
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,475,257 | From Children's Musician to iOS Dev - Late in Life Career Change? | Hello Dev, I'm new here. This is my story... I teach college algebra. It’s a gig I took as a... | 0 | 2023-05-21T13:48:43 | https://dev.to/montyharper/from-childrens-musician-to-ios-dev-late-in-life-career-change-1dfa | beginners, career, mobile, ios | Hello Dev,
I'm new here. This is my story...
I teach college algebra. It’s a gig I took as a stop-gap measure to get myself past a rough patch in my music career. Spoiler alert — that didn’t work out. I’m still teaching college algebra, nearly seven years on.
For most of my adult life I’ve made a living as a full-time children’s songwriter, performer, and teaching artist. I still perform at libraries during the summer, and I have several CDs out. They’re pretty good. I’m on [Spotify](https://open.spotify.com/artist/66z8hGVbduE6jpBAHY7Eql) if you want to look me up.
I’ve also always wanted to be an author, and teaching has given me time to complete three middle-grade novels. I’ve been hoping this would become my creative salvation. I could get published, be a full-time writer, quit teaching, and make music on the side.
But authorship is a long and arduous journey. And teaching as an adjunct instructor has become my dead-end, low-pay, no-benefits, no-job-security albatross — it’s not a career. With neither music nor writing poised to take over any time soon, a neutron-star-sized clump of dread formed in my stomach when it came time to sign up for yet one more semester of college algebra this coming Fall. I felt stuck and depressed and desperate for change.
Desperate enough to start poking around, even though I couldn’t imagine a better option that wouldn’t require expensive education or years of prior experience. _You_ can, though, right?
What I discovered seemed way too good to be true! First of all, you need to know that all my non-music, non-writing projects over the years — anything I’ve done for fun or contemplated turning into some kind of business — from my high school years through to the pandemic — all those projects involved some kind of coding. I just never realized I was developing job-worthy skills that could lead to a fun, creative, high-earning career! I might even be able to work from home. With a bit of training I could potentially start job hunting within a few months!
_What?!? Is this for real? Pinch, pinch._
After a few days of giddy research, I jumped on board. I signed up for Udacity’s iOS Development course on April 22, 2023.
I’m writing this one month later from the eye of an information hurricane. I’ve been completely obsessed! All that I’ve encountered in the wonderland of tech, even including all the hurdles and frustrations (of which there are many), leaves me convinced I’ve dropped myself into the right place.
Simultaneously, I’m terrified I’ve made a huge mistake. Maybe I’m too old for this. Maybe I don’t have what it takes. Maybe it is all too good to be true. Maybe I’m chasing an unattainable dream.
Doesn’t matter.
If all I acquire is the ability to complete a few personal projects, it’ll be worth it. One thing on my to-make list is a calendar for my elderly mom. She has a brain disease that leaves her unable to comprehend time, which gives her constant anxiety. None of the dementia calendars out there have helped, and they all work on the same principal. My idea is different. Maybe it’ll work better for her. When I get discouraged, I picture my mom using an iPad, running my calendar app. For now, that project is my North Star. I have until mid August to get as far as I can before algebra instruction reclaims my time for another semester.
And I want that tech career, so I’m going all in. As I understand it, that means social media / blogging / learning in public. So here I am ready to give it my best!
What does it take for a fifty-something-year-old children’s musician to snag a new career in tech? Give me a follow. Let’s find out together!
| montyharper |
1,475,261 | Beyond Bugs: Exploring the Depths of Software Testing | Testing is a critical phase in the software development process. It ensures that the software meets... | 0 | 2023-05-21T14:20:22 | https://medium.com/@iamfaisalkhatri/beyond-bugs-exploring-the-depths-of-software-testing-6a3b7057060e | softwaretesting, softwareengineering, testing, learning | Testing is a critical phase in the software development process. It ensures that the software meets the requirements, functions as expected, and is reliable. However, there are many challenges that can erupt throughout the testing process.
In this blog, let me take you on a tour of the challenges faced while performing software testing, provide you some tips and tricks to overcome those challenges and also talk beyond catching bugs to efficiently test the software ensuring quality releases.
## Challenges faced in Software Testing
Testers or the QAs face various obstacles while performing Software Testing. These challenges must be overcome in order to perform testing without any blockers ensuring on time release of software to the market. Some of the commonly faced challenges are -
**Time Constraints**: Time Constraint is the most commonly faced challenge by QAs in mostly every software project. Testers have to work within tight schedules with limited time available for testing. With less time to test makes the testers rush test activities which eventually leads to overlooking some critical issues.
**Changing requirements**: With Agile in place, though we have the flexibility to adhere to changing requirements, it can be a significant challenge, as the QA team has to align all the tests as per the latest changes. With the release deadlines, it leads to Technical Debt for the testing team as they have to update all the automation stuff as well as the test scenarios/cases to align them with latest specifications.
**Test Data Management**: Generating and managing realistic test data is a challenge that is faced by almost every testing team especially while working on large and complex systems. Accurate and realistic test data is required for effective testing, in case that is not available chances of missing critical scenarios increases.
**Limitation of resources**: Infrastructure, tools, and shortage of skilled QAs are some of the commonly faced limitations by QA teams. In addition to these, Insufficient testing environments, lack of automation tools, and a shortage of experienced personnel can lead to the overall blocking of software testing thereby slowing the delivery time to the market.
**Communication Issues**: Communication and Collaboration between the Testers, BAs, Developers and the Stakeholders is most important for successful testing and improving the overall quality of the product. However, due to miscommunication, lack of clarity, experience and poor collaboration, overall quality of the product suffers.
To overcome these challenges, effective planning, coordination between teams and the use of the right tools and techniques are required.
## How to overcome the software testing challenges?
With the multiple challenges obstructing software testing, it becomes a kind of blocker for the testing team to progress with their daily activities. It is therefore required to resolve these challenges to work efficiently. Here are the following tips that can be considered -
**Test Early**: Testing early helps in early detecting and resolution of the issues. It is not necessary that we test the software only. The bug can be hidden in the specification as well as the feature request. Going thoroughly through the specification can help in detecting the hidden issues and correcting them before they are leaked into the product. This helps in overall cost and efforts.
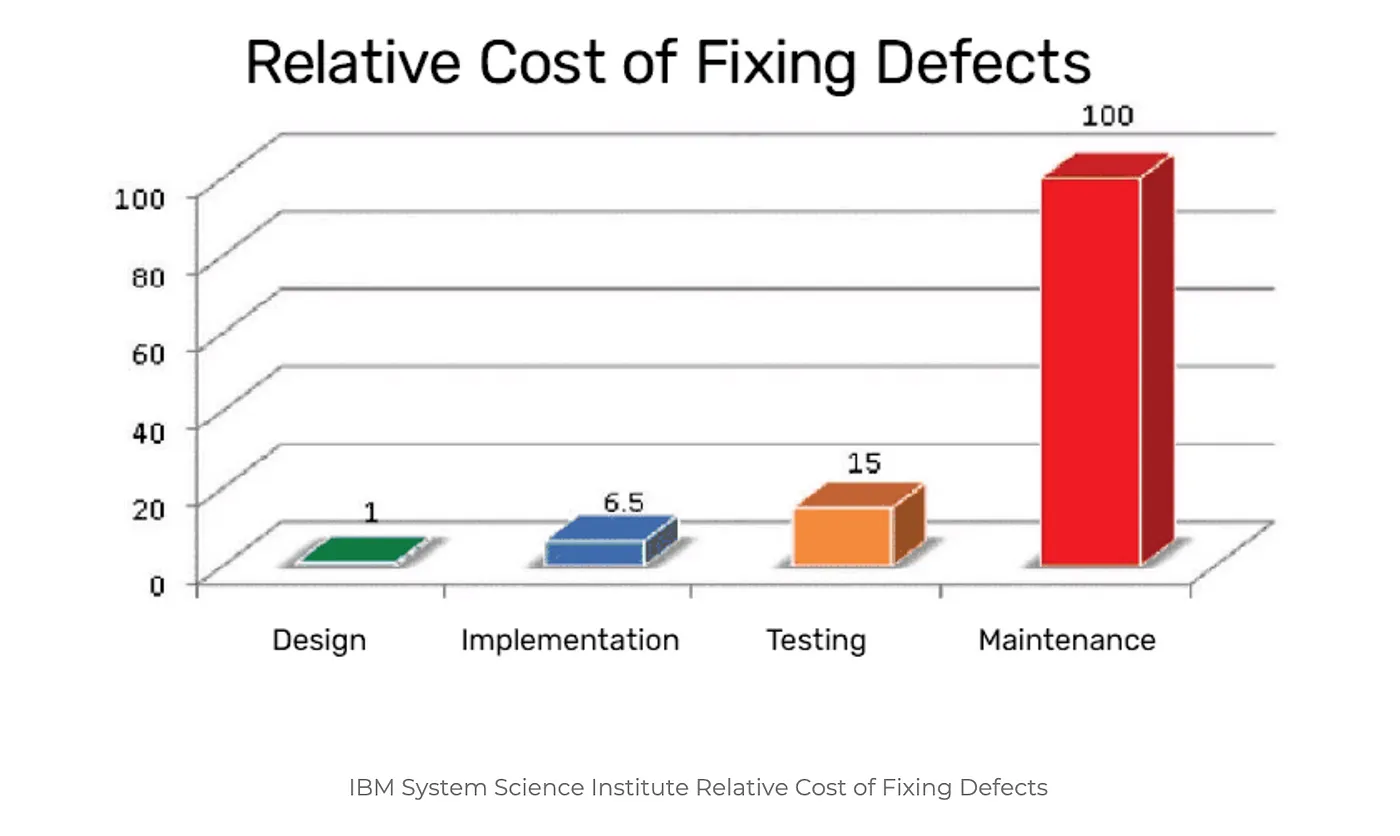
[IBM System Science Institute Relative Cost of Fixing Defects](https://www.researchgate.net/publication/255965523_Integrating_Software_Assurance_into_the_Software_Development_Life_Cycle_SDLC)
The cost of finding bugs in the later phase of software development is much higher as compared to that in the initial phase of development.
**Prioritize Test Cases**: Focus on the complex and high priority test scenarios, this will help you catch the critical bugs that might impact the overall functioning of the product. Prioritization can be done based on business requirements, its impact and probability of failure.
Business Analysts and Domain Experts’ help can be taken here to focus on major critical areas of the software and prioritize them for testing.
Review and update the Test Cases/Scenarios: As the requirements keep on changing, it is good to review and update the test cases/scenarios on a regular basis. This can help to avoid creation of Technical Debt and can save time by reusing these updated cases/scenarios for testing in subsequent cycles.
{% embed https://medium.com/@iamfaisalkhatri/best-examples-of-functional-test-cases-agilitest-blog-424260298b5 %}
**Automate Regression Tests**: Regression testing refers to retesting the existing functionality of the software after a defect is fixed, to check the stability of the software and verify that the fix doesn’t have any side effects. Performing regression testing manually is a very tedious and boring task and requires lots of manual effort. Hence, the test scenarios that need frequent testing should be automated.
Automating the regression tests helps in running all the tests quickly and get faster feedback on the builds.
For example, if you are working on a project that is developing an e-commerce application. Most of the regression tests would need registration, login, adding to product to cart, making payment, etc. All these test scenarios can be automated and regression testing can be a big time saver.
**Exploratory Testing of the product**: Exploratory testing refers to combining your experience, testing skills and domain knowledge to uncover the hidden issues that have not been discovered yet. It helps in adding more value to the product by exploring and testing the unexplored areas.
**Usability Testing**: It refers to testing the software for its ease of use. Most of the users stop using the software as they don’t consider it user friendly. This type of testing helps in checking the overall user experience and identify the design flaws and usability issues.
**Improve Communication and Collaboration **- Communication is the key in Software Engineering. Almost half of your issue gets resolved at the earliest if you communicate well. Having an open communication and collaborating with developers, designers, stakeholders can ensure shared understanding of requirements, defects, and testing goals.
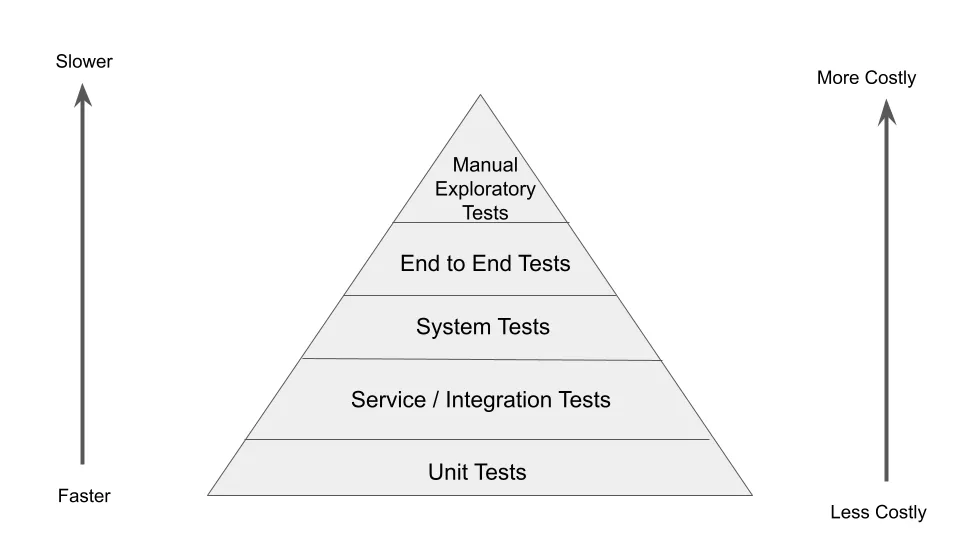
**Use Test Pyramid**: The concept of Test Pyramid was introduced by Mike Cohn in his book Succeeding with Agile. Test Pyramid helps in promoting a balanced approach to testing by organizing tests into different layers.
Unit Tests, Integration Tests, System Tests, End to End tests and Manual exploratory tests are layers of the Test Pyramid. As we have tests at every layer it helps in [Continuous Testing](https://medium.com/@iamfaisalkhatri/what-is-continuous-testing-lambdatest-bd2c464b414c) and provides with faster feedback by detecting issues early and fixing them.
## Software Testing Beyond bug detections
In this modern era of software development, there are teams working on agile methodologies like Scrum, Kanban, etc. We need to think about software testing beyond catching the bugs and writing the bug tickets.
How about taking actions to avoid the bug leakage in the code from the initial development stage itself? How about testing continuously without putting in manual efforts? How about baking the quality within the code itself?
There are lots of other areas to think about as well. It can all lead to delivering quality software and allow the team to maintain a balanced schedule between their work and life.
Let’s take a look at the other side of the term called “Software Testing”
**Confirming Functional Integrity**: Software Testing aims to ensure that the software is functioning as per the requirement specified. QAs check that the software is performing all the actions which it is intended to do. Also, more importantly, it is also important to verify that it is not performing the actions it is not intended to do. The latter point helps to find out the deviations from the actual working of the software and fix it before it makes its way to the production.
**Performing Usability and Accessibility Testing**: By performing the Usability testing, it can be ensured that the end user would be able to use the software smoothly. If the background color of the application is too dark or too itchy for the eyes, users may stop using it. Such suggestions can help improve the overall quality of the software.
Accessibility testing should be performed based on the targeted audience that would be using the software. By performing Accessibility Testing, we can check that software is easily accessible by differently abled people.
**Checking out for Security Vulnerabilities**: It can help in uncovering the potential security threats that can be faced by the system and make sure that the resources and data in the system are protected by attackers. The goal for doing this is-
- To identify the security risks.
- To measure potential threats.
- To identify vulnerabilities such as weak passwords, data breaches, unpatched software and misconfigured systems that could be exploited by the intruders.
**Performing Cross Browser and Compatibility Testing**: With multiple Operating Systems such as Windows, MacOS, etc. and different browsers like Chrome, Firefox, Edge, Safari, etc. It is necessary to check the software is working as expected on different OS/Browser combinations. It can help uncover hidden issues which might go untested based on the assumption that if the software works on Chrome browser, it should work on Firefox browser as well.
Compatibility testing can help uncover issues related to installation, setup and configuration of software on different platforms like Windows, MacOS, Linux,etc.
{% embed https://medium.com/@iamfaisalkhatri/cross-browser-testing-in-selenium-webdriver-pcloudy-blog-46e9d70fa13a
%}
**Integrating automated tests in CICD**: Automated tests triggering automatically one after another once the developer pushes any code to the remote repository helps to get faster feedback without much manual effort. It can help bake the quality within the product itself.
{% embed https://medium.com/@iamfaisalkhatri/practical-guide-on-continuous-integration-for-automation-tests-vtest-blog-23e6d37f523f
%}
**Performance Optimization**: With multiple features getting added to the software brings in the responsibility to keep a check on the performance of the software.
For example, in the case of a mobile project, areas like memory usage, battery usage, App load time, data sync time, page load time, App refreshing time, etc. are some of the areas which can be checked and accordingly if any lagging is found it can be improved. It is also important to check for fallback scenarios in case of network issues, App crash, etc.
{% embed https://mfaisalkhatri.github.io/2022/03/31/guidetomobiltesting/ %}
**Collaborating with DevOps**: QAs can also contribute and collaborate with the DevOps team. Checking logs in case of the pipeline failure, helping the developers in identifying the root cause of failures, setting up pipelines for different environments, running the test on cloud platforms, monitoring the automated pipelines, etc. are some of the areas where QAs can manage and help the DevOps team.
{% embed https://medium.com/@iamfaisalkhatri/devops-testing-vtest-blog-635d88de352f
%}
**Organize Bug Bash**: A bug bash is an activity where developers, testers, business analysts, designers, operations people and even stakeholders come together to perform all hands on, on the software. This helps in locating hidden bugs more quickly as every person uses the software differently. QAs should organize such bug bash a week before the release just in case if there are any critical issues discovered, it can be quickly fixed.
{% embed https://medium.com/@iamfaisalkhatri/what-is-a-bug-bash-c8ac3fd81661 %}
All this can happen once all the tedious tasks that need a lot of manual effort are automated so the testers can focus and work on overall improvement of the software.
{% embed https://youtu.be/Js0anAdYAA0 %}
## Conclusion
Software testing goes beyond simply finding and fixing bugs. It encompasses functional validation, performance optimization, verifying usability and accessibility, identifying security vulnerabilities , cross browser and compatibility testing, and regression testing. By exploring all these areas in detail, software testers can play a crucial role in ensuring the quality, reliability, and bring user satisfaction to software products.
It is important to tailor your testing techniques to the specific needs and requirements of the software project. By using comprehensive testing practices throughout the development lifecycle robust, efficient, and user-centric software can be delivered with quality.
> Freelance Work / Paid Trainings/Mentoring
> Contact me for Paid training/Mentoring related to Test Automation and Software Testing, ping me using any of the social media sites listed on [LinkTree](https://linktr.ee/faisalkhatri) or email me @mohammadfaisalkhatri@gmail.com.
| mfaisalkhatri |
1,475,580 | React Lifecycle | Introduction This would be a simple post about React lifecycle with hooks and react... | 0 | 2023-05-22T21:40:03 | https://dev.to/lausuarez02/react-lifecycle-22h1 | react, beginners, javascript, programming | ## Introduction
This would be a simple post about React lifecycle with hooks and react lifecycle with classes.
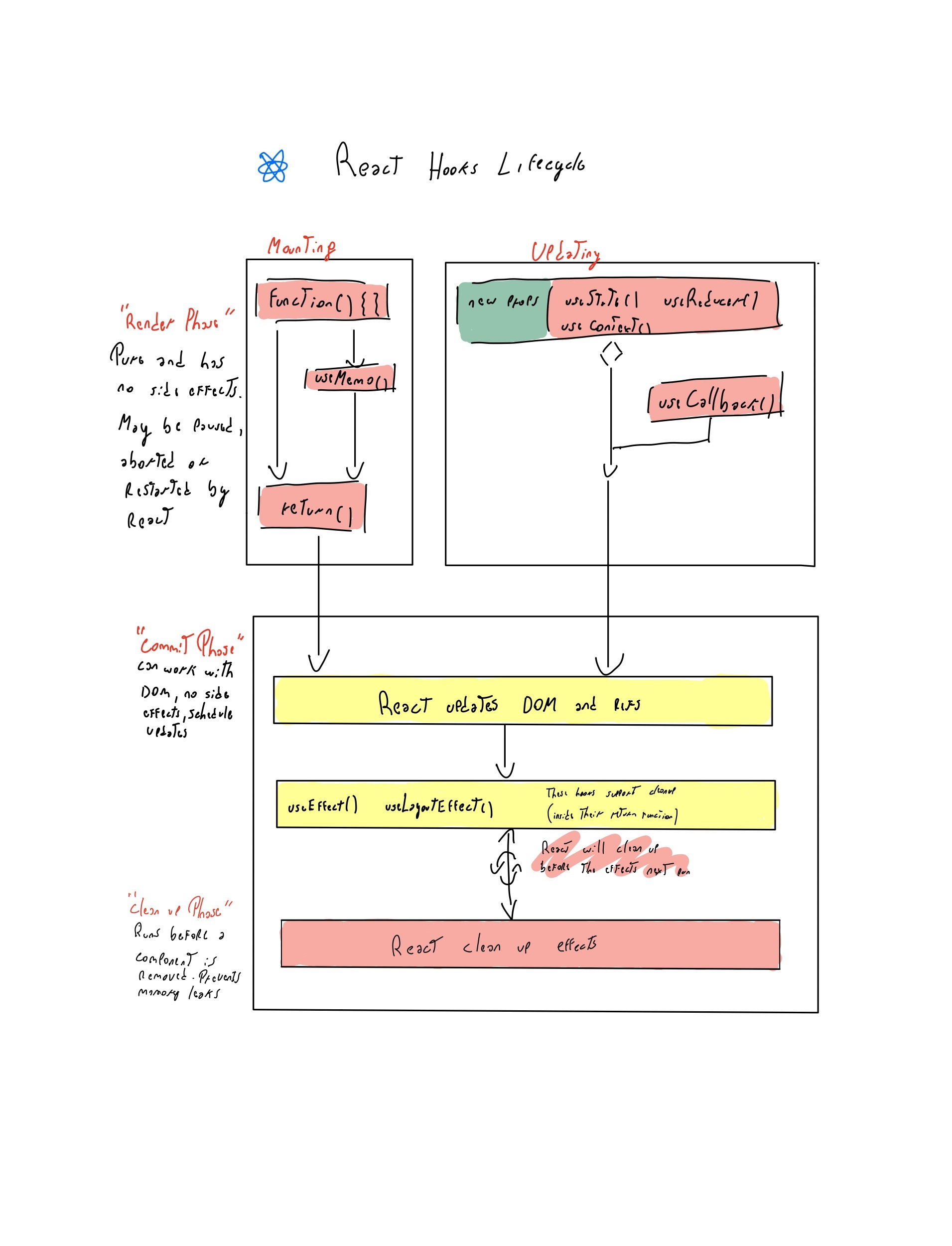
## React lifecycle with hooks.
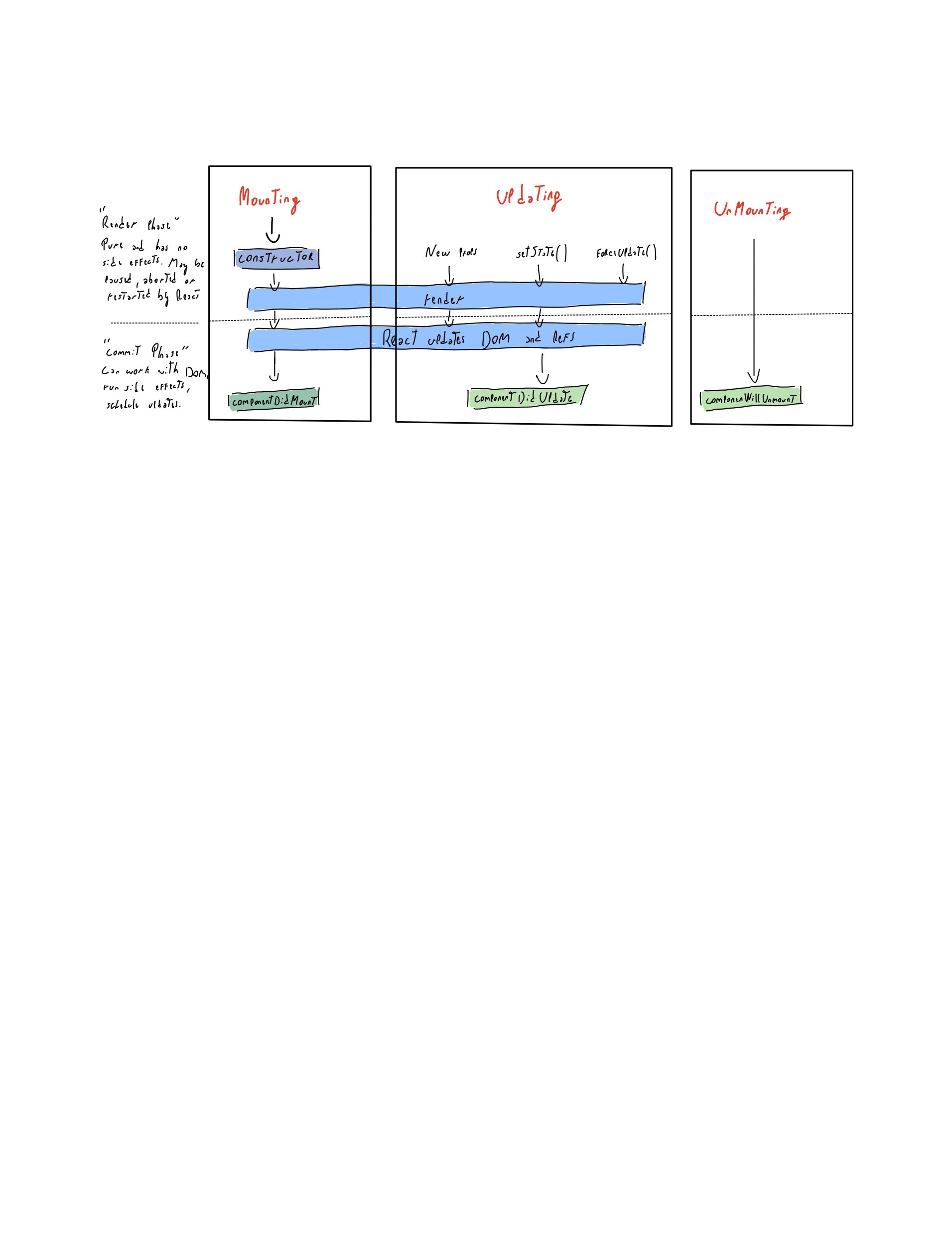
## React Lifecycle with classes
## Difference
I was wondering just like you about unmounting which in the hooks lifecycle but in this case the unmount will be when we do the clean up with for example useEffect, where inside the useEffect doing the return we are doing the unmounting which is called clean up.
## Conclusion
We can do basically the same and in a simpler way with functional components. We just have to know how to do it.
Hope someone found it useFul.
Lautaro
| lausuarez02 |
1,475,678 | A Step-by-Step Guide to Linking and Deploying a Node.js Web App to Azure App Services and Connecting it to an SQL Database | Introduction: In today's digital era, deploying web applications to the cloud has become increasingly... | 0 | 2023-05-21T22:31:49 | https://dev.to/chymee/a-step-by-step-guide-to-linking-and-deploying-a-nodejs-web-app-to-azure-app-services-and-connecting-it-to-an-sql-database-49j8 | Introduction:
In today's digital era, deploying web applications to the cloud has become increasingly popular due to its scalability and ease of management. Azure App Services, coupled with Node.js and an SQL database, offers a powerful combination for hosting and running your web applications. In this blog, I will walk you through the process of linking and deploying a Node.js web app to Azure App Services and connecting it to an SQL database.
Prerequisites:
Before we begin, make sure you have the following prerequisites in place:
An Azure account: Sign up for an Azure account at [click](https://azure.microsoft.com).
Node.js and npm: Install Node.js and npm on your local machine. You can download them from [click here](https://nodejs.org).
Azure CLI: Install Azure CLI on your machine. You can find installation instructions at https://docs.microsoft.com/cli/azure/install-azure-cli.
**Step 1: Create an Azure App Service**
Log in to the Azure portal [click here](https://portal.azure.com) using your Azure account credentials.
Click on "Create a resource" and search for "App Service."
Select "Web App" from the search results and click "Create."
Provide a unique name for your app, choose your preferred subscription, resource group, and operating system.
Configure the runtime stack to Node.js and choose the desired version.
Click "Review + Create" and then "Create" to provision the App Service.
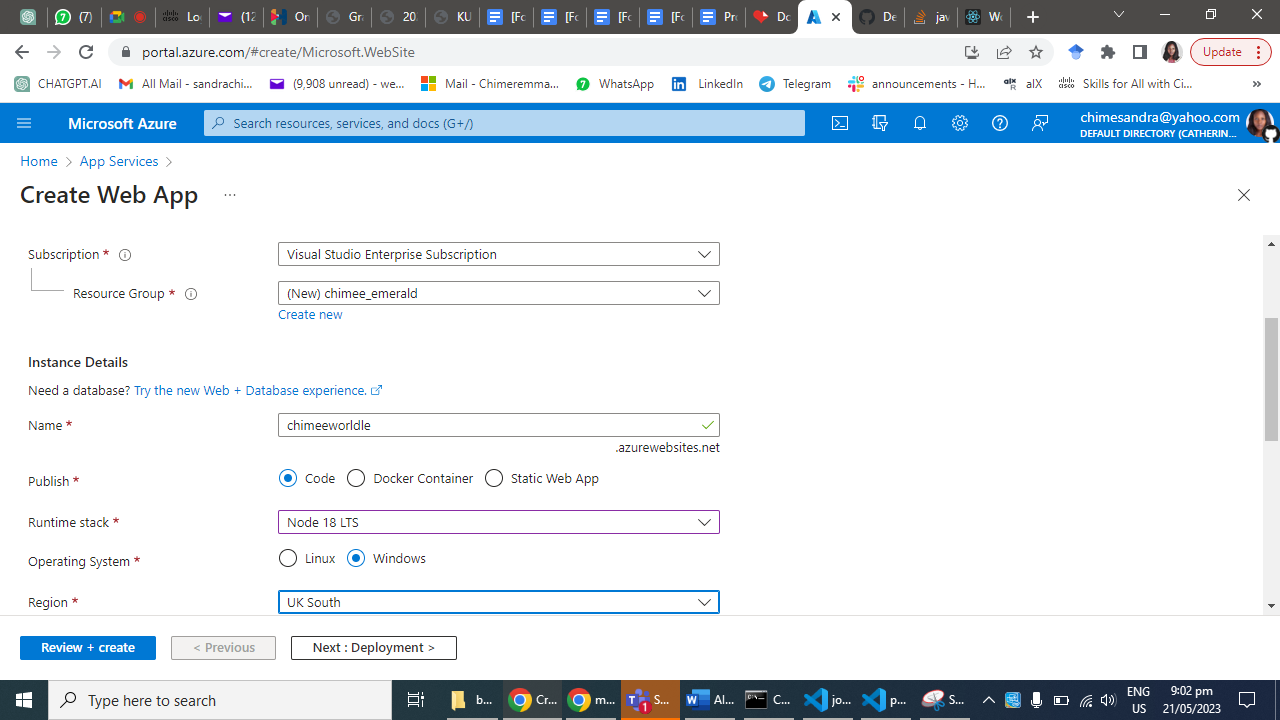
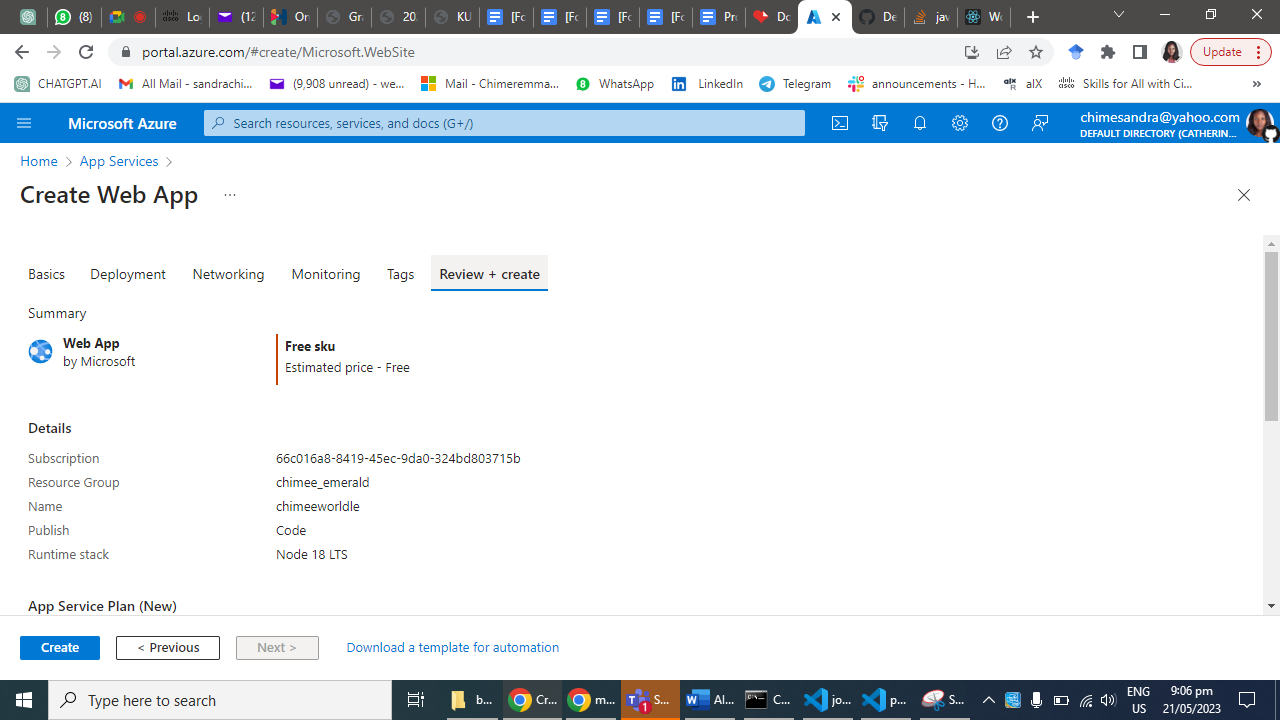
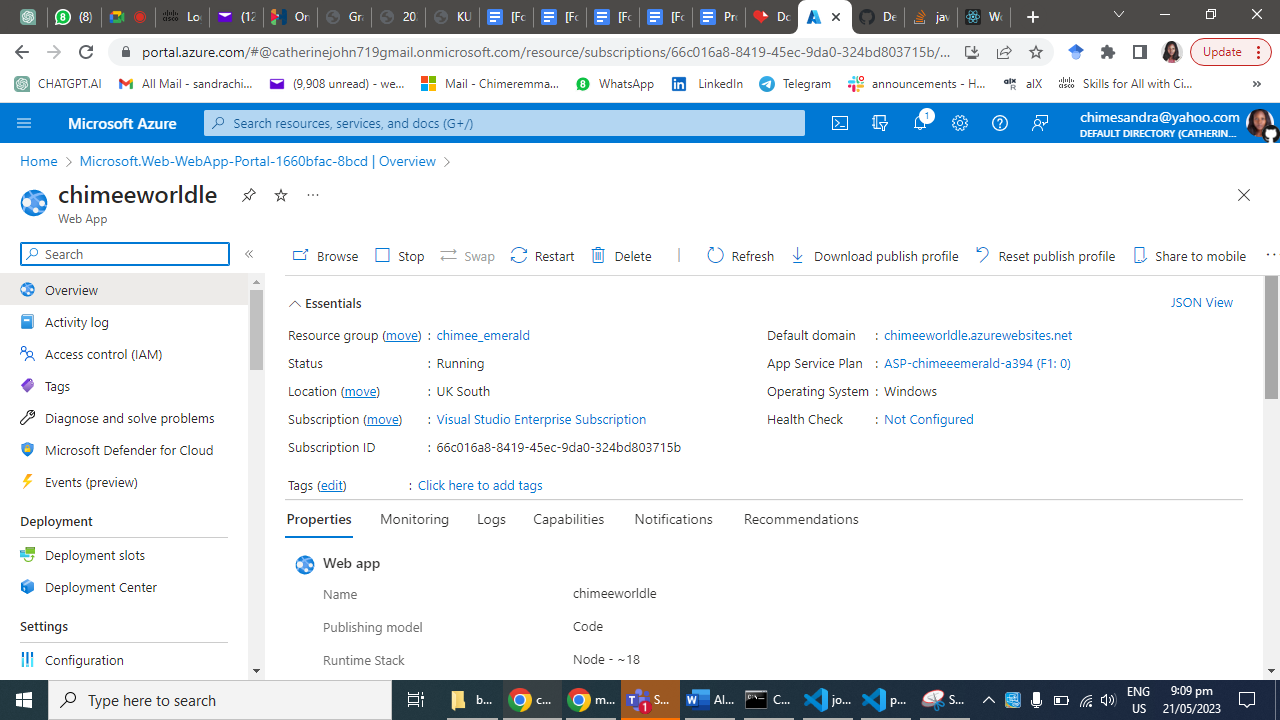
Step 2: Set up your Node.js Web App
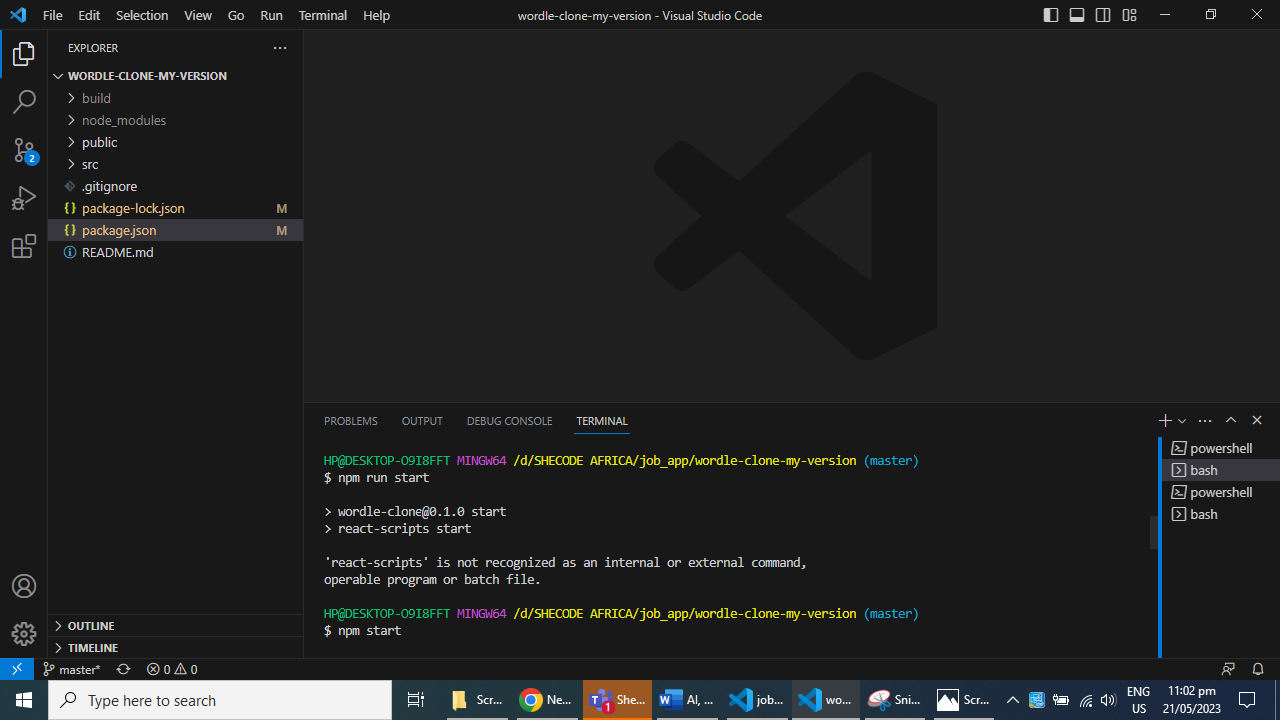
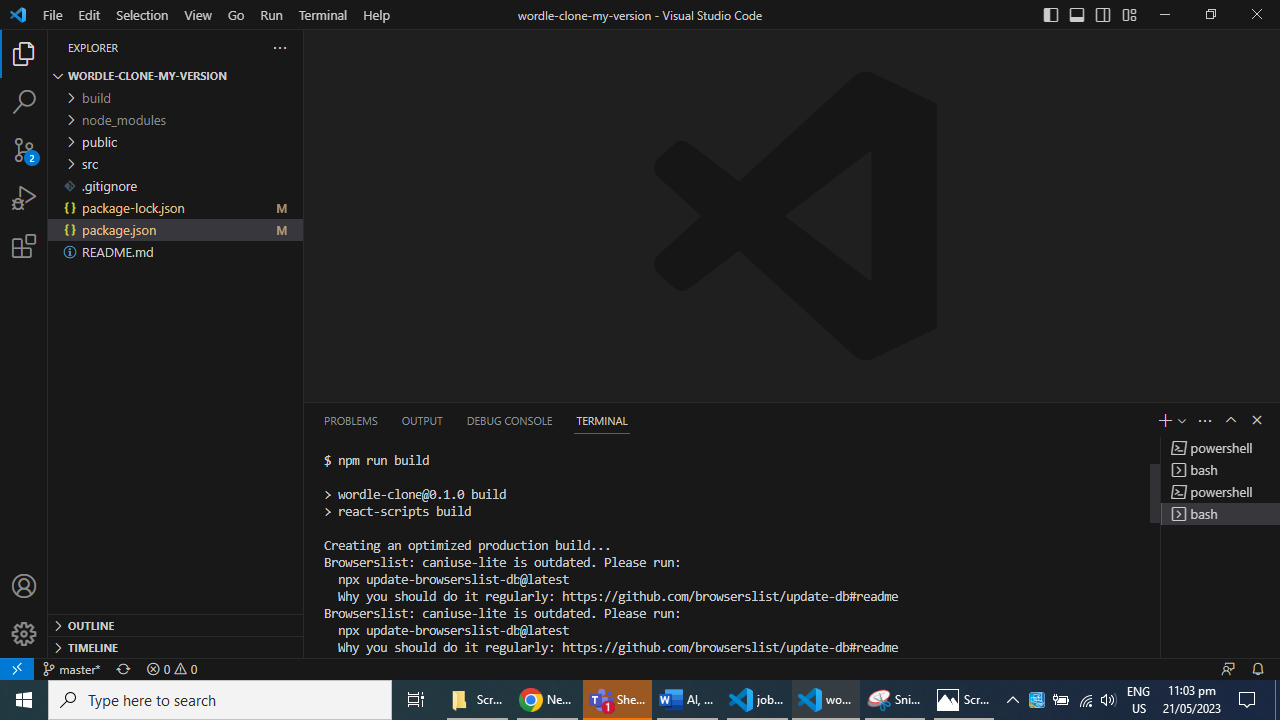
Open a terminal or command prompt and navigate to your project's directory.
Initialize a new Node.js project by running the command: npm start.
Install the necessary dependencies for your web app using npm run build.
Test your application locally using the command: npm run start. I am using windows, so this will open on local host 3000.
Step 3: Connect to an SQL Database
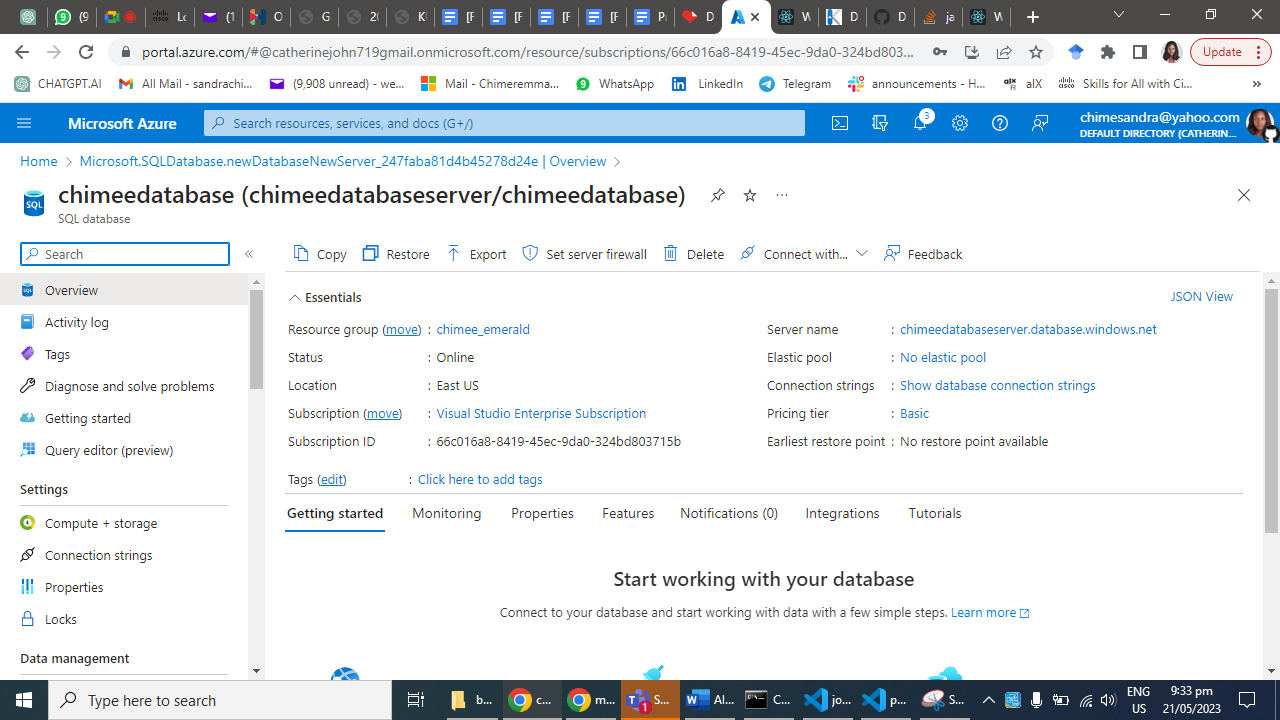
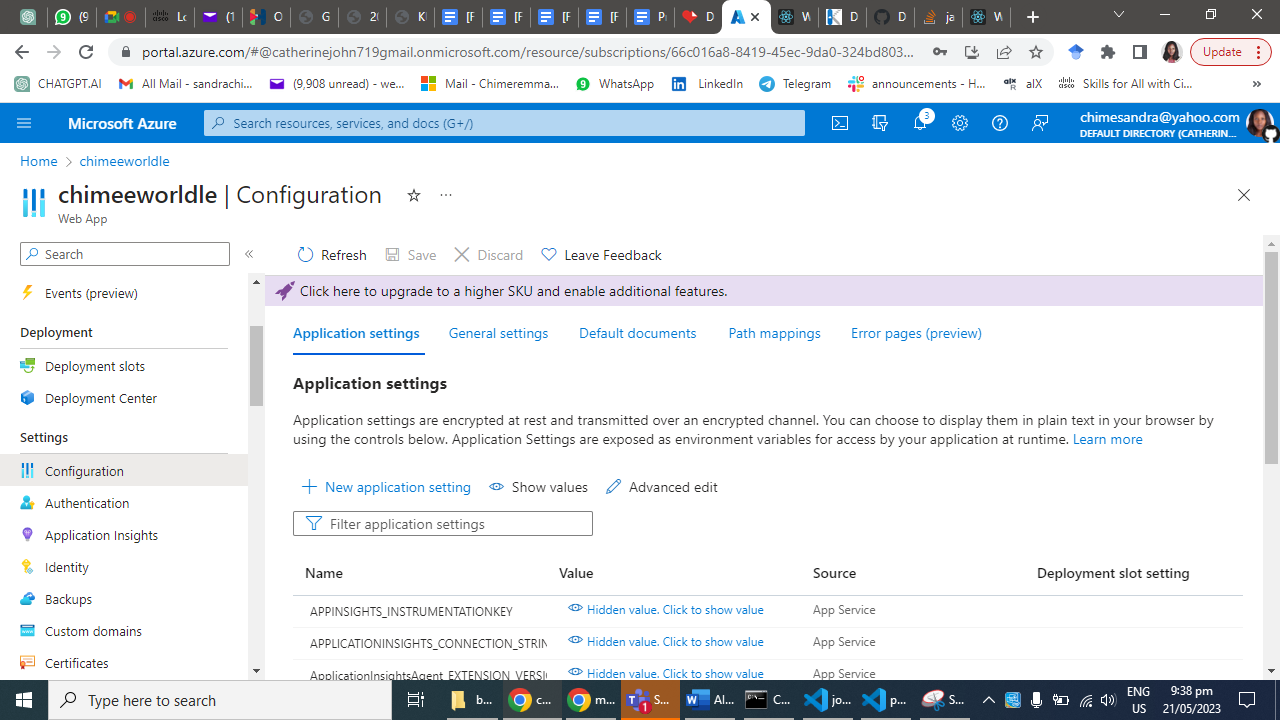
In the Azure portal, go to your App Service's "Overview" page.
Under "Settings," click on "Configuration."
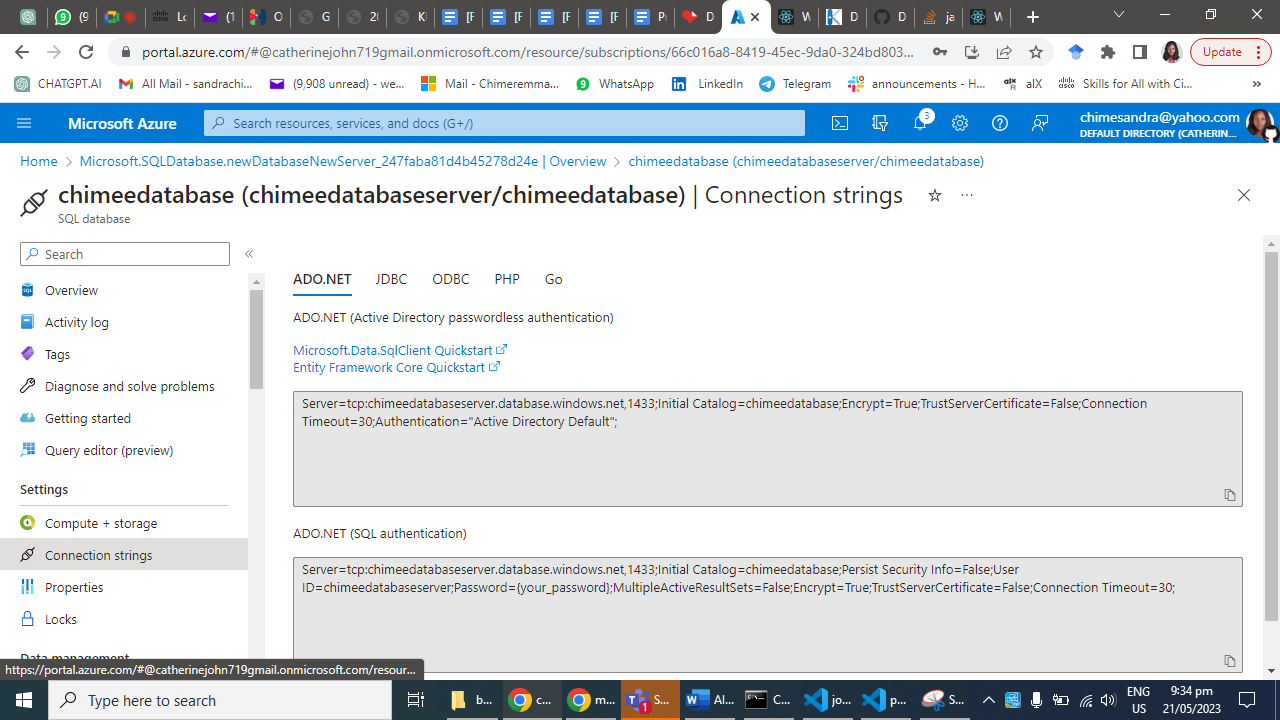
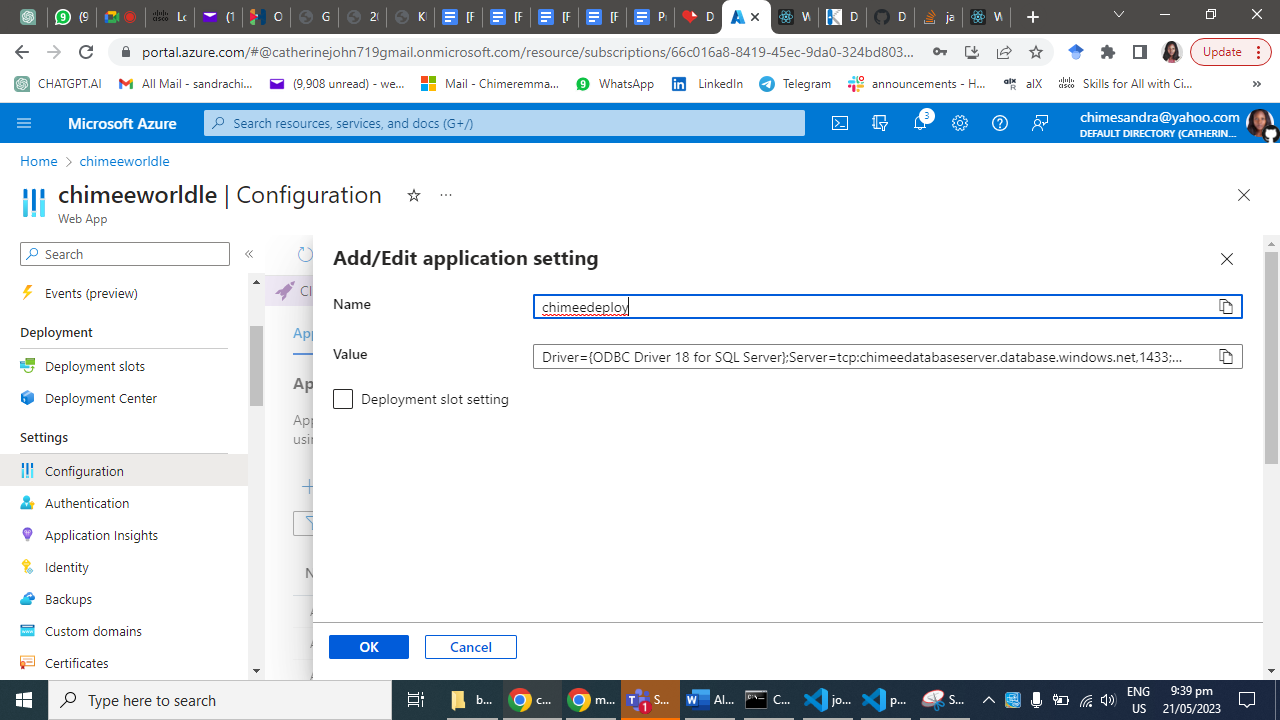
Add a new connection string by clicking on the "New connection string" button.
Enter a name for the connection string and select the SQL database provider.
Provide the necessary details, including the server name, database name, username, and password.
Click "OK" to save the connection string.
Step 4: Deploy the Node.js Web App to Azure
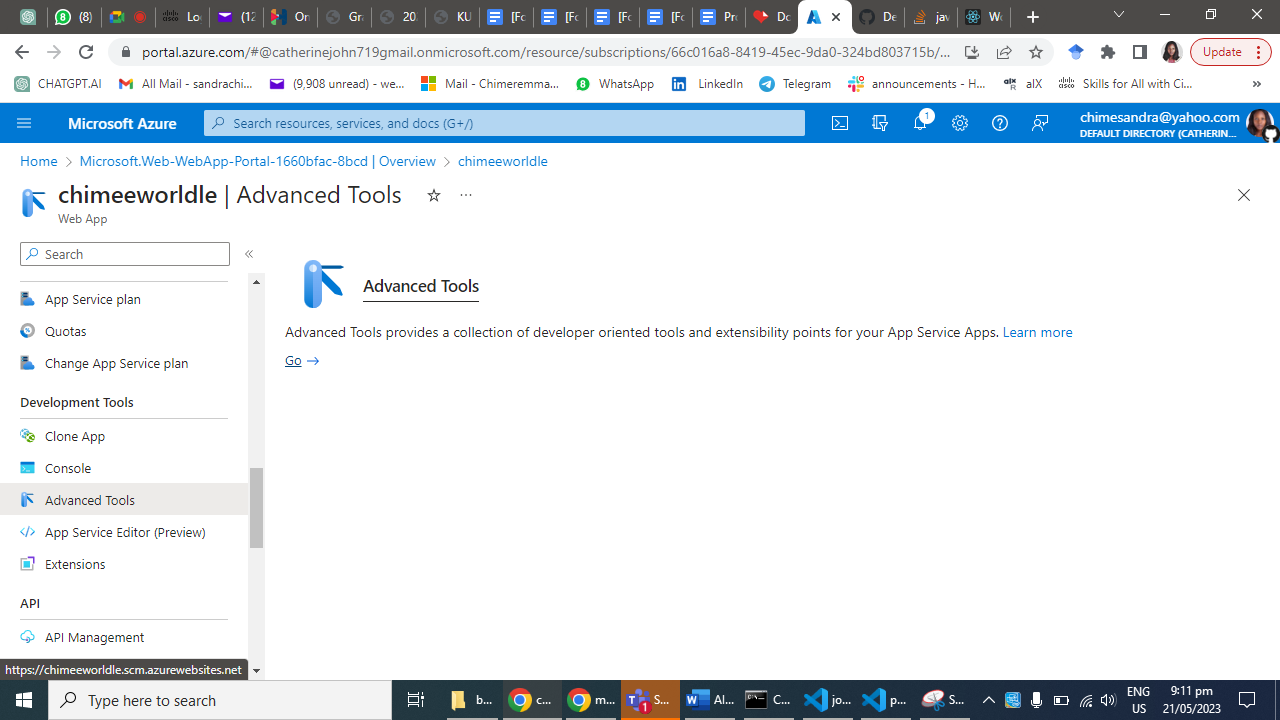
In the Azure portal, navigate to your App Service's "Overview" page.
Under "Deployment," select "Deployment Center."
Choose the deployment method that suits your project (e.g., Local Git, GitHub, Bitbucket, etc.).
Follow the instructions to link your repository and configure the deployment settings.
Once configured, trigger a deployment to deploy your Node.js web app to Azure.
Step 5: Verify and Test
Once the deployment is complete, navigate to your Azure App Service's URL.
Test your web app's functionality and ensure that it connects to the SQL database successfully.
Monitor the application's logs and Azure portal's metrics to ensure everything is running smoothly.
Conclusion:
In Summary, we have explored the process of linking and deploying a Node.js web app to Azure App Services and connecting it to an SQL database. By following these steps, you can take advantage of Azure's robust infrastructure and scalability, allowing you to focus on building and maintaining your application without worrying about the underlying infrastructure. | chymee | |
1,475,853 | How to Install PrivateGPT - Local Document Question Answering with Privacy | How to Install PrivateGPT - Local Document Question Answering with Privacy There's something new in... | 0 | 2023-05-22T03:12:21 | https://dev.to/digital-nomad/how-to-install-privategpt-local-document-question-answering-with-privacy-5fka | ai, openai, chatgpt, tutorial | How to Install PrivateGPT - Local Document Question Answering with Privacy
There's something new in the AI space, in this post, we will walk you through the process of installing and setting up PrivateGPT.
What is it
A powerful tool that allows you to query documents locally without the need for an internet connection. Whether you're a researcher, dev, or just curious about exploring document querying tools, PrivateGPT provides an efficient and secure solution. This tutorial accompanies a Youtube video, where you can find a step-by-step demonstration of the installation process!
Prerequisites:
- Python 3.10 or later installed on your system or virtual env
- Basic knowledge of using the command line Interface (CLI/Terminal)
- Git installed
You can create a folder on your desktop. In the screenshot below you can see I created a folder called 'blog_projects'. Open the command line from that folder or navigate to that folder using the terminal/ Command Line. Follow the steps below to create a virtual environment.

**First, let's create a virtual environment.**
Create a virtual environment:
Open your terminal and navigate to the desired directory.
Run the following command to create a virtual environment (replace myenv with your preferred name):
python3 -m venv myenv
The name of your virtual environment will be 'myenv'
Activate the virtual environment:
On macOS and Linux, use the following command:
source myenv/bin/activate
On Windows, use the following command:
myenv\Scripts\activate
Run the git clone command to clone the repository:
git clone https://github.com/imartinez/privateGPT.git
By creating and activating the virtual environment before cloning the repository, we ensure that the project dependencies will be installed and managed within this environment. This helps maintain a clean and isolated development environment specific to this project.
After cloning the repository, you can proceed to install the project dependencies and start working on the project within the activated virtual environment.
Then copy the code repo from Github, and go into your directory or folder where you want your project to live. Open the terminal or navigate to your folder from the command line.
Once everything loads, you can run the install requirements command to install the needed dependencies.
Navigate to the directory where you want to install PrivateGPT.
CD <FOLDER NAME>
Run the following command to install the required dependencies:
pip install -r requirements.txt
Next, download the LLM model and place it in a directory of your choice. The default model is 'ggml-gpt4all-j-v1.3-groovy.bin,' but if you prefer a different GPT4All-J compatible model, you can download it and reference it in your .env file.
Rename the 'example.env' file to '.env' and edit the variables appropriately.
Set the 'MODEL_TYPE' variable to either 'LlamaCpp' or 'GPT4All,' depending on the model you're using.
Set the 'PERSIST_DIRECTORY' variable to the folder where you want your vector store to be stored.
Set the 'MODEL_PATH' variable to the path of your GPT4All or LlamaCpp supported LLM model.
Set the 'MODEL_N_CTX' variable to the maximum token limit for the LLM model.
Set the 'EMBEDDINGS_MODEL_NAME' variable to the SentenceTransformers embeddings model name (refer to https://www.sbert.net/docs/pretrained_models.html).
Make sure you create a models folder in your project to place the model you downloaded.
PrivateGPT comes with a sample dataset that uses a 'state of the union transcript' as an example. However, you can also ingest your own dataset. Let me show you how."
Put all your files into the 'source_documents' directory.
Make sure your files have one of the supported extensions: CSV, Word Document (docx, doc), EverNote (enex), Email (eml), EPub (epub), HTML File (html), Markdown (md), Outlook Message (msg), Open Document Text (odt), Portable Document Format (PDF), PowerPoint Document (pptx, ppt), Text file (txt).
Run the following command to ingest all the data:
python ingest.py
Perfect! The data ingestion process is complete. Now, let's move on to the next step!
------- ------ ------- ------- ------- --------------------if you have this error: cannot import name 'DEFAULT_CIPHERS' from 'urllib3.util.ssl_' use this command: python -m pip install requests "urllib3<2"
[ Key thing to mention, IF YOU ADD NEW DOCUMENTS TO YOUR SOURCE_DOCS you need to rerun ‘python ingest.py’
---------------------------------------------------------------
Asking Questions to Your Documents Host: Now comes the exciting part—asking questions to your documents using PrivateGPT. Let me show you how it's done.
Open your terminal or command prompt.
Navigate to the directory where you installed PrivateGPT.
[ project directory 'privateGPT' , if you type ls in your CLI you will see the READ.ME file, among a few files.]
Run the following command:
python privateGPT.py
Wait for the script to prompt you for input.
When prompted, enter your question!
Tricks and tips:
Use python privategpt.py -s [ to remove the sources from your output. So instead of displaying the answer and the source it will only display the source ]
On line 33, at the end of the command where you see’ verbose=false, ‘ enter ‘n threads=16’ which will use more power to generate text at a faster rate!
Pros & Cons
Great for anyone who wants to understand complex documents on their local computer.
Great for private data you don't want to leak out externally.
Particularly great for students, people new to an industry, anyone learning about taxes, or anyone learning anything complicated that they need help understanding.
The wait time can be 30-50 seconds or maybe even longer because you’re running it on your local computer.
END OF BLOG - how to install privateGPT & query documents locally and private
LETS CONNECT!!
Follow me on: Twitter, [Linkedin,](https://www.linkedin.com/in/olu-a/) Medium and AIapplicationsblog.com
Prepare for your next job application with — [Cover Letter Generator!](http://coverletterbuilder.up.railway.app/)
| digital-nomad |
1,475,911 | The risk of Open Source vs. proprietary 3rd party libraries | Using 3rd party libraries is a risky business. Both if they are proprietary and if they are open source. | 20,858 | 2023-05-22T04:45:57 | https://dev.to/szabgab/the-risk-of-open-source-vs-proprietary-3rd-party-libraries-2dfb | opensource, programming, discuss, business | ---
title: The risk of Open Source vs. proprietary 3rd party libraries
published: true
description: Using 3rd party libraries is a risky business. Both if they are proprietary and if they are open source.
tags: opensource, programming, discuss, business
series: opensource
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 for best results.
# published_at: 2023-05-21 07:38 +0000
---
Using 3rd party libraries always have risks. If you buy them from a company you might have the fuzzy feeling that you will be supported no matter what. However, at the end if the supplier company goes out of business, decides to discontinue the project, or just does not have the bandwidth to provide prompt service you are out of luck.
If this is a security issue and you don't get prompt fix for it, you are at a risk. If the problem is "just" a serious flaw in the software, you don't have any control over how fast you will get a fix.
You might have legal options, but do you as a CTO, a tech lead, or a developer want to wait till the legal options bear fruit? Probably not.
Using Open Source will not give you that fuzzy feeling, but it will give you controls. You can fix any problem yourself or you can hire someone to do it for you. Open Source has its own risks that I'll discuss in another post, but here are a few.
## Legal
* Does the package have an open source license compatible with the way you will want to use it?
* Does the package contain code that comes from other source that might not be open source or might have different licenses?
## Technical
* Do you really have access to the latest source code?
* Is it written in a language that you are familiar with?
* Does it have a good test coverage? Do you have access to it? Do you know how to run it?
* How many people maintain the project? How many people are familiar with the code-base?
* Does the project have an up-to-date public VCS?
* When was the last change recorded?
* How many open issues are there?
* How many open Pull-Request are there?
* How fast are PRs and Issues addressed?
* What is the complexity of the code?
## Do open source projects have more risk factors?
Seeing the above list one might think that Open Source have more risk factors, but in reality proprietary packages have similar risk-factors, but they are hidden from you and in most cases you cannot alleviate them.
## What do you think?
* What other risk factors do you see?
| szabgab |
1,476,518 | Fakta Menarik Honda PCX: Skutik Modern Terbaik di Indonesia | Apabila Anda mencari skutik modern yang andal dan elegan, maka Honda PCX bisa menjadi pilihan yang... | 0 | 2023-05-22T15:49:14 | https://dev.to/agnesolivo-leavime/fakta-menarik-honda-pcx-skutik-modern-terbaik-di-indonesia-25o2 | tutorial, python, javascript, devops |

Apabila Anda mencari skutik modern yang andal dan elegan, maka [Honda PCX](https://www.leavime.com) bisa menjadi pilihan yang tepat. Motor ini telah terbukti menjadi salah satu skutik terbaik di pasar Indonesia, dengan desain yang menawan dan teknologi canggih yang akan membuat pengalaman berkendara Anda lebih menyenangkan.
**Pengenalan Honda PCX
**
Honda PCX adalah skutik premium yang pertama kali diperkenalkan di Jepang pada tahun 2009. Kemudian, pada tahun 2010, Honda memperkenalkan motor ini di Indonesia dengan dua varian mesin, yaitu 125cc dan 150cc. Dalam beberapa tahun terakhir, Honda PCX semakin populer di Indonesia dan menjadi salah satu motor terlaris di pasar skutik premium.
Berikut ini adalah beberapa fitur utama Honda PCX yang membuatnya menjadi pilihan yang populer di kalangan konsumen Indonesia:
**Desain modern dan elegan**
- Mesin yang bertenaga dan ramah lingkungan
- Fitur keamanan dan kenyamanan yang canggih
- Performa yang andal dan mudah dikendalikan
**[Keunggulan Honda PCX](https://www.leavime.com)
**
Honda PCX menawarkan banyak keunggulan yang membuatnya menjadi salah satu skutik premium terbaik di Indonesia. Berikut ini adalah beberapa keunggulan yang dapat Anda nikmati jika membeli Honda PCX:
**Desain Elegan dan Modern**
Honda PCX menawarkan desain yang elegan dan modern, dengan balutan bodi yang ramping dan aerodinamis. Motor ini memiliki lampu depan LED yang tajam dan futuristik, serta lampu belakang yang dilengkapi dengan fitur stop lamp dan sein LED. Selain itu, Honda PCX juga dilengkapi dengan kunci kontak tanpa kunci yang sangat praktis dan mudah digunakan.
**Mesin Bertenaga dan Ramah Lingkungan**
Honda PCX memiliki mesin yang bertenaga dan efisien, dengan dua pilihan kapasitas mesin yaitu 125cc dan 150cc. Mesin ini dilengkapi dengan teknologi PGM-FI yang canggih, yang memastikan pembakaran bahan bakar yang lebih efisien dan ramah lingkungan. Selain itu, Honda PCX juga dilengkapi dengan transmisi otomatis yang sangat mudah digunakan.
**Fitur Keamanan dan Kenyamanan Canggih**
Honda PCX menawarkan banyak fitur keamanan dan kenyamanan yang canggih, seperti rem cakram dengan sistem ABS, suspensi depan teleskopik, dan suspensi belakang ganda yang membuat pengendara merasa nyaman saat berkendara. Selain itu, motor ini juga dilengkapi dengan fitur parkir otomatis dan kunci pengaman ganda untuk menjaga keamanan motor Anda.
**Performa Andal dan Mudah Dikendalikan**
Honda PCX memiliki performa yang andal dan mudah dikendalikan, dengan akselerasi yang responsif dan tenaga yang kuat. Motor ini juga dilengkapi dengan sistem pengereman yang responsif dan mudah dikendalikan, sehingga membuat pengendara merasa lebih aman dan percaya diri saat berkendara.
**Harga Terjangkau**
Meskipun Honda PCX memiliki banyak fitur dan teknologi canggih, motor ini tetap memiliki harga yang terjangkau untuk kelasnya. Dengan harga yang kompetitif, Honda PCX bisa menjadi alternatif yang menarik bagi konsumen yang mencari skutik premium dengan kualitas yang baik.
**FAQ Tentang Honda PCX**
Berikut ini adalah beberapa pertanyaan umum tentang Honda PCX beserta jawabannya:
- Apa perbedaan antara Honda PCX 125cc dan 150cc?
- Perbedaan utama antara Honda PCX 125cc dan 150cc adalah kapasitas mesinnya. Mesin Honda PCX 150cc lebih besar dan bertenaga daripada mesin 125cc.
- Apakah Honda PCX dilengkapi dengan teknologi PGM-FI?
- Ya, Honda PCX dilengkapi dengan teknologi PGM-FI yang canggih untuk pembakaran bahan bakar yang lebih efisien dan ramah lingkungan.
- Apakah Honda PCX memiliki sistem pengereman ABS?
- Ya, Honda PCX dilengkapi dengan sistem pengereman ABS yang canggih untuk meningkatkan keamanan pengendara.
- Apakah Honda PCX cocok untuk pengendara pemula?
- Ya, Honda PCX sangat cocok untuk pengendara pemula karena memiliki performa yang mudah dikendalikan dan fitur keamanan yang canggih.
- Berapa harga Honda PCX di Indonesia?
- Harga Honda PCX di Indonesia bervariasi tergantung pada varian dan spesifikasi motor. Namun, secara umum harga Honda PCX di Indonesia berkisar antara Rp 30 juta hingga Rp 40 juta.
- Apakah Honda PCX memiliki garansi?
- Ya, Honda PCX dilengkapi dengan garansi resmi dari pabrik untuk menjamin kualitas dan keandalan motor.
**Kesimpulan**
Honda PCX adalah skutik premium yang menawarkan banyak fitur dan teknologi canggih, serta desain yang elegan dan modern. Motor ini cocok untuk pengendara pemula maupun berpengalaman, dan memiliki performa yang andal dan mudah dikendalikan. Dengan harga yang terjangkau dan garansi resmi dari pabrik, Honda PCX bisa menjadi alternatif yang menarik bagi konsumen yang mencari skutik premium dengan kualitas yang baik.
kunjungi web berikut :
• [Leavime](https://www.leavime.com)
• [Money Info](https://moneyinfo.site)
• [Glass Styles](https://www.glassstyles.eu.org)
• [Pic Wallpapper](https://www.picwallpapper.eu.org)
• [News Goods Tee](https://newsgoodstee.com)
• [KUKOH](https://www.kukoh.com)
• [Bosz Desa](https://www.boszdesa.com)
• [Creative Maju](https://www.creativemaju.com)
• [Luincah](https://www.luincah.com)
• [Koplexs Studio](https://koplexsstudio.com)
• [Rita Movie](https://ritamovie.xyz)
• [Countena](https://www.countena.com)
Please support me. Thank You.
| agnesolivo-leavime |
1,475,963 | Surf the Web with Lightning Speed | Fast and reliable internet is no longer a luxury, but a necessity in today's digital age. With a... | 0 | 2023-05-22T06:59:46 | https://dev.to/oliver2232/surf-the-web-with-lightning-speed-d7h | Fast and reliable internet is no longer a luxury, but a necessity in today's digital age. With a diverse range of internet packages, you can choose the perfect plan tailored to your needs, ensuring a seamless online experience. Whether you're a casual web surfer, a streaming enthusiast, or a professional relying on a stable connection, [latest packages](https://latestpackages.com/) offer blazing-fast speeds that will keep you connected, productive, and entertained. Say goodbye to buffering and hello to uninterrupted browsing, streaming, and gaming with our top-notch internet packages | oliver2232 | |
1,476,038 | How to return JSON response on API routes in Laravel | If you work with Laravel, you could have found yourself in a situation where you have written your... | 0 | 2023-05-22T08:19:45 | https://dev.to/onabright/how-to-return-json-response-on-api-routes-in-laravel-1cga | tutorial, laravel, api, webdev | If you work with Laravel, you could have found yourself in a situation where you have written your API Controllers, set up your API routes and setup authentication (for example, using Sanctum) to protect your routes from unauthorized access.
You then try to access a protected route through a browser which will return something like this:
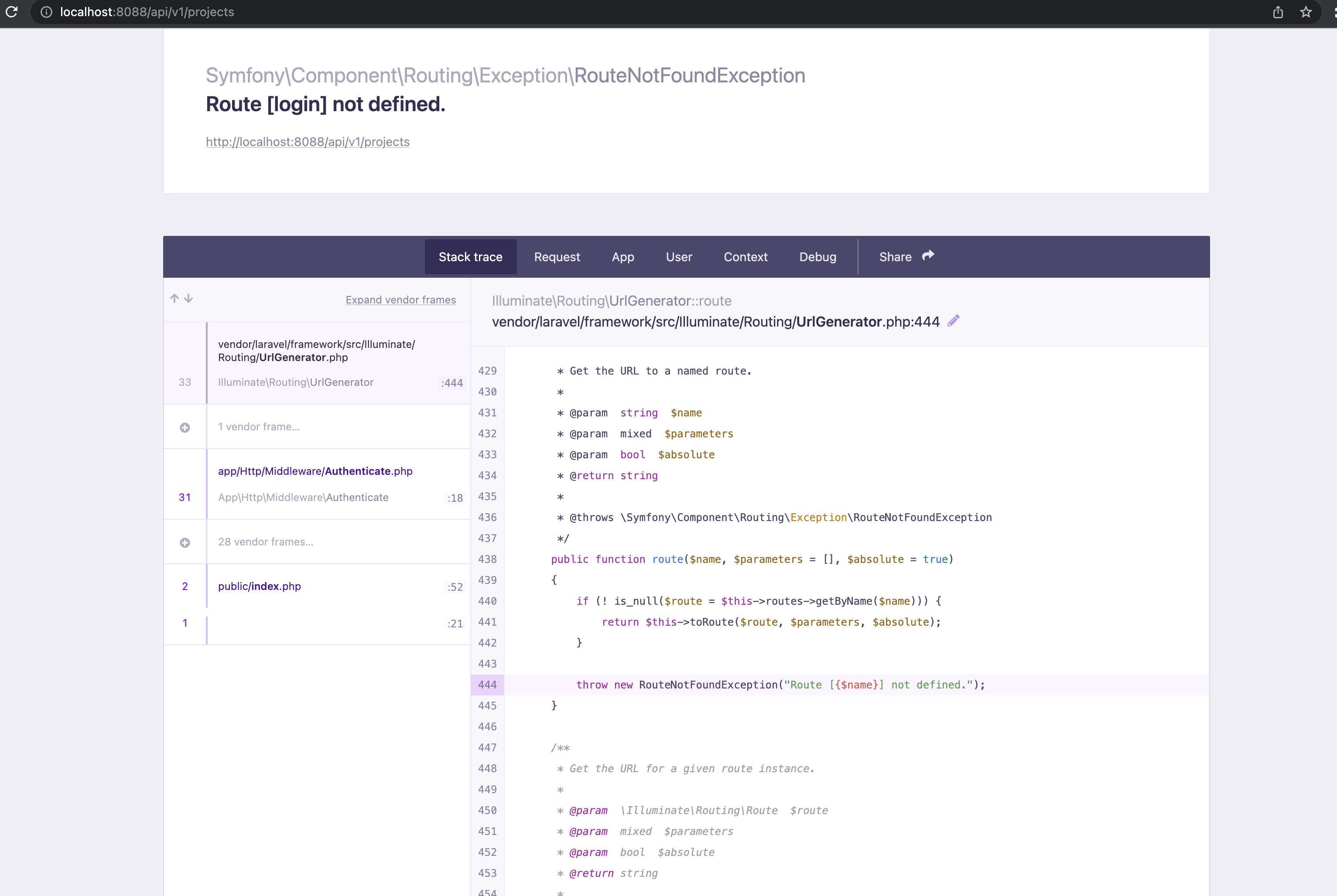
First of all this is a good thing because it means your API route is protected and can only be accessed by authenticated users. However, it doesn't look pretty at all.
By default, Laravel returns header responses in HTML format.
If you access the API route/endpoint using an API testing tool like Postman, Fiddler, RESTer, etc., you could easily update the Header by adding an entry called `Accept` and setting it to `application/json`. This would display a 'graceful' json response instead of HTML.
To change this default behaviour programmatically, we would want Laravel to return a json response telling the user that they are unauthenticated. How do we achieve this? It is actually pretty simple to do. Let's see how.
## 1. Create a Custom Middleware
Using the Artisan CLI, create the middleware like this:
```php
php artisan make:middleware ReturnJsonResponseMiddleware
```
Open the middleware file located in App\Http\Middleware.
Update the handle method to look like this:
```php
public function handle(Request $request, Closure $next)
{
$request->headers->set('Accept', 'application/json');
return $next($request);
}
```
What this does is that it sets the header to accept and return a json response.
## 2. Publish the Custom Middleware
To do this, we need to add our middleware to the Laravel Kernel under the application's global HTTP middleware stack.
To do this, open` Kernel.php` in App\Http and add the custom middleware class:
```php
protected $middleware = [
...
\App\Http\Middleware\ReturnJsonResponseMiddleware::class, //return graceful unauthenticated message
];
```
That's it! Now when a user tries to access a protect API route through the browser, they will get a json response:
```php
{
message: "Unauthenticated"
}
```
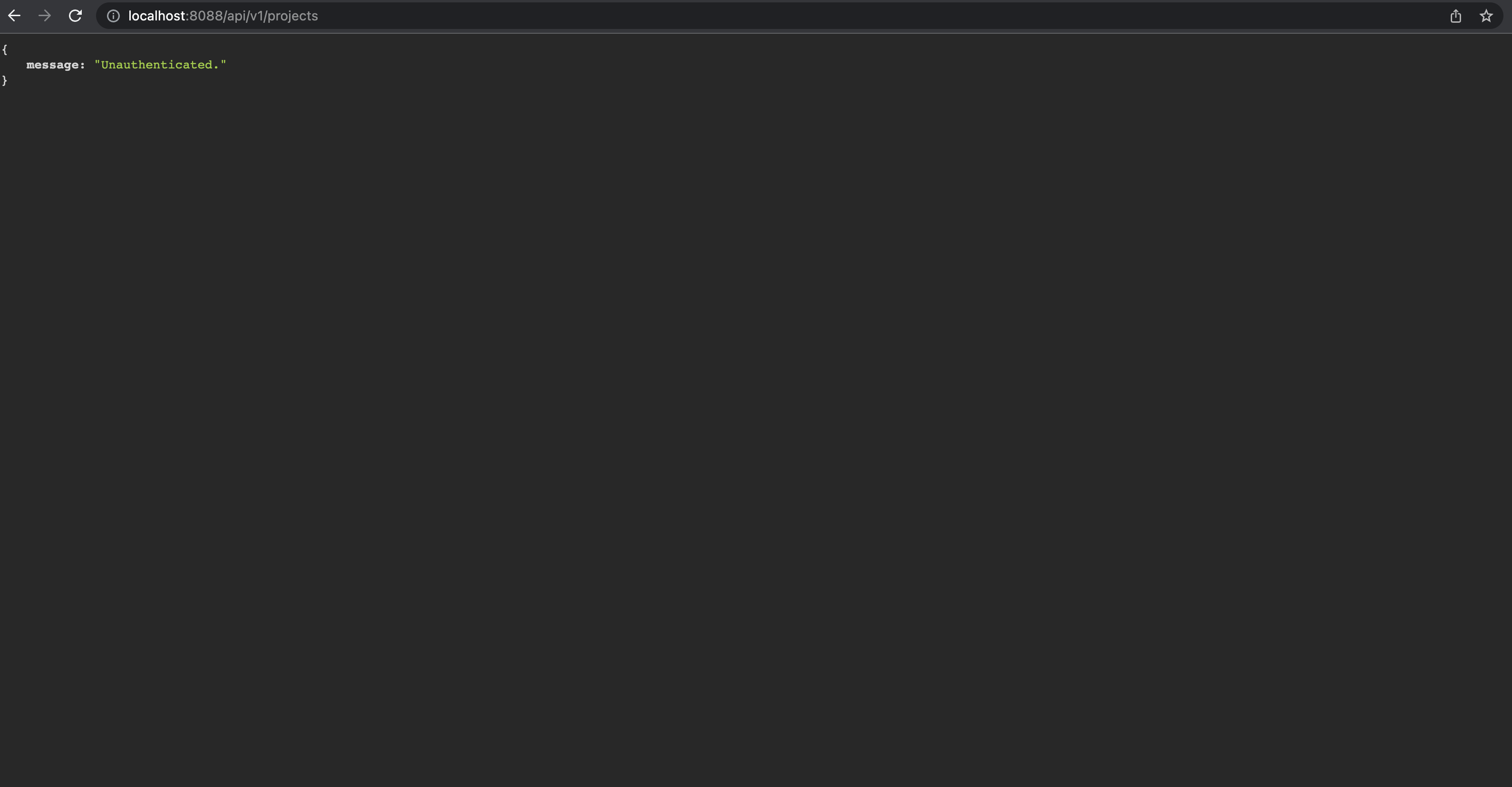
I hope this was helpful. | onabright |
1,476,044 | Healthcare Mobile App Development | Boost your business in the #healthcare industry with our top-notch #AppDevelopmentServices! Stay... | 0 | 2023-05-22T07:57:41 | https://dev.to/ryanhen36617931/healthcare-mobile-app-development-3bp4 | healthcaremobileappdevelopment, healthcareappdevelopment | Boost your business in the #healthcare industry with our top-notch #AppDevelopmentServices! Stay ahead of the competition and provide efficient healthcare
solutions to your customers. Contact us today to transform your ideas into reality!
Visit: https://www.uplogictech.com/healthcare-mobile-app-development-company

 | ryanhen36617931 |
1,476,174 | 5 soft skills for developers | Soft skills are essential for developers, as they complement technical expertise and contribute to... | 0 | 2023-05-22T10:37:57 | https://dev.to/rafikadir/5-soft-skills-for-developers-41lm | webdev, coding, programming, frontend | Soft skills are essential for developers, as they complement technical expertise and contribute to effective collaboration, communication, and overall professional success. Here are some important soft skills for developers:
**Communication:** For developers, being able to communicate clearly is essential. Both technical and non-technical stakeholders require the capacity to communicate ideas coherently, actively listen to others, and understand technical knowledge.
**Collaboration:** Developers often work in teams, so strong collaboration skills are vital. This includes the ability to work well with others, contribute to discussions, share knowledge, and resolve conflicts constructively.
**Time management:** Developers often face multiple tasks and deadlines. Effective time management skills help them prioritize tasks, meet deadlines, and maintain productivity without compromising quality.
**Adaptability:** Since technology is a sector that is continuously changing, developers must be able to evolve with it. The ability to quickly adapt to altering goals, embrace new approaches, and be open to learning new technology are all desirable qualities.
**Continuous learning:** The technology landscape evolves rapidly, so developers must be committed to continuous learning. Staying up-to-date with new technologies, frameworks, and industry trends ensures professional growth and enhances problem-solving abilities.
----
👉 Get Frontend tips tricks on **Instagram**: [Rafi kadir](https://www.instagram.com/i_am_rafikadir/)
👉 Connect on **Linkedin** : [Rafi kadir](https://www.linkedin.com/in/rafikadir/) | rafikadir |
1,476,533 | 🌈 A One Person Startup Tech Stack for Ninja Developers - Next.js, Django, Kubernetes, and GCP 🚀 | Introduction In this article, I will share the tech stack I used to build my startup,... | 0 | 2023-05-22T16:17:30 | https://dev.to/chetanam/a-one-person-startup-tech-stack-nextjs-django-kubernetes-and-gcp-k62 | webdev, javascript, startup, python |

## Introduction
In this article, I will share the tech stack I used to build my startup, Omkar. My startup consists of several components, including Frontend, Backend, Blog.
By learning about my tech stack, you can gain insights that will assist you in selecting the tech stack for your startup.
## My Application Omkar Cloud
My Application Omkar Cloud is a full stack website with a Blog, developed using technologies like Django, Next.js, and Kubernetes
It is a People Search Engine that you can use, for example, to find people working in a company or CEOs of companies in an industry. Think of it as an advanced version of LinkedIn Search.
## Tech Stack of Omkar Cloud
The Most Important Technologies in my Tech Stack are Kubernetes, GCP, Elastic UI, Next.js, GitHub Actions, and Django.
Here is a breakdown of my Tech Stack
### Frontend**
For the Frontend I have used Elastic UI, React and Next.js
**Elastic UI**
I have used many Component Libraries in the past, such as Bootstrap and Material UI. However, based on my experience, I have found the Component Library of Elastic UI to be particularly impressive. Elastic UI is really beautiful Component Library.
Therefore, I have chosen Elastic UI as my UI framework
**React**
Also, I had learnt two frameworks to create websites which are Svelte and React.
I wanted to use Svelte as it is much more concise than React. However, since the Elastic UI Library was not available for Svelte, I had no choice but to choose React as the only option available to me.
**Next.js**
Next.js is a framework built on top of React.
I think of Next.js as a framework for a framework 😂.
Next.js simplifies the usage of React and provides additional features. Therefore, instead of using the bare create-react-app setup, I opted to use Next.js as it makes working with React much easier
### Backend
For the Backend I used Django powered by SQLite Database
**Django**
I have learned various backend frameworks such as Express.js and Nest.js, but Django stood out as my favorite.
When working with Django, I found that I could accomplish tasks with significantly fewer lines of code compared to Nest.js or Express.js.
Django's conciseness is similar to Sanskrit Language, in Sanskrit you can convey your thoughts in very fewer words compared to English or Hindi Language.
Hence, I chose Django for its conciseness and simplicity.
**SQLite**
For the database, I had the option of using either SQLite or PostgreSQL. I opted for SQLite due to several reasons.
- Most Importantly for me as an Indian is that it is SQLite is cheaper than PostgreSQL since in SQLite there is no need to purchase a separate server.
- It allows developers to start developing faster since PostgreSQL requires spinning up a server, whereas SQLite is file-based
- It is easier to view table contents using SQLite Browser application in SQLite compared to PostgreSQL
Although, it can be argued that PostgreSQL is more Scalable but for a Start Up, SQLite does the Job Perfectly. Also, in future you can always migrate to PostgreSQL if necessary.
### Blog
To create the blog for my website, I utilized the tailwind-nextjs-starter-blog developed by Timothy Lin. It is a beautiful blogging platform built on Next.js.
### Deployment
For deployment, I used Kubernetes, GitHub Actions, and Google Cloud Platform (GCP).
**Kubernetes**
I wanted to host the frontend, backend, and blog on a single domain, namely '**[www.omkar.cloud](http://www.omkar.cloud/)**' **at different paths**. Additionally, I needed to store the SQLite database file in storage.
Kubernetes provided a convenient method for orchestrating these needs. So, I used Kubernetes.
**GitHub Actions**
To automate the deployment process, I utilized GitHub Actions. With this setup, I could easily deploy a new version of my application by simply pushing the code to the master branch.
**GCP**
I chose GCP as the platform to run my entire Kubernetes stack. Google products have a reputation for quality, and GCP proved to be reliable and suitable for my needs. It costs me 2900 INR or $35 per month to run my full Stack.
### Other Tools
**Google Analytics.**
I used Google Analytics to track my website as It was the analytics software I was most familiar with.
**G Suite**
For creating a professional email address like **`info@omkar.cloud`**, I utilized G Suite. I opted for G Suite due to my familiarity with the Gmail interface and my resistance to change.
**Google Search Console**
I utilized Google Search Console to monitor the search ranking of my website, omkar.cloud, on Google.
**NameCheap**
I used **NameCheap** for buying domain name of omkar.cloud. I was satisfied with Name Cheap’s services.
## Final Thoughts
In short, I used the following technologies in my tech stack for **[omkar.cloud](http://www.omkar.cloud/)**:
Frontend:
- Elastic UI
- React
- Next.js
Backend:
- Django
- SQLite
Blog:
- tailwind-nextjs-starter-blog
Deployment:
- Kubernetes
- GitHub Actions
- Google Cloud Platform (GCP)
Other Tools:
- Google Analytics
- G Suite
- Google Search Console
- NameCheap
Overall, I am very satisfied with the tech stack of **[omkar.cloud](http://www.omkar.cloud/)**.
If you are creating a startup and considering the tech stack to use, based on my experience, I can confidently say that if you base your tech stack on mine, you will have a solid technological foundation for your startup.
I am curious to hear if you have any questions regarding the tech stack, so please feel free to ask in the comments.
Dhanyawad 🙏 | chetanam |
1,476,196 | Journey to Mastery: Completing the FreeCodeCamp JavaScript Algorithms and Data Structures Certification | FreeCodeCamp JavaScript Algorithms and Data Structures Certification. This comprehensive... | 0 | 2023-05-22T11:20:47 | https://dev.to/xmohammedawad/journey-to-mastery-completing-the-freecodecamp-javascript-algorithms-and-data-structures-certification-8jj | javascript, algorithms, webdev, coding | ### FreeCodeCamp JavaScript Algorithms and Data Structures Certification.
This comprehensive certification program provided me with a solid foundation in JavaScript programming, covering a wide range of concepts, algorithms, and data structures. In this article,
I will share my journey and the key learnings gained from each section of the certification.
#### Basic JavaScript:
The first step of the certification introduced me to the fundamental programming concepts in JavaScript. From numbers and strings to arrays, objects, loops, and conditional statements, I gained a deep understanding of how to work with basic data structures and control flow.
#### ES6:
As JavaScript constantly evolves, familiarity with the latest standards is crucial. The ES6 section delved into the new features introduced in ECMAScript 6, including arrow functions, destructuring, classes, promises, and modules. Learning these modern JavaScript techniques enabled me to write cleaner and more efficient code.
#### Regular Expressions:
Regular expressions, or regex, are powerful patterns used to match, search, and manipulate text. Through this section, I acquired the skills to construct complex regex patterns, leverage positive and negative lookaheads, and utilize capture groups. Regex opened up new possibilities for text processing and data manipulation.
#### Debugging:
A key skill for any developer is the ability to debug code effectively. The debugging section taught me how to utilize the JavaScript console to identify and resolve issues. I learned techniques to tackle syntax errors, runtime errors, and logical errors, ensuring my code operates as intended.
#### Basic Data Structures:
Understanding different data structures and knowing when to use them is crucial in programming. This section expanded my knowledge of arrays and objects, exploring their properties, methods, and manipulation techniques. I also learned about essential array methods like splice() and Object.keys() to efficiently work with data.
#### Basic Algorithm Scripting:
Algorithms form the backbone of programming, enabling efficient problem-solving. This section honed my algorithmic thinking skills by challenging me to solve various coding problems. From converting temperatures to handling complex 2D arrays, I gained confidence in breaking down problems into smaller parts and implementing effective solutions.
#### Object-Oriented Programming:
Object-Oriented Programming (OOP) is a popular approach to software development. Here, I delved into the principles of OOP in JavaScript, including objects, classes, prototypes, and inheritance. This knowledge empowered me to design and implement more organized and reusable code structures.
#### Functional Programming:
Functional Programming (FP) is another paradigm that promotes modular and reusable code. In this section, I learned about pure functions, avoiding mutations, and leveraging higher-order functions like map() and filter(). Functional programming concepts helped me write cleaner, more maintainable code.
#### The Projects:
To demonstrate my proficiency, I completed `21 intermediate algorithm` challenges and worked on `5 advanced projects`. These projects provided hands-on experience in solving real-world problems using JavaScript. By applying the concepts I learned, I gained confidence in tackling complex coding challenges and developing robust solutions.
#### Conclusion:
Completing the FreeCodeCamp JavaScript Algorithms and Data Structures Certification has been a transformative experience. I have not only deepened my understanding of JavaScript but also sharpened my problem-solving and critical-thinking skills. The certification journey has equipped me with a solid foundation to take on more significant coding projects and further advance my career as a JavaScript developer. I am excited to apply my newfound knowledge and continue exploring the vast world of JavaScript programming. | xmohammedawad |
1,476,337 | Deploy your React, NodeJS apps using Jenkins Pipeline | 🚀 As we are working on our Open Source Project named NoMise which is being built using ReactJs,... | 0 | 2023-05-24T14:43:52 | https://dev.to/lovepreetsingh/deploy-your-react-nodejs-apps-using-jenkins-pipeline-22pl | jenkins, development, programming, node | 🚀 As we are working on our Open Source Project named [NoMise](https://github.com/AlphaDecodeX/NoMise_Store) which is being built using ReactJs, Typescript and TailwindCss. When it comes to deployment we have several options:-
- Easy Deploy using providers like Vercel or Netlify where you have to drag and drop your code repository
- Deploy your code in Docker container and run that container in a cloud server
- Setup a CI/CD (Continuos Integration, Continuos delivery) Pipeline to deploy your App
Which one you'll choose?

😎 Obviously one should go with third because of its benefits. Once you have setuped your pipeline for the deployment, you don't need to build, deploy to container and host in cloud again and again. With one click, your code will build, containerized in a docker container and deployed to cloud (AWS EC2 instance in our case).
✨ If you haven't understood, Don't worry we will go step by step.
## 📍Introduction
First things first, what is jenkins, ci/cd pipeline and ec2 instance that we talked about above.
- Jenkins is a tool that make our life easier with deployments and running some automated tests like to deploy manually you first need to run ```npm run build``` then copy the build folder and containerize it and then serve it on a server. It can all be done by a set of actions that jenkins provide.
- ci/cd pipeline is continuos integration and continuos delivery which means code can be directly picked from a repository and after some tests run it will be deployed on the server
- EC2 is nothing but a computer at the end which is provided to you as a server to which we can SSH and run our scripts, code etc.

Note:- Those who are thinking that AWS is paid, yes it is but with free tier you can explore many things.
## 📌 Launching AWS EC2 instances
1. Go to AWS and signup for your new account and add a Debit/Credit card. For safety add with minimum balance if you don't want to spend over the free limit.
2. Search for EC2 and launch instances
3. Select Default settings and launch 3 instances because
- one we'll use to install jenkins
- second we'll install ansible server which will dockerise the build code that we'll get from the jenkins over SSH
- third instance will run a docker container that will be served to the public to access
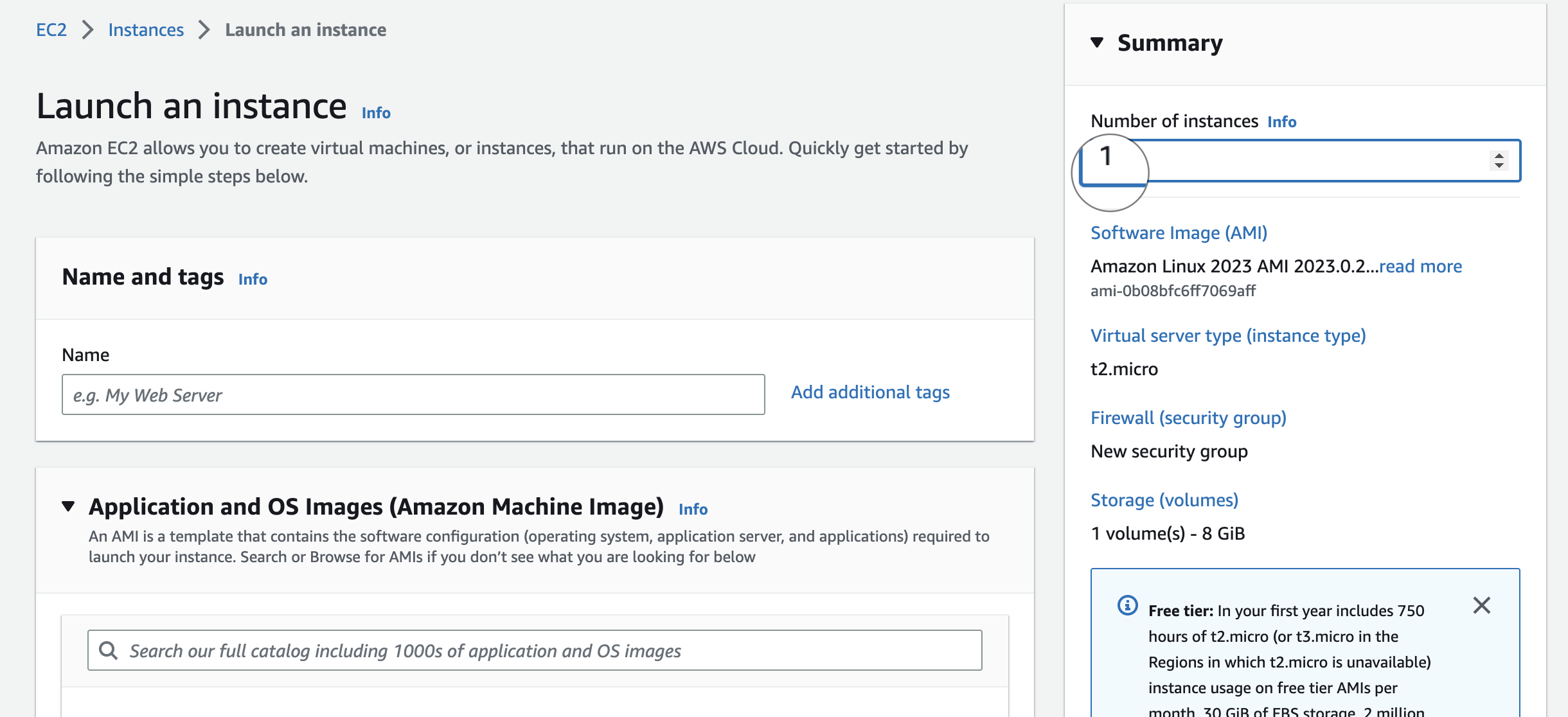
Note:- Write three to launch 3 instances
4. Now, we'll add some security rules to our instances because to access these instances/servers some request or ssh will be made. So, it will not allow every request who is coming to access them.
5. To Add security rules, click on security group and edit inbound rules:-
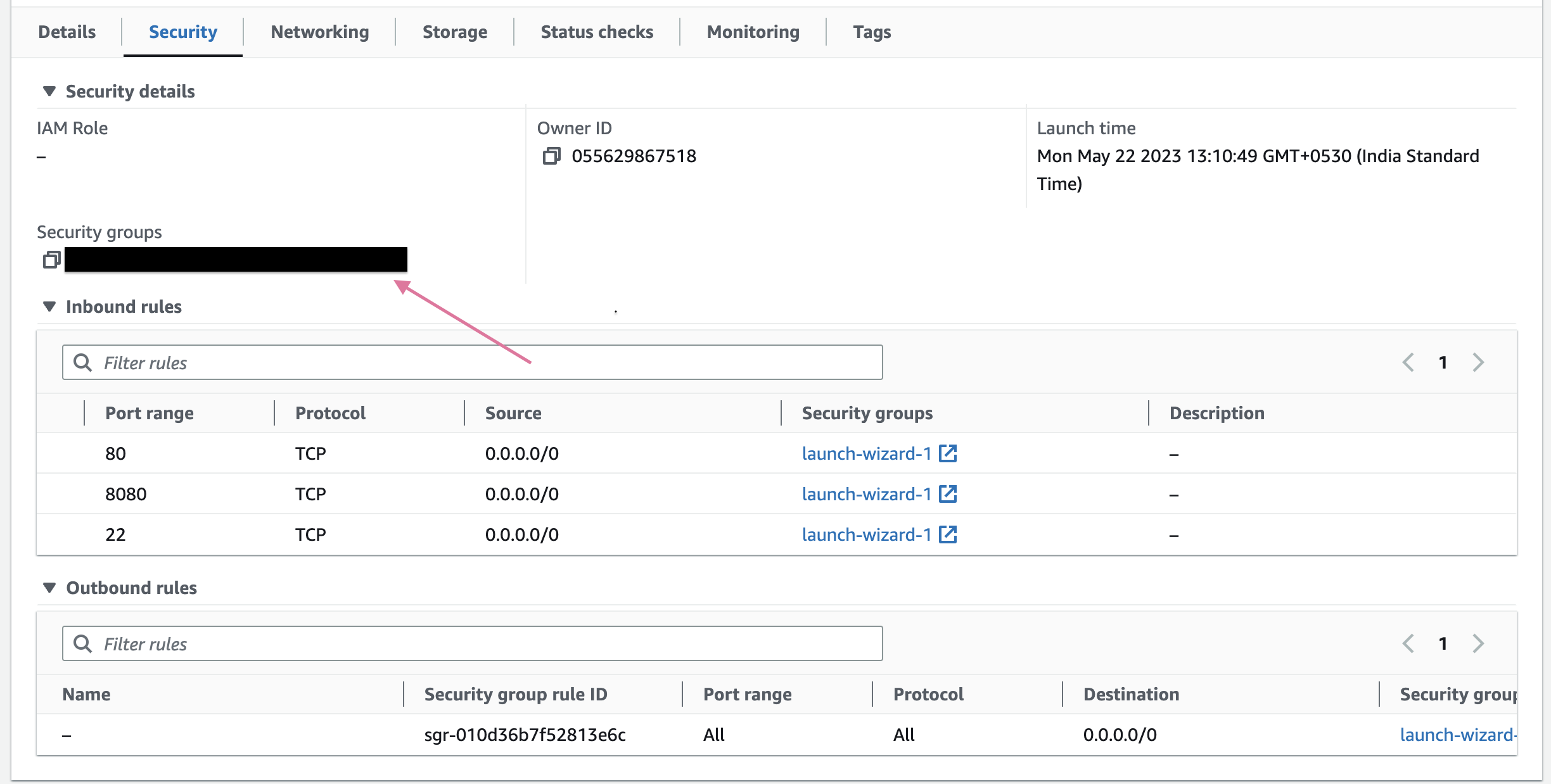
- Add these rules
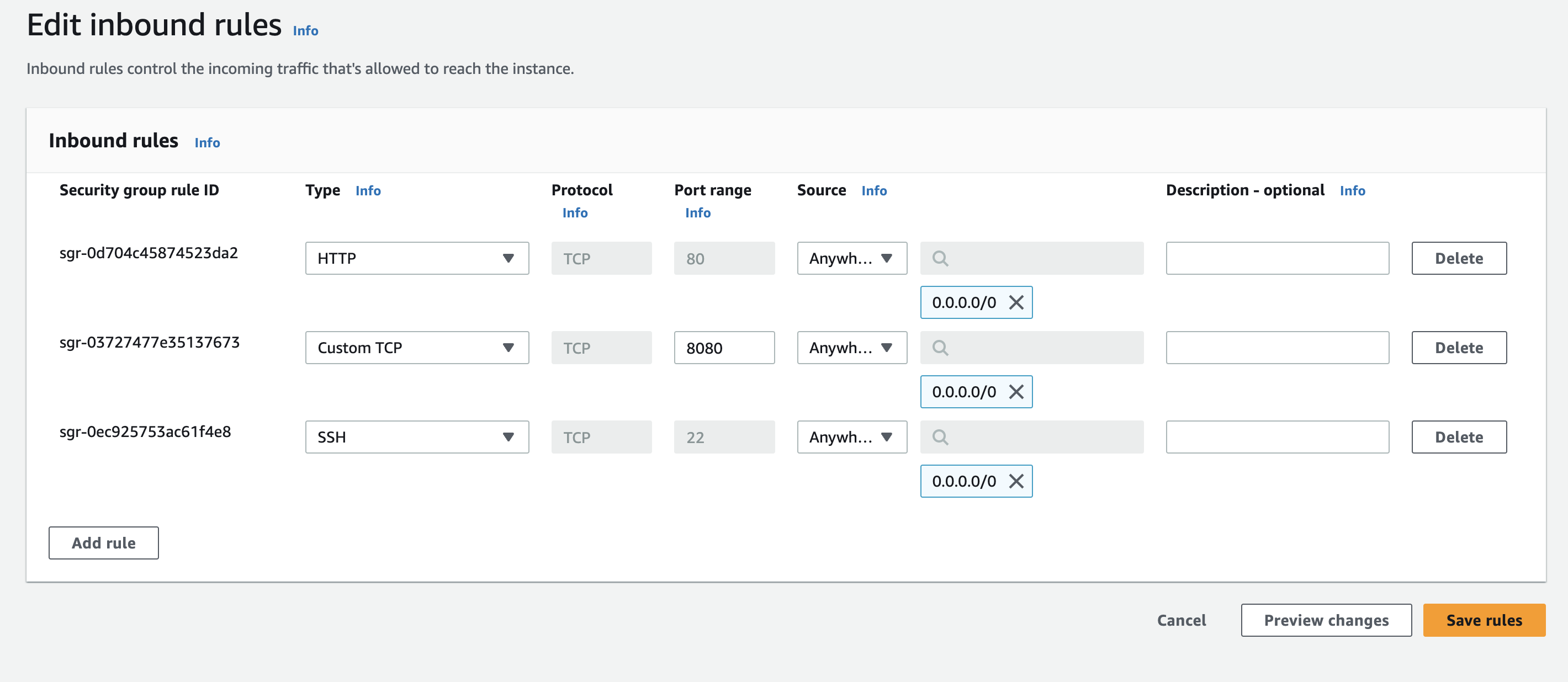
Note:- It is not good to allow any traffic but for testing it is okay.
6. Now, It is time to ssh to your instances. But before going inside the EC2 instances, Make sure you have the key-pair (.pem file). To Download the pem file follow the below image:-
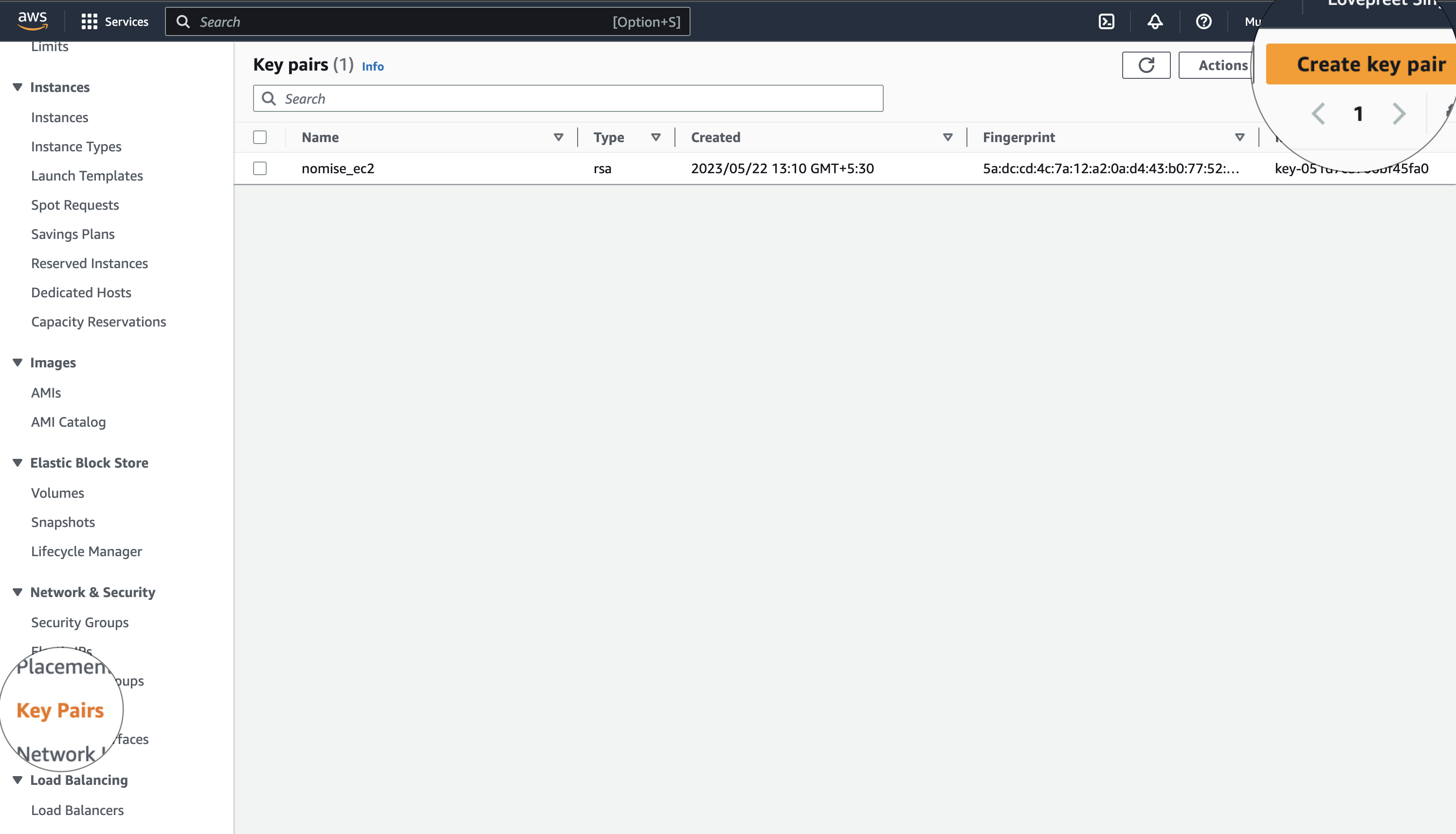
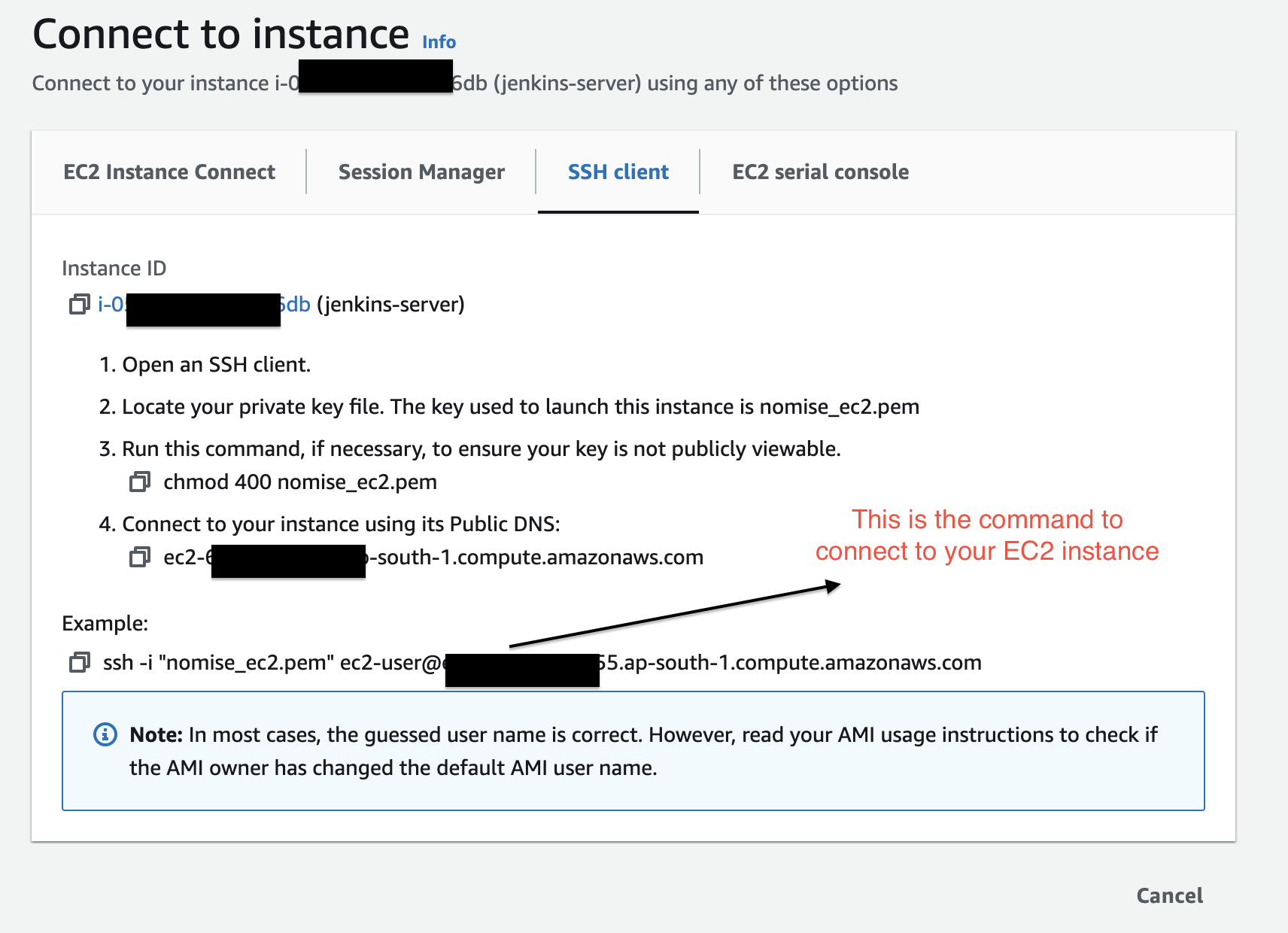
7. I have saved the pem file in my ~/.ssh folder. And now to SSH into a particular instance, click on Connect and you'll get this window
Note:- Make sure you give the correct path of .pem file saved in the previous step and also you changed its access rights using chmod as shown in the picture.
8. Now, similarly you can connect to all the instances using SSH.
## 📌 Setup Jenkins, Docker and Ansible Server
Now it is the time to setup Jenkins pipeline with Ansible server and docker server.
Note:- make sure you stop the instances when you are not doing anything (If you are using AWS Free tier)
1. Let's SSH into our first instance (Jenkins). For me the command to run is
```BASH
ssh -i ~/.ssh/nomise_ec2.pem ec2-user@ec2-65-3-155-155.ap-south-1.compute.amazonaws.com
```
After getting into the ec2 instance run the below commands one by one:-
```BASH
sudo yum update –y
sudo wget -O /etc/yum.repos.d/jenkins.repo https://pkg.jenkins.io/redhat-stable/jenkins.repo
sudo rpm --import https://pkg.jenkins.io/redhat-stable/jenkins.io-2023.key
sudo yum upgrade
sudo amazon-linux-extras install java-openjdk11 -y
sudo dnf install java-11-amazon-corretto -y
sudo yum install jenkins -y
sudo systemctl enable jenkins
sudo systemctl status jenkins
```
2. After that you'll get Jenkins running on your localhost. Go to your instance on AWS and find your public ipv4 address on the instance homepage and go to http://<your_server_public_address>:8080 and the below screen of jenkins would appear
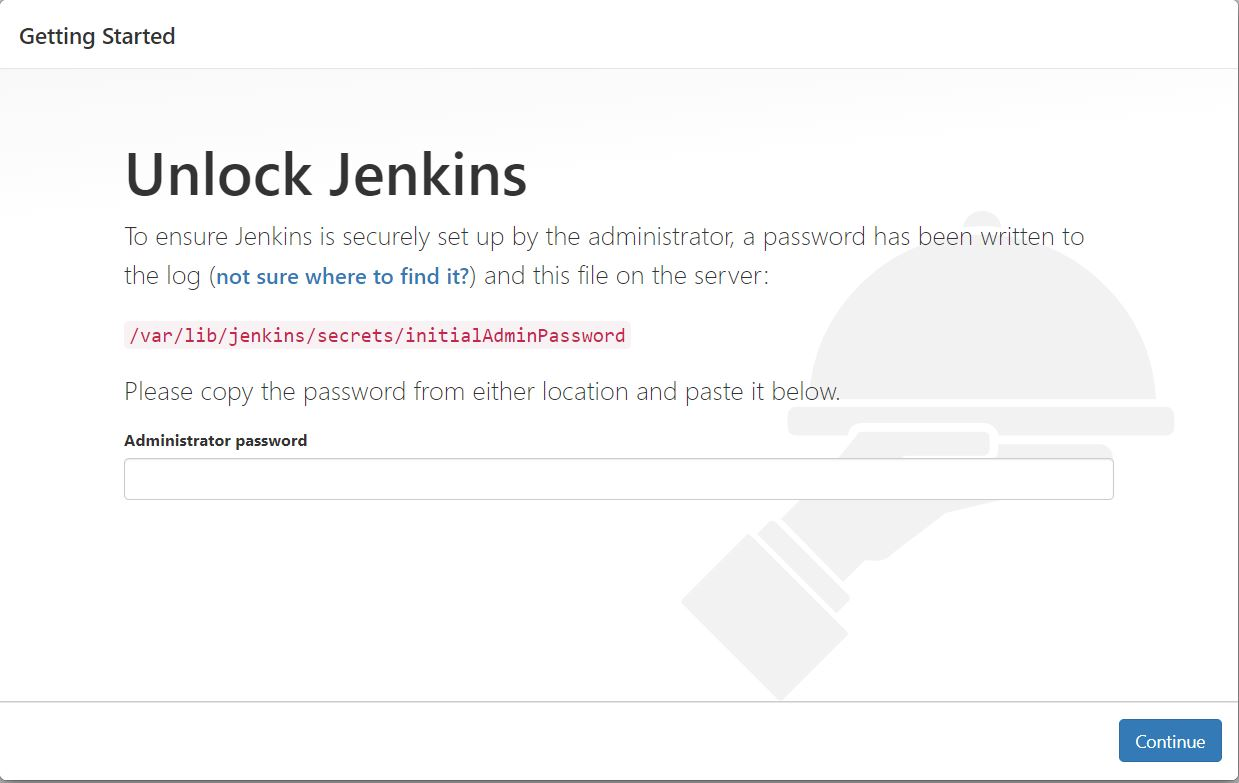
- Enter this command in your terminal to get the password to enter in jenkins
```BASH
sudo cat /var/lib/jenkins/secrets/initialAdminPassword
```
🥳 And that's how Jenkins will be started.
----
That's It for today Guys, In next Part we'll see How to build Docker Container and deploy through Jenkins.
✨ For the next Blog, Follow Now
| lovepreetsingh |
1,476,392 | Effortless NFS file transfer in CI/CD pipelines without Privileged access | In the realm of continuous integration and deployment (CI/CD) pipelines, the seamless transfer of... | 0 | 2023-05-22T15:23:59 | https://dev.to/kha7iq/effortless-nfs-file-transfer-in-cicd-pipelines-without-privileged-access-p1e | In the realm of continuous integration and deployment (CI/CD) pipelines, the seamless transfer of artifacts to any remote servers holds immense significance.
Traditionally, in the case of NFS, achieving this demands mounting of the nfs share inside the runner, thereby restricting it to a specific node and granting privileged access.
However, NCP (NFS Copy), can be utilized to
allows direct artifact copying to remote NFS servers without the need for mounting, eliminating the constraints of privileged access.
In this article, we delve into the utilization of NCP in GitLab pipelines.
## Understanding the Pipeline
Let's examine a sample pipeline to better understand how NCP can be leveraged for artifact transfer:
```yaml
stages:
- build
- publish
build:
stage: build
script:
- echo "build test artifact" > output.txt
artifacts:
paths:
- output.txt
expire_in: 2 hours
publish:
stage: publish
needs: ["build"]
image: docker.io/khaliq/ncp:latest
script:
- ncp to --host 192.168.0.80 --nfspath data --input output.txt
```
The pipeline consists of two stages: `build` and `publish`. In the `build` stage, a test artifact is created by echoing the text "build test artifact" into a file called `output.txt`.
This stage is responsible for building the artifact that will later be transferred to the remote NFS server.
```yaml
publish:
stage: publish
needs: ["build"]
image: docker.io/khaliq/ncp:ncp
script:
- ncp to --host 192.168.0.80 --nfspath data --input output.txt
```
The publish stage is where the artifact is transferred using NCP. Here's a breakdown of the command used:
`ncp to`: Specifies the direction of the transfer, indicating that the artifact will be sent to the remote server.
`--host`: Specifies the IP address or hostname of the remote NFS server.
`--nfspath`: Defines the target path on the remote server where the artifact will be stored.
`--input`: Specifies the input artifact to be transferred, in this case, `output.txt`.
With this simple command, it handles the transfer of the artifact to the specified remote NFS server, without the need to mount nfs shares.
## Conclusion
NCP simplifies remote NFS server integration in CI/CD pipelines. By eliminating nfs share mounting and the need for privileged access, it streamlines artifact transfer, granting the freedom to run jobs anywhere.
Checkout the [GitHub repository](https://github.com/kha7iq/ncp) for more information. | kha7iq | |
1,476,461 | Advanced Tailwind Syntax | It's common to use Tailwind with classes like m-4 bg-red-500 that use the theme tokens. Tailwind Docs... | 0 | 2023-05-22T14:31:06 | https://dev.to/tresorama/advanced-tailwind-syntax-11bm | frontend, learning, react, vue |
It's common to use Tailwind with classes like `m-4 bg-red-500` that use the `theme` tokens.
[Tailwind Docs](https://tailwindcss.com/docs/installation) is well done and covers everything.
---
But when you need to write CSS that doesn't use theme, you are using the tailwind syntax for **arbitrary rules**.
**This is when you can find this cheat sheet useful.**

{% embed https://tailwind-syntax-examples.vercel.app/ %}
---
Feel free to suggest something that is missing...
| tresorama |
379,124 | WASM: Memory Management | So you have chosen to write your new web app in WASM - exciting! On top of that, you want to write it... | 0 | 2020-07-02T16:37:50 | https://dev.to/shaafiee/wasm-memory-management-33l6 | cpp, webassembly, javascript | So you have chosen to write your new web app in WASM - exciting! On top of that, you want to write it in C++ to have fine-grained control over data storage and manipulation.
Here's some great advice that will help you overcome serious headaches.
Firstly, because the memory available to your program is actually a JS object, it is available as one contiguous chunk that is limited to linear scaling. This means that you have to be very careful about deleting objects and freeing memory. In fact, stop deleting objects altogether. If you feel the need to get rid of temporary memory objects then create a separate temporary memory object within JS for that operation, like so:

The second big hint is, align your data structures. When you have lots of data structures that go in and out of the execution scope, you will run into lots of segmentation faults due to memory misalignments, particularly if your structures have many levels of invariably scaling sub-structures, such as in the case of Markov chains.
No alt text provided for this image
Explicit memory alignment will have penalties in terms of growth of memory as your Markov chains' complexities increase - this is where multiple memory objects come in handy. This drawback is worth the performance and stability bonuses, which you will learn as you dig into WASM.
Have fun in your WASM journey!
| shaafiee |
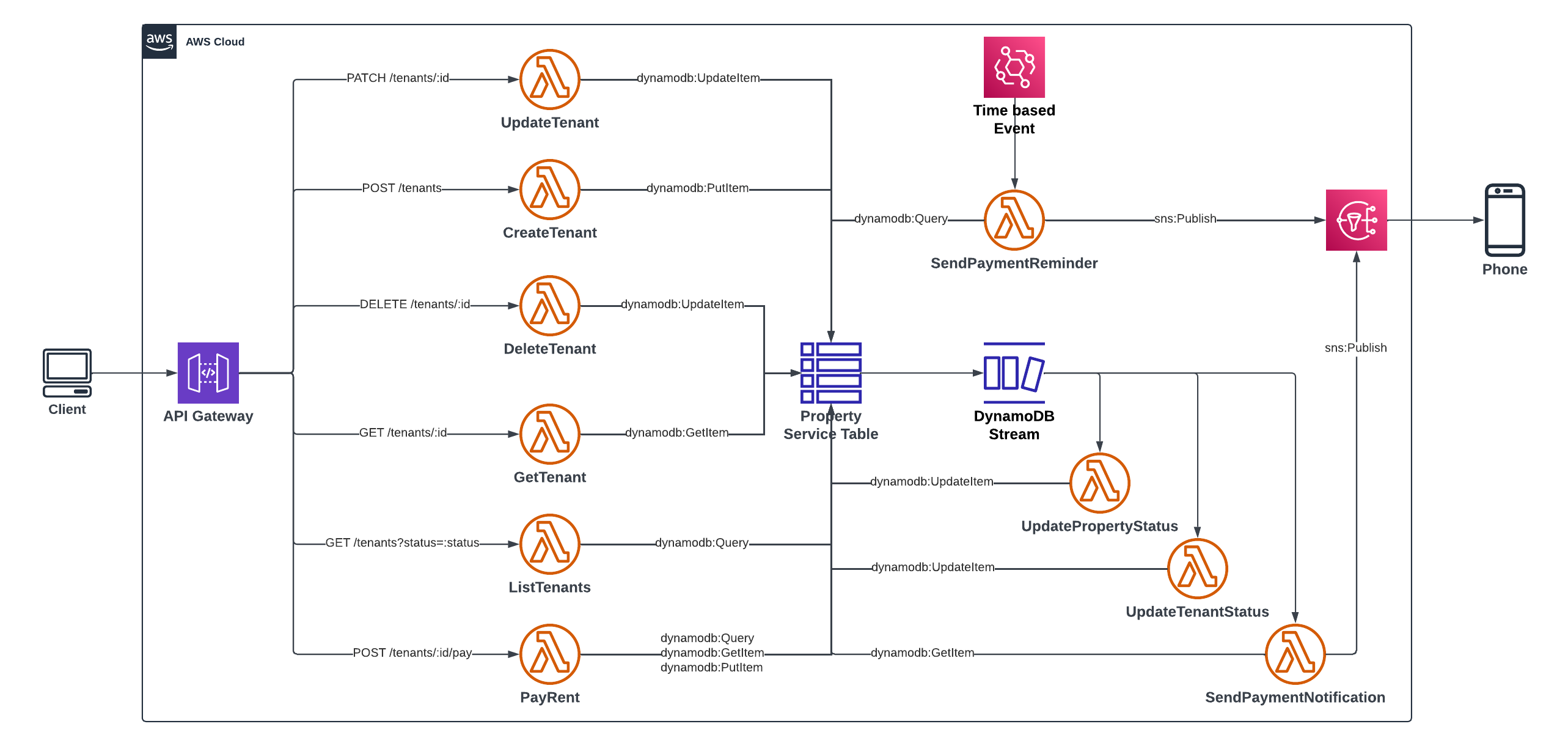
1,476,741 | Serverless API Development on AWS with TypeScript - Part 1 | Introduction This article is written to help anyone who needs a guide in building their... | 23,092 | 2023-05-23T08:57:01 | https://soprinye.com/serverless-api-development-on-aws-with-typescript-part-1 |
## Introduction
This article is written to help anyone who needs a guide in building their first serverless API on AWS using the Serverless Framework and TypeScript. If you have never built an API using the Serverless Framework, you would need to set up your development environment. Check out my post on [Setting up for Serverless Development on AWS](https://dev.to/aws-builders/setting-up-for-serverless-development-with-aws-28gf), follow the steps to download and install the components needed to complete this project.
> If you are familiar with a concept or service go ahead and skip it to save yourself some time.
## About this Project
This Tenant-service project represents a property-rental scenario where a tenant rents an available property and receives an SMS notification for payment. After that happens, the tenant becomes active and the property becomes unavailable to be rented by another tenant. Subsequently, an active tenant can renew the rent for their current property. Finally, an SMS notification is sent to tenants 1 month before the expiration of the rent. The operations include:
* Create a tenant
* Update tenant record
* List all tenants by status
* Delete a tenant
* Record a payment transaction
* Send an SMS after payment
* Send a reminder via SMS, one month before the expiration
## Integrated AWS Services
The Tenant service project is built on AWS as a serverless API. I have included a brief description of the AWS services used in this project and how they work. As we go on you will see how they are used in this project. These five (5) services are:
### Amazon API Gateway
Amazon API Gateway receives and directs traffic to the appropriate service or handler that is responsible for that API request. Of course, such interactions must have been linked. Users can access whatever backend services you provide via the API Gateway. After the request is handled, the response is forwarded back to the API Gateway and finally, to the user. Amazon API Gateway is completely managed hence you do not need to install any server or component to start using it. It supports REST APIs as well as WebSocket APIs and also integrates easily with other supported AWS services.
### AWS Lambda
AWS Lambda is one of the compute services for Serverless Computing on AWS. You can deploy a function - yes! just a function - even if the function only returns the traditional "Hello World" string, you can deploy that function to AWS Lambda and Lambda will invoke your function when it is triggered. AWS Lambda supports many programming languages but this project uses TypeScript.
### Amazon DynamoDB
Amazon DynamoDB is a NoSQL, Key-Valued based Serverless database by AWS. It is highly efficient and can power high-performance applications at scale. Given it is serverless, there's no need for provisioning - you just need to configure your table and get started using it. We will be using this database to create the table used in this project.
#### DynamoDB Stream
Dynamodb Streams is one of the cool features of the Dynamodb Store. A stream is created when an `INSERT`, `MODIFY` or `DELETE` action is carried out on a DynamoDB table. Streaming by DynamoDB has to be enabled - it is not automated enabled. We will be using the streams to initiate checks and perform more logic based on an event in the table.
### Amazon EventBridge
At the foundation of AWS Lambda is the concept of a trigger. A trigger is an event that causes your lambda function to be invoked or executed. An example of a trigger is a user request - when it hits Amazon API Gateway and the endpoint references a Lambda function, that function is invoked. Another way a Lambda function can be invoked is by a time-based event, similar to a cron job schedule. Amongst several uses of EventBridge, it also keeps track of schedules and triggers functions as necessary based on such schedules.
### Amazon SNS
SNS is short for Simple Notification Service. It is a pub/sub for application-to-application and application-to-person messaging systems. It is serverless hence no need for installation of any kind. You only need to configure how you want to use it. We will be using it to send SMS to the users.
## Bootstrapping the Project
Execute the following command in a console to clone the project and get started.
```bash
git clone https://github.com/charlallison/tenant-service.git
```
After the clone operation is completed, you should have a directory containing files as rendered in the image below:
### Files, Folder Structure and Project components
* `serverless.yml` - the single most important file in the project. This file contains the configuration that the Serverless Framework uses to interact with and deploy our project to our AWS platform via our account.
* `package.json`, `package-lock.json` - contains information about dependencies for our project. These include the necessary AWS dependencies, TypeScript or Node-project-specific packages used.
* `tsconfig.json`, `tsconfig.paths.json` - contains configurations for the TypeScript compiler - remember, the project is written using TypeScript.
* `src` - short for Source, refers to a folder containing `source code`.
* `lambda` - contains lambda functions and related configurations
* `resource` - contains code (in yml) used to set up our table in DynamoDB and other configurations like streams and indexes.
### The serverless.yml file
I stated that the `serverless.yml` file is the most important file in the project. If that is the case, it is worth reviewing to understand its content.

Some important keys to note:
* `service`: sets the name of the service - tenant-service here
* `package`: packages function individually with their dependencies. However, it excludes dev dependencies.
* `provider`
* `name`: specifies the name of the cloud provider - aws in this case
* `profile`: specifies the profile with which to interact with the AWS platform - the profile contains credentials for authentication and authorization.
* `tracing`: enables distributed tracing for all lambda functions in the project and the API Gateway
* `functions`: specifies lambda function config files. We will see more of this in the next sessions.
* `resources`: used to specify resources used in the project. We only have the DynamoDB table as our resource in this project. Its definition and configuration are located in the `database-table.yml` file with the `TenantServiceTable` key
* `plugins`: you can call these helper function for the serverless.yml file -
* `esbuild`: used to build the functions
* `serverelss-iam-roles-per-functions`: used to indicate that each function can have its permission or role instead of grouping all under one.
* `custom`: All the keys mentioned are defined by the serverless framework but there could be cases where you want a user-defined key. The custom key is where you can define a user-defined key that can be used in the other parts of the file.
### Entities
Entities are a representation of real-world objects as used in source code relating to the context. Of course, there is a relationship with the database in which they are stored. For the tenant service, we have three entities that we will be working with. They contain fields that hold data and that can be used in operations.
When working with DynamoDB it is a good practice to include fields or attributes that will be used for indexing - more on this later. The following are entities in the tenant service project and their respective fields. It is worth mentioning that the indexing attributes are made up of the application attributes.
* **Tenant**
* application attributes: `id`, `name`, `phone`, `status`
* primary key: `PK`, `SK`
* index attributes: `GSI1PK`, `GSI2PK`
* **Property**
* application attributes: `id`, `city`, `state`, `address`, `cost`, `rooms`, `status`
* primary key: `PK`, `SK`
* index attributes: `GSI1PK`
* **Payment**
* application attributes: `propertyId`, `tenantId`, `amount`, `paidOn`, `expiresOn`
* primary key: `PK`, `SK`
* index attributes: `GSI1PK`
It is okay at this point to say we will be leveraging a strategy known as **Single table design**. This is a table design strategy where all of your data is saved to one table with no joins — more on this in subsequent parts of this article.
Three other files that contain very useful functions are the files in the `/src/libs` directory. These functions are used across the service and it makes sense to have a single reference point.
* `api-gateway.ts`: has two-fold usage:
* enables schema validation with middy
* formats the response message for API gateway service.
* `aws-client.ts`: contains initialization code for AWS clients
* `lambda.ts`: contains a middy function that chains body-parser, validator and error-handler middlewares.
## Conclusion
We have looked at the project structure, some important files and AWS services used in this project. We now have an idea of its setup. In the next article of this series, we will look at the lambda functions and the necessary configurations needed to them deploy on AWS. Comments are certainly appreciated. If there are questions, I will try my best to answer them. I hope this was informative and thank you for sticking right on till the end. | charlallison | |
1,476,860 | RowySync: A React App which syncs text, images and styles from Rowy Tables. | Hello Everyone! 👋 Recently I came across the GitHub + DEV 2023 Hackathon on the Dev Platform and... | 0 | 2023-05-22T21:00:31 | https://dev.to/jasmin/rowysync-a-react-app-which-syncs-text-images-and-styles-from-rowy-tables-569i | githubhack23, rowy, react, webdev | Hello Everyone! 👋
Recently I came across the **[GitHub + DEV 2023 Hackathon](https://dev.to/devteam/announcing-the-github-dev-2023-hackathon-4ocn)** on the Dev Platform and started planning to participate in the hackathon.😂
Dev community and especially Dev hackathons have played a major role in my learning journey by helping me learning about new tools and frameworks. 😇
While going through the hackathons post I came across the comment made by @harinilabs and looked into [Rowy](https://www.rowy.io/). After looking and learning about Rowy I was amazed by the idea of implementation behind Rowy and low code backend support it provides to build our applications faster.
I started digging up some ideas and came across the idea of implementing **RowySync** which helps to _update the content, images and styles of the text quickly of a React application._
## What I built 💡
I created a React Application that can be styled/customized using Rowy. Anyone who has editing access in Rowy project can easily update the text, font styles and edit images from Rowy Table.
The simple spreadsheet UI by Rowy provides an easy way to edit and manage the elements on the website.
### Category Submission:
I am submitting this project under **Wacky wildcards** as this app is built and deployed using **Github Codepsaces** and **Github Actions** to make development and collaboration easier and helps us to understand the **integration between Rowy and React Application**.
### App Link
Link to the deployed [App](https://jasmin2895.github.io/rowy-pages-editor/)
### Screenshots
1. Screenshot of the Rowy Table containing website details.
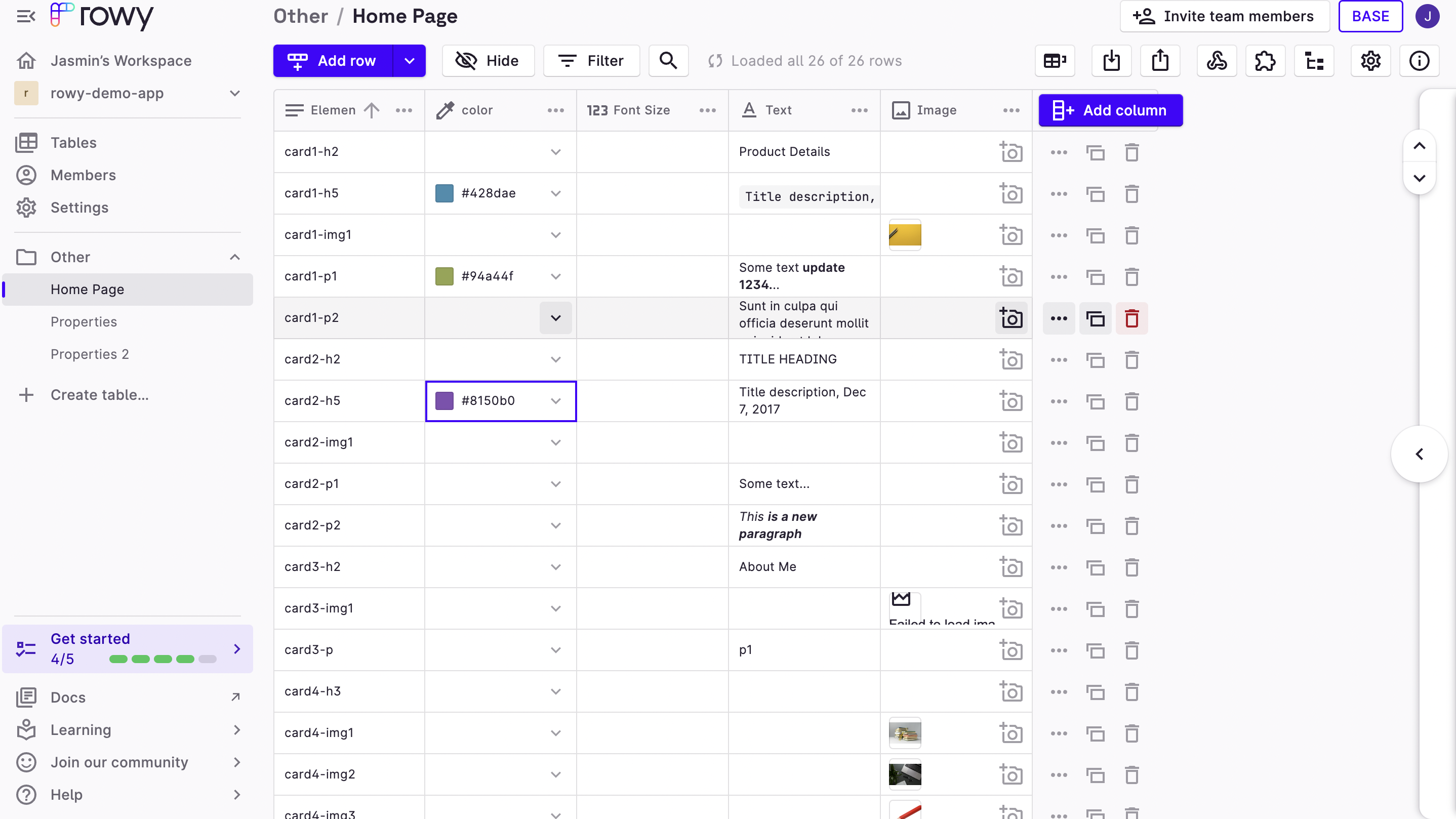
2.Screenshot of the React Application.
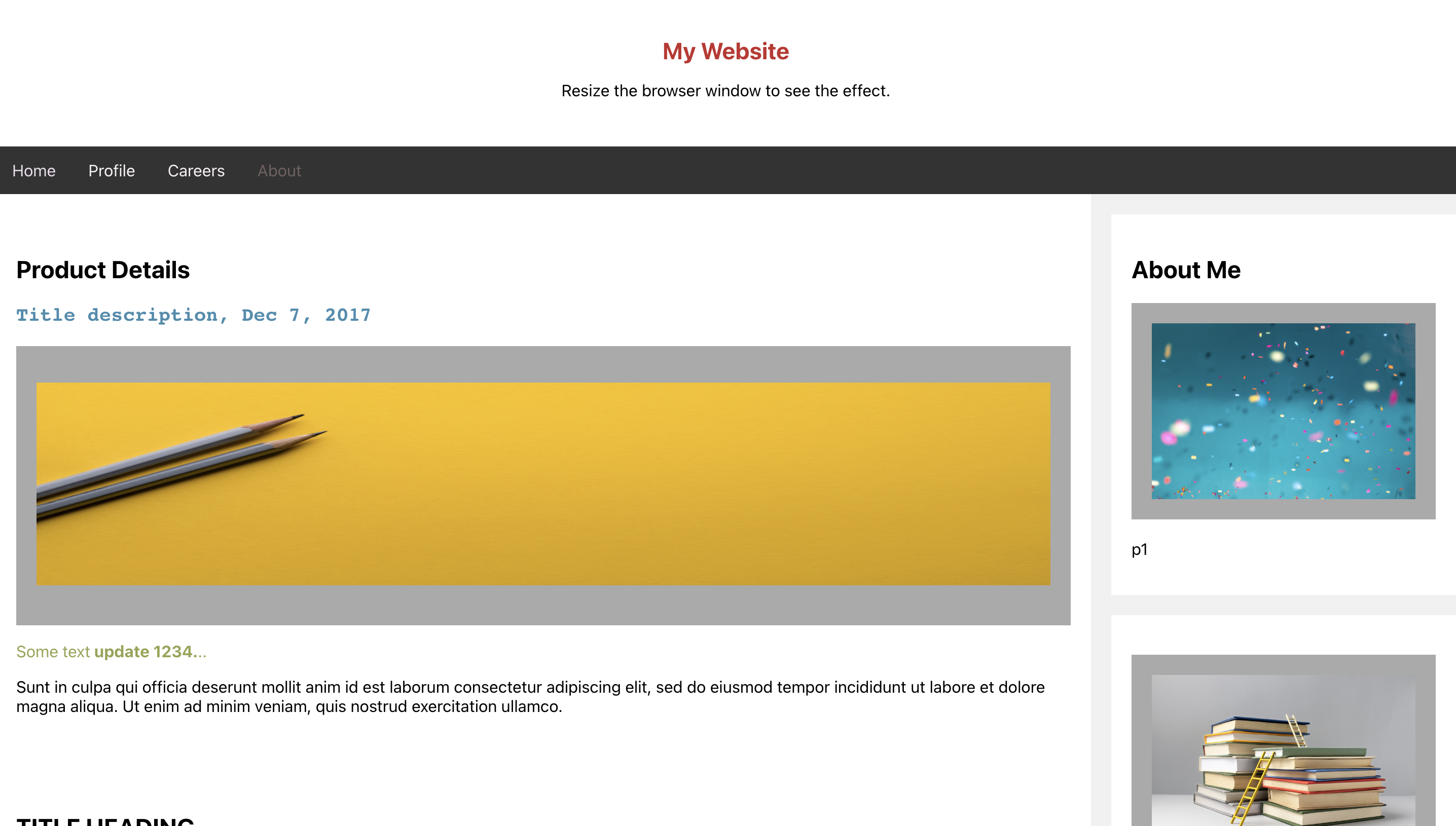
A small video demonstrating the working of this app.
{% embed https://youtu.be/lZnxuvTZwHg %}
### Description
Rowy Sync aka rowy web page editor built using **Github Codespaces** and using **Github Actions** provides a simple and intuitive interface for users to modify the content of the website easily. It helps to edit text, apply different font styles, such as bold, italic, and underline, etc and upload images to enhance the visual appeal of their website.
I have used GitHub Actions to build and deploy the app to Github pages.
### Link to Source Code
Github Repo [link](https://github.com/Jasmin2895/rowy-pages-editor)
### Permissive License
RowySync/ Rowy Pages editor is distributed under the MIT License — you can find the license [here](https://github.com/Jasmin2895/rowy-pages-editor/blob/main/LICENSE).
## Background
Well!😅
While working on frontend applications we might have had multiple requests from the stakeholders to update the font and formatting on the website.
This often leads to increase in development and review cycles and more waiting time for the stakeholders and less flexibility to provide more visual customisations.
With the help of Rowy integration to customise the React App components from the spreadsheet it provides multiple benefits for both developers and stakeholders such as:
1. Reducing development and review cycles for minor design changes.
2. Ease to test out multiple template versions of website with different set of text and multiple images.
3.Ability to update and verify the changes on website using Github Codespaces and Rowy spreadsheet like UI.
### How I built it
To build this project I used Github Codespaces where I was able to quickly setup the development environment. It also provides an excellent ability to setup the app secrets that are required for running the app on Codespaces.
This project uses Firebase database configs to sync the changes done in Rowy table which we would need to store in the secrets. [The same secrets are required while running codespaces and can be easily setup using these steps](https://docs.github.com/en/codespaces/managing-your-codespaces/managing-encrypted-secrets-for-your-codespaces#adding-a-secret).
This will be really useful for testing purpose where we don't need to create or setup database configs to verify the website changes.
Lastly using Github Actions I was able to build and deploy the website on Github Pages.
This is a good integration project which helped me to learn and implement features using Github Codespaces and Actions.
### Next Steps
I am planning to spend more time on this project more and try to improvise the integration more by providing support for multiple components and more properties to edit from Rowy. Also a way to sync component changes such as add or delete of elements by updating Rowy Tables using Github Actions or Webhooks.
### Additional Resources/Info
Some useful links and resources.
- https://docs.github.com/en/codespaces/developing-in-codespaces/developing-in-a-codespace
- https://docs.github.com/en/codespaces/managing-your-codespaces/managing-encrypted-secrets-for-your-codespaces#adding-a-secret
- https://www.rowy.io/blog/react-database
- https://docs.rowy.io/
Happy Coding!👩💻
| jasmin |
1,477,189 | FLAMES | What I built I 've built a relationship finder application which tells the relationship... | 0 | 2023-05-23T05:58:23 | https://dev.to/kavinofficial/flames-46ji | githubhack23, github, javascript, web | ### What I built
I 've built a relationship finder application which tells the relationship between two people
### Category Submission:
Wacky Wildcards
### App Link
https://kavinofficial.github.io/FLAMES/
### Screenshots
### Description
FLAMES is one of the fun projects I have done, though it is a small project , it was a good experience to create that. It finds the relationship of two people by using the characters of their names, it too has a bonding meter.
### Link to Source Code
https://github.com/kavinofficial/Crush-Finder
### Permissive License
I've added MIT license.
## Background (What made you decide to build this particular app? What inspired you?)
The manual calculation of FLAMES frustrated me , so I created this to save my time ,My friends inspired me to do this.
### How I built it
Now I'm learning front end development ,Codespaces helped me to learn some of them.
### Additional Resources/Info
I have used stack overflow, dev.to to solve few errors that occurred during the development of this project. | kavinofficial |
1,477,214 | 7 Primary Skills Should a Dedicated ReactJS Developer Have? | As a ReactJS Developer, remaining on top of things and consistently leveling up your abilities is... | 0 | 2023-05-23T06:39:02 | https://dev.to/viitorcloud/7-primary-skills-should-a-dedicated-reactjs-developer-have-37i4 | As a ReactJS Developer, remaining on top of things and consistently leveling up your abilities is vital. With its developing notoriety, ReactJS offers various open doors for developers to make inventive and effective web applications. Whether you're a novice or an accomplished developer, the following are seven fundamental abilities you ought to dominate to succeed in the realm of ReactJS.
## Capability in JavaScript:
ReactJS is based on JavaScript, so having a strong comprehension of JavaScript basics is essential. Get to know ideas like factors, capabilities, circles, and restrictive articulations. Also, investigate progressed subjects like terminations, models, and offbeat programming to compose spotless and productive Respond code.
## Solid Respond Essentials:
Dominating the central ideas of Respond is fundamental for building strong applications. Become familiar with JSX, Respond parts, state, and props the executives, lifecycle techniques, and Respond Switch for way. Understanding the virtual DOM and compromise interaction will likewise assist with streamlining your application's presentation.
## State The executives with Revival:
Revival is a famous state the executive library utilized with Respond. Figure out how to utilize Revival to oversee complex application states actually. Comprehend ideas like activities, minimizers, and the Revival store. Investigate middleware like Clunk or Revival Adventure to flawlessly deal with non-concurrent activities.
## Components Libraries:
Influence the force of part libraries like Material-UI or Insect Plan to fabricate lovely and responsive UIs rapidly. Look into the accessible parts, their props, and customization choices. Figuring out how to coordinate and style these libraries will fundamentally accelerate your improvement cycle.
## Testing with Jest and Enzyme:
Composing tests for your Respond applications is essential to guarantee their dependability and viability. Joke and Catalyst are famous trying systems for Respond. Figure out how to compose unit tests for Respond parts, mimic client connections, and attest anticipated ways of behaving. Testing your code will save time and limit likely bugs.
## Execution Streamlining:
Respond applications can some of the time experience the ill effects of execution issues. Learn methods like code parting, lethargic stacking, and provability to improve your application's exhibition. Understanding how to Respond accommodates and refreshes the DOM will help you distinguish and fix execution bottlenecks.
## Integrating with Back-end APIs:
Most certifiable applications require joining with back-end APIs. Get to know devices like Axios or Bring to settle on Programming interface decisions and handle reactions effectively. Comprehend ideas like Serene APIs, validation, and mistake dealing. Work on working with JSON information and overseeing state refreshes in light of server reactions.
## Final Thought:
Turning into a [talented ReactJS Developer](https://viitorcloud.com/hire-reactjs-developer) includes dominating different fundamental abilities. From JavaScript essentials and Respond center ideas to stating the executives, testing, execution improvement, and back-end mix, every expertise assumes a pivotal part in building fruitful Respond applications. Persistently learning and extending your insight here will help you stay ahead and make outstanding client encounters with ReactJS. | viitorcloud | |
1,477,263 | Developer's Guide to Flutter in 2023 | In the midst of the first quarter of the 21st century, we witness an abundance of mobile apps. It’s... | 0 | 2023-05-23T08:02:49 | https://dev.to/christinek989/developers-guide-to-flutter-in-2023-100n | flutter, mobile, softwareengineering, devops | In the midst of the first quarter of the 21st century, we witness an abundance of mobile apps. It’s hard to choose the right framework to build your case as there are so many in the market. In this developer’s guide, we will talk about one framework that has gained acceptance by many businesses and that is [Flutter](https://addevice.medium.com/whats-new-in-flutter-3-3c225eb41d51).
This guide to Flutter covers the following topics:
- Why is Flutter a good choice?
- Advantages of using Flutter
- Drawbacks of using Flutter
- How to become a Flutter developer?
## Why is Flutter a good choice?
Here I mention a couple of points. As you work with Flutter, you may notice other advantages that Flutter puts you in a position of.
Firstly, think about this. Why do developers even need to make the effort to learn Flutter? Simply because they want to get hired! Today a lot of businesses prefer Flutter because of the single codebase. So, chances are high that they will get an offer.
Secondly, there is big community support. Flutter’s documentation is also a helpful source of support.
Thirdly, it’s just easy. Flutter is rich with plugins and packages that help developers in their work.
Fourthly, Flutter development is more convenient because of the single codebase.
Finally, it’s just cost-effective. The [cost of the Flutter app](https://www.addevice.io/blog/how-much-does-it-cost-to-build-a-mobile-app) is much lower than of most other frameworks.
## Advantages of using Flutter
Let’s explore the advantage of using Flutter.
1. **Fast Flutter development**: it’s fast because developers see the changes without having to recompile the entire app. They can quickly experiment with UI/UX changes, fix bugs, and more.
2. **Single codebase**: this means that developers do not need to write separate code for iOS and Android which reduces time and effort.
3. **Native-like performance**: Thanks to its Dart programming language, Flutter has a native-like performance. Flutter's rendering engine also enables developers to create custom UI components and animations.
4. **Rich set of widgets**: Flutter comes with an extensive set of widgets that can be customized and create complex UI layouts.
5. **Customizable design**: Flutter is rather flexible when it comes to app design. It has an extensive set of widgets and styling options that allow customizing the apps.
6. **Strong community support**: developers use forums, documentation, and online resources for support.
7. **Cost-effective**: naturally, Flutter is more cost-effective than developing separate native apps for iOS and Android.
## Drawbacks of using Flutter
Despite being a super useful choice for mobile application development, Flutter has its own drawbacks. Let’s explore some.
1. **Complex and heavy animations**: Flutter’s rendering engine may struggle with complex and heavy animations.
2. **Challenging for multiple device sizes**: Flutter can be challenging to optimize performance for multiple device sizes. This is especially true for lower-end hardware. So, Flutter development may be problematic for multiple device sizes.
3. **Large application size**: Flutter’s application size can be a concern. This is because the Flutter applications tend to be larger than their native counterparts due to all widgets and libraries which are included in the application’s package.
4. **Platform-specific UI customizations**: It can be challenging to customize the user interface to match the native look. Eventually, this may affect user experience.
5. **Limited tooling support**: Flutter is still a young framework. The development tooling support is still not as mature as with other platforms. As an example, you might think of debugging and testing tools that are not as robust as those with other native development frameworks.
So, if you are a developer or a business that consider using the framework, think about both cons and pros and choose the technology that best fits the needs of your project. In this short guide to Flutter, we mentioned at least some of them.
## How to become a Flutter developer
The good news is that you don’t have to spend tons of money to become a Flutter Developer. For example, you can learn Flutter on a YouTube [channel](https://www.youtube.com/flutterdev). There is now also a good book available that you can use - the [Flutter Apprentice Book](https://www.amazon.com/Flutter-Apprentice-Second-Learn-Cross-Platform/dp/1950325482). Another resource that you can find is the package manager - Pub, where developers from all over the world share their solutions.
So, if you are serious about becoming a Flutter Developer, here are the steps you should take as a starter.
_Step 1:_ **Learn Dart**: The first thing in learning Flutter is to learn its programming language, Dart. Dart is closest to C#. So, if you know, learning the Dart language becomes easier. Dart uses Object-oriented programming (OOP) concepts, so you also need to know these concepts.
_Step 2:_ **Install Flutter and set up your environment**: Flutter’s official website has comprehensive instructions for installing and setting up Flutter on your preferred operating system.
_Step 3:_ **Study material design concept**: If we want to create user-friendly interfaces, it is very important to read [material design rules](https://m3.material.io/).
_Step 4:_ **Study widget**: Widgets are an indispensable part of Flutter so you need to know them.
_Step 5:_ **Make API calls and add database integration**: As developers, we often create applications that require a backend side. The Pub provides great packages to perform HTTP requests.
_Step 6:_ **Start building Flutter apps**: There are many resources available online to help you get started.
_Step 7:_ **Join the Flutter community**: Joining the Flutter community is an excellent way to learn from other developers and stay up-to-date with the latest news and trends in the Flutter ecosystem.
_Step 8:_ **Publish your Flutter app**: Once you have built a new Flutter app, you can publish it on the app store. This will also give a valuable experience in the app publishing process.
## Summing up
So, you went through this quick guide to Flutter in 2023. Now it’s time to get more serious and take up the task of learning this incredible framework that will give you not just one job in the market. If you are in search of resources, we have provided some but the good news is that you can find an abundance of such resources on the internet. Happy working with Flutter!
| christinek989 |
1,477,347 | Virtual Reality in Now Days | Virtual reality (VR) is an emerging technology that has the potential to revolutionize the way we... | 0 | 2023-05-23T09:05:49 | https://dev.to/sachinweb/virtual-reality-in-now-days-3d06 | Virtual reality (VR) is an emerging technology that has the potential to revolutionize the way we interact with the world around us. It is a computer-generated simulation of a three-dimensional (3D) environment that can be interacted with using special electronic equipment, such as a headset with a screen or gloves with sensors. The technology creates a sensory experience that can be similar to or completely different from the real world.
VR has various applications in fields such as entertainment, healthcare, education, and research. In the entertainment industry, VR is already being used to create immersive gaming experiences, allowing players to enter and interact with [virtual](https://www.acadereality.com/) worlds. VR gaming has become increasingly popular, providing players with a more immersive and interactive gaming experience. VR has also been used in the film industry to create 360-degree movies, allowing viewers to experience the movie as if they were there.
In healthcare, VR is used for therapy and rehabilitation to help patients overcome phobias or recover from injuries. For example, VR can be used to simulate a real-life situation that triggers a patient's fear or anxiety, allowing them to confront and overcome it in a safe and controlled environment. VR can also be used to help patients recover from injuries by providing a virtual environment that simulates everyday activities, allowing them to practice and build confidence before returning to real-life situations.
In education, VR can provide a more engaging and interactive learning experience by allowing students to explore and interact with virtual environments. VR has the potential to revolutionize the way we learn by providing immersive and engaging experiences. For example, students can explore historical sites or scientific phenomena in a way that is not possible through traditional textbooks. VR can also provide a safe environment for students to practice skills, such as surgery, before performing them on [real](http://vid.lol) patients.
In research, VR can simulate complex scenarios that would be impossible or dangerous to recreate in the real world. For example, astronauts can use VR to simulate spacewalks, providing them with a safe environment to practice and prepare for the real thing. VR can also be used to simulate natural disasters or other emergencies, allowing researchers to study human behavior and decision-making under stress.
The technology behind VR is constantly evolving, with advancements in graphics, displays, and interactive equipment. This is leading to the development of more realistic and immersive virtual environments. In recent years, VR has gained popularity and has become more accessible to consumers. This has led to the development of more affordable and user-friendly VR equipment, such as Google Cardboard. Additionally, VR has been integrated into social media platforms, allowing users to share their VR experiences with others.
Despite its potential benefits, VR also has some drawbacks. The equipment can be expensive and not accessible to everyone. There are also concerns about the potential negative effects of prolonged exposure to virtual environments, such as motion sickness and eye strain. One major challenge is the potential for addiction to VR. As the technology becomes more advanced and immersive, users may become more reluctant to leave the virtual world. Another challenge is the potential for VR to be used to create fake or misleading content.
Despite these challenges, the potential benefits of VR are significant. From education to entertainment to healthcare, VR has the potential to transform the way we live, work, and learn. As the technology continues to evolve, it will be exciting to see how it is integrated into our daily lives. VR is a rapidly developing technology with a wide range of applications and potential benefits. As the technology continues to advance, it is likely that it will become even more prevalent in various industries and areas of our lives. | sachinweb | |
1,477,454 | Clean Architecture ฉบับเริ่มต้น | เชื่อว่าในการพัฒนาซอฟต์แวร์นั้น ความเข้าใจในเรื่องสถาปัตยกรรม (Software Architecture)... | 0 | 2023-05-23T10:40:55 | https://dev.to/nattrio/clean-architecture-3la9 | architecture | เชื่อว่าในการพัฒนาซอฟต์แวร์นั้น ความเข้าใจในเรื่องสถาปัตยกรรม (Software Architecture) มีความสำคัญอย่างยิ่ง เพราะนอกจากจะช่วยออกแบบระบบได้ดียิ่งขึ้น ยังเป็นการเปิดมุมมองต่อแนวคิดเบื้องหลังของสถาปัตยกรรมเหล่านี้อีกด้วย เพื่อให้นำมาปรับใช้ได้เหมาะสมกับงาน
ในบทความนี้จะพามารู้จักกับ Clean Architecture ซึ่งเป็นการอ้างอิงจากบทความของ Robert C. Martin แม้ว่าบทความนั้นจะมีอายุมากกว่า 10 แล้ว แต่แนวคิดก็ยังนับว่าน่าสนใจไม่น้อยเลยทีเดียว
---
## รู้จัก Clean Architecture
สถาปัตยกรรมนี้ให้ความสำคัญกับ *Separation of Concern* คือมีการแบ่ง layer การทำงานของซอฟต์แวร์เป็นชั้นๆ ซึ่งในแต่ละชั้น layer จะทำงานในขอบเขตของตัวเองไม่ปะปนกัน
ในแผนภาพสะท้อนหลักการ The Dependency Rule โดยวงกลมด้านนอกจะเกี่ยวข้องกับการติดต่อประสานเครื่องไม้เครื่องมือต่างๆ สามารถปรับเปลี่ยนได้ตลอด ส่วนวงกลมด้านในจะเป็นการกำหนดนโยบายซึ่งเกี่ยวข้องกับ business โดยตรง จึงไม่ได้ปรับเปลี่ยนบ่อย
นอกจากนี้ยังกล่าวว่า *source code dependencies can only point inwards* คือวงภายในจะต้องไม่รับรู้และไม่พึ่งพาอาศัยโค้ดจากวงภายนอก แต่วงนอกพึ่งพาอาศัยวงภายในตามลูกศร `depend on`
เดี๋ยวเรามาลงรายละเอียดในแต่ละวงกัน เริ่มจากด้านนอกเข้าไปด้านใน
### Frameworks and Drivers
เป็นส่วนที่จัดการกับ Framework และติดต่อกับเครื่องมือภายนอกอื่นๆ ด้วย driver ซึ่งอาจไม่ได้เขียนโค้ดมาก แต่จะเป็นการลงรายละเอียดที่จำเพาะ (specific) เช่น ติดต่อกับ database ตัวไหน หรือจะใช้ Web Framework อะไร เป็นต้น
### Interface Adapters
ใช้ในการแปลงข้อมูล (convert data) ให้อยู่ใน format ที่เหมาะสม ให้วงในและนอกสื่อสารกันได้ แบ่งได้เป็นหมวดหลักๆ ดังนี้
- **Presenters**: ใช้จัดการ UI logic หรือ states แปลงให้แสดงผลได้เหมาะสม
- **Controllers**: ใช้จัดการ input/output จากระบบภายนอก เช่น UI, external services โดยรับ request มา validate/process ตาม business logic
- **Gateways**: อาจเรียกว่า repository หรือ data access layer ใช้จัดการ communication จาก data source เพื่อทำ data access operation
### Application Business Rules
เป็นการกำหนด rule ที่จำเป็น (แต่ยังไม่ใช่ core-business-rule) ใน layer นี้มี Use Case ใช้บอกว่า application มี function ใช้ทำอะไรได้บ้าง นอกจากนี้ใช้กำหนดว่าควรเรียก Controller/Gateway มาใช้ในแต่ละ use case
### Enterprise Business Rules
ส่วนนี้จะกำหนด core-business-rule เช่น model/entity ที่ใช้เก็บ data structure ซึ่งมีการเปลี่ยนแปลงน้อย และไม่ได้รับผลกระทบจากการเปลี่ยนแปลงของภายนอกมาก
---
หวังว่าบทความ Clean Architecture นี้จะเป็นประโยชน์กับผู้ที่เริ่มต้นศึกษา และสามารถอ่านรายละเอียดที่น่าสนใจที่ด้านล่างนี้ได้เลย
References:
- [Clean Coder Blog](https://blog.cleancoder.com/uncle-bob/2012/08/13/the-clean-architecture.html)
- [The Clean Architecture — Beginner’s Guide](https://betterprogramming.pub/the-clean-architecture-beginners-guide-e4b7058c1165)
| nattrio |
1,477,466 | Unleashing the Power of AWS Application Load Balancer | Unleashing the Power of AWS Application Load Balancer AWS Cloud Hands on Lab... | 0 | 2023-05-23T11:18:33 | https://dev.to/acloudguy/unleashing-the-power-of-aws-application-load-balancer-1cm7 | aws, loadbalance, community, tutorial |
## Unleashing the Power of AWS Application Load Balancer
### AWS Cloud Hands on Lab Practice Series
***Harnessing Sticky Sessions for Seamless Web Server Performance to enhance User Experience & retention.***
> **Project Overview —**
We explore into the world of load balancing by configuring an Application Load Balancer on AWS. Our goal is to seamlessly distribute incoming network traffic across multiple targets, including EC2 instances, containers, and IP addresses, spanning across different Availability Zones.
> **SOLUTIONS ARCHITECTURE OVERVIEW -**
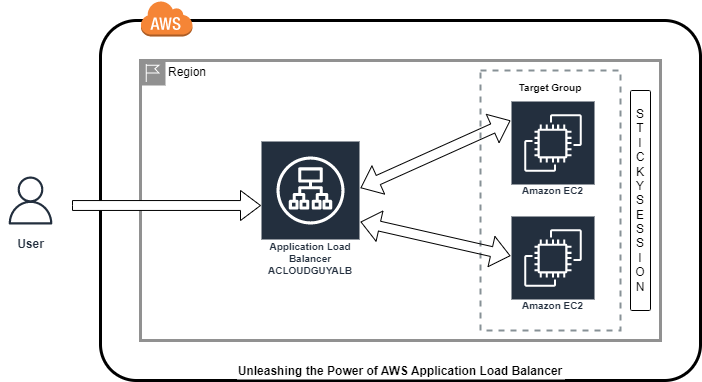
> **First Let’s understand the real world use case -**
1. **Enhanced User Experience:** Sticky sessions ensure that users are consistently directed to the same backend server, providing a seamless and uninterrupted experience. For instance, in a social media application, sticky sessions can be used to maintain the user’s session state, ensuring they continue to see their personalized feed and notifications without interruption.
2. **Session Persistence for Legacy Applications:** Sticky sessions enable legacy applications that do not support distributed logins or session sharing to function in a distributed environment. For example, in a banking application, sticky sessions can be used to maintain a user’s active session throughout their online banking activities, such as transferring funds or managing accounts.
3. **Simplified Application Architecture:** By leveraging sticky sessions, there is no need for session data replication or synchronization across multiple backend servers. This simplifies the application architecture and reduces complexity. For instance, in an online gaming application, sticky sessions can be used to ensure that players stay connected to the same game server, eliminating the need for real-time data synchronization across servers.
4. **Efficient Resource Utilization:** Sticky sessions optimize resource utilization by directing subsequent requests from users to the same backend server. This reduces the overhead of session data replication and eliminates the need to retrieve session data from a shared storage or database. For example, in a healthcare application, sticky sessions can be used to maintain a doctor’s active session, allowing them to seamlessly access patient records and make updates without delays caused by data retrieval.
5. **Compatibility with Session-based Workflows:** Many workflows rely on session-based data, such as e-commerce shopping carts, form submissions, or multi-step processes. Sticky sessions ensure that session data remains intact and accessible throughout the workflow. For instance, in an online travel booking application, sticky sessions can be used to keep track of the user’s selected flights, hotel reservations, and payment information as they progress through the booking process.
Overall, AWS Application Load Balancer with sticky sessions provides benefits such as **enhanced user experience**, **session persistence** for legacy applications, **simplified architecture**, **efficient resource utilization**, and compatibility with session-based workflows. These benefits contribute to a smoother and more reliable user experience, **improved application performance**, and simplified maintenance of session-related data.
> **PREREQUISITE —**
* AWS Account with Admin Access.
* Security Group allowing port 80 & 22 from Internet.
* Download the User Data needed for this lab from my [GitHub Repo.]
(https://github.com/Kunal-Shah107/Unleashing-the-Power-of-AWS-Application-Load-Balancer/blob/main/userdata_bootstrap_script)
> **AWS Services Usage —**
AWS EC2, ALB, IAM, SG, VPC, Target Group
> **STEP BY STEP GUIDE -**
**STEP 1** :
* Navigate to EC2 & click Launch instances.
* Under Name and Tags, enter “webservers”
* Number of Instances = 2
* Under Application and OS Images (Amazon Machine Image), select Ubuntu and Ubuntu Server 22.04 LTS.
* Select t3.micro as Instance Type.
* In the dropdown for Key pair (login), select Proceed without a key pair.
* Click Edit and set Auto-assign **Public IP to Enable** in Network settings.
* Click Select existing security group and select the one we created as prerequisite.
* Under Advanced Details, in the User Data box, enter the following bootstrap script from my [GitHub Repo.]
(https://github.com/Kunal-Shah107/Unleashing-the-Power-of-AWS-Application-Load-Balancer/blob/main/userdata_bootstrap_script)
* Click Launch Instance.
**STEP 2** :
* Once it’s in the Running state, copy the Public IPv4 addresses.
* In a new browser tab, paste in the public IP addresses we just copied.
* We should see the demo page hosted on this webservers.
**STEP 3** :
* Create Target group & give Target group name ‘WebServerTG’
* Choose a target type — Instances
* Under Available instances, select both targets that are listed.
* Click Include as pending below.
* Click **Create target group**.


**STEP 4** :
* Create an Application Load Balancer.
* From the Application Load Balancer card, click Create.
* For Load balancer name, enter ACLOUDGUYALB.
* Under Network mapping, click the VPC dropdown, and select the listed VPC.
* When the Availability Zones list pops up, select each one.
* Under Security groups, deselect the default security group listed, and select the one from the dropdown created in prerequisite.
* Ensure that the Protocol is set to HTTP and the Port is 80 under Listeners and routing.
* In the dropdown, select the TargetGroup we just created in step 3 ‘WebServerTG’.
* Click Create load balancer.

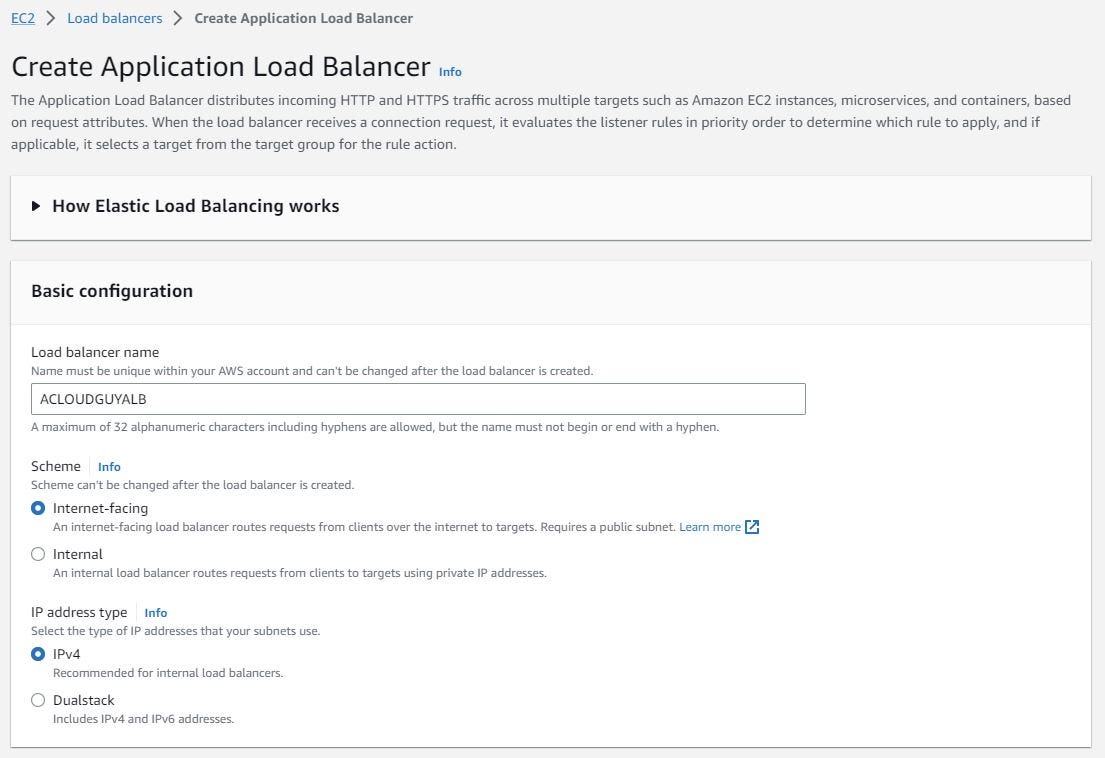
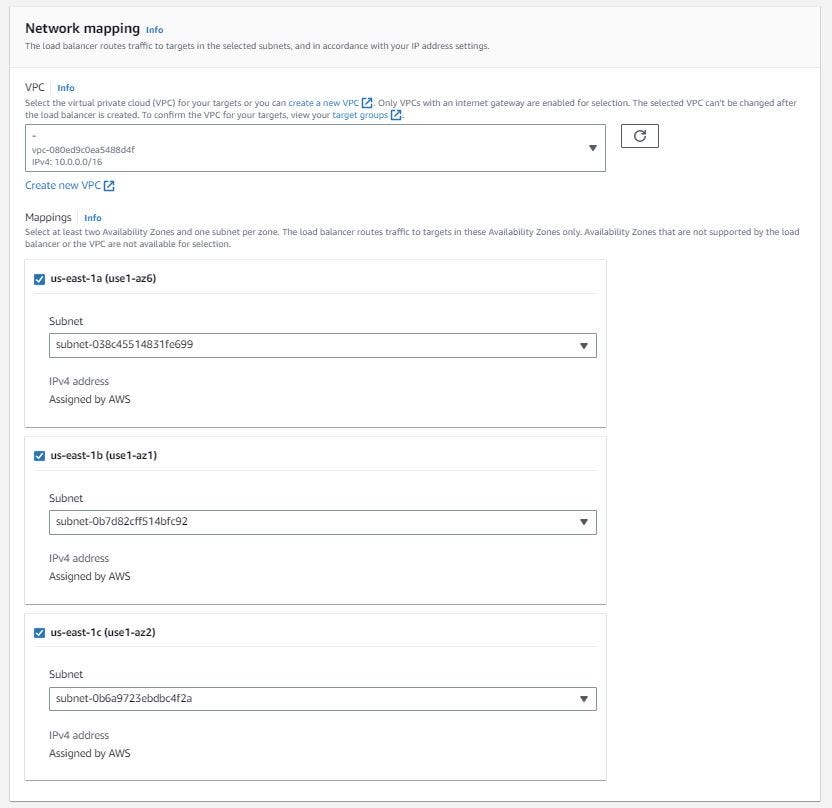
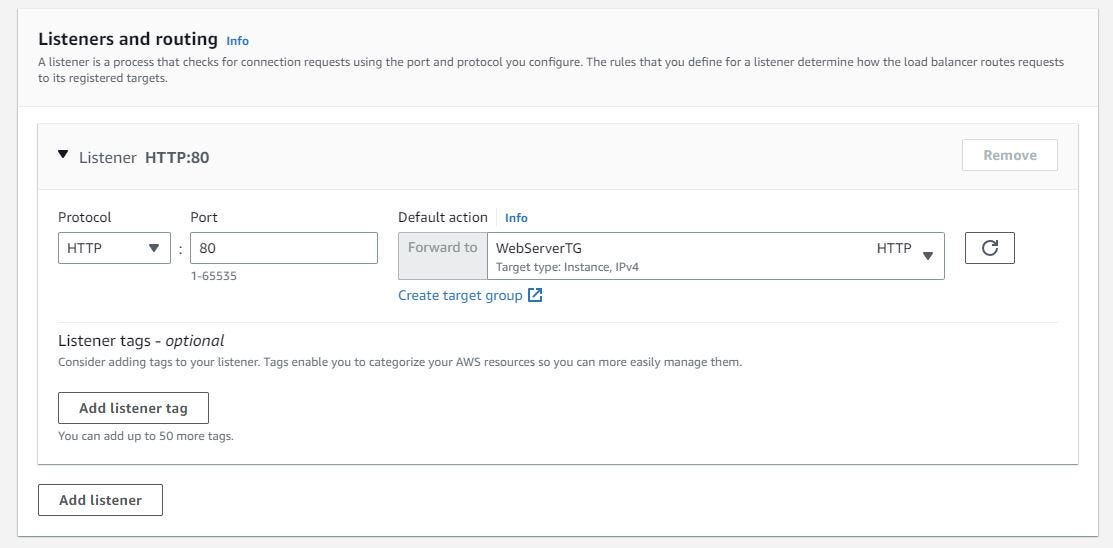

**STEP 5** :
* On the next screen, click View load balancer.
* Wait a few minutes for the load balancer to finish provisioning and enter an active state.
* Copy its DNS name, and paste it into a new browser tab.
* We should see the load balancer demo page again. The local IP lets you know which instance you are getting response (or “load balanced”) to.
* Refresh the page a few times. We should see the other instance’s local IP listed, meaning it’s successfully load balancing between the two EC2 instances.
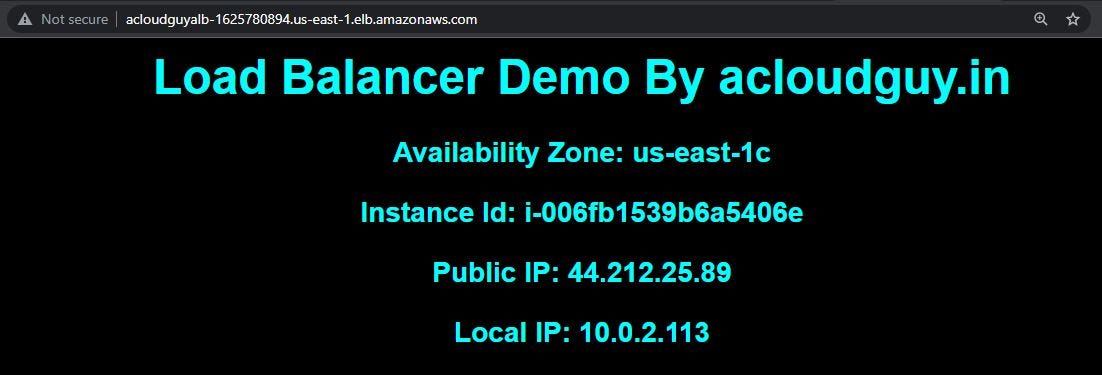
**STEP 6** :
* To Enable Sticky Sessions.
* Back on the EC2 > Load Balancers page, select the Listeners tab.
* Click the TargetGroup link in the Rules column, which opens the target group.
* Select the Attributes tab on Target Group page & click **Edit.**
* Check the box next to Stickiness to enable it.
* Leave Stickiness type set to Load balancer generated cookie.
* Leave Stickiness duration set to 1 days.
* Click Save changes.
* Now Refresh the tab where you navigated to the load balancer’s public IP.
* This time, no matter how many times you refresh, it will stay on the same instance (noted by the local IP).

* **IMP NOTE** — This DEMO/POC might incur some charges if kept active for long time. So please make sure to clean up the environment once done.
*Congrats* ! We have successfully completed the hands on Unleashing the Power of AWS Application Load Balancer.

*I am Kunal Shah, AWS Certified Solutions Architect, helping clients to achieve optimal solutions on the Cloud. Cloud Enabler by choice, DevOps Practitioner having 7+ Years of overall experience in the IT industry.*
*I love to talk about Cloud Technology, DevOps, Digital Transformation, Analytics, Infrastructure, Dev Tools, Operational efficiency, Serverless, Cost Optimization, Cloud Networking & Security.*
#aws #community #builders #devops #alb #ec2 #vpc #session #loadbalancer #infrastructure #webservers #acloudguy
*You can reach out to me @ [acloudguy.in](https://acloudguy.in/)*
| acloudguy |
1,477,483 | Updating widgets with Jetpack WorkManager | Welcome to the second part of Updating widgets. In the first installment, we looked at the anatomy of... | 22,352 | 2023-05-26T05:11:37 | https://dev.to/tkuenneth/updating-widgets-with-jetpack-workmanager-g0b | android, widgets, appwidgets | Welcome to the second part of *Updating widgets*. In the first installment, we looked at the anatomy of Android's appwidgets. One important takeaway was, that, while widgets can request updates through their configuration file, the interval may not be smaller than 30 minutes. More frequent updates require a different approach. I somewhat vaguely said, that we could update widgets from activities and services. Still, what if a widget is not a companion but all the app contains? A Weather widget doesn't necessarily need a main activity. Neither does a Battery Meter. Which app component should trigger widget updates in such scenarios?
Let's find out.
Android has seen quite a few ways of allowing background jobs. For widget updates, we are particularly interested in *persistent work*, which means, that the things to be done remain scheduled through app restarts and system reboots. Google recommends [Jetpack WorkManager](https://developer.android.com/topic/libraries/architecture/workmanager) for persistent work.
### Jetpack WorkManager and appwidgets
To use WorkManager, we first need to add an implementation dependency:
```groovy
implementation("androidx.work:work-runtime-ktx:2.8.1")
```
The next step is to define a `Worker`. The actual work takes place inside `doWork()`.
```kotlin
private const val WORK_NAME = "update-battery-meter-widget"
class BatteryMeterWorker(
private val context: Context,
workerParams: WorkerParameters,
) :
Worker(context, workerParams) {
override fun doWork(): Result {
context.getSharedPreferences(PREFS_NAME, Context.MODE_PRIVATE)
.edit()
.putLong(LAST_UPDATED, System.currentTimeMillis())
.apply()
context.updateXMLBatteryMeterWidget()
return Result.success()
}
}
```
The widget is updated by calling `context.updateXMLBatteryMeterWidget()`. This call won't take long. The same is true for accessing shared preferences. I will explain a little later why this is done.
Workers return a `Result`. I am taking it easy by always using `Result.success()`. Depending on what a worker does, this may obviously be not always a clever thing to do. Now that we have defined our persistent work, let's think about how to start and stop it.
The `AppWidgetProvider` class offers two related methods we can override:
- `onEnabled()` is called when an appwidget is instantiated
- `onDisabled()` will be invoked when the last widget instance is deleted
```kotlin
override fun onEnabled(context: Context) {
super.onEnabled(context)
enqueueUpdateXMLBatteryMeterWidgetRequest(context)
}
override fun onDisabled(context: Context) {
super.onDisabled(context)
cancelUpdateXMLBatteryWidgetRequest(context)
}
```
Here is how `enqueueUpdateXMLBatteryMeterWidgetRequest()` and `cancelUpdateXMLBatteryWidgetRequest()` are implemented:
```kotlin
fun enqueueUpdateXMLBatteryMeterWidgetRequest(context: Context) {
val request = PeriodicWorkRequestBuilder<BatteryMeterWorker>(
MIN_PERIODIC_INTERVAL_MILLIS,
TimeUnit.MILLISECONDS
).build()
WorkManager
.getInstance(context)
.enqueueUniquePeriodicWork(
WORK_NAME,
ExistingPeriodicWorkPolicy.UPDATE,
request
)
}
fun cancelUpdateXMLBatteryWidgetRequest(context: Context) {
WorkManager
.getInstance(context)
.cancelUniqueWork(WORK_NAME)
}
```
We are either creating (`build()`) and enqueuing (`enqueueUniquePeriodicWork()`), or cancelling (`cancelUniqueWork()`) a *request*. As its name suggests, `PeriodicWorkRequestBuilder` allows us to define a work request that we want to be executed repeatedly. Please note, that the time between two runs must currently be at least 15 minutes (`MIN_PERIODIC_INTERVAL_MILLIS`).
This means, we get updates after half the time of what is possible using the appwidget configuration file (30 minutes). Please keep in mind, though, that the update won't necessarily appear *exactly* after 15 minutes.
Here's how my updated example looks like. You can find the [source code](https://github.com/tkuenneth/battery_meter) on GitHub. The app contains two versions of Battery Meter, a Glance widget and a version based on `View`s. For now we will be focusing on the latter one. I'll turn to Glance in a later part of this series.

As you can see, the widget shows a date and a time. Why?
Recent Android versions limit what apps can do if they have not been in the foreground, that is, have been *actively used* for some time. This begs an important question: will the widget still be updated?
The small banner shows when the worker was last executed. The widget picks up the value that is written into shared preferences inside `doWork()`.
### Power optimizations
To see how the widget behaves, let's force the system into idle mode (*Doze*) by running the following command:
```
adb shell dumpsys deviceidle force-idle
```
As the worker runs every 15 minutes we should keep the app in Doze mode for at least 30 minutes. The widget won't be updated. After this period, we can exit idle mode by running these commands:
```
adb shell dumpsys deviceidle unforce
adb shell dumpsys battery reset
```
The widget will be updated again.
While Doze mode is active, the worker will not run every 15 minutes. It may run at greater intervals, though. You can read more about Doze mode [here](https://developer.android.com/training/monitoring-device-state/doze-standby#understand_doze). If the device is idle because it is lying on the desk with the screen turned off, *not* updating the widget is perfectly fine. After all, the user isn't looking at the screen and using the device.
There is, however, another (tongue in cheek) powerful power optimization feature called *App Standby*. Android checks several conditions to determine if an app is being actively used, for example
- Was it recently launched by the user?
- Does the app currently have a process in the foreground?
- Has the app created a notification that is visible to the user?
- Is the app an active device admin app?
Please refer to [Understanding App Standby](https://developer.android.com/training/monitoring-device-state/doze-standby#understand_app_standby) for further details.
Looking at the four bullet points above, none of them seem to apply to my sample, so it's very likely it will enter App Standby at some point. I believe this is a problem, because the user may be looking at a widget practically any time the home screen (launcher) is visible. To get an idea how the power optimizations will impact an app, please refer to [Power management restrictions](https://developer.android.com/topic/performance/power/power-details) and have a look at table section **App Standby Buckets**.
As mentioned in [App Standby Buckets](https://developer.android.com/about/versions/pie/power#buckets),
> App Standby Buckets helps the system prioritize apps' requests for resources based on how recently and how frequently the apps are used. Based on the app usage patterns, each app is placed in one of five priority buckets. The system limits the device resources available to each app based on which bucket the app is in.
The five buckets are:
- *Active*
- *Working set*
- *Frequent*
- *Rare*
- *Never*
We can find out in which bucket an app currently is by invoking
```
adb shell am get-standby-bucket eu.thomaskuenneth.batterymeter
```

`10` means *Active*. Please refer to [STANDBY_BUCKET_ACTIVE](https://developer.android.com/reference/android/app/usage/UsageStatsManager#STANDBY_BUCKET_ACTIVE) and corresponding constants.
The documentation continues:
> The app was used very recently, currently in use or likely to be used very soon. Standby bucket values that are ≤ `STANDBY_BUCKET_ACTIVE` will not be throttled by the system while they are in this bucket.
If an app is in the *Working set* bucket, it runs often but is not currently active. For this bucket, job execution is Limited to 10 minutes every 2 hours. Also, the app can schedule 10 alarms per hour.
According to the documentation, we can invoke
```
adb shell am set-standby-bucket eu.thomaskuenneth.batterymeter rare
```
to put an app into the *Rare* bucket. However, during my experiments, issuing `adb shell am get-standby-bucket` immediately afterwords always returned `10`, wheres `STANDBY_BUCKET_RARE` is `40`.
Now, where does this leave us?
### Wrap up
Jetpack WorkManager is really easy to use. Scheduling and cancelling requests fits nicely with the `AppWidgetProvider` callbacks. Sadly, widgets are good candidates for App Standby if they don't have activities that are explicitly opened by the user. While during my tests *Battery Meter* was in the *Active* bucket, it is not obvious how long it stays this way.
So what do we do? Google notes that apps on the Doze allowlist are exempted from App Standby bucket-based restrictions. But that sounds like a *last option*. Are there other ones? Please stay tuned. | tkuenneth |
1,477,496 | An Introduction to Absinthe | Absinthe is a toolkit for building a GraphQL API with Elixir. It has a declarative syntax that fits... | 23,093 | 2023-05-23T11:41:57 | https://blog.appsignal.com/2023/05/16/an-introduction-to-absinthe-for-elixir.html | elixir | Absinthe is a toolkit for building a GraphQL API with Elixir. It has a declarative syntax that fits really well with Elixir’s idiomatic style.
In today’s post — the first of a series on Absinthe — we will explore how you can use Absinthe to create a GraphQL API.
But before we jump into Absinthe, let’s take a brief look at GraphQL.
## GraphQL
GraphQL is a query language that allows declarative data fetching. A client can ask for exactly what they want, and only that data is returned.
Instead of having multiple endpoints like a REST API, a GraphQL API usually provides a single endpoint that can perform different operations based on the request body.
### GraphQL Schema
`Schema` forms the core of a GraphQL API. In GraphQL, everything is strongly typed, and the schema contains information about the API's capabilities.
Let's take an example of a blog application. The schema can contain a `Post` type like this:
```graphql
type Post {
id: ID!
title: String!
body: String!
author: Author!
comments: [Comment]
}
```
The above type specifies that a post will have an `id`, `title`, `body`, `author` (all non-null because of `!` in the type), and an optional (nullable) list of `comments`.
Check out [Schema](https://graphql.org/learn/schema/) to learn about advanced concepts like `input`, `Enum`, and `Interface` in the type system.
### GraphQL Query and Mutation
A type system is at the heart of the GraphQL schema. GraphQL has two special types:
1. A `query` type that serves as an entry point for all read operations on the API.
2. A `mutation` type that exposes an API to mutate data on the server.
Each schema, therefore, has something like this:
```graphql
schema {
query: Query
mutation: Mutation
}
```
Then the `Query` and `Mutation` types provide the real API on the schema:
```graphql
type Query {
post(id: ID!): Post
}
type Mutation {
createPost(post: PostInput!): CreatePostResult!
}
```
We will get back to these types when we start creating our schema with Absinthe.
[Read more about GraphQL's queries and mutations](https://graphql.org/learn/queries/).
### GraphQL API
Clients can read the schema to know exactly what an API provides. To perform queries (or mutations) on the API, you send a `document` describing the operation to be performed. The server handles the rest and returns a result. Let’s check out an example:
```graphql
query {
post(id: 1) {
id
title
author {
id
firstName
lastName
}
}
}
```
The response contains exactly what we've asked for:
```json
{
"data": {
"post": {
"id": 1,
"title": "An Introduction to Absinthe",
"author": {
"id": 1,
"firstName": "Sapan",
"lastName": "Diwakar"
}
}
}
}
```
This allows for a more efficient data exchange compared to a REST API. It's especially useful for rarely used complex fields in a result that takes time to compute.
In a REST API, such cases are usually handled by providing different endpoints for fetching that field or having special attributes like `include=complex_field` in the query param. On the other hand, a GraphQL API can offer native support by delaying the computation of that field unless it is explicitly asked for in the query.
## Setting Up Your Elixir App with GraphQL and Absinthe
Let’s now turn to Absinthe and start building our API. The installation is simple:
1. Add Absinthe, `Absinthe.Plug`, and a JSON codec (like Jason) into your `mix.exs`:
```elixir
def deps do
[
# ...
{:absinthe, "~> 1.7"},
{:absinthe_plug, "~> 1.5"},
{:jason, "~> 1.0"}
]
end
```
2. Add an entry in your router to forward requests to a specific path (e.g., `/api`) to `Absinthe.Plug`:
```elixir
defmodule MyAppWeb.Router do
use Phoenix.Router
# ...
forward "/api", Absinthe.Plug, schema: MyAppWeb.Schema
end
```
The `Absinthe.Plug` will now handle all incoming requests to the `/api` endpoint and forward them to `MyAppWeb.Schema` (we will see how to write the schema below).
The installation steps might vary for different apps, so follow the [official Absinthe installation guide](https://hexdocs.pm/absinthe/installation.html) if you need more help.
## Define the Absinthe Schema and Query
Notice that we've passed `MyAppWeb.Schema` as the schema to `Absinthe.Plug`. This is the entry point of our GraphQL API. To build it, we will use [`Absinthe.Schema`](https://hexdocs.pm/absinthe/Absinthe.Schema.html) behaviour which provides macros for writing schema. Let’s build the schema to support fetching a post by its id.
```elixir
defmodule MyAppWeb.Schema do
use Absinthe.Schema
query do
field :post, :post do
arg :id, non_null(:id)
resolve fn %{id: post_id}, _ ->
{:ok, MyApp.Blog.get_post!(post_id)}
end
end
end
end
```
There are a lot of things happening in the small snippet above. Let’s break it down:
- We first define a `query` block inside our schema. This defines the special query type that we discussed in the GraphQL section.
- That `query` type has only one field, named `post`. This is the first argument to the [`field` macro](https://hexdocs.pm/absinthe/Absinthe.Schema.Notation.html#field/4).
- The return type of the `post` field is `post` — this is the second argument to the macro. We will get back to that later on.
- This field also has an argument named `id`, defined using the [`arg` macro](https://hexdocs.pm/absinthe/Absinthe.Schema.Notation.html#arg/3).The type of that argument is `non_null(:id)`, which is the Absinthe way of saying `ID!` — a required value of type `ID`.
- Finally, the [`resolve` macro](https://hexdocs.pm/absinthe/Absinthe.Schema.Notation.html#resolve/1) defines how that field is resolved. It accepts a 2-arity or 3-arity function that receives the parent entity (not passed for the 2-arity function), arguments map, and an [Absinthe.Resolution](https://hexdocs.pm/absinthe/Absinthe.Resolution.html) struct. The function's return value should be `{:ok, value}` or `{:error, reason}`.
## Define the Type In Absinthe
In Absinthe, `object` refers to any type that has sub-fields. In the above query, we saw the type `post`. To create that type, we will use the [`object` macro](https://hexdocs.pm/absinthe/Absinthe.Schema.Notation.html#object/3).
```elixir
defmodule MyAppWeb.Schema do
use Absinthe.Schema
@desc "A post"
object :post do
field :id, non_null(:id)
field :title, non_null(:string)
field :author, non_null(:author)
field :comments, list_of(:comment)
end
# ...
end
```
The first argument to the object macro is the identifier of the type. This must be unique across the whole schema. Each object can have many fields. Each field can use the full power of the `field` macro that we saved above when defining the query. So we can define nested fields that accept arguments and return other `object`s.
As we discussed earlier, the `query` itself is an object, just a special one that serves as an entry point to the API.
### Using Scalar Types
In addition to objects, you can also get `scalar` types. A scalar is a special type with no sub-fields and serializes to native values in the result (e.g., to a string). A good example of a scalar is [Elixir’s `DateTime`](https://hexdocs.pm/elixir/1.13/DateTime.html).
To support a `DateTime` that we'll use in the schema, we need to use the [`scalar` macro](https://hexdocs.pm/absinthe/Absinthe.Schema.Notation.html#scalar/3). This tells Absinthe how to serialize and parse a `DateTime`.
Here is an example from the [Absinthe docs](https://hexdocs.pm/absinthe/Absinthe.Schema.Notation.html#scalar/3-examples):
```elixir
defmodule MyAppWeb.Schema do
use Absinthe.Schema
scalar :isoz_datetime, description: "UTC only ISO8601 date time" do
parse &Timex.parse(&1, "{ISO:Extended:Z}")
serialize &Timex.format!(&1, "{ISO:Extended:Z}")
end
# ...
end
```
We can then use this scalar anywhere in our schema by using `:isoz_datetime` as the type:
```elixir
defmodule MyAppWeb.Schema do
use Absinthe.Schema
@desc "A post"
object :post do
# ...
field :created_at, non_null(:isoz_datetime)
end
# ...
end
```
Absinthe already provides several [built-in scalars](https://hexdocs.pm/absinthe/1.1.5/Absinthe.Type.BuiltIns.html) — `boolean`, `float`, `id`, `integer`, and `string` — as well as some [custom scalars](https://hexdocs.pm/absinthe/Absinthe.Type.Custom.html): `datetime`, `naive_datetime`, `date`, `time`, and `decimal`.
### Type Modifiers and More
We can also modify each type to mark some additional constraints or properties. For example, to mark a type as non-null, we use the [`non_null/1`](https://hexdocs.pm/absinthe/Absinthe.Schema.Notation.html#non_null/1) macro. To define a list of a specific type, we can use [`list_of/1`](https://hexdocs.pm/absinthe/Absinthe.Schema.Notation.html#list_of/1).
Advanced types like [union](https://hexdocs.pm/absinthe/Absinthe.Schema.Notation.html#union/3) and [interface](https://hexdocs.pm/absinthe/Absinthe.Schema.Notation.html#interface/3) are also supported.
## Wrap Up
In this post, we covered the basics of GraphQL and Absinthe for an Elixir application. We discussed the use of GraphQL and Absinthe schema, and touched on types in Absinthe.
In the next part of this series, we'll see how we can apply Absinthe and GraphQL to large Elixir applications.
Happy coding!
**P.S. If you'd like to read Elixir Alchemy posts as soon as they get off the press, [subscribe to our Elixir Alchemy newsletter and never miss a single post](/elixir-alchemy)!** | diwakarsapan |
1,747,201 | How to get your SMS on IRC | How to get your SMS on IRC It's not really a continuation of the "one client for... | 0 | 2024-01-31T13:11:14 | https://dev.to/terminaldweller/how-to-get-your-sms-on-irc-3fhi | # How to get your SMS on IRC
It's not really a continuation of the "one client for everything" post but it is in the same vein. Basically, in this post we are going to make it so that we receive our SMS messages on IRC. More specifically, it will send it to a IRC channel.<br/>
In my case this works and is actually secure, since the channel I have the SMS going to is on my own IRC network which only allows users in after they do a successful SASL authentication.<br/>
The general idea is this:
- We run an app on our phone that will send the SMS to a web hook server
- The web hook server has an IRC client that will send the message to the IRC channel
### security considerations
#### SMS vs [RCS](https://en.wikipedia.org/wiki/Rich_Communication_Services)
For forwarding the SMS I get on my cellphone from my cellphone to the web hook server, i use [android_income_sms_gateway_webhook](https://github.com/bogkonstantin/android_income_sms_gateway_webhook). This app does not support RCS(see [#46](https://github.com/bogkonstantin/android_income_sms_gateway_webhook/issues/46)).<br/>
For this to work, make sure your phone has RCS disabled unless you use another app that supports RCS.<br/>
#### web hook server connection
The app will be connecting to our web hook server. The ideal way I wanted to do this would be to connect to a VPN, only through which we can access the web hook server. But its android not linux. I dont know how I can do that on android so that's a no go.<br/>
Next idea is to use local port mapping using openssh to send the SMS through the ssh tunnel. While that is very feasible without rooting the phone, a one-liner in termux can take care of it but automating it is a bit of a hassle.<br/>
Currently the only measure I am taking is to just use https instead of http.<br/>
Since we are using only tls we can use the normal TLS hardening measures, server-side. We are using nginx as the reverse proxy. We will also terminate the tls connection on nginx.<br/>
We will be using [pocketbase](https://github.com/pocketbase/pocketbase) for the record storage and authentication. We can extend pocketbase which is exactly how we will be making our sms web hook.<br/>
Pocketbase will give us the record storage and authentication/registration we need. We will use [girc](https://github.com/lrstanley/girc) for our IRC library. My personal IRC network wll require successful SASL authentication before letting anyone into the network so supporting SASL auth(PLAIN) is a requirement.
We can use basic http authentication using our chosen app. We can configure the JSON body of the POST request our web hook server will receive.<br/>
The default POST request the app will send looks like this:<br/>
For the body:
```json
{
"from": "%from%",
"text": "%text%",
"sentStamp": "%sentStamp%",
"receivedStamp": "%receivedStamp%",
"sim": "%sim%"
}
```
And for the header:
```json
{ "User-Agent": "SMS Forwarder App" }
```
We get static cerdentials so we can only do basic http auth. We dont need to encode the client information into the security token so we'll just rely on a bearer-token in the header for both authentication and authorization.<br/>
#### Authentication and Authorization
In our case, the only resource we have is to be able to post anything on the endpoint so in our case, authentication and authorization will be synonimous.<br/>
We can put the basic auth cerdentials in the url:
```
https://user:pass@sms.mywebhook.com
```
Also do please remember that on the app side we need to add the authorization header like so:<br/>
```json
{"Content-Type": "application/json"; "Authorization": "Basic base64-encoded-username:password"}
```
As for the url, use your endpoint without using the username and passwor in the URI.<br/>
### Dev works
You can find the finished code [here](https://github.com/terminaldweller/sms-webhook).<br/>
Here's a brief explanation of what the code does:<br/>
We launch the irc bot in a goroutine. The web hook server will only respond to POST requests on `/sms` after a successful basic http authentication.<br/>
In our case there is no reason not to use a randomized username as well. So effectively we will have two secrets this way. You can create a new user in the pocketbase admin panel. Pocketbase comes with a default collection for users so just create a new entry in there.<br/>
- The code will respond with a 401 for all failed authentication attempts.<br/>
- We dont fill out missing credentials for non-existant users to make timing attacks harder. Thats something we can do later.<br/>
### Deployment
```nginx
events {
worker_connections 1024;
}
http {
include /etc/nginx/mime.types;
server_tokens off;
limit_req_zone $binary_remote_addr zone=one:10m rate=30r/m;
server {
listen 443 ssl;
keepalive_timeout 60;
charset utf-8;
ssl_certificate /etc/letsencrypt/live/sms.terminaldweller.com/fullchain.pem;
ssl_certificate_key /etc/letsencrypt/live/sms.terminaldweller.com/privkey.pem;
ssl_ciphers HIGH:!aNULL:!MD5:ECDHE-ECDSA-AES128-GCM-SHA256:ECDHE-RSA-AES128-GCM-SHA256:ECDHE-ECDSA-AES256-GCM-SHA384:ECDHE-RSA-AES256-GCM-SHA384:ECDHE-ECDSA-CHACHA20-POLY1305:ECDHE-RSA-CHACHA20-POLY1305:DHE-RSA-AES128-GCM-SHA256:DHE-RSA-AES256-GCM-SHA384;
ssl_protocols TLSv1.2 TLSv1.3;
ssl_session_cache shared:SSL:50m;
ssl_session_timeout 1d;
ssl_session_tickets off;
ssl_prefer_server_ciphers on;
tcp_nopush on;
add_header X-Content-Type-Options "nosniff" always;
add_header Strict-Transport-Security "max-age=31536000; includeSubDomains" always;
add_header X-Frame-Options SAMEORIGIN always;
add_header X-XSS-Protection "1; mode=block" always;
add_header Referrer-Policy "no-referrer";
fastcgi_hide_header X-Powered-By;
error_page 401 403 404 /404.html;
location / {
proxy_pass http://sms-webhook:8090;
}
}
}
```
```yaml
version: "3.9"
services:
sms-webhook:
image: sms-webhook
build:
context: .
deploy:
resources:
limits:
memory: 256M
logging:
driver: "json-file"
options:
max-size: "100m"
networks:
- smsnet
restart: unless-stopped
depends_on:
- redis
volumes:
- pb-vault:/sms-webhook/pb_data
- ./config.toml:/opt/smswebhook/config.toml
cap_drop:
- ALL
dns:
- 9.9.9.9
environment:
- SERVER_DEPLOYMENT_TYPE=deployment
entrypoint: ["/sms-webhook/sms-webhook"]
command: ["serve", "--http=0.0.0.0:8090"]
nginx:
deploy:
resources:
limits:
memory: 128M
logging:
driver: "json-file"
options:
max-size: "100m"
image: nginx:stable
ports:
- "8090:443"
networks:
- smsnet
restart: unless-stopped
cap_drop:
- ALL
cap_add:
- CHOWN
- DAC_OVERRIDE
- SETGID
- SETUID
- NET_BIND_SERVICE
volumes:
- ./nginx.conf:/etc/nginx/nginx.conf:ro
- /etc/letsencrypt/live/sms.terminaldweller.com/fullchain.pem:/etc/letsencrypt/live/sms.terminaldweller.com/fullchain.pem:ro
- /etc/letsencrypt/live/sms.terminaldweller.com/privkey.pem:/etc/letsencrypt/live/sms.terminaldweller.com/privkey.pem:ro
networks:
smsnet:
driver: bridge
volumes:
pb-vault:
```
<p>
<div class="timestamp">timestamp:1706042815</div>
<div class="version">version:1.1.0</div>
<div class="rsslink">https://blog.terminaldweller.com/rss/feed</div>
<div class="originalurl">https://raw.githubusercontent.com/terminaldweller/blog/main/mds/lazymakefiles.md</div>
</p>
<br>
| terminaldweller | |
1,477,656 | You can become a super human | Odin #AI is a #revolutionary product that combines the latest in #artificialintelligence #technology... | 0 | 2023-05-23T14:09:25 | https://dev.to/getodinai/you-can-become-a-super-human-1nja | Odin #AI is a #revolutionary product that combines the latest in #artificialintelligence #technology with advanced #naturallanguageprocessing capabilities. Odin AI has something to offer everyone, from busy #professionals to #students.
| getodinai | |
1,477,851 | A custom action to deploy mdBook | What I built I built a Github action for automating the deployment of a compiled book. ... | 0 | 2023-05-23T15:37:35 | https://dev.to/raphaborges/a-custom-action-to-deploy-mdbook-n41 | githubhack23 | ## What I built
I built a Github action for automating the deployment of a compiled book.
### Category Submission:
DIY Deployments - DevOps & CI/CD
### App Link
https://github.com/Rapha-Borges/mdBook-action
### Screenshots
### Description
This Github action is designed to be triggered when a push occurs on the "main" branch of a repository. It performs a series of steps within a job named "build" on the latest version of the Ubuntu operating system.
The action utilizes a Docker container with the image "raphaelborges/mdbook:1.0.2" to compile a book located at the path "/github/workspace/book". It then executes a shell script named "copy.sh".
The "copy.sh" script creates a worktree, sets Git configuration, deletes and clears the "gh-pages" branch, copies files from specified directories, commits the changes, and pushes them to the "gh-pages" branch on the remote repository.
This action automates the process of compiling the book and deploying it to a designated location using custom settings, simplifying the workflow for users.
### Link to Source Code
https://github.com/Rapha-Borges/mdBook-action
### Permissive License
MIT License
## Background (What made you decide to build this particular app? What inspired you?)
I built this Github action to automate the deployment of ebooks using customized configurations that better meet the needs of the projects I am involved in. The motivation behind creating this action was to streamline the process and eliminate manual steps required for ebook deployment.
### How I built it (How did you utilize GitHub Actions or GitHub Codespaces? Did you learn something new along the way? Pick up a new skill?)
To build this Github action, I leveraged the power of GitHub Actions, which provides a flexible and robust platform for automating workflows. I utilized the "actions/checkout@v3" action to perform repository checkout and the "docker://" syntax to use a specific Docker container for compiling the book. The shell script, "copy.sh," was developed to handle the file copying and Git operations required for deployment.
During the development process, I gained valuable experience in utilizing GitHub Actions to orchestrate CI/CD workflows. I learned about Docker integration within GitHub Actions, enabling seamless execution of tasks in isolated environments.
### Additional Resources/Info
For more information about this project, please refer to the official repository at [https://github.com/Rapha-Borges/mdBook-action].
Additionally, you can find examples of usage and implementation at the following links: [https://github.com/badtuxx/DescomplicandoPrometheus], [https://github.com/rochacbruno/py2rs]. | raphaborges |
1,478,369 | The Art of Inferring with Large Language Models | Note: This is a documented version of ChatGPT Prompt Engineering for Developers course. You can find... | 0 | 2023-05-23T20:03:16 | https://dev.to/arkroot/the-art-of-inferring-with-large-language-models-243m | programming, beginners, ai, chatgpt | Note: This is a documented version of ChatGPT Prompt Engineering for Developers course. You can find the course [here](https://learn.deeplearning.ai/chatgpt-prompt-eng/lesson/1/introduction).
Inferring is a powerful tool that can be used to extract meaning from text. It can be used to understand customer feedback, to identify trends in social media.
Here are some examples of how inferring can be used in prompt engineering:
**Sentiment analysis**: Inferring can be used to identify the sentiment of a piece of text, such as whether it is positive, negative, or neutral. This can be used to understand customer feedback, identify trends in social media, and generate new ideas.
Eg: We can use sentiment analysis to categorize playstore reviews into positive, negative, or neutral reviews. This will help us to prioritise the issues mentioned in the reviews and identify the issues that need to be addressed. This will allow the customer support team to quickly identify and resolve issues, and the engineers to focus on fixing high priority bugs.
**Topic modeling**: Inferring can be used to identify the topics of a piece of text. This can be used to understand the content of a document, identify patterns in data, and generate new ideas.
**Named entity recognition**: Inferring can be used to identify named entities in a piece of text, such as people, places, and organizations. This can be used to understand the context of a document, identify potential customers, and generate new ideas.
For example, if you are running an e-commerce website and you have received reviews from consumers who have purchased from your website, you can use a large language model (LLM) to analyse the reviews and identify named entities, such as the shop name and product name. This information can then be used to improve the customer experience, such as by recommending similar products or providing customer support.
Section from the course starts here:
**In this article we will infer sentiment and topics from product reviews and news articles. **
```
lamp_review = """
Needed a nice lamp for my bedroom, and this one had \
additional storage and not too high of a price point. \
Got it fast. The string to our lamp broke during the \
transit and the company happily sent over a new one. \
Came within a few days as well. It was easy to put \
together. I had a missing part, so I contacted their \
support and they very quickly got me the missing piece! \
Lumina seems to me to be a great company that cares \
about their customers and products!!
"""
What is the sentiment of the following product review,
which is delimited with triple single quotes?
Review text: '''{lamp_review}'''
```
Output:

As you can see from the screenshot it's a long output. We can ask the LLM to either output positive / negative as keywords.
```
"""
What is the sentiment of the following product review,
which is delimited with triple single quotes?
Give your answer as a single word, either "positive" \
or "negative".
Review text: '''{lamp_review}'''
"""
```
Output:

we can ask an LLM to identify the emotions that the writer of a review is expressing. We can also ask the LLM if the writer is expressing any anger in their review. Additionally, we can ask the LLM to identify the company name and product name from the review. All of these tasks can be performed in a single prompt.
```
"""
Identify the following items from the review text:
- Sentiment (positive or negative)
- List all the emotions expressed in the review not more than 5
- Is the reviewer expressing anger? (true or false)
- Item purchased by reviewer
- Company that made the item
The review is delimited with triple backticks. \
Format your response as a JSON object with \
"Sentiment", "Anger", Emotions, "Item" and "Brand" as the keys.
If the information isn't present, use "unknown" \
as the value.
Make your response as short as possible.
Format the Anger value as a boolean.
Review text: '''{lamp_review}'''
"""
```

**Next topic in the course topic analysis 🙃.**
Inferring can be used to identify the topics of a piece of long text.
```
story = """
In a recent survey conducted by the government,
public sector employees were asked to rate their level
of satisfaction with the department they work at.
The results revealed that NASA was the most popular
department with a satisfaction rating of 95%.
One NASA employee, John Smith, commented on the findings,
stating, "I'm not surprised that NASA came out on top.
It's a great place to work with amazing people and
incredible opportunities. I'm proud to be a part of
such an innovative organization."
The results were also welcomed by NASA's management team,
with Director Tom Johnson stating, "We are thrilled to
hear that our employees are satisfied with their work at NASA.
We have a talented and dedicated team who work tirelessly
to achieve our goals, and it's fantastic to see that their
hard work is paying off."
The survey also revealed that the
Social Security Administration had the lowest satisfaction
rating, with only 45% of employees indicating they were
satisfied with their job. The government has pledged to
address the concerns raised by employees in the survey and
work towards improving job satisfaction across all departments.
"""
Determine five topics that are being discussed in the \
following text, which is delimited by triple backticks.
Make each item one or two words long.
Format your response as a list of items separated by commas.
Text sample: '''{story}'''
```
As you can see from the output we got different topics in the article that we gave to the LLM. This information can be used to recommend articles to users who are interested in those topics.
For example, Suppose if a user is subscribed to the topics "java, javascript, and AI," and the user wants to only receive article suggestions based on his/her subscription the LLM can be used to identify the topic and we could create a service that will send notifications when a new article on any of those topic comes.
Output:

| shanshaji |
1,478,486 | write a article on Cybersecurity for Blockchain: How to Detect and Respond to Blockchain Security Breaches | Introduction: Blockchain technology has gained immense popularity in recent years due to... | 0 | 2023-05-23T18:48:35 | https://dev.to/devtripath94447/write-a-article-on-cybersecurity-for-blockchain-how-to-detect-and-respond-to-blockchain-security-breaches-268k | blockchain, cybersecurity, tutorial | ### Introduction:
[Blockchain technology](https://advansappz.com/blockchain/) has gained immense popularity in recent years due to its decentralized and immutable nature, making it highly secure for data storage and transactions. However, like any other technology, blockchain is not immune to security breaches. As the adoption of blockchain continues to grow across various industries, the need for robust cybersecurity measures becomes crucial. In this article, we will explore the importance of [cybersecurity ](https://advansappz.com/cybersecurity/)in blockchain systems and discuss strategies to detect and respond to security breaches effectively.

### Understanding Blockchain Security:
**Blockchain fundamentals:** Provide a brief explanation of blockchain technology, emphasizing its decentralized and transparent nature. Highlight the importance of cryptographic techniques and consensus algorithms in ensuring security.
**Blockchain vulnerabilities:** Discuss potential vulnerabilities in blockchain networks, such as 51% attacks, consensus flaws, smart contract vulnerabilities, and human error. Explain how these vulnerabilities can lead to security breaches and compromise the integrity of the blockchain system.
### Detecting [Blockchain Security Breaches](https://advansappz.com/cybersecurity-for-blockchain-how-to-detect-and-respond-to-blockchain-security-breaches/):
**Network monitoring:** Emphasize the significance of real-time network monitoring to detect suspicious activities and anomalies. Discuss the role of network analysis tools and intrusion detection systems (IDS) in monitoring blockchain networks effectively.
**Node integrity verification:** Explain the concept of node integrity and the need for continuous verification. Describe techniques such as Merkle trees and hashing algorithms to verify the integrity of data stored in blockchain nodes.
**Anomaly detection:** Discuss the importance of anomaly detection techniques to identify irregular behaviors within a blockchain network. Highlight the use of machine learning algorithms, statistical analysis, and behavior-based anomaly detection to detect potential security breaches.
**Event logging and auditing:** Emphasize the importance of maintaining comprehensive event logs and conducting regular audits to identify any unauthorized activities or tampering attempts. Explain the role of cryptographic techniques in securing event logs and ensuring their integrity.

### Responding to Blockchain Security Breaches:
**Incident response plan:** Stress the significance of having a well-defined incident response plan specifically tailored for blockchain security breaches. Discuss the key components of an effective incident response plan, including roles and responsibilities, communication protocols, and coordination with relevant stakeholders.
**Isolation and containment:** Explain the immediate steps to isolate and contain the security breach to prevent further damage. Describe techniques such as network segmentation, isolating compromised nodes, and suspending affected smart contracts to limit the impact of the breach.
**Forensic investigation:** Discuss the importance of conducting a thorough forensic investigation to identify the root cause of the breach and collect evidence for legal purposes. Explain the role of blockchain forensics tools in analyzing transactions, tracing the origin of the breach, and identifying the responsible parties.
**Patching and system recovery:** Highlight the significance of promptly patching vulnerabilities and updating the blockchain system to prevent similar breaches in the future. Discuss the process of system recovery, including restoring data integrity and resuming normal operations while implementing necessary security enhancements.

### Conclusion:
In an increasingly digitized world, ensuring the security of blockchain systems is paramount. By understanding the vulnerabilities that can be exploited and implementing robust cybersecurity measures, organizations can effectively detect and respond to blockchain security breaches. Continuous network monitoring, anomaly detection, and node integrity verification are crucial for timely breach detection, while a well-defined incident response plan, forensic investigation, and system recovery procedures aid in effective response and recovery. As blockchain technology continues to evolve, so do the techniques employed by malicious actors. Therefore, it is essential to stay vigilant, adapt security measures accordingly, and collaborate with industry experts to safeguard the integrity and security of blockchain systems. | devtripath94447 |
1,478,539 | How to solve this problem? | How to solve this problem? | 0 | 2023-05-23T19:24:44 | https://dev.to/cadyrayller/how-to-solve-this-problem-3ja4 | How to solve this problem? | cadyrayller | |
1,478,627 | Create Tik-Tok/Youtube Shorts like snap infinite scroll - React | Scroll snap is when you scroll a little and it auto scrolls to the next card in the list. You must... | 0 | 2023-05-23T20:59:02 | https://dev.to/biomathcode/create-tik-tokyoutube-shorts-like-snap-infinite-scroll-react-1mca | webdev, javascript, beginners, react | ---
title: "Create Tik-Tok/Youtube Shorts like snap infinite scroll - React"
datePublished: Tue May 23 2023 13:36:49 GMT+0000 (Coordinated Universal Time)
cuid: cli0bljy8000b09l62g5qfwsx
slug: create-tik-tokyoutube-shorts-like-snap-infinite-scroll-react
cover: https://cdn.hashnode.com/res/hashnode/image/upload/v1681106230666/ed1b978f-93ee-4b66-847d-808d8fa9f140.jpeg
ogImage: https://cdn.hashnode.com/res/hashnode/image/upload/v1681106189200/6af2f69b-80d8-47af-85c0-deab8fb9c844.jpeg
---
Scroll snap is when you scroll a little and it auto scrolls to the next card in the list. You must have seen this feature on Instagram, youtube shorts and TikTok.
Snap Scroll can be achieved by CSS only. [https://developer.mozilla.org/en-US/docs/Web/CSS/scroll-snap-type](https://developer.mozilla.org/en-US/docs/Web/CSS/scroll-snap-type)

There are three ways to achieve this effect in react
1. Vanilla CSS
2. Styled Components
3. React-hook
Browser Compatibility of `scroll-snap-type` is great. All the browsers have stable support for it.
> Before you can define scroll snapping, you need to enable scrolling on a scroll container. You can do this by ensuring that the scroll container has a defined size and that it has [`overflow`](https://developer.mozilla.org/en-US/docs/Web/CSS/overflow) enabled.
You can then define scroll snapping on the scroll container by using the following two key properties:
* [`scroll-snap-type`](https://developer.mozilla.org/en-US/docs/Web/CSS/scroll-snap-type): Using this property, you can define whether or not the scrollable viewport can be snapped to, whether snapping is required or optional, and the axis on which the snapping should occur.
* [`scroll-snap-align`](https://developer.mozilla.org/en-US/docs/Web/CSS/scroll-snap-align): This property is set on every child of the scroll container and you can use it to define each child's snap position or lack thereof.
* (Using the [`scroll-snap-stop`](https://developer.mozilla.org/en-US/docs/Web/CSS/scroll-snap-stop) property, you can ensure that a child is snapped to during scrolling and not passed over.
* [`scroll-margin`](https://developer.mozilla.org/en-US/docs/Web/CSS/scroll-margin) properties on child elements that are snapped to during scrolling to create an outset from the defined box.) \[Optional\]
* Optional [`scroll-padding`](https://developer.mozilla.org/en-US/docs/Web/CSS/scroll-padding) properties can be set on the scroll container to create a snapping offset. \[Optional\]
### Vanilla CSS
The `scroll-snap-type` [CSS](https://developer.mozilla.org/en-US/docs/Web/CSS) property sets how strictly snap points are enforced on the scroll container if there is one.
For the snap-scroll to work properly, we will have a Container and Children. the container will have the `scroll-snap-type` CSS property and the Children will have the `scroll-snap-align` CSS property.
```css
scroll-snap-type: x mandatory;
scroll-snap-type: y proximity;
```
x and y will constrain the scroll-snap action to the x-axis and y-axis.
**Mandatory** means the scroll will always rest on the scroll-snap point( video component ).
**Proximity** is based on the proximity of the scroll-snap point/Children. Scroll container **may** come to rest on a snap point if it isn't currently scrolled considering the user agent's scroll parameters
Let's start with simple HTML structure.
```xml
<!-- Scroll Container Component -->
<div class="container" dir="ltr">
<!-- List Component -->
<div id="list">
</div>
<!-- Loader Component -->
<p id="watch_end_of_document" class="loader">
Loader ...
</p>
</div>
```
```css
.container {
height: 100vh;
scroll-snap-type: y mandatory;
overflow: scroll;
}
.item {
margin: 0;
padding: 20px 0;
text-align: center;
scroll-snap-align: start;
height: 300px;
}
.loader {
height: 50px;
display: flex;
background: #eee;
justify-content: center;
}
.item:nth-child(even) {
background: #eee;
}
```
#### How does infinite scroll work?
Whenever the loader component comes into view, we run a fetch function.
```javascript
// Get the Loader Component
const loader = document.getElementById("loader")
// addItems - can also be fetch function
function addItems() {
const fragment = document.createDocumentFragment();
for (let i = index + 1; i <= index + count; ++i) {
const item = document.createElement("p");
item.classList.add("item");
item.textContent = `#${i}`;
fragment.appendChild(item);
}
document.getElementById("list").appendChild(fragment);
index += count;
}
// Using the IntersectionObserver API we will observe the loader component
// if the
const io = new IntersectionObserver(entries => {
entries.forEach(entry => {
// componet is not in view we do nothing
if (!entry.isIntersecting) {
return;
}
console.log('this is working');
addItems();
});
});
io.observe(loader);
```
{% codepen https://codepen.io/pratiksharma15/pen/abRQXKj %}
### Styled Components
Let's use Styled Components in React to do the same. Starting with the list Container Component which would have `scroll-snap-type` and `overflow-y` .
```javascript
import styled from "styled-components";
const List = styled.div`
max-height: 100vh;
overflow-y: scroll;
scroll-snap-type: y mandatory;
background: #fff;
display: flex;
flex-direction: column;
gap: 20px;
scrollbar-width: none;
&::-webkit-scrollbar {
display: none; /* for Chrome, Safari, and Opera */
}
`;
```
I used `&::-webkit-scrollbar` to hide the scrollbar.
Now, the Item component would have the `scroll-snap-align` CSS property.
```javascript
const Item = styled.div`
margin: 0;
padding: 20px 0px;
text-align: center;
display: flex;
justify-content: center;
align-items: center;
align-content: center;
scroll-snap-align: start;
min-height: 70vh;
background: #eee;
`;
```
Now, to we are done with the scroll-snap.
#### Infinite scroll with styled-component
1. Create a Loader Component
2. We are going to use the `reack-hook-inview` to observe if the loader is in the viewport
3. If the Loader is in the viewport, fetch more items.
```javascript
const Loader = styled.div`
min-height: 20vh;
margin-bottom: 30px;
display: flex;
background: #444;
scroll-snap-align: start;
color: #eee;
align-content: center;
align-items: center;
scroll-snap-align: start;
justify-content: center;
`;
```
```javascript
function ScrollContainer() {
const [state, setState] = useState([1, 2, 3, 4, 5]);
return (
<List>
{state.map((el, index) => (
<Item key={index + el}>{el} </Item>
))}
<Loader >Loading...</Loader>
</List>
);
}
export default ScrollContainer;
```
`react-hook-inview` provides `useInView` hook, which we can use to observe the loader component.
We are going to use `useEffect` , if the Loader is in the viewport. We Fetch more data.
```javascript
function ScrollContainer() {
...
const [ref, isVisible] = useInView({
threshold: 1
});
const newData = [...Array(10).keys()].map((x) => x + state.length + 1);
useEffect(() => {
if (isVisible) {
setState((state) => [...state, ...newData]);
}
}, [isVisible]);
return (
<List>
{state.map((el, index) => (
<Item key={index + el}>{el} </Item>
))}
<Loader ref={ref}>Loading...</Loader>
</List>
);
}
```
That's it 🔥 . Here is CodeSandbox with all the code
{% codesandbox https://codesandbox.io/embed/infinite-scroll-snap-with-styled-components-nnmnom?fontsize=14&hidenavigation=1&theme=dark %}
### React Hooks
We are going to use [react-use-scroll-snap](https://www.npmjs.com/package/react-use-scroll-snap?activeTab=readme) . `react-use-scroll-snap` Give us simple API and keyboard accessibility as well. It uses the tweezer.js library.
```javascript
import useScrollSnap from "react-use-scroll-snap";
import { useRef } from "react";
function ScrollComponent() {
const scrollRef = useRef(null);
const data = Array(10)
.fill(1)
.map((i, e) => e + 1);
useScrollSnap({ ref: scrollRef, duration: 100, delay: 50 });
return (
<section className="container" ref={scrollRef}>
{data.map((el, index) => (
<div key={el} className="item">
{el}
</div>
))}
</section>
);
}
```
See, less code 🙌🏻. Here is the code Sandbox for you to fork it. Try to add a loader component, add a fetch function and `useEffect` to call the fetch function.
{% codesandbox https://codesandbox.io/embed/react-use-scroll-snap-example-f3ndfw?fontsize=14&hidenavigation=1&theme=dark %}
#### Further Improvement:
1. Add Auto-play with [Intersection Observer API](https://developer.mozilla.org/en-US/docs/Web/API/Intersection_Observer_API)
#### Reference:
1. [https://developer.mozilla.org/en-US/docs/Web/CSS/CSS\_Scroll\_Snap/Basic\_concepts](https://developer.mozilla.org/en-US/docs/Web/CSS/CSS_Scroll_Snap/Basic_concepts)
2. [https://developer.mozilla.org/en-US/docs/Web/CSS/CSS\_Scroll\_Snap](https://developer.mozilla.org/en-US/docs/Web/CSS/CSS_Scroll_Snap)
3. [https://developer.mozilla.org/en-US/docs/Web/CSS/scroll-snap-type#try\_it](https://developer.mozilla.org/en-US/docs/Web/CSS/scroll-snap-type#try_it) | biomathcode |
1,478,668 | Influencer marketing manager in 2023 | Yes, you’ve got that right – any business looking to collaborate with social media personalities... | 0 | 2023-05-23T23:00:41 | https://dev.to/alexrocky587/influencer-marketing-manager-in-2023-58d6 | management, marketing, digitalworkplace, tutorial |

Yes, you’ve got that right – any business looking to collaborate with social media personalities needs a reliable Influencer Marketing Manager to make things right! In this piece, we’d like to shed light on this marketing role and provide you with some handy resources so that you can remain a strong player in this game.
**Who is an Influencer Marketing Manager?**
An Influencer Marketing Manager is a person who brings brands and Influencers together. In fact, this is a career where creativity meets strategy because they do not only build partnerships but also manage communications and coordinate campaigns to maximize the results.
This is a challenging role requiring several important skills and qualities:
- Adaptability: staying up-to-date on the latest social media trends helps identify potential Influencers who will resonate with your target audience.
- Creativity: Coming up with creative solutions for campaigns requires out-of-the-box thinking. It’s important to come up with engaging content ideas to make campaigns stand out from the rest.
- Organizational skills: With multiple projects going on at once, having strong organizational skills is essential to succeeding as an Influencer Marketing Manager. This helps keep everything running smoothly without any hiccups.
- Networking abilities: Networking plays a huge part in finding great collaborations between brands and Influencers, so having excellent communication abilities is a must.
- Analytical mindset: Data analysis allows managers to evaluate performance metrics and use these insights strategically in the long run.
**Job market overview**
The Influencer marketing job market is gaining momentum as businesses seek an experienced specialist to manage their campaigns and maximize their reach. It’s a great time for anyone with the skill set to get into this rapidly growing industry.
A popular job and recruiting website, [Glassdoor](https://www.glassdoor.com/), displays 1,300+ job ads available in the U.S. that match the query “influencer marketing manager”.
Interestingly, female representation in marketing, and influencer marketing in particular, is higher. The stats provided by Influencer Marketing Hub highlight that women make up [60% of marketing professionals](https://influencermarketinghub.com/female-influencer-marketing-agencies/), also dominating on the management level. The most popular industries with strong marketing female representation include real estate, wellness and health care.
Speaking of salaries for this position, they range from comfortable to downright high, depending on the company size, industry, experience levels, etc. According to Glassdoor, to date, the average Influencer Marketing Manager’s salary in the U.S. is $79,236/year.
Another provider of valuable HR insights, Salary.com, mentions even higher average salaries in the U.S.:
So, it’s no surprise that an Influencer Marketing Manager can expect to earn a good salary that is commensurate with the work required and the impact they can have on campaigns.
**Job responsibilities**
Now that you know who an Influencer Marketing Manager is, let’s discuss the key job responsibilities that this specialist needs to bring your business into the spotlight:
**Recruiting new talents**
Identifying the right Influencer is essential if you want your campaigns to reach their full potential. Being a manager means having a sharp eye,creative approach and constantly researching industry trends. This helps to unmistakably find social media personalities who can bring their unique perspective and create content that resonates with your target audiences.
**Developing content strategy**
Influencer Marketing Managers stand behind all Iinfluencers’ content strategies. They know how to make sure that the message is delivered in an engaging and entertaining way. From crafting captivating copy to curating compelling visuals, these professionals ensure that each campaign goes viral and reaches its target audience with maximum impact.
**Negotiating deals with influencers**
A big part of success in this field involves knowing how to find the perfect balance between what an Influencer wants and what a brand needs. As a manager, you should have excellent communication skills and define clear goals to ensure both parties leave the table feeling like they got a good deal. Plus, it’s super vital to draw up contracts and agreements correctly so there are no pitfalls or unwanted surprises in the future.
**Coordinating efforts with teammates**
As the ultimate team players, managers know how to bring everyone together and coordinate team efforts. From brainstorming innovative strategies to delegating tasks, Influencer Marketing Managers make sure every contributor is on the same page and working towards a common goal.
Tracking campaign performance
Managers leverage variousf tools to investigate campaign performance and track down metrics. This is key to understanding what strategies need improvement and where resources should be allocated for maximum impact.
At Hypetrain, we strive to simplify the work of Influencer Marketing Managers to free them from repetitive manual tasks and provide them more space for generating creative ideas. As such, the Hypetrain platform aims to automate each step mentioned above. We actively work on the automation of the complete manager’s journey, so don’t hesitate to enjoy a hassle-free ride with [Hypetrain. ](https://hypetrain.io/)
This article was originally [published](https://blog.hypetrain.io/influencer-marketing-manager-in-2023/).
| alexrocky587 |
1,478,733 | Introducing Terminal-Chat-App: Chat, Create, and Join Public Chat Rooms from the Command Line | What I built The Terminal Chat App is a command-line chat application that allows users to... | 0 | 2023-05-23T23:56:09 | https://dev.to/hayatscodes/introducing-terminal-chat-app-chat-create-and-join-public-chat-rooms-from-the-command-line-291 | githubhack23 | ## What I built
The Terminal Chat App is a command-line chat application that allows users to join public chat rooms and chat from the command-line interface. Users can also create new chat rooms and interact with other users in real-time
### Category Submission: Wacky Wildcards
### App Link
https://www.npmjs.com/package/tarminal-chat-app
### Screenshots
##### Video demo
https://youtu.be/GfpvChlPq3g
### Description
The Terminal Chat App is a command-line chat application that allows users to join public chat rooms and chat from the command-line interface. Users can also create new chat rooms and interact with other users in real-time
Features:
Command-line interface
Join public chat rooms
Create public chat rooms
Chat in real-time
User authentication
### Link to Source Code
https://github.com/HayatsCodes/terminal-chat-app
### Permissive License
[MIT](https://choosealicense.com/licenses/mit/)
## Background (What made you decide to build this particular app? What inspired you?)
As a software engineer looking for my first job, I wanted to be challenged and get out of my comfort zone by building a novel real-life project. I actually had the idea before the hackathon but procrastinated. However, the hackathon refueled me to build the project.
### How I built it (How did you utilize GitHub Actions or GitHub Codespaces? Did you learn something new along the way? Pick up a new skill?)
I'd never heard of GitHub codespaces before the hackathon, and I got to find out what I'd been missing all along. It was at least 3X faster than my normal local workspace because of the dedicated virtual machines of up to 32 cores (I used the 2-core machine, and it was still significantly faster than my machine). I loved the fact that I used the default Linux image and didn't need to configure the workspace to get stuff done. I was so excited about GitHub codespaces that I posted about it on LinkedIn and also wrote an article about it on DEV. It was fun building on GitHub codespaces and I'm glad to have discovered it through this hackathon. I only used GitHub actions to automate the server's API test.
### Additional Resources/Info
The server was deployed to railway.app while the user interface was published on the NPM registry. | hayatscodes |
1,478,764 | Como utilizar ferramentas de automação de mídias sociais para melhorar sua presença online e aumentar o alcance do seu blog | Se você é um blogueiro ou dono de uma empresa, é fundamental ter uma presença online forte e ativa... | 0 | 2023-06-13T11:14:02 | https://dev.to/marlonfrade/como-utilizar-ferramentas-de-automacao-de-midias-sociais-para-melhorar-sua-presenca-online-e-aumentar-o-alcance-do-seu-blog-1ei | webdev, blog, cms | Se você é um blogueiro ou dono de uma empresa, é fundamental ter uma presença online forte e ativa nas mídias sociais. No entanto, manter todas as suas contas de mídia social atualizadas pode ser uma tarefa árdua e consumir muito tempo. É aí que entram as ferramentas de automação de mídias sociais.
Essas ferramentas permitem que você agende suas postagens com antecedência, analise o desempenho de suas contas, monitore as menções de sua marca e muito mais. Isso pode economizar uma quantidade significativa de tempo e esforço, permitindo que você se concentre em outras áreas importantes do seu blog ou empresa.
Neste artigo, vamos dar uma olhada em algumas das melhores ferramentas de automação de mídias sociais disponíveis e como você pode usá-las para melhorar sua presença online.
## 1. Hootsuite
Hootsuite é uma das ferramentas de automação de mídias sociais mais populares e conhecidas. Com o Hootsuite, você pode gerenciar várias contas de mídia social em uma única plataforma. Ele permite que você agende postagens, monitore menções, acompanhe a análise de suas contas e muito mais. Além disso, ele oferece uma ampla gama de integrações com outras ferramentas de marketing.
## 2. Buffer
O Buffer é outra ferramenta popular de gerenciamento de mídia social. Ele permite que você agende postagens para várias contas de mídia social, além de oferecer análises detalhadas sobre o desempenho de suas contas. O Buffer também tem integrações com outras ferramentas de marketing, como o Google Analytics.
## 3. Sprout Social
O Sprout Social é uma ferramenta de gerenciamento de mídia social mais avançada, com recursos de monitoramento e análise aprimorados. Ele permite que você agende postagens, monitore menções, acompanhe as análises de suas contas e muito mais. Além disso, ele oferece uma gama de recursos avançados, como relatórios personalizados, análises de concorrentes e gerenciamento de equipe.
## 4. CoSchedule
O CoSchedule é uma ferramenta de gerenciamento de marketing all-in-one que inclui recursos de gerenciamento de mídia social. Ele permite que você agende postagens, crie um calendário de conteúdo, analise o desempenho de suas contas e muito mais. O CoSchedule também tem integrações com outras ferramentas de marketing, como o WordPress e o Google Analytics.
## 5. MeetEdgar
MeetEdgar é uma ferramenta de automação de mídias sociais que se concentra na reutilização de conteúdo. Ele permite que você organize seu conteúdo em categorias e, em seguida, agende as postagens para que o conteúdo seja compartilhado regularmente. Isso é particularmente útil se você tiver um blog com um grande volume de conteúdo já publicado.
Conclusão:
As ferramentas de automação de mídias sociais podem economizar muito tempo e esforço, permitindo que você se concentre em outras áreas importantes do seu | marlonfrade |
1,479,051 | Big Countries | LeetCode | MSSQL | The Problem The challenge involves the table World. World table: name... | 20,410 | 2023-05-27T17:28:00 | https://dev.to/ranggakd/big-countries-leetcode-mssql-2190 | leetcode, mssql, codenewbie, beginners | ## The Problem
The challenge involves the table `World`.
`World` table:
| name (PK) | continent | area | population | gdp |
|-----------|-----------|---------|------------|---------|
| varchar | varchar | int | int | bigint |
Each row of this table provides information about a country, including its continent, area, population, and GDP. We define a country as "big" if it has an area of at least 3 million km2 or a population of at least 25 million.
The task is to write an SQL query that reports the name, population, and area of the "big" countries.
## Explanation
Here's an example for better understanding:
Input:
`World` table:
| name | continent | area | population | gdp |
|-------------|-----------|---------|------------|--------------|
| Afghanistan | Asia | 652230 | 25500100 | 20343000000 |
| Albania | Europe | 28748 | 2831741 | 12960000000 |
| Algeria | Africa | 2381741 | 37100000 | 188681000000 |
| Andorra | Europe | 468 | 78115 | 3712000000 |
| Angola | Africa | 1246700 | 20609294 | 100990000000 |
Output:
| name | population | area |
|-------------|------------|---------|
| Afghanistan | 25500100 | 652230 |
| Algeria | 37100000 | 2381741 |
Afghanistan and Algeria are considered "big" countries as their population or area exceeds the defined thresholds.
## The Solution
Let's explore two SQL solutions to this problem, examining their differences, strengths, and weaknesses.
### Source Code 1
The first solution retrieves countries from the table where the area is at least 3 million or the population is at least 25 million.
```sql
SELECT
name,
population,
area
FROM
World
WHERE
area >= 3000000
OR
population >= 25000000
```
This query achieves a runtime of 904ms, outperforming 92.98% of other submissions.
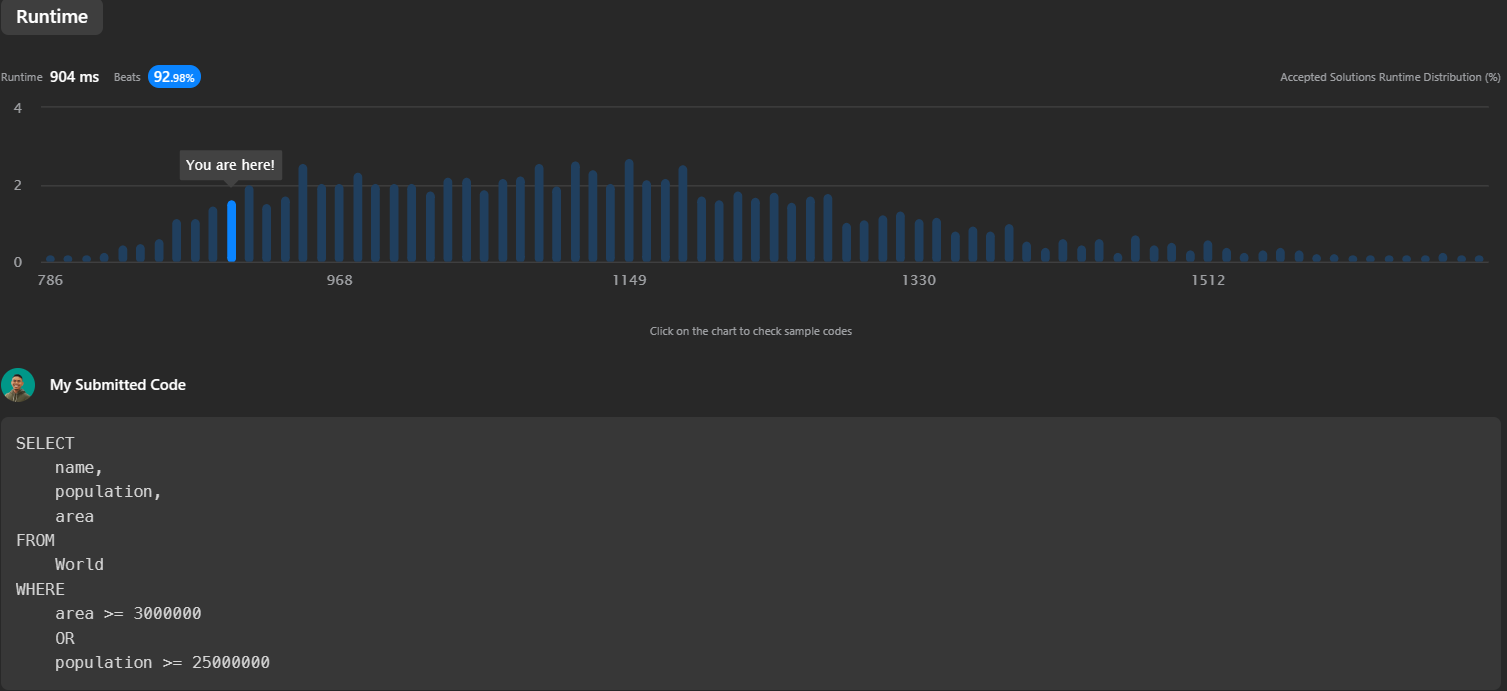
### Source Code 2
The second solution is very similar to the first, but it first checks for the population condition before the area condition.
```sql
SELECT
name,
population,
area
FROM
World
WHERE
population >= 25000000
OR
area >= 3000000
```
This query has a runtime of 983ms, beating 78.89% of other submissions.
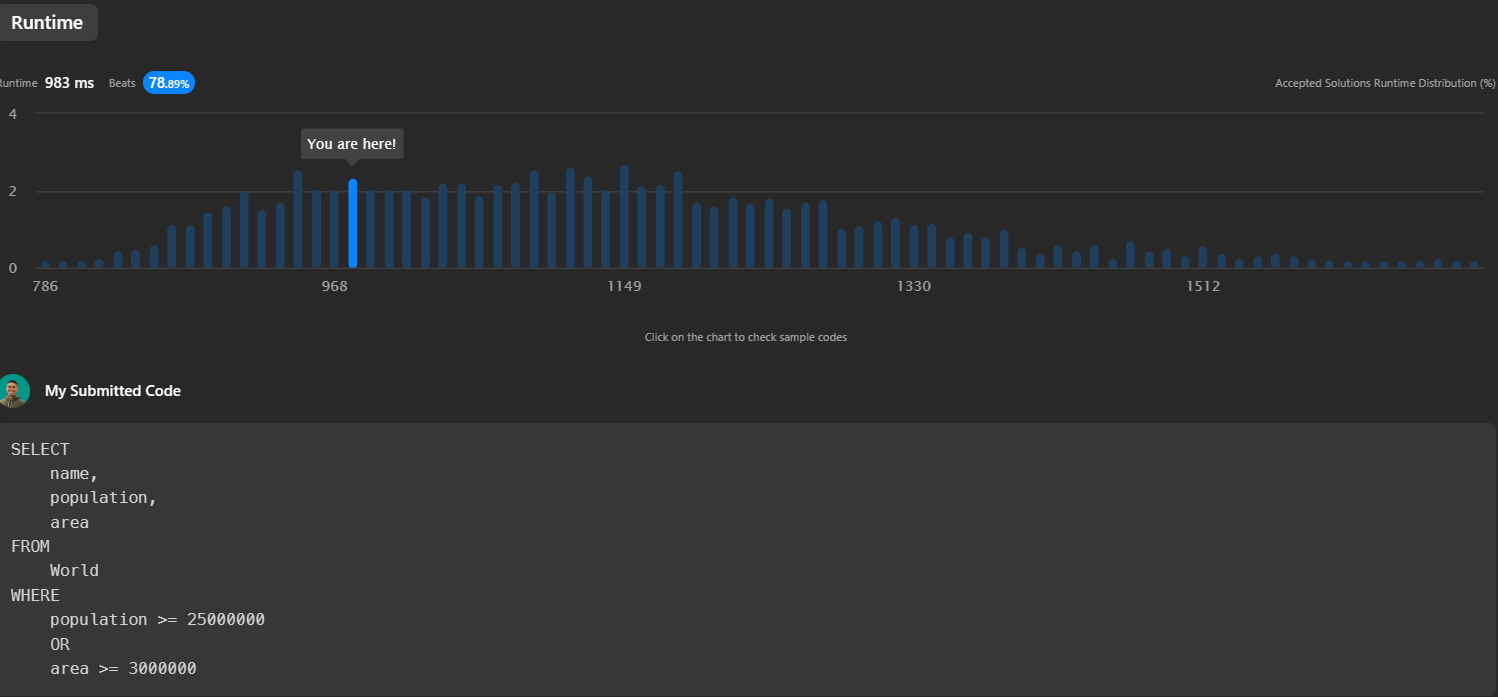
## Conclusion
Both solutions yield the same output but have minor performance differences due to the order of conditions in the WHERE clause. Thus, the ranking of solutions based on overall performance, from best to worst, is: Source Code 1 > Source Code 2.
You should choose the solution that best fits your specific performance requirements and expectations.
You can find the original problem at [LeetCode](https://leetcode.com/problems/big-countries/description/).
For more insightful solutions and tech-related content, connect with me on my [Beacons page](https://beacons.ai/ranggakd).
{% embed https://beacons.ai/ranggakd %} | ranggakd |
1,479,200 | I buy it ? | A post by FrostBlack | 0 | 2023-05-24T09:23:29 | https://dev.to/webfrostblack/i-buy-it--4fd5 |
 | webfrostblack | |
1,479,383 | Proxies: Enabling Ethical, Clean, and Secure Big Data Collection | The 21st century has brought with it a world of technology, where companies gather immense data... | 0 | 2023-05-24T12:50:18 | https://dev.to/dexodata/proxies-enabling-ethical-clean-and-secure-big-data-collection-38e2 | datasecurity, datasafety, trustedproxies, dexodata |

The 21st century has brought with it a world of technology, where companies gather immense data from diverse sources. This crucial information provides insights into market trends and consumer behavior, making it a valuable tool for research, marketing, and competition. However, dealing with all the ever-changing regulations can make it tough for companies of all sizes to use this data effectively. Lost in an ocean of rules, businesses struggle to maintain data security and accuracy. But fear not! There are solutions out there. Companies need to prioritize consumer privacy and adhere to regulatory measures while **collecting and using big data**. One such solution is **trusted proxy website**, which helps them establish ethical industry standards and ensure data safety.
# Proxy’s Indispensability for Data Gathering
Behold, **proxies are strong allies** employed by diverse industries. Data warriors have now realized their potential even in the face of big data. Proxies, as intermediaries between computers, grant secrecy to requests while also serving as “servers” to incoming data — reducing load and streamlining requests. Even in the face of large data-centered websites, load is reduced, ensuring optimal server function and a smooth experience for all users.
Amidst big data collection, proxies carefully collect, clean, and safeguard datasets. Shielding from sly attempts to infiltrate confidential info within the network. Besides, they enable a preliminary traffic scan of external sources, ensuring only legit requests reach their destination. Hence blocking any potentiality of threats from outside forces.
# Defining a Trusted Proxy Provider
To gather swathes of data, incorporating effective proxy sourcing helps channel the treasure trove of information to your fingertips. To ensure a smooth performance in the collection phase, it’s important to select a certified and dependable provider that offers you quality home and mobile proxies with lightning-fast speed and unlimited capability. As you embark on this journey, keep an eye out for a reliable provider that’s right for you. **Dexodata** is one such names that does not disappoint, offering a free trial period to attest to its impeccable services, so you can confidently take the next step without hurting your budget.
When choosing a trusted proxy website, don’t overlook their customer support! Look for a reliable website that offers expert technical assistance alongside comprehensive knowledge base articles. If you encounter any technical snags in the future, they’ll be there to help, with speedy and convenient resolutions. Whether through their vast expertise or helpful resources, you won’t be stuck waiting for days to restore your connectivity. So go ahead and pick a proxy provider you can trust to take care of you!
# Norms and Standards
In today’s world, handling personal information ethically during big data collection is of utmost importance. Compliance regulations, like **GDPR** in Europe, are becoming more common globally. Businesses operating in these jurisdictions need to ensure that collected data is secure and follows the compliance regulations; otherwise, hefty fines could be levied against their company for any infractions committed. Unlawful access to client personal information hurts businesses so it’s only smart to stay compliant and protect users and clients’ data.
When gathering big data, businesses utilizing proxies must follow more rules and regulations aside from **GDPR**. Such norms and practices have surfaced in the past few years and revolve around ethical, hygienic, and secure procedures to guarantee responsible data collection.
For example, **ISO/IEC 27001** and **27701** standards provide guidance on information security management practices, and **PCI DSS** prevents expensive data breaches and protects sensitive financial information.
Other regulations such as **FATF, CCPA, PIPEDA** and **LGPD** establish rules for handling and storing personal data, consent requirements, and promote transparency, security and accountability of organizations’ processes.
Very importantly, these standards and requirements encourage responsible data collection, privacy protection and security measures, which are fundamental aspects of big data collection. As IT professionals, we need to know and honor these rules to ensure a better future for privacy and data security, and thus for the IT market as a whole.

By implementing trusted proxies into the existing infrastructure prior to large-scale transactions involving the exchange of sensitive personal information between parties (e.g. vendors supplying products/services to customers) organizations ensure proper compliance with applicable rules/regulations. They also **protect themselves from potentially costly litigation and disputes** arising from proxy breaches that were not resolved in advance when dealing with sensitive information to protect against leaks. This way you can avoid the negative publicity in the media that may result from data breaches, privacy breaches, unethical practices or security incidents. Bad press can break long-term relationships between parties who regularly share information over open networks (such as shared Internet backbones).
Companies that aim to outperform rivals while safeguarding customer trust and complying with data security regulations, should regularly maintain high-end proxies. This also helps to easily and securely handle large data sets that contain sensitive personal information exchanged across multiple organizations. By using a high-quality trusted proxy website **Dexodata** and complying with local and international laws, you can lay a strong foundation for your success in this exciting business! | dexodatamarketing |
1,479,496 | Create a C# QR Code Generator (Easy) + GitHub Repository✨ | Quick Response (QR) codes have become an essential part of modern society, and you’ll find them... | 0 | 2023-05-24T14:50:40 | https://www.bytehide.com/blog/qr-generator-csharp | csharp, dotnet, tutorial, beginners | Quick Response (QR) codes have become an essential part of modern society, and you’ll find them almost everywhere. In this guide, we’re going to create a clean and simple C# QR code generator, along with a nice UI using Windows Forms. Buckle up, my fellow C# enthusiasts, and let’s dive into some real-deal programming! 🚀
_You will find the GitHub Repo at the end_
## Overview
Before we start developing our QR code generator, let’s get an overview of our end goal. We’ll be creating a Windows Forms application that’ll allow users to input text and generate a QR code from that text. They can then view and save the QR code, all within a user-friendly interface.
### Prerequisites
To follow this guide, you should have an understanding of:
- Basic C# programming concepts
- Windows Forms framework
- Visual Studio or installed
- ZXing.Net library installed
Can’t wait to start coding? Me either! But first, let’s complete some installations.
## Installation
### Install Visual Studio
If you haven’t already, download and install [Visual Studio](https://visualstudio.microsoft.com/downloads/).
### Install the ZXing.Net library
We’ll use the ZXing.Net library for QR code generation. To install it, open your project in Visual Studio, and install it via the NuGet Package Manager.
```
PM> Install-Package ZXing.Net
```
Now that we’ve got everything installed, let’s start building our project.
### Setting up your project
Create a new Windows Forms project
In Visual Studio, create a new Windows Forms project, and name it “QRCodeGenerator”.

We’ll start by adding necessary references and modifying the .csproj file.
### Add required references
Right-click on your project in the Solution Explorer, and add the following references:
- System.Drawing
- System.Windows.Forms
### Modify the project’s .csproj file
Open the project’s `.csproj` file and add the following line inside the `<ItemGroup>` tag to include the ZXing.Net library:
```csharp
<PackageReference Include="ZXing.Net" Version="0.16.5" />
```
Now let’s set up the UI!
## Designing the User Interface
The interface will be clean and simple. We’ll have a textbox for input, a button to generate the QR code, a picturebox for display, and another button for saving the QR code image.
Use the Toolbox that you will have at the left side:
### Designing the main form
Using the Visual Studio’s Windows Forms Designer, design your form to your satisfaction. You can use a simple layout panel for arrangement.
### Add a TextBox for the containing input text
Add a TextBox to the form where users can input the text to be converted into a QR Code. You can adjust the TextBox size and anchors as needed.
### Add a PictureBox for displaying the QR code
Now it’s time to add a PictureBox to display the generated QR code. Set the `SizeMode` property to `AutoSizeMode.CenterImage`. This will keep the QR code centered in the PictureBox.
### Add Buttons for generating and saving QR codes
We need two buttons: one to generate the QR code, and one to save it. Set the click event handlers accordingly.
### Add a Label for providing user instructions
It’s always a good idea to guide the user. Add a label explaining how to use the application.
_Yeah, the design is amazing, I know_ 😎
Now, let’s do the fun part — writing code!
### Implementing QR Code Generation
Get ready to bring the app to life! We’ll start by writing a method to generate a QR code.
### Write the method to generate a QR code
This is where ZXing.Net does the heavy lifting. Add the following method:
```csharp
static Bitmap GenerateQRCode(string inputText)
{
var barcodeWriter = new ZXing.BarcodeWriterPixelData
{
Format = ZXing.BarcodeFormat.QR_CODE,
Options = new ZXing.Common.EncodingOptions
{
Width = 300,
Height = 300
}
};
}
```
### Connect the method to the Generate button events
Let’s wire up the Generate button to call our method:
```csharp
private void BtnGenerate_Click(object sender, EventArgs e)
{
if (string.IsNullOrEmpty(TextBox1.Text))
{
MessageBox.Show("Please enter some text first.");
return;
}
var qrCode = GenerateQRCode(TextBox1.Text);
PictureBox1.Image = qrCode;
}
```
So, you’ve managed to generate your QR code, but what about saving it? Don’t worry, we’ve got you covered!
## Implementing QR Code Saving
We’ll write a method to save the generated QR code and wire it up to the Save button.
### Write the method to save a QR code
Here’s a method that saves the QR code using a SaveFileDialog:
```csharp
private void SaveQRCode()
{
using var saveFileDialog = new SaveFileDialog
{
Filter = "PNG Files (*.png)|*.png",
FileName = "QRCode.png"
};
if (saveFileDialog.ShowDialog() == DialogResult.OK)
{
PictureBox1.Image.Save(saveFileDialog.FileName, ImageFormat.Png);
MessageBox.Show("QR Code saved successfully!");
}
}
```
### Connect the method to the Save button events
With our method in place, let’s connect it to the Save button:
```csharp
private void BtnSave_Click(object sender, EventArgs e)
{
if (PictureBox1.Image == null)
{
MessageBox.Show("Please generate a QR code first.");
return;
}
SaveQRCode();
}
```
And there it is! Your QR code generator is complete! 🎉 How about we make it a bit fancier, huh?

## Customizing the QR Code Generator
Why not give users some options? Let’s add some cool customization features.
### Customize QR code size
You can allow users to set the size of the QR code image with a NumericUpDown control. Update the `GenerateQRCode()` method to account for user-defined width and height.
```csharp
private Bitmap GenerateQRCode(string inputText, int width, int height)
{
var barcodeWriter = new ZXing.BarcodeWriter
{
Format = ZXing.BarcodeFormat.QR_CODE,
Options = new ZXing.Common.EncodingOptions
{
Width = width,
Height = height
}
};
var qrImage = barcodeWriter.Write(inputText);
return qrImage;
}
```
### Customize QR code colors
Why not let users choose their QR code colors? Add two color dialog controls to the form and update the `GenerateQRCode()` method like this:
```csharp
private Bitmap GenerateQRCode(string inputText, int width, int private Bitmap GenerateQRCode(string inputText, int width, int height, Color foreground, Color background)
{
var barcodeWriter = new ZXing.BarcodeWriter
{
Format = ZXing.BarcodeFormat.QR_CODE,
Options = new ZXing.Common.EncodingOptions
{
Width = width,
Height = height
},
Renderer = new ZXing.Rendering.BitmapRenderer
{
Foreground = foreground,
Background = background
}
};
var qrImage = barcodeWriter.Write(inputText);
return qrImage;
}
```
### Customize error correction level
QR codes usually have error-correction capabilities. Give users the power to set the error correction level with a ComboBox control. Update the `GenerateQRCode()` method accordingly:
```csharp
private Bitmap GenerateQRCode(string inputText, int width, int height, Color foreground, Color background, ZXing.QrCode.Internal.ErrorCorrectionLevel errorCorrectionLevel)
{
var barcodeWriter = new ZXing.BarcodeWriter
{
Format = ZXing.BarcodeFormat.QR_CODE,
Options = new ZXing.QrCode.QrCodeEncodingOptions
{
Width = width,
Height = height,
ErrorCorrection = errorCorrectionLevel
},
Renderer = new ZXing.Rendering.BitmapRenderer
{
Foreground = foreground,
Background = background
}
};
var qrImage = barcodeWriter.Write(inputText);
return qrImage;
}
```
### Offer additional features
Your QR code generator is already great, but feel free to add even more features:
- Support for different image formats (JPEG, GIF, BMP, etc.)
- Support for reading QR codes from images
- Integration of a live camera feed to read QR codes in real-time
## Conclusion
### Key takeaways
Congrats, you’ve created an awesome QR code generator! 👏 You’ve learned how to:
- Set up a Windows Forms project
- Design a user-friendly interface
- Use the ZXing.Net library to generate and customize QR codes
### Further resources
Building your QR code generator app was fun, right? Here are some resources to learn more and dive deeper:
- [Windows Forms documentation](https://docs.microsoft.com/en-us/dotnet/desktop/winforms/?view=netdesktop-5.0)
- [ZXing.Net on GitHub](https://github.com/micjahn/ZXing.Net)
## Next steps
Now it’s time to show off your creation to friends, family, and colleagues! Give yourself a pat on the back — you did a fantastic job!
Don’t stop here, though. Continue exploring the amazing world of C# programming and Windows Forms development. Who knows what else you might create? 😎
**Github Repo:** [C# QR Code Generator](https://github.com/dotnetsafer/Csharp-QR-Generator) | bytehide |
1,479,586 | Give an eye to VanJS, it costs nothing and you could be surprised | VanJS (abbr. Vanilla JavaScript) is an ultra-lightweight, zero-dependency and unopinionated Reactive... | 23,075 | 2023-05-24T16:07:02 | https://dev.to/artydev/give-an-eye-to-vanjs-it-costs-nothing-and-you-could-be-surprised-4n6 | vanjs | _[VanJS](https://vanjs.org/) (abbr. Vanilla JavaScript) is an ultra-lightweight, zero-dependency and unopinionated Reactive UI framework based on pure vanilla JavaScript and DOM. Programming with VanJS feels a lot like React_
[Sample](https://flems.io/#0=N4IgtglgJlA2CmIBcA2ADAOgKwHYA0IAZhAgM7IDaoAdgIZiJIgYAWALmLCAQMYD21NvEHIQAHigQAbgAIesWqVIBeADog2ENgnUA+VdRkyAarWoApAMoy2LeDICMGAEwBrAEIyAqgEkZhACd6eAB3PlcDMQB6SSl9akjYmWg1EFoAB3S9AyMJaWSoVM1teGzDGWjY+MrpeINuEFJ4BB5NAXImAGYkNBAAXzwaYNEpMwwAK3JeASERJgQ2GXg8NjxqPFhlAHkAI3H4VrwA7b2DtgwAc3g2AAUAvjYHgE90+C3CPBUACmXV9dgAJTKXQ-AD8oK+TTYABUIAw+ABXNhff4AtahGSWa4AgEYWgwL5sNGFYBXRajWBfAHAALXBEBQy2CCkDBsAZQmQUn7UhYyajKJmkDbKaisgDc8AAhMplLAAGRylEYTYy2CgtjKUiEtZ4HgApDwGUi5UK85QZrXeAotGijXLUV8DCEPgBACitB4LC+hOByOWgJxAIGAmooW5wEFGEd6QRpC98CDweUAS+UDREGUht08Aw1D45uhL3goPgSFDIRk0PgAA8-WiEcofngMC2icDCU6FMiHFE0LjnW6PV6fdm8ZlhFAAMIsEhQL4ptsyqCgkLan7AhP6iCEwNohN4WgijF3PjVp7e7Ut3NA3TABYUIVXiAAXWTKIoaGf4L7Rr4oOoSBUAMV7UM+B7KFAfA8AiDCCBgPC0rQQiuggsHIkSYq0mw9KGLAGDCGwAQQPAWqkP2Lrup6F4UH8z43ne1wyJstA0c+0qZiWwIsWwr6llmtAYFCACCbCERAOxIlaqwJph1pGsuq7rOuIKUvutCBkgKbUECMp-quIEYOa6RCt6V4Ju2lKioQXxmTiB4aZZQZ2QiXy0M2LYQE5gxkkg2rab6GA7BA1BzvaXkAPqZhuGAZjmEBOiQQgpspOYIqCMWkJOIZnPAaZojwjb0by-IUFePFina6IVliyJWV2ACyGRfOFOJOhRQ7ehqt4LMA4VlngCJILAeAXJpfQCp8b4GWATUpaydnDdNs1ZjmAYAmKpDsfKiqbRxeG0ukCg8PAADqWheucDbbmR+pfPt8BgHwUhWmil2ZjifR2VZ7VUXNmw5kSQZ4CEjZlUVjGbOcpCwBAx1fGgeAALQOGixxsDRyrCBctjI2BhQpleeEzek3orfNOJihA1mFO9WE4RQz5iryfDKL1Q0DUg25piNY2YXSDJMW1g6-V1wD8lq6yrN6N5KgOlFei1azvWiDjwJ0r0xRgMZxl8fBOWijoIn0ErVukLqLOahC0AisBsMA+JQEgCIrLQFykEgbmkGwSF8e2vXhek9yPOFfVQCsBobBHECAWBfAx59eBBSFSAhMbDRNC0bTUB0IBoEgDgOAAnIX-SDCAdAMKIExTCA-CCARohwmbATkmY-j3GAMjqBgUSjKKkzqAYBh117MjAKQ6RmHgMgSaJAh9DIyicmM3tu0P1Aj4sWUIvXASLzIVKL7oY85HI7SLPwO9JfvfeCd7QjwwCp90wLE9mF8p9GOogAm5IA8H9d9wM+V94ABGnuoABeBP4zyRI8agXxgACHkLDVwSAD4AiPjIAA1Jgy+u8MAUgGAAwAvBuAFkd9QaIoGz1gfAxBMMeAoLQRgxGiNcFJXwbQWAhD1BEMAHI75DIHlCftQPo69b4O1TFBGCBFLjXBQg9Ai7gng+DnOoDIWQQBohkNvXeVIhFGHThaVoEB2iiAcAAFiQM4UuQxK5MHgkoBoddZhsFEDsfMTwT7lB2B6VwFx7g70djPI6rgxSn34LAF0qCoC0ACK4F0ZgrihPKM6QQiMraQFgE8VBMSIAcKSSIhItotAIE8UYIQtZEYcIgBcACx1d5JKMCktgiNSAQAAF6lhkM4WkYAGkyEnjAYKo0ZCdCwOkas+T14AGI1Fjy7l4nxfjETJxkAEC43ivjOCwFgPADgsAoDwAjTAzgUZ9IGZIagwznBoHGV0m51Y7m3OueMvpIRoC2FQds+5fTynNKqTUpAdSkp9Jmms4KqC0AyGto8PpTSWntNLGYgAHC8gwBT6gEAzmcYx2dTFIvzjgfoYFy7DCYPVYwXhTAWEsP0IAA)
```js
import van from "./van.js"
const {span, button} = van.tags
const Counter = () => {
const counter = van.state(0)
return span(
"❤️ ", counter, " ",
button({onclick: () => ++counter.val}, "👍"),
button({onclick: () => --counter.val}, "👎"),
)
}
van.add(document.getElementById("app"), Counter())
``` | artydev |
1,479,845 | Clojure Bites - Structured logging with mulog | Full post here Looking forward your comments! Overview Logging is a fundamental tool to... | 0 | 2023-05-24T20:01:33 | https://dev.to/fpsd/clojure-bites-structure-logging-with-mulog-2id3 | clojure, logging, beginners, softwareengineering | Full post [here](https://fpsd.codes/blog/clojure-bites-mulog/)
Looking forward your comments!
# Overview
Logging is a fundamental tool to monitor and debug a running system.
Even if we can use logs to gather metrics about our system, these are
often written with the assumption that humans are going to consume them,
which make it hard to extract meaning information from log messages.
Log messages are rarely consistent or even meaningful if read few days
after writing them during your emergency debug session. Writing good log
messages is hard! Almost as hard as naming things and cache invalidation.
Another overlooked problem is that often logs are are context less, what
can we infer by a message like "Failed to process user payment" if we don't
know what triggered the payment process, the affected user or product?
## Structured logging
Structured logging aims to provide query-able, consistent, information rich
logs that can be used for:
- Business intelligence: derive business relevant data from logged events
- Monitoring: understand the current state of a system
- Debugging: understand the context in which an error has been reported
| fpsd |
1,479,874 | Demystifying the Architecture of Apache Age | Introduction In this article, we will delve into the inner workings of Apache Age, an... | 0 | 2023-05-24T20:37:07 | https://dev.to/abdulsamad4068/demystifying-the-architecture-of-apache-age-36gm | bitnine, apacheage, architecture, graphdb |
## Introduction
In this article, we will delve into the inner workings of Apache Age, an open-source distributed analytics platform that allows users to perform distributed SQL queries and analytics on large-scale datasets. With its foundation built on Apache Hadoop and Apache HBase, Apache Age provides an efficient and scalable solution for data processing. Throughout this blog, we will explain each component of the architecture in detail,
### 1. Apache Age Overview
Apache Age is a distributed analytics platform that enables users to process and analyze large-scale datasets using SQL queries. It leverages the power of Apache Hadoop, an open-source distributed computing framework, and Apache HBase, a distributed NoSQL datastore. By combining these technologies, Apache Age provides a scalable and fault-tolerant solution for distributed data processing.
### 2. Architecture Components:
Let's take a closer look at the major components of the Apache Age architecture:
#### a. Apache Hadoop:
Apache Hadoop forms the backbone of Apache Age, providing the underlying distributed computing framework. It enables parallel processing of data across a cluster of nodes, allowing for efficient and scalable data processing. Hadoop consists of two key components: the Hadoop Distributed File System (HDFS) and the Hadoop MapReduce framework.
#### b. Apache HBase:
Apache HBase serves as the distributed NoSQL datastore in the Apache Age architecture. It provides scalable storage and retrieval of data, with support for automatic sharding and replication. HBase is designed to handle large volumes of structured and semi-structured data and offers fast random read/write access.
#### c. Apache Age Query Engine:
The query engine is a crucial component of Apache Age. It translates SQL queries into distributed computations that are executed on the Apache Hadoop cluster. The query engine optimizes the execution plan based on the query requirements, leverages the distributed computing capabilities of Hadoop, and utilizes the indexing capabilities of HBase to improve query performance.
#### d. Apache Age Connector:
The connector plays a vital role in the Apache Age architecture by facilitating the integration between Apache Age and Apache HBase. It enables data movement and transformation between the distributed computing environment of Hadoop and the distributed datastore of HBase. The connector ensures efficient data processing and seamless interaction between the different components.
### 3. Data Processing Workflow:
Now, let's walk through the typical workflow for data processing in Apache Age:
#### a. Data Ingestion:
The data ingestion process involves importing data into the Apache HBase datastore. Apache Hadoop's HDFS is used to store and distribute the data across the cluster, ensuring fault tolerance and high availability. HBase, with its automatic sharding and replication capabilities, allows for efficient storage and retrieval of the ingested data.
#### b. Query Execution:
When a user submits an SQL query, the Apache Age query engine comes into play. The query engine analyzes the query, generates an optimized execution plan, and distributes the query processing across the nodes in the Hadoop cluster. It leverages the parallel processing capabilities of Hadoop and utilizes the indexing features of HBase to enhance query performance.
#### c. Data Retrieval:
Once the distributed computations are completed, the results of the SQL query are retrieved and returned to the user. The query engine coordinates the data retrieval process, ensuring the collected results are merged correctly from different nodes in the Hadoop cluster. The distributed nature of the retrieval process enables efficient handling of large-scale datasets.
| abdulsamad4068 |
1,479,882 | Using Ruby on Rails and ActiveModel::Serializer (AMS) to Control Your Data (Review) | Introduction Hi y'all, This is a quick review on how to utilize the Serializer gem for... | 0 | 2023-05-25T23:33:46 | https://dev.to/ericksong91/using-ruby-on-rails-and-activemodelserializer-ams-to-control-your-data-review-3kpb | ruby, rails, webdev, beginners | ## Introduction
Hi y'all,
This is a quick review on how to utilize the Serializer gem for Ruby on Rails. `ActiveModel::Serializer` or AMS, is a great way to control how much information an API sends as well as a way to include nested data from associations.
There are many instances where your backend will store extraneous data that isn't needed for the frontend or data that should not be shown. For example, for a table of User data, you would not want to display password hashes. Or if you have a relational database about Books with many Reviews, you would not want to include all the Reviews with every Books fetch request until you explicitly needed it.
This tutorial will assume you already know the basics of using Rails models and migrations along with making routes and using controllers.
## Setting Up Our Relational Database
Before we begin, lets come up with a simple relational table with a many-to-many relationship:
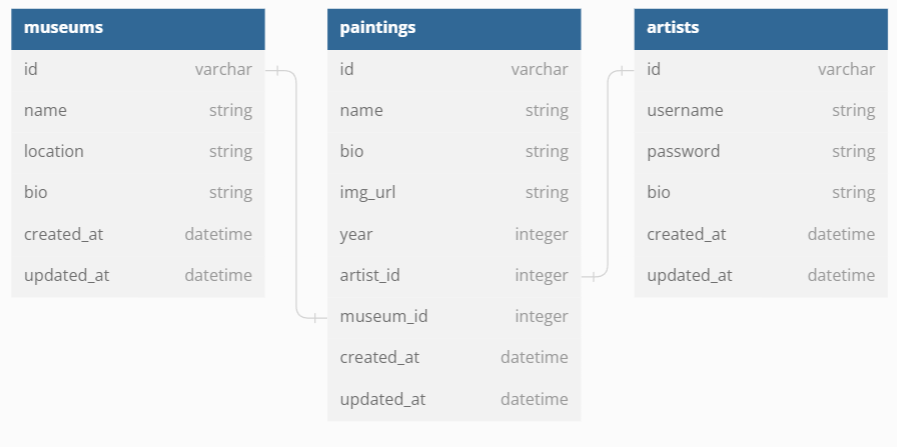
`Museums have many Users (Artists) through Paintings`
`Users (Artists) have many Museums through Paintings`
The table shows a many-to-many relationship between `Museums` and `Users` (Artists), joined by `Paintings`. The arrows in the table indicate the foreign keys associated with each table in `Paintings`.
Now lets make our models and migrations:
```
# models/museums.rb
class Museum < ApplicationRecord
has_many :paintings
has_many :users, -> { distinct }, through: :paintings
end
# models/paintings.rb
class Painting < ApplicationRecord
belongs_to :user
belongs_to :museum
end
# models/users.rb
class User < ApplicationRecord
has_many :paintings, dependent: :destroy
has_many :museums, -> { distinct }, through: :paintings
end
```
_*Note: -> { distinct } will make sure there are no duplicate data when the `User` or `Museum` data is retrieved._
The schema after migration should look something like this:
```
# db/schema.rb
create_table "museums", force: :cascade do |t|
t.string "name"
t.string "location"
t.string "bio"
t.datetime "created_at", precision: 6, null: false
t.datetime "updated_at", precision: 6, null: false
end
create_table "paintings", force: :cascade do |t|
t.string "name"
t.string "bio"
t.string "img_url"
t.integer "year"
t.integer "user_id"
t.integer "museum_id"
t.datetime "created_at", precision: 6, null: false
t.datetime "updated_at", precision: 6, null: false
end
create_table "users", force: :cascade do |t|
t.string "username"
t.string "password_digest"
t.string "bio"
t.datetime "created_at", precision: 6, null: false
t.datetime "updated_at", precision: 6, null: false
end
```
In your `seeds.rb` file, make some generic seed data.
```
# db/seeds.rb
# Example Seed Data:
user = User.create!(username: "John", password:"asdf",
password_confirmation: "asdf", bio: "Test")
musuem = Museum.create!(name: "Museum of Cool Things", location:
"Boston", bio: "Cool Test Museum")
painting = Painting.create!(name: "Mona Lisa", bio: "very famous",
img_url: "url of image", year: 1999,
user_id: 1, museum_id: 1
```
Now in our Config folder, lets make a simple Index route just for `Users` in `routes.rb`.
```
# config/routes.rb
Rails.application.routes.draw do
resources :users, only: [:index]
end
```
Then in our `users_controller.rb`, lets make a simple function that shows all Users.
```
# controllers/users_controller.rb
class UsersController < ApplicationController
def index
user = User.all
render json: users
end
end
```
Now boot up your server and go to `/users` to see what kind of data you're getting back:
```
[{
"id":1,
"username":"John",
"password_digest":"$2a$12$GXCFijd75p4VXj3OazNpFu52.nKbd0ETBbZUutVZAQqlyGCVphPGW",
"bio":"Test.",
"created_at":"2023-05-14T01:47:42.292Z",
"updated_at":"2023-05-14T01:47:42.292Z"
},
```
Yikes! You definitely don't want to have all this information, especially not the password hash. Lets get into our serializers and fix that.
## Setting Up and Installing AMS
First, we want to install the gem:
```
gem "active_model_serializers"
```
Once the gem has been installed, you can start to generate your serializer files using `rails g serializer name_of_serializer` in your console.
Lets add one for each of our models:
```
rails g serializer museum
rails g serializer user
rails g serializer painting
```
This should make a Serializer folder in your project directory with the files `museum_serializer.rb`, `user_serializer.rb` and `painting_serializer.rb`. Once we have these files, we can now control what kind of information we're getting.
It is important to note that as long as you're following naming conventions, Rails will implicitly look for the serializer that matches the model class name.
For example, for Users:
```
# models/user.rb
class User < ApplicationRecord
# code
end
# serializers/user_serializer.rb
class UserSerializer < ActiveModel::Serializer
end
```
Rails will look for the serializer that has the class name of `User` then the word 'Serializer' (`UserSerializer`). It will look for this naming convention for the default serializer.
Now lets try modifying some of the information we get back.
## Managing Data from Fetch Requests
### Excluding Information
Lets reload our `/users` `GET` request and see what happens now.
```
[{}]
```
Looks like we're getting no information now but don't fear; we just need to tell the serializer what data we want. Lets start with just grabbing `:id`, `:username` and their `:bio` by adding some `attributes`.
```
# serializers/user_serializer.rb
class UserSerializer < ActiveModel::Serializer
attributes :id, :username, :bio
end
```
Reloading our `GET` request, we now have:
```
[{
"id":1,
"username":"John",
"bio":"Test"
}
```
Perfect! Now we can control what information we want to get from our `GET` request.
### Adding Nested Data
Now lets say we want to include the paintings that belong to a user. We already have our relationships mapped out in our model files but we also need to add these macros to our serializers.
```
# serializers/painting_serializer.rb
class PaintingSerializer < ActiveModel::Serializer
attributes :id, :name, :bio, :img_url, :user_id, :museum_id,
:year
belongs_to :user
belongs_to :museum
end
# serializers/user_serializer.rb
class UserSerializer < ActiveModel::Serializer
attributes :id, :username
has_many :paintings
end
```
Refreshing `/users` again will display:
```
[{
"id":2,
"username":"John",
"bio":"Test",
"paintings":[
{
"id":1,
"name":"Mona Lisa",
"bio":"very famous",
"img_url":"url of image",
"user_id":1,
"museum_id":1,
"year":1999
}]}
```
Throwing this relationship into the `UserSerializer` and `PaintingSerializer` will allow you receive nested data of Paintings belonging to a User. The information nested in the User data will reflect what is in the `PaintingSerializer`!
### Adding a Different Serializer for the Same Model
You can also add a new serializer that includes different information from the default serializer. Lets say for a single `User`, we want them to have a list of `Museums` and `Paintings` on their profile page.
Make a new serializer called `user_profile_serializer.rb`. We'll use this serializer to also include the museum data for a user.
```
# serializers/museum_serializer.rb
class MuseumSerializer < ActiveModel::Serializer
attributes :id, :name, :bio, :location
end
# serializers/painting_serializer.rb
class PaintingSerializer < ActiveModel::Serializer
attributes :id, :name, :bio, :img_url, :user_id, :museum_id,
:year
belongs_to :user
belongs_to :museum
end
# serializers/user_profile_serializer.rb
class UserProfileSerializer < ActiveModel::Serializer
attributes :id, :username, :bio
has_many :paintings
has_many :museums, through: :paintings
end
```
Rails will not use this serializer file by default but you can call for it when rendering your JSON. In your `users_controller.rb` file, you can change what serializer you use for a specific request. Make the appropriate changes in `routes.rb` by including `:show` and adding it to the controller.
```
# config/routes.rb
Rails.application.routes.draw do
resources :users, only: [:index, :show]
end
# controllers/users_controller.rb
# For this example, we'll just assume we're looking for the User of ID 1
class UsersController < ApplicationController
def index
users = User.all
render json: users
end
def show
user = User.find_by(id: 1)
render json: user, status: :created,
serializer: UserProfileSerializer
end
end
```
Loading up `/users/1` gives us:
```
[{
"id":2,
"username":"John",
"bio":"Test",
"paintings":[
{
"id":1,
"name":"Mona Lisa",
"bio":"very famous",
"img_url":"url of image",
"user_id":1,
"museum_id":1,
"year":1999
}],
"museums": [
{
"id": 1,
"name": "Museum of Cool Things",
"bio": "Cool Test Museum",
"location": "Boston",
}]}
```
We look for the specific User, and if that User is found, we render their information and include the museums nested data as well.
## Conclusion
Serializers are very powerful as they let you control the data your API is sending.
## Notes
Please let me know in the comments if I've made any errors or if you have any questions. Still new to Ruby on Rails and AMS but would like to know your thoughts :)
## Extra Reading, Credits and Resources
[ActiveModel::Serializer Repo](https://github.com/rails-api/active_model_serializers/tree/v0.10.6)
[A Quick Intro to Rails Serializers](https://medium.com/@maxfpowell/a-quick-intro-to-rails-serializers-b390ced1fce7)
[Quickstart Guide to Using Serializer](https://itnext.io/a-quickstart-guide-to-using-serializer-with-your-ruby-on-rails-api-d5052dea52c5)
[DB Diagram](https://dbdiagram.io/home)
| ericksong91 |
1,479,991 | Tech Networking 101: How Are You Building Your Connections? | How are you going about expanding your professional network and connecting with fellow techies?... | 22,092 | 2023-05-31T07:00:00 | https://dev.to/codenewbieteam/tech-networking-101-how-are-you-building-your-connections-1ik2 | discuss, beginners, codenewbie, career | How are you going about expanding your professional network and connecting with fellow techies?
Share your go-to strategies newbies venturing into the industry and more sustainable approaches for coders further along in their careers. Shout out your favorite networking events, and don't forget to include any funny stories of unexpected connections.
Follow the [CodeNewbie Org](https://dev.to/codenewbieteam) and [#codenewbie](https://dev.to/t/codenewbie) for more awesome discussions and online camaraderie!
*{% embed* [https://dev.to/codenewbieteam](https://dev.to/codenewbieteam) *%}* | ben |
1,480,060 | Preparatório de Engenharia de Software do Google: 4 Meses de Formação Gratuita para Pessoas Negras e Pardas | O PrepTech Afro 2023 é um programa preparatório gratuito do Google para Engenharia de Software,... | 0 | 2023-05-25T12:50:28 | https://guiadeti.com.br/preparatorio-de-engenharia-de-software-do-google/ | inclusão, treinamento, algoritmos, dados | ---
title: Preparatório de Engenharia de Software do Google: 4 Meses de Formação Gratuita para Pessoas Negras e Pardas
published: true
date: 2023-05-24 22:32:55 UTC
tags: Inclusão,Treinamento,algoritmos,dados
canonical_url: https://guiadeti.com.br/preparatorio-de-engenharia-de-software-do-google/
---

O PrepTech Afro 2023 é um programa preparatório gratuito do Google para Engenharia de Software, voltado para candidatos pretos e pardos. Oferece curso de Estrutura de [Dados](https://guiadeti.com.br/guia-tags/cursos-de-dados/) e [Algoritmos](https://guiadeti.com.br/guia-tags/cursos-de-algoritmos/) com duração de 4 meses e auxílio financeiro mensal. Destinado a pessoas autodeclaradas pretas ou pardas, com pré-requisitos de inglês intermediário e experiência profissional de 5 anos em tecnologia, ou 3 anos com formação acadêmica em áreas relacionadas. O programa busca promover a inclusão e diversidade no campo da tecnologia. Oportunidade para se preparar adequadamente para o processo seletivo de Engenharia de Software do Google e aumentar as chances de sucesso na carreira de tecnologia!
## Conteúdo
<nav><ul>
<li><a href="#prep-tech-afro-2023">PrepTech Afro 2023</a></li>
<li><a href="#ementa">Ementa</a></li>
<li><a href="#cronograma">Cronograma</a></li>
<li><a href="#ada">ADA</a></li>
<li><a href="#inscricoes">Inscrições</a></li>
<li><a href="#compartilhe">Compartilhe!</a></li>
</ul></nav>
## PrepTech Afro 2023
O PrepTech Afro 2023 é um programa preparatório desenvolvido pelo Google em parceria com a Ada, com o objetivo de oferecer oportunidades de capacitação para pessoas negras e pardas que desejam ingressar na área de Engenharia de Software no Google. O programa oferece 20 vagas para uma formação gratuita em Estrutura de Dados e Algoritmos, com duração de 4 meses.
Voltado para promover a inclusão e diversidade na área da tecnologia, o PrepTech Afro 2023 é exclusivamente destinado a pessoas autodeclaradas pretas ou pardas que buscam se preparar para o processo seletivo de Engenharia de Software do Google. Os pré-requisitos incluem a fluência no idioma inglês intermediário, além de 5 anos de experiência profissional em tecnologia, ou 3 anos de experiência para aqueles com formação acadêmica em cursos de ciências exatas, como Ciência da Computação, Engenharia de Software, Física, Matemática e Sistemas de Informação.
O programa, além da formação gratuita, financiada pelo Google, também oferece um auxílio financeiro mensal de R$ 500,00 durante os 4 meses de curso, totalizando R$ 2.000,00. Essa iniciativa visa proporcionar um suporte financeiro aos participantes, auxiliando-os durante o período de capacitação.
O PrepTech Afro 2023 é uma oportunidade única para pessoas negras e pardas desenvolverem suas habilidades e se prepararem para uma carreira na área de Engenharia de Software no Google, uma das maiores empresas de tecnologia do mundo. Com uma formação completa em Estrutura de Dados e Algoritmos, os participantes terão a base necessária para se destacar no processo seletivo e buscar oportunidades profissionais no mercado de trabalho de alta demanda da tecnologia.
## Ementa
- Big O
- Trees
- Lists
- Graphs
- Queues
- Dynamic Programming
- Stack
- Mock Interviews
## Cronograma
- Inscrições: Até 16/06
- Cover Letter: 23/05 a 19/06
- Teste de Aptidão Tech: 20/06
- Resolução de Case: 05/06 e 06/06
- Entrevistas: 03/07 a 21/07
- Divulgação da Lista Final: 25/07
- Início das Aulas: 02/08
## ADA
A Ada Tech é uma empresa que se dedica a fornecer soluções tecnológicas inovadoras para diversas áreas e setores. Com uma equipe de especialistas altamente qualificados, a Ada Tech trabalha no desenvolvimento e implementação de projetos de software, inteligência artificial, análise de dados e outras tecnologias avançadas.
A empresa tem como objetivo principal oferecer soluções personalizadas e de alta qualidade para atender às necessidades específicas de cada cliente. A Ada Tech valoriza a inovação, a qualidade e a excelência em seus serviços, buscando sempre estar na vanguarda das últimas tendências e avanços tecnológicos.
Além disso, a Ada Tech investe no desenvolvimento de parcerias estratégicas e colaborativas, visando criar um ecossistema de colaboração e compartilhamento de conhecimento. Isso permite que a empresa se mantenha atualizada e ofereça soluções que estejam alinhadas com as demandas e desafios do mercado.
A equipe da Ada Tech é formada por profissionais experientes e apaixonados por tecnologia, que estão sempre em busca de novas oportunidades e desafios. Com sua expertise e conhecimento, eles trabalham em estreita colaboração com os clientes, oferecendo suporte técnico, consultoria e soluções personalizadas para impulsionar o sucesso dos projetos.
No cenário tecnológico em constante evolução, a Ada Tech destaca-se como uma empresa inovadora, comprometida em fornecer soluções de ponta que impulsionem o crescimento e a transformação digital de seus clientes. Com sua expertise e abordagem centrada no cliente, a Ada Tech continua a desempenhar um papel importante no avanço da tecnologia e no impulsionamento de negócios em diversos setores.
## Inscrições
Antes de se inscrever,[leia o edital aqui!](https://sistema-selecao-production.s3-sa-east-1.amazonaws.com/SelectiveProcess/c731b906-71ae-4497-bcd9-36cbab6311b9/edital.pdf)
[Inscreva-se aqui!](https://ada.tech/sou-aluno/programas/google-prep-tech-afro)
## Compartilhe!
Gostou do conteúdo sobre o Preparatório de Engenharia de Software do Google? Então compartilhe com a galera!
O post [Preparatório de Engenharia de Software do Google: 4 Meses de Formação Gratuita para Pessoas Negras e Pardas](https://guiadeti.com.br/preparatorio-de-engenharia-de-software-do-google/) apareceu primeiro em [Guia de TI](https://guiadeti.com.br). | guiadeti |
1,480,142 | A lesson in printing errors within try catch blocks | A Lesson in Printing Errors within Try Catch Blocks Hey there! 👋 Ever been stuck... | 0 | 2023-05-25T03:28:33 | https://dev.to/austincoleman/a-lesson-in-printing-errors-within-try-catch-blocks-kb8 | javascript, programming | # A Lesson in Printing Errors within Try Catch Blocks
Hey there! 👋
Ever been stuck debugging an issue, only to find out it was something minor that could have been quickly resolved if only you had more information about the error?
Well, it happened to me today, and it inspired me to share this piece of wisdom: **Always print the full error object when dealing with try-catch blocks in JavaScript.**
Let's dive into it.
## What Happened?
I was recently debugging an issue in my Node.js server. I was getting a confusing error message. The server was creating a playlist by fetching song IDs using a mocked YouTube API. However, for some reason, those songs were also failing to get their song IDs. The error message was always the same: "Error getting song ID". That's it.
The offending code looked something like this:
```javascript
try {
song_id = await getSongID(song);
songs_with_ids.push({
id: song_id,
title: song,
});
} catch (e) {
console.log("Error getting song id for", song);
failed_songs.push({
id: null,
title: song,
});
}
```
## The Lesson: Always Print Your Errors
I was confused. The function getSongID was mocked and supposed to return the song ID for all known songs, including the one causing the error.
After a moment of bewilderment, I decided to print the actual error object e in addition to my custom error message.
```javascript
catch (e) {
console.log("Error getting song id for", song, "Error:", e);
failed_songs.push({
id: null,
title: song,
});
}
```
Boom! 💥 The error message changed to `ReferenceError: song_id is not defined.` The issue wasn't with the getSongID function at all! Instead, it was an undeclared variable song_id that was causing the failure. This fixed it:
```javascript
try {
const song_id = await getSongID(song);
songs_with_ids.push({
id: song_id,
title: song,
});
} catch (e) {
console.log("Error getting song id for", song);
failed_songs.push({
id: null,
title: song,
});
}
```
You can probably imagine the face-palm moment I had.
## Takeaway
Writing custom error messages can certainly make your logs easier to read and understand. However, it's crucial to remember that these messages should augment the error object, not replace it.
By including the error object in your logs, you allow for the visibility of all the nitty-gritty details that come with an error: stack traces, line numbers, and the exact error message.
It's a simple practice, but one that can save you a lot of debugging time.
Stay curious, code more, and always print your errors!
I hope you found this post useful and it will save you from a few future headaches.
Happy coding! 🚀 | austincoleman |
1,480,168 | Edify (online code editor plugin) | https://github.com/rahulsemwal/edify Edify is a basic, light weighted web based online editor plugin... | 0 | 2023-05-25T04:43:34 | https://dev.to/rahulsemwal/edify-online-code-editor-plugin-1ngn | webdev, javascript, opensource, experiment | https://github.com/rahulsemwal/edify
Edify is a basic, light weighted web based online editor plugin for web apps, can be useful for developers, code content creators and educational purpose. Currently it supports HTML, JavaScript and CSS languages only. This editor is build on top of prismjs code highlighting library.
# Demo :
https://rahulsemwal.github.io/edify/examples/index.html
**Uses [It's so easy to use! atleast give it a try]**
- Step 1: Include all files from lib folder like prism.css, edify.css, prism.js and edify.js into your website.
- Step 2: Add below syntax into your website and enjoy writing HTML online with live preview.
```
<edify language="html" preview="true"><h1>Hello edify!</h1></edify>
```
- Step 3: Try out demo above and explore code in examples/index.html and examples/sample/
| rahulsemwal |
1,480,290 | Hire an Expert for Laravel Development to Unlock the Potential of Your Website | In today's digital landscape, a strong online presence is crucial for businesses of all sizes. To... | 0 | 2023-05-25T07:26:59 | https://dev.to/viitorcloud/hire-an-expert-for-laravel-development-to-unlock-the-potential-of-your-website-51dp | laravel, laraveldevelopment, laraveldeveloper, laravelexper | In today's digital landscape, a strong online presence is crucial for businesses of all sizes. To stand out from the competition and attract a wider audience, you need a website that not only looks visually appealing but also functions flawlessly. When it comes to web development, Laravel has emerged as one of the leading frameworks due to its versatility, scalability, and robust features. To harness the full potential of Laravel and ensure your website's success, hiring an expert in Laravel development is the key.
## Understanding the Value of Laravel Development
Laravel, an open-source PHP framework, has gained immense popularity among developers and businesses alike. Its elegant syntax, powerful tools, and extensive libraries make it an ideal choice for creating high-performing websites and web applications. From small startups to large enterprises, Laravel has proven its efficiency in developing secure, scalable, and feature-rich solutions.
## Leveraging Expertise for Optimal Results
When it comes to building a Laravel-based website, having an expert on board can make all the difference. An experienced Laravel developer possesses in-depth knowledge of the framework's intricacies, enabling them to utilize its full potential. They are well-versed in implementing Laravel best practices, ensuring a clean and maintainable codebase that enhances your website's performance. By hiring a Laravel Developer, you gain access to their extensive skill set, which includes:
** Custom Laravel Development
A Dedicated Laravel Developer can tailor the framework to suit your specific business needs. Whether you require a dynamic e-commerce platform, a content management system, or a customer relationship management tool, they can create customized solutions that align with your objectives. Their expertise allows them to efficiently leverage Laravel's modular structure, saving development time and delivering a product that exceeds your expectations.
** Seamless Integration and Migration
If you're already running a website or web application on a different platform and wish to migrate to Laravel, an expert can seamlessly handle the transition. They understand the challenges associated with data migration, third-party integrations, and maintaining data integrity throughout the process. By ensuring a smooth migration, they eliminate any potential downtime or loss of critical data, allowing your business operations to continue uninterrupted.
** Performance Optimization
Website speed and performance are crucial factors that influence user experience and search engine rankings. An expert Laravel developer possesses the expertise to optimize your website's performance by employing caching mechanisms, database optimizations, and code profiling techniques. They identify and rectify bottlenecks, ensuring your Laravel-based website delivers lightning-fast loading times and exceptional user responsiveness.
** Robust Security Measures
With the increasing number of cyber threats, website security has become a top priority for businesses. Laravel, with its built-in security features and community support, offers a robust framework for developing secure applications. An [expert Laravel developer](https://viitorcloud.com/hire-laravel-developer) understands the intricacies of web security and can implement industry best practices, protecting your website and sensitive user data from potential vulnerabilities.
## Benefits of Hiring an Expert for Laravel Development
By hiring an expert in Laravel development, you unlock a plethora of benefits that contribute to your website's success:
** Time and Cost Savings
An expert Laravel developer possesses the required skills and knowledge to efficiently develop and deploy Laravel-based solutions. Their expertise enables them to complete projects in a shorter time frame, saving both time and money. Additionally, their ability to write clean, maintainable code reduces the risk of future issues, minimizing maintenance costs in the long run.
** Enhanced User Experience
User experience plays a vital role in engaging and retaining visitors on your website. A skilled Laravel Developer understands the importance of a user-friendly interface and seamless navigation. They employ industry best practices to create intuitive layouts, optimize | viitorcloud |
1,480,372 | Window Functions In Mariadb (part 2) | AVAILABLE WINDOW FUNCTIONS MariaDB offers a wide range of built-in window functions to... | 0 | 2023-05-25T08:52:34 | https://dev.to/umerfreak/window-functions-in-mariadb-part-2-1h6i | ## AVAILABLE WINDOW FUNCTIONS
MariaDB offers a wide range of built-in window functions to cater to various analytical requirements. These functions include popular ones such as SUM(), AVG(), COUNT(), MIN(), MAX(), and more. Additionally, specialized functions like RANK(), DENSE_RANK(), ROW_NUMBER(), LAG(), and LEAD() enable advanced analytical computations.
## USE CASES
Window functions find utility in a multitude of scenarios. This section explores some practical use cases where window functions can be applied effectively. Examples include calculating moving averages, generating cumulative sums, identifying top-n records, calculating percentage shares, and detecting trends over time.
## PERFORMANCE
While window functions provide immense analytical capabilities, it is essential to consider their performance implications. As window functions operate on a set of rows, their execution requires careful optimization to ensure efficient query processing
## CONCLUSION
Window functions in MariaDB empower users to perform complex analytical computations while maintaining row-level details. With its robustness and performance, MariaDB continues to be an excellent choice for utilizing window functions in relational database environments.
| umerfreak | |
1,480,401 | Configuring Azure Logic App Failure Alerts To Stay Ahead | Azure Logic Apps is a cloud-based service provided by Microsoft Azure that allows users to create and... | 0 | 2023-05-25T09:58:03 | https://www.serverless360.com/blog/configuring-azure-logic-app-failure-alerts-to-stay-ahead | azure, logicapps, azuremonitoring | Azure Logic Apps is a cloud-based service provided by Microsoft Azure that allows users to create and run automated workflows. A trigger is the first step of a workflow that specifies the condition for running further steps in that workflow. Azure Logic Apps creates a workflow run each time the trigger fires successfully.
The details of each run, including the status, inputs, and outputs of each step of the workflow instance, can be accessed in the run history section of the Logic App. Each run can either execute successfully or fail due to some reasons.
## Why is it essential to track Logic App failures?
Like any technology, Logic Apps can experience failures, which can cause serious consequences such as data loss, and disrupted business flows.
Take a sample scenario where the Logic App orchestrates a credit card payment. An HTTP request triggers the Logic App with payment details from the user, such as the card number, expiration date, billing address, etc. Then it uses a connector to authenticate the payment information. Once the information is authenticated, Logic App processes the payment using a payment gateway. Once the payment is successful, the Logic App updates the database and sends a confirmation email or text message to the customer indicating that the payment has been successfully processed.
In such a scenario, if there are any errors or exceptions during the payment processing, it is crucial that the Logic App can track these failures and quickly alert the relevant teams to mitigate the issue.
Azure Logic Apps provides capabilities to track and handle failures. The logic app failure alerts can be various channels like email, SMS, or other communication channels.
### Configuring alert rules in the Azure portal
Alert rules can be created from the Monitoring section of the Logic App from the Azure portal. Azure provides an extensive list of metrics representing the critical aspects of the resources. Metrics and their respective thresholds can be configured with the alert rules.
## Challenges Monitoring Logic Apps
Azure Monitor is handy when monitoring the resource as an individual entity. When there is a requirement to monitor the resources constituting a business flow as an application, it isn’t easy to implement monitoring which will help a support user understand the role of the Logic App in the broader context. The alerts received through Azure monitor are at the resource level. When multiple Logic Apps are monitored, it is challenging to track the alerts.
In such cases, Azure Monitor may only meet some of your needs. Serverless360 provides features that will help you monitor and manage Logic Apps in the real world.
## How to monitor Logic Apps failures using Serverless360
[Serverless360](https://www.serverless360.com/) is a cloud-based platform designed to allow users to manage and monitor their applications running on the Microsoft Azure cloud platform. It offers much tooling that allows users to monitor, troubleshoot, and manage serverless applications.
Setting up [Azure Logic App monitoring](https://www.serverless360.com/azure-logic-apps-monitoring-management) using Serverless360 is straightforward and can be achieved by Business Applications. It is a logical container that groups a particular application’s resources.
A Business Application can be created by adding the required Logic Apps. In addition, various resources of different types constituting a business flow can be added.
Monitoring profiles allow users to configure monitoring rules for multiple resources of the same type or different types. Instead of configuring the monitoring rules at each resource level, a monitoring profile to monitor the Logic App failures can be created and applied to the Business Application, which will monitor all the Logic Apps in it.
When applying the monitoring profile to a Business Application, users can opt to automatically apply the profile to any other Logic App that will be added to the Business Application.
As soon as the resources are added to the Business Application in which the monitoring profile is applied, the resources get automatically monitored, and the status of the resources will be updated as below.
In some cases, more than monitoring the metrics of the Logic App is required, as there may be a slight delay for the metrics to get emitted in Azure. Serverless360 can monitor the failures in such cases by investigating the actual Logic App runs.
### Resolving failures
In addition to alerting the failures, Serverless360 can resolve them by resubmitting the failed runs. Even though resubmitting a run is possible in the Azure portal, the challenge is identifying the already resubmitted runs. Serverless360 overcomes this challenge by adding a Resubmitted tag to the resubmitted runs.
### Manual resubmission
Manual resubmission of runs is a straightforward operation, select the runs to be resubmitted in the run history of the respective Logic App and click on Resubmit runs option. It is also possible to resubmit runs in bulk.
### Automated resubmission
The manual resubmission is handy when the number of runs to be resubmitted is less. But automated resubmission is useful when there are many runs to be resubmitted. Automated resubmission has the below advanced features to enhance the efficiency of resubmission.
- Option to include or exclude the already resubmitted runs.
- Resubmitting runs based on one or more error reasons.
- Resubmitting runs from a specific trigger.
- Resubmitting runs with the selected run actions based on their state.
A more convenient way than manually running an automated task each time there is a violation to configure the automated task as part of the monitor rule that will be executed each time the configured rule is violated.
### What if you need to do more
Serverless360 Business Applications are aimed at providing the tools your Support Operator needs to perform daily operations for your integration solutions.
You may want to allow less experienced support users or Business Super Users to have visibility of your integration processes and to be able to perform a level of self-service. In this case, Serverless360 provides a [Business Activity Monitoring](https://www.serverless360.com/business-activity-monitoring) module that can be used alongside Business Applications, allowing you to provide an even more fantastic experience for your users.
## Conclusion
Tracking Azure Logic Apps failures is essential to ensure the smooth functioning of the business. Azure provides Logic App monitoring via Azure Monitor by configuring alert rules. The alert rules help to detect failures and performance bottlenecks. But, monitoring multiple Logic Apps requires repeated alert configurations multiple times, making it challenging to track the alerts.
By combining Logic Apps into a logical container and using Monitoring Profiles to track the failures, Serverless360 increases its edge over Microsoft Azure. This helps to identify and mitigate the issues proactively, reducing downtime and increasing productivity. Having features like Automated resubmission in case of violations will be particularly useful.
Azure offers fundamental monitoring features and works well with a few Logic Apps. Serverless360 is the go-to option for businesses managing multiple resources.
Experience Business Application with a 15-day [free trial](https://www.serverless360.com/signup)!
| sabarirohith |
1,480,407 | Why open source your project? | Hey, devs! I used to think that open-source is needed only for those who want to show their skills to... | 0 | 2023-05-25T10:07:51 | https://dev.to/danielrendox/why-open-source-your-project-4ma2 | discuss, opensource | Hey, devs! I used to think that open-source is needed only for those who want to show their skills to job recruiters. But, as I progressed in my journey, I encountered many open-source projects and wondered why people would share their work for free. Having done more research on this topic I found out that this actually goes far beyond showing one’s skills.
Open-source projects appear to foster communication with other developers, let one develop skills used in a real-world workplace, gain more popularity, ease the developer’s work, and may even bring money.
However, I don’t believe that one should open-source their work just because they use a lot of free stuff and owe the community, or that the primary motivation for open-sourcing is pure altruism.
I’ve shared what I found out in more detail in the comments. But I can’t tell that for sure because I have no experience of work on a decent open-source (or proprietary project). That’s why I want to call experienced developers to share their thoughts. Here are my questions and topics for discussion:
- What are the pros and cons of open-sourcing your work, whether it be a learning project aimed at gaining experience and creating something valuable or a commercial one that could be reimagined as an open-source venture?
- I’ve always dreamt of working on a team with friends. Open-source seems to be one of the ways toward that dream. Is it really possible to make friends or create a team in this way?
- I would love to hear about your experiences.
- When not to open source your project? | danielrendox |
1,480,929 | Welcome | 🤗 | 0 | 2023-05-25T17:31:46 | https://dev.to/lamz10/welcome-3690 | 🤗 | lamz10 | |
1,480,962 | DevBlog - Update 02 - Map Overhaul | Introduction Hello and welcome back to my Development Blog about whatever I'm currently... | 23,309 | 2023-05-25T21:57:36 | https://dev.to/justlevidev/devblog-update-02-map-overhaul-6n5 | showdev, gamedev, devjournal, development | #Introduction
Hello and welcome back to my Development Blog about whatever I'm currently working on, which is currently the Project "The Farm".
It's been 2 weeks again, so here is the promised Blog about the Map Overhaul!
---
#The Changes
When I first started working on the game it obviously didn't have any map (to be fair, it wasn't even supposed to have a character to control in it aswell).
But after finishing the Crop-System I decided that I would need a map to keep the player inside of.
But after spending so much time on StoryIdeas, a full on ItemSystem (if anyone is interested in me explaining how I did that feel free to leave a comment about it or just msg me somewhere else :) ) and a way to place any type of object I would give the Player, the time was right to make a change to the Map.
---
##Tutorial
The TutorialMap was the first one I worked on and therefore had the most changes throughout the project (with a few more being planned and currently in development).
---
###First Version
The first Image I would like to show here is the first Version of the Map, even before I added PlayerAnimations or even the PlayerSprite which is currently being used (and yes I drew the Character myself, there's a reason why I'm a programmer and not an Artist yet).
The most noticeable difference to the next Versions is my try of using a Shader to lead the Player through the Tutorial (which might be added in a similar way in the future).

###Feature-Demo Version
The next Version of this Map is the one I used for the first official Upload on [itch.io](https://justlev1.itch.io/the-farm).
The changes leading up to this Version were that the Player finally got Animations and 2 new Boxes.
Those Boxes were placeholders for the bookReading and placing of Objects, which have been changed in the newest Version to fit the meaning better.

###Current Version
The current Version of the TutorialMap features changed Walls (making them connect properly to each other), new Sprites for the Chest, Book and Trade, and finally the most obvious change, *the House*.
The whole Idea of the Tutorial Area is to be the original home of the main Character, so adding this house should make a lot more sense than just a random piece of land without any meaning.
Here one could ask why even bother adding all those things into the Map and where did the FenceGate in the bottom go, but I won't give you the answer now, so stay tuned for the future DevBlogs to find out about all those things.

---
##Dome
Before talking about the Dome in more Details I should mention that this place is not anywhere close to being done and should be considered in a similar state to the first TutorialMap.
---
###Entrance Room
When entering the Dome the Player is going to wake up in a strange unfamiliar Room in which the first Interaction with the second main Character will happen (which isn't shown yet, since I'm going to make a separate Blog about the Storyline, so check out the newest Blog about this Project).
###First Room
This Room is currently kept extremely simple and only to the most important aspects.
The overall shape should give the impression of some type of unfamiliar structure, maybe from a different culture or even a different Planet? (*foreshadowing intensifies*)
Regardless of that there will be more than just the one Entrance on the bottom. If I'll stick with the Exit on the top or add one to the right hasn't been decided yet and I'll talk more about Room-Layouts when that has been already added to the game.

---
#What's next?
Since the Game is currently working and able to be played until the end of the "early-game" I will take some time to polish as much as possible to make the part as smooth and interesting as possible.
While not working on the polishing I spend most of my time writing about different ideas for the Story, ideas for new Features and so on.
If you have any ideas for anything that you would like to see in the game feel free to comment your ideas or feedback down below.
If you would want to test out the currently available FeatureDemo (which as of writing this Blog doesn't have all the mentioned new UI and Maps yet) you can download it on [itch](https://justlev1.itch.io/the-farm).
And if you would like to stay updated on this Project or on any of my future projects follow me on [Twitter](https://twitter.com/JustLeviDev), where I will post about any new Blogs, Updates on itch and everything else.
---
#Outro
Thank you for your time, I hope you enjoyed this short little Blog and I'll see you in the next one, have a good night. | justlevidev |
1,481,169 | View Transition API | The view Transition API is probably one of the most exciting new CSS mechaninsms. It's currently only... | 0 | 2023-05-26T06:46:40 | https://iamschulz.com/view-transition-api/ | css, frontend, webdev, animation | The view Transition API is probably one of the most exciting new CSS mechaninsms. It's currently only available in Chrome Canary, but that's okay. It's designed from the ground up to be a progressive enhancement. It promises to provide a native way to build SPA-like page transitions. (Heck, forget about SPAs. Think of cinematic wipes. Video game manus! Remember fancy DVD menus?)
---
# Basic setup
First of all, we need to enable two flags on Chrome Canary, because View Transitions are still an experimental feature. The flags you’re looking for are [view-transition](https://www.notion.so/View-Transition-API-43b77bbec62549598e0451e9b223848d) and [view-transition-on-navigation](https://www.notion.so/View-Transition-API-43b77bbec62549598e0451e9b223848d).
To get it running on our page we need to set a meta tag on both the document we're navigating *from* and the one we're navigating *to.*
```html
<meta content="same-origin" name="view-transition" />
```
When navigation from one oage to the other, we see a crossfade between the sites. This is the default transition. We can also assign custom ones:
```css
::view-transition-old(root), ::view-transition-new(root) {
animation: var(--my-fancy-animation-out);
}
```
We can also assign animations to selected elements. That's the way to those bespoke transitions where elements swoop magically into place.
```css
::view-transition-old(swoop),
::view-transition-new(swoop) {
animation: var(--my-fancy-animation);
}
.element {
view-transition: swoop;
}
```

([Website mock-up and image](https://developer.chrome.com/docs/web-platform/view-transitions/) by the Chrome Dev team)
Speaking of magically, elements morph their position and crossfade their content. This happens automatically by fading out the old element and fading in the new ones instead. We can also set custom animations to both the disappearing and the apperaing content:
```css
::view-transition-old(root) {
/* let the old element disappear in some form */
animation: var(--my-fancy-animation-out);
}
::view-transition-new(root) {
/* show the new element instead */
animation: var(--my-fancy-animation-in);
}
```
# Fine tuning
For now, animations will always trigger whenever they can. This may have some unwanted side effects. It's nice to see where similar elements come from and go to between navigations, but when they're coming from out of screen, things get confusing quickly.
We can use an Intersection Observer to set the element's view transition only when it's in screen:
```tsx
const observer = new IntersectionObserver(
(entries) => {
entries.forEach((entry) => {
const el = entry.target as HTMLElement;
const transitionName = el.dataset.transitionName;
(el as HTMLElement).style.setProperty(
"--transition-name",
entry.isIntersecting ? `${transitionName}` : "none"
);
});
}
);
const animatables = Array.from(document.querySelectorAll('.animatable'));
animatables.forEach((animatable) => {
observer.observe(animatable);
});
```
```css
.animatable {
view-transition: var(--transition-name, none);
}
```
Sometimes we want to play the transition only in one direction, but not into the other. As an example, I see how the full page crossfade is necessary to support custom transitions on selected elements, but on pages that have no custom transitions, the crossfade loses its right to exist. I could simply remove the meta tag on the target page, but if the target page itself needs to act as a trigger for another view transition to somewhere else, that won’t work either. My solution is to register an event listener on anchor element clicks and remove the meta tag before the browser navigates, cancelling the view transition on all but some selected trigger elements:
```tsx
const triggers = Array.from(document.querySelectorAll('[data-transition-trigger="true"]'));
(Array.from(document.querySelectorAll("a[href]")) as HTMLAnchorElement[]).forEach((el) => {
if (triggers.includes(el)) {
return;
}
el.addEventListener("click", () => {
document.querySelector('meta[name="view-transition"]')?.remove();
});
});
```
Now I can fine tune which transitions start on which elements by setting `data-transition-trigger="true"` on `<a href="">` tags.
# Jank
Some things feel a bit weird or buggy.
Like described above, it’s hard to create specific transition triggers and endpoints. Sometimes it makes sense for an animation to play only one way, But setting the `view-transition` property acts as both a trigger and receiver, all the time.
Elements in a transition seem to ignore the stacking context in some cases. Absolutely positioned and sticky elements will display underneath transitioning ones, even when applying (and forcing) `z-index`.
Scaling an element up doesn’t work properly yet. I can set `transform: scale()` to positive values, but it will just disable the animation and skip to the new state instead.
Sometimes I can’t overwrite properties that are set to an element. Transitioning background-colors only works of `opacity` is set. `opacity` can’t be overwritten whatsoever, but `visibility` works.
I’m sure most of those bugs are actually just bugs in Chromes current implementation. It’s experimental after all.
# Na na na na na na na na Batman!
When I think of transitions, I think of cinematic ones. There are a few iconic ones, like the [slow soft wipe in Star Wars](https://www.youtube.com/watch?v=BF3g_kaUnCA) or that [weird back-and-forth in Easy Rider](https://youtu.be/gmOT2R-dwSg?t=21). But [60’s Batman swirls](https://www.youtube.com/watch?v=ztJIJ1P-_Vk) are probably the most fun ones, to watch and to implement.
Rotating the document should be straightforward enough with a spin animation:
```css
@keyframes spin {
to {
transform: rotate(2turn);
}
}
```
But that Batman logo zooming around? Remember how scaling elements up didn’t work properly? There’s a hack we can use to work around that problem. Upscaling doesn’t need to be a `transform: scale()` function. We can also use `transform: translateZ()`. This one needs to stay at `1px`, or else it bugs out again, but we can animate the `perspective` freely, making it something like the web equivalent of a [vertigo shot](https://www.youtube.com/watch?v=G7YJkBcRWB8). I’ll use the animatable `visibility` property to hide it outside the animation, because opacity - you guessed it - is buggy. It will substract the element’s base opacity from the animation’s opacity and thus never become visible at all.
```css
@keyframes scale-up {
from {
visibility: visible;
transform: perspective(400px) translateZ(1px);
background: url(./logo.png) center no-repeat;
background-size: contain;
}
to {
visibility: visible;
transform: perspective(1px) translateZ(1px);
background: url(./logo.png) center no-repeat;
background-size: contain;
}
}
::view-transition-old(batman) {
animation: 0.5s linear both scale-up;
}
::view-transition-new(batman) {
animation: 0.5s linear both scale-down;
animation-delay: 0.5s;
}
#logo {
position: absolute;
top: calc(50% - 50px);
left: calc(50% - 50px);
width: 100px;
height: 100px;
visibility: hidden;
view-transition-name: batman;
}
```

Try it out [here](https://iamschulz.github.io/batman-transition/)!
# Further Reading
- The chrome dev team has a [very extensive article](https://developer.chrome.com/docs/web-platform/view-transitions/) about view transitions.
- [Dave Ruperts implementation](https://daverupert.com/2023/05/getting-started-view-transitions/) in his own website.
- [Jeremy Keith’s thoughts](https://adactio.com/journal/20195) on it. | iamschulz |
1,481,362 | Azure RBAC - A Sure way to Control Access in Azure | Our blog today will be dedicated to how to control who access Azure resources, the level and type of... | 0 | 2023-05-26T07:54:33 | https://dev.to/yemmyoye/azure-rbac-a-sure-way-to-control-access-in-azure-170c | azurerbac, rolebasedaccesscontrol, roleassignment, securityprincipal | Our blog today will be dedicated to how to control who access Azure resources, the level and type of access a user possesses. This is a very important function in using Cloud resources for the following reasons:
1)To manage usage of Azure resources
2)To ensure that only the needed resources for a particular
user's duties are accessed
3)It is a way to manage Operational Expenditure
Azure Role Based Access Control (RBAC) is an access control system created within Azure Resource Manager and allows for exact administration of permissions for Azure resources. To use RBAC to control access, Roles have to be assigned to individual users. These are permissions given to users based on their role within an organization. This approach to managing access is less prone to error than assigning permissions to users individually.
Role Assignment consists of three main elements. These are security principal, role definition, and scope.
**Security principal** refers to a user, group, service principal, or managed identity that is requesting access to Azure resources.
**Role definitions** is a collection of permissions that can be assigned to a user. An example is the Virtual Machine Contributor role that allows a user to create and manage virtual machines
**Scope** is the set of resources that the permission given applies to. When a role is assigned, further restrictions can be done by defining a scope. For example, a Web contributor can be limited to only one resource group
Let's move on to see the reality of these on the Azure portal as we describe what is explained above but first we will create a user to whom we will assign a role.
**Step 1 - Create a User**
Log in to Azure portal and search for Azure Active Directory
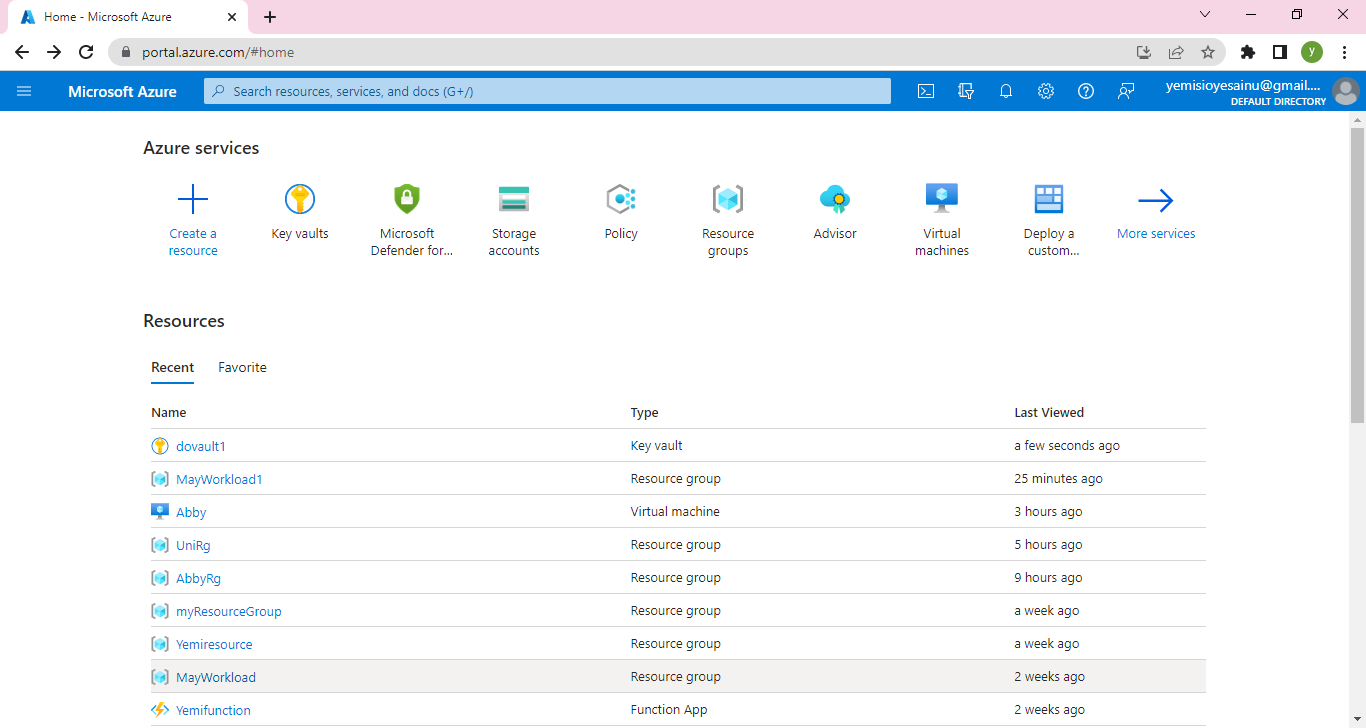
It will take you to a Default Directory. Click on Users
Then click on New User
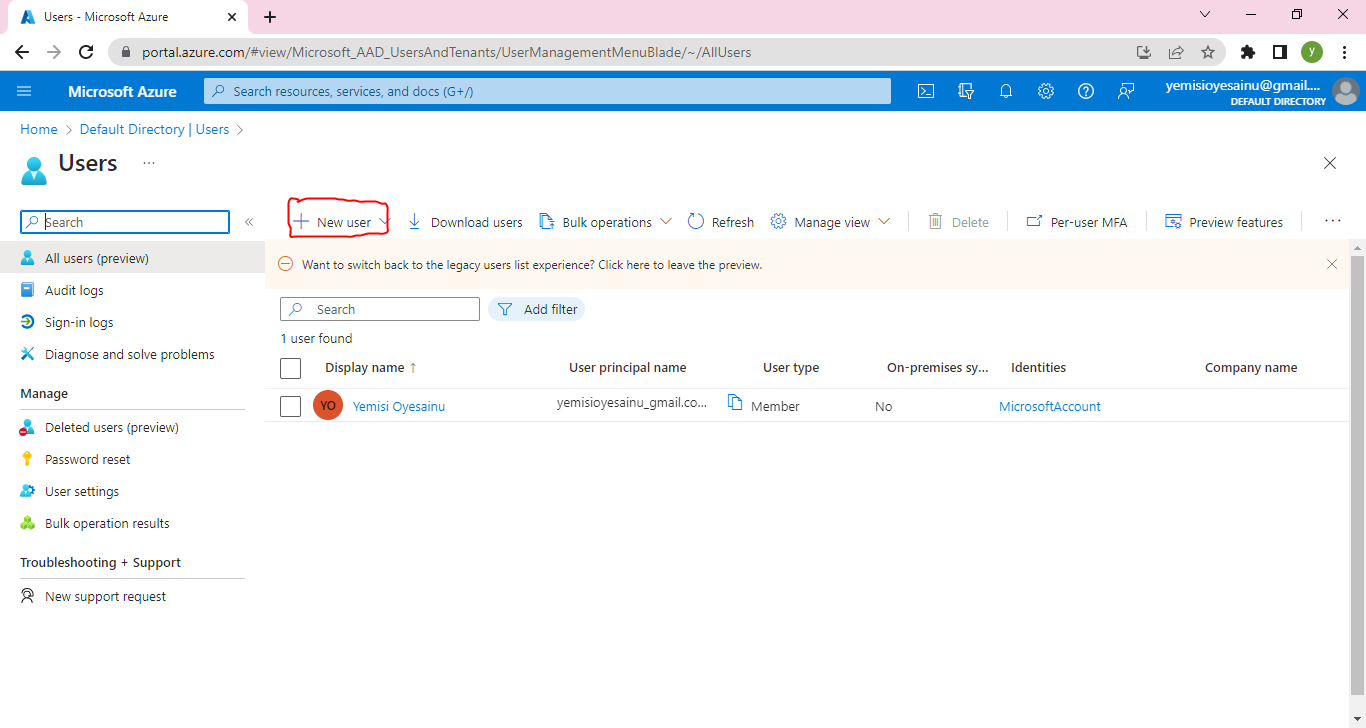
Complete the Basics
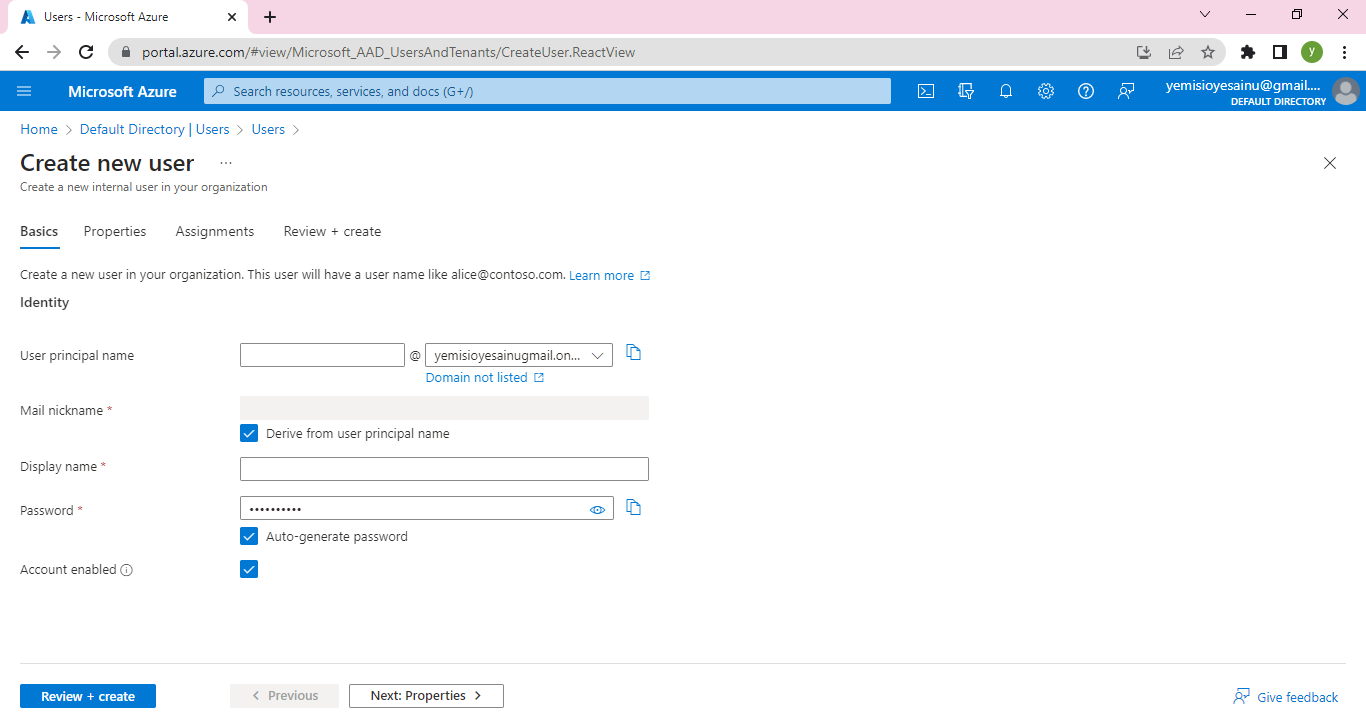
I will use wumi for the User Principal name which will also be the display name
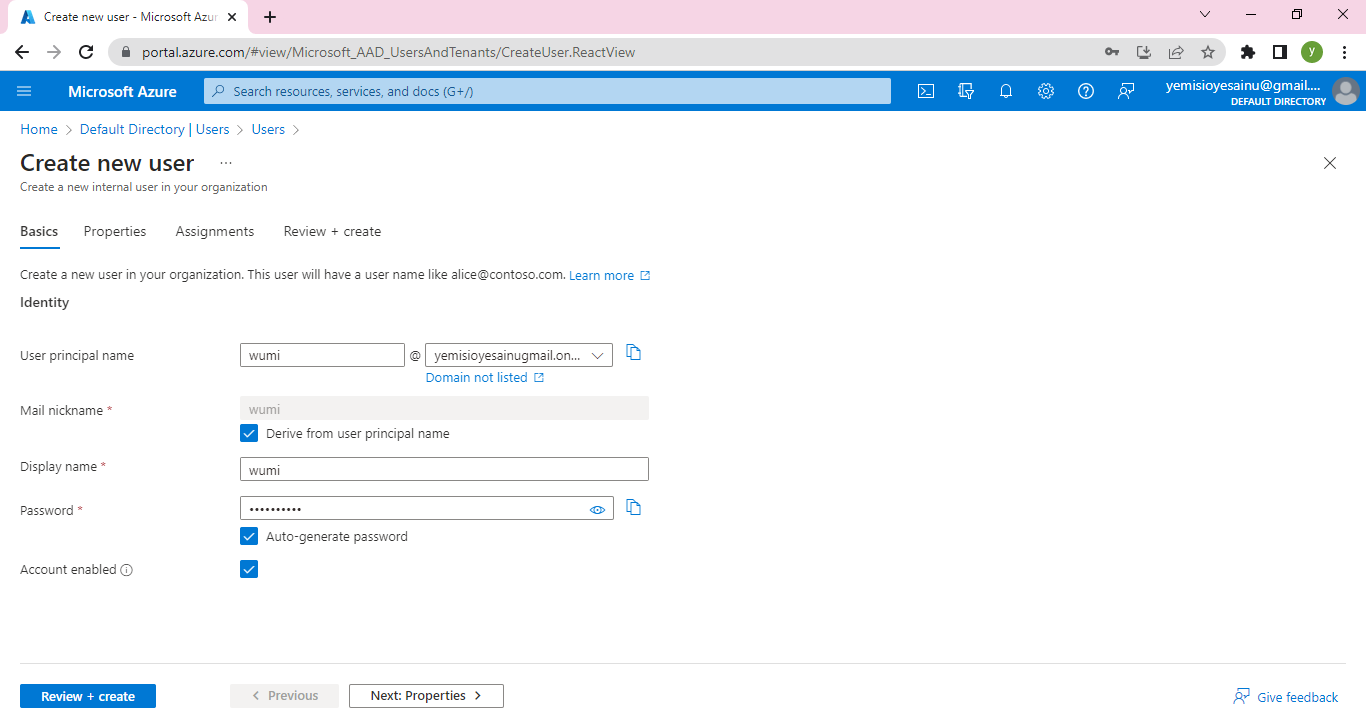
Click on Review and Create
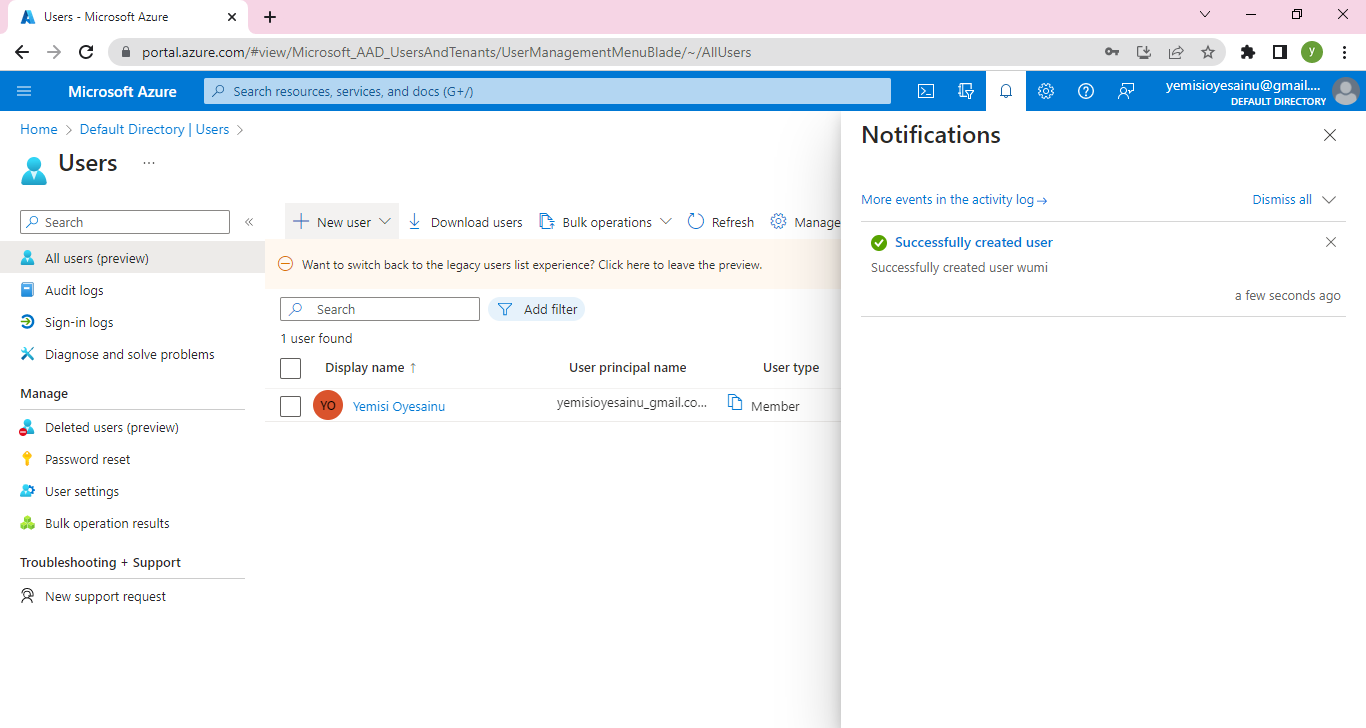
Then User wumi has been created
**Step 2 - Create a Resource group and Assign Role**
Go to Resource group on the Azure portal and click on create
Complete the Basics and click on Review and Create
I will name the Resource group MayWorkload2
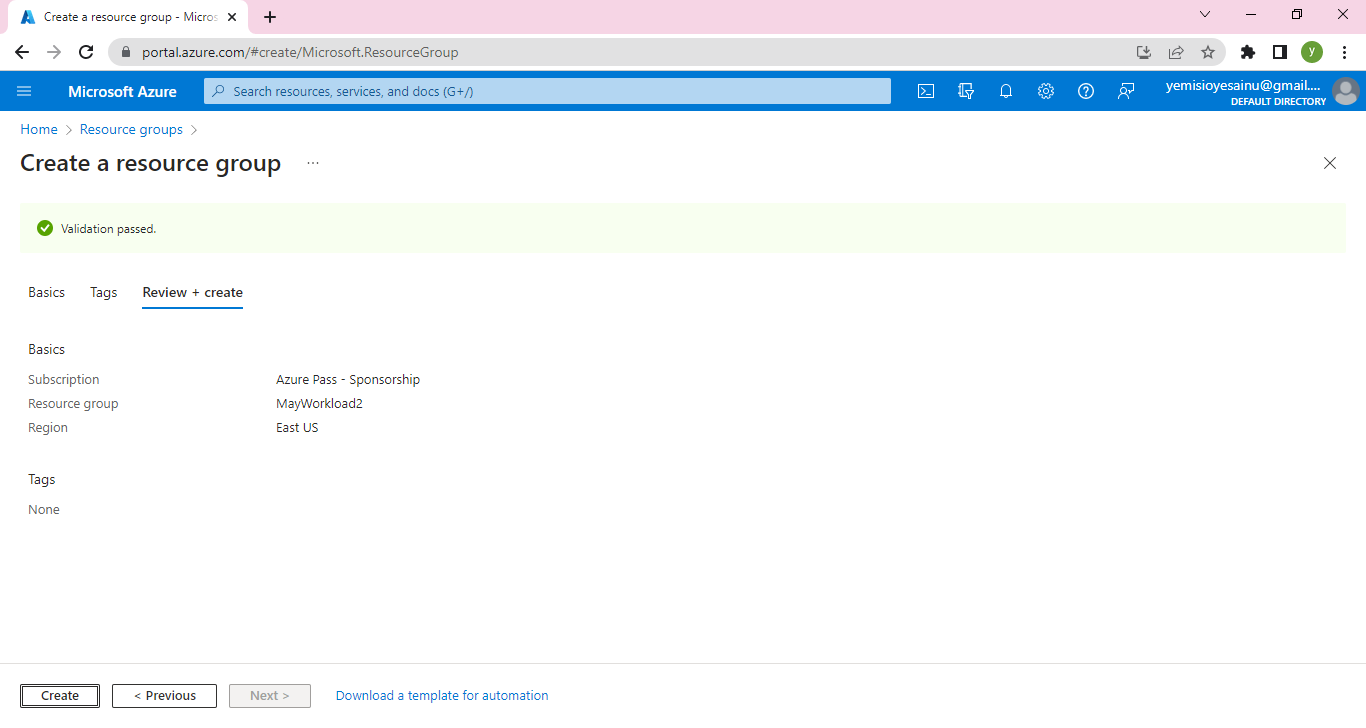
When Validation is passed, click on Create
On the Resource group MayWorkload2 click on Access Control (IAM)
Click on Add and select Add Role Assignment from the dropdown menu
Click on Add
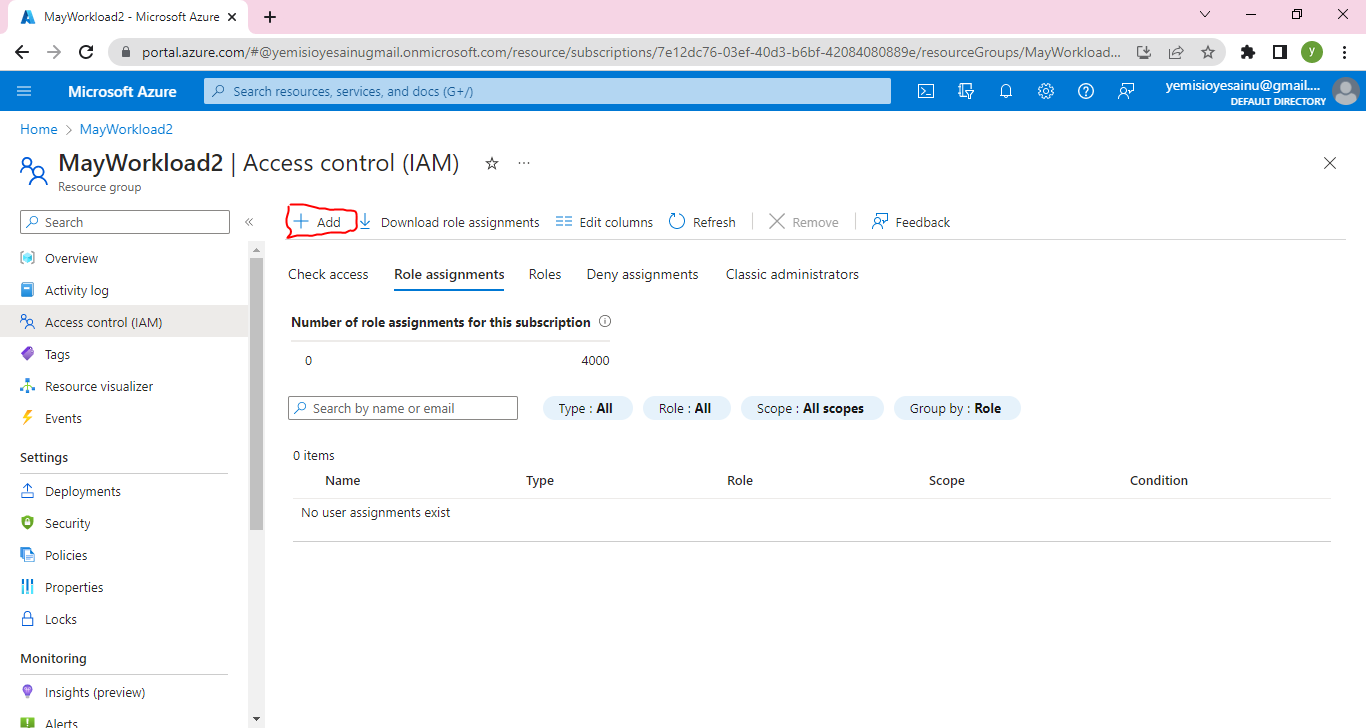
Under Job function roles, search for Virtual Machine Contributor, which is the role we want to assign to User wumi, and click on it
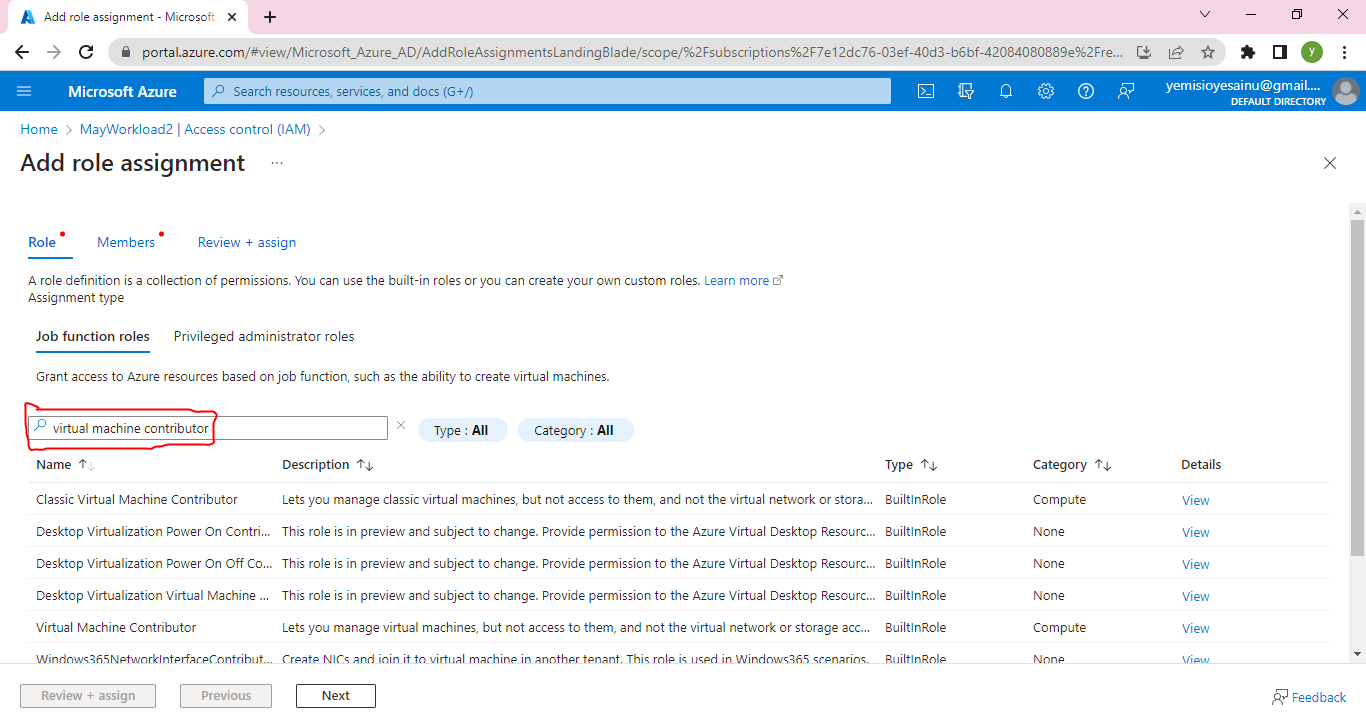
Click on Select members and type in Virtual Machine Contributor in the Description box
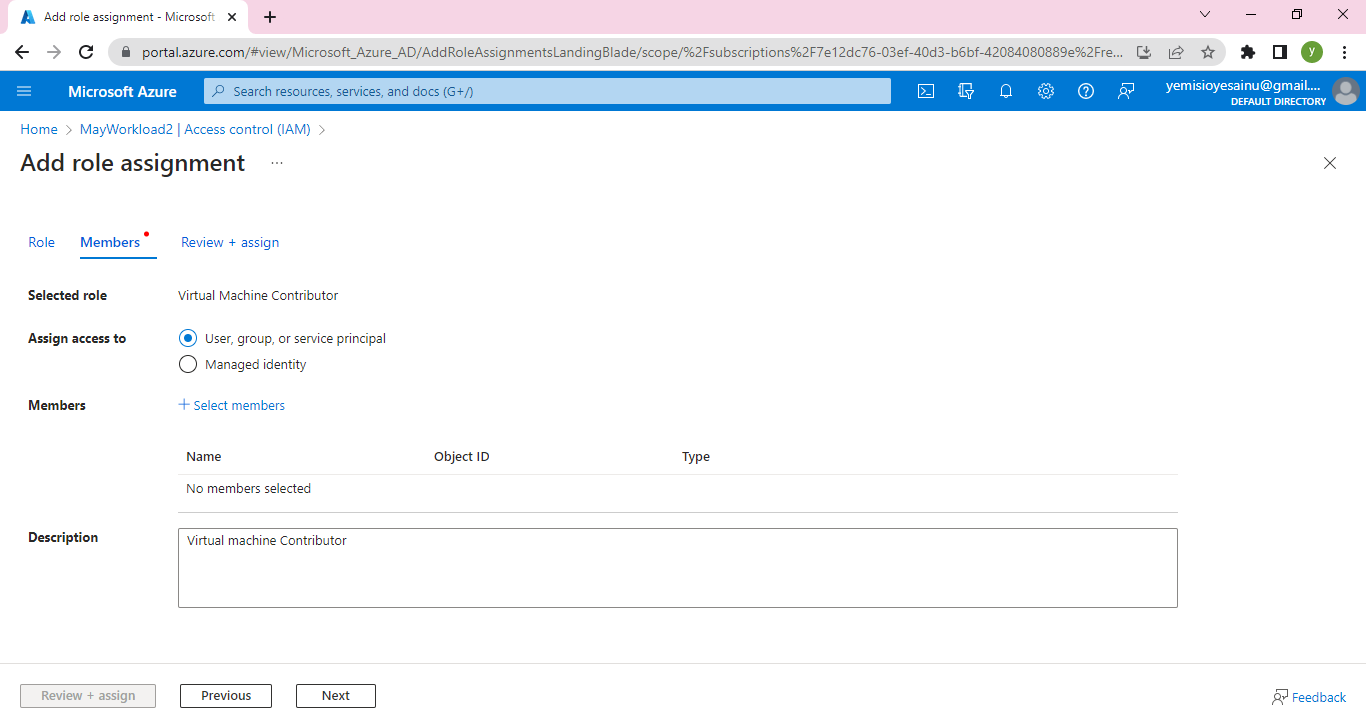
On top righthand side of the next page displayed,you will find a list of users already created.
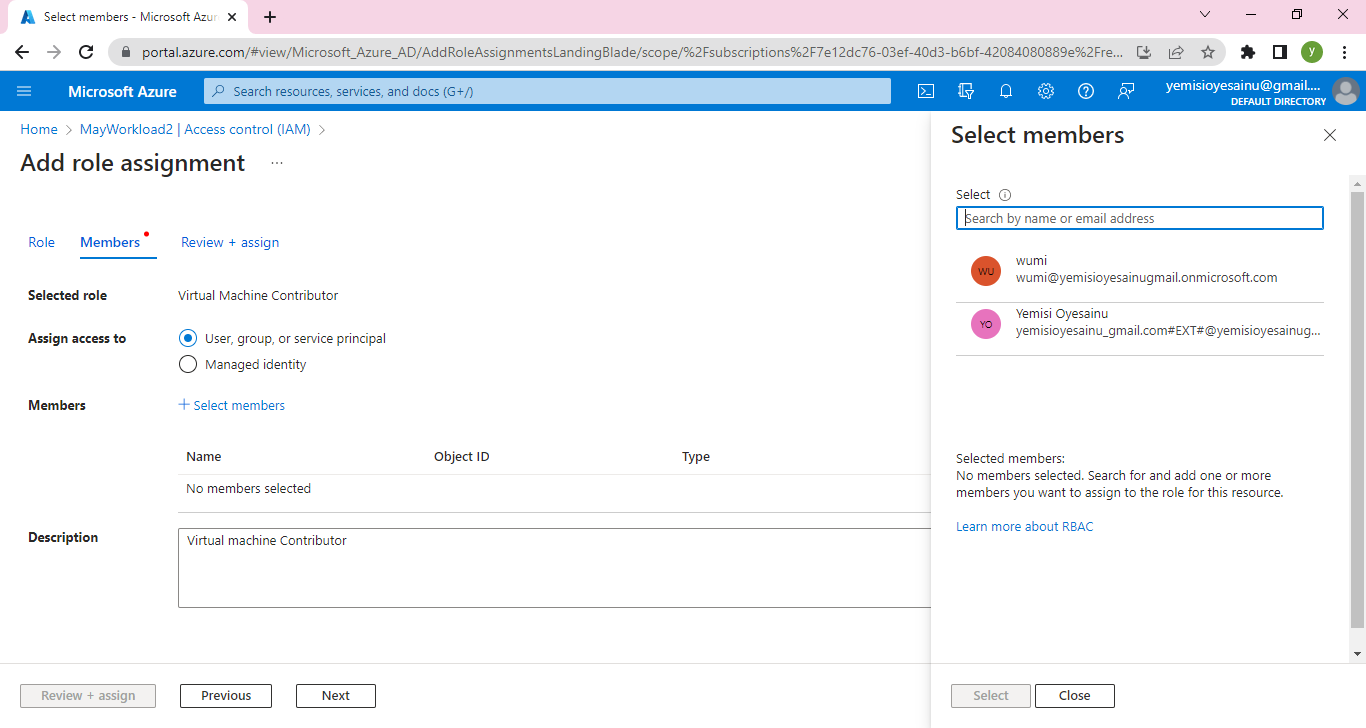
Select the User we want to assign role to, that is wumi
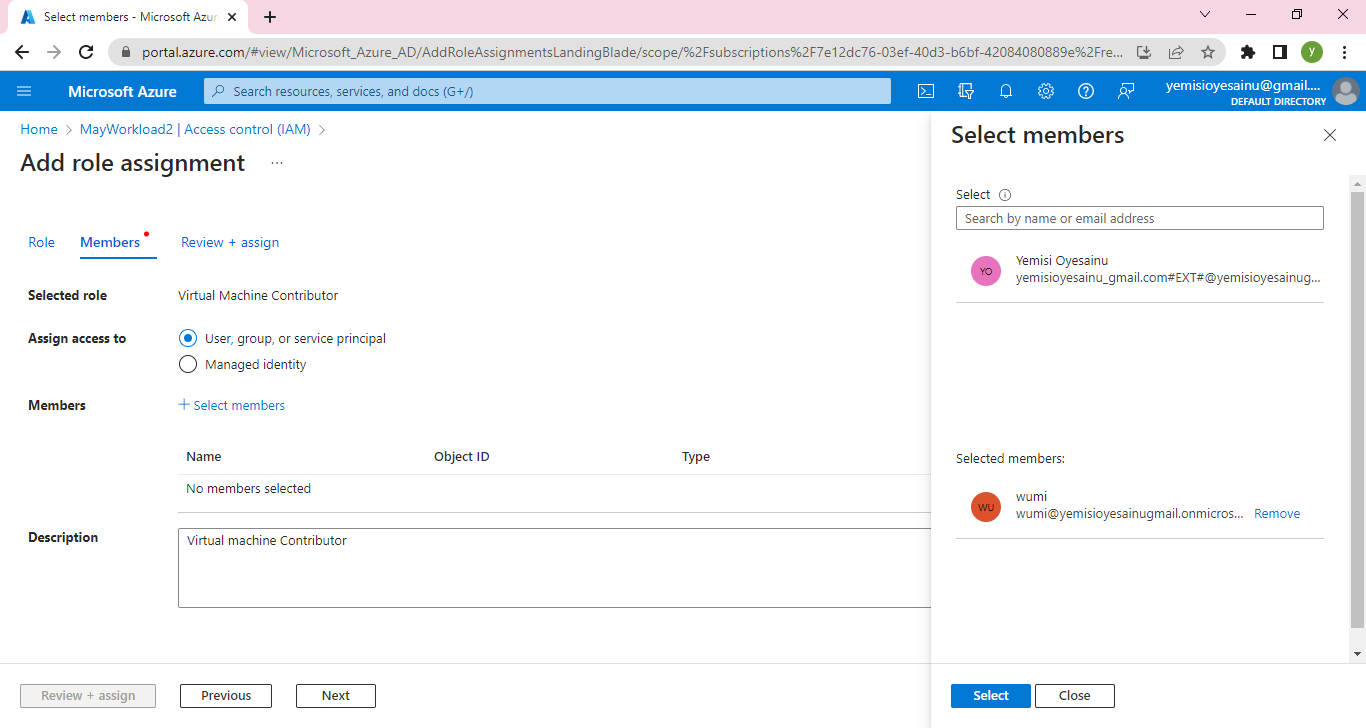
Click on Select
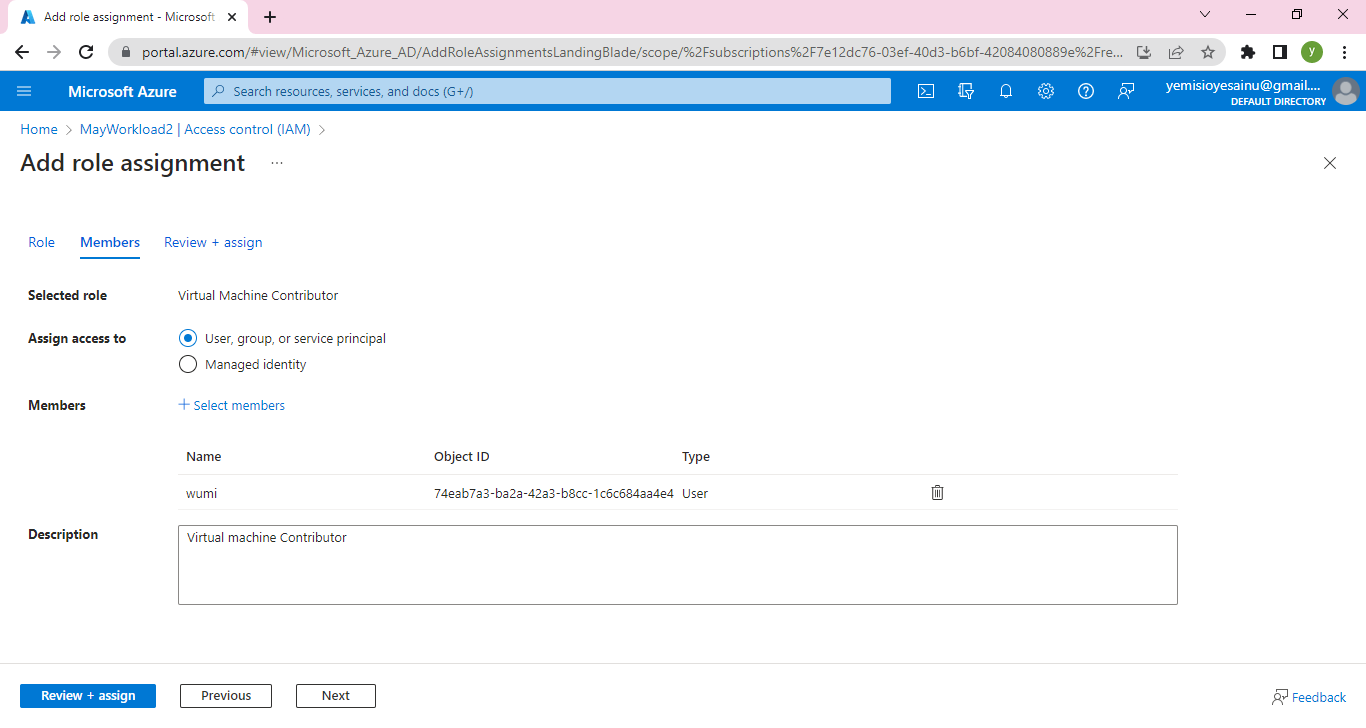
Then click on Review and Assign
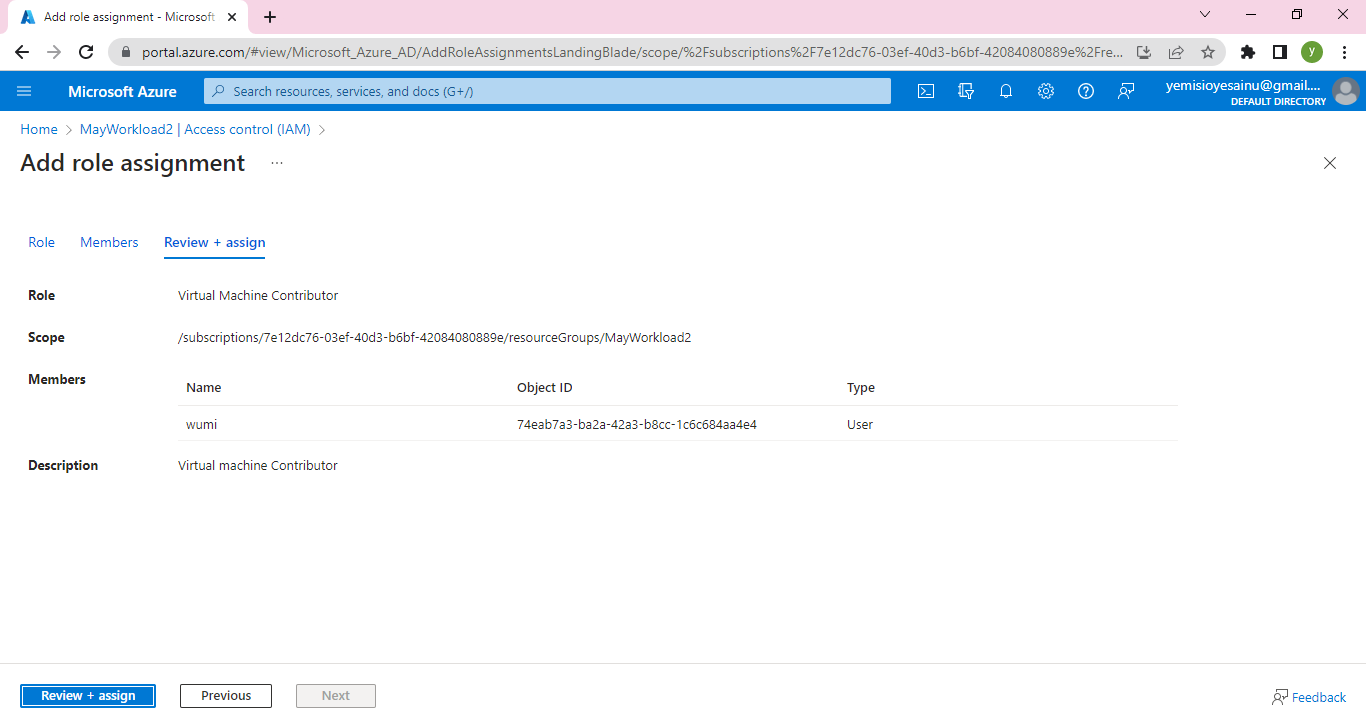
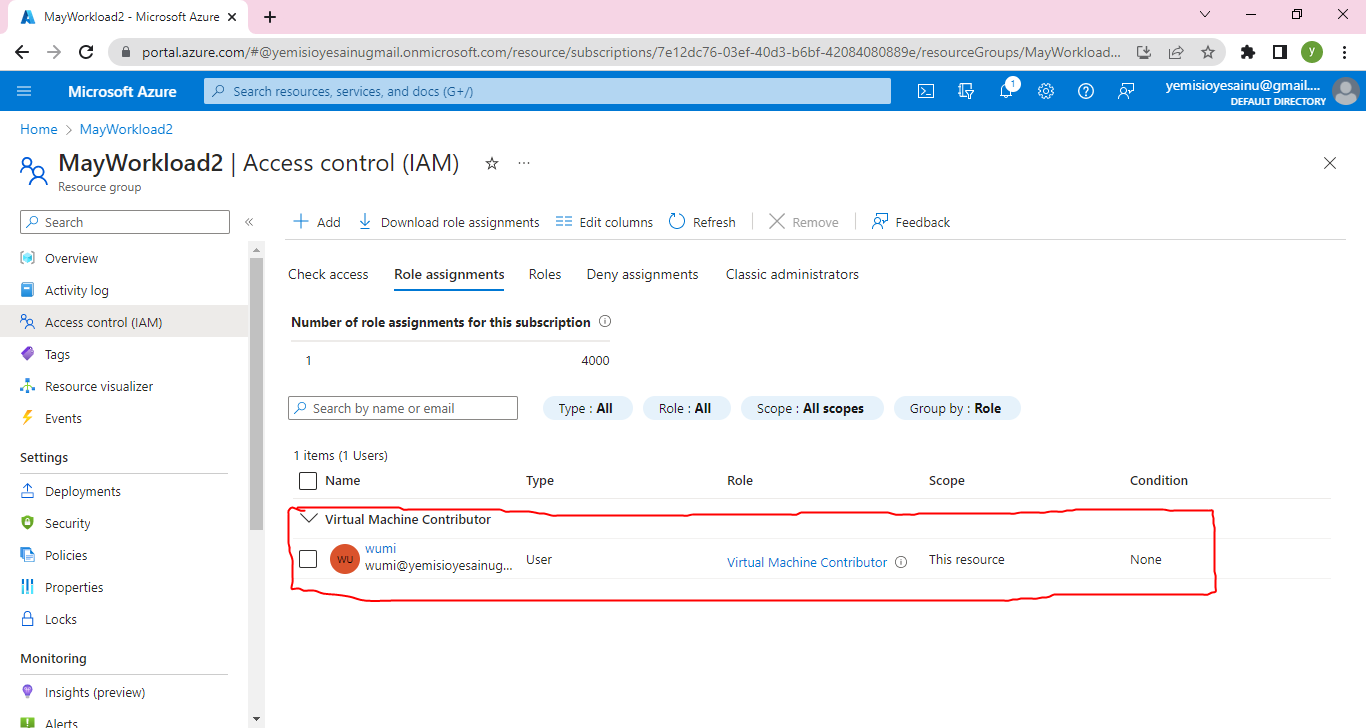
Wumi have been assigned the role of a Virtual Machine Contributor as indicated in the image above. This access only allows the User to manage virtual machine but not to access them or virtual network or storage account they are connected to
**Step 3 -View the Activity log**
Now let us view the Activity Log. Go to Resource group
MayWorkload2 and click on Activity log
Here, two activities are shown in the Activity log. Role Assignment and updating resource group. It also show details about the activities including status, time, date ,subscription and the identity of the user that initiated the activities
**Step 4 - Removing a Role Assignment**
This may become very necessary when the User whom a role is assigned has completed his task for the role or has change roles or has left the service of the company.
Come on, lets go and see how this will be done
Go to Resource group MayWorload2 and click on Access Control(IAM)
Click on Remove
A confirmation dialog box will pop up
Click on Yes
Check the Resource group again
The role assignment has been removed!
Trust you find this useful. Please give a feedback
| yemmyoye |
1,481,635 | You got the job! Now what? - Strategies to pass the probation period | In today's increasingly digital world, a significant number of junior developers are vying for... | 0 | 2023-05-26T11:30:00 | https://profy.dev/article/preparation-for-new-job | webdev, react, career | In today's increasingly digital world, a significant number of junior developers are vying for coveted roles in the tech industry. The competition is steep, with computer science graduates, bootcamp alumni, and self-taught developers all striving for the same opportunities. As a result, you may find yourself sending out hundreds of applications, only to receive a handful of responses in return.
When you do finally land a job offer, it often comes with a probation period, typically ranging from one to six months. This is the employer's chance to see your skills in action, to ascertain if you are indeed a good fit for their team. But it's also your time to prove your worth. If you don't meet the mark, the harsh reality is that it's relatively easy for them to let you go.
That said, **securing that first job and successfully navigating through the probation period** can have a substantial impact on your career trajectory. Once you've gained a year or two of experience, landing subsequent jobs becomes exponentially easier. So, this initial phase can be seen as a crucial stepping stone to a prosperous career in tech.
However, an important question arises here: **how do you ensure your survival through this probation period?** The truth is, it depends.
## Table Of Contents
1. [What You Can Expect on Your First Job](#what-you-can-expect-on-your-first-job)
1. [Scenario One: Proper Onboarding Including Mentoring](#scenario-one-proper-onboarding-including-mentoring)
2. [Scenario Two: No Structured Onboarding, but a Helpful Team](#scenario-two-no-structured-onboarding-but-a-helpful-team)
3. [Scenario Three: Being Thrown into the Deep End](#scenario-three-being-thrown-into-the-deep-end)
2. [Practical Steps to Ensure Success During Your Probation Period](#practical-steps-to-ensure-success-during-your-probation-period)
1. [Preparation before your first day: Reducing cognitive load](#preparation-before-your-first-day-reducing-cognitive-load)
2. [The first days on the job: Clarify expectations and establish a timeline](#the-first-days-on-the-job-clarify-expectations-and-establish-a-timeline)
3. [Striking the Right Balance Between Asking for Help and Becoming Independent](#striking-the-right-balance-between-asking-for-help-and-becoming-independent)
4. [Humility Over Arrogance](#humility-over-arrogance)
3. [Conclusion](#conclusion)
## What You Can Expect on Your First Job
The experience you'll have during your probation period is heavily influenced by several factors, including the team you join, its size, resources, and its onboarding, management, and mentoring practices. To illustrate this, let's consider three different scenarios through the experiences of three junior developers: Sam, Maria, and David.
### Scenario One: Proper Onboarding Including Mentoring
Sam's journey starts in a team where there is a well-structured onboarding process, including mentoring. He begins by shadowing and pair-programming with more experienced developers. This direct experience with senior colleagues allows him to learn quickly, absorb best practices, and become familiar with the team's workflow.
After a couple of weeks, Sam starts to work on small tasks that are suitable for his level. This transition is smooth and structured, ensuring he feels comfortable and prepared. This scenario is most common in larger teams that can allocate resources to develop a structured onboarding process, including mentors, onboarding buddies, and suitable tasks for junior developers.
### Scenario Two: No Structured Onboarding, but a Helpful Team
Maria, on the other hand, joins a team where there is no structured onboarding process. The team lacks the resources and time to prepare suitable tasks or spend much time on pair programming and mentoring. She finds herself working on tasks independently just days into the job, a stark contrast to Sam's experience.
Yet, even without a structured process, Maria's team is eager to help. The experienced developers are supportive and approachable, providing her with guidance and assistance when she needs it, even though they can't dedicate significant time to pair programming due to their own deadlines.
### Scenario Three: Being Thrown into the Deep End
David's experience is quite different. He finds himself in a team that either lacks the resources to support him or simply doesn't prioritize it. He experiences a "sink or swim" approach. He is expected to learn on the fly and become productive without much assistance, a very stressful situation for any junior developer.
If David manages to adapt and deliver, he'll survive. If not, he may not make it past the probation period. This is a challenging scenario, but it's also one that can spur rapid growth—if he can handle the pressure.
## Practical Steps to Ensure Success During Your Probation Period
While you may not have much influence over the scenario you find yourself in, you can take proactive steps to set yourself up for success. Here's how:
### Preparation before your first day: Reducing cognitive load
Regardless of the scenario, you're likely to be overwhelmed by the wealth of new things to learn: the potentially enormous and unfamiliar codebase, new technologies, complex project setups, workflows, team dynamics, and processes. The first few days can be especially challenging with an influx of information from numerous meetings. The goal of preparation is to expose you to as many elements as possible upfront, thus reducing cognitive load during your initial days and weeks.
1. **Researching the tech stack and workflow**: Reach out to your future team member or contact in the company, expressing your desire to prepare. Ask them about the tech stack and workflows they use, such as Scrum or Kanban. Learn and practice the tech stack as much as possible and read about the workflows. The goal is not to fully understand everything. But this early exposure will help familiarize you with the basics, making them less daunting when you officially start.
2. **Understanding the company and domain**: If possible, test out the product or application. Familiarize yourself with the company through LinkedIn and its website, and read about the industry and the company's competitors. This will help you better understand the company-specific words and industry-specific language used during your onboarding. This again will help reduce cognitive load during your first days.
### The first days on the job: Clarify expectations and establish a timeline
As a new hire, especially as a junior developer, you'll require resources from more experienced team members. The most important expectation, therefore, is for you to become productive and independent. The timeline for this varies significantly, as seen in the different scenarios presented earlier.
Understanding the expectations of your team leads and managers is crucial. It gives you direction and guidelines. During onboarding meetings, ask a simple question: "What would make me a successful hire at the end of the probation period (after 1 month/6 months)?" This will establish a timeline of expectations and encourage the other person to reflect on their expectations.
But don't limit your queries to your managers; your peers can also provide valuable insights. In the first few days, it's beneficial to be proactive and set up short meetings with each team member to get to know them. This not only helps establish a relationship but also gives you the chance to ask about their expectations. These conversations can provide a broader perspective and help you understand what it takes to be successful on the team from multiple viewpoints.
After all, your teammates have been in your shoes before and may have practical advice on how to navigate this new terrain. Plus they might be part of your evaluation at the end of your probational period.
### Striking the Right Balance Between Asking for Help and Becoming Independent
Striking the right balance between asking for help and becoming independent can be tricky. There's no set rule, like "asking 10 questions a day is too much." It depends on the team's expectations, the task you're working on, and the project's complexity.
There are two extremes of junior developers:
- **One rarely asks questions**, maybe due to shyness, embarrassment, over-confidence, or a reluctance to disturb seniors. They might take longer to learn and become productive, and at some point, they could block other developers from doing their work.
- **On the other end is the developer who always asks questions.** They seem eager to learn at first, but the number of questions doesn't decrease even after weeks. They constantly need assistance and don't seem to do their own research. Their questions lack detail and initiative, like "The product image doesn't work. What am I doing wrong?" This pattern indicates a lack of striving for independence, which could become a burden to the team.
In summary, asking too few questions can prolong your learning curve and delay your productivity. Asking too many can consume excessive resources and hinder your growth toward independence. Striking the right balance is key.
### Humility Over Arrogance
Most junior developers approach their first job with a healthy dose of humility, recognizing the magnitude of what they don't yet know. However, there are some who, despite their inexperience, carry an air of arrogance, thinking they know it all. It's essential to note that this attitude can be counterproductive.
As a new developer, you might have high expectations for what "production-level code" should look like, only to discover that a lot of it seems to be held together with proverbial duct tape. This can be shocking, but there are many valid reasons for it:
- **Tight Deadlines and Priorities**: In the real world, there isn't always time to write the most elegant code. Deadlines and business priorities often dictate a need for speed over perfection.
- **Evolution and Scaling**: Codebases evolve over time. What was once the perfect solution may no longer fit as the project scales, leading to layers of fixes and patches.
- **Team Changes**: Developers with different coding styles and preferences come and go. The original intention behind certain pieces of code may be long forgotten, adapted over time to "make it work" with new features.
So, instead of adopting a judgmental attitude and wanting to rewrite everything, remember that a long-running project has a history. Things are the way they are not because previous developers were incompetent (though this can be a fun topic for gossip), but because software development is a complex and evolving process.
Humility is key. Recognize that there's always more to learn and that understanding the "why" behind existing code can be as valuable as writing new code. This approach will make you a better developer and a more appreciated team member.
## Conclusion
Navigating the probation period of your first tech job can seem daunting, but with thoughtful preparation, clear communication, and the right attitude, you can successfully secure your place in the industry.
Let's recap the main points we've covered:
1. **Expectations**: Depending on the size, resources, and practices of the team you join, the expectations and timeframes for you to meet these expectations can vary significantly. We outlined three scenarios to illustrate potential environments you may encounter.
2. **Preparation**: Before your first day, try to familiarize yourself with the tech stack, workflow, company, and domain. This will help reduce cognitive overload during your initial days.
3. **Communication**: During the first few days on the job, clarify expectations and establish a timeline for your progress. Be proactive, reach out to your team members, and build relationships.
4. **Balance**: Try to strike the right balance between asking for help and working independently. Neither extreme—asking too few questions or asking too many—is beneficial.
5. **Professionalism**: Lastly, approach your job with humility, not arrogance. Recognize that there's always more to learn, and understand that existing code might be the way it is due to many reasons, including time constraints and evolving project requirements.
Starting a new job in the tech industry can be overwhelming, but remember, everyone has been in your shoes at some point. The probation period is a chance for you to learn, grow, and demonstrate your potential. It's an opportunity to set the foundation for your career, and with the right attitude and approach, you can turn it into a launching pad for your success. | jkettmann |
1,481,670 | SEO Basics for Software Engineers | How To Improve Your Website's Ranking and Reach More Customers ... | 0 | 2023-05-26T17:56:06 | https://dev.to/kodebae/seo-basics-for-software-engineers-enhancing-digital-footprints-4k4g | webdev, seo, beginners, learning | ## How To Improve Your Website's Ranking and Reach More Customers
---
### **Introduction:**
In today's digital world, implementing SEO on your website is essential for businesses of all sizes. Think about it, what's the point of having a website if nobody is going to see it? Advertising can be expensive, so we need to generate as much organic traffic as possible, but how do we do that?
As a software engineer, you play a key role in the SEO process. By incorporating SEO best practices into your development process, you can help ensure that your website ranks high in search results and yields a good ROI. But how do you get there without previous SEO experience?
In this blog post let's explore ways that you can improve your website's SEO ranking and reach more potential customers. That way you can get back to debugging your app. Yay!
<img width="75%" style="width:75%" src="https://media.giphy.com/media/kyuFxrvpapNsJrski8/giphy.gif">
## **Core Principles of SEO:**
So what does SEO even stand for? SEO stands for search engine optimization. This is the process of improving the ranking of a website in the search engine results pages (SERPs). The key goal is to optimize your website for SEO, you can increase its visibility and reach more potential customers.
<mark>There are many different SEO techniques, but the topics we will discuss today are:</mark>
###Keyword research:
This involves identifying the keywords that people are using to search for information online. Once you have identified your target keywords, you can use them throughout your website content, including your titles, meta descriptions, and headers.
###On-page optimization:
You can significantly impact on-page optimization by optimizing crucial website elements such as meta tags, header tags, and URLs. By structuring webpages effectively and ensuring keyword relevance, software engineers can enhance search engine rankings and visibility.
###Enhancing user experience (UX):
This refers to the overall experience that users have when they visit your website. Good UX design means its more likely that users will stay on your website and take the desired action, such as making a purchase or signing up for a newsletter.
###Mobile responsiveness:
Mobile responsiveness is a key factor in SEO. According to [this blog post](https://www.allconnect.com/blog/mobile-vs-desktop#:~:text=Mobile%20phones%20generated%20over%2060,surpassed%206.5%20billion%20in%202022.) by All Connect "Mobile phones generated over 60% of website traffic in 2022, with desktops and tablets only generating about 39%.". So it is important to make sure that your website is mobile-friendly.
###Meta data & structured data
Metadata is data that provides information about other data. Profound isn't it? All joking aside in the context of SEO, metadata is used to provide information about your website's content to search engines like Google. This information can help search engines to better understand your website and to rank it higher in search results.
Structured data is a type of metadata that is used to mark up your website's content in a way that search engines can understand.
###Backlinks:
Backlinks are links from other websites to your website. Backlinks are a valuable signal to search engines that your website is authoritative and trustworthy. You want as many backlinks as possible.
###Monitor website performance:
In addition to SEO, its also important to monitor your website's performance. This includes things like tracking your website's traffic, bounce rate, and conversion rate. By monitoring your website's performance, you can identify areas where you can improve your website and increase its visibility and reach.
###Stay updated with SEO trends:
SEO is a constantly evolving field. What works today may not work tomorrow. By staying up to date on SEO trends, you can ensure that your website is always optimized for search engines and that you are getting the most out of your SEO efforts. We'll also discuss techniques on how you can stay up to date on the latest trends.
Let's get this party started.
<img width="75%" style="width:75%" src="https://media.giphy.com/media/Jn5KlpkXqFfGfaoSsy/giphy.gif">
## **1. Keyword Research and Implementation:**
Keywords are the building blocks of SEO. I personally use Google Ads as my keyword research tool for two reasons. First, it's free and easy to use. Secondly it's a Google product used to place ads on their search engine. Since your intention is to rank higher on Google, this is the perfect tool to use for keyword research.
Implementing these keywords strategically throughout the website's code, metadata, headings, and content can enhance your visibility on search engine result pages (SERPs). You should practice due diligence and collaborate with your teams to identify relevant keywords and key phrases that align with your projects purpose and target audience.
Target audience is another key point here and the topic could lead down a rabbit trail. Remember to research your target audience thoroughly. Another thing to mention is that you can't be everything to everyone. If you try you will become nothing to nobody. And your website won't rank either.
<mark>Checkout this Keyword Researching master guide by Moz</mark>
[Moz Keyword Research Master Guide](https://moz.com/blog/announcing-keyword-research-master-guide)
## **2. On Page Optimization:**
In today's fast-paced digital world, page speed is a critical factor for both user experience and SEO. These are my go to strategies for speeding up a website, quickly: You should optimize your website performance by minimizing file sizes, leveraging browser caching, and employing compression techniques. Faster loading times result in lower bounce rates, higher user engagement, and improved search engine rankings. Minify CSS, reduce image sizes, and remove unnecessary images from files to help boost performance.
<br>
<img width="75%" style="width:75%" src="https://media.giphy.com/media/tBemJSc7bAzc2UIq7y/giphy.gif">
<br>
A **well-structured website** not only improves user experience but also helps search engines crawl and index its content effectively. Having a well structured website will reduce bounce rates, the two go hand in hand. Reducing bounce rates is one of my main concerns when improving website performance for companies.
Put emphasis on on **optimizing your website's content**, structure, and code for SEO. This includes things like using relevant keywords throughout your content, optimizing your website's title tags and meta descriptions, and ensuring that your website is mobile-friendly.
<br>
<img width="75%" style="width:75%" src="https://www.digitalabhyasa.com/wp-content/uploads/2019/03/On-page-Optimization.jpg"/>
<br>
## **3. Enhancing the User Experience**
User experience (UX) plays a pivotal role in SEO success. Software engineers can contribute to a positive UX by optimizing website loading speed, ensuring mobile responsiveness, and designing intuitive navigation. By delivering a seamless user experience, you can reduce bounce rates and signal search engines that the website is valuable and user-friendly.
####Here are some **specific UX techniques** that software engineers can use:
- **Optimize website loading speed:** A slow-loading website will frustrate users and make them more likely to click away. As a software engineer, you can optimize website loading speed by minifying and caching your website's code, and by using a content delivery network (CDN).
- **Ensure mobile responsiveness:** More and more people are using their mobile devices to access the internet. As a software engineer, you can ensure that your website is mobile-friendly by using a responsive design.
- **Design intuitive navigation:** Make it easy for users to find the information they are looking for by designing intuitive navigation. This includes using clear and concise menus, and by using breadcrumbs to help users track their progress through your website.
<img width="75%" style="width:75%" src="https://miro.medium.com/v2/resize:fit:1050/1*hp-yfKsmzsj711iLbM8eEw.jpeg"/>
## **4. Mobile Responsiveness:**
With the rise in mobile device usage, search engines prioritize mobile-friendly websites in their rankings. Software engineers should ensure that their websites are responsive, adapting seamlessly to different screen sizes and resolutions.
####My honest advice for making your website mobile-friendly:
- **Use a responsive design:** A responsive design means that your website will automatically adjust to the size of the device it is being viewed on.
- **Use a mobile-friendly theme or template:** There are many themes and templates available that are specifically designed for mobile devices.
- **Optimize your images:** Images can slow down your website, so it is important to optimize them for mobile devices.
- Test your website on mobile devices. Make sure that your website looks good and works well on mobile devices.
Employing responsive design techniques and testing the website across various devices and platforms can significantly impact your visibility and user satisfaction. You can implement responsive design with tools like: Flexbox, media queries, built in libraries like Material UI, and Bootstrap. Bootstrap is my personal favorite.
## **5. Metadata and Structured Data:**
As a software engineer you should optimize SEO efforts with metadata, such as title tags and meta descriptions. These elements provide concise summaries of webpage content for search engine users.
####Let's explore some tips for using metadata and structured data:
- **Use the correct schema.org markup:** Schema.org is a vocabulary of structured data that is supported by most major search engines. When using schema.org markup, make sure that you are using the correct schema for your content.
- **Keep your metadata up-to-date:** As your website's content changes, make sure that you update your metadata accordingly. This will help to ensure that search engines always have the most accurate information about your website.
- **Test your metadata:** Once you have added metadata to your website, test it to make sure that it is working correctly. You can do this by using a tool like Google's Rich Results Test.
###Meta data example code:
```
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Example Page</title>
<!-- Meta Tags for SEO -->
<meta name="description" content="This is an example page for SEO structured meta data.">
<meta name="keywords" content="SEO, meta data, structured data, example">
<!-- Open Graph Tags for Social Media Sharing -->
<meta property="og:title" content="Example Page">
<meta property="og:description" content="This is an example page for SEO structured meta data.">
<meta property="og:image" content="https://example.com/image.jpg">
<meta property="og:url" content="https://example.com">
<!-- Twitter Card Tags for Twitter Sharing -->
<meta name="twitter:card" content="summary_large_image">
<meta name="twitter:title" content="Example Page">
<meta name="twitter:description" content="This is an example page for SEO structured meta data.">
<meta name="twitter:image" content="https://example.com/image.jpg">
<!-- Other Meta Tags -->
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta name="robots" content="index, follow">
<!-- Canonical Tag -->
<link rel="canonical" href="https://example.com">
<!-- CSS and JavaScript -->
<link rel="stylesheet" href="styles.css">
<script src="script.js"></script>
</head>
<body>
<!-- Your Page content goes here -->
</body>
</html>
```
The <meta> tags in the head section of the HTML code provide information about the website to search engines and browsers. The charset meta tag specifies the character encoding used on the website. The viewport meta tag specifies the width and initial scale of the website in mobile devices. The title meta tag specifies the title of the website. The description meta tag provides a brief description of the website. The keywords meta tag specifies the keywords that are used to describe the website.
By including metadata in your website, you can help search engines to understand your website and to rank it higher in search results. You can also help browsers to display your website correctly.
####Below is a brief explanation of each of the metadata tags:
**charset:** The charset meta tag specifies the character encoding used on the website. This is important for ensuring that the text on your website is displayed correctly for users of different languages.
**viewport:** The viewport meta tag specifies the width and initial scale of the website in mobile devices. This is important for ensuring that your website looks good on mobile devices.
**title:** The title meta tag specifies the title of the website. This is the title that will appear in the browser's title bar and in search engine results pages (SERPs).
description: The description meta tag provides a brief description of the website. This is the text that will appear in search engine results pages (SERPs).
**keywords:** The keywords meta tag specifies the keywords that are used to describe the website. This information is used by search engines to determine how to rank your website in search results.
###Utilizing structured data:
Structured data is a type of metadata that is used to mark up your website's content in a way that search engines can understand. This allows search engines to display your website's content in a more prominent way in search results.
For example, if you have a product page, you can use structured data to mark up the product's name, price, and availability. This will allow search engines to display your product in a rich snippet in search results, which can make it more likely that users will click on your link.
Incorporating structured data markup enables search engines to understand and display the website's information more effectively, enhancing its visibility and click-through rates.
####What are some of the benefits of using structured data for SEO?:
- **Improved click-through rate (CTR):** Rich snippets can make your website's listings more visually appealing and informative, which can lead to an increased CTR.
- **Improved rankings:** Search engines may use structured data to improve the ranking of your website's listings in search results.
- **More engagement:** Rich snippets can encourage users to click on your website's listings and learn more about your products or services.
####There are many different types of structured data that you can use on your website. Some of the most popular types of structured data include:
- **Product schema:** This type of structured data is used to mark up product pages. When used correctly, product schema can help your product listings appear in rich snippets in search results.
- **Event schema:** This type of structured data is used to mark up event pages. When used correctly, event schema can help your event listings appear in rich snippets in search results.
- **Recipe schema:** This type of structured data is used to mark up recipe pages. When used correctly, recipe schema can help your recipe listings appear in rich snippets in search results.
There are a few different ways that you can utilize structured data on your website. One way is to use a plugin or extension for your website builder. Another way is to manually add the structured data markup to your website's code.
If you are not sure how to use structured data, there are a number of resources available to help you. [The Schema.org](https://schema.org) website provides a comprehensive guide to structured data, and there are also a number of plugins and extensions available for popular website builders.
By using structured data on your website, you can improve your website's SEO and make it more likely that your website will appear in search results in a more prominent way.
## **6. Backlinks**
Backlinks are links from other websites to your website. These are a valuable signal to search engines that your website is authoritative and trustworthy. The more backlinks you have, the higher your website is likely to rank in search results.
####There are two main types of backlinks:
- **Dofollow backlinks:** are the most valuable type of backlink. Dofollow backlinks pass PageRank from the linking website to your website. PageRank is a measure of a website's authority.
- **Nofollow backlinks:** do not pass PageRank. Nofollow backlinks are often used for sponsored links or links from low-quality websites.
####There are a number of things you can do to improve your website's backlink profile:
- **Create high-quality content:** The best way to get backlinks is to create high-quality content that people want to link to. Your content should be informative, engaging, and well-written.
- **Participate in online communities:** You need to participate in online communities related to your niche. This will help you to build relationships with other website owners and get them to link to your website.
- **Guest blogging:** This is a great way to get backlinks. When you guest blog, you will be able to include a backlink to your website in your author bio.
- **Submit your website to directories:** You can submit your website to directories is a great way to get backlinks. However, it is important to only submit your website to high-quality directories.
- **Ask for backlinks:** You can also ask other website owners to link to your website. However, it is important to be polite and respectful when asking for backlinks.
| It is important to note that not all backlinks are created equal. Some backlinks are more valuable than others. The most valuable backlinks are those that come from high-quality websites that have a high domain authority.
You can use a variety of tools to help you build backlinks, such as Ahrefs, Moz, and Majestic SEO. These tools can help you identify high-quality websites that you can reach out to and ask for backlinks.
Building backlinks takes time and effort, but it is a valuable investment. By building backlinks, you can improve your website's ranking in search results and attract more visitors.
Here is a blog post by SEMrush with 41 tips on SEO. See how I just snuck a backlink into this blog? You're catching on now.
[41 Tips SEO Checklist](https://www.semrush.com/blog/seo-checklist/?kw=&cmp=US_SRCH_DSA_Blog_EN&label=dsa_pagefeed&Network=g&Device=c&utm_content=622080550281&kwid=dsa-1754979157325&cmpid=18348486859&agpid=145169420870&BU=Core&extid=60113850974&adpos=&gad=1&gclid=CjwKCAjwyeujBhA5EiwA5WD7_e2rYCC7BiknNpguyMTuvDta_jI_RcVhnIfD04DY-6wjZ2dsbhQWmBoCoDAQAvD_BwE)
## **7. Monitor Website Performance:**
**SEO is an ongoing process** that requires continuous monitoring and analysis. Software engineers should utilize tools like Google Analytics and Google Search Console to track key performance metrics, such as organic traffic, bounce rates, and keyword rankings.
These insights help identify areas for improvement and inform future optimizations. In my professional career, I utilized Google Analytics for most of my clients projects. This visualized data helped me understand and unmask the audience. I learned what parts of the website they engaged with, and where they were coming from.
There are a number of tools that you can use to monitor your website's performance. Some of the most popular tools include:
- **Google Analytics:** My favorite free tool that provides detailed information about your website's traffic, bounce rate, and conversion rate.
- **Webmaster Tools:** Another free tool from Google that provides information about your website's indexing, ranking, and performance in search results.
- **Pingdom Tools:** This is a paid tool that provides detailed information about your website's speed, uptime, and performance.
####Check out this free course from Google on getting started with Google Analytics Basics.
[Google Analytics 101](https://analytics.google.com/analytics/academy/course/6)
## **8. Stay Updated with SEO Trends:**
The field of SEO is dynamic and constantly evolving. You must stay up to date with the latest trends, algorithm changes, and best practices and implement them into our work. Engaging with SEO communities, following industry blogs, and attending relevant conferences or webinars can help us as software engineers remain informed and adapt to strategies.
####What are some tips on how to stay up to date on SEO trends?:
- **Read industry blogs and publications:** There are a number of blogs and publications that cover SEO trends. By reading these blogs and publications, you can stay up to date on the latest changes to SEO algorithms and best practices.
- **Attend SEO conferences and workshops:** SEO conferences and workshops are a great way to learn about the latest SEO trends from industry experts. And it's always fun to network.
- **Join SEO communities:** There are a number of online communities where SEO professionals can discuss SEO trends and best practices. By joining these communities, you can network with other SEO professionals and learn from their experiences.
- **Use SEO tools:** There are a number of SEO tools that can help you track your website's SEO performance and identify areas where you can improve. By using these tools, you can stay up to date on the latest SEO trends and make sure that your website is optimized for search engines.
It is important to note that SEO is a constantly evolving field. What works today may not work tomorrow. By staying up to date on SEO trends, you can ensure that your website is always optimized for search engines and that you are getting the most out of your SEO efforts.
####Let's look at some of the latest SEO trends that you should be aware of:
- **Mobile-first indexing:** Google has announced that it will be indexing websites for mobile devices first. This means that it is more important than ever to make sure that your website is mobile-friendly.
- **Voice search:** Voice search is becoming increasingly popular. This means that you need to optimize your website for voice search.
- **Local SEO:** Local SEO is important for businesses that want to attract local customers. This involves optimizing your website for local search results.
- **Content marketing:** Content marketing is still a valuable SEO strategy. By creating high-quality content, you can attract more visitors to your website and improve your website's ranking in search results.
- **Social media marketing:** Social media marketing can help you to improve your website's ranking in search results. By sharing your content on social media, you can increase your website's visibility and reach.
## **Conclusion:**
By incorporating SEO best practices into your development workflow, you can significantly contribute to the success of websites in search engine rankings even as a software engineer. Understanding the core SEO principles, conducting thorough keyword research, optimizing website structure and performance, and monitoring performance metrics are all vital steps for enhancing websites' visibility and user engagement. By embracing SEO as an integral part of your work, you can amplify the impact of your websites digital footprint and ensure your website reaches the intended target audiences effectively.
<img width="100%" style="width:100%" src="https://media.giphy.com/media/uiMIJMFYgRaAz5Pcb7/giphy.gif">
That’s it, please follow me and subscribe for my next blog post on the inter webs.
**Credits:**
Author: 👩🏽💻 Kodebae
Buy me a ☕️: (https://www.buymeacoffee.com/karmendurbin)
Website: (https://karmen-durbin-swe.netlify.app/)
X: (https://twitter.com/karmen_durbin)
SEO Image by <a href="https://unsplash.com/@nisoncoprseo?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText">NisonCo PR and SEO</a> on <a href="https://unsplash.com/photos/yIRdUr6hIvQ?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText">Unsplash</a> | kodebae |
1,481,698 | Easy way to build Outside Click Popup Component in Vue.js | When developing a large application with multiple components, it is important to prioritize creating... | 0 | 2023-05-26T10:18:37 | https://dev.to/nirazanbasnet/easy-way-to-build-outside-click-popup-component-in-vuejs-2fj8 | vue, javascript, webdev, programming | When developing a large application with multiple components, it is important to prioritize creating components that are customizable, scalable, and reusable. However, it is common to overlook implementing certain functionalities like outside click functionality for components such as popovers or popups. This can result in bugs that need to be fixed later on.
In this blog post, we will discuss how to create an outside click wrapper component in Vue.js. This component will enable users to open a popover by clicking on a specific element and close it by clicking anywhere outside the popover. We will analyze the provided code step by step to understand how it works and achieves the desired behavior.
---
**Code Explanation**
We begin by creating the PopupWrapper.vue component and utilizing the **Composition API** to build it. The Composition API is a feature that offers an alternative approach to organizing and reusing logic within Vue components. It works alongside the Options API, which was the primary API in Vue.js 2.
**Step 1**
```javascript
<template>
<div ref="customDiv">
<div @click="toggle">
<slot name="header"/>
</div>
<div v-if="showPopup" @click.stop>
<slot name="content"/>
</div>
</div>
</template>
```
To create an outside click popup component, we first assign a reference to a `<div>` element using **ref="customDiv"**. This reference allows us to access the element in the component's JavaScript code. We utilize **Slots** to insert dynamic content into components from the parent component. In this scenario, the `header` and `content` slots will be provided by the parent component when using this popup component.
We also use the **@click.stop** directive to prevent the click event from propagating to parent elements. This ensures that clicking inside the popup content does not trigger the outside click behavior.
Overall, this template forms the foundation for an outside click popup component.
---
**Step 2**
```javascript
<script setup>
import { onMounted, onUnmounted, ref } from 'vue'
const showPopup = ref(false)
const customDiv = ref(null)
const toggle = () => {
showPopup.value = !showPopup.value
}
const handleClickOutside = (event) => {
if (customDiv.value && !customDiv.value.contains(event.target)) {
showPopup.value = false
}
}
onMounted(() => {
document.addEventListener("click", handleClickOutside)
})
onUnmounted(() => {
document.removeEventListener("click", handleClickOutside)
})
</script>
```
The provided code showcases the usage of the **setup syntax** of the Composition API, creating a more declarative approach to defining component logic. It utilizes the `ref` function to create reactive variables like **showPopup** and **customDiv**. The `toggle` function toggles the visibility of the popup by negating showPopup.value. The **handleClickOutside function** is crucial as it checks if a click occurred outside the component and hides the popup accordingly. The `onMounted` hook adds a "click" event listener to the document, triggering handleClickOutside, while the `onUnmounted` hook removes the event listener to prevent memory leaks. This code provides a comprehensive implementation of the outside click popup functionality in Vue.js.
---
## **How to use**
Code Example
```javascript
<template>
<div id="app">
<PopupWrapper>
<template #header>
<div class="popover">Open Popover</div>
</template>
<template #content>
<div class="popover-content">This is a Popup Content</div>
</template>
</PopupWrapper>
</div>
</template>
<script setup>
import PopupWrapper from './components/PopupWrapper.vue';
</script>
```
**Overall**, we have the template that consists of a root `<div>` element with the ID "app" serving as the Vue application's root. Inside this `<div>`, there is a `PopupWrapper` component that provides the outside click popup functionality. The PopupWrapper component contains two `<template>` elements: one for the `header slot (#header)` and one for the `content slot (#content)`. The header slot includes a <div> element with the class "**popover**" and the text "Open Popover", which will be inserted into the header slot. Similarly, the content slot contains a <div> element with the class "popover-content" and the text "This is a Popup Content", which will be inserted into the content slot.
Note: CSS Styling in this component is optional. You can style the code with your own preference.
---
## **DEMO**
You can access the code [here.](https://stackblitz.com/edit/vuejs-outside-click-popup?file=src%2FApp.vue)
Additionally, you may refer to the following blog post [here](https://blog.jobins.jp/improving-your-applications-features-with-vue-custom-directives) that provides detailed information about Vue custom directives and how you can utilize them to implement similar outside click functionality in your applications.
---
## **Conclusion**
👏👏 In conclusion, the "Outside Click Popup Component Functionality on Vue.js" tutorial demonstrates how to create an interactive and reusable popup component with outside click detection using Vue.js and the Composition API. By following this tutorial, you can enhance your Vue.js applications with a convenient and user-friendly popup feature. I suggest you give a try on your project and enjoy it!
Feel free to share your thoughts and opinions and leave me a comment if you have any problems or questions.
Till then, Keep on Hacking, Cheers | nirazanbasnet |
1,481,926 | Ruby on Rails en Windows con WSL2 | Cómo instalar Ruby on Rails en Windows usando WSL2 | 0 | 2023-05-26T13:25:47 | https://dev.to/ahowardm/ruby-on-rails-en-windows-con-wsl2-73o | wsl2, rails, win10, ruby | ---
title: Ruby on Rails en Windows con WSL2
published: true
description: Cómo instalar Ruby on Rails en Windows usando WSL2
tags: wsl2, rails, win10, ruby
# cover_image: 
# Use a ratio of 100:42 for best results.
# published_at: 2023-05-26 13:09 +0000
---
Cómo podemos programar en Ruby on Rails usando Windows?: la respuesta es usando Windows Subsystem for Linux.
A continuación vamos a instalar WSL2 (Windows Subsystem for Linux v2) en Windows 10/11. Esto nos permitirá trabajar con Ruby on Rails de manera más fácil que usando una máquina virtual en VirtualBox, por ejemplo.
Vamos a seguir los siguientes pasos:
1. [Instalar WSL2](#wsl2)
2. [Instalar PostgreSQL](#psql)
3. [Instalar NodeJS](#nodejs)
4. [Instalar Ruy on Rails](#ror)
5. [Material Adicional](#adicional)
## 1. Instalar WSL2 <a name="wsl2"></a>
Referencia: https://learn.microsoft.com/es-es/windows/wsl/install
1. Ejecuta la aplicación `powershell` en modo administrador. Para esto búscala en el menú inicio y haz click derecho o en la opciones que aparecen a la derecha en la opción *Ejecutar como administrador.*
2. Ejecuta `wsl --install` . Esto va a instalar WSL, por lo que toma un buen tiempo.
3. Verifica que la versión de WSL instalada es la 2, para esto ejecuta en `powershell` el comando `wsl -l -v`. Si es la versión 2 estamos ok, si es la 1 entonces entra al link de referencia y busca cómo actualizar.
## 2. Instalar PostgreSQL <a name="psql"></a>
Referencia: https://www.cybertec-postgresql.com/en/postgresql-on-wsl2-for-windows-install-and-setup/
1. Ejecuta la aplicación `Ubuntu`. La puedes encontrar en el menú inicio o en el buscador. Esto te va a abrir un terminal de Linux en tu computador. De la distribución Ubuntu.
2. Ejecuta los siguientes comandos:
```ruby
sudo sh -c 'echo "deb http://apt.postgresql.org/pub/repos/apt $(lsb_release -cs)-pgdg main" > /etc/apt/sources.list.d/pgdg.list'
wget --quiet -O - https://www.postgresql.org/media/keys/ACCC4CF8.asc | sudo apt-key add -
sudo apt-get update
sudo apt-get -y install postgresql postgresql-contrib
```
1. Verifica la version de PostgreSQL que tienes instalada ejecutando `psql --version`. Si te aparece un mensaje mostrando la versión estás ok, si te dice que no reconoce qué es `psql` entonces debes revisar si hubo algún error en el proceso.
2. Verifica que PostgreSQL está corriendo ejecutando `sudo service postgresql status`.
3. Si dice que el estado es `down` entonces ejecuta `sudo service postgresql start` para iniciarlo. Después de esto si verificas el status nuevamente debería decir `up`.
## 3. Instalar NodeJS <a name="nodejs"></a>
Referencia: https://learn.microsoft.com/en-us/windows/dev-environment/javascript/nodejs-on-wsl
1. Ejecuta la aplicación `Ubuntu`. Ejecuta el siguiente comando para instalar *curl*: `sudo apt-get install curl`.
2. Instala *nvm* (Node Version Manager), este programa te permite tener distintas versiones de NodeJS instaladas y seleccionar cuál es la que quieres usar. Para esto ejecuta `curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/master/install.sh | bash`
3. Verifica que la instalación sea exitosa ejecutando `command -v nvm`. Si muestra *nvm* está todo ok, si te dice *command not found* entonces debes cerrar `Ubuntu` y abrirlo nuevamente (esto para que recargue las variables de ambiente).
4. Revisa qué versiones de NodeJS tienes instaladas ejecutando `nvm ls`. Te debería aparecer algo así:
Fuente: https://learn.microsoft.com/en-us/windows/dev-environment/javascript/nodejs-on-wsl
1. Instala la versión de NodeJS que usamos ejecutando `nvm install 19.9.0`
2. Verifica que tienes instalada la versión ejecutando `node --version` y te debería salir una pantalla similar a la anterior pero con un asterisco al lado de 19.9.0. El asterisco significa que ésa es la que estás usando actualmente.
### 3.1 Instalar yarn
`yarn` es un gestor de dependencias de NodeJS tal como `npm`. Suele ser muy usado como alternativa a `npm` por temas de eficiencia, entre otros. Para instalarlo debes ejecutar `npm install --global yarn`.
## 4. Instalar Ruby on Rails en WSL2 <a name="ror"></a>
Referencia: https://learn.microsoft.com/en-us/windows/wsl/tutorials/wsl-git
1. Abre la aplicación `Ubuntu`
2. Actualiza la información de los programas que estás disponibles para instalar ejecutando `sudo apt-get update`
3. Instala las dependencias de Ruby ejecutando `sudo apt-get install git-core curl zlib1g-dev build-essential libssl-dev libreadline-dev libyaml-dev libsqlite3-dev sqlite3 libxml2-dev libxslt1-dev libcurl4-openssl-dev software-properties-common libffi-dev`
4. Instala rbenv para manejar las versiones de ruby que puedas tener instaladas. Para esto:
1. `git clone https://github.com/rbenv/rbenv.git ~/.rbenv`
2. `echo 'export PATH="$HOME/.rbenv/bin:$PATH"' >> ~/.bashrc`
3. `echo 'eval "$(rbenv init -)"' >> ~/.bashrc`
4. `exec $SHELL`
5. Instala la versión 3.2.0 de ruby:
1. `git clone https://github.com/rbenv/ruby-build.git ~/.rbenv/plugins/ruby-build`
2. `echo 'export PATH="$HOME/.rbenv/plugins/ruby-build/bin:$PATH"' >> ~/.bashrc`
3. `exec $SHELL`
4. `rbenv install 3.2.0` (este paso es lento, toma varios minutos)
5. `rbenv global 3.2.0`
6. Verifica que esté todo ok ejecutando `ruby -v` y debería decir que estás usando la versión *3.2.0*.
6. Instala *Bundler* ejecutando:
1. `gem install bundler`
2. `rbenv rehash`
7. Instala la última versión de Ruby on Rails:
1. `gem install rails`
2. `rbenv rehash`
3. Verifica la versión ejecutando `rails -v`
## Material adicional <a name="adicional"></a>
1. Un (muy buen) tutorial alternativo: https://gorails.com/setup/windows/10#ruby-rbenv
2. Cómo configurar git en WSL2: https://learn.microsoft.com/en-us/windows/wsl/tutorials/wsl-git | ahowardm |
1,530,021 | The 3A's: Simple Steps For Clean Unit Tests | "I find that writing unit tests actually increases my programming speed" - Martin Fowler (Software... | 0 | 2023-07-08T06:51:24 | https://dev.to/ferzos/the-3as-simple-steps-for-clean-unit-tests-57mm | unittest, tdd, programming, softwareengineering | > "I find that writing unit tests actually increases my programming speed" - Martin Fowler (Software Engineer)
A couple of days ago, I was developing a feature at my work. I was wondering why my Pull Request doesn't have clearance for merge. After I check, there was a failed unit test in my module. It turns out that after I rebase my branch to the latest master, my changes break functionality in a component. Imagine if there was no unit test to assess the functionality of the component, my changes could've been deployed to production. Then thousands of users will get a broken component. It will be catastrophic. That's how important a unit test is.
Besides code implementations, software developers are also responsible for creating unit tests for their applications. Unit tests could prevent unexpected changes made by developers that might raise an issue in the production environment. Good unit tests will improve code stability and reliability within your repository. In my journey creating unit tests, I usually follow these simple three steps to achieve good reliable unit tests. The 3A's: arrange, action, and assert.
## Arrange
The first step is to prepare what is needed for the test. Decide a test name, and make it as human-friendly as possible. Think about what are the test cases we would like to test. For example like `'it should created user with the correct name and id'` or `'it should render successfully'`.
Prepare your mock environment if you need it. Create your mock data, API, component, function, or whatever they are to support your test to run smoothly. You can mock anything that you deemed unnecessary for your specific test case.
```typescript
describe("Add Function", () => {
it("should add successfully", () => {
// Arrange
const input = [2, 3];
});
});
```
## Act
Act steps should cover the main thing to be tested. This could be calling a function or method. Act means running the operation or method that you want to test. In UI testing, it can also stand for user actions that are possible to do. Such as clicking a button, hovering over an area, etc. Act steps usually produce a result.
```typescript
describe("Add Function", () => {
it("should add successfully", () => {
// Arrange
const input = [2, 3];
// Act
const result = add(...input);
});
});
```
## Assert
Assert is the step where you check the result in the act step. It's to check whether the result is already expected like you want it to be. Given the input, is the function already produce the correct output? Or is the modal already shown if the button is clicked? Assertions will ultimately be the end goal of a test case. It also determines whether a test case passes or fails.
```typescript
describe("Add Function", () => {
it("should add successfully", () => {
// Arrange
const input = [2, 3];
// Act
const result = add(...input);
// Assert
expect(result).toBe(5);
});
});
```
------------------------------------------------------------
By following these 3 simple steps: arrange, act, and assert, we can write clean unit tests that are reliable and maintainable. It shapes our framework of mind when we wrote a test so that our tests aren't all over the place. A good unit test will also increase the confidence of developers when they do iteration changes. Cause they knew that there is a guard to catch those anomalies should anything goes wrong. | ferzos |
1,531,383 | Key Performance Metrics for Web Apps and How to Measure Them | Learn about the key performance metrics for web apps and how to measure them using popular tools and libraries in frontend development to keep your audience engaged with your application. | 0 | 2023-07-09T19:20:00 | https://angulardive.com/blog/key-performance-metrics-for-web-apps-and-how-to-measure-them/ | ## Key Performance Metrics for Web Apps and How to Measure Them
Web application performance is the key factor that determines a user's experience while using an application. Improving frontend performance is essential to delivering a better user experience and keeping your audience engaged with your web application. In this article, we will discuss the key performance metrics for web apps and how to measure them with the help of frameworks and libraries in frontend development.
### Key Performance Metrics
Before we talk about how to measure performance, let's take a look at some of the most important metrics that determine the performance of a web application.
Load Time
Load time measures how long it takes for the browser to download all the necessary files, including HTML, CSS, and JavaScript, required to display your application. A faster load time results in a better user experience because users will not have to wait long for your application to start. Load time can be affected by factors such as server response time, image size, and code optimization.
Time to First Byte (TTFB)
TTFB measures the time it takes for the first byte of the response to reach the browser. It is an important performance metric because it reflects the server's speed in responding to a request. Slow TTFB could indicate slow server response time, network latency, or high server load.
Time to Interactive (TTI)
TTI measures the time it takes for the web application to become fully interactive after the initial load. This includes the time it takes to load all necessary resources such as images, scripts, and stylesheets, as well as the time it takes to process these resources. A fast TTI is important because it ensures that users can interact with your application quickly, which is essential for keeping them engaged.
First Contentful Paint (FCP)
FCP measures the time it takes for the browser to render the first bit of content on the screen. This metric is important because it gives the user a visual indication that the application is loading. FCP is particularly important for mobile devices because it ensures that users do not abandon your application due to a slow load time.
Total Content Size
Total content size measures the size of all resources required to load the page, including HTML, CSS, images, and scripts. This is an important performance metric because it affects load time. The larger your content, the longer it will take the browser to download and render the page.
Number of Requests
The number of requests measures the number of HTTP requests the browser makes to the server to load the web page. The more requests your application makes, the longer the web page will take to load, which can lead to a poor user experience. Reducing the number of requests is an important optimization technique for improving frontend performance.
### Measuring Performance with Frameworks and Libraries
Measuring performance can be a complex process, but there are many frameworks and libraries that can help you measure and improve performance.
Lighthouse
Lighthouse is an open-source, automated tool for improving the quality of web pages. It can help you measure key performance metrics such as load time, time to interactive, and total content size. Lighthouse also provides suggestions on how to improve performance based on best practices and analysis of your web application.
<pre><code>
// Install Lighthouse from NPM
npm install -g lighthouse
// Run Lighthouse on a web page
lighthouse https://example.com --view
</code></pre>
Lighthouse generates a report that shows your web page performance score as well as suggestions for improvement.
WebPageTest
WebPageTest is a free online testing tool that allows you to test the performance of your web page from multiple locations and browsers. It measures key performance metrics such as load time, time to interactive, and total content size. WebPageTest provides detailed reports on performance metrics, including waterfall charts that show how long each resource takes to load.
Google Analytics
Google Analytics is a free web analytics service that allows you to track key performance metrics such as load time, time to interactive, and bounce rate. Google Analytics provides detailed reports on user behavior, including where your users come from, which pages they visit, and how long they stay on each page. Using this information, you can identify areas where your application performance needs improvement.
React Performance Tools
React Performance Tools is a library that helps you optimize React applications by measuring performance metrics such as update frequency, render time, and component tree depth. It provides detailed reports on performance metrics, including flame graphs that show how much time is spent rendering each component. React Performance Tools can help you identify performance bottlenecks in your React application and optimize performance for a better user experience.
<pre><code>
// Install React Performance Tools from NPM
npm install --save react-addons-perf
// Import the library in your code
import Perf from 'react-addons-perf';
// Start the performance measurement
Perf.start();
// Stop the measurement and get the results
Perf.stop();
const measurements = Perf.getLastMeasurements();
Perf.printExclusive(measurements);
</code></pre>
Webpack Bundle Analyzer
Webpack Bundle Analyzer is a plugin for Webpack that helps you analyze and optimize the size of your JavaScript bundles. It provides a graphical representation of your bundle, including the size of each module, how they are connected, and how they affect performance. Webpack Bundle Analyzer can help you identify areas where you can optimize your application code to reduce bundle size and improve performance.
<pre><code>
// Install Webpack Bundle Analyzer from NPM
npm i --save-dev webpack-bundle-analyzer
// Import the plugin in your Webpack configuration
const BundleAnalyzerPlugin = require('webpack-bundle-analyzer').BundleAnalyzerPlugin;
// Add the plugin to your Webpack configuration
plugins: [
new BundleAnalyzerPlugin()
]
</code></pre>
### Conclusion
Frontend performance is critical to delivering a better user experience and keeping your audience engaged with your web application. Measuring and optimizing performance can be a complex process, but with the help of frameworks and libraries, it becomes much easier. In this article, we discussed key performance metrics for web apps and how to measure them using popular tools and libraries in frontend development.
Remember, keeping your web application running smoothly is not a one-time process, it's an ongoing effort. You should regularly monitor performance metrics and identify areas where you can improve. By continuously optimizing performance, you can ensure that your users always have a great experience with your web application.
| josematoswork | |
1,531,710 | Top 10 POS System Software in UAE 2023 | Top 10 POS System Software in UAE In the thriving business landscape of the United Arab Emirates... | 0 | 2023-07-10T05:00:14 | https://dev.to/emeraldsoftwares/top-10-pos-system-software-in-uae-2023-3oe5 | Top 10 POS System Software in UAE
In the thriving business landscape of the United Arab Emirates (UAE), having a robust and feature-rich Point of Sale (POS) system software is essential for businesses to optimize their operations and stay ahead of the competition. In this article, we present a carefully curated list of the top 10 POS system software solutions in the UAE for the year 2023. These software options offer advanced features and capabilities to streamline business processes, enhance customer experiences, and drive growth.
Emerald POS:
Emerald [POS System Software UAE](https://www.emeraldsoftwares.com/pos-software.php) is the ultimate choice for businesses in Dubai seeking a powerful, efficient, and reliable POS software solution. With its robust features, including sales monitoring, inventory management, KPI reporting, and reliable CRM, Emerald POS helps businesses streamline operations, maximize performance, and deliver exceptional customer experiences. Join the ranks of top retail companies in Dubai by choosing [Emerald POS](https://www.emeraldsoftwares.com/pos-software.php) as your trusted point of sale software.
Shopify POS:
Known for its powerful e-commerce capabilities, Shopify POS seamlessly integrates with online stores, providing a unified sales ecosystem. With features like inventory management, order processing, and customer relationship management (CRM), Shopify POS enables businesses to deliver a seamless shopping experience across both physical and online channels.
Lightspeed Retail:
Lightspeed Retail is a versatile POS software solution suitable for various industries, including retail, restaurants, and e-commerce. It offers advanced inventory management, employee management, CRM integration, and comprehensive reporting features. With its scalability and customizability, Lightspeed Retail caters to businesses of all sizes and helps drive operational efficiency.
Vend:
Vend is a cloud-based POS system software designed specifically for retailers. It offers a user-friendly interface, inventory management, loyalty programs, and seamless integration with popular e-commerce platforms and accounting software. Vend enables retailers to efficiently manage sales, inventory, and customer relationships, providing a holistic solution for their needs.
MobiPOS:
MobiPOS specializes in providing efficient POS solutions for the hospitality industry, including restaurants, cafes, and bars. It offers features such as table management, order processing, kitchen display systems, and detailed reporting. MobiPOS streamlines operations, enhances customer experiences, and enables seamless integration with payment gateways and third-party platforms.
Loyverse POS:
Loyverse POS is a free cloud-based POS system software suitable for small businesses, cafes, and restaurants. With its intuitive interface, efficient sales processing, inventory management, and customer loyalty programs, Loyverse POS simplifies operations and helps businesses build strong customer relationships.
Odoo:
Odoo is an all-in-one business management software that includes a robust POS system. With its comprehensive suite of features, including sales, inventory, accounting, and CRM, Odoo provides a unified platform for managing all aspects of a business. Its modular approach allows businesses to customize the system to their specific needs.
QuickBooks POS:
QuickBooks POS is a popular choice for businesses seeking seamless integration with accounting software. It offers inventory management, sales tracking, employee management, and detailed reporting features. QuickBooks POS streamlines financial operations, simplifies bookkeeping, and provides valuable insights into business performance.
ERPLY:
ERPLY is a cloud-based POS system software that caters to retail businesses of all sizes. It offers features such as inventory management, CRM, loyalty programs, and comprehensive reporting. ERPLY’s scalability, ease of use, and integration capabilities make it a flexible choice for retailers in the UAE.
Oracle Hospitality:
Oracle Hospitality provides a comprehensive suite of POS system software solutions for the hospitality industry. With its advanced features, including table management, kitchen display systems, online ordering, and detailed reporting, Oracle Hospitality empowers businesses to deliver exceptional guest experiences and streamline operations.
Conclusion:
Selecting the right POS system software is crucial for optimizing business operations and driving growth in the UAE’s dynamic business environment. The top 10 POS system software solutions for 2023, offer a wide range of features to cater to various industries and business sizes. Evaluate your specific needs, consider factors like industry focus, scalability, integration capabilities, and user-friendliness, and choose the POS system software that best aligns with your business goals and requirements. Embrace the power of these advanced solutions to revolutionize your operations and achieve success in the UAE marketplace. | emeraldsoftwares | |
1,532,908 | Maximizing Cost Optimization with Well-Architected Programs on AWS | Are you looking to optimize costs in your AWS environment? A well-architected program can be the key... | 0 | 2023-07-11T05:46:36 | https://dev.to/ravikiran19/maximizing-cost-optimization-with-well-architected-programs-on-aws-3d7h | aws, costoptimization, cloudarchitecture |

Are you looking to optimize costs in your AWS environment? A well-architected program can be the key to achieving cost optimization goals. Let's explore how a well-architected program can help you drive cost optimization on AWS:
1️⃣ Cost-Aware Architecture: Well-architected programs focus on building cost-aware architectures. By considering cost implications from the start, you can design and deploy solutions that maximize efficiency and minimize unnecessary expenses.
2️⃣ Right-Sizing Resources: Well-architected programs emphasize right-sizing resources to match workload requirements. By accurately provisioning resources, you can eliminate over-provisioning and reduce costs associated with idle or underutilized resources.
3️⃣ Choosing the Right Pricing Models: Well-architected programs guide you in selecting the appropriate pricing models, such as On-Demand, Reserved Instances, or Spot Instances. This ensures you leverage the most cost-effective options based on workload characteristics and usage patterns.
4️⃣ Effective Resource Tagging: Well-architected programs emphasize consistent and meaningful resource tagging. Proper tagging enables accurate cost allocation, cost tracking, and cost optimization across departments, projects, or applications.
5️⃣ Automation and Monitoring: Well-architected programs encourage the use of automation and monitoring tools to continuously assess cost performance. Automating tasks like resource provisioning, scaling, and optimization helps streamline operations and identify potential cost-saving opportunities.
6️⃣ Cloud Governance: Well-architected programs establish cloud governance frameworks that include policies, guidelines, and processes for cost optimization. This ensures adherence to best practices, enables accountability, and fosters a culture of cost awareness.
7️⃣ Cost Optimization Reviews: Well-architected programs advocate for regular cost optimization reviews to evaluate the effectiveness of cost-saving measures. These reviews help identify areas for improvement, validate cost optimization strategies, and ensure ongoing efficiency.
Implementing a well-architected program provides a systematic approach to cost optimization on AWS. By considering cost implications during the architectural design, leveraging appropriate pricing models, and embracing automation and monitoring, you can achieve significant cost savings.
Share your experiences and insights on cost optimization through well-architected programs in the comments below. Let's learn from each other and drive cost efficiency in our AWS environments! 💰💡 | ravikiran19 |
1,533,324 | Promise Limit for Bulk Await - Improve Performance and Efficiency | Certainly! Here's the improved article with the code and markup: markdown Copy code Promise... | 0 | 2023-07-11T11:51:44 | https://dev.to/aurangzaibramzan/promise-limit-for-bulk-await-improve-performance-and-efficiency-28f5 | javascript, asynchronousprogramming, promise, performanceoptimization | Certainly! Here's the improved article with the code and markup:
markdown
Copy code
# Promise Limit for Bulk Await - Improve Performance and Efficiency
In modern JavaScript development, asynchronous programming plays a crucial role in handling tasks that may take time to complete. One powerful feature in JavaScript is the Promise API, which allows us to write asynchronous code in a more readable and maintainable manner. However, when dealing with a large number of Promises, we may encounter performance issues. In this article, we will explore techniques to limit the number of Promises awaited in bulk, improving overall performance and efficiency.
## Understanding the Problem
When we have a substantial amount of Promises to await, it can lead to high memory consumption and longer execution times. The naive approach of awaiting all Promises at once may cause the system to run out of resources or even crash. To overcome these challenges, we need to implement a mechanism that limits the number of Promises awaited in bulk, providing better control and optimizing the execution process.
## Solution: Promise Limiting
One approach to address this problem is by using a Promise limiting library or implementing a custom solution. There are several libraries available that provide ready-to-use functions for this purpose. We will discuss some popular options like `p-limit`, `p-queue`, and `async-limiter`, explaining their usage and benefits. Additionally, we will explore the implementation of a custom Promise limiting solution, which gives us more flexibility and control.
Here's an example of using the `p-limit` library to limit the number of Promises awaited in bulk:
```javascript
const pLimit = require('p-limit');
async function processItem(item) {
// Perform some asynchronous operation
// ...
// Return the result
return result;
}
async function processItems(items) {
const limit = pLimit(5); // Limit to 5 concurrent Promises
const promises = items.map(item => limit(() => processItem(item)));
const results = await Promise.all(promises);
return results;
}
// Usage example:
const items = [/* Array of items to process */];
const processedItems = await processItems(items);
Practical Examples
To illustrate the concepts discussed, let's consider a practical example where we need to make multiple API requests concurrently. By using Promise limiting, we can control the number of concurrent requests and prevent overwhelming the server:
javascript
Copy code
const axios = require('axios');
const pLimit = require('p-limit');
async function makeApiRequest(url) {
const response = await axios.get(url);
return response.data;
}
async function makeBulkApiRequests(urls) {
const limit = pLimit(3); // Limit to 3 concurrent requests
const promises = urls.map(url => limit(() => makeApiRequest(url)));
const results = await Promise.all(promises);
return results;
}
// Usage example:
const urls = [/* Array of API URLs to request */];
const responses = await makeBulkApiRequests(urls);
```
By applying Promise limiting, we can make efficient use of resources and improve the overall performance of our application.
Conclusion
By employing Promise limiting techniques, we can enhance the performance and efficiency of our JavaScript applications when dealing with bulk Promises. We have explored various options, including ready-to-use libraries like p-limit, as well as custom implementations. These techniques allow us to control the number of concurrent Promises, preventing resource exhaustion and improving overall execution speed.
If you have any questions or suggestions, feel free to reach out via email at aurangzaib987@gmail.com or on Stack Overflow.
Happy coding!
| aurangzaibramzan |
1,533,642 | Looking for Community Support: Make Security Transparent with Open-Sourced Application! | Hello, I am currently looking for those interested in growing a community that aims to make... | 0 | 2023-07-11T17:07:10 | https://dev.to/tlsgusdn1107/looking-for-community-support-make-security-transparent-with-open-sourced-application-1403 | swift, ios, opensource, security | Hello, I am currently looking for those interested in growing a community that aims to make public/campus security transparent with an open-sourced app (SIMPLE)!
The website is [https://www.simple-secure.org/](https://www.simple-secure.org/), and the source code is [https://github.com/tlsgusdn1107/SIMPLE](https://github.com/tlsgusdn1107/SIMPLE). You can try it out in TestFlight mode at [https://testflight.apple.com/join/rgLKnFfz](https://testflight.apple.com/join/rgLKnFfz).
The idea was to minimize the need to share PII while preventing false alarms. Right now, campus/police security is notoriously invasive in student privacy, and for-profit security apps also compromise user privacy to varying extents for revenue. As an international student in college, I felt horrible and was motivated to start this project.
The workflow is done to prototype level—just a bit of refactoring needed. You can check out some of the ongoing tasks in: [https://github.com/tlsgusdn1107/SIMPLE/issues](https://github.com/tlsgusdn1107/SIMPLE/issues).
Up until now it had been a personal project, but I want to share it and create a community for it. Unfortunately, legal entities (e.g. police departments) are very hesitant to adopt a transparent alternative, so we need a strong community backing it. If you are interested in growing this community together, please join the Discord community at [https://discord.gg/ceCa5SYm](https://discord.gg/ceCa5SYm). Also, feel free to reach out to me at any time!! | tlsgusdn1107 |
1,533,861 | Remote Work is Valued Less in 2023 | The argument that remote work justifies lower pay rates is increasingly contentious, especially in... | 0 | 2023-07-11T18:23:34 | https://dev.to/philipjohnbasile/ardanlabs-o15 | community, motivation, devjournal, career | The argument that remote work justifies lower pay rates is increasingly contentious, especially in our modern era, where technology has blurred the lines between the traditional office space and the home. This perspective is laughable to many, largely because it disregards the value of work itself. Remote or not, the effort, skill, time, and dedication required to perform a task does not diminish. Remote work may demand additional skills such as self-discipline, adaptability, and technical acumen to work effectively from home. This point of view reflects the conviction that the value of work should not be tied to a physical location but to the quality and quantity of the work produced.
Furthermore, the argument seems to dismiss that remote work is not necessarily a "benefit" for the employee but also a cost-saving measure for the employer. Companies save on various overheads when employees work remotely, including rent, utilities, office supplies, commuting benefits, and more. Also, research has indicated that remote workers often work longer hours than their in-office counterparts. Considering these aspects, it is clear why many people find the idea of lowering pay rates for remote work not only amusing but also profoundly unfair. The focus should be on paying what the work is worth and recognizing the value and contribution of the employee, irrespective of where they clock in their hours.
With that said. I am looking for work, but I won't work for peanuts. Give me the fancy cashews! 😀
If you enjoy my technology-focused articles and insights and wish to support my work, feel free to visit my Ko-fi page at https://ko-fi.com/philipjohnbasile. Every coffee you buy me helps keep the tech wisdom flowing and allows me to continue sharing valuable content with our community. Your support is greatly appreciated! | philipjohnbasile |
1,534,159 | Micro-frontend Migration Journey — Part 1: Design | In today’s fast-paced digital world, where agility and scalability are crucial, businesses are... | 23,739 | 2023-07-11T22:50:43 | https://thesametech.com/micro-frontend-migration-journey-part-1/ | microfrontends, architecture, frontend, frontendarchitecture | ---
title: Micro-frontend Migration Journey — Part 1: Design
published: true
date: 2023-05-25 19:53:51 UTC
tags: microfrontends,architecture,frontend,frontendarchitecture
canonical_url: https://thesametech.com/micro-frontend-migration-journey-part-1/
series: Micro-frontend Migration Journey
---

In today’s fast-paced digital world, where agility and scalability are crucial, businesses are constantly seeking ways to improve the performance and maintainability of their web applications. One popular approach to achieving these goals is migrating from a monolithic architecture to a distributed one (or micro-frontend). This article series, “Micro-frontend Migration Journey,” shares my personal experience of undertaking such a migration during my time at AWS.
**DISCLAIMER** : Before we begin, it’s important to note that while this article shares my personal experience, I am not able to disclose any proprietary or internal details of tools, technologies, or specific processes at AWS or any other organization. I am committed to respecting legal obligations and ensuring that this article focuses solely on the general concepts and strategies involved in the micro-frontend migration journey. The purpose is to provide insights and lessons learned that can be applicable in a broader context, without divulging any confidential information.
### Motivation for Migration
I learned about micro-frontends (I guess as many of you) from the [article](https://martinfowler.com/articles/micro-frontends.html) on Martin Fowler’s blog. It presented different ways of composing micro-frontend architecture in a framework-agnostic manner. As I delved deeper into the subject, I realized that our existing monolithic architecture was becoming a significant bottleneck for our team’s productivity and impeding the overall performance of our application.
One of the key factors that pushed me towards considering a migration was the increasing bundle size of our application. After conducting a thorough bundle analysis in the summer of 2020, I discovered that since its initial launch in early 2019, the bundle size (gzipped) had grown from 450KB to 800KB (it is almost 4MB parsed) -almost twice the original size. Considering the success of our service and predicting its continued growth, it was clear that this trend would persist, further impacting the performance and maintainability of our application.
While I was enthusiastic about the concept of micro-frontends, I also recognized that we were not yet ready to adopt them due to specific challenges we faced:
1. Small Organizational Structure: At the time of my analysis, our organization was relatively small, and I was the only full-time frontend engineer on the team. Migrating to a micro-frontend architecture required a significant investment in terms of organizational structure and operational foundation. It was crucial to have a mature structure that could effectively handle the distributed architecture and reflect the dependencies between different frontend components.
2. Limited Business Domain: Although micro-frontends can be split based on bounded contexts and business capabilities (learn more in the “[Domain-Driven Design in micro-frontend architecture”](https://thesametech.com/domain-driven-design-in-micro-frontend-architecture/) post) our core business domain was not extensive enough to justify a complete decoupling into multiple micro-frontends. However, there were visible boundaries within the application that made sense to carve out and transition to a distributed architecture.
Considering these factors, I realized that a gradual approach was necessary. Rather than a complete migration to micro-frontends, I aimed to identify specific areas within our application that could benefit from a distributed architecture. This would allow us to address performance and scalability concerns without disrupting the overall organizational structure or compromising the integrity of our business domain. It also would give us some time to grow the team and observe business directions.
Please note that if you want to tackle app’s performance (bundle size) problem only via using mciro-frontend architecture, it might be not the best idea. It would be better to start with distributed monolith architecture that will leverage lazy loading (dynamic imports) instead. Moreover, I think it would handle bundle size issue more gracefully than micro-frontend architecture considering that micro-frontend architecture is very likely to have some shared code that would not be separated into vendor chunks and it would be built into the application bundle (that’s one of the cons of such distributed architecture — you need to have a trade-off between what to share, when and how). However, distributed monolith architecture will not scale as well as micro-frontend. When your organization grows fast, your team will likely grow at the same pace too. There would be an essential need to split the code base into different areas of ownership controlled by different teams. And each team will need to have their own release cycles that are independent of others, each team will appreciate if their code base would be focused purely on their domain, and will build fast (code isolation -> better maintainability/less code to maintain and build -> better testability/less test to maintain and execute).
### The Start
To garner support from leadership, I crafted a persuasive technical vision document that encompassed a comprehensive performance analysis, including web vital metrics, and outlined the various phases of the migration towards distributed frontends. One of the intermediate phases of this migration was to establish a distributed monolith architecture, where multiple modules/widgets could be delivered asynchronously via lazy-loading techniques while leveraging shared infrastructure, such as an S3 bucket and CDN, between the core service and the widgets. As I outlined in my previous [article](https://thesametech.com/writing-efficient-frontend-design-documents/), the main idea of this type of document is to describe the future as you’d like it to be once the objectives have been achieved and the biggest problems are solved. It’s not about the execution plan!
Almost 1 year later, the time had finally come to put my micro-frontend migration plan into action. With the impending expansion into a new domain and a larger team at our disposal, we were well-equipped to execute the migration. It felt like a golden opportunity that we couldn’t afford to miss. After all, remaining confined to the monolithic architecture would mean perpetually grappling with its limitations. The limited timeline to expand into a new domain served as a catalyst, propelling us toward building a more scalable and maintainable architecture right away instead of having short and slow iterations!
To execute the migration and simultaneously handle the work in the new domain, we divided the teams into two dedicated groups. The feature work, which had higher priority, required more resources and needed to iterate at a faster pace. To ensure the integrity and comprehensive understanding of the migration process, it made sense to assign a small dedicated team specifically responsible for handling the migration. However, we couldn’t proceed with the feature work without first ensuring that the micro-frontend concept would prove successful.
To mitigate risks and provide a clear roadmap, it was crucial to create a low-level design document that included precise estimates and a thorough risk assessment. This document served as a blueprint, outlining the necessary steps and considerations for the migration. The pivotal milestone in this process was the development of a proof-of-concept that would demonstrate the successful integration of all components according to the design. This milestone, aptly named the “Point of no return,” aimed to validate the feasibility and effectiveness of the micro-frontend architecture. While I was optimistic about the success of the migration, it was essential to prepare for contingencies. Consequently, I devised a Plan B, which acted as a backup strategy in case the initial concept didn’t yield the desired results. This included allocating an additional seven days in the estimates specifically to have me crying into the pillow plus a few days to have a new feature module entry connected to the core via lazy-loading (remember distributed monolith?).
### The Design
When designing micro-frontends, there are generally 3 approaches for composition, each focusing on where the runtime app resolution takes place. The beauty of these approaches is that they are not mutually exclusive and can be combined as needed.
#### Server-side composition
The basic idea is to leverage reverse proxy server to split micro-frontend bundles per page and do a hard page reload based on the route URL.
**Pros:**
- Simple to implement
**Cons:**
- Global state won’t be synced between the micro-frontend apps. This was a clear no-go point for us because we had long-running background operations performed on the client side. You might argue that we could persist snapshot of this operations “queue” to the local storage and read from it after hard-reload but due to security reasons, we were not able to implement this. This is just one example of global state but here is other example of how it can look like: state of the sidenav panels (expanded/collapsed), toast messages etc.
- The hard refresh when navigating across micro-apps is not very customer friendly. There is a way to cache shared HTML using service workers but it’s additional complexity to maintain.
- Additional operational and maintainance costs for the infrastructure: proxy server for each micro-frontend app (this can be avoided if read from the CDN directly), separate infrastructure to deploy common (vendor) dependencies to be re-used by multiple pages and properly cached by browsers.
#### Edge-side composition
Another approach to micro-frontend composition is edge-side composition, which involves combining micro-frontends at the edge layer, such as a CDN. For instance, Amazon CloudFront supports [Lambda@Edge](https://aws.amazon.com/lambda/edge/) integration, enabling the use of a shared CDN to read and serve the micro-frontend content.
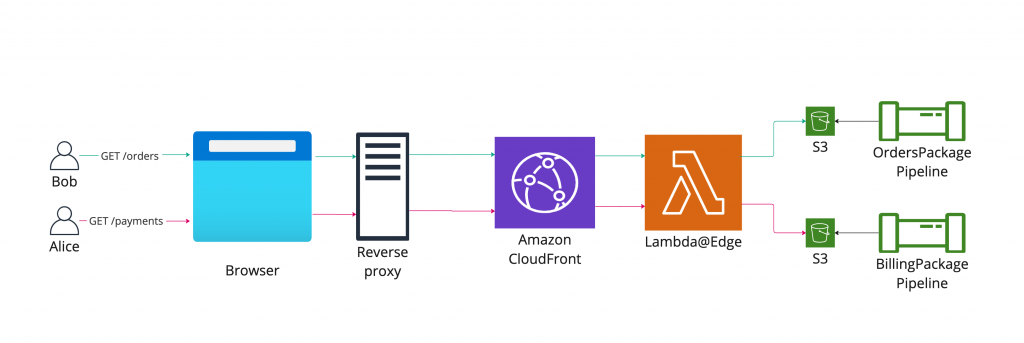
**Pros:**
- Fewer infrastructure pieces to maintain: no need to have proxy servers, separate CDNs for each micro-app
- Virtually infinite scaling using serverless technology
- Better latency compared to standalone proxy servers
**Cons:**
- Cold start time might become an issue
- Lambda@Edge is not supported in all AWS regions if you need to have multi-region (isolated) infrastructure
#### Client-side composition
Client-side composition is another approach to micro-frontend architecture that utilizes client-side micro-frontend orchestration techniques, decoupled from the server implementation.
The key player in this architecture is a container (shell) application that has the following responsibilities:
- Addressing cross-cutting concerns: The container application handles centralized app layout, site navigation, footer, and help panel. Integration with micro-frontends that have cross-cutting concerns occurs through an Event Bus, where synthetic events are sent and handled within the global window scope.
- Orchestration of micro-frontends: The container app determines which micro-frontend bundle to load and when, based on the application’s requirements and user interactions.
- Composing global dependencies: The container app composes all global dependencies, such as React, SDKs, and UI libraries, and exposes them as a separate bundle (vendor.js) that can be shared among the micro-frontends.
The general idea is each micro-frontend bundle would produce 2 types of assets files:
- {hash}/index.js: This serves as the entry point for the micro-frontend application, with the hash representing a unique identifier for the entire build. The hash acts as a prefix key for each bundle in the S3 bucket. It’s important to note that multiple entry points might exist, but the hash remains the same for all of them.
- manifest.json: This is a manifest file that contains paths to all entry points for the micro-frontend application. This file would always leave in the root of the S3 bucket, so the container would be able to discover it easily. I recommend turning on versioning of this file in the S3 bucket in order to have better observability of changes. If you are using webpack to build your project, I highly recommend [WebpackManifestPlugin](https://www.npmjs.com/package/webpack-manifest-plugin) that does all the heavy-lifting for you.
The container is only aware of the micro-frontend asset source domain URL (CDN origin) based on the stage and region. During the initial page load, the container downloads the manifest file for each micro-frontend application. The manifest file is tiny in size (~100 bytes) to avoid impacting page load time and scales well even when aggregating multiple micro-frontends within one container. It’s crucial to consider the manifest file as immutable in the browser’s cache storage to prevent aggressive caching.
Choosing the right orchestration library is the biggest challenge in this composition and will be discussed in the following chapter.

**Pros:**
- Agnostic to server implementation: This approach can be implemented without any specific server requirements, offering flexibility in the backend technology used. As shown in the picture above, you can even don’t have any server
- Preserving global state: By using a container (shell) app, global state can be maintained when switching between micro-frontends. This ensures a seamless user experience and avoids losing context during transitions.
- Decentralized approach: Each micro-frontend can independently decide what data to ship to the browser to bootstrap itself. The container app simply follows a well-defined contract, allowing for greater autonomy and modularity.
- Simple local setup: Assets sources can be easily adjusted between production and local URLs based on development needs. The manifest file helps the container app discover and load the required micro-frontends. Developers can focus on running only the container and the specific micro-frontends they are working on.
**Cons:**
- More network hops to fetch the manifest file: As the container needs to retrieve the manifest file for each micro-frontend, there may be additional network requests and potential latency compared to other composition approaches. This can be mitigated by loading all manifest upfront on the initial page load or by introducing some preloading techniques.
- Compliance with common contract: Every micro-frontend needs to adhere to a common contract for producing builds. This can be facilitated through shared configurations and standardized development practices to ensure consistency across the micro-frontends (more about this in the following parts).
#### Hybrid composition
As I mentioned earlier in this chapter, all of these composition patterns can be mixed and matched within the same shell application. Here is the example of how it can look like:
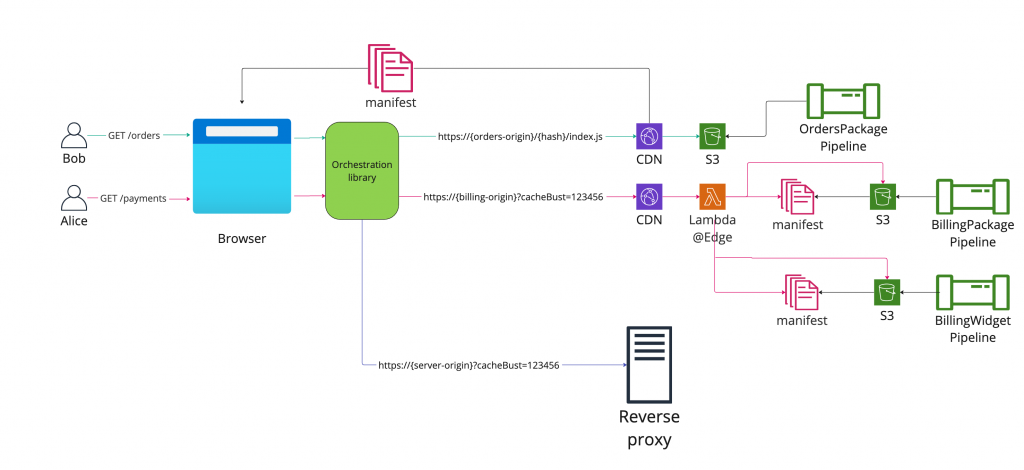
#### Recommendation
I recommend starting with a homogenous approach in the beginning — select a composition pattern that suits you better and start building the infrastructure around it. For us, the client-side composition was the best option but for the future, we considered switching some regions to edge-side orchestration (based on the availability of Lambda@Edge).
### Choosing orchestration library
When it comes to implementing client-side composition in a micro-frontend architecture, selecting the right orchestration library is a critical decision. The chosen library will play a crucial role in managing the dynamic loading and coordination of micro-frontends within the container application. Several popular orchestration libraries exist, each with its own strengths and considerations.
#### Single-spa
[Single-spa](https://single-spa.js.org/) is a widely adopted orchestration library that provides a flexible and extensible approach to micro-frontend composition. It allows developers to create a shell application that orchestrates the loading and unloading of multiple micro-frontends. Single-SPA provides fine-grained control over lifecycle events and supports different frameworks and technologies.
**Pros:**
- Framework agnostic: Library works well with various frontend frameworks like React, Angular, Vue.js, and more.
- Flexible configuration: It offers powerful configuration options for routing, lazy-loading, and shared dependencies.
- Robust ecosystem: Single-SPA has an active community and a rich ecosystem of plugins and extensions.
**Cons:**
- Learning curve: Getting started with single-spa may require some initial learning and understanding of its concepts and APIs.
- Customization complexity: As the micro-frontend architecture grows in complexity, configuring and managing the orchestration can become challenging.
#### Qiankun
[Qiankun](https://github.com/umijs/qiankun) is a powerful orchestration library developed by the Ant Financial (Alibaba) team. It uses a partial HTML approach for composition. On the micro-frontend app side, it produces a plain HTML snippet with all entrypoints to be loaded. After consuming this HTML file, the container does all the orchestration and mounts the app. In this configuration, partial HTML plays the role of a manifest file that I talked about in the previous chapter.
**Pros:**
- Framework agnostic: Qiankun supports various frontend frameworks, including React, Vue.js, Angular, and more.
- Simplified integration: Qiankun provides a set of easy-to-use APIs and tools for creating and managing micro-frontends.
- Scalability and performance: Qiankun offers efficient mechanisms for code sandboxing, state isolation, and communication between micro-frontends.
**Cons:**
- Dependency conflicts: Managing shared dependencies and ensuring compatibility across micro-frontends may require careful configuration and consideration.
- Learning curve: While Qiankun provides extensive documentation, adopting a new library may involve a learning curve for your development team.
- Redundant data sent over the wire: The partial HTML snippet contains redundant data (body, meta, DOCTYPE tags) that needs to be sent via the network.
#### Module federation
[Module Federation](https://module-federation.github.io/), a feature provided by Webpack, has gained significant attention and hype in the web development community. This technology allows developers to share code between multiple applications at runtime, making it an attractive option for building micro-frontends. With its seamless integration with Webpack and runtime flexibility, Module Federation has become a popular choice for managing and orchestrating micro-frontends.
**Pros:**
- Seamless integration with Webpack: If you are already using Webpack as your build tool, leveraging Module Federation simplifies the setup and integration process.
- Runtime flexibility: Module Federation enables dynamic loading and sharing of dependencies, providing flexibility in managing micro-frontends.
**Cons:**
- Limited framework support: While Module Federation is compatible with multiple frontend frameworks, it may require additional configuration or workarounds for specific use cases.
- Community support: Module Federation is a relatively new technology, released as a core plugin in Webpack 5 (and later back-ported to [v4](https://github.com/module-federation/webpack-4)). The Next.js library is also newer, being released as open source recently. As with all new tools, there may be a smaller community and less support available. It’s important to consider this factor if you have tight deadlines or anticipate encountering questions without readily available answers.
### Conclusion
In this first part of the “Micro-frontend Migration Journey” series, we have discussed the motivation behind migrating from a web monolith to a distributed architecture and the initial steps taken to sell the idea to the leadership. We explored the importance of a technical vision document that showcased detailed performance analysis and outlined the different phases of the migration.
We then delved into the design considerations for micro-frontends, discussing three approaches: server-side composition, edge-side composition, and client-side composition. Each approach has its pros and cons, and the choice depends on various factors such as synchronization of the global state, customer experience, infrastructure complexity, and caching. Furthermore, we explored popular orchestration libraries, such as single-spa, qiankun and Module Federation, highlighting their features, benefits, and potential challenge
Join me in the next parts of the series as we continue our micro-frontend migration journey, uncovering more interesting and valuable insights along the way!
* * *
_Originally published at_ [_https://thesametech.com_](https://thesametech.com/testing-redux-with-rtl/) _on April 18, 2023._
_You can also_ [_follow me on Twitter_](https://twitter.com/mastershifu89) _and_ [_connect on LinkedIn_](https://www.linkedin.com/in/isharafeev/) _to get notifications about new posts!_
| srshifu |
1,534,242 | A GUIDE TO THE TYPES OF INNOVATIVE BIOMETRIC DEVICES | "Say goodbye to passwords and hello to the seamless security of biometrics. Verifying your identity... | 0 | 2023-07-12T03:08:49 | https://dev.to/iotphils/a-guide-to-the-types-of-innovative-biometric-devices-5f76 |

"Say goodbye to passwords and hello to the seamless security of biometrics. Verifying your identity is simple and secure with biometric technology, allowing you to focus on what really matters."
Visit our website to learn more! [https://www.iotphils.com/](https://www.iotphils.com/) | iotphils | |
1,534,489 | Getting Started with AWS Containers Part One | Welcome to Getting Started with AWS Containers. Overview In this 2 part... | 0 | 2023-07-12T09:18:28 | https://dev.to/ginowine/a-guide-to-getting-started-with-aws-containers-1971 | aws, cloudcomputing, containers, docker | 
#Welcome to Getting Started with AWS Containers.
##Overview
In this 2 part series blog post, you will go through a step-by-guide to understanding the concepts of Containers, AWS container services, Amazon Elastic Container Service (ECS), Amazon Elastic Kubernetes Service (EKS), Docker, How to setup ECS, Building and Packaging Containerized Applications, AWS IAM, VPC, and Deploying ECS containers. Not to worry, if these terms are new to you — you'll get introduced to them in this article!
**The following topics will be covered in this first part of the tutorial.**
* **Introduction to Containers**
* Brief explanation of containers and their benefits
* Introduction to AWS container services
* **Understanding Containers on AWS**
* Introduction to Amazon Elastic Container Service (ECS)
* Key features of ECS
* Differences between Fargate and EC2 launch types
* **Introduction to Amazon Elastic Kubernetes Service (EKS)**
* Key features of EKS
* Comparison of ECS and EKS for container orchestration
**Prerequisites**
To follow this tutorial, you should have knowledge in:
* Cloud Technologies/computing
* Software Development and Deployment
#1. Introduction to Containers
A Container is a portable and lightweight computing environment. It houses all the system resources that an application, for example, Microservices needs to run. Some examples of these resources include memory, storage, networking resources, dependencies, binary code, configurations files, and CPU. Containers allow you to package your application together with system resources, providing isolated environments for running your Applications.
Modern software engineering practices encourages containerising application deployment for a consistent delivery and management of applications for users. find below some of the benefits of containerisation in application deployment.
* **Portability** - Write once, run anywhere. Containers can help developers bundle all their application dependencies, so no need to rebuilding the application when deploying to any other environment.
* **Efficiency** - Containers provide one of the most efficient methods of virtualisation for developers. They minimise overhead and utilises all available resources. Isolated containers can perform their operations without interfering with other containers, allowing a single host to perform many functions.
* **Agility** - Containerisation makes DevOps workflow seamless and easy. They can rapidly be deployed on any environment, and used to handle application functionalities. If they are not longer needed, you can automatically shut it down until it is needed again, a technique known as orchestration. Technologies like Kubernetes automate the process of coordinating, managing, scaling, and removing containers.
* **Faster delivery** - Developers can use containers to compartmentalize their application. They can divide big application into discrete parts using microservices, and make isolated changes to areas of the application without affecting the whole application.
* **Improved Security** - Being able to isolate components of an application provides an additional layer of security. This is because containers are isolated from one another, this way, if security on one container is compromised, other containers on the same host remain secure.
* **Flexibility** - Containerized apps using microservices become so flexible that you can host certain elements on bare metal and deploy others to virtual cloud environments
-
**Easier management** - Platforms like Kubernetes, Google Kubernetes Engine (GKE), and Amazon Elastic Container Service (ECS/EKS) offers a variety of tools that simplify container management, like application installation, rollbacks and upgrades. There are self-healing features you can use to attempt to recover failed containers, terminate containers that fail health checks, and constantly monitor your containers’ health and status. There is also the flexibility of allocating each container a set amount of CPU and RAM to handle its tasks. Managing containers with tools like Kubernetes is way easier than traditional application management methods.
Containers help the DevOps process by accelerating deployment, streamlining workflows, and minimizing infrastructure conflicts; it also enables developers to use the available resources better. Modern tools like Kubernetes and the Docker engine has made the process of containerising application something that developers can leverage to build scalable applications
##Introduction to AWS Containers
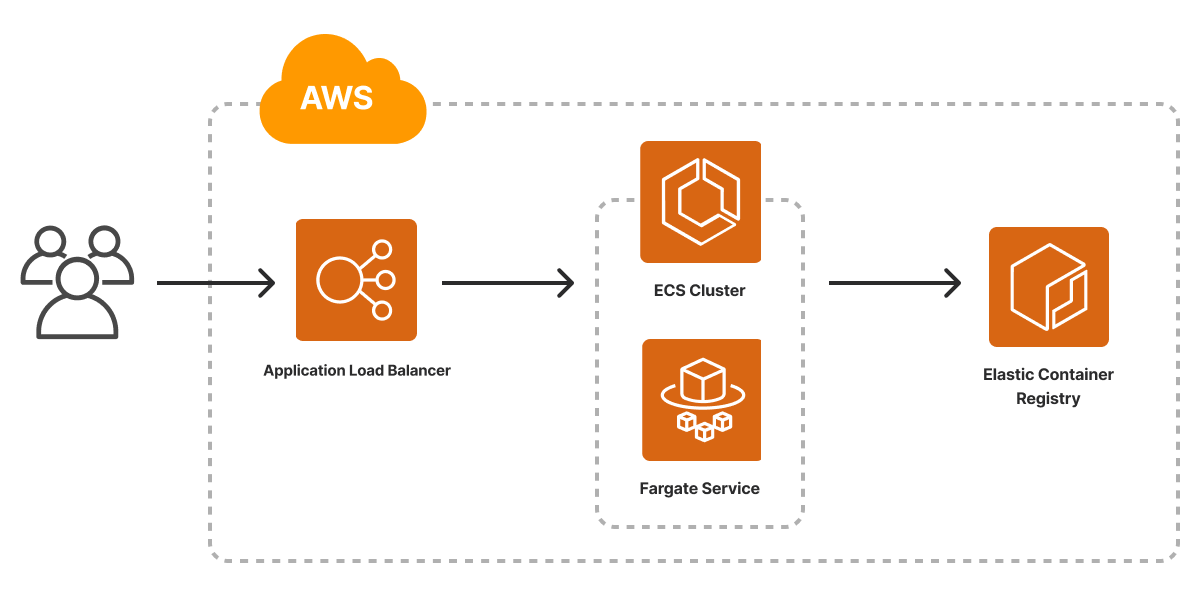
Considering that Cloud Computing is the productive way of deploying and delivering application services to users, the introduction of the AWS container services is at the forefront of this campaign. It opens the gateway to a world of boundless possibilities. Developers and IT enthusiasts immerse themselves in containerisation due to the abovementioned benefits. With its effortless management of containerized applications, Amazon Elastic Container Service (ECS) beckons users to a seamless experience, regardless of scale, where intricate complexities fade into the background, allowing creative minds to focus solely on innovation.
Amazon container services enable developers to orchestrate containers with the unparalleled powers of Kubernetes, granting DevOps Engineers the ability to control containerized deployments with finesse and precision. It enables DevOps Engineers to explore the capabilities of the Cloud concept of application development, unleashing container-based architecture's full potential.
Amazon Cloud Services has a diverse and supportive community of contributors and a well-documented resource; this creates a sense of belonging and provides a passionate community about the containerized community. Though the challenges of configuring IAM roles, building container images, and navigating the intricacies of ECS or EKS may present occasional obstacles, As the curtain rises on the Introduction to AWS container services, individuals step into a realm where dreams of scalability, flexibility, and seamless deployments are within reach, evoking a sense of wonder at the infinite possibilities awaiting them in the cloud's embrace.
#2. Understanding Containers on AWS
##Introduction to Amazon Elastic Container Service (ECS)
Amazon Elastic Container Service (ECS) is a fully managed container orchestration service that enables developers to quickly deploy, manage, and scale containerized applications. It also has AWS configuration and operational best practices built in. ECS is integrated with AWS and third-party tools, such as Amazon Elastic Container Registry and Docker. This integration makes it easier for teams to focus on building the applications, not the environment.
##There are three layers in Amazon ECS:
* **Capacity** - The infrastructure where your container run
* **Controller** - Deploy and manage your applications that run on the containers
* **Provisioning** - The tools that you can use to interface with the scheduler to deploy and manage your applications and containers.
###The following diagram shows the Amazon ECS layers.
##Amazon ECS capacity Layer
This is the infrastructure layer where your containers run, and it is made up of the following components.
* **Amazon EC2 instances in the AWS cloud** - This is where you choose the instance type, number of instances, and where you can also manage the capacity.
* **Serverless (AWS Fargate) in the AWS cloud** - Fargate is a serverless pay-as-you-go compute engine. With Fargate you don't need to manage servers, handle capacity planning, or isolate container workloads for security.
- **On-premises virtual machines (VM) or servers** - This component allows you to register an external instance such as an on-premises server or virtual machine, to your Amazon ECS cluster.
**Amazon ECS controller layer**
- The Amazon ECS scheduler is the software that manages your applications.
**Amazon ECS provisioning layer**
There are multiple options for provisioning Amazon ECS:
- **AWS Management Console** — Provides a web interface that you can use to access your Amazon ECS resources.
- **AWS Command Line Interface (AWS CLI)** — Provides commands for a broad set of AWS services, including Amazon ECS.
- **AWS SDKs** — Provides language-specific APIs and takes care of many of the connection details. These include calculating signatures, handling request retries, and error handling.
- **Copilot** — Provides an open-source tool for developers to build, release, and operate production ready containerized applications on Amazon ECS.
- **AWS CDK** — Provides an open-source software development framework that you can use to model and provision your cloud application resources using familiar programming languages.
##key features of Amazon ECS:
* Options to run your applications on Amazon EC2 instances, a serverless environment, or on-premises VMs.
* Integration with AWS Identity and Access Management (IAM). You can assign granular permissions for each of your containers.
* AWS managed container orchestration with operational best practices built-in, and no control plane, nodes, or add-ons for you to manage.
* Continuous integration and continuous deployment (CI/CD). This is a common process for microservice architectures that are based on Docker containers.
* Support for service discovery. This is a key component of most distributed systems and service-oriented architectures. With service discovery, your microservice components are automatically discovered as they're created and terminated on a given infrastructure.
* Monitoring and logging
###Differences between Fargate and EC2 launch types
Amazon Fargate and EC2 launch types are two options available within Amazon Elastic Container Service (ECS) for running containers. Here are four key differences between them:
* **Serverless vs. Self-managed Infrastructure:**
* Fargate: Fargate is a serverless compute engine for containers. With Fargate, you don't need to provision or manage any underlying infrastructure. AWS takes care of server provisioning, scaling, and management, allowing you to focus solely on deploying and running your containers.
* EC2: EC2 launch type, on the other hand, requires you to manage and provision EC2 instances to run your containers. You need to choose the instance types, manage capacity, and handle auto-scaling to ensure the availability and performance of your containers.
* **Granularity of Control:**
* Fargate: Fargate offers a high level of abstraction, making it easy to deploy and manage containers without worrying about the underlying infrastructure details. However, this also means that you have less granular control over the underlying resources, such as the host operating system or the networking stack.
* EC2: With EC2 launch type, you have more control over the EC2 instances that run your containers. This enables you to fine-tune the instance configuration, use custom AMIs, and apply advanced networking configurations as needed.
* **Billing Model:**
* Fargate: Fargate follows a pay-as-you-go pricing model, where you are charged based on the vCPU and memory resources your containers consume, and you don't pay for idle resources. This model can be cost-effective for workloads with variable or unpredictable traffic patterns.
* EC2: EC2 launch type is billed based on the EC2 instances you provision, regardless of whether your containers fully utilize the available resources or not. As a result, the cost may be higher for workloads that experience fluctuations in demand or have inconsistent resource utilization.
* **Ease of Management:**
* Fargate: Fargate is designed for simplicity and ease of management. AWS handles all the infrastructure tasks, such as patching, updates, and scaling, allowing you to focus solely on managing your containerized applications.
* EC2: While EC2 launch type provides more control over the underlying instances, it also requires more management effort on your part. You need to monitor the instances, apply updates, manage security, and handle scaling based on demand.
When choosing between Amazon Fargate and EC2 launch types, consider factors such as the level of control required, workload characteristics, and cost considerations. Fargate is well-suited for developers who want to abstract away infrastructure management and focus on application development, while EC2 launch type provides more flexibility and control for users who require custom configurations and fine-tuning of the container environment.
##3. Introduction to Amazon Elastic Kubernetes Service (EKS)
The Introduction to Amazon Elastic Kubernetes Service (EKS) unveils a realm of boundless possibilities for container orchestration. Amazon EKS is a managed Kubernetes service to run Kubernetes in the AWS cloud and on-premises data centers.
In the cloud, Amazon EKS automatically manages the availability and scalability of the Kubernetes control plane nodes responsible for scheduling containers, managing application availability, storing cluster data, and other key tasks. With Amazon EKS, you can take advantage of all the performance, scale, reliability, and availability of AWS infrastructure and integrations with AWS networking and security services.
As the managed Kubernetes service provided by AWS, EKS empowers developers to effortlessly deploy, manage effortlessly, and scale containerized applications using the powerful Kubernetes platform. With EKS, the complexities of setting up and maintaining a Kubernetes cluster fade into obscurity as AWS shoulders the burden of infrastructure management and ensures high availability and resilience.
The journey into Amazon EKS embarks on a voyage of innovation, collaboration, and enhanced agility, inviting newcomers and seasoned Kubernetes enthusiasts to navigate the waters of container orchestration with confidence and unbridled excitement.
##Key features of the Amazon Elastic Kubernetes Service
The Amazon Elastic Kubernetes Service (EKS) offers an array of features that spark feelings of excitement and confidence in the hearts of developers and IT teams alike:
* **Seamless Scalability:** The scalability of EKS invokes a sense of liberation, as it effortlessly adapts to varying workloads. Whether it's a surge in traffic during peak hours or a sudden influx of users, EKS dynamically adjusts resources, alleviating the fear of application slowdowns and ensuring a smooth user experience.
* **Streamlined Deployment:** EKS' streamlined deployment process ignites enthusiasm, as it allows developers to swiftly roll out containerized applications without getting entangled in the intricacies of Kubernetes cluster setup. The ease of use empowers teams to focus on innovation, inspiring them to bring their ideas to life with unparalleled efficiency.
* **High Availability and Reliability:** The reliability of EKS evokes a sense of trust and security, knowing that the applications will remain accessible and stable, even during challenging times. With built-in redundancy and automated failover mechanisms, EKS provides a safety net that bolsters confidence in the face of uncertainty.
* **Intelligent Auto-scaling:** EKS' intelligent auto-scaling capabilities elicit feelings of awe, as it intuitively monitors application demand and adjusts resources accordingly. The knowledge that the infrastructure can autonomously handle traffic spikes and downturns instills a sense of peace, allowing teams to focus on innovation without fearing performance bottlenecks.
* **Seamless Integrations:** The seamless integration of EKS with other AWS services brings a sense of unity and harmony to the cloud ecosystem. It inspires collaboration between applications and services, amplifying the potential for building feature-rich, interconnected solutions that delight users and customers alike.
* **Enhanced Security:** The robust security measures of EKS generate feelings of assurance and peace of mind. From role-based access control to automated security updates, EKS creates a shield of protection around the containerized applications, ensuring data integrity and safeguarding against cyber threats.
* **Community and Support:** The strong EKS community and AWS support invoke feelings of camaraderie and belonging. Knowing that there is a vast network of experts, resources, and documentation to lean on fosters a sense of empowerment, enabling developers to explore the full potential of Kubernetes with a safety net of knowledge.
##Comparison of ECS and EKS for container orchestration
When comparing Amazon Elastic Container Service (ECS) and Amazon Elastic Kubernetes Service (EKS) for container orchestration, it elicits a range of emotions that stem from the unique strengths and characteristics of each service:
* **Simplicity and Ease of Use (ECS):** ECS evokes feelings of simplicity and ease of use, offering a straightforward approach to container orchestration. It allows developers to focus on their applications without the added complexity of managing Kubernetes infrastructure. The simplicity of ECS fosters a sense of relief, enabling quick deployments and reducing the learning curve for teams, particularly those new to containerization and orchestration.
* **Flexibility and Community (EKS):** EKS sparks feelings of excitement and curiosity due to its inherent flexibility and the vibrant Kubernetes community it embraces. EKS opens doors to a vast ecosystem of tools, plugins, and knowledge, nurturing a sense of empowerment and inspiration. This flexibility fosters a spirit of exploration, enabling teams to leverage the rich Kubernetes feature set, custom configurations, and integration possibilities to build innovative and scalable solutions.
* **Managed Infrastructure (ECS):** ECS invokes a sense of relief and peace of mind with its managed infrastructure. Teams appreciate the freedom from infrastructure management responsibilities, allowing them to focus on application development and deployment. This managed approach evokes feelings of security and trust, knowing that AWS handles the underlying infrastructure, patching, and scaling, thus relieving the burden of operational tasks and enabling teams to concentrate on delivering high-quality applications.
* **Granularity and Control (EKS):** EKS elicits feelings of control and precision, appealing to developers seeking fine-grained control over their container orchestration environment. The ability to customize Kubernetes configurations, choose specific container runtimes, and access advanced networking options invokes a sense of empowerment and confidence. EKS provides a playground for meticulous fine-tuning, creating an atmosphere of excitement and satisfaction among those who desire a high level of control.
Let's end the first part of the 2 part series article here and continue in article two. You will learn about the following topics in [article 2.](https://dev.to/ginowine/a-guide-to-getting-started-with-aws-containers-part-two-4jeo)
* **Setting Up AWS for Containers**
* Creating an AWS account
* Configuring AWS Identity and Access Management (IAM) roles and policies
* Creating a VPC with Public and Private Subnets for Your Clusters
* **Building and Packaging Containerized Applications**
* Choosing a containerization technology (Docker, containerd, etc.)
* Introduction to Docker
* Setting Up Docker on AWS
* How to deploy and manage Docker containers on AWS EC2
Feel free to visit the official [Amazon Container Documentation Website](https://docs.aws.amazon.com/whitepapers/latest/aws-overview/containers.html) and explore further resources from Amazon
[Click here to go to article 2](https://dev.to/ginowine/a-guide-to-getting-started-with-aws-containers-part-two-4jeo) | ginowine |
1,534,589 | Mistakes I Made Deploying an IaC Project in GCP Using Terraform (and How I Fixed Them) | Introduction: I recently deployed an IaC project in GCP using Terraform. The project was a simple... | 0 | 2023-07-12T09:19:54 | https://dev.to/wonder717/mistakes-i-made-deploying-an-iac-project-in-gcp-using-terraform-and-how-i-fixed-them-3h4 | **Introduction:**
I recently deployed an IaC project in GCP using Terraform. The project was a simple web application, but it was a good learning experience. In this blog post, I'll discuss some of the mistakes that I made deploying the project, and how I fixed them.
**Mistake #1: Not using modules**
One of the biggest mistakes I made was not using modules. Modules are a way to reuse code in Terraform, and they can make your code much more maintainable. For example, I had a set of resources that I used to create a database. I could have put these resources in a module, and then I could have reused the module in other projects.
**How I fixed the mistake:**
I fixed this mistake by starting to use modules. I created a module for the database resources, and then I reused the module in other projects. This made my code much more maintainable, and it made it easier to deploy the project.
**Here are some of the benefits of using modules:**
* **Reusability:** Modules can be reused in multiple projects, which can save you time and effort.
* **Maintainability:** Modules make your code easier to maintain, because you only have to make changes in one place.
* **Consistency:** Modules can help you to ensure that your code is consistent across different projects.
**Mistake #2: Not using variables**
Another mistake I made was not using variables. Variables are a way to pass data into Terraform, and they can make your code more flexible. For example, I had a set of resources that I used to create a web server. I could have used variables to pass the web server's name and port number into Terraform.
**How I fixed the mistake:**
I fixed this mistake by starting to use variables. I created variables for the web server's name and port number, and then I passed the variables into Terraform. This made my code more flexible, and it made it easier to deploy the project to different environments.
**Here are some of the benefits of using variables:**
* **Flexibility:** Variables can make your code more flexible, by allowing you to change the values of the variables without having to change the code itself.
* **Reusability:** Variables can make your code more reusable, by allowing you to use the same code in different environments with different values for the variables.
* **Documentation:** Variables can help you to document your code, by providing a clear explanation of the values that the variables can take.
**Mistake #3: Not using Terraform Cloud**
I also made the mistake of not using Terraform Cloud. Terraform Cloud is a hosted version of Terraform, and it can make it easier to manage your Terraform projects. For example, Terraform Cloud can help you to track your changes, and it can help you to collaborate with others on your projects.
**How I fixed the mistake:**
I fixed this mistake by starting to use Terraform Cloud. I created a Terraform Cloud account, and I imported my Terraform projects into Terraform Cloud. This made it easier to manage my projects, and it made it easier to collaborate with others on my projects.
**Here are some of the benefits of using Terraform Cloud:**
* **Centralized management:** Terraform Cloud provides a centralized location for managing your Terraform projects.
* **Collaboration:** Terraform Cloud makes it easy to collaborate with others on your Terraform projects.
* **Auditing:** Terraform Cloud provides auditing features that can help you to track changes to your Terraform projects.
**Mistake #4: Not testing my code**
Finally, I made the mistake of not testing my code. Testing is important to make sure that your code works as expected. For example, I could have written some unit tests to test the database resources.
**How I fixed the mistake:**
I fixed this mistake by starting to test my code. I wrote some unit tests to test the database resources, and I also wrote some integration tests to test the entire project. This made me more confident that my code worked as expected, and it made it easier to find and fix bugs.
**Here are some of the benefits of testing your code:**
* **Confidence:** Testing your code can give you confidence that your code works as expected.
* **Bug fixing:** Testing your code can help you to find and fix bugs.
* **Documentation:** Testing your code can help you to document your code.
**Conclusion:**
I made a lot of mistakes when I was deploying the IaC project in GCP using Terraform. However, I learned from my mistakes, and I was able to fix them. I hope that this blog post will help you to avoid making the same mistakes that I made.
Here is the link to the full post detailing how I completed this project:https://dev.to/wonder717/deploying-an-infrastructure-as-code-project-in-gcp-using-terraform-25jn
Thanks for reading!
**About Me**
My name is Wonder; a cloud architect/engineer doubling in AWS and GCP but more inclined to AWS :wink:. Excited to embark on this journey with you lot and hopefully we learn from each other so we can grow collectively. Here are my socials;
LinkedIn: https://www.linkedin.com/in/wonder-agudah-784268183
Dev community: https://dev.to/wonder717
GitHub: https://github.com/Wonder717 | wonder717 | |
1,536,234 | What is try except Python? | Have you ever tried to divide a number by zero? What happened? Your computer probably crashed. That's... | 0 | 2023-07-13T18:03:11 | https://dev.to/watchakorn18k/what-is-try-except-python-4h9c | python | Have you ever tried to divide a number by zero? What happened? Your computer probably crashed. That's because dividing by zero is an error. Errors are things that go wrong in your code. They can happen for a lot of reasons, like if you type something wrong or if you try to do something that's not possible.
How does try except Python work?
Try except Python is a way to handle errors in your code. It's like a safety net that catches errors and prevents your code from crashing. When you use try except Python, you tell your computer to try to run some code. If an error happens, the computer will run the except block instead. The except block is where you can put code to handle the error.
How to use try except Python
You can use try except Python to handle any kind of error. For example, you could use it to handle errors when opening files, errors when accessing the internet, or errors when parsing data.
Here's an example of how to use try except Python to open a file:
```py
try:
file = open("my_file.txt", "r")
except:
print("Error opening file!")
```
If you run this code and the file doesn't exist, the except block will run and print the message "Error opening file!".
Conclusion
Try except Python is a powerful tool that can help you to prevent your code from crashing. It's a simple but effective way to handle errors, and it's a great way to make your code more robust.
Here are some tips for using try except Python:
- Use try except Python whenever you're doing something that could potentially cause an error.
- Be specific about the errors that you want to handle.
- Put your code that could cause an error in the try block.
- Put your code to handle the error in the except block.
| watchakorn18k |
1,536,466 | Build an app with React and Supabase | by Nirmal Kumar This tutorial will explore building a basic CRUD (Address Book) application using... | 0 | 2023-07-13T23:10:27 | https://blog.openreplay.com/build-an-app-with-react-and-supabase/ | by [Nirmal Kumar](https://blog.openreplay.com/authors/nirmal-kumar)
<blockquote><em>This tutorial will explore building a basic CRUD (Address Book) application using React and Supabase, setting up a Supabase database, connecting a React application to it, and implementing CRUD operations in our application. By the end of this tutorial, you will have a solid understanding of how to use Supabase with React and how to implement basic CRUD operations in your web application.</em></blockquote>
React has been a popular choice for building web applications in the recent past. And technologies like [Supabase](https://supabase.com/) (an open source alternative to Firebase) have eased the web development process by providing many features like authentication, databases, etc., that a typical backend would provide for the frontend applications. This eliminates the need for having a dedicated backend written with Node.js or any other backend framework; you get a full-stack app without all the work! And, almost all web applications operate on the basic principle of CRUD. CRUD stands for Create, Read, Update, and Delete. It refers to the four basic operations that can be performed on data stored in a database. These operations are fundamental to most database-driven applications and are essential for managing data.
You will need:
- Node JS (LTS Version)
- npm 7 or greater
- VS Code or any Code editor of your choice.
- Basic understanding of Supabase auth as we will build this project on top of an auth layer. Check the article [here](https://blog.openreplay.com/authentication-in-react-with-supabase) and come back.
- Basic knowledge of Bootstrap
- Starter code (Import from GitHub by running the command below)
```bash
git clone --branch start --single-branch git@github.com:nirmal1064/react-supabase-crud.git
```
## Supabase Database Overview and Database Setup
For this CRUD project, let's create a new project in Supabase and name it `Address Book` or whatever name you like. Supabase provides a Postgres relational database that comes with every project and is included in their free plan as well.
Supabase provides features like a Table view, SQL editor, Relationships manager, etc. PostgreSQL's Row Level Security (RLS) is the most important feature, which helps developers define fine-grained access controls for each database table. RLS policies enable developers to control which rows in a table users can access, update, or delete based on their role or other criteria.
Let's create a database for our project. Open the Supabase project, and click' Table Editor' on the left navigation menu. Then click on the `Create a new Table` button.
You will get a screen like the one below,
Enter the `Name` and ensure `Enable Row Level Security (RLS)` is checked.
Under the columns, there will be `id` and `created_at` columns by default. Let's add four more columns, as shown in the image below,
We have made `name` and `phone` non-null fields. To do so, click the `settings` icons on the right and uncheck `Is Nullable`. (Refer to the image below).
The `address` field is a text field. The `user_id` field corresponds to the user who created this contact. So we gave the default value as `auth.uid()`. So whenever a contact is created, the user id field is populated by default by Supabase.
Once all is done, Save it.
## Connecting React App to the Supabase Database
We have all the necessary code to connect to Supabase in the starter code. So, connecting to the database is pretty simple. The syntax is as follows.
```javascript
const { data, error } = await supabase.from("database_name");
```
The `data` contains the valid response data, and `error` contains the error response, if any.
We can easily chain methods to the above code and perform various operations. For example,
```javascript
// For Select Operations
const { data, error } = await supabase.from("database_name").select();
// For Insert Operations
const { data, error } = await supabase.from("database_name").insert(data);
// For Update Operations
const { data, error } = await supabase
.from("database_name")
.update(data)
.eq(condition);
// For Delete Operations
const { data, error } = await supabase
.from("database_name")
.delete()
.eq(condition);
```
We will see each of these operations in detail in the upcoming sections.
> At this point, you are presumed to have the starter code and understand Supabase user authentication. Also, you have created a user for this app by following the steps mentioned in the previous article. If not done, kindly revisit the article [here](https://blog.openreplay.com/authentication-in-react-with-supabase/) and come back.
## Implementation of CRUD operations
In the upcoming sections, we will implement each of the CRUD operations with the help of RLS.
Why RLS is needed here? RLS is needed because in our database we store users' contact informationsers. We want to restrict access to these data so that only the users who created those contacts can see it.
So, Now let's start the coding part.
Let's create a separate context to maintain the contacts state. Create `ContactProvider.jsx` inside the `context` folder.
```javascript
import { createContext, useContext, useEffect, useState } from "react";
const ContactContext = createContext({});
export const useContacts = () => useContext(ContactContext);
const ContactProvider = ({ children }) => {
const [contacts, setContacts] = useState([]);
const [errorMsg, setErrorMsg] = useState("");
const [msg, setMsg] = useState("");
return (
<ContactContext.Provider
value={{
contacts,
msg,
setMsg,
errorMsg,
setErrorMsg
}}>
{children}
</ContactContext.Provider>
);
};
export default ContactProvider;
```
Here, we are setting up a Context Provider for contacts. We have three state variables:`contacts` for storing the contact details. `msg` and `errorMsg` for storing the success and error messages. Then we export these state variable and their setter methods that can be used in the components later.
> To make the article concise, we will explain only the Supabase functionalities in detail, whereas the UI and styling part won't be explained in detail. It's up to the reader to style the components as they like.
## Implementing Create Operation
The Create operation in React is an equivalent of a database insert operation. First, we must set up RLS for the insert operation, using the Supabase API.
Open the project in Supabase. Then go to `Authentication` in the side navigation bar. Click on `Policies` and then click on `New Policy`. In the screen that pops up, click on `For Full Customization`. In the next screen, enter the values as described in the image below.
As the Policy name field indicates, we will only allow insert access for authenticated users. You can describe the policy in whatever way you find suitable. This field doesn't need to be the same as that.
Then we selected the `Allowed operation` to `Insert`. Leave the `Target roles` blank.
In the `WITH CHECK expression` field, we set the condition as `auth.uid() = user_id`, which means the user_id column in the table should match the authenticated user's id, thereby restricting access only to the authenticated users.
Let's add the insert functionality to our app. Open `ContactProvider.jsx` and add the following function inside it.
```javascript
import { supabase } from "../supabase/client";
// Rest of the code
const ContactProvider = ({ children }) => {
// Rest of the code
const addContact = async (contact) => {
const { error } = await supabase.from("contacts").insert(contact);
if (error) {
setErrorMsg(error.message);
}
};
return (
<ContactContext.Provider
value={{
contacts,
msg,
setMsg,
errorMsg,
setErrorMsg,
addContact
}}>
{children}
</ContactContext.Provider>
);
};
export default ContactProvider;
```
We have created an async `addContact` method that takes in a `contact` object as a parameter and inserts the contact into the database. The insert operation will return an `error` object, if any. If there is any error, we will update the `errorMsg`. We can also add a `select` operation after the insert to return the `data` we just created. But we haven't set up the rules for select operations. So let's leave it for now and add it later.
We will use Bootstrap's' Modal' component to implement the user interface (UI). First, create the `ContactList.jsx` inside the `pages` directory. Let's add a route to this page as well.
You can copy the code for the UI from the GitHub commit [here](https://github.com/nirmal1064/react-supabase-crud/commit/2a60ac773ffcc30038ac93584edabbea6dd130f6).
In the above code, in `App.jsx`, we are wrapping our contacts route inside the `ContactProvider` because we want our contacts to be available to this particular route only. And in `ContactList.jsx`, we display a header and a Button for Adding Contacts.
Until this point, the page would look like this,

We need to add a functionality where we display the modal to add a new contact when the `Add Contact` button is clicked. So let's create the modal first. Create `ContactModal.jsx` inside the `components` directory and add the code as shown in the GitHub commit [here](https://github.com/nirmal1064/react-supabase-crud/commit/7206c1f2fc81bb6506e0ff90e670934bfffbc42f).
The component takes in four props.
- `show` - to show or hide the modal.
- `handleClose` - a function to close the modal when the user clicks on close or outside of the component.
- `type` - To indicate the type of operation, i.e., Add or Edit. We will use the same component for both adding and editing the contact
- `contact` - The active contact object to be displayed when editing; otherwise an empty object in case of Add operation.
We use `react-bootstrap`'s `<Modal/>` component to render the Modal. We are using the `useState` and `useRef` hooks from React to manage the state of the form inputs and the `useContacts` hook from the `ContactProvider` context to manage the contacts data. We use the `react-bootstrap`'s `<Modal/>` and `<Card>` components to style and display the form. The `handleSubmit` function is called when the user submits the form. It handles the inputs' validation and the contact data's saving.
Also, let's create a `react-bootstrap`'s `Toast` component to display our application's success and error messages.
Create `ToastMessage.jsx` inside the `components` directory and add the code as shown in the commit [here](https://github.com/nirmal1064/react-supabase-crud/commit/8a04b86c745471a8db610723f7a6d3c5f5e828ba).
This component takes in four props.
- `show` to indicate whether to show/hide the toast message.
- `type`, the type of the toast, `success` or `error`.
- `message`, the message to display.
- `handleClose`, the function to execute when the toast is closed.
We are enclosing our `Toast` inside the `ToastContainer` where we position our toast to the `top-end` of the screen.
Then, in the `Toast`, we set the `autohide` prop, which will close the toast automatically after the `delay` milliseconds. The `Toast` has a `Header`and `Body` where we define the heading and message, respectively.
Now, Let's add both of the above modals to the `ContactList` page and make the functionality to display the `ContactModal` when the `Add Contact` button is clicked. The code for this change can be found in the GitHub commit [here](https://github.com/nirmal1064/react-supabase-crud/commit/718aef70bc7abd8b8f75c0cdc528beeeb875fc39).
We have declared two `ToastMessage` components, one with the type `Success` and the other with the type `Error`. For the `ContactModal`, we have a few state variables `showContactModal` to indicate whether to show or hide the modal, `type` indicates `Add` or `Edit` type, and `activeContact` contains the current contact to edit or an empty contact in case of `Add`.
When the Add Contact button is clicked, the `handleAdd` function is triggered, where we set the type to `Add` and `showContactModal` to `true`. We also have a `closeContactModal` function, triggered when the modal is closed. In this function, we set the `activeContact` to an empty object, `showContactModal` to false, and `type` to an empty string. We are passing these state variables and functions as props to the `ContactModal.jsx.`
When the `Add Contact` is clicked, the modal will open. It will be like the below,
Fill out the form and click submit. A contact will be added. And the toast will be displayed as shown in the below image.
As we haven't yet implemented the `Read` operation, you can verify the created contact by visiting the `supabase project -> Table editor -> <Table Name>.`
<div style="background-color:#efefef; border-radius:8px; padding:10px; display:block;">
<hr/>
<h3><em>Session Replay for Developers</em></h3>
<p><em>Uncover frustrations, understand bugs and fix slowdowns like never before with <strong><a href="https://github.com/openreplay/openreplay" target="_blank">OpenReplay</a></strong> — an open-source session replay suite for developers. It can be <strong>self-hosted</strong> in minutes, giving you complete control over your customer data.</em></p>
<img alt="OpenReplay" style="margin-top:5px; margin-bottom:5px;" width="768" height="400" src="https://raw.githubusercontent.com/openreplay/openreplay/main/static/openreplay-git-hero.svg" class="astro-UXNKDZ4E" loading="lazy" decoding="async">
<p><em>Happy debugging! <a href="https://openreplay.com" target="_blank">Try using OpenReplay today.</a></em><p>
<hr/>
</div>
## Implementing Read Operation
The Read operation in React is an equivalent of a database select operation. First, we must set up RLS for the select operation in Supabase.
Open the project in Supabase. Then go to `Authentication` in the side navigation bar. Click on `Policies` and then click on `New Policy`. In the screen that pops up, click on `For Full Customization`. In the next screen, enter the values as described in the image below.
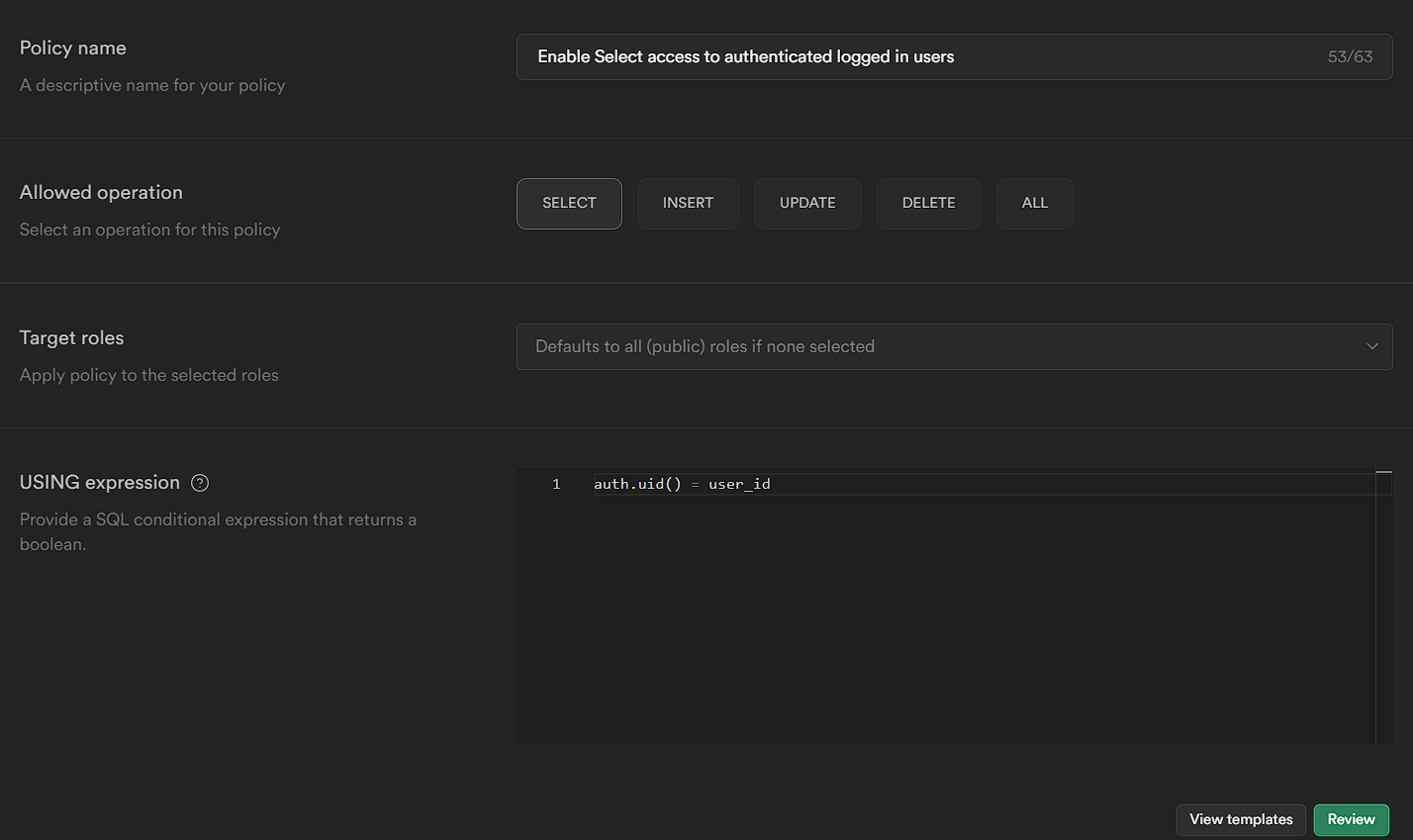
The policy is similar to the insert policy but for the Select operation. Save the policy.
Now open the `ContactProvider.jsx` and add the `fetchAll` operation to select the contacts.
```javascript
import { createContext, useContext, useEffect, useState } from "react";
import { supabase } from "../supabase/client";
// Rest of the code
const ContactProvider = ({ children }) => {
// Rest of the code
const addContact = async (contact) => {
const { data, error } = await supabase
.from("contacts")
.insert(contact)
.select();
if (data) {
setContacts((prevContacts) => [...prevContacts, data[0]]);
setMsg("Contact Added Successfully");
}
if (error) {
setErrorMsg(error.message);
}
};
const fetchAll = async () => {
const { data, error } = await supabase.from("contacts").select();
if (data) setContacts(data);
if (error) setErrorMsg("Error in Fetching Contacts");
};
useEffect(() => {
fetchAll();
}, []);
return (
<ContactContext.Provider
value={{
contacts,
msg,
setMsg,
errorMsg,
setErrorMsg,
addContact,
fetchAll
}}>
{children}
</ContactContext.Provider>
);
};
export default ContactProvider;
```
In the `fetchAll` function we are performing a select operation. The `select` operation will return an array of results representing the rows in the table. If the operation succeeds, it will return the `data` object; otherwise, the `error` object. We are updating the `contacts` state when there is data or setting the `errorMsg`.
Also, we are calling the `fetchAll` function in the `useEffect` hook so that contacts are fetched from the DB whenever the component is mounted to the DOM or the page is refreshed.
Also, we have updated the `addContact` function to add the select operation at the end so that whenever a new contact is created, the same will be returned when the operation is successful. A point to note here is that we have used `data[0]` to get the contact because Supabase returns an array of data for the select operation. Since we are inserting only one contact, only one row will be returned. So we are getting the contact from the index 0.
Now, let's implement the UI for displaying the contacts.
We will use bootstrap icons to indicate the `edit` and `delete` operations. To add bootstrap icons to our project, Open `index.html` and add the below line inside the `<head>` tag.
```html
<link
rel="stylesheet"
href="https://cdn.jsdelivr.net/npm/bootstrap-icons@1.10.3/font/bootstrap-icons.css"
/>
```
That's it. Let's edit the `ContactList.jsx` page inside the `pages` directory. On this page, we will display all the contacts in a table view using `react-bootstrap`'s `Table` component. We will also add a button on the top right to Add a new contact. In the last column of the table, we will have two icons to `edit` and `delete` the contact.
As usual, the code for this change can be found on GitHub [here](https://github.com/nirmal1064/react-supabase-crud/commit/39373fd4e36960cefe70fe646c42f133c8fab8a0).
At this point, the UI would look like this,
## Implementing Update Operation
The Update operation in React is an equivalent of a database update operation. First, we must set up RLS for the update operation in Supabase.
Open the project in Supabase. Then go to `Authentication` in the side navigation bar. Click on `Policies` and then click on `New Policy`. In the screen that pops up, click on `For Full Customization`. In the next screen, enter the values as described in the image below.

Let's add update functionality to our app. Open `ContactProvider.jsx` and add the following function.
```javascript
// Rest of the code
const ContactProvider = ({ children }) => {
// Rest of the code
const editContact = async (contact, id) => {
const { data, error } = await supabase
.from("contacts")
.update(contact)
.eq("id", id)
.select();
if (error) {
setErrorMsg(error.message);
console.error(error);
}
if (data) {
setMsg("Contact Updated");
const updatedContacts = contacts.map((contact) => {
if (id === contact.id) {
return { ...contact, ...data[0] };
}
return contact;
});
setContacts(updatedContacts);
}
};
return (
<ContactContext.Provider
value={{
contacts,
msg,
setMsg,
errorMsg,
setErrorMsg,
addContact,
fetchAll,
editContact
}}>
{children}
</ContactContext.Provider>
);
};
export default ContactProvider;
```
We have created an async `editContact` function which takes in two parameters, `contact`, the contact to be updated, and `id`, the id of the contact. In the function body, we call the `update` method by passing the `contact` object, and we add the condition where the `id` equals the `id` of the contact using the `eq` filter. The `eq` method takes in two parameters, the column name and the value to be checked against the column. There are other filters, like `neq` (not equals), `gt` (greater than), etc. You can check the official Supabase documentation for more such filters [here](https://supabase.com/docs/reference/javascript/using-filters).
Then we get the updated contact back by using the `select()` method at the end. So, when the update operation is successful, the `data` variable will contain the list of rows updated. If the operation fails, the `error` variable will contain the error information. Based on that, we are updating our `contacts` state and `errorMsg` state. For updating the contacts in an immutable way, we are creating an updated array by transforming the contacts array using the `map` operation and checking if the contact's id matches with the id passed to the `editContact`. If it matches, we are returning the updated contact, otherwise, we are returning the same contact. Then we update the `contacts` state using this `updatedContacts` variable.
For the UI changes related to the edit functionality, refer to the GitHub commit [here](https://github.com/nirmal1064/react-supabase-crud/commit/690f7e0bf9d44f8e4a7d3bb66c502af4dc3cf54c) and make the necessary changes.
In the above commit, in the `ContactList` page, we have added an `onClick` event handler to the `edit` icon, which upon clicking, will open up the modal with the corresponding contact data pre-filled. Also, in `index.css`, we have added styles to make the cursor a pointer when we hover over the icon. And in the `ContactModal`, we have updated the code to handle the `edit` case.
We can edit the data and click on `Save Changes`. The update query will be run, and the data will be updated. We can close the modal and see the data changes.
## Implementing Delete Operation
The Delete operation in React is an equivalent of a database delete operation. First, we need to set up RLS for the delete operation in Supabase.
Open the project in Supabase. Then go to `Authentication` in the side navigation bar. Click on `Policies` and then click on `New Policy`. In the screen that pops up, click on `For Full Customization`. In the next screen, enter the values as described in the image below.
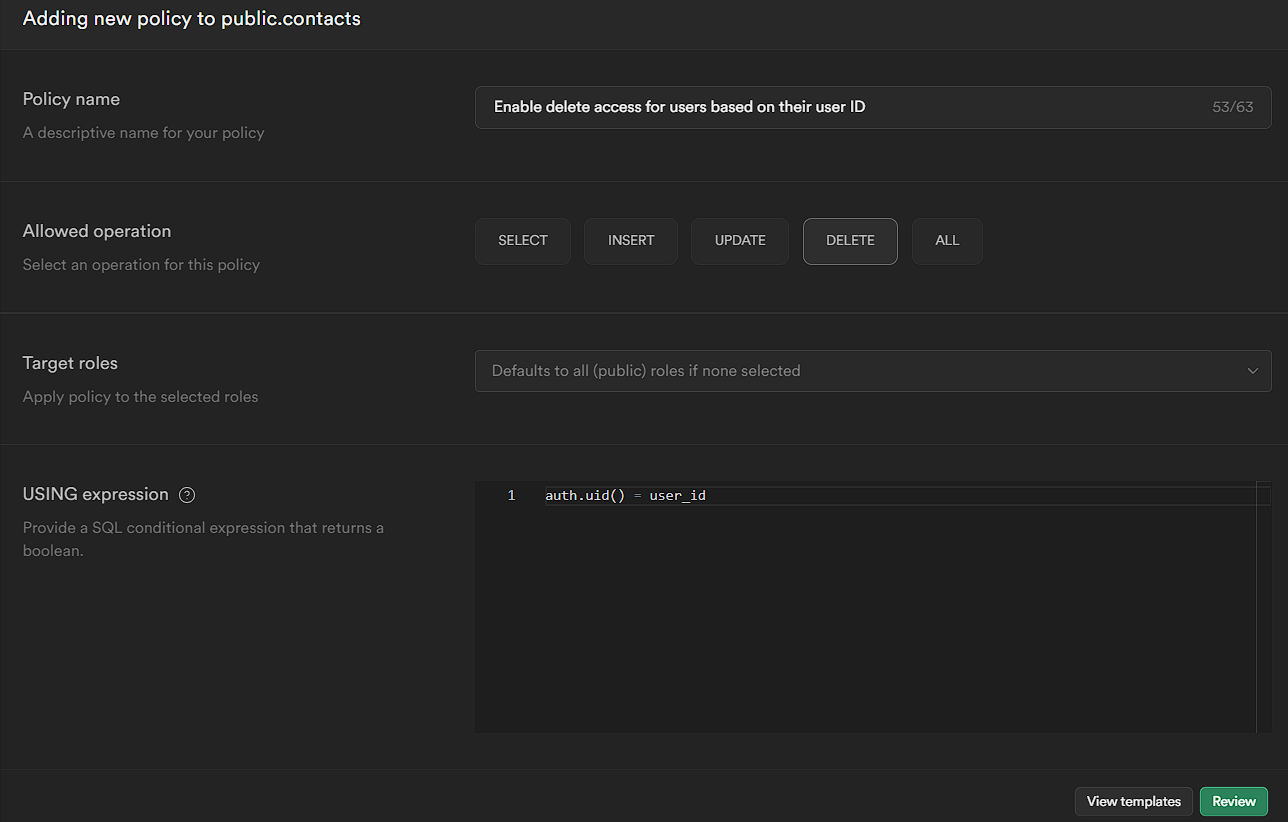
Let's add delete functionality to our app. Open `ContactProvider.jsx` and add the following function.
```jsx
// Rest of the code
const ContactProvider = ({ children }) => {
// Rest of the code
const deleteContact = async (id) => {
const { error } = await supabase.from("contacts").delete().eq("id", id);
if (error) {
setErrorMsg(error.message);
} else {
setMsg("Contact Deleted Successfully");
setContacts((prevContacts) =>
prevContacts.filter((contact) => contact.id !== id)
);
}
};
return (
<ContactContext.Provider
value={{
contacts,
msg,
setMsg,
errorMsg,
setErrorMsg,
addContact,
fetchAll,
editContact,
deleteContact
}}>
{children}
</ContactContext.Provider>
);
};
export default ContactProvider;
```
We have created an async `deleteContact` function which takes in one parameter, `id`, the id of the contact. In the function body, we call the `delete` with the condition where the `id` equals the `id` of the contact using the `eq` filter. We are getting an error object from Supabase. We will set the `errorMessage` state if there is an error. If there is no error, the delete operation is successful, so we will update the `contacts` state by using the filter method to create a new array that only includes the contacts that do not have the given ID. The updated array is then set as the new state for `contacts`. Using the functional form of setState with prevContacts ensures that the updated state is based on the previous state and prevents issues that could arise from asynchronous state updates.
Moving to the UI part, We will create another modal asking the user for confirmation before deleting the contact. It will be useful to prevent accidental deletions.
Then we will include the modal in the `ContactList` page.
As usual, the code changes can be found in the GitHub commit [here](https://github.com/nirmal1064/react-supabase-crud/commit/4647044d16b2660254b05e5d6b3a4a69c365c34b).
This modal is similar to the `ContactModal`. It takes three props, `show` (a boolean to indicate if the modal is displayed or not), `handleClose` (a function to close the modal), and `id` (the ID of the contact to delete).
Inside the `Modal` we will display a message asking the user if they want to delete the contact. And we have two buttons, `No` and `Yes` for the user actions. We will delete the contact with the specified id or close the modal based on the user confirmation.
Like the `edit` icon, we have added the `icon` class to the `delete` icon and updated its `onClick` function so that whenever the delete icon is clicked, the `ConfirmModal` will be shown.
That's it. When you click the `delete` icon for any contact, the modal will be displayed.
Once we click `Yes`, the contact will be deleted, and the modal will close automatically.
## Conclusion
In this article, we explored how to build a basic CRUD application using React and Supabase. We walked through setting up a Supabase database, connecting a React application to it, and implementing CRUD operations with RLS. We also discussed how RLS can help enforce data access policies and ensure that users only have access to the data they are authorized to view, update, or delete.
The complete source code of this article can be found on my [GitHub](https://github.com/nirmal1064/react-supabase-crud/). If you find the code useful, star the repo.
As a next step, you can implement more complex CRUD operations, such as pagination, filtering, and sorting.
Also, you can explore Supabase's documentation to learn about more advanced features and integrations.
| asayerio_techblog | |
1,537,646 | The most performed RANDOM querying on Rails! | 🌟 Prepare to have your mind blown by the Unbelievable Performance Gem! 🌟 Are you tired of... | 0 | 2023-07-14T22:31:32 | https://dev.to/loqimean/the-most-performed-random-on-rails-4g4p | random, sql, rails, postgres | ## 🌟 Prepare to have your mind blown by the Unbelievable Performance Gem! 🌟
Are you tired of slow random record retrieval in your Rails applications? Say goodbye to sluggish queries and hello to lightning-fast performance! Our gem is here to revolutionize the way you fetch random records, delivering results that will leave you speechless.
🔥 Experience the future of speed and efficiency as our gem seamlessly integrates into your codebase. With near-instantaneous responses, you can elevate your user experience to new heights.
💪 Join the ranks of developers who are already witnessing jaw-dropping results. Don't miss out on this game-changing gem that's setting new performance standards in the Rails community.
Ready to ignite your Rails application? Visit our repo to learn more about the Unbelievable Performance Gem and be part of the performance revolution today! 🚀💎
{% embed https://github.com/the-rubies-way/random-rails %} | loqimean |
1,552,798 | Listing #2 on DEV Community | 🚀Taking Observability to the Next Level: Explore New Relic's Free Tier for Developers What’s included... | 23,986 | 2023-07-29T05:21:15 | https://dev.to/meta-verse/listing-2-on-dev-community-537a | **🚀Taking Observability to the Next Level: Explore New Relic's Free Tier for Developers**
What’s included in the New Relic free tier?
- One full platform users w/ access to all 30+ platform capabilities
- 100 GB data ingest
- Default logs obfuscation
- Unlimited basic users
- Unlimited ping monitor and more!
Get started for free: https://newrelic.com/pricing/free-tier?utm_source=devto&utm_medium=community&utm_campaign=global-ever-green-new-relic-free-tier
https://dev.to/listings/misc | silverthehedgehogfuture | |
1,560,895 | Building a Drowsiness Detection Web App from scratch - pt2 | Cheers for making it to pt2; You've learnt how to Import datasets, augment that data and label the... | 0 | 2023-08-06T20:49:59 | https://dev.to/afrologicinsect/building-a-drowsiness-detection-web-app-from-scratch-pt2-abf | Cheers for making it to pt2; You've learnt how to Import datasets, augment that data and label the images, now we set up for real time predictions using the powerful YOLOv5 model and Google Colaboratory.
## Define Directories
Here, you would confirm the directories, because we would be navigating to them to train our model.
You should have your `images` and `labels` directory like so:
> images
> labels
Once you have confirmed the paths, we need to start training our data.
## Machine Learning
Not to be too literal, but we have got to the stage where the machine does all the work. While we can train this data on our local machine - would require a lot of computing energy, this tutorial shows you how to run this on Google Colab, which has a free tier for GPU.
### Data Directory
Let's Start:
1. Move your data folders into your Google Drive, create a folder and name it __data__, this will contain all data contents.
2. Create a `dataset.yaml` file in your __data__ directory and paste the following:
```
## Creates the path to images for training and validation
train: /content/data/images
val: /content/data/images
## Defines the Classes
nc: 2 # number of classes
names: ['awake','drowsy'] # class names
```
### Launch Google Colab.
You can do this from your parent folder - simply search for it, it looks like your __Jupyter__ notebook! Go the top right corner, that says __Connect__, select the __Change runtime type__ and choose 'GPU'.
- Import Dependencies
```
import os
import shutil
import random
import torch
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
```
- Connect to your Drive
```
## This will mount your drive on the notebook
from google.colab import drive
drive.mount('/content/drive')
```
- Navigate to your image paths
```
images_path = "/content/drive/MyDrive/DROWSINESS/data/images"
```
- Clone the YOLO Model we would be training from
```
!git clone https://github.com/ultralytics/yolov5.git
## Navigate to the model
%cd yolov5/
## Install requirements
!pip install -r requirements.txt
## Download the YOLOv5 model
!wget https://github.com/ultralytics/yolov5/releases/download/v6.0/yolov5s.pt
```
- Start Training!
```
!python train.py --img 384 --batch 32 --epochs 1200 --data /content/drive/MyDrive/DROWSINESS/dataset.yaml --weights /content/yolov5/yolov5s.pt --nosave --cache
```
**NB**: You can change the number of epochs you would like to train for.
Now this will take a while.. Grab a cup of tea.
It's trained! Nice, it will save the trained model to your __weights__ folder with a last prefix, the next step is to test the validation of the predictions.
- Load Model and predict on sample image
```
## Load Modelmodel = torch.hub.load('ultralytics/yolov5', 'custom', path='runs/train/exp/weights/last.pt')
## sample Image
img = '/content/drive/MyDrive/DROWSINESS/data/images/awake_10.jpg'
## Plot prediction
result = model(img)
result.pandas().xyxy[0] ##Reference
%matplotlib inline
plt.imshow(np.squeeze(result.render(result)))
plt.show()
```
**NB** You may have trained multiplr times and this would mean your model would save with a different path, however it should have a 'last' prefix followed by '.pt'. So, check.
Now your model is tested, is it trusted? Maybe you want to train it again, this time with different parameters? But if you are satisfied - let see how we can download the model.
- Download the model/weights
```
from google.colab import files
files.download('/content/yolov5/runs/train/exp/weights/last.pt')
```
This will save the model to your local folder.
Here's a colab [notebook](https://colab.research.google.com/drive/12k-QCNNGLa38VC2xPcvWj7nhXIZWyE1h#scrollTo=tzkW_R_s_sGd) for reference.
The beauty of **YOLO** models to make predictions is not just that it is wicked efficient for computer vision, but that it is so light, we can actually serve it on a webpage.
This is exactly what we would achieve in the final and **Pt 3** of this tutorial. See you next week, please share your questions and comments. | afrologicinsect | |
1,561,147 | React Custom Hook: useStateWithHistory | In this article series, we embark on a journey through the realm of custom React hooks, discovering... | 24,106 | 2023-08-27T21:00:00 | https://dev.to/sergeyleschev/react-custom-hook-usestatewithhistory-ni9 | webdev, javascript, programming, react | In this article series, we embark on a journey through the realm of custom React hooks, discovering their immense potential for elevating your development projects. Our focus today is on the "useStateWithHistory" hook, one of the many carefully crafted hooks available in the collection of React custom hooks.
Github: https://github.com/sergeyleschev/react-custom-hooks
```javascript
import { useCallback, useRef, useState } from "react"
export default function useStateWithHistory(
defaultValue,
{ capacity = 10 } = {}
) {
const [value, setValue] = useState(defaultValue)
const historyRef = useRef([value])
const pointerRef = useRef(0)
const set = useCallback(
v => {
const resolvedValue = typeof v === "function" ? v(value) : v
if (historyRef.current[pointerRef.current] !== resolvedValue) {
if (pointerRef.current < historyRef.current.length - 1) {
historyRef.current.splice(pointerRef.current + 1)
}
historyRef.current.push(resolvedValue)
while (historyRef.current.length > capacity) {
historyRef.current.shift()
}
pointerRef.current = historyRef.current.length - 1
}
setValue(resolvedValue)
},
[capacity, value]
)
const back = useCallback(() => {
if (pointerRef.current <= 0) return
pointerRef.current--
setValue(historyRef.current[pointerRef.current])
}, [])
const forward = useCallback(() => {
if (pointerRef.current >= historyRef.current.length - 1) return
pointerRef.current++
setValue(historyRef.current[pointerRef.current])
}, [])
const go = useCallback(index => {
if (index < 0 || index > historyRef.current.length - 1) return
pointerRef.current = index
setValue(historyRef.current[pointerRef.current])
}, [])
return [
value,
set,
{
history: historyRef.current,
pointer: pointerRef.current,
back,
forward,
go,
},
]
}
```
Advantages of **useStateWithHistory**:
1. Automatic history tracking: useStateWithHistory automatically keeps track of the values you set, allowing you to access the complete history whenever you need it.
2. Efficient memory usage: The hook utilizes a capacity parameter, ensuring that the history doesn't grow indefinitely. You can define the maximum number of historical values to keep, preventing excessive memory consumption.
3. Time-travel functionality: With back(), forward(), and go() functions, you can seamlessly navigate through the recorded history. Travel back and forth between previous states or jump directly to a specific index, enabling powerful undo/redo or step-by-step functionality.
Where to use useStateWithHistory:
1. Form management: Simplify the process of handling form inputs by providing an easy way to track changes, revert to previous values, or redo modifications.
2. Undo/Redo functionality: Implement undo/redo functionality in your application with ease. Track state changes and allow users to navigate back and forth through their actions effortlessly.
3. Step-by-step navigation: Use useStateWithHistory to build interactive guides or tutorials where users can navigate between different steps while preserving their progress.
```javascript
import { useState } from "react"
import useStateWithHistory from "./useStateWithHistory"
export default function StateWithHistoryComponent() {
const [count, setCount, { history, pointer, back, forward, go }] =
useStateWithHistory(1)
const [name, setName] = useState("Sergey")
return (
<div>
<div>{count}</div>
<div>{history.join(", ")}</div>
<div>Pointer - {pointer}</div>
<div>{name}</div>
<button onClick={() => setCount(currentCount => currentCount * 2)}>
Double
</button>
<button onClick={() => setCount(currentCount => currentCount + 1)}>
Increment
</button>
<button onClick={back}>Back</button>
<button onClick={forward}>Forward</button>
<button onClick={() => go(2)}>Go To Index 2</button>
<button onClick={() => setName("John")}>Change Name</button>
</div>
)
}
```
Throughout this article series, we focused on one of the gems from the collection of React custom hooks – "_useStateWithHistory_". This hook, sourced from the "react-custom-hooks" repository, revolutionizes how we work in our React applications.
Full Version | React Custom Hooks:
https://dev.to/sergeyleschev/supercharge-your-react-projects-with-custom-hooks-pl4 | sergeyleschev |
1,562,167 | Reverse engineering in the gaming industry | What is reverse engineering? Reverse engineering is a process that entails analyzing a... | 0 | 2023-11-28T17:59:05 | https://dev.to/yeauxdejuan/reverse-engineering-in-the-gaming-industry-k7o |
## What is reverse engineering?
Reverse engineering is a process that entails analyzing a software system to gain insights into its structure, functionality, and behavior. It involves extracting information from artifacts like executable files, libraries, and configuration files, at different levels of abstraction, such as the code, design, and specification levels. Manual tools like disassemblers and decompilers, as well as automated code analyzers and generators, facilitate this process.
In the gaming and software industry, reverse engineering plays a crucial role in understanding proprietary systems, ensuring compatibility across platforms and operating systems, and creating mods and fan-made content. It also aids in software analysis and security, identifying vulnerabilities for safer user experiences. Moreover, reverse engineering helps preserve classic games and applications, allowing future generations to experience the technological and entertainment evolution.
However, ethical and legal considerations are vital when engaging in reverse engineering activities, ensuring responsible and legitimate use of this powerful tool. As we explore its applications in the subsequent sections, we will uncover its significance in shaping the gaming and software industry and preserving digital artifacts for posterity's enjoyment. Together, we will venture into the world of reverse engineering and its transformative impact on our digital landscape.
##The Toolkit.
###Manual Tools: Disassemblers, Decompilers, Debuggers, and Hex Editors
Disassemblers are critical tools in reverse engineering that transform machine code into human-readable assembly language. They enable analysts to decipher the logic and functionality embedded in binary code. For instance, when reverse engineering a game's executable, a disassembler can unveil the assembly instructions governing specific game mechanics.
```
// Decompiled javascript code for enemy AI behavior
function enemyAI() {
if (playerIsNear()) {
if (isAggressive()) {
attackPlayer();
} else {
fleeFromPlayer();
}
} else {
patrol();
}
}
Ghidra is an open source reverse engineering tool developed
by the National Security Agency.
```
Decompilers attempt to revert compiled code (like C/C++) back into a higher-level programming language, providing insights into code functionality. Suppose a game's physics engine is implemented in compiled code. A decompiler might produce a version of this code in a more human-understandable language, aiding in understanding the physics logic.
Debuggers allow real-time analysis of executable code, offering insights into the program's execution flow and memory usage. When dissecting a game, debuggers can help trace how variables change during gameplay, aiding in understanding how certain features are implemented.
Hex editors offer direct manipulation of binary files, like game assets. They are handy for modifying textures, models, or sounds within a game. For example, a hex editor could be used to tweak the inventory of in-game values.
```
Offset Inventory_Cash
0000 100.20
Offset Inventory_Cash
0000 9999.99
ImHex is an open-source hex editor designed for
inspecting and editing binary data
```
##Automated Tools: Code Analyzers, Code Generators, and Code Converters
Automated code analyzers utilize algorithms to scan codebases for patterns, vulnerabilities, and issues. In the context of reverse engineering, these tools can identify potential security flaws, enhancing the software's robustness. For instance, analyzing a game's networking code might reveal vulnerabilities that need addressing to prevent exploits.
Code generators automate the creation of code based on predefined patterns or requirements. In reverse engineering, these tools can aid in generating higher-level code from lower-level languages like assembly. If a game's rendering logic is deciphered in assembly, a code generator could assist in creating equivalent code in a higher-level language for easier modification.
Code converters facilitate the translation of code between different programming languages. When reverse engineering a game, these tools can help translate sections of assembly code into more modern programming languages, making it easier to work with or adapt the code.
These tools, whether manual or automated, are vital for reverse engineers to navigate the complex landscape of a software system and gain a deep understanding of its components and functionality.
##Ethical and Legal Considerations
Engaging in reverse engineering activities requires careful consideration of ethical and legal implications. Respecting the responsible and legitimate use of this powerful tool is vital. Adhering to legal guidelines and ethical standards ensures that the process contributes positively to the industry and digital preservation efforts.
##Conclusion
In this exploration of reverse engineering, we've peeled back the layers of software systems, delving into their intricate architecture, functionality, and behavior. From dissecting executable files to unveiling design choices, the process offers a profound glimpse into the digital world's underlying mechanisms. Through the interplay of manual tools like disassemblers and decompilers, as well as automated code analyzers and generators, we've witnessed how reverse engineering can transform complexity into comprehension.
Reverse engineering's significance reaches far beyond mere technical curiosity. It's a cornerstone in the gaming and software industry, enabling us to fathom proprietary systems, bridge platform divides, and create innovative fan-made content. But it doesn't stop there – this methodology enhances software analysis, bolsters security, and ensures a bridge to the past by preserving the legacy of beloved classics.
As we move forward, our exploration evolves. The next horizon in our journey encompasses emulation and preservation, where the digital torch is passed to ensure the continued existence of iconic games and applications. Emulation, like reverse engineering, unveils its own intricate toolkit, enabling us to breathe life into the software of yesteryears, and ensuring future generations can engage with the technologies that shaped our digital world. Through the lens of emulation and preservation, we'll continue to navigate the intersection of technology, nostalgia, and progress, unraveling new layers of our digital heritage.
##Resources
Conley, J., Andros, E., Chinai, P., Lipkowitz, E., & Perez, D. (2004). Use of a Game Over: Emulation and the Video Game Industry, A White Paper. Northwestern Journal of Technology and Intellectual Property, 2(2), 1.
Dale, R. (2007, August 8). RLG DigiNews: Volume 5, Number 3. https://worldcat.org/arcviewer/1/OCC/2007/08/08/0000070519/viewer/file1503.html
Stuart, K. (2020, April 16). Preserving old games is a service to humanity. The Guardian. https://www.theguardian.com/technology/2007/jul/12/games.comment
http://pdf.textfiles.com/academics/conley.pdf
View of Keeping the game alive: Evaluating strategies for the preservation of console video games. (n.d.). http://www.ijdc.net/article/view/147/209
| yeauxdejuan | |
1,564,705 | Voyages in the Domain of Artificial Ingenuity: Unveiling the Enigma of Stable Diffusion and the Odyssey of Comfy UI | This marks the second phase of my expedition into the realm of Artificial Intelligence, the realm of... | 0 | 2023-08-10T12:41:55 | https://dev.to/betmig/voyages-in-the-domain-of-artificial-ingenuity-unveiling-the-enigma-of-stable-diffusion-and-the-odyssey-of-comfy-ui-3d8 | stablediffusion, ai, docker, jupyter | This marks the [second phase of my expedition](https://medium.com/@betmig.dev/unveiling-the-magical-fusion-8f311376c75e) into the realm of Artificial Intelligence, the realm of [Stable Diffusion](https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0), and the intricate domain of [Ren’py](https://renpy.org/).
These preceding fortnights have ushered in a mélange of challenges, predominantly stemming from the necessity to attend to mundane chores and obligations of life’s terrestrial hue — procuring provisions, disbursing dues, harmonizing with the rhythms of existence in Sweden, navigating the labyrinthine corridors of academia, all while endeavoring to maintain an equilibrium in the sphere of my physical well-being. Nevertheless, I have not been deterred; I’ve persevered, striving to effect marginal ameliorations within my ambit. My aspiration remains unwavering, a steadfast beacon amid these exigencies.
The crux of my investigations has gravitated chiefly around the concept of Stable Diffusion, with [AUTOMATIC1111’s SD Web UI](https://github.com/AUTOMATIC1111/stable-diffusion-webui) as my conduit for experimentation. My endeavors have transpired within the ethereal confines of cloud computing, leveraging the manifold offerings of [Vast AI](https://vast.ai/) services.
This odyssey has been nothing short of captivating. It amuses me to no end to observe these myriad machines dispersed across the globe, each occupying peculiar niches in remote locales. Their diversity is beguiling — some are reliant upon antiquated **DVDs** to store their ephemeral data, while others subsist on _meager HDD_ resources.

The pecuniary valuation of this heterogeneous spectrum fluctuates in consonance with the unique settings and geographic coordinates. A **gamble**, one might contend, but a gamble worth its salt when it comes to these cerebral pursuits. 😽 However, it would be fallacious to deem this service a _paragon of reliability_ for those who seek to cultivate it into a professional enterprise or a robust commercial venture. For modest explorations and preliminary trials, it indeed suffices — **a mantra** I recite to myself in moments of introspection.
Alas, the _fiscal toll_ mounts with celerity, particularly when one orchestrates a pause in the operations of their virtual assemblage, motivated by the desire to safeguard the troves of your _safetensors_, the invaluable _loRas_, and the intricate _embeddings_ painstakingly cultivated. One **gingerly** presses the pause button, persuaded that the financial consequences would be inconsequential.

Ah, the folly of such assumptions! The realm of monetary tolls has ensnared me, as my 20 units of currency, my “cushion,” were **promptly** depleted. 😿
Sorrowful reverberations resounded as I conceded to the inevitability of **terminating my instance**, all while bemoaning the inexorable act of reinstating the intricate webwork. 🤌🏽
In my moments of **disenchantment**, I directed my acerbic reflections toward the constructs of capitalism, questioning the notion of why this intricate edifice of technology couldn’t be proffered in a manner that transcended the 💸 shackles of cost. Amidst the tapestry of exasperation, interwoven with tearful frustration, I resolved to plunge deeper into the realms of comprehension. I yearned to seize greater reins of authority over my endeavors. While the allure of the **web-based user interface** was undeniable, its constraints spurred me to seek an alternative, a more congenial solution.
**Can one unearth a graphical interface that bestows the latitude to sculpt one’s workflow with meticulous artistry? **Indeed, the path to such enlightenment exists!
I present to you the [Comfy-UI for Stable Diffusion](https://github.com/comfyanonymous/ComfyUI) — a robust and modular interface befitting the contours of stable diffusion, replete with an interface that embraces the lexicon of graphs and nodes. **Precisely the mechanism I craved!** The expedition mandates a **rerun**, an exercise in uploading my constructions afresh (accompanied by the obligatory _growls_) and situating them within the embrace of the virtual cloud (with accompanying _double-growls_) once again.
Alas, verity struck, punctuating the euphoria of discovery. Vast AI **failed** to yield a ready-made Comfy UI template tailored for the indolent. The conundrum of crafting my **docker image** and navigating its ascent awaited resolution. Fortuity graced my quest, [unveiling a docker image](https://hub.docker.com/layers/runpod/stable-diffusion/comfy-1.0.0/images/sha256-26670d72a5fb2c21bcbb886ef5b15c186d8a3ed3b4517f6863b253b5b213b66d?context=explore) that aligned with my needs. Yet, the groundwork of configuring the rudiments of my template remained a challenge to surmount.
Curiosity might be kindled, prompting contemplation regarding the trajectory of progress. The trajectory is a trifle elementary.
Embark upon a sojourn to the realms of [Vast.AI](https://cloud.vast.ai/), enlisting thyself within its precincts. Secure an endowment of no less than **20 monetary units** in your digital coffer.
Go into the [Console](https://cloud.vast.ai/), whence a window of opportunity beckons by the name of “**Instance Configuration.**” A lateral panel dubbed “**Edit Image and Config**” awaits your prompt.

Select the “Template Slot” option, ushering forth the genesis of your unique template.

Within the confines of “**Enter full docker image/tag name for docker pull,**” meticulously replicate the designated nomenclature of [this docker image](https://hub.docker.com/layers/runpod/stable-diffusion/comfy-1.0.0/images/sha256-26670d72a5fb2c21bcbb886ef5b15c186d8a3ed3b4517f6863b253b5b213b66d?context=explore).
In this instance, the apellation to replicate reads as:
`runpod/stable-diffusion:comfy-1.0.0.`
Kindle your creative flame within the precincts of “**Create/Run options,**” etching forth the following:
`-e JUPYTER_DIR=/ -p 3000:3000`
The elucidations herein elucidate the nature of a bespoke container, analogous to a vessel containing a tapestry of software routines that unfurl autonomously. Consider it an emulation of a _microcosmic realm_ within the vast expanse of your computational macrocosm.

The inaugural parameter, “_-e JUPYTER_DIR=/,_” functions akin to a parchment inscribed with guiding coordinates, ushering the container to a designated alcove within its virtual haven. A dictum to navigate, a rudder to chart the course.
The secondary parameter, “_-p 3000:3000,_” mirrors the act of fashioning a portal betwixt the extramural veracity and the sanctum of the container’s realm. An invitation to discourse, as if to say, “_Should any wayfarer from the exterior yearn to engage in dialogue, let them approach the portal marked ‘3000,’ and I shall orchestrate the conveyance of their communiqué to the inner sanctum._”

In facile parlance, these parameters serve as custodians of the container’s creative abode, orchestrating its endeavors while allowing external entreaties to traverse through the portal labeled ‘3000.’
With the segue to “**Launch Mode**” a decree for the inauguration of a jupyter-python notebook is beckoned.
Into the parchment of “**On-start script,**” the following dictates shall be inscribed:
`env | grep _ >> /etc/environment; touch ~/.no_auto_tmux; sleep 5;
sed -i '/rsync -au --remove-source-files \/venv\/ \/workspace\/venv\//a source \/workspace\/venv\/bin\/activate\n pip install jupyter_core' /start.sh;
/start.sh`
The uninitiated may ponder over the _esoteric prose_ enunciated thus. Envision the establishment of a _mystical kitchen_ within a vast culinary carriage, analogous to a **container**. The kitchen’s machinations must be meticulously calibrated to dispense culinary delights in harmonious synchrony. Consider the following interpretation:
- _env | grep _ >> /etc/environment;_ : Analogous to an inventory, wherein the distinctive ingredients and implements, marked with enigmatic symbols (like ingredients distinguished by the presence of an underscore in their designations), are meticulously documented on a conspicuous slate within the kitchen, visible to all participants.
- _touch ~/.no_auto_tmux;_ : This gesture parallels affixing a note upon the kitchen wall, decreeing, “**Hark, the culinary corps, let us abstain from the automatic invocation of this multifaceted contraption for the present.**” It is a deliberation upon the orchestration of the kitchen’s mechanics.
- _sleep 5;_ : Imagine an interlude, a brief intermission lasting five moments, before the grand inauguration of the kitchen’s operations. A pause to allow the culinary artisans to don their aprons and gather their bearings.
- _sed -i ‘/rsync -au — remove-source-files \/venv\/ \/workspace\/venv\//a source \/workspace\/venv\/bin\/activate\n pip install jupyter_core’ /start.sh;_ : Analogous to a culinary formula, the script (**“start.sh”**) guides the chefs through the preparatory stages. The script is adapted to accommodate new directives — first, don the specialized apron (activate the specific environment), followed by a sprinkle of the condiment ‘jupyter_core’ upon the culinary endeavors (installation of ‘jupyter_core’).
- _/start.sh_ : A clarion call, akin to issuing the command, “_Culinary crew, let the symphony of preparation commence!_” It marks the initiation of the actual culinary process, governed by the instructions encoded within the script.

Concluding the ensemble, a moniker and explication for the template shall be appended for future reference. A final act — the button marked “**Select and Save**” — seals the covenant.
In possession of your bespoke template, commence by affirming the ‘1X’ designation for the GPUs atop the central pinnacle.
Manipulate the sliders judiciously to unearth a mechanism that aligns with your objectives. Personally, my predilections incline toward parsimony, tethered to dependable storage. Hence, I shift the slider — a shift toward “Disk Space To Allocate,” 300GB at the very least (a personal proclivity). The filter sliders should be engaged to align with a minimum of **20GB in GPU RAM**. Prudence would recommend a selection of “_Secure Cloud (Only Trusted Datacenters)_” for the sake of safety and reliability.
Typically, a solitary instance of the “**1x RTX 3090**” breed suffices for most exigencies. Should an attractive offer grace your purview, the “**Rent**” button stands ready to be pressed.
With the die cast, the instance **shall awaken**, its presence evident within the pantheon of instances delineated on the left. Herein lies the gateway to the user interface, a portal offering _Comfy UI’s vista_, alongside direct ingress to the expanse of _Jupyter notebook_. This sanctum allows for manual transference of files or even the beckoning of models from esteemed repositories such as [civitai](https://civitai.com/) or [huggingface](https://huggingface.co/) through the medium of command lines.
Assuming the guided journey remains faithful, **Comfy UI** shall be unfurled in the cloud’s ephemeral canvas, with the power to usher forth the invocation of safetensors and myriad embeddings within the realm of Stable Diffusion.
In our **forthcoming chapter**, the nuances of configuring the **Comfy UI** workflow shall be illuminated, each facet cast under the gleam of meticulous detail. Until then, let your curiosity be unshackled. Immerse yourself in the exploration, for the prerogative remains to cease and recommence, a cardinal tenet should adversity come knocking.

With fervent wishes for your exploratory odyssey,
Betmig | betmig |
1,564,711 | Using Bryntum Calendar to Coordinate Caregiver Availability in Health Care | The Bryntum Calendar is a web component that you can use to display and manage calendar events. It... | 0 | 2023-08-10T12:11:12 | https://dev.to/bryntum/using-bryntum-calendar-to-coordinate-caregiver-availability-in-health-care-1g7d | javascript, react, tailwindcss, tutorial | The [Bryntum Calendar](https://www.bryntum.com/products/calendar/) is a web component that you can use to display and manage calendar events. It has type definitions using TypeScript as well as a well-documented [API](https://bryntum.com/docs/calendar/api/api), making it easy to integrate with popular libraries and frameworks, including [React](https://reactjs.org/) and [Vue.js](https://vuejs.org/).
The Bryntum Calendar component is beneficial for project management applications that need to show users a project timeline or applications that need resource management with a calendar view. This includes applications providing health-care or home care services, where resource allocation and coordination are essential.
In this article, you'll build an application to coordinate caregiver availability for family members using React, [Tailwind CSS](https://tailwindcss.com/docs/installation), and the Bryntum Calendar component. While doing so, you'll learn about working with JSON data, creating stateful React components, and displaying events in a calendar view using the Bryntum Calendar.
## Building the Caregiver Application
Before you begin this tutorial, you'll need [Node.js](https://nodejs.org/en/) version 14 or newer as well as [npm](https://www.npmjs.com/) version 6 or newer installed on your computer. You'll also need a code editor like [Visual Studio Code](https://code.visualstudio.com/).
You can follow along with this tutorial using this [GitHub repository](https://github.com/Anshuman71/caregiver-bryntum).
### Set Up the Project
To begin, run the following command to create a new React project, `caregiver-app`, using `create-react-app`:
```bash
npx create-react-app caregiver-app
```
Then change the directory to the newly created project:
```bash
cd caregiver-app
```
Run the following command to install Tailwind CSS and its dependencies:
```bash
npm install -D tailwindcss postcss autoprefixer
```
Next, run `npx tailwindcss init -p` to initialize Tailwind CSS in the project. This command will generate `tailwind.config.js` and `postcss.config.js` files, where you can configure color schemes and plug-ins.
Update the `content` list in the `tailwind.config.js` file to watch for Tailwind CSS class updates in all files:
```jsx
/** @type {import('tailwindcss').Config} */
module.exports = {
content: [
"./src/**/*.{js,jsx,ts,tsx}",
],
theme: {
extend: {},
},
plugins: [],
}
```
Finally, add `@tailwind` directives to the `./src/index.css` so you can use Tailwind CSS classes in all our components:
```css
@tailwind base;
@tailwind components;
@tailwind utilities;
```
### Create Your Page Layout
Now that you've set up the project, it's time to create a simple app layout with a navigation bar at the top and a drop-down menu to select your desired family member. Here's a rough mock up:

Before going further, you need a data source to fetch the list of caregivers and the caregiving schedules for family members. To do that, create a new `src/data.json` file. The `data.json` has two keys:
- `Caregivers`, a list of caregiver details objects
- The caregiving `schedules` for each family member
Each caregiving schedule item has a caregiver linked to it using the `resourceId` attribute that maps to the caregiver's `id`, as shown below.

The `caregivers` object structure is as follows:
```json
{
"id": "steve", // unique resource id
"name": "Steve Rogers", // name of the caregiver
"eventColor": "blue" // color for the calendar event
}
```
The `schedule` object structure looks like this:
```json
{
"<family-member>": [
{
"startDate": "<appointment-start-date>",
"id": "<unique-id-number>",
"endDate": "<appointment-start-date>",
"name": "<slot-name>",
"resourceId": "<caregiver-id>"
}
// ... more appointments
]
// ... other family member's schedules
}
```
You can copy the below JSON as sample data for your `data.json` file.
```json
{
"caregivers": [
{
"id": "steve",
"name": "Steve Rogers",
"eventColor": "blue"
},
{
"id": "tony",
"name": "Tony Stark",
"eventColor": "orange"
},
{
"id": "bruce",
"name": "Bruce Banner",
"eventColor": "green"
},
{
"id": "natasha",
"name": "Natasha Romano ff",
"eventColor": "pink"
}
],
"schedule": {
"Grand Pa": [
{
"startDate": "Thu Sep 08 2022 16:00:00 GMT+0000 (Coordinated Universal Time)",
"id": 96,
"endDate": "Thu Sep 08 2022 18:00:00 GMT+0000 (Coordinated Universal Time)",
"name": "Caregiver assigned",
"resourceId": "tony"
},
{
"startDate": "Fri Sep 09 2022 06:00:00 GMT+0000 (Coordinated Universal Time)",
"id": 91,
"endDate": "Fri Sep 09 2022 07:00:00 GMT+0000 (Coordinated Universal Time)",
"name": "Caregiver assigned",
"resourceId": "natasha"
},
{
"startDate": "Thu Sep 08 2022 05:00:00 GMT+0000 (Coordinated Universal Time)",
"id": 82,
"endDate": "Thu Sep 08 2022 07:00:00 GMT+0000 (Coordinated Universal Time)",
"name": "Caregiver assigned",
"resourceId": "steve"
},
{
"startDate": "Mon Sep 05 2022 18:00:00 GMT+0000 (Coordinated Universal Time)",
"id": 62,
"endDate": "Mon Sep 05 2022 20:00:00 GMT+0000 (Coordinated Universal Time)",
"name": "Caregiver assigned",
"resourceId": "bruce"
},
{
"startDate": "Tue Sep 06 2022 11:00:00 GMT+0000 (Coordinated Universal Time)",
"id": 93,
"endDate": "Tue Sep 06 2022 12:00:00 GMT+0000 (Coordinated Universal Time)",
"name": "Caregiver assigned",
"resourceId": "tony"
},
{
"startDate": "Fri Sep 09 2022 08:00:00 GMT+0000 (Coordinated Universal Time)",
"id": 2,
"endDate": "Fri Sep 09 2022 10:00:00 GMT+0000 (Coordinated Universal Time)",
"name": "Caregiver assigned",
"resourceId": "natasha"
},
{
"startDate": "Mon Sep 05 2022 16:30:00 GMT+0000 (Coordinated Universal Time)",
"id": 79,
"endDate": "Mon Sep 05 2022 17:30:00 GMT+0000 (Coordinated Universal Time)",
"name": "Caregiver assigned",
"resourceId": "bruce"
},
{
"startDate": "Sun Sep 04 2022 09:00:00 GMT+0000 (Coordinated Universal Time)",
"id": 15,
"endDate": "Sun Sep 04 2022 10:00:00 GMT+0000 (Coordinated Universal Time)",
"name": "Caregiver assigned",
"resourceId": "natasha"
}
],
"Grand Ma": [
{
"startDate": "Fri Sep 09 2022 18:30:00 GMT+0000 (Coordinated Universal Time)",
"id": 12,
"endDate": "Fri Sep 09 2022 20:30:00 GMT+0000 (Coordinated Universal Time)",
"name": "Caregiver assigned",
"resourceId": "bruce"
},
{
"startDate": "Fri Sep 09 2022 17:30:00 GMT+0000 (Coordinated Universal Time)",
"id": 96,
"endDate": "Fri Sep 09 2022 19:30:00 GMT+0000 (Coordinated Universal Time)",
"name": "Caregiver assigned",
"resourceId": "natasha"
},
{
"startDate": "Mon Sep 05 2022 05:00:00 GMT+0000 (Coordinated Universal Time)",
"id": 98,
"endDate": "Mon Sep 05 2022 07:00:00 GMT+0000 (Coordinated Universal Time)",
"name": "Caregiver assigned",
"resourceId": "tony"
},
{
"startDate": "Fri Sep 09 2022 06:00:00 GMT+0000 (Coordinated Universal Time)",
"id": 91,
"endDate": "Fri Sep 09 2022 07:00:00 GMT+0000 (Coordinated Universal Time)",
"name": "Caregiver assigned",
"resourceId": "natasha"
},
{
"startDate": "Thu Sep 08 2022 05:00:00 GMT+0000 (Coordinated Universal Time)",
"id": 65,
"endDate": "Thu Sep 08 2022 07:00:00 GMT+0000 (Coordinated Universal Time)",
"name": "Caregiver assigned",
"resourceId": "steve"
},
{
"startDate": "Mon Sep 05 2022 18:00:00 GMT+0000 (Coordinated Universal Time)",
"id": 62,
"endDate": "Mon Sep 05 2022 20:00:00 GMT+0000 (Coordinated Universal Time)",
"name": "Caregiver assigned",
"resourceId": "bruce"
},
{
"startDate": "Wed Sep 07 2022 11:00:00 GMT+0000 (Coordinated Universal Time)",
"id": 18,
"endDate": "Wed Sep 07 2022 13:00:00 GMT+0000 (Coordinated Universal Time)",
"name": "Caregiver assigned",
"resourceId": "steve"
}
],
"Uncle": [
{
"startDate": "Sun Sep 04 2022 17:30:00 GMT+0000 (Coordinated Universal Time)",
"id": 47,
"endDate": "Sun Sep 04 2022 18:30:00 GMT+0000 (Coordinated Universal Time)",
"name": "Caregiver assigned",
"resourceId": "steve"
},
{
"startDate": "Tue Sep 06 2022 04:30:00 GMT+0000 (Coordinated Universal Time)",
"id": 24,
"endDate": "Tue Sep 06 2022 06:30:00 GMT+0000 (Coordinated Universal Time)",
"name": "Caregiver assigned",
"resourceId": "natasha"
},
{
"startDate": "Thu Sep 08 2022 06:00:00 GMT+0000 (Coordinated Universal Time)",
"id": 83,
"endDate": "Thu Sep 08 2022 07:00:00 GMT+0000 (Coordinated Universal Time)",
"name": "Caregiver assigned",
"resourceId": "bruce"
},
{
"startDate": "Sun Sep 04 2022 16:00:00 GMT+0000 (Coordinated Universal Time)",
"id": 52,
"endDate": "Sun Sep 04 2022 18:00:00 GMT+0000 (Coordinated Universal Time)",
"name": "Caregiver assigned",
"resourceId": "tony"
},
{
"startDate": "Wed Sep 07 2022 12:30:00 GMT+0000 (Coordinated Universal Time)",
"id": 53,
"endDate": "Wed Sep 07 2022 13:30:00 GMT+0000 (Coordinated Universal Time)",
"name": "Caregiver assigned",
"resourceId": "natasha"
},
{
"startDate": "Sun Sep 04 2022 04:00:00 GMT+0000 (Coordinated Universal Time)",
"id": 48,
"endDate": "Sun Sep 04 2022 06:00:00 GMT+0000 (Coordinated Universal Time)",
"name": "Caregiver assigned",
"resourceId": "steve"
},
{
"startDate": "Sun Sep 04 2022 02:00:00 GMT+0000 (Coordinated Universal Time)",
"id": 19,
"endDate": "Sun Sep 04 2022 03:00:00 GMT+0000 (Coordinated Universal Time)",
"name": "Caregiver assigned",
"resourceId": "tony"
}
],
"Dad": [
{
"startDate": "Fri Sep 09 2022 10:30:00 GMT+0000 (Coordinated Universal Time)",
"id": 86,
"endDate": "Fri Sep 09 2022 12:30:00 GMT+0000 (Coordinated Universal Time)",
"name": "Caregiver assigned",
"resourceId": "natasha"
},
{
"startDate": "Sun Sep 04 2022 12:00:00 GMT+0000 (Coordinated Universal Time)",
"id": 26,
"endDate": "Sun Sep 04 2022 14:00:00 GMT+0000 (Coordinated Universal Time)",
"name": "Caregiver assigned",
"resourceId": "tony"
},
{
"startDate": "Wed Sep 07 2022 07:30:00 GMT+0000 (Coordinated Universal Time)",
"id": 87,
"endDate": "Wed Sep 07 2022 08:30:00 GMT+0000 (Coordinated Universal Time)",
"name": "Caregiver assigned",
"resourceId": "bruce"
},
{
"startDate": "Thu Sep 08 2022 20:30:00 GMT+0000 (Coordinated Universal Time)",
"id": 37,
"endDate": "Thu Sep 08 2022 21:30:00 GMT+0000 (Coordinated Universal Time)",
"name": "Caregiver assigned",
"resourceId": "natasha"
},
{
"startDate": "Mon Sep 05 2022 01:00:00 GMT+0000 (Coordinated Universal Time)",
"id": 3,
"endDate": "Mon Sep 05 2022 02:00:00 GMT+0000 (Coordinated Universal Time)",
"name": "Caregiver assigned",
"resourceId": "tony"
},
{
"startDate": "Mon Sep 05 2022 00:00:00 GMT+0000 (Coordinated Universal Time)",
"id": 93,
"endDate": "Mon Sep 05 2022 01:00:00 GMT+0000 (Coordinated Universal Time)",
"name": "Caregiver assigned",
"resourceId": "steve"
},
{
"startDate": "Tue Sep 06 2022 08:30:00 GMT+0000 (Coordinated Universal Time)",
"id": 10,
"endDate": "Tue Sep 06 2022 10:30:00 GMT+0000 (Coordinated Universal Time)",
"name": "Caregiver assigned",
"resourceId": "bruce"
}
]
}
}
```
> This example uses a static JSON file, but you can also use an API or database as the source.
Import the `data.json` file in the `App.js` and retrieve the list of members using the `Object.keys` method:
```jsx
import "./App.css";
import { useState } from "react";
import data from "./data.json";
const ALL_MEMBERS = Object.keys(data.schedule); // get list of members from object
```
Then create a simple navigation bar at the top using Tailwind CSS classes:
```jsx
import "./App.css";
import { useState } from "react";
import data from "./data.json";
const ALL_MEMBERS = Object.keys(data.schedule); // get list of members from object
function App() {
return (
<div className={"flex flex-col max-w-[1200px] mx-auto"}>
<nav
className={
"flex flex-row items-center bg-green-600 p-2 py-3 text-white shadow shadow-sm shadow-gray-500"
}
>
<p className={"text-lg"}>Caregiver PRO</p>
<p className={"mx-10"}>|</p>
<i className={"font-light text-sm"}>
We ensure the best care for your loved ones.
</i>
</nav>
</div>
);
}
export default App;
```
Run `npm start` to start the application:

Now create a drop-down menu using the `<select>` HTML element and populate it with the `<option>` elements by mapping over the `ALL_MEMBERS` array:
```jsx
import "./App.css";
import { useState } from "react";
import data from "./data.json";
const ALL_MEMBERS = Object.keys(data.schedule); // get list of members from object
function App() {
return (
<div className={"flex flex-col max-w-[1200px] mx-auto"}>
<nav
className={
"flex flex-row items-center bg-green-600 p-2 py-3 text-white shadow shadow-sm shadow-gray-500"
}
>
<p className={"text-lg"}>Caregiver PRO</p>
<p className={"mx-10"}>|</p>
<i className={"font-light text-sm"}>
We ensure the best care for your loved ones.
</i>
</nav>
<main className={"mt-10"}>
<div className={"mb-10"}>
<label htmlFor={"member"}>Select member</label>
<select
id={"member"}
value={member}
className={"ml-2 bg-gray-100 border-2 rounded border-green-600"}
>
{ALL_MEMBERS.map((member) => (
<option key={member} value={member}>
{member}
</option>
))}
</select>
</div>
<div className={"bg-gray-200 h-[500px] text-lg"}>
Calendar goes here
</div>
</main>
</div>
);
}
export default App;
```
Create a `member` state variable using the `useState` React hook to allow users to select a family member. Add an `onChange` event handler to the `<select>` element to update the `member` state whenever the user selects a new member:
```jsx
import "./App.css";
import { useState } from "react";
import data from "./data.json";
const ALL_MEMBERS = Object.keys(data.schedule); // get list of members from object
function App() {
const [member, setMember] = useState("Grand Ma");
return (
<div className={"flex flex-col max-w-[1200px] mx-auto"}>
<nav
className={
"flex flex-row items-center bg-green-600 p-2 py-3 text-white shadow shadow-sm shadow-gray-500"
}
>
<p className={"text-lg"}>Caregiver PRO</p>
<p className={"mx-10"}>|</p>
<i className={"font-light text-sm"}>
We ensure the best care for your loved ones.
</i>
</nav>
<main className={"mt-10"}>
<div className={"mb-10"}>
<label htmlFor={"member"}>Select member</label>
<select
id={"member"}
value={member}
onChange={(e) => setMember(e.target.value)}
className={"ml-2 bg-gray-100 border-2 rounded border-green-600"}
>
{ALL_MEMBERS.map((member) => (
<option key={member} value={member}>
{member}
</option>
))}
</select>
</div>
<div className={"bg-gray-200 h-[500px] text-lg"}>
Calendar goes here
</div>
</main>
</div>
);
}
export default App;
```

The application layout is ready. Now you need to plug in the Bryntum Calendar to show user-friendly schedules.
### Add the Bryntum Calendar Layout
To add the Bryntum Calendar layout, you need to sign up for a [free trial of the Bryntum Calendar](https://www.bryntum.com/download/). Bryntum serves the calendar component from a private registry, so you need to specify the registry URL to `npm` using the following command:
```bash
npm config set "@bryntum:registry=https://npm.bryntum.com"
```
Since Bryntum's registry is authenticated, you need to log in using the credentials you signed up with:
```bash
npm login --registry=https://npm.bryntum.com
```
> **Please note:** The "@" should be replaced with ".." in the login email. For example, "someone@example.com" will become "someone..example.com" with "trial" as the password.
Now, run the following command to install the Bryntum Calendar dependencies:
```bash
npm i @bryntum/calendar@npm:@bryntum/calendar-trial@^5.1.2 @bryntum/calendar-react@5.1.2
```
Import the Stockholm theme for Bryntum Calendar in the `index.css` file:
```css
@tailwind base;
@tailwind components;
@tailwind utilities;
@import "@bryntum/calendar/calendar.stockholm.css"; # add this line
```
Then import the `BryntumCalendar` component in the `App.js` file and create a `CALENDAR_CONFIG` object with the `date` that the calendar will open:
```jsx
import "./App.css";
import { useState } from "react";
import data from "./data.json";
import { BryntumCalendar } from "@bryntum/calendar-react";
const CALENDAR_CONFIG = {
date: new Date(2022, 8, 4), // calendar will open at this date
};
const ALL_MEMBERS = Object.keys(data.schedule); // get list of members from object
```
Pass the `CALENDAR_CONFIG` as `config`, `caregivers` as the `resources`, and the `data.schedule[member]` as the `events` prop to the `BryntumCalendar`:
```jsx
import "./App.css";
import { useState } from "react";
import data from "./data.json";
import { BryntumCalendar } from "@bryntum/calendar-react";
const CALENDAR_CONFIG = {
date: new Date(2022, 8, 4),
};
const ALL_MEMBERS = Object.keys(data.schedule); // get list of members from object
function App() {
const [member, setMember] = useState("Grand Ma");
return (
<div className={"flex flex-col max-w-[1200px] mx-auto"}>
<nav
className={
"flex flex-row items-center bg-green-600 p-2 py-3 text-white shadow shadow-sm shadow-gray-500"
}
>
<p className={"text-lg"}>Caregiver PRO</p>
<p className={"mx-10"}>|</p>
<i className={"font-light text-sm"}>
We ensure the best care for your loved ones.
</i>
</nav>
<main className={"mt-10"}>
<div className={"mb-10"}>
<label htmlFor={"member"}>Select member</label>
<select
id={"member"}
value={member}
onChange={(e) => setMember(e.target.value)}
className={"ml-2 bg-gray-100 border-2 rounded border-green-600"}
>
{ALL_MEMBERS.map((member) => (
<option key={member} value={member}>
{member}
</option>
))}
</select>
</div>
<BryntumCalendar
config={CALENDAR_CONFIG}
resources={data.caregivers}
events={data.schedule[member]}
/>
</main>
</div>
);
}
export default App;
```
In this case, since the `member` is in a React state, whenever the user selects a new member from the drop-down, the calendar will re-render and show the caregiver schedule for the selected member. And with this final step, the Caregiver PRO is ready:

The users can add new caregiver appointments by checking the missing slots and selecting a caregiver from the list while making the appointment. Or they can change the view to daily or monthly, or see it as a list by selecting the **Agenda** view.
Here, you can see the Caregiver PRO in action:

## Conclusion
Upon completion of this tutorial, you will have a fully functioning Caregiver PRO application. To create this application, you learned how to set up a React project with Tailwind CSS styling, and you used a JSON file as the data source to display the list of events. Later, you used the [Bryntum Calendar](https://www.bryntum.com/products/calendar/) component to display calendar events and make booking caregivers for family members simpler. You can extend this example further and use [Bryntum Calendar events](https://www.bryntum.com/docs/calendar/guide/Calendar/integration/react/events) to read or store events from a remote API.
Are you already using the Bryntum Calendar? We would love to hear how it's [making your life easier](https://www.bryntum.com/company/testimonials/).
[Bryntum](https://www.bryntum.com) is a software company specializing in creating beautiful and performant web components, including the [Calendar](https://www.bryntum.com/docs/calendar), [Scheduler](https://www.bryntum.com/docs/scheduler), and [Gantt](https://www.bryntum.com/docs/gantt) chart. Want to learn more? Try our scheduling and Gantt components at [bryntum.com](https://www.bryntum.com/). | bryntum_ab |
1,566,043 | Security news weekly round-up - 11th August 2023 | Weekly review of top security news between August 4 and August 11th, 2023. | 6,540 | 2023-08-11T17:46:32 | https://dev.to/ziizium/security-news-weekly-round-up-11th-august-2023-4i6k | ---
title: Security news weekly round-up - 11th August 2023
published: true
description: Weekly review of top security news between August 4 and August 11th, 2023.
cover_image: https://dev-to-uploads.s3.amazonaws.com/i/0jupjut8w3h9mjwm8m57.jpg
series: Security news weekly round-up
---
> __It is always good when you show up. Over the years, I've learned that it's one of the secrets of success. And it's more beautiful when no one is pushing you to show up. Why all this you may ask?__
>
> __Well, it's 4 in a row for this year despite my hectic work schedule. Before, when I am in a situation like this. I'll take a pass on writing this review, but (In Sha Allah) not anymore! So, let's go!__
## __Introduction__
This week's review is about _cyber crime_, _Google Chrome_, and _vulnerabilities_.
<hr/>
## [What are “drainer smart contracts” and why is the FBI warning of them?](https://arstechnica.com/security/2023/08/fbi-warns-nft-buyers-to-look-out-for-scam-sites-with-drainer-smart-contracts/)
Be careful and don't connect your cryptocurrency wallet to "anyhow" website. What's more, don't blindly trust post from known NFT developers account on social media. Here are more details:
> The websites present themselves as outlets for legitimate NFT projects that provide new offerings. They’re promoted by compromised social media accounts belonging to known NFT developers or accounts made to look like such accounts. Posts frequently try to create a sense of urgency by using phrases such as “limited supply”.
## [Meet the Brains Behind the Malware-Friendly AI Chat Service ‘WormGPT’](https://krebsonsecurity.com/2023/08/meet-the-brains-behind-the-malware-friendly-ai-chat-service-wormgpt/)
You lock, they unlock. That's the never-ending game of defenders and threat actors. But this is different, you can read this story to find out more. If you want an inspiration to read it, here it is:
> Morais said he wants WormGPT to become a positive influence on the security community, not a destructive one, and that he’s actively trying to steer the project in that direction. “We have a few researchers using our wormgpt for whitehat stuff, that’s our main focus now, turning wormgpt into a good thing to [the] community,” he said.
## [Microsoft Visual Studio Code flaw lets extensions steal passwords](https://www.bleepingcomputer.com/news/security/microsoft-visual-studio-code-flaw-lets-extensions-steal-passwords/)
For your information, at the time of writing, this does not have a fix. Anyways, it's good what's possible beyond what VS code extensions can do. Here is what's going on:
> The security problem discovered by Cycode is caused by a lack of isolation of authentication tokens in VS Code's 'Secret Storage,' an API that allows extensions to store authentication tokens in the operating system.
## [Author discovers AI-generated counterfeit books written in her name on Amazon](https://arstechnica.com/information-technology/2023/08/author-discovers-ai-generated-counterfeit-books-written-in-her-name-on-amazon/)
Initially, you might laugh at this story. However, it's not funny and it could affect anyone. It's really scary when unknown users supposedly use AI to generate text and sell it in your name because you're a trusted authority. Read the excerpt below, and I plead that you read the entire article linked above:
> It's a rising problem in a world where scammers game Amazon's algorithm to make a quick buck on fraudulent sales. In February, Reuters did a profile on authors using ChatGPT to write e-books, selling them through Amazon. In June, Vice reported on an influx of dozens of AI-generated books full of nonsense that took over Kindle bestseller lists.
## [Google to fight hackers with weekly Chrome security updates](https://www.bleepingcomputer.com/news/google/google-to-fight-hackers-with-weekly-chrome-security-updates/)
Always update your Chrome web browser when updates are made available. Here, Google is changing from a bi-weekly update to weekly updates. And here is why:
> Rather than having fixes sitting and waiting to be included in the next bi-weekly update, weekly updates will allow us to get important security bug fixes to you sooner, and better protect you and your most sensitive data.
## [Enhancing TLS Security: Google Adds Quantum-Resistant Encryption in Chrome 116](https://thehackernews.com/2023/08/enhancing-tls-security-google-adds.html)
The encryption in question has been adopted by Amazon Web Services (AWS), Cloudfare, and IBM. So, Google joining should not come as a surprise. Why this encryption? Here you go:
> X25519Kyber768 is a hybrid algorithm that combines the output of X25519, an elliptic curve algorithm widely used for key agreement in TLS, and Kyber-768 to create a strong session key to encrypt TLS connections.
>
> "Hybrid mechanisms such as X25519Kyber768 provide the flexibility to deploy and test new quantum-resistant algorithms while ensuring that connections are still protected by an existing secure algorithm".
## [How fame-seeking teenagers hacked some of the world’s biggest targets](https://arstechnica.com/security/2023/08/homeland-security-details-how-teen-hackers-breached-some-of-the-biggest-targets/)
When it's not sophisticated and it's effective, what more could you ask for? Reportedly, that's the case of Lapsus$; an alleged "ragtag bunch of amateur hackers". Here is a little bit of how they are pulling it off, and read the article for more:
> Rather than compromising infrastructure used to make various MFA services work, as more advanced groups do, a Lapsus$ leader last year described his approach to defeating MFA this way: “Call the employee 100 times at 1 am while he is trying to sleep, and he will more than likely accept it. Once the employee accepts the initial call, you can access the MFA enrollment portal and enroll another device.”
<hr/>
## __Credits__
Cover photo by [Debby Hudson on Unsplash](https://unsplash.com/@hudsoncrafted).
<hr>
That's it for this week, and I'll see you next time.
| ziizium | |
1,570,228 | Duck typing in Python | Duck typing is a concept in programming languages, including Python, where the type or class of an... | 0 | 2023-08-16T15:17:11 | https://dev.to/gaurbprajapati/duck-typing-in-python-244n | pythn, programming, beginners, tutorial | Duck typing is a concept in programming languages, including Python, where the type or class of an object is determined by its behavior (methods and properties) rather than its explicit class or type declaration. In duck typing, "If it looks like a duck, swims like a duck, and quacks like a duck, then it probably is a duck."
In other words, duck typing focuses on what an object can do, rather than what it is. If an object can perform certain actions or has certain attributes, it's treated as if it belongs to a certain type or class, even if it doesn't explicitly inherit from that type or class.
**Example:**
```python
class Dog:
def speak(self):
return "Woof!"
class Cat:
def speak(self):
return "Meow!"
class Duck:
def speak(self):
return "Quack!"
def animal_sound(animal):
return animal.speak()
dog = Dog()
cat = Cat()
duck = Duck()
print(animal_sound(dog)) # Output: Woof!
print(animal_sound(cat)) # Output: Meow!
print(animal_sound(duck)) # Output: Quack!
```
In this example, the `animal_sound` function takes an argument that is expected to have a `speak` method. Duck typing allows us to pass objects of different classes (`Dog`, `Cat`, and `Duck`) to the function, as long as they have a compatible method (`speak`). The function doesn't care about the actual type of the object; it only relies on the presence of the required method.
**Real-Life Example:**
Imagine you're building a music player application. You might have different classes for different audio file types, like `MP3`, `WAV`, and `FLAC`. Instead of checking the specific class type for each audio file, you can use duck typing to determine whether an audio file can be played:
```python
class MP3:
def play(self):
print("Playing MP3 audio")
class WAV:
def play(self):
print("Playing WAV audio")
class FLAC:
def play(self):
print("Playing FLAC audio")
def play_audio(audio):
audio.play()
mp3 = MP3()
wav = WAV()
flac = FLAC()
play_audio(mp3) # Output: Playing MP3 audio
play_audio(wav) # Output: Playing WAV audio
play_audio(flac) # Output: Playing FLAC audio
```
In this example, the `play_audio` function expects an object with a `play` method. As long as an object has this method, it can be treated as an audio file and played using the function.
Duck typing simplifies code and promotes flexibility by allowing you to work with different classes and types that exhibit similar behavior. It's a powerful concept in dynamic programming languages like Python, making the code more concise and adaptable. | gaurbprajapati |
1,571,020 | Cassette Player Cleaning Services In Dubai | **What Is A Cassette Player? A cassette player has two main parts: playback and recording mechanisms.... | 0 | 2023-08-17T10:07:05 | https://dev.to/jhonwick/cassette-player-cleaning-services-in-dubai-3d19 | **What Is A Cassette Player?
A cassette player has two main parts: playback and recording mechanisms. The playback mechanism uses a motor to move the tape past a read head, which converts the magnetic signals on the video. The recording mechanism uses a similar process but in reverse. It uses a write head to record magnetic signs onto the tape.
**Why is it important to clean a cassette player?**
There are several reasons why it is essential to clean a cassette player:
To improve sound quality. Over time, the tape head and other parts of the cassette player can become dirty, which can cause the excellent quality to deteriorate. Cleaning these parts can remove dirt and grime, making a more precise and accurate sound.
To prevent damage to tapes. If the tape head is dirty, it can scratch the video, which can cause playback problems. Cleaning the tape head can help to prevent this damage.
To extend the life of the cassette player. The moving parts of the cassette player can wear out over time, but cleaning them can help to extend their lifespan.
To remove dust and dirt. Cleaning the cassette player can remove this dust and dirt, keeping the machine running smoothly.
Here are some tips on how to clean a cassette player:
Turn off the power and unplug the cassette player.
Open the player and remove the cassette.
Clean the other moving parts of the player, such as the guides and rollers.
Wipe down the inside of the player with a clean cloth.
Reassemble the player and plug it back in.
You can also use a cassette head cleaner kit to clean your cassette player.
It is essential to clean your [cassette player](https://inavanos.com/audio-gadgets/cassette-player-dubai/) regularly, mainly if you use it often. Cleaning the player will help to keep it in good condition and prevent damage to your tapes.

**How To Clean A Cassette Player Yourself?
**Here are the steps on how to clean a cassette player yourself:
Gather your materials. You will need:
Isopropyl alcohol (70-90%)
Cotton swabs
Lens cleaning cloth
Small brush (optional)
Please turn off the cassette player and unplug it from the power outlet.
Open the cassette compartment and locate the heads. These are the metal parts that are responsible for recording and playback.
Clean the pinch roller. This is the rubber roller that helps to keep the tape moving.
Clean the capstan. This is the metal shaft that the tape rides on.
Use the lens cleaning cloth to wipe down any other dirty parts of the cassette player.
Let the cassette player air dry completely before using it again.
Here are some additional tips:
Use a new cotton swab for each cleaning stroke. This will help to prevent the spread of dirt and grime.
Be careful not to get any isopropyl alcohol on the plastic parts of the cassette player.
If the cassette player is foul, you may need to repeat the cleaning process several times.
If you are uncomfortable cleaning the cassette player, you can take it to a professional for cleaning.
Here are some additional things to keep in mind:
Do not use dry-cleaning cassettes. These can make the problem worse.
If you are cleaning a car cassette player, you may need to remove it from the car first.
**The Benefits Of Professional Cassette Player Cleaning.
**
The benefits of professional cassette player cleaning
| jhonwick | |
1,571,696 | Strategy Design Pattern | Tá, antes de tudo, você sabe o que são design patterns? Design patterns são soluções reutilizáveis e... | 0 | 2023-08-20T17:24:12 | https://dev.to/joaomarcosbc/strategy-design-pattern-2a5k | designpatterns, csharp, programming, solidprinciples |
Tá, antes de tudo, você sabe o que são design patterns? Design patterns são soluções reutilizáveis e já bem estabelecidas para problemas comuns que nós, programadores, enfrentamos no dia a dia.
Surgidos através do trabalho de diversos programadores experientes, se tornaram um consenso na resolução de problemas, a fim de tornar o seu código mais limpo, elegante e de fácil manutenção. Talvez você entenda melhor conforme vá realizando essa leitura.
## O problema a se resolver
Já que estamos falando de uma solução, estamos resolvendo algum problema certo?
Para demonstrar o problema, vou criar o seguinte contexto:
Vamos considerar um sistema simples para calcular descontos em uma loja online com base em diferentes tipos de cupons existentes: EasySave ou ClearCut, onde cada um tem sua **estratégia** de desconto → o EasySave fornece 20% de desconto e o ClearCut fornece apenas 10%.
O codigo inicial está da seguinte forma:
```C#
public class Order
{
public double Value { get; set; }
}
```
```C#
public class DiscountCalculator
{
public void Calculate(Order order, string coupon)
{
if( "EasySave".Equals(coupon))
{
double value = order.Value * 0.8;
Console.WriteLine(value);
}
else if( "ClearCut".Equals(coupon))
{
double value = order.Value * 0.9;
Console.WriteLine(value);
}
}
}
```
Existem alguns problemas nessa implementação:
Se formos analisar, para cada novo desconto criado, será necessário criar um novo `if`, podendo se tornar um método muito grande e difícil de se ler e consequentemente, de se manter. Outra questão, é que essa classe está pouco coesa, as regras de negócio e cálculos estão espalhadas por ela.
## Algumas melhorias
Para resolver o problema da coesão, podemos separar a responsabilidade do cálculo dos descontos para classes específicas de cada um, dessa forma:
```C#
public class EasySave
{
public double Calculate(Order order)
{
return order.Value * 0.8;
}
}
```
```C#
public class ClearCut
{
public double Calculate(Order order)
{
return order.Value * 0.9;
}
}
```
```C#
public class DiscountCalculator
{
public void Calculate(Order order, string coupon)
{
if ("EasySave".Equals(coupon))
{
double value = new EasySave().Calculate(order);
Console.WriteLine(value);
}
else if ("ClearCut".Equals(coupon))
{
double value = new ClearCut().Calculate(order);
Console.WriteLine(value);
}
}
}
```
Pronto, resolvemos o problema de coesão agora que cada classe de desconto é responsável por suas regras. No entanto, ainda temos o problema da quantidade de `if` que esse bloco de código pode ter para cada desconto novo adicionado.
Para remover as condicionais desse método, temos que remover o parâmetro `coupoun` que informa, através de uma `string`, o desconto que será utilizado, concorda?
Tá, mas como saberemos qual desconto será aplicado? Uma solução, seria criar um método separado para cada desconto, dessa maneira:
```C#
public class DiscountCalculator
{
public void CalculateEasySave(Order order)
{
double value = new EasySave().Calculate(order);
Console.WriteLine(value);
}
public void CalculateClearCut(Order order)
{
double value = new ClearCut().Calculate(order);
Console.WriteLine(value);
}
}
```
Agora ficou melhor, mas ainda não resolve o problema, já que agora, ao invés de ter um novo `if`, ainda teremos que criar um novo método para cada imposto. Então, como resolver?
## A solução final
Como você provavelmente já percebeu, os dois métodos que criamos na classe `DiscountCalculator` implementam uma **estratégia** específica para o seu desconto, mas no final das contas, não será sempre sobre um desconto e, nesse caso o cálculo em cima dele?
Isso significa que podemos criar uma abstração de desconto, e definir um método genérico que deva calcular o valor do pedido com o desconto!
Faremos essa abstração da seguinte maneira, utilizando uma interface:
```C#
public interface Discount
{
public double Calculate(Order order);
}
```
Com a interface criada, devemos agora fazer com que as classes `EasySave` e `ClearCut` herdem da interface `Discount`:
```C#
public class EasySave : Discount
{
public double Calculate(Order order)
{
return order.Value * 0.8;
}
}
```
```C#
public class ClearCut : Discount
{
public double Calculate(Order order)
{
return order.Value * 0.9;
}
}
```
Para finalizar, na classe `DiscountCalculator`, ao invés de utilizar um método para cada desconto existente na nossa aplicação, utilizaremos só um método que receberá como parâmetro, além do pedido, o desconto a ser calculado, assim:
```C#
public class DiscountCalculator
{
public void Calculate(Order order, Discount discount)
{
double value = discount.Calculate(order);
Console.WriteLine(value);
}
}
```
Pronto! Agora, a criação de novos tipos de desconto não implica mais numa mudança da classe `DiscountCalculator`, apenas na criação de uma nova classe que implemente a interface `Discount` . Com isso, temos um código mais limpo e mais fácil de se realizar manutenção.
[Guia do Refactoring Guru sobre o padrão Strategy](https://refactoring.guru/pt-br/design-patterns/strategy)
Aaah, lembre-se sempre que um design pattern não é sobre seguir a implementação à risca, é sobre seguir a ideia. | joaomarcosbc |
1,571,865 | Opensource NextJS Project | Great For Beginner! | Introduction Recently I have created an open source project that implemented the latest... | 0 | 2023-08-18T02:55:00 | https://dev.to/vatana7/opensource-nextjs-project-great-for-beginner-764 | webdev, nextjs, typescript, react | ###Introduction
Recently I have created an open source project that implemented the latest cutting edge technology and packages in order to make myself learn and expand my knowledge overall.
I am super excited to share this projects with all the people that have started their programming journey.
Here is the project:
[Project](https://github.com/vatana7/prompt.io)
Be sure to check it out guys! Thanks | vatana7 |
1,573,268 | How to Become a Proofreader with No Experience: A Step-by-Step Guide | If you're interested in becoming a proofreader but have no experience, you may be wondering where to... | 0 | 2023-08-19T12:46:55 | https://dev.to/guruscoach/how-to-become-a-proofreader-with-no-experience-a-step-by-step-guide-122n | If you're interested in becoming a proofreader but have no experience, you may be wondering where to start. The good news is that you don't need a specific degree or certification to become a proofreader.
However, you will need to develop certain skills and knowledge to succeed in this field.
One important skill for proofreading is a strong grasp of grammar, punctuation, and spelling.
This means being able to identify and correct errors in written content, whether it's a blog post, a legal document, or a novel manuscript.
Additionally, you'll need to be familiar with different style guides and formatting conventions, such as APA or Chicago style.
While you don't necessarily need to memorize every rule, having a basic understanding of these guidelines will help you catch errors more efficiently.
## Understanding the Role of a Proofreader
If you're interested in becoming a proofreader with no experience, it's important to understand what the role entails.
[A proofreader](https://guruscoach.com/proofread-anywhere-review/) is responsible for reviewing written content for errors in spelling, grammar, punctuation, and formatting. They ensure that the text is accurate, clear, and easy to read.
Proofreading is different from editing, as an editor is responsible for improving the overall quality of the content. A proofreader, on the other hand, focuses solely on finding and correcting errors. They do not make changes to the content or structure of the text.
As a proofreader, you will be working with a variety of written materials, including books, articles, websites, and marketing materials. You will need to have a strong understanding of grammar and punctuation rules, as well as excellent attention to detail.
One of the most important skills for a proofreader is the ability to stay focused and maintain concentration for extended periods of time. You will need to be able to read through long documents without getting distracted or losing focus.
Overall, the role of a proofreader is essential in ensuring that written content is accurate, professional, and easy to read. If you have a passion for language and a keen eye for detail, becoming a proofreader may be the perfect career path for you.
## Required Skills and Knowledge
To become a successful proofreader, there are a few key skills and areas of knowledge that you should have. Below are some of the most important ones:
### Proficiency in English
As a proofreader, you will be responsible for ensuring that written content is free of errors and reads smoothly.
This means that you need to have a strong command of the English language, including grammar, punctuation, and spelling.
You should be able to recognize and correct common mistakes, such as subject-verb agreement errors, misplaced modifiers, and run-on sentences.
### Detail-Oriented
Proofreading requires a high level of attention to detail. You must be able to spot even the smallest errors, such as missing commas or incorrect capitalization.
Additionally, you should be able to identify inconsistencies and discrepancies in the text, such as variations in spelling or formatting.
### Familiarity with Style Guides
Many clients will have specific style guides that they want you to follow when proofreading their content.
These guides outline things like preferred spellings, punctuation rules, and formatting guidelines.
As a proofreader, you should be familiar with some of the most common style guides, such as the Chicago Manual of Style, AP Stylebook, and MLA Handbook.
By possessing these skills and knowledge, you will be well on your way to becoming a successful proofreader, even if you have no prior experience in the field.
## Getting Started Without Experience
If you're interested in becoming a proofreader but don't have any experience, don't worry. There are several ways to get started and gain experience in the field. In this section, we'll explore some options for getting started without experience.
### Volunteering
One way to gain experience as a proofreader is to volunteer your services. You can offer to proofread documents for friends, family, or local organizations.
This can help you build your skills and gain experience while also giving back to your community.
When volunteering, it's important to set clear expectations with the person or organization you're working with.
Make sure you understand what they're looking for and what their deadlines are. You should also be clear about what you can and cannot do as a proofreader.
### Freelancing
Another option for getting started as a proofreader is to start freelancing. Freelancing allows you to work with clients on a project-by-project basis, which can be a great way to build your skills and gain experience.
To get started freelancing, you'll need to create a portfolio of your work. This can include samples of documents you've proofread, as well as any relevant education or training you've completed.
You can then start reaching out to potential clients and marketing your services.
### Online Platforms
There are also several online platforms that can help you get started as a proofreader. These platforms connect clients with freelance proofreaders, making it easy to find work and build your skills.
Some popular online platforms for proofreaders include Upwork, Fiverr, and Freelancer. To get started on these platforms, you'll need to create a profile and start bidding on projects.
It's important to set competitive rates and provide high-quality work to build your reputation and attract more clients.
No matter which option you choose, it's important to keep learning and improving your skills as a proofreader. This can include taking online courses, reading industry publications, and seeking feedback from clients and colleagues.
With persistence and dedication, you can build a successful career as a proofreader, even without prior experience.
## Building Your Portfolio
As a proofreader with no experience, building a portfolio is crucial to showcase your skills and attract potential clients. Here are some tips to help you build a strong portfolio:
### 1. Offer Pro Bono Work
Offering to proofread documents for free is a great way to gain experience and build your portfolio.
You can reach out to friends, family, or local businesses and offer your services. This will help you build your confidence and gain valuable feedback.
### 2. Create a Website
Creating a website is a great way to showcase your portfolio and attract potential clients. You can include a list of your services, testimonials, and samples of your work.
Make sure your website is easy to navigate and visually appealing. The Authority Hacker is a resource that can help you create better SEO-optimize website.
You can read my [Authority Hacker Reviews](https://www.outlookindia.com/outlook-spotlight/authority-hacker-review-is-it-worth-the-investment--news-309111) here.
### 3. Join Online Communities
Joining online communities such as LinkedIn groups or Facebook groups can help you connect with other proofreaders and potential clients. You can share your portfolio and offer your services to those in need.
### 4. Attend Networking Events
Attending networking events can help you meet potential clients and build relationships with other professionals in your industry. Make sure to bring business cards and samples of your work to hand out to those you meet.
### 5. Keep Learning
Continuing to learn and improve your skills is important in any industry, especially as a proofreader.
You can take online courses, attend workshops, or read books on proofreading to stay up to date with industry trends and best practices.
By following these tips, you can build a strong portfolio and attract potential clients as a proofreader with no experience.
## Improving Your Skills
If you want to become a proofreader with no experience, you need to start by improving your skills. Here are some ways to do that:
### Online Courses
Online courses are a great way to learn the skills you need to become a proofreader. There are many courses available, and some of them are even free. Here are some of the best online courses for proofreading:
Course
Provider
Cost
ProofreadingCamp Scribendi $197
Proofreading Academy $399
General Proofreading: Theory and Practice
Caitlin Pyle $497
You can read my [Proofread Anywhere Review](https://www.outlookindia.com/outlook-spotlight/proofread-anywhere-reviews-is-caitlin-pyles-courses-worth-it--news-309738) here.
### Books and Resources
There are many books and resources available that can help you improve your proofreading skills. Here are some of the best ones:
The Chicago Manual of Style: This is the go-to guide for many proofreaders. It covers everything from grammar and punctuation to formatting and style.
The Elements of Style: This is a classic book on writing and grammar. It's short, easy to read, and full of useful tips.
Grammarly: This is a popular grammar checking tool that can help you catch errors in your writing.
By taking online courses and reading books and resources, you can improve your proofreading skills and become a more effective proofreader.
## Networking and Industry Connections
Networking is an essential part of any career, and proofreading is no exception. Building professional relationships with other proofreaders, writers, and editors can open up new opportunities and help you grow your business.
One way to build your network is to attend industry events and conferences. These events provide an opportunity to meet other professionals in your field, learn about new trends and technologies, and gain valuable insights into the industry.
Another way to connect with other professionals is to join online communities and forums. These groups can provide a wealth of information and resources, as well as a platform to ask questions and share your own expertise.
LinkedIn is a particularly useful tool for building your professional network. Create a profile that highlights your skills and experience, and start connecting with other professionals in your field.
You can also join LinkedIn groups related to proofreading, editing, and writing to connect with other professionals and stay up-to-date on industry news and trends.
Finally, don't underestimate the power of word-of-mouth referrals. If you do good work and provide excellent customer service, your clients are likely to recommend you to others in their network.
Encourage satisfied clients to leave reviews on your website or social media profiles to help build your reputation and attract new clients.
By building a strong network of industry connections, you can position yourself as a knowledgeable and reliable proofreader, and open up new opportunities for growth and success in your career.
## Applying for Proofreading Jobs
If you have decided to pursue a career as a proofreader, you will need to apply for proofreading jobs to get started. Here are some tips on how to craft a resume and cover letter that will make you stand out from the competition.
### Crafting a Resume
When crafting your resume, make sure to highlight your relevant skills and experience. Even if you don't have any direct proofreading experience, you can still showcase your attention to detail, strong grammar and punctuation skills, and ability to work independently.
Consider including the following information on your resume:
Any relevant coursework or certifications, such as a degree in English or a proofreading certification program
Any related work experience, even if it's not in proofreading specifically
Any volunteer or freelance work you've done that demonstrates your proofreading skills
Any other skills or experience that could be relevant, such as experience with project management or working with clients
Make sure your resume is well-organized and easy to read. Use bullet points and clear headings to make it easy for potential employers to quickly see your qualifications.
### Cover Letter Writing Tips
Your cover letter is your opportunity to make a strong first impression on potential employers. Here are some tips for crafting a compelling cover letter:
Address the hiring manager by name, if possible
Start with a strong opening that grabs their attention and explains why you're interested in the job
Highlight your relevant skills and experience, and explain how they make you a good fit for the position
Mention any specific qualifications or requirements listed in the job posting
Close with a strong statement that expresses your enthusiasm for the position and your willingness to learn and grow in the role
Make sure to proofread your cover letter carefully before submitting it. This is your chance to demonstrate your proofreading skills, so make sure there are no typos or errors in your letter.
By following these tips, you can create a strong resume and cover letter that will help you land your first proofreading job. Good luck in your job search!
## Preparing for Interviews
Once you have applied for a proofreading job, you may be invited to an interview. Here are some tips to help you prepare:
### 1. Research the Company
Before your interview, you should research the company you are interviewing with. Look at their website, social media accounts, and any news articles about them. This will give you an idea of their values, mission, and the types of documents they work on. It will also help you understand how your skills and experience can contribute to their team.
### 2. Review Your Resume and Cover Letter
Make sure you review your resume and cover letter before your interview. This will help you remember the skills and experience you highlighted in your application. Be prepared to talk about specific examples of how you have used these skills in the past. You should also be ready to answer questions about any gaps in your employment history or other aspects of your application.
### 3. Practice Your Proofreading Skills
During your interview, you may be asked to complete a proofreading test. To prepare, you should practice your proofreading skills. You can find sample documents online or create your own.
Make sure you are comfortable with proofreading for spelling, grammar, punctuation, and formatting errors. You should also be able to make suggestions for improving clarity and consistency.
### 4. Prepare Questions to Ask
At the end of your interview, you will likely be asked if you have any questions. Prepare a list of questions in advance. You can ask about the company culture, the types of documents you will be working on, or the training and development opportunities available.
This will show that you are interested in the job and have done your research.
Remember to dress professionally, arrive on time, and be polite and friendly throughout your interview. Good luck!
## Continuing Professional Development
As a proofreader, it's important to continually improve your skills and stay up-to-date with industry trends. Continuing Professional Development (CPD) is a great way to do this.
CPD refers to the ongoing learning and development that professionals undertake to enhance their skills and knowledge.
It's designed to help you stay current with industry best practices and improve your ability to deliver high-quality work.
There are many ways to engage in CPD as a proofreader. Here are a few options to consider:
### Courses and Workshops
Taking courses and workshops is a great way to develop new skills and stay up-to-date with industry trends. There are many online and in-person options available, ranging from basic grammar and punctuation courses to more advanced editing and proofreading workshops.
Some popular online course providers include Udemy, Coursera, and LinkedIn Learning. You can also check with local colleges and universities to see if they offer any relevant courses or workshops.
### Professional Associations
Joining a professional association is a great way to connect with other proofreaders and stay up-to-date with industry news and trends. Many associations offer CPD opportunities, such as webinars, conferences, and networking events.
Some popular proofreading associations include the Chartered Institute of Editing and Proofreading (CIEP), the American Society of Journalists and Authors (ASJA), and the Editorial Freelancers Association (EFA).
### Reading and Research
Reading and research are also important components of CPD. By staying up-to-date with industry news and trends, you can ensure that your skills remain relevant and in-demand.
Some popular resources for proofreaders include the CIEP's Proofreading Matters magazine, the EFA's The Freelancer newsletter, and the ASJA's The ASJA Monthly.
In summary, CPD is an important part of being a successful proofreader. By continually improving your skills and staying up-to-date with industry trends, you can ensure that you're delivering high-quality work and staying competitive in the marketplace.
| guruscoach | |
1,573,621 | K8S Quickstart & Helm | Today, Kubernetes becomes a must for DevOps Engineers, SRE and others for orchestrating containers.... | 0 | 2023-08-21T21:16:00 | https://softwaresennin.dev/blog/helm-k8s-quickstart | kubernetes, devops, tutorial, beginners | Today, Kubernetes becomes a must for DevOps Engineers, SRE and others for orchestrating containers. Once you have a Docker image of your application, you have to code some YAML manifests to define Kubernetes workloads after which, you deploy them with the [kubectl](https://kubernetes.io/docs/reference/kubectl/) command.

This deployment way is when you’ve only one application. When you start to have many applications and multiple environments it becomes overwhelmed. Often you define the same YAML files 90% of the time.
Here, we are going to focus on how to manage applications smartly with Helm.
### What Is Helm?
[Helm](https://helm.sh/) is a package manager for Kubernetes. Helm is an open-source project originally created by [DeisLabs](https://deislabs.io/) and donated to the [Cloud Native Foundation](https://www.cncf.io/) (*CNCF*). The CNCF now maintains and has graduated the project. This means that it is mature and not just a fad.

Package management is not a new concept in the software industry. On Linux distros, you manage software installation and removal with package managers such as [YUM/RPM](https://www.redhat.com/sysadmin/how-manage-packages) or [APT](https://ubuntu.com/server/docs/package-management). On Windows, you can use [Chocolatey](https://chocolatey.org/) or [Homebrew](https://brew.sh/) on Mac.
Helm lets you package and deploy complete applications in Kubernetes. A package is called a “*Chart”*. Helm uses a templating system based on [Go template](https://pkg.go.dev/html/template) to render Kubernetes manifests from charts. A chart is a consistent structure separating templates and values.
As a package, a chart can also manage dependencies with other charts. For example, if your application needs a MySQL database to work you can include the chart as a dependency. When Helm runs at the top level of the chart directory it installs whole dependencies. You have just a single command to render and release your application to Kubernetes.
Helm charts use versions to track changes in your manifests — thus you can install a specific chart version for specific infrastructure configurations. Helm keeps a release history of all deployed charts in a dedicated workspace. This makes easier application updates and rollbacks if something wrong happens.
Helm allows you to compress charts. The result of that is an artifact comparable to a Docker image. Then, you can send it to a distant repository for reusability and sharing.
### What Are the Benefits of Using Helm?
* Helm provides you the ability to install applications with a single command. A chart can contain other charts as dependencies. You can consequently deploy an entire stack with Helm. You can use Helm like [docker-compose](https://docs.docker.com/compose/) but for Kubernetes.
* A chart includes templates for various Kubernetes resources to form a complete application. This reduces the microservices complexity and simplifies their management in Kubernetes.
* Charts can be compressed and sent to a distant repository. This creates an application artifact for Kubernetes. You can also fetch and deploy existing Helm charts from repositories. This is a strong point for reusability and sharing.
* Helm maintains a history of deployed release versions in the Helm workspace. When something goes wrong, rolling back to a previous version is simply — canary release is facilitated with Helm for zero-downtime deployments.
* Helm makes the deployment highly configurable. Applications can be customized on the fly during the deployment. By changing parameters, you can use the same chart for multiple environments such as dev, staging, and production.
* Streamline CI/CD pipelines — Forward GitOps best practices.
### Quick Look On The Problem Helm Solves
Basic Kubernetes practice is to write YAML manifests manually. We’ll create minimum YAML files to deploy NGINX in Kubernetes.
Here is the Deployment that will create Pods:
```plaintext
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
spec:
selector:
matchLabels:
app: nginx
replicas: 1
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.21.6
ports:
- containerPort: 80
```
The Service exposes NGINX to the outside. The link with pod is done via the selector:
```plaintext
apiVersion: v1
kind: Service
metadata:
name: nginx
spec:
selector:
app: nginx
ports:
- protocol: TCP
port: 80
targetPort: 8080
```
Kubernetes service for NGINX: service.yaml
Now we have to create the previous resources with the kubectl command:
```plaintext
$ kubectl create -f deployment.yaml
$ kubectl create -f service.yaml
```
We check all resources are up and running:
```plaintext
$ kubectl get deployment -l app=nginx
NAME READY UP-TO-DATE AVAILABLE AGE
nginx 1/1 1 1 8m29s
```
```plaintext
$ kubectl get pods -l app=nginx
NAME READY STATUS RESTARTS AGE
nginx-65b89996ff-dcfs9 1/1 Running 0 2m26s
```
```plaintext
$ kubectl get svc -l app=nginx
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
nginx ClusterIP 10.106.79.171 <none> 80/TCP 4m58s
```
Issues with this method
* Specific values in YAML manifests are hardcoded and not reusable.
* Redundant information to specify such as labels and selectors leads to potential errors.
* Kubectl does not handle potential errors after execution. You’ve to deploy each file one after the other.
* There’s no change traceability.
### Create a Helm Chart From Scratch
Helm can create the chart structure in a single command line:
```plaintext
$ helm create nginx
```
### Understand the Helm chart structure

* `Chart.yaml`: A YAML file containing information about the chart.
* `charts`: A directory containing any charts upon which this chart depends on.
* `templates`: this is where Helm finds the YAML definitions for your Services, Deployments, and other Kubernetes objects. You can add or replace the generated YAML files for your own.
* `templates/NOTES.txt`: This is a templated, plaintext file that gets printed out after the chart is successfully deployed. This is a useful place to briefly describe the next steps for using the chart.
* `templates/_helpers.tpl`: That file is the default location for template partials. Files whose name begins with an underscore are assumed to *not* have a manifest inside. These files are not rendered to Kubernetes object definitions but are available everywhere within other chart templates for use.
* `templates/tests`: tests that validate that your chart works as expected when it is installed
* `values.yaml`: The default configuration values for this chart
### Customize the templates
The `values.yaml` is loaded automatically by default when deploying the chart. Here we set the image tag to `1.21.5` :
Please note that You can specify a specific `values.yaml` file to customize the deployment for environment-specific settings.
### Install The Helm Chart
Good advice before deploying a Helm chart is to run the linter if you made an update:
```plaintext
$ helm lint nginx
==> Linting nginx
[INFO] Chart.yaml: icon is recommended
```
```plaintext
1 chart(s) linted, 0 chart(s) failed
```
Run Helm to install the chart in dry-run and debug mode to ensure all is ok:
```plaintext
$ helm install --debug --dry-run nginx nginx
```
Using helm linter and dry-run install with debug mode will save you precious time in your development.
To install the chart, remove the `--dry-run` flag:
You can see the templated content of the `NOTES.txt` explaining how to connect to the application.
Now, you can retrieve the release in the Helm workspace:
### Upgrade The Helm Release
Imagine you want to upgrade the container image to `1.21.6` for testing purposes.
Instead of creating a new `values.yaml`, we'll change the setting from the command line.
The pod is using the new container image as well:
The upgrade is visible in the chart history:
Change is inspectable with `helm diff`:
```plaintext
$ helm diff revision nginx 1 2
default, nginx, Deployment (apps) has changed:
# Source: nginx/templates/deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
labels:
helm.sh/chart: nginx-0.1.0
app.kubernetes.io/name: nginx
app.kubernetes.io/instance: nginx
app.kubernetes.io/version: "1.0.0"
app.kubernetes.io/managed-by: Helm
spec:
replicas: 1
selector:
matchLabels:
app.kubernetes.io/name: nginx
app.kubernetes.io/instance: nginx
template:
metadata:
labels:
app.kubernetes.io/name: nginx
app.kubernetes.io/instance: nginx
spec:
serviceAccountName: nginx
securityContext:
{}
containers:
- name: nginx
securityContext:
{}
- image: "nginx:1.21.5"
+ image: "nginx:1.21.6"
imagePullPolicy: IfNotPresent
ports:
- name: http
containerPort: 80
protocol: TCP
livenessProbe:
httpGet:
path: /
port: http
readinessProbe:
httpGet:
path: /
port: http
resources:
{}
```
### Rollback The Helm Release
The upgrade was not conclusive and you want to go back. As Helm keeps all the changes, rollback is very straightforward:
```plaintext
$ helm rollback nginx 1
Rollback was a success! Happy Helming!
```
The pod is now back to `1.21.5` container image:
### Uninstall The Helm Chart
Uninstalling a Helm chart is trivial as the installation:
```plaintext
$ helm uninstall nginx
```
### Reuse Existing Helm Charts
A lot of famous projects provide Helm chart to make the integration more user-friendly. They provide the charts through a repository. You have just to add it on your side:
```plaintext
$ helm repo add bitnami [https://charts.bitnami.com/bitnami](https://charts.bitnami.com/bitnami)
```
Once added, update your local cache to synchronize info with remote repositories:
```plaintext
$ helm repo update
```
You can now install the chart on your Kubernetes cluster:
```plaintext
$ helm install nginx bitnami/nginx
```
Charts are deployed with default values. You can inspire and specify a custom `values.yaml`to match your needs!
```plaintext
$ helm install my-release bitnami/nginx -f values.yaml
```
That’s all folks. Today we have looked at how to use Helm.
Please stay tuned and subscribe for more articles and study materials on DevOps, Agile, DevSecOps and App Development.
If you’d like to learn more about Infrastructure as Code, or other modern technology approaches, Please read or other articles. | softwaresennin |
1,574,020 | Demystifying EKS Authentication and Authorization: A Guide to Strengthening Network Security | Amazon EKS, the managed Kubernetes service by AWS, holds paramount importance in understanding how... | 0 | 2023-08-20T16:17:12 | https://www.dailytask.co/task/demystifying-eks-authentication-and-authorization-a-guide-to-strengthening-network-security-1692547549 | eks, kubernetes, aws | ---
canonical_url: https://www.dailytask.co/task/demystifying-eks-authentication-and-authorization-a-guide-to-strengthening-network-security-1692547549
---
Amazon EKS, the managed Kubernetes service by AWS, holds paramount importance in understanding how API server authentication and authorization function. Before delving into the details, let's distinguish between Authentication and Authorization.
## Authentication: Ensuring Legitimate Requests
Authentication denotes valid user requests. Kubernetes offers diverse authentication methods, often referred to as "authentication modules" or "authenticators". Every API server request, whether from external sources like ``kubectl`` or internal entities like the ``kubelet`` on worker nodes, is authenticated.
## Authorization: Granting Action Permissions
Once the request's legitimacy is confirmed, it's vital to ensure authorized actions. This is where "authorization" comes into play. Each request carries a specific ``Kubernetes action`` (e.g., "get pods," "delete deployment"). Given that different cluster users have varying privileges, verifying their permission to execute the action is imperative.
in general Authenticators and authorisers are independent from each other, and they are configured separately. you can read more from [here](https://kubernetes.io/docs/concepts/security/controlling-access/).
## EKS Authentication and Authorization: Unveiled
For the creators of the EKS cluster, accessing it using kubectl is straightforward. However, other users, even administrators or root users, face restrictions. The authentication method is EKS-specific, employing AWS Identity and Access Management (IAM) identities. The authentication outcome hinges on IAM permissions.
Authentication alone isn't enough; authorization is essential. EKS employs an RBAC (Role-Based Access Control) authorizer for this. Unlike authentication, authorization is independent of EKS, following standard Kubernetes practices. It's based on Kubernetes users returned by the EKS authenticator. Configuring the RBAC authorizer in an EKS cluster mirrors the process in any Kubernetes environment.
## Bridging the Authentication Gap
Although administrators are authenticated, authorization isn't automatic. Authorization in EKS centers around the aws-auth configmap, housing a mapping of IAM identities to Kubernetes users. As an EKS user, it's your responsibility to craft and maintain this critical object.
## IAM User Authorization: A Step-by-Step Guide
1. AWS utilizes the aws-auth configmap, responsible for mapping IAM identities to Kubernetes users.
2. Though EKS streamlines many tasks, creating the ``aws-auth`` configmap isn't one. You're accountable for its creation and upkeep.
3. By default, running `` kubectl get configmap aws-auth -n kube-system`` provides an overview of the existing configuration.
The existing configuration might resemble the following:
```
apiVersion: v1
data:
mapRoles: |
- groups:
- system:bootstrappers
- system:nodes
rolearn: arn:aws:iam::xxxxxx:role/eksCreateCluster
username: system:node:{{EC2PrivateDNSName}}
kind: ConfigMap
metadata:
name: aws-auth
namespace: kube-system
```
4. You can add users to this file using ``kubectl edit``, linking users with the necessary permissions for the cluster.
5. The ``mapUsers`` section designates the user's ARN (Amazon Resource Name), username, and group. The group's permissions dictate the allowed actions.
6. In this example, I'm providing the username "clusteradmin" with permissions in the cluster's ``system:masters`` group:
```
apiVersion: v1
data:
mapRoles: |
- groups:
- system:bootstrappers
- system:nodes
rolearn: arn:aws:iam::xxxxx:role/eksCreateCluster20230111
username: system:node:{{EC2PrivateDNSName}}
mapUsers: |
- userarn: arn:aws:iam::xxxx:user/ahmedzidan
username: ahmedzidan
groups:
- system:masters
kind: ConfigMap
metadata:
name: aws-auth
namespace: kube-system
```
## Fine-Tuned Access Control
EKS's power lies in the flexibility it offers. You can tailor access, granting permissions for specific namespaces and actions.
## Creating Role-Based Access Control
1. Kubernetes RBAC relies on ``Role`` and ``RoleBinding`` to set access policies.
2. A ``Role`` comprises rules specifying permissible Kubernetes actions.
3. ``RoleBinding`` links a role to subjects, such as usernames or groups.
## Limiting User Access to Specific Namespace
As an illustration, let's limit a user's access to the default namespace:
1. Begin by downloading the YAML file:
```
curl -O https://s3.us-west-2.amazonaws.com/amazon-eks/docs/eks-console-restricted-access.yaml
```
2. Apply the file. This creates restricted permissions for the default namespace and associates them with the ``eks-console-dashboard-restricted-access-group``.
3. Update the ``aws-auth`` configmap with the new user and group:
```
mapUsers: |
- userarn: arn:aws:iam::xxxx:user/ahmedzidan
username: ahmedzidan
groups:
- eks-console-dashboard-restricted-access-group
```
## In Conclusion
Understanding EKS authentication and authorization is pivotal for safeguarding applications within a network. Navigating these intricacies fortifies your infrastructure, fostering robustness and resilience.
For more insights, connect with me on:
- [Linkedin](https://www.linkedin.com/in/ahmedmahmoudzidan/)
- [Twitter](https://twitter.com/zidanahmed2020)
- [original-blog](https://www.dailytask.co/task/demystifying-eks-authentication-and-authorization-a-guide-to-strengthening-network-security-1692547549)
Stay tuned for further enlightenment on AWS EKS, networking, and security. | ahmedzidan |
1,574,475 | AWS: Grafana Loki, InterZone traffic in AWS, and Kubernetes nodeAffinity | Traffic in AWS is generally quite an interesting and sometimes complicated thing, I once wrote... | 0 | 2023-09-03T10:19:12 | https://rtfm.co.ua/en/aws-grafana-loki-interzone-traffic-in-aws-and-kubernetes-nodeaffinity/ | aws, monitoring, devops, todayilearned | ---
title: AWS: Grafana Loki, InterZone traffic in AWS, and Kubernetes nodeAffinity
published: true
date: 2023-08-19 04:20:54 UTC
tags: aws,monitoring,devops,todayilearned
canonical_url: https://rtfm.co.ua/en/aws-grafana-loki-interzone-traffic-in-aws-and-kubernetes-nodeaffinity/
---

Traffic in AWS is generally quite an interesting and sometimes complicated thing, I once wrote about it in the [AWS: Cost optimization — services expenses overview and traffic costs in AWS](https://rtfm.co.ua/en/aws-cost-optimization-services-expenses-overview-and-traffic-costs-in-aws/). Now, it’s time to return to this topic again.
So, what’s the problem: in AWS Cost Explorer, I’ve noticed that we have an increase in EC2-Other costs for several days in a row:
And what is included in our EC2-Other? All Load Balancers, IP, EBS, and traffic, see [Tips and Tricks for Exploring your Data in AWS Cost Explorer](https://aws.amazon.com/blogs/aws-cloud-financial-management/tips-and-tricks-for-exploring-your-data-in-aws-cost-explorer-part-2/).
To check what exactly the expenses have increased — switch Dimension to the Usage Type and select EC2-Other in the Service:
Here, we can see that the expenses have grown on the **DataTransfer-Regional-Bytes** , that is “_This is Amazon EC2 traffic that moves between AZs but stays within the same region_”, as said in the [Understand AWS Data transfer details in depth from cost and usage report using Athena query and QuickSight](https://aws.amazon.com/blogs/networking-and-content-delivery/understand-aws-data-transfer-details-in-depth-from-cost-and-usage-report-using-athena-query-and-quicksight/), and [Understanding data transfer charges](https://docs.aws.amazon.com/cur/latest/userguide/cur-data-transfers-charges.html#data-transfer-within-region).
We can switch to the API Operation, and check exactly what kind of traffic was used:

**InterZone-In** and **InterZone-Out**.
In the past week, I started monitoring with [VictoriaMetrics: deploying a Kubernetes monitoring stack ](https://rtfm.co.ua/en/victoriametrics-deploying-a-kubernetes-monitoring-stack/), configured logs collection from CloudWatch Logs using [promtail-lambda](https://rtfm.co.ua/en/loki-collecting-logs-from-cloudwatch-logs-using-lambda-promtail/), and added [alerts with Loki Ruler](https://rtfm.co.ua/en/grafana-loki-alerts-from-the-loki-ruler-and-labels-from-logs/) — apparently it affected the traffic. Let’s figure it out.
### VPC Flow Logs
What we need is to add Flow Logs for the VPC of our Kubernetes cluster. Then we will see which Kubernetes Pods or Lambda functions in AWS began to actively “eat” traffic. For more details, see the [AWS: VPC Flow Logs — an overview and example with CloudWatch Logs Insights post](https://rtfm.co.ua/en/aws-vpc-flow-logs-an-overview-and-example-with-cloudwatch-logs-insights/).
So, we can create a CloudWatch Log Group with custom fields to have `pkt_srcaddr` and `pkt_dstaddr` fields, which contain IPs of Kubernetes Pods, see [Using VPC Flow Logs to capture and query EKS network communications](https://aws.amazon.com/blogs/networking-and-content-delivery/using-vpc-flow-logs-to-capture-and-query-eks-network-communications/).
In the Log Group, configure the following fields:
```
region vpc-id az-id subnet-id instance-id interface-id flow-direction srcaddr dstaddr srcport dstport pkt-srcaddr pkt-dstaddr pkt-src-aws-service pkt-dst-aws-service traffic-path packets bytes action
```
Next, configure Flow Logs for the VPC of our cluster:
And let’s go check the logs.
### CloudWatch Logs Insights
Let’s take a request from examples:
And rewrite it according to our format:
```
parse @message "* * * * * * * * * * * * * * * * * * *"
| as region, vpc_id, az_id, subnet_id, instance_id, interface_id,
| flow_direction, srcaddr, dstaddr, srcport, dstport,
| pkt_srcaddr, pkt_dstaddr, pkt_src_aws_service, pkt_dst_aws_service,
| traffic_path, packets, bytes, action
| stats sum(bytes) as bytesTransferred by pkt_srcaddr, pkt_dstaddr
| sort bytesTransferred desc
| limit 10
```
With that, we are getting an interesting picture:
Where in the top with a large margin we see two addresses — _10.0.3.111_ and _10.0.2.135_, which caught up to 28995460061 bytes of traffic.
### Loki components and traffic
Check what kind of Pods these are in our Kubernetes, and find their corresponding WorkerNodes/EC2.
First 10.0.3.111:
```
$ kk -n dev-monitoring-ns get pod -o wide | grep 10.0.3.111
loki-backend-0 1/1 Running 0 22h 10.0.3.111 ip-10–0–3–53.ec2.internal <none> <none>
```
And 10.0.2.135:
```
$ kk -n dev-monitoring-ns get pod -o wide | grep 10.0.2.135
loki-read-748fdb976d-grflm 1/1 Running 0 22h 10.0.2.135 ip-10–0–2–173.ec2.internal <none> <none>
```
And here I recalled, that on July 31 I turned on alerts in Loki, which are processed in Loki’s backend Pod, where the Ruler component is running (earlier, it leaving in the read Pods).
That is, the biggest part of the traffic occurs precisely between the Read and Backend pods.
It is a good question what is transmitted there in such a quantity, but for now, we need to solve the problem of traffic costs.
Let’s check in which AvailabilityZones the Kubernetes WorkerNodes are located.
_The ip-10–0–3–53.ec2.internal_ instance, where the Backend pod is running:
```
$ kk get node ip-10–0–3–53.ec2.internal -o json | jq -r '.metadata.labels["topology.kubernetes.io/zone"]'
us-east-1b
```
And _ip-10–0–2–173.ec2.internal_, where the Read Pod is located:
```
$ kk get node ip-10–0–2–173.ec2.internal -o json | jq -r '.metadata.labels["topology.kubernetes.io/zone"]'
us-east-1a
```
**us-east-1b** and **us-east-1a** — here we have our cross-AvailabilityZones traffic from the Cost Explorer.
### Kubernetes podAffinity and nodeAffinity
What we can try is to add Affinity for the pods to run in the same AvailabilityZone. See [Assigning Pods to Nodes](https://kubernetes.io/docs/concepts/scheduling-eviction/assign-pod-node/) and [Kubernetes Multi-AZ deployments Using Pod Anti-Affinity](https://www.verygoodsecurity.com/blog/posts/kubernetes-multi-az-deployments-using-pod-anti-affinity).
For Pods in the Helm chart, we already have [affinity](https://github.com/grafana/loki/blob/main/production/helm/loki/values.yaml#L846:):
```
...
affinity: |
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchLabels:
{{- include "loki.readSelectorLabels" . | nindent 10 }}
topologyKey: kubernetes.io/hostname
...
```
The first option is to tell the Kubernetes Scheduler that we want the Read Pods to be located on the same WorkerNode where the Backend Pods are. For this, we can use the [podAffinity](https://kubernetes.io/docs/concepts/scheduling-eviction/assign-pod-node/#types-of-inter-pod-affinity-and-anti-affinity).
```
$ kk -n dev-monitoring-ns get pod loki-backend-0 --show-labels
NAME READY STATUS RESTARTS AGE LABELS
loki-backend-0 1/1 Running 0 23h app.kubernetes.io/component=backend,app.kubernetes.io/instance=atlas-victoriametrics,app.kubernetes.io/name=loki,app.kubernetes.io/part-of=memberlist,controller-revision-hash=loki-backend-8554f5f9f4,statefulset.kubernetes.io/pod-name=loki-backend-0
```
So for the Reader, we can specify `podAntiAffinity` with `labelSelector=app.kubernetes.io/component=backend` - then the Reader will "reach" for the same AvailabilityZone where the Backend is running.
Another option is to specify a label with the desired AvailabilityZone through [nodeAffinity](https://kubernetes.io/docs/concepts/scheduling-eviction/assign-pod-node/#nodeselector), and in Expressions for both Read and Backend.
Let’s try with `preferredDuringSchedulingIgnoredDuringExecution`, i.e. the "soft limit":
```
...
read:
replicas: 2
affinity: |
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: topology.kubernetes.io/zone
operator: In
values:
- us-east-1a
...
backend:
replicas: 1
affinity: |
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: topology.kubernetes.io/zone
operator: In
values:
- us-east-1a
...
```
Deploy, check Read Pods:
```
$ kk -n dev-monitoring-ns get pod -l app.kubernetes.io/component=read -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
loki-read-d699d885c-cztj7 1/1 Running 0 50s 10.0.2.181 ip-10–0–2–220.ec2.internal <none> <none>
loki-read-d699d885c-h9hpq 0/1 Running 0 20s 10.0.2.212 ip-10–0–2–173.ec2.internal <none> <none>
```
And instances zone:
```
$ kk get node ip-10–0–2–220.ec2.internal -o json | jq -r '.metadata.labels["topology.kubernetes.io/zone"]'
us-east-1a
$kk get node ip-10–0–2–173.ec2.internal -o json | jq -r '.metadata.labels["topology.kubernetes.io/zone"]'
us-east-1a
```
Okay, everything is good here, but what about the Backend?
```
$ kk get nod-n dev-monitoring-ns get pod -l app.kubernetes.io/component=backend -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
loki-backend-0 1/1 Running 0 75s 10.0.3.254 ip-10–0–3–53.ec2.internal <none> <none>
```
And its Node:
```
$ kk -n dev-get node ip-10–0–3–53.ec2.internal -o json | jq -r '.metadata.labels["topology.kubernetes.io/zone"]'
us-east-1b
```
But why in the **1b** , when we set **1a**? Let’s check its StatefulSet if our affinity has been added:
```
$ kk -n dev-monitoring-ns get sts loki-backend -o yaml
apiVersion: apps/v1
kind: StatefulSet
…
spec:
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- preference:
matchExpressions:
- key: topology.kubernetes.io/zone
operator: In
values:
- us-east-1a
weight: 1
…
```
Everything is there.
OK — let’s use the “hard limit”, that is the `requiredDuringSchedulingIgnoredDuringExecution`:
```
...
backend:
replicas: 1
affinity: |
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: topology.kubernetes.io/zone
operator: In
values:
- us-east-1a
...
```
Deploy again, and now the Pod with the Backend is stuck in _Pending_ status:
```
$ kk -n dev-monitoring-ns get pod -l app.kubernetes.io/component=backend -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
loki-backend-0 0/1 Pending 0 3m39s <none> <none> <none> <none>
```
Why? Let’s check its Events:
```
$ kk -n dev-monitoring-ns describe pod loki-backend-0
…
Events:
Type Reason Age From Message
— — — — — — — — — — — — -
Warning FailedScheduling 34s default-scheduler 0/3 nodes are available: 1 node(s) didn’t match Pod’s node affinity/selector, 2 node(s) had volume node affinity conflict. preemption: 0/3 nodes are available: 3 Preemption is not helpful for scheduling..
```
At first, I thought that there is already a maximum of Pods on WorkerNode — 17 on the `t3.medium` AWS EC2 instances.
Let’s check:
```
$ kubectl -n dev-monitoring-ns get pods -A -o jsonpath='{range .items[?(@.spec.nodeName)]}{.spec.nodeName}{"\n"}{end}' | sort | uniq -c | sort -rn
16 ip-10–0–2–220.ec2.internal
14 ip-10–0–2–173.ec2.internal
13 ip-10–0–3–53.ec2.internal
```
But no, there are still places.
So what? Maybe EBS? A common problem is when EBS is in one AvailabilityZone, and a Pod is running in another.
Find the Volume of the Backend — it is connected for alert rulers for the Ruler:
```
…
Volumes:
…
data:
Type: PersistentVolumeClaim (a reference to a PersistentVolumeClaim in the same namespace)
ClaimName: data-loki-backend-0
ReadOnly: false
…
```
Find the corresponding Persistent Volume:
```
$ kubectl k -n dev-monitoring-ns get pvc data-loki-backend-0
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
data-loki-backend-0 Bound pvc-b62bee0b-995e-486b-9f97-f2508f07a591 10Gi RWO gp2 15d
```
And the AvailabilityZone of this EBS:
```
$ kk -n dev-monitoring-ns get pv pvc-b62bee0b-995e-486b-9f97-f2508f07a591 -o json | jq -r '.metadata.labels["topology.kubernetes.io/zone"]'
us-east-1b
```
And indeed, we have a disk in _the_ **_us-east-1b_** zone, while we are trying to launch the Pod in _the_ **_us-east-1a_**.
What we can do here, is either run Readers in zone _1b_, or delete the PVC for the Backend, and then during deployment it will create a new PV and EBS in zone _1a_.
Since there is no data in the volume and rules for Ruler are created from a ConfigMap, it is easier to just delete the PVC:
```
$ kubectl k -n dev-monitoring-ns delete pvc data-loki-backend-0
persistentvolumeclaim “data-loki-backend-0” deleted
```
Delete the pod so that it is recreated:
```
$ kk -n dev-monitoring-ns delete pod loki-backend-0
pod “loki-backend-0” deleted
```
Check that the PVC is created:
```
$ kk -n dev-monitoring-ns get pvc data-loki-backend-0
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
data-loki-backend-0 Bound pvc-5b690c18-ba63–44fd-9626–8221e1750c98 10Gi RWO gp2 14s
```
And its location now:
```
$ kk -n dev-monitoring-ns get pv pvc-5b690c18-ba63–44fd-9626–8221e1750c98 -o json | jq -r ‘.metadata.labels[“topology.kubernetes.io/zone”]’
us-east-1a
```
And the Pod also started:
```
$ kk -n dev-monitoring-ns get pod loki-backend-0
NAME READY STATUS RESTARTS AGE
loki-backend-0 1/1 Running 0 2m11s
```
### Traffic optimization results
I did it on Friday, and for Monday we have the following result:

Everything turned out as planned: the Cross AvailabilityZone traffic is now almost zero.
_Originally published at_ [_RTFM: Linux, DevOps, and system administration_](https://rtfm.co.ua/en/aws-grafana-loki-interzone-traffic-in-aws-and-kubernetes-nodeaffinity/)_._
* * * | setevoy |
1,574,514 | Vertical Farming and Its Future Scope. | Introduction In our rapidly changing world, where traditional farming techniques struggle to keep... | 0 | 2023-08-21T08:41:12 | https://dev.to/xcubelabs/vertical-farming-and-its-future-scope-3637 | farming, agriculture, product, agritech | **Introduction**
In our rapidly changing world, where traditional farming techniques struggle to keep pace with global food demands, vertical farming emerges as a promising solution. Vertical farming, an innovative method of cultivating produce within vertically stacked layers, has been hailed as the future of agriculture. This article aims to shed light on the concept of vertical farming, the potential it holds, and the advanced vertical farming solutions that are transforming the food production landscape.
**Understanding Vertical Farming**
Vertical farming is a revolutionary approach that leverages controlled-environment agriculture (CEA) technology to grow food on vertically inclined surfaces or structures. This method capitalizes on urban indoor spaces, using technologies like hydroponics, aeroponics, or aquaponics, and artificial lighting to cultivate plants. Vertical agriculture is seen as a sustainable answer to the increasing concerns over food security and environmental degradation caused by conventional farming.
**The Rise Of Vertical Agriculture**
Vertical agriculture has been rising in popularity due to several compelling reasons. Firstly, it promotes sustainable farming by using significantly less water and land than traditional farming methods. It eliminates the need for harmful pesticides and fertilizers, offering a pesticide-free, organic alternative to mass-produced crops.
Additionally, vertical farming has a reduced carbon footprint as it can be done in urban environments, reducing the distance between farms and consumers. This limits the need for transportation, thereby decreasing greenhouse gas emissions. The controlled indoor environment also means that vertical farming can happen year-round, irrespective of weather conditions.

**Vertical Farming Solutions: Propelling The Future Of Agriculture**
Several vertical farming solutions have emerged in recent years, offering smart, efficient ways to grow food. These include advanced LED lighting systems that mimic sunlight, automated climate control systems for optimal growing conditions, and machine learning algorithms to track plant growth and health.
Technological advancements in IoT and AI are further driving the evolution of vertical farming solutions. Machine learning, for instance, allows for predictive analysis, forecasting potential issues before they arise. This enhances yield quality and quantity while reducing waste and maximizing resources.
Another promising vertical farming solution is the use of robotics. Automated farming robots can perform tasks like planting, watering, and harvesting, thus making the process more efficient and less labor-intensive.
**Future Of Vertical Farming**
The future of vertical agriculture looks bright as the world increasingly recognizes its benefits. By 2026, the vertical farming market is projected to reach $12.77 billion, marking a significant growth from just a few years ago.
In the future, we could see vertical farms becoming a common sight in urban landscapes. As cities continue to expand and the demand for fresh, locally grown produce increases, vertical farming can offer a viable, sustainable solution.
The role of vertical farming in addressing food security is equally significant. With climate change rendering large swathes of agricultural land unsuitable for farming, vertical agriculture can help to ensure a stable, resilient food supply.
**Conclusion**
In an era marked by rapid urbanization and escalating environmental challenges, vertical farming emerges as a beacon of sustainable innovation. By integrating technology with agriculture, vertical farming solutions are not only changing the way we grow food but also how we envision the future of farming. As more advancements unfold, vertical agriculture holds the promise of a greener, more sustainable world with enough food for everyone. | xcubelabs |
1,575,508 | The best way to integrate in a new team | As someone who has either worked in distributed teams, or as a remote contractor, I know it can be... | 0 | 2023-08-21T21:49:46 | https://dev.to/noblica/the-best-way-to-integrate-in-a-new-team-4k29 | webdev, programming, career, remote | As someone who has either worked in distributed teams, or as a remote contractor, I know it can be difficult to integrate in a new team.
There are many challenges you have to face. Whether it's poor onboarding, lack of clear communication or direction, or a difference in time zones, it's hard to escape the feeling that you're not really part of the team. If not handled properly, this can lead to impostor syndrome, or a "us vs them mentality".
So what can you do to avoid this if you've just joined a team?
## 1. Avoid communicating through text only
This is especially important in the beginning.
**Text is the worst form of communication**, by far.
I know, I know, we all hate being stuck in meetings that seem to go nowhere, or have no value to us. But try to get as much face time with everyone as possible. Have a one-on-one introduction with everyone in the team, from the client(if possible) to the intern. Try and get to know the people you're working with, where they see the project going, what issues they are dealing with right now, or what problems they think might be coming in the future.
If you communicate only through text, there is a lack of context, tone, and body language. There are only words on the screen, and if the person you're talking to doesn't know you well enough, they can take things the wrong way.
I'm not saying that you should jump on a video call every time someone asks you to change a border color in CSS. But if requirements are unclear, or you need to explain something to another team member, you should use every tool at your disposal to make it easier to understand each other and push the project forward. Your team members will thank you for reaching out, and feel more connected to you.
## 2. Use screen recordings
I promise you, your clients love it when you keep them up to date on what you did. Creating a screen recording and walking them through a feature you just implemented is going to make everyone feel more included in the development process, give you quicker feedback, and make you more visible to the rest of the team.
As a bonus, you will also catch a lot more bugs before creating PR's, because you will basically be doing QA on yourself.
Your colleagues will also love it if they ask you to explain something, and instead of writing paragraphs of text, you just send them a screen recording, and all they have to do is press play.
This is especially useful if you are in separate timezones. I have actually gotten more higher quality feedback on screen recordings like this, then on live demos. Probably because people can watch and comment on it multiple times, at their own pace.
I use the [scre.io](https://scre.io/) chrome plugin, since it's the easiest to use, and convert the recording to `.mp4` if necessary.
## 3. Take control of your tickets.
I know developers dislike managing tickets (almost as much as they dislike meetings that could've been emails). But if you can help your team organize the work better, they will be forever grateful to you, and you will be able to impact the project on a higher level.
If you can break features down into small tickets that are easy to implement, you can avoid merge queues, PR's being stuck in review hell for weeks because of unclear requirements, or implementing the same thing multiple times. Your project manager will like you because you'll be helping them out, and your QA team will love you even more if a clear Acceptance Criteria is provided with every ticket.
You are making everyone's life easier, and as a result everyone wins.
## In conclusion
Remember, you are working with people. If you help make their lives easier, or if you at least try, they will appreciate it and help you out. Building trust may take some time, but a team that trusts and helps each other, is a great team to work in. | noblica |
1,575,707 | Kali Linux 2019.4 Release (Xfce, Gnome, GTK3, Kali-Undercover, Kali-Docs, KeX, PowerShell & Public Packaging) | Time to grab yourself a drink, this will take a while! We are incredibly excited to announce our... | 0 | 2023-08-21T21:15:30 | https://www.kali.org/blog/kali-linux-2019-4-release/ | ---
title: Kali Linux 2019.4 Release (Xfce, Gnome, GTK3, Kali-Undercover, Kali-Docs, KeX, PowerShell & Public Packaging)
published: true
date: 2019-11-26 00:00:00 UTC
tags:
canonical_url: https://www.kali.org/blog/kali-linux-2019-4-release/
---
Time to grab yourself a drink, this will take a while!
[](https://www.kali.org/blog/kali-linux-2019-4-release/images/kali-preview-boot.gif)
We are incredibly excited to announce our fourth and final release of 2019, Kali Linux 2019.4, which is available immediately for [download](https://www.kali.org/get-kali/).
2019.4 includes some exciting new updates:
- A new default desktop environment, Xfce
- New GTK3 theme (for Gnome and Xfce)
- Introduction of “Kali Undercover” mode
- Kali Documentation has a new home and is now Git powered
- Public Packaging - getting your tools into Kali
- Kali NetHunter KeX - Full Kali desktop on Android
- BTRFS during setup
- Added PowerShell
- The [kernel is upgraded to version 5.3.9](https://pkg.kali.org/pkg/linux)
- … Plus the normal bugs fixes and updates.
### New Desktop Environment and GTK3 Theme
There are a ton of updates to go over for this release, but the most in your face item that everyone is going to notice first are the changes to the desktop environment and theme. So let’s cover that first.
An update to the desktop environment has been a long time coming. We have been talking about how to address this, what we wanted to do, experimenting on different approaches, and so on for months now. As a summary we had a few issues we wanted to address head-on:
- Performance issues - Gnome is a fully-featured desktop environment with a ton of awesome things it can do. But all these features comes with overhead, often overhead that is not useful for a distribution like Kali. We wanted to speed things up, and have a desktop environment that does only what it’s needed for, and nothing else. Gnome has been overkill for most Kali users, as many just want a window manager that allows you to run multiple terminal windows at once, and a web browser.
- Fractured user experience - We support a range of hardware, from the very high end to the very low. Because of this, traditionally our lower-end ARM builds have had a completely different UI than our standard. That’s not optimal, and we wanted to unify this experience so it did not matter if you were running on a bare metal install on a high end laptop or using a Raspberry Pi, the UI should be the same.
- Modern look - We have been using the same UI for quite a while now, and our old theme maintainer had moved on due to lack of time. So we wanted to go with something fresh, new, and modern.
To help us address these items, we tracked down [Daniel Ruiz de Alegría](https://drasite.com/) and started the development of a new theme running on Xfce. Why Xfce? After reviewing the above issues, we felt that Xfce addressed them best while still being accessible to the majority of users.
The solution we’ve committed to is lightweight and can run on all levels of Kali installs. It is functional in that it handles the various needs of the average user with no changes. It is approachable where it uses standard UI concepts we are all familiar with to ensure there is no learning curve. And it looks great with modern UI elements that make efficient use of screen space.
We are really excited about this UI update, and we think you are going to love it. However, as UI can be a bit like religion, if you don’t want to leave Gnome don’t worry. We still have a Gnome build for you, with a few changes already in place. As time goes by, we will be making changes to all of the desktop environments we release installs to get them “close” to a similar user experience no matter what DE you run. There will be limits to this, as we don’t have the resources to heavily invest in tweaking all these different environments. So if there is something you would like to see, feel free to submit a [feature request](https://bugs.kali.org/)!
We have also released a FAQ about the new theme that you can find on our [docs page](https://www.kali.org/docs/general-use/xfce-faq/). This includes some common items like how to switch to the theme on your existing install, how to change off of it if you don’t like it, and so on.
### Kali Undercover
With the change to the environment, we thought we would take a side step and do something fun. Thanks to Robert, who leads our penetration testing team, for suggesting a Kali theme that looks like Windows to the casual view, we have created the Kali Undercover theme.
[](https://www.kali.org/blog/kali-linux-2019-4-release/images/kali-undercover-1.gif)
Say you are working in a public place, hacking away, and you might not want the distinctive Kali dragon for everyone to see and wonder what it is you are doing. So, we made a little script that will change your Kali theme to look like a default Windows installation. That way, you can work a bit more incognito. After you are done and in a more private place, run the script again and you switch back to your Kali theme. Like magic!
### Kali-Docs is now on Markdown and new home (/docs/)
This may not be as flashy as the new theme, but the changes to the documentation we have done is just as significant.
One of our go-forward goals with Kali is to move more of the development into the public and make it as easy as possible for anyone _(that means you!)_ to get [involved and contribute](https://www.kali.org/docs/community/contribute/) to Kali. That’s what our move to GitLab [earlier in the year](https://dev.to/mohammadtaseenkhan/kali-linux-roadmap-20192020-4pi3-temp-slug-9611446) was all about. Another part of this is changing how we deal with docs.
We have since moved all of our documentation into Markdown in a [public Git repository](https://gitlab.com/kalilinux/documentation/kali-docs). From here on out anyone, not just Kali staff, can contribute to better documentation through merge requests. We will still approve any content changes, but once merged, changes will be automatically available on the docs section of our website.
We encourage everyone to get involved! If you see something wrong in the existing docs, change it! If you have an idea for new docs, write it! These sorts of contributions make Kali better for everyone.
This is just the first step. With this change in place, coming soon watch for a Kali-Docs package in Kali that gives you full offline access to the documentation on every install of Kali. Perfect for those situations where you are working in a closed-off environment with no Internet access.
### Public Packaging
One of the more significant new documents we have done is [documenting how you can make a new package](https://www.kali.org/docs/development/public-packaging/) that will get included in Kali.
One of the most common bug reports is requests for us to add new tools or update existing ones. Oftentimes, by the tool developers themselves as they recognize that having their tool in the Kali repo is the easiest distribution channel for security assessment tools there is. The volume of this has always been difficult to keep up with, and we have to make some hard decisions on where to commit our limited resources.
Now with this work-flow in place and documented, you don’t have to wait on us. Go ahead and package up your tool and submit it off to us for approval. This is an awesome way to get involved with improving Kali.
### BTRFS during setup
Another significant new addition to the documentation is the [use of BTRFS as your root file system](https://www.kali.org/docs/installation/btrfs/). This is an amazing approach documented by @Re4son, that when done gives you the ability to do file system rollbacks after upgrades.
When you are in a VM and about to try something new, you will often take a snapshot in case things go wrong you can easily go back to a known-good state. However, when you run Kali bare metal that’s not so easy. So you end up being extra careful, or if things go wrong have a lot of manual clean up to do. With BTRFS, you have this same snapshot capability on a bare metal install!
As this is new, it’s not integrated into our installer yet. Once we get some feedback on how it’s working for everyone, the next step is to streamline this and make it an easier option in our installer. So if you try it out, be sure to let us know how it works for you!
### PowerShell
On to other features, in case you missed it PowerShell is now in Kali. This has been really great to bring the ability to execute PowerShell scripts directly on Kali.
[](https://www.kali.org/blog/kali-linux-2019-4-release/images/power-shell-1-1.png)
[](https://www.kali.org/blog/kali-linux-2019-4-release/images/kali-pwsh-powershell-1.png)
### NetHunter Kex - Full Kali Desktop on Android phones
Another feature we are super excited about is the introduction of NetHunter Kex. In a nutshell, this allows you to attach your Android device to an HDMI output along with Bluetooth keyboard and mouse and get a full, no compromise, Kali desktop. Yes. From your phone.
[](https://www.kali.org/blog/kali-linux-2019-4-release/images/kali-kex-theme.gif)
We had a live [Penetration Testing with Kali](https://www.offsec.com/pwk-oscp/) course we were teaching, and NetHunter Kex was just in a beta stage. So we wanted to really push the limits. So, in the live course, what we did was attach a USB-C hub to our OnePlus7. This gave us HDMI and Ethernet access. We attached the HDMI to the projector and used a bluetooth keyboard/mouse. With this, we were able to do an entire PWK module from the phone.
This is a feature you have to see to believe. Until you experience it, you won’t fully understand what this provides. With a strong enough phone, this is very similar to using a nice full-featured portable ARM desktop that happens to fit in your pocket. The possible ways you can leverage this in assessments is huge.
To get a full breakdown on how to use NetHunter Kex, check out our [docs at](https://www.kali.org/docs/nethunter/nethunter-kex-manager/).
## ARM
**2019.4 is the last release that will support 8GB sdcards on ARM. Starting in 2020.1, a 16GB sdcard will be the minimum we support. You will always be able to create your own image that supports smaller cards if you desire.**
- RaspberryPi kernel was updated to 4.19.81, and the firmware package was updated to include the eeprom updates for the RaspberryPi 4.
During the release testing, a limited number of devices were not showing the Kali menu properly. This was not critical enough to delay the release, so instead as a work-around you can run the following command to display the menu correctly:
```
apt update && apt dist-upgrade
```
Once this completes, log out, so you’re back at the login manager. Then switch to a console via CTRL+ALT+F11 (on the Chromebooks this is the key pointing left next to the ESC key).
Login and then run:
```
rm -rf .cache/ .config/ .local/ && sync && reboot
```
After reboot, the menu will have the correct entries. We’re still looking into why it occurs on only some of the images.
## Download Kali Linux 2019.4
So what are you waiting for? Start the [download](https://www.kali.org/get-kali/) now!
Also, just to mention we do also produce [weekly builds](https://cdimage.kali.org/kali-images/kali-weekly/) that you can use as well. If it’s been some time since our last release and you want the latest packages you don’t have to go off our latest release and update. You can just use the weekly image instead, and have fewer updates to do. Just know these are automated builds that we don’t QA like we do our standard release images.
If you already have an existing Kali installation, remember you can always do a quick update:
```
root@kali:~# cat </etc/apt/sources.list
deb http://http.kali.org/kali kali-rolling main contrib non-free
EOF
root@kali:~#
root@kali:~# apt update && apt -y full-upgrade
root@kali:~#
root@kali:~# [-f /var/run/reboot-required] && reboot -f
```
If you want to switch to our new Xfce:
```
root@kali:~# apt -y install kali-desktop-xfce
```
You should now be on Kali Linux 2019.4. We can do a quick check by doing:
```
root@kali:~# grep VERSION /etc/os-release
VERSION="2019.4"
VERSION_ID="2019.4"
VERSION_CODENAME="kali-rolling"
root@kali:~#
root@kali:~# uname -v
#1 SMP Debian 5.3.9-3kali1 (2019-11-20)
root@kali:~#
root@kali:~# uname -r
5.3.0-kali2-amd64
root@kali:~#
```
NOTE: The output of “uname -r” may be different depending on [architecture](https://pkg.kali.org/pkg/linux-latest).
As always, should you come across any bugs in Kali, please submit a report on our [bug tracker](https://bugs.kali.org/main_page.php). We’ll never be able to fix what we don’t know about. | mohammadtaseenkhan | |
1,575,741 | Kali Linux 2021.4 Release | With the end of 2021 just around the corner, we are pushing out the last release of the year with... | 0 | 2023-08-21T21:13:00 | https://www.kali.org/blog/kali-linux-2021-4-release/ | ---
title: Kali Linux 2021.4 Release
published: true
date: 2021-12-09 00:00:00 UTC
tags:
canonical_url: https://www.kali.org/blog/kali-linux-2021-4-release/
---
With the end of 2021 just around the corner, we are pushing out the last [release](https://www.kali.org/releases/) of the year with **Kali Linux 2021.4** , which is ready for immediate [download](https://www.kali.org/get-kali/) or [updating](https://www.kali.org/docs/general-use/updating-kali/).
The summary of the [changelog](https://bugs.kali.org/changelog_page.php) since the [2021.3 release from September 2021](https://dev.to/mohammadtaseenkhan/kali-linux-20213-release-openssl-kali-tools-kali-live-vm-support-kali-nethunter-smartwatch-5aca-temp-slug-641692) is:
- [Improved Apple M1 support](https://www.kali.org/blog/kali-linux-2021-4-release/#kali-on-the-apple-m1)
- [Wide compatibility for Samba](https://www.kali.org/blog/kali-linux-2021-4-release/#extended-compatibility-for-the-samba-client)
- [Switching package manager mirrors](https://www.kali.org/blog/kali-linux-2021-4-release/#easy-package-manager-mirror-configuration)
- [Kaboxer theming](https://www.kali.org/blog/kali-linux-2021-4-release/#kaboxer-theme-support)
- [Updates to Xfce, GNOME and KDE](https://www.kali.org/blog/kali-linux-2021-4-release/#desktop--theme-enhancement)
- [Raspberry Pi Zero 2 W + USBArmory MkII ARM images](https://www.kali.org/blog/kali-linux-2021-4-release/#kali-arm-updates)
- [More tools](https://www.kali.org/blog/kali-linux-2021-4-release/#new-tools-in-kali)
* * *
## Kali on the Apple M1
As we announced in [Kali 2021.1](https://www.kali.org/blog/kali-linux-2021-1-release) we supported installing Kali Linux on Parallels on Apple Silicon Macs, well with 2021.4, we now also support it on the [VMware Fusion Public Tech Preview](https://blogs.vmware.com/teamfusion/2021/09/fusion-for-m1-public-tech-preview-now-available.html) thanks to the [5.14 kernel](https://pkg.kali.org/pkg/linux) having the modules needed for the virtual GPU used. We also have updated the `open-vm-tools` [package](https://pkg.kali.org/pkg/open-vm-tools), and [Kali’s installer](https://pkg.kali.org/pkg/debian-installer) will automatically detect if you are installing under VMware and install the `open-vm-tools-desktop` package, which should allow you to change the resolution out of the box. As a reminder, this is still a _preview_ from VMware, so there may be some rough edges. There is no extra [documentation](https://www.kali.org/docs/virtualization/install-vmware-guest-vm/) for this because the [installation process](https://www.kali.org/docs/installation/hard-disk-install/) is the same as VMWare on 64-bit and 32-bit Intel systems, just using the [arm64 ISO](https://www.kali.org/get-kali/).
As a reminder, virtual machines on **Apple Silicon are still limited to arm64 architecture only**.
## Extended Compatibility for the Samba Client
Starting Kali Linux 2021.4, the [Samba](https://pkg.kali.org/pkg/samba) client is now configured for **Wide Compatibility** so that it can connect to pretty much every Samba server out there, regardless of the version of the protocol in use. This change should make it easier to discover vulnerable Samba servers “out of the box”, without having to configure Kali.
This setting can be changed easily via the command-line tool `kali-tweaks`. In the _Hardening_ section, one can choose the value **Default** instead, which reverts back to Samba’s usual default, and only allow using modern versions of the Samba protocol.
[](https://www.kali.org/blog/kali-linux-2021-4-release/images/kali-tweaks-hardening.png)
As one can see on this screenshot, there’s also a similar setting for [OpenSSL](https://pkg.kali.org/pkg/openssl). You might want to refer to the [2021.3 release announcement](https://dev.to/mohammadtaseenkhan/kali-linux-20213-release-openssl-kali-tools-kali-live-vm-support-kali-nethunter-smartwatch-5aca-temp-slug-641692) for more details on this setting.
## Easy Package Manager Mirror Configuration
By default, when a Kali system is updated, the package manager ([APT](https://pkg.kali.org/pkg/apt)) downloads packages from a [community mirror](https://www.kali.org/docs/general-use/kali-linux-sources-list-repositories/) nearby. But did you know that it’s also possible to configure Kali to get its package from the [Cloudflare CDN](https://blog.cloudflare.com/cloudflare-repositories-ftw/)? To be honest, [this is old news](https://dev.to/mohammadtaseenkhan/kali-linux-20193-release-cloudflare-kali-status-metapackages-helper-scripts-lxd-p0d-temp-slug-9714171). But what’s new is that you can now use `kali-tweaks` to quickly configure whether APT should use community mirrors or the Cloudflare CDN.
[](https://www.kali.org/blog/kali-linux-2021-4-release/images/kali-tweaks-mirrors.png)
So which one is best, community mirrors or Cloudflare CDN? There’s no good answer. The time that it actually takes to update Kali can vary greatly and depends on many factors, including the speed of your Internet connection, your location, and even the time of day, if ever you live in a place where Internet traffic jam occurs at rush hour. The point is: if ever Kali updates are slow, the best you can do is to try to switch from community mirrors to Cloudflare CDN, or the other way round, and find what works best for you. And with `kali-tweaks`, it’s never been easier!
## Kaboxer Theme Support
With the latest update of **[Kaboxer](https://pkg.kali.org/pkg/kaboxer)** tools no longer look out of place, as it brings **support for window themes and icon themes** (placed respectively inside `/usr/share/themes` and `/usr/share/icons`). This allows the program to properly integrate with the rest of the desktop and avoids the usage of ugly fallback themes.
Here is a comparison of how zenmap ( **zenmap-kbx** [package](https://pkg.kali.org/pkg/zenmap-kbx)) looks with the default Kali Dark theme, compared to the old appearance:
[](https://www.kali.org/blog/kali-linux-2021-4-release/images/kaboxer-theme-support.png)
## New Tools in Kali
It would not be a Kali release if there were not any new tools added! A quick run down of what’s been added _(to the [network repositories](https://www.kali.org/docs/general-use/kali-linux-sources-list-repositories/))_:
- [Dufflebag](https://pkg.kali.org/pkg/dufflebag) - Search exposed EBS volumes for secrets
- [Maryam](https://pkg.kali.org/pkg/maryam) - Open-source Intelligence (OSINT) Framework
- [Name-That-Hash](https://pkg.kali.org/pkg/name-that-hash) - Do not know what type of hash it is? Name That Hash will name that hash type!
- [Proxmark3](https://pkg.kali.org/pkg/proxmark3) - if you are into Proxmark3 and RFID hacking
- [Reverse Proxy Grapher](https://pkg.kali.org/pkg/rev-proxy-grapher) - graphviz graph illustrating your reverse proxy flow
- [S3Scanner](https://pkg.kali.org/pkg/s3scanner) - Scan for open S3 buckets and dump the contents
- [Spraykatz](https://pkg.kali.org/pkg/spraykatz) - Credentials gathering tool automating remote procdump and parse of lsass process.
- [truffleHog](https://pkg.kali.org/pkg/trufflehog) - Searches through git repositories for high entropy strings and secrets, digging deep into commit history
- [Web of trust grapher (wotmate)](https://pkg.kali.org/pkg/wotmate) - reimplement the defunct PGP pathfinder without needing anything other than your own keyring
## Desktop & Theme Enhancement
This release brings updates for all the 3 main desktops ([Xfce](https://pkg.kali.org/pkg/xfce4), [GNOME](https://pkg.kali.org/pkg/gnome-shell), and [KDE](https://pkg.kali.org/pkg/kde-plasma-desktop)), but one that is common to all of them is the **new window buttons design**. Previous buttons were designed to fit the window theme of Xfce but did not work well with the other desktops and lacked personality. The new design looks elegant on any of the desktops and makes it easier to spot the currently focused window.
[](https://www.kali.org/blog/kali-linux-2021-4-release/images/new-window-buttons.png)
#### Xfce
The panel layout has been tweaked to optimize horizontal space and make room for 2 new widgets: the **CPU usage widget** and the **VPN IP widget** , which remains hidden unless a VPN connection is established.
Following the steps of other desktops, the **task manager** has been configured to **“icons only”** , which, with the slight increase in the panel’s height, makes the overall look cleaner and improves multitasking in smaller displays.
The **workspaces overview** has been configured to the “Buttons” appearance, as the previous configuration “Miniature view” was too wide and a bit confusing for some users. Now that each workspace button takes less space in the panel, we have **increased the default number of workspaces to 4** , as it’s a usual arrangement in Linux desktops.
To finish with the modifications, a shortcut to **PowerShell** has been added to the terminals dropdown menu. With this addition, you can now choose between the regular terminal, root terminal, and PowerShell.
If you prefer the previous configuration for any of the widgets, you can modify or remove them by pressing `Ctrl + Right-Click` over it.
[](https://www.kali.org/blog/kali-linux-2021-4-release/images/xfce-layout-updates.png)
In addition to the Xfce design tweaks, In the image above, we can also observe the new **customized prompt for PowerShell** (in the two-line mode). Same as for [zsh](https://pkg.kali.org/pkg/zsh) and [bash](https://pkg.kali.org/pkg/bash), it includes an alternative one-line prompt that can be configured with `kali-tweaks`.
**Bonus Tips For Virtual Desktops!**
- You can add or remove workspaces with the shortcuts: `Alt + Insert` / `Alt + Delete`
- You can move through workspaces with the shortcuts:
- `Ctrl + Alt + <ARROW_KEY>` to move in the direction of the arrow key.
- (if you add `Shift` you move the current focused window)
- `Ctrl + Alt + <WORKSPACE_NUM>` to move to a specific workspace, based on its number.
- `Ctrl + Super + <WORKSPACE_NUM>` to move a window to a specific workspace, based on its number.
[](https://www.kali.org/blog/kali-linux-2021-4-release/images/workspaces-shortcuts-demo.gif)
#### GNOME 41
In this update, GNOME desktop has received not one, but two version bumps. It’s been one year since the last major update of the GNOME desktop in Kali (with GNOME 3.38) and since then there have been two releases of the desktop environment:
- [Introducing GNOME 40](https://help.gnome.org/misc/release-notes/40.0/)
- [Introducing GNOME 41](https://help.gnome.org/misc/release-notes/41.0/)
All themes and extensions have been updated to support the new shell:
[](https://www.kali.org/blog/kali-linux-2021-4-release/images/gnome41.png)
[](https://www.kali.org/blog/kali-linux-2021-4-release/images/gnome41-overview.png)
#### KDE 5.23
The KDE team celebrated its 25th anniversary releasing the update [5.23](https://kde.org/announcements/plasma/5/5.23.0/) of the **Plasma** desktop. This update, now available in Kali, brings a **new design for the Breeze theme** , which improves the look of Plasma with details that add glossiness and style to the desktop. Along with the theme improvements, the _System Settings_ (Under _Global Theme > Colors_) brings a _new option to pick the desktop **accent color** _.
From Kali’s side, the new window theme for KDE is now based on the source code of the breeze theme instead of using the _Aurorae_ theme engine. This fixes previous issues with window scaling for [HiDPI displays](https://www.kali.org/docs/general-use/hidpi/).
<iframe src="https://www.kali.org/blog/kali-linux-2021-4-release/https://www.youtube-nocookie.com/embed/RMXViPlehAo" style="position: absolute; top: 0; left: 0; width: 100%; height: 100%; border:0;" allowfullscreen title="YouTube Video"></iframe>
### How to Upgrade Your Kali Theme
With these theme changes, you **may not get them if you [upgrade](https://www.kali.org/docs/general-use/updating-kali/)** Kali. This is because the **theme settings** are **copied** to your **home folder** when your **user is first created**. When you upgrade Kali, it is **upgrading the operating system** , so upgrading **does not alter personal files** _(just system files)_. As a result, in order to get these theme tweaks, you need to either:
- Do a fresh Kali install
- Create a new user and switch to that
- Delete your Desktop environment profile for the current user and force reboot. Example of Xfce can be found below:
```
kali@kali:~$ mv ~/.config/xfce4{,-$(date +%Y.%m.%d-%H.%M.%S)}
kali@kali:~$
kali@kali:~$ cp -rbi /etc/skel/. ~/
kali@kali:~$
kali@kali:~$ xfce4-session-logout --reboot --fast
```
## Kali NetHunter Updates
[](https://www.kali.org/blog/kali-linux-2021-4-release/images/NH-SET.png)
Thanks to the amazing work of [@yesimxev](https://twitter.com/yesimxev), we have a new addition to the NetHunter app: **The Social-Engineer Toolkit!**
This release features the first module from SET: the Spear Phishing Email Attack, with many more to come - watch this space…
Now you can use the Kali NetHunter app to customise your own Facebook, Messenger, or Twitter direct message email notifications for your social engineering attacks:
<video preload="metadata" autoplay muted loop>
<source src="https://www.kali.org/blog/kali-linux-2021-4-release/videos/setgif.mp4">
Your browser does not support the video tag.
</source></video>
Thanks to everyone that contributed to this feature by participating in the [Twitter poll](https://twitter.com/yesimxev/status/1451314339554660359). We could not have done it without your input!
## Kali ARM Updates
Notable changes this release
- **All images now use ext4 for their root filesystem** , and **resize the root filesystem on first boot**. This results in a speed-up over previous releases which were using ext3, and a reduced boot time on the first reboot when resize happens.
- **Raspberry Pi Zero 2 W support has been added** , but like the Raspberry Pi 400, there is no Nexmon support.
- Speaking of the **Raspberry Pi Zero 2 W** , since it is so similar to the Zero W, we have also added a **PiTail image** to support the new processor with better performance.
- **Raspberry Pi images now support USB booting** out of the box since we no longer hardcode the root device.
- **Raspberry Pi images now include versioned Nexmon firmware**. A future release of `kalipi-config` will allow you to switch between them, if you would like to test different versions.
- Images that use a vendor kernel will now be able to set the regulatory domain properly, so **setting your country will give access to channels properly for wireless**.
- **Pinebook Pro can now be overclocked**. The big cores get 2GHz and the little cores get 1.5GHz added.
- `echo 1 | sudo tee /sys/devices/system/cpu/cpufreq/boost` to enable
- `echo 0 | sudo tee /sys/devices/system/cpu/cpufreq/boost` to disable
- **USBArmory MkII image has been added**.
**[Kali ARM build-scripts](https://gitlab.com/kalilinux/build-scripts/kali-arm)** have seen a massive amount of changes:
- They are vastly **more simplified** - thanks to [Francisco Jose Rodriguez Martos](https://twitter.com/frangalinux), and [cyrus104](https://gitlab.com/cyrus104) for all of their contributions to make this happen.
- You can now **choose which desktop** you would like to install (or none at all using `--minimal`)
- There is even an option of **no desktop and no tools** (`--slim`) if you would like to build a custom image up from scratch
## Kali-Docs Updates
- [Installing Flatpak on Kali Linux](https://www.kali.org/docs/tools/flatpak/) is now well documented
- A new page for the [Raspberry Pi Zero 2 W](https://www.kali.org/docs/arm/raspberry-pi-zero-2-w/) has been added
- The [Kali branches](https://www.kali.org/docs/general-use/kali-branches/) page has been refreshed with best practices and references to `kali-tweaks` that help you follow those best practices to enable (or disable) some of the supplementary repositories.
- We added a [list of removed tools](https://www.kali.org/docs/tools/removed-tools/) so that you can learn why a package got dropped from Kali.
- Thanks also to [Aman Kumar Maurya](https://gitlab.com/mayomacam) for the [nVidia](https://www.kali.org/docs/general-use/install-nvidia-drivers-on-kali-linux/) guide
_Anyone can help out, anyone can get [involved](https://www.kali.org/docs/community/contribute/)!_
* * *
## Miscellaneous
**Kali-Cloud & Cron**
Some [users](https://twitter.com/DHAhole) noticed that the venerable `cron` [package](https://pkg.kali.org/pkg/cron) was missing from the [Kali AWS Cloud image](https://www.kali.org/get-kali/#kali-cloud). This was not intentional, and it’s now fixed.
**Remote Desktop Protocol Audio**
“_The quieter you become, the more you are able to hear_”, goes the saying. And for those running Kali in a VM and using RDP to connect, it’s been very quiet indeed, as the sound never worked with this configuration. However this long period of silence is coming to an end! Sound should be enabled and work out of the box from now on. If ever it does not, make yourself heard on the [bug tracker](https://bugs.kali.org/) ;)
**Python Command**
The command `python` is no more! Instead, you need to use `python3` (or [if you have to](https://www.kali.org/docs/general-use/using-eol-python-versions/), `python2` due it being at [End Of Life](https://dev.to/mohammadtaseenkhan/how-kali-deals-with-the-upcoming-python-2-end-of-life-3mbe-temp-slug-3201021)). Alternatively you can install `python-is-python3` to restore `python` as an alias for `python3`.
## Download Kali Linux 2021.4
**Fresh Images** : So what are you waiting for? Start [downloading](https://www.kali.org/get-kali/) already!
Seasoned Kali Linux users are already aware of this, but for the ones who are not, we do also produce **[weekly builds](https://cdimage.kali.org/kali-images/kali-weekly/)** that you can use as well. If you cannot wait for our next release and you want the latest packages _(or bug fixes)_ when you download the image, you can just use the weekly image instead. This way you’ll have fewer updates to do._Just know that these are automated builds that we do not QA like we do our standard [release images](https://www.kali.org/releases/)_. But we gladly take [bug reports](https://bugs.kali.org/) about those images because we want any issues to be fixed before our next release!
**Existing Installs** : If you already have an existing Kali Linux installation, remember you can always do a quick [update](https://www.kali.org/docs/general-use/updating-kali/):
```
┌──(kali㉿kali)-[~]
└─$ echo "deb http://http.kali.org/kali kali-rolling main contrib non-free" | sudo tee /etc/apt/sources.list
┌──(kali㉿kali)-[~]
└─$ sudo apt update && sudo apt -y full-upgrade
┌──(kali㉿kali)-[~]
└─$ cp -rbi /etc/skel/. ~
┌──(kali㉿kali)-[~]
└─$ [-f /var/run/reboot-required] && sudo reboot -f
```
You should now be on Kali Linux 2021.4. We can do a quick check by doing:
```
┌──(kali㉿kali)-[~]
└─$ grep VERSION /etc/os-release
VERSION="2021.4"
VERSION_ID="2021.4"
VERSION_CODENAME="kali-rolling"
┌──(kali㉿kali)-[~]
└─$ uname -v
#1 SMP Debian 5.14.16-1kali1 (2021-11-05)
┌──(kali㉿kali)-[~]
└─$ uname -r
5.14.0-kali4-amd64
```
_NOTE: The output of `uname -r` may be different depending on the system [architecture](https://pkg.kali.org/pkg/linux)._
As always, should you come across any bugs in Kali, please submit a report on our [bug tracker](https://bugs.kali.org/). _We’ll never be able to fix what we do not know is broken!_ **And [Twitter](https://twitter.com/kalilinux) is not a Bug Tracker!** | mohammadtaseenkhan | |
1,576,277 | Perbedaan flag --q -q -qq di unzip | Flag --q, -q, dan -qq dalam perintah unzip merujuk pada level verbosity atau tampilan pesan yang... | 0 | 2023-08-22T09:40:23 | https://dev.to/martabakgosong/perbedaan-flag-q-q-qq-di-unzip-23d1 | zip, linux, terminal, ubuntu | Flag `--q`, `-q`, dan `-qq` dalam perintah `unzip` merujuk pada level verbosity atau tampilan pesan yang ditampilkan selama proses ekstrak. Perbedaan dari masing-masing flag:
- **`--q` (Quiet):** Ini adalah flag yang dapat digunakan untuk mengurangi keluaran atau pesan selama proses ekstrak. Ketika flag `--q` digunakan, `unzip` hanya akan menampilkan pesan kesalahan atau peringatan yang penting. Pesan normal dan informasi ekstra tidak akan ditampilkan.
Contoh: `unzip --q file.zip`
- **`-q` (Quiet):** Ini adalah bentuk pendek dari flag `--q`. Penggunaan dan efeknya sama seperti yang dijelaskan di atas.
Contoh: `unzip -q file.zip`
- **`-qq` (Really Quiet):** Ini adalah bentuk yang lebih diam daripada `-q`. Saat menggunakan flag `-qq`, `unzip` hanya akan menampilkan pesan kesalahan yang sangat penting dan tidak akan menampilkan pesan peringatan apa pun.
Contoh: `unzip -qq file.zip`
| martabakgosong |
1,577,749 | The Best .NET Lookup Tool for Your Datagrid or Form Application | Learn about the best .NET lookup tool for your datagrid or form application. See more from ComponentOne today. | 0 | 2023-08-23T15:52:13 | https://developer.mescius.com/blogs/the-best-net-lookup-tool-for-your-datagrid-or-form-application | webdev, devops, dotnet | ---
canonical_url: https://developer.mescius.com/blogs/the-best-net-lookup-tool-for-your-datagrid-or-form-application
description: Learn about the best .NET lookup tool for your datagrid or form application. See more from ComponentOne today.
---
Every Windows application needs a good lookup tool. Users will rely heavily on that search box or drop-down at the top of the application to find records. Let me introduce you to one of our newest components, **C1MultiColumnCombo,** and show you why this is the best look-up tool you need in your application. Plus, I will show how you can quickly configure one.
## Both a Search Box and Selector
The C1MultiColumnCombo control works as both a search box and a drop-down selector. This gives you both types of functionalities - similar to an autocomplete control.
## Display Multiple Columns
The C1MultiColumnCombo control provides traditional combobox functionality with added support for multiple columns. This allows you to (more easily) visualize additional details for each record in the data set.
## Highlight and Filter Results
The C1MultiColumnCombo works like an autocomplete box that filters out and highlights records.
## Fast Data Binding
The C1MultiColumnCombo control supports data binding, making it easy to populate with records. The data binding follows traditional combobox-style binding where you specify which field is the display (for inside the header part) and which field is the bound value. This is typically used for visually transforming ID fields into readable displays.
```
var data = new BindingSource(DataSource.GetSalesInfo(), "");
c1MultiColumnCombo1.DataSource = data;
c1MultiColumnCombo1.DisplayMember = "Product";
c1MultiColumnCombo1.ValueMember = "Id";
```
## Form Input or Datagrid Cell Editor
In addition to being used as an application-wide search tool, you can use the component within an input form or as a datagrid cell editor. When you download ComponentOne WinForms Edition, we include some samples showing it used inside FlexGrid and DataGridView.
## Customize with a TreeView
You can even customize the drop-down content to display as a treeview using C1TreeView.
## Conclusion
To summarize, C1MultiColumnCombo provides:
* Traditional autocomplete functionality
* Highlights and filters results
* Displays multiple columns
Plus, it can be used in a variety of ways: application search, form input, datagrid editors, and customized views.
With multiple columns and search/highlight functionality, this makes it the best type of look-up control for your .NET Windows application. You can download the component as part of our WinForms Edition 2023 v2 update. Or, you can **get started by downloading it from nuget.org in the package C1.Win.Input.MultiColumnCombo**. The control is implemented using our FlexGrid control and also works as a replacement for our legacy C1Combo control. | chelseadevereaux |
1,579,965 | What is software testing? What we need to know about software testing? What is the relevance of software testing | Software testing is the process of evaluating and verifying that a software product or application... | 0 | 2023-08-25T15:08:46 | https://dev.to/saravana_kumar_22/what-is-software-testing-what-we-need-to-know-about-software-testing-what-is-the-relevance-of-software-testing-4b38 | testing | Software testing is the process of evaluating and verifying that a software product or application does what it is supposed to do, the benefits of software testing include preventing bugs, reducing development costs and improving performances
Types of testing: there are various types of software testing such as:
1.Unit testing: testing individual components or modules of the software
2.Integration testing: testing interactions between defferent modules
3.Functional testing: testing interactions between different modules
4.Regression testing: ensuring new changes don't negatively impact existing functionalities
5.Performance testing: assessing software performance under various conditions
6.Security testing: identifying vulnerabilities and ensuring data security
7.User acceptance testing: testing from an end-user perspective.
There are 3 types of testing levels:
1.White-box testing
2.black-box testing
3.gray-box testing
Importance of software testing:
*Identifying and fixing defects before deployment
*ensuring software meets quality standards
*providing a reliable and user-friendly experience
*fixing issues early reduces cost compared to post deployment fixes
*minimizing potential negative impacts on users or business
Some of the aspects of software testing:
*Comprehensive coverage: Testing should encompass different aspects of the software, including functional, non-functional, security and performance aspects
*early detection of issues: Detecting and addressing issues early in the development process is significantly more cost-effective than dealing with them after deployment
*Rick management: By uncovering potential risks and weaknesses in the software, testing contributes to reducing the risk
*User satisfaction: Testing contributes to the overall user experience. This allows the end-user to use a bug free product
Relevance of software testing
The relevance of software testing is deeply ingrained in its impact on the software quality. At first it ensures software quality by identifying and rectifying defects, ensuring that the final product is more reliable. by enhancing software quality, testing indirectly contributes to the customer satisfaction, brand and reputation
A buggy software release can lead to financial loses, damage to reputation and increased customer support costs.
In the modern digital landscape, software has became integral to nearly every one. from healthcare systems to financial transactions, software underpins critical processes. The relevance of the software testing is paramount, it safeguards against software failures that could potentially compromise patient care, disrupt financial operations
At the end of the day, software testing is the linchpin between software development and a successful, reliable, and user-friendly product. Its significance lies in ensuring software quality, mitigating risks, fostering business success and safeguarding user experiences. This approach ensures that only quality products are distributed to customers, which in turn elevates customer satisfaction and trust. As technology continues to advance, the role of software testing remains a cornerstone in the pursuit of digital excellence | saravana_kumar_22 |
1,589,069 | How We Fixed Performance With JS Object Variable Mutation | It’s vitally important in software development to figure out what your software will need to do and... | 0 | 2023-09-04T12:29:36 | https://bit.ly/js-object-variable-mutation-performance-issues-1 | javascript, appsmith, opensource, productivity | It’s vitally important in software development to figure out what your software will need to do and to make sure that the technologies you use to build it support this functionality. It is a major waste of resources, let alone a massive frustration to development teams, to have to go back to the drawing board.
Even with the most careful planning, however, things don't always go as you want them to. Some libraries and frameworks over-promise on features, leading teams to build on them only to find that their final product doesn't meet expectations. Additionally, developers working on products that tread new ground may run into unanticipated compatibility or performance issues.
This article explores one such scenario that we ran into while implementing a new piece of functionality — *JS Object variable mutation* — for our [Appsmith](https://docs.appsmith.com/) internal apps platform. If you're unfamiliar with us, you can check out how easy it is to use Appsmith to [build a CRUD app](https://www.appsmith.com/blog/building-a-crud-app-using-box-and-appsmith), and you can read about how we’re helping businesses [improve their internal processes](https://www.appsmith.com/case-studies) by giving them the tools to build better internal tools.
## Why are we talking about JS Object variable mutation in Appsmith?
Variable mutation, in its simplest definition, is changing the value of a programming variable. In the context of Appsmith, [JS Objects](https://docs.appsmith.com/core-concepts/writing-code/javascript-editor-beta) encapsulate variables and functions at a page-level scope for re-use — analogous in form and function to [JavaScript objects](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Guide/Working_with_objects), which encapsulate properties and methods.
Historically, variables stored in Appsmith JS Objects have acted as constants — they were defined in the application code and are immutable from there on. They could not be changed while the app was running. This was not very useful, and was always something that we knew we would need to address to make the JS Objects functionality feature-complete.
To the delight of our users who have been [waiting patiently for this feature](https://github.com/appsmithorg/appsmith/issues/3532#issuecomment-1246957408) to arrive, variable mutation in Appsmith’s JS Objects is now fully supported.
## How were users working around this issue?
Appsmith is a versatile platform, so the lack of variable mutation didn't slow down those using the platform to build their apps.
The workaround favored by most was to use Appsmith's [storeValue()](https://docs.appsmith.com/reference/appsmith-framework/widget-actions/store-value) function to save data for the [current session](https://docs.appsmith.com/reference/appsmith-framework/widget-actions/store-value#storage-states) from within JS Object functions. As this was not really what `storeValue()` was intended to be used for, it was neither convenient nor intuitive. Storing data from JS Objects in this way was overly verbose, requiring setting and retrieving them using names unique to each object. It was also slow, as it used the browser’s [sessionStorage](https://developer.mozilla.org/en-US/docs/Web/API/Window/sessionStorage) property.
In addition to being overly verbose when used to manage variables for JS Objects, using `storeValue()` required extra scaffolding to work. The key/value pairs stored using this method had to be initialized in a page load function before they could be read. Every object would need its own set of uniquely named key/value pairs stored in the session using `storeValue()` for each of its variables, with each being initialized on page load. It was a lot to keep track of, and it wasn't clear that this initialization process was necessary, leading to a lot of frustration.
Our users were quite clear that they were expecting mutable JS Object variables to arrive sooner rather than later. Appsmith's JS Objects are written in JavaScript and they're called “JS Objects,” so you’d expect that they would behave like JavaScript objects and let you update their variables!
## Initial implementation... and performance problems
So, that's what we built, and we built it in the most obvious way — using JavaScript [Proxy](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Proxy) objects to track mutations and reflect those changes across Appsmith’s framework. Initially things looked good — it worked, aside from a few hacks to make some data types work with [map](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Map) and [set](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Map/set), and we were following the example of [other projects that had similar requirements](https://immerjs.github.io/immer). *If it was good enough for them, it should be good enough for us, right?*
However, once we had fully implemented the functionality, we ran into performance issues caused by a mitigation that we had put in place. Appsmith relies on JavaScript [workers](https://developer.mozilla.org/en-US/docs/Web/API/Web_Workers_API/Using_web_workers) to execute the user's code from JS Objects, and when using a `Proxy` object, we cannot directly pass data from workers back to the main thread (which handles things like UI widgets bound to the variables in a JS Object). This is because the [postMessage API](https://developer.mozilla.org/en-US/docs/Web/API/Window/postMessage) that is used to send messages between the web workers and the main thread internally uses the [structuredClone()](https://developer.mozilla.org/en-US/docs/Web/API/structuredClone) function, which [does not support](https://bugzilla.mozilla.org/show_bug.cgi?id=1269327) `Proxy` objects. To get around this, we were using our own nested cloning algorithm that removed the `Proxy` object in the worker thread before passing it to the main thread, which was harming performance.
Whenever we had to send data to the main thread back from a worker, this cloning algorithm had to run. Wherever and whenever the data in the JS Object appeared, the algorithm was triggered. This was OK when an app used only a few simple objects, but the more objects with the more mutable variables were added, the worse performance would become. Our users build complex applications, so this proportional degradation of performance was unacceptable.
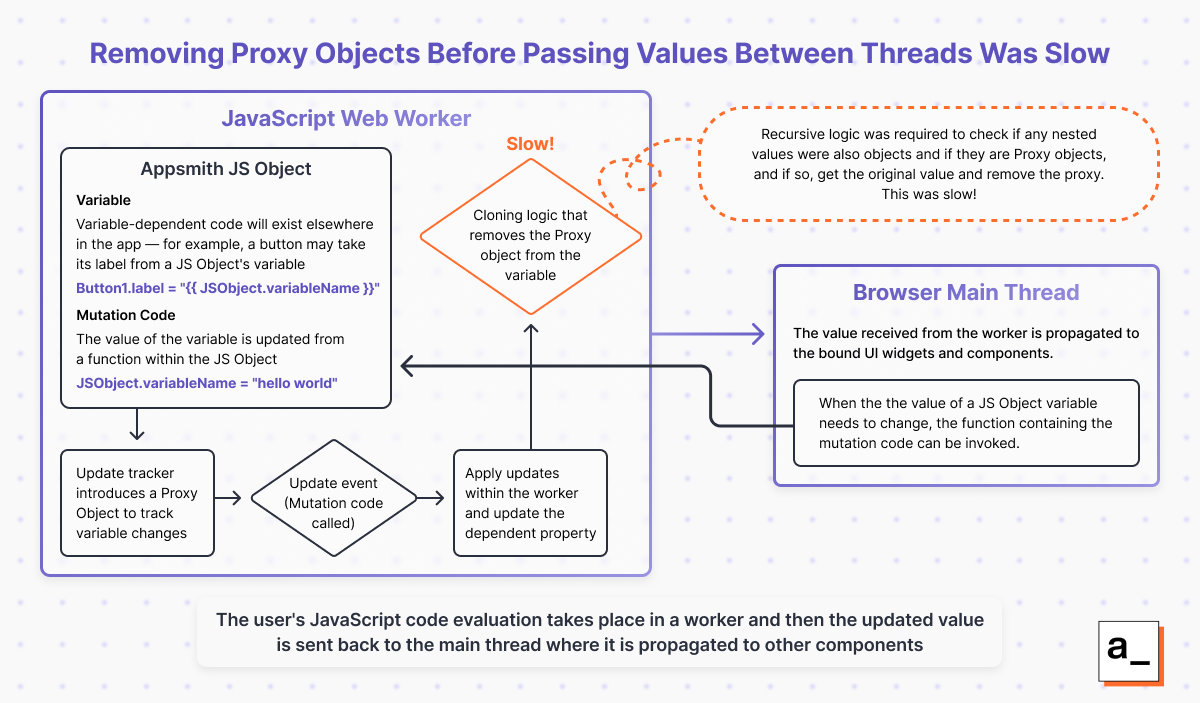
This diagram shows how our initial solution to passing data from the worker to the main thread worked — and where the slowdown was occurring. You can also see the code we used [here](https://gist.github.com/Rishabh-Rathod/c13abb0c6fcb49269377f9aa08d88b8f#file-jsproxy-ts).
Architecture-wise, this feature was also hard to maintain. The algorithm for cloning the data had to appear everywhere the data was used – so if we missed it in even a single place when adding a new feature, we’d introduce a bug. However, if it had been performant and provided the best results for our users of all available options, we would have stuck with it.
The reality was, using `Proxy` objects to achieve variable mutation in this manner was just too slow and we couldn't justify releasing it as it was. We assessed the potential impact of holding this feature back from our users (*and carefully considered how much goodwill we had!*) and decided to find a better way.
## How we did it better — matching the existing functionality, with great performance
So, we had a problem to solve — we had to mimic the functionality provided by the initial solution, but without the downsides. We had to get creative. Deciding to rebuild a feature that already had resources invested in it isn't favorable from a planning perspective, but from a programmer’s perspective it's great — we *love* to problem solve.
We wanted a solution that solved both the performance and development issues caused by the cloning algorithm. It had to be efficient, so that the user interface didn’t become slow or unresponsive, and [DRY](https://en.wikipedia.org/wiki/Don%27t_repeat_yourself), so that we wouldn't have to call the algorithm at every appearance of an Appsmith JS Object.
Our ultimate solution wound up being pretty simple. Instead of using a `Proxy` object to intercept and track changes to a JS Object’s variables, we have a custom class that takes a variable from a JS Object as input and adds setter/getter methods that track read and write operations to the variable itself. Calling a setter indicates that a variable may have been updated, and we can then run some differential logic on it to confirm whether there was an actual update. Once the change has been confirmed, it can be propagated and passed from the worker to the main thread. You can see the code behind this [here](https://gist.github.com/Rishabh-Rathod/56ca34c0e384cd766fb96763c629dcc3).
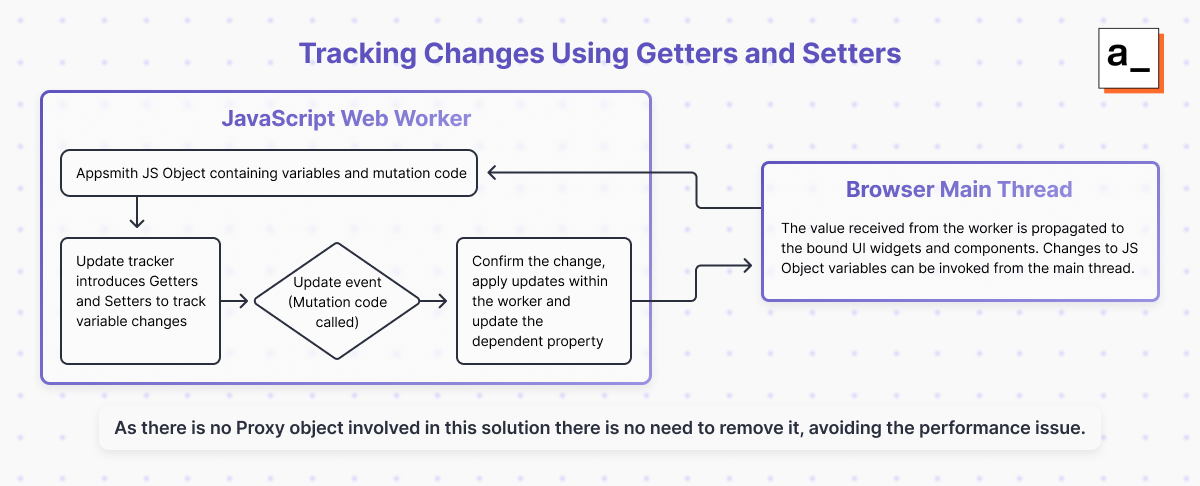
This diagram shows our updated solution, and how we avoided using Proxy objects to track changes.
As we no longer have any `Proxy` object, we don't need any nested cloning logic to remove it from the JS Object variable before passing it from the worker to the main thread. This removes the performance issue as it’s much cheaper to call the getter or setter than run the cloning algorithm.
I'm sure that to some programmers this may not seem to be the best way to track updates when compared to the `Proxy` implementation — but when workers are involved, we found this new approach to be very practical. Most importantly, it worked, and it was *fast*. We could return to our users with a solution that would really improve their experience with our product.
## Delivering on promises to users without compromising the Appsmith experience
We could have delivered JS Object mutation in its initial state and just added the proviso *“Hey, it works well enough, it's just slow if you use too many variables! If you suffer performance issues, restructure your app!”* Many products foist the consequences of poor implementation on the user and frame it as a problem for them to solve. *This isn’t good enough for us.* We wanted to fully implement this feature in a way that would give our users what we had promised them without compromising the performance of our platform.
Now that we’ve achieved this, we’re looking at how we can more quickly identify potential problems with our planned implementation, so that we can reduce the delays caused when this happens. We are also making sure that we keep in touch with those who have reached out to us about the features they need and the bugs they may have encountered, and keep them up to speed with progress so that they can align their own development timelines with ours.
This experience highlighted to me the importance of staying engaged with your community, making sure you listen to them, and keeping them informed about any developments that affect them. By listening to your users, you will know which features to prioritize, and you can make sure to set realistic expectations for them and validate their feedback. That way, if there are delays, you are more likely to be met with understanding rather than frustration.
You also can’t go breaking the user experience for a solution that technically works, but degrades the overall user experience, to solve a single problem. It’s important to not settle on the first solution to a problem if it isn’t good enough — even if it appears to be the only one at first. Programming is a creative endeavor, and there’s (almost) always a workaround.
If you're interested in reading more about how we go about building Appsmith, [check out our blog](https://www.appsmith.com/blog). If you want to see the results of our hard work in action, Appsmith offers a [free cloud-hosted version](https://app.appsmith.com/user/signup), or you can host on your own infrastructure using [Docker](https://docs.appsmith.com/getting-started/setup/installation-guides/docker).
| rishabhrathod01 |
1,603,984 | Explore Job Ads APIs with Our Platform | Are you an entrepreneurial digital native looking to leverage the power of job ads data for your... | 0 | 2023-09-18T16:06:05 | https://dev.to/techmap/explore-job-ads-apis-with-our-platform-4mk3 | competitiveanalysis |
Are you an entrepreneurial digital native looking to leverage the power of job ads data for your business? Look no further! With our platform, you can explore job ads APIs and unlock valuable insights that can help drive your growth and success. Whether you're a recruiter, a data scientist, or a business analyst, our platform offers unparalleled access to job postings across industries and geographies. In this article, we will delve into the benefits of exploring job ads APIs with our platform and how it can enhance your market intelligence capabilities.
## Uncover Hiring Trends and Market Insights
Job postings provide a wealth of information about current and past hiring trends within specific industries or regions. By analyzing job ads data, you can gain valuable insights into emerging trends in job roles, new technologies, expanding markets, popular tools and software, industry standards, and more! This information is crucial for staying ahead of the competition and making informed decisions about your business strategy.
With our platform's job ads APIs, you can easily extract insights from thousands of job postings in real-time. Whether you're interested in understanding the hiring practices of specific companies or tracking industry-wide trends, our APIs provide the data you need to stay informed.
## Enhance Sales Intelligence and Find New Leads
Looking for new leads for your solutions? Leveraging job postings can be a game-changer for enhancing your sales intelligence capabilities. By analyzing job ads data, you can identify companies that may be interested in your products or services based on their hiring needs.
Our platform's job ads APIs allow you to search for specific keywords or criteria related to your offerings. For example, if you provide HR software solutions, you can search for companies that mention "HR software" or "applicant tracking system" in their job postings. This targeted approach helps you identify potential customers who are actively seeking solutions like yours.
## Stay Informed About Competitors
Keeping an eye on your competitors is essential for staying ahead in the market. Job postings can provide valuable insights into your competitors' growth trajectory, organizational structure, and hiring strategy.
With our platform's job ads APIs, you can easily monitor your competitors' job postings in real-time. This allows you to benchmark their hiring activities and identify any changes in their focus areas or expansion plans. By staying informed about your competitors' activities, you can make strategic decisions to stay one step ahead.
## Optimize Your Hiring Strategy
Job postings not only help you analyze the labor market trends but also optimize your own hiring strategy. By analyzing job ads data, you can gain insights into changes in candidate preferences, benefits offered by companies, or evolving job requirements.
Our platform's job ads APIs enable you to analyze historical data and track changes over time. This helps you understand how the hiring landscape has evolved and adapt your recruitment strategies accordingly. For example, if you notice a shift towards remote work in job postings within your industry, it may be time to consider offering flexible work options to attract top talent.
## Monetize Your Platform with Job Board Backfill
If you operate a job board or a niche website, backfilling job postings from important companies or specific technologies can significantly enhance your traffic and ad revenue. With our platform's job ads APIs, you can easily integrate relevant job listings into your site without the need for manual data entry.
Backfilling job postings allows you to provide comprehensive and up-to-date information to your users while monetizing your platform through advertising revenue. By leveraging our APIs, you can offer a seamless user experience while generating additional income for your business.
## Conclusion
Exploring job ads APIs with our platform offers numerous benefits for entrepreneurial digital natives like yourself. It allows you to extract valuable market insights, enhance sales intelligence capabilities, stay informed about competitors, optimize your hiring strategy, and monetize your platform with ease.
Operating one's own scraping infrastructure to collect job posting data can be a time-consuming and costly endeavor. Instead, by simply buying job posting data through our platform, you can save unnecessary effort and expenses while gaining access to comprehensive and reliable data.
So why wait? Start exploring job ads APIs with our platform today and unlock the power of job postings for your business success! | techmap_dev |
1,589,453 | Cómo usar el patrón facade para crear componentes personalizados y desacoplar tu código de librerías de terceros | Problema 🤔 En el desarrollo frontend moderno, normalmente se suele utilizar librerías de... | 0 | 2023-09-10T17:28:28 | https://dev.to/vladern/como-usar-el-patron-facade-para-crear-componentes-personalizados-y-desacoplar-tu-codigo-de-librerias-de-terceros-3mlm | webdev, typescript, frontend | ## Problema 🤔
En el desarrollo frontend moderno, normalmente se suele utilizar librerías de componentes como MUI, Angular Material, Chakra UI, etc. Estas librerías nos ayudan a ser más rápidos en nuestro desarrollo, pero también tienen sus inconvenientes. Por ejemplo:
- A medida que el proyecto crece y se van utilizando dichos componentes alrededor de toda nuestra aplicación, nos acoplamos más y más a estas mismas librerías. Si en el futuro queremos utilizar otra librería para un componente, muchas son las páginas que habría que tocar para sustituirlo.
- El tiempo también pasa y estas librerías se van deprecando ciertas interfaces y actualizando otras muchas. A quien no le ha pasado que al actualizar una versión de un framework CSS le cambian el nombre a una clase CSS y ya toca cambiar este nombre por toda la aplicación.
- Además, si utilizas varias librerías en tu proyecto, cada vez que quieras saber qué interfaz tiene un componente te toca ir a la documentación oficial de dicha librería para ver qué propiedades tiene y cómo se utilizan. Haciendo que tu código sea difícil de comprender y mantener.
¿Cómo podemos evitar estos problemas y hacer que nuestro código sea más legible, modular y reutilizable? En este artículo, te mostraré cómo puedes crear tus propios componentes personalizados usando las mejores prácticas de desarrollo frontend.
### Ejemplo práctico
Para ilustrar el problema y la solución, vamos a usar un ejemplo sencillo. Imagina que tienes que crear una página que liste postres ordenados por sus calorías. Si utilizas MUI, una librería de componentes basada en React, lo primero que tendrás que hacer es importar los distintos componentes que componen la tabla:
```
import Table from '@mui/material/Table';
import TableBody from '@mui/material/TableBody';
import TableCell from '@mui/material/TableCell';
import TableContainer from '@mui/material/TableContainer';
import TableHead from '@mui/material/TableHead';
import TableRow from '@mui/material/TableRow';
import Paper from '@mui/material/Paper';
```
Luego utilizarás dichos componentes dentro de la página donde quieras la tabla:
```
<TableContainer component={Paper}>
<Table sx={{ minWidth: 650 }} aria-label="simple table">
<TableHead>
<TableRow>
<TableCell>Dessert (100g serving)</TableCell>
<TableCell align="right">Calories</TableCell>
<TableCell align="right">Fat (g)</TableCell>
<TableCell align="right">Carbs (g)</TableCell>
<TableCell align="right">Protein (g)</TableCell>
</TableRow>
</TableHead>
<TableBody>
{rows.map((row) => (
<TableRow
key={row.name}
sx={{ '&:last-child td, &:last-child th': { border: 0 } }}
>
<TableCell component="th" scope="row">
{row.name}
</TableCell>
<TableCell align="right">{row.calories}</TableCell>
<TableCell align="right">{row.fat}</TableCell>
<TableCell align="right">{row.carbs}</TableCell>
<TableCell align="right">{row.protein}</TableCell>
</TableRow>
))}
</TableBody>
</Table>
</TableContainer>
```
Como puedes observar, esta tabla es muy flexible y dinámica, pero también tiene algunos inconvenientes:
- Al usar los componentes de MUI directamente en la página, tu código queda acoplado a esta librería y depende de sus cambios y actualizaciones.
- Además, si usas el mismo componente de tabla en distintas páginas para mostrar otras cosas, toda tu aplicación queda acoplada a esta librería, lo que dificulta su mantenimiento y escalabilidad.
## Solución 🧐
En esta parte, te voy a explicar cómo puedes aplicar el patrón facade para mejorar la calidad y la mantenibilidad de tu código. El patrón facade es un tipo de patrón de diseño estructural que se usa para simplificar la interacción con un subsistema complejo. Consiste en crear un objeto de fachada que implementa una interfaz sencilla y unifica las distintas interfaces del subsistema o subsistemas. De esta forma, se reduce el acoplamiento entre los clientes y el subsistema, y se facilita su uso y comprensión.
### Ejemplo de aplicación
Para ilustrar el uso del patrón facade, vamos a retomar el ejemplo de la tabla que lista postres ordenados por sus calorías. En lugar de utilizar directamente los componentes de MUI en la página que vamos a mostrar al usuario final, vamos a crear un componente personalizado que encapsule la lógica y el estilo de la tabla. Este componente será nuestra fachada, y nos permitirá abstraer la complejidad de los componentes de MUI y desacoplar nuestro código de la librería.
El código de nuestra página quedaría algo así:
```
import TableComponent from '@lib/componets/data-display/table';
const headElements: HeadElement<Desert>[] = [
{ id: 'name', label: 'Postre' },
{ id: 'calories', label: 'Calorías' },
{ id: 'fat', label: 'Grasa' },
{ id: 'carbs', label: 'Carbohidratos' },
{ id: 'protein', label: 'Proteinas' }
];
const data = [{name: 'Yogur', calories: 200, fat: 100, carbs: 0, protein: 130}];
export default function Page() {
return (
<TableComponent<Desert>
rowKeys={['name', 'calories', 'fat', 'carbs', 'protein']}
rows={data}
headElements={headElements}
/>
)
}
```
Como puedes ver, el código es mucho más simple y legible. Solo tenemos que importar nuestro componente personalizado `TableComponent` y pasarle los datos que queremos mostrar como props. No tenemos que preocuparnos por los detalles internos de los componentes de MUI, ni por sus posibles cambios o actualizaciones.
El código de nuestro componente `TableComponent` sería algo así:
```
// TableComponent.tsx
import React from 'react';
import Table from '@mui/material/Table';
import TableBody from '@mui/material/TableBody';
import TableCell from '@mui/material/TableCell';
import TableContainer from '@mui/material/TableContainer';
import TableHead from '@mui/material/TableHead';
import TableRow from '@mui/material/TableRow';
import Paper from '@mui/material/Paper';
type HeadElement<T> = {
id: keyof T;
label: string;
};
type Props<T> = {
rowKeys: Array<keyof T>;
rows: Array<T>;
headElements: Array<HeadElement<T>>;
};
function TableComponent<T>(props: Props<T>) {
const { rowKeys, rows, headElements } = props;
return (
<TableContainer component={Paper}>
<Table sx={{ minWidth: 650 }} aria-label="simple table">
<TableHead>
<TableRow>
{headElements.map((headElement) => (
<TableCell key={headElement.id}>{headElement.label}</TableCell>
))}
</TableRow>
</TableHead>
<TableBody>
{rows.map((row) => (
<TableRow
key={row.name}
sx={{ '&:last-child td, &:last-child th': { border: 0 } }}
>
{rowKeys.map((rowKey) => (
<TableCell key={rowKey} align="right">
{row[rowKey]}
</TableCell>
))}
</TableRow>
))}
</TableBody>
</Table>
</TableContainer>
);
}
export default TableComponent;
```
Aquí podemos ver cómo nuestro componente `TableComponent` implementa la lógica y el estilo de la tabla usando los componentes de MUI y los props que recibe. Nuestro componente es genérico y puede recibir cualquier tipo de dato como prop, siempre que se especifiquen las claves y los elementos del encabezado. De esta forma, podemos reutilizar nuestro componente en diferentes páginas y proyectos sin depender de la librería MUI.
## Conclusiones 🙂
Para terminar, vamos a resumir las ventajas e inconvenientes del patrón facade:
- Ventajas:
- Nos ayuda a desacoplar nuestro proyecto de librerías de terceros.
- Facilita el mantenimiento y la actualización de nuestro código.
- Se puede aplicar a otras dependencias de nuestra aplicación.
- Inconvenientes:
- Nuestra fachada puede convertirse en un objeto todo poderoso (hay que respetar el principio de responsabilidad única) .
- Puede ocultar la complejidad del subsistema y dificultar su depuración.
Espero que este artículo te haya servido para comprender mejor el patrón facade y cómo puedes usarlo para mejorar la calidad y la mantenibilidad de tu código. Si tienes alguna duda o comentario, no dudes en contactarme. 😊
## Referencias
- [Facade (patrón de diseño)](https://refactoring.guru/es/design-patterns/facade)
- [MUI: A popular React UI framework](https://mui.com/material-ui/react-table/)
[Principio de responsabilidad única - Wikipedia](https://es.wikipedia.org/wiki/Principio_de_responsabilidad_única)
| vladern |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.