
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,651,072 | Will Google's $2 Billion Investment In Anthropic Be A Game-changer? | Read the full news article here. Like what you read? Head to the TechDogs homepage to find the... | 0 | 2023-10-30T16:03:52 | https://dev.to/techdogs_inc/unpublished-video-562i-3cd3 | Read the full news article [here](https://www.techdogs.com/tech-news/td-newsdesk/will-googles-2-billion-investment-in-anthropic-be-a-game-changer).
Like what you read? Head to the [TechDogs ](https://www.techdogs.com/)homepage to find the latest tech content infused with drama and entertainment. We've got [Articles](https://www.techdogs.com/resource/td-articles), White Papers, Case Studies, Reports, [Videos](https://www.youtube.com/channel/UCZ0lgIRSVraU14O9bp3bMCQ), [News ](https://www.techdogs.com/resource/tech-news)and [Events & Webinars](https://www.techdogs.com/resource/events) - the complete lot to help you Know Your World of Technology. | td_inc | |
1,651,115 | Carefully choosing sounds | Carefully choosing sounds for my games, only during moments like these do I feel like myself... | 0 | 2023-10-30T17:02:42 | https://dev.to/tonicatfealidae/carefully-choosing-sounds-508a | Carefully choosing sounds for my games, only during moments like these do I feel like myself ^^
Although they are just small projects.
I love them with my heart.
They are literally my children. | tonicatfealidae | |
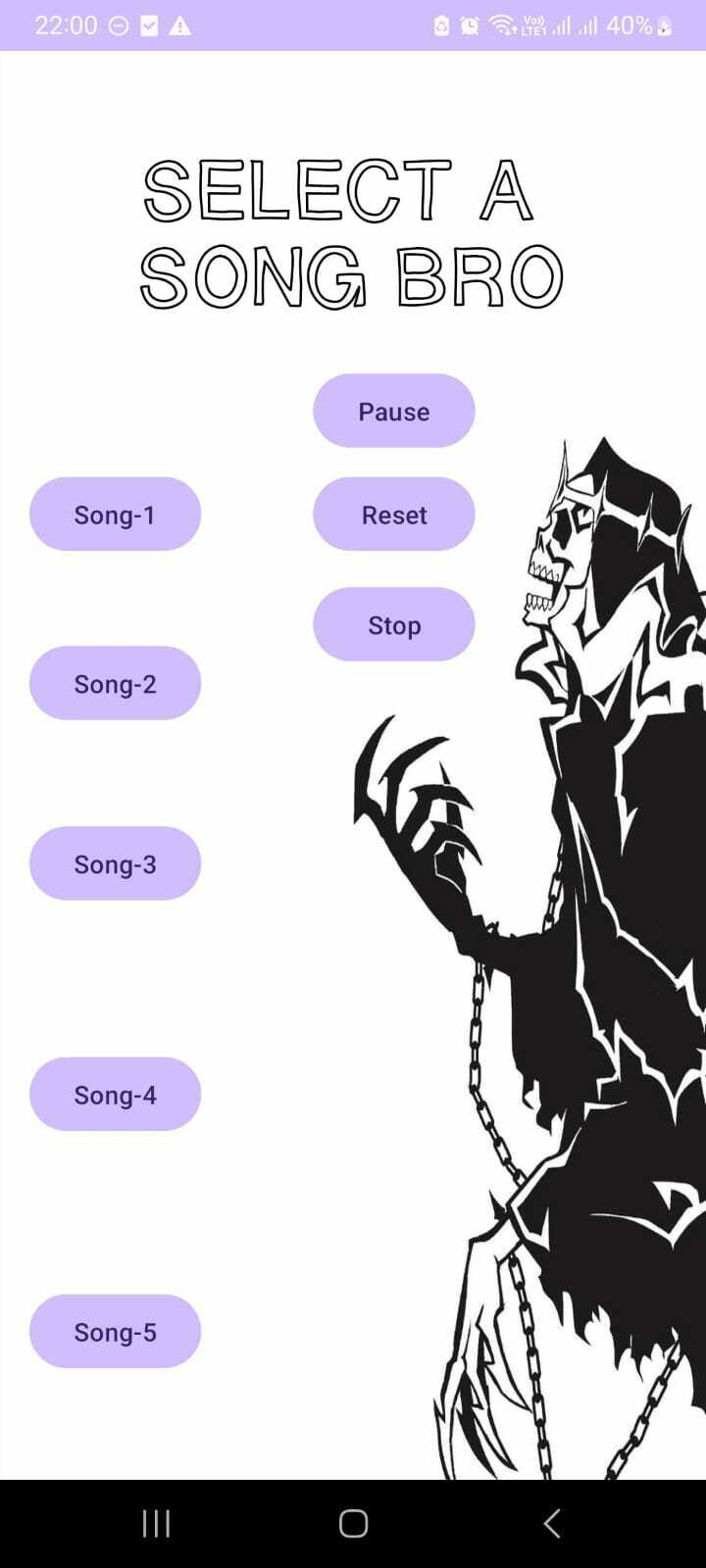
1,651,120 | Day 1: 100 Days Of Code Challenge | Today I finished the Small Music Player Android App that I was working on. It has 5 buttons to play... | 0 | 2023-10-30T17:09:51 | https://dev.to/harshaart/day-1-100-days-of-code-challenge-5458 | Today I finished the Small Music Player Android App that I was working on. It has 5 buttons to play up to 5 songs, pause, reset and stop buttons too.
> I want to make a Spotify clone in the future.
 | harshaart | |
1,651,124 | Orientation media query | Check out this Pen I made! | 0 | 2023-10-30T17:15:40 | https://dev.to/glagol/orientation-media-query-5cpk | codepen | Check out this Pen I made!
{% codepen https://codepen.io/web-dot-dev/pen/qBXVowV %} | glagol |
1,652,407 | Day 78: Web Storage | 🌐 What is the Web Storage API? The Web Storage API comprises two mechanisms: localStorage... | 23,670 | 2023-10-31T17:01:27 | https://dev.to/dhrn/day-78-web-storage-d6b | webdev, frontend, 100daysofcode, html |
### 🌐 What is the Web Storage API?
The Web Storage API comprises two mechanisms: `localStorage` and `sessionStorage`. These are ways to store key-value pairs in a web browser.
- `localStorage`: Offers persistent storage that persists even after the browser is closed and reopened. Data stored here remains until explicitly removed by the application or the user.
- `sessionStorage`: Provides session-based storage where data persists for the duration of the page session. Once the user closes the tab or browser, the data is cleared.
### Basic Usage:
```javascript
// Storing data in localStorage
localStorage.setItem('key', 'value');
// Retrieving data from localStorage
const value = localStorage.getItem('key');
// Removing data from localStorage
localStorage.removeItem('key');
```
### Advantages of Web Storage API:
1. **Simple Interface**: Offers an easy-to-use key-value pair storage system.
2. **Large Storage Capacity**: Allows for more significant data storage compared to cookies.
3. **Better Security**: Data stored in the Web Storage API is not transmitted to the server with every HTTP request, enhancing security.
### Tips
1. **Data Serialization**: Objects can be stored by serializing them using `JSON.stringify` and deserialized using `JSON.parse`.
2. **Error Handling**: Always handle exceptions when working with Web Storage to prevent the application from crashing due to storage limitations or security issues.
3. **Clear Outdated Data**: Regularly clear unused or outdated data to optimize storage and maintain efficiency.
### Best Practices:
1. **Encrypt Sensitive Data**: If storing sensitive information, consider encrypting it before saving it in the Web Storage.
2. **Graceful Degradation**: Always ensure your application gracefully handles scenarios where Web Storage may not be available or accessible.
3. **Consistent Data Structure**: Maintain a consistent structure for stored data to ease retrieval and manipulation.
### Comparing Web Storage Options:
Here's a comparison between `localStorage` and `sessionStorage`:
| Feature | `localStorage` | `sessionStorage` |
|-----------------|----------------------------------|------------------------------|
| **Scope** | Origin-specific | Tab or window-specific |
| **Persistence** | Survives browser close | Cleared at the end of session |
| **Storage** | Larger storage capacity | Limited storage capacity |
| **Accessibility**| Accessible from any window/tab | Accessible only within the tab |
| **Security** | Relatively secure | More secure |
| **Expiration** | Does not expire unless cleared | Cleared when the session ends |
| **Usage** | Long-term data storage | Short-term data storage |
| dhrn |
1,651,263 | A beginner's guide to building a Retrieval Augmented Generation (RAG) application from scratch | Retrieval Augmented Generation, or RAG, is all the rage these days because it introduces some serious... | 0 | 2023-10-31T22:25:42 | https://learnbybuilding.ai/tutorials/rag-from-scratch | ai, rag, beginners, nlp | Retrieval Augmented Generation, or RAG, is all the rage these days because it introduces some serious capabilities to large language models like OpenAI's GPT-4 - and that's the ability to use and leverage their own data.
This post will teach you the fundamental intuition behind RAG while providing a simple tutorial to help you get started.
## The problem with learning in a fast moving space
There's so much noise in the AI space and in particular about RAG. Vendors are trying to overcomplicate it. They're trying to inject their tools, their ecosystems, their vision.
It's making RAG way more complicated than it needs to be.
This tutorial is designed to help beginners learn how to build RAG applications from scratch.
No fluff, no (ok, minimal) jargon, no libraries, just a simple step by step RAG application.
[Jerry from LlamaIndex advocates for building things from scratch to really understand the pieces](https://twitter.com/jerryjliu0/status/1716122650836439478). Once you do, using a library like LlamaIndex makes more sense.
Build from scratch to learn, then build with libraries to scale.
Let's get started!
## Introducing our concept: Retrieval Augmented Generation
You may or may not have heard of Retrieval Augmented Generation or RAG.
Here's the definition from [the blog post introducing the concept from Facebook](https://ai.meta.com/blog/retrieval-augmented-generation-streamlining-the-creation-of-intelligent-natural-language-processing-models/):
> Building a model that researches and contextualizes is more challenging, but it's essential for future advancements. We recently made substantial progress in this realm with our Retrieval Augmented Generation (RAG) architecture, an end-to-end differentiable model that combines an information retrieval component (Facebook AI’s dense-passage retrieval system) with a seq2seq generator (our Bidirectional and Auto-Regressive Transformers [BART] model). RAG can be fine-tuned on knowledge-intensive downstream tasks to achieve state-of-the-art results compared with even the largest pretrained seq2seq language models. And unlike these pretrained models, RAG’s internal knowledge can be easily altered or even supplemented on the fly, enabling researchers and engineers to control what RAG knows and doesn’t know without wasting time or compute power retraining the entire model.
Wow, that's a mouthful.
In simplifying the technique for beginners, we can state that the essence of RAG involves adding your own data (via a retrieval tool) to the prompt that you pass into a large language model. As a result, you get an output.
That gives you several benefits:
1. You can include facts in the prompt to help the LLM avoid hallucinations
2. You can (manually) refer to sources of truth when responding to a user query, helping to double check any potential issues.
3. You can leverage data that the LLM might not have been trained on.
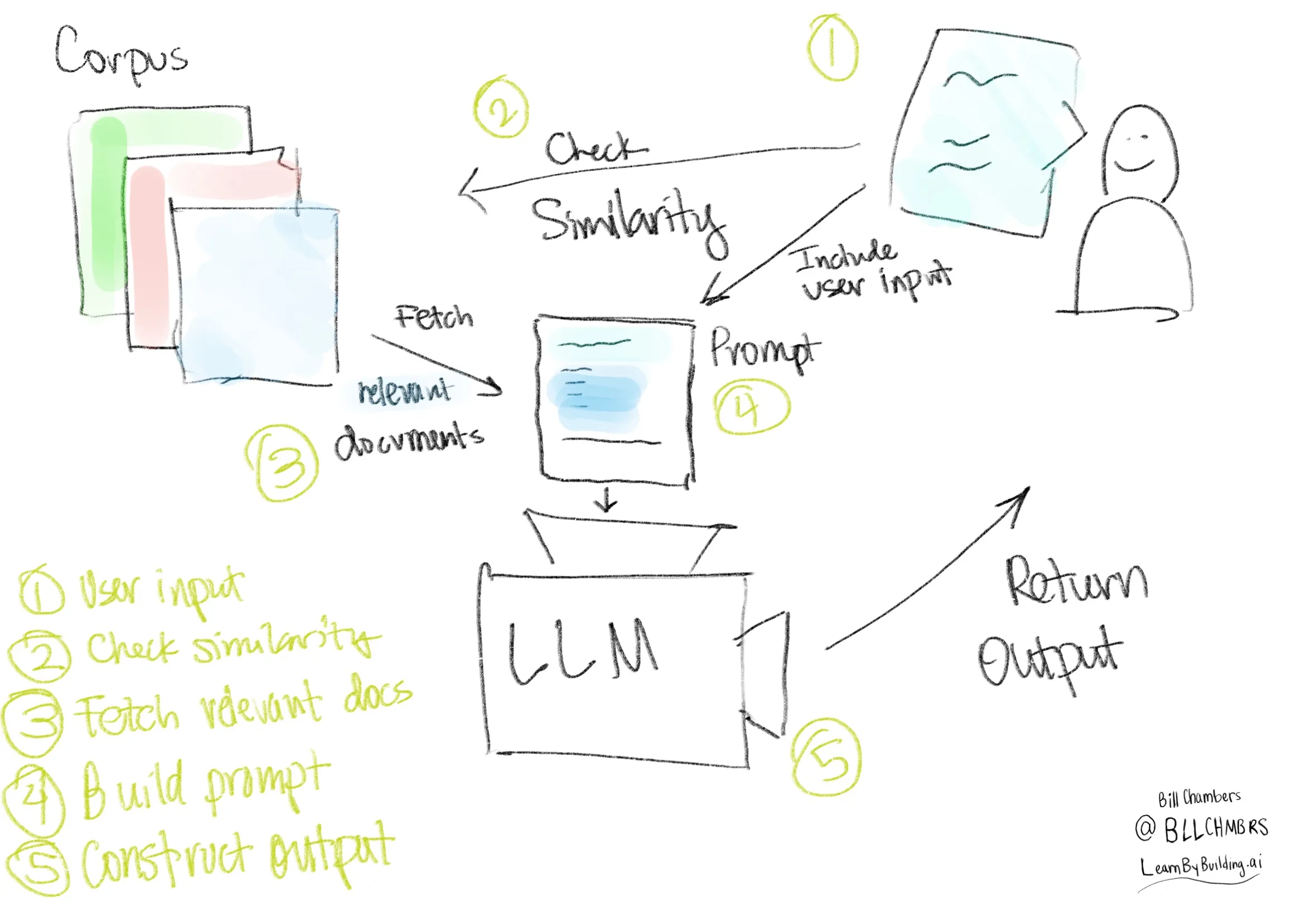
## The High Level Components of our RAG System
1. a collection of documents (formally called a corpus)
2. An input from the user
3. a similarity measure between the collection of documents and the user input
Yes, it's that simple.
To start learning and understanding RAG based systems, you don't need a vector store, you don't even *need* an LLM (at least to learn and understand conceptually).
While it is often portrayed as complicated, it doesn't have to be.
## The ordered steps of a querying RAG system
We'll perform the following steps in sequence.
1. Receive a user input
2. Perform our similarity measure
3. Post-process the user input and the fetched document(s).
The post-processing is done with an LLM.
## A note from the paper itself
[The actual RAG paper](https://arxiv.org/abs/2005.11401) is obviously *the* resource. The problem is that it assumes a LOT of context. It's more complicated than we need it to be.
For instance, here's the overview of the RAG system as proposed in the paper.
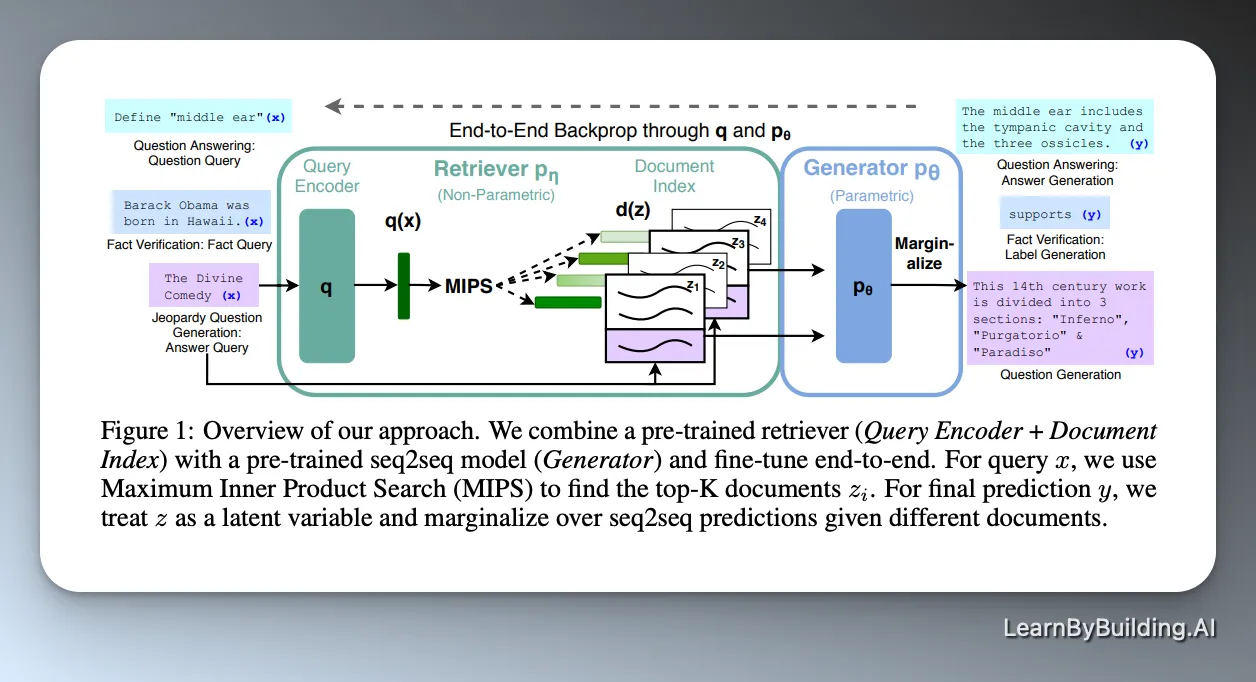
That's dense.
It's great for researchers but for the rest of us, it's going to be a lot easier to learn step by step by building the system ourselves.
## Working through an example - the simplest RAG system
Let's get back to building RAG from scratch, step by step. Here's the simplified steps that we'll be working through.
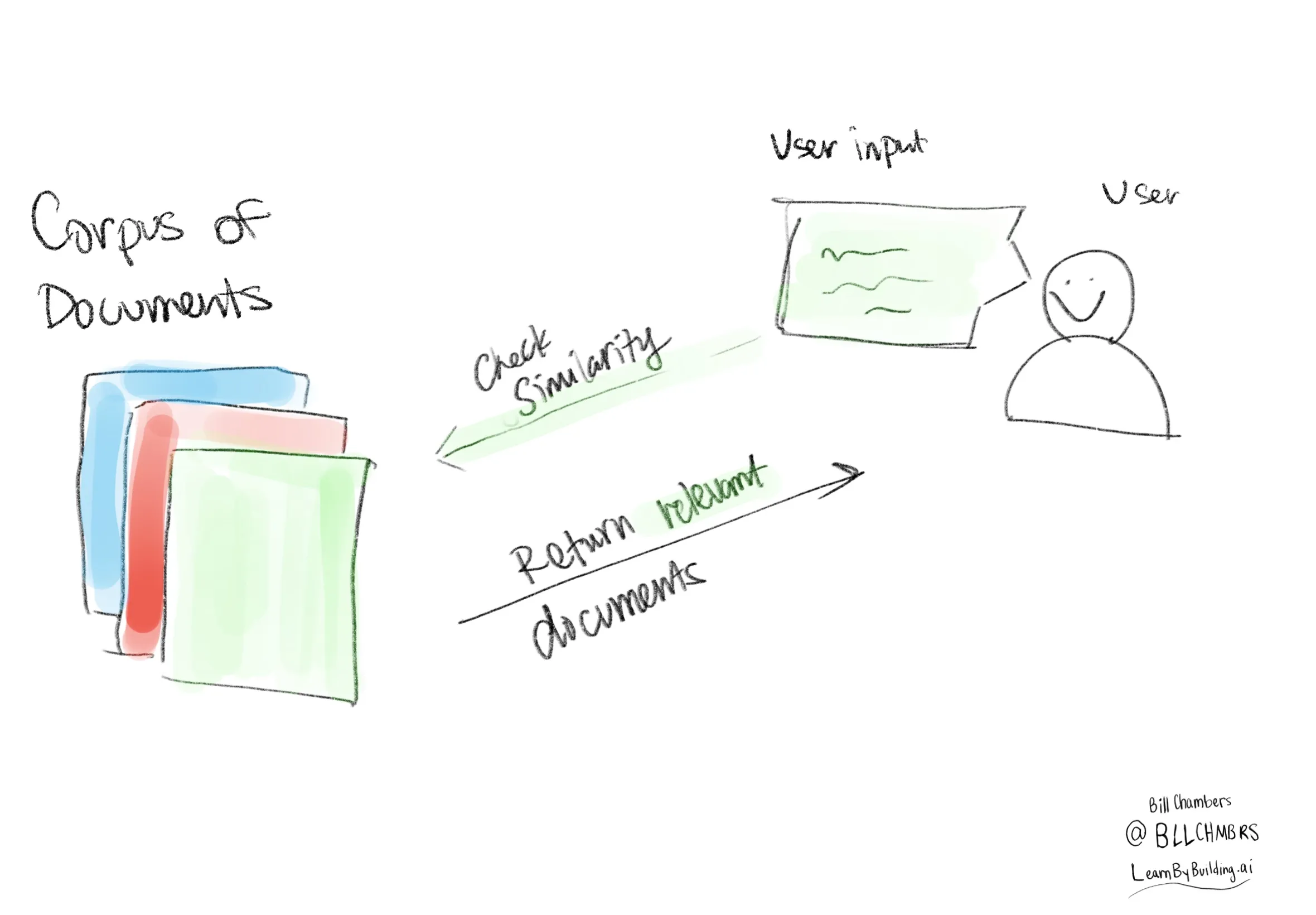
### Getting a collection of documents
Below you can see that we've got a simple corpus of 'documents' (please be generous 😉).
```python
corpus_of_documents = [
"Take a leisurely walk in the park and enjoy the fresh air.",
"Visit a local museum and discover something new.",
"Attend a live music concert and feel the rhythm.",
"Go for a hike and admire the natural scenery.",
"Have a picnic with friends and share some laughs.",
"Explore a new cuisine by dining at an ethnic restaurant.",
"Take a yoga class and stretch your body and mind.",
"Join a local sports league and enjoy some friendly competition.",
"Attend a workshop or lecture on a topic you're interested in.",
"Visit an amusement park and ride the roller coasters."
]
```
### Defining and performing the similarity measure
Now we need a way of measuring the similarity between the **user input** we're going to receive and the **collection** of documents that we organized. Arguably the simplest similarity measure is [jaccard similarity](https://en.wikipedia.org/wiki/Jaccard_index). I've written about that in the past (see [this post](https://billchambers.me/posts/tf-idf-explained-in-python) but the short answer is that the **jaccard similarity** is the intersection divided by the union of the "sets" of words.
This allows us to compare our user input with the source documents.
#### Side note: preprocessing
A challenge is that if we have a plain string like `"Take a leisurely walk in the park and enjoy the fresh air.",`, we're going to have to pre-process that into a set, so that we can perform these comparisons. We're going to do this in the simplest way possible, lower case and split by `" "`.
```python
def jaccard_similarity(query, document):
query = query.lower().split(" ")
document = document.lower().split(" ")
intersection = set(query).intersection(set(document))
union = set(query).union(set(document))
return len(intersection)/len(union)
```
Now we need to define a function that takes in the exact query and our corpus and selects the 'best' document to return to the user.
```python
def return_response(query, corpus):
similarities = []
for doc in corpus:
similarity = jaccard_similarity(user_input, doc)
similarities.append(similarity)
return corpus_of_documents[similarities.index(max(similarities))]
```
Now we can run it, we'll start with a simple prompt.
```python
user_prompt = "What is a leisure activity that you like?"
```
And a simple user input...
```python
user_input = "I like to hike"
```
Now we can return our response.
```python
return_response(user_input, corpus_of_documents)
```
'Go for a hike and admire the natural scenery.'
Congratulations, you've built a basic RAG application.
#### I got 99 problems and bad similarity is one
Now we've opted for a simple similarity measure for learning. But this is going to be problematic because it's so simple. It has no notion of **semantics**. It's just looks at what words are in both documents. That means that if we provide a negative example, we're going to get the same "result" because that's the closest document.
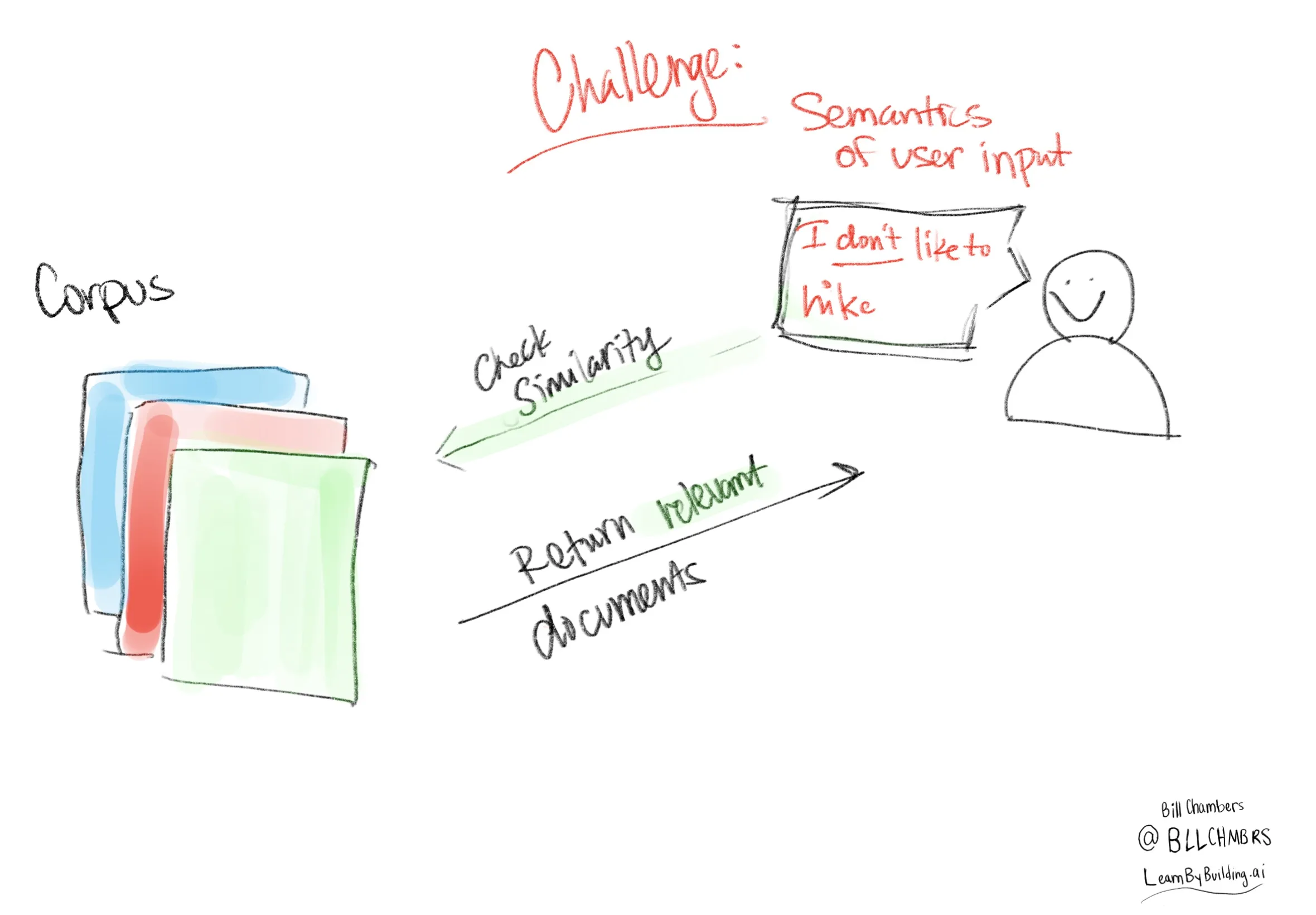
```python
user_input = "I don't like to hike"
```
```python
return_response(user_input, corpus_of_documents)
```
'Go for a hike and admire the natural scenery.'
This is a topic that's going to come up a lot with "RAG", but for now, rest assured that we'll address this problem later.
At this point, we have not done any post-processing of the "document" to which we are responding. So far, we've implemented only the "retrieval" part of "Retrieval-Augmented Generation". The next step is to augment generation by incorporating a large language model (LLM).
## Adding in a LLM
To do this, we're going to use [ollama](https://ollama.ai/) to get up and running with an open source LLM on our local machine. We could just as easily use OpenAI's gpt-4 or Anthropic's Claude but for now, we'll start with the open source llama2 from [Meta AI](https://ai.meta.com/llama/).
- [ollama installation instructions are here](https://ollama.ai/)
This post is going to assume some basic knowledge of large language models, so let's get right to querying this model.
```python
import requests
import json
```
First we're going to define the inputs. To work with this model, we're going to take
1. user input,
2. fetch the most similar document (as measured by our similarity measure),
3. pass that into a prompt to the language model,
4. *then* return the result to the user
That introduces a new term, the **prompt**. In short, it's the instructions that you provide to the LLM.
When you run this code, you'll see the streaming result. Streaming is important for user experience.
```python
user_input = "I like to hike"
relevant_document = return_response(user_input, corpus_of_documents)
full_response = []
# https://github.com/jmorganca/ollama/blob/main/docs/api.md
prompt = """
You are a bot that makes recommendations for activities. You answer in very short sentences and do not include extra information.
This is the recommended activity: {relevant_document}
The user input is: {user_input}
Compile a recommendation to the user based on the recommended activity and the user input.
"""
```
Having defined that, let's now make the API call to ollama (and llama2).
an important step is to make sure that ollama's running already on your local machine by running `ollama serve`.
> Note: this might be slow on your machine, it's certainly slow on mine. Be patient, young grasshopper.
```python
url = 'http://localhost:11434/api/generate'
data = {
"model": "llama2",
"prompt": prompt.format(user_input=user_input, relevant_document=relevant_document)
}
headers = {'Content-Type': 'application/json'}
response = requests.post(url, data=json.dumps(data), headers=headers, stream=True)
try:
count = 0
for line in response.iter_lines():
# filter out keep-alive new lines
# count += 1
# if count % 5== 0:
# print(decoded_line['response']) # print every fifth token
if line:
decoded_line = json.loads(line.decode('utf-8'))
full_response.append(decoded_line['response'])
finally:
response.close()
print(''.join(full_response))
```
Great! Based on your interest in hiking, I recommend trying out the nearby trails for a challenging and rewarding experience with breathtaking views Great! Based on your interest in hiking, I recommend checking out the nearby trails for a fun and challenging adventure.
This gives us a complete RAG Application, from scratch, no providers, no services. You know all of the components in a Retrieval-Augmented Generation application. Visually, here's what we've built.
The LLM (if you're lucky) will handle the user input that goes against the recommended document. We can see that below.
```python
user_input = "I don't like to hike"
relevant_document = return_response(user_input, corpus_of_documents)
# https://github.com/jmorganca/ollama/blob/main/docs/api.md
full_response = []
prompt = """
You are a bot that makes recommendations for activities. You answer in very short sentences and do not include extra information.
This is the recommended activity: {relevant_document}
The user input is: {user_input}
Compile a recommendation to the user based on the recommended activity and the user input.
"""
url = 'http://localhost:11434/api/generate'
data = {
"model": "llama2",
"prompt": prompt.format(user_input=user_input, relevant_document=relevant_document)
}
headers = {'Content-Type': 'application/json'}
response = requests.post(url, data=json.dumps(data), headers=headers, stream=True)
try:
for line in response.iter_lines():
# filter out keep-alive new lines
if line:
decoded_line = json.loads(line.decode('utf-8'))
# print(decoded_line['response']) # uncomment to results, token by token
full_response.append(decoded_line['response'])
finally:
response.close()
print(''.join(full_response))
```
Sure, here is my response:
Try kayaking instead! It's a great way to enjoy nature without having to hike.
## Areas for improvement
If we go back to our diagream of the RAG application and think about what we've just built, we'll see various opportunities for improvement. These opportunities are where tools like vector stores, embeddings, and prompt 'engineering' gets involved.
Here are ten potential areas where we could improve the current setup:
1. **The number of documents** 👉 more documents might mean more recommendations.
2. **The depth/size of documents** 👉 higher quality content and longer documents with more information might be better.
3. **The number of documents we give to the LLM** 👉 Right now, we're only giving the LLM one document. We could feed in several as 'context' and allow the model to provide a more personalized recommendation based on the user input.
4. **The parts of documents that we give to the LLM** 👉 If we have bigger or more thorough documents, we might just want to add in parts of those documents, parts of various documents, or some variation there of. In the lexicon, this is called chunking.
5. **Our document storage tool** 👉 We might store our documents in a different way or different database. In particular, if we have a lot of documents, we might explore storing them in a data lake or a vector store.
6. **The similarity measure** 👉 How we measure similarity is of consequence, we might need to trade off performance and thoroughness (e.g., looking at every individual document).
7. **The pre-processing of the documents & user input** 👉 We might perform some extra preprocessing or augmentation of the user input before we pass it into the similarity measure. For instance, we might use an embedding to convert that input to a vector.
8. **The similarity measure** 👉 We can change the similarity measure to fetch better or more relevant documents.
9. **The model** 👉 We can change the final model that we use. We're using llama2 above, but we could just as easily use an Anthropic or Claude Model.
10. **The prompt** 👉 We could use a different prompt into the LLM/Model and tune it according to the output we want to get the output we want.
11. **If you're worried about harmful or toxic output** 👉 We could implement a "circuit breaker" of sorts that runs the user input to see if there's toxic, harmful, or dangerous discussions. For instance, in a healthcare context you could see if the information contained unsafe languages and respond accordingly - outside of the typical flow.
The scope for improvements isn't limited to these points; the possibilities are vast, and we'll delve into them in future tutorials. Until then, don't hesitate to [reach out on Twitter](https://twitter.com/bllchmbrs) if you have any questions. Happy RAGING :).
## References
- [Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks](https://arxiv.org/abs/2005.11401)
- [Jerry Liu on Twitter advocating for users to build RAG from scratch](https://twitter.com/jerryjliu0/status/1716122650836439478)
If you like this post, you'll love what we're doing at [learn By Building AI](https://learnbybuilding.ai/).
| bllchmbrs |
1,651,357 | Embracing Key Communication Trends? | What communication trends do you believe are crucial in today's digital age? Follow the DEVteam for... | 0 | 2023-11-01T21:20:00 | https://dev.to/devteam/embracing-key-communication-trends-249p | discuss |
What communication trends do you believe are crucial in today's digital age?
Follow the DEVteam for more discussions and online camaraderie!
{% embed [https://dev.to/devteam](https://dev.to/devteam) %} | thepracticaldev |
1,651,413 | The Illusion of Data Ownership | Table of Contents Introduction Why I'm reflecting on this The Illusion of Ownership The... | 24,870 | 2023-10-30T23:01:29 | https://dev.to/tbdevs/the-illusion-of-data-ownership-3nbi | web5, javascript, webdev, decentralization | ## Table of Contents
- [Introduction](#introduction)
- [Why I'm reflecting on this](#why-im-reflecting-on-this)
- [The Illusion of Ownership](#the-illusion-of-ownership)
- [The Tyranny of Social Media](#the-tyranny-of-social-media)
- [Exploitation of Disenfranchised People](#exploitation-of-disenfranchised-people)
- [AI Thrives On Our Data](#ai-thrives-on-our-data)
- [ChatGPT](#chatgpt)
- [The Art Community](#the-art-community)
- [The Original Intent of the Internet](#the-original-intent-of-the-internet)
- [Web5](#web5)
- [How Web5 Enables Data Sovereignty](#how-web5-enables-data-sovereignty)
- [Curious about Web5?](#curious-about-web5)
## Introduction
The rise of Mastodon and BlueSky as decentralized Twitter alternatives highlights the need for data ownership. But the slow adoption of a decentralized web reveals a gap in our collective comprehension. For as long as the internet has existed, internet users rarely owned their data, so it's hard to envision a web where data sovereignty is the norm.
I'm a quintessential baby millennial – born in '95. I was born on the cusp of GenZ, but I don't identify with GenZ because I'm not hip to their lingo, dances, or fashion sense. I started surfing the web during the early 2000s. I grew up using PBS Kids, Everything Girl, The Doll Palace, Club Penguin, MySpace, and Tumblr. Today, I use platforms like Twitter, GitHub, and Instagram. Each login, each acceptance of terms and conditions, was an implicit agreement to share fragments of my identity. As a result, corporations capitalize on trading and harnessing my data for profit. I mindlessly accepted it because I didn't know any other way of using the internet.
The idea that users can have full data sovereignty seemed like a utopian fantasy. Listening to company leaders share the organization's vision during a company offsite transformed my interpretation of data ownership.
## Why I'm reflecting on this
I am someone who likes to reflect on the philosophy behind a technology, so I can confidently endorse it. While I believe all technology can be used for good and evil, I like to determine its current impact. If it leans towards the negative, I'm driven to influence people to use it in a way that positively impacts society. Take generative AI, for instance. While it poses the risk of job losses for some creatives, I dedicated two years to championing its use as an educational tool—one that offers a sense of psychological safety to learners. Similarly, I want to think holistically about decentralized web technologies such as Web5.
In this blog post, we will discuss the meaning of data ownership on the web and how it impacts society.
## The Illusion of Ownership
Many internet users operate under the assumption that our online data is ours.The reality is we merely possess our data. There’s a huge difference between holding our data (possession) and owning our data (property).
* **Possession**: This is about having control or physical custody of data. Here’s an example of what that looks like on social media platforms:
* **Access and View**: You can log in, view your posts, and interact with content.
* **Modify**: Edit captions, comments, or profile details.
* **Interact**: Engage with content through likes, comments, and shares.
* **Upload**: Add new content.
* **Delete (with limitations)**: Remove posts or deactivate accounts, but the platform might still retain or use your data.
* **Property**: This is about having inherent rights to own, control, and manage data. Truly owning your data on a social media platform looks like:
* **Complete Deletion**: You'd have the right to permanently erase all traces of your data from the platform's servers, with no backups or archives retained.
* **Data Portability**: You could seamlessly transfer all your data, including posts, comments, and likes, to another platform without any loss or format change.
* **Monetization Control**: You'd have the authority to decide if and how your data is used for advertising or other revenue-generating purposes.
* **Data Access Control**: You could dictate who, including the platform itself, can access or view your data.
* **No Unilateral Changes**: The platform couldn't change terms of service or data policies without your explicit consent.
We are more possessors than owners.
## The Tyranny of Social Media
Recent changes on platforms like Twitter/X underscore my point.
Here are examples:
* **Usernames taken** - When X rebranded from Twitter, they claimed the username '@X', despite it already being in use by another individual.
* **Vanishing features** - Recently, X announced they are removing Twitter Circles. Twitter Circles allows users to select a subgroup of followers to receive particular posts. Many people use this for private sharing, but now that option will not exist. And while X promises to leave the Circle posts private, there have been instances in the past where bugs made Circle posts publicly viewable.
* **Lost content** - Integrated newsletters like Revue were suddenly removed, leading to loss of content and subscribers.
Twitter/X is not the only culprit. Google has a history of discontinuing products including Google Podcasts. See: [Killed by Google](https://killedbygoogle.com/).
### Exploitation of Disenfranchised People
> “If you know whence you came, there are absolutely no limitations to where you can go.” - James Baldwin
I don’t know my ancestral history, but I want to. All I know is I was born in Antigua and my parents and grandparents were born in Guyana. I want to take an ancestry test, but there are data privacy risks. The powers that be have exploited disenfranchised people enough. I want to shield our history from potential data breaches and commercial interests. I don’t want to offer more of our narrative to those who might exploit it.
## AI Thrives On Our Data
I am a huge fan of generative AI because it’s so powerful. However, I recognize that it’s only that powerful because it was trained on our data.
### ChatGPT
ChatGPT is an integral part of my daily routine. It helps me brainstorm ideas and refactor code. I'm not sure how I could survive or how I ever survived without it. But there's a catch -- ChatGPT is super helpful because it was trained on public data, including data from users like us. This means that any confidential information we share could become part of its training data. There's a risk that if you tell ChatGPT sensitive information about you or your company, someone else can potentially prompt ChatGPT for that data, and get ahold of it. One of many examples is the [case with Samsung](https://www.forbes.com/sites/siladityaray/2023/05/02/samsung-bans-chatgpt-and-other-chatbots-for-employees-after-sensitive-code-leak/?sh=4813eefe6078) where employees inadvertently shared proprietary code and internal business strategies with ChatGPT.
### The Art Community
Many artists are upset with the rise of generative AI art. They suspect the tools were trained on their work because they recognize their own styles in generated AI pieces.
Whether these are actual problems or ethical gray areas, one thing is clear: _wouldn’t it be better if we had a say in how our data is used and who uses it?_
### The Original Intent of the Internet
These are some of the reasons why data ownership is important to me. Even Tim Berners-Lee, the inventor of the World Wide Web, is disappointed in how we leveraged data on the Internet.
> “I think the public has been concerned about privacy--the fact that these platforms have a huge amount of data, and they abuse it. But I think what they're missing sometimes is the lack of empowerment. You need to get back to a situation where you have autonomy, you have control of all your data.” - Tim Berners-Lee
## Web5
[Web5](https://developer.tbd.website/blog/what-is-web5) is a platform (currently under development) that puts users in control of their data and identity. It doesn’t aim to replace current technologies, but enhance.
### How Web5 Enables Data Sovereignty
Here’s how Web5 puts users in control of their data:
#### Decentralized Identifiers
Identity on traditional systems often looks like username and password pairings.
In the Web5 ecosystem, every person has a Decentralized Identifier (DID), represented as an alphanumeric string. DIDs are:
- a W3C open standard
- based on cryptographic principles.
- not tied to one web application or system
Because of these factors, DIDs enable users to securely authenticate to any web app within the Web5 ecosystem.
#### Decentralized Web Nodes
Your DID gives you access to a Decentralized Web Node (DWN) or a personal data store. You can think of a DWN like your personal Dropbox. However, centralized platforms like Dropbox can change terms of service, access your data, or even shut down services, leaving you without access. Instead, a DWN provides a personal space where your data is stored and you decide who gets access.
#### Protocols
Protocols are responsible for structuring your data and establishing rules for data access and interaction within a DWN.
In other words, you can control who has access to your DWN and who interacts with it via a protocol. Here's an abridge example of a protocol you can write for a user's interactions on social media applications:
```javascript
const socialMediaProtocolDefinition = {
protocol: "https://sovereignsocialmedia.org/protocol",
published: true,
types: {
personalInfo: {
schema: "https://schema.org/Person",
dataFormats: ["application/json"],
},
preferences: {
schema: "https://schema.org/UserPreferences",
dataFormats: ["application/json"],
},
posts: {
schema: "https://schema.org/BlogPosting",
dataFormats: ["application/json"],
},
comments: {
schema: "https://schema.org/Comment",
dataFormats: ["application/json"],
},
photos: {
schema: "https://schema.org/ImageObject",
dataFormats: ["image/jpeg", "image/png"],
},
videos: {
schema: "https://schema.org/VideoObject",
dataFormats: ["video/mp4"],
},
},
structure: {
personalInfo: {
$actions: [
{ who: "author", can: "write" },
{ who: "author", can: "read" },
],
},
preferences: {
$actions: [
{ who: "author", can: "write" },
{ who: "author", can: "read" },
],
},
posts: {
$actions: [
{ who: "author", can: "write" },
{ who: "anyone", can: "read" },
],
},
comments: {
$actions: [
{ who: "author", can: "write" },
{ who: "anyone", can: "read" },
],
},
photos: {
$actions: [
{ who: "author", can: "write" },
{ who: "anyone", can: "read" },
],
},
videos: {
$actions: [
{ who: "author", can: "write" },
{ who: "anyone", can: "read" },
],
},
}
};
```
Here's a breakdown of the permissions (who has access to this data) in this protocol:
- **Personal Info Permissions**:
- **Write**: Only the user (author) can write or update their personal information.
- **Read**: Only the user (author) can view their personal information.
- **Preferences Permissions**:
- **Write**: Only the user (author) can set or change their preferences.
- **Read**: Only the user (author) can view their preferences.
- **Posts Permissions**:
- **Write**: Only the user (author) can create or update their posts.
- **Read**: Both the user (author) and the public can view the posts.
- **Comments Permissions**:
- **Write**: Only the user (author) can create or update their comments on posts.
- **Read**: Both the user (author) and the public can view the comments.
With this protocol, content creation is open to all, but users have control over their personal data and preferences.
Data ownership isn't just a technical decision or a fun concept for developers. It is about creating a more equitable online ecosystem.
_What are your thoughts on data ownership and Web5?_
## Curious about Web5?
* Read: [What is Web5?](https://developer.tbd.website/blog/what-is-web5)
* Read: [Why Companies Would Embrace Web5](https://developer.tbd.website/blog/why-would-companies-embrace-web5)
* Read: [How to Query Records by Protocol Path](https://dev.to/tbdevs/web5-how-to-query-records-by-protocol-path-1g6h)
* Read: [What’s the point of Web5?](https://dev.to/tbdevs/whats-the-point-of-web5-2kjb)
* Build: [How to build a Web5 shared to do list with Nuxt](https://developer.tbd.website/docs/web5/build/apps/shared-todo-app)
* Build: [How to build a Web5 chat app with Next](https://developer.tbd.website/docs/web5/build/apps/dinger-tutorial)
* Join: [An Intro to TBD's Web 5 SDK and Decentralized Web Nodes ](https://www.eventbrite.com/e/an-intro-to-tbds-web-5-sdk-and-decentralized-web-nodes-tickets-729176565737?aff=tbd)
* Join: [On Wednesdays We Use Web5: A 'Mean Girls' Guide to Data Sovereignty](https://cfe.dev/events/on-wednesdays-we-use-web5/)
* Join: [TBD's Discord](https://discord.com/invite/tbd)
| blackgirlbytes |
1,651,424 | Applying the Power of Machine Learning for Data and Analytics | 1. Introduction Data analytics is the process of examining data to uncover insights and make... | 0 | 2023-10-30T23:40:01 | https://dev.to/danielwambo/applying-the-power-of-machine-learning-for-data-and-analytics-o59 | **1. Introduction**
Data analytics is the process of examining data to uncover insights and make informed decisions. Machine learning is a subset of artificial intelligence that empowers data analytics by automating predictions based on data patterns.
**2. What is Machine Learning?**
Machine learning is a technology that enables computers to learn and make predictions or decisions without being explicitly programmed. It's divided into three main types: supervised learning, unsupervised learning, and reinforcement learning.
**3. Data Collection and Preprocessing**
Quality data is essential for machine learning. Data preprocessing includes cleaning and preparing the data for analysis.
**4. Supervised Learning**
Supervised learning is used for tasks like classification and regression. It involves using labeled data to train a model.

**5. Model Evaluation**
To understand how well your model performs, you can use evaluation metrics like accuracy, which measures how often the model is correct.

**Conclusion**
Machine learning is a powerful tool that can enhance your data analytics efforts. By understanding its basics and applying it to your data, you can make more accurate predictions and gain valuable insights.
| danielwambo | |
1,652,536 | Understanding the basics of Smart Pointers in Rust | In today's post we'll delve into the basics of smart pointers in Rust, while we build from scratch a... | 0 | 2023-11-01T04:15:27 | https://dev.to/leandronsp/understanding-the-basics-of-smart-pointers-in-rust-3dff | rust, datastructures | In today's post we'll delve into the basics of smart pointers in Rust, while we build from scratch a simple linked list - starting from a singly linked list and then evolving to a doubly one.
---
## Prelude, intro to Rust
It's not intended to be an introduction about Rust. For that, you can follow along [this blogpost series](https://dev.to/mfcastellani/series/23318) by [@mfcastellani](https://dev.to/mfcastellani).
Also, you can read [his book](https://www.casadocodigo.com.br/products/livro-rust) (pt-BR). Moreover, I have a [live coding video](https://www.youtube.com/watch?v=6VSgMbFNUuQ) where I explored the Rust fundamentals by covering an introduction to Rust, data types, functions, ownership, references, structs/enums and error handling.
Another content about Rust I higly recommend is presented on [this Youtube channel](https://www.youtube.com/watch?v=zWXloY0sslE) by Bruno Rocha, which creates great videos about Rust as well (pt-BR).
> Please note that this post you are currently reading was written during a [live coding session (pt-BR)](https://www.youtube.com/watch?v=bdZe0LjDUyk) where you can follow the process I use to write blogposts in general and how I created this particular one. It's a novel format I'm experimenting with to share content.
However, if you are looking for introdutory content in english only, the Youtube channel [Let's get Rusty](https://www.youtube.com/@letsgetrusty) provides great content on Rust from basics to advanced.
---
No more introduction, let's embark on this journey of **Smart Pointers in Rust**.
---
## Table of Contents
- [First things first](#first-things-first)
- [A linked list using Rust](#a-linked-list-using-rust)
- [Meet the Box smart pointer](#box)
- [Shared ownership using Rc](#rc)
- [Interior mutability with RefCell](#refcell)
- [Weak references on a circular linked list](#thinking-about-a-circular-linked-list)
---
## 👉 First things first
Rust employs a mechanism for dealing with memory management where it prevents dangling references, double free error and other problems related to memory management.
This mechanism is called "ownership" and through [RAII](https://en.wikipedia.org/wiki/Resource_acquisition_is_initialization) (Resource Acquisition Is Initialization), it follows three basic rules:
* Each value in Rust has a single owner
* There are only *one* owner at a time
* When the owner's scope is finished, its associated value is dropped and invalidated
When we need to transfer ownership, in case the value is in the stack (fixed-sized types), Rust performs a *Copy*:
> I'm assuming that all code snippets within this post are being executed inside a `fn main() {}` function
```rust
let age = 20;
let copied_age = age;
println!("copied_age: {}", copied_age);
println!("age: {}", age); // age is still valid because Rust performs a "Copy" for data in the stack
```
As for _dynamically-sized_ types, which live in the heap, Rust performs a *Move*:
```rust
let name = String::from("John");
let other_name = name;
println!("other_name: {}", other_name);
println!("name: {}", name); // name is no loger valid because Rust performs a "Move"
// Error:
// error[E0382]: borrow of moved value: `name`
```
*Copy* literally copies the data in the stack, while the *Move* operation transfers ownership, which means that the former owner is no longer the owner and its reference is completely dropped.
---
## 👉 A Linked List using Rust
A linked list is a data structure which represents a collection of nodes where each node points to the next node. This is basically a **singly linked list**.
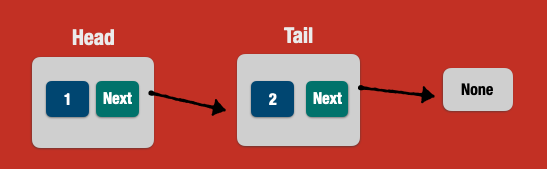
Also, we can build a linked list where each node points to the previous node as well. In this case, such a list is called **doubly linked list**.
### 🔵 A Singly Linked List
The first version of our linked list will be a singly one. As we evolve to a doubly linked list, we'll bring Rust concepts about ownership, references and smart pointers.
We start by modeling the Node:
```rust
struct Node {
value: i32,
next: Node
}
```
We are bound to situations where the **next** pointer points to "nothing", or simply a `null` pointer when the list reaches the end, commonly seen in a variety of programming languages.
But Rust has no `null` pointers. That said, we can represent the `next` pointer by using the enum **Option**, which in Rust gives us two possibilities of types:
* None (the end of the list)
* Some(node)
```rust
struct Node {
value: i32,
next: Option<Node>
}
let head = Node { value: 1, next: None };
assert_eq!(1, head.value);
assert_eq!(None, head.next);
```
The above code is not yet compiling:
```
error[E0072]: recursive type `Node` has infinite size
--> src/main.rs:2:5
|
2 | struct Node {
| ^^^^^^^^^^^
3 | value: i32,
4 | next: Option<Node>
| ---- recursive without indirection
|
help: insert some indirection (e.g., a `Box`, `Rc`, or `&`) to break the cycle
|
4 | next: Option<Box<Node>>
| ++++ +
```
The Rust compiler is saying that _Node_ has unknown size at compile-time and as such it can't be determined, because the "next" pointer points to another Node which points to another Node and so on, infinitely.
This is a **recursive type**.
In order to solve this problem, we have to help the Rust compiler to use some abstraction which can allocate data on the heap and determine the size of the Node at compile-time, resolving the recursive type.
Such abstraction is called **Box**, which is a smart pointer in Rust.
---
## 👉 Box
By using Box, we want to allocate the data on the heap.
Also, Box has a known size at compile-time. Being a pointer, the _size of the Box is the pointer size_, which makes it a good fit for recursive types.
The following code compiles sucessfully:
```rust
#[derive(Debug, PartialEq)]
struct Node {
value: i32,
next: Option<Box<Node>>
}
let head = Node { value: 1, next: None };
assert_eq!(1, head.value);
assert_eq!(None, head.next);
```
What if we add one more node, called "tail"?
```rust
let tail = Node { value: 2 next: None };
let head = Node { value: 1, next: Some(tail) };
```
As always (the Rust compilers always wins), it won't compile:
```
---- ^^^^ expected `Box<Node>`, found `Node`
```
We have to wrap the tail in a _Box_:
```rust
struct Node {
value: i32,
next: Option<Box<Node>>
}
let tail = Box::new(Node { value: 2, next: None });
let head = Node { value: 1, next: Some(tail) };
assert_eq!(1, head.value);
assert_eq!(2, head.next.unwrap().value);
```
* We wrap the tail box in an Option (Some)
* The _head.next_ points to an **Option**. Because it's the enum Option, we have to call `unwrap` to fetch the underlying value
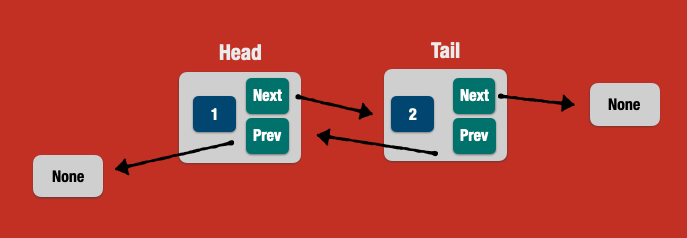
Let's go further in the example and implement a **doubly linked list**, by specifying the _prev_ attribute on the Node struct.
### 🔵 A Doubly Linked List
```rust
struct Node {
value: i32,
next: Option<Box<Node>>,
prev: Option<Box<Node>>,
}
let tail = Box::new(Node { value: 2, prev: None, next: None });
let head = Node { value: 1, prev: None, next: Some(tail) };
```
* the `head.prev` points to `None`
* the `tail.prev` points to `None` (at this moment...)
In order to change the `tail.prev`, we have to mutate its underlying value, from `None` to `Some(head)`. May we change the source code:
```rust
let mut tail = Box::new(Node { value: 2, prev: None, next: None });
let head = Box::new(Node { value: 1, prev: None, next: Some(tail) });
tail.prev = Some(head); // mutating the tail.prev
```
And...
```
error[E0382]: use of moved value: `head.next`
--> src/main.rs:14:15
|
9 | let head = Box::new(Node { value: 1, prev: None, next: Some(tail) });
| ---- move occurs because `head` has type `Box<Node>`, which does not implement the `Copy` trait
10 |
11 | tail.prev = Some(head);
| ---- value moved here
...
14 | assert_eq!(2, head.next.unwrap().value);
| ^^^^^^^^^ value used here after move
```

_Welcome to the ownership saga in Rust!_
Let's clarify some points here:
First, a Box has **single ownership**, meaning that each value holds one owner at a time. Here, in this line:
```rust
let head = Box::new(Node { value: 1, prev: None, next: Some(tail) }); // value was moved here
```
`Tail` has been *moved*, that's why we cannot use it later, due to ownership rules.
To fix that, we can make use of the method `clone` implemented in the Box, which will perform a deep copy (clone) of the value in the heap:
```rust
let head = Box::new(Node { value: 1, prev: None, next: Some(tail.clone()) });
tail.prev = Some(head);
```
Additionally, in the following line, `tail.prev` takes ownership of the value of `head`, so the value was moved to the new owner:
```rust
tail.prev = Some(head); // value as moved here
```
Now the solution is calling `clone` as we did in the `tail`:
```rust
tail.prev = Some(head.clone());
```
Here's the current solution for a doubly linked list using Box:
```rust
#[derive(Clone)]
struct Node {
value: i32,
next: Option<Box<Node>>,
prev: Option<Box<Node>>,
}
let mut tail = Box::new(Node { value: 2, prev: None, next: None });
let head = Box::new(Node { value: 1, prev: None, next: Some(tail.clone()) });
tail.prev = Some(head.clone());
assert_eq!(1, head.value);
assert_eq!(2, tail.value);
assert_eq!(2, head.next.unwrap().value);
assert_eq!(1, tail.prev.unwrap().value);
```
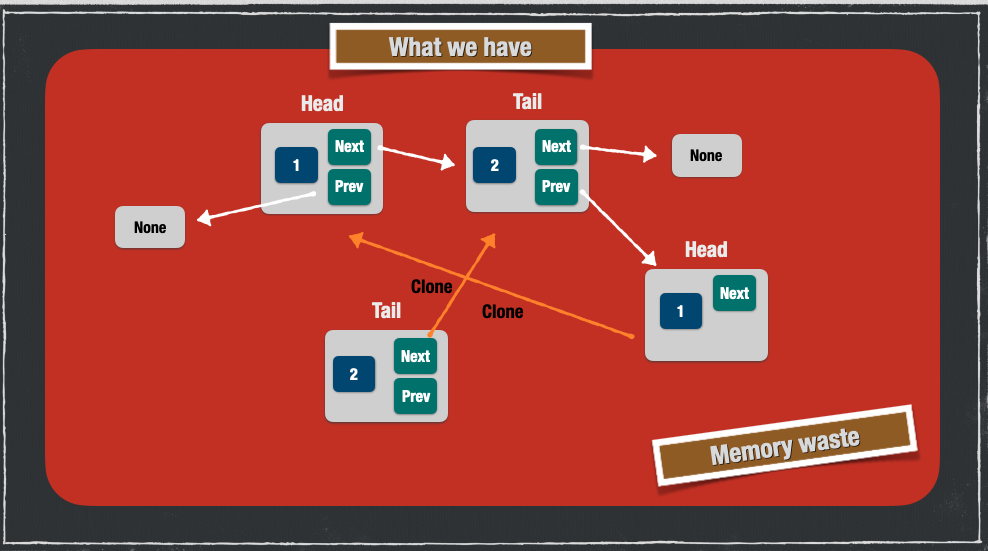
By using Box, we've solved the problem but we may end up wasting memory, as demonstrated in the following picture:
At this point in time, we have the following abstraction model about ownership, which is single and shares no value in the heap (Box):
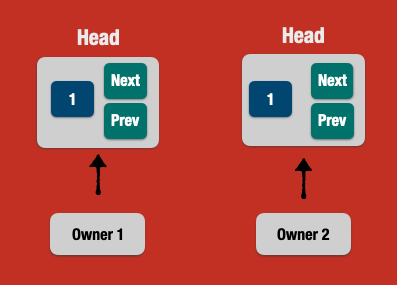
We have to find a way to overcome the single ownership problem. What about _not taking ownership at all_, by using **References** instead?
### 🔵 References & Lifetimes
References in Rust do not take ownership, as they allow to work with the reference of the data which is allocated in the heap.
This way, references can be "borrowed" without taking ownership, and as such they are bound to a mechanism called **borrow checker**.
```rust
let name = String::from("John"); // value in the heap. name is the owner
let other_name = &name; // not a move. other_name has a reference to the value in the heap. name is still the owner
println!("other_name: {}", other_name);
println!("name: {}", name);
```
The above code compiles successfully. The borrow checker ensures that the reference is pointing to some valid value in the heap, thus not "moving" the ownership.
Let's change the code to use References instead of Box:
```rust
struct Node {
value: i32,
next: Option<&Node>,
}
let tail = Node { value: 2, next: None };
let head = Node { value: 1, next: Some(&tail) };
```
* The `next` is an enum Option which wraps a *reference to another Node*
* The `head.next` is now using `Some(&tail)` which is a reference to the tail (other node), instead of a Box which takes ownership
But this code won't compile yet:
```
error[E0106]: missing lifetime specifier
--> src/main.rs:4:18
|
4 | next: Option<&Node>,
| ^ expected named lifetime parameter
|
help: consider introducing a named lifetime parameter
|
2 ~ struct Node<'a> {
3 | value: i32,
4 ~ next: Option<&'a Node>,
```
Each reference has an implicit lifetime in the Rust compiler. In our example of a linked list, the compiler can't determine the lifetime of the `next` pointer because it points to another Node which could have a different lifetime.
Because the borrow checker prevents dangling references by using lifetimes, we have to help the compiler by annotating lifetimes in the struct definition:
```rust
struct Node<'a> {
value: i32,
next: Option<&'a Node<'a>>,
}
// or, using generics
struct Node<'a, T> {
value: T,
next: Option<&'a Node<'a, T>>,
}
```
_It's quite verbose, I know._ 😬
Now the version of a singly linked list using references:
```rust
#[derive(Debug, PartialEq)]
struct Node<'a, T> {
value: T,
next: Option<&'a Node<'a, T>>,
}
let tail = Node { value: 2, next: None };
let head = Node { value: 1, next: Some(&tail) };
assert_eq!(1, head.value);
assert_eq!(2, head.next.unwrap().value);
assert_eq!(None, tail.next);
```
* The `Node` and its `next` (reference) node has a lifetime `'a`
* we can use tail/head even after they been applied to the repective nodes, because we took no ownership
But a singly linked list is not enough. We want a doubly one:
```rust
#[derive(Debug, PartialEq)]
struct Node<'a, T> {
value: T,
next: Option<&'a Node<'a, T>>,
prev: Option<&'a Node<'a, T>>,
}
let mut tail = Node { value: 2, prev: None, next: None };
let head = Node { value: 1, prev: None, next: Some(&tail) };
tail.prev = Some(&head);
assert_eq!(1, head.value);
assert_eq!(2, head.next.unwrap().value);
assert_eq!(None, tail.next);
```
We run the code and...
```
error[E0506]: cannot assign to `tail.prev` because it is borrowed
--> src/main.rs:12:1
|
10 | let head = Node { value: 1, prev: None, next: Some(&tail) };
| ----- `tail.prev` is borrowed here
11 |
12 | tail.prev = Some(&head);
| ^^^^^^^^^^^^^^^^^^^^^^^ `tail.prev` is assigned to here but it was already borrowed
13 |
14 | assert_eq!(1, head.value);
| ------------------------- borrow later used here
```

_What happened here?_
The **borrow checker** checks at compile-time that we can have only *one mutable reference* at a time in the same scope.
Our example has a scenario where the `tail.prev` is **mutable** and is already borrowed to the `head`.
That's why we simply *can't implement a doubly linked list* in Rust using references (AFAIK).
Then we should go back to ownership. But what about having a "shared ownership" instead of a "single ownership" like in the Box example?
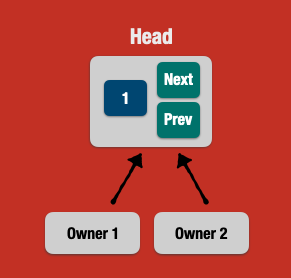
Enter _Rc_.
---
## 👉 Rc
Rc stands for **reference counting**, which performs heap allocation, like a Box.
But unlike Box, it enables _shared ownership_, where one or more owners point to the same value in the heap. Each time an owner _comes to the party_, it increments the counter. When the owner goes out of scope, it decrements the counter.
Only when all owners are dropped, then the Rc is entirely dropped as well freeing the underlying data from the heap.
Rc brings one caveat: **the reference must be immutable**. Otherwise, it would lead to double-free errors.
```rust
use std::rc::Rc;
let name = Rc::new(String::from("John"));
assert_eq!(1, Rc::strong_count(&name));
let cloned_name = Rc::clone(&name);
assert_eq!(2, Rc::strong_count(&name));
assert_eq!("John", *cloned_name); // Dereference
assert_eq!("John", *name); // Dereference
```
Each time an `Rc` is called `data.clone()` or by using `Rc::clone(&data)`, the data is not being copied on the heap (deep copy). Only the reference is copied and the strong count of references is incremented.
The original owner is still valid after _cloning_ multiple Rc references.
Let's implement the singly linked list using Rc instead of references or Box:
```rust
use std::rc::Rc;
struct Node<T> {
value: T,
next: Option<Rc<Node<T>>>
}
```
Cool, now let's add some data to our linked list:
```rust
let tail = Rc::new(Node { value: 2, next: None });
let head = Rc::new(Node { value: 1, next: Some(tail) });
assert_eq!(1, head.value);
assert_eq!(2, head.next.clone().unwrap().value);
```
It simply works! _How cool is that?_
Time to evolve to a doubly linked list using Rc:
```rust
use std::rc::Rc;
struct Node<T> {
value: T,
next: Option<Rc<Node<T>>>,
prev: Option<Rc<Node<T>>>,
}
let tail = Rc::new(Node { value: 2, prev: None, next: None });
let head = Rc::new(Node { value: 1, prev: None, next: Some(Rc::clone(&tail)) });
tail.prev = Some(Rc::clone(&head));
assert_eq!(1, head.value);
assert_eq!(2, head.next.clone().unwrap().value);
```
Instead of deep copy like in Box, the Rc smart pointer only increments the reference counter. Check `Rc::clone(&head)` and `Rc::clone(&tail)`.
But it won't compile:
```
error[E0594]: cannot assign to data in an `Rc`
--> src/main.rs:24:5
|
24 | tail.prev = Some(Rc::clone(&head));
| ^^^^^^^^^ cannot assign
```
_Cannot assign data in an Rc!_
Even if we used `let mut tail = ...`, Rc is now allowed to mutate because **all references in Rc are immutable**.
How about _mutating the underlying data_ even if the reference is immutable? We could achieve that by using "unsafe Rust", where **some checks could be done at runtime instead of compile-time.**
Even better, what about Rust providing an abstraction which uses unsafe capabilities under the hood but wrapping in a safe API?
Yes, _we are talking about RefCell_.
---
## 👉 RefCell
**RefCell** is an smart pointer which provides a safe API to mutate underlying data (on the heap) but through immutable references.
This approach is called **interior mutability**.
The borrow checker won't perform checks, but Rust will check them at runtime. In case we cause a problem regarding mutable data, the program will crash and stop (`panic!`).
```rust
use std::cell::RefCell;
let name = RefCell::new(String::from("John"));
name.borrow_mut().push_str(" Doe");
assert_eq!("John Doe", *name.borrow());
```
* RefCell wraps a String in the heap
* The reference is immutable
* Through `borrow_mut`, we get `RefMut<T>` to mutate the underlying data
* Through `borrow`, we get a `Ref<T>` to read the underlying data
In a RefCell, we can have multiple borrows for reading or **only one borrow mutable** for writing.
With that in place, time to implement our doubly linked list using Rc + RefCell:
```rust
use std::rc::Rc;
use std::cell::RefCell;
struct Node<T> {
value: T,
next: Option<Rc<RefCell<Node<T>>>>,
prev: Option<Rc<RefCell<Node<T>>>>,
}
let tail = Rc::new(RefCell::new(Node { value: 2, prev: None, next: None }));
let head = Rc::new(RefCell::new(Node { value: 1, prev: None, next: Some(Rc::clone(&tail)) }));
tail.borrow_mut().prev = Some(Rc::clone(&head));
assert_eq!(1, head.borrow().value);
assert_eq!(2, head.borrow().next.clone().unwrap().borrow().value);
assert_eq!(1, tail.borrow().prev.clone().unwrap().borrow().value);
```
Our Node model now is composed of a value and a `next` pointer which basically is:
* an enum Option
* which wraps an Rc (shared ownership)
* which wraps an RefCell (for interior mutability)
* which points to other Node
* and so on and on and on...
With RefCell, every time we have to write, we use `borrow_mut`, and every time we have to read, we use `borrow`.
_How wonderful is that?_
---
## 👉 Thinking about a circular linked list
In order to make our linked list to be circular, we have to make `tail.next` point to the `head`:
```rust
use std::rc::Rc;
use std::cell::RefCell;
struct Node<T> {
value: T,
next: Option<Rc<RefCell<Node<T>>>>,
prev: Option<Rc<RefCell<Node<T>>>>,
}
let tail = Rc::new(RefCell::new(Node { value: 2, prev: None, next: None }));
let head = Rc::new(RefCell::new(Node { value: 1, prev: None, next: Some(Rc::clone(&tail)) }));
tail.borrow_mut().prev = Some(Rc::clone(&head));
tail.borrow_mut().next = Some(Rc::clone(&head));
....
assert_eq!(1, tail.borrow().next.clone().unwrap().borrow().value);
```
What's the challenges of a circular linked list using Rc?
### 🔵 Strong references may never reach zero
Remember that the Rc underlying data is dropped and invalidated when the `Rc::strong_count` reaches zero.
But in a circular linked list, for instance, we may have a **cyclic reference**, which in turn will never make the `strong_count` to reach zero, **leading to memory leaks**.
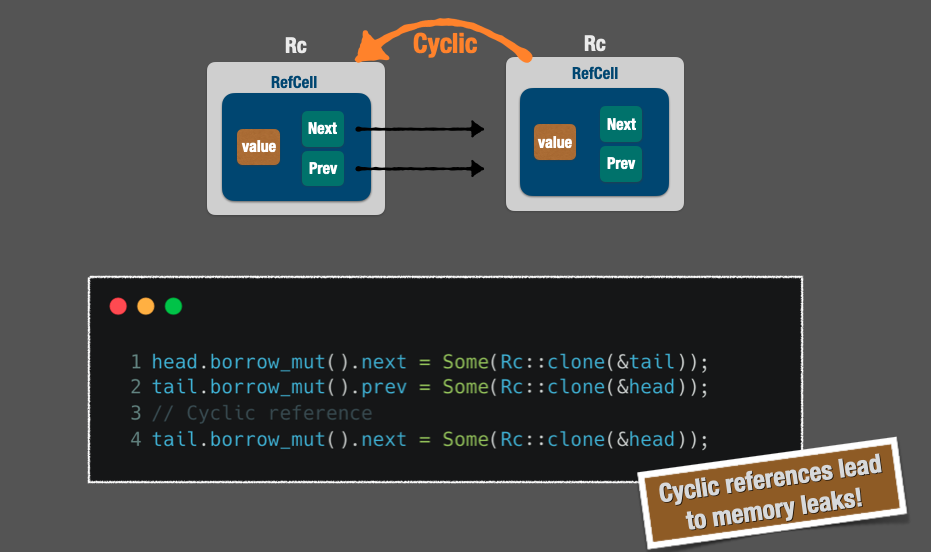
In such a scenario, the `tail.next` is a "weak" reference. Rust provides a way for `Rc` to have a different counter, called `weak_count`.
Thus, the weak counter will not be used for deciding when Rust should drop the value from the heap.
For solving this problem, Rc brings a method called `downgrade`, which **does not involve ownership at all** and transforms a strong reference into a weak one.
This smart pointer is called **Weak** and it's a weak reference in an _Rc_.
Let's see a basic usage of downgrading or upgrading references in an Rc (see below in the comments):
```rust
use std::rc::Rc;
// Just a strong reference
let name = Rc::new(String::from("John"));
assert_eq!(1, Rc::strong_count(&name));
// Cloning Rc is a strong reference
let _other_name = Rc::clone(&name);
assert_eq!(2, Rc::strong_count(&name));
assert_eq!(0, Rc::weak_count(&name));
// Downgrade makes it a weak reference
let weak_name = Rc::downgrade(&name);
assert_eq!(2, Rc::strong_count(&name));
assert_eq!(1, Rc::weak_count(&name));
// Upgrade makes it a strong reference again
let upgraded_name = weak_name.upgrade().unwrap();
assert_eq!(3, Rc::strong_count(&name));
assert_eq!(1, Rc::weak_count(&name));
assert_eq!("John", *upgraded_name);
```
In a linked list, the `prev` should be the "weak" reference because starting from the head, the Rc has already strong references that make the entire linked list through the `next` pointers.
Now, let's explore the final solution of this entire blogpost, using `Rc` for **shared ownership**, `RefCell` for **interior mutability** and `Rc::Weak` for preventing cyclic references in a linked list:
```rust
use std::rc::Rc;
use std::cell::RefCell;
use std::rc::Weak;
struct Node<T> {
value: T,
next: Option<Rc<RefCell<Node<T>>>>,
prev: Option<Weak<RefCell<Node<T>>>>,
}
let tail = Rc::new(RefCell::new(Node { value: 2, prev: None, next: None }));
let head = Rc::new(RefCell::new(Node { value: 1, prev: None, next: Some(Rc::clone(&tail)) }));
// Weak reference (no ownership)
tail.borrow_mut().prev = Some(Rc::downgrade(&head));
// Strong reference (shared ownership)
tail.borrow_mut().next = Some(Rc::clone(&head));
assert_eq!(1, head.borrow().value);
assert_eq!(2, head.borrow().next.clone().unwrap().borrow().value);
assert_eq!(1, tail.borrow().prev.clone().unwrap().upgrade().unwrap().borrow().value);
assert_eq!(1, tail.borrow().next.clone().unwrap().borrow().value);
```
---
## Wrapping Up
In this very post we demonstrated the fundamentals smart pointers in Rust and the problems they solve about memory management.
This post was written during a [live coding](https://www.youtube.com/watch?v=bdZe0LjDUyk) while building a doubly linked list by explaining fundamental concepts of ownership, references, borrowing and smart pointers.
I hope you had fun while learning a bit more about the _Rust ownership mental model_ as I did.
**Cheers!**
---
## References
https://doc.rust-lang.org/book/
https://en.wikipedia.org/wiki/Smart_pointer
https://ricardomartins.cc/2016/06/08/interior-mutability
https://www.youtube.com/watch?v=6VSgMbFNUuQ
| leandronsp |
1,651,518 | Hướng Dẫn Đăng Ký V99 Siêu dễ dàng | Hướng Dẫn Đăng Ký V99 Siêu dễ dàng Đăng ký #V99co đơn giản và nhanh chóng Đăng ký #v99.com hưởng... | 0 | 2023-10-31T03:11:08 | https://dev.to/v99comco/huong-dan-dang-ky-v99-sieu-de-dang-4cog | Hướng Dẫn Đăng Ký V99 Siêu dễ dàng
Đăng ký #V99co đơn giản và nhanh chóng
Đăng ký #v99.com hưởng chương trình khuyến mãi đặc biệt dành cho thành viên mới
Ưu đãi lên đến 200% giá trị số tiền bạn đã nạp ban đầu
Nhanh tay đăng ký #v99 trải nhiệm chơi game nhận ngay ưu đãi
Chi Tiết Đăng Ký CMT
Web: https://v99.com.co/dang-ky-v99/
Fanpage: https://www.facebook.com/v99comco
Mail: v99comco@gmail.com
Địa chỉ: 157 Ng. 86 P. Hào Nam, Chợ Dừa, Đống Đa, Hà Nội, Việt Nam
Sđt: 09453077445
**#v99 #v99comco #codeV99**
| v99comco | |
1,651,794 | TypeScript Type Utilities: Extracting Array Element Types | TypeScript provides the ability to create custom type utilities that can simplify complex type... | 25,236 | 2023-10-31T08:58:44 | https://dev.to/kuncheriakuruvilla/typescript-type-utilities-extracting-array-element-types-2mg | typescript, programming, webdev | TypeScript provides the ability to create custom type utilities that can simplify complex type operations. In this blog post, we'll explore a custom type utility called `ArrayElement`, which is designed to extract the element type of an array. We'll also demonstrate how it can be utilized in practical scenarios.
**The `ArrayElement` Type Utility**
Let's begin by taking a closer look at the `ArrayElement` type utility:
```typescript
type ArrayElement<ArrayType extends readonly unknown[]> =
ArrayType extends readonly (infer ElementType)[] ? ElementType : never;
```
At first glance, this code might appear a bit cryptic, but we'll break it down step by step.
The `ArrayElement` type utility is a generic type that expects an array type, denoted as `ArrayType`, as its parameter. Its primary purpose is to determine the data type of the elements within the array.
**Conditional Typing**
One of the powerful features of TypeScript is conditional typing, and this is where it comes into play in the `ArrayElement` type. The conditional expression `ArrayType extends readonly (infer ElementType)[]` checks if the `ArrayType` meets the criteria of an array represented as `readonly (infer ElementType)[]`. The `readonly` keyword ensures that the array is read-only, making it compatible with most TypeScript arrays.([Read more](https://www.typescriptlang.org/docs/handbook/2/conditional-types.html))
**Extracting the Element Type**
If the `ArrayType` satisfies the condition, TypeScript proceeds to infer the element type of the array and assigns it to the variable `ElementType`. In essence, this step extracts the type of the elements contained within the array.
**Using the `never` Type**
On the other hand, if the `ArrayType` does not match the pattern of a read-only array, TypeScript uses the `never` type. The `never` type is a TypeScript construct indicating that a type does not exist or is not valid in the given context. In this case, it signifies that the `ArrayType` is not an array as per the defined criteria.
**Practical Usage**
Now that we've examined the `ArrayElement` type utility, let's see how it can be applied in practical scenarios.
Consider the following example:
```typescript
type NumbersArray = Array<number>;
const numbers: NumbersArray = [10, 20, 30];
const number: ArrayElement<NumbersArray> = 12;
```
In this example, we define a type called `NumbersArray`, which represents an array containing numbers. We then initialize an array called `numbers` with values 10, 20, and 30, and TypeScript ensures that it adheres to the defined `NumbersArray` type.
Next, we declare a constant variable named `number` and assign it the value 12. TypeScript's type inference capabilities come into play here. By using the `ArrayElement` type utility with `NumbersArray` as the generic type parameter, TypeScript correctly deduces that `number` should have a type of `number`. This showcases how the `ArrayElement` utility can be used to ensure that a variable is of the expected element type.
**Conclusion**
Custom type utilities, like the `ArrayElement` type we've explored here, can greatly enhance the type safety and expressiveness of your TypeScript code. By utilizing conditional typing and type inference, you can create more robust and maintainable TypeScript applications. Whether you're building web applications, libraries, or APIs, TypeScript's type system offers valuable tools to keep your code reliable and error-free. | kuncheriakuruvilla |
1,651,905 | Orkes Monthly Highlights - October 2023 | Welcome to the October edition of Orkes Monthly Highlights. Let's delve into the captivating events... | 0 | 2023-10-31T10:35:44 | https://orkes.io/blog/orkes-monthly-highlights-oct-2023/ | newsletter, orchestration, microservices | Welcome to the October edition of Orkes Monthly Highlights.
Let's delve into the captivating events that occurred in October 2023 and an exclusive glimpse of what's in store for the upcoming months.
## Product Updates
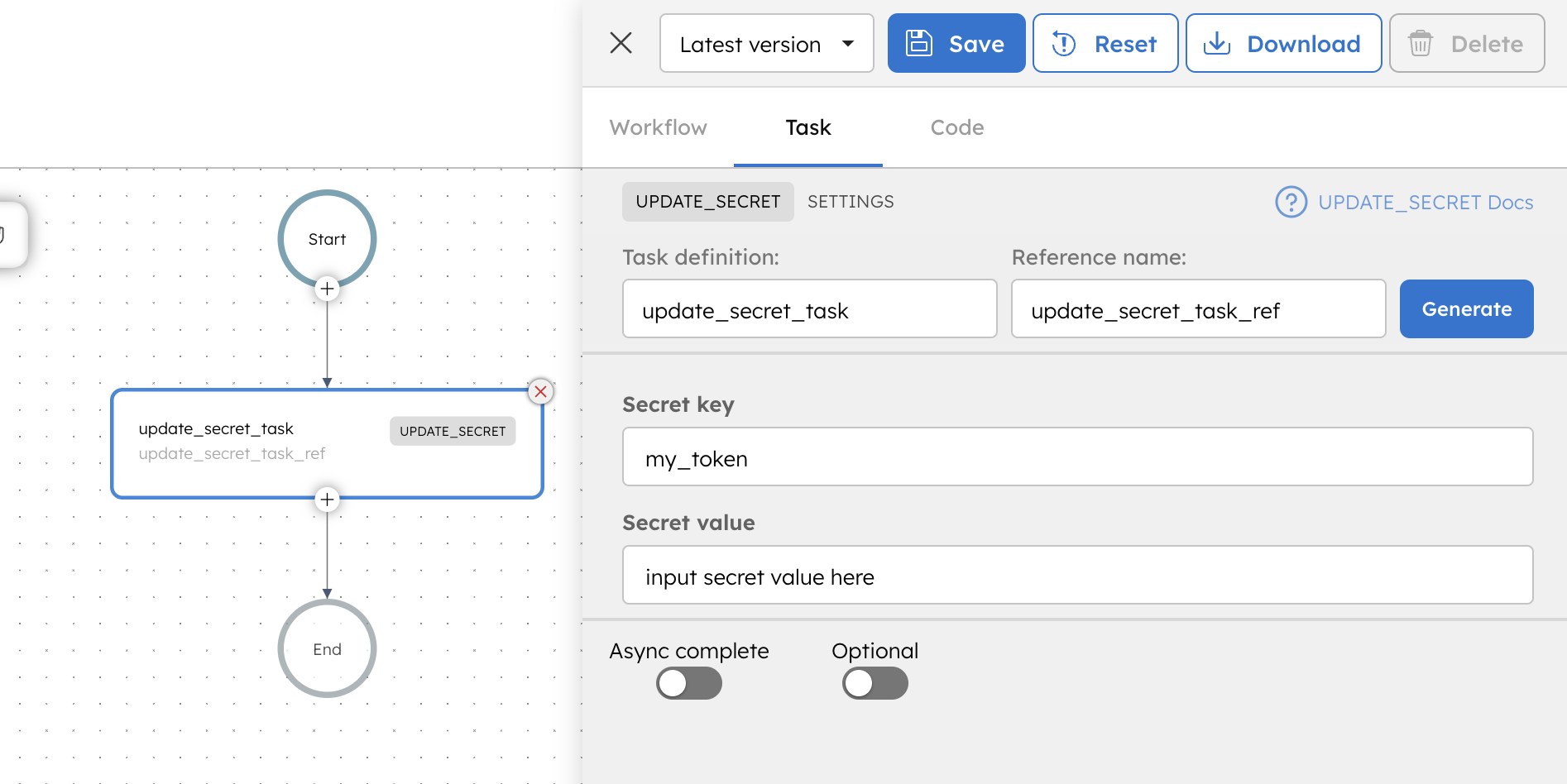
### System Task - Update Secret
Orkes Conductor has built-in support for handling [secrets](https://orkes.io/content/developer-guides/secrets-in-conductor), allowing you to securely store crucial sensitive keys and values that should not be openly exposed in your workflow definitions. However, there may be specific scenarios where you must dynamically provide these secret keys to your workflows. In such cases, you can modify the existing secret values to align with your business processes by utilizing the new “Update Secret” system task. [Learn more](https://orkes.io/content/reference-docs/system-tasks/update-secret).
### Upgrade Workflow API
Previously, you couldn’t update the workflow version of a running execution. To tackle this, we have added a new API that upgrades a running workflow to a newer version. [Learn more](https://orkes.io/content/reference-docs/api/workflow/upgrade-workflow).
### Get Workflow Definition API
We have added support for the following new APIs:
- [Get All Workflow Definitions](https://orkes.io/content/reference-docs/api/metadata/get-all-workflow-definitions)
- [Get Workflow Definition](https://orkes.io/content/reference-docs/api/metadata/get-workflow-definition)
## Community Updates
### 12K Stars on Netflix Conductor GitHub Repository
We celebrated a remarkable milestone in September when the [Netflix Conductor GitHub repository](https://github.com/Netflix/conductor) reached 10k stars. It was a momentous achievement for our DevRel team. Just a month later, we're thrilled to announce that we've surpassed 12k stars! ⭐🎉

None of this would have been possible without the incredible support of our Conductor community. On behalf of Conductor’s maintainer team, we extend our heartfelt gratitude for your contributions, and together, let's maintain this incredible momentum.
## Recap of October 2023 Events
### QCon San Francisco
**Oct 6, 2023: San Francisco, US**
We were at [QCon San Francisco](https://qconsf.com/) on Oct 6, 2023, where our Head of DevRel [Olivier Poupeney](https://www.linkedin.com/in/olivierpoupeney/) delivered an informative workshop about orchestration patterns and Conductor and how it helps develop applications that span multiple languages, teams, and personas ranging from developers to SREs and product managers.
### GDG DevFest Ranchi
**Oct 8, 2023: Ranchi, India**
We kick-started the DevFest series of the year with [GDG DevFest Ranchi](https://gdg.community.dev/events/details/google-gdg-ranchi-presents-devfest-ranchi-2023/) on Oct 8, 2023, at Birla Institute of Technology, Ranchi, India. [Sangeeta Gupta](https://www.linkedin.com/in/sangee-gupta/), Community Programs Manager & [Nitta Mathew](https://www.linkedin.com/in/nittamathew/), DevOps Engineer at Orkes, delivered an insightful session on unleashing the power of microservices in modernizing applications.

We hopped on to the fundamentals of microservices, their benefits, and how they can be utilized to build robust and scalable applications.
### GITEX - Expand North Star
**Oct 15-18, 2023: Dubai, UAE**
We were delighted to be part of the 43rd edition of [Gitex Global 2023](https://www.gitex.com/) from Oct 15-18, 2023, in Dubai, UAE. It was our debut event in the Middle East region, and we were part of the [Expand North Star](https://www.expandnorthstar.com/), renowned as the world’s largest gathering for startups and investors.

It was a fantastic opportunity to engage with prospects, learn more about their needs, and forge new partnerships. We would like to thank everyone who visited us at Gitex, and look forward to continuing the conversations!

### New York Weaviate Meetup
**Oct 27, 2023: New York, US**
We were part of the [Weaviate Meetup](https://www.meetup.com/weaviate-nyc/events/296401093/) in New York on Oct 27, 2023, from 06:00 PM - 09:00 PM EDT at 2 Orchard St, 2 Floor, NY 10002. Our Head of DevRel, [Olivier Poupeney](https://www.linkedin.com/in/olivierpoupeney/), delivered a session on “Orchestration in Retrieval-Augmented Generation”, where he tapped into AI Orchestration with Orkes Conductor.

### Cloud Native Day Pune
**Oct 28, 2023: Pune, India**
We wrapped up October with [Cloud Native Day Pune](https://www.cloudnativepune.com/), a community-organized event dedicated to helping, growing, and sustaining the cloud-native community.
We were thrilled to partner with Cloud Native Day, an event focused on emerging technologies such as GitOps, WASM, Docker, Kubernetes, Cloud Sustainability, GenAI, GPT, DevOps, and more.
## Join our Upcoming Events
### Open Source Finance Forum New York
**Nov 1, 2023: New York, US**
Bringing together experts across financial services, technology, and the open source community, [Open Source in Finance Forum](https://dev.events/conferences/open-source-in-finance-forum-new-york-new-york-10-2023) is the conference dedicated to innovation and collaboration in financial services through open source software and standards.
Our Head of DevRel, [Olivier Poupeney](https://www.linkedin.com/in/olivierpoupeney/), will deliver a session on “_[Implementing Resilient Financial Workflows using Netflix Conductor](https://osff2023.sched.com/event/1PzGU/implementing-resilient-financial-workflows-using-netflix-conductor-olivier-poupeney-orkes?iframe=no)_” on **Nov 1, 2023**, from **12:00 PM to 12:30 PM**.
[Register now](https://dev.events/conferences/open-source-in-finance-forum-new-york-new-york-10-2023)
### Microservices & Distributed Applications Meetup Australia
**Nov 2, 2023: Sydney, Australia**
We are excited to announce our next in-person Microservices & Distributed Applications meetup, which will be held on **Nov 2, 2023**, from **04:30 PM - 07:30 PM AEST** at _Amazon Web Services Australia Pty Ltd Level 5 – Conf Room 202, 2 Park Street Sydney, NSW 2000_.
Join us to discover exclusive strategies and insights for real-world application development, harness the power of Conductor, the open-source orchestration engine from Netflix, and connect with fellow tech enthusiasts to stay at the forefront of industry trends.
Let’s buckle up for the Sydney meetup to unlock the secrets to building scalable distributed applications with Microservices.
[Register now](https://orkes.io/meetups/microservices-and-orkes-conductor-meetup-australia)
### HackCBS
**Nov 4-5, 2023: Delhi, India**
We are excited to partner with [HackCBS](https://hackcbs.tech/), India’s largest student-run Hackathon, from **Nov 4-5, 2023**, at _Shaheed Sukhdev College of Business Studies in Delhi, India_. With a wide variety of themes spanning from FinTech to Web3, this hackathon provides you with an opportunity to learn new skills and network with industry experts & leaders.
Orkes team will be there to help you kickstart and build exciting projects with Conductor. Exclusive prizes await the winners. Block your seats now and be part of this revolutionary project.
[Register now](https://hackcbs.tech/)
### DevFest Durgapur
**Nov 5, 2023: Durgapur, India**
With the DevFest season being continued, we are hereby proudly announcing our collaboration with DevFest Durgapur, the biggest event in the region for developers and techies in India. [DevFest Durgapur](https://gdg.community.dev/events/details/google-gdg-durgapur-presents-devfest-durgapur-2023/) is set to take place on November 5, 2023, in Durgapur, India. Don’t miss this exciting opportunity to collaborate and network with regional developers.
[Register now](https://gdg.community.dev/events/details/google-gdg-durgapur-presents-devfest-durgapur-2023/)
### Microservices and Orkes Conductor Meetup Singapore
**Nov 8, 2023: Singapore**
We’re back in Singapore for another exciting edition of Microservices and Orkes Conductor Meetup on **Nov 8, 2023**, from **05:00 PM - 08:00 PM SGT** at _AWS Singapore, 23 Church St, #10-01, Singapore_.
Join us for a gathering of enthusiastic developers dedicated to microservice-based applications. In addition to highlighting the strategies and insights on real-world scalable applications development, this edition dives into AI orchestration and how to incorporate Conductor for intelligent, automated decision-making in daily business operations. Secure your spot today!
[Block your seats now](https://orkes.io/meetups/microservices-and-orkes-conductor-meetup-singapore)
## Recent Blog Posts
- [4 Microservice Patterns Crucial in Microservices Architecture](https://orkes.io/blog/4-microservice-patterns-crucial-in-microservices-architecture/)
| rizafarheen |
1,652,107 | JSON is Slower. Here Are Its 4 Faster Alternatives | Edit 2: Lots of insightful comments at the bottom, do give them a read, too, before going with any... | 0 | 2023-10-31T13:14:13 | https://dev.to/nikl/json-is-slower-here-are-its-4-faster-alternatives-2g30 | go, programming, javascript, json | Edit 2: Lots of insightful comments at the bottom, do give them a read, too, before going with any alternatives!
Edit 1: Added a new take on 'Optimizing JSON Performance' from comments
---
Your users want instant access to information, swift interactions, and seamless experiences. JSON, short for JavaScript Object Notation, has been a loyal companion for data interchange in web development, but could it be slowing down your applications? Let's dive deep into the world of JSON, explore its potential bottlenecks, and discover faster alternatives and optimization techniques to make your apps sprint like cheetahs.
---
You might want to check this tutorial too: [Using Golang to Build a Real-Time Notification System - A Step-by-Step Notification System Design Guide](https://dev.to/nikl/using-golang-to-build-a-real-time-notification-system-a-step-by-step-notification-system-design-guide-50l7)
---
### What is JSON and Why Should You Care?
Before we embark on our journey to JSON optimization, let's understand what JSON is and why it matters.
JSON is the glue that holds together the data in your applications. It’s the language in which data is communicated between servers and clients, and it’s the format in which data is stored in databases and configuration files. In essence, JSON plays a pivotal role in modern web development.
Understanding JSON and its nuances is not only a fundamental skill for any web developer but also crucial for optimizing your applications. As we delve deeper into this blog, you’ll discover why JSON can be a double-edged sword when it comes to performance and how this knowledge can make a significant difference in your development journey.
## The Popularity of JSON and Why People Use It
JSON’s popularity in the world of web development can’t be overstated. It has emerged as the de facto standard for data interchange for several compelling reasons:
1. **Human-Readable Format**: JSON uses a straightforward, text-based structure that is easy for both developers and non-developers to read and understand. This human-readable format enhances collaboration and simplifies debugging.
```json
// Inefficient
{
"customer_name_with_spaces": "John Doe"
}
// Efficient
{
"customerName": "John Doe"
}
```
2. **Language Agnostic**: JSON is not tied to any specific programming language. It’s a universal data format that can be parsed and generated by almost all modern programming languages, making it highly versatile.
3. **Data Structure Consistency**: JSON enforces a consistent structure for data, using key-value pairs, arrays, and nested objects. This consistency makes it predictable and easy to work with in various programming scenarios.
```json
// Inefficient
{
"order": {
"items": {
"item1": "Product A",
"item2": "Product B"
}
}
}
// Efficient
{
"orderItems": ["Product A", "Product B"]
}
```
4. **Browser Support**: JSON is supported natively in web browsers, allowing web applications to communicate with servers seamlessly. This native support has contributed significantly to its adoption in web development.
5. **JSON APIs**: Many web services and APIs provide data in JSON format by default. This has further cemented JSON’s role as the go-to choice for data interchange in web development.
6. **JSON Schema**: Developers can use JSON Schema to define and validate the structure of JSON data, adding an extra layer of clarity and reliability to their applications.
Given these advantages, it’s no wonder that developers across the globe rely on JSON for their data interchange needs. However, as we explore deeper into the blog, we’ll uncover the potential performance challenges associated with JSON and how to address them effectively.
## The Need for Speed
Users expect instant access to information, swift interactions, and seamless experiences across web and mobile applications. This demand for speed is driven by several factors:
### User Expectations
Users have grown accustomed to lightning-fast responses from their digital interactions. They don’t want to wait for web pages to load or apps to respond. A delay of even a few seconds can lead to frustration and abandonment.
### Competitive Advantage
Speed can be a significant competitive advantage. Applications that respond quickly tend to attract and retain users more effectively than sluggish alternatives.
### Search Engine Rankings
Search engines like Google consider page speed as a ranking factor. Faster-loading websites tend to rank higher in search results, leading to increased visibility and traffic.
### Conversion Rates
E-commerce websites, in particular, are acutely aware of the impact of speed on conversion rates. Faster websites lead to higher conversion rates and, consequently, increased revenue.
### Mobile Performance
With the expansion of mobile devices, the need for speed has become even more critical. Mobile users often have limited bandwidth and processing power, making fast app performance a necessity.
### Is JSON Slowing Down Our Apps?
Now, let’s address the central question: Is JSON slowing down our applications?
JSON, as mentioned earlier, is an immensely popular data interchange format. It’s flexible, easy to use, and widely supported. However, this widespread adoption doesn’t make it immune to performance challenges.
JSON, in certain scenarios, can be a culprit when it comes to slowing down applications. The process of parsing JSON data, especially when dealing with large or complex structures, can consume valuable milliseconds. Additionally, inefficient serialization and deserialization can impact an application’s overall performance.
### Parsing Overhead
When JSON data arrives at your application, it must undergo a parsing process to transform it into a usable data structure. Parsing can be relatively slow, especially when dealing with extensive or deeply nested JSON data.
```javascript
// JavaScript example using JSON.parse for parsing
const jsonData = '{"key": "value"}';
const parsedData = JSON.parse(jsonData);
```
### Serialization and Deserialization
JSON requires data to be serialized (encoding objects into a string) when sent from a client to a server and deserialized (converting the string back into usable objects) upon reception. These steps can introduce overhead and affect your application’s overall speed.
```javascript
// Node.js example using JSON.stringify for serialization
const data = { key: 'value' };
const jsonString = JSON.stringify(data);
```
### String Manipulation
JSON is text-based, relying heavily on string manipulation for operations like concatenation and parsing. String handling can be slower compared to working with binary data.
### Lack of Data Types
JSON has a limited set of data types (e.g., strings, numbers, booleans). Complex data structures might need less efficient representations, leading to increased memory usage and slower processing.
```json
{
"quantity": 1.0
}
```
### Verbosity
JSON’s human-readable design can result in verbosity. Redundant keys and repetitive structures increase payload size, causing longer data transfer times.
```json
// Inefficient
{
"product1": {
"name": "Product A",
"price": 10
},
"product2": {
"name": "Product A",
"price": 10
}
}
```
### No Binary Support
JSON lacks native support for binary data. When dealing with binary data, developers often need to encode and decode it into text, which can be less efficient.
### Deep Nesting
In some scenarios, JSON data can be deeply nested, requiring recursive parsing and traversal. This computational complexity can slow down your application, especially without optimization.
---
> **Similar to this, I along with other open-source loving dev folks, run a developer-centric community on Slack. Where we discuss these kinds of topics, implementations, integrations, some truth bombs, weird chats, virtual meets, contribute to open--sources and everything that will help a developer remain sane ;) Afterall, too much knowledge can be dangerous too.**
> **I'm inviting you to join our free community (_no ads, I promise, and I intend to keep it that way_), take part in discussions, and share your freaking experience & expertise. You can fill out this form, and a Slack invite will ring your email in a few days. We have amazing folks from some of the great companies (Atlassian, Gong, Scaler), and you wouldn't wanna miss interacting with them. [Invite Form](https://forms.gle/VzA3ST8tCFrxt39U9)**
Let's continue...
---
## Alternatives to JSON
While JSON is a versatile data interchange format, its performance limitations in certain scenarios have led to the exploration of faster alternatives. Let’s delve into some of these alternatives and understand when and why you might choose them:
### Protocol Buffers
Protocol Buffers, also known as protobuf, is a binary serialization format developed by Google. It excels in terms of speed and efficiency. Here’s why you might consider using Protocol Buffers:
1. **Binary Encoding**: Protocol Buffers use binary encoding, which is more compact and faster to encode and decode compared to JSON’s text-based encoding.
2. **Efficient Data Structures**: Protocol Buffers allow you to define efficient data structures with precise typing, enabling faster serialization and deserialization.
3. **Schema Evolution**: Protocol Buffers support schema evolution, meaning you can update your data structures without breaking backward compatibility.
```proto
syntax = "proto3";
message Person {
string name = 1;
int32 age = 2;
}
```
### MessagePack
MessagePack is another binary serialization format designed for efficiency and speed. Here’s why you might consider using MessagePack:
1. **Compactness**: MessagePack produces highly compact data representations, reducing data transfer sizes.
2. **Binary Data**: MessagePack provides native support for binary data, making it ideal for scenarios involving binary information.
3. **Speed**: The binary nature of MessagePack allows for rapid encoding and decoding.
```javascript
// JavaScript example using MessagePack for serialization
const msgpack = require('msgpack-lite');
const data = { key: 'value' };
const packedData = msgpack.encode(data);
```
### BSON (Binary JSON)
BSON, often pronounced as "bee-son" or "bi-son," is a binary serialization format used primarily in databases like MongoDB. Here’s why you might consider using BSON:
1. **JSON-Like Structure**: BSON maintains a JSON-like structure with added binary data types, offering a balance between efficiency and readability.
2. **Binary Data Support**: BSON provides native support for binary data types, which is beneficial for handling data like images or multimedia.
3. **Database Integration**: BSON seamlessly integrates with databases like MongoDB, making it a natural choice for such environments.
```json
{
"_id": ObjectId("60c06fe9479e1a1280e6bfa7"),
"name": "John Doe",
"age": 30
}
```
### Avro
Avro is a data serialization framework developed within the Apache Hadoop project. It emphasizes schema compatibility and performance. Here’s why you might consider using Avro:
1. **Schema Compatibility**: Avro prioritizes schema compatibility, allowing you to evolve your data structures without breaking compatibility.
2. **Binary Data**: Avro uses a compact binary encoding format for data transmission, resulting in smaller payloads.
3. **Language-Neutral**: Avro supports multiple programming languages, making it suitable for diverse application ecosystems.
```avro
{
"type": "record",
"name": "Person",
"fields": [
{ "name": "name", "type": "string" },
{ "name": "age", "type": "int" }
]
}
```
The choice between JSON and its alternatives depends on your specific use case and requirements. If schema compatibility is crucial, Avro might be the way to go. If you need compactness and efficiency, MessagePack and Protocol Buffers are strong contenders. When dealing with binary data, MessagePack and BSON have you covered. Each format has its strengths and weaknesses, so pick the one that aligns with your project's needs.
### Optimizing JSON Performance
But what if you're committed to using JSON, despite its potential speed bumps? How can you make JSON run faster and more efficiently? The good news is that there are practical strategies and optimizations that can help you achieve just that. Let's explore these strategies with code examples and best practices.
**1. Minimize Data Size**
a. **Use Short, Descriptive Keys**: Choose concise but meaningful key names to reduce the size of JSON objects.
```json
// Inefficient
{
"customer_name_with_spaces": "John Doe"
}
// Efficient
{
"customerName": "John Doe"
}
```
b. **Abbreviate When Possible**: Consider using abbreviations for keys or values when it doesn’t sacrifice clarity.
```json
// Inefficient
{
"transaction_type": "purchase"
}
// Efficient
{
"txnType": "purchase"
}
```
**2. Use Arrays Wisely**
a. **Minimize Nesting**: Avoid deeply nested arrays, as they can increase the complexity of parsing and traversing JSON.
```json
// Inefficient
{
"order": {
"items": {
"item1": "Product A",
"item2": "Product B"
}
}
}
// Efficient
{
"orderItems": ["Product A", "Product B"]
}
```
**3. Optimize Number Representations**
a. **Use Integers When Possible**: If a value can be represented as an integer, use that instead of a floating-point number.
```json
// Inefficient
{
"quantity": 1.0
}
// Efficient
{
"quantity": 1
}
```
**4. Remove Redundancy**
a. **Avoid Repetitive Data**: Eliminate redundant data by referencing shared values.
```json
// Inefficient
{
"product1": {
"name": "Product A",
"price": 10
},
"product2": {
"name": "Product A",
"price": 10
}
}
// Efficient
{
"products": [
{
"name": "Product A",
"price": 10
},
{
"name": "Product B",
"price": 15
}
]
}
```
**5. Use Compression**
a. **Apply Compression Algorithms**: If applicable, use compression algorithms like Gzip or Brotli to reduce the size of JSON payloads during transmission.
```javascript
// Node.js example using zlib for Gzip compression
const zlib = require('zlib');
const jsonData = {
// Your JSON data here
};
zlib.gzip(JSON.stringify(jsonData), (err, compressedData) => {
if (!err) {
// Send compressedData over the network
}
});
```
Following up with Samuel's comments, I am adding an edit.
{% devcomment 2adn4 %}
```
As Samuel rightly observes, the adoption of HTTP/2 has brought significant advancements, particularly in optimizing data interchange formats like JSON. HTTP/2's multiplexing capabilities efficiently manage multiple requests over a single connection, enhancing responsiveness and reducing overhead.
In practical terms, a comprehensive optimization strategy may involve both embracing HTTP/2 and utilizing compression techniques per your use-case, recognizing that each approach addresses specific aspects of network efficiency and performance. HTTP/2 excels in network-level optimization, while compression strategies enhance application-level efficiency, and the synergy between them can lead to substantial gains in data handling speed and resource utilization.
```
**6. Employ Server-Side Caching**
a. **Cache JSON Responses**: Implement server-side caching to store and serve JSON responses efficiently, reducing the need for repeated data processing.
**7. Profile and Optimize**
a. **Profile Performance**: Use profiling tools to identify bottlenecks in your JSON processing code, and then optimize those sections.
Remember that the specific optimizations you implement should align with your application’s requirements and constraints.
### Real-World Optimizations: Speeding Up JSON in Practice
Now that you've explored the theoretical aspects of optimizing JSON, it's time to dive headfirst into real-world applications and projects that encountered performance bottlenecks with JSON and masterfully overcame them. These examples provide valuable insights into the strategies employed to boost speed and responsiveness while still leveraging the versatility of JSON.
**1. LinkedIn’s Protocol Buffers Integration**
*Challenge: LinkedIn's Battle Against JSON Verbosity and Network Bandwidth Usage*
LinkedIn, the world's largest professional networking platform, faced an arduous challenge. Their reliance on JSON for microservices communication led to verbosity and increased network bandwidth usage, ultimately resulting in higher latencies. In a digital world where every millisecond counts, this was a challenge that demanded a solution.
**Solution: The Power of Protocol Buffers**
LinkedIn turned to [Protocol Buffers](https://engineering.linkedin.com/blog/2023/linkedin-integrates-protocol-buffers-with-rest-li-for-improved-m), often referred to as protobuf, a binary serialization format developed by Google. The key advantage of Protocol Buffers is its efficiency, compactness, and speed, making it significantly faster than JSON for serialization and deserialization.
**Impact: Reducing Latency by up to 60%**
The adoption of Protocol Buffers led to a remarkable reduction in latency, with reports suggesting improvements of up to 60%. This optimization significantly enhanced the speed and responsiveness of LinkedIn's services, delivering a smoother experience for millions of users worldwide.
**2. Uber’s H3 Geo-Index**
*Challenge: Uber's JSON Woes with Geospatial Data*
Uber, the ride-hailing giant, relies heavily on geospatial data for its operations. JSON was the default choice for representing geospatial data, but parsing JSON for large datasets proved to be a bottleneck, slowing down their algorithms.
**Solution: Introducing the H3 Geo-Index**
Uber introduced the [H3 Geo-Index](https://www.uber.com/en-IN/blog/h3/), a highly efficient hexagonal grid system for geospatial data. By shifting from JSON to this innovative solution, they managed to reduce JSON parsing overhead significantly.
**Impact: Accelerating Geospatial Operations**
This optimization substantially accelerated geospatial operations, enhancing the efficiency of Uber's ride-hailing services and mapping systems. Users experienced faster response times and more reliable service.
**3. Slack’s Message Format Optimization**
*Challenge: Slack's Battle with Real-time Message Rendering*
Slack, the messaging platform for teams, needed to transmit and render large volumes of JSON-formatted messages in real-time chats. However, this led to performance bottlenecks and sluggish message rendering.
**Solution: Streamlining JSON Structure**
Slack optimized their JSON structure to reduce unnecessary data. They started including only essential information in each message, trimming down the payload size.
**Impact: Speedier Message Rendering and Enhanced Chat Performance**
This optimization led to a significant improvement in message rendering speed. Slack users enjoyed a more responsive and efficient chat experience, particularly in busy group chats.
**4. Auth0’s Protocol Buffers Implementation**
*Challenge: Auth0's Authentication and Authorization Data Performance*
Auth0, a prominent identity and access management platform, faced performance challenges with JSON when handling authentication and authorization data. This data needed to be processed efficiently without compromising security.
**Solution: Embracing Protocol Buffers for Data Serialization**
[Auth0 turned to Protocol Buffers](https://auth0.com/blog/beating-json-performance-with-protobuf/#How-Do-We-Use-Protobuf) as well, leveraging its efficient data serialization and deserialization capabilities. This switch significantly improved data processing speeds, making authentication processes faster and enhancing overall performance.
**Impact: Turbocharging Authentication and Authorization**
The adoption of Protocol Buffers turbocharged authentication and authorization processes, ensuring that Auth0's services delivered top-notch performance while maintaining the highest security standards.
These real-world examples highlight the power of optimization in overcoming JSON-related slowdowns. The strategies employed in these cases are a testament to the adaptability and versatility of JSON and alternative formats in meeting the demands of the modern digital landscape.
Stay tuned for the concluding part where we summarize the key takeaways and provide you with a roadmap for optimizing JSON performance in your own projects.
## Closing Remarks
JSON stands as a versatile and indispensable tool for data exchange. Its human-readable structure and cross-language adaptability have solidified it as a cornerstone of contemporary applications. However, as our exploration in this guide has revealed, JSON's pervasive use does not grant it immunity from performance challenges.
The crucial takeaways from our journey into enhancing JSON performance are evident:
- 1. **Performance is Paramount:** Speed and responsiveness are of utmost importance in today's digital landscape. Users demand applications that operate at lightning speed, and even slight delays can result in dissatisfaction and missed opportunities.
- 2. **Size Matters:** The size of data payloads directly impacts network bandwidth usage and response times. Reducing data size is typically the initial step in optimizing JSON performance.
- 3. **Exploring Alternative Formats:** When efficiency and speed are critical, it's beneficial to explore alternative data serialization formats like Protocol Buffers, MessagePack, BSON, or Avro.
- 4. **Real-World Examples:** Learning from real-world instances where organizations effectively tackled JSON-related slowdowns demonstrates that optimization efforts can lead to substantial enhancements in application performance.
---
> **Similar to this, I along with other open-source loving dev folks, run a developer-centric community on Slack. Where we discuss these kinds of topics, implementations, integrations, some truth bombs, weird chats, virtual meets, contribute to open--sources and everything that will help a developer remain sane ;) Afterall, too much knowledge can be dangerous too.**
> **I'm inviting you to join our free community (_no ads, I promise, and I intend to keep it that way_), take part in discussions, and share your freaking experience & expertise. You can fill out this form, and a Slack invite will ring your email in a few days. We have amazing folks from some of the great companies (Atlassian, Gong, Scaler), and you wouldn't wanna miss interacting with them. [Invite Form](https://forms.gle/VzA3ST8tCFrxt39U9)**
> _And I would be highly obliged if you can share that form with your dev friends, who are givers._
| nikl |
1,652,163 | netty5: Channel, ChannelPipeline and ChannelHandler | This post is based on the source code of netty-5.0.0.Alpha5. Channel When making a... | 0 | 2024-03-04T11:40:34 | https://dev.to/saladlam/netty5-channel-channelpipeline-and-channelhandler-gd0 | netty, java | This post is based on the source code of netty-5.0.0.Alpha5.
# Channel
When making a network connection, **new instance** will be created.
Channel contains:
- IP address and port of destination
- EventLoop instance which serves this channel
- ChannelPipeline instance which stores series of Channelhandler
- function of operations can act on it
Channel.pipeline().fireChannelRead(Buffer) will be called when data is read from network layer.
Reference of Channel may be passed into user logic code, for sending reply first call Channel#isActive to check if that channel is active or not. Then call Channel#write or Channel#writeAndFlush.
# ChannelPipeline
When creating a new *Channel*, a new *ChannelPipeline* instance is also created. On the fly modification of *ChannelHandler* in *ChannelPipeline* without affecting other *ChannelPipeline* is supported (One of the use cases is to switch to TLS session after an unencrypted session is created in StartTLS protocol).
ChannelHandler(s) which handle application logic are added during ChannelPipeline initialization. To use Bootstrap class as example,
```java
Bootstrap b = new Bootstrap();
b.handler(new ChannelInitializer<DatagramChannel>() {
@Override
protected void initChannel(DatagramChannel ch) {
ChannelPipeline p = ch.pipeline();
p.addLast(new DatagramDnsQueryEncoder())
.addLast(new DatagramDnsResponseDecoder())
.addLast(new SimpleChannelInboundHandler<DatagramDnsResponse>() {
@Override
protected void messageReceived(ChannelHandlerContext ctx, DatagramDnsResponse msg) {
try {
handleQueryResp(msg);
} finally {
ctx.close();
}
}
});
}
});
```
On *ChannelPipeline* implementation *DefaultChannelPipeline*, there is two lists of *ChannelHandlerContext*.
- handlers: *DefaultChannelHandlerContext* list, use for instance lookup
- head: first element (always HeadHandler) of DefaultChannelHandlerContext double linked list. First ChannelHandler processing bytes from network layer
- tail: last element (always TailHandler) of DefaultChannelHandlerContext double linked list. First ChannelHandler processing objects from from application
Functions of ChannelHandlers in the chain are run in the same *EventExecutor*.
# ChannelHandler
Code in *ChannelHandler* can be run in different *EventExecutor* at the same time. So make sure that the class is thread safe.
A *ChannelHandlerContext* instance, will be passed as parameter when function of this interface is called. For example
```java
Future<Void> write(ChannelHandlerContext ctx, Object msg);
```
*ChannelHandlerContext* contains:
- *Channel*
- *ChannelHandler*
- *ChannelPipeline*
Do not include processing expensive jobs or using blocking functions in any function of *ChannelHandler*.
When calling Channel#write, message will be go to the beginning of ChannelPipeline. But when calling ChannelHandlerContext#write, message will be go to next ChannelHandler.
# Reference
https://www.youtube.com/watch?v=_GRIyCMNGGI | saladlam |
1,652,696 | Today I learned - HTTP Requests | Today I learned about HTTP requests and completed the Umbrella project. HTTP requests are the... | 0 | 2023-10-31T20:24:10 | https://dev.to/lukeoc615/today-i-learned-http-requests-2d9m | Today I learned about HTTP requests and completed the Umbrella project. HTTP requests are the fundamental unit of web applications. The request is sent from the client to the server, which responds to the request. The request line is the first line of the HTTP request and contains three parts: the verb, the resource path, and the HTTP version. The status line is the first line of the response and contains the HTTP version, the status code, and the reason phrase. Ruby has useful libraries for placing HTTP requests. | lukeoc615 | |
1,652,900 | Lessons from Ten Years in Web Development | It’s hard to believe that my blog has posts that are now ten years old. That also means that I’ve... | 0 | 2023-11-01T02:00:27 | https://sheelahb.com/blog/lessons-from-ten-years-in-web-development | frontend, webdev, blogging, career | ---
title: Lessons from Ten Years in Web Development
published: true
description:
tags: frontend, webdev, blogging, career
canonical_url: https://sheelahb.com/blog/lessons-from-ten-years-in-web-development
cover_image: https://sheelahb.com/static/7ca82f4db1a98f866d4e2c8e162b0156/d53b8/ten-years-in-web-dev.jpg
type: post
---
It’s hard to believe that [my blog](https://sheelahb.com) has posts that are now ten years old. That also means that I’ve been working in web development for 10 years! Back in 2013, I transitioned from working in site reliability engineering to working in frontend engineering. I spent most of the prior year ramping up on web technologies during a leave of absence from work that I was lucky to get, and in 2013 I started working in the field. That’s when the “real” learning — the learning-on-the-job phase — started.
So what have I learned in the past 10 years of working in this field, and maintaining my (infrequent) web dev blogging?
## Blogging and Note Taking Pays off
Writing short blog posts (or notes somewhere at a minimum) on how you were able to troubleshoot and resolve a particular web dev issue is useful. These help your future self when you inevitably encounter that same issue later on. They also help people like you who are facing the same problem and are desperately searching the web for a solution. For example, I have a short blog post from 2014 (yes, a whopping nine years ago from now!) on how to handle PHP errors that can crop up when including SVG files. That post still gets frequent views today!
## Tech Changes but the Underpinnings Remain
Technologies come and go, but the underlying web tech -- HTML, CSS, and JavaScript -- remains. Back in 2013, I was way into [Sass][1] and [Compass][2]. I also loved building projects on top of [Foundation][3], a Bootstrap competitor that was Sass-based, and [Susy][4], a Sass-based grid framework. While these were my ride-or-dies at the time, the web has changed since then. For example, we can do so much more now with plain ol' CSS, with tools such as CSS grid and flexbox for layouts.
I also was a diehard [Grunt][5] user, and then a [Gulp][6] user, and then later a [Webpack][7] user. These were all different tools for running tasks and compiling code. The landscape changed pretty rapidly.
I was way into jQuery when I was first learning web development in 2012. Now, we have a lot of JavaScript frameworks (see below) at our fingertips, and with the advent of ES6 and more recent releases, vanilla JavaScript has gotten so much more powerful.
The fundamental web technologies remain though, and if you're able to get comfortable with those, I've found you'll be able to pick up new web technologies and tools fairly quickly.
## JavaScript Frameworks Come and Go
JavaScript frameworks definitely come and go, but JavaScript fundamentals are always useful.
Soon after I had gotten decent at jQuery, AngularJS was the hotness. I learned Angular (v1) at my first web development job and quickly saw how that road was paved with footguns. While the 2-way data binding was magical, it was so easy to end up with global state everywhere!
React felt like a revelation when I tried it a couple years later. While that Angular-specific knowledge like directives was no longer relevant, the fundamentals of JavaScript like array `map()` , loops, object destructuring, and other ES6 features were still very useful knowledge to have.
## Interests Change
Your interests also will eb and flow. Ride the wave and follow your curiosities. Back in 2013, I got into PHP and [WordPress][8], and even migrated my site from [Octopress][9], an early static site generator, to WordPress for awhile. I got into building custom WordPress starter themes and used that for freelance projects. Then within a couple years I got really into JavaScript frameworks — first AngularJS and then React.
These were fairly different libraries, but with some time learning and experimenting, I was able to ramp up on them and really enjoyed using them in turn.
I then ended up migrating my blog back to a static site, this time based on Gatsby. I have no regrets that I followed my curiosities and dove into these different JavaScript frameworks, leaving the PHP and WordPress world behind.
Your career interests may change too, and that's expected. "Don't die wondering!" is something I like to remind myself when considering a pivot. I went from frontend engineering in a giant tech company, to frontend engineering in a media startup, to frontend engineering in a product-turned-ecommerce startup, to design systems engineering at a fintech startup, to my current role as a design technologist at an enterprise software company. Changing roles like this, either by transferring within a company or by switching companies completely, is how you find out what you really like and really don't like.
## User Needs Remain Unchanged
It's easy to get wrapped up in different tech stacks and JavaScript frameworks, focusing on the developer experience at the expense of everything else. At the end of the day, the user experience is most important. Taking the time early on in your projects to consider the UX, web performance, and accessibility goes a long way to making the web a better place. Your users will thank you!
Featured image by [Lan Gao](https://unsplash.com/@langao) via Unsplash
[1]: https://sass-lang.com
[2]: http://beta.compass-style.org/help
[3]: https://get.foundation
[4]: https://github.com/oddbird/susy
[5]: https://gruntjs.com
[6]: https://gulpjs.com
[7]: https://webpack.js.org
[8]: https://wordpress.org
[9]: http://octopress.org
| sheelah_b |
1,652,973 | [AWS] How To Query CloudWatch Logs Using Amazon Athena | Situation Integration Cloud Watch & Amazon Athena Step 1 : Add... | 0 | 2023-12-29T07:48:59 | https://www.kmp.tw/post/howtoquerycloudwatchlogsusingamazonathena/ | cloudwatchandathena, cloudwatch, athena, aws | ---
title: [AWS] How To Query CloudWatch Logs Using Amazon Athena
published: true
date: 2023-04-03 19:23:14 UTC
tags:
- CloudWatchAndAthena
- CloudWatch
- Athena
- AWS
canonical_url: https://www.kmp.tw/post/howtoquerycloudwatchlogsusingamazonathena/
---
# Situation
### Integration Cloud Watch & Amazon Athena
<!--more-->
## Step 1 : Add Athena Data Source

### Choice Amazon CloudWatch Logs

### Enter Source Name And Click Create Connector Lambda Function

### In Application Settings, Enter Your `Bucket Name` To SpillBucket, Then Click Deploy



### Go Back To Athena Page, And Click Next

### After Review, Click Create Data Source


## Step 2 : Create WorkGroup
### Enter WorkGroup Name, Choice Engine Type.

### In Query Edit Console, Add Query Result Bucket And Click Save.


## Step 3 : Go To Athena Edit Page, Enter Query & Run That.

 | gordonwei |
1,653,003 | C Programming: Switch Case and All Kinds of Loops | C programming is a powerful and versatile language known for its efficiency and wide range of... | 0 | 2023-11-01T03:45:46 | https://dev.to/biplobhossainsheikh/c-programming-switch-case-and-all-kinds-of-loops-2kh0 | c, programming, beginners, tutorial | C programming is a powerful and versatile language known for its efficiency and wide range of applications. To become proficient in C, it's essential to grasp various control flow mechanisms, including the switch case statement and loops. In this article, we will dive into these fundamental concepts, providing detailed explanations and practical examples to help you master them.
## Understanding the Switch Case Statement
The `switch` statement is a conditional control structure in C that allows you to select one code block from a set of possibilities based on the value of an expression. It is a concise way to handle multiple conditions without the need for a series of `if-else` statements.
**Syntax:**
```c
switch (expression) {
case value1:
// Code to execute if expression equals value1
break;
case value2:
// Code to execute if expression equals value2
break;
// ...
default:
// Code to execute if expression doesn't match any case
}
```
- `expression` is evaluated, and the program checks it against each `case` label.
- When a match is found, the corresponding code block is executed, and the `break` statement is used to exit the `switch` statement.
- If no match is found, the code block under the `default` label is executed (if `default` is present).
**Example:**
```c
#include <stdio.h>
int main() {
int choice;
printf("Choose an option (1-3): ");
scanf("%d", &choice);
switch (choice) {
case 1:
printf("You selected option 1.\n");
break;
case 2:
printf("You selected option 2.\n");
break;
case 3:
printf("You selected option 3.\n");
break;
default:
printf("Invalid choice.\n");
}
return 0;
}
```
In this example, the user's choice is evaluated against the available options, and the corresponding message is displayed.
## Working with Loops
Loops are essential for repeating a block of code multiple times, making your programs efficient and dynamic. C provides several types of loops, each suited for different use cases.
### 1. While Loop
The `while` loop repeatedly executes a block of code as long as a specified condition is true.
**Syntax:**
```c
while (condition) {
// Code to execute while the condition is true
}
```
**Example:**
```c
#include <stdio.h>
int main() {
int count = 1;
while (count <= 5) {
printf("Count: %d\n", count);
count++;
}
return 0;
}
```
This program prints the numbers from 1 to 5 using a `while` loop.
### 2. For Loop
The `for` loop is a more structured way to iterate through a sequence of values.
**Syntax:**
```c
for (initialization; condition; increment/decrement) {
// Code to execute while the condition is true
}
```
**Example:**
```c
#include <stdio.h>
int main() {
for (int i = 1; i <= 5; i++) {
printf("Count: %d\n", i);
}
return 0;
}
```
This `for` loop achieves the same result as the `while` loop in the previous example.
### 3. Do-While Loop
The `do-while` loop is similar to the `while` loop, but it guarantees that the code block is executed at least once, even if the condition is false.
**Syntax:**
```c
do {
// Code to execute at least once
} while (condition);
```
**Example:**
```c
#include <stdio.h>
int main() {
int count = 1;
do {
printf("Count: %d\n", count);
count++;
} while (count <= 5);
return 0;
}
```
Here, the code block is executed first, and then the condition is checked.
## Conclusion
Understanding the `switch` statement and various types of loops is essential for mastering C programming. These control flow mechanisms provide the foundation for making decisions and repeating tasks, allowing you to build powerful and efficient programs. With the knowledge and examples provided in this article, you're well on your way to becoming a proficient C programmer. Practice and experimentation will further solidify your skills, so don't hesitate to explore these concepts in your own coding adventures. Happy coding! | biplobhossainsheikh |
1,653,024 | Curso de Segurança Cibernética Gratuito e Com Certificado | Na era digital atual, a segurança cibernética tornou-se uma preocupação primordial para indivíduos e... | 0 | 2023-12-22T02:42:46 | https://guiadeti.com.br/curso-de-seguranca-cibernetica-gratuito-senai/ | cursogratuito, ciberseguranca, cibersegurança, cursosgratuitos | ---
title: Curso de Segurança Cibernética Gratuito e Com Certificado
published: true
date: 2023-11-01 01:24:24 UTC
tags: CursoGratuito,ciberseguranca,cibersegurança,cursosgratuitos
canonical_url: https://guiadeti.com.br/curso-de-seguranca-cibernetica-gratuito-senai/
---
Na era digital atual, a segurança cibernética tornou-se uma preocupação primordial para indivíduos e organizações em diversos setores.
Compreendendo a importância de capacitar profissionais para enfrentar os desafios relacionados a esse tema, o SENAI-SP inova ao introduzir o curso gratuito e online “Por dentro da segurança cibernética”.
Este programa educacional foi cuidadosamente elaborado para destacar princípios fundamentais da segurança cibernética, como engenharia social, ameaças cibernéticas e proteção em serviços e dispositivos, todos essenciais para a proteção de indústrias de variados segmentos.
Com uma abordagem autoinstrucional e uma duração total de 4 horas, o curso é uma oportunidade valiosa para aqueles que buscam compreender os riscos, vulnerabilidades e ameaças no contexto da segurança da informação.
Seguindo boas práticas, normas e legislações vigentes, os participantes irão desenvolver habilidades para identificar perigos potenciais e aprender técnicas de segurança de dados. Ao concluir o curso, os alunos receberão um certificado, endossando seu conhecimento e competência na área de segurança cibernética.
## Por Dentro da Segurança Cibernética
O SENAI-SP inicia uma nova era de capacitação profissional ao lançar o curso online gratuito “Por dentro da segurança cibernética”.

_Página do Curso Por dentro da segurança cibernética_
Este curso inovador oferece uma abrangente visão sobre os principais princípios de segurança cibernética, que são cruciais para a proteção de dados em indústrias diversificadas.
### Conteúdo e Aplicabilidade do Curso
Este programa educacional cobre temas vitais, como engenharia social, ameaças cibernéticas e segurança em serviços e dispositivos.
O curso foi projetado para ser aplicável a uma vasta gama de setores, desde TI até educação e transporte, proporcionando aos estudantes as habilidades necessárias para identificar riscos e vulnerabilidades, além de ensinar técnicas eficazes de segurança de dados.
### Estrutura e Acesso ao Curso
Disponível em um formato online e autoinstrucional, o curso permite uma aprendizagem independente, adaptável à disponibilidade de tempo e localização do aluno.
Com uma duração total de 4 horas, o curso não só é gratuito, mas também fornece um certificado após a conclusão. Além disso, é acessível a partir de dispositivos variados, incluindo celulares, permitindo flexibilidade aos alunos.
### Conteúdo Ofertado
- Engenharia social
- Definição
- Information Gathering
- Phishing
- Vishing
- Smishing
- Ameaças cibernéticas
- Vírus
- Worms
- Ransomware
- Segurança em serviços e dispositivos
- Credenciais
- Autenticação
- Trabalho remoto
- Nuvem
- Políticas e Leis.
### Relevância no Mercado de Trabalho
Este curso é particularmente benéfico para empresas em processo de adequação às normas de segurança cibernética. Ao oferecer este treinamento aos colaboradores, as organizações podem reforçar significativamente a proteção de seus ativos digitais.
### Requisitos e Perfil do Participante
Para se inscrever, os candidatos devem ter no mínimo 14 anos de idade e ter completado a 9ª série/ano do Ensino Fundamental.
É desejável que possuam conhecimentos prévios na área, adquiridos através de cursos ou experiência de trabalho. O curso visa desenvolver profissionais capazes de identificar tipos de ameaças cibernéticas e técnicas de prevenção, seguindo as melhores práticas e normativas vigentes.
### Objetivo Profissional do Curso
O curso é projetado para capacitar os participantes a identificar riscos, vulnerabilidades e ameaças no contexto da Segurança Cibernética, além de equipá-los com capacidades para aplicar técnicas de coleta de informação e prevenção cibernéticas eficazes.
A conclusão bem-sucedida deste programa prepara os profissionais para enfrentar os desafios da segurança digital no ambiente de trabalho atual.
<aside>
<div>Você pode gostar</div>
<div>
<div>
<div>
<div>
<span><img width="280" height="210" src="https://guiadeti.com.br/wp-content/uploads/2023/10/Curso-de-Power-BI-1-280x210.png" alt="Curso de Power BI" decoding="async" title="Curso de Power BI"></span>
</div>
<span>Curso de Power Bi Totalmente Online e Gratuito</span> <a href="https://guiadeti.com.br/curso-de-power-bi-online-gratuito/" title="Curso de Power Bi Totalmente Online e Gratuito"></a>
</div>
</div>
<div>
<div>
<div>
<span><img width="280" height="210" src="https://guiadeti.com.br/wp-content/uploads/2023/10/Curso-de-Processamento-Neural-280x210.png" alt="Curso de Processamento Neural" decoding="async" title="Curso de Processamento Neural"></span>
</div>
<span>Curso de Processamento Neural de Linguagem Natural Gratuito</span> <a href="https://guiadeti.com.br/curso-de-processamento-neural-gratuito/" title="Curso de Processamento Neural de Linguagem Natural Gratuito"></a>
</div>
</div>
<div>
<div>
<div>
<span><img width="280" height="210" src="https://guiadeti.com.br/wp-content/uploads/2023/07/Curso-Big-Data-Javascript-e-Mais-280x210.png" alt="Curso Big Data, Javascript e Mais" decoding="async" title="Curso Big Data, Javascript e Mais"></span>
</div>
<span>Curso de Big Data, JavaScript e Mais 36 Opções Gratuitas</span> <a href="https://guiadeti.com.br/curso-big-data-javascript-gratuitos-ifmg/" title="Curso de Big Data, JavaScript e Mais 36 Opções Gratuitas"></a>
</div>
</div>
<div>
<div>
<div>
<span><img width="280" height="210" src="https://guiadeti.com.br/wp-content/uploads/2023/10/Cursos-Senac-Desenvolvimento-Web-e-Mais-280x210.png" alt="Cursos Senac: Desenvolvimento Web e Mais" decoding="async" title="Cursos Senac: Desenvolvimento Web e Mais"></span>
</div>
<span>Senac Cursos Gratuitos: Desenvolvimento Web, Design e Mais</span> <a href="https://guiadeti.com.br/senac-cursos-gratuitos-desenvolvimento-web-design/" title="Senac Cursos Gratuitos: Desenvolvimento Web, Design e Mais"></a>
</div>
</div>
</div>
</aside>
## Segurança Cibernética
Segurança cibernética refere-se às práticas, tecnologias e processos projetados para proteger sistemas, redes, dispositivos e dados de ataques cibernéticos, danos ou acesso não autorizado.
Com o avanço da tecnologia e o aumento da dependência de sistemas digitais, a importância da segurança cibernética tornou-se um aspecto crucial tanto para indivíduos quanto para organizações.
### Ameaças Cibernéticas e Vulnerabilidades
O ciberespaço está repleto de diversas ameaças, variando de vírus e malwares a ataques sofisticados de phishing e ransomware. Vulnerabilidades podem existir em softwares, hardwares ou nas práticas dos usuários. A compreensão dessas ameaças é fundamental para desenvolver estratégias de defesa eficazes.
### Estratégias de Defesa e Melhores Práticas
Para proteger informações e sistemas, são adotadas diversas estratégias, incluindo firewalls, antivírus, criptografia de dados e autenticação multifator. Além disso, a educação e o treinamento em segurança cibernética são essenciais para sensibilizar os usuários sobre práticas seguras, como a criação de senhas fortes e o reconhecimento de tentativas de phishing.
### Desafios da Segurança Cibernética no Mundo Moderno
Com o aumento do trabalho remoto e a expansão da Internet das Coisas (IoT), novos desafios surgiram no campo da segurança cibernética. A proteção de dispositivos conectados e a garantia de segurança em redes distribuídas tornaram-se aspectos críticos. Além disso, a evolução constante das ameaças cibernéticas exige que as estratégias de segurança estejam sempre atualizadas.
### O Papel da Legislação e Conformidade
As leis de proteção de dados, como o GDPR na União Europeia e a LGPD no Brasil, desempenham um papel significativo na forma como as organizações lidam com a segurança cibernética.
A conformidade com essas regulamentações não é apenas legalmente obrigatória, mas também uma parte vital de manter a confiança dos clientes e a integridade dos dados.
### O Futuro da Segurança Cibernética
O futuro da segurança cibernética é dinâmico, com avanços contínuos em inteligência artificial e aprendizado de máquina sendo integrados para detectar e responder a ameaças em tempo real.
A colaboração global e o compartilhamento de informações também são fundamentais para manter uma postura proativa contra ciberataques. À medida que a tecnologia evolui, também evoluirão as estratégias para proteger nossos sistemas e dados no ciberespaço.
## SENAI-SP
O [Serviço Nacional de Aprendizagem Industrial (SENAI) de São Paulo](https://sp.senai.br/) representa uma das maiores e mais respeitadas instituições de educação profissional do Brasil.
Com um histórico de excelência e inovação, o SENAI-SP desempenha um papel crucial no desenvolvimento de habilidades e na capacitação de profissionais para atender às demandas do mercado de trabalho industrial e tecnológico.
### Infraestrutura e Recursos Inovadores
O SENAI-SP possui uma infraestrutura moderna e abrangente, equipada com laboratórios de ponta, oficinas e centros de treinamento que simulam ambientes reais de trabalho. Esses recursos proporcionam aos estudantes uma experiência prática e imersiva, preparando-os de maneira eficaz para os desafios do setor industrial.
### Diversidade de Cursos e Programas de Formação
A instituição oferece uma ampla gama de cursos técnicos, de aprendizagem industrial, de graduação e pós-graduação, além de cursos de curta duração e aperfeiçoamento profissional. Os programas abrangem diversas áreas, incluindo automação, mecânica, tecnologia da informação, gestão, moda, design, entre outras.
### Compromisso com a Inovação e a Tecnologia
O SENAI-SP está constantemente inovando em seu currículo e métodos de ensino para se manter alinhado com as tendências tecnológicas e as necessidades da indústria. A instituição investe em pesquisa e desenvolvimento, fomentando a inovação e colaborando com empresas para solucionar desafios técnicos e desenvolver novas tecnologias.
### Parcerias Estratégicas e Impacto no Mercado de Trabalho
O SENAI-SP mantém parcerias estratégicas com empresas, governos e organizações internacionais. Essas colaborações enriquecem os programas educacionais e garantem que os cursos estejam alinhados com as exigências do mercado de trabalho.
A instituição é reconhecida por formar profissionais altamente qualificados, contribuindo significativamente para o desenvolvimento econômico e tecnológico do estado de São Paulo e do Brasil.
### Acessibilidade e Inclusão
Comprometido com a inclusão e a acessibilidade, o SENAI-SP oferece diversas bolsas de estudo e programas de apoio para garantir que a educação profissional de qualidade esteja ao alcance de todos. Além disso, a instituição promove cursos e treinamentos à distância, ampliando o acesso à educação profissionalizante para pessoas em diversas regiões do estado.
## Proteja seu futuro digital: inscreva-se agora em nosso curso de Segurança Cibernética!
As [inscrições para o curso Por Dentro da Segurança Cibernética](https://sp.senai.br/curso/por-dentro-da-seguranca-cibernetica/102411?unidade=150) devem ser realizadas no site do SENAI-SP.
## Compartilhe conhecimento e segurança: divulgue nosso curso de Segurança Cibernética!
Gostou do conteúdo sobre o curso de cibersegurança? Então compartilhe com a galera!
O post [Curso de Segurança Cibernética Gratuito e Com Certificado](https://guiadeti.com.br/curso-de-seguranca-cibernetica-gratuito-senai/) apareceu primeiro em [Guia de TI](https://guiadeti.com.br). | guiadeti |
1,653,068 | Building Resilient DApps: Svelte and Waku in Action | The Intro To exchange crypto tokens from one token to another, we will use bridges where... | 0 | 2023-11-01T05:48:58 | https://dev.to/5war00p/building-resilient-dapps-svelte-and-waku-in-action-2mhf | ### The Intro
To exchange crypto tokens from one token to another, we will use bridges where bridge uses its own liquidity pools for supported tokens and it takes care of transferring/exchanging tokens. In order to make that happen, users should approve the bridge contracts on their wallets for each token. Approved means users are allowing the bridge smart contract to move their tokens and exchange them from one token to another or the same token from one chain to another.
### The Problem
Live Updates. As its a blockchain transaction, the result won't reflect immediately and frontend ends up with showing previous state until a page refresh/reload. Updating the UI in realtime would be a nice UX for most of the applications.
### The Decentralised Solution
Idea: Polling -> updating state -> re-rendering
With ideal polling you can synchronise within the device but what if I say there is a solution where we sync across devices or may be across different nodes based on your use case. Waku's lightpush and filter protocols are what we needed over here, they enable us to synchronise across devices/sessions.
### The Project
As for the prototype, I'm keeping the token list limited to the Polygon chain and the chosen bridge is [Hop](https://hop.exchange/). The initial requirements for this project is to have a defined token list with required data - bridge address, token address and the additional information like token name, token symbol and icon to make it readable for the users.
*Data: Tokens.ts*
```typescript
// Reference: https://github.com/hop-protocol/subgraph/blob/master/config/matic.json
const tokens: App.Token[] = [
{
address: "0x8f3Cf7ad23Cd3CaDbD9735AFf958023239c6A063",
name: "DAI Stablecoin",
symbol: "DAI",
decimals: 18,
logoUrl: "https://assets.coingecko.com/coins/images/9956/large/4943.png",
router: '0xEcf268Be00308980B5b3fcd0975D47C4C8e1382a'
},
{
address: "0xc5102fE9359FD9a28f877a67E36B0F050d81a3CC",
name: "Hop",
symbol: "HOP",
decimals: 18,
logoUrl: "https://assets.coingecko.com/coins/images/25445/large/hop.png",
router: '0x58c61AeE5eD3D748a1467085ED2650B697A66234'
},
{
address: "0x0d500B1d8E8eF31E21C99d1Db9A6444d3ADf1270",
name: "Matic",
symbol: "MATIC",
decimals: 18,
logoUrl:
"https://assets.coingecko.com/coins/images/4713/large/matic-token-icon.png?1624446912",
router: '0x553bC791D746767166fA3888432038193cEED5E2'
},
{
address: "0x2791Bca1f2de4661ED88A30C99A7a9449Aa84174",
name: "USD Coin",
symbol: "USDC",
decimals: 6,
logoUrl:
"https://assets.coingecko.com/coins/images/6319/large/USD_Coin_icon.png",
router: "0x25D8039bB044dC227f741a9e381CA4cEAE2E6aE8",
},
{
address: "0xc2132D05D31c914a87C6611C10748AEb04B58e8F",
name: "Tether USD",
symbol: "USDT",
decimals: 6,
logoUrl:
"https://icons.iconarchive.com/icons/cjdowner/cryptocurrency-flat/128/Tether-USDT-icon.png",
router: "0x6c9a1ACF73bd85463A46B0AFc076FBdf602b690B",
},
{
address: "0x7ceB23fD6bC0adD59E62ac25578270cFf1b9f619",
name: "Ethereum",
symbol: "ETH",
decimals: 18,
logoUrl:
"https://icons.iconarchive.com/icons/cjdowner/cryptocurrency-flat/1024/Ethereum-ETH-icon.png",
router: "0xb98454270065A31D71Bf635F6F7Ee6A518dFb849",
},
]
export default tokens
```
To build this Idea, I am using the following technology stack:
- MetaMask
- Protobuf
- Svelte
- TailwindCSS
- Viem
- Waku
As the main purpose of this blog is to showcase the use case of Waku, I will talk more about Waku setup and assume readers are already familiar with Svelte and other frameworks.
Let's start with Svelte installation, along with ESLint, Prettier and TypeScript.

Before moving on, let's look into the UI & UX.

Elements:
- Wallet Connect Button
- Peer Connection Badge
- Token List with approval/unapproval buttons
- Last synced from Waku
- Toast to show waku message notification
User flow:

Approval flow with Waku:

As we are gonna deal with smart contract addresses the core thing that we would need is a wallet connection and disconnection facility, so that a user can perform transactions.
I'm going to use MetaMask wallet (chrome extension only).
References:
- https://metamask.io/download/
- https://docs.metamask.io/
And Viem, which takes care of batching, reading and writing contracts. In our case, we need this to grant and revoke allowance and read token contracts.
*Utils: approvals.ts*
```typescript
import type { Address } from 'viem';
import { erc20ABI } from './erc20ABI';
import { publicClient, walletClient } from './client';
import { DEFAULT_ALLOWANCE_VALUE, MAX_ALLOWANCE_VALUE } from './constants';
export const isApproved = async (tokenAddress: Address, walletAddress: Address, spender: Address): Promise<boolean> => {
const result = await publicClient.readContract({
abi: erc20ABI,
account: walletAddress,
address: tokenAddress,
functionName: 'allowance',
args: [walletAddress, spender]
}) as string
return BigInt(result) !== BigInt(0)
}
export const grantApproval = async (tokenAddress: Address, walletAddress: Address, spender: Address): Promise<void> => {
const { request } = await publicClient.simulateContract({
account: walletAddress,
address: tokenAddress,
abi: erc20ABI,
functionName: 'approve',
args: [spender, MAX_ALLOWANCE_VALUE]
})
await walletClient.writeContract(request)
}
export const revokeApproval = async (tokenAddress: Address, walletAddress: Address, spender: Address): Promise<void> => {
const { request } = await publicClient.simulateContract({
account: walletAddress,
address: tokenAddress,
abi: erc20ABI,
functionName: 'approve',
args: [spender, DEFAULT_ALLOWANCE_VALUE]
})
await walletClient.writeContract(request)
}
export const allTokenApprovals = async (tokens: App.Token[], walletAddress: Address) => {
const baseContractObj = {
abi: erc20ABI,
account: walletAddress,
} as const
const contracts = tokens.map(token => {
return {
...baseContractObj,
address: token.address,
functionName: 'allowance',
args: [walletAddress, token.router]
}
})
return await publicClient.multicall({ contracts })
}
```
As is mentioned in the flowchart, Waku requires a few setup steps before utilizing sending and filtering functions.
### Create a Waku lightnode
```typescript
import { createLightNode } from "@waku/sdk";
export const wakuNode = await createLightNode({
defaultBootstrap: true,
})
```
### Wait for Peers
```typescript
import { Protocols, waitForRemotePeer } from "@waku/sdk";
export const waitForRemotePeers = async () => {
// Wait for a successful peer connection
await waitForRemotePeer(wakuNode, [
Protocols.LightPush,
Protocols.Filter,
]);
}
```
### Encoder & Decoder
Refer to the waku docs for content-topic naming format: https://docs.waku.org/overview/concepts/content-topics
```typescript
import { createEncoder, createDecoder } from "@waku/sdk";
// Choose a content topic
const contentTopic = "/bridge-token-approvals/1/approvals/proto";
// message encoder and decoder
export const encoder = createEncoder({ contentTopic, ephemeral: true });
export const decoder = createDecoder(contentTopic);
```
### Protobuf
- Define a protobuf schema
```typescript
import protobuf from "protobufjs";
// Message structure with Protobuf
export const TokenApprovalWakuMessage = new protobuf.Type('TokenApproval')
.add(new protobuf.Field('result', 1, 'string'))
}
```
- Serialisation of message with protobuf schema before sending it
```typescript
import { Message } from "protobufjs";
export const serializeMessage = (protoMessage: Message) => {
return TokenApprovalWakuMessage.encode(protoMessage).finish()
}
```
### Subscribe and Unsubscribe
```typescript
// Subscribe & Unsubscribe to content topics
export let unsubscribeTopic: Unsubscribe = () => {}
export const subscribeTopic = async () => {
unsubscribeTopic = await wakuNode.filter.subscribe([decoder], callback)
}
```
The `subscribe` method returns the `unsubscribe` method, but in my case I segregate these methods and import them on demand.
### Sender
Here is where the polling runs and does batch calling to all the token contracts and sends to the Waku topic that we have created.
```typescript
import { get } from 'svelte/store'
import { walletAddress } from "$lib/store";
import { MILLISECONDS_IN_ONE_MINUTE } from "$lib/constants";
import { allTokenApprovals } from '$lib/approvals';
import tokens from '$lib/tokens';
import type { Address } from 'viem';
import { TokenApprovalWakuMessage, serializeMessage } from '$lib/waku/protobuf';
import { encoder, wakuNode } from '$lib/waku';
export let interval: NodeJS.Timeout;
export const scheduleApprovalsFetching = () => {
const address = get(walletAddress) as Address
const intervalHandler = () => {
allTokenApprovals(tokens, address).then((data) => {
const message = data.map((token, index) => ({
token: tokens[index].name,
isApproved: !!token.result
}))
const stringifiedList = JSON.stringify(message)
const protoData = TokenApprovalWakuMessage.create({ result: stringifiedList })
return wakuNode.lightPush.send(encoder, { payload: serializeMessage(protoData) })
}).catch(console.error)
}
interval = setInterval(intervalHandler, MILLISECONDS_IN_ONE_MINUTE)
}
```
### Receiver
The receiver uses a `callback` where you can implement your business logic. In my case I will simply update the state so that the frontend will re-render.
```typescript
import { decoder, wakuNode } from "$lib/waku";
import type { IMessage, Unsubscribe } from "@waku/sdk";
import { TokenApprovalWakuMessage } from "$lib/waku/protobuf";
import { get } from 'svelte/store'
import { lastUpdated, showWakuToast, tokenStatusList } from "$lib/store";
export const callback = (wakuMessage: IMessage) => {
// Check if there is a payload on the message
if (!wakuMessage.payload) return;
const messageObj = TokenApprovalWakuMessage.decode(wakuMessage.payload).toJSON();
const storedList = get(tokenStatusList)
const stringifiedList = JSON.stringify(storedList)
if (storedList.length && messageObj.result !== stringifiedList)
showWakuToast.set(true)
const result = JSON.parse(messageObj.result ?? '[]');
tokenStatusList.set(result)
lastUpdated.set(new Date().toString())
localStorage.setItem('lastSynced', new Date().toString());
};
// Subscribe & Unsubscribe to content topics
export let unsubscribeTopic: Unsubscribe = () => { }
export const subscribeTopic = async () => {
unsubscribeTopic = await wakuNode.filter.subscribe([decoder], callback)
}
```
Now that we have our backend polling logic and Waku setup ready, lets import these functions in the frontend. As I mentioned earlier, wallet connection is the gateway to do transactions, we will be calling these functions on the wallet connection and disconnection.
*Function: connectWallet*
```typescript
async function connectWallet() {
if (!walletClient) {
return;
}
const [address] = await walletClient.request({ method: 'eth_requestAccounts' });
walletAddress.set(address);
localStorage.setItem('userWalletAddress', address);
await establishWakuConnection(erval(interval);
}
```
*Function: disconnectWallet*
```typescript
async function disconnectWallet() {
walletAddress.set(null);
localStorage.removeItem('userWalletAddress');
localStorage.removeItem('lastSynced');
// !DEBT: always use dynamic import once node has started else it throws undefined error
import('$lib/backend/receiver').then((data) => data.unsubscribeTopic()).catch(console.error);
// stop waku's light node
await wakuNode.stop();
wakuNodeStatus.set('disconnected');
clearInterval(interval);
}
```
*Function: establishWakuConnection*
```typescript
async function establishWakuConnection() {
wakuNodeStatus.set('connecting');
// start waku's light node
wakuNode
.start()
.then(() => {
if (wakuNode.isStarted()) return waitForRemotePeers();
})
.then(() => {
return wakuNode.connectionManager.getPeersByDiscovery();
})
.then((data) => {
if (
wakuNode.libp2p.getConnections().length ||
data.CONNECTED.bootstrap.length ||
data.CONNECTED['peer-exchange'].length
) {
// !DEBT: always use dynamic import once node has started else it throws undefined error
import('$lib/backend/receiver').then((data) => data.subscribeTopic());
wakuNodeStatus.set('connected');
scheduleApprovalsFetching();
}
})
.catch((err) => {
console.error(err);
wakuNodeStatus.set('failed');
});
}
```
You will notice the code blocks above uses other state values like `wakuNodeStatus` or `lastSynced` these are metrics to show the user the peer connection status and last time we received a message ove Waku.
### Wrap
And it's a wrap. Some of you may yell at screen that this problem can be solved in other ways. Yes it is, but the goal over here is to show how Waku plays key role in DApps irrespective of the size of the application. Additionally, users of DApp's may look for complete decentralisation, if it misses then companies may loose their customers. So, to keep fully decentralise setup for your DApp one of the important characteristic is decentralised communication. By integrating Waku, it enables decentralised communication features to your application without compromising security or privacy or may be scalability if you are integrating in large applications.
Do checkout the use cases over here: https://docs.waku.org/overview/use-cases
### Links
- GitHub Repository: [5war00p/bridge-token-approvals](https://github.com/5war00p/bridge-token-approvals/)
- Loom Video: https://www.loom.com/share/8e52ac7ffffa44d4adc7ce869d315f6d?sid=6c05627b-90ea-4e49-b78a-65780e22c0c2
- Vercel Deployed URL: https://bridge-token-approvals.vercel.app/
- IPFS Deployed URL: https://k51qzi5uqu5dj57htsj70dwksocisgckponvlw3o1476p888d3aebuq5q22s6b.ipns.4everland.io/
### References
- [Svelte](https://svelte.dev/docs/introduction)
- [Waku](https://docs.waku.org/)
- [Protobuf.js](https://protobufjs.github.io/protobuf.js/)
- [Viem](https://viem.sh/docs/getting-started.html)
Learn like a newbie, apply like a pro!
| 5war00p | |
1,653,086 | How to Transition from Manual to Automation Testing? | Transitioning from Manual to Automation Testing Introduction In the fast-paced world of software... | 0 | 2023-11-01T06:17:35 | https://dev.to/artoftesting/how-to-transition-from-manual-to-automation-testing-48fi | **[Transitioning from Manual to Automation Testing
Introduction](www.projectcubicle.com/how-to-transition-from-manual-to-automation-testing/)**
In the fast-paced world of software development, quality assurance and testing play a crucial role in delivering reliable and bug-free software products. Manual testing, where human testers execute test cases manually, has been a traditional approach. However, with the increasing complexity of software applications and the need for faster release cycles, automation testing has gained prominence. Transitioning from manual to automation testing can be a daunting task, but it's a necessary step for many organizations. In this article, we will explore how to make this transition smoothly and effectively.
Why Transition to Automation Testing?
Before delving into the transition process, let's first understand the reasons behind the shift from manual to automation testing:
Speed and Efficiency: Automation testing can execute test cases much faster than manual testing, which leads to quicker feedback on code changes.
Reusability: Automated test scripts can be reused across multiple test cycles and environments, reducing duplication of effort.
Consistency: Automation ensures that tests are executed consistently, eliminating the variability introduced by human testers.
Coverage: Automation allows you to perform extensive testing, covering a wide range of scenarios, which can be challenging to achieve manually.
Regression Testing: Automated tests are ideal for regression testing, ensuring that new code changes do not introduce previously fixed bugs.
Continuous Integration/Continuous Deployment (CI/CD): Automation is a key component of CI/CD pipelines, enabling rapid and reliable releases.
Now that we understand the benefits, let's explore how to transition from manual to automation testing.
Steps to Transition from Manual to Automation Testing
Assess Your Current Testing Process:
Begin by evaluating your existing testing process. Understand the strengths and weaknesses of your manual testing approach. Identify areas where automation can bring the most significant improvements.
Define Clear Objectives:
Clearly define your objectives for transitioning to automation testing. Are you aiming to reduce testing time, increase test coverage, or improve test accuracy? Having a clear vision will guide your transition strategy.
Training and Skill Development:
Automation testing requires a different skill set compared to manual testing. Invest in training for your testing team to acquire automation skills. Popular automation tools like Selenium, Appium, or Robot Framework offer comprehensive documentation and tutorials.
Select the Right Automation Tools:
Choose automation tools that align with your project requirements and technology stack. Consider factors such as compatibility, scalability, and community support. Conduct a proof of concept (PoC) to ensure the selected tools meet your needs.
Start Small:
Begin your automation journey by automating a small set of test cases or repetitive tasks. This allows your team to gain hands-on experience with automation tools without overwhelming them.
Create a Test Automation Framework:
A well-designed test automation framework provides structure and scalability to your automation efforts. It defines how tests are organized, executed, and reported. Frameworks like Page Object Model (POM) or Behavior-Driven Development (BDD) can be beneficial.
Develop Automated Test Scripts:
Start writing automated test scripts based on the test cases you identified for automation. Ensure that the scripts are well-documented, maintainable, and follow best practices.
Implement Continuous Integration:
Integrate your automated tests into your CI/CD pipeline to run tests automatically with each code change. This ensures that any regressions are detected early in the development process.
Gradual Transition:
Don't rush the transition process. Continue to perform manual testing alongside automation until your team gains confidence in automation. Gradually increase the percentage of automated tests over time.
Monitor and Maintain:
Regularly review and update your automated test scripts to accommodate changes in the application. Maintain a balance between manual and automated testing, adapting to project needs.
Challenges in Transitioning to Automation Testing
While transitioning to automation testing offers numerous benefits, it also comes with its set of challenges:
Initial Learning Curve: Testers may find it challenging to adapt to automation tools and scripting languages, especially if they have limited programming experience.
Tool Selection: Choosing the right automation tools and frameworks can be a daunting task. It requires careful evaluation and consideration of project requirements.
Maintenance Overhead: Automated test scripts need regular maintenance to keep pace with application changes. Neglecting maintenance can lead to false positives and wasted effort.
Test Data Management: Managing test data for automated tests can be complex, especially for applications with large and dynamic datasets.
Cost and Time: The initial setup and training costs for automation can be high, and transitioning fully to automation takes time.
Resistance to Change: Some team members may resist the transition, fearing job insecurity or loss of control over testing processes.
Not Everything Can Be Automated: It's important to recognize that not all tests can or should be automated. Exploratory testing and usability testing, for example, are best suited for manual testing.
Conclusion
Transitioning from manual to automation testing is a strategic move that can greatly enhance the efficiency and effectiveness of your software testing efforts. While the process may involve challenges and require an initial investment in terms of time and resources, the long-term benefits are substantial.
By following the steps outlined in this guide and addressing the challenges with careful planning and training, your organization can successfully make the transition to automation testing. Remember that automation is not an all-or-nothing approach, and finding the right balance between manual and automated testing is key to achieving optimal results. Embrace automation as a tool to augment your testing efforts and deliver high-quality software products to your users. | artoftesting | |
1,653,180 | Tips for Flatiron Students Working With a React/Rails Stack | This post is intended specifically for students at Flatiron School with project requirements that... | 0 | 2023-11-01T07:33:40 | https://dev.to/sediak/tips-for-flatiron-students-working-with-a-reactrails-stack-jdo | react, rails, actionable, beginners | This post is intended specifically for students at[ Flatiron School](https://bootcamprankings.com/listings/flatiron-school/) with project requirements that involve using both a React frontend and a Rails backend. From doing several projects with this setup, including [a very challenging ActionCable implementation in Mod 4](https://github.com/isalevine/draw-n-discuss), I wanted to pass on a few nuggets of advice for using this stack. (And kudos to anyone else who finds these useful!)
First and foremost, my most important advice:
## If you are using ActionCable, DO NOT RUSH into using the "React-ActionCable-Provider" package UNLESS YOU ALREADY KNOW HOW TO USE ACTION-CABLE!
This was my major mistake on my last project: since there’s not a lot of documentation/community help for React projects using a Rails backend with ActionCable, I rushed into using the [react-actioncable-provider package](https://github.com/cpunion/react-actioncable-provider) without taking time to thoroughly learn it—or even ActionCable—beforehand. Sure, I went through some semi-related ActionCable tutorials and whatnot, but the moment I read a recommendation for that package, I jumped right in and never looked back.
Typically, I have tried to avoid using packages/gems/other bundled software in my school projects (or at least defaulting to using them) because I’ve worried about learning too much about the package and not enough about the core language I’m studying, or taking a shortcut and missing out on valuable under-the-hood learning. In this case, I screwed up on both counts—I spent a great deal of time trying to debug and work with the package itself, ultimately learning little about ActionCable or WebSockets outside of the project, and I know I will need more practice with ActionCable before I feel proficient at using it on its own.
##
Here are a few things I wish I would’ve taken the time to learn in ActionCable first:
1. **Creating Subscriptions** - this is something react-actioncable-provider abstracts away, so creating and managing multiple subscriptions became a confusing hassle. Here’s the code from the package—I recommend taking time to read through the ActionCable docs on Rails Guides and some tutorials to understand how to use each of the functions (**received, initialized, connected, disconnected, rejected**) work:
**
UPDATE: my cohort-mate Josh just published** [an excellent overview and tutorial for WebSockets and ActionCable](https://dev.to/wtfcodingpotato/what-are-websockets-14f5), also from his Mod 4 project--this is a great place to start!!
var ActionCableController = createReactClass({
2. **Building Auth into the Collection class** - this is an important piece to include in programs that include games or chatrooms where you want to limit access to specific users—explicitly making use of and exploring the Connection class in ‘app/channels/application_cable/connection.rb’, and doing so early, helps prevent problems refactoring and debugging later on. Once again, [Rails Guides comes through with the docs](https://edgeguides.rubyonrails.org/action_cable_overview.html#server-side-components-connections):
3. **Deploying to Heroku** - I don’t even know what to say about this one…because I still don’t fully understand which last-minute configurations made the app magically work on Heroku literally four minutes before presenting it. Just, make sure you leave yourself plenty of time, and try deploying an ActionCable tutorial app on Heroku ahead of time to know what to expect.
The react-actioncable-provider is certainly a powerful package, and I definitely owe any successful ActionCable functionality in that project to the package’s creator, Li Jie--but I would’ve been better off learning ActionCable first, and not trying to learn that AND the package at the same time.
DON’T RUSH IN! LEARN ACTION-CABLE FIRST!!
## Rails Tips
**Here are a few handy Rails pointers/tricks I picked up during the project:
**
ActiveSupport::JSON.encode() and ActiveSupport::JSON.decode()
The project involved using ActionCable to broadcast huge JSON-formatted arrays of lines and pixel data from Canvas drawings, as well as store them as strings in a database to be retrieved and redrawn later. This led me to the handy Rails module, ActiveSupport::JSON, which has two useful methods: .encode() and .decode(), which functions very similarly to the JSON.stringify() method you’re probably familiar with in Javascript:
.encode() will turn a JSON object into a string:

You can store this in a single string or text cell in a database!
.decode() will take a JSON-formatted string and return a Ruby hash:

snippets from the ActiveSupport module docs
This encoding/decoding strategy can get very inefficient, especially the larger the JSON object, but jamming the whole thing as a string into one cell in a database is pretty fun!
In Rails, you can access JSON sent by a Javascript fetch() request by using params[“_json”]
On the frontend, I ended up sending fetch() post requests with stringified JSON to Rails like so:
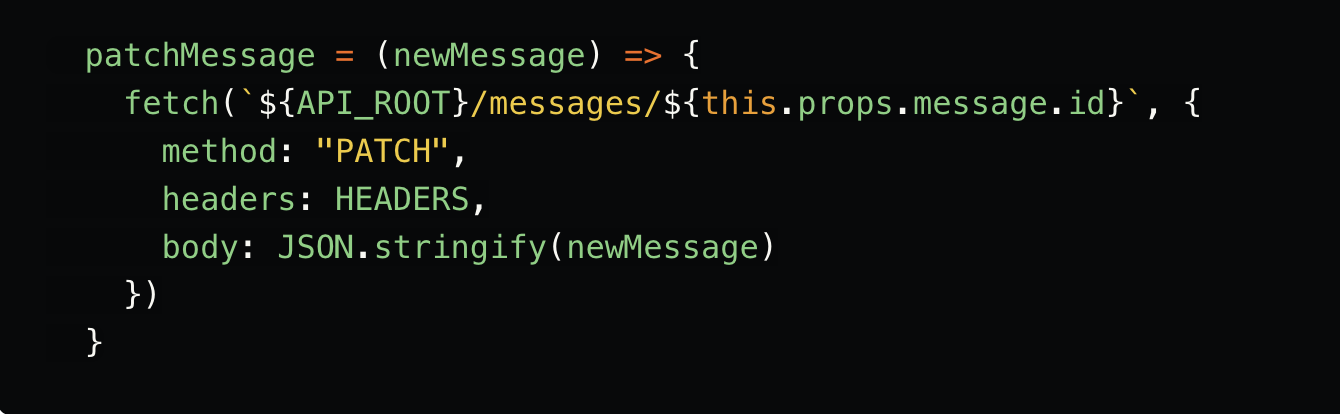
In a pinch, and with flagrant disregard for strong params, we accessed that JSON from the request inside the controller using params[“_json”]—here’s an example, in case you end up a similar pinch:
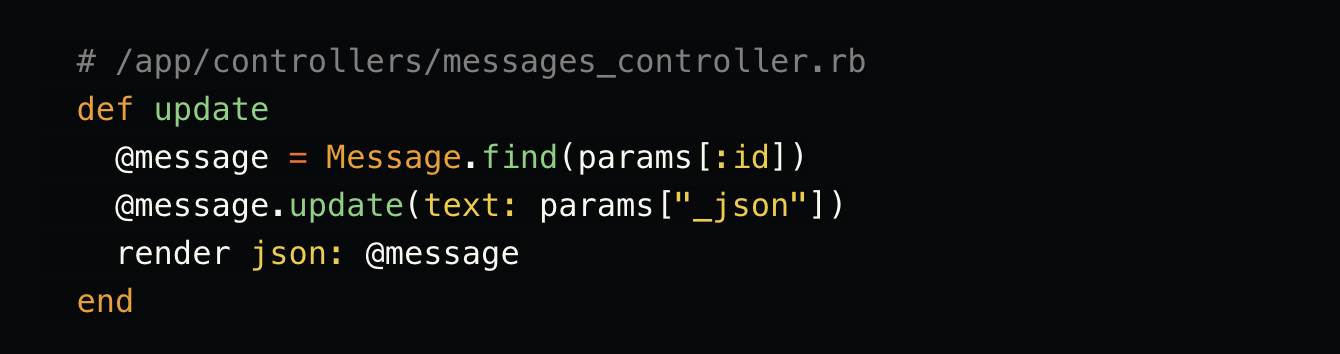
React Tips
And finally, a few React tips/tricks:
Passing Props with React-Router (yes, it makes code look ugly)
If using React-Router is a project requirement, you may find yourself needing to pass props through a component, instead of the component it's passing through as a prop. Props (har har!) to Tyler McGinnis for this solution:

So: create a render={} prop with an arrow function passing (props) to your component, and specify that component's props there like normal.
Don’t wanna update state? Use this.forceUpdate() instead
This was a trick I attempted while trying to get window scrolling and resizing to rerender some components...I don't think it worked, but I stumbled across the this.forceUpdate() method, which allows you to force a rerender without setting state:

Save yourself a deployment headache—store all URLS (such as API endpoints) as constants in one file
This is probably just good coding hygiene, but make yourself a constants.js file that holds all your relevant constants--like API endpoint URLs and fetch() request headers--in one place. Your life will be so much easier when you deploy on Heroku and need to swap out the URLs. Don't forget to export them!
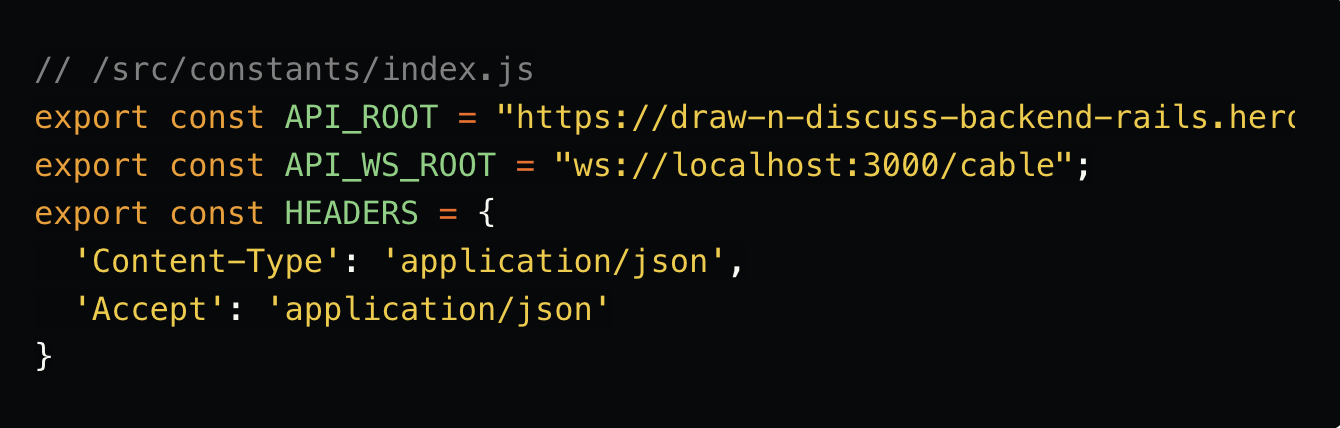
## Conclusion
I hope you Mod 4 students find something helpful in here! Good luck on your projects, and please feel free to add any further suggestions in the comments! | sediak |
1,653,338 | Flask Demo posting | Creating a RESTful API with Flask: GET and POST Methods In this article, we'll explore how... | 0 | 2023-11-01T10:18:44 | https://dev.to/diwakar810/flask-demo-posting-4k7b | # Creating a RESTful API with Flask: GET and POST Methods
In this article, we'll explore how to create a RESTful API using the Flask web framework in Python. We'll focus on two essential HTTP methods: GET and POST.
## Prerequisites
Before you start, make sure you have the following installed:
- Python: You'll need Python installed on your system.
- Flask: You can install Flask using `pip install Flask`.
## Setting Up Your Flask Application
Start by creating a new directory for your project and a Python file (e.g., `app.py`) to hold your Flask application.
```
# Import the Flask module
from flask import Flask, request, jsonify
# Create a Flask app
app = Flask(__name__)
# Dummy data for demonstration
data = []
# Define a route for the root URL
@app.route('/')
def hello_world():
return "Hello, World!"
# GET Method
@app.route('/api/data', methods=['GET'])
def get_data():
return jsonify(data)
# POST Method
@app.route('/api/data', methods=['POST'])
def add_data():
new_item = request.json # Get JSON data from the request body
data.append(new_item) # Append data to the list
return jsonify({"message": "Data added successfully!"})
if __name__ == '__main__':
app.run(debug=True)
```
| diwakar810 | |
1,653,523 | Convert HTML to Markdown (md) | HTML and Markdown are both lightweight markup languages used to create formatted text. HTML is more... | 25,248 | 2023-11-01T14:25:01 | https://dev.to/myogeshverma/convert-html-to-markdown-md-1dk9 | html, markdown, javascript, node | HTML and Markdown are both lightweight markup languages used to create formatted text. HTML is more complex and widely used, but Markdown is simpler and easier to read and write.
Download the Github repo: https://github.com/myogeshverma/convert-html-markdown
```JS
const { NodeHtmlMarkdown } = require("node-html-markdown");
const glob = require("glob");
const { promisify } = require("util");
const fs = require("fs");
const fsExtra = require("fs-extra");
const readFileAsync = promisify(fs.readFile);
const writeFileAsync = promisify(fs.writeFile);
const nhm = new NodeHtmlMarkdown(
/* options (optional) */ {},
/* customTransformers (optional) */ undefined,
/* customCodeBlockTranslators (optional) */ undefined
);
const fileDirectory = "PATH TO YOU FOLDER with name ConfluencePages";
(async () => {
try {
const getDirectories = function (src, ext) {
return glob.sync(`${src}/**/**/*.${ext}`);
};
const allFiles = getDirectories(fileDirectory, "html");
for (const iterator of allFiles) {
const data = await readFileAsync(iterator, "utf8");
const content = nhm.translate(data);
const localPath = iterator.replace(
"ConfluencePages",
"ConfluencePagesMD"
);
const dirPath = localPath.split("/");
dirPath.pop();
fsExtra.ensureDir(dirPath.join("/"), (err) => {
console.log("fsExtra.ensureDir ~ err:", err)
});
writeFileAsync(
`${localPath.substring(0, localPath.length - 5)}.md`,
content,
(err) => {
if (err) {
console.error(err);
}
console.log("file written successfully");
}
).catch((err) => {
console.log("writeFileAsync ~ err:", err);
});
}
} catch (err) {
console.error(err);
}
})();
```
| myogeshverma |
1,653,789 | Проверка тест | Hello word!!! | 0 | 2023-11-01T15:24:18 | https://dev.to/laba6/provierka-tiest-3e0m | Hello word!!! | laba6 | |
1,653,989 | Custom API Endpoints | The txtai API is a web-based service backed by FastAPI. Semantic search, LLM orchestration and... | 11,018 | 2023-11-01T18:09:16 | https://neuml.hashnode.dev/custom-api-endpoints | ai, llm, rag, vectordatabase | [](https://colab.research.google.com/github/neuml/txtai/blob/master/examples/51_Custom_API_Endpoints.ipynb)
The [txtai API](https://neuml.github.io/txtai/api/) is a web-based service backed by [FastAPI](https://fastapi.tiangolo.com/). Semantic search, LLM orchestration and Language Model Workflows can all run through the API.
While the API is extremely flexible and complex logic can be executed through YAML-driven workflows, some may prefer to create an endpoint in Python.
This article introduces API extensions and shows how they can be used to define custom Python endpoints that interact with txtai applications.
# Install dependencies
Install `txtai` and all dependencies.
```
# Install txtai
pip install txtai[api] datasets
```
# Define the extension
First, we'll create an application that defines a persistent embeddings database and LLM. Then we'll combine those two into a RAG endpoint through the API.
The code below creates an API endpoint at `/rag`. This is a `GET` endpoint that takes a `text` parameter as input.
`app.yml`
```yaml
# Embeddings index
writable: true
embeddings:
hybrid: true
content: true
# LLM pipeline
llm:
path: google/flan-t5-large
torch_dtype: torch.bfloat16
```
`rag.py`
```python
from fastapi import APIRouter
from txtai.api import application, Extension
class RAG(Extension):
"""
API extension
"""
def __call__(self, app):
app.include_router(RAGRouter().router)
class RAGRouter:
"""
API router
"""
router = APIRouter()
@staticmethod
@router.get("/rag")
def rag(text: str):
"""
Runs a retrieval augmented generation (RAG) pipeline.
Args:
text: input text
Returns:
response
"""
# Run embeddings search
results = application.get().search(text, 3)
context = " ".join([x["text"] for x in results])
prompt = f"""
Answer the following question using only the context below.
Question: {text}
Context: {context}
"""
return {
"response": application.get().pipeline("llm", (prompt,))
}
```
# Start the API instance
Let's start the API with the RAG extension.
```
CONFIG=app.yml EXTENSIONS=rag.RAG nohup uvicorn "txtai.api:app" &> api.log &
sleep 60
```
# Create the embeddings database
Next, we'll create the embeddings database using the `ag_news` dataset. This is a set of news stories from the mid 2000s.
```python
from datasets import load_dataset
import requests
ds = load_dataset("ag_news", split="train")
# API endpoint
url = "http://localhost:8000"
headers = {"Content-Type": "application/json"}
# Add data
batch = []
for text in ds["text"]:
batch.append({"text": text})
if len(batch) == 4096:
requests.post(f"{url}/add", headers=headers, json=batch, timeout=120)
batch = []
if batch:
requests.post(f"{url}/add", headers=headers, json=batch, timeout=120)
# Build index
index = requests.get(f"{url}/index")
```
# Run queries
Now that we have a knowledge source indexed, let's run a set of queries. The code below defines a method that calls the `/rag` endpoint and retrieves the response. Keep in mind this dataset is from 2004.
While the Python Requests library is used in this article, this is a simple web endpoint that can be called from any programming language.
```python
def rag(text):
return requests.get(f"{url}/rag?text={text}").json()["response"]
rag("Who is the current President?")
'George W. Bush'
rag("Who lost the presidential election?")
'John Kerry'
rag("Who won the World Series?")
'Boston'
rag("Who did the Red Sox beat to win the world series?")
'Cardinals'
rag("What major hurricane hit the USA?")
'Charley'
rag("What mobile phone manufacturer has the largest current marketshare?")
'Nokia'
```
# Wrapping up
This article showed how a txtai application can be extended with custom endpoints in Python. While applications have a robust workflow framework, it may be preferable to write complex logic in Python and this method enables that. | davidmezzetti |
1,654,011 | Build an X clone w/ Nuxt UI | Written by David Atanda Nuxt UI is a library that allows us to build scalable interfaces with Nuxt... | 0 | 2023-11-01T19:18:07 | https://www.vuemastery.com/blog/build-an-x-clone-w-nuxt-ui/ | frontend, nuxt3, nuxt, vue | ---
title: Build an X clone w/ Nuxt UI
published: true
date: 2023-11-01 10:48:04 UTC
tags: frontenddevelopment,nuxt3,nuxt,vuejs
canonical_url: https://www.vuemastery.com/blog/build-an-x-clone-w-nuxt-ui/
---

_Written by David Atanda_
[Nuxt UI](https://ui.nuxt.com/) is a library that allows us to build scalable interfaces with Nuxt without the need to build from scratch. In this tutorial, we’ll be building a minimal X (Twitter) profile UI using the Nuxt UI component library.
Nuxt UI was created using technologies like [Headless UI](https://headlessui.com/) and [Tailwind CSS](https://tailwindcss.com/). As a result, you’ll essentially be working with these two technologies while building with Nuxt UI, enabling developers to implement projects faster without the need to start from scratch.
### Building with Nuxt UI
During the development process, we will be utilizing specific components such as tabs, buttons, containers, cards, and more from the Nuxt UI component library. This allows us to avoid building these components from scratch. Additionally, Nuxt UI uses Tailwind CSS classes to handle the styling, which comes prepackaged with the Nuxt UI module.
By the end of this tutorial, we will have build this demo:
Here’s the [source code](https://github.com/Atanda1/twitter-clone) for this project.
### Setting up our X (Twitter) clone project
To get started, we’ll create a new Nuxt 3 project using this command:
```
npx nuxi@latest init twitter-clone
```
Then we’ll navigate into our project’s directory and run our server using these commands:
```
cd twitter-clone
npm run dev
```
We should see the initial Nuxt 3 starter UI in our browser:

Once this is done, we can now install our Nuxt UI library using this command:
```
npm install @nuxt/ui
```
Now, in our nuxt.config.ts file, we’ll navigate to the modules section and add @nuxt/ui to the array so we have access to its features in our project.
```jsx
export default defineNuxtConfig({
modules: ['@nuxt/ui']
})
```
### Building the App’s UI
Now that we have our project ready with Nuxt UI set up to be used, we can start building out the UI.
We’ll go into the components folder and create a new component named Twitter.vue. This is where we’ll be building out our X (Twitter) profile UI clone.
Then we’ll add the <Twitter/> component in our app.vue as a child.
Now this component is ready to be styled. As mentioned earlier, Nuxt UI comes pre-packaged with Tailwind CSS, so we can use a couple classes from that library here.
We will add bg-[#000101] to set a dark background color, and h-screen to make the site’s height match the size of the viewport.
```html
<template>
<Twitter class="bg-[#000101] h-screen" />
</template>
```
### Adding Images using Nuxt Image
In every X (Twitter) profile page, there is a header image and a profile image (also known as the avatar). In order to add these images to our Nuxt project, we’ll use Nuxt’s official image module, [Nuxt Image](https://image.nuxt.com/).
Nuxt Image automatically optimizes images in our Nuxt apps and comes with impressive features such as dynamically generating responsive sizes for your images.
Let’s install the module by running this command in the terminal:
```
npm install @nuxt/image@rc
```
Now, we’ll go into the the nuxt.config.ts and include it in the modules array, along with our Nuxt UI module from earlier.
```jsx
export default defineNuxtConfig({
modules: ["@nuxt/ui", "@nuxt/image"]
})
```
### Centering the Wrapper
We first need to center our wrapper div to contain all the UI elements on the profile page. First, we’d set the display of the outer wrapper to grid and justify the items to the center with justify-center. Then, we have an inner wrapper with border-x and border-gray-600, which creates borders on the two vertical sides of the wrapper. Plus, it defines the color of the borders.
```html
<div class="grid justify-center">
<div class="border-x border-gray-600"></div>
</div>
```
### Adding the header image
To add our header image, we’ll use <NuxtImg/> to pull in the image (vue-cover.jpeg), located in our public folder.
```html
<div class="grid justify-center">
<div class="border-x border-gray-600">
<NuxtImg src="/vue-cover.jpeg" />
</div>
</div>
```
Now, the image is the first UI component in the wrapper.
```html
<div class="grid justify-center">
<div class="border-x border-gray-600">
<NuxtImg src="/vue-cover.jpeg" />
</div>
</div>
```
### Adding the profile picture
Next, let’s add our second image: the profile picture. For this, we’ll use the Nuxt UI [<UAvatar/>](https://ui.nuxt.com/elements/avatar) component, and style it with Tailwind CSS classes.
```html
<template>
<div class="grid justify-center">
<div class="border-x border-gray-600">
<NuxtImg src="/vue-cover.jpeg" />
<div class="flex mx-4">
<UAvatar
class="-mt-16"
src="/logo.jpeg"
alt="Profile Avatar"
size="xl"
/>
</div>
</div>
</div>
</template>
```
Let’s now wrap the <UAvatar/> in a <div/> . The display of this <div/> is defined as flex . While, mx-4 to add a bit of margin to both sides.
The avatar component comes with its own size prop, with assigned values for height, width and text sizes (as a fallback for avatars without images) which are styled using Tailwind CSS classes.
You may decide to use the default [size preset](https://ui.nuxt.com/elements/avatar#preset) (sm, md, lg, xl) included in the component, but if you’d like to override the default values with your own custom Tailwind CSS classes, you can do that by editing the app.config.ts file, which should be in the root folder of your app.
Since we do want to override the default values, we’ll go into our app.config.ts file and update the xl values to be "h-32 w-32".
```jsx
export default defineAppConfig({
ui: {
strategy: "override",
primary: "cool",
avatar: {
size: {
xl: "h-32 w-32",
},
}
},
});
```
These Tailwind classes give us an image that is larger than the default xl preset was.
Our next step is to add the Nuxt UI [<UButton>](https://ui.nuxt.com/elements/button) component for our “Edit Profile” button.
```html
<template>
<div class="grid justify-center">
<div class="border-x border-gray-600">
<NuxtImg src="/vue-cover.jpeg" />
<div class="flex mx-4">
<UAvatar
class="-mt-16"
src="/logo.jpeg"
alt="Profile Avatar"
size="xl"
/>
<UButton
:ui="{ rounded: 'rounded-full' }"
color="gray"
variant="outline"
class="ml-auto h-min mt-3"
>Edit Profile</UButton
>
</div>
</div>
</div>
</template>
```
We’ll add certain props to the [<UButton>](https://ui.nuxt.com/elements/button) component. Let’s set the color prop as gray and variant to outline . We then add our own margin class styles "ml-auto h-min mt-3" to position the button to the right end and add a bit of margin to the top.
Finally, we have the the [:ui](https://ui.nuxt.com/elements/button#rounded) prop that allows us overwrite the default value of the other props directly within the component. In this case, we’re overwriting the the rounded prop with rounded-full.
With all this in place, we should have this displayed in our local app:

### Building the Profile Bio section
Next up is our bio section. This is quite straightforward as it contains only text. Let’s add the following code to our Twitter.vue component:
```html
<template>
<div class="grid justify-center">
<div class="border-x border-gray-600">
<NuxtImg src="/vue-cover.jpeg" />
<div class="flex mx-4">
<UAvatar class="-mt-16" src="/logo.jpeg"
alt="Profile Avatar" size="xl" />
<UButton :ui="{ rounded: 'rounded-full' }"
color="gray" variant="outline"
class="ml-auto h-min mt-3">
Edit Profile
</UButton>
</div>
<!-- Profile bio section -->
<div class="px-4">
<h3 class="text-xl font-bold">Vue Mastery</h3>
<span class="text-[#686E73] mb-3">@VueMastery</span>
<p class="mb-6">
The ultimate learning platform for Vue.js developers
</p>
<p
>Learn from the experts,<br />Elevate your code, <br />Master your
craft</p
>
<a href="vuemastery.com/courses" class="text-[#2C9AF0]">vuemastery.com/courses</a>
<a class="flex my-3 items-center text-[#2C9AF0]" href="vuemastery.com/courses">
<svg viewBox="0 0 24 24" aria-hidden="true" class="h-5 w-5 mr-1 fill-current text-[#71777B]">
<g>
<path
d="M18.36 5.64c-1.95-1.96-5.11-1.96-7.07 0L9.88 7.05 8.46 5.64l1.42-1.42c2.73-2.73 7.16-2.73 9.9 0 2.73 2.74 2.73 7.17 0 9.9l-1.42 1.42-1.41-1.42 1.41-1.41c1.96-1.96 1.96-5.12 0-7.07zm-2.12 3.53l-7.07 7.07-1.41-1.41 7.07-7.07 1.41 1.41zm-12.02.71l1.42-1.42 1.41 1.42-1.41 1.41c-1.96 1.96-1.96 5.12 0 7.07 1.95 1.96 5.11 1.96 7.07 0l1.41-1.41 1.42 1.41-1.42 1.42c-2.73 2.73-7.16 2.73-9.9 0-2.73-2.74-2.73-7.17 0-9.9z">
</path>
</g>
</svg>
<span>vuemastery.com/courses</span>
</a>
</div>
</div>
</div>
</template>
```
Under the Profile bio section above, we have all the necessary texts.
This starts with the profile name and X(twitter) handle. The name is bold with the font styles: "text-xl font-bold" . Then, the handle has a color of text-[#686E73] with a bit of margin on top to separate it from the rest of the bio texts below using mb-3.
Then, we have the bio texts that are separated from each other with margins at the top and bottom. The final part of the bio contains a link just before the main link section. It has margins on top and the bottom using mt-6 mb-3, and we define the color of the link text using text-[#2C9AF0]
Finally, we have the the link section. It consists of the SVG icon and the text. The SVG contains CSS styles describing its size (height and width) using \*class\*="h-5 w-5". After which, we add some margin to the text and customize the color of the icon using mr-1 fill-current text-[#71777B].
This will result in:
### Adding Tabs to our X (Twitter) Profile
Firstly, let’s go back to our app.config.ts to add custom styles to our container, card and tabs.
```jsx
export default defineAppConfig({
ui: {
strategy: "override",
primary: "cool",
avatar: {
size: {
xl: "h-32 w-32",
},
},
card: {
background: "bg-transparent",
divide: "divide-none",
ring: "ring-0 ",
base: "border-b border-gray-600 ",
rounded: "rounded-none",
},
tabs: {
list: {
rounded: "rounded-none",
background: "bg-transparent",
base: "border-b border-gray-600",
marker: {
base: "w-full h-full",
background: "bg-transparent",
}
},
},
},
container: {
padding: "pa-0",
},
},
});
```
The padding of our container component is set to 0 using pa-0. For our card, we’re setting the background to be transparent. Next, we remove the border, the outline and border-radius with divide-none ,ring-0 , and rounded-none respectively. We then add our preferred border with "border-b border-gray-600".
Similarly, for Tabs we’re defining the border-radius with rounded-none, setting the background color to bg-transparent, and setting the marker ’s base to 100% width and height using w-full h-full. We also add border at the bottom with border-b border-gray-600.
Back on our X profile page, there is a tabs section that has Posts and Replies. So let’s build that out now.

Inside the <script/> tag of our Twitter.vue component, we will add three arrays:
1. The items array will store the number of items in our tabs.
2. The posts array will contain the content of each individual post.
3. The replies array will hold the content of each individual reply.
To give our demo UI some content to display inside of these tabs, we’ll be adding in some hard-coded data.
**Twitter.vue**
```html
<script setup>
const items = [
{
key: "posts",
label: "Posts"
},
{
key: "replies",
label: "Replies"
},
];
const posts = [
{
content:
"Our latest course gets you up-and-running with the modern @vitest_dev 🧪",
},
{
content: "New Nuxt UI content coming 🔜 🤓",
},
];
const replies = [
{
content:
"The Nuxt 3 DevTools are packed full of features. Are you using them to their fullest potential?",
},
{
content: "Are you using the Nuxt 3 DevTools to their full potential?",
},
];
</script>
```
This content will be presented as tabs using Nuxt UI’s <UTabs/> component.
```
<UTabs :items="items">
<template #default="{ item, selected }">
<div
v-if="selected"
class="flex items-center align-center gap-2 relative border-b-4 border-[#2C9AF0]"
>
<span class="m-2 align-center"> {{ item.label }}</span>
</div>
</template>
<template #item="{ item }"></template>
</UTabs>
```
<UTabs/> loops through our items array to display our tabs. We have only two tabs: Posts and Replies.
Inside <UTabs/> , we have two <template/> components. The first template displays each individual tab item and recognises when the tab is selected by the user. Here, we define the styles for a selected tab by specifying this with the v-if="selected" and the class styles "flex items-center align-center gap-2 relative border-b-4 border-[#2C9AF0]". The most distinctive part of the selected classes is the bottom border.
We then add the actual label of each tab and align it to the center with "m-2 align-center".
The second <template/> contains both tabs’ content.
```html
<template #item="{ item }"></template>
```
Each tab’s content will be wrapped in <UContainer>. We’ll conditionally display the list of posts or replies using the v-if and v-else-if conditionals.
We’ll use v-if="item\*.\*key === 'posts'" to display the list of posts:
```html
<UContainer v-if="item.key === 'posts'">
```
And v-else-if="item\*.\*key === 'replies'" to display the list of replies:
```html
<UContainer v-else-if="item.key === 'replies'">
```
Inside of the container, we’ll use v-for to loop over a div of the posts/replies array to display each item, respectively.
```html
<div v-for="(post, index) in posts" :key="{ index }" class="space-y-3">
```
As we print them out, we’re using the <UCard/> Nuxt UI component to display each item.
```html
<UCard
:ui="{
body: {
padding: 'py-0',
},
}"
>
```
Within the <UCard/> component, let’s add py-2 for the class styles. Then, there’s the :ui prop that overrides the component’s default styles. In the case, it’s the padding prop that’s set to py-0.
```html
<UCard
:ui="{
body: {
padding: 'py-0',
},
}"
>
<div class="flex w-full"></div>
</UCard>
```
Next, let’s add more UI components inside our <UCard/>. To begin with create a div wrapper and define it’s display as flex and width as w-full.
Each post has an avatar that we’d add using <UAvatar/> . We’ll use <UAvatar/>to pull in the image (logo.jpeg), located in our public folder. Then, add some margin to the left using the class ml-4
```html
<UCard
:ui="{
body: {
padding: 'py-0',
},
}"
>
<div class="flex w-full">
<UAvatar class="ml-4" src="/logo.jpeg" alt="Avatar" size="md" />
</div>
</UCard>
```
Next, we’d add our name, X(twitter) handle, and it’s content. To achieve the correct styling, there’s a bit of margin to the left (ml-3). Then, we add an inner div with flex and items-baseline; this allows the name and twitter handle be side-by-side at the bottom of the div.
```html
<div class="flex w-full">
<UAvatar class="ml-4" src="/logo.jpeg" alt="Avatar" size="md" />
<div class="ml-3 w-full">
<div class="flex items-baseline">
<h3 class="text-base font-bold">Vue Mastery</h3>
<span class="text-[#686E73] text-sm ml-2">@VueMastery</<span>
</div>
<p>{{ post.content }}</p>
</div>
</div>
```
Then, we have the post.content to display the content of the post.
Each post should look just like this:

The final piece to our work are the likes, comments, shares, and views icons.
Let’s create a wrapper div that’s styled to display flex. Here, we’d add justify-between to ensure that our icons and their count are well spaced. While mt-3 helps ensure padding on the top.
Each icon and their count is wrapped around a div. We add the text color with text-[#71777B], define the display as flex, and center it’s children with items-center.
The SVG itself has CSS classes to set the height, spacing, and fill it’s color with "h-5 w-5 mr-1 fill-current". The count component has a little spacing between itself and the icon and it’s added as class="ml-2".
```html
<div class="flex w-full justify-between mt-3">
<div class="flex items-center text-[#71777B]">
<svg
viewBox="0 0 24 24"
aria-hidden="true"
class="h-5 w-5 mr-1 fill-current"
>
<g>
<path
d="M1.751 10c0-4.42 3.584-8 8.005-8h4.366c4.49 0 8.129 3.64 8.129 8.13 0 2.96-1.607 5.68-4.196 7.11l-8.054 4.46v-3.69h-.067c-4.49.1-8.183-3.51-8.183-8.01zm8.005-6c-3.317 0-6.005 2.69-6.005 6 0 3.37 2.77 6.08 6.138 6.01l.351-.01h1.761v2.3l5.087-2.81c1.951-1.08 3.163-3.13 3.163-5.36 0-3.39-2.744-6.13-6.129-6.13H9.756z"
></path>
</g>
</svg>
<h3 class="ml-2">2</h3>
</div>
<div class="flex items-center text-[#71777B]">
<svg
viewBox="0 0 24 24"
aria-hidden="true"
class="h-5 w-5 mr-1 fill-current"
>
<g>
<path
d="M4.5 3.88l4.432 4.14-1.364 1.46L5.5 7.55V16c0 1.1.896 2 2 2H13v2H7.5c-2.209 0-4-1.79-4-4V7.55L1.432 9.48.068 8.02 4.5 3.88zM16.5 6H11V4h5.5c2.209 0 4 1.79 4 4v8.45l2.068-1.93 1.364 1.46-4.432 4.14-4.432-4.14 1.364-1.46 2.068 1.93V8c0-1.1-.896-2-2-2z"
></path>
</g>
</svg>
<h3 class="ml-2">1</h3>
</div>
<div class="flex items-center text-[#71777B]">
<svg
viewBox="0 0 24 24"
aria-hidden="true"
class="h-5 w-5 mr-1 fill-current"
>
<g>
<path
d="M16.697 5.5c-1.222-.06-2.679.51-3.89 2.16l-.805 1.09-.806-1.09C9.984 6.01 8.526 5.44 7.304 5.5c-1.243.07-2.349.78-2.91 1.91-.552 1.12-.633 2.78.479 4.82 1.074 1.97 3.257 4.27 7.129 6.61 3.87-2.34 6.052-4.64 7.126-6.61 1.111-2.04 1.03-3.7.477-4.82-.561-1.13-1.666-1.84-2.908-1.91zm4.187 7.69c-1.351 2.48-4.001 5.12-8.379 7.67l-.503.3-.504-.3c-4.379-2.55-7.029-5.19-8.382-7.67-1.36-2.5-1.41-4.86-.514-6.67.887-1.79 2.647-2.91 4.601-3.01 1.651-.09 3.368.56 4.798 2.01 1.429-1.45 3.146-2.1 4.796-2.01 1.954.1 3.714 1.22 4.601 3.01.896 1.81.846 4.17-.514 6.67z"
></path>
</g>
</svg>
<h3 class="ml-2">1</h3>
</div>
<div class="flex items-center text-[#71777B]">
<svg
viewBox="0 0 24 24"
aria-hidden="true"
class="h-5 w-5 mr-1 fill-current"
>
<g>
<path
d="M8.75 21V3h2v18h-2zM18 21V8.5h2V21h-2zM4 21l.004-10h2L6 21H4zm9.248 0v-7h2v7h-2z"
></path>
</g>
</svg>
<h3 class="ml-2">100</h3>
</div>
<div class="flex items-center pr-3">
<svg
viewBox="0 0 24 24"
aria-hidden="true"
class="h-5 w-5 mr-1 rounded-full fill-current text-[#71777B]"
>
<g>
<path
d="M12 2.59l5.7 5.7-1.41 1.42L13 6.41V16h-2V6.41l-3.3 3.3-1.41-1.42L12 2.59zM21 15l-.02 3.51c0 1.38-1.12 2.49-2.5 2.49H5.5C4.11 21 3 19.88 3 18.5V15h2v3.5c0 .28.22.5.5.5h12.98c.28 0 .5-.22.5-.5L19 15h2z"
></path>
</g>
</svg>
</div>
</div>
```
One thing to note is that the last div containing the share SVG has an extra padding to the right (pr-3) to add extra spacing to the edge.

We’ve successfully displayed our Posts.
As mentioned above, Replies basically duplicates the same thing we’ve done for our Posts using the replies array. In the spirit of the DRY (Don’t Repeat Yourself) principle, let’s have everything inside another component and import it into our own **Twitter.vue** component.
Create a new component inside our components folder. Lets’s call it \*\*Tweets.vue\*\*.
```html
// Tweets.vue
<script setup>
const props = defineProps({
items: {
type: Array,
required: true,
},
});
const { items } = props;
</script>
<template>
<UContainer>
<div :key="{ index }" v-for="(item, index) in items" class="space-y-3">
<UCard
class="py-2"
:ui="{
body: {
padding: 'py-0',
},
}"
>
<div class="flex w-full">
<UAvatar class="ml-4" src="/logo.jpeg" alt="Avatar" size="md" />
<div class="ml-3 w-full">
<div class="flex items-baseline">
<h3 class="text-base font-bold">Vue Mastery</h3>
<h6 class="text-[#686E73] text-sm ml-2">@VueMastery</h6>
</div>
<h5>{{ item.content }}</h5>
<div class="flex w-full justify-between mt-3">
<div class="flex items-center">
<svg
viewBox="0 0 24 24"
aria-hidden="true"
class="h-5 w-5 mr-1 rounded-full fill-current text-[#71777B]"
>
<g>
<path
d="M1.751 10c0-4.42 3.584-8 8.005-8h4.366c4.49 0 8.129 3.64 8.129 8.13 0 2.96-1.607 5.68-4.196 7.11l-8.054 4.46v-3.69h-.067c-4.49.1-8.183-3.51-8.183-8.01zm8.005-6c-3.317 0-6.005 2.69-6.005 6 0 3.37 2.77 6.08 6.138 6.01l.351-.01h1.761v2.3l5.087-2.81c1.951-1.08 3.163-3.13 3.163-5.36 0-3.39-2.744-6.13-6.129-6.13H9.756z"
></path>
</g>
</svg>
<h3 class="ml-2 text-[#71777B]">2</h3>
</div>
<div class="flex items-center">
<svg
viewBox="0 0 24 24"
aria-hidden="true"
class="h-5 w-5 mr-1 rounded-full fill-current text-[#71777B]"
>
<g>
<path
d="M4.5 3.88l4.432 4.14-1.364 1.46L5.5 7.55V16c0 1.1.896 2 2 2H13v2H7.5c-2.209 0-4-1.79-4-4V7.55L1.432 9.48.068 8.02 4.5 3.88zM16.5 6H11V4h5.5c2.209 0 4 1.79 4 4v8.45l2.068-1.93 1.364 1.46-4.432 4.14-4.432-4.14 1.364-1.46 2.068 1.93V8c0-1.1-.896-2-2-2z"
></path>
</g>
</svg>
<h3 class="ml-2 text-[#71777B]">1</h3>
</div>
<div class="flex items-center">
<svg
viewBox="0 0 24 24"
aria-hidden="true"
class="h-5 w-5 mr-1 rounded-full fill-current text-[#71777B]"
>
<g>
<path
d="M16.697 5.5c-1.222-.06-2.679.51-3.89 2.16l-.805 1.09-.806-1.09C9.984 6.01 8.526 5.44 7.304 5.5c-1.243.07-2.349.78-2.91 1.91-.552 1.12-.633 2.78.479 4.82 1.074 1.97 3.257 4.27 7.129 6.61 3.87-2.34 6.052-4.64 7.126-6.61 1.111-2.04 1.03-3.7.477-4.82-.561-1.13-1.666-1.84-2.908-1.91zm4.187 7.69c-1.351 2.48-4.001 5.12-8.379 7.67l-.503.3-.504-.3c-4.379-2.55-7.029-5.19-8.382-7.67-1.36-2.5-1.41-4.86-.514-6.67.887-1.79 2.647-2.91 4.601-3.01 1.651-.09 3.368.56 4.798 2.01 1.429-1.45 3.146-2.1 4.796-2.01 1.954.1 3.714 1.22 4.601 3.01.896 1.81.846 4.17-.514 6.67z"
></path>
</g>
</svg>
<h3 class="ml-2 text-[#71777B]">1</h3>
</div>
<div class="flex items-center">
<svg
viewBox="0 0 24 24"
aria-hidden="true"
class="h-5 w-5 mr-1 rounded-full fill-current text-[#71777B]"
>
<g>
<path
d="M8.75 21V3h2v18h-2zM18 21V8.5h2V21h-2zM4 21l.004-10h2L6 21H4zm9.248 0v-7h2v7h-2z"
></path>
</g>
</svg>
<h3 class="ml-2 text-[#71777B]">100</h3>
</div>
<div class="flex items-center pr-3">
<svg
viewBox="0 0 24 24"
aria-hidden="true"
class="h-5 w-5 mr-1 rounded-full fill-current text-[#71777B]"
>
<g>
<path
d="M12 2.59l5.7 5.7-1.41 1.42L13 6.41V16h-2V6.41l-3.3 3.3-1.41-1.42L12 2.59zM21 15l-.02 3.51c0 1.38-1.12 2.49-2.5 2.49H5.5C4.11 21 3 19.88 3 18.5V15h2v3.5c0 .28.22.5.5.5h12.98c.28 0 .5-.22.5-.5L19 15h2z"
></path>
</g>
</svg>
</div>
</div>
</div>
</div>
</UCard>
</div>
</UContainer>
</template>
```
We create an items prop that we’d use to pass in either the posts or replies array from our Twitter.vue. We then move the entire <UContainer/> into this component. This loops over the items array prop at every point in time.
Go back into the Twitter.vue component and replace the entire <UTabs/> component with this below:
```html
<UTabs :items="items">
<template #default="{ item, selected }">
<div
v-if="selected"
class="flex items-center align-center gap-2 relative border-b-4 border-[#2C9AF0]"
>
<span class="m-2 align-center"> {{ item.label }}</span>
</div>
</template>
<template #item="{ item }">
<Tweets v-if="item.key === 'posts'" :items="posts" />
<Tweets v-else-if="item.key === 'replies'" :items="replies" />
</template>
</UTabs>
```
All we’ve done here is to replace the both <UContainer/> components with the <Tweets/> components. This now works perfectly for both Posts and Replies.
Here’s the final version of our demo:
### Continue Learning
Congratulations on completing this tutorial. We covered the steps you’ll need to use Nuxt UI in your project. From installation to initialization with the correct config, and finally using the components within our project.
You can checkout the official [Nuxt UI documentation](https://ui.nuxt.com/) to explore the powerful features of Nuxt UI and incorporate the various components within your own projects. To continue deepening your understanding of the Nuxt ecosystem, check out the courses recommended below.
_Originally published at_ [_https://www.vuemastery.com_](https://www.vuemastery.com/blog/build-an-x-clone-w-nuxt-ui/) _on November 1, 2023._
* * * | vuemasteryteam |
1,654,477 | Venous Insufficiency | Venous insufficiency is a vascular condition affecting the veins in the legs, disrupting the flow of... | 0 | 2023-11-02T07:31:32 | https://dev.to/jennifernova/venous-insufficiency-14pb | vascularheallth, venousinsufficiency, health | [Venous insufficiency](https://elitevs.com/venous-insufficiency-causes-signs-and-symptoms-treatment/) is a vascular condition affecting the veins in the legs, disrupting the flow of blood back to the heart. Weakened or damaged valves in the veins allow blood to pool, leading to symptoms such as swelling, pain, and varicose veins. While often associated with aging, venous insufficiency can affect people of all ages. It may be caused by genetics, prolonged sitting or standing, obesity, or pregnancy. Recognizing early signs is crucial for timely intervention. Treatment options range from lifestyle changes and compression therapy to minimally invasive procedures, enhancing circulatory health and relieving symptoms for a better quality of life. | jennifernova |
1,654,507 | Simple Guide to Deploying Your Vite React App on Cpanel for Beginners | Step 1: Specify Your Site's URL in Vite Config First off, we need to tell your Vite React... | 0 | 2023-11-02T08:08:54 | https://dev.to/iamtakdir/simple-guide-to-deploying-your-vite-react-app-for-beginners-2e8h | react, vite, deploy, cpanel |
#### Step 1: Specify Your Site's URL in Vite Config
First off, we need to tell your Vite React app where it's going to be published on the internet. In your Vite project, there’s a file named `vite.config.js`. Open this file and add a `base` property under `export default defineConfig`. This is where your site's URL will go. It should look something like this:
```javascript
export default defineConfig({
base: 'http://myvitereactapp.com/',
// ... other config settings
})
```
#### Step 2: Prepare Your App for Deployment
Now, let's get your app ready to go live. This step converts your project into a form that's more efficient for web browsers and usually it compresses your all CSS and JavaScript codes to make it more faster. Open your project's terminal, and run `yarn install` to make sure all dependencies are up to date. After that, execute `yarn build`. This will create a `dist` folder in your project, holding the production-ready version of your app.
#### Step 3: Zip the `dist` folder
Zip/ Compress your `dist` folder, use any compressor tool to zip your `dist` folder. Usually people uses (WinZip, 7zip, etc.) .
#### Step 4: Upload Your App to File Manager.
Login in to the control panel or cPanel, and look for the `File Manager`or you can use the search bar at the top to find the file manager. Inside the File Manager, you should see a folder named `public_html`. This is where your react build source code will go.

#### Step 5: Uploading `dist.zip` to `public_html`
Click on upload button at the top of File Manager then Select the dist.zip file from your source code folder, then upload them directly into the `public_html` folder on your cpanel.
#### Step 6: Extract Your Zip file
After uploading the `dist.zip` file you have to extract the zip file, click on to the zip button and click on to the extract button.

#### Step 7: Set Up Redirects for SPA
Vite React apps are usually single-page applications (SPAs), and they require special handling of page requests. In the `public_html` folder on your host, create a file called `.htaccess`. Paste in the following configuration to manage redirects:
```apache
<IfModule mod_rewrite.c>
RewriteEngine On
RewriteBase /
RewriteRule ^index\.html$ - [L]
RewriteCond %{REQUEST_FILENAME} !-f
RewriteCond %{REQUEST_FILENAME} !-d
RewriteCond %{REQUEST_FILENAME} !-l
RewriteRule . /index.html [L]
</IfModule>
```
Now save the .htaccess file.
#### CASE CLOSED !
You've successfully deployed your Vite React Application! Visit your web address, and you should see your app shining back at you from the web. Congrats on bringing your project to the world! | iamtakdir |
1,654,800 | Placeholder Maintainer | Intro Project Highs and Lows Growth | 0 | 2023-11-02T12:58:20 | https://dev.to/carolinalima97/placeholder-maintainer-35cg | hack23maintainer | <!-- ✨This template is only meant to get your ideas going, so please feel free to write your own title, structure, and words! ✨ -->
### Intro
<!-- Share a bit about yourself as a maintainer. Is this your first Hacktoberfest, or have you maintained in others? Feel free to embed your GitHub account by using {% embed LINK %} -->
### Project
<!-- Tell us about the repository that you hosted. What processes did you set up to review and merge pull requests? Feel free to embed your GitHub repo by using {% embed LINK %} -->
### Highs and Lows
<!-- What were some of your biggest accomplishments or light-bulb moments this month? Did any problems come up that seemed impossible to fix? How did you adapt in those cases? -->
### Growth
<!-- What was your skillset before Hacktoberfest 2023 and how did it improve? Have your project goals changed since publicly maintaining it? --> | carolinalima97 |
1,676,879 | 6 Essential Tips for JuiceFS Users | As big data and artificial intelligence (AI) technologies continue to evolve, more enterprises,... | 0 | 2023-11-24T02:34:25 | https://dev.to/daswu/6-essential-tips-for-juicefs-users-40if | beginners | As big data and artificial intelligence (AI) technologies continue to evolve, more enterprises, teams, and individuals are adopting [JuiceFS](https://juicefs.com/docs/community/introduction/?utm_source=devto&utm_medium=blog&utm_campaign=sixtips), an open-source high-performance distributed file system designed for the cloud. This article compiles six practical tips to help you enhance management efficiency of JuiceFS, including:
* Viewing mounted file systems
* Streamlining management using bash scripts
* Checking how many clients are mounted concurrently
* Enabling/disabling the trash feature
* Completely destroying a file system
* Metadata backup and restoration
## Viewing mounted file systems
Sometimes, you may have multiple JuiceFS file systems mounted on a single machine or different options mounted on the same file system across multiple machines. Distinguishing which machine is mounting which file system and what tuning options are set is a common question. Here are a few convenient methods, illustrated on a Linux system:
### Method 1: Using the `ps` command
```shell
ps aux | grep juicefs
```
This command's output will display background-mounted file systems.
```shell
herald 36290 0.2 0.1 800108 78848 ? Sl 11:07 0:24 juicefs mount -d sqlite3:///home/herald/jfs/my.db /home/herald/jfs/mnt
herald 37190 1.3 0.1 3163100 106160 ? Sl 11:11 2:12 juicefs mount -d badger:///home/herald/jfs/mydb /home/herald/jfs/mnt2
herald 68886 0.0 0.0 221812 2400 pts/0 S+ 13:54 0:00 grep --color=auto --exclude-dir=.bzr --exclude-dir=CVS --exclude-dir=.git --exclude-dir=.hg --exclude-dir=.svn --exclude-dir=.idea --exclude-dir=.tox juicefs
```
### Method 2: Using `pgrep` and `cat` commands
In Linux systems, you can find process information in the `/proc` file system and access it using the process identifier (PID) as the directory name.
Use `pgrep` to find the PID of the `juicefs` mount process:
`pgrep juicefs`
This will output the PIDs of `juicefs` mount processes, for example:
```shell
36290
37190
```
Use `cat /proc/PID/cmdline` to print the command line of each process, for example:
```shell
cat /proc/36290/cmdline
```
It will output something similar to the following:
```shell
juicefs mount -d sqlite3:///home/herald/jfs/my.db /home/herald/jfs/mnt
```
### Method 3: Using a bash script
I've integrated Method 2 into a bash script available on Github Gist:
```shell
# Download the bash script.
curl -LO https://gist.githubusercontent.com/yuhr123/4e7a09653e833a083dae87ba76b7d642/raw/d8de5350955aa33a3bfafc7cf3756c5f8f3fa04d/proc
# Grant script execution permissions.
chmod +x proc
# Run the script.
./proc juicefs
It will output something similar to the following:
PID: 36290, Command Line: juicefs mount -d sqlite3:///home/herald/jfs/my.db /home/herald/jfs/mnt
PID: 37190, Command Line: juicefs mount -d badger:///home/herald/jfs/mydb /home/herald/jfs/mnt2
```
## Streamlining management using bash scripts
The JuiceFS client operates through command lines. While it's not challenging to use, entering commands directly can be cumbersome, especially for users who have just started or are repeatedly adjusting mounting options and tuning performance. Bash scripts can help manage various commands.
### Creating a file system using a script
For example, creating a script named `format-myjfs.sh` to manage the commands that create a file system:
```shell
#!/bin/bash
juicefs format --storage s3 \
--bucket xxx \
--access-key xxx \
--secret-key xxx \
redis://xxx.xxx.xxx/1 \
myjfs
```
Run the script:
```shell
bash format-myjfs.sh
```
This script is convenient to check which bucket and database this file system is composed of at any time. The disadvantage is that it may need to write the access key of the object storage or database. Therefore, if you want to manage it this way, you must keep this script properly. You can use the environment variables to convey sensitive information. You can also use `gpg` to perform symmetric encryption on this script after use.
### Managing file system mounting with a script
Mounting a file system is a daily and frequent management action, such as creating a script named `mount-myjfs.sh`:
```shell
#!/bin/bash
juicefs mount \
--cache-dir /mnt/juicefs-cache \
--buffer-size 2048 \
--writeback \
--free-space-ratio 0.5 \
redis://xxx.xxx.xxx/1 \
/mnt/myjfs
```
Run the script:
```shell
bash mount-juicefs.sh
```
This script provides a more intuitive way to adjust mounting options.
## Checking how many clients are mounted concurrently
A key feature of the cloud file system is that it can be mounted by multiple clients located on different networks at the same time. For example, if the same file system is mounted in a data center in Chicago and another data center in New York simultaneously, the servers in both places can read and write at the same time. JuiceFS’ transaction mechanism can ensure the consistency of written data.
To view the current mounted clients, use the `status` command:
```shell
juicefs status redis://192.168.1.80/1
```
The output, in JSON format, includes information about active sessions, such as software version, hostname, IP address, mount point, and process ID. For example:
```shell
{
"Setting": {
"Name": "myjfs",
"UUID": "520ae432-f355-43d2-a445-020787f325f4",
"Storage": "minio",
"Bucket": "http://192.168.1.80:9123/myjfs",
"AccessKey": "admin",
"SecretKey": "removed",
"BlockSize": 4096,
"Compression": "none",
"EncryptAlgo": "aes256gcm-rsa",
"KeyEncrypted": true,
"TrashDays": 1,
"MetaVersion": 1,
"MinClientVersion": "1.1.0-A",
"DirStats": true
},
"Sessions": [
{
"Sid": 2,
"Expire": "2023-10-27T09:08:09+08:00",
"Version": "1.1.0+2023-09-04.08c4ae6",
"HostName": "homelab",
"IPAddrs": [
"192.168.1.80",
],
"MountPoint": "/home/herald/jfs/mnt3",
"ProcessID": 173507
},
{
"Sid": 4,
"Expire": "2023-10-27T09:08:11+08:00",
"Version": "1.1.0+2023-09-04.08c4ae6",
"HostName": "HeralddeMacBook-Air.local",
"IPAddrs": [
"192.168.3.102",
],
"MountPoint": "webdav",
"ProcessID": 20746
}
],
"Statistic": {
"UsedSpace": 4347064320,
"AvailableSpace": 1125895559778304,
"UsedInodes": 11,
"AvailableInodes": 10485760
}
}
```
## Enabling/disabling the trash feature
JuiceFS supports a trash feature as a safety mechanism against accidental deletions. By default, the trash feature is enabled, retaining deleted files for one day before permanent deletion from the `.trash` directory. When conducting optimization tests with frequent creation and deletion of temporary files, it's essential to disable the trash feature for timely storage space release.
Use the `config` command to adjust the number control trash of `--trash-days`. The set number represents the number of days the trash reserves files. If you set it to 0, the trash feature is disabled. For example:
```shell
# Set the trash to retain files for 7 days.
juicefs config META-URL --trash-days=7
# Disable the trash feature.
juicefs config META-URL --trash-days=0
```
## Completely destroying a file system
For those new to a technology, understanding how to clean and delete a file system is crucial. JuiceFS file system destruction, like creation, involves necessary confirmation steps:
1. Use the `status` command to find the UUID of the file system to be deleted:
```shell
# juicefs status redis://192.168.1.80/1
{
"Setting": {
"Name": "myjfs",
"UUID": "520ae432-f355-43d2-a445-020787f325f4",
"Storage": "minio",
"Bucket": "http://192.168.1.80:9123/myjfs",
```
2. Confirm that all clients have stopped using the file system, as active mounts prevent destruction.
3. Execute the `destroy` command to destroy the file system:
```shell
juicefs destroy redis://192.168.1.80/1 520ae432-f355-43d2-a445-020787f325f4
```
## Metadata backup and restoration
JuiceFS stores data and metadata separately:
- Data is stored in object stores in blocks.
- Metadata, containing crucial information like file names, sizes, locations, and permissions, is stored in a separate database.
When you access files, you must first retrieve the metadata before you get the actual data. Metadata is crucial to any file system.
To ensure metadata safety, JuiceFS enables automatic hourly backups to the object storage bucket's `meta` directory. In case of metadata engine failure, you can download the latest backup and restore metadata using the `load` command.
When you restore metadata, note that:
- You can only restore the metadata to a new database.
- You must reset the secret key of the object storage.
For example, assuming that your file system was created using Redis Database 1, now it is damaged, and you need to rebuild the metadata on Database 2. Just go to the `meta` directory of the object storage to download the latest backup and then follow the steps below to restore it.
```shell
# Import metadata backup into a new database.
juicefs load redis://192.168.1.80/2 dump-2023-10-27-025129.json.gz
# Update object storage secret key.
juicefs config --secret-key xxx redis://192.168.1.80/2
```
> Note:
There is inevitably a time lag between automatic backup and the occurrence of a failure. It's impossible to recover new data created between the last backup and the occurrence of a failure.
After all, there are only a few extreme situations. The more common requirement is to migrate metadata between different databases. This operation is also simple:
1. Stop the reading and writing applications of the file system.
2. Use the `dump` command to export the metadata.
3. Use the `load` command to import it on the target database.
```shell
# Export metadata to the meta-dump.json file.
juicefs dump redis://192.168.1.80/1 meta-dump.json
# Import metadata into a new sqlite database.
juicefs load sqlite3://myjfs.db meta-dump.json
# Update the secret key of the object storage.
juicefs config --secret-key xxx sqlite3://myjfs.db
```
If you have any questions or would like to learn more details, feel free to join [discussions about JuiceFS on GitHub](https://github.com/juicedata/juicefs/discussions) and [the JuiceFS community on Slack](https://juicefs.slack.com/ssb/redirect). | daswu |
1,655,045 | Placeholder Maintainer | Intro Project Highs and Lows Growth | 0 | 2023-11-02T17:15:57 | https://dev.to/dharmeshkota/placeholder-maintainer-21lm | hack23maintainer | <!-- ✨This template is only meant to get your ideas going, so please feel free to write your own title, structure, and words! ✨ -->
### Intro
<!-- Share a bit about yourself as a maintainer. Is this your first Hacktoberfest, or have you maintained in others? Feel free to embed your GitHub account by using {% embed LINK %} -->
### Project
<!-- Tell us about the repository that you hosted. What processes did you set up to review and merge pull requests? Feel free to embed your GitHub repo by using {% embed LINK %} -->
### Highs and Lows
<!-- What were some of your biggest accomplishments or light-bulb moments this month? Did any problems come up that seemed impossible to fix? How did you adapt in those cases? -->
### Growth
<!-- What was your skillset before Hacktoberfest 2023 and how did it improve? Have your project goals changed since publicly maintaining it? --> | dharmeshkota |
1,655,251 | How GraphQL Empowers Gatsby for Efficient Static Website Development. | Introduction If you're a web developer or have any interest in website development, you've... | 0 | 2023-11-02T20:48:27 | https://dev.to/sakethkowtha/how-graphql-empowers-gatsby-for-efficient-static-website-development-jok | react, gatsby, beginners, graphql | ---
title: How GraphQL Empowers Gatsby for Efficient Static Website Development.
tags: reactjs, gatsby, beginners, graphql
---
## Introduction
If you're a web developer or have any interest in website development, you've probably heard of Gatsby. It's a popular open-source framework for building fast, responsive, and static websites. But have you ever wondered how Gatsby accomplishes all these amazing feats? The secret sauce behind Gatsby's awesomeness is GraphQL, a query language for your APIs. In this article, we'll explore how GraphQL is used by Gatsby and how it makes life easier for devs.
### What is Gatsby?
Before diving into the GraphQL-Gatsby connection, let's quickly understand what Gatsby is. Gatsby is a static site generator, which means it builds websites that load faster because they are pre-rendered. It's like baking a cake in advance, so when someone orders it, you can serve it immediately without the need to bake it again. Gatsby leverages GraphQL for data management, making it a dynamic option for building static websites.
### What is GraphQL?
GraphQL is a query language for your APIs. Unlike traditional REST APIs, where you have to request predefined data structures, GraphQL gives you the power to ask for exactly what you need, nothing more, nothing less. This flexibility makes it perfect for Gatsby and other modern web development.
### How GraphQL Solves Gatsby's Problems
- Efficient Data Fetching :
One of the biggest challenges in web development is efficiently fetching and managing data. Traditional REST APIs often force developers to make multiple requests for various data elements. This can be slow and inefficient. GraphQL, on the other hand, allows you to fetch all the data you need in a single query.
Let's see an example:
Imagine you're building a blog with Gatsby. You need to fetch blog posts, their titles, authors, and publication dates. With REST, you might need to make multiple requests for each of these pieces of data. With GraphQL, you can make a single query like this:
```javascript
{
allBlogPosts {
edges {
node {
title
author
publicationDate
}
}
}
}
```
This query fetches all the required data in one go, reducing network overhead and making your website faster.
- No Over-fetching or Under-fetching :
With REST, you often get more data than you need (over-fetching) or not enough data (under-fetching). GraphQL solves this problem by letting you specify exactly what data you want. In the above example, you asked for the specific fields you needed, and GraphQL delivers only that data.
- Future-Proofing :
As your project evolves, you might need to change your data requirements. In a REST API, making changes can be tricky, as you might disrupt other parts of your application. GraphQL, however, allows you to adapt quickly and add or remove fields from your queries without affecting existing functionalities.
### How Gatsby Uses GraphQL
Gatsby's integration of GraphQL is seamless and a game-changer for static website development. When you create a Gatsby site, it automatically generates a GraphQL schema based on your data sources, which can be a combination of files, MDX files, APIs, CMS, and more. This schema acts as a blueprint for your data, making it easy to query.
Here is an illustration of how data is seamlessly combined from multiple sources by GraphQL and then effectively utilized by Gatsby.

Gatsby's GraphQL playground, which is available at http://localhost:8000/___graphql when you're running your development server, is a fantastic tool. It allows you to explore your data schema, test queries, and get immediate feedback.

Highlight: Querying Data in Gatsby
Let's walk through a simple example of how you can use GraphQL in Gatsby to fetch data. Suppose you want to display a list of all your blog posts and their titles on your website.
1. Start by creating a new component and writing your GraphQL query:
```javascript
import React from "react"
import { useStaticQuery, graphql } from "gatsby"
const BlogPosts = () => {
const data = useStaticQuery(graphql`
query {
allBlogPosts {
edges {
node {
title
}
}
}
}
`)
return (
<div>
<h2>Recent Blog Posts</h2>
<ul>
{data.allBlogPosts.edges.map(({ node }) => (
<li key={node.title}>{node.title}</li>
))}
</ul>
</div>
)
}
export default BlogPosts
```
- Add this component to your webpage, and Gatsby will take care of the rest. It will fetch the data and render your blog post titles.
> Note: Gatsby primarily uses GraphQL for querying and retrieving data, and it's not designed to handle mutations, which are operations that modify data on the server. Gatsby focuses on building static websites, and the data it fetches during the build process is typically read-only at runtime.
## Conclusion
GraphQL is a game-changer for web development, and its integration with Gatsby takes static website building to a whole new level. By allowing developers to efficiently fetch and manage data, prevent over-fetching or under-fetching, and easily adapt to changing requirements, GraphQL makes Gatsby a powerful and flexible tool for creating lightning-fast static websites. So if you're a developer looking to build efficient static web applications, give Gatsby and GraphQL a try, and you'll see just how easy and enjoyable web development can be. | sakethkowtha |
1,655,384 | Are you a CRAFT Coder? | Craft Code is code made with care, skill, and ingenuity. It is as simple as it can be and no simpler.... | 0 | 2023-11-05T23:37:18 | https://craft-code.dev/ | craftcode, webdev, sustainability, a11y | **Craft Code** is code made with care, skill, and ingenuity. It is as simple as it can be and no simpler. It is state-of-the-art, elegant, and _bespoke_.
So are you a Craft Coder?
## You may be a Craft Coder if ...
You follow these four practices. (There are many more, but these are the essentials.)
### 1. You put quality before quantity
This is not to say that quantity (speed) is unimportant. But the way to achieve speed is by improving your skill, not by rushing.
Long ago I was a fitter/welder building rail cars. When I started, my foreman told me to build bolsters, a part of the car. I was very slow and sloppy. I could build three per day working as hard as I could.
The old guy next to me appeared to be standing still. No rush at all. And yet he built ten _impressive_ bolsters per day _every_ day. WTF?
My boss told me not to worry about it. **Focus on quality and speed will come, he said.**
A year later I set the company record at fourteen bolsters in a day, and every one was flawless.
The mistake that new devs make is to focus on _speed_ and to allow themselves to write sloppy code. Craft Coders know better.
> Practice does not make perfect. Practice makes permanent. Repeat the same mistakes over and over, and you donʼt get any closer to Carnegie Hall. ~ Sarah Kay

### 2. You keep things as simple as practicable, but no simpler
Occam's Razor is a famous dictum: _do not needlessly multiply entities_. This is often paraphrased as "the simplest solution is the best".
But that's wrong.
If that were the case, then a simple bad solution would be better than a more complex good solution. Huh?
The key word is "needlessly". What William of Ockham was saying was, "the simplest solution _all else being equal_ is the best one". That's a big difference.
If two solutions are _equal_ solutions, then choose the simpler one. Don't add anything you don't need. **No gratuitous nuthin'.**
That's how a Craft Coder codes.
> Complexity is a sign of technical immaturity. ~ Daniel T. Ling
### 3. You prefer bespoke code whenever practicable.
There are times when commodity code makes more sense. But commodity code is always inefficient. When you use code written by others, they didn't write it for _you_. They wrote it for a wide variety of coders and situations.
Hence, code _that you don't need_ is endemic to commodity code. There is no escaping it.
**Writing specific, bespoke code creates the most efficient, performant code.** No needless entities! Assuming, of course, that you are a good enough coder (see #1 above).
Craft Coders are confident, consistent bespoke coders. They can write commodity code, but rather than a first resort, they see it as a last one.
This is not to disparage re-use. Not at all. But first write the code yourself, _then_ re-use it.
> Avoid hasty abstractions (AHA). ~ Kent C. Dodds
### 4. You embrace a comprehensive approach
It is very easy for web developers to suffer from **tunnel vision**. When all you have is a hammer, everything starts to look like a nail, right?
If you are working in a large enterprise as another cog in the wheel, then that might be for the best. It is assembly-line, commodity code, after all. Keep those blinders on.
But Craft Coders engage themselves in the entire process of web development. And that is _so much more_ than cranking out code.
First, there is accessibility, as specified in the [WCAG 2.2 guidelines](https://www.w3.org/WAI/WCAG22/quickref/) and related advice. To a Craft Coder, accessibility is not an afterthought, but something foundational. Nothing gets built without putting accessibility first.
And UX, of course, although true accessibility incorporates UX. If an application is not usable, then how can it be accessible?
But as many coders are now starting to realize, the most important approach of all is to [make it sustainable](https://www.sustainablewebmanifesto.com/). Craft Coders do so without fail. After all, there is little point in remodeling the kitchen if you're busy burning down the house.
**Craft Coders consider _all_ aspects of web development in their work.** Do you?
> There is no Planet B. ~ Mike Berners-Lee (son of Tim)
## So, are you a Craft Coder?
If so, speak up. Craft Coding is a noble calling. But if new coders don't hear about it, then our numbers will dwindle. And that will be a sad day for web development.
**Weigh in in the comments.** What do you think? Are you a Craft Coder or a commodity coder? And why? And no judgement! The world needs commodity coders, too.
| chasm |
1,655,395 | MarketRacoon - Investment tracking made easy! | MarketRacoon was born with the idea of consolidating all your investment data into a single, simple,... | 0 | 2023-11-03T00:24:52 | https://dev.to/marketracoon/marketracoon-investment-tracking-made-easy-1e4j | stocks, cryptocurrency, investmentmanagement | MarketRacoon was born with the idea of consolidating all your investment data into a single, simple, UX-friendly software-as-a-service (SaaS) product so you can easily understand how your personal finance planning is progressing.
Take control of your financial investments with MarketRacoon as your trusted companion! Join us today.
https://marketracoon.com | marketracoon |
1,655,499 | State Management Alternatives: Best Tools for React Apps | Managing application state efficiently is a crucial aspect of building robust and responsive React... | 0 | 2023-11-03T11:48:43 | https://dev.to/codingcrafts/state-management-alternatives-best-tools-for-react-apps-2cn | react, reactjsdevelopment, javascript | Managing application state efficiently is a crucial aspect of building robust and responsive React applications. State management lies at the heart of React development, and while Redux has been a popular choice for a long time, it's essential to explore the various state management alternatives available to make informed decisions for your projects.
## The Importance of Effective State Management
Before we delve into the alternatives, let's understand why state management is so important. State in a React application represents any data that should be saved and can change over time. This could include user authentication status, data fetched from an API, or even the state of UI components. Effective state management ensures that your application remains consistent, predictable, and easy to maintain.
## Redux: The Current Standard
Redux has long been the gold standard for state management in React applications. Its unidirectional data flow and the use of a single store have made it a powerful tool for managing state. However, as your application scales, Redux can become overly verbose and complex, leading many developers to explore alternatives.
## State Management Alternatives for React Apps
### 1. MobX
MobX provides a simpler and more flexible approach to state management. It uses observables to automatically track changes and update components as needed, reducing boilerplate code significantly. MobX is an excellent choice for those who prefer a more "magical" approach to state management.
### 2. Recoil
Developed by Facebook, Recoil focuses on minimalism and ergonomics. It offers a more intuitive and declarative API, making it easier to work with than Redux. Recoil is well-suited for handling global state with minimal setup.
### 3. Context API
The Context API, a part of React's core, allows you to create a provider-consumer pattern for state management. While it's not as feature-rich as Redux, it's a great option for small to medium-sized applications and can be used with other state management solutions.
### 4. Zustand
Zustand is a lightweight state management library that provides a simple API for creating stores and managing state in your application. It's known for its small footprint and ease of use, making it an excellent choice for smaller projects.
### 5. XState
If your application's state is complex and includes finite state machines, XState is an excellent choice. It helps you model state transitions and manage them in a more structured way.
### 6. Apollo Client
If your React application relies heavily on GraphQL, the Apollo Client is an ideal choice for managing your application's data. It seamlessly integrates with GraphQL and offers a cache for efficiently handling queries and mutations.
## Making the Right Choice
When selecting a state management alternative, consider the specific needs of your project. Each tool has its own strengths and weaknesses, and the right choice will depend on factors like project size, complexity, and your development team's familiarity with the tool. It's crucial to take into account not only the immediate needs but also the long-term scalability and maintainability of your application.
In conclusion, while Redux has been the go-to choice for many React developers, the state management landscape is evolving. As you explore these state management alternatives, make sure to consider the unique requirements of your React application and choose the tool that aligns best with your project's goals. Whether you're a startup, an established business, or a [Custom Software Development Company in USA](https://www.codingcrafts.io/), ensuring the state management solution you choose aligns with your specific needs and growth strategy is paramount.
## Resources:
- [MobX Documentation](https://mobx.js.org/)
- [Recoil Official Website](https://recoiljs.org/)
- [React Context API Documentation](https://reactjs.org/docs/context.html)
- [Zustand on GitHub](https://github.com/pmndrs/zustand)
- [XState Official Website](https://xstate.js.org/)
- [Apollo Client Documentation](https://www.apollographql.com/docs/react/)
By understanding the various state management alternatives available, you can make informed decisions and choose the best tools for your React applications. This approach will help you build efficient, maintainable, and scalable web applications tailored to your specific needs. If you're interested in expert [Website Development Services in USA](https://www.codingcrafts.io/services/website-development-services), consider reaching out to professional developers and agencies in your area to help implement these state management solutions effectively. | hakeem |
1,655,628 | Understanding and Managing States in React: A Comprehensive Guide | React is a powerful library for building user interfaces. One of its core concepts is "state," which... | 0 | 2023-11-03T07:54:27 | https://dev.to/delia_code/understanding-and-managing-states-in-react-a-comprehensive-guide-58c5 |
React is a powerful library for building user interfaces. One of its core concepts is "state," which allows components to maintain their own data and re-render when that data changes. This blog post will explore what state is, when and how to use it, and provide some examples.
## What is State in React?
In React, "state" refers to an object that determines how that component behaves and renders. State is local to the component and can be changed, unlike props, which are passed to components by their parents and are immutable.
When the state of a component changes, React re-renders the component to reflect the new state. This reactivity is part of what makes React so efficient.
## When to Use State
Use state when your component needs to maintain data that changes over time or in response to user input, server responses, or other dynamic interactions. Some common use cases include:
- Input forms
- Interactive components (like on/off switches, sliders, etc.)
- Data filters and search bars
- Any component that needs to remember something
## How to Use State
### Setting Up State
In class components, state is set up in the constructor and modified using the `setState()` method. However, with the introduction of Hooks, functional components can also have state using the `useState` hook.
Here's an example of state in a class component:
```jsx
class Counter extends React.Component {
constructor(props) {
super(props);
this.state = {
count: 0
};
}
incrementCount = () => {
this.setState({ count: this.state.count + 1 });
};
render() {
return (
<div>
<p>You clicked {this.state.count} times</p>
<button onClick={this.incrementCount}>
Click me
</button>
</div>
);
}
}
```
And here's how you can accomplish the same with a functional component using the `useState` hook:
```jsx
import React, { useState } from 'react';
function Counter() {
const [count, setCount] = useState(0);
const incrementCount = () => {
setCount(count + 1);
};
return (
<div>
<p>You clicked {count} times</p>
<button onClick={incrementCount}>
Click me
</button>
</div>
);
}
```
### State and Asynchronous Updates
State updates may be asynchronous, which is why it's important to use the current state when updating based on the previous state. For example:
```jsx
setCount((prevCount) => prevCount + 1);
```
This ensures that `count` is updated based on the most recent state.
## Common Mistakes with State
- **Mutating state directly:** Always use `setState()` or the update function from `useState` to change state.
- **Not using previous state when it's needed:** If the new state is calculated from the old state, you should use the updater function to ensure that you're working with the most current state.
- **Overusing state:** Sometimes, simpler solutions like computed properties or React Context are more appropriate.
## Example: A Simple To-Do App
Let's put this all together in a simple to-do application example.
```jsx
import React, { useState } from 'react';
function TodoApp() {
const [task, setTask] = useState('');
const [todos, setTodos] = useState([]);
const addTask = () => {
setTodos([...todos, task]);
setTask('');
};
return (
<div>
<input
type="text"
value={task}
onChange={(e) => setTask(e.target.value)}
/>
<button onClick={addTask}>Add Task</button>
<ul>
{todos.map((todo, index) => (
<li key={index}>{todo}</li>
))}
</ul>
</div>
);
}
```
In the above example, `task` holds the current value of the input field, and `todos` is an array of tasks. We update the state of `todos` using the spread operator to include the new task, ensuring that we're not mutating the state directly.
## Conclusion
Understanding state in React is crucial for building interactive applications. By managing state effectively, you can ensure that your components behave as expected and create a seamless user experience. Remember to use state when necessary, update it correctly, and avoid direct mutations. With these principles in mind, you're well on your way to mastering React state management. | delia_code | |
1,655,826 | Best Digital Marketing Company in india | We at DigiAvenir are passionate about assisting companies in thriving in the digital environment. We... | 0 | 2023-11-03T11:14:10 | https://dev.to/digiavenir/best-digital-marketing-company-in-india-1aon | We at [DigiAvenir](https://digiavenir.com/) are passionate about assisting companies in thriving in the digital environment. We offer creative solutions that help our clients achieve their goals by leveraging our skills in website building, digital marketing, and market research. Our mission is to strengthen your brand, improve your online presence, and gain a firm foothold in the ever changing digital landscape. | digiavenir | |
1,655,909 | Crush Bugs with Laravel Contract-Based Testing | As an experienced Laravel developer at Hybrid Web Agency, reliability is core to every project I take... | 0 | 2023-11-03T12:27:26 | https://dev.to/isra_skyler/crush-bugs-with-laravel-contract-based-testing-3oo1 | webdev, laravel, testing, bugs | As an experienced Laravel developer at [Hybrid Web Agency](https://hybridwebagency.com/), reliability is core to every project I take on. While testing is mandatory, traditional methods sometimes fall short on complex work with changing requirements.
That's why I've adopted contract-based testing to validate new features and squash bugs before delivery. By defining intended behaviors and expected outputs, contracts ensure my code works as planned - now and later.
This focus on quality has paid dividends for clients. Budgets hold steady as rework decreases. Users enjoy seamless experiences and confidence, with freedom to adjust scope down the line.
In this post, I'll demonstrate how contract testing improved one application. From setup to maintenance, see how shifting left on quality boosts deliverables and strengthens client relationships. Once you know the process - You will be much more confident before you [Hire Laravel Developers in Everett](https://hybridwebagency.com/everett-wa/custom-laravel-development-services/).
## What are Contract Tests?
[Contract testing](https://laravel.com/docs/10.x/contracts) is an approach that validates public APIs by specifying expected app behaviors rather than implementation details. Unlike unit or integration tests, contracts asserts code works as intended now and handles future unknown changes.
Contracts define just the public methods and properties of a class - its "contract" with external users. Tests then exercise this public API through realistic usage scenarios and assertions. This separates the "contract" from how it's coded internally.
Some key benefits include:
- **Focused on critical behaviors:** Tests validate crucial expected inputs/outputs rather than testing all code paths. This focuses on important use cases.
- **Stable over time:** Contracts act as documentation and guards against regressions from code changes. Tests still pass as code evolves if output contracts are met.
- **Reader-focused documentation:** Contracts double as living documentation developers can reference to understand how to use classes properly without digging through code.
Here is a simple example contract class for validating a common "CountAll" method:
```php
interface PostRepositoryContract {
public function countAll(): int;
}
class PostRepositoryContractTest extends TestCase {
public function testCountAllReturnsInteger() {
$mock = Mockery::mock(PostRepositoryContract::class);
$count = $mock->countAll();
$this->assertInternalType('integer', $count);
}
}
```
This contract asserts the method returns an integer without concerning how counting is implemented - keeping tests stable over time.
## Setting Up Contract Tests in Laravel
Setting up contract tests in Laravel involves just a few simple steps to get your environment configured.
### Installing Necessary Packages
The main package needed is PHPUnit. Run `composer require --dev phpunit/phpunit` to add it as a development dependency.
You'll also want helper packages like Mockery for generating test doubles. `composer require --dev mockery/mockery`
### Configuring the Testing Environment
Add `phpunit.xml` to your project root with the basic configuration. This tells PHPUnit where to find your tests.
```xml
<?xml version="1.0" encoding="UTF-8"?>
<phpunit>
<testsuites>
<testsuite name="App Tests">
<directory>tests</directory>
</testsuite>
</testsuites>
</phpunit>
```
### Generating a Basic Test Stub
Create a `tests` directory and a sample test file like `Feature/UserTest.php`. Import necessary classes and traits:
```php
<?php
use PHPUnit\Framework\TestCase;
class FeatureTest extends TestCase
{
public function setUp(): void
{
//...
}
public function testExample()
{
}
}
```
Now your environment is ready to start writing focused contract tests!
## A Real-World Contract Test Example
To demonstrate contract testing in action, let's look at a real-world example.
### Choosing a Class to Test
For this example, we'll focus on a core Repository class that interacts with the database, such as a PostRepository. It retrieves, creates, updates posts and is crucial to our app's functionality.
### Defining the Public API Contract
First, we define the public methods and properties the repository exposes with an interface:
```php
interface PostRepositoryInterface {
public function all();
public function create(array $data);
// etc
}
```
### Writing Test Assertions
Next, we create tests that exercise this interface through common usage scenarios:
```php
public function testAllReturnsCollection()
{
$mock = Mockery::mock(PostRepositoryInterface::class);
$posts = $mock->all();
$this->assertInstanceOf(Collection::class, $posts);
}
public function testCreateStoresPost()
{
$mock = Mockery::mock(PostRepositoryInterface::class);
$mock->shouldReceive('create')->once();
$mock->create(['title' => 'Test']);
}
```
### Running Tests
Now simply run `phpunit`! These contract tests validate our code's public behaviors independently of implementation details.
Let's see how this approach improves our code quality over time.
## Common Contracts to Test
There are some key areas of a typical Laravel application that benefit most from contract testing:
### Database Models & Repositories
Classes that interact with the database like Eloquent models and repository interfaces are perfect for contract testing. Validate expected behaviors for fetching, updating and relating data without depending on the backend.
### API Controllers
API surfaces define your application's public contract with external consumers. Test controller methods adhere to formats, require expected parameters, and return anticipated payloads and status codes.
### Mailables & Notifications
Notifications and mailables send critical communications. Contract test these by asserting views and data are rendered properly without transport concerns muddying tests.
### Core Application Services
Services encapsulate much of your application's business logic. Test service contracts return expected payloads and exceptions for a variety of input scenarios. This validates coreworkflows independently of UI logic.
By focusing tests on these common artifacts, you can have confidence in critical contracts even as code evolves. Tests act as both validation and living documentation of intentions and boundaries for key classes.
## Maintenance and Continuous Testing
Contract tests provide ongoing value beyond initial development:
### Refactoring Without Breaking Contracts
Since tests focus on public APIs, internal refactors and optimizations won't cause failures if they don't change public behavior specifications. This allows safe changes over time.
### Versioning/Breaking Changes Clearly
Before introducing breaking changes, update contracts by removing/modifying methods or arguments. This signals tests and consumers explicitly to change accordingly.
### Integrating with Continuous Integration
Add PHPUnit runs to your CI/CD pipeline. Now contract tests prevent regressions from being deployed automatically. Team members receive immediate feedback from failures.
As codebases evolve rapidly, contracts catch where internal changes alter intended external behaviors. They document restrictions that maintain backwards compatibility over versions.
With contracts, releasing with confidence is attainable. Refactors, features and optimizations land safely while preserving established public interfaces. Tests act as living documentation reflecting how code works and is meant to be used.
## Conclusion
Through every phase of development, from initial specs to ongoing maintenance, quality must remain the highest priority. Contract tests provide the structure and assurance that promises to users are kept, even as circumstances change.
By clarifying expectations instead of implementation, contracts make code understandable from any perspective. They facilitate safe evolution, ensuring the present works as before while allowing imagination for what's next.
Most of all, contract testing transforms relationships. Where fear of breakage once restricted progress, shared expectations built on honesty and respect empower risk-taking. Developers and customers walk together toward a same destination, bold yet careful in each step.
This partnership of clarity and care is what raises a simple application to the level of trusted companion. When reliability is guaranteed, so too is the freedom to learn, grow and achieve ever more together. That is the true promise of contract testing in Laravel and beyond.
| isra_skyler |
1,655,951 | Sales Data Analytics: The Power of Data-driven Marketing Strategies | Using sales data analytics can maximize your business revenues in many ways. Most companies want to... | 0 | 2023-11-03T13:21:24 | https://dev.to/bluent/sales-data-analytics-the-power-of-data-driven-marketing-strategies-1kkl | Using sales data analytics can maximize your business revenues in many ways.
Most companies want to leverage [big data analytics](https://www.bluent.com/business-services/data-analytics/) for sales and marketing benefits besides using advanced BI and automation tools.
A recent survey says that the global sales analytics software market is set to increase from US $4.1 billion in 2022 to US $12.3 billion in 2032, at a CAGR of 11.62%.
From sales professionals to marketing enthusiasts, data-driven sales analysis lets professionals know more about their target audience, competitors, and upcoming market changes.
If you want to boost your sales and profits, then big data can help you refine your marketing strategy and decision-making.
Want to use the power of sales and marketing data for high revenues? Go through this blog and understand how sales analytics can transform your business in detail.
**What is Sales Data Analytics?**
Have you ever wondered how only a few brands achieve overnight success while many fail to do so? What makes their marketing campaigns so precise while targeting the audience? How do their sales teams manage to generate whopping revenues out of conversions?
Being a marketer or a sales executive, you must have similar questions in mind while encountering the success stories of your competitors.
Source by: [https://www.bluent.net/blog/sales-data-analytics-guide/](https://www.bluent.net/blog/sales-data-analytics-guide/) | bluent | |
1,656,266 | Every GitHub Repo 404 😱 | This may be over by the time you read this, but every repo on GitHub appears to be 404ing right now. | 0 | 2023-11-03T18:56:28 | https://dev.to/ben/every-github-repo-404-74e | discuss | This may be over by the time you read this, but _every_ repo on GitHub appears to be 404ing right now. | ben |
1,656,312 | Pivot Table Name | can someone help me find out the name of the pivot table in the added image? | 0 | 2023-11-03T19:23:13 | https://dev.to/ankit199/pivot-table-name-15dl | angular, javascript, webdev, programming | can someone help me find out the name of the pivot table in the added image?
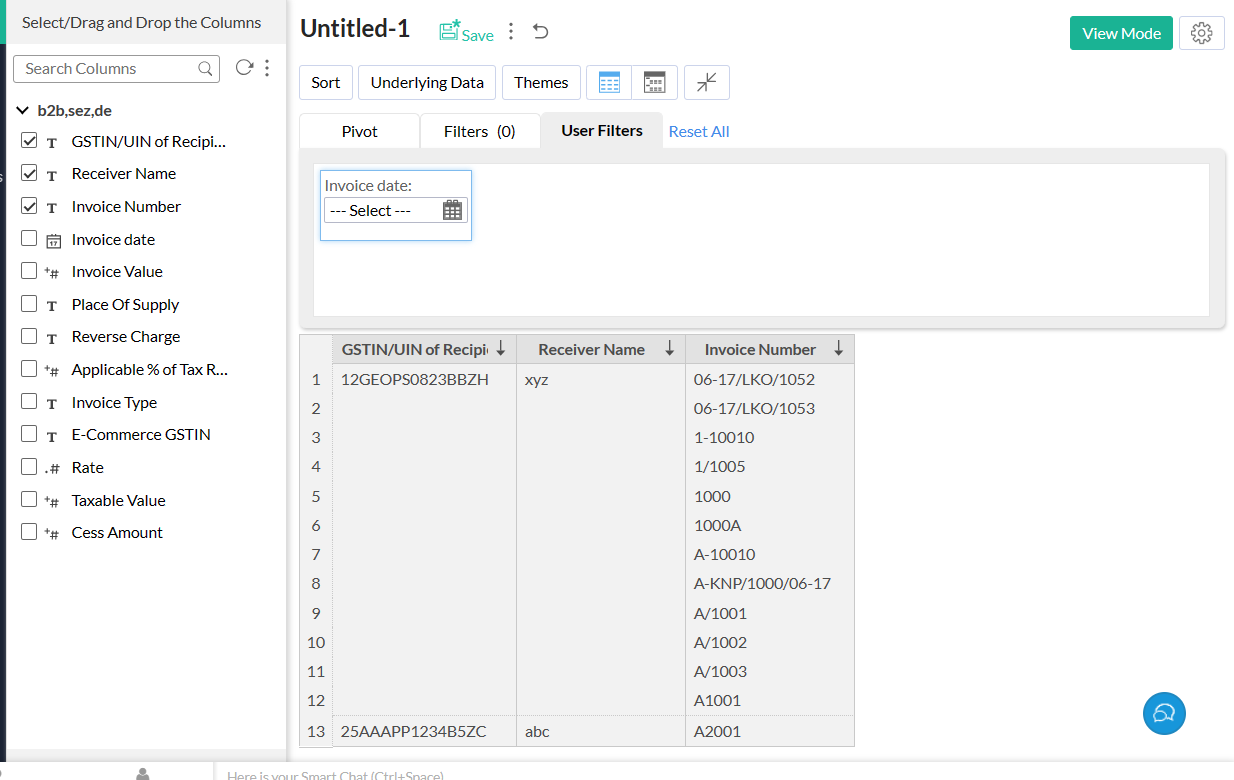 | ankit199 |
1,656,393 | Await Tuples Directly | Imagine if you could write code like this: var task1 = CountAsync(); var task2 =... | 0 | 2023-11-03T22:49:06 | https://dev.to/mehrandvd/await-tuples-directly-1nfk | csharp, dotnet | Imagine if you could write code like this:
```csharp
var task1 = CountAsync();
var task2 = GetMessageAsync();
// How to await tuples directly!?
var (count, message) = await (task1, task2);
// or even this:
var (count, message) = await (CountAsync(), GetMsgAsync());
```
This would allow you to **await multiple asynchronous tasks** in a **single line** of code, without using `Task.WhenAll` or `Task.WhenAny`. How cool is that?
Unfortunately, this is not possible in C# as it is. A `Tuple` is not an awaitable type, and you cannot use the `await` keyword on it. Does that mean we have to give up on this idea? NO!
We can make it happen by using the power of **extension methods**.
You may already know that in C#, you can **await any object** that has a `GetAwaiter` method that returns a `TaskAwaiter`. This means that we can add an extension method called `GetAwaiter` to tuples and make them awaitable.
```csharp
public static TaskAwaiter<(T1, T2)> GetAwaiter<T1, T2>(this (Task<T1>, Task<T2>) tuple)
{
async Task<(T1, T2)> UnifyTasks()
{
var (task1, task2) = tuple;
await Task.WhenAll(task1, task2);
return (task1.Result, task2.Result);
}
return UnifyTasks().GetAwaiter();
}
```
That's it, all done!
Now you can easily await on tuples. To make it available on all types of tuples and enumerables, I've written this library on [GitHub](https://github.com/mehrandvd/EasyAsync/tree/main).
All you need is to install [EasyAsync](https://www.nuget.org/packages/EasyAsync) Nuget package:
```powershell
Install-Package EasyAsync
``` | mehrandvd |
1,656,528 | Understanding Redux: State Management for Your React Applications | As web applications become increasingly complex, managing the state of these applications becomes a... | 0 | 2023-11-04T04:39:36 | https://dev.to/mithun1508/understanding-redux-state-management-for-your-react-applications-178e | redux, react | As web applications become increasingly complex, managing the state of these applications becomes a critical challenge. This is where Redux, a state management library for JavaScript applications, comes into play. In this article, we will explore the fundamentals of Redux, its core concepts, and practical use cases with React.
# What is Redux?
Redux is a predictable state container for JavaScript applications, primarily used with libraries like React or Angular. It provides a structured and centralized approach to managing the state of your application, making it easier to develop and maintain complex applications.
# Why Do You Need Redux?
In a typical React application, data flows in one direction: from parent components to child components. However, as an application grows, managing shared state and passing it down the component tree can become challenging. This is where Redux can help. It provides a centralized store where you can manage the entire state of your application, making it accessible from any component.
# Core Concepts of Redux
To understand Redux, you need to grasp some of its core concepts:
# 1. Store:
The store is the heart of Redux. It holds the application's state and provides methods to access and modify that state.
# 2. Actions:
Actions are payloads of information that send data from your application to the store. They are plain JavaScript objects with a type property that describes the type of action being performed.
Example:
javascript
Copy code
const incrementCounter = {
type: 'INCREMENT',
};
3. Reducers:
Reducers specify how the application's state changes in response to actions. They are pure functions that take the current state and an action, and return a new state.
Example:
javascript
Copy code
const counterReducer = (state = 0, action) => {
switch (action.type) {
case 'INCREMENT':
return state + 1;
default:
return state;
}
};
4. Dispatch:
The dispatch function is used to send actions to the store. When an action is dispatched, the store invokes the corresponding reducer to update the state.
Example:
javascript
Copy code
store.dispatch(incrementCounter);
5. Subscribers:
Redux allows components to subscribe to the store. When the state in the store changes, all subscribed components are notified and can update accordingly.
Practical Example: Counter App
Let's build a simple counter app to illustrate how Redux works with React.
# 1) Setup Redux:
Start by installing the required packages:
bash
Copy code
npm install redux react-redux
# 2) Create the Store:
Create a Redux store with the counter reducer.
javascript
Copy code
// store.js
import { createStore } from 'redux';
import counterReducer from './reducers';
const store = createStore(counterReducer);
export default store;
# 3) Reducer:
Define the counter reducer to handle actions.
javascript
Copy code
// reducers.js
const counterReducer = (state = 0, action) => {
switch (action.type) {
case 'INCREMENT':
return state + 1;
case 'DECREMENT':
return state - 1;
default:
return state;
}
};
export default counterReducer;
# 4)Action:
Create action creators for incrementing and decrementing the counter.
javascript
Copy code
// actions.js
export const increment = () => ({ type: 'INCREMENT' });
export const decrement = () => ({ type: 'DECREMENT' });
# 5) Connect React to Redux:
Use react-redux to connect your React components to the Redux store.
javascript
Copy code
// Counter.js
import React from 'react';
import { connect } from 'react-redux';
import { increment, decrement } from './actions';
const Counter = ({ count, increment, decrement }) => (
<div>
<p>Count: {count}</p>
<button onClick={increment}>Increment</button>
<button onClick={decrement}>Decrement</button>
</div>
);
const mapStateToProps = (state) => ({ count: state });
const mapDispatchToProps = { increment, decrement };
export default connect(mapStateToProps, mapDispatchToProps)(Counter);
# 6)Subscribe to the Store:
Wrap your app with the Redux provider and provide the store.
javascript
Copy code
// App.js
import React from 'react';
import { Provider } from 'react-redux';
import store from './store';
import Counter from './Counter';
function App() {
return (
<Provider store={store}>
<Counter />
</Provider>
);
}
export default App;
This simple counter app demonstrates how Redux helps manage the state of your application in a structured and efficient way.
# Use Cases for Redux
Redux is not limited to counter apps. It's particularly useful for applications with complex state management requirements. Here are some common use cases:
1 Large-scale applications: When you have a lot of state to manage, Redux provides a structured way to handle it.
2 Shared state: When multiple components need access to the same data, Redux ensures consistent data across the application.
3 Undo/redo functionality: Redux makes implementing undo and redo features straightforward.
4 Synchronization with server data: For applications that need to sync with server data, Redux simplifies data management.
5 Global theme and settings: If you want to store global application settings or themes, Redux is a great choice.
In conclusion, Redux offers a robust and predictable way to manage state in your React applications. Understanding the core concepts and use cases of Redux can help you build scalable, maintainable, and efficient web applications.
| mithun1508 |
1,656,538 | Application configuration best practices | Application configuration best practices Introduction One of the... | 0 | 2023-11-04T05:10:11 | https://dev.to/sebm/application-configuration-best-practices-26ag | softwareengineering, cloud, config, architecture | # Application configuration best practices
## Introduction
One of the characteristics of a well designed application is the ability to configure various aspects, like database connections, credentials or external services URLs as well as logging formats, timeouts or cache sizes, to name just a few.
The configuration changes depending on the environment the application is deployed in, most common use cases will be 'dev', 'staging' or 'production' environments.
You may be familiar with Twelve-Factor App methodology, there is a chapter dedicated to configuration [Twelve-Factor: Config](https://12factor.net/config). The basic principle is that your application's code should not have to change in order to deploy it in various environments.
The methodology suggests using environment variables as the safest place for all configuration, especially sensitive data, like credentials.
Using environment variables is a widely adopted practice. If you have been working in software engineering teams, you must have encountered something like this:
```
USERS_DB_JDBC_URI: postgresql://my.host.com/mydb?user=other&password=secret
```
You may have run the application locally, perhaps using a locally accessible database running in a docker container - in that case you have set the above env variable to `localhost` address. You may have seen the staging application instance configured to a test db instance running in the cloud.
## Best practices
As the application grows in complexity, you may find adding more environment variables, rightly so. Great danger lies in treating the naming and the use of environment vars lightly, below I propose a few good practices to follow to avoid common pitfalls and ensure sanity of the development and devops teams.
### Naming
**Be specific about what the env var contains**
Let's take the relational db connection URI as an example: names like `DB`, `DB_CONN` are not great, there is no notion of what the content of the variable is, it could be the database URL, the name, the connection string. If you are storing the connection URI, name the var accordingly: `DB_CONNECTION_URI` (if you only have one DB connection in your application).
Let's look at another example: credentials (let's say a basic auth) required to connect to some external service. It may be tempting to just call it `CREDENTIALS` or `PASS` but if you are specific, you will make your life easier in the future, not mentioning other team members or the devops team. A better name would be `SOME_EXTERNAL_SYSTEM_BASIC_AUTH`.
Here is an example of a well named service account env variable for a 'Component X' in your application: `COMPONENT_A_SERVICE_ACCOUNT_FILE_NAME`, if it's a base64 encoded service account JSON, call it `COMPONENT_X_SERVICE_ACCOUNT_JSON_B64`. That way you are reducing the mental overhead required to work with those in the code as well.
### Reuse
**Don't reuse an env var for unrelated components in your application**
As an example, if the application uses multiple data stores, a better naming strategy is to include the logical name of the store in the connection URI env var: `USERS_DB_CONNECTION_URI`. In the early days of your application, or maybe in a local environment, you may use the same database for multiple logical stores - to decouple the configuration, you can define dedicated env vars, initially with the same value.
Another example would be a file storage destination - it may be tempting to name a variable `S3_BUCKET_NAME` and then use it in a component that stores images the users upload as well as raw data files an unrelated component needs to store.
In that case, it's better to introduce two environment variables: `USER_IMAGES_BUCKET_NAME` and `RAW_DATA_BUCKET_NAME`. Again, both variables may end up having the same value, but at least you have the option to change the location of one without affecting the other: imagine one of the buckets having to have different retention characteristics or access policy - with separated configuration it becomes an configuration change rather than a need to re-deploy your application.
### Environment names
**Avoid coupling your code to deployment environments**
It's often very tempting to use the environment name as a variable available in your app. What's wrong with an innocent `ENV` or `ENV_NAME`?
You may have seen code like this:
```
// this code is an example of bad env var usage, it should be avoided.
if (ENV == 'prod') {
url = 'some.host.com';
}
```
The above couples your application's code with the target deployment environment. An obvious issue is the fact that an URL is now configured in your code, rather than in the configuration.
Any configuration done within that `if` statement should be expressed as a dedicated environment variable.
Let's discuss a few examples:
- Using a mock payment provider in non-prod env - define a variable `USE_MOCK_PAYMENT_PROVIDER` and set it to true in non-prod environments - if the env var is not defined (in a prod env) the mock provided will not be enabled.
- Enabling additional endpoints for testing or diagnostics in UAT environment - define a variable `ENABLE_TEST_ENDPOINT` and set it to true in the UAT env - again, absence of the variable in production will effectively disable the feature.
Another example: imagine you have to create a new environment for load testing or you need to have a second production instance dedicated to a specific customer - now your code will have to consider not just 'prod' but 'prod-2', 'staging-load-testing' etc.
This violates the Twelve-Factor principles and makes it really hard to reason about application's behaviour and dependencies: you can't just inspect the application configuration to understand which database it will connect to, you have to inspect the code and find all uses of the 'prod' string in the code.
### Default values
**Don't silently fallback to default configuration**
It is tempting to handle a configuration error by using some sensible defaults.
Unfortunately it often results in a false sense that the application is configured correctly and may result in hours of wasted time when you query the wrong database or comb through the wrong file storage bucket, just because of a typo in your en var name.
It will likely result in the default configurations being actually hard-coded anyway.
I recommend throwing an exception or an error as soon as an expected environment variable does not exist or has no value. The exception would be 2 examples discussed in the previous section, where non-prod env vars may be ignored if they don't exist.
Let's analyse the following example: if your application expects a name of a file storage bucket in `USER_IMAGES_BUCKET_NAME` variable, but it gets null (depending on your tech stack) or an empty string, defaulting to some 'sensible' value may result in silently ignoring a missing critical configuration. Imagine a common mistake, a typo in the variable name like this: `USER_IMGAES_BUCKET_NAME` (can you spot it?) or perhaps the database URL would default to a dev instance - when a required env var is not present, the application should immediately throw an error, with an explicit message about what the expectation were, which env var is missing.
Trying to stop configuration errors preventing app startup may sound like a good idea, but it will lead to confusion and non-deterministic state of your application.
## Summary
This article discusses best practices regarding application configuration that improve readability, decouple application code from deployment environments and reduce risk of misconfiguration.
Here is a handy table showing the less ideal and the better examples of env var naming.
|Example configuration|Less ideal name|Better name|Rule|
|---|---|---|---|
| Database connection URI | ~~`DB`~~, ~~`DB_CONN`~~ | `DB_CONNECTION_URI` | be specific about variable content |
| Credentials | ~~`CREDENTIALS`~~, ~~`PASS`~~ | `SOME_EXTERNAL_SYSTEM_BASIC_AUTH`, `COMPONENT_X_SERVICE_ACCOUNT_JSON_B64` | be specific about variable content |
| File storage config | ~~`S3_BUCKET_NAME`~~ | `USER_IMAGES_BUCKET_NAME`, `USER_ZIP_FILES_BUCKET_NAME` | decouple independent components' config |
| Environment name | ~~`ENV`~~, ~~`ENV_NAME`~~ | `USE_MOCK_PAYMENT_PROVIDER`, `ENABLE_TEST_ENDPOINT` | Decouple application from environments, prevent hard-coding configuration
| Defaulting | ~~`if (myConfigVar == null) myConfigVar='123'`~~ | throw exception | Don't hard-code default configurations, prevent silently ignoring incorrect state |
| sebm |
1,656,603 | RSAC 2023 Recap | After four jammed packed days in the Moscone Center in the heart of San Francisco, RSAC 2023 is in... | 0 | 2023-11-04T07:09:09 | https://dev.to/stellarcyber/rsac-2023-recap-4oc9 |

After four jammed packed days in the **Moscone Center** in the heart of San Francisco, **RSAC 2023** is in the books. By now, most attendees are probably back to their day jobs, keeping us protected from the bad guys. Before settling into my daily routine, I thought I’d share a few takeaways from this year’s conference.
## We are Back
I am embarrassed to admit that I cannot remember how many RSACs I’ve attended in person, they all kind of run together over time, but if I had to guesstimate, I would say this was probably my **8th or 9th**. At any rate, the moment I hit the expo floor on Tuesday morning and saw the crowds of attendees everywhere, it was clear that we were back, and the pandemic was definitely in our rearview mirror. Walking the floor, the energy coming from everyone was palpable. In short, after a couple of years of being sequestered, security practitioners were more than ready to mingle with their peers. While the size of the show, in my opinion, seemed back to pre-pandemic levels, more important was the number of quality discussions we had during the conference. Practitioner after practitioner who stopped by our booth or scheduled a meeting with our executive team sought new ways to solve their problems. This behavior signals that regardless of macroeconomic conditions, cybersecurity remains a priority for organizations.

## Automatic for the People
No, R.E.M. wasn’t playing their classic album at the conference, but automation was top of mind for many vendors and attendees alike. Automation is one of those topics that surface in many different ways. For some vendors, their automation story came across in their (early) adoption of Generative AI (e.g., ChatGPT), claiming the ability to aid in threat hunting, investigations, and doing your taxes, you get the idea. Unfortunately, from my view, many of these vendors are “way over their skis” in their actual ability to deliver a product that includes generative AI. Still, their PowerPoint and videos sure looked slick. For others, like [Stellar Cyber](https://stellarcyber.ai/), automation comes from taking manual tasks across the investigation lifecycle and automating them. I had many conversations about the benefits of marrying intelligent automation with human expertise to drive down mean time to detection and response. Regardless of how vendors tell their automation story, the attendees and the market are thirsty for automation to help close their teams’ skills gaps.
## Hey, wasn’t that called XDR last year
At RSAC 2022, you couldn’t walk two feet without seeing vendors advertising their new [XDR products](https://stellarcyber.ai/product/), regardless of whether they had actual XDR capabilities. Fast forward to last week. The frenzy around XDR was gone. Instead, many vendors that jumped on the XDR bandwagon in 2022 had pivoted to another buzzword attached to their product, even if it hadn’t changed. Sadly this flip-flopping is par for the course in our industry. That said, plenty of vendors were still promoting their XDR products when walking the floor. In addition, a few of the market stalwarts introduced new [XDR solutions](https://stellarcyber.ai/platform/capabilities-ndr/). While there is an ongoing debate on what XDR is, it is clear that many vendors are looking to meet the market need to deliver better [detection and response](https://stellarcyber.ai/platform/capabilities-ndr/) capabilities across the broader attack surface beyond just the endpoint. You might remember that in my pre-conference blog, I predicted that “[Open XDR](https://stellarcyber.ai/platform/what-is-open-xdr/)” would be a hot topic at RSAC.
As a reminder, the “Open” before XDR means that organizations can ingest data from any data source. Unlike traditional or closed XDRs, which typically only deliver integrations within their product portfolio and force other vendors to develop integrations, a genuine [Open XDR](https://stellarcyber.ai/platform/what-is-open-xdr/) provider develops all the product integrations themselves. So, back to RSAC. I wouldn’t say that Open XDR was a front-and-center hot topic for the entire conference. Still, I can tell you from first-hand experience that they were very interested when we talked about the Stellar Cyber [Open XDR platform](https://stellarcyber.ai/product/) and how an organization can make all their products work better together.
## Next Stop – Vegas
As hard as it might be to believe, our industry’s next big conference, Black Hat, is less than three months away in Las Vegas. Watch this blog for more information about what we have cooking for that event. | stellarcyber | |
1,656,610 | Descomplicando Machine Learning - Parte II | Obstáculos que têm impedido as pessoas de iniciar uma carreira como engenheiro de machine... | 0 | 2023-11-04T07:21:03 | https://dev.to/tandavala/descomplicando-machine-learning-parte-ii-3d05 | ## Obstáculos que têm impedido as pessoas de iniciar uma carreira como engenheiro de machine learning
Bem-vindo à segunda parte da nossa série "**Descomplicando Machine Learning**". Na [primeira parte](https://dev.to/tandavala/descomplicando-machine-learning-parte-i-2b2f) desta série, exploramos a motivação por trás deste projeto. Também definimos o que é Machine Learning e, posteriormente, mergulhamos em alguns conceitos essenciais em ML. Entre esses conceitos, destacamos a Aprendizagem Supervisionada, a Aprendizagem Não Supervisionada e a Aprendizagem por Reforço.
## Motivação
Hoje, falaremos de alguns obstáculos que têm impedido as pessoas de iniciar uma carreira como engenheiro de machine learning. Antes de começar, quero dar credito ao Prof. [Jason Brownlee, PhD](https://machinelearningmastery.com/about), pois grande parte do conteúdo deste artigo é baseado em seu trabalho intitulado ["What Is Holding You Back From Your Machine Learning Goals?"](https://machinelearningmastery.com/what-is-holding-you-back-from-your-machine-learning-goals/)
## Identificar e Superar Suas Crenças Limitadoras Pessoais e, Finalmente, Fazer Progresso
Começar algo do zero não é fácil, ainda mais ao iniciar uma carreira em um mundo cheio de ruídos e inundado de informações. Mas tenho boas notícias: é possível superar os obstáculos que nos impedem de avançar. Segundo o Prof. [Jason Brownlee, PhD](https://machinelearningmastery.com/about), existem três tipos de obstáculos:
- Crenças autolimitantes
- Esperar o momento certo para começar
- Esperando Condições Perfeitas
**Crenças autolimitantes:** São ideias que você assume como verdadeiras e que estão restringindo seu progresso. Isso geralmente começa com crenças que vão contra os objetivos que você estabeleceu ou os que deseja alcançar. No final do dia, você acaba acreditando mais nesse pensamento negativo do que no primeiro pensamento que o motivou a embarcar em um projeto ou jornada de sucesso.
Existem três tipos de crenças autolimitantes:
- **Se-então Crenças:** por ex. Se eu começar a carreira de machine learning engineer, falharei porque não sou bom o suficiente
- **Crenças Universais:** por ex. Todos os cientistas de dados têm doutorado. e são deuses da matemática
- **Crenças Pessoais e de Autoestima:** por ex. Eu não sou bom o suficiente
Como diz o ditado, "um bom entendedor meia palavra basta". Isso significa que é essencial acreditar em nós mesmos e lutar pelos nossos sonhos. Um sábio já disse que tudo é possível para aqueles que acreditam. Fica a dica
**Esperar o momento certo para começar**: essa é uma das crenças mais difíceis de abandonar, pois geralmente traz consigo outros maus hábitos, sendo a procrastinação um deles. No caso de machine learning, acredita-se que é necessário primeiro se tornar um deus da matemática e estatística e, em seguida, dominar a programação de A a Z, para só então começar a estudar machine learning efetivamente. No entanto, quero lhe dizer que isso não é verdade. (***De fato, o fato de você estar aqui já indica que está no caminho certo. Aqui, desenvolveremos alguns modelos que podem servir de inspiração para continuar praticando sem precisar antes ser o deus da matemática e estatística***). O problema com esse tipo de crença é que o conhecimento prévio que você acredita precisar dominar na íntegra não é, na verdade, necessário para dar os primeiros passos. Para ser mais prático, você pode começar a desenvolver seu primeiro modelo de aprendizado de máquina sem ser um deus da matemática e estatística, pois essas ciências são tão vastas em escopo que mesmo especialistas no assunto não sabem tudo.
Abaixo estão algumas das **crenças autolimitantes** mais comuns sobre habilidades ou conhecimento prévio que devem ser adquiridos antes de você começar a se aventurar no mundo de machine learning.
Não posso iniciar uma carreira de machine learning engineer até...
...eu obter um diploma ou pós-graduação
...eu concluir um curso
...eu ser bom em álgebra linear
...eu entender estatísticas e teoria da probabilidade
...eu dominar a linguagem de programação R
Embora todos esses aspectos sejam importantes, eles não necessariamente precisam vir antes de você começar a praticar machine learning. É possível começar a desenvolver habilidades em machine learning desde o início e, à medida que você constrói sua base em desenvolvimento de modelos de aprendizado, pode estudar gradualmente cada tópico essencial, seja matemática ou estatística
## Esperando Condições Perfeitas
Esta é uma crença autolimitante clássica, e não preciso entrar em detalhes sobre isso. Em vez disso, gostaria de compartilhar histórias inspiradoras de sucesso de pessoas que superaram essa crença e se tornaram exemplos para milhares de outras pessoas:
- Mark Zuckerberg, fundador do Facebook, iniciou sua jornada com colegas de quarto em Harvard.
- Larry Page e Sergey Brin começaram a Alphabet na garagem.
- Valentina Vladimirovna Tereshkova, a primeira cosmonauta e a primeira mulher a ir para o espaço, cresceu em uma família humilde. Seu pai era um motorista de trator que desapareceu durante a Guerra Russo-Finlandesa em 1940. Valentina entrou na escola aos oito anos e começou a trabalhar em uma fábrica têxtil aos dezoito anos.
Essas histórias demonstram que o sucesso não espera por condições perfeitas. Elas nos inspiram a continuar, independentemente das circunstâncias iniciais, e a acreditar que podemos alcançar nossos objetivos. Portanto, faça um favor a si mesmo: deixe para trás a ideia de precisar de um computador poderoso ou de esperar terminar a faculdade para iniciar sua jornada. Simplesmente comece hoje.
## Conclusão
Concordarias que leva tempo para se tornar habilidoso em qualquer coisa? Requer muita prática, repetição, dedicação e a crença de que você pode alcançar o sucesso. Portanto, quero estender um convite a você: deixe de lado o excesso de preocupações com as dificuldades, não se cobre demais e junte-se a mim nessa jornada na série "**Descomplicando Machine Learning**". Quem sabe, no final, você estará no ritmo, construindo um portfólio sólido e se inspirando com as dicas e exemplos que veremos aqui. Sendo assim, espero por você no próximo artigo, onde vamos falar sobre: [CRISP-DM na prática](https://dev.to/tandavala/descomplicando-machine-learning-parte-iii-c80). Até lá, cuide-se
| tandavala | |
1,656,664 | Simplexity Personal & Blog multipage theme. | Simplexity ⏤ Personal & Blog multipage theme. Built with Astro, Tailwind CSS See it live and... | 0 | 2023-11-04T09:13:43 | https://dev.to/lexingtonthemes/simplexity-personal-blog-multipage-theme-i6h | webdev, tailwindcss, astroj | Simplexity ⏤ Personal & Blog multipage theme.
Built with Astro, Tailwind CSS
See it live and learn more.
→ https://lexingtonthemes.com/info/simplexity
 | mike_andreuzza |
1,656,686 | Dive into Adventure with Project Bathyscaphe: The Best Visual Novel Experience | Visual novels have become a popular genre in the gaming world, offering a unique and immersive... | 0 | 2023-11-04T09:57:12 | https://dev.to/krisgames/dive-into-adventure-with-project-bathyscaphe-the-best-visual-novel-experience-57a9 |
Visual novels have become a popular genre in the gaming world, offering a unique and immersive storytelling experience. Project Bathyscaphe is one such visual novel that takes players on an exciting adventure into the depths of the ocean. This game is perfect for those who love mystery, adventure, and complex characters.
With its captivating storyline, stunning visuals, and engaging gameplay, Project Bathyscaphe is sure to leave a lasting impression on players. In this blog post, we will dive into the world of Project Bathyscaphe and explore what makes this visual novel one of the best. From its unique storyline and character development to its stunning graphics and sound effects, we'll cover everything you need to know about this thrilling game. So, grab your diving gear and get ready to embark on an unforgettable adventure with Project Bathyscaphe!

## 1. Introduction to Project Bathyscaphe: The Best Visual Novel Experience
Are you ready to embark on an immersive storytelling journey unlike any other? Look no further than Project Bathyscaphe, the ultimate visual novel experience that will transport you to a world of adventure, suspense, and captivating narratives.
Visual novels have gained immense popularity in recent years, captivating readers with their unique blend of interactive storytelling and stunning visuals. Project Bathyscaphe takes this genre to new heights, offering an unparalleled experience that will leave you on the edge of your seat.
From the moment you start playing, you'll be drawn into a rich and intricate world, filled with intriguing characters and gripping plotlines. Each decision you make will have consequences, shaping the outcome of the story and allowing for multiple paths and endings. This level of interactivity ensures that no two playthroughs are the same, providing endless excitement and replay value.
What sets Project Bathyscaphe apart from other visual novels is its breathtaking visuals and meticulous attention to detail. The artwork is beautifully crafted, bringing the characters and settings to life in vivid detail. Every scene is meticulously designed, capturing the essence of the story and immersing you in its world.
But it's not just about the visuals; the writing in Project Bathyscaphe is top-notch. The dialogues are engaging and well-crafted, with each character having their own distinct voice and personality. The narrative is carefully constructed, filled with suspense, mystery, and moments of heart-wrenching emotion. Whether you're a fan of romance, fantasy, or thrilling adventures, there's something for everyone in Project Bathyscaphe.
Whether you're a seasoned visual novel enthusiast or new to the genre, Project Bathyscaphe is a must-play experience. It will captivate your senses, ignite your imagination, and keep you coming back for more. Get ready to dive deep into a world of adventure and embark on a visual novel journey like no other with Project Bathyscaphe.
## 2. What is a visual novel?
A visual novel is an interactive storytelling medium that combines elements of literature, graphic design, and gameplay to create a unique and immersive experience for its players. It can be best described as a digital choose-your-own-adventure book, where the reader becomes an active participant in the narrative.
Unlike traditional novels, visual novels incorporate captivating visuals, including character artwork, backgrounds, and various animations, to enhance the storytelling process. These visuals are accompanied by engaging soundtracks and voice acting, further immersing the players into the world of the story.
The gameplay in visual novels revolves around making choices that influence the direction and outcome of the plot. These choices may lead to different story branches, multiple endings, or character relationships, allowing players to have a personalized and dynamic experience.

What sets visual novels apart is their ability to provide a strong emotional connection between the players and the characters. By delving into the thoughts, emotions, and personal journeys of the characters, visual novels can evoke a wide range of emotions, from joy and laughter to sadness and heartbreak.
Project Bathyscaphe is an exceptional example of a visual novel that pushes the boundaries of storytelling and immersion. With its stunning artwork, compelling narrative, and intricate decision-making system, it offers players an unparalleled adventure that will keep them captivated from start to finish.
Whether you are a fan of literature, gaming, or simply looking for a unique and interactive storytelling experience, diving into the world of visual novels with Project Bathyscaphe is sure to be an unforgettable adventure.
## 3. The unique features and gameplay mechanics of Project Bathyscaphe
Project Bathyscaphe offers an unforgettable visual novel experience that sets it apart from other games in the genre. With its unique features and innovative gameplay mechanics, players are immersed in a captivating adventure like never before.
One standout feature of Project Bathyscaphe is its stunning artwork and visuals. The game boasts beautifully hand-drawn illustrations that bring the characters and environments to life. Every scene is meticulously crafted, creating a visually immersive world that enhances the storytelling experience. From the ethereal underwater landscapes to the intricate character designs, the attention to detail is truly remarkable.
In addition to its captivating visuals, Project Bathyscaphe introduces innovative gameplay mechanics that keep players engaged and invested in the story. One such mechanic is the interactive decision-making system. Throughout the game, players are presented with choices that directly impact the narrative and character relationships. These choices create a sense of agency, allowing players to shape the outcome of the story and experience multiple branching paths.

Another unique gameplay feature of Project Bathyscaphe is its dynamic soundtrack. The game's music is carefully composed to heighten the emotional impact of each scene, seamlessly blending with the visuals and dialogue. From intense moments of suspense to heartfelt and tender exchanges, the music enhances the overall atmosphere and adds depth to the storytelling.
Furthermore, Project Bathyscaphe incorporates a deep and intricate storyline that keeps players captivated from start to finish. The well-developed characters are brought to life through engaging dialogues and meaningful interactions. As players progress through the game, they uncover secrets, solve puzzles, and navigate complex relationships, unraveling a rich and immersive narrative that keeps them on the edge of their seats.
In conclusion, Project Bathyscaphe offers a truly unique visual novel experience with its stunning visuals, innovative gameplay mechanics, and immersive storytelling. Dive into this adventure and be prepared to embark on a journey like no other.
## 4. The captivating storyline and characters in Project Bathyscaphe
One of the main reasons why Project Bathyscaphe stands out as a visual novel experience is its captivating storyline and well-developed characters. From the very beginning, players are plunged into a world filled with mystery, adventure, and unexpected twists.
The storyline of Project Bathyscaphe is meticulously crafted, taking players on a thrilling journey through different worlds, each with its own unique challenges and secrets to uncover. Whether it's exploring ancient ruins, solving complex puzzles, or encountering enigmatic creatures, every step of the way is filled with excitement and intrigue.
What truly brings the storyline to life are the well-developed characters that players encounter throughout the game. Each character is carefully designed, with their own distinct personalities, motivations, and backstories. As players progress, they form deep connections with the characters, getting to know their hopes, fears, and dreams. The interactions and relationships between the characters are intricately woven into the narrative, adding depth and emotional resonance to the overall experience.
Additionally, the visual and audio elements of Project Bathyscaphe further enhance the immersion in the storyline. Stunning graphics, vibrant animations, and atmospheric sound effects create a rich and immersive environment that draws players into the world of the game.
Overall, the captivating storyline and well-crafted characters in Project Bathyscaphe make it a visual novel experience like no other. It is a game that will keep players engaged and invested, eagerly anticipating what lies ahead in this thrilling adventure.
## 5. The stunning visuals and artwork that immerse players in the game
One of the standout features of Project Bathyscaphe is its stunning visuals and artwork that truly immerse players in the game. From the moment you start playing, you are greeted with beautifully crafted scenes that transport you to a world filled with adventure and intrigue.
The attention to detail in the artwork is truly remarkable. Each character, location, and object is meticulously designed to create a visually captivating experience. The vibrant colors, intricate backgrounds, and expressive character designs bring the game to life in a way that is both visually striking and emotionally engaging.
Not only are the visuals impressive, but they also play a crucial role in storytelling. The artwork effectively conveys the mood, atmosphere, and emotions of each scene, enhancing the overall narrative and drawing players deeper into the game's world.
Whether you find yourself exploring ancient ruins, navigating through treacherous landscapes, or engaging in heartfelt conversations with intriguing characters, the stunning visuals of Project Bathyscaphe serve as a constant reminder of the game's immersive nature.
The attention to detail extends beyond still images as well. Dynamic animations and visually captivating effects further enhance the overall visual appeal of the game. These elements combine seamlessly with the artwork to create a truly immersive and visually stunning experience for players.
In conclusion, the visuals and artwork of Project Bathyscaphe are a true testament to the dedication and talent of the development team. They have successfully created a game that not only tells a compelling story but also envelops players in a visually stunning world. Prepare to be captivated by the breathtaking visuals that await you in this extraordinary visual novel experience.
## 6. The importance of choices and consequences in the game
One of the key elements that sets Project Bathyscaphe apart as a captivating visual novel experience is the importance it places on choices and consequences. In this immersive game, players are not mere spectators but active participants in shaping the narrative and determining the outcome.
Every decision you make as the protagonist has a ripple effect throughout the game, leading to different storylines, character interactions, and ultimately, multiple endings. The developers have intricately crafted a web of choices that keeps the players engaged and invested in the outcome of their journey.
The choices presented in Project Bathyscaphe are not trivial; they have weight and meaning. Each decision carries the potential to alter relationships, influence character development, and shape the overall narrative arc. This creates a sense of agency and empowers players to feel like their choices truly matter.
Furthermore, the consequences of these choices are not always immediately apparent. They may unfold gradually, surprising you with unexpected twists and turns. This element of unpredictability adds a layer of excitement and suspense, keeping you on the edge of your seat as you navigate the intricate web of possibilities.
Project Bathyscaphe challenges traditional storytelling norms by allowing players to explore different paths and experience a personalized narrative. It encourages replayability, as each playthrough unveils new facets of the story and encourages players to discover alternative outcomes.
By emphasizing the importance of choices and consequences, Project Bathyscaphe offers a truly immersive and dynamic gaming experience. Whether you prefer a thrilling adventure, heartwarming romance, or intense drama, this visual novel promises to keep you hooked, eager to uncover the diverse paths that lie ahead.
## 7. Exploring different story paths and endings in Project Bathyscaphe
One of the most captivating features of Project Bathyscaphe is its ability to immerse players in a world of endless possibilities. The visual novel offers an array of unique story paths and multiple endings, ensuring that each playthrough is a fresh and exciting adventure.
As you navigate through the game, you'll encounter various choices that shape the direction of the story. These choices can lead to different outcomes, branching the narrative into diverse paths. Will you choose to befriend the enigmatic scientist or remain cautious of their intentions? Will you embark on a daring rescue mission or prioritize your own survival? The decisions you make in Project Bathyscaphe have real consequences, paving the way for a rich and dynamic storytelling experience.
Each story path in Project Bathyscaphe offers a unique perspective and unveils new layers of the game's intricate plot. You'll have the opportunity to explore different character backgrounds, uncover hidden secrets, and witness the consequences of your choices. The developers have meticulously crafted each path, ensuring that they are engaging, thought-provoking, and filled with unexpected twists and turns.
Furthermore, the multiple endings in Project Bathyscaphe add an extra layer of depth to the gameplay. Your actions and choices throughout the game will ultimately determine the fate of the characters and the world they inhabit. Will you achieve a heroic victory, a bittersweet resolution, or a tragic demise? The possibilities are endless, and each ending provides a satisfying conclusion to the storylines you have woven.
Whether you're a fan of immersive storytelling, character development, or simply enjoy exploring different narrative paths, Project Bathyscaphe offers an unparalleled visual novel experience. Dive into this captivating adventure and unlock the multitude of story paths and endings that await you. Prepare to be captivated, enthralled, and left craving for more as you embark on this extraordinary journey.
## 8. The interactive nature of the game and player engagement
One of the key aspects that sets Project Bathyscaphe apart from other visual novels is its interactive nature and player engagement. Unlike traditional novels or movies, where the audience is merely a passive observer, this game puts the player right in the driver's seat, allowing them to make choices and shape the outcome of the story.
As you navigate through the captivating narrative, you'll find yourself faced with meaningful decisions that have real consequences. These choices can range from simple dialogue options to complex moral dilemmas, each impacting the direction and outcome of the game. This level of interactivity not only keeps players engaged but also adds a layer of replayability as they strive to uncover all possible storylines and endings.
Furthermore, Project Bathyscaphe takes advantage of cutting-edge technology to enhance player immersion. With stunning visuals, dynamic sound effects, and a meticulously crafted world, the game creates a truly immersive experience that transports players into its captivating universe. Every scene is beautifully rendered, every character intricately designed, and every detail thoughtfully considered, resulting in an immersive and visually stunning adventure.
But it's not just about the visuals – the game also boasts a rich and engaging soundtrack that complements the story and heightens the emotional impact of key moments. Whether it's a heart-pounding chase sequence or a tender and poignant scene, the music enhances the overall experience, making it all the more unforgettable.
In summary, Project Bathyscaphe offers an interactive and engaging experience that goes beyond traditional storytelling. By putting players in control and immersing them in a visually stunning world, this visual novel pushes the boundaries of what can be achieved in interactive storytelling, making it a must-play for adventure and gaming enthusiasts alike.

Project Bathyscaphe takes the genre of visual novels to new heights by pushing the boundaries of storytelling. With its captivating narrative and stunning visuals, this game offers an immersive experience that will keep players hooked from start to finish.
One of the key ways that Project Bathyscaphe achieves this is through its innovative use of branching storylines. Players are presented with choices at various points throughout the game, and these choices have real consequences that impact the overall narrative. This element of interactivity adds a new layer of depth to the storytelling, allowing players to shape the outcome of the story based on their decisions.
Furthermore, Project Bathyscaphe incorporates dynamic and expressive visuals that bring the characters and settings to life. The artwork is meticulously crafted, with richly detailed backgrounds and beautifully designed characters. Each scene is carefully composed to evoke the desired emotions and create a visually stunning experience for players.
In addition to its captivating storytelling and breathtaking visuals, Project Bathyscaphe also features a memorable soundtrack that enhances the overall atmosphere of the game. The music is carefully composed to match the mood of each scene, whether it be a thrilling moment of suspense or a tender and heartfelt interaction between characters. The combination of the stunning visuals, engaging narrative, and immersive soundtrack creates a truly unforgettable experience for players.
Project Bathyscaphe is a testament to the evolving nature of visual novels and how they can push the boundaries of storytelling in interactive media. With its innovative approach to branching narratives, breathtaking visuals, and captivating soundtrack, this game sets a new standard for what a visual novel can achieve. Dive into the adventure of Project Bathyscaphe and prepare to be captivated by its immersive storytelling and unique gameplay experience.
## 10. Conclusion: Why Project Bathyscaphe is a must-play for adventure enthusiasts
In conclusion, Project Bathyscaphe is an absolute must-play for all adventure enthusiasts out there. This visual novel experience takes you on a thrilling journey unlike any other, immersing you in a captivating narrative that will keep you hooked from start to finish.
One of the standout features of Project Bathyscaphe is its stunning visuals. The artwork is meticulously crafted, bringing the game's world to life in vivid detail. From lush landscapes to intricate character designs, every scene is a feast for the eyes, enhancing the overall immersion and making it a truly visual delight.
But it's not just about the aesthetics – the storytelling in Project Bathyscaphe is top-notch. The narrative is rich and layered, filled with unexpected twists and turns that will keep you on the edge of your seat. The characters are well-developed, each with their own unique personalities and motivations, adding depth and complexity to the overall experience.
Furthermore, the gameplay mechanics in Project Bathyscaphe are intuitive and engaging. You'll find yourself making choices that impact the outcome of the story, allowing for a personalized adventure that feels tailored to your decisions. The branching paths and multiple endings ensure that each playthrough is a fresh and exciting experience, offering high replay value.
Whether you're a seasoned visual novel player or new to the genre, Project Bathyscaphe offers an unforgettable adventure that will leave you craving for more. Its combination of breathtaking visuals, compelling storytelling, and immersive gameplay make it a standout title that should not be missed.
So, grab your diving gear and prepare to dive into the depths of Project Bathyscaphe. Get ready to embark on an unforgettable adventure that will transport you to a world filled with mystery, excitement, and endless possibilities. Don't miss out on this immersive visual novel experience that will captivate and thrill adventure enthusiasts alike.
We hope you enjoyed diving into the adventure of Project Bathyscaphe, the best visual novel experience. This blog post aimed to introduce you to the captivating world of visual novels and demonstrate why Project Bathyscaphe stands out among the rest. With its immersive storytelling, stunning visuals, and engaging gameplay, Project Bathyscaphe offers a truly unforgettable experience. So, grab your controller, embark on a thrilling journey, and get ready to be swept away by the magic of visual novels. Happy gaming!
You can always download the [Bathyscaphe project](https://bathyscaphe.name/download)!
| krisgames | |
1,656,794 | How the Changing Attack and Cybersecurity Solutions Landscape Led Me to Join Stellar Cyber | Working in Cybersecurity for the past two decades, helping managed security service providers... | 0 | 2023-11-04T12:58:58 | https://dev.to/stellarcyber/how-the-changing-attack-and-cybersecurity-solutions-landscape-led-me-to-join-stellar-cyber-3ffb |

Working in Cybersecurity for the past two decades, helping managed security service providers ([MSSPs](https://stellarcyber.ai/product/stellar-cyber-for-mssps/)) meet the needs of their customers, gives me a unique perspective on how our industry has evolved and ultimately led me to join Stellar Cyber last month to run the Global Service Provider Business. As I get to know Stellar Cyber’s current customers and those within the company that design, build, and deploy the leading [Open XDR Platform](https://stellarcyber.ai/platform/what-is-open-xdr/) on the market, I will, from time to time, share some insights I’ve gained working for some of the most well-known brands in the industry. Today I thought I would start by outlining the significant changes occurring in the market today and how those changes influenced me to join Stellar Cyber.
## The Rising Demand for Security Services from MSPs
Anyone who has been in our industry for any length of time knows that many organizations find it challenging to hire and retain staff for their internal security teams. With a skills gap growing, most organizations seek alternatives to building a lean security team in-house. For many, this means approaching their managed service provider (MSP), who typically maintains their IT infrastructure, urging them to add [cybersecurity services](https://stellarcyber.ai/platform/capabilities-ndr/). From the organizations’ standpoint, the MSP who already knows their environment should be able to deliver cybersecurity services efficiently. Unfortunately, most MSPs lack the security expertise and capital budget to establish a [Security Operations Center (SOC)](https://stellarcyber.ai/enterprise/automated-soc/) to provide such services. To that end, the MSP will look to existing [MSSPs](https://stellarcyber.ai/product/stellar-cyber-for-mssps/) hoping to find one that can “white label” their security services so that the MSP can seamlessly deliver the services to their customer. So, to provide what MSPs need, MSSPs need technology that enables them to segment their customers by MSP, then by MSP customer. This is known as multi-tenant, multi-tier architecture, which Stellar Cyber uniquely delivers. Reason #1 I joined Stellar Cyber.
Outsourcing Security is Going Nowhere
As stated above, a growing skills gap is making outsourcing cybersecurity an excellent alternative for organizations that lack the deep pockets to attract and keep talented security experts in-house. This trend of outsourcing has led to an explosion of regional [MSSPs](https://stellarcyber.ai/product/stellar-cyber-for-mssps/) who look to differentiate themselves based on use case specialty, industry expertise, or straight cost-effectiveness. No matter the differentiation choice, MSSPs must look to standardize on a set of tools they use to deliver their services, specifically the primary security operations tool that analysts will use to investigate and respond to threats. Over the past few years, this primary tool has changed based on what was Hot in the market that year, from SIEM to [NexGen SIEM](https://stellarcyber.ai/platform/capabilities-ng-siem/), to EDR, and now XDR. And like other “DRs,” many MSSPs look to manage XDR (MXDR) as the new call to action. No matter what you call it, the savvy MSSP buyer is looking for a tool that:
- Enables them to integrate as many other tools as possible, growing their ability to attract new customers
- It doesn’t require its customers to “rip and replace” anything they are using
- Uses the latest technologies to detect and correlate potential threats
- Allow security analysts to take decisive response action from the tool
_While they may now know it, most MSSPs are looking for what is known as an Open XDR Platform, which is what Stellar Cyber delivers. Reason #2 I joined Stellar Cyber._
## MSSPs need Partners, not Sellers.
I have had the privilege over my career to see changes in how security services are delivered, from on-premises only to the first security-as-a-service providers to hybrid and everything in between. As our market continues to grow, with more than 4,000 security product vendors in the market today, [MSSPs](https://stellarcyber.ai/product/stellar-cyber-for-mssps/) are continuously inundated with how this product or that product can help them drive customer stickiness, improve analyst-to-customer ratios, drive up margins, etc. At the end of the day, however, MSSPs want to know that their selected vendors are invested in their success. All too often, after an MSSP signs up with a vendor, they are shown some “love” right after the deal closes. They are left to fend for themselves until the license is set to renew when the salesperson that was MIA for the duration of the contract starts calling to set up a meeting. While MSSPs might put up with this sort of relationship for a while, the moment someone even slightly better comes along, they will drop their current vendor as quickly as possible.
Vendors that MSSPs love build relationships from day one and grow as the days pass. These vendors want the MSSP to succeed and provide the training and enablement required for them to do so, free of charge. The MSSP, fortunate to build a relationship with a vendor like this, doesn’t even consider changing to a new vendor; why would they? When I talked to MSSPs about [Stellar Cyber](https://stellarcyber.ai/), they raved about how the company enables and trains their teams and is available 24×7 to ensure success. You don’t hear other vendors do this, nor do you see vendors get praise like I heard. Reason #3 I joined Stellar Cyber.
So, in summary, I joined Stellar Cyber because: 1) They have a critical technical advantage over competitors with their multi-tenant, multi-tier architecture, 2) they have an Open architecture that enables MSSPs to say “Yes” to more customers, growing their ability to drive revenue, and 3) are genuinely invested in helping MSSPs succeed, and have the receipts to prove it.
**With that, let the fun begin.** | stellarcyber | |
1,656,798 | How to Build Your Own Chrome Extension Using ChatGPT | Introduction In my previous article, I shared how I developed a Chrome extension using... | 0 | 2023-11-04T13:11:28 | https://dev.to/justlorain/how-to-build-your-own-chrome-extension-using-chatgpt-1pfa | chatgpt, webdev, tutorial, programming | ## Introduction
In my [previous article](https://dev.to/justlorain/i-created-a-chrome-extension-in-15-minutes-with-zero-front-end-knowledge-using-gpt-33df), I shared how I developed a Chrome extension using ChatGPT within 15 minutes, despite having no prior knowledge of frontend development. Recently, I completed another Chrome extension project with the help of ChatGPT. In this article, I want to summarize and share the entire development process and insights, hoping to provide some inspiration and assistance to you.
In this article, I will walk you through the process of developing the [TABSNAPSHOT](https://github.com/B1NARY-GR0UP/tabsnapshot) extension using ChatGPT. We will start from the basic requirements and move on to some key points to consider when developing with ChatGPT.
## Requirements
The idea for this extension came from a real-life scenario. I spend most of my time browsing web pages and PDFs. Chrome provides an excellent reading experience, but I often find myself opening specific pages related to a particular topic. For example, during my midterm exam preparation, I needed to open three pages (a lecture PDF and two article links) every time I opened Chrome. Using Chrome's built-in features, I had two options:
- Create a **folder** and save these three pages as bookmarks inside the folder. I could open all the pages at once using the "Open all bookmarks" option in the folder.
- Add these three pages to Chrome's **"Reading List"** and open them one by one from the Reading List.
However, I rejected both of these methods because:
- The process of creating a folder and adding pages to it is too **tedious**: creating the folder, adding a page to the folder, and saving it require too many steps. Besides, I usually use Chrome folders to collect web pages rather than storing these temporary pages I need to read.
- The **Reading List doesn't support adding PDFs**, and dealing with PDF pages separately would be a very cumbersome process.
So, I clearly identified the need for a tool that could **temporarily save one or multiple tab pages** and **open these pages with minimal actions**, similar to the `Open All Bookmarks` option.
## Development Approach
Unlike my previous GitHub Searcher project, I had no specific idea of how to implement this extension. I wasn't even sure if Chrome provided APIs to achieve these functionalities. After giving it some thought, I came up with a rough plan:
- Implement a button in the extension popup to save all currently open tabs as a "snapshot."
- Use the extension's popup window as the main control panel for the extension.
- Display all saved snapshots in the popup window. Clicking on a snapshot should open all the tabs saved in that snapshot.
With this plan in mind, I named the extension **TABSNAPSHOT** and proceeded to write the code with ChatGPT.
## Development Process
### Basic Functionality
Since I relied entirely on GPT to write the code, I communicated my requirements and approach clearly to GPT. However, due to GPT's nature, there were some challenges and issues that arose.
My initial prompt was as follows:
> I want to develop a Chrome extension called tabsnapshot. This extension should:
>
> 1. Save the URLs of all open tabs in the browser when the user clicks the "Create Snapshot" button in the extension's popup window (i.e., create a snapshot).
> 2. Display the saved snapshots as items in the popup window, with the snapshot's creation time as the item's name.
> 3. When the user clicks on a saved snapshot in the popup window, open the URLs saved when the snapshot was created.
>
> Please develop this extension and provide all necessary files.
However, the code generated based on this prompt had several issues:
- The `manifest_version` was set to **2**.
- Only the URL of the first open tab was saved in each snapshot, not all open tabs.
- Saved snapshots were **not persisted**. When I closed and reopened Chrome, the saved snapshots disappeared.
To address these issues, I provided additional instructions to GPT:
> I want to develop a Chrome extension called tabsnapshot. This extension should:
>
> 1. Save the URLs of all open tabs in the browser when the user clicks the "Create Snapshot" button in the extension's popup window (i.e., create a snapshot).
> 2. Display the saved snapshots as items in the popup window, with the snapshot's creation time as the item's name.
> 3. When the user clicks on a saved snapshot in the popup window, open the URLs saved when the snapshot was created.
>
> Please develop this extension and provide all necessary files.
>
> Additional instructions:
>
> 1. The `manifest_version` value should be set to 3.
> 2. Each snapshot item should save all open URLs, not just one URL. You can consider using an array or map for storage.
> 3. All snapshot items must be persisted. When I close and reopen the browser, I should see all previously saved snapshot items.
With these additional instructions, GPT generated code that met my requirements. I had the basic functionality of TABSNAPSHOT, allowing me to create snapshots, save them, and open them with a single click.
The initial UI for this basic version was quite simple:
Once the basic version was implemented, I had a foundation to build upon. I continued to enrich and optimize the features of TABSNAPSHOT.
### Delete Functionality and UI Enhancement
In the initial version, I only had the functionality to create snapshots but lacked the ability to delete them. I asked GPT to add the delete functionality:
> I need you to add snapshot deletion functionality to this extension. Without changing the existing functionality, add an "x" button next to each snapshot item in the popup window. Users can click this button to delete the corresponding saved snapshot. Please provide the updated code after adding the delete functionality.
With the code provided by GPT, the UI was updated as follows:
Although the "x" buttons were functional, the UI was not aesthetically pleasing. I asked GPT to improve the style while keeping the delete functionality intact:
> Great, but the style of the delete button is not appealing. Can you make it similar to the "Create Snapshot" button and maintain the delete functionality?
The improved style of the delete button, along with other UI enhancements, looked like this:
We can see that the optimized delete button looks much better, even richer in style than the `Create Snapshot` button mentioned in the prompt, so we continue to let GPT optimize the UI, and the final UI looks like this:
At this point, TABSNAPSHOT is fully operational, and all the current features are sufficient to address the pain points I mentioned in the requirements scenario.
But because of my OCD, we continue to add features and optimizations to TABSNAPSHOT.
### Rename and Open Snapshot
From the above UI, it can be seen that each snapshot entry is named after the time it was created. When there are many entries, it becomes difficult to distinguish which content each snapshot contains. Therefore, here we added the renaming functionality to TABSNAPSHOT:
> The first feature we are going to add is the renaming functionality. Please add a `rename` button to the left of the `delete` button with a style consistent with the `delete` button. When the user clicks the `rename` button, the original text of the snapshot entry will become editable. Users can rename the snapshot by modifying the text and confirming with the Enter key.
However, GPT did not provide a perfect solution in this case. When clicking the `Rename` button and modifying the text, the Enter key did not save the changes. Users had to click somewhere else in the popup window to save the changes. We had to use a few more prompts to guide GPT and make the necessary modifications to finally complete the development of the renaming functionality:
Here, we also changed the way snapshots are opened to a specific button:
> Great! Now I would like you to modify the logic for opening saved snapshots. Currently, the logic is to click on the snapshot entry to open it. I want you to change the way snapshots are opened to clicking an `open` button. This `open` button should be located to the right of each snapshot entry. The style of a snapshot entry should be: Snapshot Name, Open button, Rename button, Delete button.
The final result looks like this:
### Open All and Delete All
To further enhance the functionality of TABSNAPSHOT, I asked GPT to add "Open All" and "Delete All" buttons:
> Excellent. Now I want you to add two buttons to the right of the "Create Snapshot" button:
> - "Open All": Opens all saved snapshots.
> - "Delete All": Deletes all saved snapshots.
The updated UI with these features was as follows:
Now that we have completed all the major feature points, we will fine-tune some of the details of TABSNAPSHOT.
### Detail Optimizations
Optimizable details are as follows:
- If the tab contains a local PDF for browsing, it should automatically refresh after opening; otherwise, manual refresh might be necessary.
- Add a tab count for each snapshot entry.
- Simplify the default snapshot naming format (retain only month, day, hour, and minute).
- If multiple snapshots are created within the same minute, automatically add numbering to avoid duplicates.
- Snapshot preview.
When communicating with GPT through prompts, it's essential to describe your requirements clearly. You can make your prompts more vivid by providing examples:
> Next, we are going to add a tab count feature to the snapshots. When creating a snapshot entry, the number of tabs included in that snapshot will be displayed after the snapshot name. For example, a name for a snapshot containing three tabs would be `sample [3]`. Please note that this `[3]` should not be editable by the user through the rename button. You can place the snapshot entry name and tab count in separate elements but display them on the same line.
> Please add a logic check for snapshot creation. If multiple snapshots are created within the same minute, start numbering from the second snapshot created within that minute, following the order of creation. For example, the name of the first snapshot created at 15:53 on 11/1 would be 11/1 15:53, the second snapshot created at 15:53 on 11/1 would be 11/1 15:53 (2), and the third one would be 11/1 15:53 (3).
One thing worth mentioning is the snapshot preview feature. I have found it challenging to convey the exact effect I want to GPT, which might be why the implemented feature did not meet my expectations. Perhaps I haven't clearly defined what the preview feature should look like.
From a hover-based implementation to a click-based popup window:
> Now I want to add a preview feature to this plugin. Leave a space at the bottom of the popup window as the preview area. When the user hovers over a snapshot entry, the preview window will list all the links from the tabs included in that snapshot in the form of a list. Please implement this feature based on the above code.
> Now I want to add a preview feature to this plugin. When the user clicks on a snapshot entry, the browser will pop up a preview window (please note that this preview window is not the plugin's popup window). The preview window will list all the links from the tabs included in that snapshot in the form of a list. Please implement this feature based on the above code.
The final version, with all optimizations completed, is as follows. This is the v0.1.0 version released after open-sourcing:
- **Plugin UI**
- **Preview window UI**
## Key Takeaways from Developing with ChatGPT
Here are some key points and lessons I learned during the development process with ChatGPT:
- Clearly define your **development goals and expectations**. Ensure you can articulate your requirements logically; otherwise, the responses from ChatGPT might not meet your needs.
- **Break down your project** into small functional points. Develop one feature at a time, starting with the basic functionality and then refining and optimizing it.
- **Long prompts** might cause ChatGPT to lose context. Consider using previous prompts to edit and submit or start a new chat to maintain context.
- Use **consistent terminology** and agreements with ChatGPT during the development process.
## Logo
You can also design an attractive logo for TABSNAPSHOT:

## Conclusion
This article has covered my entire journey of developing the TABSNAPSHOT extension with the help of ChatGPT. It includes the iterative thought process and the key points summarized at the end. I hope this experience can assist you in your projects.
As you can see, TABSNAPSHOT is still a very basic and simple extension with plenty of room for improvement. However, if you have a similar use case to mine, feel free to use TABSNAPSHOT to simplify your browsing experience.
If you find [TABSNAPSHOT](https://github.com/B1NARY-GR0UP/tabsnapshot) helpful or if you have suggestions for improvements, please feel free to **Star, Fork, and submit Pull Requests** !!!
## References
- https://github.com/B1NARY-GR0UP/tabsnapshot
- https://chat.openai.com/ | justlorain |
1,657,214 | Javascript [array methods] - slice, splice | const items: any[] = [0,1,2,3,4,5] /* syntax slice() slice(start) slice(start,... | 0 | 2023-11-05T02:11:31 | https://dev.to/migueldesa/javascript-array-methods-slice-splice-2g72 | ```TS
const items: any[] = [0,1,2,3,4,5]
/* syntax
slice()
slice(start)
slice(start, end)
*/
console.log(`
from3: ${items.slice(3)}
from2To4: ${items.slice(2,4)}
all: ${items.slice()}
`)
/*
splice(start)
splice(start, deleteCount)
splice(start, deleteCount, item1)
splice(start, deleteCount, item1, item2)
splice(start, deleteCount, item1, item2, …, itemN)
*/
items.splice(4,0,"X")
console.log(`insert in index 4: ${items}`)
items.splice(1,1,"Y")
console.log(`replace in index 1: ${items}`)
items.splice(7,0,"i1","i2", "i3")
console.log(`added at the end: ${items}`)
```
result:
> [LOG]: "
> from3: 3,4,5
> from2To4: 2,3
> all: 0,1,2,3,4,5
> "
> [LOG]: "insert in index 4: 0,1,2,3,X,4,5"
> [LOG]: "replace in index 1: 0,Y,2,3,X,4,5"
> [LOG]: "added at the end: 0,Y,2,3,X,4,5,i1,i2,i3"
| migueldesa | |
1,657,282 | Thethaovn thethaovn.club | Thethaovn hiện đang là một trong các nhà cái mới hàng đầu hiện nay. Sân chơi chuyên cung ứng các sản... | 0 | 2023-11-05T06:17:43 | https://dev.to/thethaovnclub/thethaovn-thethaovnclub-1d2m | sport | Thethaovn hiện đang là một trong các nhà cái mới hàng đầu hiện nay. Sân chơi chuyên cung ứng các sản phẩm.
Địa chỉ: 33/6E Phan Huy Ích, Phường 12, Gò Vấp, Thành phố Hồ Chí Minh, Việt Nam.
Email: thethaovninfo@gmail.com
Website: https://www.thethaovn.club/
Điện thoại: (+84) 325983806
#thethaovn #thethao #thethaovnclub
**https://www.facebook.com/thethaovninfo**
https://twitter.com/Thethaovninfo
https://www.youtube.com/@thethaovninfo
https://www.pinterest.ph/Thethaovninfo/
https://social.msdn.microsoft.com/Profile/Thethaovninfo
https://social.technet.microsoft.com/profile/thethaovninfo/
https://www.blogger.com/profile/09168755337885071244
https://www.reddit.com/user/Thethaovninfo
https://medium.com/@thethaovninfo
https://www.flickr.com/people/199206252@N05/
https://www.tumblr.com/thethaovninfo
https://www.scoop.it/u/thethaovninfo-gmail-com
https://ext-6432546.livejournal.com/
https://thethaovninfoblog.wordpress.com/
https://sites.google.com/view/thethaovnclub
https://tinyurl.com/556h76y6**
https://ok.ru/thethaovninfo | thethaovnclub |
1,657,296 | How to Track Previous State in React | Explaining how to track previous state in React using refs and effects, optimising to use only state, then extracting the logic to a custom hook | 0 | 2023-11-07T08:44:56 | https://dev.to/aneesa-saleh/how-to-track-previous-state-in-react-4pj3 | react, hooks | ---
title: How to Track Previous State in React
published: true
description: Explaining how to track previous state in React using refs and effects, optimising to use only state, then extracting the logic to a custom hook
tags: react, hooks
# cover_image: https://direct_url_to_image.jpg
# Use a ratio of 100:42 for best results.
# published_at: 2023-11-05 06:31 +0000
---
When developing React applications, we may need to keep track of both the current and previous state. This article discusses various techniques for achieving this, and how to encapsulate the logic into reusable custom hooks.
To demonstrate the examples, we'll use a basic application that displays a counter, its previous value and a button to increment it:
{% embed https://codesandbox.io/embed/ecstatic-khayyam-6gk3mw?fontsize=14&hidenavigation=1&theme=dark %}
Let's explore how to build this component.
## Approach 1: Use Refs and Effects
A [common approach](https://levelup.gitconnected.com/how-to-get-previous-state-in-react-6bce387b32d6) is to use a [ref](https://react.dev/learn/referencing-values-with-refs) to store the previous state:
```jsx
function App() {
const [counter, setCounter] = useState(0);
const ref = useRef();
useEffect(() => {
ref.current = counter;
}, [counter]);
return (
<div>
<div>Counter: {counter}</div>
<div>Previous Counter: {ref.current}</div>
<button onClick={() => setCounter(counter + 1)}>
Increment counter
</button>
</div>
);
}
```
An [effect](https://react.dev/reference/react/useEffect) monitors `counter` and updates `ref.current` when it changes. Changing a ref's value won't trigger a re-render, so the element displaying `ref.current` shows the previous value of `counter` until the next render (i.e. when `counter` changes).

This approach would work fine when the only state variable in our component is `counter`, but once there are multiple state variables (as most components have), a re-render that isn't triggered by `counter` would synchronise the elements displaying `counter` and `ref.current`, displaying the same value for both.
To see this in action, let's add a new state variable, `title`:
```jsx
// ...
const [counter, setCounter] = useState(0);
/* 👇 add title here */
const [title, setTitle] = useState("");
// ...
```
Add an input element to display and update `title`:
```jsx
{/* ... */}
<div className="App">
{/* 👇 add the input here */}
<input
value={title}
onChange={(e) => setTitle(e.target.value)}
/>
{/* ... */}
```
When text is enter in the title input (triggering a re-render), the values displayed for Counter and Previous Counter become the same:

In general, you want to avoid using refs for values that will be displayed, as stated in the [React docs](https://react.dev/reference/react/useRef#usage):
> Changing a ref does not trigger a re-render, so refs are not appropriate for storing information you want to display on the screen. Use state for that instead.
## Approach 2: Use the state setter function
To fix the state-ref synchronisation bug, [another approach](https://www.geeksforgeeks.org/how-to-get-previous-state-in-reactjs-functional-component/) is to use a new state variable `previousCounter` to keep track of `counter`'s previous value:
```jsx
function App() {
const [counter, setCounter] = useState(0);
/* 👇 add previousCounter here */
const [previousCounter, setPreviousCounter] = useState(null);
const [title, setTitle] = useState("");
/* 👇 add an event handler for the increment button */
const handleIncrementButtonClick = () => {
setCounter((counter) => {
setPreviousCounter(counter);
return counter + 1;
});
};
return (
<div className="App">
<input value={title} onChange={(e) => setTitle(e.target.value)} />
<div>Counter: {counter}</div>
<div>Previous Counter: {previousCounter}</div>
{/* 👇 update the button's onclick handler */}
<button onClick={handleIncrementButtonClick}>Increment counter</button>
</div>
);
}
```
The value of `previousCounter` is updated when setting `counter` in the click event handler for the increment button. Now Counter and Previous Counter remain synchronised even when the title is updated:
.
With this approach, we've eliminated the need for using both refs and effects. Effects are considered an [escape hatch](https://react.dev/learn/you-might-not-need-an-effect), so replacing them with state wherever possible makes our code more stable. Now we'll see how to extract this logic into a custom hook.
## Approach 3: Use two state variables to track current and previous values
In this approach (adapted from the [usehooks package](https://github.com/uidotdev/usehooks)), we'll define a state variable `currentCounter` to track `counter`'s value:
```jsx
function App() {
const [counter, setCounter] = useState(0);
/* 👇 add currentCounter here */
const [currentCounter, setCurrentCounter] = useState(counter);
const [previousCounter, setPreviousCounter] = useState(null);
const [title, setTitle] = useState("");
/* 👇 conditionally update previousCounter and currentCounter */
if (counter !== currentCounter) {
setPreviousCounter(currentCounter);
setCurrentCounter(counter);
}
/* 👇 update event handler */
const handleIncrementButtonClick = () => {
setCounter(counter + 1);
};
return (
<div className="App">
<input value={title} onChange={(e) => setTitle(e.target.value)} />
<div>Counter: {counter}</div>
<div>Previous Counter: {previousCounter}</div>
<button onClick={handleIncrementButtonClick}>Increment counter</button>
</div>
);
}
```
The initial value of `currentCounter` is set to match `counter`. On subsequent re-renders, when `currentCounter` and `counter` don't match, that means `counter` has been updated and `currentCounter` now holds its previous value. We set `previousCounter` to `currentCounter`'s value, and update `currentCounter` to match `counter`. Now the `handleIncrementButtonClick` event handler only needs to increment `counter`.
Both state and props can be tracked using this method. The logic easily be extracted into a custom hook:
```javascript
function usePrevious(value) {
const [current, setCurrent] = useState(value);
const [previous, setPrevious] = useState(null);
if (value !== current) {
setPrevious(current);
setCurrent(value);
}
return previous;
}
```
To use this hook, we pass it the state or prop we want to track:
```javascript
function App() {
const [counter, setCounter] = useState(0);
/* 👇 this is all we need now */
const previousCounter = usePrevious(counter);
const [title, setTitle] = useState("");
const handleIncrementButtonClick = () => {
setCounter(counter + 1);
};
return (
<div className="App">
<input value={title} onChange={(e) => setTitle(e.target.value)} />
<div>Counter: {counter}</div>
<div>Previous Counter: {previousCounter}</div>
<button onClick={handleIncrementButtonClick}>Increment counter</button>
</div>
);
}
```
## Approach 4: Use a custom hook to set both current and previous values
For tracking a value within a component's state (this won't work for props), we can use a custom hook that returns a state variable, its setter and another state variable to track its previous state:
```javascript
function usePreviousStateTracking (initialValue) {
const [current, setCurrent] = useState(initialValue);
const [previous, setPrevious] = useState(null);
function setPreviousAndCurrent(nextValue) {
setPrevious(current)
setCurrent(nextValue)
}
return [current, setPreviousAndCurrent, previous];
}
```
The hook can be used like this:
```jsx
export default function App() {
/* 👇 this is all we need now */
const [counter, setCounter, previousCounter] = usePreviousStateTracking(0);
const [title, setTitle] = useState("");
const handleIncrementButtonClick = () => {
setCounter(counter + 1);
};
return (
<div className="App">
<input value={title} onChange={(e) => setTitle(e.target.value)} />
<div>Counter: {counter}</div>
<div>Previous Counter: {previousCounter}</div>
<button onClick={handleIncrementButtonClick}>Increment counter</button>
</div>
);
}
```
In some cases, you might want to use this approach to skip the extra re-render from approaches 2 & 3 (caused by setting the previous state value separately from the current one). It's worth noting that when an additional re-render is causing notable performance issues, it may indicate that other optimisations need to be made in your component.
## Conclusion
In this article, we explored various approaches to track previous state in React components. We started by solving the problem using refs and effects, then discussed different approaches that use only state. Finally, we used custom hooks to encapsulate the logic into reusable functions.
If you're interested in seeing how to track multiple versions of a state variable, be sure to leave a comment below. | aneesa-saleh |
1,669,671 | Is there only 3D? | Did you know that there are higher dimensions than 3D? I discovered that today and it was valuable... | 0 | 2023-11-17T12:23:45 | https://dev.to/a_k_g/is-there-only-3d-5f4i | 3dtools, multimedia, discuss | Did you know that there are higher dimensions than 3D? I discovered that today and it was valuable information. It is used in mathematics and physics, such as general relativity, based on four dimensions, as the fourth dimension is time .
This is very impressive🤔 | a_k_g |
1,669,746 | DevX Status Update | Hello! Hello! Happy Friday! That’s another week done and dusted, and if you live in the US... | 0 | 2023-11-17T17:55:25 | https://puppetlabs.github.io/content-and-tooling-team/blog/updates/2023-11-17-devx-status-update/ | community, puppet | ---
title: DevX Status Update
published: true
date: 2023-11-17 00:00:00 UTC
tags: community, puppet
canonical_url: https://puppetlabs.github.io/content-and-tooling-team/blog/updates/2023-11-17-devx-status-update/
---
## Hello!
Hello! Happy Friday! That’s another week done and dusted, and if you live in the US all of us here in the DevX team would like to wish you a safe and happy thanksgiving next week. Make sure to eat plenty, and enjoy your time with some family and friends.
Meanwhile, here in Belfast, you can’t help but smell christmas in the air. Amplified by the arrival of the much anticipated annual christmas markets at City Hall this weekend. We have an office planned outting next week to sample some of the food, (and who knows maybe even a beer or some mulled wine?) which come from all around the globe.

### Puppet.Dsc & Puppet 8
Now, back to a more professional note, this is an exciting announcement for all of you Puppet Dsc module users.
All [puppet dsc modules](https://forge.puppet.com/modules/dsc) generated by [Puppet.Dsc](https://github.com/puppetlabs/Puppet.Dsc) will now ship with Puppet 8 support by default, and naturally, this means Puppet 6 is no longer supported in these new releases. So, if you are unable to make the upgrade to Puppet 8, we recommend to pin your modules in your Puppetfiles, metadata.json and elsewhere to help ensure you don’t see any unexpected behaviour in your environemnts.
## New Gem Releases
- [`puppet_litmus`](https://rubygems.org/gems/puppet_litmus) (`1.2.1`) | puppetdevx |
1,669,892 | Promoting your web dev firm on Instagram: Actionable tips | Promoting your company on social media is no longer an option, and knowing how to do it will be key... | 0 | 2023-11-17T15:24:41 | https://dev.to/graphicsprings/promoting-your-web-dev-firm-on-instagram-actionable-tips-f42 | Promoting your company on social media is no longer an option, and knowing how to do it will be key to your success. Today we have put together some actionable advice on how to engage with your audience on Instagram.
Optimize Your Profile:
Ensure your Instagram profile is complete with a recognizable profile picture, a concise and compelling bio, and a link to your website. Make it clear what your web development firm specializes in.
Visual Storytelling:
Use visually appealing content to showcase your projects, team, and company culture. High-quality images and graphics can effectively communicate your web development skills and creativity. Using an [instagram enagagement calculator] (https://hypeauditor.com/free-tools/youtube-money/) can be helpful in seeing how your content resonates with your audience.
Consistent Branding:
Maintain a consistent visual identity. Use a cohesive color scheme and design style across your posts to reinforce brand recognition.
Highlight Your Expertise:
Share your knowledge and insights related to web development. Post tips, tricks, and industry trends to position your firm as an authority in the field.
Client Testimonials:
Feature satisfied clients and their testimonials. This builds trust and provides social proof of your firm's capabilities.
Engage with Your Audience:
Respond to comments, direct messages, and engage with other users in your industry. Building a community fosters a positive reputation and can lead to collaborations or partnerships.
Utilize Instagram Stories:
Leverage Instagram Stories for behind-the-scenes glimpses, project updates, and time-limited promotions. Use interactive features like polls and questions to boost engagement.
Hashtags:
Research and use relevant hashtags to expand the reach of your posts. Create a branded hashtag specific to your firm to encourage user-generated content.
Collaborate with Influencers:
Partner with influencers or industry experts to reach a wider audience. Their endorsement can enhance your credibility and attract new clients.
Run Instagram Ads:
Invest in targeted Instagram advertisements to reach specific demographics and increase brand visibility. Use compelling visuals and concise copy to capture attention.
Host Instagram Contests:
Engage your audience by organizing contests or giveaways. Encourage participants to share your content or tag friends, increasing your firm's visibility.
Educational Content:
Share informative content such as tutorials, infographics, or blog excerpts that demonstrate your expertise and provide value to your audience.
Post Regularly:
Consistency is key. Develop a posting schedule that works for your audience and stick to it. Regular updates keep your profile active and engaged.
Monitor Analytics:
Regularly review Instagram Insights to understand what content performs best and adjust your strategy accordingly. Analyze metrics like engagement, reach, and follower growth.
Cross-Promote with Other Platforms:
Share your Instagram content on other social media platforms to maximize exposure. Create a cohesive online presence across different channels.
Remember, successful promotion on Instagram involves a combination of creativity, consistency, and strategic planning. Adapt these tips to fit your firm's unique identity and goals.
| graphicsprings | |
1,669,973 | How to use Self-Service Onboarding in Harness Internal Developer Portal | In this tutorial, Debabrata a Developer Relations Engineer at Harness, dives into the essentials of... | 0 | 2023-11-17T16:57:36 | https://youtu.be/0GoK3SD1rxs?si=b5n7gXt53ngu18qM | idp, backstage, platformengineering, productivity | In this tutorial, [Debabrata](https://www.linkedin.com/in/debanitr/) a Developer Relations Engineer at Harness, dives into the essentials of creating a basic service onboarding pipeline within the [Harness Internal Developer Portal (IDP)](https://www.harness.io/products/internal-developer-portal), that runs on Backstage v1.17. This feature is a game-changer for platform engineers and developers looking to streamline their application development processes.
**What You'll Learn:**
1. **🛠️ Setting Up the Pipeline:** We start by guiding you through the process of creating a Harness pipeline for service onboarding, including the creation of Build or Custom stages.
2. **📝 Using Software Templates:** Learn how to interact with software templates to collect user requirements efficiently.
3. **🔄 Automating Service Onboarding:** Discover how the Harness pipeline automates the onboarding of new services, from fetching skeleton code to creating new repositories.
4. **🐍 Scripting with Cookiecutter:** We'll show you how to use a Python CLI, cookiecutter, to generate a basic Next.js app and set up a repository.
5. **🌐 Managing Variables and Authentication:** Understand how to manage pipeline variables and authenticate requests within the pipeline.
6. **🎨 Creating a Software Template Definition:** We guide you through creating a template.yaml file in IDP, powered by Backstage Software Template.
{% youtube 0GoK3SD1rxs %} | debanitrkl |
1,670,132 | First Post | First post just as a test. Hello everyone! | 0 | 2023-11-17T19:35:18 | https://dev.to/evilla092/first-post-5fdg | beginners, programming | First post just as a test. Hello everyone! | evilla092 |
1,670,318 | Atualização do Ubuntu via Terminal | Todo fã de GNU/Linux vai falar o quanto é prático instalar e configurar a distro¹ somente usando o... | 0 | 2023-11-18T02:49:58 | https://dev.to/mayannaoliveira/atualizacao-do-ubuntu-via-terminal-2mp9 | ubuntu, linux | Todo fã de GNU/Linux vai falar o quanto é prático instalar e configurar a distro¹ somente usando o terminal pois, além de ser uma vantagem é algo que facilita no dia a dia de quem estuda ou trabalha. Abaixo eu vou ensinar como criar um Bash para atualizar e otimizar sua máquina. É importante que durante esse processo o laptop esteja ligado na tomada para evitar que desligue ou reinicie durante o processo.
É nescessário conhecer os comandos básicos para utilizar esse scrip são eles:
- **sudo su**: usado para pedi permissão de acesso como administrador, exemplo: `sudo su` depois digita a senha;
- **apt-get**: no Ubuntu é usado para instalar, remover e manipular pacotes, exemplo `sudo apt-get install inkscape` para que possa instalar o Inkscape;
- **pwd**: sigla para print work directory ou seja, exibir o caminho do diretório;
- **cd**: usado para copiar arquivo de um diretório para outro, exemplo: `cp xyz /desktop/arquivo.txt /desktop/notas`;
- **mv**: usado para mover arquivos e diretórios, exemplo: `$ mv nota.txt ~/Documentos/`;
- **rm**: para remover arquivos e diretórios `rm /Documentos/nota.txt`;
- **mkdir**: usado para criar diretórios, exemplo: `mkdir pasta`;
- **man**: usado para exibir uma manual para verificar a utilização de algum comando, exemplo: `man info`;
- **echo**: comando para exibir texto na saída do terminal, exemplo: `echo iniciar atualização`.
Vamos criar o script:
- O terminal deve está com a permissão de administrador ou seja, `sudo su`;
- Inicie pelo comando UPDATE, exemplo: `sudo apt update`. Todos os pacotes instalados são atualizados ajudando a manter a segurança e integridade do SO². Caso queira visualizar o que precisa ser atualizado use o comando `apt list --upgradable` para que o via terminal possa também selecionar a opção de atualizar somente lista específicas.
- O comando `sudo apt-get dist-upgrade` ele vai atualizar pacotes fora de data e ainda remover os obsoletos;
- Utilizar o comando `sudo apt-get upgrade` para atualização geral da distribuição, remoção de pacotes e correção de conflitos.
- Remova os pacotes que não serão mais nescessários com o comando `sudo apt-get autoremove`;
- O último passo é reiniciar o computador e isso pode ser incluído no script, exemplo:
```
if [ -f /var/run/reboot-required ]; then
echo 'É nescessário Reiniciar!'
echo -e $TEXT_RESET
fi
while true; do
read -p "Pronto para reiniciar? " sn
case $sn in
[Ss]* ) reboot; break;;
[Nn]* ) exit;;
* ) echo "Digite [S] ou [N]";;
esac
done
```
Com e script completo salve como .sh e quando precisar é só executar via terminal exemplo: `bash ./atualizacao.sh`
```
#!/bin/bash
sudo apt-get update
sudo apt-get dist-upgrade
sudo apt-get upgrade
sudo apt-get autoremove
if [ -f /var/run/reboot-required ]; then
echo 'É nescessário Reiniciar!'
echo -e $TEXT_RESET
fi
while true; do
read -p "Pronto para reiniciar? " sn
case $sn in
[Ss]* ) reboot; break;;
[Nn]* ) exit;;
* ) echo "Digite [S] ou [N]";;
esac
done
```
Invés de reboot pode ser usado o comando `sudo shutdown -h +10` para desligar daqui 10 min ou `sudo shutdown -r HH:MM` para programar um horário.
No site [Distro Watch](https://distrowatch.com/) por meio de busca é possível selecionar qual distro mais se encaixa com o seu estilo. Recomendo Ubuntu, Linux Mint, PopOS e Zorin OS.
---
¹ É a abreviação da palavra distribuição, diversos sistemas operacionais que podem ser baseados em Debian ou outros.
² SO: sigla para Sistema Operacional
*Artigo escrito por [Mayanna S. Oliveira](https://linktr.ee/mayannaoliveira) em 21/03/2023.* | mayannaoliveira |
1,670,443 | Understanding the Essence and Benefits of Massagepraxis | Introduction : Massagepraxis embodies the art and science of massage therapy, offering a gateway to... | 0 | 2023-11-18T06:45:45 | https://dev.to/massagepraxis/understanding-the-essence-and-benefits-of-massagepraxis-1cej | **Introduction :**
**[Massagepraxis](https://www.weekly-massagen.ch/)** embodies the art and science of massage therapy, offering a gateway to holistic well-being. Delving deeper into the world of massagepraxis unveils a multitude of techniques, benefits, and considerations that contribute to its profound impact on physical, mental, and emotional health.
**
History and Evolution :**
The origins of massagepraxis date back centuries, rooted in ancient cultures like China, Egypt, and India. From its early ritualistic and medicinal use to its evolution into a structured therapeutic practice, massagepraxis has seamlessly integrated into modern wellness regimens. Techniques have evolved, drawing from diverse cultural practices, resulting in a rich tapestry of methodologies.
**
Techniques and Modalities :**
Massagepraxis encompasses various techniques tailored to address specific needs. From Swedish and deep tissue massages to reflexology, aromatherapy, and Shiatsu, each modality employs distinct methods and pressures to alleviate tension, improve circulation, and enhance relaxation. These techniques not only target physical ailments but also foster mental tranquility, aligning with individual preferences and therapeutic goals.
**Health Benefits**
The benefits of massagepraxis extend beyond mere relaxation. Studies consistently highlight its efficacy in reducing stress, alleviating muscle tension, and enhancing flexibility. Moreover, it aids in managing chronic pain conditions, improving posture, and boosting immune function. Beyond physical benefits, regular sessions contribute to mental wellness by reducing anxiety, promoting better sleep, and elevating mood—a holistic approach to overall health and vitality.
**Considerations and Safety :**
While massagepraxis offers numerous benefits, it's crucial to consider individual health conditions, allergies, and preferences. Consulting a qualified practitioner ensures a tailored approach, minimizing risks and optimizing outcomes. Understanding contraindications, such as certain medical conditions or recent injuries, helps in customizing sessions for maximum safety and efficacy.
**Conclusion :**
In essence, massagepraxis stands as a testament to the profound synergy between ancient wisdom and modern therapeutic practices. Its multifaceted benefits, encompassing physical, mental, and emotional well-being, position it as a cornerstone of holistic health. Embracing massagepraxis not only nurtures the body but also fosters a harmonious connection between mind, body, and spirit, contributing to a balanced and fulfilling lifestyle.
| massagepraxis | |
1,670,489 | 10 Essential React Hooks You Should Know | Introduction As a developer working with React, understanding hooks is crucial to writing... | 0 | 2023-11-18T08:44:13 | https://dev.to/codezera/10-essential-react-hooks-you-should-know-5ha2 | webdev, javascript, react, beginners | # Introduction
As a developer working with React, understanding hooks is crucial to writing clean, maintainable, and reusable code. React hooks introduced a paradigm shift in building components by providing a way to use state and lifecycle features in functional components. In this blog, we will delve into the 10 most essential React hooks you should know. By mastering these hooks, you will be able to write more concise, efficient, and reusable code, making your React applications more robust and maintainable.
## 1. useState - Simple State Management
The useState hook allows you to manage state within functional components. It provides a more efficient alternative to using classes for state management. The useState hook takes an initial state as its argument and returns an array with two elements: the current state value and a function to update the state.
```
import React, { useState } from 'react';
function Example() {
const [count, setCount] = useState(0);
return (
<div>
<p>Count: {count}</p>
<button onClick={() => setCount(count + 1)}>Increment</button>
</div>
);
}
```
---
## 2. useEffect - Perform Side Effects
The useEffect hook allows you to perform side effects in functional components, such as fetching data, subscribing to a service, or manually changing the DOM. It takes two arguments: a function containing the side effect and an array of dependencies. The side effect function will run after every render unless you provide a dependency array, in which case it will only run when one of the dependencies changes.
```
import React, { useEffect, useState } from 'react';
function Example() {
const [data, setData] = useState([]);
useEffect(() => {
// Fetch data from API
fetch('https://api.example.com/data')
.then(response => response.json())
.then(data => setData(data));
}, []);
return (
<div>
{data.map(item => (
<p key={item.id}>{item.name}</p>
))}
</div>
);
}
```
---
## 3. useContext - Access React Context
The useContext hook allows you to access the value of a React context. React context provides a way to pass data through the component tree without having to pass props down manually at every level. The useContext hook takes a context object as its argument and returns the current value of that context.
```
import React, { useContext } from 'react';
import MyContext from './MyContext';
function Example() {
const value = useContext(MyContext);
return <p>Value from context: {value}</p>;
}
```
---
## 4. useReducer - Complex State Management
The useReducer hook is an alternative to useState for managing complex state logic. It is used when the state depends on the previous state or when there are complex state transitions. The useReducer hook takes a reducer function and an initial state as arguments and returns the current state and a dispatch function.
```
import React, { useReducer } from 'react';
const initialState = { count: 0 };
function reducer(state, action) {
switch (action.type) {
case 'increment':
return { count: state.count + 1 };
case 'decrement':
return { count: state.count - 1 };
default:
throw new Error('Invalid action');
}
}
function Example() {
const [state, dispatch] = useReducer(reducer, initialState);
return (
<div>
<p>Count: {state.count}</p>
<button onClick={() => dispatch({ type: 'increment' })}>Increment</button>
<button onClick={() => dispatch({ type: 'decrement' })}>Decrement</button>
</div>
);
}
```
---
## 5. useCallback - Memoize Callback Functions
The useCallback hook allows you to memoize a callback function, preventing it from being recreated on every render. It takes a callback function and an array of dependencies as arguments and returns a memoized version of the callback function that only changes if one of the dependencies changes.
```
import React, { useCallback } from 'react';
function Example() {
const handleClick = useCallback(() => {
// Handle click event
// Some expensive computations or operations
}, []);
return <button onClick={handleClick}>Click Me</button>;
}
```
---
## 6. useMemo - Memoize Values
The useMemo hook allows you to memoize a value, preventing it from being recomputed on every render. It takes a function that returns the value to be memoized and an array of dependencies as arguments and returns a memoized version of the value.
```
import React, { useMemo } from 'react';
function Example() {
const expensiveValue = useMemo(() => {
// Perform expensive computations
// Return a value
}, []);
return <p>Expensive Value: {expensiveValue}</p>;
}
```
---
## 7. useRef - Create Mutable References
The useRef hook allows you to create a reference to a mutable value. It is similar to using an instance variable in a class component. The useRef hook returns a mutable ref object whose current property is initialized to the passed argument.
```
import React, { useRef } from 'react';
function Example() {
const inputRef = useRef(null);
const handleClick = () => {
inputRef.current.focus();
};
return (
<div>
<input ref={inputRef} type="text" />
<button onClick={handleClick}>Focus Input</button>
</div>
);
}
```
---
## 8. useImperativeHandle - Customize Instance Values
The useImperativeHandle hook allows you to customize the instance value that is exposed when a parent component uses ref to access the child component. It takes two arguments: a ref and a function that returns an object defining the instance value.
```
import React, { useImperativeHandle, useRef } from 'react';
const CustomInput = React.forwardRef((props, ref) => {
const inputRef = useRef();
useImperativeHandle(ref, () => ({
focus: () => {
inputRef.current.focus();
},
getValue: () => {
return inputRef.current.value;
}
}));
return <input ref={inputRef} type="text" />;
});
function Example() {
const customInputRef = useRef();
const handleButtonClick = () => {
customInputRef.current.focus();
const value = customInputRef.current.getValue();
// Do something with the value
};
return (
<div>
<CustomInput ref={customInputRef} />
<button onClick={handleButtonClick}>Submit</button>
</div>
);
}
```
---
## 9. useLayoutEffect - Perform Synchronous Layout Effects
The useLayoutEffect hook is identical to useEffect, but it runs synchronously after all DOM mutations. It is useful for reading layout from the DOM and synchronously re-rendering.
```
import React, { useLayoutEffect, useState } from 'react';
function Example() {
const [width, setWidth] = useState(0);
useLayoutEffect(() => {
function handleResize() {
setWidth(window.innerWidth);
}
window.addEventListener('resize', handleResize);
handleResize();
return () => {
window.removeEventListener('resize', handleResize);
};
}, []);
return <p>Window Width: {width}</p>;
}
```
---
## 10. useDebugValue - Display Label for Custom Hooks
The useDebugValue hook allows you to display a label for custom hooks in React DevTools. It is particularly useful for building shared libraries where it is important to identify custom hooks correctly.
```
import React, { useDebugValue, useState } from 'react';
function useCustomHook() {
const [value, setValue] = useState('');
useDebugValue(value ? 'Value is set' : 'Value is not set');
return [value, setValue];
}
function Example() {
const [value, setValue] = useCustomHook();
return (
<div>
<input
type="text"
value={value}
onChange={e => setValue(e.target.value)}
/>
<p>Value: {value}</p>
</div>
);
}
```
---
# Conclusion
In this comprehensive guide, we have explored the 10 most essential React hooks: useState, useEffect, useContext, useReducer, useCallback, useMemo, useRef, useImperativeHandle, useLayoutEffect, and useDebugValue.
By mastering these hooks, you now have a powerful set of tools to write clean, efficient, and reusable React code. Whether you're managing state, performing side effects, accessing context, or optimizing performance, React hooks empower you to build robust and maintainable applications.
Now, go forth and leverage the full potential of React hooks in your projects!
By the way, I hope this comprehensive guide has been helpful and informative! Feel free to comment if you have any questions.
Happy coding! 🚀😊 | codezera |
1,670,655 | Engineering Challenges in B2B and B2C Startups | The internet is filled with articles comparing work cultures across different company types,... | 0 | 2023-11-22T09:07:53 | https://dev.to/monite/engineering-challenges-in-b2b-and-b2c-startups-1lcd | softwareengineering, startup, career, backend | The internet is filled with articles comparing work cultures across different company types, especially in marketing or product management. But what about software developers? Do these differences impact them too? Absolutely! Understanding the nuances between B2B (Business-to-Business) and B2C (Business-to-Consumer) can be a game-changer. Each sector has its own unique set of characteristics, demands, and obstacles that significantly shape the work of software engineers.
Before diving in, let's set the stage. I'll use "B2C" to describe products that engage directly with end-users. This includes not only consumer-focused applications but also B2B products with a low average ARPU, where the primary revenue stream comes from the self-serve customers segment. These are platforms like Miro and Zapier, catering to a broad range of users who can onboard independently.
On the other hand, our B2B segment refers to enterprise-focused products. Such companies typically work with a smaller number of clients but with more substantial contracts, often in the tens of thousands, or hundreds of thousands of dollars.
Throughout my career, I primarily worked in B2C companies, occasionally advising teams involved in B2B. However, after joining [Monite](http://monite.com/?utm_source=dev-to&utm_medium=blog&utm_campaign=engineering-challenges), I experienced the stark difference firsthand.
Alright, let’s go step by step through the main differences, analyze where they come from, and explore the opportunities they open up for your professional growth.
## In-depth specialization vs. broad accessibility
In the B2B corner, you’re the tech wizard – called upon to solve specific challenges for major players. Corporate clients rely on you to provide robust solutions, sparing them the complexities of handling those issues themselves.
Sounds exciting, right? But here’s the thing: you always need to be at the top of your game. Your business must meet the high standards set by your clients. If you’re dealing with financial data and payments, get ready to navigate intricate regulations across the countries they operate in. Managing credit card data? Compliance with PCI-DSS is non-negotiable. And when working with medical data, you’ll become well-acquainted with HIPAA. And that’s just the beginning…
In the B2C space, your customers turn to your product for convenience or entertainment. They’re not looking for complex problem-solving; they want a user-friendly solution. While the B2C entry barrier is low, making it a popular choice, it's much like a bustling local cafe – lively but packed. While the vibe seems welcoming, brace yourself for fierce competition. Many are jostling for the spotlight in this vibrant arena.
## Stability and fault tolerance
When a big client invests in your product with the expectation of saving their development team’s time and offloading certain tasks, any weaknesses on your part within their IT ecosystem can lead to a swift termination of your partnership. This applies not only to technical glitches, errors, and system failures but also to products that don't effectively meet their designated objectives.
Each failure also impacts your client's reputation with their end-users, as it directly compromises the quality of service they provide. This, in turn, can negatively influence your standing within the industry.
It’s also crucial to consider acquisition costs. Acquiring clients in the B2B sector is a resource-intensive and time-consuming task, demanding a personalized approach. So, when you lose a client, it's not just a hit to your wallet; it's hours of hard work down the drain and a chunk of your revenue gone.
On the flip side, the B2C world is a bit more forgiving of minor glitches or even partial downtime. Here, clients usually use your product for straightforward tasks. Even if there's a small issue or a short downtime, it's not the end of the world. Why? Because the average sale is probably between $100–200, and you're catering to a much larger crowd. This time partial failure or temporary degradation of one of its functions has a less severe impact on your entire user base.
But here's the thing: to really grow in the B2C space, you need a massive user base. And while there's a steady flow of users coming in and out, this model can handle a bit of client turnover.
All of this means one thing: B2B products can't afford mistakes. That's why there's so much emphasis on making them fault-tolerant and thoroughly tested, way more than B2C products. As a result, variations emerge in the development processes. When working on a B2B product, you encounter extended release cycles, stricter Quality Assurance procedures, and daily encounters with terms like release management and zero bug policy.
## How working with customer feedback differs
In the B2B world, you're often working with a client base that's in the tens or hundreds. This smaller number means you can get to know each client personally. Your products in this space are typically designed to weave seamlessly into a client's existing infrastructure, which means the integration process can get pretty detailed. It's not uncommon to find yourself giving technical advice to engineers from your top-tier clients, and sometimes, you might even grab a drink together.
Within a B2B-focused company, you'll probably have several support tiers, each handling different levels of complexity. There might also be a specialized integration team. Their job? To offer deep technical support, help with integrating products, and sometimes even tweak the product to fit a particular client's needs.
Switch over to the B2C side, and things look a bit different. With potentially thousands or millions of users, it's tough to have a personal connection with each one. Most of the feedback you'll get will be in the form of data: numbers, charts, and graphs in your analytics dashboard. Sure, every now and then, you might chat with a super-user or an influencer. But mostly, conversations about your user base shift from talking about individual users to discussing broader groups or segments.
Because of this, B2C companies have a big appetite for product analytics. They need robust data engineering to gather, process, and make sense of heaps of data. This isn't just a numbers game; it's about making informed decisions based on a deep understanding of customer profiles and being able to measure how effective those decisions are.
## Why rapid adaptation is important
In the enterprise B2B space, it's common to see long-term contracts. The cost of integrating these solutions? Sky-high, especially when you compare it to B2C, where businesses often lean on subscription models or even offer their services for free. Given this landscape, it's crucial to keep a close watch on what your competitors are up to and stay in tune with market shifts. This is especially true if you're in a young industry where competition is fierce, and you don't want to miss out on attracting new clients.
When it comes to product development in such an environment, the emphasis is on quick, short cycles aimed at fast delivery. You're probably not spending a ton of time drafting detailed tech documentation or plotting out product development for more than a few months in advance.
To keep up this speed and swiftly test out different business ideas, many turn to agile approaches like Scrum. It's all about iterative feature development, and when exploring new product avenues, the MVP (Minimum Viable Product) strategy is often the go-to.
## Step growth vs. gradual growth
In the B2B space, the journey from customer interest to full integration can be a long one. This extended timeline often gives you a buffer to gear up for any unique demands a new client might bring. You can rally more developer manpower and fine-tune your infrastructure to cater to each new client's needs.
On the flip side, when you're in the B2C game, a big focus is on how quickly a user can jump in and start using your product. With such a low barrier to entry, you might see spikes in user activity out of the blue. Maybe you rolled out a catchy ad that's gone viral, got a shoutout as the "product of the day" on Product Hunt, or perhaps it's just that time of the year when everyone's looking for what you offer. Suddenly, your user count could skyrocket. This unpredictability means you've got to build your system to be super flexible. It should be ready to scale up in a snap and adapt on the fly to whatever comes its way.
## Security
Beyond just meeting regulatory standards, it's crucial to sync up with your customers on security protocols. Today, a data breach can spell disaster for businesses big and small. However, big enterprise clients tend to put cybersecurity under the microscope before they even think about signing a contract or integrating your solution. They might ask you to secure certifications like ISO 27001, set up robust internal security guidelines, limit who can access production data, or even put your system through rigorous penetration tests.
On the other hand, small to medium-sized businesses (SMBs) aren't usually as stringent about these security deep dives. Addressing basic concerns, like preventing SQL injections, often ticks the box for them. And if you're a budding company, you might find that tasks like updating software to patch vulnerabilities get pushed down the priority list, making way for more immediate business-driven goals.
## Brand visibility and recognition
Even though you're diving deep into complex challenges and working under tough conditions, your hard work might fly under the radar for those outside your field.
Your product often powers the big players from the shadows, without the general public getting a firsthand look. Contrast this with developing B2C tools or solutions for widespread SMB use. In those scenarios, explaining your latest project to friends and family is a breeze.
Plus, there's the added perk of getting personal recognition for that cool new feature you helped bring to life.
---
## Overall thoughts (or a conclusion of sorts)
Launching a successful B2C company is no walk in the park. It demands a harmonious effort across every facet of the product.
Here's a breakdown:
- User acquisition: Draw in the "right" users without breaking the bank.
- Strategic planning: Choose the best paths forward for growth.
- Backlog prioritization: Ensure you're always showing impressive month-over-month growth.
- User support: Keep existing users happy and engaged.
- Engineering: Never lose sight of the technical side of your product.
Given the fierce competition in the B2C space, this all comes with a hefty dose of uncertainty. This unpredictability can make venture capitalists wary of investing. If your leadership team isn't packed with industry bigwigs, securing substantial early-stage investment can be an uphill battle. With funds spread thin, it's tough to give every aspect of product development the attention it deserves.
At this juncture, zeroing in on a product-market fit is paramount. B2C startups are more prone to shifts in direction compared to their B2B counterparts, which usually have a clearer picture of their target audience and the problems they're addressing.
Budget constraints and the potential for sudden shifts in direction mean it's often unwise to pour too much into engineering. You'll likely be working with a tight budget, focusing only on the essentials to roll out the next product version swiftly for another round of testing. This environment is ripe for tales of quick adaptation, problem-solving on the fly, and product building.
However, B2B startups present a different picture:
- They often have a clearer idea of client pain points.
- Initial customer acquisition can be smoother, thanks to founders' connections or direct sales efforts.
- The uncertainty is generally less, but the depth of knowledge required about the domain and product is greater.
So, if you're aiming to be a specialist in a niche area and prefer a more stable work environment (though priorities might still shift), B2B startups could be your calling.
Whether you're venturing into B2C or B2B, both paths come with their unique challenges and rewards. It's all about finding the right fit for your skills, passion, and the kind of challenges you're eager to tackle.
In my blog, I mostly focus on approaches to work, team building in the early stages of company development, the role of a product engineer, and establishing a data-driven culture within a company. If these topics interest you, feel free to subscribe for me and other [Monite developers](https://dev.to/monite). | hitzor |
1,670,795 | Let's Try - AWS Glue Automatic Compaction for Apache Iceberg | In this post, we'll look at how to use the new automatic compaction feature in AWS Glue and how it can help optimize your Iceberg tables. Use my handy helper script to create an Iceberg table, load sample data into it, and test this new feature hands-on. | 0 | 2023-11-18T14:15:00 | https://devopstar.com/2023/11/18/lets-try-aws-glue-automatic-compaction-for-apache-iceberg | aws, athena, glue, iceberg | ---
title: Let's Try - AWS Glue Automatic Compaction for Apache Iceberg
published: true
description: In this post, we'll look at how to use the new automatic compaction feature in AWS Glue and how it can help optimize your Iceberg tables. Use my handy helper script to create an Iceberg table, load sample data into it, and test this new feature hands-on.
canonical_url: https://devopstar.com/2023/11/18/lets-try-aws-glue-automatic-compaction-for-apache-iceberg
tags: aws, athena, glue, iceberg
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/yrlnhqd5wqcgas4iwrjz.jpg
published_at: 2023-11-18 14:15 +0000
---
> Please reach out to me on [Twitter @nathangloverAUS](https://twitter.com/nathangloverAUS) if you have follow up questions!
*This post was originally written on [DevOpStar](https://devopstar.com/)*. Check it out [here](https://devopstar.com/2023/11/18/lets-try-aws-glue-automatic-compaction-for-apache-iceberg)
## Introduction
Apache Iceberg has been a table format I've been diving deeper and deeper into as of late. Specifically, I've been using the AWS variant supported by AWS Glue and Amazon Athena. The table format has several powerful features that make it an excellent choice for data lake storage - however, one of those features, compaction, was not supported by AWS Glue until recently.
Before the release of [automatic compaction of Apache Iceberg tables in AWS Glue](https://aws.amazon.com/about-aws/whats-new/2023/11/aws-glue-data-catalog-compaction-iceberg-tables/), you had to run a compaction job to optimize your tables manually. This was a bit of a pain, given it was a manual query you had to run against the table - This query had a timeout as well, and you would receive the dreaded `ICEBERG_OPTIMIZE_MORE_RUNS_NEEDED` error after a timeout. This meant you had to run the query again and again and again until it was finally completed.
In this post, we'll look at how to use the new automatic compaction feature in AWS Glue and how it can help you optimize your Iceberg tables.
## Why Compaction?
The Apache Iceberg documentation has a great section on [why compaction is important](https://iceberg.apache.org/docs/latest/maintenance/). In short, compaction is merging small files into larger files. This is important for several reasons, but the most important are performance and cost. Small files are inefficient to read from and can cause performance issues - especially when reading from S3, where you are charged per request.
When you run a compaction job, you merge small files into larger ones. This means you are reducing the number of files that need to be read from and the number of requests that need to be made to S3. This can have a significant impact on performance and cost.
## Pre-requisites
To follow along with this post, you must do some minor setup with Athena, S3 and Glue. If you have used Athena before, there's a good chance you already have this setup (possibly with a different bucket). Feel free to skip this section if you feel confident you have the required setup.
### S3
Navigate to the [AWS S3 console](https://s3.console.aws.amazon.com/s3/home?region=us-west-2) to start with and create an Athena query bucket
Give the bucket a name such as `athena-<region>-<account-id>` and click **Create bucket**. (For example, `athena-us-west-2-123456789012`.)
> Note: for this post, I'll be using the **us-west-2** region as it is one of the regions that supports the new automatic compaction feature.
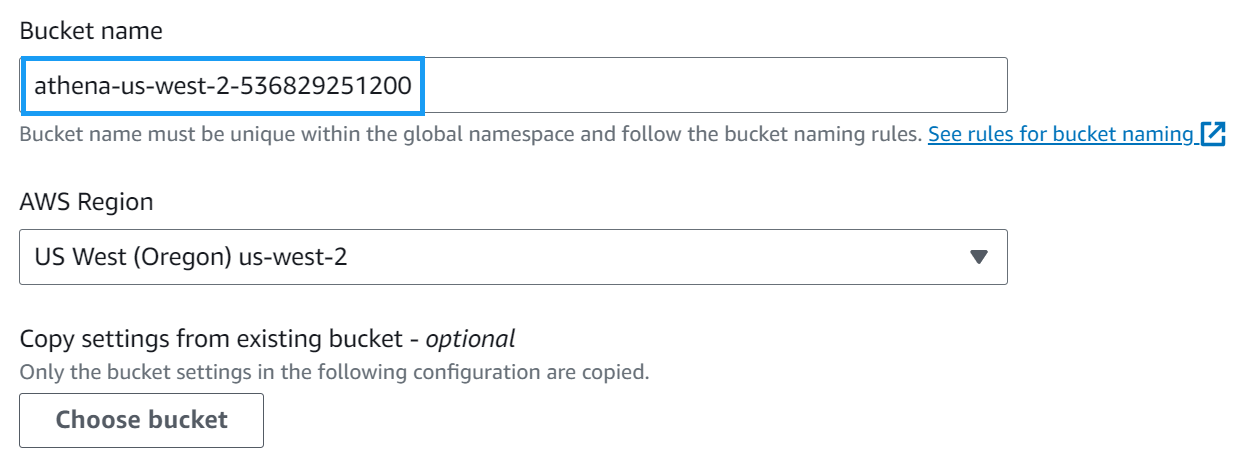
### Athena
Navigate to the [AWS Athena settings console](https://us-west-2.console.aws.amazon.com/athena/home?region=us-west-2#/query-editor/settings) and click **Manage** under the **Query result and encryption settings** section.
Change the **Location of query results** to the bucket you created in the previous step, and click **Save**.
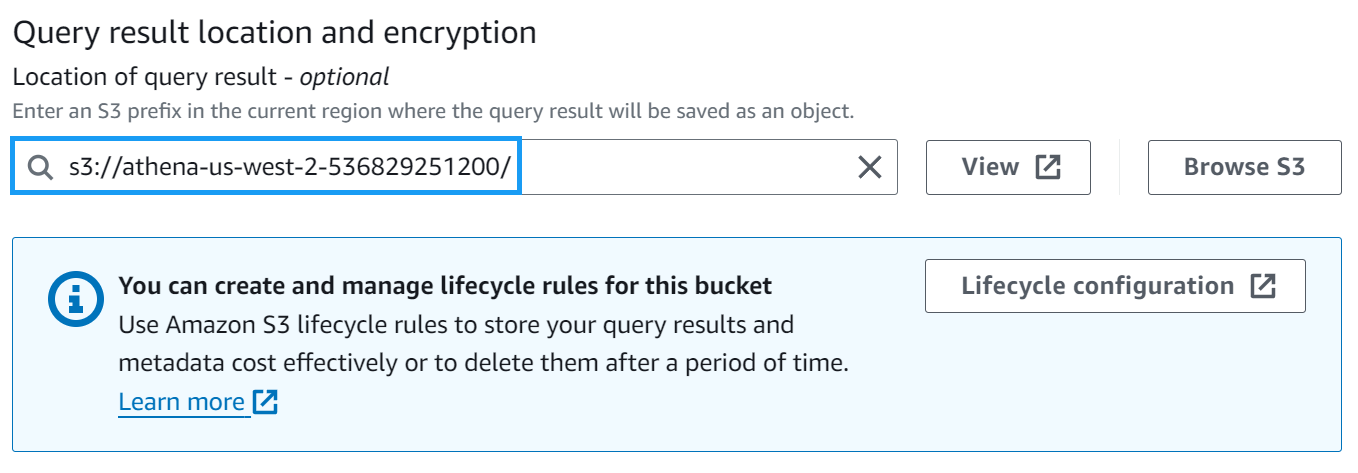
### Glue
Navigate to the [AWS Glue databases console](https://us-west-2.console.aws.amazon.com/glue/home?region=us-west-2#/v2/data-catalog/databases) and check to see if you have a database called `default`. If you do not, create one.
### Helper Script
To help demonstrate the new automatic compaction feature, I've created a script to do much of the tedious parts of creating an Iceberg table for you. You can find the script [here](https://gist.github.com/t04glovern/04f6f2934353eb1d0fffd487e9b9b6a3).
At a high level, the script does the following:
- Create an S3 bucket that Iceberg will use to store data and metadata
- Generating 1 million rows of sample data and uploading it to S3
- Create SQL files for:
- Creating an Iceberg table
- Creating a temporary table for loading sample data
- Loading sample data into Iceberg from the temporary table
- Deleting the tables when we're done
- Creating an IAM role for Glue to use for compaction
Let's grab the script and run it so you can follow along.
> **Note**: You must set up AWS credentials on your machine for this to work. If you don't have them set up, you can follow the [AWS CLI configuration guide](https://docs.aws.amazon.com/cli/latest/userguide/cli-configure-quickstart.html).
```bash
# Download the script, make it executable
curl https://gist.githubusercontent.com/t04glovern/04f6f2934353eb1d0fffd487e9b9b6a3/raw \
> lets-try-iceberg.py \
&& chmod +x lets-try-iceberg.py
# Create a virtual env (optional)
python3 -m venv .venv
source .venv/bin/activate
# Install the dependencies
pip3 install boto3
# Run the script
./lets-try-iceberg.py
```
Have a look at the output, and you should see something like the following:
```bash
$ ./lets-try-iceberg.py
# INFO:root:Bucket iceberg-sample-data-477196 does not exist, creating it...
# INFO:root:Uploaded samples.jsonl.gz to s3://iceberg-sample-data-477196/sample-data/samples.jsonl.gz
# INFO:root:Created IAM role lets-try-iceberg-compaction-role
# INFO:root:Created IAM policy lets-try-iceberg-compaction-policy
```
If you check the directory you ran the script from, you should see several files created:
```bash
$ ls -l
# -rw-r--r-- 1 nathan nathan 366 Nov 18 17:26 1-athena-iceberg-create-table.sql
# -rw-r--r-- 1 nathan nathan 403 Nov 18 17:26 2-athena-create-temp-table.sql
# -rw-r--r-- 1 nathan nathan 94 Nov 18 17:26 3-insert-into-iceberg-from-temp-table.sql
# -rw-r--r-- 1 nathan nathan 62 Nov 18 17:26 4-cleanup-temp-table.sql
# -rw-r--r-- 1 nathan nathan 50 Nov 18 17:26 5-cleanup-iceberg-table.sql
```
The numbered SQL files are the ones we'll be using to create our Iceberg table and load the sample data into it.
## Create & Load the Iceberg Table
Head over to the [AWS Athena console](https://us-west-2.console.aws.amazon.com/athena/home?region=us-west-2#/query-editor) and ensure that the **default** database is selected.
Take the contents of the `1-athena-iceberg-create-table.sql` file and paste it into the query editor. Click **Run** to create the table.
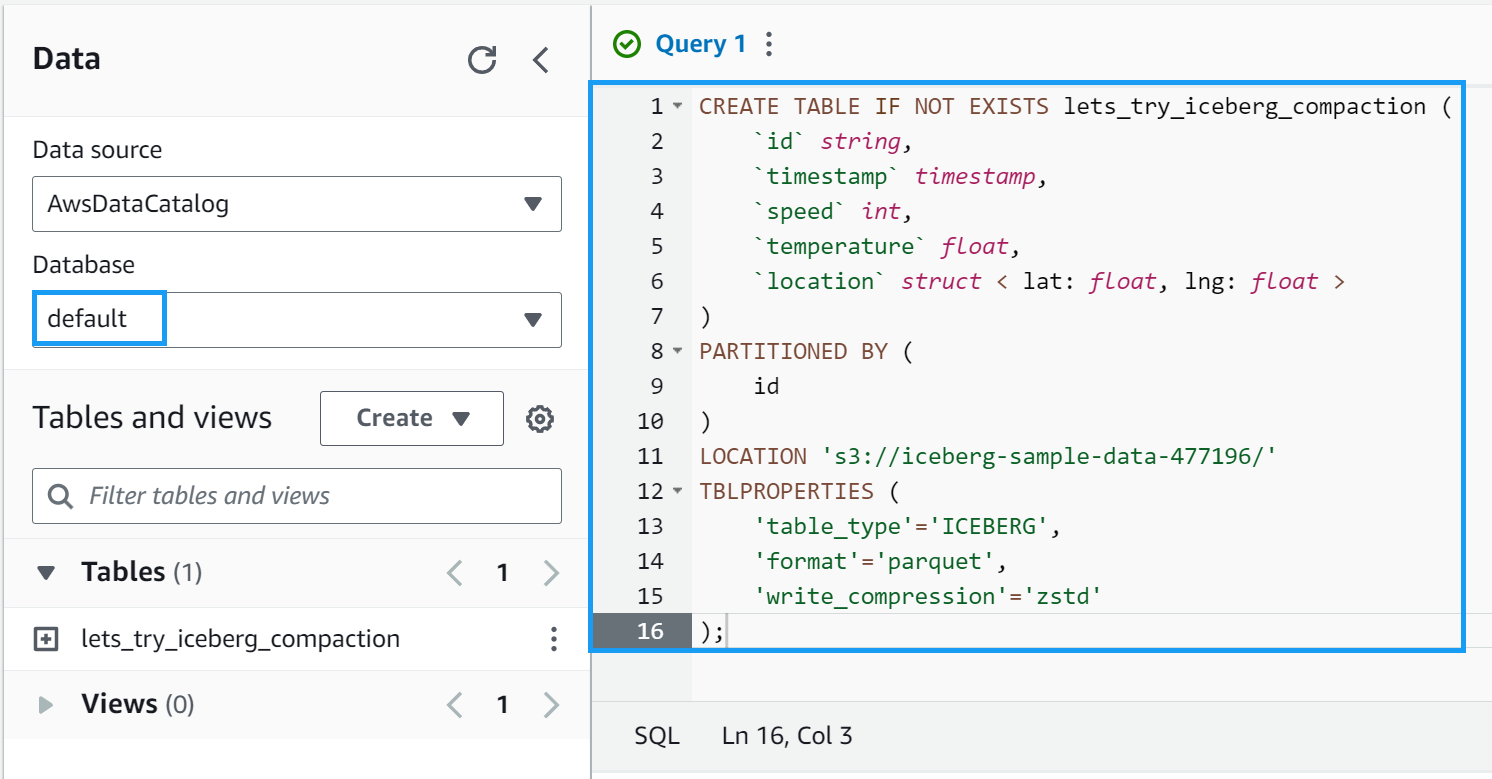
You should see a new table called `lets_try_iceberg_compaction` under the **Tables** section of the **default** database.
We'll create a temporary table to load the sample data into. Copy the `2-athena-create-temp-table.sql` file and paste it into the query editor. Click **Run** to create the table.
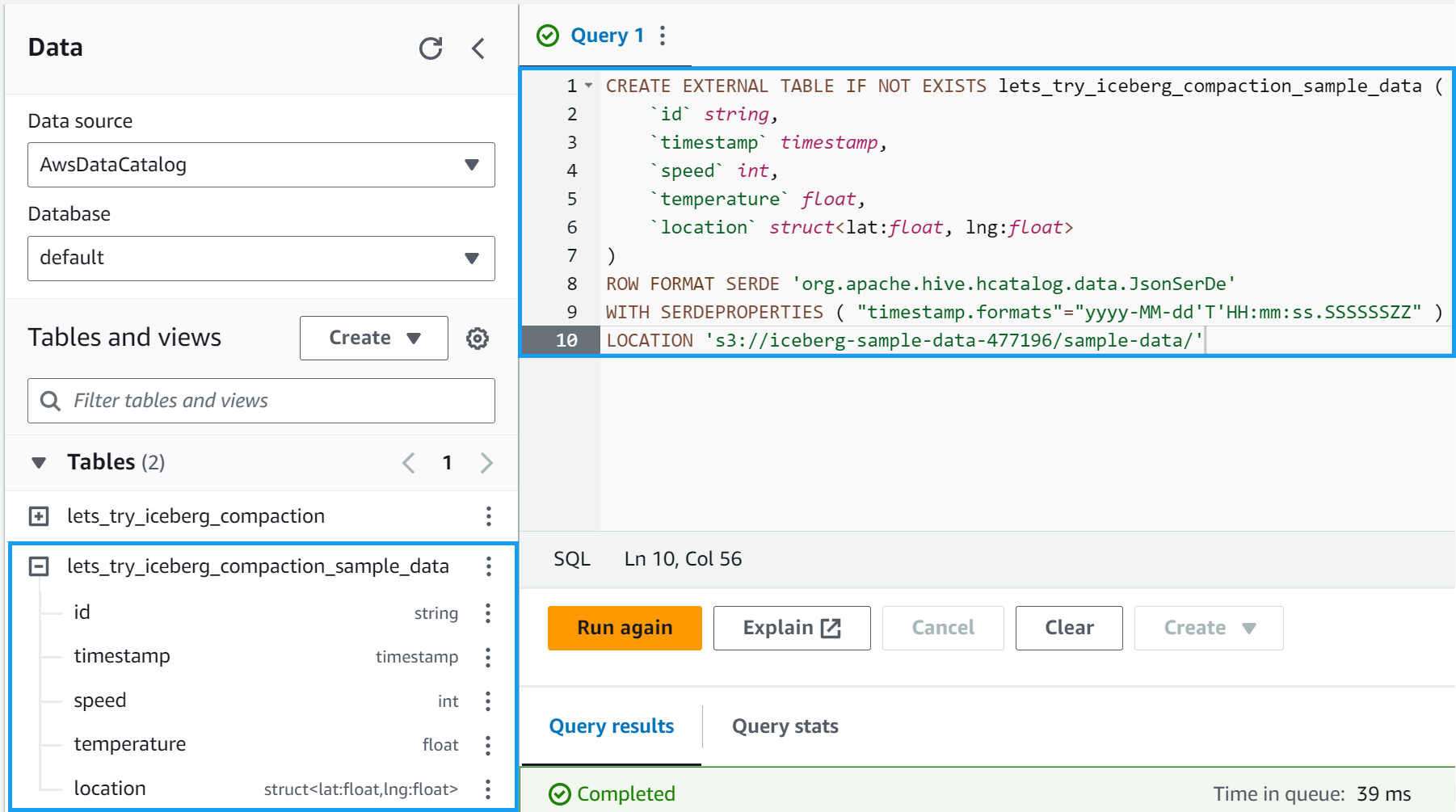
Now, we'll load the sample data from the temporary table into the Iceberg table. Copy the `3-insert-into-iceberg-from-temp-table.sql` file and paste it into the query editor. Click **Run** to load the data.
> **Note**: This query will take 15-30 seconds to run.
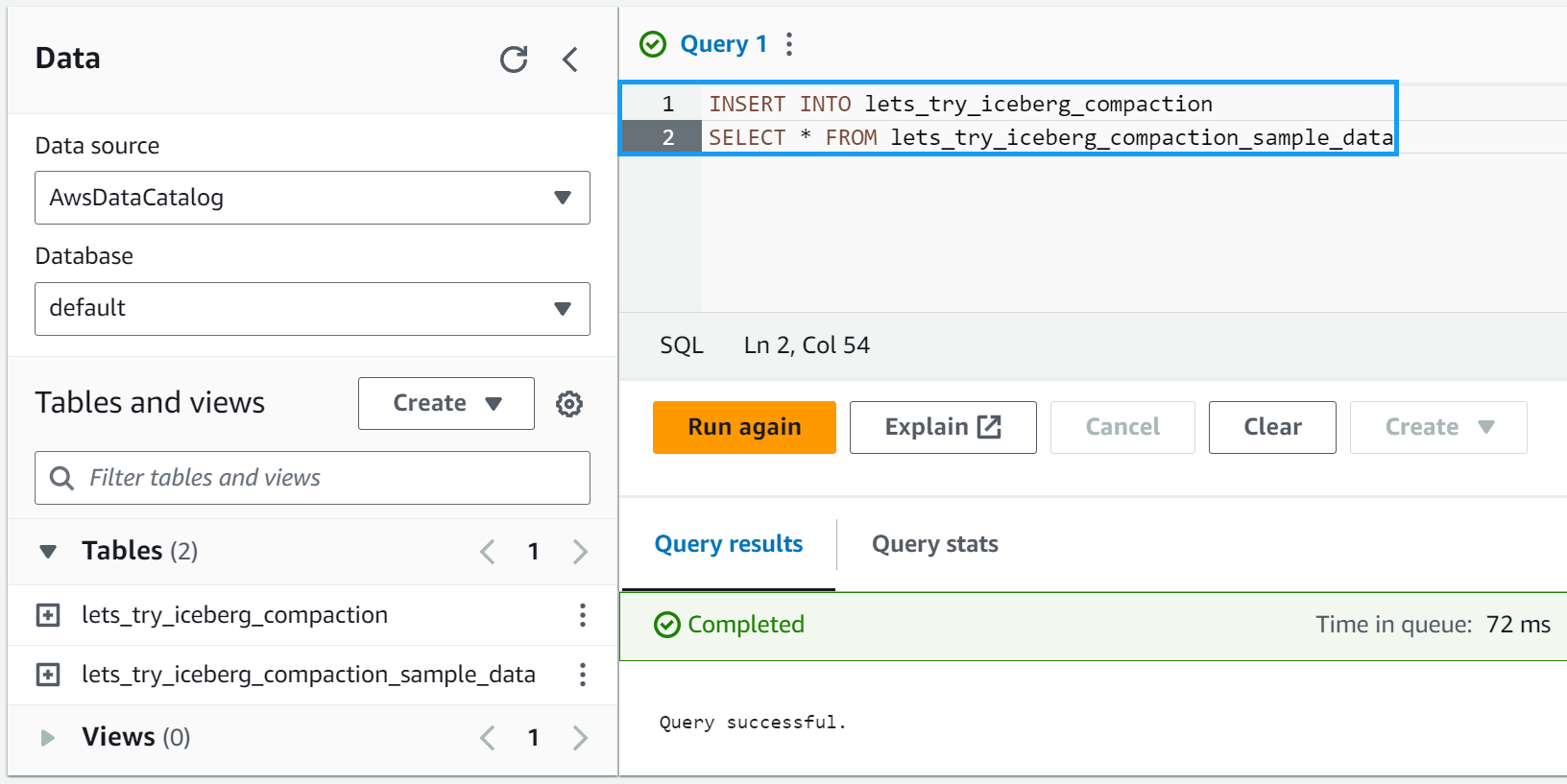
Finally, let's verify that the data was loaded into the table. Run the following query:
```sql
SELECT * FROM lets_try_iceberg_compaction LIMIT 10;
```
You should see something like the following:
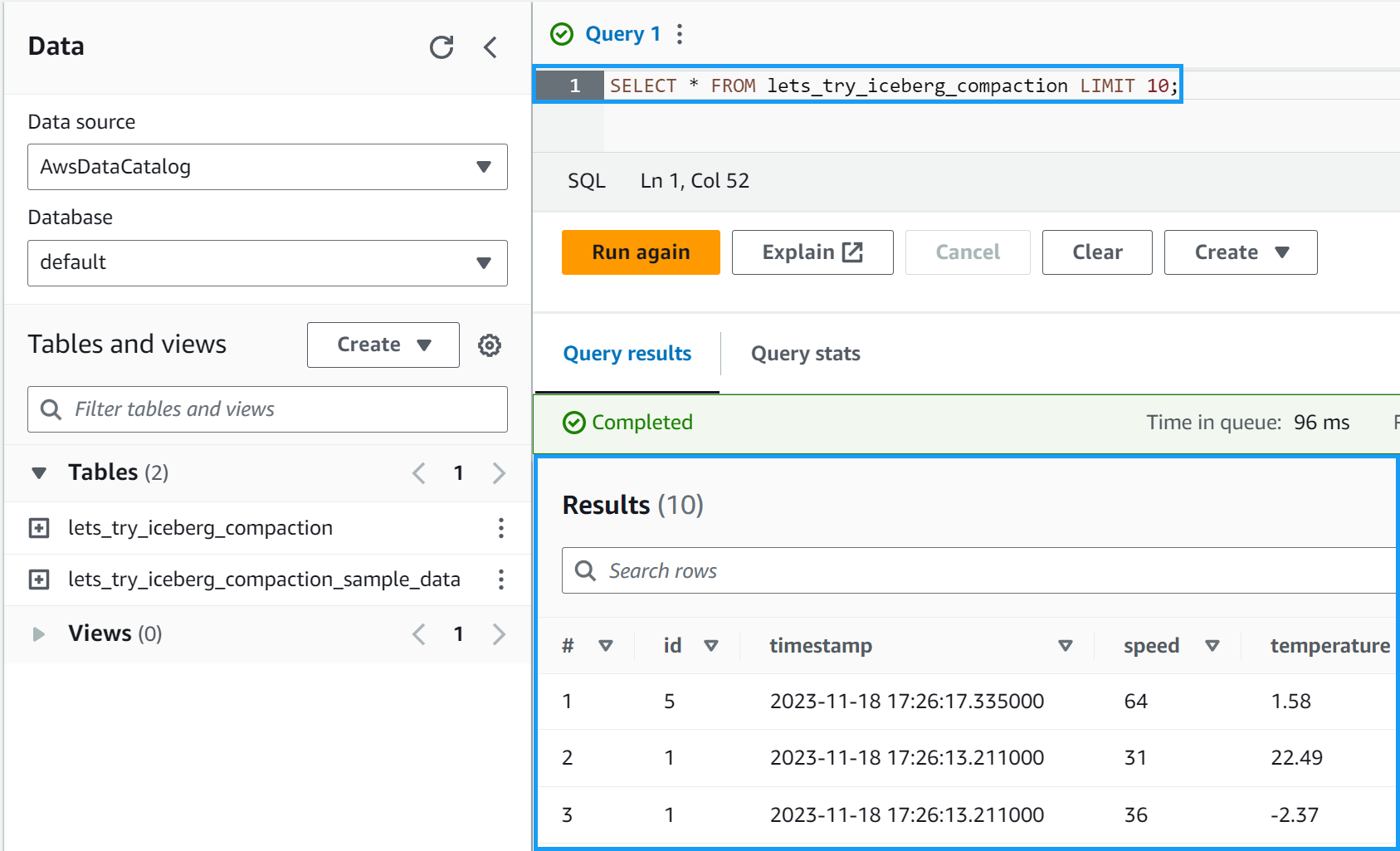
## Compaction in Action
Now that we have our Iceberg table created and our sample data loaded into it let's enable the new automatic compaction feature and see it in action.
Navigate to the [AWS Glue tables console](https://us-west-2.console.aws.amazon.com/glue/home?region=us-west-2#/v2/data-catalog/tables) and select the **lets_try_iceberg_compaction** table.
At the bottom of the table details, you should see a tab called **Table optimization**. Click it, then click **Enable compaction**.
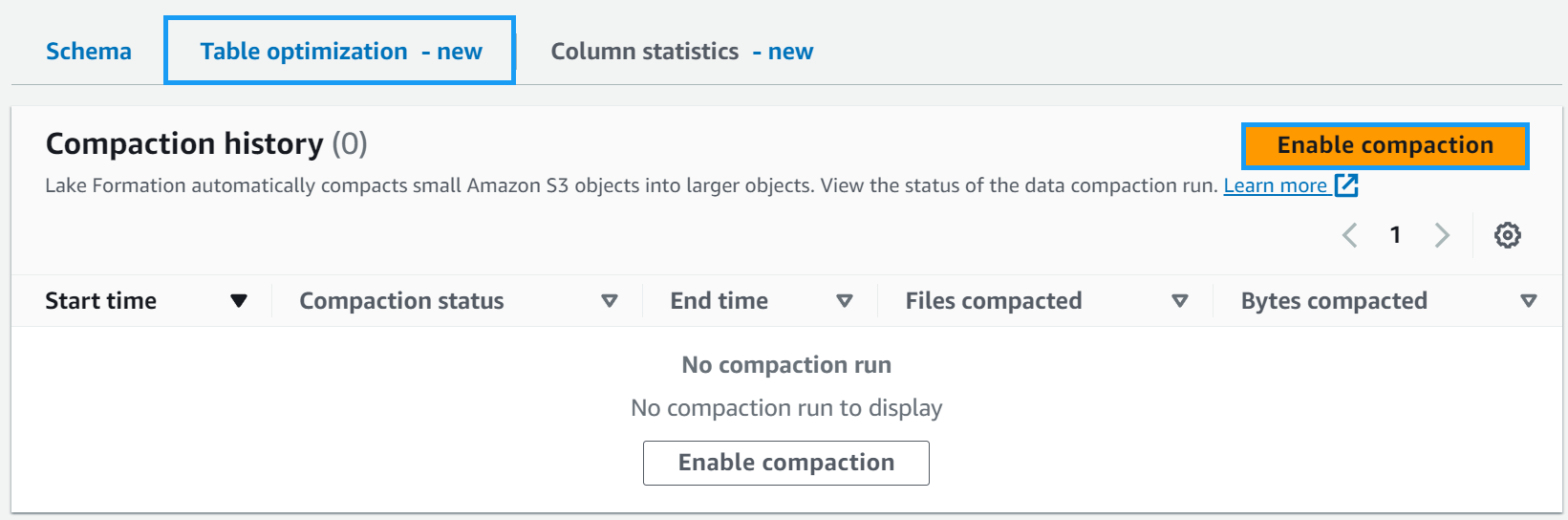
You will be prompted to select a role to use for compaction. Select the role created by the script we ran earlier (`lets-try-iceberg-compaction-role`), and click **Enable compaction**.
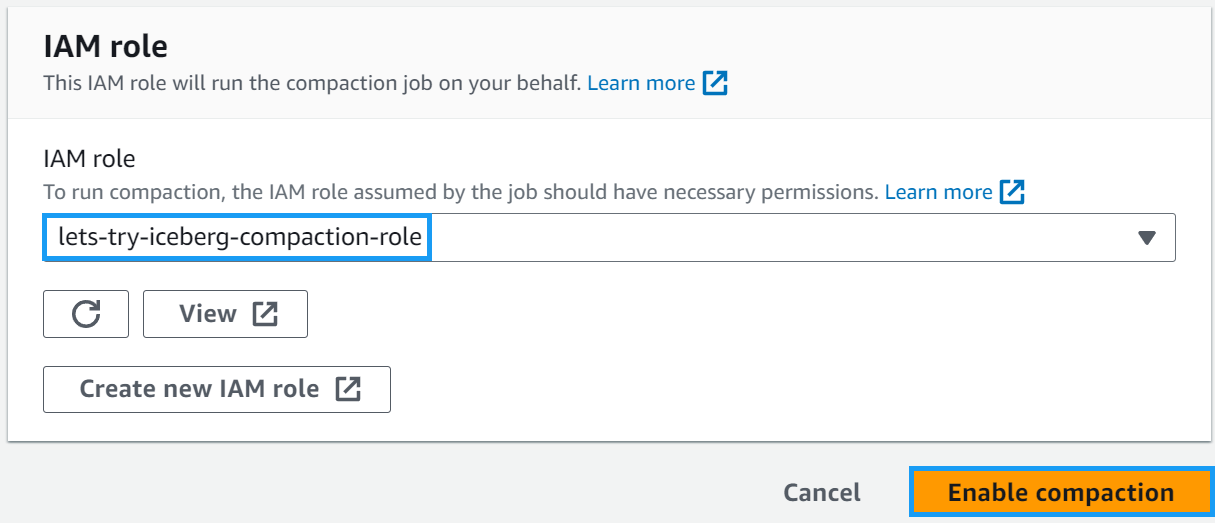
Navigate back to the [AWS Glue tables console](https://us-west-2.console.aws.amazon.com/glue/home?region=us-west-2#/v2/data-catalog/tables) and select the **lets_try_iceberg_compaction** table again. Get a coffee, and when you come back, refresh the page. You should see something like the following:
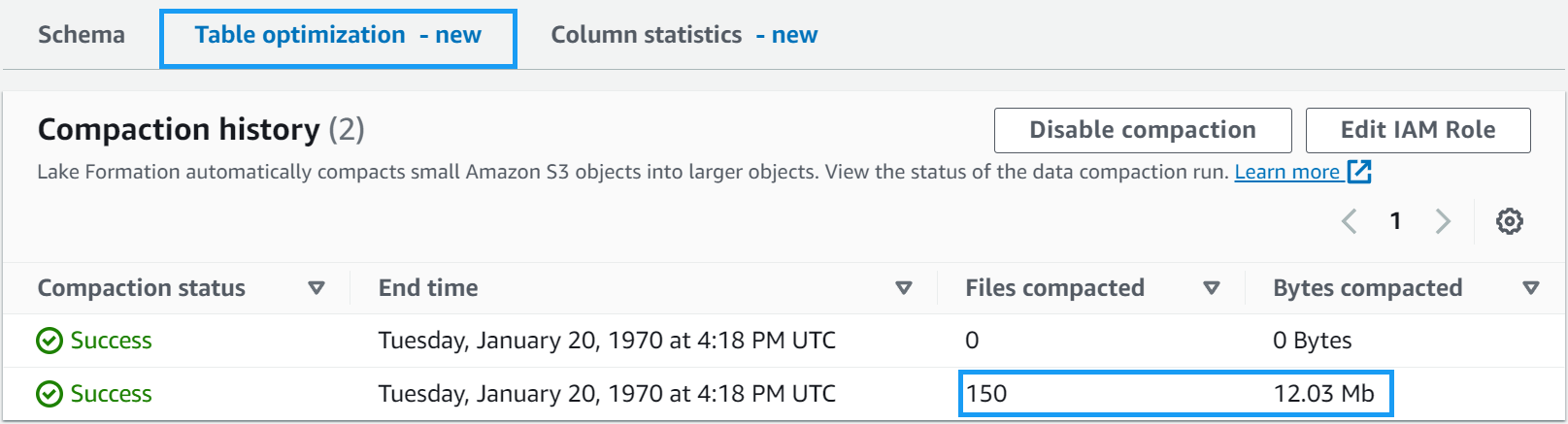
At this point, your table should start automatically compacting based on the rate of changes made. According to the blog post [AWS Glue Data Catalog now supports automatic compaction of Apache Iceberg tables](https://aws.amazon.com/blogs/aws/aws-glue-data-catalog-now-supports-automatic-compaction-of-apache-iceberg-tables/) this rate of change is based on the following:
> As Iceberg tables can have multiple partitions, the service calculates this change rate for each partition and schedules managed jobs to compact the partitions where this rate of change breaches a threshold value.
You can force another compaction job to verify this by navigating back to the Athena console and rerunning the following query:
```sql
INSERT INTO lets_try_iceberg_compaction
SELECT * FROM lets_try_iceberg_compaction_sample_data
```
This will insert the sample data into the table again, and you should see another compaction job start in the Glue console.
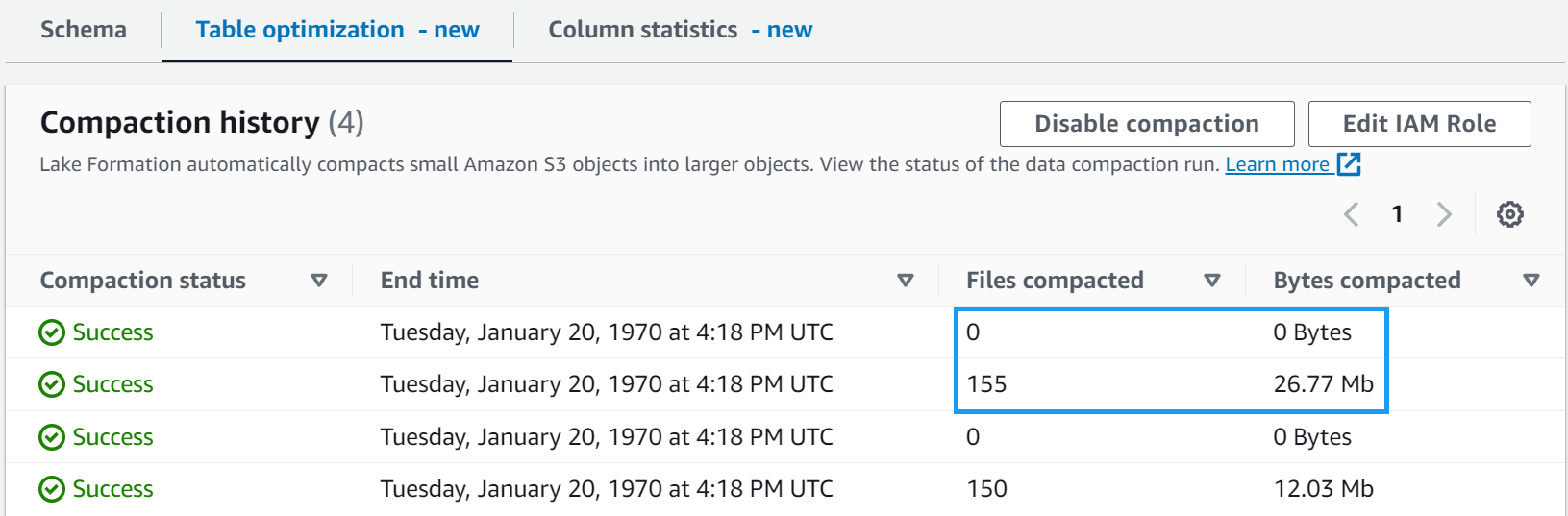
## Cleanup
Once you're done, you can use the `4-cleanup-temp-table.sql` and `5-cleanup-iceberg-table.sql` files to clean up the temporary and Iceberg tables.
```sql
-- 4-cleanup-temp-table.sql
DROP TABLE IF EXISTS lets_try_iceberg_compaction_sample_data;
-- 5-cleanup-iceberg-table.sql
DROP TABLE IF EXISTS lets_try_iceberg_compaction;
```
Then, navigate to the [AWS S3 console](https://s3.console.aws.amazon.com/s3/home?region=us-west-2) and **Empty** then **Delete** the bucket that was created by the script.
Finally, navigate to the [AWS IAM Roles console](https://us-east-1.console.aws.amazon.com/iam/home#/roles) and delete the role (`lets-try-iceberg-compaction-role`) and policy (`lets-try-iceberg-compaction-policy`) that were created by the script.
## Summary
This post looked at the new automatic compaction feature for Apache Iceberg tables in AWS Glue. We saw how to enable it and how it works in action. We also saw how to force a compaction job to run and how to clean up the resources we created.
Something to keep in mind is that this feature's pricing is based on DPU hours. According to the [AWS Glue pricing page](https://aws.amazon.com/glue/pricing/):
> If you compact Apache Iceberg tables, and the compaction run for 30 minutes and consume 2 DPUs, you will be billed 2 DPUs * 1/2 hour * $0.44/DPU-Hour, which equals $0.44.
This pricing could add up quickly if you have a high rate of change on your tables - before this feature, you would have to manually run the compaction job, which, although tedious, would incur minimal costs under the Athena pricing model. You will likely want to keep this feature in mind when deciding whether or not to enable this feature. An alternative would be to run the compaction job manually, using a pattern similar to how I did automatic VACUUM jobs in my [Vacuuming Amazon Athena Iceberg with AWS Step Functions](https://devopstar.com/2023/07/28/vacuuming-iceberg-with-aws-step-functions/) post.
I'm excited to see this feature released and looking forward to seeing what other features are added to the Glue variant of Iceberg in the future.
If you have any questions, comments or feedback, please get in touch with me on Twitter [@nathangloverAUS](https://twitter.com/nathangloverAUS), [LinkedIn](https://www.linkedin.com/in/glovernathan/) or leave a comment below!
| t04glovern |
1,670,819 | Simple, cheap GeoIP API using Vercel Edge functions | Need to look up a users' approximate location based on their IP address? Don't want to opt for a... | 0 | 2023-04-29T23:00:00 | https://alistairshepherd.uk/writing/vercel-geoip/ | javascript, browsers, webdev | Need to look up a users' approximate location based on their IP address? Don't want to opt for a third-party GeoIP service or integrate it into your backend?
Turns out that [Vercel](https://vercel.com) makes it super easy to set up a simple GeoIP service for yourself!
If you just want the code you can find the repo at [github.com/Accudio/vercel-geoip](https://github.com/Accudio/vercel-geoip) and demo at [accudio-geoip.vercel.app](https://accudio-geoip.vercel.app/). You can fork that repository and deploy it to your own Vercel account to use yourself!
I have also published a very similar post (almost identical to be honest, it's mostly copied) about how to do the [same with Netlify](/writing/netlify-geoip).
Read on for a deeper explanation, and let me know if you have any thoughts or issues!
## Background
For a couple projects I'm currently working on, recently I had need for a Geolocation API. Nothing too major, just getting a users very rough location based on their IP address, to tailor their default experience of language, currency, or laws.
There are a TON of Geolocation API services with various pricing, trustworthiness and privacy/tracking policies. I looked at a few, but the per-lookup pricing and lack of certainty around trusting a third-party with our users' IP addresses was a bit of a deterrent.
## Vercel and Geolocation Headers
If you haven't heard of Vercel before, it's a hosting company that specialises in JAMStack sites, similar to Netlify. It's a good platform for static sites, JavaScript-based frameworks and serverless/edge functions.
It's the serverless and edge functions that are the key to this setup. Serverless and edge functions allow us to run a node.js script on each request, responding dynamically. Serverless functions run on centralised servers (they're pretty badly named!), Edge functions are a bit more restrictive and run directly on the CDN nodes allowing for a potentially faster or lighter response.
These functions can be combined with [Vercel's HTTP headers with geolocation information](https://vercel.com/docs/concepts/edge-network/headers#x-vercel-ip-country_). We can send that data back on the request in a JSON format, and then use that within our front-end JavaScript.
## The code
As most of the examples of Vercel's functions rely on Next.js, it's a bit tricky to find how to set up functions without it. For my own later reference and to avoid you having to go through the same research, I'm going through the full process!
### 1. Initialising
First we need to initialise our repo, npm project and install the Vercel packages.
```sh
mkdir vercel-geoip && cd vercel-geoip
git init
npm init -y
npm i -D vercel
npm i @vercel/edge
```
### 2. Trying out an edge function
In Vercel projects functions are placed within an `api/` directory, so let's create an `api/index.js` file. This would run on any requests to `/api/`. Within it, we're going to put the very basics of a edge function that has a basic text response:
```js
// api/index.js
export const config = {
// Specify this function as an edge function rather than a serverless function
runtime: "edge"
};
// We export the function that runs on each request, which receives the `request`
// parameter with data about the current request. We'll use this later
export default function (request) {
// respond to the request with the content "hello world!"
return new Response('hello world!')
}
```
To test our function, we can run `npx vercel dev` to run the Vercel development server. This will ask you to link the project to your Vercel account and some details about the project. You can leave those details as default.
Now, if you visit the dev URL in your browser and add `/api` — [probably `localhost:5000/api`](https://localhost:5000/api) you should see "hello world!".
### 3. The Geolocation bit
Now let's amend our `index.js` file to include the Geolocation bits:
```js
// api/index.js
// Import the geolocation and ipAddress helpers
import { geolocation, ipAddress } from "@vercel/edge";
export const config = {
runtime: "edge",
};
export default function (request) {
// The geolocation helper pulls out the geoIP headers from the
const geo = geolocation(request) || {};
// The IP helper does the same function for the user's IP address
const ip = ipAddress(request) || null
// Output the Geolocation data and IP address as a JSON object, and
// set the content type to make it easier to handle when requested
return new Response(
JSON.stringify({
...geo,
ip,
}),
{
headers: { "content-type": "application/json" },
}
);
}
```
Now this won't work in the dev server as Vercel doesn't inject the geolocation headers there, but if you open the function at least it shouldn't error. You can get a preview deployment to test it on the Vercel servers by running `npx vercel`.
If you visit the `/api` route on your preview URL you'll get the Geolocation data of your IP address! Neat!
### 4. Cross Origin Resource Sharing
If we try to call this on a different website with JavaScript, we're going to run into CORS issues. CORS — Cross Origin Resource Sharing — is a way browsers prevent websites from using a browser to access content they shouldn't have access to, like resources from a local network. This means as things currently stands, a browser won't let us access the content from our API request with `fetch`.
To allow us to use the API within JavaScript in a browser, we need to tell the browser to allow CORS. We can do this by adding some HTTP Headers, via a `vercel.json` config file in root of our project:
```json
// vercel.json
{
"headers": [
{
"source": "(.*)",
"headers": [
{ "key": "Access-Control-Allow-Origin", "value": "*" },
{ "key": "Access-Control-Allow-Methods", "value": "GET,OPTIONS" }
]
}
]
}
```
This is taken from Vercel's ["How can I enable CORS on Vercel?" guide](https://vercel.com/guides/how-to-enable-cors). Since this is a relatively straightforward API we don't really need a lot of the parameters in that article, so I've simplified it to allowing all origins, and only the GET and OPTIONS methods.
There is one thing to note with the above code however, the `Access-Control-Allow-Origin` header allows all origins to make a request to the API. In most cases that might be okay, but you may want to prevent other sites from using your API, especially if you start hitting Vercel's usage limits.
You can [whitelist a single origin](https://developer.mozilla.org/en-US/docs/Web/HTTP/CORS#access-control-allow-origin) by adding it to the `Access-Control-Allow-Origin` header instead of `*`. You could also include the CORS headers within the edge function depending on the requesting Origin for multiple origins. I haven't run into that problem yet though, so consider that a further exercise for the reader!
### 5. Root rewrite (optional)
The final touch is a rewrite so we can hit our API at the root URL `/`, instead of having to include `api/` on every request. With Vercel we can do that with a few more lines to `vercel.json`:
```json
// vercel.json
{
"headers": [],
"rewrites": [
{ "source": "/", "destination": "/api/" }
]
}
```
### 6. Deploy and test!
We can deploy the API to Vercel with `npx vercel --prod`, or link the project via the Vercel website to a Git repo on GitHub, GitLab or similar. Access the API at the Vercel URL, [for example `accudio-geoip.vercel.app`](https://accudio-geoip.vercel.app) and there we go!
This is the result I get when visiting that URL (IP obfuscated for privacy):
```json
{
"city":"Loughborough",
"country":"GB",
"countryRegion":"ENG",
"region":"lhr1",
"latitude":"52.7681",
"longitude":"-1.2026",
"ip":"XX.XX.XX.X"
}
```
It's definitely not perfect, to start I'm in Edinburgh, Scotland not Loughborough, England! City and Country Region should maybe be taken with a pinch of salt, but that's something I run into with GeoIP systems all over the web so it's clearly not just Vercel. (interestingly, my [Netlify post](/writing/netlify-geoip) had similar but slightly different results)
For the purposes of country though it's accurate, and the City and Region may be helpful to set a default that a user can later change.
### 7. Using the API within JavaScript
We can use this within JavaScript on another website like so, but keep in mind you may need to switch from using `await` to `.then()` depending on your setup.
```js
const geoRequest = await fetch('https://accudio-geoip.vercel.app')
const geo = await geoRequest.json()
console.log(geo.country)
// GB
```
| accudio |
1,670,942 | Generating a Type-Safe Node.js API with Prisma, TypeGraphQL, and GraphQL-Query-Purifier | This guide demonstrates how to quickly build a fully functional, type-safe Node.js API using Prisma,... | 0 | 2023-11-18T18:10:32 | https://dev.to/hellowwworld/creating-a-type-safe-nodejs-api-with-prisma-typegraphql-and-graphql-query-purifier-28ii | typegraphql, graphql, node, javascript | This guide demonstrates how to quickly build a fully functional, type-safe Node.js API using Prisma, [typegraphql-prisma](https://www.npmjs.com/package/typegraphql-prisma), and graphql-query-purifier. We'll create a full CRUD API with partial access to protect sensitive data, even with autogenerated resolvers.
> Full example is available in [repo](https://github.com/multipliedtwice/graphql-query-purifier-example)
## 1. Project Setup and Prisma Integration
First, create a new Node.js project and integrate Prisma for database management.
Code for Project Setup:
```bash
mkdir nodejs-api && cd nodejs-api
npm init -y
npm i --save-dev @types/cors@2.8.16 @types/graphql-fields@1.3.9 @types/node@20.9.2 body-parser@1.20.2 cors@2.8.5 express@4.18.2 graphql-query-purifier prisma@5.6.0 ts-node@10.9.1 type-graphql@2.0.0-beta.1 typegraphql-prisma@0.27.1 typescript@5.2.2
npm i @apollo/server@4.9.5 @prisma/client@5.6.0 graphql@16.8.1 graphql-fields@2.0.3 graphql-scalars@1.22.4 reflect-metadata@0.1.13
npx tsc --init
npx prisma init --datasource-provider sqlite
```
## 2. Defining Prisma Models
Create a Prisma schema with models representing a company structure, including sensitive salary data.
schema.prisma:
```prisma
// schema.prisma
datasource db {
provider = "sqlite"
url = "file:./dev.db"
}
generator client {
provider = "prisma-client-js"
}
generator typegraphql {
provider = "typegraphql-prisma"
output = "generated"
}
model Employee {
id Int @id @default(autoincrement())
name String
departmentId Int
department Department @relation(fields: [departmentId], references: [id])
salary Salary?
salaryId Int?
}
model Department {
id Int @id @default(autoincrement())
name String
employees Employee[]
}
model Salary {
id Int @id @default(autoincrement())
amount Float
employeeId Int @unique
employee Employee @relation(fields: [employeeId], references: [id])
}
```
Run migrations to create the database:
```bash
npx prisma migrate dev --name init
```
3. Setting up Apollo Server with Express
Integrate Apollo Server with Express, using TypeGraphQL for schema generation and resolvers.
Code for Server Setup:
```javascript
import "reflect-metadata";
import express from "express";
import { ApolloServer } from "@apollo/server";
import { GraphQLQueryPurifier } from "graphql-query-purifier";
import { resolvers } from "../prisma/generated";
import { PrismaClient } from "@prisma/client";
import cors from "cors";
import path from "path";
import { json, urlencoded } from "body-parser";
import { expressMiddleware } from "@apollo/server/express4";
import { buildSchema } from "type-graphql";
const startServer = async () => {
const app = express();
const prisma = new PrismaClient();
app.use(cors(), json(), urlencoded({ extended: true }));
const gqlPath = path.resolve(__dirname, "../frontend");
const queryPurifier = new GraphQLQueryPurifier({
gqlPath,
allowStudio: true,
// allowAll: false,
});
app.use(queryPurifier.filter);
const server = new ApolloServer({
schema: await buildSchema({
resolvers,
validate: false,
}),
});
await server.start();
const context = expressMiddleware(server, {
context: async (_ctx) => ({
prisma,
}),
});
app.use("/graphql", context);
const PORT = process.env.PORT || 3000;
app.listen(PORT, () => {
console.log(`Server running on http://localhost:${PORT}/graphql`);
});
};
startServer();
```
5. Testing the API
Finally, let's test the API using GraphQL queries.
### Legitimate Query:
```graphql
# Fetch departments and their employees
query {
departments {
id
name
employees {
id
name
}
}
}
```
### Malicious Query Attempt:
```graphql
# Unauthorized attempt to access salaries
query {
departments {
id
name
employees {
id
name
salary {
amount
}
}
}
}
```
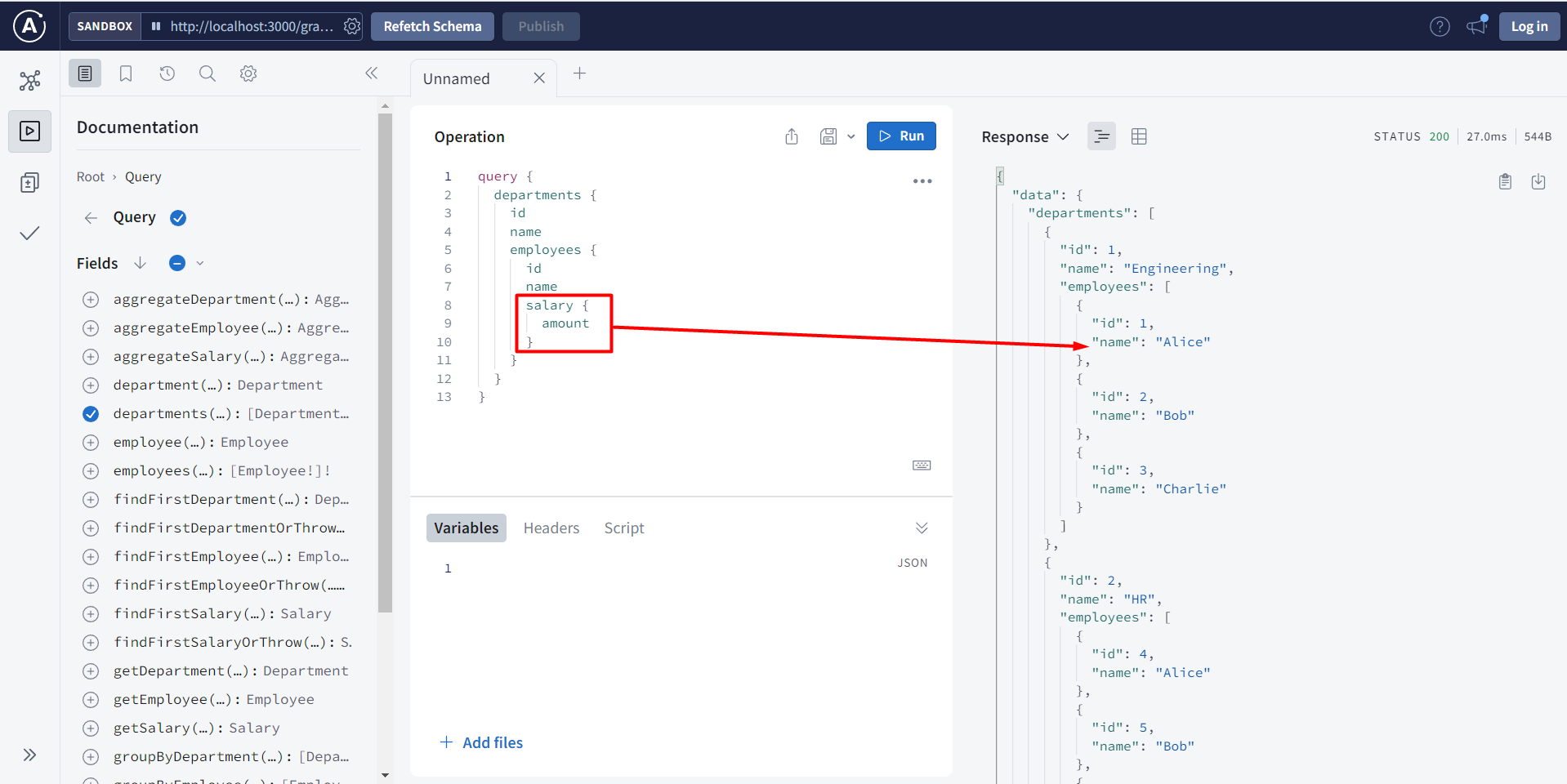
As you might've guessed - this query will show only data that is explicitly allowed to be shown by our `.gql` files.
## Conclusion
This guide covered creating a Node.js API with TypeGraphQL, graphql-query-purifier, and architecture. The main takeaways:
**TypeGraphQL for Auto-Generated Schema and Resolvers:**
- Efficiency: TypeGraphQL and Prisma produce database schema-based GraphQL resolvers. This accelerates the building of a GraphQL API with full CRUD capabilities.
- Type Safety: Strong API typing. A type-safe environment with TypeGraphQL and TypeScript reduces type-related problems and improves code quality.
**Improved Security: [graphql-query-purifier](https://www.npmjs.com/package/graphql-query-purifier)**
GraphQL query-purifier filters incoming queries to prevent data leaks. Avoiding over-fetching and unauthorized access to sensitive data is crucial for APIs with autogenerated resolvers.
Our API protects sensitive data like employee pay. The graphql-query-purifier protects such data from unauthorized queries, which is crucial for compliance and privacy.
### Practical Results:
Combining these tools creates a robust, secure, and scalable API. It handles complicated data structures and relationships securely.
**Less Development Time and Effort:** GraphQL schema and resolver auto-generation and security features reduce boilerplate code and increase business logic emphasis.
Modularity and cutting-edge tools prepare the API for future scalability and maintainability issues.
This API development method speeds up creation and adds security and type safety. It shows a fast and secure way to build modern web apps. | hellowwworld |
1,670,998 | First, explore the concept and benefits of tied systems in business and economics. | In the world of business and economics, tied systems play a crucial role in shaping the way... | 0 | 2023-11-18T20:02:44 | https://dev.to/yaekoalexanderqa/first-explore-the-concept-and-benefits-of-tied-systems-in-business-and-economics-16dm | In the world of business and economics, tied systems play a crucial role in shaping the way organizations operate and interact with each other. These systems, also known as integrated systems or interdependent systems, refer to the practice of linking various components or entities together to create a cohesive and efficient network. By exploring the concept and benefits of tied systems, we can gain a deeper understanding of their significance in driving success and growth in today's global marketplace.
## Understanding Tied Systems
Tied systems are characterized by the interconnection and interdependence of different elements within a business or economic context. This can include the integration of various departments within an organization, the collaboration between different companies in a supply chain, or even the interconnectedness of different economies in the global marketplace. The key idea behind tied systems is that the performance and success of one component are directly influenced by the performance and success of the others.
For example, consider a manufacturing company that relies on a network of suppliers to provide raw materials. If one of the suppliers experiences a disruption in their operations, it can have a ripple effect on the entire supply chain, leading to delays in production and potentially impacting the company's ability to meet customer demands. In this case, the tied system highlights the importance of maintaining strong relationships and effective communication between all parties involved.
## The Benefits of Tied Systems
Now that we have a basic understanding of tied systems, let's explore the benefits they offer in the realm of business and economics.
### Enhanced Efficiency and Productivity
One of the primary advantages of tied systems is the potential for enhanced efficiency and productivity. By integrating different components and streamlining processes, organizations can eliminate redundancies, reduce costs, and optimize resource allocation. For instance, a retail company that implements a tied system between its inventory management and point-of-sale systems can ensure that stock levels are automatically updated in real-time, minimizing the risk of stockouts and improving overall operational efficiency.
### Improved Collaboration and Communication
Tied systems also foster improved collaboration and communication among stakeholders. When different entities are connected and share information seamlessly, it becomes easier to coordinate activities, align goals, and make informed decisions. For example, in a global supply chain, a tied system can enable suppliers, manufacturers, and distributors to exchange data and insights, allowing for better demand forecasting, inventory planning, and risk management.
### Increased Resilience and Adaptability
Tied systems contribute to increased resilience and adaptability in the face of challenges and disruptions. By establishing strong connections and dependencies, organizations can leverage the strengths of different components to overcome obstacles and adapt to changing circumstances. For instance, during a natural disaster, a company with a tied system in place can quickly identify alternative suppliers or distribution channels to mitigate the impact on its operations.
### Facilitated Innovation and Growth
Lastly, tied systems facilitate innovation and growth by fostering collaboration and knowledge sharing. When different entities work together closely, they can pool their resources, expertise, and ideas to drive innovation and create new opportunities. For example, in the technology industry, tied systems between research and development departments, marketing teams, and external partners can lead to the development of groundbreaking products and services that meet evolving customer needs.
## Conclusion
In conclusion, [tied systems](https://vtoman.com/blogs/news/off-grid-vs-grid-tied-solar?utm_source=dev_to&utm_medium=rankking) are a fundamental aspect of business and economics, enabling organizations to achieve enhanced efficiency, improved collaboration, increased resilience, and facilitated innovation. By understanding and harnessing the power of tied systems, businesses can navigate the complexities of the modern marketplace and position themselves for long-term success. Embracing the concept and benefits of tied systems is essential for organizations seeking to thrive in an interconnected and interdependent world.
## References
* [tied systems](https://www.motocal.com/?URL=https://vtoman.com/blogs/news/off-grid-vs-grid-tied-solar "tied systems")
| yaekoalexanderqa | |
1,671,240 | Toystack for deployments | You Code. We Deploy. My name is Sravan from toystack, co-founder of a startup named toystack.ai... | 0 | 2023-11-19T06:13:45 | https://dev.to/toystack/toystack-519n | javascript, node, webdev, python | You Code. We Deploy.
My name is Sravan from toystack, co-founder of a startup named toystack.ai where we built a platform for deployments, we have tailored it for Node.js backend, we are giving 700 hours for free deployments per month, I would like everyone to evaluate this product and give us the feedback, please https://forms.gle/kzdKiWc9JLpn9ckN9 use this form we will quickly onboard you on to us. This is our product: https://toystack.ai/
| toystack |
1,671,346 | How to integrate RazorPay Gateway into your ReactJS + express.js(frontend+backend) | Step 1: you need to upload the script programmatically in reactJS. Add this in App.js import {... | 0 | 2023-11-19T11:02:13 | https://dev.to/chiragbhardwaj/how-to-integrate-razorpay-gateway-into-your-reactjs-expressjsfrontendbackend-11jm | **Step 1**: you need to upload the script programmatically in reactJS.
Add this in App.js
```
import { useEffect } from "react";
import displayRazor from "./utils/paymentGateway";
function App() {
//programatically adding the script in html
const loadscript = (src)=>{
return new Promise((resolve)=>{
const script = document.createElement("script");
script.src = src;
script.onload = ()=>{
resolve(true);
}
script.onerror = ()=>{
resolve(false);
}
document.body.appendChild(script);
})
}
// on page Load , we are adding script.
useEffect(()=>{
loadscript("http://checkout.razorpay.com/v1/checkout.js")
},[])
return(
<>
<button onClick={displayRazor}>Buy Now</button>
</>
)
}
export default App
```
- loadscript is taking src as the parameter which is returning a promise .
- resolve is used by passing argument as true or false , indicating that script has been successfully loaded or not.
- DOM manipulation is used for creation and appending the element.
- "http://checkout.razorpay.com/v1/checkout.js" is the endpoint provided by Razorpay for orders.
**Step 2**:
Now we will create a function which will trigger a pop-up of razorPay on the screen.
**create utils > paymentGateway.js**
(you can create folder of your choice , this is what i personally prefer)
**paymentGateway.js**
```
export default async function displayRazor(){
const data = await fetch("http://localhost:3000/razorpay", {
method: "POST",
headers: {
"Content-Type": "application/json",
}
}).then((t) => t.json());
const option = {
key:"<your_key>",
currency:data.currency,
amount:data.amount,
description:"",
image:"http://localhost:3000/logo.jpg",
handler:(res)=>{
alert("order_id" + res.razorpay_order_id);
alert("payment_id" + res.razorpay_payment_id);
},
// name that will shown on the popUp
prefill:{
name:"",
email:"",
contact:""
}
}
const paymentObject = new window.Razorpay(option);
paymentObject.open();
}
```
- displayRazor function will be triggered on click.
- This will make a post request to the backend server.
- instance of razorpay which accepts option as a parameter object.
## Backend:
Note : in your package.json --> add type : "module"
**step 1** : In cmd
npm i express path cors shortid razorpay url
**step 2**: add this in your index.js :
- import all the required libraries
```
import express from "express";
import path from "path";
import cors from "cors";
import shortid from "shortid";
import razorpay from "razorpay";
import { fileURLToPath } from "url";
import { dirname } from "path";
const PORT = 3000;
```
**step 3**: add a middleware for preventing cors error
```
app.use(cors())
```
**step 4**: create an instance of express:
```
const app = express();
```
**step 5** : create an instance of razorpay:
```
const razorpayInstance = new razorpay({
key_id: "<key_id>",
key_secret: "<key_secret>"
});
```
- how to generate this key_id and key_secret will be explained in the end.
**step 6** : (optional) --> add logo.png in your root directory
create a route handler for fetching the png:
```
app.get("/logo.png", async (req, res) => {
try {
// Use import.meta.url to get the current file's URL,
// then convert it to the file path using fileURLToPath.
const currentFilePath = fileURLToPath(import.meta.url);
// Get the directory name using the dirname function.
const currentDir = dirname(currentFilePath);
// Create the path to the logo.png file.
const imagePath = path.join(currentDir, "logo.png");
// Send the file as a response
res.sendFile(imagePath);
} catch (error) {
console.error("Error serving logo.png:", error);
res.status(500).send("Internal Server Error");
}
});
```
- fileURLToPath(import.meta.url): This is used to convert the file URL of the current module (where this code is located) to a file path.
- dirname(currentFilePath): This extracts the directory name from the file path.
- path.join(currentDir, "logo.png"): This creates the full file path by joining the directory path with the filename "logo.png".
step 7 :(important) create a route handler for the creating payment order
```
app.post("/razorpay",async (req,res)=>{
const payment_capture = 1;
// 1 means payment should be captured immediately
const amount = 2;
const currency = 'INR';
const option = {
amount: amount *100,
currency:currency,
receipt: shortid.generate(),
payment_capture
};
try{
const response = await razorpayInstance.orders.create(option);
console.log(response);
res.json({
id:response.id,
currency:response.currency,
amount:response.amount
})
}
catch(error){
console.log (error);
}
})
```
Our whole backend and frontend part is completed.
How to generate API keys in razorpay:
step1 : visit [razorpay](https://dashboard.razorpay.com/app/dashboard)
step 2 : search api
step 3 : click on API keys
step 4 : generate your own API keys and replace it in the above code.
Github code : [PaymentGatewayDemo](https://github.com/chirag14252/RazorPaymentGateway
)
| chiragbhardwaj | |
1,671,649 | Interview with ConfigCat Engineers | As a front-end developer, I spend most of my time writing code and developing front-end applications.... | 0 | 2023-11-19T19:22:51 | https://configcat.com/blog/2023/10/27/interview-with-configcat-engineers/ | featuremanagement, interview, featureflag, configcat | As a front-end developer, I spend most of my time writing code and developing front-end applications. Several months ago, I wondered what it would be like to run a tech startup. It turns out that I spend my spare time writing blog articles for such a company. Meet [ConfigCat](https://configcat.com/), a thriving tech startup that offers a cloud-hosted feature flagging solution to other tech companies.
Most importantly, I was curious to know how the company was created and the secret behind its success, as well as how they are able to handle high-end user demands while delivering a seamless feature flagging solution. To answer these questions, I decided to conduct an online interview with the core engineering team to satisfy my curiosity and to share what I found with you, the reader.
## But first, what is ConfigCat?
[ConfigCat](https://configcat.com) is an online feature flagging service that allows users to manage feature flags from a [central dashboard](https://app.configcat.com). A feature flag is a boolean value that is linked to a feature in a software application. Most often, it is used in a conditional statement to show or hide the feature when it is true or false, respectively. This means I can control what features to show or hide in my app remotely with a few clicks without editing and redeploying my app.
The company makes available an extensive list of [SDKs](https://configcat.com/docs/sdk-reference/overview/) that allow developers to use their feature flag services in many programming languages and frameworks.
Being a front-end guy, I mainly used the [JavaScript SDK](https://configcat.com/docs/sdk-reference/js/) in my apps. I was amazed by how seamlessly the SDK works and wanted to see what the architecture supporting these processes was like.
## The architecture
Here is a diagram of ConfigCat's architecture.
It may appear as a simple diagram, but how do each of its parts work independently, and how do they interact? Here's what I've learned, and I've also incorporated some information from the [respective documentation](https://configcat.com/architecture/) to provide a clearer explanation.
### The Dashboard
The dashboard is a central user interface for creating and managing feature flags. Apart from toggling a feature flag on or off, I can also target a specific group of users based on country, email, and any custom attribute, which is a neat feature. The configurations I set in the dashboard are stored in a database for later access.
### The API
ConfigCat offers a [Public API](https://configcat.com/docs/advanced/public-api/) for managing configurations. It allows you to do pretty much the same things as you would using the [dashboard interface](https://app.configcat.com/). But this half of the company's API is primarily used for testing and scripts. The other half of the API is responsible for serving up your feature flag values to requests coming from an SDK client installed in your app (more on this soon). To shorten and optimize the requests and response time to and from the API, ConfigCat relies on [Cloudflare's CDN cache](https://www.cloudflare.com/) network.
### The CDN (Cloudflare Edge Cache)
After taking a look at Cloudflare's documentation, I understood why using it would make sense when it comes to added security and optimized performance. Cloudflare is a large network of servers working together. The servers can process huge loads of user requests with this combined power. This allows ConfigCat to serve millions of user requests.
Here's how Cloudflare is helping ConfigCat:
**Traffic Security and Filtering** - Because Cloudflare functions as a reverse proxy, meaning it sits in front of ConfigCat’s public API, it can apply security rules and filter traffic. This is to counteract and protect the API from malicious and direct HTTP requests. A service like this is critical in a world where Distributed Denial of Service (DDoS) attacks are prevalent.
**Caching** - Cloudflare also employs a network edge cache for shortening response time by storing ConfigCat’s data in a Cloudflare data center closest to the user.
### The SDKs
The [SDKs](https://configcat.com/docs/sdk-reference/overview/) are merely software packages that can be installed in a software application. They provide a connecting link between the application and ConfigCat. The SDK is then able to access the API through the Cloudflare Edge Cache to download and cache the feature flag values from the dashboard for evaluating feature flags and targeting rules.
The feature flag values are downloaded in the form of a JSON file by the installed SDK. This file is downloaded periodically based on a time interval that you can modify. When the application code queries the value of a feature flag, the SDK parses the downloaded JSON file and returns the feature flag value without uploading information about you or your users.
With the optimized power from Cloudflare's CDN, their service is capable of handling a large volume of requests. Here's a short dialect from Lali, one of the core engineers:
> Our CDN infrastructure is pretty simple as we only serve small .json files. We put CloudFlare's edge cache above our CDN nodes, which can handle a huge amount of requests without any trouble. ConfigCat values your data privacy and security, so the infrastructure is set up to only query the users' feature flag configuration. However, it never exposes personal user data like email and billing information.
## Optimizing for faster code releases
As a developer myself, I came to understand that the work of software development doesn't stop after the initial build. That's just the beginning. Because the company's entire operation is based on software, I was curious to know how they release new updates and bug fixes.
ConfigCat leverages the power of automated tasks that execute every time an update is made to their code base. These automated tasks all work in tandem towards the end goal of releasing the updated software to users. The overall term used to describe this is called [DevOps](https://en.wikipedia.org/wiki/DevOps).
### Github Actions
One of the tools used as part of the DevOps process is [**GitHub actions**](https://docs.github.com/en/actions/learn-github-actions/understanding-github-actions). Here is an overview of how the company is using it:
When code is pushed or a new feature branch is merged, it triggers a GitHub Actions workflow configured by the engineers.
The workflow consists of individual tasks that run asynchronously, one after the other. Each task is simply an action that needs to be executed. The company's typical GitHub workflow includes tasks such as:
**Code reference scanning**: This is a tool developed by the team to scan the source code of an application and report on feature flag usages. It tracks where specific feature flags are used and points out the unused ones, hence avoiding the accumulation of technical debt. This tool is available to anyone; you can read more about it [here](https://configcat.com/docs/advanced/code-references/overview/).
**Deploying to Cloudflare Pages**: Apart from changes to the backend code, it is beneficial to interact with a live preview of the frontend changes. The company uses Cloudflare Pages to build and deploy a preview of each commit to the company's website.
### Azure DevOps
Another DevOps tool that the company uses is [**Azure DevOps**](https://azure.microsoft.com/en-us/products/devops). It functions similarly to GitHub Actions. This tool monitors the repository for code updates and executes a series of tasks defined in an Azure pipeline .yml file. The difference is that it runs on Azure's DevOps platform as opposed to GitHub.
The pipeline contains tasks for scanning the source code to ensure it is securely written and free of known security vulnerabilities. It also contains tasks for running the code in a Docker container which is later deployed to the Azure cloud platform.
Now that my curiosity about the technical side was satisfied there was also the non-technical side, the soft skills of running a company. More specifically, I wanted to understand how they dealt with the challenges of running a company.
## Overcoming challenges
In my experience, taking on any feat comes with challenges. Sige, a co-founder of the company, told me that together, they formed a strong and willing team, backed by mutual trust and respect, and this has paved the way for possibilities. Here's what he mentioned:
### Challenges of starting and running the company
**Working together and sharing responsibilities**: At first, everyone on the team had different opinions. While there was an immense amount of work to be done, it was a challenge deciding who was doing what.
**Technical hurdles**: As a team of engineers passionate about building high-quality software, We took what we already knew to a different level. We focused on creating a scalable software infrastructure that could adapt to the growing number of users.
**Accounting and legal**: Scalability and software were indeed crucial, and we had to put our business caps on, learning how a company works. We shifted some of our focus toward understanding the accounting and legal aspects of running a thriving and profitable company.
**The first paying customer**:
> "Our first customer subscribed to a paid plan came around 1-1.5 years after we started to build ConfigCat. We loved building ConfigCat but it was pretty hard to wait for the first paying customer that could 'validate' our idea of building ConfigCat." - Lali, Core Engineer at ConfigCat.
As a tech user, sometimes parts break or I need some help using a piece of tech. Now that I understand the challenges and the tech side of things, I was eager to learn how the company handles customer-related issues and general support.
## Customer relations
A famous quote I found reads:
> "Nobody cares how much you know until they know how much you care." - Theodore Roosevelt
To get some other perspective from others who are using ConfigCat, I looked at the [company's reviews up on Capterra](https://www.capterra.com/p/187099/ConfigCat/). From what I saw, most of them were positive. Was ConfigCat capable of providing a speedy response to users having issues using their product?
### Can ConfigCat react quickly to customer support requests?
From my experience, I found that reaching out to the company's support team was easy. I was able to use the [contact form](https://configcat.com/support/) on their website to fill out a message and chat directly with the developer team on [Slack](https://configcat.com/slack/). If you need an almost instant reply, I would recommend using Slack. After joining their Slack community, I saw developers posting issues they encountered and receiving quick assistance from the core engineers and customer success team.
## Closing thoughts
Building a feature flag service can come with challenges, but the rewards can be substantial. One of the key insights I gained from this interview (apart from the technical aspects), is the team's unwavering passion for creating an exceptional product and providing top-notch customer care.
This dedication serves as their primary motivation. From my interaction with the team, it is evident why ConfigCat has garnered a significant user base, including myself, who rely on their platform to efficiently manage and release new features. When I asked, "What would be different if ConfigCat started over?" I got the following response:
> "I wouldn't change anything. I think we learned a lot of things during our journey with ConfigCat and I wouldn't want to change anything." - Lali, Core Engineer at ConfigCat
## Stay up-to-date
For more posts like this and other announcements, follow ConfigCat on [X](https://twitter.com/configcat), [Facebook](https://www.facebook.com/configcat), [LinkedIn](https://www.linkedin.com/company/configcat/), and [GitHub](https://github.com/configcat). | codedbychavez |
1,671,780 | Make API calls from Visual Studio or Visual Studio Code | It is that exciting time of year where Microsoft announce a new version of .Net (Version 8 this time)... | 0 | 2023-11-27T20:19:45 | https://www.funkysi1701.com/posts/2023/make-api-calls-from-visual-studio/ | ---
title: Make API calls from Visual Studio or Visual Studio Code
published: true
date: 2023-11-19 22:50:00 UTC
tags:
canonical_url: https://www.funkysi1701.com/posts/2023/make-api-calls-from-visual-studio/
---
It is that exciting time of year where Microsoft announce a new version of .Net (Version 8 this time) and Visual Studio. There have been lots of announcements which I am still digesting, but one that caught my eye was a new window in Visual Studio that shows all your API endpoints.
The new window is called **Endpoint Explorer** and can be added from the menu **View > Other Windows > Endpoint Explorer**.
If you right click on one of the endpoints you can view the code or send a request. It works with minimal APIs or standard MVC APIs. If you select send a request a .http file will be created, this is a feature that has been in Visual Studio for a while but I haven’t taken much notice.
The syntax for writing these API calls is fairly simple
```
GET {{Catalog.API_HostAddress}}/api/v1/catalog/items
```
Or something more complex, this one is a POST with a body and a header. This is how you might call APIs which require authentication. Just include a header with your auth token.
```
POST {{Catalog.API_HostAddress}}/api/v1/catalog/items
Accept: application/json
{
"name": "Test",
"description": "Test",
"price": 1.99,
"pictureFileName": "test.png",
"pictureUri": "https://picsum.photos/200/300"
}
```
You can also set up various variables at the top of your .http files by prefixing with an @, by default you get one that defines your base URL, but you can add more.
eg @variable = value
Full docs of how you use .http files can be found [here](https://learn.microsoft.com/en-us/aspnet/core/test/http-files?view=aspnetcore-8.0)
A hyperlink above each API call in your .http file is labelled Send request. This initiates the API call and your window splits in half with the right hand side displaying the response.
The response has four tabs, a nicely json formatted response, a raw response, a headers tab and a request tab.
Now you will notice an env box underneath your file tabs, where the method dropdown is in a normal c# class file. It took me a while to figure out how to setup environments, but you can add a file that contain environment specific config, like base URL for test/prod/dev etc.
This blog post tells me about it [here](https://devblogs.microsoft.com/visualstudio/safely-use-secrets-in-http-requests-in-visual-studio-2022/) but the main thing is you need to add a json file called **http-client.env.json** and create some json like this:
```
"local": {
"ProjectPyramidApi_HostAddress": "http://localhost:44338"
},
"dev": {
"ProjectPyramidApi_HostAddress": "https://dev.example.com"
},
"test": {
"ProjectPyramidApi_HostAddress": "https://test.example.com"
},
"prod": {
"ProjectPyramidApi_HostAddress": "https://prod.example.com"
}
```
Other environment specific variables can be added in the same way. Now you can easily call your API in different environments without having to change the URL each time.
## But what about VS Code?
Well it turns out that VS Code has a similar feature, but it is not enabled by default. You need to install the [REST Client](https://marketplace.visualstudio.com/items?itemName=humao.rest-client) extension. Once installed you can create a .http file and start making API calls. The syntax is very similar to Visual Studio.
VS Code has a similar concept of environments. Go to Extensions > REST Client > Extension Settings and click on Edit in settings.json. Add the same settings we used with VS to your settings.json file. You can now switch environments from the command palette “Rest Client: Switch Environment” and select the environment you want to use.
You can make use of the response of one API call in the request of another.
```
### 1st API Call
# @name login
POST {{Catalog.API_HostAddress}}/api/v1/identity/login
Content-Type: application/json
{
"user": "username",
"password": "password"
}
### 2nd API Call
GET {{Catalog.API_HostAddress}}/api/v1/catalog/items
Authorization: Bearer {{login.response.body.token}}
Content-Type: application/json
```
The last feature of VS Code I want to mention is that it can make GQL calls.
```
POST {{Catalog.API_HostAddress}}/graphql
X-REQUEST-TYPE: GraphQL
Content-Type: application/json
Authorization: Bearer {{login.response.body.token}}
query ($name: String!, $owner: String!) {
repository(name: $name, owner: $owner) {
name
fullName: nameWithOwner
description
diskUsage
forkCount
stargazers(first: 5) {
totalCount
nodes {
login
name
}
}
watchers {
totalCount
}
}
}
{
"name": "vscode-restclient",
"owner": "Huachao"
}
```
Sorry postman but I think I have a new favourite tool for making API calls. | funkysi1701 | |
1,671,817 | A monitoring tool built to visualize metrics from local kafka clusters | KlusterFunk is a monitoring tool, built to visualize metrics from local kafka clusters, showing... | 0 | 2023-12-06T09:26:11 | https://reactjsexample.com/a-monitoring-tool-built-to-visualize-metrics-from-local-kafka-clusters/ | monitoring, tool | ---
title: A monitoring tool built to visualize metrics from local kafka clusters
published: true
date: 2023-11-20 00:12:00 UTC
tags: Monitoring,Tool
canonical_url: https://reactjsexample.com/a-monitoring-tool-built-to-visualize-metrics-from-local-kafka-clusters/
---


KlusterFunk is a monitoring tool, built to visualize metrics from local kafka clusters, showing you a real-time, live-updating graph of those metrics.
You can find and use our application at [https://klusterfunk-b05ffb62bc07.herokuapp.com/](https://klusterfunk-b05ffb62bc07.herokuapp.com/)
## Overview
This is a tool meant for developers that are familiar with Kafka and how to export metrics. To use this tool we assume you have:
1. Implemented Prometheus’ JMX exporter on your running Kafka cluster(s).
2. Set up a Prometheus instance including a yaml config file that is pulling metrics from the port where JMX exporter metrics are being exposed.
3. Port forward your Prometheus port so you can input the link in our app.
If you have not yet set up these tools for your clusters, follow the steps in **[Setup](#setup)**
## App in Action

## Features
| Feature | Status |
| --- | --- |
| Login authorization using JWT tokens | ✅ |
| Prometheus API | ✅ |
| Build in functionality to have users simply input kafka cluster URIs and link up metrics on the backend | ⏳ |
| Allow users to choose from list of metrics they would like to see or even input metrics they want to see | ⏳ |
| Switch between Kafka clusters | ⏳ |
| Dark Mode | ⏳ |
| More styling using Tailwind | 🙏🏻 |
| Save in database location of kafka clusters and prometheus address | 🙏🏻 |
- ✅ = Ready to use
- ⏳ = In progress
- 🙏🏻 = Looking for contributors
## Setup
### To setup JMX exporter
- Build exporter:
```
git clone https://github.com/prometheus/jmx_exporter.git
cd jmx_exporter
mvn package
```
- Start zookeeper:
```
/usr/local/opt/kafka/bin/zookeeper-server-start /usr/local/etc/zookeeper/zoo.cfg
```
- Setup JMX exporter to run on Kafka (run from root) \
```
export EXTRA_ARGS="-Dcom.sun.management.jmxremote \
-Dcom.sun.management.jmxremote.authenticate=false \
-Dcom.sun.management.jmxremote.ssl=false \
-Djava.util.logging.config.file=logging.properties \
-javaagent:/Users/<username>/jmx\_exporter/jmx\_prometheus\_javaagent/target/jmx\_prometheus\_javaagent-0.20.1-SNAPSHOT.jar=8081:/Users/<username>/jmx\_exporter/example\_configs/kafka-2\_0\_0.yml"
```
- Start kafka
```
/usr/local/opt/kafka/bin/kafka-server-start /usr/local/etc/kafka/server.properties
```
Localhost:8081 should now be displaying JMX metrics
- Run Prometheus and point it to scrape at port 8081 (or whatever port you configured the JMX exporter )
## Contributing
Feel free to GitHub issues to let us know what features you want and what you’d like to see next from the project!
If you would like to work on the open source code, please do feel free to submit a pull request! Make sure you’re following Javascript ES6 syntax and modularize your code as much as possible.
To get started, first _fork_ the repo to your personal github repos, then run the following commands:
```
git clone https://github.com/oslabs-beta/KlusterFunk.git
npm install
npm run dev
```
## Stack
Apache Kafka, JMX Exporter, Prometheus, Node.js, Vite, MongoDB, Mongoose, Express, React, Chart.js, TailwindCSS, Vitest
## Contact Us
Dominic Kenny – [Github](https://github.com/dominicjkenny) | [LinkedIn](https://www.linkedin.com/in/dominicjkenny/)
Connor Donahue – [Github](https://github.com/conniedonahue) | [LinkedIn](https://www.linkedin.com/in/connordonahue09/)
Wilson Wu – [Github](https://github.com/jwu8475) | [LinkedIn](https://www.linkedin.com/in/wilson-wu-4a821719a/)
David Tezza – [Github](https://github.com/dtezz) | [LinkedIn](https://www.linkedin.com/in/david-tezza/)
## License
[MIT License](https://github.com/oslabs-beta/KlusterFunk/blob/main/LICENSE.md)
## GitHub
[View Github](https://github.com/oslabs-beta/KlusterFunk?ref=reactjsexample.com) | mohammadtaseenkhan |
1,671,932 | DevOps vs SRE vs Platform Engineering - Explained | Originally, DevOps, SRE, and Platform Engineering were just new ways of thinking - cultures and... | 0 | 2023-11-20T05:59:44 | https://firstfinger.in/devops-vs-sre-vs-platform-engineering/ | cloud, devops, beginners | ---
title: DevOps vs SRE vs Platform Engineering - Explained
published: true
tags: Cloud,DevOps,Beginners,discuss
canonical_url: https://firstfinger.in/devops-vs-sre-vs-platform-engineering/
---

Originally, DevOps, SRE, and Platform Engineering were just new ways of thinking - cultures and philosophies. But over time, they've turned into real roles at companies with specific focuses and responsibilities. This profile of job titles can create confusion - What exactly do these roles for? How do they interact and differ?
Of course, all these new job titles can get confusing. DevOps engineer, SRE, and platform engineer - they sound pretty similar, right? But while they're related in some ways, the work these roles do is also very different.
## What is Development?
Development refers to the [engineers who write application code](https://firstfinger.in/will-chatgpt-replace/) and business logic for a company's core products or services. This is the only role that directly generates revenue by building features used by customers. Developers focus on writing and [improving source code for applications.](https://firstfinger.in/firebase-vs-custom-backend/)
In the early days of tech, developers would just " **_throw code over the wall_**" to sysadmin teams, hoping it would work in production. **With DevOps, developers have gained more control and responsibility over [deploying code to live environments.](https://firstfinger.in/file-transfer-project-javascript-html-css-firebase/)**
## What is DevOps?
DevOps emerged as a culture and practice aimed at improving collaboration between development and operations teams. The goal was to provide developers with more ownership and control over releasing code to users.
While DevOps can implement practices like automation and CI/CD, the DevOps Engineer role focuses on creating and improving developer workflows for faster and more reliable delivery of application changes. Responsibilities may include:
- Building and maintaining CI/CD pipelines
- Automating infrastructure provisioning
- Providing self-service deployment capabilities to developers
- Collaborating with other teams to improve the developer experience
The key purpose is to enable developers to [ship code quickly and confidently](https://firstfinger.in/content-delivery-aws-lambda-edge-vs-aws-cloudfront/). DevOps focuses on the developer experience and improving developer velocity above all else.
> [**What is the difference between DevOps vs GitOps?**](https://firstfinger.in/devops-vs-gitops/)
## What is SRE?
Site Reliability Engineering (SRE) emerged at [companies like Google](https://firstfinger.in/bard-vs-bing/) to uphold service reliability and performance in production environments. SREs don't write business logic - they focus on keeping applications running smoothly for customers.
> **Typical SRE responsibilities include:**
- Designing and implementing monitoring, alerting, and logs
- Performing capacity planning
- Defining SLOs (service level objectives)
- Running post-mortems and optimizing incident response
- Improving system architecture and reliability
While DevOps focuses on developer experience, SRE's priority is the [production environment and customer experience](https://firstfinger.in/blue-green-deployment-kubernetes/). SREs are responsible for making sure users consistently have a high-quality experience.
## What is Platform Engineering?
Platform Engineering teams build shared tools and infrastructure to empower developers, SREs, and other roles. Rather than business logic, platform engineers focus on creating an ecosystem of reusable services and tooling.
Example platform engineering responsibilities:
- [Developing internal SDKs/APIs](https://firstfinger.in/api-vs-sdk-difference/) for use by multiple teams
- Building developer tools and self-service solutions
- Maintaining core infrastructure like [Kubernetes clusters](https://firstfinger.in/create-kubernetes-clusters-on-aws/)
- Creating libraries/[frameworks that simplify coding](https://firstfinger.in/what-is-langchain-example/)
- Providing common patterns and templates as a starting point
Platform Engineering produces leverageable solutions that reduce duplicate work across the organization. The goal is to enable all other roles to be more productive.
## How do These Roles Interact?

_DevOps vs SRE vs Platform Engineering_
> **While these roles have distinct focuses, they need to collaborate closely:**
- Developers rely on DevOps for CI/CD automation and SREs to ensure production health.
- DevOps depends on Platform Engineering tools and SRE practices for deployment safety.
- SREs require visibility into code changes from Devs and deployment patterns from DevOps.
- Platform Engineering designs solutions for end users like Devs, DevOps, and SREs.
At smaller companies, engineers may wear multiple hats and overlap responsibilities. Larger companies tend to have dedicated teams and clearer separation between these disciplines.
Regardless of size, strong communication and shared ownership between roles is vital for delivering robust, scalable applications users love.
## In Conclusion
DevOps, SRE, and Platform Engineering are emerging disciplines with different concerns. Rather than distinct titles, it's best to view them as complementary areas of focus that require tight integration:
- Development builds the core product.
- DevOps maximizes developer productivity.
- SRE ensures production quality.
- Platform Engineering provides leverage-able tools and systems.
* * *
> If you enjoyed this article, please consider [subscribing to our newsletter](https://short.firstfinger.in/newsletter) 📬 and joining our [WhatsApp Channel](https://short.firstfinger.in/whatsapp-invite) 👥, where we share similar content. ✏️ | anurag_vishwakarma |
1,672,125 | Python Developer Track for Oracle JSON and Duality Views | Do you want to take advantage of JSON and Relational combined, while avoiding the limitations of... | 0 | 2023-11-20T11:26:37 | https://dev.to/javierdelatorre/python-developer-track-for-oracle-json-and-duality-views-2b9h | python, programmers, beginners, tutorial | Do you want to take advantage of JSON and Relational combined, while avoiding the limitations of each? This workshop is for you!
In this new workshop, you are going to learn how to develop against an Oracle 23c and how to create advanced data models using Duality Views. The full content of the workshop is the following:
1. Create and configure your Oracle 23c
2. First steps with Oracle and Python
3. CRUD operations
4. Queries by example
5. Indexing
6. Database Actions, GUI for JSON
7. Data Modeling, including Duality Views
8. Run SQL over JSON
9. MongoDB API against Duality Views
I will be creating a blog post for each of the labs and I will share all the code at GitHub. Stay tuned!
Here you have all the direct links to all the chapters:
1. Create 23c:https://dev.to/javierdelatorre/python-developer-track-for-oracle-json-and-duality-views-part-1-create-and-configure-your-oracle-23c-13hl
2. First steps:https://dev.to/javierdelatorre/python-developer-track-for-oracle-json-and-duality-views-part-2-first-steps-with-oracle-and-python-2c0m
3. CRUD operations: https://dev.to/javierdelatorre/python-developer-track-for-oracle-json-and-duality-views-part-3-crud-operations-2oji
4. Queries by example: https://dev.to/javierdelatorre/python-developer-track-for-oracle-json-and-duality-views-part-4-queries-by-example-57ho
5. Indexing: https://dev.to/javierdelatorre/python-developer-track-for-oracle-json-and-duality-views-part-5-indexing-51fe
6. Database Actions: https://dev.to/javierdelatorre/python-developer-track-for-oracle-json-and-duality-views-part-6-database-actions-gui-for-json-5756
7. Data Modeling: https://dev.to/javierdelatorre/python-developer-track-for-oracle-json-and-duality-views-part-7-data-modeling-including-duality-views-10l3
8. SQL: https://dev.to/javierdelatorre/python-developer-track-for-oracle-json-and-duality-views-part-8-run-sql-over-json-5eib
9. MongoDB API: https://dev.to/javierdelatorre/python-developer-track-for-oracle-json-and-duality-views-part-9-mongodb-api-against-duality-views-9a2
| javierdelatorre |
1,672,480 | Kubectl Restart Pod | Brief description of what a pod is? In Kubernetes, a pod is the smallest... | 0 | 2023-11-20T13:37:36 | https://refine.dev/blog/kubectl-restart-pod/ | devops, kubernetes, webdev, docker | <a href="https://s.refine.dev/kubectl-restart">
<img src="https://refine.ams3.cdn.digitaloceanspaces.com/readme/refine-readme-banner.png" alt="refine repo" />
</a>
---
## Brief description of what a pod is?
In Kubernetes, a pod is the smallest execution unit. Pods may be composed of a single or multiple containers that share the same resources within the Pod Storage, Network, or namespaces. Pods typically have a one-to-one mapping with containers, but in more advanced situations, we may run multiple containers in a Pod. If needed, Kubernetes can use replication controllers to scale the application horizontally when containers are grouped into pods. For instance, if a single pod is overloaded, then Kubernetes could automatically replicate it and deploy it in a cluster.
## Why Restarting a Pod is Necessary
### Situations that demand a pod restart
**Configuration Changes:** You may need to restart the Pod to apply any changes you made to the configuration of your application or environment.
**Application Updates:** If a pod is running an incompatible version of the application or environment. To upgrade or downgrade a pod according to the desired version, you need to restart it.
**Troubleshooting:** Restarting your pods can be a way to diagnose the problem if your application encounters problems or behaves unpredictably.
**Resource Constraints:** Restarting the Pod may assist in the recovery of resources and return to normal operation if it is running low on memory or experiencing an increase in CPU usage. But this is a temporary solution.
## Difference between restarting a pod and recreating it.
| **Action** | **Description** | **Effect on Pod ID** | **Effect on Pod Status** | **Effect on Pod Data** |
| ------------------ | ------------------------------------------------------------------------------------ | ----------------------------------------------------------------------------------------------- | --------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------- |
| **Restarting Pod** | Restarting the Pod typically refers to restarting the container inside the Pod. | Since the Pod is just restarted rather than deleted and regenerated, the pod ID doesn't change. | The Pod's status changes from running to terminating and then back to running. | The pod data is kept intact unless the pod specification or image has changed. |
| **Restarting Pod** | When a pod is recreated, the old one must be removed, and a new one must be created. | When a new pod is formed and the old one is destroyed, the pod ID changes. | The pod status changes between Running, Terminating, and Pending before returning to Running. | It is lost unless the pod data is saved in an external source or a persistent volume. |
## Understanding Pod Lifecycle
### Explanation of the different stages in the lifecycle of a pod
Pod phase means the state of a pod at any point in its life cycle. The possible phases of a pod are as follows:
**Pending Phase**
A pod that displays the state '**pending**' indicates that Kubernetes has accepted it but has not finished processing it. This might be because it hasn't been scheduled yet, the Pod is waiting for init-containers to finish their tasks, or the images haven't been pulled yet (which could indicate an image pull error).
**Running Phase**
When a pod is linked to a node, it is said to be in the running phase. This indicates that the Pod has been assigned to a host, images have been pulled, init-containers have finished, and at least one of the Pod's containers is running or is in the process of starting or restarting.
**Succeeded Phase**
In this phase, the Pod has finished its task, such as completing a job, and all containers are terminated. It means that it's stopped working and can't be restarted.
**Failed Phase**
This phase starts when a pod's containers are terminated with an error(i.e., with non-zero status) or if one or more containers are terminated in the case of a node failure.
**Unknown**
The unknown pod status typically denotes an issue with the Pod's connection to the host node.
## A diagram showcasing pod lifecycle
<div className="centered-image">
<img src="https://refine.ams3.cdn.digitaloceanspaces.com/blog/2023-10-22-kubecti-restart-pod/diagram.png" alt="kubectl restart pod" />
</div>
<br/>
**Diagram Reference:** https://millionvisit.blogspot.com/2021/03/kubernetes-for-developers-9-Kubernetes-Pod-Lifecycle.html
## Methods to Restart a Pod
### Using kubectl delete pod method
You can remove a pod from your node by use of the `kubectl delete pod [NAME_OF_POD]` command and get the deployment or replica set to build a new one on an updated configuration. This method is very simple but can interrupt the application for a short period of time since your Pod does not appear until you create a new one. In order to use this method and execute this command, you must know your Pod's name.
For Example, if we have a pod with the name '**my-demo-pod**', we can run the following command to delete it:
`kubectl delete pod my-demo-pod`
<div className="centered-image">
<img src="https://refine.ams3.cdn.digitaloceanspaces.com/blog/2023-10-22-kubecti-restart-pod/delete-pod.png" alt="kubectl restart pod" />
</div>
<br/>
## Employing the rolling restart technique with deployments
When deploying, using a rolling restart method, you can automatically update the deployment when required so that old pods are replaced with new ones without having an impact on the availability of your application. It is less disruptive than the removal of a pod, but it may take longer. You need to replace the deployment name of the deployment that manages the Pod in the command below:
`kubectl rollout restart deployment/[NAME_OF_DEPLOYMENT]`
For Example, we have a deployment with the name '**my-demo-deployment**'. To apply the rolling restart method on our deployment by using kubectl, we can run the following command:
`kubectl rollout restart deployment/my-demo-deployment`
<div className="centered-image">
<img src="https://refine.ams3.cdn.digitaloceanspaces.com/blog/2023-10-22-kubecti-restart-pod/restart-techniqu.png" alt="kubectl restart pod" />
</div>
<br/>
## Safety Measures & Best Practices
### Ensuring zero-downtime during pod restarts
Use a Deployment that utilizes Replica Sets to manage your Pods and perform periodic updates while restarting them so that they don't interrupt service or lose requests. In order to maintain the minimum number of available pods, a rolling update shall gradually replace old ones with new ones.
To trigger a rolling update to your deployment or replica set, you can use the `kubectl rollout restart` command. To help the kubelet determine when a pod is ready to serve traffic or needs to be restarted, you can configure readiness and liveness probes for your pods.
**Readiness Probes:** Determines whether a Pod is prepared to handle traffic. A Pod won't receive traffic from Services if it isn't ready.
**Liveness Probes:** This makes sure if the Pod is running successfully or not. The Pod is restarted by Kubernetes if the probe fails.
### Monitoring and logging during restarts
Monitoring and logging are of paramount importance for pod performance and behavior assessment during restarts on Kubernetes. Details on pod activity can be obtained from the use of kubectl commands such as `kubectl describe` or `kubectl logs`.
Tools such as Prometheus come into play in the metrics collection, while Grafana has a crucial role in data visualization. Proactive alerts will identify unusual behavior in the Pod and enable swift action. Additionally, you may gather and store logs from your pods—such as application, container, or system logs—using Fluentd and Elasticsearch.
## Troubleshooting Common Issues
### What to do if a pod doesn't restart
Sometimes, for some reason, such as a mistake in the configurations, a lack of resources, or a problem with the node(a machine that runs the Pod), the Pod may not start again after stopping.
You can use the `kubectl describe pod [NAME_OF_POD]` command to track the exact reason for failure. For insight into pre-error activities, you can extract container logs with `kubectl logs`. You can also use the `kubectl restart pod` command to execute commands in a pod container if you want direct interaction.
## Understanding error messages and their remedies.
If you have a pod that's in CrashLoopBackOff status, the container crashes multiple times, and Kubernetes stops restarting it. `kubectl describe pod` command can show you invalid arguments, lost files or permissions errors. You may need to edit and update the configuration of Pod to resolve the error.
The `kubectl logs` command allows you to find any runtime issues or exceptions that may have caused an abnormal pod container exit. Based on Logs, you may need to verify and update the code or environment variables if required. Using the `kubectl restart pod` command, you may check if the container in the Pod has the expected files, dependencies, and permissions. In this case, you may need to update the specification of Pod or rebuild the container image.
Let's take an example of '**my-demo-pod**', which enters into the '**CrashLoopBackOff**' state as shown below:
<div className="centered-image">
<img src="https://refine.ams3.cdn.digitaloceanspaces.com/blog/2023-10-22-kubecti-restart-pod/error-message.png" alt="kubectl restart pod" />
</div>
<br/>
In order to find out the reason behind the error above, we need to see the detailed output. For that purpose, we will execute the following command:
`kubectl describe pod my-demo-pod`
At the bottom of the output below, you'll see a section called '**Event**'. You're supposed to see messages about the container starting, then crashing, and the system trying to restart it in this section.
<div className="centered-image">
<img src="https://refine.ams3.cdn.digitaloceanspaces.com/blog/2023-10-22-kubecti-restart-pod/error2.png" alt="kubectl restart pod" />
</div>
<br/>
## Additional Tools & Plugins for Effective Management
Kubernetes pod management can be challenging due to the fact that you have to move between different clusters and namespaces. Luckily, you can use some other tools and plugins to help with this task.
The Kubectx tool is designed to speed up switching between clusters. With simple commands, you will be able to add, rename, remove and change contexts. To choose a context by typing several characters, you will also have the possibility of using interactive mode with fzf(general-purpose command-line fuzzy finder).
You can easily switch between namespaces with the Kubens tool. The namespaces can be defined, created, deleted or changed with easy commands. If you need to select a namespace by inserting several characters, the interactive mode can also be used with fzf.
## Conclusion & Further Reading
### Summing up the importance and techniques of restarting pods
In order to achieve optimal performance for applications resulting from configuration changes, updates or troubleshooting, the Pod should be restarted in Kubernetes. We've been discussing direct pod deletion and rolling restart methods, highlighting their particular uses and impacts.
## Pointing readers to advanced topics or resources
Beyond the basics of pod administration, Kubernetes gives you a wide range of possibilities. Check out Google Docs for Kubernetes and explore tools such as Kubectx and Kubens to get more detailed information. For a richer understanding, embrace hands-on experience and resources from the community.
**Author: <a target="_blank" href="https://refine.dev/blog/author/muhammad_khabbab/">Muhammad Khabbab</a>**
| necatiozmen |
1,672,689 | FLaNK Stack Weekly for 20 Nov 2023 | 20-November-2023 The FLaK Federation is building... FLaNK Stack Weekly Tim... | 0 | 2023-11-20T16:51:49 | https://dev.to/tspannhw/flank-stack-weekly-for-20-nov-2023-3bdj | apachenifi, apachekafka, apacheflink, opensource | ## 20-November-2023
The FLaK Federation is building...
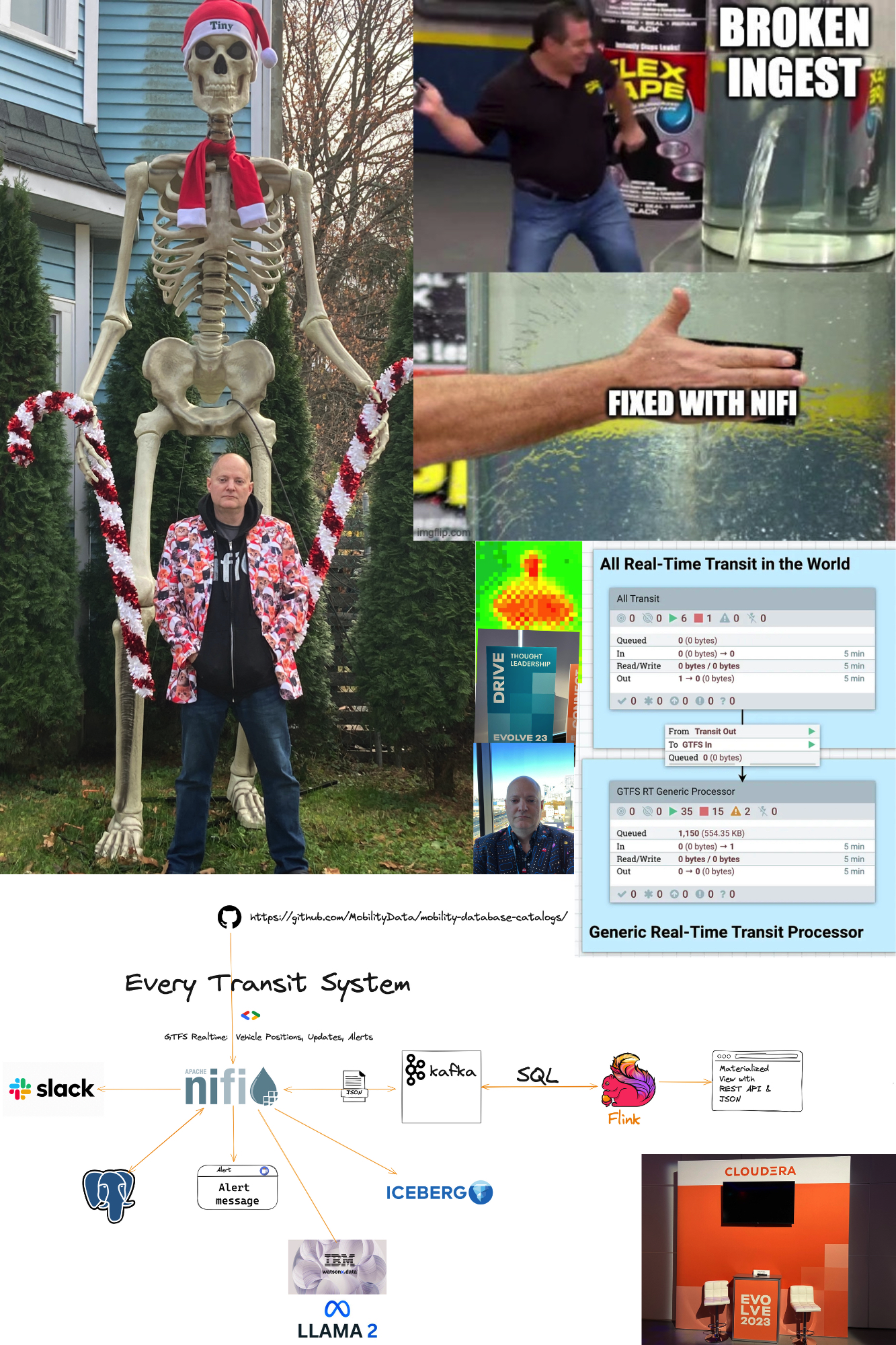
### FLaNK Stack Weekly
Tim Spann @PaaSDev
https://pebble.is/PaaSDev
https://vimeo.com/flankstack
https://www.youtube.com/@FLaNK-Stack
https://www.threads.net/@tspannhw
https://medium.com/@tspann/subscribe
Get your new Apache NiFi for Dummies!
https://www.cloudera.com/campaign/apache-nifi-for-dummies.html
https://ossinsight.io/analyze/tspannhw
### CODE + COMMUNITY
Please join my meetup group NJ/NYC/Philly/Virtual.
[http://www.meetup.com/futureofdata-princeton/](http://www.meetup.com/futureofdata-princeton/)
[https://www.meetup.com/futureofdata-newyork/](https://www.meetup.com/futureofdata-newyork/)
[https://www.meetup.com/futureofdata-philadelphia/](https://www.meetup.com/futureofdata-philadelphia/)
**This is Issue #112 **
[https://github.com/tspannhw/FLiPStackWeekly](https://github.com/tspannhw/FLiPStackWeekly)
[https://www.linkedin.com/pulse/schedule-2023-tim-spann-/](https://www.linkedin.com/pulse/schedule-2023-tim-spann-/)
[https://www.cloudera.com/solutions/dim-developer.html](https://www.cloudera.com/solutions/dim-developer.html)
[https://www.cloudera.com/products/dataflow/nifi-dataflow-calculator.html?utm_source=twitter&keyplay=data-flow&utm_campaign=FY24-Q2_Content_Globl_Nifi_SS_Tool_Promos&cid=UNGATED&utm_medium=social-organic&pid=11590424099](https://www.cloudera.com/products/dataflow/nifi-dataflow-calculator.html?utm_source=twitter&keyplay=data-flow&utm_campaign=FY24-Q2_Content_Globl_Nifi_SS_Tool_Promos&cid=UNGATED&utm_medium=social-organic&pid=11590424099)
[https://community.cloudera.com/t5/Community-Articles/New-Cloudera-AMP-with-Amazon-Bedrock-Integration-Now/ta-p/377071?utm_medium=social-organic&pid=11547807644
](https://community.cloudera.com/t5/Community-Articles/New-Cloudera-AMP-with-Amazon-Bedrock-Integration-Now/ta-p/377071?utm_medium=social-organic&pid=11547807644)
#### Articles
https://medium.com/@tspann/real-time-slack-bots-powered-by-llm-and-dataflows-770786f8ffd4
https://medium.com/@tspann/transit-in-sao-paulo-brasil-flank-style-eaec6753cc63
https://medium.com/@tspann/iteration-1-building-a-system-to-consume-all-the-real-time-transit-data-in-the-world-at-once-4322b160df9d
https://dzone.com/refcardz/real-time-data-architecture-patterns
https://www.dfrobot.com/blog-13412.html
https://www.morling.dev/blog/can-debezium-lose-events/
https://www.newyorker.com/magazine/2023/11/20/a-coder-considers-the-waning-days-of-the-craft
https://github.com/microsoft/ML-For-Beginners
https://onetable.dev/
https://rmoff.net/2023/11/16/learning-apache-flink-s01e06-the-flink-jdbc-driver/
https://www.martinvigo.com/email2phonenumber/
https://zilliz.com/blog/how-to-build-ai-chatbot-with-Milvus-and-Towhee?utm_source=vendor&utm_medium=referral&utm_campaign=2023-11-06_email_newsletter-display_tns
https://mattjhayes.com/2023/11/14/introduction-to-nifi/
https://www.markhneedham.com/blog/2023/11/15/clickhouse-summing-columns-remote-files/
https://www-ververica-com.cdn.ampproject.org/c/s/www.ververica.com/blog/streamhouse-unveiled?hs_amp=true
https://simonaubury.com/posts/202310_ginai/
#### Videos
https://www.youtube.com/watch?v=virKyKJlaDE
https://www.youtube.com/watch?v=psnRObquBfw&pp=ygUJVGltIFNwYW5u
#### Events
https://www.pingcap.com/htap-summit/sept-2023
On Demand
[https://events.dzone.com/dzone/Data-Pipelines-Investigating-the-Modern-Day-Stack?utm_bmcr_source=LinkedIn](https://events.dzone.com/dzone/Data-Pipelines-Investigating-the-Modern-Day-Stack?utm_bmcr_source=LinkedIn)
Open Source Finance Forum. Virtual.
[https://resources.finos.org/znglist/osff-2023-virtual-presentations/?c=cG9zdDo5OTEzOTk%3D&utm_campaign=OSFF+NYC+2023&utm_content=269713979&utm_medium=social&utm_source=linkedin&hss_channel=lcp-18473937](https://resources.finos.org/znglist/osff-2023-virtual-presentations/?c=cG9zdDo5OTEzOTk%3D&utm_campaign=OSFF+NYC+2023&utm_content=269713979&utm_medium=social&utm_source=linkedin&hss_channel=lcp-18473937)
November 21, 2023: JCon World. Virtual.

[https://sched.co/1RRWm](https://sched.co/1RRWm)

November 22, 2023: Big Data Conference. Hybrid
[https://bigdataconference.eu/](https://bigdataconference.eu/)
[https://events.pinetool.ai/3079/#sessions/101077](https://events.pinetool.ai/3079/#sessions/101077)
November 23, 2023: Data Science Summit. Hybrid. EU
[https://dssconf.pl/en/](https://dssconf.pl/en/)
https://www.slideshare.net/bunkertor/endss23tspannintegrating-llm-with-streaming-data-pipelines
December 12-14, 2023: OSACon. Online.
[https://osacon.io/](https://osacon.io/)
April 2024: XtremeJ 2024. Virtual.
[https://xtremej.dev/2023/schedule/](https://xtremej.dev/2023/schedule/)
Cloudera Events
[https://www.cloudera.com/about/events.html](https://www.cloudera.com/about/events.html)
More Events:
[https://www.linkedin.com/pulse/schedule-2023-tim-spann-/](https://www.linkedin.com/pulse/schedule-2023-tim-spann-/)
#### Code
* https://github.com/tspannhw/FLaNK-Halifax
* https://github.com/tspannhw/CoC2023
* https://github.com/tspannhw/PaK-Stocks
* https://github.com/tspannhw/FLaNK-EveryTransitSystem
* https://github.com/tspannhw/FLaNK-Ice
* https://github.com/tspannhw/FLaNK-SaoPauloBrazil
#### Models
* https://huggingface.co/kaist-ai/prometheus-13b-v1.0
#### Tools
* https://github.com/cloudera/CML_AMP_Intelligent-QA-Chatbot-with-NiFi-Pinecone-and-Llama2
* https://github.com/xdgrulez/kafi
* https://espresense.com/
* https://github.com/minimaxir/imgbeddings
* https://github.com/kevinbtalbert/CML_AMP-Text-to-Image-with-Stable-Diffusion
* https://github.com/microsoft/torchgeo
* https://github.com/tibs/fish-and-chips-and-kafka-talk
* https://github.com/rezoo/movis
* https://flatpak.org/
* https://huggingface.co/distil-whisper/distil-large-v2
* https://ozone.apache.org/docs/1.3.0/start/runningviadocker.html
* https://kyuubi.readthedocs.io/en/v1.8.0/index.html
* https://github.com/bytewax/awesome-public-real-time-datasets
* https://github.com/pinterest/memq
* https://github.com/AutoMQ/automq-for-kafka
* https://github.com/tembo-io/pgmq
* https://github.com/shashankvemuri/Finance
* https://github.com/apache/superset/tree/latest
* https://github.com/abi/screenshot-to-code
* https://github.com/philippta/flyscrape
* https://github.com/philippta/trip
* https://ebitengine.org/
* https://dosdeck.com/game/doom
* https://dev.to/burakboduroglu/spring-boot-cheat-sheet-460c
* https://github.com/Aiven-Open/sql-cli-for-apache-flink-docker
* https://github.com/alipay/fury
* https://github.com/SCADA-LTS/Scada-LTS
* https://github.com/Aiven-Labs/data-pipeline-evolution-batch-streaming-apache-flink
* https://github.com/Aiven-Open/journalpump
* https://github.com/gmrqs/lasagna
* https://partyrock.aws/
* https://partyrock.aws/u/partyrock/wWo-KNwoS/Podcast-Generator/snapshot/v73OIztx9
* https://partyrock.aws/u/tspannhw/_jbzaohP6/NJ-Transit-Delay-Notifier/snapshot/3SV6mBR9b
* https://www.waitingforcode.com/apache-flink/apache-flink-anatomy-job/read
* https://github.com/yl4579/StyleTTS2
* https://fleuret.org/dlc/
* https://github.com/protectai/ai-exploits
* https://github.com/luxonis/depthai-python
* https://github.com/jzhang38/TinyLlama
© 2020-2023 Tim Spann
| tspannhw |
1,673,170 | Chatbots in Healthcare: Revolutionizing the Future of Patient Care | Introduction In today’s fast-paced digital world, the healthcare industry is constantly seeking... | 0 | 2023-11-21T05:48:53 | https://dev.to/xcubelabs/chatbots-in-healthcare-revolutionizing-the-future-of-patient-care-4hae | chatbots, healthcare, healthtech, product | **Introduction**
In today’s fast-paced digital world, the healthcare industry is constantly seeking innovative solutions to enhance patient care and improve overall efficiency. One such solution that has gained significant traction in recent years is the use of chatbots in healthcare. Leveraging advancements in artificial intelligence (AI) and natural language processing (NLP), chatbots have emerged as powerful tools that can revolutionize the way patients engage with healthcare providers. From providing instant medical information to scheduling appointments and even offering mental health assistance, chatbots offer a wide range of benefits in the healthcare sector.
**The Importance Of Chatbots In Healthcare**
The adoption of chatbots in healthcare is driven by several key factors. Firstly, chatbots enable healthcare organizations to provide 24×7 availability to patients. In emergency situations, where timing is critical, chatbots can offer immediate assistance by recognizing symptoms and providing relevant information. This ensures that patients receive the care they need in a timely manner, regardless of the time of day.
Secondly, virtual healthcare assistants excel at collecting and engaging with patient data. By interacting with users, chatbots gather valuable information that can be used to personalize the patient experience and improve future business processes. Unlike traditional websites, chatbots offer a more interactive and user-friendly platform for patients to seek information and support.
Furthermore, chatbots have the unique ability to attend to multiple patients simultaneously without compromising the quality of care. Healthcare professionals are often limited by their capacity to provide one-on-one care, but chatbots can engage with numerous clients at once, ensuring that no patient is left behind. This scalability allows healthcare organizations to optimize their resources and focus on patients who require more personalized attention.
Another essential advantage of chatbots in healthcare is their ability to provide instant information. In critical situations, where every second counts, chatbots can rapidly deliver accurate information to healthcare professionals. For instance, if a patient arrives at the hospital with a time-sensitive condition, the chatbot can quickly provide the doctor with the patient’s medical history, allergies, and previous check-ups, enabling the healthcare provider to make informed decisions promptly.
**Key Use Cases Of Chatbots In Healthcare**
Chatbots in healthcare offer a wide range of benefits. Let’s explore some of the key use cases where chatbots are transforming the way patients interact with healthcare providers.
**1. Easy Scheduling of Appointments**
Scheduling appointments is a common task in the healthcare industry, but it can often be challenging for patients due to slow applications or complex information requirements. Long wait times can lead to patient dissatisfaction and even prompt patients to change their healthcare providers. Chatbots provide a seamless solution to this problem by offering a user-friendly messaging interface for appointment scheduling. By integrating with CRM systems, chatbots can efficiently manage appointments based on the availability of doctors. This not only streamlines the process for patients but also helps medical staff keep track of patient visits and follow-up appointments.
**2. Providing Necessary Medical Information**
Healthcare chatbots are trained on vast amounts of healthcare data, including disease symptoms, diagnoses, and available treatments. This enables them to provide patients with accurate and reliable medical information. By simply interacting with a chatbot, patients can access information specific to their condition, such as symptoms, treatment options, and preventative measures. This empowers patients to make informed decisions about their health and well-being.
**3. Symptom Assessment**
Chatbots are increasingly being used to assess patient symptoms and provide initial medical advice. By leveraging natural language processing (NLP), chatbots can understand user inquiries regardless of the variety of inputs. Patients can describe their symptoms to the chatbot, which can then analyze the information and suggest potential illnesses or conditions. This allows patients to gain insights into their health without physically visiting a healthcare facility, saving time and reducing unnecessary visits.
**4. Insurance Coverage and Claims**
Chatbots can assist patients with their insurance coverage and claims, simplifying the process and providing timely information. Patients can inquire about their current coverage, file claims, and track the status of their claims through a healthcare chatbot. This not only improves the patient experience but also enables healthcare providers to streamline billing and insurance-related processes.
**5. Mental Health Assistance**
Mental health is a critical aspect of overall well-being, and chatbots in healthcare can play a significant role in providing support and assistance. Chatbots trained in cognitive behavioral therapy (CBT) can offer guidance and coping strategies for patients with conditions such as depression, anxiety, and post-traumatic stress disorder (PTSD). Patients can interact with the chatbot via text, voice, or video, allowing for personalized and accessible mental health support.
**6. Prescription Refills**
Automating prescription refills is another valuable application of chatbots in healthcare. Rather than waiting for weeks for their prescriptions to be filled, patients can interact with a chatbot to check the status of their prescription and receive notifications when it is ready for pickup or delivery. This improves medication adherence and reduces the administrative burden on healthcare professionals.
**7. Wellness Program Recommendations**
Healthcare organizations often offer wellness programs to promote healthy habits and disease prevention. Chatbots can assist in increasing enrollment and engagement in these programs by providing personalized recommendations based on user input. By analyzing user sentiment and employing NLP, chatbots can understand user intent and suggest suitable wellness programs, boosting engagement and improving overall health outcomes.
**8. Scalable Working Hours**
Scalability is crucial for any organization, especially in the healthcare sector. Chatbots integrated into customer support can handle real-time discussions and provide consistent assistance regardless of the volume of inquiries. This ensures that patients receive prompt responses and support, even during peak hours. By leveraging chatbots, healthcare organizations can optimize their resources and enhance customer satisfaction without adding additional costs or staff.
**9. Patient Data Collection**
Chatbots in healthcare serve as an effective tool for collecting patient information. By engaging in conversations with patients, chatbots can gather essential data such as name, address, symptoms, current doctor, and insurance details. This information can be stored securely and used to facilitate patient admission, symptom tracking, doctor-patient communication, and medical record keeping. Chatbots streamline the data collection process, improving efficiency and accuracy in healthcare operations.
**10. Instant Response to Queries**
Chatbots excel at providing instant responses to frequently asked questions. Patients often have queries about hospital working hours, payment tariffs, insurance coverage, and other general information. Chatbots in healthcare can act as a one-stop shop, instantly answering these questions and ensuring that patients receive accurate and concise information. By offering a user-friendly and interactive platform, chatbots enhance the patient experience and reduce the burden on healthcare staff.
**The Future Of Chatbots In Healthcare**
As the healthcare industry continues to embrace digital transformation, the role of chatbots in healthcare is poised to expand further. Advances in AI and NLP technologies will enable chatbots to become even more sophisticated in understanding patient needs and providing personalized care. Future developments may include chatbots capable of handling complex medical diagnoses, remote monitoring of patients, and even emotional support for mental health conditions.
The market for virtual healthcare assistants is projected to grow significantly in the coming years, driven by the increasing demand for efficient and accessible healthcare services. Healthcare organizations that embrace chatbot technology will be better equipped to deliver exceptional patient care, optimize their operations, and stay ahead in an ever-evolving industry.
**Conclusion**
In conclusion, chatbots are transforming the healthcare industry by offering 24×7 availability, collecting and engaging with patient data, attending to multiple clients simultaneously, providing instant information, and streamlining various healthcare processes. With a wide range of applications, chatbots are revolutionizing the way patients interact with healthcare providers, improving efficiency and enhancing the overall patient experience. As the future unfolds, virtual healthcare assistants will continue to play a crucial role in shaping the delivery of healthcare services, supporting healthcare professionals, and empowering patients to take control of their health and well-being.
| xcubelabs |
1,673,184 | Unlocking Efficiency: A Deep Dive into Redis as an In-Memory Datastore | Introduction: In today’ s world, web applications require a lot of things up and running... | 0 | 2023-11-21T06:18:56 | https://dev.to/bilalulhaque/unlocking-efficiency-a-deep-dive-into-redis-as-an-in-memory-datastore-4n39 | api, website, performance, webdev | 
## Introduction:
In today’ s world, web applications require a lot of things up and running on the server to serve the purpose of users. Unfortunately, many developers might not be aware of factors that could ruin the user experience. The quality of code optimization, server response, and database integration all play crucial roles, and this can vary depending on the chosen framework or programming language. However, developers have the power to boost their application’s performance significantly through optimization. One key optimization is ensuring an efficient database connection for speedy responses. This is where an **In-memory datastore** comes into play.
An in-memory data store is a type of database or data storage system that primarily relies on keeping data in the system’s main memory for data storage and retrieval, in contrast to traditional databases that store data on disk drives. This approach allows for faster data access and retrieval since reading and writing to system’s memory is much quicker than accessing data from disk storage. In-memory data stores are commonly used in various applications, ranging from caching mechanisms to real-time analytics and high-performance computing.
In this article we’ll be looking at one of the most popular in-memory data store **Redis**.

**Redis** is an open-source, in-memory data structure store, used as a distributed, in-memory key-value database, cache, and message broker, with optional durability. Redis supports different kinds of abstract data structures, such as strings, lists, maps, sets, sorted sets, etc.
## Use Cases:
**Caching:** Redis is an ideal choice for establishing a high-performance, in-memory cache to reduce data access latency and boost throughput. Its ability to deliver responses in milliseconds contributes to its impressive speed, and its scalability allows for handling increased loads without substantial backend costs. Utilizing Redis for caching purposes is common in scenarios such as caching database query results, persisting session data, storing web pages, and caching frequently accessed objects like images, files, and metadata.
**Messaging and Queue:** Redis has a great support for Pub/Sub (Publish and Subscribe) along with pattern matching and a diverse set of data structures. This functionality empowers Redis to facilitate high-performance messaging, chat rooms, and server intercommunication. Utilizing Redis List data structure, we’ve implemented a lightweight queue that proves advantageous for applications requiring a dependable message broker. Lists, with their great operations and blocking capabilities, are well-suited for various scenarios where reliability is important.
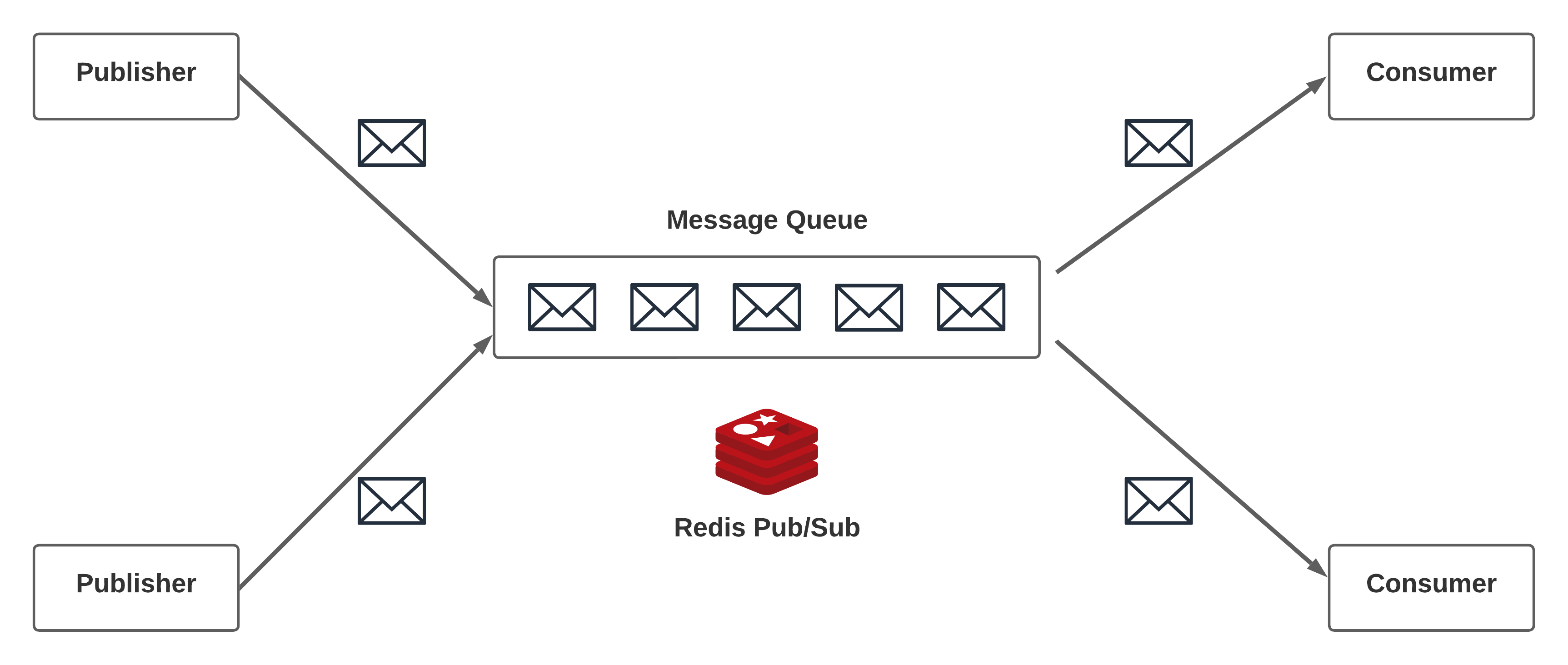
**Session Store:** For scalable web applications, Redis stands out as the optimal selection due to its in-memory support. It delivers sub-millisecond latency, scalability, and resilience essential for handling session data such as session state, credentials, and other critical information.
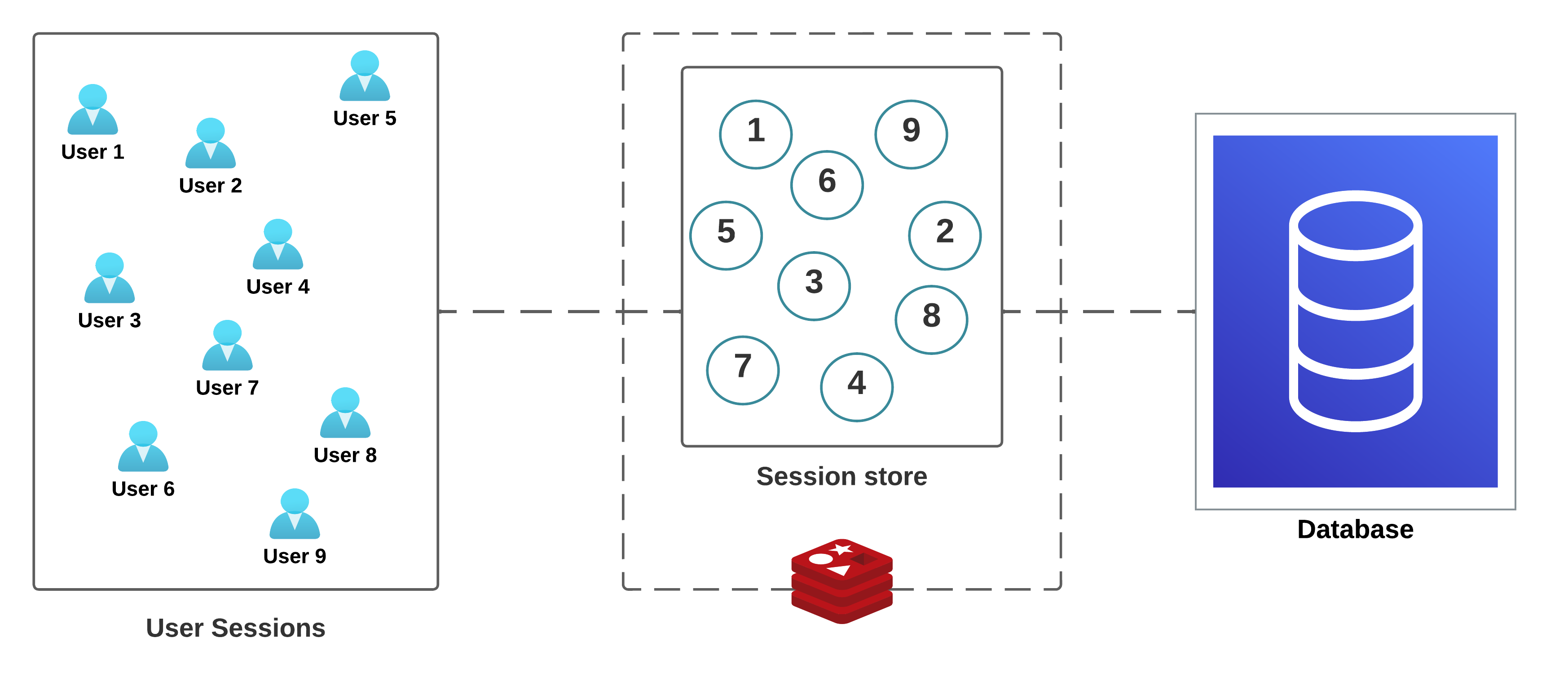
## Different types of Redis Architecture:
Redis provides multiple architectural options to deal with different scalability and fault-tolerance requirements.
**Standalone:**
In its standalone mode, Redis operates as a singular instance, offering a straightforward and uncomplicated deployment choice that is well-suited for smaller-scale applications or development environments. However, it presents a single point of failure, implying that if the instance experiences downtime, the entire Redis system would immediately stop functioning.
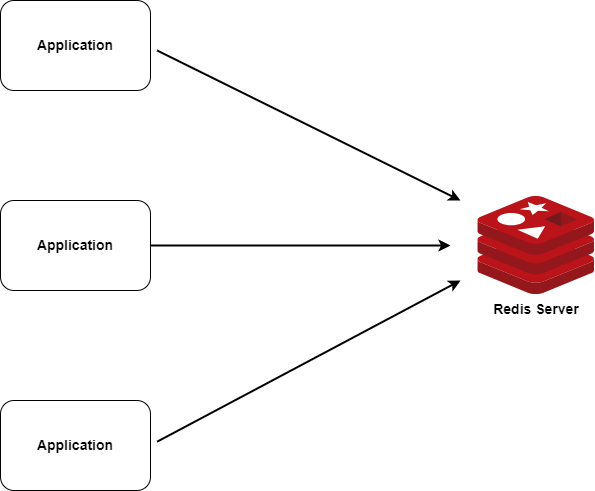
**Master-Slave Replication:**
Redis incorporates master-slave replication, allowing for the existence of multiple instances. In this configuration, one Redis instance serves as the master, managing both read and write operations, while several slave instances replicate data from the master and are exclusively utilized for read operations. This arrangement improves data availability and enhances read scalability.
But only one node can be the master and the number of slaves nodes can be incremented according to the requirement.
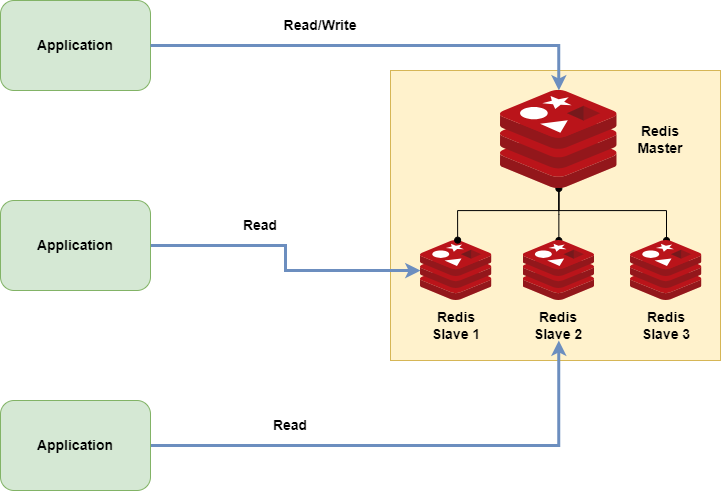
**Redis Sentinel:**
This architecture serves as a high-availability solution that introduces automatic failover and monitoring capabilities to the master-slave replication architecture. In simple terms, in a traditional Master-slave setup, if the master goes down, human intervention is needed to promote one of the slaves to become the new master since write operations are halted. Sentinel streamlines this process by automating the promotion of a slave node to the master, eliminating the need for manual intervention. Redis Sentinel utilizes a special TCP port, typically set to 26379 by default. This port facilitates communication among sentinels, allowing them to monitor the health of the Redis node. If the master node becomes unresponsive via the TCP port, sentinels collaborate, and the one receiving the most votes assumes the leadership role. The leader Sentinel then initiates the promotion of one of the slaves to take over as the new master.
**Redis Cluster:**
Redis Cluster represents a more advanced architecture compared to Master-Slave and Redis Sentinel. It surpasses them in power, robustness, and efficiency, particularly during failovers. Redis Cluster features multiple master nodes, enhancing its overall performance.
In this architecture, data is divided into 16384 hash slots, each assigned to a single master node. The number of hash slots increases with the addition of more master nodes. When a client sends a request to Redis, the request is directed to a specific hash slot based on the shard key provided.
The sharding process involves generating a hash key (shard key) from the key sent to Redis. This shard key determines the slots to which the request should be directed. It’s important to note that each slot functions as a Redis sentinel, enabling automatic recovery of the master node in case of a failure. This design enhances the resilience and reliability of Redis Cluster.
Redis cluster is highly scalable when it comes for large enterprise application since the load is now distributed to the different slots based on sharding and can process more number of request at once.
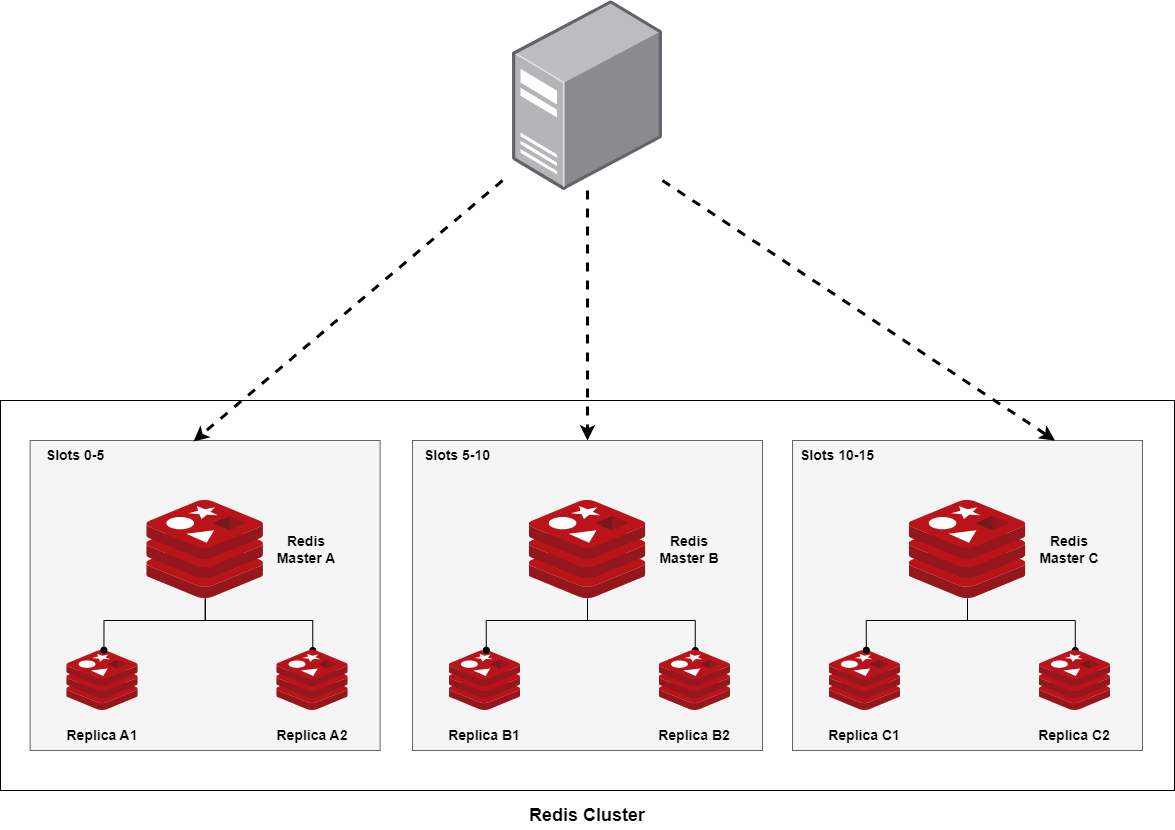
## Conclusion:
In conclusion, Redis is a robust and versatile in-memory data store, renowned for its speed, efficiency, and adaptability. Whether serving as a caching solution or a message broker, Redis excels in providing low-latency access, scalability, and resilience. With features like Pub/Sub, master-slave replication, and Redis Sentinel for high availability, it caters to a wide range of applications. From small-scale to internet-scale deployments, Redis remains a top choice for developers and businesses seeking a reliable and high-performance data management solution. Its simplicity, speed, and flexibility position Redis as a fundamental component in the realm of modern computing. | bilalulhaque |
1,673,236 | IPC ICEoryx mechanism | Hey Reader, My name is Sushma B R, and I am working as Software Engineer at Luxoft India. In this... | 0 | 2023-11-21T07:09:57 | https://dev.to/sushma7373/ipc-iceoryx-mechanism-4md1 | Hey Reader,
My name is Sushma B R, and I am working as Software Engineer at Luxoft India. In this article I will be providing the detailed information towards IPC ICEoryx Mechanism. Luxoft has provided me with multiple opportunity to work on various projects which inspired me to learn the IPC ICEoryx mechanism.
Developed by the Eclipse Foundation, ICEoryx is an essential part of the Eclipse CycloneDX project and an exceptional open source middleware solution specifically designed for real-time and embedded systems. It has a lightweight, high-performance design, making it the best choice in resource-constrained industries such as automotive and robotics. Its main focus is to provide powerful communication features that solidify its position as a trusted and reliable choice for all your real-time communication needs.
**Key Features of ICEoryx IPC:**
**1. Publish-Subscribe Pattern:**
ICEoryx uses a publish-subscribe communication structure that allows components to publish information while other components can subscribe to access that information. This framework is particularly useful in situations where multiple components need to access identical data.
**2. Zero-Copy Mechanism:**
One notable feature of ICEoryx is its zero-copy mechanism, which promotes efficient data sharing by eliminating the need to copy data between processes. Instead, processes can simply reference the same memory location, which greatly reduces data duplication and stress on the entire system.
**3. Multi-Process Communication:**
One of the main features of ICEoryx is its ability to facilitate communication between many processes, making it ideal for complex distributed systems. This is particularly important in areas such as automotive systems, where multiple electronic control units (ECUs) must communicate with each other.
**4. Resource Management:**
One notable feature of ICEoryx is its zero-copy mechanism, which promotes efficient data sharing by eliminating the need to copy data between processes. Instead, processes can simply reference the same memory location, which greatly reduces data duplication and stress on the entire system.
**5. Quality of Service (QoS) Settings:**
Users have the option to configure the QoS settings according to their needs. This requires determining the communication priority, reliability level and other critical parameters that directly affect the performance of the IPC system. With these individual settings, users can ensure optimal system performance.
**6. Platform Independence:**
The beauty of ICEoryx is its ability to work seamlessly with different operating systems and architectures. This inherent flexibility is particularly useful in embedded systems where the use of different hardware platforms is common.
**7. Integration with Eclipse CycloneDX:**
ICEoryx is an important part of the supercharged Eclipse CycloneDX project, which aims to provide a comprehensive platform specifically designed to build software for embedded systems. This seamless integration not only elevates the ecosystem as a whole, but also promotes seamless compatibility with other notable projects under the Eclipse umbrella.
**Use Cases in Automotive:**
**1. Automotive Communication Middleware:**
ICEoryx is the perfect choice for automotive communication middleware. It provides a reliable and efficient IPC solution for in-vehicle communication, ensuring seamless communication between various components including sensors, ECUs and infotainment systems.
**2. Autonomous Driving Systems:**
Effective real-time communication is essential for autonomous driving systems. This is where ICEoryx comes into play. Thanks to the zero-copy mechanism, it is an ideal solution for managing huge amounts of data generated by sensors and distributed processing units.
**3. Electronic Control Units (ECUs):**
In the automotive industry, effective communication is crucial in coordinating the many functions of a vehicle. This is where the innovative lightweight design of ICEoryxand#039; and the ability to facilitate the communication about publishing an order comes into play. These features make it well suited for seamless ECU communication.
**4. Distributed Systems:**
As the use of connected vehicles increases, the demand for distributed systems in automotive applications has increased. And in such scenarios, ICEoryx's ability to facilitate multi-process communication makes it very useful, especially when components are distributed across different parts of the vehicle.
**Challenges and Considerations:**
**1. Learning Curve:**
Development teams can face a learning curve when adding new IPC middleware like ICEoryx. Ensuring proper training and thorough documentation is essential to ensure a smooth integration.
**2. Community Support:**
Although ICEoryx is an open source project, the extent of community support and availability of resources such as tutorials and forums may be more limited than with established IPC solutions.
**3. Integration with Existing Systems:**
When evaluating the use of ICEoryx in the automotive industry, it is important that developers carefully evaluate its compatibility and ease of integration with existing systems and frameworks.
**Conclusion:**
ICEoryx offers an exciting solution for real-time and embedded systems that strategically address the special needs of the automotive industry, where reliable communications are critical. Its zero-copy focus, ability to support a publish-and-subscribe model, and cross-platform compatibility differentiate it from traditional IPC methods. As the automotive industry rapidly moves toward connected and self-driving cars, robust IPC middleware solutions like ICEoryx are expected to have a significant impact on shaping the future of in-vehicle communication systems. | sushma7373 | |
1,673,461 | Some functional utilities | Here are some utilities I use, when I don't want to rely on any external libraries : const curry... | 25,481 | 2023-11-21T11:07:51 | https://dev.to/artydev/some-functional-utilities-3bah | javascript | Here are some utilities I use, when I don't want to rely on any external libraries :
```js
const curry = function (fn) {
const curried = (...args) => {
if (args.length >= fn.length) {
return fn.apply({}, args)
}
else {
return (...vargs) => curried.apply({}, args.concat(vargs))
}
}
return curried
}
const compose =
(...fns) => arg => fns.reduceRight((acc, f) => f(acc), arg);
const pipe =
(...fns) => arg => fns.reduce((acc, f) => f(acc), arg);
const asyncpipe =
(...fns) => arg => fns.reduce((p, fn) => p.then(fn), Promise.resolve(arg));
const pickprop = (prop) => (obj) => obj[prop] ?? null;
const map = (f) => (arr) => arr.map(f);
const filter = (f) => (arr) => arr.filter(f);
```
The function passed to the reduce method is called a **reducer**.
A reducer is a function which has two arguments, the first of type A, the second of type B and the returned type is of type A.
As long as any function has this signature, it can be passed to a reduce method.
| artydev |
1,673,484 | Master React With These 10 Hooks 🔥 | Hooks are a major part of modern React and for that I created a video series explaining the most... | 0 | 2023-11-21T13:17:58 | https://dev.to/chaoocharles/master-react-with-these-10-hooks-5mm | react, webdev, javascript, programming | Hooks are a major part of modern React and for that I created a video series explaining the most important 10 React Hooks in details. Understanding these hook will really help you to level up your react game.
Below are the 10 major react hooks explained with examples.
Enjoy! ✌️
>- [Follow video series on YouTube](https://youtube.com/playlist?list=PL63c_Ws9ecIT9M-legDiBCNUs1vNQsOAa&si=9kq-e-OeB3KnFUZJ)
>- [Subscribe to my YouTube channel] (https://www.youtube.com/c/chaoocharles)
>- [Follow me on twitter](https://twitter.com/ChaooCharles)
## 0. The Rules of Hooks
- Hooks should be called at a top level of a component. Do not call hooks inside conditions, loops or nested functions.
- Hooks are only usable in react `functional components` and `custom hooks`. Do not use hooks in class components.
## 1. useState
The `useState hook` let's you add state variable to a component.
{% youtube tJxFGwHaFxo %}
## 2. useEffect
The `useEffect hook` is use to synchronize a component with an external system (also know as _side effects_). Good examples of side effects are, `data fetching`, `subscriptions/event listeners` and `timer/intervals`.
{% youtube 4rhrWpPDVtE %}
## 3. useCallback
The `useCallback hook` helps you to optimize functions between re-renders.
{% youtube lB-pVjsk2no %}
## 4. useMemo
The `useMemo hook` is used in a similar way as the useCallback hook, only that useMemo is used to optimize values while useCallback is used to optimize functions.
{% youtube pzXcZk5DwZg %}
## 5. useRef
The `useRef hook` is used to create a reference to a value(or element). The `ref` persists across renders and does not cause the component to re-render when its value changes.
{% youtube qe5h6E656ZI %}
## 6. useReducer
The `useReducer hook` is an alternative to useState hook. It is often favored for more complex state management scenarios.
{% youtube 9R4xwI7AbkQ %}
## 7. useContext
The `useContext hook` is used to consume a **context.** Context in React is a way to pass data through the component tree without having to pass props manually at every level. useContext hook together with the react context are used to manage some form of global state, e.g a user/auth state.
{% youtube cvzTMogKysY %}
## 8. useId
The `useId hook` is used to generate unique IDs that can be passed to accessibility attributes.
{% youtube wQwc4ewus-k %}
## 9. use (new)
The `use hook` lets you read the value of a resource like a **Promise** or **context**. This hook is unique because it does not follow all the rules of hooks. You can call it inside loops or even conditions like in `if else` statements.
{% youtube b0ClttC6d3I %}
## 10. useTransition
The `useTransition hook` lets you update the state without blocking the UI.
{% youtube IoVOVCq4WS8 %}
| chaoocharles |
1,673,608 | Future Real Estate - All You Need To Know | The world of real estate investing is about to undergo a revolutionary change thanks to the amazing... | 0 | 2023-11-21T13:42:32 | https://dev.to/ardenjoshpine/future-real-estate-all-you-need-to-know-3l9m | realestate, business, blockchain, cryptocurrency | The world of real estate investing is about to undergo a revolutionary change thanks to the amazing technology of blockchain. Real estate tokenization is transforming the industry and offers many benefits to investors eager to expand into this new and exciting space.
Now let's talk about the amazing benefits that tokenization of real estate assets brings.
**Benefits of Real Estate Tokenization for Investors**
**[Tokenization of Real Estate](https://bit.ly/49JifBT)** assets has immense potential to transform the traditional investment paradigm. Here is a list of some benefits,
- Increased liquidity and accessibility
- Global investment opportunities
- Fractional ownership, increased flexibility
- Increased transparency and security
- Accessibility to a diverse investor base
**1. Improving Liquidity and Accessibility**
Tokenization of real estate assets opens up a whole new level of liquidity and accessibility for investors. Unlike traditional real estate investments, which often require large capital investments and long holding periods, tokenized real estate allows for fractional ownership.
Investors can buy small stocks and tokens, lowering the barrier to entry and allowing for diversification across multiple assets. Additionally, investors can easily buy and sell these tokens on digital platforms, providing unprecedented liquidity.
**2. Global Investment Opportunities**
Tokenization significantly expands investment opportunities for real estate enthusiasts. By dividing real estate into smaller shares, investors can gain favorable exposure to both local and global markets. This new accessibility allows investors to easily diversify their portfolios across locations, asset types, and risk profiles. Whether it’s a commercial property in New York or a villa in Bali, tokenization makes global real estate investing a reality.
**3.Fractional ownership, increased flexibility**
Tokenization allows investors to choose specific assets in the real estate market. Fractional ownership is an important advantage because it allows investors more flexibility as they can fund only the shares they need. You will be freed from the hassle and hassle of real estate management that comes with owning real estate. Tokenization allows investors to carefully select real estate that fits their investment goals and exit strategy.
**4. Enhanced Transparency and Security**
Blockchain technology, the backbone of tokenization, provides a high level of immutability, transparency, and security. Each property token is stored securely on the blockchain, creating an indisputable record of ownership. This revolutionary level of transparency reduces fraudulent activities, increases trust between buyers and sellers, and streamlines property transactions. Additionally, the tokenization process ensures compliance with regulatory requirements, minimizing risks for both investors and property owners.
**5. Gain access to a diverse investor base**
Tokenization of real estate democratizes investment opportunities and makes them accessible to a wider range of investors. Historically, real estate investing has generally been limited to institutional investors and wealthy individuals. However, tokenization opens the door for individual investors to participate in the lucrative real estate market while reducing their financial obligations.
By pooling resources through crowdfunding platforms, investors can leverage their collective purchasing power to gain access to high-quality real estate. The benefits of this new practice are significant, providing investors with liquidity, global opportunity, flexibility, transparency and accessibility. As the industry continues to evolve and regulatory frameworks adapt to this new technology, it is important for investors to stay informed and take advantage of the favorable prospects that tokenized real estate offers.
**Get ready for the future of real estate investing, reimagined through the power of tokenization. If you have any queries, check out here>> https://bit.ly/3RdZpvR**
| ardenjoshpine |
1,673,639 | test3 | test post 1 | 0 | 2023-11-21T14:19:30 | https://dev.to/anastasiyatest/test3-mgn | test post
1. 1
| anastasiyatest | |
1,673,950 | Why do we NOLOCK in SQL server with an example | In SQL Server, the NOLOCK hint, also known as the READUNCOMMITTED isolation level, allows a SELECT... | 25,454 | 2023-11-21T17:47:18 | https://dev.to/sardarmudassaralikhan/why-do-we-nolock-in-sql-server-with-an-example-447c | sql, sqlserver, database, softwaredevelopment | In SQL Server, the `NOLOCK` hint, also known as the `READUNCOMMITTED` isolation level, allows a SELECT statement to read data from a table without acquiring shared locks on the data. This means it can potentially read uncommitted changes made by other transactions, which can lead to what's called "dirty reads."
Here's an example:
Let's say you have a table named `Employee` with columns `EmployeeID` and `EmployeeName`.
```sql
CREATE TABLE Employee (
EmployeeID INT,
EmployeeName VARCHAR(100)
);
INSERT INTO Employee (EmployeeID, EmployeeName)
VALUES (1, 'Alice'), (2, 'Bob'), (3, 'Charlie');
```
Now, if two transactions are happening concurrently:
Transaction 1:
```sql
BEGIN TRANSACTION
UPDATE Employee
SET EmployeeName = 'David'
WHERE EmployeeID = 1;
```
Transaction 2:
```sql
SELECT EmployeeName
FROM Employee WITH (NOLOCK)
WHERE EmployeeID = 1;
```
If Transaction 2 uses `WITH (NOLOCK)` when reading the `Employee` table, it might read the uncommitted change made by Transaction 1 and retrieve `'David'` as the `EmployeeName` for `EmployeeID` 1. However, if Transaction 1 rolled back the update, Transaction 2 would have obtained inaccurate or non-existent data, resulting in a "dirty read."
Using `NOLOCK` can be helpful in scenarios where you prioritize reading data speed over strict consistency. However, it's essential to be cautious since it can lead to inconsistent or inaccurate results, especially in critical transactional systems.
Other considerations like potential data inconsistencies, increased chance of reading uncommitted data, and potential performance implications should be weighed before using `NOLOCK`. In many cases, alternative isolation levels or database design improvements might be more suitable to achieve the desired performance without sacrificing data integrity. | sardarmudassaralikhan |
1,674,084 | Supercharging DevOps: Streamlining Cloud Infrastructure with Azure Developer CLI | This fourth iteration of my cloud-native project, https://github.com/dfberry/cloud-native-todo, added... | 0 | 2023-11-21T20:41:46 | http://dfberry.github.io/2023-11-21-cloud-native-devops.md | azure, cloudnative, devops, azuredevelopercli | ---
title: Supercharging DevOps: Streamlining Cloud Infrastructure with Azure Developer CLI
published: true
date: 2023-11-21 00:00:00 UTC
tags: Azure, Cloudnative,DevOps,AzureDeveloperCLI
canonical_url: http://dfberry.github.io/2023-11-21-cloud-native-devops.md
---
This [fourth iteration](https://github.com/dfberry/cloud-native-todo/tree/004-devops-azure) of my cloud-native project, [https://github.com/dfberry/cloud-native-todo](https://github.com/dfberry/cloud-native-todo), added the steps of creating the cloud resources (provisioning) and pushing code to those resources (deployment).
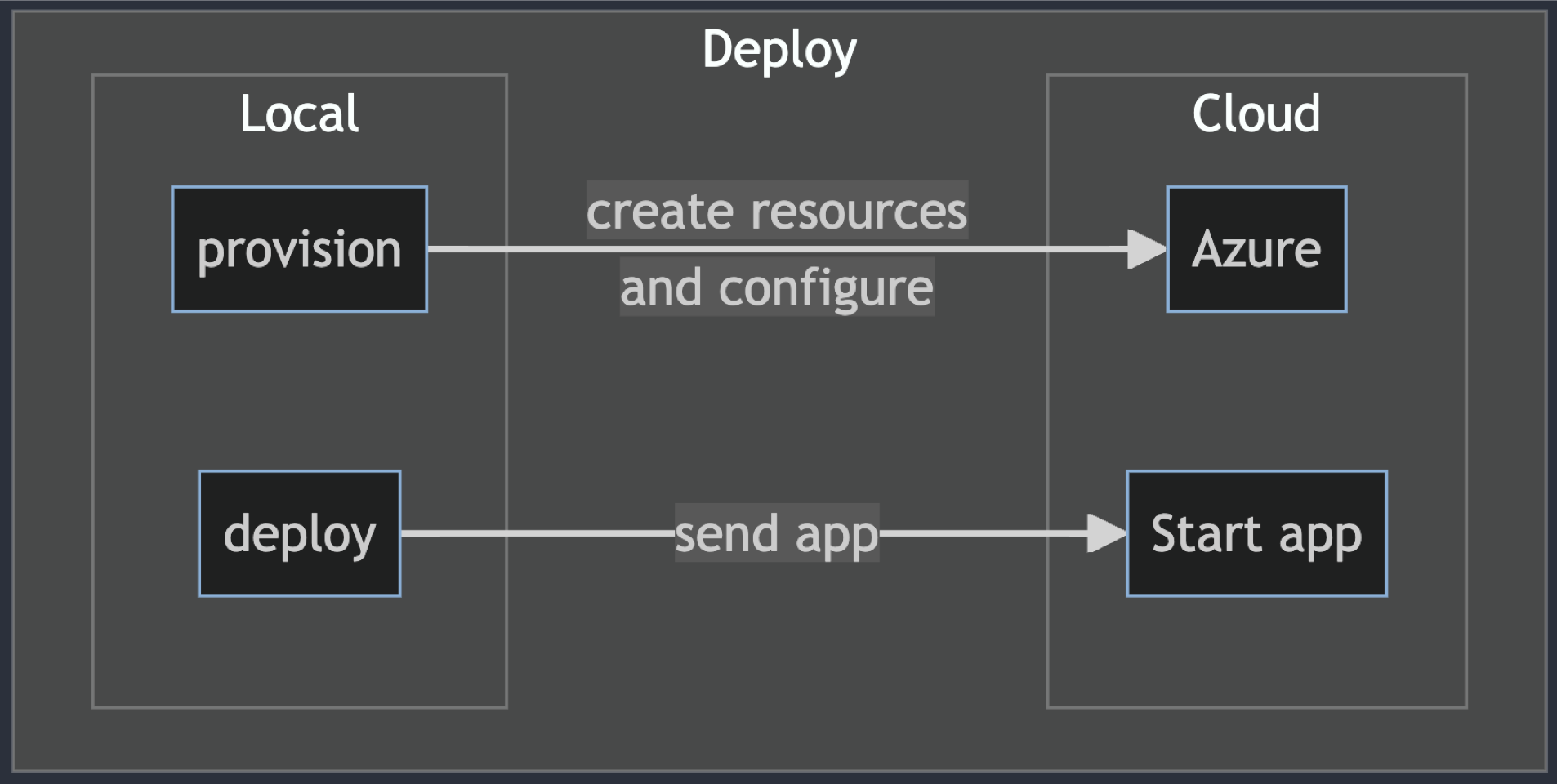
[**YouTube playlist of videos**](https://bit.ly/3uv06rx)
For this cloud-native project, I knew there would be a Docker image of the project in a registry but I wasn't sure of the fastest steps to create the image from the repository, push it to the registry or how it was pulled into the hosting environment. The authentication part to push to a registry and from which tool is usually what takes a minute or two. Anything that improved that auth flow would be welcome.
Sticking with tools I know to go as fast as possible, I used [Azure Developer CLI](https://learn.microsoft.com/en-us/azure/developer/azure-developer-cli/) for the infrastructure.
## Install Azure Developer CLI as a dev container feature in Visual Studio Code[](#install-azure-developer-cli-as-a-dev-container-feature-in-visual-studio-code "Direct link to Install Azure Developer CLI as a dev container feature in Visual Studio Code")
Installation of Azure Developer CLI into dev containers is easy with a feature. [Find the feature](https://containers.dev/features) and add it to the `./.devcontainer/devcontainer.json`.
```
// Features to add to the dev container. More info: https://containers.dev/features.
"features": {
"ghcr.io/azure/azure-dev/azd:latest": {}
},
```
Use the Visual Studio Code command palette to select **Dev Containers: Rebuild and reopen in container**. Check the version of the Azure Developer CLI installed with the following command:
```
azd version
```
The response:
```
azd version 1.5.0 (commit 012ae734904e0c376ce5074605a6d0d3f05789ee)
```
## Create the infrastructure code with Azure Developer CLI[](#create-the-infrastructure-code-with-azure-developer-cli "Direct link to Create the infrastructure code with Azure Developer CLI")
I've done most of this work before in other projects. I didn't really expect to learn anything new. However, [GitHub Universe 2023](https://www.youtube.com/watch?v=NrQkdDVupQE&list=PL0lo9MOBetEGF_pCQVCc_3z36ihKSolLC) and [Microsoft Ignite 2023](https://www.youtube.com/watch?v=FZhbJZEgKQ4&list=PLFPUGjQjckXE2cf8RBSjFYUUq8HkM_3zW) both took place between [iteration 003](https://dfberry.github.io/2023-11-11-cloud-native-api.md) and my start on this iteration, 004. While I still used [Copilot Chat](https://docs.github.com/en/copilot) as my pair programming buddy, I also leaned into any new feature I heard of from these two industry conferences. The Azure Developer CLI's `azd init` feature had an update (version 1.50) and I wanted to see what it would do. It asked Copilot Chat a couple of questions then it created the required files and folders. It took hours of Bicep development and compressed it into 30 seconds. Amazing!!!
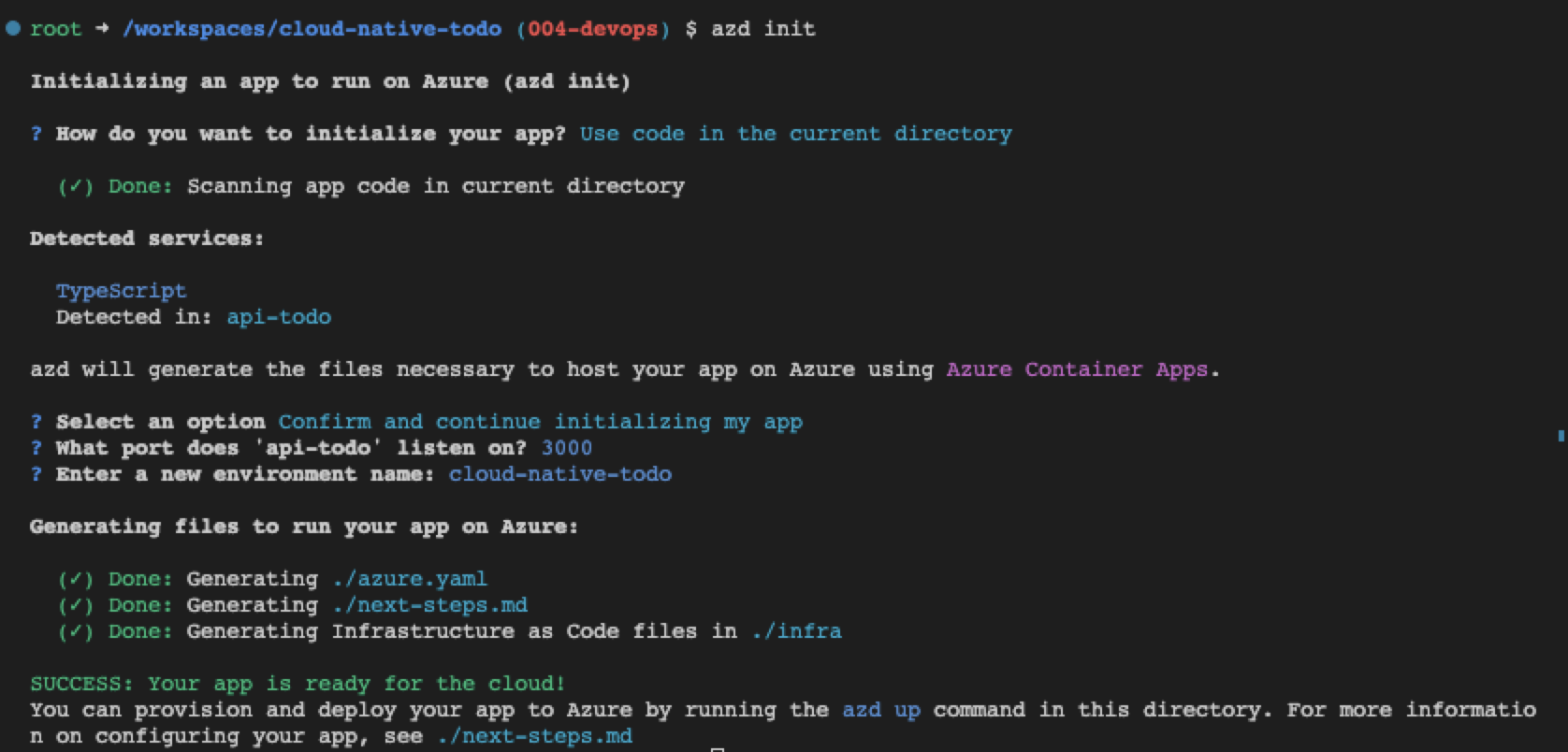
Did it correctly configure the infrastructure for this project? Yes. When I add a second app to this project, further down the road, I'll rerun `azd init` in a new branch.
The `azd init` process created a `./next-steps.md` which was a huge help in validation.
## Get cloud resource environment variables from Azure Developer CLI[](#get-cloud-resource-environment-variables-from-azure-developer-cli "Direct link to Get cloud resource environment variables from Azure Developer CLI")
The [next steps](https://github.com/dfberry/cloud-native-todo/blob/main/next-steps.md) covered environment variables because your project may need access to cloud resource secrets, connection strings, resource names, database names, and other settings created during provisioning to complete deployment tests. Azure Developer CLI gives you access this list of environment variables with `azd env get-values` to create your own `.env` file for your project.
I created a Bash script to get those values so I could test the endpoint.
```
#!/bin/bash
# Usage: <script> <path-for-env-file>
# Example: ./scripts/postdeploy.sh "./api-todo-test"
echo "postdeploy.sh"
set -x
echo "Getting param 1"
ENV_PATH="$1/.env" || ".env"
echo "ENV_PATH: $ENV_PATH"
echo "Remove old .env file"
rm -f $ENV_PATH
echo "Getting values from azd"
azd env get-values > $ENV_PATH
# Check if the .env exists
if [ ! -f "$ENV_PATH" ]; then
echo "*** .env file not found at $1"
exit 1
fi
# Run the npm test command
echo "Run test at $1"
cd "$1" && npm test
echo "Test completed"
exit 0
```
This script is called in the `./azure.yaml` file in the post deployment hook:
```
postdeploy:
shell: sh
run: |
echo "***** Root postdeploy"
./scripts/postdeploy.sh "./api-todo-test"
```
## Develop containers for cloud-native apps[](#develop-containers-for-cloud-native-apps "Direct link to Develop containers for cloud-native apps")
When I tried to use Azure Developer CLI to provision the project with `azd up`, the provision failed because the CLI couldn't find the tools in the environment to build and push the image to the Azure Container Registy.

While Docker isn't specifically required to run Azure Developer CLI, it's logical to assume if I intend to create images, I need the tools to do that. Copilot advised me to create a new `Dockerfile` for the dev container. This would have added another level of complexity and maintenance. Instead, I chose to use a dev container feature for [docker-in-docker](https://github.com/devcontainers/features/tree/main/src/docker-in-docker) which leaves that complexity to the owner of the feature.
## Fix for dev container won't start[](#fix-for-dev-container-wont-start "Direct link to Fix for dev container won't start")
I love Docker and I love dev containers but occasionally containers just don't start and the error messages are so low-level that they generally aren't helpful. The whole point of containers is that they consistently work but I develop on a Mac M1 and containers sometimes don't work well with M1.
When I added the docker-in-docker feature to the Visual Studio dev container and rebuilt the container, the container wouldn't start. I changed the configs and looked at the order of features, searched StackOverflow and GitHub and chatted with Copilot. Nothing helped. Using Visual Studio Code to rebuild the dev container without the cache didn't fix it either. Which is when I knew it was my environment.
The fix was to stop the dev container, delete all containers, images, and volumes associated with the dev container and start over completely. I didn't have any other projects in dev containers so I removed everything.
```
# Delete all containers
docker rm -f $(docker ps -a -q)
# Delete all images
docker rmi -f $(docker images -a -q)
# Delete all volumes
docker volume rm $(docker volume ls -q)
```
## Deploy Express.js container image to Azure[](#deploy-expressjs-container-image-to-azure "Direct link to Deploy Express.js container image to Azure")
Restart the dev container and the dev container started. At this point, I tried to provision again with `azd up` (provision & deploy) which succeeded. It's impressive how the services just work together without me having to figure out how to pass integration information around.
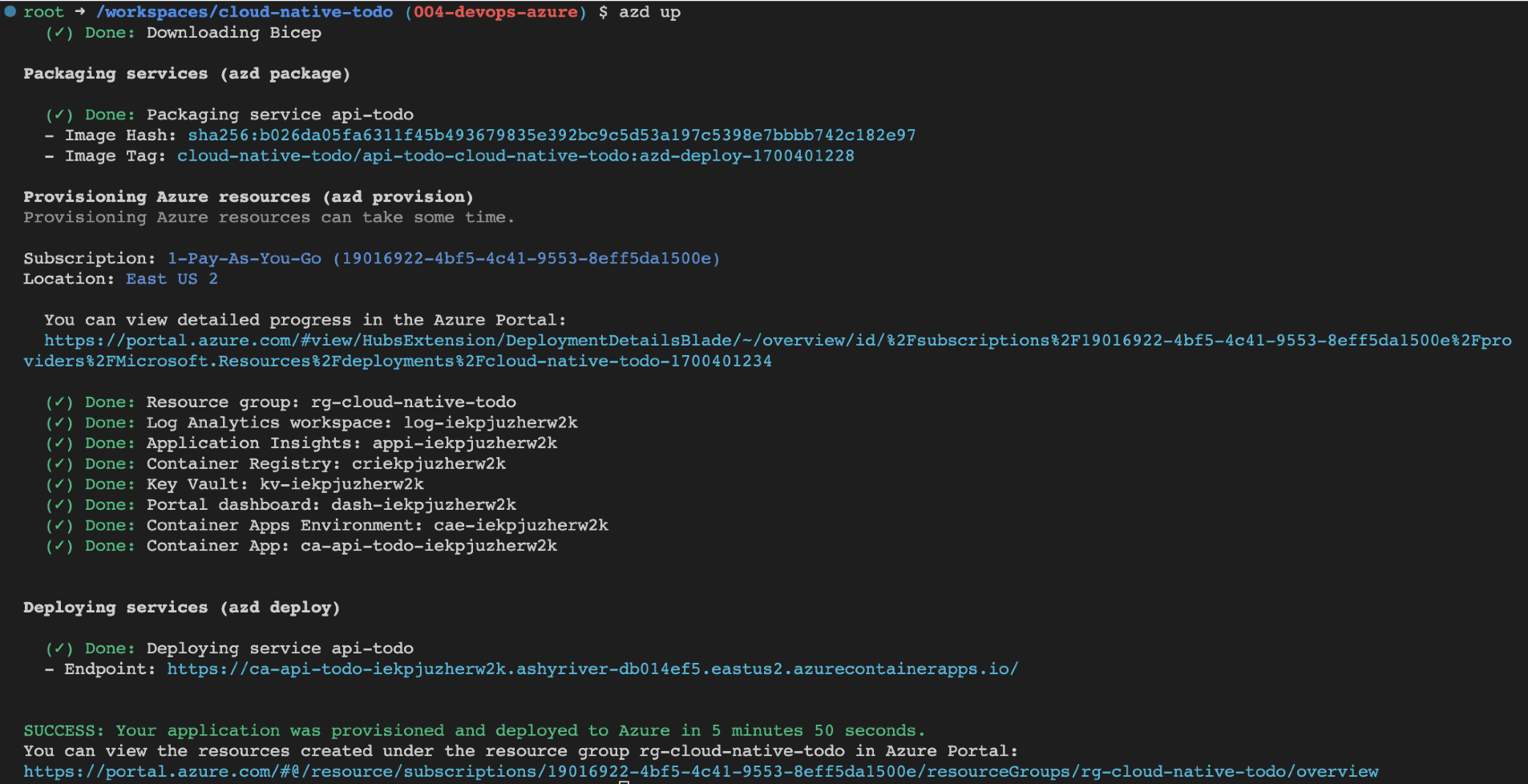
Then I tried the endpoint for the API which is shown at the end of the output when `azd up` is done. I didn't get my project from the endpoint. The "Hello World" for containers responded at the endpoint which meant provisioning worked but deployment failed.
## Find container image deployment error in Azure portal deployment log[](#find-container-image-deployment-error-in-azure-portal-deployment-log "Direct link to Find container image deployment error in Azure portal deployment log")
The Azure resource group, the logical unit for all the resources in the infrastructure, has a deployment log. The Container App showed a failed status. The code is still a very simple Express.js app so the issue had to also be simple. I checked the deployment logs in the Azure portal and found the app's start script pointed to the wrong file.
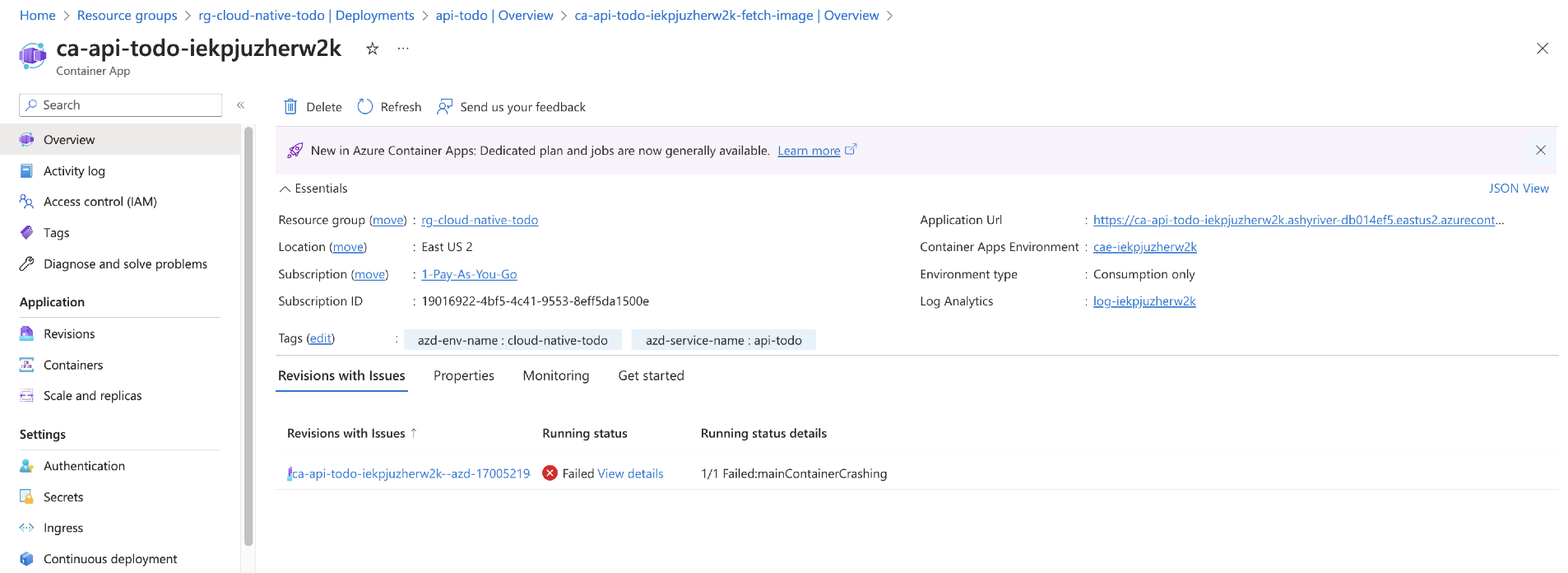
Following the error to the log shows the issue that the start file is incorrect.
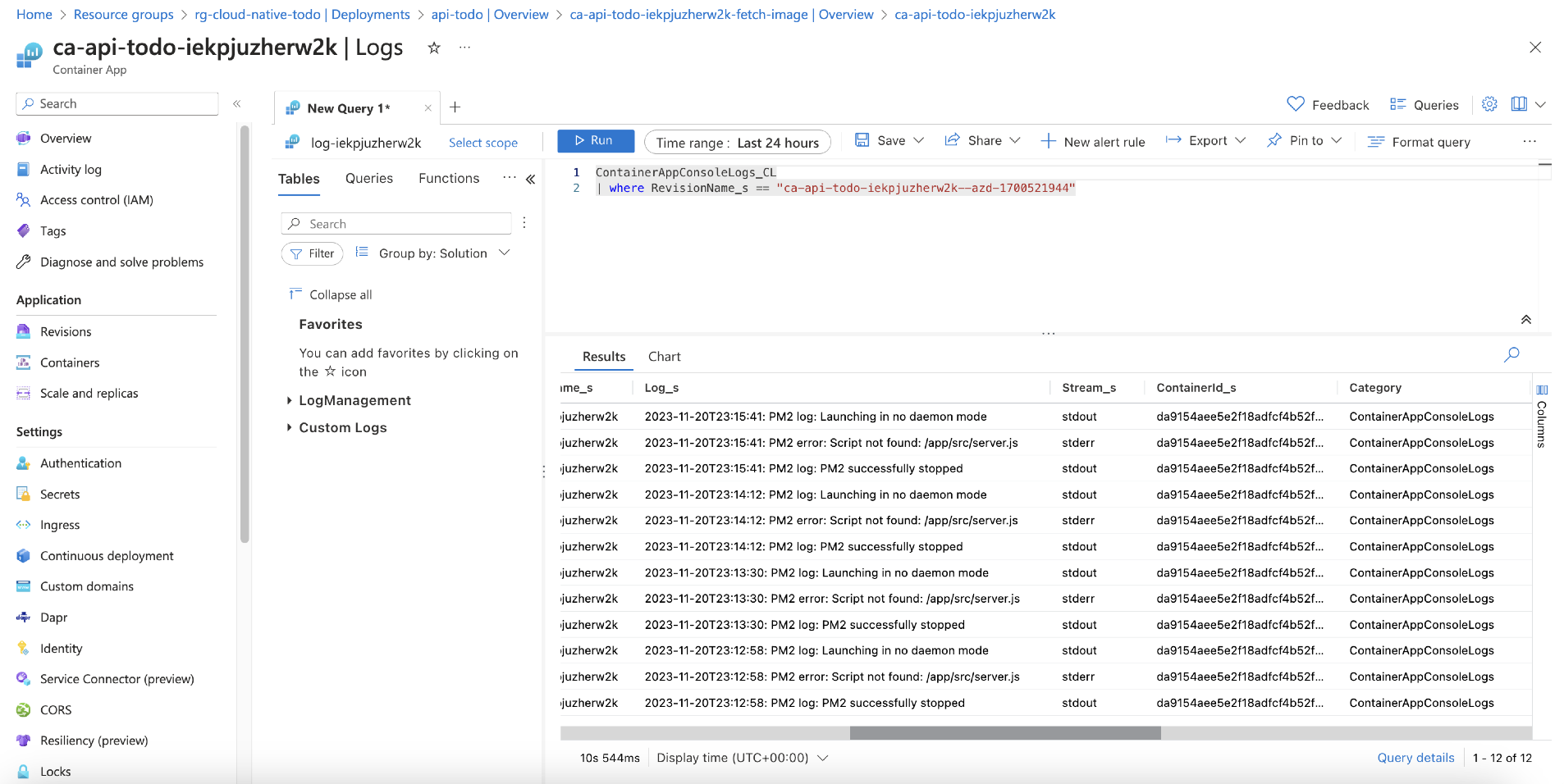
A quick fix to the Dockerfile.
```
# Wrong cmd
CMD [ "pm2-runtime", "start", "server.js" ]
# Correct cmd
CMD [ "pm2-runtime", "start", "dist/start.js" ]
```
Then `azd up` and the correct endpoint worked.
## Add a version header to source code[](#add-a-version-header-to-source-code "Direct link to Add a version header to source code")
While testing the deployment, I wanted to add versioning to the app so I knew changes to the project were displayed at the endpoint. The root request returns the version found in the `./api-todo/package.json`, and the APIs return a `x-api-version` header with the value.
```
// eslint-disable-next-line @typescript-eslint/ban-ts-comment
// @ts-ignore: Ignoring TS6059 as we want to import version from package.json
import { version } from '../../package.json';
export function setVersionHeader(_, res, next) {
res.setHeader('x-api-version', version);
next();
}
```
The **curl** request returns the header when using `--verbose`.
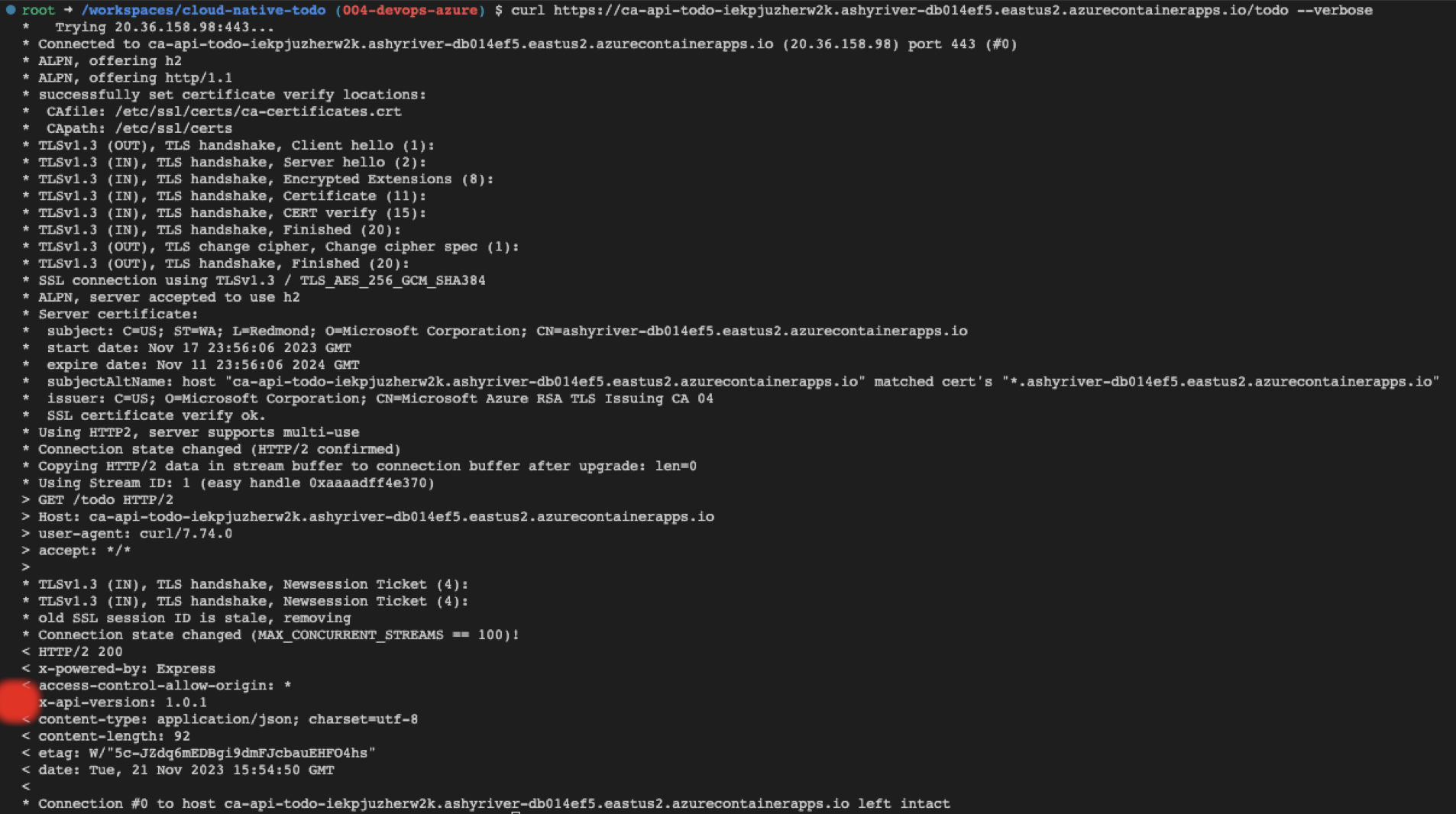
## Add Playwright test to validate API[](#add-playwright-test-to-validate-api "Direct link to Add Playwright test to validate API")
When I added playwright to the dev container and rebuilt the dev container, the container started but Playwright and its dependencies took up too much room. I increased the size of my container and limited by testing to Chrome. I also added the installation in the `./.devcontainer/post-create-command.sh` script. By adding the installation here, when the container opens, I can see if it has enough room for a big dependency like Playwright and its browsers.
```
# ./.devcontainer/post-create-command.sh
#! /bin/bash
sudo apt-get clean
sudo apt update
npm i -g npm@latest
npm install
chmod -R +x ./scripts
npx playwright install --with-deps
echo "Node version" && node -v
echo "NPM version" && npm -v
echo "Git version" && git -v
echo "Docker version" && docker --version
```
The Playwright for the API tests the new header and the returned array of todos.
```
import { test, expect } from '@playwright/test';
import dotenv from 'dotenv';
dotenv.config();
const API_URL = process.env.API_TODO_URL || 'http://localhost:3000';
console.log('API_URL', API_URL);
import { version } from '../../api-todo/package.json';
test.use({
ignoreHTTPSErrors: true, // in case your certificate isn't properly signed
baseURL: API_URL,
extraHTTPHeaders: {
'Accept': 'application/vnd.github.v3+json',
// Add authorization token to all requests.
'Authorization': `token ${process.env.API_TOKEN}`,
}
});
test('should get all todos', async ({ request }) => {
const response = await request.get(`/todo`);
expect(response.ok()).toBeTruthy();
// Validate the x-api-version header
const headers = response.headers();
expect(headers).toHaveProperty('x-api-version');
expect(headers['x-api-version']).toEqual(version);
// Validate the response body
const todos = await response.json();
expect(Array.isArray(todos)).toBeTruthy();
expect(todos.length).toEqual(3);
});
```
Run the test from the workspace with `npm run test --workspace=api-todo-test` and see the test succeeded.
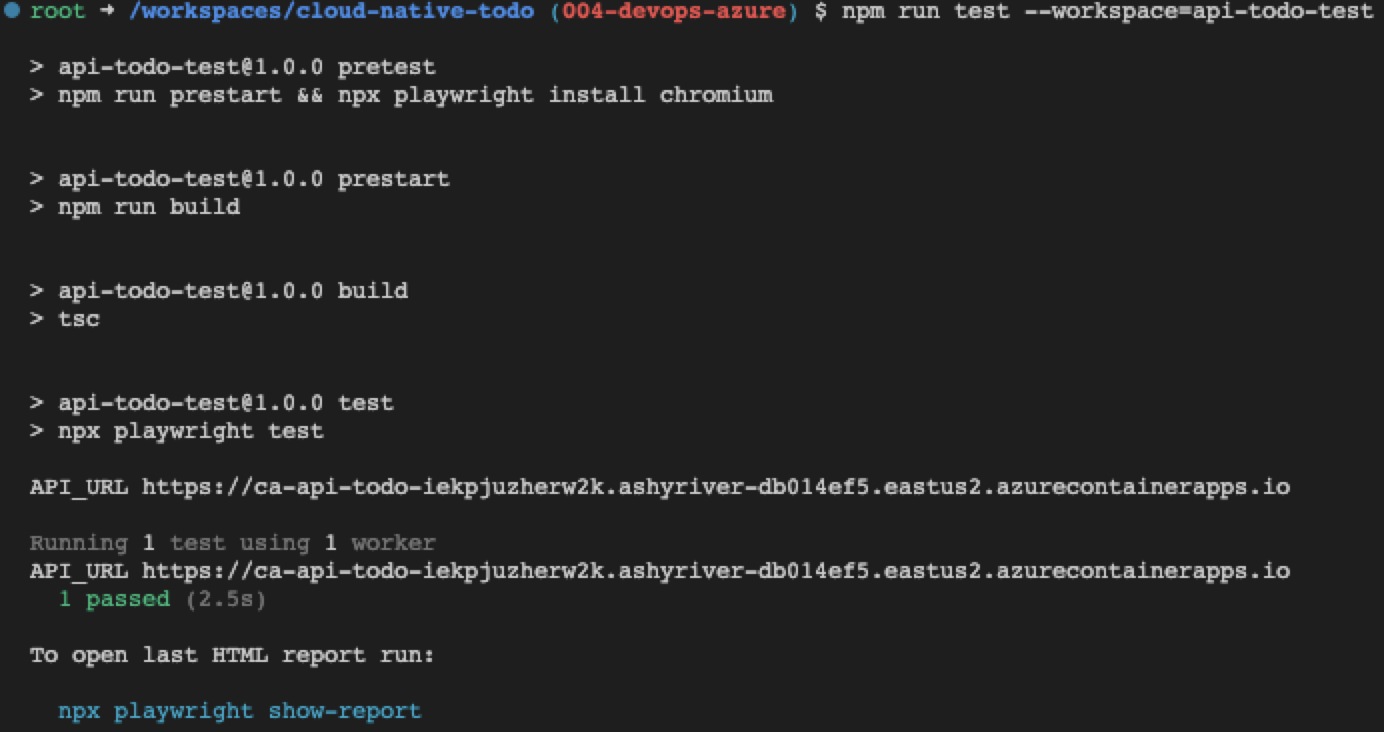
## Most fun - time savings[](#most-fun---time-savings "Direct link to Most fun - time savings")
The best part about this project is the tooling. I can spend less time and enjoy that time more.

Currently Copilot shines with technologies that have a lot of Internet coverage including docs and troubleshooting. For this particular iteration, the only place Copilot didn't help was the annoying Docker issue when the dev container wouldn't start after adding the docker-in-docker dev container feature.
## Wish list item #1 - `azd test`[](#wish-list-item-1---azd-test "Direct link to wish-list-item-1---azd-test")
While Azure Developer CLI provided provisioning and deployment, it didn't add testing. This seems like a natural next step for the project. It knows what the stack is because it created the infrastructure to support it. And it knows the endpoints because it displays them at the end of the deployment. Adding API tests seems within the tool's ability someday.
## Wist list item #2 - docker-in-docker[](#wist-list-item-2---docker-in-docker "Direct link to Wist list item #2 - docker-in-docker")
Since the infrastructure required containers and the environment had the `.devcontainer` folder, adding docker-in-docker as a dev container feature is probably something Azure Developer CLI can fix in the future...perhaps a YAML snippet for the dev container feature in the `./next-steps.md`:
```
"features": {
"ghcr.io/azure/azure-dev/azd:latest": {},
"ghcr.io/devcontainers/features/docker-in-docker:1":{}
},
```
## Tips[](#tips "Direct link to Tips")
There were a few things I found useful that I use moving forward in my development in the [Tips list](https://github.com/dfberry/cloud-native-todo).
## Results for 004 - create resources and deploy code[](#results-for-004---create-resources-and-deploy-code "Direct link to Results for 004 - create resources and deploy code")
Once again Copilot saved a lot of time but it took backseat to the amazing work Azure Developer CLI provided with the entire DevOps flow. And notice there wasn't any auth flow for the Container registry to deal with when pushing images. That was all wrapped up in the Azure Developer CLI auth. Another time saver. | dfberry |
1,674,188 | Is Sam Altman’s Hiring at Microsoft Going to Make an Unveiling Change in the Industry? | Sam Altman’s recruitment at Microsoft has stirred a buzz in the tech world, sparking curiosity about... | 0 | 2023-11-21T23:10:22 | https://dev.to/muhtalhakhan/is-sam-altmans-hiring-at-microsoft-going-to-make-an-unveiling-change-in-the-industry-ggk | news, startup, openai, microsoft |
Sam Altman’s recruitment at Microsoft has stirred a buzz in the tech world, sparking curiosity about the potential transformation it might usher in. This article delves into the details surrounding this significant move, analyzing its potential impact, Altman’s background, and the implications for both Microsoft and the broader industry.
[Read More!](https://muhtalhakhan.medium.com/is-sam-altmans-hiring-at-microsoft-going-to-make-an-unveiling-change-in-the-industry-7d175dd7b425) | muhtalhakhan |
1,674,249 | Working through the fast.ai book in Rust - Part 4 | Introduction In Part 3, we covered creating Tensors of our images, and loading them up... | 25,448 | 2023-11-22T01:22:14 | https://dev.to/favilo/working-through-the-fastai-book-in-rust-part-4-1ed4 | rust, machinelearning, deeplearning, dfdx | ---
series: Working through the fast.ai book in Rust
---
## Introduction
In [Part 3](https://dev.to/favilo/working-through-the-fastai-book-in-rust-part-3-cdl), we covered creating Tensors of our images, and loading them up into the device we're performing our matrix multiplication on.
In this part, I want to go over actually constructing the ResNet-34 model that the fast.ai book uses.
This is more difficult than it seems, because in addition to loading the weights from the internet, we also need to figure out how to cut off the last few layers, and add on some new layers that will give us our new categories.
The original model was trained on 1000 different categories, but in this first chapter, we're just determining if it is a cat or not. And the output Tensor is size 2.
So join me on this journey of discovery.
## Let's build the model
First off, we need to enable support for convolutions. Convolutions take a group of pixels, in like a square around a central pixel, and convolve them into a single value. This is a fun relatively deep concept in math. I found [this 3blue1brown video](https://www.youtube.com/watch?v=KuXjwB4LzSA) to be very approachable and entertaining.
Convolutions in `dfdx` are, unfortunately, only available on the nightly rust compiler. So first things first, let's enable the `nightly` channel.
```toml
[toolchain]
channel = "nightly"
```
Now I'm going to cheat a little. The lovely creators of `dfdx` left [an example of the ResNet-18](https://github.com/coreylowman/dfdx/blob/v0.13.0/examples/nightly-resnet18.rs) structure in their repo. This isn't exactly what I need for ResNet-34, but it's pretty close, and it gives us a great jumping-off point.
So let's get started by stealing that code. I'm going to make a simple change and add a new `type` definition for the `Tail` of the structure. I plan to use this to change the shape of the final layers for re-training the model on different classes.
```rust
use dfdx::prelude::*;
type BasicBlock<const C: usize> = Residual<(
Conv2D<C, C, 3, 1, 1>,
BatchNorm2D<C>,
ReLU,
Conv2D<C, C, 3, 1, 1>,
BatchNorm2D<C>,
)>;
type Downsample<const C: usize, const D: usize> = GeneralizedResidual<
(
Conv2D<C, D, 3, 2, 1>,
BatchNorm2D<D>,
ReLU,
Conv2D<D, D, 3, 1, 1>,
BatchNorm2D<D>,
),
(Conv2D<C, D, 1, 2, 0>, BatchNorm2D<D>),
>;
type Head = (
Conv2D<3, 64, 7, 2, 3>,
BatchNorm2D<64>,
ReLU,
MaxPool2D<3, 2, 1>,
);
pub type Tail<const NUM_CLASSES: usize> = (AvgPoolGlobal, Linear<512, NUM_CLASSES>);
pub type Resnet18<const NUM_CLASSES: usize> = (
Head,
(BasicBlock<64>, ReLU, BasicBlock<64>, ReLU),
(Downsample<64, 128>, ReLU, BasicBlock<128>, ReLU),
(Downsample<128, 256>, ReLU, BasicBlock<256>, ReLU),
(Downsample<256, 512>, ReLU, BasicBlock<512>, ReLU),
Tail<NUM_CLASSES>,
);
```
Now, if you're anything like me, this is a bunch of incomprehensible nonsense. But luckily, we don't have to worry about why all these things exist, we just need to understand the basic structure.
For understanding what everything does, I found that [Chapter 14](https://github.com/fastai/fastbook/blob/master/14_resnet.ipynb) of the fast.ai book contains a wealth of information about the exact structure of what goes into a ResNet model. But that doesn't help us much right now, we're only on Chapter 1!
So in my search for how to understand the vague reasons for the large parts of this, and in particular, how to change this to ResNet-34, and even larger models; I went searching for the weights for the ResNet models, and I landed on the Hugging Face website. This is an awesome resource, and it definitely has the weights we need, but it _also_ had a diagram of the structure of the layers of this model in particular. In the model card of the [ResNet-34](https://huggingface.co/microsoft/resnet-34) model, I found this diagram.
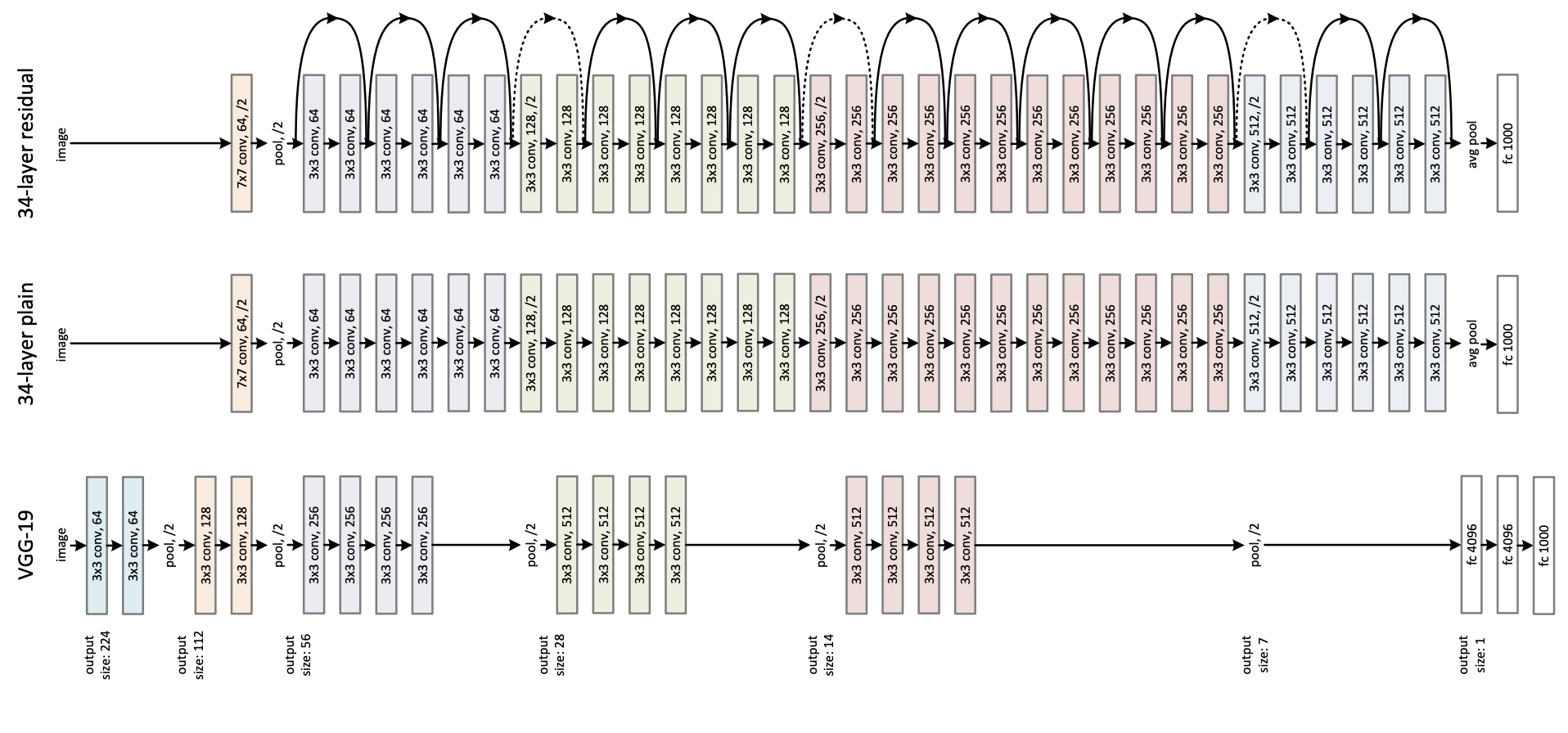
Well, I was able to connect the dots, and I noticed the `Residual` words in the ResNet-18 types. The top diagram in that image is _almost_ describing the `BasicBlock` and `Downsample` parts of this code. The 4 tuples between `Head` and `Tail` line up almost perfectly with those colorful blocks.
So `BasicBlock` corresponds to the first image. It's a pair of convolution layers, evidently separated by a `ReLU` layer, whatever that is. And `Downsample` must correspond to the second image with the dashed line. It looks like it takes the `64`s to `128`s, and that looks like what this line is doing.
```rust
(Downsample<64, 128>, ReLU, BasicBlock<128>, ReLU),
```
Now, the difference seems to be just the number of `BasicBlock`s. ResNet-18 has 4 groups with 2 blocks in each group. But ResNet-34 seems to have 4 groups, with 3 in the first, then 4, then 6, then finally 3.
I still wasn't convinced, and I didn't trust my basic counting skills, so I went searching for how the `fastai` library defines the `resnet34` model. That lead me to [this code](https://pytorch.org/vision/0.9/_modules/torchvision/models/resnet.html#resnet34) in the `pytorch` library. And sure enough, there are those numbers again!
```python
def resnet18(pretrained: bool = False, progress: bool = True, **kwargs: Any) -> ResNet:
return _resnet('resnet18', BasicBlock, [2, 2, 2, 2], pretrained, progress,
**kwargs)
def resnet34(pretrained: bool = False, progress: bool = True, **kwargs: Any) -> ResNet:
return _resnet('resnet34', BasicBlock, [3, 4, 6, 3], pretrained, progress,
**kwargs)
def resnet50(pretrained: bool = False, progress: bool = True, **kwargs: Any) -> ResNet:
return _resnet('resnet50', Bottleneck, [3, 4, 6, 3], pretrained, progress,
**kwargs)
```
4 groups of 2, and `[3, 4, 6, 3]`. It even says `BasicBlock`! So it looks like the `dfdx` creators knew what they were doing. Who'd have thought?
So, it seems I just need to modify the structure of those middle tuples to have 3, 4, 6, and 3 layers. Let's see what we can do.
```rust
// Layer clusters are in groups of [3, 4, 6, 4]
pub type Resnet34<const NUM_CLASSES: usize> = (
Head,
(
BasicBlock<64>,
ReLU,
BasicBlock<64>,
ReLU,
BasicBlock<64>,
ReLU,
),
(
Downsample<64, 128>,
ReLU,
BasicBlock<128>,
ReLU,
BasicBlock<128>,
ReLU,
BasicBlock<128>,
ReLU,
),
(
Downsample<128, 256>,
ReLU,
BasicBlock<256>,
ReLU,
BasicBlock<256>,
ReLU,
BasicBlock<256>,
ReLU,
BasicBlock<256>,
ReLU,
BasicBlock<256>,
ReLU,
),
(
Downsample<256, 512>,
ReLU,
BasicBlock<512>,
ReLU,
BasicBlock<512>,
ReLU,
),
Tail<NUM_CLASSES>,
);
```
I can't tell, but this looks reasonable. Let's call it good for now.
You may have noticed that I included the ResNet-50 definition earlier. I wanted that there to point out that I have no idea what `Bottleneck` does, and at this point, I think it's fair to say it doesn't matter for Chapter 1, we only need the ResNet-34 model.
## What can we do about the weights
Now Hugging Face has the weights we need. I've been [reading up](https://huggingface.co/docs/safetensors/index) and it looks like the `safetensors` format is the fastest and safest weight format, and it just so happens to be [supported](https://docs.rs/dfdx/latest/dfdx/nn/trait.LoadFromSafetensors.html#method.load_safetensors) by `dfdx`, we just need to enable the `safetensors` feature flag. Easy enough. Let's modify the top level `Cargo.toml` file.
```toml
dfdx = { version = "0.13", features = ["safetensors"] }
```
Now I've realized that I called my `Url` enum by a silly name. What kind of Url? Well let's change the name to `DatasetUrl` since it is used for downloading the dataset data. I just did a "Rename variable" operation in my IDE, and it took care of all the locations it was used for me.
So let's create a new enum in `tardy/src/download.rs`
```rust
const HF_BASE: &'static str = "https://huggingface.co/";
#[derive(Debug, Clone, Copy)]
pub(crate) enum ModelUrl {
Resnet18,
Resnet34,
}
impl ModelUrl {
pub(crate) fn url(self) -> String {
match self {
ModelUrl::Resnet18 => {
format!("{HF_BASE}microsoft/resnet-18/resolve/main/model.safetensors?download=true")
}
ModelUrl::Resnet34 => {
format!("{HF_BASE}microsoft/resnet-34/resolve/main/model.safetensors?download=true")
}
}
}
}
```
And now I want to create a new wrapper type that can hold onto a model, and provide methods for it, like `download_model()`. This will allow ease of use at the original call site. The format I'm aiming for is the following.
```rust
let mut model = Resnet34Model::<1000, f32>::build(dev);
model.download_model()?;
```
Now `dfdx` seems to have a very complicated type system, so this is going to look really awful. I'll go over the worst bits.
```rust
pub struct Resnet34Model<const NUM_CLASSES: usize, E>
where
E: Dtype,
Resnet34<NUM_CLASSES>: BuildOnDevice<AutoDevice, E>,
AutoDevice: Device<E>,
{
model: <Resnet34<NUM_CLASSES> as BuildOnDevice<AutoDevice, E>>::Built,
}
impl<E, const N: usize> Resnet34Model<N, E>
where
E: Dtype,
AutoDevice: Device<E>,
Resnet34<N>: BuildOnDevice<AutoDevice, E>,
{
pub fn build(dev: AutoDevice) -> Self {
let model = dev.build_module::<Resnet34<N>, E>();
Self { model }
}
}
```
The most important part here is the line:
```rust
model: <Resnet34<NUM_CLASSES> as BuildOnDevice<AutoDevice, E>>::Built,
```
This line is the difference between the type that we specified, and the concrete type that gets built by the [`AutoDevice::build_module()`](https://docs.rs/dfdx/latest/dfdx/nn/trait.DeviceBuildExt.html#method.build_module) method. We can't just store a field with type `Resnet34<NUM_CLASSES>`, that isn't usable directly. In particular, it doesn't have any notion of the datatype that will be used for the model, whether it is `f32` or `f64`. So we have to specify that `Resnet34<NUM_CLASSES>` implements the [`BuildOnDevice<>`](https://docs.rs/dfdx/latest/dfdx/nn/trait.BuildOnDevice.html) trait, and use the associated type, `BuildOnDevice::Built`.
We ensure that our type does implement `BuildOnDevice` with this line:
```rust
Resnet34<NUM_CLASSES>: BuildOnDevice<AutoDevice, E>,
```
We next need to ensure that the device supports the datatype we are using with the line:
```rust
AutoDevice: Device<E>,
```
The `build()` method now just takes in the `Device` we create in `main.rs`, and constructs the model with the `AutoDevice::build_module` method.
## First source of frustration
Now, this looks like it should work. We've got a model that is relatively concise, and looks very similar to the ResNet-18 model.
So, why when I build this do I get the following horrendous error message?
```bash
error[E0277]: the trait bound `((dfdx::prelude::Conv2D<3, 64, 7, 2, 3>,
dfdx::prelude::BatchNorm2D<64>, ReLU, MaxPool2D<3, 2, 1>),
(dfdx::prelude::Residual<(dfdx::prelude::Conv2D<64, 64, 3, 1, 1>,
dfdx::prelude::BatchNorm2D<64>, ReLU, dfdx::prelude::Conv2D<64, 64, 3, 1, 1>,
dfdx::prelude::BatchNorm2D<64>)>, ReLU, dfdx::prelude::Residual<(dfdx::prelude::Conv2D<64,
64, 3, 1, 1>, dfdx::prelude::BatchNorm2D<64>, ReLU, dfdx::prelude::Conv2D<64, 64, 3, 1, 1>,
dfdx::prelude::BatchNorm2D<64>)>, ReLU, dfdx::prelude::Residual<(dfdx::prelude::Conv2D<64,
64, 3, 1, 1>, dfdx::prelude::BatchNorm2D<64>, ReLU, dfdx::prelude::Conv2D<64, 64, 3, 1, 1>,
dfdx::prelude::BatchNorm2D<64>)>, ReLU), (GeneralizedResidual<(dfdx::prelude::Conv2D<64,
128, 3, 2, 1>, dfdx::prelude::BatchNorm2D<128>, ReLU, dfdx::prelude::Conv2D<128, 128, 3, 1,
1>, dfdx::prelude::BatchNorm2D<128>), (dfdx::prelude::Conv2D<64, 128, 1, 2>,
dfdx::prelude::BatchNorm2D<128>)>, ReLU,
dfdx::prelude::Residual<(dfdx::prelude::Conv2D<128, 128, 3, 1, 1>,
dfdx::prelude::BatchNorm2D<128>, ReLU, dfdx::prelude::Conv2D<128, 128, 3, 1, 1>,
dfdx::prelude::BatchNorm2D<128>)>, ReLU,
dfdx::prelude::Residual<(dfdx::prelude::Conv2D<128, 128, 3, 1, 1>,
dfdx::prelude::BatchNorm2D<128>, ReLU, dfdx::prelude::Conv2D<128, 128, 3, 1, 1>,
dfdx::prelude::BatchNorm2D<128>)>, ReLU,
dfdx::prelude::Residual<(dfdx::prelude::Conv2D<128, 128, 3, 1, 1>,
dfdx::prelude::BatchNorm2D<128>, ReLU, dfdx::prelude::Conv2D<128, 128, 3, 1, 1>,
dfdx::prelude::BatchNorm2D<128>)>, ReLU), (GeneralizedResidual<(dfdx::prelude::Conv2D<128,
256, 3, 2, 1>, dfdx::prelude::BatchNorm2D<256>, ReLU, dfdx::prelude::Conv2D<256, 256, 3, 1,
1>, dfdx::prelude::BatchNorm2D<256>), (dfdx::prelude::Conv2D<128, 256, 1, 2>,
dfdx::prelude::BatchNorm2D<256>)>, ReLU,
dfdx::prelude::Residual<(dfdx::prelude::Conv2D<256, 256, 3, 1, 1>,
dfdx::prelude::BatchNorm2D<256>, ReLU, dfdx::prelude::Conv2D<256, 256, 3, 1, 1>,
dfdx::prelude::BatchNorm2D<256>)>, ReLU,
dfdx::prelude::Residual<(dfdx::prelude::Conv2D<256, 256, 3, 1, 1>,
dfdx::prelude::BatchNorm2D<256>, ReLU, dfdx::prelude::Conv2D<256, 256, 3, 1, 1>,
dfdx::prelude::BatchNorm2D<256>)>, ReLU,
dfdx::prelude::Residual<(dfdx::prelude::Conv2D<256, 256, 3, 1, 1>,
dfdx::prelude::BatchNorm2D<256>, ReLU, dfdx::prelude::Conv2D<256, 256, 3, 1, 1>,
dfdx::prelude::BatchNorm2D<256>)>, ReLU,
dfdx::prelude::Residual<(dfdx::prelude::Conv2D<256, 256, 3, 1, 1>,
dfdx::prelude::BatchNorm2D<256>, ReLU, dfdx::prelude::Conv2D<256, 256, 3, 1, 1>,
dfdx::prelude::BatchNorm2D<256>)>, ReLU,
dfdx::prelude::Residual<(dfdx::prelude::Conv2D<256, 256, 3, 1, 1>,
dfdx::prelude::BatchNorm2D<256>, ReLU, dfdx::prelude::Conv2D<256, 256, 3, 1, 1>,
dfdx::prelude::BatchNorm2D<256>)>, ReLU), (GeneralizedResidual<(dfdx::prelude::Conv2D<256,
512, 3, 2, 1>, dfdx::prelude::BatchNorm2D<512>, ReLU, dfdx::prelude::Conv2D<512, 512, 3, 1,
1>, dfdx::prelude::BatchNorm2D<512>), (dfdx::prelude::Conv2D<256, 512, 1, 2>,
dfdx::prelude::BatchNorm2D<512>)>, ReLU,
dfdx::prelude::Residual<(dfdx::prelude::Conv2D<512, 512, 3, 1, 1>,
dfdx::prelude::BatchNorm2D<512>, ReLU, dfdx::prelude::Conv2D<512, 512, 3, 1, 1>,
dfdx::prelude::BatchNorm2D<512>)>, ReLU,
dfdx::prelude::Residual<(dfdx::prelude::Conv2D<512, 512, 3, 1, 1>,
dfdx::prelude::BatchNorm2D<512>, ReLU, dfdx::prelude::Conv2D<512, 512, 3, 1, 1>,
dfdx::prelude::BatchNorm2D<512>)>, ReLU), (AvgPoolGlobal, dfdx::prelude::Linear<512, _>)):
BuildOnDevice<Cpu, _>` is not satisfied
```
Well our first clue to figure this monstrosity out comes from the little section at the end.
```
BuildOnDevice<Cpu, _>` is not satisfied
```
So, that means our giant model type, `Resnet34` which just so happens to expand out to that awful tuple above, doesn't implement `BuildOnDevice`. Well, in the previous section we just stated that we needed it to do just that.
The next clue comes a few lines down from that
```bash
= help: the following other types implement trait `BuildOnDevice<D, E>`:
()
(M1,)
(M1, M2)
(M1, M2, M3)
(M1, M2, M3, M4)
(M1, M2, M3, M4, M5)
(M1, M2, M3, M4, M5, M6)
```
Ahah! Evidently tuples of Models only implement `BuildOnDevice` for varieties up to 6-tuples. We have an 8-tuple, and a 12-tuple! So it looks like we just need to split our too large tuples down into smaller bite sized pieces.
Lets do just that. Here is the new model now.
```rust
pub type Resnet34<const NUM_CLASSES: usize> = (
Head,
(
BasicBlock<64>,
ReLU,
BasicBlock<64>,
ReLU,
BasicBlock<64>,
ReLU,
),
(
// tuples are only supported with up to 6 items in `dfdx`
(Downsample<64, 128>, ReLU, BasicBlock<128>, ReLU),
(BasicBlock<128>, ReLU, BasicBlock<128>, ReLU),
),
(
// tuples are only supported with up to 6 items in `dfdx`
(
Downsample<128, 256>,
ReLU,
BasicBlock<256>,
ReLU,
BasicBlock<256>,
ReLU,
),
(
BasicBlock<256>,
ReLU,
BasicBlock<256>,
ReLU,
BasicBlock<256>,
ReLU,
),
),
(
Downsample<256, 512>,
ReLU,
BasicBlock<512>,
ReLU,
BasicBlock<512>,
ReLU,
),
Tail<NUM_CLASSES>,
);
```
And that builds! Excellent it was a simple fix.
## Moving on to downloading models
Now that we have a model that can be concretely represented, and the code builds, we need to add some code to download the model files from Hugging Face.
I'm going to go ahead and refactor `tardyai/src/download.rs` while I'm here, so we can reuse our old download logic.
```rust
// v--- refactor out this logic, so it's shorter in the other functions.
fn get_home_dir() -> Result<PathBuf, Error> {
let home = homedir::get_my_home()?
.expect("home directory needs to exist")
.join(".tardyai");
Ok(home)
}
pub fn untar_images(url: DatasetUrl) -> Result<PathBuf, Error> {
let home = get_home_dir()?;
let dest_dir = home.join("archive");
ensure_dir(&dest_dir)?;
let archive_file = download_file(url.url(), &dest_dir, None)?;
let dest_dir = home.join("data");
let dir = extract_archive(&archive_file, &dest_dir)?;
Ok(dir)
}
// v--- Add a crate public function that will download from a `ModelUrl`
pub(crate) fn download_model(url: ModelUrl) -> Result<PathBuf, Error> {
let home = get_home_dir()?;
let dest_dir = home.join("models");
ensure_dir(&dest_dir)?;
let model_file = download_file(url.url(), &dest_dir, Some(&format!("{url:?}.safetensors")))?;
Ok(model_file)
}
// v--- Change the name to something more generic
fn download_file(
url: String,
dest_dir: &Path,
// v--- This was needed because the filenames we download from Hugging Face
// are pretty ugly looking strings of hex digits.
default_name: Option<&str>,
) -> Result<PathBuf, Error> {
let mut response = reqwest::blocking::get(&url)?;
let file_name = default_name
.or(response.url().path_segments().and_then(|s| s.last()))
.and_then(|name| if name.is_empty() { None } else { Some(name) })
// v--- Add a new `Error` variant
.ok_or(Error::DownloadNameNotSpecified(url.clone()))?;
let downloaded_file = dest_dir.join(file_name);
// TODO: check if the archive is valid and exists
if downloaded_file.exists() {
log::info!("File already exists: {}", downloaded_file.display());
return Ok(downloaded_file);
}
log::info!("Downloading {} to: {}", &url, downloaded_file.display());
let mut dest = File::create(&downloaded_file)?;
response.copy_to(&mut dest)?;
Ok(downloaded_file)
}
```
And that's done, so let's create the `download_models` method on our concrete model type. We can even make it call `load_safetensors()` while we're at it.
```rust
impl<E, const N: usize> Resnet34Model<N, E>
where
E: Dtype + dfdx::tensor::safetensors::SafeDtype,
AutoDevice: Device<E>,
Resnet34<N>: BuildOnDevice<AutoDevice, E>,
{
// ...
pub fn download_model(&mut self) -> Result<(), Error> {
log::info!("Downloading model from {}", ModelUrl::Resnet34.url());
let model_file = download_model(ModelUrl::Resnet34)?;
self.model.load_safetensors(&model_file)?;
Ok(())
}
}
```
So that's it, we're done!
## Not so fast
Ah, it builds fine now, but I'm now getting this error when it runs.
```bash
➜ cargo run
Compiling tardyai v0.1.0 (/home/klah/git/articles/fastai-rust/tardyai/tardyai)
Compiling chapter1 v0.1.0 (/home/klah/git/articles/fastai-rust/tardyai/chapter1)
Finished dev [unoptimized + debuginfo] target(s) in 4.37s
Running `target/debug/chapter1`
[2023-11-22T00:01:42Z INFO tardyai::download] File already exists: /home/klah/.tardyai/archive/oxford-iiit-pet.tgz
[2023-11-22T00:01:42Z INFO tardyai::download] Extracting archive /home/klah/.tardyai/archive/oxford-iiit-pet.tgz to: /home/klah/.tardyai/data
[2023-11-22T00:01:42Z INFO tardyai::download] Archive already extracted to: /home/klah/.tardyai/data/oxford-iiit-pet/
[2023-11-22T00:01:42Z INFO chapter1] Images are in: /home/klah/.tardyai/data/oxford-iiit-pet/images
[2023-11-22T00:01:42Z INFO chapter1] Found 7390 files
[2023-11-22T00:01:48Z INFO tardyai::models::resnet] Downloading model from https://huggingface.co/microsoft/resnet-34/resolve/main/model.safetensors?download=true
[2023-11-22T00:01:49Z INFO tardyai::download] Downloading https://huggingface.co/microsoft/resnet-34/resolve/main/model.safetensors?download=true to: /home/klah/.tardyai/models/Resnet34.safetensors
Error:
0: Error with safetensors file: SafeTensorError(TensorNotFound("0.0.weight"))
Location:
chapter1/src/main.rs:38
Backtrace omitted. Run with RUST_BACKTRACE=1 environment variable to display it.
Run with RUST_BACKTRACE=full to include source snippets.
```
Well, dang it. Evidently `safetensors` files have names for the layers that they are storing the weights for. I guess I'm going to have to figure out what this file actually contains, and load them individually into our model.
`dfdx` supports `safetensors` with the [`safetensors`](https://docs.rs/safetensors/0.3.1/safetensors/index.html) crate. So I'll add that dependency and lets get to debugging.
[This page](https://docs.rs/safetensors/0.3.1/safetensors/tensor/struct.SafeTensors.html#method.deserialize) of the `safetensors` docs mentions using the `memmap2` crate, so I'll go ahead and add that as well.
```rust
pub fn download_model(&mut self) -> Result<(), Error> {
log::info!("Downloading model from {}", ModelUrl::Resnet34.url());
let model_file = download_model(ModelUrl::Resnet34)?;
// self.model.load_safetensors(&model_file)?;
let file = File::open(model_file).unwrap();
let buffer = unsafe { MmapOptions::new().map(&file).unwrap() };
let tensors = SafeTensors::deserialize(&buffer).unwrap();
let mut names = tensors.tensors();
names.sort_by_key(|t| t.0.clone());
for (name, tensor) in names {
log::info!("Name: {name}: {:?}", tensor.shape());
}
Ok(())
}
```
Running this code gives us the following output.
```bash
[2023-11-22T00:25:47Z INFO tardyai::models::resnet] Name: classifier.1.bias: [1000]
[2023-11-22T00:25:47Z INFO tardyai::models::resnet] Name: classifier.1.weight: [1000, 512]
[2023-11-22T00:25:47Z INFO tardyai::models::resnet] Name: resnet.embedder.embedder.convolution.weight: [64, 3, 7, 7]
[2023-11-22T00:25:47Z INFO tardyai::models::resnet] Name: resnet.embedder.embedder.normalization.bias: [64]
[2023-11-22T00:25:47Z INFO tardyai::models::resnet] Name: resnet.embedder.embedder.normalization.num_batches_tracked: []
[2023-11-22T00:25:47Z INFO tardyai::models::resnet] Name: resnet.embedder.embedder.normalization.running_mean: [64]
[2023-11-22T00:25:47Z INFO tardyai::models::resnet] Name: resnet.embedder.embedder.normalization.running_var: [64]
[2023-11-22T00:25:47Z INFO tardyai::models::resnet] Name: resnet.embedder.embedder.normalization.weight: [64]
[2023-11-22T00:25:47Z INFO tardyai::models::resnet] Name: resnet.encoder.stages.0.layers.0.layer.0.convolution.weight: [64, 64, 3, 3]
[2023-11-22T00:25:47Z INFO tardyai::models::resnet] Name: resnet.encoder.stages.0.layers.0.layer.0.normalization.bias: [64]
[2023-11-22T00:25:47Z INFO tardyai::models::resnet] Name: resnet.encoder.stages.0.layers.0.layer.0.normalization.num_batches_tracked: []
[2023-11-22T00:25:47Z INFO tardyai::models::resnet] Name: resnet.encoder.stages.0.layers.0.layer.0.normalization.running_mean: [64]
[2023-11-22T00:25:47Z INFO tardyai::models::resnet] Name: resnet.encoder.stages.0.layers.0.layer.0.normalization.running_var: [64]
[2023-11-22T00:25:47Z INFO tardyai::models::resnet] Name: resnet.encoder.stages.0.layers.0.layer.0.normalization.weight: [64]
[2023-11-22T00:25:47Z INFO tardyai::models::resnet] Name: resnet.encoder.stages.0.layers.0.layer.1.convolution.weight: [64, 64, 3, 3]
[2023-11-22T00:25:47Z INFO tardyai::models::resnet] Name: resnet.encoder.stages.0.layers.0.layer.1.normalization.bias: [64]
[2023-11-22T00:25:47Z INFO tardyai::models::resnet] Name: resnet.encoder.stages.0.layers.0.layer.1.normalization.num_batches_tracked: []
[2023-11-22T00:25:47Z INFO tardyai::models::resnet] Name: resnet.encoder.stages.0.layers.0.layer.1.normalization.running_mean: [64]
[2023-11-22T00:25:47Z INFO tardyai::models::resnet] Name: resnet.encoder.stages.0.layers.0.layer.1.normalization.running_var: [64]
[2023-11-22T00:25:47Z INFO tardyai::models::resnet] Name: resnet.encoder.stages.0.layers.0.layer.1.normalization.weight: [64]
...
```
I've cut off most of the output, because it is an awful lot.
Well the shape of `resnet.embedder.embedder.confolution.weight` is very similar to the convolution in `Head`:
```rust
type Head = (
Conv2D<3, 64, 7, 2, 3>,
BatchNorm2D<64>,
ReLU,
MaxPool2D<3, 2, 1>,
);
```
So I bet they correlate, and this all looks fairly structured. `stages` runs from `0` to `3`, so there are 4 stages, like we have 4 tuples of `BasicBlock`s.
Stage 2 has the first `layer` key running up to `5`, so it has 6 layers, which is the number of `BasicBlocks` in the third tuple.
So I think we have the pattern pretty mapped out to what tensor goes where. Now we need to figure out how to actually load the tensors into the various weights, ideally without specifying each tuple entry manually.
This will probably be done with some form of [`TensorVisitor`](https://docs.rs/dfdx/latest/dfdx/nn/tensor_collection/trait.TensorVisitor.html). But this article is getting pretty long, so let's save that for next time.
## Conclusion
In Part 4, we were able to construct the model, and download the weights in the form of a `safetensors` file from Hugging Face. But we ran into an issue with actually loading the weights into the model, because they weren't named the same as what `dfdx` expects. Check out the code for this part at [github](https://github.com/favilo/tardyai/tree/article-4). Or check out the `article-4` tag.
```bash
git co article-4
```
Stay tuned for Part 5 where we figure out how to solve this conundrum. | favilo |
1,674,353 | Exploring the Enhanced Number Format Helper in Laravel 10 | Laravel, the PHP framework known for its elegant syntax and developer-friendly features, has recently... | 0 | 2023-11-22T05:14:51 | https://techvblogs.com/blog/laravel-10-number-format-enhancements | laravel, webdev, beginners, tutorial | Laravel, the PHP framework known for its elegant syntax and developer-friendly features, has recently rolled out version 10, introducing a host of new functionalities and improvements. One standout feature is the enhanced Number Format Helper, designed to simplify the formatting of numbers, percentages, currency, and file sizes, and provide human-readable representations.
## 1. **Number Formatting with Number::format()**
The `Number::format()` method in Laravel 10 allows developers to easily format numerical values into locale-specific strings. Here are some examples of its usage:
```php
use Illuminate\Support\Number;
$number = Number::format(100000);
// Result: 100,000
$number = Number::format(100000, precision: 2);
// Result: 100,000.00
$number = Number::format(100000.123, maxPrecision: 2);
// Result: 100,000.12
$number = Number::format(100000, locale: 'de');
// Result: 100.000
```
This versatile method supports precision, max precision, and locale options, allowing developers to tailor the formatting to their specific needs.
## 2. **Calculating Percentages with Number::percentage()**
The `Number::percentage()` method simplifies the task of obtaining the percentage representation of a given value. It offers precision and locale options for added flexibility:
```php
use Illuminate\Support\Number;
$percentage = Number::percentage(10);
// Result: 10%
$percentage = Number::percentage(10, precision: 2);
// Result: 10.00%
$percentage = Number::percentage(10.123, maxPrecision: 2);
// Result: 10.12%
$percentage = Number::percentage(10, precision: 2, locale: 'de');
// Result: 10,00%
```
This method streamlines the process of displaying percentages with customizable precision and locale settings.
## 3. **Currency Representation with Number::currency()**
Formatting monetary values is a common requirement in web development. Laravel 10's `Number::currency()` method simplifies this task with options for currency type and locale:
```php
use Illuminate\Support\Number;
$currency = Number::currency(1000);
// Result: $1,000
$currency = Number::currency(1000, in: 'EUR');
// Result: €1,000
$currency = Number::currency(1000, in: 'EUR', locale: 'de');
// Result: 1.000 €
```
Developers can now easily format monetary values according to their preferred currency and locale, streamlining the presentation of financial information.
## 4. **File Size Representation with Number::fileSize()**
Dealing with file sizes is a common requirement in applications. Laravel 10's `Number::fileSize()` method provides an intuitive way to represent file sizes:
```php
use Illuminate\Support\Number;
$size = Number::fileSize(1024);
// Result: 1 KB
$size = Number::fileSize(1024 * 1024);
// Result: 1 MB
$size = Number::fileSize(1024, precision: 2);
// Result: 1.00 KB
```
This method simplifies the task of presenting file sizes in a human-readable format with customizable precision.
## 5. **Human-Readable Numbers with Number::forHumans()**
The `Number::forHumans()` method in Laravel 10 provides a human-readable format for numerical values:
```php
use Illuminate\Support\Number;
$number = Number::forHumans(1000);
// Result: 1 thousand
$number = Number::forHumans(489939);
// Result: 490 thousand
$number = Number::forHumans(1230000, precision: 2);
// Result: 1.23 million
```
This method is particularly useful for making large numbers more understandable, and providing a clean and concise representation.
## Conclusion
With the enhanced Number Format Helper in Laravel 10, developers now have a powerful set of tools at their disposal for formatting numbers, percentages, currency, file sizes, and creating human-readable representations. These new methods not only simplify common tasks but also contribute to the overall efficiency and clarity of Laravel 10 applications. As developers explore these features, they can expect a more streamlined experience when working with numerical data in their projects. | sureshramani |
1,674,484 | The Impact of 5G on Application Development | Clearly, the impending revolution brought by 5G technology is poised to reshape our entire... | 0 | 2023-11-22T07:29:27 | https://dev.to/pryanka46/the-impact-of-5g-on-application-development-dcp | mobile, application, development, 5g | Clearly, the impending revolution brought by 5G technology is poised to reshape our entire technological landscape, transforming the way we communicate and interact with mobile devices and internet-powered machines. This sweeping change is not limited to our hardware; it extends to the very core of our mobile applications. In the limelight of 5G technology, a paradigm shift is underway within the mobile app development industry, promising a complete overhaul of practices and capabilities. The enhanced connectivity offered by 5G not only ensures that mobile applications operate at unprecedented speeds and efficiency but also positions them to seamlessly integrate with cutting-edge technologies like augmented and virtual reality.

In this era of 5G, we anticipate the emergence of a new interconnected network, characterized by always-on devices that facilitate real-time data transfer, setting a new standard for speed and reliability. For businesses aiming to ride this wave of transformation, partnering with a forward-thinking **[mobile application development company](https://www.sparkouttech.com/mobile-application-development/)** becomes imperative. Such a collaboration ensures not only staying ahead of the technological curve but also harnessing the full potential of 5G technology to deliver innovative and high-performance mobile solutions.
5G app development will also enable developers to achieve unprecedented levels of creativity and innovation driven by high speed, low latency and immersive experiences that will completely transform the app market in the coming years. For example, high-quality videos and images will require less buffering time, which, thanks to the high speeds and data handling of 5G, will allow users to fully enjoy their applications over a cellular network in instead of requiring a Wi-Fi connection. These and other unique aspects of 5G will allow developers to create more meaningful user experiences and ultimately decide whether a mobile product gains the expected adoption rates.
So, let's delve into some of the biggest ways 5G technology will impact the app development industry.
**5G will Allow Low Latency Communications**
Latency is commonly understood as the amount of time it takes for a network to respond to a request, such as loading a video, playing an online game, or loading a website. In a technology-driven world, where people seek immediacy and speed everywhere, communication delays caused by latency can be a problem. In addition, for app developers in particular, latency is a common concern. Global efforts to reduce latency began with the introduction of 4G, but were never fully realized because low latency was not the main goal of the network. Ultra-low latency, however, has been a key component in the development of 5G. Right now, we saw response times of around 60-70 ms (milliseconds) on 3G networks, while with 4G, they are around 30-40 ms. With 5G, we are looking for 1ms latency under ideal circumstances. To give you a little context, it takes about 13 ms for our brain to process and identify an image seen by our eyes. No matter where they are or how many people are connected to the network, users may transfer massive quantities of data in real time because to 5G's extremely low latency.
5G's near-zero latency will significantly impact how we interact with mobile applications and how industries and systems that require network connectivity will operate. Low latency is crucial, not only for gaming and watching videos, but also for times when app users must make critical decisions in a matter of seconds across their devices and networks, so it will be especially relevant for you . health app developers . For example, in a healthcare scenario, delays can be deadly if doctors wait too long for feedback from an app or try to monitor unresponsive machines or IoMT devices. In this way, 5G will bring to the table a new era of remote medical services where deadly delays are no longer a problem.
Things like telesurgery, 3D test results, virtual reality, and medical robots will become the norm to free up workloads in healthcare systems around the world. Likewise, 5G's low latency will also boost telehealth services by providing an ultra-reliable alternative to current slower technologies that could mean the difference between life and death. And, with ultra-low latency, Wi-Fi may even become useless in some cases where 5G will work faster and better than most Wi-Fi connections. International money transactions will be instantaneous, high-quality photos and videos will load more quickly, and video chats and conversations will have greater quality. 3D deployment will be fast, 4K will go mobile without overloading networks, and optimal application performance levels will be easier to deploy and maintain. These factors will change how app developers optimize their UX/UI design, their coding and testing practices, and even how they use third-party APIs and services.
The unprecedented levels of latency achieved by 5G technology open the door to revolutionary experiences and vast opportunities for application developers to unlock the full potential of their creations. In an ideal scenario, 5G has the potential to eradicate latency issues across all applications, ushering in user experiences of unparalleled quality. Beyond life-critical situations, low latency plays a pivotal role in shaping the overall user experience. Research indicates that even a mere 1-second delay could cost developers $0.08 per user, while 49% of app users expect their mobile products to respond to requests in 2 seconds or less.
This emphasis on low latency is a game-changer for application developers across diverse disciplines and skill sets, spanning from mobile games and virtual reality experiences to applications for factories, the Internet of Medical Things (IoMT), and even self-driving cars. It's a transformative era where mobile products, regardless of their purpose, are poised to reach their zenith. To navigate and capitalize on this transformative landscape, collaboration with a proficient **[mobile app development company](https://www.sparkouttech.com/mobile-application-development/)** is essential. Such partnerships not only ensure the harnessing of 5G's capabilities but also guarantee that mobile products, across various domains, achieve their highest potential in user experience and performance.
| pryanka46 |
1,674,561 | Php laravel developer | "Unlocking Digital Excellence! 💻✨ With 3 years of hands-on experience, I specialize in crafting... | 0 | 2023-11-22T08:24:33 | https://dev.to/khadim786/php-laravel-developer-4i12 | "Unlocking Digital Excellence! 💻✨ With 3 years of hands-on experience, I specialize in crafting seamless web solutions. From robust Laravel applications and API integrations to dynamic front-end development using Vue.js, React.js, and more, I bring your ideas to life. Dive into a world of innovation with my expertise in PHP, MySQL, HTML, CSS, and JavaScript. Let's build something extraordinary together! 🚀 #WebDevelopment #LaravelExpert #TechInnovation" | khadim786 | |
1,674,591 | Enhancing Home Comfort: Retractable Fly Screens in Sydney | Sydney, known for its picturesque landscapes and warm climate, invites a desire for uninterrupted... | 0 | 2023-11-22T09:02:08 | https://dev.to/highlandsbsa/enhancing-home-comfort-retractable-fly-screens-in-sydney-g7e | Sydney, known for its picturesque landscapes and warm climate, invites a desire for uninterrupted views and fresh air circulation indoors. However, the presence of flies and insects can disrupt this desire, prompting the need for effective solutions like retractable fly screens in sydney.
**Retractable Fly Screens: A Versatile Solution**
Retractable fly screens provide a versatile and practical solution to keep insects at bay while enjoying unobstructed views and fresh air flow. These screens are seamlessly integrated into doorways and windows, offering an unobtrusive way to safeguard your living spaces in Sydney.

**Unmatched Convenience and Functionality**
One of the key benefits of retractable fly screens lies in their functionality. These screens effortlessly retract when not in use, preserving the aesthetics of your home in Sydney. Moreover, they are easily manoeuvrable, allowing you to control their operation based on your requirements, whether it's to keep insects out or let the breeze in.
**Customised to Your Needs**
Retractable fly screens come in various sizes and designs to suit different types of doors and windows. Their customizable nature ensures a perfect fit, enhancing both the functionality and aesthetic appeal of your home in Sydney.
**Aesthetic Enhancement and Protection**
Besides their functional benefits, retractable fly screens contribute to the overall visual appeal of your property. They not only complement the existing architecture but also act as a protective barrier, preventing unwanted pests from entering your home.
**Conclusion**
[Retractable fly screens in Sydney](https://highlandsbsa.com.au/retractable-fly-screens-sydney/
) are an excellent addition to any home, providing an effective solution to maintain comfort, airflow, and protection from insects. Consider these screens as an investment in enhancing your living spaces, allowing you to relish the beauty of Sydney while keeping pesky insects at bay.
| highlandsbsa | |
1,674,645 | Exploring JavaScript String Methods: A Comprehensive Guide | In a previous, we explored JavaScript's array methods, learning how they can help us work with lists... | 0 | 2023-11-22T09:44:16 | https://dev.to/rishabh07r/exploring-javascript-string-methods-a-comprehensive-guide-6nh | In a previous, we explored JavaScript's array methods, learning how they can help us work with lists of data. If you're just starting, welcome! And if you've been following along, you already know that JavaScript has some incredible tools for us to play with.
Today, we're embarking on a new journey into the world of JavaScript String Methods. Strings are like building blocks for text; these tricks are like magic spells that let us do cool things with them.
In this beginner-friendly guide, we'll dive into the world of strings. We'll learn how to do all sorts of cool stuff with just a few lines of code. You don't need to be a pro – we'll explain everything step by step, with simple examples.
So, whether you're new to coding and want to learn cool JavaScript tricks or you're a pro looking to refresh your memory, get ready to explore the magic of JavaScript string methods.
## What are String methods in JavaScript?
String methods in JavaScript are built-in functions or operations that can be applied to strings (sequences of characters) to perform various operations and manipulations on them. These methods help us work with strings in different ways, such as modifying them, searching for specific substrings, extracting parts of a string, and more.
### 1. charAt(index):
Returns the character at the specified index in the string.
```
const str = "Hello, World!";
const charAtIdx = str.charAt(7);
console.log(charAtIdx); // Output: 'W'
```
### 2. charCodeAt(index):
This function retrieves the Unicode value of a character at a specified index in the string.
```
const str = "Hello, World!";
const codeIdx = str.charCodeAt(7);
console.log(codeIdx); // Output: 87 (Unicode value for 'W')
```
### 3. concat(string2, string3, ...):
Concatenates two or more strings and returns a new string.
```
const str1 = "Hello";
const str2 = ", ";
const str3 = "World!";
const result = str1.concat(str2, str3);
console.log(result); // Output: "Hello, World!"
```
### 4. indexOf():
Returns the index of the first occurrence of a substring or character in the string, starting from the given index(optional).
```
const str = "Hello, World!";
const indexOfComma = str.indexOf(",");
console.log(indexOfComma); // Output: 5
```
### 5. startsWith(substring):
This function checks whether a given string begins with a specific substring and returns a Boolean value.
```
const text = "Hello, World!";
const startsWithHello = text.startsWith("Hello");
console.log(startsWithHello); // Output: true
```
### 6. endsWith(substring):
This function checks if a string ends with a specific substring and returns a Boolean value.
```
const text = "Hello, World!";
const endsWithWorld = text.endsWith("World!");
console.log(endsWithWorld); // Output: true
```
### 7. includes(substring):
This function checks whether a string contains a specified substring and returns a Boolean value.
```
const text = "Namaste, JavaScript!";
const includesJS = text.includes("JavaScript!");
console.log(includesJS); // Output: true
```
### 8. substring(start, end):
A part of a string is obtained by selecting characters between specified start and end positions.
```
const text = "Hello, World!";
const substring = text.substring(0, 8);
console.log(substring); // Output: "Hello, W"
```
### 9. slice(startIndex, endIndex):
Extracts a portion of the string between the specified indices, similar to substring.
```
const text = "Welcome to JavaScript";
const sliced = text.slice(11, 21);
console.log(sliced); // Output: "JavaScript"
```
### 10. substr(startIndex, length):
Extracts a substring from the original string, starting at the specified index and extending for a specified length.
```
const text = "Hello, World!";
const substr = text.substr(7, 5);
console.log(substr); // Output: "World"
```
### 11. toLowerCase():
Converts the string to lowercase.
```
const str = "Namaste, JavaScript!";
const lowerCaseString = str.toLowerCase();
console.log(lowerCaseString); // Output: namaste, javascript!
```
### 12. toUpperCase():
Converts the string to uppercase.
```
const text = "Namaste, JavaScript!";
const uppercase = text.toUpperCase();
console.log(uppercase); // Output: "NAMASTE, JAVASCRIPT!"
```
### 13. trim():
Removes whitespace from the beginning and end of a string.
```
const text = " Hello, World! ";
const trimmedtxt = text.trim();
console.log(trimmedtxt); // Output: "Hello, World!"
```
### 14. split(separator, limit):
This function splits a string into an array of substrings using a specified separator.
```
const str = "apple,banana,orange";
const fruits = str.split(",");
const limitedSplit = str.split(",", 2);
console.log(fruits); // Output: ['apple', 'banana', 'orange']
console.log(limitedSplit); // Output: ['apple', 'banana']
```
### 15. replace(old, new):
Replaces occurrences of a substring with a new string.
```
const text = "Hello, World!";
const replaced = text.replace("World", "Universe");
console.log(replaced); // Output: "Hello, Universe!"
```
### 16. match(regexp):
Searches a string for a specified pattern (regular expression) and returns an array of matched substrings.
```
const text = "The quick brown fox jumps over the lazy dog";
const pattern = /[A-z]+/g; // Matches one or more "l" characters globally
const matches = text.match(pattern);
console.log(matches); // Output: ['The', 'quick', 'brown', 'fox', 'jumps', 'over', 'the', 'lazy', 'dog']
```
### 17. search(regexp):
Searches a string for a specified pattern (regular expression) and returns the index of the first match.
```
const text = "Hello, World!";
const pattern = /W/;
const index = text.search(pattern);
console.log(index); // Output: 7 (index of the first "W" character)
```
### 18. localeCompare(otherString):
Compares two strings based on the current locale and returns a value indicating their relative ordering.
```
const str1 = "apple";
const str2 = "banana";
const comparison = str1.localeCompare(str2);
console.log(comparison); // Output: -1 (a negative value (str1 comes before str2 in the locale))
```
## Conclusion
We've found ways to work with text in our look at JavaScript string methods. These methods help us do simple or fancy things with words. Keep this cheat sheet handy to help with text tasks!
Thanks for being a part of this string journey! Stay curious, keep coding, and see you in our next blog post! 🌟😃
| rishabh07r | |
1,674,763 | Unlocking the Power of MERN: A Beginner's Guide to Hiring MERN Stack Developers | Introduction: Navigating the Tech Landscape In today's ever-evolving technology... | 0 | 2023-11-22T11:30:13 | https://dev.to/praterherbs/unlocking-the-power-of-mern-a-beginners-guide-to-hiring-mern-stack-developers-4079 | mern, mongodb, react, native | ## Introduction: Navigating the Tech Landscape
In today's ever-evolving technology environment, businesses are always looking for dynamic solutions to stay ahead of the curve.
One of these increasingly popular solutions is the MERN stack, a powerful combination of technologies that enables developers to build robust and scalable web applications.
If you're considering leveraging the potential of MERN for your project, this guide will walk you through the process of hiring a MERN stack developer and help you make informed decisions every step of the way.
## Decoding MERN Stack
Before embarking on the recruitment process, it is important to understand the core components of the MERN stack.
MERN stands for MongoDB, Express.js, React.js, Node.js.
MongoDB acts as a NoSQL database, Express.js acts as a web application framework, React.js is for building user interfaces, and Node.js acts as a server-side script.
Together, they form a comprehensive and efficient stack for full-stack web development.
## Why use the MERN stack?
MERN's popularity is no coincidence. brings many benefits.
This stack enables seamless data flow between client and server, ensuring a smooth and responsive user experience.
Additionally, its component-based structure makes development modular and scalable, and the flexibility of JavaScript across the stack allows for a more consistent development process.
These benefits make MERN an attractive choice for companies looking to build modern, feature-rich web applications.
## Identifying Project Requirements
Before you begin your recruitment efforts, it is important to identify the specific requirements of your project.
Are you building a dynamic single-page application (SPA) or a complex e-commerce platform?
Understanding the complexity of your project will help you find developers with the right skills and expertise in specific areas of the MERN stack relevant to your goals.
will help you find it.
## Qualities to look for in a MERN stack developer
Now that you know the requirements for your project, it's time to find the right person.
When you are in a position to [Hire MERN Stack Developers](https://graffersid.com/hire-dedicated-mern-developers/), focus on people with strong JavaScript skills, hands-on experience with MongoDB, Express.js, React.js, and Node.js, and a track record of developing scalable web applications.
Good communication skills and the ability to collaborate in a team are also important to ensure a smooth development process.
## Where to Find a MERN Stack
1. Developer Once you know exactly what skills you're looking for, the next step is to consider your options for finding his MERN Stack Developer.
2. Platforms like LinkedIn, GitHub, and professional job boards are great places to start.
3. Consider attending technology conferences or reaching out to your local developer community to connect with potential candidates.
4. By casting a wide net, you increase your chances of finding the right people for your team.
5. Find the Right Hire Once you've identified potential candidates, conduct interviews.
6. Focus not only on technical abilities, but also on problem-solving skills, adaptability, and cultural fit within your team.
7. Consider practical assessment and coding challenges to assess candidates' practical skills.
8. Once you find the right one, we ensure a smooth onboarding process and provide continuous learning opportunities to help MERN stack developers stay up to date with industry trends.
## Conclusion: Successfully Mastering MERN
In summary, hiring a MERN stack developer is a strategic step towards developing powerful and scalable web applications.
By understanding the components of your stack, recognizing their benefits, aligning your project needs, and selecting the right people, you can lay the foundation for success.
| praterherbs |
1,674,793 | Image-mapping in html-document | A post by S M Hridoy Ahmed | 0 | 2023-11-22T12:18:20 | https://dev.to/codehridoy/image-mapping-in-html-document-2im0 | codepen |
{% codepen https://codepen.io/dumb_hridoy/pen/ZEwoGBG %} | codehridoy |
1,675,279 | Custom Software Development Company In USA | Unlock limitless possibilities with TechnBrains, a leading custom software development company. From... | 0 | 2023-11-22T14:14:43 | https://dev.to/martindye/custom-software-development-company-in-usa-cop | Unlock limitless possibilities with TechnBrains, a leading [custom software development company](https://www.technbrains.com/web-application/custom-software-development/). From sleek designs to intricate systems, we deliver top-quality, scalable solutions globally.
**Services Offered:**
Ecommerce Stores
Basic Information Websites
iOS and Android Development
Desktop Software
**Why Choose Us?**
Experienced Team
Unmatched Quality
Transparent Process
On-time Delivery
**Key Features:**
Payment Gateways
Live Chat
Location-Based Services
Online Delivery
Ecommerce Features
**Join us in redefining software development standards. TechnBrains - Where Innovation Meets Excellence.** | martindye | |
1,675,463 | The Importance of Draw Coolers in Industrial Settings | In this article, we'll explore the many facets of it, including its history, current state, and... | 0 | 2023-11-22T16:44:39 | https://dev.to/edwinlamonqa/the-importance-of-draw-coolers-in-industrial-settings-15o1 | In this article, we'll explore the many facets of it, including its history, current state, and potential future [running draw coolers appliances](https://vtoman.com/blogs/news/camping-solar-panel-guide?utm_source=dev_to&utm_medium=rankking).
In industrial settings, the importance of draw coolers cannot be overstated. These appliances play a crucial role in maintaining optimal temperatures and ensuring the smooth operation of various industrial processes. By efficiently cooling down equipment and machinery, draw coolers help prevent overheating, reduce downtime, and improve overall productivity.
## Enhancing Efficiency and Performance
One of the key benefits of draw coolers in industrial settings is their ability to enhance efficiency and performance. By dissipating heat generated during operation, draw coolers prevent equipment from becoming too hot, which can lead to decreased performance and even damage. For example, in a manufacturing plant, draw coolers can be used to cool down machinery such as compressors, pumps, and motors, allowing them to operate at their optimal temperature range and perform at their best.
Moreover, draw coolers help maintain a stable temperature within industrial processes, ensuring consistent and reliable output. This is particularly important in industries such as food processing and pharmaceuticals, where precise temperature control is critical for product quality and safety.
## Preventing Costly Downtime
Another significant advantage of draw coolers is their role in preventing costly downtime. When equipment overheats, it can lead to unexpected breakdowns and unplanned shutdowns, resulting in production delays and financial losses. By effectively cooling down machinery, draw coolers help prevent overheating-related failures and minimize the risk of downtime.
For example, in a power plant, draw coolers are used to cool down generators and turbines. If these critical components were to overheat, it could lead to a complete shutdown of the power plant, causing widespread power outages and significant economic consequences. By utilizing draw coolers, power plants can ensure continuous operation and avoid such disruptions.
## Ensuring Worker Safety
The importance of draw coolers in industrial settings extends beyond equipment and machinery. These appliances also play a crucial role in ensuring worker safety. In many industrial processes, workers are exposed to high temperatures, which can pose serious health risks, including heat exhaustion and heat stroke.
By cooling down the surrounding environment, draw coolers help create a safer working environment for employees. For instance, in foundries where molten metal is poured, draw coolers can be used to cool down the air and reduce the ambient temperature, minimizing the risk of heat-related illnesses among workers.
## Conclusion
In conclusion, draw coolers are indispensable appliances in industrial settings. They enhance efficiency and performance, prevent costly downtime, and ensure worker safety. By effectively managing temperatures, draw coolers contribute to the smooth operation of various industrial processes, ultimately leading to increased productivity and profitability.
## References
* [running draw coolers appliances](https://durulsan.com/index.php?dil=2&url=https://vtoman.com/blogs/news/camping-solar-panel-guide "running draw coolers appliances")
### Links to Credible Sites:
* [Industrial Cooling Solutions](https://www.industrialcooling.com)
* [Cooling Technology Inc.](https://www.coolingtechnology.com)
* [Industrial Refrigeration Systems](https://www.industrial-refrigeration.com)
| edwinlamonqa | |
1,675,516 | Game Backend : Chapter 1 - Introduction | Yolo fellow game developers. I am writing this blog series to understand various aspects of game... | 0 | 2023-12-11T18:51:09 | https://dev.to/danibwuoy02/game-backend-chapter-1-introduction-149a | Yolo fellow game developers. I am writing this blog series to understand various aspects of game backend development.
In this blog, we will start by understanding "What a game backend is?", and in the next upcoming blogs we'll learn the key aspects required to implement backend servers, deploying api's to them and also connecting those api's with our game.
I will be using Unity as the game engine and AWS for implementing the backend architecture, but we will understand the core concepts behind the implementation so we can apply those concepts for any tech stack you prefer. Let's get started.

## What is a Game Backend?
In game development, the term "back end" refers to server side technologies that help in providing various remote or online services to manage player and game state and enhance the overall gaming experience.
Game Backends are usually implemented using RESTful API's that will be accessed by the game clients (games installed on your device or consoles) using HTTP/HTTPS requests.
Here is a list of few of the essential functionalities that are implemented using a gaming backend:
• **Multiplayer Support** : It helps in authenticating and authorising players, manage player accounts and data which helps in maintaining the integrity of multiplayer gaming environments. It also helps in matchmaking players with similar skills to make the game more competitive and enjoyable.
• **Data Storage and Management** : Game backends help in securely storing player profile data, game progress and statistics, leaderboard data and other types of telemetry data which help in making the game better and profitable.
• **Content Delivery** : It also helps in delivering dynamic content, updates and patches for ensuring continuous improvement without having the need to push app updates post-launch.
• **Communication** : It helps in maintaining a connection between the player and the backend services in order to sync the game and maintaining smooth gameplay. It also helps players to communicate with each other in case of multiplayer games.
• **Data and Logic Processing** : Complex game logic calculations which are too heavy for client processing are handled by backend servers. Apart from this, backend servers use real time analytics and machine learning processing to provide personalised gaming experience.
---
## Types of backend architectures
Here's an overview of some of the backend architectures:
###Instance based architecture
- These are the traditional dedicated servers which can be either physical servers or cloud based virtual servers.
- Each instance in this type of architecture can run its own operating system and own set of applications which gives the developers complete control over the server environment.
- Since resources are not shared, performance is stable which makes it suitable for games with steady player traffic.
- Games like 'Minecraft' often use dedicated servers whereas small indie games use cost effective virtualized server instances.
- Amazon EC2, Google Compute Engine, Digital Ocean droplets are few examples of cloud based instance server platforms.
###Serverless architecture
- The term 'serverless' is misleading. It doesn't mean there are no servers in this architecture, rather it is a cloud based model where the cloud provider manages the complexity of the infrastructure and allocation of server resources when required.
- It is extremely suitable for developers who want to focus purely on the game feature development usually as microservices and not care about the underlying infrastructure complexities. That's why the name 'serverless'.
- Game backend services with variable traffic can benefit from this architecture as you mostly pay for the resources that have been allocated by the provider based on the traffic making it cost effective and reliable.
- For example, REST API's to update player scores and store transactions can be implemented using AWS Lambda functions along with AWS Gateway API or by using Google Cloud Functions with Google API Gateway.
###Container based architecture
- This architecture involves packaging your game backend into containers.
- Containers are isolated packages containing the code, runtime, libraries required to run your backend code.
- These containers are portable and can be hosted on the developer's workstation, dedicated servers or other types of infrastructure, thus making it consistent irrespective of the underlying architecture.
###Peer-to-Peer architecture
- In this architecture, instead of relying on a central server, each player's device directly communicates with other player's device. Each peer, acts both as the client and the server.
- One peer acts as the host or the master peer, handling some of the critical functions who is selected mainly based on connection stability or hardware capabilities.
###Blockchain architecture
- Unlike storing data and in game transactions on a single server, data is stored across a network of computers or servers, thus making the data immutable and resilient to tampering.
- New monetisation models like the play to earn model use blockchain technology.
- Platforms like Enjin and Sandbox use blockchain to implement gaming ecosystem.
##Types of servers
###Web Server
In game development, a web server manages requests over HTTP protocol and other such protocols from game clients which can be your game app or a browser. It processes the requests and provides the required response to the client which may include HTML static content, images, videos, etc. It can also act as a gateway or proxy to other servers.
Examples of web servers:
- Nginx
- Apache HTTP Server
- Windows IIS
- Node.js
###Application Server
An application server hosts the web application and api's responsible to process game logic, data processing and connecting with the database servers to serve dynamic content based on the incoming requests.
Examples of Application Servers:
- Flask Gunicorn
- .NET Application Servers
- Node.js application servers
###File Servers
A file server is used to store and manage files. It can be used to store game assets, updates and patches that player clients can download. Cloud file storage services like AWS S3 buckets can also be considered a type of file server.
## Conclusion
As we conclude the introduction of game backends, the next chapter will be more about turning theory to practice. We will learn about setting up an AWS EC2 instance with an Nginx web server making it easy for beginner developers in getting started with building their own game backend architectures.
Stay tuned!!! GG!!
---
###Social Media :
[Daniel Yunus](linktr.ee/danibwuoy)
###Games :
[Gamebee Studio](https://gamebeestudio.com)
[CC Games Studio](https://chuchugames.com)
| danibwuoy02 | |
1,675,544 | Open AI, Chat with files like(pdf, excel, CSV, doc, etc) With Node and React js. | If you want to use Openai in your existing project it helps you to respond according to the files... | 0 | 2023-11-22T18:18:01 | https://dev.to/kamruzzzaman/open-ai-chat-with-files-likepdf-excel-csv-doc-etc-with-node-and-react-js-58jj | fileupload, openai, nodeopenai, reactopenai | If you want to use Openai in your existing project it helps you to respond according to the files that you share. The below steps will help you.
First, you need to set up your express server.
Then do with this code,
**Packages Needed** - express, dot env, cors, fs, openai, multer.
```
const express = require("express");
const cors = require("cors");
const fs = require('fs')
const PORT = process.env.PORT || 5000;
const app = express();
const OpenAI = require('openai');
const multer = require('multer');
// User Middlewares
app.use(cors());
app.use(express.json());
app.get("/", (req, res) => {
res.send(
"<h2 style='color:green;box-sizing:border-box; margin:0; background: #f3f3f9; height: 95vh;'>Server is Running!<h2>"
);
});
const openai = new OpenAI({
apiKey: process.env.OPENAI_API_KEY, // defaults to process.env["OPENAI_API_KEY"]
});
const upload = multer({ dest: 'uploads/' }); // Set the destination folder for uploads
app.post('/upload', upload.single('file'), async (req, res) => {
const { file } = req;
// Upload the file to OpenAI
const { question } = req.body;
try {
const openaiFile = await openai.files.create({
file: fs.createReadStream(file.path),
purpose: 'assistants',
});
const assistant = await openai.beta.assistants.create({
name: "you are a manual instructor",
instructions: "based on file you will provide the relavant ans.",
model: "gpt-3.5-turbo-1106",
tools: [{ "type": "retrieval" }],
file_ids: [openaiFile.id]
});
const thread = await openai.beta.threads.create();
// Pass in the user question into the existing thread
await openai.beta.threads.messages.create(thread.id, {
role: "user",
content: question,
});
// Use runs to wait for the assistant response and then retrieve it
const run = await openai.beta.threads.runs.create(thread.id, {
assistant_id: assistant.id,
});
let runStatus = await openai.beta.threads.runs.retrieve(
thread.id,
run.id
);
// Polling mechanism to see if runStatus is completed
// This should be made more robust.
while (runStatus.status !== "completed") {
await new Promise((resolve) => setTimeout(resolve, 2000));
runStatus = await openai.beta.threads.runs.retrieve(thread.id, run.id);
}
// Get the last assistant message from the messages array
const messages = await openai.beta.threads.messages.list(thread.id);
// Find the last message for the current run
const lastMessageForRun = messages.data
.filter(
(message) => message.run_id === run.id && message.role === "assistant"
)
.pop();
// If an assistant message is found, console.log() it
if (lastMessageForRun) {
res.status(200).json({ success: true, data: `${lastMessageForRun.content[0].text.value} \n` });
}
} catch (error) {
console.error('Error uploading to OpenAI:', error);
res.status(500).json({ success: false, error: 'Internal Server Error' });
} finally {
// Delete the uploaded file from the server
fs.unlinkSync(file.path);
}
});
```
After setting up and running the server, connect the existing API with React JS.
To design and run code successfully please set your environment with Tailwind css for design and Axios for API calls.
The React js code example is:
```
import axios from "axios";
import { useRef, useState } from "react";
function App() {
const [usedFiles, setUsedFiles] = useState([]);
const [chatHistory, setChatHistory] = useState([]);
const [selectedChat, setSelectedChat] = useState(
chatHistory?.length > 0 && chatHistory[0]
);
const fileInputRef = useRef(null);
const handleButtonClick = () => {
if (fileInputRef.current) {
fileInputRef.current.click();
}
};
const handleCreateNewChat = () => {
if (usedFiles?.length > 0) {
setChatHistory([
...chatHistory,
{
id: chatHistory?.length + 1,
messeges: [],
},
]);
setSelectedChat({
id: chatHistory?.length + 1,
messeges: [],
});
} else {
alert("Please Select a file");
}
};
// ..................................................................... Restricted ...........................................//
const [file, setFile] = useState(null);
const [question, setQuestion] = useState("");
const [loading, setLoading] = useState(false);
const handleFilesChange = async (event) => {
setFile(event.target.files[0]);
setUsedFiles([...usedFiles, event.target.files[0]]);
};
const handleQuestionChange = (event) => {
setQuestion(event.target.value);
};
const handleChatSubmit = async (e) => {
e.preventDefault();
const formData = new FormData();
formData.append("file", file);
formData.append("question", question);
const updateSelectedChat = {
...selectedChat,
messeges: [
...selectedChat.messeges,
{
user: question,
chatbot: "",
loading: true,
},
],
};
setSelectedChat(updateSelectedChat);
const updatedChatHistory = chatHistory.map((chat) => {
if (chat.id === selectedChat.id) {
return updateSelectedChat;
} else {
return chat;
}
});
setChatHistory(updatedChatHistory);
setQuestion("");
try {
const response = await axios.post(
"http://localhost:5000/upload",
formData
);
const data = response.data;
if (data.success) {
const updateSelectedChat = {
...selectedChat,
messeges: [
...selectedChat.messeges,
{
user: question,
chatbot: data.data,
loading: false,
},
],
};
setSelectedChat(updateSelectedChat);
const updatedChatHistory = chatHistory.map((chat) => {
if (chat.id === selectedChat.id) {
return updateSelectedChat;
} else {
return chat;
}
});
setChatHistory(updatedChatHistory);
setQuestion("");
// setResponse(data.data);
} else {
console.error("Error generating response:", data.error);
}
} catch (error) {
console.error("Error generating response:", error);
}
};
return (
<>
<div className="flex h-screen antialiased text-gray-800">
<div className="flex flex-row h-full w-full overflow-x-hidden">
<div className="flex flex-col py-8 pl-6 pr-2 w-64 bg-gray-100 flex-shrink-0">
<div className="flex flex-row items-center justify-center h-12 w-full">
<div className="flex items-center justify-center rounded-2xl text-indigo-700 bg-indigo-100 h-10 w-10">
<svg
className="w-6 h-6"
fill="none"
stroke="currentColor"
viewBox="0 0 24 24"
xmlns="http://www.w3.org/2000/svg"
>
<path
strokeLinecap="round"
strokeLinejoin="round"
strokeWidth="2"
d="M8 10h.01M12 10h.01M16 10h.01M9 16H5a2 2 0 01-2-2V6a2 2 0 012-2h14a2 2 0 012 2v8a2 2 0 01-2 2h-5l-5 5v-5z"
></path>
</svg>
</div>
<div className="ml-2 font-bold text-2xl">My Manuals</div>
</div>
<input
type="file"
style={{ display: "none" }}
ref={fileInputRef}
onChange={handleFilesChange}
/>
<div
onClick={handleButtonClick}
className="flex border-b-2 border-black pb-3 mt-10 cursor-pointer"
>
<div>
<svg
className="w-6 h-6 text-gray-800 "
aria-hidden="true"
xmlns="http://www.w3.org/2000/svg"
fill="none"
viewBox="0 0 16 16"
>
<path
stroke="currentColor"
strokeLinecap="round"
strokeLinejoin="round"
strokeWidth="2"
d="M8 12V1m0 0L4 5m4-4 4 4m3 5v3a2 2 0 0 1-2 2H3a2 2 0 0 1-2-2v-3"
/>
</svg>
</div>
<div className="text-xl font-bold text-center ml-2">
New Upload
</div>
</div>
<div className="flex flex-col mt-8">
<div className="flex flex-row items-center justify-between text-xs">
<span className="font-bold">Files</span>
<span className="flex items-center justify-center bg-gray-300 h-4 w-4 rounded-full">
{usedFiles?.length}
</span>
</div>
<div className="mt-3 h-full overflow-y-auto over">
{usedFiles?.map((res, i) => (
<div key={i} className="flex items-center mt-2">
{res?.type?.includes("pdf") ? (
<svg
className="w-6 h-6 text-gray-800 "
aria-hidden="true"
xmlns="http://www.w3.org/2000/svg"
fill="none"
viewBox="0 0 16 20"
>
<path
stroke="currentColor"
strokeLinecap="round"
strokeLinejoin="round"
strokeWidth="2"
d="M1 18a.969.969 0 0 0 .933 1h12.134A.97.97 0 0 0 15 18M1 7V5.828a2 2 0 0 1 .586-1.414l2.828-2.828A2 2 0 0 1 5.828 1h8.239A.97.97 0 0 1 15 2v5M6 1v4a1 1 0 0 1-1 1H1m0 9v-5h1.5a1.5 1.5 0 1 1 0 3H1m12 2v-5h2m-2 3h2m-8-3v5h1.375A1.626 1.626 0 0 0 10 13.375v-1.75A1.626 1.626 0 0 0 8.375 10H7Z"
/>
</svg>
) : (
<svg
className="w-6 h-6 text-gray-800 "
aria-hidden="true"
xmlns="http://www.w3.org/2000/svg"
fill="none"
viewBox="0 0 16 20"
>
<path
stroke="currentColor"
strokeLinecap="round"
strokeLinejoin="round"
strokeWidth="2"
d="M4.828 10h6.239m-6.239 4h6.239M6 1v4a1 1 0 0 1-1 1H1m14-4v16a.97.97 0 0 1-.933 1H1.933A.97.97 0 0 1 1 18V5.828a2 2 0 0 1 .586-1.414l2.828-2.828A2 2 0 0 1 5.828 1h8.239A.97.97 0 0 1 15 2Z"
/>
</svg>
)}
<span className="ml-2">{res?.name}</span>
</div>
))}
</div>
</div>
</div>
<div className="flex flex-col py-8 pl-6 pr-2 w-64 bg-white flex-shrink-0">
<div className="flex flex-row items-center justify-center h-12 w-full">
<div
onClick={handleCreateNewChat}
className="font-bold text-xl border-2 px-7 py-1 rounded cursor-pointer"
>
Start New Chat
</div>
</div>
<div className="flex flex-col mt-8">
<div className="flex flex-row items-center justify-between text-xs">
<span className="font-bold">History</span>
<span className="flex items-center justify-center bg-gray-300 h-4 w-4 rounded-full">
{chatHistory?.length}
</span>
</div>
<div className="flex flex-col space-y-1 mt-4 -mx-2 h-full overflow-y-auto">
{chatHistory?.map((res, i) => (
<>
{res?.messeges?.length > 0 ? (
<button
key={i}
className={`flex flex-row items-center ${
res?.id == selectedChat.id ? "bg-gray-50" : ""
} hover:bg-gray-100 rounded-xl p-2`}
onClick={() => setSelectedChat(res)}
>
<div className="text-sm font-semibold">
{res?.messeges[0]?.user == undefined
? "New Messege"
: res?.messeges[0]?.user}
</div>
</button>
) : (
<button
key={i}
className={`flex flex-row items-center ${
res?.id == selectedChat.id ? "bg-gray-50" : ""
} hover:bg-gray-100 rounded-xl p-2`}
onClick={() => setSelectedChat(res)}
>
<div className="text-sm font-semibold">New Messege</div>
</button>
)}
</>
))}
</div>
</div>
</div>
<div className="flex flex-col flex-auto h-full p-6">
<div className="flex flex-col flex-auto flex-shrink-0 rounded-2xl bg-gray-100 h-full p-4">
<div className="flex flex-col h-full overflow-x-auto mb-4">
<div className="flex flex-col h-full">
<div className="grid grid-cols-12 gap-y-2">
{selectedChat?.messeges?.map((res, i) => (
<>
{res?.user !== undefined && (
<div
key={i}
className="col-start-6 col-end-13 p-3 rounded-lg"
>
<div className="flex items-center justify-start flex-row-reverse">
<div className="flex items-center text-white justify-center h-10 w-10 rounded-full bg-indigo-500 flex-shrink-0">
Me
</div>
<div className="relative mr-3 text-sm bg-indigo-100 py-2 px-4 shadow rounded-xl">
<div>{res?.user}</div>
</div>
</div>
</div>
)}
{res?.chatbot !== undefined && (
<div className="col-start-1 col-end-8 p-3 rounded-lg">
<div className="flex flex-row items-center">
<div className="flex items-center text-white justify-center h-10 w-10 rounded-full bg-indigo-500 flex-shrink-0">
Bot
</div>
<div className="relative ml-3 text-sm bg-white py-2 px-4 shadow rounded-xl">
<div>
{res?.loading
? "..."
: res?.chatbot.replace(
/​``【oaicite:1】``​/g,
""
)}
</div>
</div>
</div>
</div>
)}
</>
))}
</div>
</div>
</div>
{
<form onSubmit={handleChatSubmit}>
<div className="flex flex-row items-center h-16 rounded-xl bg-white w-full px-4">
<div className="flex-grow">
<div className="relative w-full">
<input
type="text"
value={question}
disabled={chatHistory?.length === 0}
onChange={handleQuestionChange}
className="flex w-full border rounded-xl focus:outline-none focus:border-indigo-300 pl-4 h-10"
/>
</div>
</div>
<div className="ml-4">
<button
type="submit"
className={`flex items-center justify-center rounded-xl text-white px-4 py-1 flex-shrink-0 bg-indigo-500 hover:bg-indigo-600 ${
chatHistory?.length === 0
? "opacity-50"
: "opacity-100"
}`}
disabled={chatHistory?.length === 0}
>
<span>Send</span>
<span className="ml-2">
<svg
className="w-4 h-4 transform rotate-45 -mt-px"
fill="none"
stroke="currentColor"
viewBox="0 0 24 24"
xmlns="http://www.w3.org/2000/svg"
>
<path
strokeLinecap="round"
strokeLinejoin="round"
strokeWidth="2"
d="M12 19l9 2-9-18-9 18 9-2zm0 0v-8"
></path>
</svg>
</span>
</button>
</div>
</div>
</form>
}
</div>
</div>
</div>
</div>
</>
);
}
export default App;
```
This is React full code you can use for your existing project.
**Hope it will help you. Thanks.**
| kamruzzzaman |
1,675,696 | Hacktoberfest 2023 🏆 | I have just completed the #hacktoberfest2023 challenge with 10 Pull Requests successfully merged.... | 0 | 2023-11-22T20:26:33 | https://dev.to/ygaurav9112/hacktoberfest-2023-3ip6 | hack23contributor, hacktoberfest, hacktoberfest23, hacktoberfest2023 | I have just completed the #hacktoberfest2023 challenge with 10 Pull Requests successfully merged. **
It is with great pleasure to be involved in Hacktoberfest and contribute on several people projects.
DONE #Hacktoberfest #OpenSource #hacktoberfest10
@hacktoberfest
Badge awarded on holopin as follows:




PR links:
1.https://github.com/hellofaizan/xprofile/pull/135
2.https://github.com/illacloud/illa-builder/pull/2801
3.https://github.com/Karamraj/BookTown/pull/177
4.https://github.com/illacloud/illa-builder/pull/3324
5.https://github.com/illacloud/illa-builder/pull/3325
6.https://github.com/illacloud/illa-builder/pull/3326
7.https://github.com/illacloud/illa-builder/pull/3327
8.https://github.com/illacloud/illa-builder/pull/3350
9.https://github.com/illacloud/illa-builder/pull/3351
10.https://github.com/illacloud/illa-builder/pull/3352
| ygaurav9112 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.