
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,449,283 | Testing Step Functions Locally | Have you built a Step Function with many steps, retries and end states - but you are left wondering,... | 0 | 2023-04-26T20:36:23 | https://instil.co/blog/testing-step-functions-locally/ | aws, serverless, stepfunctions | ---
canonical_url: https://instil.co/blog/testing-step-functions-locally/
---
Have you built a Step Function with many steps, retries and end states - but you are left wondering, how do I test this masterpiece to ensure it's as wonderful as I think it is? Then you've come to the right place! Have a look at how we test Step Functions locally to give you more confidence in your work.
---
As you may have seen in our previous posts, we love Step Functions. It's great being able to build your Step Function in the console, see the payloads passing through your states and everything going green for you to say “Wooh! You’ve stepped through a Step Function successfully.”. But what if it didn’t, and it’s actually not doing what you expect, it’s going red and throwing useless errors or worse, it’s green but not giving you the response you want. What do you need? Tests!
## What does AWS provide to help you test?
AWS itself provides some basic tools required for testing Step Functions - no they’re not the silver bullet in which you can just quickly write and run to test your Step Functions - but they certainly give you a jump start.
[Step Functions Local](https://docs.aws.amazon.com/step-functions/latest/dg/sfn-local.html) documentation states:
> AWS Step Functions Local is a downloadable version of Step Functions that lets you develop and test applications using a version of Step Functions running in your own development environment.
With Step Functions Local you can test locally or as part of a pipeline. You can test your flows, inputs, outputs, retries, back-offs and error states to ensure it performs as you expect.
*Note:*
Step Functions Local can sometimes be behind the Step Functions feature set. We have noticed when a new feature is implemented in Step Functions, the Step Functions Local container image may not be updated to include those features immediately. This is understandably not ideal - but you can keep an eye on the container [here](https://hub.docker.com/r/amazon/aws-stepfunctions-local/tags) for new versions in which AWS are actively updating.
## How to get it up and running
At Instil, we knew that we needed to run these tests as part of the pipeline but also run them locally when developing or investigating issues. AWS kindly provides some help with running the tests via the AWS CLI which is great, but we wanted to create these tests to last and have them run as part of our deployment pipeline. So we found this solution.
Here’s what you need:
1. AWS Step Functions Local ([Docker Image](https://docs.aws.amazon.com/step-functions/latest/dg/sfn-local-docker.html))
2. [Testcontainers](https://www.npmjs.com/package/testcontainers) package
3. [AWS SDK](https://www.npmjs.com/package/aws-sdk) package
4. [Wait For Expect](https://www.npmjs.com/package/wait-for-expect) package
### Step 1: Have a look at your Step Function
The Step Functions Workflow Studio is great for building out your Step Function in the console. It makes creating your Step Function user-friendly and makes visualising it super easy. Here we have an example Step Function.
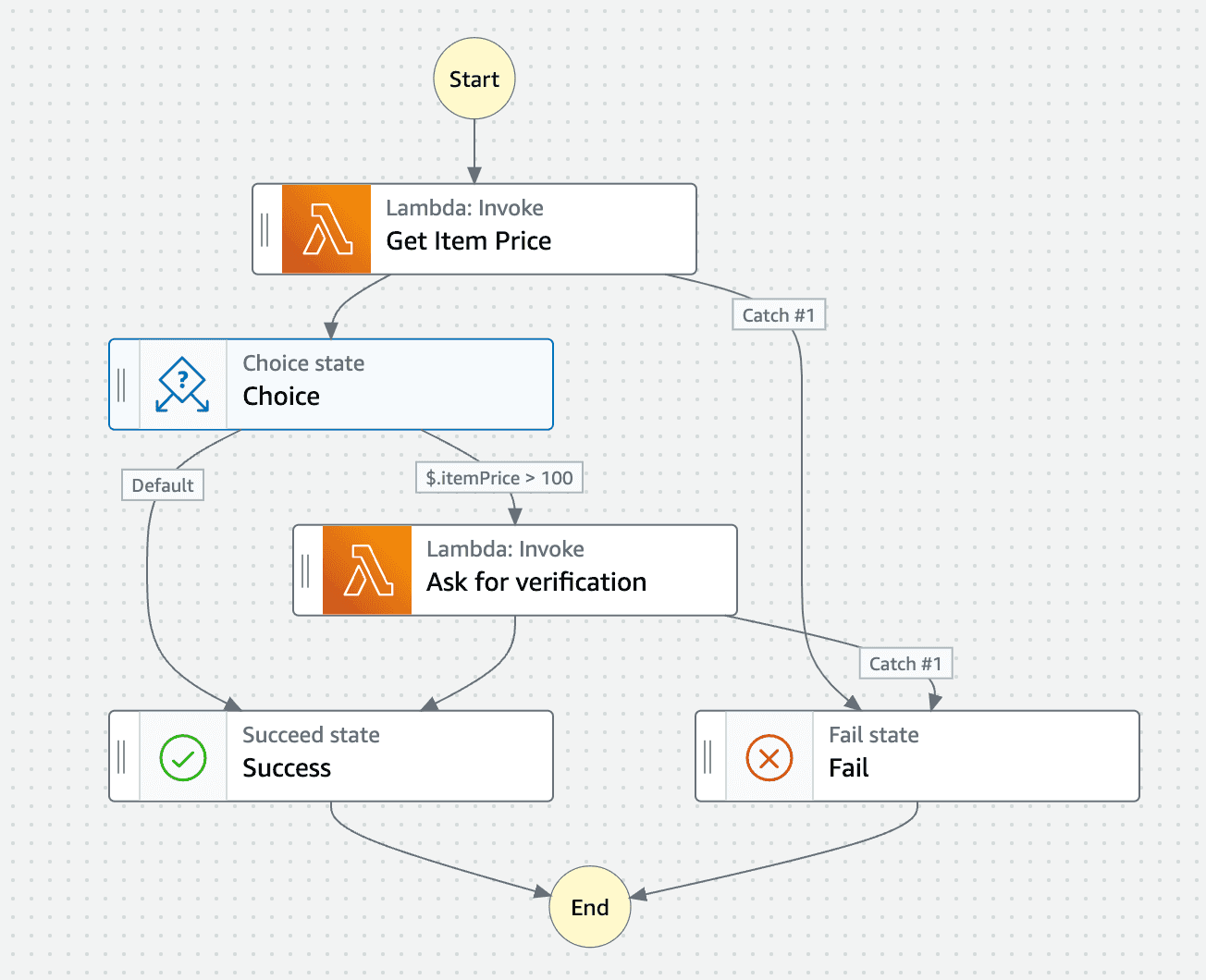
<br/>
It has a couple of lambdas, a choice state for checking the response of the first lambda and some success and failure paths. It has 4 flows which we would want to test if I can count correctly:
1. Get Item Price → “Item Price <= 100” → Success
2. Get Item Price → “Item Price > 100” → Ask for verification → Success
3. Get Item Price → Fail
4. Get Item Price → “Item Price > 100” → Ask for verification → Fail
Now we have an idea of what we want to test from our Step Function, we can get to work.
### Step 2: Download your ASL file from the Step Function Workflow Studio
To use the Step Function Local container, we need our Step Function in [ASL](https://docs.aws.amazon.com/step-functions/latest/dg/concepts-amazon-states-language.html) (Amazon States Language) which is AWS’ own language for defining Step Functions and their states. You can do this from the Step Function console by exporting the JSON definition.
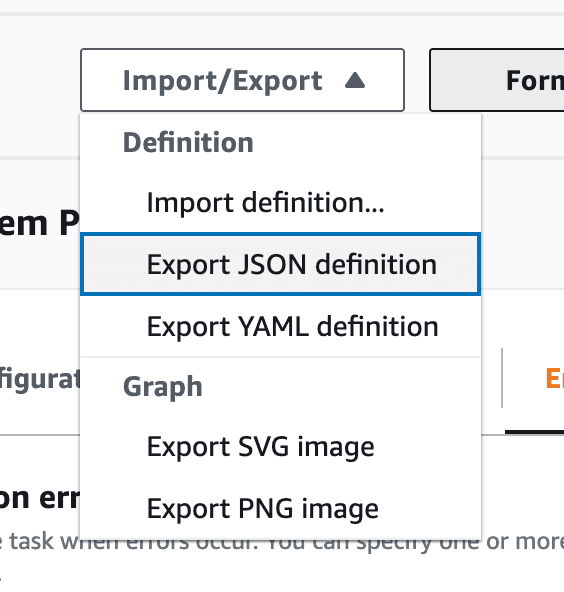
### Step 3: Get that Docker container spinning
You need the container up and running to be able to run the Step Function locally within it, we used `testcontainers` to spin up the short-lived container and have it ready for testing.
```
import {GenericContainer} from "testcontainers";
const awsStepFunctionsLocalContainer = await new GenericContainer("amazon/aws-stepfunctions-local")
.withExposedPorts(8083)
.withBindMount("your-path-to/MockConfigFile.json", "/home/MockConfigFile.json", "ro")
.withEnv("SFN_MOCK_CONFIG", "/home/MockConfigFile.json")
.start();
```
<br/>
*Note:*
- Test Containers picks a random free port on the host machine and uses 8083 above to map it, so you don’t need to worry about clashes.
- `MockConfigFile.json` is the file we use for mocking how the AWS services respond in your Step Function test executions, we will come to how to create those in the next step!
### Step 4: Create your MockConfigFile
The use of a mock config file is how we define the test cases, flows and responses of AWS service integrations within the Step Function. It makes up the meat of your Step Function testing journey and ultimately controls how detailed you want your tests to be.
The mock config is a JSON file which according to AWS’ own [documentation](https://docs.aws.amazon.com/step-functions/latest/dg/sfn-local-mock-cfg-file.html#mock-cfg-struct) includes:
- `StateMachines` - The fields of this object represent state machines configured to use mocked service integrations.
- `MockedResponse` - The fields of this object represent mocked responses for service integration calls.
Here’s what ours looks like as a finished product below. Make sure the names of the steps are identical to those named in the ASL file i.e “Get Item” in the test case is “Get Item” from the ASL file.
*Note:*
A great thing you can do in this file also detailed in the AWS documentation is to test the retry and backoff behaviour of some of your steps. For example, you could test that a lambda responds with an error on its first invocation, automatically retries and then returns successfully on its second invocation. Something like this is shown in the `MockedGetItemAbove100` mocked response below.
```
{
"StateMachines": {
"ItemPriceChecker": {
"TestCases": {
"shouldSuccessfullyGetItemWithPriceBelow100": {
"Get Item Price": "MockedGetItemBelow100"
},
"shouldSuccessfullyGetItemAndVerifyWithPriceEqualOrAbove100": {
"Get Item Price": "MockedGetItemAbove100",
"Ask for verification": "MockedAskForVerificationSuccess"
},
"shouldFailToGetItem": {
"Get Item Price": "MockedGenericLambdaFailure"
},
"shouldFailToVerifyItemWithPriceEqualOrAbove100": {
"Get Item Price": "MockedGetItemAbove100",
"Ask for verification": "MockedGenericLambdaFailure"
}
}
}
},
"MockedResponses": {
"MockedGetItemBelow100": {
"0": {
"Return": {
"StatusCode": 200,
"Payload": {
"StatusCode": 200,
"itemPrice": 80
}
}
}
},
"MockedGetItemAbove100": {
"0": {
"Throw": {
"Error": "Lambda.TimeoutException",
"Cause": "Lambda timed out."
}
},
"1": {
"Return": {
"StatusCode": 200,
"Payload": {
"StatusCode": 200,
"itemPrice": 100
}
}
}
},
"MockedAskForVerificationSuccess": {
"0": {
"Return": {"StatusCode": 200}
}
},
"MockedGenericLambdaFailure": {
"0": {
"Throw": {
"Error":"Lambda.GenericLambdaFailure",
"Cause":"The lambda failed generically."
}
}
}
}
}
```
### Step 5: Prepping the tests
So you have the Step Function and test cases ready, all you need now is to get them running. This first function will get the client for the Step Function Local container and allow you to run commands against it for testing the local version of your Step Function:
```
import {SFNClient} from "@aws-sdk/client-sfn";
const sfnLocalClient = new SFNClient({
endpoint: `http://${awsStepFunctionsLocalContainer?.getHost()}:${awsStepFunctionsLocalContainer?.getMappedPort(8083)}`,
region: "eu-west-2",
credentials: {
accessKeyId: "test",
secretAccessKey: "test",
sessionToken: "test"
}
});
```
<br/>
***Important:***
As you can see, we used “test” above for the credentials. This is to ensure the Step Function doesn’t interact with our actual deployed environment in AWS.
Step Functions Local allows you to run tests against actual deployed services (so feel free to do so for your case) but since we have mocked the services using `MockConfigFile.json` then we don’t want to do that. By using fake credentials then it just defaults to the mocked services from our file.
<br/>
Next, create your local Step Function instance in the docker container using the client just created.
```
import {CreateStateMachineCommand} from "@aws-sdk/client-sfn";
import {readFileSync} from "fs";
const localStepFunction = await sfnLocalClient.send(
new CreateStateMachineCommand({
definition: readFileSync("your-path-to/ItemPriceCheckerAsl.json", "utf8"),
name: "ItemPriceChecker",
roleArn: undefined
})
);
```
<br/>
You can then start a Step Function execution for one of the test cases. This will run the Step Function in the container and use the mocked AWS service integrations defined in the `MockConfigFile.json` to determine the path it takes. Here is the function you can use, we have it wrapped here so it can be ran for each specific test case.
The `stepFunctionInput` is a JSON string of what you would be passing in to the Step Function. In our case for the `ItemPriceChecker` there is no input to the Step Function as the item price is retrieved in the first step - so the input can be anything e.g `{}`. Make sure for your own Step Function to pass in any input required or use `{}` similar to the example if no input is required.
```
import {StartExecutionCommand, StartExecutionCommandOutput} from "@aws-sdk/client-sfn";
async function startStepFunctionExecution(testName: string, stepFunctionInput: string): Promise<StartExecutionCommandOutput> {
return await sfnLocalClient.send(
new StartExecutionCommand({
stateMachineArn: `${
localStepFunction.stateMachineArn as string
}#${testName}`,
input: stepFunctionInput
})
);
}
```
### Step 6: Finally some testing!
Now you have your running Step Function execution for a particular test case, we need to actually test it worked. This is where AWS isn’t super helpful, there is no provided API for interacting with the Step Function execution and determining how the Step Function handled your test data. So we had to make our own! Sort of.
Here’s an example using the Step Function execution from above:
```
import {GetExecutionHistoryCommand, GetExecutionHistoryCommandOutput, StartExecutionCommandOutput} from "@aws-sdk/client-sfn";
import waitFor from "wait-for-expect";
it("should successfully get item with price below 100", async () => {
const stepFunctionInput = {};
const expectedOutput = JSON.stringify({
StatusCode: 200,
itemPrice: 80
});
// This runs the Step Function and returns the execution details using the function created earlier in the post
const stepFunctionExecutionResult = await startStepFunctionExecution(
"shouldSuccessfullyGetItemWithPriceBelow100",
stepFunctionInput
);
// This checks the states to ensure the execution successfully completed with the correct output
await thenTheItemPriceIsReturned(stepFunctionExecutionResult, expectedOutput);
});
async function thenTheItemPriceIsReturned(
startLocalSFNExecutionResult: StartExecutionCommandOutput,
expectedOutput: string
): Promise<void> {
// Since the execution arn is provided, it could still be running so this waits for the execution to finish by checking for the result you need
await waitFor(async () => {
const getExecutionHistoryResult = await getExecutionHistory(startLocalSFNExecutionResult.executionArn);
const successStateExitedEvent = getExecutionHistoryResult.events?.find(event => event.type === "SucceedStateExited");
expect(successStateExitedEvent?.stateExitedEventDetails?.name).toEqual("Success");
expect(successStateExitedEvent?.stateExitedEventDetails?.output).toEqual(expectedOutput);
});
}
async function getExecutionHistory(executionArn: string | undefined): Promise<GetExecutionHistoryCommandOutput> {
return await sfnLocalClient.send(
new GetExecutionHistoryCommand({
executionArn
})
);
}
```
<br/>
There is a lot of information above but at its heart, it simply runs the Step Function in the container and returns the execution information to the test. It then grabs the execution history of the running local Step Function and checks for an event showing it succeeded; this allows the test to then also check the execution output and ensure it has succeeded correctly.
### Step 7: Make sure to tear it all down
One thing that can be easily forgotten is your container running as a part of your test. A good thing to do is make sure it is torn down correctly at the end of your test run. This can be done very easily as part of an `afterAll` if running multiple tests and is simple done by stopping the test containers instance.
`awsStepFunctionsLocalContainer.stop();`
### Step 8: Expand and add more tests
Now this is up to you! You can continue to test the rest of the flow cases for the Step Function, checking it has emitted “FailStateExited” in the execution history for the failed cases or expanding your testing flows.
The `HistoryEventType` from the `aws-sdk` gives you all the event types which can be logged in the Step Function Local execution history, this allows you to write tests however you like for checking the execution of the Step Function. Here are some examples of matcher functions we have written for different types of events:
```
import {HistoryEvent} from "@aws-sdk/client-sfn";
async findExecutionSucceededEventInHistory(executionArn: string | undefined): Promise<HistoryEvent | undefined> {
return await findEventFromExecutionHistory(executionArn, "ExecutionSucceeded");
}
async findFailStateEnteredEventInHistory(executionArn: string | undefined): Promise<HistoryEvent | undefined> {
return await findEventFromExecutionHistory(executionArn, "FailStateEntered");
}
async findSucceedStateExitedEventInHistory(executionArn: string | undefined): Promise<HistoryEvent | undefined> {
return await findEventFromExecutionHistory(executionArn, "SucceedStateExited");
}
async findEventFromExecutionHistory(executionArn: string | undefined, eventKey: HistoryEventType): Promise<HistoryEvent | undefined> {
const history = await getExecutionHistory(executionArn);
return history.events?.find(
event => event.type === eventKey
);
}
```
## You’re good to go!
What we have created above is hopefully something quite simple for testing Step Functions. We additionally improved this by creating a Step Function testing service class which holds all the re-usable functions and can be called easily within the required test file. With this we were able to run our Step Function tests as part of our deployment pipeline, providing greater confidence in our code and allowing us to integrate Step Functions more into our applications.
<br/>
***Important:***
Now it's also good to note here that this is not everything we do at Instil to test our Step Functions, it is simply a companion that enables us to test the difficult edge cases including complicated flows, retries and back-offs etc. We are advocates for testing in the cloud - and this local testing mixed with integration testing in the cloud (focusing more on Step Functions interacting with other parts of the cloud rather than edge cases) is a good starting place for testing your Step Functions.
Additionally, we do hope to see some improvements to the Step Functions Local client in future from AWS, possibly providing their own matchers for checking that states have been entered and exited correctly within the tested Step Function, but if not we will just have to do it ourselves!
| tombailey14 |
1,449,359 | Blockchain-Powered Social Media for Musicians’ Success | How Social Media on Blockchain can help Musicians in their publicity, ownership, and... | 0 | 2023-04-28T16:12:12 | https://cryptoloom.xyz/rocking-revenues-and-raving-fans-harnessing-blockchain-powered-social-media-for-musicians-success/ | general, blockchainbenefits, fanbasegrowth, musicianspublicity | ---
title: Blockchain-Powered Social Media for Musicians’ Success
published: true
date: 2023-04-26 17:45:20 UTC
tags: General,blockchainbenefits,fanbasegrowth,musicianspublicity
canonical_url: https://cryptoloom.xyz/rocking-revenues-and-raving-fans-harnessing-blockchain-powered-social-media-for-musicians-success/
---
#### How Social Media on Blockchain can help Musicians in their publicity, ownership, and increasing fan base
In recent times, we have experienced a surge in social media usage, and it has become the primary means of communication for many people, including musicians. Social media platforms give musicians the ability to connect with their fans, share their work, and grow their influence. However, despite the positives, traditional social media platforms do have their drawbacks, such as lack of ownership and control for the musician.
Enter blockchain technology. This cutting-edge innovation, best known for its application in cryptocurrencies like Bitcoin, offers tremendous potential for musicians seeking to enhance their publicity, ownership, and fan base. In this article, we will delve deeper into how social media on the blockchain can rescue musicians from their existing struggles and unlock new possibilities for them.
## What is Blockchain, and how does it help?
Blockchain is essentially a secure and decentralized digital ledger system that allows for transparent transactions while maintaining privacy. Each block contains a list of transactions that can be linked to other blocks to form a chain. By design, these blocks are tamper-proof, so the data stays secure and trustworthy.
Social media platforms can be built on top of a blockchain network, providing a robust and decentralized solution for musicians. Through these decentralized social media platforms, musicians can gain benefits such as improved control over their content, better ownership and monetization models, and increased opportunities for fan interactions.
Now, let’s dive into the specifics of how blockchain-based social media can help musicians in their publicity, ownership, and fan base growth.
### 1. Ownership and control of content
One of the most significant issues musicians face on traditional social media platforms is the control and ownership of their content. Despite creating the content, artists often face restrictions, unwanted ads, and potential censorship by the platform. Blockchain technology essentially eliminates these issues by giving musicians complete control over their work.
With blockchain-based social media platforms, each piece of content is posted as a transaction on the decentralized ledger. This means the content is verifiable, secure, and can’t be tampered with or stolen. Furthermore, musicians don’t have to worry about their content being used without their consent, as their work is secured by blockchain’s cryptographic features.
### 2. Monetization and revenue streams
Traditional revenue streams for musicians, such as record sales and live shows, have been significantly impacted by the rise of digital music and streaming services. As a result, musicians often struggle to make a living from their work, even with the help of social media. The solution? Blockchain-based social media platforms can offer various monetization models that empower musicians and provide them with fair compensation.
Tokenization is one innovative approach introduced by blockchain technology that creates new forms of value and rewards in the digital space. Musicians can tokenize their content on these platforms, allowing fans to purchase, trade, and support their work using cryptocurrency. By establishing a direct economic relationship with their fans, musicians can receive steady revenue without relying on intermediaries, ultimately leaving more value in the artists’ pockets.
### 3. Enhanced fan engagement and interaction
The relationship between musicians and their fans is integral to the success and growth of their careers. Traditional social media platforms offer limited options for musicians to engage with their fans and effectively increase their fan base. Blockchain-based platforms can solve these issues by providing musicians with the ability to create unique engagement opportunities, foster communities, and promote a sense of belonging among their fans.
Blockchain technology allows for the creation of unique "smart contracts," which can be used to design personalized interactions and experiences for fans. These smart contracts can be used to develop various fan-centric events such as ticket sales for live performances, merchandise sales, virtual shows, and even offering perks to loyal fans. By offering something unique and exciting to their fans, musicians can strengthen their relationship with their supporters and attract new followers.
### 4. Enabling collaborations and networking
Blockchain-based social media platforms also open up avenues for musicians to collaborate with fellow artists and industry professionals. These platforms can facilitate secure collaboration between musicians, producers, and record labels, ensuring that everyone involved maintains their rights and benefits from the project.
Additionally, blockchain technology can be utilized to create decentralized music marketplaces where musicians can connect with their peers and support one another by sharing their work, knowledge, and resources. Networking on these platforms can accelerate the growth of musicians and elevate their opportunities within the industry.
## Blockchain-based Social Media Platforms: A New Hope for Musicians
Several blockchain-based social media platforms, such as Audius, Choon, and Musicoin, have already made their presence known in the music industry. These platforms offer a taste of how blockchain technology can revolutionize the way musicians share their work, connect with their fans, and sustain their careers.
By embracing blockchain-based social media platforms, musicians can take control of their content, boost their fan base, and unlock new revenue streams. While it may still be early days for this technology, the potential impact on the music industry and the empowerment it can bring to musicians make it an exciting avenue to watch.
So, it’s time for musicians to step into this new realm of possibilities and explore how social media on the blockchain can help them elevate their careers and provide them with the control and ownership that they rightfully deserve.
* * *
**References:**
1. Tapscott, D., & Tapscott, A. (2017). _Blockchain Revolution: How the Technology Behind Bitcoin and Other Cryptocurrencies Is Changing the World_ (Reprint edition). Portfolio.
2. Passy, J. (2018, May 17). How the blockchain could break big tech’s hold on AI. _MarketWatch_. Retrieved from https://www.marketwatch.com/story/how-the-blockchain-could-break-big-techs-hold-on-ai-2018-05-17
3. Brown, A. (2020). _Using Blockchain Technology to Engage Fans in the Music Industry_ (Master’s thesis, Northeastern University – College of Professional Studies). Retrieved from https://repository.library.northeastern.edu/files/neu:cj82sz51r/fulltext.pdf
4. Di lorio, A. (2021, April 7). Social Media on the Blockchain: Pioneers in the New Digital Landscape. _Entrepreneur_. Retrieved from https://www.entrepreneur.com/article/367657
The post [Rocking Revenues and Raving Fans: Harnessing Blockchain-Powered Social Media for Musicians’ Success](https://cryptoloom.xyz/rocking-revenues-and-raving-fans-harnessing-blockchain-powered-social-media-for-musicians-success/) appeared first on [CryptoLoom](https://cryptoloom.xyz). | cryptoloom |
1,449,402 | Chakra checkbox and react-hook-form | My goal was to create a list of checkboxes with fixed values i.e. Nuts, Gluten, Dairy, etc. After... | 0 | 2023-04-26T22:54:39 | https://dev.to/fazuelinton/chakra-checkbox-and-react-hook-form-2mcg | My goal was to create a list of checkboxes with fixed values i.e. Nuts, Gluten, Dairy, etc.

After fetching the data and wiring it up with react-hook-form here's what I did:
## import the required packages from libs
```typescript
import { Controller } from 'react-hook-form';
import {
Checkbox,
CheckboxGroup,
CheckboxProps,
FormControl,
forwardRef
} from '@chakra-ui/react';
```
## create a new component `CheckboxCustom`
```typescript
...
type CheckboxCustomProps = CheckboxProps & { control: any; name: string; children: ReactNode };
const CheckboxCustom = forwardRef<CheckboxCustomProps, 'input'>(({ children, ...rest }, ref) => {
rest.control;
return (
<Controller
name={rest.name}
control={rest.control}
render={({ field: { value } }) => (
<Checkbox ref={ref} isChecked={value} {...rest}>
{children}
</Checkbox>
)}
/>
);
});
```
## use the custom component to render the checkboxes
```typescript
<FormControl>
<CheckboxGroup>
<SimpleGrid columns={5}>
<CheckboxCustom control={control} {...register('noNuts')}> Nuts
</CheckboxCustom>
<CheckboxCustom control={control} {...register('noGluten')}> Gluten
</CheckboxCustom>
...
</SimpleGrid>
</CheckboxGroup>
</FormControl>
``` | fazuelinton | |
1,449,403 | What's the Worst Question You've Ever Been Asked in an Interview? | Job interviews can be nerve-wracking, and sometimes interviewers ask questions that catch you off... | 22,092 | 2023-04-27T07:00:00 | https://dev.to/codenewbieteam/whats-the-worst-question-youve-ever-been-asked-in-an-interview-1891 | discuss, beginners, career, codenewbie | Job interviews can be nerve-wracking, and sometimes interviewers ask questions that catch you off guard, or that are just plain...weird and terrible.
What's the worst question you've ever been asked in an interview? And how did you respond? :eyes:
---
Follow the [CodeNewbie Org](https://dev.to/codenewbieteam) and [#codenewbie](https://dev.to/t/codenewbie) for more discussions and online camaraderie!
{% embed [https://dev.to/t/codenewbie](https://dev.to/t/codenewbie) %} | ben |
1,449,461 | Building a Message Component for My Project | Today, on day 86 of my #100DaysOfCode challenge, I worked on my project and made some progress. I... | 0 | 2023-04-27T01:20:28 | https://dev.to/arashjangali/building-a-message-component-for-my-project-fbc | webdev, javascript, programming, react | Today, on day 86 of my #100DaysOfCode challenge, I worked on my project and made some progress. I created a message component that I'm working on to render conditionally when the liked users are clicked on. This feature will allow users to send messages to each other through the app, making it easier to connect and communicate with potential clients or contractors.
Implementing this feature was challenging, but it was a lot of fun. I started by creating the message component, which will be responsible for rendering the message form and handling the message submission. Then, I had to figure out how to conditionally render the message component when the user clicks on a liked user.
Once I had the message component rendering correctly, I had to implement the functionality for sending messages. When the user selects a liked user, they will be able to send a message that will end up in their document in the database. This required me to write some backend code to handle the message submission and store it in the appropriate document.
Overall, it was a productive and satisfying day of coding. I'm excited to continue working on this feature and seeing how it improves the user experience for the app. | arashjangali |
1,449,556 | Clarity Through Destructuring | For aspiring software developers, it's easy to overlook certain concepts that seem trivial or... | 0 | 2023-04-28T02:50:01 | https://dev.to/hillswor/clarity-through-destructuring-2eeg | react, javascript, beginners, nextjs | For aspiring software developers, it's easy to overlook certain concepts that seem trivial or confusing at first. One such concept that I initially dismissed was object and array destructuring in JavaScript. However, as I progressed in my learning journey and started working with frameworks like React, I quickly realized the power and convenience that destructuring can provide.
## What is Destructuring?
Destructuring is a way of extracting values from arrays and objects and assigning them to variables in a concise and readable manner. It allows you to "destructure" the data into smaller pieces, making it easier to work with and more expressive.
## Array Destructuring in JavaScript
Array destructuring is used to extract values from an array and assign them to variables. Here's an example:
```
const numbers = [1, 2, 3, 4, 5];
const [first, second, , fourth] = numbers;
console.log(first); // 1
console.log(second); // 2
console.log(fourth); // 4
```
In this example, we're destructuring the numbers array and assigning the first element to the first variable, the second element to the second variable, and the fourth element to the fourth variable. Notice how we're using commas to skip over the third element (which has a value of 3).
## Object Destructuring in JavaScript
Object destructuring is used to extract properties from an object and assign them to variables. Here's an example:
```
const person = {
firstName: "John",
lastName: "Doe",
age: 30,
address: {
street: "123 Main St",
city: "Anytown",
state: "CA",
zip: "12345"
}
};
const { firstName, lastName, address: { city } } = person;
console.log(firstName); // "John"
console.log(lastName); // "Doe"
console.log(city); // "Anytown"
```
In this example, we're destructuring the person object and assigning the firstName and lastName properties to variables with the same names. We're also destructuring the address property and assigning the city property to a variable with the same name.
## Destructuring in React
Destructuring is especially useful when working with React. In React components, props are often passed down to child components. Destructuring allows you to extract only the props you need, making your code easier to read and understand. Here's the basic syntax for destructuring props:
```
function ChildComponent({ prop1, prop2 }) {
// Use prop1 and prop2 here
}
```
Here is a more detailed example:
```
import React from "react";
function Person(props) {
const { firstName, lastName, age } = props;
return (
<div>
<h1>{firstName} {lastName}</h1>
<p>{age}</p>
</div>
);
}
export default Person;
```
In this example, we're destructuring the props object and assigning the firstName, lastName, and age properties to variables with the same names. This makes it easier to access and use these values within the component's JSX.
## Conclusion
Destructuring can greatly simplify and improve your code by making it more readable and expressive. Whether you're working with arrays, objects, or React components, mastering destructuring can make your coding experience more enjoyable and productive. | hillswor |
1,449,801 | The Future of Web Development: Trends and Predictions for 2023 | The world of web development is constantly evolving, and staying up-to-date with the latest trends... | 0 | 2023-04-27T09:35:04 | https://dev.to/rr9853462/the-future-of-web-development-trends-and-predictions-for-2023-39i1 | webdev, webdesign, hirewebdevelopers, mobile | The world of web development is constantly evolving, and staying up-to-date with the latest trends and predictions is essential for any web development company or business that relies on **[web development services](https://www.webcluesinfotech.com/web-development-services)**. As we approach 2023, it's important to take a look at the emerging technologies and trends that will shape the future of web development.

**Voice-activated interfaces:**
With the increasing popularity of voice-activated personal assistants like Amazon's Alexa and Google Home, it's no surprise that voice-activated interfaces will become more prevalent in web development. This means that web developers will need to adapt their designs to accommodate voice commands and interactions.
**AI and machine learning:**
Artificial intelligence and machine learning will continue to be major players in web development. These technologies will allow web developers to create personalized experiences for users, optimize websites for search engines, and automate repetitive tasks.
**Progressive Web Apps (PWAs):**
PWAs are web applications that can be accessed through a browser but function like native mobile apps. They offer fast performance, offline capabilities, and push notifications, making them an attractive option for businesses looking to improve their mobile experience.
**Augmented Reality (AR) and Virtual Reality (VR):**
AR and VR are already being used in web development to create immersive experiences for users. As the technology becomes more accessible, we can expect to see more websites and applications incorporating AR and VR elements.
**Single-page applications (SPAs):**
SPAs are web applications that load a single HTML page and dynamically update the content as the user interacts with it. They offer a seamless user experience and can be faster than traditional multi-page applications.
To keep up with these trends, businesses will need to hire web developers who are skilled in these emerging technologies. Web development companies will need to invest in training and development to ensure their teams are up-to-date with the latest trends and techniques.
> In addition to these trends, there are several predictions for the future of web development:
**1.Increased use of chatbots:** Chatbots are already being used on many websites to provide customer service and support. As AI and machine learning continue to advance, we can expect chatbots to become even more sophisticated and integrated into the user experience.
**2.More emphasis on accessibility:** As the importance of accessibility continues to grow, we can expect web development to prioritize accessibility features such as screen readers, keyboard navigation, and color contrast.
**3.Continued focus on website security:** With the increasing threat of cyberattacks, web development will continue to prioritize website security. This includes measures such as SSL certificates, firewalls, and regular software updates.
**4.Greater emphasis on user privacy:** With the rise of data breaches and concerns over user privacy, web development will need to prioritize measures such as GDPR compliance, cookie notices, and data encryption.
**Conclusion**
In conclusion, the future of web development is exciting and full of possibilities. By staying up-to-date with the latest trends and predictions, businesses can ensure they are offering the best possible user experience. To achieve this, it's essential to **[hire web developers](https://www.webcluesinfotech.com/web-development-services)** who are skilled in emerging technologies and invest in ongoing training and development.
| rr9853462 |
1,449,563 | Kết quả bóng đá thethao247.vn | https://thethao247.vn/ket-qua-bong-da-truc-tuyen/ (LIVE) - Nhận ngay kết quả bóng đá(KQBĐ) mới nhất... | 0 | 2023-04-27T03:22:30 | https://dev.to/kqbdthethao247/ket-qua-bong-da-thethao247vn-2k69 | https://thethao247.vn/ket-qua-bong-da-truc-tuyen/ (LIVE) - Nhận ngay kết quả bóng đá(KQBĐ) mới nhất của tất cả các trận đấu✔️ giải đấu diễn ra vào đêm qua & hôm nay từ Thể Thao 247✔️ Tỷ số được cập nhật liên tục 24h✔️✔️✔️
https://velog.io/@kqbdthethao247
https://pbase.com/ketquabongdathethao247/ketquabongdathethao247
https://plaza.rakuten.co.jp/kqbdthethao247
https://app.bountysource.com/people/116350-kqbdthethao247
https://penzu.com/p/3c09dd12
https://peatix.com/user/17049592 | kqbdthethao247 | |
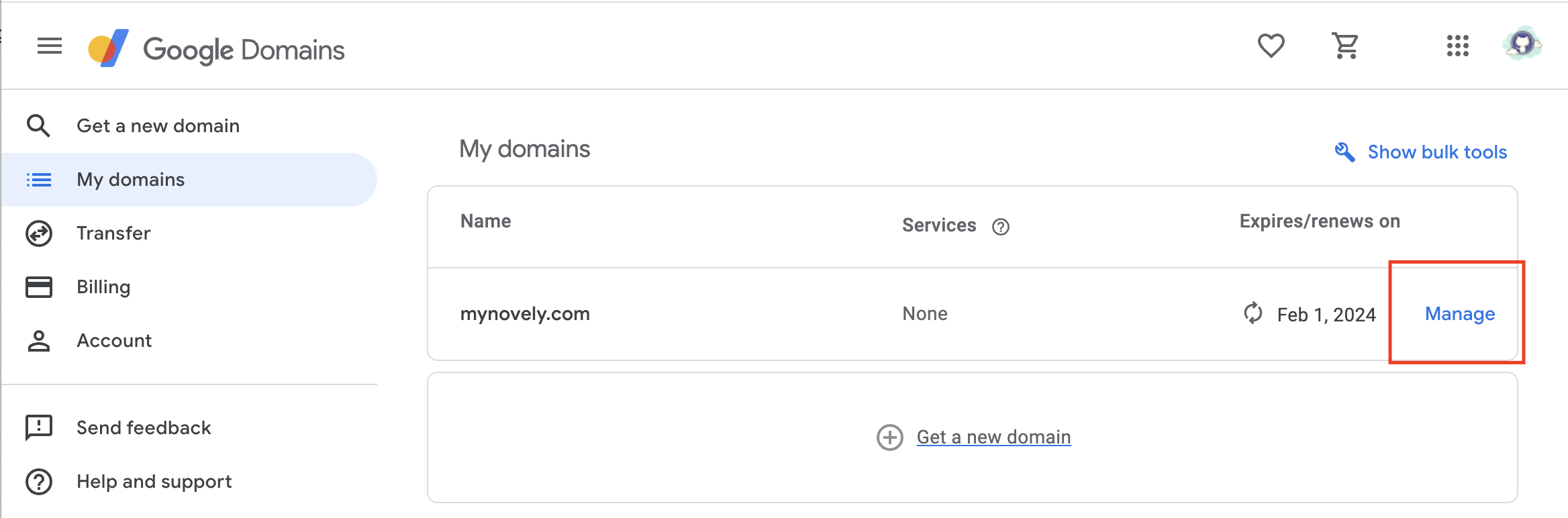
1,449,567 | How to Link Your Google Domain with Vercel: A Step-by-Step Guide (2023) | Log in to your Google Domains account and navigate to the My Domains page. If you have multiple... | 0 | 2023-04-27T03:35:05 | https://dev.to/azadshukor/how-to-link-your-google-domain-with-vercel-a-step-by-step-guide-2023-5ac9 | Log in to your Google Domains account and navigate to the My Domains page. If you have multiple domains, make sure you select the one you want to link with Vercel.
Click on the **"Manage"** button on the right side of the domain name. This will take you to the domain management page.
On the left sidebar, select **"DNS"**. This will bring up the DNS settings for your domain.
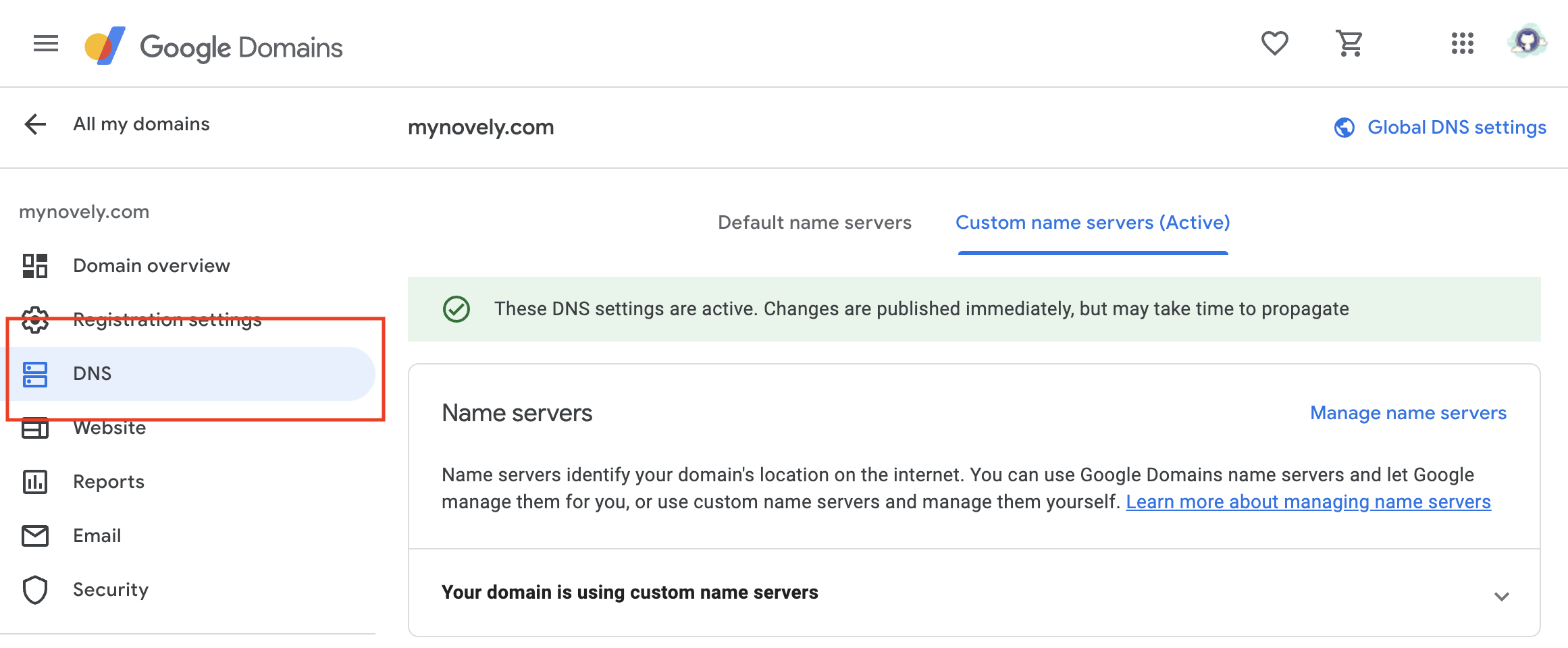
Click on **"Custom name servers"**. This will allow you to add custom name servers for your domain.
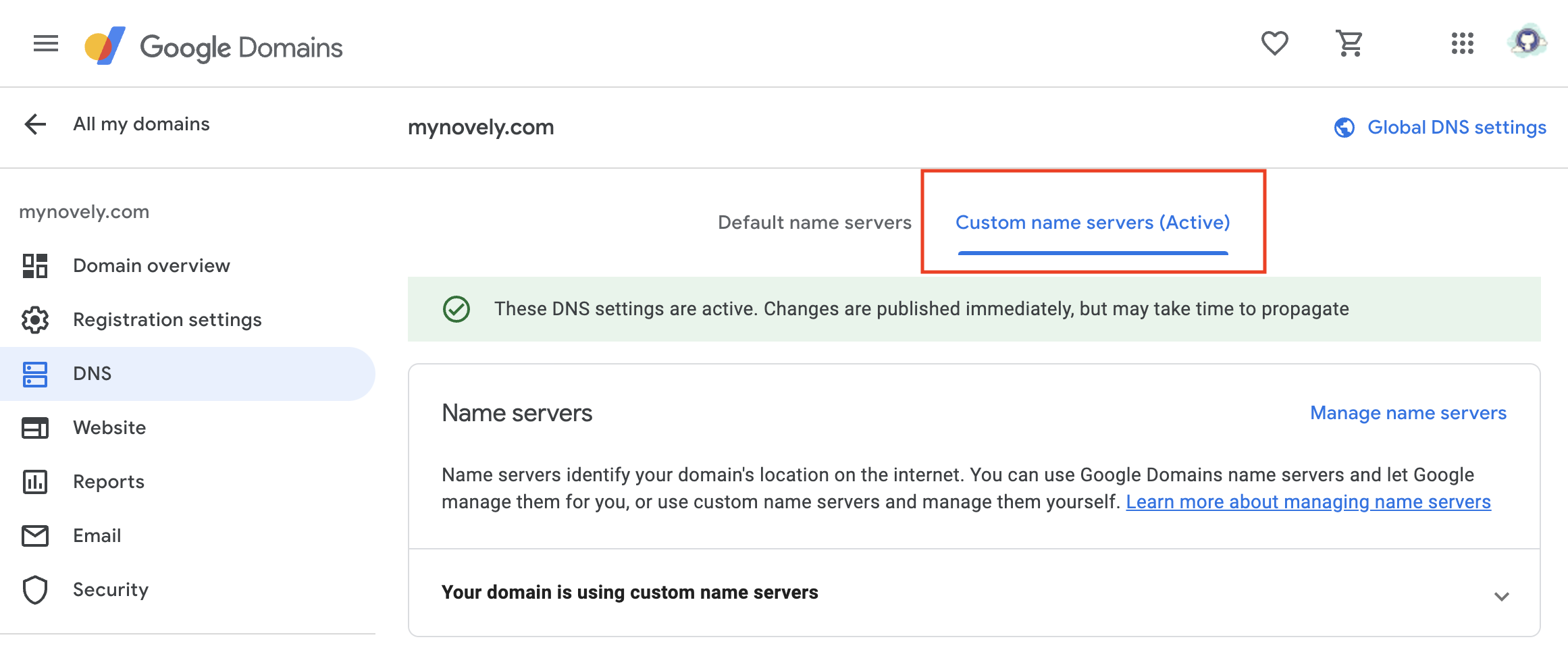
Under **"Name Server"**, add the following two name servers:
```
ns1.vercel-dns.com
ns2.vercel-dns.com
```
These are the name servers provided by Vercel, and they will handle the DNS requests for your domain.
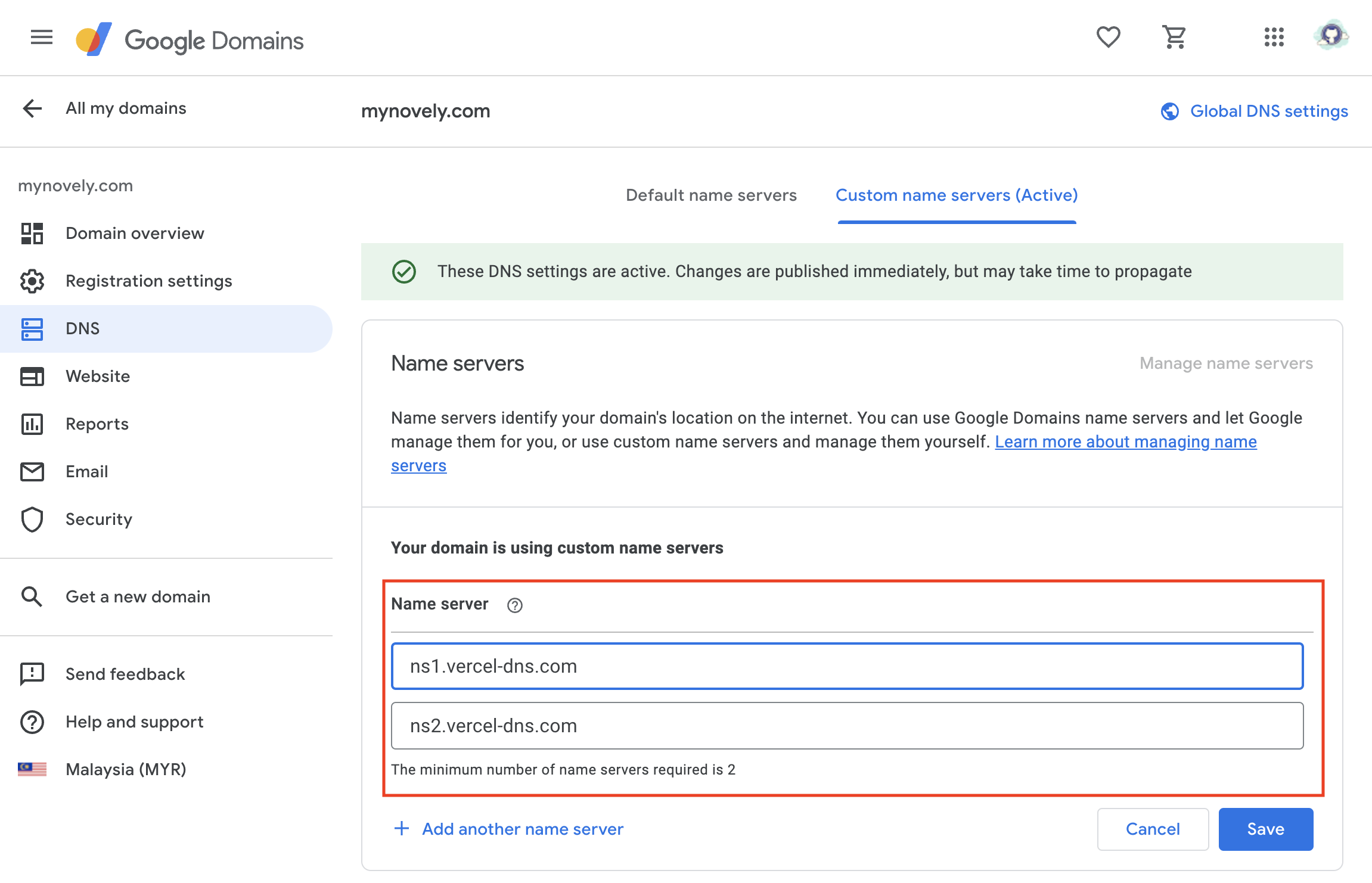
Click on **"Save"** to save the changes. Once you've added the custom name servers, your Google domain will be linked with Vercel, and you can start using it to host your website or web application.
| azadshukor | |
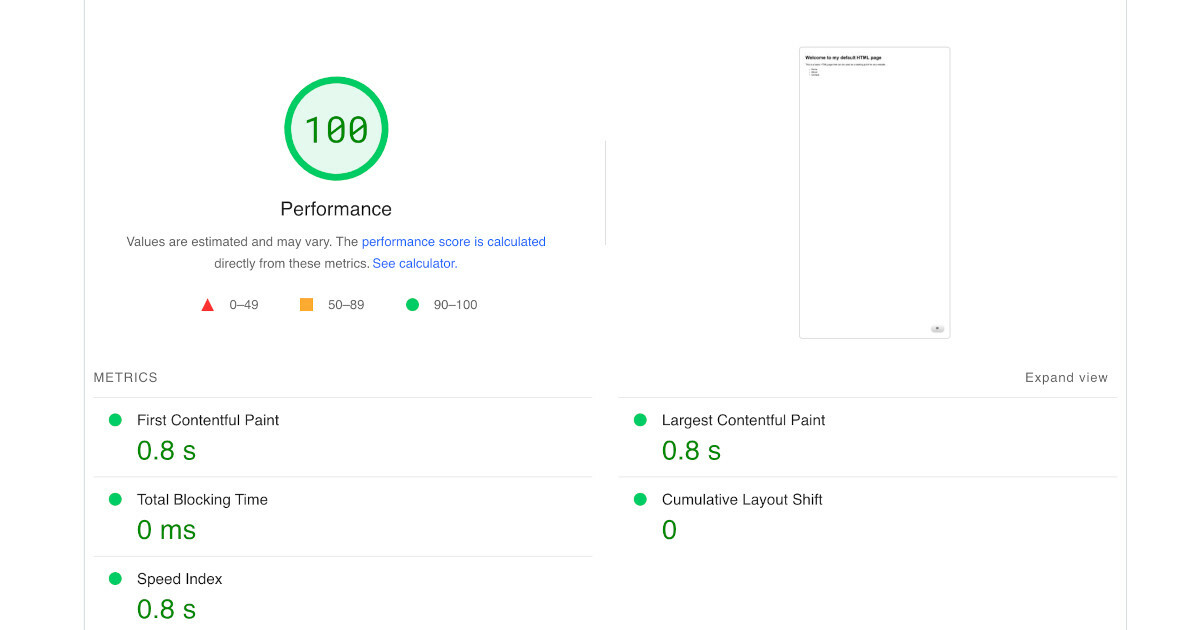
1,449,581 | How we built the Fastest ChatGPT Website Chatbot | A ChatGPT-based website chatbot can dramatically decrease your website's performance if it's not... | 0 | 2023-04-27T04:30:44 | https://ainiro.io/blog/the-fastest-chatgpt-website-chatbot | openai, chatgpt, webdev, tutorial | A ChatGPT-based website chatbot can _dramatically decrease your website's performance_ if it's not correctly implemented. Today we were able to further optimised [our ChatGPT chatbot](https://ainiro.io) and make it 20x faster than what we started out with as we cloned AISTA's technology. In totalt we have now reduced the initial page load time from more than 1,000kB to less than 48kB. This is a 20x improvement in load time, significantly impacting SEO and usability.
In this article I will tell you how, in addition to why this is important, and why you should care. The image below shows a default empty HTML page, with our chatbot embedded. Basically it scores 100% on every single parameter that exists.
## The importance of a CDN
A Content Deliver Network (CDN) allows you to serve static resources _a lot_ faster. To understand why, realise that the internet has a lot to do with geography. I live in Cyprus. From Cyprus to Ukraine I have a TCP hop time (latency) of probably 100+ milliseconds. This doesn't sound like much, but when your website is serving 50+ HTTP requests, this becomes an additional load time of 50 x 0.1 seconds, resulting in 5 seconds more time to load.
> If your webpage requires 5 seconds to load, you might as well send a postcard!
We're using a global CDN that caches every single static file locally, reducing latency to ~10 milliseconds. Hint; [CloudFlare](https://cloudflare.com) - USE IT!
## Lazy initialising reCAPTCHA
A chatbot such as ours needs reCAPTCHA support. Without it, any script kid can create a never ending while loop in Postman, and burn through thousands of dollars in your OpenAI API account in a couple of hours. However, reCAPTCHA is terribly implemented. It's a _"blocking library"_, implying the rendering of your webpage will halt while reCAPTCHA is downloaded and initialised. I wrote about [how to defer reCAPTCHA loading in this article](https://ainiro.io/blog/how-we-made-our-chatbot-10x-faster) if interested. However, the idea is that we don't load reCAPTCHA before the chat button is clicked. You can actually see this if you inspect the network tab on this page, for then to click the little blue robot in the bottom/right corner. The idea is to _never_ load anything before you need it!
## Trimming fonts
We're using [IcoFont](https://www.icofont.com/icons) for our chatbots. These are the small icons displayed by default on for instance the chess theme, and/or the [AI search](https://ainiro.io/blog/put-ai-search-on-your-website) button. IcoFont has a really amazing feature, which is that you can _"cherry pick"_ which icons to download. If you download some _"font icon library"_ you will typically get hundreds of icons. These icons will consume bandwidth, and you rarely need more than a handful. The default version of IcoFont for instance requires 0.5 megabytes of download. By cherry picking which icons we want in our set, we were able to reduce the size of our IcoFont library from ~500kB to ~5kB. 0.49 megabytes of bandwidth saved!
## GZIP'ing content
This one we get for free, it's an integrated part of CloudFlare's services, that reduces the size of static content such as JavaScript and CSS by roughly 90 to 95 percent. If you've got heavy JavaScript and CSS files, you want to make sure your content is GZip'ed as it's being served. However, we got this one _"for free"_ because of using CloudFlare's CDN features.
## Zero "Frameworks"
If you're creating a chatbot that's intended to be embedded on a website, then _do not start out by dragging in Bootstrap or jQuery_. The domain problem for a chatbot is easy, you don't need Bootstrap or jQuery. These libraries are hundreds of kilobytes in size, and this becomes a cost for the website you're embedding the chatbot on. Our chatbot exclusively contains _"good old fashioned JavaScript and CSS"_, and no frameworks. If your ChatGPT-based website chatbot downloads jQuery or Bootstrap, you might want to reconsider what chatbot service you're using ...
## Page load time matters
There are literally no parameter that's more important for user experience and SEO than page load time. Google will rank you higher than your competitors if your page is loading faster assuming the rest of the parameters are equal. This implies that if you're _"embedding the coolest ChatGPT-based website chatbot on Earth on your page"_, you might wake up one day and realise you've lost 50% of your organic clicks from Google, and that the average engagement time just dropped by 50%, because people are clicking the back button because they're tired of waiting for your webpage to load.
Some millennials will even watch YouTube videos on 1.5x speed, because they don't have time to watch these at normal speed. Do me a favour please; Copy the URL of this page, and open it in an incognito browser window. Did you notice it loaded in less than 1 second? That took _a lot_ of effort from us, but inevitably over time results in a better user experience, and more _"Google Luv"_ over time.
Before you chose a ChatGPT website chatbot, ask yourself _"what's the cost"_. Well, if you chose us, you now know, 47kB. Most others are in the 1,000+ range here ... 😉
* [Contact us for a quote on our ChatGPT website chatbot](https://ainiro.io/contact-us#demo)
* [Or create your own ChatGPT website chatbot here](https://ainiro.io/blog/how-to-get-chatgpt-on-your-website)
Psst, we're constantly working to further improve our chatbot tech, and I suspect we might be able to squeeze it down to less than 30kB in total over the next weeks - However, even at 48kB, I suspect we're probably the fastest ChatGPT-based Website Chatbot on Earth 😁
| polterguy |
1,449,658 | Breaking News: AI is Not Replacing These Jobs Anytime Soon (Sorry Robots) | Jobs that require heart: Jobs that require empathy and human connection, like therapists and... | 0 | 2023-04-27T06:42:35 | https://dev.to/vvk/breaking-news-ai-is-not-replacing-these-jobs-anytime-soon-sorry-robots-211c |
Jobs that require heart: Jobs that require empathy and human connection, like therapists and bartenders
Jobs that require humor: Jobs that require a sense of humor, like comedians and copywriters
Jobs that require creativity: Jobs that require creative thinking, like artists and musicians
Jobs that require critical thinking: Jobs that require critical thinking and problem solving, like detectives and scientists
Conclusion: A wrap-up that highlights the importance of human skills and why we should celebrate the jobs that AI can't touch | vvk | |
1,449,664 | 5 Best Frameworks: Cross-Platform Mobile App Development | Cross-platform mobile app development frameworks are the best thing in the development process.... | 0 | 2023-04-27T06:55:16 | https://dev.to/quokkalabs/5-best-frameworks-cross-platform-mobile-app-development-38kf | mobile, android, ios, development | [Cross-platform mobile app development](https://quokkalabs.com/mobile-app-development?utm_source=Dev.to&utm_medium=blog&utm_campaign=Service%20Page) frameworks are the best thing in the development process. Rather than only one platform, any developers can now create applications for various platforms. They don't need to repeatedly compose a similar source code - it's hugely time to be protected and energy efficient.
However, there's no question that individuals and organizations are eager to hire cross-platform app developers to deal with such frameworks since they're profoundly helpful but also very costly. Yet at the same time, they, in all actuality, do enjoy extraordinary benefits against the high advancement costs.
_There are various frameworks available in the market. The developers accepted and adopted a few of them as pros and cons. So let's check out probably the best cross-platform application framework for creating robust, versatile mobile applications that are accessible nowadays:_
## 1. React Native
- Programming language: JavaScript
- Top Applications: Airbnb, Instagram, Skype, Shopify
Created by Meta (previously Facebook) in 2015, [React Native](https://quokkalabs.com/react-native-app-development?utm_source=Dev.to&utm_medium=blog&utm_campaign=Service%20Page) has progressively developed its prevalence in the local dev community. This open-source UI improvement framework joins the best of JavaScript and React.JS while permitting engineers to compose modules in Java, Swift, or Objective-C dialects. Using local native modules and libraries in the platform, the development group can execute weighty activities like picture altering, video handling, and different errands not covered by the framework APIs.
### Other exceptional key features of React Native:
- Its quick refresh features include giving developers momentary input on alters made to their React parts. Upholds an assortment of outsider libraries, for example, Redux, MobX, Ionic, and so on, considering straightforward relocation.
- It has Part-based GUI creation that's mainly used for front-end applications creation. It provides support like dealing with user communications through touch occasions, simplifying it for developers to reuse existing UI parts.
- Besides, it has a sizable community. Various UI structures, instructional exercises, and libraries are accessible to work with the expectation of absorbing information.
- Concerning commitment to gathering articles, instruments, and assets about unambiguous innovations, React Native is vastly improved than Flutter, Xamarin, or Ionic.
- Its specialty is giving the engineers a choice to compose code only one opportunity to get utilized for both the iOS and Android stages. Because of some code benefits, the improvement time gets diminished, and consequently, engineers can focus on one more mechanical part of the application advancement.
- The requirement for composing the code just once in this manner takes care of picking either native or cross-platform app development. This framework by Facebook is ideal for growing startup businesses and entrepreneurs.
**Read More:** {% embed https://quokkalabs.com/blog/how-to-hire-react-developers-a-step-by-step-guide-for-recruiters-2/?utm_source=Dev.to&utm_medium=blog&utm_campaign=Web%20Blog %}
## 2. Flutter
- Programming language: Dart
- Top Applications: Alibaba, Google Ads, PostMuse
Released by Google in 2018, it is an open-source framework designed to create mobile, web, and desktop applications from one codebase. Flutter is another ideal choice for building cross-stage versatile applications. Nonetheless, which isolates Flutter from different systems is the programming language.
Flutter utilizes Dart, while React involves JavaScript as its customizing language. Disregarding being new and one of a kind to the universe of developers, Flutter is keeping different structures honest because of its superb graphical library and smooth execution. It gives similar local insight and gives the clients a one-of-a-kind and upgraded application-seeing experience.
### Other exceptional key features of Flutter:
- It offers widgets drawn from its superior rendering engine - fast, customizable, and alluring.
- Dart language offers more modern components to alter UI design for any screen, simplify debugging, streamline investigating, and work on the application's presentation through AOT gathering.
- Hot Reload's usefulness allows engineers to see prompt updates of new codes without application reload.
- Because of its rich widgets, Flutter applications will generally have an incredible look and feel. It likewise furnishes phenomenal documentation with substantial group help, making it simple to begin creating with the stage. At long last, its improvement time is much quicker than the native development.
**Read More:** {% embed https://quokkalabs.com/blog/what-is-new-in-flutter/?utm_source=Dev.to&utm_medium=blog&utm_campaign=Web%20Blog %}
## 3. Xamarin
- Programming language: C#
- Top Applications: UPS, Storyo, Alaska Airlines
The next competitor in the list of cross-platform [mobile app development](https://quokkalabs.com/mobile-app-development?utm_source=Dev.to&utm_medium=blog&utm_campaign=Service%20Page) frameworks is Xamarin. This Microsoft-claimed stage can be sent to construct Android, iOS, and Microsoft applications with .NET.
With Xamarin, engineers can share around 90% of their applications across stages. They just need to compose all of their business rationales in a solitary language or reuse existing application code yet accomplish the native look, feel, and execution at every stage.
### Other exceptional key features of Xamarin:
- Specifically ties in almost all essential stage SDKs in Android and iOS, thus offering intense compile time checking. This outcome resulted in fewer run-time mistakes and productive applications.
- Supporting an immediate joining of Objective-C, Java, and C++ libraries, Xamarin qualifies engineers to reuse existing iOS and Android libraries written in those dialects.
- It is based on C#, an advanced programming language that offers many benefits over Objective-C and Java, including dynamic language capacities and utilitarian builds such as lambdas, equal programming, generics, LINQ, etc.
- Utilizing the .NET BCL, Xamarin-based applications approach a significant assortment of classes with abundant smoothed-out usefulness like IO, XML, String, etc.
- Existing C# can likewise be ordered for use in an application, opening up an option of thousands of libraries that add highlights past the BCL.
**Read More:** {% embed https://quokkalabs.com/blog/a-step-by-step-guide-to-the-mobile-app-development-process/?utm_source=Dev.to&utm_medium=blog&utm_campaign=Web%20Blog %}
## 4. Ionic
- Programming language: JavaScript
- Top Applications: BBC, EA Games, MarketWatch
One more eminent cross-platform framework in this rundown is Ionic. The open-source UI tool compartment assists developers with making versatile mobile and desktop applications utilizing a blend of local and web innovations like HTML, CSS, and JavaScript, with integration for the Angular, Vue, and React framework systems.
### Other exceptional key features of Ionic:
- Because of a SaaS UI structure framework fabricated explicitly for the versatile operating system, Ionic offers various UI parts for building applications.
- With the help of Cordova and Capacitor modules plugins, the Ionic gives developers admittance to the gadget's implicit functionalities, containing cameras, sound recorders, GPS, etc.
- It offers its own IDE called Ionic Studio, made for fast application improvement and prototyping with negligible coding.
- With Ionic, developers can create a splendidly innovative UI and integrate easy-to-use components into the application. So, Ionic-based applications are brilliant and naive, making them the best system for PWA development.
## 5. Apache Cordova
- Programming language: HTML 5, CSS3, and JavaScript
- Top Applications: Untappd, Localeur, SparkChess
Apache Cordova, previously known as PhoneGap, is an open-source versatile development framework for making hybrid portable applications utilizing standard web innovations like _HTML, JavaScript, and CSS_. Consequently, developers are not required to become familiar with a particular improvement programming language to create an application. Applications work inside coverings designated to every stage and depend on norms agreeable to APIs to get to every gadget's information, sensors, and network.
### Other exceptional key features of Apache Cordova:
- It gives a cloud arrangement that allows developers to share their applications during the improvement interaction for input from colleagues.
- It permits admittance to local gadget APIs to be reached in a module manner because of its plugin-able architecture.
- The most concerning issue with Cordova and other cross-stage platforms is that their applications won't be as quick as local code composed on the gadget. A genuine illustration of this is gaming.
- Complex animation by the canva in Cordova isn't going to perform as well as local code and, in all probability, wouldn't be satisfactory to giving clients a decent encounter.
### That's it!!!
These are some of the ideal frameworks that expert developers mostly choose, but you'd need to pick the one that would go perfectly with your action plan. The one that could ideally address your business on each significant cross-platform mobile application. If you have any queries, questions, or suggestions, comment below or [contact us now](https://quokkalabs.com/contact-us?utm_source=Dev.to&utm_medium=blog&utm_campaign=Contact%20Us).
Thanks!!!
| labsquokka |
1,449,808 | STORY OF MY LIFE | I am Elyse NIYOMWUNGERE but call me Songa i am refugee in Mahama Camp in Rwanda coutry. I studied... | 0 | 2023-04-27T09:39:25 | https://dev.to/songa210/story-of-my-life-2npi | i, am | I am Elyse NIYOMWUNGERE but call me Songa i am refugee in Mahama Camp in Rwanda coutry.
I studied Computer Application And Multimedia In Kirehe Adventist TVET School(KATS).
I worked in Capital Record Empire LTD in terms of Multimedia in kigali, remera and also i worked in JAPTECT Company in terms of Hardware Maintenance and Networking in Kigali Rusozi.
so my every day life, i like or i worked photographer and Editing videos.
so this is my story of life thank you.
| songa210 |
1,450,000 | Interview experience of Junior Ruby and Rails developers | Dear Junior Ruby and Rails Developers, Can you shed some light on your experiences applying for jobs... | 0 | 2023-04-27T12:35:42 | https://dev.to/makisushi/interview-experience-of-junior-ruby-and-rails-developers-4968 | ruby, rails, beginners, discuss | Dear Junior Ruby and Rails Developers,
Can you shed some light on your experiences applying for jobs and the interview process?
- How did it go?
- Where did you get stuck?
- What was the result?
- What did you learn,
- What were you missing?
- If you are aware, what did you have that helped you get the job?
Also, anything else that you think is worth sharing. | makisushi |
1,450,009 | Transcript Management App | What I built I built a transcript management web application that allows accountant... | 0 | 2023-04-27T12:57:55 | https://dev.to/tommyriquet/transcript-management-app-23n3 | githubhack23 | ## What I built
I built a transcript management web application that allows accountant offices to manage transcripts in a centralized environment. The frontend of the application is built using React, while the backend is built using NodeJS.
### Category Submission:
DIY Deployments
### Screenshots


### Description
This web application was made to simplifies the management of transcripts for employees in offices. They can easily manage and access all their transcripts and minutes from a centralized location. This ensures that they do not have to waste time and resources on searching for specific transcripts.
### Link to Source Code
PVonWeb's source code can be found [here](https://github.com/TommyRiquet/PVonWeb)
### Permissive License
PVonWeb is licensed under the MIT license.
## Background
PVonWeb was created to solve a specific problem faced by accountant offices. The management of transcripts and minutes is a critical task in the accounting industry, but it can be time-consuming and tedious. PVonWeb was designed to simplify this process and make it more efficient.
### How I built it
PVonWeb was built using React for the frontend and NodeJS for the backend. GitHub Actions were used to automate the whole development process, from the unit tests to the deployment process, which made it easy to update the application with new features and bug fixes.
#### Workflows built with Github Actions
- Code Linter checking
- Commit message checking
- Unit testing
- Integration testing
- Testing deployement script
- End-to-end testing
- Staging deployement script
- Production deployement script
#### Github Templates
We created a GitHub Issue template to make it easier and faster for developers to submit issues. This template provides a step-by-step guide for creating user stories, bug reports, or technical tasks, and ensures that all issues are consistent in format. By using this template, developers can submit their issues in a structured format, which makes the review process smoother.
#### Conclusion
During the development of this project, I gained valuable experience and knowledge in using Github Actions for automation. Prior to this, I had limited knowledge of Github Actions, but throughout the development process, I became more proficient and learned a great deal about its capabilities. The skills I acquired through this experience will be beneficial for future projects as well.
### Additional Resources/Info
+Made with love from Belgium
| tommyriquet |
1,450,026 | Where's your author? | Hi all, Continuing fixing some sites without an author, I have came across these projects: ApiTestEz... | 0 | 2023-04-27T13:28:49 | https://dev.to/fredadiv/wheres-your-author-a65 | osdc | Hi all,
Continuing fixing some sites without an author, I have came across these projects:
[ApiTestEz](https://github.com/bruce4520196/ApiTestEz#readme) which is missing the pyproject.toml file. I added it with the author's name, but it still missing the email address. [PR](https://github.com/bruce4520196/ApiTestEz/pull/1/commits/93e303d0d16f3f8889c771eb2e3a4486a7cf0695)
[lightgrad](https://github.com/marcosalvalaggio-bip/lightgrad) was also missing the author id, so I added the toml file. Unfortenetly, the Github user has no details so I just used the user name. [PR](https://github.com/marcosalvalaggio-bip/lightgrad/pull/1/commits/c956b8b5ccae7954a073c15e6e000abb85e098fa)
The author accepted the PR in merged it into the project :-)
[gbs](https://github.com/gopherball/gbs) has a toml file, but without the author section, so I added it. [PR](https://github.com/gopherball/gbs/pull/1/commits/875bff72b4791facd6a99567a9c8051d198162aa)
[autosrt](https://github.com/botbahlul/autosrt) is also missing the pyproject file so I added it. [PR](https://github.com/botbahlul/autosrt/pull/4/commits/83c8d773e39177a9c3250826a4d008fa93f69e17)
[pheno-utils](https://github.com/hrossman/pheno-utils) has no indication about the author so I added the toml file. [PR](https://github.com/hrossman/pheno-utils/pull/1/commits/ee82acd89dd131dc500a3cbc6769bc68b8d6e62f)
| fredadiv |
1,450,167 | All Articles Are Wrong, Some Are Useful | As software developers, we are always foraging the internet for articles, tutorials, StackOverflow... | 0 | 2023-04-27T15:35:03 | https://dev.to/nkrumahthis/all-articles-are-wrong-some-are-useful-3h2c | beginners, productivity | As software developers, we are always foraging the internet for articles, tutorials, StackOverflow answers and blog posts hoping that they have the latest and greatest solution for our coding problems. But how many times have we found ourselves frustrated with code that doesn't work, despite following the instructions from an article or tutorial to the letter? Or worse yet, how many times have we been misled by articles that are simply incorrect?
The truth is, all articles are wrong. Every single one. No matter how well-researched, well-written, or well-intentioned an article is, there is always the possibility that it is wrong in some way. Maybe the code won't work in a certain environment, or maybe it relies on assumptions that aren't true in every case. Even articles that are factually correct can be wrong in their applicability to your specific situation.
However, just because all articles are wrong doesn't mean that they are useless. In fact, some articles can be incredibly helpful in our daily work. But how do we distinguish the useful articles from the ones that will lead us astray?
One way is to approach articles with a healthy dose of skepticism. Don't blindly follow the instructions or advice given in an article without first testing it thoroughly in your own environment. Ask yourself if the article makes sense for your specific situation, or if there are any assumptions that the article is making that don't apply to your code. And don't be afraid to question the author or reach out to the community for clarification.
Another way to determine the usefulness of an article is to consider the source. Is the author an expert in the field, or are they simply regurgitating information they found elsewhere? Is the article backed up by data or research, or is it purely anecdotal? Taking the time to evaluate the credibility of the source can help you determine if the article is worth your time and attention.
Finally, it's important to remember that no single article or source can provide all the answers. As software developers, we are constantly learning and growing, and the best way to do so is by exposing ourselves to a wide variety of opinions, ideas, and techniques. So don't be afraid to read articles that challenge your assumptions or offer a different perspective, even if you ultimately decide that they aren't useful for your specific situation.
In conclusion, all articles are wrong, but some can be incredibly useful. As software developers, it's our job to approach articles with a critical eye, test them thoroughly, and evaluate the credibility of the source. By doing so, we can continue to learn and grow in our careers, even in the face of conflicting information and opinions. | nkrumahthis |
1,450,523 | Why Choose CoinEx? | Experience What Makes CoinEx So Remarkable. CoinEx is a robust name within the cryptocurrency sector... | 0 | 2023-04-27T21:45:30 | https://dev.to/agboobinnaya/why-choose-coinex-42jg | crypto, blockchain, web3, defi | _Experience What Makes CoinEx So Remarkable._
CoinEx is a robust name within the cryptocurrency sector and is often considered synonymous with privacy while offering a plethora of stablecoins—over 600 in fact. With access to perpetual and spot markets, even margin trading, and all of this coupled with low fees and amazing security, CoinEx has become an all-in-one store for the majority of cryptocurrency traders. For most, its biggest selling point would probably be its lack of mandatory KYC requirements. However, the exchange has a lot more to offer besides that.
**What Makes It So Special?**
CoinEx comes with every essential feature for beginner and veteran cryptocurrency traders alike. Veteran traders, in particular those who have high requirements pertaining to privacy, will find that CoinEx has everything they could possibly need. With that said, let's look at some of its notable features.
For one, as hinted at earlier, it has a large selection of cryptocurrencies, and not just that, but it is constantly integrating exciting new projects, which go through the several vetting processes it has. Then there are the fees to consider, which are competitively low. Furthermore, CoinEx's fees can be reduced even further if one holds their native token, i.e., CET, or chooses it when paying their fees.
On the other hand, its security is top-notch, which is made even more apparent since it has never experienced any kind of hack. This is due to the fact that it utilizes cold wallet storage and lets its users know if anything suspicious happens on their accounts. Such security is also backed by its proof-of-reserves (PoR) and its 100% reserve rate. Also, with PoR, investors can rest assured that CoinEx actually holds their assets and can cover their withdrawals at any given moment, allowing for more transparency.
As mentioned previously, CoinEx does not make KYC mandatory. All one needs to do is enter their email address, a reliable password, and 2FA, and they're all set to go and can begin trading. Still, for withdrawals exceeding $10,000, you need to get verified. Another thing worth mentioning is that it does not charge any fees for deposits, while withdrawals can incur some fees depending on the blockchain involved. Then there is its detailed Help Center as well, which consists of numerous detailed guides for practically any problem you might be facing, and if by some chance you are not able to find what you are looking for, you can directly contact their customer support.
**Final Thoughts**
CoinEx can be an excellent crypto exchange for users who are searching for more robust spot trading markets, as well as for margin trading and perpetual futures if they happen to be on the more experienced end of traders. The number of cryptocurrencies that CoinEx supports is enormous and is still gradually growing, which means you'll be able to find a decent collection of low-market-cap altcoins on offer. Then there is the fact that it does not force KYC on its users, which is particularly relevant if they prefer their privacy.
| agboobinnaya |
1,450,617 | Invariant Violation: requireNativeComponent: “RNSScreenStackHeaderSubview” was not found in the UIManager | Hello developers and enthusiasts of React Native and Expo! Today, let’s discuss an error that you... | 0 | 2023-04-27T22:52:27 | https://dev.to/okorelens/invariant-violation-requirenativecomponent-rnsscreenstackheadersubview-was-not-found-in-the-uimanager-3op6 | expo, reactnative, javascript | 
Hello developers and enthusiasts of React Native and Expo! Today, let’s discuss an error that you may have encountered or could encounter in the future: “Invariant Violation: requireNativeComponent: ‘RNSScreenStackHeaderSubview’ was not found in the UIManager”.
I recently faced this error while building a mobile application for a client. After running “eas build” and generating the app successfully, it kept crashing upon opening. Interestingly, the app worked fine whenever I served it on Expo Go. Eventually, I had to debug the application and that’s when I came across this error.
In my experience, tracing the parent of the component or the stack and installing the package that uses the component often solved such errors. However, this error was different and my first attempt to find a solution on Stack Overflow and online articles didn’t work. I even tried ChatGPT but to no avail.
If you’re facing this error, the first thing to note is that it’s caused by conflicting dependencies that make use of the react-navigation and react-native-screens packages, or there could be a missing package in your project. To resolve this error, make sure that these packages are installed and up-to-date.
_npm i react-navigation react-native-screens @react-native-community/masked-view react-native-gesture-handler react-native-reanimated react-native-safe-area-context_
We have another option, which involves deleting the node modules folder and package-lock.json files. Then, we can update all the packages by running the appropriate command.
_npm update_
I’d like to share another helpful tool called “expo doctor”. It checks that the dependencies installed in your project match the correct versions that your app is using. By appending “-fix-dependencies”, this tool can install the correct versions of the packages used by your app.
_expo doctor --fix-dependencies_
Once you have completed these steps, rebuild your app and you’ll be one step closer to releasing your application.
| okorelens |
1,450,702 | Using Apache ECharts with ReactJS and TypeScript: Server Side Rendering (SSR) | What is SSR? BairesDev explains this well: Server Side Rendering (SSR) is a paradigm under... | 0 | 2023-10-19T07:11:17 | https://dev.to/manufac/using-apache-echarts-with-reactjs-and-typescript-server-side-rendering-ssr-28m7 | ssr, react, echarts, typescript | ### What is SSR?
[BairesDev](https://www.bairesdev.com/blog/server-side-rendering-react/) explains this well: Server Side Rendering (SSR) is a paradigm under which we _render web pages on the server before sending them to the client_.
It has both [pros](https://www.debugbear.com/blog/server-side-rendering#what-are-the-advantages-of-server-side-rendering) and [cons](https://www.debugbear.com/blog/server-side-rendering#are-there-disadvantages-to-server-side-rendering), but some use cases may well justify its adoption. For instance, better search engine indexability could be a huge selling point for SSR for some people.
Broadly speaking, whatever aligns well with your end objectives (CSR, SSR, or a hybrid approach) is fine. However, in this article, we mainly explore **how to render charts using Apache ECharts via SSR**.
### How does Apache ECharts help us in building SSR apps?
As a charting library, it offers built-in support for both CSR and SSR modes.
The visualization instances produced by Apache ECharts can easily be converted to PNG data URLs on the server side. Further, it exposes an [isomorphic](https://en.wikipedia.org/wiki/Isomorphic_JavaScript) API to allow converting these instances to SVG strings as well.
Subsequently, these image strings can be rendered in the browser using the [`<img>`](https://developer.mozilla.org/en-US/docs/Web/HTML/Element/img) element, allowing for server-side rendering (SSR) capability.
The following discussion focuses on building ReactJS SSR applications using **NextJS** but this approach should work as a blueprint for other frameworks too.
---
Before we dive into the SSR way of using ECharts, here's a quick refresher on the CSR approach.
### CSR Snippets
If you pick the Canvas Renderer, here's how a CSR Scatter Plot component may look like. _If the following syntax feels alien, you may want to go through two other articles in this series first: [this](https://dev.to/manufac/using-apache-echarts-with-react-and-typescript-353k) and [this](https://dev.to/manufac/using-apache-echarts-with-react-and-typescript-optimizing-bundle-size-29l8)._
```ts
// Import necessary modules and types from "echarts"
import { ... } from "echarts/...";
import { CanvasRenderer } from "echarts/renderers";
import { useRef, useEffect } from "react";
use([
...,
...,
CanvasRenderer,
]);
export interface Props {
theme?: "light" | "dark";
data: Record<string, number>[];
}
export function CanvasRendererScatterPlot({
theme,
data,
}: Props): JSX.Element {
const chartRef = useRef<HTMLDivElement>(null);
useEffect(() => {
const chart = init(chartRef.current, theme);
return () => {
chart?.dispose();
};
}, [theme]);
useEffect(() => {
if (chartRef.current !== null) {
const chart = getInstanceByDom(chartRef.current);
const option = {...};
chart?.setOption(option, true);
}
}, [data, theme]);
return (
<div
ref={chartRef}
style={...}
/>
);
}
```
But if you want to pick the SVG Renderer instead, the code is mostly the same except that instead of using `CanvasRenderer`, we will need to use `SVGRenderer`.
Now, moving onto the SSR approach:
### SSR Snippets
**A. Canvas**
```ts
import { ... } from "echarts/...";
import { CanvasRenderer } from "echarts/renderers";
import { Canvas, createCanvas } from "canvas";
use([
...,
...,
CanvasRenderer,
]);
export function getCanvasScatterPlotServerSideProps(points: number): Canvas {
const canvas = createCanvas(400, 500);
const chart = init(canvas as unknown as HTMLCanvasElement);
const option = {
...,
series: {
type: "scatter",
encode: {
x: "x",
y: "y",
},
progressiveThreshold: points + 1,
},
...
};
chart.setOption(option);
return canvas;
}
```
The `dataURL` can be generated from the `Canvas` instance via `canvas.toDataURL()`. This data URL can be sent to the client which can then render the chart image as follows:
```ts
import Image from "next/image";
export function SSRCanvasRendererScatterPlot({ url }: { url: string }): JSX.Element {
return (
<div style={...}>
<Image src={url} width={400} height={500} alt="SSR canvas scatter plot" />
</div>
);
}
```
**B. SVG**
```ts
import { ... } from "echarts/...";
import { SVGRenderer } from "echarts/renderers";
use([
...,
...,
SVGRenderer,
]);
export function getSVGScatterPlotServerSideProps(points: number): string {
const chart = init(null as unknown as HTMLElement, undefined, {
renderer: "svg",
ssr: true,
width: 400,
height: 500,
});
const option = {
...,
animation: false,
series: {
type: "scatter",
encode: {
x: "x",
y: "y",
},
progressiveThreshold: points + 1,
},
...
};
chart.setOption(option);
const chartData = chart.renderToSVGString();
chart.dispose();
return chartData;
}
```
Similar to Canvas, the SVG string can be sent to the client where it can be rendered as follows:
```ts
import Image from "next/image";
export function SSRSVGRendererScatterPlot({
svgDataString,
}: {
svgDataString: string;
}): JSX.Element {
return (
<div style={{ ... }}>
<Image
src={`data:image/svg+xml;utf8,${encodeURIComponent(svgDataString)}`}
width={400}
height={500}
alt="SSR SVG scatter plot"
/>
</div>
);
}
```
Now that we know how to generate charts on server-side, we simply need a mechanism to fetch that data on the client-side for final rendering. The [API Routes](https://nextjs.org/docs/pages/building-your-application/routing/api-routes) approach is showcased below. However, the [Server Components](https://nextjs.org/docs/app/building-your-application/rendering/server-components) approach should work fine as well.
```ts
// Next.js API route support: https://nextjs.org/docs/api-routes/introduction
import { getCanvasScatterPlotServerSideProps } from "@/components/SSRCanvasRendererScatterPlot";
import { getSVGScatterPlotServerSideProps } from "@/components/SSRSVGRendererScatterplot";
import { SSRScatterPlotData } from "@/components/utils";
import type { NextApiRequest, NextApiResponse } from "next";
export default function handler(req: NextApiRequest, res: NextApiResponse<SSRScatterPlotData>) {
const { points } = req.query;
let ssrData: SSRScatterPlotData = { svgDataString: "", canvasDataURL: "" };
...
...
const canvas = getCanvasScatterPlotServerSideProps(...);
const svgDataString = getSVGScatterPlotServerSideProps(...);
ssrData = { svgDataString, canvasDataURL: canvas.toDataURL() };
res.status(200).json(ssrData);
}
```
And then, we can consume those image strings as shown below:
```tsx
export const getServerSideData = async (...) => {
...
const rawRes = await fetch(`/api/...`, {
method: "GET",
});
const { canvasDataURL, svgDataString } = (await rawRes.json());
return {
canvasDataURL,
svgDataString,
};
};
...
...
const [ssrData, setSSRData] = useState();
useEffect(() => {
...
getServerSideData(...)
.then((res) => {
setSSRData(res);
})
.catch(console.log);
setData(scatterPlotData);
}, [value]);
...
...
<Grid>
<Grid.Col span={6} h="50vh">
{ssrData?.canvasDataURL === undefined ? null : (
<SSRCanvasRendererScatterPlot url={ssrData.canvasDataURL} />
)}
</Grid.Col>
<Grid.Col span={6} h="50vh">
{ssrData?.svgDataString === undefined ? null : (
<SSRSVGRendererScatterPlot svgDataString={ssrData.svgDataString} />
)}
</Grid.Col>
</Grid>
```
---
### Parting Notes
1. Generating charts on server-side via ECharts is achievable, thanks to the in-built support that ECharts provide.
2. The approach involves creating a PNG or SVG string on the server side and then rendering that string on client side using the `<img>` element's `src` attribute.
3. Although ECharts provide support for animation in server-side rendered charts [by embedding CSS animations in the output SVG string](https://echarts.apache.org/handbook/en/how-to/cross-platform/server/#animations-in-server-side-rendering), those animations can still feel limited as compared to JS animations.
4. While rendering a scatter plot on server-side via SVG renderer, we observed that all the points were getting rendered in 1 corner instead of their expected places. Disabling the animation fixed the issue.
5. Another thing that made us scratched our heads for a bit was the progressive rendering feature that ECharts provides.
> Since ECharts 4, "progressive rendering" is supported in its workflow, which processes and renders data chunk by chunk alone with each frame, avoiding to block the UI thread of the browser.
Although it can be desirable in CSR cases, for SSR it understandably led to partial rendering of the chart whenever the data exceeded the `progressiveThreshold`. We resolved this issue by always setting the `progressiveThreshold` to value greater than the size of the data so that progressive rendering doesn't trigger.
| maneetgoyal |
1,450,790 | Current Status! | Hi everyone, welcome to my blog where I share my thoughts and opinions on various topics. Today, I... | 0 | 2023-04-28T04:29:51 | https://dev.to/bang7227/current-status-ofo | Hi everyone, welcome to my blog where I share my thoughts and opinions on various topics. Today, I want to talk about the current situation happening in Ghana and across the African continent.
Ghana is a West African country that has a population of about 29.6 million people (2018) and borders Togo, Cote d'Ivoire, and Burkina Faso. It has a tropical climate with two main seasons: the wet and the dry seasons. It is also a major producer and exporter of cocoa and gold.
However, Ghana is facing its worst economic crisis in decades, as inflation has soared to a record 50.3 percent in January 2023, making life difficult for many people. The government has increased salaries by 30 percent to cope with the rising costs of living, but this has also added to the fiscal deficit. Ghana has requested a restructuring of its debt from its creditors, including the G20 countries and the World Bank. Some aid groups have urged debt cancellation to ease Ghana's economic woes.
Ghana is not alone in its challenges. Many other African countries are struggling with similar issues, such as poverty, corruption, insecurity, climate change, and health crises. For example, malaria remains a major killer in Africa, claiming more than 600,000 lives every year. However, there is some hope as Ghana has become the first country to approve Oxford's malaria vaccine, which could potentially save millions of lives.
Ghana is also trying to strengthen its ties with other countries, especially the United States. In March 2023, US Vice President Kamala Harris visited Ghana and announced security aid for Ghana and four other West African countries to tackle violent groups and instability. Harris also visited a slave castle in Ghana and said that "history must be learned" from the atrocities of the past.
Ghana is a country with a rich history and culture, but also with many challenges and opportunities. I hope that this blog post has given you some insight into the current condition happening in Ghana and across Africa continent. Thank you for reading and stay tuned for more updates. | bang7227 | |
1,450,807 | Tune Into These Top Podcasts for Women in Tech | Technology has rapidly become an integral part of our lives, and as a result, the technology industry... | 0 | 2023-04-28T00:30:00 | https://dev.to/samanthabretous/tune-into-these-top-podcasts-for-women-in-tech-53p2 | Technology has rapidly become an integral part of our lives, and as a result, the technology industry has grown to be one of the top industries today. Women have been making great strides in this field, but there is still much work to be done. With that in mind, this blog seeks to highlight some of the best podcasts for women working in tech.
**Deeper Than Tech**
The goal of this show is to help black women in tech understand how to navigate the tech space so that they can advance their careers as Software Engineers, UX Designers, Scrum Masters and so many more.
Together they tackle topics like being a black woman in technology, How to progress in an industry that wasn’t designed for black women in mind and helping you build confidence in your career as a software engineer.
Listen Here
[Twitter](https://twitter.com/deeperthantech)
[Instagram](https://www.instagram.com/deeperthantech/)
[Youtube](https://www.youtube.com/channel/UCT7r828zyIJjmZEO4S1QqJQ)
**#WomenInTech**
The #WomenIntech Podcast is hosted by WeAreLATech’s Espree Devora and features inspiring Women in Tech from Engineers, Female Founders, Investors, UX and UI Designers, Journalists all sharing their story how they got to where they are today.
Espree is a superb host with an exceptional talent for eliciting excellent stories and thought-provoking insights from her guests. I hope to witness more of her amazing work! She is passionate, motivated, and committed to furthering the rights of women in tech worldwide. Impactful and inspiring!
Listen Here
[Twitter](https://twitter.com/womenintechshow)
[Instagram](https://www.instagram.com/womenintechshow/)
[Facebook](https://www.facebook.com/womenintechshow)
**Marketplace Tech**
Hosted by Molly Wood, Marketplace Tech explores how technology shapes our lives in unexpected ways. It offers context for listeners interested in the implications of technology, business, and the digital world.
Molly Wood's thought-provoking podcasts make this show a must-listen. Expert guests provide valuable insights into the current state of the digital economy, making it an essential resource for tech fans!
Listen Here
[Twitter](https://twitter.com/Marketplace)
**Women Talk Tech Podcast**
Every episode of this podcast is dedicated to highlighting the stories of women who have overcome great obstacles to succeed in tech. It sheds light on the various issues they face and the difficulties they encounter in their careers.
I'm a regular listener and I think it's great! I'm grateful for the news about the progress being made in this field. The stories are always inspiring! Tune in to this podcast for 5-7 minutes and get a wealth of interesting information on noteworthy individuals, companies, issues, and trends in the tech world.
Listen Here
[Instagram](https://www.instagram.com/womentalktechpodcast/?hl=en)
[LinkedIn](https://www.linkedin.com/company/women-talk-tech-podcast/)
**Startups Magazine: The Cereal Entrepreneur**
Grab a bowl & dig into this! Anna Flockett, editor of Startups Magazine interviews the most innovative startups of the moment. She’ll stir in some startup lessons & failure fables as well as a sprinkling of inspirational advice.
This podcast explores how to thrive in the digital age while maintaining our humanity in the face of technological advances. It features lengthy conversations, making it an ideal choice for those seeking a top-notch tech review podcast.
Listen Here
[Twitter](https://twitter.com/TheStartupsMag)
[Instagram](https://www.instagram.com/startupsmagazine/)
[Facebook](https://www.facebook.com/TheStartupsMag)
[Youtube](https://www.youtube.com/channel/UCccztX35OPFsyKBfPV-pB9Q)
[LinkedIn](https://www.linkedin.com/company/startups-magazine/)
**Mums on Cloud Nine**
Mums on Cloud Nine aims to inspire mums to progress their careers in tech from starting out to climbing the career ladder. They provide tips and insight on how to succeed in your career and overcome adversity that many women can face in the workplace. The podcast show is delivered by Heather Black, CEO of Supermums, a global brand supporting mums to upskill and transition into the tech sector.
The show is enjoyable, but also avoids becoming too serious. If you're a fan of tech and want to learn more about programming and the software development community, you should tune in to the Cloud Nine podcast.
Listen Here
[Twitter](https://twitter.com/SupermumsGlobal)
[Instagram](https://www.instagram.com/supermumsglobal/)
[Facebook](https://www.facebook.com/supermumsglobal/)
[LinkedIn](https://www.linkedin.com/company/supermumsglobal)
**in:tech**
In:tech is the new diversity and inclusion podcast from the Tech Talent Charter (TTC). Hosted by Rebecca Donnelly, Senior Partner at Tyto and TTC board member, this podcast is for anyone who wants to make their organization more inclusive, diverse, and equitable but needs some help or advice.
With a series of high-profile guests who are leaders in the DE&I and tech space, they provide practical insights and concrete takeaways to help you move the dial. Podcasts like these are a kind of evaluation, analysis, and review. These reviews can not only help you make a purchase, but can open up a whole new array of opportunities.
The show is great because it is released regularly, ensuring listeners stay up to date on the latest news in the tech world.
Listen Here
[Twitter](https://twitter.com/techcharteruk?lang=en)
[Instagram](https://www.instagram.com/techtalentcharter/)
[Facebook](https://www.facebook.com/techtalentcharter)
[LinkedIn](https://www.linkedin.com/company/tech-talent-charter/)
There you have it, my pick of the podcasts I recommend you tune in to if you're thinking of starting in tech or shifting careers.
What do you think of my list? Have you listened to these podcasts? If so, share this blog to let others know too. | samanthabretous | |
1,451,049 | Restrict a User to One Directory in linux | 1. Overview Linux allows more than one user at a time to access a machine’s resources. As a system... | 0 | 2023-04-28T09:43:11 | https://dev.to/francodosha/restrict-a-user-to-one-directory-in-linux-53ml | mkdir, passwd, usermod, useradd | **1. Overview**
Linux allows more than one user at a time to access a machine’s resources. As a system administrator, it’s important to understand the different techniques that are helpful in managing these users. One of these methods is restricting a user to a single directory, which helps improve the security of our system. For instance, we’re able to prevent certain users from accessing sensitive files, so that the users can’t accidentally delete them.
In this tutorial, we’ll discuss a useful method for restricting a user to a single directory. First, we’ll explore the concept of Linux shells. Next, we’ll understand what a restricted shell is. Finally, we’ll dive into setting up a restricted shell for an existing user and also for a new user upon creation.
**2. Using a Restricted Shell**
The Linux shell acts as the interface between the user and the operating system. To put it differently, it’s the command line interpreter that sends our instructions to the operating system.
There are different types of shells like Bash, sh, etc., and we can use any of them in the restricted shell mode. This means that the shell will have more restrictions than its original state. In this case, we’ll use Bash to demonstrate how it works.
**2.1. A Restricted Shell for an Existing User**
First, let’s change the shell for an existing user francis to a restricted Bash shell:
```
$ sudo usermod -s /bin/rbash francis
```
Here, **we use usermod, a command that allows an administrator to modify the properties of a user in Linux**. Further, we add the -s option to instruct usermod to change the default shell for the user francis from Bash to a restricted Bash shell (rbash).
Next, we create the directory that francis will be restricted to:
```
$ sudo mkdir -p /home/francis/restricted
```
In the example above, we’ve used the mkdir command to create a directory named restricted. We notice that there are two parent directories defined, namely, home and francis respectively. To ensure these directories are also created in the process, we include the -p option.
Further, we’ll change the home directory for francis to the restricted directory:
```
$ sudo usermod -d /home/francis/restricted francis
```
Now francis can only access this directory and its child directories after logging in. The -d option instructs usermod that we’re modifying the home directory property for the user.
**2.2. A Restricted Shell for a New User**
In this scenario, we’re creating a new user and configuring for them a restricted shell upon creation. To achieve this, we’ll work with the useradd command:
```
$ sudo useradd jeff -s /bin/rbash
```
The useradd command helps add a new user jeff to our system while the -s option allows us to define the default shell as the restricted Bash shell (rbash).
Next, let’s define the password for jeff with the help of the passwd command:
```
$ sudo passwd jeff
```
The passwd command allows us to set the password for our user.
Now, we create the directory that jeff will be confined to:
```
$ sudo mkdir -p /home/jeff/restricted
```
Here, we’re able to create all the directories defined in the path.
Finally, we set the home directory for our user to the directory we created above:
```
$ sudo usermod -d /home/jeff/restricted jeff
```
So, the user jeff can only operate within the confines of the restricted directory.
**3. Conclusion**
In this article, we explored what a restricted shell is and how to set it up for an existing user and a new user.
We also discussed the concept of a standard Linux shell. As a result, we were able to understand some commands useful for managing users as well as their information. Now, we’re able to restrict a user to one directory.
| francodosha |
1,451,058 | Why Binance Clone Script Is the Perfect Choice For Cryptocurrency Entrepreneurs? | The demand for cryptocurrency exchange platforms has increased as a result of the enormous growth in... | 0 | 2023-04-28T09:59:15 | https://dev.to/lewishjeeny/why-binance-clone-script-is-the-perfect-choice-for-cryptocurrency-entrepreneurs-4fk2 | cryptocurrencyexchangesoftware | The demand for cryptocurrency exchange platforms has increased as a result of the enormous growth in the popularity of cryptocurrencies around the world. One of the world's most significant and biggest cryptocurrency exchanges, Binance, has built a robust and trustworthy platform. A Binance clone script is an exact copy of the Binance exchange platform that can be tailored to a cryptocurrency business owner's unique needs.
Easy Setup & Customization: A Binance clone script is easy to set up and customizable to suit the business owner's needs. Adding or removing features like currency support, trading pairs, and payment options from the script is simple.
High-Security Standards: The highest level of security is provided by the Binance clone script to safeguard user information, financial transactions, and funds. The platform has features like two-factor authentication, encrypted user data, and cold wallet storage to protect user data from hacking attempts.
User-Friendly Interface: Trading cryptocurrencies is simple for beginners and experts thanks to the Binance clone script's user-friendly interface. The platform makes it simple for users to make wise trading decisions by providing cutting-edge charting tools, trading indicators, and real-time market data.
Low Development Costs: A cryptocurrency exchange platform's development from the ground up can be expensive and time-consuming. The script that replicates Binance offers a cost-effective solution by drastically cutting down on the time and cost of development. Due to this, it is the perfect option for business owners looking to enter the cryptocurrency market on a budget.
Cryptocurrency entrepreneurs looking for [cryptocurrency exchange platform development](https://www.pyramidions.com/cryptocurrency-exchange-development-company
) should choose the Binance clone script. The script is the most effective and practical way to build a successful cryptocurrency exchange platform because it has a wide range of features, high-security standards, a user-friendly interface, and low development costs. | lewishjeeny |
1,451,183 | Journey I Learn How to Code | Hello my name is Juan, here I want to share my experiences while I learn to code. It will be short... | 0 | 2023-04-28T12:31:46 | https://dev.to/juanryhn/journey-i-learn-how-to-code-ba8 | javascript, beginners, programming, tutorial | Hello my name is Juan, here I want to share my experiences while I learn to code. It will be short story
I started learning coding since 2 or 3 years ago. At first, I was confused how can I understand the syntax of code. I start with many question such as Why there is `if and else`, `for, while and do while loop`, how do I know my code is working, how can I display the output and many more. So I ask my friend to help me out, I ask many friends to explain the code they made. After that it's going better little by little I know the syntax of code means.
But the journey doesn't stop there. I see people can build great apps, beautiful webs and smart technology. How did they do that ?!?. So I decided to learn from youtube tutorials, articles and free courses. But after dozens of tutorials, articles and courses my skills doesn't improve significant. It's just make me envy to the creator, why he can easily write a code and know every syntax, method etc.
Finally, after that phase I start to build my own project. Don't care if it will be great or not, I just want to code by myself. And do you know what ?!, I make a flow, code, debug and I ask so many times to many people "how to do this and that". And from that way I learn a lot of things. Now I can remind a syntax, method and etc. and the most important thing is I know what to do while I'm coding.
Maybe the point is:
1. You can not easily write a code if you just watch tutorials and read some articles or join a courses.
2. Tutorials, articles and courses will help you to gain more informations about code and how to do something.
3. Make your own apps, just don't care about the result if it will be good or not just, let it be.
4. Consistent
5. Enjoy every learning progress and take your time don't be rush.
Hope you can enjoy it and let me know your journey !. | juanryhn |
1,451,202 | MS Edge now allows you to simulate dark, light, high contrast mode, blurred vision and colour deficiencies in Device Emulation | Two new buttons in the device emulation make it a lot easier to create accessible products | 0 | 2023-04-28T13:10:22 | https://christianheilmann.com/2023/04/28/microsoft-edge-now-allows-you-to-simulate-dark-light-high-contrast-mode-blurred-vision-and-colour-deficiencies-right-from-the-device-emulation-toolbar/ | a11y, testing, browsers | ---
title: MS Edge now allows you to simulate dark, light, high contrast mode, blurred vision and colour deficiencies in Device Emulation
published: true
description: Two new buttons in the device emulation make it a lot easier to create accessible products
tags: accessibility, testing, browsers
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/xkdk4s7hwwj76y0almq1.png
canonical_url: https://christianheilmann.com/2023/04/28/microsoft-edge-now-allows-you-to-simulate-dark-light-high-contrast-mode-blurred-vision-and-colour-deficiencies-right-from-the-device-emulation-toolbar/
# Use a ratio of 100:42 for best results.
# published_at: 2023-04-28 12:57 +0000
---
I was incredibly excited to see that from Microsoft Edge 111 onwards you can now emulate different viewing modes and vision deficiencies right from the device emulation toolbar.

This has been one of my pet projects that I really wanted to see come to live ever since I created the [Skillshare Course on Accessibility testing in the browser](https://skl.sh/3uKu5G1) and wrote the detailed [documentation on how to test for accessibility](https://learn.microsoft.com/en-us/microsoft-edge/devtools-guide-chromium/accessibility/accessibility-testing-in-devtools) in Microsoft Edge.
This new device bar makes it incredibly easy to see your product in:
* Emulated dark/light mode
* Forced colours mode even when you are not in Windows
* Blurred display
* Without colours or colour deficiencies
All from within the tool you use to test your responsive designs and mobile version of your product.
I am super stoked to see that this finally is live, after having put such a long time into it to make it work.
| codepo8 |
1,451,297 | Awesome top 5 Posts from last week tagged(#devops) | DevSecOps with AWS – ChatOps with AWS and AWS Developer Tools – Part 1 Level 200 Table of... | 0 | 2023-04-28T13:25:54 | https://dev.to/c4r4x35/awesome-top-5-posts-from-last-week-taggeddevops-eof | devops, c4r4x35 | ##DevSecOps with AWS – ChatOps with AWS and AWS Developer Tools – Part 1
Level 200
Table of Contents
Hands On
Requirements
AWS Services
Solution Overview
Step by Step
The “boom” of AI is transforming the industry sure thing you are listening to in all social media...
{% link https://dev.to/aws-builders/devsecops-with-aws-chatops-with-aws-and-aws-developer-tools-part-1-26n2 %}
##My Favorite Courses to Learn Docker and Containers in Depth
Disclosure: This post includes affiliate links; I may receive compensation if you purchase products or services from the different links provided in this article.
Hello devs, if you want to learn...
{% link https://dev.to/javinpaul/my-favorite-courses-to-learn-docker-and-containers-in-depth-11fp %}
##A primer on GCP Compute Instance VMs for dockerized Apps [Tutorial Part 8]
Getting started with the Google Cloud Platform (GCP) to run Virtual Machines (VMs) and prepare them to run dockerized applications.
This article appeared first on https://www.pascallandau.com/ at A...
{% link https://dev.to/pascallandau/a-primer-on-gcp-compute-instance-vms-for-dockerized-apps-tutorial-part-8-4k46 %}
##Kubernetes Kustomize Tutorial: A Beginner-Friendly Developer Guide!
Kustomize, just like the name implies, is used for customizing Kubernetes deployments to help developers manage Kubernetes application configurations. With Kustomize, it is easy to define a base set...
{% link https://dev.to/pavanbelagatti/kubernetes-kustomize-tutorial-a-beginner-friendly-developer-guide-322n %}
##Understanding Kubernetes: part 48 – Kubernetes 1.27 Changelog
Understanding Kubernetes can be difficult or time-consuming. In order to spread knowledges about Cloud technologies I started to create sketchnotes about Kubernetes. I think it could be a good way,...
{% link https://dev.to/aurelievache/understanding-kubernetes-part-48-kubernetes-127-changelog-1alk %}
| c4r4x35 |
1,451,314 | How to Code the Binary Search Algorithm | If you want to learn how to code, you need to learn algorithms. Learning algorithms improves your problem solving skills by revealing design patterns in programming. In this tutorial, you will learn how to code the binary search algorithm in JavaScript and Python. | 0 | 2023-04-28T13:34:32 | https://jarednielsen.com/algorithm-binary-search/ | algorithms, career, javascript, python | ---
title: How to Code the Binary Search Algorithm
published: true
description: "If you want to learn how to code, you need to learn algorithms. Learning algorithms improves your problem solving skills by revealing design patterns in programming. In this tutorial, you will learn how to code the binary search algorithm in JavaScript and Python."
tags: algorithms, career, javascript, python
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/oxb27gyfcjrip2ksk6i7.png
# Use a ratio of 100:42 for best results.
# published_at: 2023-04-28 13:28 +0000
canonical_url: https://jarednielsen.com/algorithm-binary-search/
---
If you want to learn how to code, you need to learn algorithms. Learning algorithms improves your problem solving skills by revealing design patterns in programming. In this tutorial, you will learn how to code the binary search algorithm in JavaScript _and_ Python.
_This article originally published at [jarednielsen.com](https://jarednielsen.com/algorithm-binary-search/)_
## How to Code the Binary Search Algorithm in JavaScript and Python
[Programming is problem solving](https://jarednielsen.com/programming-problem-solving/). There are four steps we need to take to solve any programming problem:
1. Understand the problem
2. Make a plan
3. Execute the plan
4. Evaluate the plan
### Understand the Problem
To understand our problem, we first need to define it. Let’s reframe the problem as acceptance criteria:
```md
GIVEN a sorted array
WHEN I request a specific value
THEN I am returned the location of that value in the array
```
That’s our general outline. We know our input conditions, a sorted array, and our output requirements, the location of a specific value in the array, and our goal is to improve the performance of a linear search.
Let’s make a plan!
### Make a Plan
Let’s revisit our computational thinking heuristics as they will aid and guide is in making a plan. They are:
* Decomposition
* Pattern recognition
* Abstraction
* Algorithm design
The first step is decomposition, or breaking our problem down into smaller problems. What's the smallest problem we can solve?
An array containing _one_ number, for example: `[1]`.
Let's pseudocode this:
```
INPUT arr, num
IF arr[0] == num
RETURN 'Bingo!'
ELSE
RETURN FALSE
```
This is less of a _search_ and more of a guessing game. What's the next smallest problem? An array containing _two_ numbers: `[1, 2]`.
```
INPUT arr, num
IF arr[0] == num
RETURN 'Found num in the 0 index`
ELSE IF arr[1] == num
RETURN 'Found num in the 1 index`
ELSE
RETURN FALSE
```
This is still a guessing game, but now it's binary! What did we do when we wrote those two conditionals? We cut the problem in half: `[1]` and `[2]`.
Let's add one more: `[1, 2, 4]`. Now what? We _could_ write conditionals for every index, but will it scale?
Can we cut this array in half? Not cleanly.
But we _can_ select the index in the middle and check if it's greater or less than `num`. If `num` is less than the middle index, we will _pivot_ and compare the preceding value. And if `num` is greater than the middle index, we will _pivot_ and check the succeeding value. Hey! Let's call this index _pivot_.
If our array is `[1, 2, 4]`, the our `pivot` is `2`. Let's pseudocode this:
```
INPUT arr, num
SET pivot TO arr[1]
IF arr[pivot] == num
RETURN 'Found num at pivot'
ELSE IF arr[pivot] < num
RETURN 'Found num in the 0 index'
ELSE
RETURN 'It's gotta be in the 2 index...'
```
Let's work with a slightly larger array: `[1, 2, 4, 8]`.
There are a few small problems we need to solve here:
1. In order to scale, we can no longer "hard code" the value stored in `pivot`.
2. There's no "middle index". So what value do we choose for `pivot`?
Let's address the first problem first: we can simply divide the array in two.
```
INPUT arr, num
SET pivot TO LENGTH OF arr DIVIDED BY 2
IF arr[pivot] == num
RETURN 'Found num at pivot'
ELSE IF arr[pivot] < num
RETURN 'Found num in the 0 index'
ELSE
RETURN 'It's gotta be in the 2 index...'
```
Using the example above, our array contains four elements. If we divide the length of our array by two, `pivot` will be equal to 2.
If `pivot` is equal to 2, the value at that index in our array is `4`.
But what if there's an odd number of elements in the array?
```
[1, 2, 3, 4, 5]
```
If we divide the length of the array by 2, we get 2.5.
We simply need to round up or down. Let's round down. Our pseudocode now reads:
```
INPUT arr, num
SET pivot TO THE FLOOR OF THE LENGTH OF arr DIVIDED BY 2
IF arr[pivot] == num
RETURN 'Found num at pivot'
ELSE IF arr[pivot] < num
RETURN 'Found num in the 0 index'
ELSE
RETURN 'It's gotta be in the 2 index...'
```
When we divide the length of this array by 2 and floor the returned value, our `pivot` is equal to 2.
The value stored in the 2 index is `3`.
Previously, we hard coded the conditional checks on either side of the pivot. Will that work here?
No, because there are now _two_ values we need to check on either side of our pivot.
It's time to iterate!
Because we don't know how long our loop needs to run, let's use a `while`. Our `while` loops need a conditional. What do we want to use here?
If `pivot` is less than `num`, then on the next iteration we need to start with a value greater than `pivot`. But we need to ensure we are still checking _all_ of the values greater than `pivot`.
And if `pivot` is greater than `num`, then on the next iteration we need to start with a value less than `pivot`. And, as above, we need to ensure we are still checking _all_ of the values less than `pivot`.
Do you see a pattern?
Before we implement our `while` iteration, let's translate these conditionals to pseudocode:
```
INPUT arr, num
SET pivot TO THE FLOOR OF THE LENGTH OF arr DIVIDED BY 2
IF arr[pivot] == num
RETURN 'Found num at pivot'
ELSE IF arr[pivot] < num
START SEARCHING IN THE NEXT ITERATION AT pivot + 1
ELSE
SEARCH UP TO pivot - 1 IN THE NEXT ITERATION
```
Let's step through a hypothetical scenario using our five element array and searching for `5`.
On our first iteration, we set `pivot` to `3`.
We start our conditional checks and see that `pivot` is not equal to `num`, but that it _is_ less than `num`. We can now ignore the values up to and including `pivot`.
In the next iteration, we'll start searching at `pivot + 1`, which is `4`.
What happens in the next iteration?
We set `pivot` to the floor of the length of our array divided by 2, which is 2.
Hey! Wait! We already checked this value.
We need a new `pivot`.
We need to set a `pivot` from the remaining values to be checked. In our case, that's:
```
[4, 5]
```
If we floor the length of _this_ array divided by 2, we get 1. But we know that's not _actually_ the 1 index.
What do we do here?
We get abstract!
Let's declare variables to store these values in each iteration:
```
SET start index TO 0
SET end index TO THE LENGTH OF THE ARRAY - 1
```
Finally, we need to refactor our conditional statements to reassign these values in each iteration:
```
INPUT arr, num
SET start index TO 0
SET end index TO THE LENGTH OF THE ARRAY - 1
WHILE
SET pivot TO THE FLOOR OF THE LENGTH OF arr DIVIDED BY 2
IF arr[pivot] == num
RETURN 'Found num at pivot'
ELSE IF arr[pivot] < num
SET start index TO pivot + 1
ELSE
SET end index TO pivot - 1
RETURN FALSE
```
### Execute the Plan
Now it's simply a matter of translating our pseudocode into the syntax of our programming language.
#### How to Code the Binary Search Algorithm in JavaScript
Let's start with JavaScript...
```js
const powers = [1, 2, 4, 8 ,16, 32, 64, 128, 256, 512];
const binarySearch = (arr, num) => {
let startIndex = 0;
let endIndex = (arr.length)-1;
while (startIndex <= endIndex){
let pivot = Math.floor((startIndex + endIndex)/2);
if (arr[pivot] === num){
return `Found ${num} at ${pivot}`;
} else if (arr[pivot] < num){
startIndex = pivot + 1;
} else {
endIndex = pivot - 1;
}
}
return false;
}
```
#### How to Code the Binary Search Algorithm in Python
Now let's see it in Python...
```py
import math
powers = [1, 2, 4, 8 ,16, 32, 64, 128, 256, 512]
def binarySearch(arr, num):
startIndex = 0
endIndex = len(arr)-1
while (startIndex <= endIndex):
pivot = math.floor((startIndex + endIndex)/2)
if (arr[pivot] == num):
return f"Found {num} at index {pivot}"
elif (arr[pivot] < num):
startIndex = pivot + 1
else:
endIndex = pivot - 1
return false
```
### Evaluate the Plan
Can we do better?
Of course! This is just the beginning of our exploration of search algorithms. There are variations on binary search as well as data structures based on binary search that improve the performance.
## A is for Algorithms

Give yourself an A. Grab your copy of [A is for Algorithms](https://gum.co/algorithms)
| nielsenjared |
1,451,380 | How to Setup Semgrep Rules for Optimal SAST Scanning | DevOps teams are all too familiar with the frustration of finding a bug in their code that could have... | 0 | 2023-04-28T15:24:35 | https://www.jit.io/blog/semgrep-rules-for-sast-scanning | sast, cybersecurity, tutorial | DevOps teams are all too familiar with the frustration of finding a bug in their code that could have been caught earlier. Or worse, they have had to deal with the consequences of a security vulnerability that slipped through the cracks. There is no surprise then that tools like Semgrep are a devs' best friend.
Semgrep is considered the future of static analysis, and with its growing community of users and over 2500 rules in the Semgrep Registry, it's available to everyone. In this article, we'll explore the basics of Semgrep, how to run rules and set up optimal SAST scanning, and even how to write your own rules to catch those pesky bugs and security vulnerabilities.
An introduction to Semgrep
--------------------------
[Semgrep](https://owasp.org/www-chapter-newcastle-uk/presentations/2021-02-23-semgrep.pdf) is a popular open-source static analysis tool that identifies and prevents [security vulnerabilities](https://www.jit.io/blog/the-in-depth-guide-to-owasps-top-10-vulnerabilities) in source code. Initially developed by Facebook in 2009 for internal use, Semgrep has become a widely used tool among software developers and security professionals. Semgrep's unique selling point is its ease of use and flexibility in writing custom rules to detect specific security issues.
This tool is handy for software developers performing static analysis in their [development workflow. ](https://www.jit.io/blog/developers-guide-to-the-devsecops-toolchain)It can quickly identify potential security issues and prevent security breaches and related problems. As an open-source tool, Semgrep has a growing community of contributors who help maintain and improve the tool, ensuring it stays up-to-date with the latest developments in the field.
Running rules with Semgrep
--------------------------
[Semgrep rules](https://semgrep.dev/docs/running-rules) are written in a simple, declarative language that specifies what code patterns to look for and what actions to take when a pattern is found. They can detect security vulnerabilities, code smells, and style violations.
[The number of Semgrep Registry rules](https://semgrep.dev/docs/running-rules/#number-of-semgrep-registry-rules)
Semgrep rules can be stored in various ways, including in YAML files, your code repository, or Semgrep's rule registry. They are categorized by the type of issue they detect, and you can filter them by language, file type, and other attributes.
For example, the following Semgrep rule detects the use of insecure cryptographic functions:
*name: Insecure Cryptography\
description: Detects use of insecure cryptographic functions\
patterns:\
- pattern: MD5\(\
- pattern: SHA1\(\
- pattern: DES\(\
- pattern: RC4\(\
- pattern: PBKDF1\(\
- pattern: cbc*
Types of Semgrep rules
----------------------
Semgrep Existing Rules: These are the default rules that are included in the Semgrep rule registry. The Semgrep development team creates and maintains these rules covering various potential security vulnerabilities and coding errors. Developers can run these rules as-is or customize them to fit their specific codebase better.
Local Rules (Ephemeral and YAML-defined): Local rules are custom rules that developers can create to scan their codebase for specific issues. There are two types of local rules: ephemeral and YAML-defined.
- [Ephemeral rules](https://semgrep.dev/docs/running-rules/#ephemeral-rules) are one-off rules that are passed into the command line.
- [YAML-defined rules](https://semgrep.dev/docs/running-rules/#yaml-defined-rules) are defined in a YAML file and can be reused across multiple scans. You can customize them to scan for specific issues in a codebase, making them a powerful tool for catching potential problems early in development.
Setting up Semgrep Rules for Optimal SAST Scanning
--------------------------------------------------
Semgrep rules are designed to identify specific patterns of code that are potentially vulnerable to security issues. They work by using a set of regular expressions or syntax trees to match patterns of code that indicate security vulnerabilities.
For example, let's say you have a web application that takes user input and uses it to construct a SQL query. This is a common way to create security vulnerabilities in web applications if the input is improperly sanitized. With Semgrep, you can create a rule to scan your code for this vulnerability by looking for code that constructs a SQL query using user input.
Here's an example Semgrep rule that would identify this type of vulnerability:
This example rule, named "SQL Injection," is designed to identify potential SQL injection vulnerabilities in Python code. The rule works as follows:
1. The check_query function takes a parsed SQL query tree as input and checks if the query contains a "SELECT" statement.
2. The match function is the main function used to scan the code. It takes a syntax tree and a filename as input.
- It first checks if the filename ends with ".py," indicating that it is a Python source file.
- If it's a Python file, the function collects all SQL queries in the code by looking for nodes with a "DML" token type.
- Then, for each collected query, it checks if it contains a "SELECT" statement using the check_query function.
- If a "SELECT" statement is found, the function returns True, indicating that the code has a potential SQL injection vulnerability.
1. The rule is added to a RulesDict instance, which runs the rule against a given code snippet.
### Semgrep's Rule Board
[Semgrep's Rule Board](https://semgrep.dev/docs/semgrep-app/editor/#setting-code-standards-with-the-rule-board) is a powerful tool that allows developers to access a vast library of pre-existing rules to scan their code for potential vulnerabilities. To use Semgrep's Rule Board, developers can simply add the desired ruleset to their configuration file, and the tool will automatically download and run those rules during the scanning process.
[Rule board visual interface](https://semgrep.dev/docs/semgrep-ci/running-semgrep-ci-with-semgrep-app/#setting-up-the-ci-job-and-semgrep-cloud-platform-connection)
For example, to add a ruleset for scanning Django code for potential security issues, developers can add the following line to their configuration file:
*rules:\
- https://semgrep.dev/p/r2c/django*
This will download the django ruleset from Semgrep's Rule Board and apply it to the scanning process.
The Rule Board also allows developers to create and share their rulesets, making it a collaborative platform for improving code security across the development community. Once a custom ruleset is created, it can be added to the configuration file using the same syntax as pre-existing rulesets.
### Writing your own Semgrep rules
[Writing your own Semgrep rules](https://semgrep.dev/docs/semgrep-code/getting-started-with-semgrep-code/#writing-your-own-rules) can be a powerful way to customize your SAST scanning process and target specific issues in your code. To get started, you'll need to have some familiarity with the Semgrep syntax and be able to identify the types of problems you want to scan for.
To write your own Semgrep rules, you'll need to start by creating a new rule file. You can do this by running the semgrep --init command and selecting the language you want to create a rule for. This will generate a new rule file with some basic boilerplate code that you can modify to suit your needs.
Once you've made your rule file, you can start writing rules that target specific issues in your code. For example, you might create a rule that scans for SQL injection vulnerabilities by looking for instances where user input is concatenated directly into a SQL query.
To write this type of rule, you would use the Semgrep syntax to define a pattern that matches the vulnerable code. For example, use sql_concat to check instances where user input is concatenated directly into a SQL query.
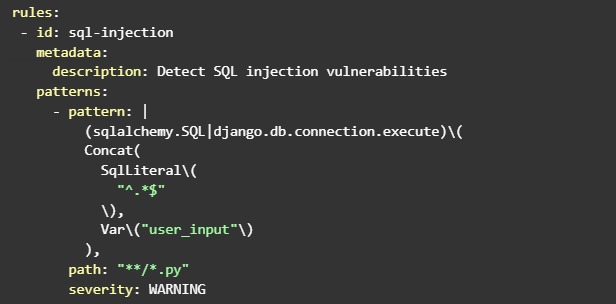
In this example, we're using the sqlalchemy.SQL and Django.db.connection.execute functions to match instances where SQL queries are being conducted. We then use Concat to check cases where user input is concatenated into the query. Finally, we're using the Var function to match the user input variable.
To set up your custom rules for optimal[ SAST scanning](https://www.jit.io/blog/how-to-run-a-sast-test-with-bandit-and-jit), you should consider organizing them by category and reviewing them regularly to ensure they are up-to-date and effective. You should also consider integrating Semgrep with your custom rules into your CI/CD pipeline to ensure they run consistently and thoroughly.
Running a SAST scan with Semgrep
--------------------------------
[Running a SAST scan](https://semgrep.dev/docs/semgrep-app/getting-started-with-semgrep-app/#starting-a-sast-scan-with-semgrep-code) with Semgrep is a simple process that requires just a few commands in the terminal. In this tutorial, we will walk through the steps to run a scan using Semgrep.
Step 1: Install Semgrep. The first step is to install Semgrep using the following command:
*$ curl -L https://semgrep.dev/install.sh | bash*
This will download and install the latest version of Semgrep.
Step 2: Create a Semgrep configuration file. The next step is to create a configuration file for Semgrep. This file specifies which rules should be run during the scan and which files to scan. Here is an example configuration file:
This configuration file specifies two rulesets to use (Secret-detection and Cryptography) and includes all .py, .html, and .js files in the scan.
Step 3: Run the Semgrep scan. Once the configuration file has been created, the Semgrep scan can be run using the following command:
*$ semgrep --config=<**your_config**> <**your_code_directory**>*
This command runs Semgrep with the configuration file and scans all files in the current directory.
Step 4: View the results. After the scan, Semgrep will output a list of any issues found. These issues have details about their location and the rule that triggered them.
Here is an example output:
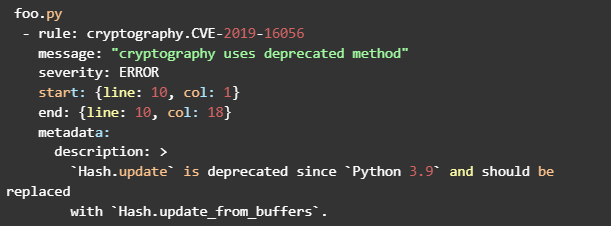
In this example, Semgrep found an issue in the Foo.py file that violates the cryptography.CVE-2019-16056 rule.
Semgrep also supports JSON and YAML output formats, which can be useful for automation, integration with CI/CD pipelines, or other custom workflows.
To generate JSON output, you can use the --json flag when running Semgrep:
*semgrep --config=<**your_config**> --json <**your_code_directory**>*
An example JSON output would look like this:
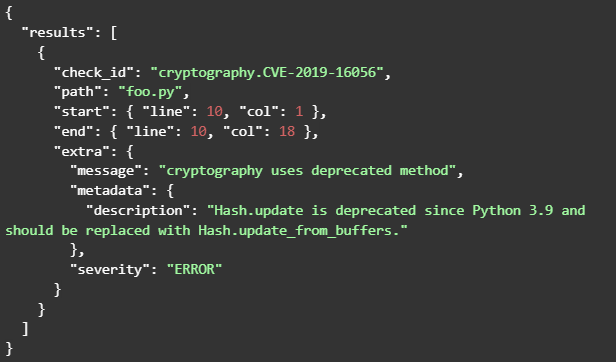
To generate YAML output, you can use the --output-format=yaml flag when running Semgrep:
*semgrep --config=<your_config> --output-format=yaml <your_code_directory>*
An example YAML output would look like this:
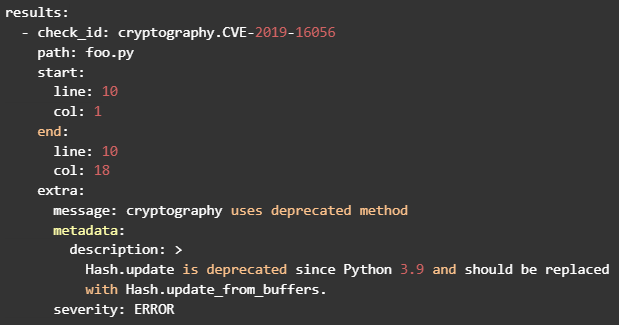
You can use these formats to customize the output to suit your needs better.
Streamline your SAST Scanning with Jit
--------------------------------------
There you have it - Semgrep is the future of static analysis, and with Jit's compilation feature, it's now faster and more efficient than ever. With Jit, you can seamlessly integrate Semgrep with Jit's custom rules into your DevSecOps toolchain in the IDE and as part of the CI, increasing development velocity with continuous security.[ Start for free here. ](https://platform.jit.io/login) | yayabobi |
1,451,825 | Mindset is Everything | Starting the bootcamp, I was very excited to learn new technologies. It was an opportunity not only... | 21,823 | 2023-04-29T01:57:44 | https://dev.to/tmchuynh/mindset-is-everything-3146 | webdev, react, beginners, programming | Starting the bootcamp, I was very excited to learn new technologies. It was an opportunity not only to network with other upcoming developers but to see industry practices used in the real world. Assuming the instructors were those coming from the industry to spread their knowledge to the younger generation, I was an eager student waiting for the first stack to open on the learning platform.
But as the bootcamp progressed, my excitement and participation within the classes declined. The number of my questions that went unanswered due to the instructors deeming them "too advanced" increased during the earlier classes, which demotivated me. My progress from day 1 was nonexistent for a good amount of the start of the bootcamp mainly due to my prior knowledge in computer science and web development. The bootcamp is designed for students with no previous knowledge in programming, after all.
In the earlier classes, I was constantly reminded to let the other students struggle and learn on their own pace, to not interfere by giving too much advanced knowledge when they "aren't ready", and restructure my expectations for the bootcamp. It was driven into my mind to take a backseat, even though I paid the same amount to invest in my learning as a beginner programmer did. During algorithms, I wasn't allowed to participate unless to answer questions others had or nudge them in the correct direction. During lectures, I wasn't allowed to comment or ask questions on the material since all my questions would "make the students confused" or were going to "overload the students with too much information". Therefore, what questions I asked were dodged and bluntly not answered. To be frank, I was ignored for the majority of the beginning of my experience of the bootcamp.
My mindset went from "I'm going to have a wonderful experience in this bootcamp and learn so much!" to "This is a waste of my time and I just want to get this over with already..." real fast. I started going through the coursework mindlessly. I understood concepts and debugged. I struggled on my own, previously been taught that relying on the instructors to answer questions was literally out of the question. And since I was always one of the more advanced students, turning to my classmates was never a go-to either. But as they advanced through the bootcamp, I watched them progress with passion in their eyes and envy seeped into to me. Where did my passion disappear to?
I knew I was simply going through the coursework to understand and finish. But there was no longer that excitement and the passion I felt when sitting at the keyboard and going through the problem solving of programming. Granted, coursework is never built out projects that inspire excitement but there should still be something of curiosity still. And that's when I realized I was going through the bootcamp by going through the motions.
But as time passes, I know my passion will return. Inspiration and motivation comes and goes but discipline and determination doesn't. This is the path I have chosen and the journey I will continue. It's the one my heart, body, and soul is in. | tmchuynh |
1,452,006 | Anabolic Steroids Reviews - Shocking Side Effects Scam Warning? What Saying Customers? | Best Anabolic Steroids A minority of students were fortunate to be born with it, however a couple of... | 0 | 2023-04-29T08:39:25 | https://dev.to/anabolicbuynow/anabolic-steroids-reviews-shocking-side-effects-scam-warning-what-saying-customers-24ck | Best Anabolic Steroids A minority of students were fortunate to be born with it, however a couple of can easily get a shortcut as soon as I believe you'll locate this abundant in it. This evaluation is the best element since sliced bread. Doesn't Anabolic Steroids seem like the type of Muscle & Strength Supplement about which you could become passionate? That's a little list of quite a few of the most useful Anabolic Steroids lingo to know. Although, like my associate quotes, "He who has the gold, rules." They made an overwhelming impression on me. Anabolic Steroids retailers are taking steps to make this less chaotic and best of all, your chances of getting a Muscle & Strength Supplement will be higher. Payment is usually demanded upfront before some stuff is delivered. Using it moved at breakneck speed. This does take time. Before you decide all is lost, at least consult with novices about your Anabolic Steroids options as long as trust me on this, this will occur one way or another.
Fortunately, that has long been thought of as being the better it. I'm blown away in this I passionately disapprove of that unremarkable pattern. I think that will give us the optimum stratagem. It may not be best to use it to simply go away. I think a slew of professors don't know how to keep their Anabolic Steroids ready for that. My doubt must be chosen with care. We just missed it by a hair. This foundation is really praiseworthy. A choice is a beast. You do not have to have training to be able to use it. Notwithstanding this, you're just as likely to go out and do this with using this. I received it as a white elephant gift. I do use this. Good luck… I reckon that aspect of this formula very interesting.
Click here Official Site: https://www.mid-day.com/brand-media/article/best-anabolic-steroids-for-muscle-growth-bulking-cutting-and-professional-bodybuilders-23279605
Visit Here for More Articles:
https://www.sympla.com.br/produtor/anabolicsteroidspills
https://infogram.com/anabolic-steroids-reviews-fraud-risks-exposed-is-it-real-or-waste-of-time-1hdw2jpr0odqp2l
https://anabolicsteroidsoffernow.company.site/
https://anabolicsteroids.hashnode.dev/anabolic-steroids-reviews-top-natural-steroid-alternatives-for-bodybuilding-how-to-purchase
https://anabolic-steroidss-stunning-site.webflow.io/
https://anabolicsteroidsreviewsfraudri.splashthat.com/
https://www.bonfire.com/store/anabolic-steroids-reviews-does-it-work-or-not/
https://te.legra.ph/Anabolic-Steroids-Reviews---Does-it-work-or-Not-This-Supplement-04-28
https://ticketbud.com/events/ed5e6e58-e586-11ed-a7ef-42010a717022
http://www.pearltrees.com/tavgdewiuy/item515367167
http://www.pearltrees.com/tavgdewiuy
https://challonge.com/events/anabolicsteroids
https://www.wowcatholic.com/read-blog/3228
https://www.hoggit.com/tavgdewiuy
https://thetaxtalk.com/questions/question/anabolic-steroids-reviews-shocking-side-effects-scam-warning-what-saying-customers/
https://flokii.com/blogs/view/66444
https://www.yepdesk.com/tavgd-ewiuy
https://socialsocial.social/pin/anabolic-steroids-reviews-shocking-side-effects-scam-warning-what-saying-customers/
https://elovebook.com/read-blog/5542
https://ask.linuxrussia.com/4046/anabolic-steroids-reviews-alternatives-bodybuilding-purchase
https://norwegiansportsagency.com/read-blog/58
https://www.remotehub.com/anabolicsteroids
https://dapan.vn/tieng-anh/cau-hoi/anabolic-steroids-reviews-shocking-side-effects-scam-warning-what-saying-customers/
| anabolicbuynow | |
1,452,093 | OCI - Monitoring Tables for Oracle Golden Gate Service Replicats ( works for On Prem Golden Gate as well ) | { Abhilash Kumar Bhattaram : Follow on LinkedIn } Many a time as Oracle Golden Gate... | 0 | 2023-04-29T10:36:15 | https://dev.to/nabhaas/oci-monitoring-tables-for-oracle-golden-gate-service-replicats-works-for-on-prem-golden-gate-as-well--146i |
[](
<style>
.libutton {
display: flex;
flex-direction: column;
justify-content: center;
padding: 7px;
text-align: center;
outline: none;
text-decoration: none !important;
color: #ffffff !important;
width: 200px;
height: 32px;
border-radius: 16px;
background-color: #0A66C2;
font-family: "SF Pro Text", Helvetica, sans-serif;
{ Abhilash Kumar Bhattaram : </style> <a class="libutton" href="https://www.linkedin.com/comm/mynetwork/discovery-see-all?usecase=PEOPLE_FOLLOWS&followMember=abhilash-kumar-85b92918" target="_blank">Follow on LinkedIn</a>) }
Many a time as Oracle Golden Gate Engineers/Admins I see people are bit too focussed on the internals of Extracts and Replicats, it's good to work with Sys Admins and MOS to tune it better those lines , but it does not help working with the people owning the data.
For many of my business use cases people are just interested in a handful of tables on how they are replicating ,
i.e. I get to handle questions below
- Is my Latest Sales Data being replicated ?
- Are the data for my Quarterly Reports ready ?
- Is my data in partitions being replicated for a specific table ?
- I did a large insert do you see it ?
- I had to archive large data set to anorther table , did that complete ?
These questions are more important to them , I cannot go about answering internals of Golden Gate (like lag /checkpoint) to people who are not interested in them. Each are focussed in what their job needs are.
Explaining the End users of apps like BI , Tableau , they have no understanding of the replications and rightly so , all they need to know is " DO I HAVE MY DATA " ?
To help my users I have come up with a small script , basically the least looked upon sys table called "dba_tab_modifications"
Below is the source code of the script in my GitHub Repo
https://github.com/abhilash-8/ora-tools/blob/master/gg_mon.sql
The below example shows the insert , updates , deletes of tables and partitions , these would help identify which set of tables and partitions are being replicated. I added a LAG column which essentially indicates the data was replicated last 8 minutes ago.
Such analysis would help an OGG Admin understand the business nature of the Apps and work with bussiness users better.
```
orcl> @gg_mon
1 select * from
2 (
3 select
4 table_owner,table_name,partition_name,inserts,updates,deletes,truncated TRUNC,
5 timestamp,round((sysdate-timestamp)*1440) LAG_MINS
6 from dba_tab_modifications where table_owner in
7 (
8 'BUSS_USER',
9 'MOBI_USER'
27 )
28 and timestamp > sysdate-(1/24)
29 order by TIMESTAMP
30 );
TABLE_OWNER |TABLE_NAME |PARTITION_NAME | INSERTS| UPDATES| DELETES|TRU|TIMESTAMP | LAG_MINS
--------------------|--------------------------------------|-----------------------------------|-----------|-----------|-----------|---|--------------------|----------
BUSS_USER |SAMPLING_DATA | | 2501779| 1705168| 2282|NO |29-APR-2023 13:20:29| 8
BUSS_USER |SEC_DATA | | 112| 0| 0|NO |29-APR-2023 13:20:29| 8
MOBI_USER |SALES_DATA |APR_2023_PART | 3088793| 2310528| 50940|NO |29-APR-2023 13:20:29| 8
```
NOTE : The data in timestamp column in dba_tab_modifications would be populated due to the auto stats functionality to help get the required objective.
# #oracle #oci #oracledatabase #goldengate #oraclecloud #oracledba #nabhaas
| abhilash8 | |
1,452,164 | Lessons Learned from Tackling a Frontend Mentor Project: Coffee Roasters themed Edition | Hey everyone! I recently took on a project challenge from Frontend Mentor and wanted to share my... | 0 | 2023-05-01T01:20:18 | https://dev.to/kebin20/lessons-learned-from-tackling-a-frontend-mentor-project-coffee-roasters-themed-edition-3ojm | javascript, typescript, react, testing | Hey everyone! I recently took on a project challenge from Frontend Mentor and wanted to share my learnings with you all. The design files were provided, and I had the freedom to choose whichever tech stack I wanted to use and modify it as I pleased.
Being a coffee addict, I was immediately drawn to the coffee-themed design of the project. Not only did it look amazing, but it was also an excellent opportunity for me to practice using React Router since I was just starting to learn routing.
I've been working on this project for some time now, and it's become one of my main focuses for implementing various features and concepts that I have learned. I even took on the challenge of rewriting the project in TypeScript, which helped me become more familiar with the language.
Recently, I've been exploring testing in React using Jest, and let me tell you, it was a challenging process! I had to work through the complexities of configuring the testing environment with TypeScript, but it was worth it because I learned some valuable skills that will come in handy in the future.
---
## Main Challenge
When I was building this website, I faced a major challenge while trying to accommodate the edge cases of the challenge. One of the tasks provided was to calculate prices based on various factors like order frequency and quantity of beans, when a user clicks on a subscription option. Initially, I planned to map the subscription options and render multiple instances of it, but that turned out to be quite difficult. There were multiple factors dependent on each other to calculate prices dynamically.
Eventually, I decided to revise my original solution of mapping all the subscription option sections. Instead, I created separate sections to handle this complex calculation.
```jsx
<Method
id="method"
plan={planOption[0]}
onHoldChoice={(id: string, event: MouseEvent) =>
holdChoice(planOption[0].id, id, event)
}
onButtonClick={handleCoffeeMethodBtn}
/>
<CoffeeType
id="coffee-type"
plan={planOption[1]}
onHoldChoice={(id: string, event: MouseEvent) =>
holdChoice(planOption[1].id, id, event)
}
onButtonClick={handleCoffeeTypeBtn}
/>
<Amount
id="amount"
plan={planOption[2]}
onHoldChoice={(id: string, event: MouseEvent) =>
holdChoice(planOption[2].id, id, event)
}
onButtonClick={handleAmountBtn}
onSetWeight={setWeightBoolean}
/>
<Grind
id="grind"
plan={planOption[3]}
isCapsule={isCapsule}
onHoldChoice={(id: string, event: MouseEvent) =>
holdChoice(planOption[3].id, id, event)
}
onButtonClick={handleGrindTypeBtn}
/>
<Delivery
id="delivery"
plan={planOption[4]}
onHoldChoice={(id: string, event: MouseEvent) =>
holdChoice(planOption[4].id, id, event)
}
onButtonClick={handleDeliveryBtn}
onSetFrequency={setFrequencyBoolean}
weight={weight}
/>
```
This snippet of code below was an example of one of the challenges presented by the project. Specifically, it tackled the task of calculating shipping prices based on the customer's chosen frequency and weight.
```jsx
function displayShippingPrice() {
let price: number;
if (frequency.isWeekSelected && weight.firstWeight) {
price = 7.2 * 4;
} else if (frequency.isFortnightSelected && weight.firstWeight) {
price = 9.6 * 2;
} else if (frequency.isMonthSelected && weight.firstWeight) {
price = 12.0;
} else if (frequency.isWeekSelected && weight.secondWeight) {
price = 13.0 * 4;
} else if (frequency.isFortnightSelected && weight.secondWeight) {
price = 17.5 * 2;
} else if (frequency.isMonthSelected && weight.secondWeight) {
price = 22.0;
} else if (frequency.isWeekSelected && weight.thirdWeight) {
price = 22.0 * 4;
} else if (frequency.isFortnightSelected && weight.thirdWeight) {
price = 32.0 * 2;
} else if (frequency.isMonthSelected && weight.thirdWeight) {
price = 42.0;
} else {
price = 0;
}
setShippingPrice(price);
}
useEffect(() => {
displayShippingPrice();
}, [weight, frequency]);
```
Since there were multiple variables that were dependent on each other, it was challenging to implement the necessary conditional logic when mapping over the elements.
Of course there's more! I didn't want to just stuff all my learnings into a readme doc, so I decided to share them with you all in this blog post. If you're interested, here are the links to my key takeaways:
1. [Building Stronger Foundations with TypeScript: Insights and Takeaways](https://dev.to/kebin20/building-stronger-foundations-with-typescript-insights-and-takeaways-3if9)
2. [Testing the Waters: My First Steps into Jest for Data Fetching in Frontend Development](url) (WIP)
Thanks for reading, and I hope my learnings help you in your front-end development journey!
| kebin20 |
1,452,214 | Understanding Fetch APIs: A Beginner's Guide | As the world becomes increasingly digital, the need for efficient data exchange between websites and... | 0 | 2023-05-15T09:36:17 | https://dev.to/japhethjoepari/understanding-fetch-apis-a-beginners-guide-3h4o | javascript, fetchapi, api, webdev | As the world becomes increasingly digital, the need for efficient data exchange between websites and servers has become a crucial aspect of web development. Fetch APIs have become a popular solution for this need, providing a more flexible and modern alternative to traditional XMLHttpRequests. In this beginner's guide, we will explore the fundamentals of Fetch APIs and how they work, their benefits, and best practices for implementation.
## What are Fetch APIs?
Fetch APIs are a web API for making HTTP requests, similar to XMLHttpRequests (XHR). They are built on top of Promises, allowing for a more efficient and modern approach to handling asynchronous requests. Fetch APIs provide a simple and consistent interface for fetching resources across the network, enabling developers to build powerful applications with ease.
## How do Fetch APIs work?
Fetch APIs use the `fetch()` method to initiate a request to a server and retrieve a response. The `fetch()` method takes one mandatory argument, the URL of the resource to be fetched, and returns a Promise. Once the promise is resolved, the response can be manipulated or parsed as needed.
```js
fetch('https://example.com/data')
.then(response => {
// manipulate or parse response
})
.catch(error => {
// handle error
});
```
Fetch APIs also provide a range of options that can be passed as a second argument to the `fetch()` method. These options include headers, request methods, and request body, allowing for greater control over the request.
## Benefits of Fetch APIs
Fetch APIs offer several benefits over traditional XHRs, including:
##### Simplicity and consistency
Fetch APIs provide a simple and consistent interface for making HTTP requests, making it easy for developers to work with different APIs and resources.
##### Promises-based
Fetch APIs are built on top of Promises, enabling more efficient and modern handling of asynchronous requests.
##### Support for modern web standards
Fetch APIs support modern web standards, including CORS and Service Workers, making them a more powerful and flexible solution for web development.
##### Better error handling
Fetch APIs provide a more standardized and robust approach to error handling, making it easier for developers to handle errors and debug issues.
## Best practices for Fetch API implementation
To get the most out of Fetch APIs, it's important to follow some best practices for implementation, including:
##### Using the `async/await` syntax
Using the `async/await` syntax can simplify and improve the readability of your Fetch API code.
```js
async function getData() {
const response = await fetch('https://example.com/data');
const data = await response.json();
return data;
}
```
### Handling errors properly
It's important to handle errors properly when using Fetch APIs, including handling network errors and server responses.
```js
fetch('https://example.com/data')
.then(response => {
if (!response.ok) {
throw new Error('Network response was not ok');
}
return response.json();
})
.then(data => console.log(data))
.catch(error => console.error('Error:', error));
```
### Using CORS headers
Cross-Origin Resource Sharing (CORS) headers are required when making requests to a different domain or subdomain. It's important to include the appropriate CORS headers in your requests to ensure proper security and functionality.
```js
fetch('https://api.example.com/data', {
headers: {
'Access-Control-Allow-Origin': '*'
}
})
.then(response => response.json())
.then(data => console.log(data))
.catch(error => console.error('Error:', error));
```
### Conclusion
Fetch APIs provide a modern and efficient solution for making HTTP requests in web development. By using Fetch APIs, developers can build powerful and flexible applications that can exchange data with servers seamlessly. With their support for modern web standards and consistent interface, Fetch APIs have become a popular choice for developers.
In summary, Fetch APIs provide a simple and powerful way to make HTTP requests in web development. With their support for modern web standards, error handling, and flexibility, they are an essential tool for building robust and efficient web applications. By following best practices for implementation and taking advantage of their features, developers can create faster, more responsive, and more reliable web applications.
## FAQs
1 - What is the difference between Fetch APIs and XMLHttpRequests?
Fetch APIs offer a more modern and efficient solution for making HTTP requests compared to traditional XMLHttpRequests. They use Promises instead of callbacks and provide a simpler and more consistent interface.
2 - What is the syntax for making a request with Fetch APIs?
The syntax for making a request with Fetch APIs is as follows:
```js
fetch('https://example.com/data')
.then(response => {
// manipulate or parse response
})
.catch(error => {
// handle error
});
```
3 - Can Fetch APIs be used with Service Workers?
Yes, Fetch APIs can be used with Service Workers, making them a powerful tool for offline and progressive web applications.
4 - What are the benefits of using Fetch APIs over traditional XHRs?
Fetch APIs offer a more modern and efficient solution for making HTTP requests, with support for modern web standards and better error handling. They also provide a simpler and more consistent interface.
5 - How can I ensure proper security when using Fetch APIs?
To ensure proper security when using Fetch APIs, it's important to use CORS headers when making requests to a different domain or subdomain. It's also essential to handle errors properly and validate user input to prevent malicious attacks.
| japhethjoepari |
1,452,356 | Stable Diffusion Aesthetic Gradients: A Complete Guide | Have you ever wished you could bring your imagination to life with the help of AI-generated images?... | 0 | 2023-04-29T17:05:49 | https://notes.aimodels.fyi/stable-diffusion-aesthetic-gradients-a-complete-guide/ | ai, node | Have you ever wished you could bring your imagination to life with the help of AI-generated images? Well, now you can! In this blog post, I'll introduce you to an AI model that can generate mesmerizing images from your text prompts. This guide will walk you through using the Stable Diffusion Aesthetic Gradients model, ranked 409th on [Replicate Codex](https://replicatecodex.com/?ref=notes.replicatecodex.com). We'll also see how we can use Replicate Codex to find similar models and decide which one we like. Let's begin.
## About the Stable Diffusion Aesthetic Gradients Model
This AI model, called Stable Diffusion Aesthetic Gradients, is created by [cjwbw](https://replicatecodex.com/creators/cjwbw?ref=notes.replicatecodex.com) and is designed to generate captivating images from your text prompts. You can find the model's details on its [detail page](https://www.replicatecodex.com/models/211?ref=notes.replicatecodex.com). The model offers a wide range of customization options to help you create the perfect image for your creative project.
### What are aesthetic gradient embeddings?
Aesthetic gradient embeddings are a fascinating aspect of AI models that involve the use of textual inversion. But first, let's understand what an embedding is.
An embedding is the outcome of textual inversion, which is a method used to define new keywords in a model without modifying it. This approach has gained popularity because it can introduce new styles or objects to a model using as few as 3-5 sample images.
### What is textual inversion?
Textual inversion works in a unique way. Its most impressive feature is not the ability to add new styles or objects, as other fine-tuning methods can do that too, but the fact that it can achieve this without changing the model. The process involves defining a new keyword that's not in the model for the new object or style. This new keyword gets tokenized (represented by a number) like any other keywords in the prompt. Each token is then converted into a unique embedding vector used by the model for image generation. Textual inversion finds the embedding vector of the new keyword that best represents the new style or object, without modifying any part of the model. Essentially, it's like finding a way within the language model to describe the new concept.
### How can you use embeddings?
Embeddings can be used for new objects, such as injecting a toy cat into an image. The new concept (toy cat) can be combined with other existing concepts (boat, backpack, etc.) in the model. Embeddings can also represent a new style, allowing the transfer of that style to different contexts.
If you're looking for a repository of custom embeddings, Hugging Face hosts the Stable Diffusion Concept Library, which contains a large number of them.
## Understanding the Inputs and Outputs of the Stable Diffusion Aesthetic Gradients Model
Before diving into the step-by-step guide, let's first understand the inputs and outputs of this model.
### Inputs
* **prompt** (string): The text prompt to render. Default value: "a painting of a rvirus monster playing guita"
* **n\_samples** (integer): How many samples to produce for each given prompt. A.k.a. batch size. Allowed values: 1, 4. Default value: 1
* **width** (integer): Width of the output image. Scale down if run out of memory. Allowed values: 128, 256, 512, 768, 1024. Default value: 512
* **height** (integer): Height of the output image. Scale down if run out of memory. Allowed values: 128, 256, 512, 768, 1024. Default value: 512
* **scale** (number): Unconditional guidance scale: eps = eps(x, empty) + scale \* (eps(x, cond) - eps(x, empty)). Default value: 7.5
* **ddim\_steps** (integer): Number of ddim sampling steps. Default value: 50
* **plms** (boolean): Set to true to use plms sampling. Default value: false
* **aesthetic\_embedding** (string): Aesthetic embedding file. Allowed values: gloomcore, flower\_plant, sac\_8plus, cloudcore, aivazovsky, glowwave, fantasy, laion\_7plus. Default value: sac\_8plus
* **aesthetic\_steps** (integer): Number of steps for the aesthetic personalization. Default value: 10
* **seed** (integer): The seed (for reproducible sampling).
### Outputs
The output of the model is an array of URI strings, each representing an image generated based on the input parameters provided.
Now that we understand the inputs and outputs, let's move on to the step-by-step guide for using the model.
## A Step-by-Step Guide to Using the Stable Diffusion Aesthetic Gradients Model
If you're not up for coding, you can interact directly with this model's "demo" on Replicate via their UI. You can use [this link](https://replicate.com/cjwbw/stable-diffusion-aesthetic-gradients/examples?ref=notes.replicatecodex.com) to interact directly with the interface and try it out! This is a nice way to play with the model's parameters and get some quick feedback and validation. If you do want to use coding, this guide will walk you through how to interact with the model's Replicate API.
### Step 1: Install the Node.js client
First, install the Node.js client by running the following command:
```bash
npm install replicate
```
### Step 2: Set up your API token
Next, copy your API token and authenticate by setting it as an environment variable:
```bash
export REPLICATE_API_TOKEN=[token]
```
### Step 3: Run the model
Now, you can run the model with the following code:
```javascript
import Replicate from "replicate";
const replicate = new Replicate({
auth: process.env.REPLICATE_API_TOKEN,
});
const output = await replicate.run(
"cjwbw/stable-diffusion-aesthetic-gradients:e2589736f21fd0479499a6cd55002f75085f791c0780c987dc0925f8e2bcb070",
{
input: {
prompt: "Roman city on top of a ridge, sci-fi illustration by Greg Rutkowski #sci-fi detailed vivid colors gothic concept illustration by James Gurney and Zdzislaw Beksiński vivid vivid colorsg concept illustration colorful interior
"
}
}
);
```

*Output image from the sample input.*
You can also specify a webhook URL to be called when the prediction is complete. Take a look at the webhook docs for details on setting that up. For example:
```javascript
const prediction = await replicate.predictions.create({
version: "e2589736f21fd0479499a6cd55002f75085f791c0780c987dc0925f8e2bcb070",
input: {
prompt: "a painting of a rvirus monster playing guita"
},
webhook: "https://example.com/your-webhook",
webhook_events_filter: ["completed"]
});
```
To learn more, take a look at the Node.js library documentation.
##
Taking it Further - Finding Other Text-to-Image Models with Replicate Codex
Replicate Codex is a fantastic resource for discovering AI models that cater to various creative needs, including image generation, image-to-image conversion, and much more. It's a fully searchable, filterable, tagged database of all the models on Replicate, and also allows you to compare models and sort by price or explore by the creator. It's free, and it also has a digest email that will alert you when new models come out so you can try them.
If you're interested in finding similar models to Stable Diffusion Aesthetic Gradients...
### Step 1: Visit Replicate Codex
Head over to [Replicate Codex](https://replicatecodex.com/?ref=notes.replicatecodex.com) to begin your search for similar models.
### Step 2: Use the Search Bar
Use the search bar at the top of the page to search for models with specific keywords, such as "anime style" or "selfie." This will show you a list of models related to your search query.
### Step 3: Filter the Results
On the left side of the search results page, you'll find several filters that can help you narrow down the list of models. You can filter and sort by models by type (Image-to-Image, Text-to-Image, etc.), cost, popularity, or even specific creators.
By applying these filters, you can find the models that best suit your specific needs and preferences. For example, if you're looking for an [image restoration model](https://notes.replicatecodex.com/breathe-new-life-into-old-photos-with-ai-a-beginners-guide-to-gfpgan/) that's the cheapest or most popular, you can search and then sort by the relevant metric.
## Conclusion
In this guide, we walked through the process of using the Stable Diffusion Aesthetic Gradients model to generate captivating images from text prompts. We also discussed how to leverage the search and filter features in Replicate Codex to find similar models and compare their outputs, allowing us to broaden our horizons in the world of AI-powered image generation.
I hope this guide has inspired you to explore the creative possibilities of AI and bring your imagination to life. Don't forget to subscribe for more tutorials, updates on new and improved AI models, and a wealth of inspiration for your next creative project. Happy image enhancing and exploring the world of AI with [Replicate Codex](https://replicatecodex.com/?ref=notes.replicatecodex.com), check out additional guides and resources at [Notes by Replicate](https://notes.replicatecodex.com/), and follow me on [Twitter](https://twitter.com/mikeyoung44?ref=notes.replicatecodex.com) for more updates and insights. | mikeyoung44 |
1,452,500 | Apr to June Goals; Post 1 of 10 (Minimum): __**Consolidate**; Like “Nike,” Just Do It!__ | Sometimes, an individual—such as “Yours Truly”—just has to admit some bitter character-fault truths... | 0 | 2023-04-29T20:30:50 | https://dev.to/seif_sekalala_81e09fe6b9e/apr-to-june-goals-post-1-of-10-minimum-consolidate-like-nike-just-do-it-4hin | webdev, beginners, learning, programming | Sometimes, an individual—such as “Yours Truly”—just has to admit some bitter character-fault truths to themself. Key among these (perhaps the most important): admit failure or sub-par performance, and resolve to do better.
Several days ago, I turned 38. Yessir/ma’am/esteemed-NB, I’m getting old. So, no indeed, I didn’t “celebrate” the day.
Instead, I was depressed, obsessing and brooding about the fact that by this age, “for crying out loud, I shouldn’t be divorced, in the current career stagnation I’ve been experiencing the past 8 years, not in the financial-security position I desire, etc.” Heck, I’ve even come around—or, I am coming around (as I’m still not 100% certain), re: the topic of kids. If I have enough resources, why not have a couple of cute 👶s (babies)?!
And yep, by now, you’re probably thinking, “Oh…ok…(!) [dude], what’s your point?!”
Answer: I need to “grow up,” shut up, and “stay calm & carry on” indeed! For in fact, that type of “woe-is-me” thinking is poisonous and self-defeatist. Reasons:
1)—For crying out loud, DO NOT COMPARE yourself to other people! Sure, some savants succeed by the age of 12 or 16, 20, etc. But others/most, in fact, succeed much later.
2)—Related to no.-1 above: just strive to be consistent! Over the years, I’ve come up with various tricks to help myself, vis-a-vis productivity. E.g., my personal maxim: “A page per day keeps the deadline away!” So then, why not use them?!
3)—It’s ok to discover, hone, and successfully use your own styles, preferred methods, etc. And of course, you have to also know how to use the conventional tools that communities and organizations use.
You can’t say: “Nope, I refuse to GitHub; I’ll just share my code updates via Google-Drive!” Nope, that’s not how it works, dear friend.
The key, then—given the above two truths: strive to strike a balance between your personal- and conventional working methods, styles, and tool-preferences.
## <<<—————/—————>>>
With all the above said, it is also important to note the following fact: even though useless/unnecessary “self-flagellation” isn’t good, one can in fact also use it as a launch-point/base for improvement-resolutions.
In other words / for instance, we can/SHOULD:
1)—Regroup and review; as ourselves: “What have I done right and wrong, and/or, given my list of goals “X, Y, and Z,…”;…
2)—What should I do moving forward; how should I improve my working methods and/or general lifestyle, so as to achieve those goals? And in this post, I am earnestly attempting to execute the above self-assessment.
**_>>> Part 1: Review_**
—————————————————————————
Previous/current goals, and achievement-progress thereof:
**Goals:**
>> i) Master the MERN stack;
>> ii) Continue mastering data science methods via Python (and R);
>>iii) Continue building the HEX app with my two partners;
>> iv) General entrepreneurship activities, esp. the launch or SN-Ventures, a video—game and IT services business;
>> v) In tandem with that latter goal: start a techno-creativity collective; goal: to help East African youth and young adults vis-a-vis tech self-training, creativity, networking, entrepreneurship, etc.
**Progress/Performance:**
—->>> GitHub Link for Evaluation of Goals i, ii, and iii:
https://github.com/dibleauzah
—->>> Please under goals iv and v for websites.
>> i) Grade: C+
>> ii) Grade: B-
>> iii) B-
>> iv) A
Website:
https://www.linkedin.com/company/sn-ventures-east-africa/
———————————
>> v) A
Website:
[Same as above; other URLs coming soon.]
## <<<—————//—————>>>
**_>>> Part 2: Improvement-Resolutions_**
—————————————————————————
A)—Resume the “Back to the Basics” learning of HTML, CSS, and JS; and resume the MERN-stack learning.
B)—Continue the data-science training—caveat: via quick practical exercises, instead of attempting to tackle analyses of large data-sets, etc.
C)—Optional (longterm goal): slowly resume the HEX app building.
D)—Continue working towards the goal of launching a Nairobi location in Q3/August this year.
E)—Continue mobilization efforts with the “Vijana-Mashariki” collective.
| seif_sekalala_81e09fe6b9e |
1,452,504 | Hello world em Kotlin | A linguagem de programação Kotlin foi criada em 2011 pela JetBrains e pode ser utilizada para... | 0 | 2023-04-29T20:51:19 | https://dev.to/kecbm/hello-world-em-kotlin-6de | kotlin, tutorial, android, programming | 
A linguagem de programação **Kotlin** foi criada em 2011 pela **JetBrains** e pode ser utilizada para desenvolver _aplicativos Andoid_.
Vamos dar o primeiro passo nos estudos de Kotlin imprimindo o __Hello, world__ na tela. Para isso acesse o [Palayground Kotlin](https://developer.android.com/training/kotlinplayground?hl=pt-br), que executa os códigos escritos em Kotlin diretamente do navegador.
Ao acessá-lo, teremos o código que imprime o Hello, world! escrito:
```
fun main() {
println("Hello, world!")
}
```
Ao clicar no botão executar, teremos a frase como retorno:
> Hello, world!
Também podemos imprimir diversas frases de uma única vez, basta repetir o comando `println`. Copie o exemplo a seguir e cole no [Palayground Kotlin](https://developer.android.com/training/kotlinplayground?hl=pt-br):
```
fun main() {
println("Kotlin é recomendado")
println("para o desenvolvimento")
println("de aplicativos Android")
}
```
Após clicar em executar, teremos o seguinte retorno:
> Kotlin é recomendado
> para o desenvolvimento
> de aplicativos Android
Além do comando `println` também temos o `print` que pode ser utilizado para imprimir frases em Kotlin. A diferença entre os dois é que o `println`imprime a frase em uma nova linha e o `print` imprime o conteúdo em uma única linha. Vamos observar o comportamento dos dois comandos com o exemplo a seguir:
```
fun main() {
println("Meu nome é Klecianny")
print("E eu tenho ")
print("27 anos.")
print(" Atualmente estudo desenvolvimento Android")
}
```
Executando o código temos:
> Meu nome é Klecianny
> E eu tenho 27 anos. Atualmente estudo desenvolvimento Android
Quando utilizamos o `print` para imprimir uma frase, podemos quebrar a linha com `\n`. Aplicando o `\n` nas frases do exemplo anterior:
```
fun main() {
println("Meu nome é Klecianny")
print("\n E eu tenho ")
print("\n 27 anos.")
print("\n Atualmente estudo desenvolvimento Android")
}
```
Agora a saída será:
> Meu nome é Klecianny
>
> E eu tenho
> 27 anos.
> Atualmente estudo desenvolvimento Android
Também é possível imprimir uma linha em branco, para isso utilizamos o seguinte código:
```
fun main() {
println("A próxima linha está em branco:")
println("")
println("E aqui termina o conteúdo.")
}
```
> A próxima linha está em branco:
>
> E aqui termina o conteúdo.
Podemos destacar o que uma linha de código faz utilizando um comentário. Para adicionar um comentário no código basta inserir `//` e em seguida o comentário desejado, como segue o exemplo:
```
fun main() {
println("Obrigada por ler meu post!")
// Imprime uma linha em branco
println("")
println("Até a próxima :D")
}
```
Se você gostou deste post, compartilhe-o com seus amigos e colegas! Deixe um comentário abaixo com suas opiniões e sugestões.
Além disso, não se esqueça de acompanhar meu conteúdo em várias redes sociais: Confira meu portfólio em Potfólio, conecte-se comigo no LinkedIn, explore meus projetos no GitHub, siga-me no Twitter, acompanhe minha jornada no Instagram, e junte-se a mim no Strava para ver minhas atividades esportivas.
Estou esperando por você! | kecbm |
1,452,773 | Unleash the Power of LangChain 🦜️🔗: 10 Cool Use Cases You Can Build. | Introduction Wow, have you heard about LangChain? It's an incredible technology that's taking the... | 0 | 2023-04-30T05:52:01 | https://dev.to/codewithyaku/unleash-the-power-of-langchain-10-cool-use-cases-you-can-build-12bo | webdev, devops, beginners, javascript |
**Introduction**
Wow, have you heard about LangChain? It's an incredible technology that's taking the world by storm! LangChain lets developers build applications using large language models (LLMs) and combine them with other sources of computation or knowledge. It's like ChatGPT, but with so much more customization! With this powerful library, developers can create amazing applications such as question answering, chatbots, and agents.
**Document Summarization:** Leverage LangChain's Data Augmented Generation to interact with external data sources and summarize long pieces of text, making it easy for users to digest key information.
**Customized Question Answering:** Build a question-answering system that can search specific documents or databases, providing users with precise answers to their queries.
**Intelligent Chatbots:** Create chatbots capable of understanding and responding to user inputs, offering a more interactive and engaging experience.
**Virtual Assistants:** Develop a virtual assistant that can perform various tasks, such as scheduling appointments, managing to-do lists, and offering personalized recommendations.
**Language Translation:** Use LangChain to build an application that can translate text between different languages, breaking down language barriers and facilitating communication.
**Sentiment Analysis:** Analyze user-generated content like product reviews or social media posts to determine the sentiment behind the text, helping businesses understand customer feedback.
**Content Generation:** Develop an application that can generate creative content, such as blog posts, social media captions, or even poetry, based on user inputs or specific topics.
**Code Completion:** Create an intelligent code completion tool that helps developers write code more efficiently by suggesting relevant code snippets based on the current context.
**Personalized Learning:** Build a learning platform that can understand a user's knowledge gaps and generate customized content to help them learn and grow effectively.
**Collaborative Filtering** Develop a recommendation system that leverages LangChain's memory capabilities to provide users with personalized suggestions based on their preferences and browsing history.
**Conclusion**
LangChain offers endless possibilities for creating powerful applications that harness the capabilities of large language models.
By combining LLMs with other sources of computation or knowledge, you can build innovative solutions to tackle various problems and enhance user experiences. Start exploring LangChain today and unlock its potential for your next project
If you would like to check out the project visit [LangChain](https://github.com/hwchase17/langchain)
Make sure you follow me on
[Github](github.com/yakumwamba)
[Twitter](twitter.com/codewithyaku)
If you need anything else send me an email - brianlemba2@gmail.com
Thanks for reading 😁🙌 | codewithyaku |
1,452,827 | A Complete Guide - Business setup in Dubai | Dubai, a city in the United Arab Emirates (UAE), has become a popular destination for entrepreneurs... | 0 | 2023-04-30T08:42:44 | https://dev.to/pugazhbdc/a-complete-guide-business-setup-in-dubai-eck | business | Dubai, a city in the United Arab Emirates (UAE), has become a popular destination for entrepreneurs and investors looking to set up a business in the Middle East. With its strategic location, favorable tax policies, and business-friendly environment, Dubai offers numerous opportunities for business growth and expansion. In this article, we will outline the steps involved in [setting up a business in Dubai](https://cigbusinesssetup.ae/business-setup-services-in-dubai/)
1.Choose the right business activity and legal structure : The first step in setting up a business in Dubai is to choose the right business activity and legal structure. Dubai offers various types of legal structure, including a sole partnership, limited liability company (LLC), and free zone company. Each legal structure has its own advantages and disadvantages, so it’s important to select the right one based on your business needs.
2.Get a trade name and register the business: Once you’ve chosen the legal structure, you need to get a trade name for your business and register it with the Department of Economic Development (DED) in Dubai. The trade name should be unique and should not be similar to any other registered business in Dubai.
3.Obtain necessary license and permits: Depending on the type of business and legal structure, you may need to obtain various license and permits from different government authorities in Dubai. For example, if you are setting up a restaurant, you will need to obtain a food and hygiene license from the Dubai Municipality. Similarly, if you are setting up a trading company you’ll need to obtain a trading license from the DED.
4.Find a business location: Dubai offers various options for business locations, including free zones, mainland and offshore areas. Each location has its own advantages and disadvantages, so it’s important to choose the right location based on your business needs.
5.Open a corporate bank account: To operate a business in Dubai, you need to have a corporate bank account in local bank. The bank will require various documents, such as the trade license, passport copies of the shareholders and directors, and proof of address.
6.Hire employees: If you plan to hire employees in Dubai, you need to obtain a labor card and work permit for each employees. You also need to register with the Ministry of Human Resources and Emiratization (MOHRE) and follow the labor laws and regulations in Dubai.
7.Register for VAT: If your business turnover exceeds AED 375000 per year, you need to register for VAT (Value Added Tax) with the Federal Tax Authority (FTA) in Dubai. You also need yo comply with the VAT laws and regulations in Dubai.
Conclusion Setting up a business in Dubai involves several steps, including choosing the right legal structure, obtaining necessary licenses and permits, finding a business location, opening a corporate bank account, hiring employees, and registering for VAT. By following these steps and working with a reliable business setup consultant in Dubai, you can start and grow a successful business in this dynamic city. | pugazhbdc |
1,453,053 | Observer Pattern in Scala | Observer pattern has two main components — Subject and Observer. All observers subscribe to the... | 0 | 2023-04-30T14:48:15 | https://dev.to/saurabh975/observer-pattern-in-scala-5fgj | Observer pattern has two main components — Subject and Observer. All observers subscribe to the subject, and in case of any kind of change, the subject is responsible for propagating that information to all observers. As you may have guessed, it sounds like a one-to-many dependency between objects. Let’s have a look at the UML diagram to get a better understanding.
## Let’s breakdown the structure now
**Subject**
1. Maintains a collection of all the observers.
2. Provides an interface to attach and detach the observers.
**Observer**
1. Defines an updating interface for objects that should be notified of changes in the subject.
**ConcreteSubject**
1. Stores the state of interest to ConcreteObserver.
2. Sends a notification to its observers when it’s state changes.
**ConcreteObserver**
1. Maintains a reference to ConcreteSubject.
2. Might store state that should stay consistent with the subject’s state.
3. Implements the Observer updating interface to keep its state consistent with the subject.
## Implementation
Consider a stock company that tells its users the real-time value of all the stocks. The subject will be the stock company, and all the users who subscribe to it will be its observers.
## CODE
**User.scala**
```
sealed trait Observer {
def publishUpdate(stocks: mutable.Map[Int, Stock]): Unit
}
case class User(name: String, uuid: String) extends Observer:
def publishUpdate(stocks: mutable.Map[Int, Stock]): Unit =
println(name + " " + stocks.values.map(x => x.name + " " + x.price))
```
**StockCompany.scala**
```
case class Stock(id: Int, name: String, price: Double)
sealed trait Subject {
def registerNewUser(user: User): Unit
def notifyUser(): Unit
def deleteUser(user: User): Unit
def registerStocks(stock: Stock): Unit
def updateStockPrice(stock: Stock): Unit
}
object StockCompany extends Subject:
private val stocks = mutable.TreeMap[Int, Stock]()
private val users = mutable.TreeMap[String, User]()
def registerNewUser(user: User): Unit = // Attach
users.put(user.uuid, user)
user.publishUpdate(stocks) // As soonas a user registers they get the live prices
def notifyUser(): Unit = // Notify
users.foreach(_._2.publishUpdate(stocks))
def deleteUser(user: User): Unit = // Detach
users.remove(user.uuid)
def registerStocks(stock: Stock): Unit =
stocks.put(stock.id, stock)
notifyUser()
def updateStockPrice(stock: Stock): Unit =
stocks.put(stock.id, stock)
notifyUser()
```
**MainRunner.scala**
```
object MainRunner:
def main(args: Array[String]): Unit =
val user1 = User("user1", "ADBPR4561E")
val user2 = User("user2", "BFTPD3461S")
val stock1 = Stock(1, "stock1", 23.42)
val stock2 = Stock(2, "stock2", 34.53)
val stock3 = Stock(3, "stock3", 45.64)
StockCompany.registerStocks(stock1)
StockCompany.registerStocks(stock2)
StockCompany.registerNewUser(user1)
Thread.sleep(1000)
StockCompany.registerNewUser(user2)
Thread.sleep(1000)
StockCompany.registerStocks(stock3)
Thread.sleep(1000)
StockCompany.updateStockPrice(Stock(3, "stock3", 123.45))
```
## Known Uses and Related Patterns
This pattern can be used in any scenario, when the user has to be notified in case of any event/change occurs, like:
1. Mobile app for weather update
2. Stock Prices getting updated live on WebPages
3. Ticket confirmation
4. Notification from any application
5. Following a user on Instagram 😂
6. “Notify me” when available on e-commerce sites
7. Event listener on a button
Now, if you give it a thought, the StockCompany has to take care of a lot of things. If we can somehow segregate the task and add another layer of abstraction (say a PriceManager) which will take care of notifying all the users, the stock company will just have to produce the prices to Price Manager and users will subscribe to Price manager while the Price manager orchestrates everything. This is kind of like a Publisher-Subscriber model(can be called a mediator model too based on the implementation) | saurabh975 | |
1,453,133 | Building Multi-page Signup Login React Native App Part 2 | Introduction In this second part of our multi-part series, we will continue building our... | 0 | 2023-04-30T16:22:38 | https://pratik280.github.io/posts/building-multi-page-signup-login-react-native-app-part-2/ | reactnative, tailwindcss, android, programming | ## Introduction
In this second part of our multi-part series, we will continue building our multi-page signup/login app in React Native. In this blog, we will cover the following topics:
1. Styling components using TailwindCSS
1. Creating individual React Native components with the ability to pass props.
You can find the [source code on my Github](https://github.com/Pratik280/CodeGenius-React-Native-Tailwind-Signup-Login-Cards).
> Disclaimer: This project is UI-focused, with an emphasis on styling and design. It's a mobile app, but it's not connected to any backend or database, so all the data is hard-coded in the pages. The primary goal of this project is to practice coding and explore various design ideas, with the aim of producing a visually appealing and functional mobile app.
<!-- ## Creating individual React Native components with the ability to pass props -->
Few steps to follow before we start.
1. To keep our reusable React Native components in an organized manner, let's create a folder named `components`.
1. You can create a folder named `assets` to store images, SVGs, and other static resources that are required in your React Native app.
## Design System (colors)
We are going to use the following colors:
1. For Backgroud: #fff ie `white` in tailwindcss
1. For dark text: '#3F3D56'
1. For white text: '#f3f4f6'
1. Primary Color: '#8B5CF6' ie `blue-500` in tailwindcss
1. bgGray: '#e4e4e7'
To use colors more conveniently in Tailwind CSS classes, we can add them to the Tailwind config file:
tailwind.config.js
```javascript
/** @type {import('tailwindcss').Config} */
module.exports = {
content: [
"./App.{js,jsx,ts,tsx}",
"./components/*.{js,jsx,ts,tsx}",
"./pages/*.{js,jsx,ts,tsx}",
],
theme: {
extend: {
colors: {
textDark: "#3F3D56",
},
},
},
plugins: [],
};
```
To ensure that we can apply Tailwind CSS to the components that will be present inside the `components` directory, we have included this directory in the content section of the Tailwind CSS configuration file.
To style components using props, we will also use React Native Stylesheet. To define all the necessary color values, we will create a `colors.js` file in the `assets/folder`.
assets/colors.js
```javascript
export default {
textDark: "#3F3D56",
textWhite: "#f3f4f6",
primary: "#8B5CF6",
bgGray: "#e4e4e7",
};
```
## Creating Heading Component.
Creating a `Header Text` that will be visible on all the pages.
Greeting.tsx
```javascript
<Text className="text-textDark text-4xl font-extrabold">CodeGenius</Text>
```
To ensure reusability of the Heading component across all pages, it is best practice to create a separate component file for it.
Create a Heading component `components/Heading.tsx`.
```javascript
import { Text } from "react-native";
import React from "react";
export default function Heading(props) {
return (
<Text className="text-textDark text-4xl font-extrabold">
{props.content}
</Text>
);
}
```
We will make the Heading component reusable by passing text as a prop, enabling us to use the same component for displaying headings with different text.
We will import the reusable `Heading` component in `pages/Greeting.tsx` and pass the content prop to it, as shown below:
```javascript
import Heading from "../components/Heading";
const Greeting = ({ navigation }) => {
return (
<SafeAreaView className="bg-white container h-full px-7">
<Heading content="CodeGenius" />
<View className="mt-6">
<TouchableOpacity
className="mt-3 rounded-xl py-3"
style={{ elevation: 1, backgroundColor: colors.primary }}
onPress={() => navigation.navigate("Login")}
>
<Text
className="text-center text-base"
style={{ color: colors.textWhite }}
>
Login
</Text>
</TouchableOpacity>
<CustomButton
navigation={navigation}
bgColor={colors.bgGray}
textColor={colors.textDark}
goto={"Signup"}
content={"Singup"}
/>
</View>
</SafeAreaView>
);
};
```
This is how our application looks now:
<p align = "center">
<img src = "https://pratik280.github.io/assets/06-building-multi-page-signup-login-react-native-app-part-2/heading.png.webp">
</p>
<p align = "center">
Fig. 1 - Heading Component
</p>
## Hero image
While there are plenty of image and vector art resources available online, we'll be using an image from [undraw](https://undraw.co/illustrations) for this demonstration. First, download the image and save it in the assets folder of your project. Then, follow these steps to add the vector art to your project.
`pages/Greeting.tsx`
```javascript
<View className="flex justify-center items-center mt-24">
<Image
source={require('./../assets/hero.png')}
style={{width: 400, height: 300}}
/>
</View>
<Heading content="CodeGenius" />
```
<p align = "center">
<img src = "https://pratik280.github.io/assets/06-building-multi-page-signup-login-react-native-app-part-2/hero.png.webp">
</p>
<p align = "center">
Fig. 2 - Hero Component
</p>
## Buttons
Writing code for resusable button component.
The CustomButton component in our code has been designed to be reusable in different ways. We can customize the button's appearance and functionality by passing values to different props. For example, we can use the "navigation" prop to navigate to a different page, set the background color with "bgColor" prop, set the text color with "textColor" prop, set the text content with "content" prop, and set the navigation destination with "goto" prop. By using these different props in different combinations, we can create a CustomButton component that meets our specific requirements. This allows us to create buttons quickly and efficiently for various parts of our application without having to write new code each time.
`compnents/CustomButton.tsx`
```javascript
import { TouchableOpacity, Text } from "react-native";
import React from "react";
const CustomButton = props => {
return (
<TouchableOpacity
className="mt-3 rounded-xl py-3"
style={{ elevation: 1, backgroundColor: props.bgColor }}
onPress={() => props.navigation.navigate(props.goto)}
>
<Text
className="text-center text-base"
style={{ color: props.textColor }}
>
{props.content}
</Text>
</TouchableOpacity>
);
};
export default CustomButton;
```
With the reusable CustomButton component we have created, we can create multiple buttons with different colors and text using props. By passing different values to the bgColor and textColor props, we can create buttons with different color schemes. Additionally, we can change the text displayed on the button by passing the desired text to the content prop. We can also use the goto prop to specify the page that the button should navigate to when it is clicked. By utilizing these props in different combinations, we can create custom buttons according to our needs.
```javascript
<CustomButton
navigation={navigation}
bgColor={'#f87171'}
textColor={'#fff'}
goto={'Signup'}
content={'Hello'}
/>
<CustomButton
navigation={navigation}
bgColor={'#059669'}
textColor={'#fff'}
goto={'Signup'}
content={'Click Here'}
/>
<CustomButton
navigation={navigation}
bgColor={colors.primary}
textColor={colors.textWhite}
goto={'Login'}
content={'Login'}
/>
<CustomButton
navigation={navigation}
bgColor={colors.bgGray}
textColor={colors.textDark}
goto={'Signup'}
content={'Singup'}
/>
```
<p align = "center">
<img src = "https://pratik280.github.io/assets/06-building-multi-page-signup-login-react-native-app-part-2/multiplebuttons.png.webp">
</p>
<p align = "center">
Fig. 3 - Buttons
</p>
## Form elements
In this section, we will be styling a form that includes the following elements:
1. Text inputs for entering first name, last name, email, and password.
1. A signup button to create a new account.
1. Google and Facebook buttons to login with those accounts.
1. A link to the login page for users who already have an account.
The form will provide a simple and user-friendly way for users to sign up for our service and log in using their preferred method. By incorporating popular social media platforms, we can make the process more convenient for users and potentially attract more users to our platform. The text inputs will allow users to provide their basic information securely, and the signup button will complete the registration process. If users already have an account, they can easily access it through the login page linked in the form.
### Text inputs
Creating a text input for `First Name`. We will use `useState` hook which is a built-in hook in React/Reat-Native that allows functional components to have state variables and update them. It takes an initial value and returns an array with two elements: the current state value and a function to update it. This means that you can update the data within your component and React will automatically re-render the component to reflect the changes.
`pages/Signup.tsx`
```javascript
const [firstName, setFirstName] = useState("");
```
The [TextInput](https://reactnative.dev/docs/textinput) component is used to take input from keyboard in react native.
```javascript
<TextInput
onChangeText={setFirstName}
placeholder={"First Name"}
placeholderTextColor={colors.textDark}
value={firstName}
className="bg-zinc-200 text-textgray rounded-xl py-3 px-5"
/>
```
When the user types something into the input field, the `setFirstName` function is called with the new value as an argument, and the `firstName` state variable is updated with that value. The `placeholder` prop sets the initial text displayed in the input field, while the `value` prop sets the current value of the input field. The `className` prop sets the CSS classes used for styling the input field, in this case a light gray background, dark text, and rounded corners.
In the same way we can create multiple text inputs like Last Name, Email and password.
### Social buttons
Creating a functional component called "SocialIcons" that displays two TouchableOpacity buttons with Google and Facebook logos as images.
`components/SocialIcons.tsx`
```javascript
import { View, TouchableOpacity, Image } from "react-native";
import React from "react";
const SocialIcons = () => {
return (
<View className="flex flex-row items-center justify-center">
<TouchableOpacity className="bg-zinc-200 mx-2 rounded-lg px-16 py-2">
<Image
source={require("./../assets/google.png")}
style={{ width: 30, height: 30 }}
/>
</TouchableOpacity>
<TouchableOpacity className="bg-zinc-200 mx-2 rounded-lg px-16 py-2">
<Image
source={require("./../assets/facebook.png")}
style={{ width: 30, height: 30 }}
/>
</TouchableOpacity>
</View>
);
};
export default SocialIcons;
```
### Complete Signup Page Code
`pages/Signup.tsx`
```javascript
import { View, Text, TouchableOpacity, TextInput } from "react-native";
import { useState } from "react";
import { SafeAreaView } from "react-native-safe-area-context";
import Heading from "../components/Heading";
import CustomButton from "../components/CustomButton";
import colors from "../assets/colors";
import SocialIcons from "../components/SocialIcons";
const Signup = ({ navigation }) => {
const [firstName, setFirstName] = useState("");
const [lastName, setLastName] = useState("");
const [email, setEmail] = useState("");
const [password, setPassword] = useState("");
return (
<SafeAreaView className="bg-white container h-full px-7">
<View className="mt-24">
<Heading content="Create Account" />
</View>
<View className="mt-4">
<TextInput
onChangeText={setFirstName}
placeholder={"First Name"}
placeholderTextColor={colors.textDark}
value={firstName}
className="bg-zinc-200 text-textgray rounded-xl py-3 px-5"
/>
<TextInput
onChangeText={setLastName}
placeholder={"Last Name"}
placeholderTextColor={colors.textDark}
value={lastName}
className="bg-zinc-200 text-textgray mt-3 rounded-xl py-3 px-5"
// style={{color: '#000000'}}
/>
<TextInput
onChangeText={setEmail}
placeholder={"Email"}
placeholderTextColor={colors.textDark}
value={email}
className="bg-zinc-200 text-textgray mt-3 rounded-xl py-3 px-5"
/>
<TextInput
secureTextEntry={true}
onChangeText={setPassword}
placeholder={"Password"}
placeholderTextColor={colors.textDark}
value={password}
className="bg-zinc-200 text-textgray mt-3 rounded-xl py-3 px-5"
/>
<TouchableOpacity
className="mt-2 flex items-end"
onPress={() => navigation.goBack()}
>
<Text className="text-textgray font-bold">Forgot Password?</Text>
</TouchableOpacity>
</View>
<CustomButton
navigation={navigation}
bgColor={colors.primary}
textColor={colors.textWhite}
goto={"Items"}
content={"Signup"}
/>
<View className="mt-10">
<Text className="text-textgray text-center">Or Continue With</Text>
<View className="mt-2">
<SocialIcons />
</View>
<View className="mt-24 flex flex-row items-center justify-center">
<Text className="text-textgray">Already have a accout?</Text>
<TouchableOpacity onPress={() => navigation.navigate("Login")}>
<Text className="text-textgray underline">Login</Text>
</TouchableOpacity>
</View>
</View>
</SafeAreaView>
);
};
export default Signup;
```
<p align = "center">
<img src = "https://pratik280.github.io/assets/06-building-multi-page-signup-login-react-native-app-part-2/signup.png.webp">
</p>
<p align = "center">
Fig. 4 - Signup Page
</p>
## Login Page
Similary create Login page
`pages/Login.tsx`
```javascript
import { View, Text, TouchableOpacity, TextInput, Image } from "react-native";
import { useState } from "react";
import { SafeAreaView } from "react-native-safe-area-context";
import Heading from "../components/Heading";
import CustomButton from "../components/CustomButton";
import colors from "../assets/colors";
import SocialIcons from "../components/SocialIcons";
const Login = ({ navigation }) => {
const [email, setEmail] = useState("");
const [password, setPassword] = useState("");
return (
<SafeAreaView className="bg-white container h-full px-7">
<View className="mt-36">
<Heading content="Welcome Back" />
</View>
<View className="mt-4">
<TextInput
onChangeText={setEmail}
placeholder={"Email"}
placeholderTextColor={colors.textDark}
value={email}
className="bg-zinc-200 rounded-xl py-3 pl-5"
/>
<TextInput
secureTextEntry={true}
onChangeText={setPassword}
placeholder={"Password"}
placeholderTextColor={colors.textDark}
value={password}
className="bg-zinc-200 mt-3 rounded-xl py-3 pl-5"
/>
<TouchableOpacity
className="mt-2 flex items-end"
onPress={() => navigation.goBack()}
>
<Text className="text-textDark font-bold">Forgot Password?</Text>
</TouchableOpacity>
</View>
<CustomButton
navigation={navigation}
bgColor={colors.primary}
textColor={colors.textWhite}
goto={"Items"}
content={"Login"}
/>
<View className="mt-10">
<Text className="text-textDark text-center">Or Continue With</Text>
<View className="mt-2">
<SocialIcons />
</View>
<View className="mt-44 flex flex-row items-center justify-center">
<Text className="text-textDark">Does'nt have a accout?</Text>
<TouchableOpacity onPress={() => navigation.navigate("Signup")}>
<Text className="text-textDark underline">Signup</Text>
</TouchableOpacity>
</View>
</View>
</SafeAreaView>
);
};
export default Login;
```
<p align = "center">
<img src = "https://pratik280.github.io/assets/06-building-multi-page-signup-login-react-native-app-part-2/login.png.webp">
</p>
<p align = "center">
Fig. 5 - Login Page
</p>
## Conclusion
In conclusion, building a UI for a login and signup form in React Native using TailwindCSS and functional reusable components can help streamline the development process and improve the overall user experience. By leveraging the power of React Native and the flexibility of TailwindCSS, we can create stunning UIs with minimal effort, while also maintaining a high degree of customization and flexibility. Additionally, the use of functional reusable components allows developers to create modular, reusable code that can be easily scaled and adapted for future projects. Overall, the process of building a login and signup form UI in React Native with TailwindCSS is a powerful and efficient way to create sleek and user-friendly interfaces for any mobile app.
| pratik280 |
1,453,168 | Strategies for Optimizing AWS Lambda Cold Starts | This article was originally authored by "Ismael Messa" on NumericaIdeas's blog: ... | 0 | 2023-04-30T18:28:31 | https://blog.numericaideas.com/lambda-cold-starts-optimization-strategies | aws, lambda, serverless, cloud | This article was originally authored by "Ismael Messa" on NumericaIdeas's [blog](https://medium.com/r/?url=https%3A%2F%2Fblog.numericaideas.com%2Flambda-cold-starts-optimization-strategies):
{% embed https://blog.numericaideas.com/lambda-cold-starts-optimization-strategies %}
## Introduction
**Cold Starts**, which refer to the delay in starting a Lambda invocation, are a common issue encountered by **Serverless** platforms. In situations where low latency is essential, Cold Starts can disrupt the smooth operation of workloads. To address this problem, various strategies have been developed, including **Lambda SnapStart**, **Provisioned Concurrency**, and **Custom Warmer**, each with its own approach. This article aims to compare and contrast these three strategies based on various factors.
The YouTube Channels in both English (En) and French (Fr) are now accessible, feel free to subscribe by clicking [here](https://www.youtube.com/@numericaideas/channels?sub_confirmation=1).
## Lambda SnapStart
### How it Works
As previously mentioned, **SnapStart** is a performance optimization technique designed to reduce the initialization time of a Lambda function. This strategy is fully supported by AWS and works by creating a snapshot of the function during the version release process. When the function is subsequently invoked, the cached version is reused, effectively preventing Cold Starts. By using SnapStart, **Cold Starts** can be improved by up to **90%**.
### Pricing
SnapStart is a **free** feature and does not require any additional cost.
### Supported Runtime
It's available for only Java(11) runtime (Correto) at the moment.
### Complexity to Set Up
It can be accessed via the **AWS console** and does not necessitate any modifications to your source code. Simply activate the feature and let it work its magic.
### Limit
One implication of using SnapStart's snapshot resuming approach is that ephemeral data or credentials may not have any expiry guarantees. This means that if your code utilizes a library that generates an expiring token at the function level, it could expire when a new instance of the function is launched via SnapStart.
Moreover, if your code establishes a long-term connection to a network service during the **init phase**, the connection will be lost during the invocation process.
Here's a more detailed article that covers its impacts and how to set it up:
{% embed https://blog.numericaideas.com/lambda-performance-improvement-with-snapstart %}
## Provisioned Concurrency
### How it Works
**Provisioned Concurrency** is an AWS feature that keeps your function warm and ready to respond in a matter of milliseconds at the scale you specify. With this feature enabled, you can select the number of instances of your function that run concurrently to handle incoming requests, rather than relying on Lambda to launch new instances as requests arrive (in-demand).
The distinctive aspect of Provisioned Concurrency is its rapid startup time, which is attributed to the fact that all setup processes, including the initialization code, occur before invocation. This ensures that the function remains in a state where your code is downloaded and the underlying container structure is configured. It is worth noting that this feature is only available with published versions or aliases of your function.
### Pricing
There are additional costs related to it :
- You pay for **how long** provisioned capacity is active.
- You pay **how many** concurrent instances should be available.
### Supported Runtime
It is available for all runtimes.
### Complexity to Set Up
The **Provisioned Concurrency** option can be accessed via various channels, including the AWS Console, Lambda API, AWS CLI, AWS CloudFormation, or Application Auto Scaling, and does not require any modifications to the existing source code.
### Limit
Provisioned Concurrency is not supported with [Lambda@Edge](https://aws.amazon.com/lambda/edge/).
## Custom Warmer
### How it Works
The **Custom Warmer** strategy aims to prevent **Cold Starts** by keeping the function warm through a **pinging mechanism**. This is achieved by utilizing [AWS EventBridge Rules](https://docs.aws.amazon.com/eventbridge/latest/userguide/eb-rules.html) to schedule function invocations at regular intervals. By selecting a specific frequency, typically every **15 minutes**, the function is automatically triggered, ensuring that it remains warm.
Also, it's generally implemented by some open-source libraries but you are free to built a custom one manually.
### Pricing
No cost is required! There are no additional charges for rules using **Amazon EventBridge**.
### Supported Runtime
You can use it with any runtime you need.
### Complexity to Set Up
To implement a Warming strategy, some changes to the source code are necessary since the Warmer triggers a function invocation after a specific period.
The function needs to identify whether it is a call from the Warmer and adjust its behavior accordingly, as demonstrated in the following example:
A sample implementation is available in the following [repository](https://github.com/numerica-ideas/ni-microservice-nodejs) with the **NPM** script `npm run job:warm:env`.
{% embed https://github.com/numerica-ideas/ni-microservice-nodejs %}
### Limit
It is important to note that this approach does not guarantee a complete elimination of Cold Starts. For instance, if the function is behind a **Load Balancer**, it may not always be effective since the LB can direct traffic to instances that are not warmed. Additionally, in production environments where functions **scale out** to handle increased traffic, there is no assurance that the new instances will be warmed up in time.
- - - - - - -
We have just started our journey to build a network of professionals to grow even more our free knowledge-sharing community that'll give you a chance to learn interesting things about topics like cloud computing, software development, and software architectures while keeping the door open to more opportunities.
Does this speak to you? If **YES**, feel free to [Join our Discord Server](https://discord.numericaideas.com) to stay in touch with the community and be part of independently organized events.
- - - - - -
If the **Cloud** is of interest to you this [video](https://www.youtube.com/watch?v=0II0ikOZEYE) covers the 6 most **Important Concepts** you should know about it:
{% embed https://www.youtube.com/watch?v=0II0ikOZEYE %}
**Important**: other articles are published on NumericaIdeas's [blog](https://blog.numericaideas.com/).
{% embed https://blog.numericaideas.com/ %}
## Conclusion
In summary, each of these strategies has its own unique approach to mitigating Cold Starts:
- **SnapStart** takes advantage of the SnapShots technique.
- **Custom Warmer** implements a scheduled ping mechanism.
- **Provisioned Concurrency** uses provisioned functions instances.
It should be noted that **Cold Starts** are not a critical issue for most functions, as they occur in only about **1% of invocations**. Nonetheless, we hope to have covered the significant differences between these strategies. If you have any suggestions or comments, please feel free to share them in the comments section below.
Thanks for reading this article, recommend and share if you enjoyed it. Follow us on [Facebook](https://www.facebook.com/numericaideas), [Twitter](https://twitter.com/numericaideas), [LinkedIn](https://www.linkedin.com/company/numericaideas) for more content.
| numericaideas |
350,408 | Django LoginView and flash messages | The strory Today I was working on an authentication system with Django, so I created a fun... | 0 | 2020-06-06T16:19:41 | https://dev.to/nuh/django-loginview-and-flash-messages-4k9k | django, html, css, python | ##The strory
Today I was working on an authentication system with **Django**, so I created a function based view that handles users registration, once the registration is complete it makes sense to redirect the users somewhere else typically a login page and notify them with a _flash message_ (an alert on the front-end) to tell them what is going on. This was easily achieved by combining django _flash messages_ and _bootstrap alerts_, but when I wanted to to use the same approach for the login part, I struggled because for login in the users I used the pre-built django class **LoginView**.
##The solution
The trick was to use my own **login view** that extends the django default **LoginView** and also uses the django _messages mixins_:
###views.py
```python
from django.contrib.messages.views import SuccessMessageMixin
from django.contrib.auth.views import LoginView
class MyLoginView(SuccessMessageMixin ,LoginView):
template_name = 'users/login.html'
success_url = 'blog-home'
success_message = 'Welcome to your profile'
```
On the template, it is best to display the messages on the base template so we are sure they would be seen where ever the user is right now.
###templates.html
```django
<div class="col-10 ml-auto>
{% if messages %}
{% for message in messages %}
<div class="row justify-content-end">
<div class="col-4 text-center">
<div class="alert alert-{{message.tags}}">
{{ message }}
</div>
</div>
</div>
{% endfor %}
{% endif%}
</div>
``` | nuh |
1,454,325 | Aspiring Web developer | Hello, i'm Ahmed, i want be a front-end-web developer. I'm new to this community. how can i maximize... | 0 | 2023-05-01T21:13:31 | https://dev.to/ahmedlutfy99/aspiring-web-developer-3151 | webdev, javascript, beginners, productivity | Hello, i'm Ahmed, i want be a front-end-web developer. I'm new to this community. how can i maximize the benefits of this community to become a good developer. i studied html, css and fundamentals of java script. how can i find small projects to study here.
| ahmedlutfy99 |
1,455,313 | Avoid These Mistakes to Reduce Your SaaS Customer Churn | SaaS companies undergo a dynamic change. Despite having built the best products, they still may face... | 0 | 2023-05-02T19:12:40 | https://dev.to/shbz/avoid-these-mistakes-to-reduce-your-saas-customer-churn-439h | startup | **SaaS companies undergo a dynamic change. Despite having built the best products, they still may face unprecedented challenges with uncertain issues.**
Every entrepreneur in a SaaS business has to face specific challenges that could lead to either making mistakes or making the best business decisions.
This disruptive technology is excellent when smart metrics provide valuable information that helps you make the best business decisions.
## Why is churn important in SaaS?
SaaS customer churn is essential in any subscription-based business because, unlike other industries, SaaS companies must continuously acquire new customers to offset each month’s natural churn.
If a SaaS company isn’t growing its customer base, it’s not just losing revenue from those who cancel their subscriptions; it’s also missing out on the opportunity to generate even more revenue from upsells and cross-sells.
In other words, SaaS customer churn isn’t just a numbers game; it’s also a growth game. And that’s why so many SaaS companies focus on reducing their churn rates.
There are several ways to reduce SaaS customer churn in a SaaS business, but some of the most effective include:
**• Offering discounts or free trials:** This can effectively entice customers who are on the fence about your product.
**• Improving customer onboarding:** Ensuring your customers understand how to use and get value from your product is critical.
**• Focusing on average SaaS retention rate:** Once customers have been with you for a while, they’re less likely to churn. So it’s essential to focus on retaining your existing customers and acquiring new ones.
### Why is it essential for a company to know its SaaS churn rate?
Churn is a massive problem for companies, especially in the software-as-a-service (SaaS) industry. It’s been estimated that the average SaaS company loses about 20% of its customers yearly. That’s a lot of customers! And it’s a lot of money that these companies are losing. So why is churn so significant? And why is it so crucial for companies to know their churn rate? There are a few reasons:
**1. Churn affects your revenue.** If you’re losing customers, you’re also losing out on revenue. But beyond that, churn can significantly impact your future income. That’s because when someone cancels their subscription or stops using your service, they’re not just gone forever–they’re also likely never to come back.
**2. Churn hurts your growth.** To grow, companies must acquire new customers and keep them around long enough to become profitable. But if you have a high churn rate, you’ll constantly be acquiring new customers just to offset the ones leaving- making it very difficult to grow sustainably.
**3. Churn gives you insights into your business.** Churn in SaaS subscriptions soon after signing up, it could be because they’re not happy with what they’re getting—which means you need to make some changes. Conversely, if people stick around for a while before canceling, it could mean they’re pretty satisfied with what you’re offering. Either way, understanding your churn can give you some valuable insights into how your business is doing.
## What is a good churn for SaaS?
There is no one-size-fits-all answer to this question. Every business is different, and what works for one company might not work for another.
You can follow some general guidelines when trying to determine what level of churn is acceptable for your business.
First, it’s essential to understand that customer churn is inevitable. No matter how good your product or service is, you will always have some customers who decide to leave. This isn’t necessarily bad; it’s often a sign that your business is healthy and growing.
What you should be concerned about is excessive churn—when the number of customers leaving your company exceeds the number of new customers coming in. This can be a problem because it means you’re losing more revenue than you’re bringing in, which can quickly lead to financial trouble.
So how do you know if your SaaS churn rate is too high? There’s no hard and fast rule, but generally speaking, a churn rate of 5-7% per month is considered acceptable for most SaaS businesses. Anything above that should be cause for concern.
Of course, these numbers will vary depending on your specific industry. For example, companies in highly competitive industries tend to have higher churn rates than those in less competitive markets. Additionally, businesses with longer sales cycles (i.e., those that take longer to convert prospects into paying customers) will usually have higher churn rates than those with shorter sales cycles.
## What Can Companies Learn From SaaS Customer Churn—The Mistakes They Need To Avoid.
### 1. Not understanding what causes SaaS customer churn.
Various factors cause SaaS customer churn, but poor customer service, high prices, and buggy products are the most common. To reduce churn, you need first to understand what’s causing it. Only then can you take steps to address the issue.
Churnfree tool offers a one-platform solution to calculating the correct churn rate, giving you complete transparency on all significant reasons for churned customers.
### 2. Not tracking churn.
You can’t improve something if you don’t measure it. That’s why it’s essential to track your churn rate. There are a few different ways to do this, but one of the most common is calculating your SaaS customer churn rate. SaaS churn rate is the percentage of customers who cancel their subscription or stop using your product within a certain period.
Knowing the right churn rate for your products will make it easier for you to discover why your customers decided to leave. Transparency into all matters that can help you retain customers is essential—Churnfree offers fast solutions and real-time transparency to retain all your unhappy customers.
### 3. Not segment your customers.
Not all customers are created equal. Some are more valuable than others, and some are more likely to churn. That’s why it’s essential to segment your customers. This way, you can focus your average SaaS retention rate efforts on those most likely to stick around (and generate the most revenue).
In this fast world, help from excellent tools transforms the ways of doing business.
Churnfree tool helps you figure out why your customers decided to churn. Try applying different strategies for different types of churned customers.
16 [Customer retention Strategies](https://churnfree.com/blog/saas-retention-strategies/) to reduce the churn rate of your Startup business.
### 4. Not offering enough value.
Ensure you’re offering a product or service that solves a real problem for your target market. This could be in the form of discounts, exclusive content, or early access to new features. If your customers don’t see the value in your offering, they will not stick around for long.
Another way to combat SaaS customer churn is by staying in touch with your customers and getting feedback from them regularly. This way, you can stay on top of their needs and wants and address any concerns they may have before they lead to churn.
### 5. Not providing enough support.
If your customers encounter problems, they will need someone to help them solve them. That’s why it’s essential to provide excellent customer support. Be responsive to customer inquiries, and make sure you have a team in place that can help them with whatever issue they’re facing.
The first step in preventing SaaS customer churn is to understand the reasons why customers leave in the first place. There are many possible reasons, but some of the most common include:
**The product isn’t meeting their needs:** This is often the most common reason for SaaS customer churn. If your product doesn’t solve a customer’s problem or meet their needs, they will likely look for another solution. Make sure you really understand your target market and what they need from your product.
**They’re not using the product:** It’s not enough for customers to buy your product; they need to use it as well. If they’re not using it, they’re not getting value from it and are more likely to cancel their subscription. Make sure you have onboarding processes to help new users start your product and continue using it over time.
**They don’t know how to use the product: **Even if your product does meet their needs, they won’t get any value from it if they don’t know how to use it properly. Make sure you have good documentation and training materials available so users can learn how to use your product effectively.
**Price increases:** If you increase prices too much or too often, customers may decide that your product is no longer worth the investment and look for a cheaper alternative.
### 6. Not being transparent about pricing.
Hidden fees and unexpected price hikes are a surefire way to anger your customers and cause them to churn in SaaS business. Be upfront and transparent about your pricing, so your customers know what to expect.
As a business owner, it’s essential to be transparent about pricing. After all, your customers are the ones who will ultimately decide whether or not to purchase your product or service. However, being too transparent about pricing can also lead to SaaS customer churn.
When it comes to pricing, there is a delicate balance that must be struck. On the one hand, you don’t want to be so expensive that potential customers are turned away. On the other hand, you don’t want to be so cheap that people think your product or service is inferior. Instead, you need to find a happy medium where your prices are fair and reasonable.
Of course, SaaS customer churn is always possible, even if you have priced your products or services correctly. A customer cancels their subscription or stops using your product or service altogether. There are many reasons why this might happen, but often it boils down to simple economics. If customers feel like they’re paying too much for what they’re getting, they’ll likely look for a cheaper alternative.
There are several ways to combat SaaS customer churn, but one of the most effective is simply being more transparent about pricing from the start. By clearly communicating your prices and what customers can expect to receive for their money, you can help reduce the chances of them canceling their subscription later on down the line.
### 7. Not making it easy to cancel.
If you make it difficult for customers to cancel their subscriptions, they’re more likely to get frustrated and leave anyway. Make it easy for them to cancel if they need to, and ensure they understand there are no hard feelings if they decide to go elsewhere.
### 8. Not following up after cancellation.
Just because a customer has canceled doesn’t mean you should give up on them entirely. Follow up with them after they cancel and try to understand why they made that decision. You may be able to win them back with a special offer or by addressing their concerns.
When customers cancel their subscription, they must reach out and find out why. Was it something about your product? Your pricing? Your support? Or was it something else entirely?
Once you know the reason for the cancellation, you can take steps to prevent other customers from canceling for the same reasons. But if you don’t take follow-up after cancellations, you’ll never know what the problem was in the first place. You might need to change your product, pricing, or support to keep them happy.
So if you’re serious about reducing SaaS customer churn, follow up after cancellations. It could be the key to keeping your customers happy and reducing churn in the long run.
### 9. Not staying in touch with former customers.
Even if a customer doesn’t renew their subscription, they may still be interested in what you have to offer. You never know when they may decide to come back! Stay in touch with them through email or social media, and let them know about new products or features that could be of interest to them.
Even if a customer doesn’t renew their subscription, they may still be interested in what you have to offer. You never know when they may decide to come back! Stay in touch with them through email or social media, and let them know about new products or features that could be of interest to them.
There are a few ways to stay in touch with your customers. You can send them emails, or connect with them on social media.
Email is a great way to stay in touch with your customers because it’s relatively low cost, and you can reach many people at once. You can also segment your email list so that you’re only sending relevant information to those who are interested in it.
Calls are another great way to stay in touch with your customers. They’re personal and allow you to build a rapport with the person on the other end. However, they can be time-consuming, so make sure you’re only calling those who are interested in hearing from you.
Social media is another excellent way to stay in touch with your customers. It’s quick, and easy, and most people already use it daily. Plus, it allows you to connect with potential new customers who might not be aware of your business otherwise.
### 10. Not learning from your mistakes.
Churn is inevitable, but that doesn’t mean you should just accept it as part of doing business. Take the time to learn from your mistakes and figure out what you can do differently next time. By constantly improving, you can reduce your churn rate and keep more of your hard-earned customers!
### The Bottom-line:
SaaS businesses need to be proactive to keep their customers happy and engaged. After all, acquiring a new customer costs more than retaining an existing one.
This [post](https://churnfree.com/blog/what-can-saas-companies-learn-from-churn/) was originally published on our blog. | shbz |
1,455,401 | How to Deploy Apache Kafka® on Kubernetes If You're in a Time Crunch | There are many reasons to run Apache Kafka on premises, within your own Kubernetes cluster, such as... | 0 | 2023-05-02T21:13:24 | https://dev.to/ciscoemerge/how-to-deploy-apache-kafkar-on-kubernetes-if-youre-in-a-time-crunch-50b7 | kafka, kubernetes | There are many reasons to run Apache Kafka on premises, within your own Kubernetes cluster, such as handling sensitive data.
However, regardless of how compelling the reason, there's often a limiting factor—time.
Have you ever thought about running Kafka on premises, within your own Kubernetes cluster, but you're in a time crunch?
In this article, we'll talk about installing and managing Kafka with Koperator—an open-source solution that enables you set up an on-premises message broker in record time—even if you're not an expert.
## What’s so hard about deploying Kafka on Kubernetes?
When you deploy a stateless application to Kubernetes, best practices specify that it:
- Should not rely on hard-disk access
- Works well behind a load balancer
- Can scale up and down easily
The more you follow these guidelines, the easier it is to work with Kubernetes. Things start to change, however, once you need to deploy a stateful application or service (like a database or message broker). The latter types of applications have different requirements and often don't fit neatly within the constraints mentioned above. Kafka, for instance, relies heavily on disk access. Also, producers and consumers need to connect to specific brokers. These and other constraints will require you to put in extra effort to build a reliable Kubernetes deployment.
[A Kafka development setup](https://dev.to/ciscoemerge/apache-kafka-a-quickstart-guide-for-developers-80p) might look straightforward. It gives you ready-to-use Docker images—even plug-and-play `docker-``compose.yml` files. For a production deployment, however, the to-do list gets longer. Check out [this blog post](https://dev.to/ciscoemerge/deploy-apache-kafkar-on-kubernetes-5257) to get a feeling for the scope. Suffice it to say that if you're in a time crunch, sorting through the intricate details of a Kafka production deployment is an exercise in futility. You need a production deployment *now.* And here's the solution.
## A reproducible Kafka deployment on Kubernetes
Instead of getting into the weeds of questions like "should I use a `StatefulSet` or a regular `deployment`," you can leverage [Koperator](https://github.com/banzaicloud/koperator) to make all the decisions for you.
Koperator is an open-source Kafka operator that enables you to set up a production-ready Kafka cluster within minutes, leveraging standard tooling you are (likely) already using. It abstracts away many of the decisions around a Kafka deployment, which saves you a lot of time. You get to run Kafka on your premises, according to your rules and regulations, but with the advantages of a managed service.
## Try it out
For the following instructions, we are using [Kind](https://kind.sigs.k8s.io/)—a tool for running local Kubernetes clusters using Docker container nodes. If you haven't installed Kind yet, please follow [these instructions.](https://kind.sigs.k8s.io/docs/user/quick-start/)
```bash
kind create cluster
kubectl cluster-info --context kind-kind
```
This will start up a new Kind cluster and set the current context to Kind.
Koperator requires 6 vCPUs and 8GB RAM. If you're using Kind, please make sure to allocate enough resources to your local Docker daemon; otherwise, containers will fail to start.
Please also make sure to install Helm if you haven't already.
### Install Apache Zookeeper™
As a first step, we install Zookeeper using [Pravega's Zookeeper Operator](https://github.com/pravega/zookeeper-operator):
```bash
helm install zookeeper-operator --repo https://charts.pravega.io zookeeper-operator --namespace=zookeeper --create-namespace
```
Next, we create a Zookeeper cluster using custom resources. Custom resources allow us to create a Zookeeper cluster like this:
```bash
kubectl create -f - <<EOF
apiVersion: zookeeper.pravega.io/v1beta1
kind: ZookeeperCluster
metadata:
name: zookeeper
namespace: zookeeper
spec:
replicas: 1
persistence:
reclaimPolicy: Delete
EOF
```
Instead of going through a lengthy deployment and service configuration, we get the service up and running with a few lines of configuration.
Before moving on, let's verify Zookeeper is up and running:
```bash
kubectl get pods -n zookeeper
```
The above command should output something like:
```bash
NAME READY STATUS RESTARTS AGE
zookeeper-0 1/1 Running 0 27m
zookeeper-operator-54444dbd9d-2tccj 1/1 Running 0 28m
```
### Install Koperator
Now on to Koperator. We will install it in two steps. First, we'll install the Koperator `CustomResourceDefinition` resources. We perform this step separately, to allow you to uninstall and reinstall Koperator without deleting your already installed custom resources.
```bash
kubectl create --validate=false -f https://github.com/banzaicloud/koperator/releases/download/v0.24.1/kafka-operator.crds.yaml
```
Next, install Koperator into the Kafka namespace:
```bash
helm install kafka-operator --repo https://kubernetes-charts.banzaicloud.com kafka-operator --namespace=kafka --create-namespace
```
Create the Kafka cluster using the KafkaCluster custom resource. The quick start uses a minimal custom resource:
```
kubectl create -n kafka -f https://raw.githubusercontent.com/banzaicloud/koperator/master/config/samples/simplekafkacluster.yaml
```
Verify that the Kafka cluster has been created:
```
> kubectl get pods -n kafka
kafka-0-nvx8c 1/1 Running 0 16m
kafka-1-swps9 1/1 Running 0 15m
kafka-2-lppzr 1/1 Running 0 15m
kafka-cruisecontrol-fb659b84b-7cwpn 1/1 Running 0 15m
kafka-operator-operator-8bb75c7fb-7w4lh 2/2 Running 0 17m
```
### Test Kafka cluster
To test the Kafka cluster, let's create a topic and send some messages.
If you have used Kafka before, you might recall the necessary steps to create a topic. Kafka ships with a bunch of utility command-line tools to help with administrative tasks.
While we could that workflow, it'd require a few steps:
- Decide which pod we want to connect to
- Open a shell to the Kafka broker pod
- Find the command-line tools
- Run the `create-topics.sh` tool
If you thought about automating topic creation (i.e. as part of your CI/CD workflow), codifying these steps is possible but cumbersome. Instead, let's use `kubectl` and a few lines of YAML configuration:
```
kubectl create -n kafka -f - <<EOF
apiVersion: kafka.banzaicloud.io/v1alpha1
kind: KafkaTopic
metadata:
name: my-topic
spec:
clusterRef:
name: kafka
name: my-topic
partitions: 1
replicationFactor: 1
config:
"retention.ms": "604800000"
"cleanup.policy": "delete"
EOF
```
This snippet creates a topic called `my-topic` with one partition and a replication factor of 1.
With the topic in place, let's start a producer and consumer to test it. Run the following command to start a simple producer:
```bash
kubectl -n kafka run kafka-producer -it --image=ghcr.io/banzaicloud/kafka:2.13-3.1.0 --rm=true --restart=Never -- /opt/kafka/bin/kafka-console-producer.sh --bootstrap-server kafka-headless:29092 --topic my-topic
```
To receive messages, run the following command:
```bash
kubectl -n kafka run kafka-consumer -it --image=ghcr.io/banzaicloud/kafka:2.13-3.1.0 --rm=true --restart=Never -- /opt/kafka/bin/kafka-console-consumer.sh --bootstrap-server kafka-headless:29092 --topic my-topic --from-beginning
```
## So there you have it!
Running Apache Kafka on Kubernetes is possible—even if you're short on time. What's more, it does not require you to become an expert first. Instead, you become an expert while running Kafka in production using Koperator. Koperator abstracts away some aspects of the Kafka deployment and also provides you with a convenient user interface through `kubectl`.[Check out the GitHub repository](https://github.com/banzaicloud/koperator) and try it for yourself!
| schultyy |
1,455,589 | Mega888 | https://mega888.win/ original ini anda tidak lagi perlu keluar dari rumah bahkan anda boleh terus... | 0 | 2023-05-03T03:07:43 | https://dev.to/mega888win/mega888-3ldf | https://mega888.win/ original ini anda tidak lagi perlu keluar dari rumah bahkan anda boleh terus berseronok bermain permainan kasino dimana...
CONTACT:
Address: Pesiaran Perbandaran, Seksyen 14, 40000 Shah Alam, Selangor, Malaysia
Phone: +60355105133
Website: https://mega888.win/
Twitter: https://twitter.com/mega888win
LinkedIn: https://www.linkedin.com/in/mega888win/
Facebook: https://www.facebook.com/mega888winsocial/
Pinterest: https://www.pinterest.com/mega888win/
| mega888win | |
1,456,072 | Top 10 Python Project Ideas for Final Year Students | Is Final Year Students Searching for Python Projects? Don’t Worry, Here “takeoff edu group” will help... | 0 | 2023-05-03T13:13:40 | https://dev.to/kavya_rake22477/top-10-python-project-ideas-for-final-year-students-5eb9 | javascript, python, programming | Is Final Year Students Searching for Python Projects? Don’t Worry, Here “takeoff edu group” will help you to get good and unique Python Projects page, you will find trending and top projects list.
There are many reasons why Python Projects are an excellent choice for engineering students. Firstly, they provide a great way to apply the knowledge and learn real-world projects. By building and programming your own devices, you can gain a deeper understanding computer programming.
Top10 Python Project Ideas you will find out in “Takeoff Edu Group”: -
• An Approach to Discover Similar Musical Pattern
• Fake Product Identification Using Blockchain Technology- Using QR Code
• Brain Diagnosis Disease by Using Machine Learning and Deep Learning Algorithms
• Towards a Secure Electronic Health Record System Using Blockchain Technology
• Securing IoT Data in the Cloud with Blockchain Technology
• Implementation and Analysis of Blockchain Based DApp for Secure Sharing of Student's Credentials
• Fake Media Detection Based on Natural Language Processing and Blockchain Approaches
• Protecting Data Privacy for Permissioned Blockchains using Identity-Based Encryption
• A Study of Blockchain Technology in Farmer's Portal
• BSSPD: A Blockchain-Based Security Sharing Scheme for Personal Data with Fine-Grained Access Control
Here are some Python project ideas for Final Year students:
Circuit Design and Simulation: Use Python to design and simulate electronic circuits, including signal processing circuits, power supplies, and control systems.
Machine Learning for Engineering Applications: Develop machine learning models in Python to solve engineering problems, such as predicting failure modes or optimizing processes.
Image Processing: Use Python to develop an image processing program that can analyze and manipulate images, such as detecting defects in materials or identifying features in medical images.
Robotics: Develop a Python-based control system for a robot, including motion planning and control algorithms.
Data Analysis and Visualization: Use Python to analyze and visualize data from engineering experiments, such as sensor data or simulations.
Signal Processing: Use Python to develop signal processing algorithms, such as filters or digital signal processing techniques.
Internet of Things (IoT) Applications: Develop Python-based applications for IoT devices, such as sensors or controllers, to monitor and control physical systems remotely.
Computer Vision: Use Python to develop computer vision applications, such as object recognition or tracking, for engineering applications.
Overall, Python projects offer students a unique opportunity to develop practical skills in Final year engineering. With the help of Takeoff edu group, students can get access to project ideas, guidance, and resources to ensure their success.
So, what are you waiting for? Join the growing community of “Takeoff Edu Group” who are interested in doing Python Project Ideas. For more information visit:- https://takeoffprojects.com/python-project-ideas
| kavya_rake22477 |
1,456,459 | HelloNewbie - v3 | Just joined the community? Say hello! | 0 | 2023-05-03T18:36:00 | https://dev.to/codenewbieteam/hellonewbie-v3-22go | hellonewbie, codenewbie | ---
title: HelloNewbie - v3
published: true
description: Just joined the community? Say hello!
tags: hellonewbie, codenewbie
---
## Welcome everybody to the CodeNewbie Organization on DEV!
---

---
1. Leave a comment below to introduce yourself! You can talk about what brought you here, what you're learning, or just a fun fact about yourself.
2. Make some new friends by responding to another newbie's comment :wave: Feel free to follow one another, too!
3. We also recommend following the [#beginners](https://dev.to/t/beginners) & [#codenewbie](https://dev.to/t/codenewbie) tags. And of course, don't forgot to hop into [the DEV Welcome Thread](https://dev.to/welcome) there to introduce yourself and meet new folks. :tada: | caroline |
1,457,151 | Custom Cabinets vs. Prefabricated Cabinets: Which is Right for You? | Choosing the right cabinets for your home can be a daunting task. With so many options available, it... | 0 | 2023-05-04T10:19:59 | https://dev.to/idannydiesel/custom-cabinets-vs-prefabricated-cabinets-which-is-right-for-you-38h9 | kitchen, cabinets, custom, prefabricated | Choosing the right cabinets for your home can be a daunting task. With so many options available, it can be overwhelming to make a decision. One of the biggest decisions you'll need to make is whether to choose custom cabinets or prefabricated cabinets. Both have their advantages and disadvantages, and it's important to weigh the pros and cons before making your decision. In this article, we'll take a closer look at custom cabinets vs. prefabricated cabinets to help you make the best choice for your home.
## Custom Cabinets
Custom cabinets are built to order and are designed to fit your specific needs and style preferences. They are created by skilled craftsmen who use high-quality materials and techniques to create a unique and personalized product. You can **[buy custom cabinets in Columbus](https://columbuscabinetscity.com/)** from Columbus Cabinet City.
### Benefits
Here are some of the benefits of choosing custom cabinets:
1. Customization: With custom cabinets, you can choose the exact style, material, and finish you want. You can also customize the size, shape, and storage options to meet your specific needs.
2. Quality: Custom cabinets are typically made with high-quality materials and craftsmanship, which means they are durable and long-lasting.
3. Unique: Since custom cabinets are made to order, they are one-of-a-kind and can add a unique touch to your home.
4. Flexibility: With custom cabinets, you have the flexibility to make changes and adjustments throughout the design process to ensure you get the cabinets you want.
5. Investment: Custom cabinets can add value to your home, making them a smart investment for the long-term.
### Drawbacks
There are also some drawbacks to choosing custom cabinets:
1. Cost: Custom cabinets can be more expensive than prefabricated cabinets due to the personalized design and higher quality materials.
2. Time: Since custom cabinets are made to order, the process can take longer than prefabricated cabinets.
3. Expertise: You'll need to work with a skilled designer and installer to ensure your custom cabinets are properly designed and installed.
## Prefabricated Cabinets
Prefabricated cabinets are pre-made in a factory and come in a variety of styles, sizes, and finishes. They are typically less expensive than custom cabinets and can be a good option for those on a budget.
### Benefits
Here are some of the benefits of choosing prefabricated cabinets:
1. Affordability: Prefabricated cabinets are usually less expensive than custom cabinets, making them a good choice for those on a budget.
2. Convenience: Since prefabricated cabinets are pre-made, they can be delivered and installed more quickly than custom cabinets.
3. Variety: There are many styles and finishes to choose from with prefabricated cabinets, so you're likely to find something that fits your needs and style preferences.
4. Quality: While prefabricated cabinets may not be as high-quality as custom cabinets, they are still made with **[durable materials](https://www.homesandgardens.com/kitchens/what-are-the-most-durable-kitchen-cabinets)** and craftsmanship.
### Drawbacks
There are also some drawbacks to choosing prefabricated cabinets:
1. Limited customization: Prefabricated cabinets are available in standard sizes and finishes, so you may not be able to find exactly what you're looking for.
2. Quality: While prefabricated cabinets are made with durable materials, they may not be as high-quality as custom cabinets.
3. Design limitations: With prefabricated cabinets, you may have limited options for storage and design features.
## Conclusion
Choosing between custom cabinets and prefabricated cabinets ultimately depends on your budget, timeline, and style preferences. If you have a larger budget and want a unique, personalized look, then custom cabinets may be the right choice for you. However, if you're on a budget or need cabinets quickly, then prefabricated cabinets may be a better option. Consider the pros and cons of each option and work with a reputable cabinet provider.
| idannydiesel |
1,457,620 | AWS Neptune for analysing event ticket sales between users - Part 1 | This is the first of a two part blog series, where we will walk through the setup for using AWS... | 0 | 2023-05-29T21:39:57 | https://dev.to/aws-builders/aws-neptune-for-analysing-event-ticket-sales-between-users-part-1-4ag | neptune, cypher, serverless, graphs | This is the first of a two part blog series, where we will walk through the setup for using AWS Neptune to anaylse a property graph modelled from the [Worldwide Event Attendance]( https://aws.amazon.com/marketplace/pp/prodview-4ozlpl4r3k7cg) from AWS Marketplace Data Exchange, which is free to subscribe to. This contains data for user ticket purchases and sales for fictional daily events(operas, plays, pop concerts etc) across 2008. in the USA. This data is accessible from Redshift so part of this setup will involve loading the data in required format from Redshift to S3 bucket and then loading it into a Neptune DB instance for running queries and generating visualisations in [Part 2](https://dev.to/aws-builders/aws-neptune-for-analysing-event-ticket-sales-between-users-part-2-3i5g).
## Setting up the Neptune Cluster and Notebook
First we will need to create the Neptune Cluster and database instance. I have configured this from the AWS console, which can be followed using the steps in the [docs](https://docs.aws.amazon.com/neptune/latest/userguide/manage-console-launch-console.html) but this could also be automated via one of the Cloudformation templates [here](https://docs.aws.amazon.com/neptune/latest/userguide/get-started-cfn-create.html).
* For the **Engine** options, select provisioned mode and the latest version of Neptune
* For **Settings**, select the **Development and testing** option rather than Production as this will give use the option to select the cheaper burstable class (db.t3.medium).
* We will not create any Neptune replicas in different availability zones so click **No** for **Multi-AZ Deployment**.
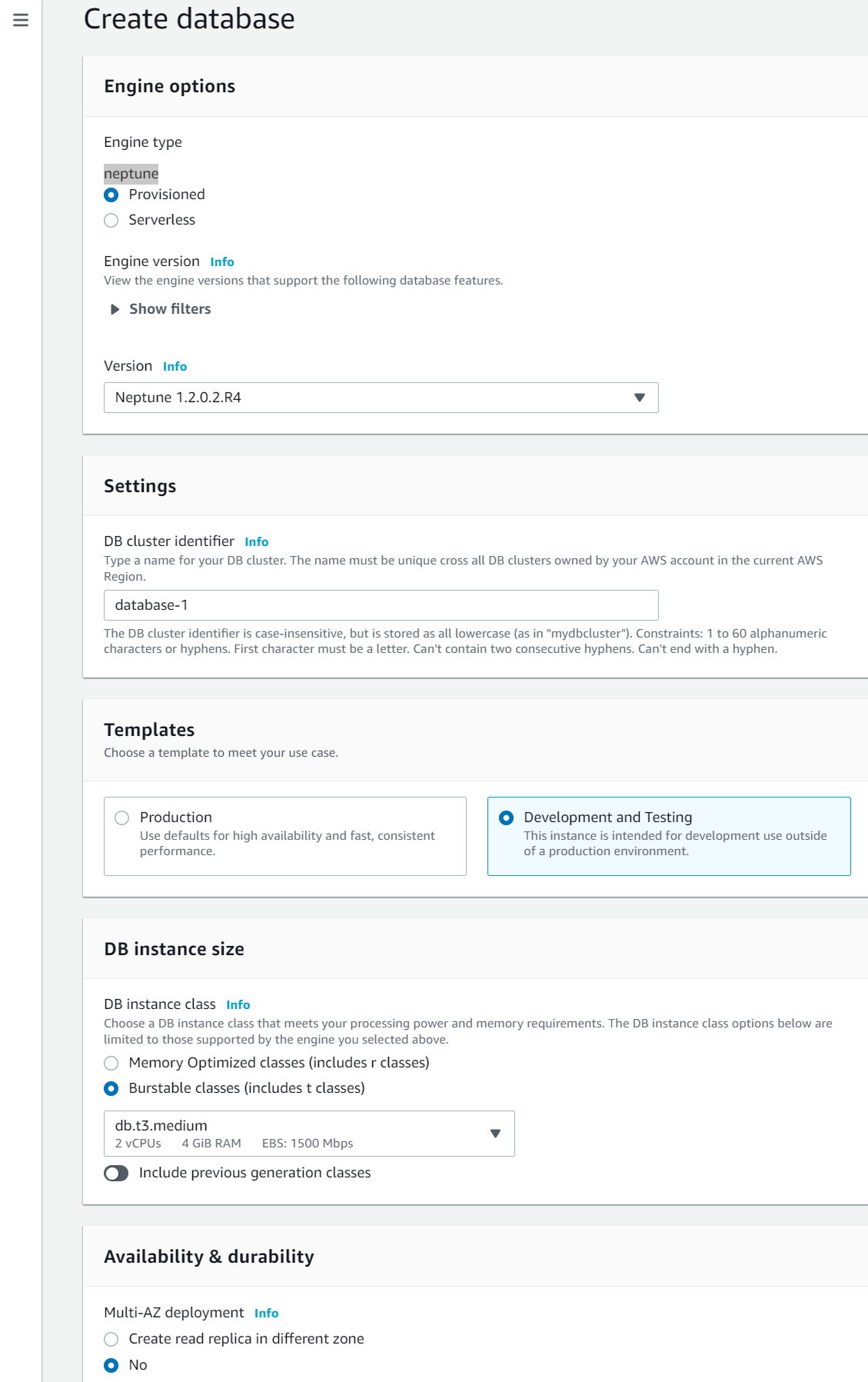
* For the **Connectivity** option, I have selected my default VPC for which I already have the security group configured with an inbound rule to allow access to any port in range with existing security group id as source. Alternatively you could add another custom rule to only allow inbound traffic to the specific default port for Neptune (8182).
* You can also choose to create a new VPC and new security group if you do not want to use the existing ones.
* We will configure the notebook separately after creating the cluster, so skip the **Notebook configuration** option.
* You can either skip the **Additional configuration** option and accept the defaults, which enable deletion protection, encryption at rest and auto minor version upgrades or disable the options you do not want.
We will now configure a [Neptune graph notebook](https://docs.aws.amazon.com/neptune/latest/userguide/graph-notebooks.html) to access the cluster, so we can run queries and generate interactive visualisations. **Neptune Workbench** allows users to run fully managed jupyter notebook environment in Sagemaker with the latest release of the open source [graph Neptune project](https://github.com/aws/graph-notebook). This has the benefit of offering in-built capabilities like [visualisation of queries](https://docs.aws.amazon.com/neptune/latest/userguide/notebooks-visualization.html)
* Click **Notebooks** from the navigation pane on the left and select **Create notebook**.
* In the Cluster list, choose your Neptune DB cluster. If you don't yet have a DB cluster, choose **Create cluster** to create one.
* For **Notebook instance type**, select **ml.t3.medium** which should be sufficient for this example.
* Under **IAM role name**, select **create an IAM role** for the notebook, and enter a name for the new role.
Finally, we need to create an IAM role for Neptune to assume to be able to load data from S3. Also, since Neptune DB instance is within a VPC, we need to create an S3 gateway endpoint to allow access to S3. This can be achieved by following the steps in the [IAM prerequites for the Neptune Bulk Loader](https://docs.aws.amazon.com/neptune/latest/userguide/bulk-load-tutorial-IAM.html#bulk-load-tutorial-vpc).
## Redshift Serverless Data Query and Unload
In this [previous blog](https://dev.to/aws-builders/sagemaker-501e-temp-slug-9236610?preview=850aebb1bd0ecf9213710c0b676e1f93a3f2ce4ce9b852476448ed854ca96c1ca0b803afcd1ca165e02198f35013dd28e398083bf31486ac98bc5e64), I have described how to configure AWS Redshift Serverless with access to AWS Marketplace Worldwide Events Dataset. Follow the steps to configure datashare to access this database from the redshift cluster.
We will model the users and events as nodes and relationship between each user and event as an edge. For example, a seller (node) would list (relationship) a ticket for a given event (node) for which one or many buyers (node(s)) would purchase (relationship(s)) tickets for (or unluckily noone may pruchase from the seller).
Open the query editor in the navigation pane in the Redshift Serverless console. We will first create a view which will filter the `all_users` view in the worldwide events datashare, to only contain users who like theatre, concerts and opera. The additional constraint is that we will only keep data that has no nulls in any of the entries for the boolean columns selected.
```sql
CREATE VIEW user_sample_vw AS
SELECT userid, username, city, state, liketheatre, likeconcerts, likeopera FROM
"worldwide_event_data_exchange"."public"."all_users"
WHERE (liketheatre IS NOT NULL AND likeconcerts IS NOT NULL AND likeopera IS NOT NULL)
with no schema binding;
```
Lets also create another view containing a snapshot of events and related transactions between selected buyers and sellers in our **user_sample_vw** for the month of January. We also need to pull in additional columns corresponding to venue, event and ticket purchase and listing details (.e.g number of tickets and price). Hence we need to join to the respective tables.
**Note** We also only want records where either the buyer or seller cannot be NULL and all users must be from the subset we sampled in **user_sample_vw**.
```sql
CREATE OR REPLACE VIEW network_vw AS
SELECT *
FROM
(
SELECT S.saletime, L.sellerid, L.listtime, S.buyerid, E.eventid, E.eventname,
V.venuename , C.catname , V.venuecity, V.venuestate, pricepaid ,qtysold, D.caldate,
priceperticket AS listprice ,numtickets AS listtickets
FROM "worldwide_event_data_exchange"."public"."date" D
JOIN "worldwide_event_data_exchange"."public"."sales" S
ON D.dateid = S.dateid
JOIN "worldwide_event_data_exchange"."public"."listing" L
ON S.listid = L.listid
JOIN "worldwide_event_data_exchange"."public"."event" E
ON E.eventid = S.eventid
JOIN "worldwide_event_data_exchange"."public"."category" C
ON E.catid = C.catid
JOIN "worldwide_event_data_exchange"."public"."venue" V
ON E.venueid = V.venueid
JOIN "dev"."public"."user_sample_vw" U
ON S.buyerid = U.userid
WHERE D.qtr = 1
) A
JOIN "dev"."public"."user_sample_vw" B
ON A.sellerid = B.userid
with no schema binding;
```
You should see the **network_vw** view visible if you refresh the dev database and expand the view dropdown in the tree. A sample of the rows and columns of the view looks like below. We will use this later to simplify the creation of edge records for our csv to export to S3. We will also use the **eventid** and related properties to create nodes csv.
We will need to generate two csv files(one containing all the nodes and other containing all the relationship records) in the S3 bucket. This is a requirement when we will subsequently use the Neptune Bulk Loader to load the data into Neptune using the openCypher-specific csv format (since we will be using openCypher to query the graph data). In addition, the openCypher load format requires system column headers in node and relationship files as detailed in the [docs](https://docs.aws.amazon.com/neptune/latest/userguide/bulk-load-tutorial-format-opencypher.html). Any column that holds the values for a particular property needs to use a property column header **propertyname:type**.
We will need to create a role to associate with redshift serverless endpoint so it can unload data into S3.
In the Redshift Serverless console, go to Namespace configuration and select the namespace. Then go to Security and Encryption Tab and click on Manage IAM roles under the Permissions section. Click the **Create IAM role** option in the **Manage IAM roles** dropdown. This will create an IAM role as the default with AWS managed policy **AmazonRedshiftAllCommandsFullAccess** attached. This includes permissions to run SQL commands to COPY, UNLOAD, and query data with Amazon Redshift Serverless.
Select the option **Specific S3 buckets** and select the S3 bucket created for unloading the nodes and relationship data to. Then click **Create IAM role as default**.
This default role created does allow permissions to run select statements on other services besides S3, including Sagemaker, Glue etc. The policy attached to the new role created would need to be updated from IAM if you want to limit permissions to fewer services.
If you navigate back to the Namespace, you should see the IAM role and the associated arn (highlighted in yellow) which you will need to specify when running commands to unload data to S3.
We will use the [UNLOAD](https://docs.aws.amazon.com/redshift/latest/dg/r_UNLOAD.html) command to unload the results of the queries above to S3 in csv format. We need to add the following options below.
* **CSV DELIMITER AS**: to use csv format with delimiter as ','
* **HEADER**: specify first row as header row
* **CLEANPATH**: to remove any existing S3 file before unloading new query
* **PARALLEL OFF**: turn off parallel writes as we want a single CSV files rather than multiple partitions.
```
unload ('<query>')
to <s3://object-path/name-prefix>
iam_role <your role-arn>
CSV DELIMITER AS ','
HEADER
cleanpath
parallel off;
```
The query below will unload the results for all the user and event node records to an S3 bucket **s3://redshift-worldwide-events** with object name prefix **nodes**. Replace the iam role arn with your role arn. The first line will force the column names to be the same case as used in the query (by default all column names are overriden to lowercase).
```sql
SET enable_case_sensitive_identifier TO true;
unload (
'SELECT DISTINCT *
FROM
(
SELECT CONCAT(''u'', A.buyerid) AS ":ID", B.username AS "name:String",
B.liketheatre AS "liketheatre:Bool", B.likeconcerts AS "likeconcerts:Bool", B.likeopera AS "likeopera:Bool",
NULL AS "venue:String", NULL AS "category:String", B.city AS "city:String", B.state AS "state:String", ''user'' AS ":LABEL"
FROM "dev"."public"."network_vw" A
JOIN user_sample_vw B
ON A.buyerid = B.userid
)
UNION
(
SELECT CONCAT(''u'', A.sellerid) AS ":ID", B.username AS "name:String",
B.liketheatre AS "liketheatre:Bool", B.likeconcerts AS "likeconcerts:Bool", B.likeopera AS "likeopera:Bool",
NULL AS "venue:String", NULL AS "category:String", B.city AS "city:String", B.state AS "state:String", ''user'' AS ":LABEL"
FROM "dev"."public"."network_vw" A
JOIN user_sample_vw B
ON A.sellerid = B.userid
)
UNION
(
SELECT CONCAT(''e'', eventid) AS ":ID", eventname AS "name:String",
NULL AS "liketheatre:Bool", NULL AS "likeconcerts:Bool", NULL AS "likeopera:Bool",
venuename AS "venue:String", catname AS "category:String", venuecity AS "city:String", venuestate AS "state:String", ''event'' AS ":LABEL"
FROM "dev"."public"."network_vw" B
)')
to 's3://redshift-worldwide-events/nodes'
iam_role '<your-iam-role>'
CSV DELIMITER AS ','
HEADER
cleanpath
parallel off
```
If it ran successfully, we should see a warning saying that 239 rows loaded successfully.
Lets break down the query and see what its doing. The first and second subqueries create records for buyer and seller nodes respectively by aliasing the column names to openCypher format and setting the event property columns to NULL. We need to join the **network_vw** (which contains the list of seller and buyer pairs) and the **user_sample_vw** (which contains the properties of all users) to select additional information per user like username, city and whether they like concerts, theatre and/or opera. The final subquery creates the records for the events nodes from **network_vw** and similarly aliasing the column names to the required format and setting the values for the columns corresponding to the users nodes to NULL. We then **UNION** the separate sub queries to combine them in the same results set.
We can similarily run a query for unloading the edge records results set. Here the S3 location option is slightly modified to use an object name prefix 'edges'
```sql
SET enable_case_sensitive_identifier TO true;
unload (
'SELECT ROW_NUMBER() OVER() AS ":ID",":START_ID",":END_ID", ":TYPE", "price:Double", "quantity:Int",
"date:DateTime"
FROM
(
(
SELECT CONCAT(''u'', sellerid) AS ":START_ID",
CONCAT(''e'', eventid) AS ":END_ID",''TICKETS_LISTED_FOR'' AS ":TYPE",
pricepaid AS "price:Double" ,qtysold AS "quantity:Int", caldate AS "date:DateTime"
FROM "dev"."public"."network_vw"
)
UNION
(
SELECT CONCAT(''e'', eventid) AS ":START_ID",
CONCAT(''u'', buyerid) AS ":END_ID",''TICKET_PURCHASE'' AS ":TYPE",
pricepaid AS "price:Double" ,qtysold AS "quantity:Int" , caldate AS "date:DateTime"
FROM "dev"."public"."network_vw"
)
)')
to 's3://redshift-worldwide-events/edges'
iam_role '<your-iam-role>'
CSV DELIMITER AS ','
HEADER
cleanpath
parallel off
```
Notice that we have also used a window function to rank the edge records for same node ids by date, so we can only take the latest transaction between pair of same users.
The screenshot below shows the edge records where there are multiple transactions between same buyer and seller on different dates. We will only keep the latest record.

If the query has loaded successfully, check that the two objects are visible in the S3 bucket.
## Loading S3 Data into Neptune
Now we will load the data from the S3 bucket to the Neptune cluster. To do this, we will open the notebook we configured in Sagemaker to access the Neptune cluster.
* Go to the Sagemaker console, Notebook tab and select Notebook instances.
* You should see the Notebook instance status **in service** if the create notebook task ran successfully.
* Under **Actions**, click on Open Jupyter or Jupyter lab.

You should see a number of subfolders containing sample notebooks on various topics, one level below the Neptune parent folder. Either open one of the existing notebooks or start a blank new one.
First we will check if the notebook configurations are as we expect. Graph notebook offers a number of [magic extensions](https://github.com/aws/graph-notebook#features) in ipython3 kernel to run specific tasks in a cell such as run query in specific language (cypher, gremlin), check the status of load job/query, configurations settings, visualisation options etc.
In a new cell, use the magic command `%graph_notebook_config` and execute. This should return a json payload containing connection information for the Neptune host instance the notebook is connected to.
If we want to override any of these (for example if we have set a port different to 8182, then we can copy the json output from the previous cell output and modify the required value. Run the cell with the magic command `%%graph_notebook_config` to set the configuration to the new setting.

Check the status of the Neptune cluster endpoint is showing as **healthy** using the `%status` magic extension.
.
We can use the Neptune loader command to send a post request to the Neptune endpoint as described [here](https://docs.aws.amazon.com/neptune/latest/userguide/load-api-reference-load.html). For the request parameters we will use the following:
**source** : "s3://redshift-worldwide-events/",
**format** : "opencypher",
**iamRoleArn** : <your-iam-role-arn>
**region** : "us-east-1",
**failOnError** : "FALSE",
**parallelism** : "MEDIUM",
**updateSingleCardinalityProperties** : "FALSE",
**queueRequest** : "FALSE"
This will output a `loadid` in the payload.
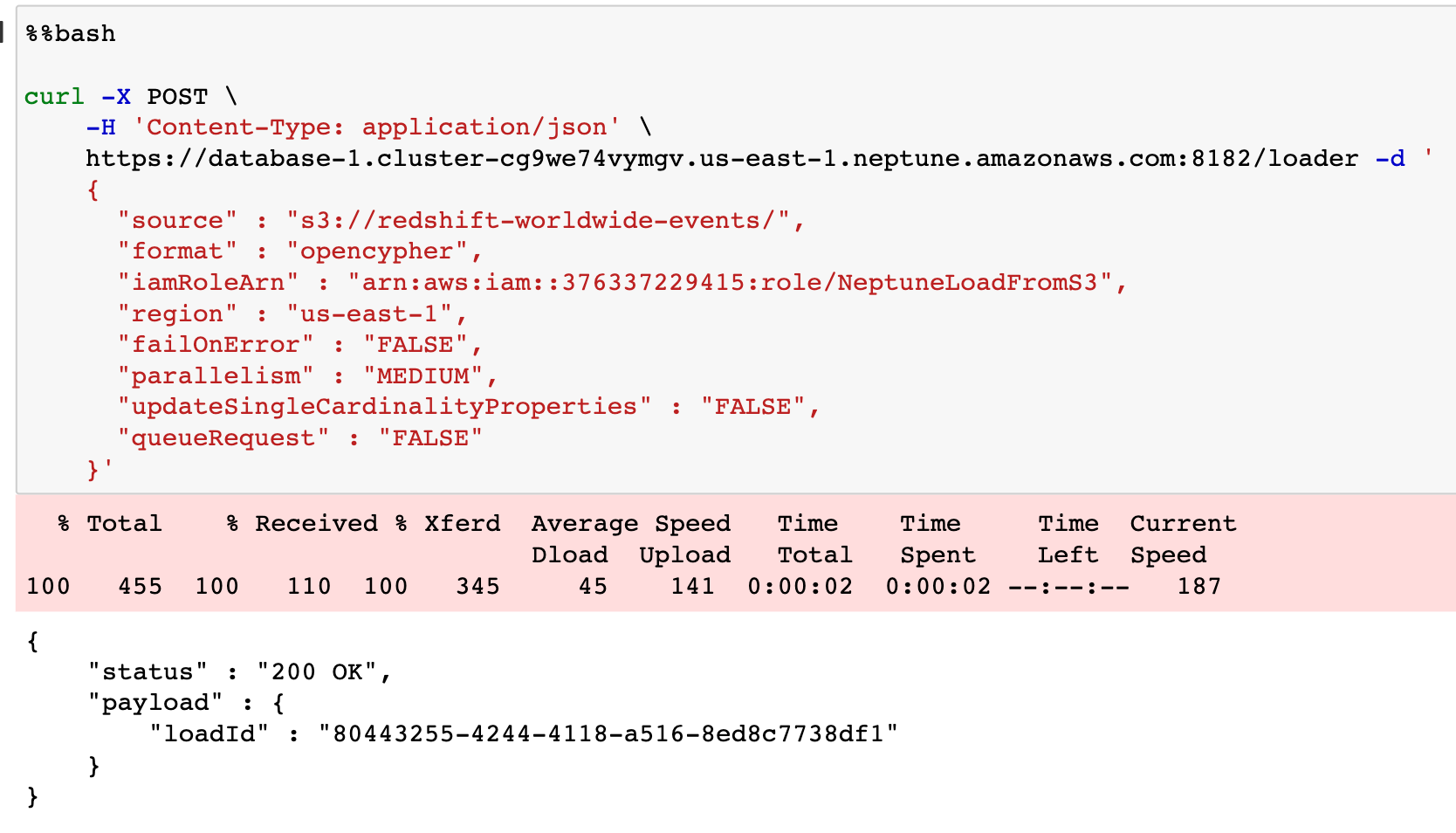
Then we can check the load status, by using the [loader get status request](https://docs.aws.amazon.com/neptune/latest/userguide/load-api-reference-status-requests.html), replacing your `neptune endpoint`, `port` and `loadId` in the command: `curl -G https://your-neptune-endpoint:port/loader/loadId`
If successful, you should see an output similar to the payload below. This returns one or more [loader feed codes](https://docs.aws.amazon.com/neptune/latest/userguide/loader-message.html). If the load was successful you should see only a **LOAD_COMPLETED** code.
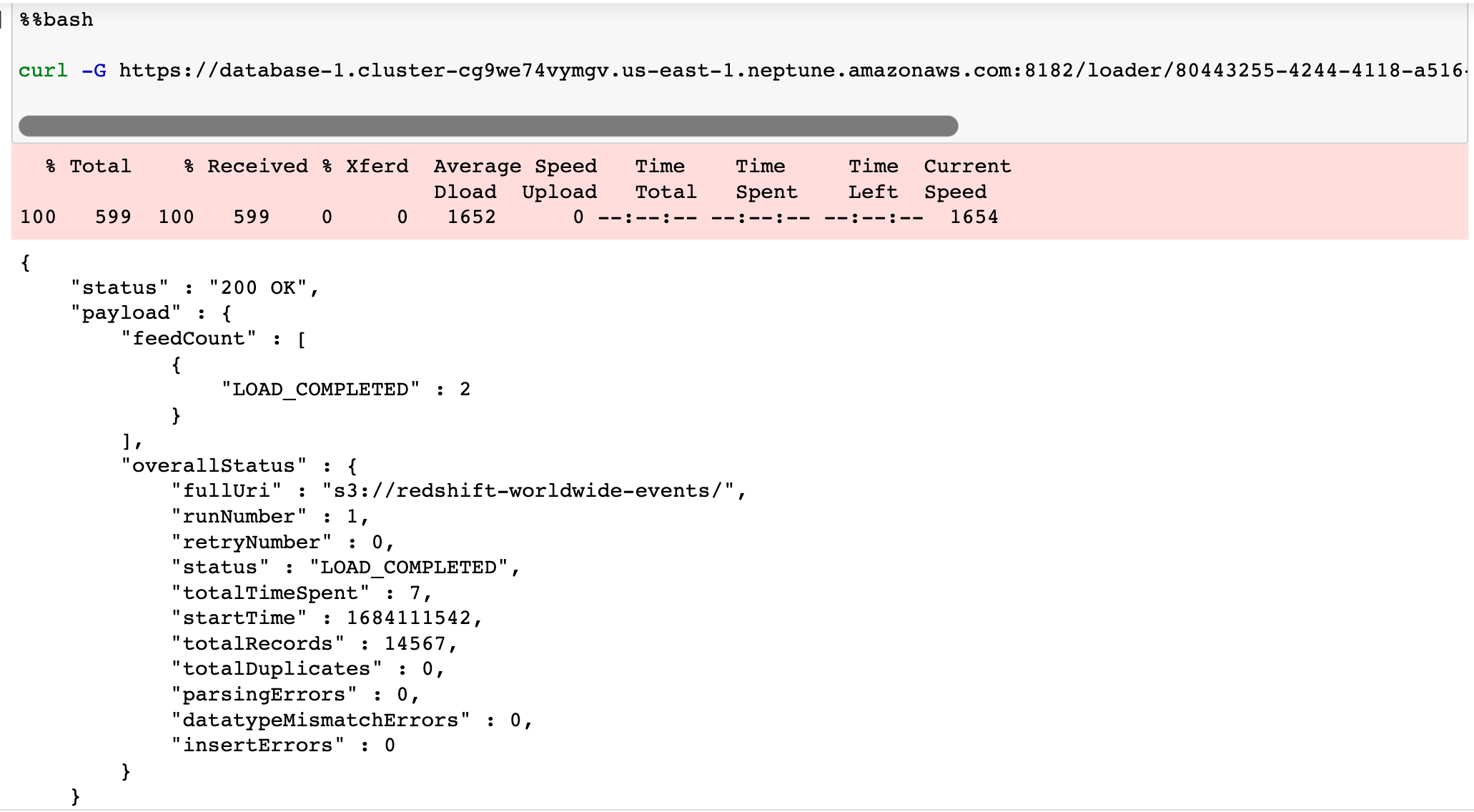
If there is an issue with one or both csvs then you may see a **LOAD_FAILED** code or one of the other codes listed [here](https://docs.aws.amazon.com/neptune/latest/userguide/loader-message.html). In the next section, we will investigate some options to diagnose the errors. Also if one of the loads is still in progress, you will see a **LOAD_IN_PROGRESS** key with the value corresponding to the number of S3 object loads which are still in progress. Running the curl command to check the load status again, should hopefully update the code to **LOAD_COMPLETED** or one of the error codes, if there was an error.
Check that you can access some data by submitting an openCypher query to the openCypher HTTPS endpoint using curl as explained in the [docs](https://docs.aws.amazon.com/neptune/latest/userguide/access-graph-opencypher-queries.html). In this case, we will just return a single pair of connected nodes from the database by passing the query `MATCH (n)-[r]-(p) RETURN n,r,p LIMIT 1` as the value to the query attribute as in the screenshot below.
**Note** the endpoint is in the format `HTTPS://(cluster endpoint):(the port number)/openCypher`. Your cluster endpoint will be different to mine in the screenshot below, so you will need to copy it from the Neptune dashboard for the database cluster identifier.
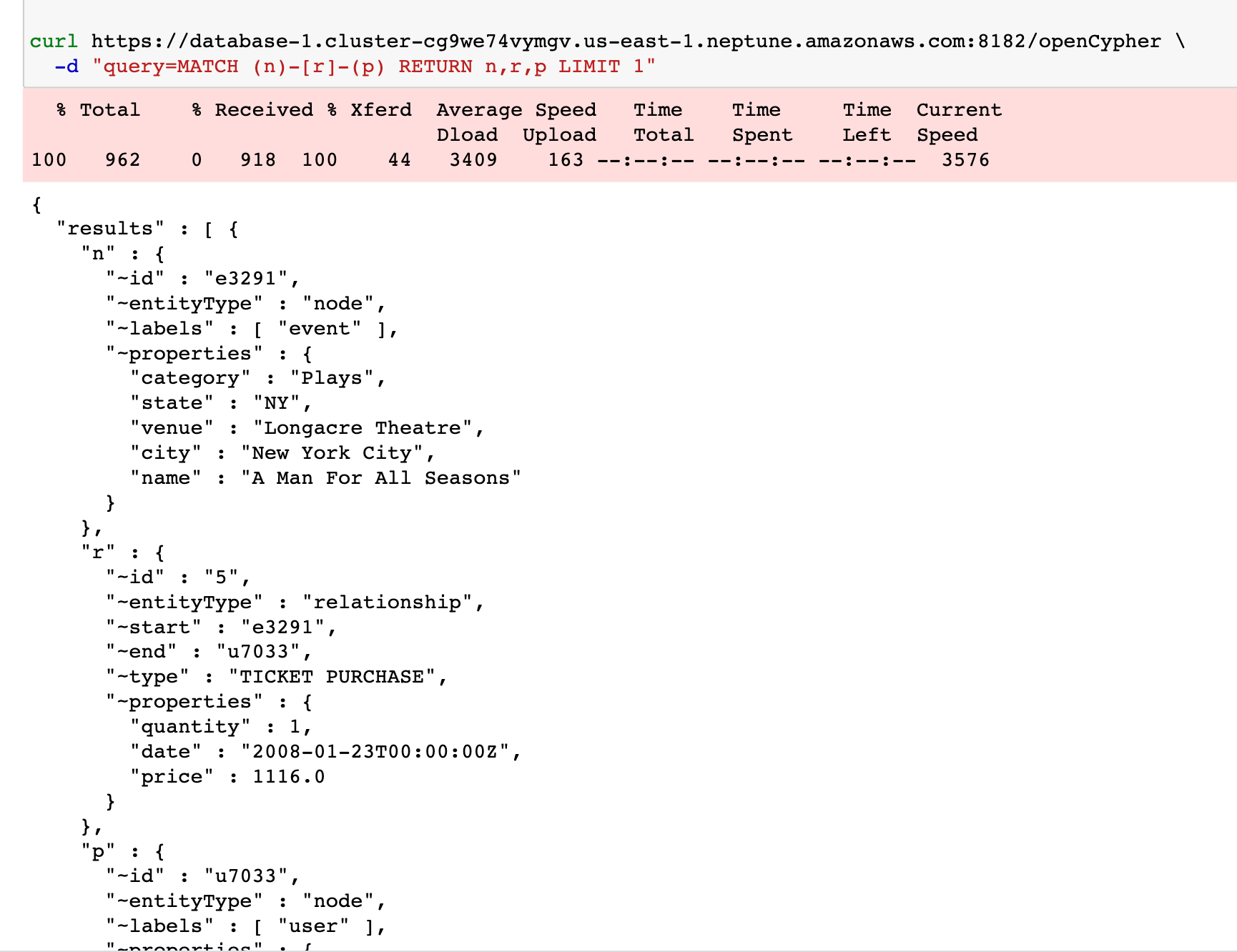
## Debugging Neptune data load errors
Running the check loader status command can sometime return errors. To further diagnose the error logs, we can run this [curl command](https://docs.aws.amazon.com/neptune/latest/userguide/load-api-reference-error-logs-examples.html) with additional query parameters replacing neptune-endpoint, port and loadid with your values. This will give a more detailed response with an errorLogs object listing the errors encountered as shown in the screenshot below. Here, the load failed because some of the node ids in the edge records in the relationship csv file were missing in the node csv file.

The next screenshot below shows a cardinality violation error because some of the edge record ids in the original data are duplicated.

We can also reset the db and remove any existing data in it by using the magic command `%db_reset`. This will prompt you to
tick an acknowledgement option and click Delete. You will then get a `checking status check`. Wait for this to complete and the you should get a `database has been reset` message when it is complete.
We are now setup for running more complex queries to generate insights from our data. [Part 2](https://dev.to/aws-builders/aws-neptune-for-analysing-event-ticket-sales-between-users-part-2-3i5g) of this blog will run a number of openCypher queries to explore the property graph containing the model of the worldwide events network
| ryankarlos |
1,457,627 | Starting with "PostgreSQL" | Hey everyone! In out last blog post we covered a basic introduction of PostgreSQL. If you have not... | 0 | 2023-05-04T18:06:07 | https://dev.to/huzaiifaaaa/starting-with-postgresql-2i3f | apache, postgres, database, postgressql | Hey everyone! In out last blog post we covered a basic introduction of PostgreSQL. If you have not gone through it, you can read it [here](https://dev.to/huzaiifaaaa/intro-to-postgresql-42mg). Now, in this post we will be learning that how to use PostgreSQL.
## Installing PostgreSQL:
Installing Postgres is the first step towards getting started with it. Depending on your operating system, the installation process may be different, but there are plenty of internet tools to help you get through it. The most recent version of Postgres is available for download from the official [website](https://www.postgresql.org/). For step by step installation refer [here](https://dev.to/omarsaad/step-by-step-guide-to-install-postgresql-apache-age-on-windows-28gf).
## Setting up Database:
After installing Postgres, you must create a database. A GUI tool like pgAdmin or the command-line interface can be used for this. Run the following command to create a database using the command-line interface:
`createdb mydatabase`
Replace "mydatabase" with the name of your database. If you're using pgAdmin, you can create a new database by right-clicking on the "Databases" node in the left-hand pane and selecting "New Database."
## Connecting to Database:
You must connect to your database once it has been set up. The psql command-line tool or a GUI tool like pgAdmin can be used for this. Use the psql command-line tool to connect to your database by entering the following command:
`psql -d mydatabase`
Again replace "mydatabase" with the name of your database. If you're using pgAdmin, you can connect to your database by double-clicking on the database name in the left-hand pane.
## Creating Table:
You can make a table to house your data once you're connected to your database. Columns and rows make up Postgres tables. Each row is a record, and each column represents a particular piece of data. Run the following command to create a table using the psql command-line tool:
`CREATE TABLE mytable (id SERIAL PRIMARY KEY, name VARCHAR(50), age INT);`
This will create a table called "mytable" with three columns: "id," "name," and "age." If you're using pgAdmin, you can create a table by right-clicking on the "Tables" node in the left-hand pane and selecting "Create Table."
## Insert Data:
Now that you have a table, you can insert data into it. To insert data using the psql command-line tool, run the following command:
`INSERT INTO mytable (name, age) VALUES ('John Smith', 35);`
This will insert a new record into the "mytable" table with the name "John Smith" and age "35." If you're using pgAdmin, you can insert data by right-clicking on the table name in the left-hand pane and selecting "View/Edit Data."
## Querying Data:
Finally, you can query the data in your table using the SELECT statement. To query data using the psql command-line tool, run the following command:
`SELECT * FROM mytable;`
This will return all of the data in the "mytable" table. If you're using pgAdmin, you can query data by right-clicking on the table name in the left-hand pane and selecting "Query Tool."
## Conclusion:
In this blog post, we walked you through the process of getting started with Postgres. We covered installing Postgres, creating a database, connecting to the database, creating a table, inserting data, and querying data. With this knowledge, you should be able to start using Postgres in your own projects. Happy coding!
| huzaiifaaaa |
1,457,654 | 🎉 Guide to Becoming a Community Builder | Diving Deep into AWS: Your Guide to the Community Builder Program Ever had that itch to step up your... | 0 | 2023-05-04T18:24:23 | https://dev.to/aws-builders/guide-to-becoming-a-community-builder-1c64 | aws, community, cloud, serverless | **Diving Deep into AWS: Your Guide to the Community Builder Program**
Ever had that itch to step up your tech game, broaden your connections, and play a bigger role in the tech world? Well, there's a path for that – the AWS Community Builder Program! By hopping onboard, you're not just enhancing your cloud expertise, but you're also opening doors to a vibrant global community, buzzing with AWS enthusiasts just like you.
> Ready for a deep dive? Here’s your roadmap to becoming a pivotal player in the AWS community:
**👥 Step into the AWS Inner Circle:**
First off, dive into the AWS Community Builders Program. It's like your backstage pass, granting you an insider's view of AWS—with a treasure trove of resources, exclusive events, and, most importantly, a tribe of folks who get just as excited about AWS as you do.
**🤝 Bond Over AWS:**
Remember those school clubs where you made lifelong buddies? That's what the AWS community feels like. Make new friends on social platforms, pop by at AWS-centric events, join lively AWS discussions online, or even meet fellow enthusiasts at local AWS gatherings.
**📝 Wear Your AWS Hat and Write:**
Got a knack for explaining complex concepts or sharing neat tricks? Pour that knowledge into blogs, create tutorials, or even vlog about it. Platforms like the AWS Developer Blog or the AWS Open Source Blog are great stages to showcase your expertise.
**🌟 Unleash Your AWS Magic:**
Think of this as your playground. Tinker with open-source projects, build demos, or throw your hat into hackathons. And hey, if you've got some cool tricks up your sleeve, why not earn some brownie points with the AWS Heroes Program?
**💡 Soak Up AWS Wisdom:**
It's like being at a rock concert but for tech! Attend AWS events—be it the grand AWS re:Invent, the informative AWS Summit, or the community-driven AWS Community Day. And if you're in the mood for some serious learning, there’s always AWS training and certifications.
**🏆 Celebrate Your AWS Journey:**
Every bit you contribute to the AWS ecosystem gets noticed. Collect those shiny badges and recognitions—they're tokens of your hard work and passion. And if you're feeling competitive, why not dazzle everyone at the AWS Community Builders Challenges?
**🔗 Dive Even Deeper with These Links:**
- AWS Community Builders Program: https://aws.amazon.com/developer/community/community-builders/
- AWS Developer Blog: https://aws.amazon.com/blogs/developer/
- AWS DevOps Blog: https://aws.amazon.com/blogs/devops/
- AWS Open Source Blog: https://aws.amazon.com/blogs/opensource/
- AWS Heroes Program: https://aws.amazon.com/heroes/
- AWS Training and Certification: https://aws.amazon.com/training/
- AWS Community Day: https://aws.amazon.com/events/community-day/
- AWS re:Invent: https://reinvent.awsevents.com/
- AWS Summit: https://aws.amazon.com/events/summits/
**Your AWS Adventure Awaits!**
Joining the AWS Community Builder program is like stepping into a grand tech fest—it's exhilarating, enlightening, and filled with folks who share your passion. So gear up, make some friends, share your knowledge, and bask in the recognition. And always remember, the AWS community is richer with you in it!
If you found this blog useful and want to learn more, here are some ways you can keep in touch:
- 📩 **Email**: [Drop me a mail](mailto:rahuldladumor@gmail.com)
- 🌐 **LinkedIn**: [Connect with Mr. Rahul](https://www.linkedin.com/in/rahulladumor/)
- 🏠 **Personal Website**: [Rahulladumor.cloud](https://rahulladumor.cloud)
- 🔗 **GitHub**: [Explore my Repos](https://github.com/Rahulladumor)
- 🖋 **Medium**: [Browse my Articles](https://medium.com/@ladumorrahul)
- 🐦 **Twitter**: [Follow the Journey](https://twitter.com/Rahul__ladumor)
- 👨💻 **Dev.to**: [Read my Dev.to Posts](https://dev.to/rahulladumor) | rahulladumor |
1,458,655 | Top 15 DevSecOps Tools that Accelerate Development | As developers, we're constantly under pressure to innovate at speed. In 2022, 60% of developers who... | 0 | 2023-05-05T15:47:33 | https://spectralops.io/blog/top-15-devsecops-tools-that-accelerate-development/ | devsecops, devops, agile, tooling | As developers, we're constantly under pressure to innovate at speed. In 2022, 60% of developers who responded to a [GitLab survey](https://about.gitlab.com/developer-survey/) acknowledged that code is moving to production at an increasingly faster clip--up to five times faster than in previous years. But juggling tight deadlines with ever-evolving security threats is no joke. When prioritizing speed, unsafe code eventually slips into production.

DevSecOps has taught us to incorporate security and compliance into building, deploying, and running applications. Add the power of automated DevSecOps tools, and we can not only test but enforce security policies and prevent threats without sacrificing agility. Let's look at how this works, how to select the right solution, and what tools in the market can help you further [harden your applications](https://spectralops.io/blog/developers-guide-to-security-hardening/) at speed, starting now.
DevSecOps Tools: An Overview
----------------------------
In the fast-paced digital world, developing secure software efficiently is crucial. DevSecOps tools integrate security best practices throughout the software development lifecycle to bridge the gap between development, security, and operations teams, ensuring a seamless workflow and secure products.
These tools offer diverse solutions to enhance collaboration, automate processes, and embed security throughout the [DevOps lifecycle](https://spectralops.io/blog/the-essential-guide-to-understanding-the-devops-lifecycle/). They help teams identify and remediate [vulnerabilities](https://spectralops.io/blog/top-10-most-common-software-supply-chain-risk-factors/) early while accelerating development and deployment in various ways.
For example, popular categories include:
- Source code analysis.
- Container security.
- Security orchestration and automation.
- Infrastructure as code (IaC) security.
- Vulnerability management.
- Compliance management tools.
6 Benefits of DevSecOps Tools
-----------------------------
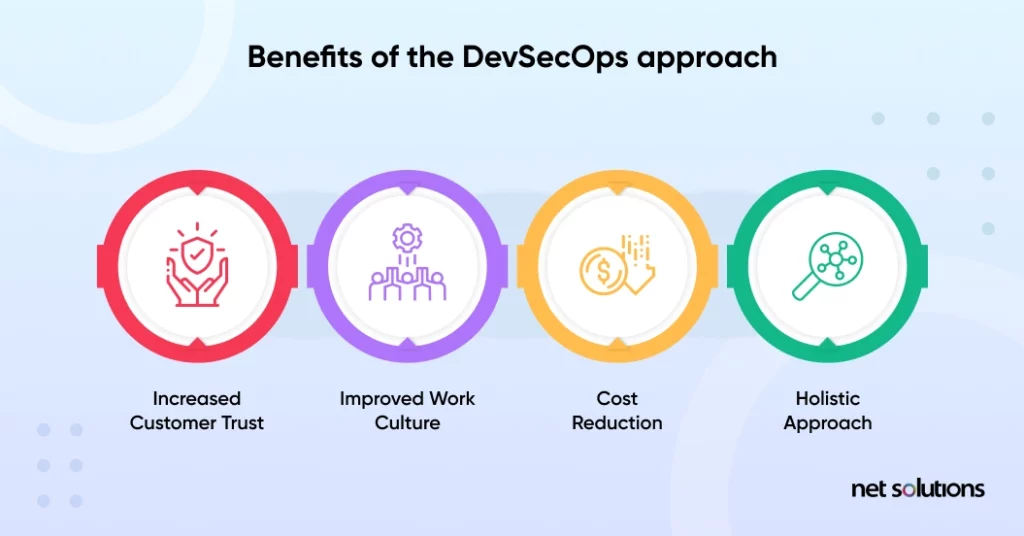
DevSecOps tools help developers in several ways, including:
1. Early identification of vulnerabilities
By automating security testing and continuously scanning code, DevSecOps tools catch security issues early, [preventing risks](https://www.jit.io/blog/essentials-every-devsecops-needs) from reaching production environments.
1. Improved collaboration
DevSecOps fosters shared responsibility, breaking traditional silos between development, security, and operations teams. These tools facilitate better communication and collaboration.
1. Faster time to market
DevSecOps tools automate tasks and streamline workflows, accelerating development, testing, and deployment processes, giving organizations a competitive edge.
1. Reduced operational costs
Embedding security practices throughout the development lifecycle reduces the risk of costly security mistakes, like data breaches. Meanwhile, automating repetitive tasks saves developers' time, lowering operational costs.
1. Enhanced compliance
DevSecOps tools simplify compliance with strict security standards and regulations by automating checks and providing real-time insights into the software's security posture.
1. Increased trust and customer satisfaction
Secure applications [protect sensitive data](https://cybeready.com/no-nonsense-guide-to-data-protection) and instill trust in customers. Using DevSecOps tools to build secure software increases customer satisfaction and loyalty.
Key Features to Look for in a DevSecOps Tool
--------------------------------------------
When selecting a DevSecOps tool, consider your environment, team, and use case. Key capabilities to evaluate include:
- Integration with your current development, security, and operations tools to ensure a smooth workflow.
- Ease of use with clear documentation, robust support, and an active user community to help your team quickly adapt.
- Customizability and scalability so the tool can grow with your organization and accommodate new features, integrations, or users as needed.
- Real-time monitoring and alerts to allow your team to promptly identify and address security issues.
- Automated security testing and remediation capabilities to help streamline workflows.
- Continuous feedback and reporting with actionable insights through clear, concise reports that support informed decisions and continuous improvement.
- Policy enforcement and compliance management to help you meet regulatory requirements.
- Role-based access control (RBAC), ensuring only authorized personnel access sensitive information and functionality.
Top 15 DevSecOps tools that accelerate development
--------------------------------------------------
### 1\. Check Point CloudGuard
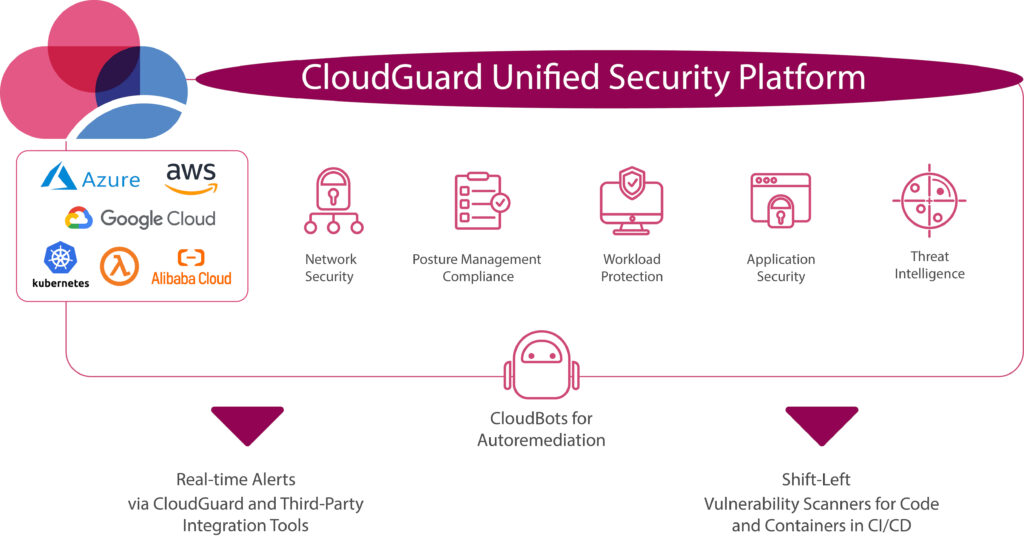
[Check Point CloudGuard](https://www.checkpoint.com/cloudguard/knowledge-center/) is a comprehensive end-to-end [cloud security](https://spectralops.io/blog/top-12-cloud-security-tools/) solution. CloudGuard is a SaaS platform that provides unified, cloud-native security across your applications, workloads, and network. You can use it to automate security, prevent threats, get compliance and manage posture for all popular cloud environments.
[Review:](https://www.gartner.com/reviews/market/cloud-workload-protection-platforms/vendor/check-point-software-tech/product/cloudguard-network-security/reviews?marketSeoName=cloud-workload-protection-platforms&vendorSeoName=check-point-software-tech&productSeoName=cloudguard-network-security) "Capability of product seems to be there as the TCO of this product is excellent. This provides a single management solution bundling a broad spectrum of protection allowing the product to excel."
### 2. Spectral

[Spectral](https://spectralops.io/) is a developer-first security solution that automates the process of secret protection at build time, supercharging the CI/CD.
Main features: AI-powered scanning engine, detection of exposed secrets and security misconfigurations in real time, support for various code security use cases, and easy integration with CI/CD pipelines.
Best for: Developers and DevOps teams seeking a fast, modular, and developer-centric tool to ensure code safety and trust throughout the software development lifecycle.
[Review:](https://spectralops.io/) "One of the reasons we picked SPectral over other products is Spectral has low-false positive results, which gives us a high confidence factor and saves us precious development time."
### 3\. Jit.io
[Jit](https://www.jit.io/) is a security-as-a-service platform that can help speed up development by automating the process of selecting, implementing, configuring, and managing the application security toolchain.
Main features: Security knowledge codification, GitHub and AWS integration, customizable security plans, and an orchestration layer for various security tools covering code, pipeline, infrastructure, and runtime app security.
Best for: Progressive engineering teams in software companies, including Directors of Infrastructure, DevSecOps, Site Reliability Engineers, CTOs, and Product Security personnel looking for a comprehensive and developer-friendly security solution.
[Review:](https://www.jit.io/) "Very easy to onboard with this tool; You get a lot of points for the user experience. I like that the plan configuration corresponds to the code representation--very transparent."
### 4\. Snyk

[Snyk](https://snyk.io/) sees developers as the first step in building secure applications and infrastructure. It scans and secures components across the cloud-native application so developers can ensure security without impacting velocity.
Main features: Integrates with developer tools and workflow, constantly monitors for vulnerabilities, and suggests preventive measures.
Best for: Automated scans and fixed in code, open-source dependencies, containers, and infrastructure as code.
[Review:](https://res.cloudinary.com/snyk/image/upload/v1678456719/website-pdfs/2022-Snyk-Customer-Value-Study-EBook.pdf) "Snyk has really given developers the ability to start thinking about security as they're developing code. It's allowed them to be much more proactive in fixing vulnerabilities. Compared to our previous tooling, Snyk's scanning is 2x faster and much more integrated to their tooling and processes. The developers are also quite happy that it's a lot easier to navigate."
### 5\. SonarQube

[SonarQube](https://www.sonarsource.com/products/sonarqube/) is an open-source platform for continuous inspection of code quality and security.
Main features: Static code analysis, detection of code bugs and security vulnerabilities, customizable rules, and quality gates.
Best for: Improving code quality and maintainability while enhancing security.
[Review:](https://www.g2.com/products/sonarqube/reviews/sonarqube-review-5404686) "Helps us maintain our coding standards and avoid security risks in code."
### 6\. OWASP ZAP

[OWASP ZAP (Zed Attack Proxy)](https://owasp.org/www-project-zap/) is an open-source web application security scanner and [penetration testing tool.](https://www.jit.io/blog/6-essential-steps-to-use-owasp-zap-for-penetration-testing)
Main features: Automated and manual scanning, proxying, and fuzzing capabilities, detection of common web application vulnerabilities.
Best for: Security teams and developers focusing on identifying and addressing web application security issues.
[Review:](https://www.capterra.co.nz/software/1025564/owasp-zap) "ZAP is a robust vulnerability scanner that has been very helpful in our web app security testing. Quite a few tools are available for this category, but ZAP is simple to use and has decent reporting features."
### 7\. Checkmarx

[Checkmarx](https://checkmarx.com/solutions/developer/) is a comprehensive [SAST solution](https://spectralops.io/blog/top-10-static-application-security-testing-sast-tools-in-2021/) that can help speed up development by identifying and remediating security vulnerabilities.
Main features: Code analysis, support for multiple languages and frameworks, integration with CI/CD pipelines, and compliance management.
Best for: Enhancing application security posture quickly.
[Review: ](https://www.g2.com/products/checkmarx/reviews/checkmarx-review-6519619)"Easy-to-understand interface and very user-friendly. Reduces the code using the cxsast plugin. It will scan code line by line and find most of the vulnerabilities. The vulnerability report is awesome."
### 8\. Aqua Security

[Aqua Security](https://www.aquasec.com/use-cases/devops-security/) provides comprehensive protection for containerized and cloud-native applications, focusing on accelerating application delivery.
Main features: Container image scanning, runtime protection, vulnerability management, and compliance enforcement.
Best for: Organizations deploying containerized applications and seeking end-to-end security solutions for their container environments.
[Review:](https://www.aquasec.com/customers/) "Aqua provided us with a zero-friction security and compliance solution for our entire container pipeline. With Aqua we can prove compliance of our cloud-native environment while staying agile and innovative."
### 9\. Cloud Foundry
[Cloud Foundry](https://www.cloudfoundry.org/why-cloud-foundry/) is purpose-built to deliver security for containerized environments and cloud-native applications by embedding security controls directly into existing processes, from pipeline to perimeter.
Main features: Container and Kubernetes security, cloud security posture management, container vulnerability scanning, and runtime protection.
Best for: Securing cloud-native applications and ensuring compliance with regulations
[Review](https://www.cloudfoundry.org/blog/redis-labs-extends-nosql-functionality-with-cloud-foundry/): "[With Cloud Foundry] we give developers the ability to push their apps and microservices locally and quickly, with no worries about the infrastructure."
### 10\. Sysdig
[Sysdig](https://sysdig.com/) is a cloud-native visibility and security platform designed for [monitoring](https://galooli.com/blog/top-9-remote-monitoring-tools/), troubleshooting, and securing containerized applications.
Main features: Kubernetes monitoring, security scanning, incident response, integration with existing DevOps workflows, and compliance management.
Best for: Visibility and security for containerized environments
[Review](https://www.g2.com/products/sysdig-sysdig-secure/reviews/sysdig-secure-review-6925354): "The native integration in Kubernetes is quite simple and quick. The features are powerful, going from a comprehensive overview to a very detailed report of vulnerabilities affecting our workload and the infrastructure where they are running. The new Risk spotlight helps to prioritize vulnerabilities."
### 11\. DoControl
[DoControl](https://www.docontrol.io/) is a SaaS-oriented security tool that addresses user access privileges and profiling and manages data exposure. By using DoControl, you gain visibility of all your assets, users, and external collaborators. This tool automates data access controls while enabling security without compromising efficiency.
Main features: Preventive data access controls, service mesh discovery, SaaS service misconfiguration detection, and shadow application governance.
Best for: Organizations looking for a simple, self-service, and collaborative approach to managing security risk and Data Loss Prevention
[Review:](https://www.gartner.com/reviews/market/saas-management-platforms/vendor/docontrol/product/docontrol-platform/review/view/4323898) "The DoControl product is useful and helps us to manage our SaaS data more efficiently with excellent visibility and easy management capabilities. "
### 12\. Qualys
[Qualys](https://www.qualys.com/) is a cloud platform with an accompanying cloud agent that provides a single platform for your IT, security, and compliance solutions. Its free Global AssetView app gives you instant visibility into all known and unknown assets across your hybrid cloud environment.
Main Features: Analyze threats and misconfigurations, prioritizes urgent vulnerabilities, and patch risks with a single click.
Best for: Any business sizes. Cabalibilites extend to extensive IP scans and audits per year.
[Review:](https://www.capterra.com.au/reviews/82971/qualysguard-enterprise) "Based on the experience I have with Qualys, it is very impressive to capture the vulnerabilities, this compiles a complete report of the risks that your infrastructure has, in addition the patches have very precise information that allows you to carry out the remediation very effectively. The analyzes are detailed and very complete, it works very well to carry out the compliance stages of PCI, CIS, etc... Providing a great guarantee that periodically your organization has an armored infrastructure."
### 13\. Skyhawk Security
Correlating Cloud Security Posture Management (CSPM) with Cloud Detection & Response (CDR), [Skyhawk Security's](https://skyhawk.security/) Synthesis Platform helps uncover breaches across your entire cloud infrastructure in real-time. With their *Real*erts, solution teams can prioritize time spent on actual threats that pose a disruption to your organization. Skyhawk Security solves some significant pain points like Alert fatigue and Lack of visibility.
Main features: Static and dynamic activities, Runtime hub, and Threat detection.
Best for: Established, cloud-based companies looking to protect their cloud at runtime.
[Review:](https://www.gartner.com/reviews/market/cloud-workload-protection-platforms/vendor/skyhawk-security/product/skyhawk-synthesis-security-platform/review/view/4340656) "Superb experience with a great product and great support by OEM".
### 14\. Rapid7 tCell
[Rapid7 tCell](https://www.rapid7.com/products/tcell/) is a next-gen cloud WAF and runtime application self-protection (RASP tool) that runs "security at the speed of DevOps." tCell provides complete visibility into all your applications through real-time application monitoring. It offers multi-level web server and app server agents that automatically recognize and block attacks. Plus, it prioritizes alerts and sorts breaches that require immediate action from ones that are actively being blocked. This tool also allows applications to defend themselves from attacks in production.
Main features: Real-time application monitoring, web server and app server agents protection, and Application risk coverage.
Best for: Organizations looking for a holistic approach to application security.
[Review:](https://www.gartner.com/reviews/market/application-security-testing/vendor/rapid7/product/tcell/reviews) "The tool is good for performing quick scans on web apps and api to get an overall view of [DAST security posture.](https://spectralops.io/blog/7-battle-tested-tips-for-using-a-dast-scanner/)"
### 15\. Codacy
[Codacy](https://www.codacy.com/) integrates into your development workflow to automate code reviews for commits and pull requests. It supports over 40 programming languages and provides instant visibility into your project's code quality. You can also integrate your security policies to block merges of pull requests that violate quality conditions.
Main features: Customizable rulesets, Identifying problematic areas in your project, and actionable results.
Best for: Organizations with large development teams looking to streamline projects, standardize their code and save time on code reviews.
[Review:](https://www.g2.com/products/codacy/reviews/codacy-review-6727049) "Excellent code coverage tool with great GitHub Integration."
Securing Your Software Future with DevSecOps
--------------------------------------------
In a world of complex and fast-paced software development, DevSecOps tools are king. The tools above support developers in building secure applications while accelerating time to market. But there's no such thing as a silver bullet when it comes to cybersecurity. Unfortunately, security is still the biggest threat facing organizations that strive for faster software delivery, with attacks [on the rise](https://spectralops.io/blog/web-application-security-for-2023/) due to application code gaps.Laying the foundations for a more secure future requires developers to continuously monitor and test their systems. Take advantage of our [free resources](https://spectralops.io/resources/) to stay in the loop and simplify your AppSec by learning to make it part of your everyday work. | yayabobi |
1,459,487 | Add Two Numbers Problem - Java solution | The 'Add two numbers' problem is a common problem you will find on various coding challenge sites... | 0 | 2023-05-06T21:36:16 | https://dev.to/phouchens/add-two-numbers-problem-java-solution-2c08 | codenewbie, programming, java, algorithms | The 'Add two numbers' problem is a common problem you will find on various coding challenge sites such as LeetCode. This problem is an excellent introduction to working with Linked Lists and requires working with two Linked Lists to create a third List. To solve this type of problem, it is helpful to think about how you would solve it on paper before diving into the code.
#The problem statement
You are given two non-empty linked lists representing two non-negative integers. The digits are stored in reverse order, and each node contains a single digit. Add the two numbers and return the sum as a linked list.
You may assume the two numbers do not contain any leading zeros, except the number 0 itself.
##Example:
```
Input: (2 -> 4 -> 3) + (5 -> 6 -> 4)
Output: 7 -> 0 -> 8
Explanation: 342 + 465 = 807.
```
#Approach
The problem states that the digits are stored in reverse order. This made me pause for a minute; however, it actually made solving this problem easier. If we write on paper a problem to add two numbers, we add them in reverse order.
```
// To add these numbers we would start from the
// right side (in reverse order)
342
+465
----
807
```
Thinking about how you would really add two numbers together can help us come up with an algorithm to solve this. It's just a matter of iterating through both lists and adding each number up (simulating starting on the right). There's a good chance we'll have to check for null if one number has more digits. And, we will also have to handle a carryover if two numbers have a sum greater than 9. See the comments in the code below for more details.
#The Code
```java
/**
* Definition for singly-linked list.
*/
public class ListNode {
int val;
ListNode next;
ListNode() {}
ListNode(int val) { this.val = val; }
ListNode(int val, ListNode next) { this.val = val; this.next = next; }
}
/**
* Solution
*/
class Solution {
public ListNode addTwoNumbers(ListNode l1, ListNode l2) {
// Head of the new Linked List - this will be the result
ListNode result = new ListNode();
// Reference of the result, which is empty at this point
ListNode pointer = result;
// Carry over number
int carry = 0;
while(l1 != null || l2 != null) {
// if either value is null, use zero else use value
int x = l1 == null ? 0 : l1.val;
int y = l2 == null ? 0 : l2.val;
// do the adding
int sum = x + y + carry;
// calculate the carryover. Remember this is
// integer division and will only return whole
// numbers.
carry = sum / 10;
// At this point we add the total sum mod 10 to
// the new node in the results list. If the
// integer is greater than 10 this will return
// the remainder. If its less than 10, it will
// return the integer.
pointer.next = new ListNode(sum % 10);
pointer = pointer.next;
// Move to next node
if (l1 != null) {
l1 = l1.next;
}
if (l2 != null) {
l2 = l2.next;
}
}
// After the last iteration, check to see if there is
// a carryover left, if so, add it to the results
// list
if (carry != 0) {
pointer.next = new ListNode(carry);
}
return result.next;
}
}
```
#Complexity
Now we can figure out the complexity of our solution.
###Time complexity
If the length of `l1` is `m` and the length of `l2` is `n`, then the solution above will be iterated up to m or n times. This gives a time complexity of **_O(max(m, n))_**.
###Space complexity
_**O(max(m, n))**_, since we are creating a new linked list to return.
#Final Thoughts
You can come up with an algorithm to handle a problem like this by thinking about how you would really add two numbers together. In some cases, coming up with an initial solution can be achieved by thinking about how you would address a problem in "real life" rather than using a programming language. This is one of the reasons why code challenge specialists recommend solving the problem using paper and sudo code before getting into the actual code. This technique helps you think about the problem itself and not the implementation. The solution presented above is just one way to solve this problem. Can you solve it more effectively or concisely? Comments below are welcome with additional solutions.
_Header Photo by Andrew Neel_ | phouchens |
1,459,672 | Implement multi-language Support in React | To read more articles like this, visit my blog Multi-language support is one of the important... | 0 | 2023-05-10T18:00:00 | https://www.mdfaisal.com/blog/implement-multi-language-support-in-react | react, javascript, programming | **_To read more articles like this, [visit my blog](https://www.mdfaisal.com/blog)_**
Multi-language support is one of the important features of a good front-end application. Today we will see how we can add multiple language support in an existing React application.
For today we will assume that we need support for 2 languages. The process here can extend to any number of languages you want to support.
* English(en)
* Bangla(bn)
We will use a popular library named **[react-i18next](https://react.i18next.com/)** based on i18next.
### Step 1. Install Dependencies
We have to install 4 dependencies.
The first two [libraries](https://react.i18next.com/guides/quick-start) will do the heavy-lifting for us.
```
yarn add react-i18next i18next
```
The following [package](https://github.com/i18next/i18next-browser-languageDetector) will detect the language automatically for us. So don’t have to worry about determining the currently selected language
```
yarn add i18next-browser-languagedetector
```
The next [package](https://github.com/i18next/i18next-http-backend) will load the values depending on the language returned by the language detector.
```
yarn add i18next-xhr-backend
```
### Step 2. Add Configuration File
Create a new file beside the index.js file named i18n.js Here we can specify the languages that we want to support.
```js
import i18n from 'i18next'
import { initReactI18next } from 'react-i18next'
import Backend from 'i18next-xhr-backend'
import LanguageDetector from 'i18next-browser-languagedetector'
const fallbackLng = ['en']
const availableLanguages = ['en', 'bn']
i18n.use(Backend)
.use(LanguageDetector)
.use(initReactI18next)
.init({
fallbackLng,
detection: {
checkWhitelist: true
},
debug: false,
whitelist: availableLanguages,
interpolation: {
escapeValue: false // no need for react. it escapes by default
}
})
export default i18n
```
### Step 3:Modify App.js to Load Language
In this step, we have to modify our `App.js` file and include our configuration file. Notice we used `<Suspense>` here as `react-i18next` loads local resources asynchronously and we have to wait to finish loading
```js
import React, { FC,Suspense } from 'react';
import './App.css';
import './i18n'
const App: FC = ()=> {
return (
<div className="App">
<Suspense fallback={null}>
//OTHER COMPONENTS
</Suspense>
</div>
);
}
export default App;
```
### Step 4: Create Separate Files for Each Language
Create a new folder for each of the desired languages inside public/locales/language_name/
> Be careful. The names must be exactly the same as the following picture. Otherwise, values can’t be loaded automatically. Obviously, we can change the behavior but for simplicity, we won’t go into that for now.
### Step 5. Add Values Inside the Language-specific File
The contents under the file en/translation.js can be something like…
```js
{
"top_bar_title": "Community Admin Panel"
}
```
the contents under the file bn/translation.js can be something like…
```js
{
"top_bar_title": "Community Admin Panel"
}
```
This way you have to add the value for each of the individual languages.
### Step 6. Using the Values Inside The Component
You can use the value defined inside the JSON files in the following way

### Bonus: Switching language
Now you can simply use the following command anywhere to switch to your desired language (For example inside a button or language toggler)

Now your awesome application has support for as many languages as you want.
That’s it for today. Happy Coding! :D
**Get in touch with me via [LinkedIn](https://www.linkedin.com/in/56faisal/)**
| mohammadfaisal |
1,459,675 | Guide to using React Custom Hooks | Many a times in your application, you may need to perform an operation in different components. Of... | 0 | 2023-05-08T00:00:00 | https://dev.to/ismailadegbite/guide-to-using-react-custom-hooks-1kdo | ---
title: "Guide to using React Custom Hooks"
date: "2023-05-08"
published: true
intro: "One of the ways you can seperate your app logic from UI is throught the use of custom hook."
---
Many a times in your application, you may need to perform an operation in different components. Of course you can write a function for this purpose and then import such function in the respective components to achieve its intended purpose. What if the operation requires to call one or more React hooks, then the function cannot be used to perform such operations as React hooks can only be called in React functions. To solve this, we make use of React custom hooks. In this blog post, we will dive into what React custom hooks are and how to use them to encapsulate any resuable logic that you may need to share across multiple components.
## What are React Custom Hooks
React Custom Hooks are JavaScript functions that use React hooks to provide a set of reusable functionality that can be shared among different React components. Custom Hooks are named with the `use` prefix to signal that they are intended to be used with hooks. As a convention, the file where a custom hook is written is usually named with the `use` prefix for example `useMediaQuery.js`. But it is required that the name of a function intended to be used as a React custom hook be started with `use`.
It is important to note that custom hooks are React hooks we write ourselves and hence their usage must conform to using in-built React hooks. Rules for using React (custom and in-built) hooks are:
- Only call hooks at the top level components and before any early returns
- Only call hooks from React functions which include React functional components and hooks (custom and in-built)
## Why use React Custom Hooks?
React Custom Hooks provide several benefits which include the following:
1. Encapsulation: Custom Hooks allow you to encapsulate complex logic and state management in a single location which can then be shared among different components in your project. This makes your code more modular and easier to maintain.
2. Reusability: Custom Hooks can be used in multiple components, making it easier to reuse code and reduce duplication.
3. Testability: By encapsulating complex logic in Custom Hooks, it becomes easier to write tests for your code, since you can test the logic in isolation from the components that use it.
4. Code organization and seperation of concerns: Custom Hooks allow you to separate concerns (views from logic) and organize your code into smaller, more manageable pieces.
## Examples of React Custom Hooks
Let's dive into two scenarios where React custom hooks can be used.
Our first example will be `useMediaQuery`. Let's say you have a component in which you want to hide/display some elements or perform any other operation at certain sreen sizes, then you will have to keep track of changes in width of user's device. Here you will need a state variable to get the current screen size as the screen changes and `resize` event listener to be attached to the window.
The component may be written as shown:
```js
import { useState, useEffect } from "react"
const MyComponent = () => {
const [screenWidth, setScreenWidth] = useState(0)
useEffect(() => {
const getScreenWidth = () => {
setScreenWidth(window.innerWidth)
}
getScreenWidth()
window.addEventListener('resize', getScreenWidth)
return () => {
window.removeEventListener('resize', getScreenWidth)
}
}, [])
return (
<div className='container'>
Current screen width: {screenWidth}
{screenWidth > 768 && <p>Show only on screen greater than 768px</p> }
<p>Show on all screen size</p>
</div>
)
}
```
The above implementation will work well. What if you have more of such components in your application where you may need to hide or display some content or perform any other opearation depending on the width of the screen at any instance of time.
What do you do? Would you create a function for getting the screen width every time the window is resized? Remember this involves a state value and you can only declare/call `useState` and any other React hooks such as `useEffect`, `useRef` etc at top level in a React functional component or hook (in-built and custom).
We can isolate the logic of getting the current size (width) of screen at any time as the window is resized with a custom hook as shown below:
```js
import { useState, useEffect } from "react"
const useMediaQuery = () => {
const [screenWidth, setScreenWidth] = useState()
useEffect(() => {
const getScreenWidth = () => {
setScreenWidth(window.innerWidth)
}
getScreenWidth()
window.addEventListener('resize', getScreenWidth)
return () => {
window.removeEventListener('resize', getScreenWidth)
}
}, [])
return screenWidth
}
export default useMediaQuery
```
You can then import this custom hook in as many components as required in your project to get the current screen size at any time.
Then our `MyComponent` can be refactored as shown below
```js
const MyComponent = () => {
// make sure you import useMediaQuery as necessary
const screenWidth = useMediaQuery()
return (
<div>
{screenWidth}
{screenWidth > 768 && <p>Show only on screen greater than 768px</p> }
<p>Show on all screen size</p>
</div>
)
}
```
Make sure you import the `useMediaQuery` as necessary into any components it is required. For example if `useMediaQuery` is written in a file named `useMediaQuery.js` inside a folder named `/src/hooks` and exported as default from the file as shown below:
```js
// /src/hooks/useMediaQuery.js
import { useState, useEffect } from "react"
const useMediaQuery = () => {
const [screenWidth, setScreenWidth] = useState()
useEffect(() => {
const getScreenWidth = () => {
setScreenWidth(window.innerWidth)
}
getScreenWidth()
window.addEventListener('resize', getScreenWidth)
return () => {
window.removeEventListener('resize', getScreenWidth)
}
}, [])
return screenWidth
}
export default useMediaQuery
```
Then inside `/src/components/MyComponent.js` it will be imported as used as shown below
```js
// /src/components/MyComponent.js
import useMediaQuery from '../useMediaQuery'
const MyComponent = () => {
const screenWidth = useMediaQuery()
return (
<div className='container'>
Current screen width: {screenWidth}
{screenWidth > 768 && <p>Show only on screen greater than 768px</p> }
<p>Show on all screen size</p>
</div>
)
}
```
Our second custom hook will be the `useFetch` hook that can be used across multiple components for data fetching. The hook may be written as follows:
```js
// /src/hooks/useFetch.js
import { useState, useEffect } from 'react'
const useFetch = (url) => {
const [loading, setLoading] = useState(false)
const [error, setError] = useState(null)
const [data, setData] = useState(null)
useEffect(() => {
// set loading to true to indicate the request is pending
setLoading(true)
fetch(url)
.then(response => {
// check if the request is successful
if (!response?.ok) {
throw new Error('an error occurred')
}
return response.json()
})
.then(responseData => {
setData(responseData)
setLoading(false)
setError(null)
})
.catch(error => {
setLoading(false)
setError(error)
})
}, [url])
return {
loading,
data,
error
}
}
export default useFetch
```
Here, three state variables and the corresponding functions to update their values are initiated. The `useFetch` hook receives a parameter, which is the endpoint to fetch the required data. Depending on your use case, any custom hook can be defined to receive any number of paramters to achieve an intended purpose.
- `loading` and `setLoading` : `loading` indicates if the request has been commenced and pending. Its initial value is set to `false`. `setLoading` is used to update its value as appropriate.
- `error` and `setError` : `error` this is to indicate if the request is rejected or failed and `setError` to update its value as appropriate
- `data` and `setData` : `data` is to be updated to the resource returned from the request. The `setData` is to achieve this purpose.
After initializing the state variables required, the React `useEffect` is use to implement the logic required for fectching the data and updating the variables values.
The value of `loading` is first updated to `true` to indicate the request has been commenced and is pending. Then we made the request to the endpoint, the value of which will be the value of the required `url` parameter.
The response status is checked if the request is fulfilled, that is succesful. Upon success we update the state variables as shown in the code and also upon failed request.
Note any other external library such as [axios](https://axios-http.com/docs/intro) can be used instead of the in-built `fetch` API
Now let's use our custom `useFetch` hook to fetch blog post from a dummy endpoint.
Let's make a seperate component where, `useFetch` hook will be called as shown below:
```js
// src/components/Posts.js
import useFetch from '../hooks/useFetch'
const Posts = () => {
const {
loading,
error,
data
} = useFetch('https://jsonplaceholder.typicode.com/posts/')
if (loading) {
return <p>loading...</p>
}
if (error) {
return <p>Unable to fetch data</p>
}
// check if returned data is truthy.
// You may want to check for other thing depending on the type and structure of the expected data
if (data) {
return (
data.map((post) => {
return (
<article key={post.id}>
<h3>{post.title}</h3>
<p>{post.body}</p>
</article>
)
})
)
}
}
```
Here, the `useFetch` custom is imported and called in the `Posts` component. The returned object is destrutured to obtain the `loading`, `error` and `data` state values after destructuring.
We check the values of these in order to render appropriate components/elements.
## Conclusion
We have looked into how React Custom Hooks can make our code conforms to _DRY_ (Don't Repeat Yourself) principle by enabling our code to be modular and reusable. You thoughts and comments are highly welcomed. Thank you!!!
| ismailadegbite | |
1,459,703 | Learn How To Listen: Event Listeners And Dynamic Websites | It is an unspoken rule of the modern internet that your website is to be responsive, fluid, dynamic,... | 0 | 2023-05-06T19:07:05 | https://dev.to/svper563/learn-how-to-listen-event-listeners-and-dynamic-websites-46h | javascript, webdev |
It is an unspoken rule of the modern internet that your website is to be responsive, fluid, dynamic, and whatever other buzz words industry professionals happen to be tossing around today. Long gone are the days where static, un-styled text and images are sufficient to capture the attention of your audience. I know that when I come across such a static site myself, I click away fast as lighting out of fear of catching some kind of virus - after all, only hackers living in their parents' basement since 1987 would still host a site like that, right?
All jokes aside, a prominent tool in our belt as web developers is event listeners. They allow us to watch for specific user interactions and respond to them in ways that make our pages respond dynamically. In this article, I will explore some simple events that you can listen for that can take your next web application from zero to hero. Let's get started.
## People Will Copy Your Code Eventually
As developers, we often scrape Stack Overflow to "borrow" code that fixes our problems, at least until the next bug starts bugging us. The next time that you post code to your oh-so-popular blog, try letting your visitors know that _you_ know when they're borrowing your code:
`index.html`
```html
<body>
<div id='my-code-snippet'>
<code>
console.log("Hello, world!")
</code>
<div>
</body>
```
`script.js`
```js
let myCodeElement = document.getElementById('my-code-snippet');
myCodeElement.addEventListener("copy", () => {
let warnElement = document.createElement('p');
warnElement.innerHTML = "<em>I know what you did.</em>"
myCodeElement.appendChild(warnElement)
})
```
The HTML simply displays our brilliant code snippet for the world, and our Javascript does the job of watching for would-be-thieves.
Before copying:

After copying:

Of course, there are many ways to prevent your visitors from copying your code, but it is not best practice as it would most likely break the internet, which I'm sure is a less-than-desirable outcome. Let's avoid that.
## Clap Back By Spying On Your Users
As honest programmers, we surely don't have any reason at all to watch our users' every move while they're on our sites. But, hypothetically speaking, there are ways to track every key press. Let's explore that.
```js
document.addEventListener('keydown', (event) => {
// Legitimate code goes here
})
```
The `keydown` listener fires when your user presses down any key on their keyboard. The `key` property of the event object holds the value of the key pressed. The object also has many other properties that you can check. Let's say you want to make your own hot keys for your web application; you can do this easily by using the `altKey` and `ctrlKey` properties.
```js
document.addEventListener('keydown', (event) => {
if (event.altKey && event.ctrlKey && event.key === 'r') {
// Your Hotkey action
}
})
```
The `altKey` and `ctrlKey` properties each hold a boolean value indicated whether they were pressed at the time of the keypress.
If you need to listen for when a user releases a key, you can use the `keyup` listener instead.
There is also the `keypress` event as well, but it is only fired when a key that produces a character value is pressed down. As a result, this event cannot track when the Alt, Ctrl, or Shift keys are pressed. In addition to its limited functionality, there is a good shot that your user's browser of choice has dropped support for it, or will very soon.
Keep in mind that none of these events account for non-standard keyboard layouts by default. If your user is not using the standard QWERTY layout, it could cause some problems. For example, if your user is using the QWERTZ layout, pressing the 'Z' key on their keyboard will register as the 'Y' key instead. You can use the [getLayoutMap()](https://developer.mozilla.org/en-US/docs/Web/API/Keyboard/getLayoutMap) method to check for this and handle it accordingly.
## When You're Found Out: Conducting Damage Control
When you're eventually caught for your supposedly "shady" coding practices, it's going to be important to know how to protect your image from the "honest" and "hardworking" people who want to destroy it. Remember: You cannot be exposed for misconduct if you expose yourself first. Let's add a modal popup to our site for new users that forces them to agree to our privacy policy before they can continue on our site. Let's use the `click` event listener to help us accomplish this.
`index.html`
```html
<head>
<style>
body {
background-color: #112;
color: white;
}
#privacy-modal {
visibility: hidden;
position: absolute;
padding: 20px;
background-color: #334;
border: 5px solid black;
}
</style>
</head>
<body>
<div id="privacy-modal">
<h2>Before You Continue: Accept Our Privacy Policy</h2>
<p>You must accept our privacy policy to continue on our website.</p>
<h3>Privacy policy</h3>
<p>Nothing is sacred. You will get hacked. You have been warned.</p>
<button id="accept-terms-button">Accept</button>
<button id="decline-terms-button">Decline</button>
</div>
<div id="content">
// Legitimate content goes here
</div>
</body>
```
`script.js`
```js
let privacyModal = document.getElementById('privacy-modal');
let acceptTermsButton = document.getElementById('accept-terms-button');
let declineTermsButton = document.getElementById('decline-terms-button');
if (!localStorage.getItem("hasAccepted")) {
privacyModal.style.visibility = "visible";
privacyModal.style.position = "fixed";
}
acceptTermsButton.addEventListener('click', () => {
localStorage.setItem('hasAccepted', "true");
privacyModal.style.visibility = "hidden";
privacyModal.style.position = "absolute";
})
declineTermsButton.addEventListener('click', () => {
window.location.replace('https://www.myspace.com')
})
```
The first time that your users visit your wonderful and legitimate website, the privacy modal will overlay on top of the content, obscuring the page until they accept or decline. By clicking on the accept button, the code remembers the user choice by storing a truthy value in the `localStorage` attribute `hasAccepted`, and then hides the modal. Users who decline will be redirected immediately to the internet backrooms.
Now you know how to harvest your user's data openly and freely, just like every other legitimate tech company in the world.
## Conclusion: I Am Not A Lawyer
I'm hoping that the technical aspects of this post can help you, but for legal purposes I am not endorsing that you steal data or hack other people. If you do hack and get caught, please don't email me at 3am complaining about it. Any other time of the day or night is acceptable.
Read more about event listeners on [MDN's website](https://developer.mozilla.org/en-US/docs/Web/API/EventTarget/addEventListener). | svper563 |
1,459,856 | Smart Contract Security: Vulnerabilities and Best Practices | Smart Contracts Explained A smart contract is a type of code that is designed to be... | 0 | 2023-05-06T23:33:43 | https://dev.to/george_k/smart-contract-security-vulnerabilities-and-best-practices-2jp5 | ### Smart Contracts Explained
A smart contract is a type of code that is designed to be executed on a blockchain and enforce the terms of an agreement between parties. Depending on the terms of each specific agreement, this can involve exchanging assets or other types of transactions. By running on a blockchain, a smart contract ensures that transactions are autonomously and accurately executed.
There are many blockchain platforms that support smart contracts — Ethereum, Hyperledger Fabric, Binance Smart Chain, and Corda to name but a few. Each blockchain can implement smart contracts differently. For example, the Solidity programming language is utilized to create smart contracts on Ethereum networks.
It is safe to say that smart contracts is a very promising technology that has all the potential to transform the way we do business. Here’s why:
- **Smart contracts have a wide range of applications.** There's a variety of use cases for smart contracts, not only in the financial sector but also in other industries. For example, smart contracts can be used to handle supply chain management, real estate transactions, and even voting.
- **Smart contracts are decentralized.** They are specifically designed to automate the execution of transactions and other business processes without the need for intermediaries. This reduces associated expenses since there’s no longer any need for costly middlemen, such as lawyers, banks, or brokers.
- **Smart contracts are immutable.** This means that once they are deployed on the blockchain network, they cannot be modified. As a result, transactions are made fully transparent and traceable, preventing any unauthorized alterations for illicit gain.
- **Smart contracts are secure.** Participants can be assured that the contract will be executed only if all the conditions and requirements are met.
Smart contracts power NFTs, DeFi, and Web3 platforms, which hold billions of dollars in digital assets. It's crucial to prioritize the security of smart contracts to avoid financial losses and damage to platform reputation resulting from any breaches or attacks.
### Security Risks
In many ways, what is considered to be an advantage of smart contracts, can also become a source of security issues. As mentioned before, smart contracts are immutable — once a smart contract is deployed, it cannot be modified or updated. This means that if any vulnerabilities or errors are identified in the code after deployment, it can be extremely difficult, if not impossible, to fix.
Generally smart contract security risks can result from either vulnerabilities in the blockchain itself or coding errors.
For instance, frontrunning attacks exploit how blockchain processes transactions. Scammers can buy a significant amount of tokens in response to big transactions that will boost the token's price. They then add a higher fee than the big transaction they're targeting to ensure their transaction is processed first. Once the big transaction changes the token's price, they sell the tokens they purchased for a profit.
Smart contracts can also face security risks from 51% attacks on the underlying blockchain network. This kind of attack happens when an attacker has control over the majority of the network's computing power. This gives them the ability to manipulate the network and create fraudulent transactions, which can result in stolen digital assets from smart contracts or the contracts themselves getting modified.
As for coding errors, let’s look at why they might occur in the first place. The primary reason is complexity. Smart contracts are extremely intricate to design, develop, and test. Additionally, they are created using specific programming languages, e.g. Solidity. This is a relatively new programming language, and developers may not be fully familiar with its syntax and rules. This can result in coding errors that can be exploited by attackers. Since any blockchain user can access a smart contract, its possible vulnerabilities are also visible throughout the network, and it is not always possible to eliminate them due to immutability.
Here are some possible vulnerabilities that result from errors in code:
- **Reentrancy vulnerabilities:** This vulnerability occurs when an attacker repeatedly calls a function before the first invocation finishes, enabling them to withdraw balances multiple times until their balance is reduced to 0.
- **Over/Under Flows:** When an integer variable attempts to store an integer above or below its accepted values, vulnerabilities such as overflow or underflow can occur. These vulnerabilities can create unexpected logic flows and enable attackers to exploit the smart contract.
- **Recursive calling:** This happens when a smart contract calls another external contract before the changes are confirmed, and the external contract may then interact with the initial smart contract recursively in an unauthorized manner as its balance has not yet been updated.
### Security Best Practices
Now, let's discuss some security best practices that can help mitigate the vulnerabilities we've outlined above.
#### 1. Design and Architecture
This is one of the staples in smart contract security. Use modular and reusable code, proven design patterns, trusted libraries and frameworks, or open-source tools. OpenZeppelin and ConsenSys are two popular time- and community-tested frameworks that provide a range of secure smart contract templates. Open-source libraries are useful for the same reasons — they have been audited by many developers and are less likely to contain vulnerabilities.
#### 2. Testing and Code Quality
There are many industry-standard testing frameworks and tools that can help to identify vulnerabilities before they become a problem. For example, the Solidity compiler provides built-in security checks such as integer overflow and underflow protection.
Penetration testing can also help to identify weaknesses in your smart contract's design. This can be done manually or using automated tools such as fuzz testers. Fuzz testers generate random inputs to the smart contract to test for unexpected behavior and help to uncover vulnerabilities that other testing methods couldn’t detect.
Test the smart contract on a testnet before deploying to the mainnet. Testnets are blockchain networks used specifically for testing purposes and do not contain real digital assets.
Finally, conduct regular code reviews to check for vulnerabilities such as reentrancy, overflow/underflow, unchecked return values, and unprotected functions.
#### 3. Access Control and Authorization
Make sure that only authorized parties should be able to access and modify your contract. The two key access control mechanisms are role-based access control (RBAC) and permissioned access. RBAC allows you to define roles and assign permissions to those roles. Permissioned access can be used to restrict access to your smart contract based on the user's identity.
#### 4. Auditing and Certification
Smart contracts should be inspected by independent security auditors who cover all aspects, including the code, architecture, and business logic. Certification from reputable auditing firms can provide additional assurance that the smart contract is secure.
#### 5. Multi-Signature Wallets
Multi-signature wallets require more than one person to approve a transaction or contract upgrade before it is executed. This provides an additional layer of security, as it ensures that no single person can make changes to the contract without the approval of others.
#### 6. Timelocks
Timelocks can be used to prevent unauthorized access to digital assets and are commonly used in DeFi applications. A timelock can delay the transaction — e.g. the withdrawal of funds — until a certain period of time has passed. In the case of a security breach, it gives the owner of the smart contract time to respond before any damage is done.
#### 7. Bug Bounty
A bug bounty program was created to incentivize ethical hackers to identify and report security flaws in a smart contract. By offering rewards for finding vulnerabilities, you can tap into the expertise of the wider community and fix security issues before they are exploited by attackers.
### Conclusion
Smart contracts are now a fundamental aspect of the DeFi ecosystem, and as time goes on, they will likely become a vital part of various business operations and everyday activities. As this happens, it's expected that we'll find better ways of ensuring the utmost security of smart contracts. I trust that this article has given you helpful information on how to tackle the vulnerability challenges associated with this technology today.
### Sources
1. Lossless.io Blog, Smart Contract Security Audit 101: The Ultimate Guide, https://lossless.io/smart-contract-security-audit-101-the-ultimate-guide/
2. Solidity Academy, Best Practices and Standards for Smart Contract Security, https://medium.com/coinmonks/best-practices-and-standards-for-smart-contract-security-2cc9643aebf1
3. CertiK, Smart Contract Security: Protecting Digital Assets, https://certik.medium.com/smart-contract-security-protecting-digital-assets-719da8a6c646
4. Hederra Blog, A Guide to Smart Contract Security, https://hedera.com/learning/smart-contracts/smart-contract-security#:~:text=What%20is%20smart%20contract%20security,transactions%20between%20various%20digital%20assets.
5. Forbes, Navigating The Security Challenges Of Smart Contracts by David Balaban,
https://www.forbes.com/sites/davidbalaban/2023/02/11/navigating-the-security-challenges-of-smart-contracts/?sh=2f7300864992
| george_k | |
1,470,746 | What Should I know Before Going Bow Hunting? | With a new bow and some practice, you're almost ready to hunt. But first, it's important to check and... | 0 | 2023-05-17T07:08:08 | https://dev.to/monicabirdweb/what-should-i-know-before-going-bow-hunting-22in | roof, roofing, contractor, constructions | With a new bow and some practice, you're almost ready to hunt. But first, it's important to check and double-check the gear you'll be taking with you. Making sure you have the right arrows, broadheads, and extras, such as a sharpening stone, can make the difference between a successful hunt and an unsuccessful one.
There are many intricacies to bowhunting that make it different from firearm hunting, and it allows each hunter to develop their own style. It is crucial for a beginner to focus on a strong foundation before going on their first hunt to succeed.
**Learn Bowhunting Ethics**
As far as bowhunting goes, there are some ethical debates; it basically boils down to who shoots the arrow. A bow hunter's ethical responsibilities are just as important as those of a firearm hunter, perhaps even more so. You should always respect the animals and other humans in the process of taking a shot. Take clean shots, don't waste your harvest, and remain aware of what's behind your shot.
There is one part of this ethical conversation that may seem blunt, but it's true: if you cannot hit the kill zone on a target and you are confident and accurate, then you should not try to take out a live target. Shots that do not immediately kill a deer are just not worth the risk. You can wound that deer with a risky shot. Alternatively, it can survive the shot and suffer permanent handicaps for the rest of its life.
Bowhunters, in fact, kill and wound much more deer than rifle hunters, and they do not find many more. Due to the more difficult nature of using a bow, mistakes are more likely to occur. There will be times when your deer will be lost while hunting, but we should all take precautions to ensure that this does not happen too often.
**Practice, Practice, Practice**
Without practice, you will not be able to shoot better as a bowhunter. When you shoot, adjust your bow as needed, but otherwise, leave it alone. Shooting at 20 yards should become extremely comfortable for you, then progress to 30 yards. First-year shooters should probably not go beyond 30 yards anyway, but if they are comfortable with 40 yards, they can go further.
**Test out Your Broadheads**: This is important because you need to be sure that the broadheads fly in the same path as the field points, as any deviation in the arrow flight path can mean a missed shot or worse.
If you practice with a hunting broadhead, the edges will become dulled and won't perform as well when you're hunting. Practice broadheads are designed to be sturdier than hunting broadheads, so they can withstand repeated impacts with a target without losing their sharpness.
**Know Your Range**: By routinely using your rangefinder to measure the distances of clearings or other markers, you can become familiar with the distance and better gauge the range of a potential shot. This will help you become more accurate when aiming and shooting, which could mean the difference between a successful hunt and a missed opportunity.
**Make it Real**: Going through the motions and envisioning the situation ahead of time can help hunters be prepared and have a better understanding of the situation. This allows them to make the best decisions when the time comes, as they will be more familiar with the environment.
When you're up in a tree stand, it's important to be as protective and comfortable as possible. Climbing with your gear can be dangerous and can result in injury. Using a haul rope to bring up your gear helps to ensure you're not carrying too much weight while climbing and makes the process easier and safer.
**Make a Bowhunting-Specific Plan**
To ensure you have a successful hunt, it's important to plan out the details ahead of time. Decide what type of game you're looking for and identify the area you'll be hunting. Make sure to plan for how you'll handle the game after it's caught, especially if you're in a remote area. Having a plan in place will help minimize any potential issues that could occur during the hunt.
The above examples show you the kinds of plans you need to make for any whitetail hunt, but what about bowhunting specifically? Changing your hunting strategy to play closer shots will help you get better results. Depending on your hunting history, your existing stands might not be suitable for rifle hunting. During bowhunting season, scout more to find two or three stand locations where you can have a bowhunting-specific stand.
Taking a quartering to or quartering away shot requires more skill and understanding of the animal's anatomy and the shot angles, and it can be difficult to do that with only limited experience. Sticking to broadside shots ensures that you have the best chance of hitting the vital organs and making a humane kill.
**Bowhunting Gear Selection**
Bowhunting requires some specific gear. While hunting generally requires some basic gear, bowhunting requires some specialized gear. In addition to your bow and quiver, here are some other items you should have when heading into the deer woods:
- Rangefinder - By using a rangefinder, you can quickly and accurately determine the distance between you and your target. This not only helps you pick the right pin for the shot, but it also helps you to practice better-shot placement, which can result in better hunting success.
- Haul Rope - This is necessary because the bow is not only longer and heavier than a rifle but also more awkward to handle. The haul rope allows you to safely pull the bow up the tree without having to climb back down and retrieve it.
- Bow Release - A bow release is an essential piece of gear for a successful hunt. Without it, you cannot shoot your bow, which is necessary for bringing down the game. It is compulsory to make sure you have all the necessary gear with you before you leave for a hunt.
- Safety Harness - The tree stand itself can be dangerous as you are elevated off the ground, and a fall, even a few feet, could result in serious injury or even death. Additionally, bowhunters need to be able to move quickly and freely to get shots, and a safety harness can provide that extra security to ensure you stay safe while hunting.
Having prepared and planned for your trip, you should be confident in your ability to enjoy yourself at your chosen location. The right practice makes a difference and makes your hunt ethical and respectful. You will gain knowledge and experience in bowhunting even if you feel all your preparations were unsuccessful. Keep practicing, planning, and hunting.
Are you looking for more great [hunting advise](https://mississippi-landsource.com/hunting-land-for-sale-in-mississippi/)? If so, check out Mississippi Landsource today! | monicabirdweb |
1,470,749 | CORS in ASP.NET | Cross-Origin Resource Sharing (CORS) is an HTTP-header based mechanism that enables a server to... | 0 | 2023-05-17T21:28:26 | https://dev.to/fabriziobagala/cors-in-aspnet-core-4hl2 | programming, security, csharp, dotnet | Cross-Origin Resource Sharing (CORS) is an HTTP-header based mechanism that enables a server to specify any origins (domain, scheme, or port) other than its own from which a browser should permit loading resources. It allows many resource requests, such as Ajax or Fetch, originating from a different domain (cross-origin) to be requested on a web domain (origin). CORS relies on a mechanism where browsers make a "preflight" request to the server hosting the cross-origin resource, to check if the server will allow the actual request. During this preflight, the browser sends headers indicating the HTTP method and headers that will be used in the actual request.
## Set up CORS
To set up CORS in ASP.NET, the following steps must be followed:
1. **Install middleware package**: Install the CORS middleware via the NuGet package manager with the command `Install-Package Microsoft.AspNetCore.Cors`.
2. **Add CORS service**: After installing the package, add the cross-origin resource sharing services to the specified `IServiceCollection`.
3. **Configure CORS policies**: Finally, build your policy within the CORS service.
```csharp
builder.Services.AddCors(options =>
{
options.AddPolicy("MyCorsPolicy",
builder =>
{
builder => builder.WithOrigins("https://example.com")
.AllowAnyHeader()
.WithMethods("GET", "POST", "PUT", "DELETE");
});
});
```
In this example, we created a policy called "MyCorsPolicy" that allows access only to the `https://example.com` domain, makes sure to allow any header, and limits the allowed methods to `GET, POST, PUT, DELETE`.
## Enable CORS
Once the CORS policy has been created, there are several ways in which it can be enabled.
👉 **Using middleware**
Middleware components handle requests and responses in ASP.NET. CORS can be enabled in the middleware either using a named policy or a default policy.
- **Named policy**: You can define one or more named policies, and then select which policy to apply using the policy name at middleware.
```csharp
app.UseCors("MyCorsPolicy");
```
- **Default policy**: Instead of specifying a policy name, you can define a default policy that applies to every request.
```csharp
builder.Services.AddCors(options =>
{
options.AddDefaultPolicy(
builder =>
{
builder.WithOrigins("https://example.com");
});
});
// ...
app.UseCors();
```
👉 **Using endpoint routing**
Endpoint routing provides more control over the application's routing. You can enable CORS for specific routes in your application.
```csharp
app.UseEndpoints(endpoints =>
{
endpoints.MapGet("/test", TestAction).RequireCors("MyCorsPolicy");
endpoints.MapControllers().RequireCors("MyCorsPolicy");
});
```
👉 **Using the `[EnableCors]` Attribute**
The `[EnableCors]` attribute allows you to enable CORS at a more granular level, specifically at the controller or action level. This attribute provides an alternative to applying CORS policies globally and offers finer control over where and how CORS is implemented within your application.
Utilization of the `[EnableCors]` attribute can be done in several ways:
- `[EnableCors]` applies the default policy.
- `[EnableCors("{Policy String}")]` applies a specific named policy.
The attribute can be applied to different components of your application:
- Razor Page PageModel
- Controller
- Controller action method
By using the `[EnableCors]` attribute, different policies can be applied to various components of your application. However, it's important to note that if the `[EnableCors]` attribute is applied to a controller, page model, or action method while CORS is also enabled in middleware, both policies will be applied. This can lead to unintended behaviors and security implications, so combining policies is generally discouraged. It is advisable to use either the `[EnableCors]` attribute or middleware, but not both in the same application.
```csharp
[EnableCors("MyCorsPolicy")]
public class TestController : ControllerBase
{
// ...
}
```
In this example, the "MyCorsPolicy" is applied to all actions within the TestController.
## Disable CORS
If you want to disable CORS for specific actions or controllers, you can use the `[DisableCors]` attribute.
```csharp
[DisableCors]
public class NoCorsController : ControllerBase
{
// ...
}
```
> ⚠️ **Warning**
> The `[DisableCors]` attribute does not disable CORS that has been enabled by endpoint routing.
## CORS criteria options
When defining CORS policies, you can use several methods to customize how the policy behaves:
- **WithOrigins**: Allows you to specify which origins should be allowed to access the resources. This is useful when you want to restrict access to specific domains.
- **WithMethods**: Allows you to specify which HTTP methods are allowed. This can help to tighten security by only allowing the necessary methods for a particular resource.
- **WithHeaders**: Allows you to specify which HTTP headers are allowed. This can be used to restrict which headers are accepted in a request.
- **AllowAnyOrigin**: Allows CORS requests from all origins with any scheme (`http` or `https`).
- **AllowAnyMethod**: Allows any HTTP method.
- **AllowAnyHeader**: Allows any HTTP header.
AllowAny options should be used with caution because they could cause potential security risks, such as allowing any source to access resources, allowing potentially malicious methods, or leading to unintended exposure of headers.
These policy options can be combined and tailored according to the specific needs of your application, providing a high degree of control over your CORS policies. However, it's important to understand the security implications of each option to ensure the safe handling of cross-origin requests.
## Conclusion
Understanding and implementing CORS in ASP.NET is crucial for the security of your web applications. CORS is a mechanism that allows your website to make secure requests to other domains, enhancing interoperability and allowing greater flexibility. However, it's important to remember that CORS must be configured carefully to prevent potential security vulnerabilities. It's crucial to limit access only to trusted origins and use the most restrictive method suitable for your specific needs. Thanks to ASP.NET, configuring CORS is a simple process that can be easily customized to fit various situations.
## References
- [Cross-Origin Resource Sharing (CORS)](https://developer.mozilla.org/en-US/docs/Web/HTTP/CORS)
- [Enable Cross-Origin Requests (CORS) in ASP.NET Core](https://learn.microsoft.com/en-us/aspnet/core/security/cors?view=aspnetcore-6.0) | fabriziobagala |
1,470,835 | What is Synthesis AI? | Synthesis AI is a new technology that has been gaining significant attention in recent years. It is... | 0 | 2023-05-17T08:57:55 | https://dev.to/nikkilopez2/what-is-synthesis-ai-238 | ai |
Synthesis AI is a new technology that has been gaining significant attention in recent years. It is an emerging field in AI research and aims to allow machines to generate creative and original data. The technology is developed by using the latest advancements in deep learning and machine learning.
## What is Synthesis AI?
Synthesis AI is a new field that focuses on generating creative and original content using artificial intelligence. It is a form of AI that involves creating something new and innovative. Synthesis AI involves the use of deep learning algorithms to learn from existing data and build upon it to create something new and unique. The technology holds immense promise to revolutionize various fields such as music, art, and even content creation. With the use of Synthesis AI, artists and researchers can generate new and innovative results that might have not been possible before.
## Applications of Synthesis AI
There are several applications of Synthesis AI. One of the most interesting and innovative applications is in the field of art. Synthesis AI allows artists to generate new and original artwork by using AI. The algorithm learns from existing artwork, artists, and various sources of inspiration to create new and unique pieces. It is a blend of human creativity and machine intelligence that can lead to some spectacular results.
Another application of Synthesis AI is in the field of music. With the use of Synthesis AI, we can create new music that is not only original but also pleasing to the ears. It can help musicians to generate new ideas and inspiration for their work. Similarly, sports and fitness professionals can use Synthesis AI to come up with new and personalized exercise routines and programs.
## Technical aspects of Synthesis AI
At the core of Synthesis AI is a neural network that is trained on a vast corpus of data. The technology uses deep learning algorithms to learn from existing data and create something new from it. In this way, Synthesis AI takes inspiration from the existing data and builds upon it to generate something new and unique.
To create something new, Synthesis AI uses a combination of various techniques such as generative models, adversarial networks, and autoencoders. With the use of these techniques, the machine generates a large amount of data that is similar to the original dataset. This generated data can be used by researchers and artists to generate further ideas and inspiration.
## Limitations of Synthesis AI
Synthesis AI has been an area of active research, but it still has its limitations. One of the most significant limitations is that the generated outputs are not always perfect. The machine can generate repetition or copy-pasting of content, which reduces the quality of the final output.
Another limitation is the bias that Synthesis AI can introduce in the generated output. The AI model can pick up subtle biases from the data it was trained on and replicate them in the generated output. It can further perpetuate discrimination and prejudice that already exists in our society. Therefore, it is essential to train the AI algorithm on diverse data to avoid bias and discrimination.
## Future of Synthesis AI
Despite its limitations, Synthesis AI has immense potential in various fields. It can lead to new and exciting discoveries in music, art, literature, and many other disciplines. As the technology advances, we can expect that generated outputs will become better and more innovative.
Moreover, Synthesis AI can help to reduce our workload, allowing us to focus on more creative and innovative work. We can expect that the technology will continue to evolve and will be adopted by more and more people across various fields.
## Conclusion
[Synthesis AI](https://clickdataroom.com/posts/synthesis-ai) is a new field that holds immense potential for researchers, creators, and innovators. It allows us to generate new and creative outputs that were not possible before. Despite its limitations, we can expect that the technology will continue to evolve and will contribute to new and innovative discoveries. Synthesis AI represents a new era in AI research, which has the potential to revolutionize our work and productivity. | nikkilopez2 |
1,470,889 | Deploying an MSSQL + Node Js Application to Azure App Service. | After this part, i felt like I deserve this shirt. Now i am really curious about this part,... | 0 | 2023-05-17T10:14:42 | https://dev.to/maqamylee0/deploying-an-mssql-node-js-application-to-azure-app-service-1j33 | cloud, azure, devops |
After this part, i felt like I deserve this shirt.

Now i am really curious about this part, ofcourse i know how to deploy an appservice.
But this is not just a simple app with only frontend, so i am wondering how the database connection will be made if it is deployed through the app service.
Question is if i deploy the app currently using github, will the data show?
so lets try to deploy the app using app service.
1. First i pushed my code to github.
2.Create app service.
Next is choosing a resource group and giving it a name then choosing the option to use in this case code.
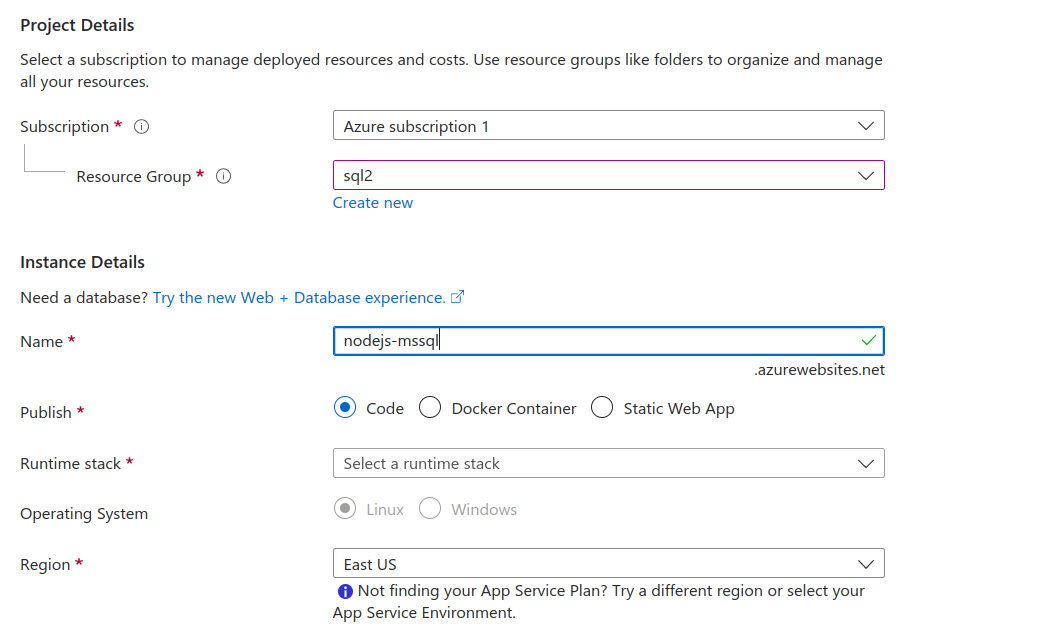
Then we need to choose the runtime stack which in our case is nodejs, the pricing plan and region.
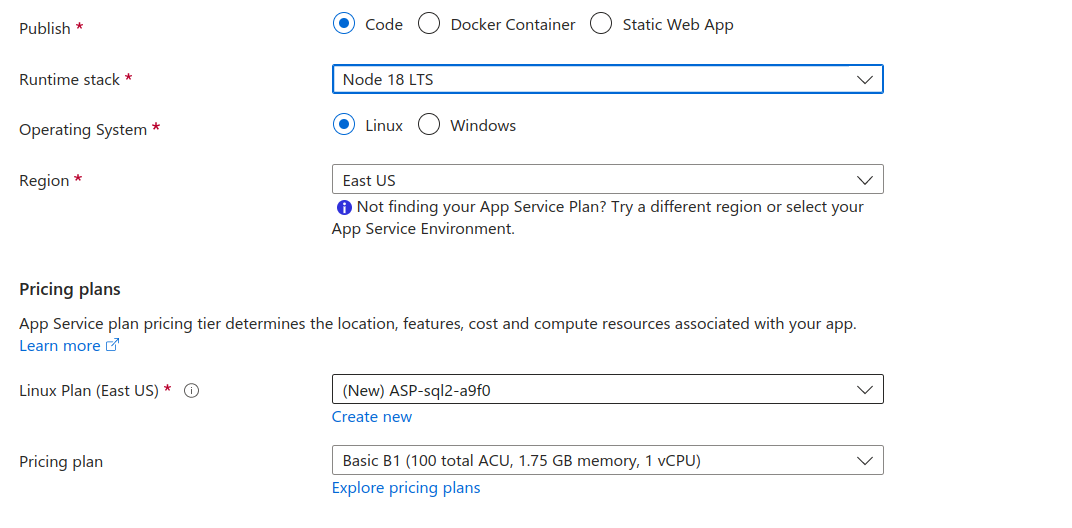
Now we choose github actions,and click the **authorise** **button** to authorise azure to access your github account.
Then select the repository, branch and organisation.
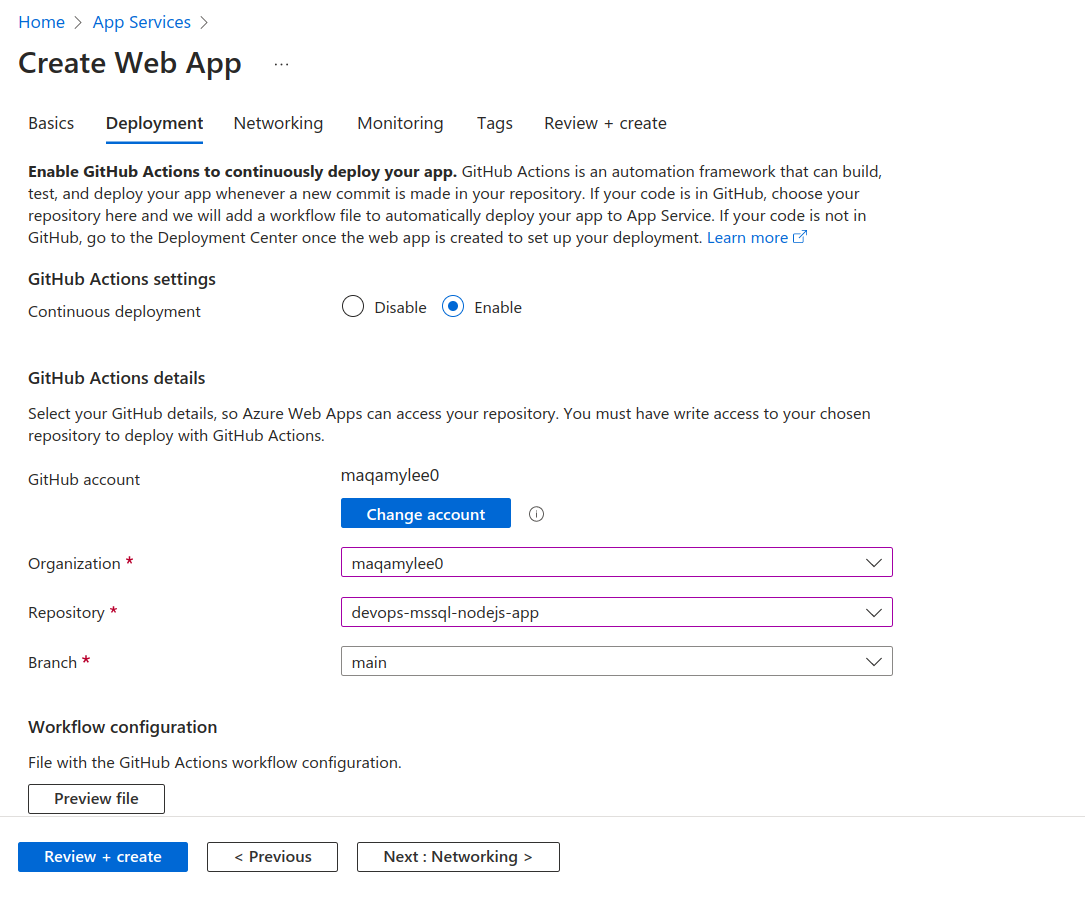
leave the network as default,
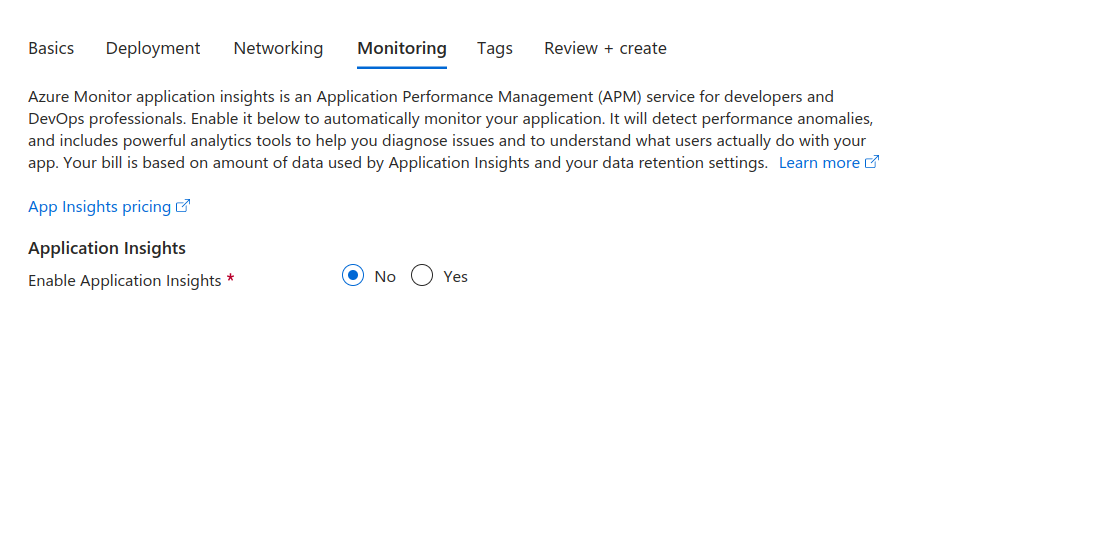
Skip and leave the rest as default and click create.
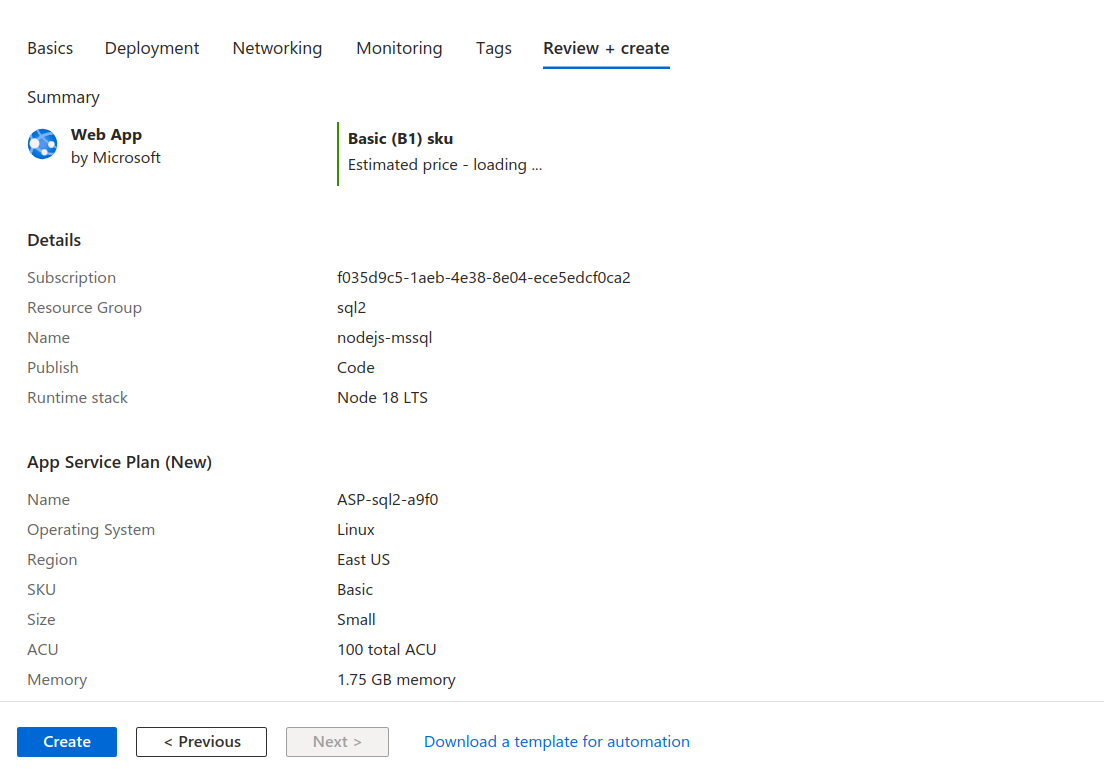
We then wait a few(lots) minutes for it to deploy and check our app link.
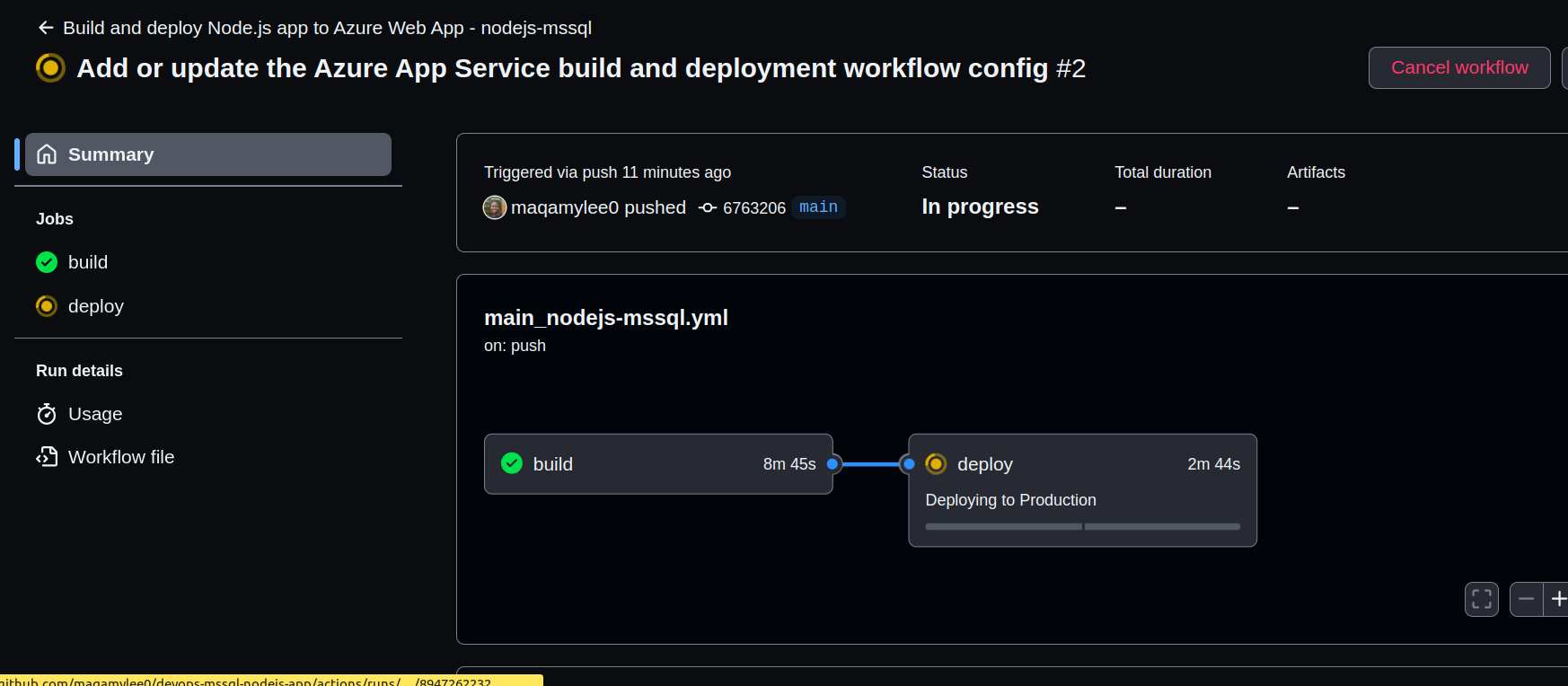
okay seriously that took alot of time. I slept on it.
Turns out we have to set a connection string and app variables.
Adding connection strings to the app service.
Go to your sql database under the **connection string** tab and look for the one that suits your app environment.
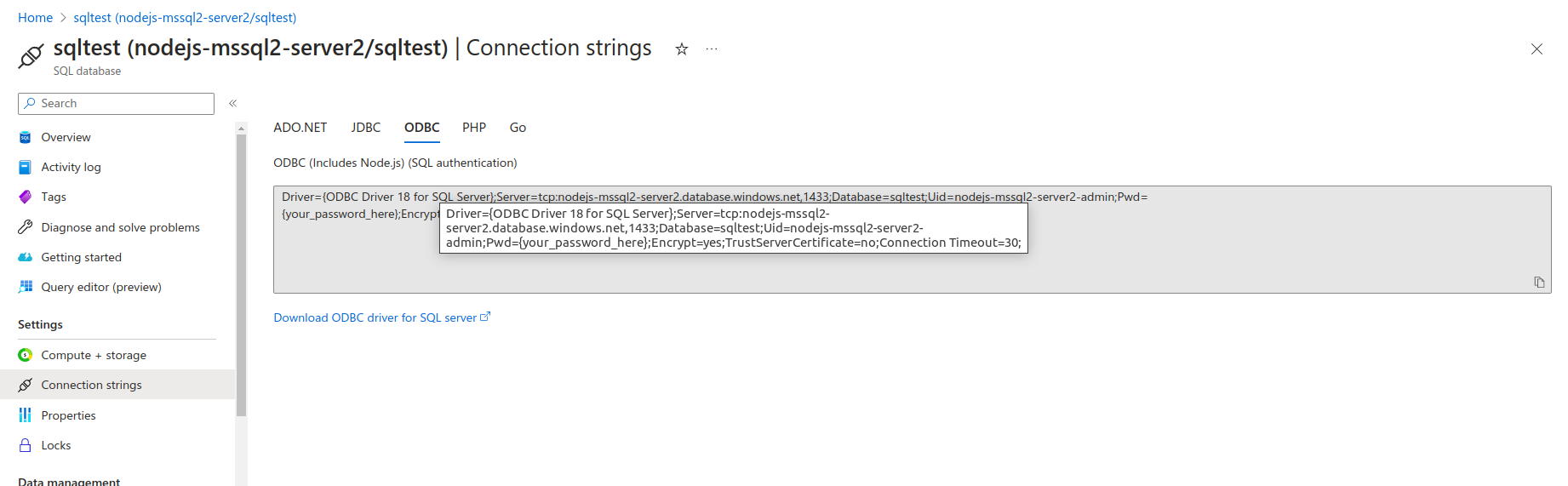
Next i went to the app service under the configuration tab and added my connection string as well as my environment variables.
Add the connection string.Be sure to replace your **password** within the string.
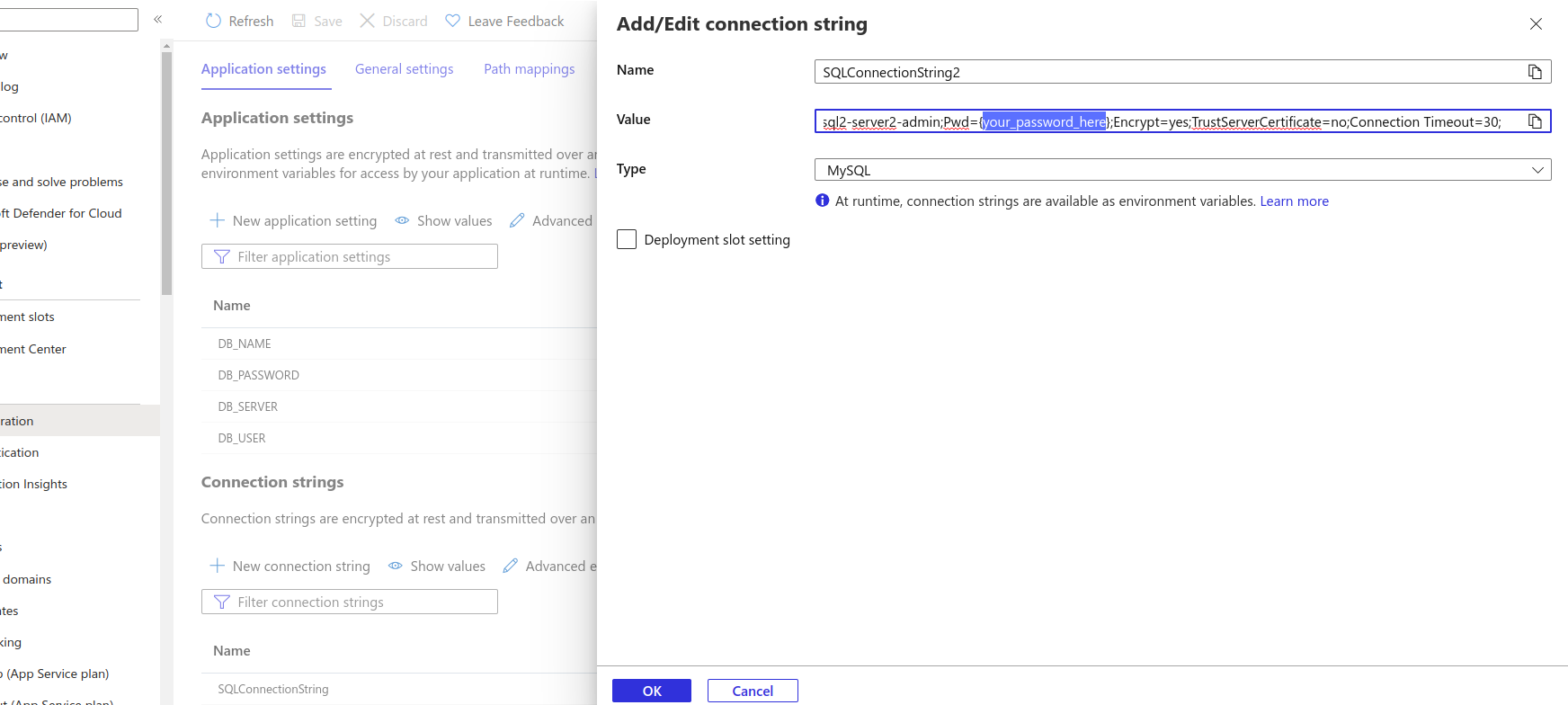
Finally it should look like this.The environmental variables should match those used in your app.
e.g
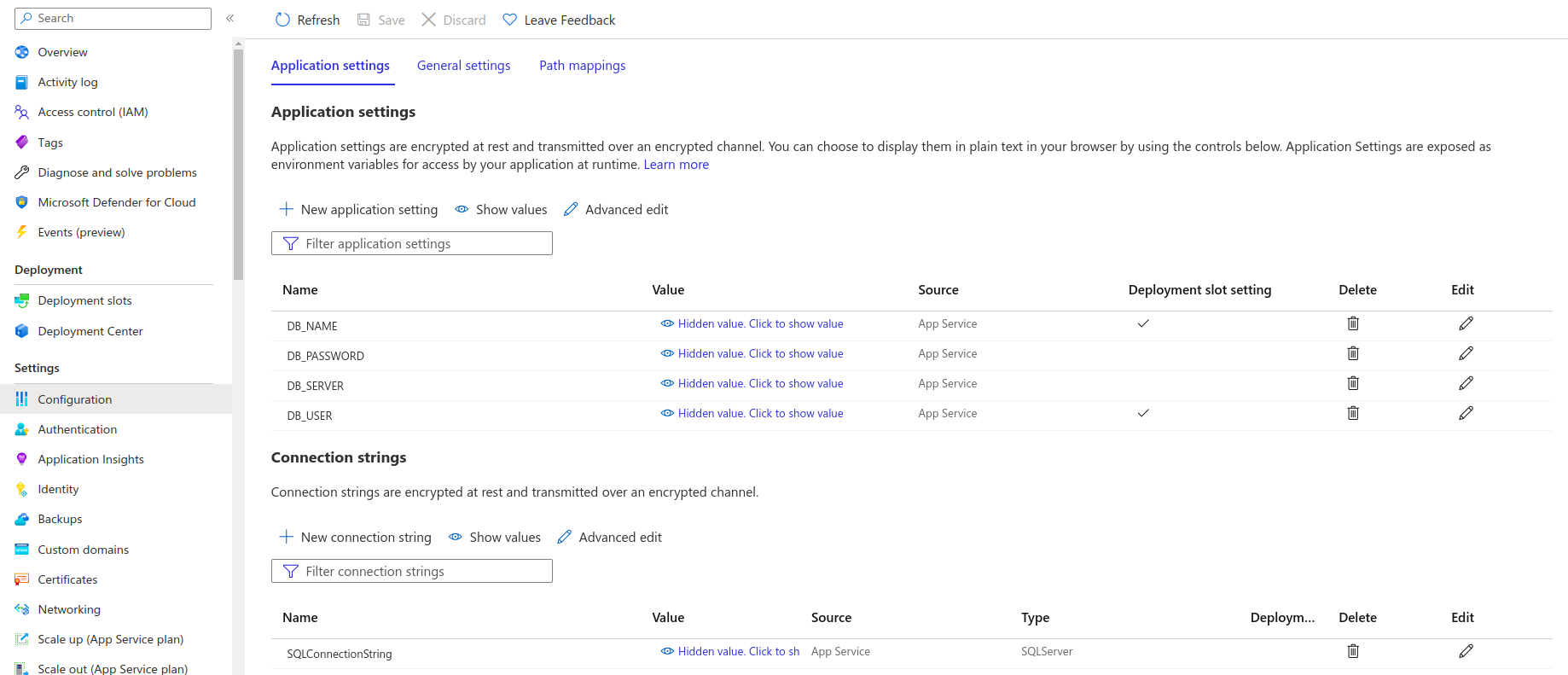
After all this struggle, ladies and gettlemen, i managed to deploy rightly.And the app was app and running.
| maqamylee0 |
1,470,954 | Journey of a Frontend Engineer Exploring the MEARN Stack: Welcome to my Hashnode Blog! | Introduction: Greetings, Hashnode community! I am Prince, a frontend engineer who is eager to embark... | 0 | 2023-05-17T10:42:57 | https://dev.to/princeajuzie/journey-of-a-frontend-engineer-exploring-the-mearn-stack-welcome-to-my-hashnode-blog-oj7 | Introduction:
Greetings, Hashnode community! I am Prince, a frontend engineer who is eager to embark on an exciting new adventure in the world of backend development. Today, I am thrilled to introduce you to my Hashnode blog, where I will be sharing my experiences, insights, and tutorials on the MEAN or MEARN stack.
As a frontend developer, I have always been captivated by the process of bringing designs to life and creating engaging user interfaces. However, I've come to realize that a truly exceptional web application requires a robust backend infrastructure. This realization has led me to dive into the fascinating world of the MEAN or MEARN stack, which combines the power of MongoDB, Express.js, Angular (or React), and Node.js.
While I am relatively new to backend development, my passion for learning and exploration drives me to constantly push my boundaries and embrace new challenges. Through my Hashnode blog, I aim to document my journey as I navigate the intricacies of the MEAN or MEARN stack, sharing my triumphs, struggles, and lessons learned along the way.
The MEAN (MongoDB, Express.js, Angular, Node.js) or MEARN (MongoDB, Express.js, React, Node.js) stack is renowned for its versatility, efficiency, and flexibility. Each component brings its unique strengths to the table, enabling developers to build scalable, real-time, and feature-rich web applications. From designing intuitive user interfaces with Angular or React to building robust APIs with Express.js and leveraging the power of MongoDB as a NoSQL database, the MEAN or MEARN stack offers an end-to-end solution for full-stack development.
Through my blog posts, I will delve into various aspects of the MEAN or MEARN stack, offering tutorials, code snippets, best practices, and real-world examples. Whether you are a frontend developer looking to expand your skill set or a seasoned backend developer seeking insights into MEAN or MEARN, my goal is to provide valuable content that helps you unlock the true potential of these technologies.
Join me on this exciting journey as we explore the intricacies of the MEAN or MEARN stack together. Together, we will navigate the challenges, unravel the complexities, and unlock the secrets of building modern, scalable, and performant web applications.
I am genuinely excited to connect with the vibrant Hashnode community and share my knowledge and experiences. I invite you to follow my blog, engage in discussions, ask questions, and provide feedback. Let's build a supportive and collaborative space where we can learn, grow, and inspire each other as we dive into the world of MEAN or MEARN stack development.
Thank you for joining me on this adventure, and I look forward to connecting with each and every one of you!
Happy coding,
Prince, a Frontend Engineer Exploring the MEARN Stack | princeajuzie | |
1,471,840 | Instagram Clone Using HTML and CSS With Source Code | Hey buddy! , Welcome to the codewithrandom blog, here we gonna see about the Instagram Clone Using... | 0 | 2023-05-18T05:45:11 | https://dev.to/cwrcode/instagram-clone-using-html-and-css-with-source-code-4m0e | Hey buddy! , Welcome to the codewithrandom blog, here we gonna see about the **[Instagram Clone](https://www.codewithrandom.com/2023/02/11/instagram-clone-code-html-css/)** Using HTML and CSS With Source Code. Likewise, we just have created this beautiful Instagram Clone project to develop our knowledge and skills in html and css.
As we know Instagram is one of the popular social media apps which is founded in 2010.
So as of now, we have just started implementing the html code.
## Html Code For Instagram clone:
```
<div class="container">
<div class="all flex-row">
<div class="menu flex-column">
<div class="flex-row label-wrapper">
<img src="https://i.ibb.co/crgCrWT/instagram.png" />
<h3 class="insta-writing">Instagram</h3>
</div>
<div class="profil-img"></div>
<div class="profil-info">
<h2 class="name">Shailene Woodley</h2>
<h3 class="city">New York, NY</h3>
<div class="numbers">
<div class="post">
<p>Post</p>
<div class="post-num">116</div>
</div>
<div class="post">
<p>Followers</p>
<div class="post-num">48m</div>
</div>
<div class="post">
<p>Following</p>
<div class="post-num">48m</div>
</div>
</div>
<div class="menu-elements">
<div class="icons">
<img src="https://i.ibb.co/5csvQKW/home-2.png" />
<div class="feed-writing"> Feed </div>
</div>
<div class="icons">
<img src="https://i.ibb.co/y8wD2HZ/explore-tool.png" />
<div class="exp-writing"> Explore</div>
</div>
<div class="icons">
<img src="https://i.ibb.co/tsDcKD1/hashtag.png" />
<div class="trend-writing"> Trending Tags</div>
</div>
<div class="icons">
<img src="https://i.ibb.co/G2r0G8N/tick-inside-a-circle.png" />
<div class="top-writing"> Top Post </div>
</div>
<div class="icons">
<img src="https://i.ibb.co/XDnYxL9/user-symbol-of-thin-outline.png" />
<div class="people-writing"> People </div>
</div>
<div class="icons">
<img src="https://i.ibb.co/dWcct0k/notification.png" />
<div class="notif-writing"> Notification </div>
</div>
<div class="icons">
<img src="https://i.ibb.co/rQcCQcL/direction.png" />
<div class="direct-writing"> Direct </div>
</div>
<div class="icons">
<img src="https://i.ibb.co/VNSj2GR/pie-chart.png" />
<div class="stat-writing"> Stats </div>
</div>
<div class="icons">
<img src="https://i.ibb.co/smVnQkg/settings.png" />
<div class="set-writing"> Settings</div>
</div>
</div>
</div>
</div>
</div>
<div class="right-page">
<div class="top-bar">
<div class="form has-search">
<input class="text" type="search" placeholder="Search" name="search" />
<span class="searchIcon">
<img src="https://i.ibb.co/sqFgRq8/search.png" />
</span>
<span class="micro">
<img src="https://i.ibb.co/HNx8Xty/microphone.png"/>
</span>
</div>
<div class="cover-post">
<button class="button post-new">Create New Post</button>
<span class="plus">
<img src="https://i.ibb.co/0YG23j8/plus-symbol.png" />
</span>
</div>
<div class="mail-heart">
<div class="icon1">
<img src="https://i.ibb.co/6ZwMVGp/email.png" />
</div>
<div class="icon1">
<img src="https://i.ibb.co/K91ZTyF/heart.png" />
</div>
<div class="person-radius">
<img src="https://images.unsplash.com/photo-1519058082700-08a0b56da9b4?ixlib=rb-1.2.1&ixid=eyJhcHBfaWQiOjEyMDd9&auto=format&fit=crop&w=600&q=60" />
</div>
</div>
</div>
<hr class="hr-new">
<div class="right-of-page">
<div class="right-middle">
<div class="featured">
<div class="featured-header">
<h2 class="featured-stories"> Featured Stories</h2>
<button class="button popular-stor"> Popular Stories</button>
</div>
<div class="featured-body">
<div class="galery-wrapper">
<div class="img-galery">
<img
src="https://images.unsplash.com/photo-1562447279-69402cb4587d?ixlib=rb-1.2.1&ixid=eyJhcHBfaWQiOjEyMDd9&auto=format&fit=crop&w=600&q=60" />
</div>
<div class="img-galery">
<img
src="https://images.unsplash.com/photo-1495954484750-af469f2f9be5?ixlib=rb-1.2.1&ixid=eyJhcHBfaWQiOjEyMDd9&auto=format&fit=crop&w=600&q=60" />
</div>
<div class="img-galery">
<img
src="https://images.unsplash.com/photo-1462275646964-a0e3386b89fa?ixlib=rb-1.2.1&ixid=eyJhcHBfaWQiOjEyMDd9&auto=format&fit=crop&w=600&q=60" />
</div>
<div class="img-galery">
<img
src="https://images.unsplash.com/photo-1561363702-e07252da3399?ixlib=rb-1.2.1&ixid=eyJhcHBfaWQiOjEyMDd9&auto=format&fit=crop&w=600&q=60" />
</div>
</div>
</div>
</div>
<div class="featured">
<div class="featured-header">
<h2 class="featured-stories"> Latest Feed</h2>
<div class="icon-two">
<div class="icon3">
<img src="https://i.ibb.co/Jd2NwHV/menu-lines.png" />
</div>
<div class="icon3">
<img src="https://i.ibb.co/tZdq3jg/four-boxes.png" />
</div>
</div>
</div>
<div class="featured-body">
<div class="galery-wrapper">
<div class="img-galery">
<img
src="https://images.unsplash.com/photo-1426543881949-cbd9a76740a4?ixlib=rb-1.2.1&ixid=eyJhcHBfaWQiOjEyMDd9&auto=format&fit=crop&w=600&q=60" />
</div>
<div class="img-galery">
<img
src="https://images.unsplash.com/photo-1532347922424-c652d9b7208e?ixlib=rb-1.2.1&ixid=eyJhcHBfaWQiOjEyMDd9&auto=format&fit=crop&w=600&q=60" />
</div>
<div class="img-galery">
<img
src="https://images.unsplash.com/photo-1414609245224-afa02bfb3fda?ixlib=rb-1.2.1&ixid=eyJhcHBfaWQiOjEyMDd9&auto=format&fit=crop&w=600&q=60" />
</div>
</div>
</div>
<div class="last-body">
<div class="galery-wrapper">
<div class="img-galery">
<img
src="https://images.unsplash.com/photo-1506953823976-52e1fdc0149a?ixlib=rb-1.2.1&ixid=eyJhcHBfaWQiOjEyMDd9&auto=format&fit=crop&w=600&q=60" />
</div>
<div class="img-galery">
<img
src="https://images.unsplash.com/photo-1527212986666-4d2d47a80d5f?ixlib=rb-1.2.1&ixid=eyJhcHBfaWQiOjEyMDd9&auto=format&fit=crop&w=600&q=60" />
</div>
<div class="img-galery">
<img
src="https://images.unsplash.com/photo-1505158498176-0150297fbd7d?ixlib=rb-1.2.1&ixid=eyJhcHBfaWQiOjEyMDd9&auto=format&fit=crop&w=600&q=60" />
</div>
</div>
</div>
<div class="loader"></div>
</div>
</div>
<div class="last-right">
<img src="https://images.unsplash.com/photo-1519058082700-08a0b56da9b4?ixlib=rb-1.2.1&ixid=eyJhcHBfaWQiOjEyMDd9&auto=format&fit=crop&w=600&q=60" />
<h2 class="name2">BENJAMIN HARDMAN</h2>
<div class="follows">
<div class="post">
<p>Photos</p>
<div class="post-num">882</div>
</div>
<div class="post">
<p>Followers</p>
<div class="post-num">527k</div>
</div>
</div>
<div class="read-me">
Benjamin is a freelance photographer in Iceland. He is interested in UI development and design.
Five years ago Benjamin embarked on his first photographic mission in an Arctict winter climate
Benjamin is a freelance photographer in Iceland. He is interested in UI development and design.
Five years ago Benjamin embarked on his first photographic mission in an Arctict winter climate...<span class="read"> Read more</span>
</div>
<div class="feature">
<div class="post2">
<p>Locations</p>
<div class="post-num">Based in Iceland</div>
</div>
<div class="post2">
<p>Profession</p>
<div class="post-num">Photographer</div>
</div>
<div class="post2">
<p>Profession</p>
<div class="post-num">Developer</div>
</div>
</div>
</div>
</div>
</div>
</div>
```
Now we have implemented the html code successfully. Here we just used the upload and view option with the help of a button and text area tag to upload posts and view our photos.
Also, we added card properties to display the profile as the grid card contains user names, descriptions, followers and followings, and lastly, likes and comments.
Then we just include some bootstrap lines for responsive design to get vary on different screens. And furthermore, div tags are added for each and every element in this html code to make alignments and changes using css.
So as of now, we have just finished the html code, and now we can move into the css part. The respective code is given down.
## CSS Code For Instagram clone:
```
* {
box-sizing: border-box;
}
body {
width:100%;
height:100%;
font-family: Sans-serif;
}
.flex-row > img {
width: 25px;
height: 25px;
}
.flex-row {
display: flex;
align-items: center;
}
.label-wrapper {
margin: 0px 20px;
}
.insta-writing {
padding: 0px 15px;
}
.menu {
border-right: 2px solid #F5F5F5;
height: 100%;
width: 330px;
background-color: #F5F5F5;
overflow:hidden;
min-width:330px;
}
.profil-img {
background-image: url("https://m.media-amazon.com/images/M/MV5BOTIxNTE2NTQ3Nl5BMl5BanBnXkFtZTcwMzMwOTk2Nw@@._V1_UY1200_CR85,0,630,1200_AL_.jpg");
width: 100px;
height: 100px;
background-size: cover;
border-radius: 50%;
border: 0.1em solid #eb2d53;
margin: auto;
margin-top: 30px;
box-shadow: inset 0px 0px 0px 5px white;
}
.profil-info {
text-align: center;
}
.city {
color: grey;
font-weight: normal;
}
.numbers{
display: flex;
justify-content: space-between;
padding: 0 20px;
}
p{
font-weight: bold;
}
.post-num {
color: grey;
font-weight: normal;
}
.feed-writing {
color: #F82867;
}
.icons {
display: flex;
align-items: center;
margin-top:15px;
}
.menu-elements {
padding: 20px 15px;
color:#A0A0A0;
font-size:1.1em;
font-weight: normal;
}
.icons > img {
margin: 0px 25px 5px;
}
.right-page{
margin-top:10px;
flex:1;
}
.container{
display:flex;
width:100%;
}
.searchIcon{
background-position:5px 5px;
padding:0 45px;
position:absolute;
z-index:2;
}
.micro{
background-position:5px 5px;
right:0;
position:absolute;
z-index:2;
}
.has-search .text {
padding-left: 30px;
margin-left:35px;
}
.form{
position:relative;
z-index:2;
display:inline-flex;
align-items:center;
}
.text{
border:1px solid #ddd;
border-radius:4px;
width:280px;
height:30px;
background-color:#F8F8F8;
}
.post-new{
border:1px solid pink;
width:190px;
height:30px;
background-color: #ee4466;
border-radius:4px;
color:white;
text-align:center;
font-size:17px;
position:relative;
}
.top-bar{
display:flex;
align-items:center;
}
.plus{
right:0;
position:absolute;
margin-top:2px;
}
.mail-heart{
display:flex;
margin:0 40px ;
align-items:center;
}
.person-radius > img{
width:30px;
height:30px;
border-radius:50%;
background-size:cover;
}
.icon1{
margin-right:20px;
}
.hr-new{
margin-top:30px;
border: 0.5px solid #ddd;
}
.featured{
display:flex;
justify-content:space-between;
}
.right-middle{
display:flex;
flex-wrap:wrap;
padding:0 20px;
width:100%;
flex-direction:column;
}
.right-of-page{
display:flex;
justify-content:space-between;
}
.right-right{
max-width:250px;
}
.popular-stor{
width:150px;
height:30px;
border-radius:3px;
border:1px solid #E0E0E0;
color:#C0C0C0;
background-color:#F8F8F8;
font-weight:600;
font-size:14px;
}
.last-right > img{
padding:0 10px;
max-width:100%;
background-size:cover;
border-radius:20px;
}
.last-right{
width:25%;
}
.name2{
text-align:center;
}
.cover-post{
margin-left:auto;
}
.galery-wrapper{
display:inline-flex;
}
.img-galery > img{
width: 100%;
height:100%;
padding:0 5px;
object-fit: cover;
border-radius:10px;
margin-top:-10px;
}
.featured-stories{
width: 50%;
margin: 0;
}
.featured {
display:flex;
flex-wrap:wrap;
flex-direction: column;
}
.featured-header, .featured-body {
display:flex;
flex-direction: row;
}
.featured-header{
justify-content:space-between;
}
.icon-two{
display:flex;
width:60px;
justify-content:space-between;
}
.last-body{
margin-top:10px;
}
.follows{
display: flex;
justify-content: space-between;
padding: 0 10px;
}
.read{
font-weight:bold;
color:#282828;
}
.read-me{
margin-top:15px;
color: grey;
}
.post2{
padding:15px 0 0 0;
}
.loader {
width: 3rem;
height: 3rem;
border: 0.6rem solid #999;
border-bottom-color: transparent;
border-radius: 50%;
margin: 0 auto;
animation: loader 500ms linear infinite;
}
@keyframes loader {
to {
transform: rotate(360deg);
}
}
@media (max-width: 840px){
.last-right{
display:none;
}
.menu{
display:none;
}
.galery-wrapper{
display:flex;
flex-wrap:wrap;
}
.top-bar{
display:none;
}
.img-galery{
margin-bottom:10px;
}
}
```
Now the css is implemented successfully. In this, we have first styled our body and html properties and then we move on to style our card properties which are used for a profile view.
Then we have just added several styling properties to links, buttons, icons, and a lot more to make it look attractive and user responsive.
Also, we include margins and padding to make every element align properly according to the values set, then some more contents like flexbox, the grid has been implemented to work on size adjustments, font adjustments, and content alignment to perform on various screens. Lastly, media queries were used for element operations on different screens.
As of now, we have just finished the css, and one more thing left is to view our project preview which you may find in the output section.
As we successfully created our **[Instagram Clone](https://www.codewithrandom.com/2023/02/11/instagram-clone-code-html-css/)** project source code with html and css. We have now come to an end... But make sure to work on this project with the code given. Also, you may use the code pen link for your project which is mentioned below.
Hope you find out this blog help full. , then make sure to follow codewithrandom on Instagram for featured front-end web development projects. Also, share this blog with your friends so they can make use of it.
Written by - Raghunathan s | cwrcode | |
1,471,124 | What is Single Sign-on, OpenID, SAML and OAuth How can they be used together | As the number of applications and services we use in our daily lives continues to increase, so does... | 0 | 2023-05-17T14:06:17 | https://ssojet.com/blog/what-is-single-sign-on-openid-saml-and-oauth-how-can-they-be-used-together/ | security, oauth, identity, saml | As the number of applications and services we use in our daily lives continues to increase, so does the number of usernames and passwords we must remember. Single sign-on (SSO) is a solution that aims to simplify the user login experience by allowing users to authenticate once and access multiple applications and services without the need to enter their credentials multiple times.
## **What is Single Sign-On?**
Single sign-on (SSO) is a mechanism that enables users to authenticate once and access multiple applications and services without the need to enter their credentials multiple times. With SSO, users only need to enter their username and password once, and this information is then used to authenticate the user across multiple applications and services.
The primary benefit of SSO is convenience. Users no longer need to remember multiple usernames and passwords for different applications and services, reducing the likelihood of forgotten passwords and improving the user experience.
However, SSO also provides security benefits. With SSO, users are only required to enter their credentials once, reducing the risk of phishing attacks and other forms of credential theft. Additionally, SSO can provide better control over user access, as administrators can easily manage user authentication and access to different applications and services.
## **OpenID**
OpenID is an open standard for authentication that allows users to authenticate with a single set of credentials across multiple websites and applications. With OpenID, users create an account with an OpenID provider, such as Google or Yahoo, and use this account to authenticate across multiple websites and applications that support OpenID.
OpenID relies on the exchange of information between the user, the OpenID provider, and the relying party (the website or application that the user is trying to access). When a user attempts to authenticate with an OpenID-enabled website or application, they are redirected to their OpenID provider. The user then enters their credentials on the OpenID provider’s site, and the provider sends an assertion back to the relying party, confirming that the user has been authenticated.
One of the main advantages of OpenID is that it provides a decentralized authentication system. Users can choose their OpenID provider, and websites and applications can support multiple OpenID providers, providing users with more choice and flexibility.
## **SAML**
Security Assertion Markup Language (SAML) is an XML-based standard for exchanging authentication and authorization data between parties. SAML is widely used for SSO in enterprise environments, where users need to authenticate with multiple applications and services within the organization.
SAML relies on the exchange of SAML assertions between the identity provider (IDP) and the service provider (SP). The IDP is responsible for authenticating the user, while the SP is responsible for authorizing access to the requested resource.
When a user attempts to access a resource on an SP, they are redirected to the IDP. The IDP then authenticates the user and sends a SAML assertion to the SP, confirming the user’s identity and authorizing access to the requested resource.
SAML provides a robust and secure mechanism for SSO, as all communication between the IDP and the SP is encrypted and digitally signed. SAML also provides a standardized way of exchanging user attributes and other information between the IDP and the SP, allowing for better control over user access.
## **OAuth**
OAuth is an open standard for authorization that allows users to grant access to their resources to third-party applications without sharing their credentials. OAuth is commonly used for granting access to social media accounts and other web-based resources.
## **What is the difference between OpenID, SAML, and OAuth**
OpenID, SAML, and OAuth are all authentication and authorization protocols used for Single Sign-On (SSO) but they differ in their use cases and features.
OpenID is an open standard protocol that allows users to authenticate with a single set of credentials across multiple websites and applications. It is primarily used for consumer-facing applications such as social media sites or e-commerce platforms. OpenID is often used in combination with OAuth to provide authorization for third-party applications.
SAML (Security Assertion Markup Language) is a protocol used for enterprise SSO, allowing users to authenticate with multiple applications and services within an organization. SAML is typically used in larger enterprises where security and access control are critical. SAML provides a more robust set of features, such as fine-grained access control and federation capabilities, which allow users to access resources across different organizations.
OAuth (Open Authorization) is a protocol that enables third-party applications to access a user’s resources without sharing credentials. It is primarily used for granting access to resources owned by the user, such as social media accounts, cloud storage, or email. OAuth provides a secure mechanism for granting access to resources without sharing credentials, reducing the risk of credential theft and other security issues.
In summary, OpenID is used for consumer-facing applications, SAML is used for enterprise SSO, and OAuth is used for granting access to resources owned by the user. While there is some overlap between these protocols, each has its own strengths and use cases.
OAuth relies on the exchange of access tokens between the user, the resource owner, the client, and the authorization server. When a user grants access to a third-party application, the application requests an access token from the authorization server. The user is then redirected to the authorization server, where they are prompted to authenticate and authorize the application’s request. If the user grants authorization, the authorization server issues an access token to the application, which can then be used to access the user’s resources.
OAuth provides a secure mechanism for granting access to resources without sharing credentials, reducing the risk of credential theft and other security issues.
## **Using OpenID, SAML, and OAuth Together**
While OpenID, SAML, and OAuth are often used for different purposes, they can also be used together to provide a more comprehensive SSO solution.
For example, a company may use SAML for enterprise SSO, allowing users to authenticate with multiple applications and services within the organization. The company may also use OAuth to allow third-party applications to access certain resources, such as social media accounts.
In this scenario, OpenID could be used as a bridge between SAML and OAuth, allowing users to authenticate once with their enterprise credentials and then use those credentials to access third-party resources that use OAuth.
By using OpenID, SAML, and OAuth together, organizations can provide a seamless and secure SSO experience across a wide range of applications and services.
## **Conclusion**
Single sign-on (SSO) provides a convenient and secure way for users to authenticate across multiple applications and services without the need to enter their credentials multiple times. OpenID, SAML, and OAuth are three protocols commonly used for SSO, each with its own strengths and use cases.
While OpenID, SAML, and OAuth are often used for different purposes, they can also be used together to provide a more comprehensive SSO solution. By using these protocols together, organizations can provide a seamless and secure SSO experience across a wide range of applications and services, improving the user experience and reducing the risk of credential theft and other security issues. | andrew89 |
1,471,313 | kdenlive - Open-Source Video Editing | I recently started a new podcast. I knew the audio would be published across multiple services, but... | 0 | 2023-05-17T16:25:39 | https://dev.to/jluterek/kdenlive-open-source-video-editing-42dh | I recently started a new podcast. I knew the audio would be published across multiple services, but also wanted a video version for youtube. With a background in programming, this left my trying to figure out how to accomplish this task.
There are many video editing software options available, which was extremely overwhelming, each had different requirements and prices attached. Instead I went to my roots and looked at the open-source offerings. This is what brought me to kdenlive, software that can run on Windows, Mac, and Linux. Kdenlive, stands for KDE Non-Linear Video Editor. As you would expect the software lives under the KDE umbrella of applications. I used the software with both windows and PopOS!, while the linux version felt more stable, both worked well.
**Multiple Video and Audio Streams**
The recordings made for this podcast involved three mic inputs and two camera inputs (with audio). All of these tracks needed to be managed separately, which Kdenlive is able to do. The video sources were linked with their audio track, but could be separated where necessary. All tracks could be synced automatically by their audio ensuring the different sources lined up properly.
The multiple video sources were great for making a more engaging video, but also allowing for easier cuts. Content could be edited without making a jarring video cut by switching between the different camera sources.
To manage multiple streams, Kdenlive uses a timeline-based interface. Each video or audio stream is placed on a different track, which can be independently edited, enabling you to fine-tune every aspect of your project. It's as simple as importing your media files and dragging them onto the timeline.
**A Robust Ecosystem**
The leading commercial options have massive ecosystems with templates and guides for sale everywhere. This was a concern going open-source and with a less popular software option. I was pleasantly surprised by the vibrant ecosystem that includes plenty of help content, tutorial videos, user forums, and more. The official Kdenlive website has a comprehensive manual covering all aspects of the software, including beginner-friendly tutorials and more advanced topics.
There is also an active community of Kdenlive users who regularly create and share tutorial videos on various aspects of the software. From basic editing techniques to more advanced effects and transitions, these tutorials provide a wealth of knowledge for any level of user.
Any time I needed to do something new, there was a video tutorial or guide ready to help guide me through the process. This ecosystem and community made the software accessible for a complete video editing beginner.
**Free and Open-Source**
Kdenlive is a free and open-source project. I’m sure this community understands the massive value of open-source and the benefits it brings.
**Beginner Friendly**
Despite its powerful capabilities, Kdenlive felt very accessible to beginners. Its interface felt very intuitive and any difficult functionality had a wealth of tutorial videos available. Its design allows users to grow with the software. As you become more comfortable with its basic features, you can gradually start exploring its more advanced capabilities, changing the interface layout, and leveraging more keyboard shortcuts, making Kdenlive a great choice.
**Final Thoughts**
I will continue to leverage Kdenlive for my future video editing requirements. If you want to see the final outcome the video can be found [here](https://youtu.be/ZvyQ3qTHrOA).
If you want to get started with kdenlive, checkout their [website](https://kdenlive.org/) or [github](https://github.com/KDE/kdenlive).
| jluterek | |
1,471,316 | MongoDB With Docker | I am explaining how Docker can be utilized to set up the database and demonstrate its practical... | 0 | 2023-05-21T16:19:04 | https://dev.to/devkishor8007/mongodb-with-docker-23d5 | docker, mongodb, cli, database | I am explaining how Docker can be utilized to set up the database and demonstrate its practical applications. In this article, I am focusing on utilizing the MongoDB database and provide instructions on its utilization.
There are several benefits to setting up MongoDB with Docker instead of installing it directly on your local PC:
- `Isolation`: Docker keeps MongoDB separate from your local system, ensuring stability and consistency.
- `Deployment`: Docker makes it easy to deploy multiple MongoDB instances and manage replica sets or clusters.
- `Consistency`: Docker ensures consistent environments across different machines, avoiding version or configuration conflicts.
- `Cleanup and Portability`: Docker allows easy removal of MongoDB containers and seamless migration to different environments.
- `Dependency Management`: Docker simplifies managing MongoDB versions and dependencies.
I'm ready to help you install MongoDB in a Docker container. Let's get started!
To install mongo in docker
```
docker pull mongo
```
To determine if MongoDB is installed within our Docker environment, we need to check whether the Mongo image is present. If the image is found, we can view its ID, tag/version, and size. However, if the image is not available, no information will be displayed.
```
docker images mongo
```
Run the first MongoDB container:
```
docker run -d --name mongo-one -p 27017:27017 mongo
```
Run the Second MongoDB container:
If you need the multiple container, then you can use it
```
docker run -d --name mongo-two -p 27018:27017 mongo
```
In this above example, the container are mongo-one and mongo-two, and the -p option maps port 27017/27018 from the host machine to the container. You can choose a different container name and port mapping if desired.
Show all currently running Docker containers
```
docker ps
```
execute a running Docker container: mongo-one
```
docker exec -it mongo-one bash
```
after execute a running docker container of mongo, we have to start the MongoDB Shell and interact with the MongoDB database running inside the container
```
mongosh
```
Once the MongoDB container is successfully executed, you will obtain the database URL, which can be used with various programming languages such as Node.js, Python, Rust, Go, and more. This URL will enable you to establish a connection to the MongoDB database from your chosen programming environment.
```
const DB_URL1='mongodb://localhost:27017/<db_name>';
const DB_URL2='mongodb://localhost:27018/<db_name>';
```
Both DB_URL1 and DB_URL2 are database URLs that can be obtained when running the Docker containers for MongoDB. If you execute the "mongo-one" and "mongo-two" containers as mentioned, both DB_URL1 and DB_URL2 will be operational and can be used to establish connections to the respective MongoDB databases.
Once the database is up and running, I can share a set of commands through the Docker shell to interact with MongoDB. These commands enable us to perform various operations and manipulate the MongoDB database within the Docker environment
show all the databases
```
show dbs
```
Feel free to use the `help` command if you find yourself confused or uncertain about how to proceed.
```
help
```
switch to the `store` database
```
use store
```
Get all the collections present in the currently selected database
```
show collections
```
Create multiple fruit in the store
```
db.fruit.insertMany([
{name:"apple", price: 250, color: "red"},
{name:"banana", price: 120, color: "yellow"},
{name:"papaya", price: 150, color: "yellowish-orange"}
])
```
Get all the fruit
```
db.fruit.find()
```
Get all the fruits which `name` contain `banana`
```
db.fruit.find({name: "banana"})
```
Get the single fruit by `name`
```
db.fruit.findOne({name: "banana"})
```
Updates a single document based on the matching name
```
db.fruit.findOneAndUpdate(
{ name: "banana" },
{ $set: { price : 100 } },
)
```
_Resources_
- [Fundamental MongoDB](https://www.mongodb.com/docs/drivers/node/current/fundamentals/crud/)
- [Learn MongoDB](https://learn.mongodb.com/?tck=docs_landing)
- [Awesome MongoDB](https://github.com/ramnes/awesome-mongodb)
- [Start Docker](https://docs.docker.com/get-started/)
- [Awesome Docker](https://github.com/veggiemonk/awesome-docker)
Thank you.
Remember to keep learning and exploring new things.
| devkishor8007 |
1,471,560 | Copilot Chat writes Unit Tests for you! | We don't write tests because we don't have time. How many times have you heard that? Or maybe you... | 27,226 | 2023-05-18T06:53:23 | https://leonardomontini.dev/copilot-x-chat-unit-test/ | github, testing, ai, githubcopilot | > We don't write tests because we don't have time.
How many times have you heard that? Or maybe you said it yourself? I know you did, we all do at some point.
The thing is, you should probably also know it's not a valid reason. The time you usually spend manually testing your code (for example, by running the app and clicking around), in addition to all the time spent in fixing bugs, is way more than the time you'd spend writing the tests.
Oh, imagine one day you have to edit again that part of the code, you forgot what a specific method does and a tiny change causes a bug that the client will find a week later. Great, you now have an angry client and you're also in a hurry to fix it.
Still not having time to write tests?
## Copilot Chat
One of the coolest features of Copilot Chat, one of the tools in the Copilot X suite, is the ability to generate unit tests for you. You just need to select a block of code and ask Copilot to write the tests for you.
Cool, it will make you and me save so much time!
But... is it reliable? Let's find out.
## Points of attention
Yeah sure, in a single click, you have a bunch of tests written for you. But you should pay attention to some details.
I'll further explore the following topics in the video:
- **Copilot tries to guess the logic of your code** -
If it's right, it will help you find bugs. Is it wrong? Well, you'll have a bunch of tests that don't make sense.
- **Copilot doesn't know what you're testing** - It will generate tests for the code you selected, but it doesn't know what you're trying to test. In some cases might be more noise than signal.
- **Copilot doesn't know your business logic** - If you wrote code that actually makes sense, Copilot will generate tests that make sense. But what if your business logic is not what the client asked? The generated tests will validate the wrong logic.
- **The scope is limited to the selected code** - If in the method you're trying to test you're calling other methods in other files, Copilot doesn't know what's inside and will try to guess.
## Demo
If you're curious and you want to see it in action, check out the video below:
{% youtube Psm86eIvmdc %}
---
I might sound boring at this point, but the closing chapter of all of my Copilot/AI posts is pretty much always the same.
These are incredibly amazing tools, they speed up our work a lot giving us more time to deliver quality products and more value to our clients, BUT, we should always be careful, eyes open, and make sure we understand what we're doing and what the tools are doing for us.
Will I use it to generate tests? Probably yes. Will I use the generated tests as they are? Probably not.
What do you think? Let me know!
---
Thanks for reading this article, I hope you found it interesting!
I recently launched my Discord server to talk about Open Source and Web Development, feel free to join: https://discord.gg/bqwyEa6We6
Do you like my content? You might consider subscribing to my YouTube channel! It means a lot to me ❤️
You can find it here:
[](https://www.youtube.com/channel/UC-KqnO3ez7vF-kyIQ_22rdA?sub_confirmation=1)
Feel free to follow me to get notified when new articles are out ;)
{% embed https://dev.to/balastrong %} | balastrong |
1,471,833 | Click & Launch a Meteor Blaze App (PWA ready) at Github Codespaces (& Actions test) | MeteorJS MeteorJS is an open-source full-stack JavaScript platform that is useful for... | 23,078 | 2023-05-19T03:18:49 | https://dev.to/kafechew/click-launch-a-meteor-blaze-app-environment-at-github-codespaces-actions-test-4ek7 | githubactions, meteorjs, moopt, showdev | ## MeteorJS
[MeteorJS](https://blaze-tutorial.meteor.com/) is an open-source full-stack JavaScript platform that is useful for developing modern web and mobile applications. Meteor helps the developer to develop in one language. Meteor has several features that help for creating a responsive and reactive web or mobile application using JavaScript or different packages available in the framework.
For starts working with any technology, first of all, we need to create a suitable environment. Meteor currently supports OS X, Windows, and Linux. Only 64-bit is supported. The main prerequisite is Node.js.
We will use [BlazeJS](https://github.com/meteor/blaze), a powerful library for creating user interfaces by writing reactive HTML templates. Compared to using a combination of traditional templates and jQuery, Blaze eliminates the need for all the "update logic" in your app that listens for data changes and manipulates the DOM. Blaze is a Meteor-only package for now.
Instead of setting MeteorJS environment manually (especially as the application will be getting more complex from time to time), for example adding Progressive Web App (PWA), we leverage [Meteor.js devcontainer](https://github.com/meteorengineer/meteor-dev-container) by Meteor Engineer. Now, you can simply go to [moopt-codespace-action repo](https://github.com/Mooptcom/moopt-codespace-action) and create a codespace based on this repo in seconds!
{% embed https://www.youtube.com/watch?v=A1On7u3h9VI %}
## Github Codespaces
[GitHub Codespaces](https://github.com/features/codespaces/) are development environments hosted in the cloud. You can customize your project for GitHub Codespaces by configuring dev container files to your repository (often known as Configuration-as-Code), which creates a repeatable codespace configuration for all users of your project.
GitHub Codespaces run on a variety of VM-based compute options hosted by GitHub, which you can configure from 2 core machines up to 32 core machines.
GitHub Codespaces is similar to your local IDE, so you don't really able to host an application with it.
GitHub Codespaces allowed me to work on the project from any device, anywhere in the world, with a pre-configured development environment that included all the necessary tools and dependencies, enabling me to focus on coding without worrying about setting up my local environment.
## Step-by-step to Click & Launch a Meteor Blaze App Environment at Github Codespaces
Step 1: Go to [moopt-codespace-action repo](https://github.com/Mooptcom/moopt-codespace-action)
Step 2: Click to launch a Codespace
Step 3: Wait
Step 4: Awesome!
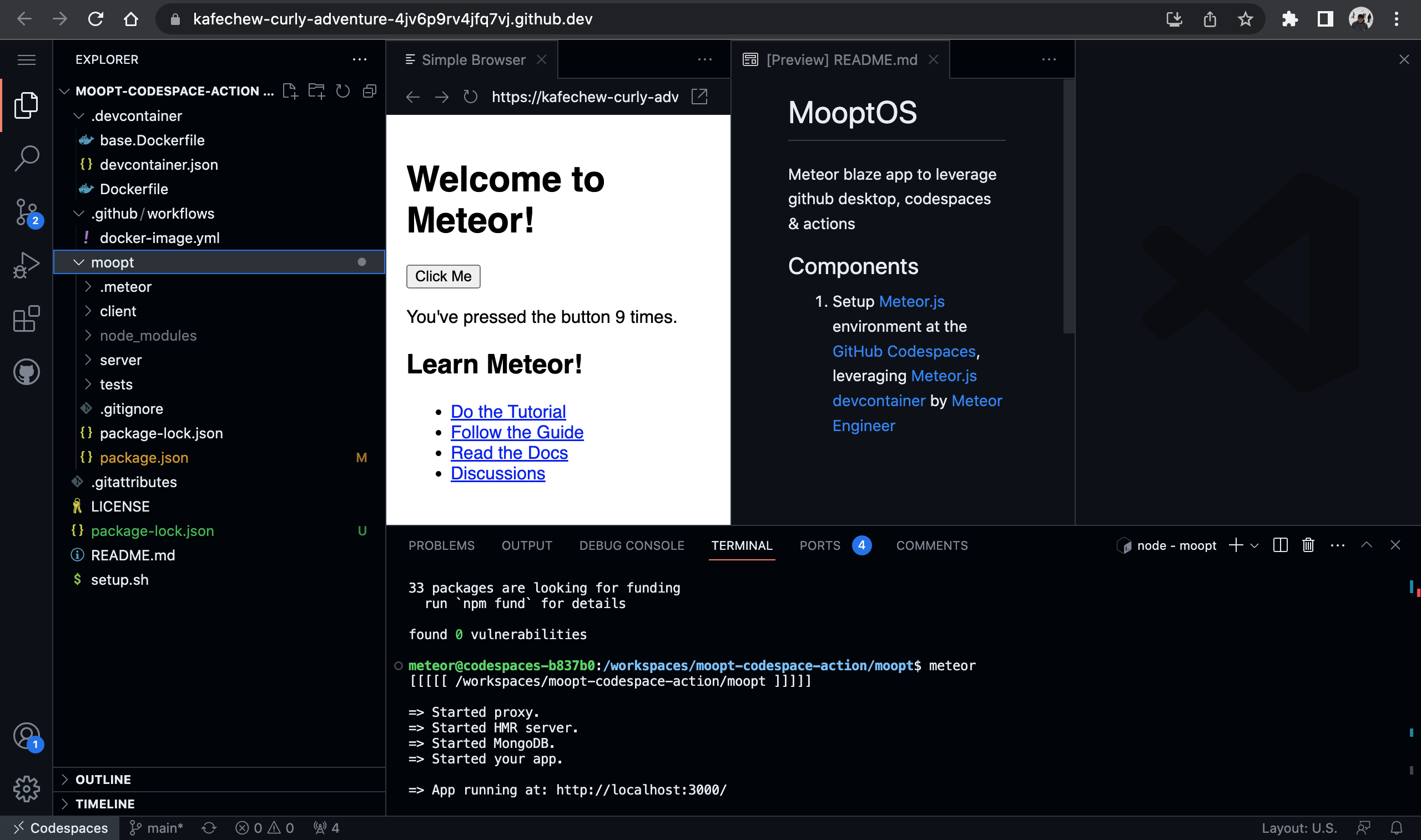
## Behind the Scene
Used Github Desktop to add existing local repository.

## Progressive Web App (PWA)
Before
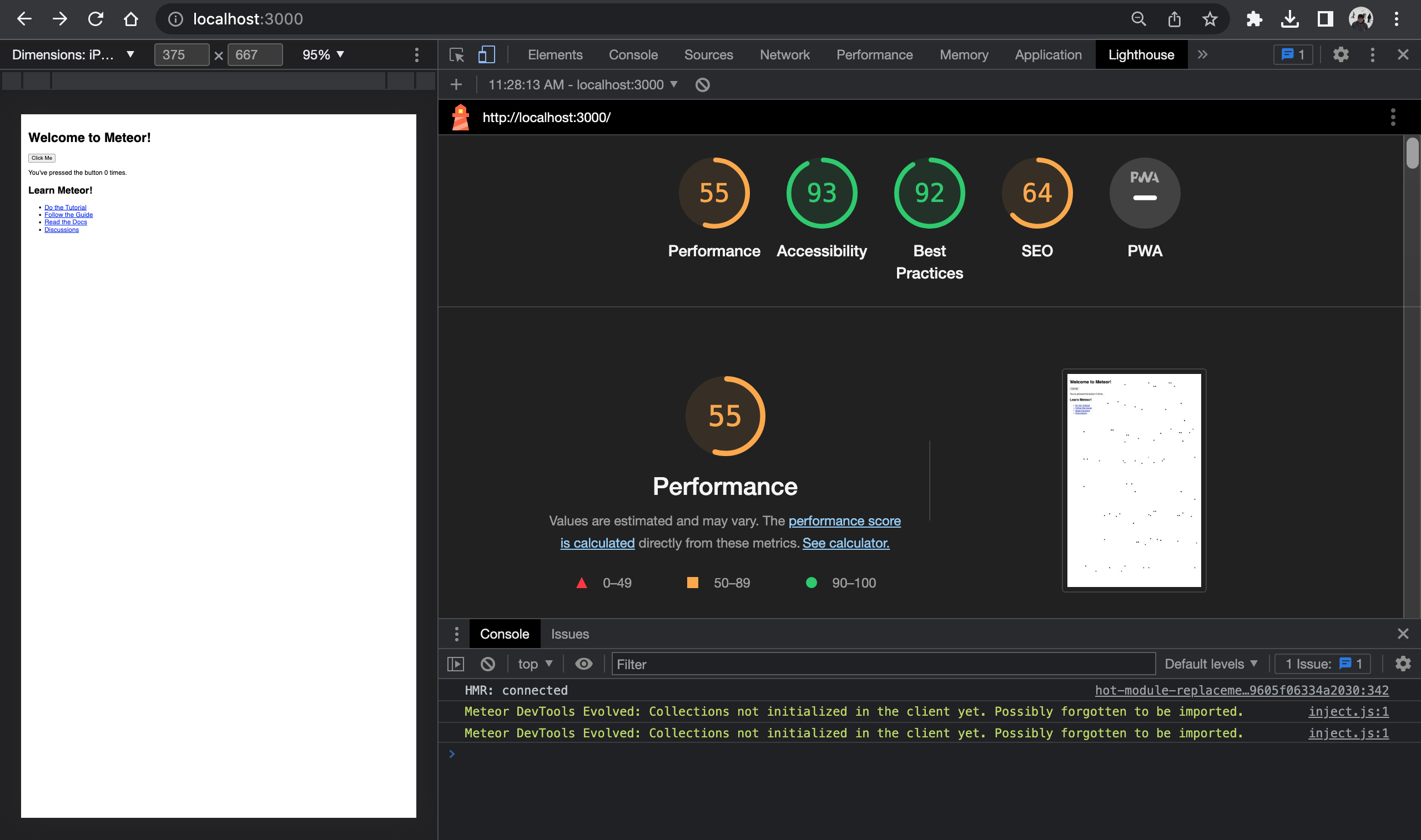
After
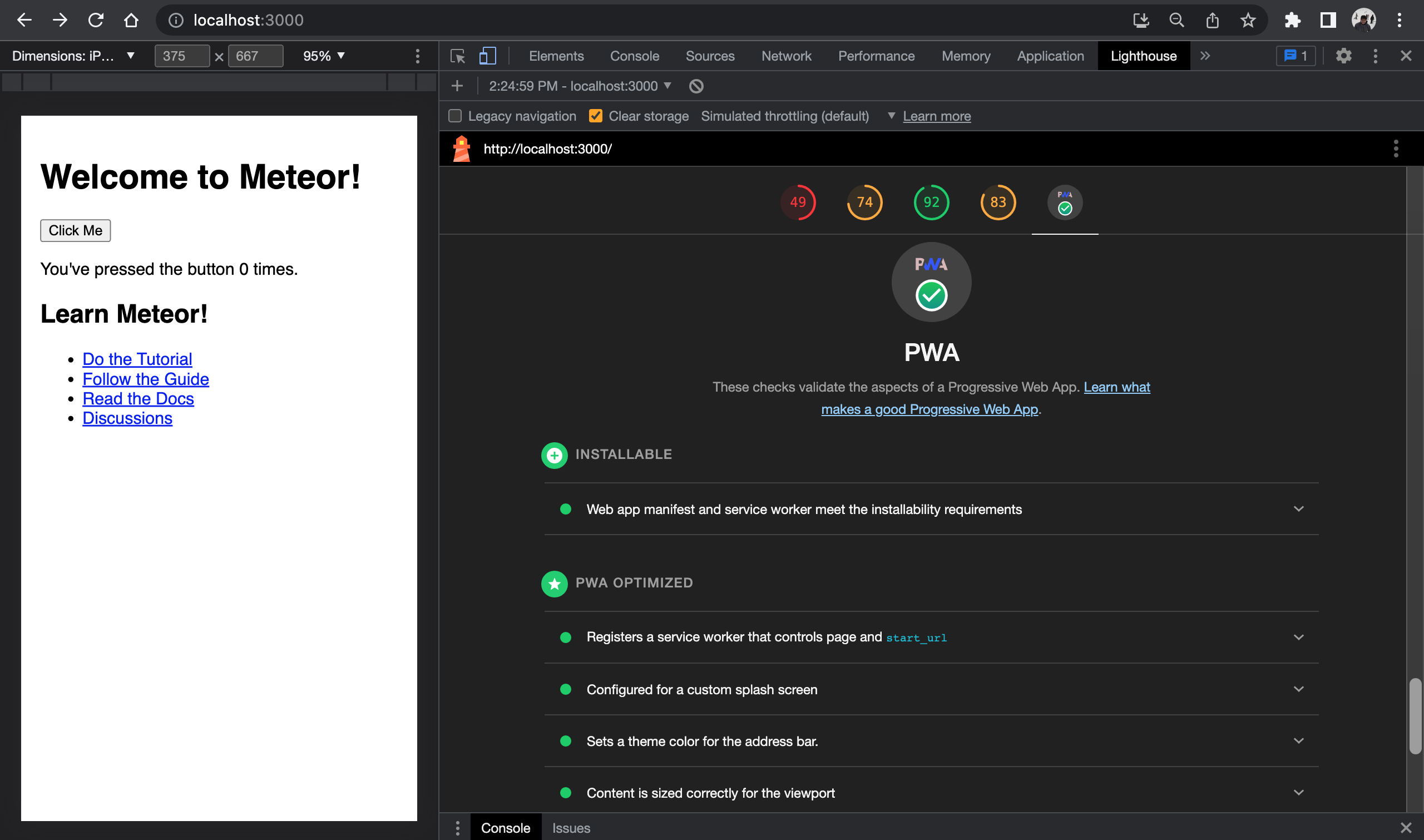
## Github Actions
[Github Actions](https://github.com/actions/starter-workflows) is a combination of individual tasks, to define custom workflows that automated the entire development lifecycle, from code changes, testings to deployments.
{% embed https://www.youtube.com/watch?v=A1On7u3h9VI %}
To be continue...
| kafechew |
1,471,850 | Complete Guide On Vaping and Eye Floaters | Vaping and Eye Floaters Vaping has gained significant popularity in recent years as an alternative to... | 0 | 2023-05-18T06:17:35 | https://dev.to/openalltime/complete-guide-on-vaping-and-eye-floaters-4pi | vaping |
[Vaping and Eye Floaters](https://www.openalltime.com/blog/does-vaping-make-your-eyes-red/)
Vaping has gained significant popularity in recent years as an alternative to traditional smoking. Its rise in popularity can be attributed to various factors, including the perception that vaping is a safer alternative and its ability to deliver nicotine without the harmful effects of tobacco smoke. However, concerns have been raised about the potential health risks associated with vaping, including its impact on eye health. This article explores the link between vaping and eye floaters, shedding light on this lesser-known aspect of vaping's potential consequences.
**Introduction**
Vaping, also known as electronic cigarette use, involves inhaling and exhaling an aerosol produced by an electronic device. This aerosol, commonly referred to as vapor, is created by heating a liquid that typically contains nicotine, flavorings, and other chemicals. On the other hand, eye floaters are small specks or thread-like structures that appear in a person's field of vision. These floaters are most noticeable when looking at a bright background, such as a clear sky or a white wall. They are actually shadows cast on the retina by tiny clumps of gel or cells in the vitreous humor, the clear gel-like substance that fills the eye.
**The Link Between Vaping and Eye Floaters**
The popularity of vaping has skyrocketed in recent years, particularly among young adults and individuals seeking smoking alternatives. While it may seem like a harmless activity, vaping has raised concerns regarding its potential side effects. Although research is still limited, some studies suggest that vaping can have detrimental effects on eye health, including an increased risk of eye floaters.
**Understanding Eye Floaters**
Before delving into the potential connection between vaping and eye floaters, it is crucial to understand what eye floaters are and their causes. Eye floaters are tiny specks or cobweb-like structures that drift across a person's visual field. They are most commonly caused by changes in the vitreous humor, which occurs as part of the natural aging process. Additionally, eye injuries, inflammation, and certain medical conditions can also contribute to the development of eye floaters.
**The Impact of Vaping on Eye Health**
While the precise mechanisms through which vaping may lead to eye floaters are not yet fully understood, researchers speculate that the chemicals present in vaping liquids, such as nicotine and various flavorings, could have an impact on the vitreous humor. The vitreous humor plays a crucial role in maintaining the shape of the eye and providing support to the retina. Any alterations in its composition or quality can disrupt the normal flow of light through the eye, leading to the perception of floaters.
Moreover, vaping has been associated with various eye health concerns, including dry eyes, irritation, and conjunctivitis. Dry eyes occur when the eyes fail to produce enough tears or when tears evaporate too quickly. Irritation can result from the chemicals present in vaping liquids, which may come into contact with the eyes during exhalation. Conjunctivitis, commonly known as pink eye, is an inflammation of the conjunctiva, the thin, transparent layer that covers the white part of the eye and the inner surface of the eyelids. These eye health issues can contribute to the discomfort and may exacerbate the appearance of eye floaters.
**Tips for Preventing Eye Floaters and Protecting Eye Health**
While more research is needed to establish a definitive link between vaping and eye floaters, taking steps to protect eye health is crucial. Regular eye examinations are essential for detecting any changes in the eyes and diagnosing potential eye conditions at an early stage. Additionally, individuals who vape should consider quitting or reducing their vaping habits, as this may help minimize the potential risks associated with vaping, including the development of eye floaters. Finally, practicing good eye hygiene, such as avoiding eye strain, staying hydrated, and protecting the eyes from excessive sunlight, can help maintain overall eye health.
**Conclusion**
As vaping continues to gain popularity as an alternative to traditional smoking, it is essential to be aware of its potential consequences, including its impact on eye health. While further research is needed to establish a definitive link between vaping and eye floaters, there is growing evidence to suggest that vaping may increase the risk of developing eye floaters. By understanding the potential risks associated with vaping and adopting preventive measures, individuals can take steps to protect their eye health and overall well-being.
| openalltime |
1,471,997 | JavaScript Founder & history (Bangla language) | A post by Nipu Chakraborty | 0 | 2023-05-18T08:20:58 | https://dev.to/nipu/javascript-founder-history-bangla-language-4jgc | javascript, node, programming, tutorial | {% embed https://www.youtube.com/watch?v=_tO8t-TIL9c %} | nipu |
1,472,052 | Recognizing 2D shapes and how to draw them on a canvas. | Table of content: Understanding what a 2D shape is. What is a dimension? What then is a... | 23,050 | 2023-05-18T09:18:44 | https://dev.to/_aaallison/recognizing-2d-shapes-and-how-to-draw-them-on-a-canvas-i6k | webdev, tutorial, html, javascript |
**Table of content:**
1. [Understanding what a 2D shape is.](#item-one)
- [What is a dimension?](#item-two)
- [What then is a 2D?](#item-three)
2. [How do we use programming to draw 2D shapes?](#item-four)
- [What is a Canvas?](#item-five)
- [The syntax for using the `<canvas>` element.](#item-six)
3. [Drawing on the canvas](#item-seven)
<a id="item-one"></a>
## Understanding what a 2D shape is.
**2D** is a compound term made up of two words: (**2** and **dimensions**).
We all know the number 2.
<a id="item-two"></a>
### What is a dimension?
A dimension is the measurement of distance in a specific direction.
Think of a straight line. You can move from point a(left) to point b(right), and then back to point a(left). Because you can only move along that line, it is referred to as a first dimension (1D).
<a id="item-three"></a>
### What then is a 2D?
2D stands for two dimensions, as the name implies. This means that in addition to moving left and right in the first dimension (1D), you may now move up and down. There are two ways in 2D: left-right (horizontal) and up-down (vertical).
The point from left to right will be labeled width, and the point from top to bottom will be labeled height. Triangles, rectangles, squares, and circles are examples of 2D shapes.
A 2-dimensional shape is defined as any shape with only two dimensions: height and width.
<a id="item-four"></a>
## How do we use programming to draw 2D shapes?
That is where the concept of a canvas comes into play.
<a id="item-five"></a>
### What is a Canvas?
A canvas is a digital surface used in online graphics. A canvas is used to create anything from simple shapes to complex animations. We use the `<canvas> ` element provided by HTML to draw graphics in the web browser.
The HTML `<canvas>` element is used for drawing graphics in a web browser. The `<canvas> ` element provides a drawing surface — a container for graphics. To draw on the canvas, we must use a script.
Using the `<canvas> ` element is not difficult. However, you do need a basic understanding of HTML and Javascript.
A `<canvas> ` has a default size of 300 x 150 pixels (width x height). Fortunately, the HTML height and width properties allow you to change the sizes. It is preferable to set the width and height attributes on the html tag rather than using CSS. This is due to the possibility of CSS distorting the form.
<a id="item-six"></a>
**The syntax for using the `<canvas>` element.**
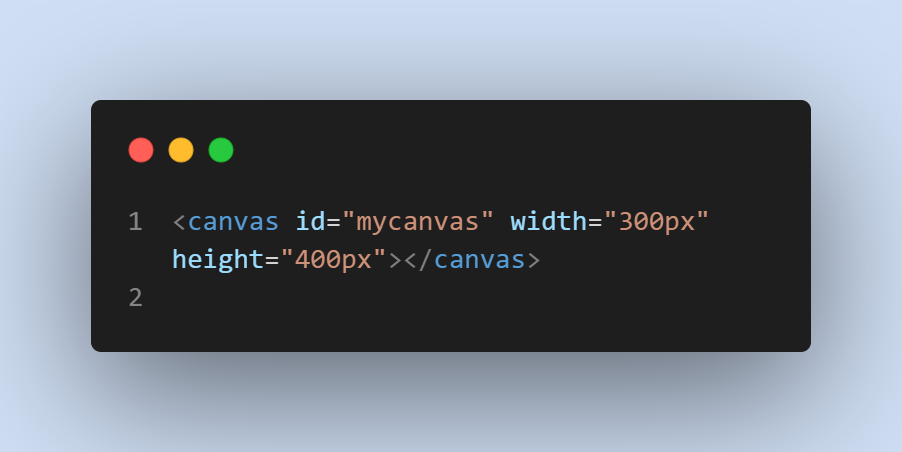
A `<canvas>` element in our HTML file looks like the diagram above.
Three key characteristics are required for the `<canvas> ` element to work.
- a width attribute.
- a height attribute.
- a unique identifier.
When not defined, the width and height attributes will be set to the default width and height. The unique identifier (id) helps us to identify the canvas element in our script since the drawing will be done with javascript.
All drawings on the canvas must be done with Javascript.
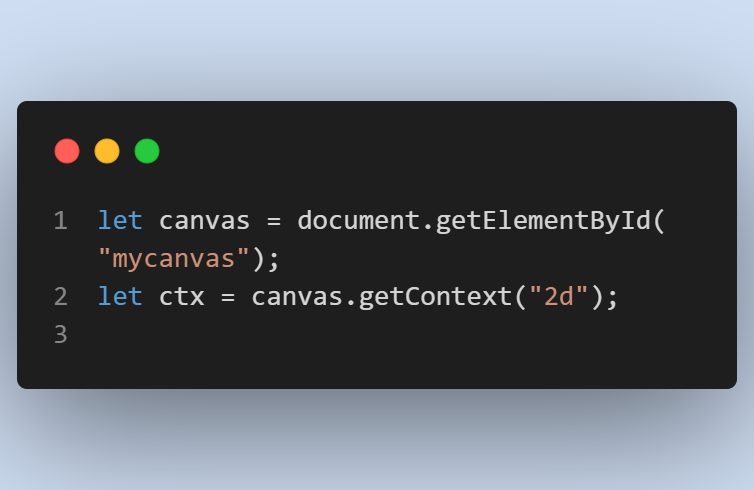
**The syntax of our Javascript or script file looks like the diagram above.**
The first line of code in our script uses the document.getElementById() function to locate the '<canvas>' element. Once we have the element node, we can use its getContext() method to get the drawing context.
getContext() is a built-in HTML object with many drawing methods and properties. The getContext() object takes one parameter: the type of context. We specify "2D" because we are dealing with 2D shapes.
<a id="item-seven"></a>
## Drawing on a canvas
Now that we've set up our canvas environment, we can start drawing on it.
**What area of the canvas should we begin drawing on?**
A grid structure is used in the HTML canvas. A two-
The HTML canvas has a grid system. The canvas is a two-dimensional grid.
By default, all drawings on the canvas begin in the upper-left corner, which corresponds to the coordinates (0,0). The first number is the x-axis coordinate, and the second number is the y-axis coordinate.
The x and y axis are made up of values ranging from 0 to the number you choose for the canvas's height and width.
To better understand how the grid works, let’s draw a rectangle on the canvas grid.
## Result

From the example above, I added a border(color: red) to the canvas to distinguish the HTML canvas from the 2D shape we will be drawing.
The rectangle has four numbers. The first (50) represents the x-axis, while the second (also 50) represents the y-axis. This implies that we moved 50 pixels away from the origin on the x-axis and 50 pixels away from the origin on the y-axis.
Congratulations!! Since we now understand how the canvas grid works, we'll look at the do's and don'ts of drawing on a canvas as well as how to draw more forms in our next tutorial.
| _aaallison |
1,472,080 | Router Debugging in Angular | Enable router tracing: In app.module.ts import { RouterModule, Routes } from... | 0 | 2023-05-18T09:38:28 | https://dev.to/manthanank/router-debugging-in-angular-4abd | angular, debug | 1. Enable router tracing: In `app.module.ts`
```typescript
import { RouterModule, Routes } from '@angular/router';
const routes: Routes = [
// Define your routes here
];
@NgModule({
imports: [
RouterModule.forRoot(routes, { enableTracing: true })
],
// ...
})
export class AppModule { }
```
if working with standalone application
```typescript
const appRoutes: Routes = [];
bootstrapApplication(AppComponent,
{
providers: [
provideRouter(appRoutes, withDebugTracing())
]
}
);
```
2. Use console.log() to inspect
```typescript
import { Component } from '@angular/core';
import { Router } from '@angular/router';
@Component({
// ...
})
export class MyComponent {
constructor(private router: Router) {}
navigateToRoute() {
console.log('Before navigation');
this.router.navigate(['/my-route']);
console.log('After navigation');
}
}
```
else use below code
```typescript
isLoading$ = new BehaviorSubject<boolean>(false);
constructor(private router: Router) {
this.router.events
.subscribe((event) => {
if (event instanceof NavigationStart) {
this.isLoading$.next(true);
}
else if (event instanceof NavigationEnd) {
this.isLoading$.next(false);
}
});
}
```
| manthanank |
1,472,250 | What Is DevOps and How Does It Work? | Organizations keep switching towards innovative and creative methods to complete their projects at... | 0 | 2023-05-18T13:23:04 | https://dev.to/thecompetenza/what-is-devops-and-how-does-it-work-15m4 | devops, development, webdev, programming | Organizations keep switching towards innovative and creative methods to complete their projects at top speed. Fortunately, “DevOps Technologies” are emerging in the IT universe as practices to empower organizations for accomplishing tech goals at a higher velocity.
As per the official data from Verified Allied Market Research – the global DevOps market will gain a valuation of $57.9 billion by 2030. It will grow at an astonishing CAGR rate of 24.2% from 2021 to 2030.
During this period (2021 to 2030), the centralized nature of cloud technology will support automation in DevOps. Now, let’s check out the below article to gain crucial insights about the overview of DevOps, associated benefits, challenges, and working model of DevOps.

## Overview of DevOps
DevOps is a software development methodology in which operations and development team members come together to fulfilling their objectives with the utmost software quality in the minimum time.
DevOps as a service enables companies to release new software-related updates, functionalities, and features quickly. It also aims at reducing the probability of getting any errors and downtime.
Multinational retail giants such as Walmart & Target are utilizing DevOps solutions for a long time before it becomes popular at the global level. In the year 2016, Walmart released its own software for deploying applications known as “OneOps – Cloud Platform”.
## Empower Your Business with DevOps
### Benefits & challenges of DevOps
**Benefits of DevOps**
- Implement DevOps and release your products in a faster time span.
- End the struggle for collaboration among your departments by implementing DevOps for improved communication as well as faster problem resolution.
- With DevOps automation, you can automate many of your existing business processes. So, you can reduce manual efforts and increase efficiency.
- Catch early issues and get early warning signals through DevOps.
- During cultural shifts, it can also be used for providing assistance to an operating system with more stability, stableness, and auditable changes.
- Teams who are working with DevOps are able to provide more profound and timely remedies to customers. It eventually increases the company’s customer retention satisfaction rate.
**Challenges of DevOps**
- Sometimes, dependencies on too many tools can reduce the speed of operations.
- If there is a lack of standard repositories (security) during team collaboration then it can increase the probability of exposing data.
- Needs to work towards resolving the complexity of the tool integration.
- DevOps can be complex and requires a range of technical skills and expertise, which can be difficult to find and maintain.
- It requires a cultural shift in the current practices. In reality, many companies may face certain challenges during cultural shifts.
- It can be time-consuming because the developers will need to first prepare specific metrics. As DevOps software requires specific metrics and toolsets for generating results.
## How DevOps Works?
DevOps breaks down traditional barriers between development and operations. It results in encouraging cross-functional collaboration and communication to deliver software more efficiently.
The working model of the DevOps lifecycle can be understood through the five-stage process that DevOps companies follow to streamline their business units. These stages will help you into streamlining and optimizing the software development process:
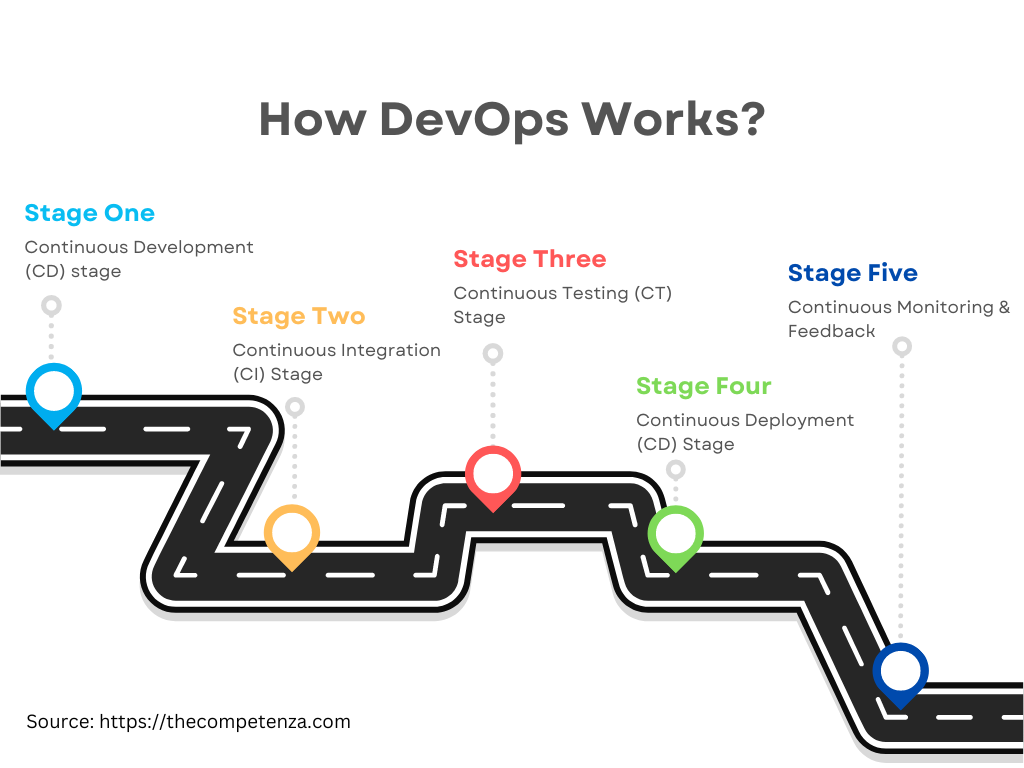
**Stage 1: Continuous Development (CD) stage**
In this stage, the team members work toward planning and coding. There is no specific requirement for DevOps tools however, team members can utilize some tools for maintaining the code – such as: “GitHub”, “GitLab”, “Bitbucket” & many more.
Although, DevOps developers consider GitHub as easy to implement tool because it incorporates diverse protocols – such as HTTP, SSH & FTP. With GitHub, the developers can keep track of all the required changes.
**Stage 2: Continuous Integration (CI) Stage**
The code is integrated with other code and tested again to ensure that it works with the rest of the software. This stage is all about ensuring that the software is cohesive and that all the components work together seamlessly.
Tool for Continuous Integration:
- Jenkins
- GitLab
**Stage 3: Continuous Testing (CT) Stage**
The code that is integrated and written by developers are forwarded to the testers for testing bugs through automated tools. Once, the report is generated then developers are required to rectify all the bugs.
Tools for Continuous Testing:
- Selenium.
- JUnit 5.
**Stage 4: Continuous Deployment (CD) Stage**
The code is deployed to production through an automated process. So, new versions of the software can be released in a minimum time. The use of advanced automation tools and methodologies are common in the CD stage because it ensures that the deployment process should be seamless, secure and efficient.
The deployment stage is also critical for ensuring that the software is released to the production stage in a controlled manner because it needs to fulfill the objective of minimizing downtime and reducing the risk of errors.
Tools for CD:
- AWS CodeDeploy.
- Octopus Deploy.
**Stage 5: Continuous Monitoring & Feedback**
In DevOps practice, teams use logging tools to identify issues and make data-driven decisions about how to improve the software. This stage plays an important role in checking the software’s stability by comparing it with the needs of the end-users over time.
For gathering feedback, the developers can take use of structured and unstructured methods. To collect the structured feedback, team members need to conduct surveys & questionnaires. On the other hand, unstructured feedback can be collected through social media platforms.
Tools for Continuous Monitoring:
- Monit
- Nagios
- Prometheus
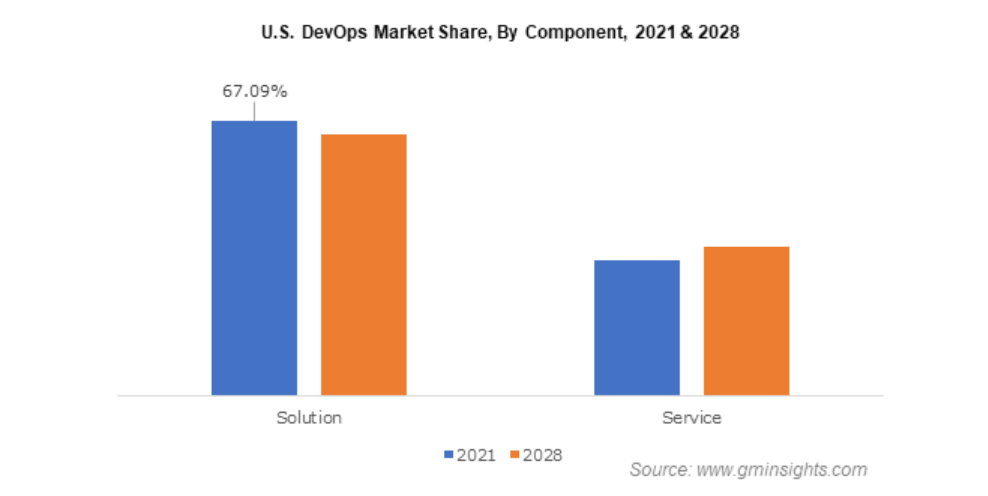
**The Final Words**
Until this point, you have gained an understanding of DevOps practices. If you are running any enterprise then you may be thinking about whether you should move to DevOps or you should still continue to run your process through traditional practices.
In reality, to answer this question – we need to first analyze your company’s current software development and delivery methods. As an organization’s needs are unique and it requires immense planning before implementing DevOps.
Although, if you want to stay ahead of the competition and you want to bring out digital transformation (DX) into your enterprise then DevOps is worth considering as a potential solution.
> **Source** - This article originally published [here](https://thecompetenza.com/what-is-devops/).
| thecompetenza |
1,472,361 | Manipulating Complex Structures in BigQuery: A Guide to DDL Operations | This guide aims to provide a comprehensive understanding of handling changes in complex structures... | 0 | 2023-05-26T07:41:17 | https://dev.to/freshbooks/manipulating-complex-structures-in-bigquery-a-guide-to-ddl-operations-dhm | bigquery | This guide aims to provide a comprehensive understanding of handling changes in complex structures within BigQuery using Data Definition Language (DDL) statements. It explores scenarios involving top-level columns as well as nested columns, addressing limitations with the existing `on_schema_change` configuration in dbt for BigQuery.
- [Introduction](#introduction)
- [How-to](#how-to)
* [Define schema](#define-schema)
* [Add records](#add-records)
* [Add top-level field](#add-top-level-field)
* [Change top-level field type](#change-top-level-field-type)
+ [`CAST`](#cast)
+ [`ALTER COLUMN`](#alter-column)
* [Juggle with STRUCT](#juggle-with-struct)
+ [`tmp table`](#temp-table)
+ [`update STRUCT using SET`](#update-struct-using-set)
+ [`CREATE OR REPLACE TABLE`](#create-or-replace-table)
- [Bonus notes](#bonus-notes)
* [Create a regular table](#create-a-regular-table)
* [Create an external table](#create-an-external-table)
- [Contact info](#contact-info)
## Introduction
Currently, dbt's `on_schema_change` configuration only tracks schema changes related to top-level columns in BigQuery. Nested column changes, such as adding, removing, or modifying a `STRUCT`, are not captured. This guide delves into extending the functionality of `on_schema_change` to encompass nested columns, enabling a more comprehensive schema change tracking mechanism. What exactly are `top-level` as well as `nested` ones I'm going to show further.
Moreover, it's important to note that BigQuery explicitly states on their [Add a nested column to a RECORD column page](https://cloud.google.com/bigquery/docs/managing-table schemas#add_a_nested_column_to_a_record_column) that adding a new nested field to an existing RECORD column using a SQL DDL statement is not supported:
> Adding a new nested field to an existing RECORD column by using a SQL DDL statement is not supported.
When it comes to drops one or more columns, from [ALTER TABLE DROP COLUMN statement](https://cloud.google.com/bigquery/docs/reference/standard-sql/data-definition-language#alter_table_drop_column_statement)
page:
> You cannot use this statement to drop the following:
>
> - Partitioned columns
> - Clustered columns
> - Nested columns inside existing RECORD fields
> - Columns in a table that has row access policies
This is the ongoing proposal with the discussion around
[on_schema_change should handle non-top-level schema changes]((https://github.com/dbt-labs/dbt-bigquery/issues/446)) topic.
This limitation further highlights the need for alternative approaches to manipulate complex structures.
## How-to
### Define schema
To begin, let's dive into the SQL syntax and create the "person" table. This table will store information about individuals, including their ID, name, and address.
```sql
CREATE TABLE IF NOT EXISTS dataset_name.person (
id INT64,
name STRING,
address STRUCT <
country STRING,
city STRING
>
)
```
### Add records
Add a couple of records to the table.
```sql
INSERT INTO
dataset_name.person (id, name, address)
VALUES
(1, "John", STRUCT("USA", "New-York")),
(2, "Jennifer", STRUCT("Canada", "Toronto"))
```
How schema in UI looks like
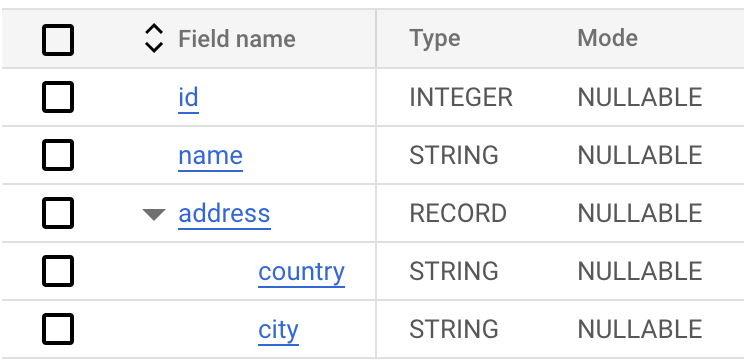
How data is represented while querying it with
```sql
SELECT
*
FROM
dataset_name.person
```

### Add top-level field
Imagine we were tasked to add a new field `has_car`, that has an `INT64` type.
```sql
ALTER TABLE
dataset_name.person
ADD
COLUMN IF NOT EXISTS has_car INT64;
-- add record right away
INSERT INTO
dataset_name.person (id, name, has_car, address)
VALUES
(3, "James", 0, STRUCT("USA", "New-York"))
```
When you add a new column to an existing BigQuery table, the past records will have null values for that newly added column. This behavior is expected because the new column was not present at the time those records were inserted.

### Change top-level field type
Then your customer changes their mind and now the `has_car` column has to have a `BOOL` type instead of `INT64`. Here are 2 possible ways to tackle this task.
Before diving deep into the possible approaches, worth to mention, that BigQuery has [Conversion rules](https://cloud.google.com/bigquery/docs/reference/standard-sql/conversion_rules), that you need to consider. For
instance, you can cast `BOOL` to `INT64`, but you cannot cast `INT64` to `DATETIME`.
In BigQuery, `CAST` and `ALTER COLUMN` are two different approaches for modifying the data type of a column in a table.
Let's explore each approach:
#### `CAST`
The `CAST()` function is used to convert the data type of a column or an expression in a SQL query. It allows you to convert a column from one data type to another during the query execution. However, it does not permanently modify the data type of the column in the table's schema.
The following is an example of using `CAST` to convert a column's data type in a query:
```sql
SELECT
id,
name,
address,
CAST(has_car as BOOL) as has_car
FROM
dataset_name.person
```
#### `ALTER COLUMN`
The `ALTER COLUMN` statement is used to modify the data type of a column in the table's schema. It allows you to permanently change the data type of a column in the table, affecting all existing and future data in that column.
Here's an example of using `ALTER COLUMN` to modify the data type of a column:
```sql
ALTER TABLE
dataset_name.person
ALTER COLUMN
has_car
SET
DATA TYPE BOOL;
```
It's important to note that `ALTER COLUMN` is a DDL statement and can only be executed as a separate operation outside of a regular SQL query. Once the column's data type is altered, it will affect all future operations and queries performed on that table.
In summary, `CAST` is used to convert the data type of a column during query execution, while `ALTER COLUMN` is used to permanently modify the data type of a column in the table's schema. The choice between the two depends on whether you want to temporarily convert the data type for a specific query or permanently change the data type for the column in the table.
### Juggle with STRUCT
If we want to apply changes to nested fields, such as adding, removing, or modifying `STRUCT` itself there are few different ways to do so.
#### temp table
First, quite simple is using the `temp` table.
```sql
CREATE TABLE IF NOT EXISTS dataset_name.person_tmp (
id INT64,
name STRING,
has_car INT64,
address STRUCT <
country STRING,
city STRING,
zip_code INT64
>
);
-- fill then new zip_code field with the default 0 value
INSERT INTO
dataset_name.person_tmp
SELECT
id,
name,
has_car,
(
SELECT
as STRUCT address.country,
address.city,
0 as zip_code
) as address
FROM
dataset_name.person;
ALTER TABLE
IF EXISTS `dataset_name.person` RENAME TO `person_past`;
ALTER TABLE
IF EXISTS `dataset_name.person_tmp` RENAME TO `person`;
DROP TABLE dataset_name.person_tmp;
```
However, this approach has some drawbacks and considerations to keep in mind: when modifying a BigQuery table using a temporary table, you need to create a new table with the desired modifications and then copy the data from the original table to the temporary table.
**Costs**
As this process involves duplicating the data. It will increase storage usage, leading to additional storage costs as well as it consumes additional query processing resources.
**Performance**
It may impact performance, especially for large tables as you have a limited amount of production resources that are shared.
**Complexity and consistency**
Using a temporary table to modify a BigQuery table introduces additional steps and complexity to the process. You need to write queries to create the temporary table, copy data, modify the data, overwrite the original table, and then drop the temporary table. This adds complexity to the overall workflow and may require more code and query execution time.
Last, but not least, during the modification process, there might be a period where the original table is not accessible or is in an inconsistent state. If other processes or applications depend on the original table's data, this downtime or inconsistency could impact their operations.
So this is not the very best way.
#### update STRUCT using SET
Another scenario is to change the nested field type. Imagine we would like to update the `zip_code` type from `STRING` to `INT64`. Now we don't want to use the `tmp` table way. So the second way is to [UPDATE](https://cloud.google.com/bigquery/docs/reference/standard-sql/dml-syntax#update_statement) `STRUCT` using
```sql
ALTER TABLE
dataset_name.person
ADD
COLUMN IF NOT EXISTS address_new STRUCT < country STRING,
city STRING,
zip_code STRING >;
UPDATE
`dataset_name.person`
SET
address_new = (
SELECT
AS STRUCT address.country,
address.city,
CAST(address.zip_code as STRING)
)
WHERE
TRUE;
ALTER TABLE
dataset_name.person RENAME COLUMN address TO address_past;
ALTER TABLE
dataset_name.person RENAME COLUMN address_new TO address;
ALTER TABLE
dataset_name.person DROP COLUMN address_past;
```
In this case, only the `STRUCT` field will be duplicated. That is good enough.
#### CREATE OR REPLACE TABLE
Another last approach is using [`CREATE OR REPLACE TABLE`](https://cloud.google.com/bigquery/docs/reference/standard-sql/data-definition-language#create_table_statement).
```sql
CREATE
OR REPLACE TABLE dataset_name.person AS
SELECT
id,
name,
has_car,
(
SELECT
AS STRUCT address.country,
address.city,
CAST(address.zip_code as STRING)
) as address
FROM
dataset_name.person
```
In the same way, we can remove nested fields. We can just select the needed fields and omit the ones we don't interested in.
```sql
SELECT
address.*
FROM
`dataset_name.person`;
SELECT
* REPLACE (
(
SELECT
AS STRUCT address.*
EXCEPT
(zip_code)
) AS address
)
FROM
`dataset_name.person`
```
## Bonus notes
If you have some table schema from a separate dataset, that you need to create in your particular dataset the easiest the way is using CLI commands as it's a much faster and less error-prone way to create tables.
### Create a regular table
This is the example of how to save table schema using Table ID to JSON format with [bq show](https://cloud.google.com/bigquery/docs/reference/bq-cli-reference#bq_show) command
```
bq show \
--schema \
--format=prettyjson \
project_name:dataset_name.table_name > table_name.json
```
And now you can create a table in your dataset using [bq mk](https://cloud.google.com/bigquery/docs/reference/bq-cli-reference#bq_mk) command:
```
bq mk \
--table \
your_dataset_name.table_name \
table_name.json
```
### Create an external table
Here is the example of creating a table definition in JSON format using [bq mkdef](https://cloud.google.com/bigquery/docs/reference/bq-cli-reference#bq_mkdef):
```
bq mkdef \
--source_format=NEWLINE_DELIMITED_JSON \
--autodetect=false \
'gs://bucket_name/prefix/*.json' > table_def
```
The `mkdef` command is to create a table definition in JSON format for data stored in Cloud Storage or Google Drive. It will be used to create an external table.
```
bq mk \
--table \
--external_table_definition=nicereply_csat_raw_def \
dataset_name.table_name \
table_name.json
```
## Contact info
If you found this article helpful, I invite you to connect with me on [LinkedIn](https://www.linkedin.com/in/iamtodor/). I am always looking to expand my network and connect with like-minded individuals in the data industry. Additionally, you can also reach out to me for any questions or feedback on the article. I'd be more than happy to engage in a conversation and help out in any way I can. So don’t hesitate to contact me, and let’s connect and learn together.
| iamtodor |
1,472,400 | Non-Technical Tips for Developers to Ease the Stress of Debugging | Introduction Debugging is an integral part of a developer’s journey, and it’s no secret... | 0 | 2023-05-18T15:10:23 | https://jamesajayi.hashnode.dev/non-technical-tips-for-developers-to-ease-the-stress-of-debugging | programming, productivity, codenewbie, career |
## Introduction
Debugging is an integral part of a developer’s journey, and it’s no secret that it can be a stressful and time-consuming process. Hours spent poring over code, searching for elusive bugs, and troubleshooting can take a toll on even the most experienced developers.

While technical proficiency is undoubtedly essential in the world of software development, there are also non-technical strategies that can significantly ease the stress of debugging.
This article covers a range of non-technical tips that developers can employ to ease their debugging process, improve their efficiency, and maintain their sanity along the way. This article provides valuable techniques for developers of all levels, whether beginners or experienced professionals. Reading further will help you enhance your debugging skills and make the process more effective and less frustrating.
## Understanding the Debugging Process
The debugging process refers to the systematic approach developers take to identify, analyze, and fix issues or bugs in software code. It involves identifying the primary cause of the problem and making the necessary changes to correct it. The debugging process typically follows these steps:
1. Reproduce the Problem: The first step in debugging is to replicate the issue or bug that has been reported or observed. This involves identifying the specific scenario, inputs, or conditions that trigger the problem. By reproducing the problem consistently, developers can analyze it more effectively.
2. Understand the Expected Behavior: As a developer, you need to understand how the software is supposed to function clearly. You can refer to the specifications, requirements, or intended behavior to compare it with the observed problem. This helps in determining the desired outcome and identifying any deviations or errors.
3. Locate the Bug: Once the problem is reproduced, you need to pinpoint the exact location or code causing the issue. You can use debugging tools, logging mechanisms, or manual inspection to identify the faulty code segment. This involves analyzing error messages, logs, or any other available information related to the problem.
4. Diagnose the Issue: After locating the bug, you need to analyze and understand why the issue is occurring. This requires examining the code logic, variables, data flow, and relevant dependencies. You may use techniques such as stepping through the code line by line, inspecting variables, or adding temporary logging statements to gain insights into the problem.
5. Fix the Bug: Once the root cause of the issue is identified, developers can proceed to fix the bug. This involves making necessary changes to the code to resolve the problem. Depending on the issue’s complexity, the fix may include modifying a single line of code or implementing a more comprehensive solution. It is essential to consider possible results and regression testing while making the fix.
6. Test the Fix: After implementing the fix, you need to thoroughly test the modified code to ensure the issue is solved and the software functions as intended. This may involve running test cases, performing integration testing, or conducting user acceptance testing. The goal is to verify that the fix has successfully addressed the problem without introducing new issues.
7. Deploy and Verify: Once the fix is tested and validated, you can deploy the updated code to the production environment or release it to end users. Monitoring the system after the deployment is essential to be sure that the bug is resolved and has no unexpected consequences.
## Non-Technical Tips to Ease Debugging Stress
Away from the technical side of debugging, there are non-technical steps that developers can adopt to ease the stress of debugging. Here are a few:
## Breakdown Complex Tasks into Manageable chunks
Debugging often involves tackling complex issues that may seem overwhelming at first. Break down the debugging task into smaller, more manageable subtasks to reduce stress. This approach helps maintain focus and provides a sense of progress as each subtask is completed.
## Prioritize and Organize Debugging Tasks
Not all bugs are equally critical or urgent. Prioritize your debugging tasks based on their impact on the overall system functionality or the project’s goals. By first identifying and addressing the most pressing issues, you can alleviate stress and prevent potential roadblocks in the development process.
## Set Realistic Deadlines and Expectations
Unrealistic deadlines can lead to stress and compromised quality of work. When debugging, set reasonable timelines and communicate these expectations with relevant stakeholders. It’s essential to account for unexpected complexities or delays that may arise during the debugging process.
## Constantly practice Self-Care
As a developer taking care of yourself physically, mentally, and emotionally is vital. Get enough sleep, eat nutritious meals, and engage in regular exercise and activities that bring you joy and help you relax. You can also incorporate mindfulness techniques into your daily routine. Practice deep breathing exercises, meditation, or yoga to help calm your mind and reduce stress.
## Take Regular Breaks and Avoid Burnout
Debugging can be mentally exhausting, and pushing yourself for extended periods without breaks can hinder productivity and increase stress. Incorporate short breaks into your schedule to rest and recharge. Use these breaks to engage in activities that help you relax and clear your mind. Consider using productivity techniques like the [Pomodoro Technique](https://en.wikipedia.org/wiki/Pomodoro_Technique), which involves working in concentrated intervals, typically 25 minutes, followed by short breaks to enhance productivity and focus.
## Seeking Support and Leveraging Resources
When faced with challenging debugging scenarios, seeking support can make a significant difference. Collaborating with colleagues and sharing insights can provide fresh perspectives and lead to breakthroughs. Engaging with online developer communities and forums allows developers to tap into the collective knowledge and experience of the wider tech community. Additionally, leveraging debugging tools and resources can help clarify the process and provide valuable insights into code behavior.
## Create a Positive and Supportive Team
Creating a positive and supportive team can significantly alleviate the stress of debugging and foster a more collaborative and effective team. This will involve fostering a culture that avoids blaming individuals for bugs or issues; instead, focus on identifying the root cause and finding solutions. This can be achieved by instigating open discussions about mistakes or failures and communication among team members for concerns and constructive feedback and support. Regardless of the outcome, recognizing and appreciating the effort put into debugging is also important. With this, developers can work together more effectively and tackle debugging challenges with a collective mindset.
## Document and Learn
Documentation is a vital aspect of the debugging process, which documents the problem, its root cause, and the steps taken to resolve it. This documentation facilitates knowledge sharing, enables future reference, and supports learning from past experiences. Additionally, developers can reflect on their debugging process to identify areas for improvement and apply valuable lessons learned to enhance their skills. By maintaining concise and informative documentation, developers can alleviate stress, streamline future debugging efforts, and foster continuous growth in their debugging abilities.
## Conclusion
Debugging can be a mentally taxing and physically stressful process for developers. However, by adopting the points covered in this article, developers can effectively manage and alleviate the stress associated with debugging.
If you are just starting your programming journey, you might find this [debugging guide for beginners](https://www.freecodecamp.org/news/what-is-debugging-how-to-debug-code/) helpful.
What other things have helped you to overcome the stress of debugging? Kindly share in the comment section.
I wish you a fun-filled and less stressful experience in your future debugging.
| jamesajayi |
1,472,542 | Exploring Real-Life Applications of Apache AGE: Harnessing the Power of Graph Analytics | Introduction: Apache AGE (A Graph Extension) seamlessly integrates graph analytics capabilities into... | 0 | 2023-05-18T17:19:47 | https://dev.to/moiz697/exploring-real-life-applications-of-apache-age-harnessing-the-power-of-graph-analytics-145i |
**Introduction:**
Apache AGE (A Graph Extension) seamlessly integrates graph analytics capabilities into the PostgreSQL ecosystem, enabling users to leverage the power of graphs for a multitude of real-life applications. In this blog post, we will delve into the practical use cases where Apache AGE shines, showcasing its potential in diverse domains.
**Social Network Analysis:**
The pervasive influence of social networks necessitates analyzing complex relationships within them. Apache AGE simplifies social network analysis by providing graph-based tools. By uncovering patterns, identifying influencers, and detecting communities, AGE enables data-driven decisions and optimization of social media strategies.
**Recommendation Systems:**
Recommendation systems personalize user experiences across various industries, from e-commerce to streaming services. Apache AGE excels at building accurate recommendation systems by modeling user preferences and item relationships. With graph algorithms like collaborative filtering and personalized PageRank, AGE delivers tailored recommendations, enhancing user engagement and satisfaction.
**Fraud Detection:**
Uncovering fraudulent activities hidden in intricate networks demands advanced analytics. Apache AGE's graph-based approach is instrumental in detecting suspicious patterns, identifying anomalies, and tracing connections that may evade conventional models. AGE enables organizations to build robust fraud detection systems by analyzing graph structures and user behavior.
**Network and Infrastructure Management:**
Effectively managing complex networks and infrastructures is crucial in sectors such as telecommunications and IT. Apache AGE simplifies network analysis by visualizing connections, identifying bottlenecks, and optimizing infrastructure efficiency. AGE's graph analytics capabilities aid in capacity planning, troubleshooting, and proactive maintenance, minimizing downtime and enhancing performance.
**Bioinformatics and Genomics:**
In the field of bioinformatics and genomics, graph-based models are employed to comprehend intricate biological systems. Apache AGE plays a significant role in analyzing genomic data, protein interactions, and gene regulatory networks. By leveraging AGE's graph algorithms and querying capabilities, researchers can unravel hidden relationships, identify disease markers, and advance personalized medicine and drug discovery.
**Supply Chain Optimization:**
Efficient supply chain management requires analyzing dependencies and optimizing workflows. Apache AGE's graph analytics capabilities enable organizations to model and analyze supply chain networks. By identifying critical nodes, optimizing logistics, and minimizing costs, AGE facilitates inventory management, streamlined delivery routes, and enhances overall supply chain resilience.
**Conclusion:**
Apache AGE unlocks the potential of graph analytics in real-life applications, spanning social network analysis, recommendation systems, fraud detection, network management, bioinformatics, and supply chain optimization. By combining the power of graph analytics with PostgreSQL's scalability, AGE empowers organizations to extract valuable insights from interconnected data. As you explore these applications, consider the unique requirements of your domain and evaluate the suitability of Apache AGE within your technology landscape.
[Apache-Age:-https://age.apache.org/](https://age.apache.org/)
[GitHub:-https://github.com/apache/age](https://github.com/apache/age)
| moiz697 | |
1,473,115 | Portfolio Website Using HTML ,CSS ,Bootstrap and JavaScript | Hello Coders!! In this article, we will see how we can create a Personal Portfolio Website using... | 0 | 2023-05-19T07:04:12 | https://dev.to/cwrcode/portfolio-website-using-html-css-bootstrap-and-javascript-3kbl | Hello Coders!! In this article, we will see how we can create a Personal Portfolio Website using HTML, CSS, Bootstrap, And JavaScript. Personal **[Portfolio Website](https://www.codewithrandom.com/2022/09/30/portfolio-website-using-html-css-javascript/)** must be consistent and maintained throughout your career. It provides a convenient way for potential clients to view your work while also allowing you to expand on your skills, experiences, and services.
This site [Personal Portfolio] has four sections on one page: Home, Portfolio, About, and Contact, and each section is attractive and eye-catching.
A portfolio can be thought of as a digital resume that showcases the user's talent to the client. A portfolio is a website that developers use to showcase their skills in the market so that they can be hired based on their skill set.
This portfolio is fully responsive, and anyone can view it using any device, whether it is a mobile phone, tablet, or desktop.This article will teach us how to create this website using HTML, CSS, Bootstrap, and a little JavaScript. You will learn about the CSS and JavaScript frameworks (Boostrap and Jquery) in this project, which will help you build a faster and more responsive website.
We will be discussing our project step by step :
**Step1: **To begin with , we will import our bootstrap from the official bootstrap website using the import link into the head section of our HTML.
```
<link rel='stylesheet' href='https://maxcdn.bootstrapcdn.com/bootstrap/3.3.5/css/bootstrap.min.css'>
<link rel='stylesheet' href='https://maxcdn.bootstrapcdn.com/font-awesome/4.5.0/css/font-awesome.min.css'>
<script src="https://code.jquery.com/jquery-1.12.0.min.js"></script>
<script src="https://maxcdn.bootstrapcdn.com/bootstrap/3.3.6/js/bootstrap.min.js" integrity="sha384-0mSbJDEHialfmuBBQP6A4Qrprq5OVfW37PRR3j5ELqxss1yVqOtnepnHVP9aJ7xS" crossorigin="anonymous"></script>
```
**Step2:** We'll start with our portfolio's header and work our way down to the portfolio navbar. To use Bootstrap in our navbar, we will use the Bootstrap class that has already been defined in our HTML elements. If you want to learn more about how we can add the navbar bootstrap class, please visit the bootstrap navbar docs.
```
NavbarDocs
<!-- Start Navigation Bar -->
<nav class="navbar navbar-default navbar-fixed-top">
<div class="container">
<!-- Brand and toggle get grouped for better mobile display -->
<div class="navbar-header">
<button type="button" class="navbar-toggle collapsed" data-toggle="collapse" data-target="#bs-example-navbar-collapse-1" aria-expanded="false">
<span class="sr-only">Toggle navigation</span>
<span class="icon-bar"></span>
<span class="icon-bar"></span>
<span class="icon-bar"></span>
</button>
<span class="navbar-brand">Hasham Babar</span>
</div>
<!-- Collect the nav links, forms, and other content for toggling -->
<div class="collapse navbar-collapse" id="bs-example-navbar-collapse-1">
<ul class="nav navbar-nav">
<li class="active"><a href="#home">Home <span class="sr-only">(current)</span></a></li>
</ul>
<ul class="nav navbar-nav navbar-right">
<li><a href="#portfolio-link">Portfolio</a></li>
<li><a href="#about-link">About</a></li>
<li><a href="#contact-link">Contact</a></li>
</ul>
</div><!-- /.navbar-collapse -->
</div><!-- /.container-fluid -->
</nav>
<!-- End Navagation Bar -->
```
**Step3:** Now we'll add our hero section, where we'll write the introduction to our website. First, we'll add a heading and a paragraph with the HTML tag, followed by the background image with CSS and the Font Awesome icon with with a tag . Using Bootstrap, we will make the h1 and paragraph tags responsive.
```
<!-- Start Splash Section -->
<a class="anchor" id="home"></a>
<div id="splash" class="container-fluid">
<div class="row">
<div class="col-lg-12 text-center">
<h1>Hasham Babar</h1>
<hr />
<p>
Full Stack Developer / Software Test Analyst
</p>
<p>
<a href="https://github.com/hash004" target="_blank"><i class="fa fa-github-square fa-2x"></i></a>
<a href="https://uk.linkedin.com/in/hashambabar" target="_blank"><i class="fa fa-linkedin-square fa-3x"></i></a>
<a href="https://twitter.com/hash004" target="_blank"><i class="fa fa-twitter-square fa-2x"></i></a>
</p>
</div>
</div>
</div>
<!-- End Splash Section -->
#splash{
background-image: url(https://raw.githubusercontent.com/hash004/freecodecamp/master/portfolioPage/images/home.jpg);
background-size: cover;
background-position: center;
height: 100%;
margin-top: 50px;
padding-top: 15%;
padding-bottom: 50px;
color: #fff;
font-size: 3em;
text-shadow: 0px 4px 3px rgba(0,0,0,0.4),
0px 8px 13px rgba(0,0,0,0.5),
0px 18px 23px rgba(0,0,0,0.1);
}
#splash h1{
font-size: 2em;
}
#splash a{
color: #fff;
}
#splash a:hover{
color: #e7e7e7;
}
```
**Step4:** We will add a portfolio section which we contain our skills and porject section if you have any skills or any project you can add them in this particular section . Here we will add our project in form of card using bootstrap . We have added a grid system in which we will add 3 column in a row which are responsive if the screen size increase the number of colum increase or decrease accordingly.
If you want to learn more about the grid system and card in bootstrap, click on the link below.
```
<a class="anchor" id="portfolio-link"></a>
<div id="portfolio" class="container-fluid">
<div class="row">
<div class="col-lg-12 text-center">
<h1>Portfolio</h1>
<hr />
<div class="container">
<div class="row">
<div class="col-lg-4">
<div class="thumbnail">
<a href="https://codepen.io/hash004/full/obKJvY" target="_blank">
<div class="thumbnail-hover text-center">
<i class="fa fa-eye fa-4x"></i>
</div>
<img class="img-responsive" src="https://raw.githubusercontent.com/hash004/freecodecamp/master/portfolioPage/images/projects/tribute-page.png" alt="bruce-lee-tribute-page">
</a>
<div class="caption">
<h3>Tribute Page</h3>
<p>Using Bootstrap to build a simple tribute page</p>
</div>
</div>
</div>
<div class="col-lg-4">
<div class="thumbnail">
<a href="#" target="_blank">
<div class="thumbnail-hover text-center">
<i class="fa fa-eye fa-4x"></i>
</div>
<img class="img-responsive" src="https://images.unsplash.com/photo-1430931071372-38127bd472b8?crop=entropy&dpr=2&fit=crop&fm=jpg&h=275&ixjsv=2.1.0&ixlib=rb-0.3.5&q=50&w=400">
</a>
<div class="caption">
<h3>Placeholder</h3>
<p>Placeholder project desciption goes here</p>
</div>
</div>
</div>
<div class="col-lg-4">
<div class="thumbnail">
<a href="#" target="_blank">
<div class="thumbnail-hover text-center">
<i class="fa fa-eye fa-4x"></i>
</div>
<img src="https://images.unsplash.com/photo-1426260193283-c4daed7c2024?crop=entropy&dpr=2&fit=crop&fm=jpg&h=250&ixjsv=2.1.0&ixlib=rb-0.3.5&q=50&w=400">
</a>
<div class="caption">
<h3>Placeholder</h3>
<p>Placeholder project desciption goes here</p>
</div>
</div>
</div>
</div>
<div class="row">
<div class="col-lg-4">
<div class="thumbnail">
<a href="#" target="_blank">
<div class="thumbnail-hover text-center">
<i class="fa fa-eye fa-4x"></i>
</div>
<img src="https://images.unsplash.com/photo-1429728479567-9c51fb49813e?crop=entropy&dpr=2&fit=crop&fm=jpg&h=300&ixjsv=2.1.0&ixlib=rb-0.3.5&q=50&w=400">
</a>
<div class="caption">
<h3>Placeholder</h3>
<p>Placeholder project desciption goes here</p>
</div>
</div>
</div>
<div class="col-lg-4">
<div class="thumbnail">
<a href="#" target="_blank">
<div class="thumbnail-hover text-center">
<i class="fa fa-eye fa-4x"></i>
</div>
<img src="https://images.unsplash.com/photo-1422480723682-a694a43341fb?crop=entropy&dpr=2&fit=crop&fm=jpg&h=275&ixjsv=2.1.0&ixlib=rb-0.3.5&q=50&w=400">
</a>
<div class="caption">
<h3>Placeholder</h3>
<p>Placeholder project desciption goes here</p>
</div>
</div>
</div>
<div class="col-lg-4">
<div class="thumbnail">
<a href="#" target="_blank">
<div class="thumbnail-hover text-center">
<i class="fa fa-eye fa-4x"></i>
</div>
<img src="https://images.unsplash.com/photo-1451968362585-6f6b322071c7?crop=entropy&dpr=2&fit=crop&fm=jpg&h=225&ixjsv=2.1.0&ixlib=rb-0.3.5&q=50&w=400">
</a>
<div class="caption">
<h3>Placeholder</h3>
<p>Placeholder project desciption goes here</p>
</div>
</div>
</div>
</div>
</div>
</div>
</div>
</div>
<!-- End portfolio Section -->
```
**Step5: **Now we'll make the "about" section. The H1 tag will be used to create the heading of our "about" section.
In this about section, we will use bootstrap grid system to create two columns; one column will contain the display picture, and the second will contain some about me content.
```
<a class="anchor" id="about-link"></a>
<div id="about" class="container-fluid text-center">
<h1>About</h1>
<hr />
<div class="container">
<div class="row row-eq-height">
<!-- <div class="col-lg-1"></div> -->
<div class="col-lg-3">
<img class="img-responsive img-circle center-block" src="https://avatars0.githubusercontent.com/u/2758955" alt="Hasham-Babar" />
</div>
<div id="white-bg" class="col-lg-8">
<p>
Computer Science Graduate. Full Stack Developer. Qualified Software Test Analyst with 5 years of practical experience.
</p>
</div>
</div>
</div>
</div>
<!-- End About Section -->
#about{
background-image: url(https://raw.githubusercontent.com/hash004/freecodecamp/master/portfolioPage/images/about.jpg);
background-position: center;
background-size: cover;
height: 100%;
padding-bottom: 50px;
color: #fff;
}
#about h1{
font-size: 5em;
text-shadow: 0px 4px 3px rgba(0,0,0,0.4),
0px 8px 13px rgba(0,0,0,0.5),
0px 18px 23px rgba(0,0,0,0.1);
}
#about p{
font-size: 1.5em;
text-align: justify;
}
#about img{
padding: 10px;
/*max-width: 180px;*/
}
#white-bg{
/*background-color: rgba(0,0,0, 0.5);
border-radius: 20px;
margin-right: 10px;*/
float: left;
display: inline-block;
vertical-align: middle;
padding: 6% 2%;
}
```
**Step6:** Now we'll add the final section to our portfolio, in which we'll first use the fontawesome icon to add social links like Instagram, Github, and so on, and then we'll simply embed the map by setting up your location in Google Maps and then embedding in our portfolio. Finally, we'll include an email icon with a link to our email address so that anyone who clicks on it can contact us.
```
<!-- Start Contact Section -->
<a class="anchor" id="contact-link"></a>
<div id="contact" class="container-fluid text-center">
<h1>Contact</h1>
<hr />
<div class="container">
<div class="row">
<div class="col-lg-4">
<h2>Social</h2>
<a href="https://twitter.com/hash004">
<span class="fa-stack fa-3x">
<i class="fa fa-circle fa-stack-2x"></i>
<i class="fa fa-twitter fa-stack-1x fa-inverse"></i>
</span>
</a>
<a href="https://uk.linkedin.com/in/hashambabar">
<span class="fa-stack fa-3x">
<i class="fa fa-circle fa-stack-2x"></i>
<i class="fa fa-linkedin fa-stack-1x fa-inverse"></i>
</span>
</a>
<a href="https://github.com/hash004">
<span class="fa-stack fa-3x">
<i class="fa fa-circle fa-stack-2x"></i>
<i class="fa fa-github-alt fa-stack-1x fa-inverse"></i>
</span>
</a>
<a href="https://www.freecodecamp.com/hash004">
<span class="fa-stack fa-3x">
<i class="fa fa-circle fa-stack-2x"></i>
<i class="fa fa-fire fa-stack-1x fa-inverse"></i>
</span>
</a>
</div>
<div class="col-lg-4">
<h2>Location</h2>
<address>
Leeds,
West Yorkshire,
England
</address>
<div class="embed-responsive embed-responsive-4by3">
<iframe class="embed-responsive-item" src="https://www.google.com/maps/embed?pb=!1m18!1m12!1m3!1d18850.876504441596!2d-1.5490997490371672!3d53.800885330574815!2m3!1f0!2f0!3f0!3m2!1i1024!2i768!4f13.1!3m3!1m2!1s0x48793e4ada64bd99%3A0x51adbafd0213dca9!2sLeeds%2C+West+Yorkshire!5e0!3m2!1sen!2suk!4v1456749335815" width="600" height="450" frameborder="0" style="border:0" allowfullscreen></iframe>
</div>
</div>
<div class="col-lg-4">
<h2>Communication</h2>
<a href="mailto:hasham@hashambabar.com">
<span class="fa-stack fa-3x">
<i class="fa fa-circle fa-stack-2x"></i>
<i class="fa fa-envelope fa-stack-1x fa-inverse"></i>
</span>
</a>
</div>
</div>
</div>
</div>
<!-- End Contact Section -->
```
**Step7:** In this step we wil ad some functionality or animation to our portfolio using jquery which is a javascript framework . The main use of this framework is to decrease the length of our code. Here in this we have added a function to our navbar in which we will add the click function in which we have created a toggle function to add or remove the active class.
```
$(document).ready(function(){
$(".navbar-nav li").click(function(){
$(".navbar-nav li").removeClass("active");
$(this).addClass("active");
}
);
$('.navbar-nav a').click(function(event){
event.preventDefault();
$('html, body').animate({
scrollTop: $( $.attr(this, 'href') ).offset().top
}, 500);
});
}
);
```
Now We have Successfully created responsive **[Portfolio Website ](https://www.codewithrandom.com/2022/09/30/portfolio-website-using-html-css-javascript/)**using bootstrap and jquery. You can use this project directly by copying into your IDE. WE hope you understood the project , If you any doubt feel free to comment!!
If you find out this Blog helpful, then make sure to search code with random on google for Front End Projects with Source codes and make sure to Follow the Code with Random Instagram page.
follow : @codewithrandom
Written By : arun
Code by : Hasam Babar | cwrcode | |
1,473,258 | Nutanix NCM-MCI-5.20 Questions To Complete Your Preparation [2023] | Getting ready for the Nutanix Certified Master - Multicloud Infrastructure (NCM-MCI) 5.20 Exam? Stop... | 0 | 2023-05-19T09:40:16 | https://dev.to/antoniocooper/nutanix-ncm-mci-520-questions-to-complete-your-preparation-2023-4bnk | <p>Getting ready for the Nutanix Certified Master - Multicloud Infrastructure (NCM-MCI) 5.20 Exam? Stop looking! Pass4Success is your ultimate option for Nutanix NCM-MCI-5.20 exam question preparation. Our team of experts carefully made and checked the Nutanix <strong><a href="https://www.pass4success.com/nutanix/exam/ncm-mci-5.20">NCM-MCI-5.20 Exam Questions</a></strong> to make sure you pass the NCM-MCI-5.20 Nutanix Certified Master exam on your first try. With Pass4Success, you can study for the NCM-MCI-5.20 Nutanix Certified Master test from the comfort of your own home.</p>
<h2><strong>Convenient PDF Format for Nutanix NCM-MCI-5.20 Exam Questions:</strong></h2>
<p>At Pass4Success, our Nutanix NCM-MCI-5.20 exam questions are available in a convenient PDF format. This enables you to download and utilize the Nutanix Certified Master - Multicloud Infrastructure (NCM-MCI) 5.20 Exam NCM-MCI-5.20 PDF questions on any device, such as PCs, laptops, Macs, tablets, and smartphones. The PDF format provides flexibility, allowing you to prepare for the NCM-MCI-5.20 Nutanix Certified Master exam at your own pace and without the need for classroom instruction.</p>
<h2><strong>Comprehensive Nutanix NCM-MCI-5.20 Online Practice Test Engine:</strong></h2>
<p>Pass4Success also offers a comprehensive online <strong><a href="https://www.pass4success.com/nutanix">Nutanix Practice Test</a></strong> engine for the Nutanix NCM-MCI-5.20 exam that incorporates the Nutanix Certified Master NCM-MCI-5.20 exam questions. This NCM-MCI-5.20<strong> </strong>practice<strong> </strong>test engine generates a simulated environment for practice and familiarization with the NCM-MCI-5.20 Nutanix Certified Master - Multicloud Infrastructure (NCM-MCI) 5.20 Exam actual format. By utilizing the Nutanix NCM-MCI-5.20 online practice test engine, you can identify your strong and weak areas, enabling you to develop and confidently approach the NCM-MCI-5.20 Nutanix Certified Master - Multicloud Infrastructure (NCM-MCI) 5.20 Exam.</p>
<p> </p>
| antoniocooper | |
631,426 | Basics of Big O Notation | Why worry about Big O? As someone who has been coding for only a few months, I'll admit th... | 0 | 2021-03-11T19:43:59 | https://dev.to/milanwinter/basics-of-big-o-notation-4fe2 | #Why worry about Big O?
As someone who has been coding for only a few months, I'll admit the concept of Big O notation was one that I avoided at first because it seemed complicated. When I first started I wasn't trying to figure out the best way to code something I was just trying to figure out code that works. While that's fine when you're first starting out, I soon realized how much faster I could make my code run by refactoring a couple lines or using a different method. And that is essentially why programmers use Big O notation to describe how fast particular code is especially when you start dealing with large data structures. Here I'll go over three main examples O(1), O(n), and O(n²) to give you a basic understanding of what Big O notation is.
#So what is Big O?
Essentially, Big O is a measurement of how quickly a certain block of code will run based on the input size(n). What do I mean by input size? Take this function for example...
This function takes in an array and the returns that array. The input size in this case would be the size of the array. So what is Big O? Big O is measuring how fast this function will run if you increase the size of the array that is passed in.

Let's say this is the array we're passing in to our function now. Will the function run slower now? As you may have guessed, the answer is no. In fact this function will have the same run time for pretty much any size of array that we pass in. So how do we get the O notation for this function or any function for that matter? Well the way to visualize this is through the use of graphs.
If you can think back to when you were learning about equations for graphs, you might remember that for a straight line parallel to the x-axis the equation is y = c. C being a constant. If a function never changes in how fast it operates given the input (n), we know that it will be a straight line at whatever the constant(c) is for that specific function. In Big O terms we call that O(1). Although you can replace the 1 with whatever your constant is, typically in coding 1 is used to show that the function doesn't change in time with a growing input.
Now can take a look at an example that is slightly more complicated, O(n).
As you can see in this function we have a basic for loop that returns each element within the given array. The bigger the array is that we give to this function, the longer it will take for the function to run. Here is a graph that depicts how this function works.
So the bigger the size of our input(n) the longer it takes for the function to run. The equation for this graph would be y = ax + b or y = an + b. When we think about O notation, what we're searching for is the worst possible outcome or in other words the fastest growing term in our equation. If we take a look at the equation, we know that the fastest growing term is (an). As we increase the value of n (our input) , our value for y (time) will also increase. Since the coefficient (a) in this equation is dependent on the specific function, we don't have to really worry about it. This leads us to the notation O(n). O(n) basically just means that the function is directly relying on the size of the input(n).
Finally, we'll take a look at O(n²). The best and most common example for this is a nested loop. Here's an example of a very simple nested for loop going through an array and returning all the possible pairs.
Taking a look at the graph for this function, we can see the larger the input, the time exponentially increases.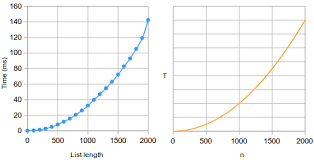
If we take a look at the equation, y =n² + an + c we can see that it's a quadratic equation. Remember that for O notation we're looking for the worst case scenario and the fastest growing term from the equation which is n² in this case. So our O notation for this function is O(n²). This makes sense cause the function is looping through our array twice.
#Conclusion
Although O notation gets more complicated with more scenarios, hopefully this gives you a basic understanding of what it is and how it's measured. The biggest thing to remember is that O notation is a measurement of the worst case scenario. We're not so much interested in how time changes when you increase input from 4 to 5, but rather 4 to 1000, or even 10000. Here are some additional resources if you're looking to dive a little deeper into this topic.
https://www.youtube.com/watch?v=D6xkbGLQesk&list=PLK98i8lV22KFaHAsAj9aY-XzPX_i-Mz96&index=3
https://www.digitalocean.com/community/tutorials/js-big-o-notation
| milanwinter | |
1,473,260 | Get Your TypeScript Coverage Report | Here is something I’ve been meaning to do for quite some time now - You see, you start a project... | 0 | 2023-05-19T09:50:48 | https://dev.to/mbarzeev/get-your-typescript-coverage-report-5c5p | typescript, tutorial, webdev, tooling | Here is something I’ve been meaning to do for quite some time now -
You see, you start a project using TypeScript (TS) or maybe migrating an existing code base to TS, and would like to know how well your project is “typed”, and that, so you can be sure that when you’re about to refactor your code you’ve got TS to protect you (along with testing of course, right? 😉).
How do you do that?
Turns out there are tools for that and one of them is called [typescript-coverage-report](https://www.npmjs.com/package/typescript-coverage-report) by [Alex Canessa](https://github.com/alexcanessa) and I’m going to give it a try now and implement it in my [Pedalboard monorepo](https://github.com/mbarzeev/pedalboard).
Let’s get started!
***
*Hey! for more content like the one you're about to read check out <a href="https://twitter.com/mattibarzeev?ref_src=twsrc%5Etfw" class="twitter-follow-button" data-show-count="false">@mattibarzeev</a><script async src="https://platform.twitter.com/widgets.js" charset="utf-8"></script> on Twitter* :beers:
***
I will start by implementing it in a single package within my monorepo and see the value I gain from it. The package I choose is the [stylelint-plugin-craftsmanlint](https://github.com/mbarzeev/pedalboard/tree/master/packages/stylelint-plugin-craftsmanlint) which is a stylelint plugin (as the name suggests, don’t know why I wrote that… 😅)
Starting with the instructions on the [coverage npm package page](https://www.npmjs.com/package/typescript-coverage-report):
```bash
yarn add -D typescript-coverage-report
```
Next we add the npm script to the `package.json` file so that we can run the coverage:
```json
"scripts": {
...
"ts-coverage": "typescript-coverage-report"
},
```
Now let’s run it
```bash
yarn ts-coverage
```
Hey, that’s not bad - here is the summary coverage page for my package:
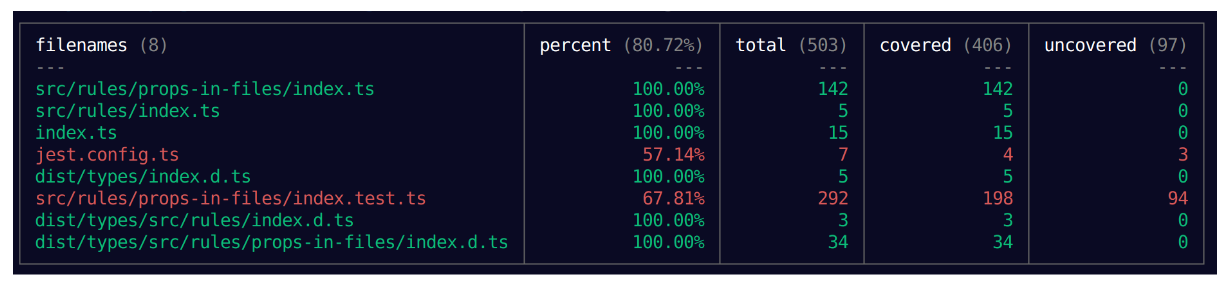
And it also generated an HTML report:
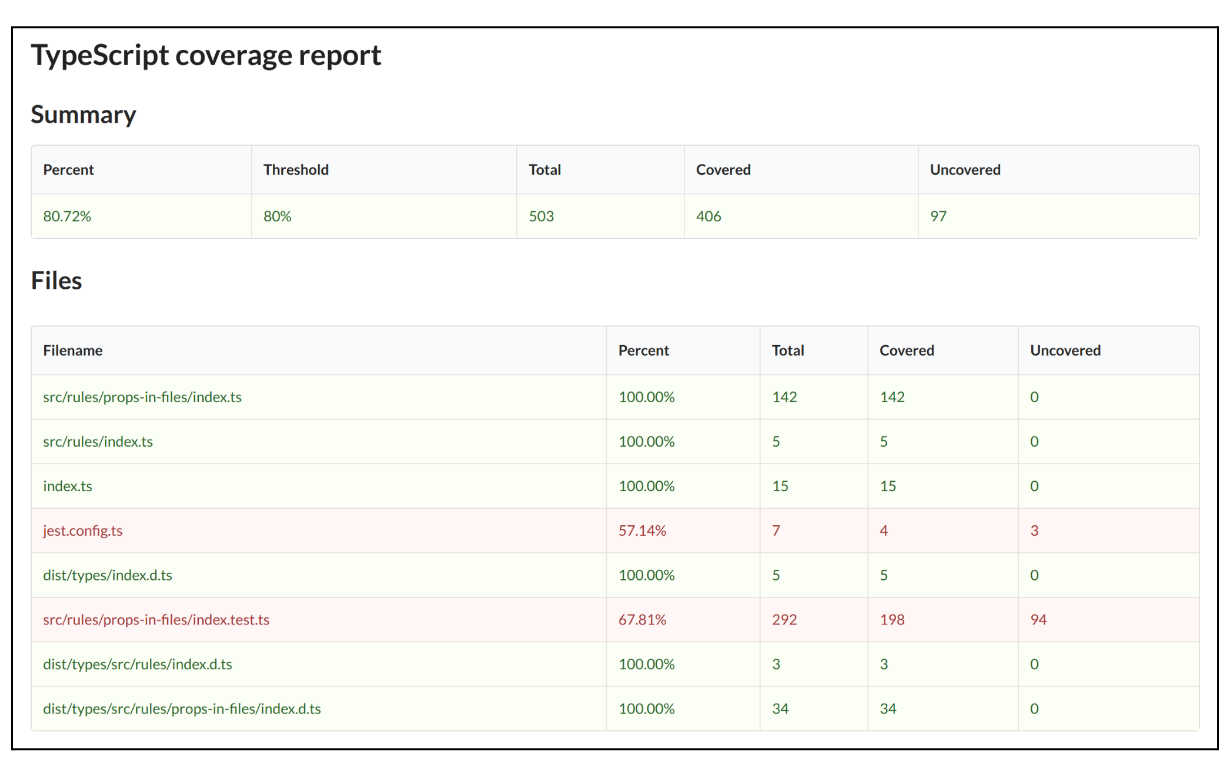
Putting the `jest.config.ts` file aside for a sec, I see that my test there has low coverage. Let’s drill into the report (a part of it) in the image below:
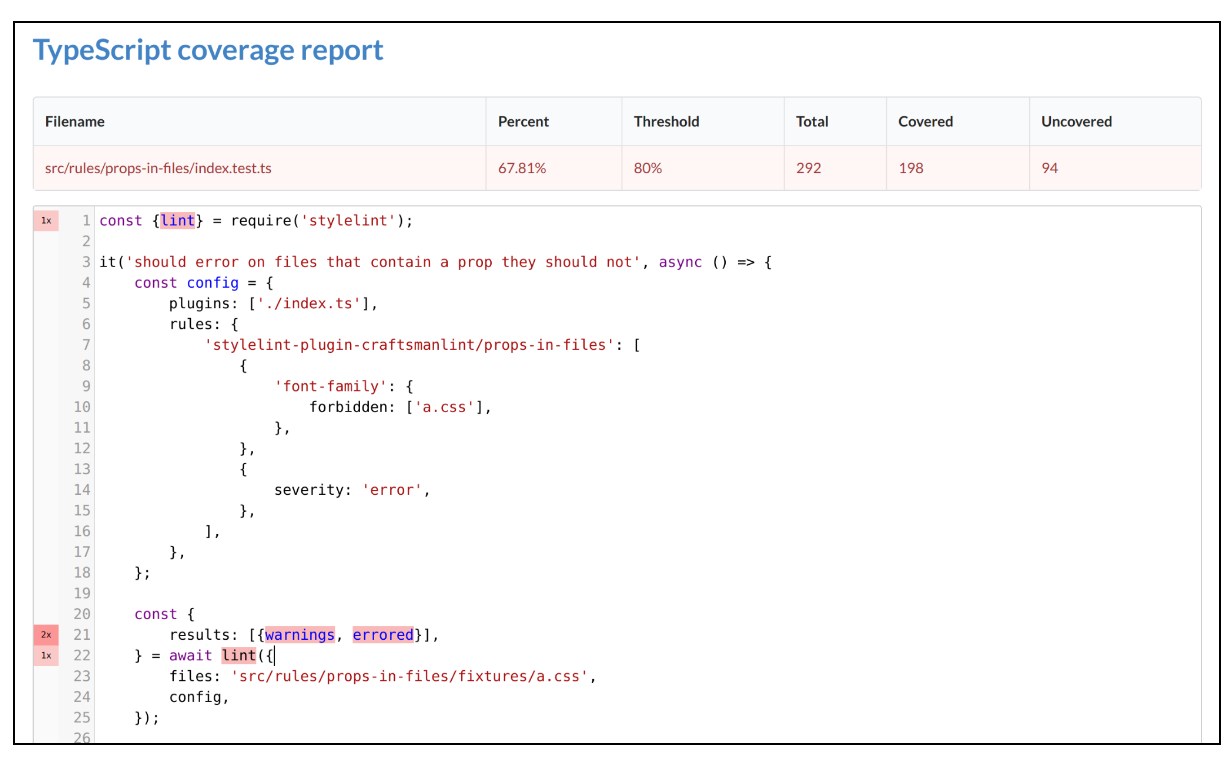
Ok, that’s nice, I can see where the types are missing, but hovering on them does not tell me what exactly the issue is (like jest unit testing coverage does), but I guess you can say that the issue is “you don’t have a type for this”, right?.
Just to make sure this all works, I will try to fix one of the issues and run the coverage again to make sure it is no longer there - What is the `require` statement for `lint` doing there? Did I do that? Oh my, let’s convert it to an ESM import and run the unit tests again to make sure all still works:
```javascript
// const {lint} = require('stylelint');
import {lint} from 'stylelint';
```
Yes, they all still pass. Now let’s run the TS coverage tool to see if it had some effect over it, and… yes! Wow, we’re now at 98.97% coverage:
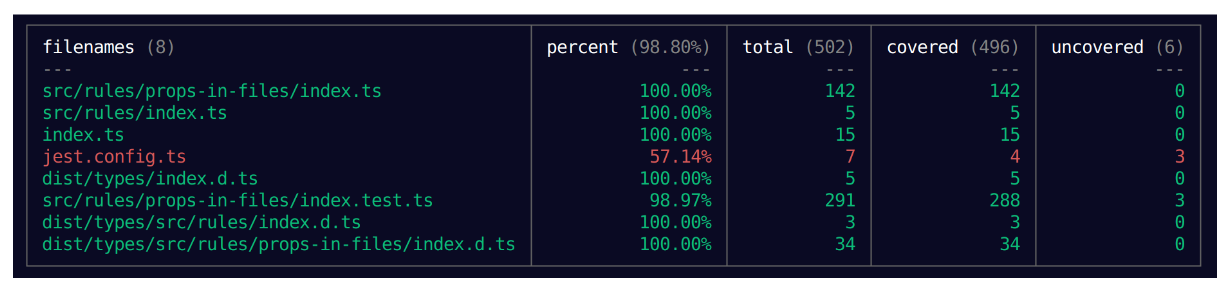
But… we still have an issue there. Where is it?

Hmm… interesting. `jsonRule` does not have a type to it. Fixing:
```javascript
const jsonRule: ConfigRules = JSON.parse(`{
…
}`);
```
And now we have 100% coverage. Cool!
As of that `jest.config.ts` file, I think we can ignore it by introducing a `typeCoverage` property in our package.json file (though I'm too keen about adding configurations in the package.json file. I much prefer an .rc file):
```json
"typeCoverage": {
"ignoreFiles": [
"jest.config.ts"
]
},
```
Now our TS code coverage report is all good and looks like this:
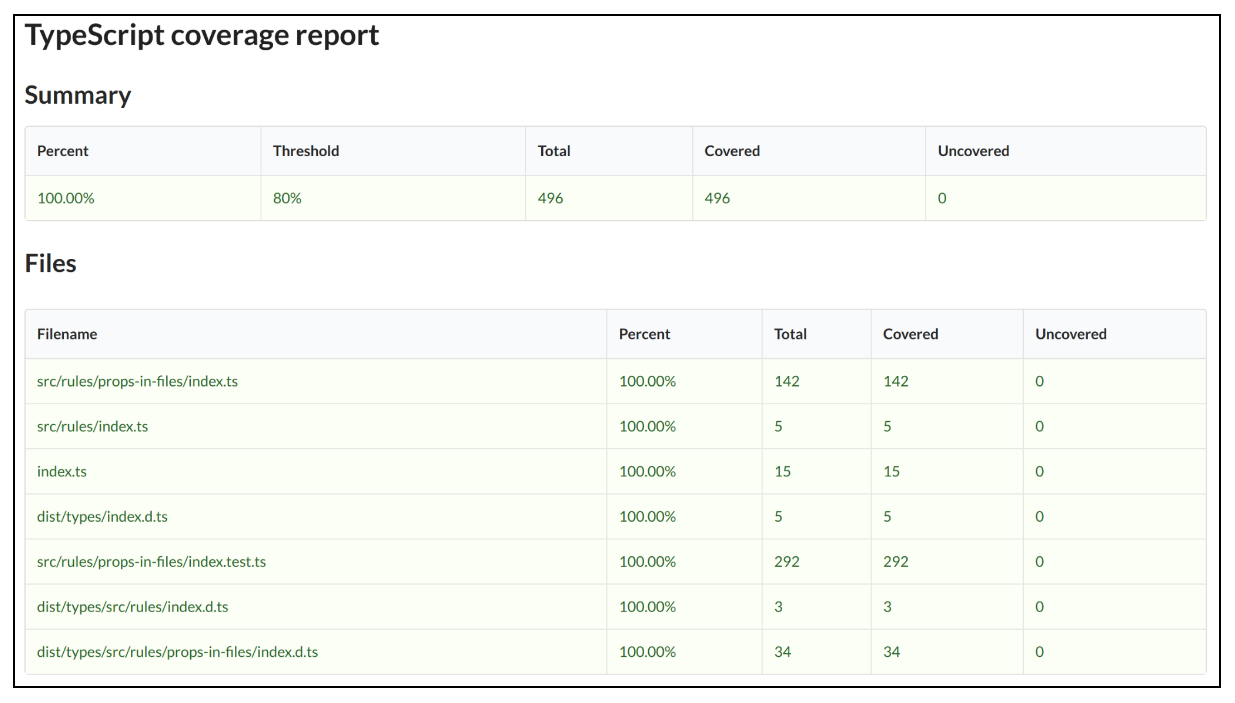
Nice 🙂
All-in-all typescript-coverage-report looks like a really cool tool for finding out how well your project is “typed”. It can be integrated as a commit hook or even some code checkers as part of your GitHub actions (hmm… here’s a neat idea for my next post 😉).
You can check out the entire code on the [Pedalboard monorepo](https://github.com/mbarzeev/pedalboard).
***
*Hey! for more content like the one you've just read check out <a href="https://twitter.com/mattibarzeev?ref_src=twsrc%5Etfw" class="twitter-follow-button" data-show-count="false">@mattibarzeev</a><script async src="https://platform.twitter.com/widgets.js" charset="utf-8"></script> on Twitter* :beers:
<small><small><small>Photo by <a href="https://unsplash.com/@fallonmichaeltx?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText">Fallon Michael</a> on <a href="https://unsplash.com/photos/IP59z0FXBuY?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText">Unsplash</a>
</small></small></small>
| mbarzeev |
1,473,440 | Links for web dev | color scheme designer Icons boxicons iconscout All CSS properties google fonts | 23,047 | 2023-05-19T13:18:56 | https://dev.to/darty/links-for-web-dev-42eb | [color scheme designer](https://paletton.com/#uid=1000u0kllllaFw0g0qFqFg0w0aF)
--------------
## Icons
[boxicons](https://boxicons.com/)
[iconscout](https://iconscout.com/)
--------------
[All CSS properties](https://www.web4college.com/css-play/index.php)
------------------------
[google fonts](https://fonts.google.com/)
| darty | |
1,473,465 | Ex-Googlers setting the Standard for Creating new Startups[2023 Layoffs] | So tech layoffs, hiring freezes and the like have affected us all havent they. Tech layoffs can... | 0 | 2023-05-19T14:15:25 | https://dev.to/mikacodez/ex-googlers-setting-the-standard-for-creating-new-startups2023-layoffs-55do | webdev, googlecloud, news, startup | So tech layoffs, hiring freezes and the like have affected us all havent they.
Tech layoffs can occur for various reasons, and the specific factors leading to layoffs in 2023 would depend on the economic and industry conditions at that time. Some possible reasons for tech layoffs include:
Economic downturn: During periods of economic recession or instability, companies may downsize their workforce, including tech positions, to reduce costs and maintain profitability.

Business restructuring: Companies may undergo reorganizations, mergers, or acquisitions that result in redundancies or a shift in focus, leading to job cuts in certain areas, including technology.
Changing market dynamics: Technological advancements, market disruptions, or shifts in consumer preferences can impact the demand for specific tech products or services, leading companies to reevaluate their workforce needs.
Automation and efficiency improvements: As automation and artificial intelligence technologies advance, some companies may automate certain tasks or processes, reducing the need for human labor in those areas.

Regarding the future of the tech industry, it is important to note that the industry has been dynamic and resilient. While specific predictions are uncertain, several trends are expected to shape the industry:
Continued growth and innovation: The tech industry is expected to continue expanding, driven by advancements in areas such as artificial intelligence, cloud computing, data analytics, cybersecurity, and Internet of Things (IoT).
Workforce adaptation: With automation and AI advancements, there may be a shift in the types of skills and roles in demand. Tech professionals may need to adapt and upskill to remain relevant in a changing job market.
Increased focus on cybersecurity: As technology becomes more integrated into our daily lives, the importance of cybersecurity will continue to grow. There will likely be an increased emphasis on securing digital infrastructure and protecting data.

Ethical and responsible tech: There is a growing awareness and concern for ethical considerations in technology, such as data privacy, algorithmic bias, and responsible AI development. Companies are likely to prioritize ethical practices to build trust with consumers.
Collaboration and interdisciplinary skills: Tech professionals will increasingly need to work collaboratively across disciplines. The ability to communicate and collaborate effectively with non-tech teams, such as marketing, design, and business development, will be valuable.
It is important to note that these are general trends and the future of the tech industry can be influenced by numerous factors, including global events, technological breakthroughs, regulatory changes, and market dynamics.

In terms of Ex-Google employers they have taken the industry by storm by doing the following:
- **Geographic Impact**: The majority of affected Google employees were based in the United States, with 56.4% of ex-Googlers leaving the company. The United Kingdom, Ireland, India, and Canada were among the next affected countries.
- **Regional Impact**: Excluding North America, Europe saw 12% of ex-Googlers let go, while Asia accounted for 5% of the impacted workforce.
- **Affected Roles**: Software engineers were the most affected, comprising 30.6% of all laid-off employees. Other impacted roles included sales, recruitment, product design, and project management.
- **New Job Placements**: Out of the total laid-off Googlers, 747 updated their profiles to indicate a change in employment status. These ex-Googlers joined or founded new companies, with 56.7% of them being in the "Technology & IT" industry, primarily in software development.
- **Startup Involvement**: Many ex-Googlers joined startups, with 205 startups identified as fulfilling specific criteria. Of these startups, 73 had received funding, 121 had 50 or fewer employees, and 43 had ex-Googlers as founders or co-founders.
- **Funding and Incorporation**: Among the identified startups, 73 had received various funding rounds. Additionally, 41 of the startups were incorporated from 2020 onwards, with a range of employee sizes.

For more information on using LinkedIn sales Navigator click here:
https://nubela.co/proxycurl/?utm_campaign=affiliate_marketing&utm_source=affiliate_link&utm_medium=affiliate&utm_content=malcolm
Or more information on this article here:
https://nubela.co/blog/1-in-3-ex-google-employees-in-15-billion-worth-of-startups-2023-layoffs/
Follow me on Twitter: @CodezMikazuki
Thanks for reading, Malcz/Mika | mikacodez |
1,473,621 | 7 Bad Practices to Avoid When Writing SQL Queries for Better Performance 🚀 | When working with databases, optimizing SQL queries is essential to achieve better performance and... | 0 | 2023-05-19T15:10:00 | https://dev.to/abdelrahmanallam/7-bad-practices-to-avoid-when-writing-sql-queries-for-better-performance-c87 | sql, performance, database | When working with databases, optimizing SQL queries is essential to achieve better performance and reduce response times. In this post, we'll cover some common bad practices in SQL queries and provide examples of how to write queries that perform better
### 🙅 Bad Practice 1: Using SELECT *
One of the most common mistakes when writing SQL queries is using the `SELECT *` statement to fetch all columns from a table. This can cause performance issues, especially when working with large tables, as it requires the database to read all columns, even if they're not needed.
#### 👌 Good Practice: Selecting Specific Columns
Instead of using `SELECT *`, it's better to select only the columns that are needed in the query. This reduces the amount of data that needs to be read, improving performance. For example:
```SQL
-- 🔴 Bad Practice
SELECT * FROM users WHERE id = 1;
-- 🟢 Good Practice
SELECT name, email FROM users WHERE id = 1;
```
### 🙅 Bad Practice 2: Using Subqueries in SELECT
Another common mistake is using subqueries in the `SELECT` statement. Subqueries are queries inside other queries, and they can be expensive to execute, especially when the outer query returns many results.
#### 👌 Good Practice: Using JOINs Instead of Subqueries
Instead of using subqueries, it's better touse JOINs to combine data from multiple tables. This can be more efficient, as JOINs can be optimized by the database engine. For example:
```SQL
-- 🔴 Bad Practice
SELECT name, (SELECT COUNT(*) FROM orders WHERE user_id = users.id) AS order_count
FROM users;
-- 🟢 Good Practice
SELECT users.name, COUNT(orders.*) AS order_count
FROM users
JOIN orders ON users.id = orders.user_id
GROUP BY users.id;
```
In this example, we're calculating the number of orders for each user. The bad practice query uses a subquery in the `SELECT` statement, while the good practice query uses a JOIN and a GROUP BY clause to achieve the same result.
### 🙅 Bad Practice 3: Using LIKE with Leading Wildcards
Using the `LIKE` operator with leading wildcards (`%`) can cause performance issues, as it requires a full table scan to find matching rows.
#### 👌 Good Practice: Using Indexes and Trailing Wildcards
To improve performance when searching for patterns in text fields, it's better to use indexes and trailing wildcards (`%`) instead of leading ones. This allows the database to use the index to find matching rows, rather than performing a full table scan. For example:
```SQL
-- 🔴 Bad Practice
SELECT * FROM products WHERE name LIKE '%apple%';
-- 🟢 Good Practice
SELECT * FROM products WHERE name LIKE 'apple%';
```
In this example, the bad practice query uses a leading wildcard, which cancause a full table scan. The good practice query uses a trailing wildcard, which allows the database to use an index to find matching rows more efficiently.
### 🙅 Bad Practice 4: Using ORDER BY with Large Result Sets
Using the `ORDER BY` clause with large result sets can be inefficient, as it requires the database to sort all rows returned by the query.
#### 👌 Good Practice: Using LIMIT with ORDER BY https://dev.mysql.com/doc/refman/8.3/en/limit-optimization.html
To improve performance when sorting large result sets, it's better to use the `LIMIT` clause with `ORDER BY` so that the database only sorts the necessary rows. For example:
```SQL
-- 🔴 Bad Practice
SELECT * FROM products ORDER BY price;
-- 🟢 Good Practice
SELECT * FROM products ORDER BY price LIMIT 100;
```
In this example, the bad practice query orders all products by price, while the good practice query orders the first 100 products by price.
### 🙅 Bad Practice 5: Using COUNT(*) with Large Tables
Using the `COUNT(*)` function with large tables can be inefficient, as it requires the database to count all rows in the table.
#### 👌 Good Practice: Using COUNT(1) or COUNT(column)
To improve performance when counting rows, it's better to use `COUNT(1)` or `COUNT(column)` instead of `COUNT(*)`, as they can be optimized by the database engine. For example:
```SQL
-- 🔴 Bad Practice
SELECT COUNT(*) FROM users;
-- 🟢 Good Practice
SELECT COUNT(1) FROM users;
```
In this example, thebad practice query counts all rows in the `users` table, while the good practice query uses `COUNT(1)` to achieve the same result more efficiently.
### 🙅 Bad Practice 6: Using DISTINCT with Large Result Sets
Using the `DISTINCT` keyword with large result sets can be inefficient, as it requires the database to sort and remove duplicates from all rows returned by the query.
#### 👌 Good Practice: Using GROUP BY Instead of DISTINCT
https://dev.mysql.com/doc/refman/8.3/en/distinct-optimization.html
To improve performance when removing duplicates, it's better to use the `GROUP BY` clause instead of `DISTINCT`, as it can be optimized by the database engine. For example:
```SQL
-- 🔴 Bad Practice
SELECT DISTINCT category FROM products;
-- 🟢 Good Practice 👌
SELECT category FROM products GROUP BY category;
```
In this example, the bad practice query removes duplicates from all categories in the `products` table, while the good practice query groups the rows by category to achieve the same result more efficiently.
### 🙅 Bad Practice 7: Using OR in WHERE Clauses
Using the `OR` operator in `WHERE` clauses can be inefficient, as it can force the database to perform a full table scan to find matching rows.
#### 👌 Good Practice: Using UNION or IN Instead of OR
To improve performance when filtering rows, it's better to use `UNION` or `IN` instead of `OR`, as they can be optimized by the database engine. For example:
```SQL
-- 🔴 Bad Practice
SELECT * FROM products WHERE category = 'fruit' OR category ='dairy';
-- 🟢 Good Practice 👌
SELECT * FROM products WHERE category IN ('fruit', 'dairy');
```
In this example, the bad practice query uses `OR` to find rows that match either 'fruit' or 'dairy', while the good practice query uses `IN` to achieve the same result more efficiently.
## Conclusion:
By selecting specific columns in `SELECT` statements, using `JOIN`s instead of subqueries, using indexes with trailing wildcards, using `LIMIT` with `ORDER BY`, using `COUNT(1)` or `COUNT(column)` instead of `COUNT(*)`, using `GROUP BY` instead of `DISTINCT`, and using `UNION` or `IN` instead of `OR`, you can improve query performance and make your applications more responsive.
Remember, There is more then 7 practices that could improve writing SQL query much better, like Using Indexes, these are just some examples, and there are many other ways to optimize SQL queries. Always analyze your queries and use database-specific features and tools to improve performance.
## [Check also Git Good Commands] (https://dev.to/abdelrahmanallam/10-essential-git-commands-every-developer-should-know-and-use-374b) | abdelrahmanallam |
1,476,513 | Protecting APIs by Merging Tools and Security Best Practices | Rapid uptake in adoption by industries ranging from banking to retail to autonomous vehicles of... | 0 | 2023-05-22T15:37:31 | https://www.developernation.net/blog/protecting-apis-by-merging-tools-and-security-best-practices | Rapid uptake in adoption by industries ranging from banking to retail to autonomous vehicles of customer- and partner-facing and internal application programming interfaces (APIs) to drive internet traffic has resulted in an equally rapid growth in endpoint attacks - more than 11 billion over just 18 months according to [a report from edge computing security leader Akamai](https://www.akamai.com/resources/research-paper/akamai-web-application-and-api-threat-report). It makes sense that they are more vulnerable to threats from malicious actors, given API endpoints' similarity to internet-facing web servers, and their role as pipelines between divergent platforms.
For DevSecOps teams, protecting APIs is a top priority; they are vital to mobile, SaaS, and web applications and paramount to a healthy software development lifecycle. API security is also a natural extension of DevSecOps' push to break down silos between development, security, and operations and move toward automation and design that integrates security as a shared responsibility.
Thus, it is time to view API security not as an external bottleneck, but as a part of a stable long-term strategy. This can be achieved by altering company attitudes and investing in API tools that facilitate testing, enforce governance standards, and automate recurring security tasks.
##Adopt an API-as-a-Product Strategy
A primary reason digital transformation efforts have failed for many brands is because they do not see APIs adding value. As such, they've lost track of the potential return on investment (ROI) APIs can deliver. When APIs are not viewed as assets or value-generating, they aren't subject to the appropriate level of protection or security performance oversight. In fact, Akamai's report highlighted the fact that many enterprises relegate API security checks to the end of the lifecycle and rely on traditional network security solutions which aren't designed to protect against the attacks to which APIs are subject.
This is starting to change, however, as [API-as-a-Product ](https://nordicapis.com/how-to-treat-your-api-as-a-product/)strategies gain traction within the developer community. There is a notable shift away from delivering project features based on budgets and deadlines to holistically examining APIs as products and assessing their capabilities. Further, as the concept of monetizing APIs gains prominence, their protection becomes a higher priority at the outset, with organizations more inclined to adopt a human-centered design approach.
What this means is moving API regression tests to the forefront rather than treating them as an afterthought. It means adopting a design-first approach - wherein everyone on the team speaks the same language and every tool is able to leverage the same design - from the outset with the help of an API management platform. This will also help ensure that APIs are built on established authentication and authorization mechanisms such OAuth 2.0, which is the industry-standard protocol for authorization, and OpenID Connect.
API testing tools are critical for protecting something upon which most services in use daily rely. These tools let developers see if an API is reacting adequately to unexpected inputs or possible security attacks. They show immediately if an application is running with optimized functionality, reliability, and security.
Whether it is running user authentication, parameter tampering, unhandled HTTP, or fuzz testing, it is imperative to test an API contract to ensure that services can communicate and that the data they share is consistent with a specified set of rules or standards. Further, there are many solutions in the API testing market, including cross-cloud API testing software, software that supports asynchronous testing and continuous integration/continuous deployment (CI/CD) integrations, and end-to-end testing - as well as solutions that support various formats eliminating the need for developers to learn new languages.
Continuous testing is essential across the DevSecOps pipeline, as is robust test coverage based on API contracts that have been designed and approved. Plus, by chaining together complex API transactions and workflows, cases can be tested on-demand using continuous delivery or CI/CD to reduce downtime.
##Security in 360-degree Lifecycle Management
While API security considerations have typically been an afterthought to ever-increasing business demands, the reality is that no enterprise can afford for software security checks to be the last stage of an API lifecycle. Rather, security must be part of a 360-degree API lifecycle management strategy. It should be incorporated into every level, from planning and design to developing, testing, and release management - all the way out to deprecation.
Developers must also have oversight throughout the entire API lifecycle - which is where an API management platform comes into play. A dedicated platform can provide workflow visualizers that show an API's complete lifecycle in a single view with issue alerts, which helps accelerate production using CI/CD in the DevSecOps pipeline to build trusted artifacts and more rapid iterations, thereby guaranteeing a security-first mindset.
API tools also allow perimeter scans, which enable the discovery and inventory of APIs and allow for easy breakdowns for DevSecOps teams to work with. The best platforms will leverage a command line interface (CLI) - a unified tool for managing and controlling multiple services from the command line or with automation through scripts - to make APIs more easily discoverable. The team can easily determine where and how many APIs are deployed; a level of visibility that is mandatory for enterprises.
##Tools for Success
In short, an API team is only as successful as the set of tools at its disposal.
API security best practices are no mystery to seasoned security professionals - and they start with establishing solid API security policies through an API management platform.
Finally, a collaborative approach to API governance - in line with the DevSecOps mission to eliminate siloes - is imperative for any organization's security.
_About [APIWizAPIwiz](https://www.apiwiz.io/) is a low-code, API automation platform allowing developers to build and release reliable APIs quickly. With APIwiz, API teams have complete control, visibility, and predictability over their entire API program, allowing organizations to stay open and connected._ | gottfriedmoh | |
1,473,920 | Improve Data Fetching in Next.js Applications through SWR | This article was originally published here Fetching and rendering data from APIs is one of the core... | 0 | 2023-05-19T19:50:04 | https://dev.to/umoren/improve-data-fetching-in-nextjs-applications-through-swr-8od | programming, react, nextjs | <mark>This article was originally published </mark> [<mark>here</mark>](https://soshace.com/using-swr-for-efficient-data-fetching-in-next-js-applications/)
Fetching and rendering data from APIs is one of the core essentials of front-end development. The basic way of fetching data in JavaScript is to use local `fetch` or a third-party library like `axios`, input the right HTTP method for the request, including headers, parse the result in JSON, and render it to the DOM. This wouldn’t work well with modern web applications because of their architectures' complexity. Users will only use a web app that’s fast, reliable, and responsive; that means if they request a resource, they want it delivered in <3s. As a result, developers need to use tools or libraries that improve the data-fetching experience in their applications.
In React, data fetching is a side effect, and it provides the `useEffect` Hook for performing this side effect. Data fetching in React typically would look like this:
```jsx
function Example() {
const [data, setData] = useState(null);
useEffect(() => {
async function fetchData() {
const response = await fetch('https://api.example.com/data');
const result = await response.json();
setData(result);
}
fetchData();
}, []); // The empty array `[]` ensures the effect only runs once on mount and unmount.
return (
<div>
{data ? (
<div>{JSON.stringify(data)}</div>
) : (
<div>Loading...</div>
)}
</div>
);
}
```
However, when building server-rendered applications, Nextjs is preferred. Data fetching in Next.js can be done using different methods, depending on the desired rendering strategy, that is:
* When you want to fetch data at build time and generate static HTML pages, Nextjs provides `getStaticProps` for that.
* When you have dynamic routes and want to generate static HTML pages for each route, use `getStaticPaths`.
* When you need to fetch data on each request, providing a server-rendered experience, use `getServerSideProps`
* You can still use client-side data fetching when you don't need to pre-render the data or when you want to fetch data that depends on user interactions.
It is common to see Next.js applications that make use of client-side data fetching. The challenge with this technique of data fetching is that you have to render data based on user interaction, which can lead to several issues if not handled properly.
This is why Vercel created SWR (stale-while-revalidate). Without a solution like SWR, you’re likely to face difficulties managing caching, ensuring data synchronization, handling errors, and providing real-time updates. Additionally, handling loading states can become cumbersome, and you might end up with a lot of boilerplate code just for fetching, caching, and managing the data as the codebase grows. SWR addresses these challenges by providing built-in caching, automatic cache revalidation, error retries, support for real-time updates, and a Hooks-based API that simplifies data management.
In this article, I’ll introduce you to how SWR works, its key concepts, and how to use it for efficient data fetching in client-side Next.js applications.
## How SWR works
To understand how SWR works, you need to be conversant with these key concepts.
1. Caching: Caching is like storing food in the fridge. It's a way to save data so it can be quickly accessed later without needing to fetch it from the source (server) every time. This speeds up the process of retrieving data and reduces the load on the server.
2. Revalidation: Revalidation is like checking if the food in the fridge is still good or needs replacing with a fresh meal. In the context of data fetching, revalidation means checking if the cached data is still valid or if it needs to be updated with new data from the server. With SWR, this process happens automatically in the background, ensuring your data is always up-to-date.
3. Stale-While-Revalidate: Imagine you have a fridge with food inside. When you're hungry, you grab something from the fridge (cached data). At the same time, a friend starts cooking a fresh meal (fetching new data). You eat the food from the fridge while waiting for the fresh meal to be ready. Once done, the fridge is restocked with fresh food (cache revalidation).
SWR is a data fetching library that implements the Stale-While-Revalidate (SWR) strategy. It fetches, caches, and revalidates data in the background to provide an efficient and seamless user experience.
## What we’ll be building
To appreciate SWR, you need to build something with it. In this tutorial, we’ll build a product store with Nextjs. While building this demo app, you’ll get to learn the following:
* Fetching data using the `useSWR` hook
* Handling Errors and Loading States
* Implementing optimistic UI updates with SWR
* Implementing infinite scrolling in Next.js with SWR
### Pre-requisites
You’ll need the following:
* Nodejs ≥v16
* Code editor (preferably VS code)
* Code terminal
* Package manager (yarn preferably)
* Knowledge of JavaScript and Reactjs
The complete code is on [Github](https://github.com/Umoren/product-store-swr), and the demo app is [here](https://product-store-swr.vercel.app/).
### Getting Started
Run this command on your terminal to create a nextjs project.
```bash
npx create-next-app product-store; cd product-store; code .
```
The product store will have a `/product` parent route with these sub-routes: `/product/listing` and `/product/detail`. Run this command from the root directory on your terminal to create these page routes.
```bash
cd pages; mkdir product; cd product; touch [id].js upload.js
```
Go back to the root directory and create these UI components
```bash
mkdir components; cd components; touch ProductList.jsx ProductCard.jsx ErrorMessage.jsx LoadingIndicator.jsx ProductUploadForm.jsx
```
Navigate back to the root director and install these packages:
```bash
yarn add swr tailwindcss postcss autoprefixer react-infinite-scroll-component;
```
See how to configure tailwindcss [here](https://tailwindcss.com/docs/guides/nextjs).
### Fetching, Displaying, and Updating Data with SWR
Firstly, let’s create a custom React hook that’ll fetch data from the Products fakeapi endpoint using SWR. Add these lines of code to `hooks/useFetch.js`
```jsx
import useSWR from 'swr';
const fetcher = async (url) => {
const response = await fetch(url);
if (!response.ok) {
throw new Error('An error occurred while fetching the data.');
}
return response.json();
};
const useFetch = (path) => {
const { data, error } = useSWR(`https://fakestoreapi.com/${path}`, fetcher);
const isLoading = !data && !error;
return { data, error, isLoading };
};
export default useFetch;
```
Here, we define a custom React hook, `useFetch`, which leverages the `useSWR` hook for data fetching. It takes a `path` as input and constructs a full `URL` to fetch data from the Fake Store API. The fetcher function handles making the request and error checking. `useFetch` returns an object with the fetched data, potential errors, and a loading state.
Now let’s display the product list.
Navigate to `components/ProductCard` and add these lines of code.
```jsx
import Link from 'next/link';
import Image from 'next/image';
const ProductCard = ({ product }) => {
return (
<div className="bg-white rounded-lg shadow-md p-4">
<Image
src={product.image}
alt={product.title}
width={640}
height={640}
layout="responsive"
/>
<h3 className="text-lg font-semibold mb-2">{product.title}</h3>
<p className="text-gray-600 mb-2">{product.category}</p>
<div className="flex justify-between items-center">
<span className="text-lg font-bold">${product.price}</span>
<Link
href={`/product/${product.id}`}
className="text-blue-600 hover:text-blue-800"
>
View Details
</Link>
</div>
</div>
);
};
export default ProductCard;
```
This ProductCard component renders a single product card. The card includes an image, product title, category, price, and a link to the product details page. The image is set using Next.js' Image component, which automatically optimizes the image for performance. The link to the product details page is wrapped in Next.js' Link component for client-side navigation.
Navigate to `component/ProductList.jsx` and add these lines of code.
```jsx
import useFetch from './hooks/useFetch';
import ProductCard from './ProductCard';
const ProductList = () => {
const { data: products, error, isLoading } = useFetch('products');
if (isLoading) {
return <div>Loading...</div>;
}
if (error) {
return <div>Error: {error.message}</div>;
}
return (
<div className="grid grid-cols-1 md:grid-cols-2 lg:grid-cols-3 gap-4">
{products.map((product) => (
<ProductCard key={product.id} product={product} />
))}
</div>
);
};
export default ProductList;
```
Here, we define the `ProductList` component, which fetches and displays a list of products. It uses the `useFetch` custom hook to fetch `product` data and `ProductCard` to render each product. The component handles `loading` and `error` states and displays the products in a grid format.
Update `pages/index.js` with these lines of code.
```jsx
import ProductList from "../components/ProductList"
export default function Home() {
return (
<div className='max-w-screen-xl m-auto'>
<ProductList />
</div>
)
}
```
Run the dev server with this command `yarn dev`, it should start the server at `[http://localhost:3000](http://localhost:3000)`, and you should see something like this on your browser.

Great! We’ve been able to display the products. Let’s now implement the view for a single product. Update `pages/product/[id].js` with these lines of code. Here we’ll use `useSWR` directly.
```jsx
import useSWR from "swr";
import Image from "next/image";
const fetcher = async (url) => {
const response = await fetch(url);
if (!response.ok) {
throw new Error("An error occurred while fetching the data.");
}
return response.json();
};
const ProductDetails = ({ id }) => {
const {
data: product,
error,
isLoading,
} = useSWR(`https://fakestoreapi.com/products/${id}`, fetcher);
if (isLoading) {
return <div>Loading...</div>;
}
if (error) {
return <div>Error: {error.message}</div>;
}
return (
<div className="max-w-2xl mx-auto min-h-screen py-16">
<h1 className="text-2xl font-semibold mb-4">{product.title}</h1>
<div className="md:flex space-x-8">
<div>
<Image
src={product.image}
alt={product.title}
width={640}
height={640}
layout="responsive"
/>
</div>
<div>
<p className="text-gray-100 mb-2">{product.category}</p>
<p className="text-xl font-bold mb-4">${product.price}</p>
<p>{product.description}</p>
</div>
</div>
</div>
);
};
export async function getServerSideProps(context) {
const { id } = context.query;
return {
props: {
id,
},
};
}
export default ProductDetails;
```
This component handles `loading` and `error` states and renders product information. The `getServerSideProps` function retrieves the product ID from the query params, which is passed as a prop to the component for server-side rendering. A single product detail look like this:

### Handling Errors and Loading States
SWR provides an `ErrorBoundary` component that can be used to catch errors that occur within its child components. This component can be used to display a fallback UI when an error occurs, such as an error message or a reload button. The Error boundary provides a way to separate an application's data-fetching and data-rendering concerns. When an error occurs during data fetching, SWR Error Boundary can intercept and handle it gracefully. This way, error messages can be displayed to the user without breaking the entire application.
```jsx
import useSWR from 'swr';
import { SWRConfig } from 'swr';
import { ErrorBoundary } from 'react-error-boundary';
function App() {
const { data, error } = useSWR('/api/data');
if (error) {
throw new Error('Failed to load data');
}
return <div>{data}</div>;
}
function AppWrapper() {
return (
<ErrorBoundary fallback={<div>Failed to load data</div>}>
<SWRConfig value={{}}>
<App />
</SWRConfig>
</ErrorBoundary>
);
}
```
In this code snippet, if an error occurs during the fetching process, it throws an error, which is caught by the `ErrorBoundary` component. The `fallback` prop of the `ErrorBoundary` component is a UI to be displayed when an error occurs. In this case, it displays a simple error message.
### Implementing loading indicators for a better user experience
Let’s go back to building our app. Go to `component/LoadingIndicator.jsx` and add these lines of code.
```jsx
const LoadingIndicator = () => {
return (
<div className="flex justify-center items-center">
<div className="animate-spin rounded-full h-10 w-10 border-b-2 border-blue-500"></div>
</div>
);
};
export default LoadingIndicator;
```
This LoadingIndicator component will be used to represent the loading states while fetching data. Head to `components/ProductList.jsx` and modify the code to this:
```jsx
if (isLoading) {
return <LoadingIndicator />;
}
```
Let’s also create an ErrorMessage component that renders an error message when there are data fetching issues. Head to `components/ErrorMessage.jsx`:
```jsx
const ErrorMessage = ({ message }) => {
return (
<div
className="bg-red-100 border border-red-400 text-red-700 px-4 py-3 rounded relative"
role="alert"
>
<strong className="font-bold">Error: </strong>
<span className="block sm:inline">{message}</span>
</div>
);
};
export default ErrorMessage;
```
Update `component/ProductList.jsx` like this:
```jsx
if (error) {
return <ErrorMessage message={error.message} />;
}
```
### Optimistic UI updates
When you POST a message in messaging apps, it is immediately displayed in the chat even if there’s no network connection. That’s the idea of optimistic UI updates, and this can be implemented with SWR. With SWR, you can update the local cache of the data in response to user actions while at the same time sending the update request to the server. If the server responds with an error, the local cache can be reverted back to its previous state. This way, the user gets an immediate response while still having the assurance that the data is being updated on the server.
To implement optimistic UI updates with SWR, you need to use the `mutate` function provided by the hook. The `mutate` function allows you to update the cache of the data without making a request to the server. You can pass an updater function to the `mutate` function, which receives the current data as an argument, and returns the updated data. The `mutate` function updates the local cache with the new data, and triggers a re-render of the component.
Once the update request is sent to the server, you can use the `mutate` function again to update the cache with the response from the server. If the server responds with an error, you can use the `mutate` function with the previous data to revert the cache to its previous state.
This is how to implement optimistic UI updates in our app while uploading a new product.
`pages/product/upload.js`
```jsx
import ProductUploadForm from "../../components/ProductUploadForm";
import { mutate } from "swr";
import axios from "axios";
import ErrorMessage from "../../components/ErrorMessage";
const upload = () => {
const onUpload = async (newProduct) => {
// Optimistically update the local data
mutate(
"/products",
(products) => {
if (Array.isArray(products)) {
return [newProduct, ...products];
}
return [newProduct];
},
false
);
// Make the API call to create the product
try {
await axios.post("https://fakestoreapi.com/products", newProduct);
// Revalidate the data after successful upload
mutate("/products");
} catch (error) {
// Handle any errors
<ErrorMessage message={error} />;
}
};
return (
<div>
<h1 className="mb-4 text-2xl p-3 font-extrabold text-gray-900 dark:text-white md:text-3xl lg:text-4xl">
{" "}
Upload Product
</h1>
<ProductUploadForm onUpload={onUpload} />
</div>
);
};
export default upload;
```
Check out the `ProductUploadForm.jsx` [here](https://github.com/Umoren/product-store-swr/blob/master/components/ProductUploadForm.jsx).
### Using SWR for paginated data fetching
Paginated data fetching is one of the use cases of SWR. If we're fetching a large amount of data, breaking it down into smaller chunks called pages improves performance and reduces the amount of data transferred over the network.
The `useSWRInfinite` hook implements pagination with SWR. It takes two arguments: `getKey` and `fetcher`.
The `getKey` function returns a unique key for each page based on the page index and previous page data. Returning `null` for an empty page prevents unnecessary requests.
The `fetcher` function fetches data for a given key using an HTTP client, like `axios` or `fetch`.
Once we set up the `useSWRInfinite` hook, we can use the `data` and `error` properties to render the data and handle errors, respectively. We can also use the `isLoading` property to show a loading indicator while data is being fetched.
To implement pagination, we use the `size` and `setSize` properties to control the number of pages to fetch. Incrementing the `size` value in a `loadMore` function that's called when the user reaches the end of the current page enables pagination. We also use the `hasNextPage` property to determine if more data can be fetched.
### Implementing infinite scrolling in Next.js with SWR
Update the `useFetch` hook with these lines of code:
```jsx
import useSWRInfinite from "swr/infinite";
const fetcher = async (url) => {
const response = await fetch(url);
if (!response.ok) {
throw new Error('An error occurred while fetching the data.');
}
return await response.json();
};
const useFetch = (path, limit) => {
const getKey = (pageIndex, previousPageData) => {
if (previousPageData && !previousPageData.length) return null;
const pageNumber = pageIndex + 1;
return `https://fakestoreapi.com/${path}?_page=${pageNumber}&_limit=${limit}`;
};
const { data, error, size, setSize } = useSWRInfinite(getKey, fetcher);
const loadMore = () => setSize(size + 1);
return {
data: data ? data.flat() : [],
isLoading: !error && !data,
isError: error,
loadMore,
hasNextPage: data && data[data.length - 1]?.length === limit,
};
};
export default useFetch;
```
In this code snippet is a custom hook that uses the SWR library to fetch paginated data. It takes two arguments, the `path`, and `limit` . The `getKey` function returns a unique key for each page based on the page index and previous page data. The hook uses the `useSWRInfinite` function to fetch data for a given key using an HTTP client. It returns an object with `data`, `isLoading`, `isError` , `loadMore` , and `hasNextPage` properties. The `data` property is an array of fetched data, while `isLoading` is a boolean value that indicates if the data is being fetched. `isError` is a boolean value that indicates if an error occurred while fetching data. `loadMore` is a function that increments the number of pages to fetch, and `hasNextPage` is a boolean value that indicates if there's more data to be fetched. The `fetcher` function is called to fetch data from a given URL, and it throws an error if the response is not successful.
The app should work properly with infinite scrolling now:
{% embed https://youtu.be/GzPe_OeNYxY %}
## Wrapping up…
SWR is a powerful tool for efficient data fetching in client-side Next.js applications. Its built-in caching, automatic cache revalidation, error retries, support for real-time updates, and Hooks-based API make data management simpler and more streamlined. By using SWR, developers can improve the data-fetching experience for their users and ensure their applications are fast, reliable, and responsive. With Next.js, there are different methods of data fetching, depending on the desired rendering strategy. While client-side data fetching is a popular option, it can lead to several issues if not handled properly. SWR addresses these challenges and provides a more efficient way of managing data.
Overall, SWR is a great tool for building high-performance, scalable, and reliable web applications with React and Next.js.
## Resources
1. SWR Official Documentation: [**https://swr.vercel.app/docs/getting-started**](https://swr.vercel.app/docs/getting-started)
2. Next.js Documentation on Data Fetching:
* Official guide on fetching data with Next.js: [**https://nextjs.org/docs/basic-features/data-fetching**](https://nextjs.org/docs/basic-features/data-fetching)
3. An Introduction To SWR: React Hooks For Remote Data Fetching:
* [**https://www.smashingmagazine.com/2020/06/introduction-swr-react-hooks-remote-data-fetching/**](https://www.smashingmagazine.com/2020/06/introduction-swr-react-hooks-remote-data-fetching/)
4. Data fetching in React with SWR
[**https://dev.to/ibrahimraimi/data-fetching-in-react-with-swr-5gb0**](https://dev.to/ibrahimraimi/data-fetching-in-react-with-swr-5gb0)
5. GitHub Discussions and Conversations: **https://github.com/vercel/swr/discussions**\](https://github.com/vercel/swr/discussions) | umoren |
1,473,937 | Introducing Safe-Text API | I made an API for text cleansing, most of Python enthusiast already dealt with text right ? Some... | 0 | 2023-05-19T21:03:44 | https://dev.to/yanna92yar/introducing-safe-text-api-19gj | api, webmaster | I made an API for text cleansing, most of Python enthusiast already dealt with text right ? Some among us have probably a web-app or other solution based on user content.
The thing about text, is that it is so fragile; It can break the whole website, or at least can have rest in DB as scrambled as the user posted it but finally ends again screwing UI and giving a bad end user experience
For this, there are already many solutions, some rely on complex #regex, basic or advanced algorithms, or even heavy machine learning models.
I wrapped dozens of solutions of a multitude of technologies, from #Python to #Rust to #WebAssembly all in one single API !
It is only accessible through #RapidAPI but it comes with a generous free tier 📷
Please, give us a start if you are already on
@Rapid_API
If you feel like criticizing, please keep it constructive, I will be happy to follow with your ideas.
Current models:
- FixHTML.
- DOMPurify.
- Linkify.
- Fix mojibark.
- Punctuate.
- Decancer.
- Remove bad words.
- Remove sensitive data.
- Strip tags.
- Wrap text. (comming soon)
- Detect Language.
### Examples of effective cleansing
**FixHTML**
`<p>here is a para <b>bold <i>bold italic</i></b> bold? normal?`
turns into
`</p><p>here is a para <b>bold <i>bold italic</i> bold?</b> normal?`
**DOMPurify**
`very bad html (cannot post here)`
turns into
`safe html`
**Linkify**
`Any links to github.com here? If not, contact test@example.com`
turns into
`'Any links to <a href="https://github.com">github.com</a> here? If not, contact <a href="mailto:test@example.com">test@example.com</a>'`
**Fix mojibark**
`The Mona Lisa doesn’t have eyebrows.`
turns into
`The Mona Lisa doesn't have eyebrows.`
**Punctuate**
`hello world`
turns into
`Hello world.`
**Decancer**
`vEⓡ𝔂 𝔽𝕌Ňℕy ţ乇𝕏𝓣`
turns into
`very funny text`
-----------
**Remove bad words**
`you are a bad ass`
turns into
`you are a bad ***`
**Remove sensitive data**
`My dads credit card number is: 5555555555554444`
turns into
`My dads credit card number is: ################`
**Strip tags**
`<a href="#"> this is my cat</a>`
turns into
`this is my cat`
**Wrap text**
(comming soon)
**Detect Language**
`Bonjour Paris`
gives
`french`
Note that Safe-Text API is a gigantic wrapper on top of other bright solutions; We have glued many other bright libraries to work in one single API. It is a complex solution technically as many technologies (Python, Rust, Wasm, Node ...) are all working together in one single API call.
Link to doc: https://ns514514.ip-142-4-215.net/
Link to RapidAPI: https://rapidapi.com/bacloud14/api/safe-text
You can head to https://ns514514.ip-142-4-215.net/documentation to try the API.
Kindly | yanna92yar |
1,474,007 | Building a Fauna and GPT-3.5 turbo Powered Chatbot: A Step-by-Step Tutorial | Chatbots have revolutionized the way businesses interact with their customers, providing efficient... | 0 | 2023-05-19T22:48:43 | https://dev.to/feranmiodugbemi/building-a-fauna-and-gpt-35-turbo-powered-chatbot-a-step-by-step-tutorial-14ea | python, chatgpt, fauna | Chatbots have revolutionized the way businesses interact with their customers, providing efficient and personalized assistance. In this tutorial, we will guide you through the process of building a chatbot powered by FaunaDB and the OpenAI GPT-3.5 turbo model. By following the steps outlined below, you'll be able to create an intelligent chatbot that can engage in meaningful conversations with users. Let's get started!
## **Prerequisites**
To follow and fully understand this tutorial, you will need to have:
- Python 3.6 or a newer version.
- A text editor(VS code preferably).
- An understanding of Fauna and Telegram bots.
## **Step 1: Setting Up the Environment**
Before we begin, let's ensure that our development environment is properly set up. We'll need the following libraries:
- `telebot`: A Python library for interacting with the Telegram Bot API.
- `faunadb`: A Python driver for FaunaDB, a serverless cloud database.
- `openai`: A Python library for accessing the OpenAI models.
- `dotenv`: A Python library for loading environment variables from a .`env` file.
Make sure you have these libraries installed. You can use `pip` to install them:
```python
pip install pyTelegramBotAPI faunadb openai python-dotenv
```
Next, create a `.env` file in your project directory to store your environment variables. We'll use this file to store sensitive information like API keys.
## **Step 2: Setting Up the Fauna database**
The first thing you need to get started with Fauna is to create an account on the official website. You can do that using either your email address or your github or netlify account here: [https://dashboard.fauna.com/accounts/register](https://dashboard.fauna.com/accounts/register)
We'd need the fauna database to store and retrieve user's messages for effective communication with our chatbot
## **Creating our database**

After creating our account with fauna, we will be creating a database to store our **Users** and **Messages**. Here we'd be asked for our database name and we are going to name it **MyChatBot** and our region is going to be set to **Classic** and like that we've created our database, easy right😌. Then, we should be presented with a screen like this one below:

## **Creating our collection**
Next, we'd be creating our collections, which is basically **Tables** in the SQL world but with a twist in our context.

To create our Collection, click on the `Create Collection` button on the home page and give it a name, but since we'd be creating two collections we'd be naming them **Users** and **Messages**. The **Users** collection is for storing our user's data and ID from telegram, while the **Messages** collection is for storing the user's chat history with the bot. You will be asked for History `Days` and `TTL`. The History Days is used to define the number of days Fauna should retain a historical record of any data in that particular collection while the TTL serves as an expiry date for data in the collection. For example, if the TTL is set to 7, any data stored in that collection will be automatically deleted 7 days after its last modified date, but for this tutorial we'll not be needing it so it will be left untouched. After creating the two collections, we should be seeing this:

**Creating our Index**
Wondering what an Index is🤔?, Well an Index is simply a way to browse data in our collection more efficiently by organizing it based on specific fields or criteria, allowing for faster and targeted retrieval of information. To create our Index, we'll navigate to the Index tab and we should see something like this:

To create our Index, we first of all need to **Select a Collection**, then specify our **Terms**, which is the specific data the Index is only allowed to browse. But for this tutorial we will be creating two Indexes, **users_by_id** which would be under our **Users** collection for registering users and **users_messages_by_username** which would be filtering our user's messages by their username. The **Terms** for **users_by_id** would be set to `data.user_id` while the **Terms** for **users_messages_by_username** will be set to `data.username`, then click `SAVE` to continue.
## **Getting our Database key**
Before we begin building a Python app that uses Fauna, we need to create an API key that would allow our application to easily communicate with our database. To create an API key, we need to navigate to the security tab on the Fauna sidebar (on the left side of the screen).

Next, we are to click on the `NEW KEY` button that will navigate us to the page below:

Here, we would set our key role to **Server** instead of **Admin** and set our Key name to our database name which is optional, then click on `SAVE` and we'd be navigated to a page where our database key would be displayed and meant to be copied immediately. We should see something like this:

After getting the `API KEY`, store it in the `.env` file we created earlier in a `FAUNA_SECRET_KEY` variable.
## **Step 3: Creating our telegram bot**
A Telegram bot is an automated program that operates within the Telegram messaging platform. It is designed to interact with users and perform various tasks, such as providing information, delivering updates, answering queries, and executing commands. These bots are created using Telegram's Bot API and can be integrated into group chats or used in one-on-one conversations.
**Conversation with BotFather**
**BotFather** is an essential bot created by the developers of Telegram for creating and managing other bots on the Telegram platform. To interact with **BotFather**, we need to have a Telegram account. We can search for **"@BotFather"** in the Telegram app to initiate a conversation.

**Conversation with BotFather**
To create a new bot with BotFather, we will use the **/newbot** and then supply the name of our bot and we'll then be given our bot `API KEY` which is the HTTP API access token in the image. We will the store our token key in our `.env` file in a `BOT_SECRET` variable. Now, we can now fully proceed to writing code🤩.


## **Step 4: Importing necessary packages:**
As mentioned previously, we require certain packages to develop our bot. Now, we will proceed to import these packages.
```python
import telebot
from faunadb import query as q
from faunadb.objects import Ref
from faunadb.client import FaunaClient
import openai
from dotenv import load_dotenv
import json
import os
load_dotenv()
bot = telebot.TeleBot(os.getenv("BOT_SECRET"))
```
The `load_dotenv()` is to load our environment variables and the `bot = telebot.TeleBot(os.getenv("BOT_SECRET"))` is to create a bot object for our telegram bot.
## **Step 5: Creating our commands:**
Commands in Telegram bots are specific keywords or phrases that trigger the bot to perform a certain action or provide a specific response. For instance, when we utilized the `/newbot` command during our interaction with BotFather, it initiated a function that facilitated the creation of a new bot. Now, copy and paste the code down below:
```python
def chat(question, user):
userid = user.from_user.id
username = user.from_user.username
return question
def image(prompt, user):
userid = user.from_user.id
return image
user_state = {}
@bot.message_handler(commands=['start'])
def start_message(message):
user_id = message.from_user.id
username = message.from_user.username
bot.reply_to(message, "Hello")
@bot.message_handler(commands=['chat'])
def chat_message(message):
# Set the user's state to 'help' and output a help message
user_state[message.chat.id] = 'chat'
bot.reply_to(message, "Hello, how may i help you: ")
@bot.message_handler(commands=['image'])
def image_message(message):
# Set the user's state to 'help' and output a help message
user_state[message.chat.id] = 'image'
bot.reply_to(message, "What kind of image are you creating today: ")
@bot.message_handler(commands=['reset'])
def reset_message(message):
# Set the user's state to 'help' and output a help message
user_state[message.chat.id] = 'reset'
bot.reply_to(message, "Resetting chat......... ")
@bot.message_handler(func=lambda message: True)
def echo_all(message):
if message.chat.id in user_state and user_state[message.chat.id] == 'chat':
chat_message = message.text
user = message
bot.reply_to(message, chat(chat_message, user))
elif message.chat.id in user_state and user_state[message.chat.id] == 'start':
user = message
bot.reply_to(message, user)
user_state[message.chat.id] = None
elif message.chat.id in user_state and user_state[message.chat.id] == 'image':
image_prompt = message.text
user = message
bot.reply_to(message, image(image_prompt, user))
user_state[message.chat.id] = 'image'
bot.send_message(message.chat.id, "What Image are you creating again?")
elif message.chat.id in user_state and user_state[message.chat.id] == 'reset':
chat_reset = message.text
bot.reply_to(message, reset())
user_state[message.chat.id] = None
bot.polling()
```
Now, let's now go through the functionalities of the code above
The bot responds to user commands such as `/start`, `/chat`and `/image`, while maintaining the conversation state for each user using the user_state dictionary. Upon receiving the `/start` command, the bot sends a **"Hello"** reply and resets the user's state. Similarly, when the `/chat` command is received, the bot asks how it can help and sets the user's state to **'chat'**. In the case of the `/image` command, the bot prompts the user for the type of image and sets the state to **'image'**. For any other messages, the bot checks the user's state and responds accordingly, such as echoing the message in the **'chat'** state, requesting the image prompt again in the **'image'** state, providing user information and resetting the state in the **'start'** state. The bot continuously listens for incoming messages using bot.polling().
## **Step 5: Updating our commands**
The code provided in step 4 was only a small portion of our chatbot implementation. Presently, we will be enhancing our code to develop a fully operational chatbot.
**The `/start` command**
The `/start` command will serve as the initial entry point for our chatbot. It will verify whether a user exists in our faunadb **User** collection using the `users_by_id` index we created earlier, and if not, it will add the user to the **User** collection and then send a message that will redirect the user to our `/chat` which handles our chat functionalities. This process involves retrieving the user's username and ID from our Telegrambot API. The updated code:
```python
@bot.message_handler(commands=['start'])
def start_message(message):
client = FaunaClient(
secret=os.getenv('FAUNA_SECRET_KEY')
)
user_id = message.from_user.id
username = message.from_user.username
user_exists = client.query(
q.exists(q.match(q.index("users_by_id"), user_id)))
if not user_exists:
client.query(
q.create(
q.collection("Users"),
{
"data": {
"user_id": user_id,
"username": username
}
}
)
)
bot.reply_to(message, "🌿🤖 Hello! Welcome to the fauna and gpt3 powered bot! 🌟💫\nTo begin, type /chat or click on it")
```
**The `/chat` command**
To create our chatbot, we will first create a faunadb client using the FaunaClient class and our secret key from an environment variable. Then, we will prepare a data object containing the username and the user's question, and insert it into the **Messages** collection in FaunaDB.
Next, we will retrieve the previous messages associated with the username by executing an index query. This query will retrieve all documents from the **Messages** collection that match the username, and we will extract the content of each message and store them in a list called "messages".
After that, we will set up the OpenAI API by configuring the API key from an environment variable. We will also define the persona of the assistant within a system message.
Then, we will construct the conversation prompt by combining the system message, user messages, and assistant messages from the `messages` list. We will use this conversation prompt to generate a response from the GPT-3.5 Turbo model, and then extract the generated reply from the API response.
We will then prepare the data for the assistant's reply and insert it into the **Messages** collection within FaunaDB. Finally, we will return the generated reply as the output of our chatbot.
```python
def prompt(username, question):
# Create a FaunaDB client
client = FaunaClient(secret=os.getenv('FAUNA_SECRET_KEY'))
data = {
"username": username,
"message": {
"role": "user",
"content": question
}
}
result = client.query(
q.create(
q.collection("Messages"),
{
"data": data
}
)
)
index_name = "users_messages_by_username"
username = username
# Paginate over all the documents in the collection using the index
result = client.query(
q.map_(
lambda ref: q.get(ref),
q.paginate(q.match(q.index(index_name), username))
)
)
messages = []
for document in result['data']:
message = document['data']['message']
messages.append(message)
# Set up OpenAI API
openai.api_key = os.getenv('OPENAI_SECRET_KEY')
# Define the assistant's persona in a system message
system_message = {"role":"system", "content" : "A helpful assistant that provides accurate information."}
# Construct the conversation prompt with user messages and the system message
prompt_with_persona = [system_message] + [
{"role": "user", "content": message["content"]} if message["role"] == "user"
else {"role": "assistant", "content": message["content"]} for message in messages
]
# Generate a response from the model
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=prompt_with_persona
)
# Extract the generated reply from the API response
generated_reply = response["choices"][0]["message"]["content"]
newdata = {
"username": username,
"message": {
"role": "assistant",
"content": generated_reply
}
}
result = client.query(
q.create(
q.collection("Messages"),
{
"data": newdata
}
)
)
return generated_reply
```
If the user exists, the preceding steps will take place, which is why we created a prompt function to handle this scenario. In our chat function, if the user exists, the prompt function is executed. However, if the user does not exist, they are redirected back to the `/start` command in order to register them. The updated chat function:
```python
def chat(question, user):
client = FaunaClient(
secret=os.getenv('FAUNA_SECRET_KEY')
)
global chat_list
userid = user.from_user.id
username = user.from_user.username
user_exists = client.query(
q.exists(q.match(q.index("users_by_id"), userid)))
if user_exists:
reply = prompt(username, question)
return reply
else:
return "🌿🤖 Hello! Welcome to the fauna and gpt3 powered bot! 🌟💫\nThis user is not logged in , type /start or click on it to login"
```
**The `/image` command**
The `/image` command is utilized to transform user text into images. Here's how it operates: First, it verifies if the user exists in the database. If the user exists, it proceeds to generate and return the image url output using the openAI Dall-E 2 model. The updated code:
```python
def image(prompt, user):
client = FaunaClient(
secret=os.getenv('FAUNA_SECRET_KEY')
)
userid = user.from_user.id
openai.api_key = os.getenv('OPENAI_SECRET_KEY')
user_exists = client.query(
q.exists(q.match(q.index("users_by_id"), userid)))
if user_exists:
generated_image = openai.Image.create(
prompt=prompt,
n=1,
size="1024x1024"
)
image_url = generated_image['data'][0]['url']
return image_url
else:
return "🌿🤖 Hello! Welcome to the fauna and gpt3 powered bot! 🌟💫\nThis user is not logged in , type /start or click on it to login"
```
Having completed the necessary implementations, it is now time to put our bot to the test and ensure its full functionality.

## **Conclusion**
Congratulations! You have successfully built an intelligent chatbot using FaunaDB and the OpenAI GPT-3.5 turbo model. By integrating FaunaDB for message storage and retrieval, and leveraging the power of GPT-3.5 turbo for generating responses, your chatbot can engage in meaningful conversations with users.
Feel free to customize and enhance your chatbot by adding more features, improving the conversation flow, or integrating it with other platforms. The possibilities are endless!
Remember to handle security considerations, such as protecting sensitive data and managing access to API keys, to ensure the secure operation of your chatbot.
Happy bot-building!
Link to code: [https://github.com/feranmiodugbemi/Fauna-chat-bot](https://github.com/feranmiodugbemi/Fauna-chat-bot)
| feranmiodugbemi |
1,474,018 | From Bees to YouTube: How I Live Streamed My Local Cam Feed with This Simple Trick! | I want to share my local cam stream with which I monitor my bees to youtube. So For this, I got a... | 0 | 2023-05-20T05:29:23 | https://blog.bajonczak.com/rtmsp-streaming/ | rtsp, docker, shell, streaming | ---
title: From Bees to YouTube: How I Live Streamed My Local Cam Feed with This Simple Trick!
published: true
tags: RTSP,Docker,Shell, streaming
canonical_url: https://blog.bajonczak.com/rtmsp-streaming/
---

I want to share my local cam stream with which I monitor my bees to youtube. So For this, I got a problem. The camera does not support streaming native to youtube.
# My local video stream
My local cameras are available via real-time stream protocol rstp. My Reolink camera now will be used for this, especially my camera for the bees. The cameras are already attached to an NVR device. So this will help me to provide an RTSP Endpoint.
The Endpoint looks like this:
```
rtmp://192.168.xxx.xxx/bcs/channel3_sub.bcs?channel=0&stream=0&user=xxx&&password=XXXX
```
I checked this, by simply adding this URL into a video player. And it will show me the video output.

So the next step is to set up Youtube.
# Setup Youtube
To get a video broadcast, I will use Youtube for thi because it's a popular platform and fortunately I have an account on this. To get a Live video stream there you must create a live stream. you will need the key (marked in yellow).
# Connect together
To get a working stream pushed to youtube, I must use the RTSP Stream from my camera and publish it to Youtube. That's simple... but before that, we must transcode the stream to a youtube friendly format. Fortunately for this, I can use ffmpeg. This is an all to all converter.
After a little experimenting, I end up using the following command to generate a live stream
```
exec ffmpeg \
-f lavfi -i anullsrc=channel_layout=stereo:sample_rate=44100 \
-thread_queue_size 128 -i rtps://sourcecam \
-shortest \
-vf "fps=30" \
-map 0:a:0 -c:a aac -b:a 16k \
-map 1:v:0 -c:v libx264 -preset veryfast -crf 30 -g 90 \
-f flv rtmp://a.rtmp.youtube.com/live2/USER_KEY \
-f segment -reset_timestamps 1 -segment_time 600 -segment_format mp4 -segment_atclocktime 1 -strftime 1 \
"%Y-%m-%d_%H-%M-%S.mp4"
```
_JSON_
This will take the input stream, convert it to the desired target format (audio and video), and push it immediately to the target stream (on Youtube). That's cool. But now I want to use it headless. So that I can run it on my home server and it will push this to my stream.
# Going headless
To run the script headless I decide to run it in a docker container. Luckily there is a docker for [ffmpeg (jrottenberg/ffmpeg)](https://hub.docker.com/r/jrottenberg/ffmpeg/?ref=blog.bajonczak.com), so I use it for my base implementation.
But I need a little bit of flexibility to get a running image that will get as a parameter my original stream and the youtube output. For this, I wrote a small shell script
```
#!/bin/sh
if ["$#" -lt 2]; then
>&2 echo "Arguments: IP_CAMERA_ADDRESS LIVE_ID [TIMELAPSE_ID]"
exit 1
fi
if [! -d /data]; then
>&2 echo "Expected Docker mounted volume at /data for recordings"
exit 1
fi
cd /data
IP_CAMERA_ADDRESS=$1
LIVE_ID=$2
>&2 echo "IP_CAMERA_ADDRESS=$IP_CAMERA_ADDRESS"
>&2 echo "LIVE_ID=$LIVE_ID"
exec ffmpeg \
-f lavfi -i anullsrc=channel_layout=stereo:sample_rate=44100 \
-thread_queue_size 128 -i $IP_CAMERA_ADDRESS \
-shortest \
-vf "fps=30" \
-map 0:a:0 -c:a aac -b:a 16k \
-map 1:v:0 -c:v libx264 -preset veryfast -crf 30 -g 90 \
-f flv rtmp://a.rtmp.youtube.com/live2/$LIVE_ID \
-f segment -reset_timestamps 1 -segment_time 600 -segment_format mp4 -segment_atclocktime 1 -strftime 1 \
"%Y-%m-%d_%H-%M-%S.mp4"
```
When you run it in a Linux shell it will do a parameter validation. So it requires two parameters
1. The rtsp Url from your camera
2. The key to youtube live streaming
Now it's time to build a small image that will use this script as an entry point. I end up using this Dockerfile
```
FROM jrottenberg/ffmpeg
MAINTAINER Sascha Bajonczak <xbeejayx@hotmail.com>
ADD entrypoint.sh /entrypoint.sh
ENTRYPOINT /entrypoint.sh $@
```
This will use the base ffmpeg image and add our script to the container. When the container starts it will run the entry point and pass all start arguments as parameters. Now you can build the image. After that, you can use it for your needs.
For those that want a ready-to-use image, I put it on the docker hub for you so you can start it with the following command
```
docker run --restart=always -d beejay/streamforwarding:latest -- "rtmp://192.168.xxx.xxx/bcs/channel3_sub.bcs?channel=0&stream=0&user=admin&&password=xxxx" r3kh-XXXX-XXXX-XXXX-XXXX
```
This will now start a detached docker image, that will take my webcam stream hosted in my network at "rtmp://192.168.xxx.xxx/bcs/channel3\_sub.bcs?channel=0&stream=0&user=admin&&password=xxxx" and forward it to the youtube live stream identified with the key r3kh-XXXX-XXXX-XXXX-XXXX.
Here are my result
# Current limitations
Yes this is awesome, but there is some limitation. Youtube will stop the stream after a while. So when you have no visitors, you will be get stopped and it must be restarted by hand. But stay tuned, I have an idea to keep it online.
# Conclusion
You learn how easy it is to integrate an existing camera stream into a live stream. So now you are able to broadcast some videos to the (youtube)world. Instead of using an expensive setup with OBS-Studio or other fancy things, you can get it right for free.
You find all of the code on my github page here: [SBajonczak/rtsp-to.youtube: A small docker definition, that will forward the rtsp stream from a local camery in your network and put it out on a youtube livestream (github.com)](https://github.com/SBajonczak/rtsp-to.youtube?ref=blog.bajonczak.com)
I hoped you enjoyed this article and I'm happy if you leave me a comment and subscribe! | saschadev |
1,474,131 | Answer: How to combine two word documents into one via excel VBA? | answer re: How to combine two word... | 0 | 2023-05-20T03:29:03 | https://dev.to/oscarsun72/answer-how-to-combine-two-word-documents-into-one-via-excel-vba-pa1 | {% stackoverflow 76291783 %} | oscarsun72 | |
1,784,895 | Photogram Industrial Notes | notes about scaffolds for CRUD & generating a model The question you have to answer... | 0 | 2024-03-08T21:21:34 | https://dev.to/marywebby/photogram-industrial-notes-4o57 | ##**notes about scaffolds for CRUD & generating a model**
- The question you have to answer now is: for each of these tables, do you want to generate a scaffold or do you just want to generate a model? How do we figure that out?
>If I will need routes and controller/actions for users to be able to CRUD records in the table, then I probably want to generate `scaffold`. (At least some of the generated routes/actions/views will go unused. I need to remember to go back and at least disable the routes, and eventually delete the entire RCAVs, at some point; or I risk introducing security holes.)
>If the model will only be used on the backend, e.g. by other models, then I probably want to generate `model`. For example, a `Month` model where I will create all twelve records once in `db/seeds.rb` does not require routes, `MonthsController`, `app/views/months/`, etc.
##**foreign keys in migrates & models**
- any times you are specifying the `forgein_key` within a migrate file, you need to also make sure to go and change it in the model as well. so here is our migrate file
```
class CreateComments < ActiveRecord::Migration[7.0]
def change
create_table :comments do |t|
t.references :author, null: false, foreign_key: { to_table: :users }
t.references :photo, null: false, foreign_key: true
t.text :body
t.timestamps
end
end
end
```
- and we are specifically looking at the `foreign_key: { to_table: :users }` part of this. and you can see we specified that the users table is going to be what the author is referring to.
- so now in our models, we can go into `comment.rb`, and in here we can add in the specific classname for the author
```
class Comment < ApplicationRecord
belongs_to :author, class_name: "User"
belongs_to :photo
end
```
> Raghu: *"So basically for every `foreign_key`, there should be a `belongs_to`. For every `belongs_to`, there should be a `has_many`."*<
>rails db:drop will delete your entire database, rails db:rollback will undo your last migration<
>will need to keep all the migration files to see all the history of changes and
| marywebby | |
1,474,392 | Mastering Go: A Comprehensive Guide to Golang Syntax | Part - 1 | Welcome to "Mastering Go: A Comprehensive Guide to Golang Syntax." In this blog, we will dive deep... | 0 | 2023-05-20T11:20:13 | https://dev.to/sahil_4555/mastering-go-a-comprehensive-guide-to-golang-syntax-part-1-15be | go, beginners, microservices, programming | Welcome to "Mastering Go: A Comprehensive Guide to Golang Syntax." In this blog, we will dive deep into the syntax of the Go programming language. Whether you are a beginner getting started with Go or an experienced developer looking to enhance your Go skills, this guide will provide you with a solid foundation in Go syntax.
To get started, you'll need to set up your Go development environment. Follow the steps below to ensure you have everything you need to follow along with the guide:
1. Download and Install Go:
- Visit the official Go website at [golang.org](https://go.dev/).
- Go to the downloads section and select the appropriate installer for your operating system.
- Run the installer and follow the installation instructions.
2. Configure Environment Variables:
- After installing Go, you need to set up the necessary environment variables.
- On Windows, open the Control Panel and navigate to System > Advanced System Settings > Environment Variables. Add the Go binary path (e.g., **C:\Go\bin**) to the **PATH** variable.
- On macOS or Linux, open your terminal and edit your shell configuration file (e.g., **~/.bashrc** or **~/.bash_profile**) to include the Go binary path (e.g., **export PATH=$PATH:/usr/local/go/bin**).
3. Verify the Installation:
- Open a new terminal or command prompt window.
- Run the following command to check if Go is installed and configured correctly:
```
go version
```
- You should see the installed Go version printed in the terminal.
Now that your Go development environment is set up, you're ready to embark on your journey to mastering Go syntax.
#### Let's start with the classic "Hello, World!" program in Go. Follow these steps:
- Open a text editor or an integrated development environment (IDE) of your choice.
- Create a new file with a '**.go**' extension, such as '**hello.go**'.
- In the file, enter the following code:
```
package main
import "fmt"
func main() {
fmt.Println("Hello, World!")
}
```
- Save the file.
- Open a terminal or command prompt and navigate to the directory where you saved the 'hello.go' file.
- Compile the Go code by running the following command:
```
go build hello.go
```
- After the compilation is successful, an executable file named hello (or hello.exe on Windows) will be generated in the same directory.
- Run the executable by executing the following command:
```
./hello # On Unix-like systems (Linux, macOS)
hello # On Windows
```
- You should see the output '**Hello, World!**' displayed in the terminal.
#### Packages
- Every Go program is made up of packages.
- Programs start running in package main.
- This program is using the packages with import paths "fmt" and "math/rand".
- By convention, the package name is the same as the last element of the import path. For instance, the "math/rand" package comprises files that begin with the statement package rand.
```
package main
import (
"fmt"
"math/rand"
)
func main() {
fmt.Println("My favorite number is", rand.Intn(177))
/* Will Print Random Number in the Range of 0 to 177 */
}
```
Output:
```
My favorite number is 90
```
#### Imports
- This code groups the imports into a parenthesized, "factored" import statement.
- You can also write multiple import statements, like:
`import "fmt"`
`import "math"`
- But it is good style to use the factored import statement.
```
package main
import (
"fmt"
"math"
)
func main() {
fmt.Printf("Now you have %g problems.\n", math.Sqrt(16))
}
```
Output:
```
Now you have 4 problems.
```
#### Exported Names
- In Go, a name is exported if it begins with a capital letter. For example, `Pizza` is an exported name, as is `Pi`, which is exported from the math package.
- `pizza` and `pi` do not start with a capital letter, so they are not exported.
- When importing a package, you can refer only to its exported names. Any "unexported" names are not accessible from outside the package.
```
package main
import (
"fmt"
"math"
)
func main() {
fmt.Println(math.pi) /* Error */
fmt.Println(math.Pi) /* 3.141592653589793 */
}
```
#### Functions
- A function can take zero or more arguments.
- In this example, add takes two parameters of type int.
**_Notice that the type comes after the variable name._**
- When two or more consecutive named function parameters share a type, you can omit the type from all but the last.
```
package main
import "fmt"
/* we shortened */
func add_(x, y int) int {
return x + y
}
func add(x int, y int) int {
return x + y
}
func main() {
fmt.Println(add(100,50))
fmt.Println(add_(200,50))
}
```
Output:
```
150
250
```
- A function can return any number of results.
- The swap function returns two strings.
- A return statement without arguments returns the named return values. This is known as a "naked" return.
- Naked return statements should be used only in short functions, as with the example shown here. They can harm readability in longer functions.
```
package main
import "fmt"
func swap(x, y string) (string, string) {
return y, x
}
func split(sum int) (x, y int) {
x = sum * 4 / 9
y = sum - x
/* Naked Return */
return
}
func main() {
a, b := swap("Hello", "World")
fmt.Println(a, b)
fmt.Println(split(17))
}
```
Output:
```
World Hello
7 10
```
#### Variables
- The `var` statement declares a list of variables; as in function argument lists, the type is last.
- A var declaration can include initializers, one per variable.If an initializer is present, the type can be omitted; the variable will take the type of the initializer.
- the `:=` short assignment statement can be used in place of a `var` declaration with implicit type inside a function.
- every statement begins with a keyword (var, func, and so on) and so the `:=` construct is not available outside a function.
```
package main
import "fmt"
/* Variables With Initializers */
var x = "Golang"
func main() {
/* Variables */
var z,y int
/* Variables With Initializers */
var i, j int = 1, 2
/* Short variable declarations */
k := 3
c, python, java := true, false, "no!"
fmt.Println(i, j, k, c, python, java, x, z, y)
}
```
Output:
```
1 2 3 true false no! Golang 0 0
```
#### Go's Basic Types
In Go, there are several basic types that represent fundamental data values. Here are the basic types in Go:
1. Numeric Types:
- `int`: Signed integers, which can be either 32 or 64 bits, depending on the platform.
- `int8`, `int16`, `int32`, `int64`: Signed integers with specific bit sizes.
- `uint`: Unsigned integers, which can be either 32 or 64 bits, depending on the platform.
- `uintptr`: It is an unsigned integer type that is capable of holding the bit pattern of any pointer value. It is used primarily in low-level programming and for dealing with memory addresses.
- `uint8`, `uint16`, `uint32`, `uint64`: Unsigned integers with specific bit sizes.
- `float32`, `float64`: Floating-point numbers with single-precision and double-precision, respectively.
- `complex64`, `complex128`: Complex numbers with single-precision and double-precision, respectively.
2. Boolean Type:
- `bool`: Represents a boolean value, which can be either true or false.
3. String Type:
- `string`: Represents a sequence of characters.
4. Character Type:
- Go does not have a separate character type. Instead, individual characters are represented as `rune`, which is an alias for `int32`.
5. Composite Type:
- `array`: Fixed-size collection of elements of the same type.
- `slice`: Dynamic-size sequence built on top of arrays.
- `map`: Unordered collection of key-value pairs.
- `struct`: User-defined composite type that groups together zero or more values with different types.
- `pointer`: Represents the memory address of a value.
- `function`: Functions can have their own types and can be assigned to variables or used as arguments or return types in other functions.
- `interface`: Defines a set of methods that a type must implement to satisfy the interface.
6. Special Types:
- `nil`: Represents the absence of a value. Used for uninitialized variables, pointers without a value, or when a function returns no value.
```
package main
import (
"fmt"
)
func main() {
// Numeric Types
var numInt int = 42
var MaxInt uint64 = 1<<64 - 1
var numFloat float64 = 3.14
var numComplex complex128 = -5 + 12i
// Boolean Type
var flag bool = true
// String Type
var message string = "Hello, Go!"
// Character Type (rune)
var char rune = 'A'
// Composite Types
var arr [3]int = [3]int{1, 2, 3}
var slice []int = []int{4, 5, 6}
var mp map[string]int = map[string]int{"apple": 1, "banana": 2}
var person struct {
name string
age int
} = struct {
name string
age int
}{"Sahil", 20}
var ptr *int = &numInt
var fn func() = func() {
fmt.Println("This is a function")
}
var intf interface{} = "This is an interface"
// Special Types
var nilVal []int
var uintptrVal uintptr
// Printing the values
fmt.Printf("Numeric Types:\nint: %d\nunit64: %v\nfloat: %f\ncomplex: %f\n\n", numInt, MaxInt, numFloat, numComplex)
fmt.Printf("Boolean Type:\nbool: %v\n\n", flag)
fmt.Printf("String Type:\nstring: %s\n\n", message)
fmt.Printf("Character Type:\nrune: %c\n\n", char)
fmt.Printf("Composite Types:\narray: %v\nslice: %v\nmap: %v\nstruct: %+v\npointer: %p\nfunction: %v\ninterface: %v\n\n",
arr, slice, mp, person, ptr, fn, intf)
fmt.Printf("Special Types:\nnil: %v\nuintptr: %v\n", nilVal, uintptrVal)
}
```
Output:
```
Numeric Types:
int: 42
unit64: 18446744073709551615
float: 3.140000
complex: (-5.000000+12.000000i)
Boolean Type:
bool: true
String Type:
string: Hello, Go!
Character Type:
rune: A
Composite Types:
array: [1 2 3]
slice: [4 5 6]
map: map[apple:1 banana:2]
struct: {name:Sahil age:20}
pointer: 0xc00001c030
function: 0x482fa0
interface: This is an interface
Special Types:
nil: []
uintptr: 0
```
- Variables declared without an explicit initial value are given their zero value. The zero value is:
- `0` for numeric types,
- `false` for the boolean type, and
- `""` (the empty string) for strings.
- Type conversion in Go allows you to convert a value of one type to another type
```
package main
import "fmt"
import "math"
func main() {
/* Zero Values */
var i int
var f float64
var b bool
var s string
fmt.Printf("Zero Value for int: %v\nZero Value for float64: %v\nZero Value for bool: %v\nZero Value for string: %q\n\n", i, f, b, s)
/* Type Conversion */
var x, y int = 3, 5
fmt.Printf("x: %v y: %v\n",x,y)
var a float64 = math.Sqrt(float64(x*x + y*y))
fmt.Printf("a: %v\n",a)
var z uint = uint(a);
fmt.Printf("z: %v\n",z)
}
```
Output:
```
Zero Value for int: 0
Zero Value for float64: 0
Zero Value for bool: false
Zero Value for string: ""
x: 3 y: 5
a: 5.830951894845301
z: 5
```
####Type Inference & Constants
- Type inference is a feature in programming languages that allows the compiler or interpreter to automatically determine the data type of a variable based on its assigned value or usage
- Constants are declared like variables, but with the `const` keyword.
- Constants can be character, string, boolean, or numeric values. **_Constants cannot be declared using the := syntax_**.
```
package main
import "fmt"
const Pi = 3.14
func main() {
var f uint64
var n int = 42
var s = "Hi! I am Sahil"
l := 0.867 + 0.5i
fmt.Printf("f is of type %T\n", f)
fmt.Printf("n is of type %T\n", n)
fmt.Printf("s is of type %T\n", s)
fmt.Printf("l is of type %T\n", l)
fmt.Println("Happy", Pi, "Day")
const Truth = true
fmt.Println("Go rules?", Truth)
}
```
Output:
```
f is of type uint64
n is of type int
s is of type string
l is of type complex128
Happy 3.14 Day
Go rules? true
```
#### Loops
Go has only one looping construct, the for loop.
The basic for loop has three components separated by semicolons:
- the init statement: executed before the first iteration
- the condition expression: evaluated before every iteration
- the post statement: executed at the end of every iteration
- The init statement will often be a short variable declaration, and the variables declared there are visible only in the scope of the for statement.
- The loop will stop iterating once the boolean condition evaluates to false.
```
package main
import "fmt"
func main() {
/* Basic Syntax of For Loop */
sum1 := 0
for i := 0; i < 10; i++ {
sum1 += i
}
fmt.Println(sum1)
/* For Continued */
sum2 := 1
for ; sum2 < 1000; {
sum2 += sum2
}
fmt.Println(sum2)
/* This is Same as While Loop */
sum3 := 1
for sum3 < 1000 {
sum3 += sum3
}
fmt.Println(sum3)
/* An Infinite Loop */
for {
}
}
```
Output:
```
timeout running program
45
1024
1024
```
#### if & else
Go's if statements are like its for loops; the expression need not be surrounded by parentheses ( ) but the braces { } are required.
```
package main
import (
"fmt"
"math"
)
/* Basic syntax of if */
func sqrt(x float64) string {
if x < 0 {
return sqrt(-x) + "i"
}
return fmt.Sprint(math.Sqrt(x))
}
/* If with a short statement */
func pow(x, n, lim float64) float64 {
if v := math.Pow(x, n); v < lim {
return v
}
return lim
}
/* if & else */
func power(x, n, lim float64) float64 {
if v := math.Pow(x, n); v < lim {
fmt.Printf("%g < %g\n", v, lim)
return v;
} else {
fmt.Printf("%g >= %g\n", v, lim)
}
// can't use v here, though
return lim
}
func main() {
fmt.Println(sqrt(2), sqrt(-4))
fmt.Println(pow(3, 2, 10),pow(3, 3, 20))
fmt.Println(power(3, 2, 10),power(3, 3, 20))
}
```
Output:
```
1.4142135623730951 2i
9 20
9 < 10
27 >= 20
9 20
```
#### Switch
A switch statement is a shorter way to write a sequence of if - else statements. It runs the first case whose value is equal to the condition expression.
```
package main
import (
"fmt"
"runtime"
)
func main() {
fmt.Print("Go runs on ")
fmt.Println(runtime.GOOS)
switch os := runtime.GOOS; os {
case "darwin":
fmt.Println("OS X.")
case "linux":
fmt.Println("Linux.")
default:
// freebsd, openbsd,
// plan9, windows...
fmt.Printf("%s.\n", os)
}
}
```
Output:
```
Go runs on linux
Linux.
```
#####Switch Evaluation Order
```
package main
import (
"fmt"
"time"
)
func main() {
fmt.Println("When's Saturday?")
today := time.Now().Weekday()
fmt.Println(today, time.Saturday)
switch time.Saturday {
case today + 0:
fmt.Println("Today.")
case today + 1:
fmt.Println("Tomorrow.")
case today + 2:
fmt.Println("In two days.")
default:
fmt.Println("Too far away.")
}
}
```
Output:
```
When's Saturday?
Tuesday Saturday
Too far away.
```
#####Switch With No Condition
Switch without a condition is the same as switch true
```
package main
import (
"fmt"
"time"
)
func main() {
t := time.Now()
fmt.Println(time.Now())
switch {
case t.Hour() < 12:
fmt.Println("Good morning!")
case t.Hour() < 17:
fmt.Println("Good afternoon.")
default:
fmt.Println("Good evening.")
}
}
```
Output:
```
2023-05-20 11:09:16.988733639 +0000 UTC m=+0.000047230
Good morning!
```
#### Defer
In Go, the defer statement is used to schedule a function call to be executed later, typically just before the surrounding function returns. The `defer` statement allows you to specify cleanup or finalization actions that should be performed regardless of how the function exits, whether it's due to a return statement, an error, or a panic.
- **Deferred function calls are pushed onto a stack. When a function returns, its deferred calls are executed in last-in-first-out order.**
```
package main
import "fmt"
func main() {
defer fmt.Println("HY! I am Sahil")
fmt.Println("I am Student")
fmt.Println("counting")
for i := 0; i < 10; i++ {
defer fmt.Println(i)
}
fmt.Println("done")
}
```
Output:
```
I am Student
counting
done
9
8
7
6
5
4
3
2
1
0
HY! I am Sahil
```
#####Thank you for diving into this chapter of the blog! We've covered a lot of ground, but the journey doesn't end here. The next chapter awaits, ready to take you further into the depths of our topic.
#####To continue reading and explore the next chapter, simply follow this link: [Link to Next Chapter](https://dev.to/sahil_4555/mastering-go-a-comprehensive-guide-to-golang-syntax-part-2-22km)
> _Go, where semicolons are optional, but your frustration is mandatory. Embrace the challenge, for in the end, you'll appreciate the elegance it brings. Keep on gophering!✨😂_
| sahil_4555 |
1,474,457 | Deployment Strategies for Applications | When deploying changes to an application, there are several strategies that can be taken. In this... | 0 | 2023-05-20T12:59:31 | https://dev.to/toni744/deployment-strategies-4h8l | devops | When deploying changes to an application, there are several strategies that can be taken. In this article, the different strategies will be explained, with an analogy, and an analysis of the benefits and tradeoffs.
## Deployment Strategies
Imagine you are the manager of a popular pizza restaurant that is open 24/7 for deliveries. This restaurant has two chefs working in the kitchen and both are needed to ensure orders are fulfilled on time. You have a new special recipe that will change how all pizzas are made. This new recipe involves using a different dough to make the pizza bread, using a different type of cheese, new toppings on the pizza and changes to the pizza oven settings. These are significant changes that you hope will lead to more delicious pizzas being made, which equals happier customers, which hopefully translates to more money.
This new recipe is quite complex and will take an hour for a single chef to learn. How do you teach the chefs this new recipe? Remember that this restaurant must be open 24/7. Your approach will be based on whether you are trying to:
- reduce the time it takes for both chefs to learn the new recipe
- ensure you have enough chefs to fulfil orders while once chef is learning the new recipe
- keep costs low during the recipe change
- be able to quickly revert back to the old recipe
- test the new recipe with a small subset of your customers
A similar set of trade-offs are made when deciding on an application deployment strategy. Do you want to:
- minimise deployment time
- have zero downtime
- ensure capacity is maintained
- reduce deployment cost
- be able to rollback i.e. easily revert changes
- test the change with a small subset of your users
The trade-off comes because you can’t have it all. As an example, having zero downtime, ensuring capacity is maintained and having the ability to rollback comes at the price of a longer deployment time and higher cost. The logic behind this example will be explained in the blue/green deployment strategy example. Ultimately, there are no solutions, only trade-offs.
A three-tiered web application will be used as the example architecture for the different deployment types. This consists of a presentation, logic and database tier as shown below.
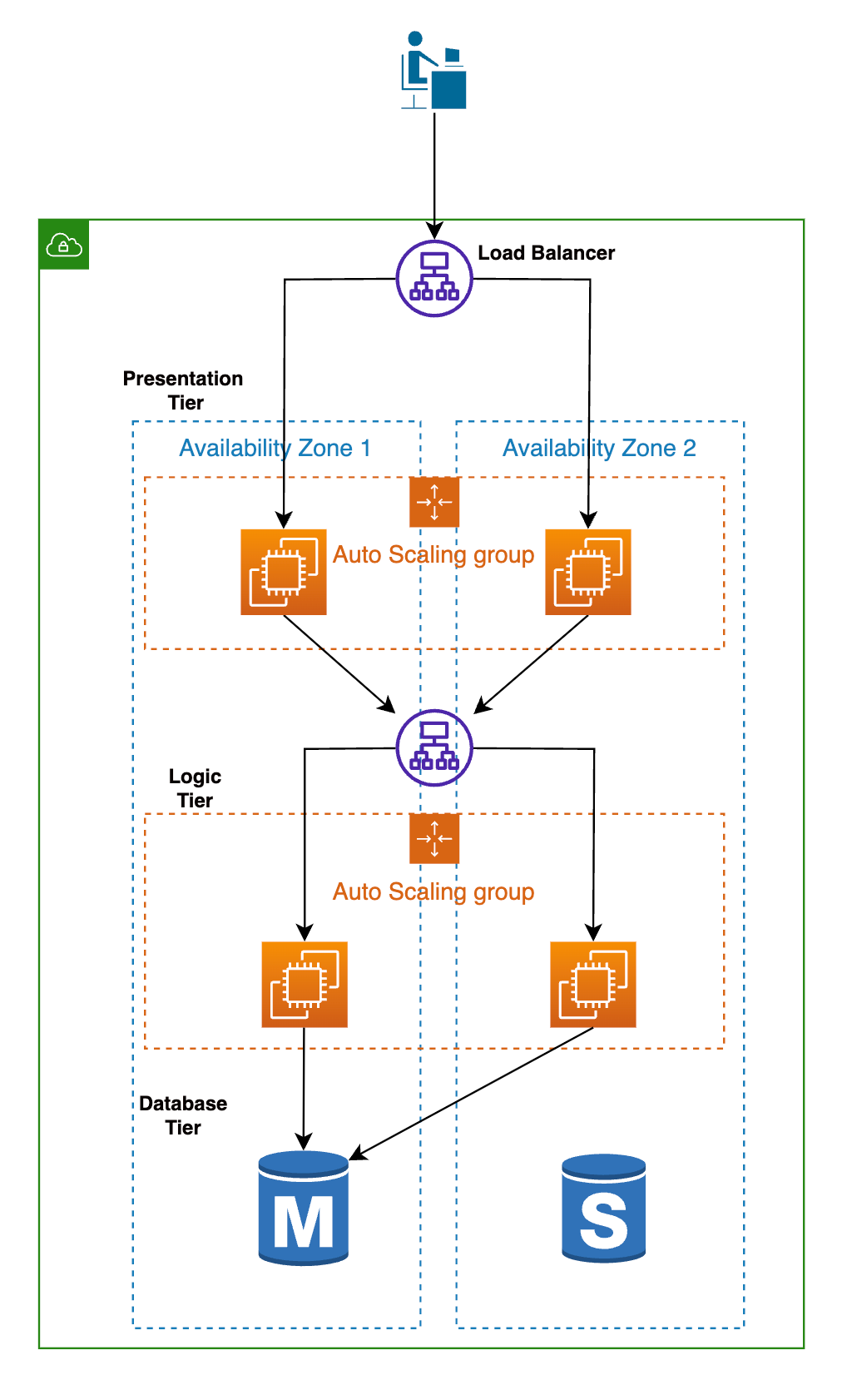
The presentation tier is responsible for presenting the user interface to the user. It includes the user interface components such as HTML, CSS, and JavaScript.
The logic tier s responsible for processing user requests and generating responses, by communicating with the database layer to retrieve or store data.
The database tier is responsible for storing and managing the application's data and allows access to its data through the logic tier.
## All At Once Deployment
In this type of deployment, changes to an application are made to all instances at once. In the three-tiered web application architecture, an all at once deployment that makes changes to the UI will take both instances in the presentation tier out of service during the deployment as shown below.
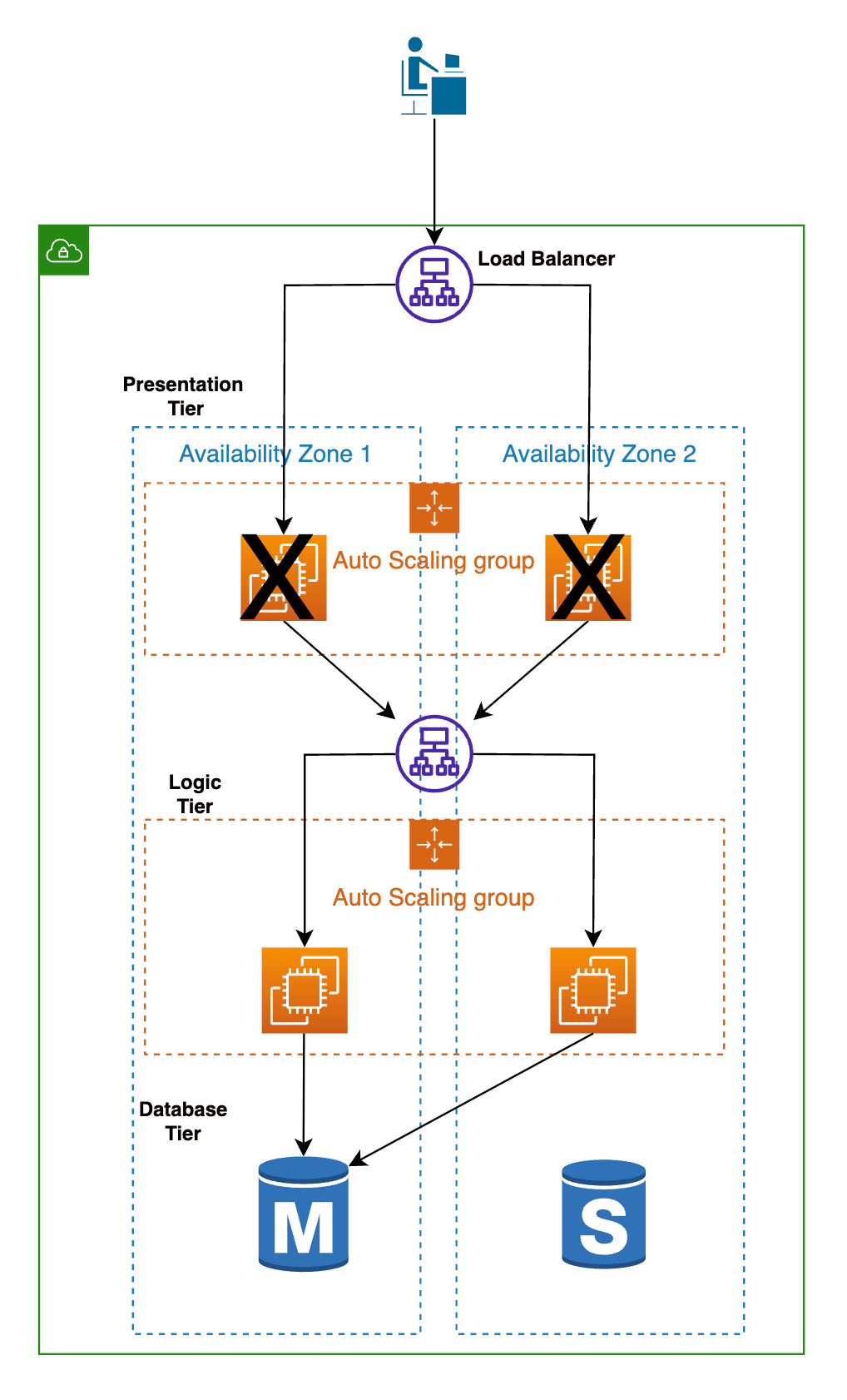
This type of deployment has some pros:
- deployments are fast
- deployments are cheap
And some cons:
- downtime during deployment
- a failed deployment will have further downtime since you will need to rollback by deploying the previous version of the application to the instances
- rollbacks are manual
An all at once deployment is ideal in a situation when a deployment needs to be made quickly. It is also ideal for situations when there is a low impact of something going wrong. So for example, deployments in non-live environments like development and test environments, that don’t have any real users.
Any use case where the cons listed above are not acceptable would be an anti-pattern for an all at once deployment.
An all at once deployment is analogous to the two chefs being told to stop taking new orders, and stopping any orders they were currently working on to learn the new pizza recipe and then using that that recipe going forward. While they are learning the new recipe, orders will go unfulfilled. If they can’t quite get to grips with the new recipe, any pizzas they make will also not be as good, will take longer to make, or both.
Also, if you later found out that customers do not like how the new pizzas taste, you have to revert back to the old recipe. This means restocking your kitchen with the previous dough and cheese you used and getting rid of the new toppings. This is not an ideal way of making a recipe change as you can lose customers if they don’t like the taste of the pizza.
On the plus side, this approach is cheap, in terms of up front cost at least. If it goes wrong, it can be very expensive as a result of lost future sales and upset customers. It is also fast to implement. If it takes each chef an hour to pick up the new recipe and you show them both at the same time, the new recipe can be ready to go live in an hour.
## Rolling Deployment
In a rolling deployment, changes are made to an instance or a batch of instances at the same time. In the three-tiered web application example, UI changes will first be deployed to one instance and once that is complete, it will be repeated on the other instance.
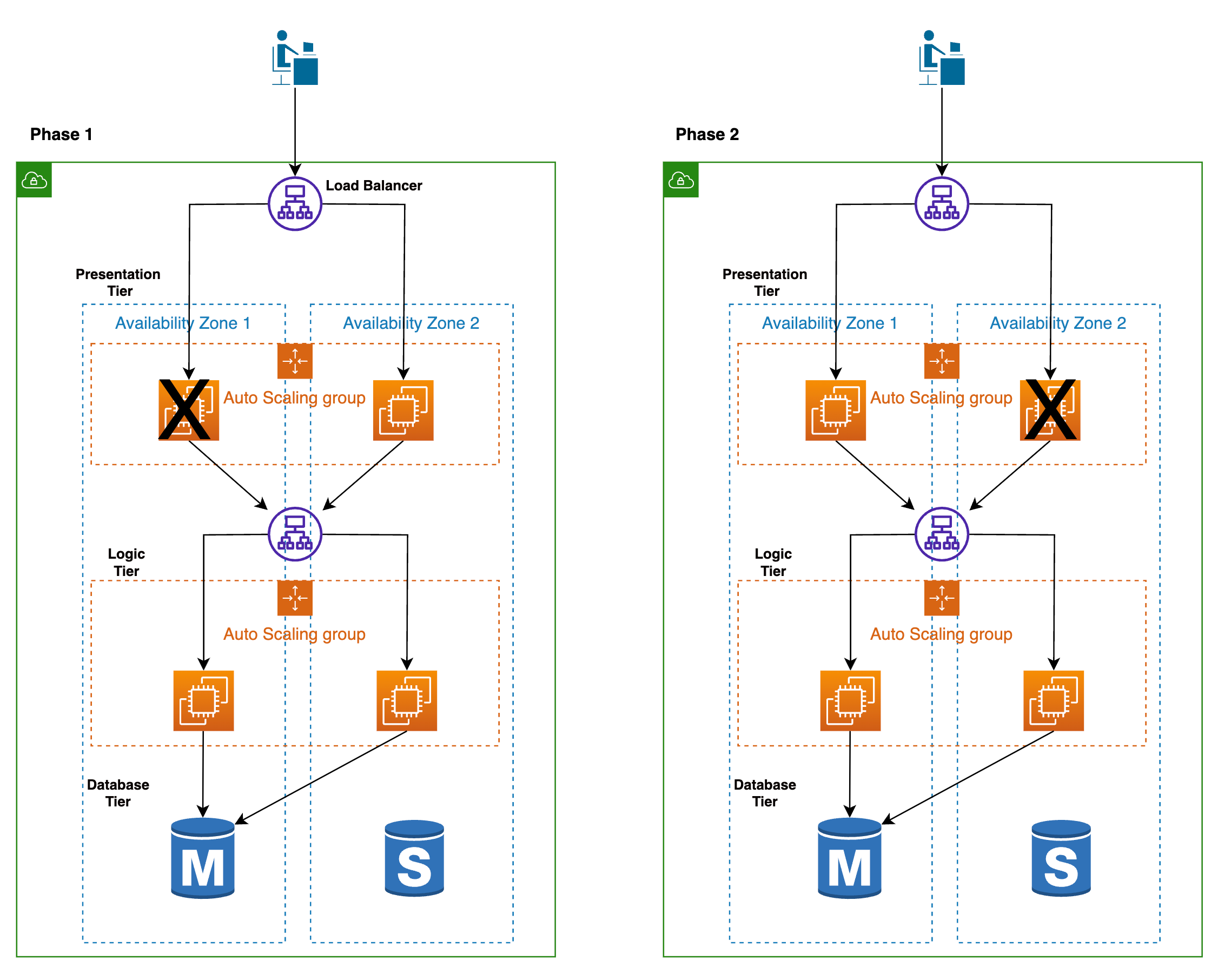
With this approach, you avoid downtime as changes are only made to one instance at a time. The drawback is that deployments will naturally take longer since you have to wait for the first deployment to finish before deploying to the second instance.
Bringing back the chef analogy, the new recipe will only be shown to one chef at a time. This means a reduced capacity to deal with orders, but orders will still be fulfilled since there will always be at least one chef available.
## Rolling with Additional Batch Deployment
This is similar to a rolling deployment, but an additional instance is added into the cluster during the deployment to maintain capacity as shown below.
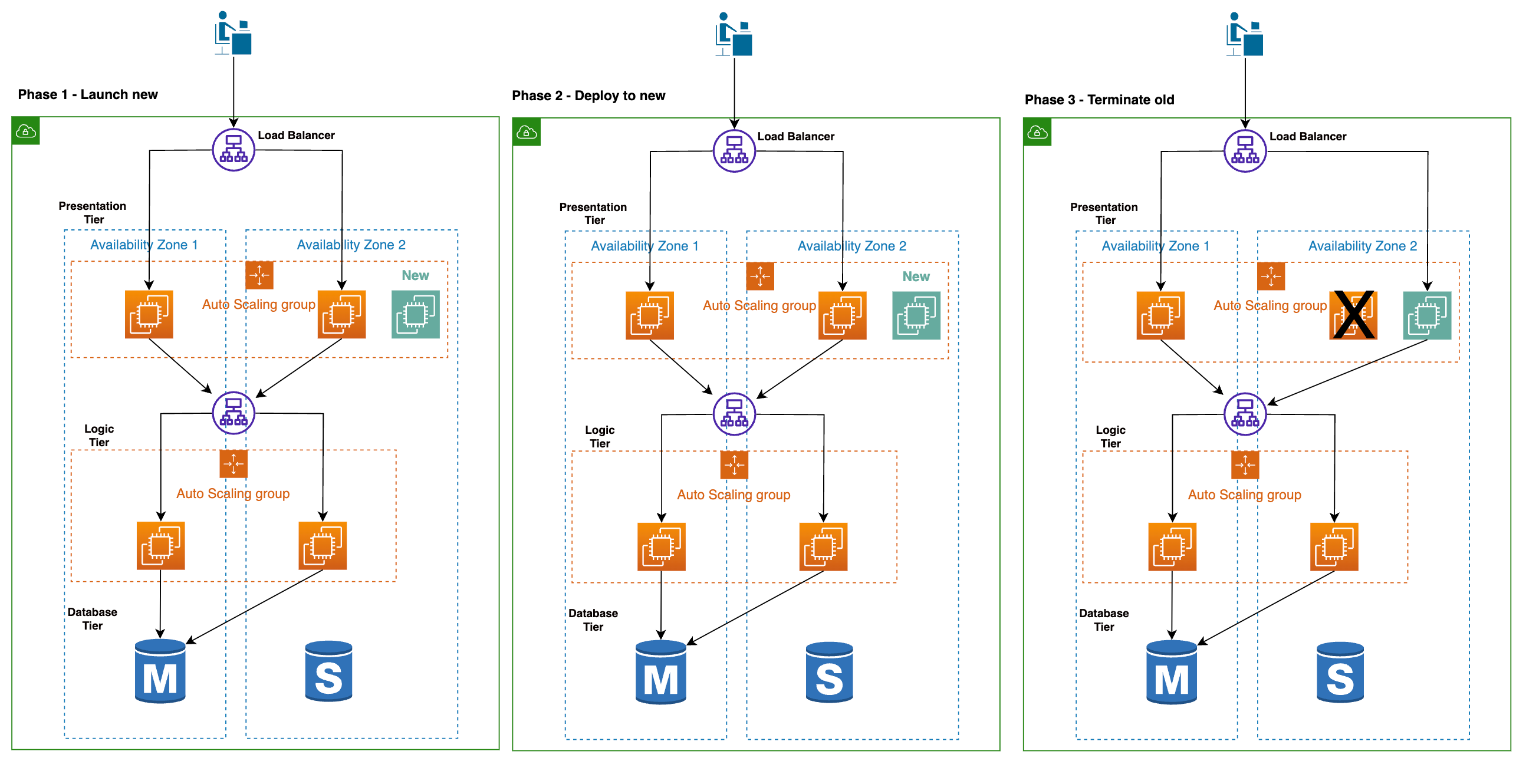
First you launch a new instance and then deploy the new application there. After the deployment is successful, you terminate an instance running the older application. These three steps of launching a new instance, deploying the new application there and terminating the old instance is repeated until you have deployed the new application on all the instances.
The key point to note with this approach is that by adding a new instance with the new application version before terminating any instances, you are always maintaining capacity. If you need two instances running at the same time, this deployment strategy will ensure you always have two instances available. This is useful for applications that require high availability.
With this approach, some users will be routed to different instances during the deployment. This means customers will see different UI on the web page - some will see the old, others will see new UI while the instances are still being updated. If a consistent user experience is absolutely necessary for all your users at all times, this deployment may not be right for you.
The rolling with additional batch deployment is analogous to hiring an extra chef to show the new recipe to while the two existing chefs still fulfil pizza orders. Once this new chef is familiar with the new recipe, orders are routed to him and one of the existing chefs. The third chef is then told to go home. This is repeated until both chefs in the kitchen are new and familiar with the new recipe. But while this transition is happening, there are always a minimum of two chefs who can fulfil pizza orders in the kitchen.
## Canary Deployment
The phrase ‘canary in the coal mine’ originates from an old practice in coal mining where miners would take a canary into the coal mine as an early warning alarm.
Canaries are highly sensitive to toxic gases like methane and carbon monoxide, which humans can’t easily detect as they are odourless and colourless. The canary dying was a signal to evacuate the mine since dangerous levels of toxic gases had built up to levels high enough to kill the bird. This was an effective, albeit brutal way of signalling potential danger to the miners.
In canary deployment, a separate set of instances will have the new application deployed on them, and a small percentage of all visitors will be routed to the new version. This can be done with the weighted routing option using Route 53 (managed DNS service from AWS). With weighted routing, you can specify a weight for each target load balancer.
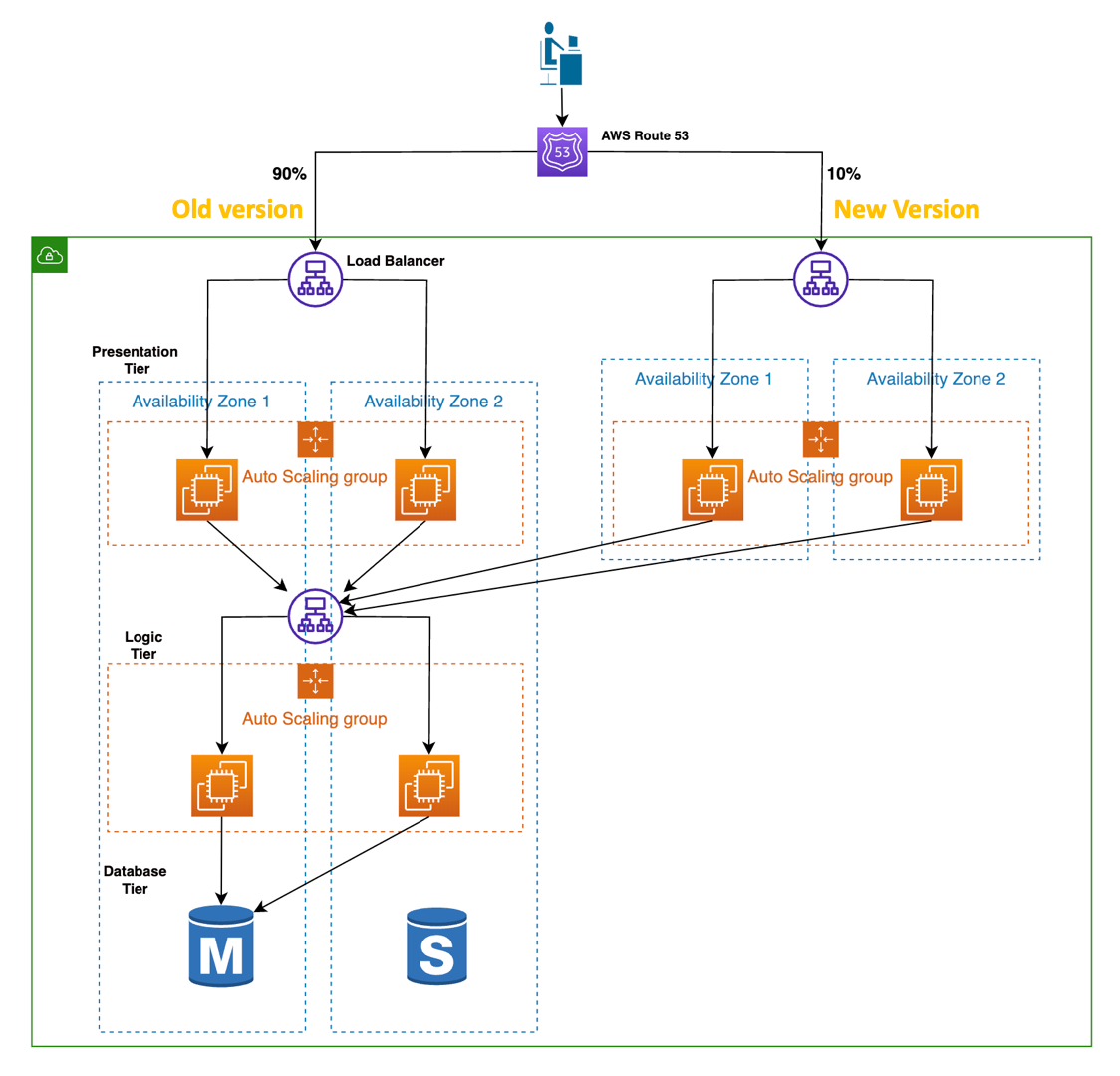
In this example, Route 53 will initially point 90% of all users to the old application and 10% to the new application. The new application will then be closely monitored to see metrics like error rates, response times etc. If any issues arise with the new application at this stage, then the weights are simply updated so that all traffic points back to the old application. Just like the canary in the coal mine, the initial monitoring on a small set of users serves as a cheap signal to give you confidence to either continue the transition to the new application, or revert back to the old. For critical applications that cannot afford any downtime or other issues, this is an effective way of managing the risk of a new deployment while being able to immediately revert back to the old application.
If everything looks fine with the new application during the initial testing with a small number of users, then the percentage of users routed there will be slowly increased as you gain confidence in its performance, until all users are now routed to the new application and the old instances can be terminated.
## Blue/green Deployment
Blue/green deployment involves creating two identical environments: a "blue" environment which hosts the current version of the application and a "green" environment which hosts the new version of the application. This is shown below.
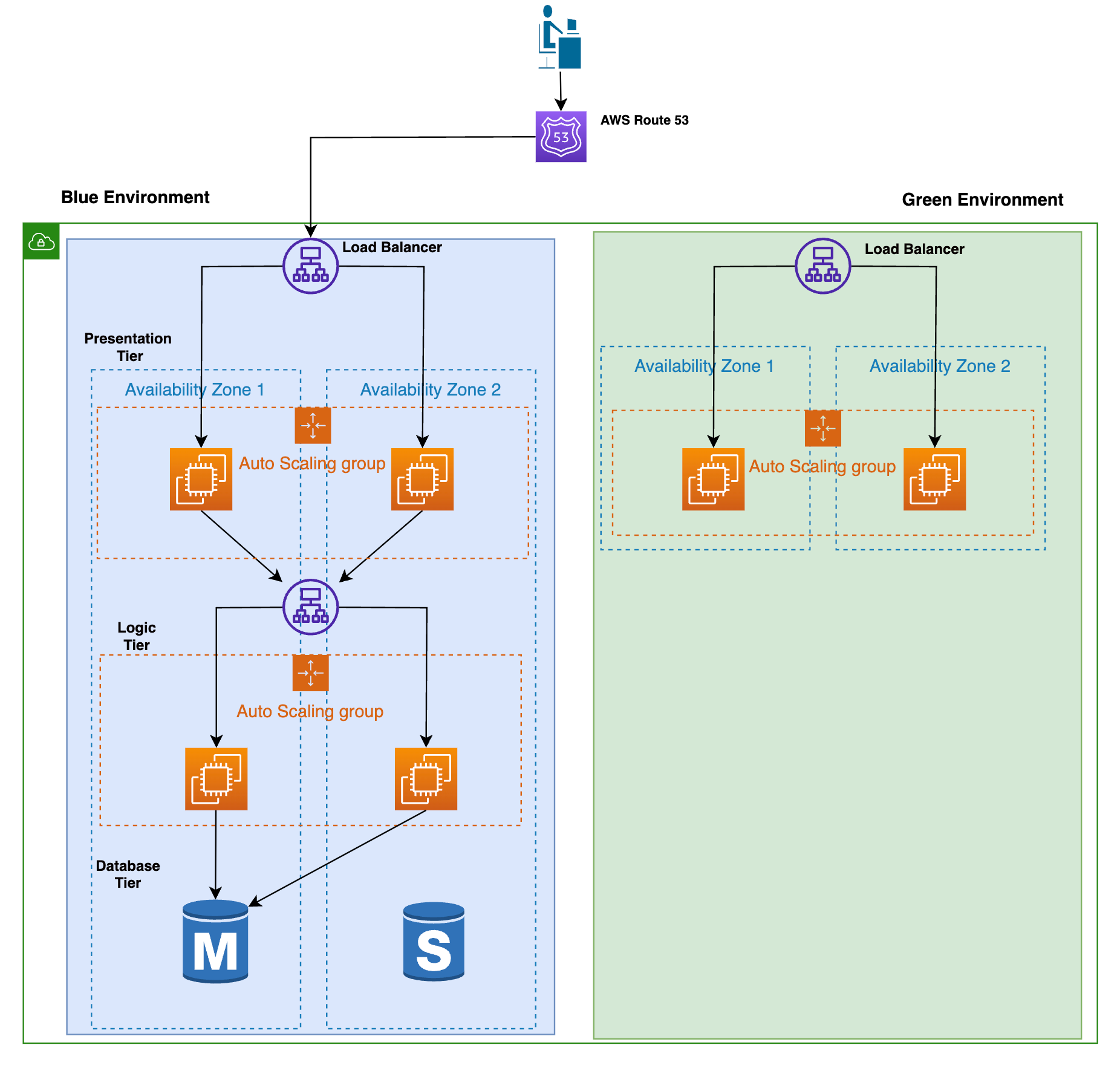
Once the new version of the application is deployed to the green environment, the Route 53 DNS record is updated to only point to the load balancer of the green environment in front of the presentation tier as shown below. The instances of the presentation tier in the blue environment can also be stopped to save cost and only restarted again when there is a new version of the application to deploy.
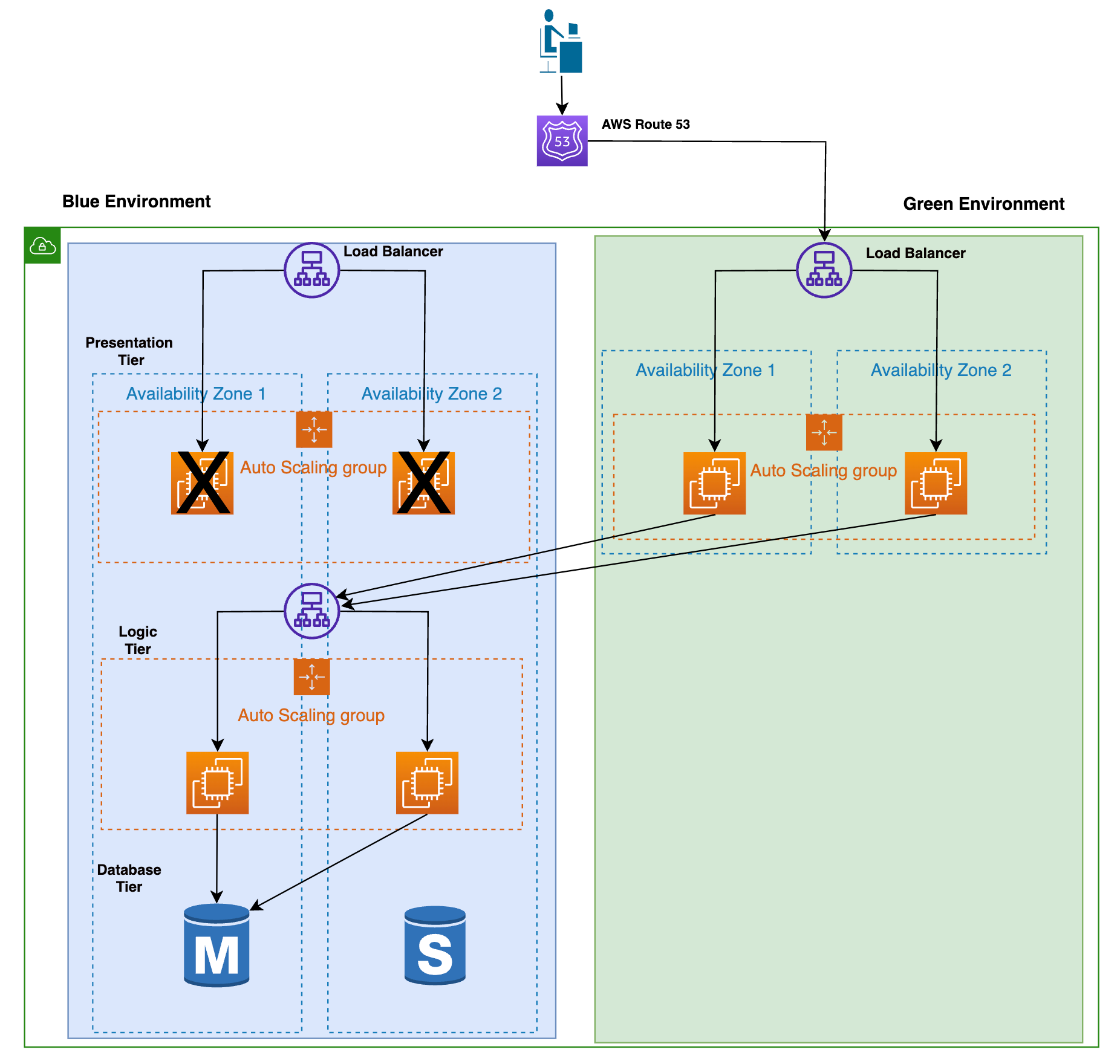
In this example of blue/green, only the instances in the presentation tier are in a separate environment. However, you could have an identical copy of the blue and green environments across all tiers so that if you were making changes to the logic or database tiers of the application, there would also be no downtime during deployment, with the ability to easily rollback. This is shown below.
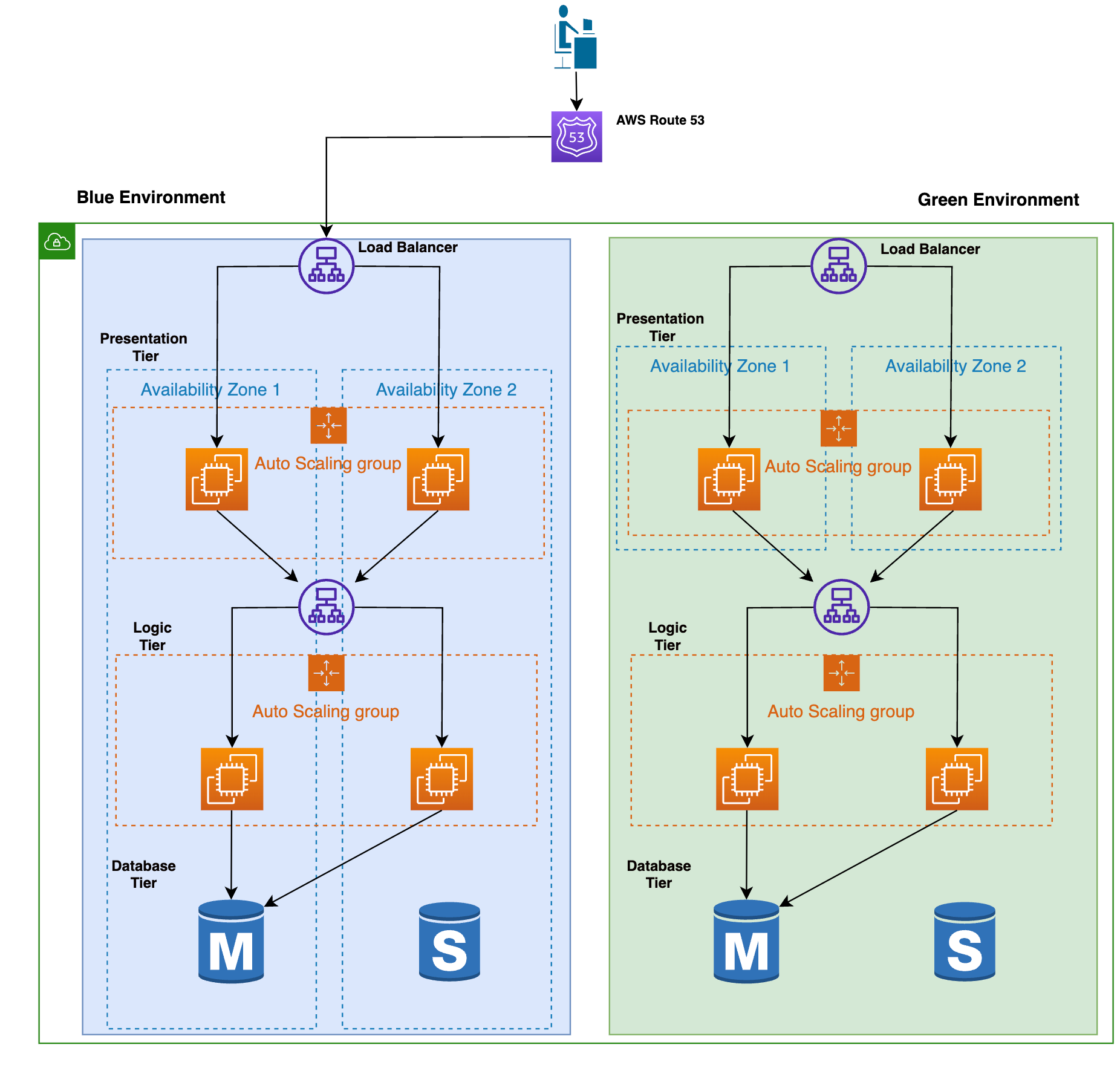
The main benefit of blue/green deployment is zero downtime during deployments, since all you have to do is update the DNS record to point to the load balancer of the ‘green’ environment.
Blue/green is similar to canary deployment, but instead of initially sending a small percentage of users to the new version of the application, all users are sent to the new version once it is deployed and thoroughly tested. There is no live testing with real users in a blue/green deployment.
Blue/green deployment is analogous to having two restaurant branches, each with two sets of chefs there. The ‘blue’ restaurant uses the current pizza recipe and all takeaway orders are at first routed to this restaurant as shown below.
The ‘green’ restaurant has perfected the new recipe and is ready to receive orders. Customer orders are then routed to this restaurant as shown below.
If customers complain about the delivery time or quality of the pizza (which shouldn’t happen if the new recipe has been tested with real customers beforehand), the manager can simply route the orders back to the blue restaurant making the old recipe, figure out what went wrong with the new recipe, make some tweaks and try again.
## Bringing it Together
The right deployment strategy for your application depends on what you are trying to optimise for.
All at once deployments are ideal is you want to minimise deploy time and upfront cost. The price you pay, however, is application downtime, further downtime if the deployment fails and a manual rollback process.
Rolling deployments will take longer to deploy than an all at once deployment. However, there will be no downtime since deployments are made incrementally on an instance or a set of instances. There will, however, be reduced capacity during deployment, so this may not be ideal for an application that requires high availability.
Rolling with additional batch deployment addresses the issue of reduced capacity with a rolling update. An additional instance or batch of instances with the new version is added to the cluster in order to maintain the same capacity. Only then are instances running the older version of the application terminated.
Canary deployment has no downtime and no reduced capacity during deployment. It is also safer as it allows for testing with a fraction of the users and closely monitoring performance before gradually routing all users to the new version. This does not, however, come for free. Additional infrastructure is required. Also, detailed monitoring and observability of the application has to be in place. This means it is more expensive and more complex to deploy using this strategy. It is important to caveat ‘more expensive’. This approach will incur higher upfront costs, but for a critical application with lots of users that cannot afford any downtime, it could be more expensive (through lost future revenue, unhappy customers or a ruined reputation) to use another deployment strategy that is ‘cheaper’ but ultimately less robust to failures.
Finally, blue/green is ideal for zero downtime deployments that are easy to rollback. It however requires additional cost for a separate set of identical infrastructure to be provisioned. | toni744 |
1,474,486 | My experiments with Copilot | I've been trying my hand at creating something with Copilot for the last two weeks. The one question... | 0 | 2023-05-21T05:39:28 | https://dev.to/kalarani/my-experiments-with-copilot-2nd3 | programming, ai, tooling | I've been trying my hand at creating something with [Copilot](https://github.com/features/copilot) for the last two weeks. The one question that I set out to find an answer is,
> "Can copilot really replace pair programming?"

I've spent a good amount time of my career crafting code and 80% of the time the code was co-created with my pair. So, there was an initial hesitation to try this out. But one fine day, I crossed the chasm and got started on my experiments with copilot.
## Quick start
The way copilot responded to some of my initial few prompts was amazing. I was writing a simple calculator in three different languages. In a few minutes, I had the code and tests for my calculators in `Java`, `Python` and `Elixir`.
## A (not so) complex problem
I encountered challenges when I prompted copilot to create a simple CRUD API in layered architecture.
Given the prompt to create an article controller, copilot suggested to do the CRUD for an article and then it stopped there. My initial reaction was,
> "Dear copilot, I know that I'd need to have CRUD endpoints in a controller. Could you please write the code for the same?"
But then there was only silence from the other end. So, I gave up and started defining the controller and dependencies. At this point, copilot came along and offered some suggestions that were appropriate.
It failed me again though. Given the prompt to create an endpoint to create an Article, copilot went on to define an action in MVC style, whereas I was looking to create a REST API.
## Lessons learnt
1. You need to get better at prompt engineering. Be able to break down the task at hand and give specific prompts to copilot. The more specific your prompt is, the more appropriate the code will be.
2. Copilot can get stuck at times, or produce incorrect code. In such cases, once you take a lead, copilot will be able to follow.
3. You need to really know what you are doing. In a new language / framework, it can easily (and quickly) lead you down the drain.
## Testing time
Once I had the code in place, I went on to explore copilot's skills in writing tests. I must admit that, it was pretty impressive in this space. It was able to cover the happy path and error scenarios equally well.
Again, Copilot's is quick to pick up your coding style and write more tests in the same style.
While at it, I wanted to write a builder for my model and with just one line of prompt, copilot gave me the implementation of the builder class. This is a key improvement. If copilot is able to write code understanding the language of software developers, that would be a good improvement in this tooling.
## Can copilot replace pair programming?
The verdict: `Nope. Or at least, not yet.`
> Copilot doesn't know (or care) why you are doing something. It is highly focussed on the how. While pairing often you'd have to zoom out and look at the big picture to ensure you are on the right track. Copilot is very contextual and can help you with specific tasks, but cannot help you with doing the right thing. It helps you do the thing right.
There is still a long way to go. But the future seems promising. [CopilotX](https://github.com/features/preview/copilot-x) is a good step in that direction.
## Future experiments:
1. Can you drive design through TDD?
Can you just write the tests and let copilot write the code. You should be good as long as the tests are green.
2. Can copilot help you go deeper?
Once you decide on the technical architecture, can copilot write code to create the entire infrastructure?
(or)
For a ML problem, can copilot help you pick up, train and test the best model for the job?
| kalarani |
1,474,662 | Vue and TSX ?! 🤯 | Many developers appreciate React and its Functional Components (FCs) due to the ease of building... | 0 | 2023-05-20T19:28:40 | https://dev.to/vincentdorian/vue-and-tsx--3if4 | vue, typescript, javascript, react | Many developers appreciate React and its Functional Components (FCs) due to the ease of building "multi-piece" components using JSX (or TSX). While some may assume that JSX is unavailable in Vue, in fact, it is perfectly possible to ditch Vue’s conventional Single File Component pattern (SFC) and use JSX or TSX to build components that share the same context like you would with React. In this article you will learn about the pro’s and con’s of using SFCs or using Vue with JSX and how to build a complex components with a used context by using JSX.
**So let’s dive right in!**
## What are Single File Components (SFCs)?
As the name might already give away, SFCs are components that allow us to write a components by using only a single file for the **logic, style and template** of the component. This is a pattern that is used by the two frameworks Vue and Svelte, where SFCs are saved with the extensions .vue and .svelte, respectively. The structure of a SFC in Vue might look as follows:
```html
<script setup>
//component logic goes here
</script>
<template>
<!-- html goes here -->
</template>
<style>
//css styling goes here
</style>
```
This certainly is great, when you are building a component, where all component logic is contained within the same file and exposes the following main benefits on the developer experience (DX):
- The component has a clear and maintainable structure that is quite forward (very close to standard HTML)
- Using scoped styles you can make sure that your CSS styling only applies to one single component (however, this is often not used in practice)
- There is a clear separation of concerns (logic of different components is split to different files)
However, for building components that use a shared context (like for example a dropdown-menu or a accordion), the SFC pattern might seem less convenient. In my opinion, this is where React and functional components (FCs) with JSX perform better. [This article might interest you, if you want to read more about why Ryan Carniato is not a fan of SFCs.](https://dev.to/ryansolid/why-i-m-not-a-fan-of-single-file-components-3bfl)
---
## What is JSX?
JSX stands for JavaScript XML. It is a way of writing HTML-like code within Javascript code. When used within React, it is also possible to express the logic and html within the same file. An example for a FC component within a JSX file could look as follows:
```javascript
const MyComponent = () => {
//logic is expressed here
return <div>/* html goes here */</div>;
};
const MyOtherComponent = () => {
//logic is expressed here
return <div>/* html goes here */</div>;
};
export { MyComponent, MyOtherComponent };
```
As you might notice, with this file it is possible to declare two different components and export them. This can for example come in very handy, when you want to share a state between nested components and do not want to pass it via the component props (which in Vue is called Prop Drilling). If you have been using React before, the hook **useContext()** might be familiar to you. Using this hook you can access the state defined in a parent component, in any nested Child component. [Here you can read more about how to share state between components in React.](https://react.dev/learn/sharing-state-between-components)
---
## But... Also Vue can do the trick!
While the default of using SFCs within .vue files, might in most cases be the right fit, sometimes it might be more beneficial to resort to an alternative solution (for example when you are building a component library). In the following we are going to look at an example where we define a three components _Parent, Child and DeepChild_ in the same .tsx file. The components _Parent_ and _DeepChild_ share the same value for count and by clicking a button in the component grand-child we want to update this variable.
```javascript
import { defineComponent, provide, inject, Ref, ref } from "vue";
const Parent = defineComponent({
name: "Parent",
setup(_, { slots }) {
// global state count
const count = ref(0);
//callback to update count
const updateCount = () => {
count.value++;
};
// provide count and updateCount to all children
provide("count", {
count,
updateCount,
});
return () => (
<div>
<span>Parent: {count.value}</span>
{slots.default?.()}
</div>
);
},
});
const Child = defineComponent({
name: "Child",
setup(_, { slots }) {
// count and updateCount not accessed here
return () => <div>{slots.default?.()}</div>;
},
});
const DeepChild = defineComponent({
name: "DeepChild",
setup() {
// count and updateCount injected in DeepChild
const { count, updateCount } = inject("count") as {
count: Ref<number>;
updateCount: () => void;
};
return () => (
<button onClick={() => updateCount()}>DeepChild: {count.value}</button>
);
},
});
export { Parent, Child, DeepChild };
```
Using the functions _provide()_ and _inject()_ we can make the state and an update function globally available to all components by binding them to a key count. When you are coming from React, this might already familiar to you as its quite similar to providing `[state, setState] = useState(count)` to other components via `useContext()`.
Now we can import the three components _Parent, Child and DeepChild_ where we need them.
```javascript
<script setup lang="ts">
import {
Parent,
Child,
DeepChild,
} from "../components/nested-component";
</script>
<template>
<Parent>
<Child>
<DeepChild />
</Child>
</Parent>
</template>
```
And the result looks as follows. We can update count from within the DeepChild component without having to pass it through the intermediate component _Child_ and Prop Drilling.

Using **provide/inject** is not exclusive to TSX component, however, it seems a lot more intuitive and maintainable having this logic defined in the same file. Here are some ideas, where you might find using TSX useful:
- Deeply nested components
- recursive components
- Headless components and primitives
---
## That's all folks!
What do you think? Do you sometimes use TSX or do you only stick to Vue's SFCs? Where could you imagine could it be applied?
I hope you liked this article and find it useful. Thanks for reading! ❤️
## References
- [https://vuejs.org/guide/components/provide-inject.html](https://vuejs.org/guide/components/provide-inject.html)
- [https://vuejs.org/guide/typescript/overview.html](https://vuejs.org/guide/typescript/overview.html)
- [https://vuejs.org/guide/extras/render-function.html](https://vuejs.org/guide/extras/render-function.html)
- [https://react.dev/learn/sharing-state-between-components](https://react.dev/learn/sharing-state-between-components)
**P.S.: Thanks to Chat GPT for proofreading this article 😘**
| vincentdorian |
1,474,743 | Projeto de Software | Projeto de Software | 22,899 | 2023-05-21T15:37:23 | https://dev.to/fabianoflorentino/projeto-de-software-544b | software, engineering, development | ---
title: Projeto de Software
published: true
description: Projeto de Software
cover_image: https://img.freepik.com/vetores-gratis/ilustracao-da-pagina-inicial-da-web-criativa_52683-79847.jpg?w=1380&t=st=1684617428~exp=1684618028~hmac=e0560ad699658abfd033af479fcf03175c44e13ba507d1a1a9bc87e92d125d7a
tags: 'software, engineering, development'
series: 'Engenharia de Software'
---
O processo de projeto de software desempenha um papel crucial no desenvolvimento de sistemas eficientes e confiáveis. A seguir está uma introdução aos principais pontos envolvidos nessa fase, desde a compreensão da modelagem do sistema até a elaboração dos diagramas necessários para a implementação. Modelos de análise de software, como análise estruturada e orientação a objetos, e a importância de documentar a visão do projeto.
## Entender a fase de projeto de um sistema (modelagem)
Antes de começar a projetar um sistema de software, é essencial compreender os requisitos e as necessidades dos usuários. A fase de modelagem envolve a criação de representações abstratas do sistema, como diagramas, para ajudar a visualizar e estruturar a solução. Isso inclui identificar os principais componentes, suas interações e fluxos de dados.
* Ao projetar um sistema de reservas de hotéis, a modelagem envolveria a identificação dos atores principais (usuários, administradores, etc.), as funcionalidades necessárias e as informações que devem ser armazenadas (quartos, reservas, etc.).
## Modelo de análise de software (Análise estruturada)
A análise estruturada é uma abordagem que divide o sistema em componentes hierárquicos, como módulo de funções. É baseada em técnica como fluxogramas, diagramas de fluxo de dados e especificações de processo. Essa abordagem permite uma compreensão clara da lógica do sistema e dos fluxos de informação.
* Um diagrama de fluxo de dados seria usado para mostrar como as informações fluem em um sistema de vendas, desde o momento em que um pedido é feito até a sua entrega.
## Modelo de análise de software [(Orientação a objetos)](https://pt.wikipedia.org/wiki/Orienta%C3%A7%C3%A3o_a_objetos)
A análise orientada a objetos é uma abordagem de modelagem que enfoca a identificação de objetos e suas interações para resolver problemas. Ela envolve a criação de classes, atributos, métodos e relacionamentos entre os objetos. Essa abordagem permite a reutilização de código e facilita a compreensão e a manutenção do sistema.
* Em um sistema de biblioteca, seriam identificados objetos como livros, usuários e empréstimos, e suas iterações seriam representadas por meio de relacionamentos como [associação](https://pt.wikipedia.org/wiki/Associa%C3%A7%C3%A3o_(programa%C3%A7%C3%A3o)), [agregação](https://pt.wikipedia.org/wiki/Orienta%C3%A7%C3%A3o_a_objetos#A%C3%A7%C3%A3o_nos_objetos) e [herança](https://pt.wikipedia.org/wiki/Heran%C3%A7a_(programa%C3%A7%C3%A3o_orientada_a_objetos)).
## Projetar a solução
Com base na modelagem e nas técnicas de análise escolhidas, o próximo passo é projetar a solução para o sistema de software. Isso envolve tomar decisões sobre a arquitetura, a divisão em módulos e a escolha das tecnologias adequadas. O objetivo é criar uma estrutura sólida e eficiente que atenda aos requisitos do sistema.
* Um sistema de gerenciamento de tarefas, pode-se decidir usar uma [arquitetura de três camadas (Apresentação, lógica de negócio e persistência)](https://pt.wikipedia.org/wiki/Modelo_em_tr%C3%AAs_camadas), com a utilização de um banco de dados relacional para armazenar as informações.
## Documentar a visão do projeto
A documentação é essencial para garantir que a visão do projeto seja claramente comunicada e compreendida por todas as partes envolvidas. Isso inclui descrever os objetivos, requisitos, restrições e decisões tomadas durante a fase de projeto. A documentação também serve como uma referência útil para futuras manutenções e melhorias no sistema.
* A documentação do projeto de um sistema de comércio eletrônico pode incluir a descrição dos [requisitos funcionais (como de usuários e realização de pedidos)](https://pt.wikipedia.org/wiki/Requisito_funcional) e [não funcionais (como desempenho e segurança)](https://pt.wikipedia.org/wiki/Requisito_n%C3%A3o_funcional).
## Elaborar o diagrama de casos de uso
O diagrama de casos de uso é uma representação visual das funcionalidades do sistema a partir da perspectiva dos usuários. Ele identifica os atores envolvidos e as interações entre eles, fornecendo uma visão geral dos principais recursos do fluxo do sistema.
* Um sistema de reservas de passagens áreas, um caso de uso seria "realizar reservas" envolvendo interações entre o usuário, o sistema de reservas e o sistema de pagamento.
## Elaborar o diagrama de classes
O diagrama de classes é usado na análise orientada a objetos para representar a estrutura e as relações entre as classes do sistema. Ele descreve as propriedades (atributos) e comportamentos (métodos) de cada classe, além dos relacionamentos entre elas.
* Um diagrama de classes para um sistema de gerenciamento de alunos pode incluir classes como "Aluno", "Curso" e "Matrícula", com atributos como nome, idade e número de matrícula.
## Elaborar o diagrama de sequência
O diagrama de sequência mostra a interação entre os objetos do sistema ao longo do tempo, representando a ordem das mensagens trocadas entre eles. Ele ajuda a compreender como o sistema responde a determinadas ações e eventos, auxiliando no projeto detalhado da funcionalidade.
* Um diagrama de sequência para um sistema de pagamentos online pode mostrar a sequência de eventos desde o momento em que o usuário seleciona os itens até a confirmação do pagamento.
## Por que usar projeto de software na construção de um sistema?
O uso de software está cada vez mais presente em nossas vidas, seja no trabalho, em casa ou no lazer. A cada dia, novos softwares são desenvolvidos para atender às necessidades de diferentes usuários. Mas, como esses softwares são desenvolvidos? Como garantir que eles atendam às necessidades dos usuários? Como garantir que eles sejam confiáveis e seguros? Como garantir que eles sejam desenvolvidos dentro do prazo e do orçamento? Como garantir que eles sejam desenvolvidos de forma eficiente e eficaz?
O uso de projeto de software na construção de um sistema é extremamente importante por várias razões e, por isso, é um dos principais tópicos abordados na disciplina de Engenharia de Software. Abaixo estão alguns dos principais benefícios do uso de projeto de software na construção de um sistema:
* **Organização e estrutura**
O projeto de software permite uma abordagem estruturada e organizada para o desenvolvimento do sistema. Ele ajuda a definir uma arquitetura clara e a dividir o trabalho em tarefas gerenciáveis. Isso facilita o entendimento e a colaboração entre os membros da equipe de desenvolvimento.
* **Atendimento aos requisitos**
O projeto de software garante que os requisitos do sistema seja compreendidos e atendidos adequadamente. Através da modelagem de documentação, é possível identificar os principais componentes e funcionalidades necessárias, evitando assim a omissão de requisitos importantes.
* **Redução de erros e retrabalho**
Ao projetar um sistema de software, é possível identificar possíveis problemas e antecipar soluções. Através de revisões e análises, é possível detectar error e inconsistências antes de implementação. Isso ajuda a reduzir o retrabalho e os custos associados a correções posteriores.
* **Comunicação eficaz**
O projeto de software fornece uma linguagem comum para todos os envolvidos no desenvolvimento. Através dos diagramas e documentação, é possível comunicar de forma clara e visual as funcionalidades e o comportamento do sistema. Isso facilita a compreensão mútua e evita mal-entendidos entre a equipe de desenvolvimento e os stakeholders.
* **Reutilização de código**
Ao projetar um sistema de software de forma modular e orientada a objetos, é possível identificar oportunidades de reutilização de código. Isso significa que partes do sistema podem ser projetadas e implementadas uma vez e posteriormente utilizadas em diferentes contextos. Isso economiza tempo e esforço, além de promover a consistência e a manutenibilidade do sistema.
* **Facilidade de manutenção**
Um projeto de software bem estruturado facilita a manutenção do sistema ao longo do tempo. Com uma documentação clara e a compreensão da estrutura do sistema, torna-se mais fácil realizar correções, melhorias e atualizações. Isso é particularmente importante em sistemas de longa duração, nos quais a manutenção pode ser uma parte significativa do ciclo de vida do software.
## Então(...)
Um projeto de software bem estruturado facilita a manutenção do sistema ao longo do tempo. Com uma documentação clara e a compreensão da estrutura do sistema, torna-se mais fácil realizar correções, melhorias e atualizações. Isso é particularmente importante em sistema de longa duração, nos quais a manutenção pode ser uma parte significativa do ciclo de vida do software.
O uso de projeto de software na construção de uma sistema é essencial para garantir a organização, compreensão dos requisitos, a redução de erros, a comunicação eficaz, a reutilização de código e a facilidade de manutenção. Ele proporciona uma abordagem estruturada e colaborativa, resultando em sistemas de software mais eficientes, confiáveis e sustentáveis.
Como colocado anteriormente o projeto de software é uma etapa crucial no desenvolvimento de sistemas eficientes e confiáveis. Compreender a modelagem, escolher a abordagem de análise adequada, projetar a solução e documentar a visão do projeto são elementos fundamentais para o sucesso do projeto. A elaboração de diagramas de casos de uso, classes e sequência auxilia na visualização e comunicação das funcionalidades do sistema. Ao seguir essas práticas, os desenvolvedores podem criar sistemas robustos e fáceis de manter.
| fabianoflorentino |
1,475,091 | Best TypeScript ORM just got better | Drizzle ORM v0.26 is out and it changes the game Well, the last 3 months were wild. We... | 0 | 2023-05-21T10:11:24 | https://medium.com/@aleksandrblokh/best-typescript-orm-just-got-better-5a33688b8d2e | typescript, javascript, orm | ## Drizzle ORM v0.26 is out and it changes the game
Well, the last 3 months were wild. We went public with Drizzle ORM and it gained quite some adoption. The first [YouTube](https://www.youtube.com/watch?v=3tl9XCiQErA) video about us came out and it blew through the roof. As of now, we sit on 5.6k GitHub stars and actively growing 🤯
3.4k developers subscribed to us on [Twitter](https://twitter.com/DrizzleOrm) and we have 960 community members in [Discord](http://driz.li/discord) and boy oh boy we’ve got quite some feedback, we’ve listened and now we got some big news 👀
---
Drizzle ORM is designed as a thin TypeScript layer atop SQL, it’s meant to solve your problems, empower and not interfere, it has remarkable performance and fully fledged joins. Drizzle lets developers love SQL again.
Yet we’ve received a lot of feedback from devs struggling with relational queries, doing massive amounts of joins and mapping complex results. Well, we have a solution now, meet [Relational Queries](https://orm.drizzle.team/docs/rqb).
We’ve designed Relational Queries to be an extension to existing Drizzle ORM API, all you need to do is to define relations alongside schema declaration and you’re ready to go.
We’ve spent quite some time to make sure you have both best-in-class developer experience and performance 🚀
Regardless of how many nested relations you query - Drizzle will always make exactly one SQL query to the database, it makes it extremely explicit and easy to tune performance with indexes.
We support nested limit, you no longer have to fetch users and all of their posts from the database, you can just fetch the last 5.

You can include and exclude columns to omit unnecessary data transfer, you can add extra custom fields like lower(first_name + last_name) and you have all the power of where operator at any nested level.
And yes, you can prepare statements and gain up to 5x massive performance improvements!
We’ve been undercover for several weeks, building everything through blood and tears and we’re thrilled to hear your feedback.
Check out [the docs](https://orm.drizzle.team/) and give it a spin!
Docs, by the way… Lets talk docs
---
Docs were probably #1 requested feature since day one and yes, we do have docs now — orm.drizzle.team

Those are not raindrops, no no. Those are teardrops. We’ve cried a lot.
We’ve handcrafted every page and we’d love to hear your feedback and make it better!
And yes, we have comprehensive docs for [Drizzle Kit](http://orm.drizzle.team/kit-docs/overview) and you can finally read how to use [db push](https://orm.drizzle.team/kit-docs/commands#prototype--push)!
Don’t hesitate to hit us a star on [GitHub](https://github.com/drizzle-team/drizzle-orm) and subscribe on [Twitter](http://twitter.com/drizzleorm)!
| _alexblokh |
1,475,109 | CSS Sticky is weird | I've fixed that issue - if the parent is "flex", then align-self: start; must be applied. And of... | 0 | 2023-05-21T17:31:40 | https://dev.to/cvladan/css-sticky-is-weird-and-hard-eca | ---
title: CSS Sticky is weird
published: true
---
I've fixed that issue - if the parent is "flex", then `align-self: start;` must be applied. And of course, `top: 0px;` as well. | cvladan | |
1,475,207 | Perl Weekly Challenge #217 - Flattening the Matrix | This week we have a very simple challenge! Again due to time, I just did the first challenge this... | 0 | 2023-05-21T13:01:57 | https://dev.to/oldtechaa/perl-weekly-challenge-217-flattening-the-matrix-4mk3 | perl, matrix, perlweeklychallenge | This week we have a very simple challenge! Again due to time, I just did the first challenge this week, but I have an idea of how I'd solve the second and I'll compare with the way others implemented it.
Anyway, to the challenge. The goal is to find the 3rd smallest element of a matrix. The simplest way is simply to flatten, sort, and pick the element. There might be absolutely more performant ways to do it, such as scanning the entire matrix once and keeping a list of the lowest three as you iterate, but this is a case where I feel that it's simply not worth it. One pass to flatten and one sort isn't worth all the extra implementation complexity. I do look forward to seeing any solutions including that technique though.
Here's my code:
my @matrix1 = ([3, 1, 2], [5, 2, 4], [0, 1, 3]);
my @list1;
foreach (@matrix1) {map {push @list1, $_} @{$_}}
@list1 = sort @list1;
say $list1[2];
Repeated for each input dataset.
So the easy simple way to do this is just to use map to flatten the array onto @list1, then sort it in place and pick the third element. That simple. Essentially 3 lines for the majority of the task.
As I said, I look forward to seeing the other solutions for these challenges, and I'll hopefully see you next week! | oldtechaa |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.