | laravel, component, custom, armanrahman | Would you like to create a component like this, or do you prefer to develop your own custom component in Laravel with a custom path?

Then you need to follow few steps
Step 1: Create a Service Provider
```
php artisan make:provider PackageServiceProvider
```
You can name it your own.
Step 2: Add `Blade::componentNamespace('App\View\Backend\Components', 'backend');` on your boot() method
```
<?php
namespace App\Providers;
use Illuminate\Support\Facades\Blade;
use Illuminate\Support\ServiceProvider;
class PackageServiceProvider extends ServiceProvider
{
/**
* Register services.
*/
public function register(): void
{
//
}
/**
* Bootstrap services.
*/
public function boot(): void
{
Blade::componentNamespace('App\View\Backend\Components', 'backend');
}
}
```
Step 3: Create a php file as per your file structure. I created my file here.
> app\View\Backend\Components\AdminSidebar.php
Step 4: Return your blade directive on render() method.
```
<?php
namespace App\View\Backend\Components;
use Illuminate\View\Component;
use Illuminate\View\View;
class AdminSidebar extends Component
{
/**
* Get the view / contents that represents the component.
*/
public function render(): View
{
return view('backend.components.sidebar');
}
}
```
Step 5: Create your blade file as you mentioned. For my case I added like this.
> resources\views\backend\components\sidebar.blade.php
Step 6: Your Component setup is done. now you can access that component by this-
```
<x-backend::admin-sidebar />
```
Hope this will help you. Thank You. | armanrahman |
1,873,601 | Top Websites Offering Student Discounts on Essential Developer Tools | Top Websites Offering Student Discounts on Essential Developer Tools As a student... | 0 | 2024-06-02T10:31:47 | https://dev.to/sh20raj/top-websites-offering-student-discounts-on-essential-developer-tools-2p02 | students, javascript, beginners, webdev | # Top Websites Offering Student Discounts on Essential Developer Tools
As a student developer, access to the right tools can significantly enhance your learning and project-building experience. Fortunately, many top companies offer incredible discounts or even free access to their products for students. Here’s a curated list of the best websites offering student discounts on essential tools for developers:
### 1. GitHub Student Developer Pack
The GitHub Student Developer Pack is a goldmine for student developers. It includes free tools, credits, and access to numerous developer resources.
- **Benefits:** GitHub Pro, Microsoft Azure, Namecheap, DigitalOcean, and more.
- **How to Get It:** [GitHub Education](https://education.github.com/pack)
### 2. JetBrains
JetBrains provides free access to their professional tools like IntelliJ IDEA, PyCharm, and WebStorm for students with a valid educational email.
- **Benefits:** Full suite of JetBrains tools.
- **How to Get It:** [JetBrains Student License](https://www.jetbrains.com/community/education/#students)
### 3. Microsoft Azure for Students
Microsoft Azure offers $100 in free credit and access to over 25 free services, no credit card required.
- **Benefits:** $100 credit, 25+ free services.
- **How to Get It:** [Microsoft Azure for Students](https://azure.microsoft.com/en-us/free/students/)
### 4. Amazon Web Services (AWS) Educate
AWS Educate provides free access to AWS resources and training, along with $100 in AWS credits.
- **Benefits:** $100 credit, free cloud resources.
- **How to Get It:** [AWS Educate](https://aws.amazon.com/education/awseducate/)
### 5. Autodesk
Autodesk offers free access to software like AutoCAD, Maya, and Fusion 360 for students and educators.
- **Benefits:** Access to Autodesk software.
- **How to Get It:** [Autodesk Education Community](https://www.autodesk.com/education/home)
### 6. Canva for Education
Canva for Education provides free access to Canva Pro features, which is perfect for designing presentations, graphics, and social media content.
- **Benefits:** Canva Pro features.
- **How to Get It:** [Canva for Education](https://www.canva.com/education/)
### 7. Adobe Creative Cloud
Adobe offers discounts on Creative Cloud plans, which include Photoshop, Illustrator, and Premiere Pro, for students and educators.
- **Benefits:** Discounted Creative Cloud plans.
- **How to Get It:** [Adobe Creative Cloud for Students](https://www.adobe.com/creativecloud/buy/students.html)
### 8. Notion
Notion provides a free personal plan for students, making it a powerful tool for note-taking, project management, and collaboration.
- **Benefits:** Notion Personal Pro plan.
- **How to Get It:** [Notion for Students](https://www.notion.so/students)
### 9. Slack
Slack offers a free upgrade to the Standard plan for students in certain educational institutions, enhancing team communication and collaboration.
- **Benefits:** Slack Standard plan.
- **How to Get It:** [Slack for Education](https://slack.com/intl/en-in/help/articles/360050781113-Slack-for-Education)
### 10. Figma
Figma provides free access to its Professional plan for students, which is excellent for UI/UX design and prototyping.
- **Benefits:** Figma Professional plan.
- **How to Get It:** [Figma for Students](https://www.figma.com/education/)
### 11. Namecheap
Namecheap offers discounts on domain registration and hosting services, including a free .me domain for students.
- **Benefits:** Discounted domains and hosting, free .me domain.
- **How to Get It:** [Namecheap for Education](https://nc.me/)
### 12. Unity
Unity offers free access to Unity Pro for students, which is ideal for game development and real-time 3D projects.
- **Benefits:** Unity Pro access.
- **How to Get It:** [Unity Student Plan](https://store.unity.com/academic/unity-student)
### Conclusion
Taking advantage of these student discounts can significantly lower the barrier to accessing professional-grade tools and services. Whether you're into coding, design, or project management, these resources will help you sharpen your skills and bring your projects to life.
Have you used any of these resources? Let us know in the comments!
---
Feel free to tweak the post to better match your style or to add any additional resources you find valuable! | sh20raj |
1,873,600 | BETVND - TRANG CHU NHA CAI BETVND CHINH THUC #1 VIET NAM | Betvnd la mot trong nhung san ca cuoc hang dau tai Viet Nam Du moi xuat hien tren thi truong ca cuoc... | 0 | 2024-06-02T10:25:49 | https://dev.to/betvndshop/betvnd-trang-chu-nha-cai-betvnd-chinh-thuc-1-viet-nam-48fd | Betvnd la mot trong nhung san ca cuoc hang dau tai Viet Nam Du moi xuat hien tren thi truong ca cuoc gan day, nhung Betvnd da nhanh chong tao dau an dac biet trong cong dong game thu toan cau. Hay nhanh tay dang ky tai khoan de nhan ngay 200% gia tri nap tien.
Email: justinowebbie@gmail.com
Website: https://betvnd.shop/
Dien Thoai: (+84) 0584328954
#betvnd #betvndcasino #nhacaibetvnd #betvndshop #betvndvip #betvnddcc
Social:
https://www.facebook.com/betvndshop/
https://twitter.com/betvndshop
https://www.youtube.com/channel/UCjDWA5GkstAb7TKwm-vK3kA
https://www.pinterest.com/betvndshop/
https://learn.microsoft.com/vi-vn/users/betvndshop/
https://vimeo.com/betvndshop
https://www.blogger.com/profile/01502302323601477291
https://www.reddit.com/user/betvndshop/
https://vi.gravatar.com/betvndshop
https://en.gravatar.com/betvndshop
https://medium.com/@betvndshop/about
https://www.tumblr.com/betvndshop
https://mattdor102.wixsite.com/betvndshop
https://betvndshop.livejournal.com/profile/
https://betvndshop.wordpress.com/
https://sites.google.com/view/betvndshop/home
https://linktr.ee/betvndshop
https://www.twitch.tv/betvndshop/about
https://tinyurl.com/betvndshop
https://ok.ru/betvndshop/statuses/157159266768199
https://profile.hatena.ne.jp/betvndshop/
https://issuu.com/betvndshop
https://www.liveinternet.ru/users/betvndshop
https://dribbble.com/betvndshop/about
https://gitlab.com/betvndshop
https://www.kickstarter.com/profile/2036273283/about
https://disqus.com/by/betvndshop/about/
https://betvndshop.webflow.io/
https://500px.com/p/betvndshop?view=photos
https://about.me/betvndshop
https://tawk.to/betvndshop
https://www.deviantart.com/betvndshop
https://ko-fi.com/betvndshop
https://www.provenexpert.com/betvndshop/
https://hub.docker.com/u/betvndshop | betvndshop | |
1,873,599 | Reclaim Protocol: Verified HTTPS Traffic for Privacy-Preserving Proofs | Hello Dev Community, We are excited to announce the launch of the Reclaim Protocol, a robust... | 0 | 2024-06-02T10:21:34 | https://dev.to/realadii/reclaim-protocol-verified-https-traffic-for-privacy-preserving-proofs-1g4j | zkproof, webdev | Hello Dev Community,
We are excited to announce the launch of the Reclaim Protocol, a robust solution for creating verifiable claims while preserving user privacy. Here’s a detailed and technical overview of how it works and why it matters.
**What is Reclaim Protocol?**
Reclaim Protocol (YC W21) leverages HTTPS session keys to generate zero-knowledge proofs (zkproofs) of users’ profile information. It creates digital signatures, known as zk proofs, of users’ identity and reputation on any website. These digital signatures are computed entirely on the client side, ensuring they are private and secure. When a user shares this proof with any application, one can be certain that its authenticity and integrity haven’t been compromised.
- **Website**: [Reclaim Protocol](https://www.reclaimprotocol.org/)
- **SDK Docs**: [Reclaim Protocol SDK Documentation](https://docs.reclaimprotocol.org/)
- **Developer Portal**: [Reclaim Developer Portal](https://dev.reclaimprotocol.org/dashboard)
- **Blog**: [Reclaim Blog](https://blog.reclaimprotocol.org/)
**How Reclaim Protocol Works**
Reclaim Protocol operates through a sophisticated mechanism that ensures the security and privacy of HTTPS traffic. Here’s a detailed technical breakdown of the process:
1. **User Interaction with HTTPS Proxy Server**:
- When a user logs into a desired website, their HTTPS request and the corresponding response are routed through an HTTPS Proxy Server known as the **Attestor**. The Attestor intercepts and monitors the encrypted packets transferred between the user and the website, ensuring that no private data is exposed during this process.
2. **Key Sharing and Attestation**:
- The user shares session keys that reveal non-private information of the request to the Attestor. The Attestor examines the request, which contains all data in plain text except for private information such as authentication credentials. The Attestor then generates a cryptographic signature to attest that the correct request was made, ensuring the transaction’s integrity without compromising user privacy.
3. **Zero-Knowledge Circuit and Regex Matching**:
- The encrypted response from the website is passed to a **ZK circuit**. This circuit uses a decryption key as a private input to extract a regex match on the encrypted data. The Attestor further attests that the public input to the ZK proof was indeed the encrypted data from the website, ensuring the response’s authenticity.
4. **Verification by Third-Party Applications**:
- With these signatures on the request and the encrypted response, along with the ZK proof itself, any third-party application can verify the existence and authenticity of the data on the user’s profile without compromising privacy. The combination of these cryptographic proofs ensures that data integrity is maintained throughout the verification process.
**Security and Efficiency**
An independent third-party research group from Purdue University has formally analyzed the security of proxy-based TLS models. The key result is that the security provided by Reclaim Protocol is equivalent to that established by much more bandwidth-intensive models such as MPC (Multiparty Computation) and garbled circuits.
This research confirms that while the proxy model is generally considered insecure for TLS, it is fully secure when used in the context of HTTPS, as implemented by Reclaim Protocol. The study explores potential attacks and mitigations, many of which are already implemented in Reclaim Protocol. Therefore, when questions about the security of Reclaim Protocol arise, we can confidently reference this formal definition of security.
The paper highlights that Reclaim Protocol’s approach is not only secure but also significantly more efficient than other industry approaches like Deco, TLSNotary, ZkPass, Pado, and Opacity, which rely on MPC. With this formal proof published in a respected publication, we have the external validation that solidifies our position as leaders in the industry.
A bonus is that Reclaim Protocol’s whitepaper has been cited in this research paper, marking our first citation. This recognition affirms the robustness and efficiency of our protocol.
**Get Involved**
We are committed to fostering an inclusive and transparent environment where all contributors have the opportunity to thrive. Whether you’re a seasoned developer, a budding entrepreneur, or simply passionate about the future of decentralized technology, we encourage you to explore and integrate Reclaim Protocol into your projects.
To learn more about Reclaim Protocol and how it can enhance your projects, please refer to our [whitepaper](https://drive.google.com/file/d/1wmfdtIGPaN9uJBI1DHqN903tP9c_aTG2/view).
Join the conversation and connect with us on Telegram: [Reclaim Protocol Telegram](https://t.me/reclaimprotocol)
We look forward to your thoughts, feedback, and any questions you may have. Join us in this exciting journey to enhance user privacy and data security!
Best regards,
Adithya Dinesh
Community & Growth, Reclaim Protocol | realadii |
1,873,592 | How to add a profile view counter to your GitHub profile in 3 steps | Hello there 😊 In this post you will learn how to setup profile view in only 3 steps. So let's... | 0 | 2024-06-02T10:19:12 | https://dev.to/perisicnikola37/how-to-add-profile-view-counter-to-your-github-profile-in-3-steps-2887 | webdev, github, programming, developers | Hello there 😊
In this post you will learn how to setup profile view in **only** 3 steps.
So let's begin! 😃
---
## 1. Create a [new repository](https://github.com/new)
Note: Please ensure that your username on GitHub <u>matches</u> the repository name. For example, my username is `perisicnikola37` on GitHub, so I named my repository like that. If you encounter an error warning, such as the one on below image, stating that the repository already exists, you can safely disregard it.
---
## 2. Go to your repository
You can access the newly created repository by entering this URL into your web browser's address bar:
```js
https://github.com/perisicnikola37/perisicnikola37
```
**Note**: Change `perisicnikola37` to your actual GitGub username
---
## 3. Edit `README.md` file
All you need to include in it is the following line of code:
```js

```
Note: Similar to the second step, replace `perisicnikola37` with your actual GitHub username
---
## Done 🚀
Now, visit your GitHub profile page by entering the following URL into your browser's address bar:
```js
https://github.com/perisicnikola37 -> change your username
```
## Voila! 🎉
[](https://postimg.cc/Z9WbdYs1)
---
📢 Connect with others!
Upload your profile in comment section to get connected!
Follow me on [GitHub](https://github.com/perisicnikola37) 🚀
| perisicnikola37 |
1,873,596 | Deep Dive on Amazon Elastic MapReduce Service Platform with Amazon EC2 Instance | “ I have checked the documents of AWS to get into deep dive on amazon elastic mapreduce service... | 0 | 2024-06-02T10:10:49 | https://dev.to/aws-builders/deep-dive-on-amazon-elastic-mapreduce-service-platform-with-amazon-ec2-instance-1ohi | amazonemr, s3bucket, iamrole, ec2instance | “ I have checked the documents of AWS to get into deep dive on amazon elastic mapreduce service platform with amazon ec2 instance. In terms of cost, need to pay for emr service, amount of storage and data transferred in and out of service for s3 bucket, amazon ec2 instance.”
Amazon Elastic MapReduce is a managed cluster platform that simplifies running big data frameworks, such as Apache Hadoop and Apache Spark, on AWS to process and analyze vast amounts of data. Using these frameworks and related open-source projects, you can process data for analytics purposes and business intelligence workloads. Amazon EMR also lets you transform and move large amounts of data into and out of other AWS data stores and databases, such as Amazon Simple Storage Service and Amazon Dynamodb.
In this post, you will experience how to deep dive on amazon elastic mapreduce service platform with amazon ec2 instance. Here I have created an amazon emr service cluster with iam roles, key pair and s3 bucket.
#Architecture Overview
The architecture diagram shows the overall deployment architecture with data flow, amazon emr service, s3 bucket, iam service role, ec2 instances.
#Solution overview
The blog post consists of the following phases:
1. Create of Amazon EMR Service Cluster with Required Configurations
2. Output of Emr Cluster as Submit of Spark Application as a Step Option
##Phase 1: Create of Amazon EMR Service Cluster with Required Configurations
1. Create a key pair, iam roles and s3 bucket with required data. Open the console of Amazon emr service, create a cluster with amazon emr running on amazon ec2 option. Specify the cluster name as Emr Cluster and choose the required parameters as choice of application, instance type, ebs volume, networking, cluster logs s3 location, key pair, emr service role, ec2 instance profile for emr role.
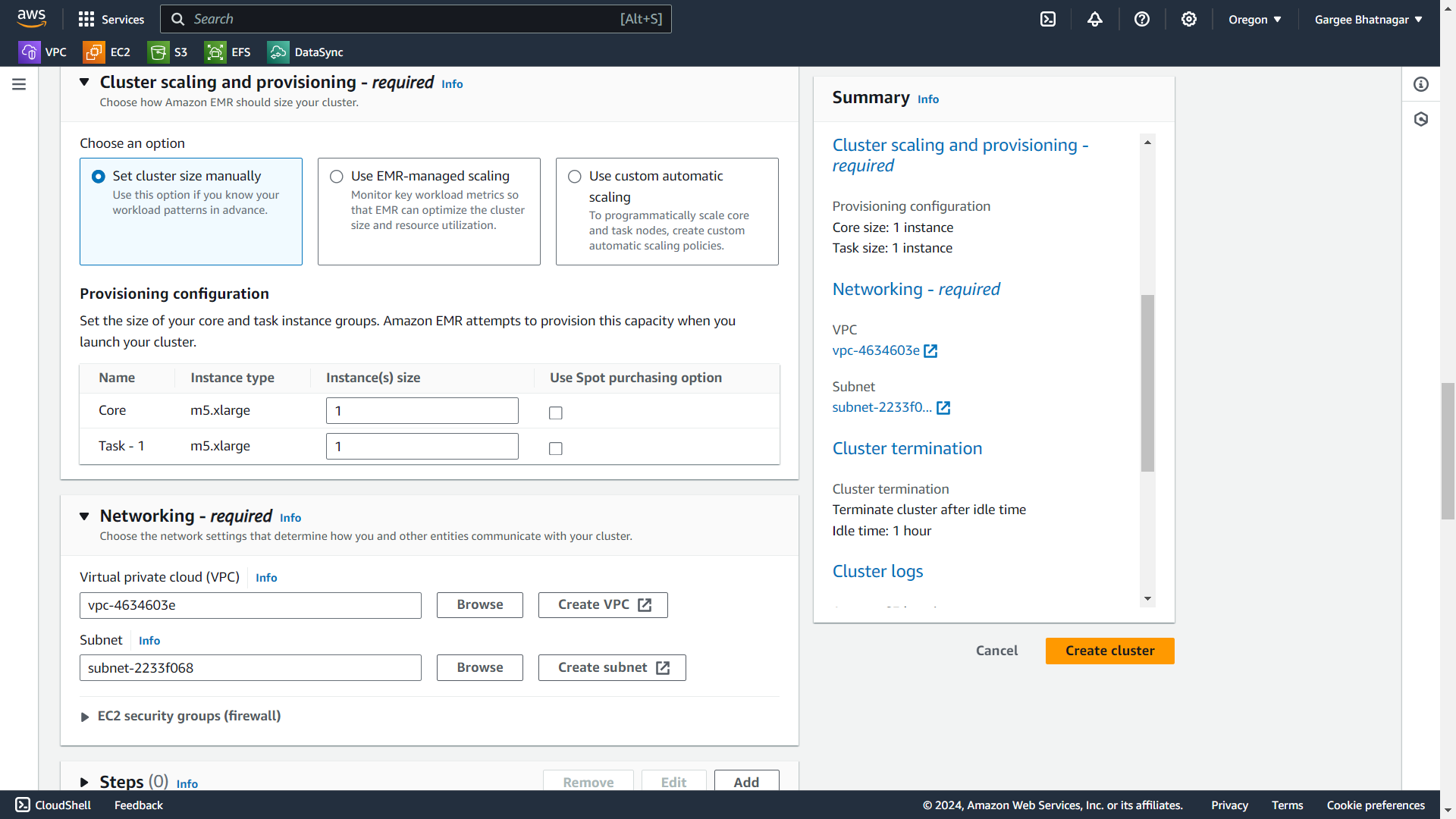
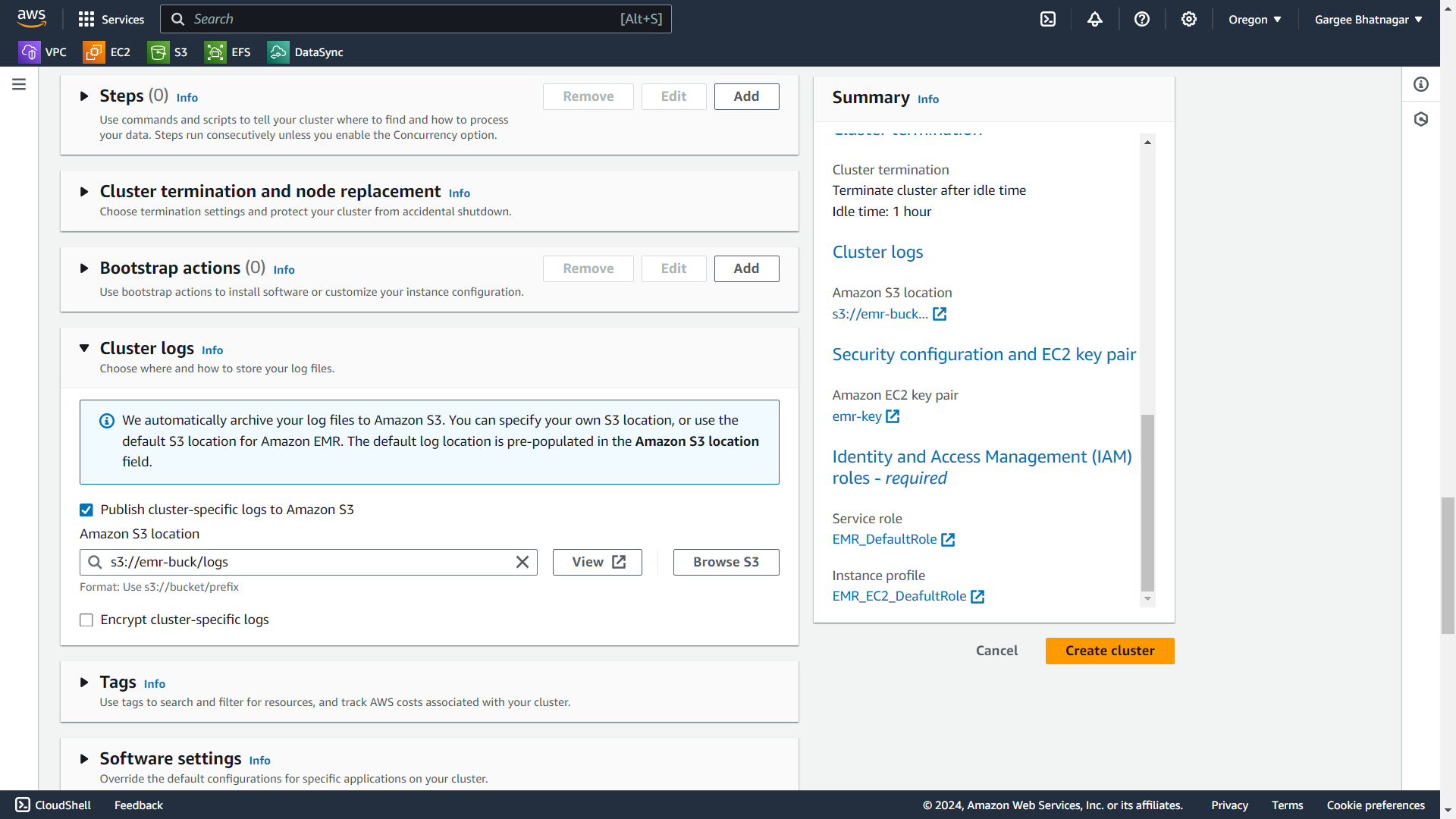
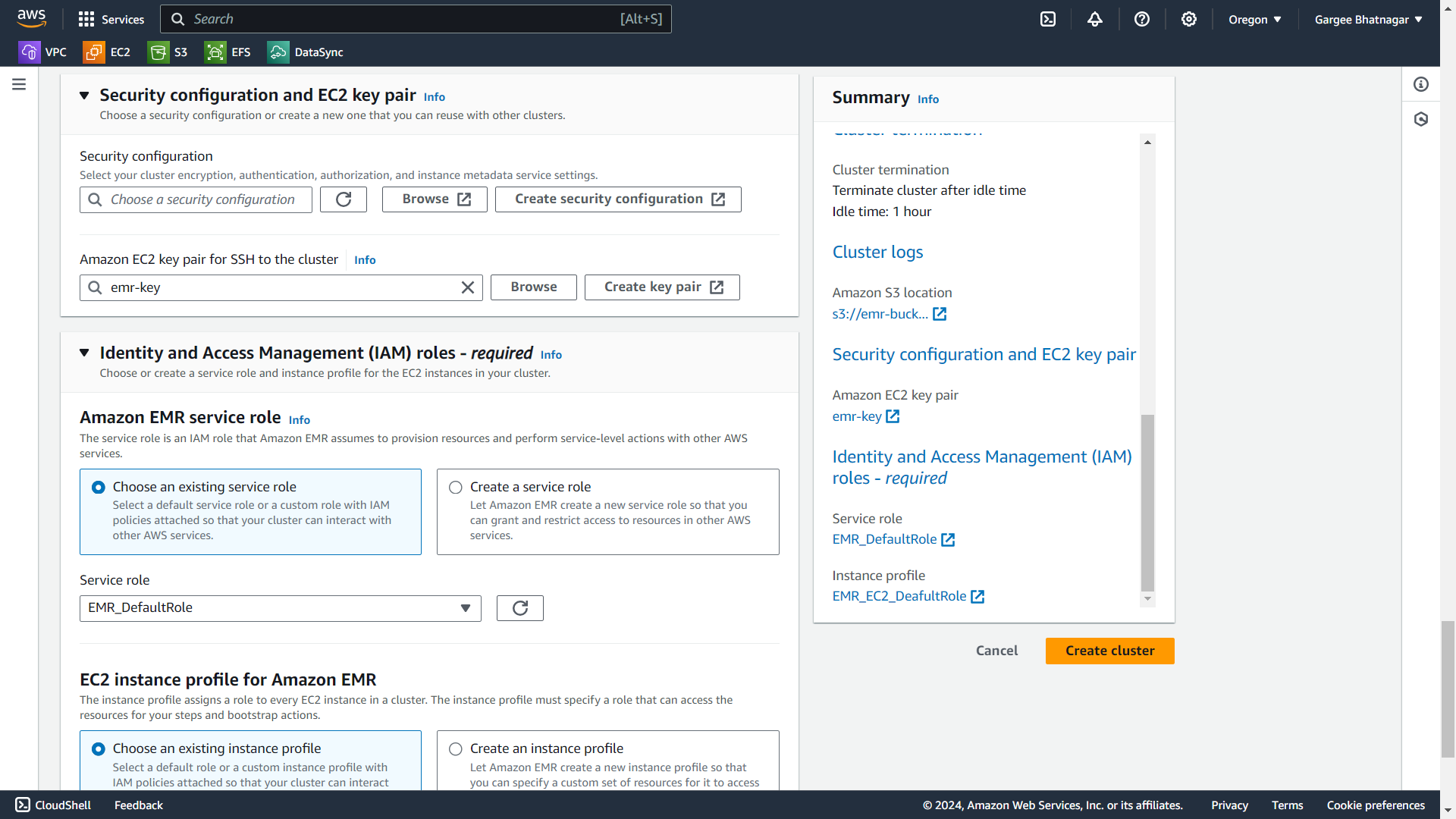
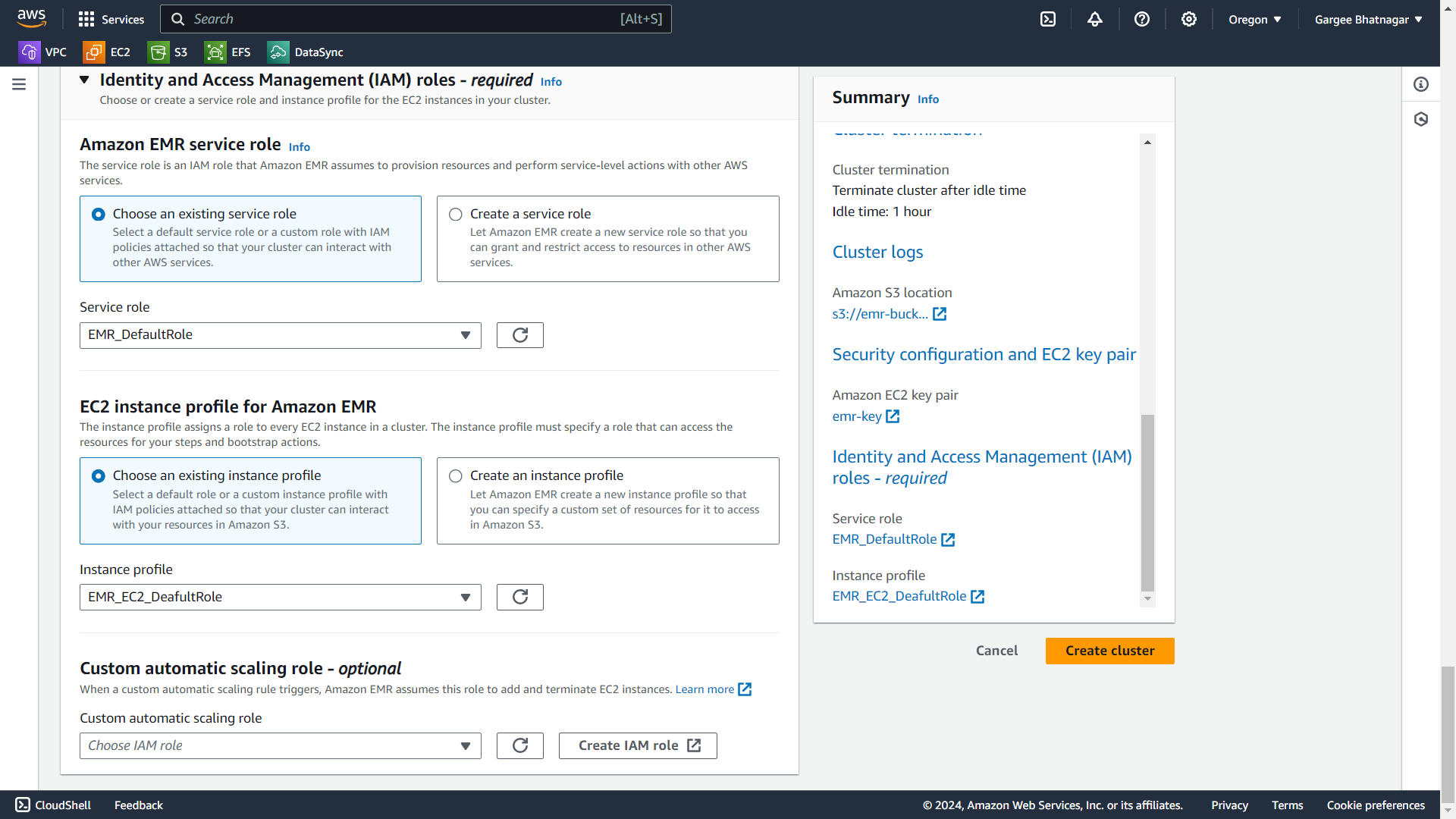
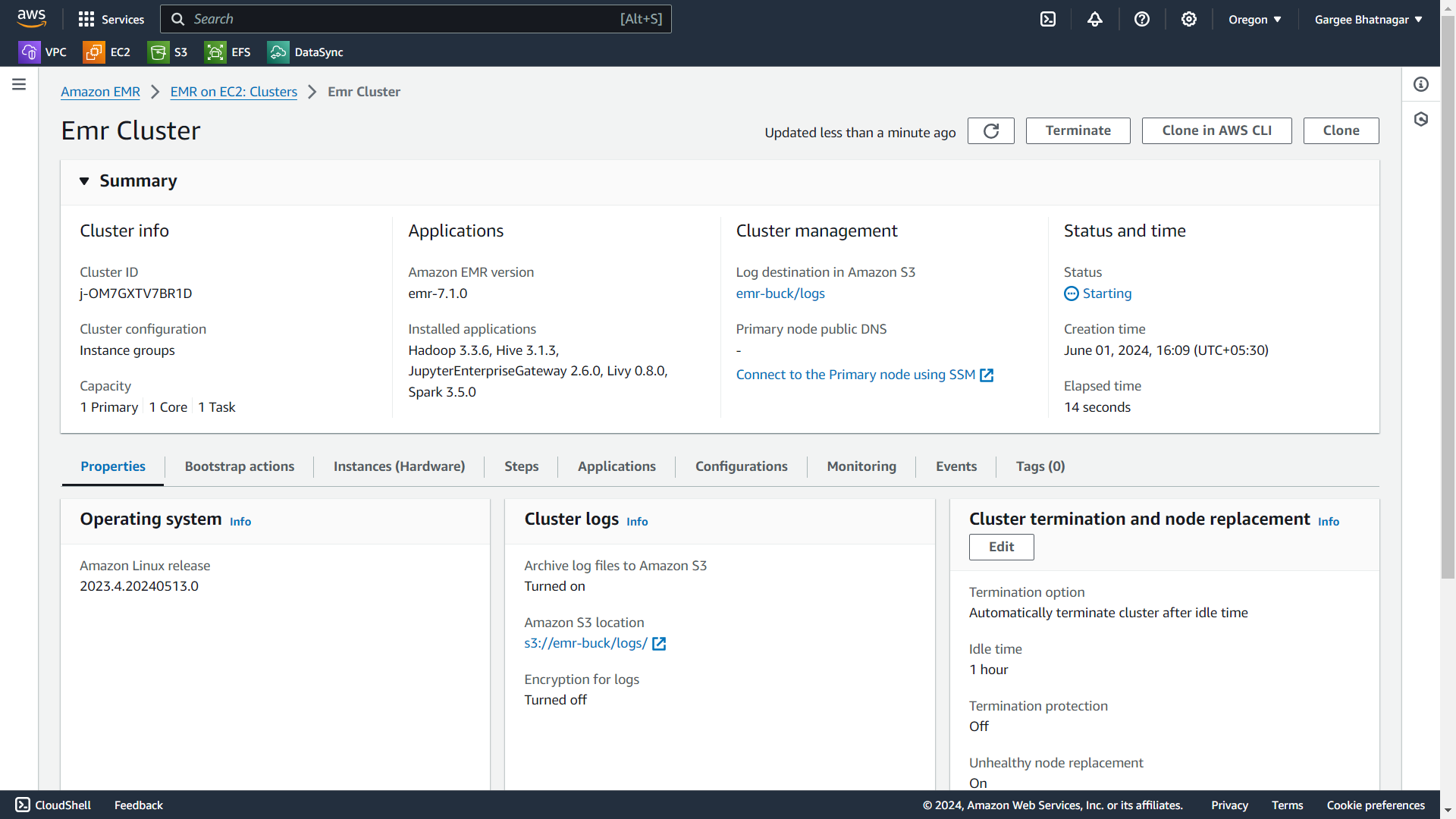
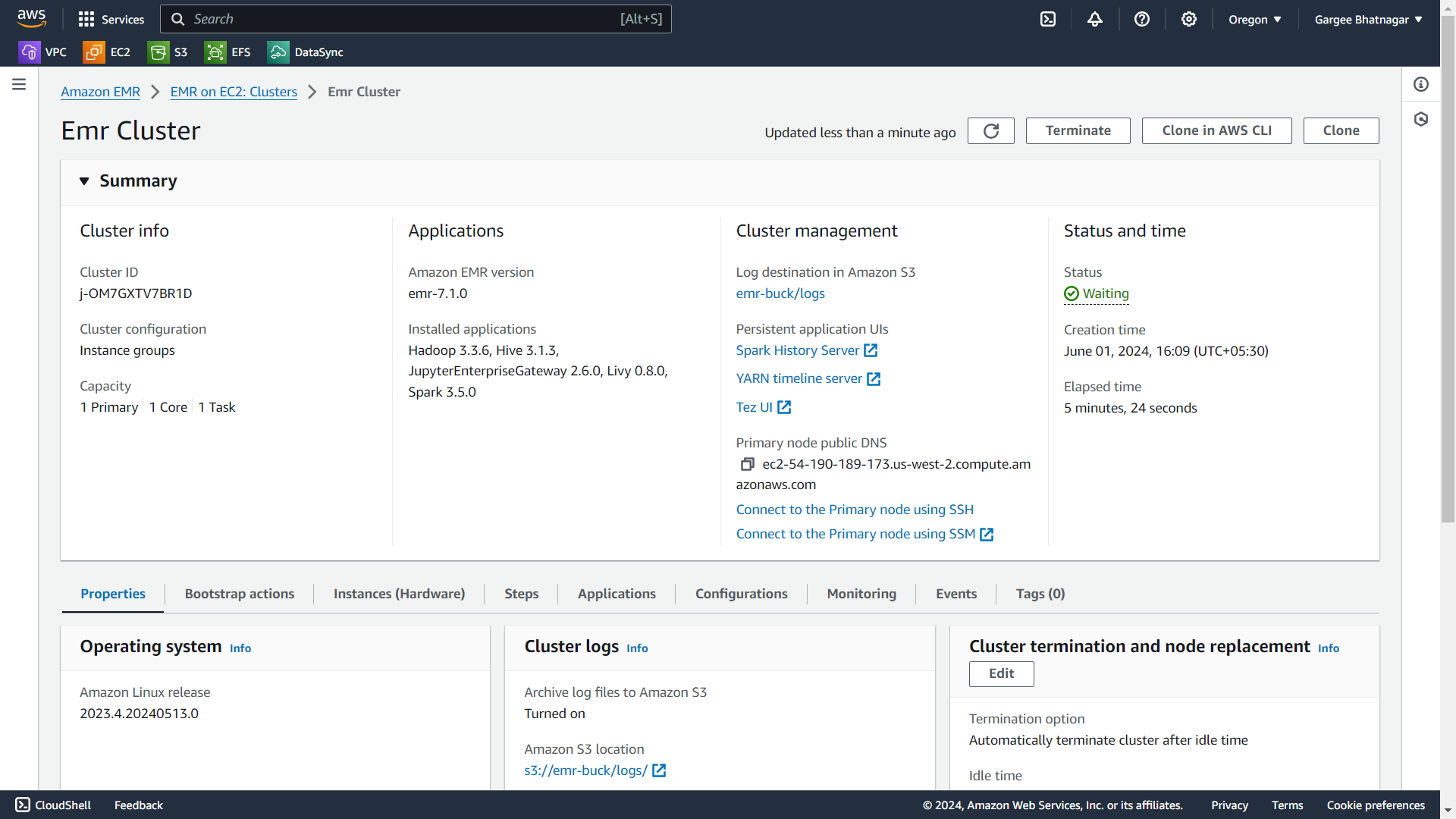
##Phase 2: Output of Emr Cluster as Submit of Spark Application as a Step Option
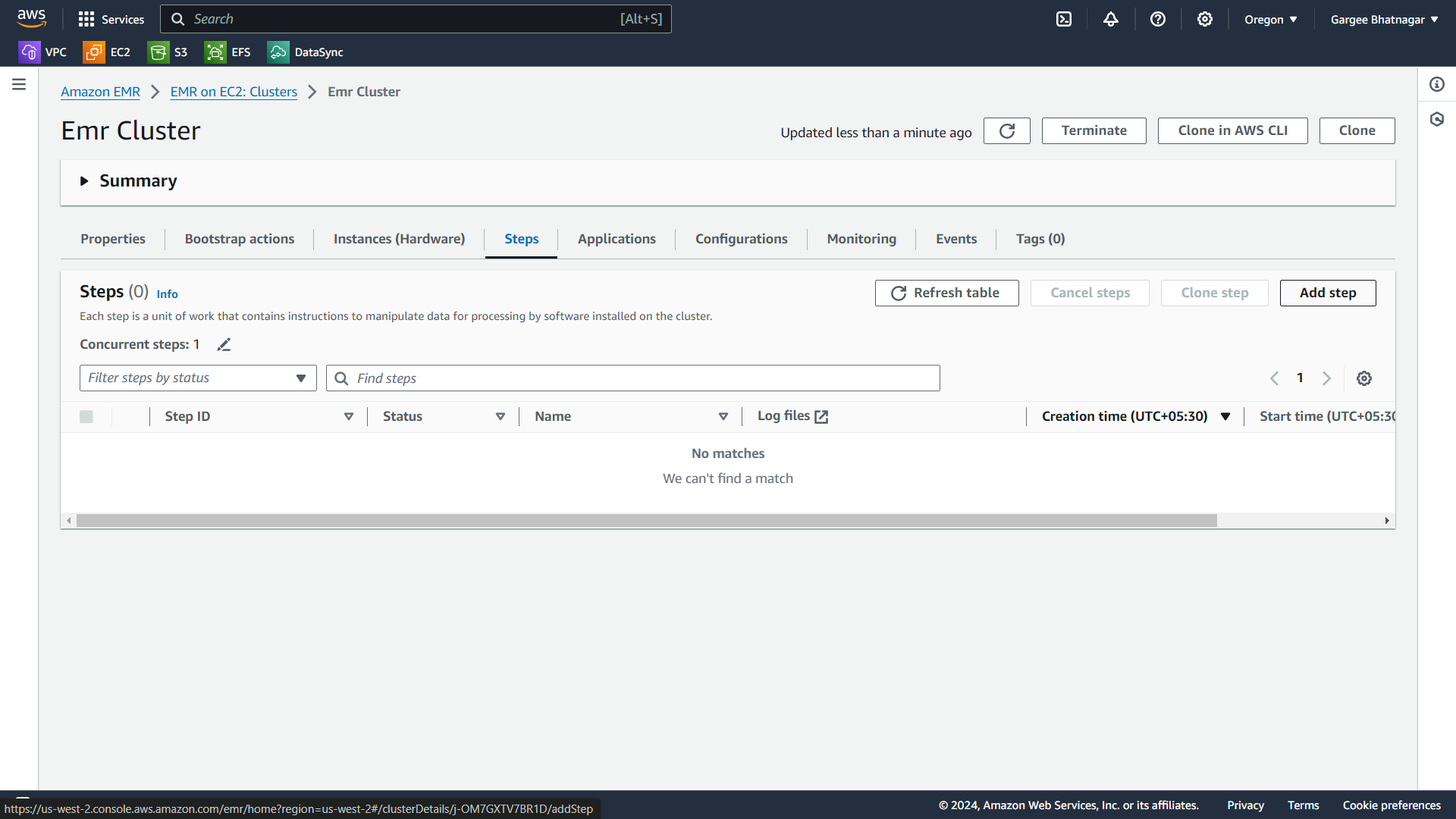
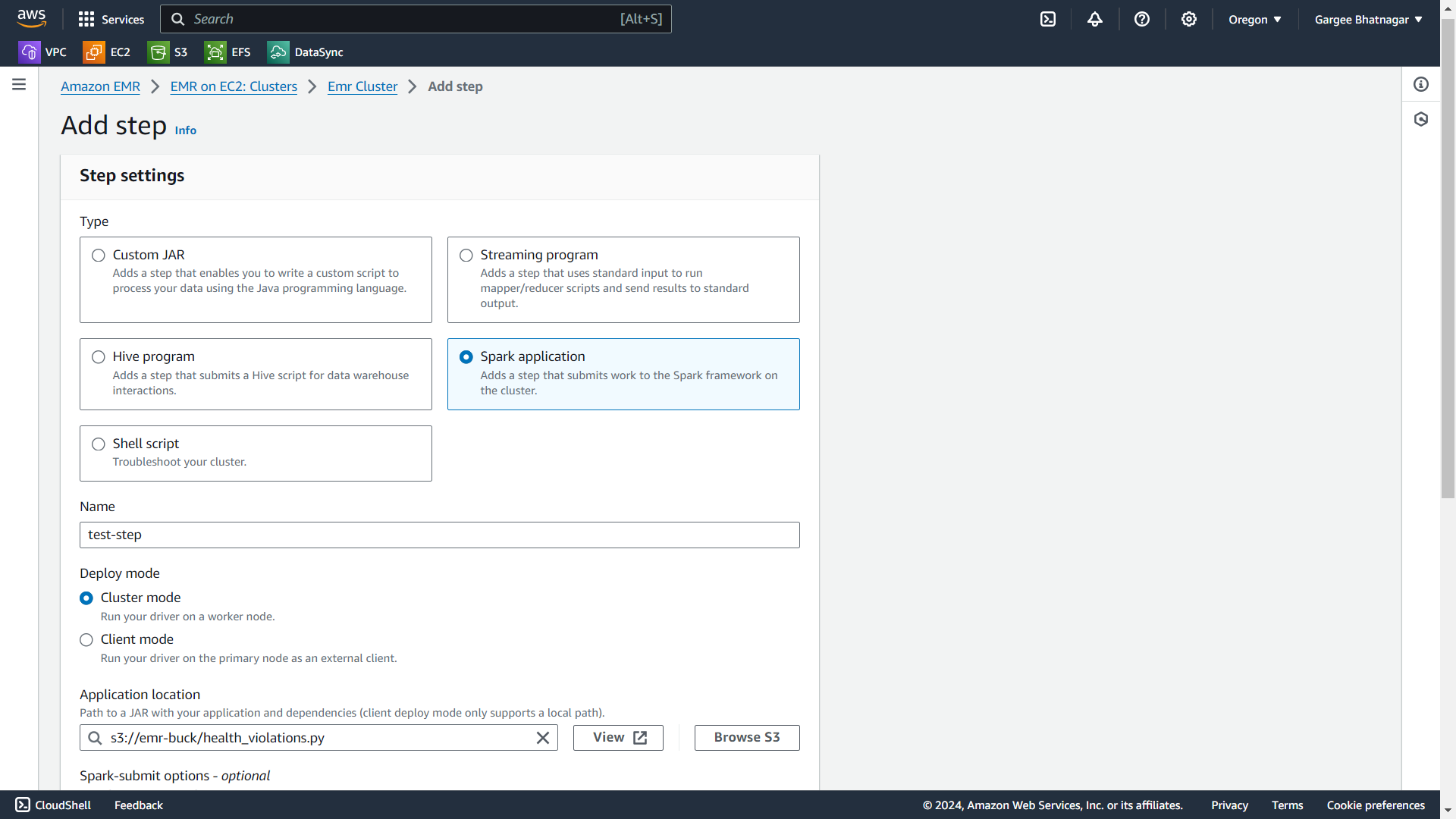
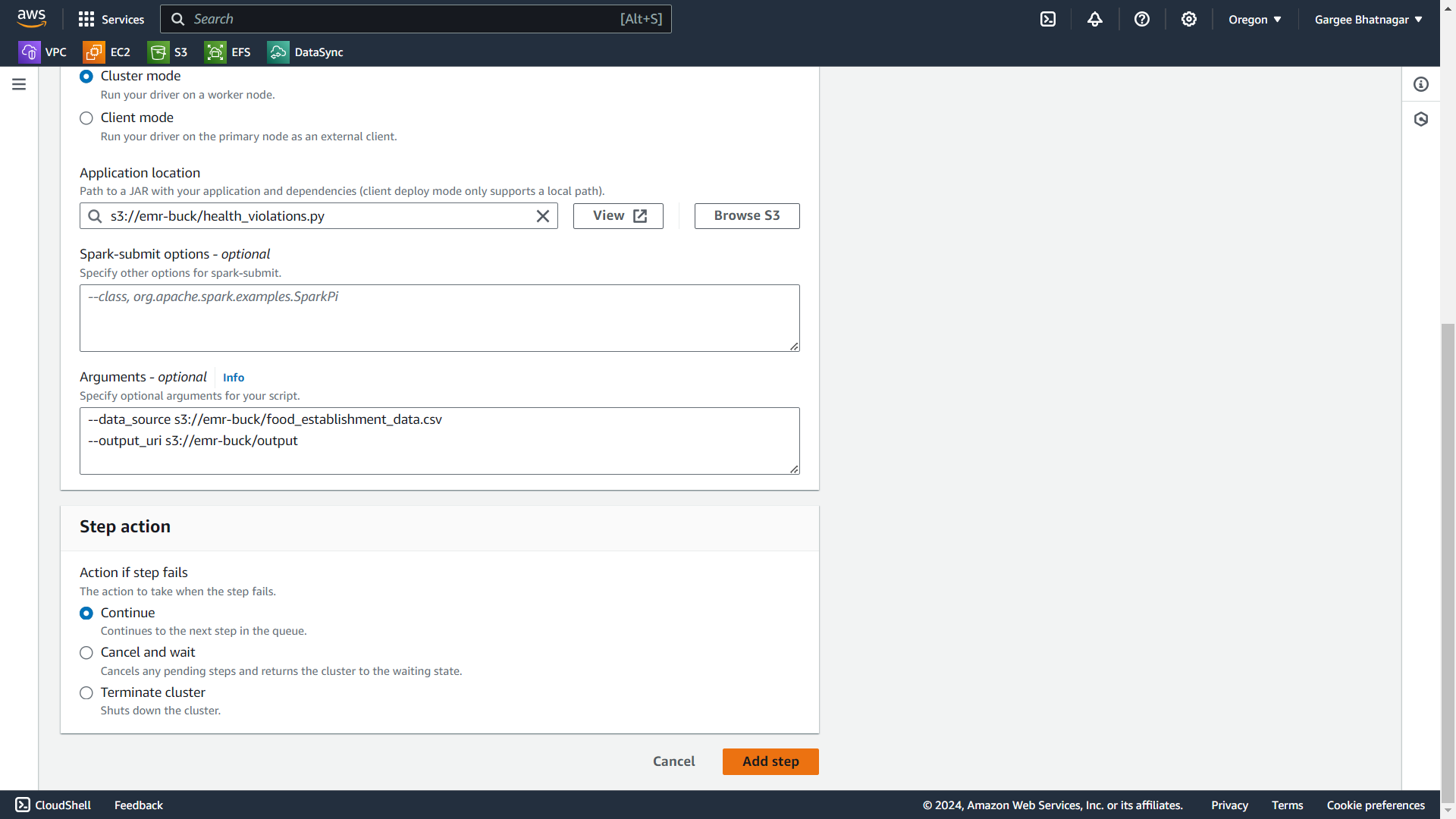
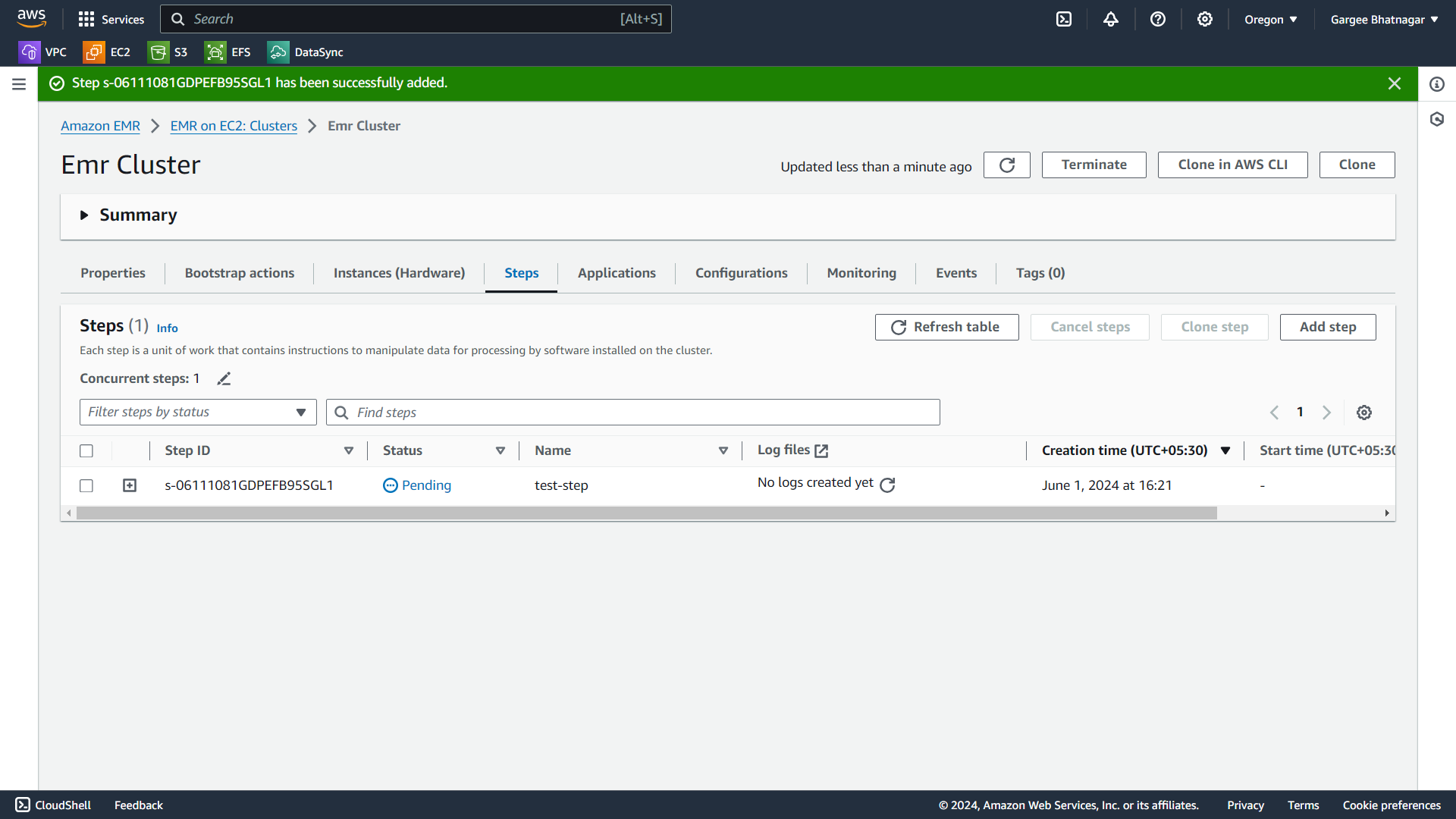
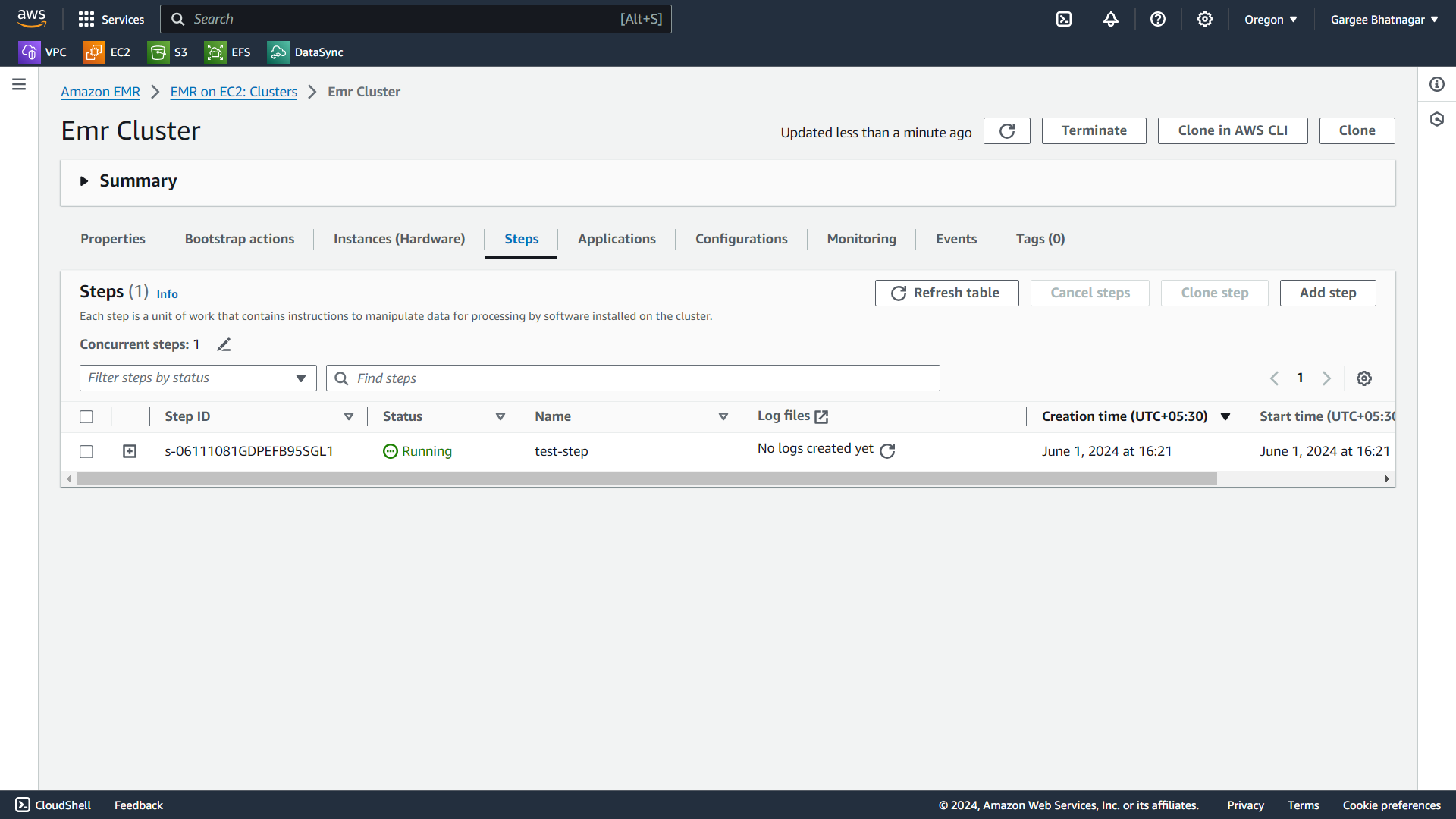
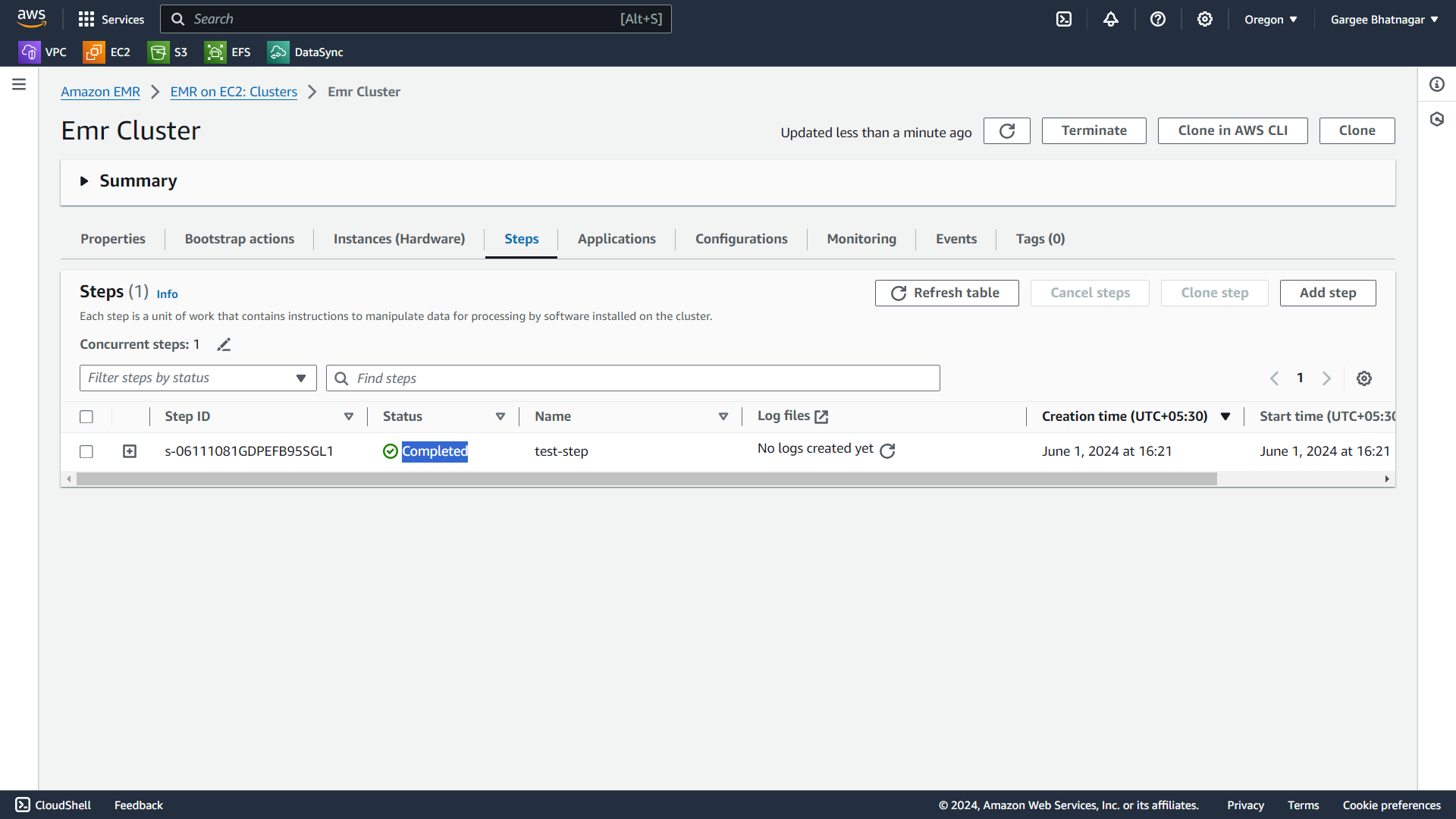
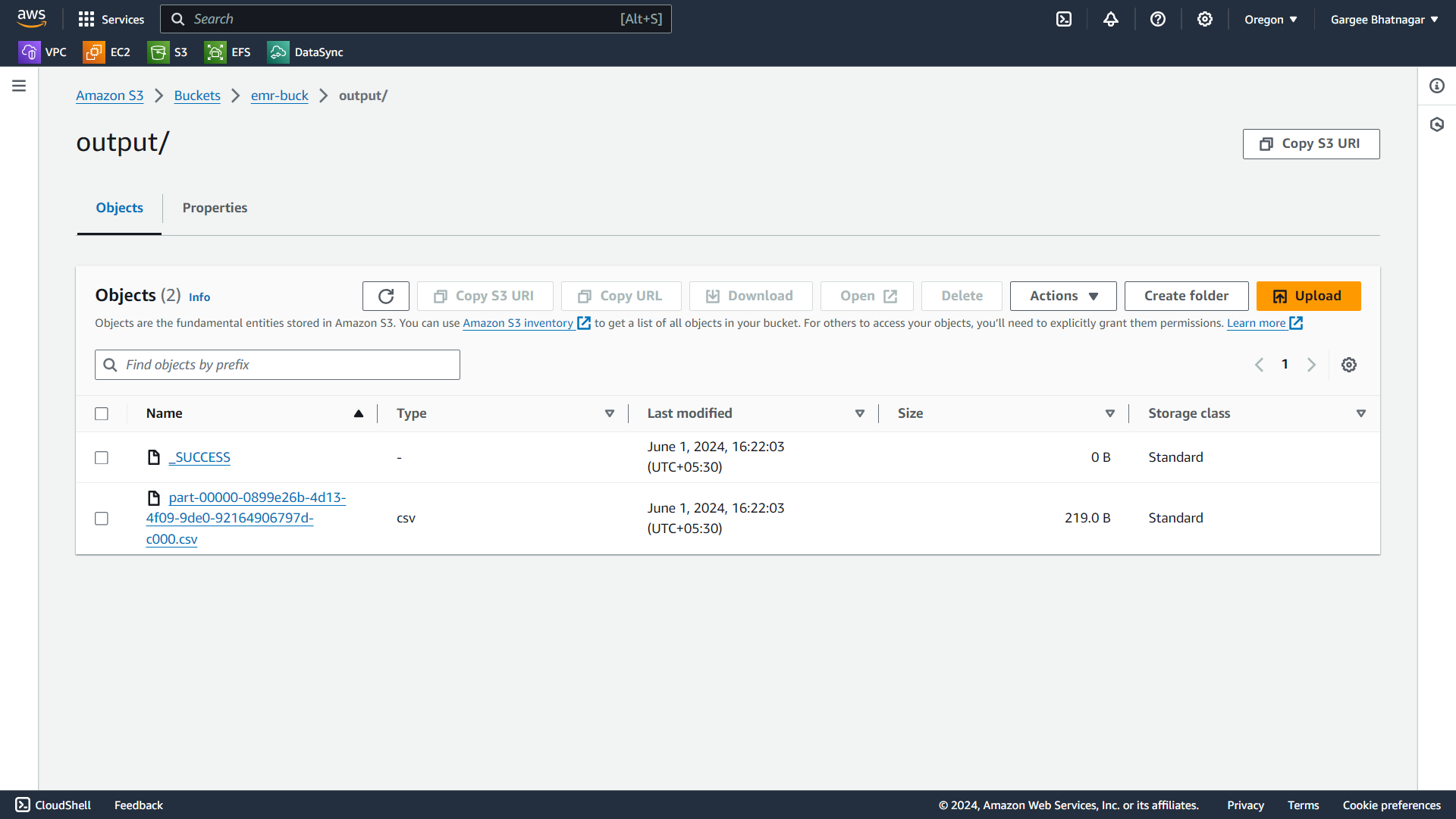
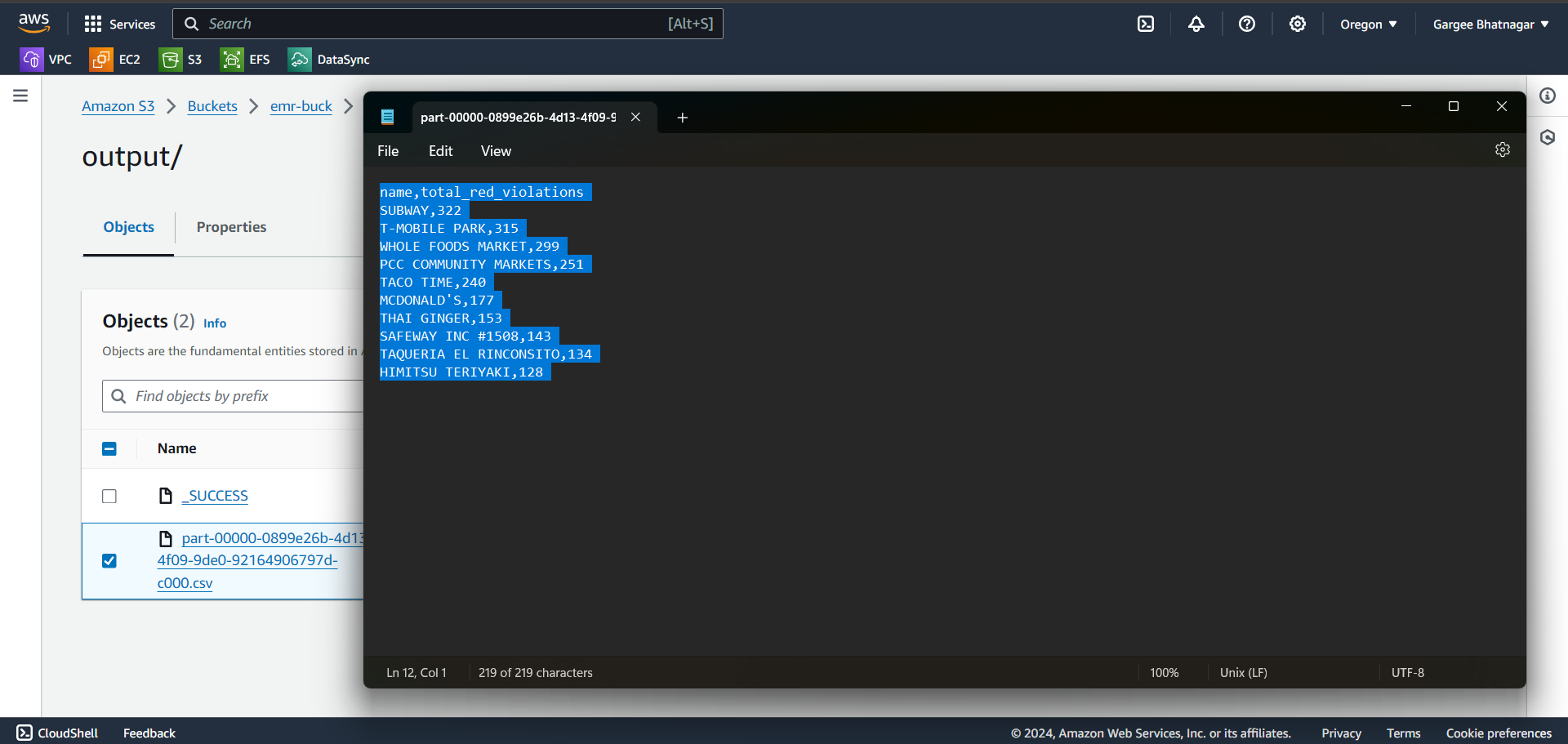
#Clean-up
Delete of Amazon EMR Cluster, IAM Roles, S3 Bucket, Key Pair.
#Pricing
I review the pricing and estimated cost of this example.
Cost of Amazon Elastic MapReduce service = $0.048 per hour for EMR m5.xlarge = $(0.048x1.086) = $0.05
Cost of Amazon Elastic Compute Cloud = $0.192 per On Demand Linux m5.xlarge Instance Hour = $(0.192x1.334) = $0.26
Cost of Amazon Simple Storage Service = $0.0
Total Cost = $0.31
#Summary
In this post, I showed “how to deep dive on amazon elastic mapreduce service platform with amazon ec2 instance”.
For more details on Amazon EMR Service, Checkout Get started Amazon EMR Service, open the [Amazon EMR Service console](https://us-west-2.console.aws.amazon.com/emr/home?region=us-west-2#/home). To learn more, read the [Amazon EMR Service documentation](https://docs.aws.amazon.com/emr/?icmpid=docs_homepage_analytics).
Thanks for reading!
Connect with me: [Linkedin](https://www.linkedin.com/in/gargee-bhatnagar-6b7223114)
 | bhatnagargargee |
1,873,589 | Pseudocode: Everything you need to know | Learn how to effectively use pseudocode with my ultimate guide. Understand what pseudocode is, and its importance in programming, and follow step-by-step instructions to master it. Includes practical examples and tips for creating clear, logical pseudocode to improve your coding skills. | 0 | 2024-06-02T10:00:33 | https://dev.to/bhargablinx/pseudocode-everything-you-need-to-know-3lj2 | coding, pseudocode, dsa, problemsolving | ---
title: Pseudocode: Everything you need to know
published: true
description: Learn how to effectively use pseudocode with my ultimate guide. Understand what pseudocode is, and its importance in programming, and follow step-by-step instructions to master it. Includes practical examples and tips for creating clear, logical pseudocode to improve your coding skills.
tags: #coding #pseudocode #dsa #problemsolving
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 for best results.
# published_at: 2024-06-01 09:34 +0000
---
## The Ultimate Pseudocode Guide | How to use it effectively
Before understanding how to use pseudocode, you must understand what it is and its importance. Let's get right onto it.
### Introduction
Pseudocode is a way of describing how a computer program should work using a human-readable language, generally English. In other words, it's a simplified version of programming code written in plain English before implementing it in a specific programming language. Think of it as a bridge between how humans think and how computers operate.
Pseudocode can also be referred to as a syntactical representation of a program and lacks strict syntax since it only represents the programmer's thinking process.
### Importance of Pseudcode
Here are the points why pseudocode is important
- **Language Agnostic**: Pseudocode helps programmers understand and write code because it is language agnostic and allows them to focus on solving the problem at hand without getting bogged down in the exact syntax of a programming language.
- **Visualization**: It also enables visualization of the entire solution to an algorithmic problem and helps break down large problems into smaller, manageable pieces.
- **Simplicity**: It uses simple, everyday words and phrases, avoiding the complex syntax and strict rules of programming languages.
### How to use pseudocode effectively?
Here is the step-by-step guide for using pseudocode effectively:
1. **Understand the Problem in Depth**: Ensure you thoroughly understand the problem without worrying about edge cases initially.
2. **Identify the Approach for Solving It**: Plan your approach and outline the steps needed to solve the problem.
3. **Start Writing**: Focus on the logic rather than syntax. Write down the steps in plain English.
4. **Use Consistent Formatting**: Maintain a consistent format throughout your pseudocode. Avoid using technical jargon.
5. **Iterate and Refine**: Review your pseudocode, refine it, and check for potential bugs.
### Examples
#### Example 1: Making a Cup of Tea
Imagine you want to write a program that makes a cup of tea. Here’s how you might write the pseudocode for that:
```
1. Boil water
2. Place a tea bag in a cup
3. Pour the boiling water into the cup
4. Let the tea steep for a few minutes
5. Remove the tea bag
6. Add sugar or milk if desired
7. Stir the tea
8. Serve the tea
```
#### Example 2: Finding the Largest Number in a List
Imagine you want to write a program that finds the largest number in a list of numbers. Here’s how you might write the pseudocode for that:
```
1. Start with an empty list of numbers
2. Initialize a variable 'largest' to be the first number in the list
3. For each number in the list:
a. If the current number is greater than 'largest':
i. Update 'largest' to be the current number
4. After checking all the numbers, 'largest' will hold the largest number in the list
5. Print or return 'largest'
```
### Conclusion
Pseudocode is a valuable tool for programmers to understand, write, and solve coding problems. By following suggested guidelines for writing pseudocode and practicing regularly, programmers can develop a personalized style that makes sense to them and improves their overall programming skills. | bhargablinx |
1,873,595 | Leveraging Next.js and Firebase for Dynamic Product Listings | Explore how to fetch and pass product data based on categories using Next.js and Firebase in server-side rendering context. | 0 | 2024-06-02T10:00:27 | https://dev.to/itselftools/leveraging-nextjs-and-firebase-for-dynamic-product-listings-44f9 | javascript, nextjs, firebase, webdev |
At [itselftools.com](https://itselftools.com), we've amassed abundant experience by developing over 30 projects using technologies like Next.js and Firebase. These tools provide robust solutions for building scalable, server-rendered web applications. Today, I’m excited to share a piece of what we’ve learned: specifically, how to dynamically fetch and display product listings based on categories using Firebase's Firestore and Next.js's `getServerSideProps`.
#### Understanding the Code Snippet
Here’s a quick look at the code we'll discuss:
```jsx
export asyncD function getServerSideProps(context) {
const categoryId = context.params.id;
const querySnapshot = await firebase.firestore().collection('products').where('categoryId', '==', categoryId).get();
const products = querySnapshot.docs.map(doc => ({ id: doc.id, ...doc.data() }));
return {
props: {
products
}
};
}
```
**Step-by-Step Breakdown:**
1. **Extracting Parameters**: The function starts by extracting `categoryId` from the dynamic route parameters using `context.params`. This parameter determines which product category the page should display.
2. **Querying Firestore**: Next, using Firebase's Firestore, the function queries the 'products' collection to find products that match the `categoryId`. Firestore's `.where()` method is perfect for this type of filtered search.
3. **Mapping Data**: Once the query is complete, the returned `querySnapshot` contains documents that match the criteria. These documents are mapped into a more convenient structure where each document’s ID and data are compiled into an object. This makes it easier to handle on the client side.
4. **Preparing for SSR**: Finally, the structured list of products is passed as a prop to the Next.js page through the `props` object in the return statement. This setup leverages Next.js’s server-side rendering capability to pre-fetch the product data before the page is served to the user, ensuring a quick load time and a dynamic, user-specific content.
#### Why Use `getServerSideProps`?
Using `getServerSideProps` in this context has several benefits:
- **SEO Friendly**: Server-side rendering improves SEO because search engine crawlers can see the fully rendered page.
- **Performance**: It reduces the initial load time since data is fetched during the server-side generation of the pages.
- **Real-time Data**: It fetches real-time data per request, making it extremely useful for applications like e-commerce sites where inventory and details might change frequently.
#### Conclusion
By integrating Next.js with Firebase, developers can create efficient, dynamic web applications that cater specifically to user needs while maintaining high performance and good SEO. If you’re curious to see these technologies in action, check out some of our applications at [Online Microphone Test](https://online-mic-test.com), [Listing Adjectives](https://adjectives-for.com), and [Word Translations](https://translated-into.com). These demonstrate practical implementations of dynamic data fetching and user-specific content rendering. | antoineit |
1,873,593 | Luna Silver: Nơi Hội Tụ Vẻ Đẹp Tinh Khiết Của Trang Sức Bạc | Luna SliverTrang sức luôn là phụ kiện không thể thiếu, góp phần tôn vinh vẻ đẹp và phong cách cá... | 0 | 2024-06-02T09:54:25 | https://dev.to/luna_sliver/luna-silver-noi-hoi-tu-ve-dep-tinh-khiet-cua-trang-suc-bac-2il0 | [Luna Sliver](https://lunasliver.com/)Trang sức luôn là phụ kiện không thể thiếu, góp phần tôn vinh vẻ đẹp và phong cách cá nhân. Trong số các loại trang sức, bạc luôn được ưa chuộng bởi sự tinh tế và thanh lịch. Luna Silver, một thương hiệu trang sức bạc uy tín, đã chinh phục được trái tim của nhiều người yêu trang sức nhờ vào chất lượng vượt trội và thiết kế độc đáo.
1. Nguồn Gốc Và Ý Nghĩa Của Luna Silver
Luna Silver được thành lập với mục tiêu mang đến cho khách hàng những món trang sức bạc hoàn hảo nhất. Lấy cảm hứng từ ánh trăng dịu dàng và tinh khiết, Luna Silver tượng trưng cho vẻ đẹp thanh thoát, bí ẩn và đầy cuốn hút. Mỗi món trang sức của Luna Silver không chỉ là phụ kiện mà còn là một tác phẩm nghệ thuật, chứa đựng những giá trị tinh thần và cảm xúc.
2. Quy Trình Chế Tác Tinh Xảo
Sự khác biệt của Luna Silver nằm ở quy trình chế tác tỉ mỉ và công phu. Bạc nguyên chất 925 được lựa chọn kỹ lưỡng, đảm bảo độ sáng bóng và bền bỉ. Các nghệ nhân tài hoa của Luna Silver luôn chăm chút từng chi tiết nhỏ nhất, từ khâu thiết kế, tạo hình cho đến hoàn thiện sản phẩm. Chính sự tỉ mỉ này đã tạo nên những món trang sức bạc độc đáo, mang đậm dấu ấn cá nhân.
3. Bộ Sưu Tập Đa Dạng
Luna Silver tự hào sở hữu những bộ sưu tập trang sức đa dạng, từ những mẫu thiết kế đơn giản, thanh lịch đến những kiểu dáng cầu kỳ, phức tạp. Dù bạn đang tìm kiếm một chiếc nhẫn bạc tinh tế, một đôi bông tai trang nhã hay một chiếc vòng cổ ấn tượng, Luna Silver đều có thể đáp ứng nhu cầu của bạn. Các bộ sưu tập của Luna Silver không chỉ bắt kịp xu hướng thời trang mà còn mang đậm nét riêng, giúp bạn thể hiện phong cách cá nhân một cách hoàn hảo.
4. Dịch Vụ Tận Tâm Và Chuyên Nghiệp
Không chỉ chú trọng đến chất lượng sản phẩm, Luna Silver còn đặc biệt quan tâm đến dịch vụ khách hàng. Từ khi bước chân vào cửa hàng cho đến khi rời đi, khách hàng luôn nhận được sự tư vấn nhiệt tình và chuyên nghiệp từ đội ngũ nhân viên. Các chính sách bảo hành, đổi trả minh bạch và linh hoạt cũng là điểm cộng giúp Luna Silver ghi điểm trong mắt người tiêu dùng.
5. Tầm Nhìn Và Sứ Mệnh
Luna Silver luôn hướng tới việc trở thành thương hiệu trang sức bạc hàng đầu, không chỉ trong nước mà còn trên thị trường quốc tế. Sứ mệnh của Luna Silver là mang đến cho khách hàng những sản phẩm trang sức không chỉ đẹp mắt mà còn có giá trị bền vững. Thương hiệu cam kết sử dụng các nguồn nguyên liệu an toàn và quy trình sản xuất thân thiện với môi trường, góp phần bảo vệ hành tinh xanh.
Luna Silver không chỉ là một thương hiệu trang sức bạc, mà còn là người bạn đồng hành đáng tin cậy của những ai yêu thích sự tinh tế và thanh lịch. Với chất lượng vượt trội, thiết kế đa dạng và dịch vụ tận tâm, Luna Silver đã và đang khẳng định vị thế của mình trong lòng người tiêu dùng. Nếu bạn đang tìm kiếm một món trang sức bạc hoàn hảo, Luna Silver chắc chắn sẽ là lựa chọn tuyệt vời dành cho bạn. | luna_sliver | |
1,872,854 | Creating a simple Message Bus: Episode 2 | Hello again to this series where I try to build a Message Bus, in the simplest way possible to... | 27,569 | 2024-06-02T09:52:58 | https://dev.to/breda/creating-a-simple-message-bus-episode-2-4nnf | go, architecture, learning, softwareengineering | Hello again to this series where I try to build a Message Bus, in the simplest way possible to understand the architecture and how it works.
In the first episode of this series, we talked about what a Message Bus is, why it's useful, and started off with the producer part of the code.
If you haven't read that one, please do as we're going to build on top of it.
Here's a simple diagram to help us see the components (Broker, Consumer, Producer) and how they interact with each other.
---
In this episode, I'm going to implement the broker part responsible of handling a new message, and storing it somewhere.
In other words, we're going to fully implement the green lines in the diagram above.
In the next episode however, we're going to tackle the consumers and that's when (hopefully, remember I don't know exactly how things are going... just going with the flow) all the pieces come together.
Enough talk, let's create out broker:
```go
// internal/broker/broker.go
type Broker struct {
config *BrokerConfig
// utils
decoder decoder.Decoder
// core
topics map[string]*Topic
}
```
- The `config` field is used to group all configuration in one place instead of having the `Broker` struct bloated with fields.
- Our broker needs to be able to "decode" messages sent by the producers, so a `Decoder` interface is needed, we'll implement it next.
- The `topics` field is a map between topic names, and `Topic` objects. We'll get back to this shortly.
### 1. Broker config
Here's how the `BrokerConfig` looks like:
```go
// internal/broker/config.go
type BrokerConfig struct {
// fields relevant to producers
ProducerHost string
ProducerPort string
}
```
For the time being, it only contains fields relevant to the producer part, but we'll add to it along the way.
### 2. Decoder
The interface of the decoder is
```go
// internal/shared/decoder/decoder.go
package decoder
import "mbus/internal/apiv1"
type Decoder interface {
Decode([]byte) (*apiv1.Message, error)
}
```
And we implement it using `msgpack`:
```go
// internal/shared/decoder/msgpack.go
package decoder
import (
"mbus/internal/apiv1"
"github.com/vmihailenco/msgpack"
)
type MsgpackDecoder struct {
}
func (*MsgpackDecoder) Decode(data []byte) (*apiv1.Message, error) {
var msg apiv1.Message
err := msgpack.Unmarshal(data, &msg)
if err != nil {
return nil, err
}
return &msg, nil
}
```
### 3. Topics
Let's zoom inside the broker's internals to understand what `map` looks like.
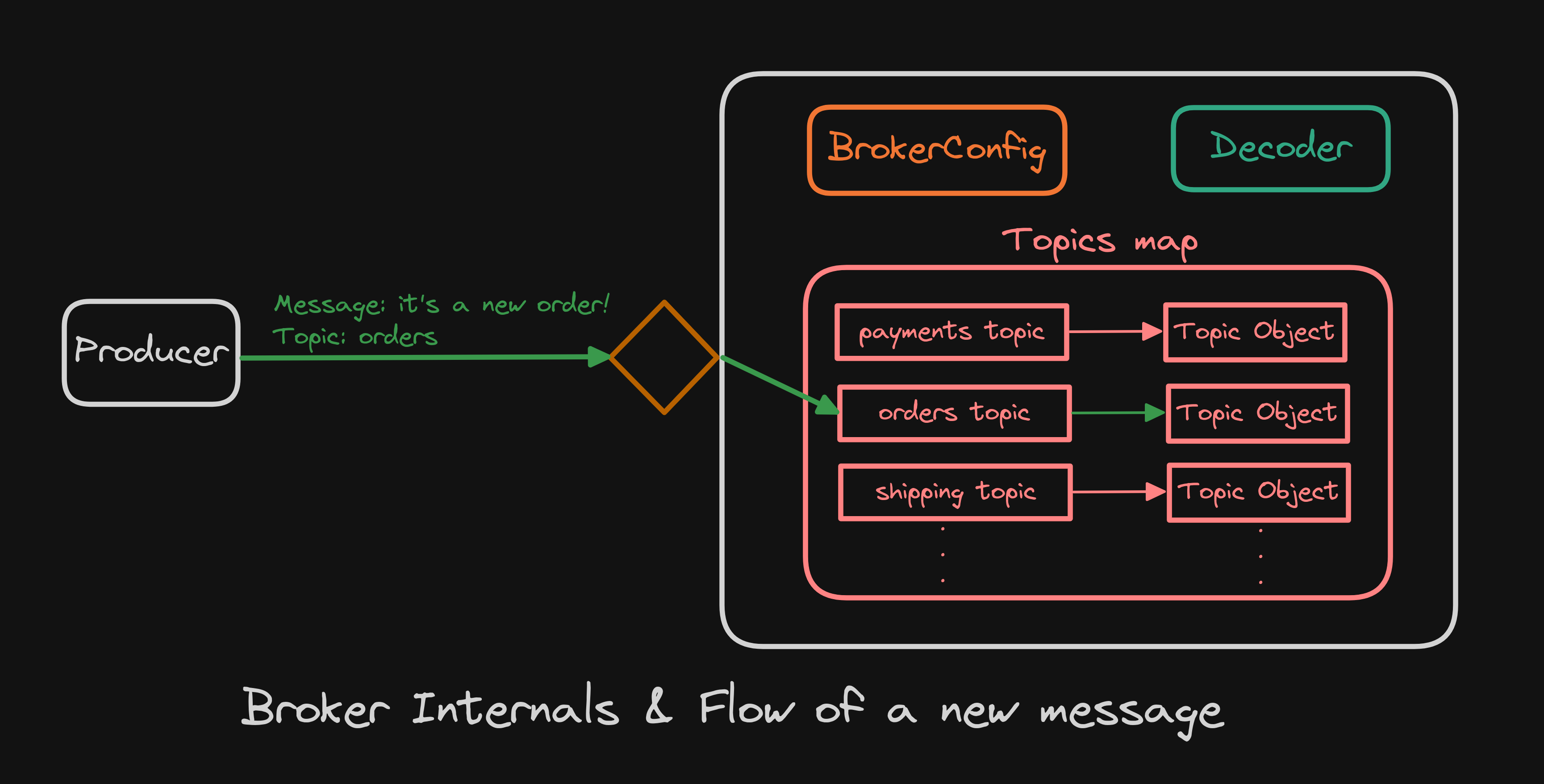
1. We receive a message from a producer on the "orders" topic (in read life, the message might be a JSON object describing the order).
2. We route it to the appropriate topic object using our `topics` map.
3. We add the message to the topic and diaptch
Note: Dispatch is a term used a lot in both event-based and messaging systems, and it just means delivering the event/message to all its listeners/consumers.
Because we don't have the consumer part of the system build yet, I wanted to just save the messages on the topic object itself until we build the consumer part.
To do that, we need the topic object to have a queue (First In, First Out) that we add messages to.
We can build a simple queue using a Go slice, but it's always best to use language-provided tools and mechanisms in its standard libary. We can use `container/list` package which implements a doubly-linked list as a queue.
Implementing a queue as a doubly-linked list is better in terms of memory reuse compared to a slice... We're not building [Kafka](https://en.wikipedia.org/wiki/Apache_Kafka) as to worry about memory optimizations but just saying.
Alright. I can hear you say "Enough talk, show me the code."
Let's first implement a queue using `container/list`:
```go
// internal/shared/queue/queue.go
package queue
import (
"container/list"
"mbus/internal/apiv1"
)
type MessageQueue struct {
list *list.List
}
func New() *MessageQueue {
return &MessageQueue{
list: list.New(),
}
}
func (q *MessageQueue) Enqueue(message *apiv1.Message) {
q.list.PushBack(message)
}
func (q *MessageQueue) Dequeue() *apiv1.Message {
if q.list.Len() == 0 {
return nil
}
message := q.list.Front()
q.list.Remove(message)
return message.Value.(*apiv1.Message)
}
func (q *MessageQueue) Len() int {
return q.list.Len()
}
```
Simple and effective.
Alright, with that done here's our `Topic`:
```go
// internal/broker/topic.go
package broker
import (
"mbus/internal/apiv1"
"mbus/internal/shared/queue"
)
type Topic struct {
Name string
Queue *queue.MessageQueue
}
func NewTopic(name string) *Topic {
return &Topic{
Name: name,
Queue: queue.New(),
}
}
func (topic *Topic) Dispatch(message *apiv1.Message) {
// for now, we only save the message in a queue
topic.Queue.Enqueue(message)
}
```
Again, quite simple stuff here.
Now that we have everything ready, let's implement the broker part responsible of handling a new message from producers.
```go
// internal/broker/broker.go
func (broker *Broker) ProducerListen() error {
listener, err := net.Listen("tcp", net.JoinHostPort(broker.config.ProducerHost, broker.config.ProducerPort))
if err != nil {
return err
}
for {
// Accept new connection
conn, err := listener.Accept()
if err != nil {
return err
}
// read it
data, err := io.ReadAll(conn)
if err != nil {
return err
}
message, err := broker.decoder.Decode(data)
if err != nil {
return err
}
// do something with the message
// for now, just print it
broker.HandleNewMessage(message)
// close it off
conn.Close()
}
}
```
Alright, let's see what `ProducerListen` does:
1. It creates a listener on the host/port combination provided in the config (we'll get them from command-line arguments once we implement the `cmd` for the broker)
2. We start by accepting a connection on the TCP listener we created. Mind you, this call will block (i.e. put our program to sleep) until a new connection is established.
3. After that, we read all data from that connection
4. We decode the raw data into a `apiv1.Message` object
5. We call `HandleNewMessage` with the message (we'll work on that function shortly)
6. Close off the connection.
7. And we keep doing steps 2-6 over and over again.
Our `ProducerListen` call is blocking in two ways:
- The call to `listener.Accept` will block the main thread (the main application path) so our broker won't be able to do anything else but to wait as well. That's kind of bad because we can't send/receive data to/from consumers.
- After we get a connection, you can see that we do a bunch of operations on it: read it, decode it and handle it. During this time, we can't receive new messages from producers because our main thread is busi handling the message we got. So if all those steps take 1 second to finish, we can only around receive 1 message per second. Our broker throughput is not its selling point.
Both of these points can be solved by introducing `goroutines` which allow us to take some of the work to the "background" and not halt the entire application when doing a blocking operation.
Introducing goroutines however, will complicate things a bit because we will need to protect ourselves from race conditions using synchronization services such as a Mutex or Semaphore.
But I said in the begenning of these series: everything will be as simple as it can be.
And I meant it. I want to avoid goroutines as much as possible, unless we need to.
Our code is trivial and easy to understand that way. Which is the goal of this series anyway.
Once we finalize everything we can gradually start making things better and better.
Alright, the `HandleNewMessage` is quite simple:
```go
// internal/broker/broker.go
func (broker *Broker) HandleNewMessage(message *apiv1.Message) {
// get the topic
topic, exists := broker.topics[message.Topic]
// if it does not exist, create it
if exists == false || topic == nil {
log.Printf("creating topic %s", message.Topic)
broker.topics[message.Topic] = NewTopic(message.Topic)
}
// add the message to the topic
log.Printf("new message dispatched on topic %s", message.Topic)
broker.topics[message.Topic].Dispatch(message)
}
```
1. We test whether we have a topic registerd with the message topic
2. If not, we create one using `NewTopic`
3. We call `Dispatch` on the topic.
If you recall from earlier, our `Dispatch` function from the `Topic` class only adds the message to a queue.
### Putting it all together
We got all the pieces, now we just need to glue them together with a command-line program:
```go
// cmd/broker/broker.go
package main
import (
"flag"
"log"
"mbus/internal/broker"
)
var (
produceHost string
producePort string
)
func main() {
parseFlags()
config := &broker.BrokerConfig{
ProducerHost: produceHost,
ProducerPort: producePort,
}
broker, err := broker.New(config)
if err != nil {
log.Fatalf(err.Error())
}
// Listen for producers sending in messages
log.Println("Broker: start listening for incoming producer messages...")
err = broker.ProducerListen()
if err != nil {
log.Fatalf(err.Error())
}
}
func parseFlags() {
flag.StringVar(&produceHost, "phost", "127.0.0.1", "The host to listen to for producer messages")
flag.StringVar(&producePort, "pport", "9990", "The port to listen to for producer messages")
flag.Parse()
}
```
1. We parse command-line flags (host and port where producers send messages to)
2. We create a `BrokerConfig` object with the config we got.
3. We create a broker instance with our config object
4. Then we start listening for new messages!
## Testing it out
At the end of each episode, we try to test our code to see if it works.
We do manual testing here. Nice.
Let's add this piece of code to our broker:
```go
// internal/broker/broker.go
func (broker *Broker) TestingThisOut() {
for _, topic := range broker.topics {
if topic == nil {
continue
}
for topic.Queue.Len() > 0 {
message := topic.Queue.Dequeue()
log.Printf("Received new message from topic '%s': '%s'", topic.Name, string(message.Data))
}
}
}
```
This will allow us to print any new messages we have in the queue of any topic that has any.
And let's add this to our broker command-line, between creating the broker and `ProducerListen`:
```go
// cmd/broker/broker.go
// broker.New call
ticker := time.Tick(3 * time.Second)
go func(ticker <-chan time.Time) {
for {
select {
case <-ticker:
broker.TestingThisOut()
}
}
}(ticker)
// calling ProducerListen here.
```
This code, will run forever in the background, periodically every 3 seconds, and will call `TestingThisOut` function (well thought of name) which will print messages stored in queues of topics.
Now we're ready to test.
Open two terminals. Make sure you run `make` to rebuild the project.
Run the broker in one of them:
```bash
./build/broker
```
And send a message in the second terminal
```bash
./build/producer -topic orders -message "look ma! a new order"
```
Get back to the terminal where you ran your broker, and you should see something like this:
```
2024/06/02 10:39:43 Broker: start listening for incoming producer messages...
2024/06/02 10:39:52 creating topic orders
2024/06/02 10:39:52 new message dispatched on topic orders
2024/06/02 10:39:55 Received message from topic orders: look ma! a new order
```
And that concludes this episode.
See you in the next one!
| breda |
1,873,591 | Clock App | Clock App with Multiple Functionalities - An Overview If you're looking for a versatile... | 0 | 2024-06-02T09:40:32 | https://dev.to/sudhanshuambastha/clock-app-1n9m | clock, css, html, javascript | ## Clock App with Multiple Functionalities - An Overview
If you're looking for a versatile clock application with a range of built-in features, look no further than the **Clock App** repository by [Sudhanshu Ambastha](https://github.com/Sudhanshu-Ambastha/Clock). This app comes packed with functionalities like a stopwatch, alarm, world clock, and timer to cater to your time management needs effectively. I drew inspiration from the mobile version but made some updates to adapt it to laptop screens and other specifications.
## Features
- **Stopwatch:** Measure time intervals with precision.
- **Alarm:** Set alarms for specific times.
- **World Clock:** Stay updated with the current time in cities around the world.
- **Timer:** Set countdown timers for your activities and tasks.
## Examples
- 
- 
- 
- 
- 
You can try out a live preview in the repo as a GIF has been added as a preview.
## How to Use
1. **Clone the repository** to your local machine.
2. **Open the `index.html`** file in a web browser.
3. **Navigate** through different clock functionalities using the tabs.
4. **Set alarms, start timers,** and explore other features as required.
**Technologies Used**
[](https://skillicons.dev)
## Contributing
You can contribute to this project by:
- **Submitting pull requests**
- **Opening issues** for bugs or feature requests
I am also attempting to add a countdown timer animation as an SVG, akin to the one present in the real clock app, but I have yet to succeed in this endeavor as I am facing error in this 😅 so you know how to do it can you suggest me something?? So that I can add this feature in it.
## Deployed Clock Model
Experience the functionalities firsthand by exploring the **[deployed clock model]()**.
Let's make time management more efficient and easier with this Clock App! 🌟
- GitHub repo link: - [Clock App](https://github.com/Sudhanshu-Ambastha/Clock)
- website link for testing: - [Clock App](https://clock-mu-self.vercel.app/)
This repo has garnered 4 stars, 6 clones, and 23 views, making he clock application popular among individuals looking for convenient ways to set alarms, check the time, and manage their daily schedules specially in laptop or pc. While many have cloned my projects, only a few have shown interest by granting them a star. **Plagiarism is bad**, and even if you are copying it, just consider giving it a star.
| sudhanshuambastha |
1,873,587 | Error v/s Exception | Have you ever been confused between an error and an exception? We often tend to use these words... | 0 | 2024-06-02T09:16:00 | https://dev.to/dipesh_the_dev/error-vs-exception-5h7d | javascript, programming, webdev, development | Have you ever been confused between an error and an exception? We often tend to use these words interchangeably. Well, they are not the same, since they have nuanced differences. Let us understand these differences with examples.
##Error
An error usually refers to a condition that hinders a program's normal execution. It can be due to issues like:
#### 1. Syntax Errors
Errors which occurs when we have mistakes in our code that prevents the compiler from parsing our program correctly.
```javascript
// Syntax error example:
function greet() {
console.log("Hello world!"; // SyntaxError: missing ) after argument list
}
```
#### 2. Runtime Errors
Errors that occur during the execution of the program.
- Reference Errors: When trying to access a variable that doesn’t exist.
- Type Errors: When an operation is performed on an incompatible type.
```javascript
// Reference error example:
console.log(person); // ReferenceError: person is not defined
// Type error example:
let age = 28;
age.toUpperCase(); // TypeError: age.toUpperCase is not a function
```
##Exception
An exception is a specific type of error that can be anticipated, caught and handled. It allows us to handle errors gracefully and does not break the program.
Exception handling involves:
#### 1. Throwing an Exception:
When an error occurs, the program "throws" an exception. We can throw an exception using `throw` keyword.
```javascript
function divide(num1, num2) {
if (num2 === 0) {
throw new Error("Division by zero");
}
return num1 / num2;
}
```
#### 2. Catching an Exception:
We can handle expections using try...catch...finally block.
```javascript
try {
divide(1, 0);
} catch (error) {
console.log(error.message); // Output: Division by zero
} finally() {
console.log("Done");
}
```
**Note**: finally block is optional and it is executed regardless of whether there was an exception or not.
## Conclusion
In simple terms, all exceptions are errors, but not all errors are exceptions. Errors are problems that can happen in a program, while exceptions are a special type of error that you can "throw" and "catch" to handle them smoothly. Knowing the difference helps you write better and more reliable code.
| dipesh_the_dev |
1,873,586 | Revolutionizing Development with Type-Safe Dropbox SDK | Hello everyone, السلام عليكم و رحمة الله و بركاته The Dropbox Software Development Kit (SDK) is a... | 0 | 2024-06-02T09:15:23 | https://dev.to/bilelsalemdev/revolutionizing-development-with-type-safe-dropbox-sdk-nod | typescript, javascript, backend, programming | Hello everyone, السلام عليكم و رحمة الله و بركاته
The Dropbox Software Development Kit (SDK) is a powerful tool that significantly streamlines the development process by offering type safety, which ensures code reliability and efficiency. By integrating Dropbox SDK into your projects, you can leverage cloud storage capabilities seamlessly, reducing development time and enhancing the overall user experience.
## Introduction to Dropbox SDK
Dropbox SDK provides developers with the means to interact with Dropbox’s API. It allows for operations such as file upload, download, sharing, and more, making it an essential tool for applications that require robust file management capabilities. The SDK supports multiple programming languages, including Python, Java, JavaScript, and Swift, catering to a wide range of development environments.
## Benefits of Type Safety in Dropbox SDK
### 1. **Error Reduction**
Type-safe SDKs ensure that variables are used consistently throughout the code. This means that many common programming errors, such as type mismatches or incorrect method calls, are caught at compile-time rather than at runtime. This preemptive error detection reduces bugs and improves code stability.
### 2. **Enhanced Code Readability and Maintenance**
Type safety makes the codebase more understandable and easier to maintain. When data types are explicitly defined, developers can quickly grasp the purpose and usage of variables and functions, facilitating smoother transitions and collaborations within development teams.
### 3. **Intelligent Code Completion**
Modern Integrated Development Environments (IDEs) leverage type information to provide intelligent code completion, helping developers write code faster. This feature not only speeds up the coding process but also ensures that the methods and properties being accessed are valid, reducing the likelihood of errors.
### 4. **Improved Refactoring**
Refactoring is a critical part of maintaining and improving code quality. Type-safe codebases make refactoring easier and safer since the IDE can reliably track where and how variables and methods are used, ensuring that changes do not introduce new bugs.
## Key Features of Dropbox SDK
### 1. **Easy Authentication**
The Dropbox SDK simplifies the authentication process with OAuth 2.0, allowing users to securely log in and grant your application access to their Dropbox files without exposing their credentials.
### 2. **File Operations**
With Dropbox SDK, developers can effortlessly implement file operations such as uploading, downloading, listing, and deleting files. The SDK handles all the complexities of interacting with the Dropbox API, enabling developers to focus on building their application's core functionalities.
### 3. **Sharing and Collaboration**
Dropbox SDK provides comprehensive tools for sharing files and folders, including generating shareable links and managing permissions. These features are crucial for applications that prioritize user collaboration and content sharing.
### 4. **Real-time Notifications**
For applications requiring real-time updates, Dropbox SDK supports webhooks and other mechanisms to notify your application of changes in the user's Dropbox account, ensuring that your application stays in sync with the latest data.
### 5. **Single and Batch File Uploads**
Dropbox SDK supports both single file uploads and batch file uploads, making it highly versatile. Whether you need to upload a single document or a large number of files simultaneously, the SDK provides the necessary functionality to handle both scenarios efficiently.
### 6. **Handling Rate Limits with Batch Uploads**
To avoid hitting rate limits imposed by Dropbox, you can use the `filesUploadSessionStartBatch` with `session_type` set to `concurrent`. This allows multiple files to be uploaded in parallel, effectively managing large numbers of upload requests without violating rate limits.
### 7. **Uploading Large Files in Chunks**
For uploading large files, the Dropbox SDK provides `filesUploadSessionStart`, allowing files to be split into smaller chunks. This method ensures that even very large files can be uploaded reliably without running into size limitations or network issues.
## Conclusion
The Dropbox SDK, with its type-safe design, revolutionizes development by ensuring code reliability, enhancing readability, and speeding up the development process. By integrating Dropbox SDK into your projects, you can harness the power of cloud storage with ease, allowing you to focus on creating innovative and user-friendly applications.
Leveraging the benefits of type safety and the robust features offered by Dropbox SDK, including single and batch file uploads, handling rate limits with concurrent sessions, and uploading large files in chunks, developers can deliver high-quality applications faster and with fewer errors, ultimately providing a superior user experience.
For more details on optimizing Dropbox SDK performance and handling large files, you can refer to the [Dropbox Performance Guide](https://developers.dropbox.com/dbx-performance-guide#:~:text=If%20uploading%20large%20files%2C%20optionally,the%20file%20over%20multiple%20requests) and for the docs of Dropbox SDK you can refer to [Dropbox SDK Docs](https://dropbox.github.io/dropbox-sdk-js/global.html). Whether you're building a small app or a large-scale enterprise solution, Dropbox SDK is a valuable tool that can help you achieve your development goals more efficiently.
| bilelsalemdev |
1,873,585 | Need idea to run my React Native runs offline no matter distance (country) | I'm working on a React-Native project that works offline and serves people that use the same Public... | 0 | 2024-06-02T09:14:49 | https://dev.to/chegmarco/need-idea-to-run-my-react-native-runs-offline-no-matter-distance-country-27cj | reactnative | I'm working on a React-Native project that works offline and serves people that use the same Public IP address or are on the same WiFi network.
But I want to internationalize (long distance) it using the same Public IP process without internet connection.
Can you give me any idea to make something like unique Public IP address for anybody that uses that application never mind where he is in the world ???
What I'm looking for is an idea that should consider anybody as local network user (with Public IP Address) no matter where (the country he) is living so that to make my application works without internet connection.
Please, give me an idea if you have. | chegmarco |
1,873,584 | Innovative Approaches in Indian Rehabilitation Centres: Combining Traditional and Modern Therapies | In the current Pearl of the Orient known as India, Rehabilitation Centre have not been left behind.... | 0 | 2024-06-02T09:10:54 | https://dev.to/tulasirehabilitation/innovative-approaches-in-indian-rehabilitation-centres-combining-traditional-and-modern-therapies-23h8 | In the current Pearl of the Orient known as India, Rehabilitation Centre have not been left behind. This transformation is especially due to the combination of conventional methods and evidence-based practices that exist in psychotherapy. These are progressive models that are currently being embraced to drive the rehabilitation strategies, which are providing comprehensive care that meets the vast wants of patients. Here are the details of how these centres are blending two worlds to ensure they offer all the rehabilitation services required.

Traditional Therapies: In chapter four, Blakely lays out the foundation of healing, describing it as the bedrock upon which all advances in medicine rest.
Ayurveda, yoga, and Siddha have deep rooted origin in the healthcare of India and has been practicing for many centuries. These early strategies of medicine and healing embrace the physiological, mental, and spiritual aspects of an individual with the intention of ensuring health and wellness.
1. Ayurveda: Most of the rehabilitation centres across India include Herbal Medicines, Panchakarma therapies which involves detoxifying , and Restriction in the type of food advisory. This is because these treatments assist in the removal, reduction and improvement on the body’s immunity in other aspects that causes stress.
2. Yoga and Meditation: Yoga entails a range of activities including exercises that involve physical body postures, special breathing patterns, and meditation, and is easily integrated in rehabilitation programs. Flexibility exercises help the body to develop strength and clarity of mind thus support its functions in healing.
3. Siddha Medicine: Siddha medicine is the traditional medicine system that has evolved from the Tamil Nadu state of India, and for its treatment does use natural products like herbs and metals. These treatments are incorporated in rehabilitation centres as a way of enabling management of chronic ailments and long term treatment.
Modern Therapies: Scientific Advancements in Rehabilitation
Modern therapies used in [Rehabilitation Centre in India ](https://www.tulasihealthcare.com/rehabilitation-centre-in-india/)however, work hand in hand with central regular approaches.
1. Physiotherapy: Electrical stimulation, ultrasound therapy and hydrotherapy which form part of the physiotherapy treatment interventions are vital components in rehabilitation processes. These techniques are useful in analgesia, rehabilitation, and treatment duration..
2. Occupational Therapy: This therapy aims more at enabling the person affected to be as independent as possible in undertaking his / her activities daily. The interventions include activities and methods of treating clients, which apply advanced informatics technology and tools, for instance virtual reality, adaptive devices, etc.
3. Cognitive Behavioural Therapy (CBT): In mental health rehabilitation specifically, CBT is common in treating the disorders such as anxiety, depression, and PTSD. It assists patients in their effort to overcome their social phobia and build optimistic mental state.
4. Robotics and Assistive Technology: Technological application of robotics in the aspect of rehabilitation, for instance, robotic exoskeleton for gait training, modern prosthetics, and robotic rehabilitation that utilizes mechanisms like robots for aiding in the rehabilitation procedures are transforming physical rehabilitation. These technologies allow for the tailored therapy and carefully planned improvement of treatment.
Combining Traditional and Modern Therapies: A Holistic Approach
The measure of change that sets Rehabilitation Centre new India apart is not the practice of modern or Traditional therapies alone, but the blending of the two methodologies. This progressive model of operation confirms that clients get total care, from physical to the psychological aspect in their bodies.
1. Personalized Treatment Plans: The treatment program can be developed based on the integrative approach of using both conventional and innovative movement practices. For instance, an elder patient that suffered a stroke may undergo physiotherapy and robotic physical therapy in addition to the Ayurvedic massaging and yoga.
2. Enhanced Recovery Rates: It is found that the existence of the facility of embracing both traditional and modern therapeutic approaches makes recovery rates faster and last longer. In this case, the strengths of both approaches becomes evident- Patients feel less pain, can move more freely and experience an improvement in their psychological well-being..
3. Cultural Sensitivity and Acceptance: Other traditional practice integrates in the rehabilitation due to cultural relevancy thus making the rehabilitation service acceptable and achievable by majority of the population. According to the culture of the patients, they feel at ease in their treatments throughout the service provision.
4. Comprehensive Wellness Programs: Several rehabilitation centres prohibit the consumption of certain foods and give a modern diet plan with the assistance of Ayurveda, psychological counselling, and exercising. These programs are helpful in ensuring adequate nutrition and avoiding a lapse back into the use of drugs.
Conclusion
For the first time in the treatment paradigms of India, Rehabilitation Centre is attempt to unify both the conventional and contemporary approaches to heal the patients. It not only helps in bringing out the best in the rehabilitation process but it also pays respect to the Indian culture and tradition. These centres are definitely expected to be developing further and to provide even more extensive, and all-sided care to the patients contributing to their general health and healing.
| tulasirehabilitation |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.