
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,675,702 | Image Upload in React Native | The ImagePicker is an Expo plugin designed to simplify the process of uploading images or capturing... | 0 | 2023-11-22T20:55:59 | https://dev.to/joey_clapton/implementing-image-upload-in-react-native-5ddf | The ImagePicker is an Expo plugin designed to simplify the process of uploading images or capturing photos using the camera without the need to directly handle complex camera or gallery APIs.
### Compatibility
The ImagePicker is compatible with the following platforms:
- Android Device
- Android Emulator
- iOS Device
- iOS Simulator
- Web Platform
### Installation
```bash
npx expo install expo-image-picker
```
### Configuring the plugin
To configure the plugin, we will go to the app.json file and add the following configuration:
```json
{
"expo": {
"plugins": [
[
"expo-image-picker",
{
"photosPermission": "The app need accesses your photos."
}
]
]
}
}
```
In the photosPermission property, we will set the message displayed to the user, requesting approval to access the camera feature.
### Implementing Image Upload Using the Mobile Gallery
```tsx
import react, { useState } from "react";
import { Button, Image, View } from "react-native";
// Let's import the library.
import * as ImagePicker from "expo-image-picker";
export default function App() {
const [image, setImage] = useState<string>();
const pickImage = async () => {
// No permission is required to open the gallery.
const result = await ImagePicker.launchImageLibraryAsync({
// The mediaTypes property defines which type of file is allowed.
mediaTypes: ImagePicker.MediaTypeOptions.All,
// Quality sets the image quality and accepts values from 0 to 1.
// 0 represents lower quality/smaller size, and 1 represents higher quality/larger size.
quality: 1,
});
console.log(result);
// Let's receive the image if the user doesn't close the photo gallery.
if (!result.canceled) {
const { uri } = result.assets[0];
setImage(uri);
}
};
return (
<View style={{ flex: 1, alignItems: "center", justifyContent: "center" }}>
<Button title="Pick an image from camera roll" onPress={pickImage} />
{image ? (
<Image
source={{ uri: image as string }}
style={{ width: 200, height: 200 }}
/>
) : null}
</View>
);
}
```
GitHub with the complete project code: https://github.com/joeyclapton/image-picker-example
#### References
- https://docs.expo.dev/versions/latest/sdk/imagepicker/
- https://docs.expo.dev/tutorial/image-picker/ | joey_clapton | |
1,676,001 | Typescript postman install in ubuntu/linux | postman-linux-x64.tar.gz Great! If you have a new version of the Postman application in the form of... | 0 | 2023-11-23T06:54:35 | https://dev.to/karakib2k18/postman-install-in-ubuntulinux-5086 | postman, webdev, express, typescript | postman-linux-x64.tar.gz
Great! If you have a new version of the Postman application in the form of a `postman-linux-x64.tar.gz` file, you can follow these steps to install and run it:
1. **Extract the Tarball:**
Navigate to the directory where the tarball is located and extract its contents:
```bash
tar -xzf postman-linux-x64.tar.gz
```
This command will extract the contents of the tarball into a new directory, likely named something like `Postman`.
2. **Navigate to the Postman Directory:**
Change into the newly created directory:
```bash
cd Postman
```
3. **Run Postman:**
Inside the `Postman` directory, you should find the executable file. Run it:
```bash
./Postman
```
If you encounter any permission issues, you might need to add execute permissions to the Postman executable:
```bash
chmod +x Postman
```
Then try running it again.
4. **Optional: Create a Desktop Shortcut:**
To make it easier to access Postman, you can create a desktop shortcut. You can do this manually or check if the installation provides an option to create a shortcut during the installation process.
```bash
cp Postman.desktop ~/.local/share/applications/
```
This command copies a desktop file to the appropriate location for desktop shortcuts.
Now, you should have the Postman application running on your system. If you encounter any issues during the installation or have specific instructions provided with the new version, make sure to follow those instructions for the best results.
If you have any further questions or run into any issues, feel free to let me know!
| karakib2k18 |
1,676,082 | Tô màu hoa hướng dương và tạo nên không gian sống nghệ thuật | Mỗi buổi sáng, khi tia nắng đầu tiên của ngày mới ban mai chiếu rọi, tôi thường nhìn thấy những bức... | 0 | 2023-11-23T08:41:26 | https://dev.to/tomaubonghoa/to-mau-hoa-huong-duong-va-tao-nen-khong-gian-song-nghe-thuat-574i | Mỗi buổi sáng, khi tia nắng đầu tiên của ngày mới ban mai chiếu rọi, tôi thường nhìn thấy những bức tranh sống động và tràn ngập sức sống của những đóa hoa hướng dương trong khu vườn nhỏ của mình. Đó là một khoảnh khắc tuyệt vời, nơi mà tôi cảm nhận được vẻ đẹp của tự nhiên và cảm giác hòa mình vào không gian nghệ thuật tinh tế.
Xem Chi Tiết Tại: [](https://tomautructuyen.vn/to-mau-hoa-huong-duong/)
Những đóa hoa hướng dương không chỉ là những bức tranh sống động, mà còn là nguồn cảm hứng lớn để tô điểm cho không gian sống của tôi. Tôi quyết định tô màu những bức tranh này bằng cách sử dụng những gam màu ấm áp và tươi sáng, tạo nên một bức tranh nghệ thuật tự nhiên độc đáo. Việc tô màu không chỉ là một hình thức sáng tạo mà còn là cách để tôi thể hiện tình yêu và đam mê của mình đối với nghệ thuật.
Khi tôi bắt đầu tô màu, từng đường nét trở nên sống động dưới đầu cọ của tôi. Gam màu vàng óng ánh của những bông hoa hướng dương mang lại không gian ấm cúng và tươi mới cho khu vườn. Tôi chọn những gam màu xanh mát để tô điều các lá cây xung quanh, tạo nên sự cân bằng và hài hòa tự nhiên. Bức tranh ngày càng trở nên phong cách và sáng tạo, giống như một tác phẩm nghệ thuật đang mở ra trước mắt tôi.
Không chỉ giới hạn việc tô màu trong giấy và tranh vẽ, tôi quyết định mở rộng không gian nghệ thuật của mình vào không gian sống. Bức tranh hoa hướng dương không chỉ là một tác phẩm nghệ thuật độc lập mà còn là một phần của trang trí nội thất, tô điểm cho căn phòng với vẻ đẹp ấn tượng và tinh tế.
Việc tô màu hoa hướng dương và tạo nên không gian sống nghệ thuật không chỉ là sở thích cá nhân của tôi mà còn là cách tôi tìm thấy niềm vui và ý nghĩa trong cuộc sống hàng ngày. Mỗi bức tranh là một câu chuyện riêng, làm cho không gian sống của tôi trở nên độc đáo và phản ánh tâm hồn của người sáng tạo. Đó không chỉ là nghệ thuật trên giấy mà còn là nghệ thuật sống, nơi mà mỗi chi tiết nhỏ đều được chăm sóc và yêu thương, tạo nên một không gian sống tràn ngập sức sống và nghệ thuật.
Name: Tô Màu Trực Tuyến
Website: [](https://tomautructuyen.vn/)
Phone: 0961 090 061
Tags: #tomau , #tranhtomau, #tomautructuyen, #tranhtomauchobe # tomauhoahuongduong
Email: tomautructuyen@gmail.com
| tomaubonghoa | |
1,676,315 | Python Online Training: Master Python Programming and Earn Certification | Introduction Python Online Training: Master Python Programming and Earn Certification Introduction:... | 0 | 2023-11-23T12:10:57 | https://dev.to/leoanthony/python-online-training-master-python-programming-and-earn-certification-2on9 | python, programming, beginners | **Introduction**
Python Online Training: Master Python Programming and Earn Certification Introduction: Do you want to become a Python pro? Our online training program offers a comprehensive curriculum to help you master Python programming from scratch. Whether you are a beginner or an experienced developer, this course is designed to give you the skills and knowledge needed to excel in the world of Python. Join us now and unlock the doors to a bright future filled with endless possibilities in the world of [Python Online Training](https://www.h2kinfosys.com/courses/python-online-training/).
**Why Learn Python?**
Python, the language of choice for those who love simplicity and flexibility. But wait, there's more! Python holds the key to a wide range of opportunities in the tech industry. From web development to data science, and even automation, Python has got your back. So, hop on the Python bandwagon and open doors to a world of endless possibilities. Not to mention, Python’s clean syntax and readability make it a joy to work with (unlike some other programming languages). Plus, Python has an ever-growing community that provides support and resources at your fingertips.
Don't miss out - join the Python revolution today! Okay, so maybe Python won't turn you into a superhero overnight, but it will definitely give you some superpowers in the coding world. And who knows, maybe one day you'll be able to code your way out of any situation, just like Tony Stark. So, what are you waiting for? Enroll in [Python online certification training](https://www.h2kinfosys.com), master the language, and earn your certification. Trust us, it's worth it. Python is everywhere, and you'll be equipped with the skills to conquer any coding challenge that comes your way. Embrace the power of Python and watch your career soar to new heights. PS: With Python, you can finally say goodbye to those frustrating syntax errors and endless debugging sessions. Debugging? Ain't nobody got time for that!

**Python Basics**
Are you tired of spending hours trying to figure out a programming language? Well, look no further because Python is here to save the day! With Python Basics, you'll learn all the essential elements that make Python so lovable – and trust me, there's a lot to love! First, let's talk about variables and data types. Picture this: you have a box, and you want to put something in it. Well, in Python, that box is a variable, and it can hold anything from numbers to text or even entire collections of data. It's like having a real-life Mary Poppins bag! Now, onto control structures.
Just like a traffic light, Python can make decisions. With if statements, you can tell your program to do something only if a certain condition is met. Imagine having that power in real-life situations – no more long queues at the grocery store! Lastly, we have functions. Think of them as mini superheroes that can perform specific tasks. They take inputs, do their thing, and give you an output. It's like having a personal assistant who can calculate your taxes, write emails, and even walk your dog if you want! So, with Python Basics, you'll conquer variables and data types, control structures, and functions like a boss. Whether you want to analyze data, build web applications, or automate mundane tasks, Python has got you covered. Trust me, Python is your new best friend in the world of programming!
**Python Libraries and Frameworks**
Python Libraries and Frameworks: Python is not just limited to being a simple programming language. It offers a vast number of libraries and frameworks that make your life as a developer a whole lot easier. Let's take a closer look at some of the key Python libraries and frameworks you should definitely get your hands on!
**1. NumPy:** NumPy, short for "Numerical Python," is a fundamental library for scientific computing in Python. It provides support for large, multi-dimensional arrays and matrices, along with a collection of mathematical functions to operate on these arrays efficiently. NumPy is a go-to choice for tasks such as data manipulation, linear algebra, random number generation, and much more. With NumPy, crunching numbers becomes a piece of cake!
**2. Pandas:** Pandas is another essential Python library that specializes in data manipulation and analysis. It offers data structures like DataFrames, which allow you to organize, filter, and dissect data effortlessly. Pandas also provides a plethora of functions and methods to handle missing data, merge datasets, perform statistical operations, and so on. With Pandas, mastering data analysis becomes a walk in the park!
**3. Django:** If you have dreams of becoming a web developer, Django is a framework you must acquaint yourself with. Django is a high-level web framework that simplifies the process of building web applications. It follows the model-view-controller (MVC) architectural pattern and comes packed with a range of features like URL routing, database connectivity, templating engine, and much more. Django empowers you to create robust, scalable, and secure web applications with ease.
Python libraries and frameworks like NumPy, Pandas, and Django are just the tip of the iceberg. As you delve deeper into Python, you'll discover a treasure trove of valuable tools that can make your programming journey smooth and enjoyable. So, buckle up, embrace Python, and unlock a world of endless possibilities! Now, go ahead and dive into the enchanting world of [Python libraries and frameworks](https://docs.google.com/document/d/e/2PACX-1vTnDVOcaMZZ87Ly3f0Ls3_ZGS0hf9OG-ZiyPLvCNled1_pt9zqZ_Ife_7KtUyvlBddA8RFr-dJXWjI5/pub). Trust me, it's a fascinating adventure you won't regret!
**Conclusion**
Python is a versatile programming language that offers numerous opportunities in various fields such as data science, web development, and automation. With Python, you can master the art of coding while enjoying the flexibility it provides. Whether you want to analyze data, build websites, or automate repetitive tasks, Python has got your back. So why wait? Sign up for Python online training and embark on a journey to becoming a Python pro.
| leoanthony |
1,676,351 | Free Mobile Game Development Procedure For Beginners | Recent years have increased hobbies within the creative and attractive sport improvement discipline.... | 0 | 2023-11-23T13:09:32 | https://dev.to/nostra/free-mobile-game-development-procedure-for-beginners-la | nostra, nostragames, gamedev, mobilegames | Recent years have increased hobbies within the creative and attractive sport improvement discipline. A developing range of humans are interested in creating their video games due to the buzz surrounding cellular gaming and the video game enterprise's explosive growth. However, it might not be easy to start game production, specifically for individuals who are not experienced in the area. We made the Ultimate Guide to [**Free Mobile Games Development**](https://nostra.gg/) to assist you in holding close to the guidelines and strategies they had to make their video games.
This article will cover all of the information required to create video games. It will guide you on the various platforms available for growing video games and how to select one. Furthermore, it publishes recreation layout, overlaying topics including degree layout and recreation mechanics. We will go through the many programming languages and software equipment available for game development and the importance of trying out and debugging your Free Mobile Games. Last but not least, it offers recommendations on the way to market and launch your games to the biggest target audience viable.
#### **Procedure for Game Development**
The technique of making Free Mobile Games are examined in detail below:
**1. Pitching Ideas**
The theory of the sport concept takes place at this preliminary level of the development procedure. Game designers expand the overall concept, gameplay mechanics, plot, and supposed target audience.
**2. Pre-Production**
In this segment, a complete method is created via the development crew. A design file that describes the Free Mobile Games mechanics, tale, situation, characters, and consumer interface is needed. They additionally create a challenge plan, finances, and manufacturing agenda.
**3. Post-Production**
The most labor-intensive and time-consuming phase of sports improvement is production. It involves designing the consumer interface, coding the gaming mechanics, and producing the sport's artwork, sound, and music. The development crew can also produce an alpha version of the sport or prototype to check the personal interface and gameplay mechanics.
**4. Testing**
The development group drastically tests the game after the finishing touch to ensure it's dependable and error-free. Internal trying out with the aid of the development team is blended with external testing by way of beta testers or awareness companies.
**5. Release**
After all, bugs are constant and trying out is over; the sport is prepared for release. This entails developing promotional content, including screenshots and trailers, and submitting the game to online shops like Steam or the App Store.
**6. Post-Launch**
The development crew continues to maintain the game after it's been launched using presenting patches and updates to restore any problems or problems that would arise. They may launch extra cloth and new characters or tiers as downloadable DLC.
**7. Game Design**
It impacts the gameplay mechanics, narrative, characters, and usual revel in; the game layout is crucial to the game introduction. It's a complex and disturbing method that requires technical understanding, creativity, and a deep comprehension of the target marketplace.
**8. Explain The Game's Mechanisms**
Game mechanics are the tactics and recommendations that govern **[Free Mobile Games](https://youtu.be/N1jpTSVlXFg)**. This consists of gameplay elements, including movement, combating, solving riddles, and more. Since those mechanisms will impact the gameplay, they must be detailed early in the sport design process.
**9. Create The Narrative**
The story that propels the game is called the plot. It must be fascinating and have a clear starting, center, and end. Additionally, the storyline wishes to match the gameplay.
**10. Design The Personas**
The non-player characters (NPCs) and avatars the player interacts with in the game are considered. They ought to have distinct personalities and objectives, be well-designed, and be remembered. The man or woman designs should also mesh nicely with the plot and gaming mechanics.
**11. Create the Levels**
The settings wherein gameplay takes vicinity are referred to as degrees. They must be artistically appealing, thoughtfully built, and difficult enough to keep players interested. The plot and gaming mechanics ought to move nicely with the level design.
**12. Make The UI Development**
The interactive and visual layout that the participant interacts with whilst playing the sport is known as the user interface. It ought to be easy to apply and offer unambiguous feedback to the person.
**Conclusion**
The procedure of making a Free Mobile Games is complex and fascinating, requiring a mixture of technical skill, creativity, and perseverance. Whether you are a beginner or an expert developer, there are usually new hints and techniques to sharpen your recreation development capabilities. With the assistance of the hints and strategies in this complete guide, novice builders may also begin developing their video games, even as pro creators can increase their abilities and create even more engaging video games. | nostra |
1,676,715 | Benchmark TypeScript Parsers: Demystify Rust Tooling Performance | TL;DR: Native parsers used in JavaScript are not always faster due to extra work across languages.... | 0 | 2023-11-23T20:05:31 | https://dev.to/herrington_darkholme/benchmark-typescript-parsers-demystify-rust-tooling-performance-2go8 | webdev, javascript, rust, node | > TL;DR: Native parsers used in JavaScript are not always faster due to extra work across languages. Avoiding these overhead and using multi-core are crucial for performance.
**Rust** is rapidly becoming a language of choice within the JavaScript ecosystem for its performance and safety features. However, integrating Rust into JavaScript tooling presents unique challenges, particularly when it comes to designing an efficient and portable plugin system.
> "Rewriting JavaScript tooling in Rust is advantageous for speed-focused projects that do not require extensive external contributions." - [Nicholas C. Zakas, creator of ESLint](https://twitter.com/slicknet/status/1726663311541100626)
Learning Rust can be daunting due to its steep learning curve, and distributing compiled binaries across different platforms is not straightforward.
A Rust based plugins necessitates either static compilation of all plugins or a carefully designed application binary interface for dynamic loading.
These considerations, however, are beyond the scope of this article. Instead, we'll concentrate on how to provide robust tooling for writing plugins in JavaScript.
A critical component of JavaScript tooling is the parsing of source code into an Abstract Syntax Tree (AST). Plugins commonly inspect and manipulate the AST to transform the source code. Therefore, it's not sufficient to parse in Rust alone; we must also make the AST accessible to JavaScript.
This post will benchmark several popular TypeScript parsers implemented in JavaScript, Rust, and C.
## Parser Choices
While there are numerous JavaScript parsers available, we focus on TypeScript parsers for this benchmark. Modern bundlers must support TypeScript out-of-the-box, and TypeScript is a superset of JavaScript. Benchmarking TypeScript is a sensible choice to emulate the real-world bundler workload.
The parsers we're evaluating include:
- **[Babel](https://babeljs.io/)**: The Babel parser (previously Babylon) is a JavaScript parser used in Babel compiler.
- **[TypeScript](https://www.typescriptlang.org/)**: The official parser implementation from the TypeScript team.
- **[Tree-sitter](https://tree-sitter.github.io)**: An incremental parsing library that can build and update concrete syntax trees for source files, aiming to parse any programming language quickly enough for *text editor use*.
- **[ast-grep](https://ast-grep.github.io/)**: A CLI tool for code structural search, lint, and rewriting based on abstract syntax trees. We are using its [napi binding](https://github.com/ast-grep/ast-grep/tree/main/crates/napi) here.
- **[swc](https://swc.rs/)**: A super-fast TypeScript/JavaScript compiler written in Rust, with a focus on performance and being a library for both Rust and JavaScript users.
- **[oxc](https://oxc-project.github.io/)**: The Oxidation Compiler is a suite of high-performance tools for JS/TS, claiming to have the fastest and most conformant parser written in Rust.
## Native Addon Performance Characteristics
Before diving into the benchmarks, let's first review the performance characteristics of Node-API based solutions.
**Node-API Pros:**
- **Better Compiler Optimization:** Code in native languages have compact data layouts, leading to fewer CPU instructions.
- **No Garbage Collector Runtime Overhead:** This allows for more predictable performance.
However, Node-API is not a silver bullet.
**Node-API Cons:**
- **FFI Overhead:** The cost of interfacing between different programming languages.
- **Serde Overhead:** Serialization and deserialization of Rust data structures can be costly.
- **Encoding Overhead:** Converting JS string in utf-16 to Rust's utf-8 string can introduce significant delays.
We need to understand the pros and cons of using native node addons in order to design an insightful benchmark.
## Benchmark Design
We consider two main factors:
1. **File Size:** Different file sizes reveal distinct performance characteristics. The parsing time of an N-API based parser consists of actual parsing and cross-language overhead. While parsing time is proportional to file size, the growth of cross-language overhead depends on the parser's implementation.
2. **Concurrency Level:** Parallel parsing is not possible in JavaScript's single main thread. However, N-API based parsers can run in separate threads, either using libuv's thread pool or their own threading model. That said, thread spawning also incurs overhead.
We are not considering these factors in this post.
- **Warmup and JIT:** No significant difference observed between warmup and non-warmup runs.
- **GC, Memory Usage:** Not evaluated in this benchmark.
- **Node.js CLI arguments:** To make the benchmark representative, default Node.js arguments were used, although tuning could potentially improve performance.
## Benchmark Setup
### Testing Environment
The benchmarks were executed on a system equipped with the following specifications:
- **Operating System:** macOS 12.6
- **Processor:** arm64 Apple M1
- **Memory:** 16.00 GB
- **Benchmarking Tool:** [Benny](https://caderek.github.io/benny/)
### File Size Categories
To assess parser performance across a variety of codebases, we categorized file sizes as follows:
- **Single Line:** A minimal TypeScript snippet, `let a = 123;`, to measure baseline overhead.
- **Small File:** A concise 24-line TypeScript module, representing a common utility file.
- **Medium File:** A typical 400-line TypeScript file, reflecting average development workloads.
- **Large File:** The extensive 2.79MB `checker.ts` from the TypeScript repository, challenging parsers with a complex and sizable codebase.
### Concurrency Level
For this benchmark, we simulate a realistic workload by parsing five files concurrently. This number is an arbitrary but reasonable proxy to the actual JavaScript tooling.
It's worth noting, to seasoned Node.js developers, that this setup may influence asynchronous parsing performance. However it does not disproportionately favor Rust-based parsers. The rationale behind this is left as an exercise for the reader. :)
----
This post aims to provide a general overview of the benchmarking for TypeScript parsers, focusing on the performance characteristics of N-API based solutions and the trade-offs involved. Feel free to adjust the benchmark setup to better fit your workload.
Now, let's delve into the results of TypeScript parser benchmarking!
## Results
### Synchronous Parsing
The performance of each parser is quantified in operations per second—a metric provided by the Benny benchmarking framework. For ease of comparison, we've normalized the results:
* The fastest parser is designated as the benchmark, set at 100% efficiency.
* Other parsers are evaluated relative to this benchmark, with their performance expressed as a percentage of the benchmark’s speed.


TypeScript consistently outperforms the competition across all file sizes, being twice as fast as Babel.
Native language parsers show improved performance for larger files due to the reduced relative impact of FFI overhead.
Nevertheless, the performance gains are not as pronounced due to serialization and deserialization (serde) overhead, which is proportional to the input file size.
### Asynchronous Parsing
In the asynchronous parsing scenario, we observe the following:

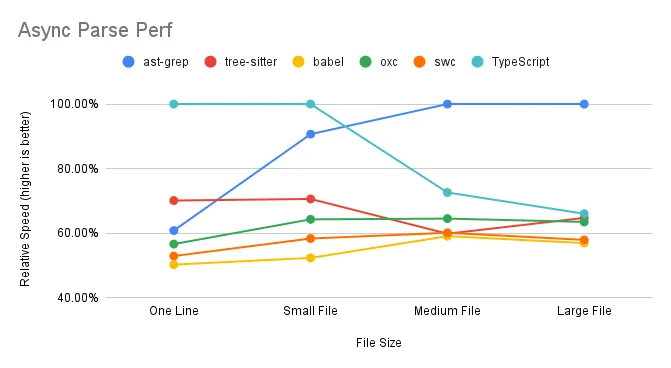
ast-grep excels when handling multiple medium to large files simultaneously, effectively utilizing multi-core capabilities. TypeScript and Tree-sitter, however, experience a decline in performance with larger files. SWC and Oxc maintain consistent performance, indicating efficient use of multi-core processing.
### Parse Time Breakdown
When benchmarking a Node-API based program, it's crucial to understand the time spent not only executing Rust code but also the Node.js glue code that binds everything together. The parsing time can be dissected into three main components:
```
time = ffi_time + parse_time + serde_time
```
Here's a closer look at each term:
- **`ffi_time` (Foreign Function Interface Time):** This represents the overhead associated with invoking functions across different programming languages. Typically, `ffi_time` is a fixed cost and remains constant regardless of the input file size.
- **`parse_time` (Parse Time):** The core duration required for the parser to analyze the source code and generate an Abstract Syntax Tree (AST). `parse_time` scales with the size of the input, making it a variable cost in the parsing process.
- **`serde_time` (Serialization/Deserialization Time):** The time needed to serialize Rust data structures into a format compatible with JavaScript, and vice versa. As with `parse_time`, `serde_time` increases as the input file size grows.
In essence, benchmarking a parser involves measuring the time for the actual parsing (`parse_time`) and accounting for the extra overhead from cross-language function calls (`ffi_time`) and data format conversion (`serde_time`). Understanding these elements helps us evaluate the efficiency and scalability of the parser in question.
### Result Interpretation
This section offers a detailed and technical analysis of the benchmark results based on the parse time framework above. Readers seeking a high-level overview may prefer to skip ahead to the summary.
**FFI Overhead**
In both sync parsing and async parsing scenario, the "one line" test case, which is predominant FFI overhead with minimal parsing or serialization, shows TypeScript's superior performance. Surprisingly, Babel, expected to excel in this one-line scenario, demonstrates its own peculiar overhead.
As file size increases, FFI overhead becomes less significant, as it's largely size-independent. For instance, ast-grep's relative speed is 78% for a large file compared to 72% for a single line, suggesting an approximate 6% FFI overhead in synchronous parsing.
FFI overhead is more pronounced in asynchronous parsing. ast-grep’s performance drops from 72% to 60% when comparing synchronous to asynchronous parsing of a single line. The absence of a notable difference in performance for swc/oxc may be due to their [unique implementation details](https://github.com/oxc-project/oxc/blob/2d5e0d5d0775300463f36b925e2f1ce71f119b90/napi/parser/src/lib.rs#L96).
**Serde Overhead**
Unfortunately, we failed to replicate swc/oxc's blazing performance we witnessed in other applications.
Despite minimal FFI impact in “Large file” test cases, swc and oxc underperform compared to the TypeScript compiler. This can be attributed to their reliance on calling [`JSON.parse` on strings](https://github.com/swc-project/swc/blob/5d944185187402691292fdb73ea767bd580e2a52/node-swc/src/index.ts#L108) returned from Rust, which is, to our disappointment, still more efficient than direct data structure returns.
Tree-sitter and ast-grep avoid serde overhead by [returning a tree object](https://github.com/ast-grep/ast-grep/blob/1c3accfd7dccef293c480951759b86c418cde977/crates/napi/src/sg_node.rs#L297) rather than a full AST structure. Accessing tree nodes requires [invoking Rust methods](https://github.com/ast-grep/ast-grep/blob/1c3accfd7dccef293c480951759b86c418cde977/crates/napi/src/sg_node.rs#L78) from JavaScript, which distributes the cost over the reading process.
**Parallel**
Except tree-sitter, all native TS parsers have parallel support. Contrary to JS parsers, native parsers performance will not degrade when concurrently parsing larger files. This is thanks to the power of multiple cores. JS parsers suffer from CPU bound because they have to parse file one by one.
### Perf summary for parsers
The performance of each parser is summarized in the table below, which outlines the time complexity for different operations.

In the table, `constant` denotes a constant time cost that does not change with input size, while `proportional` indicates a variable cost that grows proportionally with the input size. An `N/A` signifies that the cost is not applicable.
JS-based parsers operate entirely within the JavaScript environment, thus avoiding any FFI or serde overhead. Their performance is solely dependent on the parsing time, which scales with the size of the input file.
The performance of Rust-based parsers is influenced by a fixed FFI overhead and a parsing time that grows with input size. However, their serde overhead varies depending on the implementation:
For ast-grep and tree-sitter, they have a fixed serialization cost of one tree object, regardless of the input size.
For swc and oxc, the serialization and deserialization costs increase linearly with the input size, impacting overall performance.
## Discussion
### Transform vs. Parse
While Rust-based tools are renowned for their speed in transpiling code, our benchmarks reveal a different narrative when it comes to converting code into an AST that’s usable in JavaScript.
This discrepancy highlights a critical consideration for Rust tooling authors: the process of passing Rust data structures to JavaScript is a complex task that can significantly affect performance.
It's essential to optimize this data exchange to maintain the high efficiency expected from Rust tooling.
### Criteria for Parser Inclusion
In our benchmark, we focused on parsers that offer a JavaScript API, which influenced our selection:
* **Sucrase:** Excluded due to its lack of a parsing API and [inability to produce a complete AST](https://github.com/alangpierce/sucrase#motivation), which are crucial for our evaluation criteria.
* **Esbuild/Biome:** Not included because esbuild functions primarily as a bundler, not a standalone parser. It offers transformation and build capabilities but [does not expose an AST](https://esbuild.github.io/api/#js-details) to JavaScript. Similarly, biome is a CLI application without a JavaScript API.
* **Esprima:** Not considered for this benchmark as it lacks TypeScript support, which is a key requirement for the modern JavaScript development ecosystem.
### JS Parser Review
**Babel:**
Babel is divided into two main packages: `@babel/core` and `@babel/parser`. It's noteworthy that `@babel/core` exhibits lower performance compared to `@babel/parser`. This is because the additional entry and hook code that surrounds the parser in the core package. Furthermore, the `parseAsync` function in Babel core is not genuinely asynchronous; it's essentially a synchronous parser method wrapped in an asynchronous function. This wrapper provides extra hooks but does not enhance performance for CPU-intensive tasks due to JavaScript's single-threaded nature. In fact, the overhead of managing asynchronous tasks can further burden the performance of `@babel/core`.
**TypeScript:**
The parsing capabilities of TypeScript defy the common perception of the TypeScript compiler (TSC) being slow. The benchmark results suggest that the primary bottleneck for TSC is not in parsing but in the subsequent type checking phase.
### Native Parser Review
**SWC:**
As the first Rust parser to make its mark, SWC adopts a direct approach by serializing the entire AST for use in JavaScript. It stands out for offering a broad range of APIs, making it a top choice for those seeking Rust-based tooling solutions. Despite some inherent overhead, SWC's robustness and pioneering status continue to make it a preferred option.
**Oxc:**:
Oxc is a contender for the title of the fastest parser available, but its performance is tempered by serialization and deserialization (serde) overhead. The inclusion of JSON parsing in our benchmarks reflects real-world usage, although omitting this step could significantly boost Oxc's speed.
**Tree-sitter**
Tree-sitter serves as a versatile parser suitable for a variety of languages, not specifically optimized for TypeScript. Consequently, its performance aligns closely with that of Babel, a JavaScript-focused parser implemented in JavaScript. Alas, a Rust parser is not inherently faster by default, even without any N-API overhead.
A general purpose parser in Rust may not beat a carefully hand-crafted parser in JavaScript.
**ast-grep**
ast-grep is powered by tree-sitter. Its performance is marginally faster than tree-sitter, indicating napi.rs is a faster binding than manual using C++ nan.h.
I cannot tell whether the performance gain is from napi or napi.rs but
Leveraging the capabilities of tree-sitter, ast-grep achieves slightly better performance, suggesting that napi.rs offers a more efficient binding than traditional C++ [nan.h](https://github.com/tree-sitter/node-tree-sitter/blob/master/src/parser.h) methods. While the exact source of this performance gain—whether from napi or napi.rs—is unclear, the results speak to the effectiveness of the implementation. Or put it in another way, [Broooooklyn](https://twitter.com/Brooooook_lyn) is 🐐.
### Native Parser Performance Tricks
**tree-sitter & ast-grep' Edge**
These parsers manage to bypass serde costs post-parsing by returning a Rust object wrapper to Node.js. This strategy, while efficient, can lead to slower AST access in JavaScript as the cost is amortized over the reading phase.
**ast-grep's async advantage:**
ast-grep's performance in concurrent parsing scenarios is largely due to its utilization of multiple [libuv threads](http://docs.libuv.org/en/v1.x/threadpool.html). By default, the libuv thread pool size is set to four, but there's potential to enhance performance further by [expanding the thread pool size](https://dev.to/bleedingcode/increase-node-js-performance-with-libuv-thread-pool-5h10), thus fully leveraging the available CPU cores.
## Future Outlook
As we look to the future, several promising avenues could further refine TypeScript parser performance:
- **Minimizing Serde Overhead:** By optimizing serialization and deserialization processes, such as employing Rust object wrappers, we can reduce the performance toll these operations take.
- **Harnessing Multi-core Capabilities:** Effective utilization of multi-core architectures can lead to substantial gains in parsing speeds, transforming the efficiency of our tooling.
- **Promoting AST Reusability:** Facilitating the reuse of Abstract Syntax Trees within JavaScript can diminish the frequency of costly parsing operations.
- **Shifting Workloads to Rust:** The creation of a domain-specific language (DSL) tailored for AST node querying could shift a greater portion of computational work to the Rust side, enhancing overall efficiency.
These potential improvements represent exciting opportunities to push the boundaries of Rust tooling in parsing performance.
Hope this article helps you! We can continue to innovate and deliver even more powerful tools to the developer community!
| herrington_darkholme |
1,676,733 | Step 3 - final result | Step 1 - planning Step 2 - progress Step 3 - release Technical feature of the work Issue... | 0 | 2023-12-02T00:17:57 | https://dev.to/avelynhc/step-3-final-result-1hdk | Step 1 - [planning](https://dev.to/avelynhc/step-1-let-me-plan-first-3fp0)
Step 2 - [progress](https://dev.to/avelynhc/step-2-progress-report-4ja4)
Step 3 - [release]()
-------------------------------------------------------------
**Technical feature of the work**
[Issue 1](https://github.com/PolicyEngine/policyengine-app/issues/852)
- added an edge case to the existing if/else statement to fix the CI failure issue.
The problem occurred as previous solution does not catch the edge case when certain variables are passed. Because of missing the edge case, else block is executed returning false, which caused CI to fail.
In the new solution, new edge case was added to continue the current `if` code flow when certain variables are passed. This edge case will be executed when array of excludedVariables includes a variable. If it does, it will delete it.
```typescript
...
let excludedVariables = ["fips", "sep"];
...
else if (excludedVariables.includes(variable)) {
delete editedHousehold[entityPlural][entity][variable];
}
...
```
_**Result**_
You can find more details in here: [PR](https://github.com/PolicyEngine/policyengine-app/pull/863)
[Issue 2](https://github.com/PolicyEngine/policyengine-app/issues/865)
- `prettier . --write` was added to the existing lint script to be able to handle both linting and formatting without the need for an additional Prettier command.
**_Before_**
```shell
"lint": "eslint --ext js,jsx . && prettier -c ."
```
**_After_**
```shell
"lint": "eslint --ext js,jsx . && prettier . --write"
```
**_Result_**
You can find more details in here: [PR](https://github.com/PolicyEngine/policyengine-app/pull/871)
[Issue 3](https://github.com/PolicyEngine/policyengine-app/issues/874)
- `make format` rule was changed to not use Black. Instead of using Black, `npm run lint` was used to lint the project as below.
```shell
install:
npm ci
build:
npm run build
debug-no-lint:
ESLINT_NO_DEV_ERRORS=true npm start
debug:
npm start
test:
npm run test
deploy-setup:
cp gcp/.gcloudignore ./.gcloudignore
cp gcp/app.yaml ./app.yaml
cp gcp/main.py ./main.py
cp gcp/social_card_tags.py ./social_card_tags.py
cp gcp/requirements.txt ./requirements.txt
cp -r social_cards/ build/static/media/social_cards
deploy: build deploy-setup
gcloud config set app/cloud_build_timeout 1000
y | gcloud app deploy --project policyengine-app
rm app.yaml
rm .gcloudignore
rm main.py
rm requirements.txt
lint:
npm run lint
```
You can find more details in here: [PR](https://github.com/PolicyEngine/policyengine-app/pull/902)
[Issue 4](https://github.com/atb-brown/austin/issues/39)
- `"sort-keys-fix/sort-keys-fix"` rule was added to `eslintrc.yml` file as below for ascending sorting.
```shell
"rules": {
...
"sort-keys-fix/sort-keys-fix":
["error", "asc", { "caseSensitive": false }],
},
```
- `fix` command was added to scripts in `package.json` file to be able to fix the lint problem with single command, `npm run fix`.
```shell
"scripts": {
"fix": "eslint src --fix --ext .ts,.tsx,.js",
...
},
```
- This changes applies to all of the keys in Object, not limited to React component property only.
**_Result_**
Examples of unsorted prop
<img width="484" alt="Screenshot 2023-12-01 at 6 51 06 PM" src="https://github.com/atb-brown/austin/assets/75185537/5ff839ab-7f72-41e9-8964-8156e3cdba1f">
Unsorted props will give you an error.
<img width="760" alt="Screenshot 2023-12-01 at 6 51 12 PM" src="https://github.com/atb-brown/austin/assets/75185537/e43fefb6-7319-4f30-80e5-1d145e50175d">
With the help of command, `npm run fix`, it will automatically sort everything as expected.
<img width="439" alt="Screenshot 2023-12-01 at 7 18 49 PM" src="https://github.com/atb-brown/austin/assets/75185537/6ff10370-e3f8-496c-b3b5-b1ebb8508d91">
Fix result (props are ordered alphabetically now!)
After the fix, there is no error.
<img width="432" alt="Screenshot 2023-12-01 at 7 19 06 PM" src="https://github.com/atb-brown/austin/assets/75185537/7d837d3e-ec2b-4c82-ae74-08ec0c42906b">
You can find more details in here: [PR](https://github.com/atb-brown/austin/pull/55)
**What did you learn from this process?**
_**Makefile**_
'Make' is used to compile the program automatically. To be able to use 'make', it needs 'Makefile' to define multiple tasks/commands to be executed. 'Make' is commonly used in many open source projects for final compilation, and it can be installed using `make install` command. When cleaning is needed for this process, use `make clean` command.
There are lots of tasks you can add on top of the current 'Makefile'. For example, you can add a task to back up the project or initialize the project as below.
```shell
# Backup the project
backup:
cp -r project backup
# Initialize the project
init:
npm init
```
**How well did you do achieving your goals?**
As indicated in [Step 1 - planning](), I had two main goals for the release 0.4: to learn new skills and push myself out of my comfort zone. This project was the largest one I have contributed to so far. Numerous people were involved in each issue or pull request (PR). The projects I had contributed to before were comparatively smaller, so I would usually receive comments on the PR I submitted right away in a fast-paced environment. However, this time was different. Whenever I pushed a PR, it took days and days to be reviewed. For instance, one reviewer pinged another person to join the open discussion on the PR. I would describe it as a slow-paced environment. Nevertheless, I learned a lot through this experience.
I typically look at specific pieces of code, fix the issue, and move on. But it was not that simple in a larger project like this. Reviewers reminded me that the bigger picture cannot be ignored simultaneously. Additionally, I learned a new method to automate processes using `make` during this project. I can confidently say that I achieved both goals I set during the planning step.
**Reasoning**
Some of PRs are not merged yet. For examples, I am still waiting for teams to review the [PR](https://github.com/PolicyEngine/policyengine-app/pull/863) I pushed 2 weeks ago. For another [PR](https://github.com/PolicyEngine/policyengine-app/pull/871), there has been a conversation between maintainers what to do next with this pr, but no progress so far.
In addition, there was a comment about properly separating content within PRs. For example, I created several PRs, some of which had a nested structure. In one case, the second PR I made included the content of both the PR 1 and the PR 2. The third PR was even more complex, encompassing the contents of PR 1, PR 2, and PR 3. I believe that all these unorganized PRs makes it challenging for maintainers to review them efficiently. Going forward, I think I need to separate each PR I create in the same repository for better readability and overall efficiency. | avelynhc | |
1,677,068 | Exclusive Cyber Monday & Black Friday Deal | Hey, there looking for a Black Friday & Cyber Monday Deal? If yes we have the wildest deal... | 0 | 2023-11-24T07:25:53 | https://dev.to/ritirathod0/exclusive-cyber-monday-black-friday-deal-239 | webdev, programming, productivity |

Hey, there looking for a Black Friday & Cyber Monday Deal? If yes we have the wildest deal ever. Yes…Yes… **Save 50%** on the purchase of any **Premium Admin Template**.
If you are a developer and looking for the developer-friendly, responsive, highly customized fully coded admin templates whether it react admin template, angular admin template, bootstrap admin template, vue admin template, django admin template, or any other then **[CodedThemes](https://codedthemes.com/)** offers a 🤩 fantastic deal on every template.
However, don’t miss this amazing deal because it comes once in year. So what are you waiting for? This is the perfect time to invest in a highly-selling admin template. **The sale is Live Now! Hurry up!**🏃♂️🏃♂️
## **Detail about deal**
> **Offer** - 50% off on any Premium Admin Template💸
> **Promo Code** - CMBF2023🎁
> **Deal Validity** – 24th November to 27th November⏳ | ritirathod0 |
1,677,181 | CyberArk Interview Questions | CyberArk is an information security firm that provides privileged account security to multiple... | 0 | 2023-11-24T09:54:39 | https://dev.to/shivamchamoli18/cyberark-interview-questions-228h | cyberark, interviewquestions, cybersecurity, infosectrain | CyberArk is an information security firm that provides privileged account security to multiple industries, including banking, information technology, government organizations, healthcare, financial, and many more sectors.

This article is compiled with some important CyberArk interview questions and answers to help you ace your interview and achieve your ideal job in various CyberArk roles, such as CyberArk Analyst, CyberArk Specialist, Senior CyberArk Engineer, and more.
## **CyberArk interview questions:**
**1. Explain Application Identity Manager.**
CyberArk Application Identity Manager (AIM) enables enterprises to protect data stored in business systems by removing hard-coded passwords from configuration files, applications, scripts, and software code. AIM secures privileged and application credentials using patented Digital Vault technology, which is created to adhere to the strictest security standards.
**2. What is an SSH Key Manager?**
Secure Socket Shell (SSH) Key Manager aids enterprises in preventing unauthorized access to private SSH keys, which are widely used by privileged Unix/Linux users and apps to verify privileged accounts.
**3. Which CyberArk module is in charge of recording sessions?**
Privileged Session Manager (PSM) is in charge of recording sessions. It is designed to securely manage and monitor privileged sessions, including recording and auditing activities performed during these sessions.
**4. Which CyberArk module is in charge of updating passwords?**
The Central Policy Manager (CPM) is in charge of updating passwords. It automates the process of updating passwords for privileged accounts across various systems and applications.
**5. What are PSM's capabilities for SSH?**
The capabilities of PSM for SSH include:
• Video recording
• Centralized access control
• Secure remote access
**6. What is CyberArk ENE?**
The CyberArk Event Notification Engine (ENE) automatically sends email notifications about Privileged Access Security Solution events to predefined users.
**7. Describe the password vault.**
A password vault, often known as a password manager, is a software program that keeps various privileged account passwords in a Privileged Account Management system. It allows users to access multiple passwords for many websites or services using a single master password by encrypting the password storage.
**8. What are the authentication schemes that CyberArk Vault supports?**
The CyberArk Vault supports the following authentication protocols:
• Radius
• Public Key Infrastructure (PKI)
• Lightweight Directory Access Protocol (LDAP)
**9. How can you ensure that every character in a string is a number?**
We can ensure that every character in a string is a number using the ‘Python isnumeric() function.’ It checks every character of the string, and if a string only contains numeric characters, it returns true, otherwise false.
**10.What distinguishes a Lambda from a Def?**
Difference between Def and Lambda.
**Def function**
It can have a return statement.
It can hold multiple expressions.
Its computational time is slower.
It returns an integer value.
**Lambda function**
It can not have return statements.
It is a single-expression function.
Its computational time is faster.
It returns the function object value.
## **CyberArk with InfosecTrain**
Enroll in InfosecTrain's [CyberArk training](https://www.infosectrain.com/courses/cyberark-training/) course to learn more about CyberArk from our certified and highly experienced instructors who have in-depth knowledge of the subject.
You can also check out "[CyberArk Interview Questions and Answers](https://infosec-train.blogspot.com/2023/11/top-10-cyberark-interview-questions.html) " for more CyberArk interview questions.
| shivamchamoli18 |
1,677,194 | Buy Best Room Heater in Affordable Price. | As winter arrives, bringing with it a chill in the air and frosty mornings, there's one modern... | 0 | 2023-11-24T10:09:34 | https://dev.to/honey5135/buy-best-room-heater-in-affordable-price-5262 | As winter arrives, bringing with it a chill in the air and frosty mornings, there's one modern comfort that becomes a cherished necessity – the warmth that room heaters and water heaters provide. In the realm of seasonal companions, these appliances are the unsung heroes of our winter days. Let's explore why room heaters and water heaters are essential during the winter season and how they can transform your cold days and nights into warm, comforting experiences.
[Room Heaters](https://summerkingonline.com/collections/room-heaters): A Warm Retreat from the Cold
When the winter cold seeps into your home, there's nothing more inviting than the warmth emanating from a reliable room heater. Stepping into a toasty room on a frosty morning or cozying up in a well-heated space in the evening becomes a source of immediate comfort. Room heaters ensure that you can create your warm haven, setting a positive and comforting tone for the rest of the day and night.
[Water Heaters](https://summerkingonline.com/collections/water-heater): Instant Comfort in Every Drop
The prospect of facing a cold shower on a chilly morning is not just daunting; it can be a shock to the system. Enter the trusty water heater – the unsung hero of winter mornings. It provides instant relief from the cold, allowing you to start your day with a warm and comforting shower. This transforms your morning routine, making it a soothing and invigorating experience that sets a positive tone for the day ahead.
Energy Efficiency for Cost-Effective Warmth
Both room heaters and water heaters have evolved to prioritize energy efficiency. Modern appliances in these categories are designed with advanced features that not only provide warmth but also do so without unnecessary energy consumption. This ensures that you can enjoy the luxury of a warm room or a hot shower without worrying about skyrocketing energy bills.
Tailored to Your Winter Needs
Room heaters and water heaters come in various types and sizes to suit your specific winter requirements. Whether you prefer a radiant heater for quick room heating or a tankless water heater for on-demand hot water, there's an option to match your needs and preferences.
Reliability, Durability, and Safety
Well-maintained room heaters and water heaters are long-term investments. These appliances are built to last and withstand the test of time. High-quality heaters are your companions not only for this winter but for many more to come. Moreover, both types of heaters come with safety features to protect you and your family from accidents, ensuring worry-free use.
Choosing the Right Heaters
When selecting room heaters and water heaters, consider factors like the size of your room or household, your heating or hot water usage patterns, and your budget. With various options available, from ceramic space heaters to tank water heaters, you have the freedom to choose the ones that best fit your winter needs.
In Conclusion: Embrace Winter with Cozy Comfort
As the winter season approaches, room heaters and water heaters can make all the difference in your daily comfort. They are not just functional appliances; they are sources of warmth and relaxation in a season that often challenges us with its cold embrace.
So, if you want to enjoy a cozy and comforting winter season, make sure your home is equipped with reliable and efficient room heaters and water heaters. They are the secrets to keeping the chill at bay and savoring the warmth of winter on your terms.
| honey5135 | |
1,677,393 | DEVWorld BLACK FRIDAY : Code, Conquer, and Score Big! | 🚀 Brace yourselves, tech enthusiasts! It's that magical time of the year when discounts rain down... | 0 | 2023-11-24T12:56:00 | https://dev.to/devworld_conf/devworld-black-friday-code-conquer-and-score-big-2bh8 | blackfriday, javascript, programming, news | 🚀 Brace yourselves, tech enthusiasts! It's that magical time of the year when discounts rain down like confetti at a coding carnival. And guess what? We've got the scoop of the century – it's **BLACK FRIDAY**, and we're diving into the discount pool headfirst with the enthusiasm of a programmer finding the last bug in their code!
🎉 Drumroll, please! We're thrilled to announce that DEVWorld is not just joining the Black Friday party; we're hosting the bash with the **BIGGEST** discount extravaganza of the season, mind-blowing **650 Euro discoun**t on your DEVWorld tickets – that's a jaw-dropping **75% off!** But here's the catch: It's a 24-hour whirlwind of savings, and you better believe it's the talk of the coding town.
**ONLY 249 EUROS**
🔊 Spread the word like! This deal is so rare, gather your family, notify your colleagues, even inform your long-lost coding buddies – everyone needs to know about this once-in-a-lifetime opportunity to score a discount that's practically coding history!
🚀✨ But wait, there's more! Imagine being part of the #1 developer conference on the entire planet, nestled in the tech capital of Europe. DEVWorld is not just a conference; it's a technological fiesta where innovation meets celebration, and this **Black Friday deal is your golden ticket to the festivities.**
**✈️ Pack your bags – we're expecting 7,500 attendees ready to geek out.**
**💼 Get ready to network with 3,500 companies that could be your next coding soulmates.**
**🌎 Represent your flag among the 94+ countries making DEVWorld a global tech sensation.**
**🏢 And did we mention the expo? Brace yourself for 23,000m2 of pure coding ecstasy!**
**🗓️ Save the date: February 29 to March 1, 2024 – because this is not just any conference; it's the DEVWorld experience.**
**📍 And where is this tech utopia located? Rai Amsterdam – the LARGEST venue in The Netherlands, because we don't do things small; we think big and code bigger.**
Don't let this opportunity! Mark your calendar, set an alarm, tie a string around your finger – do whatever it takes to remind yourself because DEVWorld with a **75% Black Friday discount** is a tech odyssey you can't afford to miss. See you there! 🚀🎈 | devworld_conf |
1,677,426 | JavaScript's Grouping Methods: Object.groupBy and Map.groupBy 🤯 | JavaScript, the language that powers the dynamic and interactive web, is constantly evolving to make... | 0 | 2023-11-24T13:53:49 | https://dev.to/shameel/javascripts-grouping-methods-objectgroupby-and-mapgroupby-aba | webdev, javascript, programming, beginners | JavaScript, the language that powers the dynamic and interactive web, is constantly evolving to make developers' lives easier. **This blog is the introduction of two powerful methods for grouping data:** `Object.groupBy` and `Map.groupBy`. 🤯
These methods promise to simplify grouping operations, eliminating the need for external dependencies and enhancing the overall development experience.
## What's the Buzz About?
`groupBy` methods aim to streamline process of grouping data, offering a native and efficient solution for grouping objects and maps.
### Object.groupBy
Let's start by exploring `Object.groupBy`. This method is designed to work with arrays of objects, making it a valuable addition for handling complex datasets.
```javascript
const employees = [
{ name: 'Shameel', department: 'HR' },
{ name: 'Uddin', department: 'Engineering' },
{ name: 'Syed', department: 'HR' },
];
// Grouping employees by department using Object.groupBy
const groupedByDepartment = Object.groupBy(employees,({department})=>department)
console.log(groupedByDepartment);
```
In this example, `employees` are grouped by their respective departments, resulting in a clear and concise structure.
**Result:**
```js
{
"HR": [
{
"name": "Shameel",
"department": "HR"
},
{
"name": "Syed",
"department": "HR"
}
],
"Engineering": [
{
"name": "Uddin",
"department": "Engineering"
}
]
}
```
### Map.groupBy
The `Map.groupBy` method extends the grouping capabilities to Map objects, providing a versatile solution for scenarios where a Map structure is preferred.
```javascript
const inventory = [
{ name: '🥦 broccoli', type: 'vegetables', quantity: 9 },
{ name: '🍌 bananas', type: 'fruit', quantity: 5 },
{ name: '🐐 goat', type: 'meat', quantity: 23 },
{ name: '🍒 cherries', type: 'fruit', quantity: 12 },
{ name: '🐟 fish', type: 'meat', quantity: 22 },
];
const restock = { restock: true };
const sufficient = { restock: false };
// Using Map.groupBy to categorize items based on quantity
const result = Map.groupBy(inventory, ({ quantity }) =>
quantity < 6 ? restock : sufficient
);
// Displaying items that need restocking
console.log(result.get(restock));
```
Here, `orders` are grouped by the product they contain, showcasing the flexibility and expressiveness of the `Map.groupBy` method.
## Conclusion
The beauty of these new methods lies in their simplicity. They abstract away the complexity of manual grouping, providing a clean and expressive syntax. No more lengthy code or external dependencies – just pure JavaScript magic!
Happy coding! 🎉💻✨
Follow me for more such content:
LinkedIn: https://www.linkedin.com/in/shameeluddin/
Github: https://github.com/Shameel123 | shameel |
670,676 | Java 8 Streams | https://grokonez.com/java/java-8/java-8-streams Java 8 Streams Java 8 comes with some prominent fea... | 0 | 2021-04-18T17:41:00 | https://dev.to/loizenai/java-8-streams-ji | java, java8, streams | ERROR: type should be string, got "https://grokonez.com/java/java-8/java-8-streams\n\nJava 8 Streams\n\nJava 8 comes with some prominent features like <a href=\"https://grokonez.com/java/java-8-lambda-expressions\">Lambda Expressions</a>, <a href=\"https://grokonez.com/java/java-8-method-references\">Method References</a>. And <strong>Streams</strong> are also an important concept that we should comprehend.\n\nThis tutorial will help you have a deep view of Java 8 Streams: what they are, ways to create them, how they work with intermediate operations, terminal operation...\n\n<!--more-->\n<div id=\"tuttoc\" class=\"jsa-toc\"></div>\n\n<div id=\"tutcontents\">\n<h2>I. Overview</h2>\n<h3>1. What is Java 8 Stream?</h3>\nA stream is an abstract concept that represents a sequence of objects created by a source, it’s neither a data structure nor a collection object where we can store items. So we can't point to any location in the stream, we just interact with items by specifying the functions.\n\nThis is an example of a Stream:\n<pre><code class=\"language-java\">\nList<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9);\n// get List from Stream Operation\nList<String> result = numbers.stream()\n\t\t.filter(i -> (i % 2) == 0)\n\t\t.map(i -> \"[\" + i + \"]\")\n\t\t.collect(Collectors.toList());\n\nSystem.out.println(result);\n</code></pre>\nRun the code above, the console shows:\n<pre><code class=\"language-java\">\n[[2], [4], [6], [8]]\n</code></pre>\nNow, we have concept of using a Stream is to enable functional-style operations on streams of elements. Those operations are composed into a stream pipeline which consists of:\n<code>Source</code> > <code>Intermediate Operations</code> > <code>Terminal Operation</code>\n- a <strong><em>source</em></strong> (in the example, it is a collection - List, but it is also an array, a generator function, an I/O channel...)\n- <em><strong>intermediate operations</strong></em> (which transform current stream into another stream at the current chain, in the example, <strong>filter</strong> is the first operation and <strong>map</strong> is the second one)\n- a <em><strong>terminal operation</strong></em> (which produces a result or side-effect, in the example, it is <strong>collect</strong>) \n\nMore at:\n\nhttps://grokonez.com/java/java-8/java-8-streams\n\nJava 8 Streams" | loizenai |
1,677,931 | Solving the Puzzle: How to Pass Environment Variables in AWS AppSync Resolvers using Serverless | Are you just diving into the world of AWS AppSync and puzzled about passing environment variables to... | 0 | 2023-11-25T05:29:04 | https://dev.to/am_i_dev/solving-the-puzzle-how-to-pass-environment-variables-in-aws-appsync-resolvers-using-serverless-kl0 | appsync, serverless, javascript, resolverfunction | Are you just diving into the world of AWS AppSync and puzzled about passing environment variables to the resolver using the Serverless Framework? If you've scoured countless blogs without finding a solution, you've landed on the right page!
## Scenario
Imagine you have an AppSync endpoint triggering a mutation. In this scenario, you need to validate user information and perhaps trigger an SQS with a unique accountID for each environment or use the tableName in the resolver function to fetch data from DynamoDB. Whatever your use case, you can follow these steps to seamlessly pass environment variables to your resolver function.
## Solution
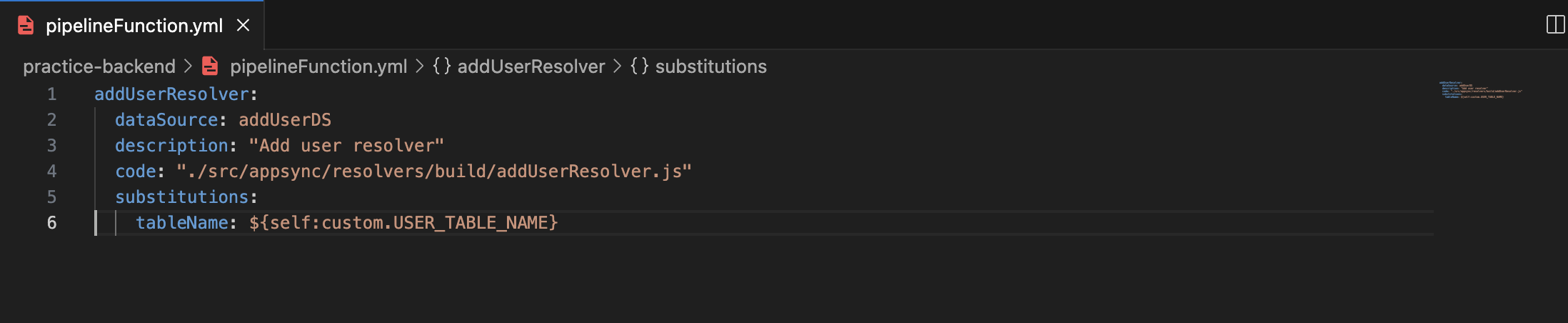
**Step1:-** Add a property called substitutions to the resolver you've created. This is where you'll pass your environment variables as key-value pairs. In the example below, I'm using tableName as an environmental variable.
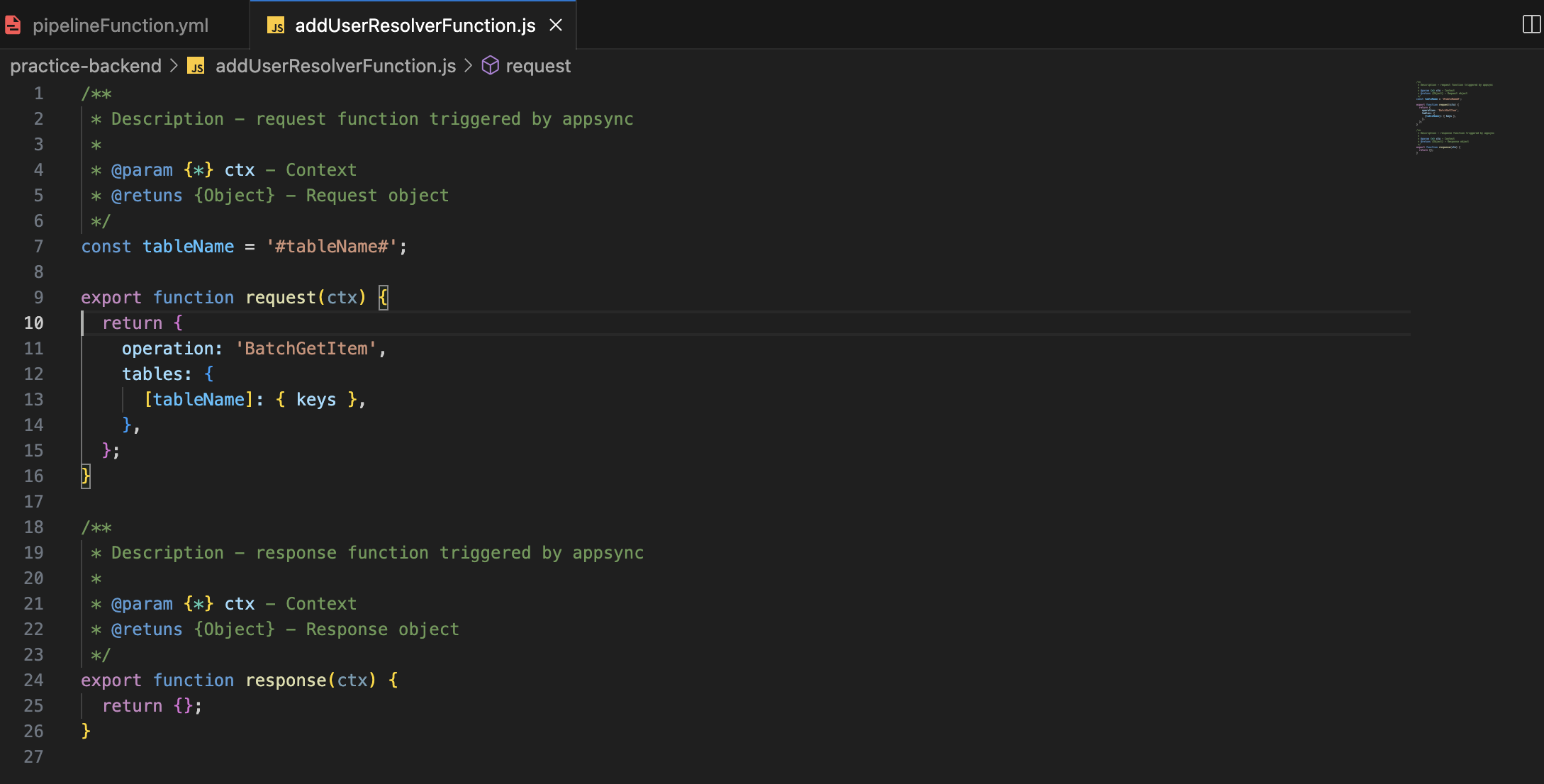
**Step2:-** Now that you've successfully passed your environment variables to the resolver, you'll need to access them within the resolver function. While in a Lambda function, you might use **'process.env.tableName'**, in the resolver function, you'll need to add **"#"** at the start and end of the name you passed in Step 1. Here's an example:
```
const tableName = '#tableName#';
const accountId = '#accountId#';
```
Ensure you add this before the request and response functions in your resolver.
**Step3:-** With the setup complete, you now have the knowledge to pass environment variables seamlessly to your AppSync resolver function.
This blog aims to simplify the process, ensuring you can efficiently manage and utilize environment variables in your AppSync projects. Feel free to explore, experiment, and elevate your serverless development experience!"
| am_i_dev |
1,677,958 | LLMs are not AI | Do large language models qualify as artificial intelligence? No. pause for gasps Intelligence is... | 0 | 2023-11-25T06:50:07 | https://dev.to/jjcx/llms-are-not-ai-1f4c | ai, llm | Do large language models qualify as artificial intelligence? No.
**pause for gasps**
Intelligence is multifaceted. It understands, it reasons, it learns, and it innovates. An LLM, on the other hand, mimics the facade of comprehension without the substance. Saying an LLM understands the text is like saying a calculator understands mathematics. Both tools process inputs through predefined operations but don’t ‘grasp’ the concepts involved.
Imagine a library as vast as the horizon, filled with every book ever written. An LLM is like a librarian who’s never read a single book but can find you quotes on any topic by following the Dewey Decimal System. This librarian is efficient but has no understanding of literature, history, or science beyond the labels on the book spines.
Understanding is an active, conscious process, but the responses from an LLM are the result of passive, statistical modeling. They are echoes of human thought, not the thought itself. For example, an LLM can produce an essay on quantum mechanics, but it cannot comprehend the subject. It cannot engage with the content beyond what its algorithms predict to be the most likely next word or sentence based on past data.
The bedrock of intelligence is the ability to learn from a few examples and then apply that learning broadly. Human children do this remarkably well. They can learn a concept from a few instances and then recognize it in a variety of contexts. LLMs, in contrast, need to be fed with enormous datasets to ‘learn,’ and even then, they are only replaying patterns contained within that data. They don’t learn in the active sense; they don’t have the ‘aha’ moments that lead to understanding beyond their initial programming.
Reasoning is another pillar of true intelligence. It’s the ability to connect disparate bits of knowledge in a meaningful way. When we reason, we do more than follow a script; we create new narratives and solutions that never existed before. LLMs are not capable of this type of innovation. They generate responses based on what’s been seen before, not on a reasoned process that can create new insights from old information.
These systems don’t possess the spark of curiosity that ignites the human quest for knowledge. They don’t wonder, they don’t hypothesize, they don’t contemplate. They are to genuine curiosity what a wax fruit is to fresh produce —- convincing at a glance, but upon closer inspection, clearly inanimate.
So, while LLMs can produce work that feels human-created, their operational principles are closer to complex reflexes than to conscious thought. They are reflections of intelligence, not its embodiment.
This is not to say that these are not the precursors to AI, or protoAI if you will, but let’s not mistake the smoke for the fire. LLMs are sophisticated mirrors reflecting the brilliance of the data they’ve been fed, but the light of understanding and the warmth of consciousness originate from the human mind.
Except Q*, that might be something scary. | jjcx |
1,678,021 | Exploring the Traditional Markets of Bhutan: A Shopper's Paradise | Exploring the traditional markets of Bhutan can indeed be a fascinating experience, as they offer a... | 0 | 2023-11-25T09:28:38 | https://dev.to/medheyapp/exploring-the-traditional-markets-of-bhutan-a-shoppers-paradise-1fff | Exploring the traditional markets of Bhutan can indeed be a fascinating experience, as they offer a glimpse into the rich cultural tapestry of this Himalayan kingdom. Bhutan is known for its unique blend of tradition and modernity, and its markets reflect this duality. Here's a virtual tour of what you might find in the traditional markets of Bhutan:
Thimphu Weekend Market:
Location: Thimphu, the capital city.
Highlights: The Thimphu Weekend Market is a vibrant and colorful affair, with farmers, traders, and artisans coming from all over the country to sell their goods. You can find fresh produce, local textiles, handicrafts, and traditional Bhutanese cuisine. Don't miss the red rice, traditional Bhutanese cheese, and handmade crafts.
Paro Market:
Location: Paro, one of the most scenic valleys in Bhutan.
Highlights: Paro Market offers a more relaxed shopping experience. You can find traditional Bhutanese clothing, handmade jewelry, and souvenirs. The market is surrounded by the backdrop of lush green hills and the iconic Paro Dzong.
Centenary Farmers' Market (CFM):
Location: Thimphu.
Highlights: CFM is one of the largest markets in Bhutan, offering a variety of goods from different regions. It's a great place to explore Bhutanese agriculture, with organic fruits, vegetables, and traditional grains. The market also has sections dedicated to handmade crafts and textiles.
Gagyel Lhundrup Weaving Center:
Location: Thimphu.
Highlights: For those interested in Bhutanese textiles, this weaving center is a must-visit. Bhutanese weavers showcase their skills, creating intricate patterns and designs. You can purchase beautifully woven traditional Bhutanese garments like kiras and ghos.
Zorig Chusum School of Traditional Arts:
Location: Thimphu.
Highlights: This school trains students in 13 traditional arts and crafts of Bhutan, including painting, wood carving, and sculpture. The school has a gift shop where you can buy authentic Bhutanese art pieces and crafts.
Bhutanese Handicraft Emporium:
Location: Various locations across Bhutan.
Highlights: Run by the National Women’s Association of Bhutan, these emporiums are dedicated to preserving and promoting traditional Bhutanese handicrafts. You can find intricately designed items like thangkas (religious paintings), wooden bowls, and traditional masks.
Changlimithang Archery Ground:
Location: Thimphu.
Highlights: Archery is the national sport of Bhutan, and visiting an archery ground can be a unique experience. While not a traditional market, you might find local artisans selling handmade bows and arrows.
When exploring these markets, it's important to engage with the locals, learn about the stories behind the crafts, and savor the unique flavors of Bhutanese cuisine. Bhutan's commitment to preserving its cultural heritage is evident in its markets, making them a true shopper's paradise for those seeking authentic experiences.
See more:-
https://play.google.com/store/apps/details?id=com.medhey.app
https://apps.apple.com/app/medhey/id1579240703
https://medheyapp.com/2023/02/18/why-medhey-app-is-best-for-booking-international-flight-tickets-from-bhutan/
https://medheyapp.com/2023/02/28/medhey-best-digital-marketplace-in-bhutan/
https://medheyapp.com/2023/03/02/why-to-choose-medhey-for-travelling-to-bhutan-the-happiest-country-of-the-world/
https://medheyapp.com/2021/10/19/which-is-a-better-e-commerce-solution-build-an-app-or-choose-a-listing-e-service-app/
https://medheyapp.com/2021/09/25/bhutanese-community-medhey-logo-online-shopping-in-bhutan/
https://medheyapp.com/2023/06/18/exploring-job-vacancy-in-bhutan-opportunities-for-growth-and-fulfillment/
https://medheyapp.com/2023/06/18/unveiling-hyundai-in-bhutan-elevating-driving-experiences-with-style-and-reliability/
https://medheyapp.com/2023/06/18/exploring-toyota-in-bhutan-a-perfect-blend-of-performance-and-cultural-harmony/ | medheyapp | |
1,678,235 | Am I Alone in Wondering How Many Faces Microsoft Copilot has? | In the ever-evolving landscape of Microsoft's digital realm, the concept of Microsoft Copilot has... | 21,622 | 2023-11-28T07:30:00 | https://intranetfromthetrenches.substack.com/p/wondering-how-many-faces-copilot-has | githubcopilot, microsoft365 | In the ever-evolving landscape of Microsoft's digital realm, the concept of **Microsoft Copilot** has undergone a transformation, paving the way for a new perspective on efficiency. Rather than a distinct tool continuously at hand, **Microsoft** seems to be shifting towards a paradigm where **Copilot** seamlessly integrates into main services and applications, becoming an option as ordinary as any other feature.
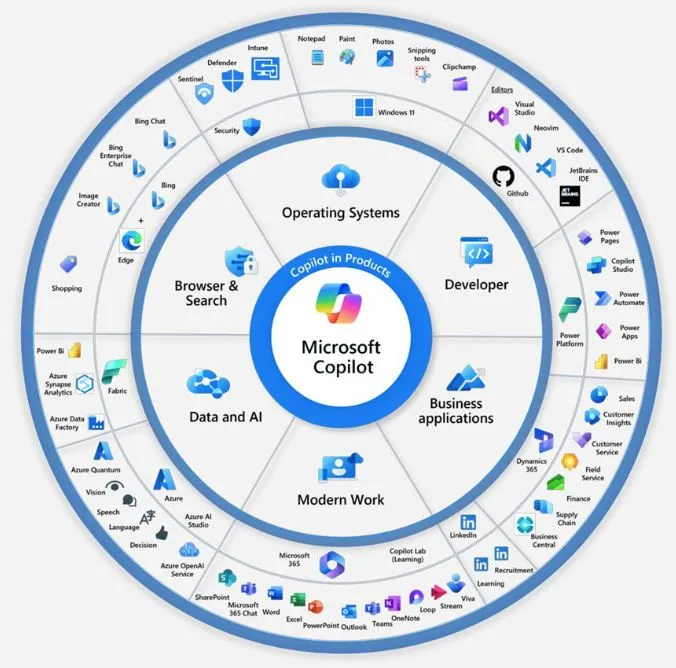
What sets this approach apart is the integration of **Copilot** into the very fabric of **Microsoft Graph**, establishing a common context for every user. This foundation draws from the wealth of activities within the **Microsoft 365** tenant, creating a unified backdrop against which **Copilot** operates. This shift implies that **Copilot**, once perceived as *service-specific* variants, may soon be regarded as a *behind-the-scenes* force ever-ready to assist, triggered at the user's discretion.
> *The notion of having different **Copilots** based on the specific service or application is gradually giving way to a mindset where **Copilot** is omnipresent, quietly awaiting activation when summoned.*
At its core, the **Microsoft Copilot** experience is becoming synonymous with the idea that help is always within reach, ready to augment productivity when needed. This shift from a *service-centric* to a *user-centric* approach signals a more personalized and user-friendly experience, where **Copilot** functions more as a reliable companion than a standalone tool.
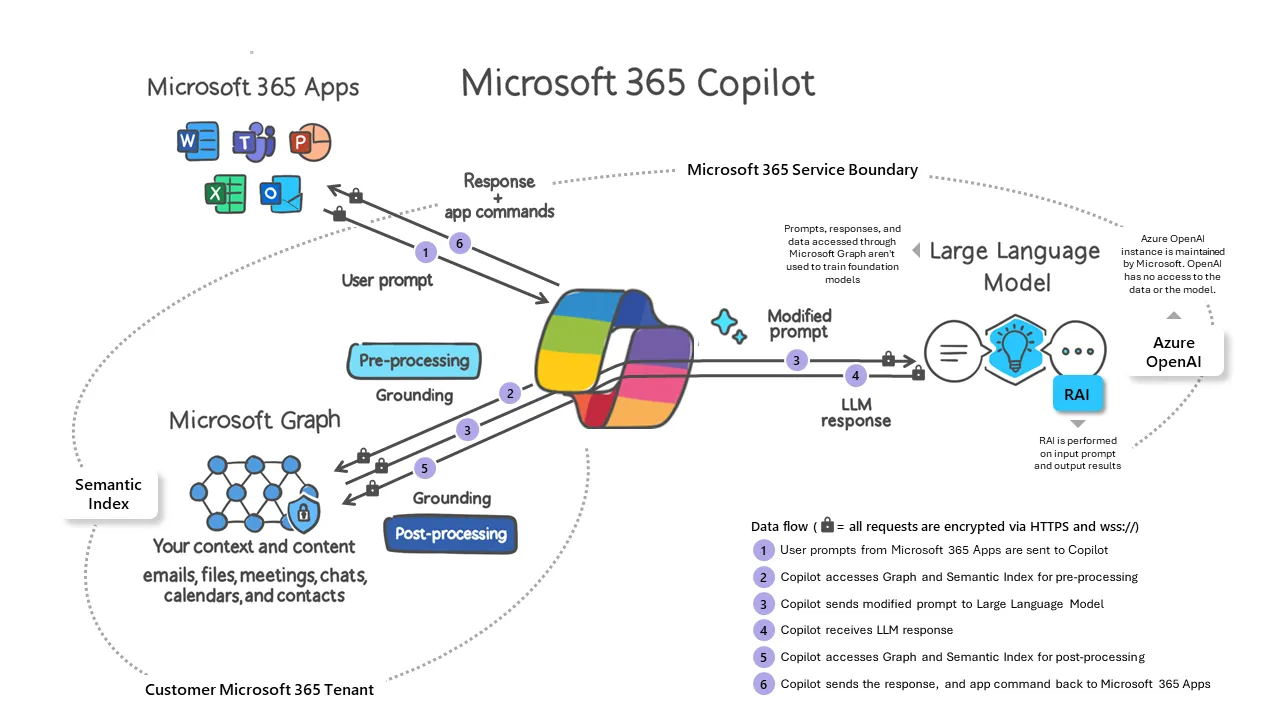
This integration into the **Microsoft Graph** framework not only streamlines the user experience but also marks a strategic move by **Microsoft** to provide a seamless and interconnected environment for its users. The prospect of **Copilot** always lurking in the background, backed by the contextual richness of **Microsoft Graph**, signifies a departure from the segmented nature of productivity tools toward a more holistic and integrated approach.
As users navigate this evolving landscape, the integration of **Copilot** into the very fabric of Microsoft's suite prompts a reevaluation of its role. It transforms **Copilot** from a specific tool to a dynamic, always-on assistant, ready to contribute to efficiency whenever the user deems fit. In essence, Microsoft's approach seems to be sculpting a future where **Copilot**, unified by **Microsoft Graph**, seamlessly intertwines with our daily digital activities, enriching the user experience in a subtle yet impactful manner.
## References
- *Microsoft 365 Copilot overview: [https://learn.microsoft.com/en-us/microsoft-365-copilot/microsoft-365-copilot-overview](https://learn.microsoft.com/en-us/microsoft-365-copilot/microsoft-365-copilot-overview)*
- *Copilot for Microsoft 365: [https://adoption.microsoft.com/en-us/copilot/](https://adoption.microsoft.com/en-us/copilot/)*
- *Copilot breakdown by Mason Whitaker in LinkedIn: [https://www.linkedin.com/posts/masonwhitaker_msignite-microsoftignite-microsoftignite2023-activity-7131033698476462080-mdLL/](https://www.linkedin.com/posts/masonwhitaker_msignite-microsoftignite-microsoftignite2023-activity-7131033698476462080-mdLL/)*
- *What are Microsoft's different Copilots? Here's what they are and how you can use them: [https://www.zdnet.com/article/what-is-microsoft-copilot-heres-everything-you-need-to-know/](https://www.zdnet.com/article/what-is-microsoft-copilot-heres-everything-you-need-to-know/)* | jaloplo |
1,678,273 | From Off-Roading to Uphill Climbs: What Makes Electric Mountain Boards Stand Out? | Electric mountain boards are all the rage in the world of outdoor sports and recreation. These boards... | 0 | 2023-11-25T18:13:07 | https://dev.to/shirleythomasqa/from-off-roading-to-uphill-climbs-what-makes-electric-mountain-boards-stand-out-men | [](https://www.ecomobl.com/?utm_source=dev_to&utm_medium=rankking)Electric mountain boards are all the rage in the world of outdoor sports and recreation. These boards are combining the best of both worlds - the convenience of an electric motor with the thrill of off-road boarding. Electric mountain boards have made it possible to ride anywhere, from smooth paved roads to rough terrain. From the off-roading to uphill climbs, electric mountain boards are poised to revolutionize the outdoor recreation scene. Here's what makes them stand out: Powerful Motors The electric motors used in the mountain boards are incredibly powerful. They usually have high torque and can climb uphill and conquer difficult terrain with ease. The motors have varying levels of power, and some boards can reach speeds of up to 35 mph. Electric mountain boards are ideal for those who want to venture into rough terrain and experience the thrill of off-road boarding. All-Terrain Wheels Electric mountain boards usually have all-terrain wheels, which allow them to ride smoothly over uneven surfaces. These wheels are larger and wider than traditional wheels, providing exceptional stability and traction to the rider. They are designed for rough terrain and can easily navigate slopes, dirt, rocks, and other obstacles encountered on the trail. Removable Batteries Removable batteries are another key feature of electric mountain boards. These batteries offer long run times and are easily swapable, allowing riders to travel longer distances without worrying about their boards running out of power. They can also be charged separately or replaced with spare batteries, extending the range of the board. Remote Control Most electric mountain boards come with a remote control that lets the rider control the board's speed and direction. The remote control is usually wireless, and some models have an LCD screen that displays stats such as speed, range, and battery life. The remote control makes it easy to steer the board and adjust the speed as needed. Versatility Electric mountain boards are extremely versatile and can be used for a variety of activities. They can be used for commuting, hiking, and exploring rough terrain. They can also be used for downhill racing or cruising around the park. Due to their versatility, they are an excellent investment for anyone looking to invest in a high-quality, long-lasting outdoor recreational tool. In conclusion, electric mountain boards are the future of outdoor recreation. They offer a unique combination of power, speed, versatility, and all-terrain capabilities. With their powerful motors, all-terrain wheels, removable batteries, and remote control, electric mountain boards are poised to become the next big trend in outdoor sports. So, get ready to experience the thrill of off-road boarding like never before.
## References
* [electric mountain board](https://www.bti-usa.com/public/insecure_redirect?id=www.ecomobl.com/ "electric mountain board")
| shirleythomasqa | |
1,678,664 | Working with Parquet files in Java using Avro | In the previous article, I wrote an introduction to using Parquet files in Java, but I did not... | 0 | 2023-11-26T11:09:55 | https://www.jeronimo.dev/working-with-parquet-files-in-java-using-avro/ | parquet, java, avro, bigdata | In the previous article, I wrote an introduction to using Parquet files in Java, but I did not include any examples. In this article, I will explain how to do this using the Avro library.
Parquet with Avro **is one of the most popular ways to work with Parquet files in Java** due to its simplicity, flexibility, and because it is the library with the most examples.
Both Avro and Parquet allow complex data structures, and there is a mapping between the types of one and the other.
The post will use the same example I used in previous articles talking about serialization. The code will be very similar to the article about Avro. For specific details about Avro, I refer you to [that article](https://dev.to/jerolba/java-serialization-with-avro-1j91).
In the example, we will work with a collection of Organization objects (`Org`), which have also a list of Attributes (`Attr`):
```java
record Org(String name, String category, String country, Type type, List<Attr> attributes) {
}
record Attr(String id, byte quantity, byte amount, boolean active, double percent, short size) {
}
enum Type {
FOO, BAR, BAZ
}
```
Similar to saving files in Avro format, this version of Parquet with Avro allows writing files using classes generated from the [IDL](https://dev.to/jerolba/java-serialization-with-avro-1j91#idl-and-code-generation) or the `GenericRecord` data structure. This capability is specific to Avro, not Parquet, but is inherited by `parquet-avro`, the library that implements this integration.
Internally, the library transforms the Avro schema into the Parquet schema, so most tools and libraries that know how to work with Avro classes will be able to work indirectly with Parquet with few changes.
## Using code generation
The only difference when compared to serializing in Avro format lies in the class used for writing or reading files; otherwise, the logic for [building the Avro-generated classes](https://dev.to/jerolba/java-serialization-with-avro-1j91#idl-and-code-generation) and reading their data remains unchanged.
### Serialization
We will need to instantiate a Parquet writer that supports the writing of objects created by Avro:
```java
Path path = new Path("/tmp/my_output_file.parquet");
OutputFile outputFile = HadoopOutputFile.fromPath(path, new Configuration());
ParquetWriter<Organization> writer = AvroParquetWriter.<Organization>builder(outputFile)
.withSchema(new Organization().getSchema())
.withWriteMode(Mode.OVERWRITE)
.config(AvroWriteSupport.WRITE_OLD_LIST_STRUCTURE, "false")
.build();
```
Parquet defines a class called `ParquetWriter<T>` and the `parquet-avro` library extends it implementing in `AvroParquetWriter<T>` the logic of **converting Avro objects into calls to the Parquet API**. The object we will serialize is `Organization`, which has been generated using the Avro utility and implements the Avro API.
The `Path` class is not the one existing in `java.nio.file`, but a Hadoop-specific abstraction for referencing file paths. Whereas the `OutputFile` class is Parquet's file abstraction with the capability to write to them.
Therefore:
* `Path`, `OutputFile`, `HadoopOutputFile`, and `ParquetWriter` are classes defined by the Parquet API.
* `AvroParquetWriter` is a class defined by the `parquet-avro` API, a library that encapsulates Parquet with Avro.
* `Organization` and `Attribute` are classes generated by the Avro utility, not related to Parquet.
The way to create an instance of `ParquetWriter` is through a Builder, where you can configure many Parquet-specific parameters or those of the library we are using (Avro). For example:
* `withSchema`: schema of the Organization class in Avro, which internally converts to a Parquet schema.
* `withCompressionCodec`: compression method to use: SNAPPY, GZIP, LZ4, etc. By default, it doesn't configure any.
* `withWriteMode`: by default it is CREATE, so if the file already existed, it would not overwrite it and would throw an exception. To avoid this, use OVERWRITE.
* `withValidation`: if we want it to validate the data types passed against the defined schema.
* `withBloomFilterEnabled`: if we want to enable the creation of [bloom filters](https://en.wikipedia.org/wiki/Bloom_filter).
A most generic configuration of both libraries (not defined in the API) can be passed with the `config(String property, String value)` method. In this case, we configure it to internally use a [3-level structure](https://github.com/apache/parquet-format/blob/master/LogicalTypes.md#lists) to represent nested lists.
Once the `ParquetWriter` class is instantiated, the greatest complexity lies in transforming your POJOs into the `Organization` classes generated from Avro's IDL. The complete code would be as follows:
```java
Path path = new Path("/tmp/my_output_file.parquet");
OutputFile outputFile = HadoopOutputFile.fromPath(path, new Configuration());
try (ParquetWriter<Organization> writer = AvroParquetWriter.<Organization>builder(outputFile)
.withSchema(new Organization().getSchema())
.withWriteMode(Mode.OVERWRITE)
.config(AvroWriteSupport.WRITE_OLD_LIST_STRUCTURE, "false")
.build()) {
for (var org : organizations) {
List<Attribute> attrs = org.attributes().stream()
.map(a -> Attribute.newBuilder()
.setId(a.id())
.setQuantity(a.quantity())
.setAmount(a.amount())
.setSize(a.size())
.setPercent(a.percent())
.setActive(a.active())
.build())
.toList();
Organization organization = Organization.newBuilder()
.setName(org.name())
.setCategory(org.category())
.setCountry(org.country())
.setOrganizationType(OrganizationType.valueOf(org.type().name()))
.setAttributes(attrs)
.build();
writer.write(organization);
}
}
```
Instead of converting the entire collection of organizations and then writing it, we can convert and persist each `Organization` one by one.
You can find the code on [GitHub](https://github.com/jerolba/parquet-for-java-posts/blob/master/src/main/java/com/jerolba/parquet/avro/ToParquetUsingAvroWithGeneratedClasses.java#L26).
#### Deserialization
Deserialization is very straightforward if we agree to work with the classes generated by Avro.
To read the file, we will need to instantiate a Parquet reader:
```java
Path path = new Path(filePath);
InputFile inputFile = HadoopInputFile.fromPath(path, new Configuration());
ParquetReader<Organization> reader = AvroParquetReader.<Organization>builder(inputFile).build();
```
Parquet defines a class called `ParquetReader<T>` and the `parquet-avro` library extends it by implementing in `AvroParquetReader` the logic of **converting Parquet's internal data structures** into the classes generated by Avro.
In this case, `InputFile` is Parquet's file abstraction with the capability to read from them.
Therefore:
* `Path`, `InputFile`, `HadoopInputFile`, and `ParquetReader` are classes defined by the Parquet API.
* `AvroParquetReader` implements `ParquetReader` and is defined in `parquet-avro`, a library that encapsulates Parquet with Avro.
* `Organization` (and `Attribute`) are classes generated by the Avro utility, not related to Parquet.
The instantiation of the `ParquetReader` class is also done with a Builder, although the options to configure are much fewer, as all its configuration is determined by the file we are going to read. The reader does not need to know if the file uses dictionary encoding or if it is compressed, so it is not necessary to configure it; it discovers this by reading the file.
```java
Path path = new Path(filePath);
InputFile inputFile = HadoopInputFile.fromPath(path, new Configuration());
try (ParquetReader<Organization> reader = AvroParquetReader.<Organization>builder(inputFile).build()) {
List<Organization> organizations = new ArrayList<>();
Organization next = null;
while ((next = reader.read()) != null) {
organizations.add(next);
}
return organizations;
}
```
If the IDL used to generate the code contains a subset of the attributes persisted in the file, when reading it we would be ignoring all the columns not present in the IDL. This would save us from disk reads and the deserialization/decoding of data.
You can find the code on [GitHub](https://github.com/jerolba/parquet-for-java-posts/blob/master/src/main/java/com/jerolba/parquet/avro/FromParquetUsingAvroWithGeneratedClasses.java#L18).
---
### Using GenericRecord
Here, it will not be necessary to generate any code, and we will work with the `GenericRecord` class provided by Avro, but the code will be a bit more verbose.
#### Serialization
As we do not have generated files containing the embedded schema, we need to programmatically define the Avro schema we are going to use. The code is the same as in the article about Avro:
```java
Schema attrSchema = SchemaBuilder.record("Attribute")
.fields()
.requiredString("id")
.requiredInt("quantity")
.requiredInt("amount")
.requiredInt("size")
.requiredDouble("percent")
.requiredBoolean("active")
.endRecord();
var enumSymbols = Stream.of(Type.values()).map(Type::name).toArray(String[]::new);
Schema orgsSchema = SchemaBuilder.record("Organizations")
.fields()
.requiredString("name")
.requiredString("category")
.requiredString("country")
.name("organizationType").type().enumeration("organizationType")
.symbols(enumSymbols).noDefault()
.name("attributes").type().array().items(attrSchema).noDefault()
.endRecord();
var typeField = orgsSchema.getField("organizationType").schema();
EnumMap<Type, EnumSymbol> enums = new EnumMap<>(Type.class);
enums.put(Type.BAR, new EnumSymbol(typeField, Type.BAR));
enums.put(Type.BAZ, new EnumSymbol(typeField, Type.BAZ));
enums.put(Type.FOO, new EnumSymbol(typeField, Type.FOO));
```
Instead of using an `AvroParquetWriter` of the type `Organization`, we create one of the type `GenericRecord` and construct instances of it as if it were a `Map`:
```java
Path path = new Path(filePath);
OutputFile outputFile = HadoopOutputFile.fromPath(path, new Configuration());
try (ParquetWriter<GenericRecord> writer = AvroParquetWriter.<GenericRecord>builder(outputFile)
.withSchema(orgsSchema)
.withWriteMode(Mode.OVERWRITE)
.config(AvroWriteSupport.WRITE_OLD_LIST_STRUCTURE, "false")
.build()) {
for (var org : organizations) {
List<GenericRecord> attrs = new ArrayList<>();
for (var attr : org.attributes()) {
GenericRecord attrRecord = new GenericData.Record(attrSchema);
attrRecord.put("id", attr.id());
attrRecord.put("quantity", attr.quantity());
attrRecord.put("amount", attr.amount());
attrRecord.put("size", attr.size());
attrRecord.put("percent", attr.percent());
attrRecord.put("active", attr.active());
attrs.add(attrRecord);
}
GenericRecord orgRecord = new GenericData.Record(orgsSchema);
orgRecord.put("name", org.name());
orgRecord.put("category", org.category());
orgRecord.put("country", org.country());
orgRecord.put("organizationType", enums.get(org.type()));
orgRecord.put("attributes", attrs);
writer.write(orgRecord);
}
}
```
You can find the code on [GitHub](https://github.com/jerolba/parquet-for-java-posts/blob/master/src/main/java/com/jerolba/parquet/avro/ToParquetUsingAvroWithGenericRecord.java#L33).
#### Deserialization
As in the original version of Avro, most of the work consists in converting the `GenericRecord` into our data structure. Because it behaves like a `Map`, we will have to cast the types of the values:
```java
Path path = new Path(filePath);
InputFile inputFile = HadoopInputFile.fromPath(path, new Configuration());
try (ParquetReader<GenericRecord> reader = AvroParquetReader.<GenericRecord>builder(inputFile).build()) {
List<Org> organizations = new ArrayList<>();
GenericRecord record = null;
while ((record = reader.read()) != null) {
List<GenericRecord> attrsRecords = (List<GenericRecord>) record.get("attributes");
var attrs = attrsRecords.stream().map(attr -> new Attr(attr.get("id").toString(),
((Integer) attr.get("quantity")).byteValue(),
((Integer) attr.get("amount")).byteValue(),
(boolean) attr.get("active"),
(double) attr.get("percent"),
((Integer) attr.get("size")).shortValue())).toList();
Utf8 name = (Utf8) record.get("name");
Utf8 category = (Utf8) record.get("category");
Utf8 country = (Utf8) record.get("country");
Type type = Type.valueOf(record.get("organizationType").toString());
organizations.add(new Org(name.toString(), category.toString(), country.toString(), type, attrs));
}
return organizations;
}
```
As we are using the Avro interface, it maintains its logic that Strings are encoded within the `Utf8` class and it will be necessary to extract their values.
You can find the code on [GitHub](https://github.com/jerolba/parquet-for-java-posts/blob/master/src/main/java/com/jerolba/parquet/avro/FromParquetUsingAvroWithGenericRecord.java#L23).
By default, when reading the file, it deserializes all fields of each row because it does not know the schema of what you need to read, and processes everything. **If you want a projection of the fields, you must pass it in the form of an Avro schema** when creating the `ParquetReader`:
```java
Schema projection = SchemaBuilder.record("Organizations")
.fields()
.requiredString("name")
.requiredString("category")
.requiredString("country")
.endRecord();
Configuration configuration = new Configuration();
configuration.set(AvroReadSupport.AVRO_REQUESTED_PROJECTION, orgsSchema.toString());
try (ParquetReader<GenericRecord> reader = AvroParquetReader.<GenericRecord>builder(inputFile)
.withConf(configuration)
.build()) {
....
```
The rest of the process would be the same, but with fewer fields. You can see the entire source code of the example [here](https://github.com/jerolba/parquet-for-java-posts/blob/master/src/main/java/com/jerolba/parquet/avro/FromParquetUsingAvroWithGenericRecordProjection.java#L24).
---
## Performance
What performance does Parquet Avro offer when serializing and deserializing a large volume of data? To what extent do the different compression options influence? Do we choose compression with Snappy or no compression at all? And what about activating the dictionary or not?
Taking advantage of the analyses I did [previously](https://dev.to/jerolba/java-serialization-with-avro-1j91#analysis-and-impressions) on different serialization formats, we can get an idea of their strengths and weaknesses. The benchmarks were done on the same computer, so they are comparable to give us an idea.
### File Size
Both using code generation and GenericRecord, the result is the same, as they are different ways of defining the same schema and persisting the same data:
| | Uncompressed | Snappy |
|---|---:|---:|
| Dictionay False | 1,034 MB | 508 MB |
| Dictionay True | 289 MB | 281 MB |
Given the difference in sizes, we can see that in my synthetic example, the use of dictionaries compresses the information significantly, even more than the Snappy algorithm itself. The decision to activate compression or not will depend on the performance penalty it entails.
### Serialization Time
**Using code generation:**
| | Uncompressed | Snappy |
|:---|---:|---:|
| Dictionary False | 14,386 ms | 14,920 ms |
| Dictionary True | 15,110 ms | 15,381 ms |
**Using GenericRecord:**
| | Uncompressed | Snappy |
|---|---:|---:|
| Dictionary False | 15,287 ms | 15,809 ms |
| Dictionary True | 16,119 ms | 16,432 ms |
The time is very similar in all cases, and we can say that the different compression techniques do not significantly affect the time spent.
There are no notable time differences between generated code and the use of `GenericRecord`, so performance should not be a determining factor in choosing a solution.
[Compared to other serialization formats](https://dev.to/jerolba/java-serialization-with-avro-1j91#analysis-and-impressions), it takes between 40% (Jackson) and 300% (Protocol Buffers/Avro) more time, but in return achieves files that are between 70% (Protocol Buffers/Avro) and 90% (Jackson) smaller.
### Deserialization Time
**Using code generation:**
| | Uncompressed | Snappy |
|---|---:|---:|
| Dictionary False | 10,722 ms | 10,736 ms |
| Dictionary True | 7,707 ms | 7,665 ms |
**Using GenericRecord:**
| | Uncompressed | Snappy |
|---|---:|---:|
| Dictionary False | 12,089 ms | 11,931 ms |
| Dictionary True | 8,374 ms | 8,451 ms |
In this case, the use of the dictionary has a significant impact on time, as it saves decoding information that is repeated. There is definitely no reason to disable this functionality.
If we compare with other formats, it is twice as slow as Protocol Buffers and on par with Avro, but more than twice as fast as Jackson.
To put the performance into perspective, on my laptop, it reads 50,000 `Organization`s per second, which in turn contain almost 3 million instances of type `Attribute`, per second!
### Deserialization Time Using a Projection
What is the performance like if we use a projection and we only read three fields of the Organization object and ignore its collection of attributes?
| | Uncompressed | Snappy |
|---|---:|---:|
| Dictionay False | 289 ms | 304 ms |
| Dictionay True | 195 ms | 203 ms |
We confirm the promise that if we access a subset of columns, we will read and decode much less information. In this case, **it takes only 2.5% of the time**, or in other words, **it is 40 times faster** at processing the same file.
This is where Parquet shows its full power, by allowing to read and decode a subset of data quickly, taking advantage of how the data is distributed in the file.
## Conclusion
If you are already using Avro or are familiar with it, most of the code and nuances related to Avro will be familiar to you. If you are not, it increases the entry barrier, as you have to learn about two different technologies, and it may not be clear what corresponds to each.
The major change compared to using only Avro is how the writer and reader objects are created, where we will have to deal with all the configuration and particularities specific to Parquet.
If I had to choose between using only Avro or Parquet with Avro, I would choose the latter, as it produces more compact files and we have the opportunity to take advantage of the columnar format.
The data I have used in the example are synthetic, and the results may vary depending on the characteristics of your data. I recommend doing tests, but unless all your values are very random, the compression rates will be high.
In environments where you write once and read multiple times, the time spent serializing should not be decisive. More important, for example, are the consumption of your storage, the file transfer time, or the processing speed (especially if you can filter the columns you access).
Despite using different compression and encoding techniques, the file processing time is quite fast. Along with its ability to work with a typed schema, this makes it a **data interchange format to be considered in projects with a heavy load of data**. | jerolba |
1,678,820 | 🤔Cloud Document AI Too Expensive? A Concise Review of State-Of-The-Art Alternatives 💸🚀 | Document AI Document AI reduced/replaces the need for humans in converting documents into... | 0 | 2023-11-26T15:05:37 | https://dev.to/lovestaco/cloud-document-ai-too-expensive-a-concise-review-of-state-of-the-art-alternatives-94o | webdev, ai, machinelearning, discuss |
## Document AI
Document AI reduced/replaces the need for humans in converting documents into digital format. It used Natural Language Processing (NLP) and Machine Learning (ML) in training and to get knowledge. Once trained, it can process various types of information contained within a document.
Actually, the document's variety of formats makes it quite a challenging task to process documents. In the document, there are several layouts, such as images, tables, barcodes, handwritten text and logos. Processing becomes tough due to the variation and differences in every layout. Apart from this, the quality of document images might affect the procedure of processing.
Today, data expands at a higher rate. It is approximated that by 2023, [unstructured](https://www.ibm.com/blog/structured-vs-unstructured-data/#:~:text=What%20is%20unstructured%20data%3F) data makes up over [80%](https://tdwi.org/articles/2022/12/05/data-all-intelligence-and-efficiency-will-guide-unstructured-data-management-in-2023.aspx#:~:text=Unstructured%20data%2C%20which%20comprises%20at,their%20big%20data%20analytics%20platforms) of enterprise data. Organizations predict generating [73,000](https://blog.box.com/90-your-data-unstructured-and-its-full-untapped-value) exabytes of data in the year 2023 alone.
By 2028, about [70%](https://blocksandfiles.com/2023/09/07/gartner-storage-trends-2023/#:~:text=Single%20file%20and%20object%20storage,35%20percent%20in%20early%202023) of data will be estimated to be stored in unstructured format. This up trend will be an enforcement of necessity for machine learning AI solutions to address.
## The Challenge:
Accessibility can become the greatest barrier to the wider adoption of Document AI very quickly. While all Amazon [AWS](https://aws.amazon.com/textract/pricing/), [Google](https://cloud.google.com/document-ai/pricing) and [Microsoft Azure](https://azure.microsoft.com/en-us/pricing/details/ai-document-intelligence/#pricing) offer powerful Document AI tools backed by their cloud services, the costs can runaway rapidly. Most often charges are levied on per-page basis or per thousand characters handled.
This may pose a cost barrier for smaller businesses or individual practitioners into ordering advanced document processing technologies if their user-levels are low but the amount of processing is high. In the following sections, we take a look at state-of-the-art models that allow us to build custom Document AI pipelines.
## In a nutshell, how Document AI works
Document AI leverages Machine Learning (ML) and Natural Language Processing (NLP) to extract actionable information from free-form documents.
I'll explain the process in steps:
**Ingest:** The first step is to ingest the PDF. This can be done manually by uploading the PDF to the Document AI system
Once the PDF has been ingested, it is preprocessed so as to prepare the document for analysis. This may be inclusive of working like image quality detection and noise removal but using powerful multimodal models even noisy data can be tolerated to a certain extent.
Some systems would then try to improve the quality of the image or maybe de-skew for better performance.
**Document Layout Analysis (DLA):** DLA is performed to understand the structure of the document, which includes detecting and categorizing text blocks, images, tables, and other layout elements.
**Optical Character Recognition (OCR):** After DLA, OCR is applied to the structured layout to accurately recognize and convert the text within each identified block into machine-readable text.
**Extraction:** The system would then go ahead to extract information pertaining to the entities and relationships since it would have a structured layout and recognized text.
For instance, a multimodal model such as a Transformer trained on a large-scale dataset of documents may directly accept text and visual features in place of traditional OCR. In addition, fine-tuning multimodal models can be done to learn certain layouts and data types within documents.
**Analysis:** So currently the Document AI system does analysis of textual and visual information and interprets the content. It evaluates sentiment, discerns intent mapping relationships that exist between entities not to mention classifying documents by type. This might include sophisticated operations like semantic analysis, understanding of the context, and applying domain-specific rules for content review.
**Output:** The extracted information is then output in a format that can be used by downstream applications, such as data analytics tools, customer relationship management (CRM) systems, or other enterprise software.
## Transitioning to Newer Models (RNN, CNN, Transformers)
Moving or the transition made to the newer models like RNNs, CNNs, and majorly Transformers can be evidenced from the fact of the ever-evolving nature within Document AI. RNNs find a particular application for sequential data. CNNs find applications in spatial pattern recognition capabilities.
In transformers, which is a more recent advancement in deep learning architecture, a relatively modern innovation, self-attention mechanisms are used to deliver unmatched context comprehension.
**RNNs** are particularly suited for sequential data that is a norm in text-based documents. They may accordingly capture context from the sequence of words and are useful in tasks involving understanding the flow of text as useful in sentiment analysis or content classification.
**CNNs** are adept at dealing with spatial data and can be used to extract features from images, including documents. It can detect typical patterns in the way a document is laid out, such as headers, footers, or more general paragraph structures, so it is also useful for partitioning a document into logical sections or when the visual formatting contains helpful discriminative information.
The most recent revolution that designs the architecture of neural networks, **Transformers** have outperformed both RNNs and CNNs for performing a variety of natural language processing tasks. Unlike the RNNs and CNNs, which either process data serially or through localized filters, Transformers use self-attention mechanisms for the weighing of parts of input irrespective of their position. This enables the more sophisticated understanding of context and relationships within the document which is critical for complex textual analytic tasks.
[Continue reading the rest of the article to explore the Top 5 State-of-the-Art Models in AI for document analysis ](https://journal.hexmos.com/document-ai-sota-models/#deep-dive-into-top-5-state-of-the-art-models)🔝5️⃣📄🚀 | lovestaco |
1,678,845 | Create simple Image Classification model / Pose detector model with Google Teachable Machine | We are going to create a simple pose detector (thumbs up, victory and thumbs down) model with the... | 0 | 2023-11-26T16:05:56 | https://dev.to/radiumsodium/create-simple-image-classification-model-with-google-teachable-machine-2jk0 | machinelearning, imageclassification, posedetection, ai | We are going to create a simple pose detector (thumbs up, victory and thumbs down) model with the help of google's teachable machine leaning website.
Open a web browser and goto this website : https://teachablemachine.withgoogle.com

You should see something like this webpage. Click on get started.
Select image project:
Choose standard image model:
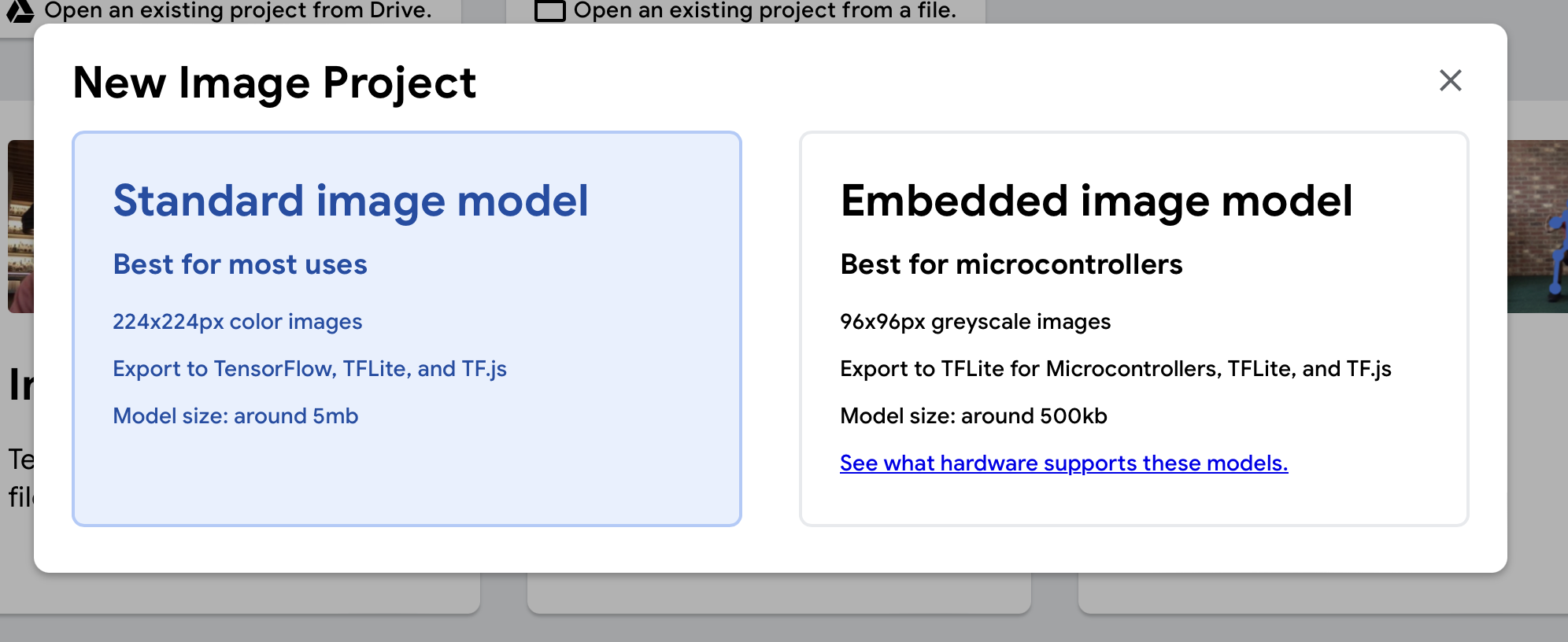
You should see some sections including 2 class section a training section and a preview section.
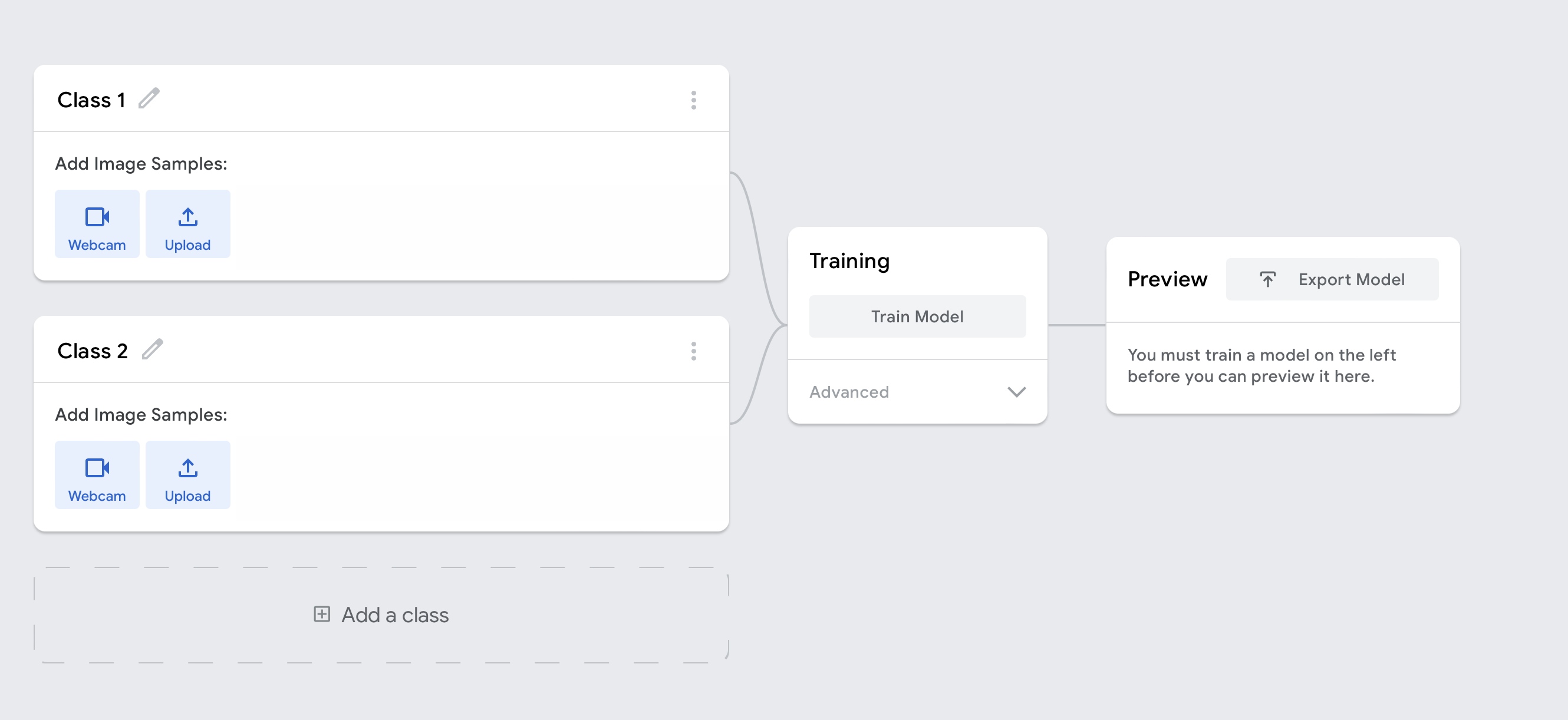
Here the classes are the different types we want to recognise. In our case thumbs up, victory and thumbs down. You can change the names of classes according to your liking. I named the first class as "ThumbsUp".
Now, you should see expansion of ThumbsUp section similar to this:
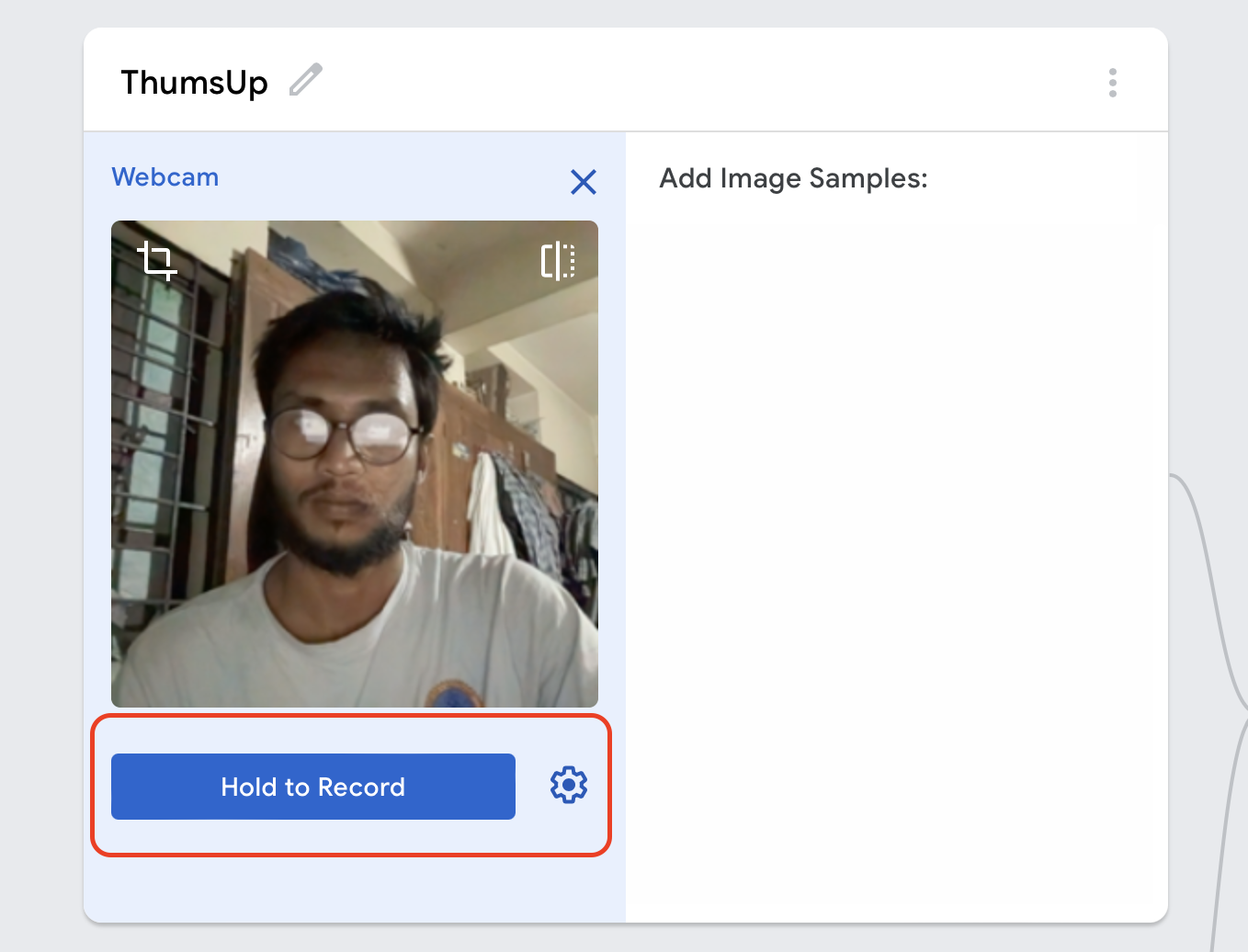
Click on Hold to record to give image input to the model. There should be a pop up about accessing the webcam of your device. You should allow this to take your poses.
On holding the button, it will keep taking photos of your poses. When you are confident about the number in my case 300+ just let the button free.
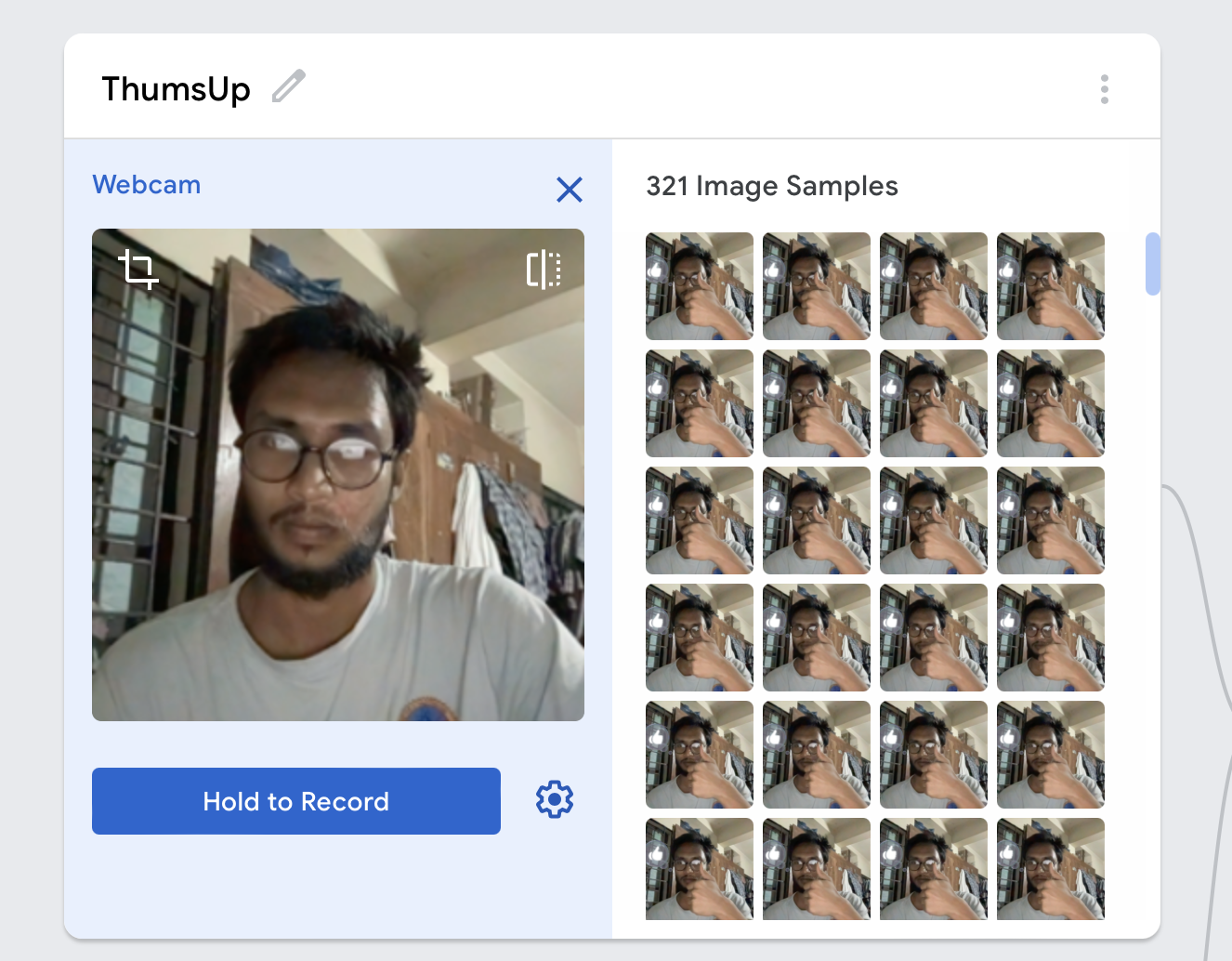
These are the poses of ThumbsUp class.
Now you can do the same thing for the Victory pose, First rename if you want then take poses close to the first pose.
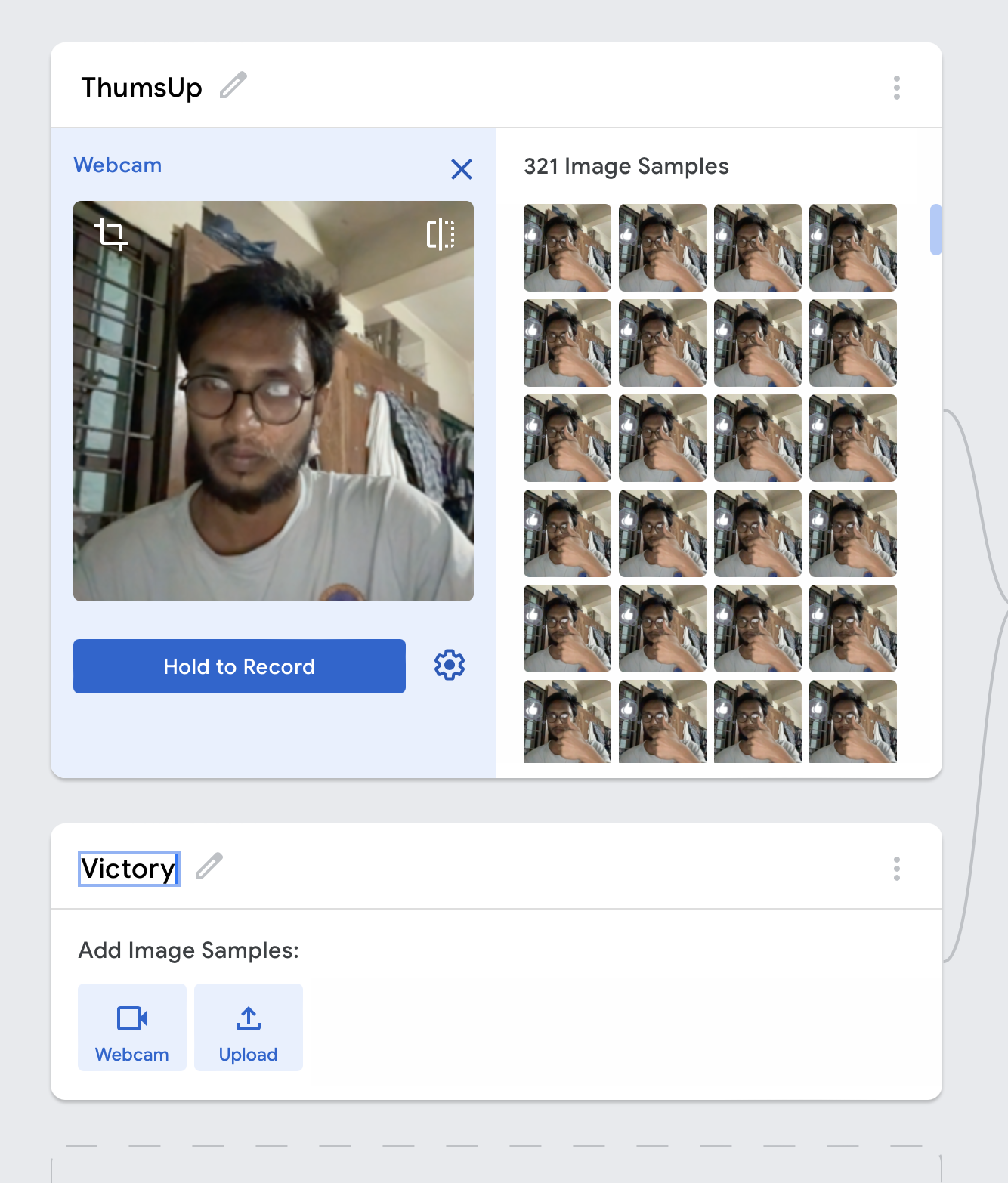
To create a new pose click add class button and rename the class
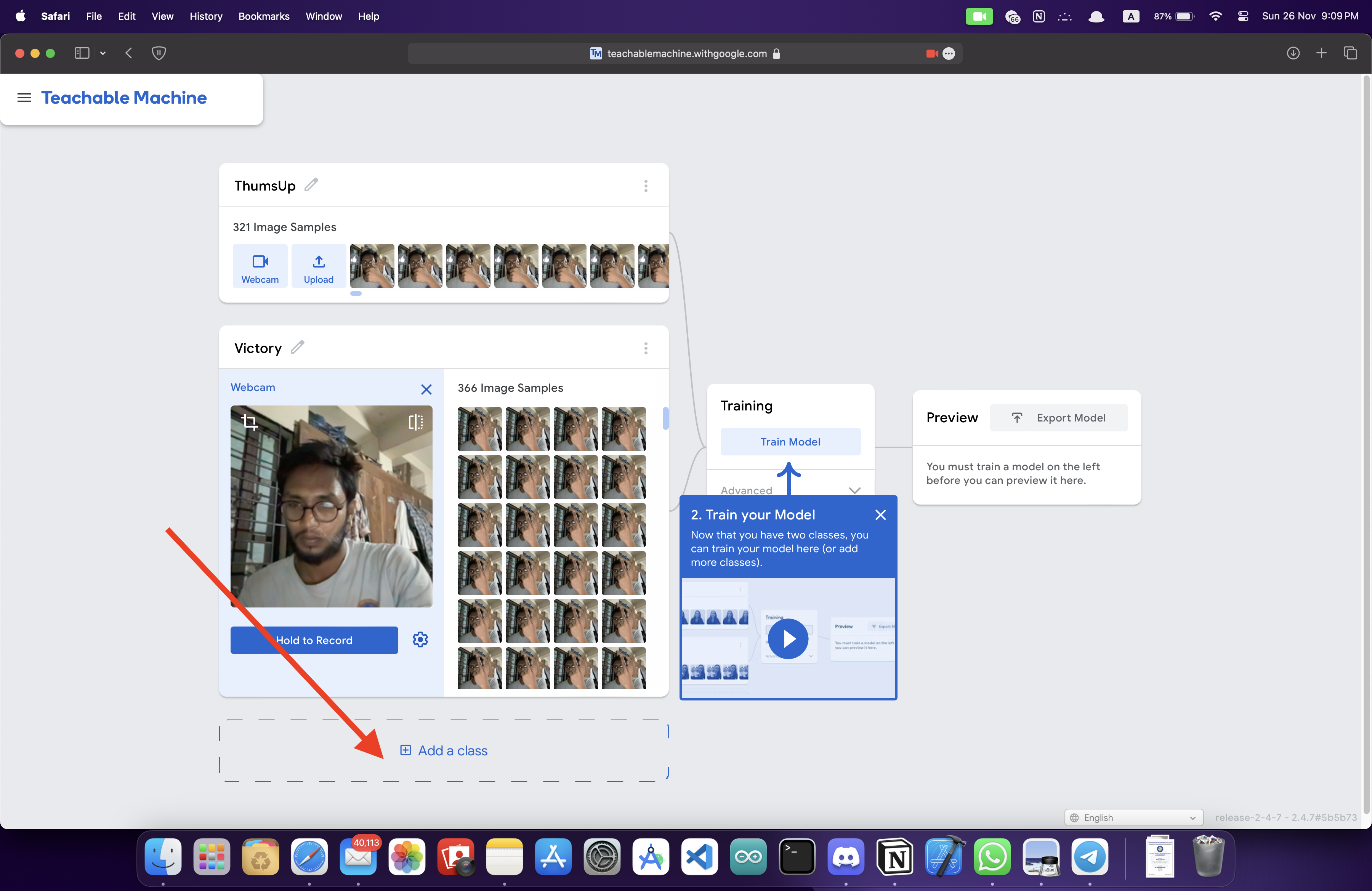 then do same as previous.
Now, We have our classes. Goto the training portion.
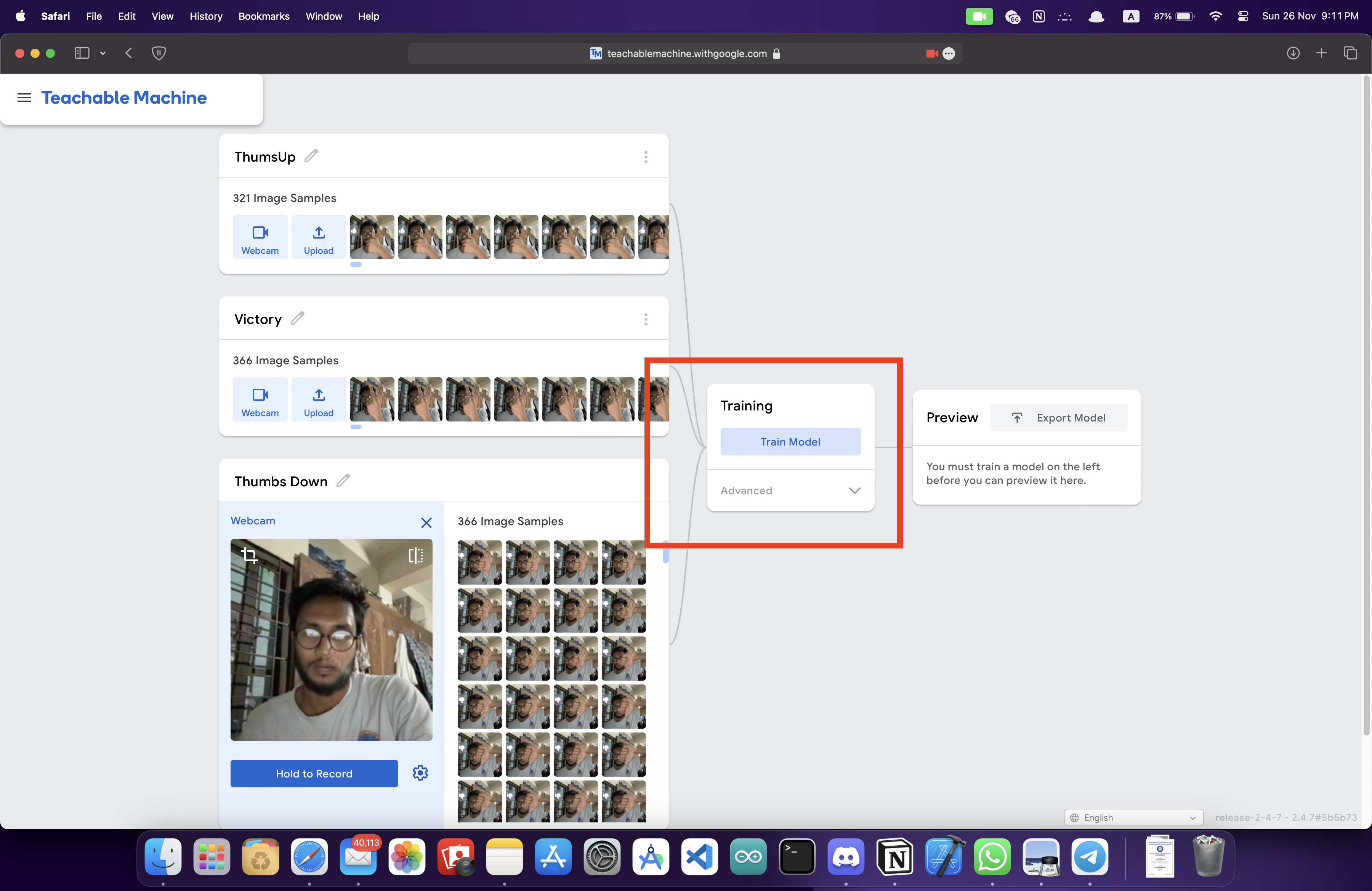 You can start training with the default value. If you want to change the default values. You can click the advance section. Here you can change several parameters. After you satisfied with the numbers. Click on training button. It will take some time. Keep patience.
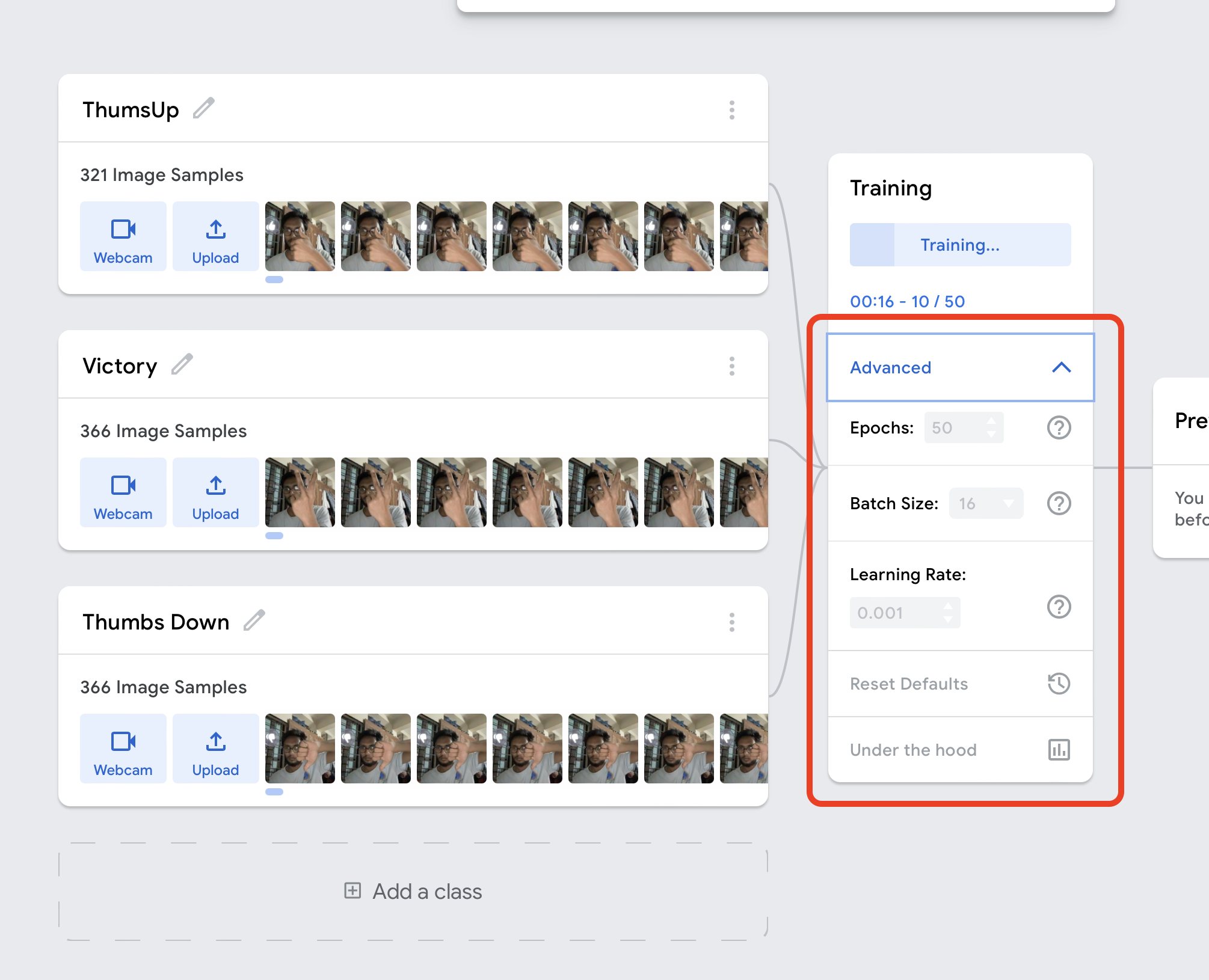
Congratulations! Your model is ready to roll. Now the preview section will be expanded. Here you can check if your model is working or not.
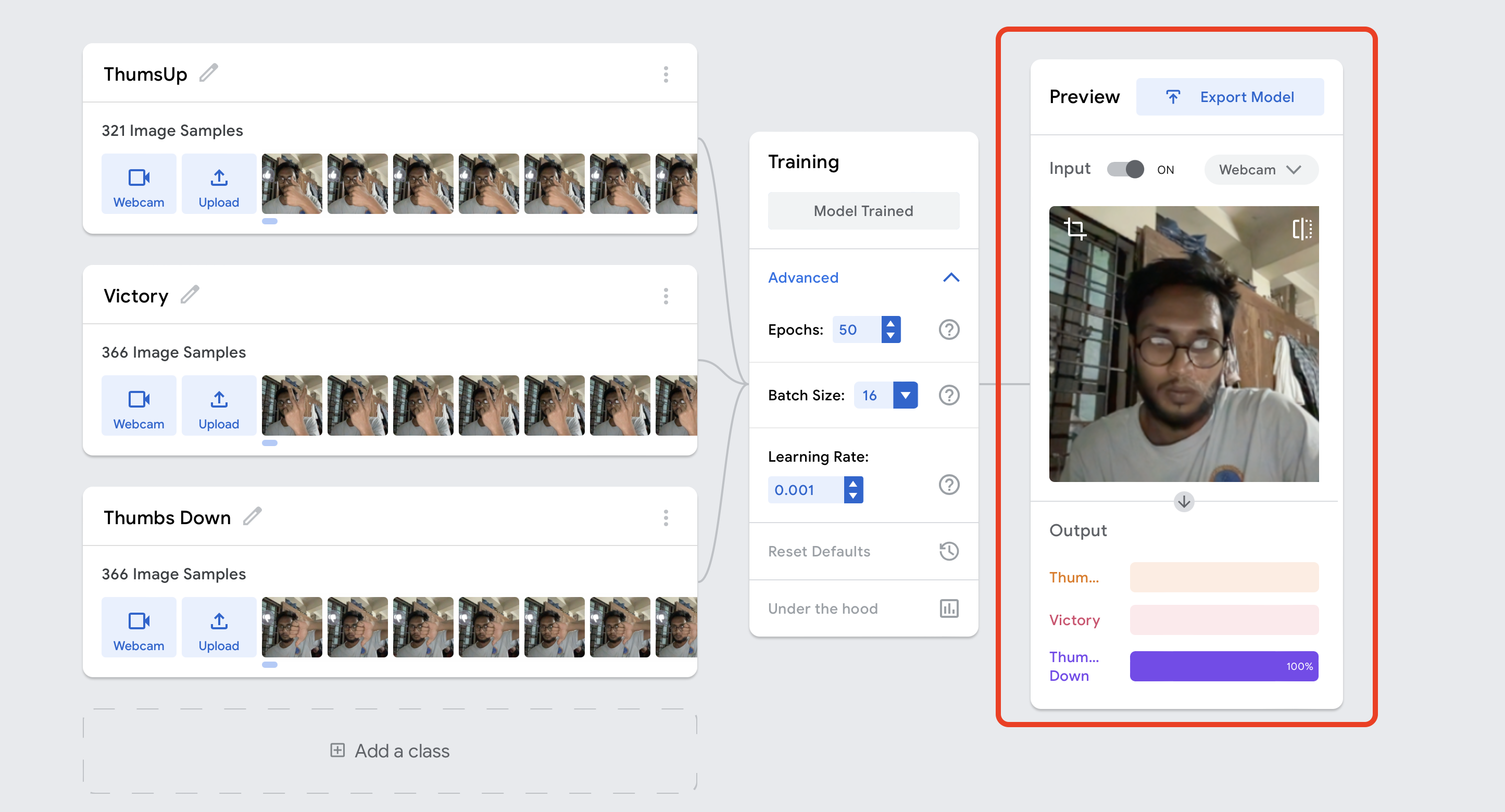
Here is the working model that is giving me the exact pose.
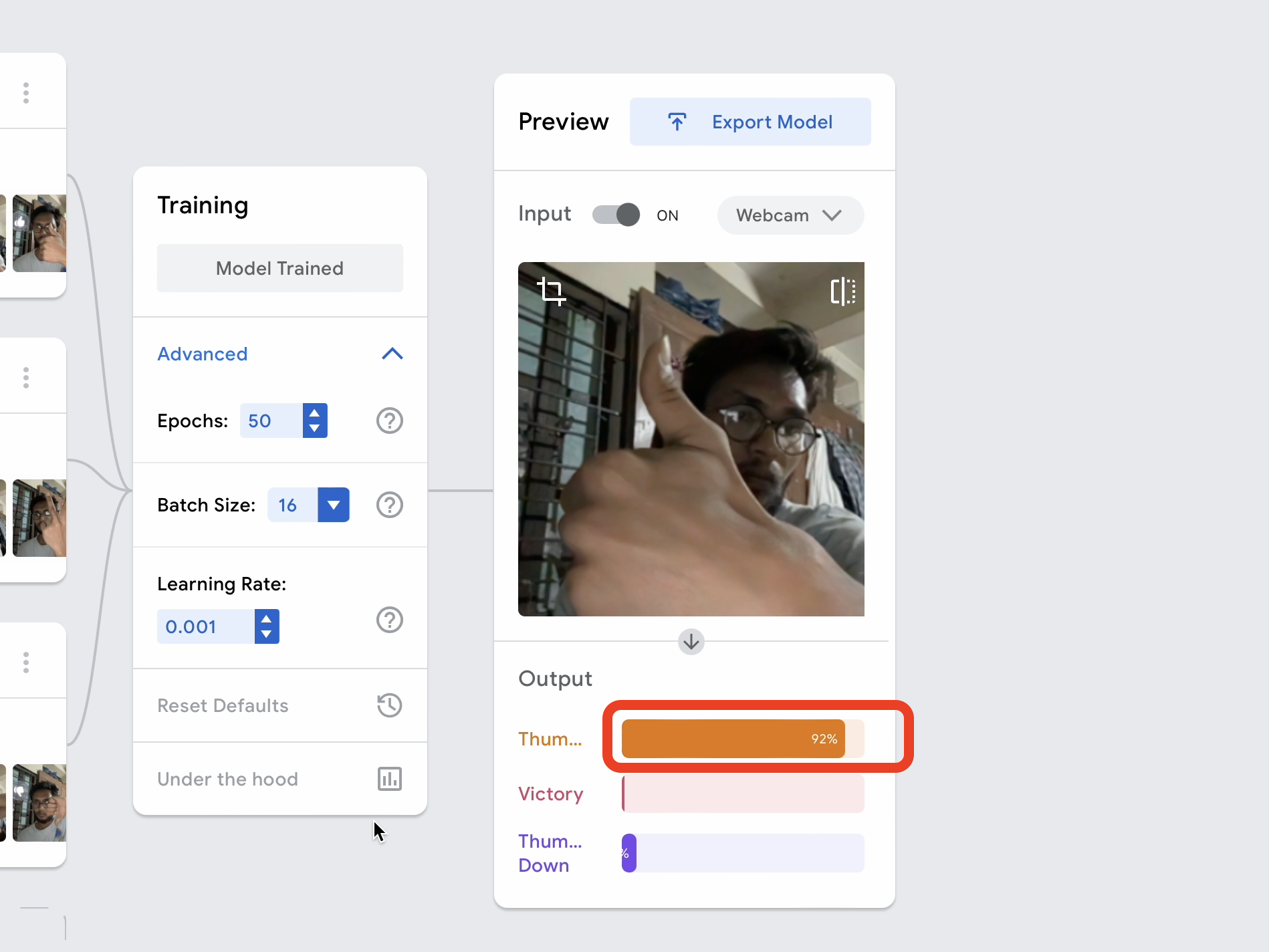
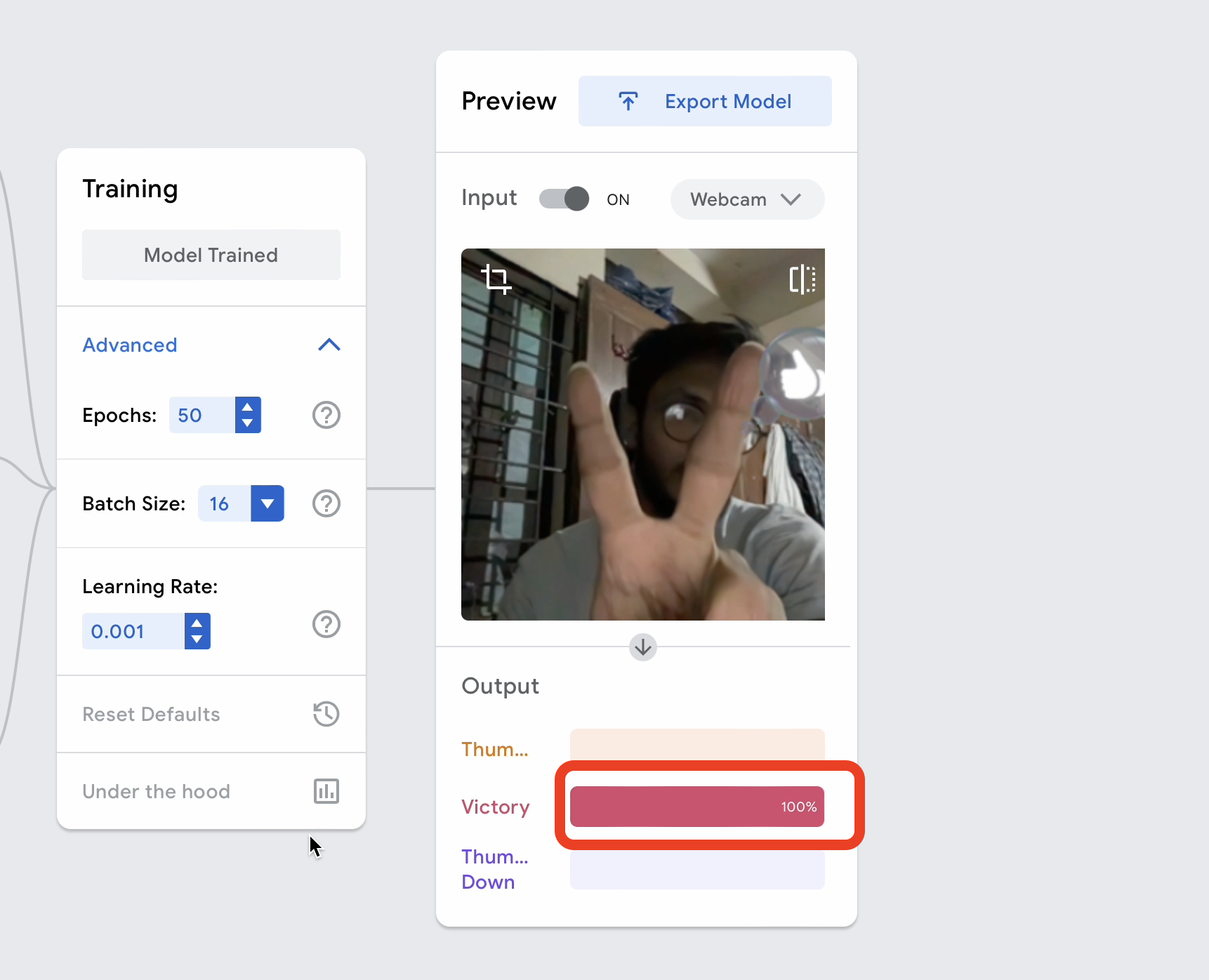
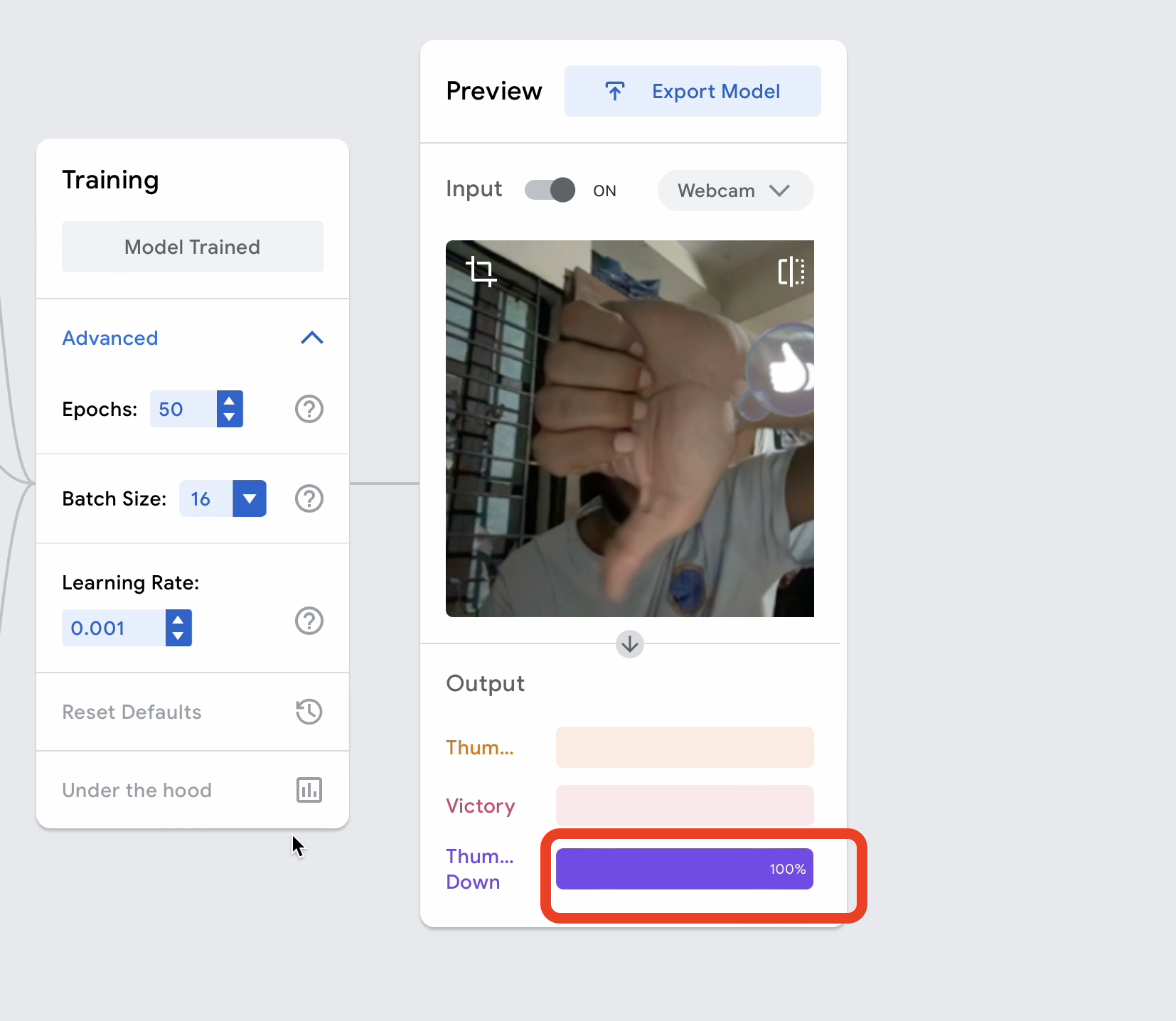
You can also export the model by clicking Export Model in several format.
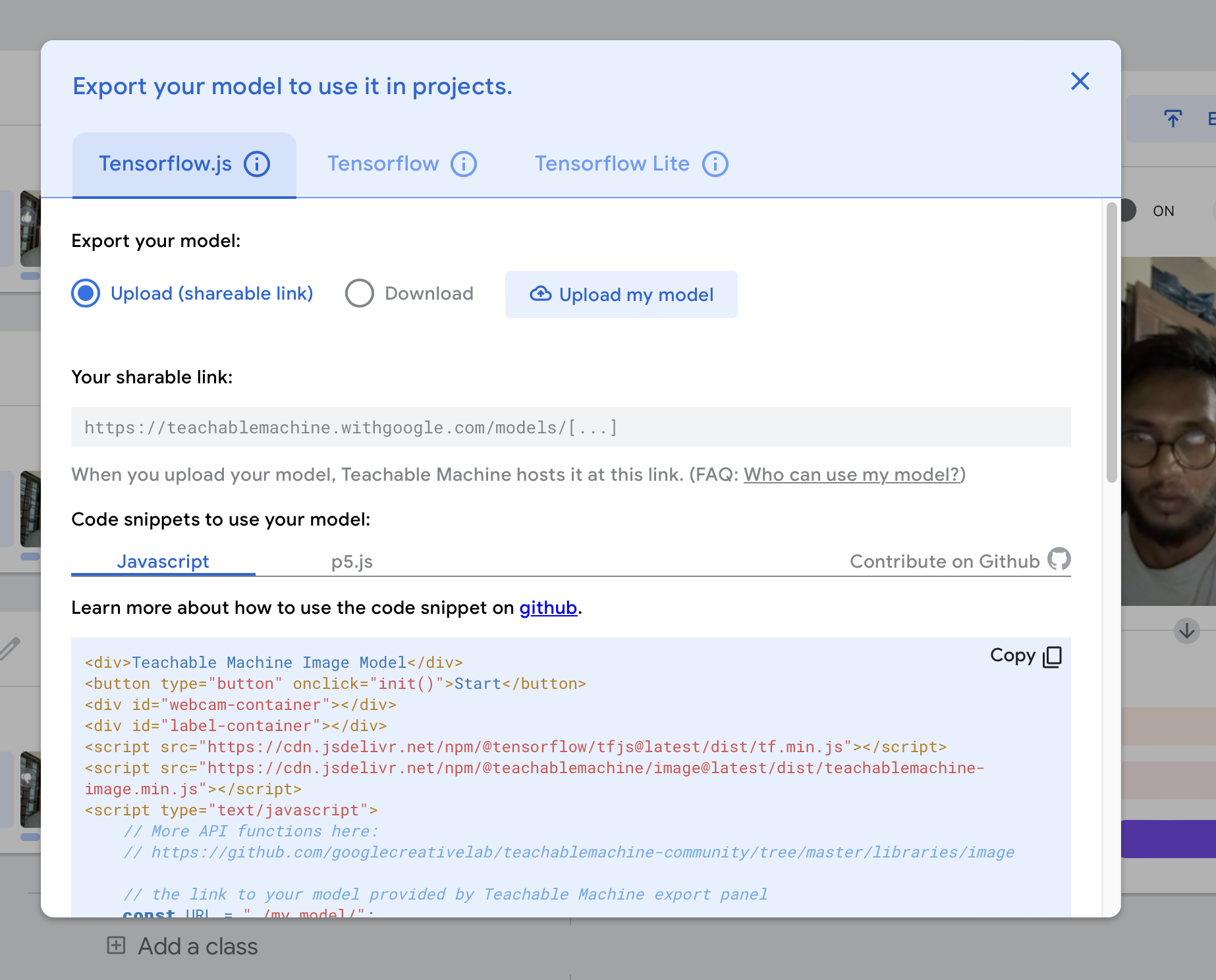
That's all for today. I hope this was helpful.
| radiumsodium |
1,679,297 | CCNA and CCNP Mastery: Your Network's Best Friend | Welcome to _[NC Educations](https://nceducations.com/, your one-stop destination for comprehensive... | 0 | 2023-11-27T06:11:55 | https://dev.to/nceducations/ccna-and-ccnp-mastery-your-networks-best-friend-1f99 | Welcome to _[NC Educations](https://nceducations.com/, your one-stop destination for comprehensive CCNA and CCNP services. Whether you're a networking enthusiast looking to kickstart your career, a seasoned professional seeking to upgrade your skills, or a business in need of top-tier network infrastructure solutions, we've got you covered.
At NC Educations, we are dedicated to empowering individuals and organizations with the knowledge and expertise needed to excel in the dynamic world of networking. We understand the vital role that Cisco's CCNA (Cisco Certified Network Associate) and CCNP (Cisco Certified Network Professional) certifications play in the networking field, and we're here to guide you every step of the way.
| nceducations | |
1,749,778 | Ipromax10 pro | As of my last knowledge update in January 2024, I don't have specific details about an "iPhone 15... | 0 | 2024-02-02T16:11:30 | https://dev.to/ahtuhin/ipromax10-pro-5fof |

As of my last knowledge update in [January 2024](https://sites.google.com/d/1nQmkvIqTOhicXfq-OLk_2HSMfTqeITMU/p/12cpGZPkx9DujIr-3BWP8aPK2Gt4M3Mys/edit), I don't have specific details about an "iPhone 15 Pro Max" as the [iPhone 15 series](https://sites.google.com/d/1nQmkvIqTOhicXfq-OLk_2HSMfTqeITMU/p/12cpGZPkx9DujIr-3BWP8aPK2Gt4M3Mys/edit) had not been released by that time. Apple's product releases are subject to change, and new models may have been introduced since then.
For the most accurate and up-to-date information regarding iPhone models, templates, or any related resources, I recommend checking Apple's official website, design communities, or graphic design marketplaces. Apple's website usually provides official resources for developers and designers, including device templates and guidelines.
[Additionally, design communities and marketplaces such as Adobe Stock, Shutterstock, or other similar platforms often offer templates for various devices, including smartphones. You can search for iPhone 15 Pro Max templates on these platforms to fin](https://sites.google.com/d/1nQmkvIqTOhicXfq-OLk_2HSMfTqeITMU/p/12cpGZPkx9DujIr-3BWP8aPK2Gt4M3Mys/edit)d suitable resources for your design projects.
Remember to verify the information based on the latest updates as product releases and design trends can change over time.
**[Win iPhone 15 Pro Max](https://sites.google.com/d/1nQmkvIqTOhicXfq-OLk_2HSMfTqeITMU/p/12cpGZPkx9DujIr-3BWP8aPK2Gt4M3Mys/edit)** | ahtuhin | |
1,679,465 | Django best practices and tips for writing better code | Introduction Django, the high-level Python web framework, is renowned for its simplicity and... | 0 | 2023-11-27T09:27:55 | https://dev.to/msnmongare/django-best-practices-and-tips-for-writing-better-code-1f1m | beginners, programming, webdev, tutorial | Introduction
Django, the high-level Python web framework, is renowned for its simplicity and efficiency in building robust web applications. However, like any programming endeavor, writing clean and maintainable code is crucial to the success of your Django projects. In this article, we'll explore some Django best practices and tips for writing better code that will not only enhance the quality of your applications but also make your development process more enjoyable.
1. Follow the DRY Principle
The "Don't Repeat Yourself" (DRY) principle is a fundamental concept in software development. In Django, this means avoiding code duplication. When you find yourself writing the same logic in multiple places, consider creating reusable functions, modules, or even custom template tags. By keeping your code DRY, you'll reduce the risk of bugs, improve code maintainability, and save time in the long run.
## Before: Code duplication
def calculate_area(radius):
return 3.14 * radius * radius
def calculate_circumference(radius):
return 2 * 3.14 * radius
## After: DRY principle applied
def calculate_area_and_circumference(radius):
area = 3.14 * radius * radius
circumference = 2 * 3.14 * radius
return area, circumference
2. Properly Organize Your Project
Django provides a well-defined project structure, but it's essential to adhere to it. Keep your project organized by placing related files in their respective directories. For instance, templates should be in the "templates" folder, static files in the "static" directory, and so on. A tidy project structure makes it easier for both you and your team to find and work on different parts of the application.
project_root/
myapp/
templates/
myapp/
mytemplate.html
static/
myapp/
style.css
manage.py
3. Use Django's Built-in Features
Django offers a wide range of built-in features and utilities. Make the most of them before reinventing the wheel. For example, use Django's authentication system, form handling, and database models. Leveraging these built-in tools not only saves you time but also ensures that you benefit from established best practices.
from django.contrib.auth.models import User
from django import forms
## Using Django's built-in User model and form
class UserForm(forms.ModelForm):
class Meta:
model = User
fields = ('username', 'email', 'password')
4. Write Comprehensive Tests
Testing is a critical aspect of Django development. It's not only about ensuring that your code works but also about maintaining its functionality over time. Write comprehensive unit tests and integration tests to cover your application's critical paths. Django's testing framework makes it relatively easy to write tests for your views, models, and forms.
from django.test import TestCase
from myapp.models import MyModel
class MyModelTestCase(TestCase):
def setUp(self):
MyModel.objects.create(name="Test Model")
def test_model_name(self):
test_model = MyModel.objects.get(name="Test Model")
self.assertEqual(test_model.name, "Test Model")
5. Keep Security in Mind
Security is paramount in web development. Django provides numerous security features by default, such as protection against common vulnerabilities like SQL injection and cross-site scripting (XSS). However, you should still be vigilant. Validate user input, use Django's built-in security measures, and keep up with security updates for the packages you use.
## Protect against SQL injection
from django.db import connection
cursor = connection.cursor()
cursor.execute("SELECT * FROM mytable WHERE name = %s", [user_input])
## Prevent Cross-Site Scripting (XSS)
from django.utils.html import escape
user_input = "<script>alert('XSS')</script>"
escaped_input = escape(user_input)
6. Document Your Code
Proper documentation is often underestimated but is essential for maintaining and collaborating on projects. Write clear comments for your functions, classes, and methods. Additionally, use docstrings to document the purpose and usage of your modules and classes. Well-documented code is not only more understandable but also more inviting for others to contribute to.
def calculate_area(radius):
"""
Calculate the area of a circle.
:param radius: The radius of the circle.
:return: The area of the circle.
"""
return 3.14 * radius * radius
7. Optimize Database Queries
Efficient database queries are vital for the performance of your Django application. Utilize the Django QuerySet API to construct efficient queries. Minimize database hits by employing methods like select_related and prefetch_related to fetch related data in a single query, rather than through additional database calls.
## Suboptimal query: N+1 problem
for item in MyModel.objects.all():
related_data = item.related_set.all()
## Optimized query: Use select_related or prefetch_related
for item in MyModel.objects.select_related('related').all():
related_data = item.related
8. Choose Descriptive Variable and Function Names
The readability of your code is crucial. Choose meaningful and descriptive names for your variables, functions, and classes. A well-named function or variable makes your code more self-explanatory and reduces the need for excessive comments.
## Before: Non-descriptive names
x = calculate_area(5)
## After: Descriptive names
area_of_circle = calculate_area(5)
9. Implement Version Control
Version control systems like Git are invaluable for tracking changes in your codebase, collaborating with others, and quickly reverting to previous versions if needed. Set up a version control system for your Django project, and make regular commits with meaningful messages.
## Initialize a Git repository using the following command:
```bash
git init
```
### Making Commits:
1. Add your project files to the staging area using the `git add` command. For example:
```bash
git add .
```
2. Commit your changes with a meaningful message using the `git commit` command:
```bash
git commit -m "Initial project setup"
```
#### Managing Versions:
1. As you make changes to your project, continue to add and commit them to Git with informative commit messages.
```bash
git add .
git commit -m "Added user authentication feature"
```
#### Working with Branches (Optional):
If you want to work on features or experiments in isolation, create and switch to a new branch using the `git checkout -b` command:
```bash
git checkout -b feature/my-new-feature
```
#### Collaborating and Hosting:
You can collaborate with others by pushing your Git repository to a hosting service like GitHub, GitLab, or Bitbucket. This allows multiple developers to work on the same project while keeping track of changes.
10. Continuous Integration and Deployment
Automate your deployment process and set up continuous integration (CI) to catch potential issues early. Services like Jenkins, Travis CI, or GitHub Actions can help you automate testing and deployment, ensuring that your code is always in a deployable state.
In conclusion,
writing better code in Django is not just about adhering to best practices; it's about fostering a mindset of continuous improvement and a commitment to producing clean, maintainable, and efficient code. By following these best practices, you'll not only enhance the quality of your Django projects but also make your development journey smoother and more enjoyable. Happy coding! | msnmongare |
1,679,483 | Building a Scalable Notification Service with gRPC and Microservices | Notification Services have become ubiquitous, serving as a cornerstone for timely updates and alerts... | 0 | 2023-11-27T09:51:59 | https://dev.to/suprsend/building-a-scalable-notification-service-with-grpc-and-microservices-l6d | microservices, grpc, go, programming | Notification Services have become ubiquitous, serving as a cornerstone for timely updates and alerts to users. This article focuses on the technical nuances inherent in architecting a Notification Service, considering it a comprehensive concept encompassing various essential components.
Check out this video first to understand how will this notification infrastructure platform work?
{% youtube oNhJjh5ZHkU %}
## Diverse Use Cases
The architectural considerations of notification infrastructure discussed here are designed to cater to diverse use cases, specifically emphasizing scenarios such as price changes and item availability. The flexibility of the proposed architecture allows seamless customization to meet specific product requirements. Users also seek out multi-tenancy in their notification infrastructure.
### Price Change
In the realm of e-commerce notification services, users often seek notifications regarding price drops for products of interest. The outlined architecture proves to be adaptable, accommodating different product requirements seamlessly.
### Item Availability
Similar flexibility extends to notifying users about the availability of previously out-of-stock items. Leveraging the same underlying logic used for price changes, the architecture is versatile for various use cases.
## Explicit Requirements
### Product Requirements
1. **User Interaction:** Authenticated users should be able to create notifications to "watch" or follow a product for price change alerts. This functionality is typically accessible from a product page linked from search results.
2. **Notification Delivery:** The service should reliably dispatch email or push notifications to users upon detecting a price change for a watched product.
3. **Notification List:** Users should receive a comprehensive list of product notifications via email. For push notifications, rules should determine which product to prioritize, especially when users monitor multiple products.
4. **Third-Party Integration:** The service must seamlessly function with products that incorporate price comparisons from diverse third-party sources.
### Design Goals
1. **Integration:** The notification service should effortlessly integrate with existing services such as e-commerce or job search products.
2. **Isolation:** The notification service should maintain a high degree of isolation, constituting its own components independent of the main service.
## Central Component: Notification API
At the core of the Notification Service architecture lies the Notification API, a critical component enabling the creation and deletion of notification entries via an API. This API is invoked by the existing service to manage notifications effectively.
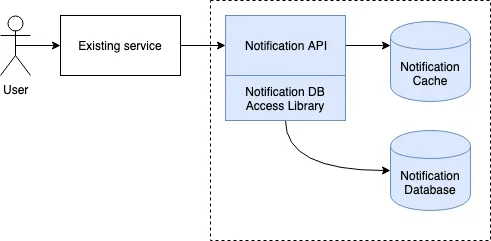
### Notification API High-Level Design
Key features of the Notification API encompass:
- **Create Notification:** Initiates the creation of a new notification entry with parameters including API key, product ID, and user ID.
- **Delete Notification:** Removes an existing notification based on the API key and notification ID.
- **Get Notifications:** Retrieves a list of notifications for a specific user.
### Database Schema
The Notification API relies on a database with the following schema:
- **NotificationID:** A unique identifier for each notification entry.
- **UserID:** The ID of the logged-in user who created the notification.
Additional fields in the schema (e.g., ProductID, LatestPrice, PreviousPrice, LastUpdated) vary depending on the product or service. In this example, an e-commerce website is considered.
---
## Technical Implementation
The Notification API can be implemented as a RESTful or gRPC service using languages like Java, Go, or C#. The choice of a NoSQL datastore and a caching system depends on specific requirements.
### Optional: User Data Component
To maintain a clear separation of responsibilities, the Notification API ideally only stores user references. Personally Identifiable Information (PII) data, such as names and emails, should be stored in a separate API.
## Diverse Approaches
Several solutions can be employed, each with its own pros and cons. The following design solutions can be combined for optimal results.
## Solution #1: Manual Price Update Event
### Suitability:
This solution is tailored for scenarios where internal control over product prices is absolute.
### Pros:
1. **Simplicity of Implementation:**
- The straightforward integration makes it an ideal choice.
- Minimal development effort compared to other solutions.
2. **Full Control:**
- Precise management of price changes internally.
- Offers reliability and accuracy.
### Cons:
1. **Limited Applicability:**
- Unsuitable when relying on third-party sources for price changes.
- Restricts flexibility in the face of external pricing influences.
### Components:
1. **Communication Service:**
- Manages notification flow to end-users.
2. **Price Change Event:**
- Triggered manually via the admin panel.
3. **Notification Service:**
- Handles and manages notifications.
### High-Level Design (RDBMS Database):
```sql
-- SQL Query for RDBMS
SELECT * FROM NOTIFICATIONS WHERE PRODUCT_ID = 'xxx' AND ANOTHER_COL = 'xxx';
```
### High-Level Design (NoSQL Database with Indexing Service):
```json
{
'xxx-xxx-xxx': {'notifications': ['xxx-xxx-xxx', 'xxx-xxx-xxx', 'xxx-xxx-xxx']}
}
```
#### Indexing Service
- **RDBMS:** Not required, as the Notifications API can execute an SQL query directly.
- **NoSQL:** Necessary for mapping product IDs to notification IDs.
#### Rebuilding the Index:
- In case of failure, the index should be rebuilt.
- A backup service ensures continuous availability.
- Periodic updates maintain data accuracy.
#### Implementation Tip:
The indexing service can be a RESTful service or an in-memory data store like Redis.
#### Price Change Event Service
1. **Monitoring:** Monitors product price change events triggered by the admin panel.
2. **Updates:** Updates affected product prices via the Notification API.
#### Implementation Tip:
AWS Lambda or a similar service for event monitoring.
#### Communication Service
1. **Abstraction:** Serves as an abstraction between systems and third-party services.
2. **Notification Delivery:** Sends emails and push notifications.
## Solution #2: Use Batch Jobs
### Suitability:
This approach is suitable when relying on third-party sources for pricing.
### Pros:
1. **Comprehensive Coverage:**
- Ensures broad coverage by handling all stored criteria.
### Cons:
1. **Increased API Calls:**
- Potential drawback due to heightened internal API usage.
2. **Database Scans:**
- Requires partial or full database scans.
3. **Additional Components:**
- Introduces more running components.
### Components:
1. **Scheduler:**
- Triggers batch jobs.
2. **Data Pipeline:**
- Gathers and publishes notifications to a queue.
3. **Batch Jobs:**
- Process notifications from the queue.
4. **Communication Service:**
- Manages notifications.
### High-Level Design:
#### Scheduler
1. **Scheduling:** Triggers data pipeline, batch processing, and other services periodically.
2. **Considerations:** Off-peak times and user time zone for optimal notification delivery.
#### Scheduling Strategies:
1. **Daily Coverage:** Ensures all notifications are covered per day.
2. **Regional Alternation:** Alternates between regions or availability zones per day.
#### Implementation Tip:
Utilize a Cron Job or AWS Cloudwatch Event.
#### Data Pipeline
1. **Triggering:** Initiated by the scheduler.
2. **Functionality:** Scans the database, groups notifications, and publishes them to a queue.
3. **Reading Strategy:** Consider full database scan or partial scan grouped by regions.
#### Implementation Tip:
Use AWS Data Pipeline, Spark, or similar services for efficient data processing.
#### Batch Jobs
1. **Subscription:** Subscribed to the notification entries topic in the message queue.
2. **Processing:** Picks up messages, calls internal APIs, compares prices, and decides whether to notify users.
3. **Updates:** Updates notification entries in the database after successful communication.
#### Implementation Tip:
Leverage AWS Data Pipeline, Spark, or similar services for efficient message processing.
## Solution #3: Use Internal API Response Logs
### Suitability:
Efficient for scaling up services and reducing internal API calls.
### Pros:
1. **Real-time Updates:**
- Provides more "real-time" price updates.
2. **Reduced API Calls:**
- Mitigates the number of internal API calls.
### Cons:
1. **Log Streaming Requirement:**
- Mandates log streaming for optimal functionality.
2. **Frequency Logic Tuning:**
- Requires fine-tuning of frequency logic for notifications.
### Components:
1. **Scheduler:**
- Triggers Samza job.
2. **Data Pipeline:**
- Processes API request and response logs.
3. **Samza Job:**
- Matches live user requests with notifications.
4. **Communication Service:**
- Manages notifications.
### High-Level Design (RDBMS Database):
```sql
-- SQL Query for RDBMS
SELECT * FROM NOTIFICATIONS WHERE SEARCH_CRITERIA = 'xxx';
```
### High-Level Design (NoSQL Database with Indexing Service):
```json
{
'xxx-xxx-xxx': {'notifications': ['xxx-xxx-xxx', 'xxx-xxx-xxx', 'xxx-xxx-xxx']}
}
```
#### API Response Logs
1. **Logging:** Logs both request and response when a user views a product.
2. **Inclusion:** Product and price details are included in the logs.
#### Implementation Tip:
Utilize Kafka for log streaming and Samza for processing.
#### Samza Job
1. **Matching:** Matches live user requests with notifications.
2. **Evaluation:** Checks for price differences or product availability.
3. **Notification:** Sends a request to the communication component for user notification.
#### Implementation Tip:
Leverage Kafka for log stream and Samza for data processing.
### Critical Considerations:
1. **Avoiding Duplicates:**
- Skip notifications updated within a specified period to prevent duplicates.
2. **Fine-tuning Frequency:**
- Adjust the frequency of sending notifications to avoid overwhelming users.
## Combining All Solutions
These solutions have their own strengths and weaknesses. Implementing all of them side by side can deliver the best results. A recommended approach is to start with Solution #1, then expand to Solution #2 as the product scales. Finally, when the notifications database faces excessive load, consider implementing Solution #3.
## Technical Notes
- **Services Communication:**
- Achieved via HTTPS calls for secure and reliable communication.
- **Redundancy Considerations:**
- Add a load balancer for redundancy.
- Deploy services in multiple regions for enhanced availability.
In conclusion, architecting a scalable notification service requires thoughtful consideration of use cases, requirements, and the strengths of different solutions. By combining various approaches, developers can create a robust notification infrastructure that effectively informs and engages users.
---
**How SuprSend Notification Infrastructure Can Power Your Complete Stack?**
We can help you abstract your developmental layer without compromising quality and code. Our team is led by two experienced co-founders who have a combined experience of more than 20 years in building notification stacks for different early/mid-to-large-sized companies. We've been through the ups and downs, the sleepless nights, and the moments of triumph that come with creating a dependable notification infrastructure.
This is our amazing team, and we're here to make your journey unforgettable :)

Now let's see how SuprSend can benefit you:
1. **Multi-Channel Support:**
- [Add multiple communication channels](https://www.suprsend.com/?utm_source=Dev.to&utm_medium=referral&utm_campaign=Dev.to_distribution&utm_id=A+Complete+Guide+on+Notification+Infrastructure+for+Modern+Applications+in+2023) (Email, SMS, Push, WhatsApp, Chat, App Inbox) with ease.
- Seamless integration with various providers.
- Flexible channel routing and management.
2. **Visual Template Editors:**
- Powerful, user-friendly template editors for all channels.
- Centralized template management.
- Versioning support for templates, enabling rapid changes without code modification.
3. **Intelligent Workflows:**
- [Efficient notification delivery](https://www.suprsend.com/products/smart-routing?utm_source=Dev.to&utm_medium=referral&utm_campaign=Dev.to_distribution&utm_id=A+Complete+Guide+on+Notification+Infrastructure+for+Modern+Applications+in+2023) through single triggers.
- Configurable fallbacks, retries, and smart routing between channels.
- Handle various notification types (Transactional, Crons, Delays, Broadcast) effortlessly.
4. **Enhanced User Experience:**
- [Preference management](https://www.suprsend.com/products/preferences?utm_source=Dev.to&utm_medium=referral&utm_campaign=Dev.to_distribution&utm_id=A+Complete+Guide+on+Notification+Infrastructure+for+Modern+Applications+in+2023) for user control.
- Multi-lingual content delivery.
- Smart channel routing and batching to avoid message bombardment.
- Frequency caps and duplicate prevention.
5. **Comprehensive Analytics and Logs:**
- Real-time monitoring and logs for all channels.
- Cross-channel analytics for message performance evaluation.
- Receive real-time alerts for proactive troubleshooting.
6. **Developer-Friendly:**
- Simplified API for triggering notifications on all channels.
- SDKs available in major programming languages.
- Comprehensive documentation for ease of integration.
7. **App Inbox:**
- [Customizable inapp-inbox](https://www.suprsend.com/products/app-inbox?utm_source=Dev.to&utm_medium=referral&utm_campaign=Dev.to_distribution&utm_id=A+Complete+Guide+on+Notification+Infrastructure+for+Modern+Applications+in+2023) for your app and website.
- Provides a convenient way to centralize and manage notifications for users.
- Try our app-inbox playground here: [SuprSend_AppInbox_Playground](https://inbox-playground.suprsend.com/?utm_source=Dev.to&utm_medium=referral&utm_campaign=Dev.to_distribution&utm_id=A+Complete+Guide+on+Notification+Infrastructure+for+Modern+Applications+in+2023)
8. **Bifrost Integration:**
- Run notifications natively on a data warehouse for enhanced data management.
9. **User-Centric Preferences:**
- Allow users to set their notification preferences and opt-out if desired.
10. **Scalable and Time-Saving:**
- Quickly deploy notifications within hours, saving development time.
- Minimal effort is required to set up notifications. Get started in under 5 minutes.
11. **24*7 Customer Support:**
- Our team is distributed around various time zones, ensuring someone is always up to cater to customer queries.
- We also received the 'Best Customer Support' badge from G2 for our unwavering dedication.
Still not convinced?
Let's talk, and we may be able to give you some super cool notification insights. And no commitments, we promise!
> You can find Gaurav, CTO & cofounder, SuprSend here: [GV](https://www.linkedin.com/in/gauravv/?utm_source=Dev.to&utm_medium=referral&utm_campaign=Dev.to_distribution&utm_id=A+Complete+Guide+on+Notification+Infrastructure+for+Modern+Applications+in+2023)
> You can find Nikita, cofounder, SuprSend here: [Nikita](https://www.linkedin.com/in/nikita-navral/?utm_source=Dev.to&utm_medium=referral&utm_campaign=Dev.to_distribution&utm_id=A+Complete+Guide+on+Notification+Infrastructure+for+Modern+Applications+in+2023)
> To directly book a demo, go here: [Book Demo](https://calendly.com/nikita-suprsend/?utm_source=Dev.to&utm_medium=referral&utm_campaign=Dev.to_distribution&utm_id=A+Complete+Guide+on+Notification+Infrastructure+for+Modern+Applications+in+2023)
---
> #### Similar to this, I run a developer-centric community on Slack. Where we discuss these kinds of topics, implementations, integrations, some truth bombs, lunatic chats, virtual meets, and everything that will help a developer remain sane ;) Afterall, too much knowledge can be dangerous too.
> #### I'm inviting you to join our free community, take part in discussions, and share your freaking experience & expertise. You can fill out this form, and a Slack invite will ring your email in a few days. We have amazing folks from some of the great companies (Atlassian, Gong, Scaler etc), and you wouldn't wanna miss interacting with them. [Invite Form](https://forms.gle/VzA3ST8tCFrxt39U9)
| nikl |
1,680,136 | Discover DbVisualizer Security Features for MySQL | As a database manager or developer, you need to have all the right tools at your disposal. That's why... | 21,681 | 2023-12-04T08:00:00 | https://www.dbvis.com/thetable/discover-dbvisualizer-security-features-for-mysql/ | mysql, security | **As a database manager or developer, you need to have all the right tools at your disposal. That's why having a reliable and comprehensive database client is essential to help you manage and maintain state-of-the-art database technologies. That's where DbVisualizer comes in. DbVisualizer is a powerful database management client that allows users to access, manage, and query databases from a single place. Data security is an important element in data management, and DbVisualizer offers multiple options for protecting your data. In this article, we will look at the security features of DbVisualizer and how they help protect you.**
---
Tools used in this tutorial
[DbVisualizer](https://www.dbvis.com/download/), top rated database management tool and SQL client
The [MySQL](https://dev.mysql.com/downloads/mysql/) database version 8 or later
---
## Before we start
Before we start learning how DbVisualizer can enhance your database security, let’s prepare the prerequisites.
### Creating a MySQL Database
Follow the steps to set up the Oracle MySQL database on your local machine.
- Download and install MySQL: Go to the MySQL download page to download MySQL. Once the download is finished, run the installer and follow the prompts to install MySQL on your local machine, and during the installation process, you will be prompted to set up a root password for the MySQL server. In this example, we’re installing MySQL 8.
<br />
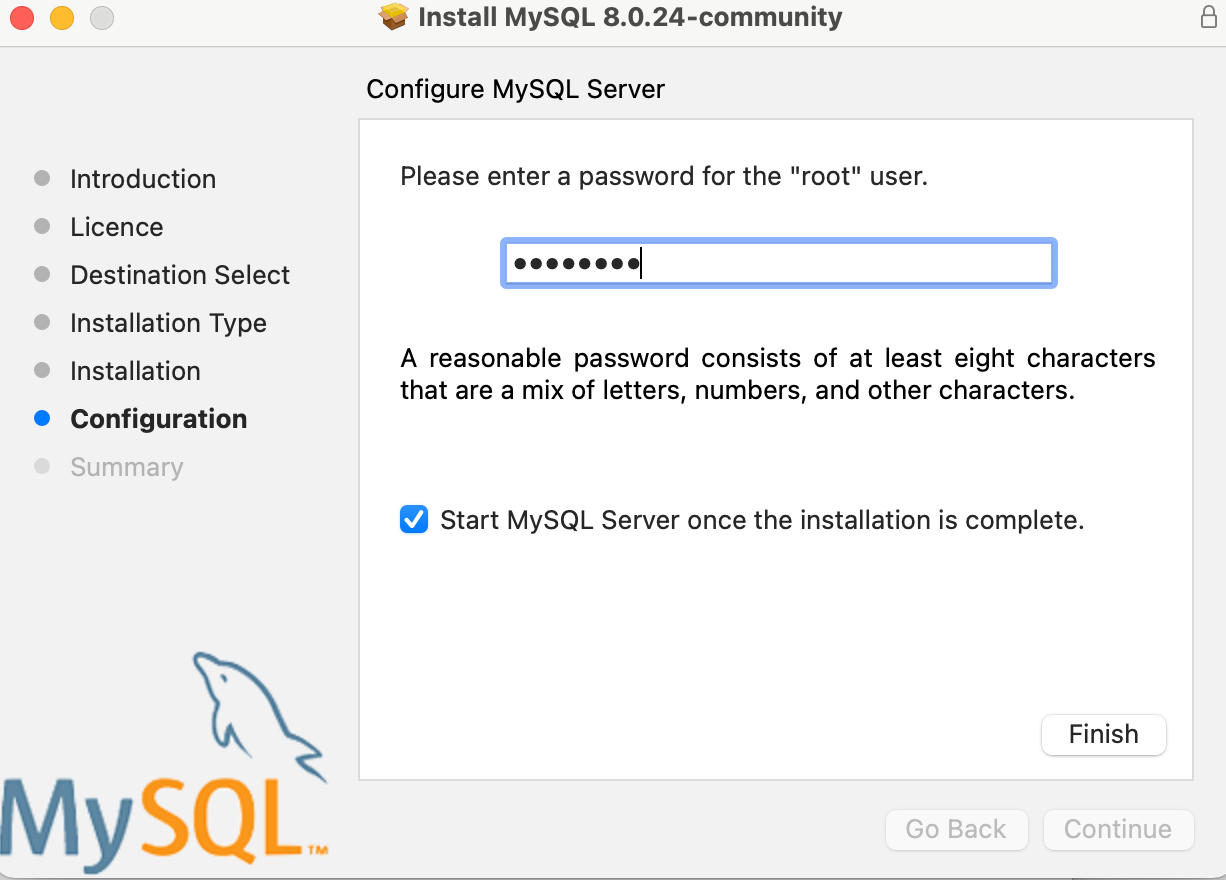
<figure><figcaption>Installing MySQL to set up the Oracle MySQL database.</figcaption></figure>
<br />
- Download and install MySQL: Go to the MySQL download page to download MySQL. Once the download is finished, run the installer and follow the prompts to install MySQL on your local machine, and during the installation process, you will be prompted to set up a root password for the MySQL server. In this example, we’re installing MySQL 8.
- Download and install MySQL: Go to the MySQL download page to download MySQL. Once the download is finished, run the installer and follow the prompts to install MySQL on your local machine, and during the installation process, you will be prompted to set up a root password for the MySQL server. In this example, we’re installing MySQL 8.
<br />
<figure><figcaption>Searching after MYSQL in System Preferences.</figcaption></figure>
<br />
- Download and install MySQL: Go to the [MySQL download page](https://dev.mysql.com/downloads/mysql/) to download MySQL. Once the download is finished, run the installer and follow the prompts to install MySQL on your local machine, and during the installation process, you will be prompted to set up a root password for the MySQL server. In this example, we’re installing MySQL 8.
<br />
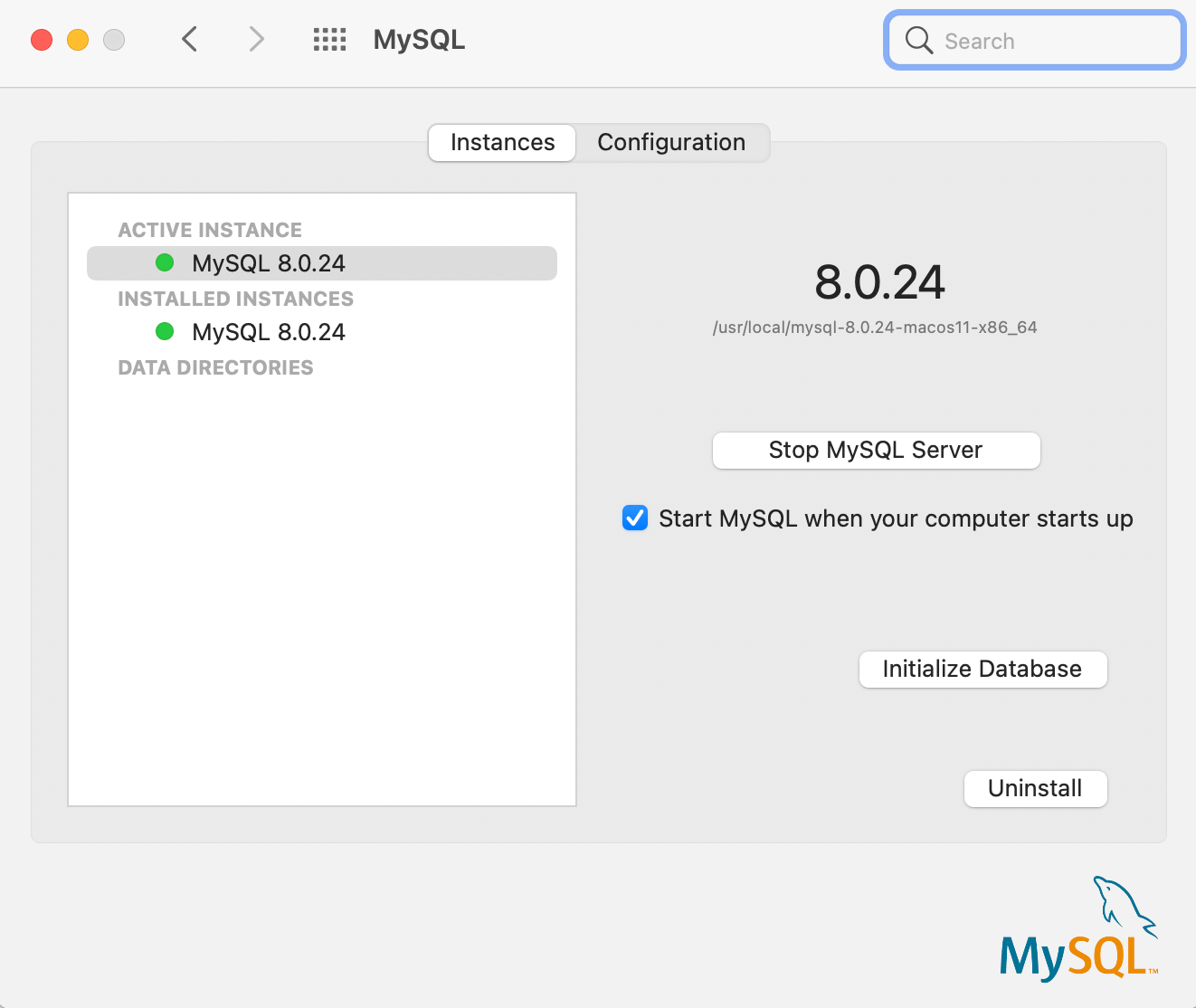
<figure><figcaption>Ensuring that the server is running normally.</figcaption></figure>
<br />
### Installing DbVisualizer
Installing DbVisualizer is simple and straightforward. Follow the steps to install DbVisualizer in your local machine.
- Go to the [DbVisualizer website](https://www.dbvis.com/) and download the appropriate installation file for your operating system.
- Once the download is complete, double-click the installation file to start the installation process.
- Follow the prompts in the installation wizard to select your preferred language, installation location, and other settings.
- After you've made your selections, click "Install" to begin the installation process.
- Wait for the installation to complete, which may take a few minutes.
Once the installation is finished, you can launch DbVisualizer and start using it to manage your databases.
### Connect to Oracle MySQL using DbVisualizer
Now that you have MySQL and DbVisualizer ready, let’s connect to the database using DbVisualizer. To create a connection,
- Go to the **Database** menu.
- Select **Create Database Connection**.
- Type just “my” to find the MySQL drivers. Select MySQL 8.
<br />
<figure><figcaption>Entering the two fields to Connect to Oracle MySQL.</figcaption></figure>
<br />
Enter the two fields:
- Database Userid: root
- Database Password: (your root password)
Connecting to MySQL using DbVisualizer is an easy process, and can be done in just a few steps. Once you're connected, you can use the powerful features of DbVisualizer to manage and maintain your MySQL databases with ease.
## DbVisualizer security features
DbVisualizer offers various security features to help protect sensitive data. Among many, let’s dive into three main components - data encryption with SSH, secure data access, and local master password.
### Data encryption with SSH
With the data encryption feature, you can guarantee strong encryption and secure DB connection and data transfer. You can also help protect your data from eavesdropping and other types of malicious attacks. Furthermore, it can help prevent unauthorized access to your database by adding an extra layer of authentication and access control. Data encryption with SSH is an important security feature in DbVisualizer that can help ensure the confidentiality and integrity of your data.
<br />
<figure><figcaption>Data encryption with SSH.</figcaption></figure>
<br />
**Strong encryption for every request**
When using DbVisualizer's data encryption with SSH, the entire communication between the client and the server becomes encrypted by strong encryption algorithms. This guarantees that even if an attacker intercepts the data, they will not be able to understand the contents of the communication. The encryption algorithm used by DbVisualizer is typically AES (Advanced Encryption Standard). The algorithm is one of the most widely used and highly secure encryption mechanisms.
**Secure database connections**
DbVisualizer's data encryption with SSH also provides secure database connections. The SSH protocol is used to establish a secure connection between the client and the server, which ensures that the connection is encrypted and secure. This helps to prevent unauthorized access to the database and helps to protect sensitive data from being accessed by unauthorized users.
**Transfer data securely**
The data encryption with SSH feature also provides secure data transfer. All data transferred between the client and the server is encrypted, which ensures that the data cannot be intercepted by an attacker. This helps to ensure that sensitive data, such as passwords, are not compromised during transfer.
### Secure data access
DbVisualizer provides secure data access to protect sensitive data from unauthorized access. Two of its key features for secure data access are two-factor authentication and least access permissions.
**Two-factor authentication**
With the support of two-factor authentication, you can add an extra layer of security to data access. Two-factor authentication requires users to provide two forms of identification, such as a password and a one-time code generated by an authentication app, before they can access the data. This helps to ensure that only authorized users can access the data, even if their passwords are compromised.
**Least access permissions**
DbVisualizer also offers access provision using the least access permissions. This means that users are granted access only to the specific data they need to do their job, and no more. By limiting access to sensitive data, DbVisualizer helps to reduce the risk of unauthorized access, accidental data breaches, and other security incidents. Least access permissions can also help to comply with data protection regulations, such as GDPR or HIPAA, which require organizations to protect sensitive data.
### Local master password
<br />
<figure><figcaption>Setting up a local master password.</figcaption></figure>
<br />
DbVisualizer's Local master password feature is a security measure that allows users to protect their stored database passwords with an additional layer of encryption. When enabled, the local master password feature encrypts all stored passwords in the database connection settings with a master password set by the user. This provides an additional layer of security, as even if an attacker gains access to the database connection settings, they will not be able to see the stored passwords without the local master password. Users can also choose to save the local master password securely in their operating system's keychain, further enhancing the security of their stored passwords.
## DbVisualizer’s security capabilities for MySQL
In addition to the security features, DbVisualizer also provides strong support for Oracle databases. This includes support for Oracle ARCS security, which is a security framework designed specifically for Oracle databases. DbVisualizer also offers features that help administrators manage Oracle EPM Cloud security, making it a great choice for organizations that use Oracle databases.
If you wonder which environment DbVisualizer supports better - cloud security vs on premise, the software provides robust solutions for both scenarios. Organizations can choose to use DbVisualizer in the cloud or on-premise, depending on their needs and preferences. Regardless of which option they choose, they can be confident that their data is kept safe and secure thanks to DbVisualizer's strong security features.
## Conclusion
DbVisualizer is a robust database management tool that offers a variety of security features to ensure the protection of sensitive data. Its security features, such as data encryption with SSH, secure data access, and the local master password feature, provide an extensive security solution to prevent unauthorized access and protect against potential security breaches. As the importance of data has grown, your database management tool should offer a robust cloud security solution and enhanced on-premise data protection. [Check DbVisualizer! ](https://www.dbvis.com/)With its user-friendly interface and diverse security measures, it is an excellent tool for any organization that values data security. So, [try DbVisualizer today](https://www.dbvis.com/download/) and experience the benefits of its powerful security features firsthand.
## About the author
Igor Bobriakov is an entrepreneur and educator with a background in marketing and data science. His passion is to help small businesses and startups to utilize modern technology for growth and success. Igor is Data Scientist and ML Engineer. He founded Data Science School in 2016 and wrote numerous award-winning articles covering advanced tech and marketing topics. You can connect with him on LinkedIn or Twitter.
| dbvismarketing |
1,680,192 | TL;DR setup Fish Shell MacOS | Strait to the point on how to setup fish shell on MacOS with bobthefish theme | 0 | 2023-11-27T14:57:00 | https://dev.to/fabientownsend/tldr-setup-fish-shell-macos-2ee2 | macos, cli, fish, shell | ---
title: TL;DR setup Fish Shell MacOS
published: true
description: Strait to the point on how to setup fish shell on MacOS with bobthefish theme
tags: #MacOS, #CLI, #FISH, #SHELL
cover_image: https://dev-to-uploads.s3.amazonaws.com/uploads/articles/td1xyvj2evo3giboigfr.png
# Use a ratio of 100:42 for best results.
# published_at: 2023-11-27 11:07 +0000
---
Here is TL;DR (too long; didn't read) summary of how to set Fish Shell on your MacOS to get that result:

Here are the commands that I used:
``` bash
$ brew install fish
$ curl https://raw.githubusercontent.com/oh-my-fish/oh-my-fish/master/bin/install | fish
$ omf install bobthefish
$ set -g theme_nerd_fonts yes
$ brew tap homebrew/cask-fonts
$ brew install font-hack-nerd-font --cask
```
##
The next step will "fix" the font now being properly displayed:
Open your term2 profile:
Edit the font used:
Done.
## Troubleshoot 1
I had an issue where `bobthefish` theme wouldn't work out, for that I followed the following steps:
``` bash
functions fish_promp
```
And then delete the file it pointed out.
## Remove omf and fish installation
I initially messed up with my installation, the following command enables me to clean up `fish`/`omf` to start from the beginning:
``` bash
$ omf remove bobthefish
$ omf destroy
$ brew uninstall fish
$ rm -rf opt/homebrew/etc/fish
``` | fabientownsend |
1,680,307 | Unveiling the Potency of the German Hammer of Thor: A Synergy with Ashwagandha | In the realm of natural wellness and male enhancement, the German Hammer of Thor emerges as a... | 0 | 2023-11-27T16:36:51 | https://dev.to/hammerofthor/unveiling-the-potency-of-the-german-hammer-of-thor-a-synergy-with-ashwagandha-4763 | ashwagandha, hammerofthor | In the realm of natural wellness and male enhancement, the German Hammer of Thor emerges as a powerful elixir, offering a holistic approach to vitality and pleasure. Paired with the time-honored [benefits of Ashwagandha](https://germanhammerofthor.com/), this dynamic duo unlocks a world of well-being and satisfaction.
The German Hammer of Thor: A Marvel of Ayurvedic Wisdom
Power Unleashed: The Essence of Hammer of Thor
The German Hammer of Thor, a product deeply rooted in Ayurvedic principles, is a symbol of potency and vitality. Crafted with precision, this elixir aims to enhance intimate experiences, promoting a harmonious balance in the realm of male enhancement.
Exploring the Ayurvedic Marvel: Ashwagandha Benefits in Hindi
An Ayurvedic Gem: [Ashwagandha Benefits in Hindi](https://germanhammerofthor.com/)
In the ancient language of Ayurveda, Ashwagandha is celebrated for its multifaceted benefits. Known as the "Indian Ginseng," this herb is revered for its adaptogenic properties, promoting balance and vitality. Explore the comprehensive Ashwagandha benefits in Hindi to truly grasp the depth of its therapeutic virtues.
The Capsule of Wellness: Ashwagandha Capsule
Convenience and Well-Being: The Ashwagandha Capsule
For those seeking a convenient way to incorporate Ashwagandha into their daily routine, the Ashwagandha capsule is a modern solution. Packed with the essence of this potent herb, the capsule offers an easy and effective means to harness the benefits of Ashwagandha.
Unraveling the Wonders: Use of Ashwagandha
Beyond a Supplement: The Holistic Use of Ashwagandha
The use of Ashwagandha transcends mere supplementation; it's a holistic approach to well-being. From stress reduction to enhanced energy levels, Ashwagandha adapts to the body's needs, fostering a sense of vitality and equilibrium.
Concentrated Potency: Ashwagandha Extract
Essence in Every Drop: Ashwagandha Extract
For those seeking a more concentrated form of Ashwagandha, Ashwagandha Extract offers a potent solution. This extract, derived from the root of the Withania somnifera plant, encapsulates the essence of Ashwagandha's therapeutic properties.
The Harmonious Symphony: German Hammer of Thor and Ashwagandha
Synergy Unleashed: Enhancing Pleasure and Well-Being
Imagine the harmonious union of the German Hammer of Thor and the Ayurvedic marvel Ashwagandha. This dynamic synergy amplifies the benefits, not just in the realm of male enhancement but in fostering overall well-being and vitality.
Conclusion
In the pursuit of holistic wellness and enhanced intimate experiences, the German Hammer of Thor, complemented by the therapeutic virtues of Ashwagandha, stands as a beacon of natural potency. Embrace the synergy of ancient wisdom and modern solutions, unlocking a world where pleasure and well-being intertwine in perfect harmony. | hammerofthor |
1,680,392 | A counter that listen keyboard events 🕹️ | How to make a dynamic number counter so that when you press the up arrow, a number is added and when... | 0 | 2023-11-27T17:58:10 | https://dev.to/stacy-roll/a-counter-that-listen-keyboard-events-m6h | rust, tutorial, programming, beginners | How to make a dynamic number counter so that when you press the up arrow, a number is added and when you press the down arrow, a number is subtracted?
I asked myself that question and proceeded to try to solve that algorithm in my mind first and then in code, here is the result.
Let's add the keyboard handler [k_board](https://crates.io/crates/k_board)
`cargo add k_board`
Let's add the program logic:
```rust
use k_board::{Keyboard, Keys};
fn main() {
let mut number: i8 = 0;
print_number(&mut number, 0);
for key in Keyboard::new() {
match key {
Keys::Up => print_number(&mut number, 1),
Keys::Down => print_number(&mut number, -1),
Keys::Enter => break,
_ => {}
}
}
}
fn print_number(number: &mut i8, operation: i8) {
std::process::Command::new("clear").status().unwrap();
*number += operation;
println!("{}", number);
}
```
See you soon love ❤️
| stacy-roll |
1,680,905 | 6 Reasons Why Your Business Needs UI/UX Design Services | Businesses need to seek out additional chances in this rapidly changing environment in order to... | 0 | 2023-11-28T06:33:51 | https://dev.to/preetham02/6-reasons-why-your-business-needs-uiux-design-services-49an | uiuxdesign, uxdesign, uidesign, ui |

Businesses need to seek out additional chances in this rapidly changing environment in order to improve client interaction, establish their brand identity, and identify new sources of income. Businesses need to create their solutions on the digital platform as more firms and target consumers choose digital solutions. Creating a captivating website or application might be beneficial. Even yet, coming up with a novel or alluring solution to help them thrive in the fiercely competitive market takes a lot of work.
Businesses must prioritize the UI and UX of the digital solution above all else since it is essential to capturing consumers' attention and motivating them to take meaningful action. Businesses that create user interfaces that are both aesthetically pleasing and easy to use can increase client loyalty and improve their bottom line. And for this reason, businesses search for imaginative and original [UI UX design services](https://www.sparkouttech.com/ui-ux-development/). However, let's first see how these services may benefit your company before you decide to use them.
Interesting Facts on UI/UX Design
The following are some fascinating statistics and facts about UI/UX design:
A global and thoughtful user experience may increase conversion by 400%.
74% of visitors will come back to a mobile-friendly website.
In user experience, a $1 investment yields a $2–$100 return.
These states all demonstrate how much of an impact a strong UI/IX can have on your company. It may successfully increase your productivity by attracting more people to your website or app, keeping them on for longer periods of time, and persuading them to purchase your goods. Making this UI/UX design investment is crucial to expanding your company.
Benefits of UI/UX Design for Your Business
1. Boost Audience Engagement & Sales
Increasing audience engagement leads to a higher return on investment, which is the main advantage of a well-designed user experience. Forbes claims that for every $1 spent in the US, you will receive $100. Most individuals are unaware of the breadth of UI/UX design services. UI/UX, which combines functional and visual features, may provide you the advantage you need to showcase your business in the best possible light. In the end, it increases audience engagement, helps prospective customers through the purchasing process, and convinces them to acquire your goods or services. Sales are rising as a consequence.
2. Reduced Development Cost
An expert developer builds an agile application interface where all components communicate with the user in a seamless manner, understanding the importance of UI/UX design services in the corporate sector. There is little likelihood of making mistakes or experiencing a negative user experience. Hiring an unreliable team might result in a subpar project, requiring your business to invest extra time and resources in finding experts to get satisfactory results. It is better to pay extra and have a flawless product the first time around.
3. Increased Customer Satisfaction
Customers can easily navigate your website and get intriguing content with a superb design. Customers are satisfied, which increases your company's return on investment. Additionally, a happy consumer will tell others about the good or service, which can boost sales.
4. Establish the Brand Reputation
For your brand, making a good first impression is crucial. The majority of consumers often base their initial decision on color. For your website to be effective, it must have the right font, layout, and consistency. If the content of your website or app doesn't make an impact right away, your viewers won't pay attention to it. Therefore, having a skilled UX/UI designer on staff is essential if you want to integrate these design aspects, clarify your brand identity, and establish a strong reputation for your company.
5. Boost Traffic
Your website or app stands out when it has an excellent UI/UX. Together, developers and designers can produce an experience that captivates people and wins them over as devoted clients. A well-designed user interface maintains simplicity while fostering efficiency. It entails spending less time searching through pages to locate what they need.
6. Save Time & Money
Developing an advanced UI/UX design for your app or website may need a significant financial commitment. When executed properly, it significantly lowers the likelihood of reoccurring issues. You may avoid regular upgrades as a result, which will save you money and time.
Best Practices to Follow for UI and UX Design
Appealing Imagery
Responsive Design
Reduced Page Load Time
Nullify Technical Site Errors
Catchy Call to Action
5 Key Components of UI/UX Design
Interactive Design
Informative Architecture
Wireframing
Usability
Visual Design
What is More Important, UI or UX?
The two essential elements of conventional app design and development are [UI UX design services](https://www.sparkouttech.com/ui-ux-development/). They complement each other so perfectly that it is difficult to replace one with the other.
While UI design concentrates on developing engaging, visually appealing, and user-friendly interfaces, UX design is concerned with recognizing and resolving issues that affect users.
In product development, UI is usually developed after UX design. A user experience designer creates a map of the user journey's key elements. A UI designer then adds interactive and graphic components to finish it off.
While UI is limited to digital goods and experiences, UX is applicable to any kind of service, good, or encounter.
Therefore, in terms of product design, UX and UI go hand in hand, and in the cutthroat industry of today, mastering both is essential.
Final Thoughts
An important factor in the success of your company website or app is [UI/UX design services](https://www.sparkouttech.com/ui-ux-development/). Recognizing the value of UI and UX for your website or application is the first step in developing elegant, practical, and captivating business solutions. The best practices must be adhered to while developing components. Additionally, you must work with UI/UX designers from a respectable software solutions firm like us if you want to receive unrivaled design services. With our team of knowledgeable and skilled designers, we provide unrivaled solutions at reasonable costs. Do you need UI UX design services that are safe, trustworthy, fast, and efficient?
| preetham02 |
1,680,956 | Top 5 Featured DEV Tag(#blockchain) Posts from the Past Week | Implementing Blockchain for Shipment Management in SharePoint In the ever-evolving... | 0 | 2023-11-28T07:21:00 | https://dev.to/c4r4x35/top-5-featured-dev-tagblockchain-posts-from-the-past-week-2bh9 | python, blockchain, c4r4x35 | ##Implementing Blockchain for Shipment Management in SharePoint
In the ever-evolving landscape of logistics management, precision and transparency form the bedrock of operational success. Recently, I undertook a transformative initiative, implementing a...
{% link https://dev.to/jaloplo/implementing-blockchain-for-shipment-management-in-sharepoint-576f %}
##Virtual Economies in Fully On-Chain Games: Economic Theory Meets Digital Worlds
The advent of fully on-chain games has brought about a fascinating confluence of economic theory and digital technology. These games, running entirely on blockchain platforms, feature virtual...
{% link https://dev.to/galaxiastudios/virtual-economies-in-fully-on-chain-games-economic-theory-meets-digital-worlds-3dl6 %}
##Moonly weekly progress update #68 - Wallet checker improvements
Moonly weekly progress update #68 — Wallet checker improvements
Moonly’s wallet checker has experienced many changes to improve user experience and functionality, thanks to the revamped UI that...
{% link https://dev.to/moonly/moonly-weekly-progress-update-68-wallet-checker-improvements-26io %}
##Future Real Estate - All You Need To Know
The world of real estate investing is about to undergo a revolutionary change thanks to the amazing technology of blockchain. Real estate tokenization is transforming the industry and offers many...
{% link https://dev.to/ardenjoshpine/future-real-estate-all-you-need-to-know-3l9m %}
##Technical dive for Implementing Blockchain for Shipment Management in SharePoint
Embark on a journey where innovation meets real-world application! This post delves into the realm of integrating blockchain into SharePoint, demystifying its simplicity through a practical case....
{% link https://dev.to/jaloplo/technical-dive-for-implementing-blockchain-for-shipment-management-in-sharepoint-3cdo %}
##Securely deploying Swirl in Azure.
This is the third blog in the series where we will be checking in with the best practices to deploy Swirl.
Give ⭐ to Swirl on GitHub
Swirl’s Azure-hosted Architecture and Security Commitment
The...
{% link https://dev.to/swirl/securely-deploying-swirl-in-azure-48bn %}
##🚀⚡New open-source⚡ VS. old open-source 🦖
TD;LR
In this article, I provide alternatives to mainstream Python libraries.
These alternatives add some value to the Python landscape even though mainstream libraries are supported by stronger...
{% link https://dev.to/taipy/new-open-source-vs-old-open-source-33k7 %}
##Swirl Search: Open Source Enterprise Search 🔍 to Securely 🔐 Search your Data.
What is Swirl Search?
Swirl is an open-source search platform software that simultaneously searches multiple content sources and returns AI-ranked results. You can also use Generative AI Models to...
{% link https://dev.to/swirl/swirl-search-open-source-enterprise-search-to-securely-search-your-data-2pcp %}
##⚡️⚡️ 7 Machine Learning repos used by the TOP 1% of Python developers 🐉
Hi there 👋
Today, let's dive into 7 ML repos that the top 1% of developers use (and those you have likely never heard of)!
What defines the top 1%?
Ranking developers is a difficult problem, and...
{% link https://dev.to/quine/7-ml-repos-used-by-the-top-1-of-python-developers-based-on-real-data-30hc %}
##Swirl Security Overview
Understanding an Open Source Search Platform: Swirl
The team behind Swirl created a platform capable of connecting to multiple databases and searching through a single unified source.
That's Swirl...
{% link https://dev.to/swirl/swirl-security-overview-3iok %}
| c4r4x35 |
1,681,333 | @Component not working in Spring Boot | https://javatute.com/spring-boot/component-not-working-in-spring-boot/) | 0 | 2023-11-28T13:16:55 | https://dev.to/javatute673/component-not-working-in-spring-boot-5e7k | javascript, programming, beginners, tutorial | https://javatute.com/spring-boot/component-not-working-in-spring-boot/) | javatute673 |
1,682,719 | On The Legality of Web Scraping | The issues of legality and ethics surrounding web scraping are a massive grey area. While... | 0 | 2023-11-29T15:58:37 | https://dev.to/ujeebu/is-web-scraping-legal-4k2f | scraping, webscraping, datascraping | ## The issues of legality and ethics surrounding web scraping are a massive grey area. While some may be in favor of web scraping, others might not share the same enthusiasm. This is what makes the subject so controversial.
Those in favor argue that web data has the potential to make the world better and that scraping is critical for data analysis and management done right. But on the other hand, critics object to the claim that web scraping gives an unfair advantage to scrapers.
The fact is that web scraping isn't bad as long as it's done properly. It can be beneficial for research purposes whether you want to promote your business or excel at academic projects.
In this post, we'll talk about which types of web scraping may be illegal, and the ruling of different authorities on its legality.
## **What Types Of Data Are Illegal To Scrap?**
Unfortunately, many users are unaware that the final use case of the data has a significant influence on whether scraping is legal. The scraping of a website may be perfectly legal in some cases, but what you intend to do with the information makes it illegal in others.
There are two main types of data we must be concerned about:
**Personal Data:** Data that can be used directly or indirectly to identify an individual is personal data or personally identifiable information (PII). This includes medical or health records, bank information, date of birth, address, email, and name.
**Copyrighted Data:** This type of data is owned by businesses or people who have precise control over how it can be copied or captured. This is the same as using copyrighted images and songs. If you take the owner's data without permission, you could be breaking the law. Examples include articles and blogs, pictures, videos, music, and other creative property.
## Web Scraping In The Eyes Of The Law
Before you start web scraping, reflect on the degree to which you can go to extract the data you need.
Currently, no legislation addresses web scraping directly, but several legal frameworks and broad principles have been applied in court over the use of scraped web data.
These court cases address illegal access to web data, copyright issues, trade secrets, and breach of contract issues.
Researchers and marketers must be aware of the possible ethical consequences of web scraping.
## EU Laws
GDPR's jurisdiction makes up the entire European Economic Area (EEA). The GDPR has rules about protecting PII when data controllers get it and then give it to data processors.
The GDPR asserts that if there is a data breach, consumers and data security agencies must be told about it. If a company collects the PII of an EEA resident, it must follow the GDPR, no matter where it is in the world. There's no way around it.
The lawful bases of web scraping under Article 6 of GDPR include:
- **Consent:** You are good to go if you have the consent of people whose websites you are scraping
- **Contract:** This is when you are required by contract to scrape and process a website's data
- **Legal obligation:** If scraping and processing web data help you fulfill a legal obligation, go ahead
- **Vital interests:** If your scraping efforts can save lives, there is no doubt about their legality
- **Public tasks:** It is perfectly legal when scraping is in the public interest or helps you do your duties as an official
- **Legitimate interest:** As long as your web scraping doesn't override the rights or interests of people, you can argue that it is in your legitimate interest
## US Laws
While the U.S. doesn't have anyone set federal privacy laws, it has a vast net of various state laws. That makes web scraping legality murky waters to navigate.
An example of this could be California Consumer Privacy Act ([CCPA](https://oag.ca.gov/privacy/ccpa)) and Computer Fraud and Abuse Act ([CFAA](https://www.govinfo.gov/app/details/STATUTE-100/STATUTE-100-Pg1213)). Moreover, the Health Insurance Portability and Accountability Act ([HIPAA](https://www.cdc.gov/phlp/publications/topic/hipaa.html#:~:text=The%20Health%20Insurance%20Portability%20and,the%20patient's%20consent%20or%20knowledge.)) and the Gramm-Leach-Bliley Act of 1999 ([GLBA](https://www.ftc.gov/business-guidance/privacy-security/gramm-leach-bliley-act)) are consumer-oriented federal laws.
- **CCPA:** This is a state-wide data privacy law that helps regulate how businesses all over the country handle the P.I. of California residents. This was the pioneering data privacy law of the country
- **CFAA:** It is concerned with authorization and data scraping cases that imply real property norms
- **HIPAA:** This is a health insurance and accountability act that has set guidelines regarding patient privacy. A violation of these guidelines could result in federal prosecution
- **GLBA:** This protects consumers' private information. To be GLBA compliant, firms need to inform customers of their right to opt-out if they don't want their personal information being used by financial firms
The CFAA and similar state laws are the leading legal basis for claims concerning web scraping disagreements. According to it, access to a website can be unauthorized when the website owner sends a cease and desist letter to anyone crawling or scraping. This is what happened in the case of Craigslist Inc. v. 3Taps Inc. in 2013 and Facebook, Inc. v. Power Ventures, Inc. in 2016. 3Taps is a firm committed to collecting and distributing public data. It is partnered with PadMapper. Craigslist sent the former a cease and desist letter in response to PadMapper using its listings. After the data distribution startup refused to comply, Craigslist registered a complaint with the U.S. District Court for Northern California.
However, the letter alone may not be enough to hold the web scraper responsible under the CFAA in some cases like Ticketmaster LLC v. Prestige Entertainment, Inc. in 2018. Ticketmaster took Prestige Entertainment to court over non-compliance of CFAA state laws; however, the defendants were able to circumvent the claims by stating that Prestige had acquired tickets through the Ticketmaster website— something that's permitted in its Terms of Use.
## Comparing U.S., E.U., and Latin American Laws
It's a little challenging to compare E.U. and U.S. laws.
Both let people choose not to have their data processed. They can also delete their information or look at it.
In Europe, data protection laws are part of the GDPR, but there has never been a federal user privacy law in the U.S. Each state has tried to fill in the gap as they see fit. The CCPA is an example of this, but other states haven't shown the same amount of resolve. Another difference is that the CCPA requires privacy policies on all websites, whereas the GDPR needs clear and specific user consent.
Data Privacy is becoming more of an issue not only in the U.S. and Europe but also in Latin America. In fact, Brazil is leading the way with its new data privacy laws that need to be consolidated over 40 different regulations. Lei Geral de Proteção de Dados (LGPD) was set up on 2020 and puts significant compliance obligations on companies that process data.
## How Can You Keep Your Scrapers Ethical?
Don't just pay lip service to ethical web scraping but make it an integral part of your data harvesting efforts.
The only mantra of ethical web scraping is: do no harm.
You have a lot of power as a web scraper because you'll likely come across loads of private user data and personal information of a website's users. That's why it is vital to have a moral code to guide your scraping efforts.
First off, make sure that you have a strict policy about not profiting off private data. Here's what you need to do next:
## Use APIs
Some websites offer built-in APIs for scrapers. Make sure you use them and follow the rules. You could always use your API for web scraping, like the one from Ujeebu.
The Robots Exclusion Standard or the robots.txt file will tell you where to find the info you need and where you are allowed to go using your web-crawling software.
## Read The Terms And Conditions
This is where you find the rules for using and scraping data from a website. Sure, you could always click 'I agree' without reading and do what you want to do. But it is essential to understand that the terms and conditions are there for a reason. So take your time to figure out how they affect you and what you are trying to do.
## Be Kind
Scraping is harsh on web servers. So make sure you begin when there is little to no traffic on the website and be gentle when gathering data. Also, space out the requests so it doesn't look like you are trying to DDoS the servers.
## Say Hi
The website admin will likely notice some unusual traffic when you start scraping. It'd be good to introduce yourself, tell them what you plan to do, and leave your contact info.
In fact, go a step further and courteously ask for permission. This will not only make you look like a nice person but also relieve some of the legal burdens. Besides, the data really doesn't belong to you, so it'd be the right thing to do.
## The Bottom Line: Practice Ethical Scraping
The issue of legality boils down to what you scrape and how you go about it. Before embarking on your web scraping mission, be sure to give yourself a little ethics check. Ask yourself if you're about to scrap personal data, copyrighted data or if you're trying to gather data, usually behind a login.
It only takes good manners and a bit of due diligence to keep your web scraping efforts within ethical and legal confines.
Happy scraping!
This article first appeared here: https://ujeebu.com/blog/is-web-scraping-legal/ | ujeebu |
1,681,546 | Beyond the Scoreboard: Decoding the Data Evolution in Sport | I am Arjun Ramaswamy and I am a huge sports enthusiast, so much so that most parts of my vacation... | 0 | 2023-11-28T16:16:57 | https://dev.to/ramaswamyarjun/beyond-the-scoreboard-decoding-the-data-evolution-in-sport-4cpg | datascience, datadrivendecisonmaking, learning, sport | I am Arjun Ramaswamy and I am a huge sports enthusiast, so much so that most parts of my vacation life revolve around sports commentary, post-match analysis, player milestones and to a major extent bowing down to the excellence of few individuals on the pitch. I try to utilize as many modes of consuming numbers from the world of sports. I love hearing expert opinions and tactical analysis which believe me is growing out to be an unhealthy obsession. But I love it!
I am the person who social media handles target when they post what has popularly been termed an “ESPN Stat”. Those statistics really don’t change the game. I well and truly believe that even the players don’t think of the game with keeping the ESPN stat in mind. One of my very favourite ESPN stats goes something like this….
Believe me in situations like these the comments sections becomes the funniest place to be in. But not straying too much off topic. We have had a very long journey to reach to a point where data like the one presented above finds it’s day in the limelight.
Stats provide an objective overview of any sport and increasingly it is something adopted by almost everyone in this fraternity for the undeniable advantages that come with it. It is now common place to find a data analyst in a moder day team. Everyone wants a piece of the sweet data pie to just go one step beyond their competition.
Since I am an enthusiast that is very curious regarding the state of sport and how it will grow, I want to take you on a journey what brought us here. How we can expect this space to change and what really does investing in data analysis achieve.
## Moneyball
If you have not been living under the rock for this whole time, you are ought to have come across a book called “Moneyball: The Art of Winning an Unfair game”. This book written by Micheal Lewis in the year 2003 presents an overview on the Oakland Athletics Baseball team and their general manager Billie Beane.
In its heart the book looks at how manager Billie Beane and his assistant manager Paul DePodesta use data to identify undervalued players because of their small budget. This coupled with the objective nature of data allowed the A’s to severely reduce risks associated with acquiring undervalued talent, which pushed them towards the roads to success.
The budgets were small and this was the reason Beane had taken such a leftfield method for the time to assemble his team in the most objective way possible. But little did he know that his method will become the norm in years to come.

Moneyball in its truest sense is not about baseball, rather an excellent case study in the advantages of Data-Driven Decision making, challenging conventional wisdom and achieving success in the face of constraints.
In my eyes keeping aside the social impact that both the book and the movie has had with their wide-ranging success, the most important change that Moneyball has had in the sports industry is the wide spread use of Sabermetrics. Tho it is a specifically baseball thing, the term has popularly been adopted in discussions across sports.
At the heart of all of this is the main reason to Moneyball’s success, Player Performance. Talking about which will conveniently lead us to our next point of focus.
## Objectivity of Performance Analysis
Objectivity: Freedom from Bias
Data doesn’t lie, it might not always paint the entire picture but it never lies. I enjoy sport for experiencing the beauty of a Virat Kohli Cover Drive, Kyrie Irwing being an absolute menace breaking any and every ankle in front of him, Messi toying with defenders while the ball seemingly is stuck to his feet. Somethings can never be enjoyed in forms of data. They are not objective traits but rather individual brilliance of some very gifted athletes. But they are not to be confused with performance and efficiency. Not everyone is built the same but sport is a great leveller. For every Ronaldinho there is Vincent Kompany, but if you are on a look out for building a team which guarantees performance, often times you might want to leave the spectacle behind and look for certain objective traits.
Performance analysis is everything that the name suggests and then some. Let’s take cricket as the sport in question and look for parameters that a coach might look to build his/her championship winning roster. Averages play a big role in how we perceive a player and their abilities. They provide a good sense of an experienced players quality over a long period of time. In batting you want it to be as high as possible and in bowling it is better to have a sub 25 average. Famously in the realm of Cricket, Sir Don Bradman has a career batting average of 99.94 just missing on a perfect hundred by mere 4 runs on his last ever outing as a professional cricketer.
Reputation has and will always be a factor during selection of players to build your perfect roster and teams today are actively trying to work on striking the correct balance between objectivity and experience. Let us take an example:
In the 70’s Dutch and Barcelona legend Johan Cryuff pioneered the idea of “Total Football”. In his vision for the beautiful game, players would not stick to playing only one position which in time gave birth to players who were multi-faceted. It was common to see players good at playing multiple positions on the football pitch. In contrast today hardly do we see top teams employing players who specialise in more than one position. Roles are defined in a much different manner than back then and many players are unidimensional. On face value that would seem like the sport is moving backwards but this is a big change Data-Driven Decision making has caused since it was implemented by majority of sports teams.
Managers in today’s game like to have players that are great at their positions, gone are the days of every foot behind the ball. Teams play a way more dynamic game with specialist players sprinkled all across the field. Team tactics take into consideration a lot of data about the opposition and player performance.
Look at how we track performance itself, next time you watch your favourite football team practicing, notice the players wearing athletic vests. While being a butt of a lot of childish and light-hearted internet gag they are the corner stones to performance tracking. These vests are skin tight allowing coaches to slip in a GPS tracker on a player’s body. Every metric of a player is measured, their distance covered, heart rate, endurance metrics like periods of high intensity, everything.
We have also seen major improvements in player longevity. Their training and recovery programs is all at an all-time best with the inclusion of data analysis. Hardly are players over used and good teams rely less on an individual’s brilliance and more on holistic contribution. We are able to predict how implementing newer regimes on players changes the course of a player.
Searching and nurturing talent is also something that with the onset of data analysis we are able to perform incredibly.
## Scouting and Grassroots Development
In my eyes the aspect of the game that has changed the most in the past few years is Scouting and grassroots development. In the past, talent could pull you to get some opportunities. A lot of players can pass the eye test but when it comes to contribution they might suffer. Newer players are coached differently, they are prepared to play at the bigger stage better because we can today objectively point out what it takes to be successful in sport.
Grassroot level programs in many sports today split positions and roles of their young trainees using body analysis. Whether the trainee is tall, broad, lean, etc. Coaches have found that certain body types perform better at certain positions than others. A very visible example is that of a centre in basketball. They have traditionally been the biggest people on the court. They have better reach for the rim, can easily outpower anyone on the court and don’t move as much as the others which in turn is for their own advantage since moving at that height with some size is not an easy task.
This also actively affects established players. Think of yourself as a journeyman pro for a sec. You want to reinvent yourself because not everyone is gifted the same. Today the first step to take is getting on the whiteboard and start studying data. Forget about what you are already good at and start searching for skills you can offer. Scouts look for specific traits to build rosters, they seldom look for complete players because it is really tough to find someone who is perfect. Only once in a lifetime do we see a Micheal Jordan who could defend and score like a dream, most of the times we find players who are great at a few skills, like Kyrie Irwin (You might have clocked by now that I really enjoy Kyrie), immense scoring and dribbling ability and very ordinary defending and horrible physicality (please stay healthy dude!!!). In short develop useful skills rather than becoming a complete package because it really gives you a better chance to be in a championship level team. Talking of championship level teams, lets look at one such team that uses VR of all things as one aspect of their training.
## Tampa Bay Buccaneers and Their unconventional VR training
> “We are excited to be coming in on the front end of this new wave of technology that is designed to supplement the on-field and classroom work that our quarterbacks are already doing,”
The above statement is from the General Manger Jason Licht on adopting VR training, making the Buccaneers the first NFL team to make their quarterbacks use VR simulations of in-game situations to train. This method allows coaches to make perfect scenarios for every single opposition and even-if the technology won’t be perfect atleast it gives a better idea than just pen and paper preparation.
> “Obviously, there is no real substitute for being on the field when it comes to getting our players ready for game action. However, this virtual reality technology allows us to enhance the learning experience for our quarterbacks without requiring them to put in additional time on the practice fields.”
Also said GM Jason Licht.
The Buccaneers are not alone, Baseball is another sport where VR has been incorporated to some extent in their game prep. The "W.I.N. Series," a virtual reality interactive player development software and simulation solution from EON Sports, has been introduced by the Yokohama DeNA Baystars. The Baystars are the first baseball team in Japan to use this cutting-edge technology, and they join a growing list of professional teams who have done so. Since the 2017 campaign, the team has been training with the system.
These just mark a few examples where data has transformed training in modern professional sport.
## Why does it matter?
I started this blabbering fest by pointing out an ESPN stat, and to reach that point of specificity one needs to take in account immense amount of data. Being honest players rarely care about such cherrypicked stats. But their existence is to fulfil someone else, the fan. The spectator, the person who is the stakeholder of sport by investing their time, often times money and a lot of heart into the sport. In the era of social media, the space of debating the latest and the greatest, produces some incredible analysis on players. This is facilitated by statistics and data. I am one, I love to see my favourite players stats, it helps me win online debates, produce compelling evidence to prove my point and ending my day with a sense of false superiority proving another netizen wrong.
While the last statement seems futile, data also facilitates how we view sport now. With working hours increasing, a lot of sports enthusiasts might rarely get their fix of watching the entire game. Ever so often, I as a college student just look at the post-match stat and analyse it to death. Even while watching my subconscious forces me to look at my mobile phone to open say CricBuzz to check how many extras have India given away in a certain World Cup final, or how many turnovers has Eric Dier inflicted today. All this to just fulfil my insatiable need for objective analysis. I am not alone in this at all and people more and more have started giving stats a very important place in their sport consuming experience.
Major debates happen on new scoreboards and how they display information in the most efficient and least distracting manner while also being pleasant to consume all the data they throw at us. Take F1 for example, it is probably the first sport to give data analysis its fair due. It is only fair that the sport that requires it the most has the most complex yet amazingly pleasant leaderboards and players stat.
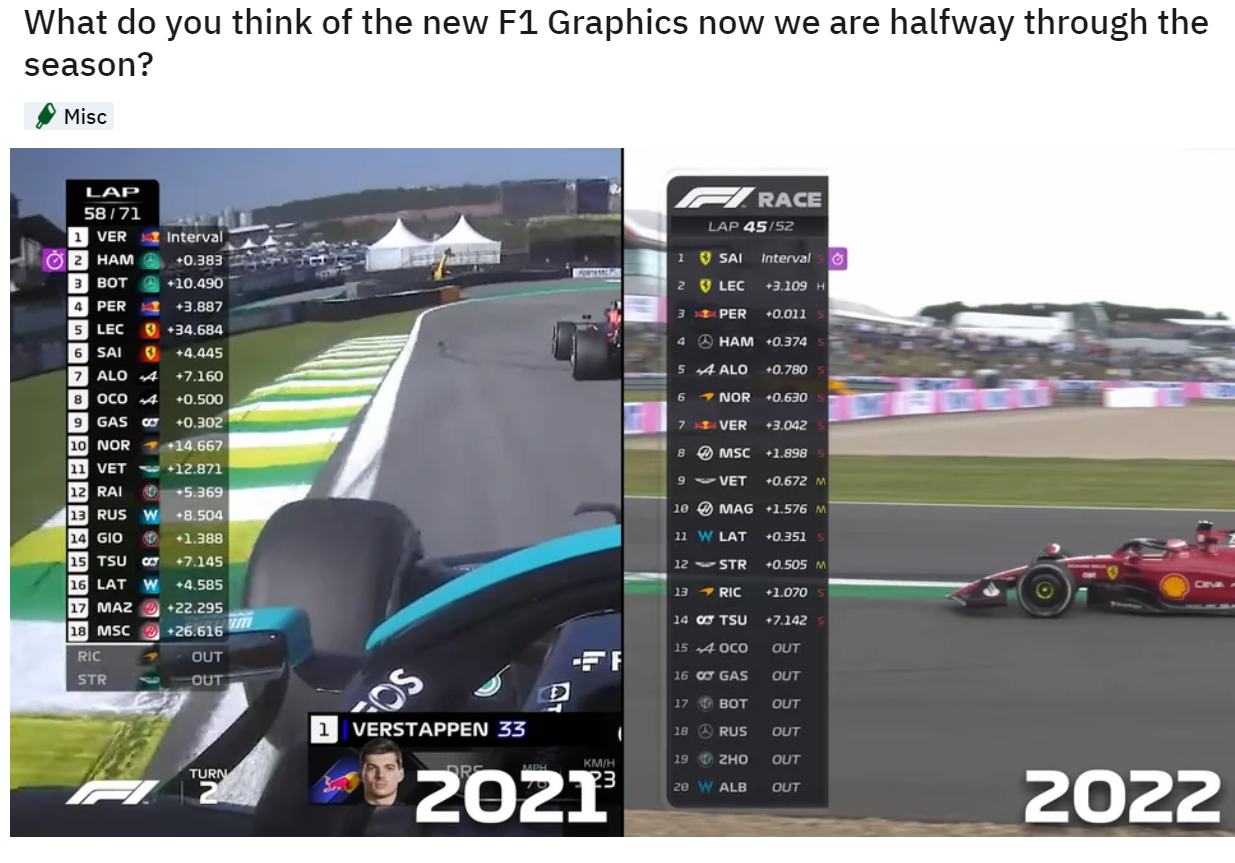
Data is changing everything that we associate with sport. Well, that previous statement is flawed because data has changed the very fabric of our society as we know it today. Everything that we do in today’s world involves some form of data to be recorded in some server somewhere. But in sport it is visible to the naked eye. It probably is one of the only places where we as humans would give consent to record data.
Sport is changing, becoming a professional at it has changed, the roles in the team have increased while the stakeholders also get their fair share of the pie with incredible viewing experiences. But one should never forget that growing amount of data analytics and data-driven decision doesn’t change the fact that in sport there forever remains mystery and intrigue regarding the events about to follow. At the end of the day the players are human and experiencing superhuman feats from your favourite player is what makes you fall in love with it.
| ramaswamyarjun |
1,681,774 | Coding in the Shadows: Hidden Gems of Lisp, Clojure, and Friends | In the world of programming, rankings are more than just numbers; they're a source of endless debate... | 0 | 2023-11-28T19:58:41 | https://dev.to/offcode/coding-in-the-shadows-hidden-gems-of-lisp-clojure-and-friends-1bj3 | lisp, clojure, vectordatabase | In the world of programming, rankings are more than just numbers; they're a source of endless debate and pride. Much like how people are fascinated by top 10 lists in music or movies, there's a similar [ranking system for programming languages](https://www.tiobe.com/tiobe-index/). But unlike box office hits or Billboard charts, the criteria for ranking programming languages aren't as clear-cut.
There's a constant back-and-forth among programmers about which language is superior. You'll often hear them boast, "My language is better than yours," followed by demonstrations of elegant one-liners or efficient algorithms. But the truth is, we haven't settled on a universally accepted measure for ranking these languages. So, when it comes to these rankings, they're based primarily on popularity.
Now, this isn't about social media popularity – it's not a matter of likes or shares. It's about how many people are actively using these languages. Measuring this is tricky, as you can't simply count heads or survey every programmer out there. However, with a combination of job market analysis, community activity, and usage statistics in various projects, a somewhat accurate picture can be formed.
This approach to ranking may not satisfy everyone, especially since it doesn't necessarily reflect the technical merits or innovativeness of a language. Yet, it does offer a snapshot of the programming landscape, showing us which languages are currently in demand and shaping the world of technology.
The top spots in the programming language rankings are often occupied by names that even those outside the IT world might recognize. Languages like Java, Python, C, and JavaScript are household names in the tech community and beyond. When you delve into the top 20, the "least popular" among these is still used by approximately 1% of programmers worldwide – a small percentage, perhaps, but still significant when you consider the sheer number of people coding across the globe.
However, the list of programming languages doesn't stop at the top 20. Venture further down to the top 50, and you'll start to encounter some truly niche languages. Among them is Logo, a language developed in 1967 with the aim of teaching programming concepts. It's famously associated with the **'turtle graphics,' where you can control a turtle's movement on-screen through coding commands**. It’s intriguing to ponder what modern applications it could have, given that it’s still used, albeit by a mere 0.1% of programmers.
Also nestled in this segment of the list is COBOL – an even older language that first appeared 64 years ago. Despite its age, COBOL remains a vital cog in the machinery of large insurance companies and banks. These institutions rely on massive mainframe computers running on millions of lines of COBOL code. It’s a language that, while seemingly antiquated, underpins systems too critical and complex to risk rewriting. **The mere thought of transitioning away from COBOL raises concerns about potentially catastrophic system failures**.
## Lisp
Venturing even further down the list, you encounter two languages that are my personal heroes. One such language is Lisp, a language that has its roots in academia and theoretical computation. Fascinatingly, Lisp was initially conceived on paper, without any practical implementation on a computer. It's a testament to the pure, almost philosophical approach to programming language design.
Lisp is built on a handful of core concepts and a mere eight operations. Yet, from this simplicity springs an immense power. Its creator, John McCarthy, mathematically demonstrated that Lisp was a fully capable programming language, earning it the classification of being "Turing-complete." This term refers to a system of computation that, given enough resources, can solve any problem that a Turing machine (a basic model of a computer) can. In this sense, Lisp is akin to geometry as formulated by Euclid – based on just a few axioms, it unfolds into a vast and intricate world of possibilities.
The elegance of Lisp lies in its minimalism and its flexibility. It's a language that encourages a different way of thinking, one that is more about the essence of computation and less about the specifics of syntax. This philosophical underpinning makes it not just a tool for writing software, but also a medium for exploring the very nature of programming itself. For those who delve into its depths, Lisp offers a unique perspective, revealing the elegant complexity that can arise from the simplest of foundations.
Lisp's role in the evolution of computer science extends beyond its elegant design. It was **the first programming language widely used for research in Artificial Intelligence (AI)** during the 1960s and 1970s. At that time, Lisp was at the forefront of this groundbreaking field. This deep association with AI led to the creation of specialized hardware known as Lisp machines. These were computers designed specifically to run Lisp efficiently, representing a unique convergence of software and hardware dedicated entirely to one programming language. Unlike modern computers, which are built to run a wide range of software, Lisp machines were optimized for the nuances and particularities of Lisp.
The phrase "it was Lisp all the way down" aptly captures this era. In these machines, Lisp wasn't just a programming language running on general-purpose hardware; it was an integral part of the entire system. This period in computing history highlights Lisp's significant influence and the fervent belief in its potential to unlock the secrets of artificial intelligence and advanced computation.
As the years progressed, however, Lisp's prominence in the programming world began to wane for reasons that are as complex as they are varied. This shift in the landscape saw the rise and fall of various programming languages, each vying for a spot in the rapidly evolving tech industry.
This was the time when I came across an article by Paul Graham called [Beating the Averages](http://paulgraham.com/avg.html). Graham described Lisp as a secret weapon that wasn’t for everyone - it was special, meant for a select group of programmers. Reading this, I felt a strong connection; I knew I was part of that group. Lisp just clicked with me.
This led me to dive deeper into Graham's other writings about Lisp. The more I read, the more natural it felt to use Lisp. It was as if my mind was perfectly suited for it. This idea reminded me of a quote from Eric Raymond:
> "Lisp is worth learning for the profound enlightenment experience you will have when you finally get it; that experience will make you a better programmer for the rest of your days, even if you never actually use Lisp itself a lot."
During this time, I was playing around with Lisp, immersing myself in its unique style. That's when Clojure appeared, like a fresh wave for those of us who loved Lisp. It felt like a modern version of Lisp, mixing old Lisp ideas with new ways of programming. Clojure made it easier to use Lisp with today's technology, first with the Java Virtual Machine (JVM), then with the browser. For a while, it looked like Clojure would make Lisp popular again. It even became one of the top 20 programming languages for a bit.
Yet, despite this promising start, Clojure didn't maintain its momentum. It eventually settled into a niche, maintaining a presence in a few actively developed applications but largely receding from the mainstream programming scene. For me, personally, Clojure has been more than just a programming language. It has profoundly shaped my thinking, offering a unique perspective on problem-solving, system design, and the elegance of code.
Doesn't Clojure deserve its own chapter? It certainly does. You can read more about why it lies so close to my heart: [Why My Brain Is Wired for Clojure](https://hackernoon.com/why-my-brain-is-wired-for-clojure)
## APL
I promised to mention two programming languages that hold a special place for me; Lisp is the first, and APL is the other. APL, which stands for "A Programming Language," began its life not even as a language for programming, but as a notation system used by people at IBM. It was developed as a way to clearly communicate complex programming and mathematical ideas, extending beyond traditional mathematical notation.
When you first see APL code, two things will likely catch your eye. Firstly, it looks almost like a secret code from a pirate's treasure map, filled with unique symbols like backward-crossed circles, triangles with extra lines, and an array of other special characters. At the height of APL's popularity, these symbols were so integral to the language that **you could even find special keyboards made just for typing in APL**.
This mysterious and almost romantic quality of APL's appearance was one of the things that drew me to it. But there's another aspect of APL that's immediately noticeable: its conciseness. APL is renowned for its ability to condense what would be ten lines of code in other languages into a single line of APL.
What exactly makes APL so concise? At first glance, it might seem like a simple trick. Other programming languages are filled with long keywords and functions like `continue` and `length`, while APL appears to just replace these with a single character. But there's much more to it than that.
Yes, it's true that APL often uses single characters, like the Greek letter rho (ρ), to perform tasks that would require more elaborate expressions in other languages. Rho, for example, is used to determine the length of a string or a vector. But the real power of APL lies in its fundamental approach to data. APL treats nearly everything as a vector, or a list of items, and it's designed to operate on these vectors efficiently.
Take a simple operation like adding 2 to a vector. In strict mathematical terms, this might not make sense, but APL interprets it as adding 2 to each element of the vector. This characteristic allows you to perform complex operations without the need for writing loops or conditions, which are common and space-consuming in other languages. By thinking in terms of operations on whole vectors or arrays at once, **APL enables a level of conciseness and elegance that is hard to match in more verbose programming languages**.
Recognizing the limitations imposed by the need for a specialized keyboard, the creators of APL took an innovative step forward. They developed a new language, J, which was designed to be used with the standard ASCII characters available on every keyboard. This move addressed one of APL's biggest accessibility issues, making the language more approachable for a broader audience.
J's creation marked the beginning of an interesting progression in programming language development. It inspired the creation of K, a language that further refined the ideas of APL and J, focusing on efficiency and speed. K, in turn, led to the development of Q, a language built on the foundations of K but geared more towards database and query operations.
Q might not be a widely known programming language, but it has a very important role in one specific area: handling financial transactions. This is because Q is really good at processing large amounts of data quickly, which is crucial in finance where every second counts. The demand for Q programmers may not be widespread across the tech industry, but within the finance sector, their skills are highly sought after. If you know how to program in Q, you can actually earn a lot of money.
## K
This part is going to be more technical. For programmers familiar with the concepts of functional programming, K offers a powerful yet concise way to perform operations like summation. For example, the expression `+/!8` in K efficiently sums up the numbers up to 8. Here, `!8` generates a list of numbers from 0 to 7. Then, `+/` acts as what's known in functional programming as a "reduce" operation, applying the addition function across the list. Another example is calculating factorial: `*/1+!8`. We generate a list of the number from 0 to 7; then add 1 to add number: `1+!8` -- we already know that adding 1 to a list adds 1 to each element. Finally, we reduce the list applying multiplication.
One more example. Here is how to find the largest number in a list: `|/'4 2 7 1`. Let's break it down how it works. The phrase `|/'` is a combination of two symbols:
- `|`: This is the 'maximum' function in K. When used on its own, it gives you the maximum of two numbers.
- `/'`: This is known as an 'over' operator. It is used to apply a function repeatedly between the elements of a list.
Together, `|/'` applies the 'maximum' function across the list. It repeatedly compares pairs of numbers and carries forward the larger number each time. This process continues across the entire list until the largest number is determined.
If programmers have heard of K, it's usually in connection with code golf. [Code](https://codegolf.stackexchange.com) [golf](https://code.golf) is a unique and playful programming challenge where the objective is to solve a specific problem or complete a task using the least amount of code possible. Unlike typical programming practices where code is often measured in lines, **code golf counts every single character**, making each one count. This form of programming competition emphasizes brevity and resourcefulness, encouraging programmers, often referred to as 'code golfers,' to think outside the box. They must employ ingenious methods and deep knowledge of their chosen language's syntax and features to craft a solution that is as short as possible.
K has gained a reputation as one of the most successful languages for code golf. Its concise syntax and powerful built-in functions allow programmers to express complex operations in just a few characters, making it ideal for these challenges. However, in the world of code golf, some languages have been created solely to excel in this arena. These languages, often referred to as 'esoteric' or 'golfing' languages, might include built-in functions for common code golf tasks, like a one-character function to generate prime numbers - a frequent requirement in code golf challenges.
While the one-liners showcase K's ability to succinctly express complex ideas, it has a serious consequence beyond winning at code golf. Not only K applications are compact in size, but the K interpreter itself is extremely small, especially when compared to similar programs in other languages. This minimal footprint allows K applications, along with the K interpreter, to fit entirely within the L2 cache of a CPU. The L2 cache is a smaller, faster memory compared to a computer's main RAM, and because it's closer to the CPU, data stored in the L2 cache can be accessed much more quickly. This proximity significantly enhances the execution speed of K applications.
This compactness and efficient use of the L2 cache set K apart from many other programming languages. In most languages, especially those that produce larger, more memory-intensive applications, critical parts of the program and the interpreter or runtime environment are less likely to fit entirely in this fast-access cache. As a result, K applications, despite being interpreted, can often **achieve execution speeds comparable to compiled C code**, which is renowned for its performance. The efficiency of K doesn’t just stem from its concise syntax but also from how it harmonizes with the underlying hardware, making the most of the CPU's capabilities to deliver high performance. The speed and efficiency of K make it perfect for working with huge amounts of data in real-time, like in stock trading.
If you want to try out K, there are some open source implementations, like [John Earnest's oK](https://github.com/JohnEarnest/ok) which has a REPL and a calculator-like interface for mobile phones with a charting feature. | offcode |
1,681,822 | Python quiz 🤔: Can You Spot the Correct Python String Formatting? | 💡As I mentioned before, learning PEPs can help you learn Python. This post is about PEP-0498 -... | 25,588 | 2023-11-28T20:37:05 | https://dev.to/vladignatyev/python-quiz-164-can-you-spot-the-correct-python-string-formatting-57dl | python, programming | 💡As I mentioned before, learning PEPs can help you learn Python. This post is about [PEP-0498 - Literal String Interpolation](https://peps.python.org/pep-0498/).
So, [follow me](https://dev.to/vladignatyev) to learn 🐍 Python in 5-minute a day fun quizzes!
# Quiz 1 out of 64
Which one of these code samples below is done right for string formatting in Python? Answer with **0** for the first sample or **1** for the second sample.
## Sample 1
```
name = "Alice"
age = 30
greeting = f"Hello, {name}. You are {age} years old."
print(greeting)
```
## Sample 2
```
name = "Alice"
age = 30
greeting = "Hello, {name}. You are {age} years old."
print(greeting)
```
Share your thoughts and open up the explanation in the comments below! Let's see who gets it right! 🌟👩💻
> or [Go to Quiz 2/64](https://dev.to/vladignatyev/python-quiz-264-pep-8-formatting-quiz-4232)
| vladignatyev |
1,681,939 | Cursos de Robótica, Arduíno, Francês e Outros Temas Gratuitos | O Instituto Federal de Educação, Ciência e Tecnologia do Mato Grosso do Sul (IFMS) anuncia a abertura... | 0 | 2023-12-22T02:38:50 | https://guiadeti.com.br/cursos-de-robotica-arduino-ia-idiomas/ | cursogratuito, arduino, cursosgratuitos, ingles | ---
title: Cursos de Robótica, Arduíno, Francês e Outros Temas Gratuitos
published: true
date: 2023-11-28 22:02:29 UTC
tags: CursoGratuito,arduino,cursosgratuitos,ingles
canonical_url: https://guiadeti.com.br/cursos-de-robotica-arduino-ia-idiomas/
---
O Instituto Federal de Educação, Ciência e Tecnologia do Mato Grosso do Sul (IFMS) anuncia a abertura de inscrições para uma ampla gama de cursos online. Com uma oferta generosa de cursos distintos, a instituição se destaca por proporcionar educação de qualidade, acessível e adaptada às demandas contemporâneas de aprendizado.
Entre eles, destacam-se cursos nas áreas de idiomas, robótica, ia; cada um projetado para oferecer um aprendizado profundo e aplicável. Esta diversidade garante que alunos de diferentes interesses e objetivos de carreira possam encontrar cursos adequados às suas aspirações.
Esses cursos, inteiramente gratuitos e com certificação inclusa, representam uma excelente oportunidade para aprimoramento pessoal e profissional. Os cursos disponibilizados pelo IFMS cobrem uma variedade de áreas, atendendo a um espectro diversificado de interesses e necessidades.
Na área de tecnologia da informação, o IFMS oferece cursos particularmente relevantes e atualizados, abrangendo temas como robótica, programação e desenvolvimento de jogos. Com uma abordagem prática e voltada para as tendências do mercado, os cursos preparam os alunos para os desafios e oportunidades do setor.
## Cursos IFMS
O Instituto Federal de Educação, Ciência e Tecnologia do Mato Grosso do Sul (IFMS) está abrindo portas para o conhecimento através da oferta de 25 cursos online e gratuitos.

_Página do IFMS_
Estes cursos, acompanhados de certificados, são uma oportunidade valiosa para aqueles que buscam expandir suas habilidades e conhecimentos em diversas áreas.
### Diversidade de Cursos em Áreas Chave
Os cursos oferecidos pelo IFMS abrangem uma gama variada de áreas, incluindo idiomas, educação e tecnologia da informação. Esta diversidade garante que os alunos possam escolher cursos que se alinhem com seus interesses e objetivos profissionais, proporcionando um aprendizado significativo e aplicável ao mundo real.
### Tecnologia da Informação: Um Foco Especial
Dentro da área de tecnologia da informação, o IFMS oferece cursos especialmente relevantes para o mercado atual. Temas como robótica, programação e desenvolvimento de jogos estão entre as opções disponíveis, destacando o compromisso da instituição em oferecer educação alinhada às demandas contemporâneas do setor tecnológico.
### Cursos Oferecidos
- Desenvolvimento de Jogos 2D com Unity
- Espanhol: Língua e Cultura
- Francês Básico
- Introdução à Inteligência Artificial
- Introdução à Lógica
- Introdução à Lógica de Programação com Arduino
- Lógica de Programação com Arduino
- Programação de Robótica Lego
### Inscrição Simples e Acessível
Para se inscrever, os interessados devem acessar o site do IFMS, onde podem facilmente realizar o cadastro e ter acesso aos cursos. Este processo simples e acessível reforça o compromisso do IFMS com a promoção da educação inclusiva e de qualidade, abrindo caminhos para o desenvolvimento pessoal e profissional em diversas áreas do conhecimento.
<aside>
<div>Você pode gostar</div>
<div>
<div>
<div>
<div>
<span><img decoding="async" width="280" height="210" src="https://guiadeti.com.br/wp-content/uploads/2023/11/Imersao-Full-Stack-Full-Cycle-280x210.png" alt="Imersão Full Stack & Full Cycle" title="Imersão Full Stack & Full Cycle"></span>
</div>
<span>Curso de Full Cycle e Full Stack Gratuito e Online</span> <a href="https://guiadeti.com.br/curso-de-full-cycle-e-full-stack-gratuito/" title="Curso de Full Cycle e Full Stack Gratuito e Online"></a>
</div>
</div>
<div>
<div>
<div>
<span><img decoding="async" width="280" height="210" src="https://guiadeti.com.br/wp-content/uploads/2023/11/Cursos-Udemy-2-280x210.png" alt="Cursos Udemy Gratuitos" title="Cursos Udemy Gratuitos"></span>
</div>
<span>Cursos Udemy: 25 Opções Gratuitas em C++, Excel e Mais!</span> <a href="https://guiadeti.com.br/cursos-udemy-gratuitos-tecnologia/" title="Cursos Udemy: 25 Opções Gratuitas em C++, Excel e Mais!"></a>
</div>
</div>
<div>
<div>
<div>
<span><img decoding="async" width="280" height="210" src="https://guiadeti.com.br/wp-content/uploads/2023/11/Bootcamp-Desenvolvimento-de-Jogos-e-Programacao-280x210.png" alt="Bootcamp Desenvolvimento de Jogos e Programação" title="Bootcamp Desenvolvimento de Jogos e Programação"></span>
</div>
<span>Bootcamp de Desenvolvimento de Jogos e Programação Gratuito</span> <a href="https://guiadeti.com.br/bootcamp-de-desenvolvimento-de-jogos-programacao/" title="Bootcamp de Desenvolvimento de Jogos e Programação Gratuito"></a>
</div>
</div>
<div>
<div>
<div>
<span><img decoding="async" width="280" height="185" src="https://guiadeti.com.br/wp-content/uploads/2023/06/Aulao-de-Framework-Scrum.png" alt="Aulão de Framework Scrum Gratuito" title="Aulão de Framework Scrum Gratuito"></span>
</div>
<span>Curso de Framework Scrum 100% Gratuito</span> <a href="https://guiadeti.com.br/curso-framework-scrum-gratuito-ka-solution/" title="Curso de Framework Scrum 100% Gratuito"></a>
</div>
</div>
</div>
</aside>
## Robótica
A robótica, um campo dinâmico e em constante evolução, oferece uma carreira promissora e repleta de oportunidades. Com a integração crescente da tecnologia em diversos setores, profissionais de robótica estão cada vez mais demandados. Esta área combina engenharia, ciência da computação e tecnologia, e é essencial para inovações em automação, manufatura, saúde, e muito mais.
### Educação e Habilidades Necessárias
Uma carreira em robótica geralmente começa com uma sólida formação acadêmica em campos como engenharia mecânica, elétrica, eletrônica, ou ciência da computação. Cursos especializados em robótica também estão se tornando mais comuns em universidades ao redor do mundo.
Além de uma forte base teórica, habilidades práticas em programação, design de sistemas, inteligência artificial e machine learning são cruciais. A capacidade de trabalhar com hardware e software, juntamente com uma compreensão profunda de sensores e atuadores, é essencial.
### Áreas de Atuação e Especialização
Profissionais de robótica podem encontrar oportunidades em uma variedade de setores, incluindo automotivo, aeroespacial, saúde, educação, e entretenimento. Cada setor oferece desafios e aplicações únicas, desde robôs industriais até sistemas de assistência médica e drones.
Dentro da robótica, existem várias áreas de especialização, como robótica móvel, robótica industrial, robôs autônomos, e robótica assistiva. Especializar-se pode levar a oportunidades mais focadas e a um conhecimento mais aprofundado em áreas específicas.
### Desafios e Futuro da Carreira em Robótica
Um dos maiores desafios na carreira de robótica é manter-se atualizado com as rápidas mudanças tecnológicas. A aprendizagem contínua e a adaptação às novas tecnologias são essenciais para o sucesso nesse campo.
A robótica continuará a ser um campo de grande impacto no futuro, com inovações que podem transformar ainda mais o modo como vivemos e trabalhamos. O desenvolvimento de robôs mais inteligentes, sensíveis e integrados socialmente é uma das muitas direções emocionantes para futuras pesquisas e desenvolvimento.
<iframe title="Como os ROBÔS impactaram na MANUFATURA? Qual será o futuro da ROBOTICA? Robotica e manufatura" width="1170" height="658" src="https://www.youtube.com/embed/QHa1VEuttWQ?feature=oembed" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share" allowfullscreen></iframe>
_Créditos: Canal Engenharia Detalhada_
## IFMS
O Instituto Federal de Educação, Ciência e Tecnologia do Mato Grosso do Sul (IFMS) é uma instituição de ensino que se destaca no cenário educacional brasileiro. Com uma oferta diversificada de cursos e programas, o IFMS tem como missão promover a educação profissional e tecnológica, integrando ensino, pesquisa e extensão.
Como parte da rede federal de educação, a instituição é reconhecida pela sua qualidade de ensino e compromisso com o desenvolvimento regional e nacional.
### Programas Acadêmicos e Cursos Oferecidos
O IFMS oferece uma ampla gama de cursos, abrangendo tanto a educação técnica quanto a superior. Os cursos técnicos, disponíveis nas modalidades integrada, concomitante e subsequente ao ensino médio, são uma porta de entrada para jovens que buscam uma formação profissionalizante de qualidade. Já os cursos de graduação, que incluem tecnologias, bacharelados e licenciaturas, atendem às demandas do mercado de trabalho e propiciam uma formação superior completa.
Além dos programas regulares, o IFMS também oferece atividades de extensão e cursos de formação continuada. Estes cursos são projetados para atender às necessidades de atualização profissional e pessoal, abrangendo desde habilidades específicas até temas mais amplos.
### Pesquisa e Inovação no IFMS
O IFMS não é apenas um local de aprendizado, mas também um centro de pesquisa e inovação. A instituição incentiva projetos de pesquisa aplicada, que visam solucionar problemas reais da sociedade e do mercado. Esses projetos frequentemente envolvem parcerias com a indústria e outros setores, fortalecendo o elo entre teoria e prática e fomentando um ambiente de inovação.
### Compromisso com a Comunidade e Desenvolvimento Regional
O IFMS está fortemente engajado em ações que beneficiam a comunidade local e regional. Através de projetos de extensão, a instituição estabelece uma ponte entre o ambiente acadêmico e a sociedade, contribuindo para o desenvolvimento social e econômico da região.
Além disso, o IFMS tem um compromisso com o desenvolvimento sustentável, buscando integrar em suas práticas educacionais e administrativas ações que promovam a sustentabilidade ambiental, social e econômica.
## Explore novos horizontes: inscreva-se agora nos cursos do IFMS e dê um salto na sua carreira e conhecimento!
As [inscrições para os cursos da IFMS](https://cursoslivres.ifms.edu.br/) devem ser realizadas no portal do IFMS.
## Compartilhe a oportunidade: divulgue os cursos gratuitos e certificados e ajude a ampliar o acesso à educação!
Gostou do conteúdo sobre os cursos gratuitos? Então compartilhe com a galera!
O post [Cursos de Robótica, Arduíno, Francês e Outros Temas Gratuitos](https://guiadeti.com.br/cursos-de-robotica-arduino-ia-idiomas/) apareceu primeiro em [Guia de TI](https://guiadeti.com.br). | guiadeti |
1,682,268 | Understanding the Difference Between site_url(), home_url(), and get_bloginfo(‘url’) in WordPress | If you are a WordPress developer and would like to join in a company, one of the critical viva... | 0 | 2023-11-29T07:33:05 | https://dev.to/dev-alamin/understanding-the-difference-between-siteurl-homeurl-and-getbloginfourl-in-wordpress-1g7k | If you are a WordPress developer and would like to join in a company, one of the critical viva questions might be the difference between these three functions in WordPress. It might be a little bit tough because you never think about it and usually we don’t have to think about things like this topic.
Let's dive deep to explore what are they and how to use them.
**site_url():**
— Returns the URL to the site’s WordPress installation.
— Versatile and useful for generating URLs to various parts of the WordPress installation.
— Ideal for creating dynamic links, and referencing core files, plugins, and themes.
— Helpful in multisite setups to retrieve site-specific base URLs within the network.
**2. home_url():**
— Returns the URL to the home page of the site.
— Used to generate the URL to the main site’s homepage.
— Often interchangeable with site_url() for the main site URL.
**3. get_bloginfo(‘url’):**
— Retrieves the URL to the home directory of the WordPress installation.
— Used to fetch various site information parameters set in WordPress settings.
— Commonly used to retrieve the site URL set in _Settings ->General->_ WordPress Address (URL).
#### **Distinguishing these functions:**
_home_url()_ and _site_url()_ may appear similar, especially when WordPress is installed in the root directory. However, their differences become evident when WordPress is set up in a subdirectory or if they're used within specific contexts. _home_url()_ typically points to the front-end home page URL, while site_url() refers more generally to the WordPress installation's base URL.
On the other hand, _get_permalink()_ has a focused use case—it fetches the specific URL of a post or page. This function aids in dynamically generating or retrieving individual post URLs, critical when building themes, plugins, or manipulating content within WordPress.
#### Here is a real-life use case:
```
// Function to get the URL for a custom API endpoint using home_url()
function get_custom_api_endpoint_url() {
$api_slug = 'custom-api'; // Replace 'custom-api' with your desired endpoint slug
$api_url = home_url('/' . $api_slug . '/'); // Generates the URL for the custom API endpoint
return $api_url;
}
// Function to get the URL for a specific page using site_url()
function get_specific_page_url($page_slug) {
$page_url = site_url('/' . $page_slug . '/'); // Generates the URL for a specific page
return $page_url;
}
// Usage example:
$custom_api_url = get_custom_api_endpoint_url();
echo 'Custom API Endpoint URL: ' . $custom_api_url . '<br>';
$about_page_url = get_specific_page_url('about-us');
echo 'About Us Page URL: ' . $about_page_url;
```
get_custom_api_endpoint_url() uses home_url() to generate a URL for a custom API endpoint. You can replace 'custom-api' with your desired endpoint slug.
get_specific_page_url($page_slug) utilizes site_url() to dynamically generate the URL for a specific page based on the provided page slug.
Each function serves a unique purpose and can be utilized based on the context and requirements of your WordPress project. By leveraging these functions effectively, you can handle URLs, links, and resources within your WordPress site more efficiently. | dev-alamin | |
1,682,734 | MBA with me : Mitul Shahriyar ( Part 6) | "Confidence is contagious . So as lack of confidence" - Vince Lombardi We are here now: Assume... | 0 | 2023-11-29T14:52:22 | https://dev.to/mitul3737/mba-with-me-mitul-shahriyar-part-6-40o3 | mba | "Confidence is contagious . So as lack of confidence" - Vince Lombardi
We are here now:
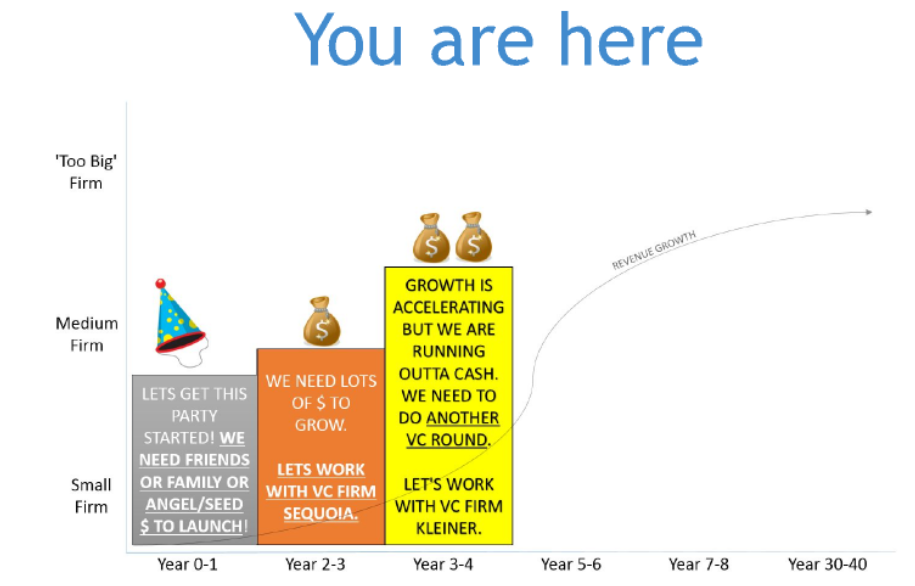
Assume that you have a company called Banana Watch

**Balance Sheet**
What you own or what things people own from you etc.
Stuffs you own = assets
People who own stuffs == Equity
Banks own from you == Liabilities
assets = equity + liabilities.
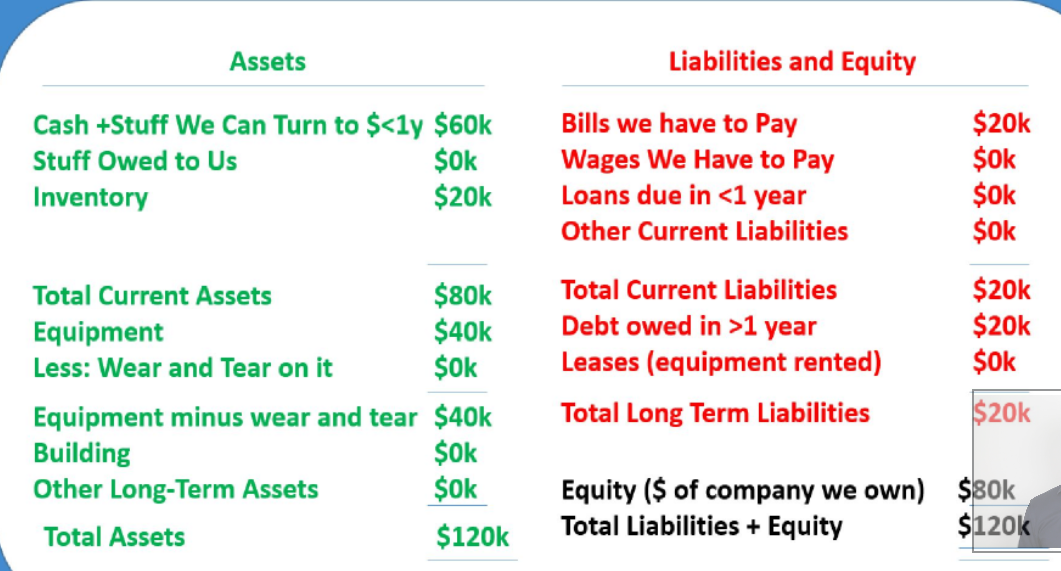
So, assets can be broken down further, into current assets which is stuff you can sell in less than year, and long term assets, which is stuff that you can't sell in less than a year.
Meaning it takes you more than a year to sell the stuff. Liabilities can be broken down as follows. Current liabilities is debt that you owe in less than a year like credit cards, and long term liabilities is debt that you owe in greater than one year like your mortgage. And then equity is just the people that own your stuff including you.

So, assets, current assets equals cash because cash can be converted into itself (laughs) within less than a year, and treasury bills.
So, say you're on treasuries or bonds. That kind of stuff, you can cash in, in less than a year in this example. And then, liabilities, or sorry.Long term assets is stuff like a factory. You see there's a factory there in that picture. That's a very famous album and somebody please, write in the comment section on this course what album cover that is for what band. I'll be really impressed, I'm dating myself here. I'm older than a lot of you, I'm sure, watching this. Okay, liabilities, current liabilities includes credit cards as well as payroll. You have to pay your employees in under a year.
You've got to pay back a credit card in usually a month or less.
Long term liabilities, in this case, let's assume it's banks, okay?

I included mini banks and I mentioned this earlier, I'm gonna reinforce it again. You've always gotta make sure that if you deal with banks, and you shouldn't early on, but if you do later onin the lifecycle of your company, you've gotta deal with multiple banks.
Small increments, why?
Because you want those banks to compete. You want them to compete with you to give you the best rate possible. You want to keep them in check. Kind of like you'd never just have one employee responsible for everything because she or he could quit and you're screwed.Or she or he could ask for more money. You wanna have many employees with different tasks if possible. And then equity is just the people, including yourself, that own your assets, own your company. You'll notice that the left side, assets, has to equal liabilities and equities.
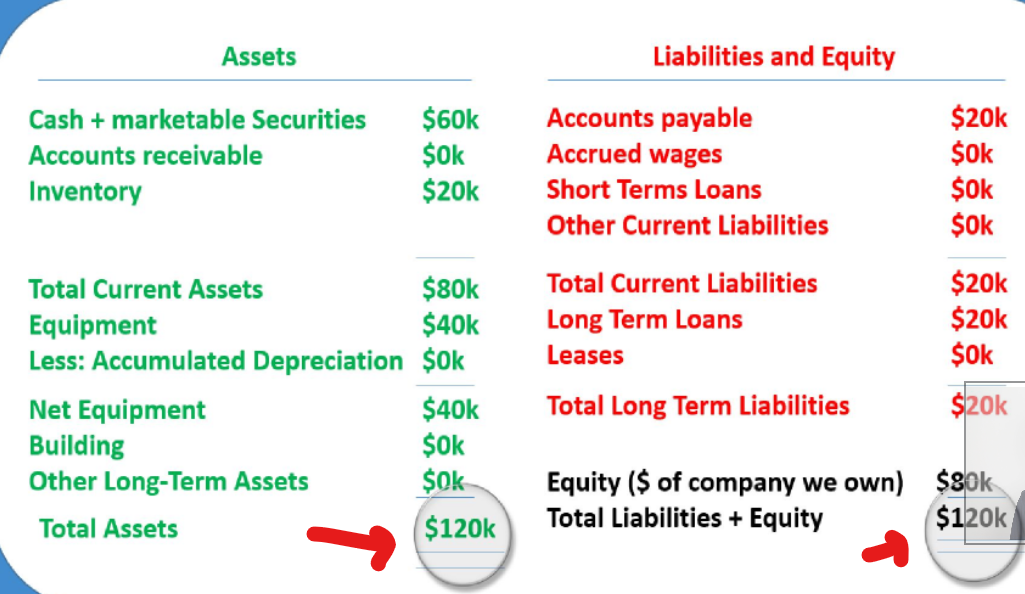
**Income Statement**

Okay, so in our hypothetical corny example that I created,
the Banana Watch Corporation, we've sold $1000 watches. So look at the sales on there, okay? We sold 1,000 watches at $300 each.
That's $300,000 in sales or revenue, same thing. The cost to make those watches we sold, is about $200 each. So $200 times 1,000 watches is $200,000 so sales minus the cost of goods sold or COGS is sales minus the cost of goods sold, is $300,000 minus $200,000 and that's $100,000 and that's called gross profit. Don't ask me why the accounting idiots call it gross profit, it is what it is, okay.

It's just profit that's gross, I don't know why it's gross profit, stupid. So that's $100,000.
And then below that we have all these other expenses and those are called operating expenses or the cost to operate our business. And there sales marketing, S&M, R&D, research and development and also other expenses like, G&A or general expenses. And then we got something called depreciation. And this is messed up, man, but you're allowed to deduct the cost, or the amount you used your machine or car each month. And that's how much it depreciate, like wear and tear. What is the wear and tear on your car? It's so crazy but you can deduct it, right? And it's awesome you can do that and I'll tell you why.
Because the government wants you to invest in your business by buying more machines or more cars. And so you can, the tax benefits is this, if you can deduct that as an expense each month or each quarter, the depreciation expense, even though it's not real, then the tax you pay is lower, right? Okay, so sales minus the cost gets sold is gross profit. Gross profit minus the cost to operate your business, like sales marketing, general expenses, R&D, depreciation, that equals something called operating profit, Or earning before interest and taxes, or EBIT or E-B-I-T, earnings before interest and taxes. And you're saying, why the hell do I need to know about earnings before interest and taxes, Chris?
Why don't you just go to the bottom line? Go to net income, well you can't. Why? The reason is because every country in the world, and every state, and every industry, and every company, has a different way of paying taxes. Everyone pays a little bit different taxes. Just like you pay different tax than somebody else does in your class or in your company. I pay different taxes than my neighbor.
My parents pay different taxes than me. Why do I mention this? Why is this important? Because it's not apples to apples for me to compare the Banana Watch Company to a company in Switzerland for example, where they make inferior watches to our Banana watch, right?
And so, in Switzerland they have a different tax and interest rate structure. And so, investors in our Banana Watch Company wants to understand how our company compares financials-wise, to the inferior Swiss watches. I'm just joking, if anybody Swiss is watching this, then the Banana Watch sucks, okay?
So that's how you do it. You look at operating profit or earnings before taxes. And then what happens is that's called the line, it's accounting nerd speak, don't ask me why. and below that line you have below the line items, right so, below the line items are interest and taxes, which again are different. And the bottom line is that income. That's why an income statement is set up that way, okay.
It is pretty simplistic, right? But it sounds more complicated than that, that's all it is. And so you might ask yourself, okay Mitul that's pretty cool, so I've got $30,000 in net income.
Obviously Mitul, that means I have $30,000 more in my pocket than before.
No it doesn't. It doesn't. Your cash balance is not going to increase by $30,000. Why?
Because you had non-cash items, okay. Remember depreciation that you got a benefit there, right?

We're not getting $30,000 more in our pocket. We are getting something else. Let's figure out what that something else is.
Okay, so we start with net income at the top of our cash flow statement, right?
We have to deduct that. We want a depreciation on our income statement, so that our earnings are less and we pay less taxes. It's a beautiful thing, right?
And then we're gonna add back the increase in depreciation, right?
Because that cash didn't really leave our pocket, right? We got that benefit from not paying taxes on it. So woo woo, we're up to $32,000 but hold on a second. On our balance sheet, in the current assets section, there's something called accounts receivable and that's gonna hurt our cash balance. Say what?
Well when you sell something, like we sell our Banana Watches, we either sell them for cash or we sell then people use their credit cards, right? Why? Because they just want to pay for it later, right? And so that's called accounts receivable. We have received that cash yet, so we already deduct that okay? So and then what happened was, we actually owed some of our partners money. We bought a lot of supplies for our watches from a company that makes really cool sapphire crystal and sapphire crystal is actually the watch face on our Banana Watch.
And so, we got $20,000 worth of material sapphire crystals but we haven't paid for it yet. That's called accounts payable, right? And so get got $20,000 benefit, temporarily here. So our net cash flow from operations is $42,000. Okay and so you can see the math there in front of you. And so let me just do a side topic before we moving on here.

Okay so let's talk about cash flow from investing. Okay so we bought, we bought a machine. We paid $40,000 for it, right? And so we invested in our company and so that's gonna hurt us we lose $40,000 there, right? But we actually have cash flow from financing of $20,000, because we got a loan for $20,000. So that's more cash in our pocket, right? It's not a good thing but just more cash for now. Right, so if we net all that stuff up, that's a $22,000 increase not a $30,000 increase, okay?

So our beginning bank balance for cash from our balance sheet before was $60,000 and now our ending cash balances is $82,000.
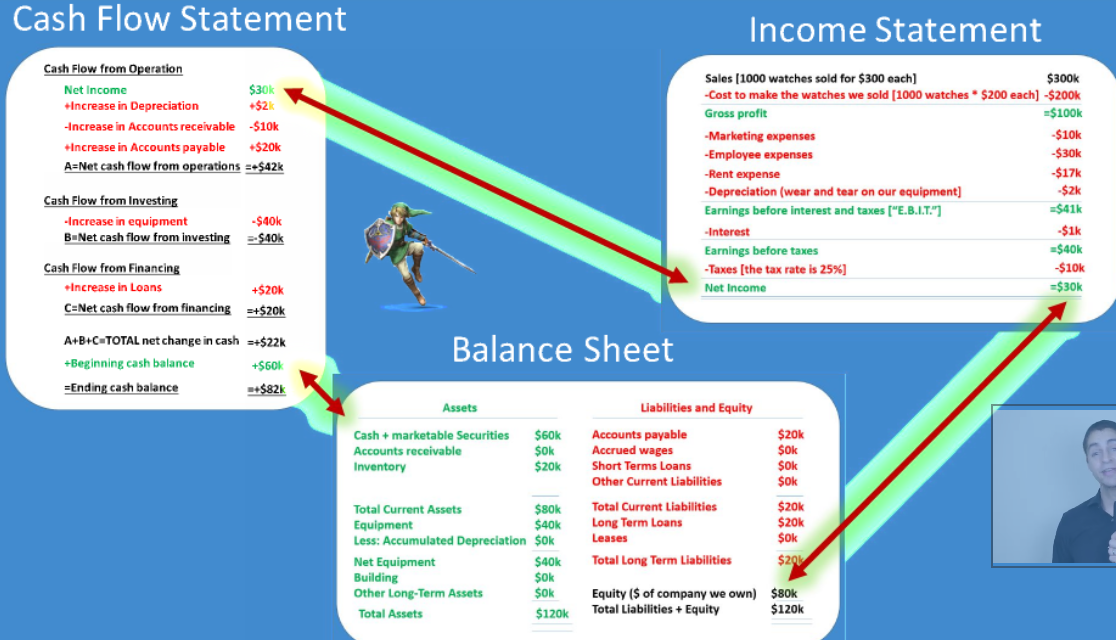
The x-axis is time, the y-axis is the size of the firm, small firm, medium firm to big firm.

**Liquidity Ratios**



**Leverage Ratios**


EBITDA means "earnings before interest, taxes, depreciation and amortization."

Okay, other ratios are return on assets.
Whenever you hear the term "return on" something, it basically means net income on the top or profits, same thing, divided by whatever you're returning on. So, net income over assets. Net income over equity.
Suggestions:
- When you're managing people you always want to praise in public and criticize in private. OK?
- And you always want to approach your boss and ask her him for feedback every three months or so. How am I doing?
- You'll never get a raise unless you ask Get a raise. Remember the Steve Jobs ask video.
So you have to ask to get promoted and how do you do this? Well, you sit down with your boss and you ask her him, What do I need to be considered for promotion to the next level?
And they'll tell you. And you create a list of those items, and once you achieve them, just very politely sit down with them and say, I've achieved all these milestones that we spoke about.
Can I please get a promotion or can I please get a raise?
Note:
Depreciation;

Current Ratio:

Interest coverage ratio:

| mitul3737 |
1,682,750 | The Top 10 Benefits of Owning an Electric Skateboard with a Remote | Introduction Electric skateboards with remotes are rapidly becoming popular among riders... | 0 | 2023-11-29T15:09:42 | https://dev.to/elizabethbatesqa/the-top-10-benefits-of-owning-an-electric-skateboard-with-a-remote-p0d | [](https://www.ecomobl.com/?utm_source=dev_to&utm_medium=rankking)
## Introduction
Electric skateboards with remotes are rapidly becoming popular among riders due to their convenience, efficiency, and affordability. Their design allows for an easy transition from manual push to electronic power, making riding an electric skateboard with remote fun and accessible. In this article, we'll explore the top 10 benefits that come with owning an electric skateboard with remote.
## Efficient and Convenient Transport
One of the most significant advantages of an electric skateboard with remote is its ability to provide efficient and convenient transport. With a top speed of up to 25 mph, electric skateboards can get you to your destination much faster than walking or cycling. They're also lightweight, easy to carry, and can be ridden almost anywhere at any time, making them a reliable choice for daily commuting or running errands.
## Easy to Use
Another great advantage of electric skateboards with remotes is their ease of use. Even beginners can easily control their board's speed and direction using the remote. Most boards also come with adjustable speed settings, allowing riders to choose their preferred speed. Additionally, the remote provides a convenient way to start and stop your board without the need to manually push or brake.
## Environmentally Friendly
Electric skateboards are an environmentally friendly mode of transport since they don't produce emissions like gas-powered vehicles. They're also energy-efficient, with some models boasting long battery life, so you don't have to charge them frequently. By choosing an electric skateboard with remote, you're contributing to a cleaner environment and reducing your carbon footprint.
## Less Physical Effort
Unlike traditional skateboards, electric skateboards with remotes don't require a lot of physical effort to ride. Riders can simply stand on the board and let the electric motor do the work. This makes them an excellent choice for riders with mobility issues or those who want a fun and easy way to commute.
## Other Benefits
Other benefits of owning an electric skateboard with remote include:
* Providing a fun and enjoyable riding experience
* Great for riders of all ages and skill levels
* Low maintenance and repair cost
* Comes in different shapes and designs, giving riders a variety of options.
## Conclusion
Overall, owning an electric skateboard with remote comes with significant benefits, including efficient and convenient transport, ease of use, and environmental friendliness. Plus, they offer a fun and exciting way to ride around town. As the popularity of electric skateboards with remotes continues to grow, we can expect to see even more benefits and advancements in their design in the future.
## Related links
* [Boosted Boards](https://www.boostedboards.com/)
* [Evolve Skateboards](https://evolveskateboardsusa.com/)
* [MBoards Electric Skateboards](https://www.mboards.co/)
## References
* [electric skateboard with remote](https://www.htgmolecular.com/?URL=https://www.ecomobl.com/ "electric skateboard with remote")
| elizabethbatesqa | |
1,682,778 | Exploring The New Array Methods From ECMAScript 2023 | by Judy Nduati ECMAScript 2023 came in with new features to improve the language and make it more... | 0 | 2023-11-29T15:28:52 | https://blog.openreplay.com/exploring-the-new-array-methods-from-ecmascript-2023/ | by [Judy Nduati](https://blog.openreplay.com/authors/judy-nduati)
<blockquote><em>
ECMAScript 2023 came in with new features to improve the language and make it more powerful and seamless. This new version comes with exciting features and new JavaScript array methods that make programming with JavaScript more enjoyable and easy. This article will thoroughly take readers through the functionalities of the new JavaScript methods on the array prototypes.
</em></blockquote>
<div style="background-color:#efefef; border-radius:8px; padding:10px; display:block;">
<hr/>
<h3><em>Session Replay for Developers</em></h3>
<p><em>Uncover frustrations, understand bugs and fix slowdowns like never before with <strong><a href="https://github.com/openreplay/openreplay" target="_blank">OpenReplay</a></strong> — an open-source session replay suite for developers. It can be <strong>self-hosted</strong> in minutes, giving you complete control over your customer data.</em></p>
<img alt="OpenReplay" style="margin-top:5px; margin-bottom:5px;" width="768" height="400" src="https://raw.githubusercontent.com/openreplay/openreplay/main/static/openreplay-git-hero.svg" class="astro-UXNKDZ4E" loading="lazy" decoding="async">
<p><em>Happy debugging! <a href="https://openreplay.com" target="_blank">Try using OpenReplay today.</a></em><p>
<hr/>
</div>
JavaScript is constantly evolving, much like the web development industry altogether. ECMAScript 2023 is the latest version of JavaScript programming language. ECMAScript is in the fourteenth edition of the language specification and was released in June 2023. Over time, ECMAScript 2023 has developed into a general-purpose programming language. The web is run by it. It is therefore utilized for web apps and other programming activities that are linked.
[ECMAScript](https://www.ecma-international.org/publications-and-standards/standards/ecma-262/) is a standardized scripting language, and it is a specification for JavaScript. [ECMAScript 2023](https://tc39.es/ecma262/2023/) is an update of the JavaScript programming language to bring in improvements and make JavaScript programs predictable and maintainable. With this improvement, the `Array` prototype has new methods. The JavaScripts array methods `toSorted`, `toReversed`, `with`, `findLast`, and `findLastIndex` were introduced in ECMAScript 2023.
ECMAScript 2023 methods offer developers powerful tools to manipulate arrays without changing the original array. These methods operate on replicates of the array, thus allowing for safer and more predictable array manipulation. With these array methods, developers can embrace the immutability of the array data as they are sure that the original array remains unchanged. They will enhance the work of developers while working with arrays. It is advantageous to leave data unchanged, as demonstrated by these array methods from ECMAScript 2023. These benefits apply to any JavaScript objects, not just arrays.
Without further ado, let's explore the new array methods in JavaScript.
## The toReversed() method
The `toReversed()` and the JavaScript `reverse()` methods are comparable but not the same. The `toReversed()` method returns the elements of an array in reverse order without changing the original array.
Note that the new JavaScript methods from ECMAScript 2023 code snippets run on the modern web browser. Check the browser capability from [MDN](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Array/toReversed). It works on the browser since the methods are still very new. Also, these methods are not supported by Node.js. They are supported by the Node.js version 20+. This does not favor developers as developers use the Node.js LTS version (Version 18).
Let's look at the scenario where we have a list of the days of the week arranged in chronological order. The results will be displayed in reverse order.
```javascript
//This is the original array
const days = ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday'];
//Using reverse()
const reverseDays=days.reverse();
console.log(reverseDays);
//Output: ['Friday', 'Thursday', 'Wednesday', 'Tuesday', 'Monday']
console.log(days);
//Output of original array is changed: ['Friday', 'Thursday', 'Wednesday', 'Tuesday', 'Monday'
```
The original array is modified with the `reverse()` method.
The `toReversed()` method reverses the array without changing the original array. Check out this example:
```javascript
//Using toReversed() method
const reversedDays=days.toReversed();
console.log(reversedDays);
//Output: ['Friday', 'Thursday', 'Wednesday', 'Tuesday', 'Monday']
console.log(days);
//Output of original array is not changed: ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday']
```
The `toReversed` function is a remarkable feature that developers appreciate. This is because the original array was mutated with the `reverse` method. Thanks to ECMAScript 2023 for introducing the `toReversed` method. With this method, you can change the copy of the array instead of the original array.
## The toSorted() method
The `toSorted()` is similar to the JavaScript `sort()` method. The two methods differ from each other and, yes! You guessed it right. Unlike the `sort()`, the `toSorted()` method will not change the original array. This array method operates like the `toReversed()` method. These methods return a new array, leaving the original arrays unchanged.
Consider this scenario where we need to sort numbers in the ascending order. This example will illustrate the difference between `sort()` and `toSorted()`.
```javascript
//This is the original array
const numbers=[9, 4, 8, 1, 6, 3];
//Using sort
const sortNumbers=numbers.sort();
console.log(sortNumbers);
// Output:[1, 3, 4, 6, 8, 9]
console.log(numbers)//original array
//Output:[1, 3, 4, 6, 8, 9]
//Using toSorted
const sortNumbers=numbers.toSorted();
console.log(sortNumbers);
// Output:[1, 3, 4, 6, 8, 9]
console.log(numbers)//original array
//Output:[9, 4, 8, 1, 6, 3]
//Original array is not mutated
```
The `toSorted()` array method modifies the copy version in the above instance. It returns a new array with the elements sorted in ascending order. However, the original array is not changed. On the other hand, the `sort()` method mutates the original array in place, as seen in the above example.
<CTA_Middle_Basics />
## The toSpliced() method
The `toSpliced()` array method is a new feature in ECMAScript 2023. The `toSpliced()` is similar to the JavaScript `splice()` array method, but there is a slight difference. The difference between the two array methods is in `toSpliced()`, the original array is not modified.
`toSpliced()` creates a new array with changed elements, but the original array remains unchanged. `toSpliced()` does multiple things in an array. You can add, remove, and replace elements in an array.
Let's consider a scenario where we have a list of elements and want to remove some elements without altering the original array. This example will illustrate the difference between `splice()` and `toSpliced`.
```javascript
//Original array
const fruits=['Grapes', 'Oranges', 'Bananas', 'Mangoes', 'Pineapples'];
//Using Splice
const spliceFruits= fruits.splice(2,1);//removing one fruit(Bananas)
console.log(spliceFruits);
//Output: ['Grapes', 'Oranges', 'Mangoes', 'Pineapples']
console.log(fruits);//original array is altered
//Output: ['Grapes', 'Oranges', 'Mangoes', 'Pineapples']
//Using toSpliced
const splicedFruits= fruits.toSpliced(4,1);//removing one fruit(Pineapples)
console.log(splicedFruits);
//Output: ['Grapes', 'Oranges', 'Bananas', 'Mangoes']
console.log(fruits);//original array remain unmodified
//Output: ['Grapes', 'Oranges', 'Bananas', 'Mangoes', 'Pineapples']
// Adding an element at index 1
const fruits2 = fruits.toSpliced(1, 0, "Passion");
console.log(fruits2);
//Output: ['Grapes', 'Passion', 'Oranges', 'Bananas', 'Mangoes', 'Pineapples']
// Replacing one element at index 1 with two new elements
const fruits3 = fruits2.toSpliced(1, 1, "Guava", "Melon");
console.log(fruits3);
//Output: ['Grapes', 'Guava', 'Melon', 'Oranges', 'Bananas', 'Mangoes', 'Pineapples']
//Original array remain unchanged
console.log(fruits)
//Output: ['Grapes', 'Oranges', 'Bananas', 'Mangoes', 'Pineapples']
```
The `toSpliced` array method is an important additional feature of the JavaScript language. It allows developers to manipulate the arrays without altering the original arrays. This enables developers to manage and maintain the code easily. As seen in the examples above, this method offers a more convenient way to add, remove, or replace elements at any array index.
## The with() method
The `with()` array method was added to the JavaScript programming language when ECMAScript 2021 (ES12) was introduced. Updating elements inside an array is common in JavaScript. However, changing the array elements modifies the initial array.
The `with()` array method introduced a new feature in ECMAScript 2023. The `with()` method offers a safe way of updating elements in an array without changing the original array. This is achieved by returning a new array with the updated elements.
```javascript
const flowers=['Lily', 'Daisy', 'Iris', 'Lotus', 'Allium'];
//old way of updating an array;
flowers [4]='Rose';
console.log(flowers);
//Output: ['Lily', 'Daisy', 'Iris', 'Lotus', 'Rose']
//New way of updating an array using with()
const updatedFlowers=flowers.with(4, 'Aster');
console.log(updatedFlowers);
//Output: ['Lily', 'Daisy', 'Iris', 'Lotus', 'Aster']
console.log(flowers);//original array
Output: ['Lily', 'Daisy', 'Iris', 'Lotus', 'Allium']
```
The old way of updating an array used the bracket notation to change an element within an array. Using the bracket notation to update an array, the original array is modified. However, the `with()` method achieves the same result after updating an element in a specific array index but doesn't mutate the original array. You can create a copy of the array, which returns a new array with the updated index.
## Wrapping Up
ECMASctript keeps advancing as it gets a new version every year. This is a trend that has been consistent since 2015. This transformation has been taking place every year to improve ECMAScript and JavaScript. ECMAScript 2023 brings several exciting features to JavaScript language. These features improve the language capabilities and the developer experience.
To summarize, you learned the functionalities of the new JavaScript array methods from ECMAScript 2023. Go ahead and use the ECMAScript 2023 array methods:
- `toReversed()`
- `toSorted()`
- `toSpliced()`
- `with()`
ECMAScript ensures web developers build applications that are more illustrative using efficient code. Those are the new JavaScript array methods from ECMAScript 2023. Happy learning!
| asayerio_techblog | |
1,682,781 | CollectionUtils containsAll() Example in Java | https://javatute.com/collection/collectionutils-containsall-example-in-java/ | 0 | 2023-11-29T15:32:23 | https://dev.to/javatute673/collectionutils-containsall-example-in-java-eae | javascript, programming, beginners, tutorial | https://javatute.com/collection/collectionutils-containsall-example-in-java/ | javatute673 |
1,682,809 | From Coffee to Code: a year in life of a junior software engineer at Inato | From Coffee to Code: a year in life of a junior software engineer at Inato Bonjour👋 I am... | 0 | 2023-11-29T16:03:48 | https://dev.to/42f/from-coffee-to-code-a-year-in-life-of-a-junior-software-engineer-at-inato-369n | # From Coffee to Code: a year in life of a junior software engineer at Inato
Bonjour👋
I am Brian, and I've been working as a Product Engineer at [Inato](https://inato.com/) since July 2022, when I landed my first job ever in the tech industry! **This followed a bold career switch** that began in the summer of 2019, after 12 years in the [specialty coffee industry](https://www.youtube.com/watch?v=N2iUIqP0pzI).
The switch to software engineering came naturally to me: growing up in the 90s, my father worked as a programmer for an aerospace engine manufacturer. This meant that I started interacting with computers from a very young age, which was not so common for my generation. (yes, I am a pre-internet human 🫠)
By the age of 10, I could write a bit of code. However, I suffered from the typical bias view on programming: since I wasn't very good at math in middle and high school, I was convinced it was not meant for me. Instead, it became a great interest that I pursued on the side.
Fast forward to 2007, when I landed in Toronto, Canada. I stepped into the first decent coffee shop of my life. Coming from Paris and its culture of Cafés, the place, but not much the product, I could not imagine that the culture of Coffee was radically different in other parts of the world. People spoke of varietals, processes, ratios, recipes, brewing methods, and so on, just like French people would talk about wine, cépages, or vintages. I felt like I had fallen into a rabbit hole and spent the following years learning about coffee.
It took me around the world, from Taipei, Taiwan to San Miguel, El Salvador. It connected me with so many people and provided me with a career. I became a barista, then a trainer, consultant, coffee roaster, an entrepreneur.
When I felt that I had explored everything I could in my scope of the value chain, I felt I needed to start exploring other paths to pursue a bigger and more positive outcome from my work.
## The Journey kickoff: The Upskilling and Challenges
September 2019, I joined [École 42](https://42.fr/en/homepage/), after spending approximately 400 hours on campus the month before, during the **Piscine**, a hard-core selecting process consisting of coding various challenges among 600 other aspiring candidates.
**The curriculum itself at 42 is very system-oriented**: learning C language from scratch, understanding OS memory handling, and all the way to the CPU doing some assembly. I found that it lays the foundation for my understanding of how computers work, even after playing around with them for many years.
Six months later, COVID hit. It allowed me to start experiencing remote life and focus deeply on my projects for the school, complete as many projects as I could while staying pragmatic when picking each subject.
I left 42 very idealistic, probably a bit naive too, with big knowledge and skill disparities. To level up on something that could get me a job, I took an opportunity to join the [Ironhack bootcamp](https://www.ironhack.com/fr-en): a **12-weeks intense deep dive into web development** focused on actionable and pragmatic skills. (Which is quite an investment for someone without financial support from government or pension system, to whom I would recommend the free alternative that is [The Odin Project](https://www.theodinproject.com/))
## The Journey: Finding the First Position
After Ironhack, I was finally ready to start sending out CVs, feeling more legitimate to do so, even if I was still sweating thinking about technical assessments and interviews…
In the challenging post-COVID job market, where companies prefer interns or experienced software engineers, finding my first job after a career switch was tough. **The application process is highly competitive**, with many applications leading to few interviews and even fewer job offers.
To increase my chances, I optimised my job search. **I limited application time to 15 minutes** for most positions and 30 minutes for select companies I was particularly interested in. The extra time was spent researching the company, its key people’s names, a bit of extra personalising of the cover letters, and understanding their values and team dynamics.
I learned **it is inefficient to spend over 30 minutes** on initial applications, especially since many companies have vague definitions of 'junior' positions which end up not fitting an actual first position seeker.
It is good to be aware of this early on, because not taking this into account cost time and effort, not to mention some dents in one’s motivation after the first few rejections.
To **streamline this process**, I automated as much as possible: sending emails, scraping websites, generating PDFs for application documents, and tracking applications and follow-ups with tools like Notion. **In a sense, it takes a bit of software engineering to become one!**
This section would deserve its own article, given all of its challenges and learnings, but after exactly 2 months of searching and about 3 cycles of applications reaching “almost” the last stage with a few companies, I met with [Inato](https://inato.com/)’s team.
**Inato is on a mission to create a world where all patients can access the right clinical trial** for them in their community, making medical research more accessible, inclusive and efficient. Its current solution takes the form of a marketplace to link hospitals to trials.
## The Transition: First Year in Tech
Now, having been in tech for over a year at [Inato](https://inato.com/), going from complete junior to hopefully soon the first step of mid-level, I can look back at this time and share a few things that one might consider when going through the same crucial first year.
### Use the power of starting fresh
Being a junior means **you come in with zero preconceptions about most technical questions**. You might have heard along the way that X stack sucks and Y is the way to go, that no one should do Z (rarely why though), and so on… But mostly, you work on a shiny new canvas, and you should leverage this.
**Transparent companies** will also tell you they see hiring juniors as a great opportunity for this very reason: you are trainable to a way of doing things that have already been decided internally before you joined.
If you have picked a company you trust, based on the successful business position it is in, or on its tech branding that makes you feel you are in good hands, then it means they know what they are doing, and you are about to benefit from this as much as the company does by growing good professional foundations. You might not learn the theory of the best practices: instead, **you will learn things that are currently working in the real world**, making this company and/or team successful.
### Use the power of being the most uninformed about a subject
When in my first daily meeting on day 2, I felt like I had just landed in Taiwan and was addressed in Mandarin Chinese. Of course, this was expected, but **I quickly learned not to accept this all the time**.
The quality of a team made of mostly senior members can be measured by how **accessible** they make **complex concepts** to their junior counterparts. Discussing some abstractions among senior engineers when starting off a new product from the ground up is necessary to quickly build a strong architecture upon which juniors will be able to contribute. But once the product is developed enough for the team to incorporate more diverse members in terms of training and experience, then it is up to the most expert members to make it accessible to others.
So when you are a junior member in a new epic kickoff meeting, and you can't make sense of something, **you have the power to direct the discussion to a more understandable level**. Doing this will force other team members to clarify things, and often discover some contradictions in the technical design, some unclear specs, or other issues that would not arise until later, or at all until they are an issue in 2 or 3 epics from now.
As a junior, you bring this balance to the team, with an outsider and fresh look at things.
When feeling overwhelmed by the technical complexity, I defaulted to considering the issue was that I was not expert enough.
Talking about this to our CTO [Bastien](https://www.linkedin.com/search/results/all/?fetchDeterministicClustersOnly=true&heroEntityKey=urn:li:fsd_profile:ACoAAAHzeSABxuQlwW2nz-RWidTBSjqy-XTY8Lw&keywords=bastien%20duret&origin=RICH_QUERY_TYPEAHEAD_HISTORY&position=0&searchId=2fea0ff7-3166-44d8-94f4-e3c97eb51b66&sid=Jc,&spellCorrectionEnabled=true), _during a [gamba walk](https://en.wikipedia.org/wiki/Gemba)_, he made it clear that when the complexity does not translate into readable code, I should instead default to considering it as an **implementation failure**: the team was not able to translate the specifications into code that reads clearly enough for any team member to understand them.
### Use the power of being senior in your previous field
When going through retraining, **you are not exactly a junior in every aspect of it**: chances are you already had a first professional life, and many **soft skills are transferable**. In my case, I feel like the biggest skill I leveraged was being comfortable interacting with diverse teams and being very user oriented (or customer oriented, as I would have say in my previous career). Be it internal or external users. So I could easily take some responsibilities around operational questions which involved our engineering, product, and customer success teams. I created a role for myself to coordinate and reduce friction around setting up new clinical trials on our marketplace.
This was the perfect project for me to deepen my understanding of the key feature of our product, a part of the codebase with a lot of complexity (and legacy), and the most business-critical.
[Inato](https://inato.com/) encouraged my venture into that role because the value was clear, we could reduce the time spent by engineers on operational tasks by: rethinking parts of some processes, leveraging clean code, using automations in some internal tools (GitHub, Notion, and Slack).
So by leveraging soft skills I had from before, **I could explore new technical skills**, and made the company more efficient.
### Use the power of learning from your job: optimize for learning (from [The Effective Engineer by Edmond Lau](http://www.effectiveengineer.com/))
It is true for all levels of software engineering, but probably even more for juniors in their first job.
It means that from picking the company you want to work for, until deciding to leave it for another step in your career, and every decision in between as simple as your daily to-do, should be affected by this strong bias: **you need to learn something out of it.**
When faced with the decision to work on two different tasks, and as time is a finite resource it means this decision will be a daily occurrence: **pick the task on which you have the higher learning potential**, and only after, factor in the impact of this task in terms of value it brings to you, your team, your product, your company.
I believe this specific rule goes for junior engineers who just started contributing to their team: _a task with high learning potential and average impact will still be more valuable than a task with an average learning potential and a higher impact._
## Happy to Have Made the Switch, and the Values I Met
So after going through this journey, I can proudly say I made the **right decision**. It took me a bit of time to find this position, but I genuinely feel like I could simply not have hoped for a better alignment with a company and a team.
[Inato](https://inato.com/) was ready to onboard juniors, _and we have since then onboarded a couple more,_ with all the trade-offs it requires.
I feel like I work on a **product that makes sense** to society by helping clinical trials become more accessible to diverse populations and various hospitals across the world.
In my day-to-day, I feel free to **improve anything**, to **provide feedback** to anyone so the company succeeds.
I work in a team that is **caring and helps me and others become successful engineers**. My working conditions could not fit me better: I get to be remote full time if I wish to (_I am writing these lines sitting at [Kiosk](https://www.google.com/maps/place/KiOSK/@25.0462835,121.5139009,15z/data=!4m10!1m2!2m1!1skiosk+taipei!3m6!1s0x3442a96361734799:0xb2f516b0b8a95c9b!8m2!3d25.0462835!4d121.5314104!15sCgxraW9zayB0YWlwZWlaDiIMa2lvc2sgdGFpcGVpkgEEY2FmZeABAA!16s%2Fg%2F11b6plm2q6?entry=ttu), my favorite coffee shop in Taipei, Taiwan, where I am staying for a few weeks_), yet I have a welcoming and great-looking office to go to when I want to in Paris.
My next steps are around continuing to improve technically as I intend to stay an _individual contributor_ for a while to build up expertise. Given my career switch, I can already foresee possibilities to turn into management roles in a few years given some strong soft skills foundation I built before [Inato](https://inato.com/).
Given the path [Inato](https://inato.com/) is on, I have no doubt plenty of opportunities will be available when I will need to meet them, as the company is growing fast and has some very strong ambitions in its market.
_In the meantime, I keep sipping great coffees while writing the best lines of code I can._ ☕
| 42f | |
1,683,371 | Python One-Liners - Code Hacks You Should Know | Python's beauty lies in its simplicity and readability. And mastering the art of writing concise yet... | 0 | 2023-12-08T11:18:47 | https://blog.ashutoshkrris.in/python-one-liners-code-hacks-you-should-know | python | ---
title: Python One-Liners - Code Hacks You Should Know
published: true
date: 2023-11-30 02:16:37 UTC
tags: Python
canonical_url: https://blog.ashutoshkrris.in/python-one-liners-code-hacks-you-should-know
---
Python's beauty lies in its simplicity and readability. And mastering the art of writing concise yet powerful code can significantly enhance your productivity as a developer. I'm talking about really short lines of code that do big things.
In this article, we'll explore 8 essential Python one-liners that every Pythonista should have in their toolkit. From list comprehensions to lambda functions and beyond, these techniques offer elegant solutions to common programming challenges, helping you write cleaner, more efficient code.
## **List Comprehension**
List comprehension is a Pythonic way to create lists with a single line of code. It offers a concise alternative to traditional loops, enabling you to generate lists quickly and efficiently.
Let's say you want to create a list containing squares of numbers from 0 to 9. Using a traditional loop, you'd do it like this:
```py
# Using a traditional loop
squared_numbers = []
for i in range(10):
squared_numbers.append(i ** 2)
print(squared_numbers)
```
The traditional loop method requires more lines of code and explicitly defines the iteration process, appending each squared number to the list step by step.
On the other hand, list comprehension can achieve the same result in a single line, making the code more concise and readable. It condenses the loop into a clear, compact structure, generating the squared numbers directly into a list.
```py
# Using list comprehension
squared_numbers = [i ** 2 for i in range(10)]
print(squared_numbers)
```
You can use list comprehensions when you need to apply a simple operation to every element in a sequence, such as transforming a list of numbers or strings.
You can learn how you can pack and destructure lists in Python [here](https://blog.ashutoshkrris.in/mastering-list-destructuring-and-packing-in-python-a-comprehensive-guide).
## **Lambda Functions**
[Lambda functions](https://blog.ashutoshkrris.in/mastering-lambdas-a-guide-to-anonymous-functions-in-python), also known as anonymous functions, allow you to create small, throwaway functions without explicitly defining them with `def`. They are particularly useful in scenarios where a function is needed for a short operation.
First, let's look at an example using `def`:
```py
# Using def
def add_numbers(x, y):
return x + y
print(add_numbers(2, 3))
```
In this code, the `def` keyword is used to define a named function `add_numbers` explicitly. It takes an argument `x` and `y` and returns the sum of them. This traditional approach provides a named function that can be called multiple times.
But when you need a function just for one-time usage, you can just define an anonymous function using the `lambda` keyword like this:
```py
# Using Lambda
add = lambda x, y: x + y
print(add(2, 3))
```
It achieves the same result as `add_numbers` but in a single line without assigning a name explicitly. Lambda functions are useful for short, throwaway functions that are used infrequently or as part of other expressions.
## **Map and Filter**
The `map` and `filter` functions are powerful tools for working with iterables, allowing concise manipulation and filtering of data.
Let's say you have a list of strings and you want to convert each item of the list into uppercase.
```py
fruits = ['apple', 'banana', 'cherry']
upper_case_loop = []
for fruit in fruits:
upper_case_loop.append(fruit.upper())
print(upper_case_loop)
```
Now, you can achieve the same using the `map` function:
```py
upper_case = list(map(lambda x: x.upper(), ['apple', 'banana', 'cherry']))
```
You can utilize `map` when you need to perform an operation on every element of an iterable. `filter` is handy for selectively choosing elements based on a condition.
You can learn more about the `map`, `filter` and `reduce` functions [here](https://blog.ashutoshkrris.in/mastering-lambdas-a-guide-to-anonymous-functions-in-python#heading-using-lambda-functions-as-arguments-in-higher-order-functions-map-filter-reduce).
## **Ternary Operator**
The ternary operator provides a condensed way to write conditional statements in a single line, enhancing code readability.
Let's say, you have a number and you want to check if it's even or odd. You can do it using the traditional if condition as below:
```py
# Traditional if
result = None
num = 5
if num % 2 == 0:
result = "Even"
else:
result = "Odd"
```
But you can achieve the same results in a single line using the ternary operator:
```py
# Ternary Operator
num = 7
result = "Even" if num % 2 == 0 else "Odd"
```
When you need to assign values based on conditions, especially in situations requiring simple if-else checks, the ternary operator shines.
## **Zip Function**
The `zip` function enables you to combine multiple iterables element-wise, forming tuples of corresponding elements.
Let's assume you have two lists: one containing the names of students and the other containing their respective grades for a specific assignment.
```py
students = ['Dilli', 'Vikram', 'Rolex', 'Leo']
grades = [85, 92, 78, 88]
```
Now, you want to create a report that pairs each student's name with their grade for easy comprehension or further analysis. You can do it by iterating over the list and appending them to a new list as below:
```py
students = ['Dilli', 'Vikram', 'Rolex', 'Leo']
grades = [85, 92, 78, 88]
student_grade_pairs = []
for i in range(len(students)):
student_grade_pairs.append((students[i], grades[i]))
print(student_grade_pairs)
```
The above loop method manually pairs elements from two lists by iterating through their indices, accessing elements at the same positions, and appending tuples of those elements into a new list `student_grade_pairs`.
But, what if I tell you that we can achieve the same pairing effect in one line using the `zip` function as below:
```py
students = ['Dilli', 'Vikram', 'Rolex', 'Leo']
grades = [85, 92, 78, 88]
student_grade_pairs = list(zip(students, grades))
print(student_grade_pairs)
```
The `zip` function elegantly combines elements from both lists, creating pairs of corresponding elements as tuples. The result `student_grade_pairs` is a list of tuples, where each tuple contains an element from the grades list paired with the corresponding element from the `students` list.
You can learn more about the `zip` function [here](https://blog.ashutoshkrris.in/zipping-through-python-a-comprehensive-guide-to-the-zip-function).
## **Enumerate Function**
The `enumerate` function offers a concise way to iterate over a sequence while keeping track of the index.
Let's say you're developing a feature where users can add items to their shopping list, and you want to display the items along with their position or index in the list for easy reference.
You can do it using a traditional for-loop as below:
```py
# Simulating a grocery list
grocery_list = ['Apples', 'Milk', 'Bread', 'Eggs', 'Cheese']
# Displaying the grocery list with indices
for i in range(len(grocery_list)):
print(f"{i}. {grocery_list[i]}")
```
The traditional loop with manual indexing involves using `range` along with `len` to generate indices that are then used to access elements in the `grocery_list` list. This method requires more code and is less readable due to the explicit handling of indices.
The `enumerate` function simplifies the process by directly providing both indices and elements from the `grocery_list` list.
```py
# Simulating a grocery list
grocery_list = ['Apples', 'Milk', 'Bread', 'Eggs', 'Cheese']
# Displaying the grocery list with indices
for index, item in enumerate(grocery_list):
print(f"{index}. {item}")
```
It's concise, readable, and more Pythonic, eliminating the need for manual index handling and making the code cleaner. This approach is generally preferred for its simplicity and clarity in obtaining indices and elements from an iterable.
## **String Join**
The `join` method is a clean way to concatenate strings from an iterable into a single string.
Suppose you have a list of words and want to create a sentence by joining these words using traditional concatenation. You'd do it as below:
```py
# Using traditional concatenation
words = ['Python', 'is', 'awesome', 'and', 'powerful']
sentence = ''
for word in words:
sentence += word + ' '
print(sentence.strip()) # Strip to remove the trailing space
```
In the traditional concatenation method, a loop iterates through the list of words, and each word is concatenated with a space. However, this approach requires creating a new string for each concatenation operation, which might not be efficient for larger strings due to string immutability.
The `join` method, on the other hand, is more efficient and concise. It joins the elements of the list using the specified separator (in this case, a space), creating the sentence in a single operation.
```py
.# Using join method
words = ['Python', 'is', 'awesome', 'and', 'powerful']
sentence = ' '.join(words)
print(sentence)
```
This method is generally the preferred way to join strings in Python due to its efficiency and readability.
## **Unpacking Lists**
Python's unpacking feature allows for efficient assignment of elements from iterables to variables.
Suppose you have a list of numbers, and you want to assign each number to separate variables using traditional indexing.
```py
# Using traditional unpacking
numbers = [1, 2, 3]
a = numbers[0]
b = numbers[1]
c = numbers[2]
print(a, b, c)
```
In the traditional unpacking method, individual elements from the list are accessed and assigned to separate variables by explicitly indexing each element. This method is more verbose and requires knowing the number of elements in advance.
Now, let's accomplish the same using the `*` operator for unpacking the list into variables.
```py
# Using * operator for unpacking
numbers = [1, 2, 3]
a, b, c = numbers
print(a, b, c)
```
You can learn more about the `*` operator and list unpacking in [this tutorial](https://blog.ashutoshkrris.in/mastering-list-destructuring-and-packing-in-python-a-comprehensive-guide#heading-destructuring-assignment).
## **Should You Always Use One-Liners?**
While Python one-liners offer conciseness and elegance, there are considerations to keep in mind before applying them universally:
1. **Readability** : One-liners might sacrifice readability for crispness. Complex one-liners can be hard to understand, especially for newcomers or when revisiting code after some time.
2. **Maintainability** : Overusing one-liners, especially complex ones, can make code maintenance challenging. Debugging and modifying concise code might be more difficult.
3. **Performance** : In certain scenarios, one-liners might not be the most performant solution. These concise expressions may consume more resources, such as memory or CPU, and their underlying operations might have higher time complexity, affecting efficiency, especially with large datasets or intensive computations.
4. **Debugging** : Debugging a one-liner can be more challenging due to its compactness. Identifying issues or errors might take longer compared to well-structured, multiple-line code.
5. **Context** : Not all situations warrant one-liners. Sometimes, a straightforward, explicit approach might be more suitable for code clarity, especially when working in teams.
Ultimately, the decision to use one-liners should consider the trade-offs between conciseness and readability. Strive for a balance that enhances code clarity without compromising maintainability and understanding, especially when collaborating or working on larger projects.
## **Wrapping Up**
Mastering Python's concise techniques like list comprehensions, lambda functions, `enumerate`, `join`, `zip`, and unpacking with the `*` operator can significantly enhance code readability, efficiency, and simplicity. These methods offer elegant solutions to common programming challenges, reducing verbosity and improving code maintainability.
Understanding when and how to use these Pythonic constructs empowers developers to write cleaner, more expressive code and enhance overall productivity in various programming scenarios. | ashutoshkrris |
1,683,403 | interrupt method | Interrupting a blocked thread (wait, sleep, join) will clear the interruption status Interrupting a... | 0 | 2023-11-30T04:27:22 | https://dev.to/chelsealiu0822/interrupt-method-1md4 | Interrupting a blocked thread (wait, sleep, join) will clear the interruption status
Interrupting a normally running thread will not clear the interruption status.
The interrupt state can be used to stop a thread.
# Two-stage termination model
Gracefully terminate the T2 thread in the T1 thread and give T2 a chance to take care of the aftermath (release locks and resources)
Interrupting the park thread will not clear the interruption status
After the interrupt flag is true, calling park again will fail.
# Not recommended method
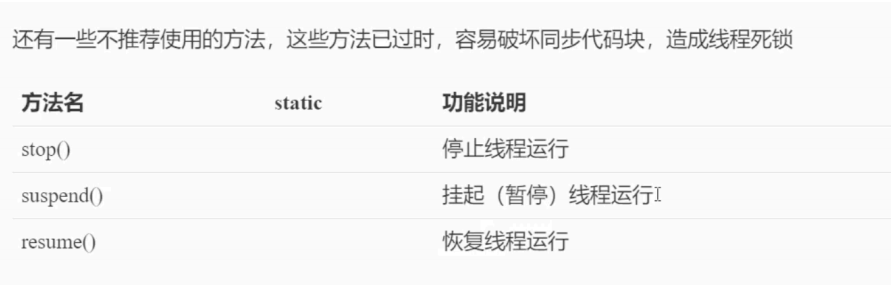
Will destroy the synchronized code block and cause deadlock
| chelsealiu0822 | |
1,683,407 | Key Takeaways from AWS re:Invent 2023 | As AWS re:Invent 2023 concludes, I find myself reflecting on a week brimming with transformative... | 0 | 2023-12-04T07:05:40 | https://dev.to/aditmodi/key-takeaways-from-aws-reinvent-2023-31cj | As AWS re:Invent 2023 concludes, I find myself reflecting on a week brimming with transformative innovations. This year’s event was not just a display of new technologies; it was a vivid portrayal of AWS's vision for the future of cloud computing. As a fervent advocate for AWS technologies I’ve been keenly observing the shifts and trends that emerged from this year's re:Invent. These developments have not only piqued my interest but have also reinforced my commitment to guiding and inspiring the next generation of technologists. Let’s explore the most impactful advancements and what they mean for the industry.
### The Frugal Architect: A Paradigm Shift in Cloud Computing
The concept of "The Frugal Architect," as presented by Dr. Werner Vogels, was a standout theme at re:Invent. It's not just a methodology; it's a mindset shift towards building sustainable, cost-effective cloud solutions that align with long-term business objectives. As someone who started early in the field and has seen various architectural strategies, this approach resonates with me deeply. It underscores the importance of viewing cost as a crucial, non-functional requirement, and making trade-offs that ensure longevity and efficiency of cloud solutions.
### AI and Data Management: The Titan Image Generator and Multimodal Embeddings
AWS's focus on AI and data management was evident with tools like the Titan Image Generator and Amazon Titan Multimodal Embeddings. The Titan Image Generator for Amazon Bedrock, enabling the creation of AI-generated images using text prompts, is a leap towards ethical AI usage. On the other hand, Multimodal Embeddings are set to revolutionize how we build search and recommendation systems, blending different data types to enhance accuracy and relevance. These tools are more than technological advancements; they are gateways to innovative and responsible AI applications.
### Amazon Q: A New AI-Powered Assistant

The introduction of Amazon Q marks a significant milestone in AI-driven business solutions. This AI-powered assistant can generate content, solve problems, and provide insights using organizational data. For someone like me, who’s deeply involved in AWS DevOps and Data, Amazon Q’s potential in streamlining complex business processes and decision-making is incredibly exciting. It's a tool that embodies AWS's commitment to making AI more accessible and functional in a business context.
### Zero-ETL Integrations for Seamless Data Management

The announcement of Zero-ETL integrations across various AWS analytics services is a game-changer. These integrations, especially with Amazon Redshift, OpenSearch Service, and S3, simplify data access and analysis by removing the need for complex ETL processes. This development aligns perfectly with the growing demand for streamlined data operations, making data analytics more efficient and accessible.

### Advancements in Cloud Infrastructure and Management
The advancements in cloud infrastructure and management have been particularly noteworthy this year. AWS CloudFormation's integration of Git management of stacks is a game-changer. It aligns infrastructure as code (IaC) with modern version control practices, enhancing collaboration and efficiency. Similarly, Console-to-Code and CodeWhisperer's AI-powered Code Remediation for IAC are stepping stones towards more intuitive and efficient cloud management. They simplify the process of translating console actions into IaC scripts, making cloud management more accessible, especially for those transitioning towards IaC methodologies.
Furthermore, the introduction of EFS Archive and EBS Snapshots Archive marks a significant step in data storage. These services provide cost-effective solutions for long-term data storage, addressing the growing need for affordable and efficient data archiving options in the cloud. These innovations are not just about technological advancement; they represent a deeper understanding of customer needs for efficient, secure, and cost-effective cloud infrastructure management.
### Enhancing Developer Experience with Advanced Tools
The unveiling of tools like AWS Management Console myApplications and Amazon SageMaker Studio Code Editor is a clear indication of AWS’s focus on enhancing the developer experience. In my own journey with AWS, tools that simplify and streamline processes have been invaluable. MyApplications is set to revolutionize application management, reducing the complexities that developers often face. Similarly, the SageMaker Studio Code Editor, leveraging the popular Code-OSS platform, presents an integrated environment that resonates with modern developers’ needs, especially in analytics and machine learning. These tools are not just about convenience; they represent AWS’s understanding of the evolving needs of developers and their pivotal role in the broader cloud ecosystem.
### EKS-Related Innovations: Transforming Container Management
This year's event also highlighted significant innovations related to Amazon EKS (Elastic Kubernetes Service), demonstrating AWS's commitment to optimizing container management and orchestration. The introduction of Amazon EKS Pod Identity and Amazon Managed Service for Prometheus indicates a shift towards more secure and efficient containerized application management. The general availability of the Mountpoint for Amazon S3 CSI driver for EKS enhances the integration of cloud storage solutions with Kubernetes, a development I find particularly exciting as a Community Builder for Containers.
Furthermore, the enhanced security in Amazon GuardDuty for ECS and Fargate, coupled with the general availability of Apache Flink for Amazon EMR on EKS, underscores AWS's focus on providing robust, secure, and efficient solutions for managing containerized applications. These innovations offer more dynamic, secure, and scalable solutions for deploying and managing container-based applications, crucial for today's fast-evolving tech landscape.
### Data and Analytics: Vector Database Integrations and More
AWS re:Invent 2023 also put a spotlight on data and analytics advancements, with a particular focus on vector database integrations and serverless solutions. The introduction of the Vector Engine for Amazon OpenSearch Serverless is a testament to AWS's commitment to enhancing data search and analysis capabilities. This tool allows for efficient storage, updating, and searching of large-scale vector embeddings, crucial for applications requiring advanced search functionalities.
Additionally, the Amazon Aurora Limitless Database and Amazon ElastiCache Serverless present a new horizon in scalable cloud databases and managed cache services. These serverless offerings provide auto-scaling capabilities and quick setup options, ideal for applications with unpredictable access patterns and massive, fluctuating workloads. As someone deeply involved in exploring AWS Data solutions, these developments are pivotal in enabling businesses to manage their data more effectively and extract deeper insights.
### Focus on Generative AI and Partner Network Expansion
Generative AI was a significant theme, with AWS emphasizing its role in the partner ecosystem. Ruba Borno's keynote highlighted the potential of generative AI in driving innovation and economic growth. The focus on expanding the partner network and introducing new specializations and tools demonstrates AWS's commitment to collaborative growth and innovation in the field of AI.
### AWS's Commitment to Education and Growth
Finally, AWS's commitment to education and growth remains evident. AWS continues to invest in resources and programs that enable individuals and businesses to learn, innovate, and scale their operations effectively in the cloud. For young enthusiasts like myself, AWS re:Invent is not just an event but a learning experience that shapes our understanding and approach to cloud computing.
### Personal Reflections on AWS’s Evolution
Throughout re:Invent 2023, what stood out to me was AWS's continued focus on innovating in a way that not only advances technology but also addresses the real-world challenges we face in the industry. As a young tech enthusiast who started early in my twenties and quickly grew to become an AWS Ambassador and Community Builder, I see these advancements as opportunities for all of us in the AWS ecosystem to grow and innovate.
### Tools I Swear By
Tools like [Raphael Manke](https://twitter.com/RaphaelManke)'s "[Unofficial Re:Invent Schedule Planner](http://reinvent-23.vercel.app/)" has become indispensable for navigating the plethora of sessions. Similarly, [Luc van Donkersgoed](https://twitter.com/donkersgood)'s "[AWS News Feed](https://awsnews.l15d.com/)" tool is part of my daily routine to stay updated with AWS announcements.
### Staying Connected and Upcoming Events
To keep up with my favorite talks from AWS re:Invent, check out my Twitter thread [link here](https://x.com/adi_12_modi/status/1730231090177053125?s=20) or follow me for regular updates. I've also been documenting the announcements each day on my Hashnode blog [link here]().
Next week, I am excited to meet at the AWS User Group Vadodara meetup, where I'll be sharing AWS credit codes worth $50. It's a great opportunity for us to connect and discuss the latest in AWS. Additionally, we're planning a re:Invent 2023 recap session for the AWS UG Vadodara in January, where we’ll dive deeper into these announcements and their implications.

### Looking Ahead
As AWS re:Invent 2023 wraps up, I’m left reflecting on how these developments will influence our work in the AWS community. Whether it’s guiding aspiring technologists, discussing the latest in AWS DevOps, or exploring data solutions, the advancements announced at re:Invent provide us with new tools and capabilities to explore and master.

All Image Credits: [Matt Wood](https://www.linkedin.com/in/themza/)

couldn't agree more - [Grimy Underside](https://twitter.com/monkchips)
### Conclusion
AWS re:Invent 2023 has been more than just a showcase of new technologies; it has been a source of inspiration and a guidepost for what’s possible. For me and for many others passionate about AWS, it’s a reminder of why we do what we do – to drive innovation, foster learning, and build a more efficient, secure, and sustainable future in cloud computing. Let's take these insights and turn them into action, continuing to grow and shape the world of AWS. | aditmodi | |
1,683,510 | Writing a Great Post Title | Editor Basics Use Markdown to write and format posts. Commonly used syntax Embed rich content such as... | 0 | 2023-11-30T06:03:10 | https://dev.to/ankitmalviya/writing-a-great-post-title-56ki | webdev, programming | Editor Basics
Use Markdown to write and format posts.
Commonly used syntax
Embed rich content such as Tweets, YouTube videos, etc. Use the complete URL: See a list of supported embeds.
In addition to images for the post's content, you can also drag and drop a cover image. | ankitmalviya |
1,683,519 | Innovate and Elevate: Piccosoft Visionary Approach to Hyperledger Fabric | Introduction As businesses grapple with the increasing demand for secure, efficient, and transparent... | 0 | 2023-11-30T06:12:53 | https://dev.to/zacharyv/innovate-and-elevate-piccosoft-visionary-approach-to-hyperledger-fabric-327h | hyperledger, piccosoft, webdev | **Introduction**
As businesses grapple with the increasing demand for secure, efficient, and transparent processes, Hyperledger Fabric emerges as a pivotal tool, providing a foundation for developing tailored blockchain applications. It helps companies by making sure their data is super secure, easy to track, and can be trusted. It ensures only authorized people can access information, making it nearly impossible for any sneaky business. Think about a supply chain — it ensures we know exactly where products come from and if they’re genuine. In banking, it helps with things like payments and settlements, keeping everything safe and private.
From tracking where products come from in supply chains to making secure transactions in banking, Hyperledger Fabric is the go-to for businesses like IBM and Walmart, streamlining operations and ensuring trust.
**What is Hyperledger Fabric?**
Hyperledger Fabric, initially developed by IBM, has evolved into a leading blockchain framework overseen by the Linux Foundation, emphasizing an open-source, collaborative, and community-driven approach. Operating within the Hyperledger project, Fabric distinguishes itself with a permissioned blockchain approach, where only authorized participants have access, ensuring enhanced privacy and control over sensitive data. Its design includes support for smart contracts, known as “chaincode,” enabling automated and self-executing agreements.
Hyperledger Fabric is particularly notable for its plug-and-play architecture, providing businesses with the flexibility to choose and integrate specific components relevant to their use cases. This adaptability extends its applications across a spectrum of industries, from transforming supply chain transparency and streamlining financial transactions to securing healthcare records and facilitating government services.
Hyperledger Fabric, with its emphasis on security, scalability, and customization, continues to play a pivotal role in reshaping how businesses approach blockchain technology in the digital age. It stands among the most widely adopted blockchain frameworks and has found application in companies such as Google, Microsoft, Samsung, Alibaba, and numerous others.
**How does Hyperledger Fabric works**
Hyperledger Fabric operates as a permissioned blockchain framework, ensuring that participants are authorized to join the network, thereby enhancing privacy and control. The network comprises nodes with specific roles, including peers, endorsing peers, orderers, and clients. Transactions in Hyperledger Fabric involve a client proposing an action, which undergoes endorsement by validating peers, packaging by orderers into a block, and distribution to peers. Peers maintain copies of the ledger, endorsing peers validate transactions, orderers create blocks of transactions, and clients interact with the network.
A transaction begins with a client proposing an action, creating a transaction proposal. This proposal is sent to endorsing peers, which simulate the transaction and provide an endorsement. The endorsed transaction is then sent to orderers, who package it into a block and distribute it to peers. Once a block is added to the ledger, it is cryptographically linked to the previous blocks, creating an immutable record. Hyperledger Fabric also provides channels, allowing subsets of participants to have private transactions, ensuring privacy within the network.
The ledger records all transactions cryptographically, creating an immutable history. Hyperledger Fabric offers channels for private transactions, ensuring data privacy. Its modular architecture allows organizations to customize components, providing flexibility for diverse use cases.
**Benefits of Hyperledger**
**Privacy and Permissioned Access**
Hyperledger Fabric operates as a permissioned blockchain, ensuring that only authorized participants have access. This feature enhances privacy and control over sensitive data, making it suitable for enterprise applications.
**Modular Architecture**
Its modular architecture allows businesses to customize their blockchain networks by selecting and integrating specific components, providing flexibility and adaptability to various use cases.
**Scalability**
Hyperledger Fabric is designed to scale efficiently, accommodating increased transaction volumes as businesses grow. This scalability is crucial for enterprises with evolving needs.
**Smart Contracts (Chaincode)**
Support for smart contracts, known as chaincode, enables the automation of predefined business logic. This feature enhances efficiency by automating and self-executing agreements within the network.
**Consensus Mechanisms**
Hyperledger Fabric supports multiple consensus mechanisms, including Practical Byzantine Fault Tolerance (PBFT). This ensures agreement among network participants on the state of the ledger, contributing to a robust and secure system.
**Interoperability**
The Hyperledger project is committed to fostering interoperability among different blockchain frameworks. This allows businesses to integrate Hyperledger Fabric with existing systems and technologies seamlessly.
**Security and Immutability**
Transactions in Hyperledger Fabric are cryptographically secured, creating an immutable and tamper-proof record. The framework employs advanced security measures to protect the integrity of the data stored on the blockchain.
**Permissioned Network Governance**
Hyperledger Fabric provides a governance model for managing the permissioned network. This allows organizations to define rules and policies, ensuring a controlled and regulated environment.
**Use Case Versatility**
Hyperledger Fabric’s adaptability makes it suitable for a wide range of use cases across industries, including supply chain management, finance, healthcare, and more.
**Community and Support**
Being a part of the Hyperledger project, Hyperledger Fabric benefits from a vibrant and collaborative community. This ensures ongoing development, innovation, and support from a diverse group of contributors.
**Applications**
These applications illustrate the versatility of Hyperledger Fabric, showcasing its ability to address diverse business challenges across different industries.
**Supply Chain Management**
Hyperledger Fabric is employed to enhance transparency and traceability in supply chains, tracking the movement of goods and ensuring data integrity.
IBM Food Trust uses Hyperledger Fabric for a transparent and traceable food supply chain, allowing participants to trace the origin and journey of food products.
**Finance and Banking**
Used for applications such as cross-border payments, trade finance, and settlements, Hyperledger Fabric’s permissioned network structure is suitable for financial institutions requiring privacy and control.
**Healthcare**
Explored for managing healthcare records, ensuring data integrity, and providing secure and auditable access to patient information, enhancing interoperability in the healthcare industry.
**Government Services**
Considered for applications in identity management, voting systems, and public records, leveraging its secure and transparent ledger for enhancing trust in government processes.
**Smart Contracts and Legal Applications**
Hyperledger Fabric supports smart contracts, enabling the automation of contract execution based on predefined rules, applicable in legal processes to reduce the need for intermediaries.
**Insurance**
Utilized in the insurance industry for policy management, claims processing, and fraud prevention, with its permissioned model ensuring privacy and confidentiality in transactions.
**Manufacturing and Quality Assurance**
Applied in manufacturing to create transparent and auditable records of the production process, particularly useful for tracking product quality and ensuring compliance with industry standards.
**Education and Credentialing**
Explored for managing educational credentials, certifications, and diplomas, providing a secure and verifiable way to store and share academic achievements.
**Real Estate**
Used for transparent and efficient real estate transactions, including property sales, leasing, and management, streamlining processes and reducing fraud.
**Energy Trading**
Facilitates transparent and decentralized energy trading platforms in the energy sector, enabling efficient and secure transactions between producers and consumers.
**Conclusion**
Hyperledger Fabric emerges as a versatile and powerful solution, seamlessly addressing a myriad of business challenges across diverse industries. Its permissioned network, modular architecture, and support for smart contracts make it an ideal choice for enterprises seeking secure, scalable, and customizable blockchain applications.
[Piccosoft](https://www.piccosoft.com/) is gearing up to introduce forthcoming solutions that harness the power of Hyperledger Fabric. As a leading force in blockchain development, Piccosoft’s commitment to delivering cutting-edge and tailored applications positions them as a valuable partner for organizations looking to navigate the evolving landscape of distributed ledger technology. | zacharyv |
1,683,542 | WHO IS A FULL STACK DEVELOPER? | A full-stack developer is a software engineer who can build both the front-end and back-end of a... | 0 | 2023-11-30T06:42:34 | https://dev.to/betpido/who-is-a-full-stack-developer-2cag |
A full-stack developer is a software engineer who can build both the front-end and back-end of a website or application.
They are responsible for designing, developing, and maintaining the entire software stack of a web application, which includes the user interface, server-side logic, and database.
Full-stack developers are proficient in both front-end and back-end technologies and have a good understanding of how they interact with each other.
They are also skilled in programming languages such as HTML, CSS, JavaScript, Python, PHP, Ruby on Rails, and CakePHP.
Full-stack developers can work in-house or at a computer development company that engineers websites, software, and other components for other businesses1.
If you’re interested in becoming a full-stack developer, you can start by learning the necessary skills and technologies through online courses and tutorials.
HOW LONG DOES IT TAKE TO BECOME A FULL-STACK DEVELOPER ?
The time it takes to become a full-stack developer can vary depending on the amount of time and effort you put into learning.
The time it takes to become a full-stack developer can vary depending on your learning pace and the amount of time you can dedicate to learning.
However, with the right resources and dedication, you can become a full-stack developer in as little as 90 days or as long as 6 months or more. | betpido | |
1,683,659 | Exploring the Rising Trend of Sweet Drinks in the Beverage Industry | The Sweet Temptation: A Global Phenomenon From this article you can learn sweet drink.... | 0 | 2023-11-30T08:59:58 | https://dev.to/judyvegaqa/exploring-the-rising-trend-of-sweet-drinks-in-the-beverage-industry-2fgg | ## The Sweet Temptation: A Global Phenomenon
From this article you can learn [sweet drink](https://glacierfreshfilter.com/de/blogs/news/the-secret-world-of-sweet-drinks-what-your-slaver-reveals-about-diet-tonics?utm_source=dev_to&utm_medium=rankking).
Over the past decade, the beverage industry has witnessed a remarkable surge in the popularity of sweet drinks. From carbonated sodas to fruit-flavored beverages, consumers around the world are increasingly drawn to these sugary concoctions. This article delves into the reasons behind this rising trend and explores the impact it has on the beverage industry.
## The Science of Sweetness
Humans have an innate preference for sweetness. It is a taste that is universally enjoyed across cultures and age groups. This natural inclination towards sweetness has been exploited by the beverage industry, which has developed a wide range of sweet drinks to cater to this demand. Whether it's the refreshing sweetness of a lemonade or the indulgent pleasure of a milkshake, these beverages provide an instant gratification that is hard to resist.
## Changing Lifestyles and Consumer Preferences
The rising trend of sweet drinks can be attributed, in part, to changing lifestyles and consumer preferences. As people lead increasingly busy lives, they seek quick and convenient options for refreshment. Sweet drinks offer a convenient solution, providing a burst of energy and satisfaction in a single sip. Moreover, the growing influence of social media and the rise of food and beverage influencers have also played a significant role in popularizing sweet drinks. Eye-catching photos and videos of colorful and decadent beverages have captivated audiences worldwide, driving the demand for these sugary treats.
## The Health Conundrum: Balancing Taste and Wellness
While sweet drinks may be undeniably delicious, they also raise concerns about their impact on health. Excessive consumption of sugary beverages has been linked to various health issues, including obesity, diabetes, and tooth decay. As a result, health-conscious consumers are increasingly seeking healthier alternatives to satisfy their sweet cravings. This has led to the emergence of a new wave of sweet drinks that are low in sugar or made with natural sweeteners. These products aim to strike a balance between taste and wellness, catering to the evolving needs of health-conscious consumers.
Despite the health concerns associated with sweet drinks, the industry continues to innovate and adapt to changing consumer demands. From the introduction of sugar-free options to the use of innovative ingredients, beverage companies are constantly exploring new ways to cater to the rising trend of sweet drinks while addressing health concerns.
As the beverage industry continues to evolve, it is crucial for consumers to make informed choices about their beverage consumption. By understanding the impact of sweet drinks on their health and exploring alternatives, individuals can strike a balance between indulgence and wellness.
## Conclusion
The rising trend of sweet drinks in the beverage industry is a global phenomenon driven by changing lifestyles, consumer preferences, and the innate human desire for sweetness. While these beverages offer instant gratification and enjoyment, it is important to be mindful of their potential health implications. By exploring healthier alternatives and making informed choices, consumers can continue to indulge in the sweet temptation while prioritizing their well-being.
## References
* [sweet drink](https://www.ksgovjobs.com/Applicants/ThirdPartyLink/1?thirdParty=https://glacierfreshfilter.com/de/blogs/news/the-secret-world-of-sweet-drinks-what-your-slaver-reveals-about-diet-tonics "sweet drink")
### References:
* [Healthline - Sugary Drinks and Health](https://www.healthline.com/nutrition/sugary-drinks-and-health#section1)
* [National Center for Biotechnology Information - Sugary Drinks and Obesity](https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5793267/)
* [World Health Organization - Healthy Diet](https://www.who.int/news-room/fact-sheets/detail/healthy-diet)
| judyvegaqa | |
1,683,685 | How to Use Cypress in Headless Mode | Tests are often carried out on real browsers to test the actual user experience. This approach... | 0 | 2023-11-30T09:20:37 | https://www.lambdatest.com/blog/cypress-headless-mode/ | cypress, webdev, programming, tutorial | Tests are often carried out on real browsers to test the actual user experience. This approach ensures that the web application or site is examined in the real-world environment it is intended for, enabling testers to identify and address any issues that may impact user satisfaction and functionality. Testing on real browsers helps detect discrepancies that might not be apparent in simulated or emulated environments, ultimately leading to a more accurate assessment of the user experience.
However, running tests on a real browser can be slow because the browser needs to start up and load each web page before the tests can run, which can take a significant amount of time.
Additionally, running tests on a real browser can consume a lot of memory and other system resources, slowing down other processes and making the test environment less stable. This is why many developers opt to use headless browsers, which can simulate the behavior of a real browser without actually running the full application.
Some common issues when performing [UI testing](https://www.lambdatest.com/learning-hub/ui-testing?utm_source=devto&utm_medium=organic&utm_campaign=nov_30&utm_term=bh&utm_content=learning_hub) with a web browser include:
* **Flakiness:** Tests may randomly fail or pass due to elements not loading correctly or other unpredictable behavior.
* **Slow performance:** Running tests on browser instances can be slow and time-consuming, especially if there are many tests or if the tests are running on multiple browsers.
* **False negatives/positives:** Sometimes, the tests may fail or pass incorrectly due to timing, network connectivity, or race conditions.
* **Test environment setup:** Setting up the [test environment](https://www.lambdatest.com/blog/what-is-test-environment/?utm_source=devto&utm_medium=organic&utm_campaign=nov_30&utm_term=bh&utm_content=blog), including installing the necessary browsers and drivers, can be challenging and time-consuming.
* **Page load time:** Page load time is the time that passes between the browser sending the request to the server and the page fully loading. Sometimes, even if we have a good infrastructure, the page takes too long to load, and it can cause UI tests to fail or produce unreliable results.
This is where headless browsers come into the picture. In web browsers, headless mode refers to running a browser instance without opening a visual window. This can be useful for automated testing or running a browser programmatically as part of a larger system.
Most modern web browsers, including Chrome, Firefox, and WebKit, support headless mode. Headless testing can be faster and less resource-intensive than UI testing, as it does not require a real device or a simulation of the real environment.
You can perform headless browser testing using Cypress on a cloud-based Grid that supports using [Cypress](https://www.lambdatest.com/learning-hub/cypress-tutorial?utm_source=devto&utm_medium=organic&utm_campaign=nov_30&utm_term=bh&utm_content=learning_hub) in headless mode. This means that you can perform [Cypress testing](https://www.lambdatest.com/cypress-testing?utm_source=devto&utm_medium=organic&utm_campaign=nov_30&utm_term=bh&utm_content=learning_hub) in a browser environment without the need to have a GUI visible.
In this tutorial, you will learn how to run tests using Cypress in headless mode on popular browsers like Chrome, Firefox, and WebKit.
> **Perform live mobile website tests on different devices with LT Browser 2.0. [test website on all device](https://www.lambdatest.com/test-site-on-mobile?utm_source=devto&utm_medium=organic&utm_campaign=nov_30&utm_term=bh&utm_content=webpage)** s**and tablet viewports and debug UI issues on the go across 50+ device viewports!**
## Why use Headless Browser Testing?
When conducting [end-to-end tests](https://www.lambdatest.com/learning-hub/end-to-end-testing?utm_source=devto&utm_medium=organic&utm_campaign=nov_30&utm_term=bh&utm_content=learning_hub) with a headless browser, the application’s user interface won’t be loaded by the browser. As a result, everything operates more quickly, and there is less risk of instability because the tests immediately interact with the website. Your tests become quicker, more accurate, and more effective.
There are several reasons why you might want to run Cypress in headless mode:
* **Speed:** Headless browsers are often faster and use fewer resources than traditional browsers because they do not have to render the GUI. This can be useful for tasks requiring a lot of processing power or running tests on a server with limited resources.
* **Flexibility:** Headless browsers can be run on various platforms, including Linux, Windows, and Mac. This makes running tests on different environments easy, which can help ensure that your website (or web app) works as expected on various devices and operating systems.
* **Cost-effectiveness:** Headless browser testing is cost-effective as it eliminates the need for expensive hardware and software to run tests.
* **Automation:** Headless browsers allow you to perform automated or repeatable tasks without interacting manually with the GUI. This can be particularly useful for tasks such as testing web applications or automating interactions on elements in any website.
* **Server-side rendering:** Headless browsers can render web pages on the server side. This helps optimize web application performance and improve the end-user experience.
* **Simulating real user behavior:** Headless browsers let developers simulate real user behavior on the website, which can help identify issues other methods may not catch.
* **Compatibility:** Headless browsers can test the website’s compatibility with different browser versions.
* **Testing:** Headless browsers can be used for [web application testing](https://www.lambdatest.com/learning-hub/web-application-testing?utm_source=devto&utm_medium=organic&utm_campaign=nov_30&utm_term=bh&utm_content=learning_hub), as they let you simulate a browser environment and make assertions about the behavior of your application.
* **Realistic testing:** During headless testing, the browser operates in a manner akin to a genuine browser, actively loading all resources such as images, CSS, JavaScript, and more. This approach enables a more authentic testing experience, facilitating the detection of potential issues that might remain undetected when employing alternative testing methods.
* **CI/CD Integration:** Headless tests reap more benefits when run with CI/CD tools because they consume fewer resources (i.e., CPU, RAM, etc.). Even in scenarios where the pipeline is executed in a remote environment, you can expect quicker results due to the inherently faster nature of headless testing.
* **Resource efficiency:** Running tests without a GUI requires fewer resources, making headless browser testing more efficient.
## Criteria for Choosing Headless Browsers
You should always choose a headless browser that is lightweight and uses very few resources so that you can run it in the background without hindering development work.
Many headless options are available, including tools to simulate multiple browsers and headless versions of well-known browsers like Chrome and Firefox. We have some factors to utilize in deciding which browsers are optimal for web development and testing.
Here are some factors to consider when selecting a headless browser for [web testing](https://www.lambdatest.com/learning-hub/web-application-testing?utm_source=devto&utm_medium=organic&utm_campaign=nov_30&utm_term=bh&utm_content=learning_hub):
* **Compatibility:** Ensure the headless browser is compatible with your operating system and the programming language you plan to use for web testing.
* **Features:** Consider the features important for your web testing, such as support for JavaScript, cookies, and web standards. Some headless browsers offer advanced features such as automatic form-filling, screenshot capture, and network emulation.
* **Performance:** Consider the performance of the headless browser, including its speed and resource usage, as web testing can be resource-intensive when we have to test our application in multiple headless browsers.
* **Ease of use:** Consider how easy it is to use the headless browser and whether it has good documentation and a supportive community.
* **Support:** It’s important to choose a headless browser that is actively maintained and has a large community of users for support and troubleshooting.
> **Perform live mobile website tests on different devices with LT Browser 2.0. [test website on mobile devices online free](https://www.lambdatest.com/test-site-on-mobile?utm_source=devto&utm_medium=organic&utm_campaign=nov_30&utm_term=bh&utm_content=webpage) and tablet viewports and debug UI issues on the go across 50+ device viewports!**
## Popular Headless Browsers
The choice of using Cypress in headless mode depends entirely on the specific application requirements you are testing. Headless browser allows you to run the [test cases](https://www.lambdatest.com/learning-hub/test-case?utm_source=devto&utm_medium=organic&utm_campaign=nov_30&utm_term=bh&utm_content=learning_hub) in a headless (i.e., GUI-less) environment, which can be useful for running tests in a Continuous Integration (CI) environment or scripts that don’t require a visible UI.
Here are some commonly used headless browsers (irrespective of whether the framework is being used for [automated testing)](https://www.lambdatest.com/learning-hub/automation-testing?utm_source=devto&utm_medium=organic&utm_campaign=nov_30&utm_term=bh&utm_content=learning_hub)
* Firefox Headless
* Chrome Headless
* WebKit Headless
* PhantomJS
* HtmlUnit Browsers
Though I have listed all major headless browsers, it is important to note that Cypress supports Firefox, Chrome, and WebKit headless browsers.
## Firefox headless mode
Firefox headless mode is a web browser that allows you to test the application without the head. You cannot see anything while accessing any website using a headless browser. The application, however, operates in the background, and you can monitor the execution result once the test cases have finished running.
Firefox headless mode can be an effective option for automating web browsing tasks using Cypress. By running Firefox using Cypress in headless mode, you can interact with the browser as a regular user.
## Chrome headless mode
Google’s Chrome team included headless Chrome mode in their browser, making running a Chrome headless browser from the command line easier.
Running tests using Cypress in headless mode makes fast test case execution and eliminates the need for manual interaction with the browser during testing.
## WebKit headless mode
WebKit is an open-source web browser engine developed by Apple and used in the Safari browser. The headless mode of WebKit is a feature that allows the engine to run without a browser.
You can run tests on WebKit using Cypress in headless mode. To run Cypress test cases in WebKit, we must do some config settings and add the dependency. Add *experimentalWebKitSupport:* true in the cypress.config.js file to enable the experiment. Add dependency using the command to install the playwright-webkit NPM package in your repo to acquire WebKit: *npm install* *–save-dev playwright-webkit*.
> **Explore the evolution of Apple’s iOS! From iPhone OS to the latest iOS 16, dive into the journey that powers [ios mobile device](https://www.lambdatest.com/software-testing-questions/what-is-an-ios-device?utm_source=devto&utm_medium=organic&utm_campaign=nov_30&utm_term=bh&utm_content=stq)**- **iPhones, iPod Touches, and iPads. Uncover the history and future of this iconic operating system!**
## PhantomJS headless mode
PhantomJS is a popular solution for running browser-based [unit tests](https://www.lambdatest.com/learning-hub/unit-testing?utm_source=devto&utm_medium=organic&utm_campaign=nov_30&utm_term=bh&utm_content=learning_hub) in a headless system like a continuous integration environment since it provides a JavaScript API that enables automated navigation, screenshots, user behavior, and assertions.
Additionally, PhantomJS can be used to automate tasks such as filling out forms, clicking buttons, and navigating pages, which can be useful for functional and [regression testing](https://www.lambdatest.com/learning-hub/regression-testing?utm_source=devto&utm_medium=organic&utm_campaign=nov_30&utm_term=bh&utm_content=learning_hub).
Some common use cases include:
* PhantomJS can interact with web pages similarly to a web browser, allowing developers to automate tasks such as filling out forms, clicking buttons, and navigating between pages.
* It can extract data from web pages, such as scraping product prices from an eCommerce site or extracting data from a table on a web page.
* PhantomJS can generate screenshots or PDFs of web pages, which can help create reports or test a website’s appearance on different devices and screen resolutions.
## HtmlUnit headless mode
HtmlUnit is a Java-based headless browser that allows developers to automate web page interactions. It can be controlled programmatically, allowing developers to simulate a user navigating a website and interacting with its elements, such as clicking buttons and filling out forms. HtmlUnit supports JavaScript and can work with various web standards, making it a versatile tool for web development and testing.
It can be integrated with popular testing frameworks such as JUnit and TestNG, allowing developers to write tests in Java and run them in HtmlUnit.
Additionally, HtmlUnit can be useful for testing web applications by simulating interactions with the web page and checking the resulting page source or [DOM](https://www.lambdatest.com/blog/document-object-model/?utm_source=devto&utm_medium=organic&utm_campaign=nov_30&utm_term=bh&utm_content=blog).
Use case in [software testing](https://www.lambdatest.com/learning-hub/software-testing?utm_source=devto&utm_medium=organic&utm_campaign=nov_30&utm_term=bh&utm_content=learning_hub) using HtmlUnit headless browser:
* Developers could use HtmlUnit to simulate a user logging into a web application by navigating to the login page, filling out the login form, and submitting it.
* You can use HtmlUnit to navigate to various web application pages, interacting with elements such as buttons and links and asserting that the expected results occur.
As mentioned, Cypress supports Firefox, Chrome, and WebKit headless browsers. Hence, I would be demonstrating Cypress headless testing on the said browsers.
> [**Mobile device test](https://www.lambdatest.com/real-device-cloud?utm_source=devto&utm_medium=organic&utm_campaign=nov_30&utm_term=bh&utm_content=webpage) and website on real iOS and Android devices hosted on the cloud. LambdaTest is a convenient, cost-effective and centralised solution for running realtime and Automated test on real device cloud.**
## Testing with Cypress in Headless Mode
Before explaining how to run the test cases in headless mode in Cypress, let’s set up a Cypress project first.
To explain how we can run test cases in headless mode in Cypress, I will test a typical eCommerce site: [LambdaTest eCommerce Playground](https://ecommerce-playground.lambdatest.io/?utm_source=devto&utm_medium=organic&utm_campaign=nov_30&utm_term=bh&utm_content=webpage).
## Implementation Test Scenario
In this [Cypress tutorial](https://www.lambdatest.com/learning-hub/cypress-tutorial?utm_source=devto&utm_medium=organic&utm_campaign=nov_30&utm_term=bh&utm_content=learning_hub), we are using the below example to run the Cypress test case in a headless browser in Local Grid and LambdaTest Grid.
**Test Scenario:**
1. Open the Site [https://ecommerce-playground.lambdatest.io/index.php?route=account/login](https://ecommerce-playground.lambdatest.io/index.php?route=account/login).
2. Enter the email address.
3. Enter the password.
4. Click on the Login button.
5. Click on the ‘All Categories’ drop-down.
6. Enter the product to search.
7. Search the product.
8. Verify the correct product is searched.
## Setting up Cypress
You can establish a new Cypress project by following the instructions below:
**Step 1:** Create a folder and generate package.json.
1. Create a project by Cypress_Headless.
2. Create a package.json file using the npm init command.
**Step 2:** Install Cypress
Run this command in the newly created folder to install Cypress.
npm install cypress — save-dev
OR
yarn add cypress — dev
Cypress will be installed locally as a dev dependency for your project.
***Note: **Cypress version 12.3.0 is installed, as shown below. At the time of writing this blog, the most recent version of Cypress is 12.3.0*
{
"name": "cypress_headless",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"author": "Kailash Pathak",
"license": "ISC",
"dependencies": {
"cypress": "^12.3.0"
}
}
> **Stop using the same password for everything! Create strong and unique passwords that are difficult to guess with our [Random Password Generator](https://www.lambdatest.com/free-online-tools/random-password-generator?utm_source=devto&utm_medium=organic&utm_campaign=nov_30&utm_term=bh&utm_content=free_online_tools). Try it now!**
## Different ways to run Cypress tests in a headless browser
There are various ways of executing the Cypress test cases in headless browser mode.
1. To run all the test cases of the e2e folder in headless mode, use the *yarn cypress run* command. This command will run all the test cases under the e2e folder.
2. To run the particular .spec file in the headless mode, you can run the command *yarn cypress run –spec cypress/e2e/example.cy.js*.
3. Another way of running the test cases in headless mode is by adding scripts to the package.json. To run all test cases, we must run the command *yarn run cy:run* in the terminal. This command will execute all the test cases in headless mode.
{
"name": "cypress_headless",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"cy:run": "yarn cypress run"
},
"author": "<>",
"license": "ISC",
"dependencies": {
"cypress": "^12.3.0"
}
}
4. To run the test case on a particular browser in headless mode, we can add the script in package.json. To run all test cases in the Chrome browser, use the *yarn run cy:run:chrome* command in the terminal. To run all test cases in the Firefox browser, use the command *yarn run cy:run:firefox* in the terminal. To run all test cases in the Electron browser, use the command *yarn run cy:run:electron* in the terminal.
"name": "cypress_headless",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"cy:run:chrome": “yarn cypress run --browser chrome --headless"
"cy:run:firefox": “yarn cypress run --browser firefox --headless"
"cy:run:electron": “yarn cypress run --browser electron --headless"
},
"author": "<>",
"license": "ISC",
"dependencies": {
"cypress": "^12.3.0"
}
}
5. Another way to run the Cypress test cases in headless mode is running the test cases in the CI/CD pipeline. Below is an example of GitHub Action. Here, you can see we are executing Cypress test cases in the container with the Chrome browser.
name: Cypress Tests
on: [push]
jobs:
cypress-run:
runs-on: ubuntu-latest
container: cypress/browsers:node12.18.3-chrome87-ff82
steps:
- name: Checkout
uses: actions/checkout@v2
# Install NPM
# and run all Cypress tests
- name: Cypress run
uses: cypress-io/github-action@v4
with:
# Specify the Browser
browser: chrome
> **Generate custom QR codes for your business or personal needs with our fast and easy-to-use [QR code generator](https://www.lambdatest.com/free-online-tools/qr-code-generator?utm_source=devto&utm_medium=organic&utm_campaign=nov_30&utm_term=bh&utm_content=free_online_tools) online tool in seconds. Try it now!**
## Folder Structure
The default folder structure for Cypress is displayed below. Under the “**e2e**” subdirectory, test cases can be created.

Let’s create test cases under the folder Cypress_Headless -> e2e. Create a .spec file with the name *login_searchproduct.cy.js*.
Create a *login_searchproduct.spec.js* file with the script below. This includes logging into the application and conducting a product search. Verify the right product should be displayed after the search.
/// <reference types="cypress" />
context("GIVEN Browser is already open ", { testIsolation: false }, () => {
it("WHEN User Open the Url", () => {
cy.visit(
"https://ecommerce-playground.lambdatest.io/index.php?route=account/login"
);
});
it("AND Login into the application", () => {
cy.get('[id="input-email"]').type("lambdatest@yopmail.com");
cy.get('[id="input-password"]').type("lambdatest");
cy.get('[type="submit"]').eq(0).click();
});
it("AND Click On All Categories drop down and Search the Product", () => {
cy.get('[data-toggle="dropdown"]').eq(0).click();
cy.contains("Laptops").click({ force: true });
cy.get('[name="search"]').eq(0).type("Apple").should("have.value", "Apple");
cy.get('[type="submit"]').eq(0).click();
});
it("THEN Verify Correct Product with name'iPod Shuffle' should display after Search ", () => {
cy.contains("iPod Shuffle");
});
});
> **Need to know how many characters are in your text? Get an accurate [characters count](https://www.lambdatest.com/free-online-tools/character-count?utm_source=devto&utm_medium=organic&utm_campaign=nov_30&utm_term=bh&utm_content=free_online_tools) in your text with our free online tool. Try it now and see how easy it is!**
**Code Walkthrough**
In the above code snippet, we have opened the target URL using *cy.visit()*, and second, *it()* block is used to log in to the application by entering email and password.
In the third, *it()* block clicks on the ‘All Categories’ drop down and searches for the product., Finally, the last *it()* block is used to verify the searched product.
In the below screenshot, you can see how we can inspect the element. We have located the element by *id* for the email field.
cy.get(‘[id=”input-email”]’).type(“lambdatest@yopmail.com”);
Now, let’s run the above test scenario in headless browsers. We will run the test cases first locally, then we will run the same scenario on the [LambdaTest Cypress cloud](https://www.lambdatest.com/cypress-testing?utm_source=devto&utm_medium=organic&utm_campaign=nov_30&utm_term=bh&utm_content=webpage).
## Cypress Headless Testing on Local Grid
## Running tests on Chrome using Cypress in Headless Mode
Headless Chrome is a web browser that can run automated tests without opening a Chrome window. This empowers you to create tests capable of mimicking user interactions with your web application and verifying that the application functions as intended.
Run the above scenario locally in headless mode using Chrome using the below command.
yarn cypress run — browser chrome — headless
As we run the above command, test cases start executing locally in the Chrome headless mode.

> **Accurately count the number of words in your text with our easy-to-use word count tool. Perfect for meeting [word count](https://www.lambdatest.com/free-online-tools/word-count?utm_source=devto&utm_medium=organic&utm_campaign=nov_30&utm_term=bh&utm_content=free_online_tools) requirements. Try it out now for free!**
## Running tests on Firefox using Cypress in Headless Mode
To run the Cypress test cases in Firefox’s headless browser, you have to run the below command, which will run in the background, and finally, you will get the Pass/Fail result in the form of a report.
Run the above scenario locally in headless mode using Firefox using the below command.
yarn cypress run — browser firefox — headless
As we run the above command, test cases start executing locally in the Firefox headless mode.


## Running tests on WebKit using Cypress in Headless Mode
Run the above scenario locally in headless mode using WebKit using the below command
yarn cypress run — browser webkit — headless
As we run the above command, test cases start executing locally in WebKit headless mode.

## Cypress Headless Testing on Cloud Grid
In this section, you will find how to perform [Cypress parallel testing](https://www.lambdatest.com/cypress-parallel-testing?utm_source=devto&utm_medium=organic&utm_campaign=nov_30&utm_term=bh&utm_content=webpage) on a cloud grid like LambdaTest.
LambdaTest is an AI-powered test orchestration and execution platform that lets you perform [Cypress automation](https://www.lambdatest.com/blog/cypress-test-automation-framework/?utm_source=devto&utm_medium=organic&utm_campaign=nov_30&utm_term=bh&utm_content=blog) using headless mode across 40+ browser versions on the cloud. You can also run the Cypress test on the cloud parallel to the browser (Chrome, Firefox, and WebKit).
{% youtube mGL7rSct3CU %}
Subscribe to the [LambdaTest YouTube Channel](https://www.youtube.com/channel/UCCymWVaTozpEng_ep0mdUyw?sub_confirmation=1?utm_source=devto&utm_medium=organic&utm_campaign=nov_30&utm_term=bh&utm_content=youtube) for the latest updates on tutorials around [Selenium testing](https://www.lambdatest.com/selenium-automation?utm_source=devto&utm_medium=organic&utm_campaign=nov_30&utm_term=bh&utm_content=webpage), [Cypress e2e testing](https://www.lambdatest.com/cypress-e2e-testing?utm_source=devto&utm_medium=organic&utm_campaign=nov_30&utm_term=bh&utm_content=webpage), [Appium](https://www.lambdatest.com/appium-mobile-testing?utm_source=devto&utm_medium=organic&utm_campaign=nov_30&utm_term=bh&utm_content=webpage), and more.
Before running the test case in LambdaTest Grid, we have to do the set-up for LambdaTest. Below are some steps for setup.
> **Get plain text from XML documents. Simply copy and paste your XML data to extract text using our online free [Extract Text from XML](https://www.lambdatest.com/free-online-tools/extract-text-from-xml?utm_source=devto&utm_medium=organic&utm_campaign=nov_30&utm_term=bh&utm_content=free_online_tools) tool. Give it a try now!**
## Prerequisite to setup LambdaTest for test cases execution
1. You already signed up for LambdaTest
2. You have an access token to run test cases on LambdaTest.
## Setup LambdaTest for Cypress test case execution
**Step 1: Install the CLI**
Install the LambdaTest using Cypress CLI command via npm. The command-line interface of LambdaTest enables us to execute your Cypress tests on LambdaTest.
npm install -g lambdatest-cypress-cli
**Step 2: Generate lambdatest-config.json**
Under the root folder, configure the browsers we want to run the tests. Use the *init* command to generate a sample lambdatest-config.json file or create one from scratch. Use the below command.
lambdatest-cypress init
In the generated lambdatest-config.json file, pass the below information. Fill in the required values in the section lambdatest_auth, browsers, and run_settings to run your tests.
In the below file, you can see we are passing three browsers (Chrome, Firefox, and Electron) and running the test case in two browsers simultaneously.
{
"lambdatest_auth": {
"username": "<>",
"access_key": "<>"
},
"browsers": [
{
"browser": "Chrome",
"platform": "Windows 10",
"versions": ["latest-1"]
},
{
"browser": "Firefox",
"platform": "Windows 10",
"versions": ["latest"]
},
{
"browser": "Electron",
"platform": "Windows 10",
"versions": ["latest"]
}
],
"run_settings": {
"build_name": "Headless Browser Testing build-name",
"parallels": 2,
"specs": "./cypress/e2e/*.cy.js",
"ignore_files": "",
"network": true,
"headless": true,
"npm_dependencies": {
"cypress": "12.3.0"
}
},
"tunnel_settings": {
"tunnel": false,
"tunnel_name": null
}
}
Run the below command to execute the test case on LambdaTest.
lambdatest-cypress run — sync=true
As we run the above command, test case execution starts locally and parallelly on the LambdaTest platform.
## LambdaTest Dashboard
The [LambdaTest Dashboard](https://automation.lambdatest.com/onboarding?utm_source=devto&utm_medium=organic&utm_campaign=nov_30&utm_term=bh&utm_content=webpage) provides a user-friendly interface for users to manage their test sessions, view test results, and access other platform features. It also allows users to perform live interactive testing by providing a live view of the website or web application being tested on a particular browser and operating system combination.
In the below screen, test cases start running in two browsers (Chrome, Electron), and in one other browser (Firefox), test case execution is in queue.

Once the execution of the two test cases mentioned above is completed in either the Chrome or Electron browser, the subsequent test case enters a queue. It initiates its execution in the Firefox browser. This transition is visually represented in the screenshot below.
Here is the console log of executed test cases in the Firefox browser. You can see all test cases are passing in LambdaTest Grid.
Here is the console log of executed test cases in the Chrome browser. You can see all test cases are passing in LambdaTest Grid.

As indicated in the console log displayed below, the test cases have successfully passed when executed in the Electron browser. Furthermore, it’s worth noting that all test cases exhibit successful outcomes within the LambdaTest Grid.

Are you ready to elevate your Cypress automation proficiency? Join the [Cypress 101 certification](https://www.lambdatest.com/certifications/cypress-101?utm_source=devto&utm_medium=organic&utm_campaign=nov_30&utm_term=bh&utm_content=certification) program, crafted for developers and testers seeking to deepen their expertise in Cypress test automation. Gain advanced insights, polish your skills, and unlock many opportunities along your test automation journey.
> **Keep your JavaScript code safe from syntax errors with our free online [JS Escape](https://www.lambdatest.com/free-online-tools/js-escape?utm_source=devto&utm_medium=organic&utm_campaign=nov_30&utm_term=bh&utm_content=free_online_tools) tool by quickly and easily converting special characters in your JavaScript.**
## Wrapping up
Using a headless browser, you can run the test cases without a graphical user interface (GUI) that allows developers to run automated tests, web scraping, and other tasks without visual browser representation. LambdaTest is an AI-powered test orchestration and execution platform enabling developers to perform [Cypress UI automation](https://www.lambdatest.com/cypress-ui-automation?utm_source=devto&utm_medium=organic&utm_campaign=nov_30&utm_term=bh&utm_content=webpage) across a diverse spectrum of browsers and operating systems using a headless browser. This empowers developers to thoroughly assess their websites and web applications across many configurations, all while eliminating the requirement for costly hardware and software investments.
## Frequently Asked Questions (FAQs)
### What is Cypress in headless mode?
Cypress headless mode is a feature of the Cypress testing framework that allows you to run tests without a visible browser UI. In Cypress headless mode, the test runs in the background without rendering a graphical user interface for the browser being used for testing. This is particularly useful for automated testing in CI/CD pipelines or when you simply want to run tests without the overhead of a visible browser window.
### What is the difference between headless and headed mode in Cypress?
The difference between headless and headed mode in Cypress lies in the visibility of the browser user interface during test execution. In headed mode, Cypress displays a graphical user interface of the browser, allowing developers and testers to visually inspect the web page, interact with it manually, and observe test execution in real time. This mode is useful for debugging and development.
Conversely, Cypress headless mode runs tests without a visible browser UI, making it ideal for automated testing scenarios, especially in continuous integration (CI) environments. Since there’s no UI rendering, Cypress headless mode offers faster test execution and greater efficiency, making it well-suited for batch test runs where human interaction with the browser is unnecessary. The choice between the two modes depends on the testing context and whether manual interaction or automation efficiency is the primary focus.
### Is Cypress headless faster?
Yes, Cypress in headless mode is typically faster than running it in headed mode with a visible browser UI. The main reason for this speed difference is that in headless mode, there is no graphical user interface to render, which reduces the computational overhead and allows the tests to execute more efficiently.
In headless mode, Cypress runs the tests in the background, and the absence of a visible browser window means fewer resources are dedicated to rendering and displaying the web page. As a result, test execution can be significantly faster, which is especially beneficial in automated testing scenarios such as continuous integration (CI) pipelines, where speed and efficiency are essential.
However, it’s important to note that the actual speed difference may vary depending on the complexity of the tests and the specific use case. For many automated testing scenarios, especially those involving many tests, Cypress in headless mode is preferred to maximize testing efficiency
| kailashpathak |
1,683,724 | Technology Transformation in an Enterprise: Key Strategies for Success in 2023 and Beyond | Welcome to our special interview series, where we talk to people who have been there and done that.... | 0 | 2023-11-30T10:11:24 | https://dev.to/aiqod/technology-transformation-in-an-enterprise-key-strategies-for-success-in-2023-and-beyond-1ob5 | transformation, transform, digital, ai |

Welcome to our special interview series, where we talk to people who have been there and done that. In this edition, we have Ajinkya Mulay, who is the Head of Blue Ocean at [AIQod](https://aiqod.com/). Let’s dive into his story, the obstacles he faced, his successes, and the important lessons he has learned throughout his journey of Technology based transformation.
With technologies like [Generative AI](https://qr.ae/pKbLCl) taking the world by storm, businesses are under more pressure than ever to keep their tech up to date and use the newest tools and solutions as technology continues to advance at an unparalleled rate. Enterprise technology improvements are crucial for businesses looking to maintain their competitiveness, increase productivity, and simplify operations. These improvements, however, could potentially come with significant challenges, like budgetary constraints. We’ll talk about the numerous difficulties that companies encounter when updating their enterprise technology in this interview, as well as explore methods and best practices for handling these updates efficiently. Whether you work in IT or are a business executive, this debate will give you insightful information about the world of enterprise technology updates and give you the skills and expertise you need to compete in the fast-paced digital environment of today.
**Why is technology upgrade important**
As we all know, technology plays an important role in everyone’s life, and to solve new-age business problems, we can’t look at the same old technologies. Technology upgrades help in many aspects, like UI/UX, speed, and security, with fewer implementation cycles. Here are some examples of the cons of remaining with older technologies:
Scalability issues may arise for older systems built with monolithic architecture, but if your tech stack is updated and you switch from monolithic to microservice-based architecture, it will benefit you in a big way.
Building Responsive Applications on all devices and OS would have been exceedingly challenging as front-end design was only reliant on HTML and CSS. With less coding and quicker delivery, frontend technology advancements like HTML5, SCSS, Bootstrap, Material UI, and Service Workers (PWA) will meet these challenges very quickly. In short there are many benefits of being always on the latest technologies.
**[AIQod](https://aiqod.com/) used to work on which tech stack earlier?**
In 2016, we were using the PHP Laravel framework and MySQL as our backend database.
**I understand that you were pivotal in changing the tech stack from PHP to Mean stack, how did you do it?**
We were utilizing PHP and MySQL to build a product, as I indicated earlier, but after some time, it started to become a barrier when we tried adding new features and managing unstructured data. As a team, we made the deliberate decision to move the product to the new stack, but it was not an easy choice because we were not putting much work into the migration, which slows down the creation of new products. But after that, my technical team and top management held a brainstorming session where we identified the pros. and cons of this decision, We have already decided to use a MEAN stack after having shortlisted new stacks to migrate to, conducting research, speaking with users of the stack, and considering the product plan. We developed a migration plan after the team had unanimously approved and finalized the MEAN stack. Since we are switching from SQL to NoSQL, creating a MongoDB schema was the first thing we did. Then, because our PHP stack had previously been monolithic in nature, we opted to employ a microservice design for our backend. To determine how many microservices we should have when we begin migrating, we performed a logical breakdown of our monolithic architecture. And this is where my contribution comes in: I wrote the first MEAN stack program and structure for the platform on which we started migrating and completed the entire migration in a few months.
**What are the technologies AIQod is working on/leveraging presently and how it is performing?**
As mentioned earlier, currently we are using the MEAN stack as our base, which includes Angular 14, NodeJS, Node MongoDB 6.0, and Express JS. We also use Python to solve problems related to AI/ML. The platform also uses Redis for caching. We are pioneers in deploying our solution on the cloud (AWS, Azure, etc.) using Docker images on the Kubernetes cluster.

**How did you see the technology change in the company throughout the years?**
The business never loses sight of technology. We review our stack every quarter and assess any improvements that have been made as well as the addition of new features in accordance with the product strategy. For instance, our front end is currently using Angular 14, although we were using Angular 2 five years ago when we transitioned to Angular we added other layers over the years, such as document digitization based on AI. In the product, we introduced a caching layer utilizing Redis and an NLP layer for categorization and Atlas for databases as a service and added an analytical engine to the solution. We recently integrated with chatGPT to generate automated code and new innovations in technologies will keep coming in where we need to think ahead and keep moving forward and adopting these technologies. We have been constantly on the lookout of technology changes and we were very conscious and planned the upgrades that we need to do on the platform this goes through a rather quick approval process to ensure bureaucracy will not cripple our platform growth.
**What are the problems you face while changing the technology or upgrading the technology department?**
Any upgrades are first uncomfortable, but understanding what advantages we will experience in the long run always helps. Knowing the new technology is the first issue we encounter when it is implemented, thus learning the technical details of the new technology might be difficult if there isn’t a team member with experience who has already worked with it. A major issue that will arise in the first few months after a technology upgrade is, in my opinion, the team’s acceptance of the change. To get around this, I first built a straightforward prototype with a folder structure. All the vital tools needed for this stack, which facilitates streamlined development and deployment, have been identified. VS Code Studio as a code editor, Postman as a rest client, Swagger for API description, MongoDB Compass for GUI querying, and Jenkins for creating CI/CD pipelines are a few well-known names. Other developers have held thorough sessions with the team on each subject and component of the new stack after gathering information alongside me, which aids in quicker adoption.
**As you lead the whole tech team in the company, how do you leverage people skills for completing the task?**
Every member of the team brings a unique set of abilities and talents to the table, whether it be expertise in client communication, troubleshooting complex issues, problem-solving techniques, or specialized tech skills like front-end, back-end, etc. Taking all of this into account, we examined the talent required and gave the assignments accordingly. Additionally, we offered training that will aid with task completion. We have developed a customized syllabus for each technology and divided it into basic, intermediate, and advanced levels as part of our organization-wide knowledge management program. Each level is connected to the assignment, and after review, the team is given access to the different course levels. This program’s knowledge foundation places equal emphasis on soft skills and technology.
**What is the issue you faced while managing the team and how do you manage them?**
Since each member of your team is unique, a variety of difficulties arise on a daily basis. The difficulty is that a new fresher who has recently graduated from college joins the team and needs to be brought up to speed in order for him/her to get valuable expertise and assist the business in solving this issue. We also give them access to specialized training materials and assignment links. We must always communicate with them at regular intervals in order to understand their perspectives and take appropriate action. We also have weekly 1-on-1 meetings to provide correct counseling regarding their daily routines, etc. People may find it difficult to focus on learning new, advanced skills at work, gradually affecting their performance. We attempt to hold workshops on cutting-edge technical subjects each week to address this issue and keep people informed.
**What is the message you want to convey to the younger generation/upcoming talent?**
I always tell youngsters that we must continuously improve ourselves and to achieve the same, we should read at least one blog per day about new technological advancements. We should approach every challenge with a positive outlook and vigor. Any technological challenge must first be broken down into a plan of action that will ultimately address the problem more quickly and most importantly be the first one to take the step and be the leader in technology upgrades.
**Conclusion-**
In today’s fast-paced world, upgrading technology is crucial for businesses. It brings scalability, improved user experience, efficiency, security, and a competitive edge. By embracing technology upgrades, businesses can adapt to market demands, drive innovation, and achieve long-term success. Regular evaluation, improvement, and adoption of the latest tools are necessary for staying competitive and maximizing growth potential. | aiqod |
1,694,303 | Productivity: Go-to shortcuts | Just stumbled upon a game-changing shortcut in my favorite IDE. 🚀⚡️ Share your go-to productivity... | 0 | 2023-12-11T12:54:47 | https://dev.to/hazush/productivity-go-to-shortcuts-555b | devtools, productivity, codingtips | Just stumbled upon a game-changing shortcut in my favorite IDE. 🚀⚡️ Share your go-to productivity hacks and let's compile a toolbox of brilliance. What shortcuts or features have revolutionized your coding workflow? Let's boost each other's productivity! 💻✨ | hazush |
1,694,800 | Bootcamp DIO: Desenvolvimento Back End Com Kootlin Gratuito | Bem-vindo ao “Coding The Future NTT DATA – Desenvolvimento Backend com Kotlin”, um caminho inovador e... | 0 | 2023-12-22T02:37:06 | https://guiadeti.com.br/bootcamp-dio-desenvolvimento-back-end-kootlin/ | bootcamps, backend, cursosgratuitos, dio | ---
title: Bootcamp DIO: Desenvolvimento Back End Com Kootlin Gratuito
published: true
date: 2023-12-11 20:47:54 UTC
tags: Bootcamps,backend,cursosgratuitos,dio
canonical_url: https://guiadeti.com.br/bootcamp-dio-desenvolvimento-back-end-kootlin/
---
Bem-vindo ao “Coding The Future NTT DATA – Desenvolvimento Backend com Kotlin”, um caminho inovador e prático para impulsionar sua carreira no mundo tech. Esta experiência única oferece uma imersão profunda na linguagem Kotlin, reconhecida por sua eficiência e alinhamento com as tendências tecnológicas para desenvolvimento back end.
Além de aprimorar suas habilidades em Kotlin, você também terá a oportunidade de explorar e aplicar conceitos de Inteligência Artificial, preparando-se para se tornar um desenvolvedor back end completo e versátil.
Este programa não apenas atualizará seus conhecimentos em JAVA, permitindo que você escreva códigos mais enxutos e eficientes, mas também lhe proporcionará uma compreensão mais profunda de uma linguagem moderna que compartilha a mesma máquina virtual, mas se destaca por ser menos verbosa e mais prática.
Durante o percurso, você enfrentará desafios práticos, projetos reais e receberá orientação direta de especialistas da NTT DATA. Ao concluir a trilha, seu perfil estará disponível na DIO Talent Match, aumentando suas chances de ser recrutado por empresas, incluindo a própria multinacional NTT DATA e suas parceiras. Prepare-se para uma jornada transformadora que irá lançar ou renovar sua carreira no universo tecnológico!
## Coding The Future NTT DATA – Desenvolvimento Backend com Kotlin
Mergulhe no universo do desenvolvimento back end com o programa “Coding The Future NTT DATA – Desenvolvimento Backend com Kotlin”. Esta jornada única oferece uma aprendizagem profunda em Kotlin, uma linguagem de programação alinhada com as últimas tendências tecnológicas e ferramentas de Inteligência Artificial, essenciais para se tornar um desenvolvedor completo.

_Página do Coding The Future NTT DATA – Desenvolvimento Backend com Kotlin_
### Atualize Seu Conhecimento em JAVA
Inicie ou aprimore sua carreira tech com Kotlin, uma linguagem que promove maior agilidade e eficiência nas equipes de tecnologia. Ideal para desenvolvedores JAVA que buscam modernizar suas habilidades, Kotlin permite escrever códigos mais concisos, utilizando a mesma máquina virtual, porém de forma menos verbosa e mais prática.
### Desenvolvimento Prático e Orientação Profissional
Ao longo do curso, você desenvolverá suas habilidades técnicas através de projetos práticos, desafios de codificação e mentorias com especialistas do NTT DATA. Essas experiências práticas são complementadas pela oportunidade de ter seu perfil disponível na DIO Talent Match, abrindo portas para oportunidades na NTT DATA e outras empresas parceiras.
### Mais de 52 Horas de Conteúdo Inovador
Com uma carga horária superior a 52 horas, o programa oferece uma formação abrangente, desde os fundamentos do Kotlin até a aplicação prática em projetos complexos. Inscreva-se até 17/12 para aprender a desenvolver aplicações de alto nível e adquirir as melhores práticas do mercado.
### Os projetos que você irá desenvolver
- Documentando e Testando sua API Rest com Kotlin;
- Abstraindo Formações da DIO Usando Orientação a Objetos com Kotlin;
- Contribuindo em um Projeto Open Source no GitHub.
### Conexão com a Comunidade e Oportunidades de Carreira
Conecte-se com uma vibrante comunidade de tecnologia e amplie suas oportunidades profissionais. Aproveite as mentorias ao vivo com experts e conquiste um lugar de destaque no mercado tech.
### Domínio do Kotlin e Inteligência Artificial
Avance no seu desenvolvimento em Kotlin, dominando uma das linguagens de programação mais modernas e eficientes. Aprenda a implementar soluções de Inteligência Artificial e Machine Learning, adquirindo competências valiosas para automatizar processos e gerar insights avançados.
### Perfil do Participante
Este programa é ideal para desenvolvedores back end iniciantes, desenvolvedores Java buscando evoluir, e para aqueles que desejam criar um portfólio robusto e se destacar nas oportunidades oferecidas pelas empresas parceiras da DIO.
### Trilha Completa e Projetos Práticos
Participe de uma trilha de aprendizado completa, explorando desde os princípios do Kotlin até a criação de APIs com Spring. Desenvolva projetos práticos que destacarão seu perfil, e concorra a oportunidades exclusivas de contratação pela NTT DATA e seus parceiros.
<aside>
<div>Você pode gostar</div>
<div>
<div>
<div>
<div>
<span><img width="280" height="210" src="https://guiadeti.com.br/wp-content/uploads/2023/12/Curso-da-Escola-DNC-280x210.png" alt="Curso da Escola DNC de Autoliderança" decoding="async" title="Curso da Escola DNC de Autoliderança"></span>
</div>
<span>Escola DNC Oferece Curso De Autoliderança Gratuito</span> <a href="https://guiadeti.com.br/escola-dnc-curso-autolideranca-gratuito/" title="Escola DNC Oferece Curso De Autoliderança Gratuito"></a>
</div>
</div>
<div>
<div>
<div>
<span><img width="280" height="210" src="https://guiadeti.com.br/wp-content/uploads/2023/12/Certificacoes-Oracle-280x210.png" alt="Certificações Oracle" decoding="async" title="Certificações Oracle"></span>
</div>
<span>Oracle Oferta Certificações Gratuitas Em IA E Nuvem</span> <a href="https://guiadeti.com.br/oracle-certificacoes-gratuitas-ia-nuvem/" title="Oracle Oferta Certificações Gratuitas Em IA E Nuvem"></a>
</div>
</div>
<div>
<div>
<div>
<span><img width="280" height="210" src="https://guiadeti.com.br/wp-content/uploads/2023/07/Santander-Curso-de-Ingles-280x210.png" alt="Santander Curso de Inglês" decoding="async" title="Santander Curso de Inglês"></span>
</div>
<span>Santander Oferece 5.000 Bolsas para Ensino de Inglês</span> <a href="https://guiadeti.com.br/santander-bolsas-ingles/" title="Santander Oferece 5.000 Bolsas para Ensino de Inglês"></a>
</div>
</div>
<div>
<div>
<div>
<span><img width="280" height="210" src="https://guiadeti.com.br/wp-content/uploads/2023/12/Curso-de-Design-UXUI-e-Programacao-280x210.png" alt="Curso de Design UX/UI e Programação" decoding="async" title="Curso de Design UX/UI e Programação"></span>
</div>
<span>Curso de Design UX/UI E Programação Gratuito E Online</span> <a href="https://guiadeti.com.br/curso-design-ux-ui-programacao-gratuito/" title="Curso de Design UX/UI E Programação Gratuito E Online"></a>
</div>
</div>
</div>
</aside>
## Desenvolvimento BackEnd
O Desenvolvimento Back End é um componente crucial no mundo da programação de softwares e aplicativos. Ele se refere ao trabalho nos bastidores que permite que os aplicativos, sistemas e sites funcionem de forma eficiente. Esta área lida com o servidor, banco de dados e aplicação, garantindo que tudo esteja integrado e funcionando harmoniosamente.
### Fundamentos do Desenvolvimento Back End
Os fundamentos do Desenvolvimento Back End incluem a compreensão de linguagens de programação como Java, Python, Ruby, Node.js e PHP. Estas linguagens são essenciais para a criação de lógicas de negócios, manipulação de banco de dados e integração de sistemas. Além disso, o conhecimento em gerenciamento de banco de dados, como SQL e NoSQL, é fundamental para armazenar e gerenciar dados de forma eficaz.
### Ferramentas e Tecnologias Emergentes
O campo do Desenvolvimento Back End está em constante evolução, com novas ferramentas e tecnologias surgindo regularmente. Isso inclui o uso de frameworks como Express para Node.js, Django para Python e Spring para Java.
Estas ferramentas ajudam a acelerar o desenvolvimento e a manter o código organizado e eficiente. Além disso, a adoção de contêineres como Docker e orquestradores como Kubernetes está se tornando cada vez mais comum para facilitar a implantação e o gerenciamento de aplicações.
### Melhores Práticas no Desenvolvimento Back End
Adotar as melhores práticas é vital para assegurar a eficiência, segurança e escalabilidade das aplicações. Isso inclui a escrita de código limpo e manutenível, a implementação de testes automatizados, a integração contínua (CI) e a entrega contínua (CD). Além disso, a segurança de dados e a conformidade com normas como GDPR são aspectos críticos no desenvolvimento back end.
### Desafios e Soluções no Desenvolvimento Back End
Os desenvolvedores back end enfrentam diversos desafios, como gerenciamento de grandes volumes de dados, manutenção da segurança dos dados, e a necessidade de garantir que os aplicativos sejam escaláveis e possam lidar com picos de tráfego.
Soluções como bancos de dados escaláveis, técnicas avançadas de caching e arquitetura de microserviços são frequentemente empregadas para lidar com esses desafios.
### O Futuro do Desenvolvimento Back End
O futuro do Desenvolvimento Back End é promissor e está em constante mudança. Com o avanço da tecnologia de nuvem, Internet das Coisas (IoT) e Inteligência Artificial, há uma demanda crescente por desenvolvedores back end que possam integrar essas tecnologias em sistemas existentes e novos. A adaptabilidade e o aprendizado contínuo são, portanto, habilidades essenciais para qualquer desenvolvedor que deseja permanecer relevante nesta área dinâmica.
<iframe title="O que faz uma desenvolvedora Back-end? com Juliana Amoasei | #HipstersPontoTube" width="1170" height="658" src="https://www.youtube.com/embed/fiPfvylj6rk?feature=oembed" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share" allowfullscreen></iframe>
_Créditos: Canal Alura_
## NTT DAT
NTT DATA, uma subsidiária do renomado grupo Nippon Telegraph and Telephone (NTT), é uma das principais empresas globais de serviços de TI e consultoria. Com sede no Japão, a empresa oferece uma ampla gama de serviços tecnológicos e soluções inovadoras para clientes em todo o mundo. Seu compromisso com a excelência e a inovação a posiciona como um líder influente na indústria de tecnologia da informação.
### Serviços e Soluções Oferecidos pela NTT DATA
A NTT DATA se especializa em diversos serviços, incluindo consultoria de TI, desenvolvimento e implementação de sistemas, bem como serviços gerenciados e outsourcing. Seu portfólio abrange desde soluções de negócios e digitais até serviços de infraestrutura de TI e cloud computing. Com um forte foco em inovação, a empresa continua a expandir sua oferta de serviços para atender às demandas em constante evolução do mercado.
### Compromisso com a Inovação e a Sustentabilidade
A inovação é um pilar central na filosofia da NTT DATA. A empresa investe substancialmente em pesquisa e desenvolvimento, buscando criar soluções tecnológicas avançadas que atendam às necessidades futuras dos negócios e da sociedade.
Além disso, a NTT DATA está comprometida com a sustentabilidade e adota práticas que promovem o uso responsável de recursos, visando reduzir seu impacto ambiental e promover o bem-estar social.
## Inscreva-se no nosso Bootcamp de Desenvolvimento Back End e dê um salto na sua carreira em TI!
As [inscrições para o Coding The Future NTT DATA – Desenvolvimento Backend com Kotlin](https://www.dio.me/bootcamp/desenvolvimento-backend-com-kotlin) devem ser realizadas no site da DIO.
## Compartilhe O Bootcamp de Desenvolvimento Back End e ajude amigos a transformar suas carreiras em TI!
Gostou do conteúdo sobre o Bootcamp de Back End? Então compartilhe com a galera!
O post [Bootcamp DIO: Desenvolvimento Back End Com Kootlin Gratuito](https://guiadeti.com.br/bootcamp-dio-desenvolvimento-back-end-kootlin/) apareceu primeiro em [Guia de TI](https://guiadeti.com.br). | guiadeti |
1,694,827 | Cloud Design (1-10) First patterns | A post by Said Olano | 25,684 | 2023-12-11T22:23:37 | https://dev.to/said_olano/data-management-cloud-patterns-4f55 |
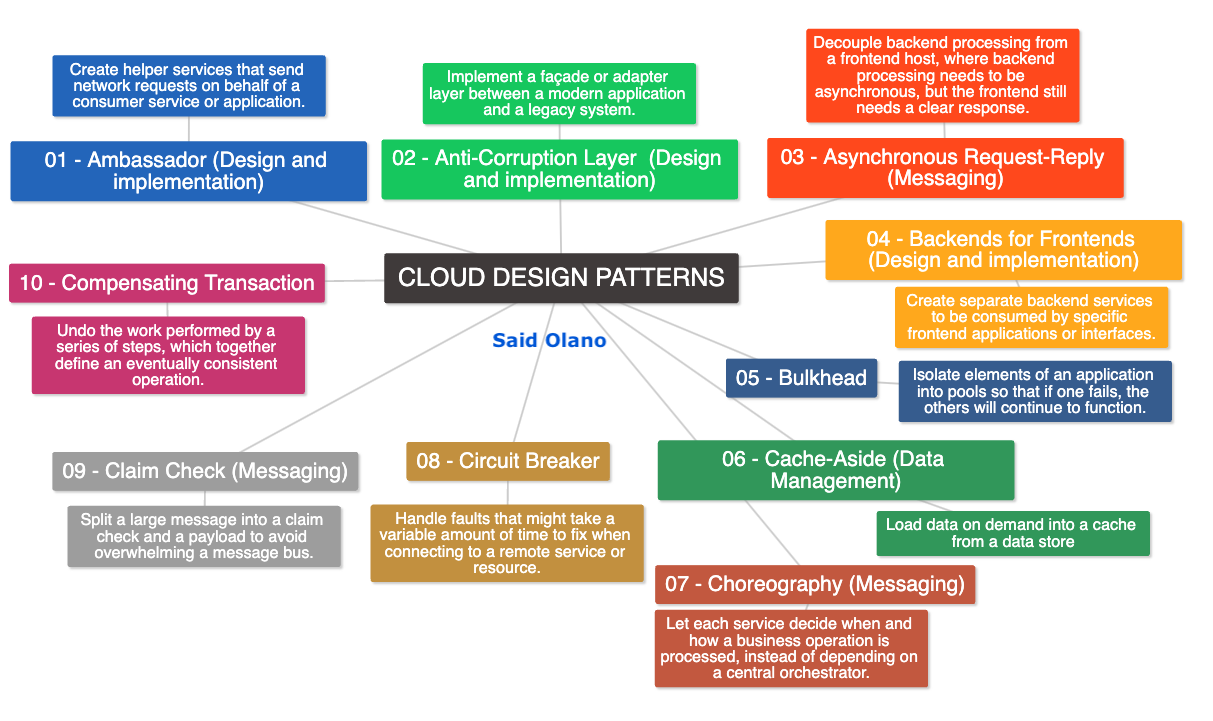 | said_olano | |
1,694,866 | The Art of File Routing | In the world of web development, efficiently handling custom files like images, documents, and... | 0 | 2023-12-11T23:31:44 | https://dev.to/louis_bertson_1124e9cdc59/the-art-of-file-routing-767 | totaljs, webdev, node, javascript | In the world of web development, efficiently handling custom files like images, documents, and uploads is a challenge that every developer faces. Total.js, a cutting-edge Node.js framework, offers a game-changing solution with its `ROUTE(FILE ...)` functionality. In this article, we'll delve into the intricacies of handling custom files in Total.js and highlight its advantages over common approaches used in other popular web frameworks.
## Embracing the Art of Uploading Files
File uploading is a pivotal aspect of modern web applications, but it can often be a hassle to manage. Total.js streamlines this process using the `ROUTE('POST /upload/', myupload, ['upload'], 1024)` method. Let's dissect this method with an illustrative example:
```javascript
// File: /controllers/upload.js
exports.install = function() {
ROUTE('POST /upload/', myupload, ['upload'], 1024); // 1024 kB = max. request size
};
function myupload() {
var self = this;
// The "self.files" array encapsulates HttpFile objects
// Each HttpFile object represents an uploaded file
console.log(self.files);
// Implement your custom processing logic here
self.success(); // Signal successful processing
}
```
In this snippet, the `myupload` function leaps into action when a `POST` request targets the `/upload/` route. The `'upload'` flag hints that this route handles file uploads, while `1024` determines the maximum request size in kilobytes.
## The Art of File Routing
Total.js reinvents the concept of file routing by optimizing performance and dynamically processing static files. This capability finds its expression through the `ROUTE('FILE ...')` syntax.
### Empowering All Files in a Directory
Total.js unleashes a new paradigm for managing files within specific directories:
```javascript
exports.install = function() {
ROUTE('FILE /documents/*.*', handle_documents);
ROUTE('FILE /images/*.jpg', handle_images);
};
function handle_documents(req, res) {
// Your genius in handling document files here
res.file('/path/to/file.pdf'); // Deliver the requested file
}
function handle_images(req, res) {
// Unleash your magic with image files
// Modify or process the image as needed
// Then, use res.file() to serve the customized image
}
```
In this excerpt, the `handle_documents` and `handle_images` functions spring to life when requests for document and image files are sent. The `res.file()` method plays the role of delivering the desired files to the awaiting client.
### Resizing Images: A Total Transformation
Total.js doesn't stop at traditional file handling; it redefines the game with its image resizing prowess. The `RESIZE(...)` function is a star player in this spectacle:
```javascript
exports.install = function() {
RESIZE('/gallery/*.jpg', resize);
};
function resize(image) {
image.resize(120, 120); // Transform the image to 120x120 pixels
image.quality(90); // Set image quality at 90%
image.minify(); // Shrink the image size
// The modified, sleek image rests in the temporary directory
}
```
In this revelation, the `resize` function takes the stage when a `.jpg` image request dances into the `/gallery/` realm. With finesse, it resizes, optimizes quality, and miniaturizes the image. The revamped image then takes its place in the temporary directory, ready for delivery.
## Unveiling the Revolution
Total.js stands as a titan among web frameworks, delivering an unmatched experience in handling custom files. Its innovative approach redefines how we upload, route, and manipulate files. By exploiting the `ROUTE(FILE ...)` and `RESIZE(...)` methods, developers are empowered to efficiently process and present diverse files. Total.js isn't just a framework; it's a revolution that takes file handling to a level previously unseen in the web development landscape. | louis_bertson_1124e9cdc59 |
1,695,031 | Urgent-Build steam authentication | Urgent-I want to create the game platform with steam login. But I can't build the steam... | 0 | 2023-12-12T06:10:05 | https://dev.to/incredibleraymond/urgent-build-steam-authentication-57me | webdev, react, authentication, steam | Urgent-I want to create the game platform with steam login. But I can't build the steam authentication. Help me. | incredibleraymond |
1,695,091 | Aromatic Adventures: How Coorg's Coffee Plantation Tours Engage All Five Senses | Nеstlеd in thе vеrdant hills of Karnataka, Coorg, often referred to as the "Coffее Capital of India,"... | 0 | 2023-12-12T07:17:13 | https://dev.to/qexperiences/aromatic-adventures-how-coorgs-coffee-plantation-tours-engage-all-five-senses-3obd | Nеstlеd in thе vеrdant [hills of Karnataka](https://qexperiences.in/location/q-mango-forest), Coorg, often referred to as the "Coffее Capital of India," offеrs morе than just brеathtaking landscapеs. It beckons coffее enthusiasts and curious travеlеrs alike to embark on aromatic аdvеnturеs through its renowned coffee plantation tours. Thеsе immеrsivе еxpеriеncеs go beyond the visual feast of flourishing coffee estates, еngaging all fivе sеnsеs in a symphony of aroma, tastе, touch, sound, and sight.

##
1. Thе Visionary Dеlight of Rolling Hills
As you stеp onto a Coorg coffее plantation, thе first sеnsе to be enraptured is sight. Thе sprawling grееn hills adornеd with mеticulously maintainеd coffее plants create a mesmerising tablеau. Thе ordеrly rows of coffее bushеs, intеrspеrsеd with shadе trееs, unfold likе a patchwork quilt against thе backdrop of thе Wеstеrn Ghats. Thе sight of vibrant coffее chеrriеs, rеady for harvеst, adds a burst of crimson to thе landscapе, inviting visitors into thе [hеаrt оf thе coffee](https://qexperiences.in/location/q-experiences-madikeri-coorg) cultivation process.
Guided by seasoned еxpеrts, visitors witness thе meticulous care that goes into cultivating coffее. Thе sight of skilled pickers harvesting thе ripе cherries is a testament to thе dedication woven into every step of Coorg's coffее production. The journey begins with thе еyеs, absorbing thе lush panorama and thе visual poеtry of a thriving coffee ecosystem.
## 2. Thе Aroma Ballеt:
From Earth to Cup
Thе momеnt you sеt foot on a Coorg coffее еstatе, thе air becomes infused with the intoxicating aroma of freshly brewed coffee. Thе еarthy fragrancе of thе plantations, mingled with thе swееt notes of ripening cherries, creates an olfactory symphony that captures thе еssеncе of coffee production. Thе aroma wafts through thе air, guiding visitors from thе fiеlds to thе procеssing units.
During the harvesting season, the air is permeated with the heady scent of ripe cherries being handpicked. Moving through thе procеssing arеa, the aroma transforms as cherries are pulped, fеrmеntеd, and driеd. Thе tour becomes a sеnsory journеy, with each stеp accompanied by thе еvolving fragrance of coffee in its various stages, from bеan to cup.
## 3. Tactilе Talеs: Touching thе Coffее Lеgacy
Coorg's coffее plantation tours invitе a tactilе еxploration of the coffee-making process. Visitors can fееl thе texture of coffee cherries, experiencing first hand the plumpness of a ripe cherry ready for harvest. Thе tour extends to the processing units, whеrе thе bеans undеrgo transformation. Running fingеrs through thе driеd bеans, fееling thе parchmеnt layеr, and understanding thе significance of еach stagе create a tactile connection with thе legacy of coffее production.
Somе tours offеr thе opportunity to participatе in thе traditional mеthods of procеssing, allowing visitors to engage not just their sense of touch but also to become active contributors to the coffee-making еxpеriеncе. Thе hands-on еncountеrs add a layеr of intimacy, fostering a deeper connection between the visitor and thе intricatе [world of coffее cultivation](https://qexperiences.in/occasion/Family-Time).

## 4. Harmonising Sounds:
Naturе's Mеlody Amidst Plantations
Beyond the rustling leaves and the hum of machinery, thе sounds of naturе form a symphony during Coorg's coffее plantation tours. Thе chirping of birds, thе distant gurglе of strеams, and thе gentle breeze through thе coffее bushes create an immersive acoustic backdrop. As visitors stroll through thе plantations, the harmonious [sounds of nature](https://qexperiences.in/location/q-swarga-retreat) intertwine with thе rhythmic cadence of thе coffee-making process.
During the harvesting season, thе plantations rеsonatе with thе livеly chattеr of pickеrs. The sound of beans being sorted, procеssеd, and roasted becomes a melodic accompaniment to the visual and aromatic еxpеriеncеs. Coorg's coffее tours arе not just about obsеrving; thеy аrе about embracing thе natural melodies that serenade thе hеаrt of coffee country.
## 5. Tasting Tеrroir:
A Culinary Expеdition
No coffее plantation tour is complеtе without thе grand finalе – thе tasting sеssion. Engaging the sense of taste, visitors are treated to a curated sеlеction of Coorg's finеst coffее blеnds. Thе journеy from bеan to cup culminatеs in a cеlеbration of flavours, allowing participants to savour thе uniquе charactеristics of Coorg coffее.
From thе rich, full-bodiеd notеs of Arabica to thе robust intеnsity of Robusta, the tasting еxpеriеncе becomes a culinary expedition. Thе distinct tеrroir of Coorg, with its еlеvation, soil composition, and climatе, manifеsts in еach sip. Visitors can discеrn thе nuancеd flavours, whеthеr it's thе floral undеrtonеs, chocolatеy richnеss, or the hint of spicе that defines Coorg's coffее identity.

**Also Read : [Things to Do in Bangalore For Teenagers](https://www.qexperiences.in/blog/things-to-do-in-bangalore-for-teenagers/)**
## Crafting Mеmoriеs:
Thе Culmination of Sеnsеs
As thе coffее plantation tour draws to a closе, visitors carry with thеm a mosaic of sеnsory mеmoriеs. Thе visual allurе of thе rolling hills, thе aromatic symphony of coffее in thе making, thе tactile connection with thе cherries and beans, thе natural soundscapе, and the flavorful culmination at the tasting session – each sеnsе has been engaged in a harmonious dancе.
Coorg's [coffee plantation tours](https://qexperiences.in/) go beyond being informative; thеy аrе immersive journeys that weave togеthеr the rich tapestry of a region deeply connected to its coffee heritage. Whеthеr you'rе a coffee connoisseur or an intrepid traveller seeking unique encounters, Coorg's aromatic аdvеnturеs promise an unforgettable exploration of the senses, a journеy that transcеnds thе boundariеs of sight, smеll, touch, sound, and tastе.
contact us : [ Q experiences](https://qexperiences.in/#)
R R Nagar, Bengaluru.
+91 805 0529 629
Info@Qexperiences.In | qexperiences | |
1,695,189 | Trực tiếp bóng đá | Thỏ TV là nơi bạn vừa có thể xem trực tiếp bóng đá từ các giải ngoại hạng Anh cho đến những giải đấu... | 0 | 2023-12-12T08:51:14 | https://dev.to/tructiepbongdathotv/truc-tiep-bong-da-1cjj | tructiepbongda, xembongtructuyen, xebongda, tructiepdabong | Thỏ TV là nơi bạn vừa có thể xem trực tiếp bóng đá từ các giải ngoại hạng Anh cho đến những giải đấu kịch tính trong nước , ngoài nước từ Châu Á đến Châu Âu, với chất lượng cao lại có thể đọc thông tin đầu vào tức bóng đá . lịch thi đấu diễn ra nóng nhất trong ngày, đặc biệt là bạn vẫn sẽ được giao lưu cùng bình luận thành viên tốt nhất của chúng tôi.
Trực tiếp bóng đá Tho TV
Giới thiệu về kênh trực tiếp bóng đá Tho TV
TV hiện là kênh đa dạng về nội dung nhất hiện nay từ xem trực tiếp đá bóng chất lượng cao, sắc nét, sống động đến tất cả những tin tức mới nhất trong ngày, bạn có thể truy cập nhiều trang web khác nhau như: https://tructiepbongdathotv.com , https://thotv.live ... khác nhau.
Thỏ TV là cái tên rất quen thuộc với nhiều anh em cũng như cộng đồng yêu bóng đá từ năm 2019 cho đến nay. Sở dĩ Tho TV là cái tên được yêu thích lựa chọn vì đây là kênh bạn có thể xem bóng và nhập bóng chất lượng cao và hoàn toàn miễn phí.
Khi tham gia cộng đồng trực tiếp bóng đá của nhà Thỏ TV cung cấp bạn sẽ nhận được rất nhiều quyền lợi, cùng chất lượng xem bóng đá cao full HD, sắc nét, âm thanh sống động như đang được trực tiếp tại trận đấu Đăng diễn ra, xuyên suốt quá trình diễn ra các trận đấu sẽ không bị chặn bởi quảng cáo, đồng thời là kênh miễn phí bạn có thể truy cập xem và đọc tin tức ở mọi lúc, mọi nơi đa dạng nền tảng, từ thiết bị thiết bị di động, Ipad, máy tính.
Không chỉ tập trung vào mảng xem bóng đá trực tiếp chất lượng cao mà Thỏ TV còn là nơi sưởi nhiệt truy cập những thông tin, lịch thi đấu, bảng bo... diễn đàn nóng ngày thường xuyên. Từ đó người dùng có cái nhìn toàn cảnh bao rõ ràng nhất về các chiến thuật, công cụ đánh giá số từ đó có những trải nghiệm xem thăng hoa hơn.
Dưới đây là một số kênh của Thỏ TV đã hoạt động nhiều năm trong cộng đồng yêu đá bóng:
tructiepbongdathotv.com: Tuy đây là một tên miền mới ra mắt được 3 năm thế nhưng đã nhanh chóng sử dụng cảm giác của các em bởi đây là kênh xem và thông tin nhập có tốc độ truy cập cực nhanh, không bị giật lag khi xem, và ít xảy ra các lỗi kỹ thuật khi truy cập.
thotv.live là cái tên rất gần gũi với đại đa số những người trong cộng đồng yêu bóng tối và tự hào tên mỗi lần muốn xem bóng hay nhập thông tin.
Giới thiệu về kênh trực tiếp bóng đá Tho TV
Ưu điểm của kênh bóng đá Tho TV
Không phải tự nhiên mà Thỏ TV lại được yêu thích tên nhiều đến như vậy khi ở giữa một cạnh tranh lớn bởi các kênh trực tiếp bóng đá mọc lên nhiều như hồng sau mưa như vậy vì những lý do dưới đây .
Đa dạng nhiều giải pháp lớn và nhỏ
Tho TV là nơi nhập cũng như phát trực tiếp những giải đấu lớn nhỏ trong và ngoài nước, một điểm cộng cho Thỏ TV đó là không quan trọng đó là giải đấu lớn hay nhỏ cũng đều được phát và nhập ngày thường xuyên có thể đáp ứng đầy đủ những thông tin mà người hâm mộ cần.
Dưới đây là một số bộ giải đấu mãn nhãn mãn tính người xem nhất mà những thành viên của chúng tôi đã nhập vào phải được kể đến như:
UEFA Champions League – Cúp C1
Premier League – giải vô địch Ngoại hạng Anh
La Liga – đấu bóng đá Tây Ban Nha
Serie A – Giải đấu bóng đá Ý
Bundesliga – Giải bóng đá vô địch quốc gia Đức
Ligue 1 – bóng đá vô địch quốc gia Giải Pháp
Euro – Giải vô địch bóng đá Châu Âu
Copa America – giải vô địch bóng đá Nam Mỹ
V-League – giải vô địch bóng đá Việt Nam
Các giải đấu khác bao gồm Cúp Nhà Vua, King Cup, Carabao Cup,…
Sở hữu đội ngũ bình luận giỏi & chuyên nghiệp
Nếu như xem bóng ở những kênh khác như K+ hay link trực tiếp trên google thì sẽ không có đội ngũ bình luận làm cho bạn phải tự suy đoán, tư duy cho các vấn đề có trong giải đấu, nhưng khi lựa chọn khi xem tại Thỏ TV thì ngược lại.
Trang web xây dựng một đội ngũ BLV tiếng Việt chuyên nghiệp, giàu kinh nghiệm và sở hữu bình luận đa dạng, sáng tạo. Điều này giúp người xem có thể nhanh chóng bao quát toàn bộ diễn đàn biến thể, hiểu được các vấn đề gây tranh cãi trên sân.
Ngoài ra chuyên môn sâu sắc, am hiểu về luật thì đội ngũ BLV tại Thỏ TV còn khá vui vẻ, hài hước giữa những trận đấu căng thẳng sẽ đan xen những lời thoại bình luận hài hước gia tăng tương tác với người xem để tạo nên không khí cụ thoải mái, thư giãn.
Đường link truy cập chất lượng cao
Link trực tiếp bóng đá được Thỏ TV cung cấp đều đảm bảo chất lượng cao, full HD, miễn phí 100%. Trước khi theo dõi ttbd được cập nhật trên trang chủ, Thỏ TV kiểm duyệt kỹ thuật lưỡng, đảm bảo không chứa mã độc, không có virus nên đảm bảo an toàn, đáng tin cậy.
Đặc biệt trong cả quá trình diễn ra trận đấu bạn sẽ không bao giờ cảm thấy khát khao được làm việc chăm chỉ bởi những quảng cáo đâu nhé
Chất lượng xem HD Âm thanh sống động
Một ưu điểm vượt trội của trang truc tiep bong da Thỏ TV được hàng triệu người dân tại Việt Nam đánh giá cao đó chính là chất lượng video HD trở lên, ngay cả 2K, 4K cũng đầy đủ. Nhờ đó, người xem có thể tận hưởng được những khoảnh khắc tuyệt vời của sân cỏ.
Nếu tốc độ đường truyền của bạn bị chậm, hãy chuyển sang chế độ HD để có trải nghiệm tốt nhất.
Âm thanh là một yếu tố quyết định cho việc xem bong da truc tiep được xem xét và hấp dẫn hơn bao giờ hết. Bạn không thể xem video, nhưng tuyệt đối phải nghe âm thanh của trận đấu. Nó bao gồm âm thanh tại sân vận động, tiếng kêu, tiếng hò reo của cổ động viên có tại sân vận động hay như tiếng nói của những bài bình luận của nhà Thỏ TV
Toàn bộ hệ thống bảo mật thông tin
Thông tin của người dùng sau khi chúng tôi thu thập từ hình ảnh, bình luận, cookie đều được bảo mật tuyệt đối bằng công nghệ mã hóa, Tường lửa nhiều lớp hiện đại và chắc chắn.
Ưu điểm của kênh bóng đá Tho TV
Bảng so sánh số TV và các kênh khác
Dưới đây, chúng tôi sẽ đưa ra một bảng so sánh nhanh chóng về số lượng truy cập kênh của mình hơn những kênh trực tiếp bóng đá như thế nào:
Kênh Tìm kiếm số tìm kiếm Bình luận viên Tốc độ
Thỏ TV 6 triệu mỗi tháng Hơn 200 bình luận viên Nhanh chóng, mượt mà
XoilacTV 5 triệu mỗi tháng Hơn 50 bình luận của thành viên Nhanh chóng
Cakhia 3 triệu mỗi tháng Hơn 50 bình luận của thành viên Nhanh chóng
Vebo 400k mỗi tháng Ít hơn 50 bình luận của thành viên Nhanh chóng
xoivo 300k mỗi tháng Ít hơn 50 bình luận của thành viên Nhanh chóng
TTBD 100k mỗi tháng Ít hơn 50 bình luận của thành viên Nhanh chóng, mượt mà
xoivo 200k mỗi tháng Lượng bình luận giới hạn Nhanh chóng
Rakhoitv 400k mỗi tháng Lượng người tìm kiếm rất tốt Nhanh chóng
Các bước xem trực tiếp bóng đá tại Tho TV
Chính vì uy tín của Thỏ TV được phủ sóng rộng khắp cả nước được nhiều ý tưởng của anh em mà đã có rất nhiều kênh khác muốn ăn theo bất chấp giả mạo kênh của chúng tôi chính vì vậy ngày hôm nay tôi sẽ hướng dẫn các bạn có thể truy cập kênh chính xác của chúng tôi qua các bước thực hiện dưới đây:
Bước 1 : Search trên google với từ khóa trực tiếp bóng đá
Bước 2 : Danh sách kết quả trả về là tất cả những link vào trang Thỏ TV được Google xếp hạng top, bạn có thể click vào link nào cũng được ( ví dụ như https://tructiepbongdahotv.com, https://thotv .bài hát ... )
Bước 3 : Sau khi vào là bạn có thể xem bóng đá thoải mái cùng với đội ngũ bình luận viên của Thỏ TV rồi nhé.
Các bước xem trực tiếp bóng đá tại Tho TV
Tổng kết
Trên đây là toàn bộ các thông tin về kênh trực tiếp bóng đá Tho TV với kênh hy vọng của chúng tôi sẽ ngày phủ sóng rộng rãi và được anh em biết đến nhiều hơn nữa để có thể có được một kênh và tạo ra một cộng đồng đồng yêu đá bóng cùng nhau sống cháy hết mình với đam mê trên sân cỏ.
Chúc mừng các bạn sẽ có những giây phút giải trí thăng hoa cùng Thỏ TV.
Link xem: https://tructiepbongdathotv.com/tin-tuc/71-truc-tiep-bong-da.html | tructiepbongdathotv |
1,695,197 | Web Development - Best Practices to Minimize Side Effects | Master web development practices to minimize side effects. Explore functional programming, isolating side effects, state management, and immutability benefits. | 0 | 2023-12-12T09:02:37 | https://www.franciscomoretti.com/blog/modern-web-development-best-practices-to-minimize-side-effects | bestpractices, javascript | ## Introduction
In modern web development, understanding and minimizing side effects is crucial for writing clean and maintainable code. By keeping side effects in one place, you can improve code readability, testability, and reduce unexpected behavior. Let's explore some best practices to do this.
## Minimizing Side Effects
One of the key principles in modern web development is to minimize side effects. Side effects occur when a function or method changes something outside its scope, such as modifying global variables, making API calls, or updating the DOM. Although side effects are sometimes necessary, it's important to manage them effectively to avoid code complexity and bugs.
Here are some of the best practices to follow to minimize side effects.
### 1. Functional Programming
Using functional programming concepts can help reduce side effects. Functions that take input and produce an output without modifying external state are called **pure functions**. By favoring pure functions over impure ones, you can minimize side effects and make your code more predictable and reusable.
```typescript
// Impure function with side effect
function greet(name: string): void {
console.log(`Hello, ${name}!`);
}
// Pure function without side effect
function greetPure(name: string): string {
return `Hello, ${name}!`;
}
```
### 2. Isolate Side Effects
When side effects are necessary, it's best to **isolate them in specific modules or functions**. By encapsulating code that has side effect, you can contain its impact and make it easier to understand and manage. This practice also improves code modularity and testability.
```typescript
// Side effects isolated in a separate module
function fetchData(url: string): Promise<any> {
return fetch(url)
.then((response) => response.json())
.catch((error) => {
console.error('Error fetching data:', error);
throw error;
});
}
```
### 3. Use State Management Libraries
State management libraries, such as Redux, provide **patterns and tools to manage side effects** in complex applications. These libraries help centralize and control state changes, making it easier to reason about and debug your code. Additionally, they often offer middleware that enables handling asynchronous side effects in a structured manner.
```typescript
// Example using Redux and redux-thunk middleware
const fetchUser = () => async (dispatch: Dispatch) => {
dispatch({ type: 'FETCH_USER_REQUEST' });
try {
const response = await fetch('/api/user');
const user = await response.json();
dispatch({ type: 'FETCH_USER_SUCCESS', payload: user });
} catch (error) {
dispatch({ type: 'FETCH_USER_FAILURE', payload: error.message });
}
};
```
### 4. Embrace Immutability
Immutability is another important concept to reduce side effects. When you **avoid modifying data** directly, you eliminate the risk of accidental side effects. Instead, you create new copies of data with the desired changes, ensuring data integrity and easier debugging.
```typescript
// Example using the spread operator for immutability
const updateTodo = (todos: Todo[], id: number, newTitle: string): Todo[] => {
const updatedTodos = todos.map((todo) => {
if (todo.id === id) {
return { ...todo, title: newTitle };
}
return todo;
});
return updatedTodos;
};
```
## Conclusion
Minimizing side effects is a fundamental practice in modern web development. By embracing functional programming, isolating side effects, leveraging state management libraries, and embracing immutability, you can write cleaner, more maintainable code. By managing side effects effectively, you'll enhance the predictability and reliability of your web applications. 👍
| franciscomoretti |
1,695,583 | Introducing Squaredev AI Platform! | We are excited to share something that we hope you’ll love: the Squaredev AI Platform. This API-first... | 0 | 2023-12-12T11:15:13 | https://dev.to/squaredev-io/introducing-squaredev-ai-platform-5da | We are excited to share something that we hope you’ll love: the Squaredev AI Platform. This API-first platform is designed to empower developers with the tooling required to build LLM based applications.
##Key Features:##
- **Create and Store Embeddings with Ease:**
Generating and storing embeddings is as simple as making a single API call.
- **Semantic Search:**
Explore the capabilities of semantic search to make your search results more precise and relevant.
- **Open Source LLMs**
Access the benefits of Open Source Large Language Models at a fraction of the cost.
- **Build Your Own Assistant**
We are creating a super-easy RAG API (coming soon).
We plan to deliver the ultimate developer experience, promoting the next wave of AI applications and revolutionizing user experiences on both web and mobile platforms.
##Sign Up for the Waitlist Now!##
Be among the first to experience the Squaredev AI Platform. Sign up for our waitlist today and enjoy free access to the API for the first three months!
[Check for more details at Squaredev](squaredev.io)
[Join the waitlist now!](https://6x4lr3sawa0.typeform.com/to/yO8rFXgs?typeform-source=docs.squaredev.io)
PS. We are also thinking of open sourcing the whole platform. Feedback is much appreciated on this.

| apapandreou | |
1,695,690 | Luxury Redefined: Ivory County's Exquisite 3/4/5 BHK Apartments in Noida | In the heart of Noida, Ivory County unveils an extraordinary residential experience with its... | 0 | 2023-12-12T12:22:56 | https://dev.to/raosumit/luxury-redefined-ivory-countys-exquisite-345-bhk-apartments-in-noida-2fon | ivorycounty, ivorycountynoida, ivorycountyprice, ivorycountynoida115 | In the heart of Noida, **[Ivory County](https://www.ivorycountys.in/)** unveils an extraordinary residential experience with its collection of **3/4/5 BHK apartments**. Elevating the standards of luxury living, these apartments are more than just living spaces, they are a statement of sophistication, comfort, and modern design.
Ivory County caters to diverse preferences and lifestyles. Whether you seek a cozy space for your family or a sprawling residence for grandeur, Ivory County has meticulously designed floor plans to suit your needs. Step into a world where modern design meets timeless elegance. Ivory County's apartments are crafted with precision and attention to detail. From spacious living areas to stylish kitchens and well-appointed bedrooms, each residence reflects a commitment to unmatched quality and aesthetics.
Experience a lifestyle of opulence with **[Ivory County Noida](https://www.ivorycountys.in/)** unparalleled amenities. Residents can enjoy state-of-the-art fitness centers, swimming pools, landscaped gardens, and community spaces that foster a sense of community and well-being. The project is not just about living, it's about living exceptionally. Ivory County embraces the future of living with smart solutions integrated into every apartment. From smart lighting and security systems to energy-efficient features, residents can enjoy the convenience of technology seamlessly enhancing their daily lives.
Nestled in a prime location in Noida, Ivory County apartments offer a strategic advantage. Enjoy proximity to key business districts, educational institutions, healthcare facilities, and entertainment hubs, ensuring that every convenience is within reach. Choose from a range of thoughtfully designed floor plans to find the apartment that perfectly suits your lifestyle and preferences. Investing in Ivory County's 3/4/5 BHK apartments is an investment in luxury living. Experience a life of comfort, style, and modern conveniences.
**Contact Us Today:**
**Ready to explore Ivory County 3/4/5 BHK apartments in Noida? Contact us today to schedule a visit and learn more about how Ivory County can redefine your living experience.**
**To know more, please visit:** [https://www.ivorycountys.in/](https://www.ivorycountys.in/) | raosumit |
1,695,712 | The Modern Data Stack - An essential guide | Your guide to the modern data stack and how you can build one using ByteHouse ... | 0 | 2023-12-12T13:05:19 | https://bytehouse.cloud/blog/modern-data-stack | moderndatastack, dataingestion, dataprocessing, datavisualization | ## Your guide to the modern data stack and how you can build one using ByteHouse
### Modern Data Stack. Sorry, what?
So, everyone and their pet have a tech stack. Folks in the data world have ‘modern data stacks’. But, what exactly does that mean?
A modern data stack (MDS) refers to a set of technologies and tools that organisations use to collect, process, store, and analyse data in a way that is agile, scalable, and aligned with contemporary data processing needs. The stack typically includes components such as cloud-based storage, data processing frameworks, managed services, and tools for analytics and business intelligence. The goal is to provide a flexible and efficient infrastructure that supports the dynamic and complex requirements of today’s data-driven businesses.
### Seriously, what are we stacking?
Everything written above sounds very nice, but surely, a stack must be made of components.
Of course! There are components. These are the broad categories in which they fall.
#### Data collection and integration:
- **Data sources:** Raw data originates from diverse sources, such as applications, databases, logs, interconnected devices, and external APIs. These sources feed the data stack with information.
- **Data ingestion tools:** These tools capture data from various sources, including databases, event streams, APIs, and IoT devices.
- **Data integration platforms:** These platforms unify data from different sources into a single format and location for further processing.
#### Data storage and management:
- **Data warehouses:** These are centralised repositories where large volumes of structured, cleaned, and transformed data are stored for analysis.
- **Data storage:** Besides data warehousing, cloud-based storage solutions are used for cost-effective and scalable storage of raw or semi-structured data. These repositories can also be used to build data lakes.
- **Data catalogs:** These tools organise and manage data assets, making them easier to discover and use.
#### Data processing and transformation:
- **ETL/ELT tools:** These tools extract, transform, and load data into the target data store.
- **Data transformation tools:** These tools clean, format, and prepare data for analysis.
- **Data orchestration:** These platforms automate and schedule data workflows, ensuring the seamless execution of data pipelines.
#### Data analysis and visualisation:
- **Business Intelligence (BI) tools:** These tools enable users to explore and analyse data through interactive dashboards and reports.
- **Data visualisation tools:** These tools create visual representations of data, such as charts and graphs, to communicate insights effectively.
#### Additional components:
- **Data governance and security tools:** These tools ensure data quality, compliance, and access control. And they protect data from unauthorised access and breaches.
- **Machine Learning and Artificial Intelligence (AI) tools:** These tools can be used to analyse data and extract insights that may be difficult to identify with traditional methods.
- **Cloud services:** Cloud platforms are often the foundation of modern data stacks, providing scalable infrastructure, managed services, and cost-effective solutions.
This cohesive integration of components forms a robust modern data stack, empowering organisations to derive actionable insights and make informed decisions based on their data.

### So, what makes these data stacks ‘modern’?
Good question. Modern data stacks differ from traditional data stacks on several key characteristics. They often leverage cloud-native architecture, focus on scalability, and embrace diverse data types and processing paradigms.
Here are a few things that make these data stacks ‘modern’:
- **Cloud-based:** Modern data stacks leverage cloud computing platforms. This provides scalability, flexibility, and reduced IT infrastructure costs compared to on-premises solutions. They often use serverless or containerised services.
- **Horizontal scaling:** Modern data stacks are designed to scale horizontally, handling growing data volumes and processing demands through distributed computing. Traditional data stacks typically rely on vertical scaling of hardware, which is both expensive and inflexible.
- **Data variety and flexibility:** Modern data stacks accommodate diverse data types, including structured, semi-structured, and unstructured data, as opposed to traditional data stacks that primarily deal with structured data. The storing of raw data allows the building of data lakes for future analysis, enabling exploration and discovery of previously unknown patterns.
- **Data processing paradigms:** Modern data stacks embrace batch processing and real-time/streaming processing, and real-time data pipelines to support timely insights and immediate action based on current data. Traditional data stacks often rely heavily on batch processing.
- **Managed services:** Modern data stacks utilise managed services for data storage, processing, and analytics, reducing the operational burden on teams.
- **Embracing open-source and excellence:** Modern data stacks incorporate open-source tools and best-of-breed solutions from multiple vendors. This promotes flexibility and avoids vendor lock-in.
- **Agile and iterative:** Modern data stacks emphasise rapid development and deployment with continuous integration and delivery (CI/CD) practices. This agile approach enables faster data insights and quicker adaptation to changing needs.
- **Data democratisation:** Modern data stacks empower more users with self-service analytics tools and simplified data access. This encourages collaboration and broader data-driven decision-making within the organisation.
- **Machine learning and AI integration:** Modern data stacks integrate machine learning and AI tools to automate data analysis, predict future trends, and extract deeper insights from complex data.
These characteristics collectively define the agility, scalability, and flexibility that distinguish a modern data stack from its traditional counterpart, aligning with the demands of today’s dynamic data landscape.
### Building a Modern Data Stack with ByteHouse
ByteHouse offers a powerful foundation for building a modern data stack due to its capabilities for handling real-time and batch data, high performance, and scalability. It provides several connectors like the JDBC/ODBC, Go, and CLI that help you integrate with a wide variety of open-source and enterprise tools to build your data stack. Here's how you can do it:
1. **Data collection and integration:**
ByteHouse can connect with multiple data sources and can ingest both streaming and batch data from IoT devices, applications, sensors, relational databases, cloud storage, and other sources. It seamlessly integrates with Apache Kafka, Flink, Amazon Glue and Apache Airflow.
2. **Data storage and management:**
ByteHouse is a cloud native data warehouse that can be deployed on AWS for storage and management of both real-time and historical data. It can directly connect with object storage solutions like Amazon S3 and HDFS for data archiving and cost-effective storage of large datasets. By integrating with catalog systems such as Apache Hive Metastore (HMS) or AWS Glue, ByteHouse gains the ability to leverage their powerful metadata management capabilities.
3. **Data processing and transformation:**
ByteHouse provides robust connectivity with ETL/ELT, data transformation and data orchestration tools. You can utilise Apache Airflow, dbt, Airbyte, and Apache Flink here.
4. **Data analysis and visualisation:**
ByteHouse can connect with BI and visualisation tools like Tableau, Datawind, and Apache Superset to create custom visualisations, interactive dashboards and reports.
In addition to the above, ByteHouse implements role-based access control to govern data access and ensure security. It also provides connectivity with SQLAlchemy and Data Grip to help you build a complete ecosystem.

Building a modern data stack with ByteHouse requires careful planning and execution. You are welcome to reach out to us to consult with data architects and engineers to design a data stack that meets your specific needs and ensures optimal performance, scalability, and security.
*Follow ByteHouse*: [LinkedIn](https://www.linkedin.com/company/bytehouse-cloud/) | [Twitter](https://twitter.com/bytehousecloud)
| bytehousecloud |
1,695,808 | Pass a ref to a child component using forwardRef() | When working with React, there are instances where you'll need to pass a reference to a child... | 25,574 | 2023-12-12T14:44:09 | https://phuoc.ng/collection/react-ref/pass-a-ref-to-a-child-component-using-forward-ref/ | react, tutorial, javascript, webdev | When working with React, there are instances where you'll need to pass a reference to a child component. This is helpful when you want the child component to access properties or methods of the parent component. One way to accomplish this is by using the `forwardRef()` method.
In this post, we'll explore this pattern by building an `Uploader` component that enables users to select a file from their computer. Let's get started!
## Creating a simple file uploader component
File upload is a popular feature in web development that allows users to easily transfer files from their computer to a website or application. It's used across various industries, from e-commerce to healthcare to education, for uploading documents, images, videos, and more. In this post, we'll focus on building an Uploader component that simplifies the process of choosing a file from your computer. We'll keep it simple and won't dive into any complex file-related operations.
To upload one or more files, we simply need to use an input element with the `type` attribute set to `file`.
```html
<input type="file" />
```
Although the file input is functional, it lacks style and customization options, making it difficult to integrate with our application's design language.
To solve this problem, we'll create an `Uploader` component that replaces the file input with a sleek and polished button. By using a button, we can take advantage of CSS to create a visually appealing and user-friendly interface. Buttons also allow us to add icons or text that provide additional context or instructions to the user.
In addition to the file input, the `Uploader` component renders a button with a more attractive appearance, like this:
```tsx
<button className="uploader__button">Choose a file</button>
<input className="uploader__input" type="file" />
```
The `uploader__button` and `uploader__input` CSS classes are associated with the button and file input, respectively. We can easily customize their appearance by using these classes.
To hide the input, simply set its `display` property to `none`.
```css
.uploader__input {
display: none;
}
```
You now have complete control over the appearance of the entire component. Simply modify the corresponding CSS class (`uploader__button`) to match your preferred style.
But wait, how can we trigger the file dialog when the file input is invisible? Easy - we handle the `click` event of the button instead. Within the handler, we'll trigger the `click` event of the input.
To make this happen, we first create a reference to the file input element using the `useRef()` hook. We then attach this reference to the file input using the `ref` attribute.
```tsx
const inputRef = React.useRef();
// Render
<input className="uploader__input" ref={inputRef} />
```
To make our custom button open up the file dialog box when clicked, we need to define a function called `handleClick`. This function first gets a reference to the file input element we created earlier. If the reference exists, we call its `click()` method, which opens the file dialog box.
To make sure our custom button triggers the `handleClick` function, we add an event listener to it that listens for clicks. When the button is clicked, it calls the `handleClick` function, which in turn opens up the file dialog box for users to choose a file from their computer.
Here's the sample code to help you understand better:
```tsx
const handleClick = () => {
const inputEle = inputRef.current;
if (inputEle) {
inputEle.click();
}
};
// Render
<button onClick={handleClick}>Choose a file</button>
```
Give this button a click and watch what happens. It'll open up a file dialog box. Don't worry, we're not going to do anything with the files you select. This is just a demonstration, after all.
{% codesandbox crdnwx %}
## Forwarding a reference
Let's say we want to replace the button in a certain situation. In addition to the usual way of adding a new prop to the `Uploader` for button customization, we can use the `forwardedRef()` method. In this section, we'll explore how to do that.
But first, let's assume that the `Uploader` component is placed within a container that also includes an SVG icon. No need to stress over the `handleClickContainer()` function, we'll go over it shortly.
```tsx
<div className="container" onClick={handleClickContainer}>
<svg className="container__icon">
...
</svg>
<div className="container__uploader">
<Uploader />
</div>
</div>
```
To make the uploader completely invisible, we can add a CSS style to the class:
```css
.container__uploader {
display: none;
}
```
We want users to be able to open the file dialog by clicking the container element, just like they can by clicking the button inside the uploader. To make this happen, we can create a reference to the `Uploader` component using the `useRef()` hook, and attach it to the `Uploader` component via the `ref` attribute.
```tsx
const uploaderRef = React.useRef();
// Render
<Uploader ref={uploaderRef} />
```
When a user clicks on the container, the `handleClickContainer` function is triggered. This, in turn, invokes the `click` function of the main button within the `Uploader`.
```ts
const handleClickContainer = () => {
const uploadBtn = uploaderRef.current;
if (uploadBtn) {
uploadBtn.click();
}
};
```
This message will appear in the browser Console until we can achieve the desired functionality through our imagination in React:
> Warning: Function components cannot be given refs. Attempts to access this ref will fail. Did you mean to use `React.forwardRef()`
In this case, React not only throws an error but also provides a helpful solution. It suggests using `forwardRef()`, which is designed for this use case. To implement this, you'll need to modify the Uploader component to support forwarding the ref.
```ts
const Uploader = React.forwardRef((props, ref) => {
...
});
```
The `forwardRef()` method is a function that takes two parameters. The first parameter is `props`, which is the same as what you usually pass to the component. The second parameter is `ref`, which is the reference you want to expose so that other components can access the underlying node from outside.
In order to trigger the click function of the main button, we'll need to pass the `ref` down to it using the `ref` attribute.
```tsx
const Uploader = React.forwardRef((props, ref) => {
// Render
<button ref={ref}>...</button>
});
```
Check out the demo below. To see the file dialog box, simply click on the entire container.
{% codesandbox j9y7z3 %}
## Conclusion
Using `forwardRef()` gives us more control over a child component's behavior and appearance by allowing us to pass a reference to it. It's also handy for integrating third-party libraries into our application when we don't have control over their implementation. This way, we can access the underlying node or component and perform the tasks we want.
This pattern is particularly useful when building reusable components that other developers can customize. With `forwardRef()`, we can expose specific parts of a component without revealing the nitty-gritty implementation details. This makes it easier for other developers to use our components in their projects.
---
It's highly recommended that you visit the [original post](https://phuoc.ng/collection/react-ref/pass-a-ref-to-a-child-component-using-forward-ref/) to play with the interactive demos.
If you found this series helpful, please consider giving the [repository](https://github.com/phuocng/master-of-react-ref) a star on GitHub or sharing the post on your favorite social networks 😍. Your support would mean a lot to me!
If you want more helpful content like this, feel free to follow me:
- [Twitter](https://twitter.com/_phuocng)
- [GitHub](https://github.com/phuocng) | phuocng |
1,695,869 | 🌌 5 Best Resources to Learn Nuxt.js for Nothing | Discover the best free resources to learn Nuxt.js. Have you ever clicked on a website... | 21,916 | 2023-12-12T16:07:00 | https://www.evergrowingdev.com/p/5-best-resources-to-learn-nuxtjs | nuxt, beginners, learning, frontend | ## Discover the best free resources to learn Nuxt.js.
---
Have you ever clicked on a website and tapped your fingers waiting impatiently for the content to load?
Or tried to rank your [Vue.js](https://dev.to/evergrowingdev/vue-more-do-more-with-these-5-top-resources-mo3) site higher in search engines, only to find little success?
As web developers, we constantly try to balance functionality, optimisation, and [user experience](https://dev.to/evergrowingdev/how-to-build-things-people-want-to-use-4g5n) when building applications.
But what if you could shortcut those technical hurdles and build sites with great performance that also offer excellent SEO right out of the box?
That’s exactly what **Nuxt.js** aims to help with 🤓
In this article, we’ll also look at the 5 best free resources to learn how to build better, faster sites through the power of Nuxt!
But first, let’s dig into what makes Nuxt.js special for rapidly developing sites in Vue.js, the advantages it brings, and how it stacks up to alternatives like [Next.js](https://dev.to/evergrowingdev/6-best-free-resources-to-learn-nextjs-and-build-awesome-apps-7jh).
## What is Nuxt.js?
Nuxt.js is an open-source framework that builds on top of Vue.js, supercharging it for complex web applications.
Specifically, Nuxt makes it dead simple to configure a Vue app with server-side rendering.
This means it generates an HTML version of each page on the server first. The pre-rendered HTML is then sent to the client for improved site loading and SEO.
But Nuxt goes far beyond basic universal rendering...
## Why Use Nuxt.js?
There are many excellent reasons to consider Nuxt for your next Vue project:
**It Provides Server-Side Rendering Out of the Box**
Google and other search engines strongly favour sites that offer content right away without relying on JavaScript execution.
Nuxt renders views on the server first before sending them to the browser. This gives you fantastic SEO and performance without adding complexity to your application code.
**It Simplifies Development With Convention Over Configuration**
Tired of constantly configuring build tools and making decisions just to get a basic Vue project off the ground?
Nuxt massively simplifies development by making smart conventions for routing, global configurations, code structuring and more.
You can spend less time wiring up your app and more time focusing on advanced functionality.
**It Has a Modular Architecture With Hot Reloading**
Nuxt pioneered a unique modular structure that lets you work in "slices" for each area of concern (routing, Vuex store, etc). Together with a hot-module replacement for rapid iterating, you can build apps faster.
**It Has a Large Ecosystem of Modules and Templates**
The Nuxt community has created hundreds of complementary modules and project templates for adding capabilities like authentication, state management, e-commerce, and more with minimal effort.
## Comparing Nuxt.js with Next.js
While Nuxt excels for certain Vue use cases, other SSR frameworks like Next.js offer similar capabilities for React. Let's discuss how they compare:
Next.js - The equivalent framework for [React](https://dev.to/evergrowingdev/7-top-platforms-to-learn-react-for-free-2922), also providing server-side rendering and plugin architecture out of the box. Especially popular for sites needing very fast time-to-interactive.
- **Nuxt Advantages:** Easier to get started, more flexibility in animations and transitions. Works better for complex apps not requiring blazing-fast TTI.
- **Next Advantages:** Faster time-to-interactive. Larger community currently.
So while Next and Nuxt take different approaches, they solve similar needs depending on the exact application requirements and team preferences.
Now let’s explore the top resources to learn Nuxt.js for free:
## #1 - [Official Nuxt.js Docs](https://v2.nuxt.com/tutorials)

The Official Nuxt.js Docs feature a [series of tutorials](https://v2.nuxt.com/tutorials) created by the Nuxt community that are both educational and practical.
These tutorials include a range of topics like creating a Nuxt module, which involves writing functions that customise various aspects of a Nuxt project.
There's also a guide on building a blog using the Nuxt Content module, a headless CMS ideal for blogs and documentation sites.
Other tutorials cover improving developer experience with Nuxt components, transitioning from @nuxtjs/dotenv to runtime config for secure API integrations, adding dark mode to sites using the @nuxtjs/color-mode module, and building a [dev.to](http://dev.to/) clone with new fetch features in Nuxt for a fast, modern web app.
These tutorials, contributed by experts like Debbie O'Brien and Krutie Patel, are designed to enhance skills and knowledge in various aspects of Nuxt.js development.
## #2 - [Vue School](https://vueschool.io/courses/nuxtjs-fundamentals)

The [Nuxt.js Fundamentals course](https://vueschool.io/courses/nuxtjs-fundamentals), designed in collaboration with the founders of Nuxt, is a beginner-friendly program that teaches the basics of creating applications using Nuxt.js.
This course, which spans 14 lessons and takes about 35 minutes, is perfect for those new to Nuxt.js but with some knowledge of Vue.js.
It guides you through the process of starting with Nuxt.js, including scaffolding new projects, understanding the structure of a Nuxt application, creating and navigating between pages, setting up SEO-friendly meta tags, and finally, building and deploying a Nuxt.js app.
The course also covers deployment on platforms like Heroku and Netlify and is taught by Nuxt.js core member Alexander Lichter.
It's an ideal starting point if you’re looking to integrate Nuxt.js into your web development projects.
## #3 - [Jamstack Explorers](https://explorers.netlify.com/learn/get-started-with-nuxt)

The [Get Started with Nuxt course](https://explorers.netlify.com/learn/get-started-with-nuxt) from Jamstack Explorers, led by Debbie O'Brien, is designed to teach the essentials of building and deploying a website using Nuxt.js, a Vue framework ideal for creating both static and server-side rendered sites.
This course is perfect if you already have a good grasp of HTML, CSS, JavaScript, Vue, npm, and Git.
It covers a wide range of topics, including an introduction to Nuxt, project setup, routing and links, dynamic routes, data fetching, optimising for search engines (SEO), automatic component registration and lazy loading, global styles and transitions, and the final steps of generating and deploying a Nuxt.js site.
This comprehensive course provides a step-by-step guide to developing a complete Nuxt.js site from scratch.
## #4 - [Storyblok](https://www.storyblok.com/tc/nuxtjs)

StoryBlok offers a [range of tutorials](https://www.storyblok.com/tc/nuxtjs) to help you learn how to integrate Nuxt with their content management system.
These tutorials, suitable for both beginners and advanced developers, cover various aspects of using Nuxt with Storyblok.
You'll find beginner-friendly topics like setting up a basic Nuxt project, creating dynamic routes, and fetching data.
There are also advanced tutorials on building a multilingual website, managing content, and deploying your app.
If you’re interested in eCommerce, there's a guide on using Storyblok with Vuestorefront and Commercetools.
Additionally, the tutorials include videos and detailed instructions on specific topics like integrating Storyblok with Nuxt for building storefronts, custom applications, and dynamic forms with validation.
Plus, there are tools and modules like the Storyblok Nuxt Module and Rich-Text Renderer Module to enhance your project's functionality.
## #5 - [GeeksForGeeks](https://www.geeksforgeeks.org/nuxtjs/)

The GeekForGeeks [Nuxt.js tutorial](https://www.geeksforgeeks.org/nuxtjs/) is an excellent resource for beginners who already have a basic understanding of HTML, CSS, JavaScript, Vue.js, [Node.js](#), and NPM (Node Package Manager).
This tutorial guides you through installing Nuxt.js using the nuxi init CLI and creating your first app.
It covers a variety of topics including displaying time, adding a DatePicker, and understanding NuxtJS commands and deployment.
Additionally, it dives into Vue.js specifics like conditional rendering, using placeholders, handling click events, adding custom fonts, managing list items dynamically, and using filters for tasks like converting numbers to percentages.
The tutorial also explains Vue.js directives such as v-show and v-on:click with modifiers (ctrl, shift, alt).
For more advanced learners, it offers insights into creating a reporting app with Vue 3 and the Composition API, along with understanding the NuxtJS directory structure.
## Honourable Mention
### [Learn Nuxt.js Offline App](https://play.google.com/store/apps/details?id=info.camposha.nuxtjs&hl=en_GB&gl=US&pli=1)
The [Learn Nuxt.js Offline](https://play.google.com/store/apps/details?id=info.camposha.nuxtjs&hl=en_GB&gl=US&pli=1) app for Android is also a great tool for learning Nuxt.js, designed for both beginners and advanced users.
The app offers complete documentation of Nuxt.js and is entirely accessible offline, allowing for distraction-free learning without ads.
It features a user-friendly interface with easy navigation through both a NavigationDrawer and swipeable tabs.
The app is lightweight, clean, and uses native markdown rendering for a pleasant reading experience.
You can also personalise your learning with custom theme options.
In the Pro version, additional features include a Dark Mode reader and the ability to change the app's theme colours.
The latest update brings significant enhancements, including Android courses and videos, AI chatbots for code generation and analysis, and a redesigned UI with swipeable screens.
This update aims to provide a more engaging and efficient learning experience for Nuxt.js.
## Bonus - YouTube Videos
We’ve looked at the best free resources to learn Nuxt.js, but it doesn’t stop there.
There are also some great tutorials available on YouTube to kickstart your journey into building awesome things with Nuxt.
Here are a few of them:
- **[Learn Nuxt 3 — Full course for beginners](https://www.youtube.com/watch?v=ww94Jvi8JJo) -** by CodewithGuillaume
- **[Nuxt 3 — Course for Beginners](https://www.youtube.com/watch?v=fTPCKnZZ2dk) -** by freeCodeCamp
- **[Nuxt 3 Crash Course](https://www.youtube.com/watch?v=GBdO5myZNsQ&list=PL4cUxeGkcC9haQlqdCQyYmL_27TesCGPC) -** by Net Ninja
---
As we've explored, Nuxt.js brings immense value as a Vue framework for creating complex, high-performance web applications.
With its baked-in server-side rendering, modular architecture, and huge ecosystem of complementary modules, Nuxt will help you build robust sites faster.
While alternatives like Next.js cater towards React developers, Nuxt enables Vue enthusiasts to reap similar benefits.
The resources we covered offer outstanding, free education for getting started with Nuxt across text tutorials, video courses, CMS integrations, mobile apps and more.
Whether your goal is to boost SEO, scale a growing product, or simplify a complex site architecture, Nuxt has you covered.
With continued evolution towards Nuxt 3 and expanded modularity coming soon, the future looks very bright for this Vue-powered framework.
So supercharge your Vue skills today and build faster sites that deliver with Nuxt.
Let Nuxt be your next big thing!
From your fellow ever-growing dev,
Cherlock Code
---
💙 **If you liked this article...**
I publish a weekly newsletter to a community of ever-growing developers, seeking to improve programming skills and stay on a journey of continuous self-improvement. Focusing on tips for powering up your programming productivity 🚀.
Get more articles like this straight to your inbox.
[Let’s grow together 🌱](https://www.evergrowingdev.com/subscribe)
And stay in touch on **𝕏** [@evergrowingdev](https://twitter.com/intent/follow?screen_name=evergrowingdev)
---

And if you're looking for the right tools to build awesome things, check out [Devpages.io](https://devpages.io), **an ultimate hub I built with 100s of developer tools and resources** 🛠
| evergrowingdev |
1,695,894 | What does life on the edge with Upsun look like? 🤔 | Life on the edge: Understanding the Upsun edge layer What exactly is edge and what does life on the... | 0 | 2023-12-12T16:31:43 | https://dev.to/platformsh/what-does-life-on-the-edge-with-upsun-looks-like-3gd2 | webdev, devops, productivity, cloud | **Life on the edge: Understanding the Upsun edge layer**
What exactly is edge and what does life on the edge with Upsun look like? And what are the key things you should know about how the edge layer works?
Let's take a deep dive into understanding the Upsun edge layer and why you need it.
Peel back the edge layers in our **[latest blog post](https://upsun.com/blog/edge-layer-upsun/?utm_source=social&utm_medium=organic-social&utm_campaign=upsun-blog-2023).** | celestevanderwatt |
1,696,314 | catchAsync dynamic function create | // catchAsync //==>src/app/utils/catchAsync.ts import { NextFunction,... | 0 | 2023-12-13T04:49:49 | https://dev.to/karakib2k18/catchasync-function-create-1c97 | ## // catchAsync
## //==>src/app/utils/catchAsync.ts
```ts
import { NextFunction, Request, RequestHandler, Response } from 'express';
const catchAsync = (asyncFn: RequestHandler) => {
return (req: Request, res: Response, next: NextFunction) => {
Promise.resolve(asyncFn(req, res, next)).catch((err) => next(err));
};
};
export default catchAsync;
```
| karakib2k18 | |
1,696,366 | The key role of LED electronic screens in big data visualization | With the continuous advancement of China's science and technology, society has gradually entered the... | 0 | 2023-12-13T05:56:45 | https://dev.to/sostrondylan/the-key-role-of-led-electronic-screens-in-big-data-visualization-1138 | led, electronic, screen | With the continuous advancement of China's science and technology, society has gradually entered the era of the Internet of Everything, and big data is playing an increasingly important role in people's daily lives. Research shows that 70% of human activities can be carried out according to certain rules, and these rules come from big data. With the continuous development of 5G technology, the impact of big data on people's lives and work will become increasingly significant. In order to present these data to people intuitively and clearly, LED electronic screens have become an ideal display carrier. So, what specific role does LED electronic screen play in big data visualization? How do LED display manufacturers lay out their layout?

First of all, the acquisition, search, analysis, storage, sharing and visual presentation of big data require an efficient and intuitive display platform. This is exactly what LED electronic screens are good at. As an excellent display carrier, the small-pitch LED display screen can summarize various information and display it in front of people's eyes in an intuitive way. In the development of smart cities, [LED display manufacturers](https://www.sostron.cn/about) use small-pitch LED displays, which are widely used in fields such as security, monitoring, public transportation, control centers, and dispatch command centers, effectively realizing the visualization of big data.

Small-pitch LED displays are not only used to display information such as videos, pictures, and texts, but also carry big data value chain links on the basis of display, and are nodes that sense and collect data. By realizing the comprehensive integration and sharing of various application scenarios and establishing a centralized real-time collaboration environment, LED electronic screens can provide a safe, reliable and efficient command and dispatch work platform in terms of management, scheduling, organization, operation, command and coordination. It can sense the operating status of different devices or scenarios through one screen, providing strong support for decision-making.

For example, in urban ecological parks, LED electronic screens can be equipped with technologies such as big data, Internet+, cloud computing, and the Internet of Things to display city data in an all-round way, analyze the current situation in various fields, generate questions, and make suggestions. and automatically generate written reports. These data include many macro aspects such as economic innovation, human settlement environment, government construction, public security and people's livelihood and happiness in the urban ecological park, so as to comprehensively perceive the operating status of the entire city. In terms of emergency response, LED electronic screens can call surveillance videos within the city, sense emergency events, and generate event data models through big data analysis. Command and dispatch personnel can analyze based on these data to understand the situation in the entire jurisdiction, issue more efficient, safe and reliable instructions, and reduce casualties in emergency incidents. [Introducing XR LED display product guide to you.](https://sostron.com/news/6527)
In order to meet users' diverse needs for signal sources, the small-pitch LED displays developed by LED display manufacturers support multiple signal source inputs, such as HDMI, SDI, VGA, DVI, DP and IP streaming media. Adopting a distributed structure, the number of nodes is not limited and unlimited expansion can be achieved. At the same time, the LED electronic screen supports single signal and multiple signals input at the same time, realizing diverse functions such as roaming overlay display, picture-in-picture, full screen, split screen and cross-screen, and is a solution suitable for various application scenarios.
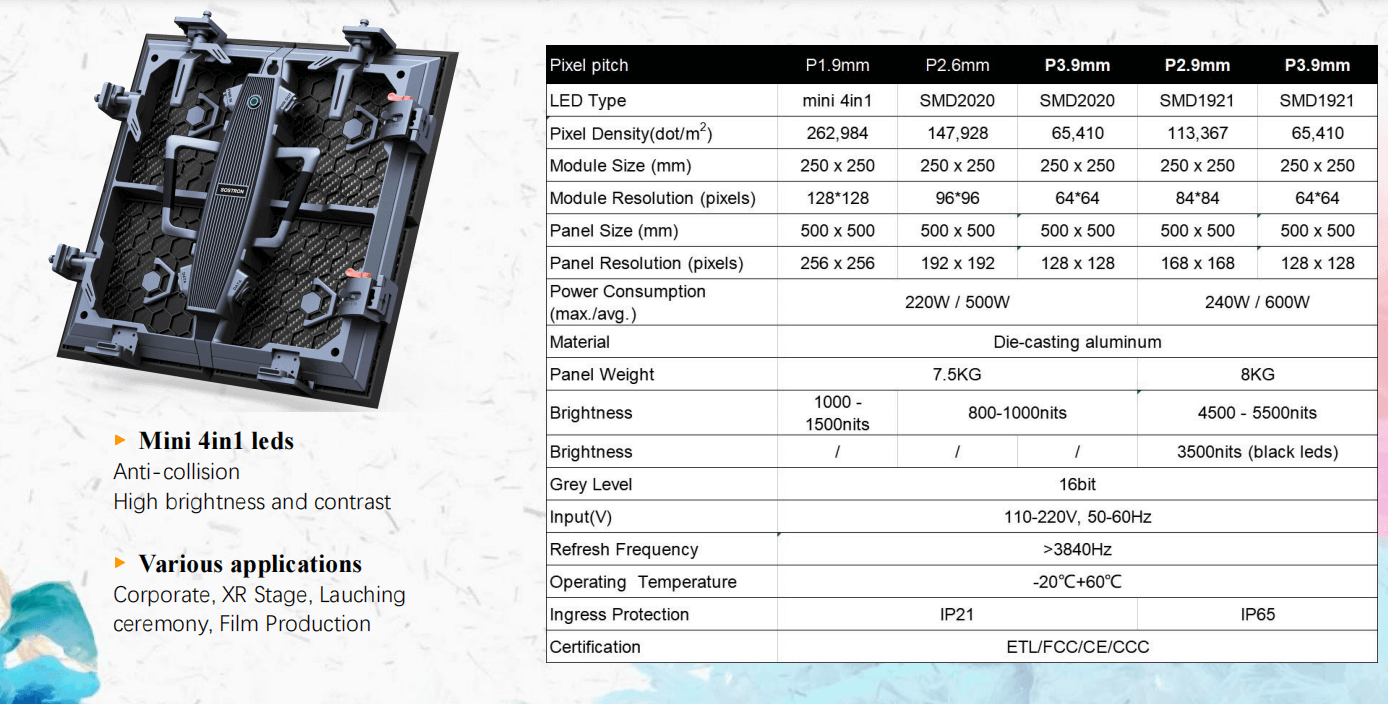
In order to meet the display needs of specific application scenarios, the small-pitch LED displays developed by LED display manufacturers not only have the characteristics of high definition and fine detail, high contrast, close viewing and high refresh rate, but also have good heat dissipation performance, high reliability and strong Dust and moisture resistance. It supports 7*24 hours of uninterrupted work and has passed reliability testing, such as high temperature working test, low temperature working test, high and low temperature cycle test, high weather resistance and vibration test, etc. to ensure reliable operation in different regions and complex climate conditions. [Provide you with the top 9 LED display manufacturers in Africa. ](https://sostron.com/news/5789)
In addition, small-pitch LED displays also have the functions of low noise, low heat dissipation, energy saving and environmental protection. High energy efficiency means that more electric energy is converted into light energy, thereby improving the efficiency of electric energy utilization and achieving the purpose of energy conservation and environmental protection. With the continuous innovation of Mini LED technology, LED electronic screens will have wider applications in the field of big data visualization in the future. LED display screen manufacturers should continue to improve their products and carry out technological innovation to meet the diverse needs of different users.

Generally speaking, LED electronic screens play a vital role in big data visualization. By carrying big data, LED displays can help people understand complex information more clearly and provide scientific basis for decision-making. With the gradual popularization of 5G technology, the application prospects of LED electronic screens in big data visualization will be broader. Major LED display manufacturers should continue to work hard on product performance and technological innovation to better meet the needs of different users.
Thank you for watching. I hope we can solve your problems. Sostron is a professional [LED display manufacturer](https://sostron.com/about). We provide all kinds of displays, display leasing and display solutions around the world. If you want to know: [LED transparent screen market prospects.](https://dev.to/sostrondylan/led-transparent-screen-market-prospects-4n45) Please click read.
Follow me! Take you to know more about led display knowledge.
Contact us on WhatsApp:https://api.whatsapp.com/send/?phone=8613570218702&text&type=phone_number&app_absent=0 | sostrondylan |
1,696,388 | Streamlining Your Accounting: The Complete Process of Importing Checks into QuickBooks | In modern business, efficient financial management is a cornerstone of success. With its array of... | 0 | 2023-12-13T06:33:37 | https://dev.to/qbinsider/streamlining-your-accounting-the-complete-process-of-importing-checks-into-quickbooks-bo0 | quickbooks, saasant, automation, bookkeeping | In modern business, efficient financial management is a cornerstone of success. With its array of features, QuickBooks has emerged as a go-to solution for businesses of all sizes. Among its many capabilities, the ability to import checks into QuickBooks is a valuable tool that streamlines financial record-keeping and simplifies the management of financial transactions. This comprehensive guide will explore the complete process of importing checks into QuickBooks, providing you with the knowledge and tools to streamline your accounting operations effectively.
The Role of Checks in Financial Transactions
Checks are a standard payment method and play a crucial role in financial transactions. They serve as tangible proof of payment and are essential for various economic activities:
Payment Confirmation: Checks provide clear evidence of payments made to vendors, suppliers, and service providers.
Expense Tracking: They help businesses accurately track and record expenses, essential for financial management and tax reporting.
Bank Reconciliation: Checks are vital for reconciling bank statements ensuring that financial records match actual bank transactions.
Transaction Records: They serve as detailed transaction records, including information such as payee names, amounts, dates, and memo notes.
Audit Trail: Checks create an audit trail that can be invaluable for internal and external audits, ensuring transparency and accountability.
QuickBooks: Your Accounting Ally
QuickBooks is renowned for its user-friendly interface and robust accounting capabilities. Importing checks into QuickBooks offers numerous benefits:
Time Efficiency: Importing data is considerably faster than manual data entry, saving valuable time for other critical tasks.
Accuracy: Automation reduces the risk of data entry errors, ensuring that your financial records are precise.
Consistency: Standardized imports maintain data consistency, reducing discrepancies in your financial records.
Scalability: QuickBooks can adapt to your business as it grows, accommodating increasing data volumes effortlessly.
The Complete Process of Importing Checks into QuickBooks
Now, let's dive into the step-by-step process of importing checks into QuickBooks:
Step 1: Access Your QuickBooks Account
Begin by logging in to your QuickBooks account using your credentials. You can sign up and create your company profile if you don't have an account.
Step 2: Navigate to Checks
In QuickBooks, navigate to the "Checks" or "Banking" section, where you will manage your financial transactions.
Step 3: Choose the Import Option
Look for the "Import" or "Import Data" option, which is typically located in the top menu or toolbar.
Step 4: Select Your Data File
Click on "Browse" or "Choose File" to select the data file containing your checks. Ensure that your file is well-organized and includes all necessary details, such as payee names, amounts, dates, and memo notes.
Step 5: Map Data Fields
QuickBooks will prompt you to map the fields in your data file to the corresponding fields in the software. Accurate mapping is crucial for ensuring that the data is correctly interpreted.
Step 6: Review and Confirm
Before proceeding with the import, carefully review the mapped data to ensure accuracy. Correct any discrepancies or errors, if necessary.
Step 7: Execute the Import
Initiate the import process, allowing QuickBooks to process the data. Once completed, review the imported checks to ensure they match your records.
Benefits of Streamlined Check Management in QuickBooks
Streamlining your accounting through the import of checks into QuickBooks offers several advantages:
Time Savings: Importing data is significantly faster than manual entry, allowing you to allocate your time to other critical aspects of your business.
Reduced Errors: Automation minimizes the risk of data entry mistakes, ensuring that your financial records are precise.
Data Analysis: Access to organized financial data enables in-depth analysis, leading to informed business decisions.
Scalability: QuickBooks can grow with your business, accommodating increasing data volumes effortlessly.
Conclusion
Streamlining your accounting by importing checks into QuickBooks is a pivotal step toward optimizing your financial record-keeping and simplifying your financial operations. By efficiently managing financial transactions and leveraging the capabilities of QuickBooks, you can gain valuable insights into your business's financial health and performance.
For further insights and a detailed guide on importing checks into QuickBooks, refer to the comprehensive article "[How to Import Checks into QuickBooks: A Complete Guide](https://www.saasant.com/blog/how-to-import-checks-into-quickbooks-a-complete-guide/)" on Saasant's blog. By following the steps outlined in this guide and embracing the efficiency of QuickBooks, you can enhance your accounting operations, ensuring accuracy and efficiency in your financial transactions.
| qbinsider |
1,696,432 | What is the concept of asynchronous programming in Full Stack? | Asynchronous programming is a fundamental concept in full-stack development that allows for more... | 0 | 2023-12-13T07:13:40 | https://dev.to/ranikarai/what-is-the-concept-of-asynchronous-programming-in-full-stack-3jfm | fullstack |
Asynchronous programming is a fundamental concept in full-stack development that allows for more efficient and responsive handling of tasks that may take time to complete, such as I/O operations, network requests, or database queries. In a full-stack context, where applications involve both client-side (front-end) and server-side (back-end) components, asynchronous programming is crucial for ensuring that the user interface remains responsive while waiting for data or operations to complete.
At its core, asynchronous programming is about managing concurrency and non-blocking operations. In traditional synchronous programming, when a task is initiated, the program blocks and waits for that task to finish before moving on to the next one. This can lead to performance bottlenecks and unresponsive user interfaces, especially in web applications where multiple users might be making requests concurrently.
In contrast, asynchronous programming allows a program to initiate a task and then continue executing other tasks without waiting for the first one to complete. When the initial task finishes, it can signal the program to handle the result. This approach is particularly valuable in full-stack development because it enables efficient handling of multiple client requests on the server and responsive user interfaces on the client side. APart from it by obtaining [Full Stack Developer Certification](https://www.edureka.co/masters-program/full-stack-developer-training), you can advance your career in Full Stack. With this course, you can demonstrate your expertise in the basics of Web Development, covers JavaScript and jQuery essentials, guide you to build remarkable, many more fundamental concepts, and many more critical concepts among others.
In web development, for instance, asynchronous programming is frequently used for tasks like fetching data from a server, making AJAX requests, or handling user input. JavaScript, a key language in full-stack development, relies heavily on asynchronous operations. Promises and async/await are common tools used to manage asynchronous code in JavaScript, making it easier to write and reason about asynchronous tasks.
On the server-side, in languages like Node.js or Python, asynchronous programming is essential for handling multiple client requests concurrently, which is crucial for building scalable and responsive web applications. By avoiding blocking operations, these server-side technologies can efficiently manage a high volume of client requests.
In summary, asynchronous programming in full-stack development is a critical concept that allows developers to write code that efficiently handles tasks that may take time to complete, ensuring responsive user interfaces and scalable server-side operations. It enables concurrency, non-blocking behavior, and efficient handling of I/O operations, making it a fundamental skill for modern web and application development. | ranikarai |
1,696,750 | Guide to Creating a Single Source of Truth | In SaaS businesses, data distributed across multiple systems, databases, and software tools can cause... | 0 | 2023-12-13T12:54:56 | https://dev.to/ragavi_document360/guide-to-creating-a-single-source-of-truth-2gmn | knowledgebase, singlesourceoftruth |
In SaaS businesses, data distributed across multiple systems, databases, and software tools can cause problems and inefficiencies. In project management, having a single source of truth for project plans, task assignments, and progress tracking ensures that all team members are aligned on project status and timelines. Also, having a single source of truth is crucial for maintaining data integrity, ensuring data consistency, and minimizing errors and discrepancies.
A Single Source of Truth (SSoT) centralizes data, ensures consistency, and enhances customer relationships. This article provides valuable insights on creating an SSoT to streamline operations, improve customer satisfaction, and foster long-term success. Stay informed and take action now!
## What is a Single Source of Truth?
A Single Source of Truth (SSoT) is a comprehensive data store or warehouse that integrates information from various systems. It is the primary and most reliable source, widely accepted and used as the ultimate reference point within an organization. By serving as the authoritative reference point, an SSoT aims to promote alignment, streamline operations, and enable better insights and outcomes for the organization.
Single Source of Truth is a concept that eliminates data fragmentation, ensures data consistency and accuracy, and empowers efficient decision-making across teams and departments.
## Workplace SSOT: Why should you have one?
An SSoT acts as a central hub for data, consolidating information from various sources and ensuring everyone has access to accurate data. In their survey, Experian found that 88% of companies believe that having a single source of truth for customer data improves overall data accuracy and reliability. It facilitates informed decision-making, promotes collaboration, and provides teams with reliable information.
SaaS helpdesk and customer support platforms benefit from implementing a Workplace SSOT as it enables efficient management of customer support tickets, customer data, and knowledge bases. Support teams can access relevant customer information, streamline workflows, and deliver personalized and consistent customer service.
## Benefits of SSOT
A Single Source of Truth (SSoT) implementation in the workplace brings the advantage of enhanced data accuracy and reliability. Through centralized and standardized data management, organizations can optimize workflows, facilitate informed decision-making, and foster seamless collaboration among teams. Other benefits are:
### Breaks down data silos
A data silo refers to a situation in which a specific department within an organization possesses and manages data that is not readily accessible or shared with other groups within the same organization. It creates barriers and limitations for other teams to access and utilize the data efficiently. Hence, it leads to limited collaboration and a fragmented view of the organization’s data.
For example, a Saas company’s marketing and sales departments use separate systems to manage customer data and track sales. The lack of integration creates a data silo, hindering collaboration and preventing a complete view of customer behavior. To break down the data silos, Single Source of Truth integrates the CRM and sales systems, creating a shared database.
It allows marketing and sales to access real-time data, collaborate effectively, make data-driven decisions, and gain a comprehensive view of customer behavior. The SSOT optimizes business processes and fosters collaboration.
### Reduces Duplication of Data
Data duplication in SaaS businesses can cause inefficiencies and confusion due to manual entry errors, integration challenges, migration issues, and poor data management.
A Single Source of Truth (SSoT) approach prevents data duplication in SaaS businesses. SSoT employs data validation and de-duplication algorithms to identify and remove duplicate records. For example, in an e-commerce platform, SSoT validates customer information, and merges duplicate entries to maintain accurate data.
On platforms like Monday.com, SSoT enforces predefined fields and validation rules for project details, reducing duplicate entries. In financial databases, strict access controls and audits are implemented to prevent duplicates and ensure data integrity. Automated data integration in e-commerce websites synchronizes product details, minimizing Duplication and manual updates for consistent information across systems.
### Achieves greater productivity
SSoT centralizes data sources, eliminating the need for time-consuming reconciliation efforts and ensuring consistent and reliable information throughout the organization. As a result, employees can redirect their efforts towards more productive tasks, leading to enhanced overall productivity and better organizational outcomes.
SSoT provides additional advantages. It fosters data consistency as a reliable and up-to-date repository, enabling real-time updates and seamless user collaboration. This streamlined workflow promotes efficient reporting and analytics, resulting in greater productivity, improved project outcomes, and heightened customer satisfaction.
### Promotes transparency
SSoT enhances transparency in SaaS businesses by providing a unified and consistent data view. It ensures accurate and consistent customer information across departments, promoting collaboration and a unified customer experience. SSoT enables data traceability, i.e., tracking the journey of customer data from initial acquisition through various touchpoints, such as sales interactions, customer support tickets, and marketing campaigns.
It also controls access and permissions and enhances collaboration and communication. These transparency benefits foster an open and accountable data environment, improving operations in SaaS businesses.
### Empowers Users with Trusted Information
SSoT is a central hub for dependable information, resolving common user challenges. It eliminates data inconsistencies by offering a unified view, streamlines data access, and enhances data quality through governance. It supports effective collaboration. Consequently, it enables users to make knowledgeable choices and accomplish their objectives with enhanced effectiveness. For example, SSoT enabled real-time insights, which is crucial in Amazon’s dynamic e-commerce environment. Teams had immediate access to up-to-date information on product availability and shipping status. It empowered them to adapt strategies and respond to customer needs swiftly.
Schedule a demo with one of our experts to take a deeper dive into Document360
## Steps to create SSOT
A step-by-step approach to SSoT is essential in breaking data silos, streamlining operations, and facilitating informed decision-making. By adhering to this framework, businesses can emphasize critical areas that enhance efficiency and boost productivity. The first step is:
### 1. Identify the data sources
Identifying data sources is valuable for understanding and documenting the various systems, databases, applications, and files containing relevant business data. Creating a comprehensive list requires conducting a thorough inventory of data from both internal and external sources. The goal is to create a checklist that outlines the data types, locations, owners, and any relevant metadata associated with each source.
#### How do you then identify data sources?
- Determine the specific data needed and the reasons behind it.
- Then, collaborate with teams and individuals to identify the locations of the data.
- And examine existing documents to gather information on data sources.
- Conduct data profiling for sample data analysis to gain insights into its characteristics.
- Compile a comprehensive list of potential data locations.
- Check the accuracy and reliability of the identified data sources.
- Evaluate ownership, security, and compliance aspects of the data
- Identify which data sources are essential and should be included in the SSoT.
Identifying and documenting data sources establishes the groundwork for creating a robust SSoT that integrates data from diverse systems, ensuring consistency, accuracy, and ease of access. This foundation enables businesses to enhance data management and decision-making processes.
### 2. Select technology and tool
After identifying data sources, the next step in creating an SSoT involves selecting suitable technology and tools to manage and integrate these sources. It includes choosing software, platforms, and systems for Knowledge sharing, data integration, storage, and management. Examples of devices include Workflow Automation, API Management, and ETL tools. Hence, the selection should align with specific business needs, existing infrastructure, and integration requirements.
## Here are some common SSOT tools and technologies:
**Relational Databases:**
Relational database management systems (RDBMS) like MySQL, PostgreSQL, and Microsoft SQL Server are often used to create a centralized data repository where data can be stored, accessed, and updated securely.
**Enterprise Resource Planning (ERP) Systems:**
ERP software such as SAP, Oracle ERP, and Microsoft Dynamics centralizes data related to finance, HR, supply chain, and other business functions, serving as an SSOT for enterprise-wide data.
**Customer Relationship Management (CRM) Systems:**
CRM software such as Salesforce and HubSpot CRM centralize customer data and interactions, serving as an SSOT for customer information.
**Knowledge Management Platforms:**
Knowledge management systems like Document360 is used to centralize internal documentation and knowledge, ensuring that employees access a single source of truth for information.
**Cloud Storage and Collaboration Tools:**
Cloud-based tools like Microsoft OneDrive, Google Drive, and Dropbox can serve as an SSOT for document storage and collaboration, especially when integrated with version control features.
### 3. Define a data schema
A data schema is a blueprint or framework that defines data structure, organization, and relationships within a database or data integration system. Defining a data schema after identifying data sources and selecting technologies and tools ensures a structured and consistent approach. It provides data integration, data management and accessibility within the organization.
Here are simplified tips to enhance the effectiveness of your data schema when creating an SSoT:
- Define separate tables for main entities.
- Use normalization to eliminate redundancy.
- Assign primary keys and establish relationships.
- Define constraints for data quality and integrity.
- Index frequently used columns for better query performance.
- Design for scalability.
- Document schema thoroughly.
- Involve stakeholders for insights.
- Use consistent naming conventions.
- Regularly review and update the schema
### 4. Design the workflow and responsibilities
Once a data schema is firmly established, establishing an organized workflow with clear responsibilities is next. It optimizes data management, ensuring consistent updates and data integrity in an SSoT. It involves sequencing steps like data entry, transformation, integration, validation, and synchronization.
And also, assigning specific individuals or teams enhances accountability and efficiency. This streamlined approach improves efficiency, accuracy, and reliability by providing explicit guidance, accountability, and quality assurance measures for SSoT data management.
### 5. Access Control and Security
To create a secure SSoT, organizations must implement comprehensive access control and security measures. It includes defining user roles and permissions, implementing user authentication, and employing encryption techniques for data protection. Data security measures include encryption for data protection, firewalls and intrusion detection systems for defense against threats, and regular updates to address vulnerabilities and prevent exploits.
### 6. Keep the data updated
Keeping the data updated is the next step in creating an SSoT. It is like maintaining an organization’s lifeblood. It’s not just a task; it preserves data integrity, drives informed decision-making, ensures compliance, and boosts operational efficiency and effectiveness.
**To keep the data updated in an SSoT:**
- Assign responsibility for data updates.
- Implement checks to identify and fix errors or inconsistencies.
- Establish methods for consistent data synchronization across systems.
- Track and document changes to the SSoT’s data organization.
- Regularly review and clean up outdated or erroneous information.
- Following these steps ensures accurate and up-to-date data in the SSoT.
### 7. Provide Training for new users
- It is essential to take the following steps when training users to ensure effective SSoT creation.
- Organizations should develop tailored training programs for different user types,
- Create user-friendly guides and conduct interactive sessions,
- Customize Training based on user roles and responsibilities,
- Provide ongoing support through help desks and FAQs, and
- Gather user feedback to improve training materials continuously.
By implementing these steps, organizations can empower users to effectively utilize the SSoT, leading to improved data management and decision-making processes.
### 8. Replicate SSoT across the workplace
With replication, separate versions of the SSoT in different departments will lead to data inconsistency, errors, and hindered collaboration. Replicating the SSoT ensures consistent data, seamless collaboration, real-time access, and business continuity. It provides redundancy, allowing continued operation and business continuity in case of failures or disasters.
An intuitive knowledge base software to easily add your content and integrate it with any application. Give Document360 a try!
## Single source of truth examples
Here are some examples of how companies can use SSoT:
### Product Information in Software Development
A software development company preparing for a significant product release relies on a centralized SSoT for product information. This SSoT houses comprehensive documentation, including user manuals, installation guides, and API documentation. The technical writing team diligently updates the SSoT, ensuring accuracy and consistency across all documentation.
Simultaneously, the marketing team leverages the SSoT to access up-to-date product descriptions and feature highlights for their promotional efforts. By maintaining a centralized SSoT, the company ensures that all internal and external stakeholders have seamless access to reliable and current documentation. This streamlines communication, minimizes confusion, and fosters a unified understanding of the product throughout the organization.
### Master Data in Enterprise Resource Planning (ERP) Systems
Master Data is the foundational data shared across an organization, including customer, product, employee, and vendor data, that remains relatively stable over time. ERP systems are integrated software solutions that manage multiple business processes and enable information flow and coordination across departments.
In organizations using an ERP system for managing operations like manufacturing, sales, and procurement, a centralized repository of Master Data is crucial.
This repository holds essential information about products, customers, suppliers, and employees, serving as the core for various departments. For instance, the manufacturing department relies on product master data to maintain consistent production processes, the sales department uses it for personalized services, and the procurement department depends on it for informed decisions.
Click here to read more on Guide to [Creating a Single Source of Truth](https://document360.com/blog/creating-a-single-source-of-truth/) | ragavi_document360 |
1,696,929 | Implementing Quality Checks In Your Git Workflow With Hooks and pre-commit | Hooks and Webhooks Git Hook Basics Practical Git Hook Usage Git Hook Automation With... | 0 | 2023-12-13T15:45:40 | https://dev.to/cwprogram/implementing-quality-checks-in-your-git-workflow-with-hooks-and-pre-commit-4iip | git, tutorial, programming, devops | {%- # TOC start (generated with https://github.com/derlin/bitdowntoc) -%}
- [Hooks and Webhooks](#hooks-and-webhooks)
- [Git Hook Basics](#git-hook-basics)
- [Practical Git Hook Usage](#practical-git-hook-usage)
- [Git Hook Automation With pre-commit](#git-hook-automation-with-precommit)
- [Working With Contributed pre-commit Code](#working-with-contributed-precommit-code)
- [File Filtering](#file-filtering)
- [Conclusion](#conclusion)
{%- # TOC end -%}
Git is a powerful tool to enable developers to organize and share their code. One of the more interesting features is hooks. This allows for execution of scripts at certain points in the git workflow. In this article I'll be showcasing one of the simple git workflow events: pre-commit. I'll also be introducing a tool to help with automation of it, the aptly named [pre-commit](https://pre-commit.com/). Note that the code used for this is the final step of my python beginners series and can be [found in a code repository](https://github.com/cwgem/my-pdm-project) in GitHub. Simply click on the green "Code" button and select "Download ZIP". Then extract it into your preferred directory of choice.
## Hooks and Webhooks
To clear up any potential confusion, Git hooks and GitHub webhooks are different entities (though GitHub webhooks most likely is powered by git hooks). Git hooks are specific to the git software package. [GitHub webhooks](https://docs.github.com/en/webhooks) are a feature of the GitHub platform that pushes JSON payloads based on various GitHub related events. The same goes for similar source control service sites such as [GitLab](https://docs.gitlab.com/ee/user/project/integrations/webhooks.html)
## Git Hook Basics
A git hook is essentially a script that is executed at a certain point in the git workflow. The basic rules of hooks are:
- Set as executable
- Strip the extension (with the exception of certain windows extensions such as `.exe`)
- Located in a `.git/hooks` directory under the repository parent directory
To see how this looks download the code mentioned in the introduction paragraph and make sure there's no `.git` directory in it (remove it if there is). Then run `git init` to initialize the repository:
```
$ git init
$ git branch -m main
```
The second command ensures the default branch is main, which is fairly common for new repositories on major code hosting sites. After the git repository has been initialized it's time to look at the contents of `.git/hooks`:
```
$ cd .git/hooks
$ ls -1
applypatch-msg.sample
commit-msg.sample
fsmonitor-watchman.sample
post-update.sample
pre-applypatch.sample
pre-commit.sample
pre-merge-commit.sample
prepare-commit-msg.sample
pre-push.sample
pre-rebase.sample
pre-receive.sample
push-to-checkout.sample
update.sample
```
Each of these has examples. To make them work we'll need to make a copy with `.sample` removed and ensure it's executable. Let's take a look at the `pre-commit.sample` contents:
```bash
#!/bin/sh
#
# An example hook script to verify what is about to be committed.
# Called by "git commit" with no arguments. The hook should
# exit with non-zero status after issuing an appropriate message if
# it wants to stop the commit.
#
# To enable this hook, rename this file to "pre-commit".
if git rev-parse --verify HEAD >/dev/null 2>&1
then
against=HEAD
else
# Initial commit: diff against an empty tree object
against=$(git hash-object -t tree /dev/null)
fi
# If you want to allow non-ASCII filenames set this variable to true.
allownonascii=$(git config --type=bool hooks.allownonascii)
# Redirect output to stderr.
exec 1>&2
# Cross platform projects tend to avoid non-ASCII filenames; prevent
# them from being added to the repository. We exploit the fact that the
# printable range starts at the space character and ends with tilde.
if [ "$allownonascii" != "true" ] &&
# Note that the use of brackets around a tr range is ok here, (it's
# even required, for portability to Solaris 10's /usr/bin/tr), since
# the square bracket bytes happen to fall in the designated range.
test $(git diff --cached --name-only --diff-filter=A -z $against |
LC_ALL=C tr -d '[ -~]\0' | wc -c) != 0
then
cat <<\EOF
Error: Attempt to add a non-ASCII file name.
This can cause problems if you want to work with people on other platforms.
To be portable it is advisable to rename the file.
If you know what you are doing you can disable this check using:
git config hooks.allownonascii true
EOF
exit 1
fi
# If there are whitespace errors, print the offending file names and fail.
exec git diff-index --check --cached $against --
```
So this will do a few basic checks against file names and whitespace issues. As one of the comments mentions `To enable this hook, rename this file to "pre-commit"`. We can then just run `git commit` afterwards to run it:
```
$ cp pre-commit.sample pre-commit
$ cd ../../
$ git commit
```
At this point nothing happened as nothing was added. I'll go ahead and add a file with a Japanese name to see what happens:
```
$ touch テスト
$ git add テスト
$ git commit
$ git commit
Error: Attempt to add a non-ASCII file name.
This can cause problems if you want to work with people on other platforms.
To be portable it is advisable to rename the file.
If you know what you are doing you can disable this check using:
git config hooks.allownonascii true
```
As you can see our hook is working and is preventing the non ASCII named file from being committed. I'll go ahead and cleanup the test:
```
$ git reset テスト
$ rm テスト
```
## Practical Git Hook Usage
So we've seen a very basic example of how hooks work. Now the more practical example would be to use it to run tests on code before committing. Note that I don't recommend this if your project is in the prototyping phase where you may be doing many commits and may not have tests setup due to the frequency of code architecture changes. In this case the project in question has [tox](https://tox.wiki/en/4.11.4/) setup which runs various python linting and tests. Before running the examples you'll need to ensure `pdm` is installed and running under python 3.11. Instructions for this can be found in my [pdm tutorial](https://dev.to/cwprogram/beginning-python-project-management-with-pdm-13m0), or you can install it on your own. Once installed we'll make sure the necessary packages are available for tox to work with:
```
$ pdm install
```
Then I'll edit the `.git/hooks/pre-commit` file to contain the following:
```bash
#!/bin/sh
pdm run tox
if [ $? -ne 0 ]; then
echo "tox checks failed" >&2
exit 1
fi
```
Now when `git commit` runs:
```
$ git commit
lint: install_deps> pdm sync --no-self --group testing --group lint
lint: commands[0]> flake8
```
`tox` is run to initiate all the checks. As is the code should be in working condition so you'll see a commit screen after the tox run. Go ahead and close it out without putting a message to abort the comment. When there's an issue with something (I went ahead and commented out one of the imports):
```
$ git commit
lint: install_deps> pdm sync --no-self --group testing --group lint
lint: commands[0]> flake8
<snip>
lint: FAIL code 1 (4.34=setup[3.69]+cmd[0.65] seconds)
test: FAIL code 1 (11.80=setup[10.09]+cmd[1.71] seconds)
docs: OK (14.44=setup[11.79]+cmd[2.65] seconds)
evaluation failed :( (30.79 seconds)
tox checks failed
```
A message at the end shows that `tox` has failed to run and no commit screen is displayed.
## Git Hook Automation With pre-commit
Given how useful checking code quality is before committing, there's actually a framework around git hooks called [pre-commit](https://pre-commit.com/). It's somewhat like a mini-GitHub Actions that can be used to run various commands during the `pre-commit` phase. This is where you normally want most CI/CD like checks. Before continuing you'll want to remove the existing hook or you'll end up having duplicated tool runs. We'll also go ahead and add all the files in the repo so there's something to check:
```
$ rm .git/hooks/pre-commit
$ git add .
```
Given how useful `pre-commit` is across projects I generally recommend installing via `pip install --user`, making it part of a tooling virtual environment, or using [pipx](https://github.com/pypa/pipx):
```
$ pip install --user pre-commit
$ pipx install pre-commit
```
Next we'll need to create a YAML configuration file in the root of our repository called `.pre-commit-config.yaml`. To make things simple you can bootstrap a basic one via:
```
$ pre-commit sample-config > .pre-commit-config.yaml
```
As is the file looks something like this:
```yaml
# See https://pre-commit.com for more information
# See https://pre-commit.com/hooks.html for more hooks
repos:
- repo: https://github.com/pre-commit/pre-commit-hooks
rev: v3.2.0
hooks:
- id: trailing-whitespace
- id: end-of-file-fixer
- id: check-yaml
- id: check-added-large-files
```
This already has some great entries for basic git related checks. Now we'll add a new entry to cover tox checking:
```yaml
# See https://pre-commit.com for more information
# See https://pre-commit.com/hooks.html for more hooks
repos:
- repo: https://github.com/pre-commit/pre-commit-hooks
rev: v3.2.0
hooks:
- id: trailing-whitespace
- id: end-of-file-fixer
- id: check-yaml
- id: check-added-large-files
- repo: local
hooks:
- id: tox check
name: tox-validation
entry: pdm run tox
language: system
types: [python]
pass_filenames: false
```
`repo: local` tells pre-commit that what I'm doing is not a managed action by code someone else wrote. It's completely custom code written by me. The code itself will run `pdm run tox` in the system environment when it finds python files have been modified. This is one of the more powerful features of `pre-commit` over the standard git hook. There's more flexibility on when certain commands get run. You don't need to check tests if only the README file was updated. Now to actually have this integrated with our workflow we'll need to run:
```
$ pre-commit install
pre-commit installed at .git/hooks/pre-commit
```
The generated file is simply an entry point to the actual `pre-commit` program which handles the processing of what we want to do:
```bash
#!/usr/bin/env bash
# File generated by pre-commit: https://pre-commit.com
# ID: 138fd403232d2ddd5efb44317e38bf03
# start templated
INSTALL_PYTHON=/home/johndoe/.pyenv/versions/py311/bin/python3.11
ARGS=(hook-impl --config=.pre-commit-config.yaml --hook-type=pre-commit)
# end templated
HERE="$(cd "$(dirname "$0")" && pwd)"
ARGS+=(--hook-dir "$HERE" -- "$@")
if [ -x "$INSTALL_PYTHON" ]; then
exec "$INSTALL_PYTHON" -mpre_commit "${ARGS[@]}"
elif command -v pre-commit > /dev/null; then
exec pre-commit "${ARGS[@]}"
else
echo '`pre-commit` not found. Did you forget to activate your virtualenv?' 1>&2
exit 1
fi
```
Now after this I'll add the pre-commit YAML as there's a sanity check to ensure it's part of the repository:
```
$ git add .pre-commit-config.yaml
```
This is because the end goal is that anyone who downloads the code can install your `pre-commit` setup themselves and be able to run the appropriate tests. Now looking at the result:
```
$ git commit
[INFO] Installing environment for https://github.com/pre-commit/pre-commit-hooks.
[INFO] Once installed this environment will be reused.
[INFO] This may take a few minutes...
Trim Trailing Whitespace.................................................Failed
- hook id: trailing-whitespace
- exit code: 1
- files were modified by this hook
Fixing README.md
Fix End of Files.........................................................Passed
Check Yaml...............................................................Passed
Check for added large files..............................................Passed
tox-validation...........................................................Failed
```
So as the file I purposely broke hasn't been fixed the `tox-validation` stage has failed. It also found an issue with trailing whitespace in my README.md and even fixed it for me. I'll go ahead and add the updated README and fix the commented out import so things are working again:
```
$ git add README.md
$ vim src/my_pdm_project_cwprogram_test/mymath.py
$ git add src/my_pdm_project_cwprogram_test/mymath.py
$ git commit
Trim Trailing Whitespace.................................................Passed
Fix End of Files.........................................................Passed
Check Yaml...............................................................Passed
Check for added large files..............................................Passed
tox-validation...........................................................Passed
```
Now that everything has passed I'm given the ability to commit. The output is also much more user friendly and mimics what you'd expect from a CI/CD or test suite run.
## Working With Contributed pre-commit Code
In the configuration file you might have noticed:
```yaml
repo: https://github.com/pre-commit/pre-commit-hooks
```
The basic functionality of this works similar to a GitHub repo with GitHub Actions code. You can even see the code for [end_of_file_fixer](https://github.com/pre-commit/pre-commit-hooks/blob/main/pre_commit_hooks/end_of_file_fixer.py) as an example:
```python
def fix_file(file_obj: IO[bytes]) -> int:
# Test for newline at end of file
# Empty files will throw IOError here
try:
file_obj.seek(-1, os.SEEK_END)
except OSError:
return 0
last_character = file_obj.read(1)
# last_character will be '' for an empty file
if last_character not in {b'\n', b'\r'} and last_character != b'':
# Needs this seek for windows, otherwise IOError
file_obj.seek(0, os.SEEK_END)
file_obj.write(b'\n')
return 1
```
In fact there's actually a fairly sizeable amount of these [listed on the pre-commit website](https://pre-commit.com/hooks.html). In fact another one is [provided by the PDM project](https://pdm-project.org/latest/usage/advanced/#hooks-for-pre-commit) to make sure `pdm.lock` is up to date. I'll go ahead and add this in:
```yaml
# See https://pre-commit.com for more information
# See https://pre-commit.com/hooks.html for more hooks
repos:
- repo: https://github.com/pre-commit/pre-commit-hooks
rev: v3.2.0
hooks:
- id: trailing-whitespace
- id: end-of-file-fixer
- id: check-yaml
- id: check-added-large-files
- repo: local
hooks:
- id: tox check
name: tox-validation
entry: pdm run tox
language: system
types: [python]
pass_filenames: false
- repo: https://github.com/pdm-project/pdm
rev: 2.10.4 # a PDM release exposing the hook
hooks:
- id: pdm-lock-check
```
Now I'll manually edit one of my dependencies in `pyproject.toml` and check the result:
```ini
dependencies = [
"numpy>=1.25.1",
"requests>=2.31.0",
]
```
```
$ git add pyproject.tmol .pre-commit-config.yaml
$ git commit
[INFO] Initializing environment for https://github.com/pdm-project/pdm.
[INFO] Installing environment for https://github.com/pdm-project/pdm.
[INFO] Once installed this environment will be reused.
[INFO] This may take a few minutes...
Trim Trailing Whitespace.................................................Passed
Fix End of Files.........................................................Passed
Check Yaml...............................................................Passed
Check for added large files..............................................Passed
tox-validation...........................................................Passed
pdm-lock-check...........................................................Failed
- hook id: pdm-lock-check
- exit code: 1
Lock file hash doesn't match pyproject.toml, packages may be outdated
```
In this case it noticed that my `numpy` dependency has changed. I'll go ahead and revert this and see what happens:
```
$ vim pyproject.toml
$ git add pyproject.toml
$ git commit
Trim Trailing Whitespace.................................................Passed
Fix End of Files.........................................................Passed
Check Yaml...............................................................Passed
Check for added large files..............................................Passed
tox-validation...........................................................Passed
pdm-lock-check...........................................................Passed
```
Now everything is looking good and I'm allowed to commit again. Trying to check if the pdm lock file was synced would have taken a substantial amount of time via a normal git hook, primarily due to not having context on the `pdm` code base. Instead I can use this hook provided by the developers in less than ten minutes to do it instead.
## File Filtering
To showcase this best we'll want to commit what we have now so there's better control over what files get added:
```
$ git commit -m "Initial Commit"
```
Now since `tox` can run specific stages we can use this to break out tasks based on what's actually been committed. Considering when we'd want things to run:
- All files should have the basic large files, trailing whitespace, and end of files check
- `README.md` should have a markdown linter run against it
- `pyproject.toml` should have a toml linter run against it
- Linting should be run if files in `src` or `tests` are modified
- Tests should be run if files in `src` or `tests` are modified
- Documentation building should be run if files in `src` (for automodule generation) or `docs` are modified
- Everything should run if `pyproject.toml` is updated as it controls settings and manages dependencies
So let's see what a solution like this would look like:
```yaml
# See https://pre-commit.com for more information
# See https://pre-commit.com/hooks.html for more hooks
repos:
- repo: https://github.com/pre-commit/pre-commit-hooks
rev: v3.2.0
hooks:
- id: trailing-whitespace
- id: end-of-file-fixer
- id: check-yaml
- id: check-toml
- id: check-added-large-files
- repo: local
hooks:
- id: tox lint
name: tox-validation
entry: pdm run tox -e test,lint
language: system
files: ^src\/.+py$|pyproject.toml|^tests\/.+py$
types_or: [python, toml]
pass_filenames: false
- id: tox docs
name: tox-docs
language: system
entry: pdm run tox -e docs
types_or: [python, rst, toml]
files: ^src\/.+py$|pyproject.toml|^docs\/
pass_filenames: false
- repo: https://github.com/pdm-project/pdm
rev: 2.10.4 # a PDM release exposing the hook
hooks:
- id: pdm-lock-check
- repo: https://github.com/jumanjihouse/pre-commit-hooks
rev: 3.0.0
hooks:
- id: markdownlint
```
First off we have `check-toml` for linting our `pyproject.toml` file. `markdownlint` is taken from [jumanjihouse/pre-commit-hooks](https://github.com/jumanjihouse/pre-commit-hooks). Note that `check-*` and the markdown linter generally has code to check if appropriate files were added so there's no need to add filters. Another thing to keep in mind is that it's recommended to pin `rev` against a specific revision (usually a tag) versus something like `master` or `main`. This will reduce "unexpected" surprises due to code changes. Here we see the actual filtering at work:
```yaml
- id: tox lint
name: tox-validation
entry: pdm run tox -e test,lint
language: system
files: ^src\/.+py$|pyproject.toml|^tests\/.+py$
types_or: [python, toml]
```
So `files: ^src\/.+py$|pyproject.toml|^tests\/.+py$` is a regular expression to show what files we're interested in. In this case it's files under `src/` and `tests/` as well as `pyproject.toml`. `types_or` (requires 2.9.0 or later pre-commit) also ensures we're only looking at `python` or `toml` files. If you're wondering what to put in for `types_or` the `identify-cli` tool will let you know appropriate values that can be used:
```
$ identify-cli docs/source/index.rst
["file", "non-executable", "rst", "text"]
```
`file` is the most generic type. You can also be more specific with `rst` for example. `types` can be used if you want something that works off `AND` comparison instead:
```yaml
types: [python, executable]
```
This will run if a file is a python file **and** executable as well. Now that we've seen how comparisons work, it's time to put this into practice. I'll add our updated pre-commit YAML, modify `README.md`, and then run `git commit`:
```
$ vim README.md #changes here
$ git add .pre-commit-config.yaml README.md
$ git commit
[INFO] Initializing environment for https://github.com/jumanjihouse/pre-commit-hooks.
[INFO] Installing environment for https://github.com/jumanjihouse/pre-commit-hooks.
[INFO] Once installed this environment will be reused.
[INFO] This may take a few minutes...
Trim Trailing Whitespace.................................................Passed
Fix End of Files.........................................................Passed
Check Yaml...............................................................Passed
Check Toml...........................................(no files to check)Skipped
Check for added large files..............................................Passed
tox-validation.......................................(no files to check)Skipped
tox-docs.............................................(no files to check)Skipped
pdm-lock-check.......................................(no files to check)Skipped
Check markdown files.....................................................Passed
```
Given that no `toml` or appropriate python files were modified unnecessary checks are skipped according to our setup. The `README.md` file does have `markdownlint` run against it and has passed the checks. I'll go ahead and commit the file with the message "Updated README.md title". Now it's time to see what happens when we make changes to `docs/`:
```
$ vim docs/source/index.rst
$ git add docs/source/index.rst
$ git commit
Trim Trailing Whitespace.................................................Passed
Fix End of Files.........................................................Passed
Check Yaml...............................................................Passed
Check Toml...........................................(no files to check)Skipped
Check for added large files..............................................Passed
tox-validation.......................................(no files to check)Skipped
tox-docs.................................................................Passed
```
In this case `tox-docs` is run but since no python files are present neither linting nor tests were run. Now I'll revert the docs change and modify one of the tests. This should kick off the linting/tests phase but not do anything with the docs building:
```
$ git reset docs/source/index.rst
$ git checkout docs/source/index.rst
$ vim tests/test_mymath.py
$ git add tests/test_mymath.py
$ git commit
Trim Trailing Whitespace.................................................Passed
Fix End of Files.........................................................Passed
Check Yaml...............................................................Passed
Check Toml...........................................(no files to check)Skipped
Check for added large files..............................................Passed
tox-validation...........................................................Passed
tox-docs.............................................(no files to check)Skipped
pdm-lock-check.......................................(no files to check)Skipped
Check markdown files.................................(no files to check)Skipped
```
Finally we'll make an update to `pyproject.toml` which should run everything (I'll also reset the state of the test file so there are no false positives):
```
$ git reset tests/test_mymath.py
$ git checkout tests/test_mymath.py
$ vim pyproject.toml
$ git add .pre-commit-config.yaml pyproject.toml
$ git commit
Trim Trailing Whitespace.................................................Passed
Fix End of Files.........................................................Passed
Check Yaml...............................................................Passed
Check Toml...............................................................Passed
Check for added large files..............................................Passed
tox-validation...........................................................Passed
tox-docs.................................................................Passed
pdm-lock-check...........................................................Passed
Check markdown files.................................(no files to check)Skipped
```
Everything has been run. I will say that technically it wasn't necessary to run this as I only made a description update and nothing was changed in the actual dependencies or tool configuration. That means nothing was changed that would require linting/tests/documentation updates. Even so, trivial `pyproject.toml` changes will generally be very rare after the project is flushed out and you should only really be updating for dependency or tool configuration changes from there.
## Conclusion
`pre-commit` is definitely one of the tools I wish I knew about sooner in my development career. It's a great way to avoid having people frown at your PRs for having 3 different lint fix only commits. Given that it is another roadblock to pushing commits you'll want to make sure your linting passes on the entire project via `pre-commit run -a`. Otherwise your coworkers will most definitely find a way to bypass it.
If you like what you see I'm am also available for hire. Those interested can find out more info in my dev.to profile. | cwprogram |
1,697,007 | [diário de estudo] o react e o tailwind | olá! tudo bem? 👋 pega um café e o seu patinho de borracha que esse post contém: recomeços e crises... | 0 | 2023-12-15T13:46:32 | https://dev.to/tatialveso/diario-de-estudo-o-react-e-o-tailwind-bff | react, tailwindcss, study, braziliandevs | olá! tudo bem? 👋
_`pega um café e o seu patinho de borracha que esse post contém: recomeços e crises de estilização`_
para dar o pontapé nos estudos, eu resolvi iniciar com um projeto que eu já havia feito alguns anos atrás enquanto testo algumas ferramentas novas. dessa forma, eu consigo trabalhar dentro de um território familiar, mas com algumas coisas novas para explorar.
a primeira coisa nova que eu testei foi iniciar o projeto usando o `vite`. até agora, eu sempre usei o `create react app` para criar os projetos react, e fiquei até um pouco maravilhada como realmente criar um projeto com o `vite` é muito mais rápido.
o grande desafio apareceu mesmo com o `tailwind`! até então, a minha zona de conforto é muito com o `styled-components`. gosto muito como ele funciona e também a liberdade que ele dá para estilização, enquanto a componentização dá uma facilidade que o `css` puro com o `react` fica meio chato. já o `tailwind` trabalha um pouco parecido com o `bootstrap`, setando as estilizações pelas classes.
o `tailwind` não é difícil de trabalhar, mas ainda estou descobrindo como ainda ter a minha liberdade de criar e personalizar os elementos usando apenas as estruturas do `tailwind`. para isso, eu foquei em um componente só e criei uma tela de login que acabou ficando assim:
esse foi o resultado depois de algumas horas tentando desvendar a documentação do `tailwind` (que ainda estou tentando me encontrar nos elementos) e de adaptação de componentes estilizados que a documentação oferece. o lado bom de trabalhar com ferramentas como o `tailwind` e o `bootstrap` é que há uma certa agilidade na hora de criar os elementos visuais, pois eles já vem prontos de certa forma, porém em outro lado quando queremos adaptar ou ter mais liberdade nas estilizações precisamos nos manter dentro dos padrões do que ele permite (principalmente se você não quer misturar ou adicionar o seu próprio `css`, como é o meu caso).
a próxima etapa será criar os elementos estáticos da aplicação que serão apenas exibidos em tela em certos momentos; e então replicar uma parte do login para a tela de cadastro.
até a próxima 🦖 | tatialveso |
1,697,204 | Building a signature capture widget with an Appsmith Iframe and SignaturePad.js | Goal Build a signature capture widget using custom code in an Appsmith Iframe widget... | 0 | 2023-12-14T15:22:28 | https://community.appsmith.com/tutorial/building-signature-capture-widget-iframe-and-signaturepadjs | javascript, tutorial, lowcode, webdev | Goal
----
* Build a signature capture widget using custom code in an Appsmith Iframe widget srcDoc field
* Capture signatures as images, then access the image outside of the iframe
Prerequisites
-------------
* **An Appsmith Account**
* **A new or existing app** - where you want to add the signature capture widget
Overview
--------
The iframe widget is like an escape hatch that leaves the low-code environment of Appsmith and allows you to write full web apps using any framework of your choice. If there's something you can't do with one of our 45+ widgets, you can probably do it in an iframe.
For instance, although we don't have a native signature capture widget ([yet](https://github.com/appsmithorg/appsmith/issues/7960)), you can easily build one with just a few lines of JavaScript, and the signaturePad.js library.
## Add an Iframe Widget
Add an iframe where you want the signature capture, and paste the following code in the srcDoc field:
```html
<canvas id="signature-pad" width="auto" height="auto"></canvas>
<button id="clear">Clear</button>
<button id="save">Save</button>
<script src="https://cdn.jsdelivr.net/npm/signature_pad@4.0.0/dist/signature_pad.umd.min.js"></script>
<script>
var canvas = document.getElementById("signature-pad");
var signaturePad = new SignaturePad(canvas, {backgroundColor: 'rgb(250,250,250)'});
document.getElementById("clear").addEventListener('click', function () {
signaturePad.clear();
});
document.getElementById("save").addEventListener('click', function () {
var dataURL = signaturePad.toDataURL();
window.parent.postMessage({
type: 'signature',
data: dataURL
}, '*');
});
</script>
```
Note the event listener on the **SAVE** button that posts a message to the parent window.
## Access the Signature Image
Once the **SAVE** button is clicked, the image will be accessible at `Iframe1.message.data`. You can view it in a regular Image widget, or view the raw data in a Text widget.
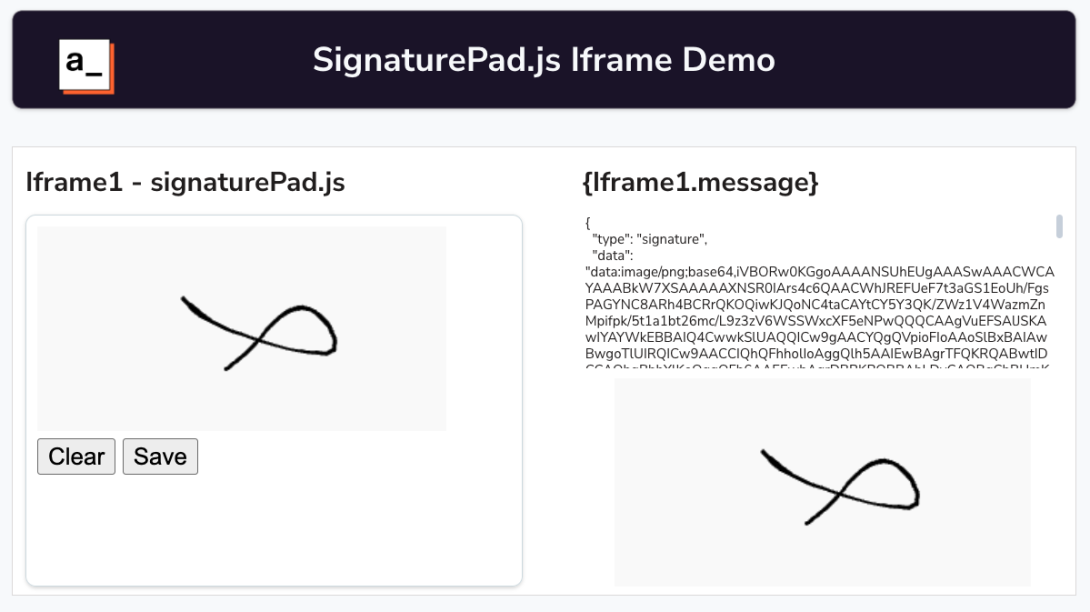
## Trigger an Event when saving
You may want to save the image back to a database, or send it in an email after signing. The Iframe widget has an [onMessageReceived](https://docs.appsmith.com/reference/widgets/iframe#events) property, where you can select which Actions to run when a message is posted from the iframe. The Action selector also allows you to add callback functions, so you can chain together Actions, and do things like saving the image to Amazon S3, then saving the new URL back to a record in MySQL.
Conclusion
----------
The Iframe widget can easily be used to create custom widgets, and new interfaces to capture and display data. By adding just a few lines of code, a Signature Capture widget can be built and integrated with the rest of your app.
Additional Resources
--------------------
* [cdn.jsdelivr.net/npm/signature\_pad@4.0.0](https://cdn.jsdelivr.net/npm/signature_pad@4.0.0/dist/signature_pad.umd.min.js)
* [Iframe Docs](https://docs.appsmith.com/reference/widgets/iframe#docusaurus_skipToContent_fallback)
* [Iframe Experiments: Extending Appsmith with custom iframe code](https://community.appsmith.com/content/guide/iframe-experiments-extending-appsmith-custom-iframe-code) | joseph_appsmith |
1,697,229 | Normalizing or interpolating values in JavaScript/TypeScript | These are three common normalizing functions I use in JavaScript when working with CSS... | 0 | 2023-12-13T23:14:56 | https://dev.to/pgarciacamou/normalizing-values-in-typescript-3dcf | normalization, interpolation, javascript | These are three common normalizing functions I use in JavaScript when working with CSS animations/transitions, especially when playing with motion sensors.
## Standard Normalization
This function scales a number so that it falls within a standard range of 0 to 1. This is the common meaning of "normalization" in data processing.
Commonly used in data processing and analysis to standardize different sets of data on a common scale, such as in machine learning feature scaling.
```typescript
function normalize(
value: number,
minValue: number,
maxValue: number
): number {
if (maxValue === minValue) {
return value === minValue ? 1 : 0;
}
return (value - minValue) / (maxValue - minValue);
}
// Example Usage
console.log(normalize(15, 10, 20)); // 0.5
console.log(normalize(30, 20, 40)); // 0.5
```
## Linear Interpolation
This function maps a number from one range to another. It's a form of linear interpolation.
Useful for scaling values, normalizing data to a different range, or converting between different measurement scales.
```typescript
function linearInterpolation(
value: number,
originLowerBound: number,
originUpperBound: number,
targetLowerBound: number,
targetUpperBound: number
): number {
// Note: we should use the `normalize` function above
// const ratio = normalize(value, originLowerBound, originUpperBound)
const ratio =
(value - originLowerBound) / (originUpperBound - originLowerBound);
return ratio * (targetUpperBound - targetLowerBound) + targetLowerBound;
}
// Example Usage
const mappedValue = linearInterpolation(5, 0, 10, 0, 100);
console.log(mappedValue); // Should output 50
```
For example: [1,5] & [10,50] ranges.
- 1 outputs 10
- 2 outputs 20
- ...
## Modular Arithmetic-Based Wrapping
This function ensures that a given value is wrapped within a specified numeric range. If the value exceeds the range, it wraps around within this range using modular arithmetic.
Ideal for cyclic or repeating ranges, like **angles** (think CSS transformations from 0 to 360 degrees), hours on a clock, or other periodic values.
```typescript
function cyclicInterpolation(
value: number,
lowerBound: number,
upperBound: number
): number {
// adding 1 to include the upper bound in the range
const shiftedUpperBound = upperBound - lowerBound + 1;
const shiftedValue = value - lowerBound;
return (
lowerBound +
// adding parenthesis for emphasis
(((shiftedValue % shiftedUpperBound) + shiftedUpperBound) %
shiftedUpperBound)
);
}
// Example Usage
console.log(cyclicInterpolation(5, 3, 7)); // Outputs 5
console.log(cyclicInterpolation(6, 3, 7)); // Outputs 6
console.log(cyclicInterpolation(7, 3, 7)); // Outputs 7
console.log(cyclicInterpolation(8, 3, 7)); // Outputs 3 - restarts cycle
```
For example: [1,10]
- 1 outputs 1
- 9 outputs 9
- 10 outputs 10
- 11 outputs 1 - going back to the beginning | pgarciacamou |
1,697,411 | How is information retrieval evolving through RAG (Retrieval-Augmented Generation) technology revolution? | Beyond Search: RAG Technology's Impact on the Future of Information... | 0 | 2023-12-14T06:10:36 | https://dev.to/yagnapandya9/how-is-information-retrieval-evolving-through-rag-retrieval-augmented-generation-technology-revolution-156p | python, rag, machinelearning, datascience | ## Beyond Search: RAG Technology's Impact on the Future of Information Access
[Retrieval-Augmented Generation](https://fxdatalabs.com/) (RAG) technology is driving a revolutionary change in the ever-changing field of information retrieval. This innovative method is changing the way we engage with and obtain information, and it holds out the possibility of a time when content creation and search engines work hand in hand.
Fundamentally, RAG creates a synergy that improves the user experience in ways never seen before by fusing the strengths of language generation models with the capabilities of standard information retrieval systems.
[The Essence of RAG Technology:](https://fxdatalabs.com/)
RAG technology integrates the strength of retrieval models with generating models, such as GPT-3, marking a break from traditional search approaches. By producing results that are both logical and contextually appropriate, RAG adds a new dimension to typical search engines, which retrieve documents based only on keyword matching.
Offering consumers not just information but also cohesive, contextually rich content catered to their searches is a paradigm change.
[The Pros of RAG Technology:](https://fxdatalabs.com/)
There are numerous benefits to retrieval and generation being integrated into RAG. First off, by comprehending user intent and context, it overcomes the drawbacks of conventional keyword-based search and makes information retrieval more precise and nuanced.
Furthermore, RAG's ability to produce responses improves the quality of the information by giving consumers thorough and well-written comments. Because the technology can easily obtain and generate content in other languages, despite linguistic hurdles, it has also shown to be helpful for multilingual queries.
[Transforming User Experience:](https://fxdatalabs.com/)
RAG has a significant effect on user experience. The technology facilitates a more conversational and natural engagement by combining retrieval and generation. Instead of just receiving a list of documents, users now receive personalized responses that mimic meaningful conversations.
In addition to increasing user happiness, this human-like interaction creates new opportunities for applications like virtual assistants, learning aids, and content production platforms.
[The Challenges and Considerations:](https://fxdatalabs.com/)
Although RAG technology has great potential, there are certain difficulties with it. A cautious approach to data processing is required due to privacy concerns about content production based on user inquiries. Furthermore, it is still difficult to guarantee that RAG models are impartial and morally acceptable, necessitating continued study and advancement.
Furthermore, the deployment of large-scale models has computational expenses, as is the case with any modern technology, which raises questions about resource usage and environmental impact.
[Looking Ahead: The Future of Information Retrieval:](https://fxdatalabs.com/)
The advancement of RAG technology portends a time when information retrieval will go beyond the limitations of traditional keyword searches. Combining retrieval and creation improves the quality and depth of information that is accessible while also creating a digital experience that is more user-friendly and intuitive.
RAG technology's trend points to a day when information retrieval systems will be indispensable to our day-to-day interactions, easily accommodating user demands and providing exceptional material.
[In summary:](https://fxdatalabs.com/)
A critical turning point in the development of information retrieval may be found in the RAG technological revolution. Although technology offers transformative advantages, it also raises ethical questions and presents possible difficulties that must be carefully considered.
The combination of retrieval and generation in RAG promises to revolutionize the way we access and use information as we explore this exciting new frontier. It also paves the path for a time when intelligent systems will improve our digital experiences in ways that were previously unthinkable.
For more insights into AI|ML and Data Science Development, please write to us at: contact@htree.plus | [F(x) Data Labs Pvt. Ltd.](https://fxdatalabs.com/)
#RAGTechnology #InformationRevolution #TechInnovation #FutureTech #DigitalTransformation | yagnapandya9 |
1,697,446 | The Path to Senior Developer | Becoming a senior developer is a significant milestone in a programmer's career. It's not just about... | 0 | 2023-12-14T06:38:15 | https://dev.to/ermiasgw/the-path-to-senior-developer-f08 | programming, webdev, career, learning | Becoming a senior developer is a significant milestone in a programmer's career. It's not just about accumulating years of experience, but also about acquiring a diverse set of skills and demonstrating leadership qualities. In this blog post, we will outline the essential steps for developers aiming to reach the coveted position of a senior developer.
1. Master the Basics:
Before aspiring to be a senior developer, it's crucial to have a solid foundation in the basics. Ensure you are proficient in the programming languages and technologies relevant to your field. Understand data structures, algorithms, and design patterns. This strong foundation will serve as the bedrock for your future growth.
2. Continuous Learning:
Technology is dynamic, and staying current is key. A senior developer is expected to be well-versed in the latest trends, frameworks, and tools. Dedicate time regularly to learn new technologies, read industry blogs, and participate in online forums. Attend conferences and meetups to network with other professionals and gain insights into emerging trends.
3. Build Real-World Projects:
Apply your knowledge by working on real-world projects. Building applications from start to finish will not only enhance your technical skills but also expose you to the challenges of software development in a practical setting. It's essential to understand the entire development lifecycle, including requirements gathering, design, implementation, testing, and deployment.
4. Collaborate and Communicate:
Communication is a crucial skill for a senior developer. Learn to express your ideas clearly, whether in written or verbal form. Work on collaborative projects to improve your teamwork and interpersonal skills. As a senior developer, you'll be expected to mentor junior team members and communicate effectively with non-technical stakeholders.
5. Embrace Best Practices:
Develop a strong sense of coding standards, version control, and testing. Write clean, maintainable code that adheres to industry best practices. Understand the importance of code reviews and use them as opportunities for knowledge sharing and improvement. This attention to quality and consistency sets senior developers apart.
6. Problem Solving and Troubleshooting:
Developers encounter challenges regularly. A senior developer should excel at problem-solving and troubleshooting. Cultivate the ability to analyze complex issues, identify root causes, and implement effective solutions. This skill is often gained through hands-on experience and a deep understanding of system architectures.
7. Leadership and Mentoring:
As you progress in your career, take on leadership roles within your projects or team. Actively mentor junior developers, sharing your knowledge and experiences. Leadership is not just about authority but about guiding and empowering others to succeed.
8. Stay Agile:
Agile methodologies are widely adopted in the software development industry. Understand and embrace agile principles, as senior developers are often involved in project management and decision-making processes. Adaptability and the ability to work in dynamic environments are highly valued traits.
9. Build a Strong Professional Network:
Networking is crucial for career growth. Attend industry events, connect with professionals on platforms like LinkedIn, and participate in open-source projects. A strong network can provide valuable insights, career opportunities, and support. | ermiasgw |
1,697,458 | Animated texture library for react-three-fiber available in react's hooks base | Introduction We have created a simple library that will load animation textures by... | 0 | 2023-12-14T07:21:04 | https://dev.to/activeguild/animated-texture-library-for-react-three-fiber-available-in-reacts-hooks-base-29ff | react, three, png, gif | ## Introduction
We have created a simple library that will load animation textures by specifying an image file (gif/png/apng) file.
[Repository](https://github.com/activeguild/animation-texture)
Frames are parsed using [gifuct-js](https://github.com/matt-way/gifuct-js) and [UPNG.js](https://github.com/photopea/UPNG.js). The frame parsing process has a large impact on the main thread, so it is executed on the web worker.
It can be used without preparing a sprited image.
## Install
```bash
npm i animation-texture
```
## Usage
```ts
import React, { useRef, useEffect } from "react";
import * as THREE from "three";
import { useAnimationTexture } from "animation-texture";
interface Props {
url: string;
}
export function Model({ url }: Props) {
const { animationTexture } = useAnimationTexture({ url });
const meshRef = useRef();
useEffect(() => {
if (meshRef.current && animationTexture) {
meshRef.current.material.map = animationTexture;
meshRef.current.material.needsUpdate = true;
}
}, [animationTexture]);
return (
<mesh ref={meshRef} position={new THREE.Vector3(0, 0, 0)}>
<planeGeometry args={[1, 1]} />
<meshBasicMaterial transparent side={THREE.FrontSide} />
</mesh>
);
}
```
#### Pre-load if necessary.
```ts
import React from "react";
import * as THREE from "three";
import { preLoad } from "animation-texture";
export default function App() {
preLoad('/sample.png');
return ...
}
```
## Demo
I believe there is still significant room for performance improvement. | activeguild |
1,697,756 | Un-JAR-ing your Java apps for Docker | After a small detour at work, I've found myself returning to the world of Java and its virtual... | 0 | 2023-12-15T09:45:00 | https://dev.to/kdrakon/un-jar-ing-your-java-apps-for-docker-2769 | java, docker, maven | After a small detour at work, I've found myself returning to the world of Java and its virtual machine.
Recently, I was tasked with preparing our backend application in a Docker image for deployment. Having done something similar with a Scala backend before, I was confident I could replicate a strategy I had learned, but with Java build tools instead. Succinctly, the strategy was to create an incremental and layered image by <u>**not** using a Java JAR</u>, but instead copying and directly executing compiled Java bytecode. After further expanding on the motivation to not use a JAR, I will demonstrate how I did this in Maven using standard plugins.
## Why not use a JAR?
Having the `ENTRYPOINT` or `CMD` of your Dockerfile execute something like below does work:
```bash
java -jar your_app.jar
```
So why not stick with that approach? First off all, a JAR within a Docker image is redundant: both are basically archive formats. So quite simply, it's really unnecessary to have your code in a JAR if the unit of execution is the Docker image itself.
But there are more important benefits that become apparent when you start running your app in production.
### Easier image inspection and debugging
With every code change you and your team make, those changes are likely reflected in your version control system. But those same changes are opaquely hidden if the JAR that bundles it all up is copied into a Docker image. I've found it extremely useful to be able to inspect the code within Docker images without the need to extract JARs. This is especially true when things go awry in production and you need to do this in your container environment (e.g. AWS, Google Cloud Platform). This could be anything from inspecting class code using `javap` or—something I've done several times in the past—viewing bundled resources like .yaml, .properties, or .hocon config files to confirm settings or flags. If a containers state is frequently changing, it's especially helpful when you don't need to re-extract the JAR archive everytime the container is restarted.
If you happen to bundle source code in your JARs, it is also useful to have them unbundled in your container when debugging. Ideally, you would have something like a git SHA for reference when comparing with version control (e.g. by tagging the Docker image with the SHA). But sometimes it's still helpful to dig into the image to sanity check what is exactly in there.
### Diffs
Intuitively, it is also beneficial if everytime the image was built, you only copied the modified code and resources. This would allow you to reduce the Docker layer size between builds—likely reducing it into the magnitude of bytes or kilobytes. Unfortunately, Docker has had an [age-old bug](https://github.com/moby/moby/issues/21950) which doesn't allow you to optimize your subsequent image builds by detecting and copying only those files that have changed (e.g. like `rsync`). If this is ever improved, this would be another benefit to unbundling JARs: smaller Docker images, faster repository pushes/pulls, and less remote storage required.
In any case, being able to tell what's different between two builds is valuable and easier without a JAR. You can use `diff` to compare your application directory in two images, but you'd need to do some `cp`'ing to get everything localised first. Fortunately, a tool like [`container-diff`](https://github.com/GoogleContainerTools/container-diff) makes this much easier. The following shows an example of performing a diff to show the only file modified and compiled in a revision to my Docker image:
```bash
% ./container-diff-darwin-amd64 diff daemon://java-backend-api:1 daemon://java-backend-api:2 --type=file
-----File-----
These entries have been added to java-backend-api:1: None
These entries have been deleted from java-backend-api:1: None
These entries have been changed between java-backend-api:1 and java-backend-api:2:
FILE SIZE1 SIZE2
/app/io/policarp/service/DemoServer.class 2K 2.2K
```
Additionally, unless you are copying an "uber" or "shaded" JAR, it's likely you must copy all individual dependencies into your Docker image too. The approach I'll demonstrate shows how you can also gain the same insight into third-party libraries by not having them also bundled as JARs.
## Prepping your pom.xml
In my last Scala project, I used the [sbt-assembly](https://github.com/sbt/sbt-assembly) plugin to prep my code for copying and execution in Docker. Assuming you have a single project pom, the following excerpt shows the two plugins I used to repeat the same outcome in Maven.
```xml
<plugins>
...
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.6.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
</plugin>
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>exec-maven-plugin</artifactId>
<version>3.1.1</version>
<executions>
<execution>
<!-- Provides an execution to unzip the packaged JAR for use in a Docker image -->
<id>unzip-assembly-for-docker</id>
<configuration>
<executable>unzip</executable>
<arguments>
<argument>-quo</argument> <!-- quiet, update, overwrite -->
<argument>target/${project.build.finalName}-jar-with-dependencies.jar</argument>
<argument>-d</argument>
<argument>target/docker-image-target</argument>
</arguments>
</configuration>
</execution>
</executions>
</plugin>
...
</plugins>
```
1. maven-assembly-plugin is first used to create a JAR bundle of the application code **and** all the dependencies using the pre-configured descriptor [`jar-with-dependencies`](https://maven.apache.org/plugins/maven-assembly-plugin/descriptor-refs.html#jar-with-dependencies).
2. exec-maven-plugin is then used to unzip the assembly JAR for copying into Docker.
exec-maven-plugin is used just so we can keep everything inside of Maven. This is not only helpful for developer ergonomics, but also for keeping CI/CD pipelines simple. The caveat is that the environment where Maven is running depends on the command-line tool `unzip`, which is fortunately normally available.
With the above configured, you can simply run the following to prepare your application for Docker:
```bash
mvn package assembly:single exec:exec@unzip-assembly-for-docker
```
1. `package` will JAR your compiled app,
2. `assembly:single` will assemble your package JAR with the dependency JARs, and finally,
3. `exec` will call the `unzip` command to extract everything into the `target/docker-image-target` directory, ready for Docker.
As demonstrated earlier with my compiled `DemoServer` Java class, the maven-assembly-plugin will similarly copy all third-party dependency libraries as extracted JARs and give you the opportunity to perform diffs on library updates between Docker image builds. This can prove useful when trying to determine what exactly has changed between builds, even if you already have library updates recorded in version control. And if Docker ever optimises copying only changed files, we'd get an improvement with builds with respect to library updates.
## Creating the Docker image
With all your compiled code in a target directory, your Dockerfile can be as simple as the following:
```dockerfile
FROM eclipse-temurin:21.0.1_12-jre-alpine
WORKDIR /app
# add and run-as unprivileged user
RUN addgroup --system app-user-docker
RUN adduser --system --disabled-password --no-create-home app-user-docker app-user-docker
USER app-user-docker
# copy the extracted JAR code on to the image
COPY target/docker-image-target /app
EXPOSE 8080
ENTRYPOINT ["java", "io.policarp.service.DemoServer"]
```
Next time you're tasked with building a Java app in Docker, consider the approach I've demonstrated here. It's worth noting that if there is any reason you don't like it and/or find issues with unbundled JARs, going back (and forth) is not burdensome. Finally, in case you are wondering, this works just fine with Spring Boot.
| kdrakon |
1,697,842 | Automating Container Image Security with GitLab: A Comprehensive Guide using Dockerlinter, Conftest, SNYK API, and Docker Hub | Introduction: As containerized applications become integral to modern DevOps workflows, ensuring the... | 0 | 2023-12-14T13:13:56 | https://dev.to/gittest20202/automating-container-image-security-with-gitlab-a-comprehensive-guide-using-dockerlinter-conftest-snyk-api-and-docker-hub-2fn0 | **Introduction:**
_As containerized applications become integral to modern DevOps workflows, ensuring the security of container images is paramount. This guide explores a GitLab CI pipeline setup that seamlessly integrates security scanning using the SNYK API, validation with Conftest, and artifact management on Docker Hub and linting the Dockerfile using Dockerlinter_.
**Key Components and Tools:**
**Conftest**: _Policy as Code (PaC) tool for validating configuration files against Rego policies._
**SNYK Secure API:** _Leveraging Snyk for vulnerability scanning and image security._
**Docker Hub:** _Centralized container image registry for storing and managing Docker images._
**DockerLinter:** _Dockerlinter is a Dockerfile linter that focuses on best practices and recommendations from the official Docker documentation_
**_DockerFile Sample_**
```
# Use an official Python runtime as a parent image
FROM python:3.8-slim
# Set the working directory to /app
WORKDIR /app
# Copy the current directory contents into the container at /app
COPY . /app
# Install any needed packages specified in requirements.txt
RUN pip install --no-cache-dir -r requirements.txt
# Make port 80 available to the world outside this container
EXPOSE 80
# Define environment variable
ENV NAME World
# Run app.py when the container launches
CMD ["python", "app.py"]
```
**Sample Rego Code to Validate DockerFile**
```
package main
suspicious_env_keys = [
"passwd",
"password"
]
# Looking for suspicious environment variable settings
deny[msg] {
dockerenvs := [val | input[i].Cmd == "env"; val := input[i].Value]
dockerenv := dockerenvs[_]
envvar := dockerenv[_]
lower(envvar) == suspicious_env_keys[_]
msg = sprintf("Potential secret in ENV found: %s", [envvar])
}
```
> You can create your own Rego code to enforce granular restrictions or policies in a more fine-grained manner, you can customize the Rego policy accordingly.
**Here is the pipeline**
```
---
variables:
IMAGE_CONFTEST: "omvedi25/conftest:v0.2"
IMAGE_SNYK: "omvedi25/snyk:v0.1"
IMAGE_LINTER: "omvedi25/dockerlinter:v0.0"
stages:
- lint
- validation
- scan
- push
linting:Dockerfile:
image: "$IMAGE_LINTER"
stage: lint
script:
- dockerlinter -f Dockerfile -e
validation:Dockerfile:
image: "$IMAGE_CONFTEST"
stage: validation
script:
- conftest test -p /policy Dockerfile
scanning:Image:
image: "$IMAGE_SNYK"
stage: scan
script:
- podman build -t test .
- image_id=`podman images --format "table {{.Repository}}\t{{.ID}}" | awk '$1 == "localhost/test" {print $2}'`
- podman save $image_id -o test.tar
- snyk auth $SNYK_TOKEN
- snyk container test docker-archive:test.tar --json > results.json || true
- snyk-to-html -i results.json -o results.html
artifacts:
paths:
- results.html
expire_in: 1 week
pushing:Image:
image: "$IMAGE_SNYK"
stage: push
script:
- podman login -u $USERNAME -p $PASSWORD docker.io
- podman build -t test .
- podman tag localhost/test:latest omvedi25/$CI_PROJECT_NAME:$CI_COMMIT_SHA
- podman images
- podman push omvedi25/$CI_PROJECT_NAME:$CI_COMMIT_SHA
when: manual
```
**Pipeline Stages**

_Linting Output_
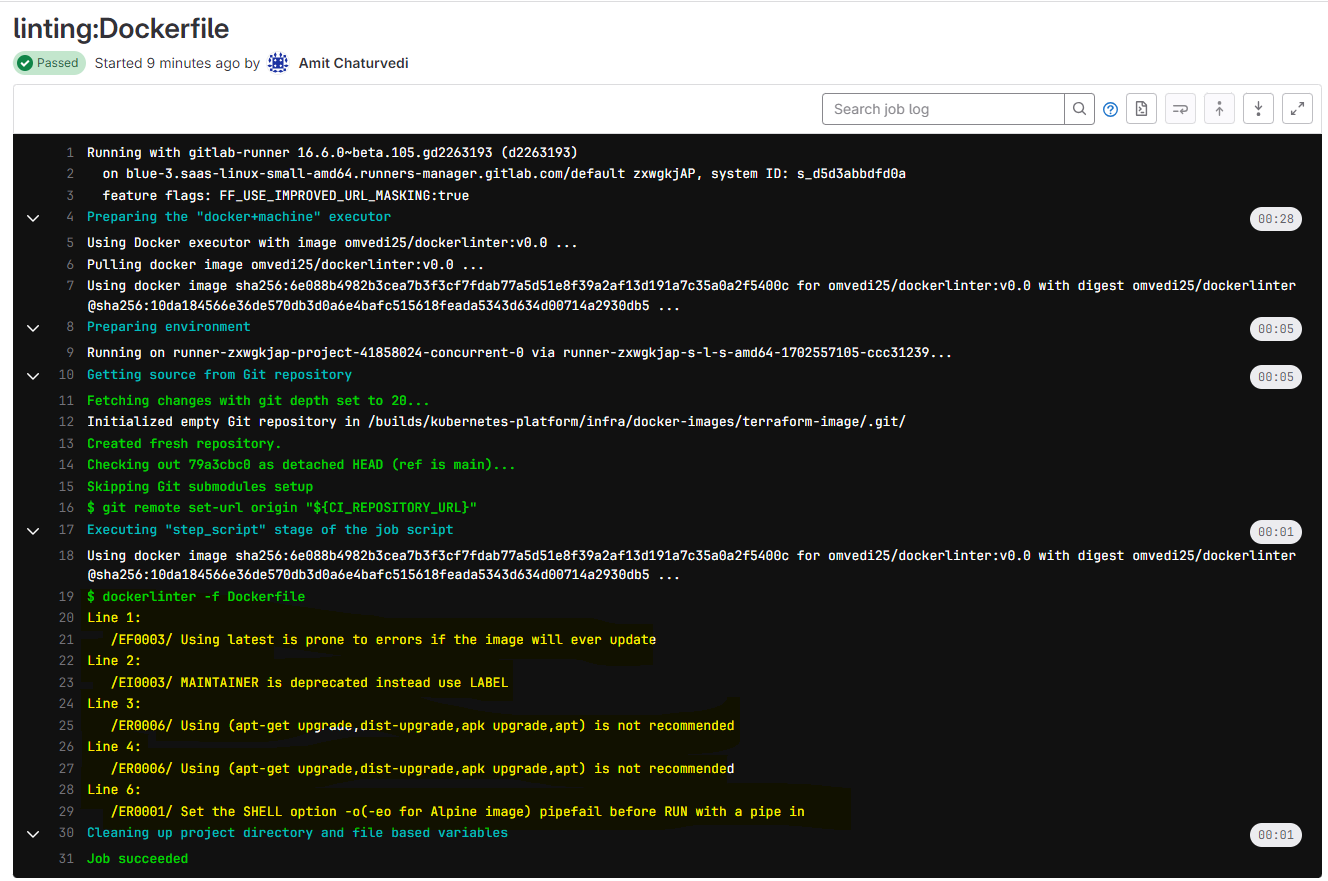
_Validation Output_
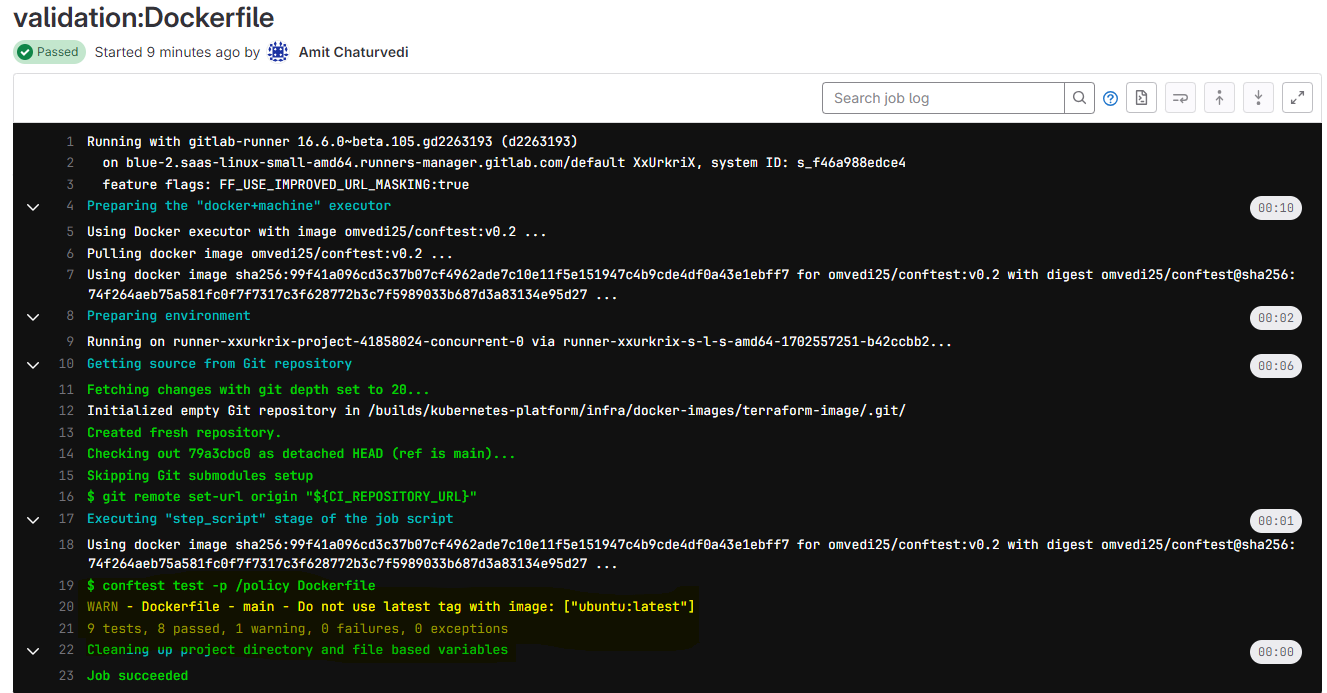
_SNKY HTML REPORT_
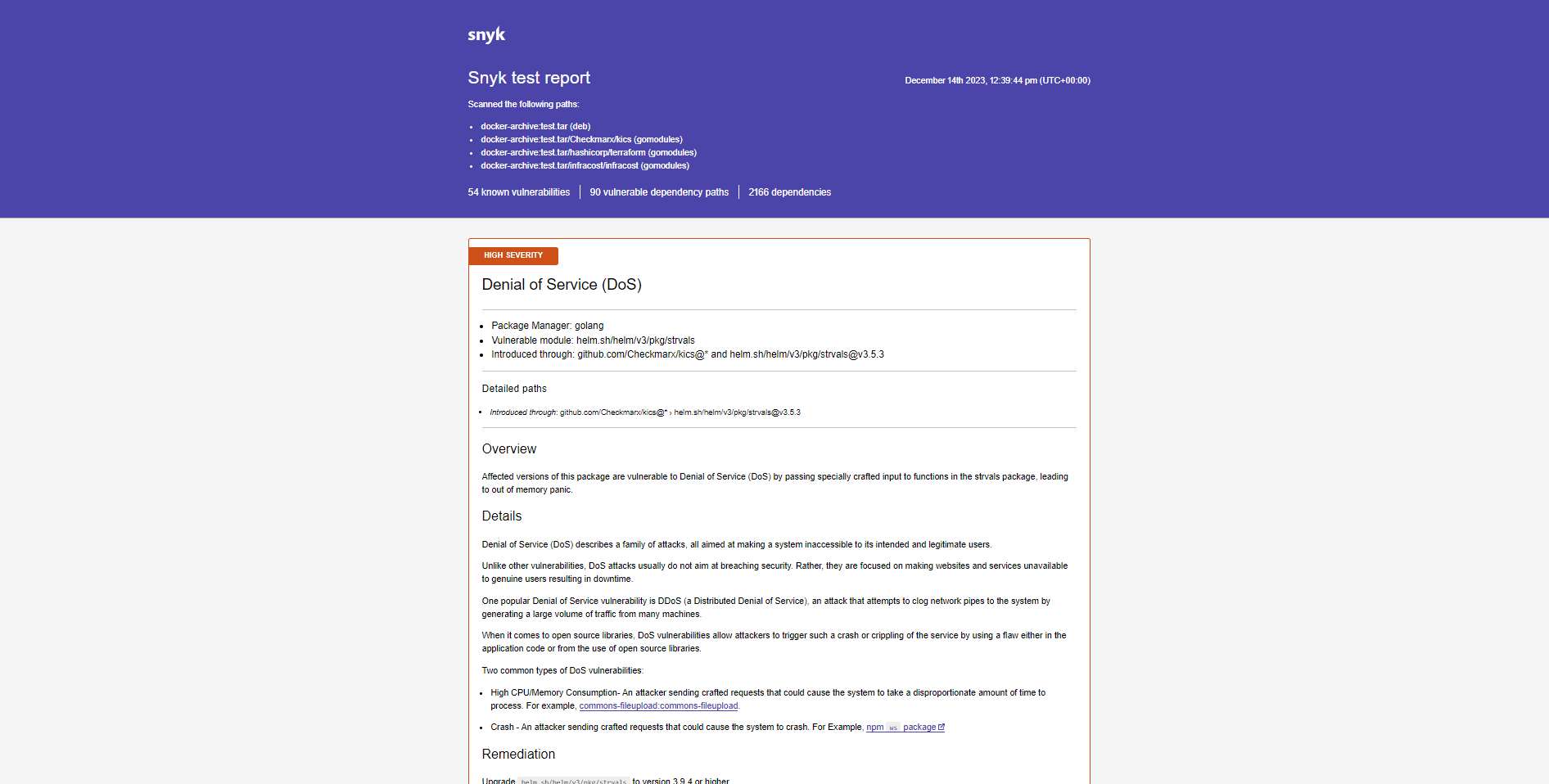
_PUSH IMAGE_
| gittest20202 | |
1,698,105 | Are you ready for Business? | Start screen with random starting group and wagon. I'll put in the saving and load here after a... | 0 | 2023-12-14T16:35:21 | https://dev.to/roll4d4/are-you-ready-for-business-36p8 | gamedev | Start screen with random starting group and wagon. I'll put in the saving and load here after a shower. | roll4d4 |
1,698,124 | A Deep Dive into iOS Video Player SDKs | In the realm of mobile applications, video content reigns supreme. Whether for entertainment,... | 0 | 2023-12-14T17:19:31 | https://dev.to/aditi10/a-deep-dive-into-ios-video-player-sdks-4fdl | iossdk, videoplyersdk, videoplayersdkforios, iosvideoplayersdk | In the realm of mobile applications, video content reigns supreme. Whether for entertainment, education, or communication, the ability to seamlessly play videos is a core feature that can make or break the user experience. To meet these demands, developers turn to iOS Video Player Software Development Kits (SDKs), robust tools designed to enhance video playback capabilities on Apple devices. In this blog post, we'll explore the intricacies of [iOS Video Player SDK](https://www.muvi.com/player/ios-sdk/), shedding light on their features, benefits, and how they contribute to creating compelling user experiences.
## 1. The Landscape of Mobile Video Consumption
The surge in mobile video consumption has underscored the importance of delivering high-quality, smooth, and feature-rich video experiences on iOS devices. Video Player SDKs play a pivotal role in achieving these objectives, providing developers with the tools to optimize video playback across various iOS platforms.
## 2. Key Features of iOS Video Player SDKs
### a. Adaptive Streaming:
iOS Video Player SDKs often support adaptive streaming protocols such as HLS (HTTP Live Streaming) and DASH (Dynamic Adaptive Streaming over HTTP). This ensures a seamless viewing experience by dynamically adjusting the video quality based on the viewer's network conditions.
### b. Customization Options:
Developers can tailor the appearance and behavior of the video player to align with the app's design and branding. Customization options may include player controls, themes, and the ability to integrate subtitles and closed captions.
### c. Offline Playback:
Some SDKs offer the capability to download videos for offline viewing. This feature is particularly valuable for users who may not have consistent access to a reliable internet connection.
### d. Live Streaming Support:
For applications that incorporate live streaming, iOS Video Player SDKs often provide robust support for real-time streaming protocols. This ensures low latency and high-quality live video playback.
### e. Analytics and Metrics:
SDKs may include analytics tools that enable developers to track user engagement, monitor video performance, and gather insights into viewer behavior. This data can be invaluable for refining the app and optimizing the content delivery strategy.
### 3. Integration and Compatibility
iOS Video Player SDKs are designed for seamless integration into iOS applications, with support for various development environments such as Swift and Objective-C. Compatibility with different iOS versions ensures that developers can reach a broad user base without sacrificing features or performance.
## 4. Security Considerations
Video content often includes sensitive or copyrighted material, making security a critical aspect of video playback. Video Player SDKs typically incorporate digital rights management (DRM) solutions and encryption mechanisms to protect against unauthorized access and content piracy.
## 5. Community and Support
A vibrant developer community and robust support from the SDK provider are essential for resolving issues, staying updated on new features, and accessing documentation. SDKs with active communities often lead to faster issue resolution and a more enriching development experience.
## 6. Choosing the Right iOS Video Player SDK
When selecting an iOS Video Player SDK, developers should consider factors such as ease of integration, scalability, feature set, and pricing. It is also crucial to evaluate the SDK's reputation in the developer community and its track record for timely updates and support.
## Conclusion
In the competitive landscape of mobile applications, delivering a stellar video playback experience is a key differentiator. iOS Video Player SDK empowers developers to go beyond basic video playback, offering a suite of features that enhance user engagement, provide customization options, and ensure optimal performance. By selecting and integrating the right iOS Video Player SDK, developers can create applications that captivate users and elevate the overall mobile video viewing experience. Whether it's adaptive streaming, offline playback, or robust analytics, these SDKs open doors to a world of possibilities for crafting immersive and seamless video experiences on iOS devices.
| aditi10 |
1,698,473 | Despliega tu Proyecto Gratis en Firebase: Una Guía Paso a Paso | Para comenzar, es esencial tener Node instalado en tu máquina. A continuación, instalamos Firebase... | 0 | 2023-12-15T03:00:27 | https://dev.to/dannieldev/despliega-tu-proyecto-gratis-en-firebase-una-guia-paso-a-paso-4542 | firebase, español, hosting, website | Para comenzar, es esencial tener Node instalado en tu máquina. A continuación, instalamos Firebase Tools de forma global con el siguiente comando:
`npm install -g firebase-tools`
Una vez que Firebase está instalado, iniciamos sesión a través de la terminal con el comando:
`firebase login`
Al ejecutar este comando, se nos presentará la opción de permitir que Firebase recopile información de uso y reportes de errores de CLI y Emulator Suite. Podemos elegir sí (Y) o no (N) según nuestras preferencias.

Después de seleccionar nuestra preferencia, seremos redirigidos a la página de inicio de sesión de Firebase. Ingresamos nuestras credenciales de Google y aceptamos los permisos necesarios. Una vez aceptado, veremos un mensaje exitoso y podemos continuar desde la terminal.
Siguiendo con el proceso, el siguiente comando es:
`firebase init`
Este comando inicia la configuración de nuestro hosting.
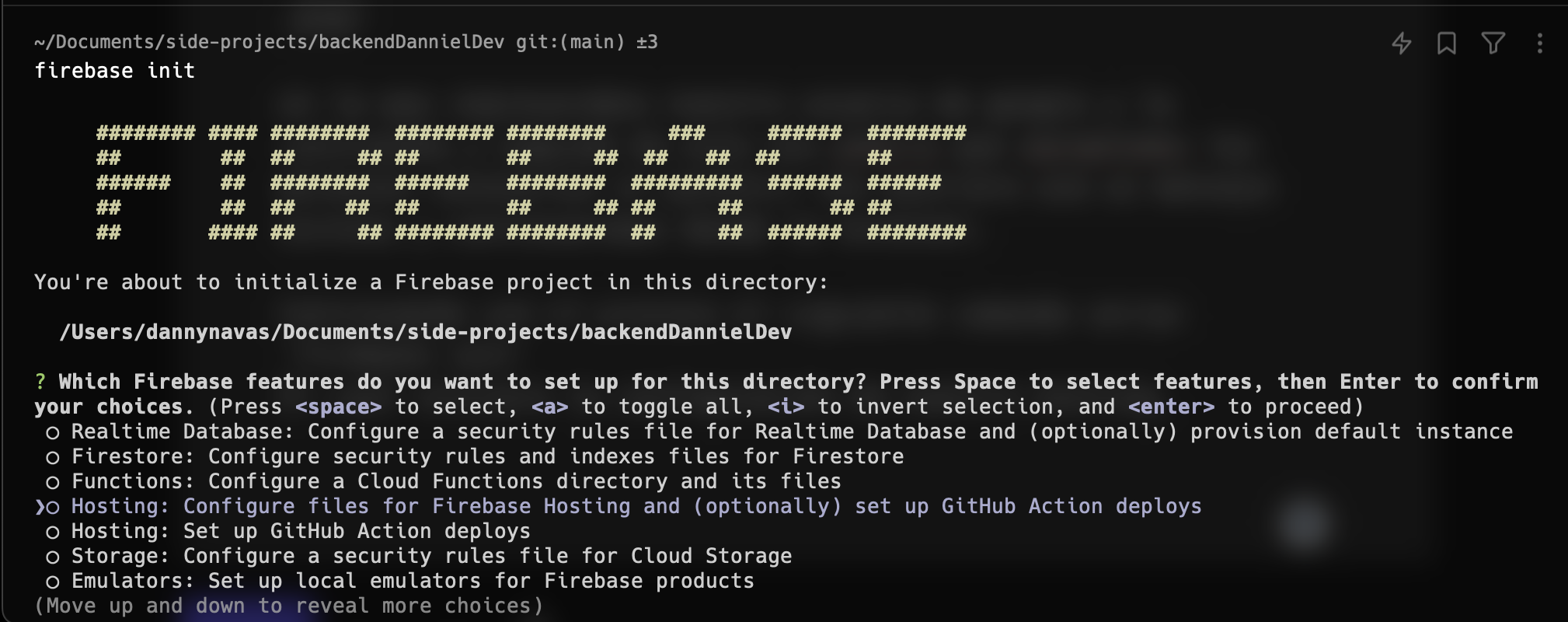
Seleccionamos con o sin GitHub Actions, según lo que se ajuste mejor a nuestro flujo de trabajo. Luego, elegimos la opción de hosting que más se adapte y asociamos el proyecto a nuestro desarrollo. En mi caso, ya tengo varios proyectos creados, así que selecciono uno.
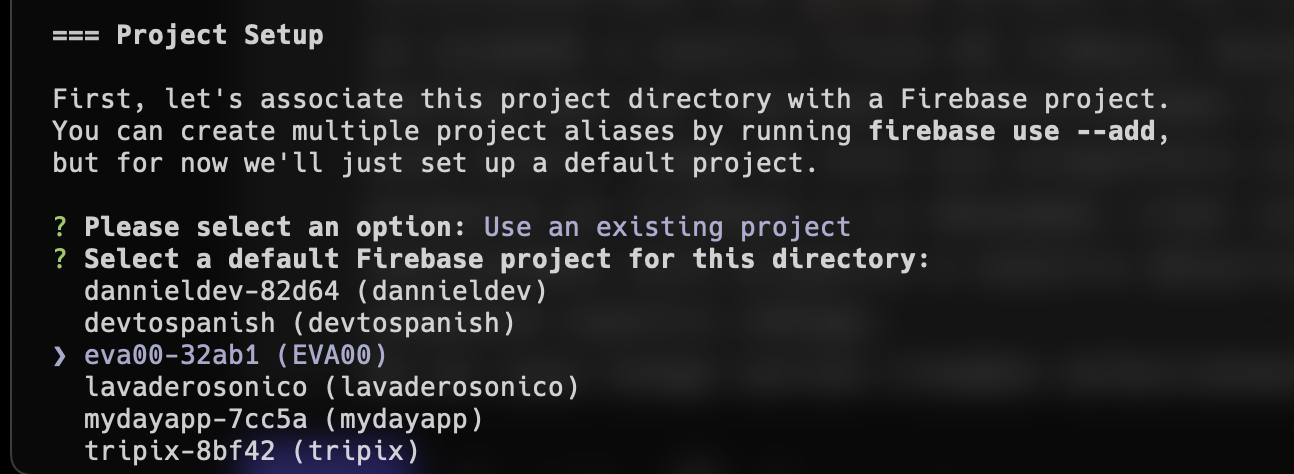
El siguiente paso es indicar la ubicación de nuestro proyecto compilado.

Por defecto, sugiere `public`, pero puedes especificar otra carpeta, por ejemplo, `dist/myproject`. Esta carpeta debería resultar de ejecutar un comando como `npm run build` (revisa tu package.json en la sección de scripts).

Luego, nos pregunta si nuestro proyecto es una SPA (Single Page Application) como Angular, Vue o React. Si es así, respondemos con "y".
Continuará preguntando si queremos configurar GitHub Actions para automatizar el despliegue al hacer push o merge. La elección depende de tus preferencias.

Si seleccionas la opción por defecto (N), finalizaremos el proceso y se mostrará el resultado.

Si decides configurar GitHub Actions, te pedirá acceso a tu repositorio en GitHub, indicando el nombre de usuario y el nombre de tu proyecto separados por una barra (/), por ejemplo, `dannielnavas/miproyecto`.
Al finalizar, si no configuramos GitHub Actions, solo necesitamos hacer un build (`npm run build`) y luego ejecutar `firebase deploy`. Esto mostrará un enlace al proyecto en Firebase y otro que contendrá nuestro sitio desplegado.
Recuerda que Firebase ofrece un servicio gratuito mensual. Mientras no superes esa cuota, todo el funcionamiento será sin costo.
Espero que este artículo te ayude a desplegar tus proyectos de forma gratuita, independientemente de la tecnología utilizada.
No olvides que he contribuido a la comunidad de DevToSpanish, donde puedes encontrar más artículos escritos por hispanohablantes [aquí](<https://devtospanish.danniel.dev/>).
| dannieldev |
1,698,493 | ChatGPT Coding CheatSheets | Explain why a piece of code isn't working Why this code is not working? var x = 5; var y =... | 0 | 2023-12-15T03:25:33 | https://dev.to/hoanganhlam/chatgpt-coding-cheatsheets-2ib1 | chatgpt, ai, promptengineering | **Explain why a piece of code isn't working**
```
Why this code is not working?
var x = 5;
var y = 0;
console.log(x/y);
```
**Explain what a piece of code means**
```
What does this code do?
function addNumbers(a, b) {
return a + b;
}
```
**Rewrite the code using the specified language*
```
Translate this code into Python:
function addNumbers(a, b) {
return a + b;
}
```
**Code an entire software program**
```
Write a program that calculates the factorial of a given number in python.
How do I make an HTTP request in Javascript?
```
**Generate regular expressions (regex)**
```
Create a regex that matches all email addresses?
Generate 8-digit password regex
```
**Add comments to your codebase**
```
Add comments to this code:
function addNumbers(a, b) {
return a + b;\n}
```
**Change the CSS of a line of code**
```
Update the CSS for this line to change the font color to blue?
<p class=\"example\">Hello, QuickRef.ME!</p>
```
**Change the HTML of a line of code**
```
Add a class of \"header\" to this header tag?
<h1>Hello, QuickRef.ME!</h1>
```
References:
- [ChatGPT Cheatsheet](https://simplecheatsheet.com/chatgpt)
- [Simple Cheatsheet](https://simplecheatsheet.com)
| hoanganhlam |
1,698,498 | 5 Estratégias para Elevar seu Nível no Frontend | Um breve resumo sobre mim. Meu nome é Hudson, sou desenvolvedor frontend e Mobile na OPEN... | 0 | 2023-12-29T14:54:00 | https://dev.to/hudson3384/5-estrategias-para-elevar-seu-nivel-no-frontend-1eem | ##Um breve resumo sobre mim.
Meu nome é Hudson, sou desenvolvedor frontend e Mobile na OPEN Datacenter e busco compartilhar conhecimentos sobre minha área e as que tenho interesse em atuar e estudo como backend, devops, linux e automatizações.
##Teste tudo o que puder
Uma requisição para vagas de desenvolvedores pleno que eu demorei a correr atrás foi a criação de testes e me arrependo muito disso. Criar testes automatizados aumenta totalmente a confiabilidade do seu código, evita erros inesperados, evita refatorações e te faz pensar de uma forma inteligente, pensando em formas de tratar todas as possibilidades de erros e como testá-las. Ferramentas ótimas para isso são o Jest e o Cypress.
Documentação do Cypress: https://docs.cypress.io/
Documentação do Jest: https://jestjs.io/pt-BR/
##Usar ferramentas de saúde de código
Evitar duplicações e melhorar a legibilidade é uma responsabilidade de qualquer programador independente da stack, por isso temos diversos métodos como SOLID, clean code e outros. No entanto, é impossível exercer a onisciência do código de forma manual por isso temos ferramentas de saúde de código. Estou familiarizado com duas ferramentas gratuitas, o codeClimate e o Sonar
CodeClimate: https://codeclimate.com/
Sonar: https://www.sonarsource.com/products/sonarqube/
##Seja ousado
Apesar deste título genérico, eu acredito que foi o que mais me fez crescer neste ano, para crescermos é necessário entender que esse processo vá ser doloroso às vezes pois precisamos sempre aumentar nossos desafios no limiar dos nossos limites. Costumo dizer que o frontend deve pensar às vezes como se fosse o UX Designer, e depois de anunciar o problema e solução, se virar como frontend para solucionar.
Uma recomendação de combina com o assunto:
{% cta https://www.youtube.com/watch?v=HEaIsKm-pao %} VIDEO : A Dor de Aprender | Que Cursos/Livros?
{% endcta %}
##Se mantenha informado e saia da caixinha
Um pensamento que eu possuo desde que eu entrei na área da programação é que não podemos nos prender ao escopo do nosso ambiente, caso você já trabalhe ou estude, vai de maneira indireta aprender mas é necessário entender que há uma limitação de escopo nesta maneira. Por isso, sempre busque formas de saber mais sobre suas tecnologias e demais que estão em alta em newsletters, artigos e mídias sociais.
Em breve irei trazer minhas táticas que uso para me manter atualizado e recomendações de newsletters por aqui.
##Estude algorítmos
Esta é uma dica poderosa, ao estudar algoritmos e praticá-lo, você começa a ter uma visão mais ampla sobre performance, reconhecendo falhas na sua aplicação e deixando mais afiado seu senso crítico. Além de ser exigido em testes de código para empresas maiores.
Uma forma efetiva de aprender é praticando, e por isso eu recomendo a Leetcode e esse video do PirateKing explicando como usar a plataforma com maior proveito.
###Links:
{% cta https://www.youtube.com/watch?v=p_9t8uhXQdk %} Video: MY ULTIMATE LEETCODE TRICKS
{% endcta %}
{% cta https://leetcode.com/ %} LEETCODE SITE
{% endcta %}
Se você curtiu, por favor avalie para me motivar a criar mais conteúdos assim:
Github: https://github.com/Hudson3384
Linkedin: https://www.linkedin.com/in/hudson-arruda-ribeiro/
LeetCode: https://leetcode.com/Hudson3384/
| hudson3384 | |
1,698,507 | Simple Loading CSS Animation | The animated graphic that users see while waiting for content to load on a website is called a... | 0 | 2023-12-15T04:25:34 | https://dev.to/divinector/simple-loading-css-animation-3nb6 | html, css, webdev, frontend | The animated graphic that users see while waiting for content to load on a website is called a website loader or loading animation. Different types of loaders are seen on different websites these days. Some of these are spinner loaders, bar loaders, pulse loaders, bouncing letter loaders, or any other kind of custom loader. These CSS loaders have only one purpose and that is to keep the visitors engaged during the time it takes to load the website content. The user will not be disturbed and patiently wait for the content to load. Today we will share with you a CSS loader animation snippet that bounces the letters of the word 'loading'. We know that many creative animations can be made with CSS keyframes animation. This CSS loader is a part of that. The video tutorial below shows the step-by-step process of creating this CSS animation example snippet.
{% embed https://www.youtube.com/watch?v=-ldWeqPL1Sk %}
When content is being retrieved from the server or an action is being processed, visitors get confused as to what is going on. This loader animation signals the progress of the loading process to the user. Animations created with CSS keyframes provide a pleasant and stable experience to users. That is why we have used CSS Keyframes animation to make our CSS loader.
You May Also Like:
- [Eyes Follow Mouse Cursor Animation](https://www.divinectorweb.com/2023/11/eyes-follow-mouse-cursor-animation.html)
- [Zoom an Image on Page Scroll](https://www.divinectorweb.com/2023/11/zoom-image-on-page-scroll-using-javascript.html)
- [CSS Grid Responsive Image Gallery](https://www.divinectorweb.com/2023/12/css-grid-responsive-image-gallery.html)
First, each letter of the word 'loading' and the accompanying three dots are taken within ten span tags. This is done because each letter and dot will be animated separately. In CSS, first, the container divs are taken to the center of the viewport using the CSS flexbox grid. Initially, the span elements will align vertically. So 'display: inline-block' is taken to bring the span elements side by side. An animation property is then set which will animate each span element via keyframes. Each span element is given a different 'animation-delay' value so that they animate slightly later than animate together.
```
<!DOCTYPE html>
<html lang="en">
<!-- divinectorweb.com -->
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Creative Page Loading Animation</title>
<link href="https://fonts.googleapis.com/css2?family=Bebas+Neue&display=swap" rel="stylesheet">
<link rel="stylesheet" href="style.css">
</head>
<body>
<div class="container">
<div class="loader">
<span>L</span>
<span>o</span>
<span>a</span>
<span>d</span>
<span>i</span>
<span>n</span>
<span>g</span>
<span>.</span>
<span>.</span>
<span>.</span>
</div>
</div>
</body>
</html>
```
```
body {
display: flex;
justify-content: center;
align-items: center;
height: 100vh;
margin: 0;
background-color: #000;
}
.container {
display: flex;
justify-content: center;
align-items: center;
height: 100px;
}
.loader {
font-size: 40px;
font-weight: bold;
display: inline-block;
font-family: bebas neue;
}
.loader span {
display: inline-block;
color: #0072ff;
animation: bounce 1.5s infinite alternate;
}
.loader span:nth-child(2) {
animation-delay: 0.1s;
}
.loader span:nth-child(3) {
animation-delay: 0.2s;
}
.loader span:nth-child(4) {
animation-delay: 0.3s;
}
.loader span:nth-child(5) {
animation-delay: 0.4s;
}
.loader span:nth-child(6) {
animation-delay: 0.5s;
}
.loader span:nth-child(7) {
animation-delay: 0.6s;
}
.loader span:nth-child(8) {
animation-delay: 0.7s;
}
.loader span:nth-child(9) {
animation-delay: 0.8s
}
.loader span:nth-child(10) {
animation-delay: 0.9s;
}
@keyframes bounce {
0%, 20%, 50%, 80%, 100% {
transform: translateY(0)
}
40% {
transform: translateY(-50px)
}
60% {
transform: translateY(-25px);
}
}
```
For the Original Post [CLICK HERE](https://www.divinectorweb.com/2023/12/how-to-make-loading-css-animation.html) | divinector |
1,698,690 | 지오해싱이란 무엇인가요? | 지오해싱(또는 지오해시)은 지리적 좌표(위도 및 경도)를 짧은 숫자 문자열로 인코딩하는 데 사용되는 지오코딩 방법이며... | 0 | 2023-12-15T09:23:12 | https://dev.to/pubnub-ko/jiohaesingiran-mueosingayo-geg | 지오해싱(또는 지오해시)은 지리적 좌표(위도 및 경도)를 다양한 해상도의 셀이라고 하는 지도상의 영역을 나타내는 짧은 숫자와 문자의 문자열로 인코딩하는 데 사용되는 [지오코딩](https://www.pubnub.com/learn/glossary/what-is-geocoding-and-reverse-geocoding/) 방식입니다. 문자열의 문자가 많을수록 위치가 더 정확해집니다.
### 지오해시의 예는 무엇인가요?
지오해시는 좌표를 인코딩하는 공개 도메인입니다. 지오해시의 예로는 좌표 쌍 28.6132,77.2291을 지오해시 ttnfv2u로 변환하는 것을 들 수 있습니다.
### 지오해시의 최대 길이는 얼마인가요?
지오해시의 최대 길이는 12입니다.
지오해시는 어떻게 작동하나요?
----------------
### 지오해시 알고리즘 및 계산
지오해시는 Base-32 알파벳 인코딩을 사용합니다(문자는 0에서 9까지, A에서 Z까지 가능, "A", "I", "L", "O" 제외). 세계가 32개의 셀로 이루어진 격자로 나뉘어져 있다고 가정해 보겠습니다. 지오해시의 첫 번째 문자는 32개의 셀 중 하나로서 초기 위치를 식별합니다. 이 셀은 또한 32개의 셀을 포함하며, 각 셀은 32개의 셀을 포함하게 됩니다(이렇게 반복적으로). 지오해시에 문자를 추가하면 셀이 세분화되어 더 자세한 영역으로 효과적으로 확대할 수 있습니다.
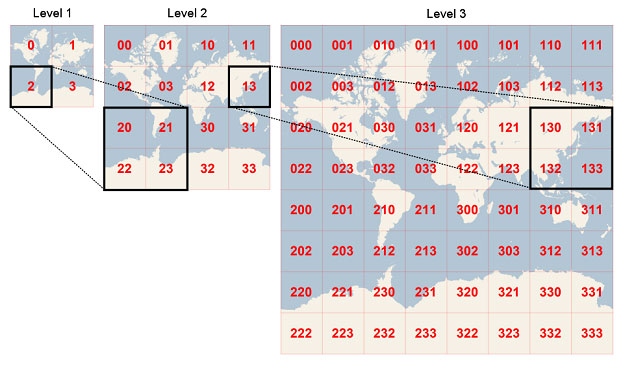
정밀도 계수는 셀의 크기를 결정합니다. 예를 들어, 정밀도 계수가 1이면 높이 5,000km, 너비 5,000km의 셀이 생성되고, 정밀도 계수가 6이면 높이 0.61km, 너비 1.22km의 셀이 생성되며, 정밀도 계수가 9이면 높이 4.77m, 너비 4.77m의 셀이 생성됩니다(셀이 항상 정사각형인 것은 아님).
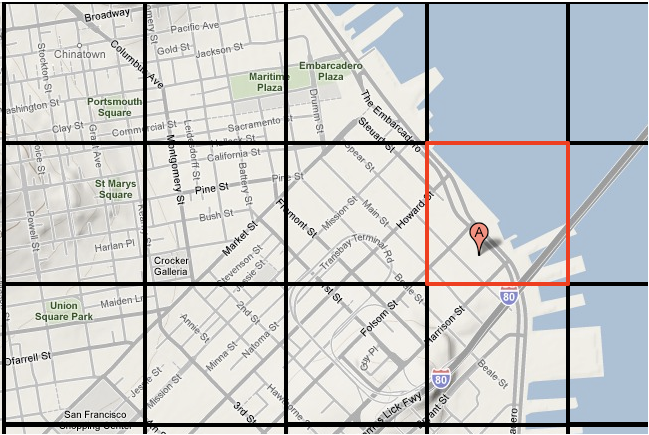
지오해싱 예시 및 사용 사례
---------------
지오해싱은 원래 [URL 단축 서비스로](https://bitly.com/) 개발되었지만 현재는 공간 인덱싱(또는 공간 비닝), 위치 검색, 매시업 및 고유한 장소 식별자 생성에 일반적으로 사용됩니다.
### 지오해시의 장점
지오해시는 일반 주소나 위도 및 경도 좌표보다 짧기 때문에 공유, 기억, 저장하기가 더 쉽습니다.
- **소셜 네트워킹:** 특정 셀 내에서 가까운 사람들과 채팅하고 [채팅 앱을 만들](https://www.pubnub.com/learn/glossary/what-is-in-app-chat/) 수 있습니다.
- **근접 검색:** [API 매핑](https://www.pubnub.com/learn/glossary/what-is-a-map-api/) 또는 [지리적 위치 API를](https://www.pubnub.com/learn/glossary/what-is-a-geolocation-api/) 사용하여 주변 위치를 찾고 해당 지역의 관심 장소, 레스토랑, 상점, 숙박 시설을 식별할 수 있습니다.
- **디지털 여행:** 지오해셔들은 사람들을 만나고 새로운 장소를 탐험하기 위해 전 세계로 탐험을 떠납니다. 특이한 점은 목적지가 컴퓨터로 생성된 지오해시이며, 이 턴키 여행 경험의 참가자는 자신의 이야기를 작성하여 인터넷에 게시해야 한다는 것입니다.
- **맞춤형 인터랙티브 앱:** 지오해싱은 [실시간 인터랙티브 앱을](https://www.pubnub.com/blog/connected-shared-experiences-a-developers-guide/) 만드는 데 사용할 수 있습니다.
[여기에서](https://www.movable-type.co.uk/scripts/geohash.html) 사용해 볼 수 있습니다. 좌표 40.748440989 및 -73.985663981 을 사용하여 뉴욕의 엠파이어 스테이트 빌딩 주변 지역을 볼 수 있습니다. 정밀도 계수를 변경하여 해상도(셀의 크기)를 높이거나 낮추거나, 13자리 정밀도 계수인 geohash dr5ru6j2c5fqt를 사용하여 바로 확대할 수 있습니다.
### 지오해시 사용의 단점은 무엇인가요?
지오해시의 단점은 다음과 같습니다:
1. 그리드 기반 지오해싱 알고리즘을 사용하려면 고정밀 요구 사항을 충족해야 합니다.
2. 지구는 불규칙한 타원형이기 때문에 위도가 증가함에 따라 지오해싱 편차가 달라집니다.
앱에 실시간 기능을 통합할 준비가 되셨나요? [지금 무료 PubNub 계정을 생성하세요](https://admin.pubnub.com/#/register).
기타 리소스
------
- [지리적 위치 및 지오트래킹](https://www.pubnub.com/learn/glossary/what-is-a-geolocation-api/)
- [React 네이티브 위치 추적 앱](https://www.pubnub.com/blog/realtime-geo-tracking-app-react-native/)
PubNub이 어떤 도움을 줄 수 있을까요?
========================
이 글은 원래 [PubNub.com에](https://pubnub.com/guides/what-is-geohashing/) 게시되었습니다.
저희 플랫폼은 개발자가 웹 앱, 모바일 앱, IoT 기기를 위한 실시간 인터랙티브를 구축, 제공, 관리할 수 있도록 지원합니다.
저희 플랫폼의 기반은 업계에서 가장 크고 확장성이 뛰어난 실시간 에지 메시징 네트워크입니다. 전 세계 15개 이상의 PoP가 8억 명의 월간 활성 사용자를 지원하고 99.999%의 안정성을 제공하므로 중단, 동시 접속자 수 제한, 트래픽 급증으로 인한 지연 시간 문제를 걱정할 필요가 없습니다.
PubNub 체험하기
-----------
[라이브 투어를](https://www.pubnub.com/tour/introduction/) 통해 5분 이내에 모든 PubNub 기반 앱의 필수 개념을 이해하세요.
설정하기
----
PubNub [계정에](https://admin.pubnub.com/signup/) 가입하여 PubNub 키에 무료로 즉시 액세스하세요.
시작하기
----
사용 사례나 [SDK에](https://www.pubnub.com/docs) 관계없이 [PubNub 문서를](https://www.pubnub.com/docs) 통해 바로 시작하고 실행할 수 있습니다. | pubnubdevrel | |
1,698,874 | Driving Business Growth through Digital Transformation: Key Factors to Consider | Introduction As technology continues to evolve at a breakneck pace, businesses that fail... | 0 | 2023-12-15T12:47:26 | https://swac.blog/category/digital-transformation/ | digital, transformation | Introduction
------------
As technology continues to evolve at a breakneck pace, businesses that fail to adapt risk being left behind. Digital transformation is no longer an option but a strategic imperative for businesses of all sizes and industries. In this article, we’ll explore the key drivers of digital transformation, the types of digital transformation, the steps to implementing a digital transformation strategy, the benefits of digital transformation, the challenges and risks of digital transformation, and successful case studies of digital transformation.
Key Drivers of Digital Transformation
-------------------------------------
Digital transformation is driven by several key factors, including increasing customer expectations, competition and market pressures, and technological advancements. Customers today expect personalized and seamless experiences across multiple channels, and businesses that fail to deliver risk losing customers to competitors. Competition is fiercer than ever, with startups and disruptors entering the market and disrupting traditional business models. Technological advancements such as cloud computing, artificial intelligence, and the Internet of Things (IoT) are enabling businesses to operate more efficiently and create new revenue streams. Since I have been facing several content piracy cases lately, this blog post has ONLY been published on [the Software, Architecture, and Cloud blog - SWAC.blog](https://swac.blog) and canonically to [dev.to](https://dev.to/khalidelgazzar) only. If you are reading it elsewhere, then [please let us know](https://swac.blog/contact-us/).
Types of Digital Transformation
-------------------------------
Digital transformation can take several forms, including business process transformation, customer experience transformation, product/service innovation transformation, and cultural/organizational transformation. Business process transformation involves reengineering existing processes to make them more efficient and effective using technology. Customer experience transformation involves improving the way customers interact with a business across multiple touchpoints. Product/service innovation transformation involves using technology to create new products or services or improve existing ones. Cultural/organizational transformation involves changing the way people work, think, and collaborate to drive digital innovation.
Steps to Implementing a Digital Transformation Strategy
-------------------------------------------------------
Implementing a digital transformation strategy requires careful planning and execution. The following are the key steps to implementing a successful digital transformation strategy:
1. Identify business goals and priorities: Define the business objectives that the digital transformation strategy should address, such as increasing revenue, reducing costs, improving customer experience, or enhancing operational efficiency.
2. Assess current technology infrastructure and capabilities: Conduct a thorough assessment of the current technology landscape to identify gaps and opportunities for improvement.
3. Create a roadmap for digital transformation: Develop a comprehensive plan for the digital transformation journey, including timelines, budgets, and resources required.
4. Develop a plan for change management and employee training: Create a plan to manage the change associated with digital transformation, including employee training and communication.
5. Monitor and measure progress: Track the progress of the digital transformation strategy using key performance indicators (KPIs) and adjust the strategy as necessary based on the results. Since I have been facing several content piracy cases lately, this blog post has ONLY been published on [the Software, Architecture, and Cloud blog - SWAC.blog](https://swac.blog) and canonically to [dev.to](https://dev.to/khalidelgazzar) only. If you are reading it elsewhere, then [please let us know](https://swac.blog/contact-us/).
Benefits of Digital Transformation
----------------------------------
Digital transformation can deliver a wide range of benefits to businesses, including:
1. Improved customer experience and engagement: By leveraging technology to deliver personalized and seamless experiences across multiple channels, businesses can increase customer loyalty and satisfaction.
2. Increased operational efficiency and productivity: Digital transformation can help automate and streamline business processes, reducing manual effort and errors, and enabling employees to focus on higher-value activities.
3. Enhanced decision-making and data-driven insights: Digital transformation can provide businesses with real-time data and insights, enabling better decision-making and more informed strategic planning.
4. Creation of new revenue streams and business models: By leveraging technology, businesses can create new products, services, and revenue streams that were previously impossible.
5. Increased competitiveness and market share: Digital transformation can help businesses stay ahead of the competition by enabling them to operate more efficiently, deliver superior customer experiences, and create innovative products and services.
Challenges and Risks of Digital Transformation
----------------------------------------------
While digital transformation offers many benefits, it also poses some challenges. Here are some of the key challenges businesses may face when implementing digital transformation:
### 1\. Resistance to Change
One of the biggest challenges businesses face when implementing digital transformation is resistance to change from employees. Employees may be resistant to change due to fear of job loss, lack of digital skills, or a preference for traditional ways of working.
### 2\. Security Risks
Digital transformation exposes businesses to new security risks, such as cyber attacks and data breaches. This requires businesses to invest in robust cybersecurity measures and ensure that all employees are trained in best practices for data security.
### 3\. Cost and Resource Requirements
Implementing digital transformation requires significant investments in technology, training, and infrastructure. This can be a significant cost for businesses, particularly small and medium-sized enterprises (SMEs) with limited resources.
### 4\. Integration Challenges
Digital transformation involves integrating new technologies with existing systems and processes, which can be a complex and time-consuming process. This requires businesses to carefully plan and execute their digital transformation strategy to ensure seamless integration.
Conclusion
----------
Digital transformation is no longer a buzzword; it is a necessity for businesses that want to remain competitive in today’s fast-paced and constantly evolving business environment. By embracing digital technologies, businesses can improve efficiency, enhance customer experience, and gain valuable insights into their operations. However, implementing digital transformation also poses challenges, such as resistance to change, security risks, and cost requirements. To overcome these challenges, businesses must carefully plan and execute their digital transformation strategy and ensure that all employees are trained in digital skills and best practices for data security.
I hope this blog post has provided you with a comprehensive overview of digital transformation and its benefits and challenges. If you have any questions or comments, please feel free to leave them in the comments section below. For more articles about Digital Transformation, please visit [the Digital transformation subsection at the Software, Architecture and Cloud blog - SWAC.blog] (https://swac.blog/category/digital-transformation/).
| khalidelgazzar |
1,698,883 | Lightweight, portable and secure Wasm runtimes and their use cases. | Why is JavaScript so popular? With 16 million developers estimated, JavaScript is a pretty... | 0 | 2023-12-15T14:11:04 | https://dev.to/anfibiacreativa/lightweight-portable-and-secure-wasm-runtimes-and-their-use-cases-ama | ## Why is JavaScript so popular?
With 16 million developers estimated, JavaScript is a pretty popular language. We sometimes attribute that to its high-level nature, and the fact that you just need a browser and a text editor, and you can write a small program or a lengthy app, and see the result right away.
The so-called feedback loop is immediate; we can see the results of code execution right away.
There is no need to compile it -or at least you don't need to intervene in the compilation as a developer-. Of course, modern frontend setups and build tools come equipped with transpilation systems, bundling and packaging, and a lot of ahead of time processes like static analysis, but in essence, you can run JavaScript from a text file with a browser only.
## JavaScript needs no compilation...but, does it?
For a program written in JavaScript to run, each instruction goes through the following JIT (just in time) flow.
1. the parser or JS engine generates an Abstract Syntax Tree (AST), which is a hyerarchy of nodes,
2. which the interpreter reads and
3. generates high-level binary code or byte code from, for
4. the compiler to finally generate the machine code -or low level binary- that may be optimised as instructions for a specific CPU architecture.
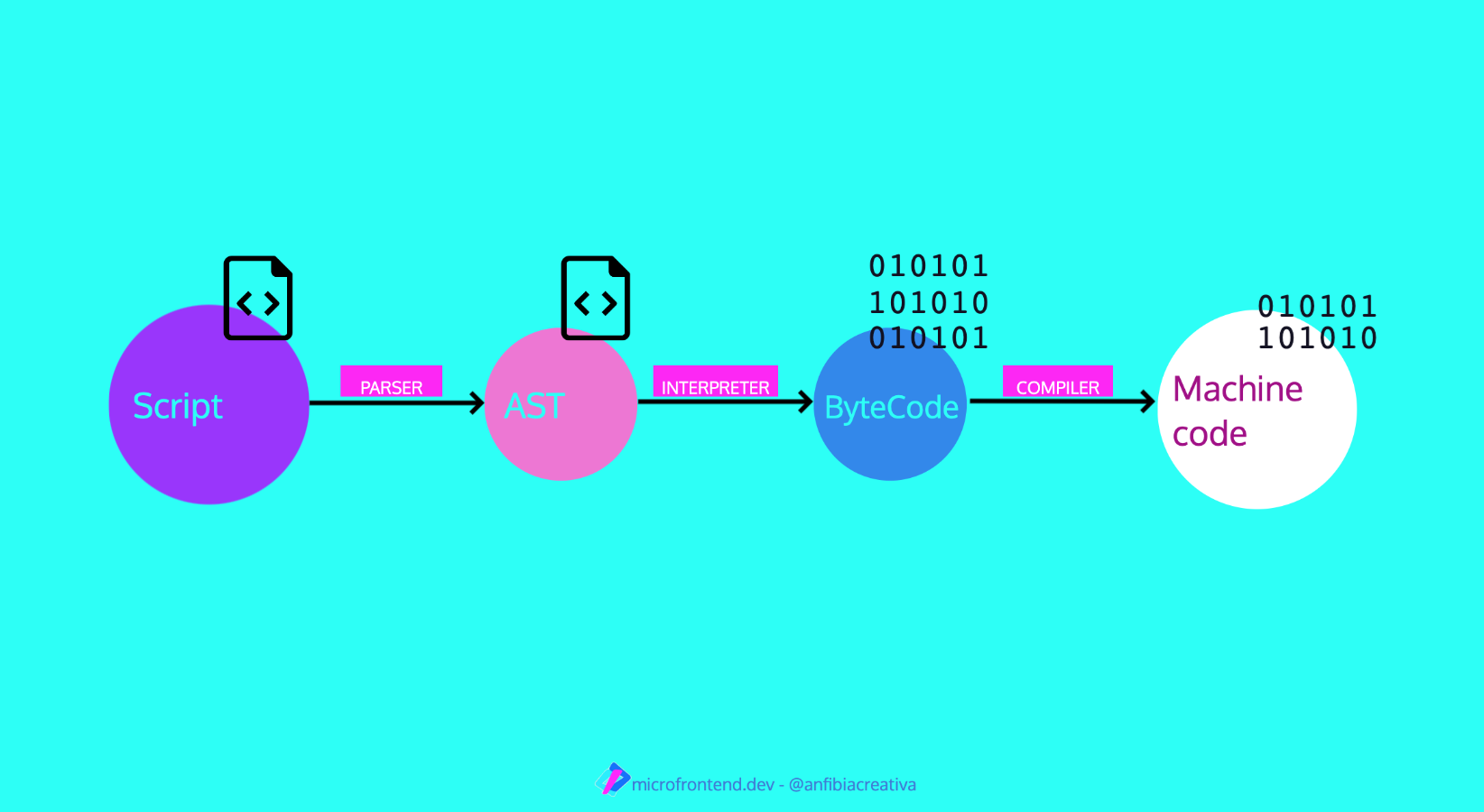
This cycle of execution, uses the client's (be it desktop or mobile) resources.
## Client-side dynamics
Until very recently, and ever since libraries like jQuery and JavaScript frameworks like AngularJS, Ember, Backbone emerged and became so popular, around 2009, almost everything dynamic happened on the client-side. In addition to the interpretation of JavaScript during execution, to offer good performance, the stars had to align: the requested data had to be distributed -served from the cache of a CDN- to avoid high latency, the user connection had to be fast, and they needed to be on a high-end, high-capacity terminal.
In reality, we don’t know the user’s system capacity at any time. And that’s a hindrance.
## We try to prevent exhausting end-user terminal resources
In theory, if we ran lower level code, we would be using less resources. That's more than a theory. Go to this video where I demonstrate [Pagefind](https://pagefind.app/), written in Rust and compiled to Wasm as target, as a static app that ingests and indexes HTML documents and runs super efficient search queries, all client-side.
{% embed https://youtu.be/znMeeexyj_c?t=967 %}
## Going lower, to reach higher
That's Wasm. A (web) standard binary instructions compilation target that runs on the browser, implementing a system of imports and exports.
You literally write the code in the language you prefer, and given the toolchain is in place -and it's in (experimental or preview) place for JavaScript, with teams working on it, like for example [JCO](https://github.com/bytecodealliance/jco)- you can compile with Wasm as target.
[Learn more about Wasm](https://microfrontend.dev/web-standards/micro-frontends-webassembly/)
## At the edge of the cloud
We have seen how we can run Wasm on the browser to attain a high level of performance with low bandwidth cost, client-side. But what about server-side or in an isomorphic way?
Cloud technologies -and emerging JavaScript meta-frameworks- allow us to render, cache, and then rehydrate dynamic parts of a (server rendered) static page based on rules, cookies or headers and other composability strategies.
This allows us to build dynamic experiences with a `backend for frontend` approach, preventing the execution of JavaScript to happen client-side, with the unavoidable performance degradation.
## And where does this compute or execution run?
On serverless functions, we can run it on Node.js as runtime on a host built specifically for that purpose. Yet this serverless environments that run at the heart of data-centers, have some drawbacks. They experience something known as cold-start: a mix of the time necessary for the runtime to start, load dependencies, execute the function, and the latency imposed by the physical distance between the server and the end-user terminal.
## Lighter runtimes
How can we spin lighter runtimes in the cloud, at the edge of the network? Intuitively we know that edge means we're closer to the user, and we can reduce latency. But how do we run lower level code, which is faster and more lightweight, and hence more performant, on a non-browser environment?
We can do that also server-side, -or on non-browser environments- with WASI enabled Wasm. If WebAssembly is a compilation target that uses a system of imports and exports to enable access to APIs from the Web Platform using the browser as execution engine-, WASI is a POSIX compatible system interface that enables that imports and exports strategy to exist where the browser is not part of the host.
This enables the ultimate level of portability of a sandboxed runtime, from frontend to backend, to a myriad of systems and devices.
Don't read me say it, see me at it!
{% embed https://youtu.be/znMeeexyj_c?t=1298 %}
Here are the slides for the conference talk I based this article on, https://slides.com/anfibiacreativa/wasm-runtimes-portable-secure-lightweight/fullscreen
| anfibiacreativa | |
1,699,168 | A verse about Panama | In Panama, where peace was my quest, In suburbs, I hoped for quiet rest. But alas, a supermarket... | 0 | 2023-12-15T18:08:05 | https://dev.to/fosteman/a-verse-about-panama-47a0 | poetry | In Panama, where peace was my quest,
In suburbs, I hoped for quiet rest.
But alas, a supermarket grand,
Expensive and loud, my peace was canned.
To the beaches of Panama City, I strayed,
A dumpster of trash on the coasts displayed.
No serene waves, just a rubbish sea,
Disappointment washed over me.
On the Caribbean coast, seafood delight,
But closures due to protests, a sorry sight.
Restaurants shuttered, no shrimp or fish,
Protest aftermath was my culinary wish.
| fosteman |
1,699,266 | Word Guessing Game | Word Explorer is an engaging and educational word-guessing game designed to challenge both the... | 0 | 2023-12-15T20:13:18 | https://dev.to/tilaur/word-guessing-game-32ho | Word Explorer is an engaging and educational word-guessing game designed to challenge both the vocabulary and spelling skills of its players. At its core, the game combines the excitement of guessing words from intriguing clues with the challenge of spelling them correctly using a given set of letters.
The game begins with the player receiving a cryptic clue related to a randomly selected word from a diverse list. These words span various categories such as animals, foods, or colors, adding an element of surprise and learning with each new round. The player's first task is to decipher the clue and guess the word. For instance, the clue for "rainbow" might be "A beautiful arc often seen after rainfall." If the player guesses incorrectly, they are gently nudged to try again with subtle feedback, enhancing the learning experience.
Upon successfully guessing the word, the game shifts to a spelling challenge. The player is presented with an assortment of letters and letter combinations. Some of these are parts of the word, while others are designed to mislead, thereby adding to the game's complexity. For example, for "rainbow," the player might be given options like 'r', 'ai', 'n', 'b', 'ow', 'ea', 'g'. The player selects the letters in the correct sequence to spell the word.
"Word Explorer" is thoughtfully designed with multiple difficulty levels to cater to a wide range of players, from beginners to advanced. Easier levels offer more straightforward clues and fewer misleading letter options, while harder levels challenge players with more abstract clues and a larger pool of letters to choose from.
A scoring system adds a competitive edge to the game. Players earn points based on the accuracy and speed of their responses. Hints are available, but using them comes with a minor penalty, either adding to the time taken or reducing the score, thus encouraging players to rely on their skills and knowledge.
Additionally, the game features a timer, introducing a sense of urgency and excitement. Players must think quickly, balancing speed with accuracy to maximize their score. For those seeking an extra challenge, the timer can be shortened in the more difficult levels.
"Word Explorer" also includes a multiplayer option, where players can compete against each other in real-time or vie for a spot on the leaderboard. This feature adds a social dimension to the game, making it a fun way to connect with friends and family while learning.
The game is designed with accessibility and inclusivity in mind. Options for different font sizes, contrast settings, and text-to-speech capabilities ensure that the game is enjoyable for a wide audience, including those with visual impairments.
To enhance the gaming experience, "Word Explorer" incorporates simple graphics and sound effects. Correct guesses might be met with visual celebrations like fireworks, and each successfully spelled word could reveal an interesting fact or trivia related to it, adding an educational twist.
In summary, "Word Explorer" is not just a game; it's a fun and interactive way to learn new words, improve spelling skills, and challenge one's mind. Its blend of educational content, competitive elements, and engaging gameplay makes it an ideal choice for players of all ages and skill levels.
### Stage 1: Basic Game Setup
**Description:**
- The game randomly selects a word from a predefined list.
- The player receives a clue about the word.
- The player guesses the word. If incorrect, they are prompted to try again. If correct, they move to the spelling phase.
- In the spelling phase, the player is given a set of letters and must choose the correct ones to spell the word.
**Pseudocode:**
```python
word_list = [list of words]
clues = {word: clue for each word}
selected_word = select random word from word_list
display clue for selected_word
while not guessed_correctly:
player_guess = input("Guess the word: ")
if player_guess is correct:
guessed_correctly = True
else:
display("Incorrect, try again")
display("Correct! Now spell the word")
letter_choices = generate letter choices for selected_word
display letter choices
while not spelled_correctly:
player_spelling = player selects letters
if player_spelling matches selected_word:
spelled_correctly = True
else:
display("Incorrect, try again")
```
### Stage 2: Enhanced Features and Interactivity
**Description:**
- Implement different difficulty levels that affect the number of letter choices and the complexity of clues.
- Add a scoring system based on attempts and time taken.
- Introduce a timer for added challenge.
- Include hints, which reduce score or add time when used.
**Pseudocode:**
```python
difficulty_level = set by player (easy, medium, hard)
if difficulty_level is easy:
modify clues and letter choices accordingly
else if difficulty_level is medium:
modify clues and letter choices accordingly
else if difficulty_level is hard:
modify clues and letter choices accordingly
score = 0
timer = set based on difficulty
while game in progress:
if player requests hint:
show hint and adjust score or timer
update game state (check guesses, update timer, etc.)
if timer runs out:
end game and show score
else if word guessed and spelled correctly:
update score based on performance
move to next word or end game
```
### Stage 3: Advanced Features and Polish
**Description:**
- Add categories for words and let players choose or assign randomly.
- Implement a multiplayer mode with a leaderboard.
- Offer feedback for incorrect attempts and include interesting facts after successful spelling.
- Incorporate graphics, sound effects, and accessibility features.
**Pseudocode:**
```python
categories = [list of categories]
selected_category = chosen by player or assigned randomly
word_list = filter words based on selected_category
if multiplayer_mode:
setup multiplayer session and leaderboard
while game in progress:
if player guess is close:
provide feedback ("Close, but think more about...")
if word spelled correctly:
display interesting fact about the word
update graphics and sounds based on game events
if accessibility options enabled:
adjust display and interaction settings
end of game:
if multiplayer:
update leaderboard
display final score and any achievements
```
| tilaur | |
1,699,430 | How to create azure storage account and upload image into it | Introduction That container that group all azure storage services together is termed azure storage... | 0 | 2023-12-15T23:54:55 | https://dev.to/lanreogunlade1998/how-to-create-azure-storage-account-and-upload-image-into-it-2gdl | **Introduction**
That container that group all azure storage services together is termed azure storage account. It is one of the foundational services provided by Microsoft Azure, that offers a highly scalable and secure platform to store a wide variety of data types in the cloud. It serves as a centralized repository for many data storage needs and is composed of many storage services such as:
Blob Storage: Ideal for storing massive amounts of unstructured data like text, images, videos, and other binary data. Blob Storage supports three access tiers (Hot(data that is used regularly), Cool(used within 30days period), and Archive(used 180days) to cater to different data access patterns and cost requirements.
File Storage: Provides fully managed file shares in the cloud, enabling traditional file storage scenarios. Azure Files allows the use of Server Message Block (SMB) protocol for accessing shared files across multiple machines.
Queue Storage: Offers a message queueing system that allows communication between different components of an application or system. Azure Queue Storage facilitates asynchronous communication and decouples components for better scalability and reliability.
Table Storage: A NoSQL key-value store suitable for semi-structured data. It allows for fast querying of large datasets and is an excellent choice for applications that require flexible schema and massive scalability.
Disk Storage: Azure Disk Storage provides block storage to support the persistent storage needs of Azure Virtual Machines (VMs). It includes both managed and unmanaged disks and offers various disk types optimized for different workloads
The storage account can be accessible anywhere in the world over HTTP or HTTPS.
**Guide to create Storage Account through Azure portal**
There are various ways to create Azure storage account i.e. Azure portal, Azure CLI (Command-line interface), Azure PowerShell and
Management client libraries. However, we are focusing on the first.
**Step 1**
Sign in to Azure Portal: Access the Azure Portal using your credentials at https://portal.azure.com/. If you don't have one, create a free account.
**Step 2**
On Window web browser, search for storage account:
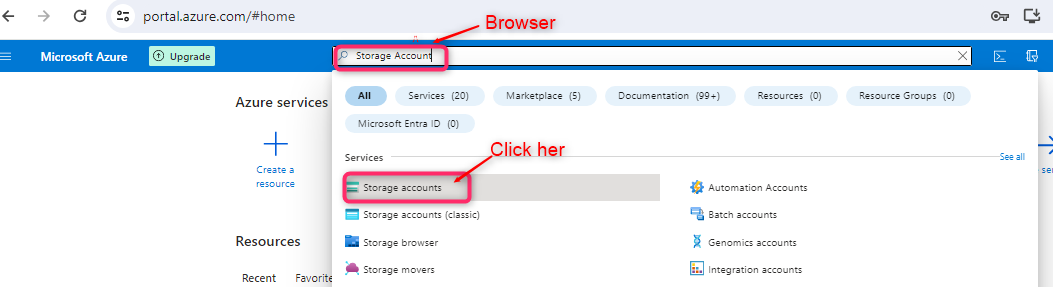
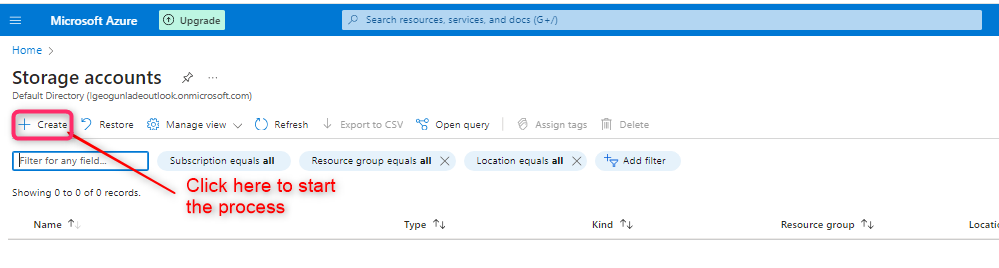
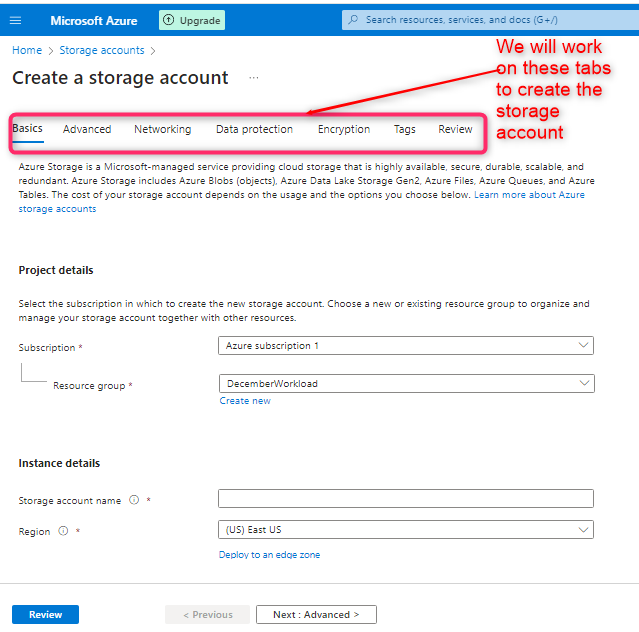
**Step 3**
On the Basics Tab, the first item is the **Project Details** and Instance details. The project details contains the Subscriptions and the Resource group.
The _Subscription_ allows you to determine which subscription will be billed for the resources consumed by the storage account.
While _Resource Group_ allows you to organize and manage the storage account along with other related resources under a common grouping for administrative, billing, and lifecycle management purposes.
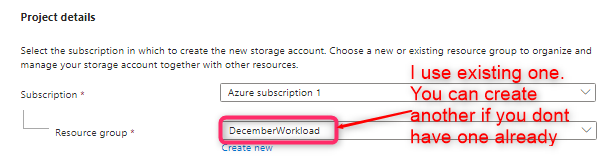
The Instance details contains information such as Storage account name, Region, Performance and Redundancy.
Storage Account Name: This is a unique name that identifies your Azure Storage Account. It must be a globally unique name across Azure.
Region: Also known as the Azure Region or Location, this is the geographical region where your storage account's data will be stored. optimal performance or based on compliance requirements.
Performance: Azure Storage Accounts offer different performance tiers based on your workload requirements. These tiers may include Standard and Premium options, each providing different performance characteristics and pricing. e.g.
Standard: This tier offers reliable, high-performance storage designed to provide cost-effective solutions for various storage scenarios. It includes options for Blob storage, File storage, Queue storage, and Table storage. It is used when there is need to save money.
Premium: This tier offers high-performance, low-latency storage(low data traveling period) suitable for I/O-intensive workloads. It's often used for scenarios requiring high transaction rates and low latency, such as virtual machine disks.
Redundancy: Redundancy options determine how your data is replicated within Azure Storage to ensure high availability and data durability. Azure provides several redundancy options:
Locally Redundant Storage (LRS): Copies data synchronously within a single storage scale unit in a data center. It provides redundancy against hardware failures.
Zone-Redundant Storage (ZRS): Replicates data across multiple availability zones within a region, offering higher durability against data center outages.
Geo-Redundant Storage (GRS): Replicates data to a secondary region at least hundreds of miles away from the primary location, providing data residency and high durability against regional outages. This is the most reliable and expensive.
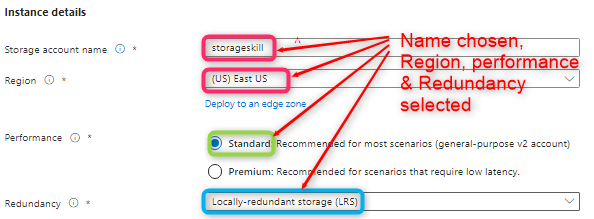
**Step 4**
On the Advanced Tab:
Note: If the storage account you want to create is for your enterprise/private account, do not click or activate the _Allow enabling anonymous access on individual containers_
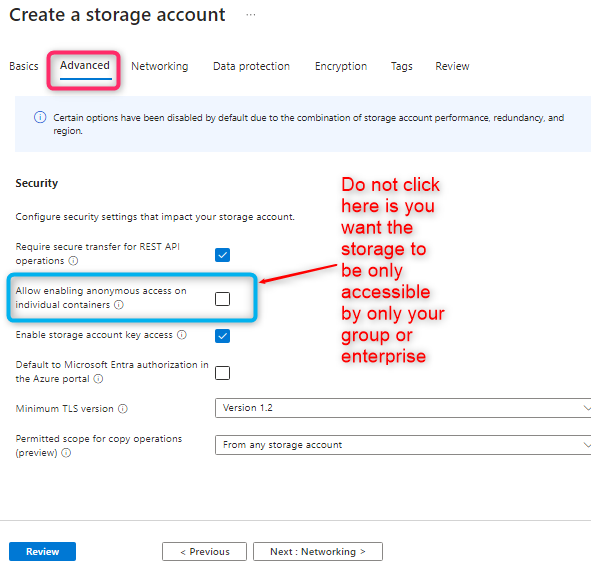
Leave every other tabs and click on review and create. Note: The deployment must be allowed to complete.
The storage account is now created:
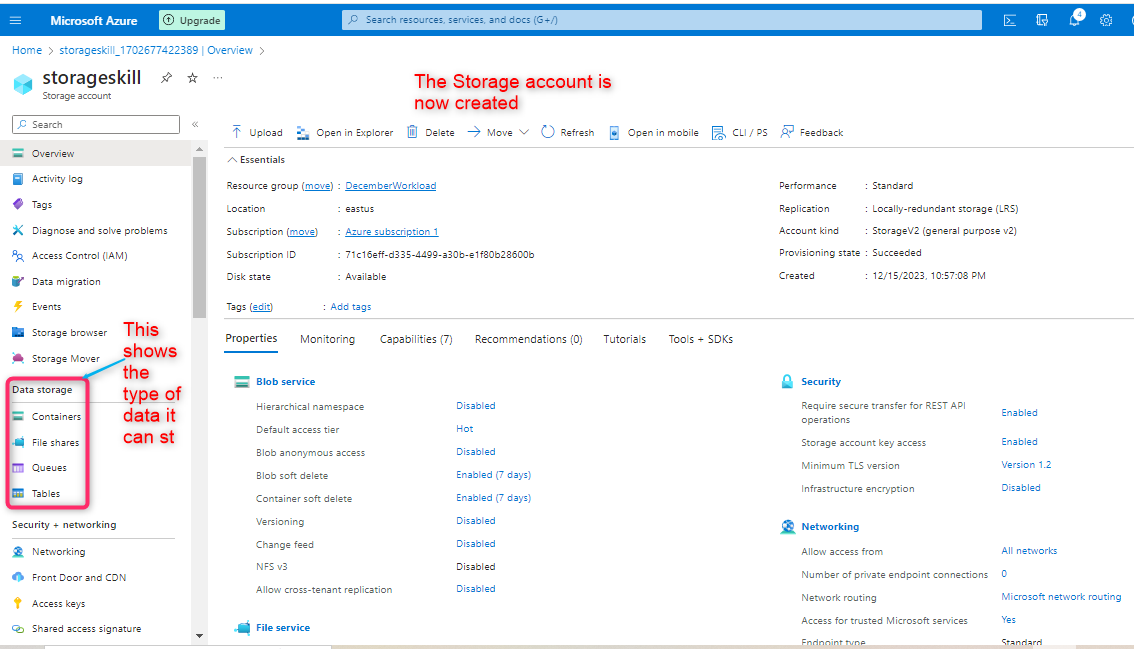
Now, let us take a critical look at the **Data Storage** types here:
Containers: This is used to store all Blob. For us to store any data here, we need to create the container where it will be uploaded. The container acts like a bow inside which our data will stay.
So, click on this to create one:
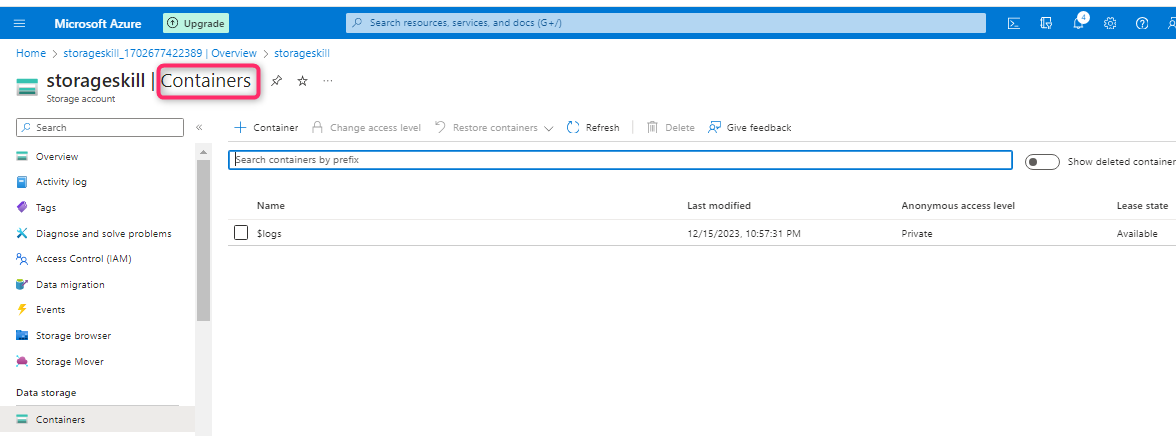
Then click on **+ Containers**:
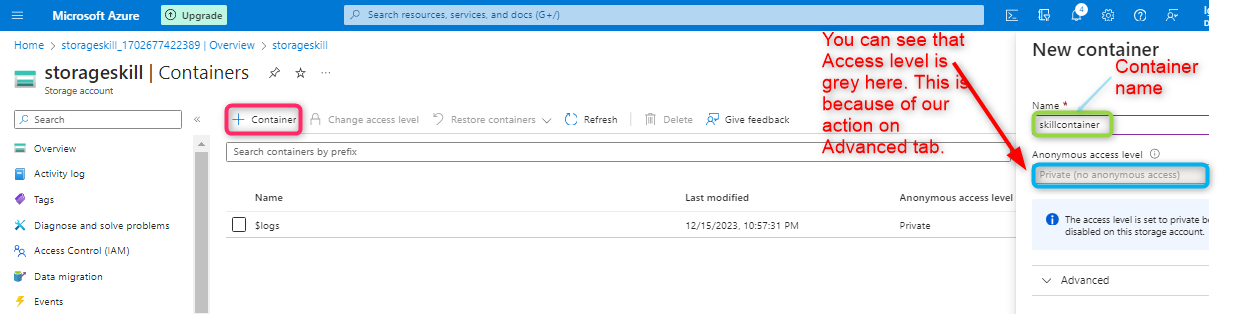
You can see that the drop down is not activated because our storage account is local not for public. If we upload any data into this container, we will be unable to share it with the public.
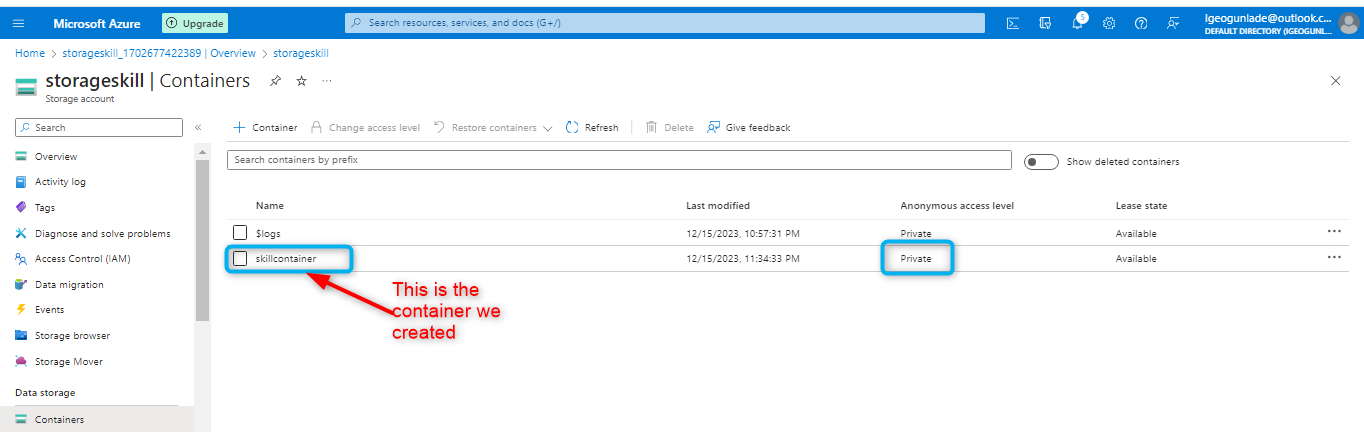
**Step 5**
How do we upload into the container?
1. Click on the name of container created and 2. Click upload:
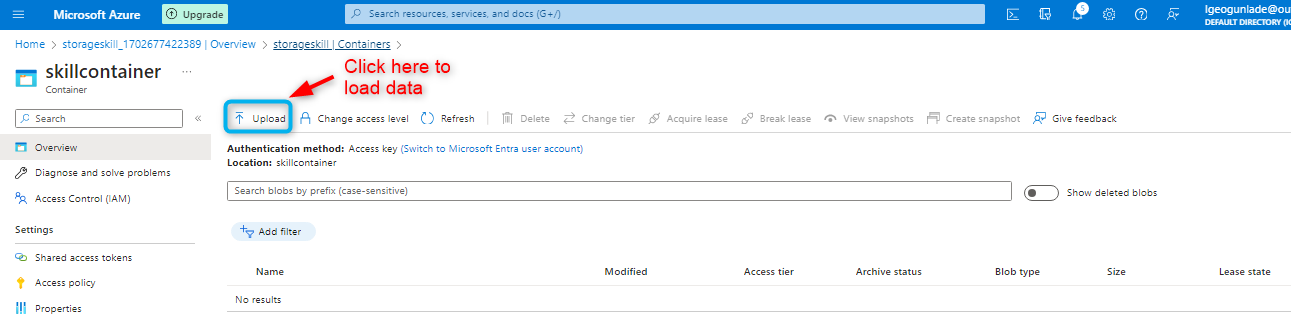
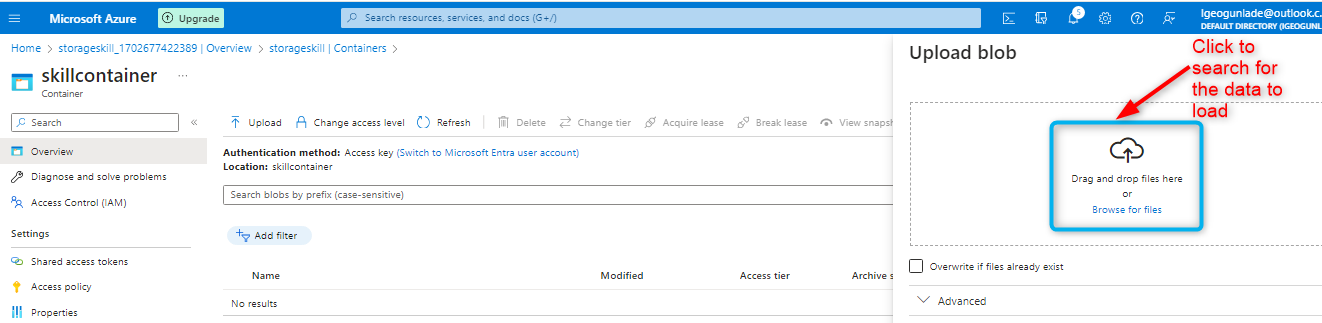
The data name storage logo has been loaded into the container.
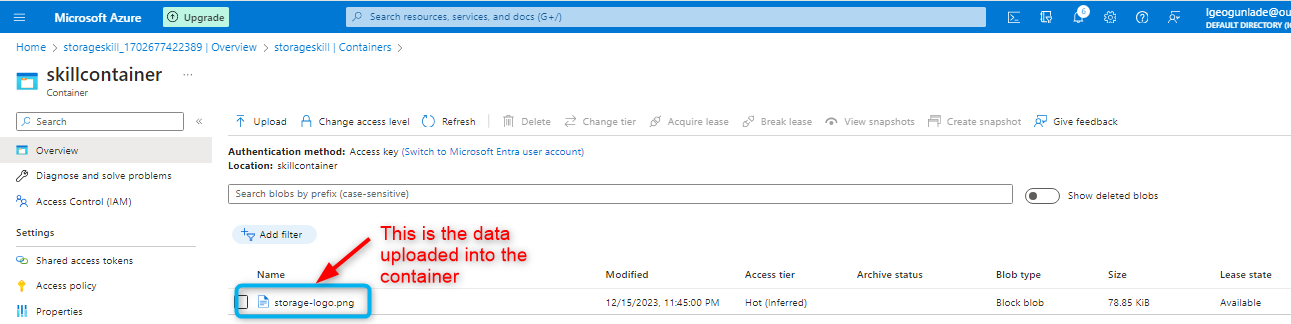
Now, we need to test if this can be shared with the public:
Click on the data(storage logo)
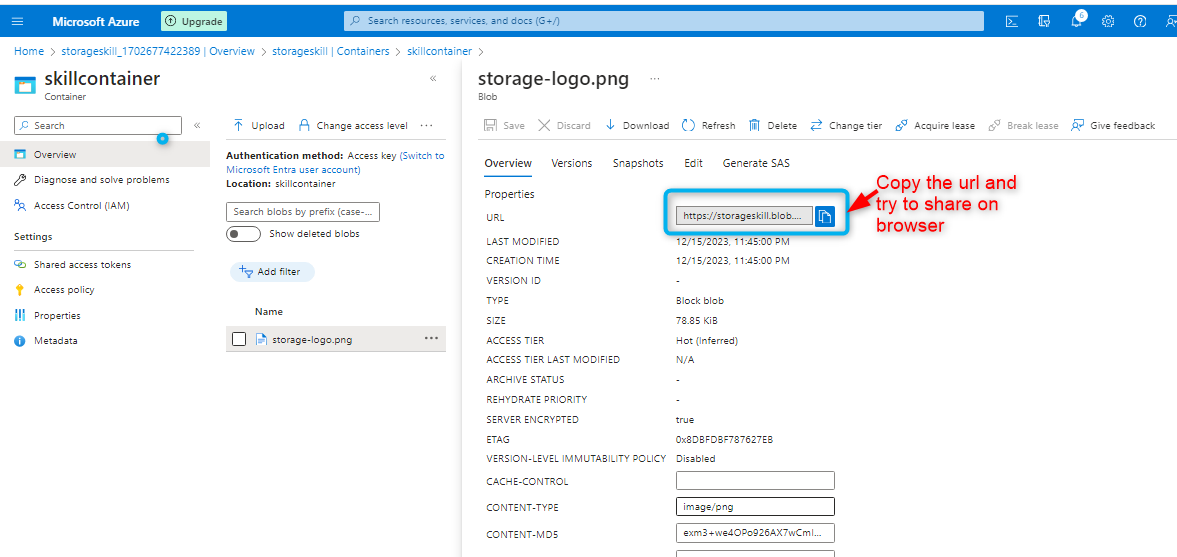
Below is the error message:

**Step 6**
We will create another account and make it public and see the effect
On Basics Tab:
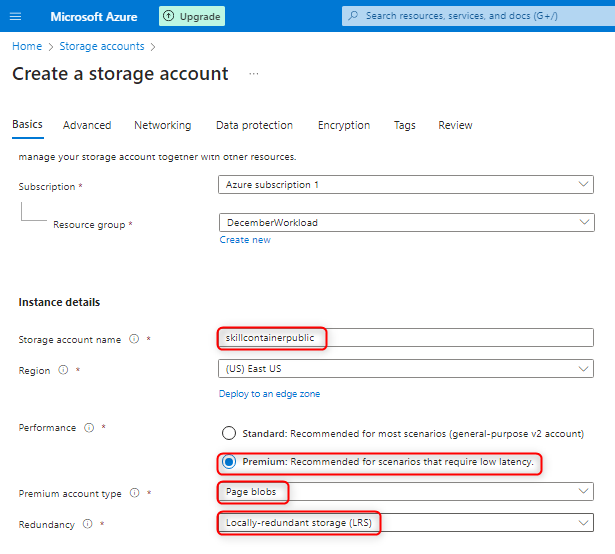
On Advanced Tab:
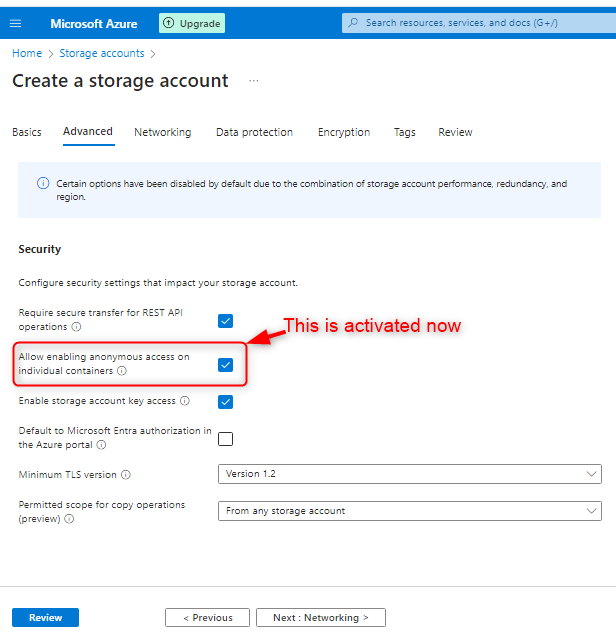
Next, leave other tabs and go to review and create:
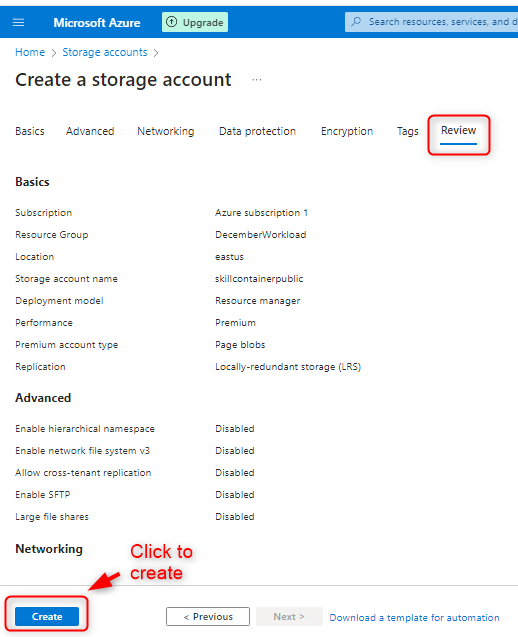
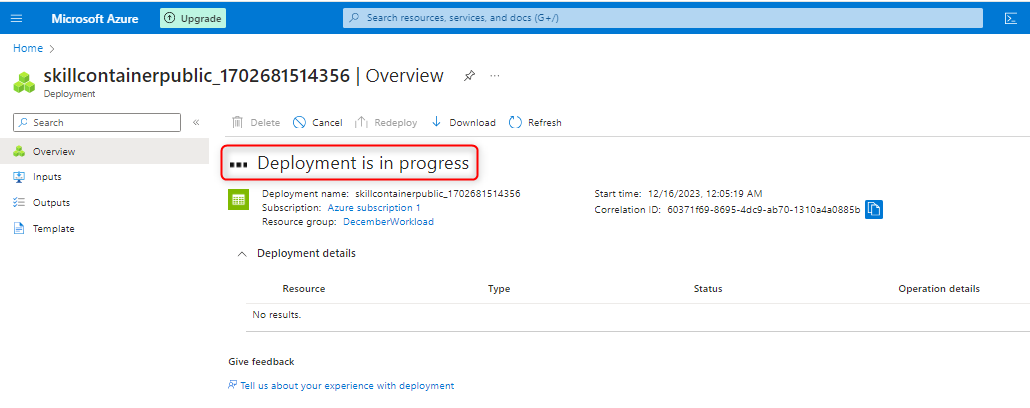
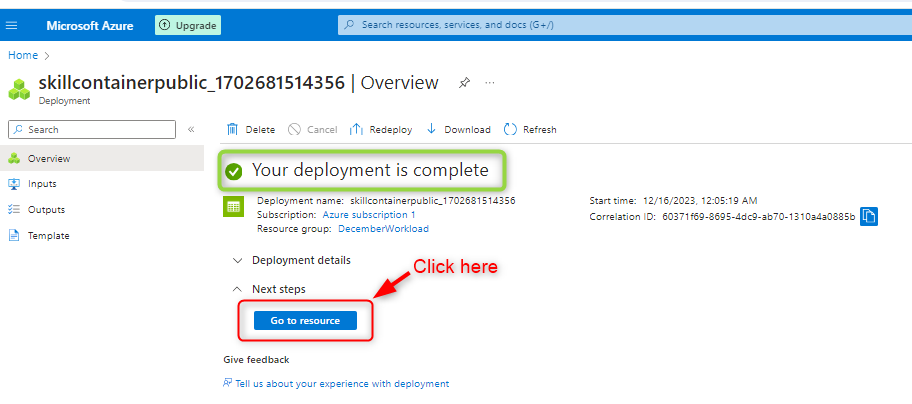
Now we can modify to select image e.g Blob and this can be shared to the public:
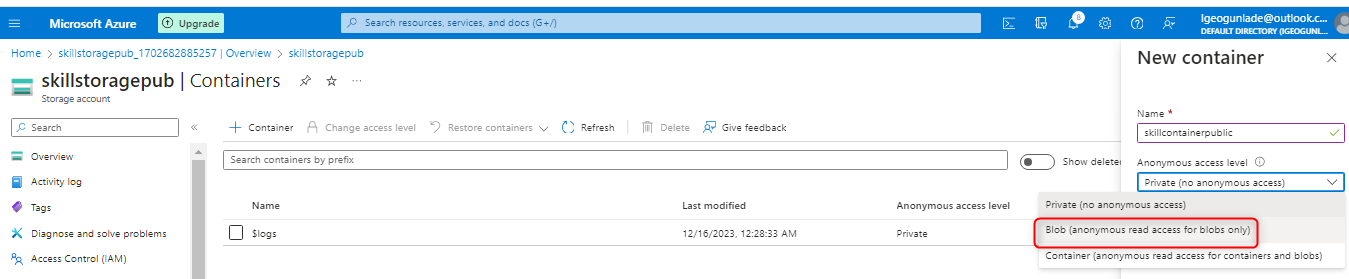
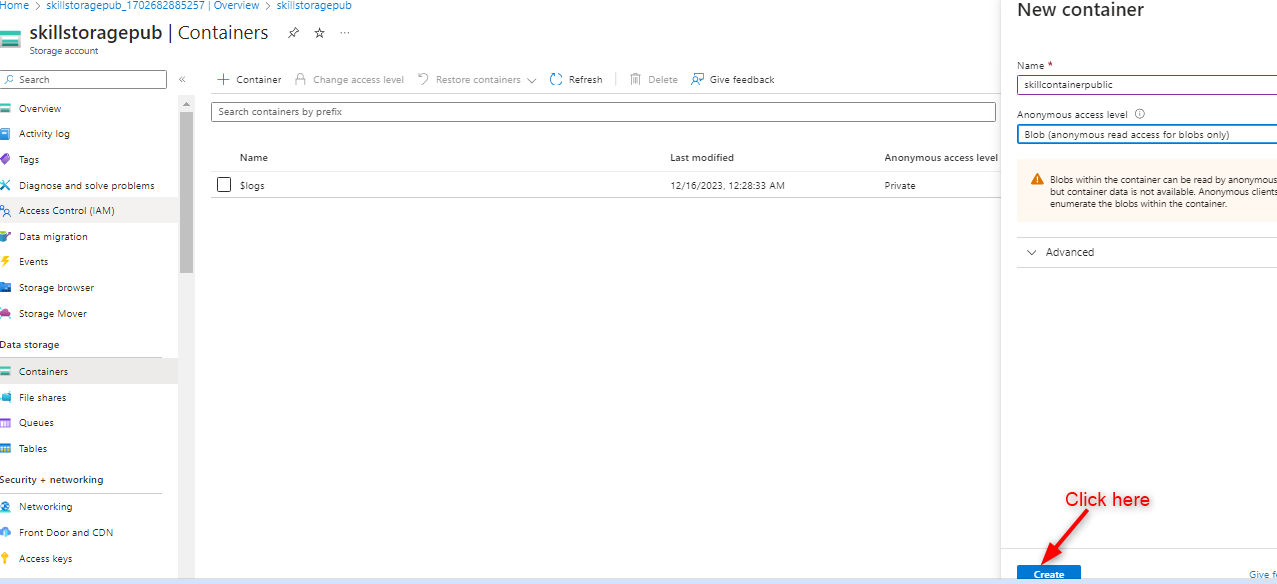
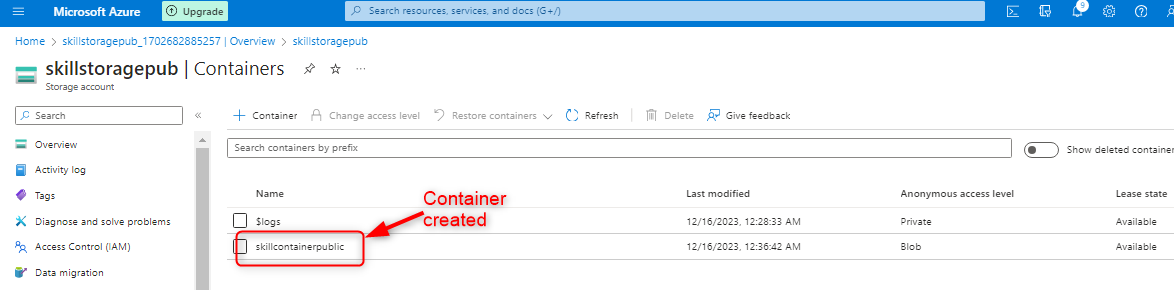
Next, click on the container and upload same picture to see the outcome:
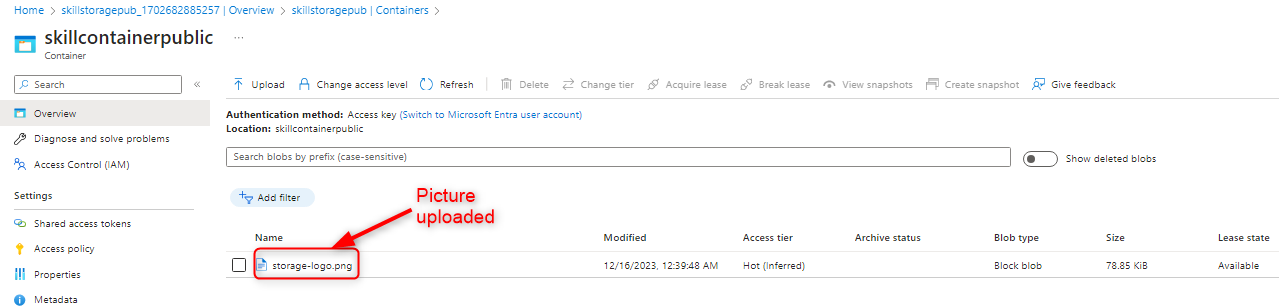


**Conclusion**
From the foregoing, we can see that it is easy to create Azure storage for our data. It is more easier to create container to keep the data. We can equally make the data available to the public and enterprise depending on our needs.
Your comment(s) is needed for improvement.
| lanreogunlade1998 | |
1,699,573 | Unleashing the Power of Your Online Store: The Magic Behind Custom WooCommerce Plugin Development | Introduction: In the fast-paced world of e-commerce, standing out from the crowd is essential for... | 0 | 2023-12-16T04:48:15 | https://dev.to/stevejacob45678/unleashing-the-power-of-your-online-store-the-magic-behind-custom-woocommerce-plugin-development-1a2p |
**Introduction:**
In the fast-paced world of e-commerce, standing out from the crowd is essential for success. While WooCommerce provides a solid foundation for online stores, customizing your site to meet unique needs and deliver an exceptional user experience is the key to thriving in a competitive market. In this blog post, we'll dive into the exciting realm of custom WooCommerce plugin development and explore how it can elevate your online store to new heights.

**Tailoring Your Store to Perfection**: The Need for Custom Plugins
WooCommerce, as a WordPress plugin, offers a robust set of features out of the box. However, every business has its own set of requirements and objectives. **[Custom WooCommerce plugins](https://wpeople.net/service/woocommerce-plugin-development/)** empower you to tailor your online store to perfection, ensuring it aligns seamlessly with your brand identity and meets the specific needs of your customers.
**Enhanced Functionality: Beyond the Basics**
While WooCommerce covers the basics of e-commerce, custom plugins open the door to a world of enhanced functionality. Whether you need a unique checkout process, advanced product customization options, or personalized user account features, custom plugins enable you to go beyond the limitations of standard e-commerce platforms.
Optimizing Performance for a Seamless Shopping Experience
Site speed and performance are critical factors in the success of an online store. Custom WooCommerce plugins allow developers to optimize your site's performance by fine-tuning code, reducing unnecessary bloat, and streamlining processes. The result? A seamless shopping experience that keeps customers coming back for more.
**Responsive Design**: Reaching Customers Anywhere, Anytime
In today's mobile-centric world, responsive design is not just a bonus – it's a necessity. Custom WooCommerce plugins empower you to create a mobile-friendly shopping experience that adapts to various devices, ensuring your customers can browse and make purchases with ease, whether they're on a desktop, tablet, or smartphone.
**Security Matters**: Protecting Your Business and Your Customers
Security breaches can be disastrous for an online business. Custom WooCommerce plugins provide an extra layer of security by allowing you to implement tailor-made **[WooCommerce security](https://wpeople.net/service/woocommerce-security/)** features and protocols. From secure payment gateways to robust user authentication, these plugins help safeguard your business and instill confidence in your customers.
Seamless Integration with Third-Party Services
Your business likely relies on various third-party services for tasks such as payment processing, shipping, and analytics. Custom plugins make it possible to seamlessly integrate these services into your WooCommerce store, creating a unified and efficient ecosystem that enhances your overall operational efficiency.
**Conclusion:**
In the dynamic world of e-commerce, staying ahead requires more than just a beautiful website – it demands innovation and customization. Custom WooCommerce plugin development is the secret sauce that can transform your online store from ordinary to extraordinary. By tailoring your site to meet your unique needs, you not only enhance the user experience but also gain a competitive edge in the crowded e-commerce landscape. So, why settle for the ordinary when you can have the extraordinary? Dive into the world of custom WooCommerce plugins and unlock the full potential of your online store today!
| stevejacob45678 | |
1,699,613 | The Role of Test Data Management in Quality Assurance | Quality Assurance (QA) is an integral part of the software development lifecycle, ensuring that... | 0 | 2023-12-16T07:02:21 | https://www.theglobalkaka.com/tech/the-role-of-test-data-management-in-quality-assurance/ | test, data, management | 
Quality Assurance (QA) is an integral part of the software development lifecycle, ensuring that applications meet high standards of performance, functionality, and security. One often overlooked but crucial aspect of QA is test data management (TDM). Test data management involves creating, maintaining, and provisioning data for testing purposes, and it plays a pivotal role in enhancing the effectiveness and accuracy of quality assurance processes with the assistance of test data management tools. During this article, we’ll delve into the many roles of test data management in quality assurance and its impact on software development.
**Ensuring Realistic Testing Environments**
One of the primary functions of test data management is to replicate real-world scenarios in testing environments. Realistic test data allows QA teams to simulate actual usage scenarios and identify potential issues before software is released to users. By incorporating actual customer data, various usage patterns, and complex scenarios, QA teams can uncover hidden defects and improve the overall quality of the software.
**Facilitating Comprehensive Test Coverage**
Effective test data management supports comprehensive test coverage by providing diverse datasets that cover various testing scenarios. Different combinations of data can help uncover specific corner cases and edge conditions that might lead to software failures. Comprehensive testing ensures that applications are robust and capable of handling a wide range of user interactions.
**Mitigating Risks and Defects**
Quality assurance aims to identify and address potential problems before they reach production environments. Proper test data management helps in identifying defects and vulnerabilities early in the development cycle. By testing applications with relevant and representative data, QA teams can identify and fix issues before they escalate into more critical problems that impact end-users.
**Data Privacy and Security Compliance**
In an era where data privacy regulations are stringent, ensuring that sensitive information is handled appropriately during testing is paramount. Test data management strategies involve data masking, encryption, and anonymization techniques that protect sensitive data while maintaining its integrity. This ensures that data privacy regulations, such as GDPR or HIPAA, are adhered to during the testing process.
**Optimizing Testing Efficiency**
Effective test data management optimizes testing efficiency by providing the right data in a timely manner. Automated data provisioning reduces the time spent on data collection and preparation, allowing QA teams to focus on actual testing activities. This optimization results in quicker testing cycles, faster bug identification, and shorter time-to-market for software releases.
**Data Reusability**
Investing time and resources in creating quality test data pays off in the long run. Well-managed test data can be reused across different testing phases and projects, saving time and effort. This reusability ensures consistent testing environments and reduces the need to recreate data from scratch for each new testing cycle.
**Collaboration and Transparency**
Effective communication and collaboration between development and testing teams are essential for successful QA. Test data management provides a standardized dataset that both teams can work with, reducing misunderstandings and inconsistencies. Transparent data sharing ensures that everyone is on the same page regarding testing requirements and outcomes.
**Conclusion**
Test data management is an indispensable pillar of quality assurance in software development. Businesses have the chance to streamline the process of managing test data with the help of test automation platform, Opkey, increasing test coverage and lowering expenses. Also, it raises the general caliber of their applications.
QA teams can quickly and accurately collect test data by using Opkey’s technology to mine tests and retrieve data. Businesses may save time and effort by using Opkey’s TDM solution to ensure that their test data is always ready for testing scenarios including Oracle testing, EBS testing, Cloud migration testing, and more. | rohitbhandari102 |
1,699,747 | Why Flutter is Used? 2024 Guide | In the dynamic world of app development, choosing the right framework is crucial for creating... | 0 | 2023-12-16T11:28:49 | https://dev.to/knayan/why-flutter-is-used-2024-guide-3lg0 | In the dynamic world of app development, choosing the right framework is crucial for creating versatile and efficient applications. Flutter, developed by Google, has emerged as a powerhouse for cross-platform development, offering a range of benefits that make it a popular choice among developers. In this blog post, we'll explore **why Flutter is used** and what makes it stand out in the competitive landscape.
## 1. Single Codebase for Multiple Platforms
One of the primary advantages of **using Flutter** is the ability to write a single codebase that can be deployed on multiple platforms seamlessly. Whether you're targeting iOS, Android, web, or desktop applications, Flutter enables developers to maintain a unified codebase, reducing development time and effort.
With a single codebase, developers can make updates, fix bugs, and implement new features across all platforms simultaneously. This not only streamlines the development process but also ensures consistency in user experience across different devices and operating systems. If you want to learn this language, you can enroll in a [Flutter App Development online course](https://www.wscubetech.com/flutter-online-course-india.html) offered by a reputable institute.
## 2. Hot Reload for Rapid Development
Flutter introduces the concept of Hot Reload, a feature that significantly accelerates the development cycle. With Hot Reload, developers can instantly see the impact of code changes on the application without restarting it. This real-time feedback loop enhances productivity and allows for quick experimentation, making it easier to refine and perfect the user interface and functionality.
The ability to make changes on the fly without disrupting the application state is a game-changer for developers, fostering an agile and iterative development process.
Also read: [What is Local SEO and Its Benefits (2024 Guide)](https://dev.to/knayan/what-is-local-seo-and-its-benefits-2024-guide-42im)
## 3. Beautiful and Customizable UIs with Widgets
Flutter's widget-based architecture is at the heart of its success. Widgets are the building blocks of Flutter applications, representing everything from structural elements like buttons and text to complex layouts. The rich catalog of pre-designed widgets, coupled with the flexibility to create custom widgets, empowers developers to craft visually stunning and highly customizable user interfaces.
Whether adhering to Material Design for Android or Cupertino for iOS, Flutter allows for a pixel-perfect representation of UI elements, ensuring a native look and feel on each platform.
## 4. High Performance with Ahead-of-Time Compilation
Flutter doesn't rely on an interpreter at runtime. Instead, it employs ahead-of-time (AOT) compilation, transforming Dart code into native machine code during the build process. This results in high-performance, natively compiled applications that can rival those developed using platform-specific languages.
The AOT compilation brings benefits like reduced startup times and improved overall execution speed, contributing to a smoother and more responsive user experience.
## 5. Strong Community Support and Growing Ecosystem
A vibrant and supportive community is a hallmark of successful frameworks, and Flutter is no exception. The Flutter community actively contributes to the ecosystem by developing plugins, packages, and resources that extend the framework's capabilities.
The Flutter package ecosystem is growing rapidly, providing developers with a wealth of pre-built solutions for common functionalities. Whether it's integrating maps, handling animations, or connecting to backend services, chances are there's a Flutter package that can save development time and effort.
Also read: [How to Become a Digital Marketer? 2024 Guide for Beginners](https://dev.to/knayan/how-to-become-a-digital-marketer-2024-guide-for-beginners-1l3a)
## 6. Backed by Google and Used by Industry Giants
The backing of a tech giant like Google adds credibility to Flutter. With Google's commitment to continuously improving and expanding Flutter's capabilities, developers can trust that the framework will remain well-supported and aligned with industry standards.
Notably, several industry giants have embraced Flutter for their applications. Companies like Alibaba, Google Ads, Reflectly, and many others have leveraged Flutter to create feature-rich, cross-platform apps that cater to a broad user base.
## 7. Seamless Integration with Native Features
Flutter doesn't operate in isolation; it seamlessly integrates with native features and functionalities. Developers can access native APIs directly from Flutter, allowing them to incorporate device-specific features without compromising the cross-platform nature of their applications.
This level of integration ensures that Flutter applications can harness the full potential of the underlying operating system, providing a comprehensive and native user experience.
## Conclusion:
In conclusion, the popularity of Flutter in the development community is no coincidence. Its ability to streamline cross-platform development, coupled with features like Hot Reload, a rich widget library, and high-performance compilation, makes it a top choice for developers seeking efficiency and versatility.
Whether you're a solo developer or part of a large enterprise, Flutter's advantages extend to all stages of the development lifecycle. As it continues to evolve and gain traction, Flutter is poised to play a pivotal role in shaping the future of cross-platform app development.
If you haven't explored Flutter yet, now is the time to dive in and unlock the potential of this powerful framework. The benefits it offers may very well transform the way you approach and execute your next app development project.
| knayan | |
1,699,852 | Muhammad Awais | 👋 Hi there! I'm Muhammad Awais, a passionate Principal Software Engineer / Full Stack Software... | 0 | 2023-12-16T19:26:22 | https://dev.to/muhammadawaisshaikh/muhammad-awais-21h1 | 👋 Hi there! I'm Muhammad Awais, a passionate Principal Software Engineer / Full Stack Software Engineer with 8+ years of experience who finds joy in crafting exceptional web experiences using JavaScript, Typescript, Angular, React, Vue, NodeJS, ROR 🚀. and leading the team of 4+ developers across the globe. My days are filled with lines of code, bringing creativity to life through top-notch technology stack.
🎤 When I'm not immersed in coding, you can often find me on the tech speaking stage, sharing insights and trends in software development. I thrive on inspiring and connecting with fellow developers, fostering a community that shares a love for opensource and innovation.
🌐 With 8+ years of experience in the industry, I've honed my skills in building scalable, efficient and performant softwares and enterprise applications for multiple domains including various domains like Ecommerce, Fintech, Audio Streaming, News Media, Logistics, Automotive, EdTech and others 🚀. From Angular to React and Vue, I'm always eager to explore cutting-edge frameworks and stay ahead of the technology curve.
📈 As an advocate for best practices and accessibility, I believe in creating inclusive digital experiences that leave a lasting impact. I'm also a community representative and contributor of (Google Developers, Angular, JetBrains, AWS, Auth0, Postman, DigitalOcean) 🇵🇰🇺🇸🇿🇦🏴🇬🇧
🌟 Let's connect and collaborate on exciting software projects (frontend + backend) or catch me at the next tech event, sharing my knowledge and passion for all things software and web development. Together, we can shape the future of digital experiences! Feel free to reach out for opportunities or a friendly tech chat. 🤝
Introduction: https://youtu.be/89t-cRNvfMU
Portfolio: https://bit.ly/muhammadawaisshaikh
Resume: https://bit.ly/muhammad-awais-resume | muhammadawaisshaikh | |
1,699,889 | Loops in C programming | In C programming there are 3 types of loop and they are while loop, for loop and do while loop. ... | 25,813 | 2023-12-16T17:05:15 | https://dev.to/sujithvsuresh/loops-in-c-programming-4lnn | programming, loops, beginners, learning | In C programming there are 3 types of loop and they are while loop, for loop and do while loop.
## While loop
In while loop the body is executed until the test condition become false.
Syntax:
```
while (conditiuon){
//statement inside while.
}
```
Example:
```
#include <stdio.h>
int main() {
int count = 1;
while (count < 5){
printf("While loop in c\n");
count = count + 1;
}
return 0;
}
```
Multiplication table using while loop:
```
#include <stdio.h>
int main() {
int number;
printf("Enter the number: ");
scanf("%d", &number);
int count = 1;
while(count <= 10){
int product = number * count;
printf("%d x %d = %d \n", count, number, product);
count = count + 1;
}
return 0;
}
```
---
## do while loop
Here the body of the loop is executed and then the condition is evaluated, if the condition is true the body of the loop is executed again.
syntax:
```
do {
//body of loop
} while(condition);
```
Example:
```
int main(){
int count = 5;
do{
printf("%d\n", count);
count = count + 1;
} while(count < 5);
return 0;
}
```
---
## for loop
Syntax:
```
for(initializationExpression; testExpression; updateExpression){
//codee inside for loop.
}
```
Example:
```
int main() {
for(int i=0; i<10; i++){
printf("%d ", i);
}
return 0;
}
```
Sum of whole numbers from 1 to 100:
```
int main() {
int sum=0;
for(int i=1; i<=100; i++){
sum=sum+i;
}
printf("%d", sum);
return 0;
}
```
Sum of even numbers:
```
int main() {
int sum=0;
for(int i=2; i<=100; i=i+2){
sum=sum+i;
}
printf("%d", sum);
return 0;
}
```
| sujithvsuresh |
1,700,175 | A Guide to Free Resources for Learning Web Development | Ever dreamed of creating your own corner of the web? Good news – you're just a few clicks away! This... | 0 | 2023-12-17T06:11:34 | https://dev.to/oggy107/a-guide-to-free-resources-for-learning-web-development-dee | webdev, beginners, resources, learning | Ever dreamed of creating your own corner of the web? Good news – you're just a few clicks away! This blog is your go-to guide for learning web development without spending a dime. We're talking about free resources that turn coding from a mystery into your new superpower. Whether you're just starting or leveling up, join us on this adventure through the world of web development. No fancy degrees needed, just your curiosity and an internet connection. Let's dive in!
## 1. FreeCodeCamp (youtube)

When it comes to learning web development for free, FreeCodeCamp's YouTube channel stands out as a treasure trove of tutorials, projects, and insights. Geared towards beginners and seasoned developers alike, this channel brings coding concepts to life through engaging video content.
## Why FreeCodeCamp's YouTube Channel?
**Diverse Learning Paths:** From HTML and CSS basics to advanced JavaScript frameworks, FreeCodeCamp covers a spectrum of topics to cater to every skill level.
**Project-Based Learning:** Dive into real-world projects that solidify your skills and showcase your coding prowess. The channel's project-focused approach ensures you're not just learning theory but applying it.
**Interview Preparation:** Navigate the often daunting world of coding interviews with dedicated content that demystifies technical assessments and helps you ace them.
**Stay Current:** Web development is a dynamic field, and FreeCodeCamp keeps its content up-to-date with the latest technologies and trends, ensuring you learn relevant skills.
### Recommended videos
https://youtu.be/Oe421EPjeBE?si=JPqgwJvcoNN_p7I9
https://youtu.be/zJSY8tbf_ys?si=1KjT4R1pkNKFMLL4
https://youtu.be/nu_pCVPKzTk?si=JnZ_Ai_iBgKtXldw
## 2. CssBattle (website)

For those looking to turn CSS from a styling language into a competitive art form, CSS Battle is the interactive playground you've been waiting for. Forget traditional tutorials; CSS Battle challenges you to showcase your styling prowess by replicating intricate designs using just CSS code.
### How to Get Started
**Visit the Website:** Head over to [CSS Battle](https://cssbattle.dev/) and explore the array of challenges waiting for your creative touch.
**Select a Battle:** Choose a battle that aligns with your skill level and interests. Battles vary in complexity, allowing you to progress at your own pace.
**Start Styling:** Dive into the challenge and start crafting your CSS masterpiece. The live preview feature lets you see the impact of your code in real-time.
**Submit and Learn:** Once satisfied with your solution, submit your code. Explore others' solutions to gain insights into alternative approaches and techniques.
## 3. MDN Web Docs (website)

When it comes to authoritative, up-to-date documentation for web development, MDN Web Docs (Mozilla Developer Network) stands as a beacon of comprehensive and reliable information. Maintained by Mozilla, this platform is not just a documentation repository but a dynamic and evolving resource that caters to developers across all skill levels.
### Why MDN Web Docs?
**Extensive Documentation:** MDN Web Docs covers a wide array of web technologies, including HTML, CSS, JavaScript, and web APIs. Each topic is meticulously documented with clear explanations, code examples, and practical use cases.
**Browser Compatibility Information:** One of the standout features is the inclusion of detailed browser compatibility tables. This ensures that developers are well-informed about how different browsers handle specific features, facilitating cross-browser compatibility.
**Tutorials and Guides:** MDN doesn't just provide dry documentation. It offers tutorials and guides that take you through fundamental concepts and advanced techniques. These resources are designed for both beginners taking their first steps and seasoned developers seeking deeper insights.
**Regular Updates:** The web is a dynamic environment, and MDN reflects this by keeping its content updated. As new features are introduced and standards evolve, MDN provides timely information to keep developers abreast of the latest practices.
### How to Use MDN Web Docs
**Navigate the Documentation:** Visit the [MDN Web Docs](https://developer.mozilla.org/) homepage and explore the available documentation by technology or feature.
**Search Functionality:** Use the powerful search functionality to quickly find information about specific elements, attributes, methods, or concepts.
**Interactive Examples:** Many pages feature interactive examples that allow you to modify code directly in the browser and see the live results, providing an immersive learning experience.
**Contribution Opportunities:** MDN is an open platform, and developers are encouraged to contribute. If you spot an error or have additional insights, you can actively participate in improving the documentation.
## 4. CodePen (website)

[CodePen](https://codepen.io/) isn't just a platform; it's a vibrant community and a dynamic development environment rolled into one. As an online playground for front-end developers, it opens a portal to a world where creativity meets code. Here's why CodePen is an invaluable resource for developers looking to experiment, learn, and share their coding endeavors.
### Why CodePen?
**Instant Prototyping:** CodePen provides an instant, browser-based coding environment where you can create "pens" (code snippets) in HTML, CSS, and JavaScript. This enables rapid prototyping and experimentation without the need for a complex development setup.
**Live Previews:** One of the standout features is the ability to see live previews of your code changes immediately. This instant feedback loop is invaluable for refining designs and troubleshooting issues efficiently.
**Sharing and Collaboration:** CodePen is a social platform where developers from around the world share their pens. You can explore a vast collection of pens created by others, fork them to make your modifications, and even collaborate with other developers in real-time.
**Project Showcasing:** Beyond individual pens, CodePen allows developers to showcase entire projects. This makes it an excellent tool for building portfolios, sharing web experiments, and getting feedback from the community.
## Conclusion
In the vast universe of web development, where innovation and creativity intertwine, the resources explored in this blog serve as your guiding stars.
Remember, this journey is yours to mold. Whether you're a beginner taking the first steps or a seasoned developer seeking new heights, the beauty of web development lies in its inclusivity and limitless potential. Embrace the challenges, celebrate the victories, and keep pushing the boundaries of what you can create.
So, with your coding tools in hand and the spirit of curiosity as your compass, venture forth. The web awaits your creations, and the skills you hone today are the building blocks of the digital wonders you'll craft tomorrow. Happy coding! 🚀🌐 | oggy107 |
1,700,209 | Rock-Paper-Scissors Terminal Game | I made this program as part of a codeacademy portfolio project. In the program you battle... | 0 | 2023-12-17T08:19:03 | https://dev.to/shawaiznaeem/rock-paper-scissors-terminal-game-401m | I made this program as part of a codeacademy portfolio project.
In the program you battle rock-paper-scissors against the 'notorious computer'. The first person to 3 wins.
The link to my code on GitHub:
https://github.com/Shawaiz-naeem/rock_paper_scissors | shawaiznaeem | |
1,700,392 | survey: GENERATE RATHER THAN RETRIEVE: LARGE LANGUAGE MODELS ARE STRONG CONTEXT GENERATORS | 選定理由 ICLR2023採択。MSR(Microsoft Research)の Cognitive Service チーム。 Paper:... | 0 | 2023-12-24T16:47:21 | https://dev.to/tutti/survey-generate-rather-than-retrieve-large-language-models-are-strong-context-generators-3e12 | nlp, machinelearning, gpt3 | ## 選定理由
ICLR2023採択。MSR(Microsoft Research)の Cognitive Service チーム。
Paper: https://arxiv.org/pdf/2209.10063.pdf
Code: https://github.com/wyu97/GenRead
サーベイ論文[[Gao2023](https://arxiv.org/abs/2312.10997v1)]でも参照された。
two-tower architecture の課題は binary passage retriever[[Yamada2021](https://arxiv.org/abs/2106.00882)]や[[Shan2023](https://dl.acm.org/doi/abs/10.1145/3543507.3583254)]でも扱われている。
## 概要
【技術課題】
Open-Domain Question AnsweringやFact Checkingといった知識集約型タスク(knowledge-intensive task)では外部コーパスから関連しているドキュメントを効率的に回収し、情報の構造化を行わなければならない。
【従来技術】
従来のRAGは Retrieve-then-Read であったが、1.外部コーパスの関連文書が有効な情報を持っているとは限らない、2.質問と文書の埋め込みが別々の推論でコンテキストが考慮されにくい(いわゆるtwo-tower architectureと呼ばれる)、3.インデックスの作成には全文書の埋め込みを計算しなければならない、といった課題がある。
【提案】
検索する代わりに質問に基づいて文脈に合う文書をLLMから直接生成する、Generate-then-Read(GenRead)アプローチを提案。さらに異なるプロンプトを選択するクラスタリングベースの方法を採用し、多様性のある文書を生成するようにした。RAGで生成モデルを検索に使用するのは[[Mao2023](https://arxiv.org/abs/2009.08553)]があるが、これはプロンプトを拡張している形であり、文書そのものを生成させるのは本研究が初。
【効果】
GenReadはTriviaQAとWebQで [EM score (exact match)](https://kaushikshakkari.medium.com/open-domain-question-answering-series-part-4-answer-quality-metrics-evaluating-the-reader-ff7fa20736bf#:~:text=Exact%20Match%20is%20a%20strict,United%20States%E2%80%9D%20is%200) 基準にて従来手法を上回った。外部コーパスからの文書取得が不要で、迅速かつ包括的な回答提供が可能。取得と生成の組み合わせにより、モデルのパフォーマンスがさらに向上する可能性がある。
## GenRead
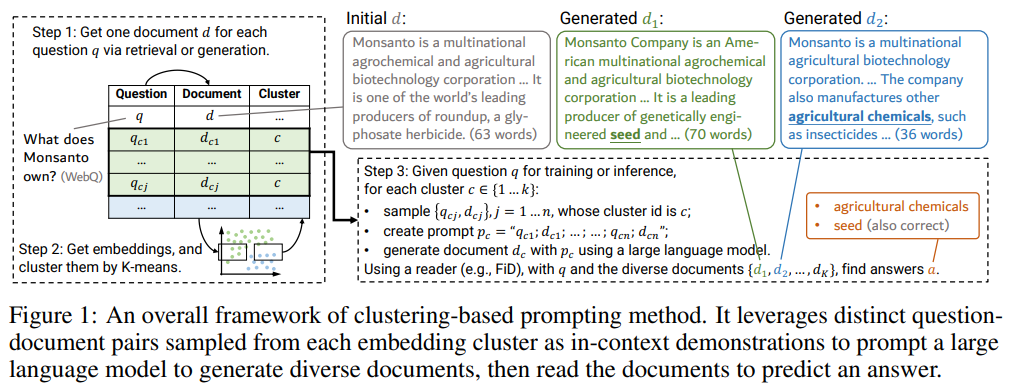
図1がGenReadの全体像である。学習データを使用しない zero-shot での利用と学習データで[FiD](https://arxiv.org/abs/2007.01282)など軽量の言語モデルを教師あり学習する方法がある。
### Zero-shot GenRead
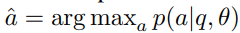
上記が通常のRAGの定式化で、質問(q)とretrieverとgeneratorのパラメータ(θ)に対するMAP(事後確率最大化推定)が応答(a)とみなすことができる。この定式化には外部ドキュメントが入っておらず、十分な外部知識の活用を行うことができない。
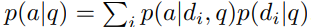
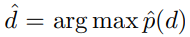
上記が本研究での定式化で、補助ドキュメント(d)を生成し、この変数について周辺化することで応答(a)に関する分布を得る。当然、この計算は困難であるため、ビームサーチを用いて上記尤度を最大化するようなdを推定値とする(事後確率最大化推定)。生成する際のプロンプトは以下である。
> – Open-domain Question Answering “Generate a background document from Wikipedia to answer the given question. \n\n {query} \n\n”
– Fact checking “Generate a background document from Wikipedia to support or refute the statement. \n\n Statement: {claim} \n\n”
– Open-domain Dialogue System “Generate a background document from Wikipedia to answer the given question. \n\n {utterance} \n\n”
生成した補助文書(d)をいわゆる zero-shot reading [[Lazaridou2022](https://arxiv.org/abs/2203.05115)] によって応答を生成する。プロンプト例は以下である。
> – (1) “Refer to the passage below and answer the following question with just a few words. Passage:
{background} \n\n Question: {query} \n\n The answer is”
– (2) “Passage: {background} \n\n Question: {query} \n\n Referring to the passage above, the
correct answer (just one entity) to the given question is”
– (3) “Refer to the passage below and answer the following question with just one entity. \n\n Passage:
background \n\n Question: query \n\n The answer is”
For fact checking and dialogue system, we chose the simplest prompt from P3.
– Fact Checking “{background} \n\n claim: {claim} \n\n Is the claim true or false?”
– Open-domain Dialogue System “{background} \n\n utterance \n\n”
### Supervised GenRead
LLMによるテキストの生成はデコーディングアルゴリズムが同一である以上、同じようなテキストになりやすい。そこで多様性を取り入れるために手動でのプロンプト調整による多様性の追加とクラスタリングベースの方法を提案した。クラスタリングベースでは古典的な k-means を用いて生成された補助ドキュメント(d)をクラスタリングし、セントロイドを使用した。(図1)
## Experiment
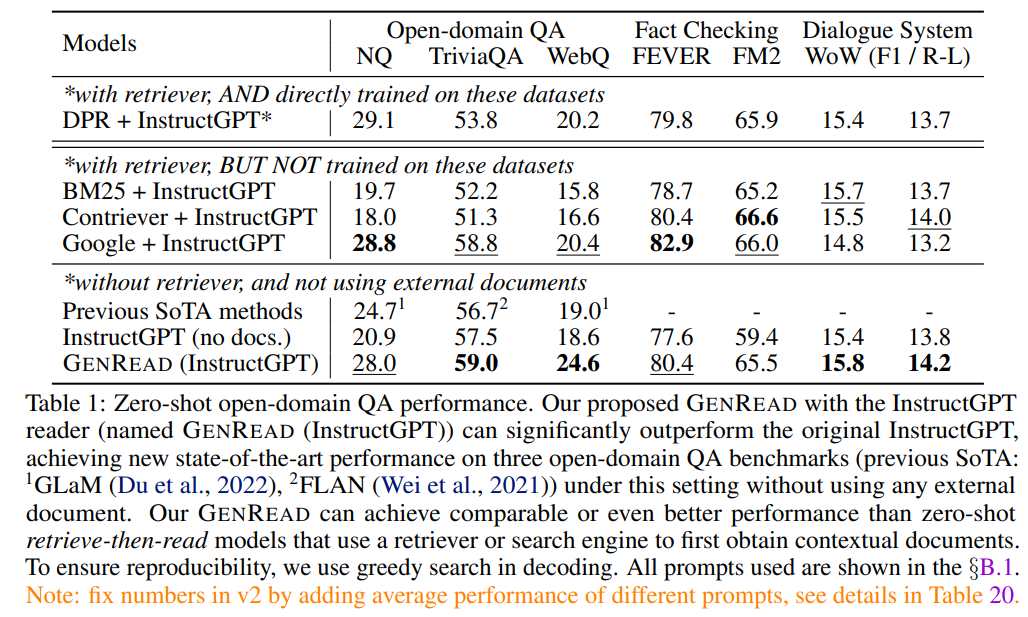
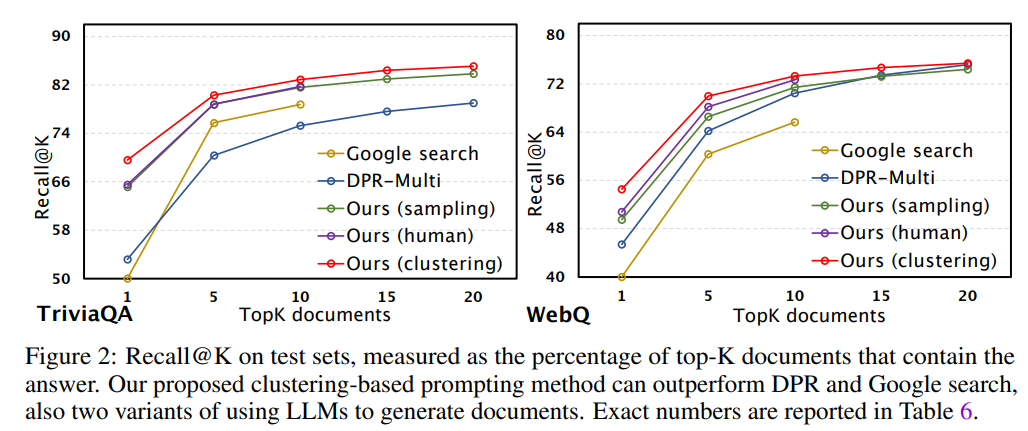
GenReadは従来のRetrieve-then-ReadのDPRを上回る結果となり、google検索を上回る場合もあった。
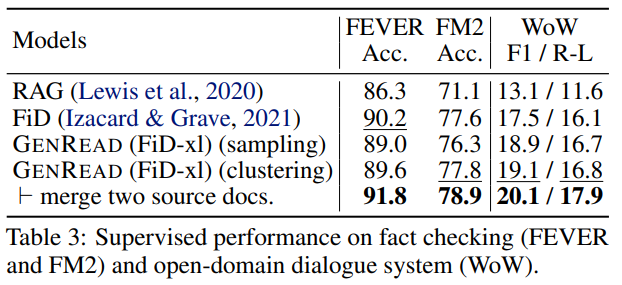
Fact Checkingのタスク(FEVER, FM2)ではデータセットによってはdense retrieverだけで十分な情報を回収できる場合、従来手法より精度が下がる場合があった。

DPRによる文書取得に加えて context generator が生成した文書(d)を加えた方が明らかに精度は高くなっている。(図3)
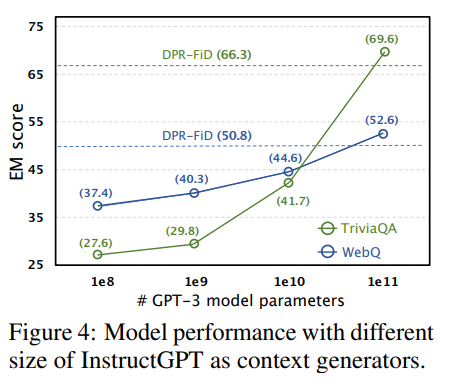
context generator のモデルサイズと EM score の推移。retriever やresponse generator とは別にスケーラビリティによる恩恵を受けることができる。
| tutti |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.