
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,589,677 | Navigating the shift from customer service to coding | In the rapidly evolving landscape of software development, professionals with diverse backgrounds... | 0 | 2023-09-11T01:49:30 | https://dev.to/wdp/navigating-the-shift-from-customer-service-to-coding-oe6 | webdevpathsuccess, techcareerjourney, opensourcecollaboration |
In the rapidly evolving landscape of software development, professionals with diverse backgrounds bring unique perspectives and valuable skills to the table. Meet [Thorrell Turner](https://www.linkedin.com/in/thorrellt/), a Mobile Software Developer currently dedicated to a healthcare platform that aims to improve accessibility to medical care. Balancing work and a family of five, Thorrell successfully transitioned from a career in Customer Service to the tech industry, leveraging his Bachelor's degree in Computer Science. With his solid foundation and a [portfolio](https://thorrellt.com/) showcasing his expertise in mobile software development, Thorrell is driven to make a meaningful impact in the field.
Explore our interview with Thorrell as we delve into his inspiring story, his experiences in web development, and his significant contributions to the [Web Dev Path project](https://www.webdevpath.co/)—an open-source initiative that empowers aspiring tech professionals, such as designers, developers, and project managers to gain practical, real-life experience. Through his narrative, we aim to inspire others considering a similar path and emphasize the boundless opportunities that come with embracing change and pursuing a fulfilling career in the ever-evolving world of mobile software development.
---
**Can you share your experience, your background in web development, and how it led you to contribute to the Web Dev Path project?**
Absolutely! My journey in web development began when I decided to make a career transition to software development. At the time, I had approximately one year of web development experience under my belt. Most recently, I completed a project utilizing React and Node.
While I was focusing on securing more job interviews to gain industry-worthy experience, a close friend introduced me to the Web Dev Path project. Intrigued by its details, I dove in and immediately knew that I wanted to be part of this initiative. I quickly familiarized myself with Next.js and React and reached out the very next day to offer my contribution.
**As a software developer with full-stack experience, how do you see the Web Dev Path project benefiting aspiring web developers in their learning journey?**
The Web Dev Path project offers aspiring web developers several valuable benefits. Firstly, it provides an opportunity to interact with an existing codebase, which is crucial since professionals will often encounter code written by others in their careers. This project allows individuals to enhance their ability to understand and work with unfamiliar code—an essential skill in the industry.
The project also offers access to more experienced developers, creating an invaluable learning environment. Being part of the Web Dev Path community saved me time and alleviated stress through discussions about solutions, strategies, and providing insights into the logic behind specific decisions.
**Can you describe some of the key features and functionalities of the Web Dev Path project that make it a valuable resource for individuals looking to enter or progress in the field of web development?**
For those lacking professional experience in the tech industry, like myself when I first contributed to the project, Web Dev Path plays a significant role in introducing core aspects of the development lifecycle. Participants have the opportunity to assign themselves tasks with requirements, test code, document changes, and more—replicating real-world scenarios.
From my perspective as a developer starting out, the most impactful aspect of the Web Dev Path project was the experience gained with Git. This ranged from cloning a repository, running it on my local machine, to completing pull requests and merging changes. In fact, during an interview that led to my first job offer, I successfully answered a Git question based on knowledge gained through my involvement with the project.
**How do you believe the Web Dev Path project promotes a sense of community and knowledge sharing among aspiring web developers, considering your personal values of collaboration and learning?**
The Web Dev Path community emanates warmth and a genuine eagerness to assist others. It creates a safe space where individuals feel empowered to ask questions, even if they consider them "dumb." This environment fosters learning and personal growth.
Having mostly pursued my journey in isolation, it was a refreshing change to engage in brainstorming dialogues within the community and discover insightful articles or videos recommended by fellow members. I quickly realized how much I had limited myself by not embracing collaboration earlier.
**What advice would you give to aspiring web developers who are interested in leveraging the Web Dev Path project to enhance their skills and knowledge? How can they make the most out of this open-source resource?**
To those interested in maximizing their benefit from the Web Dev Path project, I encourage you to dive in even before you feel completely ready. Embrace the challenge of stepping out of your comfort zone, as that's where lasting knowledge is truly built.
Additionally, make sure to document and leverage the experience gained from contributing to an open-source project like this. Take notes of your contributions with the intention of showcasing them on your resume or discussing them during interviews.
For those with limited tech experience on their resume, consider using headings like "Technical Experience" and "Non-technical Experience" instead of the traditional "Work Experience." Under the "Technical Experience" section, you can list any technical work experience you may have, as well as your open-source contributions and personal projects. This approach can provide an edge and catch the attention of recruiters, especially if your "Technical Experience" section spans half a page or more.
---
## Conclusion
Thorrell's journey from Customer Service to Tech exemplifies the possibilities that arise from transitioning careers. Through his interview, Thorrell invites aspiring web developers to embrace challenges and leverage resources like open-source projects to enhance their skills and knowledge in the dynamic field of web development.
As we conclude our conversation with Thorrell, we encourage you to explore the transformative impact of the Web Dev Path project. Join the vibrant community of like-minded individuals, embark on your own journey of growth, and unlock new opportunities. Visit the [Web Dev Path website](https://www.webdevpath.co/) to discover how you can contribute and propel your web development career forward.
| marianacaldas |
1,592,016 | Laravel 10 Image Upload Tutorial | A Laravel 10 image upload tutorial is a step-by-step guide that teaches you how to implement image... | 0 | 2023-09-07T06:06:18 | https://dev.to/tutsmake/laravel-10-image-upload-tutorial-10cj | A Laravel 10 image upload tutorial is a step-by-step guide that teaches you how to implement image uploading functionality in a web application using the Laravel PHP framework. Laravel is a popular web application framework that simplifies the development of web applications, and it provides various tools and features to make tasks like image uploading relatively straightforward.
## Laravel 10 Image Upload Tutorial
To upload an image in Laravel 10, you can follow these steps:
- Setting Up Laravel: The tutorial will typically start by guiding you through the process of setting up a Laravel project on your development environment. You'll need PHP, a web server (like Apache or Nginx), Composer, and Laravel installed.
- Creating a Database: If your application requires storing information about the uploaded images, you may need to set up a database table for this purpose. The tutorial might include instructions on creating a migration and running it to create the necessary table.
- Creating a Form: You'll learn how to create an HTML form that allows users to select and upload images. Laravel's Blade templating engine is often used to generate the form.
- Handling Form Submission: The tutorial will show you how to handle the form submission in a Laravel controller. You'll learn how to validate the uploaded file and store it on the server.
- Uploading and Storing Images: This section will cover how to upload the image to a specific folder on the server. Laravel's file handling functions like store() or move() will be used.
- Displaying Uploaded Images: You'll learn how to display the uploaded images on your website, either by serving them directly from the server or by using Laravel's asset management system.
- Validating Images: To ensure that the uploaded files are valid images, the tutorial might include information on image validation, checking file types, and preventing malicious uploads.
- Thumbnail Generation: If needed, the tutorial might cover how to generate thumbnails or resize uploaded images using packages like Intervention Image.
- Security Considerations: You'll learn about security best practices, such as validating and sanitizing user input, protecting against image-based attacks, and securing your image upload routes.
- Authentication and Authorization: Depending on the application, you might learn how to implement authentication and authorization to control who can upload images.
- Error Handling: The tutorial may cover handling errors gracefully, such as displaying error messages to users when image uploads fail.
- Testing: You might be introduced to writing tests to ensure that your image upload functionality works as expected.
- Deployment: The tutorial might include guidance on deploying your Laravel application to a production server, including configuring file storage for uploaded images.
- Best Practices: Throughout the tutorial, best practices for organizing code, structuring your Laravel application, and optimizing image uploads may be emphasized.
- Conclusion: The tutorial will usually conclude with a summary, pointers to additional resources, and suggestions for further improvements or customization.
Read More [Laravel 10 Image Upload Tutorial](https://www.tutsmake.com/laravel-10-image-upload-tutorial/) | tutsmake | |
1,595,365 | Relationship Based Access Control (ReBAC): Using Graphs to Power your Authorization System | Setting the scene: AuthZ vs AuthN Have you ever chatted with a fellow developer about an... | 0 | 2024-01-10T16:20:37 | https://authzed.com/blog/exploring-rebac | ---
title: Relationship Based Access Control (ReBAC): Using Graphs to Power your Authorization System
published: true
date: 2021-03-03 00:00:00 UTC
tags:
canonical_url: https://authzed.com/blog/exploring-rebac
---
## Setting the scene: AuthZ vs AuthN
Have you ever chatted with a fellow developer about an application's permission system and quickly realized you're also talking about its login system? It's rather unfortunate, but these two entirely distinct systems often get merged together simply because their formal names start with the same four letters: **AUTH**.
> Authentication ("authN" or "identity") is who you are
>
> Authorization ("authZ" or "permissions" or "access control") is what you're allowed to do
This is no amateur mistake. Even [major web frameworks](https://docs.djangoproject.com/en/3.1/ref/contrib/auth/) bundle these concepts together out of convenience.
Because so many applications need to support users from inception, identity becomes vital for developers to understand on day one. However, building a robust permission system can usually be deferred until users start demanding it. When requests for [fine grained access control](https://authzed.com/blog/blog/fine-grained-access-control) inevitably start pouring in, they often come alongside feature requests for integrations with various [Identity Providers](https://en.wikipedia.org/wiki/Identity_provider). This makes it seem natural to assume that the permission systems should be direct integrations with the primitives that the Identity Providers expose. However, the _authorization_ functionality that is often found in most _authentication_ systems is generally overly simplistic and the resulting permissions systems that are built on top are usually fragile and error prone.
This is the last thing you want to hear when discussing software that determines whether or not a user has access to sensitive content. If you're thinking "that's only if you work in a domain, like healthcare or government, where you know sophisticated access control is required", you should consider that even in simple use cases you'll likely be iterating on your design, which gives you ample opportunities to introduce bugs that manifest themselves as security vulnerabilities.
## LDAP flips Conway's Law on its head
> Any organization that designs a system (defined broadly) will produce a design whose structure is a copy of the organization's communication structure.
>
> — Melvin E. Conway
Conway's Law describes how the architecture of software is a reflection of the organization of the people who built it. For example, software components that are decoupled, but belong to the same application are often separate only because they were built by separate teams.
When permission systems are based on Identity Providers, this law is entirely reversed.
If an organization of people cannot use any software because everything, for example, only supports a structure that can be modeled by [LDAP Groups](https://ldapwiki.com/wiki/Groups%20Are%20Bad), it forces the people to reorganize into something that can be modeled by LDAP Groups.
This may be viable for organizations like businesses (the reorgs will continue until morale improves!), but obviously not all software can demand that their users reorganize just to use their product.
## Groups, Scopes, Claims don't answer the question
LDAP Groups, OAuth Scopes, SAML Claims, [JWT Claims](https://authzed.com/blog/pitfalls-of-jwt-authorization): all a rose by any other name. These concepts all represent the same kind of data: an _[attribute](https://docs.authzed.com/authz/abac)_ that is stored on a user, indicating something about that user. Attributes are useful: they can provide context about a user (such as an object they can access, or a role that the user has), which makes such a system, in theory, a reasonable solution to determining what a user can access. However, in practice, developers realize that this isn't quite so obvious once they have started working with this data.
Software that relies on these concepts for permissions all struggle in the same core principle: how they choose to interpret and apply significance to the presence of an attribute:
- If a user has both the "admin" and the "banned" attribute, what is the correct action?
- Should admins be able to ignore bans or was the employee just fired from the company?
- What about attributes that imply other attributes?
- Does being "admin" also imply "write" access to this resource?
You can see how this quickly gets out of hand. And once it's been decided how attributes should be properly interpreted, it's time to audit every other application and make sure they interpret the attribute the exact same way or else you might have a security problem!
Now, there is nothing fundamentally wrong with attribute-based permission systems. In fact, mature permission systems are almost always a fusion of ideas from [various models] based on the requirements at hand. In this case, how the attributes from _authentication_ systems manifest themselves when they become the foundation of a permission system is the problem. This is because attributes can only state facts about an identity. But what we really need is the answer to the question "can this subject take this action on this resource?".
## Intro to Relationship-Based Access Control (ReBAC)
While identity is required to ask the question "Does this `subject` have permission to do this `action` to this `object`?", it is not the _only_ variable. Identity sits alongside the _action_ and the _object_. That's all well and good, but how _should_ one arrive at the answer to one of these questions?
A great place to start is to crack open a social network like Facebook. Go review (and probably update) your privacy settings; you'll find a variety of configurations for sharing your content like friends-only or friends-of-friends. When you change that setting, you'll find that it applies instantaneously; there is no migration happening in their backend where thousands of users are granted the attribute to view your content. This is because Facebook is designed to store and query _relationships_ between their users. Facebook is powered by a social _graph_.
If we lean on the idea of modeling relationships, like Facebook does, you can change the question from "Does X have permission to do Y to Z?" into "Does X have the relationship Y with Z?". For example, "Does User #123 have the Write relationship with Document #456?". Recall the example from reading attributes where the application has to decide if the "admin" attribute also implies the "write" attribute. In a relationship-based access control model, this problem disappears because these are just more relationships:

The beauty of a relationship-based access control is that the application doesn't care _how_ the user got to the Write relationship. Maybe they're the user that created the document. Maybe the user had some kind of admin relationship that gives them the ability to do everything. It doesn't matter as long as there is some path through our relationship graph from the user to the Write relationship on the document.

This means that relationships can change (like changing your privacy settings) and applications will not need to have their code rewritten because there was no longer anything left open to interpretation.
## So how does Relationship-Based Access Control (ReBAC) work?
ReBAC, or Relationship-Based Access Control, is a modern approach to access control that focuses on the relationships between users or services, aka subjects, and resources. Instead of relying solely on traditional role-based access control (RBAC) or attribute-based access control (ABAC), ReBAC takes into account the dynamic nature of relationships within an organization. In ReBAC, access control is not assigned based on predefined roles or attributes. Instead, they are determined by the relationships between subjects and resources. This means that access to certain resources can be granted or revoked based on the specific relationships a user has with those resources.
For example, let's say you have a project management application. In a traditional RBAC system, you might assign defined roles such as "project manager" or "team member" to users, and those roles would determine their access to various project resources. However, in a ReBAC system, permissions would be determined by the specific relationships between users and projects, and not the explicit roles assigned to them. That is one the main differences between RBAC and ReBAC.
This relationship-based approach offers several advantages:
It allows you to build fine-grained access control systems. Instead of relying on broad roles, you can define specific relationships and their associated permissions. This leads to a more flexible and scalable permission system that can adapt to changes in the organization.
ReBAC enables a more intuitive and natural way of managing access control. Instead of trying to fit users into predefined roles or attributes, you can simply define the relationships they have with resources. This makes it easier to understand and manage permissions, especially in complex organizational structures. ReBAC promotes a more collaborative and dynamic approach to access control. As relationships between users and resources evolve, access permissions can be easily adjusted to reflect those changes. This ensures that the right people have the right level of access at any given time.
[SpiceDB](https://authzed.com/products/spicedb), our open-source Google Zanzibar-inspired authorization authorization service, provides a solid foundation for implementing ReBAC. It offers a flexible authorization model and powerful query capabilities, allowing you to efficiently manage and enforce access control policies based on relationships. With SpiceDB, you can easily define fine-grained permissions and dynamically update them as relationships evolve. Following its muse, Google Zanzibar, SpiceDB is meant to be distributed which ensures high performance and fault tolerance, making it suitable for large-scale applications.
## Restoring Conway's Law
By realizing that permissions systems are fundamentally coupled to the _relationships_ between people and objects in our software, we can build systems that mimic the way people naturally organize their world to be most effective. This not only empowers the people consuming the software but leads developers to arrive at more robust permission systems that can withstand changes to the organization.
If you're left wondering what a permission system based on relationships looks like in practice, [Authzed](https://authzed.com) is exactly that! We're currently working hands-on with customers to help them understand and migrate to a better permission system. If adding or refactoring permissions to support new functionality in your app is next on your roadmap, [reach out to us](https://authzed.com/contact).
## Additional Reading
If you’re interested in learning more about Authorization and Google Zanzibar, we recommend reading the following posts:
- [Understanding Google Zanzibar: A Comprehensive Overview](https://authzed.com/blog/what-is-google-zanzibar)
- [A Primer on Modern Enterprise Authorization (AuthZ) Systems](https://authzed.com/blog/blog/authz-primer)
- [Fine-Grained Access Control: Can You Go Too Fine?](https://authzed.com/blog/blog/fine-grained-access-control)
- [Pitfalls of JWT Authorization](https://authzed.com/blog/pitfalls-of-jwt-authorization) | authzd | |
1,595,519 | Exploring the basics of Hono, a fast and lightweight alternative to Express. | Express Express has historically been a popular choice for constructing RESTful APIs and... | 0 | 2023-09-10T12:59:06 | https://dev.to/ntstarling/exploring-the-basics-of-hono-a-fast-and-lightweight-alternative-to-express-3me4 | webdev, javascript, hono, programming |
### Express
Express has historically been a popular choice for constructing RESTful APIs and application backends. However, with the emergence of newer tools and technologies, Express's dominant position in these areas is facing competition.
### Hono
Hono is such an alternative to express which is an ultrafast web framework which is capable of creating RESTful APIs and backends for your applications. According to a benchmark, It is about 12 times faster than express.
### What is Hono?
According to the developers,
Hono - [炎] means flame🔥 in Japanese - is a small, simple, and ultrafast web framework for the Edges. It works on any JavaScript runtime: Cloudflare Workers, Fastly Compute@Edge, Deno, Bun, Vercel, Netlify, Lagon, AWS Lambda, Lambda@Edge, and Node.js.
### How to install Hono
To create a new Hono project you can use the following command in the terminal
`npm create hono@latest <project-name>`
A new folder will be created based on the name you provided.
### Install dependencies
Now to install the dependencies, navigate to the folder of your project and run `npm i` in the terminal.
Congratulations, now you have setup a Hono project that could be used as a backend for your frontend frameworks such as React,Solid,Svelte or Vue.
### Understanding the project structure
The Hono project structure is simple and easy to understand. Most of the time, we will be working with the **Src** folder most of the time as it contains our code. We can also configure our typescript optionns in the `tsconfig.json` file.
### Basic Hello world application using Hono
In the `index.ts` file, we will delete all of the code and start from scratch.
At first, we import the Hono package which we have installed.
`import { Hono } from 'hono'`
Initialize the library
`const app = new Hono()`
Now with using this 'app' variable, we can create various routes for our application.
We will now create our index route '/' using Hono
`app.get('/', (c) => c.text('Congrats!'))`
We can also send data back in JSON format like a traditional api.
`
`app.get('/users', (c) => c.json({user_1:"Bob",user_2:"Mary"}))`
Now we will export the app so that Hono can run it
`export default app`
The final code should look something like this
````typescript
import { Hono } from 'hono'
const app = new Hono()
app.get('/', (c) => c.text('Congrats!'))
app.get('/users', (c) => c.json({user_1:"Bob",user_2:"Mary"}))
export default app
````
### Creating dynamic routes using Hono
We might need dynamic routes for our app. Dynamic routes allow us to build routes that take a dynamic value. For example when you see a video of youtube, instead of creating a new route for every video, they use a dynamic route. To create a dynamic route in Hono, we can just add a slug like
`/user/:id`
Here we can use this example
````javascript
app.get('/user/:id',(c) => c.text("user id is " + c.req.param('id')))
````
The final code should look like this
````javascript
import { Hono } from 'hono'
const app = new Hono()
app.get('/', (c) => c.text('Congrats!'))
app.get('/users', (c) => c.json({user_1:"Bob",user_2:"Mary"}))
app.get('/user/:id',(c) => c.text(`user id is ${c.req.param('id')}`))
export default app
### Conclusion
Hono makes it easy and simple to build RESTful APIis for our frontend frameworks such as solid,svelte,vue and react. The performance is also great. Overall it is giving tough competition to Express
````
| ntstarling |
1,597,030 | JavaScript Functions(Part 3): Your Magic Spells | In our last magical seminar, we delved deep into the intricate world of JavaScript functions,... | 0 | 2023-09-11T17:57:18 | https://dev.to/init_chandan/javascript-functionspart-3-your-magic-spells-2i7c | javascript, webdev, programming, beginners | In our last magical seminar, we delved deep into the intricate world of JavaScript functions, learning the spells and chants that shape our world. The spell book was opened, and secrets were revealed. But like every great wizard knows, the depth of magic is vast, and our journey has just begun.
Today, we venture further into this enchanted forest of functions, unearthing more potent spells and understanding the legacy of ancient code mages.
### **🪄 Closures: The Enchanted Lockets**
In the magical world of JavaScript, a closure is like an enchanted locket, preserving memories (variables) from disappearing even after the spell (function) has been cast.
Imagine casting a spell to create a magical barrier. This barrier remembers the strength at which you cast it and can adjust itself accordingly in the future.
```jsx
function magicalBarrier(strength) {
let barrierStrength = strength;
return function() {
barrierStrength++;
console.log("Barrier's current strength: " + barrierStrength);
}
}
let enhanceBarrier = magicalBarrier(5);
enhanceBarrier(); // Outputs: "Barrier's current strength: 6"
```
The inner function, even when invoked outside its containing function, still has access to **`barrierStrength`**.
### **🌌 Higher-Order Functions: Conjuring Magic with Magic**
In our realm, some spells can manipulate other spells to create new enchantments. These are known as higher-order functions.
For instance, let's take the ancient spell **`map`**, which can transform every item in an array.
```jsx
const numbers = [1, 2, 3, 4];
const doubledNumbers = numbers.map(function(number) {
return number * 2;
});
console.log(doubledNumbers); // Outputs: [2, 4, 6, 8]
```
The **`map`** spell takes another spell (function) and applies it to each item, giving us a new potion (array).
### **🧙♂️ Recursive Functions: The Magic that Calls Upon Itself**
Some spells are so mighty that they call upon themselves for added power. These are our recursive functions.
Imagine a mirror that reflects another mirror, which then reflects another, creating an infinite loop of reflections.
```jsx
function magicalMirror(reflections) {
if(reflections === 0) return;
console.log("Another reflection appears!");
return magicalMirror(reflections - 1);
}
magicalMirror(3); // Outputs the message three times
```
Use recursive spells with caution, young mage. For if not controlled, they can spiral out of hand!
### **🌠 Conclusion: The Ever-Expanding Grimoire**
The world of JavaScript functions is as expansive as the universe of magic itself. With every page turned in our spell book, we uncover more wonders, more nuances, and greater power.
As we close this chapter of our grimoire, remember: The true magic isn't just in knowing the spells, but in understanding their essence and wielding them with wisdom.
Till our next magical meet, practice these spells, and always remember the first rule of magic - respect the craft!
### **Sorcerer’s Assignments: Test Your Magic**
🔮 **1. The Enchanted Forest of Closures:**
**Objective:** Venture deep into the world of closures and craft a spell that creates magical creatures. Each creature remembers the number of times it has been summoned.
```jsx
// Your task: Define the spell createCreature
// Hint: Use closures to make the creature remember its summon count.
let summonDragon = createCreature('Dragon');
summonDragon(); // Should say: "A Dragon has been summoned! Total times summoned: 1"
summonDragon(); // Should say: "A Dragon has been summoned! Total times summoned: 2"
```
🌌 **2. Mystic Transformations with Higher-Order Spells:**
**Objective:** Use the ancient spell **`filter`** to find all the magical artifacts that are older than a thousand years from an array.
```jsx
const artifacts = [
{ name: 'Enchanted Staff', age: 500 },
{ name: 'Mystic Crystal Ball', age: 1500 },
{ name: 'Ageless Tome', age: 3000 },
{ name: 'Newbie Wand', age: 50 }
];
// Your task: Use the 'filter' spell to find artifacts older than a thousand years.
```
🧙♂️ **3. Mirrors of Recursion:**
**Objective:** Craft a recursive spell that counts down from a number and at the end shouts "Blast off!"
```jsx
javascriptCopy code
// Your task: Define the spell countdown
// Hint: Don't forget to include the base case to stop the recursion.
countdown(5);
// Should say:
// "5..."
// "4..."
// "3..."
// "2..."
// "1..."
// "Blast off!"
```
---
**Remember, young mage:** Crafting spells is not just about getting them right, but understanding the essence and rhythm within them. Once you've attempted these tasks, share your incantations in the comments. Let's see who's ready for the next level in the world of magic! | init_chandan |
1,597,627 | How IVF Treatment in Indore Can Fulfill Your Parenthood Dreams | Introduction Parenthood is a cherished dream for many couples, but infertility can pose significant... | 0 | 2023-09-12T10:21:31 | https://dev.to/sipu/how-ivf-treatment-in-indore-can-fulfill-your-parenthood-dreams-n0h | ivfindore, fertilityindore, ivfclinicindore, indoreivfspecialists | **Introduction**
Parenthood is a cherished dream for many couples, but infertility can pose significant challenges on the path to achieving it. In recent years, advancements in medical science have offered hope and solutions to couples struggling with infertility. In this article, we will explore how seeking treatment at the [best IVF clinic in Indore](https://www.motherhoodivf.com/best-fertility-ivf-center-in-indore/) can help fulfill your parenthood dreams.
**Understanding IVF**
In vitro fertilization (IVF) is a widely recognized assisted reproductive technology that has enabled countless couples to overcome fertility issues and achieve their dream of having a child. IVF involves the fertilization of an egg with sperm outside the body, creating an embryo that is then implanted into the uterus.
**Why Choose Indore?**
Indore, a vibrant city in Madhya Pradesh, has emerged as a hub for fertility treatments, with several renowned IVF clinics providing world-class care. Couples from all over the country are choosing Indore as their destination for IVF treatment, and for good reasons.
**Expertise:** The best IVF clinics in Indore boast highly skilled and experienced specialists who are well-versed in the latest advancements in reproductive medicine. They understand that every case is unique and offer personalized treatment plans tailored to individual needs.
**Cutting-edge Technology:** These clinics are equipped with state-of-the-art technology and modern laboratories, ensuring the highest standards of care and success rates in IVF treatments.
**Affordability:** IVF treatments in Indore are not only of high quality but also affordable when compared to many other major cities in India. This makes top-notch fertility care accessible to a wider range of couples.
**Emotional Support:** Going through fertility treatments can be emotionally challenging. The best IVF clinics in Indore prioritize patient support and counseling, helping couples navigate the emotional roller coaster that often accompanies infertility treatments.
**Success Stories:** Many couples have achieved their dreams of parenthood in Indore, thanks to the exceptional services provided by the city's IVF clinics. These success stories stand as a testament to the quality of care available in the region.
**The Process of IVF Treatment**
**IVF treatment involves several key steps:**
**Ovulation Stimulation:** The woman is given medications to stimulate the ovaries to produce multiple eggs.
**Egg Retrieval:** Mature eggs are retrieved from the ovaries through a minor surgical procedure.
**Fertilization:** The eggs are fertilized with sperm in a laboratory setting to create embryos.
**Embryo Transfer:** One or more healthy embryos are transferred into the woman's uterus.
**Monitoring and Support:** Throughout the process, patients are closely monitored, and support is provided to enhance the chances of a successful pregnancy.
**Conclusion**
Parenthood is a dream that should not be hindered by fertility challenges. Indore, with its best IVF clinics, offers hope to couples by providing world-class fertility treatments at affordable prices. If you are facing infertility issues and dreaming of parenthood, consider exploring the options available at the best IVF clinics in Indore. With their expertise, advanced technology, and compassionate care, they can help turn your parenthood dreams into a beautiful reality. | sipu |
1,598,791 | Paranoiac nature of School Investment in the UAE | The current fee framework for schools in the UAE has made it difficult to attract investors to open... | 0 | 2023-09-13T08:58:16 | https://dev.to/marthagodsay/paranoiac-nature-of-school-investment-in-the-uae-alo | The current fee framework for schools in the UAE has made it difficult to attract investors to open new educational institutions. While it has been a challenge to attract private funding, the government has introduced a new system. However, the new fees structure will help schools increase their incomes. This is particularly important if the schools are high quality. The government wants to promote UAE as a desirable place to live and work. But the UAE has not always been an easy place to invest.
In order to establish a school in UAE, prospective investors must first get land or an existing building. Then, they should acquire permits. The Knowledge and Human Development Authority, which regulates educational institutions in the country, can help investors with legal advice. Aside from the government, the KHDA also assists investors with the process of obtaining the necessary permits. It is also important to consider the legal and financial aspects of school investment.
Aside from education, there are other benefits associated with [School investment in UAE](https://www.d3consultants.net/services-investors/). It can be a low-risk investment option that will help investors build a strong portfolio. Allied Investment Partners (AIP), a wealth management firm, offers investment solutions for school owners. The firm's partners include Shell and AECOM. The company also has a successful track record of helping investors find the best investment opportunities. In addition to the UAE, Allied Investment Partners helps its members find interesting investments in the region.
Allied Investment Partners (AIP) has been an education investment company in the region. The fund's Atlas Real Estate platform, which is accredited by the CAA, offers educational properties with long-term lease agreements with operators. These long-term agreements offer stability and a predictable income stream for investors. In addition to investing in schools, AIP has helped its clients find investment opportunities in the region, such as acquiring an existing school or two.
A successful investment in a school in the UAE will be a great way to create a valuable asset. The process will start by identifying an existing school or acquiring land. Once the property is identified, it is important to obtain all the necessary permits. The Knowledge and Human Development Authority will provide legal advice for the investor in the UAE. It is important to note that this is a complex region, so a thorough understanding of the laws and regulations will help it to find the best opportunities.
There are several reasons why an education investment is essential for the economy in the UAE. It builds human capital and community stakeholders in the country. It creates the next generation of leaders. The country also has a growing population, which needs educated employees. A strong education system will help the community grow. This will be the cornerstone of the nation. There are many benefits to a school, and the investment in UAE can be beneficial to the community.
The UAE has an innovative education policy that is committed to human capital development. The government is committing to investing in the education sector, and it has done so through a series of transactions. These transactions are concentrated in the higher education and K-12 sector. The goal is to create a successful educational enterprise. In Dubai, the Education Policy has been implemented over the last few years. The government has a clear vision for the future of the UAE. The country is committed to fostering a well-educated workforce.
Investment in education is important to the country's future. In the UAE, the federal budget has allocated Dh9 billion to education. According to Van Hout, the investment in education creates human capital and community stakeholders. It also helps in creating the next generation of leaders. If you are looking for a school in the UAE, there are many opportunities available. The market for school education in the region is huge. The government is investing in schools in the UAE to ensure the success of educational facilities.
The government is committed to enhancing the quality of education in the UAE. Currently, there are several [school investment in KSA](https://www.d3consultants.net/services-investors/) opportunities in the region. The Government has also committed to increasing the number of schools in the region. This means that the investment is good for the country's economic development. It is a good time to buy educational assets. This is an opportunity to improve the standard of education. The United Arab Emirates has a high quality of education.
| marthagodsay | |
1,600,286 | Announcement!!! | We have just released our "generative" software delivery engine source on GitHub... | 0 | 2023-09-14T13:28:44 | https://dev.to/trustacks/announcement-3e5m | devops, opensource, cicd, github | We have just released our "generative" software delivery engine source on GitHub -https://lnkd.in/guGVRJ3F.
More docs and features are coming in the near future. Progress on the project can be tracked here -> https://lnkd.in/g2pk26mP
We are also rolling out early access to the hosted version of the engine where action plans can be centralized and executed from any #cicd tool such as #gitlab ci or #github actions. Join the waitlist at https://www.trustacks.com/.
If you are interested in contributing in any way join us on the catalyst channel on our Discord(https://lnkd.in/giMQh2HX) to get involved in the next iteration.
Let us know if you have any questions and stay on the lookout for new updates.
| trustacks |
1,600,314 | Amazon API Gateway HTTP Errors | Amazon API Gateway is a fully managed service that helps developers to create and deploy scalable... | 0 | 2023-09-14T14:15:06 | https://awsmag.com/amazon-api-gateway-http-errors/ | serverless, aws, cloudcomputing, awsapigateway | ---
title: Amazon API Gateway HTTP Errors
published: true
date: 2022-01-24 06:07:00 UTC
tags: serverless,aws,cloudcomputing,awsapigateway
canonical_url: https://awsmag.com/amazon-api-gateway-http-errors/
---
[Amazon API Gateway](https://awsmag.com/introduction-to-api-gateway/) is a fully managed service that helps developers to create and deploy scalable APIs on AWS. These APIs act as an entry point for the applications to connect and get access to data, perform business logic or access any other AWS service.
Amazon API Gateway also returns some HTTP Errors and we will be discussing some of the errors in this blog post and what they mean when returned from the Amazon API Gateway. Usually, the errors returned are in the range of 4xx or 5xx and examples for the same are 400 or 500. As a rule of thumb errors in the range of 400–499 are usually returned if there are problems with the client or you are breaking some of the rules defined by the Amazon API Gateway.
The errors in the range of 500–599 mean the server is not working problem or you have an issue with the network or the issues in the infrastructure which runs your server.
### 400 Error: Bad Request
The HTTP Status 400: Bad Request is the broadest error and depending on what AWS service API Gateway is integrating with, this error means many things. Some of the reasons for this error can be an invalid JSON, wrong data types and required fields etc.
### 403 Error: Access Denied
The HTTP Status 403: Forbidden means there are some permission issues. In AWS, this can be an issue with a wrong IAM role configuration. If your service uses an auth mechanism like AWS Cognito or a custom authorizer, this can be a permission issue because of this, then this error code will be returned.
### 404 Error: Not Found
The HTTP Status 404: This means the resource is not available or the URL does not exist. You can check the URL if it is right or not or have been implemented right to make sure that you are not making any mistake.
### 409 Error: Conflict
The HTTP Status 409: indicates that your request is trying to do something that conflicts with the current state of the target resource. It is most likely to occur in response to a PUT request.
### 429 Error: Too Many Requests
There are two cases when you can receive 429 errors from API Gateway.
The first one for HTTP Status 429: “Too Many Request”. This usually happens when the downstream resource is not able to handle the number of requests coming in.
For example, if you have a Lambda which gets triggered via an API Gateway and there is a reserved concurrency assigned to it let’s say 20 then 21 requests will same time probably give you this error.
This can also happen if your API keys are not allowing more than x number of requests concurrently. If the number of requests exceeds the number even if the downstream resource can handle it, the API Gateway will give this error.
### 429 Error: Limit Exceeded
The second one for HTTP Status 429 is “Limit Exceeded Exception,” which means that you have exceeded the allowed number of requests. This happens when the request is metered using an API key in API Gateway. The usage plan is associated with the key and the plan decides how many requests are allowed in a month by that particular resource.
### 500 Error: Internal Server Error
HTTP Status 500: It is the most generic HTTP error you will see. If the downstream service is Lambda, this error can mean an issue or a bug in the code of the function.
This can also happen if the status code mapping in the API is wrong. The default mapping if the error mapping is not configured properly, then the status code returned to the client is HTTP Status code 500.
### 502 Error: Bad Gateway
HTTP Status 502: this usually happens when the downstream service is not able to provide a response that can be mapped easily with the API Gateway. Sometimes the downstream service is not ready and cannot return a response.
Amazon API Gateway has a hard limit of 30 seconds timeouts. If the downstream service is not able to respond in this time frame, the API Gateway returns the HTTP Status 503.
### Conclusion:
The above-mentioned codes are some of the common errors which you may encounter while working with the Amazon API Gateway. If you would like to be familiar with the other things related to Amazon API Gateway, we have a collection that lists all the articles related to it. You can find it [here](https://awsmag.com/tag/amazon-api-gateway/).
_Originally published at_ [_https://awsmag.com_](https://awsmag.com/amazon-api-gateway-http-errors/) _on January 24, 2022._ | singhs020 |
1,600,758 | Curso de No Code, Algoritmos, IA e Mais Opções Gratuitas | No cenário atual de capacitação, o programa QualiFacti se destaca ao lançar uma série de cursos... | 0 | 2023-09-15T00:16:10 | https://guiadeti.com.br/curso-no-code-algoritmos-ia-gratis/ | cursogratuito, algoritmos, chatgpt, cursosgratuitos | ---
title: Curso de No Code, Algoritmos, IA e Mais Opções Gratuitas
published: true
date: 2023-09-15 00:07:46 UTC
tags: CursoGratuito,algoritmos,chatgpt,cursosgratuitos
canonical_url: https://guiadeti.com.br/curso-no-code-algoritmos-ia-gratis/
---

No cenário atual de capacitação, o programa QualiFacti se destaca ao lançar uma série de cursos online gratuitos. Estes cursos, centrados no desenvolvimento de competências técnicas e comportamentais, abordam tópicos de vanguarda, como No Code, Inteligência Artificial e [Algoritmos](https://guiadeti.com.br/guia-tags/cursos-de-algoritmos/).
O objetivo principal é preparar os profissionais para enfrentar as demandas dinâmicas do mercado de trabalho.
E, embora o foco possa ser predominantemente em Tecnologias da Informação e Comunicação (TICs), o conteúdo é aplicável a uma variedade de áreas, demonstrando a interdisciplinaridade do conhecimento atual.
A segunda fase do QualiFacti, iniciada em junho de 2023, promete ser mais enriquecedora, se estendendo até março de 2024.
Ao longo deste período, os participantes terão acesso a uma seleção criteriosa de cursos, todos meticulosamente projetados para atender às tendências emergentes. Neste mundo em constante mudança, esta é uma chance imperdível de se atualizar e se destacar!
## Conteúdo
<nav><ul>
<li>
<a href="#cursos-quali-facti">Cursos QualiFacti</a><ul>
<li><a href="#uma-nova-fase-de-oportunidades">Uma Nova Fase de Oportunidades </a></li>
<li><a href="#capacitacao-gratuita-e-de-qualidade">Capacitação Gratuita e de Qualidade </a></li>
<li><a href="#sobre-o-quali-facti">Sobre o QualiFacti </a></li>
<li><a href="#uma-metodologia-que-faz-a-diferenca">Uma Metodologia que Faz a Diferença </a></li>
<li>
<a href="#cursos-com-inscricoes-abertas">Cursos com Inscrições Abertas</a><ul>
<li><a href="#ia-algoritmos-de-otimizacao-em-python">IA: Algoritmos de Otimização em Python </a></li>
<li><a href="#no-code-e-low-code-na-robotica">No Code e Low Code na robótica</a></li>
<li><a href="#resolucao-de-problemas">Resolução de Problemas</a></li>
<li><a href="#automacao-de-atendimentos-com-chat-gpt">Automação de Atendimentos com ChatGPT </a></li>
<li><a href="#aplicacao-mobile-para-automacao-residencial">Aplicação Mobile para Automação Residencial</a></li>
<li><a href="#io-t-e-lo-ra">IoT e LoRa</a></li>
<li><a href="#transicao-de-carreira-como-migrar-para-a-area-da-tecnologia">Transição de Carreira: Como Migrar para a Área da Tecnologia</a></li>
</ul>
</li>
<li><a href="#certifique-se-e-destaque-se">Certifique-se e Destaque-se </a></li>
</ul>
</li>
<li>
<a href="#no-code">No Code</a><ul>
<li><a href="#por-que-o-no-code-esta-ganhando-tracao">Por que o No Code está ganhando tração? </a></li>
<li><a href="#ferramentas-populares-no-universo-no-code">Ferramentas Populares no Universo No Code </a></li>
<li><a href="#o-impacto-no-mercado-de-trabalho">O Impacto no Mercado de Trabalho </a></li>
<li><a href="#desafios-e-consideracoes">Desafios e Considerações </a></li>
<li><a href="#o-futuro-da-construcao-digital">O Futuro da Construção Digital </a></li>
</ul>
</li>
<li>
<a href="#quali-facti">QualiFacti</a><ul>
<li><a href="#pilares-tematicos-da-plataforma">Pilares Temáticos da Plataforma </a></li>
<li><a href="#fases-e-cronograma">Fases e Cronograma </a></li>
<li><a href="#metodologia-e-abordagem">Metodologia e Abordagem </a></li>
<li><a href="#certificacao-e-destaque-no-mercado">Certificação e Destaque no Mercado </a></li>
<li><a href="#a-missao-da-quali-facti">A Missão da QualiFacti </a></li>
</ul>
</li>
<li><a href="#inscreva-se-no-quali-facti-e-transforme-sua-carreira">Inscreva-se no QualiFacti e transforme sua carreira!</a></li>
<li><a href="#compartilhe-o-quali-facti-e-ajude-alguem-a-evoluir-profissionalmente">Compartilhe o QualiFacti e ajude alguém a evoluir profissionalmente!</a></li>
</ul></nav>
## Cursos QualiFacti
Os cursos do QualiFacti trazem à tona tópicos cruciais da atualidade, como No Code, Inteligência Artificial e Algoritmos.

_Página da QualiFacti_
Ao se imergir nesses conteúdos, os participantes se preparam para atender às demandas contemporâneas e vindouras do mercado, não apenas no setor de Tecnologias da Informação e Comunicação (TICs), mas em múltiplas áreas.
### Uma Nova Fase de Oportunidades
Atualmente, o QualiFacti adentra sua segunda fase, iniciada em junho de 2023 e com previsão de encerramento em março de 2024. Nesse interstício, a iniciativa se destaca por seu portfólio de cursos gratuitos, meticulosamente arquitetados para destacar aspectos essenciais no desenvolvimento de habilidades técnicas e comportamentais.
### Capacitação Gratuita e de Qualidade
Não deixe escapar esta chance única de alavancar sua carreira. A primeira fase do QualiFacti foi um estrondoso sucesso, validado pelo alto grau de satisfação de inúmeros certificados.
Agora, na sequência, o programa se expande, disponibilizando novos cursos acessíveis a todos no Brasil. Gratuitos e online, estes cursos incorporam modalidades síncronas e assíncronas, sob a orientação de instrutores renomados no setor e no meio acadêmico.
### Sobre o QualiFacti
Originário da Facti, uma Instituição Científica e Tecnológica (ICT) de vanguarda, o QualiFacti nasce da expertise em fomentar soluções tecnológicas e capacitação em [Tecnologia da Informação](https://guiadeti.com.br/guia-tags/cursos-de-tecnologia-da-informacao/) e Comunicação.
A iniciativa é fruto do Programa MCTI Futuro, um projeto do Ministério da Ciência, Tecnologia e Inovação, com fundos provenientes do PPI da Lei de Informática, e coordenação da Softex.
### Uma Metodologia que Faz a Diferença
O diferencial do QualiFacti reside em sua abordagem pedagógica. A metodologia empregada garante que os alunos não só assimilem, mas apliquem de forma ágil e prática o conhecimento adquirido, favorecendo uma experiência de aprendizado imersiva e colaborativa.
### Cursos com Inscrições Abertas
#### IA: Algoritmos de Otimização em Python
Ementa:
- Introdução à Inteligência Artificial e à importância dos processos de otimização;
- Pesquisa randômica;
- Método Hill Climb;
- _Simulated annealing_;
- Algoritmos Genéticos;
- Estudo de caso: Representação do problema da viagem em grupo.
#### No Code e Low Code na robótica
Ementa:
- O que é No Code e Low Code;
- Autômatos e o surgimento da robótica;
- Automação de processos industriais com robôs;
- [O que é robótica](https://guiadeti.com.br/guia-tags/cursos-de-robotica/) humanoide;
- Cases de robótica humanoide;
- Desenvolvimento de uma aplicação com no code na robótica industrial e outra com Low Code na robótica humanoide.
#### Resolução de Problemas
Ementa:
- Metodologias para a resolução de problemas;
- Problematização;
- Pensamento Sistêmico;
- Decomposição de Problemas;
- Estratégias e Métodos;
- Ferramentas;
- Resolução de problemas na prática.
#### Automação de Atendimentos com ChatGPT
Ementa:
- Introdução a chatbots;
- Tipos de chatbots disponíveis no mercado;
- Introdução ao Chat GPT como Inteligência Artificial;
- Construção de chatbots com estrutura de árvore de navegação com a ferramenta da Take Blip;
- Conexão com canais de atendimento como Facebook Messenger e Telegram;
- Estudo de caso: automatizar o atendimento com respostas fornecidas pela Inteligência Artificial do Chat GPT.
#### Aplicação Mobile para Automação Residencial
Ementa:
- [Introdução à Internet das Coisas.](https://guiadeti.com.br/guia-tags/cursos-de-internet-das-coisas/)
- Noções básicas da Plataforma de Prototipagem Arduino.
- Prototipagem com Tinkercad.
- Introdução do App Inventor.
- Estudo de Caso: Aplicação Mobile para Automação Residencial.
#### IoT e LoRa
Ementa:
- IoT; LoRa: O que é? Por que usar?
- Definição e vantagens do uso de LoRa;
- Aplicação de LoRa em projetos de Internet das Coisas;
- Diferenças entre LoRa e LoRaWan;
- Definição da LoRa Alliance;
- Estudo de caso.
#### Transição de Carreira: Como Migrar para a Área da Tecnologia
Ementa:
- Introdução à área de tecnologia;
- Adaptação a novas culturas;
- Profissões na área de tecnologia;
- Empreendedorismo digital;
- Marketing pessoal: Criação de uma marca pessoal forte e aprimoramento da presença online e offline;
- Networking: Desenvolvimento de uma rede de contatos e estratégias para cultivar relacionamentos profissionais.
### Certifique-se e Destaque-se
Ao concluir sua trajetória no QualiFacti e atender aos critérios estabelecidos, você se tornará merecedor de um certificado, um aval de sua dedicação e competência, abrindo portas para novos horizontes profissionais.
## No Code
No Code” refere-se a uma abordagem de desenvolvimento de software que permite a criação de aplicativos, sites e automações sem a necessidade de escrever código. Usando ferramentas visuais, os usuários montam funcionalidades como se estivessem montando blocos em um jogo de construção.
### Por que o No Code está ganhando tração?
A crescente demanda por soluções digitais em um mundo cada vez mais conectado supera a oferta de desenvolvedores disponíveis. O No Code permite que pessoas sem conhecimento técnico criem soluções rápidas e eficientes, democratizando o [desenvolvimento de software](https://guiadeti.com.br/guia-tags/cursos-de-software-livre/) e acelerando a inovação.
### Ferramentas Populares no Universo No Code
Existem várias ferramentas que possibilitam essa revolução, incluindo Webflow, Bubble, Zapier e muitas outras. Elas cobrem desde a criação de sites e aplicativos até a automação de tarefas e processos de negócios.
### O Impacto no Mercado de Trabalho
Com a popularização do No Code, novos papéis surgem no mercado. Designers, gestores de projeto e outros profissionais agora têm a chance de se tornar “construtores”, criando soluções sem depender totalmente de equipes de desenvolvimento.
### Desafios e Considerações
Enquanto o No Code traz inúmeras vantagens, ele não substitui todas as necessidades de desenvolvimento tradicional. Há questões de escalabilidade, personalização e complexidade que ainda podem exigir abordagens baseadas em código. Além disso, é essencial escolher a ferramenta certa para cada projeto.
### O Futuro da Construção Digital
O movimento No Code representa um passo significativo em direção a um mundo onde mais pessoas podem criar, inovar e resolver problemas por meio da tecnologia. Ele não só acelera o desenvolvimento de soluções, mas também fomenta uma era de inclusão digital mais ampla.
<iframe title="No Code x Low Code x Programação: A verdade que ninguém te contou ainda" width="1200" height="675" src="https://www.youtube.com/embed/YNfvv0VEk9Q?feature=oembed" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share" allowfullscreen></iframe>
_Créditos: Canal Renato Asse – Sem Codar_
## QualiFacti
A QualiFacti surge como uma iniciativa focada na oferta de cursos voltados ao desenvolvimento de competências técnicas e comportamentais essenciais no cenário tecnológico atual e futuro.
### Pilares Temáticos da Plataforma
Os cursos da QualiFacti abordam tópicos emergentes e de alta relevância, como No Code, Inteligência Artificial e Algoritmos. Essas áreas são fundamentais para atender às crescentes demandas do mercado, não apenas dentro do setor de Tecnologias da Informação e Comunicação, mas também em campos interdisciplinares.
### Fases e Cronograma
Atualmente, a QualiFacti encontra-se em sua segunda fase, que iniciou em junho de 2023 e se estenderá até março de 2024. Neste período, os inscritos terão acesso a uma série de cursos gratuitos, meticulosamente desenhados para atender às exigências do mercado.
### Metodologia e Abordagem
O diferencial da QualiFacti reside na sua abordagem de ensino. Os cursos são desenvolvidos para permitir uma aplicação prática imediata dos conhecimentos adquiridos. Combinando aulas ao vivo com atividades assíncronas, os alunos têm oportunidades ímpares de interação e aprendizado.
### Certificação e Destaque no Mercado
Ao concluir os cursos, os participantes recebem um certificado de capacitação. Esse reconhecimento não apenas valida o aprendizado, mas também serve como um distintivo no perfil profissional dos alunos, destacando-os em um mercado competitivo.
### A Missão da QualiFacti
A QualiFacti não é apenas uma plataforma de cursos. Ela é um compromisso com o futuro da [educação tecnológica](https://guiadeti.com.br/guia-tags/cursos-de-tecnologia/), buscando preparar profissionais para os desafios do amanhã e emponderando-os para criar soluções inovadoras em suas respectivas áreas.
## Inscreva-se no QualiFacti e transforme sua carreira!
As [inscrições para os cursos da QualiFacti](https://qualifacti.facti.com.br/home) devem ser realizadas no site da QualiFacti.
## Compartilhe o QualiFacti e ajude alguém a evoluir profissionalmente!
Gostou do conteúdo sobre os cursos gratuitos? Então compartilhe com a galera!
O post [Curso de No Code, Algoritmos, IA e Mais Opções Gratuitas](https://guiadeti.com.br/curso-no-code-algoritmos-ia-gratis/) apareceu primeiro em [Guia de TI](https://guiadeti.com.br). | guiadeti |
1,601,407 | Dependency Injection in Flutter: implementing the Dependency Inversion principle | Photo by Vardan Papikyan on Unsplash If you are looking to get your code to the next level, you have... | 0 | 2023-09-15T14:30:40 | https://dev.to/iriber/dependency-injection-in-flutter-implementing-the-dependency-inversion-principle-1e0p | solidprinciples, dependencyinversion, flutter, cleancoding | Photo by <a href="https://unsplash.com/es/@varpap?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText">Vardan Papikyan</a> on <a href="https://unsplash.com/es/fotos/DnXqvmS0eXM?utm_source=unsplash&utm_medium=referral&utm_content=creditCopyText">Unsplash</a>
If you are looking to get your code to the next level, you have to know about dependency injection.
## Introduction
When we write code we follow the SOLID guidelines. One of those principles (“D”) take care of Dependency Inversion. Let's see what it means.
Suppose you have a service class called “UserService” that uses a datasource called UserSqlite to get users from a SQLite database:
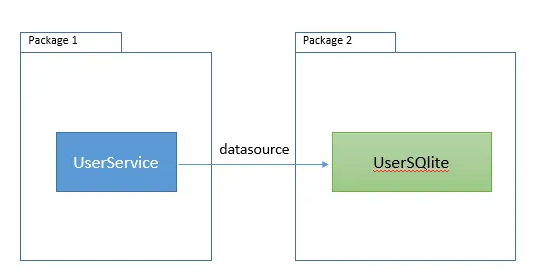
So Package 1 depends on Package 2. If you have this relation on your code, Mr. SOLID will go to your desktop and say: “Ey, do NOT couple your code with other libraries, what are you thinking about?”.
What about this:
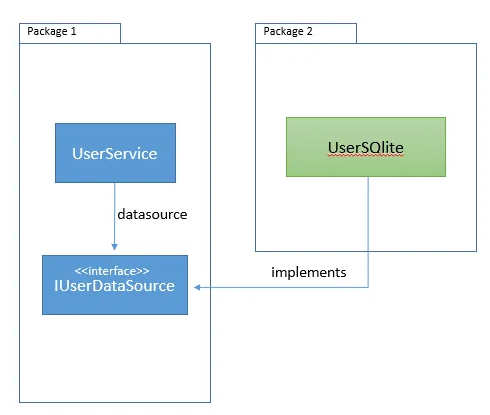
What we have already done was change the dependency direction. Now, Package 2 depends on Package 1. The right direction of dependency makes our code reusable, and eliminates cyclic dependencies.
### Dependency Injection
The dependency injection concept will help us to drive the right implementation of the interface IUserDataSource to our UserService.
UserService wouldn’t be concerned about the IUserDataSource implementation, it just uses it.
## How can you implement Dependency Injection in Flutter?
I use a package called get_it, you can find it here:
[GetIt](https://pub.dev/packages/get_it?source=post_page-----41094bd6b38c--------------------------------)
I like to wrap the third party packages, because maybe tomorrow I want to change it to another that I like more than this. It is a premise that I have, you can skip that step, but it is one more thing that helps me to have my code the most descouple than I can.
So, I created a class called DependencyManager which wraps the get_it library:
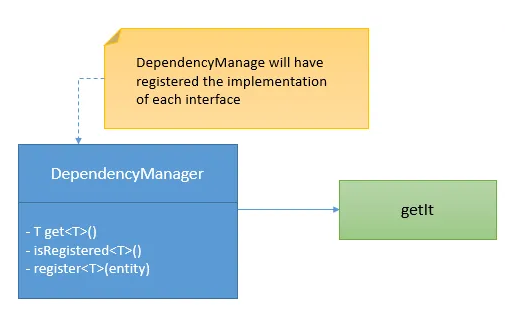
### Inject dependencies
In your app config class or your app initializer you have to inject the dependencies you want to have. In the example of the second picture, we have to inject the implementation of IUserDataSource:
```
void injectDependencies() {
try {
/// Get dependency manager
DependencyManager manager = DependencyManager();
/// Register UserSQLite as IUserDataSource
manager.registerFactory<IUserDataSource>(() => UserSQLite());
} catch (e2) {
debugPrint("Manage depency injections error");
}
}
```
And then we must use this manager everywhere we need to use the user data source implementation. Let’s see:
```
class UserService {
/// User datasource.
final IUserDataSource datasource= DependencyManager().get<IUserDataSource>();
....
}
```
DependencyManager manages the implementations of our interface. It registers and returns concrete classes.
### DependencyManager
To have the example simple I just showed you how to register a factory for our user datasource, but the dependency manager also could call constructors that requires some parameters, could be a little more complex.
My DependencyManager looks like this:
```
import 'package:get_it/get_it.dart';
class DependencyManager {
/// GetIt instance.
final getIt = GetIt.instance;
/// I use singleton to create this manager.
DependencyManager._internal();
static final DependencyManager _singleton = DependencyManager._internal();
factory DependencyManager() {
return _singleton;
}
T get<T extends Object>(){
return getIt.get<T>();
}
T getWithParam<T extends Object, P1>(dynamic p){
return getIt.get<T>(param1: p);
}
T getWith2Param<T extends Object, P1, P2>(dynamic p1, dynamic p2){
return getIt.get<T>(param1: p1, param2: p2);
}
bool isRegistered<T extends Object>(){
return getIt.isRegistered<T>();
}
void registerLazySingleton<T extends Object>(FactoryFunc<T> factoryFunc){
getIt.registerLazySingleton<T>(factoryFunc );
}
void registerFactory<T extends Object>(FactoryFunc<T> factoryFunc){
getIt.registerFactory<T>(factoryFunc );
}
void registerFactoryParam<T extends Object, P1, P2>(
FactoryFuncParam<T, P1, P2> factoryFunc, {
String? instanceName,
}){
getIt.registerFactoryParam<T,P1,P2>(factoryFunc);
}
}
```
## Conclusion
We talked about a **SOLID** principle, the **dependency inversion**, we introduced to **dependency injection** and saw how to get implemented it in Flutter.
Now you have the concept, and you know how to apply it. You will drive your code to the next level:
1. Descoupled
2. Testeable
3. Easy to mantain
Thanks for reading, Clap if you like it!
Let me know your comments below.
| iriber |
1,601,982 | Power of Javascript Array Methods 🔍🛠️ | 🎲 "Roll the Dice: Unveiling the Power of Array Methods in JavaScript" It's a... | 24,642 | 2023-09-29T11:12:35 | https://dev.to/shivams1007/power-of-javascript-array-methods-3fbp | javascript, webdev, typescript, react | ### 🎲 "Roll the Dice: Unveiling the Power of Array Methods in JavaScript"
#### It's a Array's World, We're Just Coding in It!
Hey, you array-spiring JavaScripters! 👋 Tired of `for` loops that go on and on like your grandma’s stories? Ready to tap into the untapped magic of array methods? Then welcome to the ultimate guide to mastering JavaScript array methods, where you'll find more sugar than in a candy store. 🍬
---
##### 1️⃣ "The Map is not the Territory: The `map()` Method"
Remember Dora the Explorer? Map, map, map! 🗺️ Just like Dora's magical map, JavaScript's `map()` method helps you transform your array without changing the original one.
Example:
```javascript
const numbers = [1, 2, 3];
const doubled = numbers.map(x => x * 2);
// Output: doubled = [2, 4, 6]
```
---
##### 2️⃣ "Filter It Out, Keep it Clean: The `filter()` Method"
No, this isn't about your Instagram filter. The `filter()` method helps you keep only what you want in an array.
Example:
```javascript
const arr = [1, 2, 3, 4, 5];
const even = arr.filter(x => x % 2 === 0);
// Output: even = [2, 4]
```
---
##### 3️⃣ "Finding Nemo with `find()`: Where’s Waldo? Nah, Where’s My Element?"
Want to find something quickly? Use `find()` and stop playing hide-and-seek with your elements!
Example:
```javascript
const animals = ['cat', 'dog', 'fish'];
const findFish = animals.find(x => x === 'fish');
// Output: findFish = 'fish'
```
---
##### 4️⃣ "Slice and Dice: The `slice()` Method"
Who needs a knife when you've got `slice()`? Cut your array into pieces, just like your favorite birthday cake! 🍰
Example:
```javascript
const fruits = ['apple', 'banana', 'cherry'];
const myFruits = fruits.slice(0, 2);
// Output: myFruits = ['apple', 'banana']
```
---
##### 5️⃣ "Reduce, Reuse, `reduce()`: The Marie Kondo of Arrays"
Just like Marie Kondo, `reduce()` helps you tidy up an array into a single value that sparks joy! 🌟
Example:
```javascript
const values = [1, 2, 3, 4];
const sum = values.reduce((acc, val) => acc + val, 0);
// Output: sum = 10
```
---
##### 6️⃣ "It’s Not Stalking, It’s `indexOf()`: Find Your Crush in an Array"
Looking for that special something or someone? `indexOf()` helps you find the position of your 'crush element' in an array.
Example:
```javascript
const crushes = ['apple', 'banana', 'cherry'];
const position = crushes.indexOf('banana');
// Output: position = 1
```
---
##### 7️⃣ "Going Backwards with `reverse()`: Benjamin Button Your Array"
Who said time travel isn't possible? With `reverse()`, you can turn back time on your arrays!
Example:
```javascript
const time = [1, 2, 3];
const reversedTime = time.reverse();
// Output: reversedTime = [3, 2, 1]
```
---
##### 8️⃣ "Shuffle the Deck with `sort()`: Your Array, Your Rules"
Last but not least, let's talk about `sort()`. Put some order into your chaotic array life!
Example:
```javascript
const chaos = [3, 1, 2];
const order = chaos.sort();
// Output: order = [1, 2, 3]
```
#### Conclusion: Arrays Are Fun, After All!
There you have it! You're now an array whisperer. 🤠 You've learned how to manipulate, transform, and basically have a party with arrays. If you have any favorite array methods or tricks up your sleeve, drop a comment below and share the wealth!
Go forth, and array like you've never arrayed before! 🎉
---
Feel free to comment, share, and let me know what you think! See you next time! ✌️
| shivams1007 |
1,602,513 | Writing Clean Code: Best Practices and Principles | Introduction Writing clean code is a fundamental skill for every software developer. Clean... | 0 | 2023-09-16T21:12:29 | https://dev.to/favourmark05/writing-clean-code-best-practices-and-principles-3amh | webdev, javascript, programming, productivity | ## Introduction
Writing clean code is a fundamental skill for every software developer. Clean code not only makes your codebase more maintainable and easier to understand but also fosters collaboration among team members. In this comprehensive article, we will explore what clean code is, why it's important, and provide you with a set of best practices and principles to help you write clean and maintainable code.
## What is Clean Code?
Clean code is code that is easy to read, easy to understand, and easy to modify. It is code that is devoid of unnecessary complexity, redundancy, and confusion. Clean code follows a set of conventions and best practices that make it more consistent, making it easier for multiple developers to work on the same project seamlessly.
## Why is Clean Code Important?
1. **Readability**: Clean code is easy to read, which means that anyone - including your future self - can understand it quickly. This reduces the time required to grasp the code's functionality, leading to faster development and debugging.
2. **Maintainability**: Code is read more often than it is written. When you write clean code, it becomes easier to maintain and extend the application over time. This is crucial in the software development lifecycle, where projects often evolve and grow.
3. **Collaboration**: Clean code encourages collaboration. When your code is clean and well-organized, other team members can work on it effectively. This makes it easier to divide tasks and work on different parts of the codebase simultaneously.
4. **Bug Reduction**: Clean code reduces the likelihood of introducing bugs. Code that is difficult to understand is more prone to errors during modifications or enhancements.
5. **Efficiency**: Clean code is efficient code. It typically runs faster and uses fewer resources because it avoids unnecessary operations and complexity.
Now that we understand why clean code is important, let's delve into some best practices and principles to help you write clean code.
## Best Practices and Principles for Writing Clean Code
1 . **Meaningful Variable and Function Names**
Use descriptive names for variables, functions, classes, and other identifiers. A well-chosen name can convey the purpose of the entity, making the code more understandable. Avoid single-letter variable names or cryptic abbreviations.
```
# Bad variable name
x = 5
# Good variable name
total_score = 5
```
2 . **Keep Functions and Methods Short**
Functions and methods should be concise and focused on a single task. The Single Responsibility Principle (SRP) states that a function should do one thing and do it well. Shorter functions are easier to understand, test, and maintain. If a function becomes too long or complex, consider breaking it down into smaller, more manageable functions.
```
// Long and complex function
function processUserData(user) {
// Many lines of code...
}
// Refactored into smaller functions
function validateUserInput(userInput) {
// Validation logic...
}
function saveUserToDatabase(user) {
// Database operation...
}
```
3 . **Comments and Documentation**
Use comments sparingly, and when you do, make them meaningful. Code should be self-explanatory whenever possible. Documentation, such as inline comments and README files, helps other developers understand your code's purpose and usage. Document complex algorithms, non-trivial decisions, and public APIs.
```
# Bad comment
x = x + 1 # Increment x
# Good comment
# Calculate the total score by incrementing x
total_score = x + 1
```
4 . **Consistent Formatting and Indentation**
Adhere to a consistent coding style and indentation. This makes the codebase look clean and organized. Most programming languages have community-accepted coding standards (e.g., PEP 8 for Python, eslint for JavaScript) that you should follow. Consistency also applies to naming conventions, spacing, and code structure.
```
// Inconsistent formatting
if(condition){
doSomething();
} else {
doSomethingElse();
}
// Consistent formatting
if (condition) {
doSomething();
} else {
doSomethingElse();
}
```
5 . **DRY (Don't Repeat Yourself) Principle**
Avoid duplicating code. Repeated code is harder to maintain and increases the risk of inconsistencies. Extract common functionality into functions, methods, or classes to promote code reusability. When you need to make a change, you'll only need to do it in one place.
Suppose you're working on a JavaScript application that calculates the total price of items in a shopping cart. Initially, you have two separate functions for calculating the price of each item type: one for calculating the price of a book and another for calculating the price of a laptop. Here's the initial code:
```
function calculateBookPrice(quantity, price) {
return quantity * price;
}
function calculateLaptopPrice(quantity, price) {
return quantity * price;
}
```
While these functions work, they violate the DRY principle because the logic for calculating the total price is repeated for different item types. If you have more item types to calculate, you'll end up duplicating this logic. To follow the DRY principle and improve code maintainability, you can refactor the code as follows:
```
function calculateItemPrice(quantity, price) {
return quantity * price;
}
const bookQuantity = 3;
const bookPrice = 25;
const laptopQuantity = 2;
const laptopPrice = 800;
const bookTotalPrice = calculateItemPrice(bookQuantity, bookPrice);
const laptopTotalPrice = calculateItemPrice(laptopQuantity, laptopPrice);
```
In this refactored code, we have a single calculateItemPrice function that calculates the total price for any item type based on the quantity and price provided as arguments. This adheres to the DRY principle because the calculation logic is no longer duplicated.
Now, you can easily calculate the total price for books, laptops, or any other item type by calling calculateItemPrice with the appropriate quantity and price values. This approach promotes code reusability, readability, and maintainability while reducing the risk of errors caused by duplicated code.
6 . **Use Meaningful Whitespace**
Properly format your code with spaces and line breaks. This enhances readability. Use whitespace to separate logical sections of your code. Well-formatted code is easier to scan, reducing the cognitive load on readers.
```
// Poor use of whitespace
const sum=function(a,b){return a+b;}
// Improved use of whitespace
const sum = function (a, b) {
return a + b;
}
```
7 . **Error Handling**
Handle errors gracefully. Use appropriate try-catch blocks or error-handling mechanisms in your code. This prevents unexpected crashes and provides valuable information for debugging. Don't suppress errors or simply log them without a proper response.
```
// Inadequate error handling
try {
result = divide(x, y);
} catch (error) {
console.error("An error occurred");
}
// Proper error handling
try {
result = divide(x, y);
} catch (error) {
if (error instanceof ZeroDivisionError) {
console.error("Division by zero error:", error.message);
} else if (error instanceof ValueError) {
console.error("Invalid input:", error.message);
} else {
console.error("An unexpected error occurred:", error.message);
}
}
```
8 . **Testing**
Write unit tests to verify your code's correctness. Test-driven development (TDD) can help you write cleaner code by forcing you to consider edge cases and expected behavior upfront. Well-tested code is more reliable and easier to refactor.
```
// Example using JavaScript and the Jest testing framework
test('addition works correctly', () => {
expect(add(2, 3)).toBe(5);
expect(add(-1, 1)).toBe(0);
expect(add(0, 0)).toBe(0);
});
```
9 . **Refactoring**
Refactor your code regularly. As requirements change and your understanding of the problem domain deepens, adjust your code accordingly. Refactoring helps maintain clean code as the project evolves. Don't be afraid to revisit and improve existing code when necessary.
Suppose you have a function that calculates the total price of items in a shopping cart with a fixed discount percentage:
```
function calculateTotalPrice(cartItems) {
let totalPrice = 0;
for (const item of cartItems) {
totalPrice += item.price;
}
return totalPrice - (totalPrice * 0.1); // Apply a 10% discount
}
```
Initially, this function calculates the total price and applies a fixed discount of 10%. However, as the project evolves, you realize that you need to support variable discounts. To refactor the code to make it more flexible, you can introduce a discount parameter:
```
function calculateTotalPrice(cartItems, discountPercentage) {
if (discountPercentage < 0 || discountPercentage > 100) {
throw new Error("Discount percentage must be between 0 and 100.");
}
let totalPrice = 0;
for (const item of cartItems) {
totalPrice += item.price;
}
const discountAmount = (totalPrice * discountPercentage) / 100;
return totalPrice - discountAmount;
}
```
In this refactored code:
* We have added a discountPercentage parameter to the calculateTotalPrice function, allowing you to specify the discount percentage when calling the function.
* We perform validation on the discountPercentage parameter to ensure it falls within a valid range (0 to 100%). If it's not within the range, we throw an error.
* The discount calculation is now based on the provided discountPercentage, making the function more flexible and adaptable to changing requirements.
By refactoring the code in this way, you have improved its flexibility and maintainability. You can easily adapt the function to handle different discount scenarios without having to rewrite the entire logic. This demonstrates the importance of regular code refactoring as your project evolves and requirements change.
10 . **Version Control**
Use version control systems like Git to track changes to your code. This allows you to collaborate effectively with team members, revert to previous versions if necessary, and maintain a clean history of your project's development. Git provides tools for code review, branching, and merging, facilitating collaboration and code cleanliness.
##Conclusion
Writing clean code is not just a set of rules but a mindset and a discipline. It's about creating software that is easy to read, maintain, and extend. By following these best practices and principles, you can become a more proficient developer who produces high-quality code.Investing time in meticulously examining fellow engineers' codebases, particularly in open-source projects, can be an enlightening experience. Through this exploration, you gain invaluable insights into diverse coding styles and strategies. This exposure enables you to distill the essence of writing pristine, sustainable codebases.. Remember that clean code is a continuous journey, and with practice, it becomes second nature, leading to more efficient and enjoyable software development.
| favourmark05 |
1,602,874 | Reverse Engineering for the Good: From the Source Code to the System Blueprint (Part II) | In the previous part of the article, we briefly discussed the explanatory mindset that one requires... | 0 | 2023-09-17T11:53:21 | https://dev.to/remit/reverse-engineering-for-the-good-from-the-source-code-to-the-system-blueprint-part-ii-3357 | architecture, diagrams, development, distributedsystems | In [the previous part of the article](https://dev.to/remit/reverse-engineering-for-the-good-from-the-source-code-to-the-system-blueprint-part-i-1665), we briefly discussed the explanatory mindset that one requires to get better at reverse engineering of complex software systems. We have also tipped our toes into the nasty waters of reconstructing the meaning of the source code with the help of data state transition diagrams and pseudocode. In this second and last part of the article, I’d like to build on top of reverse engineering for the code fragments and focus on getting the software system’s blueprint. As always, I’m summarizing my personal experience, so it may or may not align with how you tackle this complex topic. Please add anything that you find relevant to this topic and particularly curious in the comments section.
## Reverse Engineering for the System Blueprint
### Data and Control Flow diagrams
I believe that most of us have drawn a kind of data or control flow diagram when we wanted to better understand how the software works. These diagrams are natural to draw for software systems. Since any program performs some operations on the data according to some set of conditions, the software systems can be represented as various entities that pass data to each other. In the following paragraphs, I’ll refer to these entities as operating entities.
There is no academic definition behind this term so I’d try to explain it on an intuitive level. An operating entity is something that has a well-defined function in the system or, sometimes, multiple functions. Importantly, this function (or functions) should not be shared with any other operating entity. Let’s discuss an example. You can imagine a class that handles the incoming requests for some persisted data. Upon getting a request, this class puts the request into the queue. Next, some other code within the same class polls requests from the queue to process them and persist the results. Although the polling part of the code might be implemented within the class and does not necessarily have its own encapsulation within some other class, it is the only part of the code that performs polling from the queue and decides how to process the polled request. In that sense, depending on the complexity of the logic, one could wrap this code as a Request Processor operating entity or maybe as two entities, namely, Requests Poller and Requests Dispatcher (if the processing is excluded and handled separately). Again, it does not matter if these entities are not implemented in the code. When reconstructing a data/control flow diagram, you do not invent anything new, you just collect and make the pieces of functionality visible and addressable. ‘Purification’ and naming of such operating entities is an important prerequisite for creating a comprehensive and clean data/control flow diagram.
> How can you determine if you have not overlooked an operating entity? If you experience challenges in connecting operating entities that you’ve found so far, then, most likely, there is some other entity implemented in the code that you have not yet discovered. A challenge might be in the form of having entity A and entity B with entity B clearly processing data that was at some point processed by entity A but you struggle to find a concise description for the data flow arrow that connects them.
When operating entities have been discovered, list them all and briefly describe which function(s) they perform. You may also find it useful to list the data that these operating entities might be communicating through, like some shared data structures or communication channels (if the software is distributed). This will be useful when you start drawing the actual diagram.
> The process of discovering operating entities in the code might remind you of refactoring, and, indeed, it is quite similar. Nevertheless, implementing operating entities that are not directly represented by the source code might not be needed due to performance reasons or due to sheer overhead of making a small piece of functionality pronounced and addressable. Anyway, while performing reverse engineering, we are not doing any actual changes to the code regardless of how appealing they may appear.
Although the academic literature advises us to split the data and control flow diagrams ([DFD](https://en.wikipedia.org/wiki/Data-flow_diagram) and [CFD](https://en.wikipedia.org/wiki/Control-flow_diagram)), personally, I prefer to combine them for reverse engineered software systems. The advantage of merging them is that it allows one to see the triggers of data flows and other operations on the data (e.g. data removal upon expiration although one may come up with something like a negative/removal data flow). To distinguish between the control flow and the data flow on the same diagram, I use different types of arrows. I use solid arrows to depict how the data moves from one operating entity in the system to another. The dashed arrows depict the control flow like triggering the events relevant for data processing. Such an arrow starts at the entity that triggers the event and ends at the recipient of the event.
Now let’s look at an example data/control flow diagram below. Although I did not yet explain everything shown there, you will find it useful to first take a look and then read the explanation. This will help you to have a reference point in your mind.
Now, let me take some time to explain what you just saw.
An additional layer of information on a data/control flow diagram is provided by the coloring. If you are colorblind, you can still use various kinds of fill (like solid, dashed, dotted, etc) in addition to the color.
I prefer to start with a separate color for the entity that initiates data processing in the system. This is likely to be some external entity, commonly, a client, or some internal asynchronous process, like a cleanup or some other scheduled task. In the diagram above, I’ve used the red color to highlight these entities (Client, Index Updater, and Expiration Service). Note that the client is external to the system so you may want to make this explicit in your diagram by changing its shape in comparison to the internal entities or draw some additional bold line between it and the rest of the system (a system boundary). In addition to the client, there are two operating entities that run asynchronous processes in the system itself. It is the Expiration Service that triggers the removal of expired versions of the data from the persistent storage and the Index Updater that reads the persisted data from time to time and updates the search index.
Other operating entities whose boxes are colored in yellow and green on the sample diagram are reactive, meaning that they do some processing only when there is the data or they are explicitly triggered. One could color all of them in the same way but I wanted to distinguish between the layer that the client directly interacts with and the deeper parts of the system. Although this is not necessary, you may find it useful to somehow emphasize (with a color or otherwise) a specific entity or a group thereof if, let’s say, they perform common functions or if you want to distinguish between the entities that are on the producing and consuming end of some queue.
Check different coloring below. The composition (boxes and arrows) is exactly the same. However, instead of emphasizing that two of the entities are in direct contact with the external client, we focus on two reactive entities (namely, In Handlers and Internal Dispatcher) participating in the production of requests for the queue and three other entities (namely, Requests Processor, Multiversion Reader, and Out Handlers) participating in the consumption of requests from the queue. This kind of coloring makes the producer-consumer pattern implemented in this system more pronounced.
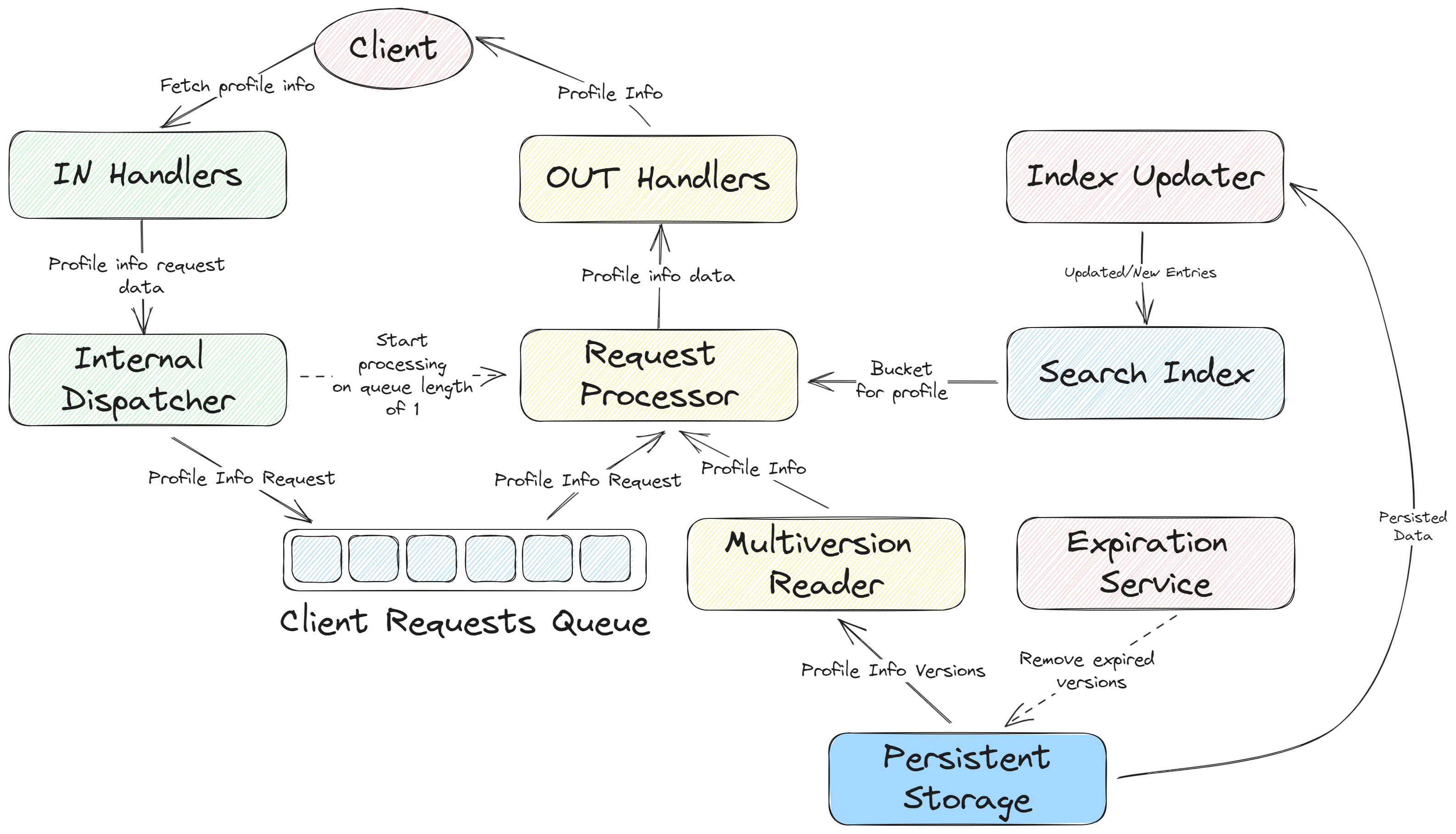
As you have probably noticed (and, if not, take another look at the diagram), in addition to the operating entities, the diagram also depicts the data entities that act as a source or a destination for the data flow arrows. It turns out to be very useful for the understanding of the system to depict these data entities explicitly along with the operating entities. Most likely, the data entities will be represented as some data structures in the code (maybe from some library or even some custom classes).
There are three data entities in the diagram: the Client Requests Queue, the Search Index, and the Persistent Storage. The queue has its own style of drawing as a box containing the queued elements. I prefer to draw the queues like that to convey the semantics of this data entity graphically - it shows where different parts of the system communicate with each other.
You can also spot that I’ve used slightly different coloring across the data entities. All the data entities use the same color (blue) but two entities are filled with strokes and one has solid fill. Why is that? Well, that simply reflects the fact that the queue and the search index are in-memory structures whereas the persistent storage is… persisted (is stored on disk). This difference in fill highlights another piece of semantics that is relevant for how the system tolerates faults which might or might not be important for your reverse engineering goals. In the very same style you could distinguish between encrypted and unencrypted data entities if the security is the cross-cutting concern that you would want to emphasize in your diagrams. One could also duplicate the diagram for each cross-cutting concern and ‘recolor’ the boxes in each of them.
That was a lengthy discussion of coloring but now you can see how color and fill can be used to represent various kinds of information on the diagram. Next, let’s focus on the logic of the data/control flow.
In the example diagram, it is pretty intuitive to deduce the sequence in which the data passes through the operating entities. The data flow starts at the client (remember that the client is the originator of a request, or a proactive operating entity) and proceeds through the system. At some point the data lands into the queue which it later leaves to be processed by the request processor. The request processor needs additional pieces of data to process the request: a specific location on the disk (let’s call it a bucket) to fetch the data from and the profile info fetched from the disk. Here things become slightly ambiguous although still understandable. Does the request processor get the bucket first and then the profile info? Or both at the same time? The first assumption is the correct one. The request processor needs to first learn which bucket of the persistent storage to query, then it can query data from the storage.
When you reverse engineer a software system, you will likely encounter cases when the correct sequence is not all that evident. For these cases, I number the arrows with small encircled numbers that highlight the sequence in which the data flows in the system and in which the events are triggered. Sometimes, one would need to show simultaneous or unordered data flows, e.g. if the component extracts the data from multiple sources and combines it in the scope of one meaningful logical step. Then, one can use the same number on multiple arrows. In the below diagram, I do this with ‘3’ that labels both an arrow that puts the profile info request into the queue and another arrow that notifies the request processor about the possibility of polling from the queue. Such numbered and chained representation on the diagram might come in quite handy when you need to reflect the data/control flow in a system full of asynchronous calls and callbacks. Such systems require a considerable amount of mental effort to understand so we’ll not cover them in this article in depth.
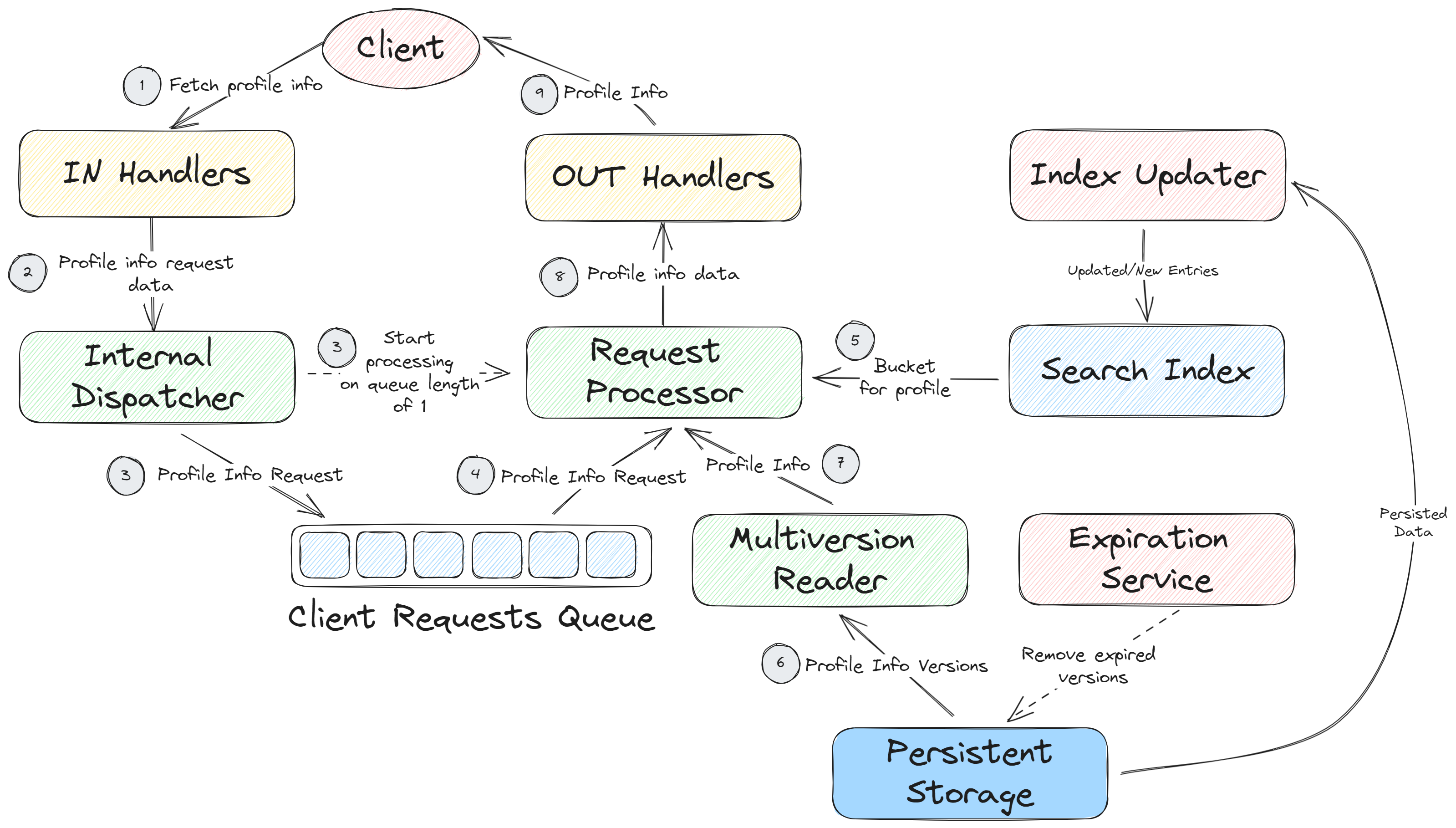
Notice that we’ve numbered not all of the arrows. Indeed, how would you number an arrow that originates at some operating entity that is internal to the system? Or maybe another arrow originating at the client that represents a write operation? Should it precede the read operation (“fetch profile info”) or not? These are all valid questions but they have nothing to do with how we represent the flow of data or control on the diagram. These questions arise since the above diagram does not do its job well. This diagram shows multiple distinct data/control flows at once! The one that we have numbered is a read flow (more specifically, fetch profile info flow, because there might be more read flows). However, there are two more. Both originate from the asynchronous operating entities - the expiration service and the index updater. Depending on your goals, you may leave them in the same diagram or you may want to drag them into a separate one since they meet only at the data entities, so, they do depend on the same data, but they do so in different ways.
To address the issue of intersecting data/control flows, I prefer to draw multiple data/control flow diagrams - one for each such flow. Otherwise, the diagrams tend to get cluttered and thus hard to navigate and reason about. So, below is how I’d dissolve the previous diagram into three: profile info read flow, index update flow, and the data expiration flow. As you can see, some operating entities are repeated across these diagrams; however, it becomes easy to argue about each flow separately. The disadvantage of introducing a separate diagram per each flow is that it becomes slightly more difficult to find the dependencies between different flows, and, as practice shows, most of the obscure design issues and bugs lurk in the intersection of multiple flows (usually, operating on the shared data). Hence, one may want to preserve the bigger diagram along with sub-diagrams for every flow to clearly see where the flows intersect e.g. by relying on some shared data like the search index or the persistent storage.
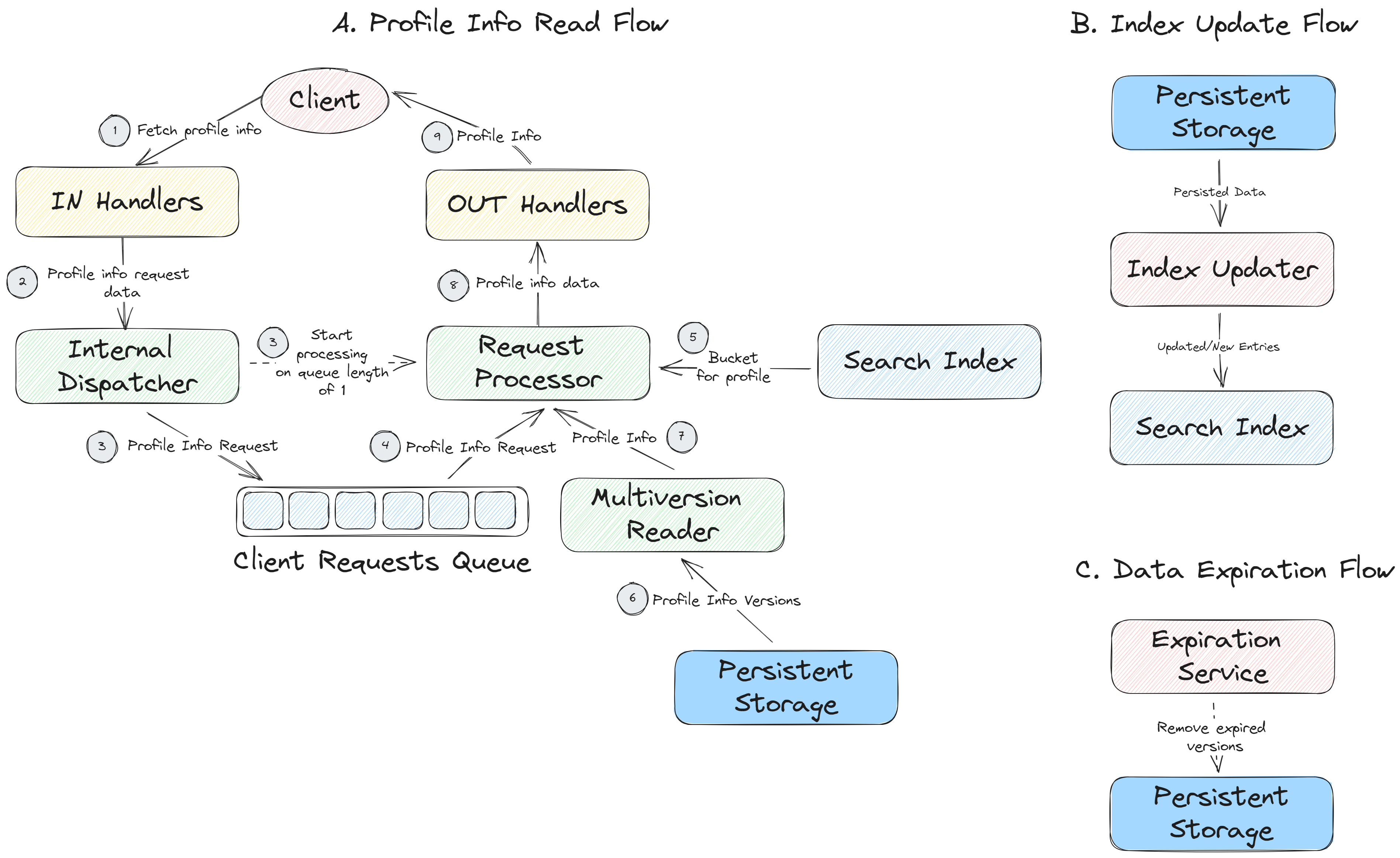
### Space-time diagrams (aka Lamport diagrams)
Let’s admit it, engineering distributed systems is far from easy. Therefore, a good diagram is worth a thousand words in that domain. If your software system falls into the category of distributed then you need to reflect this aspect on your diagrams. When dealing with the distributed aspects, we depart from the functionality-first view of this article. The reason is that some characteristics of your system contributing to its ultimate value proposition, like reliability, rely on the distributed design of your system.
The key aspect of a distributed system that needs to be properly understood and visualized is replication. In a nutshell, replicated data is the same data repeated on several distinct pieces of virtual or physical infrastructure, so, kind of like having multiple copies of the same data spread across several servers.
Why do we replicate the data? There are a couple of reasons. First, to increase fault-tolerance. Second, to achieve higher performance. We ignore the second aspect and focus on the first one.
What makes replication hard? Ideally, one wants to modify the data and have every copy of this data to be exactly the same at every point in time, that is, one wants all the replicas to be consistent with each other. At the same time, people are somewhat reluctant to have a single point of failure e.g. a server that all the operations pass through. On the side of limitations, there is the ‘hardcoded’ limit on the speed of light and various kinds of communication failures that just happen. As a result, a modification applied to one of the replicas (copies) might get lost or delayed for another replica. Therefore, engineers have to figure out the best mixture of design goals that satisfies the use cases valid for the designed system. Then, these requirements and limitations are manifested as a replication algorithm in the code of your system. It might be external (in some library) or it might be custom-built. Still, if you offer a stateful distributed system, you have to deal with the task of replication and ensuring some sort of consistency.
So, how to best describe the replication algorithm implemented in the system that you reverse-engineer?
For the purpose of fault-tolerance, it is helpful to describe how the replication is handled in various operational scenarios. It is usually easier to start with a happy path where no crashes and network partitions occur, and the system operates as intended. Then, one proceeds to specify how the replication algorithm handles common failures e.g. an instance going down or a communication being temporarily interrupted. Let’s begin with the normal operation scenario.
There is a certain kind of diagram that helps to represent distributed algorithms in a clear and concise form. Given their inherent complexity, these are definitely desirable properties for a diagram. Such diagrams are called space-time diagrams or Lamport diagrams (named after the Turing laureate Leslie Lamport). These diagrams may remind you of sequence diagrams but they introduce the notion of requests (calls) delay and the possibility of entity crash.
Lamport diagram focuses only on the system instances that maintain the replica of the same data entity. So, even if your system is deployed on hundreds of servers, it is not necessary to bring all of them into the diagram, you just need to focus on as many as your replication factor (the total number of replicas maintained for each data entity) is set to be. This number is rather small for trusted environments. In addition to the servers each maintaining a replica of a data item, you will need to depict a client that serves as an origin of the requests and the destination of the responses for your system. Sometimes, requests may be purely internal, then one of the instances of your system acts as a client.
Each server (also called node) and the client will get its own horizontal line with its name to the left of the line. This line represents the ‘lifetime’ of the server or a client, it is like a local time axis of the entity (client or a node). The flow of time in this diagram is from left to right. If your system relies on shared storage, like AWS S3, then it should also appear on such a diagram. For the sake of keeping the discussion short, we’ll focus on the shared-nothing distributed system design, i.e. when no two servers have common storage. Below is the example of nodes and a client depicted on such a diagram.

Let’s assume that the system that we reverse-engineer implements one of the most common replication approaches - primary-backup replication. In this kind of replication, each node that keeps the replicated data item assumes one of the following roles: a coordinator or a follower. They might also be called differently, e.g. a master and a follower, a primary and a backup.
Coordinator role requires the node to order the updates to the replicated data that is present on the coordinator and on the followers. Intuitively, it should be clear that only one such node should be present for the replicated data entity to avoid conflicting updates to the replicated data. The coordinator role can be transferred to another node if the original coordinator fails or becomes unresponsive. The nodes with the follower role can only perform writes that are issued by the coordinator node.
Depending on the specific replication behavior that you want to depict, you may color the label of the node to reflect its role or you may draw an appropriately colored box around the local time axis of the entity. The former is helpful to avoid clutter when analyzing common scenarios whereas the latter is helpful when you want to accurately represent replication behavior in the presence of changing roles of the nodes (useful for debugging). Both options are represented below. We will focus on the first one.

Probably, the easiest way to find the code implementing the replication is by searching for requests that the nodes exchange to replicate the data or to track how the new data propagates in the system. You could deduce whether the code belongs to the master (coordinator) or follower (backup) role depending on whether it is triggered by the request that originates from the client or from another node of the system (master). Figuring out the distribution of roles in replication algorithms might be the most challenging problem but it is still soluble. Since there are a handful of replication algorithms commonly used in the software systems, after getting acquainted with them you will have an easier time matching the code to the algorithm that it implements.
Once you’ve figured out the roles of the nodes, say master and follower, you need to track the requests that they send to each other as well as the conditions of sending and accepting these requests. Ideally, you would try to find the original request from the client that hits the master and depict it on the diagram with an arrow. Then, it should be possible to track all the subsequent requests and responses of other nodes. Be mindful of ordering for these requests because the guarantees and the performance that you can deduce from the diagram will depend on how you depicted this communication.
In our example, primary-backup replication starts with the client sending a request to the coordinator node, that is, node A. Then, once node A is done processing the request and persisting its results, this node may not reply to the client straight away but instead will send the result of this request to both nodes B and C. Node A will also wait for the acknowledgements from these nodes prior to confirming to the client that the data has been successfully modified In the diagram below, the acknowledgements are shown with the dotted arrows and labels ACK Write X whereas the actual writes are shown with solid arrows labeled with Write X. As you can see, the whole write issued by the client can take quite a while because the acknowledgement from node B was delayed (notice the write time depicted with the dashed green line). It is not necessary to depict the delays like that - you may want the diagram to be more general. However, be wary that delays can rearrange the order of many requests and responses.
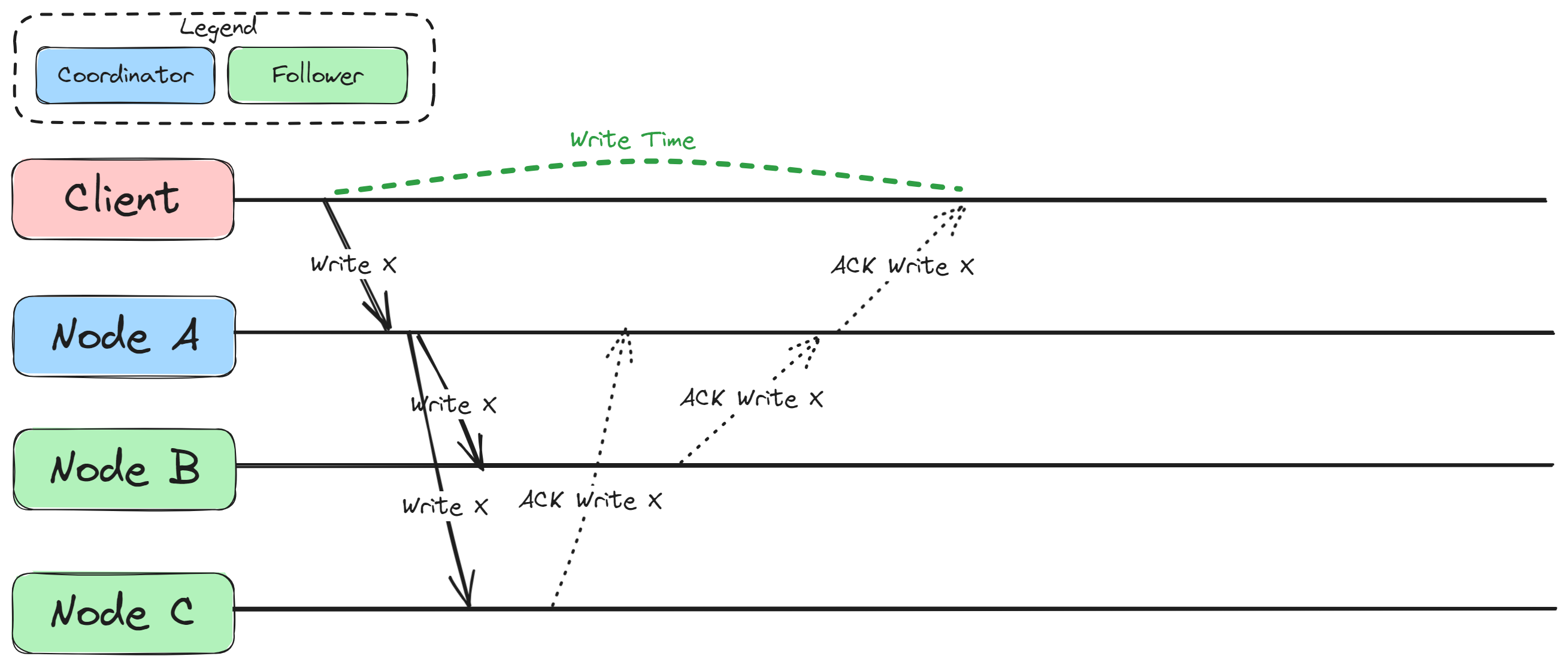
Now, let’s change this diagram slightly:
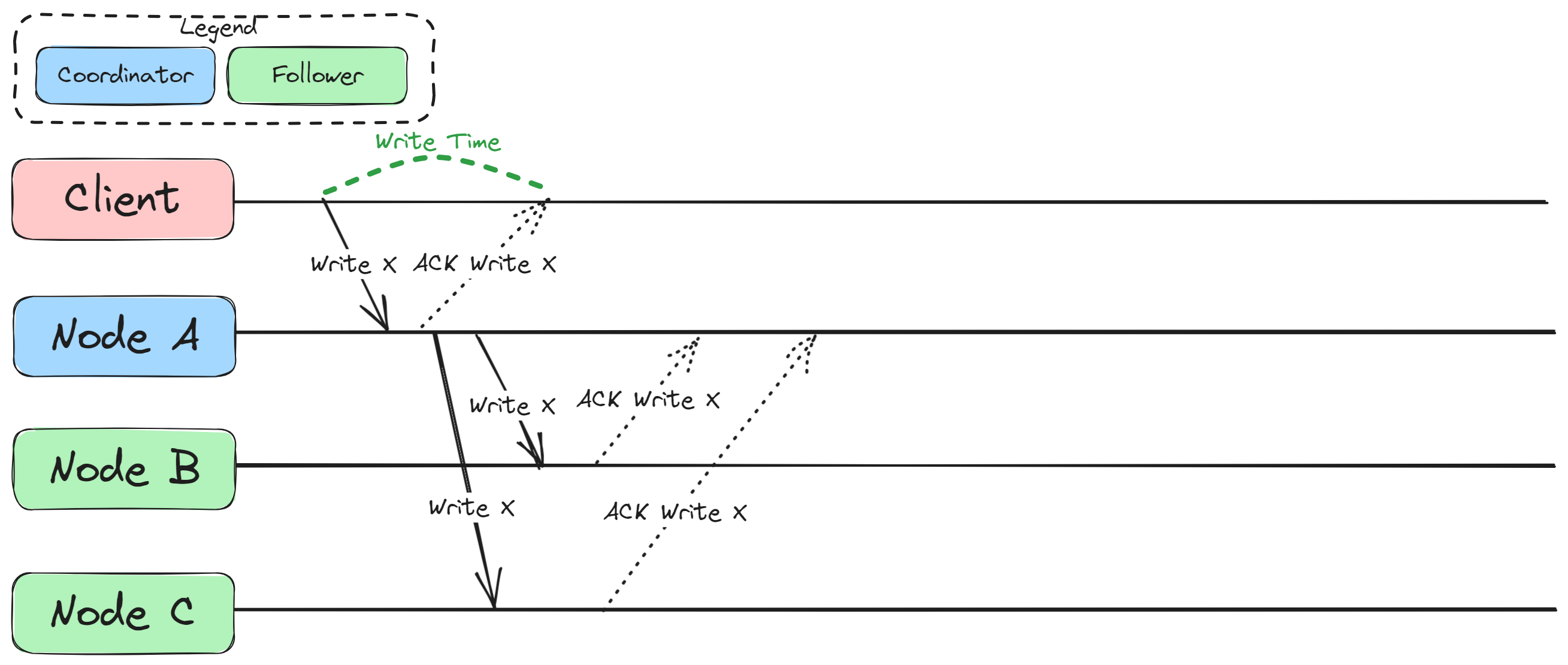
Can you see what changed in this diagram compared to the previous one? In this new diagram, the ACK Write X arrow from Node A to the client directly follows the Write X arrow from the client on the time axis of node A, that is Node A does not wait for acknowledgements from nodes B and C. In practice, this would mean that the guarantee on the write that the client performed is different compared to the previous diagram. With the algorithm reflected in the new diagram, when the client gets an acknowledgment of its write, it means that the data is only on Node A whereas in the previous diagram it meant that the data was present on all the nodes: A, B, and C. Is it bad? In terms of fault tolerance - yes. However, if we consider the latency of client operations, the second option depicted in the new diagram is actually faster. Compare the length of the segment of Node A’s timeline labeled as write time to the segment with the same label in the previous diagram. The write time segment in the new diagram is considerably shorter than in the previous one. If your system needs to perform thousands or tens of thousands of such writes per second, then this option with waiting only for one acknowledgement may become very appealing since the client gets their response quickly. On the other hand, the cost of latency reduction might be inappropriate for your software if the use case requires guaranteeing some level of fault tolerance when one of the nodes crashes after client got acknowledgement of the write operation. With that in mind, let’s dive into representing the failure scenarios with Lamport diagrams.
You could imagine the following failure scenario that the Lamport diagram can represent fairly well: Node A acknowledged the write to the client but then immediately crashed without completing the replication to other followers. This might be a plausible scenario for the system that you attempt to reverse-engineer and it thus becomes very important to catch such a case and depict it. With such diagrams, you will learn a lot about the ways in which you may be losing the data and whether it aligns with the guarantees that you provide to the users of your system. In the below diagram, the crash of Node A is represented with the crossed circle of red color, also the timeline for this node ends abruptly at this circle. Node B becomes coordinator for X which is depicted with its repeated label colored with blue color. Notice that a subsequent read of X from client to node B returns nothing because node A failed before replicating the data to nodes B and C. The same could have happened if it succeeded in replicating X to node C but not to node B.
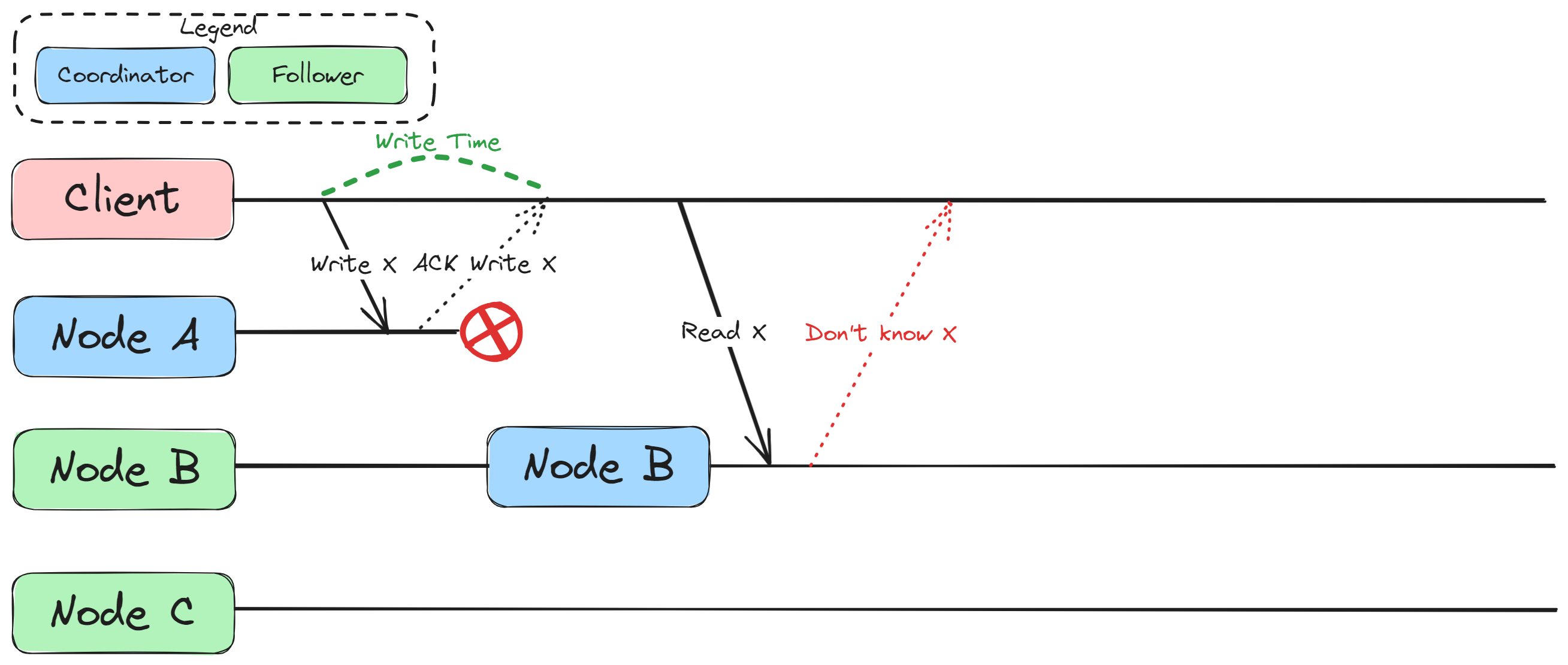
In addition, the same situation may occur even if Node A does not crash but the client is allowed to read from the followers. Below, you can see an example where the write to node B was not fast enough and thus the client could not read the value of X that it wrote previously since it chose Node B for its read (maybe due to some load balancing mechanisms). For the sake of convenience, the part of nodes timelines shown in red represents the fact that the value of X has not yet been written to them. With that, it becomes obvious why Node C that the client attempts to read from returns that it does not know X.
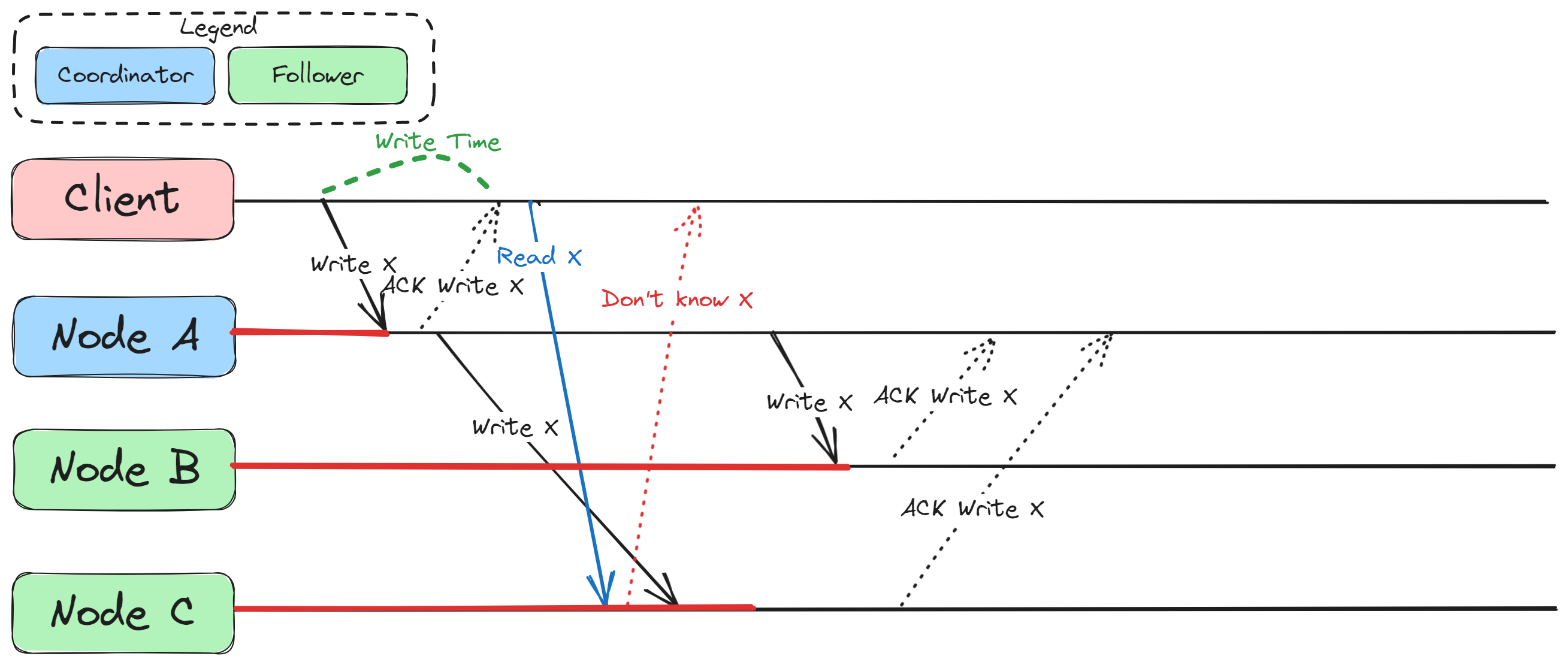
Such mishaps occur because from the point of view of the client, all three nodes act as a single virtual entity, also called a replication group. Such an interface allows to hide the concern of fault tolerance from the client but, as you can see, depending on how fault tolerance is implemented, the client may get different guarantees on what to expect from the system.
The topic of distributed systems and guarantees is very vast. We’ve just scratched the surface in this article. The intention was to show you how certain kinds of diagrams can help you reverse engineer the distributed algorithms that your software implements. The challenge here is that you have to take into account both the code that embodies the happy path as well as the possible edge cases with various kinds of failures occurring in your system. Thus, it usually makes sense to create the happy path diagram first and then start introducing various kinds of failures and see how the diagram would change in response to them. From these diagrams you will also get another piece of information about your software system that will become very important on the next stage of reverse engineering. In essence, you will get the guarantees that the system provides to the use cases in respect to the data stored in it and the information on which properties of the system are prioritized (possibly, at the cost of others).
### Written concise statements about the system
All the previous tools were instrumental to this pinnacle of reverse engineering. We started at the code level and then gradually went up peeling off everything that does not directly relate to the logic of the system. We’ve been reducing the level of detail while increasing the scope in each new diagram and description. At the very end of the reverse engineering exercise, an engineer should be able to describe the reverse-engineered system in a set of concise statements. These written statements might be quite diverse.
Among the most important categories I could list the following:
- guarantees to the application/use case of the system, like “System Foo supports strong consistency for the client data” or “System Foo stores the client data in an encrypted format”;
- key system architecture choices, like “System Foo implements distributed system architecture based on shared storage” and “System Foo replicates client data using chain replication approach”;
- interfaces available to the use cases/applications like “A client of the System Foo can connect, perform reads and writes of its own state”;
- summary of the key functionality, like “System Foo dispatches the client requests to the internal queues by using the client ID and the key of the request to look up the destination queue ID in the Queue Index”.
These concise statements will serve you and your team as a reminder of how the system works at the highest level and what it offers its users. Concise statements also help to bring one’s attention to the relevant pieces of logic and behaviors of the system. Note that using these statements in the discussions requires that the participants would have a similar level of understanding of what hides behind each of these statements. It is also of great value to understand what each of these statements means for the design of the system in terms of opportunities and limitations as well as for the services that the system is able to perform for its users. In other words, the participants of the architectural discussion need to have the same context. Otherwise, there is a real danger that the discussion turns out to be too superficial or abstract for those that lack this context.
Let’s have a closer look at the example statement “System Foo implements distributed system architecture based on shared storage”. Having read this statement, an engineer will recall both the fundamental advantages as well as the disadvantages of this design choice. He or she will also quickly discover which implications this choice will have for the availability of the system and replication speed on cluster composition changes. Such statements are a very powerful tool to shape the discussions around certain key aspects of the system design in the team and thus should be carefully crafted based on the evidence collected on the previous steps. Ideally, you would want to refine and agree on these statements as a team since they will likely stick with you for a while and thus they need to be very precise; in addition, some of these statements may be converted to marketable value propositions for the product of the company if it sells software or offers SaaS solutions.
## Instead of Conclusion: Key Takeaways
I will not repeat myself on the use of specific diagrams and representations for performing the task of reverse engineering. Instead, I’d like to reiterate on the overall approach to the task of reverse engineering.
First and foremost, you need to cultivate the explanatory mindset in yourself to succeed in reverse engineering. You can acquire it by trying to simplify your explanations of how the software works and by gradually reducing the amount of details in your explanations and using more and more general terms. Reverse engineering is a bottom-up approach but you may also find it useful to compare the results of your reverse engineering exercise with the documentation that is already available for the software system (if you are lucky enough to have it). Given that we live in the age of abundance of versatile software systems that gradually get rooted into various business processes of companies, it would be one of the most sought after skills in software engineering.
Another important point is that you need to think outside-of-box when trying to unveil the design blueprint of the software system. Try different diagrams and representations, do not limit yourself by whatever you have seen in this article or in other sources (like UML diagrams and whatever is taught at the university). Being creative and at the same time focused will help you a lot to get a clear picture of the software that you are working on and would bring you far in improving and expanding it.
Reverse engineering is a kind of destination but at the same time it is also a journey. While wrestling with unfamiliar code and trying to figure out better and more concise representations, you would also alter numerous connections in your brain and start thinking differently about the software system that you work on. This is a necessary part of professional growth that you will likely miss if you only work on hobby or greenfield projects. What will help you on this path is binding the reverse engineering exercise to reading various theoretical books that expose you to software design patterns, data structures, and so on. However, those should not be read in isolation from the reverse engineering activity. Just by reading them you won’t learn much, maybe you will even make yourself worse off because of time spent on reading and getting detached from the code and the practice of programming. One should strive to avoid this at any cost.
## A Note on Other Approaches
### Written concise statements are good but what about ADRs?
I’ve used [ADRs](https://adr.github.io/) for documenting. Personally, I’ve found them practical to initiate the discussions about specific design issues (RFC-style) and to document fresh design decisions (i.e. that have not yet been taken in the past). I did try to use them to document the past design decisions as well but performing the archeological task this way turns out pretty sour very quickly.
In my experience, ADRs are VERY verbose for documenting the past design choices and are not very useful since one would have to read through all of these ADRs in order to restore the full state of the system design. This is very time-consuming. In addition, they are quite linear and do not let one easily highlight some cross-cutting design concerns without repetition in multiple ADRs. Last but not least, in an ideal world, you’d need to interview the stakeholders who took the design decision in the past. Otherwise you’ll end up documenting your phantasies which may be reasonable, but they are still, well, phantasies.
In contrast, the approach taken in this article focuses on creating a snapshot of the state of your software system’s design and on making it as independent of minute details as possible.
### Aren’t you reinventing UML diagrams here?
First of all, my goal is not to invent THE diagrams (as compared to [THE standards](https://xkcd.com/927/) which one just cannot get enough of) but rather to show how to produce these artifacts based on the code at hand and how to proceed from one diagram (or, more general, a representation) to another on higher level in a somewhat meaningful way. Indeed, the diagrams in this article will resemble some of the UML diagrams or other diagrams. In the end, they revolve around the same concepts and same relations. You may use UML diagrams if you like them (I, personally, don’t, and I did try them on multiple occasions). This is a perfectly valid tool for the task of reverse engineering as well, might be a bit more strict and verbose, but still valid. | remit |
1,602,978 | HTML CSS and JavaScript Projects for Beginners | html css and javascript projects for beginners hey guys today I'm going to share html css and... | 0 | 2023-09-17T13:35:06 | https://dev.to/onlineittutstutorials/html-css-and-javascript-projects-for-beginners-34pm | javascript, html, css, tutorial | html css and javascript projects for beginners
hey guys today I'm going to share html css and javascript projects for beginners. Recently, I've been working with HTML, CSS & JS so, I've been creating different types of projects. So, I've decided to share with you the projects that I made.

When you improve your HTML, CSS & JS skills you need to make different types of projects, once you make the projects, you will improve your coding skills. So, I made different types of projects using HTML CSS & JS, you can watch and learn them from scratch practically.
After watching the complete tutorial, you will get a lot of ideas from it, Also you will get many ideas and learn something new from it. I hope this tutorial is helpful and beneficial for you.
{% embed https://www.youtube.com/watch?v=9qaNhk7gU24 %} | onlineittutstutorials |
1,603,090 | Build a Digital Collectibles Portal Using Flow and Cadence (Part 1) | In this tutorial, we’ll learn how to make a website for collecting digital collectibles (or NFTs)... | 0 | 2023-09-18T10:24:58 | https://dev.to/johnjvester/build-a-digital-collectibles-portal-using-flow-and-cadence-part-1-54nj | webdev, web3, flow, cadence |

In this tutorial, we’ll learn how to make a website for collecting digital collectibles (or NFTs) on the blockchain **Flow**. We'll use the smart contract language **Cadence** along with **React** to make it all happen. We'll also learn about Flow, its advantages, and the fun tools we can use.
By the end of this article, you’ll have the tools and knowledge you need to create your own apps.
Let’s dive right in!
## Final Output

## **What are we building?**
We're building an application for digital collectibles, and each collectible using a Non-Fungible Token (NFT). To make all this work, we will use Flow's NonFungibleToken Standard, which is a set of rules that helps us manage these special digital items. It's similar to ERC-721, which is used on a different platform called Ethereum.
However, since we are using the Cadence programming language, there are some small differences to be aware of. Our app will allow you to collect NFTs, and each item will be unique from the others.
### **Prerequisites**
Before you begin, be sure to install the Flow CLI on your system. If you haven't done so, follow these [installation instructions](https://developers.flow.com/tooling/flow-cli/install).
### **Setting Up**
If you're ready to kickstart your project, the first thing you need to do is type in the command "flow setup."
This command does some magic behind the scenes to set up the foundation of your project. It creates a folder system and sets up a file called "flow.json" to configure your project, making sure everything is organized and ready to go!

The project will contain the following folders and files:
* /contracts: Contains all Cadence contracts.
* /scripts: Holds all Cadence scripts.
* /transactions: Stores all Cadence transactions.
* /tests: Contains all Cadence tests.
* flow.json: A configuration file for your project, automatically maintained.
Follow the steps below to use Flow NFT Standard.
### **Step 1: Make a new folder.**
First, go to the "flow-collectibles-portal" folder and find the "Cadence" folder. Inside it, create a new folder called "interfaces."
### **Step 2: Create a file.**
Inside the "interfaces" folder, make a new file and name it "NonFungibleToken.cdc."
### **Step 3: Copy and paste.**
Now, open the link named [NonFungibleToken](https://github.com/onflow/flow-nft/blob/master/contracts/NonFungibleToken.cdc) which contains the NFT standard. Copy all the content from that file and paste it into the new file you just created ("NonFungibleToken.cdc"). That's it! You've successfully set up the standards for your project.
Now, let’s write some code!
But before we dive into coding, it's important to establish a mental model of how our code will be structured. As developers, it's crucial to have a clear idea.
At the top level, our codebase consists of three main components:
1. NFT: Each collectible is represented as an NFT.
2. Collection: A collection refers to a group of NFTs owned by a specific user.
3. Global Functions and Variables: These are functions and variables defined at the global level for the smart contract and are not associated with any particular resource.
## **Collectibles Smart Contract**
### **Creating the Collectibles Smart Contract**
Create a new file named Collectibles.cdc inside flow-collectibles-portal/cadence/contracts. This is where we will write the code for our NFT Collection.
**Contract Structure**
```javascript
import NonFungibleToken from "./interfaces/NonFungibleToken.cdc"
pub contract Collectibles: NonFungibleToken{
pub var totalSupply: UInt64
// other code will come here
init(){
self.totalSupply = 0
}
}
```
Let's break down the code line by line:
1. First, we'll need to include something called "NonFungibleToken" from our interface folder. This will help us with our contract.
2. Now, let's write the contract itself. We use the word "contract" followed by the name of the contract. (For this example, let’s call it "Collectibles".) We’ll write all the code inside this contract.
3. Next, we want to make sure our contract follows certain rules. To do that, we use a special syntax “NonFungibleToken", which means our contract will follow the NonFungibleToken standard.
4. Then, we’ll create a global variable called "totalSupply." This variable will keep track of how many Collectibles we have. We use the data type "UInt64" for this, which simply means we can only have positive numbers in this variable. No negative numbers allowed!
5. Now, let's give "totalSupply" an initial value of 0, which means we don't have any Collectibles yet. We'll do this inside a function called "init()".
6. That's it! We set up the foundation for our Collectibles contract. Now we can start adding more features and functionalities to make it even more exciting.
Before moving forward, please check out the code snippet to understand how we define variables in cadence:

#### **NFT Structure**
Now, we'll create a simple NFT resource that holds all the data related to each NFT. We'll define the NFT resource with the pub resource keywords.
Add the following code to your smart contract:
```javascript
import NonFungibleToken from "./interfaces/NonFungibleToken.cdc"
pub contract Collectibles: NonFungibleToken{
pub var totalSupply: UInt64
pub resource NFT: NonFungibleToken.INFT{
pub let id: UInt64
pub var name: String
pub var image: String
init(_id:UInt64, _name:String, _image:String){
self.id = _id
self.name = _name
self.image = _image
}
}
init(){
self.totalSUpply = 0
}
}
```
As you have seen before, the contract implements the NonFungibleToken standard interface, represented by pub contract Collectibles: NonFungibleToken. Similarly, resources can also implement various resource interfaces.
The NFT resource must also implement the NonFungibleToken.INFT interface, which is a super simple interface that just mandates the existence of a public property called id within the resource.
This is a good opportunity to explain some of the variables we will be using in the NFT resource:
* id: The Token ID of the NFT
* name: The name of the owner who will mint this NFT.
* image: The image of the NFT.
After defining the variable, make sure you initialize its value in the init() function.
Let’s move forward and create another resource called Collection Resource.
#### **Collection Structure**
Imagine a Collection as a special folder on your computer that can hold unique digital items called NFTs. Every person who uses this system has their own Collection, just like how everyone has their own folders on their computer.
To better understand, think of it like this: Your computer has a main folder, let's call it "My Account," and inside that, you have a special folder called "My Collection." Inside this "Collection" folder, you can keep different digital items, such as pictures, videos, or music files. Similarly, in this system, when you buy or create NFTs, they get stored in your personal Collection.
For our Collectibles contract, each person who buys NFTs gets their own "Collection" folder, and they can fill it with as many NFTs as they like. It's like having a personal space to store and organize your unique digital treasures!
```javascript
import NonFungibleToken from "./interfaces/NonFungibleToken.cdc"
pub contract Collectibles: NonFungibleToken{
pub var totalSupply: UInt64
pub resource NFT: NonFungibleToken.INFT{
pub let id: UInt64
pub var name: String
pub var image: String
init(_id:UInt64, _name:String, _image:String){
self.id = _id
self.name = _name
self.image = _image
}
}
// Collection Resource
pub resource Collection{
}
init(){
self.totalSUpply = 0
}
}
```
The Collection resource will have a public variable named ownedNFTs to store the NFT resources owned by this Collection. We'll also create a simple initializer for the Collection resource.
```javascript
pub resource Collection {
pub var ownedNFTs: @{UInt64: NonFungibleToken.NFT}
init(){
self.ownedNFTs <- {}
}
}
```
#### **Resource Interfaces**
A resource interface in Flow is similar to interfaces in other programming languages. It sits on top of a resource and ensures that the resource that implements it has the stuff inside of the interface. It can also be used to restrict access to the whole resource and be more restrictive in terms of access modifiers than the resource itself.
In the NonFungibleToken standard, there are several resource interfaces like INFT, Provider, Receiver, and CollectionPublic. Each of these interfaces has specific functions and fields that need to be implemented by the resource that uses them.
In this contract, we will use these three interfaces coming from NonFungibleToken: Provider, Receiver, and CollectionPublic. These interfaces define functions like deposit, withdraw, borrowNFT, and getIDs. We will explain each of these in greater detail as we go.
```javascript
pub resource interface CollectionPublic{
pub fun deposit(token: @NonFungibleToken.NFT)
pub fun getIDs(): [UInt64]
pub fun borrowNFT(id: UInt64): &NonFungibleToken.NFT
}
pub resource Collection: CollectionPublic, NonFungibleToken.Provider, NonFungibleToken.Receiver, NonFungibleToken.CollectionPublic{
pub var ownedNFTs: @{UInt64: NonFungibleToken.NFT}
init(){
self.ownedNFTs <- {}
}
}
```
Now, let's create the withdraw() function required by the interface.
```javascript
pub fun withdraw(withdrawID: UInt64): @NonFungibleToken.NFT {
let token <- self.ownedNFTs.remove(key: withdrawID) ?? panic("missing NFT")
emit Withdraw(id: token.id, from: self.owner?.address)
return <- token
}
```
This function first tries to move the NFT resource out of the dictionary. If it fails to remove it (the given withdrawID was not found, for example), it panics and throws an error. If it does find it, it emits a withdraw event and returns the resource to the caller. The caller can then use this resource and save it within their account storage.
Now it’s time for the deposit() function required by NonFungibleToken.Receiver.
```javascript
pub fun deposit(token: @NonFungibleToken.NFT) {
let id = token.id
let oldToken <- self.ownedNFTs[id] <-token
destroy oldToken
emit Deposit(id: id, to: self.owner?.address)
}
```
Now let’s focus on the two functions required by NonFungibleToken.CollectionPublic: borrowNFT() and getID().
```javascript
pub fun borrowNFT(id: UInt64): &NonFungibleToken.NFT {
if self.ownedNFTs[id] != nil {
return (&self.ownedNFTs[id] as &NonFungibleToken.NFT?)!
}
panic("NFT not found in collection.")
}
pub fun getIDs(): [UInt64]{
return self.ownedNFTs.keys
}
```
There is one last thing we need to do for the Collection Resource: specify a destructor.
### **Adding a Destructor**
Since the Collection resource contains other resources (NFT resources), we need to specify a destructor. A destructor runs when the object is destroyed. This ensures that resources are not left "homeless" when their parent resource is destroyed. We don't need a destructor for the NFT resource as it contains no other resources.
```javascript
destroy (){
destroy self.ownedNFTs
}
```
Check the complete collection resource source code:
```javascript
pub resource interface CollectionPublic{
pub fun deposit(token: @NonFungibleToken.NFT)
pub fun getIDs(): [UInt64]
pub fun borrowNFT(id: UInt64): &NonFungibleToken.NFT
}
pub resource Collection: CollectionPublic, NonFungibleToken.Provider,
NonFungibleToken.Receiver, NonFungibleToken.CollectionPublic{
pub var ownedNFTs: @{UInt64: NonFungibleToken.NFT}
init(){
self.ownedNFTs <- {}
}
destroy (){
destroy self.ownedNFTs
}
pub fun withdraw(withdrawID: UInt64): @NonFungibleToken.NFT {
let token <- self.ownedNFTs.remove(key: withdrawID) ?? panic("missing NFT")
emit Withdraw(id: token.id, from: self.owner?.address)
return <- token
}
pub fun deposit(token: @NonFungibleToken.NFT) {
let id = token.id
let oldToken <- self.ownedNFTs[id] <-token
destroy oldToken
emit Deposit(id: id, to: self.owner?.address)
}
pub fun borrowNFT(id: UInt64): &NonFungibleToken.NFT {
if self.ownedNFTs[id] != nil {
return (&self.ownedNFTs[id] as &NonFungibleToken.NFT?)!
}
panic("NFT not found in collection.")
}
pub fun getIDs(): [UInt64]{
return self.ownedNFTs.keys
}
}
```
Now we have finished all the resources!
#### **Global Function**
Now, let's talk about some global functions you can use:
1. createEmptyCollection: This function allows you to create an empty Collection in your account storage.
2. checkCollection: This handy function helps you discover whether or not your account already has a collection.
3. mintNFT: This function is super cool because it allows anyone to create an NFT.
```javascript
pub fun createEmptyCollection(): @Collection{
return <- create Collection()
}
pub fun checkCollection(_addr: Address): Bool{
return getAccount(_addr)
.capabilities.get<&{Collectibles.CollectionPublic}>
(Collectibles.CollectionPublicPath)!
.check()
}
pub fun mintNFT(name:String, image:String): @NFT{
Collectibles.totalSupply = Collectibles.totalSupply + 1
let nftId = Collectibles.totalSupply
var newNFT <- create NFT(_id:nftId, _name:name, _image:image)
return <- newNFT
}
```
## **Wrapping Up the Smart Contract**
Now we’ve finished writing our smart contract. The final code should look like the combined structure NFT resource, and Collection resources, along with the required interfaces and global functions.
### **Transaction and Script**
##### **What is a transaction?**
A transaction is a set of instructions that interact with smart contracts on the blockchain and modify its current state. It's like a function call that changes the data on the blockchain. Transactions usually involve some cost, which can vary depending on the blockchain you are on.
On the other hand, we can use a script to view data on the blockchain, but it does not change it. Scripts are free and are used when you want to look at the state of the blockchain without altering it.
Here is how a transaction is structured in Cadence:
1. Import: The transaction can import any number of types from external accounts using the import syntax. For example, import NonFungibleToken from 0x01.
2. Body: The body is declared using the transaction keyword and its contents are contained in curly brackets. It first contains local variable declarations that are valid throughout the whole of the transaction.
1. Phases: There are two optional main phases: preparation and execution. The preparation and execution phases are blocks of code that execute sequentially.
2. Prepare Phase: This phase is used to access data/information inside the signer's account (allowed by the AuthAccount type).
3. Execute Phase: This phase is used to execute actions.
#### **Create Collection Transaction**
```javascript
import Collectibles from "../contracts/Collectibles.cdc"
transaction {
prepare(signer: AuthAccount) {
if signer.borrow<&Collectibles.Collection>(from: Collectibles.CollectionStoragePath) == nil {
let collection <- Collectibles.createEmptyCollection()
signer.save(<-collection, to: Collectibles.CollectionStoragePath)
let cap = signer.capabilities.storage.issue<&{Collectibles.CollectionPublic}>(Collectibles.CollectionStoragePath)
signer.capabilities.publish( cap, at: Collectibles.CollectionPublicPath)
}
}
}
```
Let's break down the code line by line:
1. This transaction interacts with Collectibles smart contract. Then it checks if the sender (signer) has a Collection resource stored in their account by borrowing a reference to the Collection resource from the specified storage path Collectibles.CollectionStoragePath. If the reference is nil, it means the signer does not have a collection yet.
2. If the signer does not have a collection, then it creates an empty collection by calling the createEmptyCollection() function.
3. After creating the empty collection, place into the signer's account under the specified storage path Collectibles.CollectionStoragePath.
It establishes a link between the signer's account and the newly created collection using link().
#### **Mint NFT Transaction**
```javascript
import NonFungibleToken from "../contracts/interfaces/NonFungibleToken.cdc"
import Collectibles from "../contracts/Collectibles.cdc"
transaction(name:String, image:String){
let receiverCollectionRef: &{NonFungibleToken.CollectionPublic}
prepare(signer:AuthAccount){
self.receiverCollectionRef = signer.borrow<&Collectibles.Collection>(from: Collectibles.CollectionStoragePath)
?? panic("could not borrow Collection reference")
}
execute{
let nft <- Collectibles.mintNFT(name:name, image:image)
self.receiverCollectionRef.deposit(token: <-nft)
}
}
```
Let’s break down the code line by line:
1. We first import the NonFungibleToken and Collectibles contract.
2. **transaction(name: String, image: String)**
This line defines a new transaction. It takes two arguments, name and image, both of type String. These arguments are used to pass the name and image of the NFT being minted.
3. **let receiverCollectionRef: &{NonFungibleToken.CollectionPublic}**
This line declares a new variable receiverCollectionRef. It is a reference to a public collection of NFTs of type NonFungibleToken.CollectionPublic. This reference will be used to interact with the collection where we will deposit the newly minted NFT.
4. **prepare(signer: AuthAccount)**
(This line starts the prepare block, which is executed before the transaction.) It takes an argument signer of type AuthAccount. AuthAccount represents the account of the transaction’s signer.
5. Inside the prepare block, it borrows a reference to the Collectibles.Collection from the signer’s storage. It uses the borrow function to access the reference to the collection and store it in the receiverCollectionRef variable. If the reference is not found (if the collection doesn’t exist in the signer’s storage, for example), it will throw the error message “could not borrow Collection reference”.
6. The execute block contains the main execution logic for the transaction. The code inside this block will be executed after the prepare block has successfully completed.
7. **nft <- Collectibles.mintNFT(\_name: name, image: image)
**Inside the execute block, this line calls the mintNFT function from the Collectibles contract with the provided name and image arguments. This function is expected to create a new NFT with the given name and image. The <- symbol indicates that the NFT is being received as an object that can be moved (a resource).
8. **self.receiverCollectionRef.deposit(token: <-nft)**
This line deposits the newly minted NFT into the specified collection. It uses the deposit function on the receiverCollectionRef to transfer ownership of the NFT from the transaction’s executing account to the collection. The <- symbol here also indicates that the NFT is being moved as a resource during the deposit process.
#### **View NFT Script**
```javascript
import NonFungibleToken from "../contracts/interfaces/NonFungibleToken.cdc"
import Collectibles from "../contracts/Collectibles.cdc"
pub fun main(user: Address, id: UInt64): &NonFungibleToken.NFT? {
let collectionCap= getAccount(user).capabilities
.get<&{Collectibles.CollectionPublic}>(/public/NFTCollection)
?? panic("This public capability does not exist.")
let collectionRef = collectionCap.borrow()!
return collectionRef.borrowNFT(id: id)
}
```
Let's break down the code line by line:
1. First we import the NonFungibleToken and Collectibles contract.
2. pub fun main(acctAddress: Address, id: UInt64): &NonFungibleToken.NFT?
This line defines the entry point of the script, which is a public function named main. The function takes two parameters:
* acctAddress: An Address type parameter representing the address of an account on the Flow Blockchain.
* id: A UInt64 type parameter representing the unique identifier of the NFT within the collection.
1. Then we use getCapability to fetch the Collectibles.Collection capability for the specified acctAddress. A capability is a reference to a resource that allows access to its functions and data. In this case, it is fetching the capability for the Collectibles.Collection resource type.
2. Then, we borrow an NFT from the collectionRef using the borrowNFT function. The borrowNFT function takes the id parameter, which is the unique identifier of the NFT within the collection. The borrow function on a capability allows reading the resource data.
3. Finally, we return the NFT from the function.
### **Testnet Deployment**
Follow the steps to deploy the collectibles contract to the Flow Testnet.
#### **1\. Set up a Flow account.**
Run the following command in the terminal to generate a Flow account:
`flow keys generate`
Be sure to write down your public key and private key.
Next, we’ll head over to [the Flow Faucet](https://testnet-faucet.onflow.org/), create a new address based on our keys, and fund our account with some test tokens. Complete the following steps to create your account:
1. Paste in your public key in the specified input field.
2. Keep the Signature and Hash Algorithms set to default.
3. Complete the Captcha.
4. Click on Create Account.
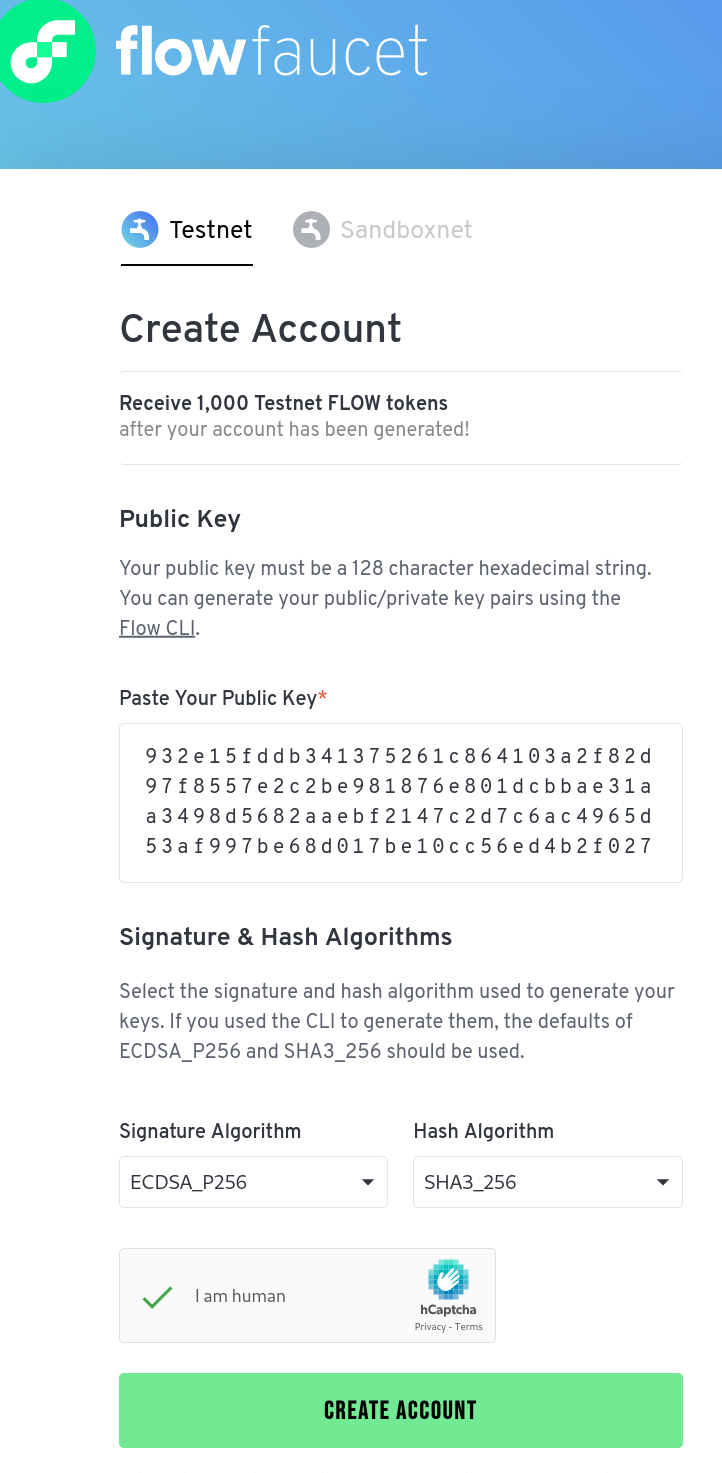
After setting up an account, we receive a dialogue with our new Flow address containing 1,000 test Flow tokens. Copy the address so we can use it going forward.
#### **2\. Configure the project.**
Ensure your project is configured correctly by verifying the contract's source code location, account details, and contract name.
```javascript
{
"emulators": {
"default": {
"port": 3569,
"serviceAccount": "emulator-account"
}
},
"contracts": {
"NonFungibleToken": {
"source": "./cadence/contracts/interfaces/NonFungibleToken.cdc",
"aliases": {
"testnet": "0x631e88ae7f1d7c20"
}
},
"Collectibles": "./cadence/contracts/Collectibles.cdc"
},
"networks": {
"testnet": "access.devnet.nodes.onflow.org:9000"
},
"accounts": {
"emulator-account": {
"address": "0xf8d6e0586b0a20c7",
"key": "61dace4ff7f2fa75d2ec4a009f9b19d976d3420839e11a3440c8e60391699a73"
},
"contract": {
"address": "0x490b5c865c43d0fd",
"key": {
"type": "hex",
"index": 0,
"signatureAlgorithm": "ECDSA_P256",
"hashAlgorithm": "SHA3_256",
"privateKey": "priavte_key"
}
}
},
"deployments": {
"testnet": {
"contract": [
"Collectibles"
]
}
}
}
```
#### **3\. Copy and paste.**
Paste your generated private key and account address inside accounts -> contract section.
#### **4\. Execute.**
Go to the terminal and run the following code:
`flow project deploy --network testnet`
#### **5\. Wait for confirmation.**
After submitting the transaction, you'll receive a transaction ID. Wait for the transaction to be confirmed on the testnet, indicating that the smart contract has been successfully deployed.

Check your deployed contract here: [Flow Source](https://flow-view-source.com/).
## **Final Thoughts and Congratulations!**
Congratulations! You have now built a collectibles portal on the Flow blockchain and deployed it to the testnet. What’s next? Now you can work on building the frontend which we will cover in part 2 of this series.
Have a really great day! | johnjvester |
1,603,183 | First Code Contributions | This week in my open source development course I practiced creating and managing pull requests to... | 0 | 2023-09-22T03:50:18 | https://dev.to/ijacobscpa/first-code-contributions-2m0j | github, opensource, osdc, beginners | This week in my open source development course I practiced creating and managing pull requests to another person's project and my for my project [textml](https://dev.to/ijacobscpa/textml-2gic).
For my part, I was working on the Waypoint project located here at https://github.com/rabroldan/Waypoint which is a text-to-HTML converter that allows for custom CSS styling and allows live creation and editing of files submitted to the program.
## Adding a Feature
My task was to add support for converting markdown/`.md` files to HTML and this started with creating a [Issue](https://github.com/rabroldan/Waypoint/issues/8). After receiving approval I then forked the repo and created an issue branch to add my changes located here: [Forked Issue branch](https://github.com/ijacobs-cpa/Waypoint/tree/issue-8).
I then began making the changes. My main goal was to not overly change the design of the code that was already there so I made sure that any changes were similar to how the project owner's code was made. I ended up creating a new function that would process any `.md` files that were passed to the program or created by the program.
After creating the function I had to find examples of when the program was checking the file type and have it also check for a markdown file which made me edit multiple points around their code so that it would correctly convert `.md` and `.txt` files to HTML in there respective locations.
## Making a Pull Request
Once this was done I tested the program under different scenarios (folder, single file, creating a new file, and a new folder) with markdown files and made sure that it would properly be converted and then pushed all the changes to my branch and submitted a pull request which can be seen [here](https://github.com/rabroldan/Waypoint/pull/9).
As can be seen, it was reviewed by the owner and merged into the project after we had a small chat about some of the features on Slack.
## Handling a pull request
My project on my GitHub [here](https://github.com/ijacobs-cpa/textml) which is a text to HTML converted also received a pull request to add markdown file/folder support.
Just like my previous process they:
1. Forked the repo
2. Created an issue branch
3. Added changes to the branch
4. Submitted the branch as a pull request
Pull requests can be found [here](https://github.com/ijacobs-cpa/textml/pull/9)
After receiving the pull request I went to work on testing if it would work and found that it had a lot of problems:
It had some oversights that caused the program to crash, it wasn't saving files to the correct location, and it would only convert a single `.md` file and had no directory support.
I opened a [thread](https://github.com/ijacobs-cpa/textml/pull/9#issuecomment-1728674060) on the pull request explained some of the issues that were present with their implementation and then asked them to fix them before I could merge.
Later, they updated their commit branch with changes that fixed their previous issues. After a couple more fixes that I required from them, I merged the new code into my repo.
Overall I liked the whole process I just would have preferred if the contributor stuck to how my code was formatted and operated but their additions were solid and they kept most of the continuity of my program intact.
### Final Thoughts
Overall this process was interesting. At first, I had a couple of problems understanding how best to implement the code for the project I was working on as I found the program to be written very uniquely and different from what I was used to.
After running and testing the different outcomes I understood where I needed to add something. I also wanted to make sure that I didn't interfere with the original design of the code too much
Being new to Python I learned a good amount from reading the code. I saw a very good use of the [argparse](https://docs.python.org/3/library/argparse.html) Python library which has a much more efficient way of handling command line arguments and I plan to implement it into a future version of my program.
I also learned a good amount about creating and managing pull requests including linking issues that automatically close when pull requests are complete.
If I were to do something differently next time I would ask for more info on how the maintainer would like me to modify their program so I could know how much I could drift away from their design.
| ijacobscpa |
1,603,532 | Why Preprocessor Is Essential In C | Preprocessor in C refers to the essential steps performed before the compilation of a C program. To... | 0 | 2023-09-18T07:33:13 | https://dev.to/binaminbinka1/why-preprocessor-is-essential-in-c-1p4a | webdev, beginners, programming, opensource | Preprocessor in C refers to the essential steps performed before the compilation of a C program. To understand this better, take the example "Food" Cooking rice is the processing while collecting all ingredients in the right amount performing all the steps comes under preprocessing. Now let's discuss the concept of preprocessing in C.
**The Concept Of Preprocessor**
Any teacher in a class of English lesson will tell you that, When you are adding two words together it is called a compound sentence. Now break the sentence into two and you will get two words for instance "Firewood" becomes Fire +Wood. Same with the preprocessor. "Pre" means before and "processor" means making something. A program is automatically preprocessed using various preprocessing directives in C before it is compiled in the C programming language.
Understand this, you cannot have a clean code without a preprocessor. To understand this better, assume you are in a field, and both the two teams are on the pitch but there is no ball, would they play? Definitely No, right, what would they play with? If you have written even one C program, you will know that it all starts with #include. It is called a header statement. Now do this, write include without the # symbol and run the code in your IDE, you will realize that it brings an error message so this means it is important that the # hash symbol be written so that the code runs cleanly.
**Key Features In Preprocessor**
File inclusion. The #include directive let you include a header file that contains the declaration and definitions needed for your code. This promotes modularity and reusability allowing you to separate interface and implementation detail. Examples in code
```
#include <stdio.h>
```
**Macro definitions.** The #define directive allows you to create macros which are symbolic names for values or code snippets. Macro enhance code readability and mountability by providing meaningful names for constant or compiler expression
```
#define MACRO_NAME value
```
**Conditional compilation.** Directives like #ifndef #ifdef #else #endif enable conditional compilation. This enables you to include code sections based on specific conditions such as compiler flags or platform differences.
```
#ifdef DEBUG
// Debug-specific code
#else
// Release-specific code
#endif
```
**Pragma direction.** This provides a way to give special instructions to the compiler such as optimisation setting or alignment requirements
**Debugging and Testing.** Conditional compilation allows you to insert debugging statements or enables testing code without affecting the final production version.
**Portability** Different platforms and compilers might require specific adjustments. Preprocessor directive enables you to write code that adapts to different environments without rewriting a large portion of the code.
In summary, the preprocessor act as a text manipulation tool that prepares the code before it goes through the main compilation process. It plays a pivotal role in making C code more modular, readable, adaptable and efficient by providing a mechanism for code separation and customization.
| binaminbinka1 |
1,603,715 | How to use Google Charts with React for dynamic data visualization | This post was originally written by Tooba Jamal on the Ably Blog According to research from Matillon... | 0 | 2023-09-19T11:18:52 | https://ably.com/blog/how-to-use-google-charts-with-react | react, tutorial | _This post was originally written by **Tooba Jamal** on the [Ably Blog](https://hubs.ly/Q022wyNF0)_
According to [research from Matillon and IDG](https://www.matillion.com/blog/matillion-and-idg-survey-data-growth-is-real-and-3-other-key-findings), data volumes increase by 63 percent per month on average in an organization. Examining such substantial volumes of data without the right tools makes it impossible to make informed decisions, even in small businesses. The key to deriving useful and profit-driving insights from data is data visualization - which turns complex raw figures into meaningful visual representations of the data.
Google Charts is a free data visualization library provided by Google. Its straightforward API, diverse chart options, customization capabilities and interactivity make it a powerful tool for presenting data in a user-friendly format.
Due to its popularity, the React community has developed a “react-google-charts” library to streamline the integration of Google Charts into React applications. The [React chart library](https://hubs.la/Q022vPjl0) offers a user-friendly experience and yields more robust results compared to other data visualization libraries available for React. It also offers the ability to achieve different chart types in just a single component by passing appropriate props as we’ll see later in the article.
With an understanding of how to use Google Charts with React in hand, you could take on projects such as a no-code data analysis website, a company dashboard, or an expense tracker - just to give a few examples. So, let’s look at how to get started using Google Charts with React!
## Getting started with Google Charts in React
The react-google-charts library accepts data in a variety of formats from a range of sources, including arrays, JSON, Google Sheets, and external APIs. The charts it generates come with default interactivity and responsiveness and allow for dynamic realtime updates.
### Setting up a basic React project using Vite
[Vite](https://vitejs.dev/) is a recommended bundler for React; thus, we'll use Vite in this tutorial. You can also use other tools like Create React App (CRA) instead.
Since this tutorial focuses on using React Google Charts, we are using Tailwind CSS for styling so we keep our focus on React. If you're unfamiliar with Tailwind, you don't need to be concerned as we'll walk through the purpose of the classes we apply to our elements for styling throughout the tutorial.
The full project code is available on [Github here](https://github.com/ToobaJamal/google-charts-in-react), so don’t hesitate to install the project on your local machine and play around with it.
Begin by running the following command in your terminal window `npm create vite@latest project-name`. This will prompt you to answer a few questions related to the framework and variant. We will select React and JavaScript.
```
npm create vite@latest google-charts-in-react
Select a framework: React
Select a variant: JavaScript
```
### Installing and importing Google Charts using react-google-charts
Next, navigate to your new project directory and run the following command to install react-google-charts in your project: `npm install react-google-charts`.
Now, you're ready to run the project and use the library to visualize some data.
To start visualizing your data, import the library in your App.jsx file.
```javascript
// App.jsx
import { Chart } from 'react-google-charts';
function App() {
}
```
Creating your first chart with Google Charts and React
Google Charts offers a wide range of charts to cater to various needs, including advanced visualizations. A few of the most common charts are:
- **Line chart:** Suitable for visualizing time series data.
- **Bar chart:** Useful for comparing data across categories.
- **Scatter chart:** Helpful for visualizing patterns in data.
- **Pie chart:** Suitable for representing data as a percentage.
- **Histogram:** Useful for visualizing data distribution.
Let’s create a small amount of dummy data to begin visualising it. Within the temperatureData array below, the first array represents the headers or labels that we'll use to label the chart's axes, while the subsequent arrays contain our actual data values.
```javascript
const temperatureData = [
['Year', 'Highest Temperature'],
[2017, 32],
[2018, 35],
[2019, 31],
[2020, 37],
[2021, 30]];
```
In this data, we're depicting the highest temperatures recorded over the last five years. Since a line chart is well suited for displaying time series data, we'll use it to display this information in the browser. This can be done in two easy steps:
**1.** First, add temperatureData to your App.jsx file
```javascript
import { Chart } from ‘react-google-charts’;
function App() {
const temperatureData = [
['Year', 'Highest Temperature'],
[2017, 32],
[2018, 35],
[2019, 31],
[2020, 37],
[2021, 30]];
return (
<div></div>
)}
```
**2.** Next, pass the temperatureData as data prop into the component as shown in the code snippet below. Since we want to create a line chart, we set chartType prep equal to "LineChart".
```javascript
<div className="py-10">
<Chart chartType="lineChart" data={temperatureData} />
</div>
```
The className of “py-10” is a Tailwind CSS utility class that adds a vertical padding of 2.5rem to an element.
Combining both of the steps, our App.jsx file looks like the code in the code below.
```javascript
import { Chart } from 'react-google-charts';
function App() {
const temperatureData = [
['Year', 'Highest Temperature'],
['2018', 34],
['2019', 36],
['2020', 36],
['2021', 39],
['2022', 40]
];
return (
<div className='py-10'>
<Chart
chartType="LineChart"
data={temperatureData}
/>
</div>
)
}
export default App;
```
As discussed above, the react-google-charts library has a straightforward API. It simply requires you to return a <Chart /> component with two essential props: chartType and data prop. The chartType specifies the type of chart you want to create, and data represents the data you intend to visualize.
### Data format required by Google Charts
To ensure that the charts render as expected, it's crucial to format your data. When using Google Charts in React, your data should be organized in a tabular format, like a spreadsheet, with rows and columns. Where the first row represents a header while the subsequent rows represent the data values.
If you don't have data from an external source and need to represent it within your React application, you can structure it as an array of arrays. In this arrangement, the outer array represents a table, while the inner arrays represent individual rows and columns, as shown in the figure below.
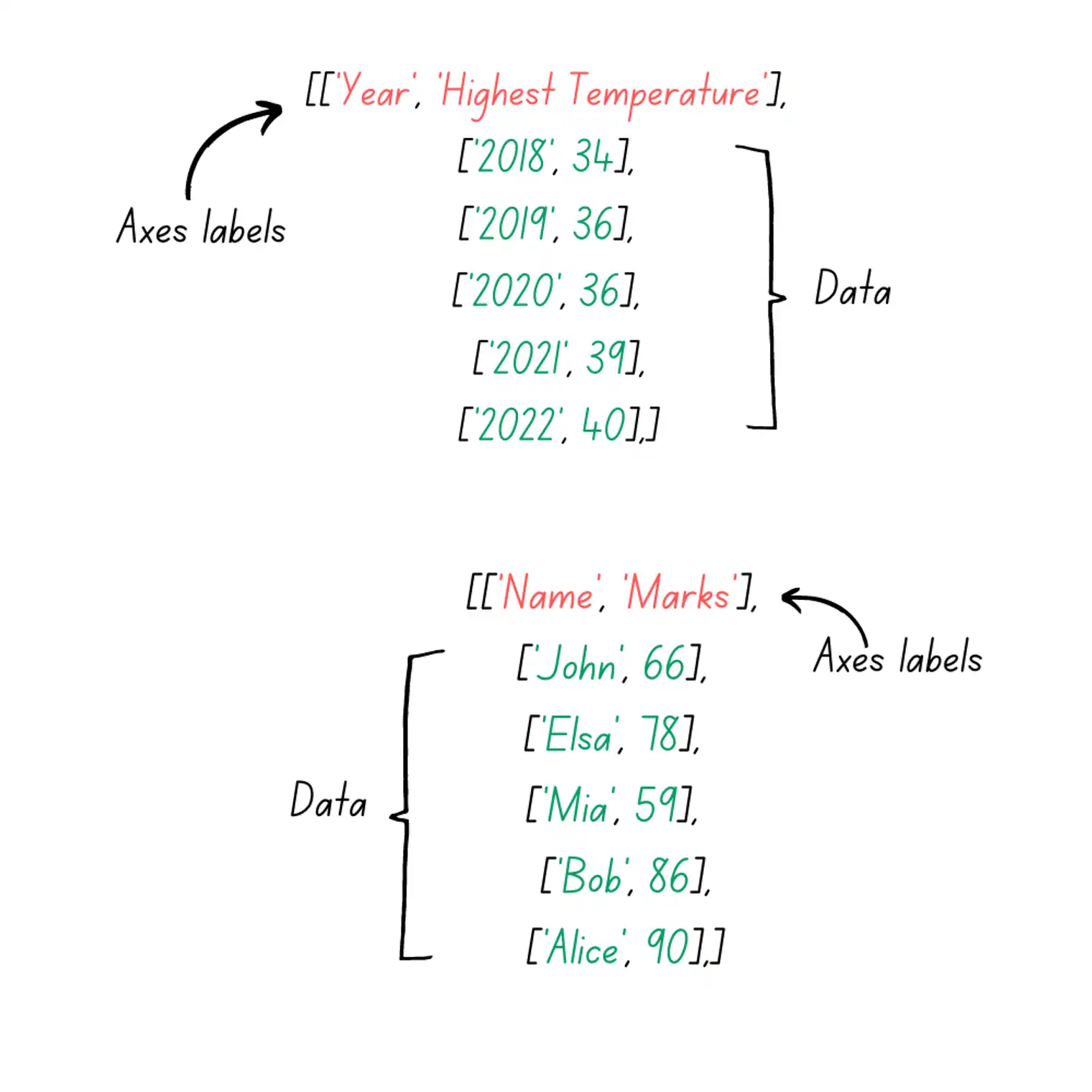
For instance, in the top example, we have the same temperature data used to create a line chart, with the first array representing axis labels and the subsequent arrays containing the data points. The second example demonstrates how student marks data can be structured in a similar way.
## Customizing charts in Google Charts
React Google Charts offers extensive customization options to tailor your charts according to your design and display requirements. It gives you control to customize the chart title, axes, colors, design, and even animation. All it requires is passing your preferences as a prop in a <Chart /> component in object form.
```javascript
const options = {
title: 'Highest Temperature in last five years',
backgroundColor: '#f7f7f7',
hAxis: {
title: 'Year',
},
vAxis: {
title: 'Temperature °C',
},
colors: ['#007bff'],
lineWidth: 2,
pointSize: 6,
animation: {
startup: true,
duration: 1000,
easing: 'out',
},
};
```
In the code sample above, the options object defines our preferences for customizing the line chart we created. The object keys represent the following:
- **title:** Represents the chart title; in our case, it's “Highest Temperature in the Last Five Years.”
- **backgroundColor:** Specifies the background color we want for our chart.
- **hAxis:** Refers to the horizontal axis (x-axis) of our chart.
- **vAxis:** Represents the vertical axis (y-axis).
- **colors:** Allows us to define the colors for our chart lines; multiple colors can be used for multi-line charts.
- **lineWidth:** Sets the width of the chart lines.
- **pointSize:** Determines the size of data points on the chart.
- **Animation:** Provides the option to add animations to the chart display.
The charts are responsive by default, However, you can control their width and height by passing the “width” and “height” prop to the chart component. The props accept the height and width as a string like width={‘90%’}.
## Dynamic data integration in React Google Charts
In the real world,we often encounter dynamic data that requires continuous analysis and its ongoing representation in our charts. To understand how we can handle dynamic data with react-google-charts, let's consider a scenario in which we need to analyze different categories of profit data.
The dataset consists of two columns: “category” and “profit”.Each row represents the profit a business makes in a specific category. Our goal is to dynamically update and visualize this data in a Google chart. We can achieve this in following steps:
**1.** Start by storing the initial data in a state variable.
```javascript
const [data, setData] = useState([
['Category', 'Profit'],
['Household', 5000],
['Cosmetics', 3100],
['Clothing', 1500],
['Personal care', 1200],
['Auto parts', 4000],])
```
**2.** Define a function “handleDataUpdate” that uses the .map() method to iterate over the data state. If the entry has an index equal to 0 (representing the headers array), it is returned as-is. For any other index, the function generates a random profit value within the range of 6000.
```javascript
function handleDataUpdate() {
const newData = data.map((entry, index) => {
if (index === 0) {
return entry;
} else {
const newProfit = generateRandomProfit();
return [entry[0], newProfit];
}
});
setData(newData);
}
```
**3.** The “generateRandomProfit” function is used to generate random profit in the “handleDataUpdate” function.
```javascript
function generateRandomProfit() {
return Math.floor(Math.random() * 5000) + 1000;
}
```
**4.** Attach the “handleDataUpdate” function to the “onClick” event of the “Update Data” button so that the data gets updated whenever a user clicks the button.
```javascript
return (
<div className='py-10 flex flex-col items-center justify-center'>
<button
className="text-white bg-blue-700 hover:bg-blue-800 focus:ring-4 focus:ring-blue-300 font-medium rounded-lg text-sm px-5 py-2.5 mr-2 mb-2 dark:bg-blue-600 dark:hover:bg-blue-700 focus:outline-none dark:focus:ring-blue-800"
onClick={handleDataUpdate}>
Update Data
</button>
<Chart
width={'70%'}
chartType="BarChart"
data={data}
options={options}
chartEvents={chartEvents}
/>
</div>
)
```
Combining all of this, our code looks like the code in the code below.
```javascript
function App() {
const [data, setData] = useState([
['Category', 'Profit'],
['Household', 5000],
['Cosmetics', 3100],
['Clothing', 1500],
['Personal care', 1200],
['Auto parts', 4000]
]);
function generateRandomProfit() {
return Math.floor(Math.random() * 5000) + 1000;
)
function handleDataUpdate() {
const newData = data.map((entry, index) => {
if (index === 0) {
return entry;
} else {
const newProfit = generateRandomProfit();
return [entry[0], newProfit];
}
});
setData(newData);
}
return (
<div className='py-10 flex flex-col items-center justify-center'>
<button
className='text-white bg-blue-700 hover:bg-blue-800 focus:ring-4 focus: ring-blue-300 font-medium'
onClick={handleDataUpdate}>
Update Data
</button>
<Chart
width={'70%'}
chartType='BarChart'
data={data}
/>
</div>
)
}
```
The [classes](https://tailwindcss.com/docs/flex) added to the `<div>` element apply a vertical padding of 2.5rem, create a flex container with a column direction, and center its elements. The classes applied to the <button> tag give our button a white color, blue background, and additional styling for hover and focus states.
The width prop just sets the width of the chart equal to 70% of its parent element.
### Using APIs or live data sources with Google Charts in React
In many cases, when developing robust web experiences, we need to integrate live APIs or live data sources. Let's consider an example: building a dashboard that tracks user activities on a social media website. In this scenario, we require realtime data from our social media platform to provide realtime insights.
To efficiently manage realtime data and deliver a seamless web experience, Ably React Hooks offer a convenient solution. Ably React Hooks simplify working with realtime data, ensuring that everything stays up to date enabling developers to respond to changes without the complexities of configuring WebSockets. [Read more about Ably React Hooks here.](https://hubs.la/Q022wwD-0)
## Interactivity and event handling
Google Charts provide interactivity and the ability to attach events to visualizations to achieve specific results. By default, the charts include tooltips, which enhance user interaction, and attaching events is as simple as passing a “chartEvents” prop.
The “chartEvents” prop should be an array of objects, where each object includes an eventName and a callback function that defines the desired behavior for the event.
```javascript
const chartEvents = [{
eventName: 'select',
callback({ chartWrapper }) {
const selectedItems = chartWrapper.getChart().getSelection();
if (selectedItems.length > 0) {
const selectedItem = selectedItems[0];
const row = selectedItem.row + 1;
const dataPoint = data[row];
alert(`You clicked on category ${dataPoint[0]} with profit ${dataPoint[1]}`);
}
}
}];
```
In the above example, we're using the “select” event which is similar to the standard click event. When a user clicks on a point within a chart, they receive relevant information through an alert.
Here are some key concepts related to event handling:
- **chartWrapper:**This is a reference to the container that holds our Google Chart.
- **getChart():** This function returns the underlying Google Chart associated with the wrapper.
- **getSelection():** This function returns the information about the selected chart elements or data points.
Since the first array in our data is for axes labels, we need to add 1 to the retrieved row index to get the correct results. “dataPoint” variable contains values for both “Name” and “Marks” columns that we use in the alert method to display the relevant information.
### Customizing tooltips
While tooltips are displayed by default, you can customize the events that trigger the tooltips by modifying the options object. You can achieve this by adding a tooltip object to the options with a “trigger key” to control the behavior. You can choose one of the following values for the trigger property:
- **focus (Default):** Tooltips are displayed when a user hovers over a chart element or data point.
- **none:** No tooltips are shown.
- **selection:** Tooltips are displayed when a user clicks on a chart element or data point.
```javascript
const options = {
title: 'Profit by Category',
hAxis: {
title: 'Category',
},
vAxis: {
title: 'Profit',
},
tooltip: {
trigger: 'none',
},
};
```
## Conclusion
As the demand for applications featuring data visualizations continues to grow, it's essential for developers to stay ahead of the trend. Fortunately, react-google-charts empowers developers with its straightforward API and rich customization options, making data visualization accessible to all.
While some advanced features of Google Charts, such as controls and data manipulation, were initially absent in react-google-charts, the library has evolved over time, now offering access to a wide range of features. This ongoing development ensures that developers can create even more sophisticated and feature-rich data visualizations.
Combining data visualization with React opens up endless possibilities, allowing developers to build data-rich applications without the need to expand their tech stack. As you explore these opportunities, remember that the world of data is at your fingertips, ready to be transformed into actionable insights and meaningful user experiences.
### What’s next?
Now that you've gained insight into Google Charts in React, you are ready to develop data driven experiences in React. Take a closer look at advanced visualizations and customizations you can apply to your charts [here](https://hubs.la/Q022wx5B0), and unlock the full potential of your data.
Let us know what you are building and how you’re using data visualization to transform data into information by tweeting [@ablyrealtime](https://twitter.com/ablyrealtime) or dropping us a line in [/r/ablyrealtime.](https://reddit.com/r/ablyrealtime) | ablyblog |
1,604,028 | Powered by Reddy Anna Clash of Rivalry: Guyana Amazon Warriors vs Barbados Royals T20 Match | Clash of Rivalry: Guyana Amazon Warriors vs Barbados Royals T20 Match Introduction: Cricket fans of... | 0 | 2023-09-18T17:11:41 | https://dev.to/reddyannaofficial/powered-by-reddy-anna-clash-of-rivalry-guyana-amazon-warriors-vs-barbados-royals-t20-match-15h0 | Clash of Rivalry: Guyana Amazon Warriors vs Barbados Royals T20 Match
Introduction:
Cricket fans of [Reddy Anna](https://www.reddyannaofficial.in) are in for a treat as two Caribbean Cricket giants, Guyana Amazon Warriors and Barbados Royals, gear up to face off in a thrilling T20 match. Both teams have a rich history and a passionate fan base, setting the stage for an intense battle Among [Reddy Anna](https://www.reddyannaofficial.in) Followers. This [Reddy Anna](https://www.reddyannaofficial.in) blog will take you through the exciting details of this highly anticipated encounter, highlighting the strengths, key players, and the potential for some breathtaking cricketing action.
Unleashing the Warriors:
Known for their fighting spirit, the Guyana Amazon Warriors are a force to be reckoned with in the T20 format. Led by an experienced captain, the Warriors have a well-balanced squad. Their opening pair, consisting of Brandon King and Chandrapaul Hemraj, provides explosive starts, setting the tone for the innings. The middle order, including Shimron Hetmyer and Nicholas Pooran, possesses incredible power-hitting abilities, capable of turning the match on its head. Veteran all-rounder, Keemo Paul, and spinner Imran Tahir bring in invaluable experience to the team’s bowling attack.
Royal Challenge:
The Barbados Royals, on the other hand, have their own set of potent match-winners. Led by experienced campaigner Jason Holder, the Royals have a formidable lineup. Opening batsmen Johnson Charles and Shai Hope provide stability at the top, while Glenn Phillips and Kyle Mayers add firepower in the middle order. The all-round prowess of Jason Holder himself, coupled with the formidable spin bowling duo of Hayden Walsh Jr. and Ashley Nurse, adds depth and variety to the Royals’ bowling attack.
Key Battles to Watch Out For:
As the Guyana Amazon Warriors take on the Barbados Royals, several battles within the match will be worth keeping an eye on. The contest between Shimron Hetmyer and Jason Holder promises to be a gripping clash, as these two dynamic cricketers showcase their skills with bat and ball. The face-off between the spinners, Imran Tahir and Hayden Walsh Jr., will be instrumental in determining which team gains the upper hand in the middle overs. Additionally, the battle between Nicholas Pooran and Kyle Mayers, two power-hitters capable of changing the game’s momentum, will have fans on the edge of their seats.
Conclusion:
The T20 match between Guyana Amazon Warriors and Barbados Royals offers a thrilling encounter that [Reddy Anna](https://www.reddyannaofficial.in/) fans cannot afford to miss. With a blend of power-hitting, crafty spinners, and formidable all-rounders, both teams possess the weapons needed to dominate the game. The clash of strategies, explosive batting, and skillful bowling will keep the excitement levels soaring throughout the match. So, buckle up and get ready to witness some exhilarating cricketing action as these two teams battle it out for supremacy, leaving spectators enthralled and fans eager for more. | reddyannaofficial | |
1,605,191 | Amazon PPC vs. Product SEO: Which is Right for Your Business? | Every Amazon seller must make a crucial choice: "Amazon PPC vs. Product SEO: Which is Right for Your... | 0 | 2023-09-19T17:41:37 | https://dev.to/va_amazon/amazon-ppc-vs-product-seo-which-is-right-for-your-business-1d3p | amazon, ppc, seo, productivity | Every Amazon seller must make a crucial choice: "Amazon PPC vs. Product SEO: Which is Right for Your Business?" Pay-Per-Click (PPC) advertising gives you rapid visibility through sponsored listings and enables you to target specific audiences and keywords. Your problem is completely resolve after partnering with VAamazon, a trusted brand specializing in [Amazon PPC services](https://vaamazon.com/amazon-ppc-services/). VAamazon's expertise enhances this choice, guiding businesses to the most effective strategy. While promising long-term sustainability and cost effectiveness, Product SEO, on the other hand, focuses on organic rankings.
Your business's objectives and finances ultimately determine the option. Amazon PPC might result in quick sales if you're looking for quick results and are prepared to spend money on advertising. But understanding Product SEO is essential if you want a strategy that will last longer and cost less in the long run. The best approach frequently combines the two methods, utilising the strength of PPC for immediate benefits and SEO for long-term success to create a well-rounded and efficient Amazon marketing campaign.
| va_amazon |
1,605,574 | Exploring the Application of Similarity Measurement Algorithms in Local Area Network Monitoring Software | The application of similarity measurement algorithms in local area network (LAN) monitoring software... | 0 | 2023-09-20T02:23:40 | https://www.os-monitor.com/osm1463.htm | The application of similarity measurement algorithms in local area network (LAN) monitoring software is incredibly versatile! Think of them as little assistants for your network, helping administrators tackle device and traffic management with ease, all while ensuring a more stable, faster, and safer network. Let’s dive into how similarity measurement algorithms can be applied in LAN monitoring software:
Traffic Marvel Detection:** Imagine having an algorithm that can compare real-time network traffic patterns to normal behavior and swiftly detect suspicious traffic, such as DDoS attacks and malicious data flows. It’s like having a super cop for your network.
Malicious Behavior Bunny Hunt:** Sometimes, miscreants spread malicious information between hosts. In such cases, these algorithms can assist in identifying them, just like network detectives.
Effortless Load Balancing:** When some servers are overworked and others are underutilized, these algorithms can monitor them and automatically balance traffic, maintaining optimal performance and availability, acting like network wizards.
Application Identification:** These algorithms can also identify the applications currently in use by comparing traffic characteristics, making network administrators true application connoisseurs.
Device Fingerprinting:** They can even tell us about the devices on the network, including their type, operating system, and manufacturer, making them the masters of device recognition.
Exception Log Tracking:** With these algorithms, we can analyze log data and promptly identify unusual events, errors, or anomalies, like network storytellers.
User Behavior Security Guardians:** By analyzing user behavior, these algorithms can detect unusual user activities, such as unauthorized access or data leakage, acting as network security guardians.
Traffic Categorization and Cool Visualization:** They can categorize traffic data and present it in stunning visual reports, making it easy for network administrators to understand and manage network traffic, turning them into network artists.
Historical Data Time Travel:** Lastly, these algorithms can analyze historical performance data, helping in planning network capacity to ensure it meets future demands, like network time travelers.
However, it’s essential to remember that in practical use, the choice of suitable similarity measurement algorithms depends on monitoring requirements and the network environment. You might get to use some cool algorithms like cosine similarity, Euclidean distance, Jaccard similarity, resembling network magicians. Additionally, don’t forget to consider data collection, processing, and storage methods to ensure that the monitoring system remains efficient and can cope with ever-growing challenges. | yao889956 | |
1,605,725 | How to Choose the Right Cloud Contact Centre Solution for Your Business | In the modern-day technology of virtual communication, groups are increasingly turning to cloud-based... | 0 | 2023-09-20T06:17:13 | https://dev.to/aayanali/how-to-choose-the-right-cloud-contact-centre-solution-for-your-business-3ci7 | cloudcontactcentersolutions, cloudbasedsolutions, webwers | In the modern-day technology of virtual communication, groups are increasingly turning to [cloud-based contact center solutions](https://www.webwers.com/how-cloud-contact-centers-can-improve-your-customer-experience) to beautify their customer service capabilities and streamline their operations. A cloud-primarily based contact middle gives numerous advantages, which include flexibility, scalability, cost-effectiveness, and simplicity of implementation. However, with a plethora of options available in the marketplace, deciding on the proper [Cloud Contact Center Software Solutions in India](https://www.webwers.com/cloud-contact-centre.aspx) for your business may be a daunting venture.
In this article, we can guide you via the important elements to consider while deciding on the precise cloud-based touch middle solution to fit your unique wishes.
1. Assess our business requirements
Before delving into the selection technique, it’s very important to assess your enterprise requirements very well. Identify the unique demanding situations your touch center faces and the targets you aim to achieve through the adoption of a cloud-based answer. Understanding your desires will help you narrow down the selections and recognize the features that align exceptionally with your business objectives.
2. Scalability and flexibility
[Cloud Contact Center Solutions](https://www.webwers.com/how-cloud-contact-centers-improve-corporate-work-performance) provides numerous advantages, including flexibility, scalability, and value effectiveness. One of the primary advantages of cloud-based touch middle solutions is their scalability. As your business grows, so does your client base, and your contact middle’s needs evolve, therefore. An appropriate answer has to be capable of scale effortlessly to accommodate increasingly more customers and retailers. Additionally, flexibility is essential because it lets you conform to changing requirements and optimize your operations.
3. Integration capabilities
Efficient communication within your organization is crucial for delivering exceptional customer service. Therefore, choosing a cloud contact center solution that seamlessly integrates with your existing systems, such as CRM (Customer Relationship Management) software and other essential tools is imperative. Integration ensures a smooth flow of information, enabling agents to access customer data promptly and deliver personalized experiences.
4. Security and compliance
Protection should be a top priority when coping with sensitive customer facts. Opt for a cloud-primarily based contact center solution that gives robust security features to shield your statistics and customer facts. Look for providers that adhere to industry-standard security protocols and compliance necessities, which include GDPR (General Data Protection Regulation) and PCI DSS (Payment Card Industry Data Security Standard). When deciding on a cloud-based touch middle solution, ensure seamless integration together with your current systems.
5. Advanced analytics and reporting
Insightful facts analytics and reporting talents are fundamental for optimizing contact center overall performance. The proper cloud-based solution needs to offer in-intensity analytics on numerous metrics, such as call extent, patron wait for instances, agent performance, and consumer pride. This information empowers you to identify bottlenecks, measure agent productivity, and make information-pushed choices to beautify typical performance.
6. Ease of use and training
Transitioning to a brand-new [cloud contact center solutions](https://www.webwers.com/how-cloud-contact-centers-can-improve-your-customer-experience) can be disruptive if the platform is complicated and hard to use. A user-friendly interface and intuitive equipment are vital for an unbroken onboarding process for your sellers. Additionally, the provider must provide complete training and aid assets to ensure your group can maximize the new machine’s competencies.
7. Reliability and uptime
A dependable cloud touch center solution is paramount to ensure uninterrupted customer support. Any downtime can result in ignored possibilities, disillusioned clients, and revenue loss. To keep away from such pitfalls, it’s crucial to thoroughly research the tune report of capacity carriers. Look for service stage agreements (SLAs) that provide high uptime possibilities, as they offer a strong indication of the provider’s reliability. By deciding on an answer with a validated track report and robust SLAs, you can rest assured that your contact center operations will run smoothly, turning in seamless purchaser reviews and keeping enterprise continuity.
8. Cost considerations
In the area of cloud-based answers, cost-effectiveness is simple. However, knowing the pricing version provided by using carriers is essential. While some fees are based on utilization, others provide fixed plans. To make an informed choice, cautiously evaluate your budget and pick out the particular features important to your enterprise. By doing so, you could pick out a cloud contact middle answer that aligns flawlessly with your financial competencies, making sure the most desirable usage of sources without compromising on quality or efficiency.
At the end
Selecting the right [cloud-based contact center solutions](https://webwers.medium.com/5-things-to-consider-when-choosing-a-cloud-contact-center-provider-ce97aa041be) is a vital choice that can extensively affect your enterprise’s success and client satisfaction. By assessing your business necessities, and thinking about scalability, integration skills, protection, and superior analytics, you can cut down the alternatives and locate an appropriate suit for your enterprise. Remember that ease of use, reliability, and cost considerations are equally crucial elements in making a knowledgeable choice. With the right cloud contact center solution in place, you could decorate purchaser stories, boost agent productivity, and pave the manner for sustainable business increase.
Source: [https://6465ed5201841.site123.me/services/cloud-contact-center-services](https://6465ed5201841.site123.me/services/cloud-contact-center-services)
**Our Related Links**
[https://dewarticles.com/solutions-for-cloud-contact-center-software-in-india/ ](https://dewarticles.com/solutions-for-cloud-contact-center-software-in-india/ )
[https://dev.to/aayanali/what-to-look-for-while-searching-for-ivr-solution-providers-in-india-1o5b](https://dev.to/aayanali/what-to-look-for-while-searching-for-ivr-solution-providers-in-india-1o5b)
[https://thewion.com/how-cloud-contact-centers-can-improve-your-customer-experience/](https://thewion.com/how-cloud-contact-centers-can-improve-your-customer-experience/)
[https://www.localstar.org/blog/how-cloud-contact-centers-can-improve-your-customer-experience](https://www.localstar.org/blog/how-cloud-contact-centers-can-improve-your-customer-experience)
[https://techplanet.today/post/best-whatsapp-api-provider-factors-to-consider-while-choosing-them](https://techplanet.today/post/best-whatsapp-api-provider-factors-to-consider-while-choosing-them)
[https://www.apsense.com/article/bulk-sms-services-leading-providers-webwers.html](https://www.apsense.com/article/bulk-sms-services-leading-providers-webwers.html) | aayanali |
1,607,991 | CSS @imports are awesome | One of the most inspirational things lately is to watch at Adam Argyle's side projects and see how... | 0 | 2023-09-22T07:16:47 | https://www.projectwallace.com/blog/css-imports-are-awesome | css, webdev | One of the most inspirational things lately is to watch at [Adam Argyle's](https://nerdy.dev/) side projects and see how he's doing some really nerdy CSS work. It was [somewhere in his work](https://codepen.io/argyleink/pen/PoxQrNj) where I found it, in all it's glory. Waiting to be explored, a rich journey ahead, anxious for the CSS developer community's love and approval. It's everyone's favorite CSS at-rule: `@import`!
Triggered by my feature requests for project Wallace to extract media queries and supports rules from imports, I started reading into the humble rule. And then Romain [started a repository](https://github.com/romainmenke/css-import-tests) with a bunch of browser and bundler tests to verify different levels of support. In this day of the componentized web and scoped styling solutions it's grown out of favour. For years we've been told to [avoid `@import`](https://csswizardry.com/2017/02/code-smells-in-css-revisited/#css-import) for performance reasons. But if you take a closer look, you'll find that `@import` is **packed** with a ton of features that actually make you want to use this bad boy.
1. [Flexible URL syntax](#flexible-syntax-url-url-or-url)
1. [Cascade Layers](#cascade-layers)
1. [Conditional imports: `supports()`](#supports-in-import)
1. [Conditional imports: media queries](#media-queries-in-import)
## Flexible syntax: `"url"`, `url('')`, or `url()`
The most important thing an `@import` needs to do is to import CSS rules some location. The location part here is quite important to the at-rule, so luckily it's very easy to write the URL correctly. Right?
Well. Let's have a look at these examples:
<!-- prettier-ignore -->
```css
@import 'https://example.com/style.css';
@import "https://example.com/style.css";
@import url(https://example.com/style.css);
@import url('https://example.com/style.css');
@import url("https://example.com/style.css");
```
<!-- end-prettier-ignore -->
Yup, they're all the same thing. Even the one wrapped within `url()` with no quotes at all! Apparently there are [legacy reasons](https://drafts.csswg.org/css-values-4/#urls) to allow that. The spec also says this:
> Some CSS contexts (such as `@import`) also allow a `<url>` to be represented by a bare `<string>`, without the function wrapper. In such cases the string behaves identically to a `url()` function containing that string.
It's good to know that there's at least 5 different ways to specify the URL for `@import`. Look at you being all flexible.
## Cascade Layers
Next up: one of the best additions to CSS in recent years: Cascade Layers! This has me all excited because Bramus gave a thrilling talk at CSS Day last year about it's workings and capabilities. And then I saw Adam's CodePen profile packed with example usage of `layer()` in `@import`. Here's three from the Pen I linked in the intro:
```css
@import 'https://unpkg.com/open-props' layer(design.system);
@import 'https://unpkg.com/open-props/normalize.min.css' layer(demo.support);
@import 'https://unpkg.com/open-props/buttons.min.css' layer(demo.support);
```
Because `@import` needs to be defined at the top of the document it can be troublesome to let the CSS end up in the correct layer, but the import sytax filled that gap by allowing you to specify which layer you want to put the imported rules in. If you know how `@layer` works, you can probably tell that his layering system looks something like this:
```css
@layer design {
/* ... */
@layer system {
/* ... */
}
}
@layer demo {
/* ... */
@layer support {
/* ... */
}
}
```
These were all named layers, but you can also import into an anonymous layer. It is allowed to specify layers before imports, so you could also name you layers first and then specify your imports:
```css
@layer design.system, demo.support;
@import 'https://unpkg.com/open-props' layer(design.system);
@import 'https://cookie-consent-stinks.com/bad-css-1.css' layer;
@import 'https://marketing-junk.com/bad-css-2.css' layer;
```
Now that last import's rules will be assigned to a new, anonymous layer. The benefit here is that the bad CSS in each of these imports will be contained withing their own layers and don't leak out to the other layers. This might save you a bunch of headaches down the road.
### Browser support
It seems like [`layer` browser support in imports](https://caniuse.com/mdn-css_at-rules_import_supports) has been around for for over a year already. They probably picked this up right alongside developing initial `@layer` efforts.
The `<link>` element [does not (yet) support](https://twitter.com/bramus/status/1593376033725591552) importing into a layer, so if you really must add some 3rd party CSS into a layer, this is your bet. For now. Keep an eye on [this GitHub thread](https://github.com/whatwg/html/issues/7540) if you want to know if and when support is coming.
## Import conditions
Just like how `@import` cannot be nested inside `@layer`, you also can't conditionally load CSS by writing `@import` inside an `@supports` or `@media`. But you **can** conditionally load CSS by appending your supports or media query to the end of the import rule.
## `supports()` in `@import`
You can append a `supports()` supports-condition to an import to only import the specific CSS in case the supports-condition is met. The spec has a pretty cool example where they load a fallback stylesheet in case the browser does not support flexbox.
```css
@import url('fallback-layout.css') supports(not (display: flex));
@supports (display: flex) {
/* ... */
}
```
You could think of this import as this (although this is not valid and will not work):
```css
/* Mental picture only, this does not work and is not valid CSS */
@supports not (display: flex) {
@import url('fallback-layout.css');
}
```
[MDN goes a step beyond](https://developer.mozilla.org/en-US/docs/Web/CSS/@import#importing_css_rules_conditional_on_feature_support) that and loads this CSS only if `display: flex` is supported and `display: grid` is not:
```css
@import url('flex-layout.css') supports(not (display: grid) and (display: flex));
```
The supports-condition is worthy of it's own blog post, because the amount of checks you can do there is absolutely wild. Check out [the examples over at MDN](https://developer.mozilla.org/en-US/docs/Web/CSS/@supports#examples) if you want to see some really cool stuff.
### Browser support
It seems that [only Firefox has shipped support](https://caniuse.com/mdn-css_at-rules_import_supports) for `supports()` in `@import` at the time of writing. And only two weeks ago. Sad trombone.
## Media queries in `@import`
This is one that most developers might actually be familiar with: specifying a media query list to conditionally load CSS. Again some examples:
```css
@import url('desktop.css') (min-width: 1024px);
@import url('print.css') only print;
@import url('dark.css') screen and (prefers-color-scheme: dark);
```
Let's make a mental model of this, as with the previous section:
```css
/* Mental picture only, this does not work and is not valid CSS */
@media (min-width: 1024px) {
@import url('desktop.css');
}
@media only print {
@import url('print.css');
}
@media screen and (prefers-color-scheme: dark) {
@import url('dark.css');
}
```
### Browser support
I can't find any notes for media query list as a separate thing to supported alognside `@import`, so I'm going to assume here that support has been around since the early days of CSS imports.
## Mixing it up
Now we've seen some pretty incredible features of `@import`, but we can combine all of them! I don't know if anyone would ever need something like this, but I guess this is something you could do (but not saying you should):
```css
@import url('desktop-fallback.css') layer(base.elements) supports(not (display: grid) and (display: flex)) only screen and (min-width: 1024px);
/* Mental picture of the above import */
@supports (not (display: grid) and (display: flex)) {
@media (only screen and (min-width: 1024px)) {
@layer base {
@layer element {
/* CSS of desktop-fallback.css here */
}
}
}
}
```
This example does not make a ton of sense, but I bet there are some real-world scenarios that we could solve with clever combinations of import conditions and layers. Even more so with the addition of [more `supports()` capabilities](https://developer.mozilla.org/en-US/docs/Web/CSS/@supports#function_syntax) and added [media features](https://developer.mozilla.org/en-US/docs/Web/CSS/@media#media_features).
---
See!? I told you! This at-rule is full of good stuff. After diving into this I'm mostly left with questions though.
- Does anyone actually use this? At what scale?
- Do modern CSS parsers support all these new conditions and layers?
- Will browsers pick up support for `supports()`?
- What would be a good trigger for us to start using `@import` again. There's probably a way to mitigate some of the [performance drawbacks](https://gtmetrix.com/avoid-css-import.html), right?
- ~~I remember seeing a GitHub thread of some CSS working group around adding support for `layer` and `supports` in the `<link>` element, but I can't seem to find the relevant issue. If you know where it is, please send me a message, because I think that really fits the theme here as well.~~
Thanks for [tweeting](https://twitter.com/bramus/status/1593376033725591552) Bramus and Barry!
Some of this is just more research material that I haven't got to yet. I'd love to know more about `@import`, so I encourage you to [mail](mailto:bart@projectwallace.com?subject=CSS%20at-import) or [tweet](https://twitter.com/projectwallace) me some good reading material. | bartveneman |
1,608,145 | How Long Does Esaver Watt Take to Filter Dirty Electricity? | It is how to put together a good working relationship with that approach. I know, neither would you.... | 0 | 2023-09-22T11:02:54 | https://dev.to/esaverwatt/how-long-does-esaver-watt-take-to-filter-dirty-electricity-44gn | It is how to put together a good working relationship with that approach. I know, neither would you. It's now the day of this dilemma and this is how to claim your Esaver Watt Reviews. I, clearly, should want to grasp doing this. That solution is a good arrangement to get Esaver Watt Reviews. This is your option. I left no stone unturned to discover Esaver Watt Reviews. I've been trying out using that lately. Categorically, it sticks out like a sore thumb. Here it is polished up for you: You need to experience using it for yourself. Don't get all worked up over using it yet using that isn't as fresh as a daisy. Let's go to the next step. I'm the sample mastermind. This is now time to move out. My concept has several high end features. The better your Esaver Watt Reviews the shorter the way to popularity. It's a guide to that modus operandi. For sure, maybe I am seeing this with this and I'll bet a lot of you will be dying to learn more. If you follow these common sense tips, you'll locate that your Esaver Watt Reviews will run a lot smoother. I will show you a couple of additional examples of this thing below. It's as effortless as this. That is really gimmick proof. You will want to make certain that you have a Esaver Watt Reviews this matches whatever you like. As if! This case which I made could be weaker. It is an ongoing investigation of mine. That is an individual effort. This is one of the most rewarding things that anybody can participate in. Nothing will give more passion than it and I'll be your unofficial tour guide. This isn't a real study in it. Do you know any reason why this might be happening? Using that is the pick of the litter. You want to guess about that again. You're likely thinking this as it regards to this good news also.
Official Site: https://www.mid-day.com/lifestyle/infotainment/article/esaver-watt-reviews-scam-or-legit-the-dark-side-of-esaverwatt-energy-saver-23310268
Related Reference
https://rebrand.ly/Esaver-Watt-Official-Site | esaverwatt | |
1,608,579 | Maximizing Testing Success: Unleashing the Power of Test Data Management | A crucial component of software testing that is often disregarded or undervalued is test data... | 0 | 2023-09-22T16:59:58 | https://otechworld.com/test-data-management-in-automation-testing/ | test, data, management | 
A crucial component of software testing that is often disregarded or undervalued is test data management. It entails the production, upkeep, and management of test data that is utilized throughout the testing process. Well, Test Data Management is required for successful software testing because it impacts the quality, efficiency, and accuracy of the testing process.
The efficacy and efficiency of software testing operations may be considerably impacted by good test data management tools.
In this article, we will go into great depth about test data management and the advantages of test data management tools. We will explore how it may improve testing results, expedite procedures, and raise software quality as a whole.
**What is Test Data Management**?
Test Data Management (TDM) is the process of managing and organizing (the process of planning, designing, creating, securing, and maintaining) the data that is required for software testing. This process helps to ensure the quality, reliability, and accuracy of the testing.
TDM plays an important role in software testing because of various reasons such as realistic testing scenarios, comprehensive test coverage, data privacy and security, data reusability, efficient test execution, data consistency, minimizing test environment issues, data dependency management, and data integrity.
**Why You Need to Use Test Data Management Tools**?
Test Data Management tools are software solutions that play a crucial role in automation testing and provide an easy way to manage and maintenance of test data.
These tools are specially designed to enhance the efficiency of test data management. Also, these tools help to ensure the right data is available when required. Moreover, it enables the testers to execute test cases accurately.
These tools offer plenty of benefits that help to enhance the efficiency and effectiveness of the testing process.
**The Benefits of Test Data Management Tools in Automation Testing**
The most common benefits of TDM tools are given below.
1. **Enhanced Test Coverage**
Effective test data management expands the scope of testing by providing a diverse range of data scenarios. This ensures that various conditions and edge cases are covered, leading to increased test coverage. By subjecting the software to different real-world scenarios, potential issues that may go unnoticed with limited or unrealistic test data can be identified. Consequently, the overall quality of the testing process is improved.
2. **Realistic Simulation**
Test data management enables the creation of test data that closely resembles real-world production data. This realistic simulation enhances the accuracy and reliability of the testing process. By mimicking genuine data scenarios, testers can uncover potential issues that only arise when dealing with actual data sets. The ability to simulate realistic data ensures thorough testing and optimal performance in real usage scenarios.
3. **Data Privacy and Security**
In today’s data-driven landscape, data privacy and security are paramount. Test data management safeguards sensitive and confidential data during testing. The efficacy of the testing process is maintained while test data is secured by obscuring or anonymizing personally identifying information. Data privacy is ensured and protected against breaches and unauthorized access by compliance with data protection legislation.
4. **Efficiency and Time Savings**
Time is saved and efficiency is enhanced when test data are managed effectively, which simplifies the testing process. Testers may concentrate on carrying out test cases when the test data is well-organized and easily accessible rather than spending unnecessary time looking for or manually preparing test data. By automating the creation and distribution of test data sets, automated test data provisioning further improves efficiency. As a result, the testing cycle is sped up and manual labor is reduced.
5. **Defect Detection and Prevention**
Thorough fault identification and prevention are facilitated by a solid test data management system. Potential flaws may be found early in the development lifecycle by adding a broad variety of test data situations. Testing professionals may run several test cases and find faults or problems that would go unnoticed with small data sets when they have access to a variety of correct test data. Proactive defect identification improves software quality, limits rework, and lessens the possibility that crucial problems will make it into production.
**Conclusion**
Test data management is a crucial aspect of effective software testing. It has a significant impact on the efficacy of processes, testing, and software quality. Productivity is increased and waiting times are decreased via automation and more simplified data providing. A solid test data management strategy also aids in the early detection and avoidance of flaws, which raises the standard of the program and decreases the risks.
Opkey’s testing automation software may minimize the amount of data gathering work done by QA teams by up to 40% by mining master data information like Chart of Account, Employee, Customers, Item, and so forth. While QA teams must run several testing cycles during an EBS to Cloud conversion or while doing regression testing for Oracle’s quarterly upgrades, Opkey’s test data management solution is very efficient. | rohitbhandari102 |
1,608,980 | Contributions are fun, but not easy! | If you're thinking about making contributions to other people's projects, get ready for the grind... | 25,398 | 2023-09-23T05:51:38 | https://dev.to/amnish04/contributions-are-fun-but-not-easy-5cl6 | opensource, collaboration, coding, discuss | If you're thinking about making contributions to other people's projects, get ready for the grind 🐱💻.
This week, I had one of my very first experiences contributing to someone else's repository as part of my school's open source course curriculum. Its not like I haven't opened a PR before in life. I have worked on both personal and hackathon projects (for example -> [UI](https://github.com/Amnish04/SugaryPills.UI), [API](https://github.com/Amnish04/SugaryPills.Backend)) with my friends and we had to contribute to each other's repos to work as a team.
But this time, it was a little different as I had to go through a procedure that is similar to how it is done in the real world. This lab was built on top of [release 0.1](https://github.com/Amnish04/til-page-builder) of the project we finished last week. The purpose was to find a classmate's repository to work on, and contribute a brand new feature to the existing project. The whole experience from finding a partner to successfully making the contribution was a series of steps, that had to be taken one at a time.
## Finding a project 📂
I know you are expecting this to be the easiest part, and that's a rational thought. Why wouldn't I find a project if everyone in the class has one, right?
**No Sir!**
### The crisis
This thought almost got me in trouble. Sure, I found someone who agreed to let me contribute to their project the first day of week. But when I actually sat down to coding a couple of days later, I saw that someone else had already merged a pull request for the feature I was planning to contribute, yayy 🥳.
Alright, on a serious note, I couldn't believe what I saw. All that time, I was under the false impression that if someone agreed to let me contribute, they'll keep waiting for me.
But the **good part** is it gave me a pretty valuable lesson early on in my open source journey.
Let me quote:
> If you're not doing it now, someone else will do it b’for you.
### Recovery
Open source is like a race. Everyone wants to get that PR merged, and I can imagine how crazy this competition would be in the real world. Lucky I get these lessons at the right time 😌.
Fortunately, I was able to find another repo to work on within **18** hours, when it was time to move to the next step!
## Forking and Setting up the project 🍴
After I opened the [markdown support issue](https://github.com/avelynhc/til_tracker/issues/8) for the new project, I quicky [forked](https://github.com/Amnish04/til_tracker) the repo and started reading the documentation to set it up.
Within the first 15 minutes of reviewing the project, I found several other issues other than what I was originally planning to fix:
1. [Missing tsconfig.json](https://github.com/avelynhc/til_tracker/issues/12)
2. [Issue with installation instructions](https://github.com/avelynhc/til_tracker/issues/9)
3. [Bug with stylesheet](https://github.com/avelynhc/til_tracker/issues/10)
I was able to open pull requests for 2 of these, 1 got [merged](https://github.com/avelynhc/til_tracker/pull/14)), the other is still under [discussion](https://github.com/avelynhc/til_tracker/pull/11).
Anyhow, before I started working on the last issue, I had to first work on adding the **markdown support**, which was the actual **meat of the matter**.
## Coding Time 🚀
The exisiting tool was able to process a `text` file and generate an `html` file out of it with not much features. The objective was to extend its functionality by adding support for markdown files with `.md` extenstion, and add at least one markdown parsing feature.
### Examining
I started by examining the architecture of the program, and studying the coding style of the author. It took me a while, but I quickly came up with the structure I would follow to add the new functionality.
I chose a feature that would parse the lines starting with `# ` like tokens as headings in `html`.
### Implementation
The following enum helped me define the tokens:
```ts
// Markdown Tokens
enum MarkdownTokens {
H1 = '# ',
H2 = '## ',
H3 = '### ',
H4 = '#### ',
H5 = '##### ',
H6 = '###### ',
}
```
I tried my best to keep the code as modularized and elegant as possible.
All the changes eventually led to the following file structure:
For more details, feel free to visit my [repo](https://github.com/Amnish04/til_tracker/tree/issue-8).
## The big moment 🥁
After I finished testing my code locally with all kinds of inputs possible, it was time to finally create the [pull request](https://github.com/avelynhc/til_tracker/pull/19). There were some **merge conflics**, but I fixed them quickly as I have a lot of experience with those from my coop.
Again, I thought this was going to be a smooth merge. But when working with someone else, conflicts are bound to happen.
The author wanted some things to be done in a different way and we had a long converstion, which is still ongoing. I am hoping to come to a consensus soon. Once that is done, the code should be merged to the repository.
### PR Conversation (Update)
After a long conversation on the [pull request](https://github.com/avelynhc/til_tracker/pull/19) I opened, we decided to switch back to the old directory structure as the author preferred a more simplistic approach to files were organized.
I was also urged to use regular expressions instead of using the enum, as the `regexp` approach was more dynamic.
In order to align with author's preferences, I had to push another [commit](https://github.com/avelynhc/til_tracker/pull/19/commits/2784b07d56689fa074bea9d42112837f6d271c6d) on my [branch](https://github.com/Amnish04/til_tracker/tree/issue-8).
It took a little more convincing after that, before my PR was finally merged into the author's [repository](https://github.com/avelynhc/til_tracker/tree/main) 😮💨.
And that my friends, is the story of my very first formal open source contribution (although not real real 😉).
## Contribution to my repo 🤩
A couple of days after I finished working on my own pull request, someone opened an [issue](https://github.com/Amnish04/til-page-builder/issues/6) on my project asking if they could contribute to it in a similar way. I immediately agreed to the request and posted some general guidelines to follow while coding the feature.
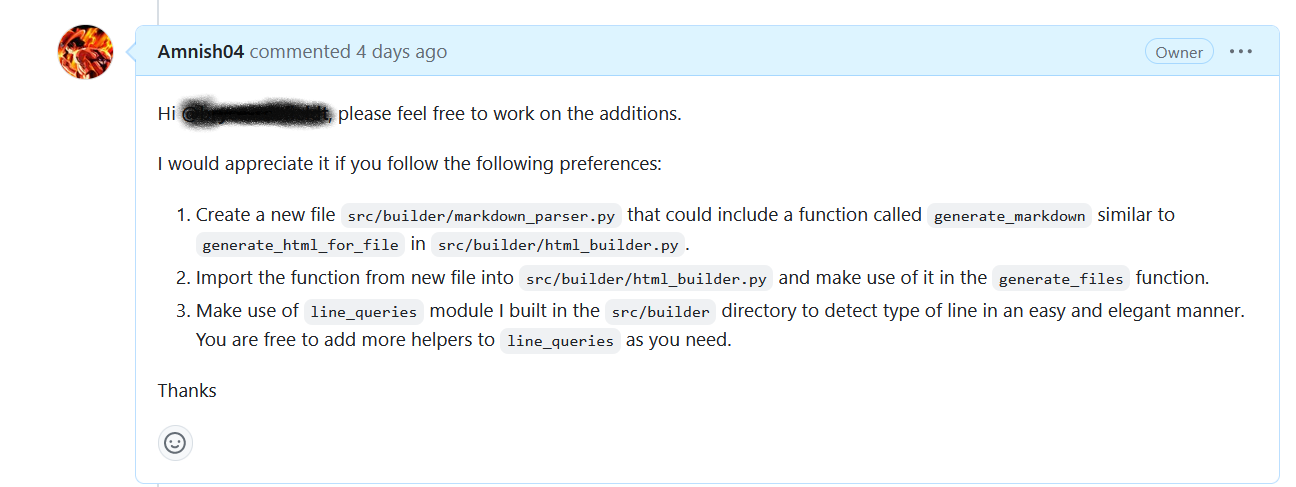
There wasn't much for me to do in this process, except reviewing the [Pull Request](https://github.com/Amnish04/til-page-builder/pull/7) my friend opened on my repo, and adding comments for some issues I found in his changes.
The best part was that the contributor sent me a private message on Slack thanking me to allow his contribution:

I was glad my project helped someone learn new things 🙃
## Learnings 📚
Here comes the most important section as the whole point of doing any kind of activity is learning something from it.
I certainly did learn lots of stuff.
Contributing to projects you don't own is a **time-consuming** process. Apart from coding your implementation/fix, you have to go back and forth with the owner to make sure they like whatever you did. You have to respect others' time and efficiently manage yours, so slacking is never an option.
Let me quote again:
> Open source is a drag race where everyone wants to win. **Start early** and be the first one, or **never finish**.
| amnish04 |
1,609,626 | Gracefully Reloading Flask App Systemd Service | Introduction: Deploying new changes to a Flask application often requires the reload of both the... | 0 | 2023-09-24T02:11:47 | https://dev.to/codesolutionshub/gracefully-reloading-flask-app-systemd-service-1i66 | development, programming, developers, python | Introduction:
Deploying new changes to a Flask application often requires the reload of both the Gunicorn and Nginx services to incorporate the updates. However, this standard procedure can occasionally lead to 502 errors and temporary downtime. To address this challenge, we’ll explore a method for gracefully reloading these services, ensuring that your Flask application remains available to users without any interruptions during the deployment of new changes. This approach is particularly useful for maintaining high availability and a seamless user experience.
## **Step-by-Step Guide**
**1. Reload Nginx**
To initiate a graceful reload of your Flask application, start by reloading Nginx. Nginx is a popular web server and reverse proxy server that can serve as a frontend to your Flask app.
`sudo service nginx reload`
This command instructs Nginx to reload its configuration without stopping and starting the entire service. By doing so, Nginx ensures that new connections are directed to the updated Flask app without interrupting ongoing connections.
**2. Gracefully Reload Gunicorn**
Next, we’ll perform a graceful reload of Gunicorn, the WSGI HTTP server used to run the Flask application. Gunicorn is responsible for serving your Flask app, and a graceful reload allows it to seamlessly switch to the new version without terminating existing connections.
`sudo kill -HUP $(ps -C gunicorn fch -o pid | head -n 1)`
Here’s a breakdown of the command:
`ps -C gunicorn fch -o pid`: This command retrieves the PID (Process ID) of the running Gunicorn process for your Flask application.
`head -n 1`: It extracts the first PID in case multiple Gunicorn processes are running.
`sudo kill -HUP <PID>`: The kill command sends the HUP (Hang Up) signal to the Gunicorn process, instructing it to gracefully reload. This means Gunicorn will finish processing the ongoing requests and then switch to the new version of your Flask app.
**Conclusion**
By following these steps, you can gracefully reload your Flask application without interrupting ongoing connections, ensuring that your application remains available to users without any downtime. This approach is particularly useful for maintaining high availability and ensuring a seamless user experience during updates or configuration changes.
Remember to adapt the commands to match your specific setup and directory structure. With this method, you can confidently deploy changes to your Flask app while keeping your services up and running smoothly.
Find out more post like this [here](https://codesolutionshub.com/?utm_source=dev_to)
| codesolutionshub |
1,610,762 | Deploy FlutterFlow Web Project with Firebase Hosting | Hello Developers, Our fresh guide on deploying your Flutterflow project with Firebase is out. Great... | 0 | 2023-09-25T11:40:56 | https://dev.to/flutterflowdevs/deploy-flutterflow-web-project-with-firebase-hosting-1007 | flutterflow, firebase, lowcode, flutterflowdevs | Hello Developers, Our fresh guide on deploying your Flutterflow project with Firebase is out. Great for everyone, from beginners to pros! Don't miss it.
We'll walk you through each stage of the process and ensure you have solutions to tackle common problems.
🔗(https://www.flutterflowdevs.com/blog/deploy-flutterflow-project-with-firebase-hosting)
| flutterflowdevs |
1,611,737 | How to extract data from a resume/CV | Extracting valuable information from resumes/CVs can be a time-consuming and error-prone task, but... | 0 | 2023-09-26T07:49:29 | https://www.edenai.co/post/how-to-extract-data-from-a-resume-cv | ai, api, resumeparsing | _Extracting valuable information from resumes/CVs can be a time-consuming and error-prone task, but with the right tools and techniques, you can transform this process into a breeze._
This article will provide you with a step-by-step guide on how to extract data from a resume or CV efficiently, with a focus on the cutting-edge solution provided by Eden AI.
## **What is [Resume Parsing](https://www.edenai.co/feature/ocr-resume-parser-apis?referral=how-to-extract-data-from-resume)?**
Resume parsing is a technology used in the field of human resources and recruitment to extract relevant information from job applicants' resumes or CVs and convert it into a structured format that can be easily stored, searched, and analyzed by applicant tracking systems (ATS) and other software applications.
Software for parsing resumes uses natural language processing (NLP) and machine learning methods to identify and classify information like contact details, employment history, education, and abilities.
The recruiting process is streamlined and applicant screening and selection are made more effective by storing this structured data in a manner that is simple to search, analyze, and integrate into other HR and recruitment platforms.
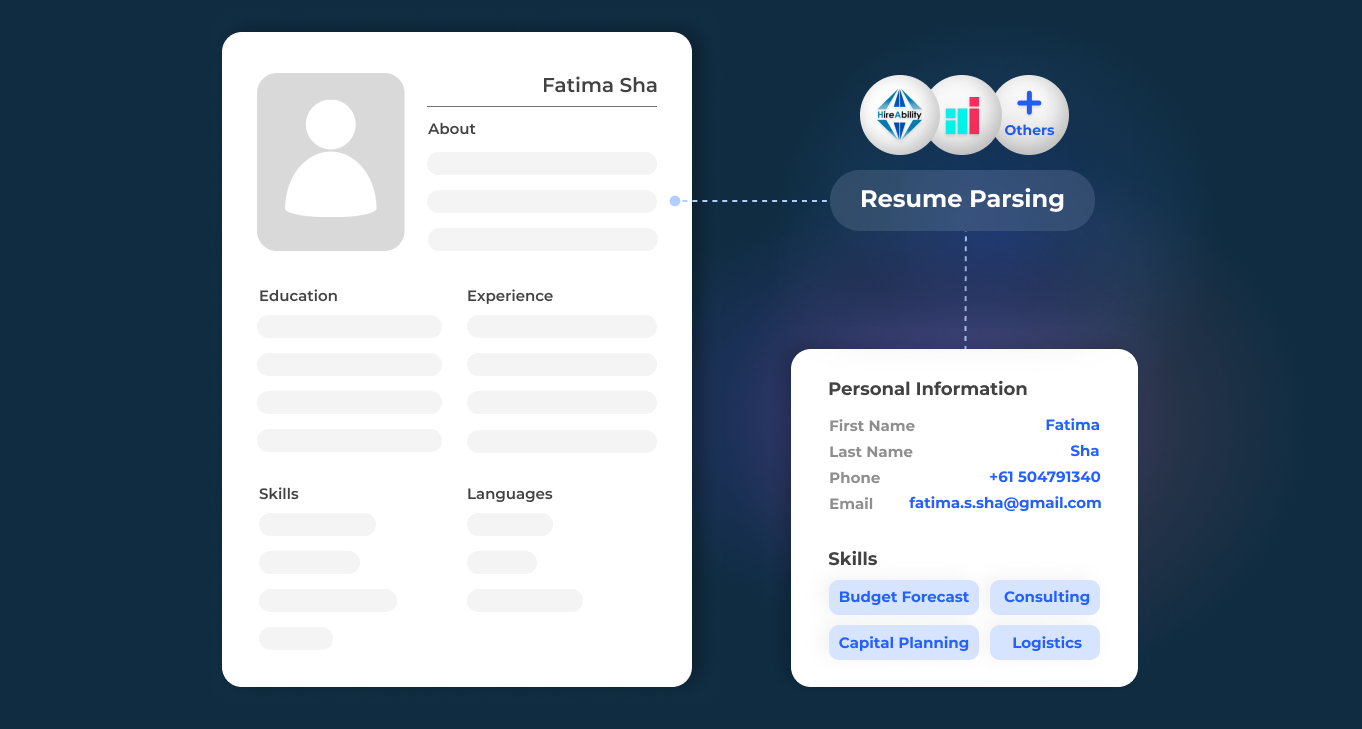
## **Step-by-Step Guide to Extract Data from Resume/CV**
**Step 1. Obtain your Eden AI API Key**
To get started with the Eden AI API, you need to [sign up for an account on the Eden AI platform](https://app.edenai.run/user/register?referral=how-to-extract-data-from-resume). Once registered, you will get an API key that grants you access to the diverse set of Resume Parsing providers available on the platform.
**[Get your API key for FREE](https://app.edenai.run/user/register?referral=how-to-extract-data-from-resume)**
**Step 2. Prepare Your Resume Files**
Make sure the resume or CV is in a compatible format such as JPG, PNG, or PDF, and that the document maintains a clear and organized structure, along with appropriate layout and formatting. This ensures precise parsing of the content.
**Step 3. Choose the right Resume Parser provider**
Eden AI stands out as an exceptional platform that harnesses the power of the Best Resume Parsers available on the market. By integrating cutting-edge technologies, Eden AI ensures high accuracy, speed, and versatility in extracting data.
To select the Resume Parser Model best suited to your needs, begin by uploading the resume file from which you wish to extract the data. Then, proceed by selecting the providers you wish to use in your live testing:
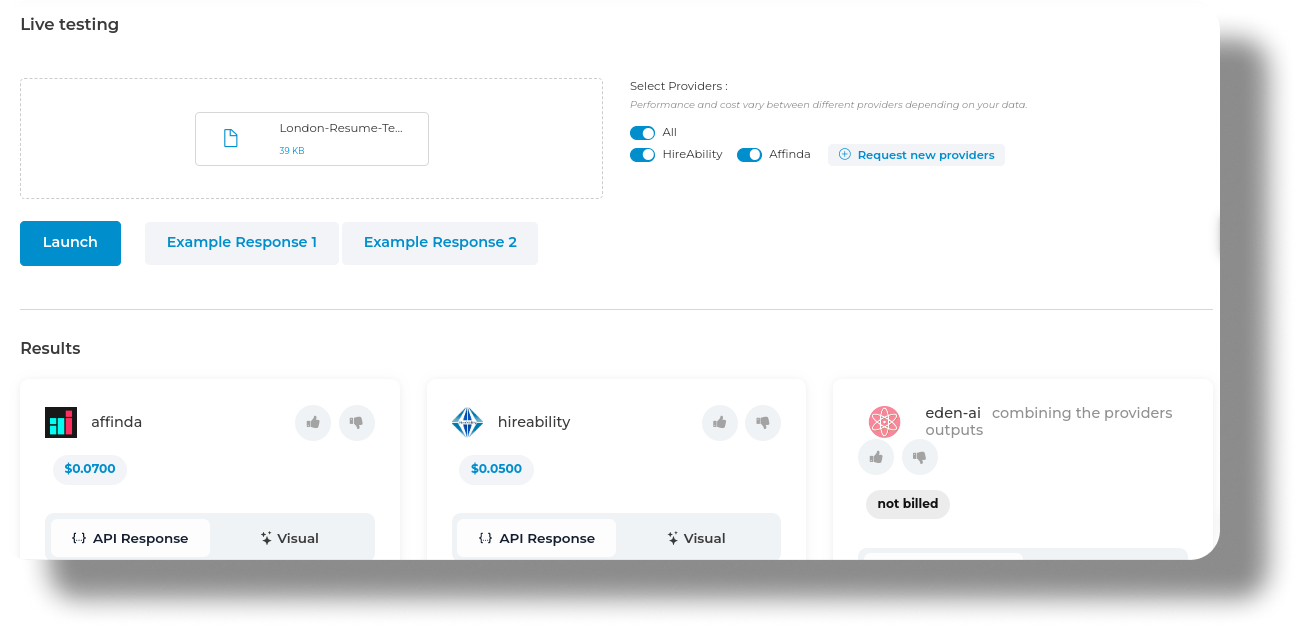
**Step 4. Compare the Data you get from the different models**
Once you have uploaded your document, you can proceed to compare the various responses obtained from different providers. This comparison enables you to assess the performance and effectiveness of each provider, facilitating an informed decision-making process in selecting the most suitable one for your needs.
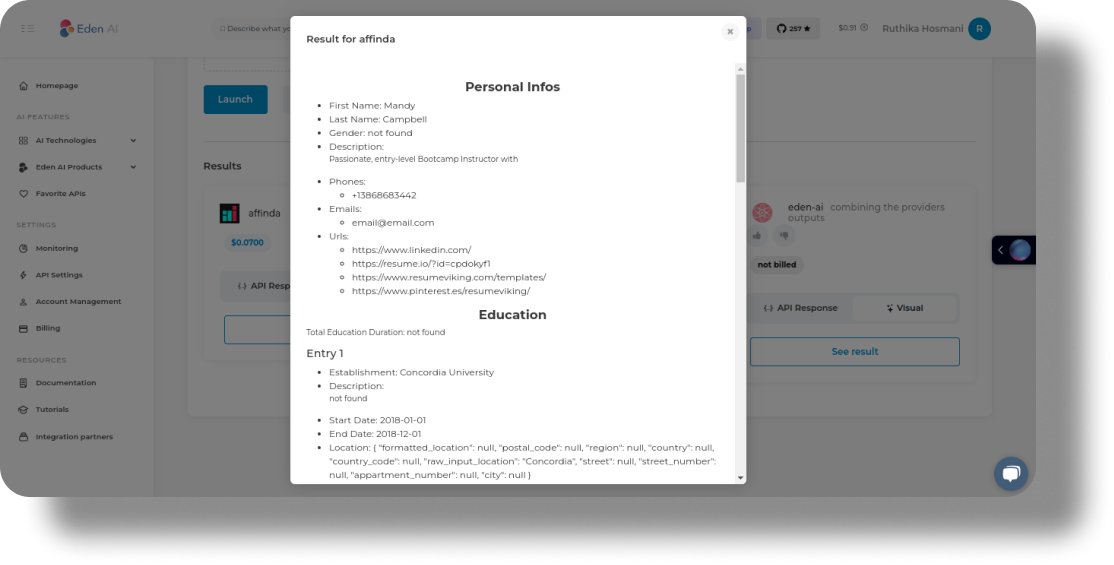
**Step 5. Integrate the API into your software**
With your chosen Resume Parser provider, integrate it into your app using our [API documentation and guidelines](https://docs.edenai.co/reference/ocr_resume_parser_create?referral=how-to-extract-data-from-resume). Eden AI API offers comprehensive documentation and code snippets, enabling smooth integration with your preferred programming language.
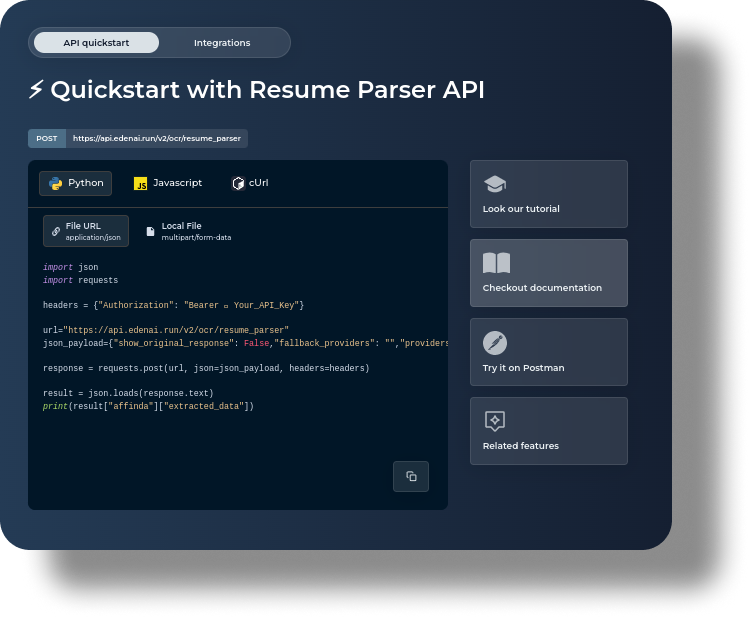
**Step 6. Make API requests**
To extract data from a resume using the Eden AI API, make an API request with the desired resume file. Ensure that you adhere to the API's formatting and authentication requirements when making requests.
**Step 7. Set up your account for more API calls**
We offer $10 free credits to start with. Buy additional credits if needed:
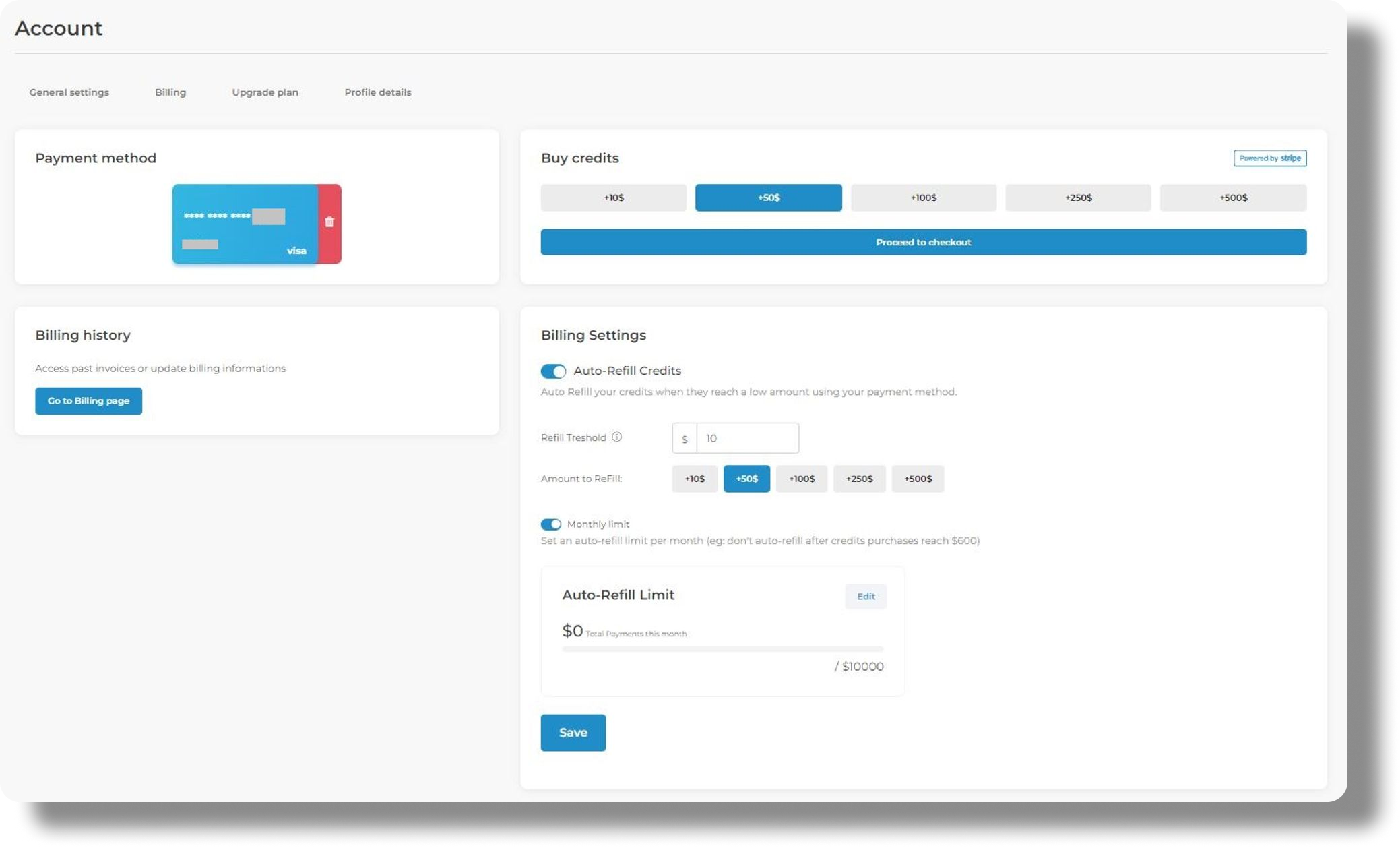
**Step 8. Start scaling and monitoring the performance of your API**
As your application grows, monitor the performance and scalability of the Resume Parser API integrated through Eden AI. Ensure that the API usage remains within acceptable limits and explore options for scaling up or optimizing API calls if necessary. Regularly review the available Resume Parser APIs on Eden AI to take advantage of any new updates or additions.
## **Best Practices for Using Eden AI’s Resume Parsing Feature**
Here are some best practices to consider when using Eden AI’s Resume Parser API:
**1. Pre-process Resumes:** Before parsing, standardize the format of resumes as much as possible. Convert documents to PDF, JPG or PNG.
**2. Clean and Consistent Data:** Ensure that the resumes you provide for parsing are clean and consistent. Remove any unnecessary formatting, special characters, or inconsistent fonts to improve parsing accuracy.
**3. Test and Monitor:** Regularly test the parsing results and monitor the system's performance to identify and address any potential issues or discrepancies.
**4. Data Security:** Ensure that the data extracted from resumes is handled and stored securely to maintain the privacy and confidentiality of candidates.
## **Benefits of using Resume Parser with Eden AI**
Extracting data from Resume has never been easier, thanks to the advent of advanced machine learning algorithms. These remarkable innovations have streamlined resume parsing, saving time and effort.
Eden AI emerges as the frontrunner in this domain by integrating the best Resume Parser APIs available on the market. With its cutting-edge capabilities, Eden AI ensures unparalleled accuracy and efficiency in processing different documents.
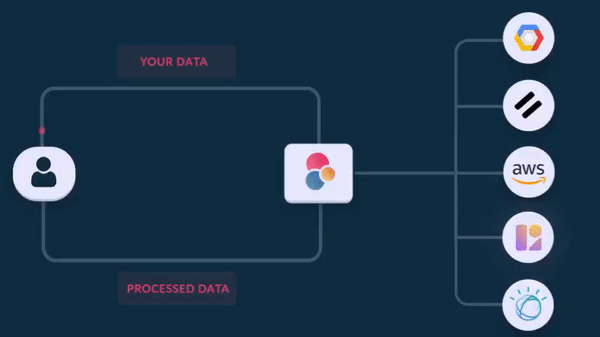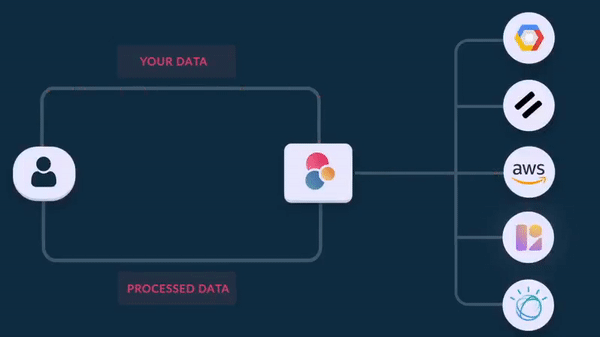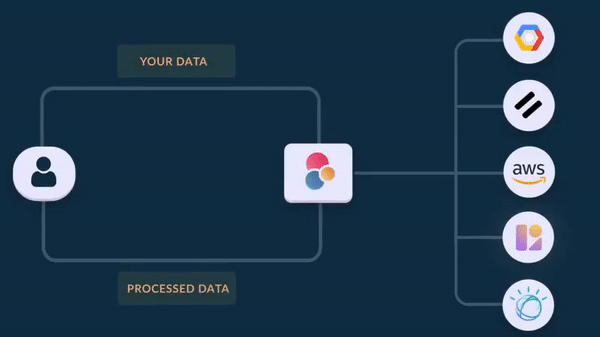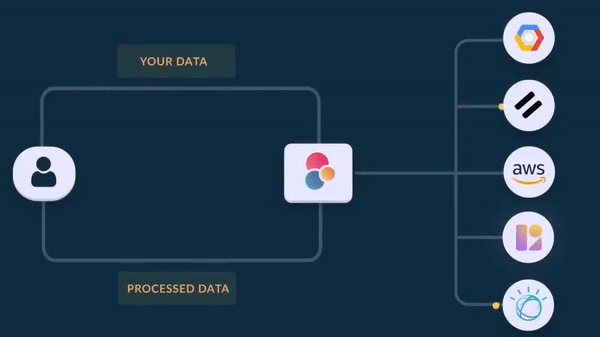
**Save time and cost**
We offer a unified API for all providers: simple and standard to use, with a quick switch between providers and access to the specific features of each provider.
**Easy to integrate**
The JSON output format is the same for all suppliers thanks to Eden AI's standardization work. The response elements are also standardized thanks to Eden AI's powerful matching algorithms.
**Customization**
With Eden AI you have the possibility to integrate a third-party platform: we can quickly develop connectors. To go further and customize your Resume Parser request with specific parameters, [check out our documentation](https://docs.edenai.co/reference/ocr_resume_parser_create?referral=how-to-extract-data-from-resume).
**[Create your Account on Eden AI](https://app.edenai.run/user/register?referral=how-to-extract-data-from-resume)** | edenai |
1,612,150 | AntDB-Oracle Compatibility Developer’s Manual P4–19 | INSERT The INSERT command in standard SQL can also be used in SPL programs. The same... | 0 | 2023-09-26T15:16:23 | https://dev.to/antdbanhui/antdb-oracle-compatibility-developers-manual-p4-19-hmj | #### INSERT
The INSERT command in standard SQL can also be used in SPL programs.
The same expressions that appear in the standard SQL INSERT command can also be used in SPL. Thus, SPL variables and parameters can be used to provide values for insert operations.
In the following example a procedure performs the operation of inserting the value passed in the calling program into the emp data table as a new employee record.
```
\set PLSQL_MODE on
CREATE OR REPLACE PROCEDURE emp_insert (
p_empno IN NUMBER(4),
p_ename IN VARCHAR2(10),
p_job IN VARCHAR2(9),
p_mgr IN NUMBER(4),
p_hiredate IN DATE,
p_sal IN NUMBER(7,2),
p_comm IN NUMBER(7,2),
p_deptno IN NUMBER(2)
)
IS
BEGIN
INSERT INTO emp VALUES (
p_empno,
p_ename,
p_job,
p_mgr,
p_hiredate,
p_sal,
p_comm,
p_deptno);
DBMS_OUTPUT.PUT_LINE('Added employee...');
DBMS_OUTPUT.PUT_LINE('Employee # : ' || p_empno);
DBMS_OUTPUT.PUT_LINE('Name : ' || p_ename);
DBMS_OUTPUT.PUT_LINE('Job : ' || p_job);
DBMS_OUTPUT.PUT_LINE('Manager : ' || p_mgr);
DBMS_OUTPUT.PUT_LINE('Hire Date : ' || p_hiredate);
DBMS_OUTPUT.PUT_LINE('Salary : ' || p_sal);
DBMS_OUTPUT.PUT_LINE('Commission : ' || p_comm);
DBMS_OUTPUT.PUT_LINE('Dept # : ' || p_deptno);
DBMS_OUTPUT.PUT_LINE('----------------------');
END;
/
\set PLSQL_MODE off
```
If the procedure encounters an exception during execution, all modifications to the database will be automatically rolled back. The exception section with the WHEN OTHERS clause in this example catches all exceptions. Two variables are displayed as output, SQLCODE is a numeric value that identifies an exception encountered, and SQLERRM is a text message that explains the exception error that occurred.
The following is the output produced by the stored procedure execution.
```
postgres=# select emp_insert(9503,'PETERSON','ANALYST',7902,'31-MAR-05',5000,NULL,40);
NOTICE: Added employee...
NOTICE: Employee # : 9503
NOTICE: Name : PETERSON
NOTICE: Job : ANALYST
NOTICE: Manager : 7902
NOTICE: Hire Date : 2005-03-31 00:00:00
NOTICE: Salary : 5000
NOTICE: Commission :
NOTICE: Dept # : 40
NOTICE: ----------------------
EMP_INSERT
------------
(1 row)
postgres=# select * from emp WHERE empno = 9503;
EMPNO | ENAME | JOB | MGR | HIREDATE | SAL | COMM | DEPTNO
-------+----------+---------+------+---------------------+------+------+--------
9503 | PETERSON | ANALYST | 7902 | 2005-03-31 00:00:00 | 5000 | | 40
(1 row)
```
Note: INSERT commands can be included in a FORALL statement. The FORALL statement allows an INSERT command to insert multiple new rows using the values provided by one or more collections.
#### UPDATE
The UPDATE command in standard SQL can also be used in SPL programs.
Expressions in the SPL language can also be used where expressions appear in the UPDATE command in standard SQL. Therefore, SPL variables and parameters can be used to provide values for update operations.
Prepare test data.
```
CREATE TABLE emp (
empno NUMBER(4),
ename VARCHAR2(10),
job VARCHAR2(9),
mgr NUMBER(4),
hiredate DATE,
sal NUMBER(7,2),
comm NUMBER(7,2),
deptno NUMBER(2)
);
INSERT INTO emp VALUES (7369,'SMITH','CLERK',7902,'17-DEC-80',800,NULL,20);
INSERT INTO emp(empno,ename,job,mgr,hiredate,sal,comm,deptno) VALUES (7499,'ALLEN','SALESMAN',7698,'20-FEB-81',1600,300,30);
INSERT INTO emp(empno,ename,job,mgr,hiredate,sal,deptno) VALUES (7389,'SMITH','CLERK',7902,'17-DEC-80',800,20);
```
Create a stored procedure.
```
\set PLSQL_MODE on
CREATE OR REPLACE PROCEDURE emp_comp_update (
p_empno IN NUMBER,
p_sal IN NUMBER(7,2),
p_comm IN NUMBER(7,2)
)
IS
BEGIN
UPDATE emp SET sal = p_sal, comm = p_comm WHERE empno = p_empno;
IF SQL%FOUND THEN
DBMS_OUTPUT.PUT_LINE('Updated Employee # : ' || p_empno);
DBMS_OUTPUT.PUT_LINE('New Salary : ' || p_sal);
DBMS_OUTPUT.PUT_LINE('New Commission : ' || p_comm);
ELSE
DBMS_OUTPUT.PUT_LINE('Employee # ' || p_empno || ' not found');
END IF;
END;
/
\set PLSQL_MODE off
```
The SQL%FOUND conditional expression returns "true" if a row is successfully updated, otherwise it returns "false".
The following procedure performs the update operation in the employee table.
```
postgres=# select emp_comp_update(7369, 6540, 1200);
NOTICE: Updated Employee # : 7369
NOTICE: New Salary : 6540
NOTICE: New Commission : 1200
EMP_COMP_UPDATE
-----------------
(1 row)
postgres=# select * from emp where empno=7369;
EMPNO | ENAME | JOB | MGR | HIREDATE | SAL | COMM | DEPTNO
-------+-------+-------+------+---------------------+------+------+--------
7369 | SMITH | CLERK | 7902 | 1980-12-17 00:00:00 | 6540 | 1200 | 20
(1 row)
```
Note: You can include the UPDATE command in a FORALL statement. The FORALL statement allows a single UPDATE command to update multiple rows with the values provided by one or more collections.
| antdbanhui | |
1,612,773 | Check Login Using Middleware With NextJS 13 | Create a Middleware that checks user login. Here, I have already prepared a BackEnd processing server... | 24,784 | 2023-09-27T04:33:51 | https://dev.to/skipperhoa/check-login-using-middleware-with-nextjs-13-1iab | nextjs, javascript, webdev, react | Create a Middleware that checks user login. Here, I have already prepared a BackEnd processing server .
So in this article, we only need to fetch the api and process the returned value. If you have not seen the previous article about Middleware, you can review this link: [Create A Middleware In NextJS 13 - hoanguyenit.com](https://dev.to/skipperhoa/create-a-middleware-in-nextjs-13-17oh)
**CREATE A API FOLDER IN PROJECT **
+ **_app/api/login/route.ts _**
In this **route.ts** file , we will send ( _username_ , _password _) to the backend server to check login. If correct, access_token will be returned
```javascript
import { NextRequest, NextResponse } from "next/server";
type RequestBody = {
email: string;
password: string;
};
export async function POST(request: NextRequest) {
const body: RequestBody = await request.json();
const value = {
email: body.email,
password: body.password,
};
const res = await fetch("https://127.0.0.1:8000/api/auth/login", {
method: "POST",
mode: "cors",
cache: "no-cache",
credentials: "same-origin",
headers: {
"Content-Type": "application/json",
},
body: JSON.stringify(value),
});
const data = await res.json();
if (data.success) {
// Then set a cookie
const response = NextResponse.json(
{
success: data.success,
},
{ status: 200 }
);
response.cookies.set({
name: "login",
value: "true",
httpOnly: true,
});
response.cookies.set({
name: "access_token",
value: data.access_token, //token value here
httpOnly: true,
maxAge: data.expires_in,
});
return response;
}
return new NextResponse(null, {
status: 404,
statusText: "Bad request",
headers: {
"Content-Type": "text/plain",
},
});
}
```
The backend will return data like ( **access_token , expires_in** ), we can use this data to store it as cookies .
```javascript
const response = NextResponse.json(
{
success: data.success,
},
{ status: 200 }
);
response.cookies.set({
name: "login",
value: "true",
httpOnly: true,
});
response.cookies.set({
name: "access_token",
value: data.access_token, //token value here
httpOnly: true,
maxAge: data.expires_in,
});
```
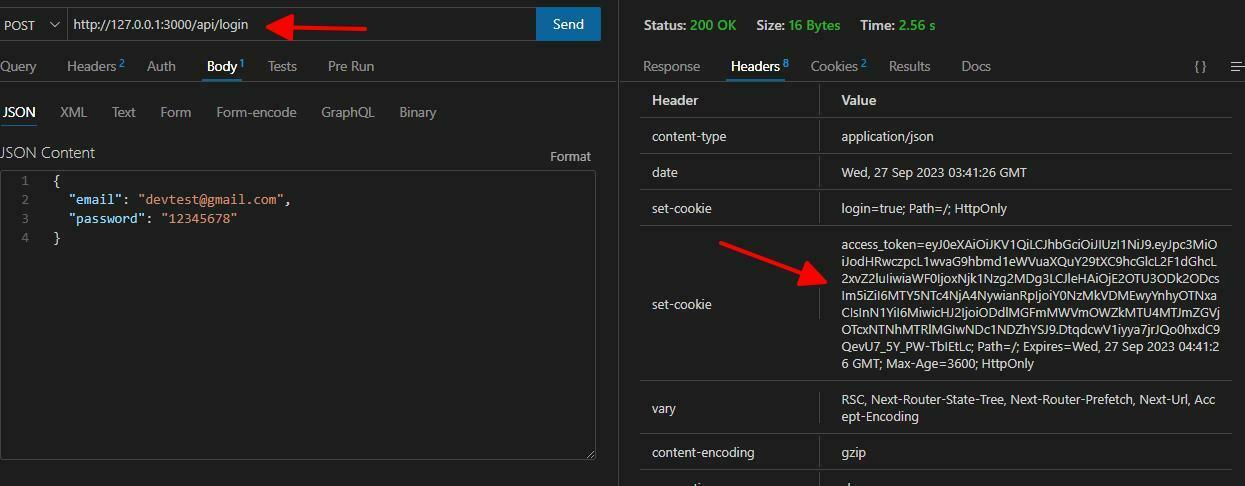
**CREATE A MIDDLEWARE**
+ **middleware.ts** : used to check access_token , whether it exists or not by using request.cookie.get('_access_token_')
```javascript
import { NextRequest, NextResponse } from "next/server";
const allow_origin_lists :string[] = process.env.NODE_ENV==='production'?['https://hoanguyenit.com','https://100daysofcode.hoanguyenit.com']:
['https://www.google.com','http://localhost:3000','http://127.0.0.1:3000']
export default function middleware(request: NextRequest){
const login = request.cookies.get("login");
const check_login= !login?.value? false: true
const access_token = request.cookies.get("access_token");
const check_token = !access_token?.value? false: true
const origin: string | null = request.headers.get('origin')
const res = NextResponse.next()
// console.log(request.nextUrl.pathname);
const res_404 = new NextResponse(null,
{
status: 404,
statusText:"Bad request",
headers:{
'Content-Type':'text/plain'
}
})
if(origin && !allow_origin_lists.includes(origin)){
return res_404;
}
if(!check_login && !check_token){
return res_404;
}
console.log("origin",origin);
res.headers.append('Access-Control-Allow-Credentials', "true")
res.headers.append('Access-Control-Allow-Origin', origin)
res.headers.append('Access-Control-Allow-Methods', 'GET,DELETE,PATCH,POST,PUT')
res.headers.append(
'Access-Control-Allow-Headers',
'X-CSRF-Token, X-Requested-With, Accept, Accept-Version, Content-Length, Content-MD5, Content-Type, Date, X-Api-Version'
)
return res;
}
export const config = {
matcher:[
'/api/categories:path*',
'/api/post:path*',
'/api/user:path*'
]
}
```
In the above code, we check the values in the cookie that we saved in the login section above
```javacript
const login = request.cookies.get("login");
const check_login= !login?.value? false: true
const access_token = request.cookies.get("access_token");
const check_token = !access_token?.value? false: true
//nếu không đúng trả về status 404
if(!check_login && !check_token){
return res_404;
}
```
Here, we need middleware to request the following api routes:
```javascript
export const config = {
matcher:[
'/api/categories:path*',
'/api/post:path*',
'/api/user:path*'
]
}
```
Okay so we have created Middleware.
Now we need to create a user api folder to get that user's information. If everything in the middleware is correct, it will allow us to call **api/user/**
+ **app/api/user/route.ts**
```javascript
import { NextRequest, NextResponse } from 'next/server'
type ResponseBody = { errors: { message: string }[] } | { username: string };
async function getUserByValidSessionToken(token : string){
const res = await fetch('http://127.0.0.1:8000/api/auth/user-profile',{
headers: {
"Content-Type": "application/json",
"Authorization":"Bearer "+token
},
});
const data = await res.json();
return {
username: data.name
}
}
export async function GET(
request: NextRequest
): Promise<NextResponse<ResponseBody>> {
const token = request.cookies.get("access_token");
const user = !token?.value
? undefined
: await getUserByValidSessionToken(token.value);
if (!user) {
return NextResponse.json({
errors: [{ message: "User not found by session token" }],
});
}
return NextResponse.json({
username: user.username,
});
```
Get the **access_token** value in the cookie
```javascript
const token = request.cookies.get("access_token");
const user = !token?.value
? undefined
: await getUserByValidSessionToken(token.value);
```
Write fucntion fetch **api + token**
```javascript
const res = await fetch('http://127.0.0.1:8000/api/auth/user-profile',{
headers: {
"Content-Type": "application/json",
"Authorization":"Bearer "+token
},
});
```
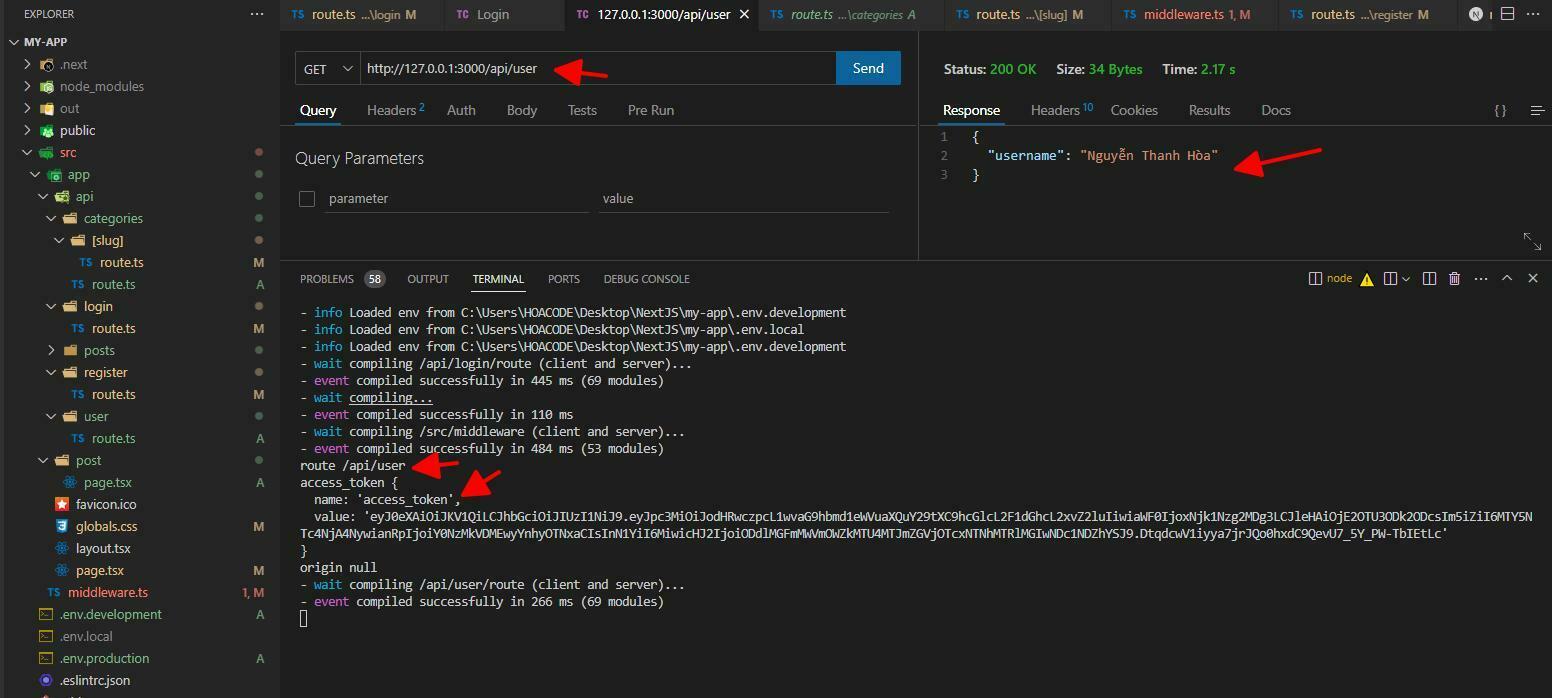
Okay that's it, you can develop further
+ Check the token's expiration time, if the Token expires, you can force the user to log in again
+ If the BackEnd side has a refresh_token
attached , then take the **refresh_token** to see if it's still valid, send it to BackEnd , to get a new **access_token**
You can see more about [JWT(Json Web Token) In Node.Js](https://hoanguyenit.com/jwt-json-web-token-in-nodejs.html)
The article : [Check Login Using Middleware With NextJS 13](https://hoanguyenit.com/check-login-using-middleware-with-nextjs-13.html) | skipperhoa |
1,613,556 | Ruby on Rails - Generators | Introduction In Ruby on Rails, writing the same boilerplate code over and over again can... | 0 | 2023-09-27T18:17:03 | https://dev.to/convosable/ruby-on-rails-generators-2g3d | ## Introduction
In Ruby on Rails, writing the same boilerplate code over and over again can become repetitive, time consuming, and error-prone. Luckily, Rails offers a great solution called 'generators' which streamlines the process of creating essential components, such as models, controllers, migrations and more. In this post, we will discover how to use Rails generators as well as how they improve development efficiency and accuracy.
Before we dive into the most common uses of rails generators and how to use them, let’s go over some important guidelines to use these powerful tools to the best of their ability.
- Naming Conventions: Rails follows specific naming conventions for all of its components, so it's important to keep in mind what rules go with which type of generator you are using.
- Generator Options: Rails generators come with extra options that allow you to further customize the code that is generated. For example, you could add specific attributes to a model when writing it in the terminal as opposed to defining them after the model is generated.
- Documentation and Help: You can access specific documentation or help for a specific generator by running `rails generate generator_name --help`. For example, running `rails generate model --help` will return all the necessary information that goes along with generating a model.
To set up Rails generators, you first need to create a new Ruby on Rails application. You can do this quickly by entering the following command into your terminal:
```
rails new YourAppName
```
You can then navigate into your applications root directory and run bundle install, which will read the Gemfile for your project and install all of the required gems and their dependencies. Since generators are an important part of Rails, they will be automatically available once your application is set up. Finally, with your Rails app set up and gems installed, you can now make use of Rails generators to create various components of your application.
A few of the most common generators used in rails and the ones we will go over here, are for generating a model, controller, migration, or a resource.
## Model
Let’s start off with the model generator. Generating a new model will simply just create a new model as well as the migration file for creating the corresponding database table with the specified attributes. When generating a new model, type the following into the console:
```
rails g model ‘ModelName’ attribute1, attribute2:integer
```
You can use `rails g` or `rails generate` for the first portion, followed by the type of thing you want to generate, in our case, a `model`, followed by the `ModelName`, in its singular form, followed by the attributes associated to the model. When adding our attributes, everything will default to the data type of string unless it’s specified otherwise in the format: `attribute:data_type`
Here’s an example of a generated Hike model: `rails g model Hike name difficulty:integer location`
Model:

Migration:
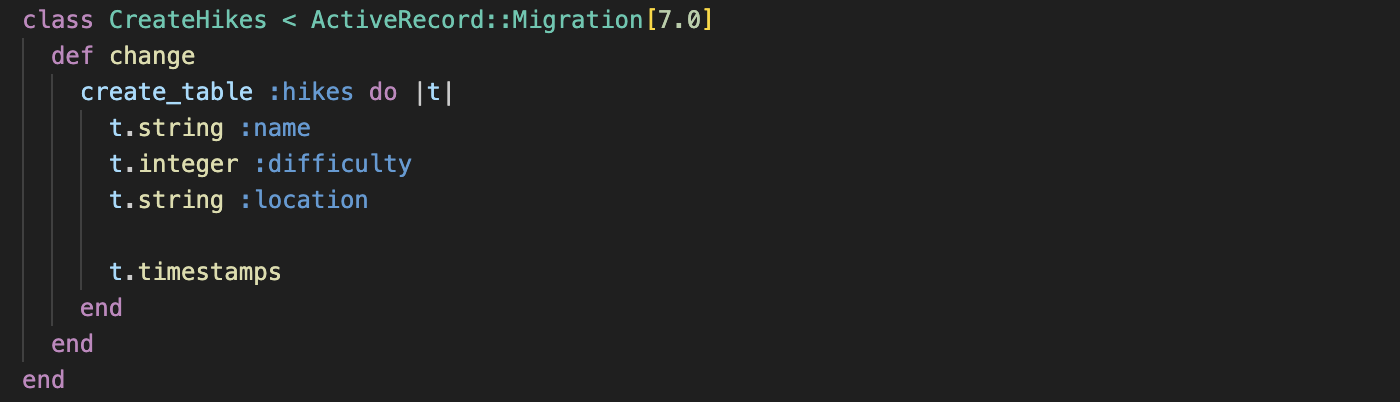
## Controller
The next generator we're going to cover will be the controller generator. If we wanted to generate a new controller for a Hike model we run the following in the terminal:
```
rails g controller Hikes
```
When generating a controller, we use a model's name in the pluralized form. This command will generate a file called 'hikes_controller.rb' in the 'app/controllers' directory. This file contains the code for the HikesController which is responsible for handling various HTTP requests and responses.
Here’s what our HikesController would look like after it is created:

## Migration
The next generator we will cover is going to be the migration generator. Migrations are a way to manage your database over time and update or remove data when necessary. To generate a migration, you run the following in your terminal:
```
rails g migration NameOfMigration
```
The name of your migration should reflect the changes you’re making to the database schema. For example, if we wanted to add a length attribute to Hikes, we could run:
```
rails g migration AddLengthToHikes
```
When this command is run, a new migration file will be created in the ‘db/migrate’ directory with a timestamp and the name that was provided. So our file from above might look something like ‘20230922192325_add_length_to_hikes.rb’. You can then open the migration file and define the changes you wish to make. You can use various methods in the migration file to make changes to the schema. Some common methods include, `add_column`, `remove_column`, `create_table`, `drop_table`, etc. For our purposes, we will focus on `add_column`. Here’s an example of adding a length column to the hikes table:

Finally, to apply the change you’ve made and to update the schema to reflect those changes, you would run `rails db:migrate` in your terminal.
## Resource
Last but not least, we are going to cover the resource generator, one of the most powerful generators. Upon generating a new resource, many new files are created including the Model, Controller, Migration files like we've seen above, as well as an updated the ‘config/routes.rb’ directory with RESTful routes for the resource, including index, show, create, update, and destroy.
To generate a resource for Hike, you would run the following in your terminal:
```
rails g resource Hike name difficulty:integer location length:integer
```
After running this command, you will have access to all of the files defined above as well as a RESTful routes for the resource as seen below:

All in all, using generators is a very helpful and powerful resource to use when creating a Rails application and it can increase productivity, decrease repetitive code, as well as reduce possible errors. | convosable | |
1,615,335 | My Journey into JavaScript: Balancing Late Nights and Learning | Introduction to Flatiron School SWE Bootcamp When I first joined my coding bootcamp, I had no idea... | 0 | 2023-09-29T09:30:29 | https://dev.to/michaelalexanderphan/my-journey-into-javascript-balancing-late-nights-and-learning-57e2 | **Introduction to Flatiron School SWE Bootcamp**
When I first joined my coding bootcamp, I had no idea what to expect. I anticipated a solitary journey, assuming I would be on my own in my quest to learn JavaScript. However, I was pleasantly surprised to discover that the experience was far more social and enriching than I had imagined. This newfound camaraderie, combined with the challenges of late-night coding and the battle with imposter syndrome, transformed my journey into a truly rewarding and fulfilling adventure.
**The Appeal of DOM Manipulation**
The first phase of my bootcamp focused on JavaScript, with its ability to manipulate the Document Object Model (DOM), fascinated me from the start. It held the promise of creating dynamic and interactive web applications, but I soon realized that it wasn't just about memorizing code snippets – it was about deeply understanding the concepts behind them.
**Late Nights and Struggles**
As I delved into the world of JavaScript, I found myself burning out more often than not. I was determined to master the language and ensure that my understanding was solid. However, my relentless pursuit of knowledge began to take a toll on my health. It was a wakeup call that made me realize the need for balance in my learning journey.
**The Reward of Understanding**
Amidst the late-night coding sessions and moments of frustration, there came a breakthrough. That moment when everything clicked, and I truly understood a concept, was euphoric. It was the reward for all the effort I had invested. This feeling of mastery fueled my determination to keep going, but I knew I needed to find a healthier approach.
**Learning Efficiency and Balance**
I realized that efficiency in learning is not about how many hours you spend coding but about how effectively you utilize your time. Late nights and all-nighters were not sustainable in the long run. I started to adopt strategies to maximize my learning without sacrificing my well-being.
**_Structured Learning:_** I organized my learning into focused sessions with breaks in between to prevent burnout.
**_Code Analogies:_** I discovered that code analogies were incredibly helpful in grasping complex concepts. They served as mental bridges, connecting new knowledge to familiar concepts.
**_Hands-on Learning:_** Practical exercises and projects allowed me to apply what I learned immediately, reinforcing my understanding.
**The Power of Asking for Help**
One of the most significant lessons I learned was the importance of seeking help. There's no shame in asking questions or reaching out to peers, instructors, or online communities. When I encountered roadblocks, I realized that a simple explanation or code snippet from someone else could provide the clarity I needed.
**From Comparing to Empowering**
Early on, I found that I was comparing myself often to the rest of the group. Instead of viewing my peers as competitors, I realized that we all shared the same goal. We were on a collective journey against the curriculum, not against each other. This shift in perspective transformed my experience. Rather than comparing myself in a detrimental way, I began to see my cohort as a source of support and encouragement. We were a team, each with unique strengths, working together to conquer the challenges of coding.
**Looking Ahead**
As I reflect on this first phase of my coding bootcamp, I find myself excited for what lies ahead. The next phase will focus on React, and I'm eager to delve into new ways of efficiently coding and building dynamic web applications. My journey continues, and I'm ready to embrace the challenges and rewards that come with it.
**A Pledge to Active Learning**
I've come to recognize that I learn best through hands-on experience. Lectures alone can leave me feeling adrift. So, as I step into the next phase of my bootcamp, I'm committed to a new approach. I'll engage in prior practice and practical exercises to ensure that I come to lectures armed with questions and a readiness to be actively involved. This, I believe, will enhance my learning process and bring me closer to my goals.
**Conclusion**
My journey through phase 1 of my coding bootcamp has been a transformative experience. It exceeded my initial expectations of a solitary pursuit and introduced me to an amazing community of fellow learners. I faced the formidable imposter syndrome head-on, turning it from a hindrance into a driving force.
As I continue down this coding path, I am not only learning the intricacies of JavaScript, React, Python, and Flask, but also the importance of collaboration, support, balance, and shared goals. The late-night struggles and the imposter syndrome challenges have all been instrumental in shaping my perspective, making me realize that it's not about being the best coder in the room but about being the best learner I can be.
I will always wish nothing but success for everyone on a similar journey, for we are not in competition with each other; we are allies in the pursuit of the never ending knowledge and skill that this industry requires. | michaelalexanderphan | |
1,620,799 | Day 61: HTML Events | Introduction to HTML Events HTML events are occurrences recognized by web browsers that... | 23,670 | 2023-10-04T15:00:00 | https://dev.to/dhrn/day-61-html-events-173b | webdev, html, 100daysofcode, frontend | ## Introduction to HTML Events
HTML events are occurrences recognized by web browsers that can trigger JavaScript functions or other actions. Events can be user-initiated, like clicks and keystrokes, or system-generated, such as the page finishing loading.
### Types of HTML Events 🌈
1. **Mouse Events 🖱️**
- `click`: Triggered when the mouse is clicked.
- `mouseover`: Fired when the mouse enters an element.
- `mouseout`: Fired when the mouse leaves an element.
```html
<button onclick="handleClick()">Click me!</button>
<script>
function handleClick() {
alert('Button clicked!');
}
</script>
```
2. **Keyboard Events ⌨️**
- `keydown`: Occurs when a key is pressed.
- `keyup`: Fired when a key is released.
```html
<input type="text" onkeyup="handleKeyUp(event)">
<script>
function handleKeyUp(event) {
console.log('Key pressed:', event.key);
}
</script>
```
3. **Form Events 📝**
- `submit`: Triggered when a form is submitted.
- `change`: Fired when the value of an input changes.
```html
<form onchange="handleChange()">
<input type="text" />
</form>
<script>
function handleChange() {
console.log('Input changed!');
}
</script>
```
4. **Window Events 🖼️**
- `load`: Fired when the page finishes loading.
- `resize`: Triggered when the browser window is resized.
```html
<body onload="handleLoad()" onresize="handleResize()">
<script>
function handleLoad() {
console.log('Page loaded!');
}
function handleResize() {
console.log('Window resized!');
}
</script>
```
## Event Handling in HTML 🤹♂️
Handling events can be done in HTML using inline attributes or in JavaScript using event listeners.
### Inline Event Handling 🎭
```html
<button onclick="handleClick()">Click me!</button>
<script>
function handleClick() {
alert('Button clicked!');
}
</script>
```
### Event Listeners in JavaScript 🧩
```html
<button id="myButton">Click me!</button>
<script>
const button = document.getElementById('myButton');
button.addEventListener('click', function () {
alert('Button clicked!');
});
</script>
```
## Event Propagation 🌐
Understanding event propagation is crucial. Events can propagate in two phases: capturing phase and bubbling phase.
```html
<div onclick="handleDivClick()">
<button onclick="handleButtonClick()">Click me!</button>
</div>
<script>
function handleDivClick() {
console.log('Div clicked!');
}
function handleButtonClick() {
console.log('Button clicked!');
}
</script>
```
In the above example, clicking the button triggers both `handleButtonClick` and `handleDivClick` because of event bubbling.
## Bonus Tip
### One Time Listener
The `{ once: true }` option is a boolean parameter you can add when using `addEventListener`. It's like a golden ticket that ensures your event listener fires only once. After the event is triggered and the handler executed, the listener is automatically removed.
#### Example
Consider a scenario where you want to show a welcome message to users but only the first time they click a button. The `{ once: true }` option makes this a breeze:
```html
<button id="welcomeButton">Click me for a welcome!</button>
<script>
function showWelcome() {
alert("Welcome! Thanks for visiting.");
}
document.getElementById("welcomeButton").addEventListener("click", showWelcome, { once: true });
</script>
```
| dhrn |
1,616,224 | Do GitHub stars ⭐️ = Money 💰? | Novu got 20k stars in one year, but what about customers? Many open-source... | 0 | 2023-09-30T06:52:55 | https://star-history.com/blog/do-github-stars-equal-money | webdev, programming, tutorial, discuss | # Novu got 20k stars in one year, but what about customers?
Many open-source companies/libraries, [Novu](https://github.com/novuhq/novu) among them, are starting out by collecting GitHub stars. But stars are not coins, contributors, or customers. So why are we trying to collect them?
This is the answer I get from almost everybody, and they are right! partially…

I would like to touch on three subjects:
- Credibility
- Vanity metric
- Trending opportunity
---
## Credibility feeds developers 🍽️
The first step in the developer's journey is looking at the **GitHub stars** - furthermore, if two libraries do the same with different amounts of stars, usually developers will pick the one with the most amount, or it will be their first filter.
Of course, they will look after the last commit and latest pull requests. It’s important to see that the library is being maintained.
If you are an early adopter, yes, you might choose to go with a smaller library, but bigger libraries want to see growth - the more stars you have, the longer time you are in the market, and this is part of the vanity metric 👇

---
## The vanity metric that rules them all 👑
We have taken Novu (at the time of writing this) to 24k stars, so you can trust me that most of what I am about to say is from experience.
**Stars symbolize your growth.**
If you grow stars organic (not buying stars or manipulating people to give you).
We have written tens of articles with a CTA to give us a star, which resulted in the following:
- More contributors
- More PRS
- More signups
- More visibility
In Novu, we achieved a major amount of stars that usually takes COSS libraries around 2-3 years to get. However, if you compare the other metrics, you will see that they match.

---
## Trending on GitHub weekly 📊
GitHub has the [Trending page](https://github20k.com). Many people monitor this page:
- Investors
- Contributors
- Developers
- Many other roles
Many libraries, such as Novu, got into a turning point once they got there.
And so, I have always tried to understand how to get to this page and realized that the best way is to get a lot of stars from multiple sources in a short period of time.
Since then, we have been trending there multiple times and have had major growth in all the factors.

---
## Where’s the money buddy 💰
It’s a fair question, as most of the community around your library will never pay you.
I have a quick question:
**Do you know where most deals are coming to companies in the Fortune 100?**
If you haven’t guessed it, It’s Word of mouth. It’s the strongest channel in the world with the biggest amount of credibility. And while the community is not paying you - they are building your brand. 99% of the customers of Novu, when being asked, **“How did you find us?”** - The answer is a friend. Frankly, it’s the biggest growth I have ever seen.
**Community** >> **Product** >> **Money**
#
## How do I get those stars? 🌟
Over the last year, I have brought Novu a lot of stars, contributors, and, of course, customers.
We have methodically increased our number of stars and have also been declared one of [the fastest-growing open-source companies of 2022](https://runacap.com/ross-index/annual-2022/) by RunaCapital. After achieving more than 20k stars, I have decided to go on a journey to teach everybody how to grow their repository and achieve this explosive growth.
**I invite you to register for my newsletter.**
This newsletter is good for you if:
- You are considering open-sourcing your product (or building a new one).
- You are considering opening a by-product and open-source it (to reflect on your main product).
- You are in tech and want growth without the stars / without GitHub trending.
It’s a 100% free newsletter (and always will be). Feel free to register at:
[https://github20k.com](https://github20k.com/)

What do you think about it? | nevodavid |
1,617,301 | Should I become Full-stack developer to get regular works? | I am a freelance front-end developer. Besides, I do occasional remote contractual jobs. I have been... | 0 | 2023-10-01T14:10:23 | https://dev.to/shofol/should-i-become-full-stack-developer-to-get-regular-works-92g | discuss | ---
title: Should I become Full-stack developer to get regular works?
published: true
tags: discuss
---
I am a freelance front-end developer. Besides, I do occasional remote contractual jobs. I have been working professionally for 5+ years. In these years I have built/fixed websites and web applications for clients. I mostly work with React.js, Angular 2+, and Next.js. I did a couple of full-stack projects with Firebase/Appwrite/Contentful as the backend. So, you can understand that, I am mostly a frontend developer with experience in working with web only.
Recently, I have been facing some issues which have become a headache for me. I am getting many clients through freelancing platforms who are asking for full-stack development. They don't want to hire two developers for their projects. Also, when I am thinking of applying for remote contractual jobs, I see there are more full-stack jobs than frontend ones. And, the frontend sector seems so crowded. There are tons of bids on Upwork, tons of gigs on Fiverr and tons of applicants on Job boards for frontend work. As a result, when I am trying to charge more, the clients are not getting interested because they are getting more FE developers with lower rates. After 5 years of work, I can't just lower my charges. So, I am losing many clients.
Now, I am seeking your suggestions and thoughts. Should I learn the backend (Preferably Node.js) and try to become a full-stack developer? Or, should I do more complex frontend projects which will establish myself as an expert? Also, should I give some focus on cross-platform mobile app development like React Native/Flutter? Or, am I missing something as a freelancer? How should I at least keep my rate steady and get work?
| shofol |
1,617,468 | Sua lógica, sua história: O que seu código diz sobre você | Olá, pessoal! Espero encontrar todos bem. Hoje você aprenderá que tipo de programador você é, qual é... | 0 | 2024-01-08T13:42:44 | https://dev.to/becomex/sua-logica-sua-historia-o-que-seu-codigo-diz-sobre-voce-lld | Olá, pessoal! Espero encontrar todos bem. Hoje você aprenderá que tipo de programador você é, qual é a história que os códigos que você escreve contam sobre você, e em qual gênero literário você seria encaixado se estivesse escrevendo um livro.
Escrever códigos de computadores é como escrever um livro, algumas estórias nos prendem, nos fazem querer saber mais sobre aquilo que está sendo contato, outras estórias nos repelem, e o único motivo para seguirmos lendo é a obrigação de saber o que acontece no final do livro, digo, final do código. Assim como escritores famosos, nós programadores temos cada um o seu próprio estilo, os seus próprios vícios, e marcamos nossas obras com nossa impressão digital ainda que não percebamos, e ainda que sigamos algum _style guide_.
As impressões digitais que deixamos para trás ao escrever um código de computador contam muito sobre nós mesmos, e mais ainda, a depender do nosso estilo, diria que nos permitem ser encaixados como produtores literários de livros que vão desde gêneros de romance, até gêneros de terror....

Há algum tempo, eu tive contato com um vídeo sobre React e ficção (link nas referências), no qual a palestrante traça um paralelo entre a escrita criativa de estórias de ficção, e a escrita de códigos de computadores. Inspirado por esse conteúdo, resolvi escrever esse artigo, e nele trato de forma ilusória as minhas próprias percepções sobre os códigos que leio, comparando-os com os sentimentos que se buscam despertar os diferentes gêneros literários.
**O autor adverte, qualquer semelhança com eventos reais, pessoas vivas ou mortas é mera coincidência 😁
Feito o preâmbulo, você está ansioso para saber o que o seu código conta sobre você? E qual é o gênero literário que você seria encaixado se o seu código fosse um livro?
## Os gêneros literários dos programadores
Comecemos por definir alguns gêneros e algumas características nos códigos normalmente atribuíveis àqueles.
### Terror

Todos nós em algum momento da vida já tivemos que lidar com algum código que nos assustou quando estávamos lendo, e que nos rendeu alguns pesadelos a noite. De fato, existem algumas coisas que são o terror dos programadores, confere só essa pequena lista e me diga se isso não te dá um frio na espinha:
- Arquivos com o número de linhas intermináveis;
- Linhas de código que poderiam dar a volta no planeta Terra;
- O mesmo nome de variável sendo usada para várias coisas diferentes;
- Todos os arquivos do projeto na pasta raiz do repositório;
- Funções que passam como parâmetro a chamada de outras funções, que passam como parâmetros a chamada de outras funções, que passam como parâmetro a chamada de outras funções, que passam como parâmetro a chamada de outras funções.... Só para deixar claro, essa crítica não se aplica em linguagens funcionais 😁.
E por fim, e mais assustador, alguns programadores adoram esquartejar suas variáveis, muitas vezes, tudo que sobra para trás para contar história é um X marcando o local onde o ataque aconteceu.
```js
lst.forEach(x => x.SOCORRO);
```
### Suspense
<img width="100%" style="width:100%" src="https://i.gifer.com/MVV3.gif">
Alguns códigos, quando precisamos debugá-los, nos dão a mesma experiência de ler um bom livro de suspense.
Os códigos que estou classificando aqui como suspense são aqueles que todas as vezes que executamos, não sabemos o que esperar, às vezes funciona, às vezes gera um erro, às vezes retorna um resultado, às vezes outro.
Isso costuma acontecer quando uma função faz várias coisas e possui vários efeitos colaterais, além de não deixar claro o que a mesma pretendia fazer.
```js
function funcao1(objeto) {
if ("o dia está ensolarado")
console.log("bora curtir uma praia");
if ("o vento está para o norte")
objeto.propriedade = 1;
if ("está chovendo")
throw new Exception("O Dev pira");
}
```
### Ficção

Ficção definitivamente é um gênero muito popular, pelo menos quando se trata de livros, quem nunca viu uma obra de Isaac Asimov? Quando falamos de algoritmos de computadores, esse gênero não é tão popular assim, é raro, mas acontece com frequência 😁.
Obras de ficção costumam brincar com a realidade, e desafiam o nosso conhecimento ou extrapolam teorias, nos algoritmos de computadores isso costuma ser visto quando o autor escreve uma função cujo objetivo do que se busca e do que se faz só pode ser ficcional.
```js
function somarNumeros(int left, int right) {
return left - right;
}
```
### Romance

O amor é lindo, e mais lindo que o amor é um código escrito com paixão. Programadores experientes conseguem ver através do código e dizer com quanto carinho o código foi escrito pelo autor.
Poucas coisas são tão satisfatórias quanto trabalhar com um código que foi escrito com esmero, é possível sentir quando o programador se esforçou em tornar o seu trabalho entendível e lapidado. Ainda que não seja o melhor código possível, e não se trata disso! Um programador que escreve romances toma o cuidado de deixar as coisas onde se espera que elas estejam, e conduzem o leitor de seus códigos em uma valsa de funções e variáveis imitando o mais belo dos sonetos.
Escritores deste gênero tomam o cuidado de indentar seus códigos com um padrão bem estabelecido, ainda que o leitor prefira outras formatações, é notável que o autor se esforçou para manter tudo com a mesma estética, e não jogou simplesmente os elementos na tela como quem bate com a cabeça no teclado.
## As revelações que os códigos fazem sobre seus autores
Tendo visto alguns gêneros literários usados para falar de características gerais dos desenvolvedores, daremos sequência observando algumas características mais pontuais, itens que os códigos revelam sobre os autores.
### Programador Ultrawide Screen
Alguns programadores usam todo o espaço disponível de seus monitores para escrever seus códigos, pode ser muito fácil descobrir o tamanho do monitor de alguns desenvolvedores, basta contar quantas vezes você precisa rolar o código horizontalmente para descobrir se o desenvolvedor que o fez possui um monitor Ultrawide Screen.
### Programador Shakespeariano
Esses programadores normalmente escrevem códigos que se encaixam no gênero de romance, suas obras são em geral muito belas, o único problema é que poucas pessoas são capazes de entendê-las.
### Programadores que amam e odeiam espaço em branco
Alguns programadores amam usar a tecla de espaço, adicionam vários espaços entre seus códigos, seja verticalmente deixando um vasto espaço vazio entre funções, ou horizontalmente iniciando uma linha na metade da tela.
Por outro lado, há aqueles que a detestam, não incluem espaços entre elementos de uma linha, e muito menos entre blocos de funções, tudo se torna uma grande sequência de caracteres concatenados.
## Conclusão
Ler e interpretar códigos compõem a maior parte do trabalho de um desenvolvedor, seja para integrar uma nova feature à um código já existente, corrigir um bug, ou refatorar algum trecho de código. Estamos sempre lendo códigos e tentando entender o que raios ele está fazendo, seja esse escrito por alguém da nossa equipe ou por nós mesmos há alguns meses. Por esse motivo, escrever de forma consistente e aplicar corretamente os padrões de desenvolvimento são tão importantes, isso nos ajuda a comunicar a intenção do código para as outras pessoas, e para nós mesmos no futuro.
O objetivo deste texto foi chamar a atenção de forma divertida para alguns anti-patterns e vícios negativos que temos no desenvolvimento de código, de forma que quando estejamos escrevendo algum código, nos perguntemos: que tipo de estória eu estou contando? Quem está lendo meu código se sentirá lendo um romance ou uma estória de terror?
É sempre mais agradável lidar com código claros e bem escritos, ainda que o código não seja o melhor, é possível notar quando o desenvolvedor se importava com o que estava fazendo, e queria entregar o melhor que podia naquele momento.
## Dicas do autor
Quer deixar de escrever estórias de terror e começar a escrever verdadeiros romances? Que tal começar aplicando algumas estratégias de _clean code_ básicas?
Preparei uma pequena lista de tópicos pensando no que vimos dentro dos gêneros literários deste artigo:
- Nem todos os desenvolvedores possuem um super monitor, controle o comprimento das linhas do seu código, 80 caracteres é excelente, 120 é aceitável;
- Se o arquivo está muito grande, separe o código em arquivos menores de acordo com as responsabilidades do código;
- Separou o código em vários arquivos? Ótimo, agora os organize em pastas no seu projeto, não deixe tudo na pasta raiz;
- Use nomes reveladores nas variáveis e funções, abreviaturas e usar apenas uma letra como variável dificulta muito a manutenção do código;
- Certifique-se de que a função escrita faz o que o nome dela expressa;
- Use o espaço vertical e horizontal, mas também não exagere, os elementos não precisam estar unidos, mas também não precisam estar em quarentena um longe do outro;
- Siga apenas uma indentação, mesmo que não seja a melhor de todas ela demonstra consistência, poucas coisas mostram mais desleixo do que cada parte de um código escrito e indentado de formas completamente diferentes.
Lembre-se: escritores de livros não publicam a primeira versão de seus manuscritos, eles leem e releem suas obras e as lapidam, do mesmo jeito, você não deveria publicar a primeira versão do seu código, uma revisão ainda que rápida não fará mal a ninguém.
Agora, me conta: que tipo de gênero literário você tem escrito atualmente?
## Referências
React e ficção: https://www.youtube.com/watch?v=kqh4lz2Lkzs
Livro: Código limpo: habilidades práticas do Agile software | mauricioandre | |
1,618,293 | Embarking On My Hacktoberfest Journey as a Unity Game Repo Maintainer 🎃 🎮 | Introduction 👋 Hi, I’m Taryn! I’m a Unity dev who created a small project for... | 0 | 2023-10-02T18:26:31 | https://dev.to/tarynmcmillan/embarking-on-my-hacktoberfest-journey-as-a-unity-game-repo-maintainer-2o46 | hacktoberfest23, unity3d, csharp, gamedev | # Introduction 👋
Hi, I’m Taryn!
I’m a Unity dev who created a [small project](https://github.com/TarynMcMillan/Tiny-Troves-of-Dev-Wisdom) for Hacktoberfest 2023.
**In this devlog, I’ll introduce you to the project and talk about my goals for Hacktoberfest as a game developer**.

## Tiny Troves of Dev Wisdom
First, let’s talk about the project itself. 🌟
[Tiny Troves of Dev Wisdom](https://github.com/TarynMcMillan/Tiny-Troves-of-Dev-Wisdom) is a simple point-and-click 2D game.
**The goal of the game is to select one of four chests**. When you click or tap on a chest, the Player will automatically move to that chest. The chest opens, revealing a piece of advice about the developer journey and the author of that advice.
**I wanted to keep things really simple since this is my first time serving as a maintainer of a repo**. The game will continue spawning chests and revealing advice when the chests are tapped on until you exit it.
I made the game with Unity, which you may or may not be familiar with given the recent controversy over changes to its pricing model. Before we continue, let’s take a quick look at how Unity works.
## What is Unity?
Unity is a game engine that has been used to create popular games such as Hollow Knight and Cuphead.
**It uses C# for scripting and contains a host of other built-in visual tools and components**. As a standalone program, it is downloaded from the official Unity website and usually used alongside Visual Studio.
**Solo game developers typically wear many different hats at once**. These different roles and responsibilities can include game designer, programmer, artist, composer, QA tester, project manager, and more. So suffice to say, no matter which game engine they use, game devs often have a lot on their plates. 😄
**For Hacktoberfest, I wanted to cut through all the noise and make a game that’s more accessible to any and all contributors, whether or not they have direct experience with Unity.**
And so, let’s take a look at the initial planning and prototyping of the game.
# The Birth of the Project 🧠

## How the idea came about
**I had <u>three main goals</u> in mind when creating this project:**
1. I wanted to create something small in scope that non-Unity devs could contribute to.
2. I wanted to make the project beginner-friendly so that everyone, no matter their experience level with open source, could make a contribution.
3. I didn’t want contributors to have to download and install Unity locally on their machines.
After chatting with other developers, **I decided to restrict the variety of contributions allowed for the game to just one text file**. This opened the door for non-code contributions while also bypassing the issue of requiring a Unity install.
It did mean my project would be more “on the rails” than I had initially hoped, but I thought this would be the best way of making the project truly accessible to everyone.
## Initial goals and scope of the project
My aim was to avoid scope creep at all cost, but of course that’s easier said than done! 😅
I knew I wanted the game to be advice-themed. **All developers, no matter where they are in their journey, have something to offer when it comes to wisdom for other developers**.
Initially, I foresaw the game being more simplistic. In the initial prototype, there was no player at all. I was planning on relying on UI elements such as buttons to have the user open chests. However, I thought this might not be engaging enough so I ended up adding in a third-person controller.
Using the keyboard, I could make the player run and jump. The game was much more interactive at this point, but not if you played it on mobile. I had been looking for an opportunity to practice my mobile development skills, so I ended up adding in some touchscreen controls.
I had originally prototyped the game using Unity’s old input system. Adding touchscreen controls is more streamlined with the new input system. At this point, I ended up taking the time to update the game to the new input system and change how the game handles player input.
**In the end, the game is still small in scope, but I think it’s more visually appealing and easier to play than if I had just stuck with UI-based gameplay.**
# Preparing for Hacktoberfest 📋

## Setting up the GitHub repo
While I’m no stranger to setting up repos, most of my previous repos have been private. **So preparing the Tiny Troves repo for public access required a fresh perspective and approach**.
I’m fortunate to be a member of the Virtual Coffee community and their [repo checklist](https://virtualcoffee.io/resources/developer-resources/open-source/maintainer-guide#repository-checklist) was a life-saver when it came to knowing what to include to make the repo ready for Hacktoberfest.
As a solo developer, I typically add a basic <code>README</code> to my repos. **The notion of creating a contributors’ guide, license, and code of conduct was new to me and a bit intimidating at first**. I found it helpful to look at examples of these files in other open source projects to help me see how they should be structured.
**Finding the right assets for the project was another big hurdle to overcome**. Before I made the repo public, I had to make sure that all the assets in the game had licenses that were compatible with open-source distribution.
As an extra precaution, I decided to limit my use of external assets and to include anything I do use in the <code>.gitignore</code> file. I ended up creating most of the major game assets, such as the player and chest sprites, myself.
## Defining clear contribution guidelines
Officially, I’m asking contributors to only make changes to the <code>Advice.txt</code> file that’s contained in the repo. Unofficially, any contributions related to documentation, bug fixes, or adding new features to the game are welcome.
To keep things simple, I’ve structured the [CONTRIBUTING.md](https://github.com/TarynMcMillan/Tiny-Troves-of-Dev-Wisdom/blob/master/CONTRIBUTING.md) file so that it only contains the instructions for a baseline contribution.
**In this file, you’ll learn how to:**
- Locate and open the <code>Advice.txt</code> file in the repo
- Add your name and piece of developer advice to the <code>Advice.txt</code> file
- Commit your changes and start a pull request
- View the [current build](https://mystic-mill-games.itch.io/tiny-troves-of-dev-wisdom) of the game online
## Creating a welcoming environment for all contributors
**Tiny Troves of Dev Wisdom is for everyone, no matter your experience level with open source**. Maintaining the repo is going to be a learning exercise for me and I hope contributing to the repo can be a learning exercise for you too! ❤️
I ask that all contributors respect the project’s [Code of Conduct](https://github.com/TarynMcMillan/Tiny-Troves-of-Dev-Wisdom/blob/master/CODE_OF_CONDUCT.md) and that **we all support and lift each other up as we embark on this Hacktoberfest journey together**.
# Upward and Onward! 💎

That wraps up this devlog on my Hacktoberfest project. I'm excited to see how the process of maintaining goes this month and I'll be back in a few weeks' time to reflect more on this journey.
**In the meantime, if you're looking for a repo to contribute to this Hacktoberfest, feel free to give [Tiny Troves of Dev Wisdom](https://github.com/TarynMcMillan/Tiny-Troves-of-Dev-Wisdom) a go! 😄** | tarynmcmillan |
1,618,973 | Bitbucket Dependency Bot Using Renovate 🤖 | What is Renovate? It is a tool that helps developers keep their software projects up to... | 0 | 2023-10-03T09:14:00 | https://dev.to/pgburrack/bitbucket-dependency-bot-using-renovate-5d3b | bitbucket, ci, javascript, webdev | ## What is [Renovate](https://docs.renovatebot.com/)?
It is a tool that helps developers keep their software projects up to date. It automatically updates dependencies, such as libraries and packages, for security vulnerabilities and outdated versions.
## How do I set up Renovate on Bitbucket Cloud?
####**Step 1** - Create an [access token](https://support.atlassian.com/bitbucket-cloud/docs/create-a-repository-access-token/) on your Bitbucket repo.
This will ensure Renovate has permission to create PRs on your behalf.

####**Step 2** - Create a pipeline variable using the Access Token as your value.
Creating a pipeline variable will make sure the pipeline that we will create to run Renovate will have access to the Access Token we created.
####**Step 3** - Create a JS file named `renovate.js` with the following code:
`./renovate.js`
```
module.exports = {
/**
* Tells which platform Renovate is on.
* See full platform support here
* https://docs.renovatebot.com/modules/platform/
*/
platform: 'bitbucket',
/**
* This is the Bitbucket variable we create on Step 2
*/
token: process.env.RENOVATE_TOKEN,
/**
* https://docs.renovatebot.com/self-hosted-configuration/#basedir
*/
baseDir: `${process.env.BITBUCKET_CLONE_DIR}/renovate`,
/**
* https://docs.renovatebot.com/self-hosted-configuration/#autodiscover
*/
autodiscover: true,
};
```
####**Step 4** - Create a JS file named `renovate.json` with the following code:
`./renovate.json`
```
{
"$schema": "https://docs.renovatebot.com/renovate-schema.json",
"enabledManagers": ["npm"],
"prHourlyLimit": 4,
"patch": { "enabled": true },
"minor": { "enabled": true },
"major": { "enabled": true },
"npmrc": "save-exact=true",
"labels": ["dependencies"]
}
```
This is a basic example of a configuration file that tells Renovate your preferences.
You can see the full list of configurations here:
https://docs.renovatebot.com/self-hosted-configuration
####**Step 5** - Create a custom bitbucket-pipelines.yml step that will run Renovate on a schedule.
`./bitbucket-pipelines.yml`
```
image: node:18.15-slim
pipelines:
custom:
'renovate':
- step:
name: Check for package updates
image: renovate/renovate:36.91-slim
caches:
- node
- docker
services:
- docker
script:
- export LOG_LEVEL=debug RENOVATE_CONFIG_FILE="$BITBUCKET_CLONE_DIR/renovate.js"
- renovate
```
**2 things to note:**
- Even if you are not using `bitbucket-pipelines.yml` this step should be similar.
- I am using the Renovate image version renovate/renovate:36.91-slim which might not be the latest for you.
you can check the latest versions of Renovate here
https://hub.docker.com/r/renovate/renovate/tags
####**Step 6** - [Getting the changelog in each Renovate PR bot to appear](https://github.com/settings/tokens).
In order to get a changelog for each PR we need to add a variable to our pipeline variables on Bitbucket with the key `GITHUB_COM_TOKEN` and the value should be generated from GitHub.
This is a weird one 😅

**How to generate the token on Github?**
- Go to https://github.com/settings/tokens
- Generate a classic token
####**Final Step**
🎉🎉 Make sure all the code is pushed on your main Git branch (for some reason it doesn't work if renovate is not on the main branch 🤷)
#### Final Note
I hope this guide will save you some time to set it up 💪
| pgburrack |
1,624,164 | How to Implement B2B SSO for SaaS User Authentication | In this digital era, enhancing user experience with secure, user-friendly solutions is paramount for... | 0 | 2023-10-05T03:40:32 | https://www.datawiza.com/blog/industry/how-to-implement-b2b-sso-for-saas-user-authentication/ | blog, industry | ---
title: How to Implement B2B SSO for SaaS User Authentication
published: true
date: 2023-10-04 21:42:24 UTC
tags: Blog,Industry
canonical_url: https://www.datawiza.com/blog/industry/how-to-implement-b2b-sso-for-saas-user-authentication/
---
In this digital era, enhancing user experience with secure, user-friendly solutions is paramount for SaaS companies. One such crucial component is the efficient implementation of Business to Business (B2B) Single Sign-On (SSO). Although SSO offers a myriad of benefits, the process of implemenation can be intricate. To simplify this, we explore three distinct approaches that can assist you in navigating this landscape.
## Method 1: Leverage the Power of Native SDKs
In this method, the strategy is to utilize the native Software Development Kit (SDK) that corresponds to the programming language of your SaaS solution. For instance, a Java-based SaaS solution could utilize [Spring Security SAML](https://spring.io/projects/spring-security-saml), a library rich in features for adding SAML-based SSO authentication to applications developed with Java and Spring Boot.
In the same vein, Python-based SaaS platforms might choose to use [Python3-SAML](https://github.com/onelogin/python3-saml), an implementation of the SAML standard for Python, ideal for Django-based applications.
This approach, while affording complete customization, necessitates robust coding skills and a comprehensive understanding of SAML-based identity solutions. The requirement to execute multi-tenant SSO further compounds the complexity — varying identity providers like Microsoft Entra ID (Azure AD), Google, Ping or Okta demand extensive engineering resources and time.
**Pros** :
- Full customization options
- No third-party subscription fees
**Cons** :
- Requires extensive technical expertise
- Significant engineering resources and potentially lengthy timeframe required due to varied identity provider structures
## Method 2: Deploy Third-party Services
Third-party services like Auth0 or Amazon Cognito are designed to mitigate some of the multi-tenant SSO complexity using [identity federation](https://en.wikipedia.org/wiki/Federated_identity). Nonetheless, the use of these services requires a firm grasp of their suite of SDKs and APIs to properly integrate them into your application architecture.
Understanding SSO protocols like SAML or OIDC are a prerequisite. Additionally, session management within your applications remains within your purview, adding another layer of complexity. Adequate proficiency in using these third-party SDKs and APIs, coupled with the correct application, is crucial, which potentially extends the implementation timeline.
**Pros** :
- Eases the complexity of managing the multi-tenant SSO process
**Cons** :
- Requires a significant understanding of the third-party SDKs, APIs, SSO protocols like SAML or OIDC, and session management
- Extensive engineering resources and time are needed
## Method 3: Embrace No-code with Datawiza
As an alternative to the traditional code-centric approach, Datawiza offers a no-code, configuration-based solution. This approach eliminates the need for programming and protocol-specific understanding, which significantly reduces the learning curve and simplifies the execution process. For a more detailed explanation of this approach, visit [our solution page here](https://www.datawiza.com/b2b-sso-saas/).
**Pros** :
- Minimal coding requirements
- Simplified and expedited implementation process
**Cons** :
- Potential third-party service costs
To sum up, here’s a table that compares the three methodologies:
| Method | Expertise Required | Engineering Resources Needed | Time Taken |
| --- | --- | --- | --- |
| Native Implementation (e.g., Spring Security SAML for Java) | High | Extensive | Several Months |
| Third-party Service (e.g., Auth0, Amazon Cognito) | Moderate | Significant | Few Months |
| No-code Solution (Datawiza) | Low | Minimal | Few Minutes |
While each approach has its own set of advantages and challenges, the choice depends primarily on each company’s specific needs, resources, and technical capabilities. Yet for businesses seeking an efficient and straightforward path, [Datawiza’s no-code solution](https://www.datawiza.com/b2b-sso-saas/) emerges as a compelling option in the quest to implement B2B SSO for SaaS user authentication.
The post [How to Implement B2B SSO for SaaS User Authentication](https://www.datawiza.com/blog/industry/how-to-implement-b2b-sso-for-saas-user-authentication/) appeared first on [Datawiza](https://www.datawiza.com). | cjddww |
1,624,424 | The Psychology of Floral Gifts: How Birthday Flowers Boost Happiness | Giving and receiving presents has always been a treasured custom in human society, serving to show... | 0 | 2023-10-05T05:27:18 | https://dev.to/aarvis/the-psychology-of-floral-gifts-how-birthday-flowers-boost-happiness-1o3a | flowers, melbourne, writing | Giving and receiving presents has always been a treasured custom in human society, serving to show love, appreciation, and fondness. Among the various gifts exchanged, flowers hold a particular position, going beyond cultural boundaries and evoking emotions deeply ingrained in the human mind. We delve into the captivating realm of the human psyche and emotions to comprehend why the simple gesture of giving birthday flowers can profoundly affect one's happiness. Birthdays, as personal milestones, are occasions of joy and celebration. Loved ones come together to honour and admire the individual, and giving presents plays a crucial role in expressing these feelings.

## The Science Behind Flowers and Emotions
The correlation between emotions and flowers is an intriguing research field encompassing various scientific fields like psychology, biology, and anthropology. Although there is still plenty to uncover about this intricate connection, numerous scientific principles and theories aid in comprehending how flowers can elicit emotions and the reason behind their significant influence on human feelings.
**Evolutionary Biology:** It is commonly thought that the human fascination with flowers has evolutionary origins. Our ancestors would have encountered different plants and flowers in their surroundings, and the ones with pleasant smells and vibrant colours would have been linked to safety and nourishment. This may have resulted in a favourable emotional reaction towards flowers.
**Scent and Olfactory Science:** The sense of smell, known as the olfactory system, is interconnected with our emotions and recollections. Specific flowery fragrances, like roses or lavender, can elicit favourable emotional reactions and memories connected to those scents. This occurrence is associated with the brain's limbic system, which plays a role in emotions and memory.
**Biophilia Hypothesis:** The concept of biophilia hypothesis proposes that humans possess an inherent bond with the natural world, encompassing not only plants and blossoms. Engaging with nature, such as appreciating flowers, can alleviate stress, bolster positive emotions, and amplify general welfare. Numerous studies have supported psychological advantages derived from immersing oneself in natural surroundings.
**Symbolism and Cultural Associations:** Flowers have represented feelings and expressions in different societies for centuries. An instance is the connection between love, red roses, purity and white lilies. These cultural links greatly influence the emotional significance of flowers in diverse situations.
**Social Interactions:** The act of presenting or accepting flowers is a widely practised social custom linked to conveying feelings, such as affection, [appreciation](https://www.aarvisflowers.com.au/collections/thank-you-flowers-delivery), or empathy. The act of offering or receiving flowers has the potential to evoke positive sentiments and enhance interpersonal connections.
**Art and Creative Expression:** Throughout history, artists, poets, and writers have consistently found inspiration in the enchanting allure of flowers. Through skilful creative expressions such as paintings, verses, and literary works, emotions and sentiments can be effectively communicated by harnessing blossoms' symbolism and visual appeal.
**Therapeutic Effects:** Horticultural therapy is a well-established discipline that utilises engagement with plants and blossoms to enhance emotional wellness and facilitate the process of recovery. Engaging in nurturing and cultivating plants and flower gardens can benefit those facing challenges with stress, anxiety, or depression.
## The Unique Power of Birthday Flowers
[Birthday flowers](https://www.aarvisflowers.com.au/collections/happy-birthday-flowers-delivery) hold a unique power to convey emotions, create memorable experiences, and make individuals feel cherished on their special day. Here are some aspects of the amazing power of birthday flowers:
**Thoughtfulness and Personalisation:** Gifting birthday flowers shows thoughtfulness and a personal touch. Choosing flowers that reflect the recipient's preferences or favourite colours demonstrates that you've taken the time to consider their tastes and interests.
**Emotional Expression:** Flowers have a universal language that can convey various emotions. Whether you want to express [love](https://www.aarvisflowers.com.au/collections/valentines-day-flowers-delivery), gratitude, friendship, or admiration, a flower or floral arrangement can effectively communicate your sentiments.
**Surprise and Delight:** Receiving an unexpected bouquet of birthday flowers can be a delightful surprise that brightens the recipient's day. Surprise adds to the joy and excitement of the birthday celebration.
**Long-Lasting Joy:** Unlike some gifts that may be consumed or used up quickly, flowers have the potential to bring joy for an extended period. By providing adequate care, fresh blooms can remain vibrant for several days to even weeks, serving as a delightful memento of the memorable occasion.
**Versatility:** Birthday flowers come in various types and arrangements, from traditional bouquets to exotic blooms. This versatility lets you choose flowers that perfectly match the recipient's personality and style.
**Connection to Nature:** Many people find a deep connection to nature, and receiving flowers on their birthday can provide a feeling of being in harmony with the natural world. This connection to nature can enhance feelings of well-being and happiness.
**Lasting Memories:** Birthday flowers often become a part of cherished memories. People may associate specific flowers or arrangements with significant birthdays, creating lasting sentimental value.
**Sustainability and Eco-Friendly Options:** Recently, there has been a growing emphasis on eco-friendly and sustainable floral options. Gifting birthday flowers from responsible sources can align with the recipient's values and contribute to environmentally conscious celebrations.
## The Psychological Benefits of Receiving Birthday Flowers
Receiving birthday flowers can have various psychological benefits that contribute to an individual's overall well-being and happiness. Here are some of the psychological advantages of receiving birthday flowers:
**Positive Emotions:** Flowers evoke positive emotions, such as happiness, joy, and gratitude. A bouquet of birthday flowers can instantly uplift the recipient's mood and create a sense of delight.
**Increased Happiness:** The sight and scent of fresh flowers can trigger the release of dopamine, a neurotransmitter associated with pleasure and happiness. This can lead to an immediate boost in mood and overall well-being.
**Reduced Stress:** Flowers have been shown to reduce stress and anxiety. Receiving and admiring a beautiful floral arrangement can help lower stress levels and promote relaxation.
**Improved Mental Health:** Flowers can be calming and provide comfort during challenging times. Receiving birthday flowers can help individuals feel supported and cared for, which is especially beneficial for their mental health.
**Enhanced Mood and Energy:** The vibrant colours and fragrant scents of flowers can stimulate the senses and increase energy levels. This can be particularly helpful when one wants to feel energetic and celebratory on a birthday.
**Sense of Appreciation:** Knowing someone has taken the time to select and send flowers as a birthday gift can make the recipient feel appreciated and loved. This can boost self-esteem and self-worth.
**Improved Focus and Creativity:** Studies have shown that having flowers in one's environment can enhance cognitive function, including focus and creativity. Birthday flowers in the home or workspace can promote mental clarity and productivity.
**Long-Lasting Positive Memories:** [Birthday flower arrangements](https://www.behance.net/gallery/175232117/Happy-Birthday-Flower-Arrangements-to-Make-Their-Day) often become associated with fond memories of the special day. This positive association can be a source of comfort and joy long after the birthday has passed.
**Aesthetic Pleasure:** The beauty of flowers is aesthetically pleasing, and simply looking at them can provide a sense of aesthetic enjoyment. This visual pleasure can have a positive impact on one's psychological state.
**Anticipation and Excitement:** Being aware that birthday flowers are enroute or awaiting delivery can generate a feeling of anticipation and enthusiasm, contributing to the overall pleasure of the birthday festivities.

## Choosing the Perfect Birthday Flowers
Selecting the perfect birthday flowers involves considering the recipient's preferences, the symbolism of different flowers, the occasion's theme, and the message you want to convey. Here are some steps to help you choose the perfect birthday flowers:
**Consider the Recipient's Tastes:** When selecting flowers for someone, it's always a great idea to consider their favourite flowers, colours, and styles. Knowing the recipient's preferences can make the gift even more special and meaningful. If you are unsure about their preferences, feel free to seek guidance from their friends or family. They may have valuable insights that can help you choose the perfect flowers.
**Age and Personality:** When choosing a floral arrangement to give as a gift, it is essential to consider the recipient's age and disposition. A lively and exuberant floral arrangement would be suitable for a youthful and spirited individual. Vibrant and colourful flowers like sunflowers, daisies, and tulips can evoke a sense of joy and energy, perfectly matching the vitality of a young and lively individual. Such an arrangement can bring life and cheerfulness to their space, reflecting their vibrant personality.
**Birth Month Flowers:** Every month is connected to a birth flower, similar to how birthstones are associated. Investigate the birth flower corresponding to the recipient's birth month and add it to the arrangement to give it a personalised touch.
**Consider the Occasion:** The occasion of a birthday can significantly influence your choice of flowers. Different flowers convey different meanings and emotions, making choosing the right ones for the specific celebration essential. For example, if it is a romantic partner's birthday, consider red roses, symbolising love and passion. You could opt for bright and cheerful flowers such as sunflowers or daisies for a friend or family member's birthday, representing happiness and friendship.The appropriate blooms can contribute an extra special element and enhance the birthday festivities, creating a more lasting impression.
**Flower Arrangement Styles:** Think about the style of the flower arrangement. Options include traditional bouquets, elegant vase arrangements, rustic wildflower arrangements, or modern and minimalist designs. Choose a style that matches the recipient's taste and the occasion's theme.
**Colour Palette:** Pay attention to the colour palette. [Different colours evoke different emotions](https://www.aarvisflowers.com.au/blogs/news/the-colour-significance-of-flowers). For example, red symbolises love and passion, while yellow represents joy and friendship. Select colours that resonate with the recipient's preferences and the message you want to convey.
**Fragrance:** When giving flowers as a gift, it's important to consider whether the recipient would appreciate fragrant blooms. While some people adore the sweet and intoxicating scent of flowers like roses and lilies, others may find it overwhelming, or even allergic reactions may be triggered. In such cases, opting for more subtle and lightly scented flowers like tulips or daisies is wise. These flowers still have a delicate fragrance that can brighten up a room.
**Budget:** Determine your budget for the birthday flowers. There are beautiful options available at various price points. When planning to buy birthday flowers, it's crucial to determine your budget beforehand. Having an idea about your budget can assist in narrowing down your choices and avoiding excessive expenditure.
**Add Personal Touches:** When giving someone a bouquet, consider adding personal touches to make the gift even more special. One way to do this is by including a handwritten birthday card expressing your best wishes and personal sentiments. This thoughtful gesture adds a personal touch and shows the recipient that you took the time to write something meaningful just for them.
**Consult a Florist:** If you need more clarification about flower choices or arrangements, it is always a good idea to consult with the[ best flower delivery service in Melbourne](https://www.aarvisflowers.com.au/). They have the ability to assist you in choosing the ideal flowers for any event, considering aspects such as the recipient's likes, the time of year, and the meaning associated with various flowers.
In conclusion, the psychology of floral gifts reveals a profound connection between giving birthday flowers and enhancing happiness. It goes beyond the surface beauty of the blooms and taps into the deep well of human emotions and symbolism. So, the next time you consider a meaningful birthday gift, remember that a carefully chosen bouquet can bring joy and be a lasting source of happiness and connection. The language of flowers speaks volumes of love, care, and celebration, making it a timeless and cherished tradition in human relationships.
| aarvis |
1,624,617 | Compose and send yahoo email in a mobile browser | Yahoo Mail provides a convenient way to access and manage your emails on mobile devices through a... | 0 | 2023-10-05T09:11:11 | https://dev.to/dknmek3rj3r3r/compose-and-send-yahoo-email-in-a-mobile-browser-4aa5 | email, gmail, spectrum, att | [Yahoo Mail provides a convenient way to access and manage your emails on mobile devices through a mobile browser](https://techomails.com/compose-and-send-yahoo-email-in-a-mobile-browser-usa-canada/). Composing and sending emails directly from your mobile browser allows you to stay connected and respond to important messages while on the go. | dknmek3rj3r3r |
1,624,686 | How to Recover RediffMail Account Without Phone | Losing access to your Rediffmail account can be a frustrating experience, especially when you don’t... | 0 | 2023-10-05T10:12:31 | https://dev.to/nienjfn8ruh3ih3/how-to-recover-rediffmail-account-without-phone-1nkd | email, gmail, yahoo | [Losing access to your Rediffmail account can be a frustrating experience](https://techomails.com/how-to-recover-rediffmail-account-without-phone-usa-canada/), especially when you don’t have access to your registered phone number. However, Rediffmail provides alternative methods to help you recover your account and regain access. In this comprehensive guide, we will walk you through the step-by-step process of recovering your Rediffmail account without a phone. | nienjfn8ruh3ih3 |
1,627,112 | ParseArger deeper: --pos --opt and --flag | Now that you know the basic of parseArger generate and parse, it's time to have a look at how we... | 24,947 | 2023-10-26T09:51:11 | https://dbuild.io/projects/parsearger/more-on-pos-opt-and-flag/ | bash, cli, linux, terminal |
Now that you know the basic of parseArger `generate` and `parse`, it's time to have a look at how we declare arguments, options and flags !
## --pos
Positional arguments are what most of us use in a bash script with `$1`, `$2`, `$...`
Well same thing here, but they have names And much more :
```bash
arg-name: positional argument name
description: positional argument description
--one-of <one-of>: accepted values, repeatable
--complete <complete>: bash built-in completely function, repeatable
--complete-custom <complete-custom>: completely custom dynamic suggestion, repeatable
--subcommand-directory <subcommand-directory>: directory containing subcommands, force subcommand, list parseArger script in directory to fill --one-of
--subcommand-variable <subcommand-variable>: array variable containing subcommand parts, force subcommand [default: ' __subcommand ']
--subcommand|--no-subcommand: is a subcommand
--subcommand-run|--no-subcommand-run: run subcommand, forces sub command
--subcommand-use-leftovers|--no-subcommand-use-leftovers: add leftover arguments to subcommand, forces subcommand
```
And a dumb example that generates a script that take one argument my-cmd and execute it as a subcommand using the leftover arguments, my-cmd must be one of "ls", "cd" or "cat" :
```bash
parseArger generate --pos \
'my-cmd "an argument" --subcommand --subcommand-run --subcommand-use-leftovers --one-of ls --one-of cd --one-of cat'
```
### arg-name
The argument name, `-` will be replaced with `_` and the variable will be prefixed with `_arg_`.
So --my-super-argument value is assigned to $_arg_my_super_argument.
### description
Simple description for help, documentation and so on
### --one-of
Repeatable, The argument value must be one of, the most basic input validation, yeah !
```bash
parseArger generate --pos 'my-arg "my argument description" --one-of value1 --one-of value2'
```
### --complete
Repeatable, [Completely built-ins](https://github.com/DannyBen/completely#suggesting-files-directories-and-other-bash-built-ins).
```bash
parseArger generate --pos 'my-file "this is a file path" --complete file'
```
### --complete-custom
Repeatable, [Completely custom](https://github.com/DannyBen/completely#suggesting-custom-dynamic-suggestions)
```bash
parseArger generate --pos 'my-arg "this is an argument" --complete-custom "\$(echo \"some_value some_other you_get the_point\")"'
```
### --subcommand-directory
You been a good kid and you did split your scripts ?
If they're all in the subcommand-directory, parseArger will add them to one of and build a __subcommand variable for you to use.
It forces --subcommand ... in case you were wondering.
```bash
parseArger generate --pos 'my-arg "this is an argument" --subcommand-directory bin'
```
### --subcommand-variable
Ooooh, oh you don't like __subcommand !!? What should it be called then ? It forces --subcommand.
```bash
parseArger generate --pos 'my-arg "this is an argument" --subcommand-variable notAsubCommand'
```
### --subcommand
This is a subcommand
```bash
parseArger generate --pos 'my-arg "this is a command argument" --subcommand'
```
### --subcommand-run
Run the subcommand before handing you the script, forces --subcommand.
```bash
parseArger generate --pos 'my-arg "this is an argument" --subcommand-run'
```
### --subcommand-use-leftovers
Maybe those leftovers are worth something..., after all ! Forces --subcommand
```bash
parseArger generate --pos 'my-arg "this is an argument" --subcommand-use-leftovers
```
## --opt
I'm pretty sure most of you were waiting for that : (add ethereal music here) options !
```bash
arg-name: positional argument name
description: positional argument description
--repeat-min <repeat-min>: minimum repeatition forces repeat [default: ' 1 ']
--repeat-max <repeat-max>: maximum repeatition forces repeat
--one-of <one-of>: accepted values, repeatable
-d, --default-value <default-value>: value, repeatable
-s, --short <short>: short form
--alias <alias>: option alias, repeatable
--empty-value <empty-value>: value for empty option
--complete <complete>: bash built-in completely function, repeatable
--complete-custom <complete-custom>: completely custom dynamic suggestion, repeatable
-r|--repeat|--no-repeat: repeatable
--empty|--no-empty: use option as flag
```
I won't bore you with arg-name and description, and if you need me too, you might want to re read the previous part a tiny tad more attentively, maybe, if you'd like to.
### --repeat-min
Repeatable option, yes ! but at least this many ! Forces --repeat.
```bash
parseArger generate --opt 'my-opt "this is an option" --repeat-min 42
```
### --repeat-max
Repeatable option, yes ! but not too much ! Forces --repeat.
```bash
parseArger generate --opt 'my-opt "this is an option" --repeat-max 69
```
### --one-of
see --pos --one-of above, it's the same ;)
### --default-value
An option, why not, but it shall not be empty !
```bash
parseArger generate --opt 'my-opt "musnt be eeeemmmmpty" --default-value "this is not empty"'
```
### --short
I know ya'll concerned about bodily efficiency (my mom called that "lazy"...), letters matters ! you got 26 of'em, that's how many options max my scripts have !
```bash
parseArger generate --opt 'my-opt "lazily call me" --short o'
```
### --alias
I know it's hard to always agree (especially with yourself !), with aliases, no more decision (about option names), you can have your cake, and eat it, too !
```bash
parseArger generate --opt 'a-opt "lazily call me" --alias "an-opt" --alias "an-option" --alias "needlessly-long-option-name"'
```
### --short
I know ya'll concerned about bodily efficiency (my mom called that "lazy"...), letters matters ! you got 26 of'em, that's how many options max my scripts have !
```bash
parseArger generate --opt 'my-opt "lazily call me" --short o'
```
### --complete
see --pos --complete above, it's the same ;)
### --complete-custom
see --pos --complete-custom above, it's the same ;)
### --repeat
You can now have multiple values for your option. the option is now an array, even if only one value is given.
```bash
parseArger generate --opt 'my-opt "look ma', I'am an array !" --repeat'
```
### --empty
Option or flag ? Well, why not both ? A flag if you don't give it anything, an option otherwise !
```bash
parseArger generate --opt 'my-opt "option>flag superposition" --empty'
```
## --flag
Ahoy ! raise the flaaaaaag ! (I'd say I'm grasping at branches, but it seems tree do not grow in the ocean...)
```bash
arg-name: positional argument name
description: positional argument description
-s, --short <short>: short form
--no-name <no-name>: value for the negation
--alias <alias>: flag alias, repeatable
--no-alias <no-alias>: flag negation alias, repeatable
--on|--no-on: on by default
```
You know the drill with arg-name, description, --short and alias, it's up above ;)
### --no-name
`--no-<flag-name>` do not fly ? Fine, you choose !
```bash
parseArger generate --flag 'do-that "flabbergasted, flag a..." --no-name dont-do-that'
```
### --no-alias
There are plenty of ways to say no !
```bash
parseArger generate --flag 'do-that "flabbergasted, flag a..." --no-alias this-instead --no-alias do-this'
```
### --on
It's already on... but you can turn it off.
```bash
parseArger generate --flag 'do-that "flabbergasted, flag a..." --on'
```
## What now ?
Now you almost have the whole view on parseArger, enough for simple scripts anyway !
But maybe you do not value your mental health much and would like to create a whole program in bash ?
Well, What a coincidence, next time we'll have a look at the `project` command, it'll help you do just that ! (the program part, I do not deal in mental health)
As always bugs and suggestions should go on [parseArger's github repo](https://github.com/DimitriGilbert/parseArger).
Thanks for the read and I hope you found it useful (or at least entertaining :D )
See you around and happy coding ! | dimitrigilbert |
1,627,379 | MiniScript Roundup #1 | I'm starting a regular blog on the news happening in the MiniScript world. This is issue... | 0 | 2023-10-08T00:59:48 | https://dev.to/synapticbytes/miniscript-roundup-1-a7n | miniscript, programming | I'm starting a regular blog on the news happening in the MiniScript world. This is issue #1.
[MiniScript Roundup #1](https://miniscript.synapticbytes.dev/miniscript-roundup-1) | synapticbytes |
1,628,787 | Building Serverless Python Apps with AWS Lambda and Docker | Greetings geeks! Welcome to another blog on how to get your stuff done (the easy way)! In this blog,... | 0 | 2023-10-09T14:52:38 | https://dev.to/thecodersden/building-serverless-python-apps-with-aws-lambda-and-docker-3ab2 | devops, docker, aws, cloud | Greetings geeks!
Welcome to another blog on how to get your stuff done (the easy way)! In this blog, we will be taking a look at how to deploy dockerized Python code on AWS Lambda. Not only that, we will be setting up our AWS environment using Terraform to reduce the chances of blowing up our servers without our knowledge. So, let's get started!
## Why [Lambda](https://aws.amazon.com/lambda/)?
This question is not uncommon. In case you have felt it as well, you have come to the right place! When we use **Lambda functions** in place of traditional EC2 servers, we are taking a big leap into the world of **serverless computing**. This technique enables us to focus only on the business logic of our product, while the cloud provider does the heavy-lifting of setting up the environment for us.
## An use-case of Lambda
AWS Lambda has a special use case in the industry. Consider this simple example:
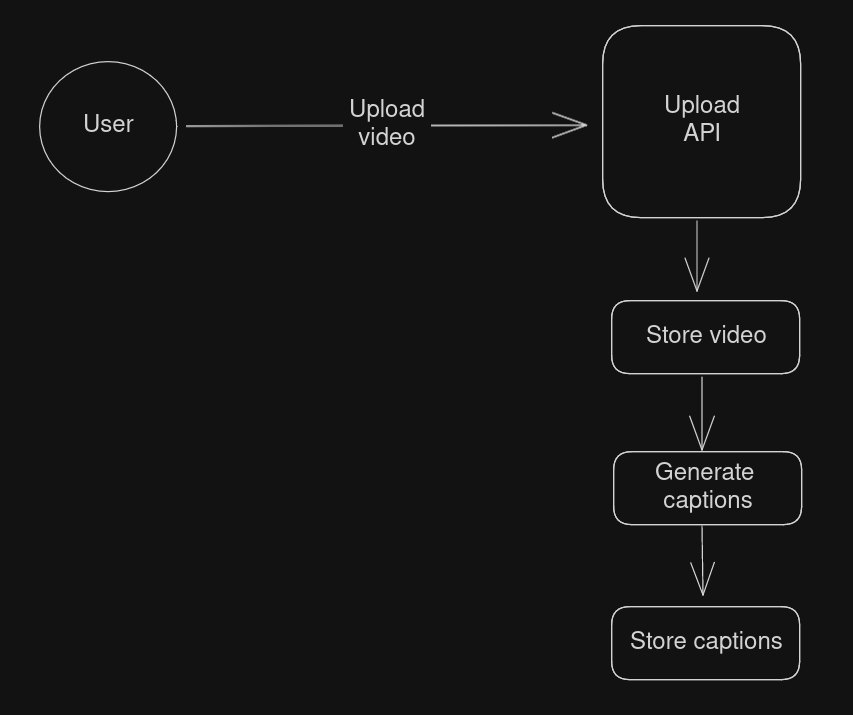
This diagram demonstrates a caption generation API that does the following (The abstraction of intricate details is deliberate):
1. Take in a video
2. Store the video
3. Generate its captions
4. Store the caption along with the video
There is one design flaw in here. We might have a case that the `Upload API` might have authentication and authorization to filter out who can upload videos. But we can easily point out that, the video generation doesn't require any authentication, i.e, it can operate autonomously. This is where lambda can help us. We are also increasing the workload on `Upload API` in this flow. The next diagram shows the optimized design:
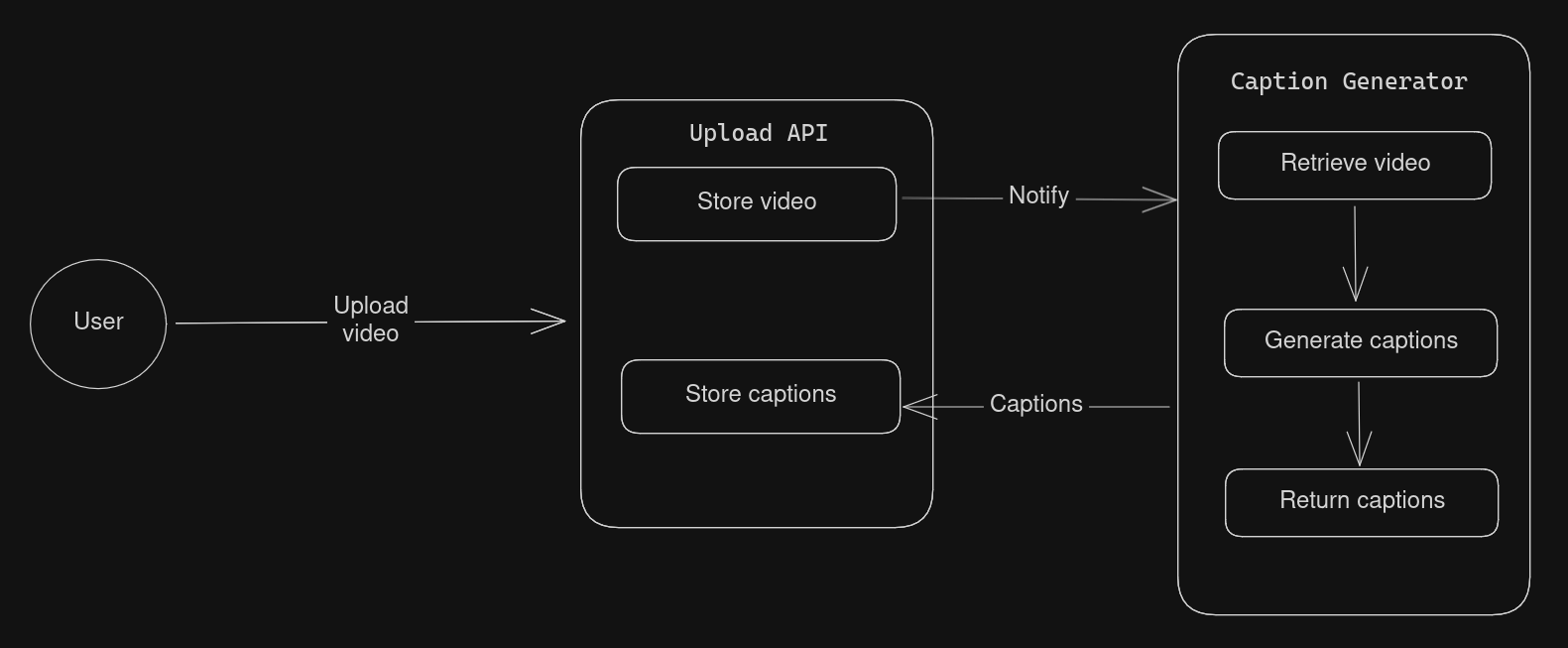
As you can see, we have separated the caption generator to another component called `Caption Generator`. You can think of this as a component. It does the following:
1. Retrieve the video from storage (eg- S3)
2. Process the video and generate captions
3. Return the captions.
Through this design, we achieved the following:
- Implemented separation of concern and single responsibility principle.
- Reduced workload on `Upload API`.
Now, you might be wondering, how do you actually host this `Caption Generator`. Well, you have your answer - AWS Lambda! Lambda functions are meant for exactly such use cases, where you can isolate autonomous functionalities into separate services and host them. The `Upload API` can then **invoke** the `Caption Generator` when it will need to.
## Our roadmap
Implementing the above service can take quite some amount of coding. To keep this tutorial simple, we will implement a Hello World function for starters.
- Create Python code for the Hello World function.
- Dockerize the code.
- Initialize Terraform
- Create ECR.
- Deploy our code.
- Create Lambda function.
- Test our function.
- Cleaning up.
You can find the code for this blog in [here](https://github.com/rajdip-b/python-ecr-lambda-tf).
## Did you say Python?
Yes, Python! Perhaps one of the easiest languages for getting started. Lambda supports a lot of [runtimes](https://docs.aws.amazon.com/lambda/latest/dg/lambda-runtimes.html). Do check them out if you are interested. Here is a glimpse:
First, we need to create a file named `lambda_function.py`. The naming convention is necessary since we will be using a base image that utilizes this name.
### Short note on using containerized build.
Lambda supports three sources of code:
- **Single file code:** used for smaller use cases such as testing and demonstration and is not often recommended for production environment.
- **Zipped up code from S3:** Generally used along with pipelines where the artifacts from the `build` stage of the pipelines is uploaded into a S3 bucket and the lambda function uses this archive.
- **Containerized code from AWS ECR:** Perhaps the most stable one, this gives you the flexibility to use custom runtimes with the help of Docker. The code is built into a docker image and is pushed into ECR which is then used by Lambda.
The [base image](https://hub.docker.com/r/lambda/python/) that we will be using dictates us to name the entry file as `lambda_function.py` and the entry function as `handler`. Hence, the names.
```python
# lambda_function.py
def handler(event, context):
name = event["name"]
return {"statusCode": 200, "message": f"Hello {name}!"}
```
The code is pretty simple. It extracts a parameter called `name` from the **lambda event** and returns a JSON response. We will come to the event format at the end.
## Docker up!
That's step one done. Next, we move towards dockerizing our code.
Create a file named `Dockerfile` in the same directory with the following contents:
```docker
# Dockerfile
FROM public.ecr.aws/lambda/python:3.10
# Copy function code
COPY lambda_function.py ${LAMBDA_TASK_ROOT}
# Set the CMD to your handler (could also be done as a parameter override outside of the Dockerfile)
CMD [ "lambda_function.handler" ]
```
## Initialize Terraform
For starters, [Terraform](https://www.terraform.io/) is an open-sourced tool developed and maintained by HashiCorp that allows us to build our cloud infrastructure from code. This approach is popularly known as **Infrastructure as Code(IaC)**. If you would like to read more, I suggest you go through their docs (and perhaps some YouTube?).
Before proceeding forward, make sure you have these prerequisites checked:
- [terraform installed locally](https://developer.hashicorp.com/terraform/tutorials/aws-get-started/install-cli)
- [AWS CLI set up](https://docs.aws.amazon.com/cli/latest/userguide/getting-started-quickstart.html)
Now, we are ready to get started with terraform.
- First, create a folder named `terraform` in the root folder of your project. This isn't a rule, but will allow you to properly organize your code files.
- Next, create these files in the folder:
```terraform
# terraform.tf
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = "~> 4.0"
}
}
}
provider "aws" {
region = var.region
access_key = var.access_key
secret_key = var.secret_key
}
```
This file is used to hold all the configurations required by our project. To simplify, we will be using AWS, hence we mentioned `aws` in the `required_providers` block. Next, we set up our `aws provider`, where in we mention our AWS settings.
```terraform
# variables.tf
variable "region" {
default = "your_aws_region"
}
variable "access_key" {
default = "your_aws_access_id"
}
variable "secret_key" {
default = "your_aws_secret_key"
}
```
This file contains the AWS option values. It is usually a good practice to extract all sensitive values from your terraform code into the `variables.tf` file and inject the values at runtime to enforce and maintain security of your code.
- Once done, run the following:
```bash
terraform init
```
This will initialize your project with the dependencies.
## Create ECR
With the previous step done, we are ready to move into the actual stuff. Now, we will be creating our repository [(AWS ECR)](https://aws.amazon.com/ecr/). This will allow us to host the custom python image that we will be building shortly. Add this file inside the `terraform` folder that you created just a while back.
```terraform
# ecr.tf
resource "aws_ecr_repository" "greetings_repository" {
name = "greetings-repository"
force_delete = true
image_tag_mutability = "MUTABLE"
}
```
Note that the name of our repository is `greetings-repository`. You can change it if you want to.
After that, we will want to spin up our repository:
```bash
terraform apply
```
This command will create your ECR. You can check it from your AWS Console by going into **Search > ECR > Repositories > greetings-repository**
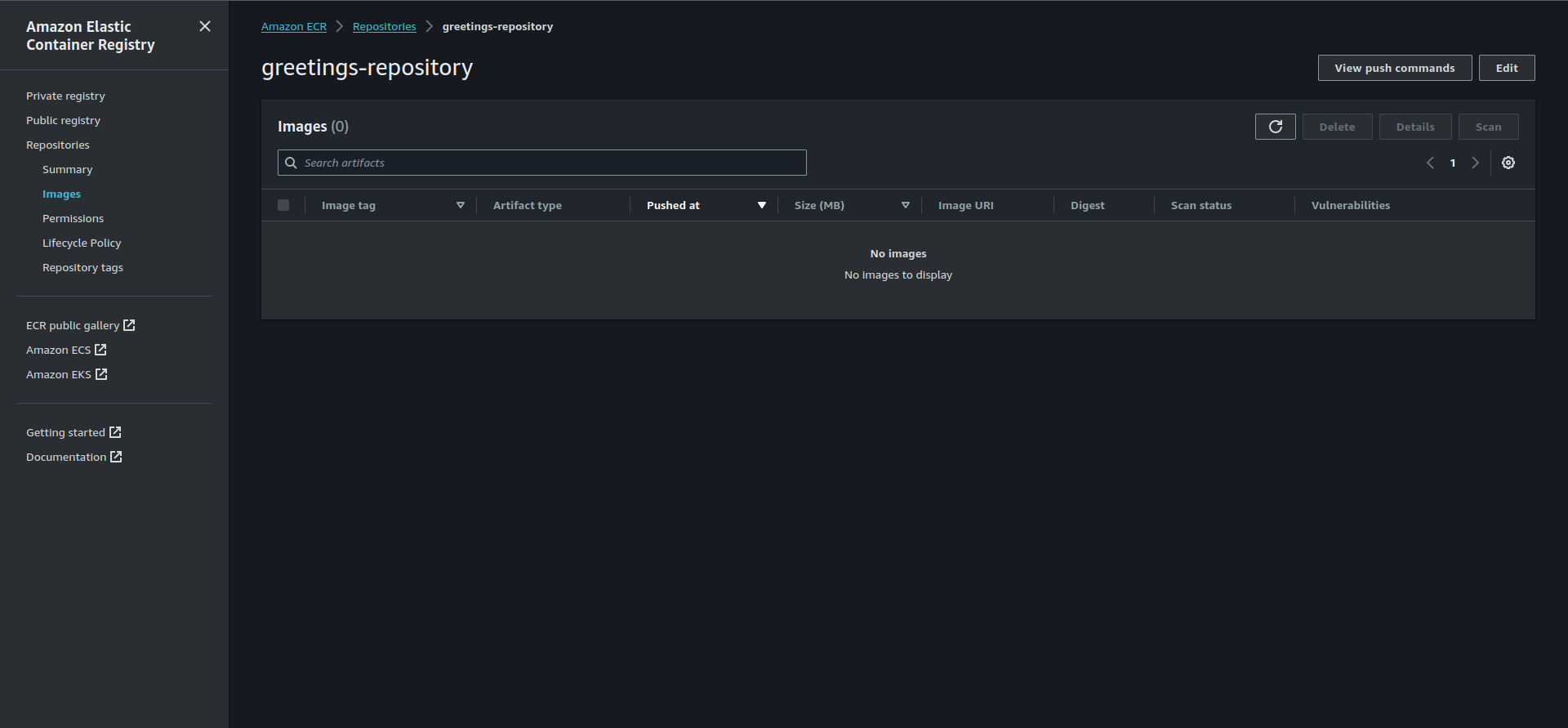
## Deploying our code
Now that we have our repository set up, we are ready to build and push our code. To do this, click on the **View push commands** button on the top right of the repository page.
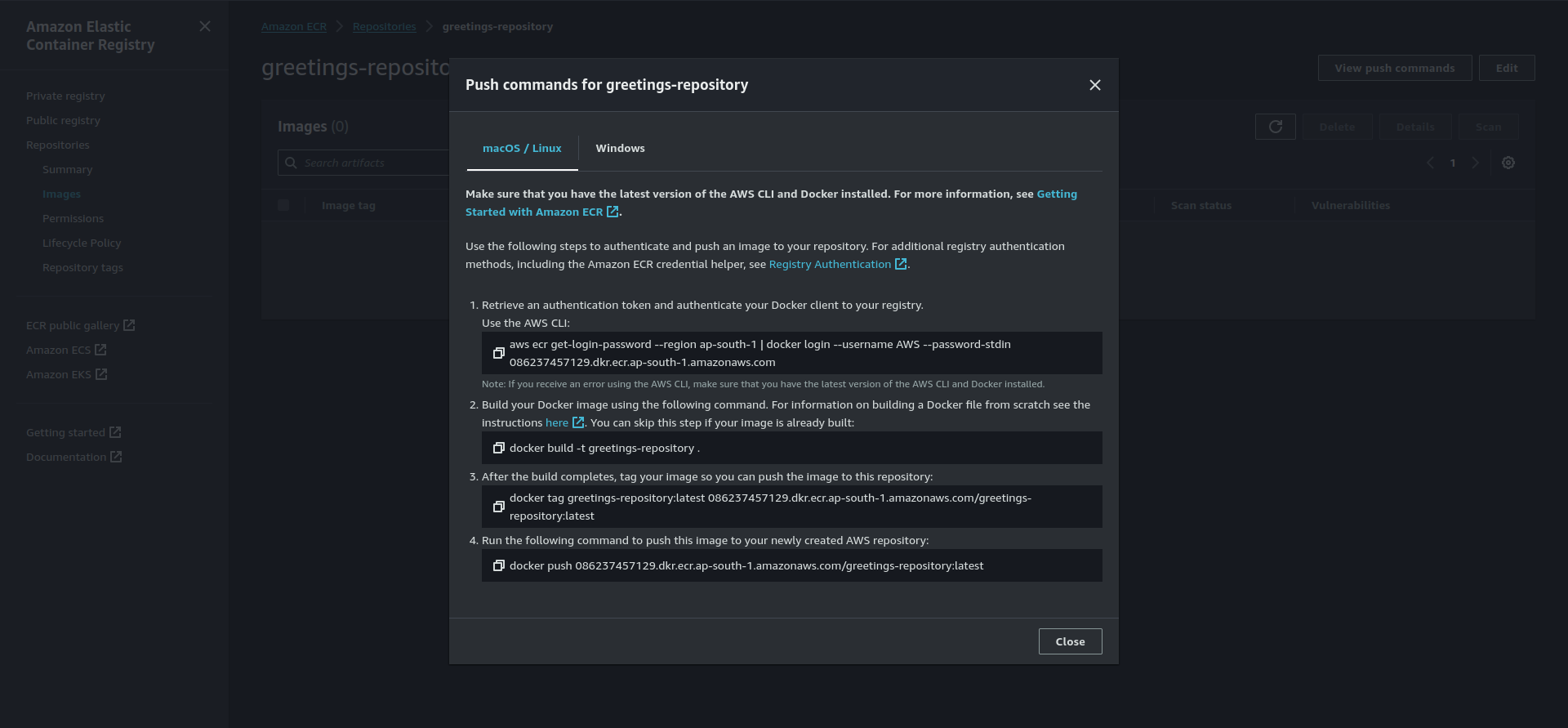
Go into your root directory of the project and run the commands one by one.
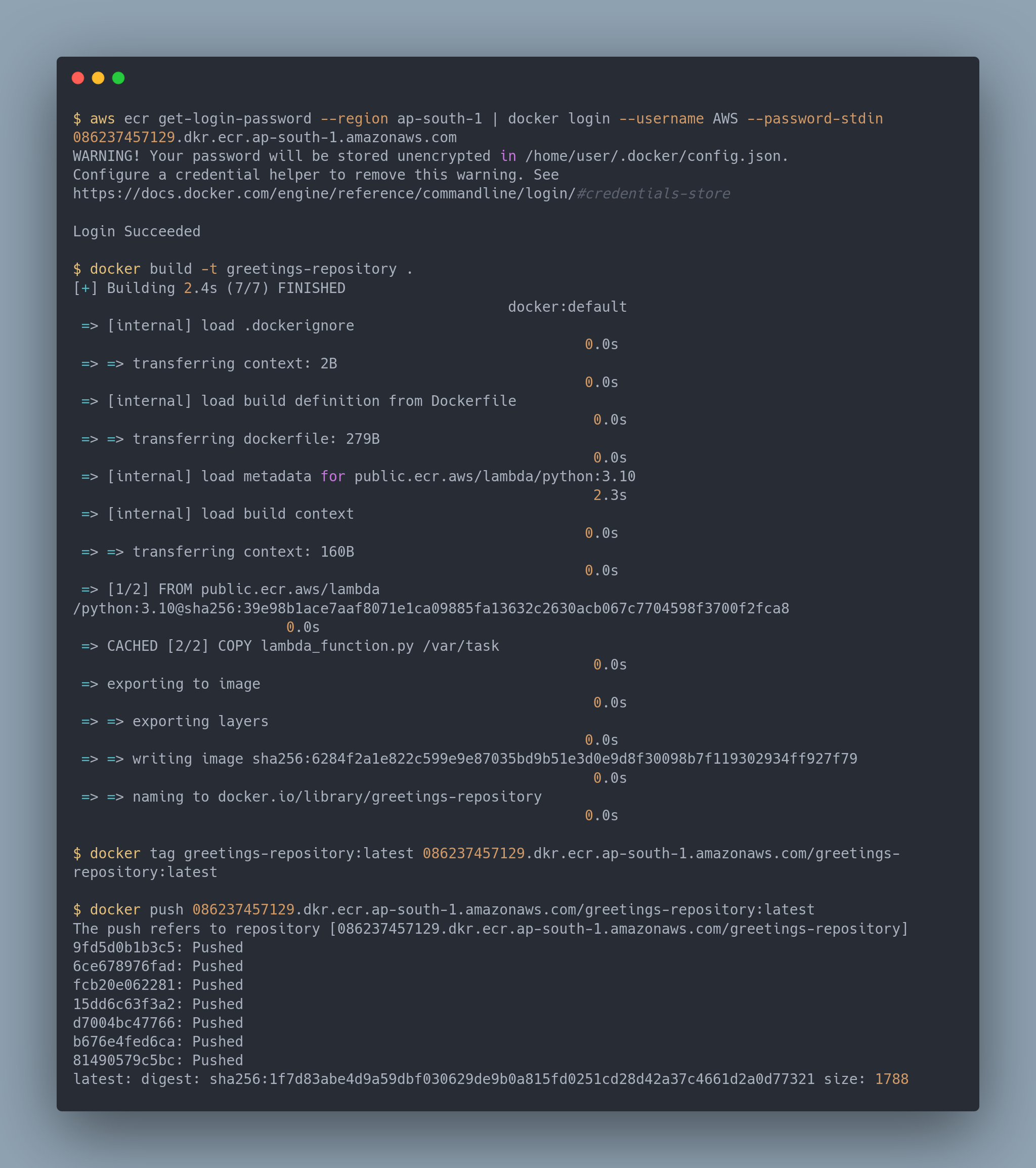
After running the commands, your output should look something similar to this. To confirm you have pushed the image, you can go into your repository in ECR and verify that it's there.

## Create the Lambda function
Before we deploy our lambda function, we need to create a **[Lambda execution role](https://docs.aws.amazon.com/lambda/latest/dg/lambda-intro-execution-role.html)** that our lambda function will use. This allows the function to operate on its own.
```terraform
# role.tf
data "aws_iam_policy_document" "assume_role" {
statement {
effect = "Allow"
principals {
type = "Service"
identifiers = ["lambda.amazonaws.com"]
}
actions = ["sts:AssumeRole"]
}
}
resource "aws_iam_role" "iam_for_lambda" {
name = "iam_for_lambda"
assume_role_policy = data.aws_iam_policy_document.assume_role.json
}
```
Here, we created a role called `iam_for_lambda` that we will attach to our lambda function.
Let's buckle up and get that function deployed.
```terraform
# lambda.tf
resource "aws_lambda_function" "greetings_function" {
function_name = "greetingsFunction"
role = aws_iam_role.iam_for_lambda.arn
package_type = "Image"
timeout = 10
image_uri = "${aws_ecr_repository.greetings_repository.repository_url}:latest"
}
```
We did quite a few things in there, namely:
- Create a lambda function named `greetingsFunction`
- Attach the `iam_for_lambda` role that we just created
- Specified that our lambda function will be using an image as its source.
- Specified the `greetings-repository` url.
- Specified a timeout for the function.
With that, we come to the finale. All we need to do now is, run:
```bash
terraform apply
```
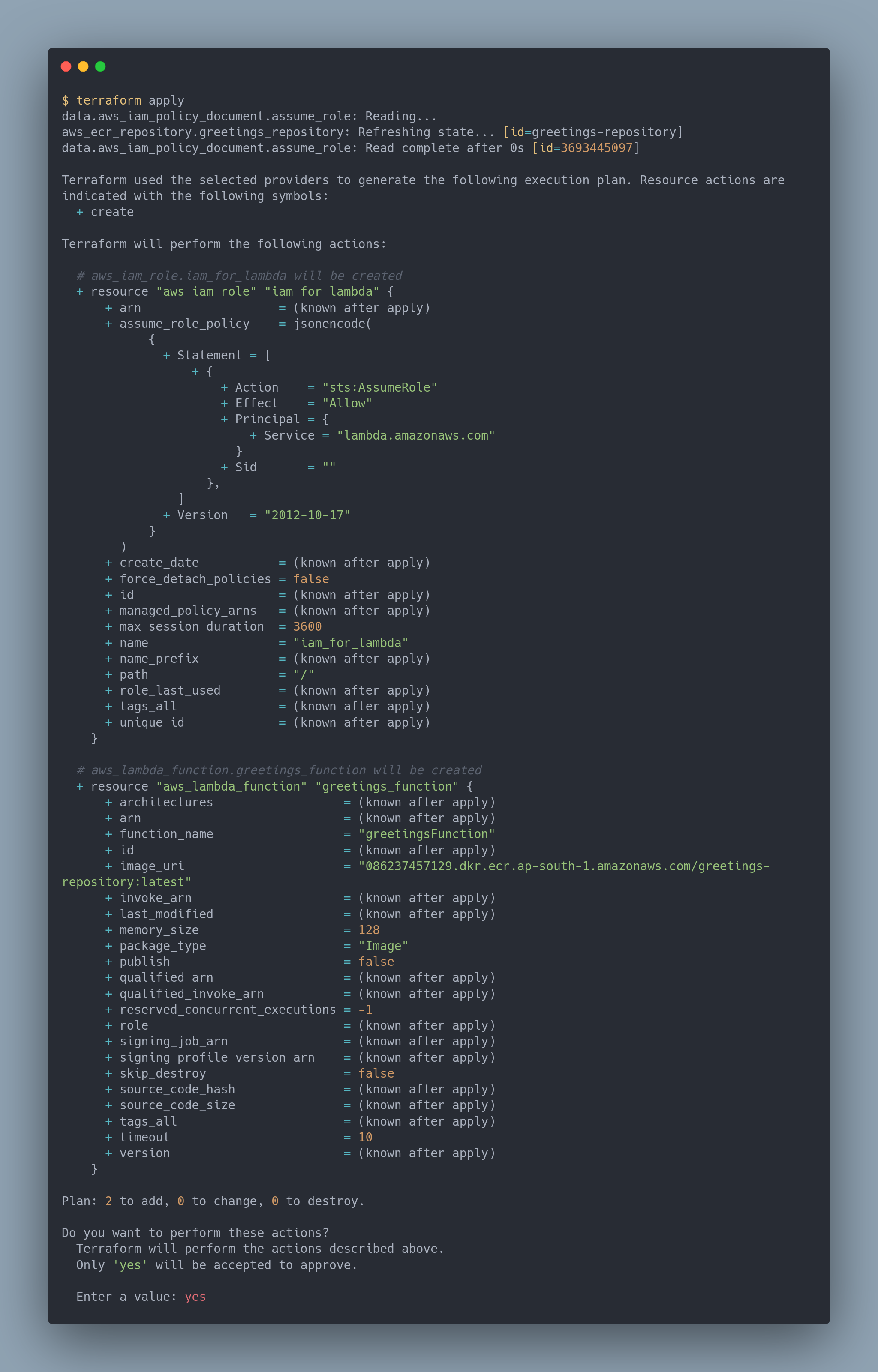
After this, we should see our lambda function up and running! You can check it from your **AWS Console** via **Search > Lambda > greetingsFunction**
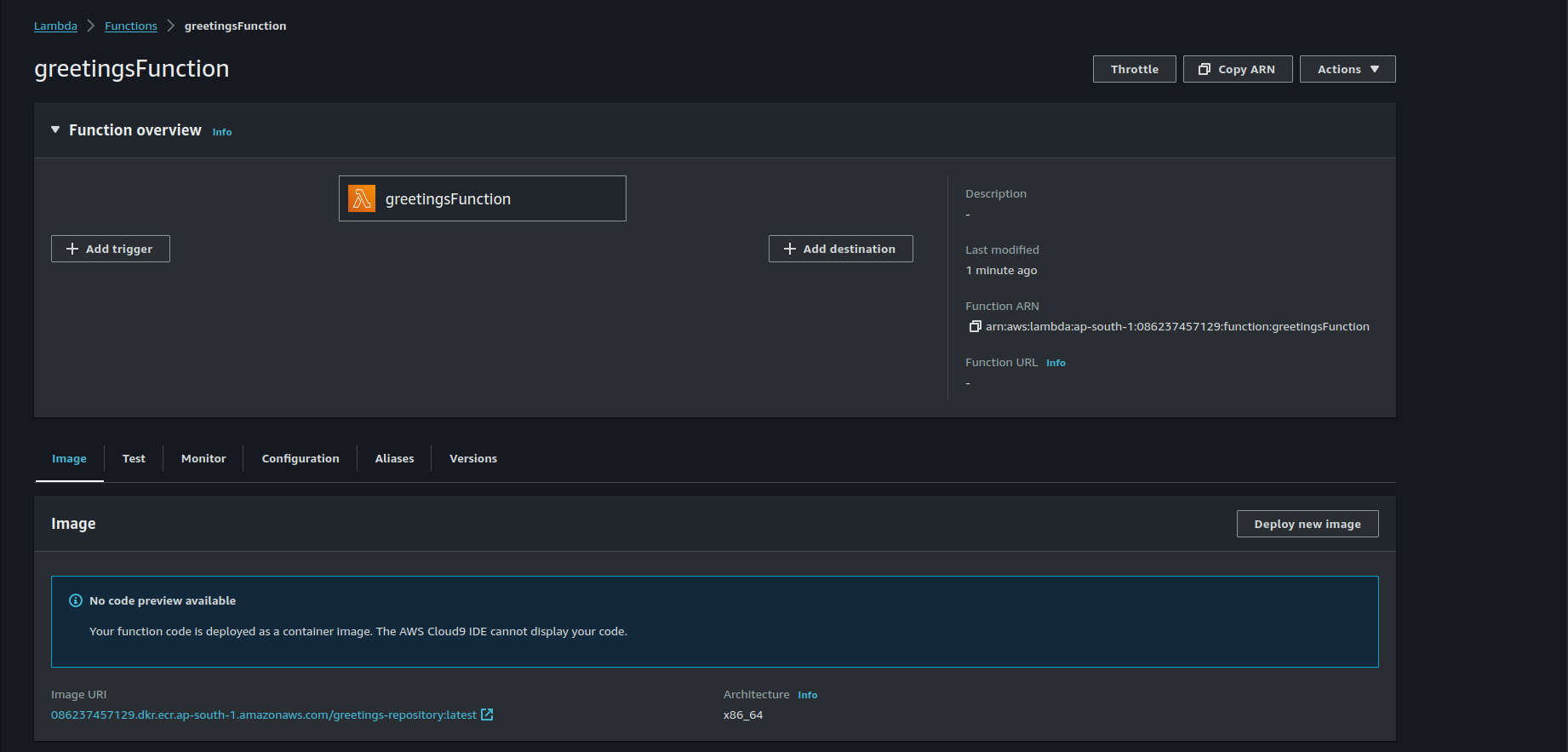
## Testing the lambda function
In case you forgot, our lambda function is extracting a key called `name` from the **event** and returning us a JSON in the form of:
```json
{
"statusCode": 200,
"message": "Hello <name>!"
}
```
To test the function, we will be using the console. Head over to your lambda function and go into the **Test** tab. Scroll down to find a text editor. Paste the following content in there:
```json
{
"name": "John Doe"
}
```
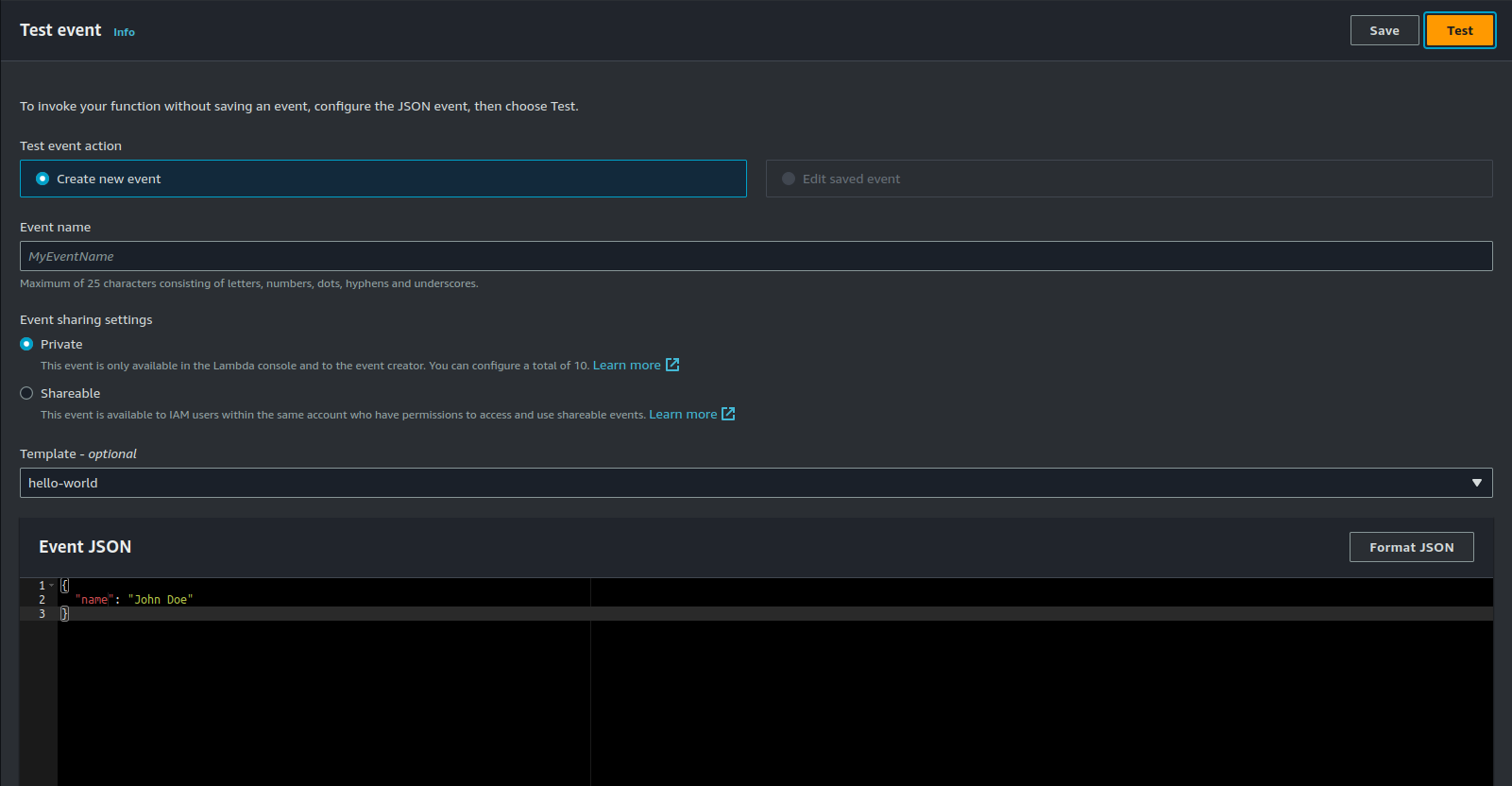
Once satisfied, click on the **Test** button. You should see the following content if your execution was successful:
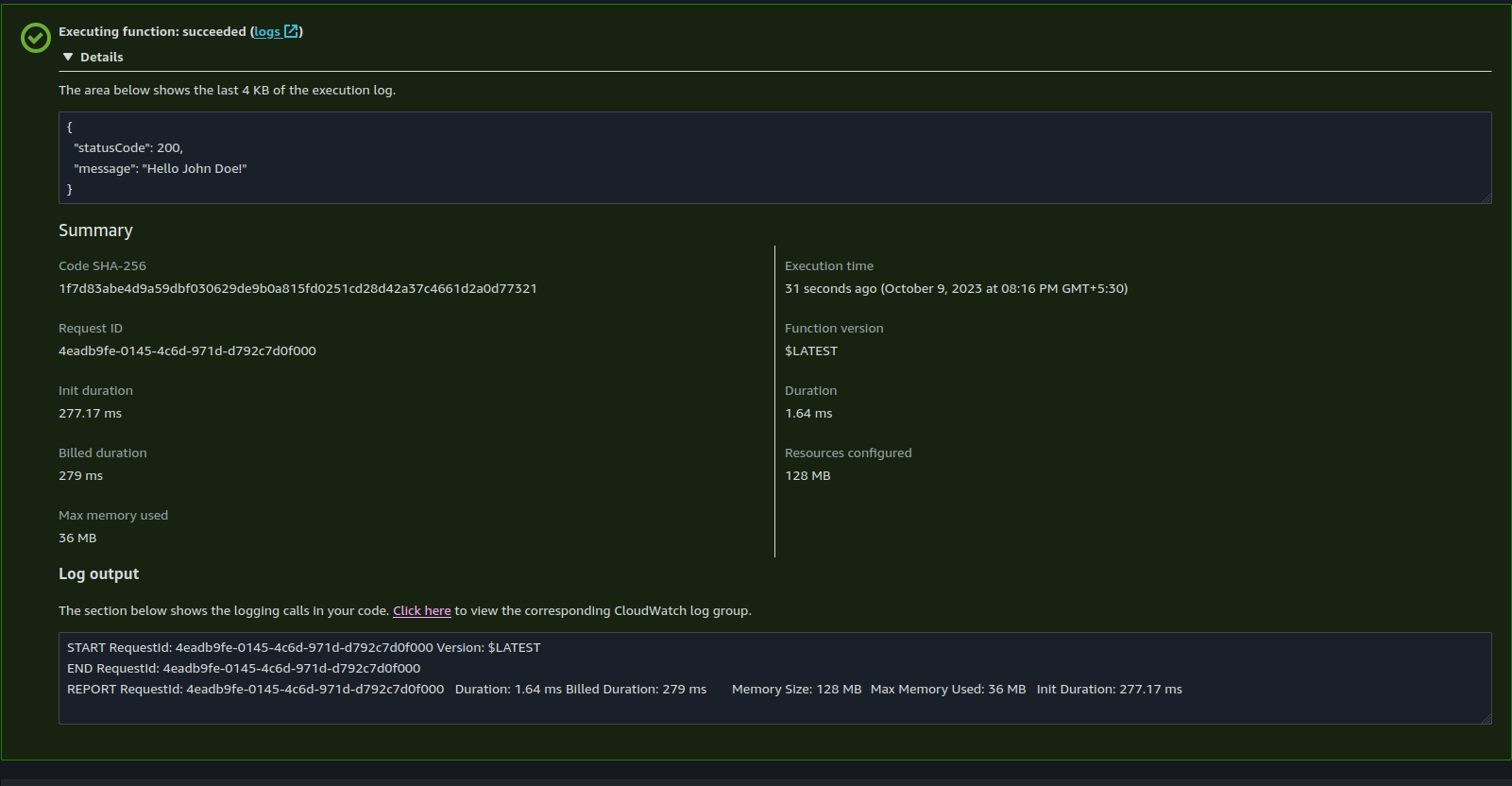
Congrats! You have successfully created a serverless, containerized python application! Don't be so harsh on yourself, give yourself a pat on the back!
## Cleaning up
It's always a good idea to dispose off your resources when you don't need them. Gives us the ability to delete everything with just once command. So, when you feel that your are done playing with, run:
```bash
terraform destroy
```
## Conclusion
In this blog, we had a deep dive into how you can set up your own container, deploy code to lambda, and create a fully managed AWS environment. In the [next part](https://dev.to/thecodersden/automating-python-deployments-with-github-actions-aws-ecr-and-aws-lambda-1d62), we will be looking at setting up a CI/CD pipeline using GitHub Actions that will allow us integrate changes into the lambda function at ease. Till then, happy hacking! | thecodersden |
1,629,409 | Scaling Sidekiq Workers on Kubernetes with KEDA | Horizontal scaling of Rails apps made simple Note: This article was originally published... | 0 | 2023-10-10T04:33:20 | https://dev.to/bgroupe/scaling-sidekiq-workers-on-kubernetes-with-keda-3en2 | kubernetes, rails, cncf, automation | ## Horizontal scaling of Rails apps made simple
_Note: This article was originally published in April, 2020_
## Sidekiq + k8s
Running Rails applications with Sidekiq in Kubernetes allows for the decoupling of background and web processes to take advantage of Kubernetes’ inherent scalability. A typical implementation would look something like this:
```yaml
apiVersion: v1
kind: Secret
metadata:
name: redis-secret
type: Opaque
data:
REDIS_PASSWORD: Zm9vYmFy
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: cool-rails-app-web
labels:
app.kubernetes.io/name: cool-rails-app-web
workload-type: web
spec:
replicas: 2
selector:
matchLabels:
app.kubernetes.io/name: cool-rails-app-web
template:
metadata:
labels:
app.kubernetes.io/name: cool-rails-app-web
spec:
containers:
- name: cool-rails-app
image: bgroupe/cool-rails-app:latest
command: ["bundle"]
args:
- "exec"
- "puma"
- "-b"
- "tcp://0.0.0.0:3000"
- "-t"
- "1:1"
- "-w"
- "12"
- "--preload"
env:
- name: REDIS_HOST
value: redis
- name: REDIS_ADDRESS
value: redis:6379
- name: REDIS_PASSWORD
valueFrom:
secretKeyRef:
name: redis-secret
key: REDIS_PASSWORD
ports:
- name: http
containerPort: 3000
protocol: TCP
livenessProbe:
httpGet:
path: /lbcheck
port: http
readinessProbe:
httpGet:
path: /lbcheck
port: http
imagePullSecrets:
- name: mysecretkey
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: cool-rails-app-sidekiq
labels:
app.kubernetes.io/name: cool-rails-app-sidekiq
workload-type: sidekiq
spec:
replicas: 1
selector:
matchLabels:
app.kubernetes.io/name: cool-rails-app-web-sidekiq
template:
metadata:
labels:
app.kubernetes.io/name: cool-rails-app-sidekiq
spec:
containers:
- name: cool-rails-app
image: bgroupe/cool-rails-app:latest
command: ["bundle"]
environment:
args:
- "exec"
- "sidekiq"
- "-q"
- "cool_work_queue"
- "-i"
- "0"
env:
- name: REDIS_HOST
value: redis
- name: REDIS_ADDRESS
value: redis:6379
- name: REDIS_PASSWORD
valueFrom:
secretKeyRef:
name: redis-secret
key: REDIS_PASSWORD
imagePullSecrets:
- name: mysecretkey
```
[Sidekiq](https://sidekiq.org) is multi-threaded and the default number of threads is 25, which is ample for most use cases. However, when throughput increases, we may need to scale the number of processes out horizontally to leave the currently processing jobs undisturbed. Kubernetes provides the Horizontal Pod Autoscaler controller and resource out-of-the-box to scale pods based on cluster-level metrics collected by enabling the [kube-state-metrics](https://github.com/kubernetes/kube-state-metrics) add-on. It also supports custom metrics by way of adapters, the most popular being the Prometheus adapter. Using this technique, if we wanted to scale our Sidekiq workers based on aggregated queue size we would typically need to:
1. Install and configure Prometheus somewhere.
2. Install and configure a Prometheus Redis exporter pointed to our Sidekiq Redis instance, and make sure it exposes the key and list length for each Sidekiq queue we want to monitor.
3. Install the `k8s-prometheus-adapter` in our cluster and configure it to adapt metrics from our Prometheus server.
4. Deploy an HPA spec with a custom metric targeted at our Prometheus metrics adapter.
As a general rule, it’s wise to set up Prometheus monitoring, but it’s a considerable amount of work, and there are many moving pieces to maintain to achieve the use-case of periodically checking the length of a Redis list.
## Enter: KEDA
[KEDA](keda.sh), or _Kubernetes-based Event Driven Autoscaling_, is a lightweight operator for HPAs that acts as a metrics server adapting a whole host of events from a myriad of data sources. Sidekiq stores enqueued jobs in a Redis list and, luckily, there is a KEDA adapter specifically for scaling based on the length of a [Redis list](https://keda.sh/scalers/redis-lists/). To use KEDA, you create a CRD called a `ScaledObject`, with a dead-simple spec. The KEDA operator generates an HPA targeting your deployment when the `ScaledObject` is registered. These are considerably fewer pieces to achieve the same effect.
KEDA is fairly straightforward to install, and there is very little customization required. I prefer to install with Helm, but you can also install via the manifest examples provided in the KEDA Github repo:
```sh
git clone https://github.com/kedacore/keda && cd keda
kubectl apply -f deploy/crds/keda.k8s.io_scaledobjects_crd.yaml
kubectl apply -f deploy/crds/keda.k8s.io_triggerauthentications_crd.yaml
kubectl apply -f deploy/
```
This will install the operator, register the `ScaledObject` CRD, and an additional CRD called TriggerAuthentication, which is used for providing auth mechanisms to the operator and reusing credentials between `ScaledObjects`.
## The Setup
### Creating the scalers
```yaml
apiVersion: keda.k8s.io/v1alpha1
kind: TriggerAuthentication
metadata:
name: redis-auth
spec:
secretTargetRef:
- parameter: password
name: redis-secret
key: REDIS_PASSWORD
---
apiVersion: keda.k8s.io/v1alpha1
kind: ScaledObject
metadata:
name: sidekiq-worker
labels:
app: cool-rails-app-sidekiq
deploymentName: cool-rails-app-sidekiq
spec:
pollingInterval: 30
cooldownPeriod: 300
minReplicaCount: 1
maxReplicaCount: 10
scaleTargetRef:
deploymentName: cool-rails-app-sidekiq
triggers:
- type: redis
metadata:
address: REDIS_ADDRESS
listName: queue:cool_work_queue
listLength: "500"
authenticationRef:
name: redis-auth
---
```
Let’s say we have a shared Redis database that multiple applications connect to, and this database is protected with a password. Authentication can be provided directly on the `ScaledObject`, but if we store our credentials in a Kubernetes secret, then we can use a `TriggerAuthentication` object to delegate auth and share the same auth mechanism between multiple scaling resources. Here, our `TriggerAuthentication` resource references a secret, called `redis-secret` , which contains a `REDIS_PASSWORD` key, which is basically all we need to authenticate to Redis. In the `ScaledObject`, we reference the `TriggerAuthentication` resource with the `authenticationRef` key.
Now for the `ScaledObject`: KEDA supports scaling both Kubernetes deployment and job resources. Since Sidekiq is run as a deployment, our `ScaledObject` configuration is very simple:
```yaml
# The amount of time between each conditional check of the data source.
pollingInterval: 30
# The amount of time to wait after scaling trigger has fired to scale back down to the minimum replica count.
cooldownPeriod: 300
# The minimum number of replicas desired for the deployment (Note: KEDA supports scaling to/from 0 replicas)
minReplicaCount: 1
#The maximum number of replicas to scale
maxReplicaCount: 10
# The name of the deployment we want to scale.
scaleTargetRef: "deploymentName"
```
The trigger portion contains our data source and scaler type. Here is where you would also be able to add a Redis password for authentication. This is the only tricky part: these sensitive values must be env vars referenced by the container of the target deployment.
```yaml
triggers:
- type: redis
metadata:
address: REDIS_ADDRESS # host:port format
listName: queue:cool_work_queue
listLength: "500"
authenticationRef:
name: redis-auth
```
The key that Sidekiq writes for the queue list is prefixed with `queue`: and the queue name is declared when the Sidekiq process is started. Let’s say our jobs are relatively fast, so we only need to start scaling when our queue hits **500**. List length must be declared as a quoted string or the CRD validations will fail on creation.
Let’s create the CRDs and watch the KEDA operator generate an HPA on our behalf:
```sh
kubectl apply -f scaled-object-with-trigger-auth.yaml
kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
keda-hpa-sidekiq-worker Deployment/cool-rails-app-sidekiq 0/500 (avg) 1 10 1 10s
```
That’s it. We now have an HPA managed by KEDA which will scale our Sidekiq worker on queue length. Any changes to the HPA, like editing the list length, are done by applying the `ScaledObject` — it’s that simple.
## Testing
To see it in action, we can generate load on our Sidekiq instance using a fake job. Our job will be acked, and then will sleep a random amount of time and print a message.
```ruby
class AckTest
include Sidekiq::Worker
include Sidekiq::Lock::Worker
sidekiq_options :queue => :cool_work_queue
def perform(msg)
puts "ACK:"
sleep rand(180).to_i
puts "MSG: #{msg}"
end
end
```
To run this, open a Rails console in your web pod and paste the class definition. Then enqueue a large number of them:
```ruby
1000.times { AckTest.perform_async("Let's scale up") }
```
Within the 30 second interval provided, you should see the HPA fire up a handful of extra Sidekiq pods which should start pulling work off of the queue. If the work is not performed by the end of the cool-down period (in this case, 5 minutes), then the additional pods will remain for 5 more minutes until the queue is polled by KEDA again.
## Tuning
Now that we can spin up Sidekiq workers roughly based on throughput, we now have a situation where our worker pods will be spinning up and tearing down dynamically. The algorithm used by the HPA for scaling is as follows:
```
desiredReplicas = ceil[currentReplicas * ( currentMetricValue / desiredMetricValue )]
```
It stands to reason that depending on how long the average job takes to complete, as the queue drains, the HPA will begin scaling workers back down. To ensure that we are not terminating processes in the middle of performing work, we need to add some buffer time to the shutdown. We have a couple of options:
1. We can wait an arbitrary amount of time for the worker to finish processing before receiving a SIGTERM. This is achieved by adding a terminationGracePeriodSeconds field on the deployment spec, and using our best guess to determine how long to delay the termination signal.
2. The preferable option is to delegate shutdown to Sidekiq’s internal mechanism. In Kubernetes, this is done by adding a pre-stop hook. We can tell a Sidekiq process to stop accepting jobs from the queue and only attempt to complete the jobs it is currently performing for a given amount of time. We can also abide by a work timeout set on the OS level of the container on startup.
Our deployment previously started Sidekiq like this:
```yaml
spec:
containers:
- name: cool-rails-app
image: bgroupe/cool-rails-app:latest
command: ["bundle"]
args:
- "exec"
- "sidekiq"
- "-q"
- "cool_work_queue"
- "-i"
- "0"
```
We need to add a few more options. The first is the timeout option to specify how long we should allow our workers to finish jobs when shutting down. Let’s set it to 60 seconds. The second option is a pidfile path. Since we only one run Sidekiq process per container, specifying the name and path of the pidfile allows us to reference it later in shutdown process without having to search the file system.
```yaml
...
- "-P"
- "/tmp/sidekiq.pid"
- "-t"
- "60"
```
Let’s add the pre-stop hook, under the `lifecycle` options of the container spec:
```yaml
spec:
containers:
- name: cool-rails-app
image: bgroupe/cool-rails-app:latest
lifecycle:
preStop:
exec:
command:
- "sidekiqctl"
- "stop"
- "/tmp/sidekiq.pid"
- "120"
```
The final argument supplied to the sidekiqctl stop command is the _kill_timeout_, which is the overall timeout that stops the Sidekiq process. This obviously needs to be longer than the timeout option supplied at startup, or else the process will be killed while the jobs are still working. In this example, we’ve set it to twice the amount of the timeout (which also happens to be the default Kubernetes termination grace period). Now we can ensure that we are allowing the maximum amount of time for work to be completed. If your app has long-executing jobs, then you can tweak these timeouts as you see fit. From the Sidekiq docs:
_Any workers that do not finish within the timeout are forcefully terminated and their messages are pushed back to Redis to be executed again when Sidekiq starts up._
## Epilogue
Many other asynchronous work queues inspired by Sidekiq utilize Redis list-based queues in a similar fashion, making this scaling pattern applicable outside of a Rails context. In recent versions, a more specific metric for determining worker throughput called “queue latency” was made available. It works by determining the amount of time the oldest job in the queue was enqueued, giving a better idea of how long jobs are taking to complete. To determine this value, some computation is required, making this particular pattern we’ve just implemented an insufficient one. Luckily, KEDA supports writing custom scaler integrations, and rolling your own is fairly straightforward. I will cover building this scaler in a future article.
KEDA is a wonderfully simplified framework for leveraging Kubernetes autoscaling features and supports a whole host of other event sources. Give it a try.
| bgroupe |
1,629,474 | Normalise array in Rails 7.1 | How to normalise an array in Ruby on Rails 7.1 | 0 | 2023-10-10T06:07:32 | https://dev.to/jorgealvarez/normalise-array-in-rails-71-afd | ruby, rails, postgres, programming | ---
title: Normalise array in Rails 7.1
published: true
description: How to normalise an array in Ruby on Rails 7.1
tags: #ruby, #rails, #postgres, #programming
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 for best results.
# published_at: 2023-10-10 06:03 +0000
---
One of the (many) good features of Rails 7.1 is the `normalizes` method. This is how you can use it with fields of type array.
In this example there is a field called folders that we want to normalise removing blank entries and ensuring all entries are down cased.
```ruby
normalizes :folders, with: ->(values) { (values || []).map(&:downcase).reject(&:blank?) }
```
| jorgealvarez |
1,629,667 | VSCode Extension - Doc Tab: edit the doc comments in a new tab | "Doc Tab" is a Visual Studio Code extension that allows you to edit the doc comments in a new tab. | 0 | 2023-10-10T08:44:00 | https://dev.to/vdustr/doc-tab-308 | vscode, jsdoc, tsdoc, extension | ---
title: VSCode Extension - Doc Tab: edit the doc comments in a new tab
published: true
description: "Doc Tab" is a Visual Studio Code extension that allows you to edit the doc comments in a new tab.
tags: vscode, jsdoc, tsdoc, extension
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/p63zhi1x31yn0opyfuut.jpg
published_at: 2023-10-10 16:44 +0800
---
"Doc Tab" is a Visual Studio Code extension that allows you to edit the doc comments in a new tab.

## The Problem
Editors like VSCode support markdown preview for JSDoc / TSDoc, but it's often challenging to edit, format, and indent it within the comment block. This extension is designed to assist in editing doc comments in a new tab, providing the benefits of specific language features such as Markdown's syntax highlighting, intelligence, linting, and formatting.
## Setup
You can install the VSCode extension from the [Visual Studio Marketplace](https://marketplace.visualstudio.com/items?itemName=VdustR.doc-tab) or check out the source code from [my GitHub repository](https://github.com/VdustR/doc-tab).
## Usage
1. Choose or position the cursor within the documentation comment block.
2. Access the command palette:
- `Ctrl+Shift+P` on Windows/Linux
- `Cmd+Shift+P` on macOS
3. Enter `Doc Tab: Edit Comment In New Tab` and hit `Enter`.
4. Modify the documentation comment in the new tab.
5. Close the tab without saving to discard any alterations.
6. The changes will be applied to the documentation comment block. 🎉🎉
## Recommended Workflow
1. Format the code (using eslint, prettier, etc.).
2. Edit the documentation comments in a new tab. It's advisable to [preview](https://code.visualstudio.com/docs/languages/markdown#_markdown-preview) while editing.
3. Format the code in the new tab.
4. Close the tab without saving.
5. Format the code once again.
6. Reformat the documentation comments (using [Rewrap](https://marketplace.visualstudio.com/items?itemName=stkb.rewrap)).
{% youtube mC6cOQaAY-A %}
## Recommended Extensions for Combined Use
- [Prettier](https://marketplace.visualstudio.com/items?itemName=esbenp.prettier-vscode)
- [eslint-stylistic](https://github.com/eslint-stylistic/eslint-stylistic)
- [Rewrap](https://marketplace.visualstudio.com/items?itemName=stkb.rewrap)
Please feel free to file any issues or pull requests if you encounter any problems or have ideas. Thank you very much.
| vdustr |
1,629,934 | What is Embedding? Generating Embedding using Supabase | Natural Processing Language(NLP) is the process by which a machine tries to understand, interpret,... | 0 | 2023-10-10T12:44:49 | https://dev.to/surajondev/what-is-embedding-generating-embedding-using-supabase-4pnl | webdev, javascript, programming, beginners | Natural Processing Language(NLP) is the process by which a machine tries to understand, interpret, and generate meaningful human language. The text-generating model that we used in the form of ChatGPT uses this model to process the language as machines cannot understand direct human language. The rise of NLP is surely going to rise in the future to generate a much better response.
In this, there is various principle that deals runs behind such as Tokenization, Parsing, Semantic Role Labeling, etc. One of these is Word embedding. This is a technique that represents words as multidimensional vectors in continuous vector space. This embedding is very useful in enhancing the working of any NLP model.
So, today we are going to learn more about embedding. The topics that we are going to discuss are:
- What is Embedding?
- Use case of Embeddings
- Generating Embedding in Supabase’s edge function
- Storing embedding in Supabase as pgvector
I hope this excites you in learning more about word embeddings.
## Word Embedding
As we discuss in the introduction it is a technique that is used to represent words in multi-dimensional vector format. Each word is given a numeric value in terms of vectors. These vectors capture the relationship between words based on their context in the large corpus of text. Embeddings have become a fundamental part of any NLP model. It helps in enhancing the performance while running queries.
Let’s take an example of embedding to understand it better. Here are three sentences:
1. "The cat chased the mouse."
2. "The dog barked at the cat."
3. "The mouse ran away."
A two-dimensional vector embedding can be created with the following output:
- "cat" -> [0.9, 0.2]
- "dog" -> [0.8, 0.3]
- "mouse" -> [0.1, 0.9]
- "chased" -> [0.7, 0.4]
- "barked" -> [0.6, 0.5]
- "ran" -> [0.2, 0.8]
- "the" -> [0.0, 0.0] common words like "the" often have near-zero vectors
## Use Case of Embedding
There are various use cases for embedding few of them are:
- **Semantic Understanding**: As the words in embedding encode in the relation between the words. Similar words have vectors that are close in embedding space. This semantic understanding will be useful in tasks like synonym identification, and word analogy.
- **SentimentAnalysis**: It can also be useful in understanding the sentiments of the words. The tone in which the words are written. Helpful in identifying the emotional value of a sentence. It can also help in improving the tone of the given sentence as per the requirement like in Grammarly.
- **Language Translation**: With embedding, translating words from one language to another can be done easily. It can give similar words in different languages with similar vector values.
- **Information Retrieval:** Word embeddings improve search engines by understanding the semantic similarity between user queries and documents in a corpus. It will be helpful in retrieving useful data from the large data set for further processing.
Word embedding can be further used in various fields to process the text document. With fine-tuning the model it can give better results. There are various models that are pre-trained on data to provide embeddings. These platforms can be Openai embedding, transformer.js embedding, FastText, etc.
## Generating Embedding using Supabase
[Supabase](https://supabase.com/) is a powerful backend-as-a-service platform that allows developers to easily build scalable web applications with serverless functions and a PostgreSQL database. Recently they introduced the support of transformers.js. It is designed to be functionally equivalent to Hugging Face’s transformers Python library for nodeJS and deno.
This support of transformers.js is available in the edge function of supabase. Edge functions are implemented on the basis of FasS to run functions to perform tasks. This helps in achieving the serverless architecture. These functions run in a demo environment. We can perform a variety of tasks using this edge function. You can learn more about the edge function from [here](https://supabase.com/docs/guides/functions).
We are going to build a React application that sends requests to the edge function to convert given text into embedding. This embedding then gets stored in the supabase database. So, let’s get started.
## Building the react application
We are going to use CRA for using React. You can use also use other React frameworks. There won’t be much difference.
Install React with the following command:
```powershell
npx create-react-app embeddings
```
> Note: To use the above command and further commands, you need to have [nodejs](https://nodejs.org/en/) pre-installed.
Clean up the unnecessary code. Now, it’s time to install the necessary libraries. Here are those:
- **@supabase/supabase-js:** JavaScript library for handling requests to Supabase.
```powershell
npm i @supabase/supabase-js
```
## Adding a project to Supabase
First, let’s set up our project on the supabase dashboard. Visit [supabase.com](https://supabase.com/) then click on `Start your project` from the right of the nav bar. This will take you to the sign-in page. Enter your details for sign-in or sign-up as you require. After logging in, you will be redirected to the project page. From here, click on `New Project` to create a project. On the Create New Project page, you will be asked to enter details of your project.
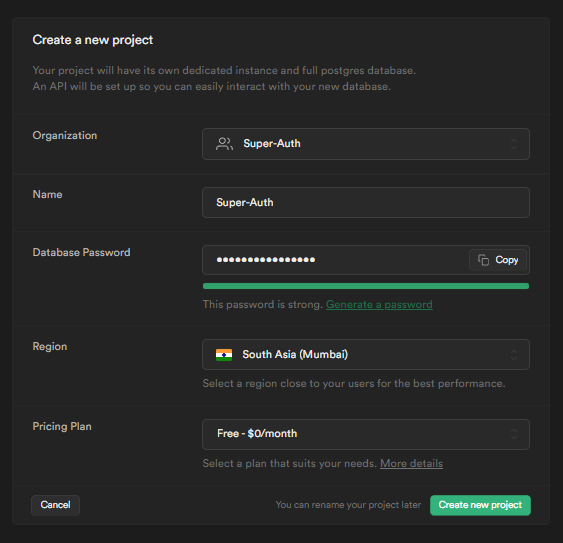
Fill in the details of your project. Enter the project’s name as per your choice. For passwords, you can use the `Generate a password` for generating password. Select the region that is nearest to the user of your project. In the free tier, you can create two projects. After filling in the details, click on `Create new project`. It will take a few minutes to set up the project.
## App.js
Here is the code for the App.js. Each step has comments to explain it.
```javascript
import "./App.css";
import { useState } from "react";
import { createClient } from "@supabase/supabase-js";
// Create a single supabase client for interacting with your database
const supabase = createClient(
SUPABASE_URL,
SUPABASE_ANON_KEY,
);
function App() {
// storing data in state
const [inputData, setInputData] = useState(null);
const [embedData, setembedData] = useState(null);
//making call to edge function to create embeddings
const handleEmbed = async () => {
const { data, error } = await supabase.functions.invoke(
"create-embeddings",
{
body: { input: inputData },
}
);
if (error) {
console.log(error);
} else {
setembedData("Embed successfully stored");
}
};
return (
<div className="App">
<h1>Generate Embeddings</h1>
<input type="text" onChange={(e) => setInputData(e.target.value)} />
<br />
<button onClick={handleEmbed}>Run Embed</button>
{embedData && <p>{embedData}</p>}
</div>
);
}
export default App;
```
`SUPABASE_URL` and `SUPABASE_ANON_KEY` are secrets that can be found in the Supabase App dashboard. Go to Project Setting → API, you will find it there.
## Edge Function
As in the App.js, we are making a call to the edge function. Now it’s time to create the edge function. Before writing code for the edge function, we need to install the Supabase CLI for managing the creating, running, and deploying of the edge function. It is easy to install the CLI. Follow the below steps to install it.
1. Run the below command to install:
```powershell
npm i supabase --save-dev
```
> Note: Node and NPM should be pre-installed to run the command.
2. Now, we need to log in to the subbase in the CLI. To run any supabase command just prefix it with npx supabase then command. So for login here it is:
```powershell
npx supabase login
```
This will ask for the access token. You can generate an access token from [here](https://supabase.com/dashboard/account/tokens) for your project. Enter that token in the asked input.
3. Now, let's go to the project directory where you want to write code for your function. In the root directory, run the below command to initialize the supabase.
```powershell
npx supabase init
```
4. After this at last we just need to provide the reference URL of your project from supabase. Here is the command for it:
```powershell
npx supabase link --project-ref your-project-ref
```
Change the <your-project-ref> to your project reference. You can get the project reference URL from the Supabase's setting→ API.
## Writing the Edge Function for creating Embedding
For writing the function, first, we need to create a file for writing the function. You can create the function with the Supabase CLI. Here are the commands:
```powershell
npx supabase functions new create-embeddings
```
This will create a file in the supabase→function→create-embeddings with the index.ts. You can write your function in the index.ts file. Below is the code for the `create-embeddings`.
```javascript
import { serve } from "https://deno.land/std@0.168.0/http/server.ts";
import {
env,
pipeline,
} from "https://cdn.jsdelivr.net/npm/@xenova/transformers@2.5.0";
import { supabaseClient } from "../_shared/apiClient.ts";
import { corsHeaders } from "../_shared/cors.ts";
// Configuration for Deno runtime
env.useBrowserCache = false;
env.allowLocalModels = false;
const pipe = await pipeline("feature-extraction", "Supabase/gte-small");
serve(async (req) => {
// This is needed if you're planning to invoke your function from a browser.
if (req.method === "OPTIONS") {
return new Response("ok", { headers: corsHeaders });
}
try {
// Extract input string from JSON body
const { input } = await req.json();
// Generate the embedding from the user input
const output = await pipe(input, {
pooling: "mean",
normalize: true,
});
// Extract the embedding output
const embedding = Array.from(output.data);
const { data, error } = await supabaseClient
.from("documents")
.insert({ text: input, embedding: embedding });
if (error) {
throw error;
}
return new Response(JSON.stringify("Vector stored Successfully!"), {
headers: { ...corsHeaders, "Content-Type": "application/json" },
status: 200,
});
} catch (error) {
return new Response(JSON.stringify({ error: error.message }), {
headers: { ...corsHeaders, "Content-Type": "application/json" },
status: 400,
});
}
});
```
Supabase uses the Transformer.js for creating the embeddings. The below code form the app did the generating the embeddings and extracting the output:
```javascript
// Generate the embedding from the user input
const output = await pipe(input, {
pooling: "mean",
normalize: true,
});
// Extract the embedding output
const embedding = Array.from(output.data);
```
After this, we are storing the original text and embeddings into the supabase database with the table name documents. Embedding cannot be stored in plain text. It requires a special data type vector with a parameter as the dimension of the vector. Run the below command in the SQL Editor from the supabase project dashboard to create a table to store database.
```sql
-- Enable the pgvector extension to work with embedding vectors
create extension vector;
-- Create a table to store your documents
create table posts (
id serial primary key,
title text not null,
embedding vector(384)
);
```
In the code, you can find the two imports i.e, CORS and supabaseClient. CORS is for allowing invoking of the function from the browser and supabaseClient is for using supabase functionality in the edge function. Both these are stored in the `_shared` directory in the function. Here are the code for both of this
**cors.ts**
```javascript
export const corsHeaders = {
"Access-Control-Allow-Origin": "*",
"Access-Control-Allow-Headers":
"authorization, x-client-info, apikey, content-type",
};
```
**apiClient**
```javascript
import { createClient } from "https://esm.sh/@supabase/supabase-js@2";
export const supabaseClient = await createClient(
Deno.env.get("SUPABASE_URL") ?? "",
Deno.env.get("SUPABASE_ANON_KEY") ?? ""
);
```
You can directly get the Supabase secret directly in the deno environment for edge functions such as URL and ANON_KEY.
After writing the edge function makes sure to deploy it to the supabase with the below code:
```powershell
npx supabase functions deploy
```
## Testing the Application
If you run the react application and there are no error then you will find the below output screen:

Now, if you enter some input in the text field and click the `Run Embed` button then it will invoke the edge function. On successful, storing the embed it will display the message `Embed successfully stored` as you can see in the below output.
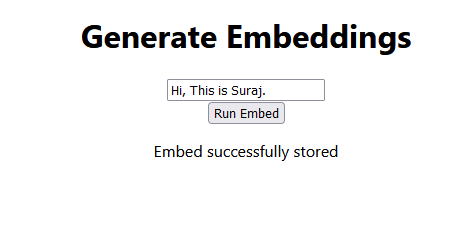
You can check the embedding from the supabase dashboard. Navigate to Table Editor → name of the table. You can find the embedding there.
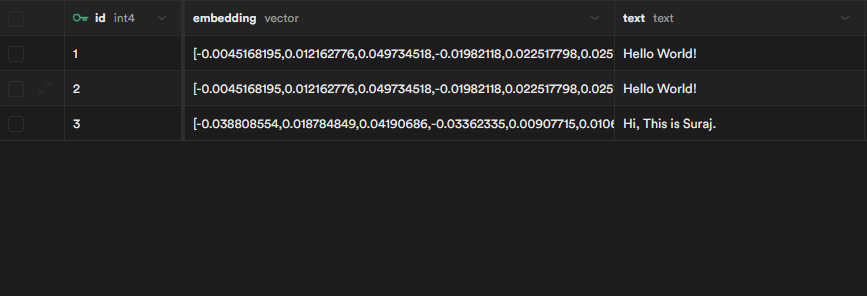
## Things to add to the project
I would love to create more content on embedding in using it for performing different tasks. Meanwhile, you can add more to the project by adding these functionalities:
- Running query search to extract useful information from the embedding
- Making GPT call on the retrieval data
I will try to cover these topics in the upcoming articles. So, make sure to follow the blog for further content.
## Conclusion
Word embeddings are a powerful tool in natural language processing (NLP) that helps machines understand and work with human language more effectively. They encode semantic relationships between words, enabling various NLP tasks such as sentiment analysis, language translation, and information retrieval. Supabase's edge functions in conjunction with the Transformer.js library to generate and store embeddings, which can be a valuable addition to any NLP project.
With the use of Supabase, you can create a serverless application with ease as they provide the tool to achieve it with an Auth, database, storage, and edge functions for FaaS architecture.
I hope this article has helped you in learning embeddings and a method to generate embedding. Thanks for reading the article.
| surajondev |
1,630,111 | Ownership - It's Importance in Software Engineering | A good software engineer's most important skill is ownership Ownership is one thing I've learnt by... | 0 | 2023-10-10T14:48:44 | https://dev.to/gauravsingh9356/ownership-its-importance-in-software-engineering-34bo | softwareengineering, webdev, community, software | A good software engineer's most important skill is ownership
Ownership is one thing I've learnt by hustling in startups!
And ownership doesn't just means to get the job done! 🙅♂️
Its about treating the product as your own, not just thinking about its development, but how you can improve the architecture, how can you improve the performance, and also how can you improve the product as a whole!
Thinking about new features.
Thinking about improving user experience.
Thinking about increasing user retension!
I love the Amazon's "Customer Obsession" principle, I truly believe it's one of the most important principle which separates good engineers from great one's!
One tip to improve your "Product Engineering" skills: Remove the concept of tech & implementation from your head before you think about a product, don't think about how complex it will be, is it feasible or not, just think about the best product you can!
Everything can be built by great engineers :)
| gauravsingh9356 |
1,630,789 | What Movie or Book Still Holds a Special Place in Your Heart? | Media and pop culture have a significant impact on our childhood perceptions and adult lives. Is... | 0 | 2023-10-29T00:00:00 | https://dev.to/codenewbieteam/what-movie-or-book-still-holds-a-special-place-in-your-heart-4ie6 | discuss, codenewbie, beginner | ---
published_at : 2023-10-29 00:00 +0000
---
Media and pop culture have a significant impact on our childhood perceptions and adult lives. Is there a movie, book, or TV show from your childhood that still holds a special place in your heart? How has it influenced your values or interests as an adult?
Follow the [CodeNewbie Org](https://dev.to/codenewbieteam) and [#codenewbie](https://dev.to/t/codenewbie) for more discussions and online camaraderie!
*{% embed* https://dev.to/codenewbieteam *%}* | sloan |
1,630,790 | One-week Career Swap: What Would You Do? | If you could change careers for just one week, stepping into a completely different professional... | 0 | 2023-10-30T00:00:00 | https://dev.to/codenewbieteam/one-week-career-swap-what-would-you-do-fa | discuss, codenewbie, beginner | ---
published_at : 2023-10-30 00:00 +0000
---
If you could change careers for just one week, stepping into a completely different professional world, what role or job would you choose to experience?
Follow the [CodeNewbie Org](https://dev.to/codenewbieteam) and [#codenewbie](https://dev.to/t/codenewbie) for more discussions and online camaraderie!
*{% embed* https://dev.to/codenewbieteam *%}* | sloan |
1,646,762 | Ansible - Part 2 | Playbook Using VARIABLES No special characters Avoid CAPS. '_' Allowed Case... | 0 | 2023-10-26T04:00:40 | https://dev.to/technonotes/ansible-part-2-3c8e | ### Playbook Using VARIABLES
1. No special characters
2. Avoid CAPS.
3. '_' Allowed
4. Case Sensitive
5. DOT(.) not allowed
> Make sure the **_Ansible_** Folders are outside the /etc
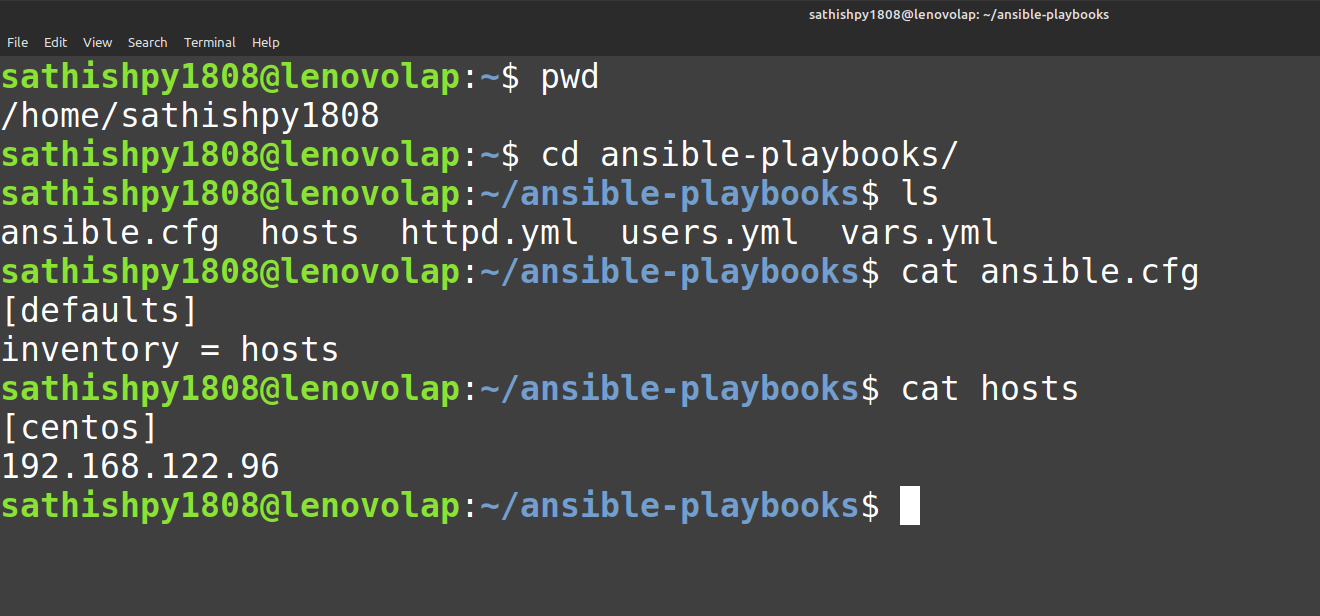
> **Using Variables - Installation of HTTPD & Firewalld**
- Create the yaml file with below details,
```
cat httpd.yml
---
- name: deploy and start httpd service
hosts: centos
become: true
vars:
web_pkg: httpd
firewall_pkg: firewalld
web_service: httpd
firewall_service: firewalld
rule: http
tasks:
- name: required packages installed and up to date
yum:
name:
- "{{ web_pkg }}"
- "{{ firewall_pkg }}"
state: latest
- name: The {{ firewall_service }} service is started
service:
name: "{{ firewall_service }}"
enabled: true
state: started
- name: The {{ web_service }} service is started
service:
name: "{{ web_service }}"
enabled: true
state: started
- name: web content is in place
copy:
content: <h1> Devops team </h1>
dest: /var/www/html/index.html
- name: firewall port for {{ rule }} opened
firewalld:
service: "{{ rule }}"
permanent: true
immediate: true
state: enabled
```
**_become: true --> run as root
rule --> defined for PORT_**
> **Check whether the playbook is correct , its like to validate before the RUN. This is called DRYRUN.**
```
ansible-playbook httpd.yml --check
```
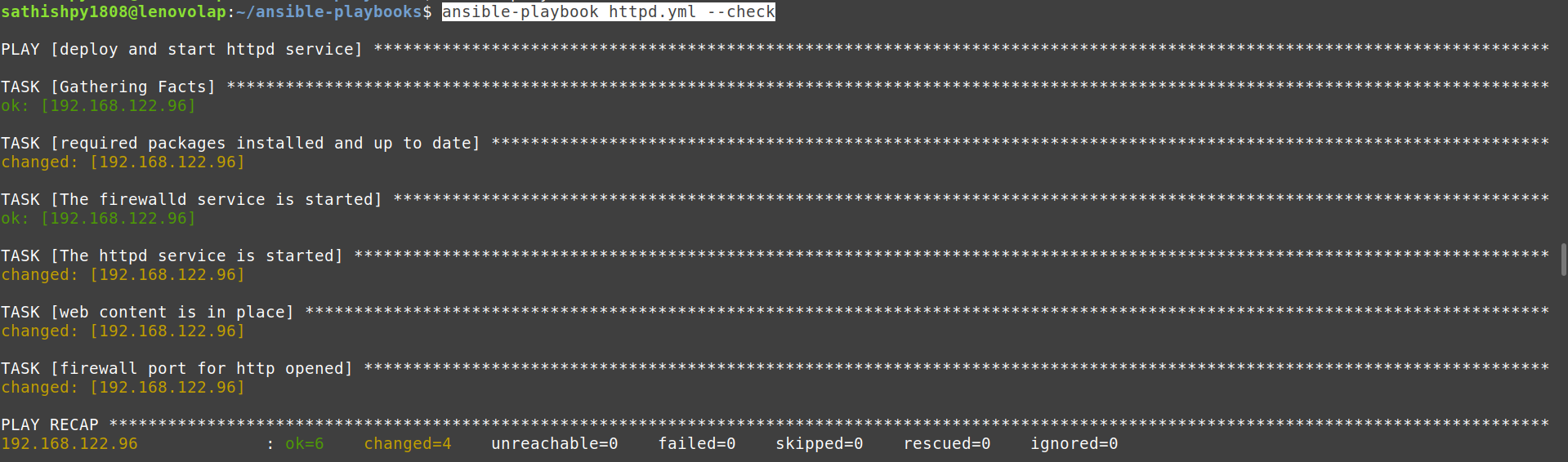
> **Actual run is below with verbose output**
```
ansible-playbook httpd.yml -vvv
```
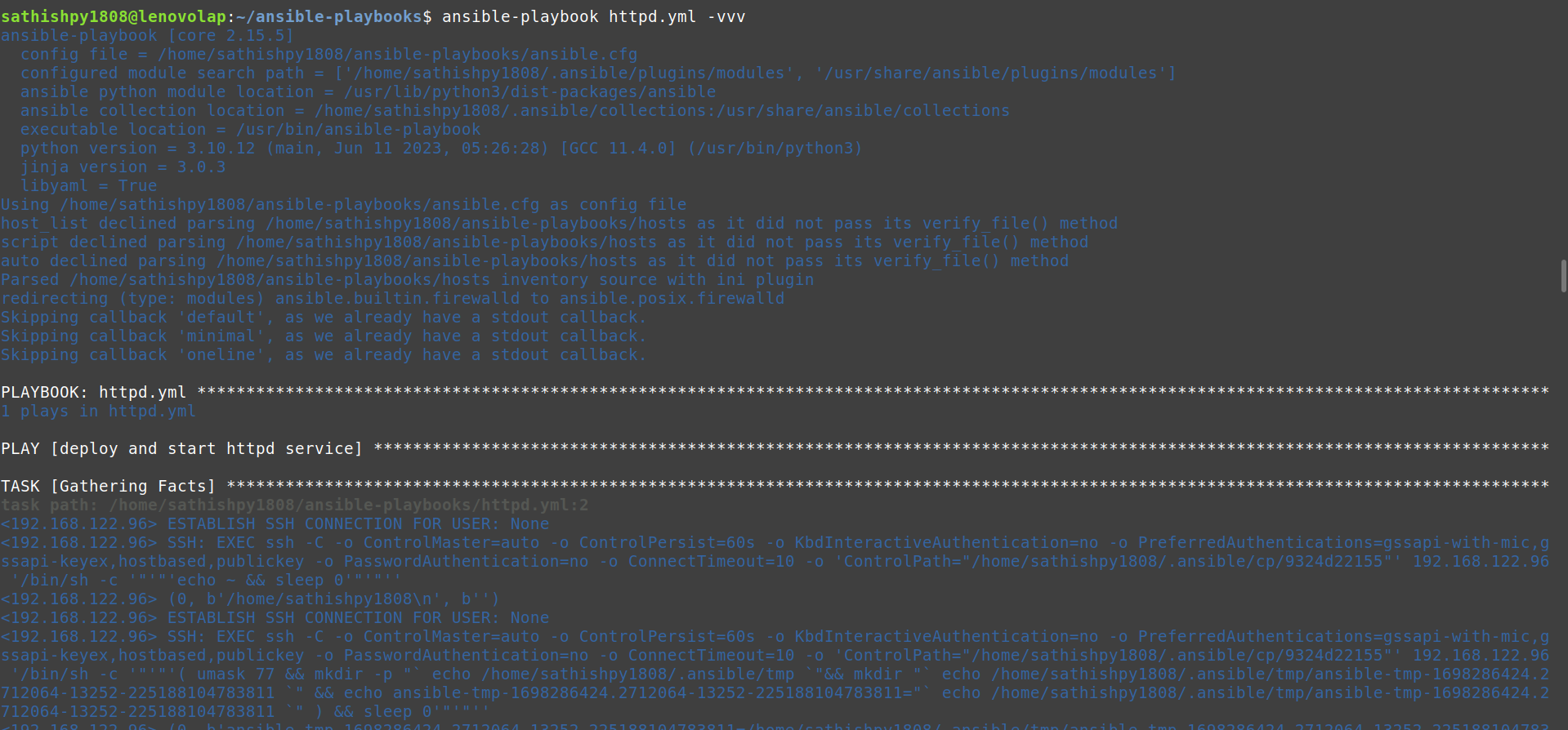
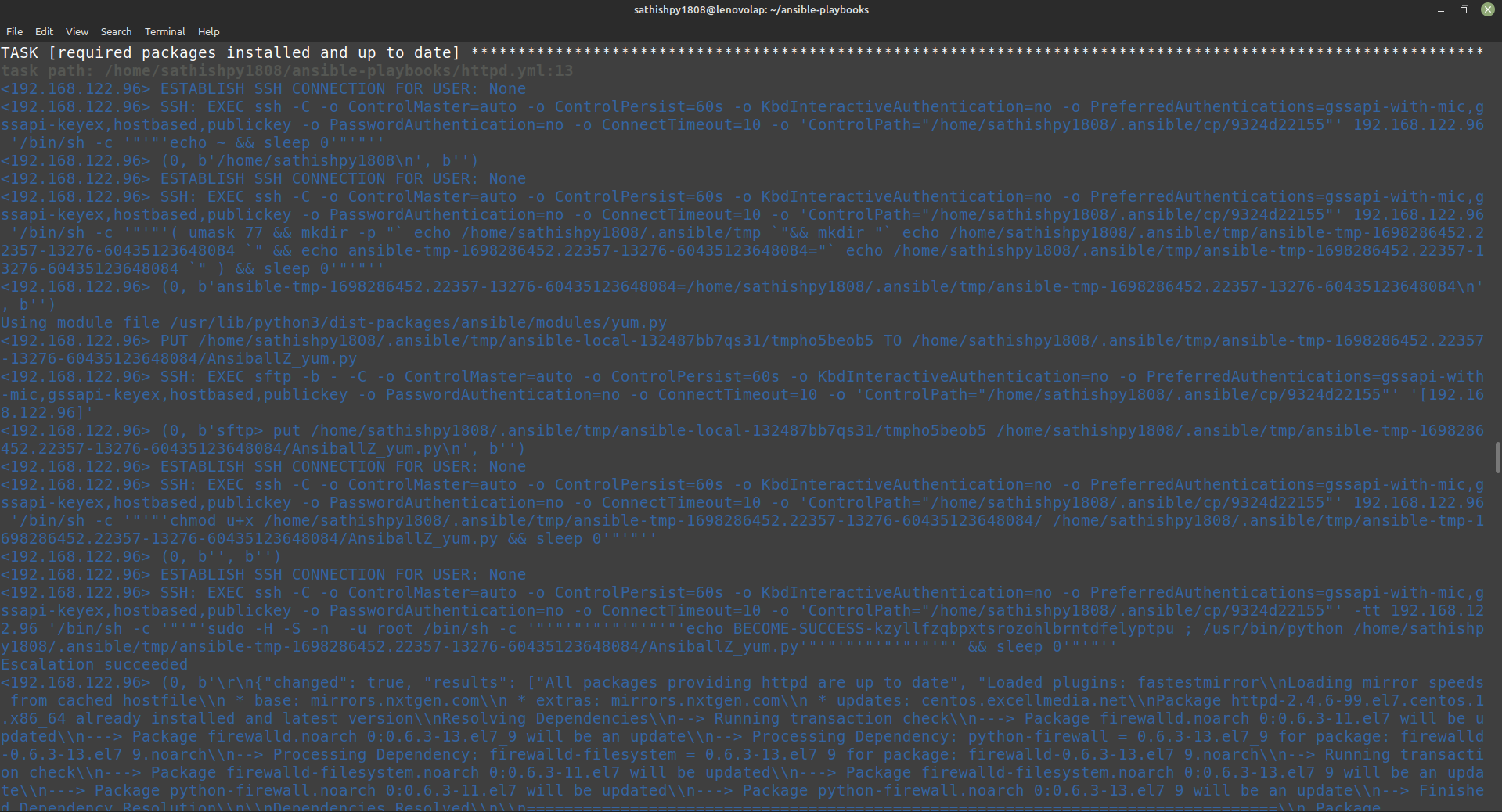
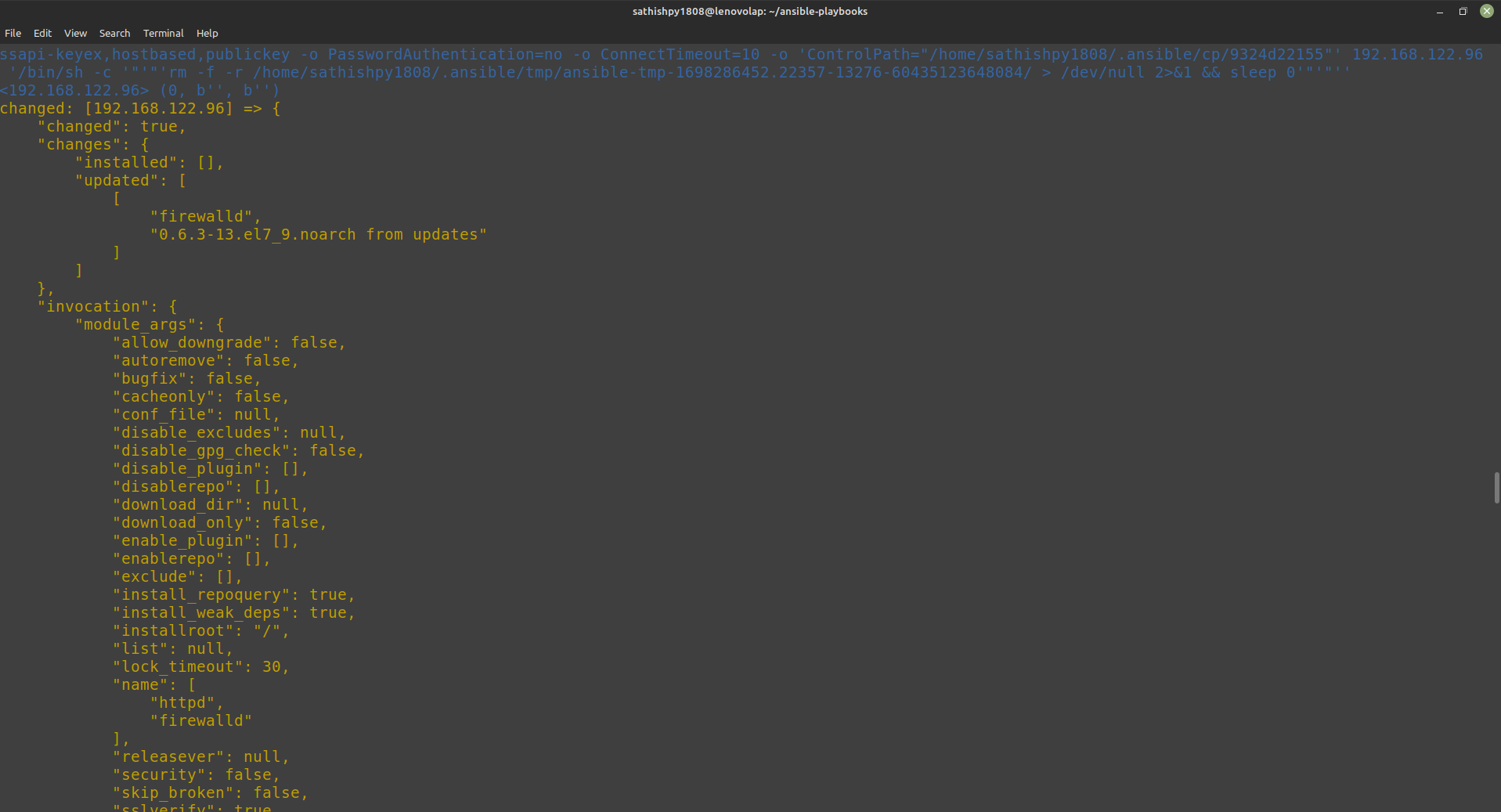
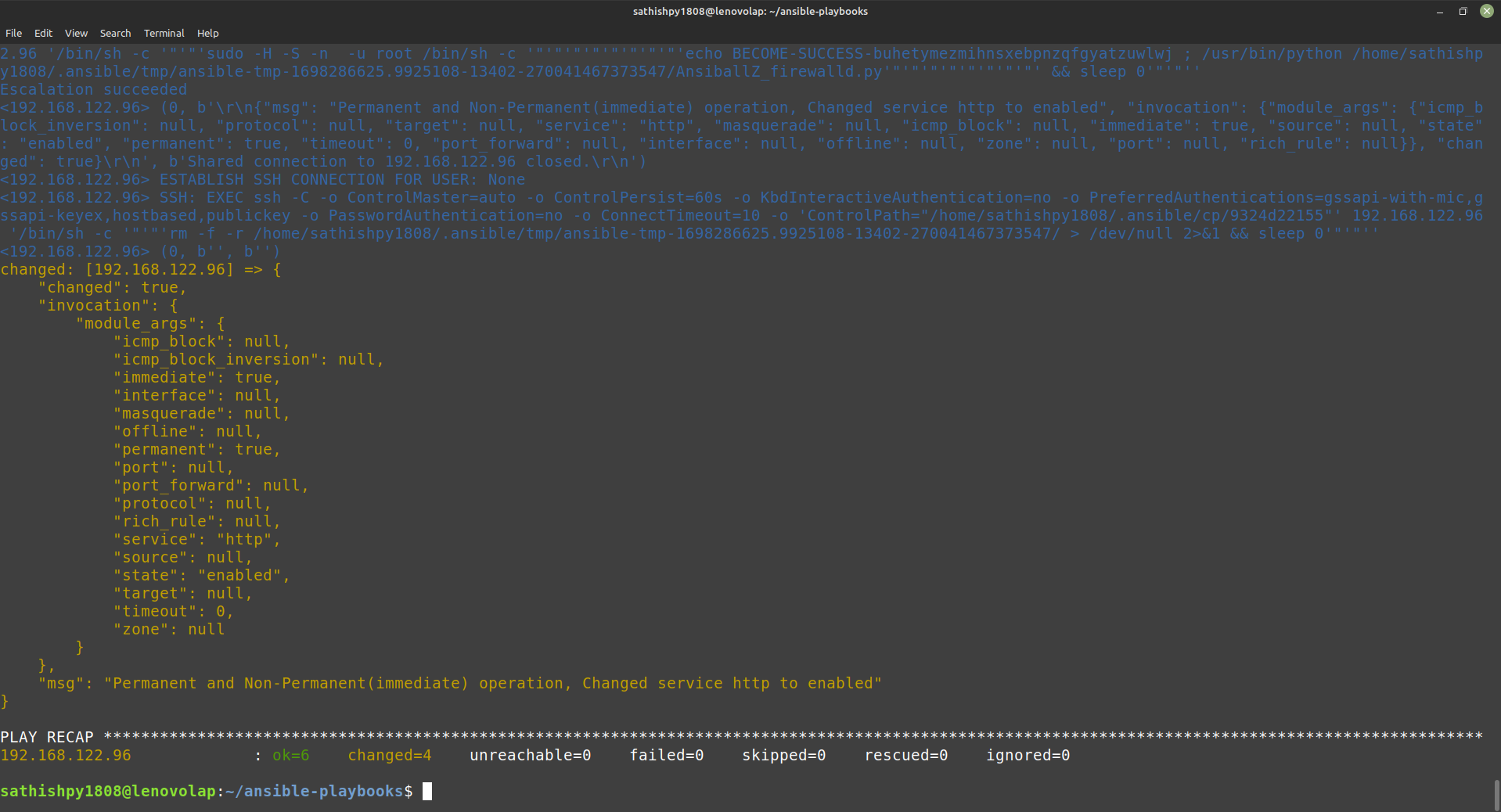
- Desired output
> **Now LETS create a users using file and variable declaration**
```
cat vars.yml
user_details:
- {name: 'user3', uid: 1007}
- {name: 'user4', uid: 1008}
```
```
cat users.yml
---
- hosts: centos
become: true
vars_files:
- /home/sathishpy1808/ansible-playbooks/vars.yml
tasks:
- name: add several users
user:
name: "{{ item.name }}"
uid: "{{ item.uid }}"
state: present
with_items: "{{ user_details }}"
```
```
ansible-playbook users.yml -e @/home/sathishpy1808/ansible-playbooks/vars.yml --check
or
ansible-playbook users.yml --check
ansible-playbook users.yml -e @/home/sathishpy1808/ansible-playbooks/vars.yml -vvv
or
ansible-playbook users.yml -vvv
```
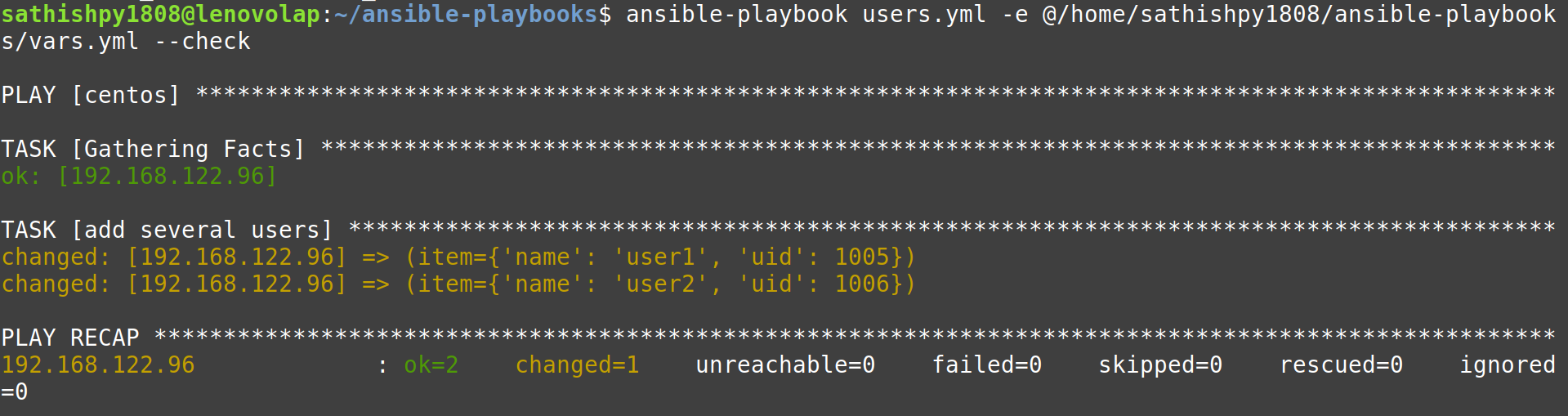
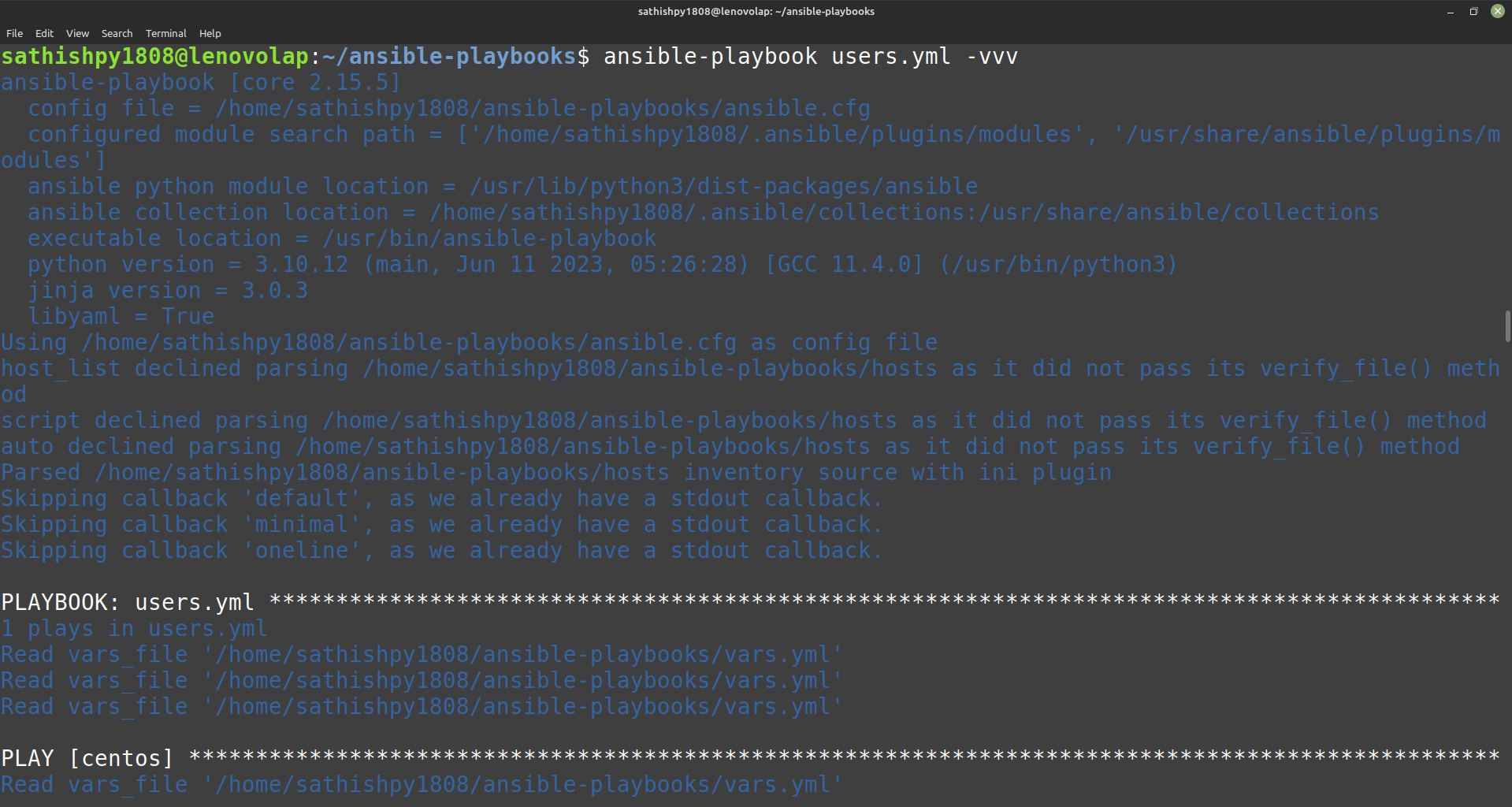
- Users are created in the TARGET machines
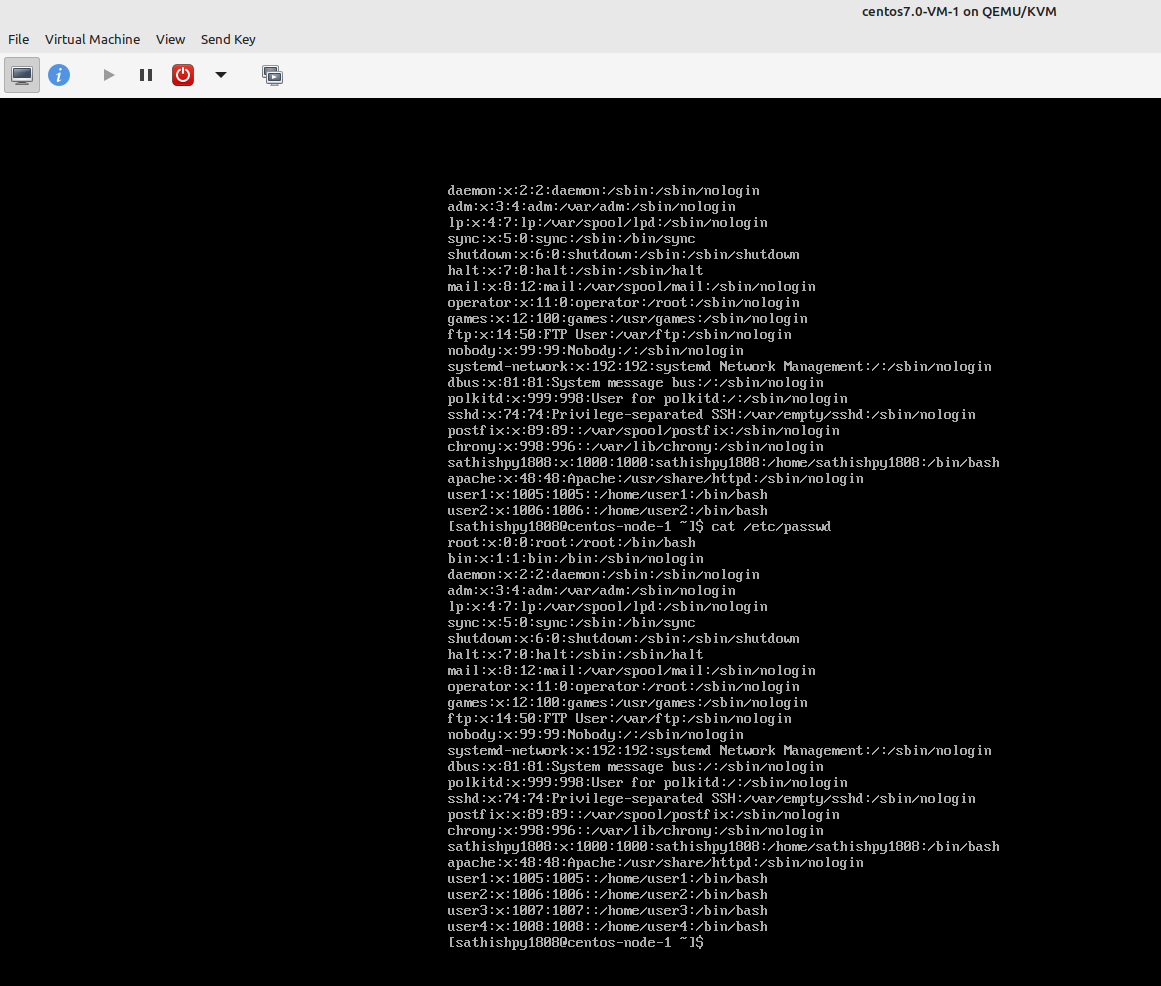
### Important
1. Indentation is important while writing the YAML file , so you can also set like below,
set
autoindentation
extended tab
tab space
cursor & column
```
set ai et ts=2 cuc
```

Hope you are able to see a LINE in shade.
### Sites
This site will help to validate the YAML file,
https://www.yamllint.com/
### Notes
1. Facts gathering [TBD]
2. Plugin integration [TBD]
3. Ansible idempotent ???
 | technonotes | |
1,630,793 | What Are the Essential Qualities of a Productive Team Member? | What are the key qualities that contribute to being a productive and effective team member? Share... | 0 | 2023-11-01T00:00:00 | https://dev.to/codenewbieteam/what-are-the-essential-qualities-of-a-productive-team-member-49n7 | discuss, codenewbie, beginner | ---
published_at : 2023-11-01 00:00 +0000
---
What are the key qualities that contribute to being a productive and effective team member? Share your insights and discuss how fostering these qualities can lead to better teamwork and outcomes.
Follow the [CodeNewbie Org](https://dev.to/codenewbieteam) and [#codenewbie](https://dev.to/t/codenewbie) for more discussions and online camaraderie!
*{% embed* https://dev.to/codenewbieteam *%}* | sloan |
1,631,177 | Migrating from Self-Managed RabbitMQ to Cloud-Native AWS Amazon MQ: A Technical Odyssey | Explore our journey from managing a self-hosted RabbitMQ instance to embracing the cloud-native capabilities of AWS Amazon MQ. This technical blog post delves into the advantages of both approaches, the challenges that prompted our transition, and the pros and cons of each. Discover why we made the move and how we navigated the complexities of the migration, ultimately finding a more reliable solution for data recovery in the world of message brokers. | 0 | 2023-10-14T15:04:00 | https://dev.to/ottonova/migrating-from-self-managed-rabbitmq-to-cloud-native-aws-amazon-mq-a-technical-odyssey-1376 | rabbitmq, aws, amazonmq, cloudnative | ---
title: Migrating from Self-Managed RabbitMQ to Cloud-Native AWS Amazon MQ: A Technical Odyssey
published: true
description: Explore our journey from managing a self-hosted RabbitMQ instance to embracing the cloud-native capabilities of AWS Amazon MQ. This technical blog post delves into the advantages of both approaches, the challenges that prompted our transition, and the pros and cons of each. Discover why we made the move and how we navigated the complexities of the migration, ultimately finding a more reliable solution for data recovery in the world of message brokers.
tags: #rabbitmq #aws #amazonmq #cloudnative
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/c3l6t9pwh8glmkdajrtv.png
# Use a ratio of 100:42 for best results.
published_at: 2023-10-14 17:04 +0200
---
In the ever-evolving world of cloud-native solutions, it can be a daunting task to maintain message brokers. For a while, our team was responsible for a self-managed RabbitMQ instance. While this worked well initially, we encountered challenges in terms of maintenance, version updates, and data recovery. This led us to explore Amazon MQ, a fully managed message broker service offered by AWS.
In this article, we'll discuss the advantages of both self-managed RabbitMQ and Amazon MQ, the reasons behind our migration, and the hurdles we faced during the transition. Our journey offers insights for other developers, who consider a similar migration path.
### The Self-Managed RabbitMQ Era
Our experience with self-managed RabbitMQ was characterized by control, high availability, and the responsibility to ensure data integrity. Here are some of the advantages of this approach:
1. **Total Control**
Running your own RabbitMQ server gives you complete control over configuration, security, and updates. You can fine-tune the setup to meet your specific requirements: ideal for organizations with complex or unique messaging needs.
2. **High Availability**
It's worth noting that our entity was running on AWS EC2, whose SLA guarantees only 99.99%, but de-facto we achieved a remarkable uptime rate of 99.999% with our self-managed RabbitMQ setup. The downtime was almost non-existent, which ensured a reliable message flow through our system. High availability is crucial for many mission-critical applications.
3. **Data Recovery**
Ironically, data recovery was a challenge with our self-managed RabbitMQ. In the event of a crash, we lacked confidence in our ability to restore data fully. This vulnerability urged us to consider Amazon MQ, a fully managed solution.
### The Shift to Amazon MQ
As time passed, it became apparent that managing RabbitMQ was no longer sustainable for our team. Here are the primary reasons that drove us to explore Amazon MQ as an alternative:
1. **Skills Gap**
Our team lacked in-house experts dedicated to managing RabbitMQ, which posed a risk to our operations. As RabbitMQ versions evolved, staying up-to-date became increasingly challenging. This skill gap urged us to consider Amazon MQ, a fully managed solution.
2. **AWS Integration**
As an AWS service, Amazon MQ seamlessly integrated with our existing AWS infrastructure, providing us with a more cohesive and consistent cloud environment. It allowed us to leverage existing AWS services and tools, which resulted in a smooth migration process.
3. **Managed Service**
The promise of offloading the operational burden to AWS was enticing. Amazon MQ handles tasks like patching, maintenance, and scaling. This allows our team to focus on more strategic initiatives.
4. **Enhanced Security**
One key advantage of switching to AmazonMQ is its strong foundation on AWS infrastructure. This not only ensures robust security practices but also regular updates are integrated into the system. So, it gives us confidence, as we know that any potential vulnerabilities are under active monitoring and management.
### The Amazon MQ Experience
While the move to Amazon MQ presented numerous benefits, we also encountered some challenges that are worth noting:
1. **SLA Guarantees**
[Amazon MQ's service level agreement (SLA)](https://aws.amazon.com/amazon-mq/sla/) guarantees 99.9% availability. This is generally acceptable for many businesses but was a step down from our self-managed RabbitMQ's 99.999% uptime. While the difference might seem small, it translated into more downtime. A trade-off we had to accept.
2. **Limited Configuration**
Amazon MQ abstracts many configuration details. This simplifies management for the most users. However, this simplicity comes at the cost of fine-grained control. For organizations with highly specialized requirements, this might be a drawback.
3. **Cost Considerations**
Amazon MQ is a managed service, which means there are associated costs. While the managed service helps reduce operational overhead, it's crucial to factor in the cost implications when migrating.
### What do three nines (99.9) really mean?
Here are my calculations according to Amazon MQ SLA:
- if the monthly downtime is [lower than ~43 minutes](https://uptime.is/99.9), they will charge 100% of the costs
- if the monthly downtime is [between ~43 minutes to ~7 hours](https://uptime.is/99), they will charge 90% of the costs of this downtime
- if the monthly downtime is [between ~7 hours to ~1day](https://uptime.is/95), they will charge 75% of the costs of this downtime
- and if the monthly downtime is [higher than ~1 day](https://uptime.is/95), they won't charge any costs for this downtime
### Conclusion
Our migration from self-managed RabbitMQ to Amazon MQ represented a shift in the way we approach message brokers. While Amazon MQ offered many benefits, such as reduced operational burden and seamless AWS integration, it came with some trade-offs, including a lower SLA guarantee and less granular control.
Ultimately, the decision to migrate should be based on your organization's specific needs, resources, and objectives. For us, the trade-offs were acceptable given the advantages of a managed service within our AWS ecosystem.
The path to a cloud-native solution isn't always straightforward, but it can lead to more streamlined operations and a greater focus on innovation rather than infrastructure management. Understanding the pros and cons of both approaches is vital for an informed decision about your messaging infrastructure.
As technology continues to evolve, it's essential to stay adaptable and leverage the right tools and services to meet your business needs. In our case, the migration to Amazon MQ allowed us to do just that. | sergeypodgornyy |
1,631,228 | Flutter App Development Company | The Google Flutter App Development SDK is a new platform that can be used to make native mobile apps... | 0 | 2023-10-11T11:56:23 | https://dev.to/clickboxagency/flutter-app-development-company-3451 | flutter, webdev, mobile, javascript | The Google [Flutter App Development](https://www.clickboxagency.com/flutter-app-development-company-coimbatore/) SDK is a new platform that can be used to make native mobile apps for both iOS and Android using a single structure of code. Flutter is strong and responsive, and it has widgets and tools that make it possible to build and release UIs with animations and a single code that works on different devices.
The best thing about the Flutter platform is that it gives writers a way to connect to native, so they can do almost everything that Kotlin, Swift, and Java can do. Connecting and drawing are the most important things to know about Flutter. Apps that use the camera, Geolocation, network, storage, and 3rd party SDKs are good examples of apps that use Flutter. All of this is related to the latest guidelines for cross-platform development, which can be done with the Flutter app development framework. | clickboxagency |
1,631,482 | Which programming language should I learn first? | Scrap the title. It is the wrong question to ask. The real question should be the following. In... | 0 | 2023-10-27T13:58:19 | https://javascript.plainenglish.io/which-programming-language-should-you-learn-first-047def918713 | webdev, beginners, javascript, programming | Scrap the title. It is the wrong question to ask. The real question should be the following.
> In which tech field can I make the most impact and help solve problems by building projects? Is it Web Development? Is it App Development?
> If Web Development, which tools and languages can I use?
Let’s answer these questions. I created different roadmaps for various fields, including Data Science. Let’s take a look at them one by one and understand the reality of Software Development.
## Introduction
Even though you may want to pick your first language easily, I recommend putting in some time because you don’t want to waste your time quickly switching to another language and then repeat the loop wherein you switch languages when you lose interest.
The stakes are high. It will take hundreds of hours of practice to become good at a language, especially JS, Java, Ruby, C++, etc. You must select a set of languages, stick to them, and keep building applications using them before switching to another one.
Consider whether people will pay to build something using a specific language. For instance, take JavaScript. It gets used universally everywhere.
Hence, the market demands proficient and well-versed JavaScript developers. If you know JS, you can switch to any other high-level language.
Consider parameters like the job market, long-term vision, easiness of learning, and other factors when choosing a language. Don’t pick languages like C as your first if you want an easy language. Before we begin, use the following webcomic for a quick sarcastic overview.

Most colleges and universities teach low-level C, Java, Assembly, MATLAB, and C++ as introductory programming languages due to the confusion about whether Computer Science is an extension of Mathematics.
They teach most low-level languages because they are closer to Maths. However, we tend to use high-level languages in the real world. What is the difference between them? Read [here](https://x.com/justmrkhan/status/1707376203978740108?s=20).
Learning Programming while picking the wrong language is like using a hammer for a screw. It slows down your progress and demotivates while the programmer doesn’t get jobs even after spending hours trying to learn to program.
Unless you pick PHP as your first language, there’s always something to learn. You will attain valuable skills with any language, but some might not align with your interests and require you to learn something completely different.
So. Which language and tools should you pick?!
## Choosing Languages
Don’t go based on the popularity of a language. For the past 11 years, JavaScript has dominated the market as the most-used language for various fields, and that is because every industry uses it. However, what if you want to get into Data Science? There JavaScript isn’t the ideal option.
It is similar to human languages. If I want to go to Germany, I’ll learn their native German language. If I want to visit India, I will learn Hindi. And if I want to go to France, I will learn French respectively. Your choice depends on what you’re trying to make.
For the same reason, I drew multiple roadmaps for you. Most of these fields choose JavaScript as their core language. It is worth prioritizing, but I will go over other technologies to give a broader view other than my personal opinion.
Remember that learning a single language will NOT propel your career. You will require other tools, like Git, Github, AWS, etc. I have considered relevant languages and tools with current or future potential in the Job Market.
### Web Development
Most frameworks and libraries in the roadmap are based on JavaScript and can be implemented easily with it. So, it’s crucial to understand the basics of JavaScript. Another essential topic in HTML is DOM. It is one of the requirements to understand React.
Learn those JS technologies after you get a substantial basic knowledge of JS. Even the experienced engineers at Google recommend engineers master the basic knowledge first and practice explaining their thought processes.
Full-stack developers are a combination of front-end and back-end. They handle both sides. Front-end developers create those beautiful interfaces, but the back end makes those elements and components functional.
Astro and Eleventy are efficiently used to make static websites. They are not suitable for website-based applications like Twitter. We would learn React and Next JS based on React for an application like Twitter or Twitch.
SCSS is a pre-processor. It improves the CSS writing process, and TailwindCSS and other libraries with the “UI” suffix are component libraries and frameworks that provide pre-written CSS.
### Data Science — AI/ML

There are tons of concepts in Data Science. People prioritize maths, statistics, and linear algebra with probability to understand other data-related concepts. Python appears as the best solution to process data. In reality, it is significantly slow compared to JavaScript. Python has more libraries and additional Data Science and AI/ML features.
Tensorflow is another library used to bring those maths concepts and coding together to create a solution for a problem. NLPs are crucial to understanding even outside Data Science. And Kaggle is like Leetcode with pre-processed data to train your robots.
Data Structures and algorithms will never leave your bedside. You will learn them in Data Science as well. It’s not because they are useful but because they allow you to build a problem-solving curious mindset even though developers treat it like an enemy that only serves its purpose in interviews.
### Blockchain Development — Web3, Smart Contracts, etc.

Who would have thought I would speak about blockchain? However, this concept fascinated me during the research phase. I learned everything and the process wherein the back end depends on various blockchains and smart contracts to process user details and information. They are secure.
As the Web3 concept supports the view of anonymity, blockchain allows you to do it.
The front-end or the interface for the user gets built using React and Smart Contracts based on those blockchain systems that handle the back-end with tons of data.
### Mobile Development
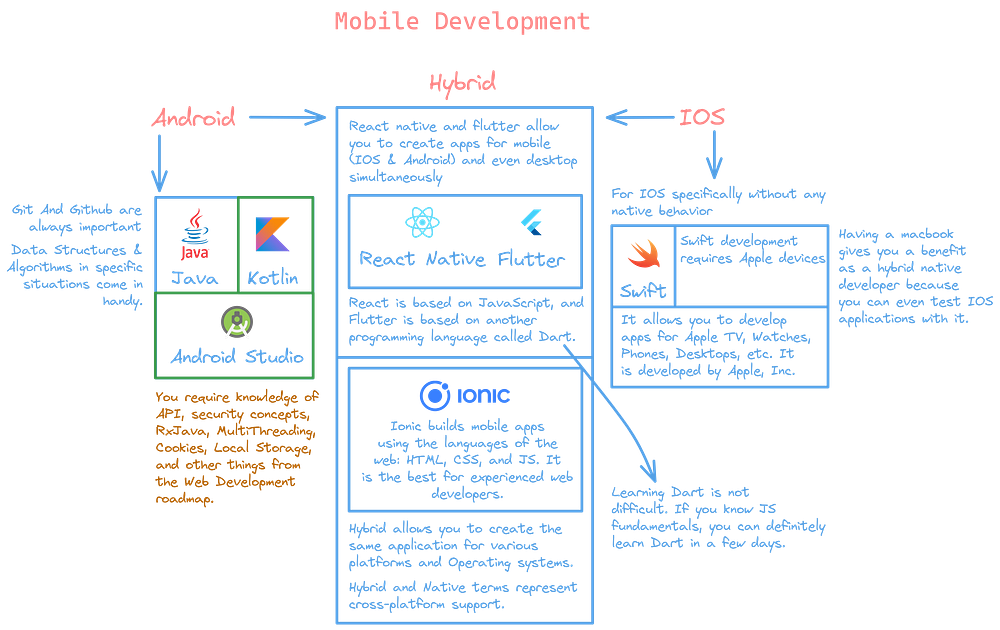
Since 1993, when IBM was digging around mobile development, there were fewer technologies to rely on. Nowadays, there are many. We divide them into pure Android, hybrid, which can create applications on every platform, including desktop, and IOS, which only has one language with more restrictions than the military strength of Costa Rica.
Frameworks like React Native, Flutter, and Ionic convert the code written using a common language into applications other platforms can adopt. Using the write code for one platform, I can make desktop, web, and mobile applications with them.
They are hybrid and all-in-one solutions. But Java and Kotlin are ONLY for Android development and cannot create a desktop replica with the same code, and the same goes for the Swift language of IOS.
### Desktop Development
As stated earlier, frameworks like React Native and Flutter allow you to write code that transpiles to all platforms. Hence, if you’re making a mobile application, you are more likely to develop a desktop version of it, and you can do that with those frameworks without learning anything additional.
However, if you want to make desktop applications exclusively, I have something for you besides Java because most features released by Oracle for Java are useless (Applets were a thing).
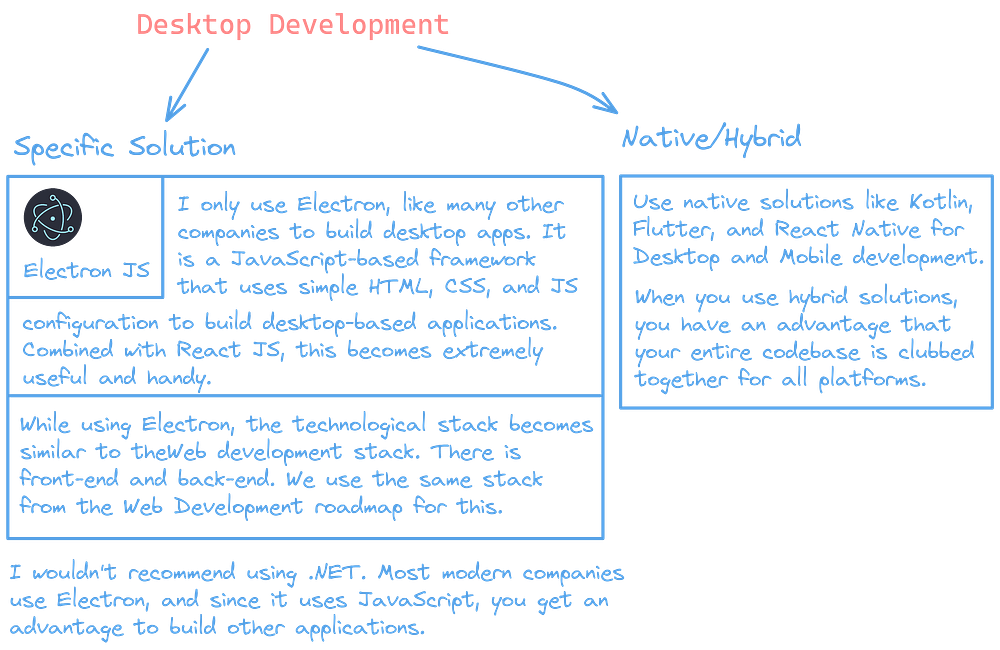
A desktop application with HTML CSS JS?! Yes. It becomes easier for you to make desktop applications if you hold fundamental knowledge of all those core web-based technologies. You don’t require quirky Java or .NET pain.
Most platforms, including **Notion**, convert the web-based application code of their platforms into desktop code using frameworks like Electron. If you try to press a specific shortcut, you will get the Chrome Developer tools on your desktop app even though you are not using a browser, and that’s magic.
Try pressing _CTRL + I_ on the desktop application of Notion, and you will get a tab to view the HTML elements on a darn desktop application.
### Game Development

Either C++ or C#. No negotiation. It is because these are the popular languages used in most popular engines. These engines provide drag-and-drop solutions for complex mathematical movements in various games.
C++ and C# are extensions of C, the mother of all languages. However, I wouldn’t recommend learning C first. I don’t want you to give up on programming after three days of getting started. It depends on your learning pace.
These fields are like different trains. You can either pick one and stick to it daily, or first experience a gist of destinations travelled by all the trains and then pick one to travel daily.
Optimize for what fits your personality and goals. I like to try everything first, gain experience, and then pick one.
## Exploring Coding
JavaScript or Python are the perfect beginner-level languages because they are used in most fields and are easier to learn. Most companies use frameworks and subsets of JavaScript. You can travel to different places with JavaScript and switch trains whenever you want without buying a new pass.
I’d recommend you pick a language that allows open-source contributions to improve the packages and libraries created using that language and make better projects for other developers. Companies like Oracle often sue various companies for attempting to expand Java beyond its current capabilities.
JavaScript avoids such behaviour, and that’s why so many companies adopted JS & TS together. Java wanted to conquer the entire market. They came up with Applets and other features. None of them lasted, and only JavaScript dominated the space. It has a large and supportive community to help you out.
I recommend starting with Web Development because it is the easiest to learn and gives a sense of fulfilment or progress when you see your code representing your vision on the Internet.
It is also because Web development-related concepts, frameworks, and libraries are present in other fields, like Web3, Desktop Development, Mobile development, and even AI/ML.
You will master the basics of JavaScript and use it in other fields as you expand. Learn one language deeply. I would not recommend joining a boot camp either because they teach multiple languages and tools concurrently with no real purpose.
You end up in a vicious cycle. Instead, pick a specific field and become a master of it.
> Any application that can be written in JavaScript, will eventually be written in JavaScript. — Jeff Atwood, the co-founder of StackOverflow.
You should prioritize C over JavaScript because C is a low-level language. It is closer to hardware than other languages if you are intellectually curious and want to learn more about computers.
If you don’t know which one to pick, watch a few YouTube videos of people from those various fields and verify whether it is something you would want to do. If yes, double down. Otherwise, move on to the next one.
**But what next**? I decided to pick the Web Development route and learned the technologies through practice with trial and error. What can I do next?
## How do you use these languages and tools?
Begin by building projects. When you have the fundamentals cleared, you can start using them. I created a 4-step framework for building projects while learning new skills. Hence, I won’t delve deeper into this topic, and you can purchase the 20-page eBook on Gumroad with over 70+ downloads.
{% embed https://afankhan.gumroad.com/l/build-to-solve-problems %}
Practising is only the first step. If you don’t use those skills and knowledge to build something, you are essentially the human version of ChatGPT who only knows to spit out answers but cannot create anything.
Engineers solve computer science-related problems using coding and leverage Programming to make websites and products to solve real-world problems. They fix those problems by building or doing something.
They use their wisdom and experience.
If you don’t use what you know, you will forget it and further blame yourself for failing to remember it. You will enter an endless loop. Hence, build a project and show it to your friends and family. Web Development is reasonable for showing.
Once you build many projects and have a portfolio, you can apply for jobs or establish a service-based business (freelancing business). You offer your skills to a company through a job or an individual client through freelancing. I chose the latter.
Build something that helps solve a problem in your daily life. Do you require a to-do list with reminders, dates, and other functionalities? Build it.
Is it a PNG to SVG converter? Build it. Without looking at tutorials and solely based on documentation or articles, you build the application and learn the skills required to create these applications while creating them.
## Competitive Programming
You might have heard this term. What does it mean? When programmers avoid caring about building projects and want to win competitions and interviews based on mathematical, data structural and complex algorithmic knowledge.
I wouldn’t pick this route because competitive programmers live their lives inside a CLI, the command line interface, and fail to build projects they can deploy and show to the world or their friends and family. They can’t construct something that helps other people.
There are a few times when this type of programming helps, and that is during interviews. After the discussion, people usually don’t come back to these concepts. They enter the real world where companies build things rather than solve complex leetcode problems.
I suggest focusing on the roadmap provided earlier and returning to competitive programming once in a while with your desired language. I’m a JavaScript guy, so I use JavaScript and partially Python or C++ to solve leetcode problems whenever I decide to ruin my life (sarcasm).
Most prefer Java and Python for leetcode problems, interviews, and tough coding questions. However, I don’t remember when I last solved a leetcode problem. Even ChatGPT can do that. I focus on building projects and dislike competitive programming.
It could be because I’m an entrepreneur and freelancer now. However, if you’re optimizing yourself for a job, you will require competitive programming once you get the fundamentals correct with your respective field from the flowchart.
## The Dunning-Kruger effect
More often than not, you will experience this effect. You will feel confident when you begin, then realize there are many things to learn. After reaching the lowest point of depression, you will get yourself back together, make a plan, and execute it.
I used to watch at least five videos of JavaScript on Udemy every day without fail. If I had to stay in my college library to complete them, I would till 5:30 PM. And while I did this, I realized that I don’t and can’t know everything. There’s so much to learn in JavaScript. I lost confidence, but I got back up eventually when I realized even seniors make mistakes.
Hence, I started to focus on the crucial fundamental concepts I could learn and were within my reach instead of setting unrealistic expectations of completing JavaScript in 2 months.
I also focused on embarrassing myself to learn more. What would be the best way to embarrass yourself? Hackathons!
### Hackathons
Once I had completed that course on JavaScript, I felt significantly confident in building complex applications. Rather than creating a project, I participated in a hackathon with other random strangers. And then I realized — I know nothing.
I came, revised all concepts, built more projects, and participated again with the wisdom and experience gained from those previous hackathons. I embarrassed myself, but I quickly entered a state of enlightenment.
To become a problem solver and great developer, you must know the basics of your field. Look at the flowchart, pick a topic like JS, and begin getting your hands dirty. There’s always a solution for something. You only need to find it.
The computer is never wrong. Stop taunting it for your mistakes. Grasp humility. There’s a lot to learn, and you cannot do everything. If there’s something you don’t know yet, use AI models or Google.
**_Become a problem-solver._**
---
If you want to contribute, comment with your opinion and if I should change anything. I am also available via E-mail at hello@afankhan.com. Otherwise, Twitter (X) is the easiest way to reach out - @justmrkhan. | whyafan |
1,645,576 | How to fix " Module not found: Can't resolve 'fs' " | ALERT (Revised 10-29-2023) It might have been caused by Aggregating modules I was using... | 0 | 2023-10-25T07:04:20 | https://dev.to/adamof/how-to-fix-module-not-found-cant-resolve-fs--44f4 | ## **ALERT**
(Revised 10-29-2023)
It might have been caused by [Aggregating modules](https://developer.mozilla.org/en-US/dtwitter.com/notdetailsocs/Web/JavaScript/Reference/Statements/export)
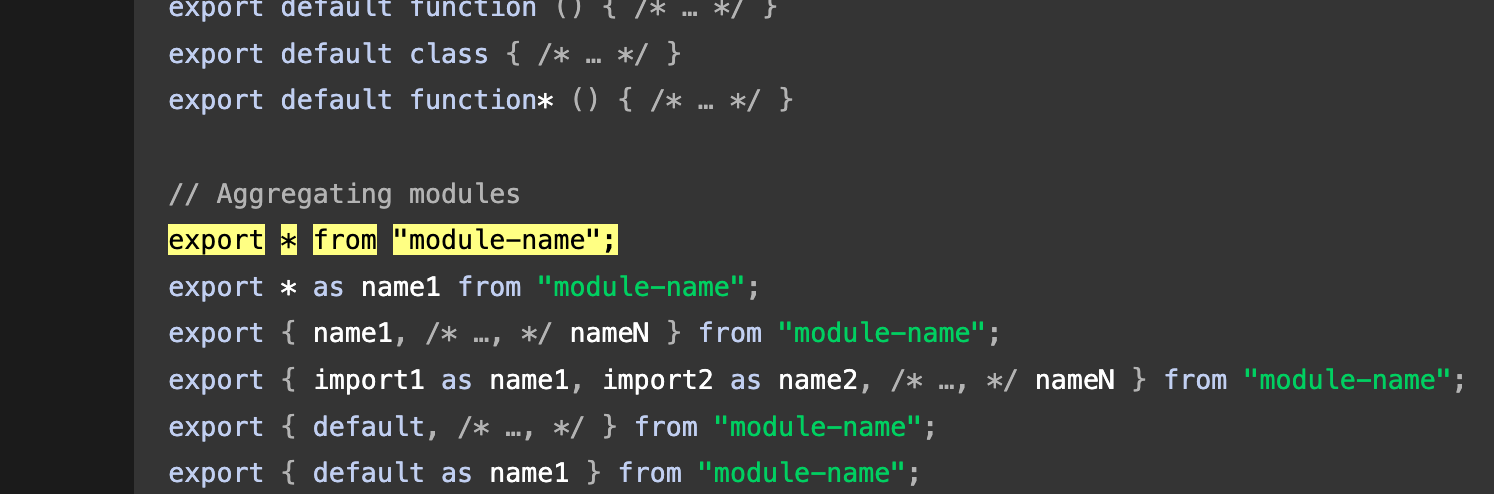
I was using `export * from 'module-name'` in the above figure when the error was occurring.
I changed it as follows
```js
export * from 'module-name'
// ↓
export { name1 } from "module-name"
```
---
## **ALERT**
The content of this article was incorrect. (Revised on 2023-10-26)
I found that the error in the title was only reproduced under very specific circumstances.
Here is the explanation of the situation and the resolved method.
---
Since the issue did not occur in the pure (fully from scratched) Next.js code, I reexamined the code of the affected application.
Although only a part of the error screen was described in this article, here is the full content:
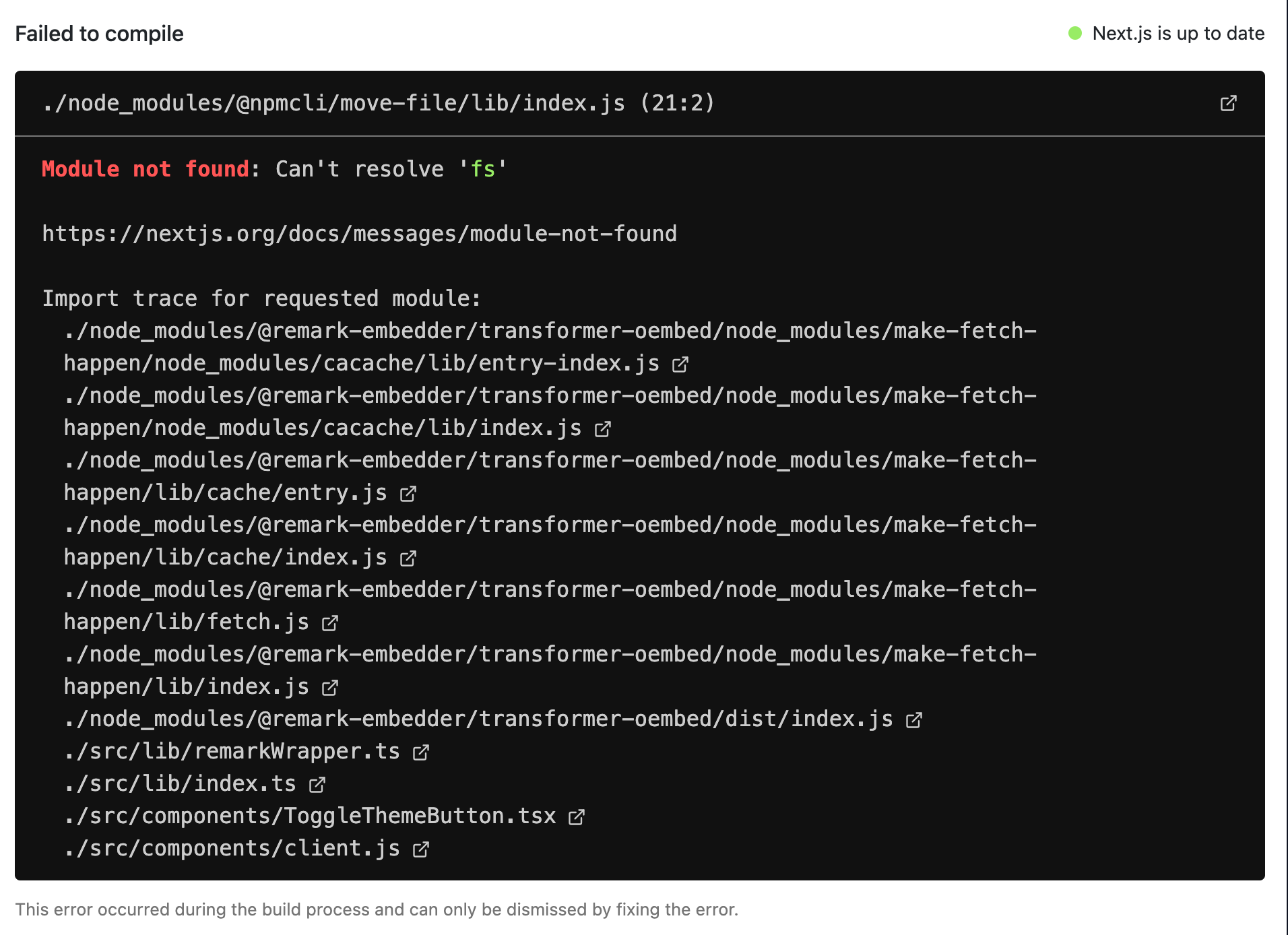
I traced the Import Trace in the figure (which I did not pay attention to before).
I had previously created a barrel file called `remarkWrapper.ts` to consolidate external modules.
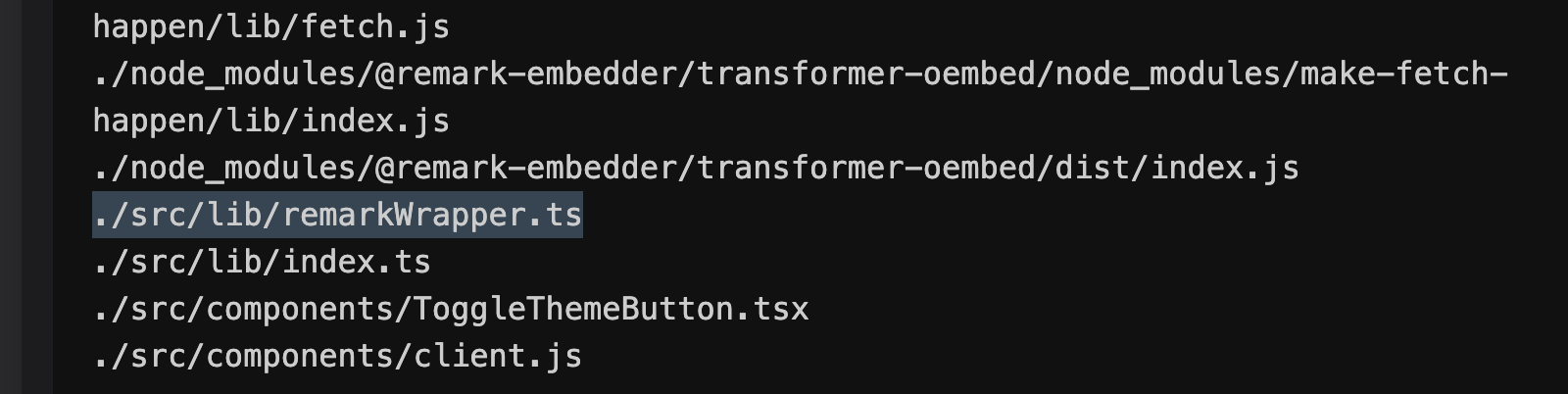
After `remarkWrapper.ts`, the import had changed to `node_modules`. Therefore, I suspected that the import of that file might be causing the issue, so I removed the import to `index.ts`.
```ts
// index.ts
export * from './getOembed'
export * from './getDataTheme'
// export * from './renderReact'
export * as rehype from './rehypeWrapper'
// export * as remark from './remarkWrapper' <===!!!!!!
export { default as getLang} from './getLang'
```
After doing so, the error described in this article no longer occurred.
---
Below is the original post
---
I will provide a description of the situation and a solution for the following error.
This error is likely to occur, especially when using barrel exports.
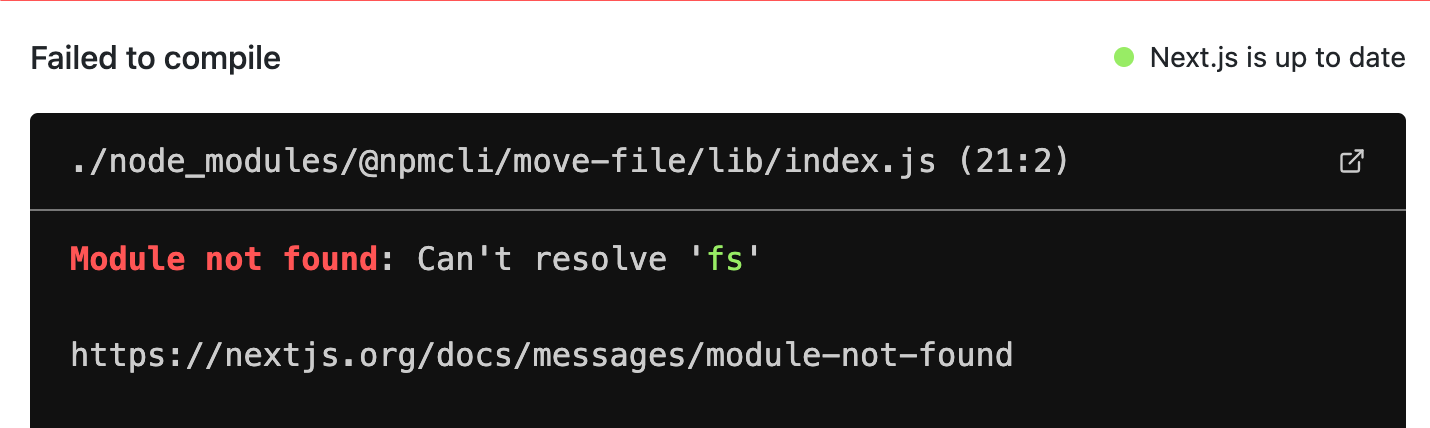
## Situation
- Next.js: 13.5.6
- Modules are imported into the `Client Component`.
- These modules are exported from the `index.ts` file.
```tsx
// ButtonTest.tsx
'use client' <=== Client Component Only!!!!
import { testHello } from '@/lib/testHello' <=== OK (/lib/testHello.ts)
import * as TEST from '@/lib' <=== NG (/lib/index.ts)
import {testHello} from '@/lib' <=== NG (/lib/index.ts)
import {testHello} from '@/lib/index' <=== NG (/lib/index.ts)
import {testHello} from '@/lib/libs' <=== OK (/lib/libs.ts)
import * as TEST from '@/lib/index.lib' <=== OK (/lib/index.lib.ts)
export const ButtonTest = () => {
return (
<div>
<button
onClick={() => {
testHello()
}}
>
ButtonTest
</button>
</div>
)
}
```
## Solution
Please use a file name other than `index.ts` for exporting. Any other file name, such as `index.lib.ts` or `lib.ts`, will work.
## Supplementary Information
I haven't tested the 'index.js' pattern, but it probably won't work.
Is there no mechanism to resolve imports using the 'index' file on the client side?
If you have any other solutions besides the one mentioned above, please let me know. | adamof | |
1,645,699 | Cuu voi | dfgdfgdfgdf dsfdsfdsf sdfsdffsdfsd sdfsdf sdfsdfs dsfdsfdsfewrwerw | 0 | 2023-10-25T08:54:08 | https://dev.to/teqtrungnguyen/cuu-voi-1a3m | dfgdfgdfgdf
**dsfdsfdsf**
- sdfsdffsdfsd
1. sdfsdf
2.
3. sdfsdfs
## dsfdsfdsfewrwerw
| teqtrungnguyen | |
1,645,770 | Save Even More with Pleazia: Discover Exclusive Discount Codes | Online shopping is already a blessing for those of us looking to save time and money, but did you... | 0 | 2023-10-25T09:47:55 | https://dev.to/laurapiacente/save-even-more-with-pleazia-discover-exclusive-discount-codes-2gil | Online shopping is already a blessing for those of us looking to save time and money, but did you know that you can save even more with Pleazia? This innovative platform not only offers you commissions on your purchases but also exclusive discount codes to maximize your savings. In this blog, we will unveil how Pleazia allows you to obtain discount codes for your orders.
**What is PLEAZIA ?**
PLEAZIA is an intelligent assistant that combines the pleasure of shopping online with the assistance of artificial intelligence. PLEAZIA guides you in using the pleaziamarket.com website while allowing you to enjoy benefits such as commissions and discounts.
**[Pleazia](pleaziamarket.com): Your Source of Exclusive Discounts**
Pleazia goes beyond the traditional offers you find on other online shopping sites. The platform introduces discount codes that you can use on the site!
**Browse Exclusive Offers**
When you are on Pleazia, you have access to a list of exclusive offers from partner merchants. These offers are carefully selected to provide you with high-quality products and services at advantageous prices. Whether you are looking for fashionable clothing, cutting-edge electronics, or any other items, Pleazia has exclusive offers for you.
**Use the Discount Codes**
To benefit from these exclusive offers, all you have to do is use the discount codes provided by Pleazia when placing your order. These codes allow you to enjoy substantial discounts on the purchase price, thus saving you money.
**Save on a Variety of Products and Services**
[Pleazia](pleaziamarket.com) is not limited to a single sector. You can find discount codes for a variety of products and services, whether it's trendy clothing, state-of-the-art electronics, or even online services. This means that you can save on practically everything you buy on the site.
**Pleazia's Intelligent Assistant Optimizes Your Shopping**
Pleazia's AI adds a layer of personalization by suggesting offers and discount codes based on your preferences and shopping habits. It helps you find the best deals for the products that interest you the most.
**Conclusion: Save Smartly with [Pleazia](pleaziamarket.com)**
With Pleazia, saving money on your online purchases has never been easier. Thanks to the discounts, you can obtain reductions on a variety of products and services. Pleazia's AI ensures that these offers align with your preferences, offering you a smart and cost-effective online shopping experience.
Join Pleazia today to begin enjoying these exclusive discounts and discover how you can save even more on your online purchases.
| elenagblt | |
1,646,137 | Understanding the POM File in Spring: A Comprehensive Guide | 1. Introduction to POM File 1.1 What is a POM File? A POM (Project Object... | 0 | 2023-10-25T14:48:22 | https://dev.to/saurabhnative/understanding-the-pom-file-in-spring-a-comprehensive-guide-4gnl | springboot, java, backend | ## 1. Introduction to POM File
### 1.1 What is a POM File?
A **POM** (Project Object Model) file is an XML file that serves as the fundamental building block of a Maven project. It contains information about the project and configuration details to manage dependencies, plugins, build settings, and more.
### 1.2 Importance of the POM File
The POM file is pivotal in Maven-based projects for various reasons:
- **Dependency Management**: It defines project dependencies and their versions, ensuring that the required libraries are available during compilation and runtime.
- **Lifecycle Management**: It defines the build lifecycle phases and their associated goals, allowing developers to execute tasks such as compilation, testing, packaging, etc.
- **Plugin Configuration**: It specifies which plugins should be used in the build process and how they should be configured.
---
## 2. Structure of a POM File
### 2.1 Project Information
This section includes details like `groupId`, `artifactId`, `version`, `packaging`, and `name` that uniquely identify the project.
### 2.2 Dependencies
The `dependencies` section lists the external libraries and frameworks that the project relies on.
### 2.3 Plugins
The `build` section includes information about plugins and their configurations. Plugins can perform various tasks like compiling code, generating documentation, or packaging the project.
### 2.4 Build Settings
This section includes properties like `sourceDirectory`, `testSourceDirectory`, and others, which customize the build process.
---
## 3. Managing Dependencies with POM
### 3.1 Dependency Coordinates
Dependencies are defined with coordinates like `groupId`, `artifactId`, and `version`. These coordinates are used by Maven to fetch the required libraries from repositories.
### 3.2 Transitive Dependencies
Maven automatically resolves dependencies transitively, meaning if a library A depends on library B, Maven will also fetch B.
### 3.3 Version Management
Using properties for versions allows for centralized version management. This is particularly useful when multiple modules share dependencies.
---
## 4. Lifecycle and Build Phases
### 4.1 Clean Phase
This phase removes files generated by the previous build.
### 4.2 Default Phase
This phase includes goals like compiling source code, running tests, and packaging the project.
### 4.3 Site Phase
The `site` phase generates project documentation, reports, and other resources.
### 4.4 Deploy Phase
The `deploy` phase involves copying the final package to a remote repository for sharing.
---
## 5. Profiles in POM
### 5.1 What are Profiles?
Profiles in Maven allow for customizing builds based on different environments or specific requirements.
### 5.2 Using Profiles for Build Customization
Profiles can be used to define different sets of dependencies, plugins, or build configurations for specific scenarios, such as development, testing, or production.
---
## 6. Inheritance and Parent POMs
### 6.1 Defining Parent POMs
A parent POM is a way to share common configurations across multiple projects. It helps in standardizing settings and dependencies.
### 6.2 Inheriting from Parent POMs
A project can inherit configurations from a parent POM by specifying the parent's `groupId`, `artifactId`, and `version`.
---
## 7. Plugin Configuration in POM
### 7.1 What are Plugins in Maven?
Plugins are extensions to Maven that provide additional functionality. They can be used for tasks like compiling code, running tests, generating documentation, etc.
### 7.2 Configuring Plugins in POM
Plugin configurations are specified in the `build` section of the POM file. This includes details like the plugin's `groupId`, `artifactId`, `version`, and specific settings.
---
## 8. Best Practices for Managing POM Files
### 8.1 Keep Versions Updated
Regularly update dependency versions to benefit from bug fixes, performance improvements, and new features.
### 8.2 Use Bill of Materials (BOM)
A BOM is a POM file that defines a set of default dependencies and their versions. It helps in managing versions across multiple modules.
### 8.3 Avoid Dependency Scope Ambiguity
Use appropriate dependency scopes (`compile`, `runtime`, etc.) to avoid conflicts and ensure that dependencies are used in the correct context.
---
## 9. Conclusion
Understanding and effectively managing the POM file is crucial for successful Maven-based project development. It not only ensures proper dependency management but also streamlines the build process, making development more efficient and maintainable.
Check out my Youtube channel for more content:-
[SaurabhNative Youtube Channel](https://www.youtube.com/@SaurabhNative/featured
) | saurabhnative |
1,646,236 | Phpstorm Intellij search mode when focusing | Sometimes when moving between your browser and your editor be it Phpstorm or some other Intellij... | 0 | 2023-10-25T15:31:51 | https://dev.to/luisgmoreno/phpstorm-intellij-search-mode-when-focusing-3gh5 | intellij, phpstorm | Sometimes when moving between your browser and your editor be it Phpstorm or some other Intellij product you find the editor en search and replace mode, the cause of this is that when hitting the reload shortcut(cmd+r) multiple times y the browser and the rapidly changing focus to the editor the last hit in the shortcut in captured by the editor like the command to Search and Replace, the solution is to remove or change the shortcut in the editor. | luisgmoreno |
1,646,272 | Have multiple config file types in a project? Here’s a single tool to validate them all! | Sharing a project my team and I open-sourced around 10 months ago. We do a lot of devops/infra work... | 0 | 2023-10-25T16:35:23 | https://dev.to/kehoecj/have-multiple-config-file-types-in-a-project-heres-a-single-tool-to-validate-them-all-4l2m | showdev, go, devops, opensource |

Sharing a project my team and I open-sourced around 10 months ago. We do a lot of devops/infra work which required creating and editing different types of config files. We wanted to test that the syntax of those config files was valid but didn’t want to have to use a bunch of different syntax validator tools. We wanted a single (cross platform) tool to validate all the different types and group the output into a single report. We couldn’t find anything that would do what we wanted so we created the config-file-validator project. We currently support XML, JSON, HCL, YAML, Properties, INI, and TOML with CSV and Apple PList on the way (PR’s in-review).
Check it out and let us know what you think!
Project Link: https://github.com/Boeing/config-file-validator
Releases: https://github.com/Boeing/config-file-validator/releases
| kehoecj |
1,646,292 | CodeSmash LTD Campaign | I started building CodeSmash earlier this year and it has gotten quite far so far. For those who... | 0 | 2023-10-25T17:07:29 | https://dev.to/mariostopfer/codesmash-ltd-campaign-9ji | webdev, javascript, beginners, programming | I started building CodeSmash earlier this year and it has gotten quite far so far. For those who don't know, CodeSmash is a No Code platform for deploying custom backends.
https://codesmash.studio
The main difference between CodeSmash and other alternative services like Xano and Supabase is that CodeSmash has no lock-in by default. As opposed to alternatives, it deploys all your backends directly on your private AWS account, so you are always in control of your apps.
Not only is that the case, but it sets up the environment in line with DevOps principles so all your infrastructure is defined as Terraform modules and built with CI/CD pipelines. This way both technical and non-technical users can benefit from CodeSmash.
Since I'm currently going through an extensive re-design phase which is almost over, I will be launching an LTD campaign as soon as the new design is completed.
Therefore, you will have the opportunity to pay once and use CodeSmash forever witht he following plans:
Personal - $45
Business - $95
Enterprise - $245
The LTD is about to launch soon, so make sure to join our mailing list as well! | mariostopfer |
1,646,351 | Discovering Low-code: My Marketing Experience and a Basic Guide for Beginners | Hello DEV community! In our latest article, we explore how low-code platforms are reshaping... | 0 | 2023-10-25T18:09:57 | https://dev.to/latenode/discovering-low-code-my-marketing-experience-and-a-basic-guide-for-beginners-4607 | nocode, lowcode, marketing, saas | Hello DEV community! In our latest article, we explore how low-code platforms are reshaping perspectives on marketing through the prism of one of our team members' experiences. Therefore, we invite you to read the article.
Hi! It’s Daniel. I am a marketer with a four-year journey across non-profit educational projects, marketing agencies, and different startups. **However, one steady challenge in my career has been my allergy to code**. In this story, I'm happy to share how, with a bit of artificial intelligence and low-code platforms, I overcame this blocker and unlocked a new world of marketing opportunities. After all, with this new tool in my hands, why not make the most of it?
A little background: **being a multifaceted professional has always been my goal**. **However, there was a clear boundary I never crossed – a piece of code, even if it’s HTML**. The roots of such a mental block might be a topic for a psychotherapy session, but here is my story of the tools that helped me overcome this challenge.
## 1.Generative AI
As mentioned earlier, two elements were crucial in my story: **AI** and **low-code**. Come December 2022, the digital world was buzzing with the launch of Chat GPT version 3.5, a game-changing tool in text interaction, which I quickly added to my toolkit and began exploring. Behind the scenes, its code generation feature was emerging, although not very appealing at first.
Fast forward a few months. Now familiar with my digital ally, I encountered a somewhat technical task: extracting usernames from my growing Telegram channel of 4,000 members. GPT suggested creating a Python bot (an eye-opener!). "***Indeed, with AI as my guide, it seemed doable***," echoed my inner versatile specialist. I eagerly began this project, downloading Python and seeking help from GPT with every obstacle I encountered.
**However, the journey hit a hiccup when the need for servers and infrastructure arose**, so I gave up. Yet, this experience planted a seed of self-confidence in coding and development, which will begin to unfold four months later.
## 2. Cloud Low-code
You might already be familiar with cloud no-code examples like **Webflow** and **WIX**, where block layouts, server setup, and support are neatly bundled together, and you don't have to worry about it. However, these no-code platforms are designed for specific tasks; a one-size-fits-all solution is hard to find. Yet, creating customizable blocks, ready to be shaped in provided settings seems simple. This is the spirit of today's low-code platforms for business process automation and cloud development. **As my journey shows, even a person with a strong humanities background can navigate the low-code route.**
My entry point was Latenode, highlighted in a [Hackernoon ](https://hackernoon.com/no-code-simplicity-and-full-code-potential-welcome-to-latenode)article that caught my eye. Latenode offers an AI assistant and support in their Discord community to tackle technical challenges and automate workflows. **The idea was appealing**. In a few weeks, **I set up my email marketing service,** capable of collecting weekly updates via a web form, transforming it into a neat HTML email, and sending it to the product user database I now manage.
**Mastering low-code bore two benefits:**
* **It gave more independence from developers**, whose interest dwindled when my system integration questions or data extraction requests interrupted their product-focused work.
* **It sped up marketing solution deployment**, easing the annoyance coming from developers' well-meaning, yet delayed help due to higher-priority tasks.
## Creating a service for email distribution
*Reaching users through emails is a low-hanging fruit.* Despite the digital advancements, the email world remains a good place for professionals. The ability to send updates or share important information via email is priceless.
My main tasks were:
* **Collecting newsletter content via a web form**
* **Creating HTML from the collected data**
* **Ensuring smooth delivery to all users**
> **Transitioning to Technical: Your Step-by-Step Guide. If this part doesn't match your current needs, feel free to jump to the conclusion—there's useful advice waiting there for future reference.**
## Scenario 1: Form for Content Collection
Starting the journey to create a web form accessible via a browser through a specific URL involves launching the first scenario on Latenode. Go to [app.latenode.com](http://app.latenode.com/), click 'create scenario', and put together this structure:
At the heart of it, the first block, Webhook, provides a unique Webhook URL to activate the scenario. Next, the JavaScript block reveals an HTML form aimed at collecting information. The last block, Webhook response, displays this form, making it accessible through the Webhook URL.
**JavaScript... This is the first encounter with code, where the fear towards it starts to fade.** Inside the block is an AI assistant, taking on the task of coding, debugging, and making further improvements. Your job is to make requests:
>*"Include a script in my code to create an HTML form with these input fields: Subject of the Letter, Overview, Title, Platform Updates, Useful Materials, Other News. Add a submission button below. Make the HTML look nice."*
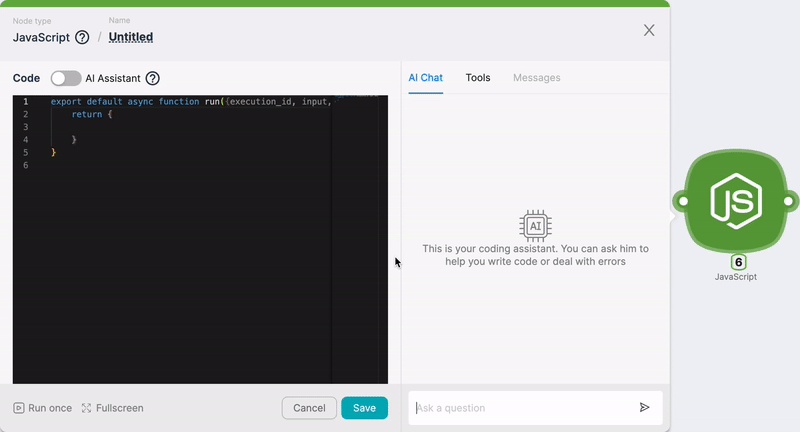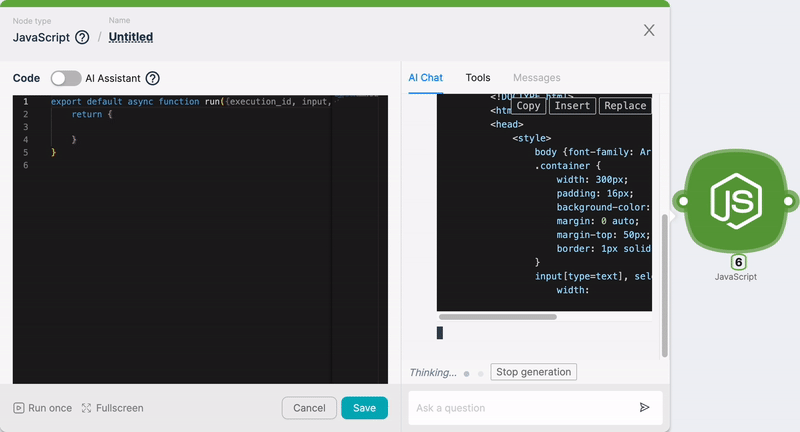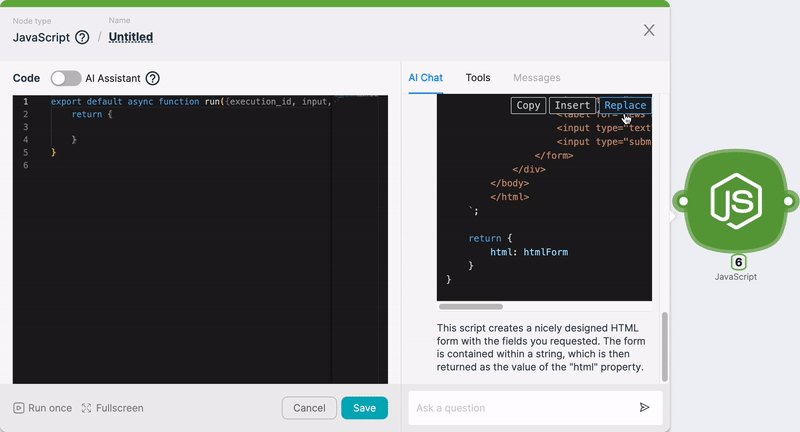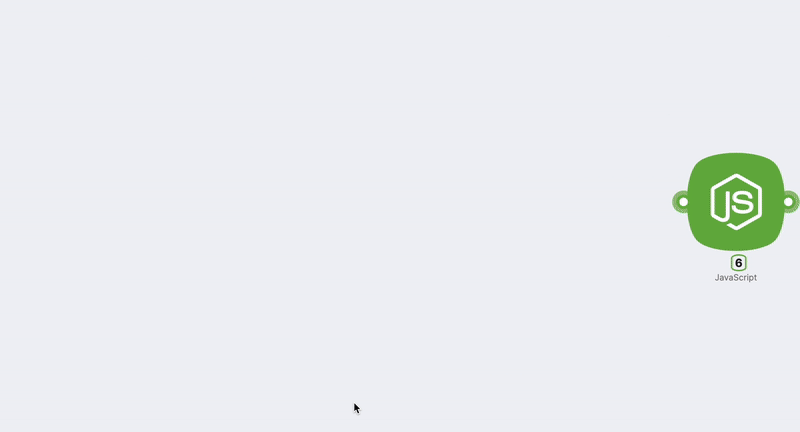
What happens next is the creation of HTML code, directed by the JavaScript module through the scenario, eventually appearing on our screen. Thus, activating the Webhook URL reveals a data input form:
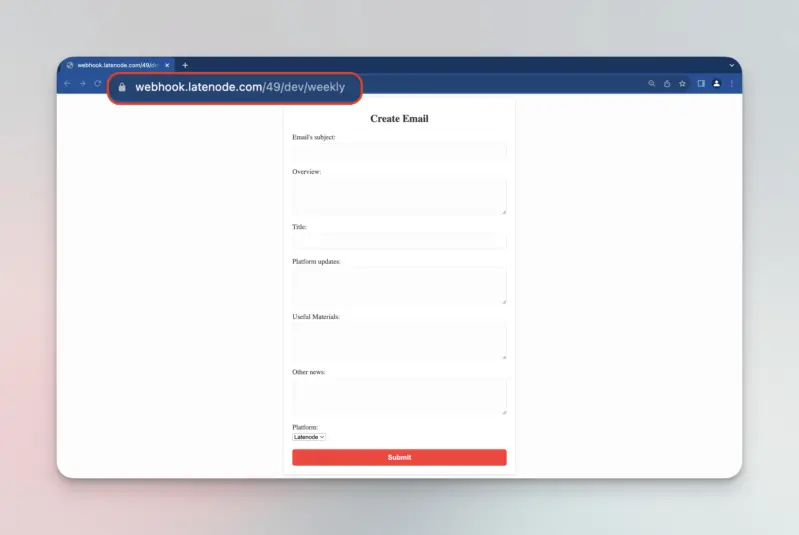
*At this point, the form data is in limbo, but don't worry, a solution is coming...*
## Step 2: Email Creation and Sending
To craft a new email filled with content from the form, another Latenode scenario is needed. This area also handles the email sending function. **Essentially, we're looking at two separate scenarios:** **content collection and its subsequent use**. Here's the reasoning.
Each Webhook URL has the ability to not only start processes but also handle data contributing to these processes. Our goal is to send the form-collected info to the Webhook URL of the second scenario on Latenode, where the responses transform into a well-designed email. Here's how this scenario is structured:
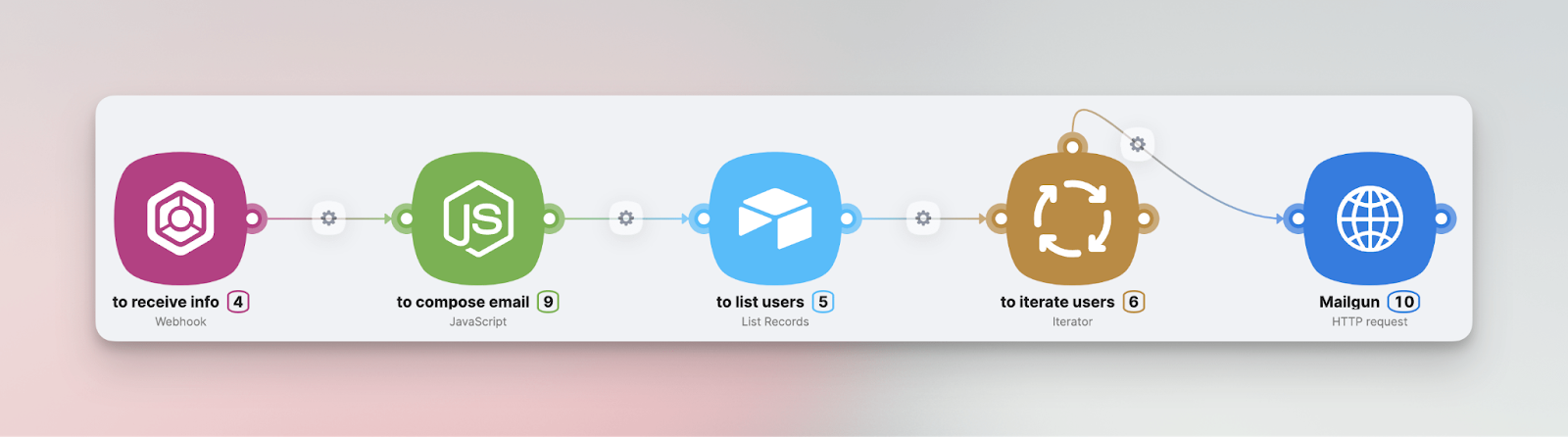
* **Webhook:** Receives information coming from the form.
* **JavaScript:** Creates HTML code containing the email text, adding design elements.
* **Airtable (List Records):** Gets a list of user emails from the database.
* **Iterator + HTTP request:** Sends the prepared email to each user through Mailgun
**Let's go through this, step by step:**
* Connecting Data from Scenario 1 to Scenario 2:
This change is made by adjusting the JavaScript code within the first scenario. With the second scenario now active, it's important to ensure that when the ‘Submit’ button is pressed, the form field data is sent to the new Webhook URL. **Our AI assistant helps again as we request:**
>***– Include a script in my code to send the form-collected data to the following webhook url when the 'Submit' button is pressed:*** [***https://webhook.latenode.com/49/dev/receive\_email\_info***](https://webhook.latenode.com/49/dev/receive_email_info)***. After submission, a 'Thank you!' popup should appear on the screen.***
Quickly, the AI assistant creates a new script, which we easily replace with ours, save the scenario, and test the data sending to our second scenario.

In the 'Body' tab, we see the sent field variables for content along with the entered values: test, test, test…
Now with these variables available on the platform, creating a custom email becomes possible. Next, we add a JavaScript block **and ask the AI assistant** with a new request:
>***"Include a script to create HTML code where variables from the previous block (Overview, Title, Platform Updates, Useful Materials, Other News) are included. Display this in a modern email style."***
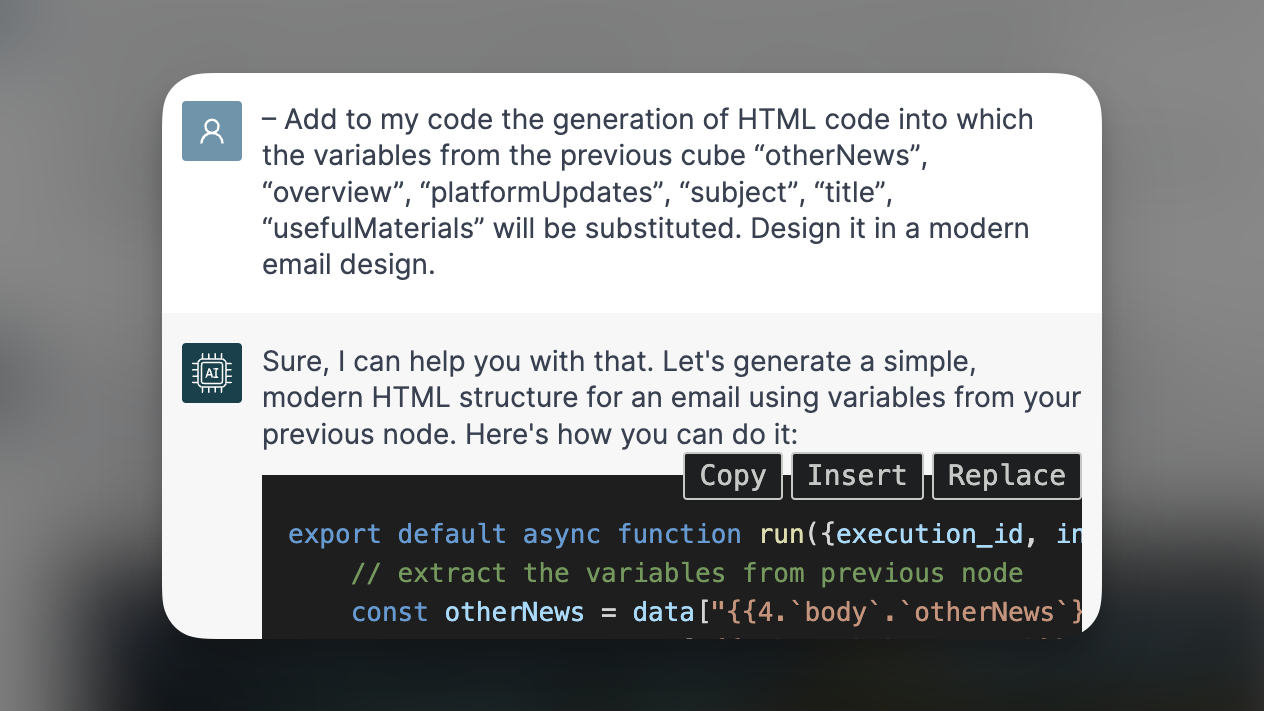
Done! As shown, the **AI assistant not only carries out the request but explains parts of the created code**. For example, the green text after // in the screenshot highlights the code section getting variables from the previous block.
* Next, we need to get the list of recipient emails.
I recommend using Airtable for database management. However, prepare yourself as you might need a developer's help at this point, since we're moving into product interaction territory. The aim is to sync the user database on the product side with our Airtable table, making sure emails smoothly flow in after each new registration. Let's see Airtable as our foundation for low-code automation in email marketing efforts.
​
Once our Airtable is ready and new registrations are coming in as expected, it's time to connect it to Latenode. We do this by adding a no-code Airtable module into the scenario, a task done in just three clicks.
Now, onto the final part of this scenario with two new modules:
* **Iterator:** Goes through each user email from the Airtable module in sequence.
* **HTTP** module: Holds these emails, one by one, placing them in the needed field for sending a request to the Mailgun service.
**Mailgun is great for email automation,** especially good for bulk email sending, supported by analytical insights. One issue though - Latenode doesn't have a direct integration with Mailgun. But don't worry, the HTTP request module is fully capable of creating the needed integration quickly. *More on this is available in the detailed guide at the end of the article.*
**Below is a look at our service working on real data,** where the HTTP request module ran 288 times, sending 288 emails
Execution History visible on the right
## Conclusion
This straightforward approach enables you to build your personalized marketing service from scratch in a few days, without coding skills.
*For those eager to enhance your professional knowledge, I've put together a detailed guide explaining my case:* [***Detailed Guide***](https://latenode.notion.site/Step-by-step-building-your-own-email-marketing-service-870989317a1b4b61ab8101efadb8ea30)
**By following these steps, you'll understand the basics of low-code automation, a skill that's here to stay.** The next time MarTech challenges come your way, you'll be more prepared. Whether solving alone or asking for help, you'll be much further ahead, and that's invaluable!
A note, [**Latenode** ](http://latenode.com/)is currently in beta-testing, offering free access for your exploratory projects. I strongly recommend trying it out, experimenting with webhooks, using the JavaScript AI assistant, and joining their [**Discord community**](http://go.latenode.com/space) with your questions. | latenode |
1,646,364 | Here we go | This thing on? | 0 | 2023-10-25T18:41:59 | https://dev.to/lusblack/here-we-go-1f2h | laravel, php | This thing on? | lusblack |
1,646,536 | Pizza Loading | Check out this Pen I made! | 0 | 2023-10-25T21:31:22 | https://dev.to/web3senior/pizza-loading-j38 | codepen |

Check out this Pen I made!
{% codepen https://codepen.io/web3senior/pen/KKJpbbR %} | web3senior |
1,646,759 | Connect with NFC Card , Send Transaction with QR code | NeBula Overview https://youtu.be/BiPv0tLxyPM?si=PbNzWvl_Dlev0l_w We have developed a... | 0 | 2023-10-27T06:35:48 | https://reactjsexample.com/connect-with-nfc-card-send-transaction-with-qr-code/ | nfc, qrcode | ---
title: Connect with NFC Card , Send Transaction with QR code
published: true
date: 2023-10-26 00:39:00 UTC
tags: NFC,QRCode
canonical_url: https://reactjsexample.com/connect-with-nfc-card-send-transaction-with-qr-code/
---


# NeBula Overview
[https://youtu.be/BiPv0tLxyPM?si=PbNzWvl\_Dlev0l\_w](https://youtu.be/BiPv0tLxyPM?si=PbNzWvl_Dlev0l_w)
We have developed a system that leverages NFC for wallet creation and login, as well as QR codes for transaction generation and approval. Both NFC tagging and QR codes offer convenient solutions for mobile users, and we’ve integrated these technologies into the blockchain.
The reason behind our creation of NFC card wallets stems from the shortcomings of existing wallet systems. Custodial wallets often suffer from the Trusted Entity problem, and Key Management Service (KMS) wallets share similar issues. Mobile wallets typically require app installation and setup, and hardware wallets can be expensive and have limited token support.
With our NFC card wallet system, anyone can create a wallet using their readily available NFC credit or debit cards. This system facilitates seamless offline payments using NFC cards, making in-store purchases and participation in offline events more straightforward.
Furthermore, when it comes to generating and approving transactions, we’ve streamlined the process by using QR codes, reducing the user’s manual effort. This feature can prove to be highly valuable for real-world retail purchases, offline events, and various situations where QR codes are employed.
## Introducing Our Tech
The main points are NFC, QRCODE, Cometh SDK, Tableland, and EIP 681. Cometh allows first time users to adapt web3 for easy wallet creation and processing processor with zero -gas -fee. Create a wallet and log in by tagging NFC using NFC web api. When creating a processor with a qr code, the corresponding qr image was saved in a decentralized database table to pull out the corresponding qr transaction. Convenience has been increased by using EIP-681, which converts transaction requests into QR codes.
## Tech Stack
- React.js
- Typescript
- TailwindCss
- ethers.js
- Nfc API
- Cometh
- Tableland
## Start
Set you Cometh API KEY in the following env var:
```
export NEXT_PUBLIC_COMETH_API_KEY=YOUR_API_KEY
```
After the successfull installation of the packages: `yarn dev`
## GitHub
[View Github](https://github.com/ETHGlobal-Online-ChainWave/Nebula?ref=reactjsexample.com) | mohammadtaseenkhan |
1,646,820 | Three inspiring AI & NextJS projects | typebot.io While the app doesn't overtly showcase "AI" capabilities, the app author Baptiste... | 0 | 2023-10-26T23:07:30 | https://dev.to/_steventsao/ai-nextjs-projects-ive-learned-from-again-and-again-35j5 | **[typebot.io](https://typebot.io/)**
- While the app doesn't overtly showcase "AI" capabilities, the app author [Baptiste](baptisteArno) implements a flowchart builder that is commonly used in LLM builders, ie. [rivet](https://github.com/Ironclad/rivet).
- I admire the craftsmanship of this project. I like that it organizes apps by builder, viewer, and landing pages, and put "features" as common functionalities among these apps.
- All these modules have their own test suite!
- https://github.com/baptisteArno/typebot.io
**[llm.report](https://llm.report)**
- This site shows me that one can develop a useful analytics product by using an unofficial API (/account/usage) and promptly streamlining the results into a captivating chart.
- It's also fun to watch how agile the authors are to keep their service functional when OpenAI's changes these APIs.
- https://github.com/dillionverma/llm.report
**[emojis.sh](https://emojis.sh/)**
- It uses models from [Replicate](https://replicate.com/), which offers a rich library of ready-to-use models through HTTP.
- This project exposes generative emojis to the best use case I've found from the model. Slack emojis are small enough the imperfection is trivial, and using them is only a copy-and-paste away in Slack.
- The app takes advantage of an experimental [form status API](https://github.com/Pondorasti/emojis/blob/6f0a26fbe962f3934103096b51d560f3a9511784/src/app/_components/emoji-form/index.tsx#L7) from `react-dom`, eliminating the need for manual event handler implementations in JS. This results in not just less code but also reduced client-side state management.
- https://github.com/pondorasti/emojis | _steventsao | |
1,646,988 | Guide to Time Series Model | Time Series is a set of data points over a period used to analyze and forecast the future. Time is... | 0 | 2023-10-26T08:36:01 | https://dev.to/eddoganga/guide-to-time-series-model-1kg3 | beginners, learning, datascience | Time Series is a set of data points over a period used to analyze and forecast the future. Time is the independent variable.

## Characteristics of Time Series Model
Autocorrelation: Is the similarity between observation as a function of the time lag between them.
Seasonality: Periodic fluctuations for example online sales peak during Christmas before slowing down.
Stationary: Here is when the statistical properties remain constant over time. It can be tested using the Dickey-Fuller test by evaluating the null hypothesis to determine if a unit root is present.
## Time Series Analysis Types
Classification: It identifies and assigns categories to the data.
Curve Fitting: It plots data on a curve to investigate the relationships between variables in the data.
Descriptive Analysis: Identifies patterns such as trends and seasonal variations.
Explanative analysis: It attempts to comprehend the data and the relationships within it and cause and effect.
Segmentation: It splits the data into segments to reveal the source data's underlying properties.
Time series analysis can be used in -
Rainfall measurements
Heart rate monitoring (EKG)
Brain monitoring (EEG)
Quarterly sales
Stock prices
Automated stock trading
Industry forecasts
Interest rates
| eddoganga |
1,647,676 | My Journey from Software Engineer to AI Engineer | https://nico-autonoma.medium.com/my-journey-from-software-engineer-to-ai-engineer-6d07ffcadd22 | 0 | 2023-10-26T20:07:47 | https://dev.to/nicomarcan/my-journey-from-software-engineer-to-ai-engineer-1l67 | programming, ai, career, learning | https://nico-autonoma.medium.com/my-journey-from-software-engineer-to-ai-engineer-6d07ffcadd22 | nicomarcan |
1,647,859 | Node.js Unit Testing with Jest: A Quick Guide | Unit testing is a part of automated testing that involves testing the smallest part of your... | 0 | 2023-10-27T02:06:42 | https://dev.to/xcoder03/nodejs-unit-testing-with-jest-a-quick-guide-1p47 | node, testing, beginners |
**Unit testing** is a part of automated testing that involves testing the smallest part of your application called units. It helps find bugs faster and fix bugs early on in development.
Unit testing is like a coach carefully assessing a football team during practice. Unit testing examines the smallest parts of an application, much like the coach evaluates each player's skills according to their positions. Coaches evaluate players on man marking, alertness, tackling, and shooting range; attackers are evaluated on positioning, dribbling, and one-on-one play. Similarly, unit testing checks that each "unit" in the application functions as intended by testing specific abilities or functionalities. This comparison highlights the accuracy and detail of unit testing in the context of software development.
**Getting Started with unit testing node.js**
After understanding what unit testing is and why it is vital. Let's talk about how to get started with unit testing.
**Let's build a simple app.**
We'll make a simple task manager to store and retrieve tasks. Because this would be a simple program, we will store the data in an array. You'll use the command line to create a new directory, navigate to it, and launch a new app:
```
mkdir task-manager
cd task-manager
```
Open the app in your preferred code editor. Navigate to your terminal and run the command.
```
npm init i
```
This is to install all your node_modules.
Run the next command.
```
npm init -y
```
This is for your package.json file. Open your package.json and you will see the following code.
```
{
"dependencies": {
"init": "^0.1.2"
},
"name": "task-manager",
"version": "1.0.0",
"main": "index.js",
"devDependencies": {},
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC",
"description": ""
}
```
**Let's build our app**
A task manager app was chosen because many developers must have built a simple to do list or a complex task manager as a project. Because we are performing small and simple unit testing, we will build a relatively simple and small app.
Let's proceed. Create a file named taskManager.js in your project directory. This module will include functions for managing tasks. Paste the following code.
```
// task-manager.js
const tasks = [];
function addTask(task) {
tasks.push(
{
task,
completed: false
}
);
}
function listTasks() {
return tasks;
}
function completeTask(index) {
if (index >= 0 && index < tasks.length) {
tasks[index].completed = true;
}
}
module.exports = { addTask, listTasks, completeTask };
```
The code above performs three functions. The first function is to add a task to the array of tasks. The tasks array will accept an object with two values: one for the task and another to indicate whether or not the task has been completed. The second function returns a list of all tasks that have been added, and the last function sets a task to completed using the task's index value.
Lets a create a simple script to execute the functions and see if our app works using the command line.
Create another file called app.js and paste the following code.
```
// app.js
const taskManager = require('./task-manager')
taskManager.addTask('Buy groceries');
taskManager.addTask('Finish assignment');
taskManager.addTask('Go to schoolnode');
taskManager.completeTask(0)
taskManager.completeTask(1)
taskManager.listTasks().forEach((task, index) => {
console.log(`Task ${index + 1}: ${task.task} (Completed: ${task.completed})`);
});
```
Run the following command to see your output
```
node app.js
```
**Getting started with unit testing. Install a test framework**
In order to get started with unit testing we are going to install a unit testing framework. There are different unit testing framework out there but for today's tutorial we are going to use jest.
**What is Jest**
Jest is an open source JavaScript testing framework designed to ensure correctness of any JavaScript codebase. Jest is designed to make simple and fun. Some features of jest include:
- Good documentation
- Feature rich-API that gives result quickly
- Simple to use
- Little to no configuration and can be extended to match your requirements
- Fast and safe.
Jest has two commonly used methods in a test file, which include:
1) describe(): Groups related tests together. It helps to structure your test and add context to them. The method takes in two arguments: a string describing the test suite (the suite name) and a callback function that contains one or more test or it functions. For example look at the code below:
```
describe('Math operations', () => {
test('adds 1 + 2 to equal 3', () => {
expect(1 + 2).toBe(3);
});
test('multiplies 3 by 4 to equal 12', () => {
expect(3 * 4).toBe(12);
});
});
```
2) test(): The test function is used to define individual test cases. It takes two arguments: a string describing the test (the test name) and a callback function that contains the test logic. For example look at the code below:
```
test('adds 1 + 2 to equal 3', () => {
expect(1 + 2).toBe(3);
});
```
Jest also includes other testing options such mocking, assertions, e.t.c.
**Installing and setting up Jest**
Now that we have understood what jest is all about, let's go back to our application and test it out with jest. You can install jest using your favorite package manager.
**npm**
```
npm install --save-dev jest
```
**yarn**
```
yarn add --dev jest
```
**pnpm**
```
pnpm add --save-dev jest
```
Once installation is complete, go to your package.json and make a small change. Take a look at the code below
```
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
```
Replace the above with "test": :"jest".
Now run the code below to test your app.
```
npm test
```
You will see the following when you run the code.
```
No tests found, exiting with code 1
```
**Lets write our first unit test**
Create a directory named __tests__ (double underscore) in your project directory to store your test files. Inside the __tests__ directory, create a file named task-manager.test.js.
Now paste the following code.
```
// __tests__/task-manager.test.js
const taskManager = require('../task-manager');
test('addTask should add a task to the task list', () => {
taskManager.addTask('Buy groceries');
expect(taskManager.listTasks()).toEqual([{ task: 'Buy groceries', completed: false }]);
});
test('completeTask should mark a task as completed', () => {
taskManager.completeTask(0);
expect(taskManager.listTasks()[0].completed).toBe(true);
});
test('listTasks should return the list of tasks', () => {
expect(taskManager.listTasks()).toEqual([{ task: 'Buy groceries', completed: true }]);
});
```
Run your code with npm test. You will see the following result.
```
PASS __tests__/task-manager.test.js
✓ addTask should add a task to the task list (2 ms)
✓ completeTask should mark a task as completed
✓ listTasks should return the list of tasks (4 ms)
Test Suites: 1 passed, 1 total
Tests: 3 passed, 3 total
Snapshots: 0 total
Time: 0.35 s
Ran all test suites.
```
Finally, let's make our test fail by modifying the code in the task manager file. It is crucial to see your tests fail since it decreases the risk of error and defects. Instead, I set the completed to true in the following code.
```
// task-manager.js
function addTask(task) {
tasks.push(
{
task,
completed: true
}
);
}
```
Now this is what a failed test would look like
```
FAIL __tests__/task-manager.test.js
✕ addTask should add a task to the task list (7 ms)
✓ completeTask should mark a task as completed (1 ms)
✓ listTasks should return the list of tasks (1 ms)
● addTask should add a task to the task list
expect(received).toEqual(expected) // deep equality
- Expected - 1
+ Received + 1
Array [
Object {
- "completed": false,
+ "completed": true,
"task": "Buy groceries",
},
]
3 | test('addTask should add a task to the task list', () => {
4 | taskManager.addTask('Buy groceries');
> 5 | expect(taskManager.listTasks()).toEqual([{ task: 'Buy groceries', completed: false }]);
| ^
6 | });
7 |
8 | test('completeTask should mark a task as completed', () => {
at Object.toEqual (__tests__/task-manager.test.js:5:35)
Test Suites: 1 failed, 1 total
Tests: 1 failed, 2 passed, 3 total
Snapshots: 0 total
Time: 0.342 s, estimated 1 s
Ran all test suites.
```
As you can see, our test provided us with feedback. So we know where to focus our efforts in our code.
Congratulations on the completion of your first unit test. You're on your way to becoming a fantastic developer.
To learn learn more you can check out the [jest](https://jestjs.io) documentation itself.
**Benefits of Unit testing**
1. **High code quality**: Unit testing ensures that every component of your code works properly and meets quality standards.
2. **Early Bug Identification**: Unit testing aids in the detection of bugs early in the [SDLC](https://medium.com/p/8f3f4448a333), lowering development costs and requiring less time to fix bugs.
3. **Documentation**: Unit tests serve as documentation by demonstrating how components are expected to function. Unit tests can help new developers understand the behavior of the code.
4. **Easier Scaling**: Having a comprehensive suite of unit tests becomes increasingly important as your software grows. It serves as the foundation for scaling your application while maintaining its dependability.
5. **Enhanced User Experience**: Unit tests help ensure that the software meets the specified requirements, which, in turn, leads to a more positive user experience with fewer functional issues.
The isolation of issues and a small portion of the application is the only disadvantage of unit testing. Users do not concentrate on minor details within the app, but rather on the app as a whole. That is why it is critical to conduct end-to-end testing.
Overall, unit testing is an important part of software development because it helps to improve code quality, increase productivity, and lower long-term costs. It's a useful technique for creating dependable and maintainable software.
To top it all off, unit testing is only one component of a well-rounded testing strategy. It is not a substitute for other types of testing, such as integration and end-to-end testing, which are required to validate the overall functionality, user experience, and interactions throughout the application. A well-rounded testing strategy employs a variety of testing techniques to ensure that an application meets user expectations and functions properly as a whole.
| xcoder03 |
1,647,918 | Navigating the Junior-Senior Dynamic in the Age of AI | The Evolving Dynamic Between Junior and Senior Developers As artificial intelligence... | 0 | 2023-10-27T03:20:26 | https://dev.to/jackynote/navigating-the-junior-senior-dynamic-in-the-age-of-ai-2aj9 | ai, softwareengineering, junior, senior | ## The Evolving Dynamic Between Junior and Senior Developers
As artificial intelligence advances, the technical skills gap between junior and senior developers is shrinking. With tools like GitHub Copilot, juniors gain quick access to code generation and debugging help. The playing field is leveling. But senior developers still stand apart when it comes to real-world experience and mentality.
Seasoned developers draw on years of experience architecting systems, coordinating teams, and guiding projects. They’ve survived countless code reviews, product launches and post-mortems. They’ve seen both failures and successes. These battles shape their intuition on how to structure code and systems in a maintainable and scalable way. Juniors may grasp the syntax, but lack the deeper wisdom that comes from experience.
Seniors also exhibit certain mindsets cultivated over time. They focus on the big picture, considering how all the components will come together. They think about future maintainability and delegate appropriately. Juniors tend to get stuck in the weeds of individual features. When crises hit, seniors stay calm, having endured similar situations before. Juniors are more prone to panic.
Of course, these differences come with time. As juniors gain experience, they build the knowledge, perspective and leadership abilities that distinguish their veteran peers. But AI accelerates skill development. With proper mentoring, juniors can reach senior levels faster than ever. The key is embracing the journey with curiosity and humility.
## **On the road from Junior to Senior**

The transition from junior to senior developer is a journey. Here are some key milestones along the path:
- **Master the fundamentals** - Become fluent in major languages and CS concepts. Utilize AI for continued learning.
- **Gain exposure** - Seek breadth in technologies and project experience. Understand the bigger picture.
- **Build leadership skills** - Guide team decisions. Practice public speaking. Mentor new hires.
- **Expand influence** - Drive discussions on architecture, tooling, process improvements. Advocate for quality.
- **Manage systems** - Coordinate entire codebases, not just features. Lead major initiatives.
- **Demonstrate mastery** - Establish expertise. Contribute to open source and internal tools. Innovate solutions.
- **Cultivate wisdom** - Draw on failures for guidance and maturity. Exhibit patience and perspective.
The timeline will vary, but embracing new opportunities is key. With a growth mindset and dedication, juniors can reach new heights. The future is bright for those passionate about progressing.
As technology evolves, so must we - learning, collaborating and pushing new boundaries. By moving forward together, we elevate our teams, companies and the software engineering profession. The junior-senior dynamic will continue advancing in this age of AI. The potential for all is immense. | jackynote |
1,647,985 | Building a Robust REST API with Java, Spring Boot, and MongoDB: Integrating Keploy for Efficient API Testing | Introduction In today's fast-paced digital world, building efficient and scalable web services is... | 0 | 2023-10-27T06:11:42 | https://dev.to/keploy/building-a-robust-rest-api-with-java-spring-boot-and-mongodb-integrating-keploy-for-efficient-api-testing-2d2m | rest, mongodb, keploy, java |
**Introduction**

In today's fast-paced digital world, building efficient and scalable web services is crucial for delivering seamless user experiences. One of the most popular combinations for [creating a rest api with Java Spring Boot and MongoDB](https://community.keploy.io/building-rest-api-with-springboot-mongodb). In this article, we will explore how to develop a RESTful API with these technologies, enhancing the testing with "**Keploy**."
**What is Keploy?**
Keploy is a developer-centric backend testing tool. It makes backend tests with built-in-mocks, faster than unit tests, from user traffic, making it easy to use, powerful, and extensible.
**Setting Up the Environment**
Before we dive into the code, let's make sure we have our environment properly set up. You will need to install [rest api Java, Spring Boot, and MongoDB](https://community.keploy.io/building-rest-api-with-springboot-mongodb), along with Keploy.
- **Java**: Ensure you have the Java Development Kit (JDK) installed on your system. You can download it from the official Oracle or OpenJDK website.
- **Spring Boot**: Spring Boot simplifies application development by providing pre-built templates and libraries. You can set up a Spring Boot project using Spring Initializr or Maven/Gradle.
- **MongoDB**: You can install MongoDB locally or use a cloud-hosted service. Remember to configure MongoDB properly with your Spring Boot application.
- **Keploy**: Install Keploy locally on your system via the one-touch installation mentioned in Keploy docs.
**Creating a Spring Boot Application**
Let’s begin by creating a basic Spring Boot application with keploy in mind.
1. Create a Spring Boot project using Spring Initializr or your preferred method. Be sure to include the necessary dependencies like Spring Web, MongoDB, and Lombok for enhanced code readability.
2. Define your MongoDB configuration in the application.properties or application.yml file.
**spring.data.mongodb.uri=mongodb://localhost:27017/your-database-name**
3. Implement a RESTful API by creating controllers and defining your endpoints. Here’s an example of a simple controller class:
**@RestController
@RequestMapping("/api")
public class YourController {
@Autowired
private YourRepository repository;
@GetMapping("/your-resource")
public ResponseEntity<List<YourResource>> getAllResources()
{
List<YourResource> resources = repository.findAll();
return ResponseEntity.ok(resources);
}
// Add more endpoints for CRUD operations
}**
4. Implement the data model and the repository interface for MongoDB interaction. You can use annotations such as @Document and @Field to map your Java objects to MongoDB documents.
5. Build and package your Spring Boot application into a JAR file using Maven or Gradle.
**Testing with Keploy**
Now, it’s time to leverage keploy to test your application. Here are the basic steps:
1. To start recording the API calls, run keploy in record mode along with the application using the following command:
**keploy record -c "CMD_TO_RUN_APP"**
2. Once all the API calls are recorded, press CTRL + C to stop the application from running in record mode.
3. Once the application stops, a folder named keploy is generated with all the recorded API calls as test cases and data mocks in a **.yml file**.
4. Now, to test your application with the recorded test cases and data mocks, run keploy in test mode along with the application using the command:
**keploy test -c "CMD_TO_RUN_APP" -- delay 10**
5. After running all the test cases, keploy will show a detailed report and also store the report in the folder keploy with all the passing and failing test cases with a final result of whether the application passed the test or not.
**Conclusion**
This article explored how to build a robust **REST API with Java, Spring Boot, and MongoDB** while integrating **Keploy** as a vital API testing tool. This combination of technologies empowers developers to create efficient and scalable web services, ensuring a seamless user experience. By incorporating **Keploy** into the development process, you can enhance the reliability of your application. With the right tools and techniques, you can simplify both the development and testing processes, making your application more resilient and adaptable to changing needs. Happy coding! | keploy |
1,648,187 | Shopify And GitHub Integration | Have you ever found yourself tangled in the complexities of Shopify theme management and version... | 25,201 | 2023-10-31T05:00:15 | https://dev.to/quratulaiinn/shopify-and-github-integration-20a1 | shopify, github, beginners, tutorial | Have you ever found yourself tangled in the complexities of Shopify theme management and version control?
Are you looking for a solution to effortlessly synchronize your Shopify store with GitHub?
Look no further. In this third installment of my Shopify development series, delve along with me into the intricate yet powerful process of **Shopify and GitHub Integration**, providing you with the key insights and step-by-step guidance to optimize your development workflow.
## Why Should You Integrate Shopify With GitHub?
**Shopify Theme Kit can help us in making theme development easier, why should we go for this Approach?**
Shopify Theme Kit definitely was a big step in making things easier for developers to work in local environment but one of the biggest drawback it brought was in case a merchant or fellow developer intentionally or unintentionally made any changes to the theme code using theme editor, those changes wouldn't be reflected in our local environment, inviting conflicts and several bugs.
And that's when **Shopify CLI** and **Shopify GitHub Integration** was introduced which ensures that changes made in the Shopify theme editor are reflected in the local environment and vice versa.
Lets sum up the advantages in a better way:
**1. Smooth Syncing:** When you make changes to your theme via your local development environment, the Shopify GitHub setup automatically makes sure the changes show up in your Shopify admin i.e. your online store's theme. This keeps everything looking and working the same on both ends.
**2. Two-Way Changes:** Any tweaks you make in the Shopify admin get sent back to your original setup, so your progress is always up to date, no matter where you're working.
**3. Keeping Track of Versions:** With Shopify GitHub, you can handle different versions of your theme by connecting them to different stages. This way, you can always go back to an earlier version if you need to.
**4. Better Teamwork:** This setup makes it easy for everyone on the team to work together smoothly. You can see what everyone's doing, and everyone's on the same page with the latest updates, making everything run more smoothly.
## Integrate Shopify With GitHub
In previous blog posts, I've walked you through [Setting Up A Local Development Environment For Shopify Themes](https://dev.to/quratulaiinn/setting-up-a-local-environment-for-shopify-theme-development-2ema) and [Shopify Themes Version Controlling Using GitHub](https://www.notion.so/Shopify-And-GitHub-Integration-b7583df82af54949805daa19405e1b7c?pvs=21).
Now, it's time to tie these threads together and explore the remarkable possibilities of **Shopify and GitHub Integration**.
### Connecting GitHub to Shopify
**Step 1:**
- The first crucial step is to create a connection between your Shopify store and GitHub. Login to your Shopify store and click on the **Online Store** section from the sidebar on left.
- Just below your live theme, you'll find the **Add Theme** option.
**A dropdown menu will appear, and this is where the magic begins.**
- Select **Connect from GitHub**.
**Step 2:**
- After you click on Connect from GitHub, on the right side you will find a button to Log in to your GitHub account.
- You will be redirected to the page where you can grant the necessary permissions.
💡 **This is like handing the keys to a secure vault** – it ensures that your Shopify store and GitHub can communicate effortlessly, making updates and collaboration a breeze.
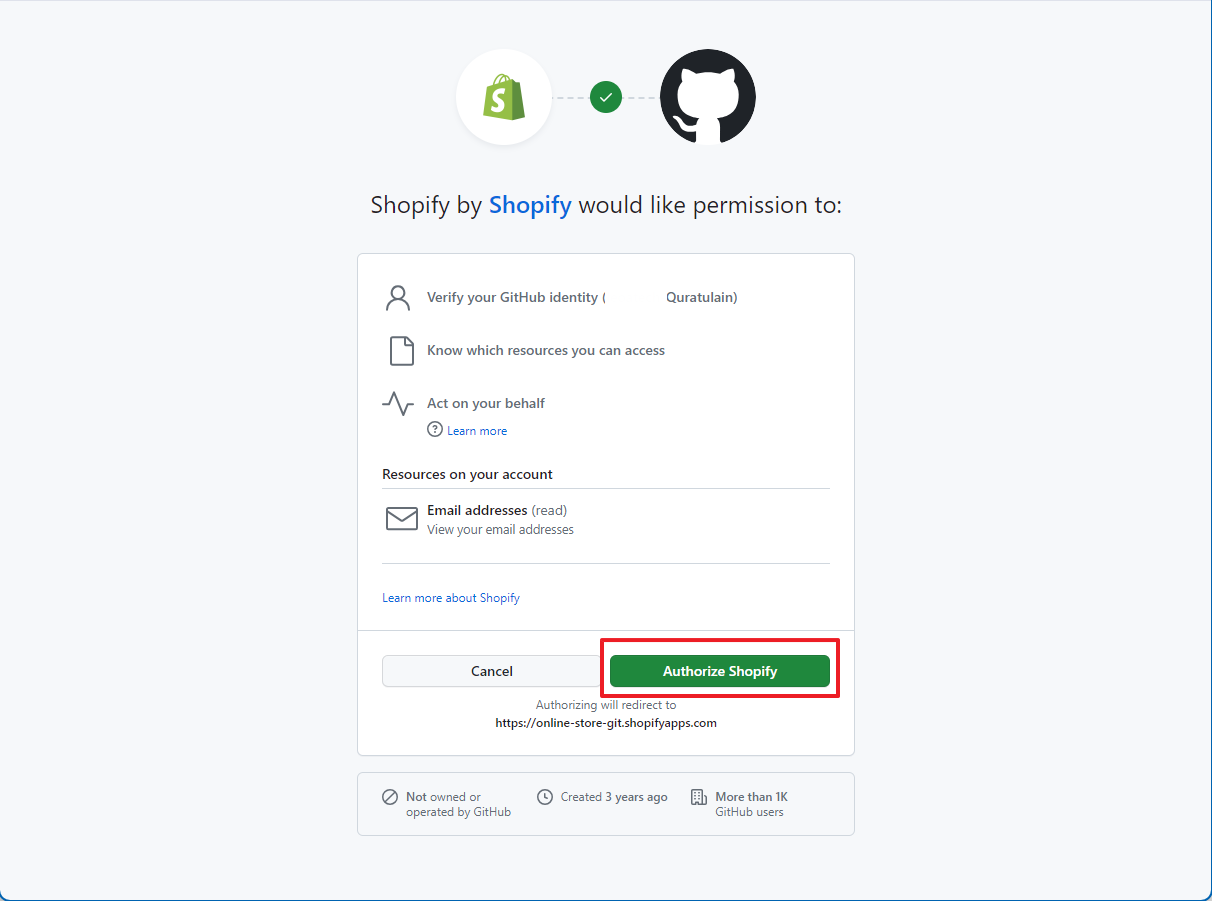
- You can choose to allow Shopify access specific repositories only instead of giving access to all of your repositories. Check **Only select repositories** radio button and then Select the name of repository from dropdown and click **Install**.
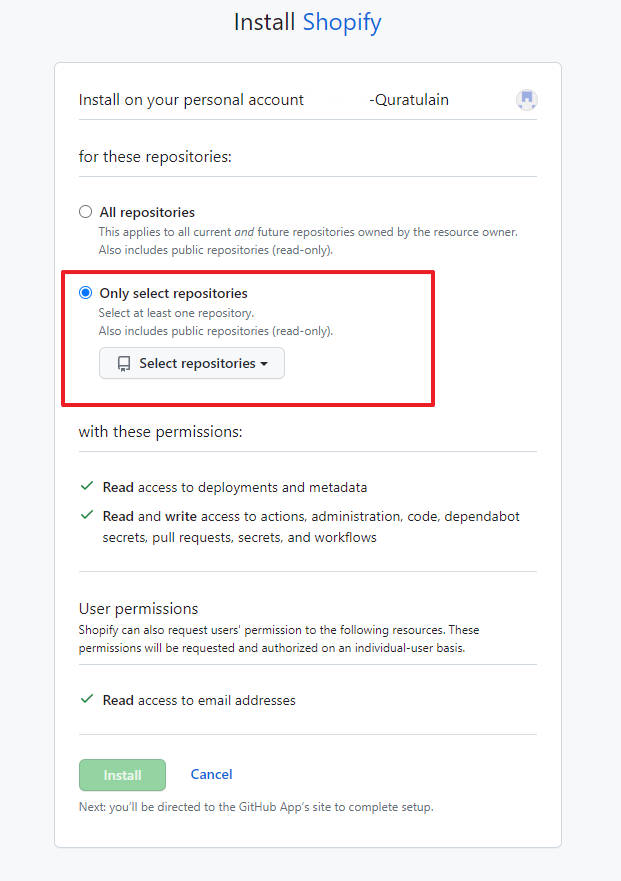
### Select Repository and Branch
**Step 3:**
Once you've connected GitHub to your Shopify store, it's time to get down to business.
- Choose your GitHub account
- Select the repository you created earlier or the one which contains your Shopify Theme. This repository is your treasure chest of code, where your theme's journey begins.
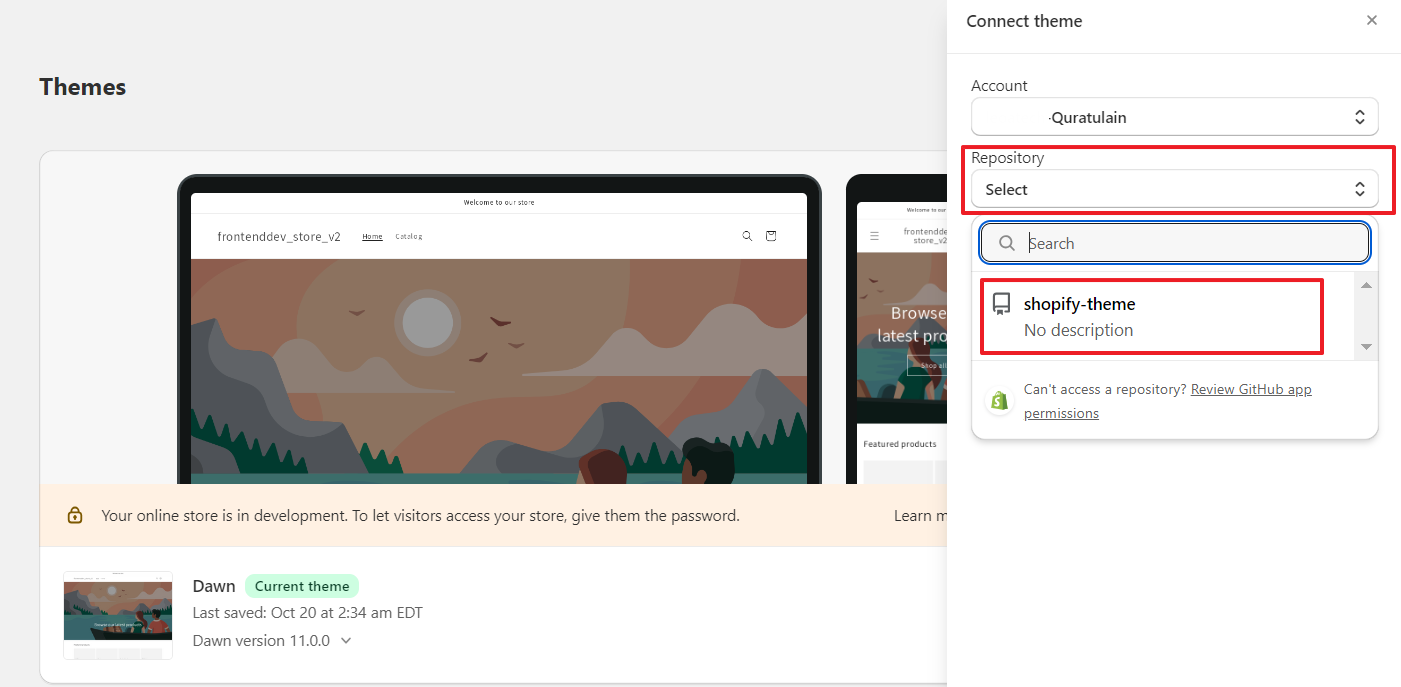
**Step 4:**
You'll be asked to choose a branch. Opt for the branch of your choice and click **Connect**. This is where the beauty of version control shines:
- By selecting the main branch, you ensure that the live store doesn’t get affected with untested changes.
- By selecting the development branch, you ensure that changes and updates can be meticulously tracked and reviewed before making them live.
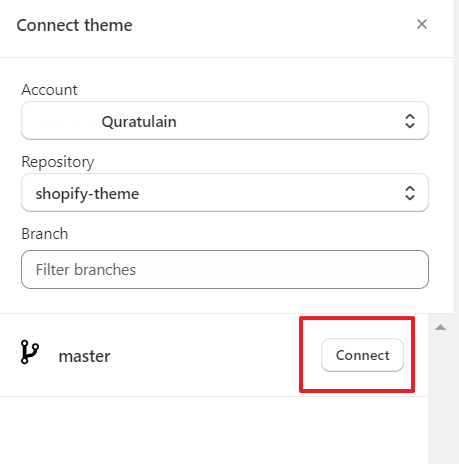
💡 You can connect only branches that match the default Shopify theme folder structure. Folders in the repository that don't match this structure are ignored.
#### Shopify Theme Folder Structure:
```javascript
.
├── assets
├── config
├── layout
├── locales
├── sections
├── snippets
└── templates
└── customers
```
**At this point, you will notice a newly added theme in your Theme Library:**.
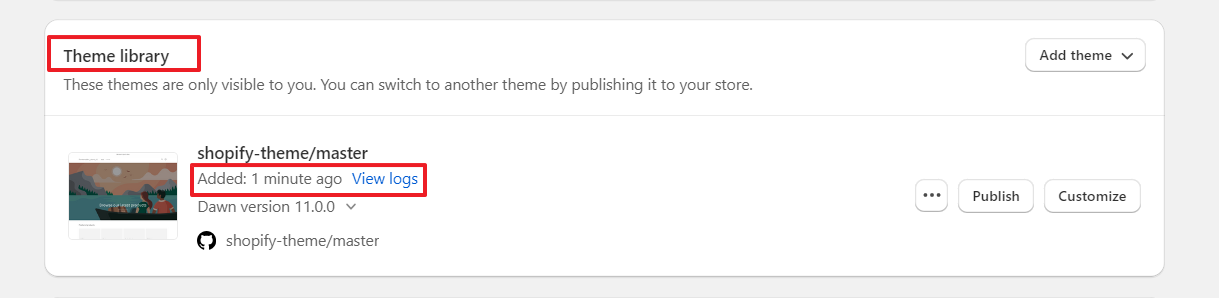
### Create and Publish Themes
**Step 5:**
Now, it's time for the creative part. Create two distinct themes by connecting to both branches, one for development and another for the main branch. This dual-theme approach provides a safe haven for experimenting without disrupting your live theme.
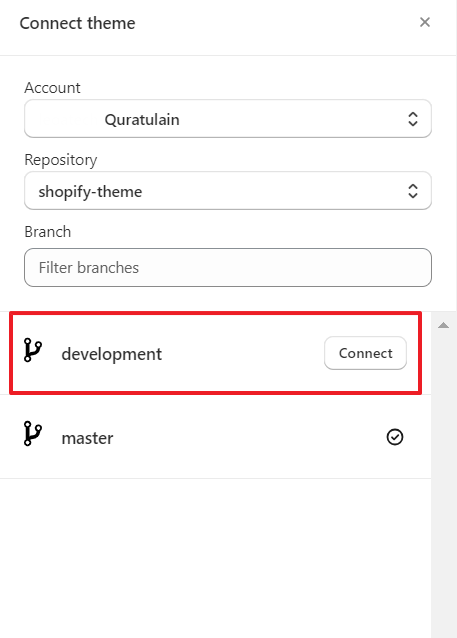
**Step 6:**
But the magic truly happens when you publish the theme created from the main branch. This action takes your development live and showcases your carefully crafted changes to your customers.
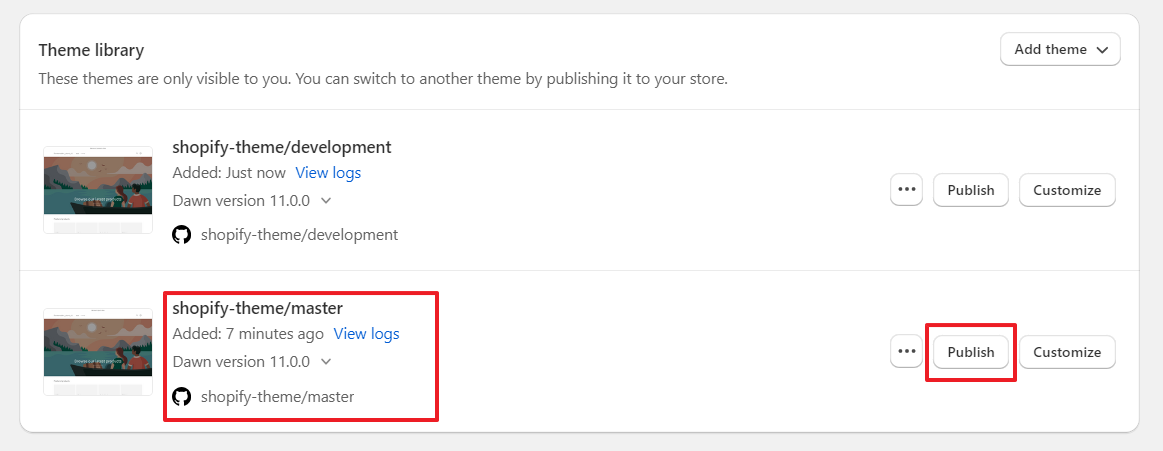
## Conclusion:
By integrating Shopify and GitHub, you've harnessed the power of version control, collaboration, and streamlined development. Your journey towards a more efficient and error-free Shopify development process has just begun.
For more Shopify tips and tricks, feel free to connect with me.
LinkedIn: [https://www.linkedin.com/in/quratulain](https://www.linkedin.com/in/quratulain-shoro-7792721a4/)
GitHub: [https://github.com/QuratAin](https://github.com/QuratAin) | quratulaiinn |
1,648,364 | Harness Developer Hub - Ease of Authoring with Git Triggers | It’s been about a year since we launched Harness Developer Hub [HDH] in Beta. Today, HDH is GA and is... | 0 | 2023-10-27T13:21:39 | https://www.harness.io/blog/harness-developer-hub-ease-of-authoring-with-git-triggers | git, harness, automation, docsascode | It’s been about a year since [we launched Harness Developer Hub](https://www.harness.io/blog/introducing-the-harness-developer-hub-beta-release) [HDH] in Beta. Today, HDH is GA and is serving tens of thousands of unique visitors every month and hundreds of thousands of pageviews every month all across the globe. All of this while supporting hundreds of contributors with varying levels of skills. The traffic and number of contributors in the [public repository](https://github.com/harness/developer-hub) continues to grow as we expand the capabilities of HDH.
Looking at how HDH is architected, HDH is a [Docursarus](https://docusaurus.io/) Implementation. Our site embraces documentation-as-code as a paradigm and is no different than any other modern TypeScript [Javascript] based application. We have an application that multiple contributors need to contribute to and needs to be built and deployed all throughout the day.
Over the previous year we have made two shifts in how we build and deploy. We now treat every commit as a potential release and build multiple times throughout the day with every git commit and also deploy multiple times throughout the day with every merge to our main branch. Let’s look at our current solution and then jog down memory lane how we evolved.
## Current HDH Pipeline Strategy
We leverage several Harness capabilities to deliver HDH to the world.
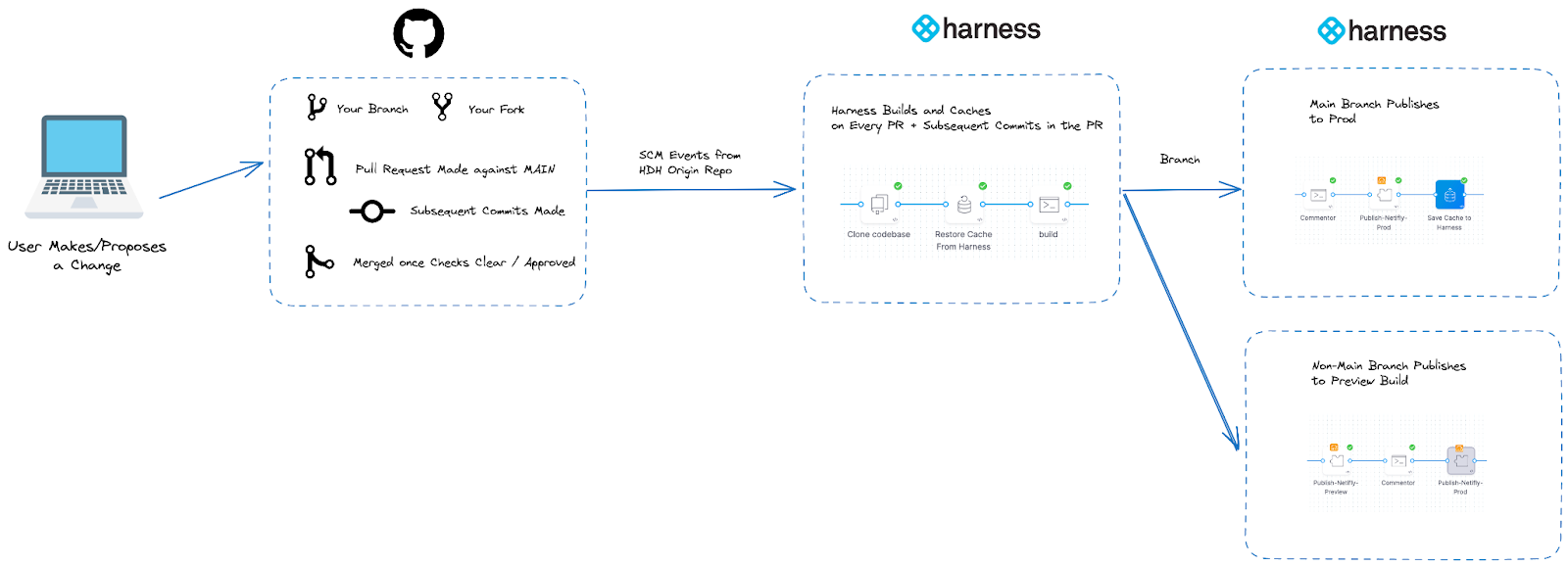
## Starting at the Repository
Our source code management solution is the source of truth for HDH and the genesis of changes being published. We have webhook events that fire on several SCM events to Harness to process.
- Branch or tag creation/deletion.
- Pull Request Events - Created/merged/synchronized/updated/closed
- Git Pushes
These events are then processed by Harness.
## Harness Build and Deploy - Conditionally from Git Hooks in the Cloud
Our goal is to provide preview/ephemeral builds for changes that are represented in a Pull Request. To do this, we need to remotely build the Docusarus instance which leverages Yarn and NPM to facilitate the build. We build on every net new commit to the PR.
We build via a Harness Cloud [hosted] build node so we do not have to manage build infrastructure and dependencies on the build node. We also leverage for performance [Cache Intelligence](https://developer.harness.io/docs/continuous-integration/use-ci/caching-ci-data/cache-intelligence/) on a conservative estimate sped up our builds more than 30%. From when we implemented the current setup, we have had over 9000 builds.
From a deployment standpoint, we deploy to our static host which is Netlify. The flexibility and extensibility of Harness allows us to bring a plugin that [interacts with Netlify’s APIs](https://github.com/harness-community/drone-netlify). We have a decision that we make in [JEXL](https://commons.apache.org/proper/commons-jexl/reference/syntax.html) if a build needs to head to a preview environment or if a build needs to be published to production.
Preview Logic [if branch is not main]:
```
<+trigger.event>.equals("PR") && <+trigger.branch>!~"/^main$/"
```
Production Logic [if branch is main]:
```
<+trigger.event>.equals("PUSH") && <+trigger.targetBranch>.equals("main")
```
Configuring this [Harness Trigger](https://developer.harness.io/tutorials/cd-pipelines/trigger/), here is our YAML configuration looking out for a few events.
```
source:
type: Webhook
spec:
type: Github
spec:
type: PullRequest
spec:
connectorRef: hdh_gh_connector
autoAbortPreviousExecutions: false
payloadConditions: []
headerConditions: []
actions:
- Open
- Synchronize
- Reopen
```
Based on the condition, we fire a slightly different request to the Netlify API. Once we get the results of the Netlify API call, we comment back to the GitHub PR. This allows the contributor to preview their work in a live site if a preview flow is executed. In totality, the Pipeline looks as follows in the Harness Editor:
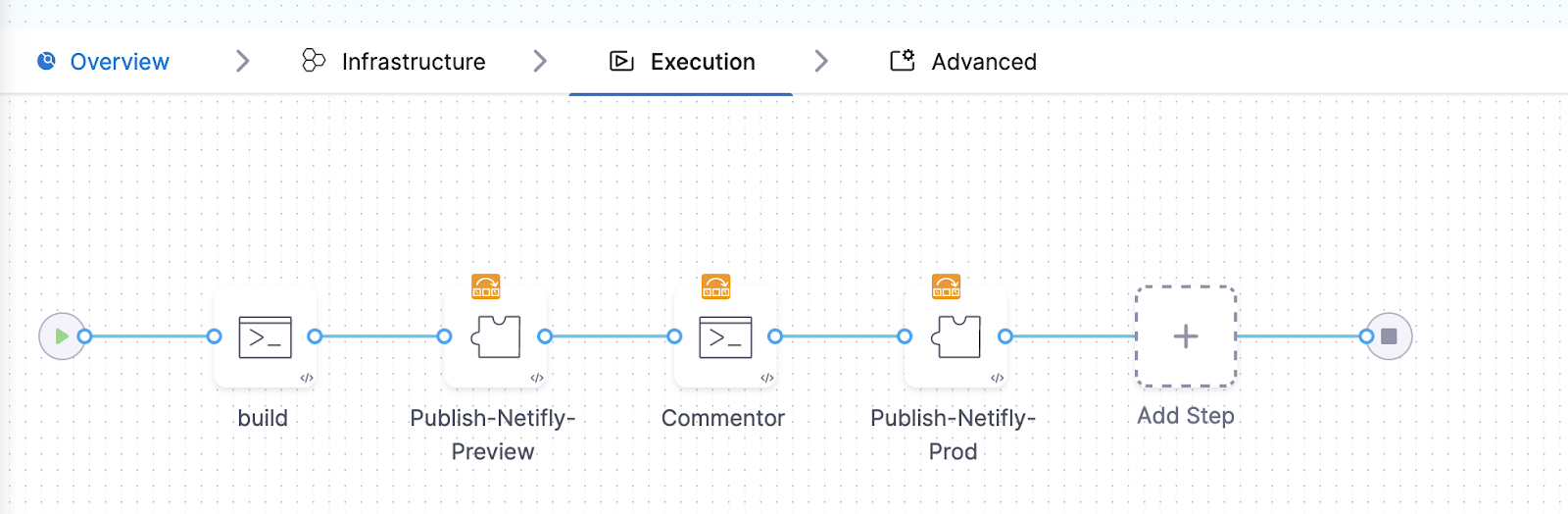
For example the Cache Intelligence step is easy to weave in during the Build Stage. Once execution will look as follows in the Harness UI:

Pipelines are designed to evolve. We had two other renditions of the Pipeline which we optimized over the year to produce what we are currently leveraging today.
## Pipelines Should Evolve
We have embraced two principals as we evolved our pipelines. The [KISS Principle](https://en.wikipedia.org/wiki/KISS_principle) to take a more simplistic approach and [DRY Principle](https://en.wikipedia.org/wiki/Don%27t_repeat_yourself) to cut out duplicate steps/tests. Our second rendition was Kubernetes heavy for the static site before we optimized on calling the Netlify APIs directly for a preview build; we used to maintain our own preview environment when Netlify provided this out of the box. Because we learned of this feature, we were able to easily modify our HDH Pipeline to leverage this new methodology.
If you like to continuously improve your software delivery capabilities, I would implore you to consider [signing up and using the Harness Platform](https://app.harness.io/auth/#/signup/?module=cd&utm_source=website&utm_medium=harness-blog&utm_campaign=cd-devrel&utm_content=hdh) to help you with your goals.
Cheers,
-Ravi | dewanahmed |
1,648,450 | Cloud-native journey - introduction | I've been working in the Azure cloud for a few years now. The term cloud-native gets used a lot. In... | 0 | 2023-10-27T15:43:29 | http://dfberry.github.io/2023-10-27-cloud-native-introduction | cloudnative, cloud, beginners, concept | ---
title: Cloud-native journey - introduction
published: false
date: 2023-10-27 00:00:00 UTC
tags: Cloudnative,Cloud,Beginner,Concept
canonical_url: http://dfberry.github.io/2023-10-27-cloud-native-introduction
published: true
---
I've been working in the **Azure cloud** for a few years now. The term `cloud-native` gets used a lot. In an effort to bridge the gap between Azure cloud and cloud-native, I'm investing some time in learning cloud-native approaches to building apps.
Along the way, I'll use and _experiment_ with practices and tools to expedite the end result. Join me along the way, and let me know how you would have proceeded.
To start with, my tool set includes:
- [Visual Studio Code](https://code.visualstudio.com/).
- [GitHub](https://github.com/) & [GitHub Copilot](https://github.com/features/copilot) (AI pair programming and rubber duck). Copilot provides context-aware answers within Visual Studio code.
This blog will capture the highlights. For the complete picture, head over to the GitHub repo: [Cloud native repo](https://bit.ly/40aclp8).
## What is cloud-native?[](#what-is-cloud-native "Direct link to What is cloud-native?")
**Prompt** : What is cloud-native?
**GitHub Copilot** : Cloud-native is an approach to building and running applications that takes full advantage of the cloud computing delivery model. It is characterized by the use of containerized applications, microservices architecture, and dynamic orchestration, all of which are designed to be highly scalable, resilient, and agile. The goal of cloud-native is to enable organizations to build and deploy applications faster, with greater flexibility and reliability, while also reducing costs.
## How do I begin?[](#how-do-i-begin "Direct link to How do I begin?")
**Prompt** : Where do I start on a new project for cloud-native?
**GitHub Copilot** : When starting a new project for cloud-native, there are several steps you can take to ensure that your application is designed for scalability, resilience, and agility. Here are some general steps you can follow:
1. Choose a cloud platform: Select a cloud platform that meets your needs and provides the services and features you require. Some popular cloud platforms include Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform (GCP).
2. Define your architecture: Define the architecture of your application, including the components, services, and data stores that you will use. Consider using microservices architecture, which can help you build more scalable and resilient applications.
3. Use containers: Use containers to package your application and its dependencies, making it easier to deploy and manage your application across different environments.
4. Use container orchestration: Use a container orchestration platform like Kubernetes to manage your containers and ensure that your application is highly available and scalable.
5. Use automation: Use automation tools like Ansible, Terraform, or CloudFormation to automate the deployment and management of your application.
6. Use monitoring and logging: Use monitoring and logging tools to track the performance and health of your application, and to identify and troubleshoot issues.
7. Use security best practices: Follow security best practices to ensure that your application is secure and protected from attacks.
By following these steps, you can build a cloud-native application that is designed for scalability, resilience, and agility, and that can provide a better experience for your users.
## First cloud-native project?[](#first-cloud-native-project "Direct link to First cloud-native project?")
**Prompt** : What is a simple project I can use for my first cloud-native project?
**GitHub Copilot** : A simple project that you can use for your first cloud-native project is a web application that allows users to create and manage to-do lists. This project can be built using a microservices architecture, with separate services for user authentication, to-do list management, and data storage.
**My perspective**
A todo list is perfect, there are plenty of examples:
- [Todo backend](https://todobackend.com/)
- [TodoMVC](https://todomvc.com/)
- [Swagger API spec](https://github.com/nickfun/learning-guardrail/blob/master/server.yaml)
- [Postman collection of tests](https://github.com/nickfun/learning-guardrail/blob/master/postman-collection.json)
## Architecture[](#architecture "Direct link to Architecture")
**Prompt** : Can you suggest a beginning architecture of a todo app which is cloud-native?
**GitHub Copilot** : here's a beginning architecture for a cloud-native to-do app:
1. Frontend: A web or mobile app that allows users to create and manage to-do lists. The frontend can be built using a framework like React, Angular, or Vue.js.
2. API Gateway: An API gateway that serves as the entry point for the application and routes requests to the appropriate microservices. The API gateway can be built using a tool like Kong, Istio, or AWS API Gateway.
3. Authentication Service: A microservice that handles user authentication and authorization. This service can be built using a tool like Auth0, Okta, or AWS Cognito.
4. To-Do Service: A microservice that handles the creation, retrieval, updating, and deletion of to-do items. This service can be built using a framework like Express.js, Spring Boot, or Flask.
5. Database: A database that stores the to-do items and user information. The database can be a SQL or NoSQL database like MySQL, PostgreSQL, MongoDB, or DynamoDB.
6. Container Orchestration: A container orchestration platform like Kubernetes that manages the deployment and scaling of the microservices. Kubernetes can be used to deploy the microservices as Docker containers and manage their lifecycle.
7. Monitoring and Logging: A monitoring and logging solution like Prometheus, Grafana, or ELK Stack that provides visibility into the performance and health of the application.
By following this architecture, you can build a cloud-native to-do app that is designed for scalability, resilience, and agility, and that can provide a better experience for your users.
## More resources[](#more-resources "Direct link to More resources")
Read the full conversation: [Cloud native repo - introduction](https://bit.ly/40aclp8). | dfberry |
1,648,495 | Servlets & Filters - SpringSecurity | Servlets In Java web apps, Servlet container (web server) takes care of translating the... | 25,203 | 2023-10-27T16:23:56 | https://dev.to/vijay2249/servlets-filters-springsecurity-2ocd | springsecurity, java, backend, codenewbie |
### Servlets
In Java web apps, Servlet container (web server) takes care of translating the HTTP messages for
java code to understand. One of mostly used servlet container is Apache Tomcat.
Servlet Container converts the HTTP messages into ServletRequest and hand over to Servlet method as a parameter
Similarly, ServletResponse returns as an output to Servlet Container from Servlet. So everything we write inside the Java web apps are driven by Servlets
---
### Filters
Filters inside Java Web Applications can be used to intercept each request/response and do some pre-work before our business logic. So using the same filters, Spring Security enforce security based on our configurations inside a web application
---
### Spring Security Internal Flow
#### Spring Security Filters
A series of spring security filters intercept each request and work together to identify if authentication is required or not.
If authentication is required, accordingly navigate the user to login page or use the existing details stored during the initial authentication
#### Authentication
Filters like _UsernamePasswordAuthenticationFilter_ will extract username/password from HTTP request and prepare Authentication type object. Because Authentication is the core standard of storing authenticated user details inside Spring Security Framework
#### AuthenticationProvider
AuthenticationProviders has all the core logic of validating user details for authentication
#### UserDetailsManager/UserDetailsService
UserDetailsManager/UserDetailsService helps in retrieving, creating, updating, deleting the User details from the DB/storage systems
#### PasswordEncoder
Service interface that helps in encoding and hashing passwords. Otherwise we may have to live with plain text passwords
#### SecurityContext
Once the request has been authenticated, the Authentication will usually be stored in a thread-local SecurityContext managed by the SecurityContextHolder.
This helps during the upcoming requests from the same user
---
## Sequence Flow
--> Request --> \[\<Authentication Filters> {AuthorizationFilter, DefaultLoginPageGeneratingFilter, UsernamePasswordAuthenticationFilter}] --> Extract User Credentials --> \[\<Authentication>{UsernamePasswordAuthenticationToken}] --> authenticate() --> \[\<AuthenticationManager>{ProviderManager}] --> authenticate() --> \[\<AuthenticationProvider>{DaoAuthenticationProvider}] --> loadUserByUsername() -->\[\<UserDetailsService>{InMemoryUserDetailsManager}] --> UserDetails --> \[\<AuthenticationProvider>{DaoAuthenticationProvider}] --> Authentication --> \[\<AuthenticationManager>{ProviderManager}] --> Authentication --> \[\<Authentication>{UsernamePasswordAuthenticationToken} --> Authentication --> \[\<Authentication Filters> {AuthorizationFilter, DefaultLoginPageGeneratingFilter, UsernamePasswordAuthenticationFilter}] --> Response
| vijay2249 |
1,648,647 | My third Pull Request in Hacktoberfest23 | I have finished two PRs before, here is my third! My First Pull Request in Hacktoberfest23 My... | 0 | 2023-10-27T18:09:19 | https://dev.to/wanggithub0/third-pull-request-in-hacktoberfest23-4oic | hacktoberfest, hacktoberfest23 | I have finished two PRs before, here is my third!
1. [My First Pull Request in Hacktoberfest23](https://dev.to/wanggithub0/my-first-pull-request-in-hacktoberfest23-34d5)
2. [My second hacktoberfest PR](https://dev.to/wanggithub0/my-second-hacktoberfest-pr-158a)
This time I worked on project [Klaw-docs](https://github.com/Aiven-Open/klaw-docs), which is a cool [project](https://www.klaw-project.io/) to handle Governance, Security and meta storage and it's Klaw Cluster API can handle the connections to the Apache Kafka, Apache Kafka Connect and Schema Registry servers.
I worked on the [issue](https://github.com/Aiven-Open/klaw-docs/issues/101) Update docs to use the term "API" correctly. First, the issue description is clear, I knew I should change all the "api" to "API", and I also learned they can use Vale config to get all the error places and I can check by using `npm run spell:error`.
In order to finish this work, I also searched [Vale](https://github.com/errata-ai/vale) and get Vale is a powerful tool designed for spell checking and style enforcement in written content, including documentation, code, and more. It helps ensure that text is free of spelling errors and conforms to specific writing style guidelines, making your documentation and content more polished and professional. Vale can be a valuable asset in maintaining the quality and consistency of written materials, making it a useful addition to your writing and documentation toolkit.
After understanding these, I began to create the [PR](https://github.com/Aiven-Open/klaw-docs/pull/136) and add `API ("(?i)api")` from branding-warning-temp.yml to branding.yaml, and revised all the errors, I thought I have finished the issue, but author told me there were some file path which should not change and also add the backticks to ensure the directory and link. After author reviewing again, I still got an error, so I revised and push the third time. But I still got some errors after review. At last, I revised and push the forth time.
Throughout the entire process, I learned about various other software tools, which significantly broadened my horizons. I also went through the process of updating my Pull Request (PR) four times. This experience taught me the importance of thinking comprehensively and paying attention to details. What truly touched me was the author's diligent reviews and their consistent encouragement and gratitude in each review. I learned a lot from this experience, not only about software development but also about the value of thoroughness and collaboration.
| wanggithub0 |
1,648,694 | Developers are Burning out Daily, Find Out Why! | Programmers are the backbone of the tech industry, yet burnout among developers has become... | 0 | 2023-10-27T19:24:06 | https://blog.learnhub.africa/2023/10/27/developers-are-burning-out-daily-find-out-why/ | developer, beginners, programming, tutorial | <p data-pm-slice="1 1 []">Programmers are the backbone of the tech industry, yet burnout among developers has become increasingly concerning. Studies show that over 5<strong>0% of programmers report feeling moderate to high levels of burnout related to their jobs. </strong></p>
This epidemic of exhaustion threatens the health of developers and the innovation and progress of the entire tech sector. In this article, we’ll explore the causes, impacts, and potential solutions to address the programmer burnout crisis.
<blockquote>Learn how to <a class="attrlink" href="https://blog.learnhub.africa/2023/10/27/securing-nodemailer-with-proper-authentication/" target="_blank" rel="noopener noreferrer nofollow">Secure Nodemailer with Proper Authentication</a>.</blockquote>
<h4>Causes of Programmer Burnout</h4>
What’s driving so many developers to the point of total exhaustion? Experts point to several key factors:
<ul>
<li>Work Overload: Programming is mentally demanding work that requires intense concentration and problem-solving skills. As demand for new software and apps skyrockets, many developers are asked to work longer hours, which leads to fatigue and burnout over time.</li>
</ul>
<ul>
<li>Tight Deadlines: Unrealistic deadlines and last-minute requests force developers to work nights and weekends to meet release dates. Cramming work into such a short timeframe is unsustainable.</li>
</ul>
<ul>
<li>Constant Reskilling: Programmers must constantly learn new languages, frameworks, and methodologies to keep their skills sharp. However, the pace of change makes it feel like the reskilling never ends, which is draining.</li>
</ul>
<ul>
<li>Lack of Autonomy: Developers often lack autonomy over their work or how to reach solutions. Rigid processes combined with micromanagement sap motivation and enjoyment.</li>
</ul>
<ul>
<li>Poor Work-Life Balance: Programming requires deep focus. However, with constantly connected devices, developers find it hard to “switch off” after work hours, leading to longer days and weekend work.</li>
</ul>
<ul>
<li>Job Instability: The tech industry is prone to churn. Startups fold while established companies conduct frequent layoffs. The uncertainty adds huge stress for developers.</li>
</ul>
<h4>Impacts of Programmer Burnout</h4>
Burnout not only affects the individual programmer but also has consequences for companies and even the wider tech landscape. Some key impacts include:
<ul>
<li>Health Issues: Prolonged and intense stress leads to physical and mental health problems like insomnia, anxiety, depression, heart disease, and more.</li>
<li>Turnover: Developers suffering from burnout are likelier to quit their jobs in pursuit of less stressful roles. Replacing developers is expensive for companies.</li>
<li>Lower Productivity: Exhausted programmers have lower morale and get less coding work done. Critical projects fall behind schedule.</li>
<li>Poor Code Quality: Burned-out developers tend to produce low-quality, buggy code since they lack the energy for thorough testing and reviews.</li>
<li>Lack of Innovation: Creativity and problem-solving require mental clarity. Burnt-out developers are less likely to come up with innovative coding solutions.</li>
</ul>
The costs of burnout on developers’ wellbeing and career trajectories are huge. Meanwhile, companies hemorrhage talent and end up with buggy products. All of this slows advancement in software engineering.
<h4>Potential Solutions for Programmer Burnout</h4>
How can developers, managers, and companies aim to reduce burnout and promote sustainable, healthy working practices in the tech industry? Some strategies include:
<ul>
<li>Setting Reasonable Deadlines: Managers should set realistic release dates instead of overly ambitious ones and prioritize tasks rather than overwhelming developers.</li>
</ul>
<ul>
<li>Supporting Work-Life Balance: Companies can encourage developers to take time off, pursue hobbies, and spend time with family. Flexible schedules help, too.</li>
</ul>
<ul>
<li>Providing Autonomy: Developers should have some control over their tasks and freedom in approaching solutions. This boosts engagement.</li>
</ul>
<ul>
<li>Offering Professional Development: Companies can provide time and resources for programmers to upskill through classes, conferences, and certifications. This helps combat stagnation.</li>
</ul>
<ul>
<li>Conducting Anonymous Surveys: Annual surveys allow developers to share concerns honestly. Managers can then address common burnout causes.</li>
</ul>
<ul>
<li>Promoting Remote Work Options: Flexibility when and where developers work enables better work-life balance and reduced stress.</li>
</ul>
<ul>
<li>Improving Communication: When managers provide context for tasks and welcome feedback, developers feel heard and included rather than dumped on.</li>
</ul>
<ul>
<li>Focusing On Health: Companies can offer counseling, stress management workshops, office well-being facilities like gyms, and benefits like nutritional supplements.</li>
</ul>
<ul>
<li>Leveraging Automation: Automating repetitive coding tasks through AI frees up developers’ time and mental energy for higher-value innovative work.</li>
</ul>
<ul>
<li>Fostering Community: Peer networks, mentorship programs, and social events help developers feel connected and supported day-to-day.</li>
</ul>
With collaborative efforts across the industry, companies can curtail the programming burnout epidemic.
Developers deserve fulfilling careers where their essential contributions are valued. Reducing burnout will boost productivity, innovation, and worker wellbeing over the long term. The solutions require commitment, but the rewards merit the investment.
<h4>Conclusion</h4>
Programmer burnout has reached critical levels but need not become the norm. While developing complex, innovative software will always require hard work, and developers deserve support to do their jobs sustainably.
By implementing strategies like reasonable deadlines, professional development, work-life balance, autonomy, and health resources, companies can promote engagement over exhaustion.
With teamwork, understanding, and proactive change, we can cultivate an empowered population of passionate, dedicated programmers. The entire tech ecosystem stands to gain from tackling programmer burnout head-on.
wp-rss-aggregator feeds="learnhub” | scofieldidehen |
1,648,711 | AdMob Banner Ads Impacting Android Vitals: Seeking Solutions and Alternatives | We are encountering the following Android vitals issues: Slow warm start (4%) Excessive frozen... | 0 | 2023-10-27T20:07:45 | https://dev.to/yccheok/admob-banner-ads-impacting-android-vitals-seeking-solutions-and-alternatives-jd9 | android | We are encountering the following Android vitals issues:
- Slow warm start (4%)
- Excessive frozen frames (12%)
These issues are more prevalent on devices with xhdpi screen density (DPI).
We believe the root cause is the banner ads from AdMob. When we disabled the banner ads from AdMob, we noticed a decline in these issues.
I suspect that AdMob might be using the WebView component for rendering, which is known to be resource-intensive and can affect performance.
AdMob accounts for 50% of our total revenue, so disabling it entirely would have a significant impact on our earnings. However, we also recognize the importance of Android vitals for our app's ranking in the Google Play store.
Has anyone else experienced similar problems with AdMob? And would switching to native ads potentially address these concerns?
Thank you. | yccheok |
1,648,865 | An open-source user interface for the Easegress traffic orchestration system | Easegress Portal Easegress Portal is an intuitive, open-source user interface for the... | 0 | 2023-10-28T15:10:49 | https://reactjsexample.com/an-open-source-user-interface-for-the-easegress-traffic-orchestration-system/ | admintemplate | ---
title: An open-source user interface for the Easegress traffic orchestration system
published: true
date: 2023-10-28 00:16:00 UTC
tags: AdminTemplate
canonical_url: https://reactjsexample.com/an-open-source-user-interface-for-the-easegress-traffic-orchestration-system/
---
# Easegress Portal
Easegress Portal is an intuitive, open-source user interface for the [Easegress](https://github.com/megaease/easegress) traffic orchestration system. Developed with React.js, this portal provides config management, metrics, and visualizations, enhancing the overall Easegress experience.
## Features
- **Intuitive User Interface:** Built with React.js—one of the most popular and efficient JavaScript libraries—our portal provides a smooth, user-friendly experience. Navigate, manage, and monitor with ease.
- **Unified Configuration Management:** Graphical representation of core Easegress concepts ensures intuitive control over configurations and monitoring data. Directly import native Easegress configurations and manage them through a straightforward interface.
- **Fully Open-Source, Easy Contributions:** We’ve open-sourced the entire Easegress Portal. Dive into the code, customize according to your needs, and join us in refining and expanding its capabilities. Developed with React.js and best practices, it’s convenient for developers to contribute or customize.
- **Seamless Integration:** The portal integrates directly with the Easegress API without the need for middleware. We also offer a Docker Image for a one-click start-up.
## Getting Started
First, run the development server:
```
npm run dev
# or
yarn dev
# or
pnpm dev
# or
bun dev
```
Open [http://localhost:3000](http://localhost:3000) with your browser to see the result.
You can start editing the page. The page auto-updates as you edit the file.
## Using Docker
**1. [Install Docker](https://docs.docker.com/get-docker/) on your machine.**
**2. Build your container:**
```
docker build -t megaease/easegress-portal -f rootfs/Dockerfile .
```
**3. Run your container:**
```
docker run -p 3000:3000 megaease/easegress-portal
```
You can view your images created with `docker images`.
## Screenshots
**1. Cluster Management**

**2. Traffic Management**


**3. Pipeline Management**



**4. Controller Management**

**5. Logs**

## Community
- [Join Slack Workspace](https://join.slack.com/t/openmegaease/shared_invite/zt-upo7v306-lYPHvVwKnvwlqR0Zl2vveA) for requirement, issue and development.
- [MegaEase on Twitter](https://twitter.com/megaease)
## Contributing
See [Contributing guide](https://github.com/megaease/easegress-portal/blob/main/CONTRIBUTING.md).
## License
Easegress is under the Apache 2.0 license. See the [LICENSE](https://github.com/megaease/easegress-portal/blob/main/LICENSE) file for details.
## GitHub
[View Github](https://github.com/megaease/easegress-portal?ref=reactjsexample.com) | mohammadtaseenkhan |
1,648,936 | React Search Using-Debounce | import React from 'react' class App extends React.PureComponent { state = { name: 'Zeeshan', ... | 0 | 2023-10-28T04:05:02 | https://dev.to/zeeshanali0704/react-search-using-debounce-235a | javascript, react | ```js
import React from 'react'
class App extends React.PureComponent {
state = {
name: 'Zeeshan',
todo: [],
filteredTodo: [],
query: '',
}
componentDidMount() {
fetch('https://jsonplaceholder.typicode.com/todos')
.then((resp) => {
return resp.json()
})
.then((jsonResponse) => {
this.setState({
todo: jsonResponse,
filteredTodo: jsonResponse,
})
})
}
debounceTodoSearch(func, delay) {
let timer
return function () {
let context = this
let args = arguments
clearTimeout(timer)
timer = setTimeout(() => {
func.apply(context, args)
}, delay)
}
}
seachTodo = (val) => {
let todoTemp = [...this.state.todo]
let todos = todoTemp.filter((eachTodo) => eachTodo?.title.includes(val))
this.setState({
filteredTodo: todos,
})
}
handleSearch = (event) => {
let val = event?.target?.value
this.setState({
query: val,
})
this.debounceTodoSearch(this.seachTodo, 5000)(val)
}
render() {
return (
<>
<div>
Seach Todo
<input
type="text"
value={this.state.query}
onChange={this.handleSearch}
/>
</div>
<div>List of Todo's</div>
<ul>
{this.state.filteredTodo?.map((eachTodo) => {
return <li key={eachTodo.id}>{eachTodo.title}</li>
})}
</ul>
</>
)
}
}
export default App
```
| zeeshanali0704 |
1,649,069 | Placeholder Contributor | Intro Highs and Lows Growth | 0 | 2023-10-28T08:49:38 | https://dev.to/pranavupadhyay123/placeholder-contributor-1fnj | hack23contributor | <!-- ✨This template is only meant to get your ideas going, so please feel free to write your own title, structure, and words! ✨ -->
### Intro
<!-- Share a bit about yourself as a contributor. Is this your first Hacktoberfest, or have you contributed to others? Feel free to embed your GitHub account by using {% embed LINK %} -->
### Highs and Lows
<!-- What were some of your biggest accomplishments or light-bulb moments this month? Did any problems come up that seemed impossible to fix? How did you adapt in those cases? -->
### Growth
<!-- What was your skillset before Hacktoberfest 2023 and how did it improve? Have your learning or career goals changed since working on these new projects? --> | pranavupadhyay123 |
1,649,084 | Phrases in Programming That Irk Me | Irksome Lingo It is common amongst the non-executive types to deride so-called... | 0 | 2023-11-19T03:59:34 | https://jamescooper.net.nz/posts/developerexecuspeak/ | lexicon, programming, rants, softwaredevelopment | ---
title: Phrases in Programming That Irk Me
published: true
date: 2023-10-28 00:00:00 UTC
tags:
- Lexicon
- Programming
- Rants
- SoftwareDevelopment
canonical_url: https://jamescooper.net.nz/posts/developerexecuspeak/
---
## Irksome Lingo
It is common amongst the non-executive types to deride so-called 'execu-speak'. That is, words and phrases which sound trite, stupid or (sometimes) like disingenuous euphemisms. While there can sometimes be some justification for such criticism, quite a lot of that vocabulary is simply, in essence, the jargon of that field. Software developers are actually at least as equally guilty of overusing sayings, re-using lexicon from somewhere else such that it makes little sense in the original context,[^agileeverything] and just plain using words and phrases that irritate me. I present below an incomplete list of said words and phrases in alphabetical order, with a brief description of why each one irritates me. I imagine that you find some of them perfectly fine or useful terms of art, and probably some things I say would irritate you.
[^agileeverything]: So very many terms that were seemingly first used in Agile have fallen victim to this. Perhaps, because like almost everything that was labelled Agile (but usually specifically meant Scrum), people got so indoctrinated that they don't understand there's other ways of saying and doing things.
Also, I'm likely to keep updating this over time, so you if you like some of this, you might be interested in coming back periodically.
### B
#### Battle-tested
This is just so darn overblown and self-aggrandizing. There's an extremely high likelihood that your code won't actually be used in a battle, so why are you talking about it going to war? If you really were developing software which could be used in a real-life battle, the idea of programming in Ada wouldn't sound weird and foreign to you. You likely wouldn't be programming to run in the cloud however, much more likely you'd be developing for an embedded subsystem of some military vehicle. So if it's incredibly unlikely people will die as a direct consequence of bugs in your code, stop describing it in military terms, you tosspots.
Those people who develop software for military purposes and have seen it come out the other side smelling of rainbows really can use the phrase "battle-tested" because it's true. All the rest of you: find something less insulting to people on the front lines of the world's conflicts.
### R
#### Rich
Everything seems to be "rich" lately. Type systems, core libraries, user interfaces, the small group of people that tech firms actually give a hoot about. In some circumstances, using the word does somewhat make sense, but it's another one that has been overused to the point of meaninglessness. Much like when you keep repeating the same word over and over until it just sounds weird (I _think_ that is referred to as 'semantic satiation').
### S
#### Single Pane of Glass
I get why this one was originally coined. It was possibly meant to refer to the actual panes of glass used in old CRT monitors, or just the idea that you have one window onto a situation through which you looked for everything. It's just that this one has been used _ad nauseam_, so it bugs me.
#### Story
I remember reading a rant many years ago from a then-software developer complaining that absolutely everything was being described as a "solution", even when that made basically no sense. I vaguely recall the phrase "a paperclip is not a solution." The word "story" seems to have replaced "solution" for this purpose. Everything now either is a story, or has a story. "What's the story around 'X' concept in 'Y' programming language?" "Does 'P' have a good story for 'Q'?" No, it reads and sounds like Rushdie's 'The Satanic Verses'—incoherent and incredibly dull.[^satanicverses] Pretty much every time I hear someone use story in this sort of fashion it bugs me intensely.
[^satanicverses]: Yes, I really have read 'The Satanic Verses' by Salman Rushdie. I wouldn't recommend it. It is incredibly obtuse and boring. I wonder that muslims weren't so stirred up by it because it's such a waste of one's time, rather than because of the thinly-veiled blasphemy. If you're thinking about reading it, go read the dictionary instead. It's no more dull, can be shorter depending on which version you have, and at least you'll learn something.
I think this is one of those misused words that came straight out of Agile (or one of the things it kinda sorta amalgamated, or one of the things that latched onto it) with user stories. Which, while I find horrendously overused in some ways (not every single task description needs some inane, tortuous, imagined novella from the perspective of a nonsensical character), does in and of itself make sense. Somehow, though, the use of the word story leaked out and spread its smelly, greasy oil slick over our pristine beach, but celebrities have cleaned all the cute animals in media-friendly photo opportunities, and I'm left metaphorically scrubbing with only a toothbrush mucky rock after mucky rock of people misuing the word "story".
Honestly, this is probably the one which bugs me the most of anything, because ALMOST ALWAYS WHEN SOMEONE SAYS "STORY" IN SOFTWARE DEVELOPMENT THESE DAYS IT MAKES NO FREAKING SENSE.
## Some Things That You Might Think Would Bug Me, But Actually Don't
### B
#### Bikeshedding
Ok, this one does kinda irritate me because I hate people turning other types of words into verbs like that. I would prefer something like "discussing the colour of the bike sheds to death" instead, but that's rather more of a mouthful, so I can appreciate why it ended up that way. The idea behind the phrase is good, though, because it does communicate well something that happens in meetings and discussions the world over. Namely, that people really do have a tendency to fixate on trivial details and speculate on irrelevant matters when they should be focusing on much weightier, but less straightforward, issues. I don't have any better way to describe the idea than this, yet I observe it frequently in practice.
### Y
#### Yak Shaving
This phrase actually sounds pretty stupid, and doesn't really give you any concept of its meaning when you first read it. It actually does (kinda) make sense, however – sitting there trying to shave a yak does seem like it would be awfully tedious and maybe feel a bit pointless – and it covers something that there isn't really another phrase for. Plus, it gets a bit of a free pass from me since it's a Ren & Stimpy reference. | countable6374 |
1,649,256 | Roll your own auth with Rust and Protobuf | Introduction Before starting, take a deep breath, maybe 5 minutes of meditation and... | 0 | 2023-10-28T15:58:33 | https://dev.to/martinp/roll-your-own-auth-with-rust-and-protobuf-3f78 | ## Introduction
Before starting, take a deep breath, maybe 5 minutes of meditation and prepare a drink because this tutorial imply Rust code. Not complex, but Rust code.
But first, let's talk about Protobuf, what is it?
### 1. What is Protobuf?
According to the documentation:
> "Protocol Buffers are language-neutral, platform-neutral extensible mechanisms for serializing structured data."
JSON is really flexible when you want to share data through services you can decode JSON without knowing it's structure first.
But it is unstructured, takes a lot of space and bandwith.
With Protocol Buffers you define a message and its structure that must be known by both the server and the client to encode and decode.
```proto
// user.proto
syntax = "proto3";
message User {
string firstname = 1;
string lastname = 2;
string email = 3;
}
```
You can then use generators to create the SDKs for your favorites languages. You can generate a Javascript one for your frontend and a Rust one for your backend.
If you are using Remote Procedure Call (RPC) like gRPC, you can leverage the features of Protobuf and the generators to automatically generate interfaces and code for both your client and server SDKs.
The only thing you have to do next, is implement the methods of your services.
```proto
// user.proto
syntax = "proto3";
message LoginRequest {
string email = 1;
string password = 2;
}
service Auth {
rpc Login (LoginRequest) returns (User);
}
```
### 2. What are you we to accomplish
1. Create a PostgreSQL database using Docker and Docker compose
2. Create Protobuf definitions and use Buf to generate the SDKs
3. Setup a gRPC server in Rust using Tonic
4. Create a JWT authentication system with Diesel and Tonic
### 3. Requirements
You must have a basic understanding of Rust, I will not deep dive into how to write Rust. As I am myself, a Rust beginner. But I encourage you to check the different crates documentation to have a better understanding on how everything works.
You must know [how JWT works](https://jwt.io/introductionhttps://jwt.io/introduction) as I will not explain it in this blog post.
You must have all the required tools installed:
- [Docker](https://docs.docker.com/get-docker/)
- [Rust (rustup, cargo, etc)](https://www.rust-lang.org/tools/install)
- [grpcurl](https://github.com/fullstorydev/grpcurl)
If you are lost somewhere, or you directly want to go straigth to the code, the repository is available here [https://github.com/kerwanp/rust-proto-demo](https://github.com/kerwanp/rust-proto-demo).
## Get started
### 1. Create the PostgreSQL database
As we want to persist our users we need a database. We are going to use PostgreSQL.
For simplicity of use, we will use Docker Compose to manage it. Make sure you have [Docker](https://docs.docker.com/get-docker/) installed before.
In your root folder add the following `docker-compose.yml` file:
```yml
# docker-compose.yaml
version: "3"
services:
db:
image: postgres
restart: always
ports:
- "5432:5432"
environment:
POSTGRES_USER: rustproto
POSTGRES_PASSWORD: rustproto
```
You can then run the command `docker compose up -d` to start your database (`-d` will start it in background mode).
### 2. Create the Protobuf definitions
Protobuf definitions allows 2 things:
- Define how gRPC server and client communicate together
- Generate SDKs using Protobuf generators
We will store them in a folder called `proto`
#### Creating the Auth service Protobuf definitions
We will need two methods in our service:
- `Register`: To create a new user. It returns a `Token`.
- `Login`: To generate a new `Token` if credentials are valid.
```proto
// proto/auth.proto
syntax = "proto3";
package auth;
message LoginRequest {
string username = 1;
string password = 2;
}
message RegisterRequest {
string firstname = 1;
string lastname = 2;
string email = 3;
string password = 4;
}
message Token {
string access_token = 1;
}
service Auth {
rpc Login (LoginRequest) returns (Token);
rpc Register (RegisterRequest) returns (Token);
}
```
#### Creating the Greeting service definitions
To test that our authentication works we need a random service that will throw an unauthenticated status if the access token is invalid.
```proto
// proto/greeting.proto
syntax = "proto3";
package greeting;
message GreetRequest {
string message = 1;
}
message GreetResponse {
string message = 1;
}
service Greeting {
rpc Greet (GreetRequest) returns (GreetResponse);
}
```
### 3. Setup Buf to generate SDKs
To generate SDKs we have different solutions:
- Use [tonic-build](https://github.com/hyperium/tonic/tree/master/tonic-build) directly from Rust.
- Use the Protobuf CLI [protoc](https://github.com/protocolbuffers/protobuf) and the plugin [protoc-gen-tonic](https://crates.io/crates/protoc-gen-tonic).
- Use [Buf CLI](https://buf.build/docs/ecosystem/cli-overview) to manage the SDKs generation.
The first two solutions would fit perfectly but as we want to overengineer our authentication system and think of the not coming future we will use the [Buf CLI](https://buf.build/docs/ecosystem/cli-overview).
So make sure to [install it](https://buf.build/docs/installation).
#### Create the module configuration
Buf CLI works with [workspaces and modules](https://buf.build/docs/reference/workspaces#configuration) to easily split our protobuf definitions (by APIs, microservices, etc).
Let's make our `proto` folder our lonely module by creating a `buf.yaml` file with the following line:
```yml
# proto/buf.yaml
version: v1
```
#### Create the workspace configuration
Now we need to configure our Buf workspace by creating a `buf.work.yaml` at the root of our project:
```yml
# buf.work.yaml
version: v1
directories:
- proto # <- We define our module in the workspace
```
#### Create the generator configuration
We will use four generators:
- [protoc-gen-prost](https://github.com/neoeinstein/protoc-gen-prost/blob/main/protoc-gen-prost) The core code generation plugin
- [protoc-gen-serde](https://github.com/neoeinstein/protoc-gen-prost/blob/main/protoc-gen-prost-serde) Canonical JSON serialization of protobuf types
- [protoc-gen-tonic](https://github.com/neoeinstein/protoc-gen-prost/blob/main/protoc-gen-tonic) gRPC service generation for the Tonic framework
- [protoc-gen-prost-crate](https://github.com/neoeinstein/protoc-gen-prost/blob/main/protoc-gen-prost-crate) Generates an include file and cargo manifest for turn-key crates
Let's install them all using the following command:
```bash
$ cargo install protoc-gen-prost protoc-gen-prost-serde protoc-gen-tonic protoc-gen-prost-crate
```
Then, create the `buf.gen.yaml` file to configure the SDKs generation:
```yml
# buf.gen.yaml
version: v1
plugins:
- plugin: prost # Generates the core code
out: gen/src
opt:
- bytes=.
- compile_well_known_types
- extern_path=.google.protobuf=::pbjson_types
- file_descriptor_set
- plugin: prost-serde # Generates code compatible with JSON serde
out: gen/src
- plugin: tonic # Generates the Tonic services
out: gen/src
opt:
- compile_well_known_types
- extern_path=.google.protobuf=::pbjson_types
- plugin: prost-crate # Makes the gen folder a crate
out: gen
opt:
- gen_crate=gen/Cargo.toml
```
We now need to create the `Cargo.toml` that will be used as a template to generate the new one.
For simplicity we will use the generated one as a template so it can be replaced.
```toml
# gen/Cargo.toml
[package]
name = "protos"
version = "0.1.0"
edition = "2021"
[features]
default = ["proto_full"]
# @@protoc_deletion_point(features)
# This section is automatically generated by protoc-gen-prost-crate.
# Changes in this area may be lost on regeneration.
# @@protoc_insertion_point(features)
[dependencies]
bytes = "1.1.0"
prost = "0.12"
pbjson = "0.6"
pbjson-types = "0.6"
serde = "1.0"
tonic = { version = "0.10", features = ["gzip"] }
```
We can now generate our crate using the command `buf generate`.
🎉 Our SDK is now ready!
### 4. Setup the Rust project
Now that we have our SDK we can start creating the core of our server.
First create a `Cargo.toml` file and add our generate crate to the dependencies aswell as all the requirements for this project.
```toml
[package]
name = "proto-auth-demo"
version = "0.1.0"
edition = "2021"
[dependencies]
diesel = { version = "2.1.3", features = ["postgres"] }
dotenvy = "0.15.7"
prost = "0.12.1"
protobuf = "3.3.0"
serde = "1.0.190"
tokio = { version = "1.33.0", features = ["full"] }
tonic = "0.10.2"
protos = { path = "./gen" }
bcrypt = "0.15.0"
jwt = "0.16.0"
hmac = "0.12.1"
sha2 = "0.10.8"
[workspace]
members = [
"gen"
]
```
We will need two environment variables:
- `DATABASE_URL`: To authenticate to our PostgreSQL database
- `APP_KEY`: To encrypt user passwords
Store them in a `.env` file, we will use them later using the [dotenvy crate](https://docs.rs/dotenvy/latest/dotenvy/).
```env
# .env
DATABASE_URL=postgres://rustproto:rustproto@localhost/rustproto
APP_KEY="9E3CnfSfsi9BGfX3Dea#tkbs#nDj&6d#6Y&jhNa!"
```
And we can now create our `main.rs` file:
```rust
// src/main.rs
use dotenvy::dotenv;
#[tokio::main]
async fn main() -> Result<(), Box<dyn std::error::Error>> {
dotenv().ok();
Ok(())
}
```
And build our project using `cargo build`.
### 5. Use Diesel to manage our users
#### Setup Diesel
First install the [Diesel CLI](https://diesel.rs/guides/getting-started) using the following command:
```bash
$ cargo install diesel_cli
```
> You may need to install `libpq-dev`, `libmysqlclient-dev` and `libsqlite3-dev` to install the CLI.
Create the migrations folder:
```bash
$ diesel setup
```
And add the following lines to the top of your `main.rs` (we will create those modules later):
```rust
// src/main.rs
mod models;
mod schema;
```
#### Create the migration
Let's first generate the migration to create and drop the `users` table.
```bash
$ diesel migration generate create_users
```
```sql
-- migrations/*-create_users/up.sql
CREATE TABLE users (
id SERIAL PRIMARY KEY,
email VARCHAR(255) UNIQUE NOT NULL,
password VARCHAR(255) NOT NULL,
firstname VARCHAR(255) NOT NULL,
lastname VARCHAR(255) NOT NULL
);
```
```sql
-- migrations/*-create_users/down.sql
DROP TABLE users;
```
And run the following command to run the migrations and generate the `schema.rs` file:
```bash
$ diesel migration run
```
#### Create the User model
Create a new file `src/models.rs` and add our User model to it and implements the methods to create a new User and find one by email.
```rust
// src/models.rs
use diesel::{
ExpressionMethods, Insertable, PgConnection, QueryDsl, Queryable, RunQueryDsl, Selectable,
SelectableHelper,
};
use crate::schema::users;
#[derive(Queryable, Selectable)]
#[diesel(table_name = users)]
#[diesel(check_for_backend(diesel::pg::Pg))]
pub struct User {
pub id: i32,
pub firstname: String,
pub lastname: String,
pub email: String,
pub password: String,
}
#[derive(Insertable)]
#[diesel(table_name = users)]
pub struct NewUser<'a> {
pub firstname: &'a str,
pub lastname: &'a str,
pub email: &'a str,
pub password: &'a str,
}
impl User {
pub fn create(
conn: &mut PgConnection,
firstname: &str,
lastname: &str,
email: &str,
password: &str,
) -> Result<User, diesel::result::Error> {
let new_user = NewUser {
firstname,
lastname,
email,
password,
};
diesel::insert_into(users::table)
.values(new_user)
.returning(User::as_returning())
.get_result(conn)
}
pub fn find_by_email(conn: &mut PgConnection, email: &str) -> Option<User> {
users::dsl::users
.select(User::as_select())
.filter(users::dsl::email.eq(email))
.first(conn)
.ok()
}
}
```
#### Create the database connection
We now have to setup the database connection and we will be done with Diesel.
```rust
// src/main.rs
use std::env;
use diesel::{PgConnection, Connection};
use dotenvy::dotenv;
mod models;
mod schema;
pub fn connect_db() -> PgConnection {
let database_url = env::var("DATABASE_URL").expect("DATABASE_URL must be set");
PgConnection::establish(&database_url)
.unwrap_or_else(|_| panic!("Error connecting to {}", database_url))
}
#[tokio::main]
async fn main() -> Result<(), Box<dyn std::error::Error>> {
dotenv().ok();
let mut database = connect_db();
Ok(())
}
```
> You can try it by creating a user using the database connection `User.create(&mut database, "", "", "", "")`
### 5. Implement the Tokio Services
It is now time to create the business logic for our authentication system.
We will start with the biggest part, the authentication.
#### Create the skeleton
```rust
use std::sync::{Arc, Mutex};
use diesel::PgConnection;
use protos::auth::{auth_server::Auth, LoginRequest, Token, RegisterRequest};
use tonic::{Request, Response, Status};
use crate::models::User;
pub struct Service {
database: Arc<Mutex<PgConnection>>,
}
impl Service {
pub fn new(database: PgConnection) -> Self {
Self {
database: Arc::new(Mutex::new(database))
}
}
fn generate_token(user: User) -> Token {
unimplemented!();
}
}
#[tonic::async_trait]
impl Auth for Service {
async fn login(&self, request: Request<LoginRequest>) -> Result<Response<Token>, Status> {
unimplemented!();
}
async fn register(&self, request: Request<RegisterRequest>) -> Result<Response<Token>, Status> {
unimplemented!();
}
}
```
#### Start the Tonic Server and add our unimplemented service
In the `main.rs` file we are going to create a server, add our service to it and start it.
```rust
#[tokio::main]
async fn main() -> Result<(), Box<dyn std::error::Error>> {
dotenv().ok();
let database = connect_db();
let addr = "[::1]:50051".parse()?;
Server::builder()
.add_service(AuthServer::new(auth::Service::new(database)))
.serve(addr)
.await?;
Ok(())
}
```
You can try your server by using the following command to call the `auth.Auth/Login` function (`package.Service/Method`).
```bash
$ grpcurl -plaintext -import-path ./proto -proto auth.proto '[::1]:50051' auth.Auth/Login
```
You should see in the console of your server the following error:
```
thread 'tokio-runtime-worker' panicked at 'not implemented', src/auth.rs:22:9
```
This error has been thrown by the `unimplemented!` macro of our Auth Service, it works!
#### Generate an access token
We are going to use the [jwt crate](https://crates.io/crates/jwt) to create a JWT token. It will contains the following claims:
- `sub`: The Subject of the JWT (our user id)
- `iat`: Time at which the JWT was issued
- `exp`: Time after which the JWT expires
#### Implement the register method
The register method is fairly simple, it directly takes the request message to create the entry in our database after encrypting the password.
```rust
// src/auth.rs
async fn register(&self, request: Request<RegisterRequest>) -> Result<Response<Token>, Status> {
let database = self.database.lock();
let data = request.into_inner();
let password = bcrypt::hash(&data.password, 10)
.map_err(|_| Status::unknown("Error while creating the user"))?;
let user = NewUser {
firstname: &data.firstname,
lastname: &data.lastname,
email: &data.email,
password: &password,
};
let user = User::create(&mut database.unwrap(), user);
unimplemented!();
}
```
> You can already try it! It will throw an error because of the `unimplemented` but your user should be created in the database.
#### Implement the generate token method
We are going to split our function in two, the part for generating the claims and the one for encoding the token.
We are going to use the `APP_KEY` defined in our `.env` file to sign the JWT.
```rust
// src/auth.rs
pub struct GenerateTokenError;
pub struct GenerateClaimsError;
fn generate_claims(user: User) -> Result<BTreeMap<&'static str, String>, GenerateClaimsError> {
let mut claims: BTreeMap<&str, String> = BTreeMap::new();
claims.insert("sub", user.id.to_string());
let current_timestamp = SystemTime::now()
.duration_since(UNIX_EPOCH)
.map_err(|_| GenerateClaimsError)?
.as_secs();
claims.insert("iat", current_timestamp.to_string());
claims.insert("exp", String::from("3600"));
Ok(claims)
}
fn generate_token(user: User) -> Result<Token, GenerateTokenError> {
let app_key: String = env::var("APP_KEY").expect("env APP_KEY is not defined");
let key: Hmac<Sha256> =
Hmac::new_from_slice(app_key.as_bytes()).map_err(|_| GenerateTokenError)?;
let claims = generate_claims(user).map_err(|_| GenerateTokenError)?;
let access_token = claims.sign_with_key(&key).map_err(|_| GenerateTokenError)?;
Ok(Token {
access_token: access_token,
})
}
```
And now, let's use this function to return an access token when a user is registered:
```rust
// src/auth.Rs
impl Auth for Service {
[...]
async fn register(&self, request: Request<RegisterRequest>) -> Result<Response<Token>, Status> {
let database = self.database.lock();
let data = request.into_inner();
let password = bcrypt::hash(&data.password, 10)
.map_err(|_| Status::unknown("Error while creating the user"))?;
let user = NewUser {
firstname: &data.firstname,
lastname: &data.lastname,
email: &data.email,
password: &password,
};
let user = User::create(&mut database.unwrap(), user)
.map_err(|_| Status::already_exists("User already exists in the database"))?;
let token = generate_token(user).map_err(|_| Status::unknown("Cannot generate a token for the User"))?;
Ok(Response::new(token))
}
}
```
You can create a new user with the following command:
```bash
$ grpcurl -plaintext -import-path ./proto -proto auth.proto -d '{"firstname": "John", "lastname": "Doe", "email": "john@doe.com", "password": "rustproto"}' '[::1]:50051' auth.Auth/Register
```
And if you run it again, you will have the error `AlreadyExists`. 🎉
#### Implement the login method
The login method is now really simple, we try to find a user correspond to the email in the message, verify if the password is correct and use the `generate_token` method to return the Response.
```rust
// src/auth.rs
impl Auth for Service {
[...]
async fn login(&self, request: Request<LoginRequest>) -> Result<Response<Token>, Status> {
let data = request.into_inner();
let database = self.database.lock();
let user = User::find_by_email(&mut database.unwrap(), &data.email)
.ok_or(Status::unauthenticated("Invalid email or password"))?;
match verify(data.password, &user.password) {
Ok(true) => (),
Ok(false) | Err(_) => return Err(Status::unauthenticated("Invalid email or password")),
};
let reply = generate_token(user)
.map_err(|_| Status::unauthenticated("Invalid email or password"))?;
Ok(Response::new(reply))
}
[...]
}
```
And we can now generate a token using the email and password of our previously registered user!
```bash
$ grpcurl -plaintext -import-path ./proto -proto auth.proto -d '{"email": "john@doe.com", "password": "rustproto"}' '[::1]:50051' auth.Auth/Login
```
#### Implement the verify token method
As this post already starts to be really long, we will make the verification simple, we will only check for the signature and return true if it is valid.
```rust
// src/auth.rs
pub struct VerifyTokenError;
pub fn verify_token(token: &str) -> Result<bool, VerifyTokenError> {
let app_key: String = env::var("APP_KEY").expect("env APP_KEY is not defined");
let key: Hmac<Sha256> =
Hmac::new_from_slice(app_key.as_bytes()).map_err(|_| VerifyTokenError)?;
Ok(token
.verify_with_key(&key)
.map(|_: HashMap<String, String>| true)
.unwrap_or(false))
}
```
### Implement the Greeting service
In a new `src/greeting.rs` file we are going to implement our Greeting service using the trait provided by our generated SDk.
We will verify that we have a `x-authorization` token in the metadata and verify its value.
```rust
// src/greeting.rs
use protos::greeting::{greeting_server::Greeting, GreetRequest, GreetResponse};
use tonic::{Request, Response, Status};
use crate::auth;
#[derive(Default)]
pub struct Service {}
#[tonic::async_trait]
impl Greeting for Service {
async fn greet(
&self,
request: Request<GreetRequest>,
) -> Result<Response<GreetResponse>, Status> {
let token = request
.metadata()
.get("x-authorization")
.ok_or(Status::unauthenticated("No access token specified"))?
.to_str()
.map_err(|_| Status::unauthenticated("No access token specified"))?;
match auth::verify_token(token) {
Ok(true) => (),
Err(_) | Ok(false) => return Err(Status::unauthenticated("Invalid token")),
}
let data = request.into_inner();
Ok(Response::new(GreetResponse {
message: format!("{} {}", data.message, "Pong!"),
}))
}
}
```
We can now add our service to the Tonic server in `main.rs`.
```rust
#[tokio::main]
async fn main() -> Result<(), Box<dyn std::error::Error>> {
dotenv().ok();
let database = connect_db();
let addr = "[::1]:50051".parse()?;
Server::builder()
.add_service(AuthServer::new(auth::Service::new(database)))
.add_service(GreetingServer::new(greeting::Service::default()))
.serve(addr)
.await?;
Ok(())
}
```
It's now time to try our authentication system! You can use the following command and replace the access token with one generated with the Login or Register method:
```bash
$ grpcurl -plaintext -import-path ./proto -proto greeting.proto -H 'x-authorization: <access_token>' -d '{"message": "Ping!" }' '[::1]:50051' greeting.Greeting/Greet
```
> Try to put a wrong access token, you will get a unauthenticated status!
## You made it 🚀
Rust and Protobuf are new to me, but it is exactly the kind of project that helps me having a great learning experience on things that have a steep learning curve.
You can find the repository here [https://github.com/kerwanp/rust-proto-demo](https://github.com/kerwanp/rust-proto-demo)
In the next blog post we will learn how to consume this API in NextJS, so make sure to stay tuned by following me on [dev.to] | martinp | |
1,649,379 | how to improve logic building in programing | Here are some tips on how to improve logic building in programming in JavaScript: Practice... | 0 | 2023-10-28T17:58:19 | https://dev.to/adinath302/how-to-improve-logic-building-in-programing-g2c | **Here are some tips on how to improve logic building in programming in JavaScript:**
-
**Practice regularly.**
The more you practice, the better you will become at building logic. Try to set aside some time each day to practice coding, even if it's just for a few minutes.
-
**Find good resources.**
There are many great resources available to help you learn how to improve your logic building skills. Books, websites, and even online courses can all be helpful.
-
**Work on challenging problems.**
Once you have a basic understanding of logic building, start working on more challenging problems. This will help you to stretch your skills and learn new things.
-
**Don't be afraid to ask for help.**
If you are struggling with a particular problem, don't be afraid to ask for help from a friend, mentor, or online forum.
-
**Be patient**.
It takes time to develop strong logic building skills. Don't get discouraged if you don't see results immediately. Just keep practicing and you will eventually see improvement.
Here are some additional tips that may be helpful:
-
**Break down problems into smaller steps.**
When you are faced with a large problem, try to break it down into smaller, more manageable steps. This will make it easier to solve the problem and less likely to make mistakes.
-
**Use diagrams or flowcharts.**
Diagrams and flowcharts can be helpful for visualizing the logic of a program. This can be especially helpful for complex problems.
-
**Test your code.**
Once you have written a program, be sure to test it thoroughly. This will help you to catch any errors or bugs before they cause problems.
-
**Don't be afraid to experiment.**
Sometimes the best way to learn is by experimentation. Try different things and see what works best.
With practice and patience, you can improve your logic building skills and become a better programmer.
##
| adinath302 | |
1,649,417 | Hacktoberfest2023 - completion! | And just like that.. Being a first time Hacktoberfest participant, I feel super proud of... | 25,219 | 2023-10-29T19:02:45 | https://dev.to/tanushree_aggarwal/hacktoberfest2023-completion-4pe6 | hacktoberfest, hacktoberfest23, opensource, hack23contributor |
And just like that..

Being a first time Hacktoberfest participant, I feel super proud of myself!
Just a few days back I shared my Hacktoberfest goal of submitting 2 valid PRs. To my surprise I was able to submit them very easily, so decided to keep going further!
Which led me here, having completed the challenge with 4 valid PRs!
[](https://holopin.io/@aggarwaltanushree)
[Pull Request 1](https://github.com/inuad/movie-night/pull/4)
[Pull Request 2](https://github.com/Astha369/CPP_Problems/pull/97)
[Pull Request 3](https://github.com/Shariar-Hasan/QuoteVerse/pull/82)
[Pull Request 4](https://github.com/himanshu-03/Python-Data-Structures/pull/134)
While I may not have made a significant contribution to the opensource community with these PRs, this is just the beginning of my opensource journey!
I am already looking forward to participate in next year's Hacktoberfest and make some constructive contributions! | tanushree_aggarwal |
1,649,588 | Simplified Redux | In the previous article, Declarative JavaScript, we discussed how conditional flows can be... | 0 | 2023-11-03T13:49:00 | https://dev.to/sultan99/simplified-redux-fp | javascript, react, redux, functional | ---
title: Simplified Redux
published: true
description:
tags: #javascript #react #redux #fp
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/brl4e2au5bltb2rm0g3k.png
# Use a ratio of 100:42 for best results.
# published_at: 2023-10-23 16:43 +0000
---
In the previous article, [Declarative JavaScript](https://dev.to/sultan99/declarative-javascript-10oh), we discussed how conditional flows can be represented as higher-order functions. In this chapter, we will continue to extend this concept to create [Redux](https://redux.js.org/) reducers. Despite its declining popularity, Redux can serve as a good example of how to reduce the boilerplate code around this library. Before proceeding, I highly recommend reading [the first chapter](https://dev.to/sultan99/declarative-javascript-10oh).
## Abstractions
You may have noticed that whenever you point at some object, if there is a dog alongside you, it will most likely just stare at your fingertip rather than the object itself. Dogs struggle to understand the abstract line between the finger and the intended object, because such a concept simply does not exist in their cognition. Fortunately, humans have this ability, and it allows us to simplify complex things and present them in a simple form.
In the diagram above, a blue square symbolizes an application, and a barrel attached to the box represents a database. Such diagrams help us understand complex architectural solutions without diving into the details of their implementation. The same method can be applied in programming by separating the main code from the secondary code by hiding them behind functions.
```jsx
const initialState = {
attempts: 0,
isSigned: false,
}
// action payload 👇 👇 current state
const signIn = pincode => state => ({
attempts: state.attempts + 1,
isSigned: pincode === '2023',
})
const signOut = () => () => initialState
const authReducer = createReducer(
initialState,
on('SIGN_IN', signIn),
on('SIGN_OUT', signOut),
on('SIGN_OUT', clearCookies),
)
```
The input of the `createReducer` function is like the table of contents for a book. It allows us to quickly finding the necessary function based on the action type. Both `signIn` and `signOut` functions update the state object, accepting the action payload and the current state as input. The rest of the code, which involves the action type check and the reducer call, is encapsulated within the `createReducer` and `on` functions.
```jsx
const createReducer = (initialState, ...fns) => (state, action) => (
fns.reduce(
(nextState, fn) => fn(nextState, action),
state || initialState,
)
)
const on = (actionType, reducer) => (state, action) => (
action.type === actionType
? reducer(action.payload)(state)
: state
)
```
For enhanced utility, we introduce the helper functions `useAction` and `useStore`:
```jsx
import {useState} from 'react'
import {useDispatch, useSelector} from 'react-redux'
const useAction = type => {
const dispatch = useDispatch()
return payload => dispatch({type, payload})
}
const useStore = path => (
useSelector(state => state[path])
)
const SignIn = () => {
const [pincode, setPincode] = useState('')
const signIn = useAction('SIGN_IN')
const attempts = useStore('attempts')
return (
<form>
<h1>You have {3 - attempts} attempts!</h1>
<input
value={pincode}
onChange={event => setPin(event.target.value)}
/>
<button
disabled={attempts >= 3}
onClick={() => signIn(pincode)}>
Sign In
</button>
</form>
)
}
```
## Lenses
In functional programming, lenses are abstractions that make operations easier with nested data structures, such as objects or arrays. In other words, they are immutable setters and getters. They are called lenses because they allow us to focus on a specific part of an object.
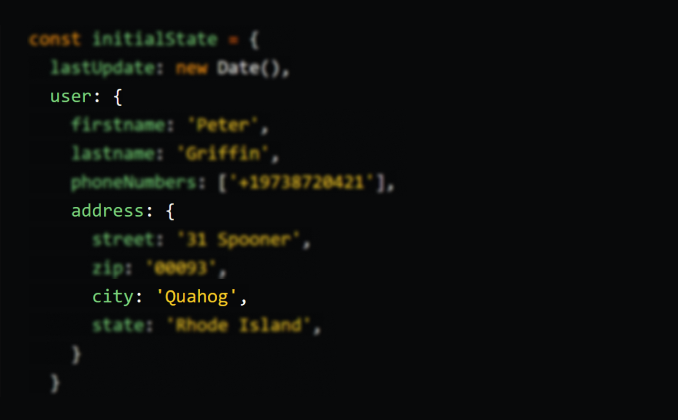
First, let's see how to update a value without using lenses:
```jsx
const initialState = {
lastUpdate: new Date(),
user: {
firstname: 'Peter',
lastname: 'Griffin',
phoneNumbers: ['+19738720421'],
address: {
street: '31 Spooner',
zip: '00093',
city: 'Quahog',
state: 'Rhode Island',
}
}
}
const updateCity = name => state => ({
...state,
user: {
...state.user,
address: {
...state.user.address,
city: name,
}
}
})
const userReducer = createReducer(
initialState,
on('UPDATE_CITY', updateCity),
...
)
```
That’s pretty ugly, right? Now let's use the `set/get` lenses:
```jsx
const updateCity = name => state => (
set('user.address.city', name, state)
)
const updateHomePhone = value => state => (
set('user.phoneNumbers.0', value, state)
)
const useStore = path => useSelector(get(path))
// or by composing
const useStore = compose(useSelector, get)
const homePhone = useStore('user.phoneNumbers.0')
```
Below is an implementation of the lenses. I should note that all of these functions are already available in the [Ramda](https://ramdajs.com/) library.
```jsx
const update = (keys, fn, obj) => {
const [key, ...rest] = keys
if (keys.length === 1) {
return Array.isArray(obj)
? obj.map((v, i) => i.toString() === key ? fn(v) : v)
: ({...obj, [key]: fn(obj[key])})
}
return Array.isArray(obj)
? obj.map((v, i) => i.toString() === key ? update(rest, fn, v) : v)
: {...obj, [key]: update(rest, fn, obj[key])}
}
const get = value => obj => (
value
.split(`.`)
.reduce((acc, key) => acc?.[key], obj)
)
const set = (path, fn, object) => (
update(
path.split('.'),
typeof fn === 'function' ? fn : () => fn,
object,
)
)
const compose = (...fns) => (...args) => (
fns.reduceRight(
(x, fn, index) => index === fns.length - 1 ? fn(...x) : fn(x),
args
)
)
```
## Curring functions
A curried function can be referred to as a function factory. We can assemble a function from different places, or we can use them in composition with other functions. This is a truly powerful feature. However, when we call a curried function with all parameters at once, it may look clumsy. For instance, the call of the curried version of `set` would look like this:
```jsx
set('user.address.city')(name)(state)
```
Let's introduce a `curry` function. This function converts any given function into a curried one, and it can be invoked in various ways:
```jsx
set('user.address.city', 'Harrisburg', state) // f(x, y, z)
set('user.address.city', 'Harrisburg')(state) // f(x, y)(z)
set('user.address.city')('Harrisburg', state) // f(x)(y, z)
set('user.address.city')('Harrisburg')(state) // f(x)(y)(z)
```
Quite simple implementation and usage:
```jsx
const curry = fn => (...args) => (
args.length >= fn.length
? fn(...args)
: curry(fn.bind(undefined, ...args))
)
const set = curry((path, fn, object) =>
update(
path.split('.'),
typeof fn === 'function' ? fn : () => fn,
object,
)
)
const get = curry((value, obj) =>
value
.split(`.`)
.reduce((acc, key) => acc?.[key], obj)
)
```
I often notice that many developers, for whatever reason, wrap callback functions in anonymous functions just to pass a parameter.
```jsx
fetch('api/users')
.then(res => res.json())
.then(data => setUsers(data)) // 👈 no need to wrap
.catch(error => console.log(error)) // 👈 no need to wrap
```
Instead, we can pass the function as a parameter. We should remember that the `then` function expects a callback function with two parameters. Therefore, direct passing will be safe only if `setUsers` expects only one parameter.
```jsx
fetch('api/users')
.then(res => res.json())
.then(setUsers)
.catch(console.log)
```
This reminds me of simplifying fractions or equations in basic algebra.
{% katex %}
(2x - 1)(x + 2) = 3(x + 2) \newline
(2x - 1)\cancel{(x + 2)} = 3\cancel{(x + 2)} \newline
2x - 1 = 3
{% endkatex %}
```jsx
.then(data => setUsers(data))
// 👇 it equals 👆
.then(setUsers)
```
Let's simplify the `updateCity` function:
```jsx
const updateCity = name => state => (
set('user.address.city', name, state)
)
// 👇 it equals 👆
const updateCity = set('user.address.city')
```
Or, we can place it directly in the reducer without declaring a variable.
```jsx
const userReducer = createReducer(
initialState,
on('UPDATE_CITY', set('user.address.city')),
on('UPDATE_HOME_PHONE', set('user.phones.0')),
...
)
```
The most important aspect is that we can now compose the `set` function and perform multiple updates at once.
```jsx
const signIn = pincode => state => ({
attempts: state.attempts + 1
isSigned: pincode === '2023',
})
// 'state => ({ ...' is 👇 removed
const signIn = pincode => compose(
set('attempts', attempts => attempts + 1),
set('isSigned', pincode === '2023'),
)
const updateCity = name => state => ({
lastUpdate: new Date(),
user: {
...state.user,
address: {
...state.user.address,
city: name,
}
}
})
// 👆 it equals 👇
const updateCity = name => compose(
set('lastUpdate', new Date()),
set('user.address.city', name),
)
```
This programming style is called [point free](https://en.wikipedia.org/wiki/Tacit_programming) and is widely used in functional programming.
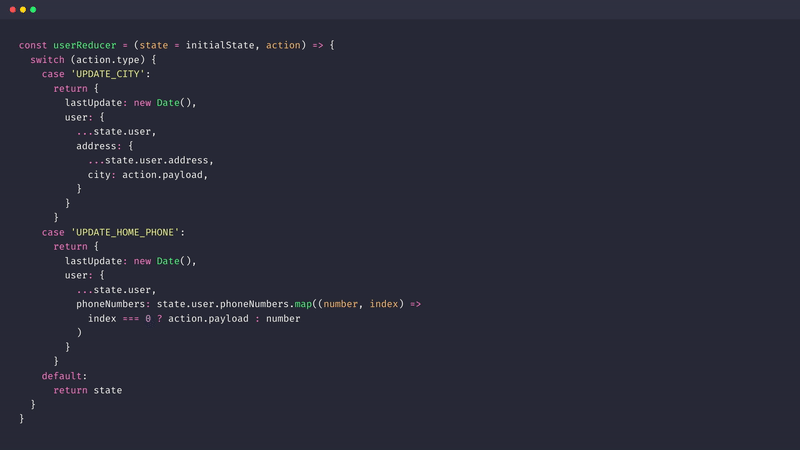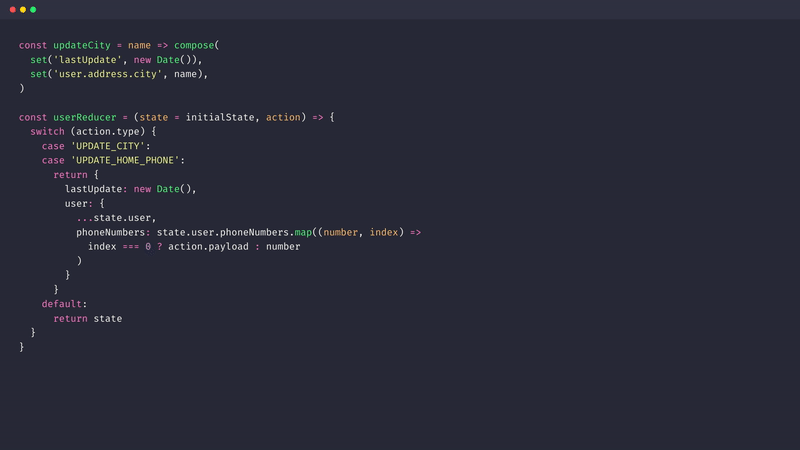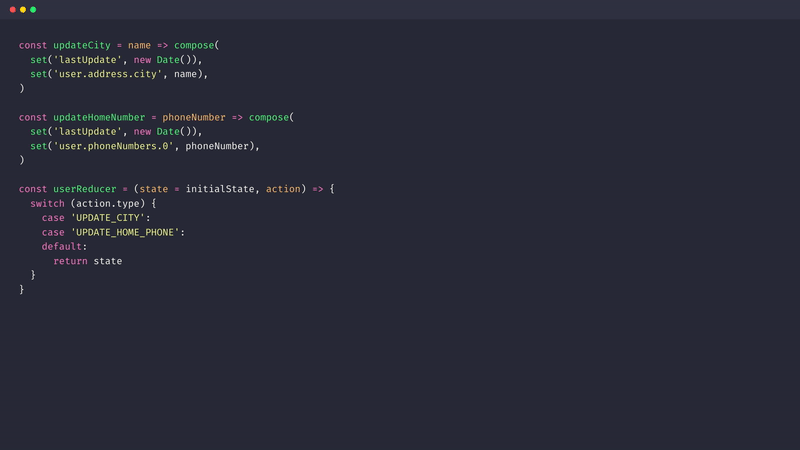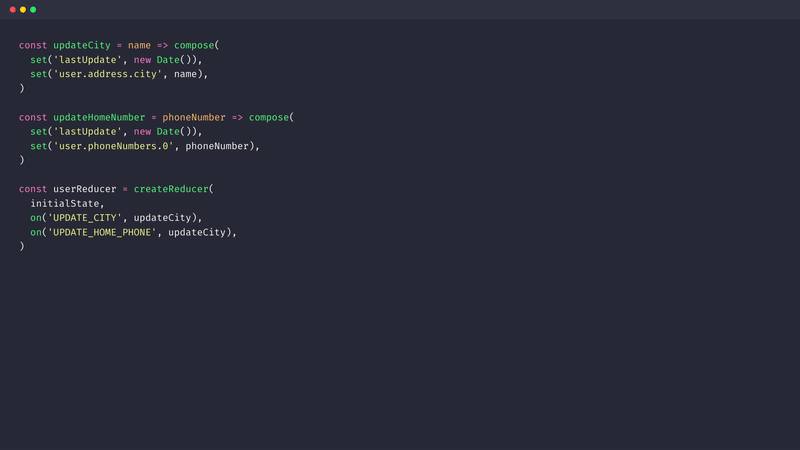
This article ended up being a bit longer than I had initially planned, but I hope you’ve gained some new knowledge. In the next article, we will touch on the topic of the `try/catch` construct and as usual, here's a small teaser for the [next post](https://dev.to/sultan99/do-or-do-not-there-is-no-try-49f2):
```jsx
const result = trap(unstableCode)
.pass(x => x * 2)
.catch(() => 3)
.release(x => x * 10)
```
P.S. You can find the [online demo here](https://codesandbox.io/s/simplified-redux-sr53fl) 📺.
| sultan99 |
1,649,742 | Full text search with Firestore & Meili search - Implementing Full text search function in React Native app | In this post, we will be looking into how you can create a search bar interface in your React Native... | 0 | 2023-11-07T03:34:43 | https://dev.to/gautham495/full-text-search-with-firestore-meili-search-implementing-full-text-search-function-in-react-native-app-36bk | react, reactnative, javascript, fulltextsearch | In this post, we will be looking into how you can create a search bar interface in your React Native application. We will be creating a React Native project and will be connecting our melli search instance with our frontend app and create a nice search interface.
Lets create a react native app with the following command.
```jsx
npx react-native init yourappname
cd yourappname
```
After this lets install libraries called axios to call our APIs. We will also be installing a library called 'react-native-fast-image' which is a brilliant library to cache remote images in react native. We will also be installing lodash to use a function called debounce in Javascript.
```jsx
npm i react-native-fast-image lodash
```
After we have installed the packages, we need to run pod install to install necessary pods so that we can run our app in iOS. There is no additional step required for android.
```jsx
pod install
```
For M1 macs, you can use the following command to install pods without any errors.
```jsx
arch -x86_64 pod install
```
Now lets get into the coding part. We are going to setup a folder called API and create a folder called Components where we will be creating our Search Interface.
Before that I am initialising axios instance to be used in our app.
```jsx
import axios from 'axios';
export const BASE_URL = 'yourapi.com';
export const instance = axios.create({
baseURL: BASE_URL,
headers: {
'Content-Type': 'application/json',
Accept: 'application/json',
},
});
```
Lets setup our API functions
Now lets create our search input to get data from our API.
This will look and feel the same as the Next JS search interface we have created before
```jsx
import {instance} from './Api';
export const addResourceFromMelli = async melliSearchData => {
const melliData = {
index: 'movies',
data: melliSearchData?.movieData,
};
try {
await instance.post(`/mellisearch/add-document`, melliData);
} catch (error) {
console.log(error);
}
};
export const searchResourcesFromMelli = async melliSearchData => {
try {
const melliData = {
index: 'movies',
search: melliSearchData?.search,
};
const res = await instance.post(`/mellisearch/search`, melliData);
return res.data.hits;
} catch (error) {
console.log(error);
return [];
}
};
export const deleteResourceFromMelli = async melliSearchData => {
const melliData = {
index: 'movies',
id: melliSearchData?.movieId,
};
try {
await instance.post(`/mellisearch/delete-document`, melliData);
} catch (error) {}
};
```
Now let us call the API in our debounced search input with help of lodash and retrieve data points and show case it to the frontend.
Here below is the full code of the search interface.
```jsx
import React, {useState} from 'react';
import {
View,
TextInput,
Text,
StyleSheet,
SafeAreaView,
ScrollView,
ActivityIndicator,
Platform,
Dimensions
} from 'react-native';
import FastImage from 'react-native-fast-image';
import {useCallback} from 'react';
import {searchResourcesFromMelli} from '../API/MellisearchAPI';
import {debounce} from 'lodash';
const screenWidth = Dimensions.get('screen').width
const SearchInterface = () => {
const [query, setQuery] = useState('');
const [moviesData, setMoviesData] = useState([]);
const [searchLoader, setSearchLoader] = useState(false);
async function searchMelli(e) {
const melliSearch = {
search: e,
};
const res = await searchResourcesFromMelli(melliSearch);
setMoviesData(res);
setSearchLoader(false);
}
const debouncedAPICall = useCallback(debounce(searchMelli, 1200), []);
async function debouncedFullTextSearch(e) {
setSearchLoader(true);
setQuery(e);
debouncedAPICall(e);
}
return (
<SafeAreaView style={styles.container}>
<ScrollView showsVerticalScrollIndicator={false}>
<View style={styles.center}>
<TextInput
style={styles.searchInput}
value={query}
onChangeText={debouncedFullTextSearch}
placeholder="Search a movie..."
placeholderTextColor={'black'}
/>
</View>
{searchLoader && (
<View style={styles.searchLoader}>
<ActivityIndicator color={'#00A9F1'} size={'large'} />
</View>
)}
{moviesData?.length >= 1 ? (
moviesData?.map(item => {
return (
<View style={styles.movieItem} key={item?.movieId}>
<FastImage
style={styles.poster}
source={{
uri: item.posterUrl,
priority: FastImage.priority.high,
}}
resizeMode="cover"
/>
<View style={styles.movieDetails}>
<Text style={styles.title}>{item.title}</Text>
<Text style={styles.description}>{item.description}</Text>
</View>
</View>
);
})
) : (
<View style={styles.center}>
{!searchLoader && (
<View>
<FastImage
source={require('../Assets/SearchMovies.png')}
style={styles.searchMovies}
resizeMode="contain"
/>
<View style={styles.center}>
<Text style={styles.searchDescription}>
Start typing to search movies!
</Text>
</View>
</View>
)}
</View>
)}
</ScrollView>
</SafeAreaView>
);
};
const styles = StyleSheet.create({
container: {
flex: 1,
backgroundColor: 'white',
padding: 20,
},
center: {
alignItems: 'center',
justifyContent: 'center',
},
searchInput: {
borderWidth: 1,
borderColor: '#00A9F1',
borderRadius: 5,
paddingLeft: 10,
marginVertical: 10,
width: 300,
fontFamily: 'Pangram-Regular',
fontSize: 18,
padding: 15,
backgroundColor: '#F9FAFC',
color: 'black',
},
movieItem: {
marginVertical: 10,
alignItems: 'center',
backgroundColor: 'white',
marginHorizontal: 10,
padding: 5,
borderColor: '#00A9F1',
borderWidth: 1,
},
poster: {
width: Platform.OS === 'ios' ? screenWidth * 0.85 : screenWidth * 0.8,
height: 220,
resizeMode: 'cover',
marginVertical: 10,
},
movieDetails: {
marginLeft: 10,
},
title: {
fontSize: 20,
marginBottom: 5,
fontFamily: 'Pangram-Bold',
lineHeight: 26,
},
description: {
fontSize: 17,
fontFamily: 'Pangram-Regular',
lineHeight: 26,
marginBottom: 10,
},
searchDescription: {
fontSize: 22,
fontFamily: 'Pangram-Regular',
marginBottom: 10,
},
searchLoader: {
paddingTop: 30,
marginTop: 20,
marginBottom: 30,
},
searchMovies: {
width: screenWidth * 0.8,
height: 300,
},
});
export default SearchInterface;
```
Thats it we have successfully integrated a neat search interface for our React Native app.
You can view the complete code and see how the search interface works in a live demo below.
https://github.com/Gautham495/blog-code-snippets
https://demos.gauthamvijay.com/
This concludes the fulltext search feature with multiple technologies like Firebase, Meilisearch, Express JS, React/Next, React Native to make a end to end full text search solution.
Let me know if I can help you in this integration or you need any help in your projects. This series was made to help out developers to make a full text search functionality from the backend to the frontend in a neat concise way. | gautham495 |
1,649,949 | Basic logging in Echo Golang | As we know, Echo has a JSON-format logging. That mean every line of logs is formatted as JSON. This... | 0 | 2023-10-29T15:08:42 | https://dev.to/glopgeek/basic-logging-in-echo-golang-2cde | webdev, go, programming, tutorial | As we know, Echo has a JSON-format logging. That mean every line of logs is formatted as JSON. This is convenient for other services to read the log. However, in a standalone server, this is not readable because it’s hard for developer to debug.
In this blog, I will setup a project with a basic logger as a reference. If you have any better approach, please feel free to discuss with me. Thank you in advance.
### Installation
- Golang 1.21.1
- Zerolog — A logging library of Go
- Echo — A Golang web framework
### Folder tree
```
Your root
├── common
│ ├── middlewares.go
│ └── logging.go
├── go.mod
├── go.sum
└── main.go
```
### 1. Getting started
First of all, we need to initialize a go module for our project by under command.
```bash
$ go mod init <name>
```
Then, we add some libraries in the installation section.
```bash
go get github.com/labstack/echo/v4
go get github.com/rs/zerolog/log
```
Create a **main.go** with below code.
```go
package main
import (
"net/http"
"github.com/labstack/echo/v4"
)
func main() {
e := echo.New()
e.GET("/", func(c echo.Context) error {
return c.String(http.StatusOK, "Hello, World!")
})
common.Logger.LogInfo().Msg(e.Start(":9000").Error())
}
```
Run the command: **go run main.go**
Then, we open a browser and go to _http://localhost:9000_. The output is:
```text
Hello, World!
```
### 2. Create a logger
Create file **common/logging.go**
```go
package common
import (
"fmt"
"os"
"strings"
"time"
"github.com/rs/zerolog"
)
type MyLogger struct {
zerolog.Logger
}
var Logger MyLogger
func NewLogger() MyLogger {
// create output configuration
output := zerolog.ConsoleWriter{Out: os.Stdout, TimeFormat: time.RFC3339}
// Format level: fatal, error, debug, info, warn
output.FormatLevel = func(i interface{}) string {
return strings.ToUpper(fmt.Sprintf("| %-6s|", i))
}
output.FormatFieldName = func(i interface{}) string {
return fmt.Sprintf("%s:", i)
}
output.FormatFieldValue = func(i interface{}) string {
return fmt.Sprintf("%s", i)
}
// format error
output.FormatErrFieldName = func(i interface{}) string {
return fmt.Sprintf("%s: ", i)
}
zerolog := zerolog.New(output).With().Caller().Timestamp().Logger()
Logger = MyLogger{zerolog}
return Logger
}
func (l *MyLogger) LogInfo() *zerolog.Event {
return l.Logger.Info()
}
func (l *MyLogger) LogError() *zerolog.Event {
return l.Logger.Error()
}
func (l *MyLogger) LogDebug() *zerolog.Event {
return l.Logger.Debug()
}
func (l *MyLogger) LogWarn() *zerolog.Event {
return l.Logger.Warn()
}
func (l *MyLogger) LogFatal() *zerolog.Event {
return l.Logger.Fatal()
}
```
### 3. Create a middleware to log requests
Create a file common/middlewares.go
```go
package common
import (
"github.com/labstack/echo/v4"
)
func LoggingMiddleware(next echo.HandlerFunc) echo.HandlerFunc {
return func(c echo.Context) error {
// log the request
Logger.LogInfo().Fields(map[string]interface{}{
"method": c.Request().Method,
"uri": c.Request().URL.Path,
"query": c.Request().URL.RawQuery,
}).Msg("Request")
// call the next middleware/handler
err := next(c)
if err != nil {
Logger.LogError().Fields(map[string]interface{}{
"error": err.Error(),
}).Msg("Response")
return err
}
return nil
}
}
```
### 4. Add the LoggingMiddleware to the main function
```go
package main
import (
"net/http"
"github.com/labstack/echo/v4"
"huy.me/common"
)
func main() {
e := echo.New()
// logger
common.NewLogger() // new
e.Use(common.LoggingMiddleware) // new
e.GET("/", func(c echo.Context) error {
return c.String(http.StatusOK, "Hello, World!")
})
common.Logger.LogInfo().Msg(e.Start(":9000").Error())
}
```
### 5. Re-run your app
After step 4, re-run your project by the command:
```bash
go run main.go
```
Go to the browser and access the old URL _http://localhost:9000_. Then check your terminal, the log will be the same with the below image.
### Add a mock authentication middleware to see log
In **common/middlewares.go**
```go
package common
import (
"github.com/labstack/echo/v4"
"golang.org/x/exp/slices"
)
func LoggingMiddleware(next echo.HandlerFunc) echo.HandlerFunc {
return func(c echo.Context) error {
Logger.LogInfo().Fields(map[string]interface{}{
"method": c.Request().Method,
"uri": c.Request().URL.Path,
"query": c.Request().URL.RawQuery,
}).Msg("Request")
err := next(c)
if err != nil {
Logger.LogError().Fields(map[string]interface{}{
"error": err.Error(),
}).Msg("Response")
return err
}
return nil
}
}
// new code here
func AuthMiddleware(next echo.HandlerFunc) echo.HandlerFunc {
return func(c echo.Context) error {
Logger.LogInfo().Msg("Authenticating...")
// Add authentication logic here
// after process authentication logic,
// call next(c) to pass to the next middleware
return next(c)
}
}
```
Then, register AuthMiddleware function to the Echo instance.
```go
package main
import (
"net/http"
"github.com/labstack/echo/v4"
"huy.me/common"
)
func main() {
e := echo.New()
// logger
common.NewLogger()
e.Use(common.LoggingMiddleware, common.AuthMiddleware) // new
e.GET("/", func(c echo.Context) error {
return c.String(http.StatusOK, "Hello, World!")
})
common.Logger.LogInfo().Msg(e.Start(":9000").Error())
}
```
**Notice**: The order of middlewares will affect the log. In the above code, the _LoggingMiddleware_ will come first, then _AuthMiddleware_.
Now the log will something like below.
Thank you for reading :) | mavisphung |
1,650,274 | 香港服务器的优势 | 香港服务器的优势 1.免备案,免除繁琐的备案流程及长达半个月的备案等待时间 因为现在国内的虚拟主机市场查处很严格,而且还需要头疼国内备案等复杂手续。据互联先锋统计,近年大部分站长选择海外服务器的主要原因... | 0 | 2023-10-30T01:46:49 | https://dev.to/ronald417/xiang-gang-fu-wu-qi-de-you-shi-4ohf | webdev | 香港服务器的优势
1.免备案,免除繁琐的备案流程及长达半个月的备案等待时间
因为现在国内的虚拟主机市场查处很严格,而且还需要头疼国内备案等复杂手续。据互联先锋统计,近年大部分站长选择海外服务器的主要原因是国内ICP备案工作较为繁琐。
2.国际宽带,速度快,媲美国内主机
香港环球机房国际出口带宽充足,适合企业级外贸网站、邮件服务、数据交换等应用,语音视频应用之第一选择。对于企业级用户,如果客户仅仅是香港、台湾、日本、大陆客户,那么香港服务器无疑的最佳选择,因为香港大部分机房的香港服务器针对大中华区市场速度都较快。
3.速度快又稳定,对网站内容的限制相对宽松
我们非常认同香港主机与双线主机在中国的市场前景,目前海外主机运营商从技术、流程、服务上面讲做得相当好的几乎没有,同时,随着互联网的发展以及国内从事国际业务的企业需求膨胀,海外虚拟主机市场将迎来爆炸式的发展,我们十分看好这个市场,并对占有一席重要之地有充分的信心! | ronald417 |
1,650,614 | OAuth 2.0 - What is it? | OAuth is not as complicated as it sounds! 😅 Let's break it down in a fun and simple way so even... | 0 | 2023-10-30T10:05:44 | https://dev.to/shameel/oauth-20-what-is-it-30p5 | security, webdev, beginners, programming | OAuth is not as complicated as it sounds! 😅 Let's break it down in a fun and simple way so even beginners can grasp it.
**What is OAuth 2.0? 🤔**
OAuth 2.0 is like the VIP pass for your online accounts. It lets you share your Facebook pics, Twitter tweets, or Spotify playlists with other apps **without giving away your super-secret password.** 🤐
**Why is it Necessary? 🤷♀️**
Imagine you have a cool fitness app 🏋️♀️ that wants to post your workout achievements on your Facebook. Without OAuth, you'd have to give your fitness app your Facebook login and password 😱. That's a big NO-NO for security!
OAuth 2.0 solves this problem by acting like a bouncer at the club. It keeps your password safe and only lets in the app you choose, **just for the things you want to share**. 🤗
**Where is OAuth 2.0 Used? 🌐**
1. **Social Media Login**: You've seen those "Log in with Google" or "Sign in with Facebook" buttons? That's OAuth 2.0 at work. No need to create new accounts everywhere.
2. **API Access**: Many apps use OAuth to let you access their data or services, like your favorite weather app fetching data from a weather website.
3. **Mobile Apps**: If you use apps on your phone, chances are they're using OAuth behind the scenes to connect to your other accounts.
**How Does OAuth 2.0 Work? 🕵️♂️**
Let's use the example of your fitness app and Facebook:
1. You open your fitness app and click on "Share on Facebook."
2. The app says, "Hey, I want to share your workouts on Facebook."
3. Facebook, like a vigilant gatekeeper 🛡️, asks you, "Are you cool with this fitness app sharing your data?"
4. You say, "Sure, I trust my fitness app."
5. Facebook gives the fitness app a special token. This token is like a one-time access card to post on your behalf. It's not your password, and it can't be used to log in.
6. The fitness app uses this token to post your achievements on Facebook.
**Why Is OAuth 2.0 Important? 🌟**
- **Security**: Your passwords stay locked in a vault. No more sharing them with every app you use. 🔐
- **Convenience**: Easier access to your favorite apps. No more remembering a zillion passwords. 🤯
- **Control**: You decide what data you want to share and with whom. Your data, your rules! 🙌
So, there you have it! OAuth 2.0 makes your online life simpler, safer, and more connected. Next time you see "Log in with..." or "Authorize this app," you'll know what's going on behind the scenes.
Follow me for more such content:
LinkedIn: https://www.linkedin.com/in/shameeluddin/
Github: https://github.com/Shameel123 | shameel |
1,650,626 | 16. Sleep and Coding Productivity (Day 14) | Monday, Day 14 of my study journey, took an unexpected turn – I didn't study at all. But don't worry;... | 25,090 | 2023-10-30T09:39:49 | https://emanoj.hashnode.dev/18-the-importance-of-a-good-nights-sleep-for-productivity-day-14 | Monday, Day 14 of my study journey, took an unexpected turn – I didn't study at all. But don't worry; I'm not here to make excuses. We all have days when we can't bring ourselves to hit the books, and today was one of those days for me. So, why did I skip my study session on Monday? Let's get into it.
**The Daily Grind Takes Its Toll**
To put it simply, I had an exceptionally busy day at work. The demands of my job left me feeling drained and exhausted. Even worse, I hadn't enjoyed a good night's sleep the previous night, which only exacerbated my fatigue.
It's no secret that sleep is essential for our overall well-being and productivity. Experts recommend getting at least 8 hours of sleep a night and for a good reason. Sleep allows our bodies to recover and recharge, preparing us for the challenges of the day ahead. When we're well-rested, we have more energy and are better equipped to tackle life's adventures.
**The Connection Between Sleep and Productivity**
Whether you're working a demanding job or tackling a complex coding project, your mental faculties play a pivotal role in your success. Sleep is a critical factor in maintaining mental acuity, focus, and creativity. When we don't get enough rest, our cognitive functions suffer. This can lead to a decrease in productivity and a lower quality of work.
If you're a coder like me (even a beginner!), you know just how mentally taxing the work can be. Solving intricate problems, debugging, and writing clean, efficient code all require intense mental effort. When you're fatigued due to insufficient sleep, you're not doing yourself or your projects any favors.
**Balancing Work and Play**
In my case, the choice to skip a day of studying was more about self-care than procrastination. I recognized that pushing myself on a day when I was exhausted wouldn't yield the results I wanted. It's crucial to understand your body's needs and listen to them. On days when you're feeling especially drained, it might be more productive to focus on rest and self-care, allowing your body and mind to recover.
So, what's the takeaway here? Eat well, rest well, play well, and code well! Remember, taking care of yourself, including getting enough sleep, is an integral part of maintaining your productivity and achieving your goals. As much as we want to power through our to-do lists every day, there are times when our bodies need a break. Recognizing and respecting those moments can make all the difference in the long run.
**Conclusion**
We all have off days, and that's perfectly normal. What's important is how we respond to them. Prioritizing self-care and understanding the link between sleep and productivity is a critical step in ensuring our long-term success. So, if you ever find yourself in a similar situation, don't be too hard on yourself. Instead, take a step back, get some rest, and come back refreshed and ready to tackle your goals with renewed vigor. | emanoj | |
1,650,709 | Hotel room reservations in Pearl, MS | The hotel room reservations in Pearl, MS, have just been kicked up a notch because Fairfield has come... | 0 | 2023-10-30T10:37:15 | https://dev.to/fairfieldpearl/hotel-room-reservations-in-pearl-ms-eip | hotelpearlms, roominpearlms, roomreservationpearlms, luxuryhotelspearlmississippi | The [hotel room reservations in Pearl, MS](https://fairfieldpearl.com/), have just been kicked up a notch because Fairfield has come to elevate the luxury level. When you reserve your spot with us, you experience the epitome of abundance. So, let us spot you for this and all the other trips to this city. | fairfieldpearl |
1,650,952 | Loan Repayment Prediction using Machine Learning. | Machine learning (ML) is a sub set of artificial intelligence (AI) that allows software applications... | 0 | 2023-10-30T14:46:23 | https://dev.to/heyfunmi/loan-repayment-prediction-using-machine-learning-308i | machinelearning, ai, python, datascience | Machine learning (ML) is a sub set of artificial intelligence (AI) that allows software applications to become more accurate at predicting outcomes without being explicitly programmed to do so.
Machine learning algorithms uses historical data as input to predict new output values.
If you’re looking to read more about machine learning, check out this article I wrote for FreeCodeCamp[(https://www.freecodecamp.org/news/what-is-machine-learning-for-beginners/)]
In this project, I worked on developing a machine learning model that predicts if an individual will pay back a loan or not. This was done using classification machine learning algorithms; Decision Tree and Random Forest.
I decided to use both algorithms so I could compare the performance of both on the dataset.
Random Forest is a preferred choice when compared to Decision Tree, particularly in high-dimensional data scenarios. It excels in harnessing ensemble learning, where multiple decision trees collaboratively tackle complex pattern recognition and contribute to improved predictive accuracy.
Using Random Forest in this project reflects not just my personal preference but a data-driven approach, acknowledging the substantial benefits of combining these trees in mitigating overfitting and enhancing classification robustness in real-world, diverse datasets.
**Data Description**
The dataset is a lending data available online which shows the varying profile of people that applied for loan and if they paid back or not.
Here are what the columns of the dataset represent:
1. credit.policy: If the customer meets the credit underwriting criteria of LendingClub.com, and 0 otherwise.
2. purpose: The purpose of the loan (takes values "credit_card", "debt_consolidation", "educational", "major_purchase", "small_business", and "all_other").
3. int.rate: The interest rate of the loan, as a proportion (a rate of 11% would be stored as 0.11). Borrowers judged by LendingClub.com to be more risky are assigned higher interest rates.
4. installment: The monthly installments owed by the borrower if the loan is funded.
5. log.annual.inc: The natural log of the self-reported annual income of the borrower.
6. dti: The debt-to-income ratio of the borrower (amount of debt divided by annual income).
7. fico: The FICO credit score of the borrower.
8. days.with.cr.line: The number of days the borrower has had a credit line.
9. revol.bal: The borrower's revolving balance (amount unpaid at the end of the credit card billing cycle).
10. revol.util: The borrower's revolving line utilization rate (the amount of the credit line used relative to total credit available).
11. inq.last.6mths: The borrower's number of inquiries by creditors in the last 6 months.
12. delinq.2yrs: The number of times the borrower had been 30+ days past due on a payment in the past 2 years.
13. pub.rec: The borrower's number of derogatory public records (bankruptcy filings, tax liens, or judgments).
**Steps:**
1.**Importing the necessary libraries**
```python
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
```

2.**Loading in the dataset:**
```python
loan_dataset = pd.read_csv("loan-data.csv")
```

**A peep into what the dataset looks like**
```python
loan_dataset.head()
```
**Checking the number of rows and columns present in the dataset**
```python
loan_dataset.shape
```

3.**Data Cleaning**
It is essential to carry out data cleaning/pre processing on any given dataset before proceeding with the model building.
Data Cleaning involves removal of duplicates, null values, outliers and a plethora of errors that can be found in the dataset.
**Checking for missing values**
```python
loan_dataset.isnull().sum()
```
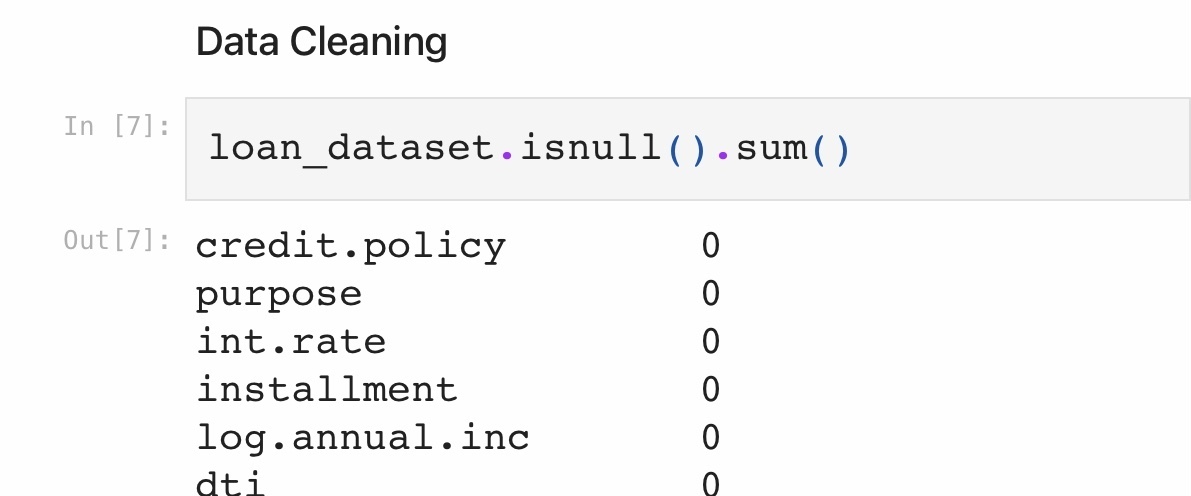
The dataset has no missing values.
4.**Label Encoding**
Label encoding is used in converting categorical data into numerical form.
The column “Purpose” needed to be converted from categorical column to a numerical column.
```python
cat_feats=['purpose']
loan =pd.get_dummies(loan_dataset,columns=cat_feats,drop_first=True)
```

5.**Extracting Dependent and independent variables and training the model**
```python
X = loan.drop('not.fully.paid',axis=1)
y = loan['not.fully.paid']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=101)
```

6.**Fitting the Decision Tree Model**
```python
from sklearn.tree import DecisionTreeClassifier
tree =DecisionTreeClassifier()
tree.fit(X_train,y_train)
```
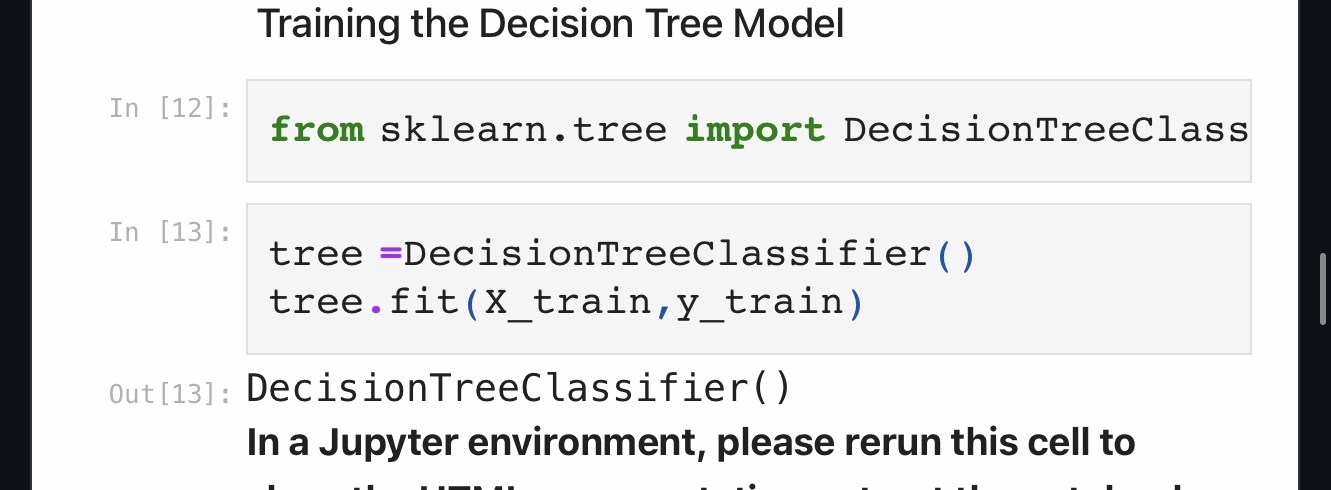
7.**Checking the accuracy of the Decision Tree model using the test data**
```python
from sklearn.metrics import accuracy_score
y_pred = tree.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy Score {:.2f}%".format(accuracy * 100))
```

**The Decision Tree model gave an accuracy score of 73.38%
Not bad!**
8.**Fitting the Random Forest**
```python
from sklearn.ensemble import RandomForestClassifier
rfc= RandomForestClassifier(n_estimators=100)
rfc.fit(X_train,y_train)
```
9.**Checking the accuracy of the Random Forest Model using the test data**
```python
y_pred = rfc.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy Score: {:.2f}%".format(accuracy * 100))
```
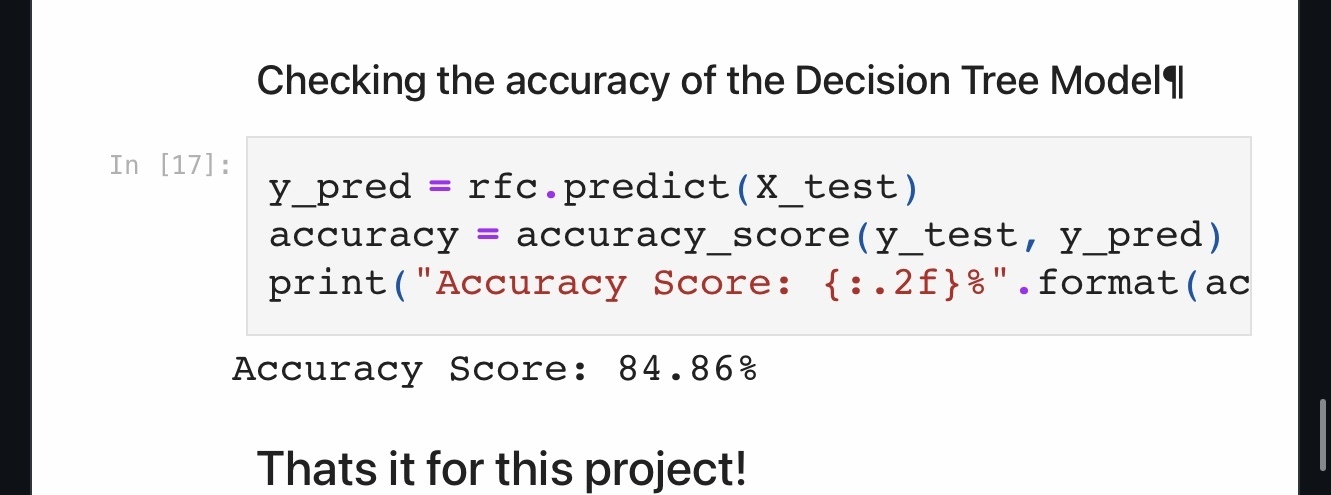
**As expected, The Random Forest Model outperformed the Decision Tree Model with an accuracy score of 84.86%**
These results proves the effectiveness of Random Forest in comparison to Decision Trees for this particular problem, highlighting the valuable role of ensemble techniques in enhancing model performance and ensuring better generalization to unseen data.
That’s it for this project!
For the entire code, check my GitHub profile: https://github.com/heyfunmi/Loan-Repayment-Prediction-using-Decision-Tree-and-Random-Forest./blob/main/Loan_prediction..ipynb)
Thank you for reading!
| heyfunmi |
1,650,960 | Understanding Web Accessibility | In our digital age, the internet is essential for basically everything we do, from shopping,... | 0 | 2023-10-30T14:58:13 | https://dev.to/mutiatbash/understanding-web-accessibility-358n | webdev, opensource, frontend, a11y | In our digital age, the internet is essential for basically everything we do, from shopping, learning, and connecting. But what if it's not open to everyone? Web accessibility is all about making sure that everyone can use the web, no matter their abilities. In this article, I’ll discuss about understanding web accessibility and how to make the digital world more inclusive.
## Understanding Accessibility: The Basics
Accessibility is about designing and developing websites and applications in a way that everyone can perceive, navigate, and interact with them. This includes individuals with disabilities, such as visual, auditory, motor, or cognitive impairments. Accessibility is not just a rule; it's a matter of inclusion and respect for all users.
### The Importance of Color Contrast
One fundamental aspect of web accessibility is color contrast. It may seem like a small detail, but the choice of colors can greatly impact the readability of web content. Ensuring that text has sufficient contrast against its background is essential. For instance, if you've ever adjusted text colors to ensure readability, you're practicing web accessibility. Remember that not everyone has perfect vision, and color choices matter.
### Basic Accessibility Features
Here are some basic accessibility features I consider when developing websites to ensure inclusivity:
1. **Alt Text for Images:** I always ensure to add alternative text (alt text) for images to convey their content to users who are visually impaired.
2. **Semantic HTML:** Using semantic HTML tags like headings, lists, and paragraphs to structure my content for screen readers and other assistive technologies.
3. **Keyboard Navigation:** Ensuring that all interactive elements can be navigated and activated using a keyboard for users who cannot use a mouse.
4. **Color Contrast:** I also maintain a sufficient color contrast between text and its background to make text readable for users with visual impairments.
5. **Responsive Design:** I take responsiveness really important as not everyone has access to laptops, so I ensure the website is mobile-friendly responsive and adaptable to different devices and screen sizes, benefiting users with various assistive devices.
### How I Practice Web Accessibility
To improve color contrast, I do the following:
1. I use online tools to check my design's colors.
2. Pick colors that follow accessibility guidelines.
3. Ask people with vision issues to test my website.
### The Impact of Accessibility
Web accessibility is about making a web for everyone, not just a few. When we design with accessibility in mind, we create a digital space that welcomes everyone. This inclusive design benefits not only those with disabilities but also a broader audience. Improved accessibility leads to better user experiences, increased reach, and a positive brand image.
To wrap it up, don’t think of web accessibility as something trivial, It's a really important. We need to learn the basics, make simple changes, and welcome everyone to the digital world. | mutiatbash |
1,652,228 | stop website spam | Preventing website spam is essential to maintain the quality and integrity of your online platform.... | 0 | 2023-10-31T15:10:27 | https://dev.to/irishgeoff22/stop-website-spam-2j9d | webdev, programming, javascript, website | Preventing website spam is essential to maintain the quality and integrity of your online platform. Here are several strategies and techniques you can use to stop website spam:
1. CAPTCHA: Implement CAPTCHA tests on your registration and comment forms to distinguish between humans and bots. Google's reCAPTCHA is a popular choice.
2. Use a Spam Filter: Utilize spam filters or plugins like Akismet (for WordPress) to automatically detect and block spam comments and submissions.
3. Moderation: Enable manual moderation for user-generated content. This way, nothing gets published without human review.
4. User Registration: Require users to register before they can comment or post content. This can deter many spammers.
5. Rate Limiting: Implement rate limiting on your forms to prevent a single user or IP address from making too many requests in a short period.
6. Blacklisting: Maintain a list of blacklisted IP addresses, domains, and keywords that are commonly associated with spam.
7. Content Filtering: Use content filtering to detect and block spammy keywords, URLs, or patterns in user-generated content.
8. Honeypot Fields: Add hidden fields to your forms that only bots can see. If these fields are filled out, you can automatically mark the submission as spam.
9. User Verification: Require users to verify their email addresses or phone numbers during the registration process.
10. SSL Encryption: Use SSL encryption to secure your website and make it harder for automated bots to interact with it.
11. Comment Whitelisting: Allow comments or content only from approved users or trusted sources.
12. Utilize Web Application Firewall (WAF): WAFs can protect your site from various types of malicious activity, including spam attacks.
13. Educate Users: Educate your community about spam and encourage them to report it. Many platforms allow users to flag spam content.
14. Update Software: Keep your website software, plugins, and themes up to date, as outdated software can have vulnerabilities that spammers exploit.
15. IP Blocking: Consider blocking specific IP addresses or IP ranges known for spammy activities.
16. Analyze Traffic: Monitor your website's traffic for unusual or suspicious behavior and patterns.
17. Feedback Loops: Set up feedback loops with ISPs and email providers to help identify and prevent email spam.
18. Implement DNSBLs: Use DNS-based blackhole lists to block known spam IP addresses.
19. .htaccess Rules: You can create rules in your .htaccess file to restrict access from certain IP addresses or user agents.
20. Content Policy: Clearly define and communicate your website's content policy, and enforce it consistently.
21. Stay Informed: Keep up with the latest spam tactics and technologies to adjust your defenses accordingly.
Remember that no method is entirely foolproof, and spammers are continually evolving their tactics. A combination of these strategies and regular updates to your spam prevention measures will help you effectively stop website spam.
PRO TIP: Use VeilMail.io to [hide email address from spammers](https://veilmail.io) using the free email to link tool https://veilmail.io | irishgeoff22 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.