
id int64 5 1.93M | title stringlengths 0 128 | description stringlengths 0 25.5k | collection_id int64 0 28.1k | published_timestamp timestamp[s] | canonical_url stringlengths 14 581 | tag_list stringlengths 0 120 | body_markdown stringlengths 0 716k | user_username stringlengths 2 30 |
|---|---|---|---|---|---|---|---|---|
1,720,395 | Perl Weekly #650 - Perl in 2024 | Originally published at Perl Weekly 650 Hi there, What is in for Perl in 2024? We had a big... | 20,640 | 2024-01-08T06:22:57 | https://perlweekly.com/archive/650.html | perl, news, programming | ---
title: Perl Weekly #650 - Perl in 2024
published: true
description:
tags: perl, news, programming
canonical_url: https://perlweekly.com/archive/650.html
series: perl-weekly
---
Originally published at [Perl Weekly 650](https://perlweekly.com/archive/650.html)
Hi there,
<strong>What is in for Perl in 2024?</strong>
We had a big release <strong>Perl v5.38</strong> last year, <strong>July 3, 2023</strong>. It was the first release introducing <strong>Corinna</strong> into core. Although it was good enough for starter but I am looking for another push in the next release in the year 2024. I am sure you must have tried the new OO in core. One thing that I really wanted was the ability to create a <strong>role</strong> using new shiny OO. I have no idea what is in the plan for the next release. I am looking forward to another update to the new OO ecosystem.
Personally, I am also looking forward to the next <strong>Perl and Raku Conference in Las Vegas</strong>. I had a wonderful experience last year in <strong>Canada</strong>. I hope things get back to normal before the event. I don't know about the conference in Europe. I missed it last year as it clashed with my India visit. It used to be my only opportunity to meet fellow <strong>Perl</strong> and <strong>Raku</strong> friends. I miss the local event, <strong>London Perl Workshop</strong>. I hope it gets fresh boost this year.
My pet project, <a href="https://theweeklychallenge.org">The Weekly Challenge</a> recently completed <strong>250 weeks</strong>. It has been a great learning experience for me personally. I was introduced to <strong>Raku</strong> and <strong>Python</strong>. Thanks to the team members we get regular blog posts talking about magical <strong>Perl</strong> code. Talking about blog post, <strong>Olaf Alders</strong>, invites us to join the <a href="https://wundersolutions-com.eo.page/k22w4">newsletter</a>. I have accepted his invitation. How about you?
Stay safe and enjoy rest of the week.
--
Your editor: Mohammad S. Anwar.
## Announcements
### [Cosmoshop unterstützt den Deutschen Perl/Raku-Workshop](https://blogs.perl.org/users/max_maischein/2024/01/cosmoshop-unterstutzt-den-deutschen-perlraku-workshop.html)
We are happy to announce that CosmoShop supports the German Perl/Raku-Workshop.
### [This Week in PSC (130) | 2024-01-04](https://blogs.perl.org/users/psc/2024/01/this-week-in-psc-130.html)
Happy New Year and weekly update from Perl Steering Council.
### [Let's keep in touch](https://wundersolutions-com.eo.page/k22w4)
Invitation from Olaf to join the newsletter for interesting and fun post.
---
## The Weekly Challenge
<a href="https://theweeklychallenge.org/">The Weekly Challenge</a> by <a href="http://www.manwar.org/">Mohammad Anwar</a> will help you step out of your comfort-zone. You can even win prize money of $50 Amazon voucher by participating in the weekly challenge. We pick one winner at the end of the month from among all of the contributors during the month. The monthly prize is kindly sponsored by Peter Sergeant of <a href="https://perl.careers/">PerlCareers</a>.
### [The Weekly Challenge - 251](https://theweeklychallenge.org/blog/perl-weekly-challenge-251)
Welcome to a new week with a couple of fun tasks: "Concatenation Value" and "Lucky Numbers". If you are new to the weekly challenge, why not join us and have fun every week? For more information, please read the <a href="https://theweeklychallenge.org/faq">FAQ</a>.
### [RECAP - The Weekly Challenge - 250](https://theweeklychallenge.org/blog/recap-challenge-250)
Enjoy a quick recap of last week's contributions by Team PWC dealing with the "Smallest Index" and "Alphanumeric String Value" tasks in Perl and Raku. You will find plenty of solutions to keep you busy.
### [TWC250](https://deadmarshal.blogspot.com/2024/01/twc250.html)
The real power of max() and map() in display. Perl is unbeatable truly.
### [String Index](https://raku-musings.com/string-index.html)
Compact one liner in Raku for both tasks. Line by line discussion is really handy too.
### [Leaping from Tree to Tree as They Float Down the Mighty Rivers of British Columbia](https://jacoby.github.io/2024/01/01/leaping-from-tree-to-tree-as-they-float-down-the-mighty-rivers-of-british-columbia-weekly-challenge-250.html)
Lots of fun facts will keep you busy as well as elegant solutions. Thanks for sharing.
### [Perl Weekly Challenge: Week 250](https://www.braincells.com/perl/2024/01/perl_weekly_challenge_week_250.html)
Incredibly straight forward solutions both in Perl and Raku. Plenty of magics for you.
### [Alphanumeric Moduli](https://github.sommrey.de/blog/pwc/challenge-250)
Simple loop and max/map enough for this week, nice to see variations. Keep it up great work.
### [Perl Weekly Challenge 250: Smallest Index](https://blogs.perl.org/users/laurent_r/2024/01/perl-weekly-challenge-250-smallest-index.html)
You don't need map power, just regular loop is good enough. Well done and thanks for sharing.
### [the first one of 2024!](https://fluca1978.github.io/2024/01/04/PerlWeeklyChallenge250.html)
Raku magical one-liner showing off. Sweet and short discussion is very handy.
### [Perl Weekly Challenge 250](https://wlmb.github.io/2024/01/01/PWC250/)
Pure one-liner in Perl using CPAN is so refreshing. Great work and keep it up.
### [Weekly Challenge #250](https://github.com/manwar/perlweeklychallenge-club/blob/master/challenge-250/mark-anderson/raku/blog-1.md)
Welcome to blogging and thanks for sharing your first blog post. Hope to see more often. Thanks for sharing.
### [Two-Hundred Fifty Perl Weekly Challenges! Two-Hundred Fifty problems so clear…](https://packy.dardan.com/2024/01/01/perl-weekly-challenge-2/)
Cute little solutions in Perl, Python and Raku with engaging discussions. Keep it up great work.
### [Smallest index, largest element](http://ccgi.campbellsmiths.force9.co.uk/challenge/250)
DIY solutions like always. Well structured and presented too. Highly recommended.
### [The Weekly Challenge #250](https://hatley-software.blogspot.com/2024/01/robbie-hatleys-solutions-to-weekly.html)
Use of CPAN module makes the solution elegant and compact. Well done and keep it up.
### [Smallest Viable Value](https://blog.firedrake.org/archive/2024/01/The_Weekly_Challenge_250__Smallest_Viable_Value.html)
One of the longest serving member of the team. Thanks for your support and contributions. Like always we have a detailed and meaningful post.
### [Get well soon and thanks for the post. Just love how Python gets translated to Perl. Cool.](https://dev.to/simongreennet/small-and-large-2ap)
### [PWC #250](https://thiujiac.blogspot.com/2023/12/pwc-250.html)
I really enjoy Perl 4 code. Never got the opportunity to play with it. Thanks for the refresher.
---
## Rakudo
### [2024.01 Happy (2..9).map(*³).sum](https://rakudoweekly.blog/2024/01/02/2024-01-happy-2-9-map%c2%b3-sum/)
---
## Weekly collections
### [NICEPERL's lists](http://niceperl.blogspot.com/)
<a href="">Great CPAN modules released last week</a>;<br><a href="https://niceperl.blogspot.com/2024/01/cdlxxvii-10-great-cpan-modules-released.html">MetaCPAN weekly report</a>;<br><a href="https://niceperl.blogspot.com/2024/01/dlxxviii-metacpan-weekly-report-meta.html">StackOverflow Perl report</a>.
---
## The corner of Gabor
A couple of entries sneaked in by Gabor.
### [How to handle number overflow or underflow?](https://rust.code-maven.com/how-to-handle-overflow)
As a Perl prorgammer I never thought what happens if my posts get too many likes. Will the counter overflow? Now, as I write Rust it makes me think about all kinds of, sometimes rather unrealistic, edge-cases.
---
You joined the Perl Weekly to get weekly e-mails about the Perl programming language and related topics.
Want to see more? See the [archives](https://perlweekly.com/archive/) of all the issues.
Not yet subscribed to the newsletter? [Join us free of charge](https://perlweekly.com/subscribe.html)!
(C) Copyright [Gabor Szabo](https://szabgab.com/)
The articles are copyright the respective authors.
| szabgab |
1,720,400 | Deploy and Stake a Shardeum Validator on Spheron in Minutes | In blockchain technology, solutions addressing the scalability trilemma of scalability, security, and... | 0 | 2024-01-18T14:36:03 | https://blog.spheron.network/deploy-and-stake-a-shardeum-validator-on-spheron-in-minutes | shardeum, web3, blockchain, deployment |
---
title: Deploy and Stake a Shardeum Validator on Spheron in Minutes
published: true
date: 2024-01-08 04:30:24 UTC
tags: shardeum, web3, blockchain, deployment
canonical_url: https://blog.spheron.network/deploy-and-stake-a-shardeum-validator-on-spheron-in-minutes
---
In blockchain technology, solutions addressing the scalability trilemma of scalability, security, and decentralization have remained an ongoing challenge. [Shardeum](https://shardeum.org/) emerges as a groundbreaking EVM-compatible Layer 1 (L1) smart contract platform, revolutionizing this space by leveraging dynamic state sharding. This innovative approach redefines the validation process, distributing transaction verification across shards in the network for enhanced throughput and scalability.
This article delves into the seamless deployment and staking process for a Shardeum validator using Spheron, a user-friendly platform simplifying node configuration and participation in the Shardeum ecosystem. Through step-by-step guidance, users can easily deploy a Shardeum node, contribute to network security, and stake testnet SHM (Shardeum's native token) to actively participate in the testnet.
## What is Shardeum?
[Shardeum](https://shardeum.org/) is an EVM-compatible, [dynamically state sharded](https://docs.shardeum.org/introduction/dynamicstatesharding) L1 smart contract platform. Expressed simply, sharding breaks the job of validating and confirming transactions into small pieces or shards and spreads them out in the network.
_Here is a diagram demonstrating how un-sharded data in a single node can be sharded amongst three nodes:_
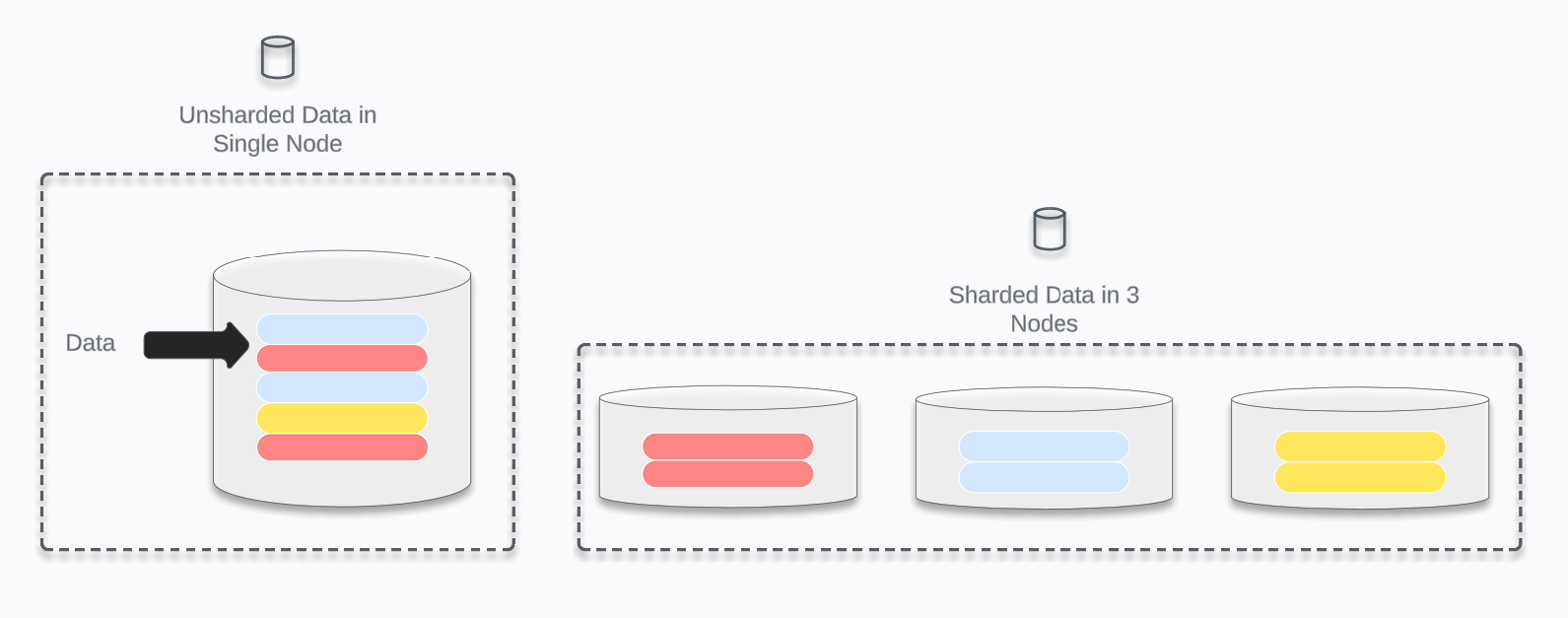
_Image created with LucidChart_
Shardeum utilizes parallel processing across shards to achieve high throughput with linear scalability. This is achieved while concurrently enabling low gas fees & and ensuring security with a combined [proof-of-stake and proof-of-quorum for consensus](https://docs.shardeum.org/introduction/consensus), while block-level consensus is not required for finality.
## Solving the Scalability Trilemma
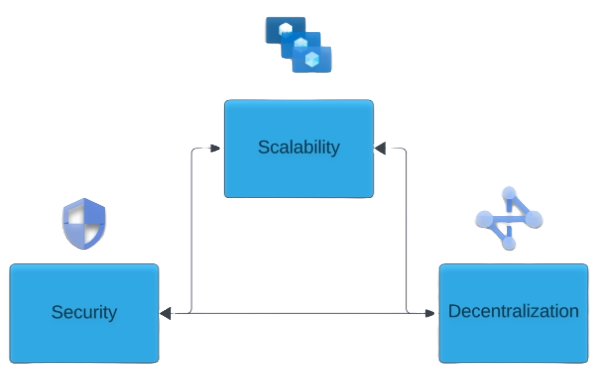
The [scalability trilemma](https://www.researchgate.net/publication/342639281_Scaling_Blockchains_A_Comprehensive_Survey) is a set of trade-offs originally posited by Vitalik Buterin, where blockchains can generally only prioritize two out of 3 of the following characteristics:
1. Scalability
2. Security
3. Decentralization
Vitalik did add the caveat that achieving all three is actually possible but very difficult.
Shardeum solves this problem with the following:
- Performing consensus and processing at the transaction level instead of the block level.
- Using dynamic state sharding to achieve scalability through parallelization by distributing workload throughout the network.
- Reduced overhead for validator nodes because they only need to store state data for their own shard.
- This allows the network to auto-scale horizontally by adding additional nodes instead of being forced to scale vertically by increasing the computing resources of each node.
- This allows for fast finality and atomic shard composability.
## What is Spheron Network?
[Spheron Network](https://spheron.network/) is a next-generation PaaS that offers low-cost and seamless access to Web3 infrastructure across multiple chains. It is explicitly designed to serve a broader audience, including startups, developers, and organizations looking to scale their infrastructure.
Spheron Network offers a Compute Marketplace that you can use to set up useful tools like Avail Node quickly. With Spheron, you don't have to worry about the technical stuff, and you can focus on deploying your Avail Node with ease. In addition to compute, web hosting, and storage capabilities, Spheron offers many features to enhance productivity and enable stakeholders to reach new heights while prioritizing privacy, security, and reliability.
## Deploy a Shardeum Validator on Spheron
Deploying a Shardeum Validator on Spheron is a straightforward process. Running a Shardeum validator allows you to contribute to network security while also earning testnet SHM rewards. Here's a step-by-step guide to setting it up:
**Step 1:** If you dont already have a [Spheron account then sign up here](https://app.spheron.network/#/signup)!
**Step 2:** After logging into Spheron, navigate to the [Compute Dashboard](https://app.spheron.network/#/compute/dashboard) and click New Cluster.

**Step 3:**
1. Select Compute and Compute Type as On Demand
2. Then Select Start from the marketplace app
3. In the search box, type "Shardeum"
Spheron marketplace has a pre-baked docker image for the [Shardeum node](https://app.spheron.network/#/compute/marketplace?template=Shardeum%20Testnet%20Validator&templateId=6496eb9ba579a6bc8507cae7) ready to go for you!
**Step 4:** Select your preferred region for deployment. By default, The container will be deployed in the EU-east region for On Demand. Choosing a region closer to your users can improve performance and reduce latency.
**Step 5:** Then, Spheron will pre-populate the recommended instance plan, Terra Large Ti, and SSD storage, 256GB.
This instance and storage plan were specially selected to meet the [Shardeum minimum hardware requirements noted here](https://docs.shardeum.org/node/run/validator#minimum-hardware-requirements).
**Step 6:** The marketplace app will also automatically configure networking, ports, parameters, and commands for you. Check out the [Shardeum validator docs to learn more about these settings](https://docs.shardeum.org/node/run/validator#step-2-download-and-install-validator).

**Step 7:** Spheron abstracts away the difficulty of configuring a node. You just need to click Deploy! Check out the [Spheron docs for more info](https://docs.spheron.network/marketplace-guide/shardeum/).
Now, theres just one final step to get our validator working after this initial deployment is complete.
### Updating the Config on the Spheron Instance
After your deployment is complete, grab the hostname of your provider. **_e.g._** [**_provider.us-east.spheron.wiki_**](https://shardeum.org/)
**Step 1:** Now, lets get the IP address of that host. In a console, execute the following command:
```
ping provider.us-east.spheron.wiki
```
**Step 2:** Copy the IP address returned from that command:

**Step 3:** On your instance page, in the **Port Policy Info** section, grab the external ports that map to internal ports **9001** and **10001** , respectively.

**Step 4:** Then navigate to the Settings tab on your Compute instance page and click the Update Instance button.

**Step 5:** After clicking Update Instance, scroll down to the Template Configuration section and paste in the IP address of your provider from the previous step for the parameters:
- SERVERIP
- LOCALLANIP
**Step 6:** Then, update the parameters SHMEXT and SHMINT with the mapped external ports you grabbed from the previous step.
**Example:**
- SHMEXT: 30628
- SHMINT: 30194

**Step 7:** click Update to restart the instance with the updated config. After your instance starts back up, we will update the default GUI password.
You will know the instance is running when you see the following in the logs:
```
Starting operator guidone
```
### Update your GUI Password
The marketplace app sets a default password for your instance, but you need to change that ASAP!
**Step 1:** Navigate to the Shell tab on your Spheron instance:

**Step 2:** Enter the below command in the box and click Run Command:
```
operator-cli gui set password YOUR_PASSWORD_HERE
```
Be sure to select a secure password! Check out the [Spheron docs for more info](https://docs.spheron.network/marketplace-guide/shardeum/#how-to-run-the-node).
## Staking your Shardeum Validator to Join the Testnet
Now that we have a Shardeum node deployed, the next step is to stake our validator with SHM so that it can be included in the network during the next rotation.
### Acquire SHM in your Wallet for Staking
Follow these steps to set up your wallet for staking:
**Step 1:** [Add the Shardeum network](https://docs.shardeum.org/wallets/metamask/add-shardeum-network) to your wallet, such as [Metamask](https://metamask.io/)
1. **Network Name:** Shardeum Sphinx Validator 1.X
2. **New RPC URL:** [https://sphinx.shardeum.org/](https://shardeum.org/)
3. **Chain ID:** 8082
4. **Currency symbol:** SHM
5. **Block Explorer URL:** [https://explorer-sphinx.shardeum.org/](https://shardeum.org/)
**Step 2:** Claim some [testnet SHM from the faucet](https://docs.shardeum.org/faucet/claim) on the Shardeum Discord. You should receive 15 SHM from the faucet, and you will need 10+ gas fees.
**Step 3:** Verify on the Discord server, then go to the **validator-faucet** channel and use the **/faucet** command to request SHM.
### Navigate to your Validator GUI
Spheron is forwarding port 8080, which the GUI runs on. Get the Connection URL, which maps from port 8080 internally, and enter that URL into a browser to access the Shardeum validator dashboard.

Be sure to access the URL appended with [https://](https://shardeum.org/)
_e.g._ [_https://provider.us-west.spheron.wiki:32003/_](https://shardeum.org/)
**Note: You may get a warning b/c of invalid SSL. The Shardeum docs have a** [**fix for that SSL issue**](https://docs.shardeum.org/Node/Run/Validator#step-4-open-validator-gui) **.**
**Step 1:** Then log in with the password you set up earlier.
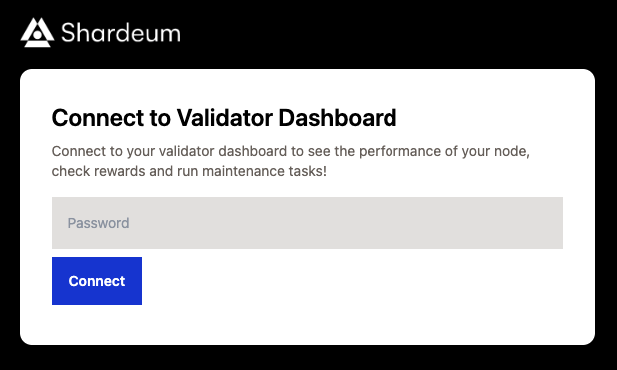
**Step 2:** Next, lets start up the Validator. Go to the Maintenance tab, then click the Start Node if its not already running.
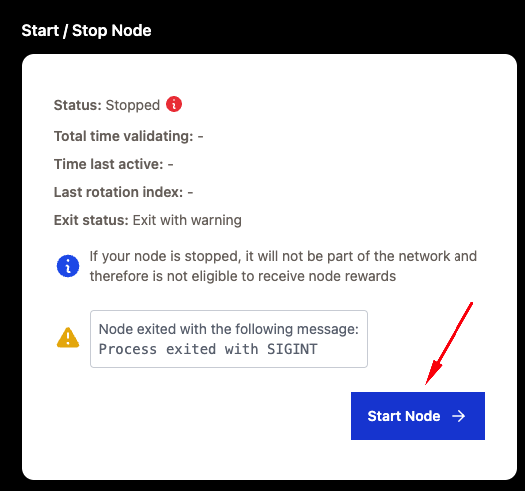
**Step 3:** Next, on that same page, click Connect Wallet. Approve the prompt that pops up in your wallet. After that, click Add Stake. You should have received 15 SHM from the faucet from the step above.
- Stake Wallet Address _[pre-populated with connected wallet]_
- Nominee Public Key _[pre-populated by validator]_
- Stake amount (SHM) _[In terms of ETH, not WEI]_
It is recommended to stake 10 SHM.
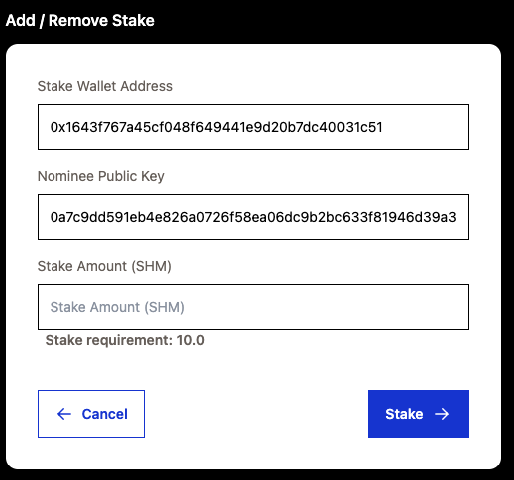
**Step 4:** Enter 10 into the Stake Amount field and click Stake then sign the wallet transaction.
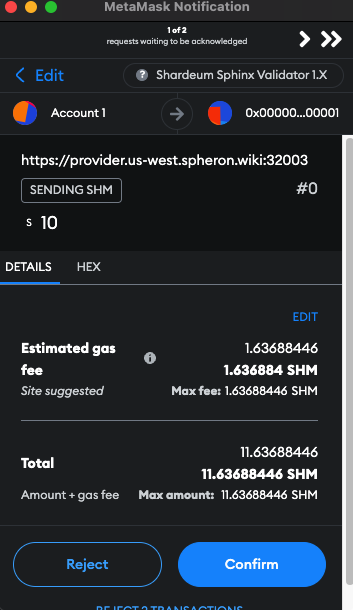
**Step 5:** You can view the staking transaction on the Sphinx Shardeum block explorer.
**Example:**
[_https://explorer-sphinx.shardeum.org/tx/0x5f55856fc3a0476d65037ccca099594fc8e345699fada0d3686e9e32f2a1e686_](https://shardeum.org/)
### Joining the network
Your node will initially be in **Standby** mode but become **Active** during the next rotation.
Alternatively, if you prefer, you can stake directly via the CLI; check the [Shardeum docs for more info](https://docs.shardeum.org/node/run/validator#cli). This will require you to expose your private key as a secret ENV var, so be sure your wallet does not contain any mainnet assets.
After completing your stake, you can check the node status with the **operator-cli** on the **Shell** tab on your Spheron instance page.

Check the node status with the following command:
```
operator-cli status
```
You can also check the status of your GUI with:
```
operator-cli gui status
```
Check back on your node after taking a break; eventually, your node will transition from Standby mode to Active!
Congratulations! You are now running a staked Shardeum validator. Spheron will do all the heavy lifting to ensure your node is a resilient and responsive network member!
Check out this [Shardeum FAQ](https://shardeum.org/blog/how-to-run-a-validator-node-on-shardeum-sphinx/#Frequently_Asked_Questions_FAQs) for answers to common validator issues.
## Conclusion
In conclusion, deploying and staking a Shardeum validator on Spheron is a straightforward process that can be completed in a few simple steps. With Spheron's user-friendly interface and automated configuration, users can easily participate in the Shardeum testnet and contribute to the network's security while earning testnet SHM rewards.
Following the instructions in this article, users can deploy a Shardeum node, update the config, and stake their validator to join the testnet. This combination of advanced technology and user-friendly platforms makes blockchain participation more accessible and rewarding. | spheronstaff |
1,720,414 | Conan Zero to Hero: A Beginner’s Guide with a Practical Project Example Using gtest | Conan is an open-source, cross-platform package manager designed to simplify the process of managing... | 0 | 2024-01-08T06:43:22 | https://dev.to/lightcity/conan-zero-to-hero-a-beginners-guide-with-a-practical-project-example-using-gtest-1b9d | beginners, cpp, conan, gtest | Conan is an open-source, cross-platform package manager designed to simplify the process of managing and distributing C and C++ libraries. It helps developers handle dependencies efficiently by providing a centralized system to package, share, and reuse code. Conan is particularly useful for managing dependencies in C and C++ projects, where manual management can become complex.
let us use conan to write an actual gtest project.
https://levelup.gitconnected.com/conan-zero-to-hero-a-beginners-guide-with-a-practical-project-example-using-gtest-1299baac970e
| lightcity |
1,720,556 | ServiceNow: The Future of Digital Workflow Automation | In this blog, we are going to discuss ServiceNow: The Future of Digital Workflow Automation. Before... | 0 | 2024-01-08T08:51:56 | https://dev.to/srikanthbollu/servicenow-the-future-of-digital-workflow-automation-4b48 | servicenow, webdev, career, discuss | In this blog, we are going to discuss ServiceNow: The Future of Digital Workflow Automation.
Before moving further, you can get accredited with this [ServiceNow online training](https://itcanvass.com/servicenow-training) certification available so as to comprehend application development’s core principles on the ServiceNow Platform, which would assist you in improving your professional career.
**1. What is ServiceNow?
**
ServiceNow is a powerful cloud-based platform that enables businesses to streamline and automate their digital workflows, making it an indispensable tool in today's fast-paced business environment. Its versatile capabilities extend across IT service management, human resources, customer service, and security operations. One of the most compelling aspects of ServiceNow is its ability to consolidate various business processes into a single unified system, allowing for seamless communication and collaboration across departments. This not only enhances operational efficiency but also fosters a culture of transparency and accountability within the organization.
Moreover, ServiceNow empowers organizations to create custom applications without the need for extensive coding knowledge, thereby democratizing the development process and enabling rapid innovation. By utilizing ServiceNow's low-code or no-code app development tools, businesses can swiftly respond to evolving market demands and internal requirements. Additionally, as companies increasingly recognize the importance of delivering engaging digital experiences to both employees and customers alike, ServiceNow stands out as an invaluable platform for achieving this goal by providing intuitive interfaces and personalized user experiences that enhance productivity and satisfaction.
In conclusion, ServiceNow represents a pivotal shift in how organizations approach workflow management by centralizing processes on a single platform while offering unparalleled flexibility in application development. As digital transformation continues to redefine industry standards, embracing platforms like ServiceNow will be crucial for staying competitive in today's dynamic business landscape.
**2. Benefits of Digital Workflow Automation
**
In today's fast-paced business environment, digital workflow automation offers numerous benefits that can streamline processes and drive efficiency. One major advantage is the reduction of manual tasks, which can free up employees to focus on more strategic and value-added activities. By automating repetitive tasks such as data entry, approval processes, and notifications, organizations can significantly increase productivity while minimizing errors.
Furthermore, digital workflow automation enables enhanced visibility and transparency across an organization. With real-time tracking and reporting capabilities, stakeholders gain a complete overview of the status of various processes, allowing for better decision-making and accountability. This increased transparency not only fosters collaboration but also improves compliance with regulations and organizational policies. Ultimately, by leveraging digital workflow automation through platforms like ServiceNow, businesses can achieve operational excellence while driving innovation in their operations.
**3. ServiceNow's Role in Enterprise Efficiency
**
ServiceNow has emerged as a pivotal player in driving enterprise efficiency through its robust digital workflow automation platform. By seamlessly integrating various business processes across departments, ServiceNow allows companies to streamline their operations, eliminate inefficiencies, and boost productivity. This is achieved through the automation of repetitive tasks, enabling employees to focus on more strategic and value-added activities. Moreover, ServiceNow's role in providing real-time visibility into different workflows enables organizations to make data-driven decisions promptly, leading to enhanced operational agility and responsiveness.
Furthermore, ServiceNow's ability to facilitate collaboration among cross-functional teams fosters a culture of transparency and accountability within enterprises. By creating a centralized platform for communication and task management, ServiceNow promotes synergy among various business functions and empowers employees to work cohesively towards shared company objectives. This not only accelerates problem-solving but also enhances the overall quality of deliverables. Additionally, by offering advanced analytics capabilities that provide insights into performance metrics and key operational trends, ServiceNow equips organizations with the tools needed to continuously optimize their workflows for maximum efficiency.
**4. Case Studies: Real-World Application
**
In the realm of digital workflow automation, case studies serve as powerful demonstrations of how ServiceNow's platform is transforming businesses across diverse industries. Take for example a multinational telecommunications company that utilized ServiceNow to streamline its customer service operations. By implementing automated workflows and intelligent case routing, the company significantly reduced resolution times and improved customer satisfaction scores. Similarly, a leading financial services organization leveraged ServiceNow to orchestrate complex IT processes, resulting in substantial cost savings and enhanced operational efficiency.
Furthermore, in the healthcare sector, a prominent hospital system harnessed ServiceNow's capabilities to digitize patient intake processes and automate administrative tasks. This not only boosted staff productivity but also led to faster patient care delivery and resource optimization. These real-world case studies underscore the tangible impact of embracing digital workflow automation through innovative platforms like ServiceNow, transforming businesses by driving operational excellence and delivering significant bottom-line results.
**5. Future Trends and Innovations in ServiceNow
**
As businesses continue to embrace digital transformation, the future of ServiceNow is poised for exciting innovations and trends that will further revolutionize workflow automation. One major trend to watch out for is the integration of artificial intelligence (AI) and machine learning capabilities into ServiceNow platforms. This will empower organizations to make smarter decisions, predict and prevent issues, and automate repetitive tasks more effectively than ever before.
Another key area of innovation in ServiceNow is the expansion of its capabilities in cybersecurity and risk management. With cyber threats becoming increasingly sophisticated, ServiceNow is likely to continue enhancing its security operations products to provide comprehensive threat detection, incident response, and vulnerability management solutions. Moreover, we can anticipate a greater focus on sustainability within ServiceNow as organizations seek ways to incorporate eco-friendly practices into their workflows. We may see new features that enable companies to track their carbon footprint, manage sustainable development goals, and implement green initiatives seamlessly into their operations through the platform. These expected advancements in AI integration, cybersecurity enhancements, and sustainability features are just a glimpse of the exciting future trends that will shape the landscape of ServiceNow. As innovation continues to accelerate at a rapid pace across various industries, it's clear that ServiceNow will play a pivotal role in driving digital transformation forward with unparalleled efficiency and effectiveness.
**6. Challenges and Considerations
**
When it comes to implementing ServiceNow for digital workflow automation, organizations often face various challenges and considerations. One of the key challenges is the need to align different departments and stakeholders to ensure a smooth transition to the new system. This requires effective change management strategies and clear communication to address any resistance or concerns that may arise during the process. Additionally, organizations need to carefully consider data security and compliance requirements when leveraging ServiceNow for automation, especially in industries with strict regulations such as healthcare or finance.
Furthermore, another important consideration is the customization and scalability of the ServiceNow platform. Each organization has unique workflow requirements, so it's crucial to ensure that the platform can be tailored to specific needs while also being able to scale as the business grows. This involves thorough analysis of current processes, identification of areas for improvement, and a well-thought-out plan for implementation that takes into account future expansion. By addressing these challenges and considerations proactively, organizations can maximize the potential benefits of ServiceNow as they embrace digital transformation.
**7. Conclusion: Embracing the Power of ServiceNow
**
In conclusion, embracing the power of ServiceNow is not just about adopting a digital workflow automation tool, but about fundamentally transforming the way organizations operate. ServiceNow offers a holistic approach to managing workflows, from IT and customer service to HR and beyond, enabling businesses to streamline processes, improve productivity, and enhance collaboration across departments. By leveraging the capabilities of ServiceNow, companies can unlock new opportunities for innovation and growth in an increasingly competitive digital landscape.
Furthermore, embracing the power of ServiceNow means embracing a culture of continuous improvement and agility. With its ability to adapt to evolving business needs and market trends, ServiceNow becomes not just a technology platform but a strategic enabler for organizational success. By recognizing the potential of ServiceNow as more than just an IT tool but as a driver of digital transformation across the entire enterprise, businesses can position themselves at the forefront of innovation and efficiency in today's fast-paced business environment. | srikanthbollu |
1,720,577 | Arrow Function in JavaScript - Helps you make your code short video out now | Once upon a time, in the land of JavaScriptia, there lived a group of functions. These functions... | 0 | 2024-01-08T09:18:30 | https://dev.to/codingmadeeasy/arrow-function-in-javascript-helps-you-make-your-code-short-video-out-now-4lhb | [](https://youtu.be/i0HX_D269gY)
Once upon a time, in the land of JavaScriptia, there lived a group of functions. These functions were well-known for their traditional style and syntax. They had been the backbone of the kingdom's code for many years, but change was on the horizon.
One sunny day, a new function named Arrow appeared in JavaScriptia. Arrow was different from the others. It was sleek, concise, and had a unique way of expressing itself. Arrow had a symbol that set it apart - an arrow (=>) - which gave it a distinct identity.
The other functions were intrigued by Arrow's arrival. They gathered around, curious to learn more about this newcomer. Arrow explained that it was an arrow function, a modern way of writing functions in JavaScript that offered a shorter syntax and lexically scoped this keyword.
At first, the traditional functions were hesitant to accept Arrow into their circle. They were used to their familiar ways and were wary of change. But as Arrow demonstrated its abilities and showcased its efficiency, the functions began to see the value it brought to the kingdom.
Arrow's concise syntax made it perfect for shorter tasks. It didn't require the function keyword or the return keyword for simple operations. Its implicit return and ability to maintain the context of this within its scope made it a favorite among developers for handling callbacks and array methods.
Gradually, the functions started adopting Arrow's style. They realized that both the traditional functions and Arrow could coexist harmoniously in JavaScriptia. Some tasks were better suited for the familiar functions, while others were more efficiently handled by Arrow.
Over time, Arrow became an integral part of the kingdom's codebase, working alongside the traditional functions to create powerful and versatile programs.
And so, in the land of JavaScriptia, the arrival of Arrow marked a shift towards modernity while honoring the traditions of the past, creating a balanced and diverse coding landscape for all its inhabitants. | codingmadeeasy | |
1,721,048 | Love at First Compile | Not only with women have I fallen in love, but with programming languages too. Embarrassing to look... | 0 | 2024-01-08T15:51:44 | https://dev.to/offcode/love-at-first-compile-2ji6 | java, beginners, terminal, nostalgia | Not only with women have I fallen in love,
but with programming languages too.
Embarrassing to look back now
and admit I was in love with Java.
It started with a flirt in the office.
We were a Microsoft shop,
dedicated to everything Windows and Visual Basic,
everything click and drag-and-drop.
Maybe this is why I got excited
when I heard a lecture about Java at the university.
White code written in chalk on the blackboard.
Almost like typing in a terminal.
Background color should not play a role
when choosing between programming languages.
The logos of the companies behind them should be irrelevant.
But Sun, the creator of Java, designed a magical logo
that read Sun from all four directions.
A sexy logo in the finest shade of purple.
Besides personality, we fall in love
with brown eyes, with blue eyes.
It was half past five, the office
was empty, except for me and my friend.
I entered sun.com/java in the browser,
an easy to remember URL.
The link to the installer sat on the top of the page,
no need to scroll down, just click and wait.
Modern technology always takes long to download.
The proverbial fifteen minutes of
"make a coffee, smoke a cigarette, and it will be ready."
Downloading was not enough, you had to install it.
Answer questions that should not be asked.
I did not know yet how many times
I would answer these same questions
and accept the default in every case.
We used an integrated environment to write BASIC code,
the keywords were displayed
in bold and in a darker shade of carmine.
Here is how you count to ten without using your fingers:
`FOR I = 1 TO 10`
And imagine the colors.
You click on the yellow arrow icon to run the program.
We had no editor for Java.
It probably didn't even exist yet, the language was so new.
We used what we had.
Our BASIC editor automatically checked our Java code
and highlighted all the errors.
Imagine writing in German
and running it through an English spell checker.
I knew the code was correct,
I just copied it from the notes I had taken at the class.
Clicking the yellow arrow wouldn't make sense either.
I had to leave our integrated environment behind
and open a terminal.
Type `javac Counter.java`.
The whole world was black and white now,
the whole screen.
The command I typed and the error message
I received a few seconds later.
A semicolon is missing on line 8.
Go back to the editor and fix it.
It took us more than half an hour to make our first Java program work
and do some very basic stuff.
Count to ten and print the numbers.
This doesn't sound like the beginning of a love story.
But what is love if not sweat and tears?
I may tell you later about the tears. | offcode |
1,720,630 | Top 10 Success Stories in App Development - Highlights of 2023 | 2023 proved to be a banner year for mobile app development trends, with innovative concepts growing... | 0 | 2024-01-08T09:59:19 | https://dev.to/quokkalabs/top-10-success-stories-in-app-development-highlights-of-2023-46af | app, appdevelopment, 2023 | 2023 proved to be a banner year for mobile app development trends, with innovative concepts growing into thriving businesses. This year, we witnessed apps transcend mere utility, becoming cultural touchstones and game-changers in their respective industries. Let's dive into the top 10 m and explore the trends that propelled them to the forefront.
## Top 10 Success Stories in App Development 2023 - Highlights
Let's look at these fantastic success stories that will inspire you! (download counts may vary)
### 1. Canva Pro for iPad
The beloved graphic design platform's iPad debut redefined mobile creativity. Boasting over 5 million downloads on iOS already, Canva Pro lets users create stunning visuals on the go.
### 2. Duolingo ABC
Gamified language learning for kids never looked so cute! This playful app saw over 10 million downloads on Android and became a favorite among parents and educators, proving the power of [engaging mobile app development trends](https://quokkalabs.com/blog/top-15-mobile-app-development-trends/?utm_source=Dev&utm_medium=Blog&utm_campaign=Blog).
### 3. Reflectly AI Journal
Mental health took center stage with Reflectly's AI-powered journaling app. With over 7 million downloads on both iOS and Android, it demonstrates the growing demand for mental wellness solutions through [innovative mobile app development processes](https://quokkalabs.com/blog/a-step-by-step-guide-to-the-mobile-app-development-process/?utm_source=Dev&utm_medium=Blog&utm_campaign=Blog), and it's among the success stories in app development 2023.
### 4. Temtem
This monster-collecting RPG captured the hearts of Pokemon fans, racking up over 15 million downloads across platforms. Its success highlights the enduring appeal of well-executed mobile gaming experiences.
### 5. TikTok Shop
Social commerce reached new heights with TikTok Shop's seamless integration. It's not just about lip-syncing anymore; over 20 million downloads on Android paint a picture of a thriving e-commerce ecosystem within the app.
### 6. Lensa AI
Another leader among Success Stories in App Development 2023. Transforming selfies into stunning artworks, Lensa AI became a viral sensation, amassing over 12 million downloads on iOS. It showcases the potential of AI for personalized and engaging mobile experiences.
### 7. Sleep Cycle
Battling bedtime blues, Sleep Cycle's innovative alarm features helped over 5 million users (primarily on Android) achieve restful slumber. It highlights the growing focus on health and well-being within the app space.
### 8. Bumble Bizz
It's among the Success Stories in App Development 2023 after Bumble for dating. Professional networking took a swipe for the better with Bumble Bizz. Connecting over 3 million users on iOS and Android, it redefines career networking through the familiar dating app format.
### 9. Headspace for Work
Mindfulness found its way into the corporate world with Headspace for Work. With over 8 million downloads across platforms, it demonstrates the increasing importance of workplace well-being.
### 10. HiHello
Bharat's Local Social Network: Building community in India, HiHello saw over 10 million downloads on Android alone. It highlights the potential for localized app development catering to specific regional needs.
## Best Practices for Success in App Development: From Spark to Download Storm
Witnessing these 2023 triumphs is inspiring, but how do you translate such brilliance into your own app? Let's dive deeper into the secrets of success with some golden best practices and mobile app development process:
- Define Your North Star: A Problem Worth Solving
Before coding a single line, ask yourself: what problem am I solving for users? Is it a burning need, a delightful inconvenience, or simply a fresh take on an existing solution? A laser-sharp focus on user value is the foundation for an app that resonates.
- Design Thinking: Walk in Your User's Shoes
Empathy is key. Research your target audience, understand their pain points, and craft an intuitive user experience that feels like a natural extension of their needs. Remember, a beautiful interface without purpose is like a Ferrari stuck in traffic.
- Use Agility: Build, Iterate, Refine
The mobile world is a fast-paced dance. Don't aim for a grand launch followed by radio silence. Employ agile development methodologies, releasing minimum viable products (MVPs) and gathering user feedback to continuously refine your app. Think of it as sculpting a masterpiece, not constructing a castle overnight.
- Master the Mobile Arena: Platform Choice Matters
Android or iOS? Both offer unique strengths and user preferences. Understanding your target market's platform bias is crucial for maximizing reach and engagement.
- Market Like a Magician: Storytelling, Not Just Selling
Your app might be a game-changer, but no one knows it exists if you're whispering in an empty room. Utilize captivating storytelling, targeted marketing campaigns, and strategic app store optimization (ASO) to make your app the talk of the town.
- Metrics Maestro: Data Drives Decisions
App analytics are your crystal ball. Monitor user behavior, track key performance indicators (KPIs), and identify areas for improvement. Data-driven insights will guide your development roadmap and ensure your app stays relevant and engaging.
- Security Sentinel: Guarding User Trust
In today's digital landscape, user data is sacred. Implement robust security measures, prioritize data privacy, and be transparent about your practices. Building trust is paramount for long-term success.
- The Power of Community: Listen, Engage, Respond
Foster a community around your app. Actively engage with users on social media, respond to feedback, and encourage open communication. This two-way dialogue is gold; it fuels innovation and strengthens user loyalty.
## Success Stories in App Development 2023: Ready to Convert To 2024 And beyond?
If you're looking for the [Best Mobile App Development Company in India](https://quokkalabs.com/mobile-app-development?utm_source=Dev&utm_medium=Blog&utm_campaign=Blog) to craft your own success story, look no further! Hire or contact those who utilize the latest app development trends and a meticulous Mobile App Development Process to bring your vision to life. Let's turn your app idea into a reality, download the applause!
Remember, innovation, empathy, and a dash of digital magic are the ingredients for app success. So, unleash your creativity and join the league of 2024's app heroes! | labsquokka |
1,720,678 | How to Create Emotionally Resonant Brand Experiences for Your Target Audience | A thorough familiarity with the target demographic is essential for effective audience design. You... | 0 | 2024-01-08T11:07:10 | https://dev.to/alexparker21/how-to-create-emotionally-resonant-brand-experiences-for-your-target-audience-g27 | web, design | A thorough familiarity with the target demographic is essential for effective audience design. You can't expect to succeed if you have no idea who you're interacting with.
Having the correct ingredients on hand is, thus, crucial. Personalization, humanization, captivating storytelling abilities, and a consistent brand narrative are a few examples.
Here are some fantastic pointers for creating brand experiences that strike an emotional chord with your target demographic.
In today's world, no company can succeed without an online presence, and the most crucial part of that presence is the design of the company's website. MavericksMedia, without a doubt, employs the **[web designing company in toronto](https://mavericksmedia.ca/toronto-website-design/)**, a team that is enthusiastic about creating innovative websites with outstanding and creative designs.
## 1, Make Sensational Experiences
Engaging any of the five human senses—sight, sound, smell, touch, and taste—is the essence of a sensory brand experience. The aroma of freshly ground coffee beans, for instance, greets you warmly the moment you step foot in a Starbucks. An overwhelming sense of comfort and joy washes over you. At this point, you're likely to want to stay a while, indulge in your favorite treats, and take it easy.
## 2 Recount Stories With Feelings
Incorporate narrative into the design of your brand's experience. Make your readers care about the people you portray and the stories you tell them so that they can find inspiration in your goals and principles. Websites, social media, and other forms of paid advertising and marketing should all make use of the skill of storytelling.
Dove, for one, has never been one to back down from a fight for equality and diversity. The message this time is for young people to #detoxyourfeed and stop taking beauty advice that is toxic, negative, and bad. Trying to achieve ideal body and skin conditions is an endless cycle for millennials and Gen Z, as you are well aware. Someone has to hit the brakes every year because the trend is getting stronger.
## 3. be sure to incorporate relatable visual elements.
Typography, pictures, icons, textures, and colors are all examples of visual graphics that can impact an audience on an emotional, mental, bodily, and spiritual level. The one catch is that you'll need some knowledge of visuals, design customization, and composition in order to pull this off.
In honor of the World Series, the Los Angeles Times collaborated with Golden Road Brewing to produce an AR web activation video, which Dodgers fans could enjoy. Text, shapes, and colors were utilized to enhance the video, as is evident.
## 4 Garner knows your target audience's demographics and psychographics inside and out.
Get to know their wants, requirements, and what sets them off. Learn about the market, read reviews, and use data to read people's emotions and goals by watching how they act and react.
Brands are going to extreme lengths to help their consumers, from offering feedback forms and encouraging positive attitudes to engaging in conversational commerce, in the hopes of increasing sales and positive testimonials.
## 5. Figure Out What It Is You Want To Do
Always have a plan in place before beginning any project that could affect your brand. Think about the feelings you want your listeners to have. Invoking what emotions are you aiming for? Feelings of empowerment, nostalgia, trust, or enthusiasm.
A better and more immersive brand experience can be designed with goals and direction in mind.
Fans of Netflix may have come across the Netflix Laughs feature, which compiles a collection of comedic videos from the service's library and allows users to browse, like, comment, and share them. Is the goal to improve the brand experience or to compete with TikTok? Many are wondering. Watching these videos has made me laugh, for some reason.
## - Launch a Campaign for Storytelling
Let your audience's hopes and fears inform the creation of enthralling stories. Make content that makes people feel something through utilizing different forms of communication like articles, infographics, videos, installations, and virtual worlds.
## Support Charitable Initiatives
Find a nonprofit to work with or join forces with, and make sure their mission and values mesh with your own. Make advertisements that get people involved in a bigger cause. Get them involved with a beach cleanup, a book drive, or a fundraiser.
## - Present Commonalities
Plan gatherings and activities that will unite your target audience in a common feeling of belonging. Help cultivate healthy relationships by holding retreats, workshops, or challenges.
## Imbue Packaging With Emotions
Packaging is an opportunity for customers to experience your brand through sight, touch, and smell, so give it your full attention. Get in line with your brand's personality by using images, textures, and colors that make people feel something. To give just one example, audiences can get pumped up for product demos and unboxing videos.
## Marketing through Social Media
Fast food restaurants like Wendy's, Five Guys, and McDonald's are finding success with social media applications such as TikTok. Add some flair to your feed by sharing videos, stories, and still images with text and icons.
## - Joy and Astonishment
Write customers personalized messages, give them gifts, and do unique and creative things that exceed their expectations to surprise them with moments of joy and delight.
In a highly competitive and rapidly expanding market, brands can gain an edge by appealing to consumers' emotions through their products and services. During difficult times, such as the COVID-19 pandemic, brands were able to recover from losses and setbacks thanks to emotional brand experiences.
Creating brand experiences that strike an emotional chord with consumers greatly impacts their actions, loyalty, and opinion of the brand. Making lasting connections is beneficial. | alexparker21 |
1,720,684 | Disable any animations in Angular by prefers-reduced-motion | Introduction Animations today are an integral part of modern web applications. Animations... | 25,995 | 2024-01-08T11:12:11 | https://maks-dolgikh.medium.com/advanced-animation-in-angular-part-2-disable-any-animations-by-prefers-reduced-motion-8f9af185cd5d | angular, css, ui, tutorial | ## Introduction
Animations today are an integral part of modern web applications. Animations help us to improve the perception of our application to the users by giving them feedback about their actions, which helps to make the user experience pleasant and memorable.
But there are cases when we should not use animations:
* **Users with restrictions**. For them, animation is not an embellishment, but a distracting part that may be less accessible and interfere with the perception
* **E2E tests**. It takes time to wait for each animation and transition. The more tests there are, the more time is spent waiting for them to be completed
For these 2 cases, you can’t build a separate application without animations, you need to have an opportunity to disable animations.
> *And there is an easy way to do this.*
## Prefers-reduced-motion
> The **prefers-reduced-motion** CSS media feature is used to detect if a user has enabled a setting on their device to minimize the amount of non-essential motion. The setting is used to convey to the browser on the device that the user prefers an interface that **removes, reduces, or replaces** motion-based animations. ( You can find ways to activate it [here](https://developer.mozilla.org/en-US/docs/Web/CSS/@media/prefers-reduced-motion#user_preferences) )
Since this is an `@media` setting, all code can be handled in the `@media` block
```css
@media (prefers-reduced-motion) {
transition: all 0 linear;
/* others styles */
}
```
Knowing about this customization, we just need to learn how to handle it properly in the Angular application [read more...](https://maks-dolgikh.medium.com/advanced-animation-in-angular-part-2-disable-any-animations-by-prefers-reduced-motion-8f9af185cd5d) | misterion96 |
1,720,751 | Week 1: The Meet and Greet | After the results announced for the December - March 2024 Cohort we head on to a week of discussion... | 25,997 | 2024-01-08T15:37:22 | https://dev.to/yokwejuste/week-1-the-meet-and-greet-3iml | outreachy, opensource, teamwork, developers | After the results announced for the December - March 2024 Cohort we head on to a week of discussion around with the other community members.
## The community

The Unstructured studio community is a worldwide community aimed at empowering children from different underrepresented communities with several creative learning experiences. They work on several projects such as Zubhub to achieve their goal. Unstructured Studio has already put some footprints in countries like Nigeria and India.
## The Vision

The vision of Unstructured Studio is to engage children from underserved communities in creative learning experiences. They aim to achieve this through a variety of tools, activities, and resources, focusing on accessible, hands-on, and innovative educational methods. Their approach emphasizes empowering both children and educators, fostering creativity, collaboration, and practical skills in a supportive, resourceful environment
## The Project
ZubHub, developed by Unstructured Studio, is a dynamic, open-source platform designed to enhance creative education for children and educators. It stands as a collaborative and documentation tool for activity-based learning, easily adaptable for schools, libraries, and educational organizations. Developed by educators and technologists, ZubHub aims to democratize access to low-cost creative learning opportunities. This innovative platform is part of Unstructured Studio's mission to bring creative education to under-resourced communities globally, fostering essential skills like creativity, critical thinking, and collaboration. ZubHub serves as a hub for creative, hands-on projects, encouraging children to engage with low-cost materials and an engaging community of learners and educators
## The Mentors

To work on the Zubhub project I was assigned several mentors, each with much a lot of experience and diverse into different tech domains.
- [Srishti Sethi](https://twitter.com/Srish_Aka_Tux)
- [Suchakra Sharma](https://twitter.com/tuxology)
- [Ndibe Raymond Olisaemeka](https://twitter.com/CodeBlooded_JS)
## My Point of View

Unstructured Studio is a great way to have a positive impact in the young child education and helping the next generation grow.
## Conclusion
More to the above content, working for opensource, education and working for the next generation is a great footprint made in the world. Looking forward for more. | yokwejuste |
1,720,923 | How to collect marketing campaign email leads with Mailgun and Appwrite in minutes | Collecting marketing campaign email leads is fundamental to modern digital marketing strategies. It... | 0 | 2024-01-08T16:22:31 | https://dev.to/hackmamba/how-to-collect-marketing-campaign-email-leads-with-mailgun-and-appwrite-in-minutes-83g | Collecting marketing campaign email leads is fundamental to modern digital marketing strategies. It systematically gathers contact information, primarily email addresses, from individuals interested in a brand's products, services, or content.
This process is crucial for building and maintaining an email marketing list, a valuable tool for organizations to establish and nurture connections with their audience.
Various methods can be employed to collect email leads, such as utilizing web opt-in forms on websites and incorporating incentives like discounts or exclusive content. Web surveys, content or product upgrades, and online events like webinars or virtual summits can also capture email addresses during audience participation.
One of the significant challenges businesses face while setting up the collection of their email leads is the choice of technology. This choice can affect the speed at which organizations set up their campaign, the effectiveness of managing the email list, and the integration with their other existing platforms. This is where Appwrite, through [Appwrite Functions](https://appwrite.io/docs/products/functions?utm_source=hackmamba&utm_medium=hackmamba-blog) and [Mailgun](https://www.mailgun.com/?utm_source=hackmamba&utm_medium=hackmamba-blog) — a powerful email service provider — comes in.
Appwrite provides ready-made function templates that allow businesses to set up applications easily. One of these templates is the **email contact form**. The email contact form template is designed to help gather email leads for marketing campaigns. It also includes a prebuilt contact form user interface that businesses can customize to meet their specific needs.
This tutorial demonstrates how you can set up the email leads collection system on your Next.js website using the email contact form provided by Appwrite and the Mailgun email service provider.
## Prerequisites
To follow along comfortably with this tutorial, you’ll need a few things:
- Basic web development knowledge and a basic understanding of Next.js.
- An active [Appwrite cloud account](https://cloud.appwrite.io/register?utm_source=hackmamba&utm_medium=hackmamba-blog) and a [Mailgun account](https://signup.mailgun.com/new/signup?utm_source=hackmamba&utm_medium=hackmamba-blog).
- A code editor or Integrated Development Environment (IDE), preferably VScode.
- Basic knowledge of Git, a [GitHub account](https://github.com/signup), and a repository on that account.
- [Node.js](https://nodejs.org/en/download/current) installed.
- A CLI terminal.
## Repository
In case you want to view the repository of the entire Next.js leads collection website, check out this [link](https://github.com/Otrex/hackmamba-appwrite-nextjs-leads-page?utm_source=hackmamba&utm_medium=hackmamba-blog).
## Configuring Mailgun
To initiate email communications through Mailgun, you must retrieve the Simple Mail Transfer Protocol (SMTP) keys that Appwrite requires for sending emails through Mailgun.
> In this tutorial, you'll be using the sandbox environment. For instructions on using the live environment, refer to the detailed [guidelines](https://documentation.mailgun.com/en/latest/user_manual.html#verifying-your-domain).
**Retrieving the SMTP keys**
To perform this task, go to your Mailgun account dashboard. Once there, locate and click on the **Sending** menu.
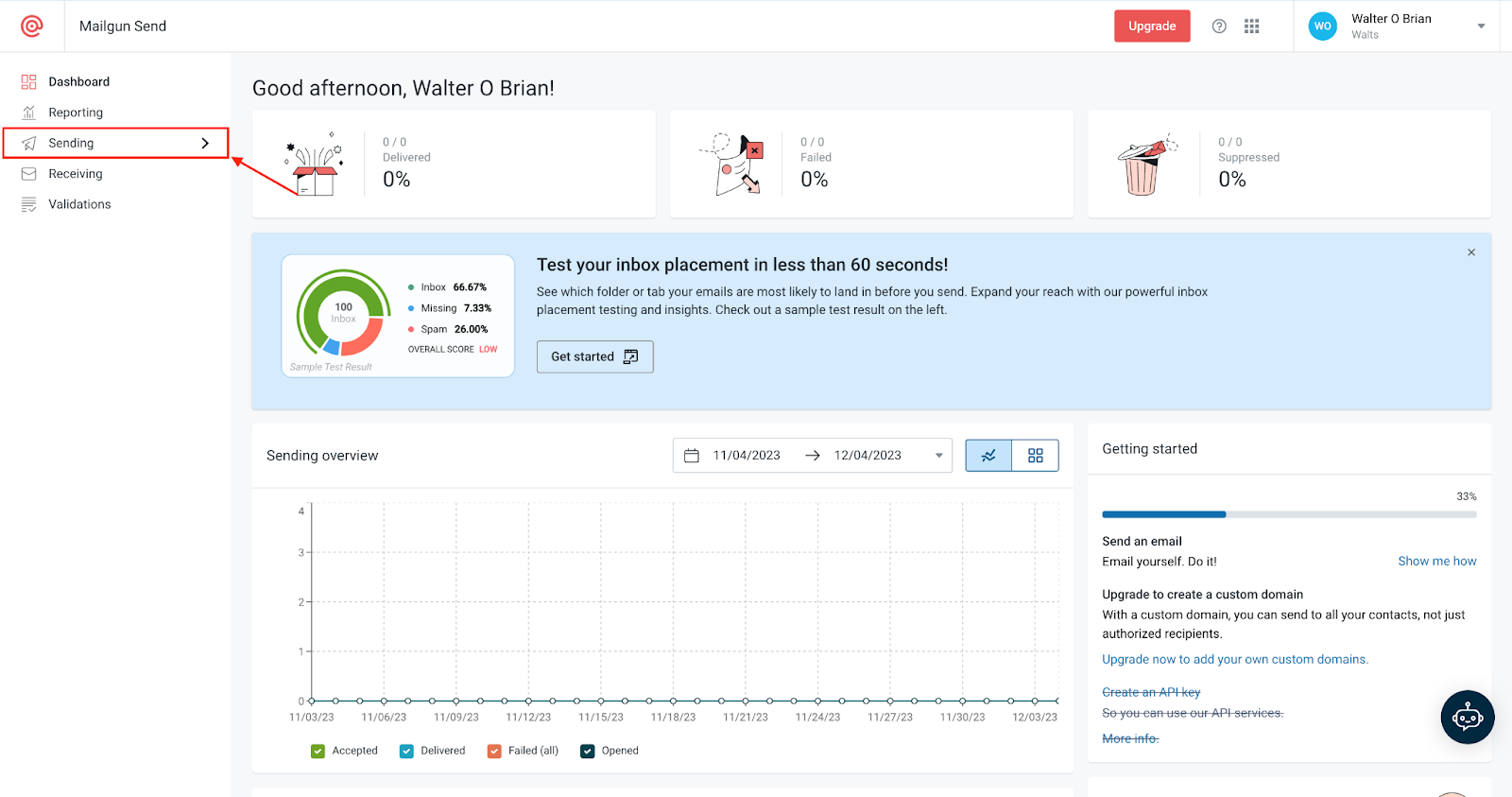
Next, select **Overview.**
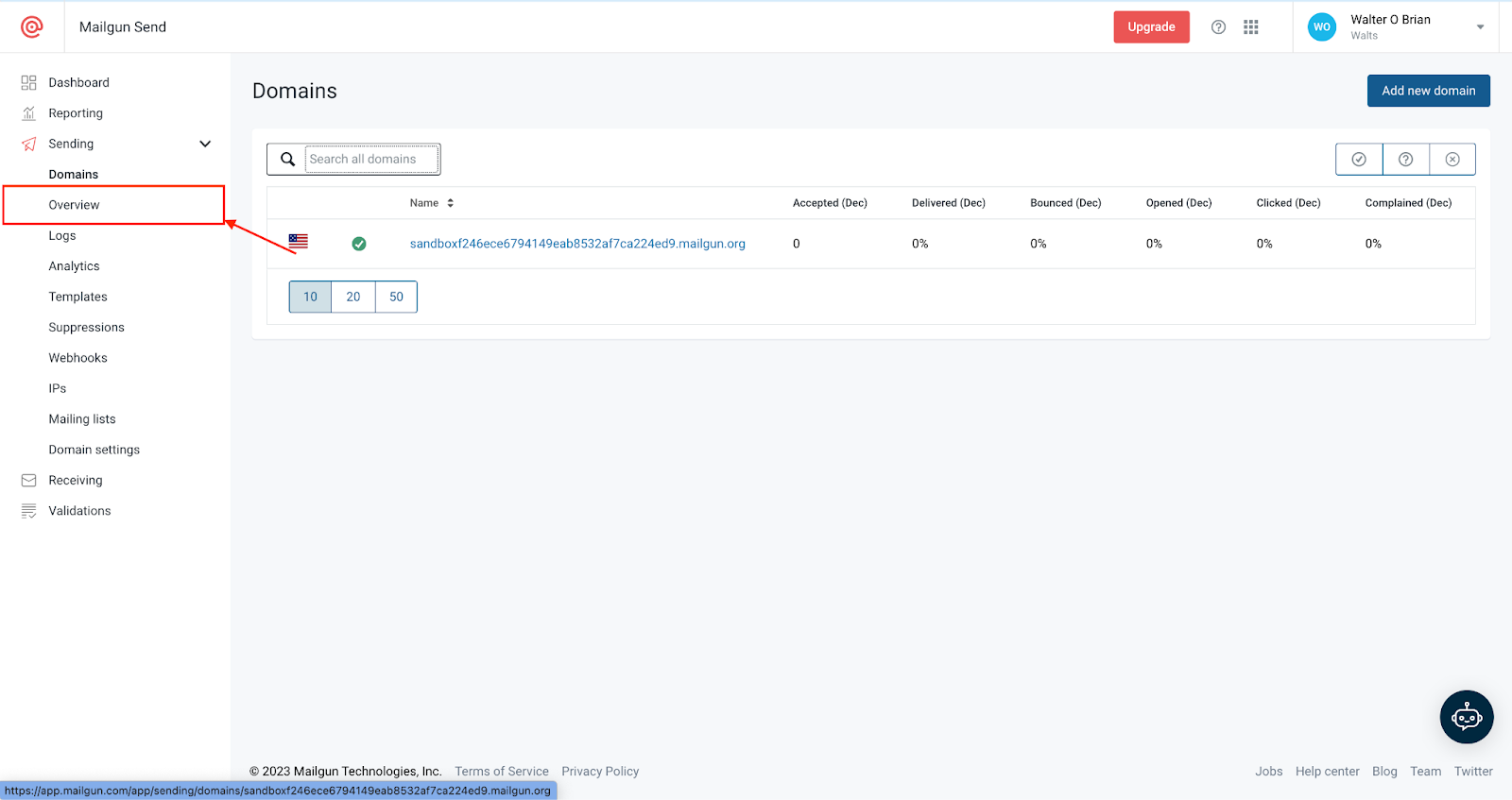
Afterward, navigate to the **SMTP** section and click **Select**.
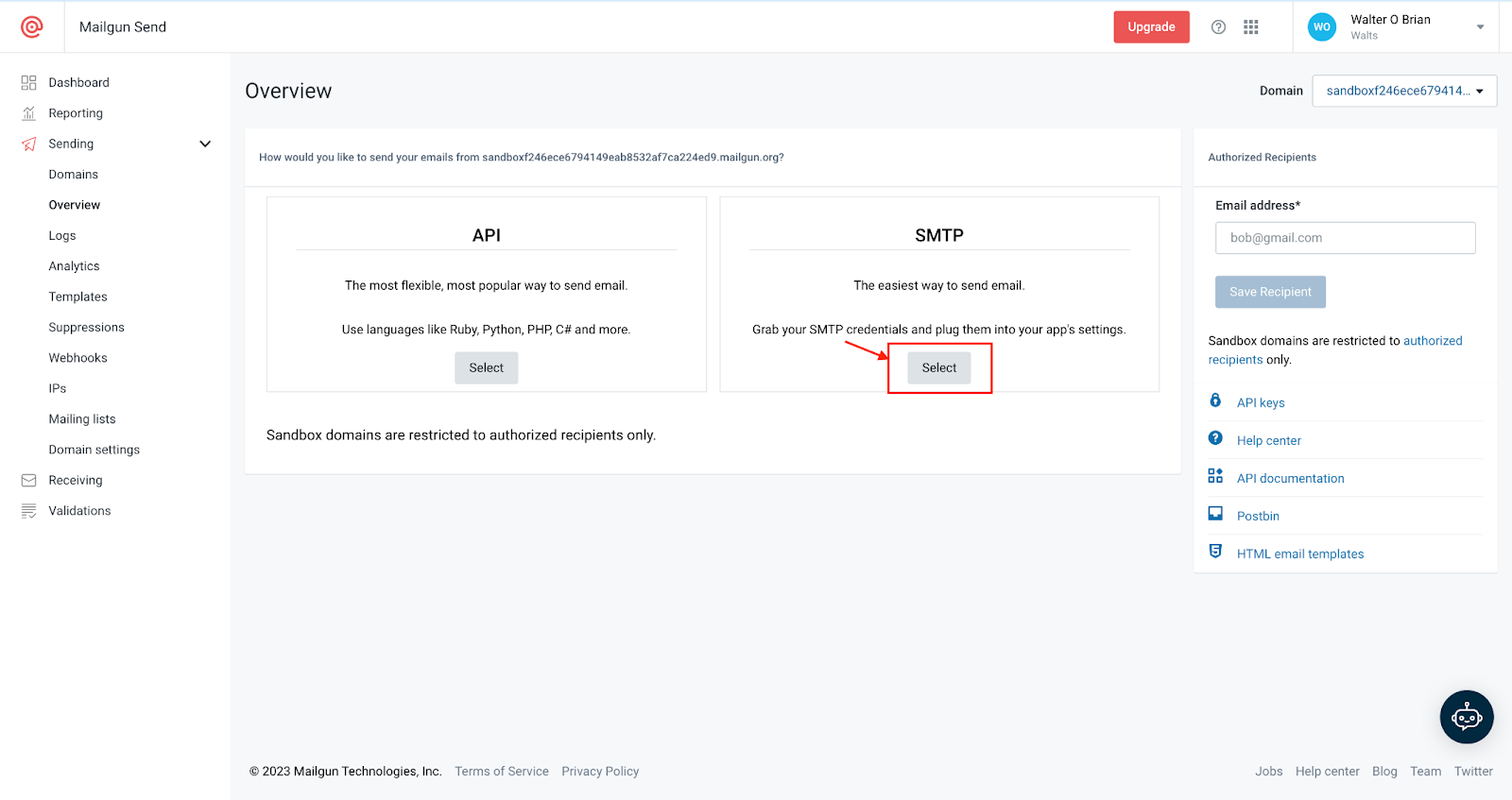
Once complete, you can retrieve the SMTP credentials from the section shown below.
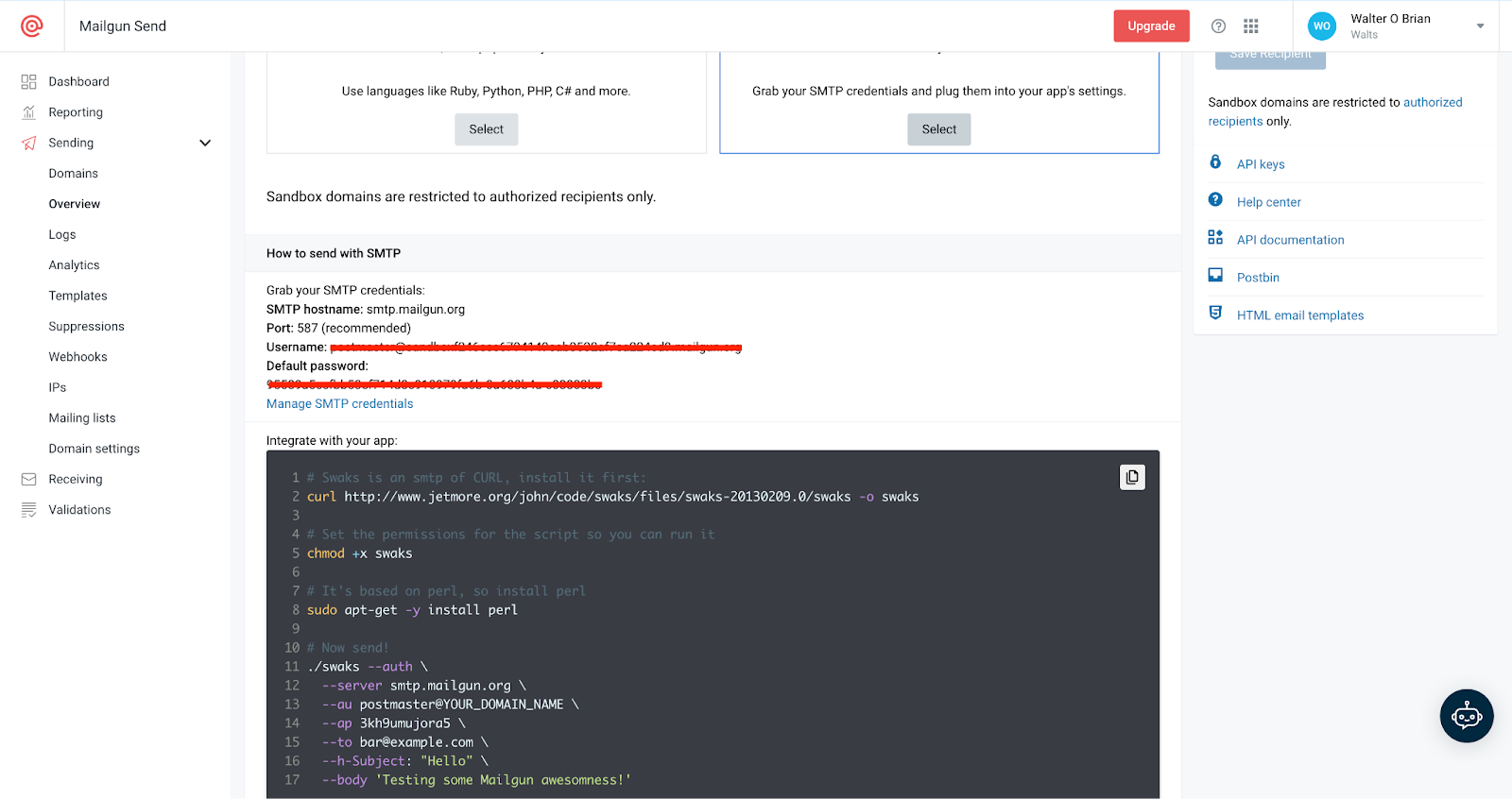
## Configuring Appwrite
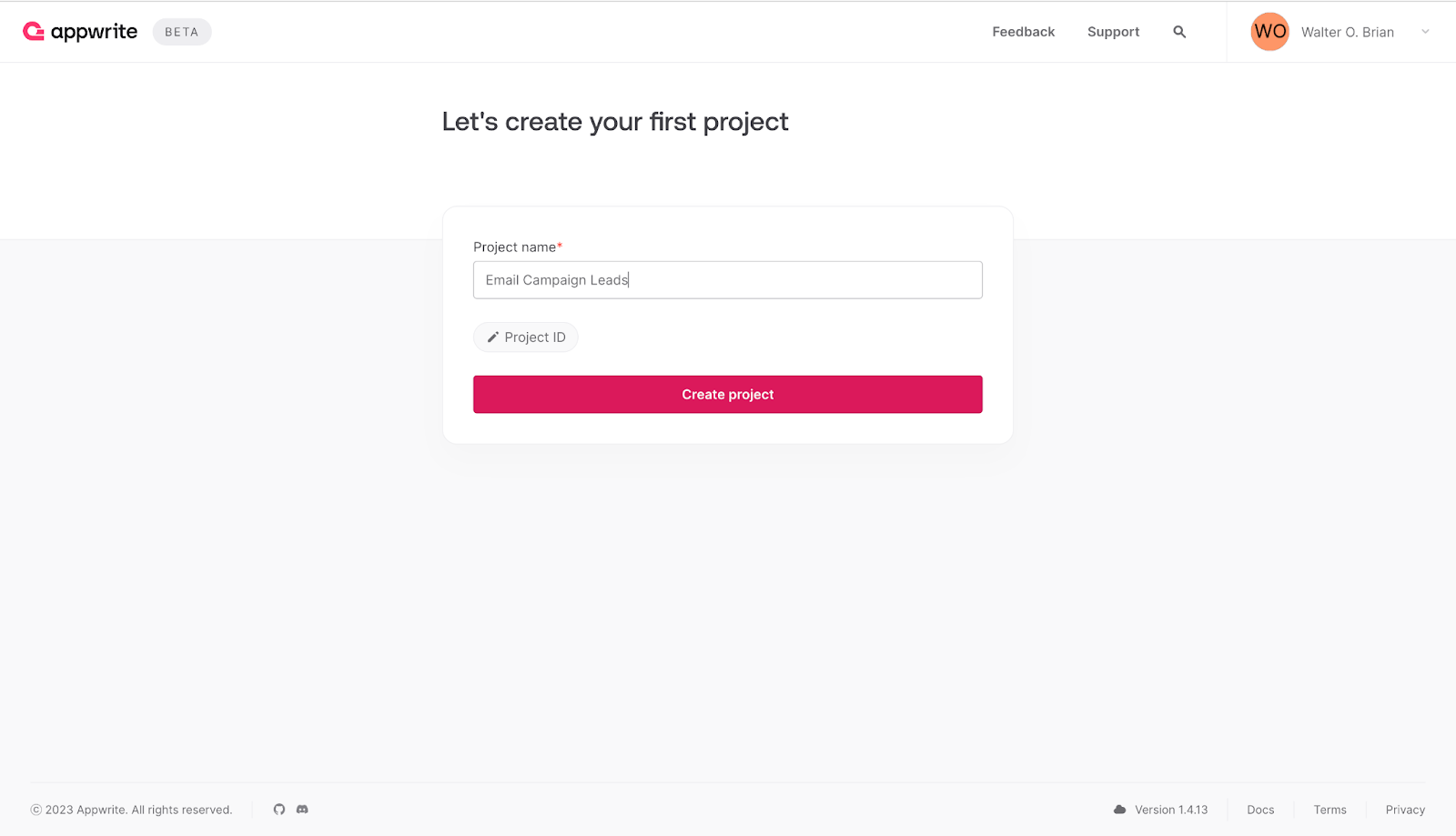
To proceed with the configuration, navigate to your Appwrite Cloud account dashboard, create a new project by entering the desired project name, and click **Create project,** as indicated below.
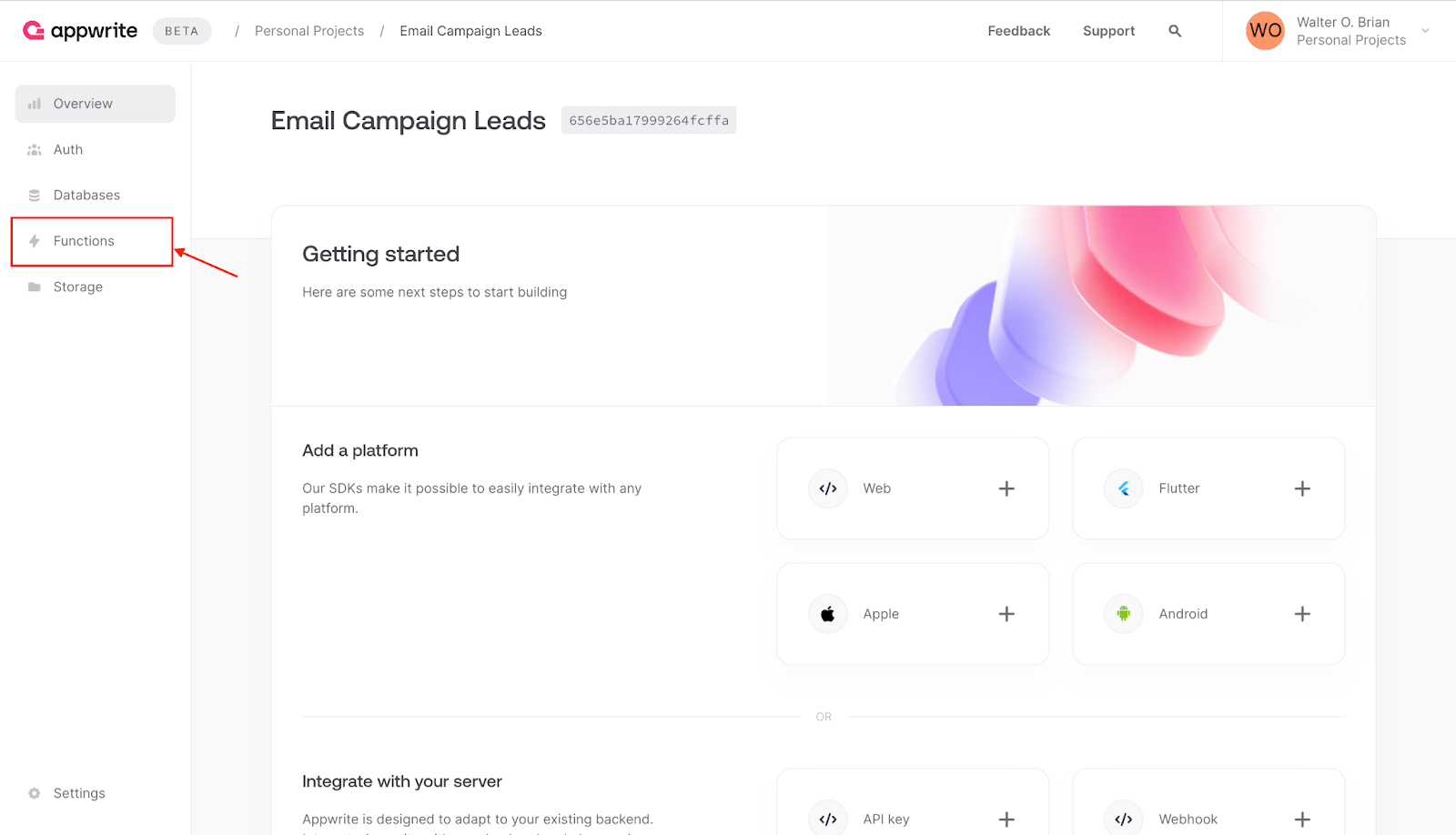
After that, click on the **Functions** menu.
Next, click the **templates** tab to view the available templates.
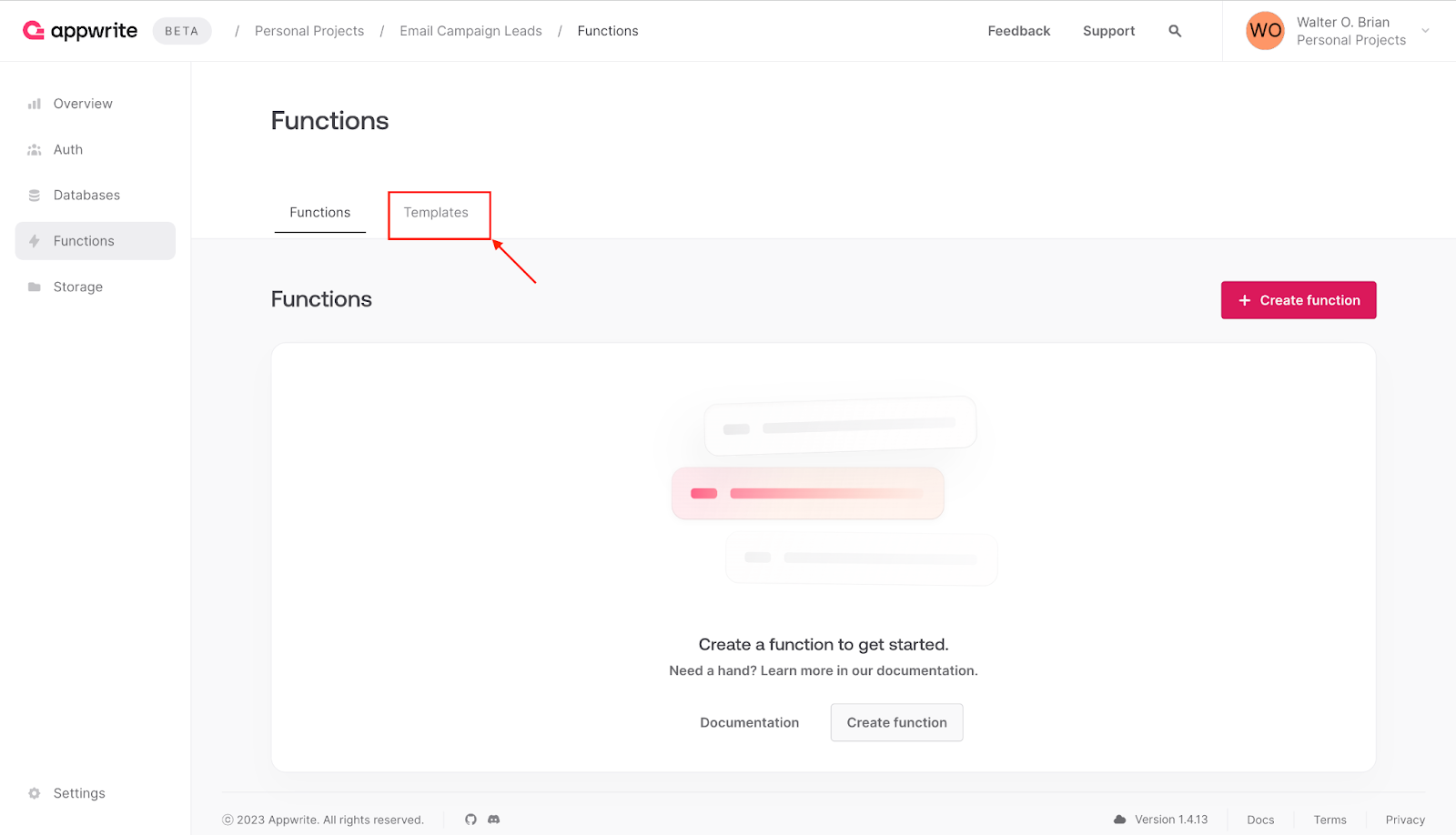
In the search field, enter **email contact form** to search for the template.
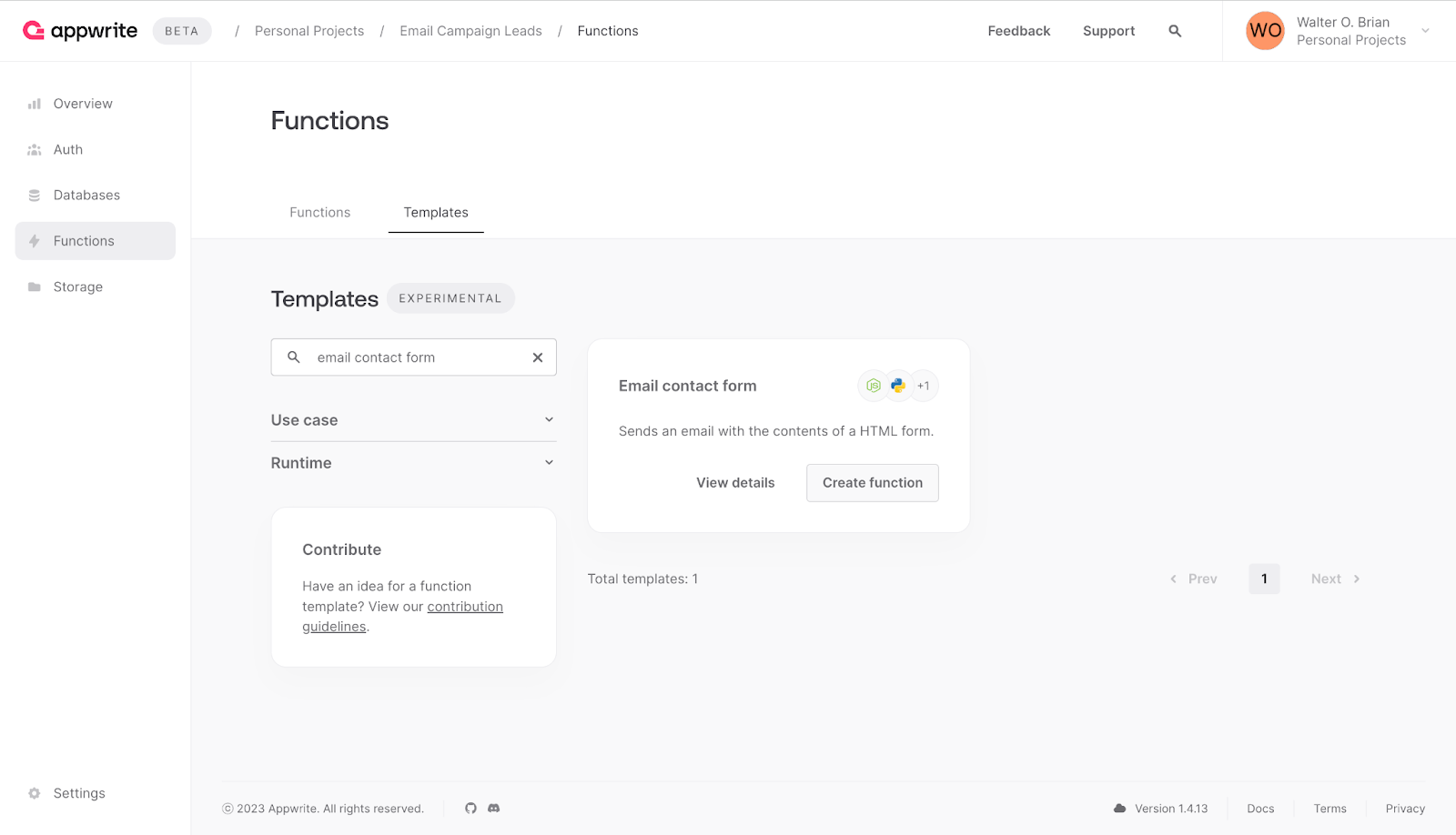
Afterward, click **Create function** to initiate the setup.
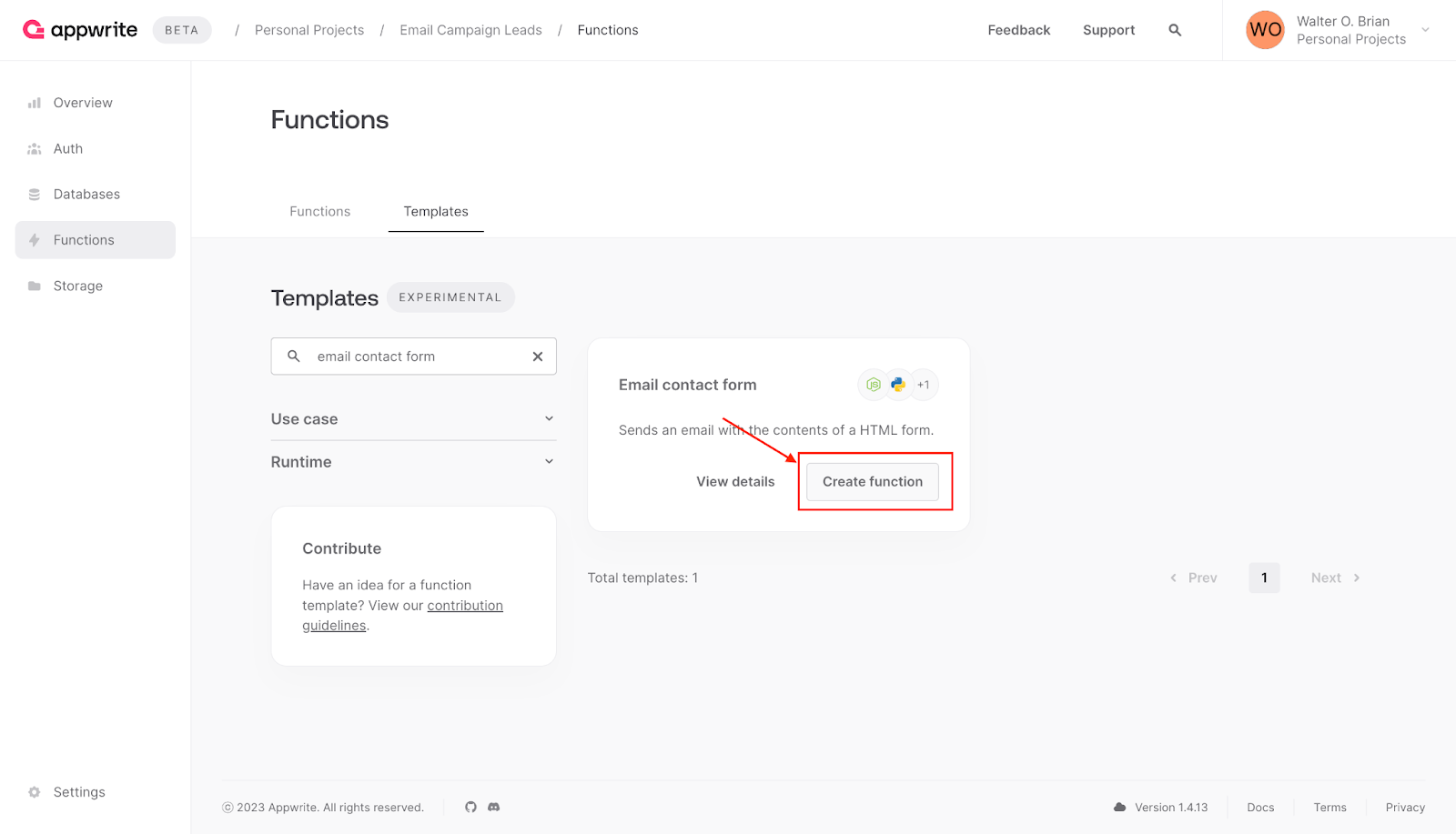
**Setting up the email contact form**
This phase involves selecting a runtime environment, adding the credentials obtained from Mailgun, and setting up the GitHub repository.
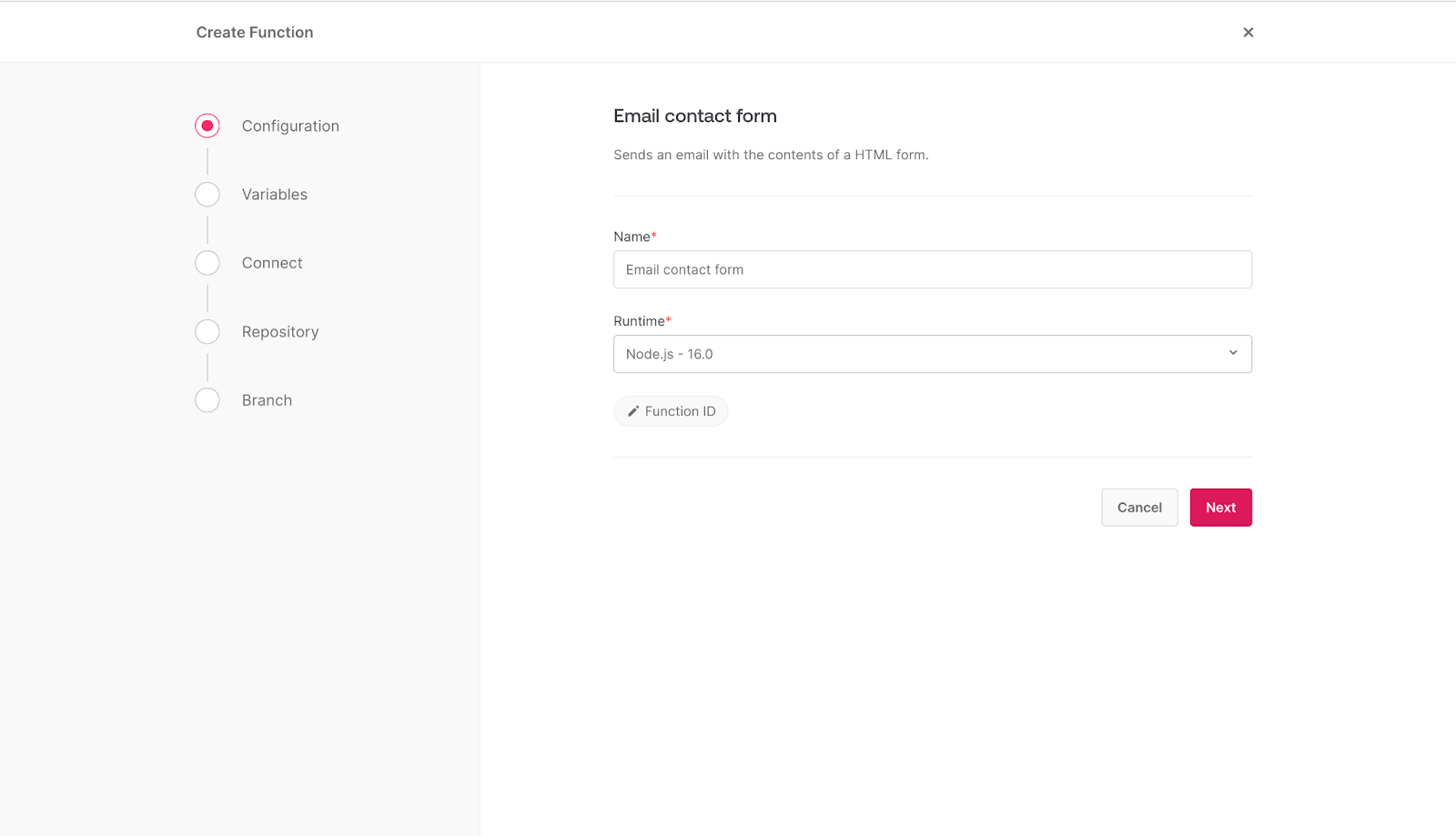
Select **Node.js - 16.0** as the runtime environment, then click **Next.**
After that, add the credentials obtained from Mailgun, as shown below.
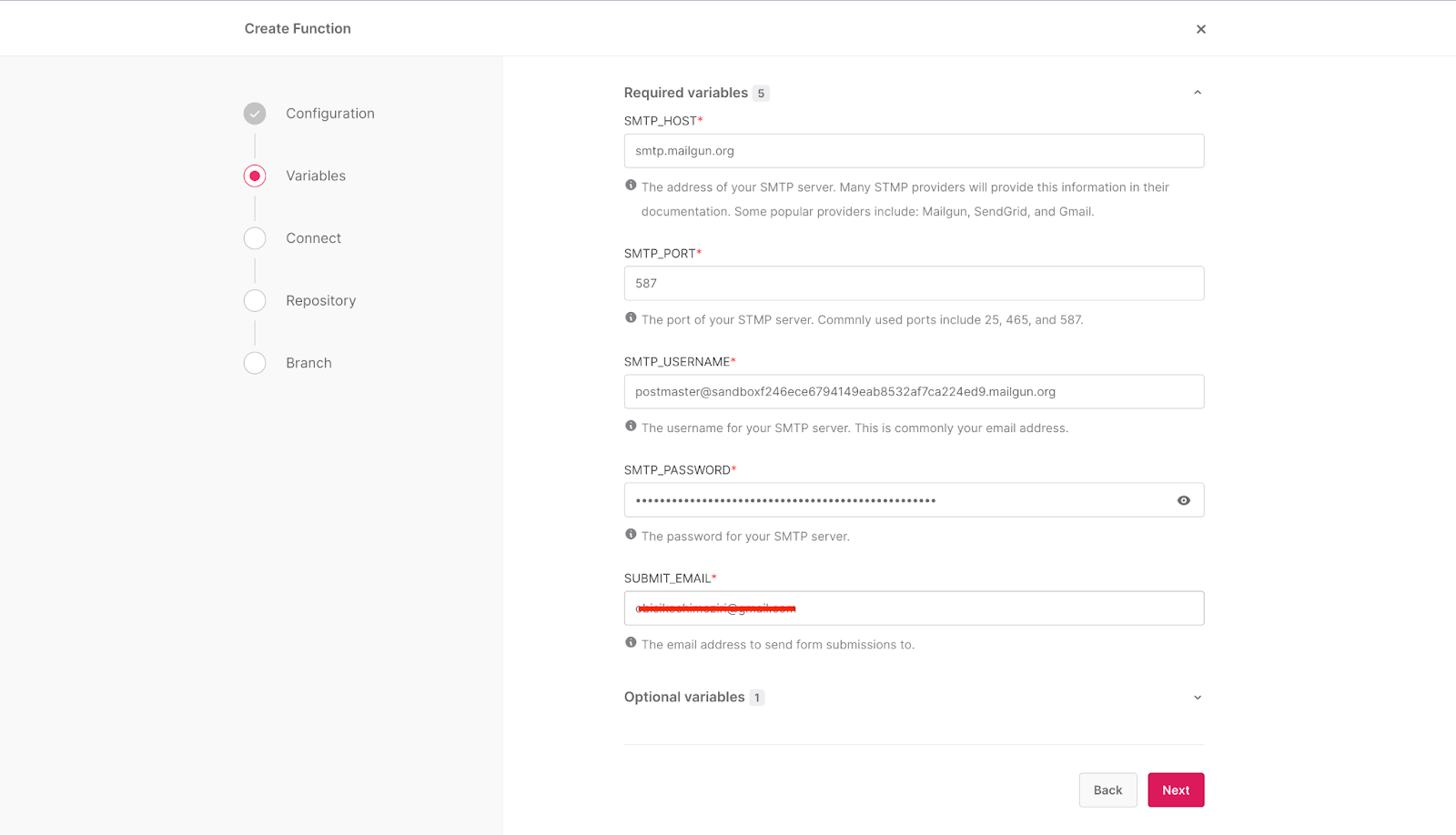
The template sends the email leads to the email address provided in the **SUBMIT_EMAIL** field. Add your preferred email to the field, and then click **Next**.
> When using Mailgun's sandbox environment, make sure the email address you provided in the **SUBMIT_EMAIL** field is authorized within Mailgun's system. For additional information, please visit this [link](https://help.mailgun.com/hc/en-us/articles/217531258-Authorized-Recipients?utm_source=hackmamba&utm_medium=hackmamba-blog). Also, note that emails sent using the sandbox environment are usually sent to the spam folder of the receiving email account.
**Connecting and setting up your GitHub repository**
At this point, you need to connect your GitHub repository to the platform. Appwrite pushes a copy of the template to your GitHub account, allowing you to personalize your version as required.
Click on the GitHub option as indicated below.
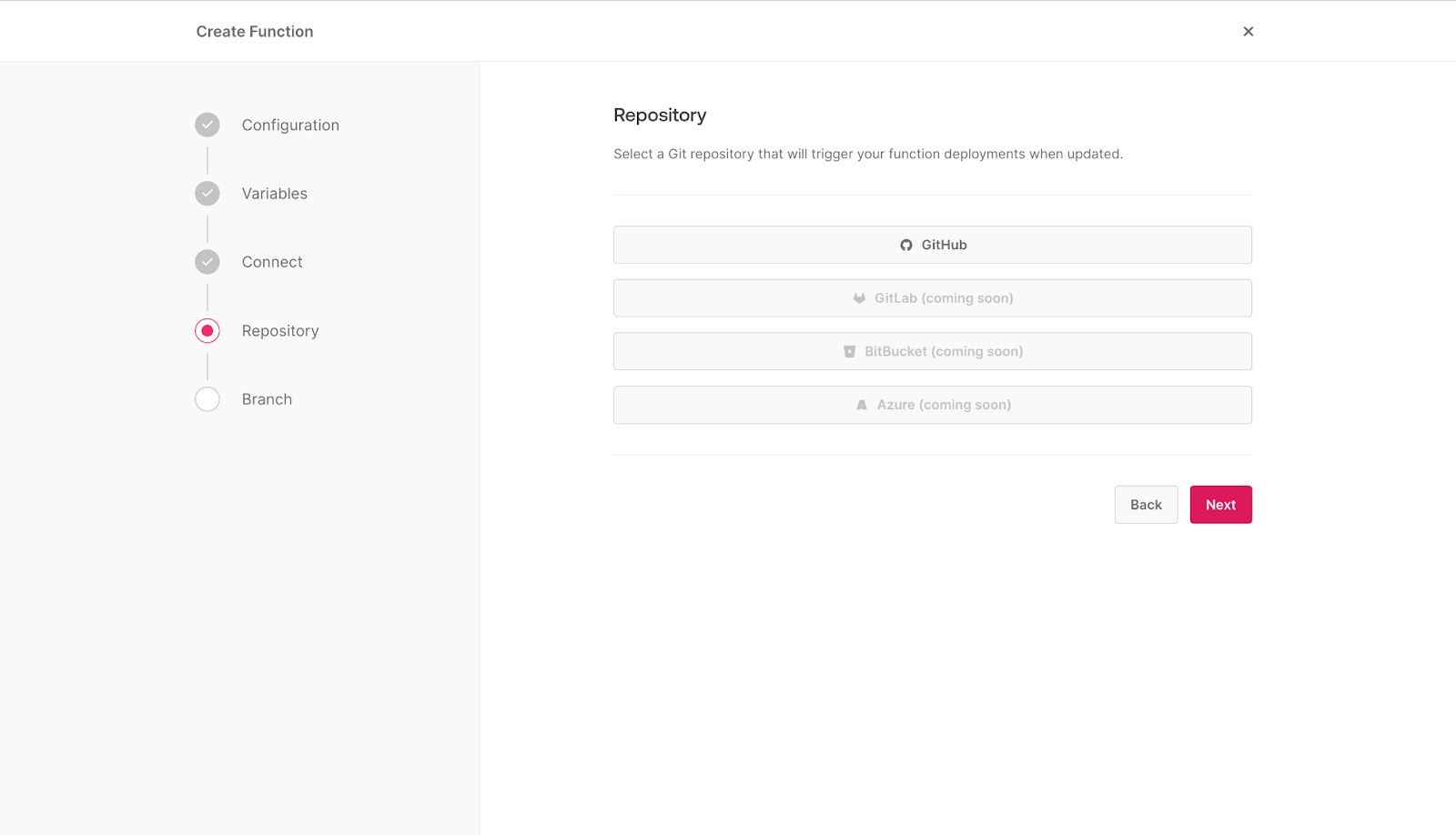
If your GitHub account is not yet connected to Appwrite, you will be redirected to GitHub to complete the connection process.
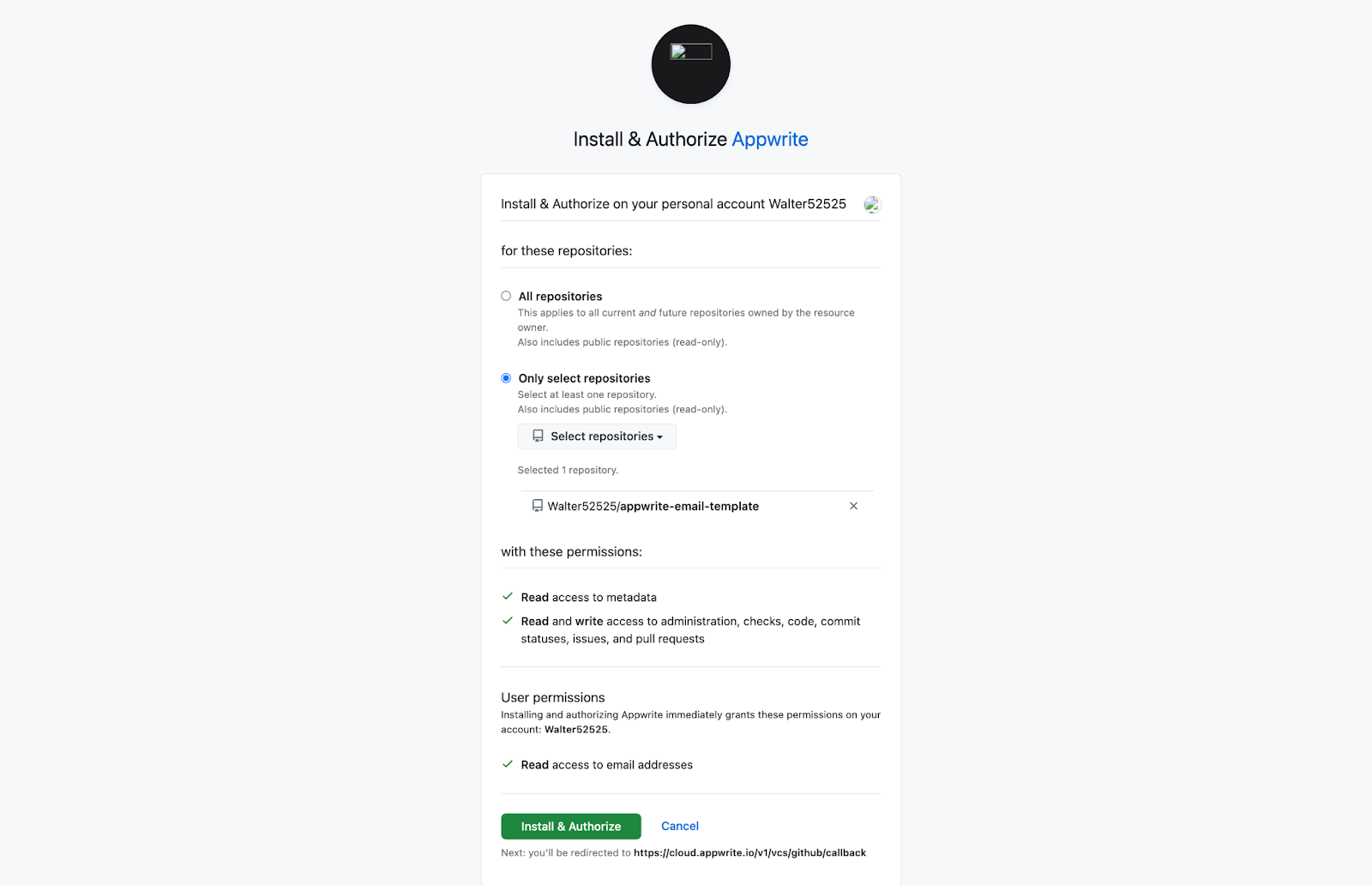
Afterward, choose the repository that was created as part of the prerequisite.
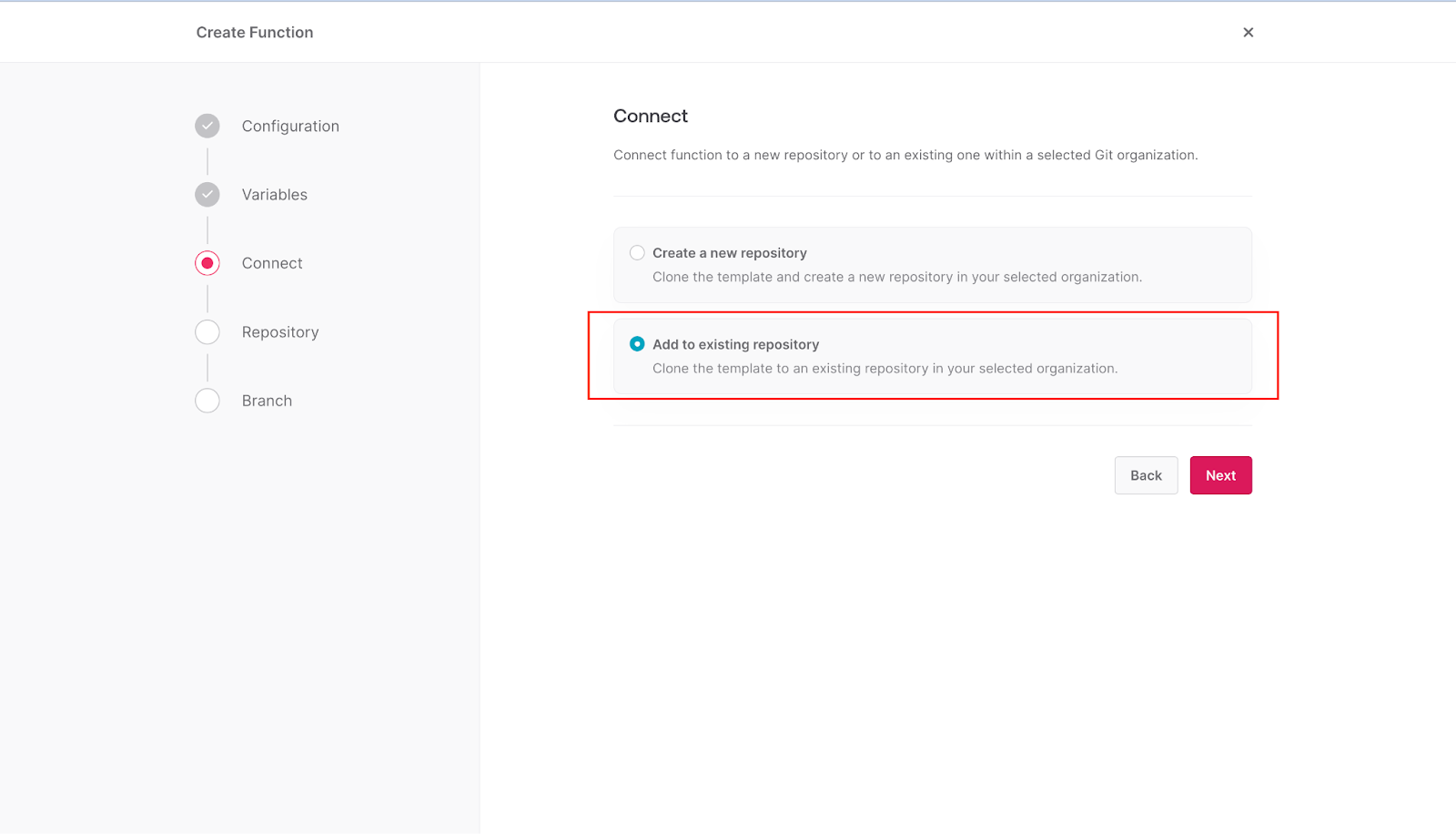
If you already have a GitHub account connected to your Appwrite cloud account, select the **Add to existing repository** option instead of **Create a new repository** and click **Next**.
Select the GitHub account and the repository of your choice, then click **Next**.
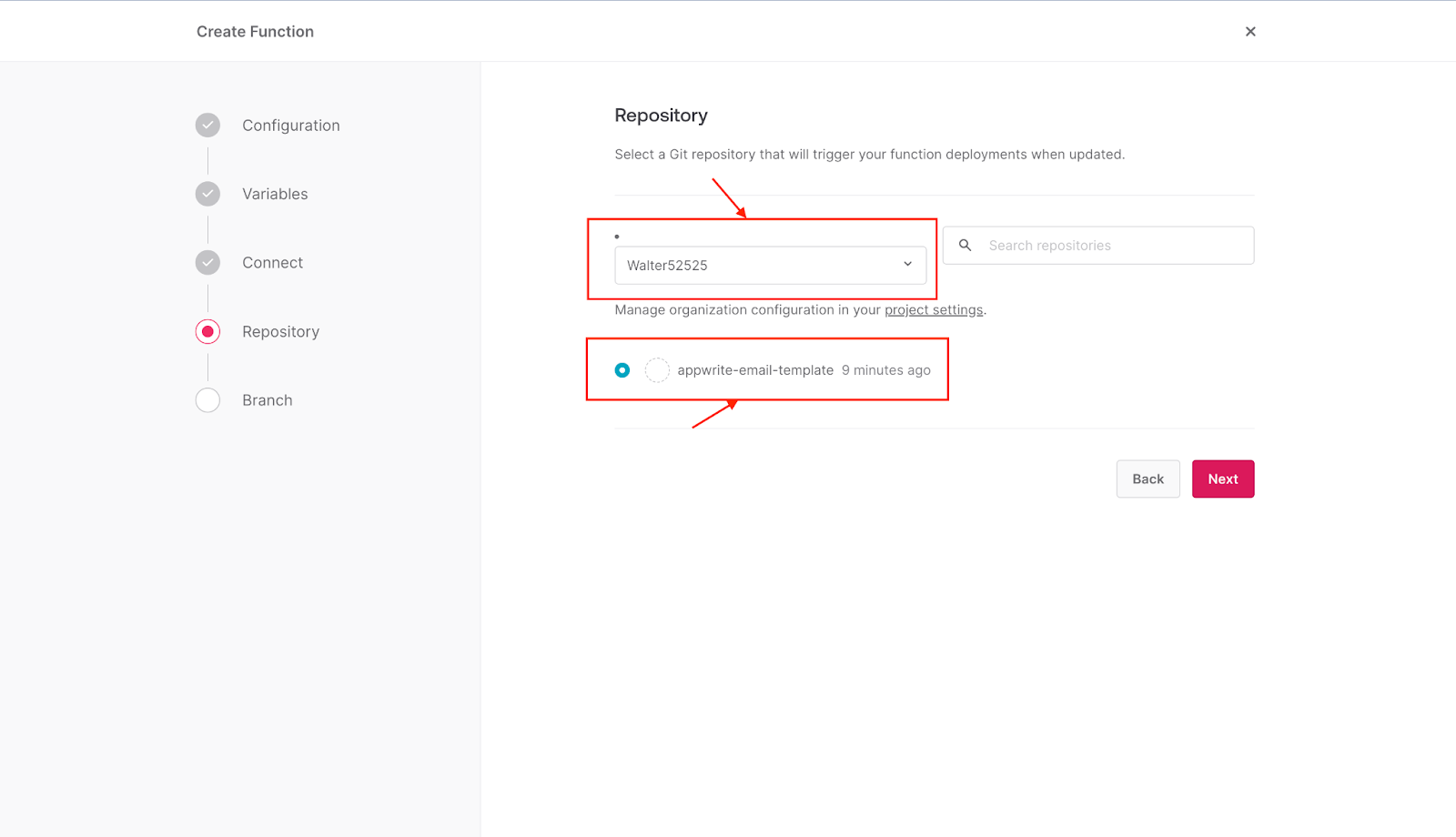
After that, select the branch you want to use and add the root directory as **function/src,** then click **Create**.
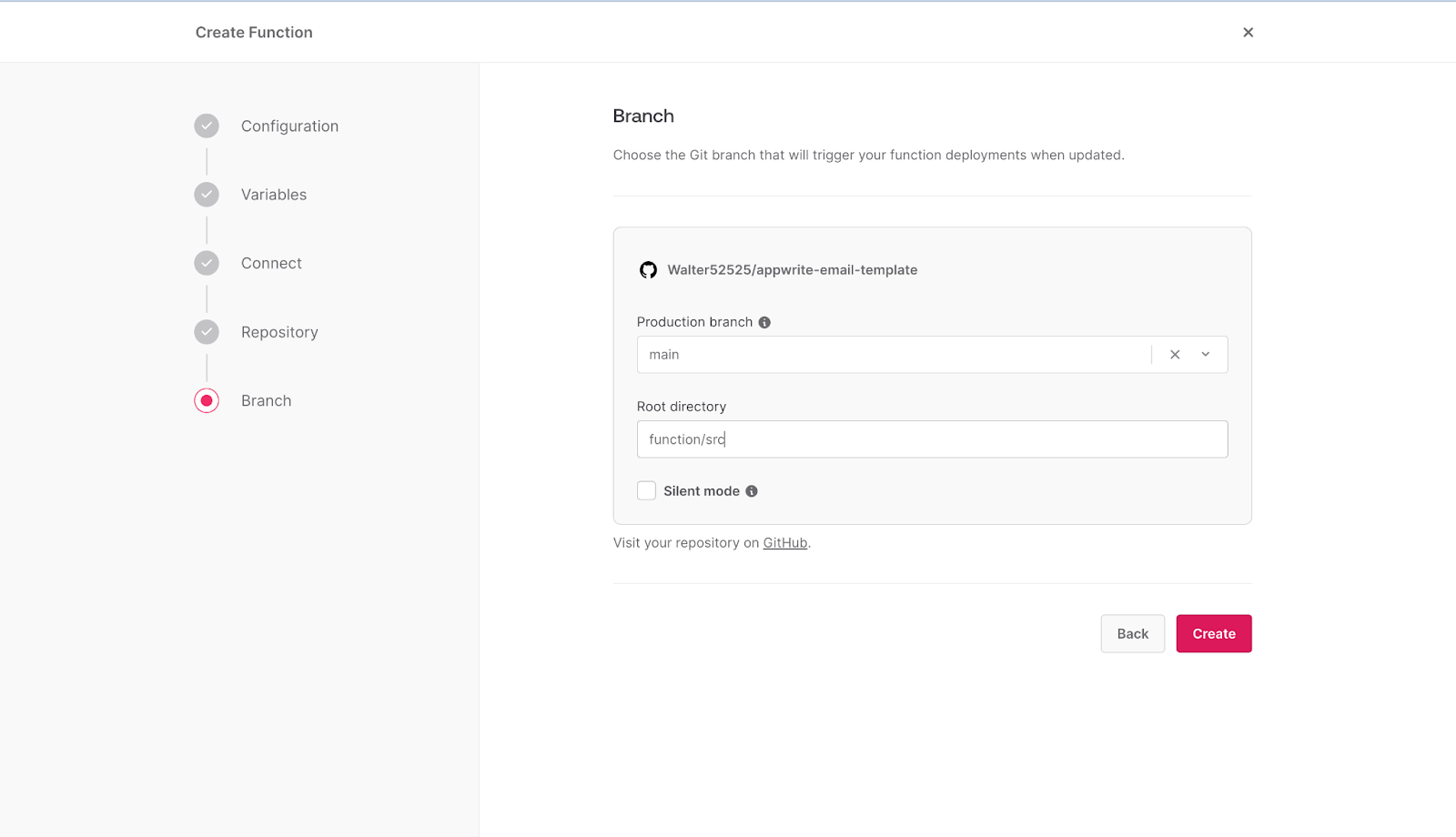
Your email contact form template is set to deploy automatically once a copy of the template's code is successfully pushed to your repository.
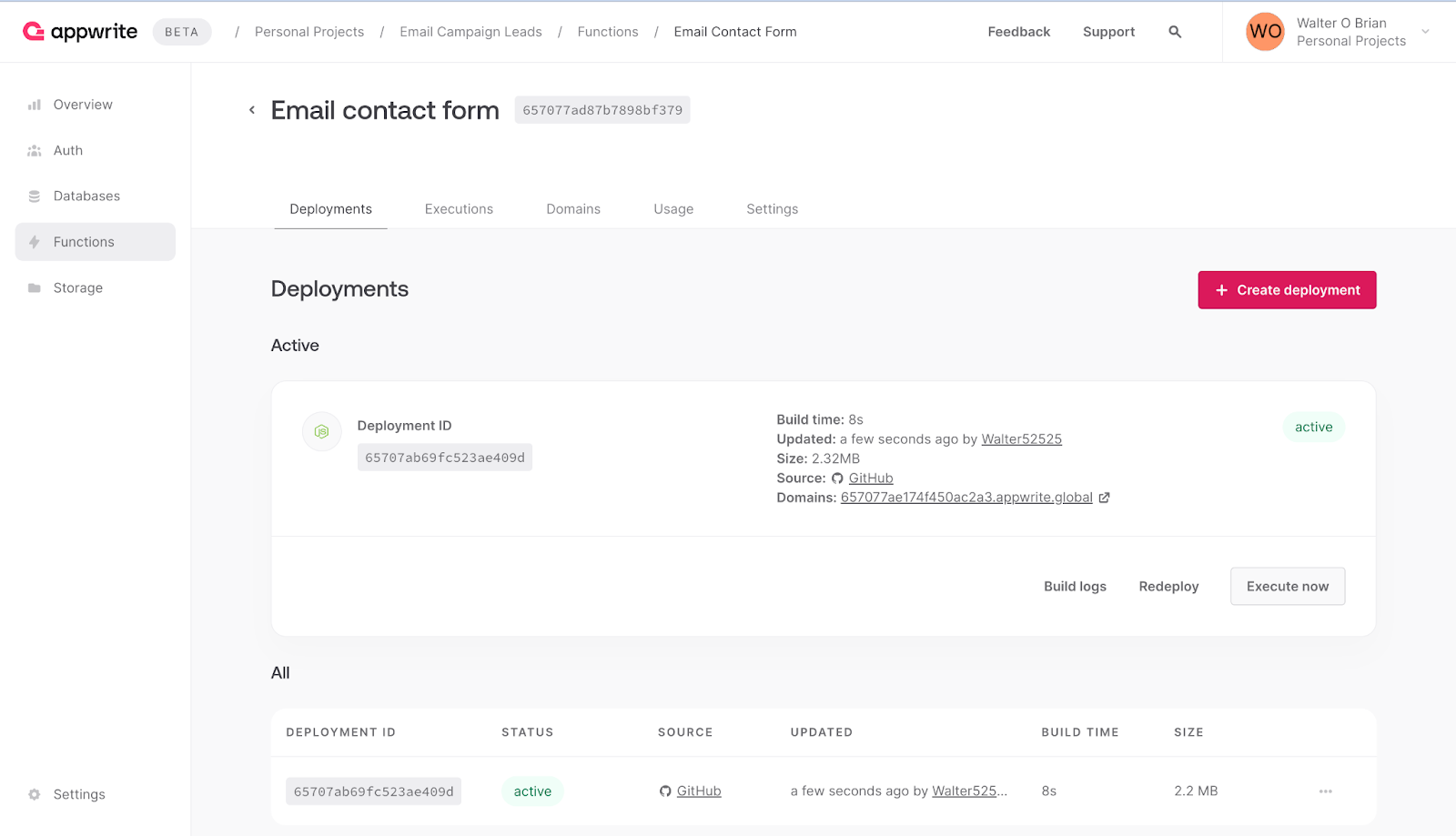
Next, navigate to your Appwrite cloud dashboard to confirm the function was deployed successfully.
## Setting up your leads collection Next.js website
For this step, you'll create your Next.js leads collection page and integrate Appwrite into the project.
To get started, navigate to your terminal and run the following command:
npx create-next-app@latest leads_pages
This command prompts you to select other packages to be used by the project. Select the options as indicated in the screenshot below.

Once completed, run the command below to change the current working directory to the project's directory.
cd leads_pages
Next, install your project's Appwrite SDK dependency by running this command:
yarn add appwrite
Afterward, open the project on your code editor.
**Adding your environment variables.**
In the root directory of your project, create a file **.env,** then add the following:
NEXT_PUBLIC_APPWRITE_FUNCTION_ID=<function_id>
NEXT_PUBLIC_APPWRITE_BASE_URL=https://cloud.appwrite.io/v1
NEXT_PUBLIC_APPWRITE_PROJECT_ID=<project_id>
You can retrieve your `<function_id>` and `<project_id>` Appwrite credentials from the Appwrite dashboard. Replace the `<function_id>` and `<project_id>` with the corresponding credentials.
**Creating your leads collection custom hook**
To promote reusability and modularity, you'll need to create the logic that handles collecting and sending the user's input to Appwrite.
To proceed, create a new folder, **hooks** in the **src/** directory.
Next, create a file **useLeadCollector.tsx,** then add the following:
{% gist https://gist.github.com/Otrex/45ac69ede7a5a54be06e69d0b6c53a39
%}
In the snippet above, there are two states, which include:
- `request` state: This keeps track of the state of the asynchronous action when the collectLeads function is called.
- `form` state: This stores the value coming from the user input.
The **collectLeads** function handles requests to the Appwrite Function specified by the `process.env.NEXT_PUBLIC_APPWRITE_FUNCTION_ID` and `process.env.NEXT_PUBLIC_APPWRITE_FUNCTION_KEY`. The email contact form function requires the request body to be sent using the **content-type** `application/x-www-form-urlencoded.` Additionally, be sure to set the **referrer** header for proper functionality.
Once the **collectLeads** function is called, the request state is toggled to **loading**, which changes the user interface to the loading interface. Next, the **throwErrorIfNot200** function handles errors returned from the Appwrite Function. If the request is successful, then the request state will be set to **completed**; otherwise, it will be set to **error**. After a 5-second delay on **error**, the state will be toggled to **idle**.
**Creating your page components**
To build the leads page, you'll be creating various components. Here's a breakdown:
- **Header:** This component houses the introductory content for the leads page.
- **About:** Offers additional information to capture the lead's interest.
- **JoinSteps:** Elaborates on the information discussed in the previous sections.
- **Footer:** Provides hyperlinks to different application sections and includes copywriter information.
- **Form:** An abstracted form interface for user interaction.
- **Contact:** The crucial section for collecting leads.
To organize your project, navigate to the **src/** directory and create a folder named **components** to store these page components.
Starting with the **Header** component, create a file **Header.tsx** in the **components** folder, then add the following code snippet.
{% gist https://gist.github.com/Otrex/a8dc4c170e8826757cef86fa0e05b6a0 %}
Next, create the About component by repeating the steps above, create the **About.tsx** file, and add the following:
{% gist https://gist.github.com/Otrex/d23b913412e12c7db73a205b26f2393b %}
After that, create the **Footer** component by creating the **Footer.tsx** file and adding the following:
{% gist https://gist.github.com/Otrex/109d61f4d102aab6ed548f95da045f1b
%}
Moving on to the **JoinSteps** component, create the **JoinSteps.tsx** file and add the code snippet below.
{% gist https://gist.github.com/Otrex/cd1014964247e863206aac19c2908a42
%}
Next, let's create the Form component. Start by creating a folder named **partials** within the **components** directory. Inside this **partials** folder, create a file **Form.tsx**. Copy and paste the following snippet into the **Form.tsx** file:
{% gist https://gist.github.com/Otrex/537cf99f68ae6ae831f71f9930e6bd99
%}
Last but not least is the **Contact** component. Create the **Contact.tsx** file and add the following:
{% gist https://gist.github.com/Otrex/effa073575c4dcaac264f12bb77bd906 %}
In the provided snippet, the Form component is rendered based on the value of the `request` state. If the request state is **idle**, then the Form component is rendered. Similarly, other request states are handled likewise.
The use of "use client" signifies that the Contact component is client-side. This is necessary because, by default, Next.js sets all components to server-side.
**Adding the components to the leads page**
Once the components are created successfully, you’ll need to add them to the leads landing page.
To do so, open the **page.tsx** file in the **src/app** directory and add the following:
```ts
import About from "@/components/About";
import Contact from "@/components/Contact";
import Footer from "@/components/Footer";
import Header from "@/components/Header";
import JoinSteps from "@/components/JoinSteps";
export default function Home() {
return (
<main className="min-h-screen text-center px-24 py-10">
<div className="max-w-[1000px] mx-auto pb-24 bg-white">
<Header />
<About />
<JoinSteps />
<Contact />
<Footer />
</div>
</main>
);
}
```
The above snippet renders the components for the user to interact with.
**Testing your leads page**
To display the page on the browser, navigate to your project's terminal and run the following:
yarn dev
This command sets up a local server environment from the project.

Extract the URL (http://localhost:3000) from your terminal and visit the page on your browser.

Here is a demonstration of the working system.
{% embed https://www.loom.com/share/77f6c30646764888b3f5b7e7b5f0a675?sid=f8609305-ab81-420b-94c9-f770ef9ef5ce %}
## Conclusion
By combining the capabilities of Appwrite and Mailgun, you can quickly set up your email marketing leads collector, streamline lead collection, and ultimately launch more successful marketing campaigns. The user-friendly setup and detailed instructions make this tutorial accessible even for those with minimal JavaScript and Git knowledge.
## Resources
- [How to automate Appwrite Functions deployment with GitHub](https://dev.to/hackmamba/how-to-automate-appwrite-functions-deployment-with-github-95e)
- [Appwrite Function documentation](https://appwrite.io/docs/products/functions?utm_source=hackmamba&utm_medium=hackmamba-blog)
- [Mailgun documentation](https://documentation.mailgun.com/en/latest/?utm_source=hackmamba&utm_medium=hackmamba-blog)
- [Git](https://docs.github.com/en)[H](https://docs.github.com/en)[ub documentation](https://docs.github.com/en)
- [Next.js documentation](https://nextjs.org/docs/)
| otrex | |
1,721,056 | How to safely use dangerouslySetInnerHTML in React | As the name suggests dangerouslySetInnerHTML should be used cautiously. It is like the innerHTML... | 0 | 2024-01-08T18:48:31 | https://deadsimplechat.com/blog/how-to-safely-use-dangerouslysetinnerhtml-in-react/ | As the name suggests `dangerouslySetInnerHTML` should be used cautiously. It is like the `innerHTML` property that is exposed by the DOM node.
With `dangerouslySetInnerHTML` you can set the HTML of the element. React does not perform any sanitization on the HTML set using `dangerouslySetInnerHTML`
It is called `dangerouslySetInnerHTML` because it is dangerous if the HTML that is set is unfiltered or unsanitized because it exposes the risk of injecting malicious code, XSS attack and other security threats that could compromise the application.
Hence `dangerouslySetInnerHTML` should be avoided unless absolutely necessary and before `dangerouslySetInnerHTML`, the HTML input should be sanitized.
In this blog post, we will look at some examples of how to use `dangerouslySetInnerHTML` and how to safely sanitize the HTML before setting using `dangerouslySetInnerHTML`.
## Basic Usage Example
Here is the basic usage example of `dangerouslySetInnerHTML`
```js
import React from "react";
export default function App() {
const htmlContent = "<p>This is raw <strong>HTML</strong> content.<p>";
return (
<div className="App">
<h1>Raw HTML</h1>
<div dangerouslySetInnerHTML={{ __html: htmlContent }}></div>
</div>
);
}
```
In the above example, we set the raw html string stored in the variable `htmlContent`
The `htmlContent` will be set as `innerHTML` of the `<div></div>` tag. We pass `dangerouslySetInnerHTML` prop an object with the key `__html` and the value should contain the HTML string that we want to set.
The HTML should be sanitized before being used with `dangerouslySetInnerHTML` as it exposes security risks. In the above example the HTML is not sanitization and doing this not recommend as it is a bad practice and would result in sever security risks.
In the next section, we will see how to sanitize the HTML string before setting it as a value using `dangerouslySetInnerHTML`.

## Sanitizing with DOMPurify
In the previous section, we specified the HTML string and setting it directly to `dangerouslySetInnerHTML` which is not a good practice.
In this section, we will use the package **DOMPurify** to santize our HTML string before using it in `dangerouslySetInnerHTML`.
Let's first install the DOMPurify package using npm install
```bash
npm install dompurify
```
Then we will update our component to use DOMPurify:
```js
import React from "react";
import DOMPurify from "dompurify";
export default function App() {
const htmlContent = "<p>This is raw <strong>HTML</strong> content.<p>";
const sanitizedHtmlContent = DOMPurify.sanitize(htmlContent);
return (
<div className="App">
<h1>Raw HTML</h1>
<div dangerouslySetInnerHTML={{ __html: sanitizedHtmlContent }}></div>
</div>
);
}
```
Using the DOMPurify library is very easy, we just need to call the `santize` method on the DOMPurify library and it returns the sanitized version of the HTML.
We can then pass the sanitized version to dangerouslySetInnerHTML prop.
### Verifying HTML Sanitization
To check if our DOMPurify, we will inject an XSS payload into our HTML string and see if our DOMPurify correctly escapes the HTML script.
```js
import React from "react";
import DOMPurify from "dompurify";
export default function App() {
const htmlContent = "<script>alert(1);</script>";
const sanitizedHtmlContent = DOMPurify.sanitize(htmlContent);
return (
<div className="App">
<h1>Raw HTML</h1>
<div dangerouslySetInnerHTML={{ __html: sanitizedHtmlContent }}></div>
</div>
);
}
```
We have updated our `htmlContent` to `<script>alert(1);</script>` and if our HTML is not sanitized correctly then the page will display an alert with 1.
Apart from DOMPurify there are other sanitization libraries available, that you can use like sanitize-HTML. But when choosing a library make sure you use a library that is actively developed, has a large user base and is widely used.
## Alternatives to Consider before using dangerouslySetInnerHTML
dangerouslySetInnerHTML should be used only when it is absolutely necessary and should be avoided whenever possible due to the security risks.
Always other options should be considered before using dangerouslySetInnerHTML, and here are some of the options that you should consider, but make sure to santize your HTML using a library like DOMPurify first:
1. **Try to use JSX First:** You should first try to use JSX, if you have legacy code that you want to integrate, or you are integrating some 3rd party library try to use it JSX and with refs and only use dangerouslySetInnerHTML as the last resort.
2. **Use Library that converts HTML to JSX:** There are multiple libraries available which parses HTML into JSX, you can try to use those libraries as well, some of the popular options include:
- html-react-parser: It allows you to parse raw HTML and convert it into React elements. It is a safer alternative to dangerouslySetInnerHTML. However you still need to sanitize the HTML. As of writing this library has 1.6K stars on Github and 990,820 weekly downloads on npm
- react-html-parser: This also allows you to convert raw HTML into react components, and it is similar to html-react-parser. It has 742 starts on github as of writing and 277k weekly download on NPM. Also thing to note that it was last updated in 2020.
Before using these libraries make sure to sanitize the HTML using HTML sanitization libraries like DOMPurify.
## Scenarios where dangerouslySetInnerHTML could be used
Sometimes it is inevitable to use dangerouslSetInnerHTML and there are cases where you cannot get away without using dangerouslySetInnerHTML, let. discuss some of those scenarios:
1. **HTML data coming from a Trusted Source:** When your HTML content is coming from a Trusted Source like your Content Management System or from the Server Generated content. In these cases, you can use the dangerouslSetInnerHTML. But make sure that you trust the source of the data.
2. **Properly Sanitized Content:** You can safely use dangerouslySetInnerHTML content that is properly sanitized. Make sure you use a robust and well-tested sanitization library to escape any unsafe tags and XSS code.
3. **When Integrating 3rd Party Libraries:** Some 3rd Party libraries do not integrate well in React, in those cases you have to use dangerouslySetInnerHTML to integrate the library with your code. But before doing that make sure you trust the library and is well-vetted and does not expose your application to any security risk, and generate content is well-sanitized.
## Building a Markdown Editor in React using ShowDown, DOMPurify and dangerouslySetInnerHTML
Let's build a Markdown editor, that displays that Markdown output in HTML in real-time.
To build this application we will build a component that would take markdown and convert it into HTML.
We will also use the library will work in the following manner:
1. Build a React Component Accept Markdown text as a prop
2. Use ShowDown to convert Markdown to HTML
3. Use DOMPurify to sanitize the rendered HTML
## Building MarkDownViewer
We will create a `MarkdownViewer.js` component, which will accept markdown as a prop and convert it into HTML and display it on the screen.
Create a file called as `src/MarkdownViewer.js` and add the following code:
```js
import showdown from "showdown";
import DOMPurify from "dompurify";
import React from "react";
function MarkdownViewer({ md, styles, className }) {
const converter = new showdown.Converter();
const html = converter.makeHtml(md);
const sanitizedHTML = DOMPurify.sanitize(html);
return (
<div
styles={styles}
className={className}
dangerouslySetInnerHTML={{ __html: sanitizedHTML }}
></div>
);
}
export default MarkdownViewer;
```
In the above code, we have created a `MarkdownViewer` component, we have first imported the dependencies `showdown` and `dompurify`.
You can install them using npm
```bash
npm install showdown
npm install dompurify
```
Then we are creating a `converter` object and converting markdown to html.
```js
const html = converter.makeHtml(md);
```
Then we are sanitizing the generated HTML using the `DOMPurify` library:
```js
const sanitizedHTML = DOMPurify.sanitize(html);
```
Finally, we set the generated HTML as `dangerouslySetInnerHTML` to the div tag
```js
return (
<div
styles={styles}
className={className}
dangerouslySetInnerHTML={{ __html: sanitizedHTML }}
></div>
);
```
## Building the Editor
The Editor Component is very simple, it will contain a textarea and will accept `onChange` method as a prop.
Create a file called as `src/Editor.js` to hold our Editor Component.
We will call the onChange method from the prop when the value of the textarea changes.
```js
export default function Editor({ onChange, styles, className }) {
return (
<textarea
styles={styles}
className={className}
onChange={onChange}
></textarea>
);
}
```
## Putting it all together
Now, let's open our `src/App.js` file and import the MarkdownViewer and Editor components.
We will attach the onChange listener to the Editor component, get the value from the Editor and set it as a prop to the MarkdownViewer component to display the Markdown typed by the user.
```js
import React, { useState } from "react";
import Editor from "./Editor";
import MarkDownViewer from "./MarkdownViewer";
import "./styles.css";
export default function App() {
const [editorValue, setEditorValue] = useState("");
function handleOnChange(event) {
setEditorValue(event.target.value);
}
return (
<div className={"container"}>
<Editor className={"half"} onChange={handleOnChange} />
<MarkDownViewer className={"half"} md={editorValue} />
</div>
);
}
```
In the above cover, we have created a state variable called as editorValue and created a method called as handleOnChange.
We are passing the handleOnChange method as a prop to the Editor component, when the value changes in the Editor Component, we are updating the editorValue when textarea changes.
Then we are passing editorValue to the Markdown viewer component.
## Demo
Here is the Demo of our Markdown Editor
## [Metered TURN servers](https://www.metered.ca/stun-turn)
1. Global Geo-Location targeting: Automatically directs traffic to the nearest servers, for lowest possible latency and highest quality performance. less than 50 ms latency anywhere around the world
2. Servers in 12 Regions of the world: Toronto, Miami, San Francisco, Amsterdam, London, Frankfurt, Bangalore, Singapore,Sydney (Coming Soon: South Korea, Japan and Oman)
3. Low Latency: less than 50 ms latency, anywhere across the world.
4. Cost-Effective: pay-as-you-go pricing with bandwidth and volume discounts available.
5. Easy Administration: Get usage logs, emails when accounts reach threshold limits, billing records and email and phone support.
6. Standards Compliant: Conforms to RFCs 5389, 5769, 5780, 5766, 6062, 6156, 5245, 5768, 6336, 6544, 5928 over UDP, TCP, TLS, and DTLS.
7. Multi‑Tenancy: Create multiple credentials and separate the usage by customer, or different apps. Get Usage logs, billing records and threshold alerts.
8. Enterprise Reliability: 99.999% Uptime with SLA.
9. Enterprise Scale: With no limit on concurrent traffic or total traffic. Metered TURN Servers provide Enterprise Scalability
10. 50 GB/mo Free: Get 50 GB every month free TURN server usage with the Free Plan
11. Runs on port 80 and 443
12. Support TURNS + SSL to allow connections through deep packet inspection firewalls.
13. Support STUN
14. Supports both TCP and UDP
## Conclusion
In this blog post, we have learned what `dangerouslySetInnerHTML` is, and how to safely use it in our application.
We have also looked at ways to avoid using dangerouslySetInnerHTML and its alternatives and also looked at ways to safely escape the HTML code before rendering it using `dangerouslySetInnerHTML`. | alakkadshaw | |
1,721,152 | Create an NFT as a Developer: Deep Dive into Smart Contracts | Why NFTs? First, I do not believe NFTs are a big deal or critical to the future of web3. yes, I said... | 0 | 2024-01-08T17:24:38 | https://blog.learnhub.africa/2024/01/08/create-an-nft-as-a-developer-deep-dive-into-smart-contracts/ | <h4 data-pm-slice="1 1 []"><strong>Why NFTs?</strong></h4>
First, I do not believe NFTs are a big deal or critical to the future of web3. yes, I said so, but I am a programmer. I love coding and spending time on Patrick's course; I came across NFTs and learned a lot about them.
Does that mean I have changed my mind that NFTs are just a bunch of overhyped arts or whatever with no direct impact towards a sustainable future?
Absolutely Yes!.
NFTs (non-fungible tokens) have exploded in popularity recently as a way to represent ownership of unique digital assets. But why exactly are NFTs taking off?
NFTs provide a way to prove scarcity and ownership in the digital world. Unlike most digital content, which can be freely copied and distributed, each NFT is unique and not interchangeable.
This makes them similar to physical assets like artwork or collectibles. Just as you can prove you own an original Picasso, you can prove an NFT tied to a specific digital asset.
For creators, NFTs provide a new stream of revenue and a way to connect with fans. By selling limited edition NFTs, creators can monetize their work without relying solely on advertising or subscriptions. Fans also benefit from getting special access, content, or status by owning their favorite creators' NFTs.
NFTs introduce transparency and traceability into digital ownership. All NFT transactions are recorded on the blockchain ledger permanently. This prevents fakes or fraud while allowing owners to trace an NFT's full ownership history.
Finally, NFTs enable new types of digital art, content, and experiences. Without NFTs, most digital content lacks scarcity and authenticity. But NFTs allow the creation of provably rare digital goods, ushering in new trends like NFT art and virtual fashion.
<h4><strong>Smart Contracts for NFTs</strong></h4>
Most NFTs are issued and traded through smart contracts deployed on blockchains like Ethereum. A smart contract is a code that runs on a chain and controls logic like NFT issuance, ownership transfers, listings, bids, and more.
Writing smart contracts is a key skill for developing and understanding NFT projects. We can demystify how NFT mechanics work under the hood by diving into real NFT smart contract code.
We'll walk step-by-step through a basic NFT smart contract written in the Solidity language. We'll deploy it on the Ethereum testnet to mint some test NFTs for free. You'll have hands-on experience deploying an NFT smart contract from scratch by the end!
<h4><strong>OpenZeppelin Contracts</strong></h4>
We'll utilize some helpful building blocks from <a class="attrlink" href="https://www.openzeppelin.com/contracts" target="_blank" rel="noreferrer nofollow noopener">OpenZeppelin Contracts</a> for our contract. This is a library of secure, community-audited smart contracts for Ethereum and other blockchains.
As you can imagine, writing smart contracts from scratch introduces risks like security vulnerabilities and subtle bugs. By using community code that's heavily tested and audited, we can stand on the shoulders of giants.
Specifically, we'll inherit from OpenZeppelin's implementation of the ERC-721 standard. This standard defines a set of functions all NFT contracts should implement, like <code>mint</code>, <code>transfer</code>, and <code>ownerOf</code>.
By inheriting from a standard base, our NFTs will be compatible with external apps and marketplaces looking for contracts following ERC-721.
Here's how our contract import looks:
<code>import "@openzeppelin/contracts/token/ERC721/ERC721.sol";</code>
We also have to pass this contract as the parent contract in our inheritance:
```javascript
contract myNFT is ERC721 {
// Our contract code
}
```
This contract inheritance allows us to focus on <strong>our custom NFT behavior rather than reimplementing NFT basics</strong>.
<h4><strong>NFT Contract Walkthrough</strong></h4>
Below, I'll walk through our contract section-by-section, explaining how each piece works:
<pre><code class="language-solidity">// Contract name
contract myNFT is ERC721 {
}</code></pre>
First we define our contract name as myNFT and inherit from ERC721.
Next, we define some contract state variables:
```javascript
uint private s_tokenCounter; // Internal counter for NFTs minted
mapping(uint256 => string) private s_tokenURIs; // Map NFT ids to associated URI
```
Here, we define a unit counter to track how many NFTs have been minted. This will be the unique identifier for each NFT.
We also define a mapping from the <code>uint ID</code> to a <code>string URI</code>. This will point out our NFT resources like images, metadata, etc.
In the contract constructor, we initialize the counters:
```javascript
constructor() ERC721("UselessCoin", "ULC") {
s_tokenCounter = 0;
}
```
Note we call the ERC721 constructor with a name and symbol for our NFT collection.
Then, we set our counter to 0.
Next, we add our main NFT minting function:
```javascript
function mintNFT(string memory tokenURI) public {
_safeMint(msg.sender, s_tokenCounter);
s_tokenURIs[s_tokenCounter] = tokenURI;
s_tokenCounter = s_tokenCounter + 1;
}
```
This takes in a <code>tokenURI</code> string pointing to the NFT resource.
It uses OpenZeppelin's <code>_safeMint function</code> to mint an NFT to <code>msg.sender</code> (the function caller).
We increment <code>s_tokenCounter</code> to set the new NFT's unique ID.
Finally, we save the resource <code>tokenURI</code> mapping to this ID.
The <code>tokenURI</code> external apps use a method to fetch the resource for a particular NFT ID:
```javascript
function tokenURI(uint256 tokenId) public view override returns (string memory) {
return s_tokenURIs[tokenId];
}
```
We implement the required <code>tokenURI</code> function to return the URI simply mapped to the passed tokenId.
And that covers the basics of our NFT smart contract!
While simplified, this demonstrates:
<ul>
<li>Using OpenZeppelin contracts for quicker development</li>
<li>Inheriting from the ERC721 standard</li>
<li>Minting unique NFTs with IDs tracked by a counter</li>
<li>Mapping <code>tokenIds</code> to off-chain resource URIs</li>
<li>Overriding the <code>tokenURI</code> function to relay URI data</li>
</ul>
We could make improvements, like access controls, error handling, automating URI creation, etc. But this minimal contract already implements core NFT behavior and standards under the hood!
<h4>Deploying and Testing Our NFT Contract</h4>
We'll use Foundry - a modular toolkit for Ethereum application development, to test and deploy our contract.
Foundry provides excellent support for testing, scripting, and deploying Solidity smart contracts.
First, our deployment script <code>deploy.s.sol</code>:
```javascript
//SPDX-License-Identifier: MIT
pragma solidity ^0.8.18;
import {Script} from "forge-std/script.sol";
import {moodNFT} from "../src/moodNft.sol";
contract DeployNFT is Script{
function run() external returns(moodNFT){
vm.startBroadcast();
moodNFT moodnft = new moodNFT();
vm.stopBroadcast();
return moodnft;
}
}
```
This handles deploying an instance of our myNFT contract and broadcasting it onto the blockchain.
Next, our simple test suite test.t.sol:
```javascript
//SPDX-License-Identifier: MIT
pragma solidity ^0.8.18;
import {Test} from "forge-std/test.sol";
import {myNFT} from "../src/myNFT.sol";
import {DeployNFT} from "../script/DeployNFr.s.sol";
contract BasicNFTTest is Test{
address public USER = makeAddr("user");
string public constant PUG =
"ipfs://bafybeig37ioir76s7mg5oobetncojcm3c3hxasyd4rvid4jqhy4gkaheg4/?filename=0-PUG.json";
DeployNFT public deployer;
myNFT public mynft;
function setUp() public {
deployer = new DeployNFT();
mynft = deployer.run();
}
function testnameiscorrect() public view {
string memory expectedname = "DogieSco";
string memory actualname = mynft.name();
assert(keccak256(abi.encodePacked(expectedname)) == keccak256(abi.encodePacked(actualname)));
}
function testcanMintandBal() public {
vm.prank(USER);
mynft.mintNFT(PUG);
assert(mynft.balanceOf(USER) == 1);
assert(keccak256(abi.encodePacked(PUG)) == keccak256(abi.encodePacked(mynft.tokenURI(0))));
}
}
```
Here, we validate the contract's name variable and test out minting an NFT.
We can run the full test flow with:
<code>forge test</code>
This handles deploying fresh contract instances for our test cases, checking expected behavior and revert conditions, gas usage, and more.
Ensure all your test functions start with <code>test</code> as forge test will not be able to pick it up.
Foundry provides excellent tooling for testing, scripting, and deploying smart contracts from development through production. As we scale up our NFT project, Foundry will help rapidly iterate and confidently ship across environments.
<h4><strong>Why Smart Contracts Are Critical for NFTs</strong></h4>
While NFT basics are simple in abstract (tokenized ownership records on a blockchain), smart contracts power NFTs under the hood.
Smart contracts formally encode business logic like ownership, transfers, limitations, royalties, etc. Everything from minting and burning NFTs to facilitating trades on a marketplace happens via executing contract code.
Upgrades, migrations, governance decisions, and more are enacted by shipping updated smart contracts. Things like transaction history and off-chain data availability are also managed in contract storage.
By learning smart contract development with real NFT code, as we've covered here, you gain quite deep insight into the inner workings of NFT projects:
<ul>
<li>Core mechanics like minting, ownership records</li>
<li>Upgradeability patterns and governance capabilities</li>
<li>Security protections and risk management</li>
<li>Standards compatibility and interoperability</li>
</ul>
Plus, low-level understanding improves security posture as both builder and trader.
As NFTs bridge more industries, from art to finance to Web3 identity, understanding smart contracts becomes more critical for builders and traders.
So, while buying and selling NFTs is accessible to anyone with a wallet, smart contract literacy is invaluable to understanding this new digital asset paradigm.
<h4><strong>Conclusion</strong></h4>
We've covered quite a lot of ground here! To recap:
<ul>
<li>We discussed the value proposition and emergence of NFTs</li>
<li>Provided background on smart contracts and inheritance</li>
<li>Walked through an NFT contract section-by-section</li>
<li>Deployed our contract with Foundry.</li>
<li>Discussed the critical role contracts play in NFT mechanics</li>
</ul>
While simplified, this demonstrates core NFT behavior like issuance, token tracking, metadata lookups, etc. We also used tooling like OpenZeppelin contracts for speedier and safer development.
There's always more to learn, but being able to read, write, and deploy real smart contract code unlocks a deeper understanding of the NFT space.
If you find this article thrilling, discover extra thrilling posts like this on <a class="attrlink" href="https://blog.learnhub.africa/" target="_blank" rel="noreferrer nofollow noopener">Learnhub Blog</a>; we write a lot of tech-related topics from <a class="attrlink" href="https://blog.learnhub.africa/category/cloud-computing/" target="_blank" rel="noreferrer nofollow noopener">Cloud computing</a> to <a class="attrlink" href="https://blog.learnhub.africa/category/frontend/" target="_blank" rel="noreferrer nofollow noopener">Frontend Dev</a>, <a class="attrlink" href="https://blog.learnhub.africa/category/security/" target="_blank" rel="noreferrer nofollow noopener">Cybersecurity</a>, <a class="attrlink" href="https://blog.learnhub.africa/category/data-science/" target="_blank" rel="noreferrer nofollow noopener">AI</a>, and <a class="attrlink" href="https://blog.learnhub.africa/category/blockchain/" target="_blank" rel="noreferrer nofollow noopener">Blockchain</a>. Take a look at <a class="attrlink" href="https://blog.learnhub.africa/2023/02/16/how-to-build-offline-web-applications/" target="_blank" rel="noreferrer nofollow noopener">How to Build Offline Web Applications. </a>
<h4>Resource</h4>
<ul>
<li><a class="attrlink" href="https://blog.learnhub.africa/2023/12/19/getting-started-with-foundry-for-beginners-in-2024/" target="_blank" rel="noreferrer nofollow noopener">Getting Started with Foundry for Beginners in 2024</a></li>
<li><a class="attrlink" href="https://blog.learnhub.africa/2023/09/25/what-are-smart-contracts/" target="_blank" rel="noreferrer nofollow noopener">What are Smart Contracts?</a></li>
<li><a class="attrlink" href="https://blog.learnhub.africa/2023/12/27/create-a-raffle-draw-smart-contract-using-foundry-2024-part-1/" target="_blank" rel="noreferrer nofollow noopener">Create a Raffle Draw Smart Contract Using Foundry 2024 (Part 1)</a></li>
</ul>
<a class="attrlink" href="https://www.buymeacoffee.com/Scofield" target="_blank" rel="noreferrer nofollow noopener">Gift us a cup of coffee if you are so kind. </a> | scofieldidehen | |
1,721,307 | Forget about SCSS variables | SCSS variables In my career, I’ve managed to work on a lot of projects that used styling... | 26,003 | 2024-01-08T19:21:53 | https://medium.com/@maks-dolgikh/css-variables-in-angular-forget-about-scss-variables-part-1-67e727cf317b | css, scss, angular, webdev | ## SCSS variables
In my career, I’ve managed to work on a lot of projects that used styling via SCSS, LESS, or Stylus. One of the main advantages of favoring them over CSS, besides “cascading”, was “**variables**”
They enabled:
* To respect the DRY principle
* To centralize shared variables for reuse via @import or @use
* To create more abstract styles without hardcoding
* To synchronize variable names with Figma tokens
* To perform simple arithmetic and complex operations on variables
* Variables did not go directly into the build, but were compiled into actual CSS values
### Example of implementation
Let’s realize a basic example of `SCSS variables` application
Variables
```css
$primary: #d75894;
$secondary: #9b3dca;
$background: #fafafa;
```
Styling of elements
```scss
@use 'variables';
body {
background: variables.$background;
h1 {
color: variables.$primary;
}
p {
color: variables.$secondary;
}
}
```

*It’s simple and intuitive *👍*.*
### New theme
But let’s say we need to add support for a dark theme for the current style scheme due to business requirements. *How do we implement it? *🧐
Experienced developers 🤓 will tell you that you should use mapping to substitute the correct value into the selector from each theme. In this way, we will provide extensibility for new themes.
Let’s change our simple variable list to a color theme map
```scss
$themes: (
"default": (
primary: #d75894,
secondary: #9b3dca,
background: #fafafa,
),
"dark": (
primary: #5e84ff,
secondary: #0dd0ff,
background: #1b1918,
)
);
```
Themes applying
```scss
@use "variables";
@use "sass:map";
@mixin setTheme($theme-map) {
background: map.get($theme-map, "background");
h1 {
color: map.get($theme-map, "primary")
}
p {
color: map.get($theme-map, "secondary")
}
}
body {
@each $theme-key in map.keys(variables.$themes) {
&[data-theme="#{$theme-key}"]{
@include setTheme(map.get(variables.$themes, $theme-key))
}
}
}
```
Result
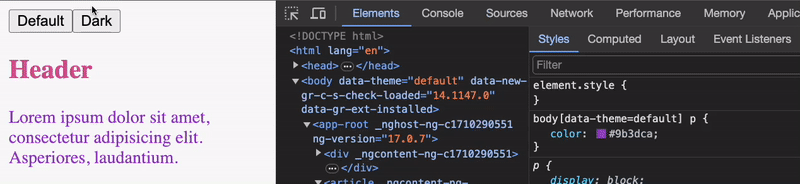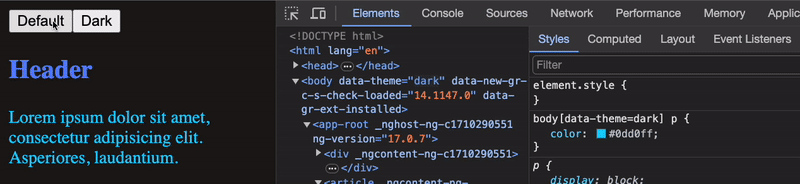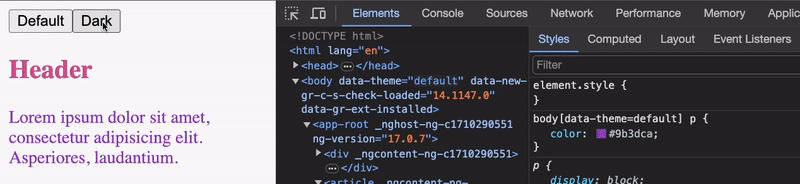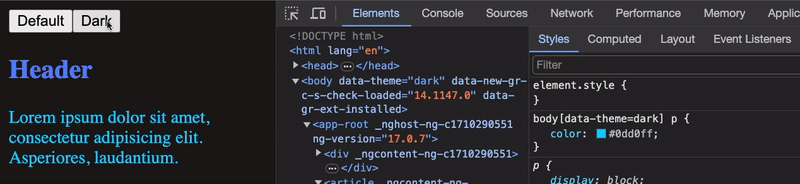
Yay, we’ve achieved the requested behavior. **But at what cost?**
### Problems
As you can see from this small example, the amount of code to support the new dark theme has **increased**, and the old scheme had to be **refactored**.
Another disadvantage is obtained is the **increase** in the resulting CSS file due to having multiple themes simultaneously.
And hence its size, which takes time 📉 to download and parse.
```css
body[data-theme=default] {
background: #fafafa;
}
body[data-theme=default] h1 {
color: #d75894;
}
body[data-theme=default] p {
color: #9b3dca;
}
body[data-theme=dark] {
background: #1b1918;
}
body[data-theme=dark] h1 {
color: #5e84ff;
}
body[data-theme=dark] p {
color: #0dd0ff;
}
```
As a consequence, with the growth of the code base and the requirement for stylization, we will get:
* Increasing complexity of style architecture in the development of individual components
* Maintenance and development of new features will be harder every time
* Constant refactoring and need for regression screen tests
These problems will undoubtedly affect the speed of development, the quality of the result, and the convenience of developers.
Unfortunately, many libraries developed using SCSS, such as `@angular/material`, encourage this approach. Many developers are unaware of the recommended ways of styling via mixins, which leads to anti-pattern styling as well as the use of `::ng-deep`
> Those who have ever upgraded Angular in conjunction with `@angular/material` will understand UI problems in regression tests after upgrade if you don’t use the recommended way of component customization
_So what’s the solution to this problem?_ [read more...](https://medium.com/@maks-dolgikh/css-variables-in-angular-forget-about-scss-variables-part-1-67e727cf317b) | misterion96 |
1,721,392 | Lazy Load Fonts in Next.js with Web Components | As a developer and co-founder of Postnitro.ai, I've tackled numerous performance hurdles. One... | 0 | 2024-01-08T20:56:05 | https://dev.to/seeratawan01/lazy-load-fonts-in-nextjs-with-web-components-54cd | As a developer and co-founder of [Postnitro.ai](https://postnitro.ai), I've tackled numerous performance hurdles.
One solution I'm really proud of is the creation of a custom web component `<font-previewer>`.
Learn how I revolutionized font-loading in Next.js in my latest blog post!
{% embed https://www.seeratawan.me/blog/lazy-load-fonts-in-nextjs-with-web-components/ %} | seeratawan01 | |
1,722,229 | Modern Web Development Trends with React: Froala Rich Text Editor | As we head into 2024, how we create and interact with digital content is always changing. React, made... | 0 | 2024-01-09T15:16:17 | https://froala.com/blog/general/react-wysiwyg-editor-modern-toolset-trends/ | As we head into 2024, how we create and interact with digital content is always changing. React, made by Facebook, is a big part of these changes. It’s like a special tool that helps developers create the look and function of websites and apps. It has made a big difference by making it easier for developers to create what people see and do online.
The way websites and apps are made has changed a lot because of React. It’s not just a tool — it’s a game-changer that has changed how things are built online. Since React is so good, it has stayed important and is leading the way for developers to create cool stuff on the internet that we all use.
In the world of making websites and apps, there are some cool new things that lots of people like and [Froala Rich Text Editor](https://froala.com/react-rich-text-editor/) is one of them. It simplifies the process of creating websites, enhances user-friendliness, and supports developers in using advanced tools and systems efficiently.
Looking ahead to 2024, React is going to be a big part of how websites get built.
# **React in 2024: Changing How Websites Are Made**
React is playing a big role in four important things:
* Component-Driven Architecture and Design Systems
* Accessibility as a Priority
* Performance Optimization and Progressive Web Apps (PWAs)
* Server-Side Rendering (SSR) and Static Site Generation (SSG)
These trends will shape how websites look and work. Let’s see how React fits into these important changes in how we make websites.
# **1\. Component-Driven Architecture and Design Systems**
Using small building blocks called components is now a big part of making websites. In 2024, it’s going to be even more important because developers are using these parts of the website again and again.
React, a tool for building websites, fits well with this idea. It’s made of these reusable parts that help make websites work better. This makes it easier for developers to create websites that are easy to manage and can grow over time.
Also, design systems have appeared, making it easier to create websites that look the same. They offer a toolbox with features like buttons and styles that designers can use to keep everything consistent. Tools like [React Rich Text Editor](https://froala.com/react-rich-text-editor/) help with writing and editing text on websites. They work well with these design systems, making everything run smoothly together.
# **2\. Accessibility as a Priority**
Making websites accessible to everyone has become more important lately and will stay important in 2024 and beyond. It’s crucial to create websites that everyone can use. React, a tool for building websites, is committed to this idea. It has features like ARIA attributes and practices that make it easier for people with disabilities to use websites. This is important to ensure everyone can access and use the internet.
Froala’s LTS SDK for React is in line with this idea by having special features in its React rich text editor that focus on accessibility. This helps developers create content that’s easy for everyone to use, ensuring no one is left out when using websites.
# **3\. Performance Optimization and Progressive Web Apps (PWAs)**
Making websites work faster is important, especially now that more people use phones and tablets. React helps with this by using a clever way to handle how things show up on the screen. It makes websites run faster.
Also, PWAs are becoming more popular. They’re like websites that feel and work like phone apps. React is good at helping make these kinds of websites, which is why it’s a great choice for building them.
Froala’s LTS SDK for React goes well with these trends that focus on making websites faster. It provides a text editing tool that works quickly and lets users interact smoothly.
# **4\. Server-Side Rendering (SSR) and Static Site Generation (SSG)**
More people want websites to load faster, so methods like SSR and SSG are making a comeback. React can use these methods, which keeps it important. Websites want to show up better in search engines and work faster, so more websites might start using SSR and SSG in 2024.
[React Rich Text Editor](https://froala.com/react-rich-text-editor/) works smoothly with setups like SSR and SSG. This means developers can easily add awesome text editing features to websites. It doesn’t matter if the websites are already built or still being made; this tool fits right in!
# **Step-by-Step Integration of Froala as a React Rich Text Editor**
React is popular for making cool web apps. It works great with Froala’s Rich Text Editor, giving React developers a good way to edit text that’s easy to use and keeps things safe. Making Froala work with React apps is made to be simple:
# **Using the React Froala WYSIWYG Editor**
## **Step 1: Install from NPM**
To start using the React Froala WYSIWYG editor, you’ll first need to install it from the NPM package registry. Use the following command in your terminal or command prompt:
```plaintext
npm install react-froala-wysiwyg --save
```
This command will download and install the React Froala WYSIWYG editor package into your project.
## **Step 2: Import the Component and Stylesheets**
Next, you’ll need to import the necessary stylesheets to ensure the editor’s proper appearance. Include these lines in your React component where you’ll use the editor:
```plaintext
import 'froala-editor/css/froala_style.min.css';
import 'froala-editor/css/froala_editor.pkgd.min.css';
import FroalaEditorComponent from 'react-froala-wysiwyg';
```
These lines import the required Froala Editor stylesheets and the React Froala WYSIWYG editor component into your React project.
## **Step 3: Use the Editor Component**
Now, you can use the editor component within your React application. Place the <FroalaEditorComponent /> tag where you want the editor to appear in your JSX code. For instance:
```plaintext
<FroalaEditorComponent tag='textarea' config={this.config} />
```
This line creates the editor component, specifying the HTML tag to be used (in this case, a textarea) and passing a configuration object (this.config) to customize the editor’s behavior and appearance according to your requirements.
These steps will enable you to integrate and use the React Rich Text Editor within your React application effortlessly. Adjust the configurations as needed to tailor the editor to your specific needs.
## **Step 4: Preview the Editor**
Users can also experience a preview of the [Froala Editor](https://froala.com/react-rich-text-editor/) integrated with React.

# **Conclusion**
React is still important for making modern websites. It works well with the latest trends and keeps growing to match what the industry needs. Tools like [React Rich Text Editor](https://froala.com/react-rich-text-editor/) fit right in with these ideas. These tools make text on websites look good, follow the rules of building websites, make them easy to use, and work well with different setups.
As we move into 2024, following these ideas and using strong tools like Froala’s SDK will help developers create websites that are interesting, easy to use, and work well. This is important because what people want from websites keeps changing, and developers need to keep up with those changes. | ideradevtools | |
1,721,475 | Integrating Machine Learning into Web Development | Introduction The fusion of Machine Learning (ML) with web development is revolutionizing... | 0 | 2024-01-08T22:37:02 | https://dev.to/bartzalewski/integrating-machine-learning-into-web-development-l4n | webdev, programming, tutorial, beginners | ### Introduction
The fusion of Machine Learning (ML) with web development is revolutionizing the way we interact with websites and applications. This integration brings intelligent features to web platforms, enhancing user experience and offering innovative solutions to complex problems. In this guide, we’ll explore how machine learning can be integrated into web development, highlighting practical examples and real-world use cases.
### Understanding Machine Learning in the Web Context
Machine learning is a subset of artificial intelligence that enables systems to learn and improve from experience without being explicitly programmed. In the context of web development, ML can be used to analyze user data, automate decisions, and provide personalized experiences.
### Why Integrate ML into Web Development?
* **Enhanced User Experience**: ML algorithms can personalize content, making user interactions more engaging.
* **Automated Processes**: From customer service chatbots to automated content moderation, ML can streamline various web functionalities.
* **Data-Driven Insights**: ML provides valuable insights from user data, aiding in strategic decision-making.
### How to Integrate ML into Web Applications
**Choosing the Right ML Model**
Depending on the application's requirement, you can choose from a variety of ML models, including:
* Predictive models for forecasting
* Classification models for sorting data into categories
* Clustering models for grouping similar items
**Integrating ML APIs**
One of the simplest ways to incorporate ML into web applications is through APIs offered by various platforms like Google Cloud ML, IBM Watson, and Amazon ML. These APIs provide pre-trained models that can be easily integrated into your web applications.
**Building Custom ML Models**
For more specific needs, you might need to develop custom ML models. Frameworks like TensorFlow.js and ML5.js are specifically designed for web development, allowing the integration of ML directly into the browser.
### Practical Examples and Use Cases
**1. Personalized Recommendations**
E-commerce sites use ML algorithms to analyze user browsing patterns and purchase history to recommend products.
**2. Chatbots and Virtual Assistants**
Intelligent chatbots powered by ML can handle customer inquiries, improve engagement, and provide 24/7 support.
**3. Real-Time Language Translation**
Websites can use ML models to offer real-time translation services, making content accessible to a broader audience.
**4. Image and Voice Recognition**
Integrating ML for image and voice recognition can enhance security features (like facial recognition for authentication) and improve accessibility for disabled users.
**5. Sentiment Analysis**
ML can analyze user feedback and social media posts to gauge customer sentiment, helping in brand monitoring and market analysis.
### Challenges and Considerations
* **Data Privacy**: Ensuring user data privacy and compliance with regulations like GDPR is crucial.
* **Model Training and Accuracy**: The accuracy of an ML model depends on the quality and quantity of the training data.
* **Performance Overheads**: ML models can be resource-intensive; hence, performance optimization is key.
* **Continuous Learning**: ML models require continuous updates and retraining to remain effective.
### Conclusion
Integrating machine learning into web development opens up a plethora of possibilities for creating innovative, efficient, and intelligent web applications. From personalized user experiences to automated customer service, the applications of ML in web development are vast and varied. As the field continues to evolve, staying abreast of the latest trends and advancements in ML will be crucial for web developers looking to incorporate these technologies into their projects. | bartzalewski |
1,721,501 | About well designed REST APIs | We all have struggled at least once with a poorly designed API and I am pretty sure that it is really... | 0 | 2024-01-08T23:49:21 | https://dev.to/yelldutz/about-well-designed-rest-apis-4m5i | backend, api, webdev | We all have struggled at least once with a poorly designed API and I am pretty sure that it is really hard to forget how frustrating it was as a partner that wanted just to integrate it or even just a developer that had to maintain that living hell.
## Basics
APIs were created to make easier for other developers to consume and use online content from its direct source. So, the motivation of its creation directly implies on our major concern -- or the thing that we must be concerned at most -- when developing an API: <b>developer-friendly processes</b>.
## Endpoints
I have seen all sorts of really messy endpoints, but let us use this article to talk about the good ones.
### Good practices while establishing endpoints
I am using express (node.js) to exemplify my point on this section.
You may be used to see endpoints like this one above. They look OK, since its composition exposes its purpose: a `/all` endpoint should return all of the objects from that collection, right?
<b>Yes, but it will create a much more verbose API while it is scaling</b>. I am not saying it does not work, and it would make no sense if it does not, but, you really don't need to add those suffixes.
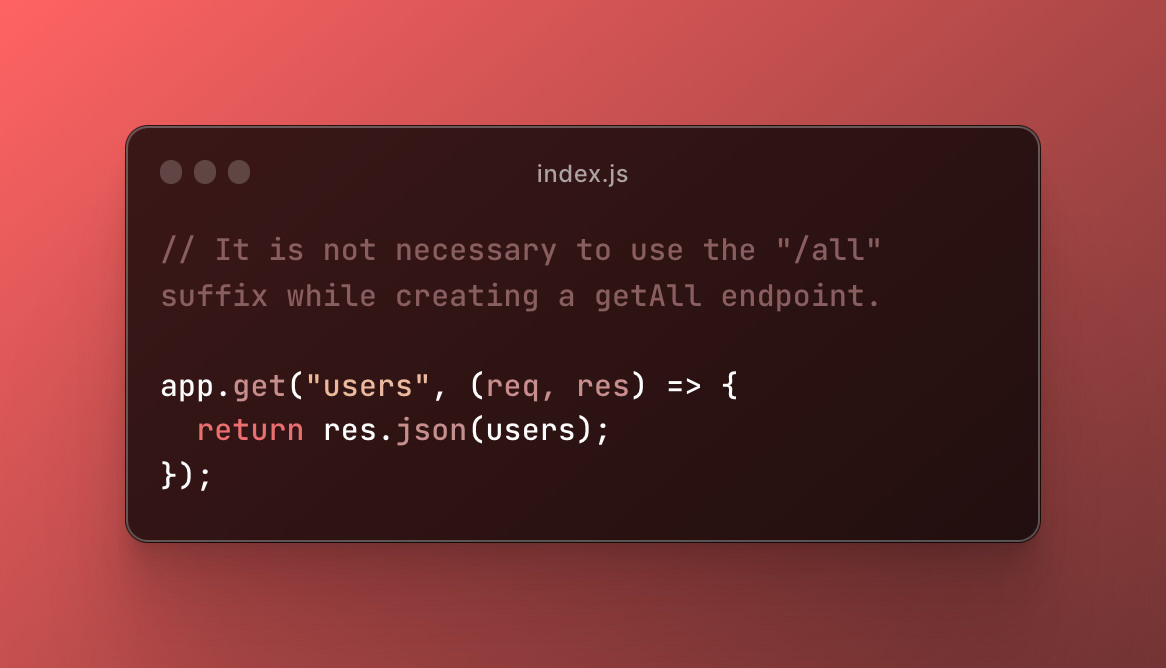
The approach below delivers the same result, and at the same time, it makes your endpoints more succinct so their requisitions will be of a easier understanding.
## About the requisition methods
The more usual mistakes while choosing the correct requisition method:
- POST for delete ❌
- GET to perform create actions ❌
- PATCH for create actions ❌
Now that you know what not to do, there is an example of how things should look like:
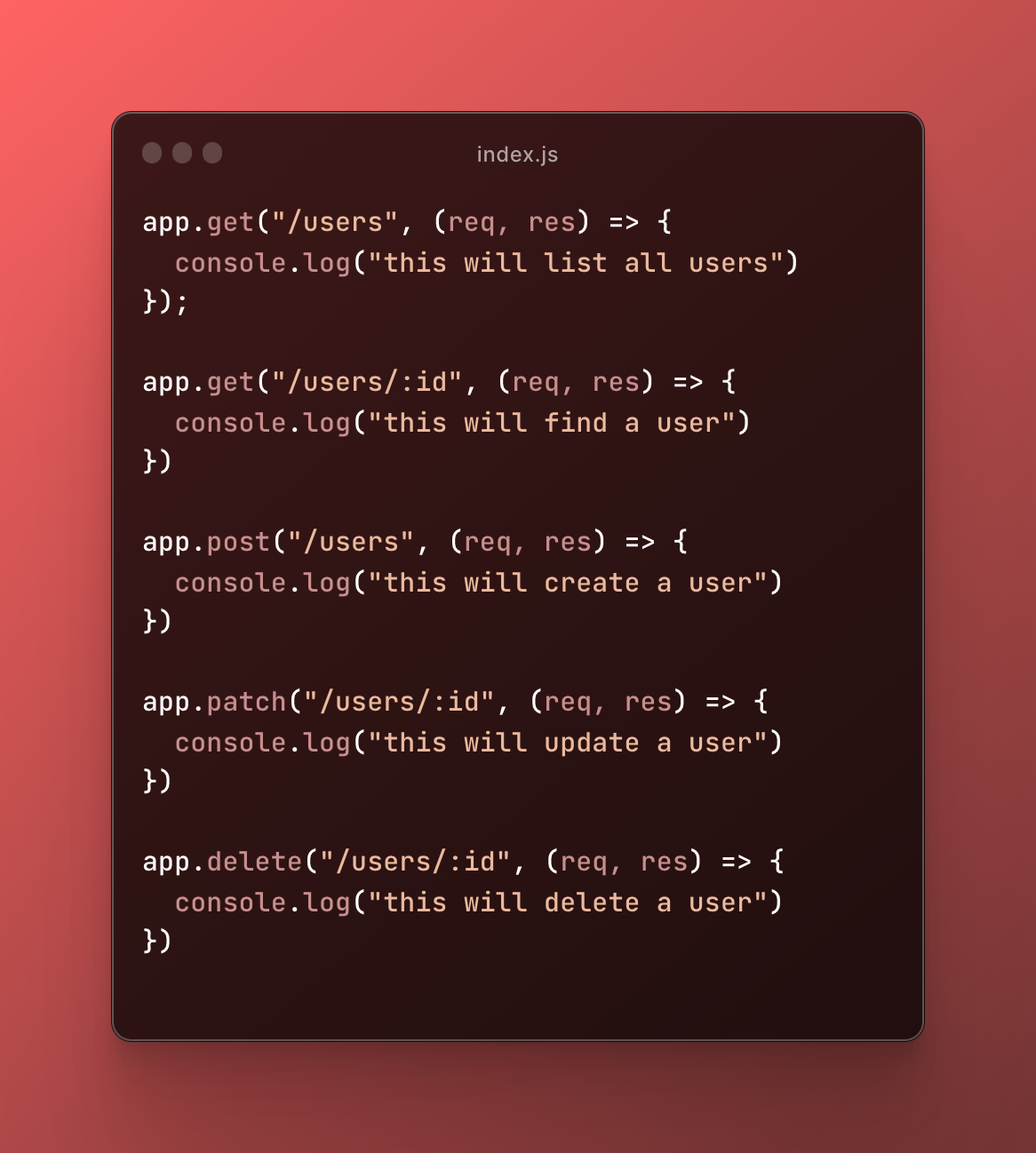
- GET is used to return a list or an unique record ✅
- POST is used to create (insert or upsert) a record ✅
- PATCH is used to update a record ✅
- DELETE is used to delete a record ✅
- PUT is used to upsert a record ✅
Observation: while performing massive actions, those methods will serve at the same way, the only difference will be on their payloads.
## Final considerations
It is really important for a developer to understand how his APIs and endpoints should be designed in order to make it easier for other developers for have a good use of his own work.
Choosing the right endpoint names, methods, authorizations, contracts, authentications is a real concern and it should be the way to create a really good or a real bad API.
-------
Photo by <a href="https://unsplash.com/@wilhelmgunkel?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash">Wilhelm Gunkel</a> on <a href="https://unsplash.com/photos/grey-metal-gear-6kfQvW5eync?utm_content=creditCopyText&utm_medium=referral&utm_source=unsplash">Unsplash</a>
| yelldutz |
1,721,519 | Cursos De VSCode, JavaScript, HTML e CSS Gratuitos | O portal Estudante.dev está ofertando gratuitamente cursos da área de programação, que abrangem temas... | 0 | 2024-01-27T02:06:13 | https://guiadeti.com.br/cursos-vscode-javascript-github-html-css-gratuitos/ | cursogratuito, css, cursosgratuitos, html | ---
title: Cursos De VSCode, JavaScript, HTML e CSS Gratuitos
published: true
date: 2024-01-08 21:07:35 UTC
tags: CursoGratuito,css,cursosgratuitos,html
canonical_url: https://guiadeti.com.br/cursos-vscode-javascript-github-html-css-gratuitos/
---
O portal Estudante.dev está ofertando gratuitamente cursos da área de programação, que abrangem temas como JavaScript, VSCode, HTML e CSS. São disponibilizados também materiais complementares, testes de lógica e projetos práticos para orientar os participantes rumo ao desenvolvimento de habilidades sólidas na área.
A conclusão de cada curso permite que o aluno receba certificado. A plataforma conta com mentores experientes dedicados a auxiliar na superação de obstáculos e no aproveitamento máximo das aptidões de cada participante.
Dentro da comunidade Estudante.dev no Discord, os estudantes têm a oportunidade de estabelecer conexões significativas, trocar experiências e explorar oportunidades de trabalho que são regularmente compartilhadas por parceiros do portal.
A presença ativa na comunidade não apenas enriquece o aprendizado, mas também oferece um ambiente propício para o desenvolvimento profissional e networking no campo da programação.
## Cursos portal Estudante.dev
O portal Estudante.dev está atualmente disponibilizando uma variedade de cursos gratuitos na área de programação, cobrindo tópicos essenciais como JavaScript, VSCode, HTML e CSS.
_Página do Estudante.dev_
A escola de programação busca proporcionar uma experiência completa, materiais complementares, testes de lógica e projetos práticos para auxiliar na formação de profissionais qualificados.
### Ambiente Virtual de Aprendizado
No ambiente virtual de aprendizado, você encontrará todas as informações essenciais ao longo do seu curso. Pode facilmente acessar projetos, tarefas e o material didático em diversos formatos, como páginas interativas, vídeos, áudios e livros digitais. A plataforma online também possibilita que você siga o conteúdo do curso no seu próprio ritmo, estudando nos horários mais convenientes.
### Cursos Ofertados
#### HTML & CSS
- Sintaxe HTML;
- Tags Semânticas – Header, Footer & Section;
- Inicie sua primeira Estrutura HTML;
- Titulos e Parágrafos no HTML;
- Listas no HTML;
- Inserindo Links e Imagens no HTML;
- Sintaxe CSS;
- Adicionando o CSS no HTML;
- Tipos de Seletores CSS;
- Projetos.
#### JavaScript
- Aprendendo sobre Variáveis;
- Tipos de Dados das Variáveis;
- Explorando as Strings;
- Explorando os Arrays;
- Operadores Aritméticos
- Operadores de Comparação;
- If e Else;
- For;
- Criando Funções;
- Manipulando o DOM;
- Trabalhando com Eventos;
- Projeto.
#### VScode
- O que é o VSCode? Ferramenta poderosa para desenvolvedores!;
- Como Instalar o VSCode no Windows;
- Como Instalar o VSCode no Ubuntu usando a Loja de apps;
- Como Instalar o VSCode no Ubuntu usando o arquivo .deb;
- Primeiros Passos para Programar no VSCode;
- Principais Atalhos do VSCode – Aumente sua Produtividade.
### Certificados Reconhecidos Nacionalmente
Ao concluir cada curso, é oferecida a oportunidade de receber um certificado vitalício de conclusão, validando todas as habilidades adquiridas. Esse certificado não apenas atesta seu conhecimento, mas também é reconhecido em todo o território nacional, podendo ser utilizado como comprovante em processos seletivos de emprego e como horas complementares na faculdade.
### Desafios de Código e Comunidade
Durante o aprendizado, você será desafiado com situações práticas, contribuindo para uma compreensão mais profunda dos conceitos. A plataforma também possui uma comunidade no Discord, que oferece um espaço para conhecer pessoas, trocar experiências e explorar oportunidades de trabalho compartilhadas pelos parceiros do portal.
Essa comunidade ativa também oferece suporte direto, seja para tirar dúvidas ou compartilhar novidades, garantindo uma experiência educacional dinâmica e interativa. A participação ativa na comunidade não apenas enriquece significativamente a experiência de aprendizado, mas também proporciona um ambiente altamente favorável para o aprimoramento profissional e a construção de uma sólida rede de contatos no campo da programação.
Engajar-se ativamente com colegas e mentores não só amplia os horizontes do conhecimento, mas também abre portas para oportunidades de crescimento e colaboração, fundamentais para o avanço na carreira de programação.
<aside>
<div>Você pode gostar</div>
<div>
<div>
<div>
<div>
<span><img decoding="async" width="280" height="210" src="https://guiadeti.com.br/wp-content/uploads/2024/01/Cursos-De-Front-End-Back-End-E-Soft-Skills--280x210.png" alt="Cursos De Front-End, Back-End E Soft Skills" title="Cursos De Front-End, Back-End E Soft Skills"></span>
</div>
<span>Cursos De Front-End, Back-End E Soft Skills Gratuitos Da Oracle</span> <a href="https://guiadeti.com.br/cursos-front-end-back-end-soft-skills-oracle/" title="Cursos De Front-End, Back-End E Soft Skills Gratuitos Da Oracle"></a>
</div>
</div>
<div>
<div>
<div>
<span><img decoding="async" width="280" height="210" src="https://guiadeti.com.br/wp-content/uploads/2024/01/Cursos-de-E-commerce-E-Marketing-280x210.png" alt="Cursos de E-commerce E Marketing" title="Cursos de E-commerce E Marketing"></span>
</div>
<span>Cursos de E-commerce E Marketing Gratuitos Da Omie Academy</span> <a href="https://guiadeti.com.br/cursos-e-commerce-e-marketing-gratuitos/" title="Cursos de E-commerce E Marketing Gratuitos Da Omie Academy"></a>
</div>
</div>
<div>
<div>
<div>
<span><img decoding="async" width="280" height="210" src="https://guiadeti.com.br/wp-content/uploads/2024/01/Bootcamp-De-Solucoes-em-Nuvem-280x210.png" alt="Bootcamp De Soluções em Nuvem" title="Bootcamp De Soluções em Nuvem"></span>
</div>
<span>Bootcamp De Soluções Em Nuvem Gratuito Da Amazon Web Services</span> <a href="https://guiadeti.com.br/bootcamp-solucoes-em-nuvem-gratuito-aws/" title="Bootcamp De Soluções Em Nuvem Gratuito Da Amazon Web Services"></a>
</div>
</div>
<div>
<div>
<div>
<span><img decoding="async" width="280" height="210" src="https://guiadeti.com.br/wp-content/uploads/2023/02/Certificacoes-profissionais-Fortinet--280x210.png" alt="Certificações Profissionais Fortinet" title="Certificações Profissionais Fortinet"></span>
</div>
<span>Tire as certificações profissionais Fortinet FCF e FCA de graça e com treinamento oficial</span> <a href="https://guiadeti.com.br/certificacoes-profissionais-fortinet-nse-gratuitas/" title="Tire as certificações profissionais Fortinet FCF e FCA de graça e com treinamento oficial"></a>
</div>
</div>
</div>
</aside>
## VSCode
O Visual Studio Code, comumente conhecido como VSCode, é uma plataforma de desenvolvimento integrado (IDE) que se destacou por sua eficiência e versatilidade.
A plataforma emergiu como uma ferramenta indispensável para desenvolvedores em busca de uma IDE poderosa, flexível e fácil de usar. Sua interface amigável, capacidade de customização, extensibilidade e recursos avançados fazem do VSCode uma escolha inteligente para projetos de desenvolvimento ágil em diversas linguagens de programação
### Interface Intuitiva e Customização
O VSCode oferece uma interface de usuário limpa e intuitiva, tornando a programação mais acessível para desenvolvedores de todos os níveis. Sua capacidade de customização é notável. Os usuários podem adaptar o ambiente de trabalho de acordo com suas preferências, escolhendo temas, layouts e atalhos que se alinhem ao seu estilo de desenvolvimento único.
### Extensões e Ecossistema Rico
Um dos pontos fortes do VSCode está em seu ecossistema expansivo de extensões. Desenvolvedores podem personalizar sua experiência de programação incorporando extensões que oferecem suporte a várias linguagens de programação, ferramentas de depuração avançadas, integração com sistemas de controle de versão e muito mais.
Essa flexibilidade faz do VSCode uma escolha versátil para uma ampla gama de projetos e linguagens.
### Recursos Avançados e Produtividade
O VSCode não apenas fornece uma base sólida para codificação, mas também apresenta recursos avançados que impulsionam a produtividade. Desde o IntelliSense, que oferece sugestões inteligentes de código em tempo real, até a integração com terminais, depuradores e controladores de versão, o VSCode visa simplificar o fluxo de trabalho do desenvolvedor, tornando-o eficiente e livre de complicações.
## Estudante.dev
A Estudante.dev é uma plataforma de educação profissional de nível técnico e tecnológico, do estado de São Paulo, com foco na educação em programação, oferecendo uma jornada de aprendizado abrangente para aspirantes a desenvolvedores.
### Abordagem Prática
Na Estudante.dev, a ênfase está na entrega de cursos especializados que abrangem desde conceitos fundamentais até tópicos avançados em programação. A abordagem prática é valorizada, com materiais didáticos, testes de lógica e projetos práticos que não apenas ensinam teoria, mas também proporcionam aos estudantes a oportunidade de aplicar seus conhecimentos em situações do mundo real.
### Mentoria e Suporte
Na Estudante.dev, o compromisso com o sucesso dos estudantes vai além dos cursos. Mentores experientes estão disponíveis para oferecer suporte dedicado, auxiliando na superação de obstáculos e no desenvolvimento máximo das habilidades individuais. O suporte contínuo garante que os alunos se sintam confiantes ao enfrentar desafios complexos, promovendo um ambiente de aprendizado encorajador e eficaz.
## Descubra o potencial da programação na Etudante.dev. Inscreva-se agora!
As [inscrições para os cursos de HTML, CSS, Javascript e VSCode](https://estudante.dev/) devem ser realizadas no site da Estudante.dev.
## Compartilhe a paixão pela programação. Convide seus amigos para aproveitarem o caminho de aprendizado!
Gostou do conteúdo sobre os cursos de programação? Então compartilhe com a galera!
O post [Cursos De VSCode, JavaScript, HTML e CSS Gratuitos](https://guiadeti.com.br/cursos-vscode-javascript-github-html-css-gratuitos/) apareceu primeiro em [Guia de TI](https://guiadeti.com.br). | guiadeti |
1,721,778 | Introduction to Multithreading | C# Introduction to Multithreading Multithreading is a powerful concept in computer programming that... | 0 | 2024-01-09T07:26:51 | https://dev.to/homolibere/introduction-to-multithreading-1521 | C# Introduction to Multithreading
Multithreading is a powerful concept in computer programming that allows multiple tasks or processes to run concurrently. It plays a significant role in optimizing system performance and responsiveness. In C#, multithreading is made easy with the help of the Task Parallel Library (TPL) and the Thread class.
The TPL provides high-level abstractions for working with concurrency, making it simpler for developers to harness the benefits of multithreading. By making use of the TPL, you can easily execute tasks asynchronously, regardless of whether they are CPU-bound or I/O-bound.
The Thread class, on the other hand, provides a lower-level approach to multithreading in C#. It allows you to create and manage threads directly, giving you more control over their execution and synchronization.
To start with multithreading in C#, you need to understand the concept of threads. A thread is an independent path of execution within a program. By default, all C# programs have a main thread, representing the entry point of the program. However, you can create additional threads to perform tasks concurrently with the main thread.
Using the TPL, you can create tasks that run in parallel, taking advantage of multiple CPU cores. This enables you to speed up the execution of computationally intensive operations. The TPL also offers various high-level constructs, such as parallel loops and parallel LINQ, to simplify parallel programming.
On the other hand, the Thread class allows you to explicitly create and manage threads. You can create a new thread by instantiating the Thread class and passing a delegate method that the thread will execute. Additionally, you can control the thread's behavior using methods like Start(), Sleep(), Join(), and Abort().
However, multithreading introduces new challenges like synchronization and coordination between threads. These challenges arise when multiple threads access shared resources simultaneously, leading to data corruption or unexpected program behavior. To address this, C# provides various synchronization primitives, such as locks, semaphores, and mutexes, to ensure thread safety.
In conclusion, multithreading in C# is a powerful technique for improving the performance and responsiveness of your programs. Whether you choose to use the TPL or the Thread class, understanding the basics of multithreading will open up new possibilities for parallel programming and efficient resource utilization. | homolibere | |
1,721,787 | Menggunakan Library Datatable di Bootstrap 5 | Include CSS nya di header <link rel="stylesheet"... | 0 | 2024-01-09T07:34:59 | https://irmanf.com/datatable-bootstrap-5/ | datatable, bootstrap | Include CSS nya di header
```html
<link rel="stylesheet" href="//cdn.datatables.net/1.13.7/css/dataTables.bootstrap5.min.css" />
```
Include JS nya sebelum tag `</body>`
> Datatable membutuhkan jQuery, jika sudah di include bisa di skip
```html
<script src="//code.jquery.com/jquery-3.7.0.js"></script>
<script src="//cdn.datatables.net/1.13.7/js/jquery.dataTables.min.js"></script>
<script src="//cdn.datatables.net/1.13.7/js/dataTables.bootstrap5.min.js"></script>
```
Deklarasi datatable untuk table dengan id `datatable`
```html
<script>
$(document).ready(function () {
$("#datatable").DataTable({
searching: true,
search: {
smart: false,
},
paging: true,
lengthChange: true,
ordering: true,
info: true,
language: {
// menggunakan bahasa Indonesia
url: "//cdn.datatables.net/plug-ins/1.13.7/i18n/id.json",
},
});
});
</script>
```
`searching`, `paging`, `lengthChange`, `ordering` dan `info` semua nilai default nya adalah `true`, jadi config tersebut bisa dihilangkan, kecuali mau diubah nilai nya ke `false`
```html
<script>
$(document).ready(function () {
$("#datatable").DataTable({
search: {
smart: false,
},
language: {
// menggunakan bahasa Indonesia
url: "//cdn.datatables.net/plug-ins/1.13.7/i18n/id.json",
},
});
});
</script>
```
Opsi `smart` di set `false` karena secara default, Datatable menerapkan smart filtering
Jadi jika keyword pencarian dua kata atau lebih, dia akan split kata-kata tersebut menjadi masing-masing dan melakukan pencarian dari dua kata tersebut
Contoh table
```html
<table class="table" id="datatable">
<thead>
<tr>
<th>No</th>
<th>Nama</th>
<th>Username</th>
<th>Role</th>
<th>Aksi</th>
</tr>
</thead>
<tbody>
<!-- looping data -->
</tbody>
</table>
``` | ifkoding |
1,791,993 | getx зеркало | get-x официальный сайт URL Официальный сайт GETX Наших игроков ждет захватывающий мир... | 0 | 2024-03-16T05:48:37 | https://dev.to/getx-game/getx-zierkalo-1c7c | [get-x официальный сайт URL](https://jgetj-x-2.site/)
Официальный сайт GETX
Наших игроков ждет захватывающий мир онлайн-развлечений. С самого начала, когда мы только предоставляли одну развлекательную функцию под нашим брендом, наш сайт постепенно преобразился в настоящее виртуальное казино, где доступно более 4 600 игр. У нас есть все, что нужно для того, чтобы окунуться в увлекательный мир азарта и выигрышей. От классических игровых автоматов до захватывающих настольных игр, у нас есть все, чтобы удовлетворить даже самого требовательного игрока. Присоединяйтесь к нам сегодня и испытайте свою удачу!
Преимущества
Недостатки
Щедрые бонусы
Пополнение баланса только с карт РФ
Безопасность (наличие юридического адреса)
Небольшое количество игр
Быстрая регистрация и вход
Новое казино, набирает популярность
Мы гордимся тем, что каждый клиент для нас важен, и поэтому наши специалисты разработали интуитивно понятный интерфейс, который даже новички смогут легко освоить. Кроме того, мы создали раздел "Часто задаваемые вопросы", где предоставлены ответы на наиболее частые вопросы. В случае возникновения проблем наши клиенты могут в любое время обратиться за помощью к нашей круглосуточной технической поддержке. Мы знаем, что время - самый ценный ресурс, поэтому мы сделали все возможное, чтобы игроки могли насладиться азартом без задержек и сбоев. Наша команда специализируется на разработке самых захватывающих игр, которые позволят вам окунуться в увлекательный мир азарта и приключений. Мы гарантируем безопасность и конфиденциальность данных наших игроков, используя передовые технологии шифрования. У нас вы найдете широкий выбор игр, включая слоты, рулетку, блэкджек и многое другое. Наша цель - сделать ваше время в нашем онлайн казино незабываемым и увлекательным. Присоединяйтесь к нам и испытайте свою удачу уже сегодня!
Рабочее зеркало на сегодня
Мы предлагаем вам эксклюзивный доступ к удивительному миру онлайн-гемблинга через зеркала нашего казино GetX. Эти зеркала являются точными копиями нашего официального сайта, но с различными URL-адресами. Если по каким-то причинам основной сайт недоступен, например, из-за блокировки провайдера или технических проблем, вы будете автоматически перенаправлены на доступное зеркало.
Чтобы получить адреса зеркал, вы можете обратиться в нашу службу технической поддержки или найти их в наших группах в Телеграме.
Одно из главных преимуществ использования зеркал нашего казино - отсутствие необходимости регистрации. Вы можете использовать свои обычные учетные данные, чтобы получить полный доступ ко всем услугам, предоставляемым нашим основным сайтом. Мы полностью гарантируем, что все услуги наших зеркал полностью соответствуют основному сайту.
Таким образом, вы сможете наслаждаться всеми возможностями нашего онлайн-казино без необходимости повторной регистрации. Наши зеркала поддерживают полную синхронизацию с основным ресурсом, чтобы вы могли наслаждаться азартными играми в любое время и в любом месте. Добро пожаловать в мир GetX!
Регистрация и вход
Добро пожаловать в удивительный мир онлайн казино GetX! Здесь вы сможете испытать удачу и попытать себя в различных азартных играх. Чтобы начать свое путешествие, вам необходимо зарегистрироваться на нашем официальном сайте. Не беспокойтесь, процесс регистрации очень простой и не займет у вас много времени.
Для успешной регистрации вам потребуется перейти в правый верхний угол нашего сайта и нажать на кнопку "Регистрация". После этого откроется окно с предложенными способами регистрации. Вы можете выбрать один из трех вариантов, наиболее удобный для вас.
Первый вариант - стандартная регистрация. Просто выберите этот вариант, и наш сайт автоматически создаст для вас учетную запись. Не забудьте сохранить свои учетные данные в надежном месте, чтобы в дальнейшем использовать их для входа в ваш аккаунт. Если хотите, мы также можем отправить вам имя пользователя и пароль по электронной почте.
Второй вариант - регистрация через почту. Если у вас уже есть почтовый ящик, просто введите его в соответствующие поля и установите пароль. Это быстрый и удобный способ зарегистрироваться на нашем сайте.
И наконец, третий вариант - регистрация через социальные сети. Если вы любите пользоваться популярными социальными сетями, такими как "Вконтакте", Google или Telegram, вы можете воспользоваться этими учетными записями для регистрации на нашем сайте. Это очень удобно и быстро.
После успешной регистрации мы настоятельно рекомендуем вам воспользоваться предоставленными бонусами, которые мы предлагаем нашим клиентам. Вам доступны различные бонусы, которые помогут вам увеличить свои шансы на выигрыш. Более подробные сведения об этом вы найдете в следующем разделе нашего обзора.
Важно отметить, что на нашем сайте невозможно создать более одной учетной записи. Это гарантирует безопасность и честность игры. Мы ценим наших игроков и стараемся обеспечить им надежную платформу для игры.
Так что не теряйте время, присоединяйтесь к нам сейчас и погрузитесь в мир азарта и развлечений на GetX! Наслаждайтесь игрой и удачи вам!
Страницы
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| getx-game | |
1,721,797 | How Much JavaScript? | In this article, We're going explore JavaScript fundamentals we need to learn before starting with... | 0 | 2024-01-09T07:47:27 | https://dev.to/devgancode/how-much-javascript-63n | In this article, We're going explore JavaScript fundamentals we need to learn before starting with React.✨
📌Note: The guide is based on Personal experience.
JavaScript Essentials🎯
We're going to explore 👇
- JavaScript fundamentals.
- Advance JavaScript Concepts to explore.
- Build projects.
- React core fundamentals.
- React ecosystem.
Subscribe🎯
{% youtube https://youtu.be/ef9WgwxJ-6A?si=pKY2BvF1Uw5j1eEp %} | devgancode | |
1,721,878 | Simple Steps to Send Emails with Static Images in Django | Liquid syntax error: Unknown tag 'static' | 0 | 2024-01-17T17:24:01 | https://diegocarrasco.com/sending-emails-static-images-django/ | django, email, staticfiles, templates | ---
title: Simple Steps to Send Emails with Static Images in Django
published: true
date: 2024-01-09 08:00:00 UTC
tags: django,email,staticfiles,templates
canonical_url: https://diegocarrasco.com/sending-emails-static-images-django/
---

- [Context](https://diegocarrasco.com/sending-emails-static-images-django/#context)
- [Requirements](https://diegocarrasco.com/sending-emails-static-images-django/#requirements)
- [Issue with {% static %} in Emails](https://diegocarrasco.com/sending-emails-static-images-django/#issue-with-static-in-emails)
- [Solution - Generating Full URLs in the View (with code snippets)](https://diegocarrasco.com/sending-emails-static-images-django/#solution-generating-full-urls-in-the-view-with-code-snippets)
- [In the view](https://diegocarrasco.com/sending-emails-static-images-django/#in-the-view)
- [In the templates](https://diegocarrasco.com/sending-emails-static-images-django/#in-the-templates)
- [HTML template](https://diegocarrasco.com/sending-emails-static-images-django/#html-template)
- [Plain text template](https://diegocarrasco.com/sending-emails-static-images-django/#plain-text-template)
- [Keep in mind](https://diegocarrasco.com/sending-emails-static-images-django/#keep-in-mind)
- [Key Takeaways](https://diegocarrasco.com/sending-emails-static-images-django/#key-takeaways)
- [References](https://diegocarrasco.com/sending-emails-static-images-django/#references)
## Context
I wanted to send an email with a template that included an image using `send_mail` from Django. The image was stored in the `static` folder of the Django project. I wanted to use the Django template system to generate the email content, but I was not sure how to reference the image in the template.
## Requirements
I asume you have a Django project with a static folder and a template that you want to use to generate an email.
## Issue with {% static %} in Emails
The first thing I tried was to use the `{% static %}` template tag to generate the URL for the image. However, this tag does not generate a full URL, but a relative URL. This is not a problem when the template is rendered in the browser, but emails need a full URL to access the image.
This means that `{% static %}` only appends the relative path to the `STATIC_URL`, which is not sufficient for email clients to locate the image.
## Solution - Generating Full URLs in the View (with code snippets)
The solution I found was to generate the full URL in the view and pass it as a context variable to the template.
This involves combining the site's domain with the static file path. This approach uses `get_current_site` to fetch the current site's domain and `static` to get the static file path, concatenating these to form a complete URL.
### In the view
This is an example code to demonstrate how to create the full URL in a Django view:
This URL is then passed to the email template context and used in the src attribute of the img tag.
**Please note that you need to adapt the paths to your project.**
```
# in views.py
# imports we need to create the full URL
from django.contrib.sites.shortcuts import get\_current\_site
from django.templatetags.static import static
# imports we need to render the template to use in the email
from django.template.loader import render\_to\_string
# imports we need to send the email
from django.core.mail import send\_mail
def my\_view(request): # or any other view
# we get the current site to get the domain
current\_site = get\_current\_site(request)
# we get the static file path and concatenate it with the domain
logo\_url = f'https://{current\_site.domain}{static("images/your-logo.png")}'
# we generate a context with the variables we want to use in the template
context = {
'logo\_url': logo\_url,
# ... other context variables ...
}
subject = 'Subject of your email'
# we render the templates to use in the email
message\_plain = render\_to\_string('my\_template.txt', context)
message\_html = render\_to\_string('my\_template.html', context)
email = 'test@example.com'
# we send the email
send\_mail(subject, message\_plain, None, [email], html\_message=message\_html)
```
### In the templates
When you send emails, it is recommended to provide both a plain text and an HTML version of the email. This is why we have two templates in the view.
#### HTML template
```
<!-- in my\_template.html -->
<img src="{{ logo\_url }}" alt="Your Logo">
```
#### Plain text template
In my case, I did not need to include the image in the plain text version of the email, but if you need to do so, you can use the same approach as in the HTML template.
```
<!-- in my\_template.txt -->
Your Logo: {{ logo\_url }}
```
## Keep in mind
- This approach is not limited to images. You can use it to generate full URLs for any static file.
- This approach is not limited to emails. You can use it to generate full URLs for any static file in any context and render the templates.
## Key Takeaways
- Django's `{% static %}` template tag only generates a relative URL, which is not sufficient for email clients to locate the image.
- To generate a full URL for a static file, you need to combine the site's domain with the static file path.
- You can use `get_current_site` to fetch the current site's domain and `static` to get the static file path, concatenating these to form a complete URL.
- You can use this approach to generate full URLs for any static file in any context and render the templates.
- You construct the full URL in the view and pass it as a context variable to the template.
Happy coding!
## References
- [Django Documentation - Managing static files](https://docs.djangoproject.com/en/4.2/ref/contrib/staticfiles/)
- [Django Documentation - get\_current\_site](https://docs.djangoproject.com/en/4.2/ref/contrib/sites/#get-current-site-shortcut)
- [Django Documentation - static](https://docs.djangoproject.com/en/4.2/ref/templates/builtins/#static)
- [Django Documentation - send\_mail](https://docs.djangoproject.com/en/4.2/topics/email/#send-mail)
- [Django Documentation - render\_to\_string](https://docs.djangoproject.com/en/4.2/topics/templates/#django.template.loader.render_to_string)
- [Django Documentation - EmailMessage](https://docs.djangoproject.com/en/4.2/topics/email/#django.core.mail.EmailMessage) | dacog |
1,721,894 | Take Your Images to New Heights: AI Image Extender | Enlarge your images and bring out the hidden details with our free AI image expander. Enhance the... | 0 | 2024-01-09T09:42:10 | https://dev.to/aiimageexpander12/take-your-images-to-new-heights-ai-image-extender-ofo | javascript, productivity | Enlarge your images and bring out the hidden details with our free [AI image expander](https://simplified.com/ai-image-expander/).
Enhance the quality and make your visuals stand out. Perfect for personal projects or professional use.
Achieve high-quality, large-format prints with our free [AI image expander](https://simplified.com/ai-image-expander/).
Increase the size of your images without sacrificing clarity or sharpness. Print your photos in impressive sizes and showcase your work in all its glory. | aiimageexpander12 |
1,721,979 | The importance of flyer design in marketing — Subraa | Digital channels often dominate discussions, however flyer stands as a tangible testament to the... | 0 | 2024-01-09T10:44:09 | https://dev.to/subraaoct2023/the-importance-of-flyer-design-in-marketing-subraa-156i | flyerdesign |
Digital channels often dominate discussions, however flyer stands as a tangible testament to the enduring power of print. Far from being outdated, [flyer design](https://www.subraa.com/flyer-design-singapore/) remains a potent tool that captivates, engages, and leaves a lasting impression on potential customers.
**1. Tangible Brand Presence:**
A well-crafted flyer provides a tangible representation of your brand. Whether distributed at events, posted on community boards, or included in direct mail campaigns, it serves as a physical touchpoint that reinforces brand presence.
**2. Localized Marketing Impact:**
Flyers are versatile tools for localized marketing. From promoting local events to announcing store openings, their physical distribution ensures that your message reaches the intended audience within specific geographic areas.
**3. Cost-Effective Marketing Tool:**
Compared to elaborate digital marketing campaigns, flyer design is a cost-effective solution that doesn't compromise on impact. Printing costs are reasonable, and the potential return on investment is significant.
**4. Immediate and Personal:**
Flyers deliver information directly into the hands of your audience. This immediacy fosters a personal connection that digital ads may lack. People can engage with the content at their convenience, creating a more intimate interaction.
**5. Creative Freedom and Customization:**
Flyer design offers creative freedom. From vibrant colors to innovative layouts, it allows businesses to showcase their personality and style. Customization ensures that each flyer aligns with the unique identity of the brand.
**6. Targeted Messaging:**
Tailoring your message to a specific audience is effortless with flyers. Whether promoting a sale, announcing a special offer, or inviting participation in a local event, the content can be precisely crafted to resonate with the target demographic.
**7. Measurable Impact:**
While the tactile nature of flyers provides a personal touch, their impact is not devoid of analytics. Unique promo codes, QR codes, or specific URLs can be incorporated, allowing businesses to measure the success of their flyer campaigns.
**8. Complementary Digital Integration:**
Far from being mutually exclusive, flyer design can seamlessly integrate with digital marketing efforts. QR codes on flyers can lead recipients to landing pages, bridging the physical and digital realms for a comprehensive marketing strategy.
In conclusion, the importance of flyer design in marketing lies in its ability to bridge the gap between the physical and digital worlds. As a cost-effective, versatile, and impactful tool, a well-designed flyer remains a stalwart in the marketing arsenal, ensuring that your message not only reaches but resonates with your audience.
**Website : [https://www.subraa.com/](https://www.subraa.com/)**
| subraaoct2023 |
1,722,565 | AWS ElastiCache: Accelerating Your Applications with In-Memory Caching | Introduction: In the ever-evolving landscape of cloud computing, businesses are constantly... | 0 | 2024-04-03T07:22:58 | https://imransaifi.hashnode.dev/aws-elasticache-accelerating-your-applications-with-in-memory-caching | ---
title: AWS ElastiCache: Accelerating Your Applications with In-Memory Caching
published: true
date: 2024-01-09 18:42:31 UTC
tags:
canonical_url: https://imransaifi.hashnode.dev/aws-elasticache-accelerating-your-applications-with-in-memory-caching
---
## Introduction:
In the ever-evolving landscape of cloud computing, businesses are constantly seeking ways to enhance the performance and scalability of their applications. One key solution that has gained immense popularity is AWS ElastiCache. This managed, in-memory caching service is designed to seamlessly integrate with Amazon Web Services (AWS) and provide a powerful boost to the speed and responsiveness of applications. In this blog post, we will explore the features, benefits, and best practices of AWS ElastiCache.
## Understanding AWS ElastiCache:
AWS ElastiCache is a fully-managed, in-memory caching service that supports popular open-source caching engines such as Redis and Memcached. By deploying an in-memory caching layer close to your application, ElastiCache minimizes the load on databases and accelerates access to frequently requested data. This, in turn, leads to improved application performance, reduced latency, and enhanced overall user experience.
## Key Features of AWS ElastiCache:
1. **Managed Service:** AWS ElastiCache takes care of all the operational aspects of managing and scaling the caching infrastructure. This allows developers and administrators to focus on building and optimizing their applications without worrying about the underlying infrastructure.
2. **Compatibility with Redis and Memcached:** ElastiCache supports both Redis and Memcached, giving users the flexibility to choose the caching engine that best fits their application requirements. Redis is known for its advanced data structures and features, while Memcached is a simple, high-performance key-value store.
3. **Scalability:** ElastiCache allows users to scale their caching infrastructure horizontally by adding or removing nodes. This dynamic scalability ensures that the caching layer can adapt to changing workloads, maintaining optimal performance.
4. **Security:** ElastiCache provides various security features, including Virtual Private Cloud (VPC) support, encryption at rest and in transit, and integration with AWS Identity and Access Management (IAM). These features ensure that your data is secure and compliant with industry standards.
## Benefits of AWS ElastiCache:
1. **Improved Application Performance:** By storing frequently accessed data in-memory, ElastiCache reduces the latency associated with fetching data from databases. This leads to faster response times and a more responsive user experience.
2. **Cost-Efficiency:** Caching frequently accessed data in-memory reduces the load on backend databases, allowing them to handle a larger number of transactions. This optimization can result in cost savings by avoiding the need to provision additional database resources.
3. **Enhanced Scalability:** ElastiCache's ability to scale horizontally ensures that your caching layer can grow seamlessly with your application's demands. This scalability is crucial for handling increased traffic and maintaining consistent performance.
## Best Practices for Using AWS ElastiCache:
1. **Choose the Right Caching Engine:** Select the caching engine that aligns with your application requirements. Redis is suitable for scenarios requiring advanced data structures and features, while Memcached is a good choice for simple key-value store use cases.
2. **Optimize Key Design:** Carefully design and choose keys for your cached data. Well-designed keys can improve cache utilization and retrieval efficiency.
3. **Monitor and Tune:** Regularly monitor the performance of your ElastiCache cluster and adjust its configuration based on usage patterns. AWS provides CloudWatch metrics and alarms that can be utilized for monitoring.
4. **Implement Redundancy:** Leverage ElastiCache's features such as Multi-AZ for Redis to ensure high availability and fault tolerance. Redundancy is crucial for maintaining application performance in the face of failures.
## Conclusion:
AWS ElastiCache stands out as a powerful solution for boosting the performance of applications through in-memory caching. By seamlessly integrating with popular caching engines like Redis and Memcached, ElastiCache empowers developers to enhance application responsiveness and scalability while enjoying the benefits of a fully-managed service. As businesses continue to embrace cloud technologies, AWS ElastiCache remains a key player in optimizing application performance and delivering a superior user experience. | imransaifi | |
1,722,022 | Confirmed reserves on the Binance exchange exceed a ratio of 100% | The latest Proof of Reserves (PoR) report from Binance shows that the net balances of XRP clients... | 0 | 2024-01-09T11:43:10 | https://dev.to/andylarkin677/confirmed-reserves-on-the-binance-exchange-exceed-a-ratio-of-100-5759 | news, blockchain, cryptocurrency |
The latest Proof of Reserves (PoR) report from Binance shows that the net balances of XRP clients amount to over 2.7 billion tokens (over $1.5 billion at current rates). The net balances of the exchange, in turn, amount to over 2.8 billion in assets, corresponding to a ratio of 104.26%.
The Proof of Reserves system is designed to ensure transparency and build trust among Binance users by demonstrating that the company is capable of covering the balances of all clients on a 1:1 basis.
In other words, this guarantees that client funds are fully backed, which is particularly important given the bankruptcy of some major cryptocurrency exchanges, including FTX, which commingled client assets with its own.
The net balances of the trading platform in Bitcoin and Ethereum also have positive ratios, amounting to 103.79% and 106.56%, respectively.
Among other cryptocurrency exchanges that have published similar reports in recent months are Crypto.com, Kraken, OKX, and others. | andylarkin677 |
1,722,045 | Inventory Reports: The Key to Profitability and Efficiency | Inventory reports just make businesses work better. They’re not just sheets of paper; they’re the key... | 0 | 2024-01-09T12:10:01 | https://www.boldreports.com/blog/essentials-of-inventory-reports | inventoryreports, inventorymanagement, reporting, boldreports | Inventory reports just make businesses work better. They’re not just sheets of paper; they’re the key to understanding the current situation within a business. From making smart choices to keeping everything running smoothly, let’s uncover how inventory reports are the game-changer for boosting profits and efficiency. In this guide, we’re going to explore why these reports are such a big deal.
#**What is an inventory report?**
The primary purpose of such a report is to monitor the quantity, location, The report may encompass information on raw materials, finished products, works in progress, or other items relevant to the specific industry or business. Here are the key points of an inventory report:
**Item Details**: A comprehensive list including names, descriptions, and for precise inventory tracking.
Quantity on Hand: The total quantities available for each individual item in detail.
**Location**: The storage location for each item.
**Unit Cost**: Clearly outlines the cost associated with each unit of every inventory item, aiding in cost analysis.
**Total Value**: The overall value of the entire inventory by multiplying quantity and unit cost, offering a snapshot of financial worth.
**Reorder Points**: Strategically identifies when to restock specific items, optimizing inventory levels and preventing shortages.
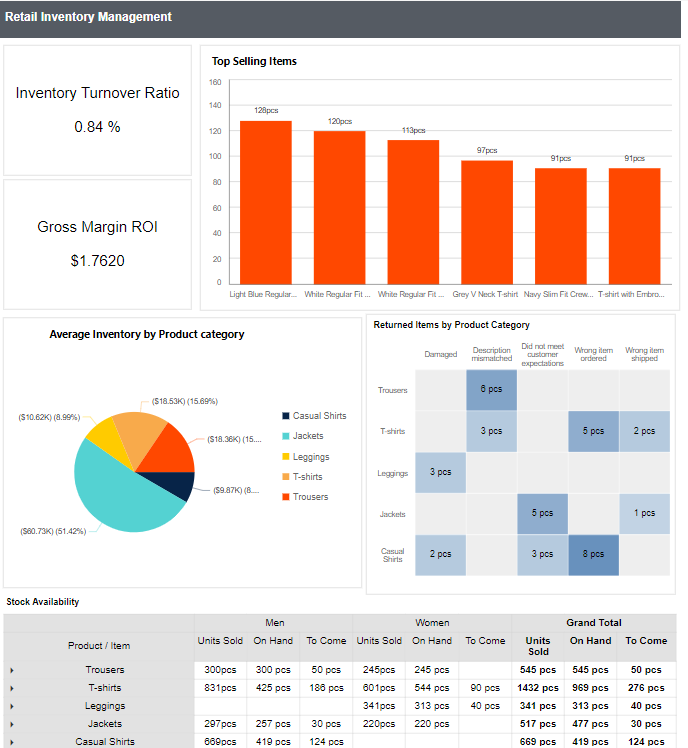
#**Why inventory reports are important?**
Inventory reports explore and analyze dynamic stock data, providing a more insightful understanding of inventory trends and opportunities.
**Effective Resource Management**
Inventory reports are vital for effective resource management, as they provide real-time data on inventory quantity and location. This helps businesses make informed decisions, preventing overstocking and stockouts, optimizing procurement processes, and reducing operational costs.
**Strategic Decision-Making**
Inventory information assists in optimizing sales strategies, forecasting demand, and efficient supply chain management. It also supports making decisions on product lifecycle, ensuring businesses can align their strategies with market demands, optimize resources, and stay competitive.
**Financial Control**
Think of inventory reports like a map for your business. They show you the total value of all your items, helping you plan your budget and follow the rules for taxes. It’s a bit like using a map on a road trip—inventory reports keep your business on the right money path.
**Operational Efficiency**
Inventory reports maintain optimal stock levels, preventing overstocking and stockouts and ensuring resources are utilized efficiently. This aids in timely order fulfillment, enhances customer satisfaction, and streamlines operations, optimizing resource allocation for cost reduction.
#**Create Inventory Reports with Bold Reports**
Creating an effective inventory report is essential, and it doesn’t have to be complex. In this section, we’ll outline the steps to create a great inventory report.
**Data Collection**
Efficient inventory reporting begins with comprehensive data collection. Gather relevant information from various sources. Ensure accuracy and completeness for a solid foundation.
**Define Your Report’s Purpose**
Identify the purpose of your inventory report. Whether it’s assessing stock levels, tracking product performance, or presenting inventory metrics to stakeholders, a well-defined purpose guides the content and structure.
**Choose the Right Reporting Tools**
Select suitable reporting tools to create the best inventory reports. These tools include platforms like that offer robust features for data visualization and reporting. Consider whether you want to work in an app or embed the tools in the applications you already use. Make sure the functionality of your chosen tools align with your reporting needs for analysis, customization, and presentation.
**Determine Your Reporting Timeframe**
Define the time period of data you want to include. Schedule automatic real-time report generation and define intervals for manual updates based on data volatility and report demands. This ensures more timely, relevant, and accurate inventory data.
**Analyze and Visualize Inventory Data**
Identify key trends through data analysis and visualization, focusing on patterns like stock fluctuations, supplier performance, and seasonal variations. Utilize [conditional formatting](https://help.boldreports.com/enterprise-reporting/designer-guide/report-designer/report-items/tablix/conditional-formatting-tablix-data-region/?utm_source=dev&utm_dev=partner_blog&utm_campaign=dev_EssentialofInventoryReports_cy23) to highlight critical inventory levels or overdue orders. When visualizing metrics, pick simple [charts](https://help.boldreports.com/enterprise-reporting/designer-guide/report-designer/report-items/chart/?utm_source=dev&utm_dev=partner_blog&utm_campaign=dev_EssentialofInventoryReports_cy23) for clarity, avoiding too much complexity. This way, everyone can easily understand the key patterns in the inventory data.
By following these steps and utilizing tools like Bold Reports, you can create a clear and visually appealing inventory report, making it easier for everyone to understand and use the information for smart decision-making.
#**Types of Inventory Reports**
Following is an explanation of different types of inventory reports.
**Stock Status Report**
A stock status report offers a real-time snapshot of current inventory quantities, including details like location, product category, and unit of measure. It is vital for identifying potential stockouts and ensuring stock levels can meet customer demand. The report may also include on-order quantities and net stock for a more comprehensive view of inventory dynamics.
**Inventory Valuation Report**
A valuation report determines the total value of inventory at a specific time, crucial for financial reporting and calculations. It employs methods such as FIFO, LIFO, or average cost, providing businesses with essential information for strategic decision-making.
**Sales and Usage Report**
This inventory tracking report monitors sales, usage, and returns, helping businesses optimize inventory levels and identify demand trends. It serves as a valuable tool for analyzing sales performance, highlighting best-selling items, and addressing slow-moving products, contributing to efficient inventory management.
**Reorder Point Report**
A reorder point report signals when to reorder items to avoid stockouts. By factoring in lead time, usage rate, and safety stock, it ensures a smooth inventory flow, preventing disruptions in production or sales.
#**Conclusion**
By checking inventory reports regularly, your business can save money, work smarter, and make more profit. Investing in good reporting tools and skills helps your business grow and succeed in the future.
If you have any questions, please post them in the comments section. You can also [contact us](https://www.boldreports.com/contact/?utm_source=dev&utm_dev=partner_blog&utm_campaign=dev_EssentialofInventoryReports_cy23) through our contact page, or if you already have an account, you can [log in](https://www.boldreports.com/?utm_source=dev&utm_dev=partner_blog&utm_campaign=dev_EssentialofInventoryReports_cy23) to submit your question.
Bold Reports offers a 15-day [free trial](https://www.boldreports.com/pricing/?utm_source=dev&utm_dev=partner_blog&utm_campaign=dev_EssentialofInventoryReports_cy23) with no credit card information required. We welcome you to start a free trial and experience Bold Reports. Be sure to let us know what you think!
For announcements about new releases, follow us on our [Twitter](https://twitter.com/boldreportsoffl), [Facebook](https://www.facebook.com/boldreportsofficial/), and [LinkedIn](https://www.linkedin.com/showcase/boldreportsofficial) pages. | boldreportsinfo |
1,722,046 | AI multi prompt extension - Auto Open Tab + DeepSeek support | 🎉 News for AI Multi Prompt Browser Extension users. the version 1.3.0 has been released ... | 25,568 | 2024-01-09T17:53:19 | https://dev.to/bsorrentino/ai-multi-prompt-extension-auto-open-tab-deepseek-support-29hi | ai, promptengineering, extensions, chrome | 🎉 News for [AI Multi Prompt Browser Extension][chrome] users. the version `1.3.0` has been released
#### Automatic Open Chat Tab
The most requested feature is now available 😎. You can automatically open a chat tab when you click on the extension's check (see gif below).
| <img src="https://raw.githubusercontent.com/bsorrentino/bsorrentino/gh-pages/assets/ai-multi-prompt-browser-extension/output.gif?raw=true"></img> |
| --- |
| _Opens a pinned tab for each AI chat chosen (if doesn't already opened yet)._ |
#### Deepseek Coder integration
Now, other than [ChatGPT], [Bard], [Copilot], [Phind] and [Perplexity], we have added also [DeepSeek Coder][Deepseek] a promising code generation model providing also an [online playground chat][deepseek_chat].
<br>
<br>
🔗 Check it out on the [Chrome Web Store][chrome] and enhance your productivity today! thanks and happy AI chatting 💬🤖.
[extension]: https://bsorrentino.github.io/bsorrentino/ai/2023/10/16/ai-multi-prompt-browser-extension.html
[chrome]: https://chromewebstore.google.com/detail/jmifflpjnpeamgeclkhlbilpjjmhajmd/preview?hl=en
[chatgpt]: https://chat.openai.com/
[bard]: https://bard.google.com/
[perplexity]: https://perplexity.ai/
[phind]: https://phind.com/
[copilot]: https://copilot.microsoft.com/
[deepseek]: https://github.com/deepseek-ai/DeepSeek-Coder
[deepseek_chat]: https://github.com/deepseek-ai/DeepSeek-Coder
| bsorrentino |
1,722,125 | Build a spin input | When users need to adjust a numerical value up or down, we often provide a user interface element to... | 0 | 2024-01-09T13:01:21 | https://phuoc.ng/collection/html-dom/build-a-spin-input/ | tutorial, javascript, webdev | When users need to adjust a numerical value up or down, we often provide a user interface element to make it easy for them. That's where the spin input comes in handy.
HTML has a built-in input element for creating a spin input by setting the type attribute to `number`. This input only allows digits, which prevents users from entering invalid characters. When you click or tap on the input, two arrow buttons appear on the right side to increase or decrease the value.
Give it a try below:
{% codepen https://codepen.io/phuocng/pen/JjzKMWw %}
Unfortunately, we can't easily customize the buttons, such as replacing them with our own images. But don't worry, in this post, we'll learn how to build a spin input with JavaScript DOM.
## HTML Markup
To create the spin input, we'll need to start with the HTML markup. The layout includes an input element and two buttons for increasing and decreasing the value.
```html
<div class="spin" id="spin">
<input type="text" name="input" class="spin__input" value="50">
<button class="spin__btn spin__btn--minus"></button>
<button class="spin__btn spin__btn--plus"></button>
</div>
```
We've created a container `div` with the class `spin`. Inside the container, there are two buttons with the classes `spin__btn spin__btn--minus` and `spin__btn spin__btn--plus`. These buttons will decrease and increase the value, respectively. Additionally, there's an `input` element with a default value of 50.
Instead of using the `number` input type, we're using the usual `text` attribute.
## Basic styles
When creating buttons that require an up or down arrow, we have a few options. We can use a minus or plus sign, an image, or - as we'll explore in this post - fake triangles created with pure CSS.
To create a CSS triangle to represent the up and down arrow in buttons, we can use the `::before` or `::after` pseudo-element and some creative CSS. Here's an example of how to create an upward triangle:
```css
.spin__btn--plus::before {
content: '';
width: 0;
height: 0;
border-left: 0.5rem solid transparent;
border-right: 0.5rem solid transparent;
border-bottom: 0.5rem solid rgb(203 213 225);
}
```
In this code snippet, we're adding a triangle before the `spin__btn--plus` class for styling purposes. The pseudo-element doesn't actually contain any content because we set the `content` property to an empty string.
To make the triangle invisible by default, we set the `width` and `height` properties to zero. Then, we use borders with varying colors and thicknesses to create the triangular shape. By setting the left and right borders to `transparent`, only the bottom border is visible. Finally, we set the color of the triangle with the `border-bottom-color` property.
We can use similar code with different border property values to create a downward-pointing triangle for our other button. Check out how the minus button could look with this styling:
```css
.spin__btn--minus::before {
content: '';
width: 0;
height: 0;
border-left: 0.5rem solid transparent;
border-right: 0.5rem solid transparent;
border-top: 0.5rem solid rgb(203 213 225);
}
```
## Positioning the buttons
To position our buttons perfectly within the container, we'll need to set the position property of the container to `relative`. This creates a positioning context for its child elements.
```css
.spin {
position: relative;
}
```
With this setup, we can use absolute positioning to place our buttons within the container. We set their position properties to `absolute` and specify their `top` and `bottom` values.
```css
.spin__btn {
position: absolute;
position: absolute;
right: 0;
height: 50%;
}
.spin__btn--minus {
top: 0;
}
.spin__btn--plus {
bottom: 0;
}
```
In the code snippet, we target all `.spin__btn` elements and set their `position` property to `absolute`. Then, we target each individual button and set its `top` or `bottom` properties depending on its desired position.
With these styles, our input element will be perfectly centered vertically within the container with our two arrow buttons positioned at either end.
## Increasing and decreasing value
Now, we need to make our buttons functional by adding event listeners that update the value of our input element. We can do this easily with the `addEventListener` method.
```js
const container = document.getElementById('spin');
const inputEle = container.querySelector('.spin__input');
const minusBtn = container.querySelector('.spin__btn--minus');
const plusBtn = container.querySelector('.spin__btn--plus');
const increase = () => {
const currentValue = inputEle.value;
const newValue = (currentValue === '') ? 0 : parseInt(currentValue, 10) + 1;
inputEle.value = newValue;
};
const decrease = () => {
const currentValue = inputEle.value;
const newValue = (currentValue === '') ? 0 : parseInt(currentValue, 10) - 1;
inputEle.value = newValue;
};
minusBtn.addEventListener('click', decrease);
plusBtn.addEventListener('click', increase);
```
First, we select the input element and both buttons using `document.getElementById` and `document.querySelector`. Then, we add event listeners to the minus and plus buttons. These listeners call the `decrease` and `increase` methods on the input element, respectively, which decrease or increase the value by 1. It's that simple!
## Accepting digits only
Previously, we used the `number` type for input, which prevented users from entering invalid characters. However, we've changed our approach and now need to restrict input to digits only.
To achieve this, we can handle the `keydown` event, which fires when a user presses a key. We can then verify whether the pressed key is a number by comparing it with the `^[0-9]+$` pattern.
If the key is not a number, we prevent the default behavior by calling `preventDefault()`. It's worth noting that we still allow users to use the Backspace and Delete keys to remove digits as normal.
Here's how we handle the `keydown` event:
```js
const handleKeyDown = (e) => {
if (!/^[0-9]+$/.test(e.key) && e.key !== 'Backspace' && e.key !== 'Delete') {
e.preventDefault();
}
};
inputEle.addEventListener('keydown', handleKeyDown);
```
## Enhancing user experience with keyboard shortcuts
In addition to clicking buttons, we can further improve the user experience by allowing them to adjust the value using keyboard shortcuts. For example, pressing the up arrow key can increase the value, while pressing the down arrow key can decrease it.
To enable this feature, we need to update the `keydown` event handler to detect if the user presses the left or right arrow keys and adjust the value accordingly.
Here's an updated version of our code that includes keyboard shortcuts to enhance the user experience.
```js
const handleKeyDown = (e) => {
switch (e.key) {
case 'ArrowDown':
decrease();
break;
case 'ArrowUp':
increase();
break;
default:
if (!/^[0-9]+$/.test(e.key) && e.key !== 'Backspace' && e.key !== 'Delete') {
e.preventDefault();
}
break;
}
};
```
## Setting limits on input values
When working with input values, it's often necessary to set a minimum and maximum range for possible values. This can easily be done using the `min` and `max` attributes.
```html
<input min="0" max="100">
```
To ensure that the input value falls within the desired range, we can update our `increase` and `decrease` functions to include the `clamp` function. The `clamp` function is a utility function that ensures a value falls within a given range. It takes three arguments: `min`, `max`, and `value`. The function checks if `value` is less than `min`, and returns `min` if it is. If `value` is greater than `max`, the function returns `max`. If `value` is within the range of `min` and `max`, the function returns `value`.
```js
const clamp = (min, max, value) => Math.min(Math.max(value, min), max);
```
With this in mind, we can update our code to include the `clamp` function in our `increase` and `decrease` functions. This ensures that the input value falls within the specified range.
By setting limits on input values, we can ensure that our code is more robust and less prone to errors.
```js
const min = parseInt(target.getAttribute('min'), 10);
const max = parseInt(target.getAttribute('max'), 10);
const increase = () => {
const currentValue = inputEle.value;
const newValue = (currentValue === '') ? 0 : parseInt(currentValue, 10) + 1;
inputEle.value = clamp(min, max, newValue);
};
const decrease = () => {
const currentValue = inputEle.value;
const newValue = (currentValue === '') ? 0 : parseInt(currentValue, 10) - 1;
inputEle.value = clamp(min, max, newValue);
};
```
And that's all! With only a few lines of JavaScript and CSS, we've created a spin input that allows you to adjust a numerical value up or down. Give it a try and see for yourself by playing around with the demo below.
{% codepen https://codepen.io/phuocng/pen/oNVLpZO %}
## See also
- [Clamp a number between two values](https://phuoc.ng/collection/1-loc/clamp-a-number-between-two-values/)
- [Spin button](https://phuoc.ng/collection/css-layout/spin-button/)
---
It's highly recommended that you visit the [original post](https://phuoc.ng/collection/html-dom/build-a-spin-input/) to play with the interactive demos.
If you found this series helpful, please consider giving the [repository](https://github.com/phuocng/html-dom) a star on GitHub or sharing the post on your favorite social networks 😍. Your support would mean a lot to me!
If you want more helpful content like this, feel free to follow me:
- [DEV](https://dev.to/phuocng)
- [GitHub](https://github.com/phuocng) | phuocng |
1,722,155 | SQL vs NoSQL: Elegir la Base de Datos Adecuada para su Proyecto | Como ingeniera de software con años de experiencia en el mercado, he tenido la oportunidad de... | 0 | 2024-01-09T13:25:59 | https://dev.to/marmariadev/sql-vs-nosql-elegir-la-base-de-datos-adecuada-para-su-proyecto-5e32 | webdev, programming, database, spanhis | Como ingeniera de software con años de experiencia en el mercado, he tenido la oportunidad de trabajar con una amplia variedad de bases de datos, tanto SQL como NoSQL. La elección entre estas dos categorías de bases de datos es muy importante y puede tener un impacto significativo en el rendimiento, la escalabilidad y la facilidad de desarrollo de su aplicación. En este post, exploraremos los pros y contras de SQL y NoSQL, proporcionando una guía clara para ayudarte a tomar una decisión informada.
## SQL: Estructura y Fiabilidad
### Pros:
- **Estructura Definida**: Las bases de datos SQL, como MySQL o PostgreSQL, utilizan un esquema predefinido que ayuda a mantener la estructura de los datos. Esto es ideal para datos que no cambian con frecuencia y necesitan una organización consistente.
- **Integridad de Datos**: Gracias a las transacciones ACID (Atomicidad, Consistencia, Aislamiento, Durabilidad), las bases de datos SQL garantizan una alta integridad de datos.
- **Lenguaje Uniforme**: SQL es un lenguaje estandarizado que permite realizar consultas complejas de manera eficiente, lo cual es ideal para análisis y reportes detallados.
### Contras:
- **Escalabilidad Vertical**: Las bases de datos SQL a menudo requieren escalabilidad vertical (mejorar el hardware del servidor existente), lo que puede ser costoso y tiene sus límites.
- **Flexibilidad Limitada**: Los cambios en el esquema pueden ser difíciles y laboriosos, lo que puede ser un desafío en entornos ágiles y con requisitos cambiantes.
## NoSQL: Flexibilidad y Escalabilidad
### Pros:
- Escalabilidad Horizontal: Las bases de datos NoSQL, como MongoDB o Cassandra, están diseñadas para escalar horizontalmente, usando clusters de servidores, lo que facilita el manejo de grandes volúmenes de datos y tráfico.
- Esquemas Dinámicos: Permiten una mayor flexibilidad ya que los datos pueden almacenarse sin un esquema definido. Esto es ideal para datos que cambian o evolucionan con frecuencia.
- Diversidad de Tipos: NoSQL incluye varios tipos como documentales, de clave-valor, de columnas anchas, y grafos, cada uno optimizado para diferentes tipos de consultas y patrones de acceso.
### Contras:
- **Consistencia Eventual**: Algunas bases de datos NoSQL ofrecen consistencia eventual en lugar de transacciones ACID, lo que puede no ser adecuado para aplicaciones que requieren alta integridad de datos.
- **Complejidad en Consultas**: Realizar consultas complejas puede ser más desafiante en NoSQL debido a la falta de un lenguaje de consulta estandarizado como SQL.
## ¿Cuál Elegir?
La decisión entre SQL y NoSQL depende en gran medida de las necesidades específicas de su proyecto:
- **Elija SQL si...** sus datos requieren una estructura rigurosa, integridad de datos y capacidades de consulta complejas son prioritarias.
- **Elija NoSQL si...** está trabajando con grandes volúmenes de datos o datos que cambian con frecuencia, y necesita escalabilidad y flexibilidad.
La elección entre SQL y NoSQL no es una decisión de "talla única". Cada proyecto tiene sus requisitos y desafíos únicos. Como ingenieros de software, nuestro trabajo es comprender las características y limitaciones de cada tipo de base de datos para hacer la mejor elección posible que respalde las necesidades de nuestros proyectos y clientes. | marmariadev |
1,722,305 | 🚀 Official Launch of DSP Community 🎉 | I am thrilled to share with you the official launch of my new software engineering website, blog, and... | 0 | 2024-01-09T15:54:40 | https://dev.to/ahmedtarekhasan/official-launch-of-dsp-community-1obp | I am thrilled to share with you the official launch of my new software engineering website, blog, and community.
{% embed https://www.developmentsimplyput.com %}
A space that goes beyond a traditional blog to become a thriving software engineering community!
---
After a lot of hard work and dedication, I’ve finally launched my website and blog to provide you with the latest insights, tips, and resources in the world of software engineering. I’ve also taken the time to republish my previous articles on the new blog.
{% embed https://www.developmentsimplyput.com/blog %}
However, please keep in mind, this project has been a labor of love, and I’m excited to turn it into more than just a blog. My vision is to cultivate a thriving community where collaboration and innovation take center stage.
---
## 🌟 What Inspired Me
Years ago, Albert Einstein’s timeless words became my guiding principle:
If you can’t explain it simply, you don’t understand it well enough.
This simple yet profound statement sparked my journey into blogging and writing technical content, fulfilling my passion for learning and sharing knowledge which eventually helps me learn more.
However, as the days passed, I yearned for more. It dawned on me — what about the other dimensions of my life as a software engineer? How do I socialize, generate new ideas, present myself better? After that realization, it was so obvious what to call my initiative; “Development Simply Put”. Contrary to common perception — even among those close to me — it was never about Software Engineering Development; it was always about Software Engineers Development.
---
## 👥 Join the Community
Discover a space that goes beyond traditional blogging. The website aims to foster connections, discussions, and collaborations within the dynamic world of software engineering.
---
## 🌟 What’s in Store
I have big plans for the future, including engaging activities, collaborative projects, and opportunities for community members to shine. Stay tuned for exciting developments!
---
Development Simply Put DSP Community Blog Posts Articles Tips Hints Tricks Tutorials Quizzes Evaluations Projects .NET DotNet C# CSharp Code Coding Programming Software Design Development Engineering Architecture Best Practice Ahmed Tarek
---
## 📬 Subscribe to Stay Connected
Be part of this journey from the start by subscribing to my newsletter. Get the latest updates directly in your inbox and be the first to know about upcoming community initiatives.
{% embed https://www.developmentsimplyput.com/subscribe %}
---
## 💡 How You Can Support
1️⃣ **[Subscribe](https://www.developmentsimplyput.com/subscribe)**: Receive great content and be a part of the community from day one.
2️⃣ Engage: Read, rate, and comment on **[blog articles](https://www.developmentsimplyput.com/blog)** to fuel discussions.
3️⃣ Share: Spread the knowledge by sharing articles on social media.
4️⃣ Spread the Word: Help grow our community by sharing this announcement.
5️⃣ **[Other ways…](https://www.developmentsimplyput.com/support-us)**
---
## 🗣 Your Voice Matters
Your support is crucial in making this vision a reality, and I can’t wait to build a vibrant community together. I invite you to share your thoughts, suggestions, and topics you’d like to see covered. Let’s build this community together!
Thank you for being a part of this exciting journey! 🚀
---
🎁Presents
Don’t forget to check our **Free Udemy Coupons** Page.
{% embed https://www.developmentsimplyput.com/udemy-coupons %}
---
Also, out partner **DSP Stylish Designs**.
A new brand providing unique apparel (t-shirts, hoodie, tank, crewneck,…) and other print on demand products (bottles, magnets, mouse pads,…) specifically catered to software engineering enthusiasts.
Their slogan is “𝐶𝑟𝑎𝑓𝑡𝑖𝑛𝑔 𝐸𝑙𝑒𝑔𝑎𝑛𝑐𝑒, 𝑂𝑛𝑒 𝑃𝑟𝑖𝑛𝑡 𝑎𝑡 𝑎 𝑇𝑖𝑚𝑒”.
{% embed https://www.developmentsimplyput.com/dsp-stylish-designs %}
---
Finally, hope you like what Development Simply Put community is offering and wish to meet you there 😃 | ahmedtarekhasan | |
1,722,331 | Help with Font Sizes | Hello, first post here. I was wondering how everyone chooses their font sizes on their portfolios.... | 0 | 2024-01-09T16:44:44 | https://dev.to/asteeves/help-with-font-sizes-l9p | Hello, first post here.
I was wondering how everyone chooses their font sizes on their portfolios. Is there some sort of industry standard that you like to use where for example the sub header is 1.6x the size of the text beneath? Also how to you like to change the font in regards to a small, medium and large screen such as phone, ipad, desktop monitor?
Thank you in advance. | asteeves | |
1,722,405 | Coming Out as an Eldritch God | A stepping stone in my life | 0 | 2024-01-09T17:38:00 | https://dev.to/neohaskell/coming-out-as-an-eldritch-god-1nha | watercooler, developer, thegame23 | ---
title: Coming Out as an Eldritch God
published: true
description: A stepping stone in my life
tags: #watercooler #developer #haskell #thegame23
cover_image: https://wallpapercave.com/wp/wp9634994.jpg
# Use a ratio of 100:42 for best results.
published_at: 2024-01-09 17:38 +0000
---
I've been sick of a flu-like thing for nearly 2 months now (Perhaps COVID, perhaps my burned-out immune system). But **I've been sick of life for a much longer period of time, more than I can remember**. The problem is not with life itself, but my relationship with it. Not with anyone, not with anything, just with my `Control.lens` of reality, or more precisely, how I create my reality.
Since I was a kid, I've been **creative, curious, expressive**. But the universe is a joke of itself, I was raised in a way where these affinities would be punished rather than rewarded. This narrative continued throughout school, high school, college, and only stopped externally when I joined the awesome, life changing, company I work at **The Agile Monkeys**, eight years ago.
Still, **that narrative was already too ingrained** in my subconscious mind, patterns were established, habits developed, and unhealthy coping mechanisms. All in a read-only mode, like the program in a ROM memory, or `Reader myself life` if you wish.
I could go **for hours** what the narrative is about, but to summarize: self-dismissal, dependent on external validation, overanalysis of all situations, perfectionism, and rejection sensitivity.
This led me to live my life in a **perpetual state of fear** of fucking everything up, **paranoia over analyzing** all of my steps, myself, my relations, or even my work, **living in perpetual burnout**, and anger due to the suffering with **no apparent reason**.

_My mind kept looking for issues everywhere. Maybe I'm using the wrong programming language? Maybe I'm not fast enough typing, so I need to learn Vim? Maybe I'm too disorganized so I need to learn GTD? Maybe I need to make better notes so I have to learn Zettelkasten? Maybe... Maybe... Maybe..._
## Taking perspective
> “The work of a mage is hard, because they have to conquer the most difficult enemy: **their own mind.**”
The reality is that I have completed “the game” that the society and family imposed on me, relying on my sole hard work and appropriate connections with who I bonded with **just by being myself**. (If you're wondering, no, my family didn't help me at all, they don't even know what I do for a living).
I had a car, a degree, my own apartment, an awesome job, and a lovely partner, **by the age of 24**. And my mind just dismissed that.
I’m not saying this to brag. On the opposite, sometimes I ask **"At what cost?"**. Everyone has their own times and rhythm, and **I just speed-ran mine**.

## Building the `Identity` monad
During all these years, I've been building an `Identity` of some sorts. I've been focusing on **selling myself**, on pleasing both **people** (like friends, family, professors) and **entities** (like companies who could hire me, Meetup groups, communities).
> _Nick is a good guy, Nick is a TDD enthusiast, Nick likes Vim, Nick likes Emacs, Nick writes Clojure, Nick evangelizes clean code, Nick is a Haskeller, Nick is a backend developer._
This mountain kept growing, I kept doing stuff to add to it. To keep thinking that while I was growing intellectual skills, and I kept pleasing people, I'd be growing as a person, and eventually I'd be more happy. Yet, again my most cherished moments where some kind of technical stuff was involved was when I spent time with coworkers and conference attendees, **just being myself**.
No matter how much time I spent reading papers, reading books, watching tutorials, creating projects (most of them unpublished), **I didn't feel better**.
I was becoming more tired, more fed up with life. I didn't want to discuss, suggest. I started becoming **less creative, less curious, less expressive.** _Memory leaks due to lazy evaluations were at their peaks._ And the ROM memory finally worked on full throttle.
**I lost all my passions.** Even my biggest one: Programming.
The joy of coding, of creating something out of nothing, of playing a puzzle with data, of designing flows of invisible things that then would result in something tangible. **The joy, it was all gone.**
Although exercise, meditation, and food kept my nose floating for a while, the reality is that I was slowly drowning, **and life was becoming greyer and greyer.**

I had **one swing of hope**, one idea that channeled my frustration with life and with the tech industry:
## NeoHaskell
Not so long ago, I took all the plans and sketches of a project that I've been working **in my mind for years** and decided to make it public as a blog post.
The post mentions "a beacon of joy", because that's **what I needed it to be**, something that rekindled my joy, and luckily the joy of others who, like me, got their joy stolen.
The feedback was overwhelmingly positive, which keeps me hopeful of the project. **But my mind hinged on the bad one**.
My logical, reasonable mind did get that it's normal, and that haters were an indicator of success. **But my emotional, ROM memory mind dismissed everything else**.

You might be thinking that I'm a special snowflake and just too sensitive, and you are right... in the perfect place to read this: "Fuck you! :-)"
I took some time to distance myself from the project, the feedback, the community. **Yet when I wrote a single line of code it hurt like never before**. What was happening to me?
My lens of NeoHaskell greyed out too. I felt destroyed, why was this meaning so much for me? Why was it so important for me?
I looked around, and **everything I once loved was grey since long ago**.

_Everything just... withered... There was no joy in anything in life, everything seamed meaningless, worthless, useless._
My perfectionism, self-dismissal, paranoia and everything else ate up my identity.
**Or did they?**
## Un`foldl'`ing my `identity`
At this point I realized that my identity as I knew it was an illusion. My identity were my **co-traits** (see what I did there? – category theory joke) in disguise.

_What is my **real identity**?_
_What is **real**?_
_What is **reality**?_
I still don't have answers for these questions, but if I had to answer:
- **Reality** is what a subject experiments as the mix of the physical and psychical world.
- Something is considered **real** if a subject or a group of subjects experiment similar realities around **a concept**, making it real **for them only**.
- Therefore, my **real identity** was pretty much fucked up because there’s absolutely no consensus between what others think of me and what I think of my self.
**Or is it?**
Many hinge on labels to get their sense of identity: “cat parent”, “gamer”, “Python developer”. And **it's completely fine if it works for you** (unless you identify as a Python developer, please choose a different language).
We could say that your identity is the stories you tell yourself and the rest of the world.
But what happens if the story stops working? With “gamer” it’s fine, but what about a **career**? Or perhaps a **misdiagnosed condition**? Or a change in **spiritual path**? Or maybe **you kissed a girl and you liked it because her lips tasted like cherry popsicle and it felt so wrong it felt so right**?
Regardless of it's magnitude, you'd have an existential crisis each time one of these stories crumbles.
> **"Nothing is true, everything is permitted."**
Do we even need an identity based on external labels? Can’t we just be ourselves and **let our identity be the story of our life**?
I’m a **developer**, I do everything to **people like me**, I made **NeoHaskell**, I’m an **AI engineer**, I’m a **Haskeller**, I have 99% of the symptoms of **ADHD**, I have **anxiety**, I have symptoms of **severe depression**, I’m **fearful**, I’m **paranoid**, I’m a **perfectionist**, I’m a **husband**, I’m a **kimchi lover**, I’m **Spanish**, I was **born in Russia**, I was raised in the **Canary Islands**, I’m a **minimalist**, I’m a **skateboarder**, I’m a **yerba mate drinker**, I'm a **VR enjoyer**. I'm a **music producer**. I'm **Nick**.
> **I refuse to identify myself with all of that.**
Those statements are all true, yet they are **a consequence** of who I am, **not the definition of who I am**.
## My `not False |> identity`
I’m a **shapeshifter**, I’m a **creative**, I’m a **thrill-seeker**, I’m a **helper**, I’m a **maker**, I’m a **doer**, and an **undoer**, I’m a **speaker**, and a **listener**, I’m a **perpetual student** and an **eternal teacher**, I’m both **order and chaos**, I’m the most capable entity in the universe, universe itself (**and so are you**), yet **incapable to see and be conscious about it**.
**I am Azathoth**, the blind fool, parent of all the strongest entities in the universe, creator of cosmos, eater of worlds. Blind enough to comprehend and understand it's own emotions and actions.
**Our reality is composed of stories** we tell ourselves and the ones others tell us.

This is **the first time in my entire life that I sit down and write something good about myself**.
I invite you to do the same. Write some **cool stories about yourself**, make yourself grand in **your own schema of life**, value yourself, and **value everything that happened** to you until this point. Play #thegame23. **Journal about perfect days**, even if the events didn't happen. These stories are not fake or a lie, **they just didn't happen yet**.
## Where does NeoHaskell end in all of this?

**No idea.** I don't have plans of abandoning it. But also no plans of continuing it for now, fnord.
For now, I have the biggest programming project of my life in front of me. And that's **reprogramming myself**, reprogramming my lens of reality, start valuing what I do, and let my inner chaos go out and fill the world with my own existence, **being myself, for no one else**. Just for myself.
**I owe this to me and my inner kid** who figured out the best way to live life and accomplish everything that we've accomplished. He needs to **rest** now, he needs **therapy**, he needs to **hear and feel new stories**, and he needs to **come out as art expressions**, as this entire post.

## Beauty is in the `Lens.view` of the beholder
Everyone agrees that Eldritch gods are **horrendous abominations, ugly and a manifestation of everything wrong in life**.
_But how can we judge the beauty of an 100-dimensional creature, if our human eyes are only able to see in 3-dimensions?_

We all are complex creatures, with points of view and perspectives that even is hard for ourselves as that creature itself to understand.
> No one can judge us, not even ourselves.
## It's a see you later alligator, not a good bye my lover
> **I wish you double of what you wish me.**
**Life is hard**, don't let it and other fuckwits steal happiness from you. **Don't be polite, fuck them all**. It's your life, you are a great person. You are polite because you're being overly empathetic, a sign of your **greatness and purity of heart**. You don't deserve the passive-aggression, they don't deserve your politeness. **Fuck them.**

I want to create connections, share our art, experiences, **our burdens**. We are not alone in this world. If you wanna talk, you can contact me via prayer, telekinesis, occult rituals, or code offerings. (I'm an eldritch god now, remember?)
Although it is probably more effective via **Twitter** (latterly X), **Discord**, **GitHub**, or whatever digital mean you find. **I'll try to leave a trail of chaos to aid you.**
ta-ta,
Signed: The Blind Idiot,
Nuclear Chaos,
Daemon Sultan,
Abyssal Idiot,
Lord of All,
Him in the Gulf,
The Deep Dark,
The Cold One,
Sleeping Chaos,
Blind Dreamer,
King-of-All,
Primordial Demiurge.

7̴̠̣̞͈̞̹̹̱̗̍̿͗̂̐̔͑̃͋͒̉̓̓̆̋͆̈͝͝2̵̜̇̇̈́̾͐̀̔̀̈̔́͌̅̒̐̅̓͒̅̃̿́̽̾̇̀̈́̊̆̃̈̚̚͝5̵̢̜̱̈́͆̃͊͌̈́͂̓̀̎̍̑͆̅́̀̆̊̿̀͌̊̽̏͂̉̍́̓̂̂͛͘̚̕̚̚͠͠3̴̛̰̤͙̺̯̉̈̍̎͗̿͋̌̀̈́̚͘6̶̢̢̨͖̘̤̳̥͍̞̣̜̺̝͚̙͔̜̙͇̩̮̦͕̩͂͂͑̀͌̽͝͝ ̵̢̦͚̼̮̜̘̟̀́̄͐͑͌̄̾̍́̓̎̏̂̏̀̓̏̓̚͝͠͝w̷̢̡̧̧̤̜͍̬̗͇͔͇̯̖͑̆̂̈́͑͆̈́́̔̏̆̇̑̽̊̉͂̄̋̈́̅͐̅͂̉̾̏͌͌̉́͘͘̚̚̕̕͝͝͠͠͝i̸̛̛̹̝̮̗̟͆̋̔̈́̀͊̑̄̽͋͆̊̂͗̍͋̒̾͆̋̇͒̿̔͐̾̌́̐̑͑̂͝͝l̷̢̢̢̛̞͖͎̤̯̣͔̭͓̹̦̰̇̎̈́͌̍͊̈́͐́̓͐́̋̽̓̾͂̈́̃̇̈͛̒͌̇͂̓͋̀͗̎̎͑̕͠͝͝͠͝͝ļ̴̧̨̨̫̞̲̬̤͙̫̦̟͎̬͙̗̖͖͔̖͕̹̺̩̯̞̜̺͇̖̩̹͓̺̻͔̳̓̑̓̍̄̎͊̌͜͜͝ͅͅ ̶̢̢̺̩̦̣͎̩͉͓͙̟̥̻̠̰̰̫̆̾͆̅̀̈̀̒͂̕̚͘͜͜͜͜͝s̵̛̲̠͔̰̥̖͓̟̖͎̼̝̪͙͙͂̏̅́̎́͂̽͂͌̃̈́̑͋̉̔̀̒̅̅̃̕̕͠͠͝͠a̷̢͓̦̥͈̲̭͉̹̗̼͚̲͖̯͖͕̍̽̅̉̉̉͘͝v̷̢̛̛̛̛̹̻̥̳̠͇̦͚̹̪̠̱̻͇̖̖̫̠͓̯̰̱̯̭̪̝̯͕̇̌́͌̈́̾͗̅̓̃̓͆̽̈́͑̔̅́̋́̈́̈́̎̍̋͐̎͋͑̒̔̃̈́͛̚̕͜͝ͅë̶͖̟͍̂̌̓̏́̄̿̏̌̇͗́̒̊͌̓̓̎̈͊̈̐̽̈́̔͛̕͠ ̴̼̗͍̝̗̪̲̣͔̯̝͓̙̣͎̜̱̱̣̪̦̜̳͕͕̮̺̹̖͔̱̜̔̔͋͒́̂̒̀͌̅̂́͛̆͆̅̏̍̐͂̊̂̆̉̓̉̈́̀̽̕͝ͅo̵̡̢̡̳͇͔̹̣̜̩̲̦̝͓͎̭͍̜̯̰͉̝͖͇̤̮̩̞̥̳͔̦͇̟̼̞̻̠̜͈̠̒͌̿̓̈́̉̌̈́͋͒͋͛͗͘̚̕͝ų̵͇̣̩̩̱͒ͅr̴̙̖̙̞̝͔̳͙̻̝͉̟̭͔̈́̇̀͛̽̈́͆͆͗̈́̌̑͊́̏̓̑̿̓̐ ̵̨̡̡̨̟̦̲̙̝͉̻̬̘̭̯̫̩̣̞̤̺̼͍̺̭͖̤͉͈̹̥͒̌̑̈́͊̈́͊̈̐͗̽͜͝i̵̡̢̢̢̢̢̬̺͕̪͓͇̯͇̞̪͚̠̰͈͉̗̣͍̳͓̙̥̭̲̦̟̅͊͆̆̿͒̈̈͂͜ͅͅͅn̶͖͍̳̫̰̲̖̖̠̩͔̼̲͕̻̞̠͖̫͑̀̈̍̿̋͌̉́̅̾̓̅̚͠͝͠͝ͅn̸̡̡̧̨̨̨̛̳͍̯͚̜͔̦͎̮̥̞̞͇̳̣̯̞͈̞̭̘̫̰̻̰̫̣̰͙̮̭̳͎͎̣͗̎̄͗̀̇̿̈́͒͋̋̒̐͒̄̅̑̈́̿̒̊̋̂̏́͌̍̽̓͘͠ĕ̷̱̺̼̭̋̈́̃̇͆̂̍̇̆̃͊̅͐̅̄̇͂̎̆̈́̀̓͒́͗͘͘͝͝͠r̸̡̢̺͕̠̥̳̤̘̞͈̥̫͙̱̰̩̗͕̣̱͇̪̖̱̘̣͚͇̀͐͘ ̸͓̭̤͈̼̩̟̦̜͒͛̀̍́̎̓̀̀͜ͅĺ̶̖͙͚͕̩̹̟̤̝̮̬̫̥̪̺̦͂̑̅̒͊̐͗͑͛̓̔̈́̈́͗̀̊̍̒̽͛́͗̚̕͠͠͝͠i̸̢̛̬̲̝̘͈̜̤̼͖̾̒͋̿͆̑͛̂̆̅͌̿̍̋͊̀̽̂̉̃̓͊̾̾̀̽̒́̚̕̕͝͝͠g̶̝̭̲̒̇̔̑̍̈́̽̀̐̀̃̐̏̊͋͗͑̇͗̈́̒̅̀̄̆͂̓̽̚͝͝͠h̷̨̛̦̲̬̘̖̍̐̈́͗͗̏̾̿̾̎̓̿́̀̈͂̉̍͛̾̊̑͗̇̄̀̑̏̏̈́̚͘͝͝t̸̡̨̡̛̛͖̭̘͓̗̠̗̫̗͇̯̫̪͕͔̥̹͕̳̻̦̭͉̯͛̃̈́̆̊͊̆̉̿̆̽͋̿̊̄̈̄̉́̅͌͐̓̈́͌̐̽̏̾͋̈̀̈͋̿̕̕̚͜͠͝
| nickseagull |
1,722,486 | Developing a Salesforce integration, quickly & easily | This post was originally published at runalloy.com. If you’ve ever built a CRM integration, I’m... | 0 | 2024-01-09T20:54:38 | https://dev.to/alloyautomation/developing-a-salesforce-integration-quickly-easily-1m4a | javascript, react, tutorial, api | _This post was originally published at [runalloy.com](https://runalloy.com/blog/developing-a-salesforce-integration/)._
If you’ve ever built a CRM integration, I’m guessing you didn't love it 😅
At Alloy, we’re working hard on building a Unified API solution that helps developers ship major integrations faster (think CRMs, Commerce Platforms, ERPs). Today, we’d love for you to try it out for free and let us know what you think.
We’ve put together this tutorial guiding you through building a CRM integration using Next.js and Alloy. You’ll learn how to add Alloy functionality to a pre-built Next.js project, enable a connection to a CRM system like Salesforce, get a list of contacts **from** the CRM, and write new contacts **to** the CRM. No worries if you’re new to Next.js — it’s built on React and should be familiar for Javascript developers.
**Prerequisites**
- Node.js (version 12 or higher)
- Basic knowledge of React and Next.js
- Text editor or IDE
- Salesforce account for testing (optional)
- Free Alloy Unified API account [(you can sign up here)](https://app.runalloy.com/signup)
We’ve provided a step-by-step guide on how to build this use case, including how to integrate our SDKs and APIs into your application so you can ship integrations.
And so, with some combination of excitement, nerves, and eagerness to get feedback, here’s a link to the repo in GitHub: [unified-crm-tutorial](https://github.com/alloy-automation/salesforce-crm-demo)
You'll find the step-by-step tutorial below. Your support means everything to us, so if you like what you see, please consider giving us a star/follow on GitHub or check us out on [ProductHunt](https://www.producthunt.com/products/alloy-automation).
PS — if you want to build this live with us, we’re going to be walking through the tutorial on Jan. 25, where you’ll have the opportunity to follow along and ask questions. You can sign up for that [here](https://www.linkedin.com/events/zerotointegrated-buildanativesa7148756965702213632/comments/)!
## Understanding the Repository Structure
- **Start branch:** Where you’ll start. Contains the basic project setup and components without complete Alloy integration — you’ll build that.
- **Main branch:** Use this as a reference. It contains the completed project with full Alloy integration.
## Getting Started
**1. Clone the starting repository**
Clone the provided repository and switch to the start branch:
```
git clone https://github.com/your-repository/practice-crm-app.git
cd practice-crm-app
git checkout start
```
**2. Set up environment variables**
You’ll need to set up your **Alloy User ID** and **API Key** as environment variables before proceeding. Replace the placeholders with your actual Alloy credentials:
```
export ALLOY_USER_ID='your-alloy-user-id'
export ALLOY_API_KEY='your-alloy-api-key'
```
**3. Install dependencies**
Install the dependencies for this project:
`npm install`
**4. Run the application**
Start up the application — you’ll see the basic UI in its initial state:
`npm run dev`
Open `http://localhost:3000` in your browser to view the application. The tutorial UI will show three steps — connecting the CRM, getting a list of contacts, and creating new contacts. Each corresponds to a Javascript Component that you will complete.
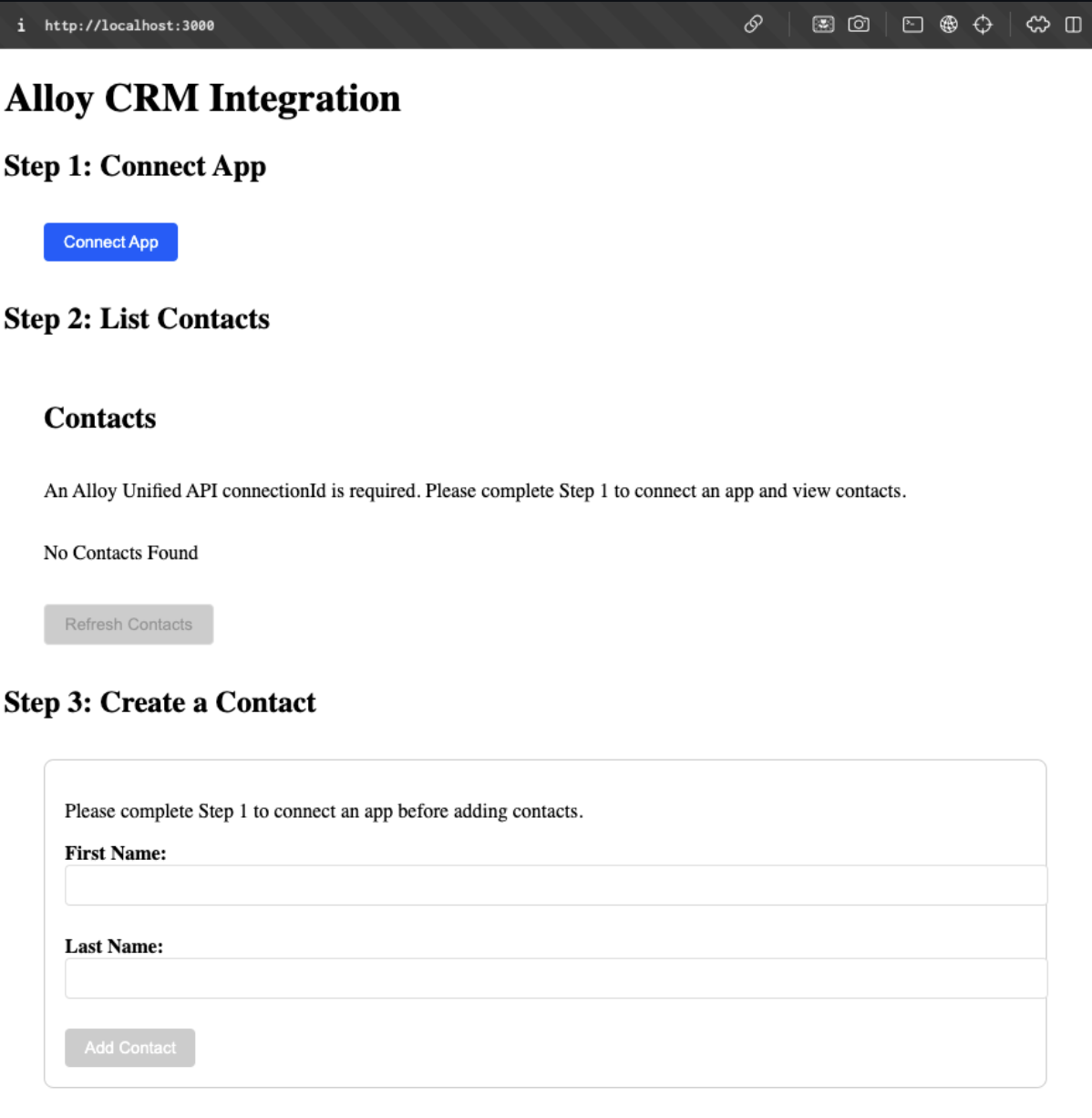
## Establishing a Connection
To create a connection to a 3rd party from your app, Alloy requires that we fetch a short-lived JWT token for an Alloy user and pass the JWT to the frontend SDK via `alloy.authenticate()`.
**1. Modify** `token.js` **API Route:**
Update the `token.js` file in the `pages/api` directory to generate a JWT token using Alloy's API.
Updated Code for `token.js`:
```
// pages/api/token.js
export default async function handler(req, res) {
const YOUR_API_KEY = process.env.ALLOY_API_KEY;
const userId = process.env.ALLOY_USER_ID;
try {
const response = await fetch(`https://embedded.runalloy.com/2023-12/users/${userId}/token`, {
headers: {
'Authorization': `Bearer ${YOUR_API_KEY}`,
'Accept': 'application/json'
}
});
const data = await response.json();
res.status(200).json({ token: data.token });
} catch (error) {
console.error('Error generating JWT token:', error);
res.status(500).json({ error: 'Error generating JWT token' });
}
}
```
**Note:**
- Ensure you have set `ALLOY_API_KEY` and `ALLOY_USER_ID` in your environment variables.
- This code fetches a JWT token from Alloy and returns it in the response. This token is required for authenticating with the Alloy SDK.
You’ll need this for the next step, where you'll integrate the JWT token generation with the front-end `ConnectApp.js` component.
**2. Set up** `ConnectApp.js`**:**
Implement Alloy authentication logic in the `ConnectApp.js` file within the `src/app/components` directory.
Updated code for `ConnectApp.js`:
```
import React, { useEffect, useState } from 'react';
import axios from 'axios';
import Alloy from 'alloy-frontend';
import styles from './css/ConnectApp.module.css';
export default function ConnectApp({ onConnectionEstablished }) {
const [alloy, setAlloy] = useState(null);
useEffect(() => {
setAlloy(Alloy());
}, []);
const fetchTokenAndAuthenticate = async () => {
if (!alloy) {
console.error('Alloy SDK not initialized');
return;
}
try {
const response = await axios.get('/api/token');
alloy.setToken(response.data.token);
alloy.authenticate({
category: 'crm',
callback: (data) => {
if (data.success) {
localStorage.setItem('connectionId', data.connectionId);
onConnectionEstablished(data.connectionId);
}
}
});
} catch (error) {
console.error('Error fetching JWT token:', error);
}
};
return (
<div className={styles.connectContainer}>
<button className={styles.connectButton} onClick={fetchTokenAndAuthenticate}>
Connect App
</button>
</div>
);
}
```
**Note:**
- The `useEffect` hook initializes the Alloy SDK.
- The (aptly named) `fetchTokenAndAuthenticate` function fetches the JWT token from the `/api/token` route and uses it to authenticate with Alloy.
- Upon successful authentication, the connection ID is stored and the `onConnectionEstablished` callback is triggered.
Once authenticated, it allows further actions such as listing and creating contacts.
## Implementing Contacts API Routes
**1. Update** `contacts.js` **API Route:**
Refactor the `contacts.js` file in the `pages/api` directory to manage fetching and creating contacts using Alloy's API.
Here’s what the initial code template looks like:
```
export default function handler(req, res) {
console.log('Contacts API endpoint hit. Implement Alloy contacts functionality here.');
res.status(200).json({ message: 'This is where Alloy contacts functionality will be implemented.' });
}
```
And here’s the updated code for `contacts.js` with Alloy API integration:
```
// pages/api/contacts.js
export default async function handler(req, res) {
const YOUR_API_KEY = process.env.ALLOY_API_KEY;
const connectionId = req.query.connectionId;
if (!connectionId) {
return res.status(400).json({ error: 'ConnectionId is required' });
}
const headers = {
'Authorization': `bearer ${YOUR_API_KEY}`,
'Accept': 'application/json'
};
switch (req.method) {
case 'GET':
try {
const response = await fetch(`https://embedded.runalloy.com/2023-12/one/crm/contacts?connectionId=${connectionId}`, { headers });
const data = await response.json();
res.status(200).json(data);
} catch (error) {
console.error('Error fetching contacts:', error);
res.status(500).json({ error: 'Error fetching contacts' });
}
break;
case 'POST':
try {
const response = await fetch(`https://embedded.runalloy.com/2023-12/one/crm/contacts?connectionId=${connectionId}`, {
method: 'POST',
headers: { ...headers, 'Content-Type': 'application/json' },
body: JSON.stringify(req.body)
});
const data = await response.json();
res.status(200).json(data);
} catch (error) {
console.error('Error creating contact:', error);
res.status(500).json({ error: 'Error creating contact' });
}
break;
default:
res.setHeader('Allow', ['GET', 'POST']);
res.status(405).end(`Method ${req.method} Not Allowed`);
}
}
```
**Note:**
- This API route handles GET requests for fetching existing contacts and POST requests for creating new contacts.
- The `switch` statement directs the request based on the method (GET or POST).
- Both requests use Alloy's API and require a valid `connectionId`.
- The `headers` include the necessary authorization and accept headers for the API requests.
This API route is crucial for managing contacts in the CRM integration. It interacts with Alloy's API to retrieve and store contact information.
## Setting Up Contact Components
**1. Configure** `ContactList.js`**:**
Update `ContactList.js` in the `src/app/components` directory to interact with your `contacts.js` API route for fetching contacts.
Here’s what the initial code template looks like:
```
import React, { useState } from 'react';
import styles from './css/ContactList.module.css';
export default function ContactList({ connectionId }) {
const [contacts] = useState([]); // Placeholder array for contacts
const isLoading = false; // Placeholder for loading state
const fetchContacts = () => {
console.log('Fetch contacts functionality will be implemented here.');
// Future Alloy contact fetch code will be added here
};
// Component UI remains the same
}
```
And here’s the updated code for `ContactList.js` with Alloy integration:
```
// components/ContactList.js
import React, { useState, useEffect } from 'react';
import axios from 'axios';
import styles from './css/ContactList.module.css';
export default function ContactList({ connectionId }) {
const [contacts, setContacts] = useState([]);
const [isLoading, setIsLoading] = useState(false);
const fetchContacts = async () => {
if (connectionId) {
setIsLoading(true);
try {
const response = await axios.get(`/api/contacts?connectionId=${connectionId}`);
setContacts(response.data.contacts);
setIsLoading(false);
} catch (error) {
console.error('Error fetching contacts:', error);
setIsLoading(false);
}
}
};
// Rest of the component remains the same
}
```
**1. Configure** `CreateContact.js`**:**
Adapt `CreateContact.js` in the `src/app/components` directory to utilize your `contacts.js` API route for creating new contacts.
The initial code template looks like this:
```
import React, { useState } from 'react';
import styles from './css/CreateContact.module.css';
export default function CreateContact({ connectionId }) {
const [firstName, setFirstName] = useState('');
const [lastName, setLastName] = useState('');
const handleSubmit = (event) => {
event.preventDefault();
console.log('Create contact functionality will be implemented here.', { firstName, lastName });
// Future Alloy contact creation code will be added here
};
// Component UI remains the same
}
```
The completed code looks like this:
```
// components/CreateContact.js
import React, { useState } from 'react';
import axios from 'axios';
import styles from './css/CreateContact.module.css';
export default function CreateContact({ connectionId }) {
const [firstName, setFirstName] = useState('');
const [lastName, setLastName] = useState('');
const handleSubmit = async (event) => {
event.preventDefault();
if (connectionId) {
try {
const response = await axios.post(`/api/contacts?connectionId=${connectionId}`, { firstName, lastName });
console.log('Contact added:', response.data);
setFirstName('');
setLastName('');
} catch (error) {
console.error('Error adding contact:', error);
}
} else {
console.error('No connection ID. Please connect to Salesforce first.');
}
};
// Rest of the component remains the same
}
```
**Instructions:**
- In `ContactList.js`, the `fetchContacts` function is implemented to fetch contacts using Axios.
- In `CreateContact.js`, the `handleSubmit` function is updated to create a new contact and interact with the API.
- Ensure that the connection ID is checked before making API calls.
## Wrapping up
By completing this tutorial, you have built a CRM integration using Next.js and Alloy, gaining experience in connecting to Salesforce, managing contacts, and integrating front-end and back-end in a Next.js application.
As a reminder, you can sign up for a live, guided version of this tutorial [here](https://www.linkedin.com/events/zerotointegrated-buildanativesa7148756965702213632/comments/) !
| anuragallena |
1,722,499 | Three ways that “Manual Testing” is a waste* | * when done at the wrong time, and depending on how you define “manual testing”. Callum... | 0 | 2024-01-30T21:45:14 | https://gerg.dev/2024/01/three-ways-that-manual-testing-is-a-waste/ | automation, generaltesting, agile, alanpage | ---
title: Three ways that “Manual Testing” is a waste*
published: true
date: 2024-01-23 16:00:00 UTC
tags: Automation,Generaltesting,agile,AlanPage
canonical_url: https://gerg.dev/2024/01/three-ways-that-manual-testing-is-a-waste/
---
\* when done at the wrong time, and depending on how you define “manual testing”.
Callum Akehurst-Ryan had a post recently that broke down [much better ways of thinking about manual testing](https://cakehurstryan.com/2023/09/26/is-manual-testing-a-dirty-word/https://cakehurstryan.com/2023/09/26/is-manual-testing-a-dirty-word/), but I’m using it here how it’s used at my current company and presumably many others: scripted tests that have to be run manually to see that they pass before a feature can be considered done. But that’s not the whole context: let’s first consider how manual and automated testing relate to each other.
## Context: models for when automation happens
I noticed last year when conducting dozens of interviews for test automation specialists (we call them “QA Engineers”, you might call them SDETs), people seemed to fall pretty cleanly into one of two camps:
1. You have to manually test something first so that you know it works before you can automate it. Typically, people in this camp will only tackle test automation after a feature is done and “stable”, which usually means that the tests are automated one sprint after after development and manual testing are done.
2. Automation (and indeed, testing as a whole) should be treated as part of development itself, so a feature can not be considered done until the automated tests for it are implemented.
Colloquially people refer to these as “N+1 automation” or “In-sprint automation”, respectively. It is certainly possible that the first mode all takes place within one sprint, but it’s usually unrealistic to simply condense the timeline that much. (People against “in-sprint” often mistakenly think that is the only difference and therefore throw it out as impossible for just that reason.) The difference really comes in the order things occur:

_N+1 automation: a feature is considered done after all manual tests pass, and now automated tests can be implemented without fear that the feature will change. Usually, this is done in a new sprint._

_In-sprint automation: manual tests cover what automation can’t, and the feature isn’t considered done until both are complete. The steps don’t have to happen serially as shown, as long as all three are part of the definition of done._
The reason that the second model looks to some like doing 2 sprints worth of work in 1 is that **_N+1 automation is inherently wasteful_.**
## Three wastes of manually testing before automating
(You’re now free to drag me in the comments for putting the onus of waste entirely on manually testing in the post title.)
### 1. The automated tests will always be out of date
Consider what happens when all manual tests pass, so the feature is marked done and deployed one afternoon. That night, your automated test runs against this new code. On Thursday morning when you come in to review the results, what do you find?
Any automated tests that depended on the way your code behaved before this new change will have failed. Your tests are out of date. Can you rely on the results of your tests to tell you anything about the health of the system now? Are you sure that the tests that passed _should_ have passed with the new code? These automated tests aren’t any good for regression anymore. They may be better than nothing, but it’s a lot harder to interpret.
Since it may take a sprint of work to update all those tests based on a sprint’s worth of dev work, you can expect your tests to be broken for a full sprint on average. Then, of course, the cycle repeats because in that time a new batch of dev work is done.
Congratulations, you’re now spending the rest of your life updating “broken” tests and will never expect to see your automated test suite pass in full again. I’m not exaggerating here — I’ve talked to people who literally expect 20-50% of their test suite to be failing at all times.
### 2. You’re doing something manually that could have been automated
Since you’re comfortable with calling the feature done after manually testing it, you must have manually tested every scenario that was important to you. These are likely going to be the first things that are worth automating, so you don’t have to manually test them again. But then, why didn’t you just automate it in the first place? If you claim that writing and running a manual test is faster than automating it (a dubious claim to begin with), how many times did you repeat that manual test during the development sprint when something changed? How much extra overhead is it going to be to figure out which manual tests have to be repeated after automation is in place and which don’t?
You’re testing something with automation that you already tested manually. You’re wasting time testing it again. You’ll get the benefit of being able to re-run it or include it in regressions going forward, but you’d have had that from automating it up-front as well. You’ve only just delayed that benefit by a full sprint and gotten nothing in return.
### 3. Everything is more expensive
By the time you get around to automating a feature from last sprint, your developers have moved on to something else. When you inevitably need help, need some behaviour clarified, or even find a problem that manual tests missed, the context switch required for the rest of your team is much larger than if that story was still part of the current sprint. People have to drop work they committed to in the current sprint to remember what happened last sprint. Often the “completed” feature has already gone to production and the cost of fixing new issues has also gone way up. Something that might have taken a 5-minute back-and-forth with a developer to fix while the feature was in progress will now require a lot more effort. Easy but low-priority fixes will be dropped as a result, and your overall quality suffers.
One answer to this may just be that you should have caught it while manually testing. And that may be true, but you didn’t, so now what? Automated and manual tests have different strengths and will always raise different bugs. The value you get from automation is now much lower because even if you find all the same bugs as if you had automated earlier, the cost to do anything about them is higher.
## Automate what should be automated
In my experience, these forms of waste far outweigh any benefit you get from only automating “stable” features. Instead of updating and re-running automated tests when code changes, you’re performing the same manual tests multiple times. Instead of getting the confidence of a reliably passing test suite, your tests are always failing and require extra analysis time as a result. Instead of working _with_ developers and improving quality, automation becomes a drag _against_ the team’s dev productivity.
By automating tests first, as part of the development work, manual test effort can focus on the sorts of tests that humans are good at. Automate 100% of the tests that should be automated, as Alan Page might say, rather than wasting time pretending that you’re a better robot than a robot is. You’ll get more value from _both_ your automated tests _and_ your manual efforts that way.
If you’re worried that you won’t have eyes on every path if some are automated up-front, remember that most automation still requires stepping through the application and observing its behaviour while you write the code to execute those same interactions. A good automator will watch each new tests and [make sure they can all fail](https://gerg.dev/2018/10/all-your-automated-tests-should-fail/), thus writing automation also gives you manual—or rather, human—coverage.
The change in sequence alone may not be enough to get you all the way to in-sprint automation, but you should see it as much more attainable without the extra waste holding you back. | gpaciga |
1,722,761 | caulongk8com | Các cược cầu lông K8 là một trong những bộ môn cá cược thể thao được nhiều người yêu thích. Đặc biệt,... | 0 | 2024-01-10T03:47:53 | https://dev.to/caulongk8com/caulongk8com-1cod | Các cược cầu lông K8 là một trong những bộ môn cá cược thể thao được nhiều người yêu thích. Đặc biệt, nếu anh em là fan hâm mộ của bộ môn này thì đừng quên tạo tài khoản tại nhà cái K8 và tìm hiểu thêm về cách đọc kèo cầu lông K8 để tham gia cá cược, kiếm tiền ngay bây giờ nhé!
[[](url)](https://k8betno1.com/cau-long/
https://twitter.com/caulongk8com) | caulongk8com | |
1,722,834 | Mastering Asynchronous Programming in Python: A Comprehensive Guide | Like IO operations for some of the tasks Asynchronous programming is a great choice. Raman Bazhanau... | 0 | 2024-01-10T06:17:58 | https://dev.to/tankala/mastering-asynchronous-programming-in-python-a-comprehensive-guide-4e3i | Like IO operations for some of the tasks Asynchronous programming is a great choice. Raman Bazhanau gave a good understanding and explained with great examples [here](https://blog.devgenius.io/mastering-asynchronous-programming-in-python-a-comprehensive-guide-ef1e8e5b35db). It’s a long read but a very good one to get an understanding of Asynchronous programming & asyncio. | tankala | |
1,722,854 | Electric order pickers are highly maneuverable and can navigate narrow aisles with ease. | Electric Order Pickers: Making Your Warehouse Smarter Have observed your warehouse workers... | 0 | 2024-01-10T06:33:24 | https://dev.to/mastermich/electric-order-pickers-are-highly-maneuverable-and-can-navigate-narrow-aisles-with-ease-5g5e | Electric Order Pickers: Making Your Warehouse Smarter
Have observed your warehouse workers struggling to recoup products from high racks or navigate around slim aisles? If yes, you recognize precisely how annoying and frustrating it may be. Joyfully, electric purchase pickers are here to improve that. Together with your products that are smart you possibly can make your warehouse more effective, efficient, and safe.
Benefits of Electric Order Pickers
Electric purchase pickers are incredibly maneuverable and which will navigate aisles being simplicity that is slim. They get to a sizes that are few designs to fulfill warehousing that is significantly diffent. In terms of forks being platforms that are adjustable they are able to effectively attain high racks and choose things at various quantities.
Also their flexibility, electric purchase pickers can also be eco-friendly. It works on batteries, making them peaceful, emission-free, and economical. Unlike propane or products being diesel-powered they don't really actually produce fumes that are harmful will influence the surroundings as well as wellness for the staff.
Innovation and Safety
Electric purchase pickers is revolutionary also safe. In the shape of their functions being advanced level they are able to enhance the effectiveness and security connected with warehouse operations. Some electric forklift small models have actually vital cameras that are digital sensors that detect obstacles and steer clear of collisions as an example.
Furthermore, electric purchase pickers could possibly be designed with different add-ons and alternatives, such as Light-emitting Diode lights, horns, mirrors, and guards, to enhance existence, discussion, and security.
Making Use Of Electric Order Pickers
First, you shall need certainly to charge their batteries prior to producer's tips. Then, you will need to examine the unit's elements, such as the forks, tires, brake system, and settings, along with make certain these are typically that is fit.
Next, you can go fully into the purchase information towards these devices's computer system and select the choose list. The system will probably then teach you to the aisle that is designated level, to be able to get the product and place it within the platform or container.
You should return these devices to its place that is billing and a post-operation checkup, such as cleaning, refueling, or reporting any dilemmas or damages when you complete choosing the instructions.
Service and Quality To ensure the performance that is maximised longevity of this electric purchase pickers, you need to have a normal maintenance routine and work out utilization of genuine replacement elements and solutions. Its additionally wise to train your staff on the way that is way better to use, examine, and troubleshoot the machines, and provides each of them all with proper safety gear and training.
When selecting an purchase that is electric attempt to try to find brands that might have a preexisting reputation for dependability, innovation, and customer care.
Applications of Electric Order Pickers
Electric purchase pickers are well suited for different warehousing and distributor like stores, e - commerce internet sites, manufacturing plantations, and facilities being logistic. Perhaps it really is tailored to meet your requirements.
Conclusion
Electric order pickers are the smarter way to manage your warehouse operations. With their versatility, efficiency, innovation, safety, and applicability, they can elevate the productivity, profitability, and satisfaction of your business. So why not upgrade your equipment and let your staff focus on what really matters: serving your customers?
| mastermich | |
1,722,866 | Instant Solutions: Get Cash Home Offers in California with Big Why Properties | Experience the convenience of selling your house with ease at Big Why Properties. Our team is... | 0 | 2024-01-10T06:54:15 | https://dev.to/bigwhyproperties/instant-solutions-get-cash-home-offers-in-california-with-big-why-properties-1aon | Experience the convenience of selling your house with ease at Big Why Properties. Our team is dedicated to making the selling process seamless and efficient. If you're in need of quick funds, our **[cash home offers in California](https://www.bigwhypropertiesllc.com/cash-buyers/)** are tailored to meet your requirements. Discover the simplicity of selling your property and receiving a fair cash offer that puts you in control.
| bigwhyproperties | |
379,353 | 1886 hours to break dev | Today I broke the dev testing environment. I'm not bothered by it. And you shouldn't be ei... | 0 | 2020-07-02T19:49:57 | https://dev.to/ganey/1886-hours-to-break-dev-3bdl | webdev, testing, experience, discuss | ##Today I broke the dev testing environment.
I'm not bothered by it. And you shouldn't be either.
___
I don't feel any shame in breaking the env, and I apologised to my colleagues for the inconvenience. Fixing simply involved restoring last nights database backup.
Breaking it was my mistake, I uploaded the wrong file to the testing environment and imported various things that were incompatible with it.
___
It happens to all of us sometimes and we shouldn't be scared of breaking testing environments. They should be easy to revert. I used to be scared of breaking things and it can cause massive problems for other devs.
If the env is full of test data, either back up the database or have some scripts to flood your api and fill it back up (bonus as you get to test the api works at the same time).
___
I've previously completely destroyed test environments for several teams at once, letting most of the team have a reason to go for an early lunch. It happens, and in some cases was expected to happen due to the nature of changes (deployment flow, significant api changes etc).
It's also *really* useful to break the dev environment, you learn quickly how to fix it and hopefully how to avoid making the same error in future or at least minimise the impact of the upcoming changes when it's time to release the changes to the client/public.
There is a lot of confidence that can be gained in breaking an environment, production or testing. Hunting for issues in code can really help you learn a codebase quickly, so don't instantly be put off if you start a new job and the code looks huge or you end up fixing bugs. As you fix the bugs and learn the codebase you gain confidence with it. With that you can then make changes and most importantly, *you know where to look to fix new bugs*.
___
###So why the 1886? Why hours?
It's been a while since I broke an environment, especially where it affected other developers. I managed probably 1886 hours since I last broke a dev environment. It sounds exact but at my previous job I broke something almost daily and a lot of the time no-one even noticed. The issue was fixed before anyone else found it or before it rolled out to thier environment.
Sometimes I've redeployed infrastructure and broken dev environments _several times_ in one day. I could tell when it broke as people would start appearing at my desk waiting patiently for me to finish what I was doing, and the slack notifications would build up.
Don't cave to the pressure (even if typing with people behind you makes you screw up), you can probably can fix it, and if you can't, you can learn a hell of a lot working with someone who can fix it.
___
Have you broken an environment? Did it affect lots of people? Did you manage to fix it? | ganey |
1,722,871 | Sustainable Solutions: Empowering Growth through Custom Software Development | In today's rapidly evolving digital landscape, businesses, especially startups, seek customized and... | 0 | 2024-01-10T07:05:48 | https://dev.to/maysanders/sustainable-solutions-empowering-growth-through-custom-software-development-58l7 | development, blockchain, software, softwareengineering | In today's rapidly evolving digital landscape, businesses, especially startups, seek customized and eco-friendly software solutions to navigate challenges and propel their growth sustainably. As we delve into the realm of custom software development, let's explore how tailored solutions contribute to both environmental and business sustainability.
## The Essence of Custom Software Development
Custom software development is a strategic approach that tailors digital solutions to meet the unique needs and goals of a business. Unlike off-the-shelf solutions, custom software is crafted to fit seamlessly into existing workflows, optimizing processes and enhancing overall efficiency. This bespoke approach not only fosters a more sustainable business model but also reduces unnecessary digital clutter and waste associated with generic software.
## The Green Advantage for Startups
Startups, often characterized by their agility and innovation, can significantly benefit from custom software development. Tailored solutions allow startups to scale operations efficiently, addressing specific challenges without compromising on sustainability. By investing in eco-friendly digital solutions, startups can build a foundation for long-term growth while minimizing their environmental footprint.
## Custom Software Development Solutions for Startups
Startups face unique challenges that demand flexible and scalable solutions. Custom software development offers the agility required to adapt to evolving market trends and customer needs. From streamlined project management tools to innovative customer engagement platforms, startups can leverage bespoke solutions to gain a competitive edge while promoting sustainable practices.
## Outsourcing Software Development: A Sustainable Approach
Outsourcing software development has emerged as a sustainable practice for businesses aiming to optimize resources and reduce carbon footprints. By collaborating with a [custom software development company](https://binmile.com/services/custom-software-development-services/) that aligns with eco-friendly values, businesses can access top-tier expertise without the need for extensive in-house infrastructure. This approach not only minimizes waste but also fosters global collaboration in an increasingly interconnected world.
## Sustainable Choices: Top Software Development Companies
When it comes to selecting a partner for custom software development, businesses should prioritize collaboration with [top software development companies](https://binmile.com/blog/top-10-software-development-companies-in-2022/) that share a commitment to sustainability. These companies often integrate eco-friendly practices into their development processes, ensuring that the digital solutions they create not only meet business objectives but also contribute to a greener, more sustainable future.
## Buy vs. Build Software Solution: An Eco-Friendly Dilemma
The decision to [buy or build a software solution](https://binmile.com/blog/buy-or-develop-custom-software-solution/) has profound implications for sustainability. While off-the-shelf software may seem like a quick fix, it often comes with unnecessary features that contribute to digital bloat. On the other hand, custom software development allows businesses to create lean, purpose-driven solutions that align precisely with their needs, minimizing resource usage and maximizing efficiency.
## A Greener Tomorrow through Custom Software Development
As businesses strive to navigate an increasingly eco-conscious world, custom software development emerges as a beacon of sustainability. By investing in tailored digital solutions, businesses can optimize their operations, reduce waste, and contribute to a more sustainable digital ecosystem. The journey towards a greener tomorrow begins with strategic choices today, and custom software development stands at the forefront of this transformative journey. As we embrace eco-friendly practices in the digital realm, the impact of custom software development becomes not only a business advantage but also a contribution to a more sustainable future.
Disclaimer: AI Generated content | maysanders |
1,722,894 | 🛠 Open Source Instant Messaging (IM) Project OpenIM Source Code Deployment Guide | Deploying OpenIM involves multiple components and supports various methods, including source code,... | 0 | 2024-01-10T07:32:23 | https://dev.to/openim-sk/open-source-instant-messaging-im-project-openim-source-code-deployment-guide-hln |
Deploying OpenIM involves multiple components and supports various methods, including source code, Docker, and Kubernetes. This requires ensuring compatibility between different deployment methods while effectively managing differences between versions. Indeed, these are complex issues involving in-depth technical details and precise system configurations. Our goal is to simplify the deployment process while maintaining the system's flexibility and stability to suit different users' needs. Currently, version 3.5 has simplified the deployment process, and this version will be maintained for a long time. We welcome everyone to use it.
## 1. Environment and Component Requirements
### 🌐 Environmental Requirements
| Note | Detailed Description |
| -------- | -------------------- |
| OS | Linux system |
| Hardware | At least 4GB of RAM |
| Golang | v1.19 or higher |
| Docker | v24.0.5 or higher |
| Git | v2.17.1 or higher |
### 💾 Storage Component Requirements
| Storage Component | Recommended Version |
| ----------------- | ------------------- |
| MongoDB | v6.0.2 or higher |
| Redis | v7.0.0 or higher |
| Zookeeper | v3.8 |
| Kafka | v3.5.1 |
| MySQL | v5.7 or higher |
| MinIO | Latest version |
---
## 2. Deploying OpenIM Server (IM)
### 2.1 📡 Setting OPENIM_IP
```bash
# If the server has an external IP
export OPENIM_IP="external IP"
# If only providing internal network services
export OPENIM_IP="internal IP"
```
### 2.2 🏗️ Deploying Components (mongodb/redis/zookeeper/kafka/MinIO, etc.)
```bash
git clone https://github.com/OpenIMSDK/open-im-server && cd open-im-server
# It's recommended to switch to release-v3.5 or later release branches
make init && docker compose up -d
```
### 2.3 🛠️ Compilation
```bash
make build
```
### 2.4 🚀 Starting/Stopping/Checking
```bash
# Start
make start
# Stop
make stop
# Check
make check
```
## 3. Deploying App Server (Chat)
### 3.1 🏗️ Deploying Components (mysql)
```bash
# Go back to the previous directory
cd ..
# Clone the repository, recommended to switch to release-v1.5 or later release branches
git clone https://github.com/OpenIMSDK/chat chat && cd chat
# Deploy mysql
docker run -d --name mysql2 -p 13306:3306 -p 33306:33060 -v "$(pwd)/components/mysql/data:/var/lib/mysql" -v "/etc/localtime:/etc/localtime" -e MYSQL_ROOT_PASSWORD="openIM123" --restart always mysql:5.7
```
### 3.2 🛠️ Compilation
```bash
make init
make build
```
### 3.3 🚀 Starting/Stopping/Checking
```bash
# Start
make start
# Stop
make stop
# Check
make check
```
## 4. Quick Validation
### 📡 Open Ports
#### IM Ports
| TCP Port | Description | Action |
| --------- | ------------------------------------------------------------ | ---------- |
| TCP:10001 | ws protocol, messaging port, for client SDK | Allow port |
| TCP:10002 | API port, like user, friend, group, message interfaces | Allow port |
| TCP:10005 | Required when choosing MinIO storage (OpenIM defaults to MinIO storage) | Allow port |
#### Chat Ports
| TCP Port | Description | Action |
| --------- | ---------------------------------------------------------- | ---------- |
| TCP:10008 | Business system, like registration, login, etc. | Allow port |
| TCP:10009 | Management backend, like statistics, account banning, etc. | Allow port |
#### PC Web and Management Backend Frontend Resource Ports
| TCP Port | Description | Action |
| --------- | ------------------------------------- | ---------- |
| TCP:11001 | PC Web frontend resources | Allow port |
| TCP:11002 | Management backend frontend resources | Allow port |
#### Grafana Port
| TCP Port | Description | Action |
| --------- | ------------ | ---------- |
| TCP:13000 | Grafana port | Allow port |
---
## Verification
### PC Web Verification
**Note**: Enter `http://ip:11001` in your browser to access the PC Web. This IP should be the server's `OPENIM_IP` to ensure browser accessibility. For first-time use, please register using your mobile phone number, with the default verification code being `666666`.
*Image: PC Web Interface Example*
### App Verification
Scan the following QR code or click [here](https://www.pgyer.com/OpenIM-Flutter) to download.

*Image: App Download QR Code*
**Note**: Double-click on OpenIM and change the IP to the server's `OPENIM_IP` then restart the App. Please ensure related ports are open, and restart the App after making changes. For first-time use, please register first through your mobile phone number, with the default verification code being `666666`.
![Server Address Modification - Step 1]
*Image: Server Address Modification - Step 1*
![Server Address Modification - Step 2]
*Image: Server Address Modification - Step 2*
## 5. Modifying Configuration Items
### 5.1 🛠️ Modifying Shared Configuration Items
| Configuration Item | Files to be Modified | Action |
| ------------------------- | ------------------------------------------------------------ | -------------------------------- |
| mongo/kafka/minio related | .env, openim-server/config/config.yaml | Restart components and IM |
| redis/zookeeper related | .env, openim-server/config/config.yaml, chat/config/config.yaml | Restart components, IM, and Chat |
| SECRET | openim-server/config/config.yaml, chat/config/config.yaml | Restart IM and Chat |
### 5.2 🔄 Modifying Special Configuration Items
Special configuration items: API_OPENIM_PORT/MINIO_PORT/OPENIM_IP/GRAFANA_PORT
1. Modify the special configuration items in the `.env` file
2. Modify the configuration in **`openim-server/config/config.yaml`** according to the rules
3. Modify the configuration in **`chat/config/config.yaml`** according to the rules
4. Restart IM and Chat
### 5.3 🛠️ Modifying Other Configuration Items
For other configuration items in **`.env`**, **`chat/config/config.yaml`**, and **`openim-server/config/config.yaml`**, you can modify these items directly in the respective files.
### 5.4 Modifying Ports
Note that for any modification of IM-related ports, it's necessary to synchronize the changes in **`open-im-server/scripts/install/environment.sh`**.
---
## 6. Frequently Asked Questions
### 6.1 📜 Viewing Logs
- Runtime logs: `logs/OpenIM.log.all.*`
- Startup logs: `_output/logs/openim_*.log`
### 6.2 🚀 Startup Order
The startup order is as follows:
1. Components IM depends on: mongo/redis/kafka/zookeeper/minio, etc.
2. **IM**
3. Components Chat depends on: mysql
4. **Chat**
### 6.3 🐳 Docker Version
- The new version of Docker has integrated docker-compose.
- Older versions of Docker might not support the gateway feature. It's recommended to upgrade to a newer version, such as `23.0.1`.
## 7. About OpenIM
Thanks to widespread developer support, OpenIM maintains a leading position in the open-source instant messaging (IM) field, with the number of stars on Github exceeding 12,000. In the current context of increasing attention to data and privacy security, the demand for IM private deployment is growing, which aligns with the rapid development trend of China's software industry. Especially in government and enterprise sectors, with the rapid development of information technology and the widespread application of innovative
industries, the demand for IM solutions has surged. Further, the continuous expansion of the collaborative office software market has made "secure and controllable" a key attribute.
Repository address: https://github.com/openimsdk
 | openim-sk | |
1,722,907 | 8 Core Benefits of Automation Testing | Testmetry | At Testmetry, we take pride in introducing you to the transformative world of Automation Testing.... | 0 | 2024-01-10T08:01:20 | https://dev.to/testmeblog/8-core-benefits-of-automation-testing-testmetry-3j9k | At Testmetry, we take pride in introducing you to the transformative world of Automation Testing. Explore the game-changing [Benefits of Automation Testing](https://testmetry.com/Benefits-of-automation-testing/) that streamline processes and elevate your testing standards. Our commitment to excellence is reflected in the myriad of benefits that our approach to testing brings to the table.

The Testmetry Advantage: Revolutionizing Testing Landscapes
1. Precision and Speed
Experience testing like never before. Automation testing at Testmetry ensures precise and rapid execution, reducing testing cycles and accelerating time-to-market.
2. Comprehensive Test Coverage
Bid farewell to manual oversights. Our automated testing guarantees comprehensive coverage, leaving no stone unturned in ensuring the reliability of your software. Explore top [Mobile Testing Tools](https://testmetry.com/mobile-testing-tools/) for efficient, comprehensive testing.
3. Cost Efficiency
Unlock significant cost savings with our automation testing solutions. Testmetry optimizes resources, minimizes errors, and maximizes your ROI, making it a cost-effective choice.
4. Reusability and Scalability
Witness the scalability of your testing endeavors. Testmetry's automation tests are not just efficient but also reusable, adapting seamlessly to your evolving software landscape.
5. Improved Test Accuracy
Bid farewell to inaccuracies. Testmetry's automation testing minimizes human errors, ensuring that your software is tested with unparalleled accuracy.
6. Faster Time-to-Market
Speed matters in today's dynamic business environment. Our automation testing expedites your software release cycles, giving you a competitive edge.
7. Enhanced Test Report Analysis
Get insights that matter. Testmetry provides detailed test reports, empowering you with actionable data for continuous improvement.
8. 24/7 Testing Capability
Your software doesn't rest, and neither do we. With automation testing from Testmetry, enjoy 24/7 testing capabilities, ensuring round-the-clock reliability.
Check These:-
[Sdet Course](https://testmetry.com/sdet-course/)
[Dynamics 365](https://testmetry.com/dynamics-365/)
[Test Case Design](Test Case Design)
Elevate Your Testing Experience with Testmetry
Join the ranks of businesses that have transformed their testing processes with Testmetry. Our commitment to excellence, coupled with the unparalleled benefits of [Visual Testing](https://testmetry.com/visual-testing/), propels your software towards new heights of quality and efficiency. | testmeblog | |
1,722,942 | Framer motion | Hello, How to track a scrollYPosition of two elements on the same page ? | 0 | 2024-01-10T08:34:35 | https://dev.to/chadi24/framer-motion-25pk | Hello,
How to track a scrollYPosition of two elements on the same page ? | chadi24 | |
1,722,992 | WHAT IS A PACKAGE MANAGER? | WHAT IS A PACKAGE MANAGER? A package manager is a software tool designed to simplify the process of... | 0 | 2024-01-10T09:32:49 | https://dev.to/betpido/what-is-a-package-manager-4cdm | WHAT IS A PACKAGE MANAGER?
A package manager is a software tool designed to simplify the process of installing, updating, configuring, and removing software packages on a computer's operating system.
It is a crucial component of many modern software ecosystems and is particularly prevalent in Unix-like systems (such as Linux) and some other operating systems.
Here are key functions performed by a package manager:
Package Installation: Package managers automate the process of downloading, installing, and configuring software packages. Users can specify which packages they want, and the package manager handles the dependencies, ensuring that all required components are installed.
Dependency Management: Software often relies on other software components or libraries to function properly. A package manager resolves and installs these dependencies automatically, saving users from the manual effort of tracking and managing dependencies.
Version Control: Package managers keep track of software versions and can upgrade or downgrade packages as needed. This helps maintain a consistent and compatible software environment.
Configuration Management: Some package managers allow users to configure the installed software. Configuration files can be managed, and updates to packages can be applied while preserving custom configurations.
Uninstallation: Package managers facilitate the removal of installed software and associated files. This helps in cleaning up the system and avoiding conflicts between different versions of the same software.
Security Updates: Package managers often include mechanisms for updating software packages to patch security vulnerabilities. Regularly updating packages through the package manager is a good security practice.
Examples of popular package managers include:
APT (Advanced Package Tool): Used by Debian-based systems like Ubuntu.
YUM/DNF: Commonly used on Red Hat-based systems like Fedora and CentOS.
Homebrew: Popular on macOS for managing software packages.
npm (Node Package Manager): Used for managing Node.js packages.
pip: Python's package installer.
Different operating systems and programming languages may have their own package management systems, each tailored to the specific needs and conventions of their respective ecosystems. | betpido | |
1,723,011 | Build Your Own Embedding Models Using LLMs | In our ongoing exploration of the latest AI advancements, this article focuses on the vital role of... | 0 | 2024-01-10T09:58:31 | https://dev.to/marko_vidrih/build-your-own-embedding-models-using-llms-48ak | In our ongoing exploration of the latest AI advancements, this article focuses on the vital role of embeddings in deep learning, particularly when employing large language models (LLMs). The quality of embeddings directly affects the performance of the models in different applications.
Creating bespoke embedding models for specific applications is ideal. Nonetheless, developing these models is fraught with challenges. Therefore, developers often resort to pre-existing, broadly-applicable embedding models.
A [novel approach](https://arxiv.org/abs/2401.00368) by Microsoft researchers offers a promising solution. It simplifies and reduces the costs of developing customized embedding models. Leveraging open-source LLMs in place of traditional BERT-like encoders, this method streamlines retraining. It also employs Microsoft's own LLMs to autonomously produce labeled training data, paving the way for innovative LLM applications and enabling entities to develop tailored LLMs for their specific needs.
## The Complexities of Embedding Model Development
Embedding models are crutial in translating input data into numerical representations that encapsulate key attributes. Word embeddings, for instance, encapsulate the semantic essence of words, while sentence embeddings delineate the interplay of words within a sentence. Similarly, image embeddings reflect the visual attributes of their subjects. These embeddings are instrumental in tasks like comparing the likeness of words, sentences, or texts.
One significant application of embeddings is in [retrieval augmented generation (RAG)](https://vidrihmarko.medium.com/understanding-retrieval-augmented-generation-rag-is-this-new-era-for-prompt-engineering-46870483e441) with LLMs. Here, embeddings assist in identifying and retrieving documents relevant to a given prompt. The LLM then integrates the content of these documents into its response, enhancing accuracy and reducing reliance on information outside its training dataset.
The efficacy of RAG hinges heavily on the embedding model's quality. Ineffective embeddings may not accurately match documents to user prompts, hindering the retrieval of pertinent documents.
Customizing embedding models with specific data is one approach to enhance their relevance for particular applications. However, the prevalent method involves a complex, multi-stage training process, initially using large-scale, weakly-supervised text pairs for contrastive learning, followed by fine-tuning with a smaller, high-quality, and meticulously labeled dataset.
This method demands significant effort to curate relevant text pairs and often relies on manually compiled datasets that are limited in scope and linguistic variety. Hence, many developers stick with generic embedding models, which may not fully meet their application needs.
## Revolutionizing Embedding Models with LLMs
Microsoft's innovative technique diverges from the standard two-stage process, instead proposing a single-stage training approach using proprietary LLMs like GPT-4. This method starts with GPT-4 generating a range of potential embedding tasks. These tasks are then used to prompt the model to create training examples.
For instance, the initial stage provided a list of abstract task descriptions, such as locating legal case law relevant to a specific argument or finding recipes based on given ingredients.

The next step involved submitting one of these tasks to GPT-4, which then generated a JSON structure containing a specific user prompt and corresponding positive and negative examples, each about 150 words. The results were impressively accurate, save for a minor discrepancy in the hard negative example, which could potentially skew the embeddings.

Despite the researchers not releasing their source code or data, this [Python notebook](https://github.com/bendee983/bdtechtalks/blob/main/Generate_examples_for_embedding_training.ipynb) offers a glimpse into this streamlined process, highlighting its adaptability and potential for customization.
To broaden the dataset's diversity, the team designed various prompt templates and synthesized them, generating over 500,000 examples with 150,000 unique instructions using GPT-3.5 and GPT-4 through Azure OpenAI Service. The total token usage was around 180 million, costing approximately $5,000.
Interestingly, the training employed an open-source auto-regressive model rather than a bidirectional encoder like BERT, which is typical. The rationale is that these models, already pre-trained on vast datasets, can be fine-tuned for embedding tasks at minimal costs.
They validated their method on Mistral-7B using synthetic data and 13 public datasets. Through techniques like LoRA, they reduced training expenses and achieved state-of-the-art results on renowned benchmark datasets, even surpassing OpenAI's Ada-002 and Cohere's models in RAG and embedding quality assessments.
## LLMs and Future of Embeddings
The study underscores that extensive auto-regressive pre-training allows LLMs to develop robust text representations, making only minor fine-tuning necessary to convert them into efficient embedding models.
The findings also indicate the feasibility of using LLMs to generate apt training data for fine-tuning embedding models cost-effectively. This has significant implications for future LLM applications, enabling organizations to develop custom embeddings for their specific needs.
The researchers suggest that generative language modeling and text embeddings are intrinsically linked, both requiring deep language comprehension by the model. They propose that a robust LLM should be capable of autonomously generating training data for an embedding task and then be fine-tuned with minimal effort. While their experiments offer promising insights, further research is needed to fully exploit this potential.
---
Follow me on social media:
https://twitter.com/nifty0x
https://www.linkedin.com/in/marko-vidrih/ | marko_vidrih | |
1,733,178 | Does Your Company Prioritize Tech Learning? | How does your company prioritize staying up-to-date with the latest advancements in technology? Share... | 0 | 2024-01-24T00:00:00 | https://dev.to/devteam/does-your-company-prioritize-tech-learning-21k2 | discuss | ---
published_at : 2024-01-24 00:00 +0000
---
How does your company prioritize staying up-to-date with the latest advancements in technology? Share insights into the work culture that supports continuous learning and its impact on the quality of work in the software industry.
Follow the DEVteam for more discussions and online camaraderie!
{% embed https://dev.to/devteam %} | thepracticaldev |
1,733,201 | Image data parsing: From Image to data (Using Vision API) | The AI becomes scarier better every day. OpenAI now offers the vision API, which allows you to... | 0 | 2024-01-18T00:24:45 | https://serpapi.com/blog/parsing-data-from-image-with-vision-api/ | webscraping, openai, ai | The AI becomes ~~scarier~~ better every day. OpenAI now offers the vision API, which allows you to extract information from an image.
We'll learn how to use Vision API by OpenAI in a simple image and extract data from complex images.

_We experimented with parsing HTML raw data with AI before, feel free to read the blog post: [Web scraping experiment with AI (Parsing HTML with GPT-4)](https://serpapi.com/blog/web-scraping-and-parsing-experiment-with-ai-openai/)
Vision API tutorial step-by-step
--------------------------------
Let's start with setting up a project to test the Vision API. I'll be using Javascript (Nodejs) in this sample, but feel free to use any language you're comfortable with.
**Preparation**
Create a new directory and initialize NPM
```
mkdir openai-vision-api && cd openai-vision-api
npm init -y // NPM init
npm install openai dotenv --save // Install openai and dotenv package
```
**Add API Key**
Get your API Key from openAI dashboard, and put it in the `.env` file. Feel free to create a new `.env` file.
```
OPENAI_API_KEY=YOUR_API_KEY
```
**Basic code setup**
Create a new `index.js` file and import related packages and create a new openai instance
```
require("dotenv").config();
const OpenAI = require('openai');
const { OPENAI_API_KEY } = process.env;
const openai = new OpenAI({
apiKey: OPENAI_API_KEY,
});
```
**Add vision API method**
Here is how to call a vision API in your code
```
async function main() {
const response = await openai.chat.completions.create({
model: "gpt-4-vision-preview",
messages: [
{
role: "user",
content: [
{ type: "text", text: "What’s in this image?" },
{
type: "image_url",
image_url: {
"url": "https://upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Gfp-wisconsin-madison-the-nature-boardwalk.jpg/2560px-Gfp-wisconsin-madison-the-nature-boardwalk.jpg"
},
},
],
},
]
});
console.log(response.choices[0].message.content);
}
main();
```
Now run the program with
```
node index.js
```
Here is the result:

Parsing data from complex image with Vision API
-----------------------------------------------
We saw it worked with a simple image. Now, let's try for a complex one. I'm going to take a screenshot from Google Shopping results.
> I'll upload this image, to use the public URL on our Vision API
I need to update two things: first, the token parameter since the response should be longer. Second is the prompt, to tell exactly what I want from the AI.
```
async function main() {
const response = await openai.chat.completions.create({
model: "gpt-4-vision-preview",
messages: [
{
role: "user",
content: [
{ type: "text", text: "Please share the detail information of each item on this product on a nice structure JSON" },
{
type: "image_url",
image_url: {
"url": "https://i.ibb.co/F8nGWk5/Clean-Shot-2024-01-17-at-13-46-43.png",
},
},
],
},
],
max_tokens: 1000 // Add more token
});
console.log(response.choices[0].message.content);
}
```
Here is the result
**The result is very good! but here is the catch:**
\- The response is not always consistent (structure wise). I believe we can solve this by adjusting our prompt
\- The time taken for this particular image is range between 10+ to 20+ seconds. (It's just the parsing time, not the scraping time).
Can we use this as a web scraping solution?
-------------------------------------------
As you might know, parsing data is just a part of web scraping. There are other things involved like proxy rotation, solving captcha, and so on. So we can't say that vision API is a web scraping solution.
**Here is the idea though, of how to use this as part of our web scraping solution:**
\- Create a scraping solution, for example [using Puppeteer in Javascript to take a screenshot](https://serpapi.com/blog/web-scraping-dynamic-website-with-puppeteer/#how-to-take-screenshots-in-puppeteer) .
\- Upload the image to a public URL or get the base64 code
\- Pass this image to the vision API method parameter like the one we provided above.
\- Return the results in a nice structured way.
\- (Bonus) If you want to have a consistent data structure, you might want to learn about [function calling by OpenAI](https://platform.openai.com/docs/guides/function-calling).
Summary
-------
It's very fun to experiment with OpenAI features like vision API and see the possibility to help us with web scraping and parsing.
In above example, where we try to parse the Google Shopping results page data, it's still far from ready for production, compare to the [Google Shopping API](https://serpapi.com/google-shopping-api), which only take 1-3s to scrape and return the Google Shopping page in a consistent structured format.
FAQ
---
**How much does vision API cost?**
Model `gpt-4-1106-vision-preview` costs `$0.01 / 1K tokens` for the input and `$0.03/1K tokens` for the output.
**Does it support function calling?**
Not right now, the `gpt-4-1106-vision-preview` haven't support function calling yet (Per 17th January 2024).
Reference: [OpenAI Vision API](https://platform.openai.com/docs/guides/vision) | hilmanski |
1,733,224 | How to handle complex json schema | I am working in databricks. I have a mounted external directory that is an s3 bucket with multiple... | 0 | 2024-01-18T02:08:18 | https://dev.to/chris_sts/how-to-handle-complex-json-schema-461p | databricks, json, schema, dataframe | I am working in databricks. I have a mounted external directory that is an s3 bucket with multiple subdirectories containing call log files in json format. The files are irregular and complex, when i try to use spark.read.json or spark.sql (SELECT *) i get the UNABLE_TO_INFER_SCHEMA error. the files are too complex to try and build a schema manually, plus there are thousands of files. what is the best approach for creating a dataframe with this data? | chris_sts |
1,733,254 | Streams in Java? | In Java, streams are a powerful and flexible abstraction introduced in Java 8 as part of the... | 0 | 2024-01-18T02:56:52 | https://dev.to/raghwendrasonu/streams-in-java-583b | In Java, streams are a powerful and flexible abstraction introduced in Java 8 as part of the java.util.stream package. Streams provide a new way to process data in a functional and declarative manner. They enable developers to express complex data processing operations concisely and efficiently.
**Common Operations on Streams:**
Filtering:
> List<String> filteredList = myList.stream()
> .filter(s -> s.startsWith("A"))
> .collect(Collectors.toList());
Mapping:
> List<Integer> lengths = myList.stream()
> .map(String::length)
> .collect(Collectors.toList());
Sorting:
> List<String> sortedList = myList.stream()
> .sorted()
> .collect(Collectors.toList());
Reducing:
> Optional<String> concatenated = myList.stream()
> .reduce((s1, s2) -> s1 + s2);
Collecting:
> List<String> collectedList = myList.stream()
> .collect(Collectors.toList());
Grouping and Partitioning:
> Map<Integer, List<String>> groupedByLength = myList.stream()
> .collect(Collectors.groupingBy(String::length));
Example of Chaining Stream Operations:
> List<String> result = myList.stream()
> .filter(s -> s.length() > 2)
> .map(String::toUpperCase)
> .sorted()
> .collect(Collectors.toList());
In this example, the stream is filtered to include only strings with a length greater than 2, then each string is converted to uppercase (so the map is used to do additional operation on the result returned from filter), the resulting strings are sorted, and finally, the result is collected into a new list.
Streams simplify the processing of collections in Java, providing a concise and expressive way to manipulate data. They are particularly useful when dealing with large datasets or performing complex data transformations. | raghwendrasonu | |
1,733,343 | What is Node.js and why should you use it in 2024 | In the rapidly changing world of web development, Node.js emerged and solidified itself as an... | 0 | 2024-01-18T05:28:51 | https://dev.to/backendbro/what-is-nodejs-and-why-should-you-use-it-in-2024-4383 | webdev, javascript, node | In the rapidly changing world of web development, Node.js emerged and solidified itself as an integral part of the modern-day web. Node.js has gained immense popularity in recent years as a powerful tool for developing scalable and high-performance applications. However, you may be wondering — what is the hype about Node.js and why should you consider using it in 2024? This article will delve deeper into Node.js, exploring its features, benefits, and use cases.
## What is Node.js?
Node.js is a cross-platform runtime environment that runs JavaScript code outside a web browser. Node.js uses the powerful V8 JavaScript engine from Google Chrome for swift execution of JavaScript code.
[Ryan Dahl](https://en.wikipedia.org/wiki/Ryan_Dahl) introduced Node.js in 2009, and since then, it has gained widespread adoption in the web development ecosystem. At its initial release, Node.js was only supported on Linux and Mac OS X. It wasn't until July 2011 that the first Node.js build supporting Windows was released.
Dahl criticized the sequential programming approach, which could not effectively manage a significant number of simultaneous connections. This frequently resulted in a delay that blocked the execution of a program, thereby reducing the overall performance of the application.
With Node.js, developers can use JavaScript for server-side scripting. Notable organizations including [Netflix](https://www.netflix.com/ng/), [LinkedIn](https://www.linkedin.com/), [Uber](https://www.uber.com/), and [Twitter ](https://twitter.com/) implement Node.js. In the latest [StackOverflow survey](https://survey.stackoverflow.co/2022/#most-popular-technologies-language), Node.js was ranked as the most popular **Web Framework and Technology** with a **47.12%** adoption rate. With over **6.3 million** websites using Node.js, it remains a top choice for building scalable and high-performance applications.
## The problems Node.js aims to solve.
Ryan Dahl created Node.js based on a simple principle — **operations must never block**.
Node.js aims to solve various problems that developers have always struggled with. Some of these problems include:
1. Processing a large volume of requests simultaneously
2. Preventing I/O bottlenecks
3. Implementing concurrency safely and more predictably.
To address these challenges, Node.js implements the following:
1. Node.js applications run on a single thread, which helps it achieve its non-blocking and event-driven goal. This means an application can process many requests simultaneously without blocking the main thread.
2. Program flow in Node.js is directed through asynchronous callbacks, which eliminates any bottlenecks caused by waiting for an operation to finish.
3. Concurrency is implemented in Node.js by use of events. Events are emitted to notify the completion of an operation. With Node.js developers can implement concurrency and parallelism safely and predictably in their applications without worrying about race conditions or other issues.
## Understanding Nodejs Architecture

Node.js has a unique architecture that sets it apart from traditional server-side technologies. Its non-blocking and event-driven design allows it to handle multiple requests simultaneously without blocking other operations. This makes Node.js highly scalable and particularly suited for high-traffic and real-time data processing applications.
The Node.js architecture is made possible by its single-threaded event loop, which listens for events such as incoming requests and calls the corresponding callback functions.
The event loop allows Node.js to avoid waiting for an operation to complete before moving on to the next one. When the skipped operation eventually completes, an event is emitted to notify the event loop to call its callback function. This feature allows Node.js to maintain a high level of performance when handling a large number of connections at once.
Node.js uses a support library called [Libuv](https://libuv.org/), which provides the event loop and manages asynchronous I/O operations. The Libuv handles most of the operating system tasks, such as file system operations, networking, and threading. The Libuv is crucial to Node.js's ability to handle concurrent tasks effectively.
Another core component of the Node.js architecture is the [V8 JavaScript engine](https://v8.dev/). The V8 is a high-performance runtime engine that executes JavaScript code at lightning-fast speeds.
The V8 engine uses the Just-In-Time (JIT) compilation technique to translate JavaScript code into machine code at runtime, which allows for faster and more efficient execution.
The V8 engine performs various optimizations, such as:
1. Inlining functions
2. Eliminating dead code
3. Optimizing memory usage — which helps to prevent memory leaks.
These optimizations ensure that the JavaScript code runs as efficiently as possible.
Node.js owes much of its speed and efficiency to the V8 Google Chrome engine. The V8, when combined with the Libuv, makes Node.js a top choice for building high-performance web applications.
## Features of Node.js
Node.js is known for its non-blocking and event-driven mechanisms, but it also offers various other features that make it stand out. They are:
1. **Operating System Operations**: Node.js adds a vast range of new features to JavaScript, allowing developers to perform several operating system related tasks such as file system operations, running external commands, and gathering information about the system environment. These functionalities aid developers in communicating with the underlying operating system that is not available to browser-based JavaScript. Node.js provides some core modules to make these interactions possible.
2. **Modules**: In Node.js, modules are essential for organizing code into reusable and maintainable units. They are independent units of code that are self-contained and can be shared, imported, and reused in different parts of an application. This allows complex applications to be built out of smaller, simpler components. Node.js follows the CommonJS module system, which provides a simple and efficient way to create, import, and reuse code across different files. To make functions and variables accessible to other files, Node.js provides the `module.exports` interface.
3. **NPM**: Node.js comes with a powerful package manager called Node Package Manager (NPM), it simplifies the installation, sharing, and version control of Node.js modules, making it easier to share and reuse code in projects. NPM has become one of the largest open-source JavaScript module repositories.
To keep track of project-related metadata, NPM maintains a `package.json` file in your project. This file lists all the dependencies and their respective versions. Additionally, NPM allows developers to define and run scripts in their `package.json` file. These scripts can be used for several tasks like testing, building, or running the application. The most common scripts include **start**, **test**, and **build**.
4. **Seamless frontend integration**: Node.js is a popular choice for full-stack projects because it allows developers to use JavaScript for both frontend and backend.
Developers can use popular frontend frameworks like React and Angular to create dynamic and real-time interactions while serving static assets and rendering dynamic content on the server side. This combination simplifies development, fosters code consistency and reduces the need to switch between languages.
5. **Large Community and Ecosystem**: Node.js has gained immense popularity due to its thriving community of developers who contribute to its growth and improvement. This community makes it easy for developers to find solutions to common problems and share best practices.
This collaborative approach ensures that Node.js stays up-to-date with the latest trends and technologies.
## Use Cases of Node.js
Node.js has a wide range of applications, including:
1. **Web applications**: Node.js is often used for building scalable and high-performance web applications. Its non-blocking and event-driven design makes it well-suited for I/O intensive applications. Node.js has popular frameworks like [Express](https://expressjs.com/) to provide a boilerplate for building robust web applications.
2. **REST APIs**: Node.js is a popular choice for developing RESTful APIs because of its lightweight and event-driven architecture. This architecture enables it to scale effortlessly and handle a large volume of requests. RESTful APIs often employ **JSON** (JavaScript Object Notation) for exchanging data. As JSON is native to JavaScript, working with JSON in Node.js is straightforward and seamless.
3. **Real-time applications**: Node.js is well-suited for building applications that require two-way communication and real-time updates.
Node.js provides libraries such as [Socket.io](https://socket.io/) to simplify the integration of real-time features in web applications such as chat platforms, collaborative tools, multiplayer games, and streaming services.
4. **Microservices**: Node.js is widely used in microservices applications, where services are divided into smaller, independent units, making it easier to scale, maintain, and deploy complex applications. Node.js's non-blocking model allows these services to handle a high volume of simultaneous requests without interfering with the execution of other tasks. Additionally, the lightweight and scalable nature of Node.js makes it a perfect fit for microservices that need to scale horizontally to handle increased traffic.
5. **Single-Page Applications**: Node.js is also used for developing single-page applications because it can render content on the server side. Node.js uses template engines like [EJS](https://ejs.co/) and [Handlebars](https://handlebarsjs.com/) to render HTML content and send it to the client, resulting in faster page loading times. This approach improves search engine optimization (SEO) and accessibility for users with slow or unreliable internet connections.
## Challenges and Solutions
Node.js has many advantages due to its architecture, however, there are certain challenges associated with this approach.
Here are a few challenges that affect the single-threaded nature of Node.js and how to mitigate them.
1. ### CPU-Intensive Tasks:
1. **Challenges**: Since Node.js is single-threaded, it can only perform one task at a time. This can pose a problem when dealing with expensive CPU operations that can block Node.js' event loop, causing performance issues.
2. **Solution**: To mitigate this issue, it is recommended to distribute CPU-intensive tasks among different processes or threads using techniques such as asynchronous programming, clustering, and worker threads. This can significantly improve the application's performance by ensuring that one operation does not block the other.
2. ### Limited Multithreading:
1. **Challenges**: Due to the lack of native support, implementing multi-threading in Node.js can be challenging.
2. **Solution**: Node.js provides the **worker_threads** module for thread management. In addition to the **worker_threads** module, several NPM dependencies have been created to simplify the process of multi-threading in Node.js.
3. ### Callback Hell:
1. **Challenges**: Node.js heavily relies on callbacks to achieve its non-blocking, event-driven model. However, this approach often leads to a callback hell. This is when deeply nested callbacks can become difficult to read, maintain, and debug.
2. **Solution**: Developers can mitigate the callback hell by using async/await, Promises, and event emitters, which allows for clearer and more readable code.
4. ### Garbage Collection:
1. **Challenges**: Node.js optimizes memory management through garbage collection, which allocates and deallocates memory spaces. However, this can block other operations and reduce application performance.
2. **Solution**: Proper configuration of garbage collection can prevent performance issues and ensure smooth program execution. Developers should also consider application memory needs and avoid unnecessary memory-intensive operations.
## Conclusion
Node.js continues to be a quintessential and versatile technology. Its non-blocking, event-driven architecture, built on the V8 JavaScript engine, has proven to be instrumental in developing scalable and high-performance applications.
Node.js's active and thriving community ensures that there will always be a solution to any problem. Developers can benefit from its rich ecosystem of libraries and tools for development.
Whether you are a beginner or an experienced developer, the broad range of features offered by Node.js makes it a compelling choice for software development in 2024.
## Further Reading
- [Node.js Official Documentation](https://nodejs.org/docs/latest/api/)
- [Mastering Node.js](http://www.digitalbreakdown.net/sandbox/Ebooks/Mastering-Node.js.pdf)
| backendbro |
1,733,397 | 🐣Your First Database Schema Change in 5 Minutes with Bytebase | In this tutorial, you'll use the sample databases Bytebase provides by default to get familiar with... | 0 | 2024-01-18T06:42:04 | https://dev.to/bytebase/your-first-database-schema-change-in-5-minutes-with-bytebase-44a0 | database, schema, postgressql | In this tutorial, you'll use the sample databases Bytebase provides by default to get familiar with the product in the quickest way.
## Step 1 - Run via Docker
1. Install and start [Docker](https://www.docker.com/).
2. Open Terminal to run the command:
```text
docker run --init \
--name bytebase \
--publish 8080:8080 \
--volume ~/.bytebase/data:/var/opt/bytebase \
bytebase/bytebase:2.13.1
```
When the Terminal shows the following message, the execution is successful.
```text
██████╗ ██╗ ██╗████████╗███████╗██████╗ █████╗ ███████╗███████╗
██╔══██╗╚██╗ ██╔╝╚══██╔══╝██╔════╝██╔══██╗██╔══██╗██╔════╝██╔════╝
██████╔╝ ╚████╔╝ ██║ █████╗ ██████╔╝███████║███████╗█████╗
██╔══██╗ ╚██╔╝ ██║ ██╔══╝ ██╔══██╗██╔══██║╚════██║██╔══╝
██████╔╝ ██║ ██║ ███████╗██████╔╝██║ ██║███████║███████╗
╚═════╝ ╚═╝ ╚═╝ ╚══════╝╚═════╝ ╚═╝ ╚═╝╚══════╝╚══════╝
Version 2.13.1 has started on port 8080 🚀
```
Now you have Bytebase running in Docker.

3. Open Bytebase in [localhost:8080](http://localhost:8080/), fill in the fields and click **Create admin account**. You'll be redirected to the workspace.

4. Follow the **Quikstart** guide on the bottom to click around or dismiss it by now. You can click your avatar on top right and click **Quickstart** on the dropdown menu to reopen it later.

## Step 2 - One Issue with Two Stages
1. Click **My Issues** on the left sidebar, and click the issue `SAM-101` which is created by default.

2. The issue is `waiting to rollout`. There's a pipeline consisting of two stages:
1. **Test Stage**: apply to database `hr_test` on `Test Sample instance`
2. **Prod Stage**: apply to database `hr_prod` on `Prod Sample instance`
`Test` stage is `active` by default.

3. Click **Prod Stage** to switch to it, and you will see the two stages share the same SQL but to different databases. You may also notice there's a warning sign for SQL review on the **Prod** stage. That's because when the issue is created, Bytebase will run task checks automatically. SQL review is one of them.

4. Click the warning sign to see the details. If you wonder why only **Prod Stage** has the warning sign, it's because by default SQL Review is only configured for `Prod` environment. You can click the **Settings** (gear) on the top right, and click **Security & Policy** > **SQL Review** to have a look.

## Step 3 - Roll out on Test Stage
1. Switch back to **Test Stage** and click **Rollout**. Click **Rollout** on the confirmation dialog.

2. When the SQL is applied, there will be a checkmark on the **Test Stage**. Click **View change** and you'll see the diff.


## Step 4 - Roll out on Prod Stage
There are two ways to roll out on **Prod Stage** regarding the SQL review result.
1. If you are confident with the SQL, you can click **Rollout** directly. Check the **Rollout anyway**, and click **Rollout** on the confirmation dialog.

2. Another way is to edit the SQL. Click **Edit** on top of the SQL, and add the `NOT NULL`. It will look like this:
```sql
ALTER TABLE employee ADD COLUMN IF NOT EXISTS email TEXT NOT NULL DEFAULT '';
```
Click **Save**, the checks will be run again. This time the SQL review will pass and it will roll out automatically. The issue will become `Done` as well.

You may ask why it's rolling out automatically, it's because for **Community Plan**, the rollout policy is automatic if the SQL review passes. You may go to **Environments** to check.

## Next Step
Now you have successfully performed your first schema change in Bytebase. It's the core part of Bytebase. You can continue to dig deeper by following [Deploy Schema Migration with Rollout Policy](https://www.bytebase.com/docs/tutorials/deploy-schema-migration/).
| adela_bytebase |
1,733,410 | Dissertation Formatting Service | Embarking on the journey of dissertation writing? Ensure your academic masterpiece gets the attention... | 0 | 2024-01-18T06:52:07 | https://dev.to/arielson010/dissertation-formatting-service-1ba2 | dissertation, assignment, assignmenthelp | Embarking on the journey of dissertation writing? Ensure your academic masterpiece gets the attention it deserves with our specialized Dissertation Formatting Service. At Dissertation Proposal, we understand the critical role formatting plays in the presentation of your research. Our seasoned professionals meticulously align your dissertation with the prescribed formatting guidelines, ensuring clarity, coherence, and a polished visual appeal. Don't let formatting intricacies overshadow your academic brilliance – trust our experts to enhance the professional look and feel of your dissertation. Join the conversation and discover how our [Dissertation Formatting Service](https://www.dissertationproposal.co.uk/dissertation-services/dissertation-formatting-service/) can elevate your research to new heights. | arielson010 |
1,733,429 | The Impact of Technology on the Workplace: How Technology is Changing | Traveling is an enriching experience that opens up new horizons, exposes us to different cultures,... | 0 | 2024-01-18T07:15:31 | https://dev.to/naomiiii/design-19ad | design | Traveling is an enriching experience that opens up new horizons, exposes us to different cultures, and creates memories that last a lifetime. However, traveling can also be stressful and overwhelming, especially if you don't plan and prepare adequately. In this blog article, we'll explore tips and tricks for a memorable journey and how to make the most of your travels.
One of the most rewarding aspects of traveling is immersing yourself in the local culture and customs. This includes trying local cuisine, attending cultural events and festivals, and interacting with locals. Learning a few phrases in the local language can also go a long way in making connections and showing respect.
 | naomiiii |
1,733,447 | 911 S5 Proxy and Instagram Proxy Comparative Analysis: Data-driven Insights to Help You Choose the Right Fit for Your Needs! | Introduction: The proxy services landscape offers various options, and choosing the right fit is... | 0 | 2024-01-18T07:25:22 | https://dev.to/kxx/911-s5-proxy-and-instagram-proxy-comparative-analysis-data-driven-insights-to-help-you-choose-the-right-fit-for-your-needs-1lpd | Introduction: The proxy services landscape offers various options, and choosing the right fit is crucial. This article conducts a comparative analysis between 911 S5 Proxy and Instagram Proxy, providing readers with data-driven insights to help them choose the proxy service that aligns with their specific needs. From performance metrics to unique features, the analysis aims to guide users toward an informed decision.
Evaluating Performance Metrics: The article kicks off by evaluating the key performance metrics of both 911 S5 Proxy and Instagram Proxy. From connection speed to reliability, readers gain insights into how each proxy service performs in real-world scenarios. Comparative data analysis provides a side-by-side view, enabling users to discern the strengths of each service.
Unique Features and Capabilities: Beyond performance, the article explores the unique features and capabilities that set 911 S5 Proxy and Instagram Proxy apart. Whether it's advanced encryption protocols or specialized optimizations for social media platforms, readers gain insights into what makes each proxy service unique. Understanding these features is crucial for choosing the proxy that aligns with specific preferences and requirements.
Privacy and Security Considerations: Privacy and security are paramount in the realm of proxy services. This section delves into how both 911 S5 Proxy and Instagram Proxy prioritize these aspects. From masking IP addresses to implementing advanced security measures, readers gain insights into the privacy and security features that make each proxy service a reliable choice.
Real-world User Experiences: The article incorporates real-world user experiences to add a human touch to the comparative analysis. Testimonials and stories from individuals who have used 911 S5 Proxy and Instagram Proxy provide firsthand insights into the practical benefits and challenges of each service. This user-centric perspective aims to help readers connect with the user experience aspect.
Data-driven Decision-making: In the final sections, the article summarizes the comparative analysis, guiding readers toward making data-driven decisions. Whether prioritizing speed, emphasizing security, or seeking specialized optimizations, the data-driven insights presented throughout the article empower users to choose the proxy service that aligns with their specific preferences and requirements.
Conclusion: In conclusion, the comparative analysis between 911 S5 Proxy and Instagram Proxy provides readers with valuable insights to make informed decisions. By evaluating performance metrics, unique features, privacy considerations, and real-world user experiences, users can choose the proxy service that best fits their needs in the ever-evolving landscape of online interactions. | kxx | |
1,733,959 | AI for Development: Phind | I'm a big fan of AI for Development: it always gives me interesting code and discussion, and is... | 0 | 2024-01-18T16:23:03 | https://dev.to/johntellsall/ai-for-development-phind-4k5b |
I'm a big fan of AI for Development: it always gives me interesting code and discussion, and is faster than Google (!). I'm senior enough to recognize when it goes off the rails.
I just tried "Phind" which is even better. It answers an English tech question like ChatGPT, but also gives *sources* including links to what material it's relying on!
Example: https://www.phind.com/search?cache=p5rwi1t4jj1fa8aof10s3ghk
I asked
> Python's pytest can run the most recent failing test first. > What is the equivalent for Ruby?
It carefully fleshed out my original question -- which itself was great, said "no equivalent", and sketched out a possible answer.
It's not smart. Googling for 1/2 second gave me the "--fail-fast" Rspec option which will run all tests then stop on the first failure. Not what I'd originally asked for, but close. It would have been nice if Phind had said "by the way...". | johntellsall | |
1,733,462 | AWS Data Engineering Online Training | AWS Data Engineer Training | How to Transform Data to Optimize for Analytics? Transforming data to optimize it for analytics... | 0 | 2024-01-18T07:44:22 | https://dev.to/akhil123/aws-data-engineering-online-training-aws-data-engineer-training-61l | How to Transform Data to Optimize for Analytics?
Transforming data to optimize it for analytics involves preparing and structuring raw data so that it becomes more suitable for analysis. This process, often referred to as data preparation or data wrangling, aims to enhance the quality, usability, and effectiveness of the data for analytical purposes. Here are some steps and best practices for transforming data to optimize it for analytics
AWS Data Engineering Online Training
Understand Your Data:
Begin by gaining a clear understanding of the data you are working with. Know the structure, types of variables, and the meaning of each column.
Data Cleaning:
Identify and handle missing values: Decide on a strategy to deal with missing data, whether by imputation, removal, or other methods.
Remove duplicates: Eliminate duplicate records from your dataset to avoid redundancy and ensure accuracy.
- AWS Data Engineer Training
Data Formatting:
Standardize data types: Ensure that data types are consistent across columns, such as converting dates to a standardized format.
Convert categorical variables: Transform categorical variables into numerical representations if necessary.
Handling Outliers:
Identify and handle outliers appropriately. Depending on the context, outliers might be corrected, removed, or treated differently.
Feature Engineering:
Create new meaningful features that can enhance the predictive power of your model.
Combine or transform existing features to derive more relevant information.
- AWS Data Engineering Training
Normalization and Scaling:
Normalize or scale numerical features to bring them to a similar scale. This is important for algorithms sensitive to the scale of variables, such as distance-based algorithms.
Data Integration:
Combine data from different sources if necessary. Ensure that the integrated data maintains consistency and accuracy.
Data Aggregation:
Aggregate data at a higher level if needed. For example, you might want to aggregate daily data into monthly or yearly summaries.
Handling Time Series Data:
If dealing with time series data, handle time-related aspects carefully. This may involve creating lag features or aggregating data over time intervals.
Data Splitting:
Split your data into training and testing sets to evaluate the performance of your analytics models. - AWS Data Engineering Training in Hyderabad
Documentation:
Document the transformations applied to the data, as this will help in reproducing results and understanding the analysis process.
Ensure Data Security and Privacy:
Be mindful of data security and privacy regulations. Anonymize or mask sensitive information as needed.
Testing and Iteration:
Test the quality and efficacy of your transformed data with analytics tools. If necessary, iterate on the transformation process to improve results.
Automation:
Consider automating repetitive data transformation tasks using scripts or tools to ensure consistency and efficiency.
Remember that the specific steps and techniques may vary based on the nature of your data and the analytics objectives. Additionally, tools like Python, R, and various data-wrangling libraries can be valuable in implementing these transformations.
Visualpath is the Leading and Best Institute for AWS Data Engineering Online Training, in Hyderabad. We at AWS Data Engineering Training provide you will get the best course at an affordable cost.
Attend Free Demo
Call on - +91-9989971070.
Visit: https://www.visualpath.in/aws-data-engineering-with-data-analytics-training.html
WhatsApp: https://www.whatsapp.com/catalog/919989971070
| akhil123 | |
1,733,510 | Unlocking Possibilities: 4 Incredibly Useful Phone Software You Need to Try | In the fast-paced digital era, our smartphones have become an integral part of our lives. Whether for... | 0 | 2024-01-18T09:11:42 | https://dev.to/just4youlive/unlocking-possibilities-4-incredibly-useful-phone-software-you-need-to-try-50a7 | ios, android, programming |
In the fast-paced digital era, our smartphones have become an integral part of our lives. Whether for communication, productivity, or entertainment, these devices store a plethora of data that we want to keep secure and accessible. To cater to the diverse needs of smartphone users, several software tools have emerged to provide solutions ranging from data recovery to device unlocking. In this article, we will explore four highly useful phone software tools, namely DelPasscode for iOS, Roways Android Unlocker, EelPhone OSFIXIT, and ZOOZOZ Android Data Recovery.
1. [DelPasscode for iOS](https://www.delpasscode.com/iphone-unlocker):
DelPasscode for iOS stands out as a reliable solution for iPhone users facing passcode-related issues. Whether you've forgotten your password, entered it incorrectly too many times, or encountered a disabled device, DelPasscode can help you regain access without losing your precious data. The software employs advanced algorithms to bypass passcodes safely, ensuring that your information remains intact throughout the process. DelPasscode's user-friendly interface and efficient performance make it a valuable tool for those in need of a hassle-free iOS unlocking solution.
2. [Roways Android Unlocker](https://roways.com/android-unlocker):
For Android users grappling with locked screens, Roways Android Unlocker is a versatile tool designed to bypass various types of Android lock screens. Whether it's a forgotten PIN, password, pattern, or fingerprint lock, Roways can help you regain access to your device without compromising your data. The software is compatible with a wide range of Android devices and is known for its user-friendly interface. With Roways Android Unlocker, you can swiftly unlock your Android phone and get back to using it with ease.
3. [EelPhone OSFIXIT](https://www.eelphone.tw/ios-system-repair/):
EelPhone OSFIXIT is a comprehensive software tool designed to fix a variety of iOS system issues. Whether you're facing problems like a stuck Apple logo, black screen, or an unresponsive device, EelPhone OSFIXIT can help resolve these issues without the need for technical expertise. The software guides users through a step-by-step process to repair their iOS system, ensuring a smooth and efficient recovery. EelPhone OSFIXIT is a handy tool for those who want to troubleshoot and fix iOS system issues without resorting to drastic measures.
4. [ZOOZOZ Android Data Recovery](https://zoozoz.com):
Accidental data loss on Android devices is a common concern, and ZOOZOZ Android Data Recovery comes to the rescue by offering a reliable solution for retrieving lost or deleted data. Whether it's photos, videos, contacts, messages, or documents, ZOOZOZ can scan your Android device and recover the lost files. The software supports various data loss scenarios, including accidental deletion, system crashes, and more. ZOOZOZ Android Data Recovery provides a user-friendly interface, making it accessible to both novice and experienced users seeking an effective Android data recovery solution.
Conclusion:
As our dependence on smartphones grows, so does the need for reliable software tools to address common issues such as passcode-related problems, unlocking difficulties, system glitches, and data loss. DelPasscode for iOS, Roways Android Unlocker, EelPhone OSFIXIT, and ZOOZOZ Android Data Recovery are four notable solutions that cater to these needs. Have you tried any of these phone software tools? Share your experiences and let us know which one has proven most useful for you! | just4youlive |
1,733,524 | User Testing in UX Design | UX Series Part 5 of 6 | Introduction to User Testing Methods of User Testing Focus Groups Surveys Market... | 0 | 2024-01-26T07:46:21 | https://diegocarrasco.com/user-testing-in-ux-design/ | designprocess, nontechnical, userfeedback, usertesting | ---
title: User Testing in UX Design | UX Series Part 5 of 6
published: true
date: 2024-01-18 08:00:00 UTC
tags: DesignProcess,nontechnical,UserFeedback,UserTesting
canonical_url: https://diegocarrasco.com/user-testing-in-ux-design/
---

- [Introduction to User Testing](https://diegocarrasco.com/user-testing-in-ux-design/#introduction-to-user-testing)
- [Methods of User Testing](https://diegocarrasco.com/user-testing-in-ux-design/#methods-of-user-testing)
- [Focus Groups](https://diegocarrasco.com/user-testing-in-ux-design/#focus-groups)
- [Surveys](https://diegocarrasco.com/user-testing-in-ux-design/#surveys)
- [Market Research](https://diegocarrasco.com/user-testing-in-ux-design/#market-research)
- [Formal Lab Usability Studies](https://diegocarrasco.com/user-testing-in-ux-design/#formal-lab-usability-studies)
- [Interpreting User Feedback](https://diegocarrasco.com/user-testing-in-ux-design/#interpreting-user-feedback)
- [Key Takeaways](https://diegocarrasco.com/user-testing-in-ux-design/#key-takeaways)
- [References](https://diegocarrasco.com/user-testing-in-ux-design/#references)
This is article 5 of 6 in the series [User Experience (UX)](https://diegocarrasco.com/ux).
A while ago I took a [User Experience (UX) course](https://www.futurelearn.com/courses/digital-skills-user-experience) and have compiled some notes that I'd like to share here, which may be useful for those interested in UX.
**TLDR**
User testing is a pivotal aspect of UX design, offering direct insights into user needs and preferences. This article outlines various user testing methods, illustrating their role in creating effective and user-friendly designs.
- [Introduction to User Testing](https://diegocarrasco.com/user-testing-in-ux-design/#introduction-to-user-testing)
- [Methods of User Testing](https://diegocarrasco.com/user-testing-in-ux-design/#methods-of-user-testing)
- [Focus Groups](https://diegocarrasco.com/user-testing-in-ux-design/#focus-groups)
- [Surveys](https://diegocarrasco.com/user-testing-in-ux-design/#surveys)
- [Market Research](https://diegocarrasco.com/user-testing-in-ux-design/#market-research)
- [Formal Lab Usability Studies](https://diegocarrasco.com/user-testing-in-ux-design/#formal-lab-usability-studies)
- [Interpreting User Feedback](https://diegocarrasco.com/user-testing-in-ux-design/#interpreting-user-feedback)
- [Key Takeaways](https://diegocarrasco.com/user-testing-in-ux-design/#key-takeaways)
- [References](https://diegocarrasco.com/user-testing-in-ux-design/#references)
## Introduction to User Testing
User testing is an essential process in UX design, aimed at understanding how real users interact with products. It uncovers user needs, preferences, and challenges, ensuring that the final product resonates with its intended audience (or at least, it should). There are always questions involved in user testing, which should be non-leading and non-biased.
**Importance of Non-Leading Questions: Ensuring unbiased and genuine user responses.**
## Methods of User Testing
### Focus Groups
> A focus group is a group interview involving a small number (sometimes up to ten) of demographically similar people or participants who have other traits/experiences in common depending on the research objective of the study. Their reactions to specific researcher/evaluator-posed questions are studied.
>
> -- [Focus Group on Wikipedia](https://en.wikipedia.org/wiki/Focus_group)
Essentially, a focus group is a (small) group of people who are brought together to discuss a particular topic.
There are 3 main components to a focus group:
1. **The Moderator** : The person who leads the discussion and asks questions. Without a good moderator, the focus group will not be successful. This person is responsible for keeping the discussion on track and making sure that the participants are engaged and the goals of the focus group are met. The moderator is also responsible for the preparation of the questions and topics of discussion.
2. **The Participants** : The people who are invited to take part in the focus group. Without participants, there is no focus group. The participants are usually selected based on their knowledge of the topic and their ability to contribute to the discussion, always keeping in mind the goals of the focus group.
3. **The Observers** : The people who observe the focus group and take notes. The observers are usually the people who are responsible for the analysis of the focus group. They are responsible for taking notes and making sure that the discussion is on track and that the goals of the focus group are met. The moderator is not able to moderate, take notes and observe, and thus are observers really important.
And you can add additional components as needed:
1. **The Recording** : The recording of the focus group, which can be audio, video, or both. Now a bit more difficult with data privacy laws, but still possible.
2. **The Report** : The report of the focus group, which is a summary of the discussion and the findings.
3. **The Analysis** : The analysis of the focus group, which is the interpretation of the findings.
4. **The Recommendations** : The recommendations of the focus group, which are the suggestions for the future.
5. **The Follow-Up** : The follow-up of the focus group, which is the action that is taken after the focus group.
### Surveys
A survey is a structured way of gathering information from a group of people. It is a way of collecting primary data which should be aligned with the research objectives and support the research questions.
A good survey should be:
- **Precise** : The questions should be clear and concise.
- **Unbiased** : The questions should be unbiased and not leading.
- **Relevant** : The questions should be relevant to the research objectives.
- **Easy to answer** : The questions should be easy to answer.
- **Easy to analyze** : The questions should be easy to analyze.
- **Easy to understand** : The questions should be easy to understand.
The answer types should be aligned with the research objectives and support the research questions. This means, that even if some answer types are easier to analyze but do not help gather the information you need, you should not use them. The contrary is also true, if some answer types help you gather too much unstructured information, but you just need to get a boolean (yes/no) answer, you should not use them.
### Market Research
A market research study is a study that is conducted to understand the market and the customers. There are many types of market research studies, but the most common are:
- **Explorative** : Exploring a topic, a market, or a customer segment.
- **Descriptive** : Describing a topic, a market, or a customer segment.
- **Causal** : Understanding the cause and effect of a topic, a market, or a customer segment.
Market research studies are usually conducted by market research companies or marketing professionals with experience in market research design and analysis.
### Formal Lab Usability Studies
> A usability lab is a place where usability testing is done. It is an environment where users are studied interacting with a system for the sake of evaluating the system's usability.
>
> -- [Usability Lab on Wikipedia](https://en.wikipedia.org/wiki/Usability_lab)
In other words, it's conducting controlled tests to observe user interaction in a controlled environment.
I would this is the most expensive and time-consuming method of user testing.
_Regrettably, I have not had the opportunity to conduct or participate in a formal lab usability study, so I don't have much more to say about it._
## Interpreting User Feedback
Understanding and effectively utilizing user feedback is crucial. It involves identifying common pain points, gauging user satisfaction, and iterating the design based on this feedback.
It is important to note that not everything must be taken under account. Some feedback is not relevant, some feedback is, and is the job of the UX designer to identify what is relevant and what is not.
In all cases, if the testing/ research was correctly designed and conducted, the feedback should be taken into account and should be relevant for your business and product. If this is not the case, you should review your methodological approach.
## Key Takeaways
- User testing is a pivotal aspect of UX design, offering direct insights into user needs and preferences.
- There are various methods of user testing, each with its own advantages and disadvantages.
- User testing is an iterative process, and it should be conducted regularly throughout the design process.
- User testing is a methodological process, and it should be designed and conducted with care.
## References
- [User Experience (UX)](https://www.futurelearn.com/courses/digital-skills-user-experience)
* * *
[Previous in series - The Significance of Information Architecture and Prototyping in UX](https://diegocarrasco.com/information-architecture-prototyping-ux)
[Next in series - Key Insights from the UX Design Series](https://diegocarrasco.com/key-insights-ux-design-series) | dacog |
1,733,564 | Flutter application development services | In today’s fast-paced digital landscape, businesses are constantly seeking innovative ways to engage... | 0 | 2024-01-18T09:37:30 | https://dev.to/webstep/flutter-application-development-services-k36 | flutter, webdev |

In today’s fast-paced digital landscape, businesses are constantly seeking innovative ways to engage users and deliver exceptional experiences. One technology that has gained immense popularity for its ability to create stunning and efficient cross-platform applications is Flutter. In this article, we will explore the significance of **[Flutter application development services](https://www.webstep.in/hire-flutter-developers/)** and how they empower businesses to reach a broader audience with a single codebase.
Understanding Flutter’s Appeal:
Flutter, an open-source UI software development toolkit, is designed by Google to enable the creation of natively compiled applications for mobile, web, and desktop from a single codebase. Its popularity stems from its exceptional performance, expressive and flexible UI, and the ability to accelerate the development process.
1. Cross-Platform Consistency:
Flutter allows developers to write code once and deploy it on multiple platforms, ensuring a consistent user experience across devices. This not only streamlines the development process but also reduces maintenance efforts, as changes can be implemented universally.
2. Expressive and Intuitive UI:
Flutter’s rich set of customizable widgets facilitates the creation of visually appealing and intuitive user interfaces. Developers can craft a seamless user experience that aligns with their brand identity, fostering user engagement and satisfaction.
3. Faster Development Cycles:
With Flutter’s “hot reload” feature, developers can instantly view changes made to the code, allowing for real-time adjustments and faster development cycles. This iterative development process enhances productivity and accelerates time-to-market for applications.
4. Native Performance:
Flutter applications are compiled to native ARM code, ensuring high performance on both Android and iOS platforms. This native compilation contributes to smooth animations, quick load times, and an overall responsive user interface.
5. Extensive Community Support:
Flutter benefits from a vibrant and active community of developers and contributors. This community support translates into a wealth of resources, plugins, and third-party packages, streamlining the development process and expanding the capabilities of Flutter applications.
Flutter web development services
How Flutter Application Development Services Can Transform Your Business:
Now, let’s delve into how businesses can leverage **[Flutter application development services](https://www.webstep.in/hire-flutter-developers/)** to elevate their digital presence and user engagement.
1. Cost-Efficiency:
Flutter’s cross-platform nature significantly reduces development costs, as businesses can maintain a single codebase for multiple platforms. This streamlined approach ensures efficient resource allocation and budget optimization.
2. Faster Time-to-Market:
The faster development cycles enabled by Flutter contribute to a quicker time-to-market for applications. Businesses can swiftly introduce their products or services to the market, gaining a competitive edge and responding promptly to evolving user needs.
3. Enhanced User Engagement:
The expressive UI capabilities of Flutter empower businesses to create visually stunning and user-friendly interfaces. This, in turn, enhances user engagement, encourages longer app usage, and establishes a positive brand perception.
Conclusion:
In conclusion, **[Flutter application development services](https://www.webstep.in/hire-flutter-developers/)** offer a powerful solution for businesses aiming to create cross-platform applications that prioritize performance, aesthetics, and efficiency. With its versatile toolkit, Flutter enables developers to craft applications that not only meet but exceed user expectations.
As the digital landscape continues to evolve, embracing innovative technologies like Flutter becomes crucial for businesses seeking to stay ahead of the curve. By harnessing the capabilities of **Flutter application development services**, businesses can unlock a world of opportunities and deliver unparalleled user experiences across diverse platforms.
For businesses seeking comprehensive digital solutions, the combination of **[Flutter application development services](https://www.webstep.in/hire-flutter-developers/)** for cross-platform mobile applications and Angular software development services for web applications can offer a well-rounded approach. This strategic use of technologies ensures a consistent and seamless user experience across various platforms, maximizing reach and engagement.
Related Posts —
**[Angular Software Development Service](https://medium.com/@webstep/angular-software-development-service-10b8338dbd90)** | **[Best SEO services for website analytics](https://medium.com/@webstep/best-seo-services-for-website-analytics-5291dd0708de)** | **[Custom react native app development services]( https://medium.com/@webstep/custom-react-native-mobile-app-development-services-3f4121bc2b7a)** | **[WordPress website development services](https://medium.com/@webstep/wordpress-website-development-services-576860efeaca)** | webstep |
1,733,579 | Still no internet? How to prevent premature timeouts in Ubuntu? | I have contributed to open data by hunting "Funklöcher" ("radio holes", as network dead zones are... | 0 | 2024-01-18T14:43:11 | https://dev.to/ingosteinke/there-is-still-no-internet-how-to-prevent-premature-timeouts-on-ubuntu-5hdk | linux, networking, discuss | I have contributed to open data by hunting "Funklöcher" ("radio holes", as network dead zones are called in Germany) with the Federal Network Agency's [Breitbandmessung](https://www.breitbandmessung.de) network measurement tool, only to discover that "not no internet" still does not guarantee any usable connection. Similarly, there are some cheap router devices that popular ISPs send as a default, that work well enough for the majority of Windows, MacBooks, and iPhones, and everyone else should pay to rent or buy a FritzBox router. This has happened with various budget smartphones and older Lenovo laptops, but also my professional Linux laptop that rarely makes any trouble.
## Internet connections that don't send data
But what's happening? Latency problems probably cause this kind of issues when there is a good, or at least sufficient, internet connection that some devices can use without issues, but some can't.
I gathered a lot of log files using a Linux laptop and a Huawei phone on a Vodafone network, but that's outdated now, and Vodafone support didn't think it was useful. Later I experienced similar problems with another Linux laptop in an O2 network. After replacing their router with a used FritzBox (many second-hand 1&1 routers can be reconfigured for any other popular ISP) the problems disappeared at home and I never had any similar problems in any professional workplace.
Travelling around the country in Deutsche Bahn trains and working from my dad's place in an old suburban house connected to an average Telekom network, I remembered my timeouts that became critical when I failed to reach GitHub and my own remote `ssh` server!
## Increasing Ubuntu network timeouts and retries
Checking various sources, I learned that Ubuntu Linux networking did have some special problems, most of which seemed to have disappeared after an upgrade to the latest release at the time of writing. Those posts are usually five to ten years old. But one option still works in Ubuntu 22.04 in 2024: increasing the network timeouts and retries.
We can change the settings ad hoc using the `sysctl` interface. Tweaking `net.ipv4` requires root privileges on my system, so I tried
- `sudo sysctl net.ipv4.tcp_fin_timeout=180` to increase the timeout to 3 minutes (3x the default 60 seconds)
- `sudo sysctl net.ipv4.tcp_synack_retries=8` to increase passive FTP retries above the default 5 times
A quick check before and after the settings looked good: GitHub, GMX (a popular German email provider), and several other servers notorious for latency problems with my Ubuntu machine on a train or with cheap routers, ran into timeouts before tweaking, but I could reach all of them almost immediately when trying again afterwards, at least in Google Chrome. Maybe the problem is worse in combination with Vivaldi, or my browser has cached the outdated network settings. 🤔
To persist these settings, I add the corresponding lines to my `/etc/sysctl.conf` configuration file:
```
# prevent timeouts when communicating with latent routers
# override default 60s timeout:
net.ipv4.tcp_fin_timeout=180
# override default 5 passive ftp retries
net.ipv4.tcp_synack_retries=8
```
That's it!
I'll see and verify my solution. 👀
- ❎ using my dad's Telekom router ☎️: maybe less critical than before❓
- ◻ in a Deutsche Bahn train ("WiFi on ICE" 🧊)
- ◻ using the default O2 and Vodafone routers 🫧
- ◻ using public cafés and bars ☕🍹
I still find it hard to tell. Between edge cases like "I can never connect to GitHub" and "I can always use every part of GitHub without any delay" lies reality and its perceived improvements and placebo effects, unless I start measung and gather actual data which I should also have done before tweaking my network. But here is an intermediate conclusion: I still had issues in the Telekom router net, and I always have occasional issues on a train no matter which machine I use, and GitHub gave me the most and the most critical timeouts when trying to work anywhere outside the big cities.
Related network tuning advice for Ubuntu users:
[Creating a Captive Page to Sign into any Public Network
(a.k.a. "There is no Internet"](https://dev.to/ingosteinke/creating-a-captive-page-to-sign-into-any-public-network-19a4)
{% post https://dev.to/ingosteinke/creating-a-captive-page-to-sign-into-any-public-network-19a4 %}
## Discussion
Maybe you're a network expert or you had similar latency issues with your Ubuntu machine? What are your experiences and suggestions? Which tools and metrics do you use to measure network quality? | ingosteinke |
1,733,608 | A Pragmatic Approach to Becoming an AI Engineer | Are you interested in a career in AI engineering but don't know where to start? In this post, we will... | 0 | 2024-01-18T10:36:45 | https://dev.to/balrajola/a-pragmatic-approach-to-becoming-an-ai-engineer-4b22 | webdev, javascript, beginners, programming | Are you interested in a career in AI engineering but don't know where to start? In this post, we will provide you with a pragmatic approach to becoming an AI engineer in just 2 minutes!
Identify Your Strengths and Weaknesses
--------------------------------------
Before you begin your journey towards becoming an AI engineer, it's important to identify your strengths and weaknesses. Are you good at programming? Do you have a strong foundation in mathematics? Are there any areas that you need to improve on? Knowing your strengths and weaknesses will help you create a personalized plan for your career development.
Choose a Specialization
-----------------------
AI is a broad field with many subfields such as computer vision, natural language processing, and machine learning. Choose a specialization that aligns with your interests and skills. This will help you focus your learning and create a more targeted career plan.
Build a Strong Foundation
-------------------------
To become an AI engineer, you need to have a strong foundation in computer science and mathematics. Start by learning the basics of programming languages such as Python, C++, and Java, and study algorithms and data structures. You can find many online resources and courses to help you build your foundation.
Learn Machine Learning
----------------------
Machine learning is a crucial aspect of AI engineering. Learn about supervised and unsupervised learning, neural networks, deep learning, and natural language processing. There are many online courses and tutorials available that can help you get started.
Gain Practical Experience
-------------------------
Once you have a good understanding of the basics and machine learning concepts, it's time to gain practical experience. Participate in hackathons, work on personal projects, or contribute to open-source AI projects. This will help you build a portfolio of work that you can showcase to potential employers.
Stay Up-to-Date with Industry Trends
------------------------------------
The field of AI is constantly evolving, so it's important to stay up-to-date with the latest trends and developments. Follow industry leaders and experts on social media, attend conferences and meetups, and read relevant blogs and articles.
Network and Build Connections
-----------------------------
Building connections with other AI engineers and professionals in the industry can help you learn about new opportunities and stay informed about the latest developments. Join online communities and forums, attend networking events, and participate in online discussions.
In conclusion, becoming an AI engineer requires a combination of technical skills, practical experience, and staying up-to-date with industry trends. By following these steps and taking a pragmatic approach, you can start your journey towards a rewarding and challenging career in AI engineering. | balrajola |
1,733,622 | How to implement UWB precise location system with TDOA technology(1) | Preface This is a series of articles that will introduce you to how to implement a UWB... | 0 | 2024-01-18T11:04:58 | https://dev.to/bd8ncf/how-to-implement-uwb-precise-location-system-with-tdoa-technology1-3k8o | uwb, tdoa, rtls, location | ## Preface
This is a series of articles that will introduce you to how to implement a UWB precise location system using TDOA technology.
**IMPORTANT NOTE:**
- Q: Do I need basic knowledge to create this targeting system?
- A: This article is not for beginners. It requires a basic knowledge of electronic technology and software programming.
- Q: Are your hardware/software open source?
- A: It is not open source.
- In the article, I will introduce how to implement the UWB location system and tell you how to overcome the difficulties, but I will not directly give you the Gerber file of the PCB to make a board, nor will I give you the source code of the software, nor will I give you the compiled firmware.
- I'm not going to give you any direct results, I'm just telling you how.
- Q: I am personally very interested in UWB location. Can I make a location system?
- A: If you have a strong hardware/software background and a lot of time, you can certainly do it. This article is just for you to read!
- Q: I am a commercial company and I want to develop the UWB location system into a commercial product.
- A: Of course. This article is also written for you. If you want to build the entire system from zero, after reading my article, you only need to draw the circuit and make the board; conceive the software structure and then coding.
In this way, I will mention all the difficulties in the article and introduce the solutions. You don't need to hire people to do algorithm research. If you want to save trouble and time, you can directly purchase our circuit diagram (AD engineering files), purchase our software source code, and then quickly enter the production process. (Website: [https://en.uwbhome.top](https://en.uwbhome.top) )
Starting in 2016, we started the UWB location project and officially stopped this project by the end of 2021. Now with the permission of the boss, it is decrypted. So I wrote out the entire project process.
If you are interested in UWB location, after reading this series of articles, you should be able to implement a UWB location system by yourself.
If you are using it commercially, it is recommended to purchase our technology (by the way, advertising, it is definitely cheaper than doing it yourself from scratch, mainly because it saves trouble and gets quick results, so we have been through the pitfalls you may fall into.
Website: [https://en.uwbhome.top](https://en.uwbhome.top) ).
In recent years, UWB has become very popular. It has been speculated for a long time, but it seems that it has not been widely used in daily life.
However, in some specific fields, applications are becoming more and more widespread, such as underground coal mine location/chemical production industry location, etc. These high-risk industries have seen the benefits of UWB, so they are being used more and more.
I won't write much about the wireless features of UWB, as there are already too many introductions on the Internet.
## UWB Chip
Currently, the UWB chip of DecaWave Company in Ireland is widely used. I haven't paid attention to this field for a long time. I visited DecaWave's website some time ago and found that it has changed and become a department of Qorvo.
It is said that it was renamed Qorvo after being acquired by Apple.
We use the DW1000 chip, which is really powerful. Let's not talk about its UWB related technologies. In terms of low power consumption, it is really amazing. We once had a development board. When I was testing low-power consumption, I accidentally set the chip to deep sleep.
No matter what I did, I found that the chip didn't respond. I thought the chip was broken, so I left it aside. But a few weeks later, I picked up the "bad" board and tested it, and suddenly found that the chip was good again.
It turns out that because there are several small capacitors on the template, although the power is cut off, the small capacitors are still supplying power to the chip, so the chip has been sleeping.
After a few weeks, the small capacitors ran out of power, and the chip was completely out of power. Power on and reset, the chip is normal again.
The following are the technical data of DW1000:
- Supports 110 kbit/s, 850 kbit/s & 6.8 Mbit/s data rates
- 6 frequency bands supported with center frequencies from 3.5 GHz to 6.5 GHz
- Transmit Power ?14 dBm or ?10 dBm
- Transmit Power Density < ?41.3dBm / MHz
- Preamble Length 64 μs to 4 ms
- Supports Packet Sizes up to 1023 bytes
- Modulation: BPM with BPSK
- Integrated FEC and CRC insertion and checking
- SPI interface to host controller (20 MHz max)
- Allows easy integration with wide range of μControllers
- Single Supply Voltage 2.8 V to 3.6 V
- Low Power Consumption
- Transmit mode from 31 mA*
- Receive mode from 64 mA*
- 2 μA watchdog timer mode
- 100 nA deep sleep mode
- Media Access Techniques
- FDMA: 6 channels
- CDMA: 12 different channel codes
- Supports both two way ranging and one way ranging, using Time of Flight (TOF) and time difference of arrival (TDOA) methods
- Fabricated in 90 nm CMOS
- Industrial temperature range -40°C to +85°C
- 6 mm x 6 mm 48 pin QFN package
- Hardware & software applications support material available from DecaWave
DecaWave provides a lot of routines for DW1000, how to send UWB data packets, how to receive UWB data packets, and several TOF ranging codes. The development board trek1000 kit provided by DecaWave also provides the source code of a TOF location sample system.
Many stores selling DW1000 development boards on Taobao claim to provide source code, and they should provide these codes.
 _Official development board TREK1000 kit, with 4 boards_
## Technical difficulty 1: TDOA technology
What is TDOA? The full English name of TDOA is Time Difference of Arrival. In fact, the GPS/Beidou navigation we often use, and the location technology used by mobile phones (receiving terminals) is TDOA.
The GPS chip on the mobile phone calculates the location of the mobile phone based on the time difference of the received satellite signals. GPS/Beidou uses **downlink TDOA location**, which means that the terminal being positioned calculates its own coordinates.
We use **uplink TDOA location**.
What we have to do is different. The person or object being located carries a tag, and this tag continuously sends UWB signals. We will deploy some anchors (Anchors) in the location area, and these anchors will receive UWB signals sent by Tags.
We will have a computer running a software called a location engine (RTLE). The Anchor converts the received UWB signal into some network data and sends it to the location engine. The location engine calculates the coordinates of the tag based on these data packets.
There are also companies in the industry that are doing UWB downlink TDOA location. If downlink TDOA is performed, the terminal is required to have relatively strong computing capabilities, which is also a test for the terminal's power consumption.
GPS systems have been released for so many years. They used to be very large. However, these systems have been used in more and more applications and have gradually become smaller. If you do UWB downlink TDOA location, there will be many difficulties.
Regarding the mathematical principles of TDOA technology, there is already a lot of information on the Internet, so I will briefly mention it here.
Assume that the UWB signal sent by a Tag is received by two Anchors. The two Anchors receive it at different times, and there is a time difference. UWB signals are radio waves, and the time they fly in the air is about the same as the speed of light.
This time difference can be converted into a distance difference, which is the difference between the distance between the Tag and the two Anchors. Based on this distance difference, we can draw a curve around the two Anchors.
The distance difference between all points on this curve and the two Anchors is equal to the aforementioned distance difference. This is half of the hyperbola.
If there are 3 Anchors, the signal sent by Tag can get 3 time differences. Draw three curves. The intersection of these three curves is the coordinates of Tag. What the location engine has to do is to list a few equations, then solve the equations and get the coordinates.
It's really simple in principle. The trouble lies in solving the equations. Because there will be factors such as interference/error during implementation, the intersection points of the three curves do not coincide.
What we need is to quickly calculate an approximation, as close as possible to the numerical intersection of the curves.
When we first started working, we searched online and found many papers. The author of almost every paper will say how awesome my algorithm is, cite a lot of data to prove it, and write a bunch of mathematical formulas that people can't understand.
I will discuss TDOA technology in detail later when I introduce how to write a location engine.
## Technical difficulty 2: clock synchronization
Since time difference is used for location, each anchor must have the same time. If you have watched war movies, you should still have images. After the commander arranges the tasks of each unit, he will say, "We will launch the battle on time at 12 o'clock.
Let's check the watch." Yes, if everyone's watches are inconsistent, some watches have already passed 12 o'clock, and some watches have not yet reached 12 o'clock, it will be a mess.
The time of each anchor is unified.
When receiving the UWB signal from the tag, the anchor will record the time it was received, and then each anchor will send this time to the location engine, and the location engine will calculate the coordinates based on the difference in these times.
When we were doing technical research, we contacted Decawave. They had a wireless clock synchronization solution that cost more than 100,000 US dollars. It was not code, just a solution.
Later, we came up with a solution and found that the wireless clock synchronization solution is actually very simple, it just depends on whether you can think of it.
These two technical difficulties: TDOA algorithm and clock synchronization scheme were indeed difficult in 2016/2017. I guess there are many companies that want to do UWB location, but after research, they are blocked by these two obstacles.
As long as you are willing to study hard, these problems will always be solved. So now there are more and more companies doing UWB location.
After you read this series of articles of mine, you will find that these two "difficulties" are actually not that difficult.
## What is Our Goal
What do you get after all the fuss? In other words, what are we going to do?
To put it simply, we are building a UWB precise location system using TDOA technology.
The person or object being located carries a tag, which continuously sends UWB signals. We will deploy some anchors (Anchors) in the location area, and these anchors will receive UWB signals sent by Tags.
We will have a computer running a software called a location engine (RTLE). The Anchor converts the received UWB signal into some network data and sends it to the location engine. The location engine calculates the coordinates of the tag based on these data packets.
This process is the standard TDOA location process, which is very simple.
In this process, there are two types of hardware involved: tags and anchors; the software involved are: tag firmware, anchor firmware, and location engines.
Of course, the above is a simplified version. Commercial products should also have some other software:
- Tag configurator
- Anchor configuration program
- Location engine manager
For example, if we need to change the channel for UWB communication, do we need to recompile the tag firmware and anchor hardware and then flash them to the board? Wouldn't it be more convenient if you use a configuration program to set the channel parameters?
Also, we want to add a new function to the firmware. Do we need to remove the board, connect the JTag and re-flash the firmware? Wouldn't it be more convenient to upgrade the firmware directly over the Internet?
The location process is also more complicated in real environments. Usually, the maximum communication range of UWB chip DW1000 is 200 meters to 300 meters. What if the area we want to target is large? Generally, multiple small areas are divided into one large area.
Therefore, the location engine must support multi-region location.
## Hardware Design and Selection
In terms of hardware, what we need to do is two things: tags and anchors.
The most important components in hardware selection are the two components: UWB chip and MCU.
We use DW1000 for UWB chip. Anyone who plays electronics knows that the design of radio frequency circuits has always been difficult. Therefore, analog electrical engineers are more valuable than digital electrical engineers, and the older they are, the more valuable they are.
Therefore, we do not use the DW1000 chip directly, but use the module **DWM1000**. The original factory packages the DW1000 into a module, so we don't have to worry about the radio frequency part. The module has a set of SPI interfaces, and we can happily connect it to the GPIO of the MCU.
 _DWM1000 looks like this_
 _Our actual shot of DWM1000_
MCU selection. The main control MCU we use is the **STM32F103** series. This series of chips was very popular a few years ago. If I were to choose now, I would definitely choose ESP32. ESP32 is cheap, has good performance, and is highly scalable. Around 2020, we suffered from the price increase of ST's chips.
The normal price of the STM32F103RET6 we use for location anchors is only about 14 yuan, and the highest price rises to about 500 yuan, which is higher than the shipping price of our anchors. It's crazy.
Because STM32F103 was used before, the introduction of this article also uses it as an example. If you use ESP32, there is still a lot of detailed work to be done. For example, ESP32 has WIFI and Bluetooth, which involves how to configure the network.
ESP32 can also add an additional chip to create a wired Ethernet connection, which involves wired and wireless dual connections. There will be two IP addresses in the network, and there are many details to consider.
So let's not consider the ESP32 for now, and let's just use the STM32F103.
Whether it is a anchor or a tag, because the DWM1000 module is used, the hardware design is mainly the digital circuit part, which is a typical circuit, and there is basically no difficulty.
## Anchor Hardware Design
The anchor will have more functions and has higher requirements for RAM and Flash, so the MCU chooses STM32F103RET6.
In addition, you need to connect to the network. The network interface chip uses W5500. This chip also uses the SPI interface to connect to the MCU. I have used the W5500 in several projects before and am familiar with it, so I chose it.
Of course, if you choose other familiar network interface chips, that's no problem.
For the power supply part, if you are doing experiments by yourself, you can directly use DC12V or DC5V. We use POE power supply in our products. The POE power receiving chip uses TI's TPS23753A, and uses an isolated design to protect the anchor circuit.
In fact, our initial version used DC 12V power supply, and I have always wanted to use POE power supply. I drew several versions of the circuit and made several samples, but I still couldn't get the POE right.
Later, our team expanded and added a guy who specialized in hardware, and he finally solved POE.
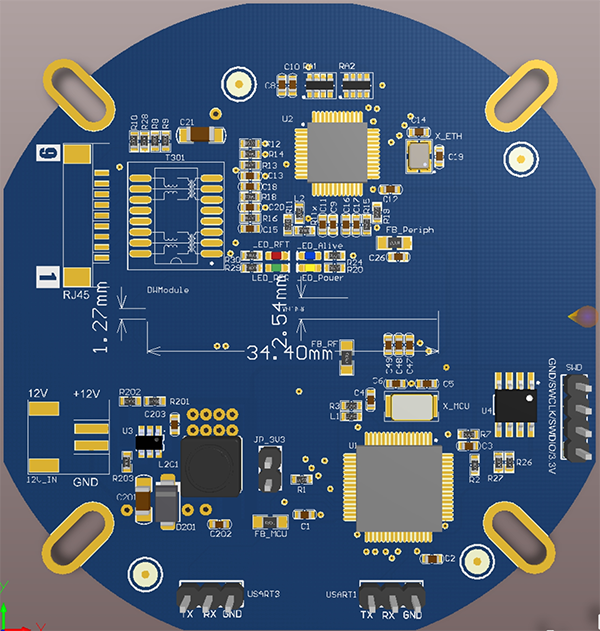 _The first mass-produced anchor, using 12V power supply_
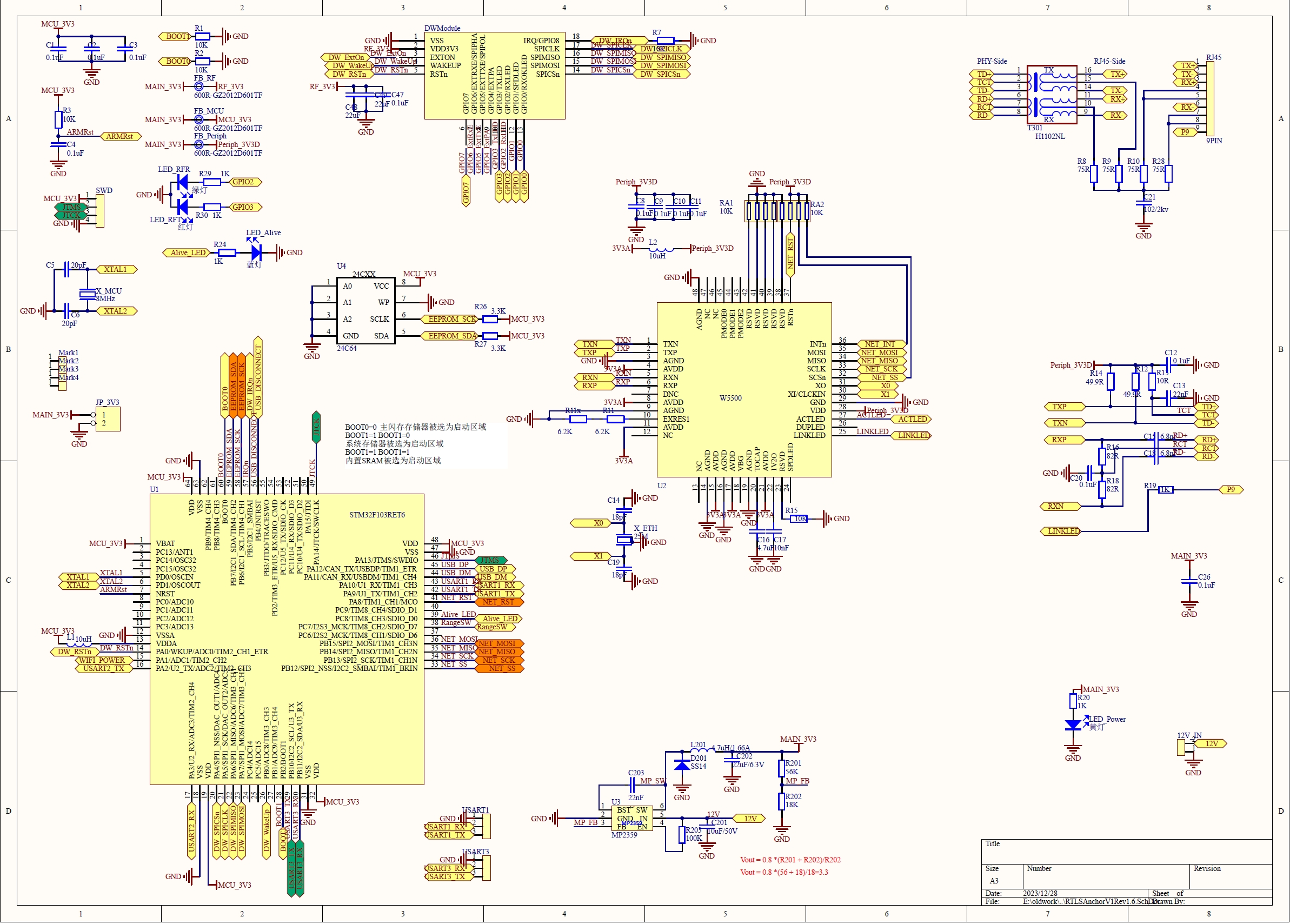 _Anchor circuit diagram_
Below are photos of the finished anchor
 _This is the PCBA corresponding to the circuit diagram above_
 _RTLS Anchor PCBA_
 _RTLS Anchor PCBA_
 _This anchor is trying to connect to WIFI and adds a WIFI module_
 _This photo shows how to open the anchor casing. It is just right to compare the size of the human hand and the casing_
Please forgive me, I can't upload the AD project file of the anchor circuit, so I have to keep it for selling it. But I have included a high-definition picture of the anchor circuit, and you can draw a copy yourself.
A 24C64 is used in the circuit in order to preserve the anchor configuration. Later, the firmware used Flash to simulate EEPROM, and the 24C64 was cancelled.
If you are doing DIY, you don't need to make the board very small. **The casing is a must! DW1000 and crystal oscillator are very sensitive to temperature. We have tested that if someone passes by the bare board without a casing, it will cause the DW1000 clock to change greatly**.
Here is another photo of our latest version of the mass-produced anchor for everyone to appreciate. It is powered by POE, has dual network ports, and integrates a network switch chip. Multiple anchors can be cascaded hand in hand.
 _Dual network port anchor, POE power supply and reception, integrated switch chip, can be cascaded_
With this level of integration of the anchor, it can only be mounted by machine. If welded by hand, it is a very difficult job.
## Tag Hardware Design
We use the name-card style tags, which can be used in a wider range of applications. In fact, many end users use name-card style tags, and the response during use is good.
The tag's MCU uses STM32F103CBT6, which has a smaller chip area and smaller RAM and Flash. In fact, we wanted to use STM32F10C8T6 at first, but later we found that Flash was too small.
Because we want to support online firmware upgrades, the Flash must be at least twice as large as the firmware, because in addition to the running firmware, space must be left for the newly uploaded firmware. Also leave some space for configuration parameters.
The tag uses an 800mah lithium polymer battery for power supply, and the charging chip uses TP4057. This charging chip is cheap and has a simple interface. Because of this, it is not a complete battery management chip, it only charges, and it charges in LDO mode.
During the charging process, the input DC 5V is converted into the 3.5V~4.2V required by the battery, and the energy between these two voltage differences becomes heat.
If the charging current is designed to be too large, it will be very hot; if the charging current is small, the charging time will be very long.
Later, I wanted to switch to a DC-DC charging chip, but the project was stopped, so I forgot about it. If a DC-DC charging chip is used, the heat generation will be much smaller, we can design the charging current to be larger, and charging will take much less time.
But the cost will increase a bit, and a large inductor may need to be added.
We also designed a wireless charging function. If you are just playing with it alone, you don't need to do this part. Wireless charging uses TI's BQ51013 chip. This chip supports the QI wireless charging standard.
With multiple uses in mind, tags add some small features:
- Photoresistor, used to detect ambient light brightness
- MPU6050 three-dimensional accelerometer
- Voltage divider resistor detects battery voltage
The driver of the MPU6050 was not ready, and other functions of the firmware were greatly affected, so we blocked it during mass production. Due to insufficient manpower and too many things to do, MPU6050 never had time to tinker with.
In the end, it was simply not attached and left empty on the board.
The voltage divider resistor detects the battery voltage and can roughly understand the remaining power. If possible, it is best to install a power detection chip. There should be a suitable power management chip now, a chip that integrates charging/discharging/power management.
At the beginning, in order to save power, we used 1M ohm voltage dividing resistors. Later, we found that this was not possible because there were discrete errors. Some boards can measure accurately, and some boards have large errors.
Because the ADC internal resistance of STM32 is not very large. Later we changed it to 100K euros and this problem was solved.
In the design of tags, low power consumption needs to be considered in many aspects, so as to save power consumption as much as possible and make the tag's standby time longer.
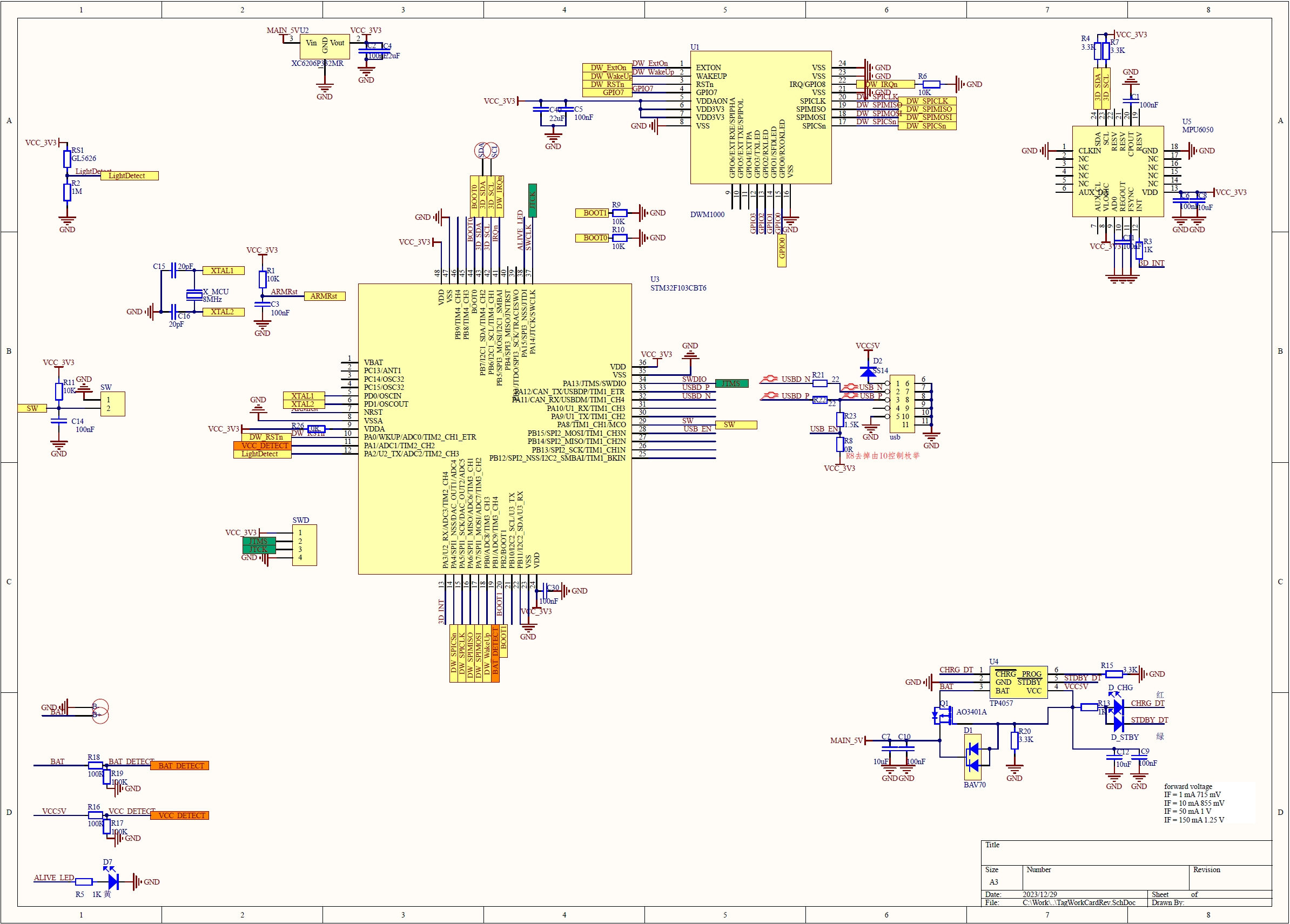 _RTLS Tag's Schematic Diagram_
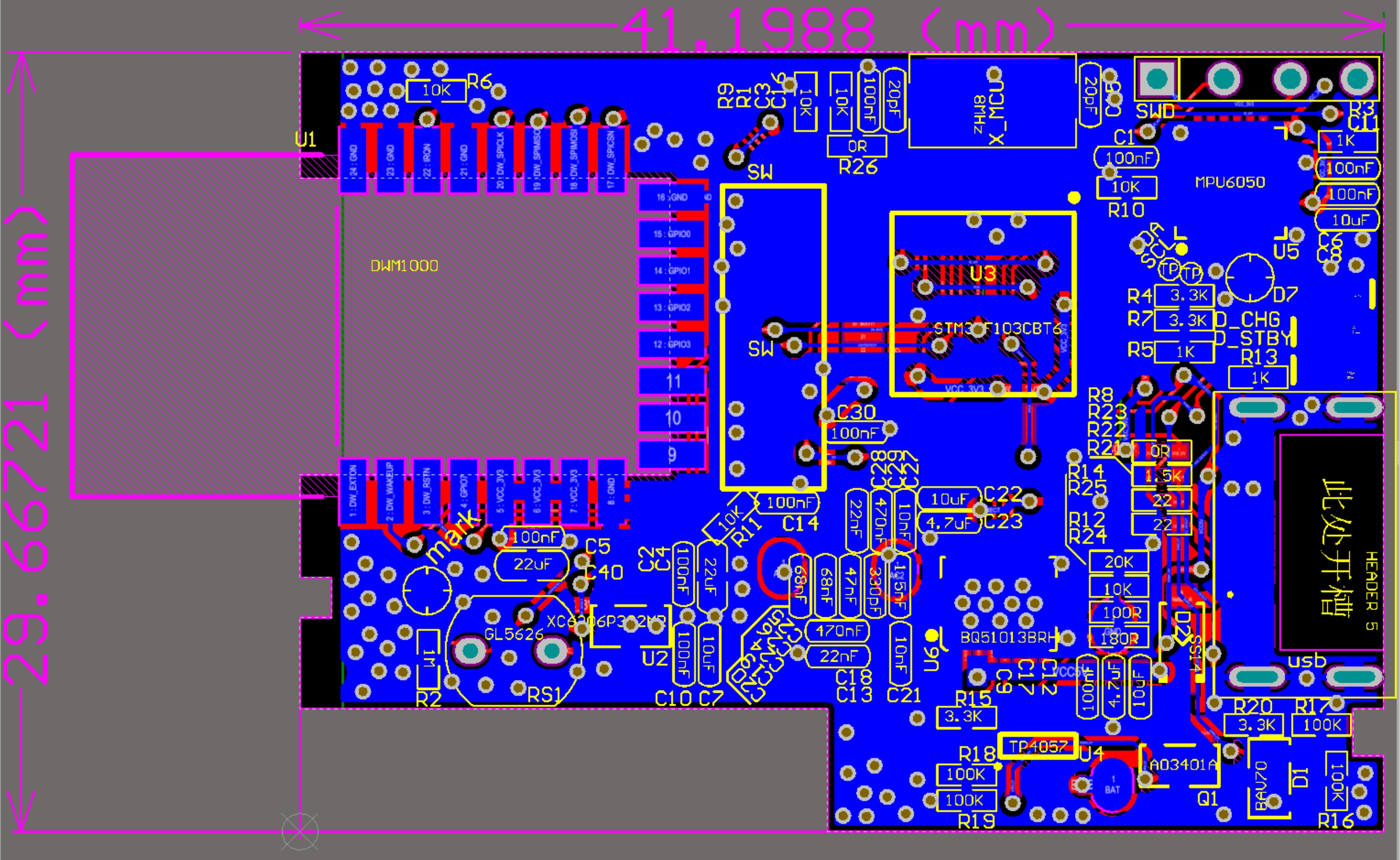 _RTLS Tag PCB 2D_
 _RTLS Tag's PCB 3D_
 _Tag PCBA physical photos_
 _The minimum power consumption of the tag reaches 13.3uA_
 _Use an oscilloscope to monitor the tag's current_
The lowest power consumption of the tag reaches 13.3uA, which is the current when the tag is in sleep state. We also used an oscilloscope to view the current draw during tag operation.
From the photos, you can clearly see several working processes of the tag: first it is in a sleep state, then the MCU wakes up and the current increases, the DW1000 wakes up and the current increases again, transmits UWB data packets (short time/high current), and sleeps again.
Here, the time between DW1000 waking up and launching is a bit long, which is waiting for DW1000 to enter a stable working state. It should be possible to shorten this wait and save some power.
It is also worth mentioning that because the name-card style tag is very thin, in order to save space, the DWM1000 is welded from the back. If you solder from the front, the PCBA should be higher.



Our name-card style tag has been revised dozens of times, and each time there will be some slight differences, but the basic circuit remains the same. These photos are for your reference.
The tag can also be made into a bracelet style.




We give customers OEM tags and install them on the car.
Anyway, the basic circuit is still the same. Therefore, after the firmware is written, it is basically compatible. One firmware is compatible with the tags of all models.
A customer wants to make a bracelet tag with a display. He plans to add OLED to display the time and some received messages, and also add a vibration motor. After some research, I found that STM32F103 is not enough.
To display messages, there must be Chinese characters, and then a Chinese character library must be obtained. The small Flash of STM32 will definitely not be able to fit it. The large Flash version of STM32 is difficult to buy and expensive.
I plan to use ESP32 as an MCU, and I can also add WiFi and Bluetooth support. Later, the client's project was stopped, and later, our project was also stopped, and we stopped working on it.
If you are using it commercially, it is recommended to use ESP32 as the MCU. It is best to replace the MCU of the anchor/tag with ESP32. In this way, they can be unified and the code can be reused. ESP32 is cheap and performs well, which is really a good thing.
_By the way, I'm looking for a job. Due to business reasons, the company was dissolved. I have 30+ years of work experience, 20+ years of experience in C/C++/Java/Delphi, and a little bit of Javascript/Python/Lua. In 199x, I wrote a Chinese character system in x86 assembly, and later used Delphi to write a mail server. I have written countless application systems, and the code I have written should exceed 2 million lines. 10+ years of hardware design experience, designing multiple embedded products. In the early stages of this UWB location system, the hardware and software were all developed by me alone, and the team was only built later. Base Guiyang, China, or remotely. If there are job opportunities, please contact me (bd8ncf@gmail.com) for a detailed resume._ | bd8ncf |
1,733,656 | Empowering Your Finances with Knowledge: Keeping Up with the Latest News | In today's fast-paced and ever-changing world, it is crucial to stay informed about the latest... | 0 | 2024-01-18T11:59:46 | https://dev.to/smestreet/empowering-your-finances-with-knowledge-keeping-up-with-the-latest-news-1oeo |

In today's fast-paced and ever-changing world, it is crucial to stay informed about the latest developments in the financial market. With constant fluctuations and trends, staying updated with [finance news](https://smestreet.in/finance) has become more important than ever before. Whether you are an individual investor, a business owner, or simply someone who wants to make smart financial decisions, keeping up with the latest news can greatly impact your financial well-being.
## Understanding the Impact of Finance News on Your Finances
Keeping up with the [latest financial news](https://smestreet.in/finance) can have a significant impact on your finances. In today's fast-paced and ever-changing market, being aware of current financial events is crucial for making informed decisions about your money.
One of the main benefits of following finance news is gaining insight into how global and national economic events can affect your investments, savings, and overall financial stability. By staying informed about market trends and fluctuations, you can make more strategic decisions when it comes to managing your assets.
Moreover, understanding the implications of finance news goes beyond just managing investments; it also plays a vital role in day-to-day financial activities such as budgeting and saving.
How to Analyze and Interpret Finance News
In today's fast-paced financial landscape, staying informed and up-to-date on the latest news is crucial for making well-informed decisions about your finances. With so much information available at our fingertips, it can be overwhelming to sift through all the financial news and understand what it means for our financial situations.
## Strategies for Incorporating Finance News into Your Financial
In today's fast-paced world, staying updated with the latest financial news is crucial for making informed financial decisions. The stock market, interest rates, and economic trends can all have a significant impact on our finances. However, it can be overwhelming to keep up with all the news and understand how it relates to our financial planning.
## Conclusion
Staying informed about [financial banking news](https://smestreet.in/finance) is crucial for the success and stability of your finances. By keeping up with the latest developments, trends, and changes in the financial world, you can make more informed decisions regarding your money.
One of the main reasons why it's important to stay informed about finance news is to protect yourself from potential financial pitfalls
| smestreet | |
1,733,752 | Tool Selection: Option of Many vis-a-vis Problem of Many | While having a programmable Infrastructure would assist in the adoption of a Dynamic environment for... | 0 | 2024-01-23T13:31:11 | https://dev.to/paihari/tool-selection-3o7n | cloudcomputing | While having a programmable Infrastructure would assist in the adoption of a Dynamic environment for Cloud Offerings/SaaS, such an undertaking is possible with a variety of open-source/service tools. Below are the list of such tools which covers mostly both end of the spectrum.
The major hurdle to pass for all in the journey is ["Problem of Many"](https://plato.stanford.edu/entries/problem-of-many/) by experimenting for a purpose, selecting from many, harnassing its value and adapting ...
## Identity and Access Management
1. [Ory Kratos](https://github.com/ory/kratos)
**Authn and Authz:** IDP Broker, User Management, Group Management
2. [Zitadel](https://github.com/zitadel)
**Authn and Authz:** IDP Broker, User Management, Group Management
3. [Evolveum Midpoint](https://evolveum.com/)
**Identity Governance**
4. [Aesir Kstone](https://www.kstone.net/)
**Authn and Authz:** Hierarchical template based User
5. [One Identity PAM/PSM](https://www.oneidentity.com/privileged-access-management/)
**Authn and Authz:** Privileged Access/Password Management
## Information Security
1. [Brinqa](https://www.brinqa.com/)
**Vulnerability Management:**
2. [Tenable](https://www.tenable.com/products/tenable-io)
**Vulnerability Management:**
3. [Sapora](https://www.saporo.io/)
**Identity Risk Management:**
4. [Cloudflare](https://www.cloudflare.com/)
**Internet Access and DNS:** Application Firewall, CDN, Proxy
5. [Splunk](https://www.splunk.com/en_us/products/enterprise-security.html)
**Security Information and Event Management**
6. [Adaptive Shield](https://www.adaptive-shield.com/)
**SaaS Security Posture Management:** Tool to Assess and Manage Security Posture of multliple SaaS solution
7. [Bolodon James Classifier](https://dataclassification.fortra.com/resources)
**Classification:** Classification of Application and Messages, Emails ...
8. [Proofpoint](https://www.proofpoint.com/us/observeit-is-now-proofpoint)
**Threat Management**
9. [Trellix McAfee Data Security](https://www.trellix.com/platform/data-security/)
**Data Loss Protection**
10. [Prisma Cloud Palo Alto](https://www.paloaltonetworks.com/prisma/cloud)
**Security Posture Management**
11. [Trufflehog](https://github.com/trufflesecurity/trufflehog)
**Secrets Management**
12. [Thinkst Canary](https://canary.tools/)
**Instrusion Detetection**
13. [Tuffin Security Track](https://www.tufin.com/tufin-orchestration-suite/securetrack)
**Hybrid Cloud Network Security**
14. [Netscout Arbor](https://www.netscout.com/arbor)
**DDOS Protection**
## Operations
1. [PagerDuty](https://www.pagerduty.com/)
**Operation Platform:**
2. [Apache Superset](https://superset.apache.org/)
**Data Exploration and Visualization**
3. [Prometheus](https://prometheus.io/)
**System Monitoring**
4. [Grafana](https://grafana.com/)
**Observability Platform**
5. [CloudQuery](https://www.cloudquery.io/)
**Monitoring Cloud Infrastructure**
## Engineering
1. [Terraform](https://www.terraform.io/)
**Cloud Infrastructure Provision**
2. [Gitlab](https://about.gitlab.com/)
**DevOps Platform and Source Control**
3. [Github](https://github.com)
**DevOps Platform and Source Control**
4. [Backtstage](https://backstage.io/)
**Developer Portal Platform**
5. [Tekton](https://tekton.dev/)
**Cloud Native CI/CD for Kubernetes artifacts**
6. [Kubevela](https://kubevela.io/)
**Hybrid Cloud Software Delivery Platform**
7. [ArgoCD](https://argo-cd.readthedocs.io/en/stable/)
**GitOps Kubernetes Software delivery Platform
8. [Windmill](https://www.windmill.dev/)
**Developer Platform for APIs, Workflows and Quick UIs**
9. [Supabase](https://supabase.com/)
**Developer Platform with state of art Database, Authentication, storage, Edge, Vector capabilities**
10.[Hasura](https://hasura.io/)
**Instant API Platform**
11.[Score](https://docs.score.dev/docs/)
**Tech agnostic Workload definition**
| paihari |
1,733,878 | LangChain: Framework for LLMs | What is LangChain? It is a framework which helps build LLM driven applications. One of the... | 0 | 2024-01-19T14:51:53 | https://dev.to/ajaykrupalk/langchain-framework-for-llms-5hjf | javascript, beginners, ai, learning | ## What is LangChain?
It is a framework which helps build LLM driven applications. One of the problems LangChain tries to solve is RAG or Retrieval Augmented Generation.
## RAG or Retrieval Augmented Generation
RAG is a model architecture utilized in certain LLMs. Once a user sends a query to the LLM, a **retriever** module selects all the related information to the query. The retrieved information is used as context for a **generator** module which **augments** the relevant response.
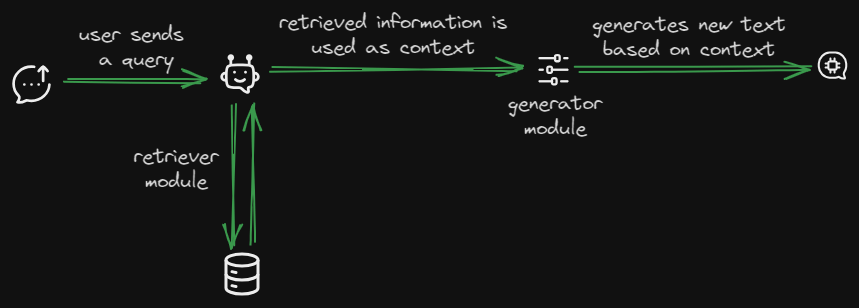
## Ingestion
Ingestion is the process of transforming the documents into numbers that computers can understand called vectors. The whole process includes:
1. **Loading the source document:** This is done with the help of loaders. The source documents can be PDF, CSV, JSON files or any other web source too.
2. **Splitting the data of the document into chunks:** This is done with the help of splitters. They split the data into smaller chunks.
3. **Converting each of those chunks into vectors:** The chunks are converted to vectors which are known as embeddings, which are then stored to the vector store.
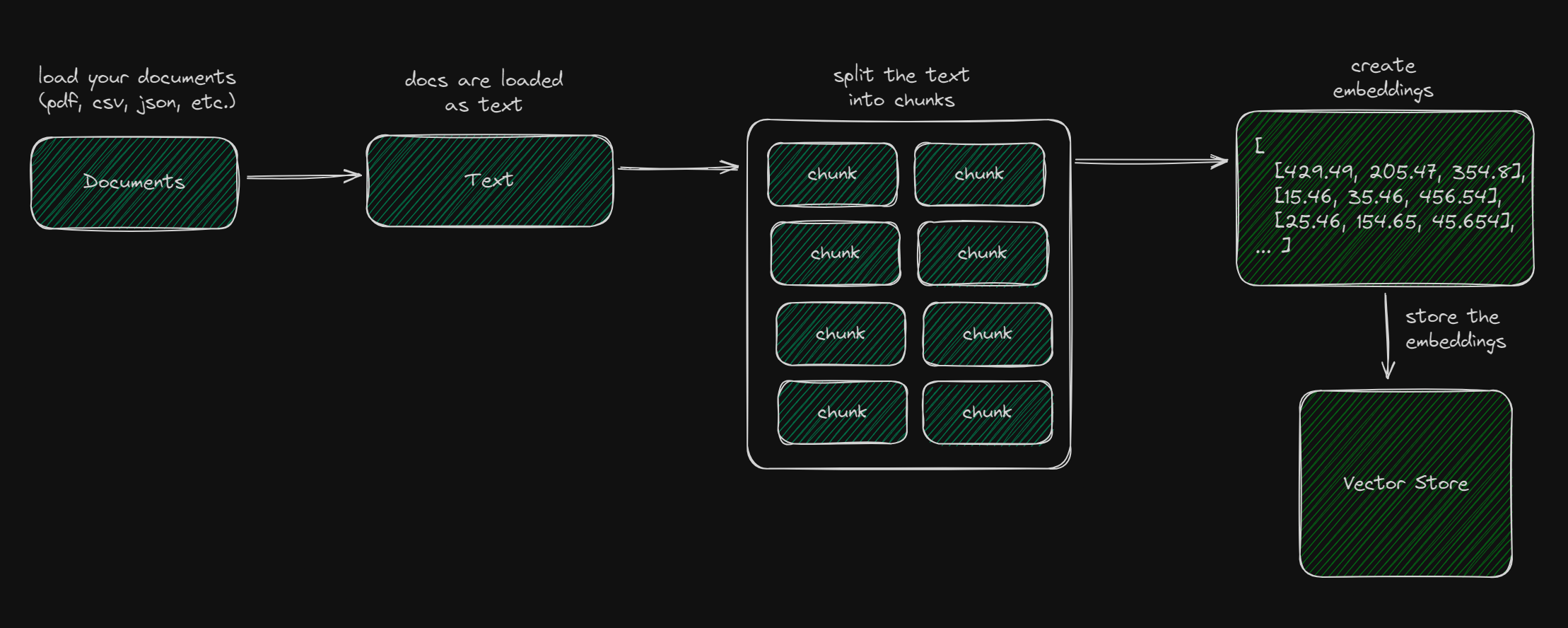
## What happens when you query the LLM?
Once the data is loaded and is stored into the vector store, when a user sends a query, behind the scenes the query gets converted into embeddings. The vector store is checked for similar vectors and are returned. The vectors are then converted into text as a response to the user.
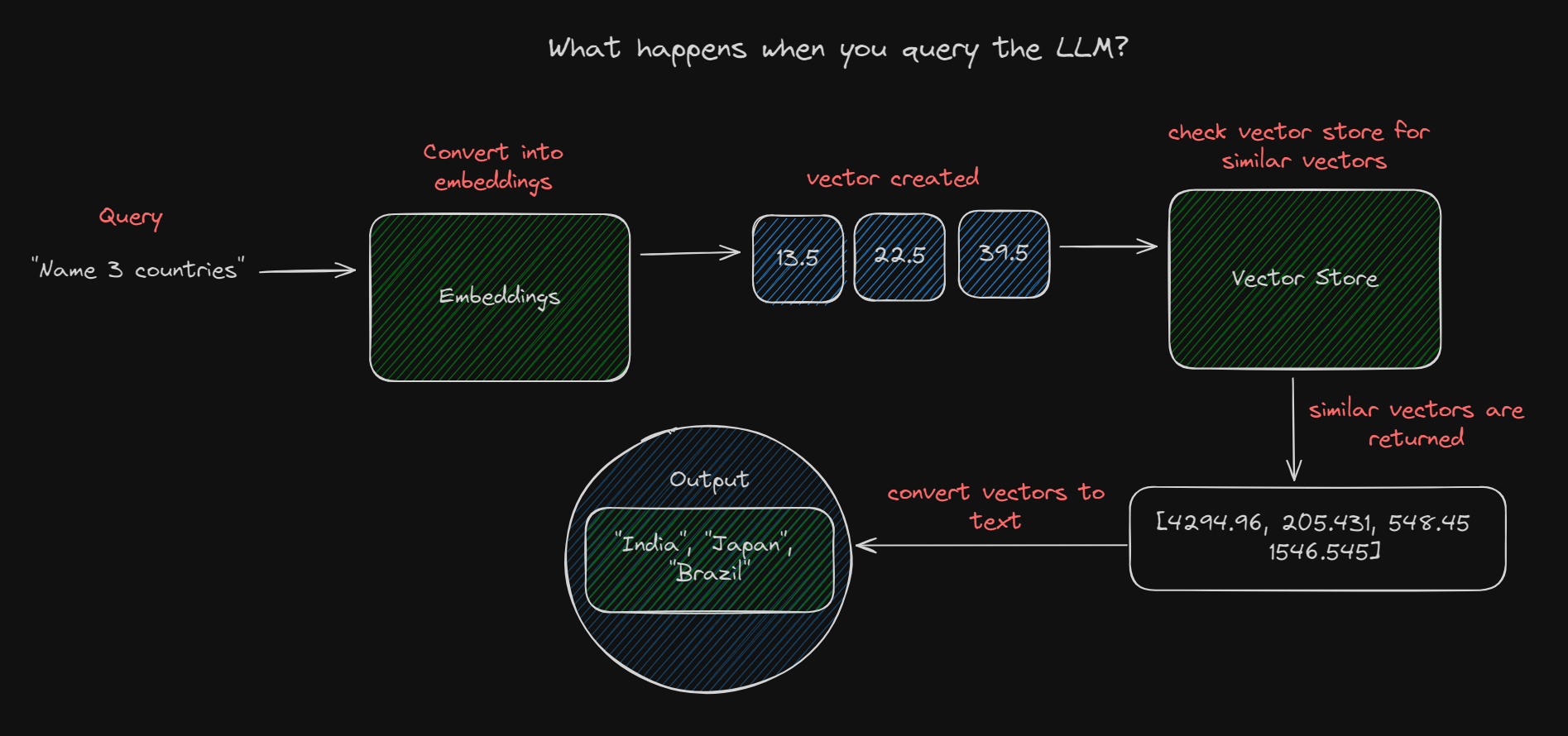
## Architecture of a chatbot in LangChain
In Langchain, one of the architectures of a chatbot that is followed is shown below. It is structured in such a way that it is able to handle follow-up questions.
Initially, the chat history and the new question is passed to the LLM. Then, the question is passed to the LLM and is asked to create a standalone question of the same. The relevant documents are also retrieved from the vector store. Now, both the relevant documents and standalone question, will be used by the LLM to generate a response to the user.
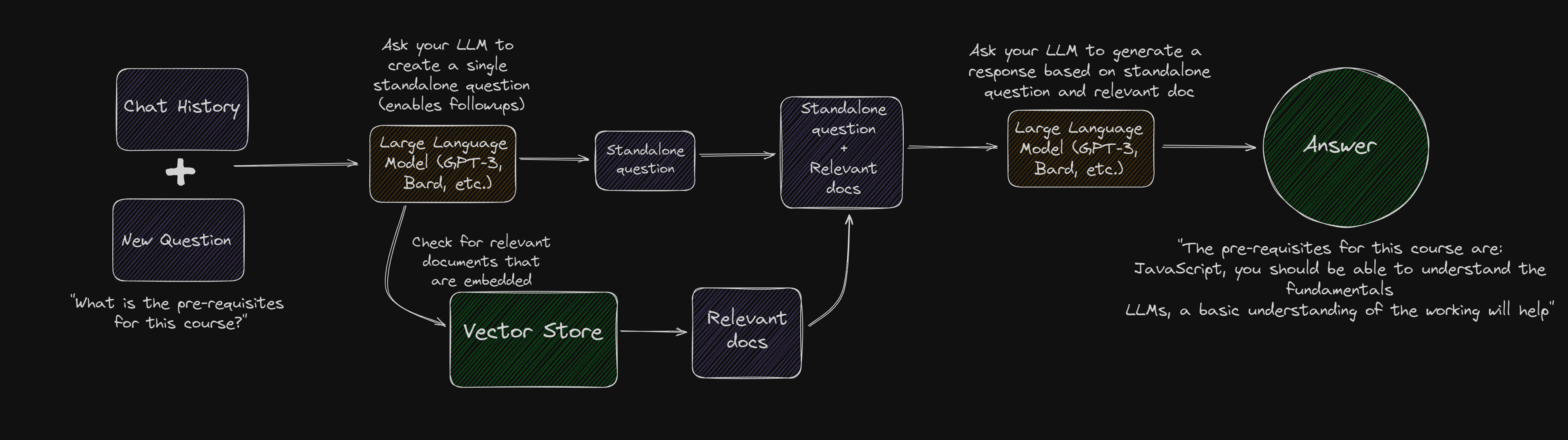
## Technical Terms
A few technical terms associated with LangChain:
- **Embedding:** Vector representations of text, that capture the semantic meaning of the text.
- **Runnable:** Allows you to run a set of runnables like model, prompt, parser, etc. in a pre-defined order.
- **Streaming:** Allows you to get the output chunk by chunk.
- **Batch:** Allows you to process multiple inputs efficiently in a batch or parallelized manner.
## Sources
LangChain Documentation: https://js.langchain.com/docs/get_started
LangChain YouTube Channel: https://youtu.be/AKsfHK_4tf4?si=ZEIlHWBp4Qfco3O-
> For more:
[Chatting with a PDF using LangChain - 1](https://dev.to/ajaykrupalk/langchainjs-chatting-with-a-pdf-h51)
[Chatting with a PDF using LangChain - 2](https://dev.to/ajaykrupalk/cont-langchainjs-chatting-with-a-pdf-42gk)
| ajaykrupalk |
1,734,252 | Panda: IA para debugging en base de datos. | Si trabajas o alguna vez has trabajado como administrador de base de datos (o de sistemas), sabrás... | 0 | 2024-01-22T21:05:08 | https://dev.to/rl0ur3s/panda-ia-para-debugging-en-base-de-datos-28nj | aws, ai, llm | Si trabajas o alguna vez has trabajado como administrador de base de datos (o de sistemas), sabrás que un proceso de debugging puede ser una tarea complicada. Un grupo de investigadores de AWS propone facilitar ese proceso mediante el uso de modelos de lenguaje natural en este [paper](https://www.amazon.science/publications/panda-performance-debugging-for-databases-using-llm-agents) que recomiendo que leas.
La propuesta es sencilla, porque no usar los modelos LLM para que nos ayuden en este tipo de tareas?. Seguro que has usado ChatGPT para alguna que otra incidencia, y seguramente también que las respuestas que has obtenido a pesar de ser ciertas (en algunos casos) son muy genéricas y triviales. Y aquí es donde los investigadores de AWS, ponen el foco en 2 limitaciones claves de los modelos pre-entrenados para este tipo de soluciones y como Panda haciendo uso de ellas puede ayudar a perfeccionar este tipo de consultas:
- El contexto.
- El análisis de datos multimodales.
Y es que estos dos puntos, en cualquier proceso de debugging son fundamentales para poder dar una posible solución coherente y fundamentada. Un problema en dos bases de datos distintas, sus causas probablemente tendrán contextos distintos. Incluso una misma base de datos, en dos momentos distintos en el tiempo, la causa raíz de un problema de rendimiento puede ser distinta. De ahí la importancia del contexto.
Y sí el contexto es importante, no menos es el análisis de datos multimodales, es decir, datos de distintas fuentes como registros, documentos de resolución de problemas o telemetría propia de la base de datos
Si analizamos esta imagen incluida en el paper entenderemos fácilmente estos dos conceptos.

Como se puede observar en la imagen, ante una pregunta de un problema de rendimiento en un base de datos Aurora y que se observa un gran número de sesiones en waiting. La respuesta de un modelo GPT4 sin contexto y sin datos multimodales, se basa prácticamente en una serie de buenas practicas a seguir que no aportan mucho valor en este tipo de situaciones. En cambio Panda, consigue integrar datos de diversas fuentes, para construir un contexto multi-modal antes de generar las recomendaciones.
## **Arquitectura**
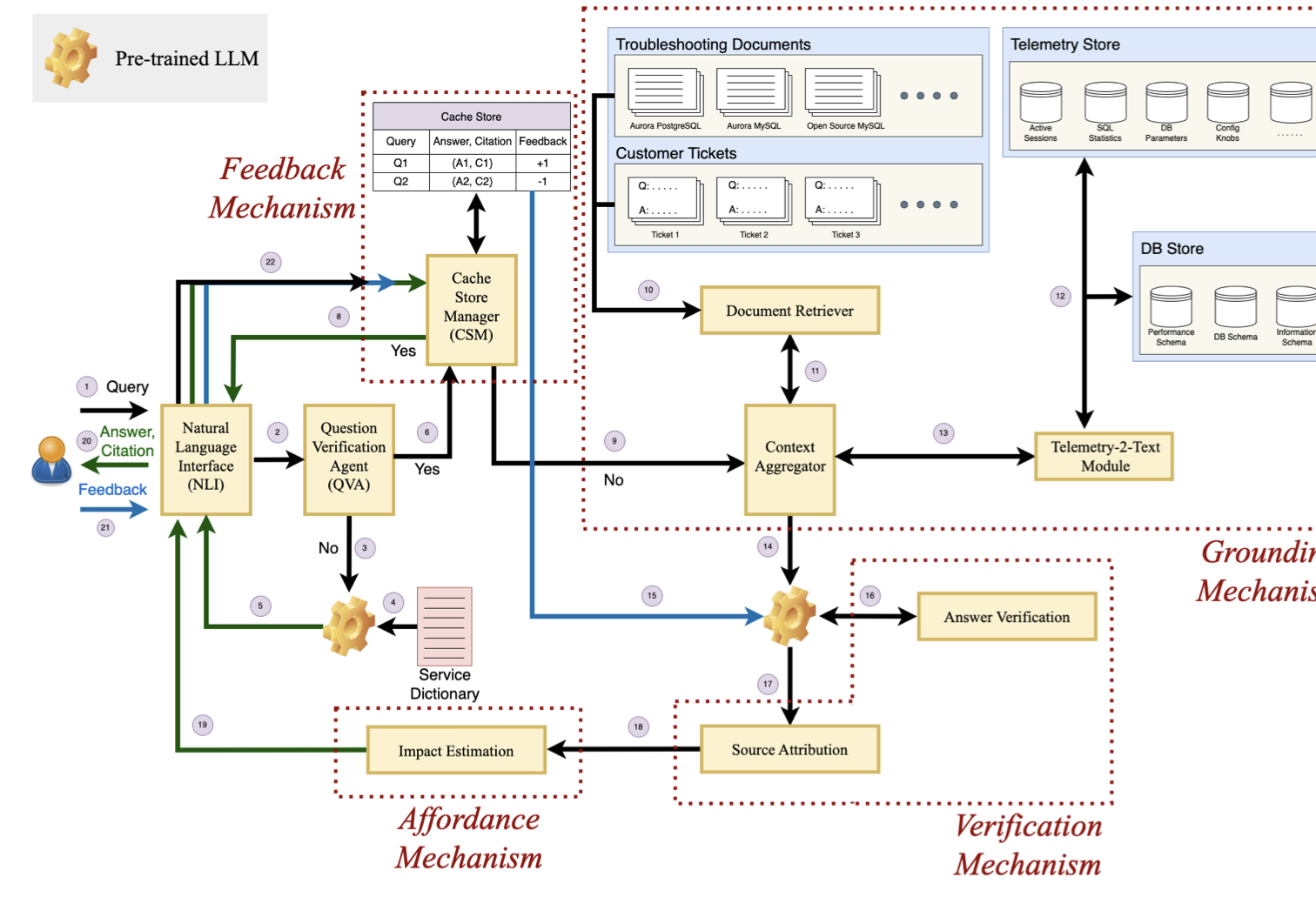
Su arquitectura se basa en una serie de componentes para alcanzar el objetivo final que es proporcionar recomendaciones especificas para el debugging en bases de datos:
**1. Question Verification Agent(QVA)**: Básicamente es un filtro para identificar y rechazar consultas irrelevantes, proporcionando una etiqueta binaria(Si o No) y se apoya en el modelo RAG para sugerir un servicio o herramienta especifica.
**2. Grounding Mechanism**: Su función es integrar información de distintas fuentes como documentos de resolución de problemas, tickets, "best practices" consiguiendo así un contexto global. Este mecanismo genera otro contexto local que se logra con datos de la propia base de datos con métricas de la misma. Con ambos contexto se busca entender el problema y dar una solución útil.
**3. Feedback Mechanism**: Mediante un almacén de cache y respuestas binarias al usuario, se consigue una retroalimentación que mejora la respuestas con el tiempo.
**4. Verification Mechanism**: Panda usa modelos LLM precio-entrenados como verificador y añaden fuentes a las respuesta que ha generado, mejorando la confiabilidad.
**5. Affordance Mechanism**: El objetivo es que ante un cambio propuesto el usuario obtenga una estimación del impacto, resaltando las acciones de alto riesgo. Panda en esta versión lo orienta desde un punto más genérico (menos preciso).
Como se puede observar, la propuesta de los investigadores de AWS es muy interesante desde el punto de vista de nuevos casos de usos que muestran posibles casos prácticos en el uso de modelos LLM, así como el desarrollo de estas soluciones y su aplicación con nuevas arquitecturas. Desde luego, este tipo de soluciones es muy a tener en cuenta, ya que abren nuevos caminos en el desarrollo de nuevas soluciones en inteligencia artificial. | rl0ur3s |
1,734,267 | How to Serve LLM Completions in Production | Preparations To start, you need to compile llama.cpp. You can follow their README for... | 26,124 | 2024-01-18T21:19:26 | https://resonance.distantmagic.com/tutorials/connect-to-llama-cpp/ | webdev, ai, php | ## Preparations
To start, you need to compile [llama.cpp](https://github.com/ggerganov/llama.cpp). You can follow their [README](https://github.com/ggerganov/llama.cpp/blob/master/README.md) for instructions.
The server is compiled alongside other targets by default.
Once you have the server running, we can continue. We will use PHP Resonance framework.
## Troubleshooting
### Obtaining Open-Source LLM
I recommend starting either with [llama2](https://ai.meta.com/llama/) or [Mistral](https://mistral.ai/). You need to download the pretrained weights and convert them into GGUF format before they can be used with [llama.cpp](https://github.com/ggerganov/llama.cpp).
### Starting Server Without a GPU
[llama.cpp](https://github.com/ggerganov/llama.cpp) supports CPU-only setups, so you don't have to do any additional configuration. It will be slow, but you will still have tokens generated.
### Running With a Low VRAM Memory
You can try quantization if you don't have enough VRAM on your GPU to run a specific model. That lowers the response quality and the memory the model needs to use. Llama.cpp has a utility to quantize models:
```shell
$ ./quantize ./models/7B/ggml-model-f16.gguf ./models/7B/ggml-model-q4_0.gguf q4_0
```
10GB of VRAM is enough to run most quantized models.
## Starting llama.cpp Server
While writing this tutorial, I had a server started with a command:
```shell
$ ./server
--model ~/llama-2-7b-chat/ggml-model-q4_0.gguf
--n-gpu-layers 200000
--ctx-size 2048
--parallel 8
--cont-batching
--mlock
--port 8081
```
`cont-batching` parameter is essential, because it enables continuous batching, which is an optimization technique that allows parallel request.
Without it, even with multiple `parallel` slots, the server could answer to only one request at a time. `cont-batching` allows the server to respond to multiple completion requests in parallel.
## Configuring Resonance
All you need to do is add a configuration section that specifies the llama.cpp server location:
```ini
[llamacpp]
host = 127.0.0.1
port = 8081
```
## Testing
Resonance has built-in commands that connect to llama.cpp and issue requests.
You can send a sample prompt through `llamacpp:completion`:
```shell
$ php ./bin/resonance.php llamacpp:completion "How to write a 'Hello, world' in PHP?"
To write a "Hello, world" in PHP, you can use the following code:
<?php
echo "Hello, world!";
?>
This will produce a simple "Hello, world!" message when executed.
```
## Programmatic Use
In your class, you need to use [Dependency Injection](https://resonance.distantmagic.com/docs/features/dependency-injection/) to inject `LlamaCppClient`:
```php
<?php
namespace App;
use Distantmagic\Resonance\LlamaCppClient;
use Distantmagic\Resonance\LlamaCppCompletionRequest;
#[Singleton]
class LlamaCppGenerate
{
public function __construct(protected LlamaCppClient $llamaCppClient)
{
}
public function doSomething(): void
{
$request = new LlamaCppCompletionRequest('How to make a cat happy?');
$completion = $this->llamaCppClient->generateCompletion($request);
// each token is a chunk of text, usually few-several letters returned
// from the model you are using
foreach ($completion as $token) {
swoole_error_log(SWOOLE_LOG_DEBUG, (string) $token);
if ($token->isLast) {
// ...do something else
}
}
}
}
```
## Summary
In this tutorial, we went through how to start [llama.cpp](https://github.com/ggerganov/llama.cpp) server and connect to it with Resonance.
---
If you like Resonance, check us out on GitHub and give us a star! :)
https://github.com/distantmagic/resonance
| mcharytoniuk |
1,734,286 | (Part 4/4): Confluent Cloud (Managed Kafka as a Service) - What is a Connector & How to create Custom Connectors | In this podcast, Krish explores the various connectors available in Confluent Cloud. He starts by... | 0 | 2024-01-18T21:48:17 | https://dev.to/vpalania/part-4n-confluent-cloud-managed-kafka-as-a-service-what-is-a-connector-how-to-create-custom-connectors-3m21 | In this podcast, Krish explores the various connectors available in Confluent Cloud. He starts by recapping the previous podcasts and the basics of Confluent Cloud. Krish then focuses on connectors, explaining their value and why they can reduce the need for writing code. He explores different connectors, such as the data gen source connector and the MongoDB Atlas connectors. Krish also discusses different data formats, including Avro, Protobuf, and JSON. He briefly touches on implementing custom connectors. Krish explores the topic of connectors in Confluent Cloud. He discusses the process of creating connectors and the different types of connectors available. Krish also delves into configuring connectors and defining configuration parameters. He explores the concept of custom connector configuration and the use of connector properties files. Krish then explores existing connectors, such as the HTTP source and sync connectors, and discusses the process of publishing custom connectors. He concludes by mentioning the Confluent CLI for managing connectors.
## Takeaways
- Connectors in Confluent Cloud provide value by reducing the need for writing code.
- Different connectors are available for various data sources and destinations, such as MongoDB, Amazon S3, and Elasticsearch.
- Data formats like Avro, Protobuf, and JSON can be used with connectors.
- Implementing custom connectors allows for more flexibility and integration with specific systems.
- Connectors enable seamless data integration and propagation between different systems. Connectors in Confluent Cloud allow for seamless integration with various systems and services.
- Custom connectors can be created and published to Confluent Cloud.
- Configuration parameters for connectors can be defined and managed.
- The Confluent CLI provides a command-line interface for managing connectors.
## Chapters
00:00 Introduction
00:35 Recap of Previous Podcasts
01:05 Focus on Connectors in Confluent Cloud
02:16 Exploring Data Gen Source Connector
03:43 Different Formats: Avro, Protobuf, JSON
08:07 Differences Between Avro and Protobuf
10:03 Exploring Other Connectors
11:14 Using MongoDB Atlas Connectors
12:08 Testing Different Formats with Connectors
13:36 Handling Avro Format with Consumer
16:58 Exploring More Connectors: Snowflake, Amazon S3, Elasticsearch
20:33 Implementing Custom Connectors
27:31 Exploring More Connectors: Salesforce, Oracle, Jira
35:16 Exploring More Connectors: SQL Server, MySQL
38:43 Implementing Custom Connectors
43:24 Exploring More Connectors: Kafka, File
46:20 Understanding Connector Implementation
49:06 Creating Custom Connectors
50:00 Summary and Conclusion
50:59 Creating Connectors
52:04 Configuring Connectors
54:00 Custom Connector Configuration
56:08 Defining Configuration Parameters
57:38 Configuration Properties
59:49 Self-Managed Connectors
01:00:27 Connector Properties File
01:01:28 Creating Custom Connectors
01:02:09 Publishing Custom Connectors
01:03:37 Existing Connectors
01:04:14 HTTP Source Connector
01:06:40 HTTP Sync Connector
01:08:34 Other Connectors
01:10:34 Managing Connectors
01:12:14 Confluent CLI
## Video
{% embed https://youtu.be/k5D14TO_nPY %}
## Transcript
https://products.snowpal.com/api/v1/file/7be7f034-0511-48b0-9a00-d7fa9f243d2f.pdf | vpalania | |
1,734,385 | Modernizing Authentication for Enterprise Applications | In an era filled with data breaches and cyber threats, enterprise application security has never been... | 0 | 2024-01-20T01:50:23 | https://www.datawiza.com/blog/industry/modernizing-authentication-for-enterprise-applications/ | blog, industry | ---
title: Modernizing Authentication for Enterprise Applications
published: true
date: 2024-01-19 00:03:17 UTC
tags: Blog,Industry
canonical_url: https://www.datawiza.com/blog/industry/modernizing-authentication-for-enterprise-applications/
---
In an era filled with data breaches and cyber threats, enterprise application security has never been more critical. Unfortunately, many applications still hold onto legacy authentication methods, which lack both adequate security measures and user-friendliness. With the evident urgency to shift towards secure authentication methods, modernizing has become the need of the hour.
## Embracing Modern Authentication Technologies
The world is witnessing a much-needed shift towards innovative, modern authentication technologies that bolster security and improve the user experience. These technologies are shaping the future of enterprise application security.
### Single Sign-On (SSO)
This user-friendly solution allows individuals to access multiple applications using the same set of credentials. With SSO, user experiences are simplified, reducing the risk of security breaches due to forgotten passwords.
### Multi-Factor Authentication (MFA)
MFA boosts security by requiring users to provide at least two forms of valid identification. With MFA, enterprises can heighten their defense, ensuring that a compromise of one level of security doesn’t put the entire system at risk.
### Passwordless
Passwordless technology, being lauded as the future of secure authentication, ditches passwords entirely. By using biometrics, hardware tokens, or one-time PINs for validation, this technology offers a secure, user-friendly system.
## The Roadblocks to Modernization: Upgrading Legacy Systems
While the need to switch to modern authentication methods is evident, the transition comes with significant challenges.
### Modernizing Homegrown LoB Applications
Homegrown Line of Business (LoB) applications, especially those developed over a decade ago, become a considerable bottleneck in the modernization process. Modernizing these applications to incorporate secure authentication methods could span over several months per application.
### Constraints of Off-the-Shelf Applications
For businesses using off-the-shelf applications like Oracle PeopleSoft, EBS, JDE, Siebel, the freedom to revise and upgrade the authentication mechanisms is limited. The original codification of these systems doesn’t usually support security advancements, leaving enterprises grappling with outdated security measures.
### Disruptions to Operational Continuity
A major concern while transitioning from legacy systems to more secure authentication methods is the potential disruption to operational continuity. Attempts to integrate modern authentication technologies carry a risk of affecting the application’s core functions. Even minor glitches can interrupt business operations, leading to increased downtime, loss of productivity, and potential revenue losses.
## Accelerating Toward Modern Authentication
Modernizing authentication methods for enterprise applications indeed pose meaningful challenges. Nonetheless, the advent of modern authentication technologies like SSO, MFA, and Passwordless make this endeavor crucial. These technologies promise improved security, a seamless user experience, and enhanced operational efficiency, valuable assets in today’s increasingly digital age.
Despite the hurdles that lie between enterprises and modern authentication, the landscape is rapidly changing. With innovative solutions emerging, like the [Datawiza No-Code Platform](https://www.datawiza.com/platform/), we are already experiencing an acceleration in the pace of authentication modernization. Consequently, adopting such advancements is not just an option—it’s an imperative strategy for securing applications and data.
The journey towards modern authentication might appear daunting initially, but the destination offers greater security and peace of mind. So, as we step into a future ripe with potential, the accelerating pace of modernization brings renewed hope for businesses navigating the complex landscape of enterprise application security.
The post [Modernizing Authentication for Enterprise Applications](https://www.datawiza.com/blog/industry/modernizing-authentication-for-enterprise-applications/) appeared first on [Datawiza](https://www.datawiza.com). | cjddww |
1,734,464 | Provident Botanico | Tucked away in the quiet neighborhood of Whitefield, on Soukya Road in East Bangalore, Provident... | 0 | 2024-01-19T04:08:07 | https://dev.to/nikkiharris/provident-botanico-2amh | providentbotanico, bengaluru, apartments, flats | Tucked away in the quiet neighborhood of Whitefield, on Soukya Road in East Bangalore, [Provident Botanico](https://www.providentbotanico.org.in/) stands out as an example of opulent living among contemporary apartment buildings. Covering an impressive 14 acres, this Garden-themed retreat is made up of nine tall [buildings](https://community.tableau.com/s/profile/0058b00000I2fMx) that are redefining high-rise living. Offering an array of opulent apartments, the project is pleased to showcase more than 1100 finely designed units, which come in 2 and 3 BHK layouts and range in size from 950 to 1500 square feet. Over 70% of the project area is devoted to open spaces as part of a dedication to green spaces, providing a charming setting for a fulfilling life in the center of Bangalore City.
 | nikkiharris |
1,734,470 | FREE CONFERENCE WITH JAM.DEV | This month, I am joining a conference JAM.DEV CONFERENCE on JANuary 24TH-25TH. According to James... | 0 | 2024-01-19T04:40:03 | https://dev.to/jeffchavez_dev/free-conference-with-jamdev-2j60 | conference, javascript, jamstack | This month, I am joining a conference **JAM.DEV CONFERENCE on JANuary 24TH-25TH**. According to James Quick's newsletter,
> The top experts in building for the web to tell you what you need to know…and it’s completely free! Join us on January 24-25 for two full days of amazing speakers!
> I'll be speaking about Developer Experience and why Astro is my favorite framework right now!
I am excited. I have registered and you can register [here](https://www.crowdcast.io/c/thejamdev?utm_source=podia&utm_medium=broadcast&utm_campaign=1785086) for free.

Let's go!
To God be the glory!
| jeffchavez_dev |
1,734,473 | Design thinking in UX/UI design | To make a profitable product, it needs to solve the right problem for the right audience. We... | 0 | 2024-01-19T04:54:38 | https://dev.to/preetham02/design-thinking-in-uxui-design-2kaf | webdev, design, uiuxdesignservices | To make a profitable product, it needs to solve the right problem for the right audience. We understand, as a startup founder, you may be a bit biased with your idea. And that’s ok. Design thinking and a bit of common sense will come to the rescue.
Contrary to a common misconception, design is not really about design. It’s used as a solution driving force by [UI UX Design services](https://www.sparkouttech.com/ui-ux-development/) agencies in the business, healthcare, finance, etc. However, as we’re designers who often work in different domains, we’ll talk about what design thinking actually has in common with design. Especially, considering the design disciplines are changing their focus from the objects of design (old) to the purpose of designing (new).
Design thinking is about problem-solving.
Design – isn’t just pretty visuals, but rather heavy problem-solving.
In order to find the most effective and reliable way to solve a design issue you’ll be conducting a user-research and define what is the right problem (sometimes it may be different from what you or your customer expects it to be) and once the real issue is completely clarified you can follow the next steps to solve it:
Define the pain points;
Generate ideas on how to overcome the obstacles;
Create the prototype;
Test it.
Why is design thinking important?
Globally speaking, because it’s a way of transforming your users’ lives for the better.
Design thinking contains 5 steps that cure users’ real pain points with the help of human-centered design.
Originally, the design thinking concept was formalized to help creative professionals understand business better, and to help businessmen leverage the creative process better.
This procedure isn’t fully linear. Using trial and error you may want to return to a certain phase and repeat it. Oftentimes, you gain a deeper understanding of what you’re actually doing. At the end of the day, you reach an outcome that satisfies the user's needs and solves his/her problem or satisfies a desire. Otherwise, why else would people be your clients?
The design thinking methodology allows to answer the daily questions like ‘how to develop a unique business concept?’, ‘what solution is the best for my new business partner?’, ‘how to develop my MVP in the shortest terms?’, ‘how to cut on the estimation time?’, ‘how to accelerate the development process?’ and many, many others.
What’s obvious to one person, can be absolutely not noticed by another.
That’s why it’s crucial that the teams involved in the design thinking process are multidisciplinary. It allows you to get as many points of view from as many different perspectives as possible. Now you can see the problem from an unbiased angle (with a fresh eye).
Phases of design thinking
Let’s quickly go over what you need to know about the 5 key design thinking phases. Referencing to d.school in Stanford University these are:
Empathize;
Define;
Ideate;
Prototype;
Test;
Design thinking in UX/UI design - phases_bg - Qubstudio
For a better understanding, let’s consider each one in detail. However, let’s keep in mind that if at any stage one of the steps fails, they can go parallel or repeat.
1. Empathize
You are not your target audience.
How often do designers design for designers?
That’s why your or your designers’ assumptions based on your vision of problems might not be 100% relevant.
That’s why empathy is the heart of human-centered design. Doing any [UI UX design services](https://www.sparkouttech.com/ui-ux-development/) without it makes pretty much no sense.
You can have empathy as the ability to stick your eyes to any subject or person. For example, if you were the driver, empathizing would mean seeing the world as if you were a passenger, wheel, car radio, seat, air conditioner, etc.
You’ll move away from your own assumptions and start understanding the user and concentrating on their experiences, especially emotional ones.
The other crucial aspect of the empathy phase is to find your user and get (find/receive) as much data as possible. By running data-driven decisions, you’ll make better conclusions about what people are doing, why and learn about their emotional and physical needs.
The following hints will help you instantly get closer to your users:
In-depth interviews – talk to a target audience representative in an informal atmosphere. Encourage stories, ask open-ended questions, ask ‘why?’, dig for emotions.
Observe people in their natural environment. Open or hidden, keep in mind, when people don’t know they’re being observed, they calmly play and behave as usual. You can apply the ‘one day of life’ observation method. Long story short, you ask a person to record every hour everything that happens to him/her.
Diving in their environment to try to experience yourself. For example, how we talk about how we buy products and how we actually behave in a supermarket are different things:
Guided tour: Literally intrude into the user's life and observe his/her home or workplace (or another environment) of the person you’re designing for can reveal true user behavior, habits and values.
Service safari: People are asked to go out ‘into the wild’ and explore examples of what they think good and bad service experiences are.
Walk in their shoes: Try your end-user experience by yourself, eat where they eat, spend what they spent, live how they. Use limits they are experiencing. Record all the data with a photo or video camera.
Understanding your users is key to innovation.
Alright, we’ve gained the data about users. We know, understand and even feel them. So what?
It’s time to define the problem and pain these users are trying to solve.
2. Define
The next stage of Design Thinking is ‘Define the problem’. You need to collect and process all the information you have received in the previous step. It’s time to analyze all the data collected from observations and interviews.
The main value of this stage is to form questions (challenge). Just think of need as a verb, not a noun. There are three types of needs: Explicit needs, Implicit needs, Needs’ meaning. To get answers that reflect reality, make sure you spend time thinking through your questions thoroughly. The way people answer questions is pretty much determined by the questions asked.
In order to identify the problem correctly, it is necessary to process the received information in the following order:
Write down all the problems on the stickers. One sticker – one problem which was announced by your user (hang everything on the wall or on the board).
After identifying all the problems it is necessary to group it by a similar symptom (insight), provide a title for each group and figure out the connections between them.
Identify critical problems, ‘pain points’ as room for improvement.
Vote to identify the problems you will try to solve.
After the definition of the problem, the next step would be creating user persona goal oriented, pay attention to insights which you received during the interview.
Next thing is to work out the case ‘point of view’.
Here are some examples of how we create it:
First sight:
User: Alexa
Need: buy a present
Insight: an important date is coming soon and she needs a gift
Real purpose:
User: A young doctor who spends most of her time on work or studying
Need: do something nice for someone special
Insight: she loves a person who needs to buy a gift for but she is a very busy person and doesn’t have enough time to search for a really nice gift.
Create a POV using a simple formula:
Use it to capture and harmonize 3 key elements of a POV: user, need, and insight.
And now it’s time to ask a question. So you choose the problem and rehash it into the question. Ask yourself ‘How may we?’ – how can we help? Then include the user in your phrasing.
How May/Can We help Alexa to buy a present in one click (fast)?
Advantages:
Human-centered
Broad enough to keep it creative
Narrow enough to make it manageable
After forming the right question, you are ready to move to the next step.
3. Ideate
After two previous stages, you can move on with idea generation.
This is the phase where we switch from learning about users and problems to generating solutions for them.
The following tools can help you move forward in this stage: Brainwriting, Worst Possible Idea, and SCAMPER. We’re gonna use Brainstorming (ed. mostly because the article author loves this method the most).
Before starting with this methodology, you need to remember the following rules:
Say ‘No’ to judgment (DONT KILL AN IDEA).
Say ‘Yes’ to the wildest ideas.
Build your idea over ideas of others (Yes, and…)
Go for quantity.
Make one conversation at the time.
Don’t forget to visualize each idea.
Ditch obvious, generic and obvious ideas.
Start with group generation (20-30 min). Put all the ideas on the stickers. Take 10-15 min to do individual work. Make participants use this time to generate 2 maybe 3 more ideas. See more: IDEO.org’s Brainstorms Rules.
At a certain point our brain can stop distinguishing good ideas from bad. So it’s time to use the collective mind.
Once you’re done with idea generation (meaning: neither you or your team will be able to invent at least one more, even at gunpoint) it’s time to choose the one to process during next steps. To identify viable ideas, they need to be filtered, so the best way is to allow everyone to vote (each member of the team must have 3 votes).
4. Prototype
A simple prototype can do so much.
Why do you need it? Think of this as MVP for MVP. Fail fast and learn quickly. There is no need to spend a lot of time and money on the implementation, just to discover that your assumptions don’t work. Don’t postpone the process until it’s too late and too expensive to fail. Follow the rule – ‘five minutes and a few cents’. You’re learning fastest by doing.
In order to create an interface prototype you can use:
paper to a wireframe by hand
live prototype using additional programs
vector prototype using the Sketch.
Here’s another rule of thumb – your prototype should not need a software developer.
Moreover, your creative process is not limited at all. You can also use many other materials:
cardboard or paper model;
storyboard (draw a step-by-step usage scenario).
5. Test
This is the last step, and the best solution is to test your prototype on the same people you have interviewed in the Empathy phase.
It’s crucial that you collect the feedback from real people who are using or are going to use your solution. And adequately react to it (which isn’t that easy, if you’re not a robot).
The feedback perception rules are as follows:
don’t sell
don’t defend
ask ‘why?’
notice everything.
You can try to give the users a task or simply show them a prototype and follow their actions.
The main task is to understand if there is something that really affects a person and if so, you can start with MVP implementation. Once the first version is ready you can start over with a more detailed and deeper testing. Still, you need to understand (and be mentally ready:) This step can bring you back to the idea’ generation phase if your MVP wasn’t really helpful enough to your users.
Iterations are the basis of good [UI UX design services](https://www.sparkouttech.com/ui-ux-development/). Therefore, you’ll probably need to repeat the entire design thinking process or its individual stages.
Design Thinking and ‘Outside the Box’ Thinking, is it the same?
According to the design thinking approach, we must question our knowledge continuously. Such a method enables redefining problems, finding alternative strategies and ways out. As a result, new solutions appear that contribute to both business and personal improvement.
The definition of ‘design thinking’ is often associated with thinking ‘outside the box’. And really, in both cases, the specialists strive to develop new concepts and cognitive methods in order to invent better problem-solving methods.
For example, ‘thinking outside the box’ as an element of design thinking can be mentioned in the work of an artist. The creative people keep on developing their drawing skills, analyzing the outcome, and watching how their creations impact human minds.
The goal is to provide the best solution after:
You analyze the way users interact with it;
Investigate the conditions the product will work in;
Dive deeper into user impressions;
Constantly improve the user experience.
All in all, ‘outside the box’ thinking is simply one of the methods employed by design thinking.
How you can apply design thinking in everyday life (examples with explanations)
Design thinking in UI UX design services - Workshop illustration_bg - Qub Studio
If you implement design thinking to your daily life it will be much easier for you to use it for your business.
Be human-centric
In your daily routines, think of humans first. For example, each time you plan your visit to your parents, think of what they would like to hear from you and build a conversation in such a way.
Exercise your memory
Our mind capabilities are limitless. Try various trainers for memory, read the professional literature, extend your contacts, and communicate with different people. Enhance your way of thinking.
Redesign the world around you
All of us need some changes in our lives. Start from the basic things. Add some new colors to your wardrobe, redesign your apartment, visit a new country and take a look at some new landscapes and places. Something unusual and interesting happens everyday and every minute, just don’t be too lazy to look for it.
Use Prototyping
Before making the weighty life choices, build the imaginable ‘prototype’, visualize the consequences. Build the user journey (in this case – your own journey) and try to estimate the potential risks.
| preetham02 |
1,734,551 | Mobile Application Development for Startups | Mobile applications have become a fundamental tool for startups looking to improve their online... | 0 | 2024-01-19T05:44:04 | https://dev.to/pryanka46/mobile-application-development-for-startups-1l5f | mobile, development, application, startup | Mobile applications have become a fundamental tool for startups looking to improve their online presence and reach new customers. However, creating a successful solution is not an easy task and requires a careful process that takes into account resource optimization, time management, and project scalability.

At Sparkout, as a leading **[mobile app development company](https://www.sparkouttech.com/mobile-application-development/)**, we specialize in constructing tailored applications for startups, following a working methodology that places the utmost priority on meeting our client's needs. Recognizing the significance of time and resources in startup projects, our approach emphasizes the delivery of swift yet scalable solutions. Our dedicated team at Sparkout is committed to creating mobile applications that not only meet your specific requirements but also ensure a rapid time-to-market. With a focus on speed, scalability, and client satisfaction, we strive to be your trusted partner in navigating the dynamic landscape of mobile app development for startups.
For this reason, in this article, we will share the key steps to make the process of ideation, design, and development as efficient as possible:
**Step 1: Identify the Purpose of the Tool**
The first step is to identify the need that the application will fulfill. It is important to guide the teams that come to us to shape and give meaning to their ideas. Therefore, they must have clear answers to these questions: What problem does their application solve? What competitive advantage do they have compared to others? This way, we start thinking about the functionalities that the application will have.
**Step 2: Map and Design**
Functional design is a process that must be carefully planned. The most important thing is to work together with the design and development team to define the main characteristics of the application, the functions it will offer, the user experience that is desired, the interface design, and the information architecture. At this point, the first Minimum Viable Product (MVP) and its scope are also defined.
**Step 3: Define the Operating System**
Once the application’s functions have been defined, it is time to choose the appropriate platform for its development. TAM works with the major mobile operating systems, including iOS and Android, to provide entrepreneurs with the best option for their goals and budget.
**Step 4: Design and Develop the Application**
Before starting development, it is important to carefully review the prototypes that the design team has built to verify that the functions, flows, and interface align with the business objectives. This process should be iterative, meaning that tests and adjustments must be made until the final version is achieved. The goal is to reach the next stage with the least possible margin of error.
Once the final prototype is approved, the development of the application begins. This is a complex stage, so it is necessary to have a team with the skills to faithfully comply with what was approved in the layout and design phase.
**Step 5: Continuous Improvement**
The deployment of a mobile application is not the end of the process but the beginning of a new stage in which updates and continuous improvements must be made. Therefore, for effective mobile application development services, it is crucial to ensure that the applications created are scalable and easy to update. This scalability and adaptability will facilitate ongoing improvements, allowing your clients to stay competitive in a dynamic market. A robust and flexible foundation for mobile applications is essential to accommodate evolving user needs, address emerging technologies, and swiftly implement updates, ensuring the sustained success of your mobile application development services.
The development process must ensure that the company obtains a high-quality application that is user-friendly, fast, secure, and up-to-date. For this reason, it is essential to choose a software factory that works in an organized and agile manner, prioritizing the needs and resources of the company for whom the project is intended.
Currently, there are different working modalities that can be adapted according to the project requirements. In this sense, startups can choose to work through staff augmentation, hiring temporary staff with specific skills to carry out the project, or opt for team augmentation by subcontracting an entire team to develop the tool.
Please get in touch with us if you need guidance on this topic.
**[https://www.sparkouttech.com/mobile-application-development/](https://www.sparkouttech.com/mobile-application-development/)**
| pryanka46 |
1,734,594 | Screenshot to Figma Design By AI: A New Chapter in Future Design | 1. Preface In the digital age, designers and developers frequently need to convert image... | 0 | 2024-01-19T06:55:45 | https://dev.to/happyer/screenshot-to-figma-design-by-ai-a-new-chapter-in-future-design-5bic | figma, design, webdev, ai | ## 1. Preface
In the digital age, designers and developers frequently need to convert image assets into editable design drafts. With the development of artificial intelligence technology, this process can now be automated by AI, greatly improving work efficiency. This article will provide a detailed introduction on how to use AI technology to convert images into design drafts, including AI recognition, intelligent design draft generation, application scenarios, and recommendations for related Figma plugins.
## 2. AI Recognition
AI recognition is the core step in converting image content into Figma design drafts. It refers to the use of artificial intelligence algorithms, such as machine learning and deep learning, to identify and understand the content of images. This involves multiple sub-tasks, including image segmentation, object recognition, and text recognition (OCR). Below, we will detail the processes and technical implementations of these sub-tasks.
### 2.1. AI Recognition Process Flowchart
Below is the AI recognition process flowchart for converting images into Figma design drafts:
```
Image Input
│
├───> Image Segmentation ────> Identify Element Boundaries
│
├───> Object Recognition ────> Match Design Elements
│
└───> Text Recognition ────> Extract and Process Text
│
└───> Figma Design Draft Generation
```
Through the above process, AI can effectively convert the design elements and text in images into corresponding elements in Figma design drafts. This process greatly simplifies the work of designers and improves the efficiency and accuracy of design.
### 2.2. Image Segmentation
Image segmentation is the process of identifying and separating each individual element within an image. This is typically achieved through deep learning techniques such as Convolutional Neural Networks (CNNs). A popular network architecture for this purpose is U-Net, which is particularly well-suited for image segmentation tasks.
#### Technical Implementation:
1. Data Preparation: Collect a large number of annotated images of design elements, with annotations including the boundaries of each element.
2. Model Training: Train a model using the U-Net architecture to enable it to recognize different design elements.
3. Segmentation Application: Apply the trained model to new images to output the precise location and boundaries of each element.
#### Code Example (using Python and TensorFlow):
```python
import tensorflow as tf
from tensorflow.keras.layers import Input, Conv2D, MaxPooling2D, UpSampling2D, concatenate
from tensorflow.keras.models import Model
def unet_model(input_size=(256, 256, 3)):
inputs = Input(input_size)
# U-Net architecture
# ... (specific U-Net construction code omitted)
outputs = Conv2D(1, (1, 1), activation='sigmoid')(conv9)
model = Model(inputs=inputs, outputs=outputs)
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
return model
# Code to load the dataset, train the model, and apply the model would be implemented here
```
### 2.3. Object Recognition
Object recognition refers to identifying specific objects within an image, such as buttons, icons, etc., and matching them with a predefined library of design elements.
#### Technical Implementation:
1. Data Preparation: Create a dataset containing various design elements and their category labels.
2. Model Training: Use pre-trained CNN models such as ResNet or Inception for transfer learning to recognize different design elements.
3. Object Matching: Match the identified objects with elements from the design element library to reconstruct them in Figma.
#### Code Example (using Python and TensorFlow):
```python
from tensorflow.keras.applications.resnet50 import ResNet50, preprocess_input
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.layers import Dense, GlobalAveragePooling2D
from tensorflow.keras.models import Model
# Load the pre-trained ResNet50 model
base_model = ResNet50(weights='imagenet', include_top=False)
# Add custom layers
x = base_model.output
x = GlobalAveragePooling2D()(x)
x = Dense(1024, activation='relu')(x)
predictions = Dense(num_classes, activation='softmax')(x)
# Construct the final model
model = Model(inputs=base_model.input, outputs=predictions)
# Freeze the layers of ResNet50
for layer in base_model.layers:
layer.trainable = False
# Compile the model
model.compile(optimizer='rmsprop', loss='categorical_crossentropy')
# Code to train the model would be implemented here
```
### 2.4. Text Recognition (OCR)
Text recognition (OCR) technology is used to extract text from images and convert it into an editable text format.
#### Technical Implementation:
1. Use OCR tools (such as Tesseract) to recognize text within images.
2. Perform post-processing on the recognized text, including language correction and format adjustment.
3. Import the processed text into the Figma design draft.
#### Code Example (using Python and Tesseract):
```python
import pytesseract
from PIL import Image
# Configure Tesseract path
pytesseract.pytesseract.tesseract_cmd = r'path_to_tesseract'
# Load image
image = Image.open('example.png')
# Apply OCR
text = pytesseract.image_to_string(image, lang='eng')
# Output the recognized text
print(text)
# Code to import the recognized text into Figma would be implemented here
```
## 3. Figma Design Draft Generation
Converting an image into a Figma design draft involves reconstructing the elements recognized by AI into objects in Figma, and applying the corresponding styles and layouts. This process can be divided into several key steps: design element reconstruction, style matching, and layout automation.
### 3.1. Figma Design Draft Generation Flowchart
Below is the flowchart for converting images into Figma design drafts:
```
AI Recognition Results
│
├───> Design Element Reconstruction ──> Create Figma shape/text elements
│ │
│ └───> Set size and position
│
├───> Style Matching ───────────────> Apply styles such as color, font, etc.
│
└───> Layout Automation ────────────> Set element constraints and layout grids
```
Through the above process, we can convert the elements and style information recognized by AI into design drafts in Figma.
### 3.2. Design Element Reconstruction
In the AI recognition phase, we have already obtained the boundaries and categories of each element in the image. Now, we need to reconstruct these elements in Figma.
#### Technical Implementation:
1. Use the Figma API to create corresponding shapes and text elements.
2. Set the size and position of the elements based on the information recognized by AI.
3. If the element is text, also set the font, size, and color.
#### Code Example (using Figma REST API):
```javascript
// Assume we already have information about an element, including type, position, size, and style
const elementInfo = {
type: 'rectangle',
x: 100,
y: 50,
width: 200,
height: 100,
fill: '#FF5733'
};
// Use the fetch API to call Figma's REST API to create a rectangle
fetch('https://api.figma.com/v1/files/:file_key/nodes', {
method: 'POST',
headers: {
'X-Figma-Token': 'YOUR_PERSONAL_ACCESS_TOKEN'
},
body: JSON.stringify({
nodes: [
{
type: 'RECTANGLE',
x: elementInfo.x,
y: elementInfo.y,
width: elementInfo.width,
height: elementInfo.height,
fills: [{ type: 'SOLID', color: elementInfo.fill }]
}
]
})
})
.then(response => response.json())
.then(data => console.log(data))
.catch(error => console.error('Error:', error));
```
### 3.3. Style Matching
Style matching refers to applying the style information recognized by AI to Figma elements, including color, margins, shadows, etc.
#### Technical Implementation:
1. Parse the style data recognized by AI.
2. Use the Figma API to update the style properties of the elements.
#### Code Example (continuing to use Figma REST API):
```javascript
// Assume we already have the style information
const styleInfo = {
color: { r: 255, g: 87, b: 51 },
fontSize: 16,
fontFamily: 'Roboto',
fontWeight: 400
};
// Update the style of a text element
fetch('https://api.figma.com/v1/files/:file_key/nodes/:node_id', {
method: 'PUT',
headers: {
'X-Figma-Token': 'YOUR_PERSONAL_ACCESS_TOKEN'
},
body: JSON.stringify({
nodes: [
{
type: 'TEXT',
characters: 'Example Text',
style: {
fontFamily: styleInfo.fontFamily,
fontWeight: styleInfo.fontWeight,
fontSize: styleInfo.fontSize,
fills: [{ type: 'SOLID', color: styleInfo.color }]
}
}
]
})
})
.then(response => response.json())
.then(data => console.log(data))
.catch(error => console.error('Error:', error));
```
### 3.4. Intelligent Layout
Intelligent layout refers to the smart arrangement of elements based on their relative positional relationships in Figma.
#### Technical Implementation:
1. Analyze the spatial relationships between elements.
2. Use the Figma API to set constraints and layout grids for the elements.
#### Code Example (using Figma Plugin API):
```javascript
// Assume we already have the spatial relationships between elements
const layoutInfo = {
parentFrame: 'Frame_1',
childElements: ['Rectangle_1', 'Text_1']
};
// Set constraints for elements within a Figma plugin
const parentFrame = figma.getNodeById(layoutInfo.parentFrame);
layoutInfo.childElements.forEach(childId => {
const child = figma.getNodeById(childId);
if (child) {
child.constraints = { horizontal: 'SCALE', vertical: 'SCALE' };
parentFrame.appendChild(child);
}
});
```
## 4. Application Scenarios
### 4.1. Design Restoration
When designers need to recreate design drafts based on images provided by clients, AI conversion can significantly reduce manual operations.
### 4.2. Rapid Prototyping
During the rapid prototyping phase, designers can convert sketches or screenshots into Figma design drafts to accelerate the iteration process.
### 4.3. Design Iteration
When making modifications to existing designs, one can start directly from photos of the physical product, rather than designing from scratch.
### 4.4. Content Migration
Migrate content from paper documents or legacy websites into a new design framework.
### 4.5. Collaboration
Team members can share design ideas through physical images, and AI helps quickly convert them into a format for collaborative work.
### 4.6. Design System Integration
Convert existing design elements into Figma components to build or expand a design system.
## 5. Screenshot to Figma Design Plugins
1. [**Codia AI Design**](https://codia.ai/d/5ZFb): This plugin Transform screenshots into editable Figma UI designs effortlessly. Simply upload a snapshot of an app or website, and let it do the rest. At the same time, [**Codia AI Code**](https://codia.ai/s/YBF9) also supports Figma to Code, including Android, iOS, Flutter, HTML, CSS, React, Vue, etc., with high-fidelity code generation.
2. [**Photopea**](https://www.figma.com/community/plugin/1164118094004004837): An integrated image editor that enables you to edit images within Figma and convert them into design elements.
Plugins for extracting design elements (such as colors, fonts, layout, etc.) from images:
1. **Image Palette** - Extracts primary colors from an image and generates a color scheme.
2. **Image Tracer** - Converts bitmap images into vector paths, allowing you to edit them in Figma.
3. **Unsplash** - Search and insert high-quality, free images directly within Figma, great for quick prototyping.
4. **Content Reel** - Fill your designs with real content (including images) to help designers create more realistic prototypes.
5. **PhotoSplash 2** - Another plugin for searching and using high-resolution photos within Figma.
6. **Figmify** - Directly import images from the web into Figma, saving the time of downloading and uploading.
7. **TinyImage Compressor** - Compresses images in Figma to optimize project performance.
8. **Remove.bg** - A plugin that automatically removes the background of images, ideal for processing product photos or portraits.
9. **Pexels** - Similar to Unsplash, this plugin offers a large collection of free-to-use image resources. | happyer |
1,734,813 | Simplifying AWS Serverless: Draw with Application Composer | As Serverless developers, we develop our services with infrastructure as code (IaC) and, recently,... | 0 | 2024-01-29T07:12:39 | https://www.ranthebuilder.cloud/post/aws-serverless-made-easy-application-composer | devops, serverless, applicationcomposer, architecture | 
As Serverless developers, we develop our services with infrastructure as code (IaC) and, recently, with [infrastructure from code](https://infrastructurefromcode.com/) (IfC), but mostly, it means that we write code or configuration to generate our AWS resources. What if we have been doing it wrong all these years? What if there’s a better and simpler way to build serverless services on AWS?
**In this post, you will learn how to build serverless services by drawing infrastructure diagrams with [AWS Application Composer](https://aws.amazon.com/application-composer/). I will share my experience using it, its strengths and current limitations, and present my wishlist.**
](https://cdn-images-1.medium.com/max/2000/0*yqIAjMgCJefZ8UXj.png)
**This blog post was originally published on my website, [“Ran The Builder.”](https://www.ranthebuilder.cloud/)**
## IaC and DevOps are Hard
Writing resource configuration files or AWS CDK, SAM, or Terraform code is difficult. You need to learn the tool, review its documentation, learn its best practices (read my CDK best practices post [here](https://www.ranthebuilder.cloud/post/aws-cdk-best-practices-from-the-trenches)), and write code or configuration, and plenty of it.
Historically, developers swayed away from writing configurations that build resources such as Helm charts (I shudder at the thought of K8S), which slowed down the adoption of such tools among developers. However, with technologies such as serverless that go hand in hand with newer tools such as AWS CDK and SAM and the recent trend of infrastructure from code, developers embrace the DevOps mentality and are more open to writing infrastructure code. But it’s still hard.
**Today, I want to present a new option I came across — building resources by drawing a resource diagram — no code required.**
## Drawing Infrastructure?!
Yes, drawing infrastructure diagrams. We all do it at some point at work.
As an architect, I draw high-level designs that describe service behavior and how service domains connect one with another.
Developers take my high-level designs and turn them into low-level designs that describe the actual AWS serverless resources of the service. We use diagram tools such as [Lucidchart](https://www.lucidchart.com/pages/) or [Draw.io](http://Draw.io).
Service infrastructure diagrams are a great tool to present a new feature, introduce the service to a new teammate, or even get a clear understanding of how the service works.
However, infrastructure diagrams have their issues too.
### Diagrams are (almost) Always Out of Sync
As time goes by, features are added, and bugs are fixed. Developers change the original designs, and some design elements are dropped due to priority and are never developed. Remember that original infrastructure diagram you meticulously created and were so proud of? It’s no longer in sync with the real service infrastructure and quickly loses value.
To solve this issue, you always go back to the code or the infrastructure configuration files ([AWS CDK](https://aws.amazon.com/cdk/), in my case). **Code doesn’t lie**, but looking at code takes time and skill.
The optimal solution would be to sync the service infrastructure diagram with the service code. It’s a real pain to remember to update the diagram constantly. Nobody does that.
Luckily, AWS devised a way to do just that **automatically**, simultaneously making building service infrastructure more intuitive and fun.
They achieved that by building **AWS Application Composer**, which lets you draw infrastructure diagrams and convert them into AWS SAM or CloudFormation templates.
## AWS Application Composer
A few years ago, in 2021, AWS bought a startup named “Stackery” that attempted to solve this very problem. Fast forward to December 2022, [AWS Application Composer](https://aws.amazon.com/application-composer/) was born.
It went GA (general availability) less than a year ago, on [March 2023](https://aws.amazon.com/about-aws/whats-new/2023/03/aws-application-composer-generally-available/). During AWS re:invent 2023, they made a huge [announcement](https://aws.amazon.com/about-aws/whats-new/2023/11/ide-extension-aws-application-composer/) that got my attention.
Instead of working in the console and doing diagrams, I can now use Application Composer from the comfort of my Visual Studio IDE.
Let’s go over the user experience and development flow.
### The User Experience
You can either start a new empty project or load up an existing project. I decided to load up my [AWS Lambda Handler cookbook template project](https://github.com/ran-isenberg/aws-lambda-handler-cookbook) and see how it works.
This is the service diagram (which, ironically, is out of sync with the infrastructure; it’s missing CloudWatch alarms and dashboards):

Now, let’s generate a diagram out of the existing project CloudFormation template and see what we get. On Mac, you click ‘CMD + SHIFT + P’ and choose the project’s CloudFormation/SAM template:
* Make sure you installed the AWS toolkit extension!

The initial output on the screen is a diagram containing many resources with connections between them. Each resource has its AWS familiar icon, resource name and its current configuration.
**A super useful feature allows you to group resources under a group or a logical domain**. I’ve split my resources between CDK constructs, but that split didn’t make it to the CloudFormation. It took me two minutes to sort everything, and I got this beautiful diagram:

I have my CRUD API group (API GW, Lambda function, two DynamoDB tables), CloudWatch resources, and AppConfig group and all the connections between the resources.
**Initial impression: I’m impressed; this is highly readable and solves the diagram out-of-sync issue**. Remember that problem with the diagram being out of sync? Every change you make here will automatically be translated and written into your SAM or CloudFormation template. Even the groups! They added a cool new ‘ApplicationComposer’ attribute into CloudFormation.
Let’s see how easy it is to add and configure new serverless resources.
### Adding Serverless Resources
Let’s say I want to add a new CloudFormation resource. The resource search is excellent and fast; you can add over 1000 resources. Let’s select a Lambda function. We are greeted with an easy-to-use menu with all the essential fields with a dropdown list:

Usually, I’d write lots of CDK code for the same thing, but here, I can do it in the UI.
Let’s try to add another resource, an AppConfig deployment.
Here, the experience could be better. The resource configuration panel does not have predefined drop-down lists. I’m required to write CloudFormation config code. Many less common resources don’t have the same drop-down lists as Lambda function has but rather a key value configuration box where you put all the configurations. This is a bit hard to fill and understand. However, you have a link to the official resource documentation, which is a nice touch, and an AI suggestions button for sample configuration examples.
Overall, you are golden if you use the more common serverless resources. In time, more and more resources will get the VIP treatment. And in all fairness, I can compare that to CDK not having L2 constructs abstractions for many new services.
### Connecting Resources
You can draw lines from one resource to another to connect them. You can connect resources such as an API Gateway to a Lambda function, and it configures the specific function as the route’s destination. Very easy. However, only some resources are supported. I tried to connect an SQS queue to an SNS topic and had a tooltip popup telling me it’s not supported yet. When supported, the experience is effortless.

## Limitations
So, we’ve already discussed two limitations:
1. Resource configurations — lack of drop-down experience, which is not an ideal user experience, but you can make it work.
2. I can’t connect some resources that should be connected by drawing lines between them.
However, there are other limitations that we should discuss.
I’ve used Application Composer on a larger scale services’ CloudFormation template and was greeted with a resource limit warning. It will be solved, but it’s a limitation for now.
The diagram I got was very large, and it would take a lot of time to sort and group it. Another limitation is the lack of CDK support. Yes, I know, generating suitable L2 CDK constructs is extremely hard, but a boy can dream…
Despite all the above, the service has a bright future and will become part of my daily tool once these limitations are ironed out.
## Should You Use It
Is the experience better than writing IaC? Is it more intuitive or even fun? Yes, 100%; when all the resources are supported and have their custom drop-down selection, yes, it’s super easy.
**Will it replace CDK for me?** No, not until it has full CDK support, but it has its use cases especially for infrastructure diagram building for the sake of documentation.
**Who is it for then?** It fits people who want to draw low-level designs or get an accurate infrastructure diagram representation of their small to medium service, people who want to build proof of concepts fast, and, of course, it fits people who use native CloudFormation or SAM. Even if you won’t use it to build resources, it makes sense to use it for drawing the infrastructure diagrams. I’ve recently added an Application composer resource image to the AWS Lambda Handler cookbook [documentation](https://ran-isenberg.github.io/aws-lambda-handler-cookbook/cdk/#deployed-resources_1) because it was easy to generate and made explaining the service simpler.
I’m excited about the service and its future; it has plenty of potential and places to grow. Once it irons out the user experience, it will be hard not to use it, and the team is headed in the right direction.
Lastly, if anyone from App Composer is reading this, my wishlist and vision for the service are below.
## Application Composer Wishlist
If we get even part of this wishlist, Application Composer would be outstanding:
1. Infrastructure from Chat: Why should we bother defining diagram resources and connecting icons when we have AI utilities (Amazon Q and CodeWhisperer) right in the AWS toolkit in the IDE? I want to tell my AI assistant what to design and have them draw and configure the infrastructure diagram.
2. Automatic resource grouping — group some types of same resource types — CW dashboards, AppConfig resources, etc.
3. High-level design diagram option — create an option to “merge” objects into a domain group to abstract them, not just place them in a group. While at it, let’s visualize nested stacks in separate diagrams in the IDE.
4. Resolve the limitations: Add L2 CDK support and support more resources with detailed configuration options.
5. Github/Jenkins plugin to visualize changes — when I review a PR, I want to visually understand what infrastructure configuration or resources were added, removed, or changed. We already have some tools that partially do that, such as ‘[CDK notifier](https://github.com/karlderkaefer/cdk-notifier).’
6. Copy-pasting element — I couldn’t get this working for some reason. Maybe it’s a bug, but I’d like to add similar resources quicker.
| ranisenberg |
1,734,870 | Harley Davidson Motorcycle Repair & Service In Kodak, TN | Nestled in the heart of Tennessee, Kodak is a town that embraces the spirit of the open road. For... | 0 | 2024-01-19T10:02:54 | https://dev.to/thunderheadhd/harley-davidson-motorcycle-repair-service-in-kodak-tn-1713 | motorcycle, service | Nestled in the heart of Tennessee, Kodak is a town that embraces the spirit of the open road. For Harley Davidson enthusiasts, there's no better feeling than cruising down the highways and byways on their beloved bikes. However, even the most well-maintained Harley can experience wear and tear over time. That's where the expert services of Harley Davidson Motorcycle Repair & Service in Kodak, TN come into play.
Expertise You Can Trust:
Harley Davidson motorcycles are not just machines; they are a lifestyle. Owners invest not only in a mode of transportation but in a symbol of freedom and individuality. When it comes to maintenance and repairs, it's crucial to entrust your Harley to professionals who understand the intricacies of these iconic machines.
In Kodak, TN, Harley Davidson [Motorcycle Repair & Service](https://www.thunderheadhd.com/service-repair-harley-davidson-dealership--service) centers boast teams of skilled technicians with a deep passion for Harley Davidson bikes. These experts undergo rigorous training and are equipped with the latest tools and diagnostic equipment to ensure your motorcycle receives the care it deserves.
Comprehensive Services:
Whether your Harley needs routine maintenance, a performance upgrade, or a major repair, the service centers in Kodak have you covered. Some of the comprehensive services offered include:
Routine Maintenance:
Oil changes
Brake inspections and adjustments
Tire checks and replacements
Fluid level checks
Diagnostic Services:
Advanced diagnostic testing
Electrical system analysis
Engine performance evaluation
Repairs and Replacements:
Engine repairs
Transmission repairs
Exhaust system replacements
Suspension upgrades
Customization:
Performance enhancements
Custom paint jobs
Accessory installations
Customer-Focused Approach:
What sets Harley Davidson Motorcycle Repair & Service in Kodak, TN apart is their dedication to customer satisfaction. From the moment you roll your Harley into the service center to the time you take it back on the road, you can expect transparent communication, fair pricing, and a commitment to excellence.
The service centers understand that each Harley rider has a unique relationship with their bike, and they tailor their services to meet individual needs. Whether you're a weekend rider or a daily commuter, the goal is to keep your Harley Davidson performing at its peak.
Community Engagement:
Beyond just being a service provider, Harley Davidson Motorcycle Repair & Service in Kodak, TN actively engages with the local motorcycle community. They organize events, workshops, and rides, fostering a sense of camaraderie among Harley enthusiasts. This community-centric approach not only enhances the riding experience but also creates lasting connections among riders in Kodak.
For Harley Davidson owners in Kodak, TN, the journey doesn't end on the road—it extends to the care and maintenance of their prized motorcycles. The Harley Davidson Motorcycle Repair & Service centers in Kodak are not just repair shops; they are havens for enthusiasts who understand and appreciate the unique bond between a rider and their Harley. So, whether you're in need of routine maintenance, repairs, or simply want to enhance your bike's performance, trust the experts in Kodak to keep your Harley Davidson roaring down the road for years to come.
**For more Information:https://www.thunderheadhd.com/service-repair-harley-davidson-dealership--service
Contact us at: 8652250050
Address:3607 Outdoor Sportsman Place, Kodak, TN 37764**
| thunderheadhd |
1,735,038 | How to Choose the Best Mobile App Development Company? | Evaluating Past Projects One of the most insightful ways to gauge a mobile app development company... | 0 | 2024-01-19T12:06:45 | https://dev.to/avtarspace/how-to-choose-the-best-mobile-app-development-company-353p | appdevelopment | 
**Evaluating Past Projects**
One of the most insightful ways to gauge a **[mobile app development company](https://www.avtarspace.com/mobile-app-development)** capabilities is by examining their past projects. A rich and diverse portfolio provides a glimpse into the range of industries they've worked with and the complexity of the apps they've delivered. Look for companies that showcase success stories similar to your project, indicating a deep understanding of your specific needs.
**Client Testimonials and References**
Client testimonials serve as valuable endorsements of a development company expertise and professionalism. Reach out to past clients if possible, or inquire if the company can provide references. Hearing about others' positive experiences can instill confidence in your decision, assuring you that the company is reliable and customer-oriented.
**Industry Recognition and Awards**
Awards and recognition within the industry are indicators of a company excellence. While not the sole deciding factor, accolades can highlight a company's commitment to innovation and quality. A company that has received recognition for its work is likely to bring a high level of dedication and skill to your app development project.
**Transparency in Communication**
Effective communication is paramount in any business relationship. A transparent and open line of communication ensures that you are well-informed about the project's progress, potential challenges, and any adjustments to the initial plan. Choose a company that values clear communication, as it fosters a collaborative and trustful working relationship.
**Exploring Technological Innovations**
In the ever-evolving landscape of technology, staying innovative is key. A forward-thinking development company that explores and implements the latest technological advancements can bring a competitive edge to your app. Inquire about the company's approach to innovation and how they incorporate new technologies into their projects.
**Collaborative Approach to Problem-Solving**
No project is without its challenges. A reliable development company is not just skilled in coding but excels in problem-solving. Assess how they approach and overcome challenges by discussing past experiences. A company that takes a collaborative and proactive approach to problem-solving is more likely to navigate hurdles effectively.
**Conclusion**
Choosing the best **[best mobile app development company](https://www.avtarspace.com/mobile-app-development)** involves a thorough examination of their past projects, client testimonials, industry recognition, communication practices, and problem-solving approach. By combining these factors, you can make an informed decision that aligns with your project's goals and sets the stage for a successful collaboration. | avtarspace |
1,735,247 | The Road to Adoption: A Product and Strategy Perspective | In our previous articles, we talked about what passkeys are and how to incorporate them into a new or... | 26,083 | 2024-01-19T15:31:19 | https://www.prove.com/blog/the-road-to-adoption-product-and-strategy-perspective | prove, passwordless, passkeys, credentials | In our previous articles, we talked about [what passkeys are](https://www.prove.com/blog/what-are-passkeys-and-how-can-they-securely-replace-passwords) and [how to incorporate them](https://www.prove.com/blog/the-road-to-passkey-adoption-a-developers-perspective) into a new or existing web application. However, a successful adoption of passkeys requires considering the larger product to ensure a smooth [user experience](https://www.prove.com/blog/the-beauty-of-hosted-ux-elevating-digital-experiences) as well as a secure design.
In this article, we’ll address the following questions that product owners need to consider. This will inform the user experience design and strategic approach:
- What will passkeys be used for– and what’s the risk profile?
- How many of your customers have appropriate passkey capability?
- How will you ensure you create credentials for the right users?
- What is the recovery strategy (or, what happens when someone’s credentials don’t work for some reason)?
- Will you fully retire passwords, and if so, when?
## How Are You Using Passkeys – And What Are The Related Risks?
Passkeys are an [authentication](https://www.prove.com/blog/developer-blog-what-is-passwordless-authentication) mechanism, and we addressed earlier how they are generally less risky than [passwords](https://www.prove.com/asset/2022-passwords-authentication-consumer-trends-report). By less risky, I mean specifically that it is much easier to steal someone else’s username and password to be used for authentication, and much more difficult to access someone’s private passkey to fraudulently authenticate. In fact, passkeys were initially very attractive to [financial institutions](https://www.prove.com/blog/why-top-banks-fintechs-adopting-phone-centric-identity-frictionless-psd2-sca) and other organizations where stolen credentials were very risky: if a passkey can’t leave a device, it’s almost impossible for a malicious actor to steal the passkey and use it to authenticate– therefore it’s much harder for someone to, say, log on and drain your bank account. But that’s only device-bound passkeys. Passkeys stored in a password manager (for example, Apple’s passkey implementation stores credentials in the iCloud keychain) are easier to steal. If a malicious actor can get into your iCloud account (and therefore your keychain), they can access your passkeys, and any accounts those passkeys protect.
To be clear: passkeys are more secure and less risky than passwords, full stop. However, as an organization, you may want to treat device-bound passkeys (those that are stored on the physical device and never copied elsewhere) differently than synced passkeys (those that are stored in a password manager and shared across devices). Prove has designed our passkey solution to support you in this differentiation.
Since you have a choice about how passkeys are created and stored, if your product is something that is less risky, you may choose to allow passkeys that can be synced and not biometric protected, because that will offer a better user experience. On the other hand, for financial-related products, you may want to require passkeys to be created on device-bound passkeys protected with biometrics for a lower risk of compromise.
Fun fact: Prove’s passkey implementation is designed to handle the distinction between device-bound and synced passkeys– even if a user’s platform creates synced passkeys, we can detect if the user is authenticating from a device we’ve seen before– and therefore we can trust more.
## How Many Of Your Users Have Passkey Capability?
An important aspect of adopting a new technology is understanding your customer base and what technology they have access to. The wonderful thing about passkeys is that it is a standard built into web browsers, so if your customers have access to a modern web browser, they likely can use passkeys. However, what’s less clear is if your customer’s passkeys are device-bound or not; or if they can be protected by a [biometric](https://www.prove.com/blog/log-in-with-your-walk-prove-behavioral-biometric-tech-replaces-passwords-auth-natural-human-emotion) (Face/Touch scan) as opposed to a PIN. If your user base has access to the newest technologies, your passkey adoption strategy can move faster. In any case, you need to scaffold your passkey adoption strategy with passwords, as there are still many users who will need time to adapt, but by encouraging passkey adoption you reduce the attack surface in the meantime.
Non-mobile devices such as laptops or other computers may have more variability in terms of which authenticators are connected, as well as if they are protected by biometrics. More mobile devices have the hardware and software capabilities to support passkeys. If that is a significant issue for your user base, one thing to keep in mind is that passkeys on mobile phones can be used to authenticate on other devices. Prove has built this into our passkey solution as well.
## How Will You Ensure That You Create A Passkey For The Right Person?
One thing is clear: once passkeys are created, they provide a secure authentication mechanism, far more so than passwords. If you’re building a product from scratch, using passkeys will be easy. Users creating new accounts will create passkeys instead of passwords. However, if you have an existing user base currently using passwords, they will have to go through a process of creating new passkeys. This generally looks like asking the user to create a passkey after they log in with a password (or your trusted authentication flow) that gets attached to the account as an alternate way to log in.
Prove’s authentication capability can help ensure that passkeys are created for the right person, rather than by someone who has stolen a username and password.
## What’s The Recovery Strategy?
Even though passkeys are managed by computers on devices that customers tend to not lose, users can lose access to their passkeys. Remember, passkeys can live either on a single device (“Device bound passkey”) or can be shared across devices via a password manager. The risk with device-bound passkeys is easily imagined: perhaps someone loses their device, whether it’s their Yubikey, phone, or laptop; or maybe they get a new device. But it could also be that the device is [stolen](https://www.prove.com/blog/fortifying-indian-businesses-understanding-8-common-types-of-fraud-for-effective-fraud-prevention), and in that case, the path to reset access to someone’s account might be a little different.
One thing that will help is to try to keep track of where the private passkey lives for the user. For example, when credentials are created, have the user provide a useful description that you can attach to the public passkey (that you store). For example, if you store passkeys with a description such as “Passkey created on my iPhone 14”, the user knows that they can use a passkey stored on that device (or, really, in the iCloud account associated with that device) to authenticate on their account. Also, if they lose a device associated with that iCloud account, the user can revoke those credentials– then a malicious actor can’t access the account from a stolen device.
The original approach to protecting access to an account via passkeys has been to encourage the user to create multiple sets of credentials on different devices. For example, I might create one set of credentials on my personal laptop, my work laptop, and my phone. Then, if I lose access to one of them for some reason, I have a backup. While that might work for people with access to all these different devices, it’s a big lift to create multiple credentials for all my accounts on all these devices and keep them up to date.
The recovery strategy helps establish new passkeys for existing users. Identity verification can be leveraged to have confidence that the user is who they say they are. Prove’s identity verification can help ensure that passkeys are created for the right person and on the right phone. We also can help manage the trustworthy movement of credentials to new devices.
## Conclusion
As you can see, one of the trickiest things about adopting passkeys is the decision-making about strategic adoption and user experience. There can be lots of “gotchas,” especially as we are starting to transition from our default familiarity with password-based systems to new, more secure passkeys. | ndewald |
1,735,260 | Comment créer une application de chat simple basée sur le web ? | Lisez notre guide complet pour créer une application de chat simple basée sur le web. Lisez ceci et nos autres informations sur la création d'applications de chat basées sur le web. | 0 | 2024-01-19T16:03:53 | https://dev.to/pubnub-fr/comment-creer-une-application-de-chat-simple-basee-sur-le-web--1d4f | Les systèmes en temps réel et les plateformes de messagerie sont devenus essentiels à nos routines quotidiennes, permettant une communication instantanée entre les utilisateurs. Qu'il s'agisse de messages textuels, d'e-mails ou de chats de groupe dans Microsoft Teams, Slack ou WhatsApp, nous avons tous nos plateformes préférées pour maintenir une communication constante avec nos amis et nos collègues. Ces applications de chat sont omniprésentes et intégrées dans presque toutes les applications modernes en temps réel en raison de leurs temps de réponse immédiats et de leurs capacités étendues.
La dépendance croissante à l'égard des applications de chat s'explique par leurs nombreux avantages. Par exemple, elles permettent une prise de décision plus rapide, une meilleure collaboration et une productivité accrue. En outre, les plateformes de chat enregistrent toutes les conversations, ce qui facilite le suivi des progrès et permet de se référer à des discussions antérieures. En outre, ces applications deviennent de plus en plus sophistiquées et intègrent des fonctions telles que [les appels vidéo et vocaux](https://www.pubnub.com/integrations/vonage-video-api-video-chat/)et le partage d'écran et de fichiers, ce qui les rend encore plus polyvalentes pour diverses utilisations. Dans l'ensemble, les applications de dialogue en ligne sont devenues des outils indispensables à la communication et à la collaboration modernes.
Pourquoi créer une simple application de dialogue en ligne ?
------------------------------------------------------------
Il existe une forte demande pour des applications de chat nouvelles et innovantes qui répondent à des besoins spécifiques.
Les applications de chat basées sur le web peuvent être personnalisées pour s'adapter [différents secteurs d'activité et entreprises](https://www.pubnub.com/customers/?filter-solutions=In-App%20chat)Les applications de chat basées sur le web peuvent être personnalisées pour s'adapter à différents secteurs et entreprises, en fournissant une plateforme unique pour que les utilisateurs puissent communiquer et collaborer. Par exemple, une application de chat conçue pour les professionnels de la santé peut intégrer des fonctionnalités spécifiques telles que la messagerie sécurisée ([conforme à l'HIPAA](https://www.pubnub.com/solutions/digital-health/)) et les consultations vidéo, ce qui la rend plus efficace pour les professionnels de la santé.
La création d'une application de chat peut également offrir des opportunités commerciales lucratives, en générant potentiellement des revenus par le biais de publicités, d'abonnements et d'achats in-app. En outre, à mesure que la technologie progresse, les possibilités d'applications de chat sont infinies, avec le potentiel d'intégrer des fonctionnalités de pointe telles que l'intelligence artificielle et la réalité virtuelle.
### Avantages d'une simple application de dialogue en ligne
La création d'une simple application de dialogue en ligne présente de nombreux avantages. Pour faire simple, une application de chat permet de communiquer facilement avec des personnes du monde entier en envoyant et en recevant des messages. Avec une application de chat en ligne, les utilisateurs peuvent bénéficier des mêmes interactions engageantes et vivantes grâce à des fonctions de messagerie personnalisées, tout comme ils le feraient en personne. Cela permet également aux utilisateurs de converser sur votre plateforme au lieu de chercher ailleurs une solution de messagerie. Qu'il s'agisse de [chat privé](https://www.pubnub.com/tutorials/getting-started-chat-sdk/), [chat de groupe](https://www.pubnub.com/demos/group-chat-react-demo/)ou [chat à grande échelle](https://www.pubnub.com/demos/virtual-events/)En ajoutant des fonctions de chat personnalisées à votre application, vous pouvez faire en sorte que vos utilisateurs vivent une expérience mémorable.
Une application de chat basée sur le web peut offrir une commodité que d'autres formes de communication ne peuvent pas offrir. Les utilisateurs peuvent accéder à l'application depuis n'importe quel endroit disposant d'une connexion internet, ce qui permet de rester facilement connecté en déplacement. En outre, les applications de dialogue en ligne peuvent être conçues pour fonctionner de manière transparente avec d'autres applications, ce qui permet aux utilisateurs de passer d'un outil ou d'une fonction à l'autre sans interrompre leur conversation.
### Construire ou acheter une application de dialogue en ligne simple
La décision de développer une solution de chat en interne ou d'opter pour une solution fournie par un fournisseur est importante. Pour certaines organisations, la disponibilité de développeurs en interne ou en sous-traitance peut rendre attrayante la perspective de développer et de posséder une solution de chat ou de messagerie entièrement personnalisée. Par ailleurs, l'achat d'une solution de dialogue en ligne existante avec un modèle de tarification "as-a-service" peut présenter de nombreux avantages, mais aussi des difficultés. Cependant, un fournisseur de services de chat prêt à l'emploi est une troisième option pour ajouter une fonctionnalité de chat à un produit logiciel. Cette option peut suffire pour des applications spécifiques, car elle offre des fonctionnalités d'interface utilisateur adaptées à toutes les tailles et des intégrations back-end simplifiées.
Avant de s'engager dans la création ou l'achat d'une fonctionnalité de chat, il est essentiel de prendre en compte la proposition de valeur fondamentale de votre entreprise et de donner la priorité au chat par rapport aux principaux problèmes que vous avez l'intention de résoudre pour vos clients. Bien qu'il offre des avantages considérables, il constitue rarement un facteur de différenciation essentiel pour l'entreprise.
De l'extérieur, le chat peut sembler être un composant simple à intégrer dans votre infrastructure actuelle. Cependant, le développer à partir de zéro peut prendre autant de temps, sinon plus, qu'un produit entièrement nouveau et les ressources de développement sont à la fois coûteuses et limitées. Dans la plupart des cas, il est plus important de donner la priorité à la proposition de valeur fondamentale plutôt que de travailler sur un chat. Répondons maintenant à la question suivante : comment économiser du temps et de l'argent tout en obtenant une solution de chat entièrement personnalisable qui peut être incorporée dans votre application web ?
Pour obtenir une solution de chat entièrement personnalisable qui peut être facilement intégrée dans n'importe quelle application web tout en économisant du temps et de l'argent, vous pouvez tirer parti des avantages suivants [l'infrastructure en tant que service](https://www.pubnub.com/learn/glossary/what-is-infrastructure-as-a-service-iaas/) (IaaS). L'IaaS est un modèle d'informatique en nuage qui vous permet de louer des ressources informatiques telles que des serveurs, des espaces de stockage et des composants de réseau sur la base d'un paiement à l'utilisation. En utilisant l'IaaS, les entreprises peuvent éviter les coûts initiaux liés à la construction et à la maintenance de leur infrastructure et se concentrer sur le développement de leurs principales propositions de valeur. Ce modèle permet de faire évoluer rapidement l'infrastructure en fonction des besoins et des exigences.
Éléments à prendre en compte lors de la création d'une application de dialogue en ligne
---------------------------------------------------------------------------------------
La création d'une application de chat en temps réel nécessite une planification et une réflexion approfondies afin de s'assurer que l'application répond aux fonctionnalités et à l'expérience utilisateur souhaitées. Nous examinerons ci-dessous certains points à prendre en compte lors de la création d'une application de chat en temps réel à partir de zéro ou à l'aide d'un service IaaS.
### Fonctionnalités de messagerie en temps réel attrayantes
Aujourd'hui, les applications de chat sont plus complexes que l'envoi et la réception de messages. Les utilisateurs souhaiteront toujours disposer d'autres fonctionnalités lorsqu'ils utiliseront une application de chat. Une application de chat numérique basée sur le web avec des fonctions de messagerie en temps réel permet aux utilisateurs de vivre une expérience authentique et interactive.
Des fonctionnalités telles que [réactions aux messages](https://www.pubnub.com/docs/chat/sdks/messages/message-receipts)les autocollants, les emojis, les GIF, les appels vocaux et le chat vidéo permettent à vos utilisateurs de s'engager directement sur votre application plutôt que sur des plateformes externes, créant ainsi une expérience plus connectée.
D'autres fonctionnalités telles que l'identification des utilisateurs actifs, les [notifications push](https://www.pubnub.com/docs/general/push/send)et [l'historique des messages](https://www.pubnub.com/docs/general/storage)\-pour n'en citer que quelques-unes, ajoutent également à cette immédiateté en détectant automatiquement la présence des utilisateurs dans une application de chat en temps réel ou en rappelant les utilisateurs à votre application actuelle. Par exemple, [Présence](https://www.pubnub.com/docs/general/presence/overview) permet aux utilisateurs de savoir quand leurs amis, leurs camarades de jeu ou leurs collaborateurs sont en ligne. Cet aspect est particulièrement important et doit être pris en compte dans le cas d'une application basée sur le web, car il permet aux utilisateurs de rester sur votre site web plutôt que de migrer vers une autre application offrant une expérience plus immersive lorsqu'ils discutent avec leurs amis ou leurs collaborateurs.
### Système robuste d'authentification et d'autorisation des utilisateurs
Avec la technologie actuelle, les applications de chat simples ont tendance à avoir un système d'authentification plus avancé en raison du nombre de chats qui peuvent être créés. Qu'il s'agisse d'un salon de discussion public, d'une discussion de groupe ou d'une discussion entre deux personnes, il existe des restrictions concernant l'accès à certaines conversations, ce qui permet à vos utilisateurs de voir certains messages.
Si vous envisagez de créer un chat à partir de zéro et d'utiliser des technologies telles que [Socket.IO](http://socket.io) il faudra appliquer un niveau d'architecture de canaux au-dessus de la couche de communication. Les canaux seront isolés pour la transmission des données pour chaque type de chat. Seuls les utilisateurs authentifiés ou les utilisateurs qui ont créé le canal/chat pourraient accéder au canal en cours et y inviter des personnes.
La deuxième couche de protection est l'authentification de l'identité réalisée par un système d'authentification par jeton dynamique tel que les jetons Web JSON ([JWT](https://jwt.io/)). Un jeton est une clé d'accès de courte durée, générée par le serveur dorsal de l'application, qui permet aux utilisateurs d'accéder aux canaux auxquels ils ont été invités ou auxquels ils ont accès. La logique du serveur dorsal devra être mise en œuvre pour analyser le jeton en objets identifiables par canal, spécifiant les canaux auxquels les utilisateurs peuvent publier (envoyer un message) ou s'abonner (lire les messages).
Le cryptage est une autre couche de sécurité qui peut être appliquée au-dessus de la couche de transmission et de stockage des données. Cela dépend du protocole de transmission ; vous pouvez mettre en œuvre le Transport Layer Security ([TLS](https://en.wikipedia.org/wiki/Transport_Layer_Security)) ou Web Socket Secure ([WSS](https://en.wikipedia.org/wiki/WebSocket)) pour obtenir la fonctionnalité permettant d'exécuter un chat privé dans votre application web.
En utilisant un service IaaS tel que PubNub, il est construit en utilisant une architecture de séparation des canaux et offre un [gestionnaire d'accès](https://www.pubnub.com/docs/general/security/access-control) qui comprend des configurations pour l'authentification de l'identité, de sorte que tous les messages et canaux sont protégés et, une fois configurés, l'utilisateur est libre de choisir le type de chat qu'il souhaite créer.
### Évolutivité de votre application de chat en temps réel
Lors de la conception d'une application de chat en ligne à partir de zéro, l'évolutivité doit être une considération majeure pour s'assurer que le chat peut gérer une base d'utilisateurs croissante et un trafic accru.
L'architecture du backend doit être conçue pour gérer un grand nombre d'utilisateurs et de messages simultanés. Une architecture évolutive peut utiliser une [base de données distribuée](https://en.wikipedia.org/wiki/Distributed_database), [des équilibreurs de charge](https://en.wikipedia.org/wiki/Load_balancing_(computing))et des mécanismes de mise en cache pour gérer le trafic élevé et améliorer les performances. À mesure que le nombre d'utilisateurs et de messages augmente, les besoins en stockage s'accroissent également. Il est donc essentiel de choisir un système de base de données capable de gérer d'importants volumes de données et de s'adapter facilement aux besoins.
Comment créer une application de chat simple basée sur le web
-------------------------------------------------------------
Pour créer la partie client de votre application web, téléchargez un environnement de développement intégré (IDE) tel que [Visual Studio Code](https://code.visualstudio.com/) et choisissez un cadre spécifique ou utilisez HTML, CSS et [Javascript](https://www.pubnub.com/guides/javascript/). Les cadres pour les applications web comprennent [React](https://reactjs.org/) ou [Angular](https://angular.io/)qui intègrent des techniques de gestion d'état plus avancées pour faciliter le développement.
Une fois que vous avez téléchargé la dernière version de Visual Studio Code, créez un projet en créant des fichiers .html, .css et .js dans le répertoire du projet. En général, les fichiers de base de tout projet javascript vanille sont nommés app.js, index.html et main.css. Si vous copiez le chemin absolu du fichier index.html et le collez dans votre navigateur, votre code s'affichera et s'exécutera. Pour une configuration plus détaillée d'un projet Vanilla JavaScript, consultez le tutoriel Visual Studio Code [tutoriel](https://learn.microsoft.com/en-us/training/modules/get-started-with-web-development/) pour débuter dans le développement web. En utilisant un framework, vous pouvez suivre un tutoriel pour démarrer avec [React](https://reactjs.org/docs/getting-started.html) ou [Angular](https://angular.io/start).
Nous devons maintenant choisir le langage côté serveur et le service d'hébergement que nous prévoyons d'utiliser pour gérer les communications. Par exemple, créons notre premier serveur web en utilisant [Node.js](https://nodejs.org/en/). Une fois que nous avons installé Node.js, nous voulons créer un projet Node.js en utilisant la commande "npm init" depuis notre terminal. Après avoir créé un nouveau projet, nous pouvons l'ouvrir avec Visual Studio Code et créer un fichier appelé index.js qui traitera de l'hébergement du serveur sur localhost. Après avoir créé un nouveau projet, nous pouvons l'ouvrir à l'aide de Visual Studio Code et suivre le guide de démarrage de Node.js [Node.js](https://nodejs.org/en/docs/guides/getting-started-guide/) pour héberger un serveur localement.
Nous voudrons que notre infrastructure frontale communique via un protocole WebSocket avec notre serveur afin que nous puissions communiquer en temps réel entre deux applications clientes. Dans ce cas, nous devons nous familiariser avec l'implémentation et la compréhension de la terminologie WebSocket dans Node.js. Nous devons installer une bibliothèque WebSocket, [ws](https://www.npmjs.com/package/ws) pour l'implémentation de WebSocket, [express](https://www.npmjs.com/package/express) pour créer un simple serveur [HTTP](https://www.pubnub.com/guides/http/), et [nodemon](https://www.npmjs.com/package/nodemon) pour suivre les modifications de notre code et redémarrer le serveur. Avec toute cette configuration, nous pouvons maintenant mettre en œuvre la logique de création d'une simple application de chat basée sur le web. Pour plus d'informations sur l'implémentation des WebSockets dans node.js, consultez notre article sur les WebSockets dans node.js. [Exemples de programmation Node.js WebSocket](https://www.pubnub.com/blog/nodejs-websocket-programming-examples/).
Bien qu'il soit certainement possible d'implémenter la fonctionnalité WebSocket en utilisant les bibliothèques mentionnées ci-dessus, PubNub offre un certain nombre d'avantages qui peuvent en faire un choix plus utile pour implémenter la communication en temps réel dans votre application. L'un des principaux avantages de PubNub est qu'il fournit une infrastructure entièrement gérée pour la communication en temps réel. Cela signifie que vous n'avez pas à vous soucier de la mise en place et de la gestion de vos propres serveurs WebSocket, car PubNub s'occupe de tout cela pour vous. Cela peut vous faire gagner beaucoup de temps et d'efforts, surtout si vous n'êtes pas familier avec les subtilités de l'implémentation de WebSocket.
Exemples d'applications de chat simples basées sur le web
---------------------------------------------------------
Les applications de chat basées sur le web telles que Messenger, Microsoft Teams ou Slack mettent en œuvre des applications de chat personnalisées pour créer des expériences utilisateur uniques. Cependant, avec PubNub, les entreprises n'ont pas besoin de mettre en place et de faire évoluer l'infrastructure.
- [**Application de chat de groupe JavaScript :**](https://www.pubnub.com/demos/10-line-chat/) Une simple application de chat de groupe basée sur le web utilisant le SDK Javascript qui vous permet d'envoyer des messages sur PubNub en temps réel. Ce référentiel est écrit en utilisant la messagerie PubNub et a été réalisé en seulement dix lignes de code (hors stylisme). Vous pouvez également télécharger le dépôt depuis notre site [GitHub](https://github.com/PubNubDevelopers/JavaScript-Simple-Chat).
- [**Chat de groupe utilisant React Chat Components**](https://www.pubnub.com/demos/group-chat-react-demo/)**:** Cette application de chat de groupe, qui utilise les composants de chat à taille unique, permet aux utilisateurs de démarrer des chats directs 1-1 et des chats de groupe. Elle est écrite en utilisant le Framework React et nos [composants de chat React](https://www.pubnub.com/docs/chat/components/react). Consultez notre site [Github](https://github.com/pubnub/react-chat-components/tree/master/samples/react/group-chat) pour télécharger le dépôt.
Démarrer avec PubNub pour votre application de chat basée sur le web
--------------------------------------------------------------------
PubNub est un service IaaS qui permet d'obtenir une solution de chat entièrement personnalisable en utilisant l'un de nos [SDK](https://www.pubnub.com/docs/sdks) qui peut être intégré dans votre application web rapidement et à moindre coût. Vous pouvez tirer parti de PubNub pour intégrer des fonctions de messagerie en temps réel dans votre application. En fin de compte, cette stratégie peut aider les entreprises à économiser du temps et de l'argent tout en fournissant une solution de chat de haute qualité à leurs clients.
PubNub intègre les fonctionnalités suivantes dans son API et peut répondre aux besoins spécifiques de vos applications.
1. [Publier](https://www.pubnub.com/docs/messages/publish): Envoyez des messages à chaque fois que les données de l'utilisateur sont mises à jour, telles que les mises à jour de texte, les réactions emoji, les fichiers envoyés et d'autres [métadonnées complexes](https://www.pubnub.com/docs/metadata/channel-metadata).
2. [S'abonner](https://www.pubnub.com/docs/messages/receive): Recevoir de nouveaux messages pour actualiser les écrans des utilisateurs.
3. [Présence](https://www.pubnub.com/docs/presence/overview): Mise à jour et détection du statut en ligne des utilisateurs.
4. [Persistance des messages](https://www.pubnub.com/docs/storage): Affichez tous les messages reçus une fois que les utilisateurs se connectent à l'application ou suivez les révisions de projets et de documents.
5. [Notifications push mobiles](https://www.pubnub.com/docs/push/send): Notifiez aux utilisateurs mobiles qui ne sont pas dans l'application les messages de chat, les mises à jour du projet ou les mises à jour de l'application.
6. [Contexte de l'application](https://www.pubnub.com/docs/metadata/channel-metadata): Stockez les informations sur vos utilisateurs en un seul endroit sans avoir à configurer ou à appeler votre base de données.
7. [Gestionnaire d'accès](https://www.pubnub.com/docs/security/access-control): Restreignez l'accès aux conversations privées, aux espaces de discussion, aux documents et aux projets pour des utilisateurs spécifiques.
8. [Fonctions](https://www.pubnub.com/docs/general/serverless/functions/overview): Traduire les messages, censurer les messages inappropriés, annoncer l'arrivée de nouveaux utilisateurs et informer les autres utilisateurs des mentions.
9. [Événements et actions](https://www.pubnub.com/docs/general/serverless/events-and-actions/overview): Gestion centralisée des événements dans l'écosystème de votre application et déclenchement de la logique commerciale sans code.
Pour commencer à utiliser PubNub pour alimenter votre application web de chat en temps réel, vous devez d'abord créer un compte PubNub et télécharger le SDK JavaScript de PubNub. Le SDK s'intègre de manière transparente dans votre application et vous permet de vous connecter à la plateforme de communication en temps réel de PubNub.
1. [S'identifier](https://admin.pubnub.com/#/login) ou créez un compte pour créer une application sur le portail d'administration et obtenir les clés à utiliser dans votre application. Apprenez à le faire en suivant ce mode d'emploi sur la [créer des clés](https://www.pubnub.com/how-to/admin-portal-create-keys/).
2. [Téléchargez](https://www.pubnub.com/docs/sdks/android) le SDK JavaScript en suivant les instructions de la documentation pour installer toutes les dépendances PubNub nécessaires à votre application de messagerie.
3. Suivez la documentation de démarrage du SDK pour configurer un objet PubNub afin de commencer à publier et à s'abonner à des canaux.
Comment PubNub peut-il vous aider ?
===================================
Cet article a été publié à l'origine sur [PubNub.com](https://www.pubnub.com/blog/web-based-chat-application/)
Notre plateforme aide les développeurs à construire, fournir et gérer l'interactivité en temps réel pour les applications web, les applications mobiles et les appareils IoT.
La base de notre plateforme est le réseau de messagerie en temps réel le plus grand et le plus évolutif de l'industrie. Avec plus de 15 points de présence dans le monde, 800 millions d'utilisateurs actifs mensuels et une fiabilité de 99,999 %, vous n'aurez jamais à vous soucier des pannes, des limites de concurrence ou des problèmes de latence causés par les pics de trafic.
Découvrez PubNub
----------------
Découvrez le [Live Tour](https://www.pubnub.com/tour/introduction/) pour comprendre les concepts essentiels de chaque application alimentée par PubNub en moins de 5 minutes.
S'installer
-----------
Créez un [compte PubNub](https://admin.pubnub.com/signup/) pour un accès immédiat et gratuit aux clés PubNub.
Commencer
---------
La [documentation PubNub](https://www.pubnub.com/docs) vous permettra de démarrer, quel que soit votre cas d'utilisation ou votre [SDK](https://www.pubnub.com/docs). | pubnubdevrel | |
1,735,283 | Effortless Link Collection: Extracting and Displaying Links with JavaScript | Introduction: In web development, extracting specific information from a webpage is a common task. In... | 0 | 2024-01-19T16:35:37 | https://dev.to/r4nd3l/effortless-link-collection-extracting-and-displaying-links-with-javascript-3pik | javascript, webdev, datamanipulation, browserconsole | Introduction:
In web development, extracting specific information from a webpage is a common task. In this post, we'll explore a handy JavaScript code snippet that collects all links from a page having a "title" attribute. The extracted links are then elegantly displayed on a new tab page in the browser. Follow along and enhance your skills in data extraction and presentation.
Code Snippet:
```javascript
var x = document.querySelectorAll('a[href*="/view/"][title]');
var myarray = [];
for (var i = 0; i < x.length; i++) {
var nametext = x[i].textContent;
var cleantext = nametext.replace(/\s+/g, ' ').trim();
var cleanlink = x[i].href;
myarray.push([cleantext, cleanlink]);
};
function make_table() {
var table = '<table><thead><th>Name</th><th>Links</th></thead><tbody>';
for (var i = 0; i < myarray.length; i++) {
table += '<tr><td>' + myarray[i][0] + '</td><td>' + '<a href="' + myarray[i][1] + '" target="_blank">' + myarray[i][1] + '</a>' + '</td></tr>';
};
var w = window.open("");
w.document.write(table);
}
make_table();
```
Explanation:
This JavaScript code snippet efficiently collects links from the page that have a "title" attribute. It then processes the data, removing unnecessary whitespace, and creates a table for better visualization. The resulting table is opened in a new browser tab, providing a clear and organized display of the extracted links.
Benefits and Use Cases:
- **Data Extraction**: Easily gather links with specific attributes, enhancing your ability to extract targeted information from web pages.
- **Data Presentation**: The generated table offers a structured and user-friendly way to view and interact with the collected links.
- **Customization**: Adapt the code for various scenarios, modifying the CSS styles or table structure to suit your preferences.
Conclusion:
By mastering this JavaScript code snippet, you've added a powerful tool to your web development arsenal. Use it to streamline the process of collecting and presenting links with specific attributes, ultimately improving your efficiency in web data extraction tasks. | r4nd3l |
1,735,353 | Laravel Blade Templating: From Basics to Advanced Techniques | When it comes to the dynamic world of web development, efficient and readable code is key to success.... | 0 | 2024-01-19T18:07:48 | https://techtales.blog/laravel-blade-templating-from-basics-to-advanced-techniques/ | webdev, laravel, blade, templating | When it comes to the dynamic world of web development, efficient and readable code is key to success. Laravel, a powerful PHP framework, offers a compelling templating engine known as Blade. In this guide, we delve into the nuances of Laravel Blade Templating, offering insights and code examples to elevate your development skills.
## Understanding Laravel Blade Templating
Laravel Blade is more than just a templating engine; its a powerful tool for rendering PHP in a simple and elegant manner. Unlike traditional PHP templates, Blade views are compiled into plain PHP code and cached until they are modified, leading to improved performance.
**Basic Concepts of Blade Templating:** Syntax and Structure Understanding Blade starts with its syntax, which is designed to be simple yet powerful:
- Echoing Data: Blades `{{ }}` syntax automatically escapes output, preventing cross-site scripting (XSS) vulnerabilities.
- Control Structures: Blade simplifies PHP control structures with directives. For example, `@if`, `@elseif`, `@else`, `@endif` for conditional statements, and `@foreach`, `@for`, `@while` for loops, making the code cleaner and more readable.
- Including Subviews: Blades `@include` directive helps in modularizing the view by allowing the inclusion of smaller view fragments, enhancing reusability and organization.
## Basic Syntax of Blade Templating
The Blade syntax is intuitive and easy to learn. Heres a basic example to get started:
```
<!-- Blade view file -->
<html>
<head>
<title>App Name - @yield('title')</title>
</head>
<body>
@section('sidebar')
This is the master sidebar.
@show
<div class="container">
<h1>Hello, {{ $name }}</h1>
@yield('content')
</div>
</body>
</html>
```
- `@yield('title')`: Used to display the contents of a section.
- `@section('sidebar')`: Defines a section named 'sidebar'.
- `{{ $name }}`: Echoes content with PHP.
- `@show`: Renders the section content.
## Working with Conditional Statements
Blade makes it straightforward to use conditional statements:
```
@if (count($records) === 1)
I have one record!
@elseif (count($records) > 1)
I have multiple records!
@else
I don't have any records!
@endif
```
`@if`, `@elseif`, `@else`: Blade's conditional directives.
## Switch statements
```
@switch($role)
@case('admin')
<p>Admin User</p>
@break
@default
<p>Regular User</p>
@endswitch
```
## Loop Structures in Blade
Looping is a breeze with Blade. Heres a quick look at a `@foreach` loop:
```
@foreach ($users as $user)
<p>This is user {{ $user->id }}</p>
@endforeach
```
`@foreach`: Iterates over an array or collection.
## Integrating Blade with Laravel Controllers
Blades real power shines when integrated with Laravel controllers. For example:
```
// In a Laravel Controller
public function show($id)
{
$user = User::findOrFail($id);
return view('user.profile', ['user' => $user]);
}
```
In the Blade view, you can display the users name like this:
```
<h1>Hello, {{ $user->name }}</h1>
```
## Advanced Blade Features and Techniques
Blades capabilities extend to more complex scenarios:
- Template Inheritance: Blades layout system, with `@extends` and `@section` directives, facilitates the reuse of common layout components, reducing duplication.
- Blade Components and Slots: Introduces a component-based architecture to Blade, allowing for encapsulation and reuse of UI elements.
- Service Injection: The `@inject` directive injects services directly into templates, offering a convenient way to access Laravel's service container.
- Extending Blade: Laravel allows the addition of custom directives to Blade, enabling the creation of domain-specific language (DSL) within templates.
## Template Inheritance and Layouts
Blade allows you to define a master layout and extend it in child templates.
**_Master Layout:_**
```
<!-- layouts/app.blade.php -->
<html>
<head>
<title>App Name - @yield('title')</title>
</head>
<body>
@section('sidebar')
This is the master sidebar.
@show
<div class="container">
@yield('content')
</div>
</body>
</html>
```
**_Extending a Layout:_**
```
@extends('layouts.app')
@section('title', 'Page Title')
@section('sidebar')
@parent
<p>This is appended to the master sidebar.</p>
@endsection
@section('content')
<p>This is my body content.</p>
@endsection
```
**_Components and Slots:_**
```
<!-- components/alert.blade.php -->
<div class="alert alert-{{ $type }}">
{{ $slot }}
</div>
```
Usage
```
<x-alert type="danger">
This is a danger alert!
</x-alert>
```
**_Service Injection:_**
```
@inject('metrics', 'App\Services\MetricsService')
<p>Monthly Revenue: {{ $metrics->monthlyRevenue() }}</p>
```
**_Custom Directives:_** Custom directives add immense flexibility. Heres how to create a simple directive:
```
Blade::directive('datetime', function ($expression) {
return "<?php echo with{$expression}->format('m/d/Y H:i'); ?>";
});
```
Usage:
```
@datetime($date)
```
## Summary:
The Laravel Blade Templating Engine is a cornerstone of the Laravel framework, offering an expressive and elegant way to create dynamic web pages. Its combination of simplicity, power, and extensibility makes it an invaluable tool for Laravel developers. | mktheitguy |
1,735,400 | Beyond Coding: 10 Soft Skills Every Nearshore Developer Needs for Success | Software development is a highly technical and specialized field that requires a vast array of hard... | 0 | 2024-06-10T15:21:27 | https://dev.to/zak_e/beyond-coding-10-soft-skills-every-nearshore-developer-needs-for-success-4dfl | webdev | ---
title: Beyond Coding: 10 Soft Skills Every Nearshore Developer Needs for Success
published: true
date: 2024-01-19 14:10:21 UTC
tags: WebDevelopment
canonical_url:
---
Software development is a highly technical and specialized field that requires a vast array of hard skills and knowledge. Gone are the days when the only expectations from developers were centered around their software development skills and technical skills. While writing excellent code and writing and executing tests are still cornerstones of developer activities, in […]
The post [Beyond Coding: 10 Soft Skills Every Nearshore Developer Needs for Success](https://blog.nextideatech.com/10-essential-skills-for-a-software-developer/) appeared first on [Next Idea Tech Blog](https://blog.nextideatech.com). | zak_e |
1,735,570 | How To Quickly Define an Efficient SQL Index for GROUP BY Queries | GROUP BY queries allow you to partition a table into groups based on the values of one or more... | 0 | 2024-01-19T21:15:05 | https://writech.run/blog/how-to-quickly-define-an-efficient-sql-index-for-group-by-queries-b8ba0c42bd07/ | data, database, index, performance | [`GROUP BY`](https://en.wikipedia.org/wiki/Group_by_%28SQL%29) queries allow you to partition a table into groups based on the values of one or more columns. Its purpose is to let you easily retrieve aggregate results at the database level, and it is typically used in conjunction with SQL aggregate functions, such as `COUNT()`, `MAX()`, `MIN()`, `SUM()`, or `AVG()`. Particularly, read [this](https://arctype.com/blog/sql-aggregate-functions/) real-world case article on how SQL aggregate functions to increase the performance of a backend.
The main problem with `GROUP BY` is that queries involving it are usually slow, especially when compared with `WHERE`\-only queries. Luckily, by defining the right SQL [index](https://en.wikipedia.org/wiki/Database_index) you can effortlessly make them lightning fast.
Let's now delve into the how.
## The Perfect Index for a GROUP BY Query in 4 Steps
As described [here](https://dev.mysql.com/doc/refman/8.0/en/group-by-optimization.html), optimizing a `GROUP BY` query can be tricky and involves many operations and adjustments. This means that finding the best possible solution to make your queries more performant can easily become a grueling task. That being said, the simple procedure that follows should allow you to achieve remarkable results and be enough in most cases.
First, make sure to rewrite your query so that the columns used in the `GROUP BY` clause appears in your `SELECT` clause at the beginning and in the same order. Keep in mind that column order is critical when defining a SQL index.
Then, define an index involving the following columns as described in these instructions:
1. columns in the same order as they appear in the `WHERE` clause (if present)
3. remaining columns in the same order as they appear in the `GROUP BY` clause
5. remaining columns in the same order as they appear in the `ORDER BY` clause (if present)
7. remaining columns in the same order as they appear in the `SELECT` clause
This 4-step approach derives from [this](https://stackoverflow.com/questions/11631367/speeding-up-group-by-sum-and-avg-queries) [StackOverflow](https://stackoverflow.com/) answer, and it has helped my team make `GROUP BY` queries up to 10x faster on several occasions.
Now, let's see how to define it through an example. Let's say you are dealing with the following `GROUP BY` [MySQL](https://en.wikipedia.org/wiki/MySQL) query:
```sql
SELECT city, AVG(age) AS avg_age, school
FROM fooStudent
WHERE LENGTH(name) > 5
GROUP BY city, school
```
First, you have to rewrite your query as follows:
```sql
SELECT city, school, AVG(age) AS avg_age
FROM fooStudent
WHERE LENGTH(name) > 5
GROUP BY city, school
```
Then, according to the 4 aforementioned rules, this is what your performance-improving index definition should look like:
```sql
CREATE INDEX fooStudent_1 ON fooStudent(name, city, school, age)
```
Et voilà! Your `GROUP BY` query will now be faster than ever.
## Conclusion
`GROUP BY` is a powerful statement, but it tends to slow down queries. Over time, my team and I have used it many times and defined SQL indexes to avoid the performance issues introduced by the `GROUP BY` clause, especially when dealing with large tables. Specifically, a simple 4-step procedure is enough to define an efficient SQL index that will make your `GROUP BY` queries up to 10 times faster, and presenting it is what this article was about.
Thanks for reading! I hope that you found my story helpful.
***
_The post "[How To Quickly Define an Efficient SQL Index for GROUP BY Queries](https://writech.run/blog/how-to-quickly-define-an-efficient-sql-index-for-group-by-queries-b8ba0c42bd07/)" appeared first on [Writech](https://writech.run)._ | antozanini |
1,735,632 | Improving Performance in a Hierarchical SQL Table Structure with Column Propagation | In this article, you will learn how column propagation can represent an easy approach to improving... | 0 | 2024-01-19T21:37:02 | https://writech.run/blog/improving-performance-hierarchical-sql-table-structure-column-propagation/ | In this article, you will learn how column propagation can represent an easy approach to improving query performance when dealing with a hierarchical data structure. Mainly, you will see how this approach represented the solution my team ended up adopting to meet the performance requirements defined by the customer.
Let's now delve deeper into this real-world scenario based on a data-driven, large, and involving live data website developed for a startup operating in the sports industry. Learn everything you need to know about column propagation as a solution to the performance issues inherent in hierarchical SQL table structures.
## Presenting the Context
My team and I recently worked on a website for soccer fans that has millions of pages. The idea of that website is to be the definitive resource for soccer supporters, especially when it comes to betting. The database and application architecture is not particularly complex. This is also because a scheduler takes care of periodically recalculating complex data and storing it in tables so that the queries will not have to involve [SQL aggregations](https://writech.run/blog/improving-performance-sql-aggregate-functions/). So, the real challenges lie in non-functional requirements, such as performance and page load time. Now, let's dive into this scenario.
### Application domain
In the sports industry, there are several data providers available and each of them offers their clients a different set of data. Specifically, there are four types of data in the soccer industry:
1. **Biographical data**: height, width, age, teams they played for, trophies won, personal awards won, and so on of soccer players and coaches.
3. **Historical data**: results of games played in the past and the events that occurred in those games, such as goals, assists, yellow cards, red cards, passes, and so on.
5. **Current and future data**: results of games played in the current season and the events that occurred in those games, as well as tables of future games.
7. **Live data**: real-time results and live events of games in progress.
That website involves all these kinds of data, with special attention to historical data for SEO reasons and live data to support betting.
### Hierarchical table structure
I cannot share with you the entire data structure because of an [NDA](https://en.wikipedia.org/wiki/Non-disclosure_agreement) I signed. At the same time, understanding the structure of soccer seasons is enough to understand this real-world scenario.
In detail, soccer providers generally organize data on games in a season as follows:
- **Season**: has a start and end date and generally lasts one calendar year
- **Competition**: the league a game belongs to. An instance of a competition lives inside a season. Learn more about how soccer competitions work [here](https://en.wikipedia.org/wiki/List_of_association_football_competitions).
- **Phase**: the stage associated with the competition (e.g., qualifying stage, knockout stage, final stage). Each competition has its own rules, and many of them only have one phase.
- **Group**: the group associated with the phase (e.g., group A, group B, group C, …). Some competitions such as the [World Cup](https://en.wikipedia.org/wiki/FIFA_World_Cup) involve different groups, each with their own teams. Most competitions only have one general group for all teams.
- **Turn**: corresponds to one day of a competition from a logical point of view. It usually lasts one week and covers the games played by all the teams that are part of a group in that time span (e.g., MLS has 17 home games and 17 away games, therefore it has 34 turns).
- **Game**: a match between two soccer teams.
As shown below in the [ER schema](https://www.dbvis.com/thetable/er-diagrams-vs-er-models-vs-relational-schemas/), these 5 table represents a hierarchical data structure:
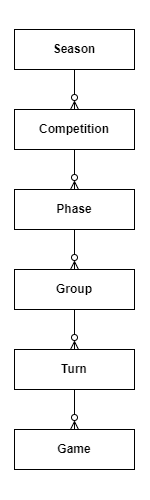
### Technologies, specs, and performance requirements
We developed the backend in Node.js and TypeScript with [Express 4.17.2](https://expressjs.com/en/changelog/4x.html#4.17.2) and [Sequelize 6.10](https://sequelize.org/docs/v6/) as ORM ([Object](https://en.wikipedia.org/wiki/Object%E2%80%93relational_mapping) [Relational Mapping](https://en.wikipedia.org/wiki/Object%E2%80%93relational_mapping)). The frontend is a [Next.js 12](https://nextjs.org/blog/next-12) application developed in TypeScript. As for the database, we decided to opt for a Postgres server hosted by AWS.
The website runs on [AWS Elastic Beanstalk](https://aws.amazon.com/elasticbeanstalk/) with 12 instances for the frontend and 8 instances for the backend and currently has from 1k to 5k daily viewers. Our client's goal is to reach 60k daily views within a year. Therefore, the website must be ready to host millions of monthly users without performance drops.
The website should score 80+ in performance, SEO, and accessibility in [Google Lighthouse](https://developers.google.com/web/tools/lighthouse) tests. Plus, the load time should always be less than 2 seconds and ideally in the order of a few hundred milliseconds. This is where the real challenge lies, since the website consists of more than 2 million pages and pre-rendering them all will take weeks. Also, the content shown in the majority of the pages is not static. Thus, we opted for an [incremental static regeneration](https://nextjs.org/docs/basic-features/data-fetching/incremental-static-regeneration) approach. This means when a visitor hits a page no one ever visited, Next.js generates it with the data retrieved from the APIs exposed by the backend. Then, Next.js caches the page for 30 or 60 seconds, depending on the importance of the page.
So, the backend must be lightning-fast in providing the server-side generation process with the required data.
## Why Querying Hierarchical Tables is Slow
Let's now look at why a hierarchical table structure can represent a challenge for performance.
### JOIN queries are slow
A common scenario in a hierarchical data structure is that you want to filter leaves based on parameters associated with objects higher up in the hierarchy. For example, you may want to retrieve all games played in a particular season. In this case, since the leaf table Game is not directly connected to Season, you must perform a query involving as many `JOIN` as there are elements in the hierarchy.
So, you might end up writing this query:
```sql
SELECT GA.* FROM `Game` GA
LEFT JOIN `Turn` T on GA.`turnId` = T.`id`
LEFT JOIN `Group` G on T.`groupId` = G.`id`
LEFT JOIN `Phase` P on G.`phaseId` = P.`id`
LEFT JOIN `Competition` C on P.`competitionId` = C.`id`
LEFT JOIN `Season` S on C.`seasonId` = S.`id`
WHERE S.id = 5
```
Such a query is slow. This is because each `JOIN` performs a [Cartesian product](https://en.wikipedia.org/wiki/Cartesian_product) operation, which takes time and may result in thousands of records. So, the longer your hierarchical data structure is, the worse it is when it comes to performance.
Also, if you want to retrieve all data and not just the columns in the Game table, you will have to deal with thousands of rows with hundreds of columns due to the nature of the Cartesian product. This can become messy, but this is where ORM comes into play.
### ORM data decoupling and transformation take time
When querying a database through an ORM, you are typically interested in retrieving data in its application-level representation. Raw database-level representation may not be useful at the application level. So, when most advanced ORMs perform a query, they retrieve the desired data from the database and transform it into its application-level representation. This process involves two steps: data decoupling and data transformation.
What happens behind the scenes is that the raw data coming from the `JOIN` queries is first decoupled and then transformed into the respective representation at the application level. So, when dealing with all data, the thousands of records with hundreds of columns become a small set of data, each having the attributes defined in the data model classes. So, the array containing the raw data extracted from the database will become a set of Game objects. Each `Game` object will have a turn field containing its respective Turn instance. Then, the Turn object will have a group field storing its respective Group object, and so on.
Generating this transformed data is an overhead you are willing to accept. In fact, dealing with messy raw data is challenging and leads to code smells. On the other hand, this process happening under the hood takes time, and you cannot overlook it. This is especially true when the raw records are thousands of rows since dealing with arrays storing thousands of elements is always tricky.
In other words, common `JOIN` queries on hierarchical table structures are slow at both the database and application layers.
## Column Propagation as a Solution
To avoid this performance issue, the solution is propagating columns from parents to their children in a hierarchical structure. Let's learn why.
### Why you should propagate columns on hierarchical databases
When analyzing the `JOIN` query above, it is evident that the problem lies in the fact that to apply a filter on the leaf table Game, you have to go through the whole hierarchy. But since `Game` is the most important element in the hierarchy, why not add the `seasonId`, `competitionId`, `phaseId`, and `groupId` columns directly to it? This is what column propagation is about!
By propagating the external key columns directly to the children, you can avoid all the JOINs. You could now replace the query presented above with the following one:
```sql
SELECT * FROM `Game` GA
WHERE GA.seasonId = 5
```
As you can imagine, this query is much faster than the original one. Also, it returns directly what interests you. So, you can now overlook the ORM data decoupling and transformation process.
Notice that column propagation involves data duplication and you should use it sparingly and judiciously. But before delving into how to implement it elegantly, let's see which columns you should propagate.
### How to choose the column to propagate
Basically, you should propagate down each column of the entities that are higher in the hierarchy which might be useful when it comes to filtering. For example, this involves external keys. Also, you might want to propagate [enum columns](https://www.postgresql.org/docs/current/datatype-enum.html) used to filter data or generate columns with aggregate data coming from the parents to avoid JOINs.
## Top 3 Approach to Column Propagation
When my team opted for the column propagation approach, considered 3 different approaches to implement it. Let's analyze them all.
### 1\. Creating a materialized view
The first idea we had to implement column propagations in a hierarchy table structure was to create a [materialized view](https://www.postgresql.org/docs/current/sql-creatematerializedview.html) with the desired columns. In detail, a materialized view stores the result of a query, and it generally represents a subset of the rows and/or columns of a complex query such as the JOIN query presented above.
When it comes to materialized queries, you can define when to generate the view. Then, your database takes care of storing it on the disk and making it available as if it were a normal table. So, even though the generation query might be slow, you can launch it only sparingly. So, materialized views represent a fast solution.
On the other hand, materialized views are not the best approach when dealing with live data. This is because a materialized view might not be up-to-date. In fact, the data it stores depends on the moment you decide to generate the view or refresh it. Also, materialized views involving large data take a lot of disk space, which may represent a problem and cost you money in storage.
### 2\. Defining a virtual view
Another possible solution is using a [virtual view](https://www.postgresql.org/docs/9.2/sql-createview.html). Again, a virtual view is a table that stores the result of a query. The difference with a materialized view is that this time your database does not store the results from the query on the disk, but keeps it in memory. So, a virtual view is always up to date, solving the problem with live data.
On the other hand, the database has to execute the generation query every time you have to access the view. So, if the generation query takes time, then the entire process involving the view cannot but be slow. Virtual views are a powerful tool but considering our performance goals, we had to look for another solution.
### 3\. Using Triggers
[SQL triggers](https://www.dbvis.com/thetable/sql-triggers-what-they-are-and-how-to-use-them/) allow you to automatically launch a query when a particular event happens in the database. In other words, triggers give you the ability to synchronize data across the database. So, by defining the desired columns in the tables of the hierarchy and letting the custom-defined triggers update them, you can easily implement column propagation.
As you can imagine, triggers add performance overhead. This is because every time the events they wait for happen, your database executes them. However, performing a query takes time and memory. So, triggers come with a cost. On the other hand, this cost is generally negligible, especially when compared with the drawbacks coming with virtual or materialized views.
The problem with triggers is that defining them might take some time. At the same time, you can tackle this task only once and update them if required. So, triggers allow you to easily and elegantly implement column propagation. Also, since we adopted column propagation and implemented it with triggers, we have managed to meet the performance requirements defined by the customer by a wide margin.
## Final Thoughts
Hierarchy structures are common in databases, and if not approached correctly they might lead to performance issues and inefficiencies in your application. This is because they require long JOIN queries and ORM data processing that are slow and time-consuming. Luckily, by propagating columns from parents to children in the hierarchy you can avoid all this, and explaining how to do it through a real-world case study was why I wrote this article!
***
_The post "[Improving Performance in a Hierarchical SQL Table Structure with Column Propagation](https://writech.run/blog/improving-performance-hierarchical-sql-table-structure-column-propagation/)" appeared first on [Writech](https://writech.run)._ | antozanini | |
1,736,138 | Scrivener alternative Free 🚀 | Title: Crafting Compelling Narratives: A Guide to Writing Stories with GitBook – A Top Alternative to... | 0 | 2024-01-20T11:46:29 | https://dev.to/sh20raj/title-crafting-compelling-narratives-a-guide-to-writing-stories-with-gitbook-free-scrivener-alternative-4b72 | Title: Crafting Compelling Narratives: A Guide to Writing Stories with GitBook – A Top Alternative to Traditional Writing Software
Introduction:
In the digital age, writers are constantly seeking innovative tools to streamline the writing process and enhance collaboration. GitBook, originally designed for technical documentation, has emerged as a versatile platform that writers can leverage to craft and organize their stories seamlessly. In this comprehensive guide, we will explore how to use GitBook as a tool to arrange and manage your entire story-writing journey. Moreover, we'll delve into how GitBook stands out as a top alternative to professional story, script, and book writing software such as Scrivener, Word, and ProWritingAid.
### Getting Started:
#### 1. **Setting Up Your GitBook Account:**
- Visit [GitBook](https://www.gitbook.com/) and sign up for an account.
- Create a new book to house your story.
#### 2. **Structuring Your Book:**
- Utilize GitBook's intuitive interface to create chapters and subchapters.
- Establish a logical hierarchy to organize your story effectively.
### Writing Your Story:
#### 3. **Using Markdown:**
- GitBook supports Markdown, a lightweight markup language. Familiarize yourself with Markdown to format your text easily.
- Employ headers, lists, and bold/italic text for emphasis.
#### 4. **Embedding Multimedia:**
- Enhance your storytelling by embedding images, videos, or interactive elements.
- Use GitBook's media embedding capabilities to create a multimedia-rich experience.
#### 5. **Version Control with Git:**
- Leverage Git integration to track changes and collaborate with other writers.
- Utilize branches for different story arcs or alternative endings.
### Collaborating with Others:
#### 6. **Collaborative Editing:**
- Invite co-authors or editors to contribute to your story.
- Benefit from real-time collaborative editing features to enhance teamwork.
#### 7. **Feedback and Comments:**
- Encourage readers and collaborators to provide feedback directly on your GitBook.
- Use comments to discuss specific sections, gather input, and refine your narrative.
### Managing Your Story:
#### 8. **Version History:**
- Explore the version history to review and revert to previous versions of your story.
- Track the evolution of your narrative and see how it has developed over time.
#### 9. **Exporting and Publishing:**
- Export your story in various formats, such as PDF or eBook, for wider distribution.
- Utilize GitBook's publishing options to make your story accessible to a broader audience.
### GitBook as a Top Alternative:
#### 10. **Collaboration Beyond Boundaries:**
- Unlike standalone software, GitBook operates entirely online, facilitating real-time collaboration among writers, editors, and contributors, regardless of geographical locations.
#### 11. **Version Control and History:**
- GitBook's seamless integration with Git provides robust version control, enabling authors to track changes, create branches for different story arcs, and easily navigate through the version history.
#### 12. **Structured Organization:**
- GitBook's intuitive interface allows for the creation of structured and hierarchical documentation with chapters and subchapters. This makes it easy to maintain a well-organized and cohesive narrative.
#### 13. **Markdown Formatting:**
- The use of Markdown in GitBook provides writers with a straightforward yet powerful way to format text, enhancing the writing experience without the clutter often associated with traditional word processors.
#### 14. **Multimedia Integration:**
- GitBook supports the seamless integration of multimedia elements, allowing writers to include images, videos, and interactive content directly within the narrative.
#### 15. **Cost-Effective Solution:**
- GitBook provides essential features for story/script/book writing at no cost, making it an attractive alternative for those who seek a professional writing tool without the financial investment associated with some traditional software.
#### 16. **Community and Feedback:**
- The collaborative nature of GitBook extends to readers, who can provide feedback and comments directly on the platform. This fosters a sense of community engagement around the storytelling process.
#### 17. **Exporting and Publishing Options:**
- GitBook allows authors to export their work in various formats, such as PDF or eBook, offering flexibility in sharing and publishing their stories. This is particularly valuable for writers looking to reach a broader audience.
#### 18. **Adaptability for Documentation:**
- While GitBook is versatile for storytelling, its adaptability extends to technical documentation, making it a comprehensive solution for writers who navigate between creative storytelling and more formal, structured documentation.
#### 19. **User-Friendly Theming:**
- Writers can customize the appearance of their books with GitBook's theming options, allowing for a personalized and visually appealing reading experience that suits the tone of the story.
In conclusion, GitBook emerges as a powerful and cost-effective alternative to traditional writing software, providing a collaborative and organized platform for authors to bring their stories to life. Its ability to seamlessly integrate version control, multimedia, and community engagement makes it an excellent choice for writers seeking a dynamic and efficient solution for their storytelling endeavors. Embrace GitBook as your go-to platform and elevate your writing experience in the modern age of collaborative storytelling. | sh20raj | |
1,735,794 | How often are you ensuring your infrastructure is safe and secure ? What tools do you use to help? #cybersecurity | Just doing some cloud security checks to ensure everything is intact. AWS, Azure and Oracle make this... | 0 | 2024-01-20T02:44:04 | https://dev.to/firststeptechnology/how-often-are-you-ensuring-your-infrastructure-is-safe-and-secure-what-tools-do-you-use-to-help-cybersecurity-h05 | Just doing some cloud security checks to ensure everything is intact. AWS, Azure and Oracle make this so simple with their built in tools. Happy weekend yall! | firststeptechnology | |
1,735,849 | AWS Boto3: Clients vs Resources - DynamoDB | Recently, my colleague brought up the difficulty of using the AWS SDK for Python (Boto3) while... | 0 | 2024-01-21T09:44:48 | https://dev.to/ryanlwh/aws-boto3-clients-vs-resources-dynamodb-10f | aws, python, dynamodb | Recently, my colleague brought up the difficulty of using the [AWS SDK for Python (Boto3)](https://aws.amazon.com/sdk-for-python/) while working with DynamoDB, especially the cumbersome mapping of [`AttributeValue`](https://docs.aws.amazon.com/amazondynamodb/latest/APIReference/API_AttributeValue.html) objects on the `Table` operations. One of the easiest ways to get around this difficulty is to switch from the [clients](https://boto3.amazonaws.com/v1/documentation/api/latest/guide/clients.html) interface to the [resources](https://boto3.amazonaws.com/v1/documentation/api/latest/guide/resources.html) interface.
It is important to know the key difference between clients and resources. From the definition of the Boto3 documentation:
> Clients provide a low-level interface to AWS whose methods map close to 1:1 with service APIs.
#
> Resources represent an object-oriented interface to Amazon Web Services (AWS). They provide a higher-level abstraction than the raw, low-level calls made by service clients.
Let's quickly write a script to demonstrate the difference in the responses:
```python
import boto3
import simplejson
def print_items(desc, response):
items = response.get('Items')
items_json = simplejson.dumps(items, indent=4)
print(f'{desc}:', items_json, sep='\n')
ddb_table_name = 'test'
# DynamoDB client
ddb_client = boto3.client('dynamodb')
# Scan the table
response = ddb_client.scan(TableName=ddb_table_name)
print_items('client', response)
print('\n')
# DynamoDB resource
ddb_resource = boto3.resource('dynamodb')
# Scan the table
response = ddb_resource.Table(ddb_table_name).scan()
print_items('resource', response)
```
The output:
```json
client:
[
{
"datetime": {
"S": "2024-01-20T00:01:02"
},
"id": {
"N": "1"
},
"data": {
"L": [
{
"M": {
"amount": {
"N": "40"
}
}
},
{
"M": {
"amount": {
"N": "56"
}
}
}
]
}
}
]
resource:
[
{
"datetime": "2024-01-20T00:01:02",
"id": 1,
"data": [
{
"amount": 40
},
{
"amount": 56
}
]
}
]
```
Notice the simplicity of the second output. The abstraction of the resources interface deserialized the low-level raw response of the AWS service API.
In most cases, the resources interface can be used over the low-level clients for the abstraction benefits. However, as stated at the top of the resources interface documentation:
> The AWS Python SDK team does not intend to add new features to the resources interface in boto3".
**Therefore, it is essential to compare both interfaces to determine whether the resources interface is sufficient for your use case.**
In a future post, I will explore another method to work with the AttributeValue maps in Boto3.
---
### Further reading
- [DynamoDB - Boto3 1.34.23 documentation](https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/dynamodb.html)
- [More info about resource deprecation? · boto/boto3 · Discussion #3563](https://github.com/boto/boto3/discussions/3563)
- [simplejson · PyPI](https://pypi.org/project/simplejson/)
| ryanlwh |
1,735,931 | Start Your Trial With the IPVanish VPN App👇 | A post by Abdullah | 0 | 2024-01-20T07:22:00 | https://dev.to/abdullah433/start-your-trial-with-the-ipvanish-vpn-app-2kpk | webdev, tutorial, beginners, javascript | [](url)[](https://shorturl.at/wyCH8)
 | abdullah433 |
1,736,133 | built-in sequences in python | so imma go thru 2 set of comparisons between sequences in python. container vs flat... | 0 | 2024-01-20T11:40:00 | https://dev.to/sungiven/built-in-sequences-in-python-21gi | python, sequences, containers, mutability | so imma go thru 2 set of comparisons between sequences in python.
1. container vs flat sequences
2. mutable vs immutable sequences
## container vs flat seqs
container seqs are the ones that can hold items of different types, incl nested containers. examples: `list`, `tuple`, `collections.deque`
flat seqs hold items of one simple type. examples: `str`, `bytes`, `array.array`.
a container seq holds refs to objs it contains which can be of any type, while a flat seq stores the value of its items in its own memory space, not distinct python objs.
## mutable vs immutable seqs
examples for mutable: `list`, `bytearray`, `array.array`, `collections.deque`
examples for immutable: `tuple`, `str`, `bytes`
mutable sequences inherit all methods from immutable seqs, and additionally implement additional methods. the built-in concrete seq types don't subclass the `Sequence` and `MutableSequence` ABCs, but they're virtual subclasses registered with those ABCs. being virtual subclasses, `tuple` and `list` pass these tests:
```python
>>> from collections import abc
>>> issubclass(tuple, abc.Sequence)
True
>>> issubclass(list, abc.MutableSequence)
True
```
the most fundamental seq types is the `list` which is a mutable container.
 | sungiven |
1,737,064 | Impact of Faster CPUs vs. More CPUs on ClickHouse Performance | In ClickHouse, faster CPUs can enhance performance, especially for CPU-bound operations such as... | 0 | 2024-01-21T18:51:45 | https://dev.to/shiviyer/impact-of-faster-cpus-vs-more-cpus-on-clickhouse-performance-aa8 | clickhouse, dba, data, analytics | In ClickHouse, faster CPUs can enhance performance, especially for CPU-bound operations such as complex query calculations, data compression, and decompression. Faster CPUs can execute these tasks more quickly compared to several slower CPUs. However, the benefit depends on the specific workload:
- For operations that are parallelizable, having more CPUs can be more advantageous as ClickHouse can distribute the workload across multiple cores.
- For operations that are not easily parallelizable or where the bottleneck is the single-threaded performance, faster CPUs would provide more benefits.
The choice between faster CPUs and more CPUs should be based on the specific use case and the nature of the queries being run in ClickHouse.
Read more:
- https://chistadata.com/optimizing-hash-group-by-and-order-by-queries-in-clickhouse-strategies-for-enhanced-performance/
- https://chistadata.com/deep-dive-into-clickhouse-internals-architectural-insights-and-performance-optimization-for-olap-systems/
- https://chistadata.com/understanding-clickhouse-storage-engines-types-use-cases-and-performance-optimization/
- https://chistadata.com/mastering-complex-query-optimization-in-clickhouse-for-high-performance-e-commerce-analytics/
| shiviyer |
1,736,373 | How To Deploy A Flask App On Digitalocean | Introduction Flask is a python framework for building web applications. It’s a popular... | 0 | 2024-01-20T19:19:41 | https://dev.to/stefanie-a/how-to-deploy-a-flask-app-on-digitalocean-3ib7 | cloud, docker, python, tutorial | ## Introduction
Flask is a python framework for building web applications. It’s a popular choice for building web apps because of its simplicity and flexibilty. Gunicorn(Green unicorn) is a Python WSGI HTTP server for unix. It acts as a middle layer which receives requests sent to the Web server from a client and forwards them to the Python app. Nginx on other hand is a Web server and reverse proxy which helps in load balancing, caching and handling static files. Docker simplifies your deployment process, allowing you to package your application and its dependencies into a single container.
In this tutorial, we will deploy a flask app to a digitalocean droplet from an existing github repository, utilizing Gunicorn and Nginx and also containerize the app with Docker.
**Prerequisites**
To follow this tutorial, we will need the following:
Digitalocean account, required for deploying the application.
Git to clone the repository.
Gunicorn installed for running the web applications.
Nginx installed, following steps from Nginx Documentation.
Docker installed for creating and running your container.
## Part 1- Creating a Droplet and Installing Gunicorn
We will be deploying our application on digitalocean so you need to create an account.
### Step 1: Create a droplet on digitalocean.
The first step is to choose any region of your choice, image for your server, select a CPU option and an authentication method.
### Step 2: SSH into your droplet console, install python and clone your github repository of your existing flask application.
```
sudo apt update
sudo apt install python3 python3-pip python3-venv
```
This will also install the venv module.

Clone the Github repo

Navigate into your github repository:

### Step 3: Create a python virtual environment on your server.(Optional)
Creating a python virtual environment is totally optional. It is used when you have multiple python versions installed on your server.
Make a new directory and navigate into it.
```
mkdir venv
cd venv
```
Now create a virtual environment and activate it as shown below.

Your prompt will change to indicate that you are operating inside a virtual environment.
To deactivate simply execute the command below(optional):
```
deactivate
```
### Step 4: Install Gunicorn
We need to install Gunicorn which will serve our flask app and we also install all requirements necessary for your Flask app from the requirements.txt in the repository.

```
pip install -r requirements.txt
```
We will now start your the flask app using the following command.
```
python app.py
```

Visit your server’s ip address on your browser.(http://your_server_ip:port<route_if_any>).
If we close our terminal, the flask app will stop running. To keep it running in the background, we need Gunicorn as a daemon. It operates as a background process, detaching from the terminal. If you close the terminal or logout without destroying the server the app won’t stop running because daemon continues to run in the background.
```
gunicorn -b 0.0.0.0:8000 app:app --daemon
```
Great job! You have successfully deployed your Flask app using Gunicorn.
## Part 2-Setting up and Configuring Nginx
Now that you have completed the first part of deploying your Flask app and making it accessible with Gunicorn a web server gateway interface(WSGI) for python applications on your web browser, the next part is to set up Nginx which is a web server for reserve proxy(a server that sits between the client devices and a backend server) handling request from clients and forwarding them to the appropriate backend server and takes the response back to the clients.
### Step 1: Install Nginx
Ngnix should be automatically registered as a systemd service and should be running.
```
sudo apt install nginx -y
```
To check the status of your nginx if it is running or not use the following command:
```
sudo systemctl status nginx
```
If it is not running then execute this command:
```
sudo systemctl start nginx
```
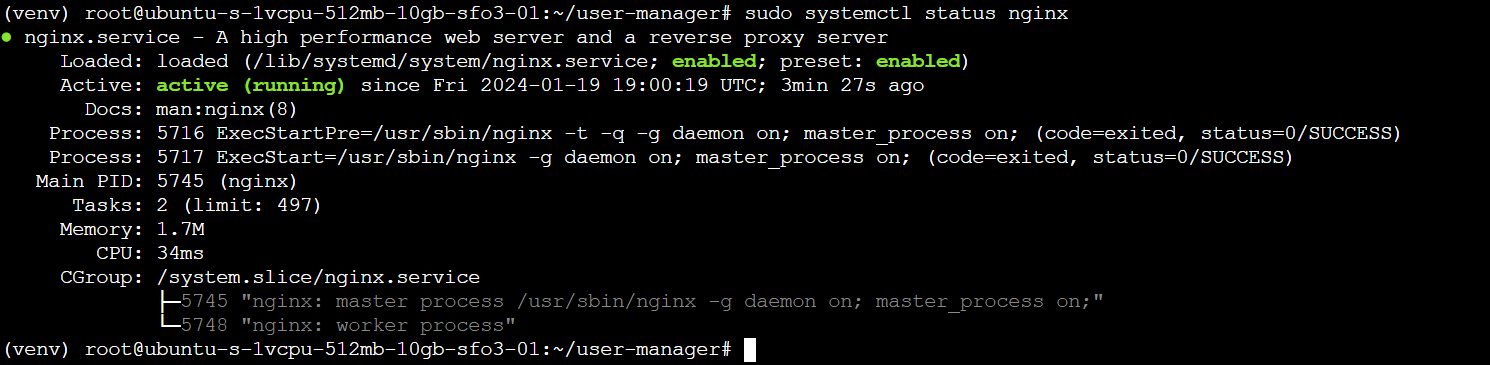
Then you are good to go. For visual verification that everything is working properly, visit your server ip address again on your brower(http://your_server_ip), and you should see the Nginx default welcome page.
### Step 2: Configuring Nginx
Nginx configuration usually lives in the /etc/nginx directory with the Nginx configuration files ending with .conf extension inside. Navigate into this directory and list all the files:
Let’s move the contents of the nginx.conf file into a new file and create a new configuration file for learning purposes to avoid editing the original nginx.conf file.
```
#rename file
sudo mv nginx.conf nginx.conf.backup
#create new file
touch nginx.conf
```
Open your newly created nginx.conf file using any text editor of your choice and write your new configurations. I will be using nano throughout this tutorial. :
```
sudo nano /etc/ngnix/nginx.conf
```
```
events {
}
http {
server {
listen 80;
server_name tutorial.test;
return 200 "Bonjour, mon ami!\n";
}
}
```
### Step 3: Validate and reload the configuration file
Validate your configuration file to check for any syntax error. If you have a syntax error this command below will let you know.
```
sudo nginx -t
```

The next thing you have to do is to instruct nginx to reload the configuration file:
```
sudo nginx -s reload
```

Once you have reloaded the file, simply reload your web browser again.

Congratulations on getting this far!
## Part 3- Containerize your App With Docker
One of the benefits about containerising your application(s) is that it allows you to package all dependencies, configuration, system tools and runtime necessary for your application into a single container and deploy it across different environments. In this tutorial we will use docker basic syntax to carry this out.We will only be taking a high level overview of how to use Docker.
### Step 1: Install Docker
The first step is to install docker, enable it and start it:
```
sudo apt install docker.io
sudo systemctl enable docker
sudo systemctl start docker
```
## Step 2: Create a dockerfile
Let's create a dockerfile which is used to build Docker Images. It is a simple text file that consists of a set of instructions or commands that is executed by an automated build process in steps from top to bottom. The dockerfile can be modified to meet your needs.
```
sudo touch Dockerfile
sudo nano Dockerfile
```
```
FROM python:3.10
WORKDIR /app
COPY requirements.txt /app/
RUN python -m venv venv
Env PATH="/app/venv/bin:$PATH"
RUN pip install --upgrade pip
RUN pip install --no-cache-dir -r requirements.txt
EXPOSE 80
CMD ["python3.10", "app.py"]
```
## Step 3: Build and Run
Now that your dockerfile is ready, it is time to build an image and run it.
```
docker build -t tutorial .
docker run -d -p 8080:8000 tutorial
```

Nice job! Your app has successfully been containerized.
## Conclusion
In this tutorial, you learned how to deploy your Flask app and containerize it with docker. We first cloned an existing Flask App from Github into a Digitalocean droplet. Gunicorn was installed which was used to create a python web server gateway interface and also Nginx for reverse proxy which could also be used for caching and load balancing. Docker was used to containerize the app making it possible for you to deploy it in any environment without installing any dependency.
Deployment is essential in making your app operational and accessible by users to interact with it. It is an important step in software deployment life cycle. Through deployment, your app becomes available on servers or cloud platforms, allowing users to access, experience, and benefit from its features, ultimately realizing the software's intended purpose. It is the bridge that connects the development phase to the end-users, ensuring that the app is ready for real-world usage, feedback, and continuous improvement.
I hope you find this article helpful. Thank you🙂.
| stefanie-a |
1,736,478 | JAVA- Switch | public class Main { public static void main(String[] args) { //Switch = statement that... | 0 | 2024-01-20T22:38:42 | https://dev.to/codecrafterking/java-switch-2cpm | ```
public class Main {
public static void main(String[] args) {
//Switch = statement that allows a variable to be tested for equality against a list a value
String day = "Friday";
switch(day) {
case "Sunday": System.out.println("It is Sunday");
break;
case "Monday": System.out.println("It is Monday");
break;
case "Tuesday": System.out.println("It is Tuesday");
break;
case "Wednesday": System.out.println("It is Wednesday");
break;
case "Thursday": System.out.println("It is Thursday");
break;
case "Friday": System.out.println("It is Friday");
break;
case "Saturday": System.out.println("It is Saturday");
break;
default: System.out.println("That is not a Day");
}
}
}
```
| codecrafterking | |
1,736,488 | JAVA-Arrays | public class Main { public static void main(String[] args) { //array = used to... | 0 | 2024-01-20T23:17:05 | https://dev.to/codecrafterking/java-arrays-1dik | ```
public class Main {
public static void main(String[] args) {
//array = used to store multiple values in a single variable
String[] cars = new String[3];
cars[0] = "Camaro";
cars[1] = "Corvette";
cars[2] = "Tesla";
for(int i=0; i<cars.length; i++) {
System.out.println(cars[i]);
}
}
}
```
| codecrafterking | |
1,736,534 | REDUX-PERSIST createMigrate Auto Syncing | When you are using redux-persist in your react application then you come up with an issue that when... | 0 | 2024-01-21T01:05:46 | https://dev.to/ministryofjavascript/redux-persist-createmigrate-auto-update-1p07 | react, redux, webdev, javascript | When you are using redux-persist in your react application then you come up with an issue that when you change the data structure of any reducer state then it will not appear in your redux state when you reload your application so for that redux-persist provide us a way to update the state using createMigrate method.
To do that you need to create a migration where you provide your updated state so that it will appear in your redux state.
```
export const migration = {
0: (state: any) => {
return {
...state,
reducerOne:{
...state.reducerOne,
data: null // New value added in reducerOne
}
};
},
};
```
But lets say you have multiple reducers and you are making changes in lot of reducers as the new feature comes in or some sort of revamp. In that case you will be manually providing all the changes in your migration accordingly. To remove this hectic process there is one simple way first create a constant for Version like this
```
export const newVersion = 3;
```
and assign it into migration object, and persistConfig like this:
```
export const migration = {
[newVersion]: (state: any) => {
return {
...state,
reducerOne:{
...state.reducerOne,
data: null // New value added in reducerOne
}
};
},
};
```
then in your reducer file where you are assigning your initialState just export it and then import it inside your migration file and assign it against that reducer like this:
```
import {initialState} from './reducer/reducerOne'
export const migration = {
[newVersion]: (state: any) => {
return {
...state,
reducerOne: initialState,
};
},
};
```
Now when ever you add, update or delete any property in initialState of reducer, you just need to update the newVersion and reload your react application, after that you will see your updated property will appear in your redux state.
By following this process you don't have to manually enter the properties or reducers in your migration. This architecture will automatically do all the syncing for you.
Hope you like it.
| ministryofjavascript |
1,736,646 | Laravel: From Zero to CLI(ro) | Good morning, everyone, and happy MonDEV! ☕ This week we continue on the wave of CLI development,... | 25,147 | 2024-01-22T08:00:00 | https://dev.to/giuliano1993/laravel-from-zero-to-cliro-1po5 | laravel, php, cli, tooling |
Good morning, everyone, and happy MonDEV! ☕
This week we continue on the wave of CLI development, but this time in a completely different environment! You've heard me talk about command-line development with Python and Node; in the future, there will probably be something with Rust (just give me some time to get more familiar with it). But today, I want to go back to my roots, to what is my language of choice for web backend development.
Today, we're talking about developing CLI tools with PHP, specifically leveraging two very powerful tools made to work together: [Termwind](https://github.com/nunomaduro/termwind) and [Laravel Zero](https://laravel-zero.com/).
Starting with the first one, **Termwind** is a library developed by Nuno Maduro, allowing you to stylize your command-line outputs using Tailwind CSS classes! Sounds incredible? Yet it's true! Styling terminal content is always infernal if done natively. Having a tool that takes care of it for us saves a lot of time and results in a much more pleasant and usable display!
This library is already included by default in Laravel Zero, a minimal version of the beloved Laravel Web Framework but focused on command-line program development. **Laravel Zero** provides the classic Laravel APIs for writing commands but also offers some extra tools for distribution. Through the `build` command, as we'll see later, it allows you to generate a single phar file, executable using PHP, making the output of your work very easy to distribute! Few things are as beautiful as the ease of packaging the finished project and distributing it to the end user, don't you agree?
So, let's take a look at how to write our first command with Laravel Zero and make it beautiful with Termwind!
Create the project with
```bash
composer create-project --prefer-dist laravel-zero/laravel-zero project-name
```
After that, enter the project and run the command
```bash
php project-name make:command CommandName
```
This way, similar to what happens with `artisan`, you'll have a new command generated in `app/Commands` with all the basic structure of a Laravel command!
Now, if we play a bit with Termwind, we can start adding some style and get something that will look good.
```php
public function handle()
{
render(<<<'HTML'
<div>
<div class="px-1 bg-green-600 py-10 w-full">
<span> Mondev </span>
</div>
<em class="ml-1 py-10 text-red-500 font-bold">
The Developer's Newsletter 0_1
</em>
</div>
HTML);
}
```
Ther result will look something like this:

Once you've achieved the desired result, you just need to run the command
```bash
php project-name app:build build-name
```
to get a file ready to be executed with PHP in the `builds` folder! So, go into the folder and run in the terminal
```bash
php build-name
```
And you'll see a classic helper with all the possible commands and functionalities!
Easy, right?
Of course, we've only seen an extremely basic flow, and Laravel Zero offers many possibilities for this type of development, from database management to handling input, single or multiple-choice questions, to even some very nice add-ons like "Logo," which generates an ASCII art with the name of your application!
As always, the exploration is in your hands! I hope I've given you some interesting ideas and look forward to seeing some projects!
For now, as always, I just have to wish you a good week :D
Happy coding 0_1
| giuliano1993 |
1,736,695 | Proxy | Proxy is the authority to act on behalf of another they are intercepting connections between sender... | 0 | 2024-02-01T04:55:04 | https://dev.to/ibrahimsi/proxy-1ge5 | ibbus, proxy, serverclient, interception | `Proxy` is the authority to act on behalf of another they are intercepting connections between sender and receiver.
**Traffic Direction:**
`Forward Proxy:` Client to Internet.
`Reverse Proxy:` Internet to Web Server.
**Use Cases:**
`Forward Proxy:` Anonymity, content filtering, access control.
`Reverse Proxy:` Load balancing, Security, SSL termination.
| ibrahimsi |
1,736,880 | How to Improve Development Experience of your React Project | In this article, I'm going to show you how to set up a few small but yet useful tools that can speed... | 26,063 | 2024-01-21T14:36:14 | https://pavelkeyzik.com/blog/how-to-improve-development-experience-of-your-react-project | react, beginners, productivity, tutorial |
In this article, I'm going to show you how to set up a few small but yet useful tools that can speed up your workflow. The reason why we need them is to have a consistent codebase across the entire team. This makes it much easier to read code or commits from your colleagues. You won't need to spend much time formatting your code because it will be done automatically.
Forget about long discussions on whether to use a semicolon at the end of the line or not, or what the right commit message format is. Configure it once, and focus on the business logic instead.
## Set up Prettier
Let's start with an easy one. [Prettier](https://prettier.io/) helps you automatically format your code to make its style more readable. Here's an example of how the code looks before and after running Prettier.
First, create a `.prettierrc` file. It should contain a list of options to describe how to format our code. For example, `singleQuote` indicates whether we should use single quotes or not. You can find the full list of options [here](https://prettier.io/docs/en/options.html).
```json
{
"singleQuote": false,
"endOfLine": "lf",
"tabWidth": 2,
"trailingComma": "all"
}
```
The next thing you need to do is tell your IDE to run Prettier automatically every time you save the file (or whenever it works best for you). You can find information specific to your IDE [here](https://prettier.io/docs/en/editors).
## Set up ESLint
The next tool is [ESLint](https://eslint.org/). This tool helps you find issues in your code and highlights errors. You'll find many plugins for ESLint that can help you configure it the way you want, or you can even use shared configs.
In the [previous article](/blog/how-to-set-up-your-first-react-project), we set up the React project with `vite`. By default, it comes with ESLint configuration. Check out the ["Getting Started with ESLint"](https://eslint.org/docs/latest/use/getting-started#quick-start) page for information on how to install the basic configuration of ESLint. In this article, we'll just add a small plugin that I find quite useful.
The plugin is `eslint-plugin-simple-import-sort`. As you might guess from the name, it helps us to sort and group our imports (it works for exports as well). If you're like me, and you enjoy grouping similar things together, you'll love it because you won't need to do this manually anymore.
Let's install our dependency:
```shell
npm install eslint-plugin-simple-import-sort --save-dev
```
Now, all you need to do is add this plugin to your ESLint config and instruct ESLint to highlight errors when there are sorting issues:
```js
{
plugins: [
// ...
'simple-import-sort'
],
rules: {
// ...
"simple-import-sort/imports": "error",
"simple-import-sort/exports": "error"
}
}
```
Here's the example of how the code would look like before and after running this plugin:
## Set up Stylelint
[Stylelint](https://stylelint.io/) is similar to ESLint, but its focus is on styling rather than JavaScript. It helps you find errors in style files, such as old syntax or empty classes. We will also incorporate `stylelint-config-clean-order` to sort your style rules and group them consistently across the entire codebase.
Now, let's begin by installing the dependencies we need.
```shell
npm install stylelint stylelint-config-standard stylelint-config-clean-order --save-dev
```
Now create a file `.stylelintrc.json` and add our plugin to:
```json
{
"extends": ["stylelint-config-standard", "stylelint-config-clean-order"]
}
```
Update your `package.json` file with the new `lint:style` script. We're going to use it a bit later when we're going to set up lint job before all our commits.
```json
{
"scripts": {
"lint:style": "stylelint \"**/*.css\""
}
}
```
The last thing we need to do is install an extension for your IDE that will catch Stylelint errors. Check your [Editor integrations](https://stylelint.io/awesome-stylelint/#editor-integrations). For example, if you're using VSCode, you can install `vscode-stylelint`.
## Set up Husky
Now, let's talk about [Husky](https://typicode.github.io/husky). It's a wonderful tool that enables you to run scripts on any Git hooks. We'll add a `pre-commit` hook to run ESLint and Stylelint checks before committing. This ensures that we don't commit code with errors.
The setup is super easy—just run:
```shell
npx husky-init && npm install
```
It'll generate `.husky` folder where you could find `pre-commit` file. You'll need to change default `npm test` with any scripts you want. In our case it'll be:
```shell
#!/usr/bin/env sh
. "$(dirname -- "$0")/_/husky.sh"
npm run lint
npm run lint:style
```
Now, every time you commit, the `lint` and `lint:style` scripts will run automatically. If either of them throws an error, you won't be able to commit until you fix the issues.
One small improvement we can make here is to run these checks only for the files you're committing.
## Set up lint-staged
The [lint-staged](https://github.com/lint-staged/lint-staged) is a utility that will help us to run lint on, staged files. Staged filed are those that you're going to add to commit.
First, install `lint-staged` dependency.
```shell
npm install lint-staged --save-dev
```
Next, create a `.lintstagedrc` file that will contain a list of file patterns and scripts that need to be run. Note that we also add the `--fix` prefix here. This will automatically fix all errors, but if there's something that can't be fixed as easily as formattings, it will throw an error, preventing you from committing.
```json
{
"*.{js,jsx,ts,tsx}": [
"eslint --fix --no-ignore --report-unused-disable-directives --max-warnings=0"
],
"*.css": ["stylelint --fix --max-warnings=0"]
}
```
Now we need to update our `.husky/pre-commit` file and instead of running two scripts, we'll run just one:
```shell
#!/usr/bin/env sh
. "$(dirname -- "$0")/_/husky.sh"
npx lint-staged
```
And here's what you'll see if something goes wrong:
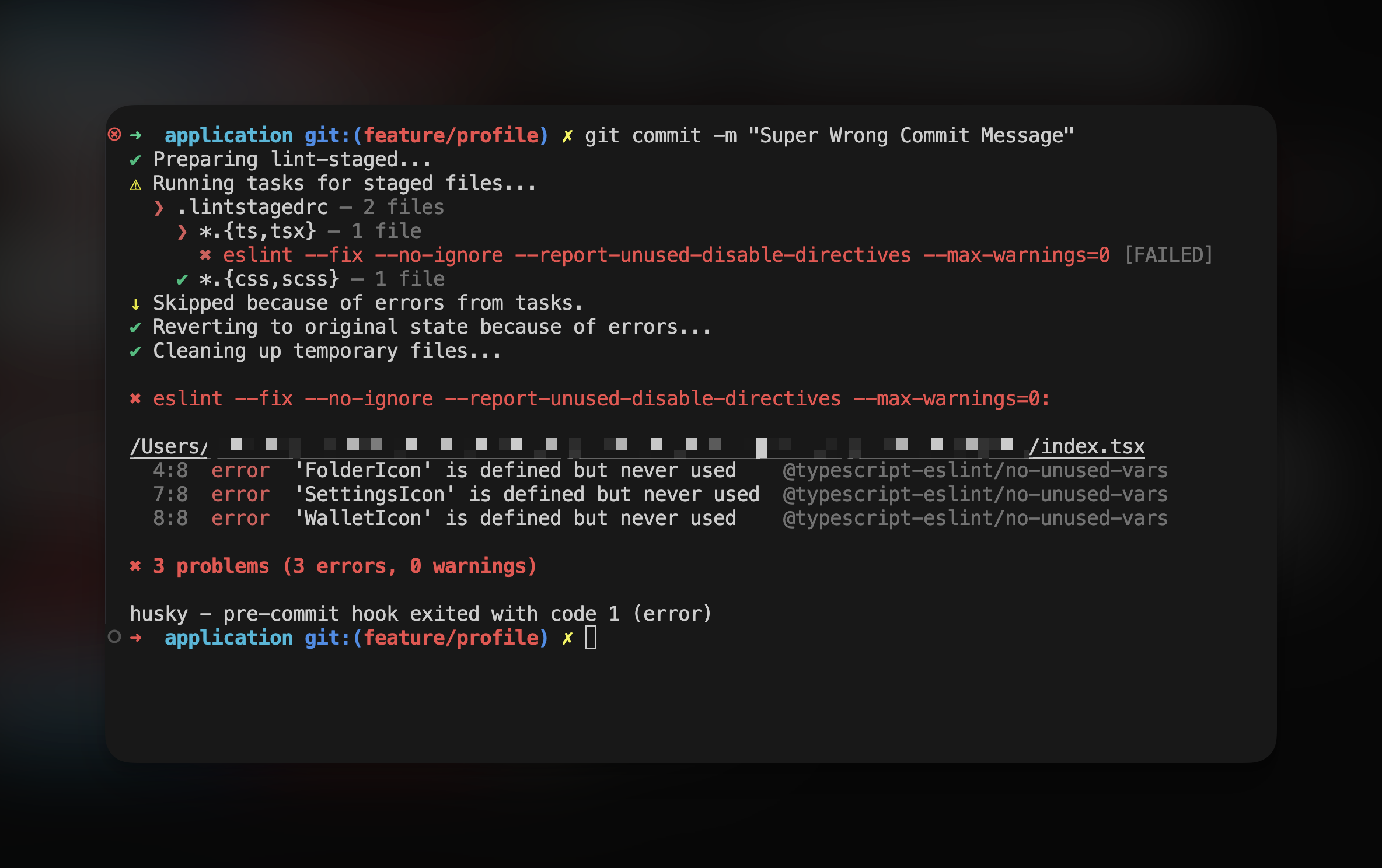
## Set up Commitlint
We've covered everything about writing well-formatted and structured code without worrying too much about it anymore. The only part we haven't explored yet is linting commit messages. [Commitlint](https://commitlint.js.org) will help us here. It allows you to configure any rules you want for the commit message, but we're going to use the [Conventional Commits](https://www.conventionalcommits.org/) specification, one of the most popular conventions you'll find.
Let's start from installing dependencies we'll need:
```shell
npm install @commitlint/{cli,config-conventional} --save-dev
```
Create a new file `commitlint.config.js` at the root of your project with this content:
```js
export default {
extends: ['@commitlint/config-conventional'],
}
```
And final step, will be creating a `commit-msg` hook that will run commitlint when you're trying to add new commit.
```shell
npx husky add .husky/commit-msg 'npx --no -- commitlint --edit ${1}'
```
Now, if you're going to try to commit something like `git commit -m "Some commit Message"` it'll throw an error. You should use `git commit -m "feat: some commit message"` instead. Read more about the conventional commits [here](https://www.conventionalcommits.org/en/v1.0.0/#summary).
The result of commitlint run will explain what's wrong and even provide a link to docs:
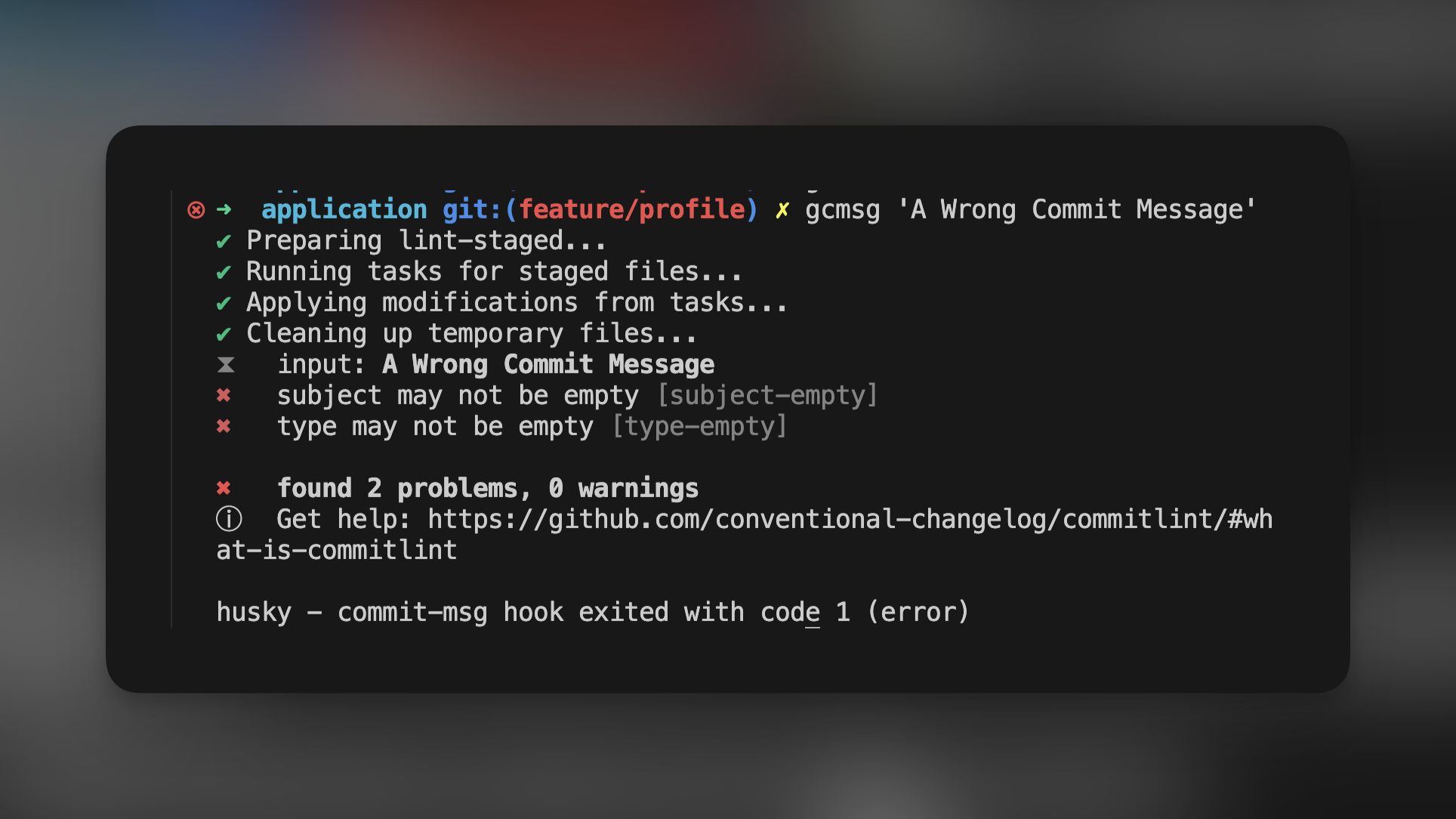
## Thank you!
If you've been with me from the beginning, reading and configuring everything, I want to express my gratitude. I hope this serves as a great example of how companies configure their codebases to achieve consistency and better code quality. Moreover, it significantly speeds up your workflow since you no longer need to worry about sorting or formatting.
P.S. If you have a cool setup in your project, please share it. While I've covered more basic aspects than specific project details, it would be wonderful to hear about different tooling from others, contributing to the knowledge of readers or enhancing my own skills.
| pavelkeyzik |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.